diff --git a/projects/pose_anything/README.md b/projects/pose_anything/README.md
new file mode 100644
index 0000000000..c00b4a914e
--- /dev/null
+++ b/projects/pose_anything/README.md
@@ -0,0 +1,82 @@
+# Pose Anything: A Graph-Based Approach for Category-Agnostic Pose Estimation
+
+## [Paper](https://arxiv.org/pdf/2311.17891.pdf) | [Project Page](https://orhir.github.io/pose-anything/) | [Official Repo](https://github.com/orhir/PoseAnything)
+
+By [Or Hirschorn](https://scholar.google.co.il/citations?user=GgFuT_QAAAAJ&hl=iw&oi=ao)
+and [Shai Avidan](https://scholar.google.co.il/citations?hl=iw&user=hpItE1QAAAAJ)
+
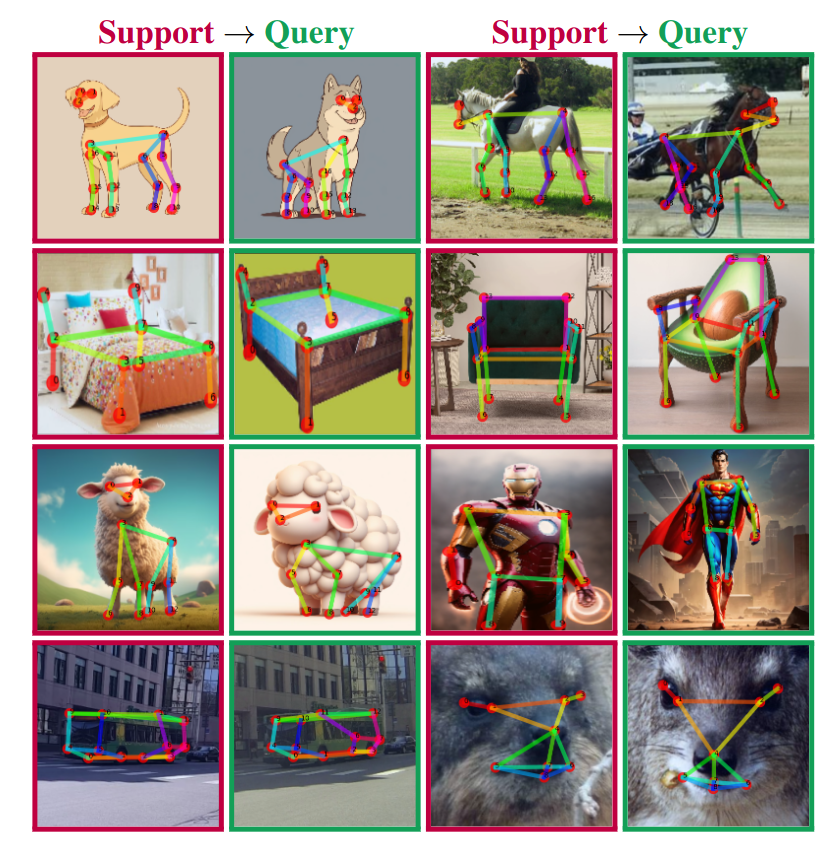
+
+
+## Introduction
+
+We present a novel approach to CAPE that leverages the inherent geometrical
+relations between keypoints through a newly designed Graph Transformer Decoder.
+By capturing and incorporating this crucial structural information, our method
+enhances the accuracy of keypoint localization, marking a significant departure
+from conventional CAPE techniques that treat keypoints as isolated entities.
+
+## Citation
+
+If you find this useful, please cite this work as follows:
+
+```bibtex
+@misc{hirschorn2023pose,
+ title={Pose Anything: A Graph-Based Approach for Category-Agnostic Pose Estimation},
+ author={Or Hirschorn and Shai Avidan},
+ year={2023},
+ eprint={2311.17891},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+}
+```
+
+## Getting Started
+
+📣 Pose Anything is available on OpenXLab now. [\[Try it online\]](https://openxlab.org.cn/apps/detail/orhir/Pose-Anything)
+
+### Install Dependencies
+
+We recommend using a virtual environment for running our code.
+After installing MMPose, you can install the rest of the dependencies by
+running:
+
+```
+pip install timm
+```
+
+### Pretrained Weights
+
+The full list of pretrained models can be found in
+the [Official Repo](https://github.com/orhir/PoseAnything).
+
+## Demo on Custom Images
+
+***A bigger and more accurate version of the model - COMING SOON!***
+
+Download
+the [pretrained model](https://drive.google.com/file/d/1RT1Q8AMEa1kj6k9ZqrtWIKyuR4Jn4Pqc/view?usp=drive_link)
+and run:
+
+```
+python demo.py --support [path_to_support_image] --query [path_to_query_image] --config configs/demo_b.py --checkpoint [path_to_pretrained_ckpt]
+```
+
+***Note:*** The demo code supports any config with suitable checkpoint file.
+More pre-trained models can be found in the official repo.
+
+## Training and Testing on MP-100 Dataset
+
+**We currently only support demo on custom images through the MMPose repo.**
+
+**For training and testing on the MP-100 dataset, please refer to
+the [Official Repo](https://github.com/orhir/PoseAnything).**
+
+## Acknowledgement
+
+Our code is based on code from:
+
+- [CapeFormer](https://github.com/flyinglynx/CapeFormer)
+
+## License
+
+This project is released under the Apache 2.0 license.
diff --git a/projects/pose_anything/configs/demo.py b/projects/pose_anything/configs/demo.py
new file mode 100644
index 0000000000..70a468a8f4
--- /dev/null
+++ b/projects/pose_anything/configs/demo.py
@@ -0,0 +1,207 @@
+log_level = 'INFO'
+load_from = None
+resume_from = None
+dist_params = dict(backend='nccl')
+workflow = [('train', 1)]
+checkpoint_config = dict(interval=20)
+evaluation = dict(
+ interval=25,
+ metric=['PCK', 'NME', 'AUC', 'EPE'],
+ key_indicator='PCK',
+ gpu_collect=True,
+ res_folder='')
+optimizer = dict(
+ type='Adam',
+ lr=1e-5,
+)
+
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=1000,
+ warmup_ratio=0.001,
+ step=[160, 180])
+total_epochs = 200
+log_config = dict(
+ interval=50,
+ hooks=[dict(type='TextLoggerHook'),
+ dict(type='TensorboardLoggerHook')])
+
+channel_cfg = dict(
+ num_output_channels=1,
+ dataset_joints=1,
+ dataset_channel=[
+ [
+ 0,
+ ],
+ ],
+ inference_channel=[
+ 0,
+ ],
+ max_kpt_num=100)
+
+# model settings
+model = dict(
+ type='TransformerPoseTwoStage',
+ pretrained='swinv2_large',
+ encoder_config=dict(
+ type='SwinTransformerV2',
+ embed_dim=192,
+ depths=[2, 2, 18, 2],
+ num_heads=[6, 12, 24, 48],
+ window_size=16,
+ pretrained_window_sizes=[12, 12, 12, 6],
+ drop_path_rate=0.2,
+ img_size=256,
+ ),
+ keypoint_head=dict(
+ type='TwoStageHead',
+ in_channels=1536,
+ transformer=dict(
+ type='TwoStageSupportRefineTransformer',
+ d_model=384,
+ nhead=8,
+ num_encoder_layers=3,
+ num_decoder_layers=3,
+ dim_feedforward=1536,
+ dropout=0.1,
+ similarity_proj_dim=384,
+ dynamic_proj_dim=192,
+ activation='relu',
+ normalize_before=False,
+ return_intermediate_dec=True),
+ share_kpt_branch=False,
+ num_decoder_layer=3,
+ with_heatmap_loss=True,
+ support_pos_embed=False,
+ heatmap_loss_weight=2.0,
+ skeleton_loss_weight=0.02,
+ num_samples=0,
+ support_embedding_type='fixed',
+ num_support=100,
+ support_order_dropout=-1,
+ positional_encoding=dict(
+ type='SinePositionalEncoding', num_feats=192, normalize=True)),
+ # training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=False,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=15,
+ scale_factor=0.15),
+ dict(type='TopDownAffineFewShot'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTargetFewShot', sigma=1),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file',
+ 'joints_3d',
+ 'joints_3d_visible',
+ 'center',
+ 'scale',
+ 'rotation',
+ 'bbox_score',
+ 'flip_pairs',
+ 'category_id',
+ 'skeleton',
+ ]),
+]
+
+valid_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffineFewShot'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTargetFewShot', sigma=1),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file',
+ 'joints_3d',
+ 'joints_3d_visible',
+ 'center',
+ 'scale',
+ 'rotation',
+ 'bbox_score',
+ 'flip_pairs',
+ 'category_id',
+ 'skeleton',
+ ]),
+]
+
+test_pipeline = valid_pipeline
+
+data_root = 'data/mp100'
+data = dict(
+ samples_per_gpu=8,
+ workers_per_gpu=8,
+ train=dict(
+ type='TransformerPoseDataset',
+ ann_file=f'{data_root}/annotations/mp100_all.json',
+ img_prefix=f'{data_root}/images/',
+ # img_prefix=f'{data_root}',
+ data_cfg=data_cfg,
+ valid_class_ids=None,
+ max_kpt_num=channel_cfg['max_kpt_num'],
+ num_shots=1,
+ pipeline=train_pipeline),
+ val=dict(
+ type='TransformerPoseDataset',
+ ann_file=f'{data_root}/annotations/mp100_split1_val.json',
+ img_prefix=f'{data_root}/images/',
+ # img_prefix=f'{data_root}',
+ data_cfg=data_cfg,
+ valid_class_ids=None,
+ max_kpt_num=channel_cfg['max_kpt_num'],
+ num_shots=1,
+ num_queries=15,
+ num_episodes=100,
+ pipeline=valid_pipeline),
+ test=dict(
+ type='TestPoseDataset',
+ ann_file=f'{data_root}/annotations/mp100_split1_test.json',
+ img_prefix=f'{data_root}/images/',
+ # img_prefix=f'{data_root}',
+ data_cfg=data_cfg,
+ valid_class_ids=None,
+ max_kpt_num=channel_cfg['max_kpt_num'],
+ num_shots=1,
+ num_queries=15,
+ num_episodes=200,
+ pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
+ pipeline=test_pipeline),
+)
+vis_backends = [
+ dict(type='LocalVisBackend'),
+ dict(type='TensorboardVisBackend'),
+]
+visualizer = dict(
+ type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
+
+shuffle_cfg = dict(interval=1)
diff --git a/projects/pose_anything/configs/demo_b.py b/projects/pose_anything/configs/demo_b.py
new file mode 100644
index 0000000000..2b7d8b30ff
--- /dev/null
+++ b/projects/pose_anything/configs/demo_b.py
@@ -0,0 +1,205 @@
+custom_imports = dict(imports=['models'])
+
+log_level = 'INFO'
+load_from = None
+resume_from = None
+dist_params = dict(backend='nccl')
+workflow = [('train', 1)]
+checkpoint_config = dict(interval=20)
+evaluation = dict(
+ interval=25,
+ metric=['PCK', 'NME', 'AUC', 'EPE'],
+ key_indicator='PCK',
+ gpu_collect=True,
+ res_folder='')
+optimizer = dict(
+ type='Adam',
+ lr=1e-5,
+)
+
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=1000,
+ warmup_ratio=0.001,
+ step=[160, 180])
+total_epochs = 200
+log_config = dict(
+ interval=50,
+ hooks=[dict(type='TextLoggerHook'),
+ dict(type='TensorboardLoggerHook')])
+
+channel_cfg = dict(
+ num_output_channels=1,
+ dataset_joints=1,
+ dataset_channel=[
+ [
+ 0,
+ ],
+ ],
+ inference_channel=[
+ 0,
+ ],
+ max_kpt_num=100)
+
+# model settings
+model = dict(
+ type='PoseAnythingModel',
+ pretrained='swinv2_base',
+ encoder_config=dict(
+ type='SwinTransformerV2',
+ embed_dim=128,
+ depths=[2, 2, 18, 2],
+ num_heads=[4, 8, 16, 32],
+ window_size=14,
+ pretrained_window_sizes=[12, 12, 12, 6],
+ drop_path_rate=0.1,
+ img_size=224,
+ ),
+ keypoint_head=dict(
+ type='PoseHead',
+ in_channels=1024,
+ transformer=dict(
+ type='EncoderDecoder',
+ d_model=256,
+ nhead=8,
+ num_encoder_layers=3,
+ num_decoder_layers=3,
+ graph_decoder='pre',
+ dim_feedforward=1024,
+ dropout=0.1,
+ similarity_proj_dim=256,
+ dynamic_proj_dim=128,
+ activation='relu',
+ normalize_before=False,
+ return_intermediate_dec=True),
+ share_kpt_branch=False,
+ num_decoder_layer=3,
+ with_heatmap_loss=True,
+ heatmap_loss_weight=2.0,
+ support_order_dropout=-1,
+ positional_encoding=dict(
+ type='SinePositionalEncoding', num_feats=128, normalize=True)),
+ # training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=False,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[224, 224],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=15,
+ scale_factor=0.15),
+ dict(type='TopDownAffineFewShot'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTargetFewShot', sigma=1),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file',
+ 'joints_3d',
+ 'joints_3d_visible',
+ 'center',
+ 'scale',
+ 'rotation',
+ 'bbox_score',
+ 'flip_pairs',
+ 'category_id',
+ 'skeleton',
+ ]),
+]
+
+valid_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffineFewShot'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTargetFewShot', sigma=1),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file',
+ 'joints_3d',
+ 'joints_3d_visible',
+ 'center',
+ 'scale',
+ 'rotation',
+ 'bbox_score',
+ 'flip_pairs',
+ 'category_id',
+ 'skeleton',
+ ]),
+]
+
+test_pipeline = valid_pipeline
+
+data_root = 'data/mp100'
+data = dict(
+ samples_per_gpu=8,
+ workers_per_gpu=8,
+ train=dict(
+ type='TransformerPoseDataset',
+ ann_file=f'{data_root}/annotations/mp100_split1_train.json',
+ img_prefix=f'{data_root}/images/',
+ # img_prefix=f'{data_root}',
+ data_cfg=data_cfg,
+ valid_class_ids=None,
+ max_kpt_num=channel_cfg['max_kpt_num'],
+ num_shots=1,
+ pipeline=train_pipeline),
+ val=dict(
+ type='TransformerPoseDataset',
+ ann_file=f'{data_root}/annotations/mp100_split1_val.json',
+ img_prefix=f'{data_root}/images/',
+ # img_prefix=f'{data_root}',
+ data_cfg=data_cfg,
+ valid_class_ids=None,
+ max_kpt_num=channel_cfg['max_kpt_num'],
+ num_shots=1,
+ num_queries=15,
+ num_episodes=100,
+ pipeline=valid_pipeline),
+ test=dict(
+ type='TestPoseDataset',
+ ann_file=f'{data_root}/annotations/mp100_split1_test.json',
+ img_prefix=f'{data_root}/images/',
+ # img_prefix=f'{data_root}',
+ data_cfg=data_cfg,
+ valid_class_ids=None,
+ max_kpt_num=channel_cfg['max_kpt_num'],
+ num_shots=1,
+ num_queries=15,
+ num_episodes=200,
+ pck_threshold_list=[0.05, 0.10, 0.15, 0.2, 0.25],
+ pipeline=test_pipeline),
+)
+vis_backends = [
+ dict(type='LocalVisBackend'),
+ dict(type='TensorboardVisBackend'),
+]
+visualizer = dict(
+ type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
+
+shuffle_cfg = dict(interval=1)
diff --git a/projects/pose_anything/datasets/__init__.py b/projects/pose_anything/datasets/__init__.py
new file mode 100644
index 0000000000..86bb3ce651
--- /dev/null
+++ b/projects/pose_anything/datasets/__init__.py
@@ -0,0 +1 @@
+from .pipelines import * # noqa
diff --git a/projects/pose_anything/datasets/builder.py b/projects/pose_anything/datasets/builder.py
new file mode 100644
index 0000000000..9f44687143
--- /dev/null
+++ b/projects/pose_anything/datasets/builder.py
@@ -0,0 +1,56 @@
+from mmengine.dataset import RepeatDataset
+from mmengine.registry import build_from_cfg
+from torch.utils.data.dataset import ConcatDataset
+
+from mmpose.datasets.builder import DATASETS
+
+
+def _concat_cfg(cfg):
+ replace = ['ann_file', 'img_prefix']
+ channels = ['num_joints', 'dataset_channel']
+ concat_cfg = []
+ for i in range(len(cfg['type'])):
+ cfg_tmp = cfg.deepcopy()
+ cfg_tmp['type'] = cfg['type'][i]
+ for item in replace:
+ assert item in cfg_tmp
+ assert len(cfg['type']) == len(cfg[item]), (cfg[item])
+ cfg_tmp[item] = cfg[item][i]
+ for item in channels:
+ assert item in cfg_tmp['data_cfg']
+ assert len(cfg['type']) == len(cfg['data_cfg'][item])
+ cfg_tmp['data_cfg'][item] = cfg['data_cfg'][item][i]
+ concat_cfg.append(cfg_tmp)
+ return concat_cfg
+
+
+def _check_vaild(cfg):
+ replace = ['num_joints', 'dataset_channel']
+ if isinstance(cfg['data_cfg'][replace[0]], (list, tuple)):
+ for item in replace:
+ cfg['data_cfg'][item] = cfg['data_cfg'][item][0]
+ return cfg
+
+
+def build_dataset(cfg, default_args=None):
+ """Build a dataset from config dict.
+
+ Args:
+ cfg (dict): Config dict. It should at least contain the key "type".
+ default_args (dict, optional): Default initialization arguments.
+ Default: None.
+
+ Returns:
+ Dataset: The constructed dataset.
+ """
+ if isinstance(cfg['type'],
+ (list, tuple)): # In training, type=TransformerPoseDataset
+ dataset = ConcatDataset(
+ [build_dataset(c, default_args) for c in _concat_cfg(cfg)])
+ elif cfg['type'] == 'RepeatDataset':
+ dataset = RepeatDataset(
+ build_dataset(cfg['dataset'], default_args), cfg['times'])
+ else:
+ cfg = _check_vaild(cfg)
+ dataset = build_from_cfg(cfg, DATASETS, default_args)
+ return dataset
diff --git a/projects/pose_anything/datasets/datasets/__init__.py b/projects/pose_anything/datasets/datasets/__init__.py
new file mode 100644
index 0000000000..124dcc3b15
--- /dev/null
+++ b/projects/pose_anything/datasets/datasets/__init__.py
@@ -0,0 +1,7 @@
+from .mp100 import (FewShotBaseDataset, FewShotKeypointDataset,
+ TransformerBaseDataset, TransformerPoseDataset)
+
+__all__ = [
+ 'FewShotBaseDataset', 'FewShotKeypointDataset', 'TransformerBaseDataset',
+ 'TransformerPoseDataset'
+]
diff --git a/projects/pose_anything/datasets/datasets/mp100/__init__.py b/projects/pose_anything/datasets/datasets/mp100/__init__.py
new file mode 100644
index 0000000000..229353517b
--- /dev/null
+++ b/projects/pose_anything/datasets/datasets/mp100/__init__.py
@@ -0,0 +1,11 @@
+from .fewshot_base_dataset import FewShotBaseDataset
+from .fewshot_dataset import FewShotKeypointDataset
+from .test_base_dataset import TestBaseDataset
+from .test_dataset import TestPoseDataset
+from .transformer_base_dataset import TransformerBaseDataset
+from .transformer_dataset import TransformerPoseDataset
+
+__all__ = [
+ 'FewShotKeypointDataset', 'FewShotBaseDataset', 'TransformerPoseDataset',
+ 'TransformerBaseDataset', 'TestBaseDataset', 'TestPoseDataset'
+]
diff --git a/projects/pose_anything/datasets/datasets/mp100/fewshot_base_dataset.py b/projects/pose_anything/datasets/datasets/mp100/fewshot_base_dataset.py
new file mode 100644
index 0000000000..2746a0a35c
--- /dev/null
+++ b/projects/pose_anything/datasets/datasets/mp100/fewshot_base_dataset.py
@@ -0,0 +1,235 @@
+import copy
+from abc import ABCMeta, abstractmethod
+
+import json_tricks as json
+import numpy as np
+from mmcv.parallel import DataContainer as DC
+from torch.utils.data import Dataset
+
+from mmpose.core.evaluation.top_down_eval import keypoint_pck_accuracy
+from mmpose.datasets import DATASETS
+from mmpose.datasets.pipelines import Compose
+
+
+@DATASETS.register_module()
+class FewShotBaseDataset(Dataset, metaclass=ABCMeta):
+
+ def __init__(self,
+ ann_file,
+ img_prefix,
+ data_cfg,
+ pipeline,
+ test_mode=False):
+ self.image_info = {}
+ self.ann_info = {}
+
+ self.annotations_path = ann_file
+ if not img_prefix.endswith('/'):
+ img_prefix = img_prefix + '/'
+ self.img_prefix = img_prefix
+ self.pipeline = pipeline
+ self.test_mode = test_mode
+
+ self.ann_info['image_size'] = np.array(data_cfg['image_size'])
+ self.ann_info['heatmap_size'] = np.array(data_cfg['heatmap_size'])
+ self.ann_info['num_joints'] = data_cfg['num_joints']
+
+ self.ann_info['flip_pairs'] = None
+
+ self.ann_info['inference_channel'] = data_cfg['inference_channel']
+ self.ann_info['num_output_channels'] = data_cfg['num_output_channels']
+ self.ann_info['dataset_channel'] = data_cfg['dataset_channel']
+
+ self.db = []
+ self.num_shots = 1
+ self.paired_samples = []
+ self.pipeline = Compose(self.pipeline)
+
+ @abstractmethod
+ def _get_db(self):
+ """Load dataset."""
+ raise NotImplementedError
+
+ @abstractmethod
+ def _select_kpt(self, obj, kpt_id):
+ """Select kpt."""
+ raise NotImplementedError
+
+ @abstractmethod
+ def evaluate(self, cfg, preds, output_dir, *args, **kwargs):
+ """Evaluate keypoint results."""
+ raise NotImplementedError
+
+ @staticmethod
+ def _write_keypoint_results(keypoints, res_file):
+ """Write results into a json file."""
+
+ with open(res_file, 'w') as f:
+ json.dump(keypoints, f, sort_keys=True, indent=4)
+
+ def _report_metric(self,
+ res_file,
+ metrics,
+ pck_thr=0.2,
+ pckh_thr=0.7,
+ auc_nor=30):
+ """Keypoint evaluation.
+
+ Args:
+ res_file (str): Json file stored prediction results.
+ metrics (str | list[str]): Metric to be performed.
+ Options: 'PCK', 'PCKh', 'AUC', 'EPE'.
+ pck_thr (float): PCK threshold, default as 0.2.
+ pckh_thr (float): PCKh threshold, default as 0.7.
+ auc_nor (float): AUC normalization factor, default as 30 pixel.
+
+ Returns:
+ List: Evaluation results for evaluation metric.
+ """
+ info_str = []
+
+ with open(res_file, 'r') as fin:
+ preds = json.load(fin)
+ assert len(preds) == len(self.paired_samples)
+
+ outputs = []
+ gts = []
+ masks = []
+ threshold_bbox = []
+ threshold_head_box = []
+
+ for pred, pair in zip(preds, self.paired_samples):
+ item = self.db[pair[-1]]
+ outputs.append(np.array(pred['keypoints'])[:, :-1])
+ gts.append(np.array(item['joints_3d'])[:, :-1])
+
+ mask_query = ((np.array(item['joints_3d_visible'])[:, 0]) > 0)
+ mask_sample = ((np.array(
+ self.db[pair[0]]['joints_3d_visible'])[:, 0]) > 0)
+ for id_s in pair[:-1]:
+ mask_sample = np.bitwise_and(
+ mask_sample,
+ ((np.array(self.db[id_s]['joints_3d_visible'])[:, 0]) > 0))
+ masks.append(np.bitwise_and(mask_query, mask_sample))
+
+ if 'PCK' in metrics:
+ bbox = np.array(item['bbox'])
+ bbox_thr = np.max(bbox[2:])
+ threshold_bbox.append(np.array([bbox_thr, bbox_thr]))
+ if 'PCKh' in metrics:
+ head_box_thr = item['head_size']
+ threshold_head_box.append(
+ np.array([head_box_thr, head_box_thr]))
+
+ if 'PCK' in metrics:
+ pck_avg = []
+ for (output, gt, mask, thr_bbox) in zip(outputs, gts, masks,
+ threshold_bbox):
+ _, pck, _ = keypoint_pck_accuracy(
+ np.expand_dims(output, 0), np.expand_dims(gt, 0),
+ np.expand_dims(mask, 0), pck_thr,
+ np.expand_dims(thr_bbox, 0))
+ pck_avg.append(pck)
+ info_str.append(('PCK', np.mean(pck_avg)))
+
+ return info_str
+
+ def _merge_obj(self, Xs_list, Xq, idx):
+ """merge Xs_list and Xq.
+
+ :param Xs_list: N-shot samples X
+ :param Xq: query X
+ :param idx: id of paired_samples
+ :return: Xall
+ """
+ Xall = dict()
+ Xall['img_s'] = [Xs['img'] for Xs in Xs_list]
+ Xall['target_s'] = [Xs['target'] for Xs in Xs_list]
+ Xall['target_weight_s'] = [Xs['target_weight'] for Xs in Xs_list]
+ xs_img_metas = [Xs['img_metas'].data for Xs in Xs_list]
+
+ Xall['img_q'] = Xq['img']
+ Xall['target_q'] = Xq['target']
+ Xall['target_weight_q'] = Xq['target_weight']
+ xq_img_metas = Xq['img_metas'].data
+
+ img_metas = dict()
+ for key in xq_img_metas.keys():
+ img_metas['sample_' + key] = [
+ xs_img_meta[key] for xs_img_meta in xs_img_metas
+ ]
+ img_metas['query_' + key] = xq_img_metas[key]
+ img_metas['bbox_id'] = idx
+
+ Xall['img_metas'] = DC(img_metas, cpu_only=True)
+
+ return Xall
+
+ def __len__(self):
+ """Get the size of the dataset."""
+ return len(self.paired_samples)
+
+ def __getitem__(self, idx):
+ """Get the sample given index."""
+
+ pair_ids = self.paired_samples[idx]
+ assert len(pair_ids) == self.num_shots + 1
+ sample_id_list = pair_ids[:self.num_shots]
+ query_id = pair_ids[-1]
+
+ sample_obj_list = []
+ for sample_id in sample_id_list:
+ sample_obj = copy.deepcopy(self.db[sample_id])
+ sample_obj['ann_info'] = copy.deepcopy(self.ann_info)
+ sample_obj_list.append(sample_obj)
+
+ query_obj = copy.deepcopy(self.db[query_id])
+ query_obj['ann_info'] = copy.deepcopy(self.ann_info)
+
+ if not self.test_mode:
+ # randomly select "one" keypoint
+ sample_valid = (sample_obj_list[0]['joints_3d_visible'][:, 0] > 0)
+ for sample_obj in sample_obj_list:
+ sample_valid = sample_valid & (
+ sample_obj['joints_3d_visible'][:, 0] > 0)
+ query_valid = (query_obj['joints_3d_visible'][:, 0] > 0)
+
+ valid_s = np.where(sample_valid)[0]
+ valid_q = np.where(query_valid)[0]
+ valid_sq = np.where(sample_valid & query_valid)[0]
+ if len(valid_sq) > 0:
+ kpt_id = np.random.choice(valid_sq)
+ elif len(valid_s) > 0:
+ kpt_id = np.random.choice(valid_s)
+ elif len(valid_q) > 0:
+ kpt_id = np.random.choice(valid_q)
+ else:
+ kpt_id = np.random.choice(np.array(range(len(query_valid))))
+
+ for i in range(self.num_shots):
+ sample_obj_list[i] = self._select_kpt(sample_obj_list[i],
+ kpt_id)
+ query_obj = self._select_kpt(query_obj, kpt_id)
+
+ # when test, all keypoints will be preserved.
+
+ Xs_list = []
+ for sample_obj in sample_obj_list:
+ Xs = self.pipeline(sample_obj)
+ Xs_list.append(Xs)
+ Xq = self.pipeline(query_obj)
+
+ Xall = self._merge_obj(Xs_list, Xq, idx)
+ Xall['skeleton'] = self.db[query_id]['skeleton']
+
+ return Xall
+
+ def _sort_and_unique_bboxes(self, kpts, key='bbox_id'):
+ """sort kpts and remove the repeated ones."""
+ kpts = sorted(kpts, key=lambda x: x[key])
+ num = len(kpts)
+ for i in range(num - 1, 0, -1):
+ if kpts[i][key] == kpts[i - 1][key]:
+ del kpts[i]
+
+ return kpts
diff --git a/projects/pose_anything/datasets/datasets/mp100/fewshot_dataset.py b/projects/pose_anything/datasets/datasets/mp100/fewshot_dataset.py
new file mode 100644
index 0000000000..bd8287966c
--- /dev/null
+++ b/projects/pose_anything/datasets/datasets/mp100/fewshot_dataset.py
@@ -0,0 +1,334 @@
+import os
+import random
+from collections import OrderedDict
+
+import numpy as np
+from xtcocotools.coco import COCO
+
+from mmpose.datasets import DATASETS
+from .fewshot_base_dataset import FewShotBaseDataset
+
+
+@DATASETS.register_module()
+class FewShotKeypointDataset(FewShotBaseDataset):
+
+ def __init__(self,
+ ann_file,
+ img_prefix,
+ data_cfg,
+ pipeline,
+ valid_class_ids,
+ num_shots=1,
+ num_queries=100,
+ num_episodes=1,
+ test_mode=False):
+ super().__init__(
+ ann_file, img_prefix, data_cfg, pipeline, test_mode=test_mode)
+
+ self.ann_info['flip_pairs'] = []
+
+ self.ann_info['upper_body_ids'] = []
+ self.ann_info['lower_body_ids'] = []
+
+ self.ann_info['use_different_joint_weights'] = False
+ self.ann_info['joint_weights'] = np.array([
+ 1.,
+ ], dtype=np.float32).reshape((self.ann_info['num_joints'], 1))
+
+ self.coco = COCO(ann_file)
+
+ self.id2name, self.name2id = self._get_mapping_id_name(self.coco.imgs)
+ self.img_ids = self.coco.getImgIds()
+ self.classes = [
+ cat['name'] for cat in self.coco.loadCats(self.coco.getCatIds())
+ ]
+
+ self.num_classes = len(self.classes)
+ self._class_to_ind = dict(zip(self.classes, self.coco.getCatIds()))
+ self._ind_to_class = dict(zip(self.coco.getCatIds(), self.classes))
+
+ if valid_class_ids is not None:
+ self.valid_class_ids = valid_class_ids
+ else:
+ self.valid_class_ids = self.coco.getCatIds()
+ self.valid_classes = [
+ self._ind_to_class[ind] for ind in self.valid_class_ids
+ ]
+
+ self.cats = self.coco.cats
+
+ # Also update self.cat2obj
+ self.db = self._get_db()
+
+ self.num_shots = num_shots
+
+ if not test_mode:
+ # Update every training epoch
+ self.random_paired_samples()
+ else:
+ self.num_queries = num_queries
+ self.num_episodes = num_episodes
+ self.make_paired_samples()
+
+ def random_paired_samples(self):
+ num_datas = [
+ len(self.cat2obj[self._class_to_ind[cls]])
+ for cls in self.valid_classes
+ ]
+
+ # balance the dataset
+ max_num_data = max(num_datas)
+
+ all_samples = []
+ for cls in self.valid_class_ids:
+ for i in range(max_num_data):
+ shot = random.sample(self.cat2obj[cls], self.num_shots + 1)
+ all_samples.append(shot)
+
+ self.paired_samples = np.array(all_samples)
+ np.random.shuffle(self.paired_samples)
+
+ def make_paired_samples(self):
+ random.seed(1)
+ np.random.seed(0)
+
+ all_samples = []
+ for cls in self.valid_class_ids:
+ for _ in range(self.num_episodes):
+ shots = random.sample(self.cat2obj[cls],
+ self.num_shots + self.num_queries)
+ sample_ids = shots[:self.num_shots]
+ query_ids = shots[self.num_shots:]
+ for query_id in query_ids:
+ all_samples.append(sample_ids + [query_id])
+
+ self.paired_samples = np.array(all_samples)
+
+ def _select_kpt(self, obj, kpt_id):
+ obj['joints_3d'] = obj['joints_3d'][kpt_id:kpt_id + 1]
+ obj['joints_3d_visible'] = obj['joints_3d_visible'][kpt_id:kpt_id + 1]
+ obj['kpt_id'] = kpt_id
+
+ return obj
+
+ @staticmethod
+ def _get_mapping_id_name(imgs):
+ """
+ Args:
+ imgs (dict): dict of image info.
+
+ Returns:
+ tuple: Image name & id mapping dicts.
+
+ - id2name (dict): Mapping image id to name.
+ - name2id (dict): Mapping image name to id.
+ """
+ id2name = {}
+ name2id = {}
+ for image_id, image in imgs.items():
+ file_name = image['file_name']
+ id2name[image_id] = file_name
+ name2id[file_name] = image_id
+
+ return id2name, name2id
+
+ def _get_db(self):
+ """Ground truth bbox and keypoints."""
+ self.obj_id = 0
+
+ self.cat2obj = {}
+ for i in self.coco.getCatIds():
+ self.cat2obj.update({i: []})
+
+ gt_db = []
+ for img_id in self.img_ids:
+ gt_db.extend(self._load_coco_keypoint_annotation_kernel(img_id))
+ return gt_db
+
+ def _load_coco_keypoint_annotation_kernel(self, img_id):
+ """load annotation from COCOAPI.
+
+ Note:
+ bbox:[x1, y1, w, h]
+ Args:
+ img_id: coco image id
+ Returns:
+ dict: db entry
+ """
+ img_ann = self.coco.loadImgs(img_id)[0]
+ width = img_ann['width']
+ height = img_ann['height']
+
+ ann_ids = self.coco.getAnnIds(imgIds=img_id, iscrowd=False)
+ objs = self.coco.loadAnns(ann_ids)
+
+ # sanitize bboxes
+ valid_objs = []
+ for obj in objs:
+ if 'bbox' not in obj:
+ continue
+ x, y, w, h = obj['bbox']
+ x1 = max(0, x)
+ y1 = max(0, y)
+ x2 = min(width - 1, x1 + max(0, w - 1))
+ y2 = min(height - 1, y1 + max(0, h - 1))
+ if ('area' not in obj or obj['area'] > 0) and x2 > x1 and y2 > y1:
+ obj['clean_bbox'] = [x1, y1, x2 - x1, y2 - y1]
+ valid_objs.append(obj)
+ objs = valid_objs
+
+ bbox_id = 0
+ rec = []
+ for obj in objs:
+ if 'keypoints' not in obj:
+ continue
+ if max(obj['keypoints']) == 0:
+ continue
+ if 'num_keypoints' in obj and obj['num_keypoints'] == 0:
+ continue
+
+ category_id = obj['category_id']
+ # the number of keypoint for this specific category
+ cat_kpt_num = int(len(obj['keypoints']) / 3)
+
+ joints_3d = np.zeros((cat_kpt_num, 3), dtype=np.float32)
+ joints_3d_visible = np.zeros((cat_kpt_num, 3), dtype=np.float32)
+
+ keypoints = np.array(obj['keypoints']).reshape(-1, 3)
+ joints_3d[:, :2] = keypoints[:, :2]
+ joints_3d_visible[:, :2] = np.minimum(1, keypoints[:, 2:3])
+
+ center, scale = self._xywh2cs(*obj['clean_bbox'][:4])
+
+ image_file = os.path.join(self.img_prefix, self.id2name[img_id])
+
+ self.cat2obj[category_id].append(self.obj_id)
+
+ rec.append({
+ 'image_file':
+ image_file,
+ 'center':
+ center,
+ 'scale':
+ scale,
+ 'rotation':
+ 0,
+ 'bbox':
+ obj['clean_bbox'][:4],
+ 'bbox_score':
+ 1,
+ 'joints_3d':
+ joints_3d,
+ 'joints_3d_visible':
+ joints_3d_visible,
+ 'category_id':
+ category_id,
+ 'cat_kpt_num':
+ cat_kpt_num,
+ 'bbox_id':
+ self.obj_id,
+ 'skeleton':
+ self.coco.cats[obj['category_id']]['skeleton'],
+ })
+ bbox_id = bbox_id + 1
+ self.obj_id += 1
+
+ return rec
+
+ def _xywh2cs(self, x, y, w, h):
+ """This encodes bbox(x,y,w,w) into (center, scale)
+
+ Args:
+ x, y, w, h
+
+ Returns:
+ tuple: A tuple containing center and scale.
+
+ - center (np.ndarray[float32](2,)): center of the bbox (x, y).
+ - scale (np.ndarray[float32](2,)): scale of the bbox w & h.
+ """
+ aspect_ratio = self.ann_info['image_size'][0] / self.ann_info[
+ 'image_size'][1]
+ center = np.array([x + w * 0.5, y + h * 0.5], dtype=np.float32)
+ #
+ # if (not self.test_mode) and np.random.rand() < 0.3:
+ # center += 0.4 * (np.random.rand(2) - 0.5) * [w, h]
+
+ if w > aspect_ratio * h:
+ h = w * 1.0 / aspect_ratio
+ elif w < aspect_ratio * h:
+ w = h * aspect_ratio
+
+ # pixel std is 200.0
+ scale = np.array([w / 200.0, h / 200.0], dtype=np.float32)
+ # padding to include proper amount of context
+ scale = scale * 1.25
+
+ return center, scale
+
+ def evaluate(self, outputs, res_folder, metric='PCK', **kwargs):
+ """Evaluate interhand2d keypoint results. The pose prediction results
+ will be saved in `${res_folder}/result_keypoints.json`.
+
+ Note:
+ batch_size: N
+ num_keypoints: K
+ heatmap height: H
+ heatmap width: W
+
+ Args:
+ outputs (list(preds, boxes, image_path, output_heatmap))
+ :preds (np.ndarray[N,K,3]): The first two dimensions are
+ coordinates, score is the third dimension of the array.
+ :boxes (np.ndarray[N,6]): [center[0], center[1], scale[0]
+ , scale[1],area, score]
+ :image_paths (list[str]): For example, ['C', 'a', 'p', 't',
+ 'u', 'r', 'e', '1', '2', '/', '0', '3', '9', '0', '_',
+ 'd', 'h', '_', 't', 'o', 'u', 'c', 'h', 'R', 'O', 'M',
+ '/', 'c', 'a', 'm', '4', '1', '0', '2', '0', '9', '/',
+ 'i', 'm', 'a', 'g', 'e', '6', '2', '4', '3', '4', '.',
+ 'j', 'p', 'g']
+ :output_heatmap (np.ndarray[N, K, H, W]): model outputs.
+
+ res_folder (str): Path of directory to save the results.
+ metric (str | list[str]): Metric to be performed.
+ Options: 'PCK', 'AUC', 'EPE'.
+
+ Returns:
+ dict: Evaluation results for evaluation metric.
+ """
+ metrics = metric if isinstance(metric, list) else [metric]
+ allowed_metrics = ['PCK', 'AUC', 'EPE']
+ for metric in metrics:
+ if metric not in allowed_metrics:
+ raise KeyError(f'metric {metric} is not supported')
+
+ res_file = os.path.join(res_folder, 'result_keypoints.json')
+
+ kpts = []
+ for output in outputs:
+ preds = output['preds']
+ boxes = output['boxes']
+ image_paths = output['image_paths']
+ bbox_ids = output['bbox_ids']
+
+ batch_size = len(image_paths)
+ for i in range(batch_size):
+ image_id = self.name2id[image_paths[i][len(self.img_prefix):]]
+
+ kpts.append({
+ 'keypoints': preds[i].tolist(),
+ 'center': boxes[i][0:2].tolist(),
+ 'scale': boxes[i][2:4].tolist(),
+ 'area': float(boxes[i][4]),
+ 'score': float(boxes[i][5]),
+ 'image_id': image_id,
+ 'bbox_id': bbox_ids[i]
+ })
+ kpts = self._sort_and_unique_bboxes(kpts)
+
+ self._write_keypoint_results(kpts, res_file)
+ info_str = self._report_metric(res_file, metrics)
+ name_value = OrderedDict(info_str)
+
+ return name_value
diff --git a/projects/pose_anything/datasets/datasets/mp100/test_base_dataset.py b/projects/pose_anything/datasets/datasets/mp100/test_base_dataset.py
new file mode 100644
index 0000000000..8fffc84239
--- /dev/null
+++ b/projects/pose_anything/datasets/datasets/mp100/test_base_dataset.py
@@ -0,0 +1,248 @@
+import copy
+from abc import ABCMeta, abstractmethod
+
+import json_tricks as json
+import numpy as np
+from mmcv.parallel import DataContainer as DC
+from torch.utils.data import Dataset
+
+from mmpose.core.evaluation.top_down_eval import (keypoint_auc, keypoint_epe,
+ keypoint_nme,
+ keypoint_pck_accuracy)
+from mmpose.datasets import DATASETS
+from mmpose.datasets.pipelines import Compose
+
+
+@DATASETS.register_module()
+class TestBaseDataset(Dataset, metaclass=ABCMeta):
+
+ def __init__(self,
+ ann_file,
+ img_prefix,
+ data_cfg,
+ pipeline,
+ test_mode=True,
+ PCK_threshold_list=[0.05, 0.1, 0.15, 0.2, 0.25]):
+ self.image_info = {}
+ self.ann_info = {}
+
+ self.annotations_path = ann_file
+ if not img_prefix.endswith('/'):
+ img_prefix = img_prefix + '/'
+ self.img_prefix = img_prefix
+ self.pipeline = pipeline
+ self.test_mode = test_mode
+ self.PCK_threshold_list = PCK_threshold_list
+
+ self.ann_info['image_size'] = np.array(data_cfg['image_size'])
+ self.ann_info['heatmap_size'] = np.array(data_cfg['heatmap_size'])
+ self.ann_info['num_joints'] = data_cfg['num_joints']
+
+ self.ann_info['flip_pairs'] = None
+
+ self.ann_info['inference_channel'] = data_cfg['inference_channel']
+ self.ann_info['num_output_channels'] = data_cfg['num_output_channels']
+ self.ann_info['dataset_channel'] = data_cfg['dataset_channel']
+
+ self.db = []
+ self.num_shots = 1
+ self.paired_samples = []
+ self.pipeline = Compose(self.pipeline)
+
+ @abstractmethod
+ def _get_db(self):
+ """Load dataset."""
+ raise NotImplementedError
+
+ @abstractmethod
+ def _select_kpt(self, obj, kpt_id):
+ """Select kpt."""
+ raise NotImplementedError
+
+ @abstractmethod
+ def evaluate(self, cfg, preds, output_dir, *args, **kwargs):
+ """Evaluate keypoint results."""
+ raise NotImplementedError
+
+ @staticmethod
+ def _write_keypoint_results(keypoints, res_file):
+ """Write results into a json file."""
+
+ with open(res_file, 'w') as f:
+ json.dump(keypoints, f, sort_keys=True, indent=4)
+
+ def _report_metric(self, res_file, metrics):
+ """Keypoint evaluation.
+
+ Args:
+ res_file (str): Json file stored prediction results.
+ metrics (str | list[str]): Metric to be performed.
+ Options: 'PCK', 'PCKh', 'AUC', 'EPE'.
+ pck_thr (float): PCK threshold, default as 0.2.
+ pckh_thr (float): PCKh threshold, default as 0.7.
+ auc_nor (float): AUC normalization factor, default as 30 pixel.
+
+ Returns:
+ List: Evaluation results for evaluation metric.
+ """
+ info_str = []
+
+ with open(res_file, 'r') as fin:
+ preds = json.load(fin)
+ assert len(preds) == len(self.paired_samples)
+
+ outputs = []
+ gts = []
+ masks = []
+ threshold_bbox = []
+ threshold_head_box = []
+
+ for pred, pair in zip(preds, self.paired_samples):
+ item = self.db[pair[-1]]
+ outputs.append(np.array(pred['keypoints'])[:, :-1])
+ gts.append(np.array(item['joints_3d'])[:, :-1])
+
+ mask_query = ((np.array(item['joints_3d_visible'])[:, 0]) > 0)
+ mask_sample = ((np.array(
+ self.db[pair[0]]['joints_3d_visible'])[:, 0]) > 0)
+ for id_s in pair[:-1]:
+ mask_sample = np.bitwise_and(
+ mask_sample,
+ ((np.array(self.db[id_s]['joints_3d_visible'])[:, 0]) > 0))
+ masks.append(np.bitwise_and(mask_query, mask_sample))
+
+ if 'PCK' in metrics or 'NME' in metrics or 'AUC' in metrics:
+ bbox = np.array(item['bbox'])
+ bbox_thr = np.max(bbox[2:])
+ threshold_bbox.append(np.array([bbox_thr, bbox_thr]))
+ if 'PCKh' in metrics:
+ head_box_thr = item['head_size']
+ threshold_head_box.append(
+ np.array([head_box_thr, head_box_thr]))
+
+ if 'PCK' in metrics:
+ pck_results = dict()
+ for pck_thr in self.PCK_threshold_list:
+ pck_results[pck_thr] = []
+
+ for (output, gt, mask, thr_bbox) in zip(outputs, gts, masks,
+ threshold_bbox):
+ for pck_thr in self.PCK_threshold_list:
+ _, pck, _ = keypoint_pck_accuracy(
+ np.expand_dims(output, 0), np.expand_dims(gt, 0),
+ np.expand_dims(mask, 0), pck_thr,
+ np.expand_dims(thr_bbox, 0))
+ pck_results[pck_thr].append(pck)
+
+ mPCK = 0
+ for pck_thr in self.PCK_threshold_list:
+ info_str.append(
+ ['PCK@' + str(pck_thr),
+ np.mean(pck_results[pck_thr])])
+ mPCK += np.mean(pck_results[pck_thr])
+ info_str.append(['mPCK', mPCK / len(self.PCK_threshold_list)])
+
+ if 'NME' in metrics:
+ nme_results = []
+ for (output, gt, mask, thr_bbox) in zip(outputs, gts, masks,
+ threshold_bbox):
+ nme = keypoint_nme(
+ np.expand_dims(output, 0), np.expand_dims(gt, 0),
+ np.expand_dims(mask, 0), np.expand_dims(thr_bbox, 0))
+ nme_results.append(nme)
+ info_str.append(['NME', np.mean(nme_results)])
+
+ if 'AUC' in metrics:
+ auc_results = []
+ for (output, gt, mask, thr_bbox) in zip(outputs, gts, masks,
+ threshold_bbox):
+ auc = keypoint_auc(
+ np.expand_dims(output, 0), np.expand_dims(gt, 0),
+ np.expand_dims(mask, 0), thr_bbox[0])
+ auc_results.append(auc)
+ info_str.append(['AUC', np.mean(auc_results)])
+
+ if 'EPE' in metrics:
+ epe_results = []
+ for (output, gt, mask) in zip(outputs, gts, masks):
+ epe = keypoint_epe(
+ np.expand_dims(output, 0), np.expand_dims(gt, 0),
+ np.expand_dims(mask, 0))
+ epe_results.append(epe)
+ info_str.append(['EPE', np.mean(epe_results)])
+ return info_str
+
+ def _merge_obj(self, Xs_list, Xq, idx):
+ """merge Xs_list and Xq.
+
+ :param Xs_list: N-shot samples X
+ :param Xq: query X
+ :param idx: id of paired_samples
+ :return: Xall
+ """
+ Xall = dict()
+ Xall['img_s'] = [Xs['img'] for Xs in Xs_list]
+ Xall['target_s'] = [Xs['target'] for Xs in Xs_list]
+ Xall['target_weight_s'] = [Xs['target_weight'] for Xs in Xs_list]
+ xs_img_metas = [Xs['img_metas'].data for Xs in Xs_list]
+
+ Xall['img_q'] = Xq['img']
+ Xall['target_q'] = Xq['target']
+ Xall['target_weight_q'] = Xq['target_weight']
+ xq_img_metas = Xq['img_metas'].data
+
+ img_metas = dict()
+ for key in xq_img_metas.keys():
+ img_metas['sample_' + key] = [
+ xs_img_meta[key] for xs_img_meta in xs_img_metas
+ ]
+ img_metas['query_' + key] = xq_img_metas[key]
+ img_metas['bbox_id'] = idx
+
+ Xall['img_metas'] = DC(img_metas, cpu_only=True)
+
+ return Xall
+
+ def __len__(self):
+ """Get the size of the dataset."""
+ return len(self.paired_samples)
+
+ def __getitem__(self, idx):
+ """Get the sample given index."""
+
+ pair_ids = self.paired_samples[idx] # [supported id * shots, query id]
+ assert len(pair_ids) == self.num_shots + 1
+ sample_id_list = pair_ids[:self.num_shots]
+ query_id = pair_ids[-1]
+
+ sample_obj_list = []
+ for sample_id in sample_id_list:
+ sample_obj = copy.deepcopy(self.db[sample_id])
+ sample_obj['ann_info'] = copy.deepcopy(self.ann_info)
+ sample_obj_list.append(sample_obj)
+
+ query_obj = copy.deepcopy(self.db[query_id])
+ query_obj['ann_info'] = copy.deepcopy(self.ann_info)
+
+ Xs_list = []
+ for sample_obj in sample_obj_list:
+ Xs = self.pipeline(
+ sample_obj
+ ) # dict with ['img', 'target', 'target_weight', 'img_metas'],
+ Xs_list.append(Xs) # Xs['target'] is of shape [100, map_h, map_w]
+ Xq = self.pipeline(query_obj)
+
+ Xall = self._merge_obj(Xs_list, Xq, idx)
+ Xall['skeleton'] = self.db[query_id]['skeleton']
+
+ return Xall
+
+ def _sort_and_unique_bboxes(self, kpts, key='bbox_id'):
+ """sort kpts and remove the repeated ones."""
+ kpts = sorted(kpts, key=lambda x: x[key])
+ num = len(kpts)
+ for i in range(num - 1, 0, -1):
+ if kpts[i][key] == kpts[i - 1][key]:
+ del kpts[i]
+
+ return kpts
diff --git a/projects/pose_anything/datasets/datasets/mp100/test_dataset.py b/projects/pose_anything/datasets/datasets/mp100/test_dataset.py
new file mode 100644
index 0000000000..ca0dc7ac6a
--- /dev/null
+++ b/projects/pose_anything/datasets/datasets/mp100/test_dataset.py
@@ -0,0 +1,347 @@
+import os
+import random
+from collections import OrderedDict
+
+import numpy as np
+from xtcocotools.coco import COCO
+
+from mmpose.datasets import DATASETS
+from .test_base_dataset import TestBaseDataset
+
+
+@DATASETS.register_module()
+class TestPoseDataset(TestBaseDataset):
+
+ def __init__(self,
+ ann_file,
+ img_prefix,
+ data_cfg,
+ pipeline,
+ valid_class_ids,
+ max_kpt_num=None,
+ num_shots=1,
+ num_queries=100,
+ num_episodes=1,
+ pck_threshold_list=[0.05, 0.1, 0.15, 0.20, 0.25],
+ test_mode=True):
+ super().__init__(
+ ann_file,
+ img_prefix,
+ data_cfg,
+ pipeline,
+ test_mode=test_mode,
+ PCK_threshold_list=pck_threshold_list)
+
+ self.ann_info['flip_pairs'] = []
+
+ self.ann_info['upper_body_ids'] = []
+ self.ann_info['lower_body_ids'] = []
+
+ self.ann_info['use_different_joint_weights'] = False
+ self.ann_info['joint_weights'] = np.array([
+ 1.,
+ ], dtype=np.float32).reshape((self.ann_info['num_joints'], 1))
+
+ self.coco = COCO(ann_file)
+
+ self.id2name, self.name2id = self._get_mapping_id_name(self.coco.imgs)
+ self.img_ids = self.coco.getImgIds()
+ self.classes = [
+ cat['name'] for cat in self.coco.loadCats(self.coco.getCatIds())
+ ]
+
+ self.num_classes = len(self.classes)
+ self._class_to_ind = dict(zip(self.classes, self.coco.getCatIds()))
+ self._ind_to_class = dict(zip(self.coco.getCatIds(), self.classes))
+
+ if valid_class_ids is not None: # None by default
+ self.valid_class_ids = valid_class_ids
+ else:
+ self.valid_class_ids = self.coco.getCatIds()
+ self.valid_classes = [
+ self._ind_to_class[ind] for ind in self.valid_class_ids
+ ]
+
+ self.cats = self.coco.cats
+ self.max_kpt_num = max_kpt_num
+
+ # Also update self.cat2obj
+ self.db = self._get_db()
+
+ self.num_shots = num_shots
+
+ if not test_mode:
+ # Update every training epoch
+ self.random_paired_samples()
+ else:
+ self.num_queries = num_queries
+ self.num_episodes = num_episodes
+ self.make_paired_samples()
+
+ def random_paired_samples(self):
+ num_datas = [
+ len(self.cat2obj[self._class_to_ind[cls]])
+ for cls in self.valid_classes
+ ]
+
+ # balance the dataset
+ max_num_data = max(num_datas)
+
+ all_samples = []
+ for cls in self.valid_class_ids:
+ for i in range(max_num_data):
+ shot = random.sample(self.cat2obj[cls], self.num_shots + 1)
+ all_samples.append(shot)
+
+ self.paired_samples = np.array(all_samples)
+ np.random.shuffle(self.paired_samples)
+
+ def make_paired_samples(self):
+ random.seed(1)
+ np.random.seed(0)
+
+ all_samples = []
+ for cls in self.valid_class_ids:
+ for _ in range(self.num_episodes):
+ shots = random.sample(self.cat2obj[cls],
+ self.num_shots + self.num_queries)
+ sample_ids = shots[:self.num_shots]
+ query_ids = shots[self.num_shots:]
+ for query_id in query_ids:
+ all_samples.append(sample_ids + [query_id])
+
+ self.paired_samples = np.array(all_samples)
+
+ def _select_kpt(self, obj, kpt_id):
+ obj['joints_3d'] = obj['joints_3d'][kpt_id:kpt_id + 1]
+ obj['joints_3d_visible'] = obj['joints_3d_visible'][kpt_id:kpt_id + 1]
+ obj['kpt_id'] = kpt_id
+
+ return obj
+
+ @staticmethod
+ def _get_mapping_id_name(imgs):
+ """
+ Args:
+ imgs (dict): dict of image info.
+
+ Returns:
+ tuple: Image name & id mapping dicts.
+
+ - id2name (dict): Mapping image id to name.
+ - name2id (dict): Mapping image name to id.
+ """
+ id2name = {}
+ name2id = {}
+ for image_id, image in imgs.items():
+ file_name = image['file_name']
+ id2name[image_id] = file_name
+ name2id[file_name] = image_id
+
+ return id2name, name2id
+
+ def _get_db(self):
+ """Ground truth bbox and keypoints."""
+ self.obj_id = 0
+
+ self.cat2obj = {}
+ for i in self.coco.getCatIds():
+ self.cat2obj.update({i: []})
+
+ gt_db = []
+ for img_id in self.img_ids:
+ gt_db.extend(self._load_coco_keypoint_annotation_kernel(img_id))
+ return gt_db
+
+ def _load_coco_keypoint_annotation_kernel(self, img_id):
+ """load annotation from COCOAPI.
+
+ Note:
+ bbox:[x1, y1, w, h]
+ Args:
+ img_id: coco image id
+ Returns:
+ dict: db entry
+ """
+ img_ann = self.coco.loadImgs(img_id)[0]
+ width = img_ann['width']
+ height = img_ann['height']
+
+ ann_ids = self.coco.getAnnIds(imgIds=img_id, iscrowd=False)
+ objs = self.coco.loadAnns(ann_ids)
+
+ # sanitize bboxes
+ valid_objs = []
+ for obj in objs:
+ if 'bbox' not in obj:
+ continue
+ x, y, w, h = obj['bbox']
+ x1 = max(0, x)
+ y1 = max(0, y)
+ x2 = min(width - 1, x1 + max(0, w - 1))
+ y2 = min(height - 1, y1 + max(0, h - 1))
+ if ('area' not in obj or obj['area'] > 0) and x2 > x1 and y2 > y1:
+ obj['clean_bbox'] = [x1, y1, x2 - x1, y2 - y1]
+ valid_objs.append(obj)
+ objs = valid_objs
+
+ bbox_id = 0
+ rec = []
+ for obj in objs:
+ if 'keypoints' not in obj:
+ continue
+ if max(obj['keypoints']) == 0:
+ continue
+ if 'num_keypoints' in obj and obj['num_keypoints'] == 0:
+ continue
+
+ category_id = obj['category_id']
+ # the number of keypoint for this specific category
+ cat_kpt_num = int(len(obj['keypoints']) / 3)
+ if self.max_kpt_num is None:
+ kpt_num = cat_kpt_num
+ else:
+ kpt_num = self.max_kpt_num
+
+ joints_3d = np.zeros((kpt_num, 3), dtype=np.float32)
+ joints_3d_visible = np.zeros((kpt_num, 3), dtype=np.float32)
+
+ keypoints = np.array(obj['keypoints']).reshape(-1, 3)
+ joints_3d[:cat_kpt_num, :2] = keypoints[:, :2]
+ joints_3d_visible[:cat_kpt_num, :2] = np.minimum(
+ 1, keypoints[:, 2:3])
+
+ center, scale = self._xywh2cs(*obj['clean_bbox'][:4])
+
+ image_file = os.path.join(self.img_prefix, self.id2name[img_id])
+
+ self.cat2obj[category_id].append(self.obj_id)
+
+ rec.append({
+ 'image_file':
+ image_file,
+ 'center':
+ center,
+ 'scale':
+ scale,
+ 'rotation':
+ 0,
+ 'bbox':
+ obj['clean_bbox'][:4],
+ 'bbox_score':
+ 1,
+ 'joints_3d':
+ joints_3d,
+ 'joints_3d_visible':
+ joints_3d_visible,
+ 'category_id':
+ category_id,
+ 'cat_kpt_num':
+ cat_kpt_num,
+ 'bbox_id':
+ self.obj_id,
+ 'skeleton':
+ self.coco.cats[obj['category_id']]['skeleton'],
+ })
+ bbox_id = bbox_id + 1
+ self.obj_id += 1
+
+ return rec
+
+ def _xywh2cs(self, x, y, w, h):
+ """This encodes bbox(x,y,w,w) into (center, scale)
+
+ Args:
+ x, y, w, h
+
+ Returns:
+ tuple: A tuple containing center and scale.
+
+ - center (np.ndarray[float32](2,)): center of the bbox (x, y).
+ - scale (np.ndarray[float32](2,)): scale of the bbox w & h.
+ """
+ aspect_ratio = self.ann_info['image_size'][0] / self.ann_info[
+ 'image_size'][1]
+ center = np.array([x + w * 0.5, y + h * 0.5], dtype=np.float32)
+ #
+ # if (not self.test_mode) and np.random.rand() < 0.3:
+ # center += 0.4 * (np.random.rand(2) - 0.5) * [w, h]
+
+ if w > aspect_ratio * h:
+ h = w * 1.0 / aspect_ratio
+ elif w < aspect_ratio * h:
+ w = h * aspect_ratio
+
+ # pixel std is 200.0
+ scale = np.array([w / 200.0, h / 200.0], dtype=np.float32)
+ # padding to include proper amount of context
+ scale = scale * 1.25
+
+ return center, scale
+
+ def evaluate(self, outputs, res_folder, metric='PCK', **kwargs):
+ """Evaluate interhand2d keypoint results. The pose prediction results
+ will be saved in `${res_folder}/result_keypoints.json`.
+
+ Note:
+ batch_size: N
+ num_keypoints: K
+ heatmap height: H
+ heatmap width: W
+
+ Args:
+ outputs (list(preds, boxes, image_path, output_heatmap))
+ :preds (np.ndarray[N,K,3]): The first two dimensions are
+ coordinates, score is the third dimension of the array.
+ :boxes (np.ndarray[N,6]): [center[0], center[1], scale[0]
+ , scale[1],area, score]
+ :image_paths (list[str]): For example, ['C', 'a', 'p', 't',
+ 'u', 'r', 'e', '1', '2', '/', '0', '3', '9', '0', '_',
+ 'd', 'h', '_', 't', 'o', 'u', 'c', 'h', 'R', 'O', 'M',
+ '/', 'c', 'a', 'm', '4', '1', '0', '2', '0', '9', '/',
+ 'i', 'm', 'a', 'g', 'e', '6', '2', '4', '3', '4', '.',
+ 'j', 'p', 'g']
+ :output_heatmap (np.ndarray[N, K, H, W]): model outputs.
+
+ res_folder (str): Path of directory to save the results.
+ metric (str | list[str]): Metric to be performed.
+ Options: 'PCK', 'AUC', 'EPE'.
+
+ Returns:
+ dict: Evaluation results for evaluation metric.
+ """
+ metrics = metric if isinstance(metric, list) else [metric]
+ allowed_metrics = ['PCK', 'AUC', 'EPE', 'NME']
+ for metric in metrics:
+ if metric not in allowed_metrics:
+ raise KeyError(f'metric {metric} is not supported')
+
+ res_file = os.path.join(res_folder, 'result_keypoints.json')
+
+ kpts = []
+ for output in outputs:
+ preds = output['preds']
+ boxes = output['boxes']
+ image_paths = output['image_paths']
+ bbox_ids = output['bbox_ids']
+
+ batch_size = len(image_paths)
+ for i in range(batch_size):
+ image_id = self.name2id[image_paths[i][len(self.img_prefix):]]
+
+ kpts.append({
+ 'keypoints': preds[i].tolist(),
+ 'center': boxes[i][0:2].tolist(),
+ 'scale': boxes[i][2:4].tolist(),
+ 'area': float(boxes[i][4]),
+ 'score': float(boxes[i][5]),
+ 'image_id': image_id,
+ 'bbox_id': bbox_ids[i]
+ })
+ kpts = self._sort_and_unique_bboxes(kpts)
+
+ self._write_keypoint_results(kpts, res_file)
+ info_str = self._report_metric(res_file, metrics)
+ name_value = OrderedDict(info_str)
+
+ return name_value
diff --git a/projects/pose_anything/datasets/datasets/mp100/transformer_base_dataset.py b/projects/pose_anything/datasets/datasets/mp100/transformer_base_dataset.py
new file mode 100644
index 0000000000..9433596a0e
--- /dev/null
+++ b/projects/pose_anything/datasets/datasets/mp100/transformer_base_dataset.py
@@ -0,0 +1,209 @@
+import copy
+from abc import ABCMeta, abstractmethod
+
+import json_tricks as json
+import numpy as np
+from mmcv.parallel import DataContainer as DC
+from mmengine.dataset import Compose
+from torch.utils.data import Dataset
+
+from mmpose.core.evaluation.top_down_eval import keypoint_pck_accuracy
+from mmpose.datasets import DATASETS
+
+
+@DATASETS.register_module()
+class TransformerBaseDataset(Dataset, metaclass=ABCMeta):
+
+ def __init__(self,
+ ann_file,
+ img_prefix,
+ data_cfg,
+ pipeline,
+ test_mode=False):
+ self.image_info = {}
+ self.ann_info = {}
+
+ self.annotations_path = ann_file
+ if not img_prefix.endswith('/'):
+ img_prefix = img_prefix + '/'
+ self.img_prefix = img_prefix
+ self.pipeline = pipeline
+ self.test_mode = test_mode
+
+ self.ann_info['image_size'] = np.array(data_cfg['image_size'])
+ self.ann_info['heatmap_size'] = np.array(data_cfg['heatmap_size'])
+ self.ann_info['num_joints'] = data_cfg['num_joints']
+
+ self.ann_info['flip_pairs'] = None
+
+ self.ann_info['inference_channel'] = data_cfg['inference_channel']
+ self.ann_info['num_output_channels'] = data_cfg['num_output_channels']
+ self.ann_info['dataset_channel'] = data_cfg['dataset_channel']
+
+ self.db = []
+ self.num_shots = 1
+ self.paired_samples = []
+ self.pipeline = Compose(self.pipeline)
+
+ @abstractmethod
+ def _get_db(self):
+ """Load dataset."""
+ raise NotImplementedError
+
+ @abstractmethod
+ def _select_kpt(self, obj, kpt_id):
+ """Select kpt."""
+ raise NotImplementedError
+
+ @abstractmethod
+ def evaluate(self, cfg, preds, output_dir, *args, **kwargs):
+ """Evaluate keypoint results."""
+ raise NotImplementedError
+
+ @staticmethod
+ def _write_keypoint_results(keypoints, res_file):
+ """Write results into a json file."""
+
+ with open(res_file, 'w') as f:
+ json.dump(keypoints, f, sort_keys=True, indent=4)
+
+ def _report_metric(self,
+ res_file,
+ metrics,
+ pck_thr=0.2,
+ pckh_thr=0.7,
+ auc_nor=30):
+ """Keypoint evaluation.
+
+ Args:
+ res_file (str): Json file stored prediction results.
+ metrics (str | list[str]): Metric to be performed.
+ Options: 'PCK', 'PCKh', 'AUC', 'EPE'.
+ pck_thr (float): PCK threshold, default as 0.2.
+ pckh_thr (float): PCKh threshold, default as 0.7.
+ auc_nor (float): AUC normalization factor, default as 30 pixel.
+
+ Returns:
+ List: Evaluation results for evaluation metric.
+ """
+ info_str = []
+
+ with open(res_file, 'r') as fin:
+ preds = json.load(fin)
+ assert len(preds) == len(self.paired_samples)
+
+ outputs = []
+ gts = []
+ masks = []
+ threshold_bbox = []
+ threshold_head_box = []
+
+ for pred, pair in zip(preds, self.paired_samples):
+ item = self.db[pair[-1]]
+ outputs.append(np.array(pred['keypoints'])[:, :-1])
+ gts.append(np.array(item['joints_3d'])[:, :-1])
+
+ mask_query = ((np.array(item['joints_3d_visible'])[:, 0]) > 0)
+ mask_sample = ((np.array(
+ self.db[pair[0]]['joints_3d_visible'])[:, 0]) > 0)
+ for id_s in pair[:-1]:
+ mask_sample = np.bitwise_and(
+ mask_sample,
+ ((np.array(self.db[id_s]['joints_3d_visible'])[:, 0]) > 0))
+ masks.append(np.bitwise_and(mask_query, mask_sample))
+
+ if 'PCK' in metrics:
+ bbox = np.array(item['bbox'])
+ bbox_thr = np.max(bbox[2:])
+ threshold_bbox.append(np.array([bbox_thr, bbox_thr]))
+ if 'PCKh' in metrics:
+ head_box_thr = item['head_size']
+ threshold_head_box.append(
+ np.array([head_box_thr, head_box_thr]))
+
+ if 'PCK' in metrics:
+ pck_avg = []
+ for (output, gt, mask, thr_bbox) in zip(outputs, gts, masks,
+ threshold_bbox):
+ _, pck, _ = keypoint_pck_accuracy(
+ np.expand_dims(output, 0), np.expand_dims(gt, 0),
+ np.expand_dims(mask, 0), pck_thr,
+ np.expand_dims(thr_bbox, 0))
+ pck_avg.append(pck)
+ info_str.append(('PCK', np.mean(pck_avg)))
+
+ return info_str
+
+ def _merge_obj(self, Xs_list, Xq, idx):
+ """merge Xs_list and Xq.
+
+ :param Xs_list: N-shot samples X
+ :param Xq: query X
+ :param idx: id of paired_samples
+ :return: Xall
+ """
+ Xall = dict()
+ Xall['img_s'] = [Xs['img'] for Xs in Xs_list]
+ Xall['target_s'] = [Xs['target'] for Xs in Xs_list]
+ Xall['target_weight_s'] = [Xs['target_weight'] for Xs in Xs_list]
+ xs_img_metas = [Xs['img_metas'].data for Xs in Xs_list]
+
+ Xall['img_q'] = Xq['img']
+ Xall['target_q'] = Xq['target']
+ Xall['target_weight_q'] = Xq['target_weight']
+ xq_img_metas = Xq['img_metas'].data
+
+ img_metas = dict()
+ for key in xq_img_metas.keys():
+ img_metas['sample_' + key] = [
+ xs_img_meta[key] for xs_img_meta in xs_img_metas
+ ]
+ img_metas['query_' + key] = xq_img_metas[key]
+ img_metas['bbox_id'] = idx
+
+ Xall['img_metas'] = DC(img_metas, cpu_only=True)
+
+ return Xall
+
+ def __len__(self):
+ """Get the size of the dataset."""
+ return len(self.paired_samples)
+
+ def __getitem__(self, idx):
+ """Get the sample given index."""
+
+ pair_ids = self.paired_samples[idx] # [supported id * shots, query id]
+ assert len(pair_ids) == self.num_shots + 1
+ sample_id_list = pair_ids[:self.num_shots]
+ query_id = pair_ids[-1]
+
+ sample_obj_list = []
+ for sample_id in sample_id_list:
+ sample_obj = copy.deepcopy(self.db[sample_id])
+ sample_obj['ann_info'] = copy.deepcopy(self.ann_info)
+ sample_obj_list.append(sample_obj)
+
+ query_obj = copy.deepcopy(self.db[query_id])
+ query_obj['ann_info'] = copy.deepcopy(self.ann_info)
+
+ Xs_list = []
+ for sample_obj in sample_obj_list:
+ Xs = self.pipeline(
+ sample_obj
+ ) # dict with ['img', 'target', 'target_weight', 'img_metas'],
+ Xs_list.append(Xs) # Xs['target'] is of shape [100, map_h, map_w]
+ Xq = self.pipeline(query_obj)
+
+ Xall = self._merge_obj(Xs_list, Xq, idx)
+ Xall['skeleton'] = self.db[query_id]['skeleton']
+ return Xall
+
+ def _sort_and_unique_bboxes(self, kpts, key='bbox_id'):
+ """sort kpts and remove the repeated ones."""
+ kpts = sorted(kpts, key=lambda x: x[key])
+ num = len(kpts)
+ for i in range(num - 1, 0, -1):
+ if kpts[i][key] == kpts[i - 1][key]:
+ del kpts[i]
+
+ return kpts
diff --git a/projects/pose_anything/datasets/datasets/mp100/transformer_dataset.py b/projects/pose_anything/datasets/datasets/mp100/transformer_dataset.py
new file mode 100644
index 0000000000..3244f2a0d7
--- /dev/null
+++ b/projects/pose_anything/datasets/datasets/mp100/transformer_dataset.py
@@ -0,0 +1,342 @@
+import os
+import random
+from collections import OrderedDict
+
+import numpy as np
+from xtcocotools.coco import COCO
+
+from mmpose.datasets import DATASETS
+from .transformer_base_dataset import TransformerBaseDataset
+
+
+@DATASETS.register_module()
+class TransformerPoseDataset(TransformerBaseDataset):
+
+ def __init__(self,
+ ann_file,
+ img_prefix,
+ data_cfg,
+ pipeline,
+ valid_class_ids,
+ max_kpt_num=None,
+ num_shots=1,
+ num_queries=100,
+ num_episodes=1,
+ test_mode=False):
+ super().__init__(
+ ann_file, img_prefix, data_cfg, pipeline, test_mode=test_mode)
+
+ self.ann_info['flip_pairs'] = []
+
+ self.ann_info['upper_body_ids'] = []
+ self.ann_info['lower_body_ids'] = []
+
+ self.ann_info['use_different_joint_weights'] = False
+ self.ann_info['joint_weights'] = np.array([
+ 1.,
+ ], dtype=np.float32).reshape((self.ann_info['num_joints'], 1))
+
+ self.coco = COCO(ann_file)
+
+ self.id2name, self.name2id = self._get_mapping_id_name(self.coco.imgs)
+ self.img_ids = self.coco.getImgIds()
+ self.classes = [
+ cat['name'] for cat in self.coco.loadCats(self.coco.getCatIds())
+ ]
+
+ self.num_classes = len(self.classes)
+ self._class_to_ind = dict(zip(self.classes, self.coco.getCatIds()))
+ self._ind_to_class = dict(zip(self.coco.getCatIds(), self.classes))
+
+ if valid_class_ids is not None: # None by default
+ self.valid_class_ids = valid_class_ids
+ else:
+ self.valid_class_ids = self.coco.getCatIds()
+ self.valid_classes = [
+ self._ind_to_class[ind] for ind in self.valid_class_ids
+ ]
+
+ self.cats = self.coco.cats
+ self.max_kpt_num = max_kpt_num
+
+ # Also update self.cat2obj
+ self.db = self._get_db()
+
+ self.num_shots = num_shots
+
+ if not test_mode:
+ # Update every training epoch
+ self.random_paired_samples()
+ else:
+ self.num_queries = num_queries
+ self.num_episodes = num_episodes
+ self.make_paired_samples()
+
+ def random_paired_samples(self):
+ num_datas = [
+ len(self.cat2obj[self._class_to_ind[cls]])
+ for cls in self.valid_classes
+ ]
+
+ # balance the dataset
+ max_num_data = max(num_datas)
+
+ all_samples = []
+ for cls in self.valid_class_ids:
+ for i in range(max_num_data):
+ shot = random.sample(self.cat2obj[cls], self.num_shots + 1)
+ all_samples.append(shot)
+
+ self.paired_samples = np.array(all_samples)
+ np.random.shuffle(self.paired_samples)
+
+ def make_paired_samples(self):
+ random.seed(1)
+ np.random.seed(0)
+
+ all_samples = []
+ for cls in self.valid_class_ids:
+ for _ in range(self.num_episodes):
+ shots = random.sample(self.cat2obj[cls],
+ self.num_shots + self.num_queries)
+ sample_ids = shots[:self.num_shots]
+ query_ids = shots[self.num_shots:]
+ for query_id in query_ids:
+ all_samples.append(sample_ids + [query_id])
+
+ self.paired_samples = np.array(all_samples)
+
+ def _select_kpt(self, obj, kpt_id):
+ obj['joints_3d'] = obj['joints_3d'][kpt_id:kpt_id + 1]
+ obj['joints_3d_visible'] = obj['joints_3d_visible'][kpt_id:kpt_id + 1]
+ obj['kpt_id'] = kpt_id
+
+ return obj
+
+ @staticmethod
+ def _get_mapping_id_name(imgs):
+ """
+ Args:
+ imgs (dict): dict of image info.
+
+ Returns:
+ tuple: Image name & id mapping dicts.
+
+ - id2name (dict): Mapping image id to name.
+ - name2id (dict): Mapping image name to id.
+ """
+ id2name = {}
+ name2id = {}
+ for image_id, image in imgs.items():
+ file_name = image['file_name']
+ id2name[image_id] = file_name
+ name2id[file_name] = image_id
+
+ return id2name, name2id
+
+ def _get_db(self):
+ """Ground truth bbox and keypoints."""
+ self.obj_id = 0
+
+ self.cat2obj = {}
+ for i in self.coco.getCatIds():
+ self.cat2obj.update({i: []})
+
+ gt_db = []
+ for img_id in self.img_ids:
+ gt_db.extend(self._load_coco_keypoint_annotation_kernel(img_id))
+
+ return gt_db
+
+ def _load_coco_keypoint_annotation_kernel(self, img_id):
+ """load annotation from COCOAPI.
+
+ Note:
+ bbox:[x1, y1, w, h]
+ Args:
+ img_id: coco image id
+ Returns:
+ dict: db entry
+ """
+ img_ann = self.coco.loadImgs(img_id)[0]
+ width = img_ann['width']
+ height = img_ann['height']
+
+ ann_ids = self.coco.getAnnIds(imgIds=img_id, iscrowd=False)
+ objs = self.coco.loadAnns(ann_ids)
+
+ # sanitize bboxes
+ valid_objs = []
+ for obj in objs:
+ if 'bbox' not in obj:
+ continue
+ x, y, w, h = obj['bbox']
+ x1 = max(0, x)
+ y1 = max(0, y)
+ x2 = min(width - 1, x1 + max(0, w - 1))
+ y2 = min(height - 1, y1 + max(0, h - 1))
+ if ('area' not in obj or obj['area'] > 0) and x2 > x1 and y2 > y1:
+ obj['clean_bbox'] = [x1, y1, x2 - x1, y2 - y1]
+ valid_objs.append(obj)
+ objs = valid_objs
+
+ bbox_id = 0
+ rec = []
+ for obj in objs:
+ if 'keypoints' not in obj:
+ continue
+ if max(obj['keypoints']) == 0:
+ continue
+ if 'num_keypoints' in obj and obj['num_keypoints'] == 0:
+ continue
+
+ category_id = obj['category_id']
+ # the number of keypoint for this specific category
+ cat_kpt_num = int(len(obj['keypoints']) / 3)
+ if self.max_kpt_num is None:
+ kpt_num = cat_kpt_num
+ else:
+ kpt_num = self.max_kpt_num
+
+ joints_3d = np.zeros((kpt_num, 3), dtype=np.float32)
+ joints_3d_visible = np.zeros((kpt_num, 3), dtype=np.float32)
+
+ keypoints = np.array(obj['keypoints']).reshape(-1, 3)
+ joints_3d[:cat_kpt_num, :2] = keypoints[:, :2]
+ joints_3d_visible[:cat_kpt_num, :2] = np.minimum(
+ 1, keypoints[:, 2:3])
+
+ center, scale = self._xywh2cs(*obj['clean_bbox'][:4])
+
+ image_file = os.path.join(self.img_prefix, self.id2name[img_id])
+ if os.path.exists(image_file):
+ self.cat2obj[category_id].append(self.obj_id)
+
+ rec.append({
+ 'image_file':
+ image_file,
+ 'center':
+ center,
+ 'scale':
+ scale,
+ 'rotation':
+ 0,
+ 'bbox':
+ obj['clean_bbox'][:4],
+ 'bbox_score':
+ 1,
+ 'joints_3d':
+ joints_3d,
+ 'joints_3d_visible':
+ joints_3d_visible,
+ 'category_id':
+ category_id,
+ 'cat_kpt_num':
+ cat_kpt_num,
+ 'bbox_id':
+ self.obj_id,
+ 'skeleton':
+ self.coco.cats[obj['category_id']]['skeleton'],
+ })
+ bbox_id = bbox_id + 1
+ self.obj_id += 1
+
+ return rec
+
+ def _xywh2cs(self, x, y, w, h):
+ """This encodes bbox(x,y,w,w) into (center, scale)
+
+ Args:
+ x, y, w, h
+
+ Returns:
+ tuple: A tuple containing center and scale.
+
+ - center (np.ndarray[float32](2,)): center of the bbox (x, y).
+ - scale (np.ndarray[float32](2,)): scale of the bbox w & h.
+ """
+ aspect_ratio = self.ann_info['image_size'][0] / self.ann_info[
+ 'image_size'][1]
+ center = np.array([x + w * 0.5, y + h * 0.5], dtype=np.float32)
+ #
+ # if (not self.test_mode) and np.random.rand() < 0.3:
+ # center += 0.4 * (np.random.rand(2) - 0.5) * [w, h]
+
+ if w > aspect_ratio * h:
+ h = w * 1.0 / aspect_ratio
+ elif w < aspect_ratio * h:
+ w = h * aspect_ratio
+
+ # pixel std is 200.0
+ scale = np.array([w / 200.0, h / 200.0], dtype=np.float32)
+ # padding to include proper amount of context
+ scale = scale * 1.25
+
+ return center, scale
+
+ def evaluate(self, outputs, res_folder, metric='PCK', **kwargs):
+ """Evaluate interhand2d keypoint results. The pose prediction results
+ will be saved in `${res_folder}/result_keypoints.json`.
+
+ Note:
+ batch_size: N
+ num_keypoints: K
+ heatmap height: H
+ heatmap width: W
+
+ Args:
+ outputs (list(preds, boxes, image_path, output_heatmap))
+ :preds (np.ndarray[N,K,3]): The first two dimensions are
+ coordinates, score is the third dimension of the array.
+ :boxes (np.ndarray[N,6]): [center[0], center[1], scale[0]
+ , scale[1],area, score]
+ :image_paths (list[str]): For example, ['C', 'a', 'p', 't',
+ 'u', 'r', 'e', '1', '2', '/', '0', '3', '9', '0', '_',
+ 'd', 'h', '_', 't', 'o', 'u', 'c', 'h', 'R', 'O', 'M',
+ '/', 'c', 'a', 'm', '4', '1', '0', '2', '0', '9', '/',
+ 'i', 'm', 'a', 'g', 'e', '6', '2', '4', '3', '4', '.',
+ 'j', 'p', 'g']
+ :output_heatmap (np.ndarray[N, K, H, W]): model outputs.
+
+ res_folder (str): Path of directory to save the results.
+ metric (str | list[str]): Metric to be performed.
+ Options: 'PCK', 'AUC', 'EPE'.
+
+ Returns:
+ dict: Evaluation results for evaluation metric.
+ """
+ metrics = metric if isinstance(metric, list) else [metric]
+ allowed_metrics = ['PCK', 'AUC', 'EPE', 'NME']
+ for metric in metrics:
+ if metric not in allowed_metrics:
+ raise KeyError(f'metric {metric} is not supported')
+
+ res_file = os.path.join(res_folder, 'result_keypoints.json')
+
+ kpts = []
+ for output in outputs:
+ preds = output['preds']
+ boxes = output['boxes']
+ image_paths = output['image_paths']
+ bbox_ids = output['bbox_ids']
+
+ batch_size = len(image_paths)
+ for i in range(batch_size):
+ image_id = self.name2id[image_paths[i][len(self.img_prefix):]]
+
+ kpts.append({
+ 'keypoints': preds[i].tolist(),
+ 'center': boxes[i][0:2].tolist(),
+ 'scale': boxes[i][2:4].tolist(),
+ 'area': float(boxes[i][4]),
+ 'score': float(boxes[i][5]),
+ 'image_id': image_id,
+ 'bbox_id': bbox_ids[i]
+ })
+ kpts = self._sort_and_unique_bboxes(kpts)
+
+ self._write_keypoint_results(kpts, res_file)
+ info_str = self._report_metric(res_file, metrics)
+ name_value = OrderedDict(info_str)
+
+ return name_value
diff --git a/projects/pose_anything/datasets/pipelines/__init__.py b/projects/pose_anything/datasets/pipelines/__init__.py
new file mode 100644
index 0000000000..762593d15b
--- /dev/null
+++ b/projects/pose_anything/datasets/pipelines/__init__.py
@@ -0,0 +1,3 @@
+from .top_down_transform import TopDownGenerateTargetFewShot
+
+__all__ = ['TopDownGenerateTargetFewShot']
diff --git a/projects/pose_anything/datasets/pipelines/post_transforms.py b/projects/pose_anything/datasets/pipelines/post_transforms.py
new file mode 100644
index 0000000000..e69de29bb2
diff --git a/projects/pose_anything/datasets/pipelines/top_down_transform.py b/projects/pose_anything/datasets/pipelines/top_down_transform.py
new file mode 100644
index 0000000000..a0c0839307
--- /dev/null
+++ b/projects/pose_anything/datasets/pipelines/top_down_transform.py
@@ -0,0 +1,317 @@
+import numpy as np
+
+
+class TopDownGenerateTargetFewShot:
+ """Generate the target heatmap.
+
+ Required keys: 'joints_3d', 'joints_3d_visible', 'ann_info'.
+ Modified keys: 'target', and 'target_weight'.
+
+ Args:
+ sigma: Sigma of heatmap gaussian for 'MSRA' approach.
+ kernel: Kernel of heatmap gaussian for 'Megvii' approach.
+ encoding (str): Approach to generate target heatmaps.
+ Currently supported approaches: 'MSRA', 'Megvii', 'UDP'.
+ Default:'MSRA'
+
+ unbiased_encoding (bool): Option to use unbiased
+ encoding methods.
+ Paper ref: Zhang et al. Distribution-Aware Coordinate
+ Representation for Human Pose Estimation (CVPR 2020).
+ keypoint_pose_distance: Keypoint pose distance for UDP.
+ Paper ref: Huang et al. The Devil is in the Details: Delving into
+ Unbiased Data Processing for Human Pose Estimation (CVPR 2020).
+ target_type (str): supported targets: 'GaussianHeatMap',
+ 'CombinedTarget'. Default:'GaussianHeatMap'
+ CombinedTarget: The combination of classification target
+ (response map) and regression target (offset map).
+ Paper ref: Huang et al. The Devil is in the Details: Delving into
+ Unbiased Data Processing for Human Pose Estimation (CVPR 2020).
+ """
+
+ def __init__(self,
+ sigma=2,
+ kernel=(11, 11),
+ valid_radius_factor=0.0546875,
+ target_type='GaussianHeatMap',
+ encoding='MSRA',
+ unbiased_encoding=False):
+ self.sigma = sigma
+ self.unbiased_encoding = unbiased_encoding
+ self.kernel = kernel
+ self.valid_radius_factor = valid_radius_factor
+ self.target_type = target_type
+ self.encoding = encoding
+
+ def _msra_generate_target(self, cfg, joints_3d, joints_3d_visible, sigma):
+ """Generate the target heatmap via "MSRA" approach.
+
+ Args:
+ cfg (dict): data config
+ joints_3d: np.ndarray ([num_joints, 3])
+ joints_3d_visible: np.ndarray ([num_joints, 3])
+ sigma: Sigma of heatmap gaussian
+ Returns:
+ tuple: A tuple containing targets.
+
+ - target: Target heatmaps.
+ - target_weight: (1: visible, 0: invisible)
+ """
+ num_joints = len(joints_3d)
+ image_size = cfg['image_size']
+ W, H = cfg['heatmap_size']
+ joint_weights = cfg['joint_weights']
+ use_different_joint_weights = cfg['use_different_joint_weights']
+ assert not use_different_joint_weights
+
+ target_weight = np.zeros((num_joints, 1), dtype=np.float32)
+ target = np.zeros((num_joints, H, W), dtype=np.float32)
+
+ # 3-sigma rule
+ tmp_size = sigma * 3
+
+ if self.unbiased_encoding:
+ for joint_id in range(num_joints):
+ target_weight[joint_id] = joints_3d_visible[joint_id, 0]
+
+ feat_stride = image_size / [W, H]
+ mu_x = joints_3d[joint_id][0] / feat_stride[0]
+ mu_y = joints_3d[joint_id][1] / feat_stride[1]
+ # Check that any part of the gaussian is in-bounds
+ ul = [mu_x - tmp_size, mu_y - tmp_size]
+ br = [mu_x + tmp_size + 1, mu_y + tmp_size + 1]
+ if ul[0] >= W or ul[1] >= H or br[0] < 0 or br[1] < 0:
+ target_weight[joint_id] = 0
+
+ if target_weight[joint_id] == 0:
+ continue
+
+ x = np.arange(0, W, 1, np.float32)
+ y = np.arange(0, H, 1, np.float32)
+ y = y[:, None]
+
+ if target_weight[joint_id] > 0.5:
+ target[joint_id] = np.exp(-((x - mu_x)**2 +
+ (y - mu_y)**2) /
+ (2 * sigma**2))
+ else:
+ for joint_id in range(num_joints):
+ target_weight[joint_id] = joints_3d_visible[joint_id, 0]
+
+ feat_stride = image_size / [W, H]
+ mu_x = int(joints_3d[joint_id][0] / feat_stride[0] + 0.5)
+ mu_y = int(joints_3d[joint_id][1] / feat_stride[1] + 0.5)
+ # Check that any part of the gaussian is in-bounds
+ ul = [int(mu_x - tmp_size), int(mu_y - tmp_size)]
+ br = [int(mu_x + tmp_size + 1), int(mu_y + tmp_size + 1)]
+ if ul[0] >= W or ul[1] >= H or br[0] < 0 or br[1] < 0:
+ target_weight[joint_id] = 0
+
+ if target_weight[joint_id] > 0.5:
+ size = 2 * tmp_size + 1
+ x = np.arange(0, size, 1, np.float32)
+ y = x[:, None]
+ x0 = y0 = size // 2
+ # The gaussian is not normalized,
+ # we want the center value to equal 1
+ g = np.exp(-((x - x0)**2 + (y - y0)**2) / (2 * sigma**2))
+
+ # Usable gaussian range
+ g_x = max(0, -ul[0]), min(br[0], W) - ul[0]
+ g_y = max(0, -ul[1]), min(br[1], H) - ul[1]
+ # Image range
+ img_x = max(0, ul[0]), min(br[0], W)
+ img_y = max(0, ul[1]), min(br[1], H)
+
+ target[joint_id][img_y[0]:img_y[1], img_x[0]:img_x[1]] = \
+ g[g_y[0]:g_y[1], g_x[0]:g_x[1]]
+
+ if use_different_joint_weights:
+ target_weight = np.multiply(target_weight, joint_weights)
+
+ return target, target_weight
+
+ def _udp_generate_target(self, cfg, joints_3d, joints_3d_visible, factor,
+ target_type):
+ """Generate the target heatmap via 'UDP' approach. Paper ref: Huang et
+ al. The Devil is in the Details: Delving into Unbiased Data Processing
+ for Human Pose Estimation (CVPR 2020).
+
+ Note:
+ num keypoints: K
+ heatmap height: H
+ heatmap width: W
+ num target channels: C
+ C = K if target_type=='GaussianHeatMap'
+ C = 3*K if target_type=='CombinedTarget'
+
+ Args:
+ cfg (dict): data config
+ joints_3d (np.ndarray[K, 3]): Annotated keypoints.
+ joints_3d_visible (np.ndarray[K, 3]): Visibility of keypoints.
+ factor (float): kernel factor for GaussianHeatMap target or
+ valid radius factor for CombinedTarget.
+ target_type (str): 'GaussianHeatMap' or 'CombinedTarget'.
+ GaussianHeatMap: Heatmap target with gaussian distribution.
+ CombinedTarget: The combination of classification target
+ (response map) and regression target (offset map).
+
+ Returns:
+ tuple: A tuple containing targets.
+
+ - target (np.ndarray[C, H, W]): Target heatmaps.
+ - target_weight (np.ndarray[K, 1]): (1: visible, 0: invisible)
+ """
+ num_joints = len(joints_3d)
+ image_size = cfg['image_size']
+ heatmap_size = cfg['heatmap_size']
+ joint_weights = cfg['joint_weights']
+ use_different_joint_weights = cfg['use_different_joint_weights']
+ assert not use_different_joint_weights
+
+ target_weight = np.ones((num_joints, 1), dtype=np.float32)
+ target_weight[:, 0] = joints_3d_visible[:, 0]
+
+ assert target_type in ['GaussianHeatMap', 'CombinedTarget']
+
+ if target_type == 'GaussianHeatMap':
+ target = np.zeros((num_joints, heatmap_size[1], heatmap_size[0]),
+ dtype=np.float32)
+
+ tmp_size = factor * 3
+
+ # prepare for gaussian
+ size = 2 * tmp_size + 1
+ x = np.arange(0, size, 1, np.float32)
+ y = x[:, None]
+
+ for joint_id in range(num_joints):
+ feat_stride = (image_size - 1.0) / (heatmap_size - 1.0)
+ mu_x = int(joints_3d[joint_id][0] / feat_stride[0] + 0.5)
+ mu_y = int(joints_3d[joint_id][1] / feat_stride[1] + 0.5)
+ # Check that any part of the gaussian is in-bounds
+ ul = [int(mu_x - tmp_size), int(mu_y - tmp_size)]
+ br = [int(mu_x + tmp_size + 1), int(mu_y + tmp_size + 1)]
+ if ul[0] >= heatmap_size[0] or ul[1] >= heatmap_size[1] \
+ or br[0] < 0 or br[1] < 0:
+ # If not, just return the image as is
+ target_weight[joint_id] = 0
+ continue
+
+ # # Generate gaussian
+ mu_x_ac = joints_3d[joint_id][0] / feat_stride[0]
+ mu_y_ac = joints_3d[joint_id][1] / feat_stride[1]
+ x0 = y0 = size // 2
+ x0 += mu_x_ac - mu_x
+ y0 += mu_y_ac - mu_y
+ g = np.exp(-((x - x0)**2 + (y - y0)**2) / (2 * factor**2))
+
+ # Usable gaussian range
+ g_x = max(0, -ul[0]), min(br[0], heatmap_size[0]) - ul[0]
+ g_y = max(0, -ul[1]), min(br[1], heatmap_size[1]) - ul[1]
+ # Image range
+ img_x = max(0, ul[0]), min(br[0], heatmap_size[0])
+ img_y = max(0, ul[1]), min(br[1], heatmap_size[1])
+
+ v = target_weight[joint_id]
+ if v > 0.5:
+ target[joint_id][img_y[0]:img_y[1], img_x[0]:img_x[1]] = \
+ g[g_y[0]:g_y[1], g_x[0]:g_x[1]]
+ elif target_type == 'CombinedTarget':
+ target = np.zeros(
+ (num_joints, 3, heatmap_size[1] * heatmap_size[0]),
+ dtype=np.float32)
+ feat_width = heatmap_size[0]
+ feat_height = heatmap_size[1]
+ feat_x_int = np.arange(0, feat_width)
+ feat_y_int = np.arange(0, feat_height)
+ feat_x_int, feat_y_int = np.meshgrid(feat_x_int, feat_y_int)
+ feat_x_int = feat_x_int.flatten()
+ feat_y_int = feat_y_int.flatten()
+ # Calculate the radius of the positive area in classification
+ # heatmap.
+ valid_radius = factor * heatmap_size[1]
+ feat_stride = (image_size - 1.0) / (heatmap_size - 1.0)
+ for joint_id in range(num_joints):
+ mu_x = joints_3d[joint_id][0] / feat_stride[0]
+ mu_y = joints_3d[joint_id][1] / feat_stride[1]
+ x_offset = (mu_x - feat_x_int) / valid_radius
+ y_offset = (mu_y - feat_y_int) / valid_radius
+ dis = x_offset**2 + y_offset**2
+ keep_pos = np.where(dis <= 1)[0]
+ v = target_weight[joint_id]
+ if v > 0.5:
+ target[joint_id, 0, keep_pos] = 1
+ target[joint_id, 1, keep_pos] = x_offset[keep_pos]
+ target[joint_id, 2, keep_pos] = y_offset[keep_pos]
+ target = target.reshape(num_joints * 3, heatmap_size[1],
+ heatmap_size[0])
+
+ if use_different_joint_weights:
+ target_weight = np.multiply(target_weight, joint_weights)
+
+ return target, target_weight
+
+ def __call__(self, results):
+ """Generate the target heatmap."""
+ joints_3d = results['joints_3d']
+ joints_3d_visible = results['joints_3d_visible']
+
+ assert self.encoding in ['MSRA', 'UDP']
+
+ if self.encoding == 'MSRA':
+ if isinstance(self.sigma, list):
+ num_sigmas = len(self.sigma)
+ cfg = results['ann_info']
+ num_joints = len(joints_3d)
+ heatmap_size = cfg['heatmap_size']
+
+ target = np.empty(
+ (0, num_joints, heatmap_size[1], heatmap_size[0]),
+ dtype=np.float32)
+ target_weight = np.empty((0, num_joints, 1), dtype=np.float32)
+ for i in range(num_sigmas):
+ target_i, target_weight_i = self._msra_generate_target(
+ cfg, joints_3d, joints_3d_visible, self.sigma[i])
+ target = np.concatenate([target, target_i[None]], axis=0)
+ target_weight = np.concatenate(
+ [target_weight, target_weight_i[None]], axis=0)
+ else:
+ target, target_weight = self._msra_generate_target(
+ results['ann_info'], joints_3d, joints_3d_visible,
+ self.sigma)
+ elif self.encoding == 'UDP':
+ if self.target_type == 'CombinedTarget':
+ factors = self.valid_radius_factor
+ channel_factor = 3
+ elif self.target_type == 'GaussianHeatMap':
+ factors = self.sigma
+ channel_factor = 1
+ if isinstance(factors, list):
+ num_factors = len(factors)
+ cfg = results['ann_info']
+ num_joints = len(joints_3d)
+ W, H = cfg['heatmap_size']
+
+ target = np.empty((0, channel_factor * num_joints, H, W),
+ dtype=np.float32)
+ target_weight = np.empty((0, num_joints, 1), dtype=np.float32)
+ for i in range(num_factors):
+ target_i, target_weight_i = self._udp_generate_target(
+ cfg, joints_3d, joints_3d_visible, factors[i],
+ self.target_type)
+ target = np.concatenate([target, target_i[None]], axis=0)
+ target_weight = np.concatenate(
+ [target_weight, target_weight_i[None]], axis=0)
+ else:
+ target, target_weight = self._udp_generate_target(
+ results['ann_info'], joints_3d, joints_3d_visible, factors,
+ self.target_type)
+ else:
+ raise ValueError(
+ f'Encoding approach {self.encoding} is not supported!')
+
+ results['target'] = target
+ results['target_weight'] = target_weight
+
+ return results
diff --git a/projects/pose_anything/demo.py b/projects/pose_anything/demo.py
new file mode 100644
index 0000000000..64490a163b
--- /dev/null
+++ b/projects/pose_anything/demo.py
@@ -0,0 +1,291 @@
+import argparse
+import copy
+import os
+import random
+
+import cv2
+import numpy as np
+import torch
+import torchvision.transforms.functional as F
+from datasets.pipelines import TopDownGenerateTargetFewShot
+from mmcv.cnn import fuse_conv_bn
+from mmengine.config import Config, DictAction
+from mmengine.runner import load_checkpoint
+from torchvision import transforms
+
+from mmpose.models import build_pose_estimator
+from tools.visualization import COLORS, plot_results
+
+
+class ResizePad:
+
+ def __init__(self, w=256, h=256):
+ self.w = w
+ self.h = h
+
+ def __call__(self, image):
+ _, w_1, h_1 = image.shape
+ ratio_1 = w_1 / h_1
+ # check if the original and final aspect ratios are the same within a
+ # margin
+ if round(ratio_1, 2) != 1:
+ # padding to preserve aspect ratio
+ if ratio_1 > 1: # Make the image higher
+ hp = int(w_1 - h_1)
+ hp = hp // 2
+ image = F.pad(image, (hp, 0, hp, 0), 0, 'constant')
+ return F.resize(image, [self.h, self.w])
+ else:
+ wp = int(h_1 - w_1)
+ wp = wp // 2
+ image = F.pad(image, (0, wp, 0, wp), 0, 'constant')
+ return F.resize(image, [self.h, self.w])
+ else:
+ return F.resize(image, [self.h, self.w])
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Pose Anything Demo')
+ parser.add_argument('--support', help='Image file')
+ parser.add_argument('--query', help='Image file')
+ parser.add_argument(
+ '--config', default='configs/demo.py', help='test config file path')
+ parser.add_argument(
+ '--checkpoint', default='pretrained', help='checkpoint file')
+ parser.add_argument('--outdir', default='output', help='checkpoint file')
+
+ parser.add_argument(
+ '--fuse-conv-bn',
+ action='store_true',
+ help='Whether to fuse conv and bn, this will slightly increase'
+ 'the inference speed')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ default={},
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. For example, '
+ "'--cfg-options model.backbone.depth=18 "
+ "model.backbone.with_cp=True'")
+ args = parser.parse_args()
+ return args
+
+
+def merge_configs(cfg1, cfg2):
+ # Merge cfg2 into cfg1
+ # Overwrite cfg1 if repeated, ignore if value is None.
+ cfg1 = {} if cfg1 is None else cfg1.copy()
+ cfg2 = {} if cfg2 is None else cfg2
+ for k, v in cfg2.items():
+ if v:
+ cfg1[k] = v
+ return cfg1
+
+
+def main():
+ random.seed(0)
+ np.random.seed(0)
+ torch.manual_seed(0)
+
+ args = parse_args()
+ cfg = Config.fromfile(args.config)
+
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+ # set cudnn_benchmark
+ if cfg.get('cudnn_benchmark', False):
+ torch.backends.cudnn.benchmark = True
+ cfg.data.test.test_mode = True
+
+ os.makedirs(args.outdir, exist_ok=True)
+
+ # Load data
+ support_img = cv2.imread(args.support)
+ query_img = cv2.imread(args.query)
+ if support_img is None or query_img is None:
+ raise ValueError('Fail to read images')
+
+ preprocess = transforms.Compose([
+ transforms.ToTensor(),
+ ResizePad(cfg.model.encoder_config.img_size,
+ cfg.model.encoder_config.img_size)
+ ])
+
+ # frame = copy.deepcopy(support_img)
+ padded_support_img = preprocess(support_img).cpu().numpy().transpose(
+ 1, 2, 0) * 255
+ frame = copy.deepcopy(padded_support_img.astype(np.uint8).copy())
+ kp_src = []
+ skeleton = []
+ count = 0
+ prev_pt = None
+ prev_pt_idx = None
+ color_idx = 0
+
+ def selectKP(event, x, y, flags, param):
+ nonlocal kp_src, frame
+ # if we are in points selection mode, the mouse was clicked,
+ # list of points with the (x, y) location of the click
+ # and draw the circle
+
+ if event == cv2.EVENT_LBUTTONDOWN:
+ kp_src.append((x, y))
+ cv2.circle(frame, (x, y), 2, (0, 0, 255), 1)
+ cv2.imshow('Source', frame)
+
+ if event == cv2.EVENT_RBUTTONDOWN:
+ kp_src = []
+ frame = copy.deepcopy(support_img)
+ cv2.imshow('Source', frame)
+
+ def draw_line(event, x, y, flags, param):
+ nonlocal skeleton, kp_src, frame, count, prev_pt, prev_pt_idx, \
+ marked_frame, color_idx
+ if event == cv2.EVENT_LBUTTONDOWN:
+ closest_point = min(
+ kp_src, key=lambda p: (p[0] - x)**2 + (p[1] - y)**2)
+ closest_point_index = kp_src.index(closest_point)
+ if color_idx < len(COLORS):
+ c = COLORS[color_idx]
+ else:
+ c = random.choices(range(256), k=3)
+
+ cv2.circle(frame, closest_point, 2, c, 1)
+ if count == 0:
+ prev_pt = closest_point
+ prev_pt_idx = closest_point_index
+ count = count + 1
+ cv2.imshow('Source', frame)
+ else:
+ cv2.line(frame, prev_pt, closest_point, c, 2)
+ cv2.imshow('Source', frame)
+ count = 0
+ skeleton.append((prev_pt_idx, closest_point_index))
+ color_idx = color_idx + 1
+ elif event == cv2.EVENT_RBUTTONDOWN:
+ frame = copy.deepcopy(marked_frame)
+ cv2.imshow('Source', frame)
+ count = 0
+ color_idx = 0
+ skeleton = []
+ prev_pt = None
+
+ cv2.namedWindow('Source', cv2.WINDOW_NORMAL)
+ cv2.resizeWindow('Source', 800, 600)
+ cv2.setMouseCallback('Source', selectKP)
+ cv2.imshow('Source', frame)
+
+ # keep looping until points have been selected
+ print('Press any key when finished marking the points!! ')
+ while True:
+ if cv2.waitKey(1) > 0:
+ break
+
+ marked_frame = copy.deepcopy(frame)
+ cv2.setMouseCallback('Source', draw_line)
+ print('Press any key when finished creating skeleton!!')
+ while True:
+ if cv2.waitKey(1) > 0:
+ break
+
+ cv2.destroyAllWindows()
+ kp_src = torch.tensor(kp_src).float()
+ preprocess = transforms.Compose([
+ transforms.ToTensor(),
+ transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
+ ResizePad(cfg.model.encoder_config.img_size,
+ cfg.model.encoder_config.img_size)
+ ])
+
+ if len(skeleton) == 0:
+ skeleton = [(0, 0)]
+
+ support_img = preprocess(support_img).flip(0)[None]
+ query_img = preprocess(query_img).flip(0)[None]
+ # Create heatmap from keypoints
+ genHeatMap = TopDownGenerateTargetFewShot()
+ data_cfg = cfg.data_cfg
+ data_cfg['image_size'] = np.array(
+ [cfg.model.encoder_config.img_size, cfg.model.encoder_config.img_size])
+ data_cfg['joint_weights'] = None
+ data_cfg['use_different_joint_weights'] = False
+ kp_src_3d = torch.cat((kp_src, torch.zeros(kp_src.shape[0], 1)), dim=-1)
+ kp_src_3d_weight = torch.cat(
+ (torch.ones_like(kp_src), torch.zeros(kp_src.shape[0], 1)), dim=-1)
+ target_s, target_weight_s = genHeatMap._msra_generate_target(
+ data_cfg, kp_src_3d, kp_src_3d_weight, sigma=2)
+ target_s = torch.tensor(target_s).float()[None]
+ target_weight_s = torch.tensor(target_weight_s).float()[None]
+
+ data = {
+ 'img_s': [support_img],
+ 'img_q':
+ query_img,
+ 'target_s': [target_s],
+ 'target_weight_s': [target_weight_s],
+ 'target_q':
+ None,
+ 'target_weight_q':
+ None,
+ 'return_loss':
+ False,
+ 'img_metas': [{
+ 'sample_skeleton': [skeleton],
+ 'query_skeleton':
+ skeleton,
+ 'sample_joints_3d': [kp_src_3d],
+ 'query_joints_3d':
+ kp_src_3d,
+ 'sample_center': [kp_src.mean(dim=0)],
+ 'query_center':
+ kp_src.mean(dim=0),
+ 'sample_scale': [kp_src.max(dim=0)[0] - kp_src.min(dim=0)[0]],
+ 'query_scale':
+ kp_src.max(dim=0)[0] - kp_src.min(dim=0)[0],
+ 'sample_rotation': [0],
+ 'query_rotation':
+ 0,
+ 'sample_bbox_score': [1],
+ 'query_bbox_score':
+ 1,
+ 'query_image_file':
+ '',
+ 'sample_image_file': [''],
+ }]
+ }
+
+ # Load model
+ model = build_pose_estimator(cfg.model)
+ load_checkpoint(model, args.checkpoint, map_location='cpu')
+ if args.fuse_conv_bn:
+ model = fuse_conv_bn(model)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**data)
+
+ # visualize results
+ vis_s_weight = target_weight_s[0]
+ vis_q_weight = target_weight_s[0]
+ vis_s_image = support_img[0].detach().cpu().numpy().transpose(1, 2, 0)
+ vis_q_image = query_img[0].detach().cpu().numpy().transpose(1, 2, 0)
+ support_kp = kp_src_3d
+
+ plot_results(
+ vis_s_image,
+ vis_q_image,
+ support_kp,
+ vis_s_weight,
+ None,
+ vis_q_weight,
+ skeleton,
+ None,
+ torch.tensor(outputs['points']).squeeze(0),
+ out_dir=args.outdir)
+
+ print('Output saved to output dir: {}'.format(args.outdir))
+
+
+if __name__ == '__main__':
+ main()
diff --git a/projects/pose_anything/models/__init__.py b/projects/pose_anything/models/__init__.py
new file mode 100644
index 0000000000..4c2fedaea2
--- /dev/null
+++ b/projects/pose_anything/models/__init__.py
@@ -0,0 +1,4 @@
+from .backbones import * # noqa
+from .detectors import * # noqa
+from .keypoint_heads import * # noqa
+from .utils import * # noqa
diff --git a/projects/pose_anything/models/backbones/__init__.py b/projects/pose_anything/models/backbones/__init__.py
new file mode 100644
index 0000000000..c23ac1d15c
--- /dev/null
+++ b/projects/pose_anything/models/backbones/__init__.py
@@ -0,0 +1 @@
+from .swin_transformer_v2 import SwinTransformerV2 # noqa
diff --git a/projects/pose_anything/models/backbones/simmim.py b/projects/pose_anything/models/backbones/simmim.py
new file mode 100644
index 0000000000..189011891a
--- /dev/null
+++ b/projects/pose_anything/models/backbones/simmim.py
@@ -0,0 +1,235 @@
+# --------------------------------------------------------
+# SimMIM
+# Copyright (c) 2021 Microsoft
+# Licensed under The MIT License [see LICENSE for details]
+# Written by Zhenda Xie
+# --------------------------------------------------------
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from timm.models.layers import trunc_normal_
+
+from .swin_transformer import SwinTransformer
+from .swin_transformer_v2 import SwinTransformerV2
+
+
+def norm_targets(targets, patch_size):
+ assert patch_size % 2 == 1
+
+ targets_ = targets
+ targets_count = torch.ones_like(targets)
+
+ targets_square = targets**2.
+
+ targets_mean = F.avg_pool2d(
+ targets,
+ kernel_size=patch_size,
+ stride=1,
+ padding=patch_size // 2,
+ count_include_pad=False)
+ targets_square_mean = F.avg_pool2d(
+ targets_square,
+ kernel_size=patch_size,
+ stride=1,
+ padding=patch_size // 2,
+ count_include_pad=False)
+ targets_count = F.avg_pool2d(
+ targets_count,
+ kernel_size=patch_size,
+ stride=1,
+ padding=patch_size // 2,
+ count_include_pad=True) * (
+ patch_size**2)
+
+ targets_var = (targets_square_mean - targets_mean**2.) * (
+ targets_count / (targets_count - 1))
+ targets_var = torch.clamp(targets_var, min=0.)
+
+ targets_ = (targets_ - targets_mean) / (targets_var + 1.e-6)**0.5
+
+ return targets_
+
+
+class SwinTransformerForSimMIM(SwinTransformer):
+
+ def __init__(self, **kwargs):
+ super().__init__(**kwargs)
+
+ assert self.num_classes == 0
+
+ self.mask_token = nn.Parameter(torch.zeros(1, 1, self.embed_dim))
+ trunc_normal_(self.mask_token, mean=0., std=.02)
+
+ def forward(self, x, mask):
+ x = self.patch_embed(x)
+
+ assert mask is not None
+ B, L, _ = x.shape
+
+ mask_tokens = self.mask_token.expand(B, L, -1)
+ w = mask.flatten(1).unsqueeze(-1).type_as(mask_tokens)
+ x = x * (1. - w) + mask_tokens * w
+
+ if self.ape:
+ x = x + self.absolute_pos_embed
+ x = self.pos_drop(x)
+
+ for layer in self.layers:
+ x = layer(x)
+ x = self.norm(x)
+
+ x = x.transpose(1, 2)
+ B, C, L = x.shape
+ H = W = int(L**0.5)
+ x = x.reshape(B, C, H, W)
+ return x
+
+ @torch.jit.ignore
+ def no_weight_decay(self):
+ return super().no_weight_decay() | {'mask_token'}
+
+
+class SwinTransformerV2ForSimMIM(SwinTransformerV2):
+
+ def __init__(self, **kwargs):
+ super().__init__(**kwargs)
+
+ assert self.num_classes == 0
+
+ self.mask_token = nn.Parameter(torch.zeros(1, 1, self.embed_dim))
+ trunc_normal_(self.mask_token, mean=0., std=.02)
+
+ def forward(self, x, mask):
+ x = self.patch_embed(x)
+
+ assert mask is not None
+ B, L, _ = x.shape
+
+ mask_tokens = self.mask_token.expand(B, L, -1)
+ w = mask.flatten(1).unsqueeze(-1).type_as(mask_tokens)
+ x = x * (1. - w) + mask_tokens * w
+
+ if self.ape:
+ x = x + self.absolute_pos_embed
+ x = self.pos_drop(x)
+
+ for layer in self.layers:
+ x = layer(x)
+ x = self.norm(x)
+
+ x = x.transpose(1, 2)
+ B, C, L = x.shape
+ H = W = int(L**0.5)
+ x = x.reshape(B, C, H, W)
+ return x
+
+ @torch.jit.ignore
+ def no_weight_decay(self):
+ return super().no_weight_decay() | {'mask_token'}
+
+
+class SimMIM(nn.Module):
+
+ def __init__(self, config, encoder, encoder_stride, in_chans, patch_size):
+ super().__init__()
+ self.config = config
+ self.encoder = encoder
+ self.encoder_stride = encoder_stride
+
+ self.decoder = nn.Sequential(
+ nn.Conv2d(
+ in_channels=self.encoder.num_features,
+ out_channels=self.encoder_stride**2 * 3,
+ kernel_size=1),
+ nn.PixelShuffle(self.encoder_stride),
+ )
+
+ self.in_chans = in_chans
+ self.patch_size = patch_size
+
+ def forward(self, x, mask):
+ z = self.encoder(x, mask)
+ x_rec = self.decoder(z)
+
+ mask = mask.repeat_interleave(self.patch_size, 1).repeat_interleave(
+ self.patch_size, 2).unsqueeze(1).contiguous()
+
+ # norm target as prompted
+ if self.config.NORM_TARGET.ENABLE:
+ x = norm_targets(x, self.config.NORM_TARGET.PATCH_SIZE)
+
+ loss_recon = F.l1_loss(x, x_rec, reduction='none')
+ loss = (loss_recon * mask).sum() / (mask.sum() + 1e-5) / self.in_chans
+ return loss
+
+ @torch.jit.ignore
+ def no_weight_decay(self):
+ if hasattr(self.encoder, 'no_weight_decay'):
+ return {'encoder.' + i for i in self.encoder.no_weight_decay()}
+ return {}
+
+ @torch.jit.ignore
+ def no_weight_decay_keywords(self):
+ if hasattr(self.encoder, 'no_weight_decay_keywords'):
+ return {
+ 'encoder.' + i
+ for i in self.encoder.no_weight_decay_keywords()
+ }
+ return {}
+
+
+def build_simmim(config):
+ model_type = config.MODEL.TYPE
+ if model_type == 'swin':
+ encoder = SwinTransformerForSimMIM(
+ img_size=config.DATA.IMG_SIZE,
+ patch_size=config.MODEL.SWIN.PATCH_SIZE,
+ in_chans=config.MODEL.SWIN.IN_CHANS,
+ num_classes=0,
+ embed_dim=config.MODEL.SWIN.EMBED_DIM,
+ depths=config.MODEL.SWIN.DEPTHS,
+ num_heads=config.MODEL.SWIN.NUM_HEADS,
+ window_size=config.MODEL.SWIN.WINDOW_SIZE,
+ mlp_ratio=config.MODEL.SWIN.MLP_RATIO,
+ qkv_bias=config.MODEL.SWIN.QKV_BIAS,
+ qk_scale=config.MODEL.SWIN.QK_SCALE,
+ drop_rate=config.MODEL.DROP_RATE,
+ drop_path_rate=config.MODEL.DROP_PATH_RATE,
+ ape=config.MODEL.SWIN.APE,
+ patch_norm=config.MODEL.SWIN.PATCH_NORM,
+ use_checkpoint=config.TRAIN.USE_CHECKPOINT)
+ encoder_stride = 32
+ in_chans = config.MODEL.SWIN.IN_CHANS
+ patch_size = config.MODEL.SWIN.PATCH_SIZE
+ elif model_type == 'swinv2':
+ encoder = SwinTransformerV2ForSimMIM(
+ img_size=config.DATA.IMG_SIZE,
+ patch_size=config.MODEL.SWINV2.PATCH_SIZE,
+ in_chans=config.MODEL.SWINV2.IN_CHANS,
+ num_classes=0,
+ embed_dim=config.MODEL.SWINV2.EMBED_DIM,
+ depths=config.MODEL.SWINV2.DEPTHS,
+ num_heads=config.MODEL.SWINV2.NUM_HEADS,
+ window_size=config.MODEL.SWINV2.WINDOW_SIZE,
+ mlp_ratio=config.MODEL.SWINV2.MLP_RATIO,
+ qkv_bias=config.MODEL.SWINV2.QKV_BIAS,
+ drop_rate=config.MODEL.DROP_RATE,
+ drop_path_rate=config.MODEL.DROP_PATH_RATE,
+ ape=config.MODEL.SWINV2.APE,
+ patch_norm=config.MODEL.SWINV2.PATCH_NORM,
+ use_checkpoint=config.TRAIN.USE_CHECKPOINT)
+ encoder_stride = 32
+ in_chans = config.MODEL.SWINV2.IN_CHANS
+ patch_size = config.MODEL.SWINV2.PATCH_SIZE
+ else:
+ raise NotImplementedError(f'Unknown pre-train model: {model_type}')
+
+ model = SimMIM(
+ config=config.MODEL.SIMMIM,
+ encoder=encoder,
+ encoder_stride=encoder_stride,
+ in_chans=in_chans,
+ patch_size=patch_size)
+
+ return model
diff --git a/projects/pose_anything/models/backbones/swin_mlp.py b/projects/pose_anything/models/backbones/swin_mlp.py
new file mode 100644
index 0000000000..0442c2fab7
--- /dev/null
+++ b/projects/pose_anything/models/backbones/swin_mlp.py
@@ -0,0 +1,565 @@
+# --------------------------------------------------------
+# Swin Transformer
+# Copyright (c) 2021 Microsoft
+# Licensed under The MIT License [see LICENSE for details]
+# Written by Ze Liu
+# --------------------------------------------------------
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.checkpoint as checkpoint
+from timm.models.layers import DropPath, to_2tuple, trunc_normal_
+
+
+class Mlp(nn.Module):
+
+ def __init__(self,
+ in_features,
+ hidden_features=None,
+ out_features=None,
+ act_layer=nn.GELU,
+ drop=0.):
+ super().__init__()
+ out_features = out_features or in_features
+ hidden_features = hidden_features or in_features
+ self.fc1 = nn.Linear(in_features, hidden_features)
+ self.act = act_layer()
+ self.fc2 = nn.Linear(hidden_features, out_features)
+ self.drop = nn.Dropout(drop)
+
+ def forward(self, x):
+ x = self.fc1(x)
+ x = self.act(x)
+ x = self.drop(x)
+ x = self.fc2(x)
+ x = self.drop(x)
+ return x
+
+
+def window_partition(x, window_size):
+ """
+ Args:
+ x: (B, H, W, C)
+ window_size (int): window size
+
+ Returns:
+ windows: (num_windows*B, window_size, window_size, C)
+ """
+ B, H, W, C = x.shape
+ x = x.view(B, H // window_size, window_size, W // window_size, window_size,
+ C)
+ windows = x.permute(0, 1, 3, 2, 4,
+ 5).contiguous().view(-1, window_size, window_size, C)
+ return windows
+
+
+def window_reverse(windows, window_size, H, W):
+ """
+ Args:
+ windows: (num_windows*B, window_size, window_size, C)
+ window_size (int): Window size
+ H (int): Height of image
+ W (int): Width of image
+
+ Returns:
+ x: (B, H, W, C)
+ """
+ B = int(windows.shape[0] / (H * W / window_size / window_size))
+ x = windows.view(B, H // window_size, W // window_size, window_size,
+ window_size, -1)
+ x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
+ return x
+
+
+class SwinMLPBlock(nn.Module):
+ r""" Swin MLP Block.
+
+ Args: dim (int): Number of input channels. input_resolution (tuple[int]):
+ Input resolution. num_heads (int): Number of attention heads. window_size
+ (int): Window size. shift_size (int): Shift size for SW-MSA. mlp_ratio (
+ float): Ratio of mlp hidden dim to embedding dim. drop (float, optional):
+ Dropout rate. Default: 0.0 drop_path (float, optional): Stochastic depth
+ rate. Default: 0.0 act_layer (nn.Module, optional): Activation layer.
+ Default: nn.GELU norm_layer (nn.Module, optional): Normalization layer.
+ Default: nn.LayerNorm
+ """
+
+ def __init__(self,
+ dim,
+ input_resolution,
+ num_heads,
+ window_size=7,
+ shift_size=0,
+ mlp_ratio=4.,
+ drop=0.,
+ drop_path=0.,
+ act_layer=nn.GELU,
+ norm_layer=nn.LayerNorm):
+ super().__init__()
+ self.dim = dim
+ self.input_resolution = input_resolution
+ self.num_heads = num_heads
+ self.window_size = window_size
+ self.shift_size = shift_size
+ self.mlp_ratio = mlp_ratio
+ if min(self.input_resolution) <= self.window_size:
+ # if window size is larger than input resolution, we don't
+ # partition windows
+ self.shift_size = 0
+ self.window_size = min(self.input_resolution)
+ assert 0 <= self.shift_size < self.window_size, ('shift_size must in '
+ '0-window_size')
+
+ self.padding = [
+ self.window_size - self.shift_size, self.shift_size,
+ self.window_size - self.shift_size, self.shift_size
+ ] # P_l,P_r,P_t,P_b
+
+ self.norm1 = norm_layer(dim)
+ # use group convolution to implement multi-head MLP
+ self.spatial_mlp = nn.Conv1d(
+ self.num_heads * self.window_size**2,
+ self.num_heads * self.window_size**2,
+ kernel_size=1,
+ groups=self.num_heads)
+
+ self.drop_path = DropPath(
+ drop_path) if drop_path > 0. else nn.Identity()
+ self.norm2 = norm_layer(dim)
+ mlp_hidden_dim = int(dim * mlp_ratio)
+ self.mlp = Mlp(
+ in_features=dim,
+ hidden_features=mlp_hidden_dim,
+ act_layer=act_layer,
+ drop=drop)
+
+ def forward(self, x):
+ H, W = self.input_resolution
+ B, L, C = x.shape
+ assert L == H * W, 'input feature has wrong size'
+
+ shortcut = x
+ x = self.norm1(x)
+ x = x.view(B, H, W, C)
+
+ # shift
+ if self.shift_size > 0:
+ P_l, P_r, P_t, P_b = self.padding
+ shifted_x = F.pad(x, [0, 0, P_l, P_r, P_t, P_b], 'constant', 0)
+ else:
+ shifted_x = x
+ _, _H, _W, _ = shifted_x.shape
+
+ # partition windows
+ x_windows = window_partition(
+ shifted_x, self.window_size) # nW*B, window_size, window_size, C
+ x_windows = x_windows.view(-1, self.window_size * self.window_size,
+ C) # nW*B, window_size*window_size, C
+
+ # Window/Shifted-Window Spatial MLP
+ x_windows_heads = x_windows.view(-1,
+ self.window_size * self.window_size,
+ self.num_heads, C // self.num_heads)
+ x_windows_heads = x_windows_heads.transpose(
+ 1, 2) # nW*B, nH, window_size*window_size, C//nH
+ x_windows_heads = x_windows_heads.reshape(
+ -1, self.num_heads * self.window_size * self.window_size,
+ C // self.num_heads)
+ spatial_mlp_windows = self.spatial_mlp(
+ x_windows_heads) # nW*B, nH*window_size*window_size, C//nH
+ spatial_mlp_windows = spatial_mlp_windows.view(
+ -1, self.num_heads, self.window_size * self.window_size,
+ C // self.num_heads).transpose(1, 2)
+ spatial_mlp_windows = spatial_mlp_windows.reshape(
+ -1, self.window_size * self.window_size, C)
+
+ # merge windows
+ spatial_mlp_windows = spatial_mlp_windows.reshape(
+ -1, self.window_size, self.window_size, C)
+ shifted_x = window_reverse(spatial_mlp_windows, self.window_size, _H,
+ _W) # B H' W' C
+
+ # reverse shift
+ if self.shift_size > 0:
+ P_l, P_r, P_t, P_b = self.padding
+ x = shifted_x[:, P_t:-P_b, P_l:-P_r, :].contiguous()
+ else:
+ x = shifted_x
+ x = x.view(B, H * W, C)
+
+ # FFN
+ x = shortcut + self.drop_path(x)
+ x = x + self.drop_path(self.mlp(self.norm2(x)))
+
+ return x
+
+ def extra_repr(self) -> str:
+ return (f'dim={self.dim}, input_resolution={self.input_resolution}, '
+ f'num_heads={self.num_heads}, '
+ f'window_size={self.window_size}, '
+ f'shift_size={self.shift_size}, '
+ f'mlp_ratio={self.mlp_ratio}')
+
+ def flops(self):
+ flops = 0
+ H, W = self.input_resolution
+ # norm1
+ flops += self.dim * H * W
+
+ # Window/Shifted-Window Spatial MLP
+ if self.shift_size > 0:
+ nW = (H / self.window_size + 1) * (W / self.window_size + 1)
+ else:
+ nW = H * W / self.window_size / self.window_size
+ flops += nW * self.dim * (self.window_size * self.window_size) * (
+ self.window_size * self.window_size)
+ # mlp
+ flops += 2 * H * W * self.dim * self.dim * self.mlp_ratio
+ # norm2
+ flops += self.dim * H * W
+ return flops
+
+
+class PatchMerging(nn.Module):
+ r""" Patch Merging Layer.
+
+ Args:
+ input_resolution (tuple[int]): Resolution of input feature.
+ dim (int): Number of input channels.
+ norm_layer (nn.Module, optional): Normalization layer. Default:
+ nn.LayerNorm
+ """
+
+ def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
+ super().__init__()
+ self.input_resolution = input_resolution
+ self.dim = dim
+ self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
+ self.norm = norm_layer(4 * dim)
+
+ def forward(self, x):
+ """
+ x: B, H*W, C
+ """
+ H, W = self.input_resolution
+ B, L, C = x.shape
+ assert L == H * W, 'input feature has wrong size'
+ assert H % 2 == 0 and W % 2 == 0, f'x size ({H}*{W}) are not even.'
+
+ x = x.view(B, H, W, C)
+
+ x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
+ x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
+ x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
+ x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
+ x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
+ x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
+
+ x = self.norm(x)
+ x = self.reduction(x)
+
+ return x
+
+ def extra_repr(self) -> str:
+ return f'input_resolution={self.input_resolution}, dim={self.dim}'
+
+ def flops(self):
+ H, W = self.input_resolution
+ flops = H * W * self.dim
+ flops += (H // 2) * (W // 2) * 4 * self.dim * 2 * self.dim
+ return flops
+
+
+class BasicLayer(nn.Module):
+ """A basic Swin MLP layer for one stage.
+
+ Args:
+ dim (int): Number of input channels.
+ input_resolution (tuple[int]): Input resolution.
+ depth (int): Number of blocks.
+ num_heads (int): Number of attention heads.
+ window_size (int): Local window size.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
+ drop (float, optional): Dropout rate. Default: 0.0
+ drop_path (float | tuple[float], optional): Stochastic depth rate.
+ Default: 0.0
+ norm_layer (nn.Module, optional): Normalization layer. Default:
+ nn.LayerNorm
+ downsample (nn.Module | None, optional): Downsample layer at the end
+ of the layer. Default: None
+ use_checkpoint (bool): Whether to use checkpointing to save memory.
+ Default: False.
+ """
+
+ def __init__(self,
+ dim,
+ input_resolution,
+ depth,
+ num_heads,
+ window_size,
+ mlp_ratio=4.,
+ drop=0.,
+ drop_path=0.,
+ norm_layer=nn.LayerNorm,
+ downsample=None,
+ use_checkpoint=False):
+
+ super().__init__()
+ self.dim = dim
+ self.input_resolution = input_resolution
+ self.depth = depth
+ self.use_checkpoint = use_checkpoint
+
+ # build blocks
+ self.blocks = nn.ModuleList([
+ SwinMLPBlock(
+ dim=dim,
+ input_resolution=input_resolution,
+ num_heads=num_heads,
+ window_size=window_size,
+ shift_size=0 if (i % 2 == 0) else window_size // 2,
+ mlp_ratio=mlp_ratio,
+ drop=drop,
+ drop_path=drop_path[i]
+ if isinstance(drop_path, list) else drop_path,
+ norm_layer=norm_layer) for i in range(depth)
+ ])
+
+ # patch merging layer
+ if downsample is not None:
+ self.downsample = downsample(
+ input_resolution, dim=dim, norm_layer=norm_layer)
+ else:
+ self.downsample = None
+
+ def forward(self, x):
+ for blk in self.blocks:
+ if self.use_checkpoint:
+ x = checkpoint.checkpoint(blk, x)
+ else:
+ x = blk(x)
+ if self.downsample is not None:
+ x = self.downsample(x)
+ return x
+
+ def extra_repr(self) -> str:
+ return (f'dim={self.dim}, input_resolution={self.input_resolution}, '
+ f'depth={self.depth}')
+
+ def flops(self):
+ flops = 0
+ for blk in self.blocks:
+ flops += blk.flops()
+ if self.downsample is not None:
+ flops += self.downsample.flops()
+ return flops
+
+
+class PatchEmbed(nn.Module):
+ r""" Image to Patch Embedding
+
+ Args:
+ img_size (int): Image size. Default: 224.
+ patch_size (int): Patch token size. Default: 4.
+ in_chans (int): Number of input image channels. Default: 3.
+ embed_dim (int): Number of linear projection output channels.
+ Default: 96.
+ norm_layer (nn.Module, optional): Normalization layer. Default: None
+ """
+
+ def __init__(self,
+ img_size=224,
+ patch_size=4,
+ in_chans=3,
+ embed_dim=96,
+ norm_layer=None):
+ super().__init__()
+ img_size = to_2tuple(img_size)
+ patch_size = to_2tuple(patch_size)
+ patches_resolution = [
+ img_size[0] // patch_size[0], img_size[1] // patch_size[1]
+ ]
+ self.img_size = img_size
+ self.patch_size = patch_size
+ self.patches_resolution = patches_resolution
+ self.num_patches = patches_resolution[0] * patches_resolution[1]
+
+ self.in_chans = in_chans
+ self.embed_dim = embed_dim
+
+ self.proj = nn.Conv2d(
+ in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
+ if norm_layer is not None:
+ self.norm = norm_layer(embed_dim)
+ else:
+ self.norm = None
+
+ def forward(self, x):
+ B, C, H, W = x.shape
+ # FIXME look at relaxing size constraints
+ assert H == self.img_size[0] and W == self.img_size[1], \
+ (f"Input image size ({H}*{W}) doesn't match model ("
+ f'{self.img_size[0]}*{self.img_size[1]}).')
+ x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
+ if self.norm is not None:
+ x = self.norm(x)
+ return x
+
+ def flops(self):
+ Ho, Wo = self.patches_resolution
+ flops = Ho * Wo * self.embed_dim * self.in_chans * (
+ self.patch_size[0] * self.patch_size[1])
+ if self.norm is not None:
+ flops += Ho * Wo * self.embed_dim
+ return flops
+
+
+class SwinMLP(nn.Module):
+ r""" Swin MLP
+
+ Args:
+ img_size (int | tuple(int)): Input image size. Default 224
+ patch_size (int | tuple(int)): Patch size. Default: 4
+ in_chans (int): Number of input image channels. Default: 3
+ num_classes (int): Number of classes for classification head.
+ Default: 1000
+ embed_dim (int): Patch embedding dimension. Default: 96
+ depths (tuple(int)): Depth of each Swin MLP layer.
+ num_heads (tuple(int)): Number of attention heads in different layers.
+ window_size (int): Window size. Default: 7
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
+ drop_rate (float): Dropout rate. Default: 0
+ drop_path_rate (float): Stochastic depth rate. Default: 0.1
+ norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
+ ape (bool): If True, add absolute position embedding to the patch
+ embedding. Default: False
+ patch_norm (bool): If True, add normalization after patch embedding.
+ Default: True
+ use_checkpoint (bool): Whether to use checkpointing to save memory.
+ Default: False
+ """
+
+ def __init__(self,
+ img_size=224,
+ patch_size=4,
+ in_chans=3,
+ num_classes=1000,
+ embed_dim=96,
+ depths=[2, 2, 6, 2],
+ num_heads=[3, 6, 12, 24],
+ window_size=7,
+ mlp_ratio=4.,
+ drop_rate=0.,
+ drop_path_rate=0.1,
+ norm_layer=nn.LayerNorm,
+ ape=False,
+ patch_norm=True,
+ use_checkpoint=False,
+ **kwargs):
+ super().__init__()
+
+ self.num_classes = num_classes
+ self.num_layers = len(depths)
+ self.embed_dim = embed_dim
+ self.ape = ape
+ self.patch_norm = patch_norm
+ self.num_features = int(embed_dim * 2**(self.num_layers - 1))
+ self.mlp_ratio = mlp_ratio
+
+ # split image into non-overlapping patches
+ self.patch_embed = PatchEmbed(
+ img_size=img_size,
+ patch_size=patch_size,
+ in_chans=in_chans,
+ embed_dim=embed_dim,
+ norm_layer=norm_layer if self.patch_norm else None)
+ num_patches = self.patch_embed.num_patches
+ patches_resolution = self.patch_embed.patches_resolution
+ self.patches_resolution = patches_resolution
+
+ # absolute position embedding
+ if self.ape:
+ self.absolute_pos_embed = nn.Parameter(
+ torch.zeros(1, num_patches, embed_dim))
+ trunc_normal_(self.absolute_pos_embed, std=.02)
+
+ self.pos_drop = nn.Dropout(p=drop_rate)
+
+ # stochastic depth
+ dpr = [
+ x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))
+ ] # stochastic depth decay rule
+
+ # build layers
+ self.layers = nn.ModuleList()
+ for i_layer in range(self.num_layers):
+ layer = BasicLayer(
+ dim=int(embed_dim * 2**i_layer),
+ input_resolution=(patches_resolution[0] // (2**i_layer),
+ patches_resolution[1] // (2**i_layer)),
+ depth=depths[i_layer],
+ num_heads=num_heads[i_layer],
+ window_size=window_size,
+ mlp_ratio=self.mlp_ratio,
+ drop=drop_rate,
+ drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
+ norm_layer=norm_layer,
+ downsample=PatchMerging if
+ (i_layer < self.num_layers - 1) else None,
+ use_checkpoint=use_checkpoint)
+ self.layers.append(layer)
+
+ self.norm = norm_layer(self.num_features)
+ self.avgpool = nn.AdaptiveAvgPool1d(1)
+ self.head = nn.Linear(
+ self.num_features,
+ num_classes) if num_classes > 0 else nn.Identity()
+
+ self.apply(self._init_weights)
+
+ def _init_weights(self, m):
+ if isinstance(m, (nn.Linear, nn.Conv1d)):
+ trunc_normal_(m.weight, std=.02)
+ if m.bias is not None:
+ nn.init.constant_(m.bias, 0)
+ elif isinstance(m, nn.LayerNorm):
+ nn.init.constant_(m.bias, 0)
+ nn.init.constant_(m.weight, 1.0)
+
+ @torch.jit.ignore
+ def no_weight_decay(self):
+ return {'absolute_pos_embed'}
+
+ @torch.jit.ignore
+ def no_weight_decay_keywords(self):
+ return {'relative_position_bias_table'}
+
+ def forward_features(self, x):
+ x = self.patch_embed(x)
+ if self.ape:
+ x = x + self.absolute_pos_embed
+ x = self.pos_drop(x)
+
+ for layer in self.layers:
+ x = layer(x)
+
+ x = self.norm(x) # B L C
+ x = self.avgpool(x.transpose(1, 2)) # B C 1
+ x = torch.flatten(x, 1)
+ return x
+
+ def forward(self, x):
+ x = self.forward_features(x)
+ x = self.head(x)
+ return x
+
+ def flops(self):
+ flops = 0
+ flops += self.patch_embed.flops()
+ for i, layer in enumerate(self.layers):
+ flops += layer.flops()
+ flops += self.num_features * self.patches_resolution[
+ 0] * self.patches_resolution[1] // (2**self.num_layers)
+ flops += self.num_features * self.num_classes
+ return flops
diff --git a/projects/pose_anything/models/backbones/swin_transformer.py b/projects/pose_anything/models/backbones/swin_transformer.py
new file mode 100644
index 0000000000..17ba4d2c1a
--- /dev/null
+++ b/projects/pose_anything/models/backbones/swin_transformer.py
@@ -0,0 +1,751 @@
+# --------------------------------------------------------
+# Swin Transformer
+# Copyright (c) 2021 Microsoft
+# Licensed under The MIT License [see LICENSE for details]
+# Written by Ze Liu
+# --------------------------------------------------------
+
+import torch
+import torch.nn as nn
+import torch.utils.checkpoint as checkpoint
+from timm.models.layers import DropPath, to_2tuple, trunc_normal_
+
+try:
+ import os
+ import sys
+
+ kernel_path = os.path.abspath(os.path.join('..'))
+ sys.path.append(kernel_path)
+ from kernels.window_process.window_process import (WindowProcess,
+ WindowProcessReverse)
+
+except ImportError:
+ WindowProcess = None
+ WindowProcessReverse = None
+ print(
+ '[Warning] Fused window process have not been installed. Please refer '
+ 'to get_started.md for installation.')
+
+
+class Mlp(nn.Module):
+
+ def __init__(self,
+ in_features,
+ hidden_features=None,
+ out_features=None,
+ act_layer=nn.GELU,
+ drop=0.):
+ super().__init__()
+ out_features = out_features or in_features
+ hidden_features = hidden_features or in_features
+ self.fc1 = nn.Linear(in_features, hidden_features)
+ self.act = act_layer()
+ self.fc2 = nn.Linear(hidden_features, out_features)
+ self.drop = nn.Dropout(drop)
+
+ def forward(self, x):
+ x = self.fc1(x)
+ x = self.act(x)
+ x = self.drop(x)
+ x = self.fc2(x)
+ x = self.drop(x)
+ return x
+
+
+def window_partition(x, window_size):
+ """
+ Args:
+ x: (B, H, W, C)
+ window_size (int): window size
+
+ Returns:
+ windows: (num_windows*B, window_size, window_size, C)
+ """
+ B, H, W, C = x.shape
+ x = x.view(B, H // window_size, window_size, W // window_size, window_size,
+ C)
+ windows = x.permute(0, 1, 3, 2, 4,
+ 5).contiguous().view(-1, window_size, window_size, C)
+ return windows
+
+
+def window_reverse(windows, window_size, H, W):
+ """
+ Args:
+ windows: (num_windows*B, window_size, window_size, C)
+ window_size (int): Window size
+ H (int): Height of image
+ W (int): Width of image
+
+ Returns:
+ x: (B, H, W, C)
+ """
+ B = int(windows.shape[0] / (H * W / window_size / window_size))
+ x = windows.view(B, H // window_size, W // window_size, window_size,
+ window_size, -1)
+ x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
+ return x
+
+
+class WindowAttention(nn.Module):
+ r""" Window based multi-head self attention (W-MSA) module with relative
+ position bias. It supports both of shifted and non-shifted window.
+
+ Args: dim (int): Number of input channels. window_size (tuple[int]): The
+ height and width of the window. num_heads (int): Number of attention
+ heads. qkv_bias (bool, optional): If True, add a learnable bias to
+ query, key, value. Default: True qk_scale (float | None, optional):
+ Override default qk scale of head_dim ** -0.5 if set attn_drop (float,
+ optional): Dropout ratio of attention weight. Default: 0.0 proj_drop (
+ float, optional): Dropout ratio of output. Default: 0.0
+ """
+
+ def __init__(self,
+ dim,
+ window_size,
+ num_heads,
+ qkv_bias=True,
+ qk_scale=None,
+ attn_drop=0.,
+ proj_drop=0.):
+
+ super().__init__()
+ self.dim = dim
+ self.window_size = window_size # Wh, Ww
+ self.num_heads = num_heads
+ head_dim = dim // num_heads
+ self.scale = qk_scale or head_dim**-0.5
+
+ # define a parameter table of relative position bias
+ self.relative_position_bias_table = nn.Parameter(
+ torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1),
+ num_heads)) # 2*Wh-1 * 2*Ww-1, nH
+
+ # get pair-wise relative position index for each token inside the
+ # window
+ coords_h = torch.arange(self.window_size[0])
+ coords_w = torch.arange(self.window_size[1])
+ coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
+ coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
+ relative_coords = (coords_flatten[:, :, None] -
+ coords_flatten[:, None, :]) # 2, Wh*Ww, Wh*Ww
+ relative_coords = relative_coords.permute(
+ 1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
+ relative_coords[:, :, 0] += self.window_size[0] - 1
+ relative_coords[:, :, 1] += self.window_size[1] - 1
+ relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
+ relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
+ self.register_buffer('relative_position_index',
+ relative_position_index)
+
+ self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
+ self.attn_drop = nn.Dropout(attn_drop)
+ self.proj = nn.Linear(dim, dim)
+ self.proj_drop = nn.Dropout(proj_drop)
+
+ trunc_normal_(self.relative_position_bias_table, std=.02)
+ self.softmax = nn.Softmax(dim=-1)
+
+ def forward(self, x, mask=None):
+ """
+ Args: x: input features with shape of (num_windows*B, N, C) mask: (
+ 0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
+ """
+ B_, N, C = x.shape
+ qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads,
+ C // self.num_heads).permute(2, 0, 3, 1, 4)
+ q, k, v = qkv[0], qkv[1], qkv[
+ 2] # make torch script happy (cannot use tensor as tuple)
+
+ q = q * self.scale
+ attn = (q @ k.transpose(-2, -1))
+
+ relative_position_bias = self.relative_position_bias_table[
+ self.relative_position_index.view(-1)].view(
+ self.window_size[0] * self.window_size[1],
+ self.window_size[0] * self.window_size[1],
+ -1) # Wh*Ww,Wh*Ww,nH
+ relative_position_bias = relative_position_bias.permute(
+ 2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
+ attn = attn + relative_position_bias.unsqueeze(0)
+
+ if mask is not None:
+ nW = mask.shape[0]
+ attn = attn.view(B_ // nW, nW, self.num_heads, N,
+ N) + mask.unsqueeze(1).unsqueeze(0)
+ attn = attn.view(-1, self.num_heads, N, N)
+ attn = self.softmax(attn)
+ else:
+ attn = self.softmax(attn)
+
+ attn = self.attn_drop(attn)
+
+ x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
+ x = self.proj(x)
+ x = self.proj_drop(x)
+ return x
+
+ def extra_repr(self) -> str:
+ return (f'dim={self.dim}, window_size={self.window_size}, num_heads='
+ f'{self.num_heads}')
+
+ def flops(self, N):
+ # calculate flops for 1 window with token length of N
+ flops = 0
+ # qkv = self.qkv(x)
+ flops += N * self.dim * 3 * self.dim
+ # attn = (q @ k.transpose(-2, -1))
+ flops += self.num_heads * N * (self.dim // self.num_heads) * N
+ # x = (attn @ v)
+ flops += self.num_heads * N * N * (self.dim // self.num_heads)
+ # x = self.proj(x)
+ flops += N * self.dim * self.dim
+ return flops
+
+
+class SwinTransformerBlock(nn.Module):
+ r""" Swin Transformer Block.
+
+ Args: dim (int): Number of input channels. input_resolution (tuple[int]):
+ Input resolution. num_heads (int): Number of attention heads. window_size
+ (int): Window size. shift_size (int): Shift size for SW-MSA. mlp_ratio (
+ float): Ratio of mlp hidden dim to embedding dim. qkv_bias (bool,
+ optional): If True, add a learnable bias to query, key, value. Default:
+ True qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. drop (float, optional): Dropout rate. Default:
+ 0.0 attn_drop (float, optional): Attention dropout rate. Default: 0.0
+ drop_path (float, optional): Stochastic depth rate. Default: 0.0
+ act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
+ norm_layer (nn.Module, optional): Normalization layer. Default:
+ nn.LayerNorm fused_window_process (bool, optional): If True, use one
+ kernel to fused window shift & window partition for acceleration, similar
+ for the reversed part. Default: False
+ """
+
+ def __init__(self,
+ dim,
+ input_resolution,
+ num_heads,
+ window_size=7,
+ shift_size=0,
+ mlp_ratio=4.,
+ qkv_bias=True,
+ qk_scale=None,
+ drop=0.,
+ attn_drop=0.,
+ drop_path=0.,
+ act_layer=nn.GELU,
+ norm_layer=nn.LayerNorm,
+ fused_window_process=False):
+ super().__init__()
+ self.dim = dim
+ self.input_resolution = input_resolution
+ self.num_heads = num_heads
+ self.window_size = window_size
+ self.shift_size = shift_size
+ self.mlp_ratio = mlp_ratio
+ if min(self.input_resolution) <= self.window_size:
+ # if window size is larger than input resolution, we don't
+ # partition windows
+ self.shift_size = 0
+ self.window_size = min(self.input_resolution)
+ assert 0 <= self.shift_size < self.window_size, ('shift_size must in '
+ '0-window_size')
+
+ self.norm1 = norm_layer(dim)
+ self.attn = WindowAttention(
+ dim,
+ window_size=to_2tuple(self.window_size),
+ num_heads=num_heads,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ attn_drop=attn_drop,
+ proj_drop=drop)
+
+ self.drop_path = DropPath(
+ drop_path) if drop_path > 0. else nn.Identity()
+ self.norm2 = norm_layer(dim)
+ mlp_hidden_dim = int(dim * mlp_ratio)
+ self.mlp = Mlp(
+ in_features=dim,
+ hidden_features=mlp_hidden_dim,
+ act_layer=act_layer,
+ drop=drop)
+
+ if self.shift_size > 0:
+ # calculate attention mask for SW-MSA
+ H, W = self.input_resolution
+ img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
+ h_slices = (slice(0, -self.window_size),
+ slice(-self.window_size,
+ -self.shift_size), slice(-self.shift_size, None))
+ w_slices = (slice(0, -self.window_size),
+ slice(-self.window_size,
+ -self.shift_size), slice(-self.shift_size, None))
+ cnt = 0
+ for h in h_slices:
+ for w in w_slices:
+ img_mask[:, h, w, :] = cnt
+ cnt += 1
+
+ mask_windows = window_partition(
+ img_mask, self.window_size) # nW, window_size, window_size, 1
+ mask_windows = mask_windows.view(
+ -1, self.window_size * self.window_size)
+ attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
+ attn_mask = attn_mask.masked_fill(attn_mask != 0,
+ float(-100.0)).masked_fill(
+ attn_mask == 0, float(0.0))
+ else:
+ attn_mask = None
+
+ self.register_buffer('attn_mask', attn_mask)
+ self.fused_window_process = fused_window_process
+
+ def forward(self, x):
+ H, W = self.input_resolution
+ B, L, C = x.shape
+ assert L == H * W, 'input feature has wrong size'
+
+ shortcut = x
+ x = self.norm1(x)
+ x = x.view(B, H, W, C)
+
+ # cyclic shift
+ if self.shift_size > 0:
+ if not self.fused_window_process:
+ shifted_x = torch.roll(
+ x,
+ shifts=(-self.shift_size, -self.shift_size),
+ dims=(1, 2))
+ # partition windows
+ x_windows = window_partition(
+ shifted_x,
+ self.window_size) # nW*B, window_size, window_size, C
+ else:
+ x_windows = WindowProcess.apply(x, B, H, W, C,
+ -self.shift_size,
+ self.window_size)
+ else:
+ shifted_x = x
+ # partition windows
+ x_windows = window_partition(
+ shifted_x,
+ self.window_size) # nW*B, window_size, window_size, C
+
+ x_windows = x_windows.view(-1, self.window_size * self.window_size,
+ C) # nW*B, window_size*window_size, C
+
+ # W-MSA/SW-MSA
+ attn_windows = self.attn(
+ x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C
+
+ # merge windows
+ attn_windows = attn_windows.view(-1, self.window_size,
+ self.window_size, C)
+
+ # reverse cyclic shift
+ if self.shift_size > 0:
+ if not self.fused_window_process:
+ shifted_x = window_reverse(attn_windows, self.window_size, H,
+ W) # B H' W' C
+ x = torch.roll(
+ shifted_x,
+ shifts=(self.shift_size, self.shift_size),
+ dims=(1, 2))
+ else:
+ x = WindowProcessReverse.apply(attn_windows, B, H, W, C,
+ self.shift_size,
+ self.window_size)
+ else:
+ shifted_x = window_reverse(attn_windows, self.window_size, H,
+ W) # B H' W' C
+ x = shifted_x
+ x = x.view(B, H * W, C)
+ x = shortcut + self.drop_path(x)
+
+ # FFN
+ x = x + self.drop_path(self.mlp(self.norm2(x)))
+
+ return x
+
+ def extra_repr(self) -> str:
+ return (f'dim={self.dim}, '
+ f'input_resolution={self.input_resolution}, '
+ f'num_heads={self.num_heads}, '
+ f'window_size={self.window_size}, '
+ f'shift_size={self.shift_size}, '
+ f'mlp_ratio={self.mlp_ratio}')
+
+ def flops(self):
+ flops = 0
+ H, W = self.input_resolution
+ # norm1
+ flops += self.dim * H * W
+ # W-MSA/SW-MSA
+ nW = H * W / self.window_size / self.window_size
+ flops += nW * self.attn.flops(self.window_size * self.window_size)
+ # mlp
+ flops += 2 * H * W * self.dim * self.dim * self.mlp_ratio
+ # norm2
+ flops += self.dim * H * W
+ return flops
+
+
+class PatchMerging(nn.Module):
+ r""" Patch Merging Layer.
+
+ Args: input_resolution (tuple[int]): Resolution of input feature. dim (
+ int): Number of input channels. norm_layer (nn.Module, optional):
+ Normalization layer. Default: nn.LayerNorm
+ """
+
+ def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
+ super().__init__()
+ self.input_resolution = input_resolution
+ self.dim = dim
+ self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
+ self.norm = norm_layer(4 * dim)
+
+ def forward(self, x):
+ """
+ x: B, H*W, C
+ """
+ H, W = self.input_resolution
+ B, L, C = x.shape
+ assert L == H * W, 'input feature has wrong size'
+ assert H % 2 == 0 and W % 2 == 0, f'x size ({H}*{W}) are not even.'
+
+ x = x.view(B, H, W, C)
+
+ x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
+ x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
+ x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
+ x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
+ x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
+ x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
+
+ x = self.norm(x)
+ x = self.reduction(x)
+
+ return x
+
+ def extra_repr(self) -> str:
+ return f'input_resolution={self.input_resolution}, dim={self.dim}'
+
+ def flops(self):
+ H, W = self.input_resolution
+ flops = H * W * self.dim
+ flops += (H // 2) * (W // 2) * 4 * self.dim * 2 * self.dim
+ return flops
+
+
+class BasicLayer(nn.Module):
+ """A basic Swin Transformer layer for one stage.
+
+ Args: dim (int): Number of input channels. input_resolution (tuple[int]):
+ Input resolution. depth (int): Number of blocks. num_heads (int): Number
+ of attention heads. window_size (int): Local window size. mlp_ratio (
+ float): Ratio of mlp hidden dim to embedding dim. qkv_bias (bool,
+ optional): If True, add a learnable bias to query, key, value. Default:
+ True qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. drop (float, optional): Dropout rate. Default:
+ 0.0 attn_drop (float, optional): Attention dropout rate. Default: 0.0
+ drop_path (float | tuple[float], optional): Stochastic depth rate.
+ Default: 0.0 norm_layer (nn.Module, optional): Normalization layer.
+ Default: nn.LayerNorm downsample (nn.Module | None, optional): Downsample
+ layer at the end of the layer. Default: None use_checkpoint (bool):
+ Whether to use checkpointing to save memory. Default: False.
+ fused_window_process (bool, optional): If True, use one kernel to fused
+ window shift & window partition for acceleration, similar for the
+ reversed part. Default: False
+ """
+
+ def __init__(self,
+ dim,
+ input_resolution,
+ depth,
+ num_heads,
+ window_size,
+ mlp_ratio=4.,
+ qkv_bias=True,
+ qk_scale=None,
+ drop=0.,
+ attn_drop=0.,
+ drop_path=0.,
+ norm_layer=nn.LayerNorm,
+ downsample=None,
+ use_checkpoint=False,
+ fused_window_process=False):
+
+ super().__init__()
+ self.dim = dim
+ self.input_resolution = input_resolution
+ self.depth = depth
+ self.use_checkpoint = use_checkpoint
+
+ # build blocks
+ self.blocks = nn.ModuleList([
+ SwinTransformerBlock(
+ dim=dim,
+ input_resolution=input_resolution,
+ num_heads=num_heads,
+ window_size=window_size,
+ shift_size=0 if (i % 2 == 0) else window_size // 2,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop,
+ attn_drop=attn_drop,
+ drop_path=drop_path[i]
+ if isinstance(drop_path, list) else drop_path,
+ norm_layer=norm_layer,
+ fused_window_process=fused_window_process)
+ for i in range(depth)
+ ])
+
+ # patch merging layer
+ if downsample is not None:
+ self.downsample = downsample(
+ input_resolution, dim=dim, norm_layer=norm_layer)
+ else:
+ self.downsample = None
+
+ def forward(self, x):
+ for blk in self.blocks:
+ if self.use_checkpoint:
+ x = checkpoint.checkpoint(blk, x)
+ else:
+ x = blk(x)
+ if self.downsample is not None:
+ x = self.downsample(x)
+ return x
+
+ def extra_repr(self) -> str:
+ return (f'dim={self.dim}, input_resolution={self.input_resolution}, '
+ f'depth={self.depth}')
+
+ def flops(self):
+ flops = 0
+ for blk in self.blocks:
+ flops += blk.flops()
+ if self.downsample is not None:
+ flops += self.downsample.flops()
+ return flops
+
+
+class PatchEmbed(nn.Module):
+ r""" Image to Patch Embedding
+
+ Args: img_size (int): Image size. Default: 224. patch_size (int): Patch
+ token size. Default: 4. in_chans (int): Number of input image channels.
+ Default: 3. embed_dim (int): Number of linear projection output channels.
+ Default: 96. norm_layer (nn.Module, optional): Normalization layer.
+ Default: None
+ """
+
+ def __init__(self,
+ img_size=224,
+ patch_size=4,
+ in_chans=3,
+ embed_dim=96,
+ norm_layer=None):
+ super().__init__()
+ img_size = to_2tuple(img_size)
+ patch_size = to_2tuple(patch_size)
+ patches_resolution = [
+ img_size[0] // patch_size[0], img_size[1] // patch_size[1]
+ ]
+ self.img_size = img_size
+ self.patch_size = patch_size
+ self.patches_resolution = patches_resolution
+ self.num_patches = patches_resolution[0] * patches_resolution[1]
+
+ self.in_chans = in_chans
+ self.embed_dim = embed_dim
+
+ self.proj = nn.Conv2d(
+ in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
+ if norm_layer is not None:
+ self.norm = norm_layer(embed_dim)
+ else:
+ self.norm = None
+
+ def forward(self, x):
+ B, C, H, W = x.shape
+ # FIXME look at relaxing size constraints
+ assert H == self.img_size[0] and W == self.img_size[1], \
+ (f"Input image size ({H}*{W}) doesn't match model "
+ f'({self.img_size[0]}*{self.img_size[1]}).')
+ x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
+ if self.norm is not None:
+ x = self.norm(x)
+ return x
+
+ def flops(self):
+ Ho, Wo = self.patches_resolution
+ flops = Ho * Wo * self.embed_dim * self.in_chans * (
+ self.patch_size[0] * self.patch_size[1])
+ if self.norm is not None:
+ flops += Ho * Wo * self.embed_dim
+ return flops
+
+
+class SwinTransformer(nn.Module):
+ r""" Swin Transformer A PyTorch impl of : `Swin Transformer: Hierarchical
+ Vision Transformer using Shifted Windows` -
+ https://arxiv.org/pdf/2103.14030
+
+ Args: img_size (int | tuple(int)): Input image size. Default 224
+ patch_size (int | tuple(int)): Patch size. Default: 4 in_chans (int):
+ Number of input image channels. Default: 3 num_classes (int): Number of
+ classes for classification head. Default: 1000 embed_dim (int): Patch
+ embedding dimension. Default: 96 depths (tuple(int)): Depth of each Swin
+ Transformer layer. num_heads (tuple(int)): Number of attention heads in
+ different layers. window_size (int): Window size. Default: 7 mlp_ratio (
+ float): Ratio of mlp hidden dim to embedding dim. Default: 4 qkv_bias (
+ bool): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float): Override default qk scale of head_dim ** -0.5 if set.
+ Default: None drop_rate (float): Dropout rate. Default: 0 attn_drop_rate
+ (float): Attention dropout rate. Default: 0 drop_path_rate (float):
+ Stochastic depth rate. Default: 0.1 norm_layer (nn.Module): Normalization
+ layer. Default: nn.LayerNorm. ape (bool): If True, add absolute position
+ embedding to the patch embedding. Default: False patch_norm (bool): If
+ True, add normalization after patch embedding. Default: True
+ use_checkpoint (bool): Whether to use checkpointing to save memory.
+ Default: False fused_window_process (bool, optional): If True, use one
+ kernel to fused window shift & window partition for acceleration, similar
+ for the reversed part. Default: False
+ """
+
+ def __init__(self,
+ img_size=224,
+ patch_size=4,
+ in_chans=3,
+ num_classes=1000,
+ embed_dim=96,
+ depths=[2, 2, 6, 2],
+ num_heads=[3, 6, 12, 24],
+ window_size=7,
+ mlp_ratio=4.,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.1,
+ norm_layer=nn.LayerNorm,
+ ape=False,
+ patch_norm=True,
+ use_checkpoint=False,
+ fused_window_process=False,
+ **kwargs):
+ super().__init__()
+
+ self.num_classes = num_classes
+ self.num_layers = len(depths)
+ self.embed_dim = embed_dim
+ self.ape = ape
+ self.patch_norm = patch_norm
+ self.num_features = int(embed_dim * 2**(self.num_layers - 1))
+ self.mlp_ratio = mlp_ratio
+
+ # split image into non-overlapping patches
+ self.patch_embed = PatchEmbed(
+ img_size=img_size,
+ patch_size=patch_size,
+ in_chans=in_chans,
+ embed_dim=embed_dim,
+ norm_layer=norm_layer if self.patch_norm else None)
+ num_patches = self.patch_embed.num_patches
+ patches_resolution = self.patch_embed.patches_resolution
+ self.patches_resolution = patches_resolution
+
+ # absolute position embedding
+ if self.ape:
+ self.absolute_pos_embed = nn.Parameter(
+ torch.zeros(1, num_patches, embed_dim))
+ trunc_normal_(self.absolute_pos_embed, std=.02)
+
+ self.pos_drop = nn.Dropout(p=drop_rate)
+
+ # stochastic depth
+ dpr = [
+ x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))
+ ] # stochastic depth decay rule
+
+ # build layers
+ self.layers = nn.ModuleList()
+ for i_layer in range(self.num_layers):
+ layer = BasicLayer(
+ dim=int(embed_dim * 2**i_layer),
+ input_resolution=(patches_resolution[0] // (2**i_layer),
+ patches_resolution[1] // (2**i_layer)),
+ depth=depths[i_layer],
+ num_heads=num_heads[i_layer],
+ window_size=window_size,
+ mlp_ratio=self.mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop_rate,
+ attn_drop=attn_drop_rate,
+ drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
+ norm_layer=norm_layer,
+ downsample=PatchMerging if
+ (i_layer < self.num_layers - 1) else None,
+ use_checkpoint=use_checkpoint,
+ fused_window_process=fused_window_process)
+ self.layers.append(layer)
+
+ self.norm = norm_layer(self.num_features)
+ self.avgpool = nn.AdaptiveAvgPool1d(1)
+ self.head = nn.Linear(
+ self.num_features,
+ num_classes) if num_classes > 0 else nn.Identity()
+
+ self.apply(self._init_weights)
+
+ def _init_weights(self, m):
+ if isinstance(m, nn.Linear):
+ trunc_normal_(m.weight, std=.02)
+ if isinstance(m, nn.Linear) and m.bias is not None:
+ nn.init.constant_(m.bias, 0)
+ elif isinstance(m, nn.LayerNorm):
+ nn.init.constant_(m.bias, 0)
+ nn.init.constant_(m.weight, 1.0)
+
+ @torch.jit.ignore
+ def no_weight_decay(self):
+ return {'absolute_pos_embed'}
+
+ @torch.jit.ignore
+ def no_weight_decay_keywords(self):
+ return {'relative_position_bias_table'}
+
+ def forward_features(self, x):
+ x = self.patch_embed(x)
+ if self.ape:
+ x = x + self.absolute_pos_embed
+ x = self.pos_drop(x)
+
+ for layer in self.layers:
+ x = layer(x)
+
+ x = self.norm(x) # B L C
+ x = self.avgpool(x.transpose(1, 2)) # B C 1
+ x = torch.flatten(x, 1)
+ return x
+
+ def forward(self, x):
+ x = self.forward_features(x)
+ x = self.head(x)
+ return x
+
+ def flops(self):
+ flops = 0
+ flops += self.patch_embed.flops()
+ for i, layer in enumerate(self.layers):
+ flops += layer.flops()
+ flops += self.num_features * self.patches_resolution[
+ 0] * self.patches_resolution[1] // (2**self.num_layers)
+ flops += self.num_features * self.num_classes
+ return flops
diff --git a/projects/pose_anything/models/backbones/swin_transformer_moe.py b/projects/pose_anything/models/backbones/swin_transformer_moe.py
new file mode 100644
index 0000000000..f7e07d540f
--- /dev/null
+++ b/projects/pose_anything/models/backbones/swin_transformer_moe.py
@@ -0,0 +1,1066 @@
+# --------------------------------------------------------
+# Swin Transformer MoE
+# Copyright (c) 2022 Microsoft
+# Licensed under The MIT License [see LICENSE for details]
+# Written by Ze Liu
+# --------------------------------------------------------
+
+import numpy as np
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.checkpoint as checkpoint
+from timm.models.layers import DropPath, to_2tuple, trunc_normal_
+
+try:
+ from tutel import moe as tutel_moe
+except ImportError:
+ tutel_moe = None
+ print(
+ 'Tutel has not been installed. To use Swin-MoE, please install Tutel;'
+ 'otherwise, just ignore this.')
+
+
+class Mlp(nn.Module):
+
+ def __init__(self,
+ in_features,
+ hidden_features=None,
+ out_features=None,
+ act_layer=nn.GELU,
+ drop=0.,
+ mlp_fc2_bias=True):
+ super().__init__()
+ out_features = out_features or in_features
+ hidden_features = hidden_features or in_features
+ self.fc1 = nn.Linear(in_features, hidden_features)
+ self.act = act_layer()
+ self.fc2 = nn.Linear(hidden_features, out_features, bias=mlp_fc2_bias)
+ self.drop = nn.Dropout(drop)
+
+ def forward(self, x):
+ x = self.fc1(x)
+ x = self.act(x)
+ x = self.drop(x)
+ x = self.fc2(x)
+ x = self.drop(x)
+ return x
+
+
+class MoEMlp(nn.Module):
+
+ def __init__(self,
+ in_features,
+ hidden_features,
+ num_local_experts,
+ top_value,
+ capacity_factor=1.25,
+ cosine_router=False,
+ normalize_gate=False,
+ use_bpr=True,
+ is_gshard_loss=True,
+ gate_noise=1.0,
+ cosine_router_dim=256,
+ cosine_router_init_t=0.5,
+ moe_drop=0.0,
+ init_std=0.02,
+ mlp_fc2_bias=True):
+ super().__init__()
+
+ self.in_features = in_features
+ self.hidden_features = hidden_features
+ self.num_local_experts = num_local_experts
+ self.top_value = top_value
+ self.capacity_factor = capacity_factor
+ self.cosine_router = cosine_router
+ self.normalize_gate = normalize_gate
+ self.use_bpr = use_bpr
+ self.init_std = init_std
+ self.mlp_fc2_bias = mlp_fc2_bias
+
+ self.dist_rank = dist.get_rank()
+
+ self._dropout = nn.Dropout(p=moe_drop)
+
+ _gate_type = {
+ 'type': 'cosine_top' if cosine_router else 'top',
+ 'k': top_value,
+ 'capacity_factor': capacity_factor,
+ 'gate_noise': gate_noise,
+ 'fp32_gate': True
+ }
+ if cosine_router:
+ _gate_type['proj_dim'] = cosine_router_dim
+ _gate_type['init_t'] = cosine_router_init_t
+ self._moe_layer = tutel_moe.moe_layer(
+ gate_type=_gate_type,
+ model_dim=in_features,
+ experts={
+ 'type': 'ffn',
+ 'count_per_node': num_local_experts,
+ 'hidden_size_per_expert': hidden_features,
+ 'activation_fn': lambda x: self._dropout(F.gelu(x))
+ },
+ scan_expert_func=lambda name, param: setattr(
+ param, 'skip_allreduce', True),
+ seeds=(1, self.dist_rank + 1, self.dist_rank + 1),
+ batch_prioritized_routing=use_bpr,
+ normalize_gate=normalize_gate,
+ is_gshard_loss=is_gshard_loss,
+ )
+ if not self.mlp_fc2_bias:
+ self._moe_layer.experts.batched_fc2_bias.requires_grad = False
+
+ def forward(self, x):
+ x = self._moe_layer(x)
+ return x, x.l_aux
+
+ def extra_repr(self) -> str:
+ return (f'[Statistics-{self.dist_rank}] param count for MoE, '
+ f'in_features = {self.in_features}, '
+ f'hidden_features = {self.hidden_features}, '
+ f'num_local_experts = {self.num_local_experts}, '
+ f'top_value = {self.top_value}, '
+ f'cosine_router={self.cosine_router} '
+ f'normalize_gate={self.normalize_gate}, '
+ f'use_bpr = {self.use_bpr}')
+
+ def _init_weights(self):
+ if hasattr(self._moe_layer, 'experts'):
+ trunc_normal_(
+ self._moe_layer.experts.batched_fc1_w, std=self.init_std)
+ trunc_normal_(
+ self._moe_layer.experts.batched_fc2_w, std=self.init_std)
+ nn.init.constant_(self._moe_layer.experts.batched_fc1_bias, 0)
+ nn.init.constant_(self._moe_layer.experts.batched_fc2_bias, 0)
+
+
+def window_partition(x, window_size):
+ """
+ Args:
+ x: (B, H, W, C)
+ window_size (int): window size
+
+ Returns:
+ windows: (num_windows*B, window_size, window_size, C)
+ """
+ B, H, W, C = x.shape
+ x = x.view(B, H // window_size, window_size, W // window_size, window_size,
+ C)
+ windows = x.permute(0, 1, 3, 2, 4,
+ 5).contiguous().view(-1, window_size, window_size, C)
+ return windows
+
+
+def window_reverse(windows, window_size, H, W):
+ """
+ Args:
+ windows: (num_windows*B, window_size, window_size, C)
+ window_size (int): Window size
+ H (int): Height of image
+ W (int): Width of image
+
+ Returns:
+ x: (B, H, W, C)
+ """
+ B = int(windows.shape[0] / (H * W / window_size / window_size))
+ x = windows.view(B, H // window_size, W // window_size, window_size,
+ window_size, -1)
+ x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
+ return x
+
+
+class WindowAttention(nn.Module):
+ r""" Window based multi-head self attention (W-MSA) module with relative
+ position bias.
+ It supports both of shifted and non-shifted window.
+
+ Args:
+ dim (int): Number of input channels.
+ window_size (tuple[int]): The height and width of the window.
+ num_heads (int): Number of attention heads.
+ qkv_bias (bool, optional): If True, add a learnable bias to query,
+ key, value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set
+ attn_drop (float, optional): Dropout ratio of attention weight.
+ Default: 0.0
+ proj_drop (float, optional): Dropout ratio of output. Default: 0.0
+ pretrained_window_size (tuple[int]): The height and width of the
+ window in pretraining.
+ """
+
+ def __init__(self,
+ dim,
+ window_size,
+ num_heads,
+ qkv_bias=True,
+ qk_scale=None,
+ attn_drop=0.,
+ proj_drop=0.,
+ pretrained_window_size=[0, 0]):
+
+ super().__init__()
+ self.dim = dim
+ self.window_size = window_size # Wh, Ww
+ self.pretrained_window_size = pretrained_window_size
+ self.num_heads = num_heads
+
+ head_dim = dim // num_heads
+ self.scale = qk_scale or head_dim**-0.5
+
+ # mlp to generate continuous relative position bias
+ self.cpb_mlp = nn.Sequential(
+ nn.Linear(2, 512, bias=True), nn.ReLU(inplace=True),
+ nn.Linear(512, num_heads, bias=False))
+
+ # get relative_coords_table
+ relative_coords_h = torch.arange(
+ -(self.window_size[0] - 1),
+ self.window_size[0],
+ dtype=torch.float32)
+ relative_coords_w = torch.arange(
+ -(self.window_size[1] - 1),
+ self.window_size[1],
+ dtype=torch.float32)
+ relative_coords_table = torch.stack(
+ torch.meshgrid([relative_coords_h, relative_coords_w])).permute(
+ 1, 2, 0).contiguous().unsqueeze(0) # 1, 2*Wh-1, 2*Ww-1, 2
+ if pretrained_window_size[0] > 0:
+ relative_coords_table[:, :, :, 0] /= (
+ pretrained_window_size[0] - 1)
+ relative_coords_table[:, :, :, 1] /= (
+ pretrained_window_size[1] - 1)
+ else:
+ relative_coords_table[:, :, :, 0] /= (self.window_size[0] - 1)
+ relative_coords_table[:, :, :, 1] /= (self.window_size[1] - 1)
+ relative_coords_table *= 8 # normalize to -8, 8
+ relative_coords_table = torch.sign(relative_coords_table) * torch.log2(
+ torch.abs(relative_coords_table) + 1.0) / np.log2(8)
+
+ self.register_buffer('relative_coords_table', relative_coords_table)
+
+ # get pair-wise relative position index for each token inside the
+ # window
+ coords_h = torch.arange(self.window_size[0])
+ coords_w = torch.arange(self.window_size[1])
+ coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
+ coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
+ relative_coords = (coords_flatten[:, :, None] -
+ coords_flatten[:, None, :]) # 2, Wh*Ww, Wh*Ww
+ relative_coords = relative_coords.permute(
+ 1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
+ relative_coords[:, :, 0] += self.window_size[0] - 1
+ relative_coords[:, :, 1] += self.window_size[1] - 1
+ relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
+ relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
+ self.register_buffer('relative_position_index',
+ relative_position_index)
+
+ self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
+ self.attn_drop = nn.Dropout(attn_drop)
+ self.proj = nn.Linear(dim, dim)
+ self.proj_drop = nn.Dropout(proj_drop)
+ self.softmax = nn.Softmax(dim=-1)
+
+ def forward(self, x, mask=None):
+ """
+ Args:
+ x: input features with shape of (num_windows*B, N, C)
+ mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or
+ None
+ """
+ B_, N, C = x.shape
+ qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads,
+ C // self.num_heads).permute(2, 0, 3, 1, 4)
+ q, k, v = qkv[0], qkv[1], qkv[
+ 2] # make torchscript happy (cannot use tensor as tuple)
+
+ q = q * self.scale
+ attn = (q @ k.transpose(-2, -1))
+
+ relative_position_bias_table = self.cpb_mlp(
+ self.relative_coords_table).view(-1, self.num_heads)
+ relative_position_bias = relative_position_bias_table[
+ self.relative_position_index.view(-1)].view(
+ self.window_size[0] * self.window_size[1],
+ self.window_size[0] * self.window_size[1],
+ -1) # Wh*Ww,Wh*Ww,nH
+ relative_position_bias = relative_position_bias.permute(
+ 2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
+ attn = attn + relative_position_bias.unsqueeze(0)
+
+ if mask is not None:
+ nW = mask.shape[0]
+ attn = attn.view(B_ // nW, nW, self.num_heads, N,
+ N) + mask.unsqueeze(1).unsqueeze(0)
+ attn = attn.view(-1, self.num_heads, N, N)
+ attn = self.softmax(attn)
+ else:
+ attn = self.softmax(attn)
+
+ attn = self.attn_drop(attn)
+
+ x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
+ x = self.proj(x)
+ x = self.proj_drop(x)
+ return x
+
+ def extra_repr(self) -> str:
+ return f'dim={self.dim}, window_size={self.window_size}, ' \
+ (f'pretrained_window_size={self.pretrained_window_size}, '
+ f'num_heads={self.num_heads}')
+
+ def flops(self, N):
+ # calculate flops for 1 window with token length of N
+ flops = 0
+ # qkv = self.qkv(x)
+ flops += N * self.dim * 3 * self.dim
+ # attn = (q @ k.transpose(-2, -1))
+ flops += self.num_heads * N * (self.dim // self.num_heads) * N
+ # x = (attn @ v)
+ flops += self.num_heads * N * N * (self.dim // self.num_heads)
+ # x = self.proj(x)
+ flops += N * self.dim * self.dim
+ return flops
+
+
+class SwinTransformerBlock(nn.Module):
+ r""" Swin Transformer Block.
+
+ Args:
+ dim (int): Number of input channels.
+ input_resolution (tuple[int]): Input resolution.
+ num_heads (int): Number of attention heads.
+ window_size (int): Window size.
+ shift_size (int): Shift size for SW-MSA.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
+ qkv_bias (bool, optional): If True, add a learnable bias to query,
+ key, value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set.
+ drop (float, optional): Dropout rate. Default: 0.0
+ attn_drop (float, optional): Attention dropout rate. Default: 0.0
+ drop_path (float, optional): Stochastic depth rate. Default: 0.0
+ act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
+ norm_layer (nn.Module, optional): Normalization layer. Default:
+ nn.LayerNorm
+ mlp_fc2_bias (bool): Whether to add bias in fc2 of Mlp. Default: True
+ init_std: Initialization std. Default: 0.02
+ pretrained_window_size (int): Window size in pretraining.
+ is_moe (bool): If True, this block is a MoE block.
+ num_local_experts (int): number of local experts in each device (
+ GPU). Default: 1
+ top_value (int): the value of k in top-k gating. Default: 1
+ capacity_factor (float): the capacity factor in MoE. Default: 1.25
+ cosine_router (bool): Whether to use cosine router. Default: False
+ normalize_gate (bool): Whether to normalize the gating score in top-k
+ gating. Default: False
+ use_bpr (bool): Whether to use batch-prioritized-routing. Default: True
+ is_gshard_loss (bool): If True, use Gshard balance loss.
+ If False, use the load loss and importance
+ loss in "arXiv:1701.06538". Default: False
+ gate_noise (float): the noise ratio in top-k gating. Default: 1.0
+ cosine_router_dim (int): Projection dimension in cosine router.
+ cosine_router_init_t (float): Initialization temperature in cosine
+ router.
+ moe_drop (float): Dropout rate in MoE. Default: 0.0
+ """
+
+ def __init__(self,
+ dim,
+ input_resolution,
+ num_heads,
+ window_size=7,
+ shift_size=0,
+ mlp_ratio=4.,
+ qkv_bias=True,
+ qk_scale=None,
+ drop=0.,
+ attn_drop=0.,
+ drop_path=0.,
+ act_layer=nn.GELU,
+ norm_layer=nn.LayerNorm,
+ mlp_fc2_bias=True,
+ init_std=0.02,
+ pretrained_window_size=0,
+ is_moe=False,
+ num_local_experts=1,
+ top_value=1,
+ capacity_factor=1.25,
+ cosine_router=False,
+ normalize_gate=False,
+ use_bpr=True,
+ is_gshard_loss=True,
+ gate_noise=1.0,
+ cosine_router_dim=256,
+ cosine_router_init_t=0.5,
+ moe_drop=0.0):
+ super().__init__()
+ self.dim = dim
+ self.input_resolution = input_resolution
+ self.num_heads = num_heads
+ self.window_size = window_size
+ self.shift_size = shift_size
+ self.mlp_ratio = mlp_ratio
+ self.is_moe = is_moe
+ self.capacity_factor = capacity_factor
+ self.top_value = top_value
+
+ if min(self.input_resolution) <= self.window_size:
+ # if window size is larger than input resolution, we don't
+ # partition windows
+ self.shift_size = 0
+ self.window_size = min(self.input_resolution)
+ assert 0 <= self.shift_size < self.window_size, ('shift_size must in '
+ '0-window_size')
+
+ self.norm1 = norm_layer(dim)
+ self.attn = WindowAttention(
+ dim,
+ window_size=to_2tuple(self.window_size),
+ num_heads=num_heads,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ attn_drop=attn_drop,
+ proj_drop=drop,
+ pretrained_window_size=to_2tuple(pretrained_window_size))
+
+ self.drop_path = DropPath(
+ drop_path) if drop_path > 0. else nn.Identity()
+ self.norm2 = norm_layer(dim)
+ mlp_hidden_dim = int(dim * mlp_ratio)
+ if self.is_moe:
+ self.mlp = MoEMlp(
+ in_features=dim,
+ hidden_features=mlp_hidden_dim,
+ num_local_experts=num_local_experts,
+ top_value=top_value,
+ capacity_factor=capacity_factor,
+ cosine_router=cosine_router,
+ normalize_gate=normalize_gate,
+ use_bpr=use_bpr,
+ is_gshard_loss=is_gshard_loss,
+ gate_noise=gate_noise,
+ cosine_router_dim=cosine_router_dim,
+ cosine_router_init_t=cosine_router_init_t,
+ moe_drop=moe_drop,
+ mlp_fc2_bias=mlp_fc2_bias,
+ init_std=init_std)
+ else:
+ self.mlp = Mlp(
+ in_features=dim,
+ hidden_features=mlp_hidden_dim,
+ act_layer=act_layer,
+ drop=drop,
+ mlp_fc2_bias=mlp_fc2_bias)
+
+ if self.shift_size > 0:
+ # calculate attention mask for SW-MSA
+ H, W = self.input_resolution
+ img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
+ h_slices = (slice(0, -self.window_size),
+ slice(-self.window_size,
+ -self.shift_size), slice(-self.shift_size, None))
+ w_slices = (slice(0, -self.window_size),
+ slice(-self.window_size,
+ -self.shift_size), slice(-self.shift_size, None))
+ cnt = 0
+ for h in h_slices:
+ for w in w_slices:
+ img_mask[:, h, w, :] = cnt
+ cnt += 1
+
+ mask_windows = window_partition(
+ img_mask, self.window_size) # nW, window_size, window_size, 1
+ mask_windows = mask_windows.view(
+ -1, self.window_size * self.window_size)
+ attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
+ attn_mask = attn_mask.masked_fill(attn_mask != 0,
+ float(-100.0)).masked_fill(
+ attn_mask == 0, float(0.0))
+ else:
+ attn_mask = None
+
+ self.register_buffer('attn_mask', attn_mask)
+
+ def forward(self, x):
+ H, W = self.input_resolution
+ B, L, C = x.shape
+ assert L == H * W, 'input feature has wrong size'
+
+ shortcut = x
+ x = self.norm1(x)
+ x = x.view(B, H, W, C)
+
+ # cyclic shift
+ if self.shift_size > 0:
+ shifted_x = torch.roll(
+ x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
+ else:
+ shifted_x = x
+
+ # partition windows
+ x_windows = window_partition(
+ shifted_x, self.window_size) # nW*B, window_size, window_size, C
+ x_windows = x_windows.view(-1, self.window_size * self.window_size,
+ C) # nW*B, window_size*window_size, C
+
+ # W-MSA/SW-MSA
+ attn_windows = self.attn(
+ x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C
+
+ # merge windows
+ attn_windows = attn_windows.view(-1, self.window_size,
+ self.window_size, C)
+ shifted_x = window_reverse(attn_windows, self.window_size, H,
+ W) # B H' W' C
+
+ # reverse cyclic shift
+ if self.shift_size > 0:
+ x = torch.roll(
+ shifted_x,
+ shifts=(self.shift_size, self.shift_size),
+ dims=(1, 2))
+ else:
+ x = shifted_x
+ x = x.view(B, H * W, C)
+ x = shortcut + self.drop_path(x)
+
+ # FFN
+ shortcut = x
+ x = self.norm2(x)
+ if self.is_moe:
+ x, l_aux = self.mlp(x)
+ x = shortcut + self.drop_path(x)
+ return x, l_aux
+ else:
+ x = shortcut + self.drop_path(self.mlp(x))
+ return x
+
+ def extra_repr(self) -> str:
+ return (f'dim={self.dim}, '
+ f'input_resolution={self.input_resolution}, '
+ f'num_heads={self.num_heads}, '
+ f'window_size={self.window_size}, '
+ f'shift_size={self.shift_size}, '
+ f'mlp_ratio={self.mlp_ratio}')
+
+ def flops(self):
+ flops = 0
+ H, W = self.input_resolution
+ # norm1
+ flops += self.dim * H * W
+ # W-MSA/SW-MSA
+ nW = H * W / self.window_size / self.window_size
+ flops += nW * self.attn.flops(self.window_size * self.window_size)
+ # mlp
+ if self.is_moe:
+ flops += (2 * H * W * self.dim * self.dim * self.mlp_ratio *
+ self.capacity_factor * self.top_value)
+ else:
+ flops += 2 * H * W * self.dim * self.dim * self.mlp_ratio
+ # norm2
+ flops += self.dim * H * W
+ return flops
+
+
+class PatchMerging(nn.Module):
+ r""" Patch Merging Layer.
+
+ Args:
+ input_resolution (tuple[int]): Resolution of input feature.
+ dim (int): Number of input channels.
+ norm_layer (nn.Module, optional): Normalization layer. Default:
+ nn.LayerNorm
+ """
+
+ def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
+ super().__init__()
+ self.input_resolution = input_resolution
+ self.dim = dim
+ self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
+ self.norm = norm_layer(4 * dim)
+
+ def forward(self, x):
+ """
+ x: B, H*W, C
+ """
+ H, W = self.input_resolution
+ B, L, C = x.shape
+ assert L == H * W, 'input feature has wrong size'
+ assert H % 2 == 0 and W % 2 == 0, f'x size ({H}*{W}) are not even.'
+
+ x = x.view(B, H, W, C)
+
+ x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
+ x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
+ x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
+ x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
+ x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
+ x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
+
+ x = self.norm(x)
+ x = self.reduction(x)
+
+ return x
+
+ def extra_repr(self) -> str:
+ return f'input_resolution={self.input_resolution}, dim={self.dim}'
+
+ def flops(self):
+ H, W = self.input_resolution
+ flops = H * W * self.dim
+ flops += (H // 2) * (W // 2) * 4 * self.dim * 2 * self.dim
+ return flops
+
+
+class BasicLayer(nn.Module):
+ """A basic Swin Transformer layer for one stage.
+
+ Args:
+ dim (int): Number of input channels.
+ input_resolution (tuple[int]): Input resolution.
+ depth (int): Number of blocks.
+ num_heads (int): Number of attention heads.
+ window_size (int): Local window size.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
+ qkv_bias (bool, optional): If True, add a learnable bias to query,
+ key, value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set.
+ drop (float, optional): Dropout rate. Default: 0.0
+ attn_drop (float, optional): Attention dropout rate. Default: 0.0
+ drop_path (float | tuple[float], optional): Stochastic depth rate.
+ Default: 0.0
+ norm_layer (nn.Module, optional): Normalization layer. Default:
+ nn.LayerNorm
+ downsample (nn.Module | None, optional): Downsample layer at the end
+ of the layer. Default: None
+ mlp_fc2_bias (bool): Whether to add bias in fc2 of Mlp. Default: True
+ init_std: Initialization std. Default: 0.02
+ use_checkpoint (bool): Whether to use checkpointing to save memory.
+ Default: False.
+ pretrained_window_size (int): Local window size in pretraining.
+ moe_blocks (tuple(int)): The index of each MoE block.
+ num_local_experts (int): number of local experts in each device (
+ GPU). Default: 1
+ top_value (int): the value of k in top-k gating. Default: 1
+ capacity_factor (float): the capacity factor in MoE. Default: 1.25
+ cosine_router (bool): Whether to use cosine router Default: False
+ normalize_gate (bool): Whether to normalize the gating score in top-k
+ gating. Default: False
+ use_bpr (bool): Whether to use batch-prioritized-routing. Default: True
+ is_gshard_loss (bool): If True, use Gshard balance loss.
+ If False, use the load loss and importance
+ loss in "arXiv:1701.06538". Default: False
+ gate_noise (float): the noise ratio in top-k gating. Default: 1.0
+ cosine_router_dim (int): Projection dimension in cosine router.
+ cosine_router_init_t (float): Initialization temperature in cosine
+ router.
+ moe_drop (float): Dropout rate in MoE. Default: 0.0
+ """
+
+ def __init__(self,
+ dim,
+ input_resolution,
+ depth,
+ num_heads,
+ window_size,
+ mlp_ratio=4.,
+ qkv_bias=True,
+ qk_scale=None,
+ drop=0.,
+ attn_drop=0.,
+ drop_path=0.,
+ norm_layer=nn.LayerNorm,
+ downsample=None,
+ mlp_fc2_bias=True,
+ init_std=0.02,
+ use_checkpoint=False,
+ pretrained_window_size=0,
+ moe_block=[-1],
+ num_local_experts=1,
+ top_value=1,
+ capacity_factor=1.25,
+ cosine_router=False,
+ normalize_gate=False,
+ use_bpr=True,
+ is_gshard_loss=True,
+ cosine_router_dim=256,
+ cosine_router_init_t=0.5,
+ gate_noise=1.0,
+ moe_drop=0.0):
+
+ super().__init__()
+ self.dim = dim
+ self.input_resolution = input_resolution
+ self.depth = depth
+ self.use_checkpoint = use_checkpoint
+
+ # build blocks
+ self.blocks = nn.ModuleList([
+ SwinTransformerBlock(
+ dim=dim,
+ input_resolution=input_resolution,
+ num_heads=num_heads,
+ window_size=window_size,
+ shift_size=0 if (i % 2 == 0) else window_size // 2,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop,
+ attn_drop=attn_drop,
+ drop_path=drop_path[i]
+ if isinstance(drop_path, list) else drop_path,
+ norm_layer=norm_layer,
+ mlp_fc2_bias=mlp_fc2_bias,
+ init_std=init_std,
+ pretrained_window_size=pretrained_window_size,
+ is_moe=True if i in moe_block else False,
+ num_local_experts=num_local_experts,
+ top_value=top_value,
+ capacity_factor=capacity_factor,
+ cosine_router=cosine_router,
+ normalize_gate=normalize_gate,
+ use_bpr=use_bpr,
+ is_gshard_loss=is_gshard_loss,
+ gate_noise=gate_noise,
+ cosine_router_dim=cosine_router_dim,
+ cosine_router_init_t=cosine_router_init_t,
+ moe_drop=moe_drop) for i in range(depth)
+ ])
+
+ # patch merging layer
+ if downsample is not None:
+ self.downsample = downsample(
+ input_resolution, dim=dim, norm_layer=norm_layer)
+ else:
+ self.downsample = None
+
+ def forward(self, x):
+ l_aux = 0.0
+ for blk in self.blocks:
+ if self.use_checkpoint:
+ out = checkpoint.checkpoint(blk, x)
+ else:
+ out = blk(x)
+ if isinstance(out, tuple):
+ x = out[0]
+ cur_l_aux = out[1]
+ l_aux = cur_l_aux + l_aux
+ else:
+ x = out
+
+ if self.downsample is not None:
+ x = self.downsample(x)
+ return x, l_aux
+
+ def extra_repr(self) -> str:
+ return (f'dim={self.dim}, input_resolution={self.input_resolution}, '
+ f'depth={self.depth}')
+
+ def flops(self):
+ flops = 0
+ for blk in self.blocks:
+ flops += blk.flops()
+ if self.downsample is not None:
+ flops += self.downsample.flops()
+ return flops
+
+
+class PatchEmbed(nn.Module):
+ r""" Image to Patch Embedding
+
+ Args:
+ img_size (int): Image size. Default: 224.
+ patch_size (int): Patch token size. Default: 4.
+ in_chans (int): Number of input image channels. Default: 3.
+ embed_dim (int): Number of linear projection output channels.
+ Default: 96.
+ norm_layer (nn.Module, optional): Normalization layer. Default: None
+ """
+
+ def __init__(self,
+ img_size=224,
+ patch_size=4,
+ in_chans=3,
+ embed_dim=96,
+ norm_layer=None):
+ super().__init__()
+ img_size = to_2tuple(img_size)
+ patch_size = to_2tuple(patch_size)
+ patches_resolution = [
+ img_size[0] // patch_size[0], img_size[1] // patch_size[1]
+ ]
+ self.img_size = img_size
+ self.patch_size = patch_size
+ self.patches_resolution = patches_resolution
+ self.num_patches = patches_resolution[0] * patches_resolution[1]
+
+ self.in_chans = in_chans
+ self.embed_dim = embed_dim
+
+ self.proj = nn.Conv2d(
+ in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
+ if norm_layer is not None:
+ self.norm = norm_layer(embed_dim)
+ else:
+ self.norm = None
+
+ def forward(self, x):
+ B, C, H, W = x.shape
+ # FIXME look at relaxing size constraints
+ assert H == self.img_size[0] and W == self.img_size[1], \
+ (f"Input image size ({H}*{W}) doesn't match model ("
+ f'{self.img_size[0]}*{self.img_size[1]}).')
+ x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
+ if self.norm is not None:
+ x = self.norm(x)
+ return x
+
+ def flops(self):
+ Ho, Wo = self.patches_resolution
+ flops = Ho * Wo * self.embed_dim * self.in_chans * (
+ self.patch_size[0] * self.patch_size[1])
+ if self.norm is not None:
+ flops += Ho * Wo * self.embed_dim
+ return flops
+
+
+class SwinTransformerMoE(nn.Module):
+ r""" Swin Transformer
+ A PyTorch impl of : `Swin Transformer: Hierarchical Vision
+ Transformer using Shifted Windows` -
+ https://arxiv.org/pdf/2103.14030
+
+ Args:
+ img_size (int | tuple(int)): Input image size. Default 224
+ patch_size (int | tuple(int)): Patch size. Default: 4
+ in_chans (int): Number of input image channels. Default: 3
+ num_classes (int): Number of classes for classification head.
+ Default: 1000
+ embed_dim (int): Patch embedding dimension. Default: 96
+ depths (tuple(int)): Depth of each Swin Transformer layer.
+ num_heads (tuple(int)): Number of attention heads in different layers.
+ window_size (int): Window size. Default: 7
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
+ qkv_bias (bool): If True, add a learnable bias to query, key, value.
+ Default: True
+ qk_scale (float): Override default qk scale of head_dim ** -0.5 if
+ set. Default: None
+ drop_rate (float): Dropout rate. Default: 0
+ attn_drop_rate (float): Attention dropout rate. Default: 0
+ drop_path_rate (float): Stochastic depth rate. Default: 0.1
+ norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
+ ape (bool): If True, add absolute position embedding to the patch
+ embedding. Default: False
+ patch_norm (bool): If True, add normalization after patch embedding.
+ Default: True
+ mlp_fc2_bias (bool): Whether to add bias in fc2 of Mlp. Default: True
+ init_std: Initialization std. Default: 0.02
+ use_checkpoint (bool): Whether to use checkpointing to save memory.
+ Default: False
+ pretrained_window_sizes (tuple(int)): Pretrained window sizes of each
+ layer.
+ moe_blocks (tuple(tuple(int))): The index of each MoE block in each
+ layer.
+ num_local_experts (int): number of local experts in each device (
+ GPU). Default: 1
+ top_value (int): the value of k in top-k gating. Default: 1
+ capacity_factor (float): the capacity factor in MoE. Default: 1.25
+ cosine_router (bool): Whether to use cosine router Default: False
+ normalize_gate (bool): Whether to normalize the gating score in top-k
+ gating. Default: False
+ use_bpr (bool): Whether to use batch-prioritized-routing. Default: True
+ is_gshard_loss (bool): If True, use Gshard balance loss.
+ If False, use the load loss and importance
+ loss in "arXiv:1701.06538". Default: False
+ gate_noise (float): the noise ratio in top-k gating. Default: 1.0
+ cosine_router_dim (int): Projection dimension in cosine router.
+ cosine_router_init_t (float): Initialization temperature in cosine
+ router.
+ moe_drop (float): Dropout rate in MoE. Default: 0.0
+ aux_loss_weight (float): auxiliary loss weight. Default: 0.1
+ """
+
+ def __init__(self,
+ img_size=224,
+ patch_size=4,
+ in_chans=3,
+ num_classes=1000,
+ embed_dim=96,
+ depths=[2, 2, 6, 2],
+ num_heads=[3, 6, 12, 24],
+ window_size=7,
+ mlp_ratio=4.,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.1,
+ norm_layer=nn.LayerNorm,
+ ape=False,
+ patch_norm=True,
+ mlp_fc2_bias=True,
+ init_std=0.02,
+ use_checkpoint=False,
+ pretrained_window_sizes=[0, 0, 0, 0],
+ moe_blocks=[[-1], [-1], [-1], [-1]],
+ num_local_experts=1,
+ top_value=1,
+ capacity_factor=1.25,
+ cosine_router=False,
+ normalize_gate=False,
+ use_bpr=True,
+ is_gshard_loss=True,
+ gate_noise=1.0,
+ cosine_router_dim=256,
+ cosine_router_init_t=0.5,
+ moe_drop=0.0,
+ aux_loss_weight=0.01,
+ **kwargs):
+ super().__init__()
+ self._ddp_params_and_buffers_to_ignore = list()
+
+ self.num_classes = num_classes
+ self.num_layers = len(depths)
+ self.embed_dim = embed_dim
+ self.ape = ape
+ self.patch_norm = patch_norm
+ self.num_features = int(embed_dim * 2**(self.num_layers - 1))
+ self.mlp_ratio = mlp_ratio
+ self.init_std = init_std
+ self.aux_loss_weight = aux_loss_weight
+ self.num_local_experts = num_local_experts
+ self.global_experts = num_local_experts * dist.get_world_size() if (
+ num_local_experts > 0) \
+ else dist.get_world_size() // (-num_local_experts)
+ self.sharded_count = (
+ 1.0 / num_local_experts) if num_local_experts > 0 else (
+ -num_local_experts)
+
+ # split image into non-overlapping patches
+ self.patch_embed = PatchEmbed(
+ img_size=img_size,
+ patch_size=patch_size,
+ in_chans=in_chans,
+ embed_dim=embed_dim,
+ norm_layer=norm_layer if self.patch_norm else None)
+ num_patches = self.patch_embed.num_patches
+ patches_resolution = self.patch_embed.patches_resolution
+ self.patches_resolution = patches_resolution
+
+ # absolute position embedding
+ if self.ape:
+ self.absolute_pos_embed = nn.Parameter(
+ torch.zeros(1, num_patches, embed_dim))
+ trunc_normal_(self.absolute_pos_embed, std=self.init_std)
+
+ self.pos_drop = nn.Dropout(p=drop_rate)
+
+ # stochastic depth
+ dpr = [
+ x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))
+ ] # stochastic depth decay rule
+
+ # build layers
+ self.layers = nn.ModuleList()
+ for i_layer in range(self.num_layers):
+ layer = BasicLayer(
+ dim=int(embed_dim * 2**i_layer),
+ input_resolution=(patches_resolution[0] // (2**i_layer),
+ patches_resolution[1] // (2**i_layer)),
+ depth=depths[i_layer],
+ num_heads=num_heads[i_layer],
+ window_size=window_size,
+ mlp_ratio=self.mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop_rate,
+ attn_drop=attn_drop_rate,
+ drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
+ norm_layer=norm_layer,
+ downsample=PatchMerging if
+ (i_layer < self.num_layers - 1) else None,
+ mlp_fc2_bias=mlp_fc2_bias,
+ init_std=init_std,
+ use_checkpoint=use_checkpoint,
+ pretrained_window_size=pretrained_window_sizes[i_layer],
+ moe_block=moe_blocks[i_layer],
+ num_local_experts=num_local_experts,
+ top_value=top_value,
+ capacity_factor=capacity_factor,
+ cosine_router=cosine_router,
+ normalize_gate=normalize_gate,
+ use_bpr=use_bpr,
+ is_gshard_loss=is_gshard_loss,
+ gate_noise=gate_noise,
+ cosine_router_dim=cosine_router_dim,
+ cosine_router_init_t=cosine_router_init_t,
+ moe_drop=moe_drop)
+ self.layers.append(layer)
+
+ self.norm = norm_layer(self.num_features)
+ self.avgpool = nn.AdaptiveAvgPool1d(1)
+ self.head = nn.Linear(
+ self.num_features,
+ num_classes) if num_classes > 0 else nn.Identity()
+
+ self.apply(self._init_weights)
+
+ def _init_weights(self, m):
+ if isinstance(m, nn.Linear):
+ trunc_normal_(m.weight, std=self.init_std)
+ if isinstance(m, nn.Linear) and m.bias is not None:
+ nn.init.constant_(m.bias, 0)
+ elif isinstance(m, nn.LayerNorm):
+ nn.init.constant_(m.bias, 0)
+ nn.init.constant_(m.weight, 1.0)
+ elif isinstance(m, MoEMlp):
+ m._init_weights()
+
+ @torch.jit.ignore
+ def no_weight_decay(self):
+ return {'absolute_pos_embed'}
+
+ @torch.jit.ignore
+ def no_weight_decay_keywords(self):
+ return {
+ 'cpb_mlp', 'relative_position_bias_table', 'fc1_bias', 'fc2_bias',
+ 'temperature', 'cosine_projector', 'sim_matrix'
+ }
+
+ def forward_features(self, x):
+ x = self.patch_embed(x)
+ if self.ape:
+ x = x + self.absolute_pos_embed
+ x = self.pos_drop(x)
+ l_aux = 0.0
+ for layer in self.layers:
+ x, cur_l_aux = layer(x)
+ l_aux = cur_l_aux + l_aux
+
+ x = self.norm(x) # B L C
+ x = self.avgpool(x.transpose(1, 2)) # B C 1
+ x = torch.flatten(x, 1)
+ return x, l_aux
+
+ def forward(self, x):
+ x, l_aux = self.forward_features(x)
+ x = self.head(x)
+ return x, l_aux * self.aux_loss_weight
+
+ def add_param_to_skip_allreduce(self, param_name):
+ self._ddp_params_and_buffers_to_ignore.append(param_name)
+
+ def flops(self):
+ flops = 0
+ flops += self.patch_embed.flops()
+ for i, layer in enumerate(self.layers):
+ flops += layer.flops()
+ flops += self.num_features * self.patches_resolution[
+ 0] * self.patches_resolution[1] // (2**self.num_layers)
+ flops += self.num_features * self.num_classes
+ return flops
diff --git a/projects/pose_anything/models/backbones/swin_transformer_v2.py b/projects/pose_anything/models/backbones/swin_transformer_v2.py
new file mode 100644
index 0000000000..0ec6f66448
--- /dev/null
+++ b/projects/pose_anything/models/backbones/swin_transformer_v2.py
@@ -0,0 +1,826 @@
+# --------------------------------------------------------
+# Swin Transformer V2
+# Copyright (c) 2022 Microsoft
+# Licensed under The MIT License [see LICENSE for details]
+# Written by Ze Liu
+# --------------------------------------------------------
+
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.checkpoint as checkpoint
+from timm.models.layers import DropPath, to_2tuple, trunc_normal_
+
+from mmpose.models.builder import BACKBONES
+
+
+class Mlp(nn.Module):
+
+ def __init__(self,
+ in_features,
+ hidden_features=None,
+ out_features=None,
+ act_layer=nn.GELU,
+ drop=0.):
+ super().__init__()
+ out_features = out_features or in_features
+ hidden_features = hidden_features or in_features
+ self.fc1 = nn.Linear(in_features, hidden_features)
+ self.act = act_layer()
+ self.fc2 = nn.Linear(hidden_features, out_features)
+ self.drop = nn.Dropout(drop)
+
+ def forward(self, x):
+ x = self.fc1(x)
+ x = self.act(x)
+ x = self.drop(x)
+ x = self.fc2(x)
+ x = self.drop(x)
+ return x
+
+
+def window_partition(x, window_size):
+ """
+ Args:
+ x: (B, H, W, C)
+ window_size (int): window size
+
+ Returns:
+ windows: (num_windows*B, window_size, window_size, C)
+ """
+ B, H, W, C = x.shape
+ x = x.view(B, H // window_size, window_size, W // window_size, window_size,
+ C)
+ windows = x.permute(0, 1, 3, 2, 4,
+ 5).contiguous().view(-1, window_size, window_size, C)
+ return windows
+
+
+def window_reverse(windows, window_size, H, W):
+ """
+ Args:
+ windows: (num_windows*B, window_size, window_size, C)
+ window_size (int): Window size
+ H (int): Height of image
+ W (int): Width of image
+
+ Returns:
+ x: (B, H, W, C)
+ """
+ B = int(windows.shape[0] / (H * W / window_size / window_size))
+ x = windows.view(B, H // window_size, W // window_size, window_size,
+ window_size, -1)
+ x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
+ return x
+
+
+class WindowAttention(nn.Module):
+ r""" Window based multi-head self attention (W-MSA) module with relative
+ position bias. It supports both of shifted and non-shifted window.
+
+ Args: dim (int): Number of input channels. window_size (tuple[int]): The
+ height and width of the window. num_heads (int): Number of attention
+ heads. qkv_bias (bool, optional): If True, add a learnable bias to
+ query, key, value. Default: True attn_drop (float, optional): Dropout
+ ratio of attention weight. Default: 0.0 proj_drop (float, optional):
+ Dropout ratio of output. Default: 0.0 pretrained_window_size (tuple[
+ int]): The height and width of the window in pre-training.
+ """
+
+ def __init__(self,
+ dim,
+ window_size,
+ num_heads,
+ qkv_bias=True,
+ attn_drop=0.,
+ proj_drop=0.,
+ pretrained_window_size=[0, 0]):
+
+ super().__init__()
+ self.dim = dim
+ self.window_size = window_size # Wh, Ww
+ self.pretrained_window_size = pretrained_window_size
+ self.num_heads = num_heads
+
+ self.logit_scale = nn.Parameter(
+ torch.log(10 * torch.ones((num_heads, 1, 1))), requires_grad=True)
+
+ # mlp to generate continuous relative position bias
+ self.cpb_mlp = nn.Sequential(
+ nn.Linear(2, 512, bias=True), nn.ReLU(inplace=True),
+ nn.Linear(512, num_heads, bias=False))
+
+ # get relative_coords_table
+ relative_coords_h = torch.arange(
+ -(self.window_size[0] - 1),
+ self.window_size[0],
+ dtype=torch.float32)
+ relative_coords_w = torch.arange(
+ -(self.window_size[1] - 1),
+ self.window_size[1],
+ dtype=torch.float32)
+ relative_coords_table = torch.stack(
+ torch.meshgrid([relative_coords_h, relative_coords_w])).permute(
+ 1, 2, 0).contiguous().unsqueeze(0) # 1, 2*Wh-1, 2*Ww-1, 2
+ if pretrained_window_size[0] > 0:
+ relative_coords_table[:, :, :, 0] /= (
+ pretrained_window_size[0] - 1)
+ relative_coords_table[:, :, :, 1] /= (
+ pretrained_window_size[1] - 1)
+ else:
+ relative_coords_table[:, :, :, 0] /= (self.window_size[0] - 1)
+ relative_coords_table[:, :, :, 1] /= (self.window_size[1] - 1)
+ relative_coords_table *= 8 # normalize to -8, 8
+ relative_coords_table = torch.sign(relative_coords_table) * torch.log2(
+ torch.abs(relative_coords_table) + 1.0) / np.log2(8)
+
+ self.register_buffer('relative_coords_table', relative_coords_table)
+
+ # get pair-wise relative position index for each token inside the
+ # window
+ coords_h = torch.arange(self.window_size[0])
+ coords_w = torch.arange(self.window_size[1])
+ coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
+ coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
+ relative_coords = coords_flatten[:, :,
+ None] - coords_flatten[:, None, :] #
+ # 2, Wh*Ww, Wh*Ww
+ relative_coords = relative_coords.permute(
+ 1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
+ relative_coords[:, :,
+ 0] += self.window_size[0] - 1 # shift to start from 0
+ relative_coords[:, :, 1] += self.window_size[1] - 1
+ relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
+ relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
+ self.register_buffer('relative_position_index',
+ relative_position_index)
+
+ self.qkv = nn.Linear(dim, dim * 3, bias=False)
+ if qkv_bias:
+ self.q_bias = nn.Parameter(torch.zeros(dim))
+ self.v_bias = nn.Parameter(torch.zeros(dim))
+ else:
+ self.q_bias = None
+ self.v_bias = None
+ self.attn_drop = nn.Dropout(attn_drop)
+ self.proj = nn.Linear(dim, dim)
+ self.proj_drop = nn.Dropout(proj_drop)
+ self.softmax = nn.Softmax(dim=-1)
+
+ def forward(self, x, mask=None):
+ """
+ Args: x: input features with shape of (num_windows*B, N, C) mask: (
+ 0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
+ """
+ B_, N, C = x.shape
+ qkv_bias = None
+ if self.q_bias is not None:
+ qkv_bias = torch.cat(
+ (self.q_bias,
+ torch.zeros_like(self.v_bias,
+ requires_grad=False), self.v_bias))
+ qkv = F.linear(input=x, weight=self.qkv.weight, bias=qkv_bias)
+ qkv = qkv.reshape(B_, N, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
+ q, k, v = qkv[0], qkv[1], qkv[
+ 2] # make torchscript happy (cannot use tensor as tuple)
+
+ # cosine attention
+ attn = (
+ F.normalize(q, dim=-1) @ F.normalize(k, dim=-1).transpose(-2, -1))
+ logit_scale = torch.clamp(
+ self.logit_scale,
+ max=torch.log(torch.tensor(1. / 0.01, device=x.device))).exp()
+ attn = attn * logit_scale
+
+ relative_position_bias_table = self.cpb_mlp(
+ self.relative_coords_table).view(-1, self.num_heads)
+ relative_position_bias = relative_position_bias_table[
+ self.relative_position_index.view(-1)].view(
+ self.window_size[0] * self.window_size[1],
+ self.window_size[0] * self.window_size[1],
+ -1) # Wh*Ww,Wh*Ww,nH
+ relative_position_bias = relative_position_bias.permute(
+ 2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
+ relative_position_bias = 16 * torch.sigmoid(relative_position_bias)
+ attn = attn + relative_position_bias.unsqueeze(0)
+
+ if mask is not None:
+ nW = mask.shape[0]
+ attn = attn.view(B_ // nW, nW, self.num_heads, N,
+ N) + mask.unsqueeze(1).unsqueeze(0)
+ attn = attn.view(-1, self.num_heads, N, N)
+ attn = self.softmax(attn)
+ else:
+ attn = self.softmax(attn)
+
+ attn = self.attn_drop(attn)
+
+ x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
+ x = self.proj(x)
+ x = self.proj_drop(x)
+ return x
+
+ def extra_repr(self) -> str:
+ return f'dim={self.dim}, window_size={self.window_size}, ' \
+ (f'pretrained_window_size={self.pretrained_window_size}, '
+ f'num_heads={self.num_heads}')
+
+ def flops(self, N):
+ # calculate flops for 1 window with token length of N
+ flops = 0
+ # qkv = self.qkv(x)
+ flops += N * self.dim * 3 * self.dim
+ # attn = (q @ k.transpose(-2, -1))
+ flops += self.num_heads * N * (self.dim // self.num_heads) * N
+ # x = (attn @ v)
+ flops += self.num_heads * N * N * (self.dim // self.num_heads)
+ # x = self.proj(x)
+ flops += N * self.dim * self.dim
+ return flops
+
+
+class SwinTransformerBlock(nn.Module):
+ r""" Swin Transformer Block.
+
+ Args: dim (int): Number of input channels. input_resolution (tuple[int]):
+ Input resolution. num_heads (int): Number of attention heads. window_size
+ (int): Window size. shift_size (int): Shift size for SW-MSA. mlp_ratio (
+ float): Ratio of mlp hidden dim to embedding dim. qkv_bias (bool,
+ optional): If True, add a learnable bias to query, key, value. Default:
+ True drop (float, optional): Dropout rate. Default: 0.0 attn_drop (float,
+ optional): Attention dropout rate. Default: 0.0 drop_path (float,
+ optional): Stochastic depth rate. Default: 0.0 act_layer (nn.Module,
+ optional): Activation layer. Default: nn.GELU norm_layer (nn.Module,
+ optional): Normalization layer. Default: nn.LayerNorm
+ pretrained_window_size (int): Window size in pre-training.
+ """
+
+ def __init__(self,
+ dim,
+ input_resolution,
+ num_heads,
+ window_size=7,
+ shift_size=0,
+ mlp_ratio=4.,
+ qkv_bias=True,
+ drop=0.,
+ attn_drop=0.,
+ drop_path=0.,
+ act_layer=nn.GELU,
+ norm_layer=nn.LayerNorm,
+ pretrained_window_size=0):
+ super().__init__()
+ self.dim = dim
+ self.input_resolution = input_resolution
+ self.num_heads = num_heads
+ self.window_size = window_size
+ self.shift_size = shift_size
+ self.mlp_ratio = mlp_ratio
+ if min(self.input_resolution) <= self.window_size:
+ # if window size is larger than input resolution, we don't
+ # partition windows
+ self.shift_size = 0
+ self.window_size = min(self.input_resolution)
+ assert 0 <= self.shift_size < self.window_size, ('shift_size must in '
+ '0-window_size')
+
+ self.norm1 = norm_layer(dim)
+ self.attn = WindowAttention(
+ dim,
+ window_size=to_2tuple(self.window_size),
+ num_heads=num_heads,
+ qkv_bias=qkv_bias,
+ attn_drop=attn_drop,
+ proj_drop=drop,
+ pretrained_window_size=to_2tuple(pretrained_window_size))
+
+ self.drop_path = DropPath(
+ drop_path) if drop_path > 0. else nn.Identity()
+ self.norm2 = norm_layer(dim)
+ mlp_hidden_dim = int(dim * mlp_ratio)
+ self.mlp = Mlp(
+ in_features=dim,
+ hidden_features=mlp_hidden_dim,
+ act_layer=act_layer,
+ drop=drop)
+
+ if self.shift_size > 0:
+ # calculate attention mask for SW-MSA
+ H, W = self.input_resolution
+ img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
+ h_slices = (slice(0, -self.window_size),
+ slice(-self.window_size,
+ -self.shift_size), slice(-self.shift_size, None))
+ w_slices = (slice(0, -self.window_size),
+ slice(-self.window_size,
+ -self.shift_size), slice(-self.shift_size, None))
+ cnt = 0
+ for h in h_slices:
+ for w in w_slices:
+ img_mask[:, h, w, :] = cnt
+ cnt += 1
+
+ mask_windows = window_partition(
+ img_mask, self.window_size) # nW, window_size, window_size, 1
+ mask_windows = mask_windows.view(
+ -1, self.window_size * self.window_size)
+ attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
+ attn_mask = attn_mask.masked_fill(attn_mask != 0,
+ float(-100.0)).masked_fill(
+ attn_mask == 0, float(0.0))
+ else:
+ attn_mask = None
+
+ self.register_buffer('attn_mask', attn_mask)
+
+ def forward(self, x):
+ H, W = self.input_resolution
+ B, L, C = x.shape
+ assert L == H * W, 'input feature has wrong size'
+
+ shortcut = x
+ x = x.view(B, H, W, C)
+
+ # cyclic shift
+ if self.shift_size > 0:
+ shifted_x = torch.roll(
+ x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
+ else:
+ shifted_x = x
+
+ # partition windows
+ x_windows = window_partition(
+ shifted_x, self.window_size) # nW*B, window_size, window_size, C
+ x_windows = x_windows.view(-1, self.window_size * self.window_size,
+ C) # nW*B, window_size*window_size, C
+
+ # W-MSA/SW-MSA
+ attn_windows = self.attn(
+ x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C
+
+ # merge windows
+ attn_windows = attn_windows.view(-1, self.window_size,
+ self.window_size, C)
+ shifted_x = window_reverse(attn_windows, self.window_size, H,
+ W) # B H' W' C
+
+ # reverse cyclic shift
+ if self.shift_size > 0:
+ x = torch.roll(
+ shifted_x,
+ shifts=(self.shift_size, self.shift_size),
+ dims=(1, 2))
+ else:
+ x = shifted_x
+ x = x.view(B, H * W, C)
+ x = shortcut + self.drop_path(self.norm1(x))
+
+ # FFN
+ x = x + self.drop_path(self.norm2(self.mlp(x)))
+
+ return x
+
+ def extra_repr(self) -> str:
+ return (f'dim={self.dim}, input_resolution={self.input_resolution}, '
+ f'num_heads={self.num_heads}, '
+ f'window_size={self.window_size}, '
+ f'shift_size={self.shift_size}, '
+ f'mlp_ratio={self.mlp_ratio}')
+
+ def flops(self):
+ flops = 0
+ H, W = self.input_resolution
+ # norm1
+ flops += self.dim * H * W
+ # W-MSA/SW-MSA
+ nW = H * W / self.window_size / self.window_size
+ flops += nW * self.attn.flops(self.window_size * self.window_size)
+ # mlp
+ flops += 2 * H * W * self.dim * self.dim * self.mlp_ratio
+ # norm2
+ flops += self.dim * H * W
+ return flops
+
+
+class PatchMerging(nn.Module):
+ r""" Patch Merging Layer.
+
+ Args: input_resolution (tuple[int]): Resolution of input feature. dim (
+ int): Number of input channels. norm_layer (nn.Module, optional):
+ Normalization layer. Default: nn.LayerNorm
+ """
+
+ def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
+ super().__init__()
+ self.input_resolution = input_resolution
+ self.dim = dim
+ self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
+ self.norm = norm_layer(2 * dim)
+
+ def forward(self, x):
+ """
+ x: B, H*W, C
+ """
+ H, W = self.input_resolution
+ B, L, C = x.shape
+ assert L == H * W, 'input feature has wrong size'
+ assert H % 2 == 0 and W % 2 == 0, f'x size ({H}*{W}) are not even.'
+
+ x = x.view(B, H, W, C)
+
+ x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
+ x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
+ x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
+ x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
+ x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
+ x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
+
+ x = self.reduction(x)
+ x = self.norm(x)
+
+ return x
+
+ def extra_repr(self) -> str:
+ return f'input_resolution={self.input_resolution}, dim={self.dim}'
+
+ def flops(self):
+ H, W = self.input_resolution
+ flops = (H // 2) * (W // 2) * 4 * self.dim * 2 * self.dim
+ flops += H * W * self.dim // 2
+ return flops
+
+
+class BasicLayer(nn.Module):
+ """A basic Swin Transformer layer for one stage.
+
+ Args: dim (int): Number of input channels. input_resolution (tuple[int]):
+ Input resolution. depth (int): Number of blocks. num_heads (int): Number
+ of attention heads. window_size (int): Local window size. mlp_ratio (
+ float): Ratio of mlp hidden dim to embedding dim. qkv_bias (bool,
+ optional): If True, add a learnable bias to query, key, value. Default:
+ True drop (float, optional): Dropout rate. Default: 0.0 attn_drop (float,
+ optional): Attention dropout rate. Default: 0.0 drop_path (float | tuple[
+ float], optional): Stochastic depth rate. Default: 0.0 norm_layer (
+ nn.Module, optional): Normalization layer. Default: nn.LayerNorm
+ downsample (nn.Module | None, optional): Downsample layer at the end of
+ the layer. Default: None use_checkpoint (bool): Whether to use
+ checkpointing to save memory. Default: False. pretrained_window_size (
+ int): Local window size in pre-training.
+ """
+
+ def __init__(self,
+ dim,
+ input_resolution,
+ depth,
+ num_heads,
+ window_size,
+ mlp_ratio=4.,
+ qkv_bias=True,
+ drop=0.,
+ attn_drop=0.,
+ drop_path=0.,
+ norm_layer=nn.LayerNorm,
+ downsample=None,
+ use_checkpoint=False,
+ pretrained_window_size=0):
+
+ super().__init__()
+ self.dim = dim
+ self.input_resolution = input_resolution
+ self.depth = depth
+ self.use_checkpoint = use_checkpoint
+
+ # build blocks
+ self.blocks = nn.ModuleList([
+ SwinTransformerBlock(
+ dim=dim,
+ input_resolution=input_resolution,
+ num_heads=num_heads,
+ window_size=window_size,
+ shift_size=0 if (i % 2 == 0) else window_size // 2,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ drop=drop,
+ attn_drop=attn_drop,
+ drop_path=drop_path[i]
+ if isinstance(drop_path, list) else drop_path,
+ norm_layer=norm_layer,
+ pretrained_window_size=pretrained_window_size)
+ for i in range(depth)
+ ])
+
+ # patch merging layer
+ if downsample is not None:
+ self.downsample = downsample(
+ input_resolution, dim=dim, norm_layer=norm_layer)
+ else:
+ self.downsample = None
+
+ def forward(self, x):
+ for blk in self.blocks:
+ if self.use_checkpoint:
+ x = checkpoint.checkpoint(blk, x)
+ else:
+ x = blk(x)
+ if self.downsample is not None:
+ x = self.downsample(x)
+ return x
+
+ def extra_repr(self) -> str:
+ return (f'dim={self.dim}, input_resolution={self.input_resolution}, '
+ f'depth={self.depth}')
+
+ def flops(self):
+ flops = 0
+ for blk in self.blocks:
+ flops += blk.flops()
+ if self.downsample is not None:
+ flops += self.downsample.flops()
+ return flops
+
+ def _init_respostnorm(self):
+ for blk in self.blocks:
+ nn.init.constant_(blk.norm1.bias, 0)
+ nn.init.constant_(blk.norm1.weight, 0)
+ nn.init.constant_(blk.norm2.bias, 0)
+ nn.init.constant_(blk.norm2.weight, 0)
+
+
+class PatchEmbed(nn.Module):
+ r""" Image to Patch Embedding
+
+ Args: img_size (int): Image size. Default: 224. patch_size (int): Patch
+ token size. Default: 4. in_chans (int): Number of input image channels.
+ Default: 3. embed_dim (int): Number of linear projection output channels.
+ Default: 96. norm_layer (nn.Module, optional): Normalization layer.
+ Default: None
+ """
+
+ def __init__(self,
+ img_size=224,
+ patch_size=4,
+ in_chans=3,
+ embed_dim=96,
+ norm_layer=None):
+ super().__init__()
+ img_size = to_2tuple(img_size)
+ patch_size = to_2tuple(patch_size)
+ patches_resolution = [
+ img_size[0] // patch_size[0], img_size[1] // patch_size[1]
+ ]
+ self.img_size = img_size
+ self.patch_size = patch_size
+ self.patches_resolution = patches_resolution
+ self.num_patches = patches_resolution[0] * patches_resolution[1]
+
+ self.in_chans = in_chans
+ self.embed_dim = embed_dim
+
+ self.proj = nn.Conv2d(
+ in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
+ if norm_layer is not None:
+ self.norm = norm_layer(embed_dim)
+ else:
+ self.norm = None
+
+ def forward(self, x):
+ B, C, H, W = x.shape
+ # FIXME look at relaxing size constraints
+ assert H == self.img_size[0] and W == self.img_size[1], \
+ (f"Input image size ({H}*{W}) doesn't match model "
+ f'({self.img_size[0]}*{self.img_size[1]}).')
+ x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
+ if self.norm is not None:
+ x = self.norm(x)
+ return x
+
+ def flops(self):
+ Ho, Wo = self.patches_resolution
+ flops = Ho * Wo * self.embed_dim * self.in_chans * (
+ self.patch_size[0] * self.patch_size[1])
+ if self.norm is not None:
+ flops += Ho * Wo * self.embed_dim
+ return flops
+
+
+@BACKBONES.register_module()
+class SwinTransformerV2(nn.Module):
+ r""" Swin Transformer A PyTorch impl of : `Swin Transformer: Hierarchical
+ Vision Transformer using Shifted Windows` -
+ https://arxiv.org/pdf/2103.14030
+
+ Args: img_size (int | tuple(int)): Input image size. Default 224
+ patch_size (int | tuple(int)): Patch size. Default: 4 in_chans (int):
+ Number of input image channels. Default: 3 num_classes (int): Number of
+ classes for classification head. Default: 1000 embed_dim (int): Patch
+ embedding dimension. Default: 96 depths (tuple(int)): Depth of each Swin
+ Transformer layer. num_heads (tuple(int)): Number of attention heads in
+ different layers. window_size (int): Window size. Default: 7 mlp_ratio (
+ float): Ratio of mlp hidden dim to embedding dim. Default: 4 qkv_bias (
+ bool): If True, add a learnable bias to query, key, value. Default: True
+ drop_rate (float): Dropout rate. Default: 0 attn_drop_rate (float):
+ Attention dropout rate. Default: 0 drop_path_rate (float): Stochastic
+ depth rate. Default: 0.1 norm_layer (nn.Module): Normalization layer.
+ Default: nn.LayerNorm. ape (bool): If True, add absolute position
+ embedding to the patch embedding. Default: False patch_norm (bool): If
+ True, add normalization after patch embedding. Default: True
+ use_checkpoint (bool): Whether to use checkpointing to save memory.
+ Default: False pretrained_window_sizes (tuple(int)): Pretrained window
+ sizes of each layer.
+ """
+
+ def __init__(self,
+ img_size=224,
+ patch_size=4,
+ in_chans=3,
+ num_classes=1000,
+ embed_dim=96,
+ depths=[2, 2, 6, 2],
+ num_heads=[3, 6, 12, 24],
+ window_size=7,
+ mlp_ratio=4.,
+ qkv_bias=True,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.1,
+ norm_layer=nn.LayerNorm,
+ ape=False,
+ patch_norm=True,
+ use_checkpoint=False,
+ pretrained_window_sizes=[0, 0, 0, 0],
+ multi_scale=False,
+ upsample='deconv',
+ **kwargs):
+ super().__init__()
+
+ self.num_classes = num_classes
+ self.num_layers = len(depths)
+ self.embed_dim = embed_dim
+ self.ape = ape
+ self.patch_norm = patch_norm
+ self.num_features = int(embed_dim * 2**(self.num_layers - 1))
+ self.mlp_ratio = mlp_ratio
+
+ # split image into non-overlapping patches
+ self.patch_embed = PatchEmbed(
+ img_size=img_size,
+ patch_size=patch_size,
+ in_chans=in_chans,
+ embed_dim=embed_dim,
+ norm_layer=norm_layer if self.patch_norm else None)
+ num_patches = self.patch_embed.num_patches
+ patches_resolution = self.patch_embed.patches_resolution
+ self.patches_resolution = patches_resolution
+
+ # absolute position embedding
+ if self.ape:
+ self.absolute_pos_embed = nn.Parameter(
+ torch.zeros(1, num_patches, embed_dim))
+ trunc_normal_(self.absolute_pos_embed, std=.02)
+
+ self.pos_drop = nn.Dropout(p=drop_rate)
+
+ # stochastic depth
+ dpr = [
+ x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))
+ ] # stochastic depth decay rule
+
+ # build layers
+ self.layers = nn.ModuleList()
+ for i_layer in range(self.num_layers):
+ layer = BasicLayer(
+ dim=int(embed_dim * 2**i_layer),
+ input_resolution=(patches_resolution[0] // (2**i_layer),
+ patches_resolution[1] // (2**i_layer)),
+ depth=depths[i_layer],
+ num_heads=num_heads[i_layer],
+ window_size=window_size,
+ mlp_ratio=self.mlp_ratio,
+ qkv_bias=qkv_bias,
+ drop=drop_rate,
+ attn_drop=attn_drop_rate,
+ drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
+ norm_layer=norm_layer,
+ downsample=PatchMerging if
+ (i_layer < self.num_layers - 1) else None,
+ use_checkpoint=use_checkpoint,
+ pretrained_window_size=pretrained_window_sizes[i_layer])
+ self.layers.append(layer)
+
+ self.norm = norm_layer(self.num_features)
+ self.avgpool = nn.AdaptiveAvgPool1d(1)
+ self.multi_scale = multi_scale
+ if self.multi_scale:
+ self.scales = [1, 2, 4, 4]
+ self.upsample = nn.ModuleList()
+ features = [
+ int(embed_dim * 2**i) for i in range(1, self.num_layers)
+ ] + [self.num_features]
+ self.multi_scale_fuse = nn.Conv2d(
+ sum(features), self.num_features, 1)
+ for i in range(self.num_layers):
+ self.upsample.append(nn.Upsample(scale_factor=self.scales[i]))
+ else:
+ if upsample == 'deconv':
+ self.upsample = nn.ConvTranspose2d(
+ self.num_features, self.num_features, 2, stride=2)
+ elif upsample == 'new_deconv':
+ self.upsample = nn.Sequential(
+ nn.Upsample(
+ scale_factor=2, mode='bilinear', align_corners=False),
+ nn.Conv2d(
+ self.num_features,
+ self.num_features,
+ 3,
+ stride=1,
+ padding=1), nn.BatchNorm2d(self.num_features),
+ nn.ReLU(inplace=True))
+ elif upsample == 'new_deconv2':
+ self.upsample = nn.Sequential(
+ nn.Upsample(scale_factor=2),
+ nn.Conv2d(
+ self.num_features,
+ self.num_features,
+ 3,
+ stride=1,
+ padding=1), nn.BatchNorm2d(self.num_features),
+ nn.ReLU(inplace=True))
+ elif upsample == 'bilinear':
+ self.upsample = nn.Upsample(
+ scale_factor=2, mode='bilinear', align_corners=False)
+ else:
+ self.upsample = nn.Identity()
+ self.head = nn.Linear(
+ self.num_features,
+ num_classes) if num_classes > 0 else nn.Identity()
+
+ self.apply(self._init_weights)
+ for bly in self.layers:
+ bly._init_respostnorm()
+
+ def _init_weights(self, m):
+ if isinstance(m, nn.Linear):
+ trunc_normal_(m.weight, std=.02)
+ if isinstance(m, nn.Linear) and m.bias is not None:
+ nn.init.constant_(m.bias, 0)
+ elif isinstance(m, nn.LayerNorm):
+ nn.init.constant_(m.bias, 0)
+ nn.init.constant_(m.weight, 1.0)
+
+ @torch.jit.ignore
+ def no_weight_decay(self):
+ return {'absolute_pos_embed'}
+
+ @torch.jit.ignore
+ def no_weight_decay_keywords(self):
+ return {'cpb_mlp', 'logit_scale', 'relative_position_bias_table'}
+
+ def forward_features(self, x):
+ B, C, H, W = x.shape
+ x = self.patch_embed(x)
+ if self.ape:
+ x = x + self.absolute_pos_embed
+ x = self.pos_drop(x)
+
+ if self.multi_scale:
+ # x_2d = x.view(B, H // 4, W // 4, -1).permute(0, 3, 1, 2) # B C
+ # H W features = [self.upsample[0](x_2d)]
+ features = []
+ for i, layer in enumerate(self.layers):
+ x = layer(x)
+ x_2d = x.view(B, H // (8 * self.scales[i]),
+ W // (8 * self.scales[i]),
+ -1).permute(0, 3, 1, 2) # B C H W
+ features.append(self.upsample[i](x_2d))
+ x = torch.cat(features, dim=1)
+ x = self.multi_scale_fuse(x)
+ x = x.view(B, self.num_features, -1).permute(0, 2, 1)
+ x = self.norm(x) # B L C
+ x = x.view(B, H // 8, W // 8,
+ self.num_features).permute(0, 3, 1, 2) # B C H W
+
+ else:
+ for layer in self.layers:
+ x = layer(x)
+ x = self.norm(x) # B L C
+ x = x.view(B, H // 32, W // 32,
+ self.num_features).permute(0, 3, 1, 2) # B C H W
+ x = self.upsample(x)
+
+ return x
+
+ def forward(self, x):
+ x = self.forward_features(x)
+ x = self.head(x)
+ return x
+
+ def flops(self):
+ flops = 0
+ flops += self.patch_embed.flops()
+ for i, layer in enumerate(self.layers):
+ flops += layer.flops()
+ flops += self.num_features * self.patches_resolution[
+ 0] * self.patches_resolution[1] // (2**self.num_layers)
+ flops += self.num_features * self.num_classes
+ return flops
diff --git a/projects/pose_anything/models/backbones/swin_utils.py b/projects/pose_anything/models/backbones/swin_utils.py
new file mode 100644
index 0000000000..f53c928448
--- /dev/null
+++ b/projects/pose_anything/models/backbones/swin_utils.py
@@ -0,0 +1,127 @@
+# --------------------------------------------------------
+# SimMIM
+# Copyright (c) 2021 Microsoft
+# Licensed under The MIT License [see LICENSE for details]
+# Written by Ze Liu
+# Modified by Zhenda Xie
+# --------------------------------------------------------
+
+import numpy as np
+import torch
+from scipy import interpolate
+
+
+def load_pretrained(config, model, logger):
+ checkpoint = torch.load(config, map_location='cpu')
+ ckpt_model = checkpoint['model']
+ if any([True if 'encoder.' in k else False for k in ckpt_model.keys()]):
+ ckpt_model = {
+ k.replace('encoder.', ''): v
+ for k, v in ckpt_model.items() if k.startswith('encoder.')
+ }
+ print('Detect pre-trained model, remove [encoder.] prefix.')
+ else:
+ print('Detect non-pre-trained model, pass without doing anything.')
+
+ checkpoint = remap_pretrained_keys_swin(model, ckpt_model, logger)
+ msg = model.load_state_dict(ckpt_model, strict=False)
+ print(msg)
+
+ del checkpoint
+ torch.cuda.empty_cache()
+
+
+def remap_pretrained_keys_swin(model, checkpoint_model, logger):
+ state_dict = model.state_dict()
+
+ # Geometric interpolation when pre-trained patch size mismatch with
+ # fine-tuned patch size
+ all_keys = list(checkpoint_model.keys())
+ for key in all_keys:
+ if 'relative_position_bias_table' in key:
+ relative_position_bias_table_pretrained = checkpoint_model[key]
+ relative_position_bias_table_current = state_dict[key]
+ L1, nH1 = relative_position_bias_table_pretrained.size()
+ L2, nH2 = relative_position_bias_table_current.size()
+ if nH1 != nH2:
+ print(f'Error in loading {key}, passing......')
+ else:
+ if L1 != L2:
+ print(f'{key}: Interpolate relative_position_bias_table '
+ f'using geo.')
+ src_size = int(L1**0.5)
+ dst_size = int(L2**0.5)
+
+ def geometric_progression(a, r, n):
+ return a * (1.0 - r**n) / (1.0 - r)
+
+ left, right = 1.01, 1.5
+ while right - left > 1e-6:
+ q = (left + right) / 2.0
+ gp = geometric_progression(1, q, src_size // 2)
+ if gp > dst_size // 2:
+ right = q
+ else:
+ left = q
+
+ # if q > 1.090307:
+ # q = 1.090307
+
+ dis = []
+ cur = 1
+ for i in range(src_size // 2):
+ dis.append(cur)
+ cur += q**(i + 1)
+
+ r_ids = [-_ for _ in reversed(dis)]
+
+ x = r_ids + [0] + dis
+ y = r_ids + [0] + dis
+
+ t = dst_size // 2.0
+ dx = np.arange(-t, t + 0.1, 1.0)
+ dy = np.arange(-t, t + 0.1, 1.0)
+
+ print('Original positions = %s' % str(x))
+ print('Target positions = %s' % str(dx))
+
+ all_rel_pos_bias = []
+
+ for i in range(nH1):
+ z = relative_position_bias_table_pretrained[:, i].view(
+ src_size, src_size).float().numpy()
+ f_cubic = interpolate.interp2d(x, y, z, kind='cubic')
+ all_rel_pos_bias.append(
+ torch.Tensor(f_cubic(dx,
+ dy)).contiguous().view(-1, 1).
+ to(relative_position_bias_table_pretrained.device))
+
+ new_rel_pos_bias = torch.cat(all_rel_pos_bias, dim=-1)
+ checkpoint_model[key] = new_rel_pos_bias
+
+ # delete relative_position_index since we always re-init it
+ relative_position_index_keys = [
+ k for k in checkpoint_model.keys() if 'relative_position_index' in k
+ ]
+ for k in relative_position_index_keys:
+ del checkpoint_model[k]
+
+ # delete relative_coords_table since we always re-init it
+ relative_coords_table_keys = [
+ k for k in checkpoint_model.keys() if 'relative_coords_table' in k
+ ]
+ for k in relative_coords_table_keys:
+ del checkpoint_model[k]
+
+ # re-map keys due to name change
+ rpe_mlp_keys = [k for k in checkpoint_model.keys() if 'rpe_mlp' in k]
+ for k in rpe_mlp_keys:
+ checkpoint_model[k.replace('rpe_mlp',
+ 'cpb_mlp')] = checkpoint_model.pop(k)
+
+ # delete attn_mask since we always re-init it
+ attn_mask_keys = [k for k in checkpoint_model.keys() if 'attn_mask' in k]
+ for k in attn_mask_keys:
+ del checkpoint_model[k]
+
+ return checkpoint_model
diff --git a/projects/pose_anything/models/detectors/__init__.py b/projects/pose_anything/models/detectors/__init__.py
new file mode 100644
index 0000000000..038450a700
--- /dev/null
+++ b/projects/pose_anything/models/detectors/__init__.py
@@ -0,0 +1,3 @@
+from .pam import PoseAnythingModel
+
+__all__ = ['PoseAnythingModel']
diff --git a/projects/pose_anything/models/detectors/pam.py b/projects/pose_anything/models/detectors/pam.py
new file mode 100644
index 0000000000..0ce1b24673
--- /dev/null
+++ b/projects/pose_anything/models/detectors/pam.py
@@ -0,0 +1,395 @@
+import math
+from abc import ABCMeta
+
+import cv2
+import mmcv
+import numpy as np
+import torch
+from mmcv import imshow, imwrite
+from mmengine.model import BaseModel
+
+from mmpose.models import builder
+from mmpose.registry import MODELS
+from ..backbones.swin_utils import load_pretrained
+
+
+@MODELS.register_module()
+class PoseAnythingModel(BaseModel, metaclass=ABCMeta):
+ """Few-shot keypoint detectors.
+
+ Args:
+ keypoint_head (dict): Keypoint head to process feature.
+ encoder_config (dict): Config for encoder. Default: None.
+ pretrained (str): Path to the pretrained models.
+ train_cfg (dict): Config for training. Default: None.
+ test_cfg (dict): Config for testing. Default: None.
+ """
+
+ def __init__(self,
+ keypoint_head,
+ encoder_config,
+ pretrained=False,
+ train_cfg=None,
+ test_cfg=None):
+ super().__init__()
+ self.backbone, self.backbone_type = self.init_backbone(
+ pretrained, encoder_config)
+ self.keypoint_head = builder.build_head(keypoint_head)
+ self.keypoint_head.init_weights()
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+ self.target_type = test_cfg.get('target_type',
+ 'GaussianHeatMap') # GaussianHeatMap
+
+ def init_backbone(self, pretrained, encoder_config):
+ if 'swin' in pretrained:
+ encoder_sample = builder.build_backbone(encoder_config)
+ if '.pth' in pretrained:
+ load_pretrained(pretrained, encoder_sample, logger=None)
+ backbone = 'swin'
+ elif 'dino' in pretrained:
+ if 'dinov2' in pretrained:
+ repo = 'facebookresearch/dinov2'
+ backbone = 'dinov2'
+ else:
+ repo = 'facebookresearch/dino:main'
+ backbone = 'dino'
+ encoder_sample = torch.hub.load(repo, pretrained)
+ elif 'resnet' in pretrained:
+ pretrained = 'torchvision://resnet50'
+ encoder_config = dict(type='ResNet', depth=50, out_indices=(3, ))
+ encoder_sample = builder.build_backbone(encoder_config)
+ encoder_sample.init_weights(pretrained)
+ backbone = 'resnet50'
+ else:
+ raise NotImplementedError(f'backbone {pretrained} not supported')
+ return encoder_sample, backbone
+
+ @property
+ def with_keypoint(self):
+ """Check if has keypoint_head."""
+ return hasattr(self, 'keypoint_head')
+
+ def init_weights(self, pretrained=None):
+ """Weight initialization for model."""
+ self.backbone.init_weights(pretrained)
+ self.encoder_query.init_weights(pretrained)
+ self.keypoint_head.init_weights()
+
+ def forward(self,
+ img_s,
+ img_q,
+ target_s=None,
+ target_weight_s=None,
+ target_q=None,
+ target_weight_q=None,
+ img_metas=None,
+ return_loss=True,
+ **kwargs):
+ """Defines the computation performed at every call."""
+
+ if return_loss:
+ return self.forward_train(img_s, target_s, target_weight_s, img_q,
+ target_q, target_weight_q, img_metas,
+ **kwargs)
+ else:
+ return self.forward_test(img_s, target_s, target_weight_s, img_q,
+ target_q, target_weight_q, img_metas,
+ **kwargs)
+
+ def forward_dummy(self, img_s, target_s, target_weight_s, img_q, target_q,
+ target_weight_q, img_metas, **kwargs):
+ return self.predict(img_s, target_s, target_weight_s, img_q, img_metas)
+
+ def forward_train(self, img_s, target_s, target_weight_s, img_q, target_q,
+ target_weight_q, img_metas, **kwargs):
+ """Defines the computation performed at every call when training."""
+ bs, _, h, w = img_q.shape
+
+ output, initial_proposals, similarity_map, mask_s = self.predict(
+ img_s, target_s, target_weight_s, img_q, img_metas)
+
+ # parse the img meta to get the target keypoints
+ target_keypoints = self.parse_keypoints_from_img_meta(
+ img_metas, output.device, keyword='query')
+ target_sizes = torch.tensor([img_q.shape[-2],
+ img_q.shape[-1]]).unsqueeze(0).repeat(
+ img_q.shape[0], 1, 1)
+
+ # if return loss
+ losses = dict()
+ if self.with_keypoint:
+ keypoint_losses = self.keypoint_head.get_loss(
+ output, initial_proposals, similarity_map, target_keypoints,
+ target_q, target_weight_q * mask_s, target_sizes)
+ losses.update(keypoint_losses)
+ keypoint_accuracy = self.keypoint_head.get_accuracy(
+ output[-1],
+ target_keypoints,
+ target_weight_q * mask_s,
+ target_sizes,
+ height=h)
+ losses.update(keypoint_accuracy)
+
+ return losses
+
+ def forward_test(self,
+ img_s,
+ target_s,
+ target_weight_s,
+ img_q,
+ target_q,
+ target_weight_q,
+ img_metas=None,
+ **kwargs):
+ """Defines the computation performed at every call when testing."""
+ batch_size, _, img_height, img_width = img_q.shape
+
+ output, initial_proposals, similarity_map, _ = self.predict(
+ img_s, target_s, target_weight_s, img_q, img_metas)
+ predicted_pose = output[-1].detach().cpu().numpy(
+ ) # [bs, num_query, 2]
+
+ result = {}
+ if self.with_keypoint:
+ keypoint_result = self.keypoint_head.decode(
+ img_metas, predicted_pose, img_size=[img_width, img_height])
+ result.update(keypoint_result)
+
+ result.update({
+ 'points':
+ torch.cat((initial_proposals, output.squeeze(1)),
+ dim=0).cpu().numpy()
+ })
+ result.update({'sample_image_file': img_metas[0]['sample_image_file']})
+
+ return result
+
+ def predict(self, img_s, target_s, target_weight_s, img_q, img_metas=None):
+
+ batch_size, _, img_height, img_width = img_q.shape
+ assert [
+ i['sample_skeleton'][0] != i['query_skeleton'] for i in img_metas
+ ]
+ skeleton = [i['sample_skeleton'][0] for i in img_metas]
+
+ feature_q, feature_s = self.extract_features(img_s, img_q)
+
+ mask_s = target_weight_s[0]
+ for target_weight in target_weight_s:
+ mask_s = mask_s * target_weight
+
+ output, initial_proposals, similarity_map = self.keypoint_head(
+ feature_q, feature_s, target_s, mask_s, skeleton)
+
+ return output, initial_proposals, similarity_map, mask_s
+
+ def extract_features(self, img_s, img_q):
+ if self.backbone_type == 'swin':
+ feature_q = self.backbone.forward_features(img_q) # [bs, C, h, w]
+ feature_s = [self.backbone.forward_features(img) for img in img_s]
+ elif self.backbone_type == 'dino':
+ batch_size, _, img_height, img_width = img_q.shape
+ feature_q = self.backbone.get_intermediate_layers(img_q, n=1)
+ ([0][:, 1:].reshape(batch_size, img_height // 8, img_width // 8,
+ -1).permute(0, 3, 1, 2)) # [bs, 3, h, w]
+ feature_s = [
+ self.backbone.get_intermediate_layers(
+ img, n=1)[0][:, 1:].reshape(batch_size, img_height // 8,
+ img_width // 8,
+ -1).permute(0, 3, 1, 2)
+ for img in img_s
+ ]
+ elif self.backbone_type == 'dinov2':
+ batch_size, _, img_height, img_width = img_q.shape
+ feature_q = self.backbone.get_intermediate_layers(
+ img_q, n=1, reshape=True)[0] # [bs, c, h, w]
+ feature_s = [
+ self.backbone.get_intermediate_layers(img, n=1,
+ reshape=True)[0]
+ for img in img_s
+ ]
+ else:
+ feature_s = [self.backbone(img) for img in img_s]
+ feature_q = self.encoder_query(img_q)
+
+ return feature_q, feature_s
+
+ def parse_keypoints_from_img_meta(self, img_meta, device, keyword='query'):
+ """Parse keypoints from the img_meta.
+
+ Args:
+ img_meta (dict): Image meta info.
+ device (torch.device): Device of the output keypoints.
+ keyword (str): 'query' or 'sample'. Default: 'query'.
+
+ Returns:
+ Tensor: Keypoints coordinates of query images.
+ """
+
+ if keyword == 'query':
+ query_kpt = torch.stack([
+ torch.tensor(info[f'{keyword}_joints_3d']).to(device)
+ for info in img_meta
+ ],
+ dim=0)[:, :, :2] # [bs, num_query, 2]
+ else:
+ query_kpt = []
+ for info in img_meta:
+ if isinstance(info[f'{keyword}_joints_3d'][0], torch.Tensor):
+ samples = torch.stack(info[f'{keyword}_joints_3d'])
+ else:
+ samples = np.array(info[f'{keyword}_joints_3d'])
+ query_kpt.append(torch.tensor(samples).to(device)[:, :, :2])
+ query_kpt = torch.stack(
+ query_kpt, dim=0) # [bs, , num_samples, num_query, 2]
+ return query_kpt
+
+ # UNMODIFIED
+ def show_result(self,
+ img,
+ result,
+ skeleton=None,
+ kpt_score_thr=0.3,
+ bbox_color='green',
+ pose_kpt_color=None,
+ pose_limb_color=None,
+ radius=4,
+ text_color=(255, 0, 0),
+ thickness=1,
+ font_scale=0.5,
+ win_name='',
+ show=False,
+ wait_time=0,
+ out_file=None):
+ """Draw `result` over `img`.
+
+ Args:
+ img (str or Tensor): The image to be displayed.
+ result (list[dict]): The results to draw over `img`
+ (bbox_result, pose_result).
+ kpt_score_thr (float, optional): Minimum score of keypoints
+ to be shown. Default: 0.3.
+ bbox_color (str or tuple or :obj:`Color`): Color of bbox lines.
+ pose_kpt_color (np.array[Nx3]`): Color of N keypoints.
+ If None, do not draw keypoints.
+ pose_limb_color (np.array[Mx3]): Color of M limbs.
+ If None, do not draw limbs.
+ text_color (str or tuple or :obj:`Color`): Color of texts.
+ thickness (int): Thickness of lines.
+ font_scale (float): Font scales of texts.
+ win_name (str): The window name.
+ wait_time (int): Value of waitKey param.
+ Default: 0.
+ out_file (str or None): The filename to write the image.
+ Default: None.
+
+ Returns:
+ Tensor: Visualized img, only if not `show` or `out_file`.
+ """
+
+ img = mmcv.imread(img)
+ img = img.copy()
+ img_h, img_w, _ = img.shape
+
+ bbox_result = []
+ pose_result = []
+ for res in result:
+ bbox_result.append(res['bbox'])
+ pose_result.append(res['keypoints'])
+
+ if len(bbox_result) > 0:
+ bboxes = np.vstack(bbox_result)
+ # draw bounding boxes
+ mmcv.imshow_bboxes(
+ img,
+ bboxes,
+ colors=bbox_color,
+ top_k=-1,
+ thickness=thickness,
+ show=False,
+ win_name=win_name,
+ wait_time=wait_time,
+ out_file=None)
+
+ for person_id, kpts in enumerate(pose_result):
+ # draw each point on image
+ if pose_kpt_color is not None:
+ assert len(pose_kpt_color) == len(kpts), (
+ len(pose_kpt_color), len(kpts))
+ for kid, kpt in enumerate(kpts):
+ x_coord, y_coord, kpt_score = int(kpt[0]), int(
+ kpt[1]), kpt[2]
+ if kpt_score > kpt_score_thr:
+ img_copy = img.copy()
+ r, g, b = pose_kpt_color[kid]
+ cv2.circle(img_copy, (int(x_coord), int(y_coord)),
+ radius, (int(r), int(g), int(b)), -1)
+ transparency = max(0, min(1, kpt_score))
+ cv2.addWeighted(
+ img_copy,
+ transparency,
+ img,
+ 1 - transparency,
+ 0,
+ dst=img)
+
+ # draw limbs
+ if skeleton is not None and pose_limb_color is not None:
+ assert len(pose_limb_color) == len(skeleton)
+ for sk_id, sk in enumerate(skeleton):
+ pos1 = (int(kpts[sk[0] - 1, 0]), int(kpts[sk[0] - 1,
+ 1]))
+ pos2 = (int(kpts[sk[1] - 1, 0]), int(kpts[sk[1] - 1,
+ 1]))
+ if (0 < pos1[0] < img_w and 0 < pos1[1] < img_h
+ and 0 < pos2[0] < img_w and 0 < pos2[1] < img_h
+ and kpts[sk[0] - 1, 2] > kpt_score_thr
+ and kpts[sk[1] - 1, 2] > kpt_score_thr):
+ img_copy = img.copy()
+ X = (pos1[0], pos2[0])
+ Y = (pos1[1], pos2[1])
+ mX = np.mean(X)
+ mY = np.mean(Y)
+ length = ((Y[0] - Y[1])**2 + (X[0] - X[1])**2)**0.5
+ angle = math.degrees(
+ math.atan2(Y[0] - Y[1], X[0] - X[1]))
+ stickwidth = 2
+ polygon = cv2.ellipse2Poly(
+ (int(mX), int(mY)),
+ (int(length / 2), int(stickwidth)), int(angle),
+ 0, 360, 1)
+
+ r, g, b = pose_limb_color[sk_id]
+ cv2.fillConvexPoly(img_copy, polygon,
+ (int(r), int(g), int(b)))
+ transparency = max(
+ 0,
+ min(
+ 1, 0.5 *
+ (kpts[sk[0] - 1, 2] + kpts[sk[1] - 1, 2])))
+ cv2.addWeighted(
+ img_copy,
+ transparency,
+ img,
+ 1 - transparency,
+ 0,
+ dst=img)
+
+ show, wait_time = 1, 1
+ if show:
+ height, width = img.shape[:2]
+ max_ = max(height, width)
+
+ factor = min(1, 800 / max_)
+ enlarge = cv2.resize(
+ img, (0, 0),
+ fx=factor,
+ fy=factor,
+ interpolation=cv2.INTER_CUBIC)
+ imshow(enlarge, win_name, wait_time)
+
+ if out_file is not None:
+ imwrite(img, out_file)
+
+ return img
diff --git a/projects/pose_anything/models/keypoint_heads/__init__.py b/projects/pose_anything/models/keypoint_heads/__init__.py
new file mode 100644
index 0000000000..b42289e92a
--- /dev/null
+++ b/projects/pose_anything/models/keypoint_heads/__init__.py
@@ -0,0 +1,3 @@
+from .head import PoseHead
+
+__all__ = ['PoseHead']
diff --git a/projects/pose_anything/models/keypoint_heads/head.py b/projects/pose_anything/models/keypoint_heads/head.py
new file mode 100644
index 0000000000..f565a63580
--- /dev/null
+++ b/projects/pose_anything/models/keypoint_heads/head.py
@@ -0,0 +1,438 @@
+from copy import deepcopy
+
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import Conv2d, Linear
+from mmengine.model import xavier_init
+from models.utils import build_positional_encoding, build_transformer
+
+# from mmcv.cnn.bricks.transformer import build_positional_encoding
+from mmpose.evaluation import keypoint_pck_accuracy
+from mmpose.models import HEADS
+from mmpose.models.utils.ops import resize
+
+
+def transform_preds(coords, center, scale, output_size, use_udp=False):
+ """Get final keypoint predictions from heatmaps and apply scaling and
+ translation to map them back to the image.
+
+ Note:
+ num_keypoints: K
+
+ Args:
+ coords (np.ndarray[K, ndims]):
+
+ * If ndims=2, corrds are predicted keypoint location.
+ * If ndims=4, corrds are composed of (x, y, scores, tags)
+ * If ndims=5, corrds are composed of (x, y, scores, tags,
+ flipped_tags)
+
+ center (np.ndarray[2, ]): Center of the bounding box (x, y).
+ scale (np.ndarray[2, ]): Scale of the bounding box
+ wrt [width, height].
+ output_size (np.ndarray[2, ] | list(2,)): Size of the
+ destination heatmaps.
+ use_udp (bool): Use unbiased data processing
+
+ Returns:
+ np.ndarray: Predicted coordinates in the images.
+ """
+ assert coords.shape[1] in (2, 4, 5)
+ assert len(center) == 2
+ assert len(scale) == 2
+ assert len(output_size) == 2
+
+ # Recover the scale which is normalized by a factor of 200.
+ scale = scale * 200.0
+
+ if use_udp:
+ scale_x = scale[0] / (output_size[0] - 1.0)
+ scale_y = scale[1] / (output_size[1] - 1.0)
+ else:
+ scale_x = scale[0] / output_size[0]
+ scale_y = scale[1] / output_size[1]
+
+ target_coords = coords.copy()
+ target_coords[:, 0] = coords[:, 0] * scale_x + center[0] - scale[0] * 0.5
+ target_coords[:, 1] = coords[:, 1] * scale_y + center[1] - scale[1] * 0.5
+
+ return target_coords
+
+
+def inverse_sigmoid(x, eps=1e-3):
+ x = x.clamp(min=0, max=1)
+ x1 = x.clamp(min=eps)
+ x2 = (1 - x).clamp(min=eps)
+ return torch.log(x1 / x2)
+
+
+class TokenDecodeMLP(nn.Module):
+ """The MLP used to predict coordinates from the support keypoints
+ tokens."""
+
+ def __init__(self,
+ in_channels,
+ hidden_channels,
+ out_channels=2,
+ num_layers=3):
+ super(TokenDecodeMLP, self).__init__()
+ layers = []
+ for i in range(num_layers):
+ if i == 0:
+ layers.append(nn.Linear(in_channels, hidden_channels))
+ layers.append(nn.GELU())
+ else:
+ layers.append(nn.Linear(hidden_channels, hidden_channels))
+ layers.append(nn.GELU())
+ layers.append(nn.Linear(hidden_channels, out_channels))
+ self.mlp = nn.Sequential(*layers)
+
+ def forward(self, x):
+ return self.mlp(x)
+
+
+@HEADS.register_module()
+class PoseHead(nn.Module):
+ """In two stage regression A3, the proposal generator are moved into
+ transformer.
+
+ All valid proposals will be added with an positional embedding to better
+ regress the location
+ """
+
+ def __init__(self,
+ in_channels,
+ transformer=None,
+ positional_encoding=dict(
+ type='SinePositionalEncoding',
+ num_feats=128,
+ normalize=True),
+ encoder_positional_encoding=dict(
+ type='SinePositionalEncoding',
+ num_feats=512,
+ normalize=True),
+ share_kpt_branch=False,
+ num_decoder_layer=3,
+ with_heatmap_loss=False,
+ with_bb_loss=False,
+ bb_temperature=0.2,
+ heatmap_loss_weight=2.0,
+ support_order_dropout=-1,
+ extra=None,
+ train_cfg=None,
+ test_cfg=None):
+ super().__init__()
+
+ self.in_channels = in_channels
+ self.positional_encoding = build_positional_encoding(
+ positional_encoding)
+ self.encoder_positional_encoding = build_positional_encoding(
+ encoder_positional_encoding)
+ self.transformer = build_transformer(transformer)
+ self.embed_dims = self.transformer.d_model
+ self.with_heatmap_loss = with_heatmap_loss
+ self.with_bb_loss = with_bb_loss
+ self.bb_temperature = bb_temperature
+ self.heatmap_loss_weight = heatmap_loss_weight
+ self.support_order_dropout = support_order_dropout
+
+ assert 'num_feats' in positional_encoding
+ num_feats = positional_encoding['num_feats']
+ assert num_feats * 2 == self.embed_dims, 'embed_dims should' \
+ (f' be exactly 2 times of '
+ f'num_feats. Found'
+ f' {self.embed_dims} '
+ f'and {num_feats}.')
+ if extra is not None and not isinstance(extra, dict):
+ raise TypeError('extra should be dict or None.')
+ """Initialize layers of the transformer head."""
+ self.input_proj = Conv2d(
+ self.in_channels, self.embed_dims, kernel_size=1)
+ self.query_proj = Linear(self.in_channels, self.embed_dims)
+ # Instantiate the proposal generator and subsequent keypoint branch.
+ kpt_branch = TokenDecodeMLP(
+ in_channels=self.embed_dims, hidden_channels=self.embed_dims)
+ if share_kpt_branch:
+ self.kpt_branch = nn.ModuleList(
+ [kpt_branch for i in range(num_decoder_layer)])
+ else:
+ self.kpt_branch = nn.ModuleList(
+ [deepcopy(kpt_branch) for i in range(num_decoder_layer)])
+
+ self.train_cfg = {} if train_cfg is None else train_cfg
+ self.test_cfg = {} if test_cfg is None else test_cfg
+ self.target_type = self.test_cfg.get('target_type', 'GaussianHeatMap')
+
+ def init_weights(self):
+ for m in self.modules():
+ if hasattr(m, 'weight') and m.weight.dim() > 1:
+ xavier_init(m, distribution='uniform')
+ """Initialize weights of the transformer head."""
+ # The initialization for transformer is important
+ self.transformer.init_weights()
+ # initialization for input_proj & prediction head
+ for mlp in self.kpt_branch:
+ nn.init.constant_(mlp.mlp[-1].weight.data, 0)
+ nn.init.constant_(mlp.mlp[-1].bias.data, 0)
+ nn.init.xavier_uniform_(self.input_proj.weight, gain=1)
+ nn.init.constant_(self.input_proj.bias, 0)
+
+ nn.init.xavier_uniform_(self.query_proj.weight, gain=1)
+ nn.init.constant_(self.query_proj.bias, 0)
+
+ def forward(self, x, feature_s, target_s, mask_s, skeleton):
+ """"Forward function for a single feature level.
+
+ Args:
+ x (Tensor): Input feature from backbone's single stage, shape
+ [bs, c, h, w].
+
+ Returns:
+ all_cls_scores (Tensor): Outputs from the classification head,
+ shape [nb_dec, bs, num_query, cls_out_channels]. Note
+ cls_out_channels should includes background.
+ all_bbox_preds (Tensor): Sigmoid outputs from the regression
+ head with normalized coordinate format (cx, cy, w, h).
+ Shape [nb_dec, bs, num_query, 4].
+ """
+ # construct binary masks which used for the transformer.
+ # NOTE following the official DETR repo, non-zero values representing
+ # ignored positions, while zero values means valid positions.
+
+ # process query image feature
+ x = self.input_proj(x)
+ bs, dim, h, w = x.shape
+
+ # Disable the support keypoint positional embedding
+ support_order_embedding = x.new_zeros(
+ (bs, self.embed_dims, 1, target_s[0].shape[1])).to(torch.bool)
+
+ # Feature map pos embedding
+ masks = x.new_zeros(
+ (x.shape[0], x.shape[2], x.shape[3])).to(torch.bool)
+ pos_embed = self.positional_encoding(masks)
+
+ # process keypoint token feature
+ query_embed_list = []
+ for i, (feature, target) in enumerate(zip(feature_s, target_s)):
+ # resize the support feature back to the heatmap sizes.
+ resized_feature = resize(
+ input=feature,
+ size=target.shape[-2:],
+ mode='bilinear',
+ align_corners=False)
+ target = target / (
+ target.sum(dim=-1).sum(dim=-1)[:, :, None, None] + 1e-8)
+ support_keypoints = target.flatten(2) @ resized_feature.flatten(
+ 2).permute(0, 2, 1)
+ query_embed_list.append(support_keypoints)
+
+ support_keypoints = torch.mean(torch.stack(query_embed_list, dim=0), 0)
+ support_keypoints = support_keypoints * mask_s
+ support_keypoints = self.query_proj(support_keypoints)
+ masks_query = (~mask_s.to(torch.bool)).squeeze(
+ -1) # True indicating this query matched no actual joints.
+
+ # outs_dec: [nb_dec, bs, num_query, c]
+ # memory: [bs, c, h, w]
+ # x = Query image feature,
+ # support_keypoints = Support keypoint feature
+ outs_dec, initial_proposals, out_points, similarity_map = (
+ self.transformer(x, masks, support_keypoints, pos_embed,
+ support_order_embedding, masks_query,
+ self.positional_encoding, self.kpt_branch,
+ skeleton))
+
+ output_kpts = []
+ for idx in range(outs_dec.shape[0]):
+ layer_delta_unsig = self.kpt_branch[idx](outs_dec[idx])
+ layer_outputs_unsig = layer_delta_unsig + inverse_sigmoid(
+ out_points[idx])
+ output_kpts.append(layer_outputs_unsig.sigmoid())
+
+ return torch.stack(
+ output_kpts, dim=0), initial_proposals, similarity_map
+
+ def get_loss(self, output, initial_proposals, similarity_map, target,
+ target_heatmap, target_weight, target_sizes):
+ # Calculate top-down keypoint loss.
+ losses = dict()
+ # denormalize the predicted coordinates.
+ num_dec_layer, bs, nq = output.shape[:3]
+ target_sizes = target_sizes.to(output.device) # [bs, 1, 2]
+ target = target / target_sizes
+ target = target[None, :, :, :].repeat(num_dec_layer, 1, 1, 1)
+
+ # set the weight for unset query point to be zero
+ normalizer = target_weight.squeeze(dim=-1).sum(dim=-1) # [bs, ]
+ normalizer[normalizer == 0] = 1
+
+ # compute the heatmap loss
+ if self.with_heatmap_loss:
+ losses['heatmap_loss'] = self.heatmap_loss(
+ similarity_map, target_heatmap, target_weight,
+ normalizer) * self.heatmap_loss_weight
+
+ # compute l1 loss for initial_proposals
+ proposal_l1_loss = F.l1_loss(
+ initial_proposals, target[0], reduction='none')
+ proposal_l1_loss = proposal_l1_loss.sum(
+ dim=-1, keepdim=False) * target_weight.squeeze(dim=-1)
+ proposal_l1_loss = proposal_l1_loss.sum(
+ dim=-1, keepdim=False) / normalizer # [bs, ]
+ losses['proposal_loss'] = proposal_l1_loss.sum() / bs
+
+ # compute l1 loss for each layer
+ for idx in range(num_dec_layer):
+ layer_output, layer_target = output[idx], target[idx]
+ l1_loss = F.l1_loss(
+ layer_output, layer_target, reduction='none') # [bs, query, 2]
+ l1_loss = l1_loss.sum(
+ dim=-1, keepdim=False) * target_weight.squeeze(
+ dim=-1) # [bs, query]
+ # normalize the loss for each sample with the number of visible
+ # joints
+ l1_loss = l1_loss.sum(dim=-1, keepdim=False) / normalizer # [bs, ]
+ losses['l1_loss' + '_layer' + str(idx)] = l1_loss.sum() / bs
+
+ return losses
+
+ def get_max_coords(self, heatmap, heatmap_size=64):
+ B, C, H, W = heatmap.shape
+ heatmap = heatmap.view(B, C, -1)
+ max_cor = heatmap.argmax(dim=2)
+ row, col = torch.floor(max_cor / heatmap_size), max_cor % heatmap_size
+ support_joints = torch.cat((row.unsqueeze(-1), col.unsqueeze(-1)),
+ dim=-1)
+ return support_joints
+
+ def heatmap_loss(self, similarity_map, target_heatmap, target_weight,
+ normalizer):
+ # similarity_map: [bs, num_query, h, w]
+ # target_heatmap: [bs, num_query, sh, sw]
+ # target_weight: [bs, num_query, 1]
+
+ # preprocess the similarity_map
+ h, w = similarity_map.shape[-2:]
+ # similarity_map = torch.clamp(similarity_map, 0.0, None)
+ similarity_map = similarity_map.sigmoid()
+
+ target_heatmap = F.interpolate(
+ target_heatmap, size=(h, w), mode='bilinear')
+ target_heatmap = (target_heatmap /
+ (target_heatmap.max(dim=-1)[0].max(dim=-1)[0] +
+ 1e-10)[:, :, None, None]
+ ) # make sure sum of each query is 1
+
+ l2_loss = F.mse_loss(
+ similarity_map, target_heatmap, reduction='none') # bs, nq, h, w
+ l2_loss = l2_loss * target_weight[:, :, :, None] # bs, nq, h, w
+ l2_loss = l2_loss.flatten(2, 3).sum(-1) / (h * w) # bs, nq
+ l2_loss = l2_loss.sum(-1) / normalizer # bs,
+
+ return l2_loss.mean()
+
+ def get_accuracy(self,
+ output,
+ target,
+ target_weight,
+ target_sizes,
+ height=256):
+ """Calculate accuracy for top-down keypoint loss.
+
+ Args:
+ output (torch.Tensor[NxKx2]): estimated keypoints in ABSOLUTE
+ coordinates.
+ target (torch.Tensor[NxKx2]): gt keypoints in ABSOLUTE coordinates.
+ target_weight (torch.Tensor[NxKx1]): Weights across different
+ joint types.
+ target_sizes (torch.Tensor[Nx2): shapes of the image.
+ """
+ # NOTE: In POMNet, PCK is estimated on 1/8 resolution, which is
+ # slightly different here.
+
+ accuracy = dict()
+ output = output * float(height)
+ output, target, target_weight, target_sizes = (
+ output.detach().cpu().numpy(), target.detach().cpu().numpy(),
+ target_weight.squeeze(-1).long().detach().cpu().numpy(),
+ target_sizes.squeeze(1).detach().cpu().numpy())
+
+ _, avg_acc, _ = keypoint_pck_accuracy(
+ output,
+ target,
+ target_weight.astype(np.bool8),
+ thr=0.2,
+ normalize=target_sizes)
+ accuracy['acc_pose'] = float(avg_acc)
+
+ return accuracy
+
+ def decode(self, img_metas, output, img_size, **kwargs):
+ """Decode the predicted keypoints from prediction.
+
+ Args:
+ img_metas (list(dict)): Information about data augmentation
+ By default this includes:
+ - "image_file: path to the image file
+ - "center": center of the bbox
+ - "scale": scale of the bbox
+ - "rotation": rotation of the bbox
+ - "bbox_score": score of bbox
+ output (np.ndarray[N, K, H, W]): model predicted heatmaps.
+ """
+ batch_size = len(img_metas)
+ W, H = img_size
+ output = output * np.array([
+ W, H
+ ])[None, None, :] # [bs, query, 2], coordinates with recovered shapes.
+
+ if 'bbox_id' or 'query_bbox_id' in img_metas[0]:
+ bbox_ids = []
+ else:
+ bbox_ids = None
+
+ c = np.zeros((batch_size, 2), dtype=np.float32)
+ s = np.zeros((batch_size, 2), dtype=np.float32)
+ image_paths = []
+ score = np.ones(batch_size)
+ for i in range(batch_size):
+ c[i, :] = img_metas[i]['query_center']
+ s[i, :] = img_metas[i]['query_scale']
+ image_paths.append(img_metas[i]['query_image_file'])
+
+ if 'query_bbox_score' in img_metas[i]:
+ score[i] = np.array(
+ img_metas[i]['query_bbox_score']).reshape(-1)
+ if 'bbox_id' in img_metas[i]:
+ bbox_ids.append(img_metas[i]['bbox_id'])
+ elif 'query_bbox_id' in img_metas[i]:
+ bbox_ids.append(img_metas[i]['query_bbox_id'])
+
+ preds = np.zeros(output.shape)
+ for idx in range(output.shape[0]):
+ preds[i] = transform_preds(
+ output[i],
+ c[i],
+ s[i], [W, H],
+ use_udp=self.test_cfg.get('use_udp', False))
+
+ all_preds = np.zeros((batch_size, preds.shape[1], 3), dtype=np.float32)
+ all_boxes = np.zeros((batch_size, 6), dtype=np.float32)
+ all_preds[:, :, 0:2] = preds[:, :, 0:2]
+ all_preds[:, :, 2:3] = 1.0
+ all_boxes[:, 0:2] = c[:, 0:2]
+ all_boxes[:, 2:4] = s[:, 0:2]
+ all_boxes[:, 4] = np.prod(s * 200.0, axis=1)
+ all_boxes[:, 5] = score
+
+ result = {}
+
+ result['preds'] = all_preds
+ result['boxes'] = all_boxes
+ result['image_paths'] = image_paths
+ result['bbox_ids'] = bbox_ids
+
+ return result
diff --git a/projects/pose_anything/models/utils/__init__.py b/projects/pose_anything/models/utils/__init__.py
new file mode 100644
index 0000000000..fe9927e37f
--- /dev/null
+++ b/projects/pose_anything/models/utils/__init__.py
@@ -0,0 +1,22 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .builder import (build_backbone, build_linear_layer,
+ build_positional_encoding, build_transformer)
+from .encoder_decoder import EncoderDecoder
+from .positional_encoding import (LearnedPositionalEncoding,
+ SinePositionalEncoding)
+from .transformer import (DetrTransformerDecoder, DetrTransformerDecoderLayer,
+ DetrTransformerEncoder, DynamicConv)
+
+__all__ = [
+ 'build_transformer',
+ 'build_backbone',
+ 'build_linear_layer',
+ 'build_positional_encoding',
+ 'DetrTransformerDecoderLayer',
+ 'DetrTransformerDecoder',
+ 'DetrTransformerEncoder',
+ 'LearnedPositionalEncoding',
+ 'SinePositionalEncoding',
+ 'EncoderDecoder',
+ 'DynamicConv',
+]
diff --git a/projects/pose_anything/models/utils/builder.py b/projects/pose_anything/models/utils/builder.py
new file mode 100644
index 0000000000..a165f98c70
--- /dev/null
+++ b/projects/pose_anything/models/utils/builder.py
@@ -0,0 +1,61 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+from mmengine import build_from_cfg
+
+from mmpose.registry import Registry
+
+TRANSFORMER = Registry('Transformer')
+BACKBONES = Registry('BACKBONES')
+POSITIONAL_ENCODING = Registry('position encoding')
+LINEAR_LAYERS = Registry('linear layers')
+
+
+def build_positional_encoding(cfg, default_args=None):
+ """Build backbone."""
+ return build_from_cfg(cfg, POSITIONAL_ENCODING, default_args)
+
+
+def build_backbone(cfg, default_args=None):
+ """Build backbone."""
+ return build_from_cfg(cfg, BACKBONES, default_args)
+
+
+def build_transformer(cfg, default_args=None):
+ """Builder for Transformer."""
+ return build_from_cfg(cfg, TRANSFORMER, default_args)
+
+
+LINEAR_LAYERS.register_module('Linear', module=nn.Linear)
+
+
+def build_linear_layer(cfg, *args, **kwargs):
+ """Build linear layer.
+ Args:
+ cfg (None or dict): The linear layer config, which should contain:
+ - type (str): Layer type.
+ - layer args: Args needed to instantiate an linear layer.
+ args (argument list): Arguments passed to the `__init__`
+ method of the corresponding linear layer.
+ kwargs (keyword arguments): Keyword arguments passed to the `__init__`
+ method of the corresponding linear layer.
+ Returns:
+ nn.Module: Created linear layer.
+ """
+ if cfg is None:
+ cfg_ = dict(type='Linear')
+ else:
+ if not isinstance(cfg, dict):
+ raise TypeError('cfg must be a dict')
+ if 'type' not in cfg:
+ raise KeyError('the cfg dict must contain the key "type"')
+ cfg_ = cfg.copy()
+
+ layer_type = cfg_.pop('type')
+ if layer_type not in LINEAR_LAYERS:
+ raise KeyError(f'Unrecognized linear type {layer_type}')
+ else:
+ linear_layer = LINEAR_LAYERS.get(layer_type)
+
+ layer = linear_layer(*args, **kwargs, **cfg_)
+
+ return layer
diff --git a/projects/pose_anything/models/utils/encoder_decoder.py b/projects/pose_anything/models/utils/encoder_decoder.py
new file mode 100644
index 0000000000..9e197efb14
--- /dev/null
+++ b/projects/pose_anything/models/utils/encoder_decoder.py
@@ -0,0 +1,637 @@
+import copy
+from typing import Optional
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmengine.model import xavier_init
+from models.utils.builder import TRANSFORMER
+from torch import Tensor
+
+
+def inverse_sigmoid(x, eps=1e-3):
+ x = x.clamp(min=0, max=1)
+ x1 = x.clamp(min=eps)
+ x2 = (1 - x).clamp(min=eps)
+ return torch.log(x1 / x2)
+
+
+class MLP(nn.Module):
+ """Very simple multi-layer perceptron (also called FFN)"""
+
+ def __init__(self, input_dim, hidden_dim, output_dim, num_layers):
+ super().__init__()
+ self.num_layers = num_layers
+ h = [hidden_dim] * (num_layers - 1)
+ self.layers = nn.ModuleList(
+ nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim]))
+
+ def forward(self, x):
+ for i, layer in enumerate(self.layers):
+ x = F.gelu(layer(x)) if i < self.num_layers - 1 else layer(x)
+ return x
+
+
+class ProposalGenerator(nn.Module):
+
+ def __init__(self, hidden_dim, proj_dim, dynamic_proj_dim):
+ super().__init__()
+ self.support_proj = nn.Linear(hidden_dim, proj_dim)
+ self.query_proj = nn.Linear(hidden_dim, proj_dim)
+ self.dynamic_proj = nn.Sequential(
+ nn.Linear(hidden_dim, dynamic_proj_dim), nn.ReLU(),
+ nn.Linear(dynamic_proj_dim, hidden_dim))
+ self.dynamic_act = nn.Tanh()
+
+ def forward(self, query_feat, support_feat, spatial_shape):
+ """
+ Args:
+ support_feat: [query, bs, c]
+ query_feat: [hw, bs, c]
+ spatial_shape: h, w
+ """
+ device = query_feat.device
+ _, bs, c = query_feat.shape
+ h, w = spatial_shape
+ side_normalizer = torch.tensor([w, h]).to(query_feat.device)[
+ None, None, :] # [bs, query, 2], Normalize the coord to [0,1]
+
+ query_feat = query_feat.transpose(0, 1)
+ support_feat = support_feat.transpose(0, 1)
+ nq = support_feat.shape[1]
+
+ fs_proj = self.support_proj(support_feat) # [bs, query, c]
+ fq_proj = self.query_proj(query_feat) # [bs, hw, c]
+ pattern_attention = self.dynamic_act(
+ self.dynamic_proj(fs_proj)) # [bs, query, c]
+
+ fs_feat = (pattern_attention + 1) * fs_proj # [bs, query, c]
+ similarity = torch.bmm(fq_proj,
+ fs_feat.transpose(1, 2)) # [bs, hw, query]
+ similarity = similarity.transpose(1, 2).reshape(bs, nq, h, w)
+ grid_y, grid_x = torch.meshgrid(
+ torch.linspace(
+ 0.5, h - 0.5, h, dtype=torch.float32, device=device), # (h, w)
+ torch.linspace(
+ 0.5, w - 0.5, w, dtype=torch.float32, device=device))
+
+ # compute softmax and sum up
+ coord_grid = torch.stack([grid_x, grid_y],
+ dim=0).unsqueeze(0).unsqueeze(0).repeat(
+ bs, nq, 1, 1, 1) # [bs, query, 2, h, w]
+ coord_grid = coord_grid.permute(0, 1, 3, 4, 2) # [bs, query, h, w, 2]
+ similarity_softmax = similarity.flatten(2, 3).softmax(
+ dim=-1) # [bs, query, hw]
+ similarity_coord_grid = similarity_softmax[:, :, :,
+ None] * coord_grid.flatten(
+ 2, 3)
+ proposal_for_loss = similarity_coord_grid.sum(
+ dim=2, keepdim=False) # [bs, query, 2]
+ proposal_for_loss = proposal_for_loss / side_normalizer
+
+ max_pos = torch.argmax(
+ similarity.reshape(bs, nq, -1), dim=-1,
+ keepdim=True) # (bs, nq, 1)
+ max_mask = F.one_hot(max_pos, num_classes=w * h) # (bs, nq, 1, w*h)
+ max_mask = max_mask.reshape(bs, nq, w,
+ h).type(torch.float) # (bs, nq, w, h)
+ local_max_mask = F.max_pool2d(
+ input=max_mask, kernel_size=3, stride=1,
+ padding=1).reshape(bs, nq, w * h, 1) # (bs, nq, w*h, 1)
+ '''
+ proposal = (similarity_coord_grid * local_max_mask).sum(
+ dim=2, keepdim=False) / torch.count_nonzero(
+ local_max_mask, dim=2)
+ '''
+ # first, extract the local probability map with the mask
+ local_similarity_softmax = similarity_softmax[:, :, :,
+ None] * local_max_mask
+
+ # then, re-normalize the local probability map
+ local_similarity_softmax = local_similarity_softmax / (
+ local_similarity_softmax.sum(dim=-2, keepdim=True) + 1e-10
+ ) # [bs, nq, w*h, 1]
+
+ # point-wise mulplication of local probability map and coord grid
+ proposals = local_similarity_softmax * coord_grid.flatten(
+ 2, 3) # [bs, nq, w*h, 2]
+
+ # sum the mulplication to obtain the final coord proposals
+ proposals = proposals.sum(dim=2) / side_normalizer # [bs, nq, 2]
+
+ return proposal_for_loss, similarity, proposals
+
+
+@TRANSFORMER.register_module()
+class EncoderDecoder(nn.Module):
+
+ def __init__(self,
+ d_model=256,
+ nhead=8,
+ num_encoder_layers=3,
+ num_decoder_layers=3,
+ graph_decoder=None,
+ dim_feedforward=2048,
+ dropout=0.1,
+ activation='relu',
+ normalize_before=False,
+ similarity_proj_dim=256,
+ dynamic_proj_dim=128,
+ return_intermediate_dec=True,
+ look_twice=False,
+ detach_support_feat=False):
+ super().__init__()
+
+ self.d_model = d_model
+ self.nhead = nhead
+
+ encoder_layer = TransformerEncoderLayer(d_model, nhead,
+ dim_feedforward, dropout,
+ activation, normalize_before)
+ encoder_norm = nn.LayerNorm(d_model) if normalize_before else None
+ self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers,
+ encoder_norm)
+
+ decoder_layer = GraphTransformerDecoderLayer(d_model, nhead,
+ dim_feedforward, dropout,
+ activation,
+ normalize_before,
+ graph_decoder)
+ decoder_norm = nn.LayerNorm(d_model)
+ self.decoder = GraphTransformerDecoder(
+ d_model,
+ decoder_layer,
+ num_decoder_layers,
+ decoder_norm,
+ return_intermediate=return_intermediate_dec,
+ look_twice=look_twice,
+ detach_support_feat=detach_support_feat)
+
+ self.proposal_generator = ProposalGenerator(
+ hidden_dim=d_model,
+ proj_dim=similarity_proj_dim,
+ dynamic_proj_dim=dynamic_proj_dim)
+
+ def init_weights(self):
+ # follow the official DETR to init parameters
+ for m in self.modules():
+ if hasattr(m, 'weight') and m.weight.dim() > 1:
+ xavier_init(m, distribution='uniform')
+
+ def forward(self,
+ src,
+ mask,
+ support_embed,
+ pos_embed,
+ support_order_embed,
+ query_padding_mask,
+ position_embedding,
+ kpt_branch,
+ skeleton,
+ return_attn_map=False):
+
+ bs, c, h, w = src.shape
+
+ src = src.flatten(2).permute(2, 0, 1)
+ pos_embed = pos_embed.flatten(2).permute(2, 0, 1)
+ support_order_embed = support_order_embed.flatten(2).permute(2, 0, 1)
+ pos_embed = torch.cat((pos_embed, support_order_embed))
+ query_embed = support_embed.transpose(0, 1)
+ mask = mask.flatten(1)
+
+ query_embed, refined_support_embed = self.encoder(
+ src,
+ query_embed,
+ src_key_padding_mask=mask,
+ query_key_padding_mask=query_padding_mask,
+ pos=pos_embed)
+
+ # Generate initial proposals and corresponding positional embedding.
+ initial_proposals_for_loss, similarity_map, initial_proposals = (
+ self.proposal_generator(
+ query_embed, refined_support_embed, spatial_shape=[h, w]))
+ initial_position_embedding = position_embedding.forward_coordinates(
+ initial_proposals)
+
+ outs_dec, out_points, attn_maps = self.decoder(
+ refined_support_embed,
+ query_embed,
+ memory_key_padding_mask=mask,
+ pos=pos_embed,
+ query_pos=initial_position_embedding,
+ tgt_key_padding_mask=query_padding_mask,
+ position_embedding=position_embedding,
+ initial_proposals=initial_proposals,
+ kpt_branch=kpt_branch,
+ skeleton=skeleton,
+ return_attn_map=return_attn_map)
+
+ return outs_dec.transpose(
+ 1, 2), initial_proposals_for_loss, out_points, similarity_map
+
+
+class GraphTransformerDecoder(nn.Module):
+
+ def __init__(self,
+ d_model,
+ decoder_layer,
+ num_layers,
+ norm=None,
+ return_intermediate=False,
+ look_twice=False,
+ detach_support_feat=False):
+ super().__init__()
+ self.layers = _get_clones(decoder_layer, num_layers)
+ self.num_layers = num_layers
+ self.norm = norm
+ self.return_intermediate = return_intermediate
+ self.ref_point_head = MLP(d_model, d_model, d_model, num_layers=2)
+ self.look_twice = look_twice
+ self.detach_support_feat = detach_support_feat
+
+ def forward(self,
+ support_feat,
+ query_feat,
+ tgt_mask=None,
+ memory_mask=None,
+ tgt_key_padding_mask=None,
+ memory_key_padding_mask=None,
+ pos=None,
+ query_pos=None,
+ position_embedding=None,
+ initial_proposals=None,
+ kpt_branch=None,
+ skeleton=None,
+ return_attn_map=False):
+ """
+ position_embedding: Class used to compute positional embedding
+ initial_proposals: [bs, nq, 2], normalized coordinates of initial
+ proposals kpt_branch: MLP used to predict the offsets for each query.
+ """
+
+ refined_support_feat = support_feat
+ intermediate = []
+ attn_maps = []
+ bi = initial_proposals.detach()
+ bi_tag = initial_proposals.detach()
+ query_points = [initial_proposals.detach()]
+
+ tgt_key_padding_mask_remove_all_true = tgt_key_padding_mask.clone().to(
+ tgt_key_padding_mask.device)
+ tgt_key_padding_mask_remove_all_true[
+ tgt_key_padding_mask.logical_not().sum(dim=-1) == 0, 0] = False
+
+ for layer_idx, layer in enumerate(self.layers):
+ if layer_idx == 0: # use positional embedding form initial
+ # proposals
+ query_pos_embed = query_pos.transpose(0, 1)
+ else:
+ # recalculate the positional embedding
+ query_pos_embed = position_embedding.forward_coordinates(bi)
+ query_pos_embed = query_pos_embed.transpose(0, 1)
+ query_pos_embed = self.ref_point_head(query_pos_embed)
+
+ if self.detach_support_feat:
+ refined_support_feat = refined_support_feat.detach()
+
+ refined_support_feat, attn_map = layer(
+ refined_support_feat,
+ query_feat,
+ tgt_mask=tgt_mask,
+ memory_mask=memory_mask,
+ tgt_key_padding_mask=tgt_key_padding_mask_remove_all_true,
+ memory_key_padding_mask=memory_key_padding_mask,
+ pos=pos,
+ query_pos=query_pos_embed,
+ skeleton=skeleton)
+
+ if self.return_intermediate:
+ intermediate.append(self.norm(refined_support_feat))
+
+ if return_attn_map:
+ attn_maps.append(attn_map)
+
+ # update the query coordinates
+ delta_bi = kpt_branch[layer_idx](
+ refined_support_feat.transpose(0, 1))
+
+ # Prediction loss
+ if self.look_twice:
+ bi_pred = self.update(bi_tag, delta_bi)
+ bi_tag = self.update(bi, delta_bi)
+ else:
+ bi_tag = self.update(bi, delta_bi)
+ bi_pred = bi_tag
+
+ bi = bi_tag.detach()
+ query_points.append(bi_pred)
+
+ if self.norm is not None:
+ refined_support_feat = self.norm(refined_support_feat)
+ if self.return_intermediate:
+ intermediate.pop()
+ intermediate.append(refined_support_feat)
+
+ if self.return_intermediate:
+ return torch.stack(intermediate), query_points, attn_maps
+
+ return refined_support_feat.unsqueeze(0), query_points, attn_maps
+
+ def update(self, query_coordinates, delta_unsig):
+ query_coordinates_unsigmoid = inverse_sigmoid(query_coordinates)
+ new_query_coordinates = query_coordinates_unsigmoid + delta_unsig
+ new_query_coordinates = new_query_coordinates.sigmoid()
+ return new_query_coordinates
+
+
+class GraphTransformerDecoderLayer(nn.Module):
+
+ def __init__(self,
+ d_model,
+ nhead,
+ dim_feedforward=2048,
+ dropout=0.1,
+ activation='relu',
+ normalize_before=False,
+ graph_decoder=None):
+
+ super().__init__()
+ self.graph_decoder = graph_decoder
+ self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
+ self.multihead_attn = nn.MultiheadAttention(
+ d_model * 2, nhead, dropout=dropout, vdim=d_model)
+ self.choker = nn.Linear(in_features=2 * d_model, out_features=d_model)
+ # Implementation of Feedforward model
+ if self.graph_decoder is None:
+ self.ffn1 = nn.Linear(d_model, dim_feedforward)
+ self.ffn2 = nn.Linear(dim_feedforward, d_model)
+ elif self.graph_decoder == 'pre':
+ self.ffn1 = GCNLayer(d_model, dim_feedforward, batch_first=False)
+ self.ffn2 = nn.Linear(dim_feedforward, d_model)
+ elif self.graph_decoder == 'post':
+ self.ffn1 = nn.Linear(d_model, dim_feedforward)
+ self.ffn2 = GCNLayer(dim_feedforward, d_model, batch_first=False)
+ else:
+ self.ffn1 = GCNLayer(d_model, dim_feedforward, batch_first=False)
+ self.ffn2 = GCNLayer(dim_feedforward, d_model, batch_first=False)
+
+ self.dropout = nn.Dropout(dropout)
+ self.norm1 = nn.LayerNorm(d_model)
+ self.norm2 = nn.LayerNorm(d_model)
+ self.norm3 = nn.LayerNorm(d_model)
+ self.dropout1 = nn.Dropout(dropout)
+ self.dropout2 = nn.Dropout(dropout)
+ self.dropout3 = nn.Dropout(dropout)
+
+ self.activation = _get_activation_fn(activation)
+ self.normalize_before = normalize_before
+
+ def with_pos_embed(self, tensor, pos: Optional[Tensor]):
+ return tensor if pos is None else tensor + pos
+
+ def forward(self,
+ refined_support_feat,
+ refined_query_feat,
+ tgt_mask: Optional[Tensor] = None,
+ memory_mask: Optional[Tensor] = None,
+ tgt_key_padding_mask: Optional[Tensor] = None,
+ memory_key_padding_mask: Optional[Tensor] = None,
+ pos: Optional[Tensor] = None,
+ query_pos: Optional[Tensor] = None,
+ skeleton: Optional[list] = None):
+
+ q = k = self.with_pos_embed(
+ refined_support_feat,
+ query_pos + pos[refined_query_feat.shape[0]:])
+ tgt2 = self.self_attn(
+ q,
+ k,
+ value=refined_support_feat,
+ attn_mask=tgt_mask,
+ key_padding_mask=tgt_key_padding_mask)[0]
+
+ refined_support_feat = refined_support_feat + self.dropout1(tgt2)
+ refined_support_feat = self.norm1(refined_support_feat)
+
+ # concatenate the positional embedding with the content feature,
+ # instead of direct addition
+ cross_attn_q = torch.cat(
+ (refined_support_feat,
+ query_pos + pos[refined_query_feat.shape[0]:]),
+ dim=-1)
+ cross_attn_k = torch.cat(
+ (refined_query_feat, pos[:refined_query_feat.shape[0]]), dim=-1)
+
+ tgt2, attn_map = self.multihead_attn(
+ query=cross_attn_q,
+ key=cross_attn_k,
+ value=refined_query_feat,
+ attn_mask=memory_mask,
+ key_padding_mask=memory_key_padding_mask)
+
+ refined_support_feat = refined_support_feat + self.dropout2(
+ self.choker(tgt2))
+ refined_support_feat = self.norm2(refined_support_feat)
+ if self.graph_decoder is not None:
+ num_pts, b, c = refined_support_feat.shape
+ adj = adj_from_skeleton(
+ num_pts=num_pts,
+ skeleton=skeleton,
+ mask=tgt_key_padding_mask,
+ device=refined_support_feat.device)
+ if self.graph_decoder == 'pre':
+ tgt2 = self.ffn2(
+ self.dropout(
+ self.activation(self.ffn1(refined_support_feat, adj))))
+ elif self.graph_decoder == 'post':
+ tgt2 = self.ffn2(
+ self.dropout(
+ self.activation(self.ffn1(refined_support_feat))), adj)
+ else:
+ tgt2 = self.ffn2(
+ self.dropout(
+ self.activation(self.ffn1(refined_support_feat, adj))),
+ adj)
+ else:
+ tgt2 = self.ffn2(
+ self.dropout(self.activation(self.ffn1(refined_support_feat))))
+ refined_support_feat = refined_support_feat + self.dropout3(tgt2)
+ refined_support_feat = self.norm3(refined_support_feat)
+
+ return refined_support_feat, attn_map
+
+
+class TransformerEncoder(nn.Module):
+
+ def __init__(self, encoder_layer, num_layers, norm=None):
+ super().__init__()
+ self.layers = _get_clones(encoder_layer, num_layers)
+ self.num_layers = num_layers
+ self.norm = norm
+
+ def forward(self,
+ src,
+ query,
+ mask: Optional[Tensor] = None,
+ src_key_padding_mask: Optional[Tensor] = None,
+ query_key_padding_mask: Optional[Tensor] = None,
+ pos: Optional[Tensor] = None):
+ # src: [hw, bs, c]
+ # query: [num_query, bs, c]
+ # mask: None by default
+ # src_key_padding_mask: [bs, hw]
+ # query_key_padding_mask: [bs, nq]
+ # pos: [hw, bs, c]
+
+ # organize the input
+ # implement the attention mask to mask out the useless points
+ n, bs, c = src.shape
+ src_cat = torch.cat((src, query), dim=0) # [hw + nq, bs, c]
+ mask_cat = torch.cat((src_key_padding_mask, query_key_padding_mask),
+ dim=1) # [bs, hw+nq]
+ output = src_cat
+
+ for layer in self.layers:
+ output = layer(
+ output,
+ query_length=n,
+ src_mask=mask,
+ src_key_padding_mask=mask_cat,
+ pos=pos)
+
+ if self.norm is not None:
+ output = self.norm(output)
+
+ # resplit the output into src and query
+ refined_query = output[n:, :, :] # [nq, bs, c]
+ output = output[:n, :, :] # [n, bs, c]
+
+ return output, refined_query
+
+
+class TransformerEncoderLayer(nn.Module):
+
+ def __init__(self,
+ d_model,
+ nhead,
+ dim_feedforward=2048,
+ dropout=0.1,
+ activation='relu',
+ normalize_before=False):
+ super().__init__()
+ self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
+ # Implementation of Feedforward model
+ self.linear1 = nn.Linear(d_model, dim_feedforward)
+ self.dropout = nn.Dropout(dropout)
+ self.linear2 = nn.Linear(dim_feedforward, d_model)
+
+ self.norm1 = nn.LayerNorm(d_model)
+ self.norm2 = nn.LayerNorm(d_model)
+ self.dropout1 = nn.Dropout(dropout)
+ self.dropout2 = nn.Dropout(dropout)
+
+ self.activation = _get_activation_fn(activation)
+ self.normalize_before = normalize_before
+
+ def with_pos_embed(self, tensor, pos: Optional[Tensor]):
+ return tensor if pos is None else tensor + pos
+
+ def forward(self,
+ src,
+ query_length,
+ src_mask: Optional[Tensor] = None,
+ src_key_padding_mask: Optional[Tensor] = None,
+ pos: Optional[Tensor] = None):
+ src = self.with_pos_embed(src, pos)
+ q = k = src
+ # NOTE: compared with original implementation, we add positional
+ # embedding into the VALUE.
+ src2 = self.self_attn(
+ q,
+ k,
+ value=src,
+ attn_mask=src_mask,
+ key_padding_mask=src_key_padding_mask)[0]
+ src = src + self.dropout1(src2)
+ src = self.norm1(src)
+ src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
+ src = src + self.dropout2(src2)
+ src = self.norm2(src)
+ return src
+
+
+def adj_from_skeleton(num_pts, skeleton, mask, device='cuda'):
+ adj_mx = torch.empty(0, device=device)
+ batch_size = len(skeleton)
+ for b in range(batch_size):
+ edges = torch.tensor(skeleton[b])
+ adj = torch.zeros(num_pts, num_pts, device=device)
+ adj[edges[:, 0], edges[:, 1]] = 1
+ adj_mx = torch.cat((adj_mx, adj.unsqueeze(0)), dim=0)
+ trans_adj_mx = torch.transpose(adj_mx, 1, 2)
+ cond = (trans_adj_mx > adj_mx).float()
+ adj = adj_mx + trans_adj_mx * cond - adj_mx * cond
+ adj = adj * ~mask[..., None] * ~mask[:, None]
+ adj = torch.nan_to_num(adj / adj.sum(dim=-1, keepdim=True))
+ adj = torch.stack((torch.diag_embed(~mask), adj), dim=1)
+ return adj
+
+
+class GCNLayer(nn.Module):
+
+ def __init__(self,
+ in_features,
+ out_features,
+ kernel_size=2,
+ use_bias=True,
+ activation=nn.ReLU(inplace=True),
+ batch_first=True):
+ super(GCNLayer, self).__init__()
+ self.conv = nn.Conv1d(
+ in_features,
+ out_features * kernel_size,
+ kernel_size=1,
+ padding=0,
+ stride=1,
+ dilation=1,
+ bias=use_bias)
+ self.kernel_size = kernel_size
+ self.activation = activation
+ self.batch_first = batch_first
+
+ def forward(self, x, adj):
+ assert adj.size(1) == self.kernel_size
+ if not self.batch_first:
+ x = x.permute(1, 2, 0)
+ else:
+ x = x.transpose(1, 2)
+ x = self.conv(x)
+ b, kc, v = x.size()
+ x = x.view(b, self.kernel_size, kc // self.kernel_size, v)
+ x = torch.einsum('bkcv,bkvw->bcw', (x, adj))
+ if self.activation is not None:
+ x = self.activation(x)
+ if not self.batch_first:
+ x = x.permute(2, 0, 1)
+ else:
+ x = x.transpose(1, 2)
+ return x
+
+
+def _get_clones(module, N):
+ return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
+
+
+def _get_activation_fn(activation):
+ """Return an activation function given a string."""
+ if activation == 'relu':
+ return F.relu
+ if activation == 'gelu':
+ return F.gelu
+ if activation == 'glu':
+ return F.glu
+ raise RuntimeError(F'activation should be relu/gelu, not {activation}.')
+
+
+def clones(module, N):
+ return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
diff --git a/projects/pose_anything/models/utils/positional_encoding.py b/projects/pose_anything/models/utils/positional_encoding.py
new file mode 100644
index 0000000000..2fe441a51c
--- /dev/null
+++ b/projects/pose_anything/models/utils/positional_encoding.py
@@ -0,0 +1,195 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import torch
+import torch.nn as nn
+from mmengine.model import BaseModule
+from models.utils.builder import POSITIONAL_ENCODING
+
+
+# TODO: add an SinePositionalEncoding for coordinates input
+@POSITIONAL_ENCODING.register_module()
+class SinePositionalEncoding(BaseModule):
+ """Position encoding with sine and cosine functions.
+
+ See `End-to-End Object Detection with Transformers
+
`_ for details.
+
+ Args:
+ num_feats (int): The feature dimension for each position
+ along x-axis or y-axis. Note the final returned dimension
+ for each position is 2 times of this value.
+ temperature (int, optional): The temperature used for scaling
+ the position embedding. Defaults to 10000.
+ normalize (bool, optional): Whether to normalize the position
+ embedding. Defaults to False.
+ scale (float, optional): A scale factor that scales the position
+ embedding. The scale will be used only when `normalize` is True.
+ Defaults to 2*pi.
+ eps (float, optional): A value added to the denominator for
+ numerical stability. Defaults to 1e-6.
+ offset (float): offset add to embed when do the normalization.
+ Defaults to 0.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ num_feats,
+ temperature=10000,
+ normalize=False,
+ scale=2 * math.pi,
+ eps=1e-6,
+ offset=0.,
+ init_cfg=None):
+ super(SinePositionalEncoding, self).__init__(init_cfg)
+ if normalize:
+ assert isinstance(scale, (float, int)), \
+ (f'when normalize is set, '
+ f'scale should be provided and in float or int type, '
+ f'found {type(scale)}')
+ self.num_feats = num_feats
+ self.temperature = temperature
+ self.normalize = normalize
+ self.scale = scale
+ self.eps = eps
+ self.offset = offset
+
+ def forward(self, mask):
+ """Forward function for `SinePositionalEncoding`.
+
+ Args:
+ mask (Tensor): ByteTensor mask. Non-zero values representing
+ ignored positions, while zero values means valid positions
+ for this image. Shape [bs, h, w].
+
+ Returns:
+ pos (Tensor): Returned position embedding with shape
+ [bs, num_feats*2, h, w].
+ """
+ # For convenience of exporting to ONNX, it's required to convert
+ # `masks` from bool to int.
+ mask = mask.to(torch.int)
+ not_mask = 1 - mask # logical_not
+ y_embed = not_mask.cumsum(
+ 1, dtype=torch.float32
+ ) # [bs, h, w], recording the y coordinate of each pixel
+ x_embed = not_mask.cumsum(2, dtype=torch.float32)
+ if self.normalize: # default True
+ y_embed = (y_embed + self.offset) / \
+ (y_embed[:, -1:, :] + self.eps) * self.scale
+ x_embed = (x_embed + self.offset) / \
+ (x_embed[:, :, -1:] + self.eps) * self.scale
+ dim_t = torch.arange(
+ self.num_feats, dtype=torch.float32, device=mask.device)
+ dim_t = self.temperature**(2 * (dim_t // 2) / self.num_feats)
+ pos_x = x_embed[:, :, :, None] / dim_t # [bs, h, w, num_feats]
+ pos_y = y_embed[:, :, :, None] / dim_t
+ # use `view` instead of `flatten` for dynamically exporting to ONNX
+ B, H, W = mask.size()
+ pos_x = torch.stack(
+ (pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()),
+ dim=4).view(B, H, W, -1) # [bs, h, w, num_feats]
+ pos_y = torch.stack(
+ (pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()),
+ dim=4).view(B, H, W, -1)
+ pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
+ return pos
+
+ def forward_coordinates(self, coord):
+ """Forward function for normalized coordinates input with the shape of.
+
+ [ bs, kpt, 2] return: pos (Tensor): position embedding with the shape
+ of.
+
+ [bs, kpt, num_feats*2]
+ """
+ x_embed, y_embed = coord[:, :, 0], coord[:, :, 1] # [bs, kpt]
+ x_embed = x_embed * self.scale # [bs, kpt]
+ y_embed = y_embed * self.scale
+
+ dim_t = torch.arange(
+ self.num_feats, dtype=torch.float32, device=coord.device)
+ dim_t = self.temperature**(2 * (dim_t // 2) / self.num_feats)
+
+ pos_x = x_embed[:, :, None] / dim_t # [bs, kpt, num_feats]
+ pos_y = y_embed[:, :, None] / dim_t # [bs, kpt, num_feats]
+ bs, kpt, _ = pos_x.shape
+
+ pos_x = torch.stack((pos_x[:, :, 0::2].sin(), pos_x[:, :, 1::2].cos()),
+ dim=3).view(bs, kpt, -1) # [bs, kpt, num_feats]
+ pos_y = torch.stack((pos_y[:, :, 0::2].sin(), pos_y[:, :, 1::2].cos()),
+ dim=3).view(bs, kpt, -1) # [bs, kpt, num_feats]
+ pos = torch.cat((pos_y, pos_x), dim=2) # [bs, kpt, num_feats * 2]
+
+ return pos
+
+ def __repr__(self):
+ """str: a string that describes the module"""
+ repr_str = self.__class__.__name__
+ repr_str += f'(num_feats={self.num_feats}, '
+ repr_str += f'temperature={self.temperature}, '
+ repr_str += f'normalize={self.normalize}, '
+ repr_str += f'scale={self.scale}, '
+ repr_str += f'eps={self.eps})'
+ return repr_str
+
+
+@POSITIONAL_ENCODING.register_module()
+class LearnedPositionalEncoding(BaseModule):
+ """Position embedding with learnable embedding weights.
+
+ Args:
+ num_feats (int): The feature dimension for each position
+ along x-axis or y-axis. The final returned dimension for
+ each position is 2 times of this value.
+ row_num_embed (int, optional): The dictionary size of row embeddings.
+ Default 50.
+ col_num_embed (int, optional): The dictionary size of col embeddings.
+ Default 50.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ """
+
+ def __init__(self,
+ num_feats,
+ row_num_embed=50,
+ col_num_embed=50,
+ init_cfg=dict(type='Uniform', layer='Embedding')):
+ super(LearnedPositionalEncoding, self).__init__(init_cfg)
+ self.row_embed = nn.Embedding(row_num_embed, num_feats)
+ self.col_embed = nn.Embedding(col_num_embed, num_feats)
+ self.num_feats = num_feats
+ self.row_num_embed = row_num_embed
+ self.col_num_embed = col_num_embed
+
+ def forward(self, mask):
+ """Forward function for `LearnedPositionalEncoding`.
+
+ Args:
+ mask (Tensor): ByteTensor mask. Non-zero values representing
+ ignored positions, while zero values means valid positions
+ for this image. Shape [bs, h, w].
+
+ Returns:
+ pos (Tensor): Returned position embedding with shape
+ [bs, num_feats*2, h, w].
+ """
+ h, w = mask.shape[-2:]
+ x = torch.arange(w, device=mask.device)
+ y = torch.arange(h, device=mask.device)
+ x_embed = self.col_embed(x)
+ y_embed = self.row_embed(y)
+ pos = torch.cat(
+ (x_embed.unsqueeze(0).repeat(h, 1, 1), y_embed.unsqueeze(1).repeat(
+ 1, w, 1)),
+ dim=-1).permute(2, 0,
+ 1).unsqueeze(0).repeat(mask.shape[0], 1, 1, 1)
+ return pos
+
+ def __repr__(self):
+ """str: a string that describes the module"""
+ repr_str = self.__class__.__name__
+ repr_str += f'(num_feats={self.num_feats}, '
+ repr_str += f'row_num_embed={self.row_num_embed}, '
+ repr_str += f'col_num_embed={self.col_num_embed})'
+ return repr_str
diff --git a/projects/pose_anything/models/utils/transformer.py b/projects/pose_anything/models/utils/transformer.py
new file mode 100644
index 0000000000..4657b81fde
--- /dev/null
+++ b/projects/pose_anything/models/utils/transformer.py
@@ -0,0 +1,340 @@
+import torch
+import torch.nn as nn
+from mmcv.cnn import build_activation_layer, build_norm_layer
+from mmcv.cnn.bricks.transformer import (BaseTransformerLayer,
+ TransformerLayerSequence,
+ build_transformer_layer_sequence)
+from mmengine.model import BaseModule, xavier_init
+from mmengine.registry import MODELS
+
+
+@MODELS.register_module()
+class Transformer(BaseModule):
+ """Implements the DETR transformer. Following the official DETR
+ implementation, this module copy-paste from torch.nn.Transformer with
+ modifications:
+
+ * positional encodings are passed in MultiheadAttention
+ * extra LN at the end of encoder is removed
+ * decoder returns a stack of activations from all decoding layers
+ See `paper: End-to-End Object Detection with Transformers
+ `_ for details.
+ Args:
+ encoder (`mmcv.ConfigDict` | Dict): Config of
+ TransformerEncoder. Defaults to None.
+ decoder ((`mmcv.ConfigDict` | Dict)): Config of
+ TransformerDecoder. Defaults to None
+ init_cfg (obj:`mmcv.ConfigDict`): The Config for initialization.
+ Defaults to None.
+ """
+
+ def __init__(self, encoder=None, decoder=None, init_cfg=None):
+ super(Transformer, self).__init__(init_cfg=init_cfg)
+ self.encoder = build_transformer_layer_sequence(encoder)
+ self.decoder = build_transformer_layer_sequence(decoder)
+ self.embed_dims = self.encoder.embed_dims
+
+ def init_weights(self):
+ # follow the official DETR to init parameters
+ for m in self.modules():
+ if hasattr(m, 'weight') and m.weight.dim() > 1:
+ xavier_init(m, distribution='uniform')
+ self._is_init = True
+
+ def forward(self, x, mask, query_embed, pos_embed, mask_query):
+ """Forward function for `Transformer`.
+ Args:
+ x (Tensor): Input query with shape [bs, c, h, w] where
+ c = embed_dims.
+ mask (Tensor): The key_padding_mask used for encoder and decoder,
+ with shape [bs, h, w].
+ query_embed (Tensor): The query embedding for decoder, with shape
+ [num_query, c].
+ pos_embed (Tensor): The positional encoding for encoder and
+ decoder, with the same shape as `x`.
+ Returns:
+ tuple[Tensor]: results of decoder containing the following tensor.
+ - out_dec: Output from decoder. If return_intermediate_dec \
+ is True output has shape [num_dec_layers, bs,
+ num_query, embed_dims], else has shape [1, bs, \
+ num_query, embed_dims].
+ - memory: Output results from encoder, with shape \
+ [bs, embed_dims, h, w].
+
+ Notes:
+ x: query image features with shape [bs, c, h, w]
+ mask: mask for x with shape [bs, h, w]
+ pos_embed: positional embedding for x with shape [bs, c, h, w]
+ query_embed: sample keypoint features with shape [bs, num_query, c]
+ mask_query: mask for query_embed with shape [bs, num_query]
+ Outputs:
+ out_dec: [num_layers, bs, num_query, c]
+ memory: [bs, c, h, w]
+
+ """
+ bs, c, h, w = x.shape
+ # use `view` instead of `flatten` for dynamically exporting to ONNX
+ x = x.view(bs, c, -1).permute(2, 0, 1) # [bs, c, h, w] -> [h*w, bs, c]
+ mask = mask.view(
+ bs, -1
+ ) # [bs, h, w] -> [bs, h*w] Note: this mask should be filled with
+ # False, since all images are with the same shape.
+ pos_embed = pos_embed.view(bs, c, -1).permute(
+ 2, 0, 1) # positional embeding for memory, i.e., the query.
+ memory = self.encoder(
+ query=x,
+ key=None,
+ value=None,
+ query_pos=pos_embed,
+ query_key_padding_mask=mask) # output memory: [hw, bs, c]
+
+ query_embed = query_embed.permute(
+ 1, 0, 2) # [bs, num_query, c] -> [num_query, bs, c]
+ # target = torch.zeros_like(query_embed)
+ # out_dec: [num_layers, num_query, bs, c]
+ out_dec = self.decoder(
+ query=query_embed,
+ key=memory,
+ value=memory,
+ key_pos=pos_embed,
+ # query_pos=query_embed,
+ query_key_padding_mask=mask_query,
+ key_padding_mask=mask)
+ out_dec = out_dec.transpose(1, 2) # [decoder_layer, bs, num_query, c]
+ memory = memory.permute(1, 2, 0).reshape(bs, c, h, w)
+ return out_dec, memory
+
+
+@MODELS.register_module()
+class DetrTransformerDecoderLayer(BaseTransformerLayer):
+ """Implements decoder layer in DETR transformer.
+
+ Args:
+ attn_cfgs (list[`mmcv.ConfigDict`] | list[dict] | dict )):
+ Configs for self_attention or cross_attention, the order
+ should be consistent with it in `operation_order`. If it is
+ a dict, it would be expand to the number of attention in
+ `operation_order`.
+ feedforward_channels (int): The hidden dimension for FFNs.
+ ffn_dropout (float): Probability of an element to be zeroed
+ in ffn. Default 0.0.
+ operation_order (tuple[str]): The execution order of operation
+ in transformer. Such as ('self_attn', 'norm', 'ffn', 'norm').
+ Default:None
+ act_cfg (dict): The activation config for FFNs. Default: `LN`
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: `LN`.
+ ffn_num_fcs (int): The number of fully-connected layers in FFNs.
+ Default:2.
+ """
+
+ def __init__(self,
+ attn_cfgs,
+ feedforward_channels,
+ ffn_dropout=0.0,
+ operation_order=None,
+ act_cfg=dict(type='ReLU', inplace=True),
+ norm_cfg=dict(type='LN'),
+ ffn_num_fcs=2,
+ **kwargs):
+ super(DetrTransformerDecoderLayer, self).__init__(
+ attn_cfgs=attn_cfgs,
+ feedforward_channels=feedforward_channels,
+ ffn_dropout=ffn_dropout,
+ operation_order=operation_order,
+ act_cfg=act_cfg,
+ norm_cfg=norm_cfg,
+ ffn_num_fcs=ffn_num_fcs,
+ **kwargs)
+ # assert len(operation_order) == 6
+ # assert set(operation_order) == set(
+ # ['self_attn', 'norm', 'cross_attn', 'ffn'])
+
+
+@MODELS.register_module()
+class DetrTransformerEncoder(TransformerLayerSequence):
+ """TransformerEncoder of DETR.
+
+ Args:
+ post_norm_cfg (dict): Config of last normalization layer. Default:
+ `LN`. Only used when `self.pre_norm` is `True`
+ """
+
+ def __init__(self, *args, post_norm_cfg=dict(type='LN'), **kwargs):
+ super(DetrTransformerEncoder, self).__init__(*args, **kwargs)
+ if post_norm_cfg is not None:
+ self.post_norm = build_norm_layer(
+ post_norm_cfg, self.embed_dims)[1] if self.pre_norm else None
+ else:
+ # assert not self.pre_norm, f'Use prenorm in ' \
+ # f'{self.__class__.__name__},' \
+ # f'Please specify post_norm_cfg'
+ self.post_norm = None
+
+ def forward(self, *args, **kwargs):
+ """Forward function for `TransformerCoder`.
+
+ Returns:
+ Tensor: forwarded results with shape [num_query, bs, embed_dims].
+ """
+ x = super(DetrTransformerEncoder, self).forward(*args, **kwargs)
+ if self.post_norm is not None:
+ x = self.post_norm(x)
+ return x
+
+
+@MODELS.register_module()
+class DetrTransformerDecoder(TransformerLayerSequence):
+ """Implements the decoder in DETR transformer.
+
+ Args:
+ return_intermediate (bool): Whether to return intermediate outputs.
+ post_norm_cfg (dict): Config of last normalization layer. Default:
+ `LN`.
+ """
+
+ def __init__(self,
+ *args,
+ post_norm_cfg=dict(type='LN'),
+ return_intermediate=False,
+ **kwargs):
+
+ super(DetrTransformerDecoder, self).__init__(*args, **kwargs)
+ self.return_intermediate = return_intermediate
+ if post_norm_cfg is not None:
+ self.post_norm = build_norm_layer(post_norm_cfg,
+ self.embed_dims)[1]
+ else:
+ self.post_norm = None
+
+ def forward(self, query, *args, **kwargs):
+ """Forward function for `TransformerDecoder`.
+ Args:
+ query (Tensor): Input query with shape
+ `(num_query, bs, embed_dims)`.
+ Returns:
+ Tensor: Results with shape [1, num_query, bs, embed_dims] when
+ return_intermediate is `False`, otherwise it has shape
+ [num_layers, num_query, bs, embed_dims].
+ """
+ if not self.return_intermediate:
+ x = super().forward(query, *args, **kwargs)
+ if self.post_norm:
+ x = self.post_norm(x)[None]
+ return x
+
+ intermediate = []
+ for layer in self.layers:
+ query = layer(query, *args, **kwargs)
+ if self.return_intermediate:
+ if self.post_norm is not None:
+ intermediate.append(self.post_norm(query))
+ else:
+ intermediate.append(query)
+ return torch.stack(intermediate)
+
+
+@MODELS.register_module()
+class DynamicConv(BaseModule):
+ """Implements Dynamic Convolution.
+
+ This module generate parameters for each sample and
+ use bmm to implement 1*1 convolution. Code is modified
+ from the `official github repo `_ .
+ Args:
+ in_channels (int): The input feature channel.
+ Defaults to 256.
+ feat_channels (int): The inner feature channel.
+ Defaults to 64.
+ out_channels (int, optional): The output feature channel.
+ When not specified, it will be set to `in_channels`
+ by default
+ input_feat_shape (int): The shape of input feature.
+ Defaults to 7.
+ with_proj (bool): Project two-dimentional feature to
+ one-dimentional feature. Default to True.
+ act_cfg (dict): The activation config for DynamicConv.
+ norm_cfg (dict): Config dict for normalization layer. Default
+ layer normalization.
+ init_cfg (obj:`mmcv.ConfigDict`): The Config for initialization.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels=256,
+ feat_channels=64,
+ out_channels=None,
+ input_feat_shape=7,
+ with_proj=True,
+ act_cfg=dict(type='ReLU', inplace=True),
+ norm_cfg=dict(type='LN'),
+ init_cfg=None):
+ super(DynamicConv, self).__init__(init_cfg)
+ self.in_channels = in_channels
+ self.feat_channels = feat_channels
+ self.out_channels_raw = out_channels
+ self.input_feat_shape = input_feat_shape
+ self.with_proj = with_proj
+ self.act_cfg = act_cfg
+ self.norm_cfg = norm_cfg
+ self.out_channels = out_channels if out_channels else in_channels
+
+ self.num_params_in = self.in_channels * self.feat_channels
+ self.num_params_out = self.out_channels * self.feat_channels
+ self.dynamic_layer = nn.Linear(
+ self.in_channels, self.num_params_in + self.num_params_out)
+
+ self.norm_in = build_norm_layer(norm_cfg, self.feat_channels)[1]
+ self.norm_out = build_norm_layer(norm_cfg, self.out_channels)[1]
+
+ self.activation = build_activation_layer(act_cfg)
+
+ num_output = self.out_channels * input_feat_shape**2
+ if self.with_proj:
+ self.fc_layer = nn.Linear(num_output, self.out_channels)
+ self.fc_norm = build_norm_layer(norm_cfg, self.out_channels)[1]
+
+ def forward(self, param_feature, input_feature):
+ """Forward function for `DynamicConv`.
+
+ Args:
+ param_feature (Tensor): The feature can be used
+ to generate the parameter, has shape
+ (num_all_proposals, in_channels).
+ input_feature (Tensor): Feature that
+ interact with parameters, has shape
+ (num_all_proposals, in_channels, H, W).
+ Returns:
+ Tensor: The output feature has shape
+ (num_all_proposals, out_channels).
+ """
+ input_feature = input_feature.flatten(2).permute(2, 0, 1)
+
+ input_feature = input_feature.permute(1, 0, 2)
+ parameters = self.dynamic_layer(param_feature)
+
+ param_in = parameters[:, :self.num_params_in].view(
+ -1, self.in_channels, self.feat_channels)
+ param_out = parameters[:, -self.num_params_out:].view(
+ -1, self.feat_channels, self.out_channels)
+
+ # input_feature has shape (num_all_proposals, H*W, in_channels)
+ # param_in has shape (num_all_proposals, in_channels, feat_channels)
+ # feature has shape (num_all_proposals, H*W, feat_channels)
+ features = torch.bmm(input_feature, param_in)
+ features = self.norm_in(features)
+ features = self.activation(features)
+
+ # param_out has shape (batch_size, feat_channels, out_channels)
+ features = torch.bmm(features, param_out)
+ features = self.norm_out(features)
+ features = self.activation(features)
+
+ if self.with_proj:
+ features = features.flatten(1)
+ features = self.fc_layer(features)
+ features = self.fc_norm(features)
+ features = self.activation(features)
+
+ return features
diff --git a/projects/pose_anything/tools/visualization.py b/projects/pose_anything/tools/visualization.py
new file mode 100644
index 0000000000..a9a4c6f37d
--- /dev/null
+++ b/projects/pose_anything/tools/visualization.py
@@ -0,0 +1,89 @@
+import os
+import random
+
+import matplotlib.pyplot as plt
+import numpy as np
+
+COLORS = ([255, 0, 0], [255, 85, 0], [255, 170, 0], [255, 255,
+ 0], [170, 255,
+ 0], [85, 255,
+ 0], [0, 255, 0],
+ [0, 255, 85], [0, 255, 170], [0, 255,
+ 255], [0, 170,
+ 255], [0, 85, 255], [0, 0, 255],
+ [85, 0, 255], [170, 0, 255], [255, 0, 255], [255, 0,
+ 170], [255, 0,
+ 85], [255, 0, 0])
+
+
+def plot_results(support_img,
+ query_img,
+ support_kp,
+ support_w,
+ query_kp,
+ query_w,
+ skeleton,
+ initial_proposals,
+ prediction,
+ radius=6,
+ out_dir='./heatmaps'):
+ img_names = [
+ img.split('_')[0] for img in os.listdir(out_dir)
+ if str_is_int(img.split('_')[0])
+ ]
+ if len(img_names) > 0:
+ name_idx = max([int(img_name) for img_name in img_names]) + 1
+ else:
+ name_idx = 0
+
+ h, w, c = support_img.shape
+ prediction = prediction[-1].cpu().numpy() * h
+ support_img = (support_img - np.min(support_img)) / (
+ np.max(support_img) - np.min(support_img))
+ query_img = (query_img - np.min(query_img)) / (
+ np.max(query_img) - np.min(query_img))
+
+ for index, (img, w, keypoint) in enumerate(
+ zip([support_img, query_img], [support_w, query_w],
+ [support_kp, prediction])):
+ f, axes = plt.subplots()
+ plt.imshow(img)
+ for k in range(keypoint.shape[0]):
+ if w[k] > 0:
+ kp = keypoint[k, :2]
+ c = (1, 0, 0, 0.75) if w[k] == 1 else (0, 0, 1, 0.6)
+ patch = plt.Circle(kp, radius, color=c)
+ axes.add_patch(patch)
+ axes.text(kp[0], kp[1], k)
+ plt.draw()
+ for limb_index, limb in enumerate(skeleton):
+ kp = keypoint[:, :2]
+ if limb_index > len(COLORS) - 1:
+ c = [x / 255 for x in random.sample(range(0, 255), 3)]
+ else:
+ c = [x / 255 for x in COLORS[limb_index]]
+ if w[limb[0]] > 0 and w[limb[1]] > 0:
+ patch = plt.Line2D([kp[limb[0], 0], kp[limb[1], 0]],
+ [kp[limb[0], 1], kp[limb[1], 1]],
+ linewidth=6,
+ color=c,
+ alpha=0.6)
+ axes.add_artist(patch)
+ plt.axis('off') # command for hiding the axis.
+ name = 'support' if index == 0 else 'query'
+ plt.savefig(
+ f'./{out_dir}/{str(name_idx)}_{str(name)}.png',
+ bbox_inches='tight',
+ pad_inches=0)
+ if index == 1:
+ plt.show()
+ plt.clf()
+ plt.close('all')
+
+
+def str_is_int(s):
+ try:
+ int(s)
+ return True
+ except ValueError:
+ return False
diff --git a/projects/rtmo/README.md b/projects/rtmo/README.md
new file mode 100644
index 0000000000..18d9cd0ba3
--- /dev/null
+++ b/projects/rtmo/README.md
@@ -0,0 +1,140 @@
+# RTMO: Towards High-Performance One-Stage Real-Time Multi-Person Pose Estimation
+
+
 +
+RTMO is a one-stage pose estimation model that achieves performance comparable to RTMPose. It has the following key advantages:
+
+- **Faster inference speed when multiple people are present** - RTMO runs faster than RTMPose on images with more than 4 persons. This makes it well-suited for real-time multi-person pose estimation.
+- **No dependency on human detectors** - Since RTMO is a one-stage model, it does not rely on an auxiliary human detector. This simplifies the pipeline and deployment.
+
+👉🏼 TRY RTMO NOW
+
+```bash
+python demo/inferencer_demo.py $IMAGE --pose2d rtmo --vis-out-dir vis_results
+```
+
+## 📜 Introduction
+
+Real-time multi-person pose estimation presents significant challenges in balancing speed and precision. While two-stage top-down methods slow down as the number of people in the image increases, existing one-stage methods often fail to simultaneously deliver high accuracy and real-time performance. This paper introduces RTMO, a one-stage pose estimation framework that seamlessly integrates coordinate classification by representing keypoints using dual 1-D heatmaps within the YOLO architecture, achieving accuracy comparable to top-down methods while maintaining high speed. We propose a dynamic coordinate classifier and a tailored loss function for heatmap learning, specifically designed to address the incompatibilities between coordinate classification and dense prediction models. RTMO outperforms state-of-the-art one-stage pose estimators, achieving 1.1% higher AP on COCO while operating about 9 times faster with the same backbone. Our largest model, RTMO-l, attains 74.8% AP on COCO val2017 and 141 FPS on a single V100 GPU, demonstrating its efficiency and accuracy.
+
+
+
+RTMO is a one-stage pose estimation model that achieves performance comparable to RTMPose. It has the following key advantages:
+
+- **Faster inference speed when multiple people are present** - RTMO runs faster than RTMPose on images with more than 4 persons. This makes it well-suited for real-time multi-person pose estimation.
+- **No dependency on human detectors** - Since RTMO is a one-stage model, it does not rely on an auxiliary human detector. This simplifies the pipeline and deployment.
+
+👉🏼 TRY RTMO NOW
+
+```bash
+python demo/inferencer_demo.py $IMAGE --pose2d rtmo --vis-out-dir vis_results
+```
+
+## 📜 Introduction
+
+Real-time multi-person pose estimation presents significant challenges in balancing speed and precision. While two-stage top-down methods slow down as the number of people in the image increases, existing one-stage methods often fail to simultaneously deliver high accuracy and real-time performance. This paper introduces RTMO, a one-stage pose estimation framework that seamlessly integrates coordinate classification by representing keypoints using dual 1-D heatmaps within the YOLO architecture, achieving accuracy comparable to top-down methods while maintaining high speed. We propose a dynamic coordinate classifier and a tailored loss function for heatmap learning, specifically designed to address the incompatibilities between coordinate classification and dense prediction models. RTMO outperforms state-of-the-art one-stage pose estimators, achieving 1.1% higher AP on COCO while operating about 9 times faster with the same backbone. Our largest model, RTMO-l, attains 74.8% AP on COCO val2017 and 141 FPS on a single V100 GPU, demonstrating its efficiency and accuracy.
+
+
+
+Refer to [our paper](https://arxiv.org/abs/2312.07526) for more details.
+
+## 🎉 News
+
+- **`2023/12/13`**: The RTMO paper and models are released!
+
+## 🗂️ Model Zoo
+
+### Results on COCO val2017 dataset
+
+| Model | Train Set | Latency (ms) | AP | AP50 | AP75 | AR | AR50 | Download |
+| :----------------------------------------------------------- | :-------: | :----------: | :---: | :-------------: | :-------------: | :---: | :-------------: | :--------------------------------------------------------------: |
+| [RTMO-s](/configs/body_2d_keypoint/rtmo/coco/rtmo-s_8xb32-600e_coco-640x640.py) | COCO | 8.9 | 0.677 | 0.878 | 0.737 | 0.715 | 0.908 | [ckpt](https://download.openmmlab.com/mmpose/v1/projects/rtmo/rtmo-s_8xb32-600e_coco-640x640-8db55a59_20231211.pth) |
+| [RTMO-m](/configs/body_2d_keypoint/rtmo/coco/rtmo-m_16xb16-600e_coco-640x640.py) | COCO | 12.4 | 0.709 | 0.890 | 0.778 | 0.747 | 0.920 | [ckpt](https://download.openmmlab.com/mmpose/v1/projects/rtmo/rtmo-m_16xb16-600e_coco-640x640-6f4e0306_20231211.pth) |
+| [RTMO-l](/configs/body_2d_keypoint/rtmo/coco/rtmo-l_16xb16-600e_coco-640x640.py) | COCO | 19.1 | 0.724 | 0.899 | 0.788 | 0.762 | 0.927 | [ckpt](https://download.openmmlab.com/mmpose/v1/projects/rtmo/rtmo-l_16xb16-600e_coco-640x640-516a421f_20231211.pth) |
+| [RTMO-t](/configs/body_2d_keypoint/rtmo/body7/rtmo-t_8xb32-600e_body7-416x416.py) | body7 | - | 0.574 | 0.803 | 0.613 | 0.611 | 0.836 | [ckpt](https://download.openmmlab.com/mmpose/v1/projects/rtmo/rtmo-t_8xb32-600e_body7-416x416-f48f75cb_20231219.pth) \| [onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmo/onnx_sdk/rtmo-t_8xb32-600e_body7-416x416-f48f75cb_20231219.zip) |
+| [RTMO-s](/configs/body_2d_keypoint/rtmo/body7/rtmo-s_8xb32-600e_body7-640x640.py) | body7 | 8.9 | 0.686 | 0.879 | 0.744 | 0.723 | 0.908 | [ckpt](https://download.openmmlab.com/mmpose/v1/projects/rtmo/rtmo-s_8xb32-600e_body7-640x640-dac2bf74_20231211.pth) \| [onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmo/onnx_sdk/rtmo-s_8xb32-600e_body7-640x640-dac2bf74_20231211.zip) |
+| [RTMO-m](/configs/body_2d_keypoint/rtmo/body7/rtmo-m_16xb16-600e_body7-640x640.py) | body7 | 12.4 | 0.726 | 0.899 | 0.790 | 0.763 | 0.926 | [ckpt](https://download.openmmlab.com/mmpose/v1/projects/rtmo/rtmo-m_16xb16-600e_body7-640x640-39e78cc4_20231211.pth) \| [onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmo/onnx_sdk/rtmo-m_16xb16-600e_body7-640x640-39e78cc4_20231211.zip) |
+| [RTMO-l](/configs/body_2d_keypoint/rtmo/body7/rtmo-l_16xb16-600e_body7-640x640.py) | body7 | 19.1 | 0.748 | 0.911 | 0.813 | 0.786 | 0.939 | [ckpt](https://download.openmmlab.com/mmpose/v1/projects/rtmo/rtmo-l_16xb16-600e_body7-640x640-b37118ce_20231211.pth) \| [onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmo/onnx_sdk/rtmo-l_16xb16-600e_body7-640x640-b37118ce_20231211.zip) |
+
+- The latency is evaluated on a single V100 GPU with ONNXRuntime backend.
+- "body7" refers to a combined dataset composed of [AI Challenger](https://github.com/AIChallenger/AI_Challenger_2017), [COCO](http://cocodataset.org/), [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose), [Halpe](https://github.com/Fang-Haoshu/Halpe-FullBody/), [MPII](http://human-pose.mpi-inf.mpg.de/), [PoseTrack18](https://posetrack.net/users/download.php) and [sub-JHMDB](http://jhmdb.is.tue.mpg.de/dataset).
+
+### Results on CrowdPose test dataset
+
+| Model | Train Set | AP | AP50 | AP75 | AP (E) | AP (M) | AP (H) | Download |
+| :------------------------------------------------------------------ | :-------: | :---: | :-------------: | :-------------: | :----: | :----: | :----: | :---------------------------------------------------------------------: |
+| [RTMO-s](/configs/body_2d_keypoint/rtmo/crowdpose/rtmo-s_8xb32-700e_crowdpose-640x640.py) | CrowdPose | 0.673 | 0.882 | 0.729 | 0.737 | 0.682 | 0.591 | [ckpt](https://download.openmmlab.com/mmpose/v1/projects/rtmo/rtmo-s_8xb32-700e_crowdpose-640x640-79f81c0d_20231211.pth) |
+| [RTMO-m](/configs/body_2d_keypoint/rtmo/crowdpose/rtmo-m_16xb16-700e_crowdpose-640x640.py) | CrowdPose | 0.711 | 0.897 | 0.771 | 0.774 | 0.719 | 0.634 | [ckpt](https://download.openmmlab.com/mmpose/v1/projects/rtmo/rrtmo-m_16xb16-700e_crowdpose-640x640-0eaf670d_20231211.pth) |
+| [RTMO-l](/configs/body_2d_keypoint/rtmo/crowdpose/rtmo-l_16xb16-700e_crowdpose-640x640.py) | CrowdPose | 0.732 | 0.907 | 0.793 | 0.792 | 0.741 | 0.653 | [ckpt](https://download.openmmlab.com/mmpose/v1/projects/rtmo/rtmo-l_16xb16-700e_crowdpose-640x640-1008211f_20231211.pth) |
+| [RTMO-l](/configs/body_2d_keypoint/rtmo/crowdpose/rtmo-l_16xb16-700e_body7-crowdpose-640x640.py) | body7 | 0.838 | 0.947 | 0.893 | 0.888 | 0.847 | 0.772 | [ckpt](https://download.openmmlab.com/mmpose/v1/projects/rtmo/rtmo-l_16xb16-700e_body7-crowdpose-640x640-5bafdc11_20231219.pth) |
+
+## 🖥️ Train and Evaluation
+
+### Dataset Preparation
+
+Please follow [this instruction](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html) to prepare the training and testing datasets.
+
+### Train
+
+Under the root directory of mmpose, run the following command to train models:
+
+```sh
+sh tools/dist_train.sh $CONFIG $NUM_GPUS --work-dir $WORK_DIR --amp
+```
+
+- Automatic Mixed Precision (AMP) technique is used to reduce GPU memory consumption during training.
+
+### Evaluation
+
+Under the root directory of mmpose, run the following command to evaluate models:
+
+```sh
+sh tools/dist_test.sh $CONFIG $PATH_TO_CHECKPOINT $NUM_GPUS
+```
+
+See [here](https://mmpose.readthedocs.io/en/latest/user_guides/train_and_test.html) for more training and evaluation details.
+
+## 🛞 Deployment
+
+[MMDeploy](https://github.com/open-mmlab/mmdeploy) provides tools for easy deployment of RTMO models. [\[Install Now\]](https://mmdeploy.readthedocs.io/en/latest/get_started.html#installation)
+
+**⭕ Notice**:
+
+- PyTorch **1.12+** is required to export the ONNX model of RTMO!
+
+- MMDeploy v1.3.1+ is required to deploy RTMO.
+
+### ONNX Model Export
+
+Under mmdeploy root, run:
+
+```sh
+python tools/deploy.py \
+ configs/mmpose/pose-detection_rtmo_onnxruntime_dynamic-640x640.py \
+ $RTMO_CONFIG $RTMO_CHECKPOINT \
+ $MMPOSE_ROOT/tests/data/coco/000000197388.jpg \
+ --work-dir $WORK_DIR --dump-info \
+ [--show] [--device $DEVICE]
+```
+
+### TensorRT Model Export
+
+[Install TensorRT](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/tensorrt.html#install-tensorrt) and [build custom ops](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/tensorrt.html#build-custom-ops) first.
+
+Then under mmdeploy root, run:
+
+```sh
+python tools/deploy.py \
+ configs/mmpose/pose-detection_rtmo_tensorrt-fp16_dynamic-640x640.py \
+ $RTMO_CONFIG $RTMO_CHECKPOINT \
+ $MMPOSE_ROOT/tests/data/coco/000000197388.jpg \
+ --work-dir $WORK_DIR --dump-info \
+ --device cuda:0 [--show]
+```
+
+This conversion takes several minutes. GPU is required for TensorRT model exportation.
+
+## ⭐ Citation
+
+If this project benefits your work, please kindly consider citing the original paper and MMPose:
+
+```bibtex
+@misc{lu2023rtmo,
+ title={{RTMO}: Towards High-Performance One-Stage Real-Time Multi-Person Pose Estimation},
+ author={Peng Lu and Tao Jiang and Yining Li and Xiangtai Li and Kai Chen and Wenming Yang},
+ year={2023},
+ eprint={2312.07526},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+}
+
+@misc{mmpose2020,
+ title={OpenMMLab Pose Estimation Toolbox and Benchmark},
+ author={MMPose Contributors},
+ howpublished = {\url{https://github.com/open-mmlab/mmpose}},
+ year={2020}
+}
+```
diff --git a/projects/rtmpose/README.md b/projects/rtmpose/README.md
index a304a69b0d..94bbc2ca2d 100644
--- a/projects/rtmpose/README.md
+++ b/projects/rtmpose/README.md
@@ -44,6 +44,8 @@ ______________________________________________________________________
## 🥳 🚀 What's New [🔝](#-table-of-contents)
+- Dec. 2023:
+ - Update RTMW models. The RTMW-l model achieves 70.1 mAP on COCO-Wholebody val set.
- Sep. 2023:
- Add RTMW models trained on combined datasets. The alpha version of RTMW-x model achieves 70.2 mAP on COCO-Wholebody val set. You can try it [Here](https://openxlab.org.cn/apps/detail/mmpose/RTMPose). The technical report will be released soon.
- Add YOLOX and RTMDet models trained on HumanArt dataset.
@@ -292,9 +294,9 @@ For more details, please refer to [GroupFisher Pruning for RTMPose](./rtmpose/pr
-Cocktail13
+Cocktail14
-- `Cocktail13` denotes model trained on 13 public datasets:
+- `Cocktail14` denotes model trained on 14 public datasets:
- [AI Challenger](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#aic)
- [CrowdPose](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#crowdpose)
- [MPII](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#mpii)
@@ -308,11 +310,15 @@ For more details, please refer to [GroupFisher Pruning for RTMPose](./rtmpose/pr
- [300W](https://ibug.doc.ic.ac.uk/resources/300-W/)
- [COFW](http://www.vision.caltech.edu/xpburgos/ICCV13/)
- [LaPa](https://github.com/JDAI-CV/lapa-dataset)
+ - [InterHand](https://mks0601.github.io/InterHand2.6M/)
| Config | Input Size | Whole AP | Whole AR | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download |
| :------------------------------ | :--------: | :------: | :------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-------------------------------: |
-| [RTMW-x
(alpha version)](./rtmpose/wholebody_2d_keypoint/rtmw-x_8xb704-270e_cocktail13-256x192.py) | 256x192 | 67.2 | 75.4 | 13.1 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmw/rtmw-x_simcc-cocktail13_pt-ucoco_270e-256x192-fbef0d61_20230925.pth) |
-| [RTMW-x
(alpha version)](./rtmpose/wholebody_2d_keypoint/rtmw-x_8xb320-270e_cocktail13-384x288.py) | 384x288 | 70.2 | 77.9 | 29.3 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmw/rtmw-x_simcc-cocktail13_pt-ucoco_270e-384x288-0949e3a9_20230925.pth) |
+| [RTMW-m](./rtmpose/wholebody_2d_keypoint/rtmw-m_8xb1024-270e_cocktail14-256x192.py) | 256x192 | 58.2 | 67.3 | 4.3 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmw/rtmw-dw-l-m_simcc-cocktail14_270e-256x192-20231122.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmw/onnx_sdk/rtmw-dw-m-s_simcc-cocktail14_270e-256x192_20231122.zip) |
+| [RTMW-l](./rtmpose/wholebody_2d_keypoint/rtmw-x_8xb704-270e_cocktail14-256x192.py) | 256x192 | 66.0 | 74.6 | 7.9 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmw/rtmw-dw-x-l_simcc-cocktail14_270e-256x192-20231122.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmw/onnx_sdk/rtmw-dw-x-l_simcc-cocktail14_270e-256x192_20231122.zip) |
+| [RTMW-x](./rtmpose/wholebody_2d_keypoint/rtmw-x_8xb704-270e_cocktail14-256x192.py) | 256x192 | 67.2 | 75.2 | 13.1 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmw/rtmw-x_simcc-cocktail14_pt-ucoco_270e-256x192-13a2546d_20231208.pth) |
+| [RTMW-l](./rtmpose/wholebody_2d_keypoint/rtmw-x_8xb320-270e_cocktail14-384x288.py) | 384x288 | 70.1 | 78.0 | 17.7 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmw/rtmw-dw-x-l_simcc-cocktail14_270e-384x288-20231122.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmw/onnx_sdk/rtmw-dw-x-l_simcc-cocktail14_270e-384x288_20231122.zip) |
+| [RTMW-x](./rtmpose/wholebody_2d_keypoint/rtmw-x_8xb320-270e_cocktail14-384x288.py) | 384x288 | 70.2 | 78.1 | 29.3 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmw/rtmw-x_simcc-cocktail14_pt-ucoco_270e-384x288-f840f204_20231122.pth) |
@@ -1017,51 +1023,51 @@ if __name__ == '__main__':
Here is a basic example of SDK C++ API:
```C++
-#include "mmdeploy/detector.hpp"
-
-#include "opencv2/imgcodecs/imgcodecs.hpp"
-#include "utils/argparse.h"
-#include "utils/visualize.h"
-
-DEFINE_ARG_string(model, "Model path");
-DEFINE_ARG_string(image, "Input image path");
-DEFINE_string(device, "cpu", R"(Device name, e.g. "cpu", "cuda")");
-DEFINE_string(output, "detector_output.jpg", "Output image path");
-
-DEFINE_double(det_thr, .5, "Detection score threshold");
+#include "mmdeploy/pose_detector.hpp"
+#include "opencv2/imgcodecs.hpp"
+#include "opencv2/imgproc.hpp"
+#include "utils/argparse.h" // See: https://github.com/open-mmlab/mmdeploy/blob/main/demo/csrc/cpp/utils/argparse.h
+
+DEFINE_ARG_string(model_path, "Model path");
+DEFINE_ARG_string(image_path, "Input image path");
+DEFINE_string(device_name, "cpu", R"(Device name, e.g. "cpu", "cuda")");
+DEFINE_int32(bbox_x, -1, R"(x position of the bounding box)");
+DEFINE_int32(bbox_y, -1, R"(y position of the bounding box)");
+DEFINE_int32(bbox_w, -1, R"(width of the bounding box)");
+DEFINE_int32(bbox_h, -1, R"(height of the bounding box)");
int main(int argc, char* argv[]) {
if (!utils::ParseArguments(argc, argv)) {
return -1;
}
- cv::Mat img = cv::imread(ARGS_image);
- if (img.empty()) {
- fprintf(stderr, "failed to load image: %s\n", ARGS_image.c_str());
- return -1;
- }
+ cv::Mat img = cv::imread(ARGS_image_path);
+
+ mmdeploy::PoseDetector detector(mmdeploy::Model{ARGS_model_path}, mmdeploy::Device{FLAGS_device_name, 0});
- // construct a detector instance
- mmdeploy::Detector detector(mmdeploy::Model{ARGS_model}, mmdeploy::Device{FLAGS_device});
-
- // apply the detector, the result is an array-like class holding references to
- // `mmdeploy_detection_t`, will be released automatically on destruction
- mmdeploy::Detector::Result dets = detector.Apply(img);
-
- // visualize
- utils::Visualize v;
- auto sess = v.get_session(img);
- int count = 0;
- for (const mmdeploy_detection_t& det : dets) {
- if (det.score > FLAGS_det_thr) { // filter bboxes
- sess.add_det(det.bbox, det.label_id, det.score, det.mask, count++);
- }
+ mmdeploy::PoseDetector::Result result{0, 0, nullptr};
+
+ if (FLAGS_bbox_x == -1 || FLAGS_bbox_y == -1 || FLAGS_bbox_w == -1 || FLAGS_bbox_h == -1) {
+ result = detector.Apply(img);
+ } else {
+ // convert (x, y, w, h) -> (left, top, right, bottom)
+ mmdeploy::cxx::Rect rect;
+ rect.left = FLAGS_bbox_x;
+ rect.top = FLAGS_bbox_y;
+ rect.right = FLAGS_bbox_x + FLAGS_bbox_w;
+ rect.bottom = FLAGS_bbox_y + FLAGS_bbox_h;
+ result = detector.Apply(img, {rect});
}
- if (!FLAGS_output.empty()) {
- cv::imwrite(FLAGS_output, sess.get());
+ // Draw circles at detected keypoints
+ for (size_t i = 0; i < result[0].length; ++i) {
+ cv::Point keypoint(result[0].point[i].x, result[0].point[i].y);
+ cv::circle(img, keypoint, 1, cv::Scalar(0, 255, 0), 2); // Draw filled circle
}
+ // Save the output image
+ cv::imwrite("output_pose.png", img);
+
return 0;
}
```
diff --git a/projects/rtmpose/README_CN.md b/projects/rtmpose/README_CN.md
index 859d0e9364..6b33a20e9f 100644
--- a/projects/rtmpose/README_CN.md
+++ b/projects/rtmpose/README_CN.md
@@ -40,6 +40,8 @@ ______________________________________________________________________
## 🥳 最新进展 [🔝](#-table-of-contents)
+- 2023 年 12 月:
+ - 更新 RTMW 模型,RTMW-l 在 COCO-Wholebody 验证集上去的 70.1 mAP。
- 2023 年 9 月:
- 发布混合数据集上训练的 RTMW 模型。Alpha 版本的 RTMW-x 在 COCO-Wholebody 验证集上取得了 70.2 mAP。[在线 Demo](https://openxlab.org.cn/apps/detail/mmpose/RTMPose) 已支持 RTMW。技术报告正在撰写中。
- 增加 HumanArt 上训练的 YOLOX 和 RTMDet 模型。
@@ -283,7 +285,7 @@ RTMPose 是一个长期优化迭代的项目,致力于业务场景下的高性
-Cocktail13
+Cocktail14
- `Cocktail13` 代表模型在 13 个开源数据集上训练得到:
- [AI Challenger](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#aic)
@@ -299,11 +301,15 @@ RTMPose 是一个长期优化迭代的项目,致力于业务场景下的高性
- [300W](https://ibug.doc.ic.ac.uk/resources/300-W/)
- [COFW](http://www.vision.caltech.edu/xpburgos/ICCV13/)
- [LaPa](https://github.com/JDAI-CV/lapa-dataset)
+ - [InterHand](https://mks0601.github.io/InterHand2.6M/)
| Config | Input Size | Whole AP | Whole AR | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download |
| :------------------------------ | :--------: | :------: | :------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-------------------------------: |
-| [RTMW-x
(alpha version)](./rtmpose/wholebody_2d_keypoint/rtmw-x_8xb704-270e_cocktail13-256x192.py) | 256x192 | 67.2 | 75.4 | 13.1 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmw/rtmw-x_simcc-cocktail13_pt-ucoco_270e-256x192-fbef0d61_20230925.pth) |
-| [RTMW-x
(alpha version)](./rtmpose/wholebody_2d_keypoint/rtmw-x_8xb320-270e_cocktail13-384x288.py) | 384x288 | 70.2 | 77.9 | 29.3 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmw/rtmw-x_simcc-cocktail13_pt-ucoco_270e-384x288-0949e3a9_20230925.pth) |
+| [RTMW-m](./rtmpose/wholebody_2d_keypoint/rtmw-m_8xb1024-270e_cocktail14-256x192.py) | 256x192 | 58.2 | 67.3 | 4.3 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmw/rtmw-dw-l-m_simcc-cocktail14_270e-256x192-20231122.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmw/onnx_sdk/rtmw-dw-m-s_simcc-cocktail14_270e-256x192_20231122.zip) |
+| [RTMW-l](./rtmpose/wholebody_2d_keypoint/rtmw-x_8xb704-270e_cocktail14-256x192.py) | 256x192 | 66.0 | 74.6 | 7.9 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmw/rtmw-dw-x-l_simcc-cocktail14_270e-256x192-20231122.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmw/onnx_sdk/rtmw-dw-x-l_simcc-cocktail14_270e-256x192_20231122.zip) |
+| [RTMW-x](./rtmpose/wholebody_2d_keypoint/rtmw-x_8xb704-270e_cocktail14-256x192.py) | 256x192 | 67.2 | 75.2 | 13.1 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmw/rtmw-x_simcc-cocktail14_pt-ucoco_270e-256x192-13a2546d_20231208.pth) |
+| [RTMW-l](./rtmpose/wholebody_2d_keypoint/rtmw-x_8xb320-270e_cocktail14-384x288.py) | 384x288 | 70.1 | 78.0 | 17.7 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmw/rtmw-dw-x-l_simcc-cocktail14_270e-384x288-20231122.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmw/onnx_sdk/rtmw-dw-x-l_simcc-cocktail14_270e-384x288_20231122.zip) |
+| [RTMW-x](./rtmpose/wholebody_2d_keypoint/rtmw-x_8xb320-270e_cocktail14-384x288.py) | 384x288 | 70.2 | 78.1 | 29.3 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmw/rtmw-x_simcc-cocktail14_pt-ucoco_270e-384x288-f840f204_20231122.pth) |
@@ -1010,51 +1016,51 @@ if __name__ == '__main__':
#### C++ API
```C++
-#include "mmdeploy/detector.hpp"
-
-#include "opencv2/imgcodecs/imgcodecs.hpp"
-#include "utils/argparse.h"
-#include "utils/visualize.h"
-
-DEFINE_ARG_string(model, "Model path");
-DEFINE_ARG_string(image, "Input image path");
-DEFINE_string(device, "cpu", R"(Device name, e.g. "cpu", "cuda")");
-DEFINE_string(output, "detector_output.jpg", "Output image path");
-
-DEFINE_double(det_thr, .5, "Detection score threshold");
+#include "mmdeploy/pose_detector.hpp"
+#include "opencv2/imgcodecs.hpp"
+#include "opencv2/imgproc.hpp"
+#include "utils/argparse.h" // See: https://github.com/open-mmlab/mmdeploy/blob/main/demo/csrc/cpp/utils/argparse.h
+
+DEFINE_ARG_string(model_path, "Model path");
+DEFINE_ARG_string(image_path, "Input image path");
+DEFINE_string(device_name, "cpu", R"(Device name, e.g. "cpu", "cuda")");
+DEFINE_int32(bbox_x, -1, R"(x position of the bounding box)");
+DEFINE_int32(bbox_y, -1, R"(y position of the bounding box)");
+DEFINE_int32(bbox_w, -1, R"(width of the bounding box)");
+DEFINE_int32(bbox_h, -1, R"(height of the bounding box)");
int main(int argc, char* argv[]) {
if (!utils::ParseArguments(argc, argv)) {
return -1;
}
- cv::Mat img = cv::imread(ARGS_image);
- if (img.empty()) {
- fprintf(stderr, "failed to load image: %s\n", ARGS_image.c_str());
- return -1;
- }
+ cv::Mat img = cv::imread(ARGS_image_path);
+
+ mmdeploy::PoseDetector detector(mmdeploy::Model{ARGS_model_path}, mmdeploy::Device{FLAGS_device_name, 0});
- // construct a detector instance
- mmdeploy::Detector detector(mmdeploy::Model{ARGS_model}, mmdeploy::Device{FLAGS_device});
-
- // apply the detector, the result is an array-like class holding references to
- // `mmdeploy_detection_t`, will be released automatically on destruction
- mmdeploy::Detector::Result dets = detector.Apply(img);
-
- // visualize
- utils::Visualize v;
- auto sess = v.get_session(img);
- int count = 0;
- for (const mmdeploy_detection_t& det : dets) {
- if (det.score > FLAGS_det_thr) { // filter bboxes
- sess.add_det(det.bbox, det.label_id, det.score, det.mask, count++);
- }
+ mmdeploy::PoseDetector::Result result{0, 0, nullptr};
+
+ if (FLAGS_bbox_x == -1 || FLAGS_bbox_y == -1 || FLAGS_bbox_w == -1 || FLAGS_bbox_h == -1) {
+ result = detector.Apply(img);
+ } else {
+ // convert (x, y, w, h) -> (left, top, right, bottom)
+ mmdeploy::cxx::Rect rect;
+ rect.left = FLAGS_bbox_x;
+ rect.top = FLAGS_bbox_y;
+ rect.right = FLAGS_bbox_x + FLAGS_bbox_w;
+ rect.bottom = FLAGS_bbox_y + FLAGS_bbox_h;
+ result = detector.Apply(img, {rect});
}
- if (!FLAGS_output.empty()) {
- cv::imwrite(FLAGS_output, sess.get());
+ // Draw circles at detected keypoints
+ for (size_t i = 0; i < result[0].length; ++i) {
+ cv::Point keypoint(result[0].point[i].x, result[0].point[i].y);
+ cv::circle(img, keypoint, 1, cv::Scalar(0, 255, 0), 2); // Draw filled circle
}
+ // Save the output image
+ cv::imwrite("output_pose.png", img);
+
return 0;
}
```
diff --git a/projects/rtmpose/app.py b/projects/rtmpose/app.py
new file mode 100644
index 0000000000..6b5be8f9bb
--- /dev/null
+++ b/projects/rtmpose/app.py
@@ -0,0 +1,200 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+import os
+from functools import partial
+
+# prepare environment
+project_path = os.path.join(os.path.dirname(os.path.abspath(__file__)))
+mmpose_path = project_path.split('/projects', 1)[0]
+
+os.system('python -m pip install Openmim')
+os.system('python -m pip install openxlab')
+os.system('python -m pip install gradio==3.38.0')
+
+os.system('python -m mim install "mmcv>=2.0.0"')
+os.system('python -m mim install "mmengine>=0.9.0"')
+os.system('python -m mim install "mmdet>=3.0.0"')
+os.system(f'python -m mim install -e {mmpose_path}')
+
+import gradio as gr # noqa
+from openxlab.model import download # noqa
+
+from mmpose.apis import MMPoseInferencer # noqa
+
+# download checkpoints
+download(model_repo='mmpose/RTMPose', model_name='dwpose-l')
+download(model_repo='mmpose/RTMPose', model_name='RTMW-x')
+download(model_repo='mmpose/RTMPose', model_name='RTMO-l')
+download(model_repo='mmpose/RTMPose', model_name='RTMPose-l-body8')
+download(model_repo='mmpose/RTMPose', model_name='RTMPose-m-face6')
+
+models = [
+ 'rtmpose | body', 'rtmo | body', 'rtmpose | face', 'dwpose | wholebody',
+ 'rtmw | wholebody'
+]
+cached_model = {model: None for model in models}
+
+
+def predict(input,
+ draw_heatmap=False,
+ model_type='body',
+ skeleton_style='mmpose',
+ input_type='image'):
+ """Visualize the demo images.
+
+ Using mmdet to detect the human.
+ """
+
+ if model_type == 'rtmpose | face':
+ if cached_model[model_type] is None:
+ cached_model[model_type] = MMPoseInferencer(pose2d='face')
+ model = cached_model[model_type]
+
+ elif model_type == 'dwpose | wholebody':
+ if cached_model[model_type] is None:
+ cached_model[model_type] = MMPoseInferencer(
+ pose2d=os.path.join(
+ project_path, 'rtmpose/wholebody_2d_keypoint/'
+ 'rtmpose-l_8xb32-270e_coco-wholebody-384x288.py'),
+ pose2d_weights='https://download.openmmlab.com/mmpose/v1/'
+ 'projects/rtmposev1/rtmpose-l_simcc-ucoco_dw-ucoco_270e-'
+ '384x288-2438fd99_20230728.pth')
+ model = cached_model[model_type]
+
+ elif model_type == 'rtmw | wholebody':
+ if cached_model[model_type] is None:
+ cached_model[model_type] = MMPoseInferencer(
+ pose2d=os.path.join(
+ project_path, 'rtmpose/wholebody_2d_keypoint/'
+ 'rtmw-l_8xb320-270e_cocktail14-384x288.py'),
+ pose2d_weights='https://download.openmmlab.com/mmpose/v1/'
+ 'projects/rtmw/rtmw-dw-x-l_simcc-cocktail14_270e-'
+ '384x288-20231122.pth')
+ model = cached_model[model_type]
+
+ elif model_type == 'rtmpose | body':
+ if cached_model[model_type] is None:
+ cached_model[model_type] = MMPoseInferencer(pose2d='rtmpose-l')
+ model = cached_model[model_type]
+
+ elif model_type == 'rtmo | body':
+ if cached_model[model_type] is None:
+ cached_model[model_type] = MMPoseInferencer(pose2d='rtmo')
+ model = cached_model[model_type]
+ draw_heatmap = False
+
+ else:
+ raise ValueError
+
+ if input_type == 'image':
+
+ result = next(
+ model(
+ input,
+ return_vis=True,
+ draw_heatmap=draw_heatmap,
+ skeleton_style=skeleton_style))
+ img = result['visualization'][0][..., ::-1]
+ return img
+
+ elif input_type == 'video':
+
+ for _ in model(
+ input,
+ vis_out_dir='test.mp4',
+ draw_heatmap=draw_heatmap,
+ skeleton_style=skeleton_style):
+ pass
+
+ return 'test.mp4'
+
+ return None
+
+
+news_list = [
+ '2023-8-1: We support [DWPose](https://arxiv.org/pdf/2307.15880.pdf).',
+ '2023-9-25: We release an alpha version of RTMW model, the technical '
+ 'report will be released soon.',
+ '2023-12-11: Update RTMW models, the online version is the RTMW-l with '
+ '70.1 mAP on COCO-Wholebody.',
+ '2023-12-13: We release an alpha version of RTMO (One-stage RTMPose) '
+ 'models.',
+]
+
+with gr.Blocks() as demo:
+
+ with gr.Tab('Upload-Image'):
+ input_img = gr.Image(type='numpy')
+ button = gr.Button('Inference', variant='primary')
+ hm = gr.Checkbox(label='draw-heatmap', info='Whether to draw heatmap')
+ model_type = gr.Dropdown(models, label='Model | Keypoint Type')
+
+ gr.Markdown('## News')
+ for news in news_list[::-1]:
+ gr.Markdown(news)
+
+ gr.Markdown('## Output')
+ out_image = gr.Image(type='numpy')
+ gr.Examples(['./tests/data/coco/000000000785.jpg'], input_img)
+ input_type = 'image'
+ button.click(
+ partial(predict, input_type=input_type),
+ [input_img, hm, model_type], out_image)
+
+ with gr.Tab('Webcam-Image'):
+ input_img = gr.Image(source='webcam', type='numpy')
+ button = gr.Button('Inference', variant='primary')
+ hm = gr.Checkbox(label='draw-heatmap', info='Whether to draw heatmap')
+ model_type = gr.Dropdown(models, label='Model | Keypoint Type')
+
+ gr.Markdown('## News')
+ for news in news_list[::-1]:
+ gr.Markdown(news)
+
+ gr.Markdown('## Output')
+ out_image = gr.Image(type='numpy')
+
+ input_type = 'image'
+ button.click(
+ partial(predict, input_type=input_type),
+ [input_img, hm, model_type], out_image)
+
+ with gr.Tab('Upload-Video'):
+ input_video = gr.Video(type='mp4')
+ button = gr.Button('Inference', variant='primary')
+ hm = gr.Checkbox(label='draw-heatmap', info='Whether to draw heatmap')
+ model_type = gr.Dropdown(models, label='Model | Keypoint type')
+
+ gr.Markdown('## News')
+ for news in news_list[::-1]:
+ gr.Markdown(news)
+
+ gr.Markdown('## Output')
+ out_video = gr.Video()
+
+ input_type = 'video'
+ button.click(
+ partial(predict, input_type=input_type),
+ [input_video, hm, model_type], out_video)
+
+ with gr.Tab('Webcam-Video'):
+ input_video = gr.Video(source='webcam', format='mp4')
+ button = gr.Button('Inference', variant='primary')
+ hm = gr.Checkbox(label='draw-heatmap', info='Whether to draw heatmap')
+ model_type = gr.Dropdown(models, label='Model | Keypoint Type')
+
+ gr.Markdown('## News')
+ for news in news_list[::-1]:
+ gr.Markdown(news)
+
+ gr.Markdown('## Output')
+ out_video = gr.Video()
+
+ input_type = 'video'
+ button.click(
+ partial(predict, input_type=input_type),
+ [input_video, hm, model_type], out_video)
+
+gr.close_all()
+demo.queue()
+demo.launch()
diff --git a/projects/rtmpose/examples/onnxruntime/main.py b/projects/rtmpose/examples/onnxruntime/main.py
index df4858c8dd..856ca1d3a1 100644
--- a/projects/rtmpose/examples/onnxruntime/main.py
+++ b/projects/rtmpose/examples/onnxruntime/main.py
@@ -178,11 +178,13 @@ def visualize(img: np.ndarray,
# draw keypoints and skeleton
for kpts, score in zip(keypoints, scores):
+ keypoints_num = len(score)
for kpt, color in zip(kpts, point_color):
cv2.circle(img, tuple(kpt.astype(np.int32)), 1, palette[color], 1,
cv2.LINE_AA)
for (u, v), color in zip(skeleton, link_color):
- if score[u] > thr and score[v] > thr:
+ if u < keypoints_num and v < keypoints_num \
+ and score[u] > thr and score[v] > thr:
cv2.line(img, tuple(kpts[u].astype(np.int32)),
tuple(kpts[v].astype(np.int32)), palette[color], 2,
cv2.LINE_AA)
diff --git a/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-l_8xb1024-270e_cocktail14-256x192.py b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-l_8xb1024-270e_cocktail14-256x192.py
new file mode 100644
index 0000000000..90484bb52c
--- /dev/null
+++ b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-l_8xb1024-270e_cocktail14-256x192.py
@@ -0,0 +1,615 @@
+_base_ = ['mmpose::_base_/default_runtime.py']
+
+# common setting
+num_keypoints = 133
+input_size = (192, 256)
+
+# runtime
+max_epochs = 270
+stage2_num_epochs = 10
+base_lr = 5e-4
+train_batch_size = 1024
+val_batch_size = 32
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.1),
+ clip_grad=dict(max_norm=35, norm_type=2),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=8192)
+
+# codec settings
+codec = dict(
+ type='SimCCLabel',
+ input_size=input_size,
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=1.,
+ widen_factor=1.,
+ channel_attention=True,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmposev1/rtmpose-l_simcc-ucoco_dw-ucoco_270e-256x192-4d6dfc62_20230728.pth' # noqa
+ )),
+ neck=dict(
+ type='CSPNeXtPAFPN',
+ in_channels=[256, 512, 1024],
+ out_channels=None,
+ out_indices=(
+ 1,
+ 2,
+ ),
+ num_csp_blocks=2,
+ expand_ratio=0.5,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU', inplace=True)),
+ head=dict(
+ type='RTMWHead',
+ in_channels=1024,
+ out_channels=num_keypoints,
+ input_size=input_size,
+ in_featuremap_size=tuple([s // 32 for s in input_size]),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=1.,
+ label_softmax=True,
+ label_beta=10.,
+ mask=list(range(23, 91)),
+ mask_weight=0.5,
+ ),
+ decoder=codec),
+ test_cfg=dict(flip_test=True))
+
+# base dataset settings
+dataset_type = 'CocoWholeBodyDataset'
+data_mode = 'topdown'
+data_root = 'data/'
+
+backend_args = dict(backend='local')
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.5, 1.5], rotate_factor=90),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PhotometricDistortion'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(
+ type='GenerateTarget',
+ encoder=codec,
+ use_dataset_keypoint_weights=True),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+train_pipeline_stage2 = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.5, 1.5],
+ rotate_factor=90),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ ]),
+ dict(
+ type='GenerateTarget',
+ encoder=codec,
+ use_dataset_keypoint_weights=True),
+ dict(type='PackPoseInputs')
+]
+
+# mapping
+
+aic_coco133 = [(0, 6), (1, 8), (2, 10), (3, 5), (4, 7), (5, 9), (6, 12),
+ (7, 14), (8, 16), (9, 11), (10, 13), (11, 15)]
+
+crowdpose_coco133 = [(0, 5), (1, 6), (2, 7), (3, 8), (4, 9), (5, 10), (6, 11),
+ (7, 12), (8, 13), (9, 14), (10, 15), (11, 16)]
+
+mpii_coco133 = [
+ (0, 16),
+ (1, 14),
+ (2, 12),
+ (3, 11),
+ (4, 13),
+ (5, 15),
+ (10, 10),
+ (11, 8),
+ (12, 6),
+ (13, 5),
+ (14, 7),
+ (15, 9),
+]
+
+jhmdb_coco133 = [
+ (3, 6),
+ (4, 5),
+ (5, 12),
+ (6, 11),
+ (7, 8),
+ (8, 7),
+ (9, 14),
+ (10, 13),
+ (11, 10),
+ (12, 9),
+ (13, 16),
+ (14, 15),
+]
+
+halpe_coco133 = [(i, i)
+ for i in range(17)] + [(20, 17), (21, 20), (22, 18), (23, 21),
+ (24, 19),
+ (25, 22)] + [(i, i - 3)
+ for i in range(26, 136)]
+
+posetrack_coco133 = [
+ (0, 0),
+ (3, 3),
+ (4, 4),
+ (5, 5),
+ (6, 6),
+ (7, 7),
+ (8, 8),
+ (9, 9),
+ (10, 10),
+ (11, 11),
+ (12, 12),
+ (13, 13),
+ (14, 14),
+ (15, 15),
+ (16, 16),
+]
+
+humanart_coco133 = [(i, i) for i in range(17)] + [(17, 99), (18, 120),
+ (19, 17), (20, 20)]
+
+# train datasets
+dataset_coco = dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='coco/annotations/coco_wholebody_train_v1.0.json',
+ data_prefix=dict(img='detection/coco/train2017/'),
+ pipeline=[],
+)
+
+dataset_aic = dict(
+ type='AicDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='aic/annotations/aic_train.json',
+ data_prefix=dict(img='pose/ai_challenge/ai_challenger_keypoint'
+ '_train_20170902/keypoint_train_images_20170902/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=aic_coco133)
+ ],
+)
+
+dataset_crowdpose = dict(
+ type='CrowdPoseDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='crowdpose/annotations/mmpose_crowdpose_trainval.json',
+ data_prefix=dict(img='pose/CrowdPose/images/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=crowdpose_coco133)
+ ],
+)
+
+dataset_mpii = dict(
+ type='MpiiDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='mpii/annotations/mpii_train.json',
+ data_prefix=dict(img='pose/MPI/images/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=mpii_coco133)
+ ],
+)
+
+dataset_jhmdb = dict(
+ type='JhmdbDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='jhmdb/annotations/Sub1_train.json',
+ data_prefix=dict(img='pose/JHMDB/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=jhmdb_coco133)
+ ],
+)
+
+dataset_halpe = dict(
+ type='HalpeDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='halpe/annotations/halpe_train_v1.json',
+ data_prefix=dict(img='pose/Halpe/hico_20160224_det/images/train2015'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=halpe_coco133)
+ ],
+)
+
+dataset_posetrack = dict(
+ type='PoseTrack18Dataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='posetrack18/annotations/posetrack18_train.json',
+ data_prefix=dict(img='pose/PoseChallenge2018/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=posetrack_coco133)
+ ],
+)
+
+dataset_humanart = dict(
+ type='HumanArt21Dataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='HumanArt/annotations/training_humanart.json',
+ filter_cfg=dict(scenes=['real_human']),
+ data_prefix=dict(img='pose/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=humanart_coco133)
+ ])
+
+ubody_scenes = [
+ 'Magic_show', 'Entertainment', 'ConductMusic', 'Online_class', 'TalkShow',
+ 'Speech', 'Fitness', 'Interview', 'Olympic', 'TVShow', 'Singing',
+ 'SignLanguage', 'Movie', 'LiveVlog', 'VideoConference'
+]
+
+ubody_datasets = []
+for scene in ubody_scenes:
+ each = dict(
+ type='UBody2dDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file=f'Ubody/annotations/{scene}/train_annotations.json',
+ data_prefix=dict(img='pose/UBody/images/'),
+ pipeline=[],
+ sample_interval=10)
+ ubody_datasets.append(each)
+
+dataset_ubody = dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/ubody2d.py'),
+ datasets=ubody_datasets,
+ pipeline=[],
+ test_mode=False,
+)
+
+face_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale', padding=1.25),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[1.5, 2.0],
+ rotate_factor=0),
+]
+
+wflw_coco133 = [(i * 2, 23 + i)
+ for i in range(17)] + [(33 + i, 40 + i) for i in range(5)] + [
+ (42 + i, 45 + i) for i in range(5)
+ ] + [(51 + i, 50 + i)
+ for i in range(9)] + [(60, 59), (61, 60), (63, 61),
+ (64, 62), (65, 63), (67, 64),
+ (68, 65), (69, 66), (71, 67),
+ (72, 68), (73, 69),
+ (75, 70)] + [(76 + i, 71 + i)
+ for i in range(20)]
+dataset_wflw = dict(
+ type='WFLWDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='wflw/annotations/face_landmarks_wflw_train.json',
+ data_prefix=dict(img='pose/WFLW/images/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=wflw_coco133), *face_pipeline
+ ],
+)
+
+mapping_300w_coco133 = [(i, 23 + i) for i in range(68)]
+dataset_300w = dict(
+ type='Face300WDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='300w/annotations/face_landmarks_300w_train.json',
+ data_prefix=dict(img='pose/300w/images/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=mapping_300w_coco133), *face_pipeline
+ ],
+)
+
+cofw_coco133 = [(0, 40), (2, 44), (4, 42), (1, 49), (3, 45), (6, 47), (8, 59),
+ (10, 62), (9, 68), (11, 65), (18, 54), (19, 58), (20, 53),
+ (21, 56), (22, 71), (23, 77), (24, 74), (25, 85), (26, 89),
+ (27, 80), (28, 31)]
+dataset_cofw = dict(
+ type='COFWDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='cofw/annotations/cofw_train.json',
+ data_prefix=dict(img='pose/COFW/images/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=cofw_coco133), *face_pipeline
+ ],
+)
+
+lapa_coco133 = [(i * 2, 23 + i) for i in range(17)] + [
+ (33 + i, 40 + i) for i in range(5)
+] + [(42 + i, 45 + i) for i in range(5)] + [
+ (51 + i, 50 + i) for i in range(4)
+] + [(58 + i, 54 + i) for i in range(5)] + [(66, 59), (67, 60), (69, 61),
+ (70, 62), (71, 63), (73, 64),
+ (75, 65), (76, 66), (78, 67),
+ (79, 68), (80, 69),
+ (82, 70)] + [(84 + i, 71 + i)
+ for i in range(20)]
+dataset_lapa = dict(
+ type='LapaDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='LaPa/annotations/lapa_trainval.json',
+ data_prefix=dict(img='pose/LaPa/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=lapa_coco133), *face_pipeline
+ ],
+)
+
+dataset_wb = dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[dataset_coco, dataset_halpe, dataset_ubody],
+ pipeline=[],
+ test_mode=False,
+)
+
+dataset_body = dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[
+ dataset_aic,
+ dataset_crowdpose,
+ dataset_mpii,
+ dataset_jhmdb,
+ dataset_posetrack,
+ dataset_humanart,
+ ],
+ pipeline=[],
+ test_mode=False,
+)
+
+dataset_face = dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[
+ dataset_wflw,
+ dataset_300w,
+ dataset_cofw,
+ dataset_lapa,
+ ],
+ pipeline=[],
+ test_mode=False,
+)
+
+hand_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[1.5, 2.0],
+ rotate_factor=0),
+]
+
+interhand_left = [(21, 95), (22, 94), (23, 93), (24, 92), (25, 99), (26, 98),
+ (27, 97), (28, 96), (29, 103), (30, 102), (31, 101),
+ (32, 100), (33, 107), (34, 106), (35, 105), (36, 104),
+ (37, 111), (38, 110), (39, 109), (40, 108), (41, 91)]
+interhand_right = [(i - 21, j + 21) for i, j in interhand_left]
+interhand_coco133 = interhand_right + interhand_left
+
+dataset_interhand2d = dict(
+ type='InterHand2DDoubleDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='interhand26m/annotations/all/InterHand2.6M_train_data.json',
+ camera_param_file='interhand26m/annotations/all/'
+ 'InterHand2.6M_train_camera.json',
+ joint_file='interhand26m/annotations/all/'
+ 'InterHand2.6M_train_joint_3d.json',
+ data_prefix=dict(img='interhand2.6m/images/train/'),
+ sample_interval=10,
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=interhand_coco133,
+ ), *hand_pipeline
+ ],
+)
+
+dataset_hand = dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[dataset_interhand2d],
+ pipeline=[],
+ test_mode=False,
+)
+
+train_datasets = [dataset_wb, dataset_body, dataset_face, dataset_hand]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=train_batch_size,
+ num_workers=4,
+ pin_memory=False,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=train_datasets,
+ pipeline=train_pipeline,
+ test_mode=False,
+ ))
+
+val_dataloader = dict(
+ batch_size=val_batch_size,
+ num_workers=4,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type='CocoWholeBodyDataset',
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json',
+ data_prefix=dict(img='data/detection/coco/val2017/'),
+ pipeline=val_pipeline,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ test_mode=True))
+
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(
+ save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoWholeBodyMetric',
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json')
+test_evaluator = val_evaluator
diff --git a/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-l_8xb320-270e_cocktail14-384x288.py b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-l_8xb320-270e_cocktail14-384x288.py
new file mode 100644
index 0000000000..3c3b3c7a26
--- /dev/null
+++ b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-l_8xb320-270e_cocktail14-384x288.py
@@ -0,0 +1,616 @@
+_base_ = ['mmpose::_base_/default_runtime.py']
+
+# common setting
+num_keypoints = 133
+input_size = (288, 384)
+
+# runtime
+max_epochs = 270
+stage2_num_epochs = 10
+base_lr = 5e-4
+train_batch_size = 320
+val_batch_size = 32
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.1),
+ clip_grad=dict(max_norm=35, norm_type=2),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ # use cosine lr from 150 to 300 epoch
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=2560)
+
+# codec settings
+codec = dict(
+ type='SimCCLabel',
+ input_size=input_size,
+ sigma=(6., 6.93),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=1.,
+ widen_factor=1.,
+ channel_attention=True,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmposev1/rtmpose-l_simcc-ucoco_dw-ucoco_270e-256x192-4d6dfc62_20230728.pth' # noqa
+ )),
+ neck=dict(
+ type='CSPNeXtPAFPN',
+ in_channels=[256, 512, 1024],
+ out_channels=None,
+ out_indices=(
+ 1,
+ 2,
+ ),
+ num_csp_blocks=2,
+ expand_ratio=0.5,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU', inplace=True)),
+ head=dict(
+ type='RTMWHead',
+ in_channels=1024,
+ out_channels=num_keypoints,
+ input_size=input_size,
+ in_featuremap_size=tuple([s // 32 for s in input_size]),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=1.,
+ label_softmax=True,
+ label_beta=10.,
+ mask=list(range(23, 91)),
+ mask_weight=0.5,
+ ),
+ decoder=codec),
+ test_cfg=dict(flip_test=True))
+
+# base dataset settings
+dataset_type = 'CocoWholeBodyDataset'
+data_mode = 'topdown'
+data_root = 'data/'
+
+backend_args = dict(backend='local')
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.5, 1.5], rotate_factor=90),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PhotometricDistortion'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(
+ type='GenerateTarget',
+ encoder=codec,
+ use_dataset_keypoint_weights=True),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+train_pipeline_stage2 = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.5, 1.5],
+ rotate_factor=90),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ ]),
+ dict(
+ type='GenerateTarget',
+ encoder=codec,
+ use_dataset_keypoint_weights=True),
+ dict(type='PackPoseInputs')
+]
+
+# mapping
+
+aic_coco133 = [(0, 6), (1, 8), (2, 10), (3, 5), (4, 7), (5, 9), (6, 12),
+ (7, 14), (8, 16), (9, 11), (10, 13), (11, 15)]
+
+crowdpose_coco133 = [(0, 5), (1, 6), (2, 7), (3, 8), (4, 9), (5, 10), (6, 11),
+ (7, 12), (8, 13), (9, 14), (10, 15), (11, 16)]
+
+mpii_coco133 = [
+ (0, 16),
+ (1, 14),
+ (2, 12),
+ (3, 11),
+ (4, 13),
+ (5, 15),
+ (10, 10),
+ (11, 8),
+ (12, 6),
+ (13, 5),
+ (14, 7),
+ (15, 9),
+]
+
+jhmdb_coco133 = [
+ (3, 6),
+ (4, 5),
+ (5, 12),
+ (6, 11),
+ (7, 8),
+ (8, 7),
+ (9, 14),
+ (10, 13),
+ (11, 10),
+ (12, 9),
+ (13, 16),
+ (14, 15),
+]
+
+halpe_coco133 = [(i, i)
+ for i in range(17)] + [(20, 17), (21, 20), (22, 18), (23, 21),
+ (24, 19),
+ (25, 22)] + [(i, i - 3)
+ for i in range(26, 136)]
+
+posetrack_coco133 = [
+ (0, 0),
+ (3, 3),
+ (4, 4),
+ (5, 5),
+ (6, 6),
+ (7, 7),
+ (8, 8),
+ (9, 9),
+ (10, 10),
+ (11, 11),
+ (12, 12),
+ (13, 13),
+ (14, 14),
+ (15, 15),
+ (16, 16),
+]
+
+humanart_coco133 = [(i, i) for i in range(17)] + [(17, 99), (18, 120),
+ (19, 17), (20, 20)]
+
+# train datasets
+dataset_coco = dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='coco/annotations/coco_wholebody_train_v1.0.json',
+ data_prefix=dict(img='detection/coco/train2017/'),
+ pipeline=[],
+)
+
+dataset_aic = dict(
+ type='AicDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='aic/annotations/aic_train.json',
+ data_prefix=dict(img='pose/ai_challenge/ai_challenger_keypoint'
+ '_train_20170902/keypoint_train_images_20170902/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=aic_coco133)
+ ],
+)
+
+dataset_crowdpose = dict(
+ type='CrowdPoseDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='crowdpose/annotations/mmpose_crowdpose_trainval.json',
+ data_prefix=dict(img='pose/CrowdPose/images/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=crowdpose_coco133)
+ ],
+)
+
+dataset_mpii = dict(
+ type='MpiiDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='mpii/annotations/mpii_train.json',
+ data_prefix=dict(img='pose/MPI/images/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=mpii_coco133)
+ ],
+)
+
+dataset_jhmdb = dict(
+ type='JhmdbDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='jhmdb/annotations/Sub1_train.json',
+ data_prefix=dict(img='pose/JHMDB/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=jhmdb_coco133)
+ ],
+)
+
+dataset_halpe = dict(
+ type='HalpeDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='halpe/annotations/halpe_train_v1.json',
+ data_prefix=dict(img='pose/Halpe/hico_20160224_det/images/train2015'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=halpe_coco133)
+ ],
+)
+
+dataset_posetrack = dict(
+ type='PoseTrack18Dataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='posetrack18/annotations/posetrack18_train.json',
+ data_prefix=dict(img='pose/PoseChallenge2018/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=posetrack_coco133)
+ ],
+)
+
+dataset_humanart = dict(
+ type='HumanArt21Dataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='HumanArt/annotations/training_humanart.json',
+ filter_cfg=dict(scenes=['real_human']),
+ data_prefix=dict(img='pose/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=humanart_coco133)
+ ])
+
+ubody_scenes = [
+ 'Magic_show', 'Entertainment', 'ConductMusic', 'Online_class', 'TalkShow',
+ 'Speech', 'Fitness', 'Interview', 'Olympic', 'TVShow', 'Singing',
+ 'SignLanguage', 'Movie', 'LiveVlog', 'VideoConference'
+]
+
+ubody_datasets = []
+for scene in ubody_scenes:
+ each = dict(
+ type='UBody2dDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file=f'Ubody/annotations/{scene}/train_annotations.json',
+ data_prefix=dict(img='pose/UBody/images/'),
+ pipeline=[],
+ sample_interval=10)
+ ubody_datasets.append(each)
+
+dataset_ubody = dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/ubody2d.py'),
+ datasets=ubody_datasets,
+ pipeline=[],
+ test_mode=False,
+)
+
+face_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale', padding=1.25),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[1.5, 2.0],
+ rotate_factor=0),
+]
+
+wflw_coco133 = [(i * 2, 23 + i)
+ for i in range(17)] + [(33 + i, 40 + i) for i in range(5)] + [
+ (42 + i, 45 + i) for i in range(5)
+ ] + [(51 + i, 50 + i)
+ for i in range(9)] + [(60, 59), (61, 60), (63, 61),
+ (64, 62), (65, 63), (67, 64),
+ (68, 65), (69, 66), (71, 67),
+ (72, 68), (73, 69),
+ (75, 70)] + [(76 + i, 71 + i)
+ for i in range(20)]
+dataset_wflw = dict(
+ type='WFLWDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='wflw/annotations/face_landmarks_wflw_train.json',
+ data_prefix=dict(img='pose/WFLW/images/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=wflw_coco133), *face_pipeline
+ ],
+)
+
+mapping_300w_coco133 = [(i, 23 + i) for i in range(68)]
+dataset_300w = dict(
+ type='Face300WDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='300w/annotations/face_landmarks_300w_train.json',
+ data_prefix=dict(img='pose/300w/images/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=mapping_300w_coco133), *face_pipeline
+ ],
+)
+
+cofw_coco133 = [(0, 40), (2, 44), (4, 42), (1, 49), (3, 45), (6, 47), (8, 59),
+ (10, 62), (9, 68), (11, 65), (18, 54), (19, 58), (20, 53),
+ (21, 56), (22, 71), (23, 77), (24, 74), (25, 85), (26, 89),
+ (27, 80), (28, 31)]
+dataset_cofw = dict(
+ type='COFWDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='cofw/annotations/cofw_train.json',
+ data_prefix=dict(img='pose/COFW/images/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=cofw_coco133), *face_pipeline
+ ],
+)
+
+lapa_coco133 = [(i * 2, 23 + i) for i in range(17)] + [
+ (33 + i, 40 + i) for i in range(5)
+] + [(42 + i, 45 + i) for i in range(5)] + [
+ (51 + i, 50 + i) for i in range(4)
+] + [(58 + i, 54 + i) for i in range(5)] + [(66, 59), (67, 60), (69, 61),
+ (70, 62), (71, 63), (73, 64),
+ (75, 65), (76, 66), (78, 67),
+ (79, 68), (80, 69),
+ (82, 70)] + [(84 + i, 71 + i)
+ for i in range(20)]
+dataset_lapa = dict(
+ type='LapaDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='LaPa/annotations/lapa_trainval.json',
+ data_prefix=dict(img='pose/LaPa/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=lapa_coco133), *face_pipeline
+ ],
+)
+
+dataset_wb = dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[dataset_coco, dataset_halpe, dataset_ubody],
+ pipeline=[],
+ test_mode=False,
+)
+
+dataset_body = dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[
+ dataset_aic,
+ dataset_crowdpose,
+ dataset_mpii,
+ dataset_jhmdb,
+ dataset_posetrack,
+ dataset_humanart,
+ ],
+ pipeline=[],
+ test_mode=False,
+)
+
+dataset_face = dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[
+ dataset_wflw,
+ dataset_300w,
+ dataset_cofw,
+ dataset_lapa,
+ ],
+ pipeline=[],
+ test_mode=False,
+)
+
+hand_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[1.5, 2.0],
+ rotate_factor=0),
+]
+
+interhand_left = [(21, 95), (22, 94), (23, 93), (24, 92), (25, 99), (26, 98),
+ (27, 97), (28, 96), (29, 103), (30, 102), (31, 101),
+ (32, 100), (33, 107), (34, 106), (35, 105), (36, 104),
+ (37, 111), (38, 110), (39, 109), (40, 108), (41, 91)]
+interhand_right = [(i - 21, j + 21) for i, j in interhand_left]
+interhand_coco133 = interhand_right + interhand_left
+
+dataset_interhand2d = dict(
+ type='InterHand2DDoubleDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='interhand26m/annotations/all/InterHand2.6M_train_data.json',
+ camera_param_file='interhand26m/annotations/all/'
+ 'InterHand2.6M_train_camera.json',
+ joint_file='interhand26m/annotations/all/'
+ 'InterHand2.6M_train_joint_3d.json',
+ data_prefix=dict(img='interhand2.6m/images/train/'),
+ sample_interval=10,
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=interhand_coco133,
+ ), *hand_pipeline
+ ],
+)
+
+dataset_hand = dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[dataset_interhand2d],
+ pipeline=[],
+ test_mode=False,
+)
+
+train_datasets = [dataset_wb, dataset_body, dataset_face, dataset_hand]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=train_batch_size,
+ num_workers=4,
+ pin_memory=False,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=train_datasets,
+ pipeline=train_pipeline,
+ test_mode=False,
+ ))
+
+val_dataloader = dict(
+ batch_size=val_batch_size,
+ num_workers=4,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type='CocoWholeBodyDataset',
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json',
+ data_prefix=dict(img='data/detection/coco/val2017/'),
+ pipeline=val_pipeline,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ test_mode=True))
+
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(
+ save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoWholeBodyMetric',
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json')
+test_evaluator = val_evaluator
diff --git a/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-m_8xb1024-270e_cocktail14-256x192.py b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-m_8xb1024-270e_cocktail14-256x192.py
new file mode 100644
index 0000000000..0788a0b6a3
--- /dev/null
+++ b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-m_8xb1024-270e_cocktail14-256x192.py
@@ -0,0 +1,615 @@
+_base_ = ['mmpose::_base_/default_runtime.py']
+
+# common setting
+num_keypoints = 133
+input_size = (192, 256)
+
+# runtime
+max_epochs = 270
+stage2_num_epochs = 10
+base_lr = 5e-4
+train_batch_size = 1024
+val_batch_size = 32
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
+ clip_grad=dict(max_norm=35, norm_type=2),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=8192)
+
+# codec settings
+codec = dict(
+ type='SimCCLabel',
+ input_size=input_size,
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=0.67,
+ widen_factor=0.75,
+ channel_attention=True,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmposev1/rtmpose-m_simcc-ucoco_dw-ucoco_270e-256x192-c8b76419_20230728.pth' # noqa
+ )),
+ neck=dict(
+ type='CSPNeXtPAFPN',
+ in_channels=[192, 384, 768],
+ out_channels=None,
+ out_indices=(
+ 1,
+ 2,
+ ),
+ num_csp_blocks=2,
+ expand_ratio=0.5,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU', inplace=True)),
+ head=dict(
+ type='RTMWHead',
+ in_channels=768,
+ out_channels=num_keypoints,
+ input_size=input_size,
+ in_featuremap_size=tuple([s // 32 for s in input_size]),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=1.,
+ label_softmax=True,
+ label_beta=10.,
+ mask=list(range(23, 91)),
+ mask_weight=0.5,
+ ),
+ decoder=codec),
+ test_cfg=dict(flip_test=True))
+
+# base dataset settings
+dataset_type = 'CocoWholeBodyDataset'
+data_mode = 'topdown'
+data_root = 'data/'
+
+backend_args = dict(backend='local')
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.5, 1.5], rotate_factor=90),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PhotometricDistortion'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(
+ type='GenerateTarget',
+ encoder=codec,
+ use_dataset_keypoint_weights=True),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+train_pipeline_stage2 = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.5, 1.5],
+ rotate_factor=90),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ ]),
+ dict(
+ type='GenerateTarget',
+ encoder=codec,
+ use_dataset_keypoint_weights=True),
+ dict(type='PackPoseInputs')
+]
+
+# mapping
+
+aic_coco133 = [(0, 6), (1, 8), (2, 10), (3, 5), (4, 7), (5, 9), (6, 12),
+ (7, 14), (8, 16), (9, 11), (10, 13), (11, 15)]
+
+crowdpose_coco133 = [(0, 5), (1, 6), (2, 7), (3, 8), (4, 9), (5, 10), (6, 11),
+ (7, 12), (8, 13), (9, 14), (10, 15), (11, 16)]
+
+mpii_coco133 = [
+ (0, 16),
+ (1, 14),
+ (2, 12),
+ (3, 11),
+ (4, 13),
+ (5, 15),
+ (10, 10),
+ (11, 8),
+ (12, 6),
+ (13, 5),
+ (14, 7),
+ (15, 9),
+]
+
+jhmdb_coco133 = [
+ (3, 6),
+ (4, 5),
+ (5, 12),
+ (6, 11),
+ (7, 8),
+ (8, 7),
+ (9, 14),
+ (10, 13),
+ (11, 10),
+ (12, 9),
+ (13, 16),
+ (14, 15),
+]
+
+halpe_coco133 = [(i, i)
+ for i in range(17)] + [(20, 17), (21, 20), (22, 18), (23, 21),
+ (24, 19),
+ (25, 22)] + [(i, i - 3)
+ for i in range(26, 136)]
+
+posetrack_coco133 = [
+ (0, 0),
+ (3, 3),
+ (4, 4),
+ (5, 5),
+ (6, 6),
+ (7, 7),
+ (8, 8),
+ (9, 9),
+ (10, 10),
+ (11, 11),
+ (12, 12),
+ (13, 13),
+ (14, 14),
+ (15, 15),
+ (16, 16),
+]
+
+humanart_coco133 = [(i, i) for i in range(17)] + [(17, 99), (18, 120),
+ (19, 17), (20, 20)]
+
+# train datasets
+dataset_coco = dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='coco/annotations/coco_wholebody_train_v1.0.json',
+ data_prefix=dict(img='detection/coco/train2017/'),
+ pipeline=[],
+)
+
+dataset_aic = dict(
+ type='AicDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='aic/annotations/aic_train.json',
+ data_prefix=dict(img='pose/ai_challenge/ai_challenger_keypoint'
+ '_train_20170902/keypoint_train_images_20170902/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=aic_coco133)
+ ],
+)
+
+dataset_crowdpose = dict(
+ type='CrowdPoseDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='crowdpose/annotations/mmpose_crowdpose_trainval.json',
+ data_prefix=dict(img='pose/CrowdPose/images/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=crowdpose_coco133)
+ ],
+)
+
+dataset_mpii = dict(
+ type='MpiiDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='mpii/annotations/mpii_train.json',
+ data_prefix=dict(img='pose/MPI/images/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=mpii_coco133)
+ ],
+)
+
+dataset_jhmdb = dict(
+ type='JhmdbDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='jhmdb/annotations/Sub1_train.json',
+ data_prefix=dict(img='pose/JHMDB/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=jhmdb_coco133)
+ ],
+)
+
+dataset_halpe = dict(
+ type='HalpeDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='halpe/annotations/halpe_train_v1.json',
+ data_prefix=dict(img='pose/Halpe/hico_20160224_det/images/train2015'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=halpe_coco133)
+ ],
+)
+
+dataset_posetrack = dict(
+ type='PoseTrack18Dataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='posetrack18/annotations/posetrack18_train.json',
+ data_prefix=dict(img='pose/PoseChallenge2018/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=posetrack_coco133)
+ ],
+)
+
+dataset_humanart = dict(
+ type='HumanArt21Dataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='HumanArt/annotations/training_humanart.json',
+ filter_cfg=dict(scenes=['real_human']),
+ data_prefix=dict(img='pose/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=humanart_coco133)
+ ])
+
+ubody_scenes = [
+ 'Magic_show', 'Entertainment', 'ConductMusic', 'Online_class', 'TalkShow',
+ 'Speech', 'Fitness', 'Interview', 'Olympic', 'TVShow', 'Singing',
+ 'SignLanguage', 'Movie', 'LiveVlog', 'VideoConference'
+]
+
+ubody_datasets = []
+for scene in ubody_scenes:
+ each = dict(
+ type='UBody2dDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file=f'Ubody/annotations/{scene}/train_annotations.json',
+ data_prefix=dict(img='pose/UBody/images/'),
+ pipeline=[],
+ sample_interval=10)
+ ubody_datasets.append(each)
+
+dataset_ubody = dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/ubody2d.py'),
+ datasets=ubody_datasets,
+ pipeline=[],
+ test_mode=False,
+)
+
+face_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale', padding=1.25),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[1.5, 2.0],
+ rotate_factor=0),
+]
+
+wflw_coco133 = [(i * 2, 23 + i)
+ for i in range(17)] + [(33 + i, 40 + i) for i in range(5)] + [
+ (42 + i, 45 + i) for i in range(5)
+ ] + [(51 + i, 50 + i)
+ for i in range(9)] + [(60, 59), (61, 60), (63, 61),
+ (64, 62), (65, 63), (67, 64),
+ (68, 65), (69, 66), (71, 67),
+ (72, 68), (73, 69),
+ (75, 70)] + [(76 + i, 71 + i)
+ for i in range(20)]
+dataset_wflw = dict(
+ type='WFLWDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='wflw/annotations/face_landmarks_wflw_train.json',
+ data_prefix=dict(img='pose/WFLW/images/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=wflw_coco133), *face_pipeline
+ ],
+)
+
+mapping_300w_coco133 = [(i, 23 + i) for i in range(68)]
+dataset_300w = dict(
+ type='Face300WDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='300w/annotations/face_landmarks_300w_train.json',
+ data_prefix=dict(img='pose/300w/images/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=mapping_300w_coco133), *face_pipeline
+ ],
+)
+
+cofw_coco133 = [(0, 40), (2, 44), (4, 42), (1, 49), (3, 45), (6, 47), (8, 59),
+ (10, 62), (9, 68), (11, 65), (18, 54), (19, 58), (20, 53),
+ (21, 56), (22, 71), (23, 77), (24, 74), (25, 85), (26, 89),
+ (27, 80), (28, 31)]
+dataset_cofw = dict(
+ type='COFWDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='cofw/annotations/cofw_train.json',
+ data_prefix=dict(img='pose/COFW/images/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=cofw_coco133), *face_pipeline
+ ],
+)
+
+lapa_coco133 = [(i * 2, 23 + i) for i in range(17)] + [
+ (33 + i, 40 + i) for i in range(5)
+] + [(42 + i, 45 + i) for i in range(5)] + [
+ (51 + i, 50 + i) for i in range(4)
+] + [(58 + i, 54 + i) for i in range(5)] + [(66, 59), (67, 60), (69, 61),
+ (70, 62), (71, 63), (73, 64),
+ (75, 65), (76, 66), (78, 67),
+ (79, 68), (80, 69),
+ (82, 70)] + [(84 + i, 71 + i)
+ for i in range(20)]
+dataset_lapa = dict(
+ type='LapaDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='LaPa/annotations/lapa_trainval.json',
+ data_prefix=dict(img='pose/LaPa/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=lapa_coco133), *face_pipeline
+ ],
+)
+
+dataset_wb = dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[dataset_coco, dataset_halpe, dataset_ubody],
+ pipeline=[],
+ test_mode=False,
+)
+
+dataset_body = dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[
+ dataset_aic,
+ dataset_crowdpose,
+ dataset_mpii,
+ dataset_jhmdb,
+ dataset_posetrack,
+ dataset_humanart,
+ ],
+ pipeline=[],
+ test_mode=False,
+)
+
+dataset_face = dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[
+ dataset_wflw,
+ dataset_300w,
+ dataset_cofw,
+ dataset_lapa,
+ ],
+ pipeline=[],
+ test_mode=False,
+)
+
+hand_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[1.5, 2.0],
+ rotate_factor=0),
+]
+
+interhand_left = [(21, 95), (22, 94), (23, 93), (24, 92), (25, 99), (26, 98),
+ (27, 97), (28, 96), (29, 103), (30, 102), (31, 101),
+ (32, 100), (33, 107), (34, 106), (35, 105), (36, 104),
+ (37, 111), (38, 110), (39, 109), (40, 108), (41, 91)]
+interhand_right = [(i - 21, j + 21) for i, j in interhand_left]
+interhand_coco133 = interhand_right + interhand_left
+
+dataset_interhand2d = dict(
+ type='InterHand2DDoubleDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='interhand26m/annotations/all/InterHand2.6M_train_data.json',
+ camera_param_file='interhand26m/annotations/all/'
+ 'InterHand2.6M_train_camera.json',
+ joint_file='interhand26m/annotations/all/'
+ 'InterHand2.6M_train_joint_3d.json',
+ data_prefix=dict(img='interhand2.6m/images/train/'),
+ sample_interval=10,
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=interhand_coco133,
+ ), *hand_pipeline
+ ],
+)
+
+dataset_hand = dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[dataset_interhand2d],
+ pipeline=[],
+ test_mode=False,
+)
+
+train_datasets = [dataset_wb, dataset_body, dataset_face, dataset_hand]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=train_batch_size,
+ num_workers=4,
+ pin_memory=False,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=train_datasets,
+ pipeline=train_pipeline,
+ test_mode=False,
+ ))
+
+val_dataloader = dict(
+ batch_size=val_batch_size,
+ num_workers=4,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type='CocoWholeBodyDataset',
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json',
+ data_prefix=dict(img='data/detection/coco/val2017/'),
+ pipeline=val_pipeline,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ test_mode=True))
+
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(
+ save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoWholeBodyMetric',
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json')
+test_evaluator = val_evaluator
diff --git a/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb320-270e_cocktail14-384x288.py b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb320-270e_cocktail14-384x288.py
new file mode 100644
index 0000000000..952df6a867
--- /dev/null
+++ b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb320-270e_cocktail14-384x288.py
@@ -0,0 +1,616 @@
+_base_ = ['mmpose::_base_/default_runtime.py']
+
+# common setting
+num_keypoints = 133
+input_size = (288, 384)
+
+# runtime
+max_epochs = 270
+stage2_num_epochs = 10
+base_lr = 5e-4
+train_batch_size = 320
+val_batch_size = 32
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.1),
+ clip_grad=dict(max_norm=35, norm_type=2),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ # use cosine lr from 150 to 300 epoch
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=2560)
+
+# codec settings
+codec = dict(
+ type='SimCCLabel',
+ input_size=input_size,
+ sigma=(6., 6.93),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=1.33,
+ widen_factor=1.25,
+ channel_attention=True,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/'
+ 'wholebody_2d_keypoint/rtmpose/ubody/rtmpose-x_simcc-ucoco_pt-aic-coco_270e-384x288-f5b50679_20230822.pth' # noqa
+ )),
+ neck=dict(
+ type='CSPNeXtPAFPN',
+ in_channels=[320, 640, 1280],
+ out_channels=None,
+ out_indices=(
+ 1,
+ 2,
+ ),
+ num_csp_blocks=2,
+ expand_ratio=0.5,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU', inplace=True)),
+ head=dict(
+ type='RTMWHead',
+ in_channels=1280,
+ out_channels=num_keypoints,
+ input_size=input_size,
+ in_featuremap_size=tuple([s // 32 for s in input_size]),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=1.,
+ label_softmax=True,
+ label_beta=10.,
+ mask=list(range(23, 91)),
+ mask_weight=0.5,
+ ),
+ decoder=codec),
+ test_cfg=dict(flip_test=True))
+
+# base dataset settings
+dataset_type = 'CocoWholeBodyDataset'
+data_mode = 'topdown'
+data_root = 'data/'
+
+backend_args = dict(backend='local')
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.5, 1.5], rotate_factor=90),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PhotometricDistortion'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(
+ type='GenerateTarget',
+ encoder=codec,
+ use_dataset_keypoint_weights=True),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+train_pipeline_stage2 = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.5, 1.5],
+ rotate_factor=90),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ ]),
+ dict(
+ type='GenerateTarget',
+ encoder=codec,
+ use_dataset_keypoint_weights=True),
+ dict(type='PackPoseInputs')
+]
+
+# mapping
+
+aic_coco133 = [(0, 6), (1, 8), (2, 10), (3, 5), (4, 7), (5, 9), (6, 12),
+ (7, 14), (8, 16), (9, 11), (10, 13), (11, 15)]
+
+crowdpose_coco133 = [(0, 5), (1, 6), (2, 7), (3, 8), (4, 9), (5, 10), (6, 11),
+ (7, 12), (8, 13), (9, 14), (10, 15), (11, 16)]
+
+mpii_coco133 = [
+ (0, 16),
+ (1, 14),
+ (2, 12),
+ (3, 11),
+ (4, 13),
+ (5, 15),
+ (10, 10),
+ (11, 8),
+ (12, 6),
+ (13, 5),
+ (14, 7),
+ (15, 9),
+]
+
+jhmdb_coco133 = [
+ (3, 6),
+ (4, 5),
+ (5, 12),
+ (6, 11),
+ (7, 8),
+ (8, 7),
+ (9, 14),
+ (10, 13),
+ (11, 10),
+ (12, 9),
+ (13, 16),
+ (14, 15),
+]
+
+halpe_coco133 = [(i, i)
+ for i in range(17)] + [(20, 17), (21, 20), (22, 18), (23, 21),
+ (24, 19),
+ (25, 22)] + [(i, i - 3)
+ for i in range(26, 136)]
+
+posetrack_coco133 = [
+ (0, 0),
+ (3, 3),
+ (4, 4),
+ (5, 5),
+ (6, 6),
+ (7, 7),
+ (8, 8),
+ (9, 9),
+ (10, 10),
+ (11, 11),
+ (12, 12),
+ (13, 13),
+ (14, 14),
+ (15, 15),
+ (16, 16),
+]
+
+humanart_coco133 = [(i, i) for i in range(17)] + [(17, 99), (18, 120),
+ (19, 17), (20, 20)]
+
+# train datasets
+dataset_coco = dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='coco/annotations/coco_wholebody_train_v1.0.json',
+ data_prefix=dict(img='detection/coco/train2017/'),
+ pipeline=[],
+)
+
+dataset_aic = dict(
+ type='AicDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='aic/annotations/aic_train.json',
+ data_prefix=dict(img='pose/ai_challenge/ai_challenger_keypoint'
+ '_train_20170902/keypoint_train_images_20170902/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=aic_coco133)
+ ],
+)
+
+dataset_crowdpose = dict(
+ type='CrowdPoseDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='crowdpose/annotations/mmpose_crowdpose_trainval.json',
+ data_prefix=dict(img='pose/CrowdPose/images/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=crowdpose_coco133)
+ ],
+)
+
+dataset_mpii = dict(
+ type='MpiiDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='mpii/annotations/mpii_train.json',
+ data_prefix=dict(img='pose/MPI/images/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=mpii_coco133)
+ ],
+)
+
+dataset_jhmdb = dict(
+ type='JhmdbDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='jhmdb/annotations/Sub1_train.json',
+ data_prefix=dict(img='pose/JHMDB/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=jhmdb_coco133)
+ ],
+)
+
+dataset_halpe = dict(
+ type='HalpeDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='halpe/annotations/halpe_train_v1.json',
+ data_prefix=dict(img='pose/Halpe/hico_20160224_det/images/train2015'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=halpe_coco133)
+ ],
+)
+
+dataset_posetrack = dict(
+ type='PoseTrack18Dataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='posetrack18/annotations/posetrack18_train.json',
+ data_prefix=dict(img='pose/PoseChallenge2018/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=posetrack_coco133)
+ ],
+)
+
+dataset_humanart = dict(
+ type='HumanArt21Dataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='HumanArt/annotations/training_humanart.json',
+ filter_cfg=dict(scenes=['real_human']),
+ data_prefix=dict(img='pose/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=humanart_coco133)
+ ])
+
+ubody_scenes = [
+ 'Magic_show', 'Entertainment', 'ConductMusic', 'Online_class', 'TalkShow',
+ 'Speech', 'Fitness', 'Interview', 'Olympic', 'TVShow', 'Singing',
+ 'SignLanguage', 'Movie', 'LiveVlog', 'VideoConference'
+]
+
+ubody_datasets = []
+for scene in ubody_scenes:
+ each = dict(
+ type='UBody2dDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file=f'Ubody/annotations/{scene}/train_annotations.json',
+ data_prefix=dict(img='pose/UBody/images/'),
+ pipeline=[],
+ sample_interval=10)
+ ubody_datasets.append(each)
+
+dataset_ubody = dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/ubody2d.py'),
+ datasets=ubody_datasets,
+ pipeline=[],
+ test_mode=False,
+)
+
+face_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale', padding=1.25),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[1.5, 2.0],
+ rotate_factor=0),
+]
+
+wflw_coco133 = [(i * 2, 23 + i)
+ for i in range(17)] + [(33 + i, 40 + i) for i in range(5)] + [
+ (42 + i, 45 + i) for i in range(5)
+ ] + [(51 + i, 50 + i)
+ for i in range(9)] + [(60, 59), (61, 60), (63, 61),
+ (64, 62), (65, 63), (67, 64),
+ (68, 65), (69, 66), (71, 67),
+ (72, 68), (73, 69),
+ (75, 70)] + [(76 + i, 71 + i)
+ for i in range(20)]
+dataset_wflw = dict(
+ type='WFLWDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='wflw/annotations/face_landmarks_wflw_train.json',
+ data_prefix=dict(img='pose/WFLW/images/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=wflw_coco133), *face_pipeline
+ ],
+)
+
+mapping_300w_coco133 = [(i, 23 + i) for i in range(68)]
+dataset_300w = dict(
+ type='Face300WDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='300w/annotations/face_landmarks_300w_train.json',
+ data_prefix=dict(img='pose/300w/images/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=mapping_300w_coco133), *face_pipeline
+ ],
+)
+
+cofw_coco133 = [(0, 40), (2, 44), (4, 42), (1, 49), (3, 45), (6, 47), (8, 59),
+ (10, 62), (9, 68), (11, 65), (18, 54), (19, 58), (20, 53),
+ (21, 56), (22, 71), (23, 77), (24, 74), (25, 85), (26, 89),
+ (27, 80), (28, 31)]
+dataset_cofw = dict(
+ type='COFWDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='cofw/annotations/cofw_train.json',
+ data_prefix=dict(img='pose/COFW/images/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=cofw_coco133), *face_pipeline
+ ],
+)
+
+lapa_coco133 = [(i * 2, 23 + i) for i in range(17)] + [
+ (33 + i, 40 + i) for i in range(5)
+] + [(42 + i, 45 + i) for i in range(5)] + [
+ (51 + i, 50 + i) for i in range(4)
+] + [(58 + i, 54 + i) for i in range(5)] + [(66, 59), (67, 60), (69, 61),
+ (70, 62), (71, 63), (73, 64),
+ (75, 65), (76, 66), (78, 67),
+ (79, 68), (80, 69),
+ (82, 70)] + [(84 + i, 71 + i)
+ for i in range(20)]
+dataset_lapa = dict(
+ type='LapaDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='LaPa/annotations/lapa_trainval.json',
+ data_prefix=dict(img='pose/LaPa/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=lapa_coco133), *face_pipeline
+ ],
+)
+
+dataset_wb = dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[dataset_coco, dataset_halpe, dataset_ubody],
+ pipeline=[],
+ test_mode=False,
+)
+
+dataset_body = dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[
+ dataset_aic,
+ dataset_crowdpose,
+ dataset_mpii,
+ dataset_jhmdb,
+ dataset_posetrack,
+ dataset_humanart,
+ ],
+ pipeline=[],
+ test_mode=False,
+)
+
+dataset_face = dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[
+ dataset_wflw,
+ dataset_300w,
+ dataset_cofw,
+ dataset_lapa,
+ ],
+ pipeline=[],
+ test_mode=False,
+)
+
+hand_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[1.5, 2.0],
+ rotate_factor=0),
+]
+
+interhand_left = [(21, 95), (22, 94), (23, 93), (24, 92), (25, 99), (26, 98),
+ (27, 97), (28, 96), (29, 103), (30, 102), (31, 101),
+ (32, 100), (33, 107), (34, 106), (35, 105), (36, 104),
+ (37, 111), (38, 110), (39, 109), (40, 108), (41, 91)]
+interhand_right = [(i - 21, j + 21) for i, j in interhand_left]
+interhand_coco133 = interhand_right + interhand_left
+
+dataset_interhand2d = dict(
+ type='InterHand2DDoubleDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='interhand26m/annotations/all/InterHand2.6M_train_data.json',
+ camera_param_file='interhand26m/annotations/all/'
+ 'InterHand2.6M_train_camera.json',
+ joint_file='interhand26m/annotations/all/'
+ 'InterHand2.6M_train_joint_3d.json',
+ data_prefix=dict(img='interhand2.6m/images/train/'),
+ sample_interval=10,
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=interhand_coco133,
+ ), *hand_pipeline
+ ],
+)
+
+dataset_hand = dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[dataset_interhand2d],
+ pipeline=[],
+ test_mode=False,
+)
+
+train_datasets = [dataset_wb, dataset_body, dataset_face, dataset_hand]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=train_batch_size,
+ num_workers=4,
+ pin_memory=False,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=train_datasets,
+ pipeline=train_pipeline,
+ test_mode=False,
+ ))
+
+val_dataloader = dict(
+ batch_size=val_batch_size,
+ num_workers=4,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type='CocoWholeBodyDataset',
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json',
+ data_prefix=dict(img='data/detection/coco/val2017/'),
+ pipeline=val_pipeline,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ test_mode=True))
+
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(
+ save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoWholeBodyMetric',
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json')
+test_evaluator = val_evaluator
diff --git a/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb704-270e_cocktail14-256x192.py b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb704-270e_cocktail14-256x192.py
new file mode 100644
index 0000000000..7a00e1171b
--- /dev/null
+++ b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb704-270e_cocktail14-256x192.py
@@ -0,0 +1,615 @@
+_base_ = ['mmpose::_base_/default_runtime.py']
+
+# common setting
+num_keypoints = 133
+input_size = (192, 256)
+
+# runtime
+max_epochs = 270
+stage2_num_epochs = 10
+base_lr = 5e-4
+train_batch_size = 704
+val_batch_size = 32
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.1),
+ clip_grad=dict(max_norm=35, norm_type=2),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=5632)
+
+# codec settings
+codec = dict(
+ type='SimCCLabel',
+ input_size=input_size,
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=1.33,
+ widen_factor=1.25,
+ channel_attention=True,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/'
+ 'wholebody_2d_keypoint/rtmpose/ubody/rtmpose-x_simcc-ucoco_pt-aic-coco_270e-256x192-05f5bcb7_20230822.pth' # noqa
+ )),
+ neck=dict(
+ type='CSPNeXtPAFPN',
+ in_channels=[320, 640, 1280],
+ out_channels=None,
+ out_indices=(
+ 1,
+ 2,
+ ),
+ num_csp_blocks=2,
+ expand_ratio=0.5,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU', inplace=True)),
+ head=dict(
+ type='RTMWHead',
+ in_channels=1280,
+ out_channels=num_keypoints,
+ input_size=input_size,
+ in_featuremap_size=tuple([s // 32 for s in input_size]),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=1.,
+ label_softmax=True,
+ label_beta=10.,
+ mask=list(range(23, 91)),
+ mask_weight=0.5,
+ ),
+ decoder=codec),
+ test_cfg=dict(flip_test=True))
+
+# base dataset settings
+dataset_type = 'CocoWholeBodyDataset'
+data_mode = 'topdown'
+data_root = 'data/'
+
+backend_args = dict(backend='local')
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.5, 1.5], rotate_factor=90),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PhotometricDistortion'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(
+ type='GenerateTarget',
+ encoder=codec,
+ use_dataset_keypoint_weights=True),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+train_pipeline_stage2 = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.5, 1.5],
+ rotate_factor=90),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ ]),
+ dict(
+ type='GenerateTarget',
+ encoder=codec,
+ use_dataset_keypoint_weights=True),
+ dict(type='PackPoseInputs')
+]
+
+# mapping
+
+aic_coco133 = [(0, 6), (1, 8), (2, 10), (3, 5), (4, 7), (5, 9), (6, 12),
+ (7, 14), (8, 16), (9, 11), (10, 13), (11, 15)]
+
+crowdpose_coco133 = [(0, 5), (1, 6), (2, 7), (3, 8), (4, 9), (5, 10), (6, 11),
+ (7, 12), (8, 13), (9, 14), (10, 15), (11, 16)]
+
+mpii_coco133 = [
+ (0, 16),
+ (1, 14),
+ (2, 12),
+ (3, 11),
+ (4, 13),
+ (5, 15),
+ (10, 10),
+ (11, 8),
+ (12, 6),
+ (13, 5),
+ (14, 7),
+ (15, 9),
+]
+
+jhmdb_coco133 = [
+ (3, 6),
+ (4, 5),
+ (5, 12),
+ (6, 11),
+ (7, 8),
+ (8, 7),
+ (9, 14),
+ (10, 13),
+ (11, 10),
+ (12, 9),
+ (13, 16),
+ (14, 15),
+]
+
+halpe_coco133 = [(i, i)
+ for i in range(17)] + [(20, 17), (21, 20), (22, 18), (23, 21),
+ (24, 19),
+ (25, 22)] + [(i, i - 3)
+ for i in range(26, 136)]
+
+posetrack_coco133 = [
+ (0, 0),
+ (3, 3),
+ (4, 4),
+ (5, 5),
+ (6, 6),
+ (7, 7),
+ (8, 8),
+ (9, 9),
+ (10, 10),
+ (11, 11),
+ (12, 12),
+ (13, 13),
+ (14, 14),
+ (15, 15),
+ (16, 16),
+]
+
+humanart_coco133 = [(i, i) for i in range(17)] + [(17, 99), (18, 120),
+ (19, 17), (20, 20)]
+
+# train datasets
+dataset_coco = dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='coco/annotations/coco_wholebody_train_v1.0.json',
+ data_prefix=dict(img='detection/coco/train2017/'),
+ pipeline=[],
+)
+
+dataset_aic = dict(
+ type='AicDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='aic/annotations/aic_train.json',
+ data_prefix=dict(img='pose/ai_challenge/ai_challenger_keypoint'
+ '_train_20170902/keypoint_train_images_20170902/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=aic_coco133)
+ ],
+)
+
+dataset_crowdpose = dict(
+ type='CrowdPoseDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='crowdpose/annotations/mmpose_crowdpose_trainval.json',
+ data_prefix=dict(img='pose/CrowdPose/images/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=crowdpose_coco133)
+ ],
+)
+
+dataset_mpii = dict(
+ type='MpiiDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='mpii/annotations/mpii_train.json',
+ data_prefix=dict(img='pose/MPI/images/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=mpii_coco133)
+ ],
+)
+
+dataset_jhmdb = dict(
+ type='JhmdbDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='jhmdb/annotations/Sub1_train.json',
+ data_prefix=dict(img='pose/JHMDB/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=jhmdb_coco133)
+ ],
+)
+
+dataset_halpe = dict(
+ type='HalpeDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='halpe/annotations/halpe_train_v1.json',
+ data_prefix=dict(img='pose/Halpe/hico_20160224_det/images/train2015'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=halpe_coco133)
+ ],
+)
+
+dataset_posetrack = dict(
+ type='PoseTrack18Dataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='posetrack18/annotations/posetrack18_train.json',
+ data_prefix=dict(img='pose/PoseChallenge2018/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=posetrack_coco133)
+ ],
+)
+
+dataset_humanart = dict(
+ type='HumanArt21Dataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='HumanArt/annotations/training_humanart.json',
+ filter_cfg=dict(scenes=['real_human']),
+ data_prefix=dict(img='pose/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=humanart_coco133)
+ ])
+
+ubody_scenes = [
+ 'Magic_show', 'Entertainment', 'ConductMusic', 'Online_class', 'TalkShow',
+ 'Speech', 'Fitness', 'Interview', 'Olympic', 'TVShow', 'Singing',
+ 'SignLanguage', 'Movie', 'LiveVlog', 'VideoConference'
+]
+
+ubody_datasets = []
+for scene in ubody_scenes:
+ each = dict(
+ type='UBody2dDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file=f'Ubody/annotations/{scene}/train_annotations.json',
+ data_prefix=dict(img='pose/UBody/images/'),
+ pipeline=[],
+ sample_interval=10)
+ ubody_datasets.append(each)
+
+dataset_ubody = dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/ubody2d.py'),
+ datasets=ubody_datasets,
+ pipeline=[],
+ test_mode=False,
+)
+
+face_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale', padding=1.25),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[1.5, 2.0],
+ rotate_factor=0),
+]
+
+wflw_coco133 = [(i * 2, 23 + i)
+ for i in range(17)] + [(33 + i, 40 + i) for i in range(5)] + [
+ (42 + i, 45 + i) for i in range(5)
+ ] + [(51 + i, 50 + i)
+ for i in range(9)] + [(60, 59), (61, 60), (63, 61),
+ (64, 62), (65, 63), (67, 64),
+ (68, 65), (69, 66), (71, 67),
+ (72, 68), (73, 69),
+ (75, 70)] + [(76 + i, 71 + i)
+ for i in range(20)]
+dataset_wflw = dict(
+ type='WFLWDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='wflw/annotations/face_landmarks_wflw_train.json',
+ data_prefix=dict(img='pose/WFLW/images/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=wflw_coco133), *face_pipeline
+ ],
+)
+
+mapping_300w_coco133 = [(i, 23 + i) for i in range(68)]
+dataset_300w = dict(
+ type='Face300WDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='300w/annotations/face_landmarks_300w_train.json',
+ data_prefix=dict(img='pose/300w/images/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=mapping_300w_coco133), *face_pipeline
+ ],
+)
+
+cofw_coco133 = [(0, 40), (2, 44), (4, 42), (1, 49), (3, 45), (6, 47), (8, 59),
+ (10, 62), (9, 68), (11, 65), (18, 54), (19, 58), (20, 53),
+ (21, 56), (22, 71), (23, 77), (24, 74), (25, 85), (26, 89),
+ (27, 80), (28, 31)]
+dataset_cofw = dict(
+ type='COFWDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='cofw/annotations/cofw_train.json',
+ data_prefix=dict(img='pose/COFW/images/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=cofw_coco133), *face_pipeline
+ ],
+)
+
+lapa_coco133 = [(i * 2, 23 + i) for i in range(17)] + [
+ (33 + i, 40 + i) for i in range(5)
+] + [(42 + i, 45 + i) for i in range(5)] + [
+ (51 + i, 50 + i) for i in range(4)
+] + [(58 + i, 54 + i) for i in range(5)] + [(66, 59), (67, 60), (69, 61),
+ (70, 62), (71, 63), (73, 64),
+ (75, 65), (76, 66), (78, 67),
+ (79, 68), (80, 69),
+ (82, 70)] + [(84 + i, 71 + i)
+ for i in range(20)]
+dataset_lapa = dict(
+ type='LapaDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='LaPa/annotations/lapa_trainval.json',
+ data_prefix=dict(img='pose/LaPa/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=lapa_coco133), *face_pipeline
+ ],
+)
+
+dataset_wb = dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[dataset_coco, dataset_halpe, dataset_ubody],
+ pipeline=[],
+ test_mode=False,
+)
+
+dataset_body = dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[
+ dataset_aic,
+ dataset_crowdpose,
+ dataset_mpii,
+ dataset_jhmdb,
+ dataset_posetrack,
+ dataset_humanart,
+ ],
+ pipeline=[],
+ test_mode=False,
+)
+
+dataset_face = dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[
+ dataset_wflw,
+ dataset_300w,
+ dataset_cofw,
+ dataset_lapa,
+ ],
+ pipeline=[],
+ test_mode=False,
+)
+
+hand_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[1.5, 2.0],
+ rotate_factor=0),
+]
+
+interhand_left = [(21, 95), (22, 94), (23, 93), (24, 92), (25, 99), (26, 98),
+ (27, 97), (28, 96), (29, 103), (30, 102), (31, 101),
+ (32, 100), (33, 107), (34, 106), (35, 105), (36, 104),
+ (37, 111), (38, 110), (39, 109), (40, 108), (41, 91)]
+interhand_right = [(i - 21, j + 21) for i, j in interhand_left]
+interhand_coco133 = interhand_right + interhand_left
+
+dataset_interhand2d = dict(
+ type='InterHand2DDoubleDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='interhand26m/annotations/all/InterHand2.6M_train_data.json',
+ camera_param_file='interhand26m/annotations/all/'
+ 'InterHand2.6M_train_camera.json',
+ joint_file='interhand26m/annotations/all/'
+ 'InterHand2.6M_train_joint_3d.json',
+ data_prefix=dict(img='interhand2.6m/images/train/'),
+ sample_interval=10,
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=num_keypoints,
+ mapping=interhand_coco133,
+ ), *hand_pipeline
+ ],
+)
+
+dataset_hand = dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[dataset_interhand2d],
+ pipeline=[],
+ test_mode=False,
+)
+
+train_datasets = [dataset_wb, dataset_body, dataset_face, dataset_hand]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=train_batch_size,
+ num_workers=4,
+ pin_memory=False,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=train_datasets,
+ pipeline=train_pipeline,
+ test_mode=False,
+ ))
+
+val_dataloader = dict(
+ batch_size=val_batch_size,
+ num_workers=4,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type='CocoWholeBodyDataset',
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json',
+ data_prefix=dict(img='data/detection/coco/val2017/'),
+ pipeline=val_pipeline,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ test_mode=True))
+
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(
+ save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoWholeBodyMetric',
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json')
+test_evaluator = val_evaluator
diff --git a/tests/data/exlpose/imgs_0212_hwangridan_vid000020_exp1200_dark_000052__gain_3.40_exposure_417.png b/tests/data/exlpose/imgs_0212_hwangridan_vid000020_exp1200_dark_000052__gain_3.40_exposure_417.png
new file mode 100644
index 0000000000..af88084c86
Binary files /dev/null and b/tests/data/exlpose/imgs_0212_hwangridan_vid000020_exp1200_dark_000052__gain_3.40_exposure_417.png differ
diff --git a/tests/data/exlpose/imgs_0212_hwangridan_vid000020_exp400_dark_000052__gain_3.40_exposure_1250.png b/tests/data/exlpose/imgs_0212_hwangridan_vid000020_exp400_dark_000052__gain_3.40_exposure_1250.png
new file mode 100644
index 0000000000..1edaba86ab
Binary files /dev/null and b/tests/data/exlpose/imgs_0212_hwangridan_vid000020_exp400_dark_000052__gain_3.40_exposure_1250.png differ
diff --git a/tests/data/exlpose/test_exlpose.json b/tests/data/exlpose/test_exlpose.json
new file mode 100644
index 0000000000..c6f13da538
--- /dev/null
+++ b/tests/data/exlpose/test_exlpose.json
@@ -0,0 +1,444 @@
+{
+ "info": {
+ "description": "CGLab of POSTECH",
+ "year": 2022,
+ "date_created": "2022/02"
+ },
+ "categories": [
+ {
+ "supercategory": "person",
+ "id": 1,
+ "name": "person",
+ "keypoints": [
+ "left_shoulder",
+ "right_shoulder",
+ "left_elbow",
+ "right_elbow",
+ "left_wrist",
+ "right_wrist",
+ "left_hip",
+ "right_hip",
+ "left_knee",
+ "right_knee",
+ "left_ankle",
+ "right_ankle",
+ "head",
+ "neck"
+ ],
+ "skeleton": [
+ [
+ 12,
+ 13
+ ],
+ [
+ 13,
+ 0
+ ],
+ [
+ 13,
+ 1
+ ],
+ [
+ 0,
+ 2
+ ],
+ [
+ 2,
+ 4
+ ],
+ [
+ 1,
+ 3
+ ],
+ [
+ 3,
+ 5
+ ],
+ [
+ 13,
+ 7
+ ],
+ [
+ 13,
+ 6
+ ],
+ [
+ 7,
+ 9
+ ],
+ [
+ 9,
+ 11
+ ],
+ [
+ 6,
+ 8
+ ],
+ [
+ 8,
+ 10
+ ]
+ ]
+ }
+ ],
+ "images": [
+ {
+ "file_name": "imgs_0212_hwangridan_vid000020_exp400_dark_000052__gain_3.40_exposure_1250.png",
+ "id": 0,
+ "height": 1198,
+ "width": 1919,
+ "crowdIndex": 0
+ },
+ {
+ "file_name": "imgs_0212_hwangridan_vid000020_exp1200_dark_000052__gain_3.40_exposure_417.png",
+ "id": 1,
+ "height": 1198,
+ "width": 1919,
+ "crowdIndex": 0
+ }
+ ],
+ "annotations": [
+ {
+ "num_keypoints": 14,
+ "iscrowd": 0,
+ "keypoints": [
+ 1399.73,
+ 332.68,
+ 2,
+ 1240.1,
+ 316.9,
+ 2,
+ 1438.03,
+ 460.36,
+ 2,
+ 1195.44,
+ 428.44,
+ 2,
+ 1438.0,
+ 576.8,
+ 2,
+ 1169.9,
+ 517.82,
+ 2,
+ 1329.5,
+ 581.66,
+ 2,
+ 1233.74,
+ 568.89,
+ 2,
+ 1297.58,
+ 741.26,
+ 2,
+ 1240.13,
+ 734.88,
+ 2,
+ 1303.97,
+ 894.48,
+ 2,
+ 1272.05,
+ 894.48,
+ 2,
+ 1318.7,
+ 190.7,
+ 2,
+ 1323.12,
+ 294.38,
+ 2
+ ],
+ "image_id": 0,
+ "bbox": [
+ 1141.75,
+ 169.89,
+ 329.81999999999994,
+ 816.16
+ ],
+ "category_id": 1,
+ "id": 0
+ },
+ {
+ "num_keypoints": 14,
+ "iscrowd": 0,
+ "keypoints": [
+ 1198.02,
+ 352.83,
+ 2,
+ 1077.6,
+ 352.83,
+ 2,
+ 1214.45,
+ 456.83,
+ 2,
+ 1046.3,
+ 434.0,
+ 2,
+ 1196.6,
+ 535.0,
+ 2,
+ 1018.5,
+ 463.0,
+ 2,
+ 1159.8,
+ 567.3,
+ 2,
+ 1086.1,
+ 560.3,
+ 2,
+ 1115.92,
+ 703.14,
+ 2,
+ 1077.6,
+ 697.67,
+ 2,
+ 1141.7,
+ 832.6,
+ 2,
+ 1080.6,
+ 859.9,
+ 2,
+ 1137.81,
+ 232.41,
+ 2,
+ 1137.81,
+ 325.46,
+ 2
+ ],
+ "image_id": 0,
+ "bbox": [
+ 1029.62,
+ 218.73,
+ 177.08000000000015,
+ 699.62
+ ],
+ "category_id": 1,
+ "id": 1
+ },
+ {
+ "num_keypoints": 14,
+ "iscrowd": 0,
+ "keypoints": [
+ 743.06,
+ 351.98,
+ 2,
+ 790.68,
+ 357.27,
+ 2,
+ 730.72,
+ 383.72,
+ 2,
+ 794.21,
+ 394.31,
+ 2,
+ 734.24,
+ 415.47,
+ 2,
+ 787.16,
+ 415.47,
+ 2,
+ 746.59,
+ 419.0,
+ 2,
+ 778.34,
+ 419.0,
+ 2,
+ 748.35,
+ 463.09,
+ 2,
+ 772.4,
+ 465.8,
+ 2,
+ 744.9,
+ 504.3,
+ 2,
+ 761.3,
+ 504.9,
+ 2,
+ 773.7,
+ 312.0,
+ 2,
+ 771.28,
+ 337.87,
+ 2
+ ],
+ "image_id": 1,
+ "bbox": [
+ 732.07,
+ 307.0,
+ 72.13,
+ 224.76
+ ],
+ "category_id": 1,
+ "id": 2
+ },
+ {
+ "num_keypoints": 12,
+ "iscrowd": 0,
+ "keypoints": [
+ 674.3,
+ 336.65,
+ 2,
+ 715.1,
+ 338.5,
+ 2,
+ 656.88,
+ 362.79,
+ 2,
+ 733.1,
+ 368.7,
+ 2,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 680.84,
+ 419.42,
+ 2,
+ 702.62,
+ 421.6,
+ 2,
+ 689.55,
+ 476.06,
+ 2,
+ 702.62,
+ 478.23,
+ 2,
+ 687.37,
+ 530.51,
+ 2,
+ 693.91,
+ 534.87,
+ 2,
+ 709.8,
+ 297.9,
+ 2,
+ 700.44,
+ 321.4,
+ 2
+ ],
+ "image_id": 1,
+ "bbox": [
+ 650.96,
+ 276.75,
+ 117.55999999999995,
+ 277.80999999999995
+ ],
+ "category_id": 1,
+ "id": 3
+ },
+ {
+ "num_keypoints": 14,
+ "iscrowd": 0,
+ "keypoints": [
+ 620.44,
+ 336.27,
+ 2,
+ 641.2,
+ 337.86,
+ 2,
+ 614.85,
+ 350.64,
+ 2,
+ 646.79,
+ 354.63,
+ 2,
+ 612.46,
+ 361.82,
+ 2,
+ 646.79,
+ 365.81,
+ 2,
+ 622.84,
+ 364.21,
+ 2,
+ 638.01,
+ 366.61,
+ 2,
+ 623.64,
+ 380.98,
+ 2,
+ 636.45,
+ 382.97,
+ 2,
+ 626.03,
+ 400.93,
+ 2,
+ 638.2,
+ 399.9,
+ 2,
+ 632.42,
+ 314.71,
+ 2,
+ 631.62,
+ 329.88,
+ 2
+ ],
+ "image_id": 1,
+ "bbox": [
+ 605.38,
+ 311.92,
+ 42.690000000000055,
+ 101.19
+ ],
+ "category_id": 1,
+ "id": 4
+ },
+ {
+ "num_keypoints": 14,
+ "iscrowd": 0,
+ "keypoints": [
+ 806.08,
+ 340.99,
+ 2,
+ 856.65,
+ 342.8,
+ 2,
+ 795.25,
+ 382.53,
+ 2,
+ 867.49,
+ 386.14,
+ 2,
+ 793.44,
+ 411.42,
+ 2,
+ 869.29,
+ 418.64,
+ 2,
+ 815.5,
+ 417.8,
+ 2,
+ 847.62,
+ 416.84,
+ 2,
+ 812.8,
+ 471.1,
+ 2,
+ 840.9,
+ 473.2,
+ 2,
+ 809.7,
+ 512.55,
+ 2,
+ 831.9,
+ 513.5,
+ 2,
+ 833.3,
+ 306.9,
+ 2,
+ 831.37,
+ 324.74,
+ 2
+ ],
+ "image_id": 1,
+ "bbox": [
+ 794.29,
+ 302.16,
+ 82.19000000000005,
+ 230.16000000000003
+ ],
+ "category_id": 1,
+ "id": 5
+ }
+ ]
+}
\ No newline at end of file
diff --git a/tests/data/h3wb/h3wb_train_sub.npz b/tests/data/h3wb/h3wb_train_sub.npz
new file mode 100644
index 0000000000..dfbaaada03
Binary files /dev/null and b/tests/data/h3wb/h3wb_train_sub.npz differ
diff --git a/tests/test_codecs/test_simcc_label.py b/tests/test_codecs/test_simcc_label.py
index b4c242ef4e..25ae243d9f 100644
--- a/tests/test_codecs/test_simcc_label.py
+++ b/tests/test_codecs/test_simcc_label.py
@@ -100,6 +100,23 @@ def test_decode(self):
f'Failed case: "{name}"')
self.assertEqual(scores.shape, (1, 17), f'Failed case: "{name}"')
+ # test decode_visibility
+ cfg = cfg.copy()
+ cfg['decode_visibility'] = True
+ codec = KEYPOINT_CODECS.build(cfg)
+
+ simcc_x = np.random.rand(1, 17, int(
+ 192 * codec.simcc_split_ratio)) * 10
+ simcc_y = np.random.rand(1, 17, int(
+ 256 * codec.simcc_split_ratio)) * 10
+ keypoints, scores = codec.decode(simcc_x, simcc_y)
+
+ self.assertEqual(len(scores), 2)
+ self.assertEqual(scores[0].shape, (1, 17), f'Failed case: "{name}"')
+ self.assertEqual(scores[1].shape, (1, 17), f'Failed case: "{name}"')
+ self.assertGreaterEqual(scores[1].min(), 0.0)
+ self.assertLessEqual(scores[1].max(), 1.0)
+
def test_cicular_verification(self):
keypoints = self.data['keypoints']
keypoints_visible = self.data['keypoints_visible']
diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_exlpose_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_exlpose_dataset.py
new file mode 100644
index 0000000000..d8ac49f6f0
--- /dev/null
+++ b/tests/test_datasets/test_datasets/test_body_datasets/test_exlpose_dataset.py
@@ -0,0 +1,147 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from unittest import TestCase
+
+import numpy as np
+
+from mmpose.datasets.datasets.body import ExlposeDataset
+
+
+class TestExlposeDataset(TestCase):
+
+ def build_exlpose_dataset(self, **kwargs):
+
+ cfg = dict(
+ ann_file='test_exlpose.json',
+ bbox_file=None,
+ data_mode='topdown',
+ data_root='tests/data/exlpose',
+ pipeline=[],
+ test_mode=False)
+
+ cfg.update(kwargs)
+ return ExlposeDataset(**cfg)
+
+ def check_data_info_keys(self,
+ data_info: dict,
+ data_mode: str = 'topdown'):
+ if data_mode == 'topdown':
+ expected_keys = dict(
+ img_id=int,
+ img_path=str,
+ bbox=np.ndarray,
+ bbox_score=np.ndarray,
+ keypoints=np.ndarray,
+ keypoints_visible=np.ndarray,
+ id=int)
+ elif data_mode == 'bottomup':
+ expected_keys = dict(
+ img_id=int,
+ img_path=str,
+ bbox=np.ndarray,
+ bbox_score=np.ndarray,
+ keypoints=np.ndarray,
+ keypoints_visible=np.ndarray,
+ invalid_segs=list,
+ area=(list, np.ndarray),
+ id=list)
+ else:
+ raise ValueError(f'Invalid data_mode {data_mode}')
+
+ for key, type_ in expected_keys.items():
+ self.assertIn(key, data_info)
+ self.assertIsInstance(data_info[key], type_, key)
+
+ def check_metainfo_keys(self, metainfo: dict):
+ expected_keys = dict(
+ dataset_name=str,
+ num_keypoints=int,
+ keypoint_id2name=dict,
+ keypoint_name2id=dict,
+ upper_body_ids=list,
+ lower_body_ids=list,
+ flip_indices=list,
+ flip_pairs=list,
+ keypoint_colors=np.ndarray,
+ num_skeleton_links=int,
+ skeleton_links=list,
+ skeleton_link_colors=np.ndarray,
+ dataset_keypoint_weights=np.ndarray)
+
+ for key, type_ in expected_keys.items():
+ self.assertIn(key, metainfo)
+ self.assertIsInstance(metainfo[key], type_, key)
+
+ def test_metainfo(self):
+ dataset = self.build_exlpose_dataset()
+ self.check_metainfo_keys(dataset.metainfo)
+ # test dataset_name
+ self.assertEqual(dataset.metainfo['dataset_name'], 'exlpose')
+
+ # test number of keypoints
+ num_keypoints = 14
+ self.assertEqual(dataset.metainfo['num_keypoints'], num_keypoints)
+ self.assertEqual(
+ len(dataset.metainfo['keypoint_colors']), num_keypoints)
+ self.assertEqual(
+ len(dataset.metainfo['dataset_keypoint_weights']), num_keypoints)
+ # note that len(sigmas) may be zero if dataset.metainfo['sigmas'] = []
+ self.assertEqual(len(dataset.metainfo['sigmas']), num_keypoints)
+
+ # test some extra metainfo
+ self.assertEqual(
+ len(dataset.metainfo['skeleton_links']),
+ len(dataset.metainfo['skeleton_link_colors']))
+
+ def test_topdown(self):
+ # test topdown training
+ dataset = self.build_exlpose_dataset(data_mode='topdown')
+ self.assertEqual(dataset.bbox_file, None)
+ self.assertEqual(len(dataset), 6)
+ self.check_data_info_keys(dataset[0], data_mode='topdown')
+
+ # test topdown testing
+ dataset = self.build_exlpose_dataset(
+ data_mode='topdown', test_mode=True)
+ self.assertEqual(dataset.bbox_file, None)
+ self.assertEqual(len(dataset), 6)
+ self.check_data_info_keys(dataset[0], data_mode='topdown')
+
+ def test_bottomup(self):
+ # test bottomup training
+ dataset = self.build_exlpose_dataset(data_mode='bottomup')
+ self.assertEqual(len(dataset), 2)
+ self.check_data_info_keys(dataset[0], data_mode='bottomup')
+
+ # test bottomup testing
+ dataset = self.build_exlpose_dataset(
+ data_mode='bottomup', test_mode=True)
+ self.assertEqual(len(dataset), 2)
+ self.check_data_info_keys(dataset[0], data_mode='bottomup')
+
+ def test_exceptions_and_warnings(self):
+
+ with self.assertRaisesRegex(ValueError, 'got invalid data_mode'):
+ _ = self.build_exlpose_dataset(data_mode='invalid')
+
+ with self.assertRaisesRegex(
+ ValueError,
+ '"bbox_file" is only supported when `test_mode==True`'):
+ _ = self.build_exlpose_dataset(
+ data_mode='topdown',
+ test_mode=False,
+ bbox_file='temp_bbox_file.json')
+
+ with self.assertRaisesRegex(
+ ValueError, '"bbox_file" is only supported in topdown mode'):
+ _ = self.build_exlpose_dataset(
+ data_mode='bottomup',
+ test_mode=True,
+ bbox_file='temp_bbox_file.json')
+
+ with self.assertRaisesRegex(
+ ValueError,
+ '"bbox_score_thr" is only supported in topdown mode'):
+ _ = self.build_exlpose_dataset(
+ data_mode='bottomup',
+ test_mode=True,
+ filter_cfg=dict(bbox_score_thr=0.3))
diff --git a/tests/test_datasets/test_datasets/test_wholebody_datasets/test_h3wb_dataset.py b/tests/test_datasets/test_datasets/test_wholebody_datasets/test_h3wb_dataset.py
new file mode 100644
index 0000000000..ffcb8d78e0
--- /dev/null
+++ b/tests/test_datasets/test_datasets/test_wholebody_datasets/test_h3wb_dataset.py
@@ -0,0 +1,75 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from unittest import TestCase
+
+import numpy as np
+
+from mmpose.datasets.datasets.wholebody3d import H36MWholeBodyDataset
+
+
+class TestH36MWholeBodyDataset(TestCase):
+
+ def build_h3wb_dataset(self, **kwargs):
+
+ cfg = dict(
+ ann_file='h3wb_train_sub.npz',
+ data_mode='topdown',
+ data_root='tests/data/h3wb',
+ pipeline=[])
+
+ cfg.update(kwargs)
+ return H36MWholeBodyDataset(**cfg)
+
+ def check_data_info_keys(self, data_info: dict):
+ expected_keys = dict(
+ img_paths=list,
+ keypoints=np.ndarray,
+ keypoints_3d=np.ndarray,
+ scale=np.ndarray,
+ center=np.ndarray,
+ id=int)
+
+ for key, type_ in expected_keys.items():
+ self.assertIn(key, data_info)
+ self.assertIsInstance(data_info[key], type_, key)
+
+ def test_metainfo(self):
+ dataset = self.build_h3wb_dataset()
+ # test dataset_name
+ self.assertEqual(dataset.metainfo['dataset_name'], 'h3wb')
+
+ # test number of keypoints
+ num_keypoints = 133
+ self.assertEqual(dataset.metainfo['num_keypoints'], num_keypoints)
+ self.assertEqual(
+ len(dataset.metainfo['keypoint_colors']), num_keypoints)
+ self.assertEqual(
+ len(dataset.metainfo['dataset_keypoint_weights']), num_keypoints)
+
+ # test some extra metainfo
+ self.assertEqual(
+ len(dataset.metainfo['skeleton_links']),
+ len(dataset.metainfo['skeleton_link_colors']))
+
+ def test_topdown(self):
+ # test topdown training
+ dataset = self.build_h3wb_dataset(data_mode='topdown')
+ dataset.full_init()
+ self.assertEqual(len(dataset), 3)
+ self.check_data_info_keys(dataset[0])
+
+ # test topdown testing
+ dataset = self.build_h3wb_dataset(data_mode='topdown', test_mode=True)
+ dataset.full_init()
+ self.assertEqual(len(dataset), 1)
+ self.check_data_info_keys(dataset[0])
+
+ # test topdown training with sequence config
+ dataset = self.build_h3wb_dataset(
+ data_mode='topdown',
+ seq_len=1,
+ seq_step=1,
+ causal=False,
+ pad_video_seq=True)
+ dataset.full_init()
+ self.assertEqual(len(dataset), 3)
+ self.check_data_info_keys(dataset[0])
diff --git a/tests/test_datasets/test_transforms/test_formatting.py b/tests/test_datasets/test_transforms/test_formatting.py
index 95fadb55b2..0db4fa250f 100644
--- a/tests/test_datasets/test_transforms/test_formatting.py
+++ b/tests/test_datasets/test_transforms/test_formatting.py
@@ -105,4 +105,5 @@ def test_transform(self):
def test_repr(self):
transform = PackPoseInputs(meta_keys=self.meta_keys)
self.assertEqual(
- repr(transform), f'PackPoseInputs(meta_keys={self.meta_keys})')
+ repr(transform), f'PackPoseInputs(meta_keys={self.meta_keys}, '
+ f'pack_transformed={transform.pack_transformed})')
diff --git a/tests/test_engine/test_hooks/test_mode_switch_hooks.py b/tests/test_engine/test_hooks/test_mode_switch_hooks.py
index fbf10bd3ef..4d149d0933 100644
--- a/tests/test_engine/test_hooks/test_mode_switch_hooks.py
+++ b/tests/test_engine/test_hooks/test_mode_switch_hooks.py
@@ -7,7 +7,7 @@
from mmengine.runner import Runner
from torch.utils.data import Dataset
-from mmpose.engine.hooks import YOLOXPoseModeSwitchHook
+from mmpose.engine.hooks import RTMOModeSwitchHook, YOLOXPoseModeSwitchHook
from mmpose.utils import register_all_modules
@@ -65,3 +65,36 @@ def test(self):
self.assertTrue(runner.model.bbox_head.use_aux_loss)
self.assertEqual(runner.train_loop.dataloader.dataset.pipeline,
pipeline2)
+
+
+class TestRTMOModeSwitchHook(TestCase):
+
+ def test(self):
+
+ runner = Mock()
+ runner.model = Mock()
+ runner.model.head = Mock()
+ runner.model.head.loss = Mock()
+
+ runner.model.head.attr1 = False
+ runner.model.head.loss.attr2 = 1.0
+
+ hook = RTMOModeSwitchHook(epoch_attributes={
+ 0: {
+ 'attr1': True
+ },
+ 10: {
+ 'loss.attr2': 0.5
+ }
+ })
+
+ # test after change mode
+ runner.epoch = 0
+ hook.before_train_epoch(runner)
+ self.assertTrue(runner.model.head.attr1)
+ self.assertEqual(runner.model.head.loss.attr2, 1.0)
+
+ runner.epoch = 10
+ hook.before_train_epoch(runner)
+ self.assertTrue(runner.model.head.attr1)
+ self.assertEqual(runner.model.head.loss.attr2, 0.5)
diff --git a/tests/test_engine/test_schedulers/test_lr_scheduler.py b/tests/test_engine/test_schedulers/test_lr_scheduler.py
new file mode 100644
index 0000000000..e790df1d71
--- /dev/null
+++ b/tests/test_engine/test_schedulers/test_lr_scheduler.py
@@ -0,0 +1,88 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from unittest import TestCase
+
+import torch
+import torch.nn.functional as F
+import torch.optim as optim
+from mmengine.optim.scheduler import _ParamScheduler
+from mmengine.testing import assert_allclose
+
+from mmpose.engine.schedulers import ConstantLR
+
+
+class ToyModel(torch.nn.Module):
+
+ def __init__(self):
+ super().__init__()
+ self.conv1 = torch.nn.Conv2d(1, 1, 1)
+ self.conv2 = torch.nn.Conv2d(1, 1, 1)
+
+ def forward(self, x):
+ return self.conv2(F.relu(self.conv1(x)))
+
+
+class TestLRScheduler(TestCase):
+
+ def setUp(self):
+ """Setup the model and optimizer which are used in every test method.
+
+ TestCase calls functions in this order: setUp() -> testMethod() ->
+ tearDown() -> cleanUp()
+ """
+ self.model = ToyModel()
+ lr = 0.05
+ self.layer2_mult = 10
+ self.optimizer = optim.SGD([{
+ 'params': self.model.conv1.parameters()
+ }, {
+ 'params': self.model.conv2.parameters(),
+ 'lr': lr * self.layer2_mult,
+ }],
+ lr=lr,
+ momentum=0.01,
+ weight_decay=5e-4)
+
+ def _test_scheduler_value(self,
+ schedulers,
+ targets,
+ epochs=10,
+ param_name='lr',
+ step_kwargs=None):
+ if isinstance(schedulers, _ParamScheduler):
+ schedulers = [schedulers]
+ if step_kwargs is None:
+ step_kwarg = [{} for _ in range(len(schedulers))]
+ step_kwargs = [step_kwarg for _ in range(epochs)]
+ else: # step_kwargs is not None
+ assert len(step_kwargs) == epochs
+ assert len(step_kwargs[0]) == len(schedulers)
+ for epoch in range(epochs):
+ for param_group, target in zip(self.optimizer.param_groups,
+ targets):
+ assert_allclose(
+ target[epoch],
+ param_group[param_name],
+ msg='{} is wrong in epoch {}: expected {}, got {}'.format(
+ param_name, epoch, target[epoch],
+ param_group[param_name]),
+ atol=1e-5,
+ rtol=0)
+ [
+ scheduler.step(**step_kwargs[epoch][i])
+ for i, scheduler in enumerate(schedulers)
+ ]
+
+ def test_constant_scheduler(self):
+
+ # lr = 0.025 if epoch < 5
+ # lr = 0.005 if 5 <= epoch
+ epochs = 10
+ single_targets = [0.025] * 4 + [0.05] * 6
+ targets = [
+ single_targets, [x * self.layer2_mult for x in single_targets]
+ ]
+ scheduler = ConstantLR(self.optimizer, factor=1.0 / 2, end=5)
+ self._test_scheduler_value(scheduler, targets, epochs)
+
+ # remove factor range restriction
+ _ = ConstantLR(self.optimizer, factor=99, end=100)
diff --git a/tests/test_models/test_losses/test_classification_losses.py b/tests/test_models/test_losses/test_classification_losses.py
index fd7d3fd898..f8f7fe67f5 100644
--- a/tests/test_models/test_losses/test_classification_losses.py
+++ b/tests/test_models/test_losses/test_classification_losses.py
@@ -3,7 +3,7 @@
import torch
-from mmpose.models.losses.classification_loss import InfoNCELoss
+from mmpose.models.losses.classification_loss import InfoNCELoss, VariFocalLoss
class TestInfoNCELoss(TestCase):
@@ -20,3 +20,45 @@ def test_loss(self):
# check if the value of temperature is positive
with self.assertRaises(AssertionError):
loss = InfoNCELoss(temperature=0.)
+
+
+class TestVariFocalLoss(TestCase):
+
+ def test_forward_no_target_weight_mean_reduction(self):
+ # Test the forward method with no target weight and mean reduction
+ output = torch.tensor([[0.3, -0.2], [-0.1, 0.4]], dtype=torch.float32)
+ target = torch.tensor([[1.0, 0.0], [0.0, 1.0]], dtype=torch.float32)
+
+ loss_func = VariFocalLoss(use_target_weight=False, reduction='mean')
+ loss = loss_func(output, target)
+
+ # Calculate expected loss manually or using an alternative method
+ expected_loss = 0.31683
+ self.assertAlmostEqual(loss.item(), expected_loss, places=5)
+
+ def test_forward_with_target_weight_sum_reduction(self):
+ # Test the forward method with target weight and sum reduction
+ output = torch.tensor([[0.3, -0.2], [-0.1, 0.4]], dtype=torch.float32)
+ target = torch.tensor([[1.0, 0.0], [0.0, 1.0]], dtype=torch.float32)
+ target_weight = torch.tensor([1.0, 0.5], dtype=torch.float32)
+
+ loss_func = VariFocalLoss(use_target_weight=True, reduction='sum')
+ loss = loss_func(output, target, target_weight)
+
+ # Calculate expected loss manually or using an alternative method
+ expected_loss = 0.956299
+ self.assertAlmostEqual(loss.item(), expected_loss, places=5)
+
+ def test_inf_nan_handling(self):
+ # Test handling of inf and nan values
+ output = torch.tensor([[float('inf'), float('-inf')],
+ [float('nan'), 0.4]],
+ dtype=torch.float32)
+ target = torch.tensor([[1.0, 0.0], [0.0, 1.0]], dtype=torch.float32)
+
+ loss_func = VariFocalLoss(use_target_weight=False, reduction='mean')
+ loss = loss_func(output, target)
+
+ # Check if loss is valid (not nan or inf)
+ self.assertFalse(torch.isnan(loss).item())
+ self.assertFalse(torch.isinf(loss).item())
diff --git a/tests/test_models/test_losses/test_heatmap_losses.py b/tests/test_models/test_losses/test_heatmap_losses.py
index 00da170389..cb8b38877c 100644
--- a/tests/test_models/test_losses/test_heatmap_losses.py
+++ b/tests/test_models/test_losses/test_heatmap_losses.py
@@ -5,7 +5,7 @@
from mmpose.models.losses.heatmap_loss import (AdaptiveWingLoss,
FocalHeatmapLoss,
- KeypointMSELoss)
+ KeypointMSELoss, MLECCLoss)
class TestAdaptiveWingLoss(TestCase):
@@ -117,3 +117,39 @@ def test_loss(self):
loss(fake_pred, fake_label, fake_weight, fake_mask),
torch.tensor(0.),
atol=1e-4))
+
+
+class TestMLECCLoss(TestCase):
+
+ def setUp(self):
+ self.outputs = (torch.rand(10, 2, 5), torch.rand(10, 2, 5))
+ self.targets = (torch.rand(10, 2, 5), torch.rand(10, 2, 5))
+
+ def test_mean_reduction_log_mode(self):
+ loss_func = MLECCLoss(reduction='mean', mode='log')
+ loss = loss_func(self.outputs, self.targets)
+ self.assertIsInstance(loss, torch.Tensor)
+
+ def test_sum_reduction_linear_mode(self):
+ loss_func = MLECCLoss(reduction='sum', mode='linear')
+ loss = loss_func(self.outputs, self.targets)
+ self.assertIsInstance(loss, torch.Tensor)
+
+ def test_none_reduction_square_mode(self):
+ loss_func = MLECCLoss(reduction='none', mode='square')
+ loss = loss_func(self.outputs, self.targets)
+ self.assertIsInstance(loss, torch.Tensor)
+
+ def test_target_weight(self):
+ target_weight = torch.rand(10) # Random weights
+ loss_func = MLECCLoss(use_target_weight=True)
+ loss = loss_func(self.outputs, self.targets, target_weight)
+ self.assertIsInstance(loss, torch.Tensor)
+
+ def test_invalid_reduction(self):
+ with self.assertRaises(AssertionError):
+ MLECCLoss(reduction='invalid_reduction')
+
+ def test_invalid_mode(self):
+ with self.assertRaises(AssertionError):
+ MLECCLoss(mode='invalid_mode')
diff --git a/tests/test_models/test_utils/test_transformers.py b/tests/test_models/test_utils/test_transformers.py
new file mode 100644
index 0000000000..294400e314
--- /dev/null
+++ b/tests/test_models/test_utils/test_transformers.py
@@ -0,0 +1,159 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from unittest import TestCase
+
+import torch
+
+from mmpose.models.utils.transformer import GAUEncoder, SinePositionalEncoding
+
+
+class TestSinePositionalEncoding(TestCase):
+
+ def test_init(self):
+
+ spe = SinePositionalEncoding(out_channels=128)
+ self.assertTrue(hasattr(spe, 'dim_t'))
+ self.assertFalse(spe.dim_t.requires_grad)
+ self.assertEqual(spe.dim_t.size(0), 128 // 2)
+
+ spe = SinePositionalEncoding(out_channels=128, learnable=True)
+ self.assertTrue(spe.dim_t.requires_grad)
+
+ spe = SinePositionalEncoding(out_channels=128, eval_size=10)
+ self.assertTrue(hasattr(spe, 'pos_enc_10'))
+ self.assertEqual(spe.pos_enc_10.size(-1), 128)
+
+ spe = SinePositionalEncoding(
+ out_channels=128, eval_size=(2, 3), spatial_dim=2)
+ self.assertTrue(hasattr(spe, 'pos_enc_(2, 3)'))
+ self.assertSequenceEqual(
+ getattr(spe, 'pos_enc_(2, 3)').shape[-2:], (128, 2))
+
+ def test_generate_speoding(self):
+
+ # spatial_dim = 1
+ spe = SinePositionalEncoding(out_channels=128)
+ pos_enc = spe.generate_pos_encoding(size=10)
+ self.assertSequenceEqual(pos_enc.shape, (10, 128))
+
+ position = torch.arange(8)
+ pos_enc = spe.generate_pos_encoding(position=position)
+ self.assertSequenceEqual(pos_enc.shape, (8, 128))
+
+ with self.assertRaises(AssertionError):
+ pos_enc = spe.generate_pos_encoding(size=10, position=position)
+
+ # spatial_dim = 2
+ spe = SinePositionalEncoding(out_channels=128, spatial_dim=2)
+ pos_enc = spe.generate_pos_encoding(size=10)
+ self.assertSequenceEqual(pos_enc.shape, (100, 128, 2))
+
+ pos_enc = spe.generate_pos_encoding(size=(5, 6))
+ self.assertSequenceEqual(pos_enc.shape, (30, 128, 2))
+
+ position = torch.arange(8).unsqueeze(1).repeat(1, 2)
+ pos_enc = spe.generate_pos_encoding(position=position)
+ self.assertSequenceEqual(pos_enc.shape, (8, 128, 2))
+
+ with self.assertRaises(AssertionError):
+ pos_enc = spe.generate_pos_encoding(size=10, position=position)
+
+ with self.assertRaises(ValueError):
+ pos_enc = spe.generate_pos_encoding(size=position)
+
+ def test_apply_additional_pos_enc(self):
+
+ # spatial_dim = 1
+ spe = SinePositionalEncoding(out_channels=128)
+ pos_enc = spe.generate_pos_encoding(size=10)
+ feature = torch.randn(2, 3, 10, 128)
+ out_feature = spe.apply_additional_pos_enc(feature, pos_enc,
+ spe.spatial_dim)
+ self.assertSequenceEqual(feature.shape, out_feature.shape)
+
+ # spatial_dim = 2
+ spe = SinePositionalEncoding(out_channels=128 // 2, spatial_dim=2)
+ pos_enc = spe.generate_pos_encoding(size=(2, 5))
+ feature = torch.randn(2, 3, 10, 128)
+ out_feature = spe.apply_additional_pos_enc(feature, pos_enc,
+ spe.spatial_dim)
+ self.assertSequenceEqual(feature.shape, out_feature.shape)
+
+ def test_apply_rotary_pos_enc(self):
+
+ # spatial_dim = 1
+ spe = SinePositionalEncoding(out_channels=128)
+ pos_enc = spe.generate_pos_encoding(size=10)
+ feature = torch.randn(2, 3, 10, 128)
+ out_feature = spe.apply_rotary_pos_enc(feature, pos_enc,
+ spe.spatial_dim)
+ self.assertSequenceEqual(feature.shape, out_feature.shape)
+
+ # spatial_dim = 2
+ spe = SinePositionalEncoding(out_channels=128, spatial_dim=2)
+ pos_enc = spe.generate_pos_encoding(size=(2, 5))
+ feature = torch.randn(2, 3, 10, 128)
+ out_feature = spe.apply_rotary_pos_enc(feature, pos_enc,
+ spe.spatial_dim)
+ self.assertSequenceEqual(feature.shape, out_feature.shape)
+
+
+class TestGAUEncoder(TestCase):
+
+ def test_init(self):
+ gau = GAUEncoder(in_token_dims=64, out_token_dims=64)
+ self.assertTrue(gau.shortcut)
+
+ gau = GAUEncoder(in_token_dims=64, out_token_dims=64, dropout_rate=0.5)
+ self.assertTrue(hasattr(gau, 'dropout'))
+
+ def test_forward(self):
+ gau = GAUEncoder(in_token_dims=64, out_token_dims=64)
+
+ # compatibility with various dimension input
+ feat = torch.randn(2, 3, 64)
+ with torch.no_grad():
+ out_feat = gau.forward(feat)
+ self.assertSequenceEqual(feat.shape, out_feat.shape)
+
+ feat = torch.randn(1, 2, 3, 64)
+ with torch.no_grad():
+ out_feat = gau.forward(feat)
+ self.assertSequenceEqual(feat.shape, out_feat.shape)
+
+ feat = torch.randn(1, 2, 3, 4, 64)
+ with torch.no_grad():
+ out_feat = gau.forward(feat)
+ self.assertSequenceEqual(feat.shape, out_feat.shape)
+
+ # positional encoding
+ gau = GAUEncoder(
+ s=32, in_token_dims=64, out_token_dims=64, pos_enc=True)
+ feat = torch.randn(2, 3, 64)
+ spe = SinePositionalEncoding(out_channels=32)
+ pos_enc = spe.generate_pos_encoding(size=3)
+ with torch.no_grad():
+ out_feat = gau.forward(feat, pos_enc=pos_enc)
+ self.assertSequenceEqual(feat.shape, out_feat.shape)
+
+ gau = GAUEncoder(
+ s=32,
+ in_token_dims=64,
+ out_token_dims=64,
+ pos_enc=True,
+ spatial_dim=2)
+ feat = torch.randn(1, 2, 6, 64)
+ spe = SinePositionalEncoding(out_channels=32, spatial_dim=2)
+ pos_enc = spe.generate_pos_encoding(size=(2, 3))
+ with torch.no_grad():
+ out_feat = gau.forward(feat, pos_enc=pos_enc)
+ self.assertSequenceEqual(feat.shape, out_feat.shape)
+
+ # mask
+ gau = GAUEncoder(in_token_dims=64, out_token_dims=64)
+
+ # compatibility with various dimension input
+ feat = torch.randn(2, 3, 64)
+ mask = torch.rand(2, 3, 3)
+ with torch.no_grad():
+ out_feat = gau.forward(feat, mask=mask)
+ self.assertSequenceEqual(feat.shape, out_feat.shape)
diff --git a/tests/test_structures/test_bbox/test_bbox_transforms.py b/tests/test_structures/test_bbox/test_bbox_transforms.py
index b2eb3da683..d70c39e08c 100644
--- a/tests/test_structures/test_bbox/test_bbox_transforms.py
+++ b/tests/test_structures/test_bbox/test_bbox_transforms.py
@@ -4,7 +4,8 @@
import numpy as np
from mmpose.structures.bbox import (bbox_clip_border, bbox_corner2xyxy,
- bbox_xyxy2corner, get_pers_warp_matrix)
+ bbox_xyxy2corner, get_pers_warp_matrix,
+ get_warp_matrix)
class TestBBoxClipBorder(TestCase):
@@ -124,3 +125,61 @@ def test_get_pers_warp_matrix_scale_rotation_shear(self):
# Use np.allclose to compare floating-point arrays within a tolerance
self.assertTrue(
np.allclose(warp_matrix, expected_matrix, rtol=1e-3, atol=1e-3))
+
+
+class TestGetWarpMatrix(TestCase):
+
+ def test_basic_transformation(self):
+ # Test with basic parameters
+ center = np.array([100, 100])
+ scale = np.array([50, 50])
+ rot = 0
+ output_size = (200, 200)
+ warp_matrix = get_warp_matrix(center, scale, rot, output_size)
+ expected_matrix = np.array([[4, 0, -300], [0, 4, -300]])
+ np.testing.assert_array_almost_equal(warp_matrix, expected_matrix)
+
+ def test_rotation(self):
+ # Test with rotation
+ center = np.array([100, 100])
+ scale = np.array([50, 50])
+ rot = 45 # 45 degree rotation
+ output_size = (200, 200)
+ warp_matrix = get_warp_matrix(center, scale, rot, output_size)
+ expected_matrix = np.array([[2.828427, 2.828427, -465.685303],
+ [-2.828427, 2.828427, 100.]])
+ np.testing.assert_array_almost_equal(warp_matrix, expected_matrix)
+
+ def test_shift(self):
+ # Test with shift
+ center = np.array([100, 100])
+ scale = np.array([50, 50])
+ rot = 0
+ output_size = (200, 200)
+ shift = (0.1, 0.1) # 10% shift
+ warp_matrix = get_warp_matrix(
+ center, scale, rot, output_size, shift=shift)
+ expected_matrix = np.array([[4, 0, -320], [0, 4, -320]])
+ np.testing.assert_array_almost_equal(warp_matrix, expected_matrix)
+
+ def test_inverse(self):
+ # Test inverse transformation
+ center = np.array([100, 100])
+ scale = np.array([50, 50])
+ rot = 0
+ output_size = (200, 200)
+ warp_matrix = get_warp_matrix(
+ center, scale, rot, output_size, inv=True)
+ expected_matrix = np.array([[0.25, 0, 75], [0, 0.25, 75]])
+ np.testing.assert_array_almost_equal(warp_matrix, expected_matrix)
+
+ def test_aspect_ratio(self):
+ # Test with fix_aspect_ratio set to False
+ center = np.array([100, 100])
+ scale = np.array([50, 20])
+ rot = 0
+ output_size = (200, 200)
+ warp_matrix = get_warp_matrix(
+ center, scale, rot, output_size, fix_aspect_ratio=False)
+ expected_matrix = np.array([[4, 0, -300], [0, 10, -900]])
+ np.testing.assert_array_almost_equal(warp_matrix, expected_matrix)
diff --git a/tools/misc/generate_bbox_file.py b/tools/misc/generate_bbox_file.py
new file mode 100644
index 0000000000..bb13dc0866
--- /dev/null
+++ b/tools/misc/generate_bbox_file.py
@@ -0,0 +1,70 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import json
+
+import numpy as np
+from mmengine import Config
+
+from mmpose.evaluation.functional import nms
+from mmpose.registry import DATASETS
+from mmpose.structures import bbox_xyxy2xywh
+from mmpose.utils import register_all_modules
+
+try:
+ from mmdet.apis import DetInferencer
+ has_mmdet = True
+except ImportError:
+ print('Please install mmdet to use this script!')
+ has_mmdet = False
+
+
+def main():
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument('det_config')
+ parser.add_argument('det_weight')
+ parser.add_argument('output', type=str)
+ parser.add_argument(
+ '--pose-config',
+ default='configs/body_2d_keypoint/topdown_heatmap/'
+ 'coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py')
+ parser.add_argument('--score-thr', default=0.1)
+ parser.add_argument('--nms-thr', default=0.65)
+ args = parser.parse_args()
+
+ register_all_modules()
+
+ config = Config.fromfile(args.pose_config)
+ config.test_dataloader.dataset.data_mode = 'bottomup'
+ config.test_dataloader.dataset.bbox_file = None
+ test_set = DATASETS.build(config.test_dataloader.dataset)
+ print(f'number of images: {len(test_set)}')
+
+ detector = DetInferencer(args.det_config, args.det_weight)
+
+ new_bbox_files = []
+ for i in range(len(test_set)):
+ data = test_set.get_data_info(i)
+ image_id = data['img_id']
+ img_path = data['img_path']
+ result = detector(
+ img_path,
+ return_datasamples=True)['predictions'][0].pred_instances.numpy()
+ bboxes = np.concatenate((result.bboxes, result.scores[:, None]),
+ axis=1)
+ bboxes = bboxes[bboxes[..., -1] > args.score_thr]
+ bboxes = bboxes[nms(bboxes, args.nms_thr)]
+ scores = bboxes[..., -1].tolist()
+ bboxes = bbox_xyxy2xywh(bboxes[..., :4]).tolist()
+
+ for bbox, score in zip(bboxes, scores):
+ new_bbox_files.append(
+ dict(category_id=1, image_id=image_id, score=score, bbox=bbox))
+
+ with open(args.output, 'w') as f:
+ json.dump(new_bbox_files, f, indent='')
+
+
+if __name__ == '__main__':
+ if has_mmdet:
+ main()
diff --git a/tools/misc/pth_transfer.py b/tools/misc/pth_transfer.py
index 7433c6771e..cf59a5bd53 100644
--- a/tools/misc/pth_transfer.py
+++ b/tools/misc/pth_transfer.py
@@ -14,6 +14,8 @@ def change_model(args):
all_name.append((name[8:], v))
elif name.startswith('distill_losses.loss_mgd.down'):
all_name.append(('head.' + name[24:], v))
+ elif name.startswith('teacher.neck'):
+ all_name.append((name[8:], v))
elif name.startswith('student.head'):
all_name.append((name[8:], v))
else:
diff --git a/tools/slurm_test.sh b/tools/slurm_test.sh
index c528dc9d45..019f995c23 100644
--- a/tools/slurm_test.sh
+++ b/tools/slurm_test.sh
@@ -10,7 +10,6 @@ CHECKPOINT=$4
GPUS=${GPUS:-8}
GPUS_PER_NODE=${GPUS_PER_NODE:-8}
CPUS_PER_TASK=${CPUS_PER_TASK:-5}
-PY_ARGS=${@:5}
SRUN_ARGS=${SRUN_ARGS:-""}
PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
@@ -22,4 +21,4 @@ srun -p ${PARTITION} \
--cpus-per-task=${CPUS_PER_TASK} \
--kill-on-bad-exit=1 \
${SRUN_ARGS} \
- python -u tools/test.py ${CONFIG} ${CHECKPOINT} --launcher="slurm" ${PY_ARGS}
+ python -u tools/test.py ${CONFIG} ${CHECKPOINT} --launcher="slurm" ${@:5}
diff --git a/tools/slurm_train.sh b/tools/slurm_train.sh
index c3b65490a5..a0df8ce259 100644
--- a/tools/slurm_train.sh
+++ b/tools/slurm_train.sh
@@ -11,7 +11,6 @@ GPUS=${GPUS:-8}
GPUS_PER_NODE=${GPUS_PER_NODE:-8}
CPUS_PER_TASK=${CPUS_PER_TASK:-5}
SRUN_ARGS=${SRUN_ARGS:-""}
-PY_ARGS=${@:5}
PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
srun -p ${PARTITION} \
@@ -22,4 +21,4 @@ srun -p ${PARTITION} \
--cpus-per-task=${CPUS_PER_TASK} \
--kill-on-bad-exit=1 \
${SRUN_ARGS} \
- python -u tools/train.py ${CONFIG} --work-dir=${WORK_DIR} --launcher="slurm" ${PY_ARGS}
+ python -u tools/train.py ${CONFIG} --work-dir=${WORK_DIR} --launcher="slurm" ${@:5}
 +
+ -For [COCO](http://cocodataset.org/) data, please download from [COCO download](http://cocodataset.org/#download), 2017 Train/Val is needed for COCO keypoints training and validation.
-[HRNet-Human-Pose-Estimation](https://github.com/HRNet/HRNet-Human-Pose-Estimation) provides person detection result of COCO val2017 to reproduce our multi-person pose estimation results.
-Please download from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
-Optionally, to evaluate on COCO'2017 test-dev, please download the [image-info](https://download.openmmlab.com/mmpose/datasets/person_keypoints_test-dev-2017.json).
-Download and extract them under $MMPOSE/data, and make them look like this:
+对于 [COCO](http://cocodataset.org/) 数据,请从 [COCO 下载](http://cocodataset.org/#download) 中下载,需要 2017 训练/验证集进行 COCO 关键点的训练和验证。
+[HRNet-Human-Pose-Estimation](https://github.com/HRNet/HRNet-Human-Pose-Estimation) 提供了 COCO val2017 的人体检测结果,以便重现我们的多人姿态估计结果。
+请从 [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) 或 [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing) 下载。
+如果要在 COCO'2017 test-dev 上进行评估,请下载 [image-info](https://download.openmmlab.com/mmpose/datasets/person_keypoints_test-dev-2017.json)。
```text
mmpose
@@ -100,9 +100,9 @@ mmpose
-For [COCO](http://cocodataset.org/) data, please download from [COCO download](http://cocodataset.org/#download), 2017 Train/Val is needed for COCO keypoints training and validation.
-[HRNet-Human-Pose-Estimation](https://github.com/HRNet/HRNet-Human-Pose-Estimation) provides person detection result of COCO val2017 to reproduce our multi-person pose estimation results.
-Please download from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
-Optionally, to evaluate on COCO'2017 test-dev, please download the [image-info](https://download.openmmlab.com/mmpose/datasets/person_keypoints_test-dev-2017.json).
-Download and extract them under $MMPOSE/data, and make them look like this:
+对于 [COCO](http://cocodataset.org/) 数据,请从 [COCO 下载](http://cocodataset.org/#download) 中下载,需要 2017 训练/验证集进行 COCO 关键点的训练和验证。
+[HRNet-Human-Pose-Estimation](https://github.com/HRNet/HRNet-Human-Pose-Estimation) 提供了 COCO val2017 的人体检测结果,以便重现我们的多人姿态估计结果。
+请从 [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) 或 [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing) 下载。
+如果要在 COCO'2017 test-dev 上进行评估,请下载 [image-info](https://download.openmmlab.com/mmpose/datasets/person_keypoints_test-dev-2017.json)。
```text
mmpose
@@ -100,9 +100,9 @@ mmpose
 -For [MPII](http://human-pose.mpi-inf.mpg.de/) data, please download from [MPII Human Pose Dataset](http://human-pose.mpi-inf.mpg.de/).
-We have converted the original annotation files into json format, please download them from [mpii_annotations](https://download.openmmlab.com/mmpose/datasets/mpii_annotations.tar).
-Extract them under {MMPose}/data, and make them look like this:
+对于 [MPII](http://human-pose.mpi-inf.mpg.de/) 数据,请从 [MPII Human Pose Dataset](http://human-pose.mpi-inf.mpg.de/) 下载。
+我们已将原始的注释文件转换为 json 格式,请从 [mpii_annotations](https://download.openmmlab.com/mmpose/datasets/mpii_annotations.tar) 下载。
+请将它们解压到 {MMPose}/data 下,并确保目录结构如下:
```text
mmpose
@@ -125,13 +125,13 @@ mmpose
```
-During training and inference, the prediction result will be saved as '.mat' format by default. We also provide a tool to convert this '.mat' to more readable '.json' format.
+在训练和推理期间,默认情况下,预测结果将以 '.mat' 格式保存。我们还提供了一个工具,以将这个 '.mat' 转换为更易读的 '.json' 格式。
```shell
python tools/dataset/mat2json ${PRED_MAT_FILE} ${GT_JSON_FILE} ${OUTPUT_PRED_JSON_FILE}
```
-For example,
+例如,
```shell
python tools/dataset/mat2json work_dirs/res50_mpii_256x256/pred.mat data/mpii/annotations/mpii_val.json pred.json
@@ -160,9 +160,9 @@ python tools/dataset/mat2json work_dirs/res50_mpii_256x256/pred.mat data/mpii/an
-For [MPII](http://human-pose.mpi-inf.mpg.de/) data, please download from [MPII Human Pose Dataset](http://human-pose.mpi-inf.mpg.de/).
-We have converted the original annotation files into json format, please download them from [mpii_annotations](https://download.openmmlab.com/mmpose/datasets/mpii_annotations.tar).
-Extract them under {MMPose}/data, and make them look like this:
+对于 [MPII](http://human-pose.mpi-inf.mpg.de/) 数据,请从 [MPII Human Pose Dataset](http://human-pose.mpi-inf.mpg.de/) 下载。
+我们已将原始的注释文件转换为 json 格式,请从 [mpii_annotations](https://download.openmmlab.com/mmpose/datasets/mpii_annotations.tar) 下载。
+请将它们解压到 {MMPose}/data 下,并确保目录结构如下:
```text
mmpose
@@ -125,13 +125,13 @@ mmpose
```
-During training and inference, the prediction result will be saved as '.mat' format by default. We also provide a tool to convert this '.mat' to more readable '.json' format.
+在训练和推理期间,默认情况下,预测结果将以 '.mat' 格式保存。我们还提供了一个工具,以将这个 '.mat' 转换为更易读的 '.json' 格式。
```shell
python tools/dataset/mat2json ${PRED_MAT_FILE} ${GT_JSON_FILE} ${OUTPUT_PRED_JSON_FILE}
```
-For example,
+例如,
```shell
python tools/dataset/mat2json work_dirs/res50_mpii_256x256/pred.mat data/mpii/annotations/mpii_val.json pred.json
@@ -160,9 +160,9 @@ python tools/dataset/mat2json work_dirs/res50_mpii_256x256/pred.mat data/mpii/an
 -For [MPII-TRB](https://github.com/kennymckormick/Triplet-Representation-of-human-Body) data, please download from [MPII Human Pose Dataset](http://human-pose.mpi-inf.mpg.de/).
-Please download the annotation files from [mpii_trb_annotations](https://download.openmmlab.com/mmpose/datasets/mpii_trb_annotations.tar).
-Extract them under {MMPose}/data, and make them look like this:
+对于 [MPII-TRB](https://github.com/kennymckormick/Triplet-Representation-of-human-Body) 数据,请从 [MPII Human Pose Dataset](http://human-pose.mpi-inf.mpg.de/) 下载。
+请从 [mpii_trb_annotations](https://download.openmmlab.com/mmpose/datasets/mpii_trb_annotations.tar) 下载注释文件。
+将它们解压到 {MMPose}/data 下,并确保它们的结构如下:
```text
mmpose
@@ -204,9 +204,9 @@ mmpose
-For [MPII-TRB](https://github.com/kennymckormick/Triplet-Representation-of-human-Body) data, please download from [MPII Human Pose Dataset](http://human-pose.mpi-inf.mpg.de/).
-Please download the annotation files from [mpii_trb_annotations](https://download.openmmlab.com/mmpose/datasets/mpii_trb_annotations.tar).
-Extract them under {MMPose}/data, and make them look like this:
+对于 [MPII-TRB](https://github.com/kennymckormick/Triplet-Representation-of-human-Body) 数据,请从 [MPII Human Pose Dataset](http://human-pose.mpi-inf.mpg.de/) 下载。
+请从 [mpii_trb_annotations](https://download.openmmlab.com/mmpose/datasets/mpii_trb_annotations.tar) 下载注释文件。
+将它们解压到 {MMPose}/data 下,并确保它们的结构如下:
```text
mmpose
@@ -204,9 +204,9 @@ mmpose
 -For [AIC](https://github.com/AIChallenger/AI_Challenger_2017) data, please download from [AI Challenger 2017](https://github.com/AIChallenger/AI_Challenger_2017), 2017 Train/Val is needed for keypoints training and validation.
-Please download the annotation files from [aic_annotations](https://download.openmmlab.com/mmpose/datasets/aic_annotations.tar).
-Download and extract them under $MMPOSE/data, and make them look like this:
+对于 [AIC](https://github.com/AIChallenger/AI_Challenger_2017) 数据,请从 [AI Challenger 2017](https://github.com/AIChallenger/AI_Challenger_2017) 下载。其中 2017 Train/Val 数据适用于关键点的训练和验证。
+请从 [aic_annotations](https://download.openmmlab.com/mmpose/datasets/aic_annotations.tar) 下载注释文件。
+下载并解压到 $MMPOSE/data 下,并确保它们的结构如下:
```text
mmpose
@@ -254,11 +254,11 @@ mmpose
-For [AIC](https://github.com/AIChallenger/AI_Challenger_2017) data, please download from [AI Challenger 2017](https://github.com/AIChallenger/AI_Challenger_2017), 2017 Train/Val is needed for keypoints training and validation.
-Please download the annotation files from [aic_annotations](https://download.openmmlab.com/mmpose/datasets/aic_annotations.tar).
-Download and extract them under $MMPOSE/data, and make them look like this:
+对于 [AIC](https://github.com/AIChallenger/AI_Challenger_2017) 数据,请从 [AI Challenger 2017](https://github.com/AIChallenger/AI_Challenger_2017) 下载。其中 2017 Train/Val 数据适用于关键点的训练和验证。
+请从 [aic_annotations](https://download.openmmlab.com/mmpose/datasets/aic_annotations.tar) 下载注释文件。
+下载并解压到 $MMPOSE/data 下,并确保它们的结构如下:
```text
mmpose
@@ -254,11 +254,11 @@ mmpose
 -For [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose) data, please download from [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose).
-Please download the annotation files and human detection results from [crowdpose_annotations](https://download.openmmlab.com/mmpose/datasets/crowdpose_annotations.tar).
-For top-down approaches, we follow [CrowdPose](https://arxiv.org/abs/1812.00324) to use the [pre-trained weights](https://pjreddie.com/media/files/yolov3.weights) of [YOLOv3](https://github.com/eriklindernoren/PyTorch-YOLOv3) to generate the detected human bounding boxes.
-For model training, we follow [HigherHRNet](https://github.com/HRNet/HigherHRNet-Human-Pose-Estimation) to train models on CrowdPose train/val dataset, and evaluate models on CrowdPose test dataset.
-Download and extract them under $MMPOSE/data, and make them look like this:
+对于 [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose)数据,请从 [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose) 下载。
+请下载标注文件和人体检测结果从 [crowdpose_annotations](https://download.openmmlab.com/mmpose/datasets/crowdpose_annotations.tar)。
+对于自上而下的方法,我们按照 [CrowdPose](https://arxiv.org/abs/1812.00324)使用[YOLOv3](https://github.com/eriklindernoren/PyTorch-YOLOv3) 的 [预训练权重](https://pjreddie.com/media/files/yolov3.weights) 来生成检测到的人体边界框。
+对于模型训练,我们按照 [HigherHRNet](https://github.com/HRNet/HigherHRNet-Human-Pose-Estimation) 在 CrowdPose 的训练/验证数据集上进行训练,并在 CrowdPose 测试数据集上评估模型。
+下载并解压缩它们到 $MMPOSE/data 目录下,结构应如下:
```text
mmpose
@@ -305,8 +305,8 @@ mmpose
-For [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose) data, please download from [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose).
-Please download the annotation files and human detection results from [crowdpose_annotations](https://download.openmmlab.com/mmpose/datasets/crowdpose_annotations.tar).
-For top-down approaches, we follow [CrowdPose](https://arxiv.org/abs/1812.00324) to use the [pre-trained weights](https://pjreddie.com/media/files/yolov3.weights) of [YOLOv3](https://github.com/eriklindernoren/PyTorch-YOLOv3) to generate the detected human bounding boxes.
-For model training, we follow [HigherHRNet](https://github.com/HRNet/HigherHRNet-Human-Pose-Estimation) to train models on CrowdPose train/val dataset, and evaluate models on CrowdPose test dataset.
-Download and extract them under $MMPOSE/data, and make them look like this:
+对于 [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose)数据,请从 [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose) 下载。
+请下载标注文件和人体检测结果从 [crowdpose_annotations](https://download.openmmlab.com/mmpose/datasets/crowdpose_annotations.tar)。
+对于自上而下的方法,我们按照 [CrowdPose](https://arxiv.org/abs/1812.00324)使用[YOLOv3](https://github.com/eriklindernoren/PyTorch-YOLOv3) 的 [预训练权重](https://pjreddie.com/media/files/yolov3.weights) 来生成检测到的人体边界框。
+对于模型训练,我们按照 [HigherHRNet](https://github.com/HRNet/HigherHRNet-Human-Pose-Estimation) 在 CrowdPose 的训练/验证数据集上进行训练,并在 CrowdPose 测试数据集上评估模型。
+下载并解压缩它们到 $MMPOSE/data 目录下,结构应如下:
```text
mmpose
@@ -305,8 +305,8 @@ mmpose
 -For [MHP](https://lv-mhp.github.io/dataset) data, please download from [MHP](https://lv-mhp.github.io/dataset).
-Please download the annotation files from [mhp_annotations](https://download.openmmlab.com/mmpose/datasets/mhp_annotations.tar.gz).
-Please download and extract them under $MMPOSE/data, and make them look like this:
+对于 [MHP](https://lv-mhp.github.io/dataset) 数据,请从 [MHP](https://lv-mhp.github.io/dataset) 下载。
+请从 [mhp_annotations](https://download.openmmlab.com/mmpose/datasets/mhp_annotations.tar.gz) 下载标注文件。
+请下载并解压到 $MMPOSE/data 目录下,并确保目录结构如下:
```text
mmpose
@@ -408,8 +408,9 @@ mmpose
-For [MHP](https://lv-mhp.github.io/dataset) data, please download from [MHP](https://lv-mhp.github.io/dataset).
-Please download the annotation files from [mhp_annotations](https://download.openmmlab.com/mmpose/datasets/mhp_annotations.tar.gz).
-Please download and extract them under $MMPOSE/data, and make them look like this:
+对于 [MHP](https://lv-mhp.github.io/dataset) 数据,请从 [MHP](https://lv-mhp.github.io/dataset) 下载。
+请从 [mhp_annotations](https://download.openmmlab.com/mmpose/datasets/mhp_annotations.tar.gz) 下载标注文件。
+请下载并解压到 $MMPOSE/data 目录下,并确保目录结构如下:
```text
mmpose
@@ -408,8 +408,9 @@ mmpose
 -For [PoseTrack18](https://posetrack.net/users/download.php) data, please download from [PoseTrack18](https://posetrack.net/users/download.php).
-Please download the annotation files from [posetrack18_annotations](https://download.openmmlab.com/mmpose/datasets/posetrack18_annotations.tar).
-We have merged the video-wise separated official annotation files into two json files (posetrack18_train & posetrack18_val.json). We also generate the [mask files](https://download.openmmlab.com/mmpose/datasets/posetrack18_mask.tar) to speed up training.
-For top-down approaches, we use [MMDetection](https://github.com/open-mmlab/mmdetection) pre-trained [Cascade R-CNN](https://download.openmmlab.com/mmdetection/v2.0/cascade_rcnn/cascade_rcnn_x101_64x4d_fpn_20e_coco/cascade_rcnn_x101_64x4d_fpn_20e_coco_20200509_224357-051557b1.pth) (X-101-64x4d-FPN) to generate the detected human bounding boxes.
-Please download and extract them under $MMPOSE/data, and make them look like this:
+关于 [PoseTrack18](https://posetrack.net/users/download.php) 的数据,请从 [PoseTrack18](https://posetrack.net/users/download.php) 下载。
+请从 [posetrack18_annotations](https://download.openmmlab.com/mmpose/datasets/posetrack18_annotations.tar) 下载标注文件。
+我们已经将分散在各个视频中的官方标注文件合并为两个 json 文件(posetrack18_train & posetrack18_val.json)。我们还生成了 [mask 文件](https://download.openmmlab.com/mmpose/datasets/posetrack18_mask.tar) 以加速训练。
+对于自上而下的方法,我们使用 [MMDetection](https://github.com/open-mmlab/mmdetection) 预训练的 [Cascade R-CNN](https://download.openmmlab.com/mmdetection/v2.0/cascade_rcnn/cascade_rcnn_x101_64x4d_fpn_20e_coco/cascade_rcnn_x101_64x4d_fpn_20e_coco_20200509_224357-051557b1.pth)(X-101-64x4d-FPN)来生成检测到的人体边界框。
+请下载并将它们解压到 $MMPOSE/data 下,目录结构应如下所示:
```text
mmpose
@@ -527,7 +575,7 @@ mmpose
│-- ...
```
-The official evaluation tool for PoseTrack should be installed from GitHub.
+官方的 PoseTrack 评估工具可以使用以下命令安装。
```shell
pip install git+https://github.com/svenkreiss/poseval.git
@@ -557,9 +605,9 @@ pip install git+https://github.com/svenkreiss/poseval.git
-For [PoseTrack18](https://posetrack.net/users/download.php) data, please download from [PoseTrack18](https://posetrack.net/users/download.php).
-Please download the annotation files from [posetrack18_annotations](https://download.openmmlab.com/mmpose/datasets/posetrack18_annotations.tar).
-We have merged the video-wise separated official annotation files into two json files (posetrack18_train & posetrack18_val.json). We also generate the [mask files](https://download.openmmlab.com/mmpose/datasets/posetrack18_mask.tar) to speed up training.
-For top-down approaches, we use [MMDetection](https://github.com/open-mmlab/mmdetection) pre-trained [Cascade R-CNN](https://download.openmmlab.com/mmdetection/v2.0/cascade_rcnn/cascade_rcnn_x101_64x4d_fpn_20e_coco/cascade_rcnn_x101_64x4d_fpn_20e_coco_20200509_224357-051557b1.pth) (X-101-64x4d-FPN) to generate the detected human bounding boxes.
-Please download and extract them under $MMPOSE/data, and make them look like this:
+关于 [PoseTrack18](https://posetrack.net/users/download.php) 的数据,请从 [PoseTrack18](https://posetrack.net/users/download.php) 下载。
+请从 [posetrack18_annotations](https://download.openmmlab.com/mmpose/datasets/posetrack18_annotations.tar) 下载标注文件。
+我们已经将分散在各个视频中的官方标注文件合并为两个 json 文件(posetrack18_train & posetrack18_val.json)。我们还生成了 [mask 文件](https://download.openmmlab.com/mmpose/datasets/posetrack18_mask.tar) 以加速训练。
+对于自上而下的方法,我们使用 [MMDetection](https://github.com/open-mmlab/mmdetection) 预训练的 [Cascade R-CNN](https://download.openmmlab.com/mmdetection/v2.0/cascade_rcnn/cascade_rcnn_x101_64x4d_fpn_20e_coco/cascade_rcnn_x101_64x4d_fpn_20e_coco_20200509_224357-051557b1.pth)(X-101-64x4d-FPN)来生成检测到的人体边界框。
+请下载并将它们解压到 $MMPOSE/data 下,目录结构应如下所示:
```text
mmpose
@@ -527,7 +575,7 @@ mmpose
│-- ...
```
-The official evaluation tool for PoseTrack should be installed from GitHub.
+官方的 PoseTrack 评估工具可以使用以下命令安装。
```shell
pip install git+https://github.com/svenkreiss/poseval.git
@@ -557,9 +605,9 @@ pip install git+https://github.com/svenkreiss/poseval.git
 -For [sub-JHMDB](http://jhmdb.is.tue.mpg.de/dataset) data, please download the [images](<(http://files.is.tue.mpg.de/jhmdb/Rename_Images.tar.gz)>) from [JHMDB](http://jhmdb.is.tue.mpg.de/dataset),
-Please download the annotation files from [jhmdb_annotations](https://download.openmmlab.com/mmpose/datasets/jhmdb_annotations.tar).
-Move them under $MMPOSE/data, and make them look like this:
+对于 [sub-JHMDB](http://jhmdb.is.tue.mpg.de/dataset) 的数据,请从 [JHMDB](http://jhmdb.is.tue.mpg.de/dataset) 下载 [图像](<(http://files.is.tue.mpg.de/jhmdb/Rename_Images.tar.gz)>),
+请从 [jhmdb_annotations](https://download.openmmlab.com/mmpose/datasets/jhmdb_annotations.tar) 下载标注文件。
+将它们移至 $MMPOSE/data 下,并使目录结构如下所示:
```text
mmpose
diff --git a/docs/zh_cn/faq.md b/docs/zh_cn/faq.md
index b1e6998396..1b198b0b61 100644
--- a/docs/zh_cn/faq.md
+++ b/docs/zh_cn/faq.md
@@ -19,6 +19,8 @@ Detailed compatible MMPose and MMCV versions are shown as below. Please choose t
| MMPose version | MMCV/MMEngine version |
| :------------: | :-----------------------------: |
+| 1.3.0 | mmcv>=2.0.1, mmengine>=0.9.0 |
+| 1.2.0 | mmcv>=2.0.1, mmengine>=0.8.0 |
| 1.1.0 | mmcv>=2.0.1, mmengine>=0.8.0 |
| 1.0.0 | mmcv>=2.0.0, mmengine>=0.7.0 |
| 1.0.0rc1 | mmcv>=2.0.0rc4, mmengine>=0.6.0 |
@@ -146,3 +148,7 @@ Detailed compatible MMPose and MMCV versions are shown as below. Please choose t
1. set `flip_test=False` in `init_cfg` in the config file.
2. use faster human bounding box detector, see [MMDetection](https://mmdetection.readthedocs.io/zh_CN/3.x/model_zoo.html).
+
+- **What is the definition of each keypoint index?**
+
+ Check the [meta information file](https://github.com/open-mmlab/mmpose/tree/main/configs/_base_/datasets) for the dataset used to train the model you are using. They key `keypoint_info` includes the definition of each keypoint.
diff --git a/docs/zh_cn/notes/changelog.md b/docs/zh_cn/notes/changelog.md
index bd89688bc0..846286d022 100644
--- a/docs/zh_cn/notes/changelog.md
+++ b/docs/zh_cn/notes/changelog.md
@@ -1,5 +1,9 @@
# Changelog
+## **v1.3.0 (04/01/2024)**
+
+Release note: https://github.com/open-mmlab/mmpose/releases/tag/v1.3.0
+
## **v1.2.0 (12/10/2023)**
Release note: https://github.com/open-mmlab/mmpose/releases/tag/v1.2.0
diff --git a/docs/zh_cn/user_guides/inference.md b/docs/zh_cn/user_guides/inference.md
index 24ba42974b..9fc1612e11 100644
--- a/docs/zh_cn/user_guides/inference.md
+++ b/docs/zh_cn/user_guides/inference.md
@@ -22,7 +22,7 @@ from mmpose.apis import MMPoseInferencer
img_path = 'tests/data/coco/000000000785.jpg' # 将img_path替换给你自己的路径
-# 使用模型别名创建推断器
+# 使用模型别名创建推理器
inferencer = MMPoseInferencer('human')
# MMPoseInferencer采用了惰性推断方法,在给定输入时创建一个预测生成器
@@ -108,13 +108,15 @@ results = [result for result in result_generator]
[MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) 提供了几种可用于自定义所使用的模型的方法:
```python
-# 使用模型别名构建推断器
+# 使用模型别名构建推理器
inferencer = MMPoseInferencer('human')
-# 使用模型配置名构建推断器
+# 使用模型配置名构建推理器
inferencer = MMPoseInferencer('td-hm_hrnet-w32_8xb64-210e_coco-256x192')
+# 使用 3D 模型配置名构建推理器
+inferencer = MMPoseInferencer(pose3d="motionbert_dstformer-ft-243frm_8xb32-120e_h36m")
-# 使用模型配置文件和权重文件的路径或 URL 构建推断器
+# 使用模型配置文件和权重文件的路径或 URL 构建推理器
inferencer = MMPoseInferencer(
pose2d='configs/body_2d_keypoint/topdown_heatmap/coco/' \
'td-hm_hrnet-w32_8xb64-210e_coco-256x192.py',
@@ -125,6 +127,24 @@ inferencer = MMPoseInferencer(
模型别名的完整列表可以在模型别名部分中找到。
+上述代码为 2D 模型推理器的构建例子。3D 模型的推理器可以用类似的方式通过 `pose3d` 参数构建:
+
+```python
+# 使用 3D 模型别名构建推理器
+inferencer = MMPoseInferencer(pose3d="human3d")
+
+# 使用 3D 模型配置名构建推理器
+inferencer = MMPoseInferencer(pose3d="motionbert_dstformer-ft-243frm_8xb32-120e_h36m")
+
+# 使用 3D 模型配置文件和权重文件的路径或 URL 构建推理器
+inferencer = MMPoseInferencer(
+ pose3d='configs/body_3d_keypoint/motionbert/h36m/' \
+ 'motionbert_dstformer-ft-243frm_8xb32-120e_h36m.py',
+ pose3d_weights='https://download.openmmlab.com/mmpose/v1/body_3d_keypoint/' \
+ 'pose_lift/h36m/motionbert_ft_h36m-d80af323_20230531.pth'
+)
+```
+
此外,自顶向下的姿态估计器还需要一个对象检测模型。[MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) 能够推断用 MMPose 支持的数据集训练的模型的实例类型,然后构建必要的对象检测模型。用户也可以通过以下方式手动指定检测模型:
```python
@@ -145,7 +165,7 @@ inferencer = MMPoseInferencer(
det_cat_ids=[0], # 指定'human'类的类别id
)
-# 使用模型配置文件和权重文件的路径或URL构建推断器
+# 使用模型配置文件和权重文件的路径或URL构建推理器
inferencer = MMPoseInferencer(
pose2d='human',
det_model=f'{PATH_TO_MMDET}/configs/yolox/yolox_l_8x8_300e_coco.py',
@@ -210,7 +230,7 @@ result = next(result_generator)
### 推理器参数
-[MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) 提供了各种自定义姿态估计、可视化和保存预测结果的参数。下面是初始化推断器时可用的参数列表及对这些参数的描述:
+[MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) 提供了各种自定义姿态估计、可视化和保存预测结果的参数。下面是初始化推理器时可用的参数列表及对这些参数的描述:
| Argument | Description |
| ---------------- | ------------------------------------------------------------ |
diff --git a/docs/zh_cn/user_guides/train_and_test.md b/docs/zh_cn/user_guides/train_and_test.md
index 6cadeab0a3..b95ae965f1 100644
--- a/docs/zh_cn/user_guides/train_and_test.md
+++ b/docs/zh_cn/user_guides/train_and_test.md
@@ -496,3 +496,16 @@ test_evaluator = val_evaluator
```
如需进一步了解如何将 AIC 关键点转换为 COCO 关键点,请查阅 [该指南](https://mmpose.readthedocs.io/zh_CN/dev-1.x/user_guides/mixed_datasets.html#aic-coco)。
+
+### 使用自定义检测器评估 Top-down 模型
+
+要评估 Top-down 模型,您可以使用人工标注的或预先检测到的边界框。 `bbox_file` 提供了由特定检测器生成的这些框。例如,`COCO_val2017_detections_AP_H_56_person.json` 包含了使用具有 56.4 人类 AP 的检测器捕获的 COCO val2017 数据集的边界框。要使用 MMDetection 支持的自定义检测器创建您自己的 `bbox_file`,请运行以下命令:
+
+```sh
+python tools/misc/generate_bbox_file.py \
+ ${DET_CONFIG} ${DET_WEIGHT} ${OUTPUT_FILE_NAME} \
+ [--pose-config ${POSE_CONFIG}] \
+ [--score-thr ${SCORE_THRESHOLD}] [--nms-thr ${NMS_THRESHOLD}]
+```
+
+其中,`DET_CONFIG` 和 `DET_WEIGHT` 用于创建目标检测器。 `POSE_CONFIG` 指定需要边界框检测的测试数据集。`SCORE_THRESHOLD` 和 `NMS_THRESHOLD` 用于边界框过滤。
diff --git a/mmpose/__init__.py b/mmpose/__init__.py
index 583ede0a4d..dda49513fa 100644
--- a/mmpose/__init__.py
+++ b/mmpose/__init__.py
@@ -6,7 +6,7 @@
from .version import __version__, short_version
mmcv_minimum_version = '2.0.0rc4'
-mmcv_maximum_version = '2.2.0'
+mmcv_maximum_version = '2.3.0'
mmcv_version = digit_version(mmcv.__version__)
mmengine_minimum_version = '0.6.0'
diff --git a/mmpose/apis/inference_3d.py b/mmpose/apis/inference_3d.py
index ae6428f187..b4151e804a 100644
--- a/mmpose/apis/inference_3d.py
+++ b/mmpose/apis/inference_3d.py
@@ -23,13 +23,13 @@ def convert_keypoint_definition(keypoints, pose_det_dataset,
ndarray[K, 2 or 3]: the transformed 2D keypoints.
"""
assert pose_lift_dataset in [
- 'h36m'], '`pose_lift_dataset` should be ' \
+ 'h36m', 'h3wb'], '`pose_lift_dataset` should be ' \
f'`h36m`, but got {pose_lift_dataset}.'
keypoints_new = np.zeros((keypoints.shape[0], 17, keypoints.shape[2]),
dtype=keypoints.dtype)
- if pose_lift_dataset == 'h36m':
- if pose_det_dataset in ['h36m']:
+ if pose_lift_dataset in ['h36m', 'h3wb']:
+ if pose_det_dataset in ['h36m', 'coco_wholebody']:
keypoints_new = keypoints
elif pose_det_dataset in ['coco', 'posetrack18']:
# pelvis (root) is in the middle of l_hip and r_hip
@@ -265,8 +265,26 @@ def inference_pose_lifter_model(model,
bbox_center = dataset_info['stats_info']['bbox_center']
bbox_scale = dataset_info['stats_info']['bbox_scale']
else:
- bbox_center = None
- bbox_scale = None
+ if norm_pose_2d:
+ # compute the average bbox center and scale from the
+ # datasamples in pose_results_2d
+ bbox_center = np.zeros((1, 2), dtype=np.float32)
+ bbox_scale = 0
+ num_bbox = 0
+ for pose_res in pose_results_2d:
+ for data_sample in pose_res:
+ for bbox in data_sample.pred_instances.bboxes:
+ bbox_center += np.array([[(bbox[0] + bbox[2]) / 2,
+ (bbox[1] + bbox[3]) / 2]
+ ])
+ bbox_scale += max(bbox[2] - bbox[0],
+ bbox[3] - bbox[1])
+ num_bbox += 1
+ bbox_center /= num_bbox
+ bbox_scale /= num_bbox
+ else:
+ bbox_center = None
+ bbox_scale = None
pose_results_2d_copy = []
for i, pose_res in enumerate(pose_results_2d):
diff --git a/mmpose/apis/inferencers/base_mmpose_inferencer.py b/mmpose/apis/inferencers/base_mmpose_inferencer.py
index d7d5eb8c19..574063e824 100644
--- a/mmpose/apis/inferencers/base_mmpose_inferencer.py
+++ b/mmpose/apis/inferencers/base_mmpose_inferencer.py
@@ -1,4 +1,5 @@
# Copyright (c) OpenMMLab. All rights reserved.
+import inspect
import logging
import mimetypes
import os
@@ -21,6 +22,7 @@
from mmengine.runner.checkpoint import _load_checkpoint_to_model
from mmengine.structures import InstanceData
from mmengine.utils import mkdir_or_exist
+from rich.progress import track
from mmpose.apis.inference import dataset_meta_from_config
from mmpose.registry import DATASETS
@@ -53,6 +55,15 @@ class BaseMMPoseInferencer(BaseInferencer):
}
postprocess_kwargs: set = {'pred_out_dir', 'return_datasample'}
+ def __init__(self,
+ model: Union[ModelType, str, None] = None,
+ weights: Optional[str] = None,
+ device: Optional[str] = None,
+ scope: Optional[str] = None,
+ show_progress: bool = False) -> None:
+ super().__init__(
+ model, weights, device, scope, show_progress=show_progress)
+
def _init_detector(
self,
det_model: Optional[Union[ModelType, str]] = None,
@@ -79,8 +90,18 @@ def _init_detector(
det_scope = det_cfg.default_scope
if has_mmdet:
- self.detector = DetInferencer(
- det_model, det_weights, device=device, scope=det_scope)
+ det_kwargs = dict(
+ model=det_model,
+ weights=det_weights,
+ device=device,
+ scope=det_scope,
+ )
+ # for compatibility with low version of mmdet
+ if 'show_progress' in inspect.signature(
+ DetInferencer).parameters:
+ det_kwargs['show_progress'] = False
+
+ self.detector = DetInferencer(**det_kwargs)
else:
raise RuntimeError(
'MMDetection (v3.0.0 or above) is required to build '
@@ -293,22 +314,45 @@ def preprocess(self,
inputs: InputsType,
batch_size: int = 1,
bboxes: Optional[List] = None,
+ bbox_thr: float = 0.3,
+ nms_thr: float = 0.3,
**kwargs):
"""Process the inputs into a model-feedable format.
Args:
inputs (InputsType): Inputs given by user.
batch_size (int): batch size. Defaults to 1.
+ bbox_thr (float): threshold for bounding box detection.
+ Defaults to 0.3.
+ nms_thr (float): IoU threshold for bounding box NMS.
+ Defaults to 0.3.
Yields:
Any: Data processed by the ``pipeline`` and ``collate_fn``.
List[str or np.ndarray]: List of original inputs in the batch
"""
+ # One-stage pose estimators perform prediction filtering within the
+ # head's `predict` method. Here, we set the arguments for filtering
+ if self.cfg.model.type == 'BottomupPoseEstimator':
+ # 1. init with default arguments
+ test_cfg = self.model.head.test_cfg.copy()
+ # 2. update the score_thr and nms_thr in the test_cfg of the head
+ if 'score_thr' in test_cfg:
+ test_cfg['score_thr'] = bbox_thr
+ if 'nms_thr' in test_cfg:
+ test_cfg['nms_thr'] = nms_thr
+ self.model.test_cfg = test_cfg
+
for i, input in enumerate(inputs):
bbox = bboxes[i] if bboxes else []
data_infos = self.preprocess_single(
- input, index=i, bboxes=bbox, **kwargs)
+ input,
+ index=i,
+ bboxes=bbox,
+ bbox_thr=bbox_thr,
+ nms_thr=nms_thr,
+ **kwargs)
# only supports inference with batch size 1
yield self.collate_fn(data_infos), [input]
@@ -384,7 +428,8 @@ def __call__(
preds = []
- for proc_inputs, ori_inputs in inputs:
+ for proc_inputs, ori_inputs in (track(inputs, description='Inference')
+ if self.show_progress else inputs):
preds = self.forward(proc_inputs, **forward_kwargs)
visualization = self.visualize(ori_inputs, preds,
diff --git a/mmpose/apis/inferencers/hand3d_inferencer.py b/mmpose/apis/inferencers/hand3d_inferencer.py
index 57f1eb06eb..a7db53cb84 100644
--- a/mmpose/apis/inferencers/hand3d_inferencer.py
+++ b/mmpose/apis/inferencers/hand3d_inferencer.py
@@ -78,11 +78,16 @@ def __init__(self,
scope: Optional[str] = 'mmpose',
det_model: Optional[Union[ModelType, str]] = None,
det_weights: Optional[str] = None,
- det_cat_ids: Optional[Union[int, Tuple]] = None) -> None:
+ det_cat_ids: Optional[Union[int, Tuple]] = None,
+ show_progress: bool = False) -> None:
init_default_scope(scope)
super().__init__(
- model=model, weights=weights, device=device, scope=scope)
+ model=model,
+ weights=weights,
+ device=device,
+ scope=scope,
+ show_progress=show_progress)
self.model = revert_sync_batchnorm(self.model)
# assign dataset metainfo to self.visualizer
diff --git a/mmpose/apis/inferencers/mmpose_inferencer.py b/mmpose/apis/inferencers/mmpose_inferencer.py
index cd08d8f6cb..4ade56cb04 100644
--- a/mmpose/apis/inferencers/mmpose_inferencer.py
+++ b/mmpose/apis/inferencers/mmpose_inferencer.py
@@ -7,6 +7,7 @@
from mmengine.config import Config, ConfigDict
from mmengine.infer.infer import ModelType
from mmengine.structures import InstanceData
+from rich.progress import track
from .base_mmpose_inferencer import BaseMMPoseInferencer
from .hand3d_inferencer import Hand3DInferencer
@@ -59,7 +60,9 @@ class MMPoseInferencer(BaseMMPoseInferencer):
'bbox_thr', 'nms_thr', 'bboxes', 'use_oks_tracking', 'tracking_thr',
'disable_norm_pose_2d'
}
- forward_kwargs: set = {'disable_rebase_keypoint'}
+ forward_kwargs: set = {
+ 'merge_results', 'disable_rebase_keypoint', 'pose_based_nms'
+ }
visualize_kwargs: set = {
'return_vis', 'show', 'wait_time', 'draw_bbox', 'radius', 'thickness',
'kpt_thr', 'vis_out_dir', 'skeleton_style', 'draw_heatmap',
@@ -76,23 +79,27 @@ def __init__(self,
scope: str = 'mmpose',
det_model: Optional[Union[ModelType, str]] = None,
det_weights: Optional[str] = None,
- det_cat_ids: Optional[Union[int, List]] = None) -> None:
+ det_cat_ids: Optional[Union[int, List]] = None,
+ show_progress: bool = False) -> None:
self.visualizer = None
+ self.show_progress = show_progress
if pose3d is not None:
if 'hand3d' in pose3d:
self.inferencer = Hand3DInferencer(pose3d, pose3d_weights,
device, scope, det_model,
- det_weights, det_cat_ids)
+ det_weights, det_cat_ids,
+ show_progress)
else:
self.inferencer = Pose3DInferencer(pose3d, pose3d_weights,
pose2d, pose2d_weights,
device, scope, det_model,
- det_weights, det_cat_ids)
+ det_weights, det_cat_ids,
+ show_progress)
elif pose2d is not None:
self.inferencer = Pose2DInferencer(pose2d, pose2d_weights, device,
scope, det_model, det_weights,
- det_cat_ids)
+ det_cat_ids, show_progress)
else:
raise ValueError('Either 2d or 3d pose estimation algorithm '
'should be provided.')
@@ -108,14 +115,8 @@ def preprocess(self, inputs: InputsType, batch_size: int = 1, **kwargs):
Any: Data processed by the ``pipeline`` and ``collate_fn``.
List[str or np.ndarray]: List of original inputs in the batch
"""
-
- for i, input in enumerate(inputs):
- data_batch = {}
- data_infos = self.inferencer.preprocess_single(
- input, index=i, **kwargs)
- data_batch = self.inferencer.collate_fn(data_infos)
- # only supports inference with batch size 1
- yield data_batch, [input]
+ for data in self.inferencer.preprocess(inputs, batch_size, **kwargs):
+ yield data
@torch.no_grad()
def forward(self, inputs: InputType, **forward_kwargs) -> PredType:
@@ -202,7 +203,8 @@ def __call__(
preds = []
- for proc_inputs, ori_inputs in inputs:
+ for proc_inputs, ori_inputs in (track(inputs, description='Inference')
+ if self.show_progress else inputs):
preds = self.forward(proc_inputs, **forward_kwargs)
visualization = self.visualize(ori_inputs, preds,
diff --git a/mmpose/apis/inferencers/pose2d_inferencer.py b/mmpose/apis/inferencers/pose2d_inferencer.py
index 5a0bbad004..8b6a2c3e96 100644
--- a/mmpose/apis/inferencers/pose2d_inferencer.py
+++ b/mmpose/apis/inferencers/pose2d_inferencer.py
@@ -12,7 +12,7 @@
from mmengine.registry import init_default_scope
from mmengine.structures import InstanceData
-from mmpose.evaluation.functional import nms
+from mmpose.evaluation.functional import nearby_joints_nms, nms
from mmpose.registry import INFERENCERS
from mmpose.structures import merge_data_samples
from .base_mmpose_inferencer import BaseMMPoseInferencer
@@ -56,7 +56,7 @@ class Pose2DInferencer(BaseMMPoseInferencer):
"""
preprocess_kwargs: set = {'bbox_thr', 'nms_thr', 'bboxes'}
- forward_kwargs: set = {'merge_results'}
+ forward_kwargs: set = {'merge_results', 'pose_based_nms'}
visualize_kwargs: set = {
'return_vis',
'show',
@@ -79,11 +79,16 @@ def __init__(self,
scope: Optional[str] = 'mmpose',
det_model: Optional[Union[ModelType, str]] = None,
det_weights: Optional[str] = None,
- det_cat_ids: Optional[Union[int, Tuple]] = None) -> None:
+ det_cat_ids: Optional[Union[int, Tuple]] = None,
+ show_progress: bool = False) -> None:
init_default_scope(scope)
super().__init__(
- model=model, weights=weights, device=device, scope=scope)
+ model=model,
+ weights=weights,
+ device=device,
+ scope=scope,
+ show_progress=show_progress)
self.model = revert_sync_batchnorm(self.model)
# assign dataset metainfo to self.visualizer
@@ -208,7 +213,8 @@ def preprocess_single(self,
def forward(self,
inputs: Union[dict, tuple],
merge_results: bool = True,
- bbox_thr: float = -1):
+ bbox_thr: float = -1,
+ pose_based_nms: bool = False):
"""Performs a forward pass through the model.
Args:
@@ -228,9 +234,29 @@ def forward(self,
data_samples = self.model.test_step(inputs)
if self.cfg.data_mode == 'topdown' and merge_results:
data_samples = [merge_data_samples(data_samples)]
+
if bbox_thr > 0:
for ds in data_samples:
if 'bbox_scores' in ds.pred_instances:
ds.pred_instances = ds.pred_instances[
ds.pred_instances.bbox_scores > bbox_thr]
+
+ if pose_based_nms:
+ for ds in data_samples:
+ if len(ds.pred_instances) == 0:
+ continue
+
+ kpts = ds.pred_instances.keypoints
+ scores = ds.pred_instances.bbox_scores
+ num_keypoints = kpts.shape[-2]
+
+ kept_indices = nearby_joints_nms(
+ [
+ dict(keypoints=kpts[i], score=scores[i])
+ for i in range(len(kpts))
+ ],
+ num_nearby_joints_thr=num_keypoints // 3,
+ )
+ ds.pred_instances = ds.pred_instances[kept_indices]
+
return data_samples
diff --git a/mmpose/apis/inferencers/pose3d_inferencer.py b/mmpose/apis/inferencers/pose3d_inferencer.py
index b0c88c4e7d..f372438298 100644
--- a/mmpose/apis/inferencers/pose3d_inferencer.py
+++ b/mmpose/apis/inferencers/pose3d_inferencer.py
@@ -88,11 +88,16 @@ def __init__(self,
scope: Optional[str] = 'mmpose',
det_model: Optional[Union[ModelType, str]] = None,
det_weights: Optional[str] = None,
- det_cat_ids: Optional[Union[int, Tuple]] = None) -> None:
+ det_cat_ids: Optional[Union[int, Tuple]] = None,
+ show_progress: bool = False) -> None:
init_default_scope(scope)
super().__init__(
- model=model, weights=weights, device=device, scope=scope)
+ model=model,
+ weights=weights,
+ device=device,
+ scope=scope,
+ show_progress=show_progress)
self.model = revert_sync_batchnorm(self.model)
# assign dataset metainfo to self.visualizer
diff --git a/mmpose/apis/inferencers/utils/default_det_models.py b/mmpose/apis/inferencers/utils/default_det_models.py
index ea02097be0..a2deca961b 100644
--- a/mmpose/apis/inferencers/utils/default_det_models.py
+++ b/mmpose/apis/inferencers/utils/default_det_models.py
@@ -7,7 +7,13 @@
mmpose_path = get_installed_path(MODULE2PACKAGE['mmpose'])
default_det_models = dict(
- human=dict(model='rtmdet-m', weights=None, cat_ids=(0, )),
+ human=dict(
+ model=osp.join(
+ mmpose_path, '.mim', 'demo/mmdetection_cfg/'
+ 'rtmdet_m_640-8xb32_coco-person.py'),
+ weights='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmposev1/rtmdet_m_8xb32-100e_coco-obj365-person-235e8209.pth',
+ cat_ids=(0, )),
face=dict(
model=osp.join(mmpose_path, '.mim',
'demo/mmdetection_cfg/yolox-s_8xb8-300e_coco-face.py'),
diff --git a/mmpose/codecs/annotation_processors.py b/mmpose/codecs/annotation_processors.py
index e857cdc0e4..b16a4e67ca 100644
--- a/mmpose/codecs/annotation_processors.py
+++ b/mmpose/codecs/annotation_processors.py
@@ -39,6 +39,14 @@ class YOLOXPoseAnnotationProcessor(BaseAnnotationProcessor):
keypoints_visible='keypoints_visible',
area='areas',
)
+ instance_mapping_table = dict(
+ bbox='bboxes',
+ bbox_score='bbox_scores',
+ keypoints='keypoints',
+ keypoints_visible='keypoints_visible',
+ # remove 'bbox_scales' in default instance_mapping_table to avoid
+ # length mismatch during training with multiple datasets
+ )
def __init__(self,
expand_bbox: bool = False,
diff --git a/mmpose/codecs/image_pose_lifting.py b/mmpose/codecs/image_pose_lifting.py
index 81bd192eb3..1665d88e1d 100644
--- a/mmpose/codecs/image_pose_lifting.py
+++ b/mmpose/codecs/image_pose_lifting.py
@@ -1,5 +1,5 @@
# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Optional, Tuple
+from typing import List, Optional, Tuple, Union
import numpy as np
@@ -20,7 +20,7 @@ class ImagePoseLifting(BaseKeypointCodec):
Args:
num_keypoints (int): The number of keypoints in the dataset.
- root_index (int): Root keypoint index in the pose.
+ root_index (Union[int, List]): Root keypoint index in the pose.
remove_root (bool): If true, remove the root keypoint from the pose.
Default: ``False``.
save_index (bool): If true, store the root position separated from the
@@ -52,7 +52,7 @@ class ImagePoseLifting(BaseKeypointCodec):
def __init__(self,
num_keypoints: int,
- root_index: int,
+ root_index: Union[int, List] = 0,
remove_root: bool = False,
save_index: bool = False,
reshape_keypoints: bool = True,
@@ -60,10 +60,13 @@ def __init__(self,
keypoints_mean: Optional[np.ndarray] = None,
keypoints_std: Optional[np.ndarray] = None,
target_mean: Optional[np.ndarray] = None,
- target_std: Optional[np.ndarray] = None):
+ target_std: Optional[np.ndarray] = None,
+ additional_encode_keys: Optional[List[str]] = None):
super().__init__()
self.num_keypoints = num_keypoints
+ if isinstance(root_index, int):
+ root_index = [root_index]
self.root_index = root_index
self.remove_root = remove_root
self.save_index = save_index
@@ -96,6 +99,9 @@ def __init__(self,
self.target_mean = target_mean
self.target_std = target_std
+ if additional_encode_keys is not None:
+ self.auxiliary_encode_keys.update(additional_encode_keys)
+
def encode(self,
keypoints: np.ndarray,
keypoints_visible: Optional[np.ndarray] = None,
@@ -161,18 +167,19 @@ def encode(self,
# Zero-center the target pose around a given root keypoint
assert (lifting_target.ndim >= 2 and
- lifting_target.shape[-2] > self.root_index), \
+ lifting_target.shape[-2] > max(self.root_index)), \
f'Got invalid joint shape {lifting_target.shape}'
- root = lifting_target[..., self.root_index, :]
- lifting_target_label = lifting_target - lifting_target[
- ..., self.root_index:self.root_index + 1, :]
+ root = np.mean(
+ lifting_target[..., self.root_index, :], axis=-2, dtype=np.float32)
+ lifting_target_label = lifting_target - root[np.newaxis, ...]
- if self.remove_root:
+ if self.remove_root and len(self.root_index) == 1:
+ root_index = self.root_index[0]
lifting_target_label = np.delete(
- lifting_target_label, self.root_index, axis=-2)
+ lifting_target_label, root_index, axis=-2)
lifting_target_visible = np.delete(
- lifting_target_visible, self.root_index, axis=-2)
+ lifting_target_visible, root_index, axis=-2)
assert lifting_target_weight.ndim in {
2, 3
}, (f'lifting_target_weight.ndim {lifting_target_weight.ndim} '
@@ -180,17 +187,18 @@ def encode(self,
axis_to_remove = -2 if lifting_target_weight.ndim == 3 else -1
lifting_target_weight = np.delete(
- lifting_target_weight, self.root_index, axis=axis_to_remove)
+ lifting_target_weight, root_index, axis=axis_to_remove)
# Add a flag to avoid latter transforms that rely on the root
# joint or the original joint index
encoded['target_root_removed'] = True
# Save the root index which is necessary to restore the global pose
if self.save_index:
- encoded['target_root_index'] = self.root_index
+ encoded['target_root_index'] = root_index
# Normalize the 2D keypoint coordinate with mean and std
keypoint_labels = keypoints.copy()
+
if self.keypoints_mean is not None:
assert self.keypoints_mean.shape[1:] == keypoints.shape[1:], (
f'self.keypoints_mean.shape[1:] {self.keypoints_mean.shape[1:]} ' # noqa
@@ -203,7 +211,8 @@ def encode(self,
if self.target_mean is not None:
assert self.target_mean.shape == lifting_target_label.shape, (
f'self.target_mean.shape {self.target_mean.shape} '
- f'!= lifting_target_label.shape {lifting_target_label.shape}')
+ f'!= lifting_target_label.shape {lifting_target_label.shape}' # noqa
+ )
encoded['target_mean'] = self.target_mean.copy()
encoded['target_std'] = self.target_std.copy()
@@ -263,7 +272,7 @@ def decode(self,
if target_root is not None and target_root.size > 0:
keypoints = keypoints + target_root
- if self.remove_root:
+ if self.remove_root and len(self.root_index) == 1:
keypoints = np.insert(
keypoints, self.root_index, target_root, axis=1)
scores = np.ones(keypoints.shape[:-1], dtype=np.float32)
diff --git a/mmpose/codecs/simcc_label.py b/mmpose/codecs/simcc_label.py
index 6183e2be73..e83960faaf 100644
--- a/mmpose/codecs/simcc_label.py
+++ b/mmpose/codecs/simcc_label.py
@@ -47,6 +47,12 @@ class SimCCLabel(BaseKeypointCodec):
will be :math:`w*simcc_split_ratio`. Defaults to 2.0
label_smooth_weight (float): Label Smoothing weight. Defaults to 0.0
normalize (bool): Whether to normalize the heatmaps. Defaults to True.
+ use_dark (bool): Whether to use the DARK post processing. Defaults to
+ False.
+ decode_visibility (bool): Whether to decode the visibility. Defaults
+ to False.
+ decode_beta (float): The beta value for decoding visibility. Defaults
+ to 150.0.
.. _`SimCC: a Simple Coordinate Classification Perspective for Human Pose
Estimation`: https://arxiv.org/abs/2107.03332
@@ -58,14 +64,18 @@ class SimCCLabel(BaseKeypointCodec):
keypoint_weights='keypoint_weights',
)
- def __init__(self,
- input_size: Tuple[int, int],
- smoothing_type: str = 'gaussian',
- sigma: Union[float, int, Tuple[float]] = 6.0,
- simcc_split_ratio: float = 2.0,
- label_smooth_weight: float = 0.0,
- normalize: bool = True,
- use_dark: bool = False) -> None:
+ def __init__(
+ self,
+ input_size: Tuple[int, int],
+ smoothing_type: str = 'gaussian',
+ sigma: Union[float, int, Tuple[float]] = 6.0,
+ simcc_split_ratio: float = 2.0,
+ label_smooth_weight: float = 0.0,
+ normalize: bool = True,
+ use_dark: bool = False,
+ decode_visibility: bool = False,
+ decode_beta: float = 150.0,
+ ) -> None:
super().__init__()
self.input_size = input_size
@@ -74,6 +84,8 @@ def __init__(self,
self.label_smooth_weight = label_smooth_weight
self.normalize = normalize
self.use_dark = use_dark
+ self.decode_visibility = decode_visibility
+ self.decode_beta = decode_beta
if isinstance(sigma, (float, int)):
self.sigma = np.array([sigma, sigma])
@@ -178,7 +190,14 @@ def decode(self, simcc_x: np.ndarray,
keypoints /= self.simcc_split_ratio
- return keypoints, scores
+ if self.decode_visibility:
+ _, visibility = get_simcc_maximum(
+ simcc_x * self.decode_beta * self.sigma[0],
+ simcc_y * self.decode_beta * self.sigma[1],
+ apply_softmax=True)
+ return keypoints, (scores, visibility)
+ else:
+ return keypoints, scores
def _map_coordinates(
self,
diff --git a/mmpose/codecs/spr.py b/mmpose/codecs/spr.py
index 8e09b185c7..fba17f1598 100644
--- a/mmpose/codecs/spr.py
+++ b/mmpose/codecs/spr.py
@@ -138,7 +138,7 @@ def _get_heatmap_weights(self,
Returns:
np.ndarray: Heatmap weight array in the same shape with heatmaps
"""
- heatmap_weights = np.ones(heatmaps.shape) * bg_weight
+ heatmap_weights = np.ones(heatmaps.shape, dtype=np.float32) * bg_weight
heatmap_weights[heatmaps > 0] = fg_weight
return heatmap_weights
diff --git a/mmpose/codecs/utils/post_processing.py b/mmpose/codecs/utils/post_processing.py
index 7bb447e199..d8637e2bc2 100644
--- a/mmpose/codecs/utils/post_processing.py
+++ b/mmpose/codecs/utils/post_processing.py
@@ -39,7 +39,9 @@ def get_simcc_normalized(batch_pred_simcc, sigma=None):
def get_simcc_maximum(simcc_x: np.ndarray,
- simcc_y: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
+ simcc_y: np.ndarray,
+ apply_softmax: bool = False
+ ) -> Tuple[np.ndarray, np.ndarray]:
"""Get maximum response location and value from simcc representations.
Note:
@@ -51,6 +53,8 @@ def get_simcc_maximum(simcc_x: np.ndarray,
Args:
simcc_x (np.ndarray): x-axis SimCC in shape (K, Wx) or (N, K, Wx)
simcc_y (np.ndarray): y-axis SimCC in shape (K, Wy) or (N, K, Wy)
+ apply_softmax (bool): whether to apply softmax on the heatmap.
+ Defaults to False.
Returns:
tuple:
@@ -76,6 +80,13 @@ def get_simcc_maximum(simcc_x: np.ndarray,
else:
N = None
+ if apply_softmax:
+ simcc_x = simcc_x - np.max(simcc_x, axis=1, keepdims=True)
+ simcc_y = simcc_y - np.max(simcc_y, axis=1, keepdims=True)
+ ex, ey = np.exp(simcc_x), np.exp(simcc_y)
+ simcc_x = ex / np.sum(ex, axis=1, keepdims=True)
+ simcc_y = ey / np.sum(ey, axis=1, keepdims=True)
+
x_locs = np.argmax(simcc_x, axis=1)
y_locs = np.argmax(simcc_y, axis=1)
locs = np.stack((x_locs, y_locs), axis=-1).astype(np.float32)
diff --git a/mmpose/codecs/video_pose_lifting.py b/mmpose/codecs/video_pose_lifting.py
index 2b08b4da85..5a5a7b1983 100644
--- a/mmpose/codecs/video_pose_lifting.py
+++ b/mmpose/codecs/video_pose_lifting.py
@@ -1,7 +1,7 @@
# Copyright (c) OpenMMLab. All rights reserved.
from copy import deepcopy
-from typing import Optional, Tuple
+from typing import List, Optional, Tuple, Union
import numpy as np
@@ -24,7 +24,8 @@ class VideoPoseLifting(BaseKeypointCodec):
num_keypoints (int): The number of keypoints in the dataset.
zero_center: Whether to zero-center the target around root. Default:
``True``.
- root_index (int): Root keypoint index in the pose. Default: 0.
+ root_index (Union[int, List]): Root keypoint index in the pose.
+ Default: 0.
remove_root (bool): If true, remove the root keypoint from the pose.
Default: ``False``.
save_index (bool): If true, store the root position separated from the
@@ -54,7 +55,7 @@ class VideoPoseLifting(BaseKeypointCodec):
def __init__(self,
num_keypoints: int,
zero_center: bool = True,
- root_index: int = 0,
+ root_index: Union[int, List] = 0,
remove_root: bool = False,
save_index: bool = False,
reshape_keypoints: bool = True,
@@ -64,6 +65,8 @@ def __init__(self,
self.num_keypoints = num_keypoints
self.zero_center = zero_center
+ if isinstance(root_index, int):
+ root_index = [root_index]
self.root_index = root_index
self.remove_root = remove_root
self.save_index = save_index
@@ -143,19 +146,19 @@ def encode(self,
# Zero-center the target pose around a given root keypoint
if self.zero_center:
assert (lifting_target.ndim >= 2 and
- lifting_target.shape[-2] > self.root_index), \
+ lifting_target.shape[-2] > max(self.root_index)), \
f'Got invalid joint shape {lifting_target.shape}'
- root = lifting_target[..., self.root_index, :]
- lifting_target_label -= lifting_target_label[
- ..., self.root_index:self.root_index + 1, :]
+ root = np.mean(lifting_target[..., self.root_index, :], axis=-2)
+ lifting_target_label -= root[..., np.newaxis, :]
encoded['target_root'] = root
- if self.remove_root:
+ if self.remove_root and len(self.root_index) == 1:
+ root_index = self.root_index[0]
lifting_target_label = np.delete(
- lifting_target_label, self.root_index, axis=-2)
+ lifting_target_label, root_index, axis=-2)
lifting_target_visible = np.delete(
- lifting_target_visible, self.root_index, axis=-2)
+ lifting_target_visible, root_index, axis=-2)
assert lifting_target_weight.ndim in {
2, 3
}, (f'Got invalid lifting target weights shape '
@@ -163,16 +166,14 @@ def encode(self,
axis_to_remove = -2 if lifting_target_weight.ndim == 3 else -1
lifting_target_weight = np.delete(
- lifting_target_weight,
- self.root_index,
- axis=axis_to_remove)
+ lifting_target_weight, root_index, axis=axis_to_remove)
# Add a flag to avoid latter transforms that rely on the root
# joint or the original joint index
encoded['target_root_removed'] = True
# Save the root index for restoring the global pose
if self.save_index:
- encoded['target_root_index'] = self.root_index
+ encoded['target_root_index'] = root_index
# Normalize the 2D keypoint coordinate with image width and height
_camera_param = deepcopy(camera_param)
@@ -237,7 +238,7 @@ def decode(self,
if target_root is not None and target_root.size > 0:
keypoints = keypoints + target_root
- if self.remove_root:
+ if self.remove_root and len(self.root_index) == 1:
keypoints = np.insert(
keypoints, self.root_index, target_root, axis=1)
scores = np.ones(keypoints.shape[:-1], dtype=np.float32)
diff --git a/mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-l_8xb1024-270e_cocktail14-256x192.py b/mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-l_8xb1024-270e_cocktail14-256x192.py
new file mode 100644
index 0000000000..a87290ecb6
--- /dev/null
+++ b/mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-l_8xb1024-270e_cocktail14-256x192.py
@@ -0,0 +1,637 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.config import read_base
+
+with read_base():
+ from mmpose.configs._base_.default_runtime import * # noqa
+
+from albumentations.augmentations import Blur, CoarseDropout, MedianBlur
+from mmdet.engine.hooks import PipelineSwitchHook
+from mmengine.dataset import DefaultSampler
+from mmengine.hooks import EMAHook
+from mmengine.model import PretrainedInit
+from mmengine.optim import CosineAnnealingLR, LinearLR, OptimWrapper
+from torch.nn import SiLU, SyncBatchNorm
+from torch.optim import AdamW
+
+from mmpose.codecs import SimCCLabel
+from mmpose.datasets import (AicDataset, CocoWholeBodyDataset, COFWDataset,
+ CombinedDataset, CrowdPoseDataset,
+ Face300WDataset, GenerateTarget,
+ GetBBoxCenterScale, HalpeDataset,
+ HumanArt21Dataset, InterHand2DDoubleDataset,
+ JhmdbDataset, KeypointConverter, LapaDataset,
+ LoadImage, MpiiDataset, PackPoseInputs,
+ PoseTrack18Dataset, RandomFlip, RandomHalfBody,
+ TopdownAffine, UBody2dDataset, WFLWDataset)
+from mmpose.datasets.transforms.common_transforms import (
+ Albumentation, PhotometricDistortion, RandomBBoxTransform)
+from mmpose.engine.hooks import ExpMomentumEMA
+from mmpose.evaluation import CocoWholeBodyMetric
+from mmpose.models import (CSPNeXt, CSPNeXtPAFPN, KLDiscretLoss,
+ PoseDataPreprocessor, RTMWHead,
+ TopdownPoseEstimator)
+
+# common setting
+num_keypoints = 133
+input_size = (192, 256)
+
+# runtime
+max_epochs = 270
+stage2_num_epochs = 10
+base_lr = 5e-4
+train_batch_size = 1024
+val_batch_size = 32
+
+train_cfg.update(max_epochs=max_epochs, val_interval=10) # noqa
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type=OptimWrapper,
+ optimizer=dict(type=AdamW, lr=base_lr, weight_decay=0.1),
+ clip_grad=dict(max_norm=35, norm_type=2),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type=LinearLR, start_factor=1.0e-5, by_epoch=False, begin=0, end=1000),
+ dict(
+ type=CosineAnnealingLR,
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=8192)
+
+# codec settings
+codec = dict(
+ type=SimCCLabel,
+ input_size=input_size,
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type=TopdownPoseEstimator,
+ data_preprocessor=dict(
+ type=PoseDataPreprocessor,
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ type=CSPNeXt,
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=1.,
+ widen_factor=1.,
+ channel_attention=True,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type=SiLU),
+ init_cfg=dict(
+ type=PretrainedInit,
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmposev1/rtmpose-l_simcc-ucoco_dw-ucoco_270e-256x192-4d6dfc62_20230728.pth' # noqa
+ )),
+ neck=dict(
+ type=CSPNeXtPAFPN,
+ in_channels=[256, 512, 1024],
+ out_channels=None,
+ out_indices=(
+ 1,
+ 2,
+ ),
+ num_csp_blocks=2,
+ expand_ratio=0.5,
+ norm_cfg=dict(type=SyncBatchNorm),
+ act_cfg=dict(type=SiLU, inplace=True)),
+ head=dict(
+ type=RTMWHead,
+ in_channels=1024,
+ out_channels=num_keypoints,
+ input_size=input_size,
+ in_featuremap_size=tuple([s // 32 for s in input_size]),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type=KLDiscretLoss,
+ use_target_weight=True,
+ beta=1.,
+ label_softmax=True,
+ label_beta=10.,
+ mask=list(range(23, 91)),
+ mask_weight=0.5,
+ ),
+ decoder=codec),
+ test_cfg=dict(flip_test=True))
+
+# base dataset settings
+dataset_type = CocoWholeBodyDataset
+data_mode = 'topdown'
+data_root = 'data/'
+
+backend_args = dict(backend='local')
+
+# pipelines
+train_pipeline = [
+ dict(type=LoadImage, backend_args=backend_args),
+ dict(type=GetBBoxCenterScale),
+ dict(type=RandomFlip, direction='horizontal'),
+ dict(type=RandomHalfBody),
+ dict(type=RandomBBoxTransform, scale_factor=[0.5, 1.5], rotate_factor=90),
+ dict(type=TopdownAffine, input_size=codec['input_size']),
+ dict(type=PhotometricDistortion),
+ dict(
+ type=Albumentation,
+ transforms=[
+ dict(type=Blur, p=0.1),
+ dict(type=MedianBlur, p=0.1),
+ dict(
+ type=CoarseDropout,
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(
+ type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True),
+ dict(type=PackPoseInputs)
+]
+val_pipeline = [
+ dict(type=LoadImage, backend_args=backend_args),
+ dict(type=GetBBoxCenterScale),
+ dict(type=TopdownAffine, input_size=codec['input_size']),
+ dict(type=PackPoseInputs)
+]
+train_pipeline_stage2 = [
+ dict(type=LoadImage, backend_args=backend_args),
+ dict(type=GetBBoxCenterScale),
+ dict(type=RandomFlip, direction='horizontal'),
+ dict(type=RandomHalfBody),
+ dict(
+ type=RandomBBoxTransform,
+ shift_factor=0.,
+ scale_factor=[0.5, 1.5],
+ rotate_factor=90),
+ dict(type=TopdownAffine, input_size=codec['input_size']),
+ dict(
+ type=Albumentation,
+ transforms=[
+ dict(type=Blur, p=0.1),
+ dict(type=MedianBlur, p=0.1),
+ ]),
+ dict(
+ type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True),
+ dict(type=PackPoseInputs)
+]
+
+# mapping
+
+aic_coco133 = [(0, 6), (1, 8), (2, 10), (3, 5), (4, 7), (5, 9), (6, 12),
+ (7, 14), (8, 16), (9, 11), (10, 13), (11, 15)]
+
+crowdpose_coco133 = [(0, 5), (1, 6), (2, 7), (3, 8), (4, 9), (5, 10), (6, 11),
+ (7, 12), (8, 13), (9, 14), (10, 15), (11, 16)]
+
+mpii_coco133 = [
+ (0, 16),
+ (1, 14),
+ (2, 12),
+ (3, 11),
+ (4, 13),
+ (5, 15),
+ (10, 10),
+ (11, 8),
+ (12, 6),
+ (13, 5),
+ (14, 7),
+ (15, 9),
+]
+
+jhmdb_coco133 = [
+ (3, 6),
+ (4, 5),
+ (5, 12),
+ (6, 11),
+ (7, 8),
+ (8, 7),
+ (9, 14),
+ (10, 13),
+ (11, 10),
+ (12, 9),
+ (13, 16),
+ (14, 15),
+]
+
+halpe_coco133 = [(i, i)
+ for i in range(17)] + [(20, 17), (21, 20), (22, 18), (23, 21),
+ (24, 19),
+ (25, 22)] + [(i, i - 3)
+ for i in range(26, 136)]
+
+posetrack_coco133 = [
+ (0, 0),
+ (3, 3),
+ (4, 4),
+ (5, 5),
+ (6, 6),
+ (7, 7),
+ (8, 8),
+ (9, 9),
+ (10, 10),
+ (11, 11),
+ (12, 12),
+ (13, 13),
+ (14, 14),
+ (15, 15),
+ (16, 16),
+]
+
+humanart_coco133 = [(i, i) for i in range(17)] + [(17, 99), (18, 120),
+ (19, 17), (20, 20)]
+
+# train datasets
+dataset_coco = dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='coco/annotations/coco_wholebody_train_v1.0.json',
+ data_prefix=dict(img='detection/coco/train2017/'),
+ pipeline=[],
+)
+
+dataset_aic = dict(
+ type=AicDataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='aic/annotations/aic_train.json',
+ data_prefix=dict(img='pose/ai_challenge/ai_challenger_keypoint'
+ '_train_20170902/keypoint_train_images_20170902/'),
+ pipeline=[
+ dict(
+ type=KeypointConverter,
+ num_keypoints=num_keypoints,
+ mapping=aic_coco133)
+ ],
+)
+
+dataset_crowdpose = dict(
+ type=CrowdPoseDataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='crowdpose/annotations/mmpose_crowdpose_trainval.json',
+ data_prefix=dict(img='pose/CrowdPose/images/'),
+ pipeline=[
+ dict(
+ type=KeypointConverter,
+ num_keypoints=num_keypoints,
+ mapping=crowdpose_coco133)
+ ],
+)
+
+dataset_mpii = dict(
+ type=MpiiDataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='mpii/annotations/mpii_train.json',
+ data_prefix=dict(img='pose/MPI/images/'),
+ pipeline=[
+ dict(
+ type=KeypointConverter,
+ num_keypoints=num_keypoints,
+ mapping=mpii_coco133)
+ ],
+)
+
+dataset_jhmdb = dict(
+ type=JhmdbDataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='jhmdb/annotations/Sub1_train.json',
+ data_prefix=dict(img='pose/JHMDB/'),
+ pipeline=[
+ dict(
+ type=KeypointConverter,
+ num_keypoints=num_keypoints,
+ mapping=jhmdb_coco133)
+ ],
+)
+
+dataset_halpe = dict(
+ type=HalpeDataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='halpe/annotations/halpe_train_v1.json',
+ data_prefix=dict(img='pose/Halpe/hico_20160224_det/images/train2015'),
+ pipeline=[
+ dict(
+ type=KeypointConverter,
+ num_keypoints=num_keypoints,
+ mapping=halpe_coco133)
+ ],
+)
+
+dataset_posetrack = dict(
+ type=PoseTrack18Dataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='posetrack18/annotations/posetrack18_train.json',
+ data_prefix=dict(img='pose/PoseChallenge2018/'),
+ pipeline=[
+ dict(
+ type=KeypointConverter,
+ num_keypoints=num_keypoints,
+ mapping=posetrack_coco133)
+ ],
+)
+
+dataset_humanart = dict(
+ type=HumanArt21Dataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='HumanArt/annotations/training_humanart.json',
+ filter_cfg=dict(scenes=['real_human']),
+ data_prefix=dict(img='pose/'),
+ pipeline=[
+ dict(
+ type=KeypointConverter,
+ num_keypoints=num_keypoints,
+ mapping=humanart_coco133)
+ ])
+
+ubody_scenes = [
+ 'Magic_show', 'Entertainment', 'ConductMusic', 'Online_class', 'TalkShow',
+ 'Speech', 'Fitness', 'Interview', 'Olympic', 'TVShow', 'Singing',
+ 'SignLanguage', 'Movie', 'LiveVlog', 'VideoConference'
+]
+
+ubody_datasets = []
+for scene in ubody_scenes:
+ each = dict(
+ type=UBody2dDataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file=f'Ubody/annotations/{scene}/train_annotations.json',
+ data_prefix=dict(img='pose/UBody/images/'),
+ pipeline=[],
+ sample_interval=10)
+ ubody_datasets.append(each)
+
+dataset_ubody = dict(
+ type=CombinedDataset,
+ metainfo=dict(from_file='configs/_base_/datasets/ubody2d.py'),
+ datasets=ubody_datasets,
+ pipeline=[],
+ test_mode=False,
+)
+
+face_pipeline = [
+ dict(type=LoadImage, backend_args=backend_args),
+ dict(type=GetBBoxCenterScale, padding=1.25),
+ dict(
+ type=RandomBBoxTransform,
+ shift_factor=0.,
+ scale_factor=[1.5, 2.0],
+ rotate_factor=0),
+]
+
+wflw_coco133 = [(i * 2, 23 + i)
+ for i in range(17)] + [(33 + i, 40 + i) for i in range(5)] + [
+ (42 + i, 45 + i) for i in range(5)
+ ] + [(51 + i, 50 + i)
+ for i in range(9)] + [(60, 59), (61, 60), (63, 61),
+ (64, 62), (65, 63), (67, 64),
+ (68, 65), (69, 66), (71, 67),
+ (72, 68), (73, 69),
+ (75, 70)] + [(76 + i, 71 + i)
+ for i in range(20)]
+dataset_wflw = dict(
+ type=WFLWDataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='wflw/annotations/face_landmarks_wflw_train.json',
+ data_prefix=dict(img='pose/WFLW/images/'),
+ pipeline=[
+ dict(
+ type=KeypointConverter,
+ num_keypoints=num_keypoints,
+ mapping=wflw_coco133), *face_pipeline
+ ],
+)
+
+mapping_300w_coco133 = [(i, 23 + i) for i in range(68)]
+dataset_300w = dict(
+ type=Face300WDataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='300w/annotations/face_landmarks_300w_train.json',
+ data_prefix=dict(img='pose/300w/images/'),
+ pipeline=[
+ dict(
+ type=KeypointConverter,
+ num_keypoints=num_keypoints,
+ mapping=mapping_300w_coco133), *face_pipeline
+ ],
+)
+
+cofw_coco133 = [(0, 40), (2, 44), (4, 42), (1, 49), (3, 45), (6, 47), (8, 59),
+ (10, 62), (9, 68), (11, 65), (18, 54), (19, 58), (20, 53),
+ (21, 56), (22, 71), (23, 77), (24, 74), (25, 85), (26, 89),
+ (27, 80), (28, 31)]
+dataset_cofw = dict(
+ type=COFWDataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='cofw/annotations/cofw_train.json',
+ data_prefix=dict(img='pose/COFW/images/'),
+ pipeline=[
+ dict(
+ type=KeypointConverter,
+ num_keypoints=num_keypoints,
+ mapping=cofw_coco133), *face_pipeline
+ ],
+)
+
+lapa_coco133 = [(i * 2, 23 + i) for i in range(17)] + [
+ (33 + i, 40 + i) for i in range(5)
+] + [(42 + i, 45 + i) for i in range(5)] + [
+ (51 + i, 50 + i) for i in range(4)
+] + [(58 + i, 54 + i) for i in range(5)] + [(66, 59), (67, 60), (69, 61),
+ (70, 62), (71, 63), (73, 64),
+ (75, 65), (76, 66), (78, 67),
+ (79, 68), (80, 69),
+ (82, 70)] + [(84 + i, 71 + i)
+ for i in range(20)]
+dataset_lapa = dict(
+ type=LapaDataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='LaPa/annotations/lapa_trainval.json',
+ data_prefix=dict(img='pose/LaPa/'),
+ pipeline=[
+ dict(
+ type=KeypointConverter,
+ num_keypoints=num_keypoints,
+ mapping=lapa_coco133), *face_pipeline
+ ],
+)
+
+dataset_wb = dict(
+ type=CombinedDataset,
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[dataset_coco, dataset_halpe, dataset_ubody],
+ pipeline=[],
+ test_mode=False,
+)
+
+dataset_body = dict(
+ type=CombinedDataset,
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[
+ dataset_aic,
+ dataset_crowdpose,
+ dataset_mpii,
+ dataset_jhmdb,
+ dataset_posetrack,
+ dataset_humanart,
+ ],
+ pipeline=[],
+ test_mode=False,
+)
+
+dataset_face = dict(
+ type=CombinedDataset,
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[
+ dataset_wflw,
+ dataset_300w,
+ dataset_cofw,
+ dataset_lapa,
+ ],
+ pipeline=[],
+ test_mode=False,
+)
+
+hand_pipeline = [
+ dict(type=LoadImage, backend_args=backend_args),
+ dict(type=GetBBoxCenterScale),
+ dict(
+ type=RandomBBoxTransform,
+ shift_factor=0.,
+ scale_factor=[1.5, 2.0],
+ rotate_factor=0),
+]
+
+interhand_left = [(21, 95), (22, 94), (23, 93), (24, 92), (25, 99), (26, 98),
+ (27, 97), (28, 96), (29, 103), (30, 102), (31, 101),
+ (32, 100), (33, 107), (34, 106), (35, 105), (36, 104),
+ (37, 111), (38, 110), (39, 109), (40, 108), (41, 91)]
+interhand_right = [(i - 21, j + 21) for i, j in interhand_left]
+interhand_coco133 = interhand_right + interhand_left
+
+dataset_interhand2d = dict(
+ type=InterHand2DDoubleDataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='interhand26m/annotations/all/InterHand2.6M_train_data.json',
+ camera_param_file='interhand26m/annotations/all/'
+ 'InterHand2.6M_train_camera.json',
+ joint_file='interhand26m/annotations/all/'
+ 'InterHand2.6M_train_joint_3d.json',
+ data_prefix=dict(img='interhand2.6m/images/train/'),
+ sample_interval=10,
+ pipeline=[
+ dict(
+ type=KeypointConverter,
+ num_keypoints=num_keypoints,
+ mapping=interhand_coco133,
+ ), *hand_pipeline
+ ],
+)
+
+dataset_hand = dict(
+ type=CombinedDataset,
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[dataset_interhand2d],
+ pipeline=[],
+ test_mode=False,
+)
+
+train_datasets = [dataset_wb, dataset_body, dataset_face, dataset_hand]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=train_batch_size,
+ num_workers=4,
+ pin_memory=False,
+ persistent_workers=True,
+ sampler=dict(type=DefaultSampler, shuffle=True),
+ dataset=dict(
+ type=CombinedDataset,
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=train_datasets,
+ pipeline=train_pipeline,
+ test_mode=False,
+ ))
+
+val_dataloader = dict(
+ batch_size=val_batch_size,
+ num_workers=4,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type=DefaultSampler, shuffle=False, round_up=False),
+ dataset=dict(
+ type=CocoWholeBodyDataset,
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json',
+ data_prefix=dict(img='data/detection/coco/val2017/'),
+ pipeline=val_pipeline,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ test_mode=True))
+
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks.update( # noqa
+ checkpoint=dict(
+ save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type=EMAHook,
+ ema_type=ExpMomentumEMA,
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type=PipelineSwitchHook,
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type=CocoWholeBodyMetric,
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json')
+test_evaluator = val_evaluator
diff --git a/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb320-270e_cocktail13-384x288.py b/mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-l_8xb320-270e_cocktail14-384x288.py
similarity index 96%
rename from projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb320-270e_cocktail13-384x288.py
rename to mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-l_8xb320-270e_cocktail14-384x288.py
index 55d07b61a8..58172f7cc5 100644
--- a/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb320-270e_cocktail13-384x288.py
+++ b/mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-l_8xb320-270e_cocktail14-384x288.py
@@ -48,7 +48,7 @@
# optimizer
optim_wrapper = dict(
type=OptimWrapper,
- optimizer=dict(type=AdamW, lr=base_lr, weight_decay=0.05),
+ optimizer=dict(type=AdamW, lr=base_lr, weight_decay=0.1),
clip_grad=dict(max_norm=35, norm_type=2),
paramwise_cfg=dict(
norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
@@ -68,7 +68,7 @@
]
# automatically scaling LR based on the actual training batch size
-auto_scale_lr = dict(base_batch_size=5632)
+auto_scale_lr = dict(base_batch_size=2560)
# codec settings
codec = dict(
@@ -91,20 +91,20 @@
type=CSPNeXt,
arch='P5',
expand_ratio=0.5,
- deepen_factor=1.33,
- widen_factor=1.25,
+ deepen_factor=1.,
+ widen_factor=1.,
channel_attention=True,
norm_cfg=dict(type='BN'),
act_cfg=dict(type=SiLU),
init_cfg=dict(
- type=PretrainedInit,
+ type='Pretrained',
prefix='backbone.',
- checkpoint='https://download.openmmlab.com/mmpose/v1/'
- 'wholebody_2d_keypoint/rtmpose/ubody/rtmpose-x_simcc-ucoco_pt-aic-coco_270e-384x288-f5b50679_20230822.pth' # noqa
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmposev1/rtmpose-l_simcc-ucoco_dw-ucoco_270e-256x192-4d6dfc62_20230728.pth' # noqa
)),
neck=dict(
type=CSPNeXtPAFPN,
- in_channels=[320, 640, 1280],
+ in_channels=[256, 512, 1024],
out_channels=None,
out_indices=(
1,
@@ -116,7 +116,7 @@
act_cfg=dict(type=SiLU, inplace=True)),
head=dict(
type=RTMWHead,
- in_channels=1280,
+ in_channels=1024,
out_channels=num_keypoints,
input_size=input_size,
in_featuremap_size=tuple([s // 32 for s in input_size]),
@@ -128,14 +128,18 @@
expansion_factor=2,
dropout_rate=0.,
drop_path=0.,
- act_fn=SiLU,
+ act_fn='SiLU',
use_rel_bias=False,
pos_enc=False),
loss=dict(
type=KLDiscretLoss,
use_target_weight=True,
- beta=10.,
- label_softmax=True),
+ beta=1.,
+ label_softmax=True,
+ label_beta=10.,
+ mask=list(range(23, 91)),
+ mask_weight=0.5,
+ ),
decoder=codec),
test_cfg=dict(flip_test=True))
@@ -168,7 +172,7 @@
min_holes=1,
min_height=0.2,
min_width=0.2,
- p=1.0),
+ p=0.5),
]),
dict(
type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True),
@@ -217,8 +221,6 @@
(3, 11),
(4, 13),
(5, 15),
- (8, 18),
- (9, 17),
(10, 10),
(11, 8),
(12, 6),
@@ -228,8 +230,6 @@
]
jhmdb_coco133 = [
- (0, 18),
- (2, 17),
(3, 6),
(4, 5),
(5, 12),
@@ -252,7 +252,6 @@
posetrack_coco133 = [
(0, 0),
- (2, 17),
(3, 3),
(4, 4),
(5, 5),
diff --git a/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb704-270e_cocktail13-256x192.py b/mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-m_8xb1024-270e_cocktail14-256x192.py
similarity index 97%
rename from projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb704-270e_cocktail13-256x192.py
rename to mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-m_8xb1024-270e_cocktail14-256x192.py
index 48275c3c11..dd46cce5ff 100644
--- a/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb704-270e_cocktail13-256x192.py
+++ b/mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-m_8xb1024-270e_cocktail14-256x192.py
@@ -39,7 +39,7 @@
max_epochs = 270
stage2_num_epochs = 10
base_lr = 5e-4
-train_batch_size = 704
+train_batch_size = 1024
val_batch_size = 32
train_cfg.update(max_epochs=max_epochs, val_interval=10) # noqa
@@ -68,7 +68,7 @@
]
# automatically scaling LR based on the actual training batch size
-auto_scale_lr = dict(base_batch_size=5632)
+auto_scale_lr = dict(base_batch_size=8192)
# codec settings
codec = dict(
@@ -91,20 +91,20 @@
type=CSPNeXt,
arch='P5',
expand_ratio=0.5,
- deepen_factor=1.33,
- widen_factor=1.25,
+ deepen_factor=0.67,
+ widen_factor=0.75,
channel_attention=True,
norm_cfg=dict(type='BN'),
act_cfg=dict(type=SiLU),
init_cfg=dict(
type=PretrainedInit,
prefix='backbone.',
- checkpoint='https://download.openmmlab.com/mmpose/v1/'
- 'wholebody_2d_keypoint/rtmpose/ubody/rtmpose-x_simcc-ucoco_pt-aic-coco_270e-256x192-05f5bcb7_20230822.pth' # noqa
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmposev1/rtmpose-m_simcc-ucoco_dw-ucoco_270e-256x192-c8b76419_20230728.pth' # noqa
)),
neck=dict(
type=CSPNeXtPAFPN,
- in_channels=[320, 640, 1280],
+ in_channels=[192, 384, 768],
out_channels=None,
out_indices=(
1,
@@ -116,7 +116,7 @@
act_cfg=dict(type=SiLU, inplace=True)),
head=dict(
type=RTMWHead,
- in_channels=1280,
+ in_channels=768,
out_channels=num_keypoints,
input_size=input_size,
in_featuremap_size=tuple([s // 32 for s in input_size]),
@@ -128,14 +128,18 @@
expansion_factor=2,
dropout_rate=0.,
drop_path=0.,
- act_fn=SiLU,
+ act_fn='SiLU',
use_rel_bias=False,
pos_enc=False),
loss=dict(
type=KLDiscretLoss,
use_target_weight=True,
- beta=10.,
- label_softmax=True),
+ beta=1.,
+ label_softmax=True,
+ label_beta=10.,
+ mask=list(range(23, 91)),
+ mask_weight=0.5,
+ ),
decoder=codec),
test_cfg=dict(flip_test=True))
@@ -168,7 +172,7 @@
min_holes=1,
min_height=0.2,
min_width=0.2,
- p=1.0),
+ p=0.5),
]),
dict(
type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True),
@@ -180,7 +184,6 @@
dict(type=TopdownAffine, input_size=codec['input_size']),
dict(type=PackPoseInputs)
]
-
train_pipeline_stage2 = [
dict(type=LoadImage, backend_args=backend_args),
dict(type=GetBBoxCenterScale),
@@ -218,8 +221,6 @@
(3, 11),
(4, 13),
(5, 15),
- (8, 18),
- (9, 17),
(10, 10),
(11, 8),
(12, 6),
@@ -229,8 +230,6 @@
]
jhmdb_coco133 = [
- (0, 18),
- (2, 17),
(3, 6),
(4, 5),
(5, 12),
@@ -253,7 +252,6 @@
posetrack_coco133 = [
(0, 0),
- (2, 17),
(3, 3),
(4, 4),
(5, 5),
diff --git a/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb320-270e_cocktail13-384x288.py b/mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb320-270e_cocktail14-384x288.py
similarity index 98%
rename from configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb320-270e_cocktail13-384x288.py
rename to mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb320-270e_cocktail14-384x288.py
index 55d07b61a8..73fe642366 100644
--- a/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb320-270e_cocktail13-384x288.py
+++ b/mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb320-270e_cocktail14-384x288.py
@@ -48,7 +48,7 @@
# optimizer
optim_wrapper = dict(
type=OptimWrapper,
- optimizer=dict(type=AdamW, lr=base_lr, weight_decay=0.05),
+ optimizer=dict(type=AdamW, lr=base_lr, weight_decay=0.1),
clip_grad=dict(max_norm=35, norm_type=2),
paramwise_cfg=dict(
norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
@@ -68,7 +68,7 @@
]
# automatically scaling LR based on the actual training batch size
-auto_scale_lr = dict(base_batch_size=5632)
+auto_scale_lr = dict(base_batch_size=2560)
# codec settings
codec = dict(
@@ -128,14 +128,18 @@
expansion_factor=2,
dropout_rate=0.,
drop_path=0.,
- act_fn=SiLU,
+ act_fn='SiLU',
use_rel_bias=False,
pos_enc=False),
loss=dict(
type=KLDiscretLoss,
use_target_weight=True,
- beta=10.,
- label_softmax=True),
+ beta=1.,
+ label_softmax=True,
+ label_beta=10.,
+ mask=list(range(23, 91)),
+ mask_weight=0.5,
+ ),
decoder=codec),
test_cfg=dict(flip_test=True))
@@ -168,7 +172,7 @@
min_holes=1,
min_height=0.2,
min_width=0.2,
- p=1.0),
+ p=0.5),
]),
dict(
type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True),
@@ -217,8 +221,6 @@
(3, 11),
(4, 13),
(5, 15),
- (8, 18),
- (9, 17),
(10, 10),
(11, 8),
(12, 6),
@@ -228,8 +230,6 @@
]
jhmdb_coco133 = [
- (0, 18),
- (2, 17),
(3, 6),
(4, 5),
(5, 12),
@@ -252,7 +252,6 @@
posetrack_coco133 = [
(0, 0),
- (2, 17),
(3, 3),
(4, 4),
(5, 5),
diff --git a/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb704-270e_cocktail13-256x192.py b/mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb704-270e_cocktail14-256x192.py
similarity index 98%
rename from configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb704-270e_cocktail13-256x192.py
rename to mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb704-270e_cocktail14-256x192.py
index 48275c3c11..b4447fa1d7 100644
--- a/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb704-270e_cocktail13-256x192.py
+++ b/mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb704-270e_cocktail14-256x192.py
@@ -48,7 +48,7 @@
# optimizer
optim_wrapper = dict(
type=OptimWrapper,
- optimizer=dict(type=AdamW, lr=base_lr, weight_decay=0.05),
+ optimizer=dict(type=AdamW, lr=base_lr, weight_decay=0.1),
clip_grad=dict(max_norm=35, norm_type=2),
paramwise_cfg=dict(
norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
@@ -128,14 +128,18 @@
expansion_factor=2,
dropout_rate=0.,
drop_path=0.,
- act_fn=SiLU,
+ act_fn='SiLU',
use_rel_bias=False,
pos_enc=False),
loss=dict(
type=KLDiscretLoss,
use_target_weight=True,
- beta=10.,
- label_softmax=True),
+ beta=1.,
+ label_softmax=True,
+ label_beta=10.,
+ mask=list(range(23, 91)),
+ mask_weight=0.5,
+ ),
decoder=codec),
test_cfg=dict(flip_test=True))
@@ -168,7 +172,7 @@
min_holes=1,
min_height=0.2,
min_width=0.2,
- p=1.0),
+ p=0.5),
]),
dict(
type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True),
@@ -180,7 +184,6 @@
dict(type=TopdownAffine, input_size=codec['input_size']),
dict(type=PackPoseInputs)
]
-
train_pipeline_stage2 = [
dict(type=LoadImage, backend_args=backend_args),
dict(type=GetBBoxCenterScale),
@@ -218,8 +221,6 @@
(3, 11),
(4, 13),
(5, 15),
- (8, 18),
- (9, 17),
(10, 10),
(11, 8),
(12, 6),
@@ -229,8 +230,6 @@
]
jhmdb_coco133 = [
- (0, 18),
- (2, 17),
(3, 6),
(4, 5),
(5, 12),
@@ -253,7 +252,6 @@
posetrack_coco133 = [
(0, 0),
- (2, 17),
(3, 3),
(4, 4),
(5, 5),
diff --git a/mmpose/datasets/datasets/body/__init__.py b/mmpose/datasets/datasets/body/__init__.py
index 3ae05a3856..c4e3cca37a 100644
--- a/mmpose/datasets/datasets/body/__init__.py
+++ b/mmpose/datasets/datasets/body/__init__.py
@@ -2,6 +2,7 @@
from .aic_dataset import AicDataset
from .coco_dataset import CocoDataset
from .crowdpose_dataset import CrowdPoseDataset
+from .exlpose_dataset import ExlposeDataset
from .humanart21_dataset import HumanArt21Dataset
from .humanart_dataset import HumanArtDataset
from .jhmdb_dataset import JhmdbDataset
@@ -16,5 +17,5 @@
'CocoDataset', 'MpiiDataset', 'MpiiTrbDataset', 'AicDataset',
'CrowdPoseDataset', 'OCHumanDataset', 'MhpDataset', 'PoseTrack18Dataset',
'JhmdbDataset', 'PoseTrack18VideoDataset', 'HumanArtDataset',
- 'HumanArt21Dataset'
+ 'HumanArt21Dataset', 'ExlposeDataset'
]
diff --git a/mmpose/datasets/datasets/body/exlpose_dataset.py b/mmpose/datasets/datasets/body/exlpose_dataset.py
new file mode 100644
index 0000000000..ad29f5d751
--- /dev/null
+++ b/mmpose/datasets/datasets/body/exlpose_dataset.py
@@ -0,0 +1,69 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class ExlposeDataset(BaseCocoStyleDataset):
+ """Exlpose dataset for pose estimation.
+
+ "Human Pose Estimation in Extremely Low-Light Conditions",
+ CVPR'2023.
+ More details can be found in the `paper
+
-For [sub-JHMDB](http://jhmdb.is.tue.mpg.de/dataset) data, please download the [images](<(http://files.is.tue.mpg.de/jhmdb/Rename_Images.tar.gz)>) from [JHMDB](http://jhmdb.is.tue.mpg.de/dataset),
-Please download the annotation files from [jhmdb_annotations](https://download.openmmlab.com/mmpose/datasets/jhmdb_annotations.tar).
-Move them under $MMPOSE/data, and make them look like this:
+对于 [sub-JHMDB](http://jhmdb.is.tue.mpg.de/dataset) 的数据,请从 [JHMDB](http://jhmdb.is.tue.mpg.de/dataset) 下载 [图像](<(http://files.is.tue.mpg.de/jhmdb/Rename_Images.tar.gz)>),
+请从 [jhmdb_annotations](https://download.openmmlab.com/mmpose/datasets/jhmdb_annotations.tar) 下载标注文件。
+将它们移至 $MMPOSE/data 下,并使目录结构如下所示:
```text
mmpose
diff --git a/docs/zh_cn/faq.md b/docs/zh_cn/faq.md
index b1e6998396..1b198b0b61 100644
--- a/docs/zh_cn/faq.md
+++ b/docs/zh_cn/faq.md
@@ -19,6 +19,8 @@ Detailed compatible MMPose and MMCV versions are shown as below. Please choose t
| MMPose version | MMCV/MMEngine version |
| :------------: | :-----------------------------: |
+| 1.3.0 | mmcv>=2.0.1, mmengine>=0.9.0 |
+| 1.2.0 | mmcv>=2.0.1, mmengine>=0.8.0 |
| 1.1.0 | mmcv>=2.0.1, mmengine>=0.8.0 |
| 1.0.0 | mmcv>=2.0.0, mmengine>=0.7.0 |
| 1.0.0rc1 | mmcv>=2.0.0rc4, mmengine>=0.6.0 |
@@ -146,3 +148,7 @@ Detailed compatible MMPose and MMCV versions are shown as below. Please choose t
1. set `flip_test=False` in `init_cfg` in the config file.
2. use faster human bounding box detector, see [MMDetection](https://mmdetection.readthedocs.io/zh_CN/3.x/model_zoo.html).
+
+- **What is the definition of each keypoint index?**
+
+ Check the [meta information file](https://github.com/open-mmlab/mmpose/tree/main/configs/_base_/datasets) for the dataset used to train the model you are using. They key `keypoint_info` includes the definition of each keypoint.
diff --git a/docs/zh_cn/notes/changelog.md b/docs/zh_cn/notes/changelog.md
index bd89688bc0..846286d022 100644
--- a/docs/zh_cn/notes/changelog.md
+++ b/docs/zh_cn/notes/changelog.md
@@ -1,5 +1,9 @@
# Changelog
+## **v1.3.0 (04/01/2024)**
+
+Release note: https://github.com/open-mmlab/mmpose/releases/tag/v1.3.0
+
## **v1.2.0 (12/10/2023)**
Release note: https://github.com/open-mmlab/mmpose/releases/tag/v1.2.0
diff --git a/docs/zh_cn/user_guides/inference.md b/docs/zh_cn/user_guides/inference.md
index 24ba42974b..9fc1612e11 100644
--- a/docs/zh_cn/user_guides/inference.md
+++ b/docs/zh_cn/user_guides/inference.md
@@ -22,7 +22,7 @@ from mmpose.apis import MMPoseInferencer
img_path = 'tests/data/coco/000000000785.jpg' # 将img_path替换给你自己的路径
-# 使用模型别名创建推断器
+# 使用模型别名创建推理器
inferencer = MMPoseInferencer('human')
# MMPoseInferencer采用了惰性推断方法,在给定输入时创建一个预测生成器
@@ -108,13 +108,15 @@ results = [result for result in result_generator]
[MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) 提供了几种可用于自定义所使用的模型的方法:
```python
-# 使用模型别名构建推断器
+# 使用模型别名构建推理器
inferencer = MMPoseInferencer('human')
-# 使用模型配置名构建推断器
+# 使用模型配置名构建推理器
inferencer = MMPoseInferencer('td-hm_hrnet-w32_8xb64-210e_coco-256x192')
+# 使用 3D 模型配置名构建推理器
+inferencer = MMPoseInferencer(pose3d="motionbert_dstformer-ft-243frm_8xb32-120e_h36m")
-# 使用模型配置文件和权重文件的路径或 URL 构建推断器
+# 使用模型配置文件和权重文件的路径或 URL 构建推理器
inferencer = MMPoseInferencer(
pose2d='configs/body_2d_keypoint/topdown_heatmap/coco/' \
'td-hm_hrnet-w32_8xb64-210e_coco-256x192.py',
@@ -125,6 +127,24 @@ inferencer = MMPoseInferencer(
模型别名的完整列表可以在模型别名部分中找到。
+上述代码为 2D 模型推理器的构建例子。3D 模型的推理器可以用类似的方式通过 `pose3d` 参数构建:
+
+```python
+# 使用 3D 模型别名构建推理器
+inferencer = MMPoseInferencer(pose3d="human3d")
+
+# 使用 3D 模型配置名构建推理器
+inferencer = MMPoseInferencer(pose3d="motionbert_dstformer-ft-243frm_8xb32-120e_h36m")
+
+# 使用 3D 模型配置文件和权重文件的路径或 URL 构建推理器
+inferencer = MMPoseInferencer(
+ pose3d='configs/body_3d_keypoint/motionbert/h36m/' \
+ 'motionbert_dstformer-ft-243frm_8xb32-120e_h36m.py',
+ pose3d_weights='https://download.openmmlab.com/mmpose/v1/body_3d_keypoint/' \
+ 'pose_lift/h36m/motionbert_ft_h36m-d80af323_20230531.pth'
+)
+```
+
此外,自顶向下的姿态估计器还需要一个对象检测模型。[MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) 能够推断用 MMPose 支持的数据集训练的模型的实例类型,然后构建必要的对象检测模型。用户也可以通过以下方式手动指定检测模型:
```python
@@ -145,7 +165,7 @@ inferencer = MMPoseInferencer(
det_cat_ids=[0], # 指定'human'类的类别id
)
-# 使用模型配置文件和权重文件的路径或URL构建推断器
+# 使用模型配置文件和权重文件的路径或URL构建推理器
inferencer = MMPoseInferencer(
pose2d='human',
det_model=f'{PATH_TO_MMDET}/configs/yolox/yolox_l_8x8_300e_coco.py',
@@ -210,7 +230,7 @@ result = next(result_generator)
### 推理器参数
-[MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) 提供了各种自定义姿态估计、可视化和保存预测结果的参数。下面是初始化推断器时可用的参数列表及对这些参数的描述:
+[MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) 提供了各种自定义姿态估计、可视化和保存预测结果的参数。下面是初始化推理器时可用的参数列表及对这些参数的描述:
| Argument | Description |
| ---------------- | ------------------------------------------------------------ |
diff --git a/docs/zh_cn/user_guides/train_and_test.md b/docs/zh_cn/user_guides/train_and_test.md
index 6cadeab0a3..b95ae965f1 100644
--- a/docs/zh_cn/user_guides/train_and_test.md
+++ b/docs/zh_cn/user_guides/train_and_test.md
@@ -496,3 +496,16 @@ test_evaluator = val_evaluator
```
如需进一步了解如何将 AIC 关键点转换为 COCO 关键点,请查阅 [该指南](https://mmpose.readthedocs.io/zh_CN/dev-1.x/user_guides/mixed_datasets.html#aic-coco)。
+
+### 使用自定义检测器评估 Top-down 模型
+
+要评估 Top-down 模型,您可以使用人工标注的或预先检测到的边界框。 `bbox_file` 提供了由特定检测器生成的这些框。例如,`COCO_val2017_detections_AP_H_56_person.json` 包含了使用具有 56.4 人类 AP 的检测器捕获的 COCO val2017 数据集的边界框。要使用 MMDetection 支持的自定义检测器创建您自己的 `bbox_file`,请运行以下命令:
+
+```sh
+python tools/misc/generate_bbox_file.py \
+ ${DET_CONFIG} ${DET_WEIGHT} ${OUTPUT_FILE_NAME} \
+ [--pose-config ${POSE_CONFIG}] \
+ [--score-thr ${SCORE_THRESHOLD}] [--nms-thr ${NMS_THRESHOLD}]
+```
+
+其中,`DET_CONFIG` 和 `DET_WEIGHT` 用于创建目标检测器。 `POSE_CONFIG` 指定需要边界框检测的测试数据集。`SCORE_THRESHOLD` 和 `NMS_THRESHOLD` 用于边界框过滤。
diff --git a/mmpose/__init__.py b/mmpose/__init__.py
index 583ede0a4d..dda49513fa 100644
--- a/mmpose/__init__.py
+++ b/mmpose/__init__.py
@@ -6,7 +6,7 @@
from .version import __version__, short_version
mmcv_minimum_version = '2.0.0rc4'
-mmcv_maximum_version = '2.2.0'
+mmcv_maximum_version = '2.3.0'
mmcv_version = digit_version(mmcv.__version__)
mmengine_minimum_version = '0.6.0'
diff --git a/mmpose/apis/inference_3d.py b/mmpose/apis/inference_3d.py
index ae6428f187..b4151e804a 100644
--- a/mmpose/apis/inference_3d.py
+++ b/mmpose/apis/inference_3d.py
@@ -23,13 +23,13 @@ def convert_keypoint_definition(keypoints, pose_det_dataset,
ndarray[K, 2 or 3]: the transformed 2D keypoints.
"""
assert pose_lift_dataset in [
- 'h36m'], '`pose_lift_dataset` should be ' \
+ 'h36m', 'h3wb'], '`pose_lift_dataset` should be ' \
f'`h36m`, but got {pose_lift_dataset}.'
keypoints_new = np.zeros((keypoints.shape[0], 17, keypoints.shape[2]),
dtype=keypoints.dtype)
- if pose_lift_dataset == 'h36m':
- if pose_det_dataset in ['h36m']:
+ if pose_lift_dataset in ['h36m', 'h3wb']:
+ if pose_det_dataset in ['h36m', 'coco_wholebody']:
keypoints_new = keypoints
elif pose_det_dataset in ['coco', 'posetrack18']:
# pelvis (root) is in the middle of l_hip and r_hip
@@ -265,8 +265,26 @@ def inference_pose_lifter_model(model,
bbox_center = dataset_info['stats_info']['bbox_center']
bbox_scale = dataset_info['stats_info']['bbox_scale']
else:
- bbox_center = None
- bbox_scale = None
+ if norm_pose_2d:
+ # compute the average bbox center and scale from the
+ # datasamples in pose_results_2d
+ bbox_center = np.zeros((1, 2), dtype=np.float32)
+ bbox_scale = 0
+ num_bbox = 0
+ for pose_res in pose_results_2d:
+ for data_sample in pose_res:
+ for bbox in data_sample.pred_instances.bboxes:
+ bbox_center += np.array([[(bbox[0] + bbox[2]) / 2,
+ (bbox[1] + bbox[3]) / 2]
+ ])
+ bbox_scale += max(bbox[2] - bbox[0],
+ bbox[3] - bbox[1])
+ num_bbox += 1
+ bbox_center /= num_bbox
+ bbox_scale /= num_bbox
+ else:
+ bbox_center = None
+ bbox_scale = None
pose_results_2d_copy = []
for i, pose_res in enumerate(pose_results_2d):
diff --git a/mmpose/apis/inferencers/base_mmpose_inferencer.py b/mmpose/apis/inferencers/base_mmpose_inferencer.py
index d7d5eb8c19..574063e824 100644
--- a/mmpose/apis/inferencers/base_mmpose_inferencer.py
+++ b/mmpose/apis/inferencers/base_mmpose_inferencer.py
@@ -1,4 +1,5 @@
# Copyright (c) OpenMMLab. All rights reserved.
+import inspect
import logging
import mimetypes
import os
@@ -21,6 +22,7 @@
from mmengine.runner.checkpoint import _load_checkpoint_to_model
from mmengine.structures import InstanceData
from mmengine.utils import mkdir_or_exist
+from rich.progress import track
from mmpose.apis.inference import dataset_meta_from_config
from mmpose.registry import DATASETS
@@ -53,6 +55,15 @@ class BaseMMPoseInferencer(BaseInferencer):
}
postprocess_kwargs: set = {'pred_out_dir', 'return_datasample'}
+ def __init__(self,
+ model: Union[ModelType, str, None] = None,
+ weights: Optional[str] = None,
+ device: Optional[str] = None,
+ scope: Optional[str] = None,
+ show_progress: bool = False) -> None:
+ super().__init__(
+ model, weights, device, scope, show_progress=show_progress)
+
def _init_detector(
self,
det_model: Optional[Union[ModelType, str]] = None,
@@ -79,8 +90,18 @@ def _init_detector(
det_scope = det_cfg.default_scope
if has_mmdet:
- self.detector = DetInferencer(
- det_model, det_weights, device=device, scope=det_scope)
+ det_kwargs = dict(
+ model=det_model,
+ weights=det_weights,
+ device=device,
+ scope=det_scope,
+ )
+ # for compatibility with low version of mmdet
+ if 'show_progress' in inspect.signature(
+ DetInferencer).parameters:
+ det_kwargs['show_progress'] = False
+
+ self.detector = DetInferencer(**det_kwargs)
else:
raise RuntimeError(
'MMDetection (v3.0.0 or above) is required to build '
@@ -293,22 +314,45 @@ def preprocess(self,
inputs: InputsType,
batch_size: int = 1,
bboxes: Optional[List] = None,
+ bbox_thr: float = 0.3,
+ nms_thr: float = 0.3,
**kwargs):
"""Process the inputs into a model-feedable format.
Args:
inputs (InputsType): Inputs given by user.
batch_size (int): batch size. Defaults to 1.
+ bbox_thr (float): threshold for bounding box detection.
+ Defaults to 0.3.
+ nms_thr (float): IoU threshold for bounding box NMS.
+ Defaults to 0.3.
Yields:
Any: Data processed by the ``pipeline`` and ``collate_fn``.
List[str or np.ndarray]: List of original inputs in the batch
"""
+ # One-stage pose estimators perform prediction filtering within the
+ # head's `predict` method. Here, we set the arguments for filtering
+ if self.cfg.model.type == 'BottomupPoseEstimator':
+ # 1. init with default arguments
+ test_cfg = self.model.head.test_cfg.copy()
+ # 2. update the score_thr and nms_thr in the test_cfg of the head
+ if 'score_thr' in test_cfg:
+ test_cfg['score_thr'] = bbox_thr
+ if 'nms_thr' in test_cfg:
+ test_cfg['nms_thr'] = nms_thr
+ self.model.test_cfg = test_cfg
+
for i, input in enumerate(inputs):
bbox = bboxes[i] if bboxes else []
data_infos = self.preprocess_single(
- input, index=i, bboxes=bbox, **kwargs)
+ input,
+ index=i,
+ bboxes=bbox,
+ bbox_thr=bbox_thr,
+ nms_thr=nms_thr,
+ **kwargs)
# only supports inference with batch size 1
yield self.collate_fn(data_infos), [input]
@@ -384,7 +428,8 @@ def __call__(
preds = []
- for proc_inputs, ori_inputs in inputs:
+ for proc_inputs, ori_inputs in (track(inputs, description='Inference')
+ if self.show_progress else inputs):
preds = self.forward(proc_inputs, **forward_kwargs)
visualization = self.visualize(ori_inputs, preds,
diff --git a/mmpose/apis/inferencers/hand3d_inferencer.py b/mmpose/apis/inferencers/hand3d_inferencer.py
index 57f1eb06eb..a7db53cb84 100644
--- a/mmpose/apis/inferencers/hand3d_inferencer.py
+++ b/mmpose/apis/inferencers/hand3d_inferencer.py
@@ -78,11 +78,16 @@ def __init__(self,
scope: Optional[str] = 'mmpose',
det_model: Optional[Union[ModelType, str]] = None,
det_weights: Optional[str] = None,
- det_cat_ids: Optional[Union[int, Tuple]] = None) -> None:
+ det_cat_ids: Optional[Union[int, Tuple]] = None,
+ show_progress: bool = False) -> None:
init_default_scope(scope)
super().__init__(
- model=model, weights=weights, device=device, scope=scope)
+ model=model,
+ weights=weights,
+ device=device,
+ scope=scope,
+ show_progress=show_progress)
self.model = revert_sync_batchnorm(self.model)
# assign dataset metainfo to self.visualizer
diff --git a/mmpose/apis/inferencers/mmpose_inferencer.py b/mmpose/apis/inferencers/mmpose_inferencer.py
index cd08d8f6cb..4ade56cb04 100644
--- a/mmpose/apis/inferencers/mmpose_inferencer.py
+++ b/mmpose/apis/inferencers/mmpose_inferencer.py
@@ -7,6 +7,7 @@
from mmengine.config import Config, ConfigDict
from mmengine.infer.infer import ModelType
from mmengine.structures import InstanceData
+from rich.progress import track
from .base_mmpose_inferencer import BaseMMPoseInferencer
from .hand3d_inferencer import Hand3DInferencer
@@ -59,7 +60,9 @@ class MMPoseInferencer(BaseMMPoseInferencer):
'bbox_thr', 'nms_thr', 'bboxes', 'use_oks_tracking', 'tracking_thr',
'disable_norm_pose_2d'
}
- forward_kwargs: set = {'disable_rebase_keypoint'}
+ forward_kwargs: set = {
+ 'merge_results', 'disable_rebase_keypoint', 'pose_based_nms'
+ }
visualize_kwargs: set = {
'return_vis', 'show', 'wait_time', 'draw_bbox', 'radius', 'thickness',
'kpt_thr', 'vis_out_dir', 'skeleton_style', 'draw_heatmap',
@@ -76,23 +79,27 @@ def __init__(self,
scope: str = 'mmpose',
det_model: Optional[Union[ModelType, str]] = None,
det_weights: Optional[str] = None,
- det_cat_ids: Optional[Union[int, List]] = None) -> None:
+ det_cat_ids: Optional[Union[int, List]] = None,
+ show_progress: bool = False) -> None:
self.visualizer = None
+ self.show_progress = show_progress
if pose3d is not None:
if 'hand3d' in pose3d:
self.inferencer = Hand3DInferencer(pose3d, pose3d_weights,
device, scope, det_model,
- det_weights, det_cat_ids)
+ det_weights, det_cat_ids,
+ show_progress)
else:
self.inferencer = Pose3DInferencer(pose3d, pose3d_weights,
pose2d, pose2d_weights,
device, scope, det_model,
- det_weights, det_cat_ids)
+ det_weights, det_cat_ids,
+ show_progress)
elif pose2d is not None:
self.inferencer = Pose2DInferencer(pose2d, pose2d_weights, device,
scope, det_model, det_weights,
- det_cat_ids)
+ det_cat_ids, show_progress)
else:
raise ValueError('Either 2d or 3d pose estimation algorithm '
'should be provided.')
@@ -108,14 +115,8 @@ def preprocess(self, inputs: InputsType, batch_size: int = 1, **kwargs):
Any: Data processed by the ``pipeline`` and ``collate_fn``.
List[str or np.ndarray]: List of original inputs in the batch
"""
-
- for i, input in enumerate(inputs):
- data_batch = {}
- data_infos = self.inferencer.preprocess_single(
- input, index=i, **kwargs)
- data_batch = self.inferencer.collate_fn(data_infos)
- # only supports inference with batch size 1
- yield data_batch, [input]
+ for data in self.inferencer.preprocess(inputs, batch_size, **kwargs):
+ yield data
@torch.no_grad()
def forward(self, inputs: InputType, **forward_kwargs) -> PredType:
@@ -202,7 +203,8 @@ def __call__(
preds = []
- for proc_inputs, ori_inputs in inputs:
+ for proc_inputs, ori_inputs in (track(inputs, description='Inference')
+ if self.show_progress else inputs):
preds = self.forward(proc_inputs, **forward_kwargs)
visualization = self.visualize(ori_inputs, preds,
diff --git a/mmpose/apis/inferencers/pose2d_inferencer.py b/mmpose/apis/inferencers/pose2d_inferencer.py
index 5a0bbad004..8b6a2c3e96 100644
--- a/mmpose/apis/inferencers/pose2d_inferencer.py
+++ b/mmpose/apis/inferencers/pose2d_inferencer.py
@@ -12,7 +12,7 @@
from mmengine.registry import init_default_scope
from mmengine.structures import InstanceData
-from mmpose.evaluation.functional import nms
+from mmpose.evaluation.functional import nearby_joints_nms, nms
from mmpose.registry import INFERENCERS
from mmpose.structures import merge_data_samples
from .base_mmpose_inferencer import BaseMMPoseInferencer
@@ -56,7 +56,7 @@ class Pose2DInferencer(BaseMMPoseInferencer):
"""
preprocess_kwargs: set = {'bbox_thr', 'nms_thr', 'bboxes'}
- forward_kwargs: set = {'merge_results'}
+ forward_kwargs: set = {'merge_results', 'pose_based_nms'}
visualize_kwargs: set = {
'return_vis',
'show',
@@ -79,11 +79,16 @@ def __init__(self,
scope: Optional[str] = 'mmpose',
det_model: Optional[Union[ModelType, str]] = None,
det_weights: Optional[str] = None,
- det_cat_ids: Optional[Union[int, Tuple]] = None) -> None:
+ det_cat_ids: Optional[Union[int, Tuple]] = None,
+ show_progress: bool = False) -> None:
init_default_scope(scope)
super().__init__(
- model=model, weights=weights, device=device, scope=scope)
+ model=model,
+ weights=weights,
+ device=device,
+ scope=scope,
+ show_progress=show_progress)
self.model = revert_sync_batchnorm(self.model)
# assign dataset metainfo to self.visualizer
@@ -208,7 +213,8 @@ def preprocess_single(self,
def forward(self,
inputs: Union[dict, tuple],
merge_results: bool = True,
- bbox_thr: float = -1):
+ bbox_thr: float = -1,
+ pose_based_nms: bool = False):
"""Performs a forward pass through the model.
Args:
@@ -228,9 +234,29 @@ def forward(self,
data_samples = self.model.test_step(inputs)
if self.cfg.data_mode == 'topdown' and merge_results:
data_samples = [merge_data_samples(data_samples)]
+
if bbox_thr > 0:
for ds in data_samples:
if 'bbox_scores' in ds.pred_instances:
ds.pred_instances = ds.pred_instances[
ds.pred_instances.bbox_scores > bbox_thr]
+
+ if pose_based_nms:
+ for ds in data_samples:
+ if len(ds.pred_instances) == 0:
+ continue
+
+ kpts = ds.pred_instances.keypoints
+ scores = ds.pred_instances.bbox_scores
+ num_keypoints = kpts.shape[-2]
+
+ kept_indices = nearby_joints_nms(
+ [
+ dict(keypoints=kpts[i], score=scores[i])
+ for i in range(len(kpts))
+ ],
+ num_nearby_joints_thr=num_keypoints // 3,
+ )
+ ds.pred_instances = ds.pred_instances[kept_indices]
+
return data_samples
diff --git a/mmpose/apis/inferencers/pose3d_inferencer.py b/mmpose/apis/inferencers/pose3d_inferencer.py
index b0c88c4e7d..f372438298 100644
--- a/mmpose/apis/inferencers/pose3d_inferencer.py
+++ b/mmpose/apis/inferencers/pose3d_inferencer.py
@@ -88,11 +88,16 @@ def __init__(self,
scope: Optional[str] = 'mmpose',
det_model: Optional[Union[ModelType, str]] = None,
det_weights: Optional[str] = None,
- det_cat_ids: Optional[Union[int, Tuple]] = None) -> None:
+ det_cat_ids: Optional[Union[int, Tuple]] = None,
+ show_progress: bool = False) -> None:
init_default_scope(scope)
super().__init__(
- model=model, weights=weights, device=device, scope=scope)
+ model=model,
+ weights=weights,
+ device=device,
+ scope=scope,
+ show_progress=show_progress)
self.model = revert_sync_batchnorm(self.model)
# assign dataset metainfo to self.visualizer
diff --git a/mmpose/apis/inferencers/utils/default_det_models.py b/mmpose/apis/inferencers/utils/default_det_models.py
index ea02097be0..a2deca961b 100644
--- a/mmpose/apis/inferencers/utils/default_det_models.py
+++ b/mmpose/apis/inferencers/utils/default_det_models.py
@@ -7,7 +7,13 @@
mmpose_path = get_installed_path(MODULE2PACKAGE['mmpose'])
default_det_models = dict(
- human=dict(model='rtmdet-m', weights=None, cat_ids=(0, )),
+ human=dict(
+ model=osp.join(
+ mmpose_path, '.mim', 'demo/mmdetection_cfg/'
+ 'rtmdet_m_640-8xb32_coco-person.py'),
+ weights='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmposev1/rtmdet_m_8xb32-100e_coco-obj365-person-235e8209.pth',
+ cat_ids=(0, )),
face=dict(
model=osp.join(mmpose_path, '.mim',
'demo/mmdetection_cfg/yolox-s_8xb8-300e_coco-face.py'),
diff --git a/mmpose/codecs/annotation_processors.py b/mmpose/codecs/annotation_processors.py
index e857cdc0e4..b16a4e67ca 100644
--- a/mmpose/codecs/annotation_processors.py
+++ b/mmpose/codecs/annotation_processors.py
@@ -39,6 +39,14 @@ class YOLOXPoseAnnotationProcessor(BaseAnnotationProcessor):
keypoints_visible='keypoints_visible',
area='areas',
)
+ instance_mapping_table = dict(
+ bbox='bboxes',
+ bbox_score='bbox_scores',
+ keypoints='keypoints',
+ keypoints_visible='keypoints_visible',
+ # remove 'bbox_scales' in default instance_mapping_table to avoid
+ # length mismatch during training with multiple datasets
+ )
def __init__(self,
expand_bbox: bool = False,
diff --git a/mmpose/codecs/image_pose_lifting.py b/mmpose/codecs/image_pose_lifting.py
index 81bd192eb3..1665d88e1d 100644
--- a/mmpose/codecs/image_pose_lifting.py
+++ b/mmpose/codecs/image_pose_lifting.py
@@ -1,5 +1,5 @@
# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Optional, Tuple
+from typing import List, Optional, Tuple, Union
import numpy as np
@@ -20,7 +20,7 @@ class ImagePoseLifting(BaseKeypointCodec):
Args:
num_keypoints (int): The number of keypoints in the dataset.
- root_index (int): Root keypoint index in the pose.
+ root_index (Union[int, List]): Root keypoint index in the pose.
remove_root (bool): If true, remove the root keypoint from the pose.
Default: ``False``.
save_index (bool): If true, store the root position separated from the
@@ -52,7 +52,7 @@ class ImagePoseLifting(BaseKeypointCodec):
def __init__(self,
num_keypoints: int,
- root_index: int,
+ root_index: Union[int, List] = 0,
remove_root: bool = False,
save_index: bool = False,
reshape_keypoints: bool = True,
@@ -60,10 +60,13 @@ def __init__(self,
keypoints_mean: Optional[np.ndarray] = None,
keypoints_std: Optional[np.ndarray] = None,
target_mean: Optional[np.ndarray] = None,
- target_std: Optional[np.ndarray] = None):
+ target_std: Optional[np.ndarray] = None,
+ additional_encode_keys: Optional[List[str]] = None):
super().__init__()
self.num_keypoints = num_keypoints
+ if isinstance(root_index, int):
+ root_index = [root_index]
self.root_index = root_index
self.remove_root = remove_root
self.save_index = save_index
@@ -96,6 +99,9 @@ def __init__(self,
self.target_mean = target_mean
self.target_std = target_std
+ if additional_encode_keys is not None:
+ self.auxiliary_encode_keys.update(additional_encode_keys)
+
def encode(self,
keypoints: np.ndarray,
keypoints_visible: Optional[np.ndarray] = None,
@@ -161,18 +167,19 @@ def encode(self,
# Zero-center the target pose around a given root keypoint
assert (lifting_target.ndim >= 2 and
- lifting_target.shape[-2] > self.root_index), \
+ lifting_target.shape[-2] > max(self.root_index)), \
f'Got invalid joint shape {lifting_target.shape}'
- root = lifting_target[..., self.root_index, :]
- lifting_target_label = lifting_target - lifting_target[
- ..., self.root_index:self.root_index + 1, :]
+ root = np.mean(
+ lifting_target[..., self.root_index, :], axis=-2, dtype=np.float32)
+ lifting_target_label = lifting_target - root[np.newaxis, ...]
- if self.remove_root:
+ if self.remove_root and len(self.root_index) == 1:
+ root_index = self.root_index[0]
lifting_target_label = np.delete(
- lifting_target_label, self.root_index, axis=-2)
+ lifting_target_label, root_index, axis=-2)
lifting_target_visible = np.delete(
- lifting_target_visible, self.root_index, axis=-2)
+ lifting_target_visible, root_index, axis=-2)
assert lifting_target_weight.ndim in {
2, 3
}, (f'lifting_target_weight.ndim {lifting_target_weight.ndim} '
@@ -180,17 +187,18 @@ def encode(self,
axis_to_remove = -2 if lifting_target_weight.ndim == 3 else -1
lifting_target_weight = np.delete(
- lifting_target_weight, self.root_index, axis=axis_to_remove)
+ lifting_target_weight, root_index, axis=axis_to_remove)
# Add a flag to avoid latter transforms that rely on the root
# joint or the original joint index
encoded['target_root_removed'] = True
# Save the root index which is necessary to restore the global pose
if self.save_index:
- encoded['target_root_index'] = self.root_index
+ encoded['target_root_index'] = root_index
# Normalize the 2D keypoint coordinate with mean and std
keypoint_labels = keypoints.copy()
+
if self.keypoints_mean is not None:
assert self.keypoints_mean.shape[1:] == keypoints.shape[1:], (
f'self.keypoints_mean.shape[1:] {self.keypoints_mean.shape[1:]} ' # noqa
@@ -203,7 +211,8 @@ def encode(self,
if self.target_mean is not None:
assert self.target_mean.shape == lifting_target_label.shape, (
f'self.target_mean.shape {self.target_mean.shape} '
- f'!= lifting_target_label.shape {lifting_target_label.shape}')
+ f'!= lifting_target_label.shape {lifting_target_label.shape}' # noqa
+ )
encoded['target_mean'] = self.target_mean.copy()
encoded['target_std'] = self.target_std.copy()
@@ -263,7 +272,7 @@ def decode(self,
if target_root is not None and target_root.size > 0:
keypoints = keypoints + target_root
- if self.remove_root:
+ if self.remove_root and len(self.root_index) == 1:
keypoints = np.insert(
keypoints, self.root_index, target_root, axis=1)
scores = np.ones(keypoints.shape[:-1], dtype=np.float32)
diff --git a/mmpose/codecs/simcc_label.py b/mmpose/codecs/simcc_label.py
index 6183e2be73..e83960faaf 100644
--- a/mmpose/codecs/simcc_label.py
+++ b/mmpose/codecs/simcc_label.py
@@ -47,6 +47,12 @@ class SimCCLabel(BaseKeypointCodec):
will be :math:`w*simcc_split_ratio`. Defaults to 2.0
label_smooth_weight (float): Label Smoothing weight. Defaults to 0.0
normalize (bool): Whether to normalize the heatmaps. Defaults to True.
+ use_dark (bool): Whether to use the DARK post processing. Defaults to
+ False.
+ decode_visibility (bool): Whether to decode the visibility. Defaults
+ to False.
+ decode_beta (float): The beta value for decoding visibility. Defaults
+ to 150.0.
.. _`SimCC: a Simple Coordinate Classification Perspective for Human Pose
Estimation`: https://arxiv.org/abs/2107.03332
@@ -58,14 +64,18 @@ class SimCCLabel(BaseKeypointCodec):
keypoint_weights='keypoint_weights',
)
- def __init__(self,
- input_size: Tuple[int, int],
- smoothing_type: str = 'gaussian',
- sigma: Union[float, int, Tuple[float]] = 6.0,
- simcc_split_ratio: float = 2.0,
- label_smooth_weight: float = 0.0,
- normalize: bool = True,
- use_dark: bool = False) -> None:
+ def __init__(
+ self,
+ input_size: Tuple[int, int],
+ smoothing_type: str = 'gaussian',
+ sigma: Union[float, int, Tuple[float]] = 6.0,
+ simcc_split_ratio: float = 2.0,
+ label_smooth_weight: float = 0.0,
+ normalize: bool = True,
+ use_dark: bool = False,
+ decode_visibility: bool = False,
+ decode_beta: float = 150.0,
+ ) -> None:
super().__init__()
self.input_size = input_size
@@ -74,6 +84,8 @@ def __init__(self,
self.label_smooth_weight = label_smooth_weight
self.normalize = normalize
self.use_dark = use_dark
+ self.decode_visibility = decode_visibility
+ self.decode_beta = decode_beta
if isinstance(sigma, (float, int)):
self.sigma = np.array([sigma, sigma])
@@ -178,7 +190,14 @@ def decode(self, simcc_x: np.ndarray,
keypoints /= self.simcc_split_ratio
- return keypoints, scores
+ if self.decode_visibility:
+ _, visibility = get_simcc_maximum(
+ simcc_x * self.decode_beta * self.sigma[0],
+ simcc_y * self.decode_beta * self.sigma[1],
+ apply_softmax=True)
+ return keypoints, (scores, visibility)
+ else:
+ return keypoints, scores
def _map_coordinates(
self,
diff --git a/mmpose/codecs/spr.py b/mmpose/codecs/spr.py
index 8e09b185c7..fba17f1598 100644
--- a/mmpose/codecs/spr.py
+++ b/mmpose/codecs/spr.py
@@ -138,7 +138,7 @@ def _get_heatmap_weights(self,
Returns:
np.ndarray: Heatmap weight array in the same shape with heatmaps
"""
- heatmap_weights = np.ones(heatmaps.shape) * bg_weight
+ heatmap_weights = np.ones(heatmaps.shape, dtype=np.float32) * bg_weight
heatmap_weights[heatmaps > 0] = fg_weight
return heatmap_weights
diff --git a/mmpose/codecs/utils/post_processing.py b/mmpose/codecs/utils/post_processing.py
index 7bb447e199..d8637e2bc2 100644
--- a/mmpose/codecs/utils/post_processing.py
+++ b/mmpose/codecs/utils/post_processing.py
@@ -39,7 +39,9 @@ def get_simcc_normalized(batch_pred_simcc, sigma=None):
def get_simcc_maximum(simcc_x: np.ndarray,
- simcc_y: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
+ simcc_y: np.ndarray,
+ apply_softmax: bool = False
+ ) -> Tuple[np.ndarray, np.ndarray]:
"""Get maximum response location and value from simcc representations.
Note:
@@ -51,6 +53,8 @@ def get_simcc_maximum(simcc_x: np.ndarray,
Args:
simcc_x (np.ndarray): x-axis SimCC in shape (K, Wx) or (N, K, Wx)
simcc_y (np.ndarray): y-axis SimCC in shape (K, Wy) or (N, K, Wy)
+ apply_softmax (bool): whether to apply softmax on the heatmap.
+ Defaults to False.
Returns:
tuple:
@@ -76,6 +80,13 @@ def get_simcc_maximum(simcc_x: np.ndarray,
else:
N = None
+ if apply_softmax:
+ simcc_x = simcc_x - np.max(simcc_x, axis=1, keepdims=True)
+ simcc_y = simcc_y - np.max(simcc_y, axis=1, keepdims=True)
+ ex, ey = np.exp(simcc_x), np.exp(simcc_y)
+ simcc_x = ex / np.sum(ex, axis=1, keepdims=True)
+ simcc_y = ey / np.sum(ey, axis=1, keepdims=True)
+
x_locs = np.argmax(simcc_x, axis=1)
y_locs = np.argmax(simcc_y, axis=1)
locs = np.stack((x_locs, y_locs), axis=-1).astype(np.float32)
diff --git a/mmpose/codecs/video_pose_lifting.py b/mmpose/codecs/video_pose_lifting.py
index 2b08b4da85..5a5a7b1983 100644
--- a/mmpose/codecs/video_pose_lifting.py
+++ b/mmpose/codecs/video_pose_lifting.py
@@ -1,7 +1,7 @@
# Copyright (c) OpenMMLab. All rights reserved.
from copy import deepcopy
-from typing import Optional, Tuple
+from typing import List, Optional, Tuple, Union
import numpy as np
@@ -24,7 +24,8 @@ class VideoPoseLifting(BaseKeypointCodec):
num_keypoints (int): The number of keypoints in the dataset.
zero_center: Whether to zero-center the target around root. Default:
``True``.
- root_index (int): Root keypoint index in the pose. Default: 0.
+ root_index (Union[int, List]): Root keypoint index in the pose.
+ Default: 0.
remove_root (bool): If true, remove the root keypoint from the pose.
Default: ``False``.
save_index (bool): If true, store the root position separated from the
@@ -54,7 +55,7 @@ class VideoPoseLifting(BaseKeypointCodec):
def __init__(self,
num_keypoints: int,
zero_center: bool = True,
- root_index: int = 0,
+ root_index: Union[int, List] = 0,
remove_root: bool = False,
save_index: bool = False,
reshape_keypoints: bool = True,
@@ -64,6 +65,8 @@ def __init__(self,
self.num_keypoints = num_keypoints
self.zero_center = zero_center
+ if isinstance(root_index, int):
+ root_index = [root_index]
self.root_index = root_index
self.remove_root = remove_root
self.save_index = save_index
@@ -143,19 +146,19 @@ def encode(self,
# Zero-center the target pose around a given root keypoint
if self.zero_center:
assert (lifting_target.ndim >= 2 and
- lifting_target.shape[-2] > self.root_index), \
+ lifting_target.shape[-2] > max(self.root_index)), \
f'Got invalid joint shape {lifting_target.shape}'
- root = lifting_target[..., self.root_index, :]
- lifting_target_label -= lifting_target_label[
- ..., self.root_index:self.root_index + 1, :]
+ root = np.mean(lifting_target[..., self.root_index, :], axis=-2)
+ lifting_target_label -= root[..., np.newaxis, :]
encoded['target_root'] = root
- if self.remove_root:
+ if self.remove_root and len(self.root_index) == 1:
+ root_index = self.root_index[0]
lifting_target_label = np.delete(
- lifting_target_label, self.root_index, axis=-2)
+ lifting_target_label, root_index, axis=-2)
lifting_target_visible = np.delete(
- lifting_target_visible, self.root_index, axis=-2)
+ lifting_target_visible, root_index, axis=-2)
assert lifting_target_weight.ndim in {
2, 3
}, (f'Got invalid lifting target weights shape '
@@ -163,16 +166,14 @@ def encode(self,
axis_to_remove = -2 if lifting_target_weight.ndim == 3 else -1
lifting_target_weight = np.delete(
- lifting_target_weight,
- self.root_index,
- axis=axis_to_remove)
+ lifting_target_weight, root_index, axis=axis_to_remove)
# Add a flag to avoid latter transforms that rely on the root
# joint or the original joint index
encoded['target_root_removed'] = True
# Save the root index for restoring the global pose
if self.save_index:
- encoded['target_root_index'] = self.root_index
+ encoded['target_root_index'] = root_index
# Normalize the 2D keypoint coordinate with image width and height
_camera_param = deepcopy(camera_param)
@@ -237,7 +238,7 @@ def decode(self,
if target_root is not None and target_root.size > 0:
keypoints = keypoints + target_root
- if self.remove_root:
+ if self.remove_root and len(self.root_index) == 1:
keypoints = np.insert(
keypoints, self.root_index, target_root, axis=1)
scores = np.ones(keypoints.shape[:-1], dtype=np.float32)
diff --git a/mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-l_8xb1024-270e_cocktail14-256x192.py b/mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-l_8xb1024-270e_cocktail14-256x192.py
new file mode 100644
index 0000000000..a87290ecb6
--- /dev/null
+++ b/mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-l_8xb1024-270e_cocktail14-256x192.py
@@ -0,0 +1,637 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.config import read_base
+
+with read_base():
+ from mmpose.configs._base_.default_runtime import * # noqa
+
+from albumentations.augmentations import Blur, CoarseDropout, MedianBlur
+from mmdet.engine.hooks import PipelineSwitchHook
+from mmengine.dataset import DefaultSampler
+from mmengine.hooks import EMAHook
+from mmengine.model import PretrainedInit
+from mmengine.optim import CosineAnnealingLR, LinearLR, OptimWrapper
+from torch.nn import SiLU, SyncBatchNorm
+from torch.optim import AdamW
+
+from mmpose.codecs import SimCCLabel
+from mmpose.datasets import (AicDataset, CocoWholeBodyDataset, COFWDataset,
+ CombinedDataset, CrowdPoseDataset,
+ Face300WDataset, GenerateTarget,
+ GetBBoxCenterScale, HalpeDataset,
+ HumanArt21Dataset, InterHand2DDoubleDataset,
+ JhmdbDataset, KeypointConverter, LapaDataset,
+ LoadImage, MpiiDataset, PackPoseInputs,
+ PoseTrack18Dataset, RandomFlip, RandomHalfBody,
+ TopdownAffine, UBody2dDataset, WFLWDataset)
+from mmpose.datasets.transforms.common_transforms import (
+ Albumentation, PhotometricDistortion, RandomBBoxTransform)
+from mmpose.engine.hooks import ExpMomentumEMA
+from mmpose.evaluation import CocoWholeBodyMetric
+from mmpose.models import (CSPNeXt, CSPNeXtPAFPN, KLDiscretLoss,
+ PoseDataPreprocessor, RTMWHead,
+ TopdownPoseEstimator)
+
+# common setting
+num_keypoints = 133
+input_size = (192, 256)
+
+# runtime
+max_epochs = 270
+stage2_num_epochs = 10
+base_lr = 5e-4
+train_batch_size = 1024
+val_batch_size = 32
+
+train_cfg.update(max_epochs=max_epochs, val_interval=10) # noqa
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type=OptimWrapper,
+ optimizer=dict(type=AdamW, lr=base_lr, weight_decay=0.1),
+ clip_grad=dict(max_norm=35, norm_type=2),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type=LinearLR, start_factor=1.0e-5, by_epoch=False, begin=0, end=1000),
+ dict(
+ type=CosineAnnealingLR,
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=8192)
+
+# codec settings
+codec = dict(
+ type=SimCCLabel,
+ input_size=input_size,
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type=TopdownPoseEstimator,
+ data_preprocessor=dict(
+ type=PoseDataPreprocessor,
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ type=CSPNeXt,
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=1.,
+ widen_factor=1.,
+ channel_attention=True,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type=SiLU),
+ init_cfg=dict(
+ type=PretrainedInit,
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmposev1/rtmpose-l_simcc-ucoco_dw-ucoco_270e-256x192-4d6dfc62_20230728.pth' # noqa
+ )),
+ neck=dict(
+ type=CSPNeXtPAFPN,
+ in_channels=[256, 512, 1024],
+ out_channels=None,
+ out_indices=(
+ 1,
+ 2,
+ ),
+ num_csp_blocks=2,
+ expand_ratio=0.5,
+ norm_cfg=dict(type=SyncBatchNorm),
+ act_cfg=dict(type=SiLU, inplace=True)),
+ head=dict(
+ type=RTMWHead,
+ in_channels=1024,
+ out_channels=num_keypoints,
+ input_size=input_size,
+ in_featuremap_size=tuple([s // 32 for s in input_size]),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type=KLDiscretLoss,
+ use_target_weight=True,
+ beta=1.,
+ label_softmax=True,
+ label_beta=10.,
+ mask=list(range(23, 91)),
+ mask_weight=0.5,
+ ),
+ decoder=codec),
+ test_cfg=dict(flip_test=True))
+
+# base dataset settings
+dataset_type = CocoWholeBodyDataset
+data_mode = 'topdown'
+data_root = 'data/'
+
+backend_args = dict(backend='local')
+
+# pipelines
+train_pipeline = [
+ dict(type=LoadImage, backend_args=backend_args),
+ dict(type=GetBBoxCenterScale),
+ dict(type=RandomFlip, direction='horizontal'),
+ dict(type=RandomHalfBody),
+ dict(type=RandomBBoxTransform, scale_factor=[0.5, 1.5], rotate_factor=90),
+ dict(type=TopdownAffine, input_size=codec['input_size']),
+ dict(type=PhotometricDistortion),
+ dict(
+ type=Albumentation,
+ transforms=[
+ dict(type=Blur, p=0.1),
+ dict(type=MedianBlur, p=0.1),
+ dict(
+ type=CoarseDropout,
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(
+ type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True),
+ dict(type=PackPoseInputs)
+]
+val_pipeline = [
+ dict(type=LoadImage, backend_args=backend_args),
+ dict(type=GetBBoxCenterScale),
+ dict(type=TopdownAffine, input_size=codec['input_size']),
+ dict(type=PackPoseInputs)
+]
+train_pipeline_stage2 = [
+ dict(type=LoadImage, backend_args=backend_args),
+ dict(type=GetBBoxCenterScale),
+ dict(type=RandomFlip, direction='horizontal'),
+ dict(type=RandomHalfBody),
+ dict(
+ type=RandomBBoxTransform,
+ shift_factor=0.,
+ scale_factor=[0.5, 1.5],
+ rotate_factor=90),
+ dict(type=TopdownAffine, input_size=codec['input_size']),
+ dict(
+ type=Albumentation,
+ transforms=[
+ dict(type=Blur, p=0.1),
+ dict(type=MedianBlur, p=0.1),
+ ]),
+ dict(
+ type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True),
+ dict(type=PackPoseInputs)
+]
+
+# mapping
+
+aic_coco133 = [(0, 6), (1, 8), (2, 10), (3, 5), (4, 7), (5, 9), (6, 12),
+ (7, 14), (8, 16), (9, 11), (10, 13), (11, 15)]
+
+crowdpose_coco133 = [(0, 5), (1, 6), (2, 7), (3, 8), (4, 9), (5, 10), (6, 11),
+ (7, 12), (8, 13), (9, 14), (10, 15), (11, 16)]
+
+mpii_coco133 = [
+ (0, 16),
+ (1, 14),
+ (2, 12),
+ (3, 11),
+ (4, 13),
+ (5, 15),
+ (10, 10),
+ (11, 8),
+ (12, 6),
+ (13, 5),
+ (14, 7),
+ (15, 9),
+]
+
+jhmdb_coco133 = [
+ (3, 6),
+ (4, 5),
+ (5, 12),
+ (6, 11),
+ (7, 8),
+ (8, 7),
+ (9, 14),
+ (10, 13),
+ (11, 10),
+ (12, 9),
+ (13, 16),
+ (14, 15),
+]
+
+halpe_coco133 = [(i, i)
+ for i in range(17)] + [(20, 17), (21, 20), (22, 18), (23, 21),
+ (24, 19),
+ (25, 22)] + [(i, i - 3)
+ for i in range(26, 136)]
+
+posetrack_coco133 = [
+ (0, 0),
+ (3, 3),
+ (4, 4),
+ (5, 5),
+ (6, 6),
+ (7, 7),
+ (8, 8),
+ (9, 9),
+ (10, 10),
+ (11, 11),
+ (12, 12),
+ (13, 13),
+ (14, 14),
+ (15, 15),
+ (16, 16),
+]
+
+humanart_coco133 = [(i, i) for i in range(17)] + [(17, 99), (18, 120),
+ (19, 17), (20, 20)]
+
+# train datasets
+dataset_coco = dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='coco/annotations/coco_wholebody_train_v1.0.json',
+ data_prefix=dict(img='detection/coco/train2017/'),
+ pipeline=[],
+)
+
+dataset_aic = dict(
+ type=AicDataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='aic/annotations/aic_train.json',
+ data_prefix=dict(img='pose/ai_challenge/ai_challenger_keypoint'
+ '_train_20170902/keypoint_train_images_20170902/'),
+ pipeline=[
+ dict(
+ type=KeypointConverter,
+ num_keypoints=num_keypoints,
+ mapping=aic_coco133)
+ ],
+)
+
+dataset_crowdpose = dict(
+ type=CrowdPoseDataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='crowdpose/annotations/mmpose_crowdpose_trainval.json',
+ data_prefix=dict(img='pose/CrowdPose/images/'),
+ pipeline=[
+ dict(
+ type=KeypointConverter,
+ num_keypoints=num_keypoints,
+ mapping=crowdpose_coco133)
+ ],
+)
+
+dataset_mpii = dict(
+ type=MpiiDataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='mpii/annotations/mpii_train.json',
+ data_prefix=dict(img='pose/MPI/images/'),
+ pipeline=[
+ dict(
+ type=KeypointConverter,
+ num_keypoints=num_keypoints,
+ mapping=mpii_coco133)
+ ],
+)
+
+dataset_jhmdb = dict(
+ type=JhmdbDataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='jhmdb/annotations/Sub1_train.json',
+ data_prefix=dict(img='pose/JHMDB/'),
+ pipeline=[
+ dict(
+ type=KeypointConverter,
+ num_keypoints=num_keypoints,
+ mapping=jhmdb_coco133)
+ ],
+)
+
+dataset_halpe = dict(
+ type=HalpeDataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='halpe/annotations/halpe_train_v1.json',
+ data_prefix=dict(img='pose/Halpe/hico_20160224_det/images/train2015'),
+ pipeline=[
+ dict(
+ type=KeypointConverter,
+ num_keypoints=num_keypoints,
+ mapping=halpe_coco133)
+ ],
+)
+
+dataset_posetrack = dict(
+ type=PoseTrack18Dataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='posetrack18/annotations/posetrack18_train.json',
+ data_prefix=dict(img='pose/PoseChallenge2018/'),
+ pipeline=[
+ dict(
+ type=KeypointConverter,
+ num_keypoints=num_keypoints,
+ mapping=posetrack_coco133)
+ ],
+)
+
+dataset_humanart = dict(
+ type=HumanArt21Dataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='HumanArt/annotations/training_humanart.json',
+ filter_cfg=dict(scenes=['real_human']),
+ data_prefix=dict(img='pose/'),
+ pipeline=[
+ dict(
+ type=KeypointConverter,
+ num_keypoints=num_keypoints,
+ mapping=humanart_coco133)
+ ])
+
+ubody_scenes = [
+ 'Magic_show', 'Entertainment', 'ConductMusic', 'Online_class', 'TalkShow',
+ 'Speech', 'Fitness', 'Interview', 'Olympic', 'TVShow', 'Singing',
+ 'SignLanguage', 'Movie', 'LiveVlog', 'VideoConference'
+]
+
+ubody_datasets = []
+for scene in ubody_scenes:
+ each = dict(
+ type=UBody2dDataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file=f'Ubody/annotations/{scene}/train_annotations.json',
+ data_prefix=dict(img='pose/UBody/images/'),
+ pipeline=[],
+ sample_interval=10)
+ ubody_datasets.append(each)
+
+dataset_ubody = dict(
+ type=CombinedDataset,
+ metainfo=dict(from_file='configs/_base_/datasets/ubody2d.py'),
+ datasets=ubody_datasets,
+ pipeline=[],
+ test_mode=False,
+)
+
+face_pipeline = [
+ dict(type=LoadImage, backend_args=backend_args),
+ dict(type=GetBBoxCenterScale, padding=1.25),
+ dict(
+ type=RandomBBoxTransform,
+ shift_factor=0.,
+ scale_factor=[1.5, 2.0],
+ rotate_factor=0),
+]
+
+wflw_coco133 = [(i * 2, 23 + i)
+ for i in range(17)] + [(33 + i, 40 + i) for i in range(5)] + [
+ (42 + i, 45 + i) for i in range(5)
+ ] + [(51 + i, 50 + i)
+ for i in range(9)] + [(60, 59), (61, 60), (63, 61),
+ (64, 62), (65, 63), (67, 64),
+ (68, 65), (69, 66), (71, 67),
+ (72, 68), (73, 69),
+ (75, 70)] + [(76 + i, 71 + i)
+ for i in range(20)]
+dataset_wflw = dict(
+ type=WFLWDataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='wflw/annotations/face_landmarks_wflw_train.json',
+ data_prefix=dict(img='pose/WFLW/images/'),
+ pipeline=[
+ dict(
+ type=KeypointConverter,
+ num_keypoints=num_keypoints,
+ mapping=wflw_coco133), *face_pipeline
+ ],
+)
+
+mapping_300w_coco133 = [(i, 23 + i) for i in range(68)]
+dataset_300w = dict(
+ type=Face300WDataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='300w/annotations/face_landmarks_300w_train.json',
+ data_prefix=dict(img='pose/300w/images/'),
+ pipeline=[
+ dict(
+ type=KeypointConverter,
+ num_keypoints=num_keypoints,
+ mapping=mapping_300w_coco133), *face_pipeline
+ ],
+)
+
+cofw_coco133 = [(0, 40), (2, 44), (4, 42), (1, 49), (3, 45), (6, 47), (8, 59),
+ (10, 62), (9, 68), (11, 65), (18, 54), (19, 58), (20, 53),
+ (21, 56), (22, 71), (23, 77), (24, 74), (25, 85), (26, 89),
+ (27, 80), (28, 31)]
+dataset_cofw = dict(
+ type=COFWDataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='cofw/annotations/cofw_train.json',
+ data_prefix=dict(img='pose/COFW/images/'),
+ pipeline=[
+ dict(
+ type=KeypointConverter,
+ num_keypoints=num_keypoints,
+ mapping=cofw_coco133), *face_pipeline
+ ],
+)
+
+lapa_coco133 = [(i * 2, 23 + i) for i in range(17)] + [
+ (33 + i, 40 + i) for i in range(5)
+] + [(42 + i, 45 + i) for i in range(5)] + [
+ (51 + i, 50 + i) for i in range(4)
+] + [(58 + i, 54 + i) for i in range(5)] + [(66, 59), (67, 60), (69, 61),
+ (70, 62), (71, 63), (73, 64),
+ (75, 65), (76, 66), (78, 67),
+ (79, 68), (80, 69),
+ (82, 70)] + [(84 + i, 71 + i)
+ for i in range(20)]
+dataset_lapa = dict(
+ type=LapaDataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='LaPa/annotations/lapa_trainval.json',
+ data_prefix=dict(img='pose/LaPa/'),
+ pipeline=[
+ dict(
+ type=KeypointConverter,
+ num_keypoints=num_keypoints,
+ mapping=lapa_coco133), *face_pipeline
+ ],
+)
+
+dataset_wb = dict(
+ type=CombinedDataset,
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[dataset_coco, dataset_halpe, dataset_ubody],
+ pipeline=[],
+ test_mode=False,
+)
+
+dataset_body = dict(
+ type=CombinedDataset,
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[
+ dataset_aic,
+ dataset_crowdpose,
+ dataset_mpii,
+ dataset_jhmdb,
+ dataset_posetrack,
+ dataset_humanart,
+ ],
+ pipeline=[],
+ test_mode=False,
+)
+
+dataset_face = dict(
+ type=CombinedDataset,
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[
+ dataset_wflw,
+ dataset_300w,
+ dataset_cofw,
+ dataset_lapa,
+ ],
+ pipeline=[],
+ test_mode=False,
+)
+
+hand_pipeline = [
+ dict(type=LoadImage, backend_args=backend_args),
+ dict(type=GetBBoxCenterScale),
+ dict(
+ type=RandomBBoxTransform,
+ shift_factor=0.,
+ scale_factor=[1.5, 2.0],
+ rotate_factor=0),
+]
+
+interhand_left = [(21, 95), (22, 94), (23, 93), (24, 92), (25, 99), (26, 98),
+ (27, 97), (28, 96), (29, 103), (30, 102), (31, 101),
+ (32, 100), (33, 107), (34, 106), (35, 105), (36, 104),
+ (37, 111), (38, 110), (39, 109), (40, 108), (41, 91)]
+interhand_right = [(i - 21, j + 21) for i, j in interhand_left]
+interhand_coco133 = interhand_right + interhand_left
+
+dataset_interhand2d = dict(
+ type=InterHand2DDoubleDataset,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='interhand26m/annotations/all/InterHand2.6M_train_data.json',
+ camera_param_file='interhand26m/annotations/all/'
+ 'InterHand2.6M_train_camera.json',
+ joint_file='interhand26m/annotations/all/'
+ 'InterHand2.6M_train_joint_3d.json',
+ data_prefix=dict(img='interhand2.6m/images/train/'),
+ sample_interval=10,
+ pipeline=[
+ dict(
+ type=KeypointConverter,
+ num_keypoints=num_keypoints,
+ mapping=interhand_coco133,
+ ), *hand_pipeline
+ ],
+)
+
+dataset_hand = dict(
+ type=CombinedDataset,
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=[dataset_interhand2d],
+ pipeline=[],
+ test_mode=False,
+)
+
+train_datasets = [dataset_wb, dataset_body, dataset_face, dataset_hand]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=train_batch_size,
+ num_workers=4,
+ pin_memory=False,
+ persistent_workers=True,
+ sampler=dict(type=DefaultSampler, shuffle=True),
+ dataset=dict(
+ type=CombinedDataset,
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=train_datasets,
+ pipeline=train_pipeline,
+ test_mode=False,
+ ))
+
+val_dataloader = dict(
+ batch_size=val_batch_size,
+ num_workers=4,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type=DefaultSampler, shuffle=False, round_up=False),
+ dataset=dict(
+ type=CocoWholeBodyDataset,
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json',
+ data_prefix=dict(img='data/detection/coco/val2017/'),
+ pipeline=val_pipeline,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ test_mode=True))
+
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks.update( # noqa
+ checkpoint=dict(
+ save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type=EMAHook,
+ ema_type=ExpMomentumEMA,
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type=PipelineSwitchHook,
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type=CocoWholeBodyMetric,
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json')
+test_evaluator = val_evaluator
diff --git a/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb320-270e_cocktail13-384x288.py b/mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-l_8xb320-270e_cocktail14-384x288.py
similarity index 96%
rename from projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb320-270e_cocktail13-384x288.py
rename to mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-l_8xb320-270e_cocktail14-384x288.py
index 55d07b61a8..58172f7cc5 100644
--- a/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb320-270e_cocktail13-384x288.py
+++ b/mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-l_8xb320-270e_cocktail14-384x288.py
@@ -48,7 +48,7 @@
# optimizer
optim_wrapper = dict(
type=OptimWrapper,
- optimizer=dict(type=AdamW, lr=base_lr, weight_decay=0.05),
+ optimizer=dict(type=AdamW, lr=base_lr, weight_decay=0.1),
clip_grad=dict(max_norm=35, norm_type=2),
paramwise_cfg=dict(
norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
@@ -68,7 +68,7 @@
]
# automatically scaling LR based on the actual training batch size
-auto_scale_lr = dict(base_batch_size=5632)
+auto_scale_lr = dict(base_batch_size=2560)
# codec settings
codec = dict(
@@ -91,20 +91,20 @@
type=CSPNeXt,
arch='P5',
expand_ratio=0.5,
- deepen_factor=1.33,
- widen_factor=1.25,
+ deepen_factor=1.,
+ widen_factor=1.,
channel_attention=True,
norm_cfg=dict(type='BN'),
act_cfg=dict(type=SiLU),
init_cfg=dict(
- type=PretrainedInit,
+ type='Pretrained',
prefix='backbone.',
- checkpoint='https://download.openmmlab.com/mmpose/v1/'
- 'wholebody_2d_keypoint/rtmpose/ubody/rtmpose-x_simcc-ucoco_pt-aic-coco_270e-384x288-f5b50679_20230822.pth' # noqa
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmposev1/rtmpose-l_simcc-ucoco_dw-ucoco_270e-256x192-4d6dfc62_20230728.pth' # noqa
)),
neck=dict(
type=CSPNeXtPAFPN,
- in_channels=[320, 640, 1280],
+ in_channels=[256, 512, 1024],
out_channels=None,
out_indices=(
1,
@@ -116,7 +116,7 @@
act_cfg=dict(type=SiLU, inplace=True)),
head=dict(
type=RTMWHead,
- in_channels=1280,
+ in_channels=1024,
out_channels=num_keypoints,
input_size=input_size,
in_featuremap_size=tuple([s // 32 for s in input_size]),
@@ -128,14 +128,18 @@
expansion_factor=2,
dropout_rate=0.,
drop_path=0.,
- act_fn=SiLU,
+ act_fn='SiLU',
use_rel_bias=False,
pos_enc=False),
loss=dict(
type=KLDiscretLoss,
use_target_weight=True,
- beta=10.,
- label_softmax=True),
+ beta=1.,
+ label_softmax=True,
+ label_beta=10.,
+ mask=list(range(23, 91)),
+ mask_weight=0.5,
+ ),
decoder=codec),
test_cfg=dict(flip_test=True))
@@ -168,7 +172,7 @@
min_holes=1,
min_height=0.2,
min_width=0.2,
- p=1.0),
+ p=0.5),
]),
dict(
type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True),
@@ -217,8 +221,6 @@
(3, 11),
(4, 13),
(5, 15),
- (8, 18),
- (9, 17),
(10, 10),
(11, 8),
(12, 6),
@@ -228,8 +230,6 @@
]
jhmdb_coco133 = [
- (0, 18),
- (2, 17),
(3, 6),
(4, 5),
(5, 12),
@@ -252,7 +252,6 @@
posetrack_coco133 = [
(0, 0),
- (2, 17),
(3, 3),
(4, 4),
(5, 5),
diff --git a/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb704-270e_cocktail13-256x192.py b/mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-m_8xb1024-270e_cocktail14-256x192.py
similarity index 97%
rename from projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb704-270e_cocktail13-256x192.py
rename to mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-m_8xb1024-270e_cocktail14-256x192.py
index 48275c3c11..dd46cce5ff 100644
--- a/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb704-270e_cocktail13-256x192.py
+++ b/mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-m_8xb1024-270e_cocktail14-256x192.py
@@ -39,7 +39,7 @@
max_epochs = 270
stage2_num_epochs = 10
base_lr = 5e-4
-train_batch_size = 704
+train_batch_size = 1024
val_batch_size = 32
train_cfg.update(max_epochs=max_epochs, val_interval=10) # noqa
@@ -68,7 +68,7 @@
]
# automatically scaling LR based on the actual training batch size
-auto_scale_lr = dict(base_batch_size=5632)
+auto_scale_lr = dict(base_batch_size=8192)
# codec settings
codec = dict(
@@ -91,20 +91,20 @@
type=CSPNeXt,
arch='P5',
expand_ratio=0.5,
- deepen_factor=1.33,
- widen_factor=1.25,
+ deepen_factor=0.67,
+ widen_factor=0.75,
channel_attention=True,
norm_cfg=dict(type='BN'),
act_cfg=dict(type=SiLU),
init_cfg=dict(
type=PretrainedInit,
prefix='backbone.',
- checkpoint='https://download.openmmlab.com/mmpose/v1/'
- 'wholebody_2d_keypoint/rtmpose/ubody/rtmpose-x_simcc-ucoco_pt-aic-coco_270e-256x192-05f5bcb7_20230822.pth' # noqa
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmposev1/rtmpose-m_simcc-ucoco_dw-ucoco_270e-256x192-c8b76419_20230728.pth' # noqa
)),
neck=dict(
type=CSPNeXtPAFPN,
- in_channels=[320, 640, 1280],
+ in_channels=[192, 384, 768],
out_channels=None,
out_indices=(
1,
@@ -116,7 +116,7 @@
act_cfg=dict(type=SiLU, inplace=True)),
head=dict(
type=RTMWHead,
- in_channels=1280,
+ in_channels=768,
out_channels=num_keypoints,
input_size=input_size,
in_featuremap_size=tuple([s // 32 for s in input_size]),
@@ -128,14 +128,18 @@
expansion_factor=2,
dropout_rate=0.,
drop_path=0.,
- act_fn=SiLU,
+ act_fn='SiLU',
use_rel_bias=False,
pos_enc=False),
loss=dict(
type=KLDiscretLoss,
use_target_weight=True,
- beta=10.,
- label_softmax=True),
+ beta=1.,
+ label_softmax=True,
+ label_beta=10.,
+ mask=list(range(23, 91)),
+ mask_weight=0.5,
+ ),
decoder=codec),
test_cfg=dict(flip_test=True))
@@ -168,7 +172,7 @@
min_holes=1,
min_height=0.2,
min_width=0.2,
- p=1.0),
+ p=0.5),
]),
dict(
type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True),
@@ -180,7 +184,6 @@
dict(type=TopdownAffine, input_size=codec['input_size']),
dict(type=PackPoseInputs)
]
-
train_pipeline_stage2 = [
dict(type=LoadImage, backend_args=backend_args),
dict(type=GetBBoxCenterScale),
@@ -218,8 +221,6 @@
(3, 11),
(4, 13),
(5, 15),
- (8, 18),
- (9, 17),
(10, 10),
(11, 8),
(12, 6),
@@ -229,8 +230,6 @@
]
jhmdb_coco133 = [
- (0, 18),
- (2, 17),
(3, 6),
(4, 5),
(5, 12),
@@ -253,7 +252,6 @@
posetrack_coco133 = [
(0, 0),
- (2, 17),
(3, 3),
(4, 4),
(5, 5),
diff --git a/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb320-270e_cocktail13-384x288.py b/mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb320-270e_cocktail14-384x288.py
similarity index 98%
rename from configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb320-270e_cocktail13-384x288.py
rename to mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb320-270e_cocktail14-384x288.py
index 55d07b61a8..73fe642366 100644
--- a/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb320-270e_cocktail13-384x288.py
+++ b/mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb320-270e_cocktail14-384x288.py
@@ -48,7 +48,7 @@
# optimizer
optim_wrapper = dict(
type=OptimWrapper,
- optimizer=dict(type=AdamW, lr=base_lr, weight_decay=0.05),
+ optimizer=dict(type=AdamW, lr=base_lr, weight_decay=0.1),
clip_grad=dict(max_norm=35, norm_type=2),
paramwise_cfg=dict(
norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
@@ -68,7 +68,7 @@
]
# automatically scaling LR based on the actual training batch size
-auto_scale_lr = dict(base_batch_size=5632)
+auto_scale_lr = dict(base_batch_size=2560)
# codec settings
codec = dict(
@@ -128,14 +128,18 @@
expansion_factor=2,
dropout_rate=0.,
drop_path=0.,
- act_fn=SiLU,
+ act_fn='SiLU',
use_rel_bias=False,
pos_enc=False),
loss=dict(
type=KLDiscretLoss,
use_target_weight=True,
- beta=10.,
- label_softmax=True),
+ beta=1.,
+ label_softmax=True,
+ label_beta=10.,
+ mask=list(range(23, 91)),
+ mask_weight=0.5,
+ ),
decoder=codec),
test_cfg=dict(flip_test=True))
@@ -168,7 +172,7 @@
min_holes=1,
min_height=0.2,
min_width=0.2,
- p=1.0),
+ p=0.5),
]),
dict(
type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True),
@@ -217,8 +221,6 @@
(3, 11),
(4, 13),
(5, 15),
- (8, 18),
- (9, 17),
(10, 10),
(11, 8),
(12, 6),
@@ -228,8 +230,6 @@
]
jhmdb_coco133 = [
- (0, 18),
- (2, 17),
(3, 6),
(4, 5),
(5, 12),
@@ -252,7 +252,6 @@
posetrack_coco133 = [
(0, 0),
- (2, 17),
(3, 3),
(4, 4),
(5, 5),
diff --git a/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb704-270e_cocktail13-256x192.py b/mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb704-270e_cocktail14-256x192.py
similarity index 98%
rename from configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb704-270e_cocktail13-256x192.py
rename to mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb704-270e_cocktail14-256x192.py
index 48275c3c11..b4447fa1d7 100644
--- a/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb704-270e_cocktail13-256x192.py
+++ b/mmpose/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb704-270e_cocktail14-256x192.py
@@ -48,7 +48,7 @@
# optimizer
optim_wrapper = dict(
type=OptimWrapper,
- optimizer=dict(type=AdamW, lr=base_lr, weight_decay=0.05),
+ optimizer=dict(type=AdamW, lr=base_lr, weight_decay=0.1),
clip_grad=dict(max_norm=35, norm_type=2),
paramwise_cfg=dict(
norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
@@ -128,14 +128,18 @@
expansion_factor=2,
dropout_rate=0.,
drop_path=0.,
- act_fn=SiLU,
+ act_fn='SiLU',
use_rel_bias=False,
pos_enc=False),
loss=dict(
type=KLDiscretLoss,
use_target_weight=True,
- beta=10.,
- label_softmax=True),
+ beta=1.,
+ label_softmax=True,
+ label_beta=10.,
+ mask=list(range(23, 91)),
+ mask_weight=0.5,
+ ),
decoder=codec),
test_cfg=dict(flip_test=True))
@@ -168,7 +172,7 @@
min_holes=1,
min_height=0.2,
min_width=0.2,
- p=1.0),
+ p=0.5),
]),
dict(
type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True),
@@ -180,7 +184,6 @@
dict(type=TopdownAffine, input_size=codec['input_size']),
dict(type=PackPoseInputs)
]
-
train_pipeline_stage2 = [
dict(type=LoadImage, backend_args=backend_args),
dict(type=GetBBoxCenterScale),
@@ -218,8 +221,6 @@
(3, 11),
(4, 13),
(5, 15),
- (8, 18),
- (9, 17),
(10, 10),
(11, 8),
(12, 6),
@@ -229,8 +230,6 @@
]
jhmdb_coco133 = [
- (0, 18),
- (2, 17),
(3, 6),
(4, 5),
(5, 12),
@@ -253,7 +252,6 @@
posetrack_coco133 = [
(0, 0),
- (2, 17),
(3, 3),
(4, 4),
(5, 5),
diff --git a/mmpose/datasets/datasets/body/__init__.py b/mmpose/datasets/datasets/body/__init__.py
index 3ae05a3856..c4e3cca37a 100644
--- a/mmpose/datasets/datasets/body/__init__.py
+++ b/mmpose/datasets/datasets/body/__init__.py
@@ -2,6 +2,7 @@
from .aic_dataset import AicDataset
from .coco_dataset import CocoDataset
from .crowdpose_dataset import CrowdPoseDataset
+from .exlpose_dataset import ExlposeDataset
from .humanart21_dataset import HumanArt21Dataset
from .humanart_dataset import HumanArtDataset
from .jhmdb_dataset import JhmdbDataset
@@ -16,5 +17,5 @@
'CocoDataset', 'MpiiDataset', 'MpiiTrbDataset', 'AicDataset',
'CrowdPoseDataset', 'OCHumanDataset', 'MhpDataset', 'PoseTrack18Dataset',
'JhmdbDataset', 'PoseTrack18VideoDataset', 'HumanArtDataset',
- 'HumanArt21Dataset'
+ 'HumanArt21Dataset', 'ExlposeDataset'
]
diff --git a/mmpose/datasets/datasets/body/exlpose_dataset.py b/mmpose/datasets/datasets/body/exlpose_dataset.py
new file mode 100644
index 0000000000..ad29f5d751
--- /dev/null
+++ b/mmpose/datasets/datasets/body/exlpose_dataset.py
@@ -0,0 +1,69 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class ExlposeDataset(BaseCocoStyleDataset):
+ """Exlpose dataset for pose estimation.
+
+ "Human Pose Estimation in Extremely Low-Light Conditions",
+ CVPR'2023.
+ More details can be found in the `paper
+