Supported algorithms:
- [x] [DeepPose](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#deeppose-cvpr-2014) (CVPR'2014) @@ -231,7 +211,7 @@ A summary can be found in the [Model Zoo](https://mmpose.readthedocs.io/en/lates - [x] [SCNet](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#scnet-cvpr-2020) (CVPR'2020) - [ ] [HigherHRNet](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#higherhrnet-cvpr-2020) (CVPR'2020) - [x] [RSN](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#rsn-eccv-2020) (ECCV'2020) -- [ ] [InterNet](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#internet-eccv-2020) (ECCV'2020) +- [x] [InterNet](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#internet-eccv-2020) (ECCV'2020) - [ ] [VoxelPose](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#voxelpose-eccv-2020) (ECCV'2020) - [x] [LiteHRNet](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#litehrnet-cvpr-2021) (CVPR'2021) - [x] [ViPNAS](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#vipnas-cvpr-2021) (CVPR'2021) @@ -240,7 +220,7 @@ A summary can be found in the [Model Zoo](https://mmpose.readthedocs.io/en/lates
+
-
Supported techniques:
- [x] [FPN](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/techniques.html#fpn-cvpr-2017) (CVPR'2017) @@ -255,7 +235,7 @@ A summary can be found in the [Model Zoo](https://mmpose.readthedocs.io/en/lates
+
-
Supported datasets:
- [x] [AFLW](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#aflw-iccvw-2011) \[[homepage](https://www.tugraz.at/institute/icg/research/team-bischof/lrs/downloads/aflw/)\] (ICCVW'2011) @@ -291,10 +271,11 @@ A summary can be found in the [Model Zoo](https://mmpose.readthedocs.io/en/lates - [x] [Horse-10](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#horse-10-wacv-2021) \[[homepage](http://www.mackenziemathislab.org/horse10)\] (WACV'2021) - [x] [Human-Art](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#human-art-cvpr-2023) \[[homepage](https://idea-research.github.io/HumanArt/)\] (CVPR'2023) - [x] [LaPa](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#lapa-aaai-2020) \[[homepage](https://github.com/JDAI-CV/lapa-dataset)\] (AAAI'2020) +- [x] [UBody](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/datasets.html#ubody-cvpr-2023) \[[homepage](https://github.com/IDEA-Research/OSX)\] (CVPR'2023)
+
[](https://mmpose.readthedocs.io/en/latest/?badge=latest)
-[](https://github.com/open-mmlab/mmpose/actions)
+[](https://github.com/open-mmlab/mmpose/actions)
[](https://codecov.io/gh/open-mmlab/mmpose)
[](https://pypi.org/project/mmpose/)
[](https://github.com/open-mmlab/mmpose/blob/main/LICENSE)
[](https://github.com/open-mmlab/mmpose/issues)
[](https://github.com/open-mmlab/mmpose/issues)
+[](https://openxlab.org.cn/apps?search=mmpose)
[📘文档](https://mmpose.readthedocs.io/zh_CN/latest/) |
[🛠️安装](https://mmpose.readthedocs.io/zh_CN/latest/installation.html) |
@@ -95,12 +96,21 @@ https://user-images.githubusercontent.com/15977946/124654387-0fd3c500-ded1-11eb-
## 最新进展
-- 我们支持了三个新的数据集:
- - (CVPR 2023) [Human-Art](https://github.com/IDEA-Research/HumanArt)
- - (CVPR 2022) [Animal Kingdom](https://github.com/sutdcv/Animal-Kingdom)
- - (AAAI 2020) [LaPa](https://github.com/JDAI-CV/lapa-dataset/)
+- 我们支持了两个新的数据集:
-
+ - (CVPR 2023) [UBody](https://mmpose.readthedocs.io/zh_CN/latest/model_zoo_papers/datasets.html#ubody-cvpr-2023)
+ - [300W-LP](https://github.com/open-mmlab/mmpose/tree/main/configs/face_2d_keypoint/topdown_heatmap/300wlp)
+
+- 支持四个新算法:
+
+ - (ICCV 2023) [MotionBERT](https://github.com/open-mmlab/mmpose/tree/main/configs/body_3d_keypoint/motionbert)
+ - (ICCVW 2023) [DWPose](https://github.com/open-mmlab/mmpose/tree/main/configs/wholebody_2d_keypoint/dwpose)
+ - (ICLR 2023) [EDPose](https://mmpose.readthedocs.io/zh_CN/latest/model_zoo/body_2d_keypoint.html#edpose-edpose-on-coco)
+ - (ICLR 2022) [Uniformer](https://github.com/open-mmlab/mmpose/tree/main/projects/uniformer)
+
+- 发布首个在 COCO-Wholebody 上精度超过 70 AP 的全身姿态估计模型 RTMW,具体请参考 [RTMPose](/projects/rtmpose/)。[在线试玩](https://openxlab.org.cn/apps/detail/mmpose/RTMPose)
+
+
- 欢迎使用 [*MMPose 项目*](/projects/README.md)。在这里,您可以发现 MMPose 中的最新功能和算法,并且可以通过最快的方式与社区分享自己的创意和代码实现。向 MMPose 中添加新功能从此变得简单丝滑:
@@ -112,59 +122,25 @@ https://user-images.githubusercontent.com/15977946/124654387-0fd3c500-ded1-11eb-
- [YOLOX-Pose](/projects/yolox_pose/)
- [MMPose4AIGC](/projects/mmpose4aigc/)
- [Simple Keypoints](/projects/skps/)
+ - [Just Dance](/projects/just_dance/)
+ - [Uniformer](/projects/uniformer/)
- 从简单的 [示例项目](/projects/example_project/) 开启您的 MMPose 代码贡献者之旅吧,让我们共同打造更好用的 MMPose!
-- 2023-07-04:MMPose [v1.1.0](https://github.com/open-mmlab/mmpose/releases/tag/v1.1.0) 正式发布了,主要更新包括: +- 2023-10-12:MMPose [v1.2.0](https://github.com/open-mmlab/mmpose/releases/tag/v1.2.0) 正式发布了,主要更新包括: - - 支持新数据集:Human-Art、Animal Kingdom、LaPa。 - - 支持新的配置文件风格,支持 IDE 跳转和搜索。 - - 提供更强性能的 RTMPose 模型。 - - 迁移 3D 姿态估计算法。 - - 加速推理脚本,全部 demo 脚本支持摄像头推理。 + - 支持新数据集:UBody、300W-LP。 + - 支持新算法:MotionBERT、DWPose、EDPose、Uniformer + - 迁移 Associate Embedding、InterNet、YOLOX-Pose 算法。 + - 迁移 DeepFashion2 数据集。 + - 支持 Badcase 可视化分析、多数据集评测、关键点可见性预测功能。 - 请查看完整的 [版本说明](https://github.com/open-mmlab/mmpose/releases/tag/v1.1.0) 以了解更多 MMPose v1.1.0 带来的更新! + 请查看完整的 [版本说明](https://github.com/open-mmlab/mmpose/releases/tag/v1.2.0) 以了解更多 MMPose v1.2.0 带来的更新! ## 0.x / 1.x 迁移 -MMPose v1.0.0 是一个重大更新,包括了大量的 API 和配置文件的变化。目前 v1.0.0 中已经完成了一部分算法的迁移工作,剩余的算法将在后续的版本中陆续完成,我们将在下面的列表中展示迁移进度。 - -
Supported backbones:
- [x] [AlexNet](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#alexnet-neurips-2012) (NeurIPS'2012) diff --git a/README_CN.md b/README_CN.md index 48672c2a88..1fe1a50a43 100644 --- a/README_CN.md +++ b/README_CN.md @@ -19,12 +19,13 @@-- 2023-07-04:MMPose [v1.1.0](https://github.com/open-mmlab/mmpose/releases/tag/v1.1.0) 正式发布了,主要更新包括: +- 2023-10-12:MMPose [v1.2.0](https://github.com/open-mmlab/mmpose/releases/tag/v1.2.0) 正式发布了,主要更新包括: - - 支持新数据集:Human-Art、Animal Kingdom、LaPa。 - - 支持新的配置文件风格,支持 IDE 跳转和搜索。 - - 提供更强性能的 RTMPose 模型。 - - 迁移 3D 姿态估计算法。 - - 加速推理脚本,全部 demo 脚本支持摄像头推理。 + - 支持新数据集:UBody、300W-LP。 + - 支持新算法:MotionBERT、DWPose、EDPose、Uniformer + - 迁移 Associate Embedding、InterNet、YOLOX-Pose 算法。 + - 迁移 DeepFashion2 数据集。 + - 支持 Badcase 可视化分析、多数据集评测、关键点可见性预测功能。 - 请查看完整的 [版本说明](https://github.com/open-mmlab/mmpose/releases/tag/v1.1.0) 以了解更多 MMPose v1.1.0 带来的更新! + 请查看完整的 [版本说明](https://github.com/open-mmlab/mmpose/releases/tag/v1.2.0) 以了解更多 MMPose v1.2.0 带来的更新! ## 0.x / 1.x 迁移 -MMPose v1.0.0 是一个重大更新,包括了大量的 API 和配置文件的变化。目前 v1.0.0 中已经完成了一部分算法的迁移工作,剩余的算法将在后续的版本中陆续完成,我们将在下面的列表中展示迁移进度。 - -
-
+MMPose v1.0.0 是一个重大更新,包括了大量的 API 和配置文件的变化。目前 v1.0.0 中已经完成了一部分算法的迁移工作,剩余的算法将在后续的版本中陆续完成,我们将在这个 [Issue 页面](https://github.com/open-mmlab/mmpose/issues/2258) 中展示迁移进度。
如果您使用的算法还没有完成迁移,您也可以继续使用访问 [0.x 分支](https://github.com/open-mmlab/mmpose/tree/0.x) 和 [旧版文档](https://mmpose.readthedocs.io/zh_CN/0.x/)
@@ -184,6 +160,9 @@ MMPose v1.0.0 是一个重大更新,包括了大量的 API 和配置文件的
- [配置文件](https://mmpose.readthedocs.io/zh_CN/latest/user_guides/configs.html)
- [准备数据集](https://mmpose.readthedocs.io/zh_CN/latest/user_guides/prepare_datasets.html)
- [训练与测试](https://mmpose.readthedocs.io/zh_CN/latest/user_guides/train_and_test.html)
+ - [模型部署](https://mmpose.readthedocs.io/zh_CN/latest/user_guides/how_to_deploy.html)
+ - [模型分析工具](https://mmpose.readthedocs.io/zh_CN/latest/user_guides/model_analysis.html)
+ - [数据集标注与预处理脚本](https://mmpose.readthedocs.io/zh_CN/latest/user_guides/dataset_tools.html)
2. 对于希望基于 MMPose 进行开发的研究者和开发者:
@@ -192,10 +171,9 @@ MMPose v1.0.0 是一个重大更新,包括了大量的 API 和配置文件的
- [实现新模型](https://mmpose.readthedocs.io/zh_CN/latest/advanced_guides/implement_new_models.html)
- [自定义数据集](https://mmpose.readthedocs.io/zh_CN/latest/advanced_guides/customize_datasets.html)
- [自定义数据变换](https://mmpose.readthedocs.io/zh_CN/latest/advanced_guides/customize_transforms.html)
+ - [自定义指标](https://mmpose.readthedocs.io/zh_CN/latest/advanced_guides/customize_evaluation.html)
- [自定义优化器](https://mmpose.readthedocs.io/zh_CN/latest/advanced_guides/customize_optimizer.html)
- [自定义日志](https://mmpose.readthedocs.io/zh_CN/latest/advanced_guides/customize_logging.html)
- - [模型部署](https://mmpose.readthedocs.io/zh_CN/latest/advanced_guides/how_to_deploy.html)
- - [模型分析工具](https://mmpose.readthedocs.io/zh_CN/latest/advanced_guides/model_analysis.html)
- [迁移指南](https://mmpose.readthedocs.io/zh_CN/latest/migration.html)
3. 对于希望加入开源社区,向 MMPose 贡献代码的研究者和开发者:
@@ -211,7 +189,7 @@ MMPose v1.0.0 是一个重大更新,包括了大量的 API 和配置文件的
各个模型的结果和设置都可以在对应的 config(配置)目录下的 **README.md** 中查看。
整体的概况也可也在 [模型库](https://mmpose.readthedocs.io/zh_CN/latest/model_zoo.html) 页面中查看。
-迁移进度
- -| 算法名称 | 迁移进度 | -| :-------------------------------- | :---------: | -| MTUT (CVPR 2019) | | -| MSPN (ArXiv 2019) | done | -| InterNet (ECCV 2020) | | -| DEKR (CVPR 2021) | done | -| HigherHRNet (CVPR 2020) | | -| DeepPose (CVPR 2014) | done | -| RLE (ICCV 2021) | done | -| SoftWingloss (TIP 2021) | done | -| VideoPose3D (CVPR 2019) | done | -| Hourglass (ECCV 2016) | done | -| LiteHRNet (CVPR 2021) | done | -| AdaptiveWingloss (ICCV 2019) | done | -| SimpleBaseline2D (ECCV 2018) | done | -| PoseWarper (NeurIPS 2019) | | -| SimpleBaseline3D (ICCV 2017) | done | -| HMR (CVPR 2018) | | -| UDP (CVPR 2020) | done | -| VIPNAS (CVPR 2021) | done | -| Wingloss (CVPR 2018) | done | -| DarkPose (CVPR 2020) | done | -| Associative Embedding (NIPS 2017) | in progress | -| VoxelPose (ECCV 2020) | | -| RSN (ECCV 2020) | done | -| CID (CVPR 2022) | done | -| CPM (CVPR 2016) | done | -| HRNet (CVPR 2019) | done | -| HRNetv2 (TPAMI 2019) | done | -| SCNet (CVPR 2020) | done | - -
+
-
支持的算法
- [x] [DeepPose](https://mmpose.readthedocs.io/zh_CN/latest/model_zoo_papers/algorithms.html#deeppose-cvpr-2014) (CVPR'2014) @@ -229,7 +207,7 @@ MMPose v1.0.0 是一个重大更新,包括了大量的 API 和配置文件的 - [x] [SCNet](https://mmpose.readthedocs.io/zh_CN/latest/model_zoo_papers/backbones.html#scnet-cvpr-2020) (CVPR'2020) - [ ] [HigherHRNet](https://mmpose.readthedocs.io/zh_CN/latest/model_zoo_papers/backbones.html#higherhrnet-cvpr-2020) (CVPR'2020) - [x] [RSN](https://mmpose.readthedocs.io/zh_CN/latest/model_zoo_papers/backbones.html#rsn-eccv-2020) (ECCV'2020) -- [ ] [InterNet](https://mmpose.readthedocs.io/zh_CN/latest/model_zoo_papers/algorithms.html#internet-eccv-2020) (ECCV'2020) +- [x] [InterNet](https://mmpose.readthedocs.io/zh_CN/latest/model_zoo_papers/algorithms.html#internet-eccv-2020) (ECCV'2020) - [ ] [VoxelPose](https://mmpose.readthedocs.io/zh_CN/latest/model_zoo_papers/algorithms.html#voxelpose-eccv-2020) (ECCV'2020) - [x] [LiteHRNet](https://mmpose.readthedocs.io/zh_CN/latest/model_zoo_papers/backbones.html#litehrnet-cvpr-2021) (CVPR'2021) - [x] [ViPNAS](https://mmpose.readthedocs.io/zh_CN/latest/model_zoo_papers/backbones.html#vipnas-cvpr-2021) (CVPR'2021) @@ -238,7 +216,7 @@ MMPose v1.0.0 是一个重大更新,包括了大量的 API 和配置文件的
+
-
支持的技术
- [x] [FPN](https://mmpose.readthedocs.io/zh_CN/latest/model_zoo_papers/techniques.html#fpn-cvpr-2017) (CVPR'2017) @@ -253,7 +231,7 @@ MMPose v1.0.0 是一个重大更新,包括了大量的 API 和配置文件的
+
-
支持的数据集
- [x] [AFLW](https://mmpose.readthedocs.io/zh_CN/latest/model_zoo_papers/datasets.html#aflw-iccvw-2011) \[[主页](https://www.tugraz.at/institute/icg/research/team-bischof/lrs/downloads/aflw/)\] (ICCVW'2011) @@ -289,10 +267,11 @@ MMPose v1.0.0 是一个重大更新,包括了大量的 API 和配置文件的 - [x] [Horse-10](https://mmpose.readthedocs.io/zh_CN/latest/model_zoo_papers/datasets.html#horse-10-wacv-2021) \[[主页](http://www.mackenziemathislab.org/horse10)\] (WACV'2021) - [x] [Human-Art](https://mmpose.readthedocs.io/zh_CN/latest/model_zoo_papers/datasets.html#human-art-cvpr-2023) \[[主页](https://idea-research.github.io/HumanArt/)\] (CVPR'2023) - [x] [LaPa](https://mmpose.readthedocs.io/zh_CN/latest/model_zoo_papers/datasets.html#lapa-aaai-2020) \[[主页](https://github.com/JDAI-CV/lapa-dataset)\] (AAAI'2020) +- [x] [UBody](https://mmpose.readthedocs.io/zh_CN/latest/model_zoo_papers/datasets.html#ubody-cvpr-2023) \[[主页](https://github.com/IDEA-Research/OSX)\] (CVPR'2023)
+
(LaPa) | FLOPS
(G) | Download | | :--------------------------------------------------------------------------: | :--------: | :----------------: | :---------------: | :-----------------------------------------------------------------------------: | -| [RTMPose-t\*](./rtmpose/face_2d_keypoint/rtmpose-t_8xb256-120e_lapa-256x256.py) | 256x256 | 1.67 | 0.652 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-face6_pt-in1k_120e-256x256-df79d9a5_20230529.pth) | -| [RTMPose-s\*](./rtmpose/face_2d_keypoint/rtmpose-m_8xb256-120e_lapa-256x256.py) | 256x256 | 1.59 | 1.119 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-face6_pt-in1k_120e-256x256-d779fdef_20230529.pth) | -| [RTMPose-m\*](./rtmpose/face_2d_keypoint/rtmpose-m_8xb256-120e_lapa-256x256.py) | 256x256 | 1.44 | 2.852 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.pth) | +| [RTMPose-t\*](./rtmpose/face_2d_keypoint/rtmpose-t_8xb256-120e_face6-256x256.py) | 256x256 | 1.67 | 0.652 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-face6_pt-in1k_120e-256x256-df79d9a5_20230529.pth) | +| [RTMPose-s\*](./rtmpose/face_2d_keypoint/rtmpose-s_8xb256-120e_face6-256x256.py) | 256x256 | 1.59 | 1.119 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-face6_pt-in1k_120e-256x256-d779fdef_20230529.pth) | +| [RTMPose-m\*](./rtmpose/face_2d_keypoint/rtmpose-m_8xb256-120e_face6-256x256.py) | 256x256 | 1.44 | 2.852 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.pth) | diff --git a/configs/face_2d_keypoint/rtmpose/face6/rtmpose_face6.yml b/configs/face_2d_keypoint/rtmpose/face6/rtmpose_face6.yml index 2cd822a337..38b8395bd9 100644 --- a/configs/face_2d_keypoint/rtmpose/face6/rtmpose_face6.yml +++ b/configs/face_2d_keypoint/rtmpose/face6/rtmpose_face6.yml @@ -42,6 +42,7 @@ Models: Architecture: *id001 Training Data: *id002 Name: rtmpose-m_8xb256-120e_face6-256x256 + Alias: face Results: - Dataset: Face6 Metrics: diff --git a/configs/face_2d_keypoint/rtmpose/wflw/rtmpose_wflw.yml b/configs/face_2d_keypoint/rtmpose/wflw/rtmpose_wflw.yml index deee03a7dd..1112fdf69d 100644 --- a/configs/face_2d_keypoint/rtmpose/wflw/rtmpose_wflw.yml +++ b/configs/face_2d_keypoint/rtmpose/wflw/rtmpose_wflw.yml @@ -1,7 +1,6 @@ Models: - Config: configs/face_2d_keypoint/rtmpose/wflw/rtmpose-m_8xb64-60e_wflw-256x256.py In Collection: RTMPose - Alias: face Metadata: Architecture: - RTMPose diff --git a/configs/face_2d_keypoint/topdown_heatmap/300wlp/hrnetv2_300wlp.md b/configs/face_2d_keypoint/topdown_heatmap/300wlp/hrnetv2_300wlp.md new file mode 100644 index 0000000000..773bc602ae --- /dev/null +++ b/configs/face_2d_keypoint/topdown_heatmap/300wlp/hrnetv2_300wlp.md @@ -0,0 +1,42 @@ + + +
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | +| :----------- | :-----------------: | :-----------------: | :--------: | :------: | :------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :------------: | +| [DWPose-t](../rtmpose/ubody/rtmpose-t_8xb64-270e_coco-ubody-wholebody-256x192.py) | [DW l-t](../dwpose/ubody/s1_dis/dwpose_l_dis_t_coco-ubody-256x192.py) | [DW t-t](../dwpose/ubody/s2_dis/dwpose_t-tt_coco-ubody-256x192.py) | 256x192 | 48.5 | 58.4 | 0.5 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-ucoco_dw-ucoco_270e-256x192-dcf277bf_20230728.pth) | +| [DWPose-s](../rtmpose/ubody/rtmpose-s_8xb64-270e_coco-ubody-wholebody-256x192.py) | [DW l-s](../dwpose/ubody/s1_dis/dwpose_l_dis_s_coco-ubody-256x192.py) | [DW s-s](../dwpose/ubody/s2_dis/dwpose_s-ss_coco-ubody-256x192.py) | 256x192 | 53.8 | 63.2 | 0.9 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-ucoco_dw-ucoco_270e-256x192-3fd922c8_20230728.pth) | +| [DWPose-m](../rtmpose/ubody/rtmpose-m_8xb64-270e_coco-ubody-wholebody-256x192.py) | [DW l-m](../dwpose/ubody/s1_dis/dwpose_l_dis_m_coco-ubody-256x192.py) | [DW m-m](../dwpose/ubody/s2_dis/dwpose_m-mm_coco-ubody-256x192.py) | 256x192 | 60.6 | 69.5 | 2.22 | 13.50 | 4.00 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-ucoco_dw-ucoco_270e-256x192-c8b76419_20230728.pth) | +| [DWPose-l](../rtmpose/ubody/rtmpose-l_8xb64-270e_coco-ubody-wholebody-256x192.py) | [DW x-l](../dwpose/ubody/s1_dis/dwpose_x_dis_l_coco-ubody-256x192.py) | [DW l-l](../dwpose/ubody/s2_dis/dwpose_l-ll_coco-ubody-256x192.py) | 256x192 | 63.1 | 71.7 | 4.52 | 23.41 | 5.67 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-ucoco_dw-ucoco_270e-256x192-4d6dfc62_20230728.pth) | +| [DWPose-l](../rtmpose/ubody/rtmpose-l_8xb32-270e_coco-ubody-wholebody-384x288.py) | [DW x-l](../dwpose/ubody/s1_dis/dwpose_x_dis_l_coco-ubody-384x288.py) | [DW l-l](../dwpose/ubody/s2_dis/dwpose_l-ll_coco-ubody-384x288.py) | 384x288 | 66.5 | 74.3 | 10.07 | 44.58 | 7.68 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-ucoco_dw-ucoco_270e-384x288-2438fd99_20230728.pth) | + +## Train a model + +### Train DWPose with the first stage distillation + +``` +bash tools/dist_train.sh configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/rtmpose_x_dis_l_coco-ubody-384x288.py 8 +``` + +### Tansfer the S1 distillation models into regular models + +``` +# first stage distillation +python pth_transfer.py $dis_ckpt $new_pose_ckpt +``` + +⭐Before S2 distillation, you should add your model path into 'teacher_pretrained' of your S2 dis_config. + +### Train DWPose with the second stage distillation + +``` +bash tools/dist_train.sh configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_l-ll_coco-ubody-384x288.py 8 +``` + +### Tansfer the S2 distillation models into regular models + +``` +# second stage distillation +python pth_transfer.py $dis_ckpt $new_pose_ckpt --two_dis +``` + +## Citation + +``` +@article{yang2023effective, + title={Effective Whole-body Pose Estimation with Two-stages Distillation}, + author={Yang, Zhendong and Zeng, Ailing and Yuan, Chun and Li, Yu}, + journal={arXiv preprint arXiv:2307.15880}, + year={2023} +} +``` diff --git a/configs/wholebody_2d_keypoint/dwpose/coco-wholebody/s1_dis/dwpose_l_dis_m_coco-256x192.py b/configs/wholebody_2d_keypoint/dwpose/coco-wholebody/s1_dis/dwpose_l_dis_m_coco-256x192.py new file mode 100644 index 0000000000..422871acbb --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/coco-wholebody/s1_dis/dwpose_l_dis_m_coco-256x192.py @@ -0,0 +1,48 @@ +_base_ = [ + '../../../rtmpose/coco-wholebody/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py' # noqa: E501 +] + +# model settings +find_unused_parameters = False + +# config settings +fea = True +logit = True + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + teacher_pretrained='https://download.openmmlab.com/mmpose/v1/projects/' + 'rtmpose/rtmpose-l_simcc-coco-wholebody_pt-aic-coco_270e-256x192-6f206314_20230124.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/' + 'rtmpose-l_8xb64-270e_coco-wholebody-256x192.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/' + 'rtmpose-m_8xb64-270e_coco-wholebody-256x192.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='FeaLoss', + name='loss_fea', + use_this=fea, + student_channels=768, + teacher_channels=1024, + alpha_fea=0.00007, + ) + ]), + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=0.1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), +) +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/dwpose/coco-wholebody/s1_dis/dwpose_x_dis_l_coco-384x288.py b/configs/wholebody_2d_keypoint/dwpose/coco-wholebody/s1_dis/dwpose_x_dis_l_coco-384x288.py new file mode 100644 index 0000000000..150cb2bbe6 --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/coco-wholebody/s1_dis/dwpose_x_dis_l_coco-384x288.py @@ -0,0 +1,48 @@ +_base_ = [ + '../../../rtmpose/coco-wholebody/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py' # noqa: E501 +] + +# model settings +find_unused_parameters = False + +# config settings +fea = True +logit = True + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + teacher_pretrained='https://download.openmmlab.com/mmpose/v1/projects/' + 'rtmposev1/rtmpose-x_simcc-coco-wholebody_pt-body7_270e-384x288-401dfc90_20230629.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/' + 'rtmpose-x_8xb32-270e_coco-wholebody-384x288.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/' + 'rtmpose-l_8xb32-270e_coco-wholebody-384x288.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='FeaLoss', + name='loss_fea', + use_this=fea, + student_channels=1024, + teacher_channels=1280, + alpha_fea=0.00007, + ) + ]), + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=0.1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), +) +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/dwpose/coco-wholebody/s2_dis/dwpose_l-ll_coco-384x288.py b/configs/wholebody_2d_keypoint/dwpose/coco-wholebody/s2_dis/dwpose_l-ll_coco-384x288.py new file mode 100644 index 0000000000..6c63f99b0c --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/coco-wholebody/s2_dis/dwpose_l-ll_coco-384x288.py @@ -0,0 +1,45 @@ +_base_ = [ + '../../../rtmpose/coco-wholebody/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py' # noqa: E501 +] + +# model settings +find_unused_parameters = True + +# dis settings +second_dis = True + +# config settings +logit = True + +train_cfg = dict(max_epochs=60, val_interval=10) + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + two_dis=second_dis, + teacher_pretrained='work_dirs/' + 'dwpose_x_dis_l_coco-384x288/dw-x-l_coco_384.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/' + 'rtmpose-l_8xb32-270e_coco-wholebody-384x288.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/' + 'rtmpose-l_8xb32-270e_coco-wholebody-384x288.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + train_cfg=train_cfg, +) + +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/dwpose/coco-wholebody/s2_dis/dwpose_m-mm_coco-256x192.py b/configs/wholebody_2d_keypoint/dwpose/coco-wholebody/s2_dis/dwpose_m-mm_coco-256x192.py new file mode 100644 index 0000000000..943ec60184 --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/coco-wholebody/s2_dis/dwpose_m-mm_coco-256x192.py @@ -0,0 +1,45 @@ +_base_ = [ + '../../../rtmpose/coco-wholebody/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py' # noqa: E501 +] + +# model settings +find_unused_parameters = True + +# dis settings +second_dis = True + +# config settings +logit = True + +train_cfg = dict(max_epochs=60, val_interval=10) + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + two_dis=second_dis, + teacher_pretrained='work_dirs/' + 'dwpose_l_dis_m_coco-256x192/dw-l-m_coco_256.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/' + 'rtmpose-m_8xb64-270e_coco-wholebody-256x192.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/' + 'rtmpose-m_8xb64-270e_coco-wholebody-256x192.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + train_cfg=train_cfg, +) + +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/dwpose_l_dis_m_coco-ubody-256x192.py b/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/dwpose_l_dis_m_coco-ubody-256x192.py new file mode 100644 index 0000000000..b3a917b96e --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/dwpose_l_dis_m_coco-ubody-256x192.py @@ -0,0 +1,48 @@ +_base_ = [ + '../../../rtmpose/ubody/rtmpose-m_8xb64-270e_coco-ubody-wholebody-256x192.py' # noqa: E501 +] + +# model settings +find_unused_parameters = False + +# config settings +fea = True +logit = True + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + teacher_pretrained='https://download.openmmlab.com/mmpose/v1/projects/' + 'rtmposev1/rtmpose-l_ucoco_256x192-95bb32f5_20230822.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-l_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-m_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='FeaLoss', + name='loss_fea', + use_this=fea, + student_channels=768, + teacher_channels=1024, + alpha_fea=0.00007, + ) + ]), + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=0.1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), +) +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/dwpose_l_dis_s_coco-ubody-256x192.py b/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/dwpose_l_dis_s_coco-ubody-256x192.py new file mode 100644 index 0000000000..c90a0ea6a7 --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/dwpose_l_dis_s_coco-ubody-256x192.py @@ -0,0 +1,48 @@ +_base_ = [ + '../../../rtmpose/ubody/rtmpose-s_8xb64-270e_coco-ubody-wholebody-256x192.py' # noqa: E501 +] + +# model settings +find_unused_parameters = False + +# config settings +fea = True +logit = True + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + teacher_pretrained='https://download.openmmlab.com/mmpose/v1/projects/' + 'rtmposev1/rtmpose-l_ucoco_256x192-95bb32f5_20230822.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-l_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-s_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='FeaLoss', + name='loss_fea', + use_this=fea, + student_channels=512, + teacher_channels=1024, + alpha_fea=0.00007, + ) + ]), + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=0.1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), +) +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/dwpose_l_dis_t_coco-ubody-256x192.py b/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/dwpose_l_dis_t_coco-ubody-256x192.py new file mode 100644 index 0000000000..01618f146a --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/dwpose_l_dis_t_coco-ubody-256x192.py @@ -0,0 +1,48 @@ +_base_ = [ + '../../../rtmpose/ubody/rtmpose-s_8xb64-270e_coco-ubody-wholebody-256x192.py' # noqa: E501 +] + +# model settings +find_unused_parameters = False + +# config settings +fea = True +logit = True + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + teacher_pretrained='https://download.openmmlab.com/mmpose/v1/projects/' + 'rtmposev1/rtmpose-l_ucoco_256x192-95bb32f5_20230822.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-l_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-t_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='FeaLoss', + name='loss_fea', + use_this=fea, + student_channels=384, + teacher_channels=1024, + alpha_fea=0.00007, + ) + ]), + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=0.1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), +) +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/dwpose_x_dis_l_coco-ubody-256x192.py b/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/dwpose_x_dis_l_coco-ubody-256x192.py new file mode 100644 index 0000000000..85a287324b --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/dwpose_x_dis_l_coco-ubody-256x192.py @@ -0,0 +1,48 @@ +_base_ = [ + '../../../rtmpose/ubody/rtmpose-l_8xb64-270e_coco-ubody-wholebody-256x192.py' # noqa: E501 +] + +# model settings +find_unused_parameters = False + +# config settings +fea = True +logit = True + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + teacher_pretrained='https://download.openmmlab.com/mmpose/v1/projects/' + 'rtmposev1/rtmpose-x_ucoco_256x192-05f5bcb7_20230822.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-x_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-l_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='FeaLoss', + name='loss_fea', + use_this=fea, + student_channels=1024, + teacher_channels=1280, + alpha_fea=0.00007, + ) + ]), + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=0.1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), +) +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/rtmpose_x_dis_l_coco-ubody-384x288.py b/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/rtmpose_x_dis_l_coco-ubody-384x288.py new file mode 100644 index 0000000000..acde64a03a --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/rtmpose_x_dis_l_coco-ubody-384x288.py @@ -0,0 +1,48 @@ +_base_ = [ + '../../../rtmpose/ubody/rtmpose-l_8xb32-270e_coco-ubody-wholebody-384x288.py' # noqa: E501 +] + +# model settings +find_unused_parameters = False + +# config settings +fea = True +logit = True + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + teacher_pretrained='https://download.openmmlab.com/mmpose/v1/projects/' + 'rtmposev1/rtmpose-x_ucoco_384x288-f5b50679_20230822.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-x_8xb32-270e_coco-ubody-wholebody-384x288.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-l_8xb32-270e_coco-ubody-wholebody-384x288.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='FeaLoss', + name='loss_fea', + use_this=fea, + student_channels=1024, + teacher_channels=1280, + alpha_fea=0.00007, + ) + ]), + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=0.1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), +) +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_l-ll_coco-ubody-256x192.py b/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_l-ll_coco-ubody-256x192.py new file mode 100644 index 0000000000..e3f456a2b9 --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_l-ll_coco-ubody-256x192.py @@ -0,0 +1,45 @@ +_base_ = [ + '../../../rtmpose/ubody/rtmpose-l_8xb64-270e_coco-ubody-wholebody-256x192.py' # noqa: E501 +] + +# model settings +find_unused_parameters = True + +# dis settings +second_dis = True + +# config settings +logit = True + +train_cfg = dict(max_epochs=60, val_interval=10) + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + two_dis=second_dis, + teacher_pretrained='work_dirs/' + 'dwpose_x_dis_l_coco-ubody-256x192/dw-x-l_ucoco_256.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-l_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-l_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + train_cfg=train_cfg, +) + +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_l-ll_coco-ubody-384x288.py b/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_l-ll_coco-ubody-384x288.py new file mode 100644 index 0000000000..3815fad1e2 --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_l-ll_coco-ubody-384x288.py @@ -0,0 +1,45 @@ +_base_ = [ + '../../../rtmpose/ubody/rtmpose-l_8xb32-270e_coco-ubody-wholebody-384x288.py' # noqa: E501 +] + +# model settings +find_unused_parameters = True + +# dis settings +second_dis = True + +# config settings +logit = True + +train_cfg = dict(max_epochs=60, val_interval=10) + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + two_dis=second_dis, + teacher_pretrained='work_dirs/' + 'dwpose_x_dis_l_coco-ubody-384x288/dw-x-l_ucoco_384.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-l_8xb32-270e_coco-ubody-wholebody-384x288.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-l_8xb32-270e_coco-ubody-wholebody-384x288.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + train_cfg=train_cfg, +) + +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_m-mm_coco-ubody-256x192.py b/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_m-mm_coco-ubody-256x192.py new file mode 100644 index 0000000000..1e6834ffca --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_m-mm_coco-ubody-256x192.py @@ -0,0 +1,45 @@ +_base_ = [ + '../../../rtmpose/ubody/rtmpose-m_8xb64-270e_coco-ubody-wholebody-256x192.py' # noqa: E501 +] + +# model settings +find_unused_parameters = True + +# dis settings +second_dis = True + +# config settings +logit = True + +train_cfg = dict(max_epochs=60, val_interval=10) + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + two_dis=second_dis, + teacher_pretrained='work_dirs/' + 'dwpose_l_dis_m_coco-ubody-256x192/dw-l-m_ucoco_256.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-m_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-m_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + train_cfg=train_cfg, +) + +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_s-ss_coco-ubody-256x192.py b/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_s-ss_coco-ubody-256x192.py new file mode 100644 index 0000000000..24a4a94642 --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_s-ss_coco-ubody-256x192.py @@ -0,0 +1,45 @@ +_base_ = [ + '../../../rtmpose/ubody/rtmpose-s_8xb64-270e_coco-ubody-wholebody-256x192.py' # noqa: E501 +] + +# model settings +find_unused_parameters = True + +# dis settings +second_dis = True + +# config settings +logit = True + +train_cfg = dict(max_epochs=60, val_interval=10) + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + two_dis=second_dis, + teacher_pretrained='work_dirs/' + 'dwpose_l_dis_s_coco-ubody-256x192/dw-l-s_ucoco_256.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-s_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-s_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + train_cfg=train_cfg, +) + +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_t-tt_coco-ubody-256x192.py b/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_t-tt_coco-ubody-256x192.py new file mode 100644 index 0000000000..c7c322ece2 --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_t-tt_coco-ubody-256x192.py @@ -0,0 +1,45 @@ +_base_ = [ + '../../../rtmpose/ubody/rtmpose-t_8xb64-270e_coco-ubody-wholebody-256x192.py' # noqa: E501 +] + +# model settings +find_unused_parameters = True + +# dis settings +second_dis = True + +# config settings +logit = True + +train_cfg = dict(max_epochs=60, val_interval=10) + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + two_dis=second_dis, + teacher_pretrained='work_dirs/' + 'dwpose_l_dis_t_coco-ubody-256x192/dw-l-t_ucoco_256.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-t_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-t_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + train_cfg=train_cfg, +) + +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb320-270e_cocktail13-384x288.py b/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb320-270e_cocktail13-384x288.py new file mode 100644 index 0000000000..55d07b61a8 --- /dev/null +++ b/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb320-270e_cocktail13-384x288.py @@ -0,0 +1,638 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from mmengine.config import read_base + +with read_base(): + from mmpose.configs._base_.default_runtime import * # noqa + +from albumentations.augmentations import Blur, CoarseDropout, MedianBlur +from mmdet.engine.hooks import PipelineSwitchHook +from mmengine.dataset import DefaultSampler +from mmengine.hooks import EMAHook +from mmengine.model import PretrainedInit +from mmengine.optim import CosineAnnealingLR, LinearLR, OptimWrapper +from torch.nn import SiLU, SyncBatchNorm +from torch.optim import AdamW + +from mmpose.codecs import SimCCLabel +from mmpose.datasets import (AicDataset, CocoWholeBodyDataset, COFWDataset, + CombinedDataset, CrowdPoseDataset, + Face300WDataset, GenerateTarget, + GetBBoxCenterScale, HalpeDataset, + HumanArt21Dataset, InterHand2DDoubleDataset, + JhmdbDataset, KeypointConverter, LapaDataset, + LoadImage, MpiiDataset, PackPoseInputs, + PoseTrack18Dataset, RandomFlip, RandomHalfBody, + TopdownAffine, UBody2dDataset, WFLWDataset) +from mmpose.datasets.transforms.common_transforms import ( + Albumentation, PhotometricDistortion, RandomBBoxTransform) +from mmpose.engine.hooks import ExpMomentumEMA +from mmpose.evaluation import CocoWholeBodyMetric +from mmpose.models import (CSPNeXt, CSPNeXtPAFPN, KLDiscretLoss, + PoseDataPreprocessor, RTMWHead, + TopdownPoseEstimator) + +# common setting +num_keypoints = 133 +input_size = (288, 384) + +# runtime +max_epochs = 270 +stage2_num_epochs = 10 +base_lr = 5e-4 +train_batch_size = 320 +val_batch_size = 32 + +train_cfg.update(max_epochs=max_epochs, val_interval=10) # noqa +randomness = dict(seed=21) + +# optimizer +optim_wrapper = dict( + type=OptimWrapper, + optimizer=dict(type=AdamW, lr=base_lr, weight_decay=0.05), + clip_grad=dict(max_norm=35, norm_type=2), + paramwise_cfg=dict( + norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True)) + +# learning rate +param_scheduler = [ + dict( + type=LinearLR, start_factor=1.0e-5, by_epoch=False, begin=0, end=1000), + dict( + type=CosineAnnealingLR, + eta_min=base_lr * 0.05, + begin=max_epochs // 2, + end=max_epochs, + T_max=max_epochs // 2, + by_epoch=True, + convert_to_iter_based=True), +] + +# automatically scaling LR based on the actual training batch size +auto_scale_lr = dict(base_batch_size=5632) + +# codec settings +codec = dict( + type=SimCCLabel, + input_size=input_size, + sigma=(6., 6.93), + simcc_split_ratio=2.0, + normalize=False, + use_dark=False) + +# model settings +model = dict( + type=TopdownPoseEstimator, + data_preprocessor=dict( + type=PoseDataPreprocessor, + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + backbone=dict( + type=CSPNeXt, + arch='P5', + expand_ratio=0.5, + deepen_factor=1.33, + widen_factor=1.25, + channel_attention=True, + norm_cfg=dict(type='BN'), + act_cfg=dict(type=SiLU), + init_cfg=dict( + type=PretrainedInit, + prefix='backbone.', + checkpoint='https://download.openmmlab.com/mmpose/v1/' + 'wholebody_2d_keypoint/rtmpose/ubody/rtmpose-x_simcc-ucoco_pt-aic-coco_270e-384x288-f5b50679_20230822.pth' # noqa + )), + neck=dict( + type=CSPNeXtPAFPN, + in_channels=[320, 640, 1280], + out_channels=None, + out_indices=( + 1, + 2, + ), + num_csp_blocks=2, + expand_ratio=0.5, + norm_cfg=dict(type=SyncBatchNorm), + act_cfg=dict(type=SiLU, inplace=True)), + head=dict( + type=RTMWHead, + in_channels=1280, + out_channels=num_keypoints, + input_size=input_size, + in_featuremap_size=tuple([s // 32 for s in input_size]), + simcc_split_ratio=codec['simcc_split_ratio'], + final_layer_kernel_size=7, + gau_cfg=dict( + hidden_dims=256, + s=128, + expansion_factor=2, + dropout_rate=0., + drop_path=0., + act_fn=SiLU, + use_rel_bias=False, + pos_enc=False), + loss=dict( + type=KLDiscretLoss, + use_target_weight=True, + beta=10., + label_softmax=True), + decoder=codec), + test_cfg=dict(flip_test=True)) + +# base dataset settings +dataset_type = CocoWholeBodyDataset +data_mode = 'topdown' +data_root = 'data/' + +backend_args = dict(backend='local') + +# pipelines +train_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict(type=RandomFlip, direction='horizontal'), + dict(type=RandomHalfBody), + dict(type=RandomBBoxTransform, scale_factor=[0.5, 1.5], rotate_factor=90), + dict(type=TopdownAffine, input_size=codec['input_size']), + dict(type=PhotometricDistortion), + dict( + type=Albumentation, + transforms=[ + dict(type=Blur, p=0.1), + dict(type=MedianBlur, p=0.1), + dict( + type=CoarseDropout, + max_holes=1, + max_height=0.4, + max_width=0.4, + min_holes=1, + min_height=0.2, + min_width=0.2, + p=1.0), + ]), + dict( + type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True), + dict(type=PackPoseInputs) +] +val_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict(type=TopdownAffine, input_size=codec['input_size']), + dict(type=PackPoseInputs) +] +train_pipeline_stage2 = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict(type=RandomFlip, direction='horizontal'), + dict(type=RandomHalfBody), + dict( + type=RandomBBoxTransform, + shift_factor=0., + scale_factor=[0.5, 1.5], + rotate_factor=90), + dict(type=TopdownAffine, input_size=codec['input_size']), + dict( + type=Albumentation, + transforms=[ + dict(type=Blur, p=0.1), + dict(type=MedianBlur, p=0.1), + ]), + dict( + type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True), + dict(type=PackPoseInputs) +] + +# mapping + +aic_coco133 = [(0, 6), (1, 8), (2, 10), (3, 5), (4, 7), (5, 9), (6, 12), + (7, 14), (8, 16), (9, 11), (10, 13), (11, 15)] + +crowdpose_coco133 = [(0, 5), (1, 6), (2, 7), (3, 8), (4, 9), (5, 10), (6, 11), + (7, 12), (8, 13), (9, 14), (10, 15), (11, 16)] + +mpii_coco133 = [ + (0, 16), + (1, 14), + (2, 12), + (3, 11), + (4, 13), + (5, 15), + (8, 18), + (9, 17), + (10, 10), + (11, 8), + (12, 6), + (13, 5), + (14, 7), + (15, 9), +] + +jhmdb_coco133 = [ + (0, 18), + (2, 17), + (3, 6), + (4, 5), + (5, 12), + (6, 11), + (7, 8), + (8, 7), + (9, 14), + (10, 13), + (11, 10), + (12, 9), + (13, 16), + (14, 15), +] + +halpe_coco133 = [(i, i) + for i in range(17)] + [(20, 17), (21, 20), (22, 18), (23, 21), + (24, 19), + (25, 22)] + [(i, i - 3) + for i in range(26, 136)] + +posetrack_coco133 = [ + (0, 0), + (2, 17), + (3, 3), + (4, 4), + (5, 5), + (6, 6), + (7, 7), + (8, 8), + (9, 9), + (10, 10), + (11, 11), + (12, 12), + (13, 13), + (14, 14), + (15, 15), + (16, 16), +] + +humanart_coco133 = [(i, i) for i in range(17)] + [(17, 99), (18, 120), + (19, 17), (20, 20)] + +# train datasets +dataset_coco = dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='coco/annotations/coco_wholebody_train_v1.0.json', + data_prefix=dict(img='detection/coco/train2017/'), + pipeline=[], +) + +dataset_aic = dict( + type=AicDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='aic/annotations/aic_train.json', + data_prefix=dict(img='pose/ai_challenge/ai_challenger_keypoint' + '_train_20170902/keypoint_train_images_20170902/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=aic_coco133) + ], +) + +dataset_crowdpose = dict( + type=CrowdPoseDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='crowdpose/annotations/mmpose_crowdpose_trainval.json', + data_prefix=dict(img='pose/CrowdPose/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=crowdpose_coco133) + ], +) + +dataset_mpii = dict( + type=MpiiDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='mpii/annotations/mpii_train.json', + data_prefix=dict(img='pose/MPI/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=mpii_coco133) + ], +) + +dataset_jhmdb = dict( + type=JhmdbDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='jhmdb/annotations/Sub1_train.json', + data_prefix=dict(img='pose/JHMDB/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=jhmdb_coco133) + ], +) + +dataset_halpe = dict( + type=HalpeDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='halpe/annotations/halpe_train_v1.json', + data_prefix=dict(img='pose/Halpe/hico_20160224_det/images/train2015'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=halpe_coco133) + ], +) + +dataset_posetrack = dict( + type=PoseTrack18Dataset, + data_root=data_root, + data_mode=data_mode, + ann_file='posetrack18/annotations/posetrack18_train.json', + data_prefix=dict(img='pose/PoseChallenge2018/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=posetrack_coco133) + ], +) + +dataset_humanart = dict( + type=HumanArt21Dataset, + data_root=data_root, + data_mode=data_mode, + ann_file='HumanArt/annotations/training_humanart.json', + filter_cfg=dict(scenes=['real_human']), + data_prefix=dict(img='pose/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=humanart_coco133) + ]) + +ubody_scenes = [ + 'Magic_show', 'Entertainment', 'ConductMusic', 'Online_class', 'TalkShow', + 'Speech', 'Fitness', 'Interview', 'Olympic', 'TVShow', 'Singing', + 'SignLanguage', 'Movie', 'LiveVlog', 'VideoConference' +] + +ubody_datasets = [] +for scene in ubody_scenes: + each = dict( + type=UBody2dDataset, + data_root=data_root, + data_mode=data_mode, + ann_file=f'Ubody/annotations/{scene}/train_annotations.json', + data_prefix=dict(img='pose/UBody/images/'), + pipeline=[], + sample_interval=10) + ubody_datasets.append(each) + +dataset_ubody = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/ubody2d.py'), + datasets=ubody_datasets, + pipeline=[], + test_mode=False, +) + +face_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale, padding=1.25), + dict( + type=RandomBBoxTransform, + shift_factor=0., + scale_factor=[1.5, 2.0], + rotate_factor=0), +] + +wflw_coco133 = [(i * 2, 23 + i) + for i in range(17)] + [(33 + i, 40 + i) for i in range(5)] + [ + (42 + i, 45 + i) for i in range(5) + ] + [(51 + i, 50 + i) + for i in range(9)] + [(60, 59), (61, 60), (63, 61), + (64, 62), (65, 63), (67, 64), + (68, 65), (69, 66), (71, 67), + (72, 68), (73, 69), + (75, 70)] + [(76 + i, 71 + i) + for i in range(20)] +dataset_wflw = dict( + type=WFLWDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='wflw/annotations/face_landmarks_wflw_train.json', + data_prefix=dict(img='pose/WFLW/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=wflw_coco133), *face_pipeline + ], +) + +mapping_300w_coco133 = [(i, 23 + i) for i in range(68)] +dataset_300w = dict( + type=Face300WDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='300w/annotations/face_landmarks_300w_train.json', + data_prefix=dict(img='pose/300w/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=mapping_300w_coco133), *face_pipeline + ], +) + +cofw_coco133 = [(0, 40), (2, 44), (4, 42), (1, 49), (3, 45), (6, 47), (8, 59), + (10, 62), (9, 68), (11, 65), (18, 54), (19, 58), (20, 53), + (21, 56), (22, 71), (23, 77), (24, 74), (25, 85), (26, 89), + (27, 80), (28, 31)] +dataset_cofw = dict( + type=COFWDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='cofw/annotations/cofw_train.json', + data_prefix=dict(img='pose/COFW/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=cofw_coco133), *face_pipeline + ], +) + +lapa_coco133 = [(i * 2, 23 + i) for i in range(17)] + [ + (33 + i, 40 + i) for i in range(5) +] + [(42 + i, 45 + i) for i in range(5)] + [ + (51 + i, 50 + i) for i in range(4) +] + [(58 + i, 54 + i) for i in range(5)] + [(66, 59), (67, 60), (69, 61), + (70, 62), (71, 63), (73, 64), + (75, 65), (76, 66), (78, 67), + (79, 68), (80, 69), + (82, 70)] + [(84 + i, 71 + i) + for i in range(20)] +dataset_lapa = dict( + type=LapaDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='LaPa/annotations/lapa_trainval.json', + data_prefix=dict(img='pose/LaPa/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=lapa_coco133), *face_pipeline + ], +) + +dataset_wb = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[dataset_coco, dataset_halpe, dataset_ubody], + pipeline=[], + test_mode=False, +) + +dataset_body = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[ + dataset_aic, + dataset_crowdpose, + dataset_mpii, + dataset_jhmdb, + dataset_posetrack, + dataset_humanart, + ], + pipeline=[], + test_mode=False, +) + +dataset_face = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[ + dataset_wflw, + dataset_300w, + dataset_cofw, + dataset_lapa, + ], + pipeline=[], + test_mode=False, +) + +hand_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict( + type=RandomBBoxTransform, + shift_factor=0., + scale_factor=[1.5, 2.0], + rotate_factor=0), +] + +interhand_left = [(21, 95), (22, 94), (23, 93), (24, 92), (25, 99), (26, 98), + (27, 97), (28, 96), (29, 103), (30, 102), (31, 101), + (32, 100), (33, 107), (34, 106), (35, 105), (36, 104), + (37, 111), (38, 110), (39, 109), (40, 108), (41, 91)] +interhand_right = [(i - 21, j + 21) for i, j in interhand_left] +interhand_coco133 = interhand_right + interhand_left + +dataset_interhand2d = dict( + type=InterHand2DDoubleDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='interhand26m/annotations/all/InterHand2.6M_train_data.json', + camera_param_file='interhand26m/annotations/all/' + 'InterHand2.6M_train_camera.json', + joint_file='interhand26m/annotations/all/' + 'InterHand2.6M_train_joint_3d.json', + data_prefix=dict(img='interhand2.6m/images/train/'), + sample_interval=10, + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=interhand_coco133, + ), *hand_pipeline + ], +) + +dataset_hand = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[dataset_interhand2d], + pipeline=[], + test_mode=False, +) + +train_datasets = [dataset_wb, dataset_body, dataset_face, dataset_hand] + +# data loaders +train_dataloader = dict( + batch_size=train_batch_size, + num_workers=4, + pin_memory=False, + persistent_workers=True, + sampler=dict(type=DefaultSampler, shuffle=True), + dataset=dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=train_datasets, + pipeline=train_pipeline, + test_mode=False, + )) + +val_dataloader = dict( + batch_size=val_batch_size, + num_workers=4, + persistent_workers=True, + drop_last=False, + sampler=dict(type=DefaultSampler, shuffle=False, round_up=False), + dataset=dict( + type=CocoWholeBodyDataset, + ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json', + data_prefix=dict(img='data/detection/coco/val2017/'), + pipeline=val_pipeline, + bbox_file='data/coco/person_detection_results/' + 'COCO_val2017_detections_AP_H_56_person.json', + test_mode=True)) + +test_dataloader = val_dataloader + +# hooks +default_hooks.update( # noqa + checkpoint=dict( + save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1)) + +custom_hooks = [ + dict( + type=EMAHook, + ema_type=ExpMomentumEMA, + momentum=0.0002, + update_buffers=True, + priority=49), + dict( + type=PipelineSwitchHook, + switch_epoch=max_epochs - stage2_num_epochs, + switch_pipeline=train_pipeline_stage2) +] + +# evaluators +val_evaluator = dict( + type=CocoWholeBodyMetric, + ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json') +test_evaluator = val_evaluator diff --git a/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb704-270e_cocktail13-256x192.py b/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb704-270e_cocktail13-256x192.py new file mode 100644 index 0000000000..48275c3c11 --- /dev/null +++ b/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb704-270e_cocktail13-256x192.py @@ -0,0 +1,639 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from mmengine.config import read_base + +with read_base(): + from mmpose.configs._base_.default_runtime import * # noqa + +from albumentations.augmentations import Blur, CoarseDropout, MedianBlur +from mmdet.engine.hooks import PipelineSwitchHook +from mmengine.dataset import DefaultSampler +from mmengine.hooks import EMAHook +from mmengine.model import PretrainedInit +from mmengine.optim import CosineAnnealingLR, LinearLR, OptimWrapper +from torch.nn import SiLU, SyncBatchNorm +from torch.optim import AdamW + +from mmpose.codecs import SimCCLabel +from mmpose.datasets import (AicDataset, CocoWholeBodyDataset, COFWDataset, + CombinedDataset, CrowdPoseDataset, + Face300WDataset, GenerateTarget, + GetBBoxCenterScale, HalpeDataset, + HumanArt21Dataset, InterHand2DDoubleDataset, + JhmdbDataset, KeypointConverter, LapaDataset, + LoadImage, MpiiDataset, PackPoseInputs, + PoseTrack18Dataset, RandomFlip, RandomHalfBody, + TopdownAffine, UBody2dDataset, WFLWDataset) +from mmpose.datasets.transforms.common_transforms import ( + Albumentation, PhotometricDistortion, RandomBBoxTransform) +from mmpose.engine.hooks import ExpMomentumEMA +from mmpose.evaluation import CocoWholeBodyMetric +from mmpose.models import (CSPNeXt, CSPNeXtPAFPN, KLDiscretLoss, + PoseDataPreprocessor, RTMWHead, + TopdownPoseEstimator) + +# common setting +num_keypoints = 133 +input_size = (192, 256) + +# runtime +max_epochs = 270 +stage2_num_epochs = 10 +base_lr = 5e-4 +train_batch_size = 704 +val_batch_size = 32 + +train_cfg.update(max_epochs=max_epochs, val_interval=10) # noqa +randomness = dict(seed=21) + +# optimizer +optim_wrapper = dict( + type=OptimWrapper, + optimizer=dict(type=AdamW, lr=base_lr, weight_decay=0.05), + clip_grad=dict(max_norm=35, norm_type=2), + paramwise_cfg=dict( + norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True)) + +# learning rate +param_scheduler = [ + dict( + type=LinearLR, start_factor=1.0e-5, by_epoch=False, begin=0, end=1000), + dict( + type=CosineAnnealingLR, + eta_min=base_lr * 0.05, + begin=max_epochs // 2, + end=max_epochs, + T_max=max_epochs // 2, + by_epoch=True, + convert_to_iter_based=True), +] + +# automatically scaling LR based on the actual training batch size +auto_scale_lr = dict(base_batch_size=5632) + +# codec settings +codec = dict( + type=SimCCLabel, + input_size=input_size, + sigma=(4.9, 5.66), + simcc_split_ratio=2.0, + normalize=False, + use_dark=False) + +# model settings +model = dict( + type=TopdownPoseEstimator, + data_preprocessor=dict( + type=PoseDataPreprocessor, + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + backbone=dict( + type=CSPNeXt, + arch='P5', + expand_ratio=0.5, + deepen_factor=1.33, + widen_factor=1.25, + channel_attention=True, + norm_cfg=dict(type='BN'), + act_cfg=dict(type=SiLU), + init_cfg=dict( + type=PretrainedInit, + prefix='backbone.', + checkpoint='https://download.openmmlab.com/mmpose/v1/' + 'wholebody_2d_keypoint/rtmpose/ubody/rtmpose-x_simcc-ucoco_pt-aic-coco_270e-256x192-05f5bcb7_20230822.pth' # noqa + )), + neck=dict( + type=CSPNeXtPAFPN, + in_channels=[320, 640, 1280], + out_channels=None, + out_indices=( + 1, + 2, + ), + num_csp_blocks=2, + expand_ratio=0.5, + norm_cfg=dict(type=SyncBatchNorm), + act_cfg=dict(type=SiLU, inplace=True)), + head=dict( + type=RTMWHead, + in_channels=1280, + out_channels=num_keypoints, + input_size=input_size, + in_featuremap_size=tuple([s // 32 for s in input_size]), + simcc_split_ratio=codec['simcc_split_ratio'], + final_layer_kernel_size=7, + gau_cfg=dict( + hidden_dims=256, + s=128, + expansion_factor=2, + dropout_rate=0., + drop_path=0., + act_fn=SiLU, + use_rel_bias=False, + pos_enc=False), + loss=dict( + type=KLDiscretLoss, + use_target_weight=True, + beta=10., + label_softmax=True), + decoder=codec), + test_cfg=dict(flip_test=True)) + +# base dataset settings +dataset_type = CocoWholeBodyDataset +data_mode = 'topdown' +data_root = 'data/' + +backend_args = dict(backend='local') + +# pipelines +train_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict(type=RandomFlip, direction='horizontal'), + dict(type=RandomHalfBody), + dict(type=RandomBBoxTransform, scale_factor=[0.5, 1.5], rotate_factor=90), + dict(type=TopdownAffine, input_size=codec['input_size']), + dict(type=PhotometricDistortion), + dict( + type=Albumentation, + transforms=[ + dict(type=Blur, p=0.1), + dict(type=MedianBlur, p=0.1), + dict( + type=CoarseDropout, + max_holes=1, + max_height=0.4, + max_width=0.4, + min_holes=1, + min_height=0.2, + min_width=0.2, + p=1.0), + ]), + dict( + type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True), + dict(type=PackPoseInputs) +] +val_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict(type=TopdownAffine, input_size=codec['input_size']), + dict(type=PackPoseInputs) +] + +train_pipeline_stage2 = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict(type=RandomFlip, direction='horizontal'), + dict(type=RandomHalfBody), + dict( + type=RandomBBoxTransform, + shift_factor=0., + scale_factor=[0.5, 1.5], + rotate_factor=90), + dict(type=TopdownAffine, input_size=codec['input_size']), + dict( + type=Albumentation, + transforms=[ + dict(type=Blur, p=0.1), + dict(type=MedianBlur, p=0.1), + ]), + dict( + type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True), + dict(type=PackPoseInputs) +] + +# mapping + +aic_coco133 = [(0, 6), (1, 8), (2, 10), (3, 5), (4, 7), (5, 9), (6, 12), + (7, 14), (8, 16), (9, 11), (10, 13), (11, 15)] + +crowdpose_coco133 = [(0, 5), (1, 6), (2, 7), (3, 8), (4, 9), (5, 10), (6, 11), + (7, 12), (8, 13), (9, 14), (10, 15), (11, 16)] + +mpii_coco133 = [ + (0, 16), + (1, 14), + (2, 12), + (3, 11), + (4, 13), + (5, 15), + (8, 18), + (9, 17), + (10, 10), + (11, 8), + (12, 6), + (13, 5), + (14, 7), + (15, 9), +] + +jhmdb_coco133 = [ + (0, 18), + (2, 17), + (3, 6), + (4, 5), + (5, 12), + (6, 11), + (7, 8), + (8, 7), + (9, 14), + (10, 13), + (11, 10), + (12, 9), + (13, 16), + (14, 15), +] + +halpe_coco133 = [(i, i) + for i in range(17)] + [(20, 17), (21, 20), (22, 18), (23, 21), + (24, 19), + (25, 22)] + [(i, i - 3) + for i in range(26, 136)] + +posetrack_coco133 = [ + (0, 0), + (2, 17), + (3, 3), + (4, 4), + (5, 5), + (6, 6), + (7, 7), + (8, 8), + (9, 9), + (10, 10), + (11, 11), + (12, 12), + (13, 13), + (14, 14), + (15, 15), + (16, 16), +] + +humanart_coco133 = [(i, i) for i in range(17)] + [(17, 99), (18, 120), + (19, 17), (20, 20)] + +# train datasets +dataset_coco = dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='coco/annotations/coco_wholebody_train_v1.0.json', + data_prefix=dict(img='detection/coco/train2017/'), + pipeline=[], +) + +dataset_aic = dict( + type=AicDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='aic/annotations/aic_train.json', + data_prefix=dict(img='pose/ai_challenge/ai_challenger_keypoint' + '_train_20170902/keypoint_train_images_20170902/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=aic_coco133) + ], +) + +dataset_crowdpose = dict( + type=CrowdPoseDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='crowdpose/annotations/mmpose_crowdpose_trainval.json', + data_prefix=dict(img='pose/CrowdPose/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=crowdpose_coco133) + ], +) + +dataset_mpii = dict( + type=MpiiDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='mpii/annotations/mpii_train.json', + data_prefix=dict(img='pose/MPI/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=mpii_coco133) + ], +) + +dataset_jhmdb = dict( + type=JhmdbDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='jhmdb/annotations/Sub1_train.json', + data_prefix=dict(img='pose/JHMDB/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=jhmdb_coco133) + ], +) + +dataset_halpe = dict( + type=HalpeDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='halpe/annotations/halpe_train_v1.json', + data_prefix=dict(img='pose/Halpe/hico_20160224_det/images/train2015'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=halpe_coco133) + ], +) + +dataset_posetrack = dict( + type=PoseTrack18Dataset, + data_root=data_root, + data_mode=data_mode, + ann_file='posetrack18/annotations/posetrack18_train.json', + data_prefix=dict(img='pose/PoseChallenge2018/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=posetrack_coco133) + ], +) + +dataset_humanart = dict( + type=HumanArt21Dataset, + data_root=data_root, + data_mode=data_mode, + ann_file='HumanArt/annotations/training_humanart.json', + filter_cfg=dict(scenes=['real_human']), + data_prefix=dict(img='pose/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=humanart_coco133) + ]) + +ubody_scenes = [ + 'Magic_show', 'Entertainment', 'ConductMusic', 'Online_class', 'TalkShow', + 'Speech', 'Fitness', 'Interview', 'Olympic', 'TVShow', 'Singing', + 'SignLanguage', 'Movie', 'LiveVlog', 'VideoConference' +] + +ubody_datasets = [] +for scene in ubody_scenes: + each = dict( + type=UBody2dDataset, + data_root=data_root, + data_mode=data_mode, + ann_file=f'Ubody/annotations/{scene}/train_annotations.json', + data_prefix=dict(img='pose/UBody/images/'), + pipeline=[], + sample_interval=10) + ubody_datasets.append(each) + +dataset_ubody = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/ubody2d.py'), + datasets=ubody_datasets, + pipeline=[], + test_mode=False, +) + +face_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale, padding=1.25), + dict( + type=RandomBBoxTransform, + shift_factor=0., + scale_factor=[1.5, 2.0], + rotate_factor=0), +] + +wflw_coco133 = [(i * 2, 23 + i) + for i in range(17)] + [(33 + i, 40 + i) for i in range(5)] + [ + (42 + i, 45 + i) for i in range(5) + ] + [(51 + i, 50 + i) + for i in range(9)] + [(60, 59), (61, 60), (63, 61), + (64, 62), (65, 63), (67, 64), + (68, 65), (69, 66), (71, 67), + (72, 68), (73, 69), + (75, 70)] + [(76 + i, 71 + i) + for i in range(20)] +dataset_wflw = dict( + type=WFLWDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='wflw/annotations/face_landmarks_wflw_train.json', + data_prefix=dict(img='pose/WFLW/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=wflw_coco133), *face_pipeline + ], +) + +mapping_300w_coco133 = [(i, 23 + i) for i in range(68)] +dataset_300w = dict( + type=Face300WDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='300w/annotations/face_landmarks_300w_train.json', + data_prefix=dict(img='pose/300w/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=mapping_300w_coco133), *face_pipeline + ], +) + +cofw_coco133 = [(0, 40), (2, 44), (4, 42), (1, 49), (3, 45), (6, 47), (8, 59), + (10, 62), (9, 68), (11, 65), (18, 54), (19, 58), (20, 53), + (21, 56), (22, 71), (23, 77), (24, 74), (25, 85), (26, 89), + (27, 80), (28, 31)] +dataset_cofw = dict( + type=COFWDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='cofw/annotations/cofw_train.json', + data_prefix=dict(img='pose/COFW/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=cofw_coco133), *face_pipeline + ], +) + +lapa_coco133 = [(i * 2, 23 + i) for i in range(17)] + [ + (33 + i, 40 + i) for i in range(5) +] + [(42 + i, 45 + i) for i in range(5)] + [ + (51 + i, 50 + i) for i in range(4) +] + [(58 + i, 54 + i) for i in range(5)] + [(66, 59), (67, 60), (69, 61), + (70, 62), (71, 63), (73, 64), + (75, 65), (76, 66), (78, 67), + (79, 68), (80, 69), + (82, 70)] + [(84 + i, 71 + i) + for i in range(20)] +dataset_lapa = dict( + type=LapaDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='LaPa/annotations/lapa_trainval.json', + data_prefix=dict(img='pose/LaPa/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=lapa_coco133), *face_pipeline + ], +) + +dataset_wb = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[dataset_coco, dataset_halpe, dataset_ubody], + pipeline=[], + test_mode=False, +) + +dataset_body = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[ + dataset_aic, + dataset_crowdpose, + dataset_mpii, + dataset_jhmdb, + dataset_posetrack, + dataset_humanart, + ], + pipeline=[], + test_mode=False, +) + +dataset_face = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[ + dataset_wflw, + dataset_300w, + dataset_cofw, + dataset_lapa, + ], + pipeline=[], + test_mode=False, +) + +hand_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict( + type=RandomBBoxTransform, + shift_factor=0., + scale_factor=[1.5, 2.0], + rotate_factor=0), +] + +interhand_left = [(21, 95), (22, 94), (23, 93), (24, 92), (25, 99), (26, 98), + (27, 97), (28, 96), (29, 103), (30, 102), (31, 101), + (32, 100), (33, 107), (34, 106), (35, 105), (36, 104), + (37, 111), (38, 110), (39, 109), (40, 108), (41, 91)] +interhand_right = [(i - 21, j + 21) for i, j in interhand_left] +interhand_coco133 = interhand_right + interhand_left + +dataset_interhand2d = dict( + type=InterHand2DDoubleDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='interhand26m/annotations/all/InterHand2.6M_train_data.json', + camera_param_file='interhand26m/annotations/all/' + 'InterHand2.6M_train_camera.json', + joint_file='interhand26m/annotations/all/' + 'InterHand2.6M_train_joint_3d.json', + data_prefix=dict(img='interhand2.6m/images/train/'), + sample_interval=10, + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=interhand_coco133, + ), *hand_pipeline + ], +) + +dataset_hand = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[dataset_interhand2d], + pipeline=[], + test_mode=False, +) + +train_datasets = [dataset_wb, dataset_body, dataset_face, dataset_hand] + +# data loaders +train_dataloader = dict( + batch_size=train_batch_size, + num_workers=4, + pin_memory=False, + persistent_workers=True, + sampler=dict(type=DefaultSampler, shuffle=True), + dataset=dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=train_datasets, + pipeline=train_pipeline, + test_mode=False, + )) + +val_dataloader = dict( + batch_size=val_batch_size, + num_workers=4, + persistent_workers=True, + drop_last=False, + sampler=dict(type=DefaultSampler, shuffle=False, round_up=False), + dataset=dict( + type=CocoWholeBodyDataset, + ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json', + data_prefix=dict(img='data/detection/coco/val2017/'), + pipeline=val_pipeline, + bbox_file='data/coco/person_detection_results/' + 'COCO_val2017_detections_AP_H_56_person.json', + test_mode=True)) + +test_dataloader = val_dataloader + +# hooks +default_hooks.update( # noqa + checkpoint=dict( + save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1)) + +custom_hooks = [ + dict( + type=EMAHook, + ema_type=ExpMomentumEMA, + momentum=0.0002, + update_buffers=True, + priority=49), + dict( + type=PipelineSwitchHook, + switch_epoch=max_epochs - stage2_num_epochs, + switch_pipeline=train_pipeline_stage2) +] + +# evaluators +val_evaluator = dict( + type=CocoWholeBodyMetric, + ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json') +test_evaluator = val_evaluator diff --git a/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw_cocktail13.md b/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw_cocktail13.md new file mode 100644 index 0000000000..54e75383ba --- /dev/null +++ b/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw_cocktail13.md @@ -0,0 +1,76 @@ + + + \
diff --git a/demo/docs/en/2d_face_demo.md b/demo/docs/en/2d_face_demo.md
index 9c60f68487..4e8dd70684 100644
--- a/demo/docs/en/2d_face_demo.md
+++ b/demo/docs/en/2d_face_demo.md
@@ -23,15 +23,15 @@ Take [aflw model](https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18
python demo/topdown_demo_with_mmdet.py \
demo/mmdetection_cfg/yolox-s_8xb8-300e_coco-face.py \
https://download.openmmlab.com/mmpose/mmdet_pretrained/yolo-x_8xb8-300e_coco-face_13274d7c.pth \
- configs/face_2d_keypoint/topdown_heatmap/aflw/td-hm_hrnetv2-w18_8xb64-60e_aflw-256x256.py \
- https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_aflw_256x256-f2bbc62b_20210125.pth \
+ configs/face_2d_keypoint/rtmpose/face6/rtmpose-m_8xb256-120e_face6-256x256.py \
+ https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.pth \
--input tests/data/cofw/001766.jpg \
--show --draw-heatmap
```
Visualization result:
-
+
If you use a heatmap-based model and set argument `--draw-heatmap`, the predicted heatmap will be visualized together with the keypoints. @@ -41,8 +41,8 @@ To save visualized results on disk: python demo/topdown_demo_with_mmdet.py \ demo/mmdetection_cfg/yolox-s_8xb8-300e_coco-face.py \ https://download.openmmlab.com/mmpose/mmdet_pretrained/yolo-x_8xb8-300e_coco-face_13274d7c.pth \ - configs/face_2d_keypoint/topdown_heatmap/aflw/td-hm_hrnetv2-w18_8xb64-60e_aflw-256x256.py \ - https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_aflw_256x256-f2bbc62b_20210125.pth \ + configs/face_2d_keypoint/rtmpose/face6/rtmpose-m_8xb256-120e_face6-256x256.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.pth \ --input tests/data/cofw/001766.jpg \ --draw-heatmap --output-root vis_results ``` @@ -55,8 +55,8 @@ To run demos on CPU: python demo/topdown_demo_with_mmdet.py \ demo/mmdetection_cfg/yolox-s_8xb8-300e_coco-face.py \ https://download.openmmlab.com/mmpose/mmdet_pretrained/yolo-x_8xb8-300e_coco-face_13274d7c.pth \ - configs/face_2d_keypoint/topdown_heatmap/aflw/td-hm_hrnetv2-w18_8xb64-60e_aflw-256x256.py \ - https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_aflw_256x256-f2bbc62b_20210125.pth \ + configs/face_2d_keypoint/rtmpose/face6/rtmpose-m_8xb256-120e_face6-256x256.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.pth \ --input tests/data/cofw/001766.jpg \ --show --draw-heatmap --device=cpu ``` @@ -69,13 +69,13 @@ Videos share the same interface with images. The difference is that the `${INPUT python demo/topdown_demo_with_mmdet.py \ demo/mmdetection_cfg/yolox-s_8xb8-300e_coco-face.py \ https://download.openmmlab.com/mmpose/mmdet_pretrained/yolo-x_8xb8-300e_coco-face_13274d7c.pth \ - configs/face_2d_keypoint/topdown_heatmap/aflw/td-hm_hrnetv2-w18_8xb64-60e_aflw-256x256.py \ - https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_aflw_256x256-f2bbc62b_20210125.pth \ + configs/face_2d_keypoint/rtmpose/face6/rtmpose-m_8xb256-120e_face6-256x256.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.pth \ --input demo/resources/ \
- --show --draw-heatmap --output-root vis_results
+ --show --output-root vis_results --radius 1
```
-
+
The original video can be downloaded from [Google Drive](https://drive.google.com/file/d/1kQt80t6w802b_vgVcmiV_QfcSJ3RWzmb/view?usp=sharing). diff --git a/demo/docs/en/2d_hand_demo.md b/demo/docs/en/2d_hand_demo.md index f47b3695e3..cea74e2be4 100644 --- a/demo/docs/en/2d_hand_demo.md +++ b/demo/docs/en/2d_hand_demo.md @@ -21,17 +21,17 @@ Take [onehand10k model](https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnet ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \ - https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth \ - configs/hand_2d_keypoint/topdown_heatmap/onehand10k/td-hm_hrnetv2-w18_8xb64-210e_onehand10k-256x256.py \ - https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_onehand10k_256x256-30bc9c6b_20210330.pth \ + demo/mmdetection_cfg/rtmdet_nano_320-8xb32_hand.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_nano_8xb32-300e_hand-267f9c8f.pth \ + configs/hand_2d_keypoint/rtmpose/hand5/rtmpose-m_8xb256-210e_hand5-256x256.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.pth \ --input tests/data/onehand10k/9.jpg \ --show --draw-heatmap ``` Visualization result: -
+
If you use a heatmap-based model and set argument `--draw-heatmap`, the predicted heatmap will be visualized together with the keypoints. @@ -39,10 +39,10 @@ To save visualized results on disk: ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \ - https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth \ - configs/hand_2d_keypoint/topdown_heatmap/onehand10k/td-hm_hrnetv2-w18_8xb64-210e_onehand10k-256x256.py \ - https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_onehand10k_256x256-30bc9c6b_20210330.pth \ + demo/mmdetection_cfg/rtmdet_nano_320-8xb32_hand.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_nano_8xb32-300e_hand-267f9c8f.pth \ + configs/hand_2d_keypoint/rtmpose/hand5/rtmpose-m_8xb256-210e_hand5-256x256.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.pth \ --input tests/data/onehand10k/9.jpg \ --output-root vis_results --show --draw-heatmap ``` @@ -53,10 +53,10 @@ To run demos on CPU: ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \ - https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth \ - configs/hand_2d_keypoint/topdown_heatmap/onehand10k/td-hm_hrnetv2-w18_8xb64-210e_onehand10k-256x256.py \ - https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_onehand10k_256x256-30bc9c6b_20210330.pth \ + demo/mmdetection_cfg/rtmdet_nano_320-8xb32_hand.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_nano_8xb32-300e_hand-267f9c8f.pth \ + configs/hand_2d_keypoint/rtmpose/hand5/rtmpose-m_8xb256-210e_hand5-256x256.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.pth \ --input tests/data/onehand10k/9.jpg \ --show --draw-heatmap --device cpu ``` @@ -67,15 +67,15 @@ Videos share the same interface with images. The difference is that the `${INPUT ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \ - https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth \ - configs/hand_2d_keypoint/topdown_heatmap/onehand10k/td-hm_hrnetv2-w18_8xb64-210e_onehand10k-256x256.py \ - https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_onehand10k_256x256-30bc9c6b_20210330.pth \ - --input demo/resources/ \
- --output-root vis_results --show --draw-heatmap
+ demo/mmdetection_cfg/rtmdet_nano_320-8xb32_hand.py \
+ https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_nano_8xb32-300e_hand-267f9c8f.pth \
+ configs/hand_2d_keypoint/rtmpose/hand5/rtmpose-m_8xb256-210e_hand5-256x256.py \
+ https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.pth \
+ --input data/tests_data_nvgesture_sk_color.avi \
+ --output-root vis_results --kpt-thr 0.1
```
-
+
The original video can be downloaded from [Github](https://raw.githubusercontent.com/open-mmlab/mmpose/master/tests/data/nvgesture/sk_color.avi). diff --git a/demo/docs/en/2d_human_pose_demo.md b/demo/docs/en/2d_human_pose_demo.md index a2e3cf59dd..4e682cc8ff 100644 --- a/demo/docs/en/2d_human_pose_demo.md +++ b/demo/docs/en/2d_human_pose_demo.md @@ -66,17 +66,17 @@ Example: ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ - https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ - configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py \ - https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_256x192-c78dce93_20200708.pth \ + demo/mmdetection_cfg/rtmdet_m_640-8xb32_coco-person.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_m_8xb32-100e_coco-obj365-person-235e8209.pth \ + configs/body_2d_keypoint/rtmpose/body8/rtmpose-m_8xb256-420e_body8-256x192.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-256x192-e48f03d0_20230504.pth \ --input tests/data/coco/000000197388.jpg --show --draw-heatmap \ --output-root vis_results/ ``` Visualization result: -
+
To save the predicted results on disk, please specify `--save-predictions`. @@ -90,10 +90,10 @@ Example: ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ - https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ - configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py \ - https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192-81c58e40_20220909.pth \ + demo/mmdetection_cfg/rtmdet_m_640-8xb32_coco-person.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_m_8xb32-100e_coco-obj365-person-235e8209.pth \ + configs/body_2d_keypoint/rtmpose/body8/rtmpose-m_8xb256-420e_body8-256x192.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-256x192-e48f03d0_20230504.pth \ --input tests/data/posetrack18/videos/000001_mpiinew_test/000001_mpiinew_test.mp4 \ --output-root=vis_results/demo --show --draw-heatmap ``` diff --git a/demo/docs/en/2d_wholebody_pose_demo.md b/demo/docs/en/2d_wholebody_pose_demo.md index ddd4cbd13d..a4f9ace061 100644 --- a/demo/docs/en/2d_wholebody_pose_demo.md +++ b/demo/docs/en/2d_wholebody_pose_demo.md @@ -56,8 +56,8 @@ Examples: ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ - https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ + demo/mmdetection_cfg/rtmdet_m_640-8xb32_coco-person.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_m_8xb32-100e_coco-obj365-person-235e8209.pth \ configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/td-hm_hrnet-w48_dark-8xb32-210e_coco-wholebody-384x288.py \ https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_384x288_dark-f5726563_20200918.pth \ --input tests/data/coco/000000196141.jpg \ @@ -76,8 +76,8 @@ Examples: ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ - https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ + demo/mmdetection_cfg/rtmdet_m_640-8xb32_coco-person.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_m_8xb32-100e_coco-obj365-person-235e8209.pth \ configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/td-hm_hrnet-w48_dark-8xb32-210e_coco-wholebody-384x288.py \ https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_384x288_dark-f5726563_20200918.pth \ --input https://user-images.githubusercontent.com/87690686/137440639-fb08603d-9a35-474e-b65f-46b5c06b68d6.mp4 \ diff --git a/demo/docs/en/3d_hand_demo.md b/demo/docs/en/3d_hand_demo.md new file mode 100644 index 0000000000..edd1a4fa6e --- /dev/null +++ b/demo/docs/en/3d_hand_demo.md @@ -0,0 +1,52 @@ +## 3D Hand Demo + +
+ +### 3D Hand Estimation Image Demo + +#### Using gt hand bounding boxes as input + +We provide a demo script to test a single image, given gt json file. + +```shell +python demo/hand3d_internet_demo.py \ + ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \ + --input ${INPUT_FILE} \ + --output-root ${OUTPUT_ROOT} \ + [--save-predictions] \ + [--gt-joints-file ${GT_JOINTS_FILE}]\ + [--disable-rebase-keypoint] \ + [--show] \ + [--device ${GPU_ID or CPU}] \ + [--kpt-thr ${KPT_THR}] \ + [--show-kpt-idx] \ + [--show-interval] \ + [--radius ${RADIUS}] \ + [--thickness ${THICKNESS}] +``` + +The pre-trained hand pose estimation model can be downloaded from [model zoo](https://mmpose.readthedocs.io/en/latest/model_zoo/hand_3d_keypoint.html). +Take [internet model](https://download.openmmlab.com/mmpose/hand3d/internet/res50_intehand3dv1.0_all_256x256-42b7f2ac_20210702.pth) as an example: + +```shell +python demo/hand3d_internet_demo.py \ + configs/hand_3d_keypoint/internet/interhand3d/internet_res50_4xb16-20e_interhand3d-256x256.py \ + https://download.openmmlab.com/mmpose/hand3d/internet/res50_intehand3dv1.0_all_256x256-42b7f2ac_20210702.pth \ + --input tests/data/interhand2.6m/image69148.jpg \ + --save-predictions \ + --output-root vis_results +``` + +### 3D Hand Pose Estimation with Inferencer + +The Inferencer provides a convenient interface for inference, allowing customization using model aliases instead of configuration files and checkpoint paths. It supports various input formats, including image paths, video paths, image folder paths, and webcams. Below is an example command: + +```shell +python demo/inferencer_demo.py tests/data/interhand2.6m/image29590.jpg --pose3d hand3d --vis-out-dir vis_results/hand3d +``` + +This command infers the image and saves the visualization results in the `vis_results/hand3d` directory. + +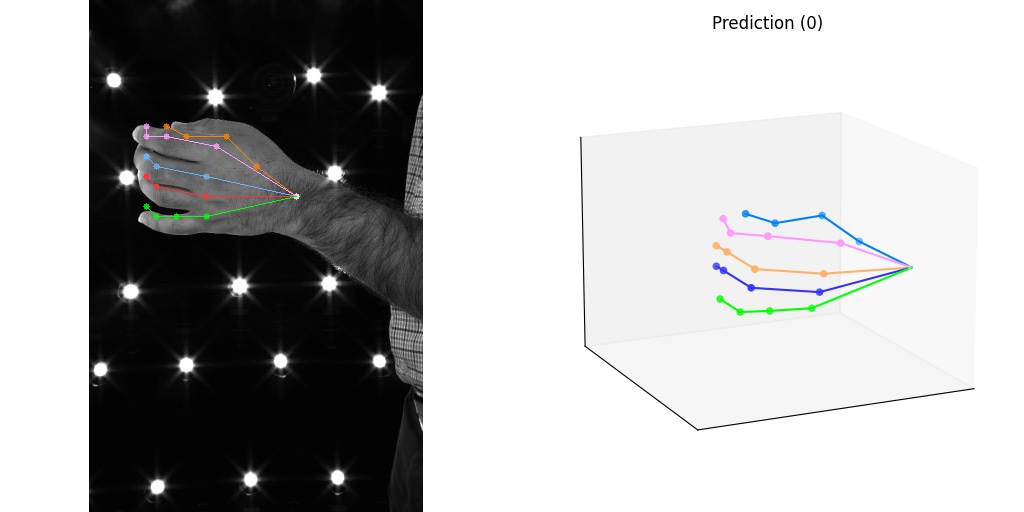 +
+In addition, the Inferencer supports saving predicted poses. For more information, please refer to the [inferencer document](https://mmpose.readthedocs.io/en/latest/user_guides/inference.html#inferencer-a-unified-inference-interface).
diff --git a/demo/docs/en/3d_human_pose_demo.md b/demo/docs/en/3d_human_pose_demo.md
index 367d98c403..d71515cd84 100644
--- a/demo/docs/en/3d_human_pose_demo.md
+++ b/demo/docs/en/3d_human_pose_demo.md
@@ -18,63 +18,59 @@ ${MMPOSE_CONFIG_FILE_3D} \
${MMPOSE_CHECKPOINT_FILE_3D} \
--input ${VIDEO_PATH or IMAGE_PATH or 'webcam'} \
[--show] \
-[--rebase-keypoint-height] \
-[--norm-pose-2d] \
-[--num-instances] \
+[--disable-rebase-keypoint] \
+[--disable-norm-pose-2d] \
+[--num-instances ${NUM_INSTANCES}] \
[--output-root ${OUT_VIDEO_ROOT}] \
-[--save-predictions]
[--save-predictions] \
[--device ${GPU_ID or CPU}] \
-[--det-cat-id DET_CAT_ID] \
-[--bbox-thr BBOX_THR] \
-[--kpt-thr KPT_THR] \
+[--det-cat-id ${DET_CAT_ID}] \
+[--bbox-thr ${BBOX_THR}] \
+[--kpt-thr ${KPT_THR}] \
[--use-oks-tracking] \
-[--tracking-thr TRACKING_THR] \
-[--show-interval INTERVAL] \
-[--thickness THICKNESS] \
-[--radius RADIUS] \
-[--use-multi-frames] [--online]
+[--tracking-thr ${TRACKING_THR}] \
+[--show-interval ${INTERVAL}] \
+[--thickness ${THICKNESS}] \
+[--radius ${RADIUS}] \
+[--online]
```
Note that
1. `${VIDEO_PATH}` can be the local path or **URL** link to video file.
-2. You can turn on the `[--use-multi-frames]` option to use multi frames for inference in the 2D pose detection stage.
-
-3. If the `[--online]` option is set to **True**, future frame information can **not** be used when using multi frames for inference in the 2D pose detection stage.
+2. If the `[--online]` option is set to **True**, future frame information can **not** be used when using multi frames for inference in the 2D pose detection stage.
Examples:
During 2D pose detection, for single-frame inference that do not rely on extra frames to get the final results of the current frame and save the prediction results, try this:
```shell
-python demo/body3d_pose_lifter_demo.py \
-demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
-https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
-configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w48_8xb32-210e_coco-256x192.py \
-https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \
-configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-243frm-supv-cpn-ft_8xb128-200e_h36m.py \
+python demo/body3d_pose_lifter_demo.py \
+demo/mmdetection_cfg/rtmdet_m_640-8xb32_coco-person.py \
+https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_m_8xb32-100e_coco-obj365-person-235e8209.pth \
+configs/body_2d_keypoint/rtmpose/body8/rtmpose-m_8xb256-420e_body8-256x192.py \
+https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-256x192-e48f03d0_20230504.pth \
+configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-243frm-supv-cpn-ft_8xb128-200e_h36m.py \
https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_cpn_ft-88f5abbb_20210527.pth \
--input https://user-images.githubusercontent.com/87690686/164970135-b14e424c-765a-4180-9bc8-fa8d6abc5510.mp4 \
---output-root vis_results \
---rebase-keypoint-height --save-predictions
+--output-root vis_results \
+--save-predictions
```
During 2D pose detection, for multi-frame inference that rely on extra frames to get the final results of the current frame, try this:
```shell
-python demo/body3d_pose_lifter_demo.py \
-demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
-https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
-configs/body_2d_keypoint/topdown_heatmap/posetrack18/td-hm_hrnet-w48_8xb64-20e_posetrack18-384x288.py \
-https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_posetrack18_384x288-5fd6d3ff_20211130.pth \
-configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-243frm-supv-cpn-ft_8xb128-200e_h36m.py \
-https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_cpn_ft-88f5abbb_20210527.pth \
+python demo/body3d_pose_lifter_demo.py \
+demo/mmdetection_cfg/rtmdet_m_640-8xb32_coco-person.py \
+https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_m_8xb32-100e_coco-obj365-person-235e8209.pth \
+configs/body_2d_keypoint/rtmpose/body8/rtmpose-m_8xb256-420e_body8-256x192.py \
+https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-256x192-e48f03d0_20230504.pth \
+configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-243frm-supv-cpn-ft_8xb128-200e_h36m.py \
+https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_cpn_ft-88f5abbb_20210527.pth \
--input https://user-images.githubusercontent.com/87690686/164970135-b14e424c-765a-4180-9bc8-fa8d6abc5510.mp4 \
--output-root vis_results \
---rebase-keypoint-height \
---use-multi-frames --online
+--online
```
### 3D Human Pose Demo with Inferencer
@@ -83,8 +79,7 @@ The Inferencer provides a convenient interface for inference, allowing customiza
```shell
python demo/inferencer_demo.py tests/data/coco/000000000785.jpg \
- --pose3d human3d --vis-out-dir vis_results/human3d \
- --rebase-keypoint-height
+ --pose3d human3d --vis-out-dir vis_results/human3d
```
This command infers the image and saves the visualization results in the `vis_results/human3d` directory.
diff --git a/demo/docs/en/mmdet_modelzoo.md b/demo/docs/en/mmdet_modelzoo.md
index 5383cb953f..3dd5e4a55a 100644
--- a/demo/docs/en/mmdet_modelzoo.md
+++ b/demo/docs/en/mmdet_modelzoo.md
@@ -14,6 +14,7 @@ For hand bounding box detection, we simply train our hand box models on OneHand1
| Arch | Box AP | ckpt | log |
| :---------------------------------------------------------------- | :----: | :---------------------------------------------------------------: | :--------------------------------------------------------------: |
| [Cascade_R-CNN X-101-64x4d-FPN-1class](/demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py) | 0.817 | [ckpt](https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth) | [log](https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k_20201030.log.json) |
+| [RTMDet-nano](/demo/mmdetection_cfg/rtmdet_nano_320-8xb32_hand.py) | 0.760 | [ckpt](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_nano_8xb32-300e_hand-267f9c8f.pth) | - |
### Face Bounding Box Detection Models
diff --git a/demo/docs/zh_cn/2d_animal_demo.md b/demo/docs/zh_cn/2d_animal_demo.md
index e49f292f56..f1932cf6eb 100644
--- a/demo/docs/zh_cn/2d_animal_demo.md
+++ b/demo/docs/zh_cn/2d_animal_demo.md
@@ -21,8 +21,8 @@ python demo/topdown_demo_with_mmdet.py \
```shell
python demo/topdown_demo_with_mmdet.py \
- demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
- https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ demo/mmdetection_cfg/rtmdet_m_8xb32-300e_coco.py \
+ https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_m_8xb32-300e_coco/rtmdet_m_8xb32-300e_coco_20220719_112220-229f527c.pth \
configs/animal_2d_keypoint/topdown_heatmap/animalpose/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256.py \
https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_animalpose_256x256-1aa7f075_20210426.pth \
--input tests/data/animalpose/ca110.jpeg \
@@ -49,8 +49,8 @@ COCO 数据集共包含 80 个类别,其中有 10 种常见动物,类别如
```shell
python demo/topdown_demo_with_mmdet.py \
- demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
- https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ demo/mmdetection_cfg/rtmdet_m_8xb32-300e_coco.py \
+ https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_m_8xb32-300e_coco/rtmdet_m_8xb32-300e_coco_20220719_112220-229f527c.pth \
configs/animal_2d_keypoint/topdown_heatmap/animalpose/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256.py \
https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_animalpose_256x256-1aa7f075_20210426.pth \
--input tests/data/animalpose/ca110.jpeg \
@@ -61,8 +61,8 @@ python demo/topdown_demo_with_mmdet.py \
```shell
python demo/topdown_demo_with_mmdet.py \
- demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
- https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ demo/mmdetection_cfg/rtmdet_m_8xb32-300e_coco.py \
+ https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_m_8xb32-300e_coco/rtmdet_m_8xb32-300e_coco_20220719_112220-229f527c.pth \
configs/animal_2d_keypoint/topdown_heatmap/animalpose/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256.py \
https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_animalpose_256x256-1aa7f075_20210426.pth \
--input tests/data/animalpose/ca110.jpeg \
@@ -73,8 +73,8 @@ python demo/topdown_demo_with_mmdet.py \
```shell
python demo/topdown_demo_with_mmdet.py \
- demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
- https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ demo/mmdetection_cfg/rtmdet_tiny_8xb32-300e_coco.py \
+ https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_tiny_8xb32-300e_coco/rtmdet_tiny_8xb32-300e_coco_20220902_112414-78e30dcc.pth \
configs/animal_2d_keypoint/topdown_heatmap/animalpose/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256.py \
https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_animalpose_256x256-1aa7f075_20210426.pth \
--input tests/data/animalpose/ca110.jpeg \
@@ -89,8 +89,8 @@ python demo/topdown_demo_with_mmdet.py \
```shell
python demo/topdown_demo_with_mmdet.py \
- demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
- https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ demo/mmdetection_cfg/rtmdet_m_8xb32-300e_coco.py \
+ https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_m_8xb32-300e_coco/rtmdet_m_8xb32-300e_coco_20220719_112220-229f527c.pth \
configs/animal_2d_keypoint/topdown_heatmap/animalpose/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256.py \
https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_animalpose_256x256-1aa7f075_20210426.pth \
--input demo/resources/
+
+In addition, the Inferencer supports saving predicted poses. For more information, please refer to the [inferencer document](https://mmpose.readthedocs.io/en/latest/user_guides/inference.html#inferencer-a-unified-inference-interface).
diff --git a/demo/docs/en/3d_human_pose_demo.md b/demo/docs/en/3d_human_pose_demo.md
index 367d98c403..d71515cd84 100644
--- a/demo/docs/en/3d_human_pose_demo.md
+++ b/demo/docs/en/3d_human_pose_demo.md
@@ -18,63 +18,59 @@ ${MMPOSE_CONFIG_FILE_3D} \
${MMPOSE_CHECKPOINT_FILE_3D} \
--input ${VIDEO_PATH or IMAGE_PATH or 'webcam'} \
[--show] \
-[--rebase-keypoint-height] \
-[--norm-pose-2d] \
-[--num-instances] \
+[--disable-rebase-keypoint] \
+[--disable-norm-pose-2d] \
+[--num-instances ${NUM_INSTANCES}] \
[--output-root ${OUT_VIDEO_ROOT}] \
-[--save-predictions]
[--save-predictions] \
[--device ${GPU_ID or CPU}] \
-[--det-cat-id DET_CAT_ID] \
-[--bbox-thr BBOX_THR] \
-[--kpt-thr KPT_THR] \
+[--det-cat-id ${DET_CAT_ID}] \
+[--bbox-thr ${BBOX_THR}] \
+[--kpt-thr ${KPT_THR}] \
[--use-oks-tracking] \
-[--tracking-thr TRACKING_THR] \
-[--show-interval INTERVAL] \
-[--thickness THICKNESS] \
-[--radius RADIUS] \
-[--use-multi-frames] [--online]
+[--tracking-thr ${TRACKING_THR}] \
+[--show-interval ${INTERVAL}] \
+[--thickness ${THICKNESS}] \
+[--radius ${RADIUS}] \
+[--online]
```
Note that
1. `${VIDEO_PATH}` can be the local path or **URL** link to video file.
-2. You can turn on the `[--use-multi-frames]` option to use multi frames for inference in the 2D pose detection stage.
-
-3. If the `[--online]` option is set to **True**, future frame information can **not** be used when using multi frames for inference in the 2D pose detection stage.
+2. If the `[--online]` option is set to **True**, future frame information can **not** be used when using multi frames for inference in the 2D pose detection stage.
Examples:
During 2D pose detection, for single-frame inference that do not rely on extra frames to get the final results of the current frame and save the prediction results, try this:
```shell
-python demo/body3d_pose_lifter_demo.py \
-demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
-https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
-configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w48_8xb32-210e_coco-256x192.py \
-https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \
-configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-243frm-supv-cpn-ft_8xb128-200e_h36m.py \
+python demo/body3d_pose_lifter_demo.py \
+demo/mmdetection_cfg/rtmdet_m_640-8xb32_coco-person.py \
+https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_m_8xb32-100e_coco-obj365-person-235e8209.pth \
+configs/body_2d_keypoint/rtmpose/body8/rtmpose-m_8xb256-420e_body8-256x192.py \
+https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-256x192-e48f03d0_20230504.pth \
+configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-243frm-supv-cpn-ft_8xb128-200e_h36m.py \
https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_cpn_ft-88f5abbb_20210527.pth \
--input https://user-images.githubusercontent.com/87690686/164970135-b14e424c-765a-4180-9bc8-fa8d6abc5510.mp4 \
---output-root vis_results \
---rebase-keypoint-height --save-predictions
+--output-root vis_results \
+--save-predictions
```
During 2D pose detection, for multi-frame inference that rely on extra frames to get the final results of the current frame, try this:
```shell
-python demo/body3d_pose_lifter_demo.py \
-demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
-https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
-configs/body_2d_keypoint/topdown_heatmap/posetrack18/td-hm_hrnet-w48_8xb64-20e_posetrack18-384x288.py \
-https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_posetrack18_384x288-5fd6d3ff_20211130.pth \
-configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-243frm-supv-cpn-ft_8xb128-200e_h36m.py \
-https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_cpn_ft-88f5abbb_20210527.pth \
+python demo/body3d_pose_lifter_demo.py \
+demo/mmdetection_cfg/rtmdet_m_640-8xb32_coco-person.py \
+https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_m_8xb32-100e_coco-obj365-person-235e8209.pth \
+configs/body_2d_keypoint/rtmpose/body8/rtmpose-m_8xb256-420e_body8-256x192.py \
+https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-256x192-e48f03d0_20230504.pth \
+configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-243frm-supv-cpn-ft_8xb128-200e_h36m.py \
+https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_cpn_ft-88f5abbb_20210527.pth \
--input https://user-images.githubusercontent.com/87690686/164970135-b14e424c-765a-4180-9bc8-fa8d6abc5510.mp4 \
--output-root vis_results \
---rebase-keypoint-height \
---use-multi-frames --online
+--online
```
### 3D Human Pose Demo with Inferencer
@@ -83,8 +79,7 @@ The Inferencer provides a convenient interface for inference, allowing customiza
```shell
python demo/inferencer_demo.py tests/data/coco/000000000785.jpg \
- --pose3d human3d --vis-out-dir vis_results/human3d \
- --rebase-keypoint-height
+ --pose3d human3d --vis-out-dir vis_results/human3d
```
This command infers the image and saves the visualization results in the `vis_results/human3d` directory.
diff --git a/demo/docs/en/mmdet_modelzoo.md b/demo/docs/en/mmdet_modelzoo.md
index 5383cb953f..3dd5e4a55a 100644
--- a/demo/docs/en/mmdet_modelzoo.md
+++ b/demo/docs/en/mmdet_modelzoo.md
@@ -14,6 +14,7 @@ For hand bounding box detection, we simply train our hand box models on OneHand1
| Arch | Box AP | ckpt | log |
| :---------------------------------------------------------------- | :----: | :---------------------------------------------------------------: | :--------------------------------------------------------------: |
| [Cascade_R-CNN X-101-64x4d-FPN-1class](/demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py) | 0.817 | [ckpt](https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth) | [log](https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k_20201030.log.json) |
+| [RTMDet-nano](/demo/mmdetection_cfg/rtmdet_nano_320-8xb32_hand.py) | 0.760 | [ckpt](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_nano_8xb32-300e_hand-267f9c8f.pth) | - |
### Face Bounding Box Detection Models
diff --git a/demo/docs/zh_cn/2d_animal_demo.md b/demo/docs/zh_cn/2d_animal_demo.md
index e49f292f56..f1932cf6eb 100644
--- a/demo/docs/zh_cn/2d_animal_demo.md
+++ b/demo/docs/zh_cn/2d_animal_demo.md
@@ -21,8 +21,8 @@ python demo/topdown_demo_with_mmdet.py \
```shell
python demo/topdown_demo_with_mmdet.py \
- demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
- https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ demo/mmdetection_cfg/rtmdet_m_8xb32-300e_coco.py \
+ https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_m_8xb32-300e_coco/rtmdet_m_8xb32-300e_coco_20220719_112220-229f527c.pth \
configs/animal_2d_keypoint/topdown_heatmap/animalpose/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256.py \
https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_animalpose_256x256-1aa7f075_20210426.pth \
--input tests/data/animalpose/ca110.jpeg \
@@ -49,8 +49,8 @@ COCO 数据集共包含 80 个类别,其中有 10 种常见动物,类别如
```shell
python demo/topdown_demo_with_mmdet.py \
- demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
- https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ demo/mmdetection_cfg/rtmdet_m_8xb32-300e_coco.py \
+ https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_m_8xb32-300e_coco/rtmdet_m_8xb32-300e_coco_20220719_112220-229f527c.pth \
configs/animal_2d_keypoint/topdown_heatmap/animalpose/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256.py \
https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_animalpose_256x256-1aa7f075_20210426.pth \
--input tests/data/animalpose/ca110.jpeg \
@@ -61,8 +61,8 @@ python demo/topdown_demo_with_mmdet.py \
```shell
python demo/topdown_demo_with_mmdet.py \
- demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
- https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ demo/mmdetection_cfg/rtmdet_m_8xb32-300e_coco.py \
+ https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_m_8xb32-300e_coco/rtmdet_m_8xb32-300e_coco_20220719_112220-229f527c.pth \
configs/animal_2d_keypoint/topdown_heatmap/animalpose/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256.py \
https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_animalpose_256x256-1aa7f075_20210426.pth \
--input tests/data/animalpose/ca110.jpeg \
@@ -73,8 +73,8 @@ python demo/topdown_demo_with_mmdet.py \
```shell
python demo/topdown_demo_with_mmdet.py \
- demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
- https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ demo/mmdetection_cfg/rtmdet_tiny_8xb32-300e_coco.py \
+ https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_tiny_8xb32-300e_coco/rtmdet_tiny_8xb32-300e_coco_20220902_112414-78e30dcc.pth \
configs/animal_2d_keypoint/topdown_heatmap/animalpose/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256.py \
https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_animalpose_256x256-1aa7f075_20210426.pth \
--input tests/data/animalpose/ca110.jpeg \
@@ -89,8 +89,8 @@ python demo/topdown_demo_with_mmdet.py \
```shell
python demo/topdown_demo_with_mmdet.py \
- demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
- https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ demo/mmdetection_cfg/rtmdet_m_8xb32-300e_coco.py \
+ https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_m_8xb32-300e_coco/rtmdet_m_8xb32-300e_coco_20220719_112220-229f527c.pth \
configs/animal_2d_keypoint/topdown_heatmap/animalpose/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256.py \
https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_animalpose_256x256-1aa7f075_20210426.pth \
--input demo/resources/ \
diff --git a/demo/docs/zh_cn/2d_face_demo.md b/demo/docs/zh_cn/2d_face_demo.md
index e8a4e550db..78091f1ffe 100644
--- a/demo/docs/zh_cn/2d_face_demo.md
+++ b/demo/docs/zh_cn/2d_face_demo.md
@@ -18,21 +18,21 @@ python demo/topdown_demo_with_mmdet.py \
用户可以在 [model zoo](https://mmpose.readthedocs.io/en/dev-1.x/model_zoo/face_2d_keypoint.html) 获取预训练好的脸部关键点识别模型。
-这里我们用 [aflw model](https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_aflw_256x256-f2bbc62b_20210125.pth) 来进行演示:
+这里我们用 [face6 model](https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_aflw_256x256-f2bbc62b_20210125.pth) 来进行演示:
```shell
python demo/topdown_demo_with_mmdet.py \
demo/mmdetection_cfg/yolox-s_8xb8-300e_coco-face.py \
https://download.openmmlab.com/mmpose/mmdet_pretrained/yolo-x_8xb8-300e_coco-face_13274d7c.pth \
- configs/face_2d_keypoint/topdown_heatmap/aflw/td-hm_hrnetv2-w18_8xb64-60e_aflw-256x256.py \
- https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_aflw_256x256-f2bbc62b_20210125.pth \
+ configs/face_2d_keypoint/rtmpose/face6/rtmpose-m_8xb256-120e_face6-256x256.py \
+ https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.pth \
--input tests/data/cofw/001766.jpg \
--show --draw-heatmap
```
可视化结果如下图所示:
-
+
如果使用了 heatmap-based 模型同时设置了 `--draw-heatmap` ,预测的热图也会跟随关键点一同可视化出来。 @@ -42,8 +42,8 @@ python demo/topdown_demo_with_mmdet.py \ python demo/topdown_demo_with_mmdet.py \ demo/mmdetection_cfg/yolox-s_8xb8-300e_coco-face.py \ https://download.openmmlab.com/mmpose/mmdet_pretrained/yolo-x_8xb8-300e_coco-face_13274d7c.pth \ - configs/face_2d_keypoint/topdown_heatmap/aflw/td-hm_hrnetv2-w18_8xb64-60e_aflw-256x256.py \ - https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_aflw_256x256-f2bbc62b_20210125.pth \ + configs/face_2d_keypoint/rtmpose/face6/rtmpose-m_8xb256-120e_face6-256x256.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.pth \ --input tests/data/cofw/001766.jpg \ --draw-heatmap --output-root vis_results ``` @@ -56,13 +56,13 @@ python demo/topdown_demo_with_mmdet.py \ python demo/topdown_demo_with_mmdet.py \ demo/mmdetection_cfg/yolox-s_8xb8-300e_coco-face.py \ https://download.openmmlab.com/mmpose/mmdet_pretrained/yolo-x_8xb8-300e_coco-face_13274d7c.pth \ - configs/face_2d_keypoint/topdown_heatmap/aflw/td-hm_hrnetv2-w18_8xb64-60e_aflw-256x256.py \ - https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_aflw_256x256-f2bbc62b_20210125.pth \ + configs/face_2d_keypoint/rtmpose/face6/rtmpose-m_8xb256-120e_face6-256x256.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.pth \ --input demo/resources/ \
- --show --draw-heatmap --output-root vis_results
+ --show --output-root vis_results --radius 1
```
-
+
这段视频可以在 [Google Drive](https://drive.google.com/file/d/1kQt80t6w802b_vgVcmiV_QfcSJ3RWzmb/view?usp=sharing) 下载。 diff --git a/demo/docs/zh_cn/2d_hand_demo.md b/demo/docs/zh_cn/2d_hand_demo.md index c2d80edd4e..886aace38e 100644 --- a/demo/docs/zh_cn/2d_hand_demo.md +++ b/demo/docs/zh_cn/2d_hand_demo.md @@ -22,17 +22,17 @@ python demo/topdown_demo_with_mmdet.py \ ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \ - https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth \ - configs/hand_2d_keypoint/topdown_heatmap/onehand10k/td-hm_hrnetv2-w18_8xb64-210e_onehand10k-256x256.py \ - https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_onehand10k_256x256-30bc9c6b_20210330.pth \ + demo/mmdetection_cfg/rtmdet_nano_320-8xb32_hand.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_nano_8xb32-300e_hand-267f9c8f.pth \ + configs/hand_2d_keypoint/rtmpose/hand5/rtmpose-m_8xb256-210e_hand5-256x256.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.pth \ --input tests/data/onehand10k/9.jpg \ --show --draw-heatmap ``` 可视化结果如下: -
+
如果使用了 heatmap-based 模型同时设置了 `--draw-heatmap` ,预测的热图也会跟随关键点一同可视化出来。 @@ -40,10 +40,10 @@ python demo/topdown_demo_with_mmdet.py \ ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \ - https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth \ - configs/hand_2d_keypoint/topdown_heatmap/onehand10k/td-hm_hrnetv2-w18_8xb64-210e_onehand10k-256x256.py \ - https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_onehand10k_256x256-30bc9c6b_20210330.pth \ + demo/mmdetection_cfg/rtmdet_nano_320-8xb32_hand.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_nano_8xb32-300e_hand-267f9c8f.pth \ + configs/hand_2d_keypoint/rtmpose/hand5/rtmpose-m_8xb256-210e_hand5-256x256.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.pth \ --input tests/data/onehand10k/9.jpg \ --output-root vis_results --show --draw-heatmap ``` @@ -54,10 +54,10 @@ python demo/topdown_demo_with_mmdet.py \ ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \ - https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth \ - configs/hand_2d_keypoint/topdown_heatmap/onehand10k/td-hm_hrnetv2-w18_8xb64-210e_onehand10k-256x256.py \ - https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_onehand10k_256x256-30bc9c6b_20210330.pth \ + demo/mmdetection_cfg/rtmdet_nano_320-8xb32_hand.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_nano_8xb32-300e_hand-267f9c8f.pth \ + configs/hand_2d_keypoint/rtmpose/hand5/rtmpose-m_8xb256-210e_hand5-256x256.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.pth \ --input tests/data/onehand10k/9.jpg \ --show --draw-heatmap --device cpu ``` @@ -68,14 +68,16 @@ python demo/topdown_demo_with_mmdet.py \ ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \ - https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth \ - configs/hand_2d_keypoint/topdown_heatmap/onehand10k/td-hm_hrnetv2-w18_8xb64-210e_onehand10k-256x256.py \ - https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_onehand10k_256x256-30bc9c6b_20210330.pth \ - --input demo/resources/ \
- --output-root vis_results --show --draw-heatmap
+ demo/mmdetection_cfg/rtmdet_nano_320-8xb32_hand.py \
+ https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_nano_8xb32-300e_hand-267f9c8f.pth \
+ configs/hand_2d_keypoint/rtmpose/hand5/rtmpose-m_8xb256-210e_hand5-256x256.py \
+ https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.pth \
+ --input data/tests_data_nvgesture_sk_color.avi \
+ --output-root vis_results --kpt-thr 0.1
```
+
+
这段视频可以在 [Google Drive](https://raw.githubusercontent.com/open-mmlab/mmpose/master/tests/data/nvgesture/sk_color.avi) 下载到。 diff --git a/demo/docs/zh_cn/2d_human_pose_demo.md b/demo/docs/zh_cn/2d_human_pose_demo.md index ff6484301a..b39e510891 100644 --- a/demo/docs/zh_cn/2d_human_pose_demo.md +++ b/demo/docs/zh_cn/2d_human_pose_demo.md @@ -65,17 +65,17 @@ python demo/topdown_demo_with_mmdet.py \ ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ - https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ - configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py \ - https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_256x192-c78dce93_20200708.pth \ + demo/mmdetection_cfg/rtmdet_m_640-8xb32_coco-person.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_m_8xb32-100e_coco-obj365-person-235e8209.pth \ + configs/body_2d_keypoint/rtmpose/body8/rtmpose-m_8xb256-420e_body8-256x192.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-256x192-e48f03d0_20230504.pth \ --input tests/data/coco/000000197388.jpg --show --draw-heatmap \ --output-root vis_results/ ``` 可视化结果如下: -
+
想要本地保存识别结果,用户需要加上 `--save-predictions` 。 @@ -87,10 +87,10 @@ python demo/topdown_demo_with_mmdet.py \ ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ - https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ - configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py \ - https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192-81c58e40_20220909.pth \ + demo/mmdetection_cfg/rtmdet_m_640-8xb32_coco-person.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_m_8xb32-100e_coco-obj365-person-235e8209.pth \ + configs/body_2d_keypoint/rtmpose/body8/rtmpose-m_8xb256-420e_body8-256x192.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-256x192-e48f03d0_20230504.pth \ --input tests/data/posetrack18/videos/000001_mpiinew_test/000001_mpiinew_test.mp4 \ --output-root=vis_results/demo --show --draw-heatmap ``` diff --git a/demo/docs/zh_cn/2d_wholebody_pose_demo.md b/demo/docs/zh_cn/2d_wholebody_pose_demo.md index 8c901d47fa..6c4d77e3df 100644 --- a/demo/docs/zh_cn/2d_wholebody_pose_demo.md +++ b/demo/docs/zh_cn/2d_wholebody_pose_demo.md @@ -55,8 +55,8 @@ python demo/topdown_demo_with_mmdet.py \ ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ - https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ + demo/mmdetection_cfg/rtmdet_m_640-8xb32_coco-person.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_m_8xb32-100e_coco-obj365-person-235e8209.pth \ configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/td-hm_hrnet-w48_dark-8xb32-210e_coco-wholebody-384x288.py \ https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_384x288_dark-f5726563_20200918.pth \ --input tests/data/coco/000000196141.jpg \ @@ -73,8 +73,8 @@ python demo/topdown_demo_with_mmdet.py \ ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ - https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ + demo/mmdetection_cfg/rtmdet_m_640-8xb32_coco-person.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_m_8xb32-100e_coco-obj365-person-235e8209.pth \ configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/td-hm_hrnet-w48_dark-8xb32-210e_coco-wholebody-384x288.py \ https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_384x288_dark-f5726563_20200918.pth \ --input https://user-images.githubusercontent.com/87690686/137440639-fb08603d-9a35-474e-b65f-46b5c06b68d6.mp4 \ diff --git a/demo/docs/zh_cn/mmdet_modelzoo.md b/demo/docs/zh_cn/mmdet_modelzoo.md index aabfb1768d..1cb12358a3 100644 --- a/demo/docs/zh_cn/mmdet_modelzoo.md +++ b/demo/docs/zh_cn/mmdet_modelzoo.md @@ -13,6 +13,7 @@ MMDetection 提供了基于 COCO 的包括 `person` 在内的 80 个类别的预 | Arch | Box AP | ckpt | log | | :---------------------------------------------------------------- | :----: | :---------------------------------------------------------------: | :--------------------------------------------------------------: | | [Cascade_R-CNN X-101-64x4d-FPN-1class](/demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py) | 0.817 | [ckpt](https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth) | [log](https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k_20201030.log.json) | +| [RTMDet-nano](/demo/mmdetection_cfg/rtmdet_nano_320-8xb32_hand.py) | 0.760 | [ckpt](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_nano_8xb32-300e_hand-267f9c8f.pth) | - | ### 脸部 Bounding Box 检测模型 diff --git a/demo/hand3d_internet_demo.py b/demo/hand3d_internet_demo.py new file mode 100644 index 0000000000..1cb10a820a --- /dev/null +++ b/demo/hand3d_internet_demo.py @@ -0,0 +1,285 @@ +# Copyright (c) OpenMMLab. All rights reserved. +import logging +import mimetypes +import os +import time +from argparse import ArgumentParser + +import cv2 +import json_tricks as json +import mmcv +import mmengine +import numpy as np +from mmengine.logging import print_log + +from mmpose.apis import inference_topdown, init_model +from mmpose.registry import VISUALIZERS +from mmpose.structures import (PoseDataSample, merge_data_samples, + split_instances) + + +def parse_args(): + parser = ArgumentParser() + parser.add_argument('config', help='Config file') + parser.add_argument('checkpoint', help='Checkpoint file') + parser.add_argument( + '--input', type=str, default='', help='Image/Video file') + parser.add_argument( + '--output-root', + type=str, + default='', + help='root of the output img file. ' + 'Default not saving the visualization images.') + parser.add_argument( + '--save-predictions', + action='store_true', + default=False, + help='whether to save predicted results') + parser.add_argument( + '--disable-rebase-keypoint', + action='store_true', + default=False, + help='Whether to disable rebasing the predicted 3D pose so its ' + 'lowest keypoint has a height of 0 (landing on the ground). Rebase ' + 'is useful for visualization when the model do not predict the ' + 'global position of the 3D pose.') + parser.add_argument( + '--show', + action='store_true', + default=False, + help='whether to show result') + parser.add_argument('--device', default='cpu', help='Device for inference') + parser.add_argument( + '--kpt-thr', + type=float, + default=0.3, + help='Visualizing keypoint thresholds') + parser.add_argument( + '--show-kpt-idx', + action='store_true', + default=False, + help='Whether to show the index of keypoints') + parser.add_argument( + '--show-interval', type=int, default=0, help='Sleep seconds per frame') + parser.add_argument( + '--radius', + type=int, + default=3, + help='Keypoint radius for visualization') + parser.add_argument( + '--thickness', + type=int, + default=1, + help='Link thickness for visualization') + + args = parser.parse_args() + return args + + +def process_one_image(args, img, model, visualizer=None, show_interval=0): + """Visualize predicted keypoints of one image.""" + # inference a single image + pose_results = inference_topdown(model, img) + # post-processing + pose_results_2d = [] + for idx, res in enumerate(pose_results): + pred_instances = res.pred_instances + keypoints = pred_instances.keypoints + rel_root_depth = pred_instances.rel_root_depth + scores = pred_instances.keypoint_scores + hand_type = pred_instances.hand_type + + res_2d = PoseDataSample() + gt_instances = res.gt_instances.clone() + pred_instances = pred_instances.clone() + res_2d.gt_instances = gt_instances + res_2d.pred_instances = pred_instances + + # add relative root depth to left hand joints + keypoints[:, 21:, 2] += rel_root_depth + + # set joint scores according to hand type + scores[:, :21] *= hand_type[:, [0]] + scores[:, 21:] *= hand_type[:, [1]] + # normalize kpt score + if scores.max() > 1: + scores /= 255 + + res_2d.pred_instances.set_field(keypoints[..., :2].copy(), 'keypoints') + + # rotate the keypoint to make z-axis correspondent to height + # for better visualization + vis_R = np.array([[1, 0, 0], [0, 0, -1], [0, 1, 0]]) + keypoints[..., :3] = keypoints[..., :3] @ vis_R + + # rebase height (z-axis) + if not args.disable_rebase_keypoint: + valid = scores > 0 + keypoints[..., 2] -= np.min( + keypoints[valid, 2], axis=-1, keepdims=True) + + pose_results[idx].pred_instances.keypoints = keypoints + pose_results[idx].pred_instances.keypoint_scores = scores + pose_results_2d.append(res_2d) + + data_samples = merge_data_samples(pose_results) + data_samples_2d = merge_data_samples(pose_results_2d) + + # show the results + if isinstance(img, str): + img = mmcv.imread(img, channel_order='rgb') + elif isinstance(img, np.ndarray): + img = mmcv.bgr2rgb(img) + + if visualizer is not None: + visualizer.add_datasample( + 'result', + img, + data_sample=data_samples, + det_data_sample=data_samples_2d, + draw_gt=False, + draw_bbox=True, + kpt_thr=args.kpt_thr, + convert_keypoint=False, + axis_azimuth=-115, + axis_limit=200, + axis_elev=15, + show_kpt_idx=args.show_kpt_idx, + show=args.show, + wait_time=show_interval) + + # if there is no instance detected, return None + return data_samples.get('pred_instances', None) + + +def main(): + args = parse_args() + + assert args.input != '' + assert args.show or (args.output_root != '') + + output_file = None + if args.output_root: + mmengine.mkdir_or_exist(args.output_root) + output_file = os.path.join(args.output_root, + os.path.basename(args.input)) + if args.input == 'webcam': + output_file += '.mp4' + + if args.save_predictions: + assert args.output_root != '' + args.pred_save_path = f'{args.output_root}/results_' \ + f'{os.path.splitext(os.path.basename(args.input))[0]}.json' + + # build the model from a config file and a checkpoint file + model = init_model( + args.config, args.checkpoint, device=args.device.lower()) + + # init visualizer + model.cfg.visualizer.radius = args.radius + model.cfg.visualizer.line_width = args.thickness + + visualizer = VISUALIZERS.build(model.cfg.visualizer) + visualizer.set_dataset_meta(model.dataset_meta) + + if args.input == 'webcam': + input_type = 'webcam' + else: + input_type = mimetypes.guess_type(args.input)[0].split('/')[0] + + if input_type == 'image': + # inference + pred_instances = process_one_image(args, args.input, model, visualizer) + + if args.save_predictions: + pred_instances_list = split_instances(pred_instances) + + if output_file: + img_vis = visualizer.get_image() + mmcv.imwrite(mmcv.rgb2bgr(img_vis), output_file) + + elif input_type in ['webcam', 'video']: + + if args.input == 'webcam': + cap = cv2.VideoCapture(0) + else: + cap = cv2.VideoCapture(args.input) + + video_writer = None + pred_instances_list = [] + frame_idx = 0 + + while cap.isOpened(): + success, frame = cap.read() + frame_idx += 1 + + if not success: + break + + # topdown pose estimation + pred_instances = process_one_image(args, frame, model, visualizer, + 0.001) + + if args.save_predictions: + # save prediction results + pred_instances_list.append( + dict( + frame_id=frame_idx, + instances=split_instances(pred_instances))) + + # output videos + if output_file: + frame_vis = visualizer.get_image() + + if video_writer is None: + fourcc = cv2.VideoWriter_fourcc(*'mp4v') + # the size of the image with visualization may vary + # depending on the presence of heatmaps + video_writer = cv2.VideoWriter( + output_file, + fourcc, + 25, # saved fps + (frame_vis.shape[1], frame_vis.shape[0])) + + video_writer.write(mmcv.rgb2bgr(frame_vis)) + + if args.show: + # press ESC to exit + if cv2.waitKey(5) & 0xFF == 27: + break + + time.sleep(args.show_interval) + + if video_writer: + video_writer.release() + + cap.release() + + else: + args.save_predictions = False + raise ValueError( + f'file {os.path.basename(args.input)} has invalid format.') + + if args.save_predictions: + with open(args.pred_save_path, 'w') as f: + json.dump( + dict( + meta_info=model.dataset_meta, + instance_info=pred_instances_list), + f, + indent='\t') + print_log( + f'predictions have been saved at {args.pred_save_path}', + logger='current', + level=logging.INFO) + + if output_file is not None: + input_type = input_type.replace('webcam', 'video') + print_log( + f'the output {input_type} has been saved at {output_file}', + logger='current', + level=logging.INFO) + + +if __name__ == '__main__': + main() diff --git a/demo/image_demo.py b/demo/image_demo.py index bfbc808b1e..6a408d1760 100644 --- a/demo/image_demo.py +++ b/demo/image_demo.py @@ -1,7 +1,9 @@ # Copyright (c) OpenMMLab. All rights reserved. +import logging from argparse import ArgumentParser from mmcv.image import imread +from mmengine.logging import print_log from mmpose.apis import inference_topdown, init_model from mmpose.registry import VISUALIZERS @@ -100,6 +102,12 @@ def main(): show=args.show, out_file=args.out_file) + if args.out_file is not None: + print_log( + f'the output image has been saved at {args.out_file}', + logger='current', + level=logging.INFO) + if __name__ == '__main__': main() diff --git a/demo/inferencer_demo.py b/demo/inferencer_demo.py index b91e91f74b..0ab816e9fb 100644 --- a/demo/inferencer_demo.py +++ b/demo/inferencer_demo.py @@ -97,19 +97,27 @@ def parse_args(): action='store_true', help='Whether to use OKS as similarity in tracking') parser.add_argument( - '--norm-pose-2d', + '--disable-norm-pose-2d', action='store_true', - help='Scale the bbox (along with the 2D pose) to the average bbox ' - 'scale of the dataset, and move the bbox (along with the 2D pose) to ' - 'the average bbox center of the dataset. This is useful when bbox ' - 'is small, especially in multi-person scenarios.') + help='Whether to scale the bbox (along with the 2D pose) to the ' + 'average bbox scale of the dataset, and move the bbox (along with the ' + '2D pose) to the average bbox center of the dataset. This is useful ' + 'when bbox is small, especially in multi-person scenarios.') parser.add_argument( - '--rebase-keypoint-height', + '--disable-rebase-keypoint', action='store_true', - help='Rebase the predicted 3D pose so its lowest keypoint has a ' - 'height of 0 (landing on the ground). This is useful for ' - 'visualization when the model do not predict the global position ' - 'of the 3D pose.') + default=False, + help='Whether to disable rebasing the predicted 3D pose so its ' + 'lowest keypoint has a height of 0 (landing on the ground). Rebase ' + 'is useful for visualization when the model do not predict the ' + 'global position of the 3D pose.') + parser.add_argument( + '--num-instances', + type=int, + default=1, + help='The number of 3D poses to be visualized in every frame. If ' + 'less than 0, it will be set to the number of pose results in the ' + 'first frame.') parser.add_argument( '--radius', type=int, diff --git a/demo/mmdetection_cfg/rtmdet_m_640-8xb32_coco-person.py b/demo/mmdetection_cfg/rtmdet_m_640-8xb32_coco-person.py new file mode 100644 index 0000000000..620de8dc8f --- /dev/null +++ b/demo/mmdetection_cfg/rtmdet_m_640-8xb32_coco-person.py @@ -0,0 +1,20 @@ +_base_ = 'mmdet::rtmdet/rtmdet_m_8xb32-300e_coco.py' + +checkpoint = 'https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-m_8xb256-rsb-a1-600e_in1k-ecb3bbd9.pth' # noqa + +model = dict( + backbone=dict( + init_cfg=dict( + type='Pretrained', prefix='backbone.', checkpoint=checkpoint)), + bbox_head=dict(num_classes=1), + test_cfg=dict( + nms_pre=1000, + min_bbox_size=0, + score_thr=0.05, + nms=dict(type='nms', iou_threshold=0.6), + max_per_img=100)) + +train_dataloader = dict(dataset=dict(metainfo=dict(classes=('person', )))) + +val_dataloader = dict(dataset=dict(metainfo=dict(classes=('person', )))) +test_dataloader = val_dataloader diff --git a/demo/mmdetection_cfg/rtmdet_m_8xb32-300e_coco.py b/demo/mmdetection_cfg/rtmdet_m_8xb32-300e_coco.py new file mode 100644 index 0000000000..6d0d3dfef1 --- /dev/null +++ b/demo/mmdetection_cfg/rtmdet_m_8xb32-300e_coco.py @@ -0,0 +1 @@ +_base_ = 'mmdet::rtmdet/rtmdet_m_8xb32-300e_coco.py' diff --git a/demo/mmdetection_cfg/rtmdet_nano_320-8xb32_coco-person.py b/demo/mmdetection_cfg/rtmdet_nano_320-8xb32_coco-person.py new file mode 100644 index 0000000000..c2f1b64e4a --- /dev/null +++ b/demo/mmdetection_cfg/rtmdet_nano_320-8xb32_coco-person.py @@ -0,0 +1,104 @@ +_base_ = 'mmdet::rtmdet/rtmdet_l_8xb32-300e_coco.py' + +input_shape = 320 + +model = dict( + backbone=dict( + deepen_factor=0.33, + widen_factor=0.25, + use_depthwise=True, + ), + neck=dict( + in_channels=[64, 128, 256], + out_channels=64, + num_csp_blocks=1, + use_depthwise=True, + ), + bbox_head=dict( + in_channels=64, + feat_channels=64, + share_conv=False, + exp_on_reg=False, + use_depthwise=True, + num_classes=1), + test_cfg=dict( + nms_pre=1000, + min_bbox_size=0, + score_thr=0.05, + nms=dict(type='nms', iou_threshold=0.6), + max_per_img=100)) + +train_pipeline = [ + dict(type='LoadImageFromFile'), + dict(type='LoadAnnotations', with_bbox=True), + dict( + type='CachedMosaic', + img_scale=(input_shape, input_shape), + pad_val=114.0, + max_cached_images=20, + random_pop=False), + dict( + type='RandomResize', + scale=(input_shape * 2, input_shape * 2), + ratio_range=(0.5, 1.5), + keep_ratio=True), + dict(type='RandomCrop', crop_size=(input_shape, input_shape)), + dict(type='YOLOXHSVRandomAug'), + dict(type='RandomFlip', prob=0.5), + dict( + type='Pad', + size=(input_shape, input_shape), + pad_val=dict(img=(114, 114, 114))), + dict(type='PackDetInputs') +] + +train_pipeline_stage2 = [ + dict(type='LoadImageFromFile'), + dict(type='LoadAnnotations', with_bbox=True), + dict( + type='RandomResize', + scale=(input_shape, input_shape), + ratio_range=(0.5, 1.5), + keep_ratio=True), + dict(type='RandomCrop', crop_size=(input_shape, input_shape)), + dict(type='YOLOXHSVRandomAug'), + dict(type='RandomFlip', prob=0.5), + dict( + type='Pad', + size=(input_shape, input_shape), + pad_val=dict(img=(114, 114, 114))), + dict(type='PackDetInputs') +] + +test_pipeline = [ + dict(type='LoadImageFromFile'), + dict(type='Resize', scale=(input_shape, input_shape), keep_ratio=True), + dict( + type='Pad', + size=(input_shape, input_shape), + pad_val=dict(img=(114, 114, 114))), + dict( + type='PackDetInputs', + meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', + 'scale_factor')) +] + +train_dataloader = dict( + dataset=dict(pipeline=train_pipeline, metainfo=dict(classes=('person', )))) + +val_dataloader = dict( + dataset=dict(pipeline=test_pipeline, metainfo=dict(classes=('person', )))) +test_dataloader = val_dataloader + +custom_hooks = [ + dict( + type='EMAHook', + ema_type='ExpMomentumEMA', + momentum=0.0002, + update_buffers=True, + priority=49), + dict( + type='PipelineSwitchHook', + switch_epoch=280, + switch_pipeline=train_pipeline_stage2) +] diff --git a/demo/mmdetection_cfg/rtmdet_nano_320-8xb32_hand.py b/demo/mmdetection_cfg/rtmdet_nano_320-8xb32_hand.py new file mode 100644 index 0000000000..278cc0bfe8 --- /dev/null +++ b/demo/mmdetection_cfg/rtmdet_nano_320-8xb32_hand.py @@ -0,0 +1,171 @@ +_base_ = 'mmdet::rtmdet/rtmdet_l_8xb32-300e_coco.py' + +input_shape = 320 + +model = dict( + backbone=dict( + deepen_factor=0.33, + widen_factor=0.25, + use_depthwise=True, + ), + neck=dict( + in_channels=[64, 128, 256], + out_channels=64, + num_csp_blocks=1, + use_depthwise=True, + ), + bbox_head=dict( + in_channels=64, + feat_channels=64, + share_conv=False, + exp_on_reg=False, + use_depthwise=True, + num_classes=1), + test_cfg=dict( + nms_pre=1000, + min_bbox_size=0, + score_thr=0.05, + nms=dict(type='nms', iou_threshold=0.6), + max_per_img=100)) + +# file_client_args = dict( +# backend='petrel', +# path_mapping=dict({'data/': 's3://openmmlab/datasets/'})) + +train_pipeline = [ + dict(type='LoadImageFromFile'), + dict(type='LoadAnnotations', with_bbox=True), + dict( + type='CachedMosaic', + img_scale=(input_shape, input_shape), + pad_val=114.0, + max_cached_images=20, + random_pop=False), + dict( + type='RandomResize', + scale=(input_shape * 2, input_shape * 2), + ratio_range=(0.5, 1.5), + keep_ratio=True), + dict(type='RandomCrop', crop_size=(input_shape, input_shape)), + dict(type='YOLOXHSVRandomAug'), + dict(type='RandomFlip', prob=0.5), + dict( + type='Pad', + size=(input_shape, input_shape), + pad_val=dict(img=(114, 114, 114))), + dict(type='PackDetInputs') +] + +train_pipeline_stage2 = [ + dict(type='LoadImageFromFile'), + dict(type='LoadAnnotations', with_bbox=True), + dict( + type='RandomResize', + scale=(input_shape, input_shape), + ratio_range=(0.5, 1.5), + keep_ratio=True), + dict(type='RandomCrop', crop_size=(input_shape, input_shape)), + dict(type='YOLOXHSVRandomAug'), + dict(type='RandomFlip', prob=0.5), + dict( + type='Pad', + size=(input_shape, input_shape), + pad_val=dict(img=(114, 114, 114))), + dict(type='PackDetInputs') +] + +test_pipeline = [ + dict(type='LoadImageFromFile'), + dict(type='Resize', scale=(input_shape, input_shape), keep_ratio=True), + dict( + type='Pad', + size=(input_shape, input_shape), + pad_val=dict(img=(114, 114, 114))), + dict( + type='PackDetInputs', + meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', + 'scale_factor')) +] + +data_mode = 'topdown' +data_root = 'data/' + +train_dataset = dict( + _delete_=True, + type='ConcatDataset', + datasets=[ + dict( + type='mmpose.OneHand10KDataset', + data_root=data_root, + data_mode=data_mode, + pipeline=train_pipeline, + ann_file='onehand10k/annotations/onehand10k_train.json', + data_prefix=dict(img='pose/OneHand10K/')), + dict( + type='mmpose.FreiHandDataset', + data_root=data_root, + data_mode=data_mode, + pipeline=train_pipeline, + ann_file='freihand/annotations/freihand_train.json', + data_prefix=dict(img='pose/FreiHand/')), + dict( + type='mmpose.Rhd2DDataset', + data_root=data_root, + data_mode=data_mode, + pipeline=train_pipeline, + ann_file='rhd/annotations/rhd_train.json', + data_prefix=dict(img='pose/RHD/')), + dict( + type='mmpose.HalpeHandDataset', + data_root=data_root, + data_mode=data_mode, + pipeline=train_pipeline, + ann_file='halpe/annotations/halpe_train_v1.json', + data_prefix=dict( + img='pose/Halpe/hico_20160224_det/images/train2015/') # noqa + ) + ], + ignore_keys=[ + 'CLASSES', 'dataset_keypoint_weights', 'dataset_name', 'flip_indices', + 'flip_pairs', 'keypoint_colors', 'keypoint_id2name', + 'keypoint_name2id', 'lower_body_ids', 'num_keypoints', + 'num_skeleton_links', 'sigmas', 'skeleton_link_colors', + 'skeleton_links', 'upper_body_ids' + ], +) + +test_dataset = dict( + _delete_=True, + type='mmpose.OneHand10KDataset', + data_root=data_root, + data_mode=data_mode, + pipeline=test_pipeline, + ann_file='onehand10k/annotations/onehand10k_test.json', + data_prefix=dict(img='pose/OneHand10K/'), +) + +train_dataloader = dict(dataset=train_dataset) +val_dataloader = dict(dataset=test_dataset) +test_dataloader = val_dataloader + +custom_hooks = [ + dict( + type='EMAHook', + ema_type='ExpMomentumEMA', + momentum=0.0002, + update_buffers=True, + priority=49), + dict( + type='PipelineSwitchHook', + switch_epoch=280, + switch_pipeline=train_pipeline_stage2) +] + +val_evaluator = dict( + type='CocoMetric', + ann_file=data_root + 'onehand10k/annotations/onehand10k_test.json', + metric='bbox', + format_only=False) +test_evaluator = val_evaluator + +train_cfg = dict(val_interval=1) diff --git a/demo/mmdetection_cfg/rtmdet_tiny_8xb32-300e_coco.py b/demo/mmdetection_cfg/rtmdet_tiny_8xb32-300e_coco.py new file mode 100644 index 0000000000..db26ca8338 --- /dev/null +++ b/demo/mmdetection_cfg/rtmdet_tiny_8xb32-300e_coco.py @@ -0,0 +1 @@ +_base_ = 'mmdet::rtmdet/rtmdet_tiny_8xb32-300e_coco.py' diff --git a/demo/topdown_demo_with_mmdet.py b/demo/topdown_demo_with_mmdet.py index 38f4e92e4e..4e39c36207 100644 --- a/demo/topdown_demo_with_mmdet.py +++ b/demo/topdown_demo_with_mmdet.py @@ -1,4 +1,5 @@ # Copyright (c) OpenMMLab. All rights reserved. +import logging import mimetypes import os import time @@ -9,6 +10,7 @@ import mmcv import mmengine import numpy as np +from mmengine.logging import print_log from mmpose.apis import inference_topdown from mmpose.apis import init_model as init_pose_estimator @@ -261,11 +263,12 @@ def main(): video_writer.write(mmcv.rgb2bgr(frame_vis)) - # press ESC to exit - if cv2.waitKey(5) & 0xFF == 27: - break + if args.show: + # press ESC to exit + if cv2.waitKey(5) & 0xFF == 27: + break - time.sleep(args.show_interval) + time.sleep(args.show_interval) if video_writer: video_writer.release() @@ -287,6 +290,13 @@ def main(): indent='\t') print(f'predictions have been saved at {args.pred_save_path}') + if output_file: + input_type = input_type.replace('webcam', 'video') + print_log( + f'the output {input_type} has been saved at {output_file}', + logger='current', + level=logging.INFO) + if __name__ == '__main__': main() diff --git a/docs/en/advanced_guides/codecs.md b/docs/en/advanced_guides/codecs.md index 610bd83a57..e874f389d3 100644 --- a/docs/en/advanced_guides/codecs.md +++ b/docs/en/advanced_guides/codecs.md @@ -8,7 +8,9 @@ MMPose 1.0 introduced a new module **Codec** to integrate the encoding and decod Here is a diagram to show where the `Codec` is: - +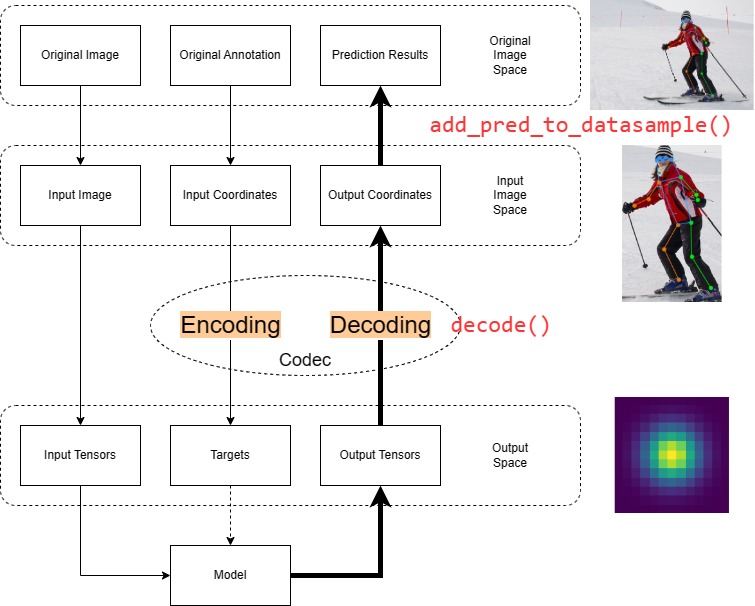 + +## Basic Concepts A typical codec consists of two parts: @@ -60,7 +62,23 @@ def encode(self, return encoded ``` -The encoded data is converted to Tensor format in `PackPoseInputs` and packed in `data_sample.gt_instance_labels` for model calls, which is generally used for loss calculation, as demonstrated by `loss()` in `RegressionHead`. +The encoded data is converted to Tensor format in `PackPoseInputs` and packed in `data_sample.gt_instance_labels` for model calls. By default it will consist of the following encoded fields: + +- `keypoint_labels` +- `keypoint_weights` +- `keypoints_visible_weights` + +To specify data fields to be packed, you can define the `label_mapping_table` attribute in the codec. For example, in `VideoPoseLifting`: + +```Python +label_mapping_table = dict( + trajectory_weights='trajectory_weights', + lifting_target_label='lifting_target_label', + lifting_target_weight='lifting_target_weight', +) +``` + +`data_sample.gt_instance_labels` are generally used for loss calculation, as demonstrated by `loss()` in `RegressionHead`. ```Python def loss(self, @@ -86,6 +104,10 @@ def loss(self, ### Omitted ### ``` +```{note} +Encoder also defines data to be packed in `data_sample.gt_instances` and `data_sample.gt_fields`. Modify `instance_mapping_table` and `field_mapping_table` in the codec will specify values to be packed respectively. For default values, please check [BaseKeypointCodec](https://github.com/open-mmlab/mmpose/blob/main/mmpose/codecs/base.py). +``` + ### Decoder The decoder transforms the model outputs into coordinates in the input image space, which is the opposite processing of the encoder. @@ -225,3 +247,225 @@ test_pipeline = [ dict(type='PackPoseInputs') ] ``` + +## Supported Codecs + +Supported codecs are in [$MMPOSE/mmpose/codecs/](https://github.com/open-mmlab/mmpose/tree/dev-1.x/mmpose/codecs). Here is a list: + +- [RegressionLabel](#RegressionLabel) +- [IntegralRegressionLabel](#IntegralRegressionLabel) +- [MSRAHeatmap](#MSRAHeatmap) +- [UDPHeatmap](#UDPHeatmap) +- [MegviiHeatmap](#MegviiHeatmap) +- [SPR](#SPR) +- [SimCC](#SimCC) +- [DecoupledHeatmap](#DecoupledHeatmap) +- [ImagePoseLifting](#ImagePoseLifting) +- [VideoPoseLifting](#VideoPoseLifting) +- [MotionBERTLabel](#MotionBERTLabel) + +### RegressionLabel + +[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/regression_label.py#L12) + +The `RegressionLabel` codec is used to generate normalized coordinates as the regression targets. + +**Input** + +- Encoding keypoints from input image space to normalized space. + +**Output** + +- Decoding normalized coordinates from normalized space to input image space. + +Related works: + +- [DeepPose](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#deeppose-cvpr-2014) +- [RLE](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#rle-iccv-2021) + +### IntegralRegressionLabel + +[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/integral_regression_label.py) + +The `IntegralRegressionLabel` codec is used to generate normalized coordinates as the regression targets. + +**Input** + +- Encoding keypoints from input image space to normalized space, and generate Gaussian heatmaps as well. + +**Output** + +- Decoding normalized coordinates from normalized space to input image space. + +Related works: + +- [IPR](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#ipr-eccv-2018) +- [DSNT](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#dsnt-2018) +- [Debias IPR](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#debias-ipr-iccv-2021) + +### MSRAHeatmap + +[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/msra_heatmap.py) + +The `MSRAHeatmap` codec is used to generate Gaussian heatmaps as the targets. + +**Input** + +- Encoding keypoints from input image space to output space as 2D Gaussian heatmaps. + +**Output** + +- Decoding 2D Gaussian heatmaps from output space to input image space as coordinates. + +Related works: + +- [SimpleBaseline2D](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#simplebaseline2d-eccv-2018) +- [CPM](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#cpm-cvpr-2016) +- [HRNet](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#hrnet-cvpr-2019) +- [DARK](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#darkpose-cvpr-2020) + +### UDPHeatmap + +[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/udp_heatmap.py) + +The `UDPHeatmap` codec is used to generate Gaussian heatmaps as the targets. + +**Input** + +- Encoding keypoints from input image space to output space as 2D Gaussian heatmaps. + +**Output** + +- Decoding 2D Gaussian heatmaps from output space to input image space as coordinates. + +Related works: + +- [UDP](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#udp-cvpr-2020) + +### MegviiHeatmap + +[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/megvii_heatmap.py) + +The `MegviiHeatmap` codec is used to generate Gaussian heatmaps as the targets, which is usually used in Megvii's works. + +**Input** + +- Encoding keypoints from input image space to output space as 2D Gaussian heatmaps. + +**Output** + +- Decoding 2D Gaussian heatmaps from output space to input image space as coordinates. + +Related works: + +- [MSPN](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#mspn-arxiv-2019) +- [RSN](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#rsn-eccv-2020) + +### SPR + +[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/spr.py) + +The `SPR` codec is used to generate Gaussian heatmaps of instances' center, and offsets as the targets. + +**Input** + +- Encoding keypoints from input image space to output space as 2D Gaussian heatmaps and offsets. + +**Output** + +- Decoding 2D Gaussian heatmaps and offsets from output space to input image space as coordinates. + +Related works: + +- [DEKR](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#dekr-cvpr-2021) + +### SimCC + +[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/simcc_label.py) + +The `SimCC` codec is used to generate 1D Gaussian representations as the targets. + +**Input** + +- Encoding keypoints from input image space to output space as 1D Gaussian representations. + +**Output** + +- Decoding 1D Gaussian representations from output space to input image space as coordinates. + +Related works: + +- [SimCC](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#simcc-eccv-2022) +- [RTMPose](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#rtmpose-arxiv-2023) + +### DecoupledHeatmap + +[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/decoupled_heatmap.py) + +The `DecoupledHeatmap` codec is used to generate Gaussian heatmaps as the targets. + +**Input** + +- Encoding human center points and keypoints from input image space to output space as 2D Gaussian heatmaps. + +**Output** + +- Decoding 2D Gaussian heatmaps from output space to input image space as coordinates. + +Related works: + +- [CID](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#cid-cvpr-2022) + +### ImagePoseLifting + +[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/image_pose_lifting.py) + +The `ImagePoseLifting` codec is used for image 2D-to-3D pose lifting. + +**Input** + +- Encoding 2d keypoints from input image space to normalized 3d space. + +**Output** + +- Decoding 3d keypoints from normalized space to input image space. + +Related works: + +- [SimpleBaseline3D](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#simplebaseline3d-iccv-2017) + +### VideoPoseLifting + +[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/video_pose_lifting.py) + +The `VideoPoseLifting` codec is used for video 2D-to-3D pose lifting. + +**Input** + +- Encoding 2d keypoints from input image space to normalized 3d space. + +**Output** + +- Decoding 3d keypoints from normalized space to input image space. + +Related works: + +- [VideoPose3D](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#videopose3d-cvpr-2019) + +### MotionBERTLabel + +[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/motionbert_label.py) + +The `MotionBERTLabel` codec is used for video 2D-to-3D pose lifting. + +**Input** + +- Encoding 2d keypoints from input image space to normalized 3d space. + +**Output** + +- Decoding 3d keypoints from normalized space to input image space. + +Related works: + +- [MotionBERT](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo/body_3d_keypoint.html#pose-lift-motionbert-on-h36m) diff --git a/docs/en/advanced_guides/customize_datasets.md b/docs/en/advanced_guides/customize_datasets.md index 1aac418812..aec7520a30 100644 --- a/docs/en/advanced_guides/customize_datasets.md +++ b/docs/en/advanced_guides/customize_datasets.md @@ -72,19 +72,15 @@ configs/_base_/datasets/custom.py An example of the dataset config is as follows. -`keypoint_info` contains the information about each keypoint. - -1. `name`: the keypoint name. The keypoint name must be unique. -2. `id`: the keypoint id. -3. `color`: (\[B, G, R\]) is used for keypoint visualization. -4. `type`: 'upper' or 'lower', will be used in data augmentation. -5. `swap`: indicates the 'swap pair' (also known as 'flip pair'). When applying image horizontal flip, the left part will become the right part. We need to flip the keypoints accordingly. - -`skeleton_info` contains information about the keypoint connectivity, which is used for visualization. - -`joint_weights` assigns different loss weights to different keypoints. - -`sigmas` is used to calculate the OKS score. You can read [keypoints-eval](https://cocodataset.org/#keypoints-eval) to learn more about it. +- `keypoint_info` contains the information about each keypoint. + 1. `name`: the keypoint name. The keypoint name must be unique. + 2. `id`: the keypoint id. + 3. `color`: (\[B, G, R\]) is used for keypoint visualization. + 4. `type`: 'upper' or 'lower', will be used in data augmentation [RandomHalfBody](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/transforms/common_transforms.py#L263). + 5. `swap`: indicates the 'swap pair' (also known as 'flip pair'). When applying image horizontal flip, the left part will become the right part, used in data augmentation [RandomFlip](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/transforms/common_transforms.py#L94). We need to flip the keypoints accordingly. +- `skeleton_info` contains information about the keypoint connectivity, which is used for visualization. +- `joint_weights` assigns different loss weights to different keypoints. +- `sigmas` is used to calculate the OKS score. You can read [keypoints-eval](https://cocodataset.org/#keypoints-eval) to learn more about it. Here is an simplified example of dataset_info config file ([full text](/configs/_base_/datasets/coco.py)). @@ -217,7 +213,7 @@ The following dataset wrappers are supported in [MMEngine](https://github.com/op ### CombinedDataset -MMPose provides `CombinedDataset` to combine multiple datasets with different annotations. A combined dataset can be defined in config files as: +MMPose provides [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) to combine multiple datasets with different annotations. A combined dataset can be defined in config files as: ```python dataset_1 = dict( @@ -254,6 +250,6 @@ combined_dataset = dict( - **MetaInfo of combined dataset** determines the annotation format. Either metainfo of a sub-dataset or a customed dataset metainfo is valid here. To custom a dataset metainfo, please refer to [Create a custom dataset_info config file for the dataset](#create-a-custom-datasetinfo-config-file-for-the-dataset). -- **Converter transforms of sub-datasets** are applied when there exist mismatches of annotation format between sub-datasets and the combined dataset. For example, the number and order of keypoints might be different in the combined dataset and the sub-datasets. Then `KeypointConverter` can be used to unify the keypoints number and order. +- **Converter transforms of sub-datasets** are applied when there exist mismatches of annotation format between sub-datasets and the combined dataset. For example, the number and order of keypoints might be different in the combined dataset and the sub-datasets. Then [KeypointConverter](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/converting.py#L11) can be used to unify the keypoints number and order. -- More details about `CombinedDataset` and `KeypointConverter` can be found in Advanced Guides-[Training with Mixed Datasets](../user_guides/mixed_datasets.md). +- More details about [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) and [KeypointConverter](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/converting.py#L11) can be found in [Advanced Guides - Training with Mixed Datasets](../user_guides/mixed_datasets.md). diff --git a/docs/en/advanced_guides/customize_evaluation.md b/docs/en/advanced_guides/customize_evaluation.md new file mode 100644 index 0000000000..95effaf9ca --- /dev/null +++ b/docs/en/advanced_guides/customize_evaluation.md @@ -0,0 +1,5 @@ +# Customize Evaluation + +Coming soon. + +Currently, you can refer to [Evaluation Tutorial of MMEngine](https://mmengine.readthedocs.io/en/latest/tutorials/evaluation.html) to customize your own evaluation. diff --git a/docs/en/advanced_guides/customize_transforms.md b/docs/en/advanced_guides/customize_transforms.md index 154413994b..b8e13459f9 100644 --- a/docs/en/advanced_guides/customize_transforms.md +++ b/docs/en/advanced_guides/customize_transforms.md @@ -1,3 +1,212 @@ # Customize Data Transformation and Augmentation -Coming soon. +## DATA TRANSFORM + +In the OpenMMLab algorithm library, the construction of the dataset and the preparation of the data are decoupled from each other. Usually, the construction of the dataset only analyzes the dataset and records the basic information of each sample, while the preparation of the data is through a series of According to the basic information of the sample, perform data loading, preprocessing, formatting and other operations. + +### The use of data transformation + +The **data transformation** and **data augmentation** classes in **MMPose** are defined in the [$MMPose/datasets/transforms](https://github.com/open-mmlab/mmpose/tree/dev-1.x/mmpose/datasets/transforms) directory, and the corresponding file structure is as follows: + +```txt +mmpose +|----datasets + |----transforms + |----bottomup_transforms # Button-Up transforms + |----common_transforms # Common Transforms + |----converting # Keypoint converting + |----formatting # Input data formatting + |----loading # Raw data loading + |----pose3d_transforms # Pose3d-transforms + |----topdown_transforms # Top-Down transforms +``` + +In **MMPose**, **data augmentation** and **data transformation** is a stage that users often need to consider. You can refer to the following process to design related stages: + +[](https://mermaid-js.github.io/mermaid-live-editor/edit#pako:eNp9UbFOwzAQ_ZXIczuQbBkYKAKKOlRpJ5TlGp8TC9sX2WdVpeq_Y0cClahl8rv3nt_d2WfRkURRC2Xo2A3gudg0rSuKEA-9h3Eo9h5cUORteMj8i9FjPt_AqCeSp4wbYmBNLuPdoBVPJAb9hRmtyJB_18zkc4lO3mlQZv4VHXpg3IPvkf-_UGV-C93nlgKu3Riv_Q0c1xZ6LJbLx_kWSdvAAc0t7aqc5Cl3Srqrroi81C5NHbJnzs26lH9zyplc_UbcGr8SC2HRW9Ay_do5e1vBA1psRZ2gRAXRcCtad0lWiEy7k-tEzT7iQsRRpomeNaSntKJWYEJiR3AfRD_15RuTF7md) + +The `common_transforms` component provides commonly used `RandomFlip`, `RandomHalfBody` **data augmentation**. + +- Operations such as `Shift`, `Rotate`, and `Resize` in the `Top-Down` method are reflected in the [RandomBBoxTransform](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/common_transforms.py#L435) method. +- The [BottomupResize](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/bottomup_transforms.py#L327) method is embodied in the `Buttom-Up` algorithm. +- `pose-3d` is the [RandomFlipAroundRoot](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/pose3d_transforms.py#L13) method. + +**MMPose** provides corresponding data conversion interfaces for `Top-Down`, `Button-Up`, and `pose-3d`. Transform the image and coordinate labels from the `original_image_space` to the `input_image_space` by using an affine transformation. + +- The `Top-Down` method is manifested as [TopdownAffine](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/topdown_transforms.py#L14). +- The `Bottom-Up` method is embodied as [BottomupRandomAffine](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/bottomup_transforms.py#L134). + +Taking `RandomFlip` as an example, this method randomly transforms the `original_image` and converts it into an `input_image` or an `intermediate_image`. To define a data transformation process, you need to inherit the [BaseTransform](https://github.com/open-mmlab/mmcv/blob/main/mmcv/transforms/base.py) class and register with `TRANSFORM`: + +```python +from mmcv.transforms import BaseTransform +from mmpose.registry import TRANSFORMS + +@TRANSFORMS.register_module() +class RandomFlip(BaseTransform): + """Randomly flip the image, bbox and keypoints. + + Required Keys: + + - img + - img_shape + - flip_indices + - input_size (optional) + - bbox (optional) + - bbox_center (optional) + - keypoints (optional) + - keypoints_visible (optional) + - img_mask (optional) + + Modified Keys: + + - img + - bbox (optional) + - bbox_center (optional) + - keypoints (optional) + - keypoints_visible (optional) + - img_mask (optional) + + Added Keys: + + - flip + - flip_direction + + Args: + prob (float | list[float]): The flipping probability. If a list is + given, the argument `direction` should be a list with the same + length. And each element in `prob` indicates the flipping + probability of the corresponding one in ``direction``. Defaults + to 0.5 + direction (str | list[str]): The flipping direction. Options are + ``'horizontal'``, ``'vertical'`` and ``'diagonal'``. If a list is + is given, each data sample's flipping direction will be sampled + from a distribution determined by the argument ``prob``. Defaults + to ``'horizontal'``. + """ + def __init__(self, + prob: Union[float, List[float]] = 0.5, + direction: Union[str, List[str]] = 'horizontal') -> None: + if isinstance(prob, list): + assert is_list_of(prob, float) + assert 0 <= sum(prob) <= 1 + elif isinstance(prob, float): + assert 0 <= prob <= 1 + else: + raise ValueError(f'probs must be float or list of float, but \ + got `{type(prob)}`.') + self.prob = prob + + valid_directions = ['horizontal', 'vertical', 'diagonal'] + if isinstance(direction, str): + assert direction in valid_directions + elif isinstance(direction, list): + assert is_list_of(direction, str) + assert set(direction).issubset(set(valid_directions)) + else: + raise ValueError(f'direction must be either str or list of str, \ + but got `{type(direction)}`.') + self.direction = direction + + if isinstance(prob, list): + assert len(prob) == len(self.direction) +``` + +**Input**: + +- `prob` specifies the probability of transformation in horizontal, vertical, diagonal, etc., and is a `list` of floating-point numbers in the range \[0,1\]. +- `direction` specifies the direction of data transformation: + - `horizontal` + - `vertical` + - `diagonal` + +**Output**: + +- Return a `dict` data after data transformation. + +Here is a simple example of using `diagonal RandomFlip`: + +```python +from mmpose.datasets.transforms import LoadImage, RandomFlip +import mmcv + +# Load the original image from the path +results = dict( + img_path='data/test/multi-person.jpeg' + ) +transform = LoadImage() +results = transform(results) +# At this point, the original image loaded is a `dict` +# that contains the following attributes`: +# - `img_path`: Absolute path of image +# - `img`: Pixel points of the image +# - `img_shape`: The shape of the image +# - `ori_shape`: The original shape of the image + +# Perform diagonal flip transformation on the original image +transform = RandomFlip(prob=1., direction='diagonal') +results = transform(results) +# At this point, the original image loaded is a `dict` +# that contains the following attributes`: +# - `img_path`: Absolute path of image +# - `img`: Pixel points of the image +# - `img_shape`: The shape of the image +# - `ori_shape`: The original shape of the image +# - `flip`: Is the image flipped and transformed +# - `flip_direction`: The direction in which +# the image is flipped and transformed + +# Get the image after flipping and transformation +mmcv.imshow(results['img']) +``` + +For more information on using custom data transformations and enhancements, please refer to [$MMPose/test/test_datasets/test_transforms/test_common_transforms](https://github.com/open-mmlab/mmpose/blob/main/tests/test_datasets/test_transforms/test_common_transforms.py#L59)。 + +#### RandomHalfBody + +The [RandomHalfBody](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/common_transforms.py#L263) **data augmentation** algorithm probabilistically transforms the data of the upper or lower body. + +**Input**: + +- `min_total_keypoints` minimum total keypoints +- `min_half_keypoints` minimum half-body keypoints +- `padding` The filling ratio of the bbox +- `prob` accepts the probability of half-body transformation when the number of key points meets the requirements + +**Output**: + +- Return a `dict` data after data transformation. + +#### Topdown Affine + +The [TopdownAffine](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/topdown_transforms.py#L14) data transformation algorithm transforms the `original image` into an `input image` through affine transformation + +- `input_size` The bbox area will be cropped and corrected to the \[w,h\] size +- `use_udp` whether to use fair data process [UDP](https://arxiv.org/abs/1911.07524). + +**Output**: + +- Return a `dict` data after data transformation. + +### Using Data Augmentation and Transformation in the Pipeline + +The **data augmentation** and **data transformation** process in the configuration file can be the following example: + +```python +train_pipeline_stage2 = [ + ... + dict(type='RandomFlip', direction='horizontal'), + dict(type='RandomHalfBody'), + dict( + type='RandomBBoxTransform', + shift_factor=0., + scale_factor=[0.75, 1.25], + rotate_factor=60), + dict( + type='TopdownAffine', + input_size=codec['input_size']), + ... +] +``` + +The pipeline in the example performs **data enhancement** on the `input data`, performs random horizontal transformation and half-body transformation, and performs `Top-Down` `Shift`, `Rotate`, and `Resize` operations, and implements affine transformation through `TopdownAffine` operations to transform to the `input_image_space`. diff --git a/docs/en/advanced_guides/how_to_deploy.md b/docs/en/advanced_guides/how_to_deploy.md deleted file mode 100644 index b4fead876c..0000000000 --- a/docs/en/advanced_guides/how_to_deploy.md +++ /dev/null @@ -1,3 +0,0 @@ -# How to Deploy MMPose Models - -Coming soon. diff --git a/docs/en/advanced_guides/implement_new_models.md b/docs/en/advanced_guides/implement_new_models.md index 4a10b0c3c9..7e73cfcbf4 100644 --- a/docs/en/advanced_guides/implement_new_models.md +++ b/docs/en/advanced_guides/implement_new_models.md @@ -1,3 +1,164 @@ # Implement New Models -Coming soon. +This tutorial will introduce how to implement your own models in MMPose. After summarizing, we split the need to implement new models into two categories: + +1. Based on the algorithm paradigm supported by MMPose, customize the modules (backbone, neck, head, codec, etc.) in the model +2. Implement new algorithm paradigm + +## Basic Concepts + +What you want to implement is one of the above, and this section is important to you because it is the basic principle of building models in the OpenMMLab. + +In MMPose, all the code related to the implementation of the model structure is stored in the [models directory](https://github.com/open-mmlab/mmpose/tree/main/mmpose/models) : + +```shell +mmpose +|----models + |----backbones # + |----data_preprocessors # image normalization + |----heads # + |----losses # loss functions + |----necks # + |----pose_estimators # algorithm paradigm + |----utils # +``` + +You can refer to the following flow chart to locate the module you need to implement: + +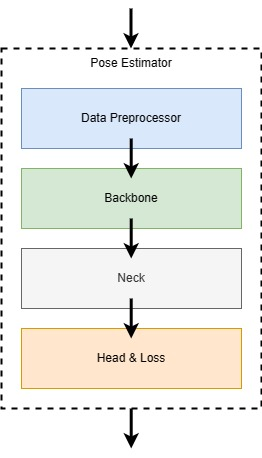 + +## Pose Estimatiors + +In pose estimatiors, we will define the inference process of a model, and decode the model output results in `predict()`, first transform it from `output space` to `input image space` using the [codec](./codecs.md), and then combine the meta information to transform to `original image space`. + + + +Currently, MMPose supports the following types of pose estimator: + +1. [Top-down](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/pose_estimators/topdown.py): The input of the pose model is a cropped single target (animal, human body, human face, human hand, plant, clothes, etc.) image, and the output is the key point prediction result of the target +2. [Bottom-up](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/pose_estimators/bottomup.py): The input of the pose model is an image containing any number of targets, and the output is the key point prediction result of all targets in the image +3. [Pose Lifting](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/pose_estimators/pose_lifter.py): The input of the pose model is a 2D keypoint coordinate array, and the output is a 3D keypoint coordinate array + +If the model you want to implement does not belong to the above algorithm paradigm, then you need to inherit the [BasePoseEstimator](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/pose_estimators/base.py) class to define your own algorithm paradigm. + +## Backbones + +If you want to implement a new backbone network, you need to create a new file in the [backbones directory](https://github.com/open-mmlab/mmpose/tree/main/mmpose/models/backbones) to define it. + +The new backbone network needs to inherit the [BaseBackbone](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/backbones/base_backbone.py) class, and there is no difference in other aspects from inheriting `nn.Module` to create. + +After completing the implementation of the backbone network, you need to use `MODELS` to register it: + +```Python3 +from mmpose.registry import MODELS +from .base_backbone import BaseBackbone + + +@MODELS.register_module() +class YourNewBackbone(BaseBackbone): +``` + +Finally, please remember to import your new backbone network in [\_\_init\_\_.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/backbones/__init__.py) . + +## Heads + +The addition of a new prediction head is similar to the backbone network process. You need to create a new file in the [heads directory](https://github.com/open-mmlab/mmpose/tree/main/mmpose/models/heads) to define it, and then inherit [BaseHead](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/heads/base_head.py) . + +One thing to note is that in MMPose, the loss function is calculated in the Head. According to the different training and evaluation stages, `loss()` and `predict()` are executed respectively. + +In `predict()`, the model will call the `decode()` method of the corresponding codec to transform the model output result from `output space` to `input image space`. + +After completing the implementation of the prediction head, you need to use `MODELS` to register it: + +```Python3 +from mmpose.registry import MODELS +from ..base_head import BaseHead + +@MODELS.register_module() +class YourNewHead(BaseHead): +``` + +Finally, please remember to import your new prediction head in [\_\_init\_\_.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/heads/__init__.py). + +### Head with Keypoints Visibility Prediction + +Many models predict keypoint visibility based on confidence in coordinate predictions. However, this approach is suboptimal. Our [VisPredictHead](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/models/heads/hybrid_heads/vis_head.py) wrapper enables heads to directly predict keypoint visibility from ground truth training data, improving reliability. To add visibility prediction, wrap your head module with VisPredictHead in the config file. + +```python +model=dict( + ... + head=dict( + type='VisPredictHead', + loss=dict( + type='BCELoss', + use_target_weight=True, + use_sigmoid=True, + loss_weight=1e-3), + pose_cfg=dict( + type='HeatmapHead', + in_channels=2048, + out_channels=17, + loss=dict(type='KeypointMSELoss', use_target_weight=True), + decoder=codec)), + ... +) +``` + +To implement such a head module wrapper, we only need to inherit [BaseHead](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/heads/base_head.py), then pass the pose head configuration in `__init__()` and instantiate it through `MODELS.build()`. As shown below: + +```python +@MODELS.register_module() +class VisPredictHead(BaseHead): + """VisPredictHead must be used together with other heads. It can predict + keypoints coordinates of and their visibility simultaneously. In the + current version, it only supports top-down approaches. + + Args: + pose_cfg (Config): Config to construct keypoints prediction head + loss (Config): Config for visibility loss. Defaults to use + :class:`BCELoss` + use_sigmoid (bool): Whether to use sigmoid activation function + init_cfg (Config, optional): Config to control the initialization. See + :attr:`default_init_cfg` for default settings + """ + + def __init__(self, + pose_cfg: ConfigType, + loss: ConfigType = dict( + type='BCELoss', use_target_weight=False, + use_sigmoid=True), + init_cfg: OptConfigType = None): + + if init_cfg is None: + init_cfg = self.default_init_cfg + + super().__init__(init_cfg) + + self.in_channels = pose_cfg['in_channels'] + if pose_cfg.get('num_joints', None) is not None: + self.out_channels = pose_cfg['num_joints'] + elif pose_cfg.get('out_channels', None) is not None: + self.out_channels = pose_cfg['out_channels'] + else: + raise ValueError('VisPredictHead requires \'num_joints\' or' + ' \'out_channels\' in the pose_cfg.') + + self.loss_module = MODELS.build(loss) + + self.pose_head = MODELS.build(pose_cfg) + self.pose_cfg = pose_cfg + + self.use_sigmoid = loss.get('use_sigmoid', False) + + modules = [ + nn.AdaptiveAvgPool2d(1), + nn.Flatten(), + nn.Linear(self.in_channels, self.out_channels) + ] + if self.use_sigmoid: + modules.append(nn.Sigmoid()) + + self.vis_head = nn.Sequential(*modules) +``` + +Then you can implement other parts of the code as a normal head. diff --git a/docs/en/dataset_zoo/2d_wholebody_keypoint.md b/docs/en/dataset_zoo/2d_wholebody_keypoint.md index a082c657c6..1c1e9f75d1 100644 --- a/docs/en/dataset_zoo/2d_wholebody_keypoint.md +++ b/docs/en/dataset_zoo/2d_wholebody_keypoint.md @@ -131,3 +131,85 @@ mmpose Please also install the latest version of [Extended COCO API](https://github.com/jin-s13/xtcocoapi) (version>=1.5) to support Halpe evaluation: `pip install xtcocotools` + +## UBody + + + +`__.
+
+ CrowdPose keypoints::
+
+ 0: 'left_shoulder',
+ 1: 'right_shoulder',
+ 2: 'left_elbow',
+ 3: 'right_elbow',
+ 4: 'left_wrist',
+ 5: 'right_wrist',
+ 6: 'left_hip',
+ 7: 'right_hip',
+ 8: 'left_knee',
+ 9: 'right_knee',
+ 10: 'left_ankle',
+ 11: 'right_ankle',
+ 12: 'top_head',
+ 13: 'neck'
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/crowdpose.py')
```
-When supporting MPII dataset, since we need to use `head_size` to calculate `PCKh`, we add `headbox_file` to `__init__()` and override`_load_annotations()`.
+For COCO-style datasets, we only need to inherit from [BaseCocoStyleDataset](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/datasets/base/base_coco_style_dataset.py) and specify `METAINFO`, then the dataset class is ready to use.
-To support a dataset that is beyond the scope of `BaseCocoStyleDataset`, you may need to subclass from the `BaseDataset` provided by [MMEngine](https://github.com/open-mmlab/mmengine). Please refer to the [documents](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/basedataset.html) for details.
+#### 3D Dataset
+
+we provide a base class [BaseMocapDataset](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/datasets/base/base_mocap_dataset.py) for 3D datasets. We recommend that users subclass [BaseMocapDataset](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/datasets/base/base_mocap_dataset.py) and override the methods as needed (usually `__init__()` and `_load_annotations()`) to extend to a new custom 3D keypoint dataset.
### Pipeline
@@ -292,7 +342,7 @@ test_pipeline = [
In a keypoint detection task, data will be transformed among three scale spaces:
-- **Original Image Space**: the space where the images are stored. The sizes of different images are not necessarily the same
+- **Original Image Space**: the space where the original images and annotations are stored. The sizes of different images are not necessarily the same
- **Input Image Space**: the image space used for model input. All **images** and **annotations** will be transformed into this space, such as `256x256`, `256x192`, etc.
@@ -300,29 +350,31 @@ In a keypoint detection task, data will be transformed among three scale spaces:
Here is a diagram to show the workflow of data transformation among the three scale spaces:
-
+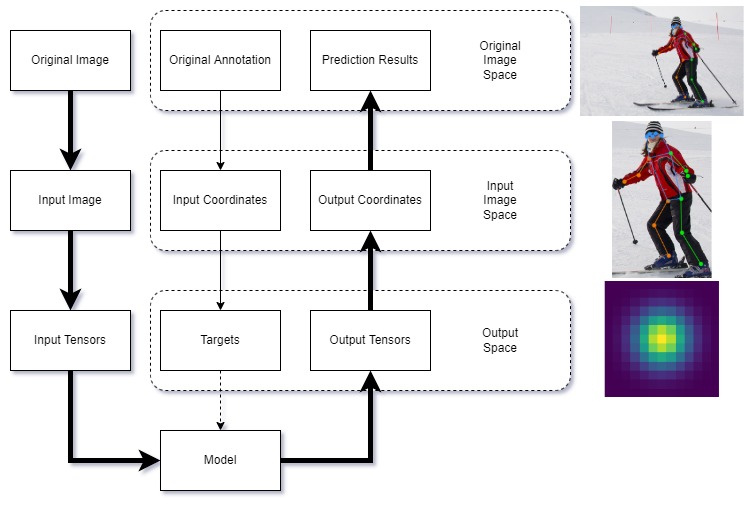
-In MMPose, the modules used for data transformation are under `$MMPOSE/mmpose/datasets/transforms`, and their workflow is shown as follows:
+In MMPose, the modules used for data transformation are under [$MMPOSE/mmpose/datasets/transforms](https://github.com/open-mmlab/mmpose/tree/main/mmpose/datasets/transforms), and their workflow is shown as follows:

#### i. Augmentation
-Commonly used transforms are defined in `$MMPOSE/mmpose/datasets/transforms/common_transforms.py`, such as `RandomFlip`, `RandomHalfBody`, etc.
+Commonly used transforms are defined in [$MMPOSE/mmpose/datasets/transforms/common_transforms.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/transforms/common_transforms.py), such as [RandomFlip](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/common_transforms.py#L94), [RandomHalfBody](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/common_transforms.py#L263), etc. For top-down methods, `Shift`, `Rotate`and `Resize` are implemented by [RandomBBoxTransform](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/common_transforms.py#L433). For bottom-up methods, [BottomupRandomAffine](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/bottomup_transforms.py#L134) is used.
-For top-down methods, `Shift`, `Rotate`and `Resize` are implemented by `RandomBBoxTransform`**.** For bottom-up methods, `BottomupRandomAffine` is used.
+Transforms for 3d pose data are defined in [$MMPOSE/mmpose/datasets/transforms/pose3d_transforms.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/transforms/pose3d_transforms.py)
```{note}
-Most data transforms depend on `bbox_center` and `bbox_scale`, which can be obtained by `GetBBoxCenterScale`.
+Most data transforms depend on `bbox_center` and `bbox_scale`, which can be obtained by [GetBBoxCenterScale](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/common_transforms.py#L31).
```
#### ii. Transformation
-Affine transformation is used to convert images and annotations from the original image space to the input space. This is done by `TopdownAffine` for top-down methods and `BottomupRandomAffine` for bottom-up methods.
+For 2D image inputs, affine transformation is used to convert images and annotations from the original image space to the input space. This is done by [TopdownAffine](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/topdown_transforms.py#L14) for top-down methods and [BottomupRandomAffine](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/bottomup_transforms.py#L134) for bottom-up methods.
+
+For pose lifting tasks, transformation is merged into [Encoding](./guide_to_framework.md#iii-encoding).
#### iii. Encoding
-In training phase, after the data is transformed from the original image space into the input space, it is necessary to use `GenerateTarget` to obtain the training target(e.g. Gaussian Heatmaps). We name this process **Encoding**. Conversely, the process of getting the corresponding coordinates from Gaussian Heatmaps is called **Decoding**.
+In training phase, after the data is transformed from the original image space into the input space, it is necessary to use [GenerateTarget](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/common_transforms.py#L873) to obtain the training target(e.g. Gaussian Heatmaps). We name this process **Encoding**. Conversely, the process of getting the corresponding coordinates from Gaussian Heatmaps is called **Decoding**.
In MMPose, we collect Encoding and Decoding processes into a **Codec**, in which `encode()` and `decode()` are implemented.
@@ -333,6 +385,7 @@ Currently we support the following types of Targets.
- `keypoint_xy_label`: axis-wise keypoint representation
- `heatmap+keypoint_label`: Gaussian heatmaps and keypoint representation
- `multiscale_heatmap`: multi-scale Gaussian heatmaps
+- `lifting_target_label`: 3D lifting target keypoint representation
and the generated targets will be packed as follows.
@@ -341,18 +394,20 @@ and the generated targets will be packed as follows.
- `keypoint_x_labels`: keypoint x-axis representation
- `keypoint_y_labels`: keypoint y-axis representation
- `keypoint_weights`: keypoint visibility and weights
+- `lifting_target_label`: 3D lifting target representation
+- `lifting_target_weight`: 3D lifting target visibility and weights
-Note that we unify the data format of top-down and bottom-up methods, which means that a new dimension is added to represent different instances from the same image, in shape:
+Note that we unify the data format of top-down, pose-lifting and bottom-up methods, which means that a new dimension is added to represent different instances from the same image, in shape:
```Python
[batch_size, num_instances, num_keypoints, dim_coordinates]
```
-- top-down: `[B, 1, K, D]`
+- top-down and pose-lifting: `[B, 1, K, D]`
-- Bottom-up: `[B, N, K, D]`
+- bottom-up: `[B, N, K, D]`
-The provided codecs are stored under `$MMPOSE/mmpose/codecs`.
+The provided codecs are stored under [$MMPOSE/mmpose/codecs](https://github.com/open-mmlab/mmpose/tree/main/mmpose/codecs).
```{note}
If you wish to customize a new codec, you can refer to [Codec](./user_guides/codecs.md) for more details.
@@ -360,9 +415,9 @@ If you wish to customize a new codec, you can refer to [Codec](./user_guides/cod
#### iv. Packing
-After the data is transformed, you need to pack it using `PackPoseInputs`.
+After the data is transformed, you need to pack it using [PackPoseInputs](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/transforms/formatting.py).
-This method converts the data stored in the dictionary `results` into standard data structures in MMPose, such as `InstanceData`, `PixelData`, `PoseDataSample`, etc.
+This method converts the data stored in the dictionary `results` into standard data structures in MMPose, such as `InstanceData`, `PixelData`, [PoseDataSample](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/structures/pose_data_sample.py), etc.
Specifically, we divide the data into `gt` (ground-truth) and `pred` (prediction), each of which has the following types:
@@ -370,7 +425,7 @@ Specifically, we divide the data into `gt` (ground-truth) and `pred` (prediction
- **instance_labels**(torch.tensor): instance-level training labels (e.g. normalized coordinates, keypoint visibility) in the output scale space
- **fields**(torch.tensor): pixel-level training labels or predictions (e.g. Gaussian Heatmaps) in the output scale space
-The following is an example of the implementation of `PoseDataSample` under the hood:
+The following is an example of the implementation of [PoseDataSample](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/structures/pose_data_sample.py) under the hood:
```Python
def get_pose_data_sample(self):
@@ -425,7 +480,7 @@ In MMPose 1.0, the model consists of the following components:
- **Head**: used to implement the core algorithm and loss function
-We define a base class `BasePoseEstimator` for the model in `$MMPOSE/models/pose_estimators/base.py`. All models, e.g. `TopdownPoseEstimator`, should inherit from this base class and override the corresponding methods.
+We define a base class [BasePoseEstimator](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/models/pose_estimators/base.py) for the model in [$MMPOSE/models/pose_estimators/base.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/pose_estimators/base.py). All models, e.g. [TopdownPoseEstimator](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/models/pose_estimators/topdown.py), should inherit from this base class and override the corresponding methods.
Three modes are provided in `forward()` of the estimator:
@@ -477,7 +532,7 @@ It will transpose the channel order of the input image from `bgr` to `rgb` and n
### Backbone
-MMPose provides some commonly used backbones under `$MMPOSE/mmpose/models/backbones`.
+MMPose provides some commonly used backbones under [$MMPOSE/mmpose/models/backbones](https://github.com/open-mmlab/mmpose/tree/main/mmpose/models/backbones).
In practice, developers often use pre-trained backbone weights for transfer learning, which can improve the performance of the model on small datasets.
@@ -515,7 +570,7 @@ It should be emphasized that if you add a new backbone, you need to register it
class YourBackbone(BaseBackbone):
```
-Besides, import it in `$MMPOSE/mmpose/models/backbones/__init__.py`, and add it to `__all__`.
+Besides, import it in [$MMPOSE/mmpose/models/backbones/\_\_init\_\_.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/backbones/__init__.py), and add it to `__all__`.
### Neck
@@ -527,7 +582,7 @@ Neck is usually a module between Backbone and Head, which is used in some algori
- Feature Map Processor (FMP)
- The `FeatureMapProcessor` is a flexible PyTorch module designed to transform the feature outputs generated by backbones into a format suitable for heads. It achieves this by utilizing non-parametric operations such as selecting, concatenating, and rescaling. Below are some examples along with their corresponding configurations:
+ The [FeatureMapProcessor](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/models/necks/fmap_proc_neck.py) is a flexible PyTorch module designed to transform the feature outputs generated by backbones into a format suitable for heads. It achieves this by utilizing non-parametric operations such as selecting, concatenating, and rescaling. Below are some examples along with their corresponding configurations:
- Select operation
@@ -559,7 +614,7 @@ Neck is usually a module between Backbone and Head, which is used in some algori
Generally speaking, Head is often the core of an algorithm, which is used to make predictions and perform loss calculation.
-Modules related to Head in MMPose are defined under `$MMPOSE/mmpose/models/heads`, and developers need to inherit the base class `BaseHead` when customizing Head and override the following methods:
+Modules related to Head in MMPose are defined under [$MMPOSE/mmpose/models/heads](https://github.com/open-mmlab/mmpose/tree/main/mmpose/models/heads), and developers need to inherit the base class `BaseHead` when customizing Head and override the following methods:
- forward()
@@ -567,13 +622,13 @@ Modules related to Head in MMPose are defined under `$MMPOSE/mmpose/models/heads
- loss()
-Specifically, `predict()` method needs to return pose predictions in the image space, which is obtained from the model output though the decoding function provided by the codec. We implement this process in `BaseHead.decode()`.
+Specifically, `predict()` method needs to return pose predictions in the image space, which is obtained from the model output though the decoding function provided by the codec. We implement this process in [BaseHead.decode()](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/heads/base_head.py).
On the other hand, we will perform test-time augmentation(TTA) in `predict()`.
A commonly used TTA is `flip_test`, namely, an image and its flipped version are sent into the model to inference, and the output of the flipped version will be flipped back, then average them to stabilize the prediction.
-Here is an example of `predict()` in `RegressionHead`:
+Here is an example of `predict()` in [RegressionHead](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/heads/regression_heads/regression_head.py):
```Python
def predict(self,
@@ -627,7 +682,7 @@ keypoint_weights = torch.cat([
])
```
-Here is the complete implementation of `loss()` in `RegressionHead`:
+Here is the complete implementation of `loss()` in [RegressionHead](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/heads/regression_heads/regression_head.py):
```Python
def loss(self,
@@ -666,3 +721,11 @@ def loss(self,
return losses
```
+
+```{note}
+If you wish to learn more about the implementation of Model, like:
+- Head with Keypoints Visibility Prediction
+- Pose Lifting Models
+
+please refer to [Advanced Guides - Implement New Model](./advanced_guides/implement_new_models.md) for more details.
+```
diff --git a/docs/en/index.rst b/docs/en/index.rst
index 044b54be0f..cc3782925e 100644
--- a/docs/en/index.rst
+++ b/docs/en/index.rst
@@ -24,6 +24,9 @@ You can change the documentation language at the lower-left corner of the page.
user_guides/configs.md
user_guides/prepare_datasets.md
user_guides/train_and_test.md
+ user_guides/how_to_deploy.md
+ user_guides/model_analysis.md
+ user_guides/dataset_tools.md
.. toctree::
:maxdepth: 1
@@ -34,10 +37,9 @@ You can change the documentation language at the lower-left corner of the page.
advanced_guides/implement_new_models.md
advanced_guides/customize_datasets.md
advanced_guides/customize_transforms.md
+ advanced_guides/customize_evaluation.md
advanced_guides/customize_optimizer.md
advanced_guides/customize_logging.md
- advanced_guides/how_to_deploy.md
- advanced_guides/model_analysis.md
.. toctree::
:maxdepth: 1
@@ -79,7 +81,6 @@ You can change the documentation language at the lower-left corner of the page.
dataset_zoo/2d_animal_keypoint.md
dataset_zoo/3d_body_keypoint.md
dataset_zoo/3d_hand_keypoint.md
- dataset_zoo/dataset_tools.md
.. toctree::
:maxdepth: 1
diff --git a/docs/en/installation.md b/docs/en/installation.md
index 47db25bb5f..4140d9ad40 100644
--- a/docs/en/installation.md
+++ b/docs/en/installation.md
@@ -68,6 +68,15 @@ Note that some of the demo scripts in MMPose require [MMDetection](https://githu
mim install "mmdet>=3.1.0"
```
+```{note}
+Here are the version correspondences between mmdet, mmpose and mmcv:
+
+- mmdet 2.x <=> mmpose 0.x <=> mmcv 1.x
+- mmdet 3.x <=> mmpose 1.x <=> mmcv 2.x
+
+If you encounter version incompatibility issues, please check the correspondence using `pip list | grep mm` and upgrade or downgrade the dependencies accordingly. Please note that `mmcv-full` is only for `mmcv 1.x`, so please uninstall it first, and then use `mim install mmcv` to install `mmcv 2.x`.
+```
+
## Best Practices
### Build MMPose from source
@@ -102,7 +111,7 @@ To verify that MMPose is installed correctly, you can run an inference demo with
mim download mmpose --config td-hm_hrnet-w48_8xb32-210e_coco-256x192 --dest .
```
-The downloading will take several seconds or more, depending on your network environment. When it is done, you will find two files `td-hm_hrnet-w48_8xb32-210e_coco-256x192.py` and `hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth` in your current folder.
+The downloading will take several seconds or more, depending on your network environment. When it is done, you will find two files `td-hm_hrnet-w48_8xb32-210e_coco-256x192.py` and `td-hm_hrnet-w48_8xb32-210e_coco-256x192-0e67c616_20220913.pth` in your current folder.
**Step 2.** Run the inference demo.
@@ -112,7 +121,7 @@ Option (A). If you install mmpose from source, just run the following command un
python demo/image_demo.py \
tests/data/coco/000000000785.jpg \
td-hm_hrnet-w48_8xb32-210e_coco-256x192.py \
- hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \
+ td-hm_hrnet-w48_8xb32-210e_coco-256x192-0e67c616_20220913.pth \
--out-file vis_results.jpg \
--draw-heatmap
```
@@ -130,7 +139,7 @@ from mmpose.utils import register_all_modules
register_all_modules()
config_file = 'td-hm_hrnet-w48_8xb32-210e_coco-256x192.py'
-checkpoint_file = 'hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth'
+checkpoint_file = 'td-hm_hrnet-w48_8xb32-210e_coco-256x192-0e67c616_20220913.pth'
model = init_model(config_file, checkpoint_file, device='cpu') # or device='cuda:0'
# please prepare an image with person
@@ -141,6 +150,15 @@ The `demo.jpg` can be downloaded from [Github](https://raw.githubusercontent.com
The inference results will be a list of `PoseDataSample`, and the predictions are in the `pred_instances`, indicating the detected keypoint locations and scores.
+```{note}
+MMCV version should match PyTorch version strictly. If you encounter the following issues:
+
+- No module named 'mmcv.ops'
+- No module named 'mmcv._ext'
+
+It means that the current PyTorch version does not match the CUDA version. You can check the CUDA version using `nvidia-smi`, and it should match the `+cu1xx` in PyTorch version in `pip list | grep torch`. Otherwise, you need to uninstall PyTorch and reinstall it, then reinstall MMCV (the installation order **CAN NOT** be swapped).
+```
+
## Customize Installation
### CUDA versions
diff --git a/docs/en/migration.md b/docs/en/migration.md
index 70ed0b5a52..a3e0099bc7 100644
--- a/docs/en/migration.md
+++ b/docs/en/migration.md
@@ -111,6 +111,16 @@ class GenerateTarget(BaseTransform):
The data normalization operations `NormalizeTensor` and `ToTensor` will be replaced by **DataPreprocessor** module, which will no longer be used as a preprocessing operation, but will be merged as a part of the model forward propagation.
+The 3D normalization methods like
+
+- `GetRootCenteredPose`
+- `ImageCoordinateNormalization`
+- `NormalizeJointCoordinate`
+
+will be merged into codecs, for example [`ImagePoseLifting`](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/image_pose_lifting.py#L11) and [`VideoPoseLifting`](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/video_pose_lifting.py#L13).
+
+The data conversion and reshaping operation `PoseSequenceToTensor` will be implemented in corresponding codecs and [`PackPoseInputs`](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/transforms/formatting.py).
+
## Compatibility of Models
We have performed compatibility with the model weights provided by model zoo to ensure that the same model weights can get a comparable accuracy in both version. But note that due to the large number of differences in processing details, the inference outputs can be slightly different(less than 0.05% difference in accuracy).
diff --git a/docs/en/notes/changelog.md b/docs/en/notes/changelog.md
index 1d1be738e3..47a73ae7c1 100644
--- a/docs/en/notes/changelog.md
+++ b/docs/en/notes/changelog.md
@@ -1,5 +1,17 @@
# Changelog
+## **v1.2.0 (12/10/2023)**
+
+Release note: https://github.com/open-mmlab/mmpose/releases/tag/v1.2.0
+
+## **v1.1.0 (04/07/2023)**
+
+Release note: https://github.com/open-mmlab/mmpose/releases/tag/v1.1.0
+
+## **v1.0.0 (06/04/2023)**
+
+Release note: https://github.com/open-mmlab/mmpose/releases/tag/v1.0.0
+
## **v1.0.0rc1 (14/10/2022)**
**Highlights**
diff --git a/docs/en/overview.md b/docs/en/overview.md
index b6e31dd239..42aa004158 100644
--- a/docs/en/overview.md
+++ b/docs/en/overview.md
@@ -43,6 +43,9 @@ We have prepared detailed guidelines for all types of users:
- [Configs](./user_guides/configs.md)
- [Prepare Datasets](./user_guides/prepare_datasets.md)
- [Train and Test](./user_guides/train_and_test.md)
+ - [Deployment](./user_guides/how_to_deploy.md)
+ - [Model Analysis](./user_guides/model_analysis.md)
+ - [Dataset Annotation and Preprocessing](./user_guides/dataset_tools.md)
3. For developers who wish to develop based on MMPose:
@@ -53,8 +56,6 @@ We have prepared detailed guidelines for all types of users:
- [Customize Data Transforms](./advanced_guides/customize_transforms.md)
- [Customize Optimizer](./advanced_guides/customize_optimizer.md)
- [Customize Logging](./advanced_guides/customize_logging.md)
- - [How to Deploy](./advanced_guides/how_to_deploy.md)
- - [Model Analysis](./advanced_guides/model_analysis.md)
- [Migration Guide](./migration.md)
4. For researchers and developers who are willing to contribute to MMPose:
diff --git a/docs/en/user_guides/configs.md b/docs/en/user_guides/configs.md
index 9d2c44f7ff..78bc00bc4e 100644
--- a/docs/en/user_guides/configs.md
+++ b/docs/en/user_guides/configs.md
@@ -2,6 +2,25 @@
We use python files as configs and incorporate modular and inheritance design into our config system, which is convenient to conduct various experiments.
+## Structure
+
+The file structure of configs is as follows:
+
+```shell
+configs
+|----_base_
+ |----datasets
+ |----default_runtime.py
+|----animal_2d_keypoint
+|----body_2d_keypoint
+|----body_3d_keypoint
+|----face_2d_keypoint
+|----fashion_2d_keypoint
+|----hand_2d_keypoint
+|----hand_3d_keypoint
+|----wholebody_2d_keypoint
+```
+
## Introduction
MMPose is equipped with a powerful config system. Cooperating with Registry, a config file can organize all the configurations in the form of python dictionaries and create instances of the corresponding modules.
@@ -114,11 +133,22 @@ Here is the description of General configuration:
# General
default_scope = 'mmpose'
default_hooks = dict(
- timer=dict(type='IterTimerHook'), # time the data processing and model inference
- logger=dict(type='LoggerHook', interval=50), # interval to print logs
- param_scheduler=dict(type='ParamSchedulerHook'), # update lr
+ # time the data processing and model inference
+ timer=dict(type='IterTimerHook'),
+ # interval to print logs,50 iters by default
+ logger=dict(type='LoggerHook', interval=50),
+ # update lr according to the lr scheduler
+ param_scheduler=dict(type='ParamSchedulerHook'),
checkpoint=dict(
- type='CheckpointHook', interval=1, save_best='coco/AP', # interval to save ckpt
+ # interval to save ckpt
+ # e.g.
+ # save_best='coco/AP' means save the best ckpt according to coco/AP of CocoMetric
+ # save_best='PCK' means save the best ckpt according to PCK of PCKAccuracy
+ type='CheckpointHook', interval=1, save_best='coco/AP',
+
+ # rule to judge the metric
+ # 'greater' means the larger the better
+ # 'less' means the smaller the better
rule='greater'), # rule to judge the metric
sampler_seed=dict(type='DistSamplerSeedHook')) # set the distributed seed
env_cfg = dict(
@@ -135,23 +165,16 @@ log_processor = dict( # Format, interval to log
log_level = 'INFO' # The level of logging
```
+```{note}
+We now support two visualizer backends: LocalVisBackend and TensorboardVisBackend, the former is for local visualization and the latter is for Tensorboard visualization. You can choose according to your needs. See [Train and Test](./train_and_test.md) for details.
+```
+
General configuration is stored alone in the `$MMPOSE/configs/_base_`, and inherited by doing:
```Python
_base_ = ['../../../_base_/default_runtime.py'] # take the config file as the starting point of the relative path
```
-```{note}
-CheckpointHook:
-
-- save_best: `'coco/AP'` for `CocoMetric`, `'PCK'` for `PCKAccuracy`
-- max_keep_ckpts: the maximum checkpoints to keep. Defaults to -1, which means unlimited.
-
-Example:
-
-`default_hooks = dict(checkpoint=dict(save_best='PCK', rule='greater', max_keep_ckpts=1))`
-```
-
### Data
Data configuration refers to the data processing related settings, mainly including:
@@ -230,10 +253,9 @@ test_dataloader = val_dataloader # use val as test by default
```{note}
Common Usages:
-- [Resume training](../common_usages/resume_training.md)
-- [Automatic mixed precision (AMP) training](../common_usages/amp_training.md)
-- [Set the random seed](../common_usages/set_random_seed.md)
-
+- [Resume training](https://mmpose.readthedocs.io/en/dev-1.x/user_guides/train_and_test.html#resume-training)
+- [Automatic mixed precision (AMP) training](https://mmpose.readthedocs.io/en/dev-1.x/user_guides/train_and_test.html#automatic-mixed-precision-amp-training)
+- [Set the random seed](https://mmpose.readthedocs.io/en/dev-1.x/user_guides/train_and_test.html#set-the-random-seed)
```
### Training
@@ -458,5 +480,5 @@ cfg.optimizer # ConfigDict(type='SGD', lr=0.01)
```
```{note}
-If you wish to learn more about advanced usages of the config system, please refer to [MMEngine Config](https://mmengine.readthedocs.io/en/latest/tutorials/config.html).
+If you wish to learn more about advanced usages of the config system, please refer to [MMEngine Config](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/config.html).
```
diff --git a/docs/en/dataset_zoo/dataset_tools.md b/docs/en/user_guides/dataset_tools.md
similarity index 76%
rename from docs/en/dataset_zoo/dataset_tools.md
rename to docs/en/user_guides/dataset_tools.md
index 44a7c96b2b..171f29493c 100644
--- a/docs/en/dataset_zoo/dataset_tools.md
+++ b/docs/en/user_guides/dataset_tools.md
@@ -1,6 +1,32 @@
-# Dataset Tools
+# Dataset Annotation and Format Conversion
-## Animal Pose
+This guide will help you tackle your datasets to get them ready for training and testing.
+
+## Dataset Annotation
+
+For users of [Label Studio](https://github.com/heartexlabs/label-studio/), please follow the instructions in the [Label Studio to COCO document](./label_studio.md) to annotate and export the results as a Label Studio `.json` file. And save the `Code` from the `Labeling Interface` as an `.xml` file.
+
+```{note}
+MMPose **DOSE NOT** impose any restrictions on the annotation tools used by users. As long as the final annotated results meet MMPose's data format requirements, they are acceptable. We warmly welcome community users to contribute more tutorials and conversion scripts for using various dataset annotation tools.
+```
+
+## Browse Dataset
+
+MMPose provides a useful tool to browse the dataset. You can visualize the raw annotations and the transformed annotations after data augmentation, which is helpful for debugging.
+
+Please refer to [this document](https://mmpose.readthedocs.io/en/dev-1.x/user_guides/prepare_datasets.html#browse-dataset) for more details.
+
+## Download Open-source Datasets via MIM
+
+By using [OpenXLab](https://openxlab.org.cn/datasets), you can obtain free formatted datasets in various fields. Through the search function of the platform, you may address the dataset they look for quickly and easily. Using the formatted datasets from the platform, you can efficiently conduct tasks across datasets.
+
+We recommend you check out this [how-to guide](https://mmpose.readthedocs.io/en/dev-1.x/user_guides/prepare_datasets.html#download-dataset-via-mim) to learn more details.
+
+## Format Conversion Scripts
+
+We provide some scripts to convert the raw annotations into the format compatible with MMPose (namely, COCO style).
+
+### Animal Pose
+
+ gt_instance_labels:
+
+ pred_instances:
+ )>
+]
+```
+
+You can obtain the predicted keypoints via `.`:
+
+```python
+pred_instances = batch_results[0].pred_instances
+
+pred_instances.keypoints
+# array([[[365.83333333, 87.50000477],
+# [372.08333333, 79.16667175],
+# [361.66666667, 81.25000501],
+# [384.58333333, 85.41667151],
+# [357.5 , 85.41667151],
+# [407.5 , 112.50000381],
+# [363.75 , 125.00000334],
+# [438.75 , 150.00000238],
+# [347.08333333, 158.3333354 ],
+# [451.25 , 170.83333492],
+# [305.41666667, 177.08333468],
+# [432.5 , 214.58333325],
+# [401.25 , 218.74999976],
+# [430.41666667, 285.41666389],
+# [370. , 274.99999762],
+# [470. , 356.24999452],
+# [403.33333333, 343.74999499]]])
+```
+
+### Visualization
+
+In MMPose, most visualizations are implemented based on visualizers. A visualizer is a class that takes a data sample and visualizes it.
+
+MMPose provides a visualizer registry, which users can instantiate using `VISUALIZERS`. Here is an example of using a visualizer to visualize the inference results:
+
+```python
+# merge results as a single data sample
+results = merge_data_samples(batch_results)
+
+# build the visualizer
+visualizer = VISUALIZERS.build(model.cfg.visualizer)
+
+# set skeleton, colormap and joint connection rule
+visualizer.set_dataset_meta(model.dataset_meta)
+
+img = imread(img_path, channel_order='rgb')
+
+# visualize the results
+visualizer.add_datasample(
+ 'result',
+ img,
+ data_sample=results,
+ show=True)
+```
+
+MMPose also provides a simpler interface for visualization:
+
+```python
+from mmpose.apis import visualize
+
+pred_instances = batch_results[0].pred_instances
+
+keypoints = pred_instances.keypoints
+keypoint_scores = pred_instances.keypoint_scores
+
+metainfo = 'config/_base_/datasets/coco.py'
+
+visualize(
+ img_path,
+ keypoints,
+ keypoint_scores,
+ metainfo=metainfo,
+ show=True)
+```
diff --git a/docs/en/dataset_zoo/label_studio.md b/docs/en/user_guides/label_studio.md
similarity index 100%
rename from docs/en/dataset_zoo/label_studio.md
rename to docs/en/user_guides/label_studio.md
diff --git a/docs/en/user_guides/mixed_datasets.md b/docs/en/user_guides/mixed_datasets.md
index f9bcc93e15..041bd7c656 100644
--- a/docs/en/user_guides/mixed_datasets.md
+++ b/docs/en/user_guides/mixed_datasets.md
@@ -1,10 +1,10 @@
# Use Mixed Datasets for Training
-MMPose offers a convenient and versatile solution for training with mixed datasets through its `CombinedDataset` tool. Acting as a wrapper, it allows for the inclusion of multiple datasets and seamlessly reads and converts data from varying sources into a unified format for model training. The data processing pipeline utilizing `CombinedDataset` is illustrated in the following figure.
+MMPose offers a convenient and versatile solution for training with mixed datasets through its [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) tool. Acting as a wrapper, it allows for the inclusion of multiple datasets and seamlessly reads and converts data from varying sources into a unified format for model training. The data processing pipeline utilizing [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) is illustrated in the following figure.
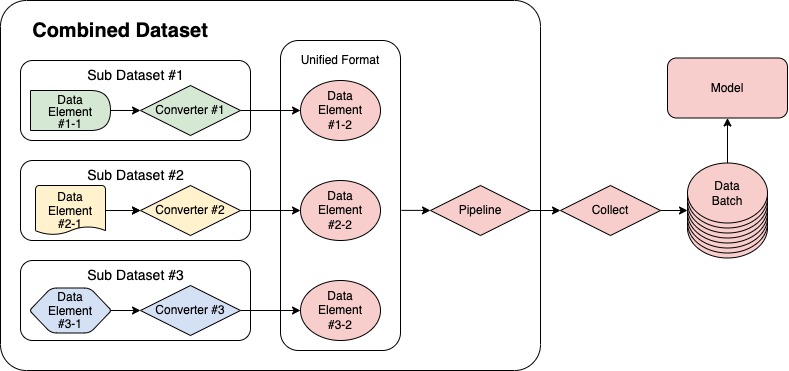
-The following section will provide a detailed description of how to configure `CombinedDataset` with an example that combines the COCO and AI Challenger (AIC) datasets.
+The following section will provide a detailed description of how to configure [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) with an example that combines the COCO and AI Challenger (AIC) datasets.
## COCO & AIC example
@@ -39,7 +39,7 @@ dataset_coco = dict(
)
```
-For AIC dataset, the order of the keypoints needs to be transformed. MMPose provides a `KeypointConverter` transform to achieve this. Here's an example of how to configure the AIC sub dataset:
+For AIC dataset, the order of the keypoints needs to be transformed. MMPose provides a [KeypointConverter](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/converting.py#L11) transform to achieve this. Here's an example of how to configure the AIC sub dataset:
```python
dataset_aic = dict(
@@ -70,9 +70,9 @@ dataset_aic = dict(
)
```
-By using the `KeypointConverter`, the indices of keypoints with indices 0 to 11 will be transformed to corresponding indices among 5 to 16. Meanwhile, the keypoints with indices 12 and 13 will be removed. For the target keypoints with indices 0 to 4, which are not defined in the `mapping` argument, they will be set as invisible and won't be used in training.
+By using the [KeypointConverter](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/converting.py#L11), the indices of keypoints with indices 0 to 11 will be transformed to corresponding indices among 5 to 16. Meanwhile, the keypoints with indices 12 and 13 will be removed. For the target keypoints with indices 0 to 4, which are not defined in the `mapping` argument, they will be set as invisible and won't be used in training.
-Once the sub datasets are configured, the `CombinedDataset` wrapper can be defined as follows:
+Once the sub datasets are configured, the [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) wrapper can be defined as follows:
```python
dataset = dict(
@@ -84,6 +84,11 @@ dataset = dict(
# The pipeline includes typical transforms, such as loading the
# image and data augmentation
pipeline=train_pipeline,
+ # The sample_ratio_factor controls the sampling ratio of
+ # each dataset in the combined dataset. The length of sample_ratio_factor
+ # should match the number of datasets. Each factor indicates the sampling
+ # ratio of the corresponding dataset relative to its original length.
+ sample_ratio_factor=[1.0, 0.5]
)
```
@@ -95,7 +100,7 @@ The previously mentioned method discards some annotations in the AIC dataset. If

-In this scenario, both COCO and AIC datasets need to adjust the keypoint indices using `KeypointConverter`: +In this scenario, both COCO and AIC datasets need to adjust the keypoint indices using [KeypointConverter](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/converting.py#L11): ```python dataset_coco = dict( @@ -157,3 +162,53 @@ dataset = dict( ``` Additionally, the output channel number of the model should be adjusted as the number of keypoints changes. If the users aim to evaluate the model on the COCO dataset, a subset of model outputs must be chosen. This subset can be customized using the `output_keypoint_indices` argument in `test_cfg`. Users can refer to the [config file](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-combine.py), which combines the COCO and AIC dataset, for more details and use it as a template to create their custom dataset. + +## Sampling Strategy for Mixed Datasets + +When training with mixed datasets, users often encounter the problem of inconsistent data distributions between different datasets. To address this issue, we provide two different sampling strategies: + +1. Adjust the sampling ratio of each sub dataset +2. Adjust the ratio of each sub dataset in each batch + +### Adjust the sampling ratio of each sub dataset + +In [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15), we provide the `sample_ratio_factor` argument to adjust the sampling ratio of each sub dataset. + +For example: + +- If `sample_ratio_factor` is `[1.0, 0.5]`, then all data from the first sub dataset will be included in the training, and the second sub dataset will be sampled at a ratio of 0.5. +- If `sample_ratio_factor` is `[1.0, 2.0]`, then all data from the first sub dataset will be included in the training, and the second sub dataset will be sampled at a ratio of 2 times its total number. + +### Adjust the ratio of each sub dataset in each batch + +In [$MMPOSE/datasets/samplers.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/samplers.py) we provide [MultiSourceSampler](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/samplers.py#L15) to adjust the ratio of each sub dataset in each batch. + +For example: + +- If `sample_ratio_factor` is `[1.0, 0.5]`, then the data volume of the first sub dataset in each batch will be `1.0 / (1.0 + 0.5) = 66.7%`, and the data volume of the second sub dataset will be `0.5 / (1.0 + 0.5) = 33.3%`. That is, the first sub dataset will be twice as large as the second sub dataset in each batch. + +Users can set the `sampler` argument in the configuration file: + +```python +# data loaders +train_bs = 256 +train_dataloader = dict( + batch_size=train_bs, + num_workers=4, + persistent_workers=True, + sampler=dict( + type='MultiSourceSampler', + batch_size=train_bs, + # ratio of sub datasets in each batch + source_ratio=[1.0, 0.5], + shuffle=True, + round_up=True), + dataset=dict( + type='CombinedDataset', + metainfo=dict(from_file='configs/_base_/datasets/coco.py'), + # set sub datasets + datasets=[sub_dataset1, sub_dataset2], + pipeline=train_pipeline, + test_mode=False, + )) +``` diff --git a/docs/en/advanced_guides/model_analysis.md b/docs/en/user_guides/model_analysis.md similarity index 84% rename from docs/en/advanced_guides/model_analysis.md rename to docs/en/user_guides/model_analysis.md index e10bb634a6..2050c01a1a 100644 --- a/docs/en/advanced_guides/model_analysis.md +++ b/docs/en/user_guides/model_analysis.md @@ -2,7 +2,7 @@ ## Get Model Params & FLOPs -MMPose provides `tools/analysis_tools/get_flops.py` to get model parameters and FLOPs. +MMPose provides [tools/analysis_tools/get_flops.py](https://github.com/open-mmlab/mmpose/blob/dev-1.x/tools/analysis_tools/get_flops.py) to get model parameters and FLOPs. ```shell python tools/analysis_tools/get_flops.py ${CONFIG_FILE} [--shape ${INPUT_SHAPE}] [--cfg-options ${CFG_OPTIONS}] @@ -42,7 +42,7 @@ This tool is still experimental and we do not guarantee that the number is absol ## Log Analysis -MMPose provides `tools/analysis_tools/analyze_logs.py` to analyze the training log. The log file can be either a json file or a text file. The json file is recommended, because it is more convenient to parse and visualize. +MMPose provides [tools/analysis_tools/analyze_logs.py](https://github.com/open-mmlab/mmpose/blob/dev-1.x/tools/analysis_tools/analyze_logs.py) to analyze the training log. The log file can be either a json file or a text file. The json file is recommended, because it is more convenient to parse and visualize. Currently, the following functions are supported: diff --git a/docs/en/user_guides/prepare_datasets.md b/docs/en/user_guides/prepare_datasets.md index 2f8ddcbc32..be47e07b8f 100644 --- a/docs/en/user_guides/prepare_datasets.md +++ b/docs/en/user_guides/prepare_datasets.md @@ -158,7 +158,7 @@ The heatmap target will be visualized together if it is generated in the pipelin ## Download dataset via MIM -By using [OpenDataLab](https://opendatalab.com/), you can obtain free formatted datasets in various fields. Through the search function of the platform, you may address the dataset they look for quickly and easily. Using the formatted datasets from the platform, you can efficiently conduct tasks across datasets. +By using [OpenXLab](https://openxlab.org.cn/datasets), you can obtain free formatted datasets in various fields. Through the search function of the platform, you may address the dataset they look for quickly and easily. Using the formatted datasets from the platform, you can efficiently conduct tasks across datasets. If you use MIM to download, make sure that the version is greater than v0.3.8. You can use the following command to update, install, login and download the dataset: @@ -166,10 +166,10 @@ If you use MIM to download, make sure that the version is greater than v0.3.8. Y # upgrade your MIM pip install -U openmim -# install OpenDataLab CLI tools -pip install -U opendatalab -# log in OpenDataLab, registry -odl login +# install OpenXLab CLI tools +pip install -U openxlab +# log in OpenXLab +openxlab login # download coco2017 and preprocess by MIM mim download mmpose --dataset coco2017 diff --git a/docs/en/user_guides/train_and_test.md b/docs/en/user_guides/train_and_test.md index 6bcc88fc3b..8b40ff9f57 100644 --- a/docs/en/user_guides/train_and_test.md +++ b/docs/en/user_guides/train_and_test.md @@ -14,7 +14,6 @@ python tools/train.py ${CONFIG_FILE} [ARGS] ```{note} By default, MMPose prefers GPU to CPU. If you want to train a model on CPU, please empty `CUDA_VISIBLE_DEVICES` or set it to -1 to make GPU invisible to the program. - ``` ```shell @@ -214,6 +213,31 @@ python ./tools/train.py \ - `randomness.deterministic=True`, set the deterministic option for `cuDNN` backend, i.e., set `torch.backends.cudnn.deterministic` to `True` and `torch.backends.cudnn.benchmark` to `False`. Defaults to `False`. See [Pytorch Randomness](https://pytorch.org/docs/stable/notes/randomness.html) for more details. +## Training Log + +During training, the training log will be printed in the console as follows: + +```shell +07/14 08:26:50 - mmengine - INFO - Epoch(train) [38][ 6/38] base_lr: 5.148343e-04 lr: 5.148343e-04 eta: 0:15:34 time: 0.540754 data_time: 0.394292 memory: 3141 loss: 0.006220 loss_kpt: 0.006220 acc_pose: 1.000000 +``` + +The training log contains the following information: + +- `07/14 08:26:50`: The current time. +- `mmengine`: The name of the program. +- `INFO` or `WARNING`: The log level. +- `Epoch(train)`: The current training stage. `train` means the training stage, `val` means the validation stage. +- `[38][ 6/38]`: The current epoch and the current iteration. +- `base_lr`: The base learning rate. +- `lr`: The current (real) learning rate. +- `eta`: The estimated time of arrival. +- `time`: The elapsed time (minutes) of the current iteration. +- `data_time`: The elapsed time (minutes) of data processing (i/o and transforms). +- `memory`: The GPU memory (MB) allocated by the program. +- `loss`: The total loss value of the current iteration. +- `loss_kpt`: The loss value you passed in head module. +- `acc_pose`: The accuracy value you passed in head module. + ## Visualize training process Monitoring the training process is essential for understanding the performance of your model and making necessary adjustments. In this section, we will introduce two methods to visualize the training process of your MMPose model: TensorBoard and the MMEngine Visualizer. @@ -261,7 +285,6 @@ python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [ARGS] ```{note} By default, MMPose prefers GPU to CPU. If you want to test a model on CPU, please empty `CUDA_VISIBLE_DEVICES` or set it to -1 to make GPU invisible to the program. - ``` ```shell @@ -367,3 +390,121 @@ Here are the environment variables that can be used to configure the slurm job. | `GPUS_PER_NODE` | The number of GPUs to be allocated per node. Defaults to 8. | | `CPUS_PER_TASK` | The number of CPUs to be allocated per task (Usually one GPU corresponds to one task). Defaults to 5. | | `SRUN_ARGS` | The other arguments of `srun`. Available options can be found [here](https://slurm.schedmd.com/srun.html). | + +## Custom Testing Features + +### Test with Custom Metrics + +If you're looking to assess models using unique metrics not already supported by MMPose, you'll need to code these metrics yourself and include them in your config file. For guidance on how to accomplish this, check out our [customized evaluation guide](https://mmpose.readthedocs.io/en/latest/advanced_guides/customize_evaluation.html). + +### Evaluating Across Multiple Datasets + +MMPose offers a handy tool known as `MultiDatasetEvaluator` for streamlined assessment across multiple datasets. Setting up this evaluator in your config file is a breeze. Below is a quick example demonstrating how to evaluate a model using both the COCO and AIC datasets: + +```python +# Set up validation datasets +coco_val = dict(type='CocoDataset', ...) +aic_val = dict(type='AicDataset', ...) +val_dataset = dict( + type='CombinedDataset', + datasets=[coco_val, aic_val], + pipeline=val_pipeline, + ...) + +# configurate the evaluator +val_evaluator = dict( + type='MultiDatasetEvaluator', + metrics=[ # metrics for each dataset + dict(type='CocoMetric', + ann_file='data/coco/annotations/person_keypoints_val2017.json'), + dict(type='CocoMetric', + ann_file='data/aic/annotations/aic_val.json', + use_area=False, + prefix='aic') + ], + # the number and order of datasets must align with metrics + datasets=[coco_val, aic_val], + ) +``` + +Keep in mind that different datasets, like COCO and AIC, have various keypoint definitions. Yet, the model's output keypoints are standardized. This results in a discrepancy between the model outputs and the actual ground truth. To address this, you can employ `KeypointConverter` to align the keypoint configurations between different datasets. Here’s a full example that shows how to leverage `KeypointConverter` to align AIC keypoints with COCO keypoints: + +```python +aic_to_coco_converter = dict( + type='KeypointConverter', + num_keypoints=17, + mapping=[ + (0, 6), + (1, 8), + (2, 10), + (3, 5), + (4, 7), + (5, 9), + (6, 12), + (7, 14), + (8, 16), + (9, 11), + (10, 13), + (11, 15), + ]) + +# val datasets +coco_val = dict( + type='CocoDataset', + data_root='data/coco/', + data_mode='topdown', + ann_file='annotations/person_keypoints_val2017.json', + bbox_file='data/coco/person_detection_results/' + 'COCO_val2017_detections_AP_H_56_person.json', + data_prefix=dict(img='val2017/'), + test_mode=True, + pipeline=[], +) + +aic_val = dict( + type='AicDataset', + data_root='data/aic/', + data_mode=data_mode, + ann_file='annotations/aic_val.json', + data_prefix=dict(img='ai_challenger_keypoint_validation_20170911/' + 'keypoint_validation_images_20170911/'), + test_mode=True, + pipeline=[], + ) + +val_dataset = dict( + type='CombinedDataset', + metainfo=dict(from_file='configs/_base_/datasets/coco.py'), + datasets=[coco_val, aic_val], + pipeline=val_pipeline, + test_mode=True, + ) + +val_dataloader = dict( + batch_size=32, + num_workers=2, + persistent_workers=True, + drop_last=False, + sampler=dict(type='DefaultSampler', shuffle=False, round_up=False), + dataset=val_dataset) + +test_dataloader = val_dataloader + +val_evaluator = dict( + type='MultiDatasetEvaluator', + metrics=[ + dict(type='CocoMetric', + ann_file=data_root + 'annotations/person_keypoints_val2017.json'), + dict(type='CocoMetric', + ann_file='data/aic/annotations/aic_val.json', + use_area=False, + gt_converter=aic_to_coco_converter, + prefix='aic') + ], + datasets=val_dataset['datasets'], + ) + +test_evaluator = val_evaluator +``` + +For further clarification on converting AIC keypoints to COCO keypoints, please consult [this guide](https://mmpose.readthedocs.io/en/latest/user_guides/mixed_datasets.html#merge-aic-into-coco). diff --git a/docs/src/papers/algorithms/dwpose.md b/docs/src/papers/algorithms/dwpose.md new file mode 100644 index 0000000000..4fd23effdc --- /dev/null +++ b/docs/src/papers/algorithms/dwpose.md @@ -0,0 +1,30 @@ +# Effective Whole-body Pose Estimation with Two-stages Distillation + + + +`__.
+
+ CrowdPose keypoints::
+
+ 0: 'left_shoulder',
+ 1: 'right_shoulder',
+ 2: 'left_elbow',
+ 3: 'right_elbow',
+ 4: 'left_wrist',
+ 5: 'right_wrist',
+ 6: 'left_hip',
+ 7: 'right_hip',
+ 8: 'left_knee',
+ 9: 'right_knee',
+ 10: 'left_ankle',
+ 11: 'right_ankle',
+ 12: 'top_head',
+ 13: 'neck'
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
- def __init__(self,
- ## 内容省略
- headbox_file: Optional[str] = None,
- ## 内容省略):
-
- if headbox_file:
- if data_mode != 'topdown':
- raise ValueError(
- f'{self.__class__.__name__} is set to {data_mode}: '
- 'mode, while "headbox_file" is only '
- 'supported in topdown mode.')
-
- if not test_mode:
- raise ValueError(
- f'{self.__class__.__name__} has `test_mode==False` '
- 'while "headbox_file" is only '
- 'supported when `test_mode==True`.')
-
- headbox_file_type = headbox_file[-3:]
- allow_headbox_file_type = ['mat']
- if headbox_file_type not in allow_headbox_file_type:
- raise KeyError(
- f'The head boxes file type {headbox_file_type} is not '
- f'supported. Should be `mat` but got {headbox_file_type}.')
- self.headbox_file = headbox_file
-
- super().__init__(
- ## 内容省略
- )
-
- def _load_annotations(self) -> List[dict]:
- """Load data from annotations in MPII format."""
- check_file_exist(self.ann_file)
- with open(self.ann_file) as anno_file:
- anns = json.load(anno_file)
-
- if self.headbox_file:
- check_file_exist(self.headbox_file)
- headbox_dict = loadmat(self.headbox_file)
- headboxes_src = np.transpose(headbox_dict['headboxes_src'],
- [2, 0, 1])
- SC_BIAS = 0.6
-
- data_list = []
- ann_id = 0
-
- # mpii bbox scales are normalized with factor 200.
- pixel_std = 200.
-
- for idx, ann in enumerate(anns):
- center = np.array(ann['center'], dtype=np.float32)
- scale = np.array([ann['scale'], ann['scale']],
- dtype=np.float32) * pixel_std
-
- # Adjust center/scale slightly to avoid cropping limbs
- if center[0] != -1:
- center[1] = center[1] + 15. / pixel_std * scale[1]
-
- # MPII uses matlab format, index is 1-based,
- # we should first convert to 0-based index
- center = center - 1
-
- # unify shape with coco datasets
- center = center.reshape(1, -1)
- scale = scale.reshape(1, -1)
- bbox = bbox_cs2xyxy(center, scale)
-
- # load keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
- keypoints = np.array(ann['joints']).reshape(1, -1, 2)
- keypoints_visible = np.array(ann['joints_vis']).reshape(1, -1)
-
- data_info = {
- 'id': ann_id,
- 'img_id': int(ann['image'].split('.')[0]),
- 'img_path': osp.join(self.data_prefix['img'], ann['image']),
- 'bbox_center': center,
- 'bbox_scale': scale,
- 'bbox': bbox,
- 'bbox_score': np.ones(1, dtype=np.float32),
- 'keypoints': keypoints,
- 'keypoints_visible': keypoints_visible,
- }
-
- if self.headbox_file:
- # calculate the diagonal length of head box as norm_factor
- headbox = headboxes_src[idx]
- head_size = np.linalg.norm(headbox[1] - headbox[0], axis=0)
- head_size *= SC_BIAS
- data_info['head_size'] = head_size.reshape(1, -1)
-
- data_list.append(data_info)
- ann_id = ann_id + 1
-
- return data_list
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/crowdpose.py')
```
-在对MPII数据集进行支持时,由于MPII需要读入 `head_size` 信息来计算 `PCKh`,因此我们在`__init__()`中增加了 `headbox_file`,并重载了 `_load_annotations()` 来完成数据组织。
+对于使用 COCO 格式标注的数据集,只需要继承 [BaseCocoStyleDataset](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/datasets/base/base_coco_style_dataset.py) 并指定 `METAINFO`,就可以十分轻松地集成到 MMPose 中参与训练。
+
+````
+
-如果自定义数据集无法被 `BaseCocoStyleDataset` 支持,你需要直接继承 [MMEngine](https://github.com/open-mmlab/mmengine) 中提供的 `BaseDataset` 基类。具体方法请参考相关[文档](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/basedataset.html)。
+#### 3D 数据集
+我们提供了基类 [BaseMocapStyleDataset](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/datasets/base/base_mocap_dataset.py)。我们推荐用户继承该基类,并按需重写它的方法(通常是 `__init__()` 和 `_load_annotations()` 方法),以扩展到新的 2D 关键点数据集。
### 数据流水线
@@ -286,7 +342,7 @@ test_pipeline = [
dict(type='TopdownAffine', input_size=codec['input_size']),
dict(type='PackPoseInputs')
]
-```
+````
在关键点检测任务中,数据一般会在三个尺度空间中变换:
@@ -298,55 +354,52 @@ test_pipeline = [
数据在三个空间中变换的流程如图所示:
-
+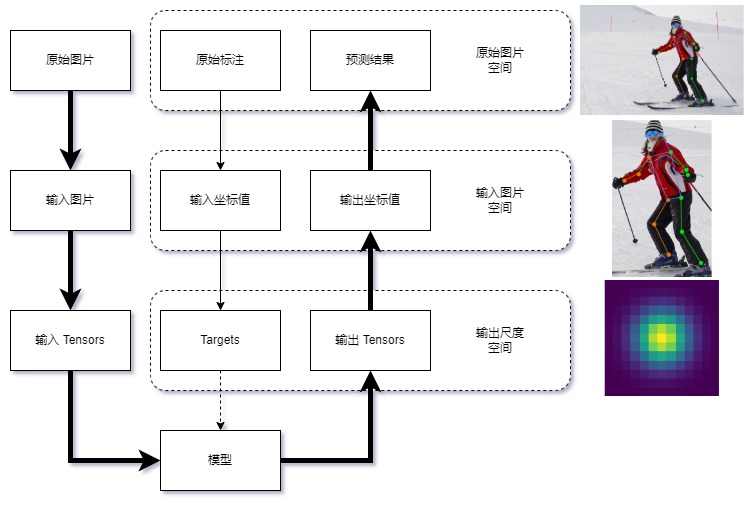
-在MMPose中,数据变换所需要的模块在`$MMPOSE/mmpose/datasets/transforms`目录下,它们的工作流程如图所示:
+在MMPose中,数据变换所需要的模块在 [$MMPOSE/mmpose/datasets/transforms](https://github.com/open-mmlab/mmpose/tree/main/mmpose/datasets/transforms) 目录下,它们的工作流程如图所示:

#### i. 数据增强
-数据增强中常用的变换存放在 `$MMPOSE/mmpose/datasets/transforms/common_transforms.py` 中,如 `RandomFlip`、`RandomHalfBody` 等。
+数据增强中常用的变换存放在 [$MMPOSE/mmpose/datasets/transforms/common_transforms.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/transforms/common_transforms.py) 中,如 [RandomFlip](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/common_transforms.py#L94)、[RandomHalfBody](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/common_transforms.py#L263) 等。对于 top-down 方法,`Shift`、`Rotate`、`Resize` 操作由 [RandomBBoxTransform](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/common_transforms.py#L433) 来实现;对于 bottom-up 方法,这些则是由 [BottomupRandomAffine](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/bottomup_transforms.py#L134) 实现。
-对于 top-down 方法,`Shift`、`Rotate`、`Resize` 操作由 `RandomBBoxTransform`来实现;对于 bottom-up 方法,这些则是由 `BottomupRandomAffine` 实现。
+3D 姿态数据的变换存放在 [$MMPOSE/mmpose/datasets/transforms/pose3d_transforms.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/transforms/pose3d_transforms.py) 中。
```{note}
-值得注意的是,大部分数据变换都依赖于 `bbox_center` 和 `bbox_scale`,它们可以通过 `GetBBoxCenterScale` 来得到。
+值得注意的是,大部分数据变换都依赖于 `bbox_center` 和 `bbox_scale`,它们可以通过 [GetBBoxCenterScale](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/common_transforms.py#L31) 来得到。
```
#### ii. 数据变换
-我们使用仿射变换,将图像和坐标标注从原始图片空间变换到输入图片空间。这一操作在 top-down 方法中由 `TopdownAffine` 完成,在 bottom-up 方法中则由 `BottomupRandomAffine` 完成。
+对于二维图片输入,我们使用仿射变换,将图像和坐标标注从原始图片空间变换到输入图片空间。这一操作在 top-down 方法中由 [TopdownAffine](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/topdown_transforms.py#L14) 完成,在 bottom-up 方法中则由 [BottomupRandomAffine](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/bottomup_transforms.py#L134) 完成。
+
+对于 3D 姿态提升任务,变换被合并进[数据编码](./guide_to_framework.md#iii-数据编码)。
#### iii. 数据编码
-在模型训练时,数据从原始空间变换到输入图片空间后,需要使用 `GenerateTarget` 来生成训练所需的监督目标(比如用坐标值生成高斯热图),我们将这一过程称为编码(Encode),反之,通过高斯热图得到对应坐标值的过程称为解码(Decode)。
+在模型训练时,数据从原始空间变换到输入图片空间后,需要使用 [GenerateTarget](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/common_transforms.py#L873) 来生成训练所需的监督目标(比如用坐标值生成高斯热图),我们将这一过程称为编码(Encode),反之,通过高斯热图得到对应坐标值的过程称为解码(Decode)。
在 MMPose 中,我们将编码和解码过程集合成一个编解码器(Codec),在其中实现 `encode()` 和 `decode()`。
目前 MMPose 支持生成以下类型的监督目标:
- `heatmap`: 高斯热图
-
- `keypoint_label`: 关键点标签(如归一化的坐标值)
-
- `keypoint_xy_label`: 单个坐标轴关键点标签
-
- `heatmap+keypoint_label`: 同时生成高斯热图和关键点标签
-
- `multiscale_heatmap`: 多尺度高斯热图
+- `lifting_target_label`: 3D 提升目标的关键点标签
生成的监督目标会按以下关键字进行封装:
- `heatmaps`:高斯热图
-
- `keypoint_labels`:关键点标签(如归一化的坐标值)
-
- `keypoint_x_labels`:x 轴关键点标签
-
- `keypoint_y_labels`:y 轴关键点标签
-
- `keypoint_weights`:关键点权重
+- `lifting_target_label`: 3D 提升目标的关键点标签
+- `lifting_target_weight`: 3D 提升目标的关键点权重
```Python
@TRANSFORMS.register_module()
@@ -362,23 +415,23 @@ class GenerateTarget(BaseTransform):
"""
```
-值得注意的是,我们对 top-down 和 bottom-up 的数据格式进行了统一,这意味着标注信息中会新增一个维度来代表同一张图里的不同目标(如人),格式为:
+值得注意的是,我们对 top-down,pose-lifting 和 bottom-up 的数据格式进行了统一,这意味着标注信息中会新增一个维度来代表同一张图里的不同目标(如人),格式为:
```Python
[batch_size, num_instances, num_keypoints, dim_coordinates]
```
-- top-down:`[B, 1, K, D]`
+- top-down 和 pose-lifting:`[B, 1, K, D]`
-- Bottom-up: `[B, N, K, D]`
+- bottom-up: `[B, N, K, D]`
-当前已经支持的编解码器定义在 `$MMPOSE/mmpose/codecs` 目录下,如果你需要自定新的编解码器,可以前往[编解码器](./user_guides/codecs.md)了解更多详情。
+当前已经支持的编解码器定义在 [$MMPOSE/mmpose/codecs](https://github.com/open-mmlab/mmpose/tree/main/mmpose/codecs) 目录下,如果你需要自定新的编解码器,可以前往[编解码器](./user_guides/codecs.md)了解更多详情。
#### iv. 数据打包
-数据经过前处理变换后,最终需要通过 `PackPoseInputs` 打包成数据样本。该操作定义在 `$MMPOSE/mmpose/datasets/transforms/formatting.py` 中。
+数据经过前处理变换后,最终需要通过 [PackPoseInputs](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/transforms/formatting.py) 打包成数据样本。
-打包过程会将数据流水线中用字典 `results` 存储的数据转换成用 MMPose 所需的标准数据结构, 如 `InstanceData`,`PixelData`,`PoseDataSample` 等。
+打包过程会将数据流水线中用字典 `results` 存储的数据转换成用 MMPose 所需的标准数据结构, 如 `InstanceData`,`PixelData`,[PoseDataSample](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/structures/pose_data_sample.py) 等。
具体而言,我们将数据样本内容分为 `gt`(标注真值) 和 `pred`(模型预测)两部分,它们都包含以下数据项:
@@ -388,7 +441,7 @@ class GenerateTarget(BaseTransform):
- **fields**(torch.tensor):像素级别的训练标签(如高斯热图)或预测结果,属于输出尺度空间
-下面是 `PoseDataSample` 底层实现的例子:
+下面是 [PoseDataSample](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/structures/pose_data_sample.py) 底层实现的例子:
```Python
def get_pose_data_sample(self):
@@ -443,7 +496,7 @@ def get_pose_data_sample(self):
- **预测头(Head)**:用于实现核心算法功能和损失函数定义
-我们在 `$MMPOSE/models/pose_estimators/base.py` 下为姿态估计模型定义了一个基类 `BasePoseEstimator`,所有的模型(如 `TopdownPoseEstimator`)都需要继承这个基类,并重载对应的方法。
+我们在 [$MMPOSE/mmpose/models/pose_estimators/base.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/pose_estimators/base.py) 下为姿态估计模型定义了一个基类 [BasePoseEstimator](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/models/pose_estimators/base.py),所有的模型(如 [TopdownPoseEstimator](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/models/pose_estimators/topdown.py))都需要继承这个基类,并重载对应的方法。
在模型的 `forward()` 方法中提供了三种不同的模式:
@@ -495,7 +548,7 @@ data_preprocessor=dict(
### 主干网络(Backbone)
-MMPose 实现的主干网络存放在 `$MMPOSE/mmpose/models/backbones` 目录下。
+MMPose 实现的主干网络存放在 [$MMPOSE/mmpose/models/backbones](https://github.com/open-mmlab/mmpose/tree/main/mmpose/models/backbones) 目录下。
在实际开发中,开发者经常会使用预训练的网络权重进行迁移学习,这能有效提升模型在小数据集上的性能。 在 MMPose 中,只需要在配置文件 `backbone` 的 `init_cfg` 中设置:
@@ -531,10 +584,12 @@ init_cfg=dict(
class YourBackbone(BaseBackbone):
```
-同时在 `$MMPOSE/mmpose/models/backbones/__init__.py` 下进行 `import`,并加入到 `__all__` 中,才能被配置文件正确地调用。
+同时在 [$MMPOSE/mmpose/models/backbones/\_\_init\_\_.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/backbones/__init__.py) 下进行 `import`,并加入到 `__all__` 中,才能被配置文件正确地调用。
### 颈部模块(Neck)
+MMPose 中 Neck 相关的模块定义在 [$MMPOSE/mmpose/models/necks](https://github.com/open-mmlab/mmpose/tree/main/mmpose/models/necks) 目录下.
+
颈部模块通常是介于主干网络和预测头之间的模块,在部分模型算法中会用到,常见的颈部模块有:
- Global Average Pooling (GAP)
@@ -543,7 +598,7 @@ class YourBackbone(BaseBackbone):
- Feature Map Processor (FMP)
- `FeatureMapProcessor` 是一个通用的 PyTorch 模块,旨在通过选择、拼接和缩放等非参数变换将主干网络输出的特征图转换成适合预测头的格式。以下是一些操作的配置方式及效果示意图:
+ [FeatureMapProcessor](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/models/necks/fmap_proc_neck.py) 是一个通用的 PyTorch 模块,旨在通过选择、拼接和缩放等非参数变换将主干网络输出的特征图转换成适合预测头的格式。以下是一些操作的配置方式及效果示意图:
- 选择操作
@@ -575,7 +630,7 @@ class YourBackbone(BaseBackbone):
通常来说,预测头是模型算法实现的核心,用于控制模型的输出,并进行损失函数计算。
-MMPose 中 Head 相关的模块定义在 `$MMPOSE/mmpose/models/heads` 目录下,开发者在自定义预测头时需要继承我们提供的基类 `BaseHead`,并重载以下三个方法对应模型推理的三种模式:
+MMPose 中 Head 相关的模块定义在 [$MMPOSE/mmpose/models/heads](https://github.com/open-mmlab/mmpose/tree/main/mmpose/models/heads) 目录下,开发者在自定义预测头时需要继承我们提供的基类 [BaseHead](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/heads/base_head.py),并重载以下三个方法对应模型推理的三种模式:
- forward()
@@ -583,11 +638,11 @@ MMPose 中 Head 相关的模块定义在 `$MMPOSE/mmpose/models/heads` 目录下
- loss()
-具体而言,`predict()` 返回的应是输入图片尺度下的结果,因此需要调用 `self.decode()` 对网络输出进行解码,这一过程实现在 `BaseHead` 中已经实现,它会调用编解码器提供的 `decode()` 方法来完成解码。
+具体而言,`predict()` 返回的应是输入图片尺度下的结果,因此需要调用 `self.decode()` 对网络输出进行解码,这一过程实现在 [BaseHead](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/heads/base_head.py) 中已经实现,它会调用编解码器提供的 `decode()` 方法来完成解码。
另一方面,我们会在 `predict()` 中进行测试时增强。在进行预测时,一个常见的测试时增强技巧是进行翻转集成。即,将一张图片先进行一次推理,再将图片水平翻转进行一次推理,推理的结果再次水平翻转回去,对两次推理的结果进行平均。这个技巧能有效提升模型的预测稳定性。
-下面是在 `RegressionHead` 中定义 `predict()` 的例子:
+下面是在 [RegressionHead](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/heads/regression_heads/regression_head.py) 中定义 `predict()` 的例子:
```Python
def predict(self,
@@ -641,7 +696,7 @@ keypoint_weights = torch.cat([
])
```
-以下为 `RegressionHead` 中完整的 `loss()` 实现:
+以下为 [RegressionHead](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/heads/regression_heads/regression_head.py) 中完整的 `loss()` 实现:
```Python
def loss(self,
@@ -680,3 +735,11 @@ def loss(self,
return losses
```
+
+```{note}
+如果你想了解更多模型实现的内容,如:
+- 支持关键点可见性预测的头部
+- 2D-to-3D 模型实现
+
+请前往 [【进阶教程 - 实现新模型】](./advanced_guides/implement_new_models.md)
+```
diff --git a/docs/zh_cn/index.rst b/docs/zh_cn/index.rst
index 2431d82e4d..c51daaa053 100644
--- a/docs/zh_cn/index.rst
+++ b/docs/zh_cn/index.rst
@@ -24,6 +24,9 @@ You can change the documentation language at the lower-left corner of the page.
user_guides/configs.md
user_guides/prepare_datasets.md
user_guides/train_and_test.md
+ user_guides/how_to_deploy.md
+ user_guides/model_analysis.md
+ user_guides/dataset_tools.md
.. toctree::
:maxdepth: 1
@@ -34,10 +37,9 @@ You can change the documentation language at the lower-left corner of the page.
advanced_guides/implement_new_models.md
advanced_guides/customize_datasets.md
advanced_guides/customize_transforms.md
+ advanced_guides/customize_evaluation.md
advanced_guides/customize_optimizer.md
advanced_guides/customize_logging.md
- advanced_guides/how_to_deploy.md
- advanced_guides/model_analysis.md
.. toctree::
:maxdepth: 1
@@ -79,7 +81,6 @@ You can change the documentation language at the lower-left corner of the page.
dataset_zoo/2d_animal_keypoint.md
dataset_zoo/3d_body_keypoint.md
dataset_zoo/3d_hand_keypoint.md
- dataset_zoo/dataset_tools.md
.. toctree::
:maxdepth: 1
diff --git a/docs/zh_cn/installation.md b/docs/zh_cn/installation.md
index ef515c8030..9343bc2e99 100644
--- a/docs/zh_cn/installation.md
+++ b/docs/zh_cn/installation.md
@@ -66,6 +66,15 @@ mim install "mmcv>=2.0.1"
mim install "mmdet>=3.1.0"
```
+```{note}
+新旧版本 mmpose、mmdet、mmcv 的对应关系为:
+
+- mmdet 2.x <=> mmpose 0.x <=> mmcv 1.x
+- mmdet 3.x <=> mmpose 1.x <=> mmcv 2.x
+
+如果遇到版本不兼容的问题,请使用 `pip list | grep mm` 检查对应关系后,升级或降级相关依赖。注意,`mmcv-full` 只对应旧版本 `mmcv 1.x`,所以请先卸载它后,再通过 `mim install mmcv` 来安装 `mmcv 2.x`。
+```
+
## 最佳实践
根据具体需求,我们支持两种安装模式: 从源码安装(推荐)和作为 Python 包安装
@@ -101,7 +110,7 @@ mim install "mmpose>=1.1.0"
mim download mmpose --config td-hm_hrnet-w48_8xb32-210e_coco-256x192 --dest .
```
-下载过程往往需要几秒或更多的时间,这取决于您的网络环境。完成之后,您会在当前目录下找到这两个文件:`td-hm_hrnet-w48_8xb32-210e_coco-256x192.py` 和 `hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth`, 分别是配置文件和对应的模型权重文件。
+下载过程往往需要几秒或更多的时间,这取决于您的网络环境。完成之后,您会在当前目录下找到这两个文件:`td-hm_hrnet-w48_8xb32-210e_coco-256x192.py` 和 `td-hm_hrnet-w48_8xb32-210e_coco-256x192-0e67c616_20220913.pth`, 分别是配置文件和对应的模型权重文件。
**第 2 步** 验证推理示例
@@ -111,7 +120,7 @@ mim download mmpose --config td-hm_hrnet-w48_8xb32-210e_coco-256x192 --dest .
python demo/image_demo.py \
tests/data/coco/000000000785.jpg \
td-hm_hrnet-w48_8xb32-210e_coco-256x192.py \
- hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \
+ td-hm_hrnet-w48_8xb32-210e_coco-256x192-0e67c616_20220913.pth \
--out-file vis_results.jpg \
--draw-heatmap
```
@@ -131,7 +140,7 @@ from mmpose.utils import register_all_modules
register_all_modules()
config_file = 'td-hm_hrnet-w48_8xb32-210e_coco-256x192.py'
-checkpoint_file = 'hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth'
+checkpoint_file = 'td-hm_hrnet-w48_8xb32-210e_coco-256x192-0e67c616_20220913.pth'
model = init_model(config_file, checkpoint_file, device='cpu') # or device='cuda:0'
# 请准备好一张带有人体的图片
@@ -141,6 +150,15 @@ results = inference_topdown(model, 'demo.jpg')
示例图片 `demo.jpg` 可以从 [Github](https://raw.githubusercontent.com/open-mmlab/mmpose/main/tests/data/coco/000000000785.jpg) 下载。
推理结果是一个 `PoseDataSample` 列表,预测结果将会保存在 `pred_instances` 中,包括检测到的关键点位置和置信度。
+```{note}
+MMCV 版本与 PyTorch 版本需要严格对应,如果遇到如下问题:
+
+- No module named 'mmcv.ops'
+- No module named 'mmcv._ext'
+
+说明当前环境中的 PyTorch 版本与 CUDA 版本不匹配。你可以通过 `nvidia-smi` 查看 CUDA 版本,需要与 `pip list | grep torch` 中 PyTorch 的 `+cu1xx` 对应,否则,你需要先卸载 PyTorch 并重新安装,然后重新安装 MMCV(这里的安装顺序**不可以**交换)。
+```
+
## 自定义安装
### CUDA 版本
diff --git a/docs/zh_cn/migration.md b/docs/zh_cn/migration.md
index 9a591dfcc9..b30ed4d680 100644
--- a/docs/zh_cn/migration.md
+++ b/docs/zh_cn/migration.md
@@ -102,6 +102,10 @@ class GenerateTarget(BaseTransform):
旧版的数据归一化操作 `NormalizeTensor` 和 `ToTensor` 方法将由 **DataPreprocessor** 模块替代,不再作为流水线的一部分,而是作为模块加入到模型前向传播中。
+旧版用于 3D 人类姿态数据变换的方法 `GetRootCenteredPose`, `ImageCoordinateNormalization` 和 `NormalizeJointCoordinate` 等,将被合并入编码器,比如 [`ImagePoseLifting`](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/image_pose_lifting.py#L11) 和 [`VideoPoseLifting`](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/video_pose_lifting.py#L13) 等。
+
+数据转换和重构操作 `PoseSequenceToTensor` 将在相应的编解码器和 [`PackPoseInputs`](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/transforms/formatting.py) 中实现。
+
## 模型兼容
我们对 model zoo 提供的模型权重进行了兼容性处理,确保相同的模型权重测试精度能够与 0.x 版本保持同等水平,但由于在这两个版本中存在大量处理细节的差异,推理结果可能会产生轻微的不同(精度误差小于 0.05%)。
diff --git a/docs/zh_cn/notes/changelog.md b/docs/zh_cn/notes/changelog.md
index 68beeeb069..bd89688bc0 100644
--- a/docs/zh_cn/notes/changelog.md
+++ b/docs/zh_cn/notes/changelog.md
@@ -1,5 +1,17 @@
# Changelog
+## **v1.2.0 (12/10/2023)**
+
+Release note: https://github.com/open-mmlab/mmpose/releases/tag/v1.2.0
+
+## **v1.1.0 (04/07/2023)**
+
+Release note: https://github.com/open-mmlab/mmpose/releases/tag/v1.1.0
+
+## **v1.0.0 (06/04/2023)**
+
+Release note: https://github.com/open-mmlab/mmpose/releases/tag/v1.0.0
+
## **v1.0.0rc1 (14/10/2022)**
**Highlights**
diff --git a/docs/zh_cn/overview.md b/docs/zh_cn/overview.md
index a790cd3be2..7c8071d888 100644
--- a/docs/zh_cn/overview.md
+++ b/docs/zh_cn/overview.md
@@ -11,30 +11,20 @@ MMPose 是一款基于 Pytorch 的姿态估计开源工具箱,是 OpenMMLab
MMPose 由 **8** 个主要部分组成,apis、structures、datasets、codecs、models、engine、evaluation 和 visualization。
- **apis** 提供用于模型推理的高级 API
-
- **structures** 提供 bbox、keypoint 和 PoseDataSample 等数据结构
-
- **datasets** 支持用于姿态估计的各种数据集
-
- **transforms** 包含各种数据增强变换
-
- **codecs** 提供姿态编解码器:编码器用于将姿态信息(通常为关键点坐标)编码为模型学习目标(如热力图),解码器则用于将模型输出解码为姿态估计结果
-
- **models** 以模块化结构提供了姿态估计模型的各类组件
-
- **pose_estimators** 定义了所有姿态估计模型类
- **data_preprocessors** 用于预处理模型的输入数据
- **backbones** 包含各种骨干网络
- **necks** 包含各种模型颈部组件
- **heads** 包含各种模型头部
- **losses** 包含各种损失函数
-
- **engine** 包含与姿态估计任务相关的运行时组件
-
- **hooks** 提供运行时的各种钩子
-
- **evaluation** 提供各种评估模型性能的指标
-
- **visualization** 用于可视化关键点骨架和热力图等信息
## 如何使用本指南
@@ -53,6 +43,9 @@ MMPose 由 **8** 个主要部分组成,apis、structures、datasets、codecs
- [配置文件](./user_guides/configs.md)
- [准备数据集](./user_guides/prepare_datasets.md)
- [训练与测试](./user_guides/train_and_test.md)
+ - [模型部署](./user_guides/how_to_deploy.md)
+ - [模型分析工具](./user_guides/model_analysis.md)
+ - [数据集标注与预处理脚本](./user_guides/dataset_tools.md)
3. 对于希望基于 MMPose 进行开发的研究者和开发者:
@@ -63,8 +56,6 @@ MMPose 由 **8** 个主要部分组成,apis、structures、datasets、codecs
- [自定义数据变换](./advanced_guides/customize_transforms.md)
- [自定义优化器](./advanced_guides/customize_optimizer.md)
- [自定义日志](./advanced_guides/customize_logging.md)
- - [模型部署](./advanced_guides/how_to_deploy.md)
- - [模型分析工具](./advanced_guides/model_analysis.md)
- [迁移指南](./migration.md)
4. 对于希望加入开源社区,向 MMPose 贡献代码的研究者和开发者:
diff --git a/docs/zh_cn/user_guides/advanced_training.md b/docs/zh_cn/user_guides/advanced_training.md
deleted file mode 100644
index dd02a7661f..0000000000
--- a/docs/zh_cn/user_guides/advanced_training.md
+++ /dev/null
@@ -1,104 +0,0 @@
-# 高级训练设置
-
-## 恢复训练
-
-恢复训练是指从之前某次训练保存下来的状态开始继续训练,这里的状态包括模型的权重、优化器和优化器参数调整策略的状态。
-
-### 自动恢复训练
-
-用户可以在训练命令最后加上 `--resume` 恢复训练,程序会自动从 `work_dirs` 中加载最新的权重文件恢复训练。如果 `work_dir` 中有最新的 `checkpoint`(例如该训练在上一次训练时被中断),则会从该 `checkpoint` 恢复训练,否则(例如上一次训练还没来得及保存 `checkpoint` 或者启动了新的训练任务)会重新开始训练。
-
-下面是一个恢复训练的示例:
-
-```shell
-python tools/train.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192.py --resume
-```
-
-### 指定 Checkpoint 恢复训练
-
-你也可以对 `--resume` 指定 `checkpoint` 路径,MMPose 会自动读取该 `checkpoint` 并从中恢复训练,命令如下:
-
-```shell
-python tools/train.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192.py \
- --resume work_dirs/td-hm_res50_8xb64-210e_coco-256x192/latest.pth
-```
-
-如果你希望手动在配置文件中指定 `checkpoint` 路径,除了设置 `resume=True`,还需要设置 `load_from` 参数。需要注意的是,如果只设置了 `load_from` 而没有设置 `resume=True`,则只会加载 `checkpoint` 中的权重并重新开始训练,而不是接着之前的状态继续训练。
-
-下面的例子与上面指定 `--resume` 参数的例子等价:
-
-```python
-resume = True
-load_from = 'work_dirs/td-hm_res50_8xb64-210e_coco-256x192/latest.pth'
-# model settings
-model = dict(
- ## 内容省略 ##
- )
-```
-
-## 自动混合精度(AMP)训练
-
-混合精度训练在不改变模型、不降低模型训练精度的前提下,可以缩短训练时间,降低存储需求,因而能支持更大的 batch size、更大模型和尺寸更大的输入的训练。
-
-如果要开启自动混合精度(AMP)训练,在训练命令最后加上 --amp 即可, 命令如下:
-
-```shell
-python tools/train.py ${CONFIG_FILE} --amp
-```
-
-具体例子如下:
-
-```shell
-python tools/train.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192.py --amp
-```
-
-## 设置随机种子
-
-如果想要在训练时指定随机种子,可以使用以下命令:
-
-```shell
-python ./tools/train.py \
- ${CONFIG} \ # 配置文件路径
- --cfg-options randomness.seed=2023 \ # 设置随机种子为 2023
- [randomness.diff_rank_seed=True] \ # 根据 rank 来设置不同的种子。
- [randomness.deterministic=True] # 把 cuDNN 后端确定性选项设置为 True
-# [] 代表可选参数,实际输入命令行时,不用输入 []
-```
-
-randomness 有三个参数可设置,具体含义如下:
-
-- `randomness.seed=2023` ,设置随机种子为 `2023`。
-
-- `randomness.diff_rank_seed=True`,根据 `rank` 来设置不同的种子,`diff_rank_seed` 默认为 `False`。
-
-- `randomness.deterministic=True`,把 `cuDNN` 后端确定性选项设置为 `True`,即把 `torch.backends.cudnn.deterministic` 设为 `True`,把 `torch.backends.cudnn.benchmark` 设为 `False`。`deterministic` 默认为 `False`。更多细节见 [Pytorch Randomness](https://pytorch.org/docs/stable/notes/randomness.html)。
-
-如果你希望手动在配置文件中指定随机种子,可以在配置文件中设置 `random_seed` 参数,具体如下:
-
-```python
-randomness = dict(seed=2023)
-# model settings
-model = dict(
- ## 内容省略 ##
- )
-```
-
-## 使用 Tensorboard 可视化训练过程
-
-安装 Tensorboard 环境
-
-```shell
-pip install tensorboard
-```
-
-在 config 文件中添加 tensorboard 配置
-
-```python
-visualizer = dict(vis_backends=[dict(type='LocalVisBackend'),dict(type='TensorboardVisBackend')])
-```
-
-运行训练命令后,tensorboard 文件会生成在可视化文件夹 `work_dir/${CONFIG}/${TIMESTAMP}/vis_data` 下,运行下面的命令就可以在网页链接使用 tensorboard 查看 loss、学习率和精度等信息。
-
-```shell
-tensorboard --logdir work_dir/${CONFIG}/${TIMESTAMP}/vis_data
-```
diff --git a/docs/zh_cn/user_guides/configs.md b/docs/zh_cn/user_guides/configs.md
index 0bcb7aa1a8..f2bc4b28d9 100644
--- a/docs/zh_cn/user_guides/configs.md
+++ b/docs/zh_cn/user_guides/configs.md
@@ -1,7 +1,26 @@
-# 配置文件
+# 如何看懂配置文件
MMPose 使用 Python 文件作为配置文件,将模块化设计和继承设计结合到配置系统中,便于进行各种实验。
+## 目录结构
+
+MMPose 的配置文件目录结构如下:
+
+```shell
+configs
+|----_base_
+ |----datasets
+ |----default_runtime.py
+|----animal_2d_keypoint
+|----body_2d_keypoint
+|----body_3d_keypoint
+|----face_2d_keypoint
+|----fashion_2d_keypoint
+|----hand_2d_keypoint
+|----hand_3d_keypoint
+|----wholebody_2d_keypoint
+```
+
## 简介
MMPose 拥有一套强大的配置系统,在注册器的配合下,用户可以通过一个配置文件来定义整个项目需要用到的所有内容,以 Python 字典形式组织配置信息,传递给注册器完成对应模块的实例化。
@@ -119,42 +138,61 @@ python tools/analysis/print_config.py /PATH/TO/CONFIG
# 通用配置
default_scope = 'mmpose'
default_hooks = dict(
- timer=dict(type='IterTimerHook'), # 迭代时间统计,包括数据耗时和模型耗时
- logger=dict(type='LoggerHook', interval=50), # 日志打印间隔
- param_scheduler=dict(type='ParamSchedulerHook'), # 用于调度学习率更新
+ # 迭代时间统计,包括数据耗时和模型耗时
+ timer=dict(type='IterTimerHook'),
+
+ # 日志打印间隔,默认每 50 iters 打印一次
+ logger=dict(type='LoggerHook', interval=50),
+
+ # 用于调度学习率更新的 Hook
+ param_scheduler=dict(type='ParamSchedulerHook'),
+
checkpoint=dict(
- type='CheckpointHook', interval=1, save_best='coco/AP', # ckpt保存间隔,最优ckpt参考指标
- rule='greater'), # 最优ckpt指标评价规则
- sampler_seed=dict(type='DistSamplerSeedHook')) # 分布式随机种子设置
+ # ckpt 保存间隔,最优 ckpt 参考指标。
+ # 例如:
+ # save_best='coco/AP' 代表以 coco/AP 作为最优指标,对应 CocoMetric 评测器的 AP 指标
+ # save_best='PCK' 代表以 PCK 作为最优指标,对应 PCKAccuracy 评测器的 PCK 指标
+ # 更多指标请前往 mmpose/evaluation/metrics/
+ type='CheckpointHook', interval=1, save_best='coco/AP',
+
+ # 最优 ckpt 保留规则,greater 代表越大越好,less 代表越小越好
+ rule='greater'),
+
+ # 分布式随机种子设置 Hook
+ sampler_seed=dict(type='DistSamplerSeedHook'))
env_cfg = dict(
- cudnn_benchmark=False, # cudnn benchmark开关
- mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0), # opencv多线程配置
- dist_cfg=dict(backend='nccl')) # 分布式训练后端设置
-vis_backends = [dict(type='LocalVisBackend')] # 可视化器后端设置
-visualizer = dict( # 可视化器设置
+ # cudnn benchmark 开关,用于加速训练,但会增加显存占用
+ cudnn_benchmark=False,
+
+ # opencv 多线程配置,用于加速数据加载,但会增加显存占用
+ # 默认为 0,代表使用单线程
+ mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
+
+ # 分布式训练后端设置,支持 nccl 和 gloo
+ dist_cfg=dict(backend='nccl'))
+
+# 可视化器后端设置,默认为本地可视化
+vis_backends = [dict(type='LocalVisBackend')]
+
+# 可视化器设置
+visualizer = dict(
type='PoseLocalVisualizer',
vis_backends=[dict(type='LocalVisBackend')],
name='visualizer')
log_processor = dict( # 训练日志格式、间隔
type='LogProcessor', window_size=50, by_epoch=True, num_digits=6)
-log_level = 'INFO' # 日志记录等级
-```
-
-通用配置一般单独存放到`$MMPOSE/configs/_base_`目录下,通过如下方式进行继承:
-
-```Python
-_base_ = ['../../../_base_/default_runtime.py'] # 以运行时的config文件位置为相对路径起点
+# 日志记录等级,INFO 代表记录训练日志,WARNING 代表只记录警告信息,ERROR 代表只记录错误信息
+log_level = 'INFO'
```
```{note}
-CheckpointHook:
-
-- save_best: `'coco/AP'` 用于 `CocoMetric`, `'PCK'` 用于 `PCKAccuracy`
-- max_keep_ckpts: 最大保留ckpt数量,默认为-1,代表不限制
+可视化器后端设置支持 LocalVisBackend 和 TensorboardVisBackend,前者用于本地可视化,后者用于 Tensorboard 可视化,你可以根据需要进行选择。详情见 [训练与测试](./train_and_test.md) 的 【可视化训练进程】。
+```
-样例:
+通用配置一般单独存放到 `$MMPOSE/configs/_base_` 目录下,通过如下方式进行继承:
-`default_hooks = dict(checkpoint=dict(save_best='PCK', rule='greater', max_keep_ckpts=1))`
+```Python
+_base_ = ['../../../_base_/default_runtime.py'] # 以运行时的config文件位置为相对路径起点
```
### 数据配置
@@ -234,12 +272,10 @@ test_dataloader = val_dataloader # 默认情况下不区分验证集和测试集
```
```{note}
-
常用功能可以参考以下教程:
-- [恢复训练](../common_usages/resume_training.md)
-- [自动混合精度训练](../common_usages/amp_training.md)
-- [设置随机种子](../common_usages/set_random_seed.md)
-
+- [恢复训练](https://mmpose.readthedocs.io/zh_CN/dev-1.x/user_guides/train_and_test.html#id7)
+- [自动混合精度训练](https://mmpose.readthedocs.io/zh_CN/dev-1.x/user_guides/train_and_test.html#amp)
+- [设置随机种子](https://mmpose.readthedocs.io/zh_CN/dev-1.x/user_guides/train_and_test.html#id10)
```
### 训练配置
@@ -462,5 +498,5 @@ cfg.optimizer # ConfigDict(type='SGD', lr=0.01)
```
```{note}
-如果你希望更深入地了解配置系统的高级用法,可以查看 [MMEngine 教程](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/config.html)。
+如果你希望更深入地了解配置系统的高级用法,可以查看 [MMEngine 教程](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/config.html)。
```
diff --git a/docs/zh_cn/dataset_zoo/dataset_tools.md b/docs/zh_cn/user_guides/dataset_tools.md
similarity index 88%
rename from docs/zh_cn/dataset_zoo/dataset_tools.md
rename to docs/zh_cn/user_guides/dataset_tools.md
index a2e6d01d97..c83fdd2d56 100644
--- a/docs/zh_cn/dataset_zoo/dataset_tools.md
+++ b/docs/zh_cn/user_guides/dataset_tools.md
@@ -1,8 +1,32 @@
-# 数据集格式转换脚本
+# 数据集标注与格式转换
+
+本章提供了一些有用的数据集处理脚本,来满足 MMPose 的数据格式要求。
+
+## 数据集标注
+
+对于 [Label Studio](https://github.com/heartexlabs/label-studio/) 用户,请依照 [Label Studio 转换工具文档](./label_studio.md) 中的方法进行标注,并将结果导出为 Label Studio 标准的 `.json` 文件,将 `Labeling Interface` 中的 `Code` 保存为 `.xml` 文件。
+
+```{note}
+MMPose **没有**对用户使用的标注工具做任何限制,只要最终的标注结果符合 MMPose 的数据格式要求即可。我们非常欢迎社区用户贡献更多的数据集标注工具使用教程和转换脚本。
+```
+
+## 浏览数据集
+
+MMPose 提供了一个有用的数据集浏览工具,通过它用户可以可视化地查看数据集的原始标注,和数据增强后的标注。这对于用户检查数据集加载和数据增强是否正确非常有用。
+
+详细的使用方法请参考 [【浏览数据集】](https://mmpose.readthedocs.io/zh_CN/dev-1.x/user_guides/prepare_datasets.html#id5)。
+
+## 通过 MIM 下载开源数据集
+
+通过使用 [OpenXLab](https://openxlab.org.cn/datasets),您可以直接下载开源数据集。通过平台的搜索功能,您可以快速轻松地找到他们正在寻找的数据集。使用平台上的格式化数据集,您可以高效地跨数据集执行任务。
+
+我们推荐用户跟随 [MIM 数据集下载教程](https://mmpose.readthedocs.io/zh_CN/dev-1.x/user_guides/prepare_datasets.html#mim) 进行开源数据集的下载。
+
+## 格式转换脚本
MMPose 提供了一些工具来帮助用户处理数据集。
-## Animal Pose 数据集
+### Animal Pose 数据集
+
+ gt_instance_labels:
+
+ pred_instances:
+ )>
+]
+```
+
+用户可以通过 `.` 来访问 PoseDataSample 中的数据,例如:
+
+```python
+pred_instances = batch_results[0].pred_instances
+
+pred_instances.keypoints
+# array([[[365.83333333, 87.50000477],
+# [372.08333333, 79.16667175],
+# [361.66666667, 81.25000501],
+# [384.58333333, 85.41667151],
+# [357.5 , 85.41667151],
+# [407.5 , 112.50000381],
+# [363.75 , 125.00000334],
+# [438.75 , 150.00000238],
+# [347.08333333, 158.3333354 ],
+# [451.25 , 170.83333492],
+# [305.41666667, 177.08333468],
+# [432.5 , 214.58333325],
+# [401.25 , 218.74999976],
+# [430.41666667, 285.41666389],
+# [370. , 274.99999762],
+# [470. , 356.24999452],
+# [403.33333333, 343.74999499]]])
+```
+
+### 可视化
+
+在 MMPose 中,大部分可视化基于可视化器实现。可视化器是一个类,它接受数据样本并将其可视化。MMPose 提供了一个可视化器注册表,用户可以使用 `VISUALIZERS` 来实例化它。以下是一个使用可视化器可视化推理结果的示例:
+
+```python
+# 将推理结果打包
+results = merge_data_samples(batch_results)
+
+# 初始化可视化器
+visualizer = VISUALIZERS.build(model.cfg.visualizer)
+
+# 设置数据集元信息
+visualizer.set_dataset_meta(model.dataset_meta)
+
+img = imread(img_path, channel_order='rgb')
+
+# 可视化
+visualizer.add_datasample(
+ 'result',
+ img,
+ data_sample=results,
+ show=True)
+```
+
+MMPose 也提供了更简洁的可视化接口:
+
+```python
+from mmpose.apis import visualize
+
+pred_instances = batch_results[0].pred_instances
+
+keypoints = pred_instances.keypoints
+keypoint_scores = pred_instances.keypoint_scores
+
+metainfo = 'config/_base_/datasets/coco.py'
+
+visualize(
+ img_path,
+ keypoints,
+ keypoint_scores,
+ metainfo=metainfo,
+ show=True)
+```
diff --git a/docs/zh_cn/dataset_zoo/label_studio.md b/docs/zh_cn/user_guides/label_studio.md
similarity index 100%
rename from docs/zh_cn/dataset_zoo/label_studio.md
rename to docs/zh_cn/user_guides/label_studio.md
diff --git a/docs/zh_cn/user_guides/mixed_datasets.md b/docs/zh_cn/user_guides/mixed_datasets.md
index fac38e3338..6839da3b3d 100644
--- a/docs/zh_cn/user_guides/mixed_datasets.md
+++ b/docs/zh_cn/user_guides/mixed_datasets.md
@@ -1,10 +1,10 @@
# 混合数据集训练
-MMPose 提供了一个灵活、便捷的工具 `CombinedDataset` 来进行混合数据集训练。它作为一个封装器,可以包含多个子数据集,并将来自不同子数据集的数据转换成一个统一的格式,以用于模型训练。使用 `CombinedDataset` 的数据处理流程如下图所示。
+MMPose 提供了一个灵活、便捷的工具 [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) 来进行混合数据集训练。它作为一个封装器,可以包含多个子数据集,并将来自不同子数据集的数据转换成一个统一的格式,以用于模型训练。使用 [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) 的数据处理流程如下图所示。

-本篇教程的后续部分将通过一个结合 COCO 和 AI Challenger (AIC) 数据集的例子详细介绍如何配置 `CombinedDataset`。
+本篇教程的后续部分将通过一个结合 COCO 和 AI Challenger (AIC) 数据集的例子详细介绍如何配置 [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15)。
## COCO & AIC 数据集混合案例
@@ -39,7 +39,7 @@ dataset_coco = dict(
)
```
-对于 AIC 数据集,需要转换关键点的顺序。MMPose 提供了一个 `KeypointConverter` 转换器来实现这一点。以下是配置 AIC 子数据集的示例:
+对于 AIC 数据集,需要转换关键点的顺序。MMPose 提供了一个 [KeypointConverter](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/converting.py#L11) 转换器来实现这一点。以下是配置 AIC 子数据集的示例:
```python
dataset_aic = dict(
@@ -70,9 +70,9 @@ dataset_aic = dict(
)
```
-`KeypointConverter` 会将原序号在 0 到 11 之间的关键点的序号转换为在 5 到 16 之间的对应序号。同时,在 AIC 中序号为为 12 和 13 的关键点将被删除。另外,目标序号在 0 到 4 之间的关键点在 `mapping` 参数中没有定义,这些点将被设为不可见,并且不会在训练中使用。
+[KeypointConverter](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/converting.py#L11) 会将原序号在 0 到 11 之间的关键点的序号转换为在 5 到 16 之间的对应序号。同时,在 AIC 中序号为为 12 和 13 的关键点将被删除。另外,目标序号在 0 到 4 之间的关键点在 `mapping` 参数中没有定义,这些点将被设为不可见,并且不会在训练中使用。
-子数据集都完成配置后, 混合数据集 `CombinedDataset` 可以通过如下方式配置:
+子数据集都完成配置后, 混合数据集 [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) 可以通过如下方式配置:
```python
dataset = dict(
@@ -84,6 +84,9 @@ dataset = dict(
# `train_pipeline` 包含了常用的数据预处理,
# 比如图片读取、数据增广等
pipeline=train_pipeline,
+ # sample_ratio_factor 参数是用来调节每个子数据集
+ # 在组合数据集中的样本数量比例的
+ sample_ratio_factor=[1.0, 0.5]
)
```
@@ -95,7 +98,7 @@ MMPose 提供了一份完整的 [配置文件](https://github.com/open-mmlab/mmp
-在这种情况下,COCO 和 AIC 数据集都需要使用 `KeypointConverter` 来调整它们关键点的顺序: +在这种情况下,COCO 和 AIC 数据集都需要使用 [KeypointConverter](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/converting.py#L11) 来调整它们关键点的顺序: ```python dataset_coco = dict( @@ -142,7 +145,7 @@ dataset_aic = dict( - 在 `skeleton_info` 中添加了“头顶”和“颈部”间的连线; - 拓展 `joint_weights` 和 `sigmas` 以添加新增关键点的信息。 -完成以上步骤后,合并数据集 `CombinedDataset` 可以通过以下方式配置: +完成以上步骤后,合并数据集 [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) 可以通过以下方式配置: ```python dataset = dict( @@ -157,3 +160,53 @@ dataset = dict( ``` 此外,在使用混合数据集时,由于关键点数量的变化,模型的输出通道数也要做相应调整。如果用户用混合数据集训练了模型,但是要在 COCO 数据集上评估模型,就需要从模型输出的关键点中取出一个子集来匹配 COCO 中的关键点格式。可以通过 `test_cfg` 中的 `output_keypoint_indices` 参数自定义此子集。这个 [配置文件](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-combine.py) 展示了如何用 AIC 和 COCO 合并后的数据集训练模型并在 COCO 数据集上进行测试。用户可以查阅这个文件以获取更多细节,或者参考这个文件来构建新的混合数据集。 + +## 调整混合数据集采样策略 + +在混合数据集训练中,常常面临着不同数据集的数据分布不统一问题,对此我们提供了两种不同的采样策略: + +1. 调整每个子数据集的采样比例 +2. 调整每个 batch 中每个子数据集的比例 + +### 调整每个子数据集的采样比例 + +在 [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) 中,我们提供了 `sample_ratio_factor` 参数来调整每个子数据集的采样比例。 + +例如: + +- 如果 `sample_ratio_factor` 为 `[1.0, 0.5]`,则第一个子数据集全部数据加入训练,第二个子数据集抽样出 0.5 加入训练。 +- 如果 `sample_ratio_factor` 为 `[1.0, 2.0]`,则第一个子数据集全部数据加入训练,第二个子数据集抽样出其总数的 2 倍加入训练。 + +### 调整每个 batch 中每个子数据集的比例 + +在 [$MMPOSE/datasets/samplers.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/samplers.py) 中,我们提供了 [MultiSourceSampler](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/samplers.py#L15) 来调整每个 batch 中每个子数据集的比例。 + +例如: + +- 如果 `sample_ratio_factor` 为 `[1.0, 0.5]`,则每个 batch 中第一个子数据集的数据量为 `1.0 / (1.0 + 0.5) = 66.7%`,第二个子数据集的数据量为 `0.5 / (1.0 + 0.5) = 33.3%`。即,第一个子数据集在 batch 中的占比为第二个子数据集的 2 倍。 + +用户可以在配置文件中通过 `sampler` 参数来进行设置: + +```python +# data loaders +train_bs = 256 +train_dataloader = dict( + batch_size=train_bs, + num_workers=4, + persistent_workers=True, + sampler=dict( + type='MultiSourceSampler', + batch_size=train_bs, + # 设置子数据集比例 + source_ratio=[1.0, 0.5], + shuffle=True, + round_up=True), + dataset=dict( + type='CombinedDataset', + metainfo=dict(from_file='configs/_base_/datasets/coco.py'), + # 子数据集 + datasets=[sub_dataset1, sub_dataset2], + pipeline=train_pipeline, + test_mode=False, + )) +``` diff --git a/docs/zh_cn/advanced_guides/model_analysis.md b/docs/zh_cn/user_guides/model_analysis.md similarity index 86% rename from docs/zh_cn/advanced_guides/model_analysis.md rename to docs/zh_cn/user_guides/model_analysis.md index 234dc5be85..b88755620e 100644 --- a/docs/zh_cn/advanced_guides/model_analysis.md +++ b/docs/zh_cn/user_guides/model_analysis.md @@ -1,8 +1,8 @@ -# Model Analysis +# 模型统计与分析 ## 统计模型参数量与计算量 -MMPose 提供了 `tools/analysis_tools/get_flops.py` 来统计模型的参数量与计算量。 +MMPose 提供了 [tools/analysis_tools/get_flops.py](https://github.com/open-mmlab/mmpose/blob/dev-1.x/tools/analysis_tools/get_flops.py) 来统计模型的参数量与计算量。 ```shell python tools/analysis_tools/get_flops.py ${CONFIG_FILE} [--shape ${INPUT_SHAPE}] [--cfg-options ${CFG_OPTIONS}] @@ -42,7 +42,7 @@ Params: 28.54 M ## 分析训练日志 -MMPose 提供了 `tools/analysis_tools/analyze_logs.py` 来对训练日志进行简单的分析,包括: +MMPose 提供了 [tools/analysis_tools/analyze_logs.py](https://github.com/open-mmlab/mmpose/blob/dev-1.x/tools/analysis_tools/analyze_logs.py) 来对训练日志进行简单的分析,包括: - 将日志绘制成损失和精度曲线图 - 统计训练速度 diff --git a/docs/zh_cn/user_guides/prepare_datasets.md b/docs/zh_cn/user_guides/prepare_datasets.md index 8b7d651e88..4452405819 100644 --- a/docs/zh_cn/user_guides/prepare_datasets.md +++ b/docs/zh_cn/user_guides/prepare_datasets.md @@ -158,7 +158,7 @@ python tools/misc/browse_dataset.py configs/body_2d_keypoint/topdown_heatmap/coc ## 用 MIM 下载数据集 -通过使用 [OpenDataLab](https://opendatalab.com/),您可以直接下载开源数据集。通过平台的搜索功能,您可以快速轻松地找到他们正在寻找的数据集。使用平台上的格式化数据集,您可以高效地跨数据集执行任务。 +通过使用 [OpenXLab](https://openxlab.org.cn/datasets),您可以直接下载开源数据集。通过平台的搜索功能,您可以快速轻松地找到他们正在寻找的数据集。使用平台上的格式化数据集,您可以高效地跨数据集执行任务。 如果您使用 MIM 下载,请确保版本大于 v0.3.8。您可以使用以下命令进行更新、安装、登录和数据集下载: @@ -166,10 +166,10 @@ python tools/misc/browse_dataset.py configs/body_2d_keypoint/topdown_heatmap/coc # upgrade your MIM pip install -U openmim -# install OpenDataLab CLI tools -pip install -U opendatalab -# log in OpenDataLab, registry -odl login +# install OpenXLab CLI tools +pip install -U openxlab +# log in OpenXLab +openxlab login # download coco2017 and preprocess by MIM mim download mmpose --dataset coco2017 diff --git a/docs/zh_cn/user_guides/train_and_test.md b/docs/zh_cn/user_guides/train_and_test.md index 452eddc928..6cadeab0a3 100644 --- a/docs/zh_cn/user_guides/train_and_test.md +++ b/docs/zh_cn/user_guides/train_and_test.md @@ -1,5 +1,498 @@ # 训练与测试 -中文内容建设中,暂时请查阅[英文版文档](../../en/user_guides/train_and_test.md) +## 启动训练 -如果您愿意参与中文文档的翻译与维护,我们团队将十分感谢您的贡献!欢迎加入我们的社区群与我们取得联系,或直接按照 [如何给 MMPose 贡献代码](../contribution_guide.md) 在 GitHub 上提交 Pull Request。 +### 本地训练 + +你可以使用 `tools/train.py` 在单机上使用 CPU 或单个 GPU 训练模型。 + +```shell +python tools/train.py ${CONFIG_FILE} [ARGS] +``` + +```{note} +默认情况下,MMPose 会优先使用 GPU 而不是 CPU。如果你想在 CPU 上训练模型,请清空 `CUDA_VISIBLE_DEVICES` 或将其设置为 -1,使 GPU 对程序不可见。 +``` + +```shell +CUDA_VISIBLE_DEVICES=-1 python tools/train.py ${CONFIG_FILE} [ARGS] +``` + +| ARGS | Description | +| ------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- | +| `CONFIG_FILE` | 配置文件路径 | +| `--work-dir WORK_DIR` | 训练日志与 checkpoint 存放目录,默认使用配置文件名作为目录存放在 `./work_dirs` 下 | +| `--resume [RESUME]` | 恢复训练,可以从指定 checkpoint 进行重启,不指定则会使用最近一次的 checkpoint | +| `--amp` | 开启混合精度训练 | +| `--no-validate` | **不建议新手开启**。 训练中不进行评测 | +| `--auto-scale-lr` | 自动根据当前设置的实际 batch size 和配置文件中的标准 batch size 进行学习率缩放 | +| `--cfg-options CFG_OPTIONS` | 对当前配置文件中的一些设置进行临时覆盖,字典 key-value 格式为 xxx=yyy。如果需要覆盖的值是一个数组,格式应当为 `key="[a,b]"` 或 `key=a,b`。也允许使用元组,如 `key="[(a,b),(c,d)]"`。注意双引号是**必须的**,且**不允许**使用空格。 | +| `--show-dir SHOW_DIR` | 验证阶段生成的可视化图片存放路径 | +| `--show` | 使用窗口显示预测的可视化结果 | +| `--interval INTERVAL` | 进行可视化的间隔(每隔多少张图可视化一张) | +| `--wait-time WAIT_TIME` | 可视化显示时每张图片的持续时间(单位:秒),默认为 1 | +| `--launcher {none,pytorch,slurm,mpi}` | 可选的启动器 | + +### 多卡训练 + +我们提供了一个脚本来使用 `torch.distributed.launch` 启动多卡训练。 + +```shell +bash ./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [PY_ARGS] +``` + +| ARGS | Description | +| ------------- | -------------------------------------------------- | +| `CONFIG_FILE` | 配置文件路径 | +| `GPU_NUM` | 使用 GPU 数量 | +| `[PYARGS]` | 其他配置项 `tools/train.py`, 见 [这里](#本地训练). | + +你也可以通过环境变量来指定启动器的额外参数。例如,通过以下命令将启动器的通信端口改为 29666: + +```shell +PORT=29666 bash ./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [PY_ARGS] +``` + +如果你想同时启动多个训练任务并使用不同的 GPU,你可以通过指定不同的端口和可见设备来启动它们。 + +```shell +CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 bash ./tools/dist_train.sh ${CONFIG_FILE1} 4 [PY_ARGS] +CUDA_VISIBLE_DEVICES=4,5,6,7 GPUS=29501 bash ./tools/dist_train.sh ${CONFIG_FILE2} 4 [PY_ARGS] +``` + +### 分布式训练 + +#### 局域网多机训练 + +如果你使用以太网连接的多台机器启动训练任务,你可以运行以下命令: + +在第一台机器上: + +```shell +NNODES=2 NODE_RANK=1 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_train.sh $CONFIG $GPUS +``` + +相比于单机多卡,你需要指定一些额外的环境变量: + +| 环境变量 | 描述 | +| ------------- | -------------------------- | +| `NNODES` | 机器总数 | +| `NODE_RANK` | 当前机器序号 | +| `PORT` | 通信端口,所有机器必须相同 | +| `MASTER_ADDR` | 主机地址,所有机器必须相同 | + +通常情况下,如果你没有像 InfiniBand 这样的高速网络,那么训练速度会很慢。 + +#### Slurm 多机训练 + +如果你在一个使用 [slurm](https://slurm.schedmd.com/) 管理的集群上运行 MMPose,你可以使用 `slurm_train.sh` 脚本。 + +```shell +[ENV_VARS] ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${WORK_DIR} [PY_ARGS] +``` + +脚本参数说明: + +| 参数 | 描述 | +| ------------- | -------------------------------------------------- | +| `PARTITION` | 指定集群分区 | +| `JOB_NAME` | 任务名,可以任取 | +| `CONFIG_FILE` | 配置文件路径 | +| `WORK_DIR` | 训练日志存储路径 | +| `[PYARGS]` | 其他配置项 `tools/train.py`, 见 [这里](#本地训练). | + +以下是可以用来配置 slurm 任务的环境变量: + +| 环境变量 | 描述 | +| --------------- | ------------------------------------------------------------------------ | +| `GPUS` | GPU 总数,默认为 8 | +| `GPUS_PER_NODE` | 每台机器使用的 GPU 总数,默认为 8 | +| `CPUS_PER_TASK` | 每个任务分配的 CPU 总数(通常为 1 张 GPU 对应 1 个任务进程),默认为 5 | +| `SRUN_ARGS` | `srun` 的其他参数,可选项见 [这里](https://slurm.schedmd.com/srun.html). | + +## 恢复训练 + +恢复训练意味着从之前的训练中保存的状态继续训练,其中状态包括模型权重、优化器状态和优化器参数调整策略的状态。 + +### 自动恢复 + +用户可以在训练命令的末尾添加 `--resume` 来恢复训练。程序会自动从 `work_dirs` 中加载最新的权重文件来恢复训练。如果 `work_dirs` 中有最新的 `checkpoint`(例如在之前的训练中中断了训练),则会从 `checkpoint` 处恢复训练。否则(例如之前的训练没有及时保存 `checkpoint` 或者启动了一个新的训练任务),则会重新开始训练。 + +以下是一个恢复训练的例子: + +```shell +python tools/train.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192.py --resume +``` + +### 指定 checkpoint 恢复 + +你可以在 `load_from` 中指定 `checkpoint` 的路径,MMPose 会自动读取 `checkpoint` 并从中恢复训练。命令如下: + +```shell +python tools/train.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192.py \ + --resume work_dirs/td-hm_res50_8xb64-210e_coco-256x192/latest.pth +``` + +如果你希望在配置文件中手动指定 `checkpoint` 路径,除了设置 `resume=True`,还需要设置 `load_from`。 + +需要注意的是,如果只设置了 `load_from` 而没有设置 `resume=True`,那么只会加载 `checkpoint` 中的权重,而不会从之前的状态继续训练。 + +以下的例子与上面指定 `--resume` 参数的例子等价: + +```Python +resume = True +load_from = 'work_dirs/td-hm_res50_8xb64-210e_coco-256x192/latest.pth' +# model settings +model = dict( + ## omitted ## + ) +``` + +## 在训练中冻结部分参数 + +在某些场景下,我们可能希望在训练过程中冻结模型的某些参数,以便微调特定部分或防止过拟合。在 MMPose 中,你可以通过在 `paramwise_cfg` 中设置 `custom_keys` 来为模型中的任何模块设置不同的超参数。这样可以让你控制模型特定部分的学习率和衰减系数。 + +例如,如果你想冻结 `backbone.layer0` 和 `backbone.layer1` 的所有参数,你可以在配置文件中添加以下内容: + +```Python +optim_wrapper = dict( + optimizer=dict(...), + paramwise_cfg=dict( + custom_keys={ + 'backbone.layer0': dict(lr_mult=0, decay_mult=0), + 'backbone.layer0': dict(lr_mult=0, decay_mult=0), + })) +``` + +以上配置将会通过将学习率和衰减系数设置为 0 来冻结 `backbone.layer0` 和 `backbone.layer1` 中的参数。通过这种方式,你可以有效地控制训练过程,并根据需要微调模型的特定部分。 + +## 自动混合精度训练(AMP) + +混合精度训练可以减少训练时间和存储需求,而不改变模型或降低模型训练精度,从而支持更大的 batch size、更大的模型和更大的输入尺寸。 + +要启用自动混合精度(AMP)训练,请在训练命令的末尾添加 `--amp`,如下所示: + +```shell +python tools/train.py ${CONFIG_FILE} --amp +``` + +具体例子如下: + +```shell +python tools/train.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192.py --amp +``` + +## 设置随机种子 + +如果你想指定随机种子,你可以通过如下命令: + +```shell +python ./tools/train.py \ + ${CONFIG} \ # 配置文件 + --cfg-options randomness.seed=2023 \ # 设置 random seed = 2023 + [randomness.diff_rank_seed=True] \ # 不同 rank 的进程使用不同的随机种子 + [randomness.deterministic=True] # 设置 cudnn.deterministic=True +# `[]` 表示可选的参数,你不需要输入 `[]` +``` + +`randomness` 还有三个参数可以设置,具体含义如下。 + +- `randomness.seed=2023`,将随机种子设置为 `2023`。 + +- `randomness.diff_rank_seed=True`,根据全局 `rank` 设置不同的随机种子。默认为 `False`。 + +- `randomness.deterministic=True`,设置 `cuDNN` 后端的确定性选项,即将 `torch.backends.cudnn.deterministic` 设置为 `True`,将 `torch.backends.cudnn.benchmark` 设置为 `False`。默认为 `False`。更多细节请参考 [Pytorch Randomness](https://pytorch.org/docs/stable/notes/randomness.html)。 + +## 训练日志说明 + +在训练中,命令行会实时打印训练日志如下: + +```shell +07/14 08:26:50 - mmengine - INFO - Epoch(train) [38][ 6/38] base_lr: 5.148343e-04 lr: 5.148343e-04 eta: 0:15:34 time: 0.540754 data_time: 0.394292 memory: 3141 loss: 0.006220 loss_kpt: 0.006220 acc_pose: 1.000000 +``` + +以上训练日志包括如下内容: + +- `07/14 08:26:50`:当前时间 +- `mmengine`:日志前缀,表示日志来自 MMEngine +- `INFO` or `WARNING`:日志级别,表示该日志为普通信息 +- `Epoch(train)`:当前处于训练阶段,如果处于验证阶段,则为 `Epoch(val)` +- `[38][ 6/38]`:当前处于第 38 个 epoch,当前 batch 为第 6 个 batch,总共有 38 个 batch +- `base_lr`:基础学习率 +- `lr`:当前实际使用的学习率 +- `eta`:预计训练剩余时间 +- `time`:当前 batch 的训练时间(单位:分钟) +- `data_time`:当前 batch 的数据加载(i/o,数据增强)时间(单位:分钟) +- `memory`:当前进程占用的显存(单位:MB) +- `loss`:当前 batch 的总 loss +- `loss_kpt`:当前 batch 的关键点 loss +- `acc_pose`:当前 batch 的姿态准确率 + +## 可视化训练进程 + +监视训练过程对于了解模型的性能并进行必要的调整至关重要。在本节中,我们将介绍两种可视化训练过程的方法:TensorBoard 和 MMEngine Visualizer。 + +### TensorBoard + +TensorBoard 是一个强大的工具,可以让你可视化训练过程中的 loss 变化。要启用 TensorBoard 可视化,你可能需要: + +1. 安装 TensorBoard + + ```shell + pip install tensorboard + ``` + +2. 在配置文件中开启 TensorBoard 作为可视化后端: + + ```python + visualizer = dict(vis_backends=[ + dict(type='LocalVisBackend'), + dict(type='TensorboardVisBackend'), + ]) + ``` + +Tensorboard 生成的 event 文件会保存在实验日志文件夹 `${WORK_DIR}` 下,该文件夹默认为 `work_dir/${CONFIG}`,你也可以通过 `--work-dir` 参数指定。要可视化训练过程,请使用以下命令: + +```shell +tensorboard --logdir ${WORK_DIR}/${TIMESTAMP}/vis_data +``` + +### MMEngine Visualizer + +MMPose 还支持在验证过程中可视化模型的推理结果。要启用此功能,请在启动训练时使用 `--show` 选项或设置 `--show-dir`。这个功能提供了一种有效的方法来分析模型在特定示例上的性能并进行必要的调整。 + +## 测试 + +### 本地测试 + +你可以使用 `tools/test.py` 在单机上使用 CPU 或单个 GPU 测试模型。 + +```shell +python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [ARGS] +``` + +```{note} +默认情况下,MMPose 会优先使用 GPU 而不是 CPU。如果你想在 CPU 上测试模型,请清空 `CUDA_VISIBLE_DEVICES` 或将其设置为 -1,使 GPU 对程序不可见。 +``` + +```shell +CUDA_VISIBLE_DEVICES=-1 python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [ARGS] +``` + +| ARGS | Description | +| ------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- | +| `CONFIG_FILE` | 配置文件路径file. | +| `CHECKPOINT_FILE` | checkpoint 文件路径,可以是本地文件,也可以是网络链接。 [这里](https://MMPose.readthedocs.io/en/latest/model_zoo.html) 是 MMPose 提供的 checkpoint 列表. | +| `--work-dir WORK_DIR` | 评测结果存储目录 | +| `--out OUT` | 评测结果存放文件 | +| `--dump DUMP` | 导出评测时的模型输出,用于用户自行离线评测 | +| `--cfg-options CFG_OPTIONS` | 对当前配置文件中的一些设置进行临时覆盖,字典 key-value 格式为 xxx=yyy。如果需要覆盖的值是一个数组,格式应当为 `key="[a,b]"` 或 `key=a,b`。也允许使用元组,如 `key="[(a,b),(c,d)]"`。注意双引号是**必须的**,且**不允许**使用空格。 | +| `--show-dir SHOW_DIR` | T验证阶段生成的可视化图片存放路径 | +| `--show` | 使用窗口显示预测的可视化结果 | +| `--interval INTERVAL` | 进行可视化的间隔(每隔多少张图可视化一张) | +| `--wait-time WAIT_TIME` | 可视化显示时每张图片的持续时间(单位:秒),默认为 1 | +| `--launcher {none,pytorch,slurm,mpi}` | 可选的启动器 | + +### 多卡测试 + +我们提供了一个脚本来使用 `torch.distributed.launch` 启动多卡测试。 + +```shell +bash ./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [PY_ARGS] +``` + +| ARGS | Description | +| ----------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------- | +| `CONFIG_FILE` | 配置文件路径 | +| `CHECKPOINT_FILE` | checkpoint 文件路径,可以是本地文件,也可以是网络链接。 [这里](https://MMPose.readthedocs.io/en/latest/model_zoo.html) 是 MMPose 提供的 checkpoint 列表 | +| `GPU_NUM` | 使用 GPU 数量 | +| `[PYARGS]` | 其他配置项 `tools/test.py`, 见 [这里](#本地测试) | + +你也可以通过环境变量来指定启动器的额外参数。例如,通过以下命令将启动器的通信端口改为 29666: + +```shell +PORT=29666 bash ./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [PY_ARGS] +``` + +如果你想同时启动多个测试任务并使用不同的 GPU,你可以通过指定不同的端口和可见设备来启动它们。 + +```shell +CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 bash ./tools/dist_test.sh ${CONFIG_FILE1} ${CHECKPOINT_FILE} 4 [PY_ARGS] +CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 bash ./tools/dist_test.sh ${CONFIG_FILE2} ${CHECKPOINT_FILE} 4 [PY_ARGS] +``` + +### 分布式测试 + +#### 局域网多机测试 + +如果你使用以太网连接的多台机器启动测试任务,你可以运行以下命令: + +在第一台机器上: + +```shell +NNODES=2 NODE_RANK=0 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_test.sh $CONFIG $CHECKPOINT_FILE $GPUS +``` + +在第二台机器上: + +```shell +NNODES=2 NODE_RANK=1 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_test.sh $CONFIG $CHECKPOINT_FILE $GPUS +``` + +相比于单机多卡,你需要指定一些额外的环境变量: + +| 环境变量 | 描述 | +| ------------- | -------------------------- | +| `NNODES` | 机器总数 | +| `NODE_RANK` | 当前机器序号 | +| `PORT` | 通信端口,所有机器必须相同 | +| `MASTER_ADDR` | 主机地址,所有机器必须相同 | + +通常情况下,如果你没有像 InfiniBand 这样的高速网络,那么测试速度会很慢。 + +#### Slurm 多机测试 + +如果你在一个使用 [slurm](https://slurm.schedmd.com/) 管理的集群上运行 MMPose,你可以使用 `slurm_test.sh` 脚本。 + +```shell +[ENV_VARS] ./tools/slurm_test.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${CHECKPOINT_FILE} [PY_ARGS] +``` + +脚本参数说明: + +| 参数 | 描述 | +| ----------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------- | +| `PARTITION` | 指定集群分区 | +| `JOB_NAME` | 任务名,可以任取 | +| `CONFIG_FILE` | 配置文件路径 | +| `CHECKPOINT_FILE` | checkpoint 文件路径,可以是本地文件,也可以是网络链接。 [这里](https://MMPose.readthedocs.io/en/latest/model_zoo.html) 是 MMPose 提供的 checkpoint 列表 | +| `[PYARGS]` | 其他配置项 `tools/test.py`, 见 [这里](#本地测试) | + +以下是可以用来配置 slurm 任务的环境变量: + +| 环境变量 | 描述 | +| --------------- | ------------------------------------------------------------------------ | +| `GPUS` | GPU 总数,默认为 8 | +| `GPUS_PER_NODE` | 每台机器使用的 GPU 总数,默认为 8 | +| `CPUS_PER_TASK` | 每个任务分配的 CPU 总数(通常为 1 张 GPU 对应 1 个任务进程),默认为 5 | +| `SRUN_ARGS` | `srun` 的其他参数,可选项见 [这里](https://slurm.schedmd.com/srun.html). | + +## 自定义测试 + +### 用自定义度量进行测试 + +如果您希望使用 MMPose 中尚未支持的独特度量来评估模型,您将需要自己编写这些度量并将它们包含在您的配置文件中。关于如何实现这一点的指导,请查看我们的 [自定义评估指南](https://mmpose.readthedocs.io/zh_CN/dev-1.x/advanced_guides/customize_evaluation.html)。 + +### 在多个数据集上进行评估 + +MMPose 提供了一个名为 `MultiDatasetEvaluator` 的便捷工具,用于在多个数据集上进行简化评估。在配置文件中设置此评估器非常简单。下面是一个快速示例,演示如何使用 COCO 和 AIC 数据集评估模型: + +```python +# 设置验证数据集 +coco_val = dict(type='CocoDataset', ...) + +aic_val = dict(type='AicDataset', ...) + +val_dataset = dict( + type='CombinedDataset', + datasets=[coco_val, aic_val], + pipeline=val_pipeline, + ...) + +# 配置评估器 +val_evaluator = dict( + type='MultiDatasetEvaluator', + metrics=[ # 为每个数据集配置度量 + dict(type='CocoMetric', + ann_file='data/coco/annotations/person_keypoints_val2017.json'), + dict(type='CocoMetric', + ann_file='data/aic/annotations/aic_val.json', + use_area=False, + prefix='aic') + ], + # 数据集个数和顺序与度量必须匹配 + datasets=[coco_val, aic_val], + ) +``` + +同的数据集(如 COCO 和 AIC)具有不同的关键点定义。然而,模型的输出关键点是标准化的。这导致了模型输出与真值之间关键点顺序的差异。为解决这一问题,您可以使用 `KeypointConverter` 来对齐不同数据集之间的关键点顺序。下面是一个完整示例,展示了如何利用 `KeypointConverter` 来对齐 AIC 关键点与 COCO 关键点: + +```python +aic_to_coco_converter = dict( + type='KeypointConverter', + num_keypoints=17, + mapping=[ + (0, 6), + (1, 8), + (2, 10), + (3, 5), + (4, 7), + (5, 9), + (6, 12), + (7, 14), + (8, 16), + (9, 11), + (10, 13), + (11, 15), + ]) + +# val datasets +coco_val = dict( + type='CocoDataset', + data_root='data/coco/', + data_mode='topdown', + ann_file='annotations/person_keypoints_val2017.json', + bbox_file='data/coco/person_detection_results/' + 'COCO_val2017_detections_AP_H_56_person.json', + data_prefix=dict(img='val2017/'), + test_mode=True, + pipeline=[], +) + +aic_val = dict( + type='AicDataset', + data_root='data/aic/', + data_mode=data_mode, + ann_file='annotations/aic_val.json', + data_prefix=dict(img='ai_challenger_keypoint_validation_20170911/' + 'keypoint_validation_images_20170911/'), + test_mode=True, + pipeline=[], + ) + +val_dataset = dict( + type='CombinedDataset', + metainfo=dict(from_file='configs/_base_/datasets/coco.py'), + datasets=[coco_val, aic_val], + pipeline=val_pipeline, + test_mode=True, + ) + +val_dataloader = dict( + batch_size=32, + num_workers=2, + persistent_workers=True, + drop_last=False, + sampler=dict(type='DefaultSampler', shuffle=False, round_up=False), + dataset=val_dataset) + +test_dataloader = val_dataloader + +val_evaluator = dict( + type='MultiDatasetEvaluator', + metrics=[ + dict(type='CocoMetric', + ann_file=data_root + 'annotations/person_keypoints_val2017.json'), + dict(type='CocoMetric', + ann_file='data/aic/annotations/aic_val.json', + use_area=False, + gt_converter=aic_to_coco_converter, + prefix='aic') + ], + datasets=val_dataset['datasets'], + ) + +test_evaluator = val_evaluator +``` + +如需进一步了解如何将 AIC 关键点转换为 COCO 关键点,请查阅 [该指南](https://mmpose.readthedocs.io/zh_CN/dev-1.x/user_guides/mixed_datasets.html#aic-coco)。 diff --git a/docs/zh_cn/user_guides/useful_tools.md b/docs/zh_cn/user_guides/useful_tools.md deleted file mode 100644 index f2ceb771b7..0000000000 --- a/docs/zh_cn/user_guides/useful_tools.md +++ /dev/null @@ -1,5 +0,0 @@ -# 常用工具 - -中文内容建设中,暂时请查阅[英文版文档](../../en/user_guides/useful_tools.md) - -如果您愿意参与中文文档的翻译与维护,我们团队将十分感谢您的贡献!欢迎加入我们的社区群与我们取得联系,或直接按照 [如何给 MMPose 贡献代码](../contribution_guide.md) 在 GitHub 上提交 Pull Request。 diff --git a/docs/zh_cn/user_guides/visualization.md b/docs/zh_cn/user_guides/visualization.md deleted file mode 100644 index a584eb450e..0000000000 --- a/docs/zh_cn/user_guides/visualization.md +++ /dev/null @@ -1,5 +0,0 @@ -# 可视化 - -中文内容建设中,暂时请查阅[英文版文档](../../en/user_guides/visualization.md) - -如果您愿意参与中文文档的翻译与维护,我们团队将十分感谢您的贡献!欢迎加入我们的社区群与我们取得联系,或直接按照 [如何给 MMPose 贡献代码](../contribution_guide.md) 在 GitHub 上提交 Pull Request。 diff --git a/mmpose/__init__.py b/mmpose/__init__.py index ad7946470d..583ede0a4d 100644 --- a/mmpose/__init__.py +++ b/mmpose/__init__.py @@ -6,7 +6,7 @@ from .version import __version__, short_version mmcv_minimum_version = '2.0.0rc4' -mmcv_maximum_version = '2.1.0' +mmcv_maximum_version = '2.2.0' mmcv_version = digit_version(mmcv.__version__) mmengine_minimum_version = '0.6.0' diff --git a/mmpose/apis/__init__.py b/mmpose/apis/__init__.py index 0c44f7a3f8..322ee9cf73 100644 --- a/mmpose/apis/__init__.py +++ b/mmpose/apis/__init__.py @@ -5,11 +5,12 @@ extract_pose_sequence, inference_pose_lifter_model) from .inference_tracking import _compute_iou, _track_by_iou, _track_by_oks from .inferencers import MMPoseInferencer, Pose2DInferencer +from .visualization import visualize __all__ = [ 'init_model', 'inference_topdown', 'inference_bottomup', 'collect_multi_frames', 'Pose2DInferencer', 'MMPoseInferencer', '_track_by_iou', '_track_by_oks', '_compute_iou', 'inference_pose_lifter_model', 'extract_pose_sequence', - 'convert_keypoint_definition', 'collate_pose_sequence' + 'convert_keypoint_definition', 'collate_pose_sequence', 'visualize' ] diff --git a/mmpose/apis/inference.py b/mmpose/apis/inference.py index 772ef17b7c..5662d6f30b 100644 --- a/mmpose/apis/inference.py +++ b/mmpose/apis/inference.py @@ -53,7 +53,8 @@ def dataset_meta_from_config(config: Config, import mmpose.datasets.datasets # noqa: F401, F403 from mmpose.registry import DATASETS - dataset_class = DATASETS.get(dataset_cfg.type) + dataset_class = dataset_cfg.type if isinstance( + dataset_cfg.type, type) else DATASETS.get(dataset_cfg.type) metainfo = dataset_class.METAINFO metainfo = parse_pose_metainfo(metainfo) diff --git a/mmpose/apis/inference_3d.py b/mmpose/apis/inference_3d.py index d5bb753945..ae6428f187 100644 --- a/mmpose/apis/inference_3d.py +++ b/mmpose/apis/inference_3d.py @@ -23,18 +23,15 @@ def convert_keypoint_definition(keypoints, pose_det_dataset, ndarray[K, 2 or 3]: the transformed 2D keypoints. """ assert pose_lift_dataset in [ - 'Human36mDataset'], '`pose_lift_dataset` should be ' \ - f'`Human36mDataset`, but got {pose_lift_dataset}.' + 'h36m'], '`pose_lift_dataset` should be ' \ + f'`h36m`, but got {pose_lift_dataset}.' - coco_style_datasets = [ - 'CocoDataset', 'PoseTrack18VideoDataset', 'PoseTrack18Dataset' - ] keypoints_new = np.zeros((keypoints.shape[0], 17, keypoints.shape[2]), dtype=keypoints.dtype) - if pose_lift_dataset == 'Human36mDataset': - if pose_det_dataset in ['Human36mDataset']: + if pose_lift_dataset == 'h36m': + if pose_det_dataset in ['h36m']: keypoints_new = keypoints - elif pose_det_dataset in coco_style_datasets: + elif pose_det_dataset in ['coco', 'posetrack18']: # pelvis (root) is in the middle of l_hip and r_hip keypoints_new[:, 0] = (keypoints[:, 11] + keypoints[:, 12]) / 2 # thorax is in the middle of l_shoulder and r_shoulder @@ -48,7 +45,7 @@ def convert_keypoint_definition(keypoints, pose_det_dataset, # rearrange other keypoints keypoints_new[:, [1, 2, 3, 4, 5, 6, 9, 11, 12, 13, 14, 15, 16]] = \ keypoints[:, [12, 14, 16, 11, 13, 15, 0, 5, 7, 9, 6, 8, 10]] - elif pose_det_dataset in ['AicDataset']: + elif pose_det_dataset in ['aic']: # pelvis (root) is in the middle of l_hip and r_hip keypoints_new[:, 0] = (keypoints[:, 9] + keypoints[:, 6]) / 2 # thorax is in the middle of l_shoulder and r_shoulder @@ -66,7 +63,7 @@ def convert_keypoint_definition(keypoints, pose_det_dataset, keypoints_new[:, [1, 2, 3, 4, 5, 6, 11, 12, 13, 14, 15, 16]] = \ keypoints[:, [6, 7, 8, 9, 10, 11, 3, 4, 5, 0, 1, 2]] - elif pose_det_dataset in ['CrowdPoseDataset']: + elif pose_det_dataset in ['crowdpose']: # pelvis (root) is in the middle of l_hip and r_hip keypoints_new[:, 0] = (keypoints[:, 6] + keypoints[:, 7]) / 2 # thorax is in the middle of l_shoulder and r_shoulder @@ -181,16 +178,11 @@ def collate_pose_sequence(pose_results_2d, pose_sequences = [] for idx in range(N): pose_seq = PoseDataSample() - gt_instances = InstanceData() pred_instances = InstanceData() - for k in pose_results_2d[target_frame][idx].gt_instances.keys(): - gt_instances.set_field( - pose_results_2d[target_frame][idx].gt_instances[k], k) - for k in pose_results_2d[target_frame][idx].pred_instances.keys(): - if k != 'keypoints': - pred_instances.set_field( - pose_results_2d[target_frame][idx].pred_instances[k], k) + gt_instances = pose_results_2d[target_frame][idx].gt_instances.clone() + pred_instances = pose_results_2d[target_frame][ + idx].pred_instances.clone() pose_seq.pred_instances = pred_instances pose_seq.gt_instances = gt_instances @@ -228,7 +220,7 @@ def collate_pose_sequence(pose_results_2d, # replicate the right most frame keypoints[:, frame_idx + 1:] = keypoints[:, frame_idx] break - pose_seq.pred_instances.keypoints = keypoints + pose_seq.pred_instances.set_field(keypoints, 'keypoints') pose_sequences.append(pose_seq) return pose_sequences @@ -276,8 +268,15 @@ def inference_pose_lifter_model(model, bbox_center = None bbox_scale = None + pose_results_2d_copy = [] for i, pose_res in enumerate(pose_results_2d): + pose_res_copy = [] for j, data_sample in enumerate(pose_res): + data_sample_copy = PoseDataSample() + data_sample_copy.gt_instances = data_sample.gt_instances.clone() + data_sample_copy.pred_instances = data_sample.pred_instances.clone( + ) + data_sample_copy.track_id = data_sample.track_id kpts = data_sample.pred_instances.keypoints bboxes = data_sample.pred_instances.bboxes keypoints = [] @@ -292,11 +291,13 @@ def inference_pose_lifter_model(model, bbox_scale + bbox_center) else: keypoints.append(kpt[:, :2]) - pose_results_2d[i][j].pred_instances.keypoints = np.array( - keypoints) + data_sample_copy.pred_instances.set_field( + np.array(keypoints), 'keypoints') + pose_res_copy.append(data_sample_copy) + pose_results_2d_copy.append(pose_res_copy) - pose_sequences_2d = collate_pose_sequence(pose_results_2d, with_track_id, - target_idx) + pose_sequences_2d = collate_pose_sequence(pose_results_2d_copy, + with_track_id, target_idx) if not pose_sequences_2d: return [] @@ -316,8 +317,10 @@ def inference_pose_lifter_model(model, T, K, ), dtype=np.float32) - data_info['lifting_target'] = np.zeros((K, 3), dtype=np.float32) - data_info['lifting_target_visible'] = np.ones((K, 1), dtype=np.float32) + data_info['lifting_target'] = np.zeros((1, K, 3), dtype=np.float32) + data_info['factor'] = np.zeros((T, ), dtype=np.float32) + data_info['lifting_target_visible'] = np.ones((1, K, 1), + dtype=np.float32) if image_size is not None: assert len(image_size) == 2 diff --git a/mmpose/apis/inferencers/__init__.py b/mmpose/apis/inferencers/__init__.py index 5955d79da9..0e2b5c8293 100644 --- a/mmpose/apis/inferencers/__init__.py +++ b/mmpose/apis/inferencers/__init__.py @@ -1,4 +1,5 @@ # Copyright (c) OpenMMLab. All rights reserved. +from .hand3d_inferencer import Hand3DInferencer from .mmpose_inferencer import MMPoseInferencer from .pose2d_inferencer import Pose2DInferencer from .pose3d_inferencer import Pose3DInferencer @@ -6,5 +7,5 @@ __all__ = [ 'Pose2DInferencer', 'MMPoseInferencer', 'get_model_aliases', - 'Pose3DInferencer' + 'Pose3DInferencer', 'Hand3DInferencer' ] diff --git a/mmpose/apis/inferencers/base_mmpose_inferencer.py b/mmpose/apis/inferencers/base_mmpose_inferencer.py index bed28b90d7..d7d5eb8c19 100644 --- a/mmpose/apis/inferencers/base_mmpose_inferencer.py +++ b/mmpose/apis/inferencers/base_mmpose_inferencer.py @@ -1,10 +1,10 @@ # Copyright (c) OpenMMLab. All rights reserved. +import logging import mimetypes import os -import warnings from collections import defaultdict from typing import (Callable, Dict, Generator, Iterable, List, Optional, - Sequence, Union) + Sequence, Tuple, Union) import cv2 import mmcv @@ -15,14 +15,23 @@ from mmengine.dataset import Compose from mmengine.fileio import (get_file_backend, isdir, join_path, list_dir_or_file) -from mmengine.infer.infer import BaseInferencer +from mmengine.infer.infer import BaseInferencer, ModelType +from mmengine.logging import print_log from mmengine.registry import init_default_scope from mmengine.runner.checkpoint import _load_checkpoint_to_model from mmengine.structures import InstanceData from mmengine.utils import mkdir_or_exist from mmpose.apis.inference import dataset_meta_from_config +from mmpose.registry import DATASETS from mmpose.structures import PoseDataSample, split_instances +from .utils import default_det_models + +try: + from mmdet.apis.det_inferencer import DetInferencer + has_mmdet = True +except (ImportError, ModuleNotFoundError): + has_mmdet = False InstanceList = List[InstanceData] InputType = Union[str, np.ndarray] @@ -42,7 +51,45 @@ class BaseMMPoseInferencer(BaseInferencer): 'return_vis', 'show', 'wait_time', 'draw_bbox', 'radius', 'thickness', 'kpt_thr', 'vis_out_dir', 'black_background' } - postprocess_kwargs: set = {'pred_out_dir'} + postprocess_kwargs: set = {'pred_out_dir', 'return_datasample'} + + def _init_detector( + self, + det_model: Optional[Union[ModelType, str]] = None, + det_weights: Optional[str] = None, + det_cat_ids: Optional[Union[int, Tuple]] = None, + device: Optional[str] = None, + ): + object_type = DATASETS.get(self.cfg.dataset_type).__module__.split( + 'datasets.')[-1].split('.')[0].lower() + + if det_model in ('whole_image', 'whole-image') or \ + (det_model is None and + object_type not in default_det_models): + self.detector = None + + else: + det_scope = 'mmdet' + if det_model is None: + det_info = default_det_models[object_type] + det_model, det_weights, det_cat_ids = det_info[ + 'model'], det_info['weights'], det_info['cat_ids'] + elif os.path.exists(det_model): + det_cfg = Config.fromfile(det_model) + det_scope = det_cfg.default_scope + + if has_mmdet: + self.detector = DetInferencer( + det_model, det_weights, device=device, scope=det_scope) + else: + raise RuntimeError( + 'MMDetection (v3.0.0 or above) is required to build ' + 'inferencers for top-down pose estimation models.') + + if isinstance(det_cat_ids, (tuple, list)): + self.det_cat_ids = det_cat_ids + else: + self.det_cat_ids = (det_cat_ids, ) def _load_weights_to_model(self, model: nn.Module, checkpoint: Optional[dict], @@ -65,15 +112,20 @@ def _load_weights_to_model(self, model: nn.Module, # mmpose 1.x model.dataset_meta = checkpoint_meta['dataset_meta'] else: - warnings.warn( + print_log( 'dataset_meta are not saved in the checkpoint\'s ' - 'meta data, load via config.') + 'meta data, load via config.', + logger='current', + level=logging.WARNING) model.dataset_meta = dataset_meta_from_config( cfg, dataset_mode='train') else: - warnings.warn('Checkpoint is not loaded, and the inference ' - 'result is calculated by the randomly initialized ' - 'model!') + print_log( + 'Checkpoint is not loaded, and the inference ' + 'result is calculated by the randomly initialized ' + 'model!', + logger='current', + level=logging.WARNING) model.dataset_meta = dataset_meta_from_config( cfg, dataset_mode='train') @@ -176,7 +228,10 @@ def _get_webcam_inputs(self, inputs: str) -> Generator: # Attempt to open the video capture object. vcap = cv2.VideoCapture(camera_id) if not vcap.isOpened(): - warnings.warn(f'Cannot open camera (ID={camera_id})') + print_log( + f'Cannot open camera (ID={camera_id})', + logger='current', + level=logging.WARNING) return [] # Set video input flag and metadata. @@ -257,6 +312,101 @@ def preprocess(self, # only supports inference with batch size 1 yield self.collate_fn(data_infos), [input] + def __call__( + self, + inputs: InputsType, + return_datasamples: bool = False, + batch_size: int = 1, + out_dir: Optional[str] = None, + **kwargs, + ) -> dict: + """Call the inferencer. + + Args: + inputs (InputsType): Inputs for the inferencer. + return_datasamples (bool): Whether to return results as + :obj:`BaseDataElement`. Defaults to False. + batch_size (int): Batch size. Defaults to 1. + out_dir (str, optional): directory to save visualization + results and predictions. Will be overoden if vis_out_dir or + pred_out_dir are given. Defaults to None + **kwargs: Key words arguments passed to :meth:`preprocess`, + :meth:`forward`, :meth:`visualize` and :meth:`postprocess`. + Each key in kwargs should be in the corresponding set of + ``preprocess_kwargs``, ``forward_kwargs``, + ``visualize_kwargs`` and ``postprocess_kwargs``. + + Returns: + dict: Inference and visualization results. + """ + if out_dir is not None: + if 'vis_out_dir' not in kwargs: + kwargs['vis_out_dir'] = f'{out_dir}/visualizations' + if 'pred_out_dir' not in kwargs: + kwargs['pred_out_dir'] = f'{out_dir}/predictions' + + ( + preprocess_kwargs, + forward_kwargs, + visualize_kwargs, + postprocess_kwargs, + ) = self._dispatch_kwargs(**kwargs) + + self.update_model_visualizer_settings(**kwargs) + + # preprocessing + if isinstance(inputs, str) and inputs.startswith('webcam'): + inputs = self._get_webcam_inputs(inputs) + batch_size = 1 + if not visualize_kwargs.get('show', False): + print_log( + 'The display mode is closed when using webcam ' + 'input. It will be turned on automatically.', + logger='current', + level=logging.WARNING) + visualize_kwargs['show'] = True + else: + inputs = self._inputs_to_list(inputs) + + # check the compatibility between inputs/outputs + if not self._video_input and len(inputs) > 0: + vis_out_dir = visualize_kwargs.get('vis_out_dir', None) + if vis_out_dir is not None: + _, file_extension = os.path.splitext(vis_out_dir) + assert not file_extension, f'the argument `vis_out_dir` ' \ + f'should be a folder while the input contains multiple ' \ + f'images, but got {vis_out_dir}' + + if 'bbox_thr' in self.forward_kwargs: + forward_kwargs['bbox_thr'] = preprocess_kwargs.get('bbox_thr', -1) + inputs = self.preprocess( + inputs, batch_size=batch_size, **preprocess_kwargs) + + preds = [] + + for proc_inputs, ori_inputs in inputs: + preds = self.forward(proc_inputs, **forward_kwargs) + + visualization = self.visualize(ori_inputs, preds, + **visualize_kwargs) + results = self.postprocess( + preds, + visualization, + return_datasamples=return_datasamples, + **postprocess_kwargs) + yield results + + if self._video_input: + self._finalize_video_processing( + postprocess_kwargs.get('pred_out_dir', '')) + + # In 3D Inferencers, some intermediate results (e.g. 2d keypoints) + # will be temporarily stored in `self._buffer`. It's essential to + # clear this information to prevent any interference with subsequent + # inferences. + if hasattr(self, '_buffer'): + self._buffer.clear() + def visualize(self, inputs: list, preds: List[PoseDataSample], @@ -340,44 +490,58 @@ def visualize(self, results.append(visualization) if vis_out_dir: - out_img = mmcv.rgb2bgr(visualization) - _, file_extension = os.path.splitext(vis_out_dir) - if file_extension: - dir_name = os.path.dirname(vis_out_dir) - file_name = os.path.basename(vis_out_dir) - else: - dir_name = vis_out_dir - file_name = None - mkdir_or_exist(dir_name) - - if self._video_input: - - if self.video_info['writer'] is None: - fourcc = cv2.VideoWriter_fourcc(*'mp4v') - if file_name is None: - file_name = os.path.basename( - self.video_info['name']) - out_file = join_path(dir_name, file_name) - self.video_info['writer'] = cv2.VideoWriter( - out_file, fourcc, self.video_info['fps'], - (visualization.shape[1], visualization.shape[0])) - self.video_info['writer'].write(out_img) - - else: - file_name = file_name if file_name else img_name - out_file = join_path(dir_name, file_name) - mmcv.imwrite(out_img, out_file) + self.save_visualization( + visualization, + vis_out_dir, + img_name=img_name, + ) if return_vis: return results else: return [] + def save_visualization(self, visualization, vis_out_dir, img_name=None): + out_img = mmcv.rgb2bgr(visualization) + _, file_extension = os.path.splitext(vis_out_dir) + if file_extension: + dir_name = os.path.dirname(vis_out_dir) + file_name = os.path.basename(vis_out_dir) + else: + dir_name = vis_out_dir + file_name = None + mkdir_or_exist(dir_name) + + if self._video_input: + + if self.video_info['writer'] is None: + fourcc = cv2.VideoWriter_fourcc(*'mp4v') + if file_name is None: + file_name = os.path.basename(self.video_info['name']) + out_file = join_path(dir_name, file_name) + self.video_info['output_file'] = out_file + self.video_info['writer'] = cv2.VideoWriter( + out_file, fourcc, self.video_info['fps'], + (visualization.shape[1], visualization.shape[0])) + self.video_info['writer'].write(out_img) + + else: + if file_name is None: + file_name = img_name if img_name else 'visualization.jpg' + + out_file = join_path(dir_name, file_name) + mmcv.imwrite(out_img, out_file) + print_log( + f'the output image has been saved at {out_file}', + logger='current', + level=logging.INFO) + def postprocess( self, preds: List[PoseDataSample], visualization: List[np.ndarray], - return_datasample=False, + return_datasample=None, + return_datasamples=False, pred_out_dir: str = '', ) -> dict: """Process the predictions and visualization results from ``forward`` @@ -392,7 +556,7 @@ def postprocess( Args: preds (List[Dict]): Predictions of the model. visualization (np.ndarray): Visualized predictions. - return_datasample (bool): Whether to return results as + return_datasamples (bool): Whether to return results as datasamples. Defaults to False. pred_out_dir (str): Directory to save the inference results w/o visualization. If left as empty, no file will be saved. @@ -405,16 +569,24 @@ def postprocess( - ``visualization (Any)``: Returned by :meth:`visualize` - ``predictions`` (dict or DataSample): Returned by :meth:`forward` and processed in :meth:`postprocess`. - If ``return_datasample=False``, it usually should be a + If ``return_datasamples=False``, it usually should be a json-serializable dict containing only basic data elements such as strings and numbers. """ + if return_datasample is not None: + print_log( + 'The `return_datasample` argument is deprecated ' + 'and will be removed in future versions. Please ' + 'use `return_datasamples`.', + logger='current', + level=logging.WARNING) + return_datasamples = return_datasample result_dict = defaultdict(list) result_dict['visualization'] = visualization for pred in preds: - if not return_datasample: + if not return_datasamples: # convert datasamples to list of instance predictions pred = split_instances(pred.pred_instances) result_dict['predictions'].append(pred) @@ -454,6 +626,11 @@ def _finalize_video_processing( # Release the video writer if it exists if self.video_info['writer'] is not None: + out_file = self.video_info['output_file'] + print_log( + f'the output video has been saved at {out_file}', + logger='current', + level=logging.INFO) self.video_info['writer'].release() # Save predictions diff --git a/mmpose/apis/inferencers/hand3d_inferencer.py b/mmpose/apis/inferencers/hand3d_inferencer.py new file mode 100644 index 0000000000..57f1eb06eb --- /dev/null +++ b/mmpose/apis/inferencers/hand3d_inferencer.py @@ -0,0 +1,339 @@ +# Copyright (c) OpenMMLab. All rights reserved. +import logging +import os +from collections import defaultdict +from typing import Dict, List, Optional, Sequence, Tuple, Union + +import mmcv +import numpy as np +import torch +from mmengine.config import Config, ConfigDict +from mmengine.infer.infer import ModelType +from mmengine.logging import print_log +from mmengine.model import revert_sync_batchnorm +from mmengine.registry import init_default_scope +from mmengine.structures import InstanceData + +from mmpose.evaluation.functional import nms +from mmpose.registry import INFERENCERS +from mmpose.structures import PoseDataSample, merge_data_samples +from .base_mmpose_inferencer import BaseMMPoseInferencer + +InstanceList = List[InstanceData] +InputType = Union[str, np.ndarray] +InputsType = Union[InputType, Sequence[InputType]] +PredType = Union[InstanceData, InstanceList] +ImgType = Union[np.ndarray, Sequence[np.ndarray]] +ConfigType = Union[Config, ConfigDict] +ResType = Union[Dict, List[Dict], InstanceData, List[InstanceData]] + + +@INFERENCERS.register_module() +class Hand3DInferencer(BaseMMPoseInferencer): + """The inferencer for 3D hand pose estimation. + + Args: + model (str, optional): Pretrained 2D pose estimation algorithm. + It's the path to the config file or the model name defined in + metafile. For example, it could be: + + - model alias, e.g. ``'body'``, + - config name, e.g. ``'simcc_res50_8xb64-210e_coco-256x192'``, + - config path + + Defaults to ``None``. + weights (str, optional): Path to the checkpoint. If it is not + specified and "model" is a model name of metafile, the weights + will be loaded from metafile. Defaults to None. + device (str, optional): Device to run inference. If None, the + available device will be automatically used. Defaults to None. + scope (str, optional): The scope of the model. Defaults to "mmpose". + det_model (str, optional): Config path or alias of detection model. + Defaults to None. + det_weights (str, optional): Path to the checkpoints of detection + model. Defaults to None. + det_cat_ids (int or list[int], optional): Category id for + detection model. Defaults to None. + """ + + preprocess_kwargs: set = {'bbox_thr', 'nms_thr', 'bboxes'} + forward_kwargs: set = {'disable_rebase_keypoint'} + visualize_kwargs: set = { + 'return_vis', + 'show', + 'wait_time', + 'draw_bbox', + 'radius', + 'thickness', + 'kpt_thr', + 'vis_out_dir', + 'num_instances', + } + postprocess_kwargs: set = {'pred_out_dir', 'return_datasample'} + + def __init__(self, + model: Union[ModelType, str], + weights: Optional[str] = None, + device: Optional[str] = None, + scope: Optional[str] = 'mmpose', + det_model: Optional[Union[ModelType, str]] = None, + det_weights: Optional[str] = None, + det_cat_ids: Optional[Union[int, Tuple]] = None) -> None: + + init_default_scope(scope) + super().__init__( + model=model, weights=weights, device=device, scope=scope) + self.model = revert_sync_batchnorm(self.model) + + # assign dataset metainfo to self.visualizer + self.visualizer.set_dataset_meta(self.model.dataset_meta) + + # initialize hand detector + self._init_detector( + det_model=det_model, + det_weights=det_weights, + det_cat_ids=det_cat_ids, + device=device, + ) + + self._video_input = False + self._buffer = defaultdict(list) + + def preprocess_single(self, + input: InputType, + index: int, + bbox_thr: float = 0.3, + nms_thr: float = 0.3, + bboxes: Union[List[List], List[np.ndarray], + np.ndarray] = []): + """Process a single input into a model-feedable format. + + Args: + input (InputType): Input given by user. + index (int): index of the input + bbox_thr (float): threshold for bounding box detection. + Defaults to 0.3. + nms_thr (float): IoU threshold for bounding box NMS. + Defaults to 0.3. + + Yields: + Any: Data processed by the ``pipeline`` and ``collate_fn``. + """ + + if isinstance(input, str): + data_info = dict(img_path=input) + else: + data_info = dict(img=input, img_path=f'{index}.jpg'.rjust(10, '0')) + data_info.update(self.model.dataset_meta) + + if self.detector is not None: + try: + det_results = self.detector( + input, return_datasamples=True)['predictions'] + except ValueError: + print_log( + 'Support for mmpose and mmdet versions up to 3.1.0 ' + 'will be discontinued in upcoming releases. To ' + 'ensure ongoing compatibility, please upgrade to ' + 'mmdet version 3.2.0 or later.', + logger='current', + level=logging.WARNING) + det_results = self.detector( + input, return_datasample=True)['predictions'] + pred_instance = det_results[0].pred_instances.cpu().numpy() + bboxes = np.concatenate( + (pred_instance.bboxes, pred_instance.scores[:, None]), axis=1) + + label_mask = np.zeros(len(bboxes), dtype=np.uint8) + for cat_id in self.det_cat_ids: + label_mask = np.logical_or(label_mask, + pred_instance.labels == cat_id) + + bboxes = bboxes[np.logical_and(label_mask, + pred_instance.scores > bbox_thr)] + bboxes = bboxes[nms(bboxes, nms_thr)] + + data_infos = [] + if len(bboxes) > 0: + for bbox in bboxes: + inst = data_info.copy() + inst['bbox'] = bbox[None, :4] + inst['bbox_score'] = bbox[4:5] + data_infos.append(self.pipeline(inst)) + else: + inst = data_info.copy() + + # get bbox from the image size + if isinstance(input, str): + input = mmcv.imread(input) + h, w = input.shape[:2] + + inst['bbox'] = np.array([[0, 0, w, h]], dtype=np.float32) + inst['bbox_score'] = np.ones(1, dtype=np.float32) + data_infos.append(self.pipeline(inst)) + + return data_infos + + @torch.no_grad() + def forward(self, + inputs: Union[dict, tuple], + disable_rebase_keypoint: bool = False): + """Performs a forward pass through the model. + + Args: + inputs (Union[dict, tuple]): The input data to be processed. Can + be either a dictionary or a tuple. + disable_rebase_keypoint (bool, optional): Flag to disable rebasing + the height of the keypoints. Defaults to False. + + Returns: + A list of data samples with prediction instances. + """ + data_samples = self.model.test_step(inputs) + data_samples_2d = [] + + for idx, res in enumerate(data_samples): + pred_instances = res.pred_instances + keypoints = pred_instances.keypoints + rel_root_depth = pred_instances.rel_root_depth + scores = pred_instances.keypoint_scores + hand_type = pred_instances.hand_type + + res_2d = PoseDataSample() + gt_instances = res.gt_instances.clone() + pred_instances = pred_instances.clone() + res_2d.gt_instances = gt_instances + res_2d.pred_instances = pred_instances + + # add relative root depth to left hand joints + keypoints[:, 21:, 2] += rel_root_depth + + # set joint scores according to hand type + scores[:, :21] *= hand_type[:, [0]] + scores[:, 21:] *= hand_type[:, [1]] + # normalize kpt score + if scores.max() > 1: + scores /= 255 + + res_2d.pred_instances.set_field(keypoints[..., :2].copy(), + 'keypoints') + + # rotate the keypoint to make z-axis correspondent to height + # for better visualization + vis_R = np.array([[1, 0, 0], [0, 0, -1], [0, 1, 0]]) + keypoints[..., :3] = keypoints[..., :3] @ vis_R + + # rebase height (z-axis) + if not disable_rebase_keypoint: + valid = scores > 0 + keypoints[..., 2] -= np.min( + keypoints[valid, 2], axis=-1, keepdims=True) + + data_samples[idx].pred_instances.keypoints = keypoints + data_samples[idx].pred_instances.keypoint_scores = scores + data_samples_2d.append(res_2d) + + data_samples = [merge_data_samples(data_samples)] + data_samples_2d = merge_data_samples(data_samples_2d) + + self._buffer['pose2d_results'] = data_samples_2d + + return data_samples + + def visualize( + self, + inputs: list, + preds: List[PoseDataSample], + return_vis: bool = False, + show: bool = False, + draw_bbox: bool = False, + wait_time: float = 0, + radius: int = 3, + thickness: int = 1, + kpt_thr: float = 0.3, + num_instances: int = 1, + vis_out_dir: str = '', + window_name: str = '', + ) -> List[np.ndarray]: + """Visualize predictions. + + Args: + inputs (list): Inputs preprocessed by :meth:`_inputs_to_list`. + preds (Any): Predictions of the model. + return_vis (bool): Whether to return images with predicted results. + show (bool): Whether to display the image in a popup window. + Defaults to False. + wait_time (float): The interval of show (ms). Defaults to 0 + draw_bbox (bool): Whether to draw the bounding boxes. + Defaults to False + radius (int): Keypoint radius for visualization. Defaults to 3 + thickness (int): Link thickness for visualization. Defaults to 1 + kpt_thr (float): The threshold to visualize the keypoints. + Defaults to 0.3 + vis_out_dir (str, optional): Directory to save visualization + results w/o predictions. If left as empty, no file will + be saved. Defaults to ''. + window_name (str, optional): Title of display window. + window_close_event_handler (callable, optional): + + Returns: + List[np.ndarray]: Visualization results. + """ + if (not return_vis) and (not show) and (not vis_out_dir): + return + + if getattr(self, 'visualizer', None) is None: + raise ValueError('Visualization needs the "visualizer" term' + 'defined in the config, but got None.') + + self.visualizer.radius = radius + self.visualizer.line_width = thickness + + results = [] + + for single_input, pred in zip(inputs, preds): + if isinstance(single_input, str): + img = mmcv.imread(single_input, channel_order='rgb') + elif isinstance(single_input, np.ndarray): + img = mmcv.bgr2rgb(single_input) + else: + raise ValueError('Unsupported input type: ' + f'{type(single_input)}') + img_name = os.path.basename(pred.metainfo['img_path']) + + # since visualization and inference utilize the same process, + # the wait time is reduced when a video input is utilized, + # thereby eliminating the issue of inference getting stuck. + wait_time = 1e-5 if self._video_input else wait_time + + if num_instances < 0: + num_instances = len(pred.pred_instances) + + visualization = self.visualizer.add_datasample( + window_name, + img, + data_sample=pred, + det_data_sample=self._buffer['pose2d_results'], + draw_gt=False, + draw_bbox=draw_bbox, + show=show, + wait_time=wait_time, + convert_keypoint=False, + axis_azimuth=-115, + axis_limit=200, + axis_elev=15, + kpt_thr=kpt_thr, + num_instances=num_instances) + results.append(visualization) + + if vis_out_dir: + self.save_visualization( + visualization, + vis_out_dir, + img_name=img_name, + ) + + if return_vis: + return results + else: + return [] diff --git a/mmpose/apis/inferencers/mmpose_inferencer.py b/mmpose/apis/inferencers/mmpose_inferencer.py index b44361bba8..cd08d8f6cb 100644 --- a/mmpose/apis/inferencers/mmpose_inferencer.py +++ b/mmpose/apis/inferencers/mmpose_inferencer.py @@ -9,6 +9,7 @@ from mmengine.structures import InstanceData from .base_mmpose_inferencer import BaseMMPoseInferencer +from .hand3d_inferencer import Hand3DInferencer from .pose2d_inferencer import Pose2DInferencer from .pose3d_inferencer import Pose3DInferencer @@ -56,15 +57,15 @@ class MMPoseInferencer(BaseMMPoseInferencer): preprocess_kwargs: set = { 'bbox_thr', 'nms_thr', 'bboxes', 'use_oks_tracking', 'tracking_thr', - 'norm_pose_2d' + 'disable_norm_pose_2d' } - forward_kwargs: set = {'rebase_keypoint_height'} + forward_kwargs: set = {'disable_rebase_keypoint'} visualize_kwargs: set = { 'return_vis', 'show', 'wait_time', 'draw_bbox', 'radius', 'thickness', 'kpt_thr', 'vis_out_dir', 'skeleton_style', 'draw_heatmap', - 'black_background' + 'black_background', 'num_instances' } - postprocess_kwargs: set = {'pred_out_dir'} + postprocess_kwargs: set = {'pred_out_dir', 'return_datasample'} def __init__(self, pose2d: Optional[str] = None, @@ -79,10 +80,15 @@ def __init__(self, self.visualizer = None if pose3d is not None: - self.inferencer = Pose3DInferencer(pose3d, pose3d_weights, pose2d, - pose2d_weights, device, scope, - det_model, det_weights, - det_cat_ids) + if 'hand3d' in pose3d: + self.inferencer = Hand3DInferencer(pose3d, pose3d_weights, + device, scope, det_model, + det_weights, det_cat_ids) + else: + self.inferencer = Pose3DInferencer(pose3d, pose3d_weights, + pose2d, pose2d_weights, + device, scope, det_model, + det_weights, det_cat_ids) elif pose2d is not None: self.inferencer = Pose2DInferencer(pose2d, pose2d_weights, device, scope, det_model, det_weights, @@ -126,7 +132,7 @@ def forward(self, inputs: InputType, **forward_kwargs) -> PredType: def __call__( self, inputs: InputsType, - return_datasample: bool = False, + return_datasamples: bool = False, batch_size: int = 1, out_dir: Optional[str] = None, **kwargs, @@ -135,7 +141,7 @@ def __call__( Args: inputs (InputsType): Inputs for the inferencer. - return_datasample (bool): Whether to return results as + return_datasamples (bool): Whether to return results as :obj:`BaseDataElement`. Defaults to False. batch_size (int): Batch size. Defaults to 1. out_dir (str, optional): directory to save visualization @@ -201,8 +207,11 @@ def __call__( visualization = self.visualize(ori_inputs, preds, **visualize_kwargs) - results = self.postprocess(preds, visualization, return_datasample, - **postprocess_kwargs) + results = self.postprocess( + preds, + visualization, + return_datasamples=return_datasamples, + **postprocess_kwargs) yield results if self._video_input: diff --git a/mmpose/apis/inferencers/pose2d_inferencer.py b/mmpose/apis/inferencers/pose2d_inferencer.py index 3f1f20fdc0..5a0bbad004 100644 --- a/mmpose/apis/inferencers/pose2d_inferencer.py +++ b/mmpose/apis/inferencers/pose2d_inferencer.py @@ -1,6 +1,5 @@ # Copyright (c) OpenMMLab. All rights reserved. -import os -import warnings +import logging from typing import Dict, List, Optional, Sequence, Tuple, Union import mmcv @@ -8,21 +7,15 @@ import torch from mmengine.config import Config, ConfigDict from mmengine.infer.infer import ModelType +from mmengine.logging import print_log from mmengine.model import revert_sync_batchnorm from mmengine.registry import init_default_scope from mmengine.structures import InstanceData from mmpose.evaluation.functional import nms -from mmpose.registry import DATASETS, INFERENCERS +from mmpose.registry import INFERENCERS from mmpose.structures import merge_data_samples from .base_mmpose_inferencer import BaseMMPoseInferencer -from .utils import default_det_models - -try: - from mmdet.apis.det_inferencer import DetInferencer - has_mmdet = True -except (ImportError, ModuleNotFoundError): - has_mmdet = False InstanceList = List[InstanceData] InputType = Union[str, np.ndarray] @@ -77,7 +70,7 @@ class Pose2DInferencer(BaseMMPoseInferencer): 'draw_heatmap', 'black_background', } - postprocess_kwargs: set = {'pred_out_dir'} + postprocess_kwargs: set = {'pred_out_dir', 'return_datasample'} def __init__(self, model: Union[ModelType, str], @@ -98,36 +91,12 @@ def __init__(self, # initialize detector for top-down models if self.cfg.data_mode == 'topdown': - object_type = DATASETS.get(self.cfg.dataset_type).__module__.split( - 'datasets.')[-1].split('.')[0].lower() - - if det_model in ('whole_image', 'whole-image') or \ - (det_model is None and - object_type not in default_det_models): - self.detector = None - - else: - det_scope = 'mmdet' - if det_model is None: - det_info = default_det_models[object_type] - det_model, det_weights, det_cat_ids = det_info[ - 'model'], det_info['weights'], det_info['cat_ids'] - elif os.path.exists(det_model): - det_cfg = Config.fromfile(det_model) - det_scope = det_cfg.default_scope - - if has_mmdet: - self.detector = DetInferencer( - det_model, det_weights, device=device, scope=det_scope) - else: - raise RuntimeError( - 'MMDetection (v3.0.0 or above) is required to build ' - 'inferencers for top-down pose estimation models.') - - if isinstance(det_cat_ids, (tuple, list)): - self.det_cat_ids = det_cat_ids - else: - self.det_cat_ids = (det_cat_ids, ) + self._init_detector( + det_model=det_model, + det_weights=det_weights, + det_cat_ids=det_cat_ids, + device=device, + ) self._video_input = False @@ -182,9 +151,21 @@ def preprocess_single(self, data_info.update(self.model.dataset_meta) if self.cfg.data_mode == 'topdown': + bboxes = [] if self.detector is not None: - det_results = self.detector( - input, return_datasample=True)['predictions'] + try: + det_results = self.detector( + input, return_datasamples=True)['predictions'] + except ValueError: + print_log( + 'Support for mmpose and mmdet versions up to 3.1.0 ' + 'will be discontinued in upcoming releases. To ' + 'ensure ongoing compatibility, please upgrade to ' + 'mmdet version 3.2.0 or later.', + logger='current', + level=logging.WARNING) + det_results = self.detector( + input, return_datasample=True)['predictions'] pred_instance = det_results[0].pred_instances.cpu().numpy() bboxes = np.concatenate( (pred_instance.bboxes, pred_instance.scores[:, None]), @@ -253,75 +234,3 @@ def forward(self, ds.pred_instances = ds.pred_instances[ ds.pred_instances.bbox_scores > bbox_thr] return data_samples - - def __call__( - self, - inputs: InputsType, - return_datasample: bool = False, - batch_size: int = 1, - out_dir: Optional[str] = None, - **kwargs, - ) -> dict: - """Call the inferencer. - - Args: - inputs (InputsType): Inputs for the inferencer. - return_datasample (bool): Whether to return results as - :obj:`BaseDataElement`. Defaults to False. - batch_size (int): Batch size. Defaults to 1. - out_dir (str, optional): directory to save visualization - results and predictions. Will be overoden if vis_out_dir or - pred_out_dir are given. Defaults to None - **kwargs: Key words arguments passed to :meth:`preprocess`, - :meth:`forward`, :meth:`visualize` and :meth:`postprocess`. - Each key in kwargs should be in the corresponding set of - ``preprocess_kwargs``, ``forward_kwargs``, - ``visualize_kwargs`` and ``postprocess_kwargs``. - - Returns: - dict: Inference and visualization results. - """ - if out_dir is not None: - if 'vis_out_dir' not in kwargs: - kwargs['vis_out_dir'] = f'{out_dir}/visualizations' - if 'pred_out_dir' not in kwargs: - kwargs['pred_out_dir'] = f'{out_dir}/predictions' - - ( - preprocess_kwargs, - forward_kwargs, - visualize_kwargs, - postprocess_kwargs, - ) = self._dispatch_kwargs(**kwargs) - - self.update_model_visualizer_settings(**kwargs) - - # preprocessing - if isinstance(inputs, str) and inputs.startswith('webcam'): - inputs = self._get_webcam_inputs(inputs) - batch_size = 1 - if not visualize_kwargs.get('show', False): - warnings.warn('The display mode is closed when using webcam ' - 'input. It will be turned on automatically.') - visualize_kwargs['show'] = True - else: - inputs = self._inputs_to_list(inputs) - - forward_kwargs['bbox_thr'] = preprocess_kwargs.get('bbox_thr', -1) - inputs = self.preprocess( - inputs, batch_size=batch_size, **preprocess_kwargs) - - preds = [] - - for proc_inputs, ori_inputs in inputs: - preds = self.forward(proc_inputs, **forward_kwargs) - - visualization = self.visualize(ori_inputs, preds, - **visualize_kwargs) - results = self.postprocess(preds, visualization, return_datasample, - **postprocess_kwargs) - yield results - - if self._video_input: - self._finalize_video_processing( - postprocess_kwargs.get('pred_out_dir', '')) diff --git a/mmpose/apis/inferencers/pose3d_inferencer.py b/mmpose/apis/inferencers/pose3d_inferencer.py index 0fe66ac72b..b0c88c4e7d 100644 --- a/mmpose/apis/inferencers/pose3d_inferencer.py +++ b/mmpose/apis/inferencers/pose3d_inferencer.py @@ -1,21 +1,17 @@ # Copyright (c) OpenMMLab. All rights reserved. import os -import warnings from collections import defaultdict from functools import partial from typing import Callable, Dict, List, Optional, Sequence, Tuple, Union -import cv2 import mmcv import numpy as np import torch from mmengine.config import Config, ConfigDict -from mmengine.fileio import join_path from mmengine.infer.infer import ModelType from mmengine.model import revert_sync_batchnorm from mmengine.registry import init_default_scope from mmengine.structures import InstanceData -from mmengine.utils import mkdir_or_exist from mmpose.apis import (_track_by_iou, _track_by_oks, collate_pose_sequence, convert_keypoint_definition, extract_pose_sequence) @@ -67,9 +63,9 @@ class Pose3DInferencer(BaseMMPoseInferencer): preprocess_kwargs: set = { 'bbox_thr', 'nms_thr', 'bboxes', 'use_oks_tracking', 'tracking_thr', - 'norm_pose_2d' + 'disable_norm_pose_2d' } - forward_kwargs: set = {'rebase_keypoint_height'} + forward_kwargs: set = {'disable_rebase_keypoint'} visualize_kwargs: set = { 'return_vis', 'show', @@ -77,10 +73,11 @@ class Pose3DInferencer(BaseMMPoseInferencer): 'draw_bbox', 'radius', 'thickness', + 'num_instances', 'kpt_thr', 'vis_out_dir', } - postprocess_kwargs: set = {'pred_out_dir'} + postprocess_kwargs: set = {'pred_out_dir', 'return_datasample'} def __init__(self, model: Union[ModelType, str], @@ -109,9 +106,9 @@ def __init__(self, # helper functions self._keypoint_converter = partial( convert_keypoint_definition, - pose_det_dataset=self.pose2d_model.cfg.test_dataloader. - dataset['type'], - pose_lift_dataset=self.cfg.test_dataloader.dataset['type'], + pose_det_dataset=self.pose2d_model.model. + dataset_meta['dataset_name'], + pose_lift_dataset=self.model.dataset_meta['dataset_name'], ) self._pose_seq_extractor = partial( @@ -132,7 +129,7 @@ def preprocess_single(self, np.ndarray] = [], use_oks_tracking: bool = False, tracking_thr: float = 0.3, - norm_pose_2d: bool = False): + disable_norm_pose_2d: bool = False): """Process a single input into a model-feedable format. Args: @@ -149,8 +146,9 @@ def preprocess_single(self, whether OKS-based tracking should be used. Defaults to False. tracking_thr (float, optional): The threshold for tracking. Defaults to 0.3. - norm_pose_2d (bool, optional): A flag that indicates whether 2D - pose normalization should be used. Defaults to False. + disable_norm_pose_2d (bool, optional): A flag that indicates + whether 2D pose normalization should be used. + Defaults to False. Yields: Any: The data processed by the pipeline and collate_fn. @@ -168,7 +166,7 @@ def preprocess_single(self, nms_thr=nms_thr, bboxes=bboxes, merge_results=False, - return_datasample=True))['predictions'] + return_datasamples=True))['predictions'] for ds in results_pose2d: ds.pred_instances.set_field( @@ -231,14 +229,24 @@ def preprocess_single(self, bbox_center = stats_info.get('bbox_center', None) bbox_scale = stats_info.get('bbox_scale', None) - for i, pose_res in enumerate(pose_results_2d): - for j, data_sample in enumerate(pose_res): + pose_results_2d_copy = [] + for pose_res in pose_results_2d: + pose_res_copy = [] + for data_sample in pose_res: + + data_sample_copy = PoseDataSample() + data_sample_copy.gt_instances = \ + data_sample.gt_instances.clone() + data_sample_copy.pred_instances = \ + data_sample.pred_instances.clone() + data_sample_copy.track_id = data_sample.track_id + kpts = data_sample.pred_instances.keypoints bboxes = data_sample.pred_instances.bboxes keypoints = [] for k in range(len(kpts)): kpt = kpts[k] - if norm_pose_2d: + if not disable_norm_pose_2d: bbox = bboxes[k] center = np.array([[(bbox[0] + bbox[2]) / 2, (bbox[1] + bbox[3]) / 2]]) @@ -247,9 +255,12 @@ def preprocess_single(self, bbox_scale + bbox_center) else: keypoints.append(kpt[:, :2]) - pose_results_2d[i][j].pred_instances.keypoints = np.array( - keypoints) - pose_sequences_2d = collate_pose_sequence(pose_results_2d, True, + data_sample_copy.pred_instances.set_field( + np.array(keypoints), 'keypoints') + pose_res_copy.append(data_sample_copy) + + pose_results_2d_copy.append(pose_res_copy) + pose_sequences_2d = collate_pose_sequence(pose_results_2d_copy, True, target_idx) if not pose_sequences_2d: return [] @@ -271,8 +282,9 @@ def preprocess_single(self, K, ), dtype=np.float32) - data_info['lifting_target'] = np.zeros((K, 3), dtype=np.float32) - data_info['lifting_target_visible'] = np.ones((K, 1), + data_info['lifting_target'] = np.zeros((1, K, 3), dtype=np.float32) + data_info['factor'] = np.zeros((T, ), dtype=np.float32) + data_info['lifting_target_visible'] = np.ones((1, K, 1), dtype=np.float32) data_info['camera_param'] = dict(w=width, h=height) @@ -287,19 +299,18 @@ def preprocess_single(self, @torch.no_grad() def forward(self, inputs: Union[dict, tuple], - rebase_keypoint_height: bool = False): + disable_rebase_keypoint: bool = False): """Perform forward pass through the model and process the results. Args: inputs (Union[dict, tuple]): The inputs for the model. - rebase_keypoint_height (bool, optional): Flag to rebase the - height of the keypoints (z-axis). Defaults to False. + disable_rebase_keypoint (bool, optional): Flag to disable rebasing + the height of the keypoints. Defaults to False. Returns: list: A list of data samples, each containing the model's output results. """ - pose_lift_results = self.model.test_step(inputs) # Post-processing of pose estimation results @@ -309,14 +320,22 @@ def forward(self, pose_lift_res.track_id = pose_est_results_converted[idx].get( 'track_id', 1e4) - # Invert x and z values of the keypoints + # align the shape of output keypoints coordinates and scores keypoints = pose_lift_res.pred_instances.keypoints + keypoint_scores = pose_lift_res.pred_instances.keypoint_scores + if keypoint_scores.ndim == 3: + pose_lift_results[idx].pred_instances.keypoint_scores = \ + np.squeeze(keypoint_scores, axis=1) + if keypoints.ndim == 4: + keypoints = np.squeeze(keypoints, axis=1) + + # Invert x and z values of the keypoints keypoints = keypoints[..., [0, 2, 1]] keypoints[..., 0] = -keypoints[..., 0] keypoints[..., 2] = -keypoints[..., 2] # If rebase_keypoint_height is True, adjust z-axis values - if rebase_keypoint_height: + if not disable_rebase_keypoint: keypoints[..., 2] -= np.min( keypoints[..., 2], axis=-1, keepdims=True) @@ -328,78 +347,6 @@ def forward(self, data_samples = [merge_data_samples(pose_lift_results)] return data_samples - def __call__( - self, - inputs: InputsType, - return_datasample: bool = False, - batch_size: int = 1, - out_dir: Optional[str] = None, - **kwargs, - ) -> dict: - """Call the inferencer. - - Args: - inputs (InputsType): Inputs for the inferencer. - return_datasample (bool): Whether to return results as - :obj:`BaseDataElement`. Defaults to False. - batch_size (int): Batch size. Defaults to 1. - out_dir (str, optional): directory to save visualization - results and predictions. Will be overoden if vis_out_dir or - pred_out_dir are given. Defaults to None - **kwargs: Key words arguments passed to :meth:`preprocess`, - :meth:`forward`, :meth:`visualize` and :meth:`postprocess`. - Each key in kwargs should be in the corresponding set of - ``preprocess_kwargs``, ``forward_kwargs``, - ``visualize_kwargs`` and ``postprocess_kwargs``. - - Returns: - dict: Inference and visualization results. - """ - if out_dir is not None: - if 'vis_out_dir' not in kwargs: - kwargs['vis_out_dir'] = f'{out_dir}/visualizations' - if 'pred_out_dir' not in kwargs: - kwargs['pred_out_dir'] = f'{out_dir}/predictions' - - ( - preprocess_kwargs, - forward_kwargs, - visualize_kwargs, - postprocess_kwargs, - ) = self._dispatch_kwargs(**kwargs) - - self.update_model_visualizer_settings(**kwargs) - - # preprocessing - if isinstance(inputs, str) and inputs.startswith('webcam'): - inputs = self._get_webcam_inputs(inputs) - batch_size = 1 - if not visualize_kwargs.get('show', False): - warnings.warn('The display mode is closed when using webcam ' - 'input. It will be turned on automatically.') - visualize_kwargs['show'] = True - else: - inputs = self._inputs_to_list(inputs) - - inputs = self.preprocess( - inputs, batch_size=batch_size, **preprocess_kwargs) - - preds = [] - - for proc_inputs, ori_inputs in inputs: - preds = self.forward(proc_inputs, **forward_kwargs) - - visualization = self.visualize(ori_inputs, preds, - **visualize_kwargs) - results = self.postprocess(preds, visualization, return_datasample, - **postprocess_kwargs) - yield results - - if self._video_input: - self._finalize_video_processing( - postprocess_kwargs.get('pred_out_dir', '')) - self._buffer.clear() - def visualize(self, inputs: list, preds: List[PoseDataSample], @@ -410,6 +357,7 @@ def visualize(self, radius: int = 3, thickness: int = 1, kpt_thr: float = 0.3, + num_instances: int = 1, vis_out_dir: str = '', window_name: str = '', window_close_event_handler: Optional[Callable] = None @@ -470,6 +418,9 @@ def visualize(self, # thereby eliminating the issue of inference getting stuck. wait_time = 1e-5 if self._video_input else wait_time + if num_instances < 0: + num_instances = len(pred.pred_instances) + visualization = self.visualizer.add_datasample( window_name, img, @@ -479,38 +430,21 @@ def visualize(self, draw_bbox=draw_bbox, show=show, wait_time=wait_time, - kpt_thr=kpt_thr) + dataset_2d=self.pose2d_model.model. + dataset_meta['dataset_name'], + dataset_3d=self.model.dataset_meta['dataset_name'], + kpt_thr=kpt_thr, + num_instances=num_instances) results.append(visualization) if vis_out_dir: - out_img = mmcv.rgb2bgr(visualization) - _, file_extension = os.path.splitext(vis_out_dir) - if file_extension: - dir_name = os.path.dirname(vis_out_dir) - file_name = os.path.basename(vis_out_dir) - else: - dir_name = vis_out_dir - file_name = None - mkdir_or_exist(dir_name) - - if self._video_input: - - if self.video_info['writer'] is None: - fourcc = cv2.VideoWriter_fourcc(*'mp4v') - if file_name is None: - file_name = os.path.basename( - self.video_info['name']) - out_file = join_path(dir_name, file_name) - self.video_info['writer'] = cv2.VideoWriter( - out_file, fourcc, self.video_info['fps'], - (visualization.shape[1], visualization.shape[0])) - self.video_info['writer'].write(out_img) - - else: - img_name = os.path.basename(pred.metainfo['img_path']) - file_name = file_name if file_name else img_name - out_file = join_path(dir_name, file_name) - mmcv.imwrite(out_img, out_file) + img_name = os.path.basename(pred.metainfo['img_path']) \ + if 'img_path' in pred.metainfo else None + self.save_visualization( + visualization, + vis_out_dir, + img_name=img_name, + ) if return_vis: return results diff --git a/mmpose/apis/inferencers/utils/default_det_models.py b/mmpose/apis/inferencers/utils/default_det_models.py index 93b759c879..ea02097be0 100644 --- a/mmpose/apis/inferencers/utils/default_det_models.py +++ b/mmpose/apis/inferencers/utils/default_det_models.py @@ -15,11 +15,10 @@ 'yolo-x_8xb8-300e_coco-face_13274d7c.pth', cat_ids=(0, )), hand=dict( - model=osp.join( - mmpose_path, '.mim', 'demo/mmdetection_cfg/' - 'ssdlite_mobilenetv2_scratch_600e_onehand.py'), - weights='https://download.openmmlab.com/mmpose/mmdet_pretrained/' - 'ssdlite_mobilenetv2_scratch_600e_onehand-4f9f8686_20220523.pth', + model=osp.join(mmpose_path, '.mim', 'demo/mmdetection_cfg/' + 'rtmdet_nano_320-8xb32_hand.py'), + weights='https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/' + 'rtmdet_nano_8xb32-300e_hand-267f9c8f.pth', cat_ids=(0, )), animal=dict( model='rtmdet-m', diff --git a/mmpose/apis/visualization.py b/mmpose/apis/visualization.py new file mode 100644 index 0000000000..3ba96401d2 --- /dev/null +++ b/mmpose/apis/visualization.py @@ -0,0 +1,82 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from copy import deepcopy +from typing import Union + +import mmcv +import numpy as np +from mmengine.structures import InstanceData + +from mmpose.datasets.datasets.utils import parse_pose_metainfo +from mmpose.structures import PoseDataSample +from mmpose.visualization import PoseLocalVisualizer + + +def visualize( + img: Union[np.ndarray, str], + keypoints: np.ndarray, + keypoint_score: np.ndarray = None, + metainfo: Union[str, dict] = None, + visualizer: PoseLocalVisualizer = None, + show_kpt_idx: bool = False, + skeleton_style: str = 'mmpose', + show: bool = False, + kpt_thr: float = 0.3, +): + """Visualize 2d keypoints on an image. + + Args: + img (str | np.ndarray): The image to be displayed. + keypoints (np.ndarray): The keypoint to be displayed. + keypoint_score (np.ndarray): The score of each keypoint. + metainfo (str | dict): The metainfo of dataset. + visualizer (PoseLocalVisualizer): The visualizer. + show_kpt_idx (bool): Whether to show the index of keypoints. + skeleton_style (str): Skeleton style. Options are 'mmpose' and + 'openpose'. + show (bool): Whether to show the image. + wait_time (int): Value of waitKey param. + kpt_thr (float): Keypoint threshold. + """ + assert skeleton_style in [ + 'mmpose', 'openpose' + ], (f'Only support skeleton style in {["mmpose", "openpose"]}, ') + + if visualizer is None: + visualizer = PoseLocalVisualizer() + else: + visualizer = deepcopy(visualizer) + + if isinstance(metainfo, str): + metainfo = parse_pose_metainfo(dict(from_file=metainfo)) + elif isinstance(metainfo, dict): + metainfo = parse_pose_metainfo(metainfo) + + if metainfo is not None: + visualizer.set_dataset_meta(metainfo, skeleton_style=skeleton_style) + + if isinstance(img, str): + img = mmcv.imread(img, channel_order='rgb') + elif isinstance(img, np.ndarray): + img = mmcv.bgr2rgb(img) + + if keypoint_score is None: + keypoint_score = np.ones(keypoints.shape[0]) + + tmp_instances = InstanceData() + tmp_instances.keypoints = keypoints + tmp_instances.keypoint_score = keypoint_score + + tmp_datasample = PoseDataSample() + tmp_datasample.pred_instances = tmp_instances + + visualizer.add_datasample( + 'visualization', + img, + tmp_datasample, + show_kpt_idx=show_kpt_idx, + skeleton_style=skeleton_style, + show=show, + wait_time=0, + kpt_thr=kpt_thr) + + return visualizer.get_image() diff --git a/mmpose/codecs/__init__.py b/mmpose/codecs/__init__.py index cdbd8feb0c..4250949a4e 100644 --- a/mmpose/codecs/__init__.py +++ b/mmpose/codecs/__init__.py @@ -1,9 +1,13 @@ # Copyright (c) OpenMMLab. All rights reserved. +from .annotation_processors import YOLOXPoseAnnotationProcessor from .associative_embedding import AssociativeEmbedding from .decoupled_heatmap import DecoupledHeatmap +from .edpose_label import EDPoseLabel +from .hand_3d_heatmap import Hand3DHeatmap from .image_pose_lifting import ImagePoseLifting from .integral_regression_label import IntegralRegressionLabel from .megvii_heatmap import MegviiHeatmap +from .motionbert_label import MotionBERTLabel from .msra_heatmap import MSRAHeatmap from .regression_label import RegressionLabel from .simcc_label import SimCCLabel @@ -14,5 +18,7 @@ __all__ = [ 'MSRAHeatmap', 'MegviiHeatmap', 'UDPHeatmap', 'RegressionLabel', 'SimCCLabel', 'IntegralRegressionLabel', 'AssociativeEmbedding', 'SPR', - 'DecoupledHeatmap', 'VideoPoseLifting', 'ImagePoseLifting' + 'DecoupledHeatmap', 'VideoPoseLifting', 'ImagePoseLifting', + 'MotionBERTLabel', 'YOLOXPoseAnnotationProcessor', 'EDPoseLabel', + 'Hand3DHeatmap' ] diff --git a/mmpose/codecs/annotation_processors.py b/mmpose/codecs/annotation_processors.py new file mode 100644 index 0000000000..e857cdc0e4 --- /dev/null +++ b/mmpose/codecs/annotation_processors.py @@ -0,0 +1,92 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from typing import Dict, List, Optional, Tuple + +import numpy as np + +from mmpose.registry import KEYPOINT_CODECS +from .base import BaseKeypointCodec + +INF = 1e6 +NEG_INF = -1e6 + + +class BaseAnnotationProcessor(BaseKeypointCodec): + """Base class for annotation processors.""" + + def decode(self, *args, **kwargs): + pass + + +@KEYPOINT_CODECS.register_module() +class YOLOXPoseAnnotationProcessor(BaseAnnotationProcessor): + """Convert dataset annotations to the input format of YOLOX-Pose. + + This processor expands bounding boxes and converts category IDs to labels. + + Args: + expand_bbox (bool, optional): Whether to expand the bounding box + to include all keypoints. Defaults to False. + input_size (tuple, optional): The size of the input image for the + model, formatted as (h, w). This argument is necessary for the + codec in deployment but is not used indeed. + """ + + auxiliary_encode_keys = {'category_id', 'bbox'} + label_mapping_table = dict( + bbox='bboxes', + bbox_labels='labels', + keypoints='keypoints', + keypoints_visible='keypoints_visible', + area='areas', + ) + + def __init__(self, + expand_bbox: bool = False, + input_size: Optional[Tuple] = None): + super().__init__() + self.expand_bbox = expand_bbox + + def encode(self, + keypoints: Optional[np.ndarray] = None, + keypoints_visible: Optional[np.ndarray] = None, + bbox: Optional[np.ndarray] = None, + category_id: Optional[List[int]] = None + ) -> Dict[str, np.ndarray]: + """Encode keypoints, bounding boxes, and category IDs. + + Args: + keypoints (np.ndarray, optional): Keypoints array. Defaults + to None. + keypoints_visible (np.ndarray, optional): Visibility array for + keypoints. Defaults to None. + bbox (np.ndarray, optional): Bounding box array. Defaults to None. + category_id (List[int], optional): List of category IDs. Defaults + to None. + + Returns: + Dict[str, np.ndarray]: Encoded annotations. + """ + results = {} + + if self.expand_bbox and bbox is not None: + # Handle keypoints visibility + if keypoints_visible.ndim == 3: + keypoints_visible = keypoints_visible[..., 0] + + # Expand bounding box to include keypoints + kpts_min = keypoints.copy() + kpts_min[keypoints_visible == 0] = INF + bbox[..., :2] = np.minimum(bbox[..., :2], kpts_min.min(axis=1)) + + kpts_max = keypoints.copy() + kpts_max[keypoints_visible == 0] = NEG_INF + bbox[..., 2:] = np.maximum(bbox[..., 2:], kpts_max.max(axis=1)) + + results['bbox'] = bbox + + if category_id is not None: + # Convert category IDs to labels + bbox_labels = np.array(category_id).astype(np.int8) - 1 + results['bbox_labels'] = bbox_labels + + return results diff --git a/mmpose/codecs/associative_embedding.py b/mmpose/codecs/associative_embedding.py index 7e080f1657..def9bfd89e 100644 --- a/mmpose/codecs/associative_embedding.py +++ b/mmpose/codecs/associative_embedding.py @@ -1,5 +1,4 @@ # Copyright (c) OpenMMLab. All rights reserved. -from collections import namedtuple from itertools import product from typing import Any, List, Optional, Tuple @@ -16,6 +15,21 @@ refine_keypoints_dark_udp) +def _py_max_match(scores): + """Apply munkres algorithm to get the best match. + + Args: + scores(np.ndarray): cost matrix. + + Returns: + np.ndarray: best match. + """ + m = Munkres() + tmp = m.compute(scores) + tmp = np.array(tmp).astype(int) + return tmp + + def _group_keypoints_by_tags(vals: np.ndarray, tags: np.ndarray, locs: np.ndarray, @@ -54,89 +68,78 @@ def _group_keypoints_by_tags(vals: np.ndarray, np.ndarray: grouped keypoints in shape (G, K, D+1), where the last dimenssion is the concatenated keypoint coordinates and scores. """ + + tag_k, loc_k, val_k = tags, locs, vals K, M, D = locs.shape assert vals.shape == tags.shape[:2] == (K, M) assert len(keypoint_order) == K - # Build Munkres instance - munkres = Munkres() - - # Build a group pool, each group contains the keypoints of an instance - groups = [] + default_ = np.zeros((K, 3 + tag_k.shape[2]), dtype=np.float32) - Group = namedtuple('Group', field_names=['kpts', 'scores', 'tag_list']) + joint_dict = {} + tag_dict = {} + for i in range(K): + idx = keypoint_order[i] - def _init_group(): - """Initialize a group, which is composed of the keypoints, keypoint - scores and the tag of each keypoint.""" - _group = Group( - kpts=np.zeros((K, D), dtype=np.float32), - scores=np.zeros(K, dtype=np.float32), - tag_list=[]) - return _group + tags = tag_k[idx] + joints = np.concatenate((loc_k[idx], val_k[idx, :, None], tags), 1) + mask = joints[:, 2] > val_thr + tags = tags[mask] # shape: [M, L] + joints = joints[mask] # shape: [M, 3 + L], 3: x, y, val - for i in keypoint_order: - # Get all valid candidate of the i-th keypoints - valid = vals[i] > val_thr - if not valid.any(): + if joints.shape[0] == 0: continue - tags_i = tags[i, valid] # (M', L) - vals_i = vals[i, valid] # (M',) - locs_i = locs[i, valid] # (M', D) - - if len(groups) == 0: # Initialize the group pool - for tag, val, loc in zip(tags_i, vals_i, locs_i): - group = _init_group() - group.kpts[i] = loc - group.scores[i] = val - group.tag_list.append(tag) - - groups.append(group) - - else: # Match keypoints to existing groups - groups = groups[:max_groups] - group_tags = [np.mean(g.tag_list, axis=0) for g in groups] - - # Calculate distance matrix between group tags and tag candidates - # of the i-th keypoint - # Shape: (M', 1, L) , (1, G, L) -> (M', G, L) - diff = tags_i[:, None] - np.array(group_tags)[None] - dists = np.linalg.norm(diff, ord=2, axis=2) - num_kpts, num_groups = dists.shape[:2] - - # Experimental cost function for keypoint-group matching - costs = np.round(dists) * 100 - vals_i[..., None] - if num_kpts > num_groups: - padding = np.full((num_kpts, num_kpts - num_groups), - 1e10, - dtype=np.float32) - costs = np.concatenate((costs, padding), axis=1) - - # Match keypoints and groups by Munkres algorithm - matches = munkres.compute(costs) - for kpt_idx, group_idx in matches: - if group_idx < num_groups and dists[kpt_idx, - group_idx] < tag_thr: - # Add the keypoint to the matched group - group = groups[group_idx] + if i == 0 or len(joint_dict) == 0: + for tag, joint in zip(tags, joints): + key = tag[0] + joint_dict.setdefault(key, np.copy(default_))[idx] = joint + tag_dict[key] = [tag] + else: + # shape: [M] + grouped_keys = list(joint_dict.keys()) + # shape: [M, L] + grouped_tags = [np.mean(tag_dict[i], axis=0) for i in grouped_keys] + + # shape: [M, M, L] + diff = joints[:, None, 3:] - np.array(grouped_tags)[None, :, :] + # shape: [M, M] + diff_normed = np.linalg.norm(diff, ord=2, axis=2) + diff_saved = np.copy(diff_normed) + diff_normed = np.round(diff_normed) * 100 - joints[:, 2:3] + + num_added = diff.shape[0] + num_grouped = diff.shape[1] + + if num_added > num_grouped: + diff_normed = np.concatenate( + (diff_normed, + np.zeros((num_added, num_added - num_grouped), + dtype=np.float32) + 1e10), + axis=1) + + pairs = _py_max_match(diff_normed) + for row, col in pairs: + if (row < num_added and col < num_grouped + and diff_saved[row][col] < tag_thr): + key = grouped_keys[col] + joint_dict[key][idx] = joints[row] + tag_dict[key].append(tags[row]) else: - # Initialize a new group with unmatched keypoint - group = _init_group() - groups.append(group) - - group.kpts[i] = locs_i[kpt_idx] - group.scores[i] = vals_i[kpt_idx] - group.tag_list.append(tags_i[kpt_idx]) - - groups = groups[:max_groups] - if groups: - grouped_keypoints = np.stack( - [np.r_['1', g.kpts, g.scores[:, None]] for g in groups]) - else: - grouped_keypoints = np.empty((0, K, D + 1)) + key = tags[row][0] + joint_dict.setdefault(key, np.copy(default_))[idx] = \ + joints[row] + tag_dict[key] = [tags[row]] - return grouped_keypoints + joint_dict_keys = list(joint_dict.keys())[:max_groups] + + if joint_dict_keys: + results = np.array([joint_dict[i] + for i in joint_dict_keys]).astype(np.float32) + results = results[..., :D + 1] + else: + results = np.empty((0, K, D + 1), dtype=np.float32) + return results @KEYPOINT_CODECS.register_module() @@ -210,7 +213,8 @@ def __init__( decode_gaussian_kernel: int = 3, decode_keypoint_thr: float = 0.1, decode_tag_thr: float = 1.0, - decode_topk: int = 20, + decode_topk: int = 30, + decode_center_shift=0.0, decode_max_instances: Optional[int] = None, ) -> None: super().__init__() @@ -222,8 +226,9 @@ def __init__( self.decode_keypoint_thr = decode_keypoint_thr self.decode_tag_thr = decode_tag_thr self.decode_topk = decode_topk + self.decode_center_shift = decode_center_shift self.decode_max_instances = decode_max_instances - self.dedecode_keypoint_order = decode_keypoint_order.copy() + self.decode_keypoint_order = decode_keypoint_order.copy() if self.use_udp: self.scale_factor = ((np.array(input_size) - 1) / @@ -376,7 +381,7 @@ def _group_func(inputs: Tuple): vals, tags, locs, - keypoint_order=self.dedecode_keypoint_order, + keypoint_order=self.decode_keypoint_order, val_thr=self.decode_keypoint_thr, tag_thr=self.decode_tag_thr, max_groups=self.decode_max_instances) @@ -463,13 +468,13 @@ def batch_decode(self, batch_heatmaps: Tensor, batch_tags: Tensor f'tagging map ({batch_tags.shape})') # Heatmap NMS - batch_heatmaps = batch_heatmap_nms(batch_heatmaps, - self.decode_nms_kernel) + batch_heatmaps_peak = batch_heatmap_nms(batch_heatmaps, + self.decode_nms_kernel) # Get top-k in each heatmap and and convert to numpy batch_topk_vals, batch_topk_tags, batch_topk_locs = to_numpy( self._get_batch_topk( - batch_heatmaps, batch_tags, k=self.decode_topk)) + batch_heatmaps_peak, batch_tags, k=self.decode_topk)) # Group keypoint candidates into groups (instances) batch_groups = self._group_keypoints(batch_topk_vals, batch_topk_tags, @@ -482,16 +487,14 @@ def batch_decode(self, batch_heatmaps: Tensor, batch_tags: Tensor # Refine the keypoint prediction batch_keypoints = [] batch_keypoint_scores = [] + batch_instance_scores = [] for i, (groups, heatmaps, tags) in enumerate( zip(batch_groups, batch_heatmaps_np, batch_tags_np)): keypoints, scores = groups[..., :-1], groups[..., -1] + instance_scores = scores.mean(axis=-1) if keypoints.size > 0: - # identify missing keypoints - keypoints, scores = self._fill_missing_keypoints( - keypoints, scores, heatmaps, tags) - # refine keypoint coordinates according to heatmap distribution if self.use_udp: keypoints = refine_keypoints_dark_udp( @@ -500,13 +503,20 @@ def batch_decode(self, batch_heatmaps: Tensor, batch_tags: Tensor blur_kernel_size=self.decode_gaussian_kernel) else: keypoints = refine_keypoints(keypoints, heatmaps) + keypoints += self.decode_center_shift * \ + (scores > 0).astype(keypoints.dtype)[..., None] + + # identify missing keypoints + keypoints, scores = self._fill_missing_keypoints( + keypoints, scores, heatmaps, tags) batch_keypoints.append(keypoints) batch_keypoint_scores.append(scores) + batch_instance_scores.append(instance_scores) # restore keypoint scale batch_keypoints = [ kpts * self.scale_factor for kpts in batch_keypoints ] - return batch_keypoints, batch_keypoint_scores + return batch_keypoints, batch_keypoint_scores, batch_instance_scores diff --git a/mmpose/codecs/base.py b/mmpose/codecs/base.py index d8479fdf1e..b01e8c4b2c 100644 --- a/mmpose/codecs/base.py +++ b/mmpose/codecs/base.py @@ -18,6 +18,10 @@ class BaseKeypointCodec(metaclass=ABCMeta): # mandatory `keypoints` and `keypoints_visible` arguments. auxiliary_encode_keys = set() + field_mapping_table = dict() + instance_mapping_table = dict() + label_mapping_table = dict() + @abstractmethod def encode(self, keypoints: np.ndarray, diff --git a/mmpose/codecs/decoupled_heatmap.py b/mmpose/codecs/decoupled_heatmap.py index da38a4ce2c..b5929e3dcf 100644 --- a/mmpose/codecs/decoupled_heatmap.py +++ b/mmpose/codecs/decoupled_heatmap.py @@ -65,6 +65,15 @@ class DecoupledHeatmap(BaseKeypointCodec): # instance, so that it can assign varying sigmas based on their size auxiliary_encode_keys = {'bbox'} + label_mapping_table = dict( + keypoint_weights='keypoint_weights', + instance_coords='instance_coords', + ) + field_mapping_table = dict( + heatmaps='heatmaps', + instance_heatmaps='instance_heatmaps', + ) + def __init__( self, input_size: Tuple[int, int], diff --git a/mmpose/codecs/edpose_label.py b/mmpose/codecs/edpose_label.py new file mode 100644 index 0000000000..0433784886 --- /dev/null +++ b/mmpose/codecs/edpose_label.py @@ -0,0 +1,153 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from typing import Optional + +import numpy as np + +from mmpose.registry import KEYPOINT_CODECS +from mmpose.structures import bbox_cs2xyxy, bbox_xyxy2cs +from .base import BaseKeypointCodec + + +@KEYPOINT_CODECS.register_module() +class EDPoseLabel(BaseKeypointCodec): + r"""Generate keypoint and label coordinates for `ED-Pose`_ by + Yang J. et al (2023). + + Note: + + - instance number: N + - keypoint number: K + - keypoint dimension: D + - image size: [w, h] + + Encoded: + + - keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D) + - keypoints_visible (np.ndarray): Keypoint visibility in shape + (N, K, D) + - area (np.ndarray): Area in shape (N) + - bbox (np.ndarray): Bbox in shape (N, 4) + + Args: + num_select (int): The number of candidate instances + num_keypoints (int): The Number of keypoints + """ + + auxiliary_encode_keys = {'area', 'bboxes', 'img_shape'} + instance_mapping_table = dict( + bbox='bboxes', + keypoints='keypoints', + keypoints_visible='keypoints_visible', + area='areas', + ) + + def __init__(self, num_select: int = 100, num_keypoints: int = 17): + super().__init__() + + self.num_select = num_select + self.num_keypoints = num_keypoints + + def encode( + self, + img_shape, + keypoints: np.ndarray, + keypoints_visible: Optional[np.ndarray] = None, + area: Optional[np.ndarray] = None, + bboxes: Optional[np.ndarray] = None, + ) -> dict: + """Encoding keypoints, area and bbox from input image space to + normalized space. + + Args: + - img_shape (Sequence[int]): The shape of image in the format + of (width, height). + - keypoints (np.ndarray): Keypoint coordinates in + shape (N, K, D). + - keypoints_visible (np.ndarray): Keypoint visibility in shape + (N, K) + - area (np.ndarray): + - bboxes (np.ndarray): + + Returns: + encoded (dict): Contains the following items: + + - keypoint_labels (np.ndarray): The processed keypoints in + shape like (N, K, D). + - keypoints_visible (np.ndarray): Keypoint visibility in shape + (N, K, D) + - area_labels (np.ndarray): The processed target + area in shape (N). + - bboxes_labels: The processed target bbox in + shape (N, 4). + """ + w, h = img_shape + + if keypoints_visible is None: + keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32) + + if bboxes is not None: + bboxes = np.concatenate(bbox_xyxy2cs(bboxes), axis=-1) + bboxes = bboxes / np.array([w, h, w, h], dtype=np.float32) + + if area is not None: + area = area / float(w * h) + + if keypoints is not None: + keypoints = keypoints / np.array([w, h], dtype=np.float32) + + encoded = dict( + keypoints=keypoints, + area=area, + bbox=bboxes, + keypoints_visible=keypoints_visible) + + return encoded + + def decode(self, input_shapes: np.ndarray, pred_logits: np.ndarray, + pred_boxes: np.ndarray, pred_keypoints: np.ndarray): + """Select the final top-k keypoints, and decode the results from + normalize size to origin input size. + + Args: + input_shapes (Tensor): The size of input image resize. + test_cfg (ConfigType): Config of testing. + pred_logits (Tensor): The result of score. + pred_boxes (Tensor): The result of bbox. + pred_keypoints (Tensor): The result of keypoints. + + Returns: + tuple: Decoded boxes, keypoints, and keypoint scores. + """ + + # Initialization + num_keypoints = self.num_keypoints + prob = pred_logits.reshape(-1) + + # Select top-k instances based on prediction scores + topk_indexes = np.argsort(-prob)[:self.num_select] + topk_values = np.take_along_axis(prob, topk_indexes, axis=0) + scores = np.tile(topk_values[:, np.newaxis], [1, num_keypoints]) + + # Decode bounding boxes + topk_boxes = topk_indexes // pred_logits.shape[1] + boxes = bbox_cs2xyxy(*np.split(pred_boxes, [2], axis=-1)) + boxes = np.take_along_axis( + boxes, np.tile(topk_boxes[:, np.newaxis], [1, 4]), axis=0) + + # Convert from relative to absolute coordinates + img_h, img_w = np.split(input_shapes, 2, axis=0) + scale_fct = np.hstack([img_w, img_h, img_w, img_h]) + boxes = boxes * scale_fct[np.newaxis, :] + + # Decode keypoints + topk_keypoints = topk_indexes // pred_logits.shape[1] + keypoints = np.take_along_axis( + pred_keypoints, + np.tile(topk_keypoints[:, np.newaxis], [1, num_keypoints * 3]), + axis=0) + keypoints = keypoints[:, :(num_keypoints * 2)] + keypoints = keypoints * np.tile( + np.hstack([img_w, img_h]), [num_keypoints])[np.newaxis, :] + keypoints = keypoints.reshape(-1, num_keypoints, 2) + + return boxes, keypoints, scores diff --git a/mmpose/codecs/hand_3d_heatmap.py b/mmpose/codecs/hand_3d_heatmap.py new file mode 100644 index 0000000000..b088e0d7fa --- /dev/null +++ b/mmpose/codecs/hand_3d_heatmap.py @@ -0,0 +1,202 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from typing import Optional, Tuple + +import numpy as np + +from mmpose.registry import KEYPOINT_CODECS +from .base import BaseKeypointCodec +from .utils.gaussian_heatmap import generate_3d_gaussian_heatmaps +from .utils.post_processing import get_heatmap_3d_maximum + + +@KEYPOINT_CODECS.register_module() +class Hand3DHeatmap(BaseKeypointCodec): + r"""Generate target 3d heatmap and relative root depth for hand datasets. + + Note: + + - instance number: N + - keypoint number: K + - keypoint dimension: D + + Args: + image_size (tuple): Size of image. Default: ``[256, 256]``. + root_heatmap_size (int): Size of heatmap of root head. + Default: 64. + heatmap_size (tuple): Size of heatmap. Default: ``[64, 64, 64]``. + heatmap3d_depth_bound (float): Boundary for 3d heatmap depth. + Default: 400.0. + heatmap_size_root (int): Size of 3d heatmap root. Default: 64. + depth_size (int): Number of depth discretization size, used for + decoding. Defaults to 64. + root_depth_bound (float): Boundary for 3d heatmap root depth. + Default: 400.0. + use_different_joint_weights (bool): Whether to use different joint + weights. Default: ``False``. + sigma (int): Sigma of heatmap gaussian. Default: 2. + joint_indices (list, optional): Indices of joints used for heatmap + generation. If None (default) is given, all joints will be used. + Default: ``None``. + max_bound (float): The maximal value of heatmap. Default: 1.0. + """ + + auxiliary_encode_keys = { + 'dataset_keypoint_weights', 'rel_root_depth', 'rel_root_valid', + 'hand_type', 'hand_type_valid', 'focal', 'principal_pt' + } + + instance_mapping_table = { + 'keypoints': 'keypoints', + 'keypoints_visible': 'keypoints_visible', + 'keypoints_cam': 'keypoints_cam', + } + + label_mapping_table = { + 'keypoint_weights': 'keypoint_weights', + 'root_depth_weight': 'root_depth_weight', + 'type_weight': 'type_weight', + 'root_depth': 'root_depth', + 'type': 'type' + } + + def __init__(self, + image_size: Tuple[int, int] = [256, 256], + root_heatmap_size: int = 64, + heatmap_size: Tuple[int, int, int] = [64, 64, 64], + heatmap3d_depth_bound: float = 400.0, + heatmap_size_root: int = 64, + root_depth_bound: float = 400.0, + depth_size: int = 64, + use_different_joint_weights: bool = False, + sigma: int = 2, + joint_indices: Optional[list] = None, + max_bound: float = 1.0): + super().__init__() + + self.image_size = np.array(image_size) + self.root_heatmap_size = root_heatmap_size + self.heatmap_size = np.array(heatmap_size) + self.heatmap3d_depth_bound = heatmap3d_depth_bound + self.heatmap_size_root = heatmap_size_root + self.root_depth_bound = root_depth_bound + self.depth_size = depth_size + self.use_different_joint_weights = use_different_joint_weights + + self.sigma = sigma + self.joint_indices = joint_indices + self.max_bound = max_bound + self.scale_factor = (np.array(image_size) / + heatmap_size[:-1]).astype(np.float32) + + def encode( + self, + keypoints: np.ndarray, + keypoints_visible: Optional[np.ndarray], + dataset_keypoint_weights: Optional[np.ndarray], + rel_root_depth: np.float32, + rel_root_valid: np.float32, + hand_type: np.ndarray, + hand_type_valid: np.ndarray, + focal: np.ndarray, + principal_pt: np.ndarray, + ) -> dict: + """Encoding keypoints from input image space to input image space. + + Args: + keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D). + keypoints_visible (np.ndarray, optional): Keypoint visibilities in + shape (N, K). + dataset_keypoint_weights (np.ndarray, optional): Keypoints weight + in shape (K, ). + rel_root_depth (np.float32): Relative root depth. + rel_root_valid (float): Validity of relative root depth. + hand_type (np.ndarray): Type of hand encoded as a array. + hand_type_valid (np.ndarray): Validity of hand type. + focal (np.ndarray): Focal length of camera. + principal_pt (np.ndarray): Principal point of camera. + + Returns: + encoded (dict): Contains the following items: + + - heatmaps (np.ndarray): The generated heatmap in shape + (K * D, H, W) where [W, H, D] is the `heatmap_size` + - keypoint_weights (np.ndarray): The target weights in shape + (N, K) + - root_depth (np.ndarray): Encoded relative root depth + - root_depth_weight (np.ndarray): The weights of relative root + depth + - type (np.ndarray): Encoded hand type + - type_weight (np.ndarray): The weights of hand type + """ + if keypoints_visible is None: + keypoints_visible = np.ones(keypoints.shape[:-1], dtype=np.float32) + + if self.use_different_joint_weights: + assert dataset_keypoint_weights is not None, 'To use different ' \ + 'joint weights,`dataset_keypoint_weights` cannot be None.' + + heatmaps, keypoint_weights = generate_3d_gaussian_heatmaps( + heatmap_size=self.heatmap_size, + keypoints=keypoints, + keypoints_visible=keypoints_visible, + sigma=self.sigma, + image_size=self.image_size, + heatmap3d_depth_bound=self.heatmap3d_depth_bound, + joint_indices=self.joint_indices, + max_bound=self.max_bound, + use_different_joint_weights=self.use_different_joint_weights, + dataset_keypoint_weights=dataset_keypoint_weights) + + rel_root_depth = (rel_root_depth / self.root_depth_bound + + 0.5) * self.heatmap_size_root + rel_root_valid = rel_root_valid * (rel_root_depth >= 0) * ( + rel_root_depth <= self.heatmap_size_root) + + encoded = dict( + heatmaps=heatmaps, + keypoint_weights=keypoint_weights, + root_depth=rel_root_depth * np.ones(1, dtype=np.float32), + type=hand_type, + type_weight=hand_type_valid, + root_depth_weight=rel_root_valid * np.ones(1, dtype=np.float32)) + return encoded + + def decode(self, heatmaps: np.ndarray, root_depth: np.ndarray, + hand_type: np.ndarray) -> Tuple[np.ndarray, np.ndarray]: + """Decode keypoint coordinates from heatmaps. The decoded keypoint + coordinates are in the input image space. + + Args: + heatmaps (np.ndarray): Heatmaps in shape (K, D, H, W) + root_depth (np.ndarray): Root depth prediction. + hand_type (np.ndarray): Hand type prediction. + + Returns: + tuple: + - keypoints (np.ndarray): Decoded keypoint coordinates in shape + (N, K, D) + - scores (np.ndarray): The keypoint scores in shape (N, K). It + usually represents the confidence of the keypoint prediction + """ + heatmap3d = heatmaps.copy() + + keypoints, scores = get_heatmap_3d_maximum(heatmap3d) + + # transform keypoint depth to camera space + keypoints[..., 2] = (keypoints[..., 2] / self.depth_size - + 0.5) * self.heatmap3d_depth_bound + + # Unsqueeze the instance dimension for single-instance results + keypoints, scores = keypoints[None], scores[None] + + # Restore the keypoint scale + keypoints[..., :2] = keypoints[..., :2] * self.scale_factor + + # decode relative hand root depth + # transform relative root depth to camera space + rel_root_depth = ((root_depth / self.root_heatmap_size - 0.5) * + self.root_depth_bound) + + hand_type = (hand_type > 0).reshape(1, -1).astype(int) + + return keypoints, scores, rel_root_depth, hand_type diff --git a/mmpose/codecs/image_pose_lifting.py b/mmpose/codecs/image_pose_lifting.py index 64bf925997..81bd192eb3 100644 --- a/mmpose/codecs/image_pose_lifting.py +++ b/mmpose/codecs/image_pose_lifting.py @@ -25,6 +25,10 @@ class ImagePoseLifting(BaseKeypointCodec): Default: ``False``. save_index (bool): If true, store the root position separated from the original pose. Default: ``False``. + reshape_keypoints (bool): If true, reshape the keypoints into shape + (-1, N). Default: ``True``. + concat_vis (bool): If true, concat the visibility item of keypoints. + Default: ``False``. keypoints_mean (np.ndarray, optional): Mean values of keypoints coordinates in shape (K, D). keypoints_std (np.ndarray, optional): Std values of keypoints @@ -37,11 +41,22 @@ class ImagePoseLifting(BaseKeypointCodec): auxiliary_encode_keys = {'lifting_target', 'lifting_target_visible'} + instance_mapping_table = dict( + lifting_target='lifting_target', + lifting_target_visible='lifting_target_visible', + ) + label_mapping_table = dict( + trajectory_weights='trajectory_weights', + lifting_target_label='lifting_target_label', + lifting_target_weight='lifting_target_weight') + def __init__(self, num_keypoints: int, root_index: int, remove_root: bool = False, save_index: bool = False, + reshape_keypoints: bool = True, + concat_vis: bool = False, keypoints_mean: Optional[np.ndarray] = None, keypoints_std: Optional[np.ndarray] = None, target_mean: Optional[np.ndarray] = None, @@ -52,10 +67,30 @@ def __init__(self, self.root_index = root_index self.remove_root = remove_root self.save_index = save_index - if keypoints_mean is not None and keypoints_std is not None: - assert keypoints_mean.shape == keypoints_std.shape - if target_mean is not None and target_std is not None: - assert target_mean.shape == target_std.shape + self.reshape_keypoints = reshape_keypoints + self.concat_vis = concat_vis + if keypoints_mean is not None: + assert keypoints_std is not None, 'keypoints_std is None' + keypoints_mean = np.array( + keypoints_mean, + dtype=np.float32).reshape(1, num_keypoints, -1) + keypoints_std = np.array( + keypoints_std, dtype=np.float32).reshape(1, num_keypoints, -1) + + assert keypoints_mean.shape == keypoints_std.shape, ( + f'keypoints_mean.shape {keypoints_mean.shape} != ' + f'keypoints_std.shape {keypoints_std.shape}') + if target_mean is not None: + assert target_std is not None, 'target_std is None' + target_dim = num_keypoints - 1 if remove_root else num_keypoints + target_mean = np.array( + target_mean, dtype=np.float32).reshape(1, target_dim, -1) + target_std = np.array( + target_std, dtype=np.float32).reshape(1, target_dim, -1) + + assert target_mean.shape == target_std.shape, ( + f'target_mean.shape {target_mean.shape} != ' + f'target_std.shape {target_std.shape}') self.keypoints_mean = keypoints_mean self.keypoints_std = keypoints_std self.target_mean = target_mean @@ -73,18 +108,20 @@ def encode(self, keypoints_visible (np.ndarray, optional): Keypoint visibilities in shape (N, K). lifting_target (np.ndarray, optional): 3d target coordinate in - shape (K, C). + shape (T, K, C). lifting_target_visible (np.ndarray, optional): Target coordinate in - shape (K, ). + shape (T, K, ). Returns: encoded (dict): Contains the following items: - keypoint_labels (np.ndarray): The processed keypoints in - shape (K * D, N) where D is 2 for 2d coordinates. + shape like (N, K, D) or (K * D, N). + - keypoint_labels_visible (np.ndarray): The processed + keypoints' weights in shape (N, K, ) or (N-1, K, ). - lifting_target_label: The processed target coordinate in shape (K, C) or (K-1, C). - - lifting_target_weights (np.ndarray): The target weights in + - lifting_target_weight (np.ndarray): The target weights in shape (K, ) or (K-1, ). - trajectory_weights (np.ndarray): The trajectory weights in shape (K, ). @@ -93,30 +130,32 @@ def encode(self, In addition, there are some optional items it may contain: + - target_root (np.ndarray): The root coordinate of target in + shape (C, ). Exists if ``zero_center`` is ``True``. - target_root_removed (bool): Indicate whether the root of - pose lifting target is removed. Added if ``self.remove_root`` - is ``True``. + pose-lifitng target is removed. Exists if + ``remove_root`` is ``True``. - target_root_index (int): An integer indicating the index of - root. Added if ``self.remove_root`` and ``self.save_index`` + root. Exists if ``remove_root`` and ``save_index`` are ``True``. """ if keypoints_visible is None: keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32) if lifting_target is None: - lifting_target = keypoints[0] + lifting_target = [keypoints[0]] - # set initial value for `lifting_target_weights` + # set initial value for `lifting_target_weight` # and `trajectory_weights` if lifting_target_visible is None: lifting_target_visible = np.ones( lifting_target.shape[:-1], dtype=np.float32) - lifting_target_weights = lifting_target_visible + lifting_target_weight = lifting_target_visible trajectory_weights = (1 / lifting_target[:, 2]) else: valid = lifting_target_visible > 0.5 - lifting_target_weights = np.where(valid, 1., 0.).astype(np.float32) - trajectory_weights = lifting_target_weights + lifting_target_weight = np.where(valid, 1., 0.).astype(np.float32) + trajectory_weights = lifting_target_weight encoded = dict() @@ -126,15 +165,22 @@ def encode(self, f'Got invalid joint shape {lifting_target.shape}' root = lifting_target[..., self.root_index, :] - lifting_target_label = lifting_target - root + lifting_target_label = lifting_target - lifting_target[ + ..., self.root_index:self.root_index + 1, :] if self.remove_root: lifting_target_label = np.delete( lifting_target_label, self.root_index, axis=-2) - assert lifting_target_weights.ndim in {1, 2} - axis_to_remove = -2 if lifting_target_weights.ndim == 2 else -1 - lifting_target_weights = np.delete( - lifting_target_weights, self.root_index, axis=axis_to_remove) + lifting_target_visible = np.delete( + lifting_target_visible, self.root_index, axis=-2) + assert lifting_target_weight.ndim in { + 2, 3 + }, (f'lifting_target_weight.ndim {lifting_target_weight.ndim} ' + 'is not in {2, 3}') + + axis_to_remove = -2 if lifting_target_weight.ndim == 3 else -1 + lifting_target_weight = np.delete( + lifting_target_weight, self.root_index, axis=axis_to_remove) # Add a flag to avoid latter transforms that rely on the root # joint or the original joint index encoded['target_root_removed'] = True @@ -145,27 +191,47 @@ def encode(self, # Normalize the 2D keypoint coordinate with mean and std keypoint_labels = keypoints.copy() - if self.keypoints_mean is not None and self.keypoints_std is not None: - keypoints_shape = keypoints.shape - assert self.keypoints_mean.shape == keypoints_shape[1:] + if self.keypoints_mean is not None: + assert self.keypoints_mean.shape[1:] == keypoints.shape[1:], ( + f'self.keypoints_mean.shape[1:] {self.keypoints_mean.shape[1:]} ' # noqa + f'!= keypoints.shape[1:] {keypoints.shape[1:]}') + encoded['keypoints_mean'] = self.keypoints_mean.copy() + encoded['keypoints_std'] = self.keypoints_std.copy() keypoint_labels = (keypoint_labels - self.keypoints_mean) / self.keypoints_std - if self.target_mean is not None and self.target_std is not None: - target_shape = lifting_target_label.shape - assert self.target_mean.shape == target_shape + if self.target_mean is not None: + assert self.target_mean.shape == lifting_target_label.shape, ( + f'self.target_mean.shape {self.target_mean.shape} ' + f'!= lifting_target_label.shape {lifting_target_label.shape}') + encoded['target_mean'] = self.target_mean.copy() + encoded['target_std'] = self.target_std.copy() lifting_target_label = (lifting_target_label - self.target_mean) / self.target_std # Generate reshaped keypoint coordinates - assert keypoint_labels.ndim in {2, 3} + assert keypoint_labels.ndim in { + 2, 3 + }, (f'keypoint_labels.ndim {keypoint_labels.ndim} is not in {2, 3}') if keypoint_labels.ndim == 2: keypoint_labels = keypoint_labels[None, ...] + if self.concat_vis: + keypoints_visible_ = keypoints_visible + if keypoints_visible.ndim == 2: + keypoints_visible_ = keypoints_visible[..., None] + keypoint_labels = np.concatenate( + (keypoint_labels, keypoints_visible_), axis=2) + + if self.reshape_keypoints: + N = keypoint_labels.shape[0] + keypoint_labels = keypoint_labels.transpose(1, 2, 0).reshape(-1, N) + encoded['keypoint_labels'] = keypoint_labels + encoded['keypoint_labels_visible'] = keypoints_visible encoded['lifting_target_label'] = lifting_target_label - encoded['lifting_target_weights'] = lifting_target_weights + encoded['lifting_target_weight'] = lifting_target_weight encoded['trajectory_weights'] = trajectory_weights encoded['target_root'] = root @@ -190,11 +256,13 @@ def decode(self, keypoints = encoded.copy() if self.target_mean is not None and self.target_std is not None: - assert self.target_mean.shape == keypoints.shape[1:] + assert self.target_mean.shape == keypoints.shape, ( + f'self.target_mean.shape {self.target_mean.shape} ' + f'!= keypoints.shape {keypoints.shape}') keypoints = keypoints * self.target_std + self.target_mean - if target_root.size > 0: - keypoints = keypoints + np.expand_dims(target_root, axis=0) + if target_root is not None and target_root.size > 0: + keypoints = keypoints + target_root if self.remove_root: keypoints = np.insert( keypoints, self.root_index, target_root, axis=1) diff --git a/mmpose/codecs/integral_regression_label.py b/mmpose/codecs/integral_regression_label.py index ed8e72cb10..a3ded1f00b 100644 --- a/mmpose/codecs/integral_regression_label.py +++ b/mmpose/codecs/integral_regression_label.py @@ -45,6 +45,12 @@ class IntegralRegressionLabel(BaseKeypointCodec): .. _`DSNT`: https://arxiv.org/abs/1801.07372 """ + label_mapping_table = dict( + keypoint_labels='keypoint_labels', + keypoint_weights='keypoint_weights', + ) + field_mapping_table = dict(heatmaps='heatmaps', ) + def __init__(self, input_size: Tuple[int, int], heatmap_size: Tuple[int, int], diff --git a/mmpose/codecs/megvii_heatmap.py b/mmpose/codecs/megvii_heatmap.py index e898004637..3af0a54ff8 100644 --- a/mmpose/codecs/megvii_heatmap.py +++ b/mmpose/codecs/megvii_heatmap.py @@ -39,6 +39,9 @@ class MegviiHeatmap(BaseKeypointCodec): .. _`CPN`: https://arxiv.org/abs/1711.07319 """ + label_mapping_table = dict(keypoint_weights='keypoint_weights', ) + field_mapping_table = dict(heatmaps='heatmaps', ) + def __init__( self, input_size: Tuple[int, int], diff --git a/mmpose/codecs/motionbert_label.py b/mmpose/codecs/motionbert_label.py new file mode 100644 index 0000000000..98024ea4e6 --- /dev/null +++ b/mmpose/codecs/motionbert_label.py @@ -0,0 +1,240 @@ +# Copyright (c) OpenMMLab. All rights reserved. + +from copy import deepcopy +from typing import Optional, Tuple + +import numpy as np + +from mmpose.registry import KEYPOINT_CODECS +from .base import BaseKeypointCodec +from .utils import camera_to_image_coord + + +@KEYPOINT_CODECS.register_module() +class MotionBERTLabel(BaseKeypointCodec): + r"""Generate keypoint and label coordinates for `MotionBERT`_ by Zhu et al + (2022). + + Note: + + - instance number: N + - keypoint number: K + - keypoint dimension: D + - pose-lifitng target dimension: C + + Args: + num_keypoints (int): The number of keypoints in the dataset. + root_index (int): Root keypoint index in the pose. Default: 0. + remove_root (bool): If true, remove the root keypoint from the pose. + Default: ``False``. + save_index (bool): If true, store the root position separated from the + original pose, only takes effect if ``remove_root`` is ``True``. + Default: ``False``. + concat_vis (bool): If true, concat the visibility item of keypoints. + Default: ``False``. + rootrel (bool): If true, the root keypoint will be set to the + coordinate origin. Default: ``False``. + mode (str): Indicating whether the current mode is 'train' or 'test'. + Default: ``'test'``. + """ + + auxiliary_encode_keys = { + 'lifting_target', 'lifting_target_visible', 'camera_param', 'factor' + } + + instance_mapping_table = dict( + lifting_target='lifting_target', + lifting_target_visible='lifting_target_visible', + ) + label_mapping_table = dict( + trajectory_weights='trajectory_weights', + lifting_target_label='lifting_target_label', + lifting_target_weight='lifting_target_weight') + + def __init__(self, + num_keypoints: int, + root_index: int = 0, + remove_root: bool = False, + save_index: bool = False, + concat_vis: bool = False, + rootrel: bool = False, + mode: str = 'test'): + super().__init__() + + self.num_keypoints = num_keypoints + self.root_index = root_index + self.remove_root = remove_root + self.save_index = save_index + self.concat_vis = concat_vis + self.rootrel = rootrel + assert mode.lower() in {'train', 'test' + }, (f'Unsupported mode {mode}, ' + 'mode should be one of ("train", "test").') + self.mode = mode.lower() + + def encode(self, + keypoints: np.ndarray, + keypoints_visible: Optional[np.ndarray] = None, + lifting_target: Optional[np.ndarray] = None, + lifting_target_visible: Optional[np.ndarray] = None, + camera_param: Optional[dict] = None, + factor: Optional[np.ndarray] = None) -> dict: + """Encoding keypoints from input image space to normalized space. + + Args: + keypoints (np.ndarray): Keypoint coordinates in shape (B, T, K, D). + keypoints_visible (np.ndarray, optional): Keypoint visibilities in + shape (B, T, K). + lifting_target (np.ndarray, optional): 3d target coordinate in + shape (T, K, C). + lifting_target_visible (np.ndarray, optional): Target coordinate in + shape (T, K, ). + camera_param (dict, optional): The camera parameter dictionary. + factor (np.ndarray, optional): The factor mapping camera and image + coordinate in shape (T, ). + + Returns: + encoded (dict): Contains the following items: + + - keypoint_labels (np.ndarray): The processed keypoints in + shape like (N, K, D). + - keypoint_labels_visible (np.ndarray): The processed + keypoints' weights in shape (N, K, ) or (N, K-1, ). + - lifting_target_label: The processed target coordinate in + shape (K, C) or (K-1, C). + - lifting_target_weight (np.ndarray): The target weights in + shape (K, ) or (K-1, ). + - factor (np.ndarray): The factor mapping camera and image + coordinate in shape (T, 1). + """ + if keypoints_visible is None: + keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32) + + # set initial value for `lifting_target_weight` + if lifting_target_visible is None: + lifting_target_visible = np.ones( + lifting_target.shape[:-1], dtype=np.float32) + lifting_target_weight = lifting_target_visible + else: + valid = lifting_target_visible > 0.5 + lifting_target_weight = np.where(valid, 1., 0.).astype(np.float32) + + if camera_param is None: + camera_param = dict() + + encoded = dict() + + assert lifting_target is not None + lifting_target_label = lifting_target.copy() + keypoint_labels = keypoints.copy() + + assert keypoint_labels.ndim in { + 2, 3 + }, (f'Keypoint labels should have 2 or 3 dimensions, ' + f'but got {keypoint_labels.ndim}.') + if keypoint_labels.ndim == 2: + keypoint_labels = keypoint_labels[None, ...] + + # Normalize the 2D keypoint coordinate with image width and height + _camera_param = deepcopy(camera_param) + assert 'w' in _camera_param and 'h' in _camera_param, ( + 'Camera parameters should contain "w" and "h".') + w, h = _camera_param['w'], _camera_param['h'] + keypoint_labels[ + ..., :2] = keypoint_labels[..., :2] / w * 2 - [1, h / w] + + # convert target to image coordinate + T = keypoint_labels.shape[0] + factor_ = np.array([4] * T, dtype=np.float32).reshape(T, ) + if 'f' in _camera_param and 'c' in _camera_param: + lifting_target_label, factor_ = camera_to_image_coord( + self.root_index, lifting_target_label, _camera_param) + if self.mode == 'train': + w, h = w / 1000, h / 1000 + lifting_target_label[ + ..., :2] = lifting_target_label[..., :2] / w * 2 - [1, h / w] + lifting_target_label[..., 2] = lifting_target_label[..., 2] / w * 2 + lifting_target_label[..., :, :] = lifting_target_label[ + ..., :, :] - lifting_target_label[..., + self.root_index:self.root_index + + 1, :] + if factor is None or factor[0] == 0: + factor = factor_ + if factor.ndim == 1: + factor = factor[:, None] + if self.mode == 'test': + lifting_target_label *= factor[..., None] + + if self.concat_vis: + keypoints_visible_ = keypoints_visible + if keypoints_visible.ndim == 2: + keypoints_visible_ = keypoints_visible[..., None] + keypoint_labels = np.concatenate( + (keypoint_labels, keypoints_visible_), axis=2) + + encoded['keypoint_labels'] = keypoint_labels + encoded['keypoint_labels_visible'] = keypoints_visible + encoded['lifting_target_label'] = lifting_target_label + encoded['lifting_target_weight'] = lifting_target_weight + encoded['lifting_target'] = lifting_target_label + encoded['lifting_target_visible'] = lifting_target_visible + encoded['factor'] = factor + + return encoded + + def decode( + self, + encoded: np.ndarray, + w: Optional[np.ndarray] = None, + h: Optional[np.ndarray] = None, + factor: Optional[np.ndarray] = None, + ) -> Tuple[np.ndarray, np.ndarray]: + """Decode keypoint coordinates from normalized space to input image + space. + + Args: + encoded (np.ndarray): Coordinates in shape (N, K, C). + w (np.ndarray, optional): The image widths in shape (N, ). + Default: ``None``. + h (np.ndarray, optional): The image heights in shape (N, ). + Default: ``None``. + factor (np.ndarray, optional): The factor for projection in shape + (N, ). Default: ``None``. + + Returns: + keypoints (np.ndarray): Decoded coordinates in shape (N, K, C). + scores (np.ndarray): The keypoint scores in shape (N, K). + """ + keypoints = encoded.copy() + scores = np.ones(keypoints.shape[:-1], dtype=np.float32) + + if self.rootrel: + keypoints[..., 0, :] = 0 + + if w is not None and w.size > 0: + assert w.shape == h.shape, (f'w and h should have the same shape, ' + f'but got {w.shape} and {h.shape}.') + assert w.shape[0] == keypoints.shape[0], ( + f'w and h should have the same batch size, ' + f'but got {w.shape[0]} and {keypoints.shape[0]}.') + assert w.ndim in {1, + 2}, (f'w and h should have 1 or 2 dimensions, ' + f'but got {w.ndim}.') + if w.ndim == 1: + w = w[:, None] + h = h[:, None] + trans = np.append( + np.ones((w.shape[0], 1)), h / w, axis=1)[:, None, :] + keypoints[..., :2] = (keypoints[..., :2] + trans) * w[:, None] / 2 + keypoints[..., 2:] = keypoints[..., 2:] * w[:, None] / 2 + + if factor is not None and factor.size > 0: + assert factor.shape[0] == keypoints.shape[0], ( + f'factor should have the same batch size, ' + f'but got {factor.shape[0]} and {keypoints.shape[0]}.') + keypoints *= factor[..., None] + + keypoints[..., :, :] = keypoints[..., :, :] - keypoints[ + ..., self.root_index:self.root_index + 1, :] + keypoints /= 1000. + return keypoints, scores diff --git a/mmpose/codecs/msra_heatmap.py b/mmpose/codecs/msra_heatmap.py index 63ba292e4d..15742555b4 100644 --- a/mmpose/codecs/msra_heatmap.py +++ b/mmpose/codecs/msra_heatmap.py @@ -47,6 +47,9 @@ class MSRAHeatmap(BaseKeypointCodec): .. _`Dark Pose`: https://arxiv.org/abs/1910.06278 """ + label_mapping_table = dict(keypoint_weights='keypoint_weights', ) + field_mapping_table = dict(heatmaps='heatmaps', ) + def __init__(self, input_size: Tuple[int, int], heatmap_size: Tuple[int, int], diff --git a/mmpose/codecs/regression_label.py b/mmpose/codecs/regression_label.py index f79195beb4..74cd21b73d 100644 --- a/mmpose/codecs/regression_label.py +++ b/mmpose/codecs/regression_label.py @@ -30,6 +30,11 @@ class RegressionLabel(BaseKeypointCodec): """ + label_mapping_table = dict( + keypoint_labels='keypoint_labels', + keypoint_weights='keypoint_weights', + ) + def __init__(self, input_size: Tuple[int, int]) -> None: super().__init__() diff --git a/mmpose/codecs/simcc_label.py b/mmpose/codecs/simcc_label.py index a22498c352..6183e2be73 100644 --- a/mmpose/codecs/simcc_label.py +++ b/mmpose/codecs/simcc_label.py @@ -52,6 +52,12 @@ class SimCCLabel(BaseKeypointCodec): Estimation`: https://arxiv.org/abs/2107.03332 """ + label_mapping_table = dict( + keypoint_x_labels='keypoint_x_labels', + keypoint_y_labels='keypoint_y_labels', + keypoint_weights='keypoint_weights', + ) + def __init__(self, input_size: Tuple[int, int], smoothing_type: str = 'gaussian', diff --git a/mmpose/codecs/spr.py b/mmpose/codecs/spr.py index add6f5715b..8e09b185c7 100644 --- a/mmpose/codecs/spr.py +++ b/mmpose/codecs/spr.py @@ -73,6 +73,13 @@ class SPR(BaseKeypointCodec): https://arxiv.org/abs/1908.09220 """ + field_mapping_table = dict( + heatmaps='heatmaps', + heatmap_weights='heatmap_weights', + displacements='displacements', + displacement_weights='displacement_weights', + ) + def __init__( self, input_size: Tuple[int, int], diff --git a/mmpose/codecs/udp_heatmap.py b/mmpose/codecs/udp_heatmap.py index c38ea17be4..7e7e341e19 100644 --- a/mmpose/codecs/udp_heatmap.py +++ b/mmpose/codecs/udp_heatmap.py @@ -57,6 +57,9 @@ class UDPHeatmap(BaseKeypointCodec): Human Pose Estimation`: https://arxiv.org/abs/1911.07524 """ + label_mapping_table = dict(keypoint_weights='keypoint_weights', ) + field_mapping_table = dict(heatmaps='heatmaps', ) + def __init__(self, input_size: Tuple[int, int], heatmap_size: Tuple[int, int], diff --git a/mmpose/codecs/utils/__init__.py b/mmpose/codecs/utils/__init__.py index eaa093f12b..b5b19588b9 100644 --- a/mmpose/codecs/utils/__init__.py +++ b/mmpose/codecs/utils/__init__.py @@ -1,5 +1,8 @@ # Copyright (c) OpenMMLab. All rights reserved. -from .gaussian_heatmap import (generate_gaussian_heatmaps, +from .camera_image_projection import (camera_to_image_coord, camera_to_pixel, + pixel_to_camera) +from .gaussian_heatmap import (generate_3d_gaussian_heatmaps, + generate_gaussian_heatmaps, generate_udp_gaussian_heatmaps, generate_unbiased_gaussian_heatmaps) from .instance_property import (get_diagonal_lengths, get_instance_bbox, @@ -7,8 +10,9 @@ from .offset_heatmap import (generate_displacement_heatmap, generate_offset_heatmap) from .post_processing import (batch_heatmap_nms, gaussian_blur, - gaussian_blur1d, get_heatmap_maximum, - get_simcc_maximum, get_simcc_normalized) + gaussian_blur1d, get_heatmap_3d_maximum, + get_heatmap_maximum, get_simcc_maximum, + get_simcc_normalized) from .refinement import (refine_keypoints, refine_keypoints_dark, refine_keypoints_dark_udp, refine_simcc_dark) @@ -19,5 +23,7 @@ 'batch_heatmap_nms', 'refine_keypoints', 'refine_keypoints_dark', 'refine_keypoints_dark_udp', 'generate_displacement_heatmap', 'refine_simcc_dark', 'gaussian_blur1d', 'get_diagonal_lengths', - 'get_instance_root', 'get_instance_bbox', 'get_simcc_normalized' + 'get_instance_root', 'get_instance_bbox', 'get_simcc_normalized', + 'camera_to_image_coord', 'camera_to_pixel', 'pixel_to_camera', + 'get_heatmap_3d_maximum', 'generate_3d_gaussian_heatmaps' ] diff --git a/mmpose/codecs/utils/camera_image_projection.py b/mmpose/codecs/utils/camera_image_projection.py new file mode 100644 index 0000000000..b26d1396f1 --- /dev/null +++ b/mmpose/codecs/utils/camera_image_projection.py @@ -0,0 +1,102 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from typing import Dict, Tuple + +import numpy as np + + +def camera_to_image_coord(root_index: int, kpts_3d_cam: np.ndarray, + camera_param: Dict) -> Tuple[np.ndarray, np.ndarray]: + """Project keypoints from camera space to image space and calculate factor. + + Args: + root_index (int): Index for root keypoint. + kpts_3d_cam (np.ndarray): Keypoint coordinates in camera space in + shape (N, K, D). + camera_param (dict): Parameters for the camera. + + Returns: + tuple: + - kpts_3d_image (np.ndarray): Keypoint coordinates in image space in + shape (N, K, D). + - factor (np.ndarray): The scaling factor that maps keypoints from + image space to camera space in shape (N, ). + """ + + root = kpts_3d_cam[..., root_index, :] + tl_kpt = root.copy() + tl_kpt[..., :2] -= 1.0 + br_kpt = root.copy() + br_kpt[..., :2] += 1.0 + tl_kpt = np.reshape(tl_kpt, (-1, 3)) + br_kpt = np.reshape(br_kpt, (-1, 3)) + fx, fy = camera_param['f'] / 1000. + cx, cy = camera_param['c'] / 1000. + + tl2d = camera_to_pixel(tl_kpt, fx, fy, cx, cy) + br2d = camera_to_pixel(br_kpt, fx, fy, cx, cy) + + rectangle_3d_size = 2.0 + kpts_3d_image = np.zeros_like(kpts_3d_cam) + kpts_3d_image[..., :2] = camera_to_pixel(kpts_3d_cam.copy(), fx, fy, cx, + cy) + ratio = (br2d[..., 0] - tl2d[..., 0] + 0.001) / rectangle_3d_size + factor = rectangle_3d_size / (br2d[..., 0] - tl2d[..., 0] + 0.001) + kpts_3d_depth = ratio[:, None] * ( + kpts_3d_cam[..., 2] - kpts_3d_cam[..., root_index:root_index + 1, 2]) + kpts_3d_image[..., 2] = kpts_3d_depth + return kpts_3d_image, factor + + +def camera_to_pixel(kpts_3d: np.ndarray, + fx: float, + fy: float, + cx: float, + cy: float, + shift: bool = False) -> np.ndarray: + """Project keypoints from camera space to image space. + + Args: + kpts_3d (np.ndarray): Keypoint coordinates in camera space. + fx (float): x-coordinate of camera's focal length. + fy (float): y-coordinate of camera's focal length. + cx (float): x-coordinate of image center. + cy (float): y-coordinate of image center. + shift (bool): Whether to shift the coordinates by 1e-8. + + Returns: + pose_2d (np.ndarray): Projected keypoint coordinates in image space. + """ + if not shift: + pose_2d = kpts_3d[..., :2] / kpts_3d[..., 2:3] + else: + pose_2d = kpts_3d[..., :2] / (kpts_3d[..., 2:3] + 1e-8) + pose_2d[..., 0] *= fx + pose_2d[..., 1] *= fy + pose_2d[..., 0] += cx + pose_2d[..., 1] += cy + return pose_2d + + +def pixel_to_camera(kpts_3d: np.ndarray, fx: float, fy: float, cx: float, + cy: float) -> np.ndarray: + """Project keypoints from camera space to image space. + + Args: + kpts_3d (np.ndarray): Keypoint coordinates in camera space. + fx (float): x-coordinate of camera's focal length. + fy (float): y-coordinate of camera's focal length. + cx (float): x-coordinate of image center. + cy (float): y-coordinate of image center. + shift (bool): Whether to shift the coordinates by 1e-8. + + Returns: + pose_2d (np.ndarray): Projected keypoint coordinates in image space. + """ + pose_2d = kpts_3d.copy() + pose_2d[..., 0] -= cx + pose_2d[..., 1] -= cy + pose_2d[..., 0] /= fx + pose_2d[..., 1] /= fy + pose_2d[..., 0] *= kpts_3d[..., 2] + pose_2d[..., 1] *= kpts_3d[..., 2] + return pose_2d diff --git a/mmpose/codecs/utils/gaussian_heatmap.py b/mmpose/codecs/utils/gaussian_heatmap.py index 91e08c2cdd..f8deeb8d9d 100644 --- a/mmpose/codecs/utils/gaussian_heatmap.py +++ b/mmpose/codecs/utils/gaussian_heatmap.py @@ -1,10 +1,122 @@ # Copyright (c) OpenMMLab. All rights reserved. from itertools import product -from typing import Tuple, Union +from typing import Optional, Tuple, Union import numpy as np +def generate_3d_gaussian_heatmaps( + heatmap_size: Tuple[int, int, int], + keypoints: np.ndarray, + keypoints_visible: np.ndarray, + sigma: Union[float, Tuple[float], np.ndarray], + image_size: Tuple[int, int], + heatmap3d_depth_bound: float = 400.0, + joint_indices: Optional[list] = None, + max_bound: float = 1.0, + use_different_joint_weights: bool = False, + dataset_keypoint_weights: Optional[np.ndarray] = None +) -> Tuple[np.ndarray, np.ndarray]: + """Generate 3d gaussian heatmaps of keypoints. + + Args: + heatmap_size (Tuple[int, int]): Heatmap size in [W, H, D] + keypoints (np.ndarray): Keypoint coordinates in shape (N, K, C) + keypoints_visible (np.ndarray): Keypoint visibilities in shape + (N, K) + sigma (float or List[float]): A list of sigma values of the Gaussian + heatmap for each instance. If sigma is given as a single float + value, it will be expanded into a tuple + image_size (Tuple[int, int]): Size of input image. + heatmap3d_depth_bound (float): Boundary for 3d heatmap depth. + Default: 400.0. + joint_indices (List[int], optional): Indices of joints used for heatmap + generation. If None (default) is given, all joints will be used. + Default: ``None``. + max_bound (float): The maximal value of heatmap. Default: 1.0. + use_different_joint_weights (bool): Whether to use different joint + weights. Default: ``False``. + dataset_keypoint_weights (np.ndarray, optional): Keypoints weight in + shape (K, ). + + Returns: + tuple: + - heatmaps (np.ndarray): The generated heatmap in shape + (K * D, H, W) where [W, H, D] is the `heatmap_size` + - keypoint_weights (np.ndarray): The target weights in shape + (N, K) + """ + + W, H, D = heatmap_size + + # select the joints used for target generation + if joint_indices is not None: + keypoints = keypoints[:, joint_indices, ...] + keypoints_visible = keypoints_visible[:, joint_indices, ...] + N, K, _ = keypoints.shape + + heatmaps = np.zeros([K, D, H, W], dtype=np.float32) + keypoint_weights = keypoints_visible.copy() + + if isinstance(sigma, (int, float)): + sigma = (sigma, ) * N + + for n in range(N): + # 3-sigma rule + radius = sigma[n] * 3 + + # joint location in heatmap coordinates + mu_x = keypoints[n, :, 0] * W / image_size[0] # (K, ) + mu_y = keypoints[n, :, 1] * H / image_size[1] + mu_z = (keypoints[n, :, 2] / heatmap3d_depth_bound + 0.5) * D + + keypoint_weights[n, ...] = keypoint_weights[n, ...] * (mu_z >= 0) * ( + mu_z < D) + if use_different_joint_weights: + keypoint_weights[ + n] = keypoint_weights[n] * dataset_keypoint_weights + # xy grid + gaussian_size = 2 * radius + 1 + + # get neighboring voxels coordinates + x = y = z = np.arange(gaussian_size, dtype=np.float32) - radius + zz, yy, xx = np.meshgrid(z, y, x) + + xx = np.expand_dims(xx, axis=0) + yy = np.expand_dims(yy, axis=0) + zz = np.expand_dims(zz, axis=0) + mu_x = np.expand_dims(mu_x, axis=(-1, -2, -3)) + mu_y = np.expand_dims(mu_y, axis=(-1, -2, -3)) + mu_z = np.expand_dims(mu_z, axis=(-1, -2, -3)) + + xx, yy, zz = xx + mu_x, yy + mu_y, zz + mu_z + local_size = xx.shape[1] + + # round the coordinates + xx = xx.round().clip(0, W - 1) + yy = yy.round().clip(0, H - 1) + zz = zz.round().clip(0, D - 1) + + # compute the target value near joints + gaussian = np.exp(-((xx - mu_x)**2 + (yy - mu_y)**2 + (zz - mu_z)**2) / + (2 * sigma[n]**2)) + + # put the local target value to the full target heatmap + idx_joints = np.tile( + np.expand_dims(np.arange(K), axis=(-1, -2, -3)), + [1, local_size, local_size, local_size]) + idx = np.stack([idx_joints, zz, yy, xx], + axis=-1).astype(int).reshape(-1, 4) + + heatmaps[idx[:, 0], idx[:, 1], idx[:, 2], idx[:, 3]] = np.maximum( + heatmaps[idx[:, 0], idx[:, 1], idx[:, 2], idx[:, 3]], + gaussian.reshape(-1)) + + heatmaps = (heatmaps * max_bound).reshape(-1, H, W) + + return heatmaps, keypoint_weights + + def generate_gaussian_heatmaps( heatmap_size: Tuple[int, int], keypoints: np.ndarray, diff --git a/mmpose/codecs/utils/post_processing.py b/mmpose/codecs/utils/post_processing.py index 75356388dc..7bb447e199 100644 --- a/mmpose/codecs/utils/post_processing.py +++ b/mmpose/codecs/utils/post_processing.py @@ -94,6 +94,54 @@ def get_simcc_maximum(simcc_x: np.ndarray, return locs, vals +def get_heatmap_3d_maximum(heatmaps: np.ndarray + ) -> Tuple[np.ndarray, np.ndarray]: + """Get maximum response location and value from heatmaps. + + Note: + batch_size: B + num_keypoints: K + heatmap dimension: D + heatmap height: H + heatmap width: W + + Args: + heatmaps (np.ndarray): Heatmaps in shape (K, D, H, W) or + (B, K, D, H, W) + + Returns: + tuple: + - locs (np.ndarray): locations of maximum heatmap responses in shape + (K, 3) or (B, K, 3) + - vals (np.ndarray): values of maximum heatmap responses in shape + (K,) or (B, K) + """ + assert isinstance(heatmaps, + np.ndarray), ('heatmaps should be numpy.ndarray') + assert heatmaps.ndim == 4 or heatmaps.ndim == 5, ( + f'Invalid shape {heatmaps.shape}') + + if heatmaps.ndim == 4: + K, D, H, W = heatmaps.shape + B = None + heatmaps_flatten = heatmaps.reshape(K, -1) + else: + B, K, D, H, W = heatmaps.shape + heatmaps_flatten = heatmaps.reshape(B * K, -1) + + z_locs, y_locs, x_locs = np.unravel_index( + np.argmax(heatmaps_flatten, axis=1), shape=(D, H, W)) + locs = np.stack((x_locs, y_locs, z_locs), axis=-1).astype(np.float32) + vals = np.amax(heatmaps_flatten, axis=1) + locs[vals <= 0.] = -1 + + if B: + locs = locs.reshape(B, K, 3) + vals = vals.reshape(B, K) + + return locs, vals + + def get_heatmap_maximum(heatmaps: np.ndarray) -> Tuple[np.ndarray, np.ndarray]: """Get maximum response location and value from heatmaps. diff --git a/mmpose/codecs/video_pose_lifting.py b/mmpose/codecs/video_pose_lifting.py index 56cf35fa2d..2b08b4da85 100644 --- a/mmpose/codecs/video_pose_lifting.py +++ b/mmpose/codecs/video_pose_lifting.py @@ -30,6 +30,10 @@ class VideoPoseLifting(BaseKeypointCodec): save_index (bool): If true, store the root position separated from the original pose, only takes effect if ``remove_root`` is ``True``. Default: ``False``. + reshape_keypoints (bool): If true, reshape the keypoints into shape + (-1, N). Default: ``True``. + concat_vis (bool): If true, concat the visibility item of keypoints. + Default: ``False``. normalize_camera (bool): Whether to normalize camera intrinsics. Default: ``False``. """ @@ -38,12 +42,23 @@ class VideoPoseLifting(BaseKeypointCodec): 'lifting_target', 'lifting_target_visible', 'camera_param' } + instance_mapping_table = dict( + lifting_target='lifting_target', + lifting_target_visible='lifting_target_visible', + ) + label_mapping_table = dict( + trajectory_weights='trajectory_weights', + lifting_target_label='lifting_target_label', + lifting_target_weight='lifting_target_weight') + def __init__(self, num_keypoints: int, zero_center: bool = True, root_index: int = 0, remove_root: bool = False, save_index: bool = False, + reshape_keypoints: bool = True, + concat_vis: bool = False, normalize_camera: bool = False): super().__init__() @@ -52,6 +67,8 @@ def __init__(self, self.root_index = root_index self.remove_root = remove_root self.save_index = save_index + self.reshape_keypoints = reshape_keypoints + self.concat_vis = concat_vis self.normalize_camera = normalize_camera def encode(self, @@ -67,19 +84,21 @@ def encode(self, keypoints_visible (np.ndarray, optional): Keypoint visibilities in shape (N, K). lifting_target (np.ndarray, optional): 3d target coordinate in - shape (K, C). + shape (T, K, C). lifting_target_visible (np.ndarray, optional): Target coordinate in - shape (K, ). + shape (T, K, ). camera_param (dict, optional): The camera parameter dictionary. Returns: encoded (dict): Contains the following items: - keypoint_labels (np.ndarray): The processed keypoints in - shape (K * D, N) where D is 2 for 2d coordinates. + shape like (N, K, D) or (K * D, N). + - keypoint_labels_visible (np.ndarray): The processed + keypoints' weights in shape (N, K, ) or (N-1, K, ). - lifting_target_label: The processed target coordinate in shape (K, C) or (K-1, C). - - lifting_target_weights (np.ndarray): The target weights in + - lifting_target_weight (np.ndarray): The target weights in shape (K, ) or (K-1, ). - trajectory_weights (np.ndarray): The trajectory weights in shape (K, ). @@ -87,33 +106,33 @@ def encode(self, In addition, there are some optional items it may contain: - target_root (np.ndarray): The root coordinate of target in - shape (C, ). Exists if ``self.zero_center`` is ``True``. + shape (C, ). Exists if ``zero_center`` is ``True``. - target_root_removed (bool): Indicate whether the root of pose-lifitng target is removed. Exists if - ``self.remove_root`` is ``True``. + ``remove_root`` is ``True``. - target_root_index (int): An integer indicating the index of - root. Exists if ``self.remove_root`` and ``self.save_index`` + root. Exists if ``remove_root`` and ``save_index`` are ``True``. - camera_param (dict): The updated camera parameter dictionary. - Exists if ``self.normalize_camera`` is ``True``. + Exists if ``normalize_camera`` is ``True``. """ if keypoints_visible is None: keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32) if lifting_target is None: - lifting_target = keypoints[0] + lifting_target = [keypoints[0]] - # set initial value for `lifting_target_weights` + # set initial value for `lifting_target_weight` # and `trajectory_weights` if lifting_target_visible is None: lifting_target_visible = np.ones( lifting_target.shape[:-1], dtype=np.float32) - lifting_target_weights = lifting_target_visible + lifting_target_weight = lifting_target_visible trajectory_weights = (1 / lifting_target[:, 2]) else: valid = lifting_target_visible > 0.5 - lifting_target_weights = np.where(valid, 1., 0.).astype(np.float32) - trajectory_weights = lifting_target_weights + lifting_target_weight = np.where(valid, 1., 0.).astype(np.float32) + trajectory_weights = lifting_target_weight if camera_param is None: camera_param = dict() @@ -128,16 +147,23 @@ def encode(self, f'Got invalid joint shape {lifting_target.shape}' root = lifting_target[..., self.root_index, :] - lifting_target_label = lifting_target_label - root + lifting_target_label -= lifting_target_label[ + ..., self.root_index:self.root_index + 1, :] encoded['target_root'] = root if self.remove_root: lifting_target_label = np.delete( lifting_target_label, self.root_index, axis=-2) - assert lifting_target_weights.ndim in {1, 2} - axis_to_remove = -2 if lifting_target_weights.ndim == 2 else -1 - lifting_target_weights = np.delete( - lifting_target_weights, + lifting_target_visible = np.delete( + lifting_target_visible, self.root_index, axis=-2) + assert lifting_target_weight.ndim in { + 2, 3 + }, (f'Got invalid lifting target weights shape ' + f'{lifting_target_weight.shape}') + + axis_to_remove = -2 if lifting_target_weight.ndim == 3 else -1 + lifting_target_weight = np.delete( + lifting_target_weight, self.root_index, axis=axis_to_remove) # Add a flag to avoid latter transforms that rely on the root @@ -150,26 +176,43 @@ def encode(self, # Normalize the 2D keypoint coordinate with image width and height _camera_param = deepcopy(camera_param) - assert 'w' in _camera_param and 'h' in _camera_param + assert 'w' in _camera_param and 'h' in _camera_param, ( + 'Camera parameter `w` and `h` should be provided.') + center = np.array([0.5 * _camera_param['w'], 0.5 * _camera_param['h']], dtype=np.float32) scale = np.array(0.5 * _camera_param['w'], dtype=np.float32) keypoint_labels = (keypoints - center) / scale - assert keypoint_labels.ndim in {2, 3} + assert keypoint_labels.ndim in { + 2, 3 + }, (f'Got invalid keypoint labels shape {keypoint_labels.shape}') if keypoint_labels.ndim == 2: keypoint_labels = keypoint_labels[None, ...] if self.normalize_camera: - assert 'f' in _camera_param and 'c' in _camera_param + assert 'f' in _camera_param and 'c' in _camera_param, ( + 'Camera parameter `f` and `c` should be provided.') _camera_param['f'] = _camera_param['f'] / scale _camera_param['c'] = (_camera_param['c'] - center[:, None]) / scale encoded['camera_param'] = _camera_param + if self.concat_vis: + keypoints_visible_ = keypoints_visible + if keypoints_visible.ndim == 2: + keypoints_visible_ = keypoints_visible[..., None] + keypoint_labels = np.concatenate( + (keypoint_labels, keypoints_visible_), axis=2) + + if self.reshape_keypoints: + N = keypoint_labels.shape[0] + keypoint_labels = keypoint_labels.transpose(1, 2, 0).reshape(-1, N) + encoded['keypoint_labels'] = keypoint_labels + encoded['keypoints_visible'] = keypoints_visible encoded['lifting_target_label'] = lifting_target_label - encoded['lifting_target_weights'] = lifting_target_weights + encoded['lifting_target_weight'] = lifting_target_weight encoded['trajectory_weights'] = trajectory_weights return encoded @@ -192,8 +235,8 @@ def decode(self, """ keypoints = encoded.copy() - if target_root.size > 0: - keypoints = keypoints + np.expand_dims(target_root, axis=0) + if target_root is not None and target_root.size > 0: + keypoints = keypoints + target_root if self.remove_root: keypoints = np.insert( keypoints, self.root_index, target_root, axis=1) diff --git a/mmpose/datasets/dataset_wrappers.py b/mmpose/datasets/dataset_wrappers.py index 28eeac9945..48bb3fc2a4 100644 --- a/mmpose/datasets/dataset_wrappers.py +++ b/mmpose/datasets/dataset_wrappers.py @@ -1,8 +1,9 @@ # Copyright (c) OpenMMLab. All rights reserved. from copy import deepcopy -from typing import Any, Callable, List, Tuple, Union +from typing import Any, Callable, List, Optional, Tuple, Union +import numpy as np from mmengine.dataset import BaseDataset from mmengine.registry import build_from_cfg @@ -18,21 +19,37 @@ class CombinedDataset(BaseDataset): metainfo (dict): The meta information of combined dataset. datasets (list): The configs of datasets to be combined. pipeline (list, optional): Processing pipeline. Defaults to []. + sample_ratio_factor (list, optional): A list of sampling ratio + factors for each dataset. Defaults to None """ def __init__(self, metainfo: dict, datasets: list, pipeline: List[Union[dict, Callable]] = [], + sample_ratio_factor: Optional[List[float]] = None, **kwargs): self.datasets = [] + self.resample = sample_ratio_factor is not None for cfg in datasets: dataset = build_from_cfg(cfg, DATASETS) self.datasets.append(dataset) self._lens = [len(dataset) for dataset in self.datasets] + if self.resample: + assert len(sample_ratio_factor) == len(datasets), f'the length ' \ + f'of `sample_ratio_factor` {len(sample_ratio_factor)} does ' \ + f'not match the length of `datasets` {len(datasets)}' + assert min(sample_ratio_factor) >= 0.0, 'the ratio values in ' \ + '`sample_ratio_factor` should not be negative.' + self._lens_ori = self._lens + self._lens = [ + round(l * sample_ratio_factor[i]) + for i, l in enumerate(self._lens_ori) + ] + self._len = sum(self._lens) super(CombinedDataset, self).__init__(pipeline=pipeline, **kwargs) @@ -71,6 +88,12 @@ def _get_subset_index(self, index: int) -> Tuple[int, int]: while index >= self._lens[subset_index]: index -= self._lens[subset_index] subset_index += 1 + + if self.resample: + gap = (self._lens_ori[subset_index] - + 1e-4) / self._lens[subset_index] + index = round(gap * index + np.random.rand() * gap - 0.5) + return subset_index, index def prepare_data(self, idx: int) -> Any: @@ -86,6 +109,11 @@ def prepare_data(self, idx: int) -> Any: data_info = self.get_data_info(idx) + # the assignment of 'dataset' should not be performed within the + # `get_data_info` function. Otherwise, it can lead to the mixed + # data augmentation process getting stuck. + data_info['dataset'] = self + return self.pipeline(data_info) def get_data_info(self, idx: int) -> dict: @@ -100,6 +128,9 @@ def get_data_info(self, idx: int) -> dict: # Get data sample processed by ``subset.pipeline`` data_info = self.datasets[subset_idx][sample_idx] + if 'dataset' in data_info: + data_info.pop('dataset') + # Add metainfo items that are required in the pipeline and the model metainfo_keys = [ 'upper_body_ids', 'lower_body_ids', 'flip_pairs', diff --git a/mmpose/datasets/datasets/__init__.py b/mmpose/datasets/datasets/__init__.py index 9f5801753f..f0709ab32f 100644 --- a/mmpose/datasets/datasets/__init__.py +++ b/mmpose/datasets/datasets/__init__.py @@ -6,4 +6,6 @@ from .face import * # noqa: F401, F403 from .fashion import * # noqa: F401, F403 from .hand import * # noqa: F401, F403 +from .hand3d import * # noqa: F401, F403 from .wholebody import * # noqa: F401, F403 +from .wholebody3d import * # noqa: F401, F403 diff --git a/mmpose/datasets/datasets/base/base_coco_style_dataset.py b/mmpose/datasets/datasets/base/base_coco_style_dataset.py index 3b592813d8..ac94961f2c 100644 --- a/mmpose/datasets/datasets/base/base_coco_style_dataset.py +++ b/mmpose/datasets/datasets/base/base_coco_style_dataset.py @@ -2,12 +2,13 @@ import copy import os.path as osp from copy import deepcopy -from itertools import filterfalse, groupby +from itertools import chain, filterfalse, groupby from typing import Any, Callable, Dict, List, Optional, Sequence, Tuple, Union import numpy as np from mmengine.dataset import BaseDataset, force_full_init from mmengine.fileio import exists, get_local_path, load +from mmengine.logging import MessageHub from mmengine.utils import is_list_of from xtcocotools.coco import COCO @@ -56,6 +57,8 @@ class BaseCocoStyleDataset(BaseDataset): max_refetch (int, optional): If ``Basedataset.prepare_data`` get a None img. The maximum extra number of cycles to get a valid image. Default: 1000. + sample_interval (int, optional): The sample interval of the dataset. + Default: 1. """ METAINFO: dict = dict() @@ -73,7 +76,8 @@ def __init__(self, pipeline: List[Union[dict, Callable]] = [], test_mode: bool = False, lazy_init: bool = False, - max_refetch: int = 1000): + max_refetch: int = 1000, + sample_interval: int = 1): if data_mode not in {'topdown', 'bottomup'}: raise ValueError( @@ -94,6 +98,7 @@ def __init__(self, 'while "bbox_file" is only ' 'supported when `test_mode==True`.') self.bbox_file = bbox_file + self.sample_interval = sample_interval super().__init__( ann_file=ann_file, @@ -108,6 +113,13 @@ def __init__(self, lazy_init=lazy_init, max_refetch=max_refetch) + if self.test_mode: + # save the ann_file into MessageHub for CocoMetric + message = MessageHub.get_current_instance() + dataset_name = self.metainfo['dataset_name'] + message.update_info_dict( + {f'{dataset_name}_ann_file': self.ann_file}) + @classmethod def _load_metainfo(cls, metainfo: dict = None) -> dict: """Collect meta information from the dictionary of meta. @@ -147,6 +159,14 @@ def prepare_data(self, idx) -> Any: """ data_info = self.get_data_info(idx) + # Mixed image transformations require multiple source images for + # effective blending. Therefore, we assign the 'dataset' field in + # `data_info` to provide these auxiliary images. + # Note: The 'dataset' assignment should not occur within the + # `get_data_info` function, as doing so may cause the mixed image + # transformations to stall or hang. + data_info['dataset'] = self + return self.pipeline(data_info) def get_data_info(self, idx: int) -> dict: @@ -162,7 +182,7 @@ def get_data_info(self, idx: int) -> dict: # Add metainfo items that are required in the pipeline and the model metainfo_keys = [ - 'upper_body_ids', 'lower_body_ids', 'flip_pairs', + 'dataset_name', 'upper_body_ids', 'lower_body_ids', 'flip_pairs', 'dataset_keypoint_weights', 'flip_indices', 'skeleton_links' ] @@ -195,18 +215,23 @@ def load_data_list(self) -> List[dict]: def _load_annotations(self) -> Tuple[List[dict], List[dict]]: """Load data from annotations in COCO format.""" - assert exists(self.ann_file), 'Annotation file does not exist' + assert exists(self.ann_file), ( + f'Annotation file `{self.ann_file}`does not exist') with get_local_path(self.ann_file) as local_path: self.coco = COCO(local_path) # set the metainfo about categories, which is a list of dict # and each dict contains the 'id', 'name', etc. about this category - self._metainfo['CLASSES'] = self.coco.loadCats(self.coco.getCatIds()) + if 'categories' in self.coco.dataset: + self._metainfo['CLASSES'] = self.coco.loadCats( + self.coco.getCatIds()) instance_list = [] image_list = [] for img_id in self.coco.getImgIds(): + if img_id % self.sample_interval != 0: + continue img = self.coco.loadImgs(img_id)[0] img.update({ 'img_id': @@ -273,6 +298,12 @@ def parse_data_info(self, raw_data_info: dict) -> Optional[dict]: else: num_keypoints = np.count_nonzero(keypoints.max(axis=2)) + if 'area' in ann: + area = np.array(ann['area'], dtype=np.float32) + else: + area = np.clip((x2 - x1) * (y2 - y1) * 0.53, a_min=1.0, a_max=None) + area = np.array(area, dtype=np.float32) + data_info = { 'img_id': ann['image_id'], 'img_path': img['img_path'], @@ -281,10 +312,11 @@ def parse_data_info(self, raw_data_info: dict) -> Optional[dict]: 'num_keypoints': num_keypoints, 'keypoints': keypoints, 'keypoints_visible': keypoints_visible, + 'area': area, 'iscrowd': ann.get('iscrowd', 0), 'segmentation': ann.get('segmentation', None), 'id': ann['id'], - 'category_id': ann['category_id'], + 'category_id': np.array(ann['category_id']), # store the raw annotation of the instance # it is useful for evaluation without providing ann_file 'raw_ann_info': copy.deepcopy(ann), @@ -350,7 +382,13 @@ def _get_bottomup_data_infos(self, instance_list: List[Dict], if key not in data_info_bu: seq = [d[key] for d in data_infos] if isinstance(seq[0], np.ndarray): - seq = np.concatenate(seq, axis=0) + if seq[0].ndim > 0: + seq = np.concatenate(seq, axis=0) + else: + seq = np.stack(seq, axis=0) + elif isinstance(seq[0], (tuple, list)): + seq = list(chain.from_iterable(seq)) + data_info_bu[key] = seq # The segmentation annotation of invalid objects will be used @@ -381,11 +419,16 @@ def _get_bottomup_data_infos(self, instance_list: List[Dict], def _load_detection_results(self) -> List[dict]: """Load data from detection results with dummy keypoint annotations.""" - assert exists(self.ann_file), 'Annotation file does not exist' - assert exists(self.bbox_file), 'Bbox file does not exist' + assert exists(self.ann_file), ( + f'Annotation file `{self.ann_file}` does not exist') + assert exists( + self.bbox_file), (f'Bbox file `{self.bbox_file}` does not exist') # load detection results det_results = load(self.bbox_file) - assert is_list_of(det_results, dict) + assert is_list_of( + det_results, + dict), (f'BBox file `{self.bbox_file}` should be a list of dict, ' + f'but got {type(det_results)}') # load coco annotations to build image id-to-name index with get_local_path(self.ann_file) as local_path: diff --git a/mmpose/datasets/datasets/base/base_mocap_dataset.py b/mmpose/datasets/datasets/base/base_mocap_dataset.py index d671a6ae94..f9cea2987c 100644 --- a/mmpose/datasets/datasets/base/base_mocap_dataset.py +++ b/mmpose/datasets/datasets/base/base_mocap_dataset.py @@ -1,14 +1,17 @@ # Copyright (c) OpenMMLab. All rights reserved. +import itertools +import logging import os.path as osp from copy import deepcopy from itertools import filterfalse, groupby from typing import Any, Callable, Dict, List, Optional, Sequence, Tuple, Union +import cv2 import numpy as np from mmengine.dataset import BaseDataset, force_full_init from mmengine.fileio import exists, get_local_path, load +from mmengine.logging import print_log from mmengine.utils import is_abs -from PIL import Image from mmpose.registry import DATASETS from ..utils import parse_pose_metainfo @@ -21,6 +24,8 @@ class BaseMocapDataset(BaseDataset): Args: ann_file (str): Annotation file path. Default: ''. seq_len (int): Number of frames in a sequence. Default: 1. + multiple_target (int): If larger than 0, merge every + ``multiple_target`` sequence together. Default: 0. causal (bool): If set to ``True``, the rightmost input frame will be the target frame. Otherwise, the middle input frame will be the target frame. Default: ``True``. @@ -63,6 +68,7 @@ class BaseMocapDataset(BaseDataset): def __init__(self, ann_file: str = '', seq_len: int = 1, + multiple_target: int = 0, causal: bool = True, subset_frac: float = 1.0, camera_param_file: Optional[str] = None, @@ -87,21 +93,29 @@ def __init__(self, _ann_file = ann_file if not is_abs(_ann_file): _ann_file = osp.join(data_root, _ann_file) - assert exists(_ann_file), 'Annotation file does not exist.' - with get_local_path(_ann_file) as local_path: - self.ann_data = np.load(local_path) + assert exists(_ann_file), ( + f'Annotation file `{_ann_file}` does not exist.') + + self._load_ann_file(_ann_file) self.camera_param_file = camera_param_file if self.camera_param_file: if not is_abs(self.camera_param_file): self.camera_param_file = osp.join(data_root, self.camera_param_file) - assert exists(self.camera_param_file) + assert exists(self.camera_param_file), ( + f'Camera parameters file `{self.camera_param_file}` does not ' + 'exist.') self.camera_param = load(self.camera_param_file) self.seq_len = seq_len self.causal = causal + self.multiple_target = multiple_target + if self.multiple_target: + assert (self.seq_len == 1), ( + 'Multi-target data sample only supports seq_len=1.') + assert 0 < subset_frac <= 1, ( f'Unsupported `subset_frac` {subset_frac}. Supported range ' 'is (0, 1].') @@ -122,6 +136,19 @@ def __init__(self, lazy_init=lazy_init, max_refetch=max_refetch) + def _load_ann_file(self, ann_file: str) -> dict: + """Load annotation file to get image information. + + Args: + ann_file (str): Annotation file path. + + Returns: + dict: Annotation information. + """ + + with get_local_path(ann_file) as local_path: + self.ann_data = np.load(local_path) + @classmethod def _load_metainfo(cls, metainfo: dict = None) -> dict: """Collect meta information from the dictionary of meta. @@ -207,10 +234,13 @@ def get_img_info(self, img_idx, img_name): try: with get_local_path(osp.join(self.data_prefix['img'], img_name)) as local_path: - im = Image.open(local_path) - w, h = im.size - im.close() + im = cv2.imread(local_path) + h, w, _ = im.shape except: # noqa: E722 + print_log( + f'Failed to read image {img_name}.', + logger='current', + level=logging.DEBUG) return None img = { @@ -241,6 +271,17 @@ def get_sequence_indices(self) -> List[List[int]]: sequence_indices = [[idx] for idx in range(num_imgs)] else: raise NotImplementedError('Multi-frame data sample unsupported!') + + if self.multiple_target > 0: + sequence_indices_merged = [] + for i in range(0, len(sequence_indices), self.multiple_target): + if i + self.multiple_target > len(sequence_indices): + break + sequence_indices_merged.append( + list( + itertools.chain.from_iterable( + sequence_indices[i:i + self.multiple_target]))) + sequence_indices = sequence_indices_merged return sequence_indices def _load_annotations(self) -> Tuple[List[dict], List[dict]]: @@ -274,7 +315,13 @@ def _load_annotations(self) -> Tuple[List[dict], List[dict]]: image_list = [] for idx, frame_ids in enumerate(self.sequence_indices): - assert len(frame_ids) == self.seq_len + expected_num_frames = self.seq_len + if self.multiple_target: + expected_num_frames = self.multiple_target + + assert len(frame_ids) == (expected_num_frames), ( + f'Expected `frame_ids` == {expected_num_frames}, but ' + f'got {len(frame_ids)} ') _img_names = img_names[frame_ids] @@ -286,7 +333,9 @@ def _load_annotations(self) -> Tuple[List[dict], List[dict]]: keypoints_3d = _keypoints_3d[..., :3] keypoints_3d_visible = _keypoints_3d[..., 3] - target_idx = -1 if self.causal else int(self.seq_len) // 2 + target_idx = [-1] if self.causal else [int(self.seq_len) // 2] + if self.multiple_target: + target_idx = list(range(self.multiple_target)) instance_info = { 'num_keypoints': num_keypoints, @@ -312,9 +361,10 @@ def _load_annotations(self) -> Tuple[List[dict], List[dict]]: instance_list.append(instance_info) - for idx, imgname in enumerate(img_names): - img_info = self.get_img_info(idx, imgname) - image_list.append(img_info) + if self.data_mode == 'bottomup': + for idx, imgname in enumerate(img_names): + img_info = self.get_img_info(idx, imgname) + image_list.append(img_info) return instance_list, image_list diff --git a/mmpose/datasets/datasets/body/__init__.py b/mmpose/datasets/datasets/body/__init__.py index 1405b0d675..3ae05a3856 100644 --- a/mmpose/datasets/datasets/body/__init__.py +++ b/mmpose/datasets/datasets/body/__init__.py @@ -2,6 +2,7 @@ from .aic_dataset import AicDataset from .coco_dataset import CocoDataset from .crowdpose_dataset import CrowdPoseDataset +from .humanart21_dataset import HumanArt21Dataset from .humanart_dataset import HumanArtDataset from .jhmdb_dataset import JhmdbDataset from .mhp_dataset import MhpDataset @@ -14,5 +15,6 @@ __all__ = [ 'CocoDataset', 'MpiiDataset', 'MpiiTrbDataset', 'AicDataset', 'CrowdPoseDataset', 'OCHumanDataset', 'MhpDataset', 'PoseTrack18Dataset', - 'JhmdbDataset', 'PoseTrack18VideoDataset', 'HumanArtDataset' + 'JhmdbDataset', 'PoseTrack18VideoDataset', 'HumanArtDataset', + 'HumanArt21Dataset' ] diff --git a/mmpose/datasets/datasets/body/humanart21_dataset.py b/mmpose/datasets/datasets/body/humanart21_dataset.py new file mode 100644 index 0000000000..e4b5695261 --- /dev/null +++ b/mmpose/datasets/datasets/body/humanart21_dataset.py @@ -0,0 +1,148 @@ +# Copyright (c) OpenMMLab. All rights reserved. +import copy +from typing import Optional + +import numpy as np + +from mmpose.registry import DATASETS +from .humanart_dataset import HumanArtDataset + + +@DATASETS.register_module() +class HumanArt21Dataset(HumanArtDataset): + """Human-Art dataset for pose estimation with 21 kpts. + + "Human-Art: A Versatile Human-Centric Dataset + Bridging Natural and Artificial Scenes", CVPR'2023. + More details can be found in the `paper +`__ .
+
+ Human-Art keypoints::
+
+ 0: 'nose',
+ 1: 'left_eye',
+ 2: 'right_eye',
+ 3: 'left_ear',
+ 4: 'right_ear',
+ 5: 'left_shoulder',
+ 6: 'right_shoulder',
+ 7: 'left_elbow',
+ 8: 'right_elbow',
+ 9: 'left_wrist',
+ 10: 'right_wrist',
+ 11: 'left_hip',
+ 12: 'right_hip',
+ 13: 'left_knee',
+ 14: 'right_knee',
+ 15: 'left_ankle',
+ 16: 'right_ankle',
+ 17: 'left_finger',
+ 18: 'right_finger',
+ 19: 'left_toe',
+ 20: 'right_toe',
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/humanart21.py')
+
+ def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
+ """Parse raw COCO annotation of an instance.
+
+ Args:
+ raw_data_info (dict): Raw data information loaded from
+ ``ann_file``. It should have following contents:
+
+ - ``'raw_ann_info'``: Raw annotation of an instance
+ - ``'raw_img_info'``: Raw information of the image that
+ contains the instance
+
+ Returns:
+ dict | None: Parsed instance annotation
+ """
+
+ ann = raw_data_info['raw_ann_info']
+ img = raw_data_info['raw_img_info']
+
+ # filter invalid instance
+ if 'bbox' not in ann or 'keypoints' not in ann:
+ return None
+
+ img_w, img_h = img['width'], img['height']
+
+ # get bbox in shape [1, 4], formatted as xywh
+ x, y, w, h = ann['bbox']
+ x1 = np.clip(x, 0, img_w - 1)
+ y1 = np.clip(y, 0, img_h - 1)
+ x2 = np.clip(x + w, 0, img_w - 1)
+ y2 = np.clip(y + h, 0, img_h - 1)
+
+ bbox = np.array([x1, y1, x2, y2], dtype=np.float32).reshape(1, 4)
+
+ # keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
+ _keypoints = np.array(
+ ann['keypoints_21'], dtype=np.float32).reshape(1, -1, 3)
+ keypoints = _keypoints[..., :2]
+ keypoints_visible = np.minimum(1, _keypoints[..., 2])
+
+ if 'num_keypoints' in ann:
+ num_keypoints = ann['num_keypoints']
+ else:
+ num_keypoints = np.count_nonzero(keypoints.max(axis=2))
+
+ data_info = {
+ 'img_id': ann['image_id'],
+ 'img_path': img['img_path'],
+ 'bbox': bbox,
+ 'bbox_score': np.ones(1, dtype=np.float32),
+ 'num_keypoints': num_keypoints,
+ 'keypoints': keypoints,
+ 'keypoints_visible': keypoints_visible,
+ 'iscrowd': ann.get('iscrowd', 0),
+ 'segmentation': ann.get('segmentation', None),
+ 'id': ann['id'],
+ 'category_id': ann['category_id'],
+ # store the raw annotation of the instance
+ # it is useful for evaluation without providing ann_file
+ 'raw_ann_info': copy.deepcopy(ann),
+ }
+
+ if 'crowdIndex' in img:
+ data_info['crowd_index'] = img['crowdIndex']
+
+ return data_info
diff --git a/mmpose/datasets/datasets/body/humanart_dataset.py b/mmpose/datasets/datasets/body/humanart_dataset.py
index 719f35fc9e..6f8aa2943d 100644
--- a/mmpose/datasets/datasets/body/humanart_dataset.py
+++ b/mmpose/datasets/datasets/body/humanart_dataset.py
@@ -5,7 +5,7 @@
@DATASETS.register_module()
class HumanArtDataset(BaseCocoStyleDataset):
- """Human-Art dataset for pose estimation.
+ """Human-Art dataset for pose estimation with 17 kpts.
"Human-Art: A Versatile Human-Centric Dataset
Bridging Natural and Artificial Scenes", CVPR'2023.
diff --git a/mmpose/datasets/datasets/body/jhmdb_dataset.py b/mmpose/datasets/datasets/body/jhmdb_dataset.py
index 7d72a7ddc5..940a4cd4dc 100644
--- a/mmpose/datasets/datasets/body/jhmdb_dataset.py
+++ b/mmpose/datasets/datasets/body/jhmdb_dataset.py
@@ -118,6 +118,8 @@ def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
keypoints_visible = np.minimum(1, _keypoints[..., 2])
num_keypoints = np.count_nonzero(keypoints.max(axis=2))
+ area = np.clip((x2 - x1) * (y2 - y1) * 0.53, a_min=1.0, a_max=None)
+ category_id = ann.get('category_id', [1] * len(keypoints))
data_info = {
'img_id': ann['image_id'],
@@ -127,9 +129,11 @@ def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
'num_keypoints': num_keypoints,
'keypoints': keypoints,
'keypoints_visible': keypoints_visible,
+ 'area': np.array(area, dtype=np.float32),
'iscrowd': ann.get('iscrowd', 0),
'segmentation': ann.get('segmentation', None),
'id': ann['id'],
+ 'category_id': category_id,
}
return data_info
diff --git a/mmpose/datasets/datasets/body/mpii_dataset.py b/mmpose/datasets/datasets/body/mpii_dataset.py
index 237f1ab2b6..5490f6f0dd 100644
--- a/mmpose/datasets/datasets/body/mpii_dataset.py
+++ b/mmpose/datasets/datasets/body/mpii_dataset.py
@@ -137,13 +137,17 @@ def __init__(self,
def _load_annotations(self) -> Tuple[List[dict], List[dict]]:
"""Load data from annotations in MPII format."""
- assert exists(self.ann_file), 'Annotation file does not exist'
+ assert exists(self.ann_file), (
+ f'Annotation file `{self.ann_file}` does not exist')
+
with get_local_path(self.ann_file) as local_path:
with open(local_path) as anno_file:
self.anns = json.load(anno_file)
if self.headbox_file:
- assert exists(self.headbox_file), 'Headbox file does not exist'
+ assert exists(self.headbox_file), (
+ f'Headbox file `{self.headbox_file}` does not exist')
+
with get_local_path(self.headbox_file) as local_path:
self.headbox_dict = loadmat(local_path)
headboxes_src = np.transpose(self.headbox_dict['headboxes_src'],
@@ -180,6 +184,12 @@ def _load_annotations(self) -> Tuple[List[dict], List[dict]]:
keypoints = np.array(ann['joints']).reshape(1, -1, 2)
keypoints_visible = np.array(ann['joints_vis']).reshape(1, -1)
+ x1, y1, x2, y2 = np.split(bbox, axis=1, indices_or_sections=4)
+ area = np.clip((x2 - x1) * (y2 - y1) * 0.53, a_min=1.0, a_max=None)
+ area = area[..., 0].astype(np.float32)
+
+ category_id = ann.get('category_id', [1] * len(bbox))
+
instance_info = {
'id': ann_id,
'img_id': int(ann['image'].split('.')[0]),
@@ -190,6 +200,8 @@ def _load_annotations(self) -> Tuple[List[dict], List[dict]]:
'bbox_score': np.ones(1, dtype=np.float32),
'keypoints': keypoints,
'keypoints_visible': keypoints_visible,
+ 'area': area,
+ 'category_id': category_id,
}
if self.headbox_file:
diff --git a/mmpose/datasets/datasets/body/mpii_trb_dataset.py b/mmpose/datasets/datasets/body/mpii_trb_dataset.py
index bb96ad876f..36f76166a9 100644
--- a/mmpose/datasets/datasets/body/mpii_trb_dataset.py
+++ b/mmpose/datasets/datasets/body/mpii_trb_dataset.py
@@ -106,7 +106,9 @@ class MpiiTrbDataset(BaseCocoStyleDataset):
def _load_annotations(self) -> Tuple[List[dict], List[dict]]:
"""Load data from annotations in MPII-TRB format."""
- assert exists(self.ann_file), 'Annotation file does not exist'
+ assert exists(self.ann_file), (
+ f'Annotation file `{self.ann_file}` does not exist')
+
with get_local_path(self.ann_file) as local_path:
with open(local_path) as anno_file:
self.data = json.load(anno_file)
diff --git a/mmpose/datasets/datasets/body/posetrack18_video_dataset.py b/mmpose/datasets/datasets/body/posetrack18_video_dataset.py
index cc5fe8646c..f862d9bc5a 100644
--- a/mmpose/datasets/datasets/body/posetrack18_video_dataset.py
+++ b/mmpose/datasets/datasets/body/posetrack18_video_dataset.py
@@ -287,12 +287,16 @@ def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
def _load_detection_results(self) -> List[dict]:
"""Load data from detection results with dummy keypoint annotations."""
- assert exists(self.ann_file), 'Annotation file does not exist'
- assert exists(self.bbox_file), 'Bbox file does not exist'
+ assert exists(self.ann_file), (
+ f'Annotation file `{self.ann_file}` does not exist')
+ assert exists(
+ self.bbox_file), (f'Bbox file `{self.bbox_file}` does not exist')
# load detection results
det_results = load(self.bbox_file)
- assert is_list_of(det_results, dict)
+ assert is_list_of(det_results, dict), (
+ f'annotation file `{self.bbox_file}` should be a list of dicts, '
+ f'but got type {type(det_results)}')
# load coco annotations to build image id-to-name index
with get_local_path(self.ann_file) as local_path:
diff --git a/mmpose/datasets/datasets/body3d/h36m_dataset.py b/mmpose/datasets/datasets/body3d/h36m_dataset.py
index 60094aa254..397738c276 100644
--- a/mmpose/datasets/datasets/body3d/h36m_dataset.py
+++ b/mmpose/datasets/datasets/body3d/h36m_dataset.py
@@ -45,6 +45,10 @@ class Human36mDataset(BaseMocapDataset):
seq_len (int): Number of frames in a sequence. Default: 1.
seq_step (int): The interval for extracting frames from the video.
Default: 1.
+ multiple_target (int): If larger than 0, merge every
+ ``multiple_target`` sequence together. Default: 0.
+ multiple_target_step (int): The interval for merging sequence. Only
+ valid when ``multiple_target`` is larger than 0. Default: 0.
pad_video_seq (bool): Whether to pad the video so that poses will be
predicted for every frame in the video. Default: ``False``.
causal (bool): If set to ``True``, the rightmost input frame will be
@@ -65,6 +69,9 @@ class Human36mDataset(BaseMocapDataset):
If set, 2d keypoint loaded from this file will be used instead of
ground-truth keypoints. This setting is only when
``keypoint_2d_src`` is ``'detection'``. Default: ``None``.
+ factor_file (str, optional): The projection factors' file. If set,
+ factor loaded from this file will be used instead of calculated
+ factors. Default: ``None``.
camera_param_file (str): Cameras' parameters file. Default: ``None``.
data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
``'bottomup'``. In ``'topdown'`` mode, each data sample contains
@@ -104,11 +111,14 @@ def __init__(self,
ann_file: str = '',
seq_len: int = 1,
seq_step: int = 1,
+ multiple_target: int = 0,
+ multiple_target_step: int = 0,
pad_video_seq: bool = False,
causal: bool = True,
subset_frac: float = 1.0,
keypoint_2d_src: str = 'gt',
keypoint_2d_det_file: Optional[str] = None,
+ factor_file: Optional[str] = None,
camera_param_file: Optional[str] = None,
data_mode: str = 'topdown',
metainfo: Optional[dict] = None,
@@ -138,9 +148,21 @@ def __init__(self,
self.seq_step = seq_step
self.pad_video_seq = pad_video_seq
+ if factor_file:
+ if not is_abs(factor_file):
+ factor_file = osp.join(data_root, factor_file)
+ assert exists(factor_file), (f'`factor_file`: {factor_file}'
+ 'does not exist.')
+ self.factor_file = factor_file
+
+ if multiple_target > 0 and multiple_target_step == 0:
+ multiple_target_step = multiple_target
+ self.multiple_target_step = multiple_target_step
+
super().__init__(
ann_file=ann_file,
seq_len=seq_len,
+ multiple_target=multiple_target,
causal=causal,
subset_frac=subset_frac,
camera_param_file=camera_param_file,
@@ -171,41 +193,55 @@ def get_sequence_indices(self) -> List[List[int]]:
sequence_indices = []
_len = (self.seq_len - 1) * self.seq_step + 1
_step = self.seq_step
- for _, _indices in sorted(video_frames.items()):
- n_frame = len(_indices)
-
- if self.pad_video_seq:
- # Pad the sequence so that every frame in the sequence will be
- # predicted.
- if self.causal:
- frames_left = self.seq_len - 1
- frames_right = 0
- else:
- frames_left = (self.seq_len - 1) // 2
- frames_right = frames_left
- for i in range(n_frame):
- pad_left = max(0, frames_left - i // _step)
- pad_right = max(0,
- frames_right - (n_frame - 1 - i) // _step)
- start = max(i % _step, i - frames_left * _step)
- end = min(n_frame - (n_frame - 1 - i) % _step,
- i + frames_right * _step + 1)
- sequence_indices.append([_indices[0]] * pad_left +
- _indices[start:end:_step] +
- [_indices[-1]] * pad_right)
- else:
+
+ if self.multiple_target:
+ for _, _indices in sorted(video_frames.items()):
+ n_frame = len(_indices)
seqs_from_video = [
- _indices[i:(i + _len):_step]
- for i in range(0, n_frame - _len + 1)
- ]
+ _indices[i:(i + self.multiple_target):_step]
+ for i in range(0, n_frame, self.multiple_target_step)
+ ][:(n_frame + self.multiple_target_step -
+ self.multiple_target) // self.multiple_target_step]
sequence_indices.extend(seqs_from_video)
+ else:
+ for _, _indices in sorted(video_frames.items()):
+ n_frame = len(_indices)
+
+ if self.pad_video_seq:
+ # Pad the sequence so that every frame in the sequence will
+ # be predicted.
+ if self.causal:
+ frames_left = self.seq_len - 1
+ frames_right = 0
+ else:
+ frames_left = (self.seq_len - 1) // 2
+ frames_right = frames_left
+ for i in range(n_frame):
+ pad_left = max(0, frames_left - i // _step)
+ pad_right = max(
+ 0, frames_right - (n_frame - 1 - i) // _step)
+ start = max(i % _step, i - frames_left * _step)
+ end = min(n_frame - (n_frame - 1 - i) % _step,
+ i + frames_right * _step + 1)
+ sequence_indices.append([_indices[0]] * pad_left +
+ _indices[start:end:_step] +
+ [_indices[-1]] * pad_right)
+ else:
+ seqs_from_video = [
+ _indices[i:(i + _len):_step]
+ for i in range(0, n_frame - _len + 1)
+ ]
+ sequence_indices.extend(seqs_from_video)
+
# reduce dataset size if needed
subset_size = int(len(sequence_indices) * self.subset_frac)
start = np.random.randint(0, len(sequence_indices) - subset_size + 1)
end = start + subset_size
- return sequence_indices[start:end]
+ sequence_indices = sequence_indices[start:end]
+
+ return sequence_indices
def _load_annotations(self) -> Tuple[List[dict], List[dict]]:
instance_list, image_list = super()._load_annotations()
@@ -214,11 +250,19 @@ def _load_annotations(self) -> Tuple[List[dict], List[dict]]:
kpts_3d = h36m_data['S']
if self.keypoint_2d_src == 'detection':
- assert exists(self.keypoint_2d_det_file)
+ assert exists(self.keypoint_2d_det_file), (
+ f'`keypoint_2d_det_file`: `{self.keypoint_2d_det_file}`'
+ 'does not exist.')
kpts_2d = self._load_keypoint_2d_detection(
self.keypoint_2d_det_file)
- assert kpts_2d.shape[0] == kpts_3d.shape[0]
- assert kpts_2d.shape[2] == 3
+ assert kpts_2d.shape[0] == kpts_3d.shape[0], (
+ f'Number of `kpts_2d` ({kpts_2d.shape[0]}) does not match '
+ f'number of `kpts_3d` ({kpts_3d.shape[0]}).')
+
+ assert kpts_2d.shape[2] == 3, (
+ f'Expect `kpts_2d.shape[2]` == 3, but got '
+ f'{kpts_2d.shape[2]}. Please check the format of '
+ f'{self.keypoint_2d_det_file}')
for idx, frame_ids in enumerate(self.sequence_indices):
kpt_2d = kpts_2d[frame_ids].astype(np.float32)
@@ -230,6 +274,18 @@ def _load_annotations(self) -> Tuple[List[dict], List[dict]]:
'keypoints_visible':
keypoints_visible
})
+ if self.factor_file:
+ with get_local_path(self.factor_file) as local_path:
+ factors = np.load(local_path).astype(np.float32)
+ else:
+ factors = np.zeros((kpts_3d.shape[0], ), dtype=np.float32)
+ assert factors.shape[0] == kpts_3d.shape[0], (
+ f'Number of `factors` ({factors.shape[0]}) does not match '
+ f'number of `kpts_3d` ({kpts_3d.shape[0]}).')
+
+ for idx, frame_ids in enumerate(self.sequence_indices):
+ factor = factors[frame_ids].astype(np.float32)
+ instance_list[idx].update({'factor': factor})
return instance_list, image_list
diff --git a/mmpose/datasets/datasets/face/__init__.py b/mmpose/datasets/datasets/face/__init__.py
index 700cb605f7..1b78d87502 100644
--- a/mmpose/datasets/datasets/face/__init__.py
+++ b/mmpose/datasets/datasets/face/__init__.py
@@ -3,10 +3,11 @@
from .coco_wholebody_face_dataset import CocoWholeBodyFaceDataset
from .cofw_dataset import COFWDataset
from .face_300w_dataset import Face300WDataset
+from .face_300wlp_dataset import Face300WLPDataset
from .lapa_dataset import LapaDataset
from .wflw_dataset import WFLWDataset
__all__ = [
'Face300WDataset', 'WFLWDataset', 'AFLWDataset', 'COFWDataset',
- 'CocoWholeBodyFaceDataset', 'LapaDataset'
+ 'CocoWholeBodyFaceDataset', 'LapaDataset', 'Face300WLPDataset'
]
diff --git a/mmpose/datasets/datasets/face/face_300wlp_dataset.py b/mmpose/datasets/datasets/face/face_300wlp_dataset.py
new file mode 100644
index 0000000000..215df09a53
--- /dev/null
+++ b/mmpose/datasets/datasets/face/face_300wlp_dataset.py
@@ -0,0 +1,55 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+from mmpose.registry import DATASETS
+from ..base import BaseCocoStyleDataset
+
+
+@DATASETS.register_module()
+class Face300WLPDataset(BaseCocoStyleDataset):
+ """300W dataset for face keypoint localization.
+
+ "300 faces In-the-wild challenge: Database and results",
+ Image and Vision Computing (IMAVIS) 2019.
+
+ The landmark annotations follow the 68 points mark-up. The definition
+ can be found in `https://ibug.doc.ic.ac.uk/resources/300-W/`.
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/300wlp.py')
diff --git a/mmpose/datasets/datasets/hand/__init__.py b/mmpose/datasets/datasets/hand/__init__.py
index d5e2222be9..72f9bc14f1 100644
--- a/mmpose/datasets/datasets/hand/__init__.py
+++ b/mmpose/datasets/datasets/hand/__init__.py
@@ -1,11 +1,12 @@
# Copyright (c) OpenMMLab. All rights reserved.
from .coco_wholebody_hand_dataset import CocoWholeBodyHandDataset
from .freihand_dataset import FreiHandDataset
+from .interhand2d_double_dataset import InterHand2DDoubleDataset
from .onehand10k_dataset import OneHand10KDataset
from .panoptic_hand2d_dataset import PanopticHand2DDataset
from .rhd2d_dataset import Rhd2DDataset
__all__ = [
'OneHand10KDataset', 'FreiHandDataset', 'PanopticHand2DDataset',
- 'Rhd2DDataset', 'CocoWholeBodyHandDataset'
+ 'Rhd2DDataset', 'CocoWholeBodyHandDataset', 'InterHand2DDoubleDataset'
]
diff --git a/mmpose/datasets/datasets/hand/coco_wholebody_hand_dataset.py b/mmpose/datasets/datasets/hand/coco_wholebody_hand_dataset.py
index dba0132f58..15ac669d40 100644
--- a/mmpose/datasets/datasets/hand/coco_wholebody_hand_dataset.py
+++ b/mmpose/datasets/datasets/hand/coco_wholebody_hand_dataset.py
@@ -87,7 +87,8 @@ class CocoWholeBodyHandDataset(BaseCocoStyleDataset):
def _load_annotations(self) -> Tuple[List[dict], List[dict]]:
"""Load data from annotations in COCO format."""
- assert exists(self.ann_file), 'Annotation file does not exist'
+ assert exists(self.ann_file), (
+ f'Annotation file `{self.ann_file}` does not exist')
with get_local_path(self.ann_file) as local_path:
self.coco = COCO(local_path)
diff --git a/mmpose/datasets/datasets/hand/interhand2d_double_dataset.py b/mmpose/datasets/datasets/hand/interhand2d_double_dataset.py
new file mode 100644
index 0000000000..e8841e6f54
--- /dev/null
+++ b/mmpose/datasets/datasets/hand/interhand2d_double_dataset.py
@@ -0,0 +1,342 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import json
+import os.path as osp
+from typing import Callable, List, Optional, Sequence, Tuple, Union
+
+import numpy as np
+from mmengine.fileio import exists, get_local_path
+from mmengine.utils import is_abs
+from xtcocotools.coco import COCO
+
+from mmpose.codecs.utils import camera_to_pixel
+from mmpose.datasets.datasets import BaseCocoStyleDataset
+from mmpose.registry import DATASETS
+from mmpose.structures.bbox import bbox_xywh2xyxy
+
+
+@DATASETS.register_module()
+class InterHand2DDoubleDataset(BaseCocoStyleDataset):
+ """InterHand2.6M dataset for 2d double hands.
+
+ "InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose
+ Estimation from a Single RGB Image", ECCV'2020.
+ More details can be found in the `paper
+ `__ .
+
+ The dataset loads raw features and apply specified transforms
+ to return a dict containing the image tensors and other information.
+
+ InterHand2.6M keypoint indexes::
+
+ 0: 'r_thumb4',
+ 1: 'r_thumb3',
+ 2: 'r_thumb2',
+ 3: 'r_thumb1',
+ 4: 'r_index4',
+ 5: 'r_index3',
+ 6: 'r_index2',
+ 7: 'r_index1',
+ 8: 'r_middle4',
+ 9: 'r_middle3',
+ 10: 'r_middle2',
+ 11: 'r_middle1',
+ 12: 'r_ring4',
+ 13: 'r_ring3',
+ 14: 'r_ring2',
+ 15: 'r_ring1',
+ 16: 'r_pinky4',
+ 17: 'r_pinky3',
+ 18: 'r_pinky2',
+ 19: 'r_pinky1',
+ 20: 'r_wrist',
+ 21: 'l_thumb4',
+ 22: 'l_thumb3',
+ 23: 'l_thumb2',
+ 24: 'l_thumb1',
+ 25: 'l_index4',
+ 26: 'l_index3',
+ 27: 'l_index2',
+ 28: 'l_index1',
+ 29: 'l_middle4',
+ 30: 'l_middle3',
+ 31: 'l_middle2',
+ 32: 'l_middle1',
+ 33: 'l_ring4',
+ 34: 'l_ring3',
+ 35: 'l_ring2',
+ 36: 'l_ring1',
+ 37: 'l_pinky4',
+ 38: 'l_pinky3',
+ 39: 'l_pinky2',
+ 40: 'l_pinky1',
+ 41: 'l_wrist'
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ camera_param_file (str): Cameras' parameters file. Default: ''.
+ joint_file (str): Path to the joint file. Default: ''.
+ use_gt_root_depth (bool): Using the ground truth depth of the wrist
+ or given depth from rootnet_result_file. Default: ``True``.
+ rootnet_result_file (str): Path to the wrist depth file.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data.
+ Default: ``dict(img='')``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ sample_interval (int, optional): The sample interval of the dataset.
+ Default: 1.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/interhand3d.py')
+
+ def __init__(self,
+ ann_file: str = '',
+ camera_param_file: str = '',
+ joint_file: str = '',
+ use_gt_root_depth: bool = True,
+ rootnet_result_file: Optional[str] = None,
+ data_mode: str = 'topdown',
+ metainfo: Optional[dict] = None,
+ data_root: Optional[str] = None,
+ data_prefix: dict = dict(img=''),
+ filter_cfg: Optional[dict] = None,
+ indices: Optional[Union[int, Sequence[int]]] = None,
+ serialize_data: bool = True,
+ pipeline: List[Union[dict, Callable]] = [],
+ test_mode: bool = False,
+ lazy_init: bool = False,
+ max_refetch: int = 1000,
+ sample_interval: int = 1):
+ _ann_file = ann_file
+ if data_root is not None and not is_abs(_ann_file):
+ _ann_file = osp.join(data_root, _ann_file)
+ assert exists(_ann_file), 'Annotation file does not exist.'
+ self.ann_file = _ann_file
+
+ _camera_param_file = camera_param_file
+ if data_root is not None and not is_abs(_camera_param_file):
+ _camera_param_file = osp.join(data_root, _camera_param_file)
+ assert exists(_camera_param_file), 'Camera file does not exist.'
+ self.camera_param_file = _camera_param_file
+
+ _joint_file = joint_file
+ if data_root is not None and not is_abs(_joint_file):
+ _joint_file = osp.join(data_root, _joint_file)
+ assert exists(_joint_file), 'Joint file does not exist.'
+ self.joint_file = _joint_file
+
+ self.use_gt_root_depth = use_gt_root_depth
+ if not self.use_gt_root_depth:
+ assert rootnet_result_file is not None
+ _rootnet_result_file = rootnet_result_file
+ if data_root is not None and not is_abs(_rootnet_result_file):
+ _rootnet_result_file = osp.join(data_root,
+ _rootnet_result_file)
+ assert exists(
+ _rootnet_result_file), 'Rootnet result file does not exist.'
+ self.rootnet_result_file = _rootnet_result_file
+
+ super().__init__(
+ ann_file=ann_file,
+ metainfo=metainfo,
+ data_mode=data_mode,
+ data_root=data_root,
+ data_prefix=data_prefix,
+ filter_cfg=filter_cfg,
+ indices=indices,
+ serialize_data=serialize_data,
+ pipeline=pipeline,
+ test_mode=test_mode,
+ lazy_init=lazy_init,
+ max_refetch=max_refetch,
+ sample_interval=sample_interval)
+
+ def _load_annotations(self) -> Tuple[List[dict], List[dict]]:
+ """Load data from annotations in COCO format."""
+
+ assert exists(self.ann_file), 'Annotation file does not exist'
+
+ with get_local_path(self.ann_file) as local_path:
+ self.coco = COCO(local_path)
+ # set the metainfo about categories, which is a list of dict
+ # and each dict contains the 'id', 'name', etc. about this category
+ if 'categories' in self.coco.dataset:
+ self._metainfo['CLASSES'] = self.coco.loadCats(
+ self.coco.getCatIds())
+
+ with get_local_path(self.camera_param_file) as local_path:
+ with open(local_path, 'r') as f:
+ self.cameras = json.load(f)
+ with get_local_path(self.joint_file) as local_path:
+ with open(local_path, 'r') as f:
+ self.joints = json.load(f)
+
+ instance_list = []
+ image_list = []
+
+ for idx, img_id in enumerate(self.coco.getImgIds()):
+ if idx % self.sample_interval != 0:
+ continue
+ img = self.coco.loadImgs(img_id)[0]
+ img.update({
+ 'img_id':
+ img_id,
+ 'img_path':
+ osp.join(self.data_prefix['img'], img['file_name']),
+ })
+ image_list.append(img)
+
+ ann_ids = self.coco.getAnnIds(imgIds=img_id)
+ ann = self.coco.loadAnns(ann_ids)[0]
+
+ instance_info = self.parse_data_info(
+ dict(raw_ann_info=ann, raw_img_info=img))
+
+ # skip invalid instance annotation.
+ if not instance_info:
+ continue
+
+ instance_list.append(instance_info)
+ return instance_list, image_list
+
+ def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
+ """Parse raw COCO annotation of an instance.
+
+ Args:
+ raw_data_info (dict): Raw data information loaded from
+ ``ann_file``. It should have following contents:
+
+ - ``'raw_ann_info'``: Raw annotation of an instance
+ - ``'raw_img_info'``: Raw information of the image that
+ contains the instance
+
+ Returns:
+ dict | None: Parsed instance annotation
+ """
+
+ ann = raw_data_info['raw_ann_info']
+ img = raw_data_info['raw_img_info']
+
+ if not self.use_gt_root_depth:
+ rootnet_result = {}
+ with get_local_path(self.rootnet_result_file) as local_path:
+ rootnet_annot = json.load(local_path)
+ for i in range(len(rootnet_annot)):
+ rootnet_result[str(
+ rootnet_annot[i]['annot_id'])] = rootnet_annot[i]
+
+ num_keypoints = self.metainfo['num_keypoints']
+
+ capture_id = str(img['capture'])
+ camera_name = img['camera']
+ frame_idx = str(img['frame_idx'])
+ camera_pos = np.array(
+ self.cameras[capture_id]['campos'][camera_name], dtype=np.float32)
+ camera_rot = np.array(
+ self.cameras[capture_id]['camrot'][camera_name], dtype=np.float32)
+ focal = np.array(
+ self.cameras[capture_id]['focal'][camera_name], dtype=np.float32)
+ principal_pt = np.array(
+ self.cameras[capture_id]['princpt'][camera_name], dtype=np.float32)
+ joint_world = np.array(
+ self.joints[capture_id][frame_idx]['world_coord'],
+ dtype=np.float32)
+ joint_valid = np.array(ann['joint_valid'], dtype=np.float32).flatten()
+
+ keypoints_cam = np.dot(
+ camera_rot,
+ joint_world.transpose(1, 0) -
+ camera_pos.reshape(3, 1)).transpose(1, 0)
+
+ if self.use_gt_root_depth:
+ bbox_xywh = np.array(ann['bbox'], dtype=np.float32).reshape(1, 4)
+
+ else:
+ rootnet_ann_data = rootnet_result[str(ann['id'])]
+ bbox_xywh = np.array(
+ rootnet_ann_data['bbox'], dtype=np.float32).reshape(1, 4)
+
+ bbox = bbox_xywh2xyxy(bbox_xywh)
+
+ # 41: 'l_wrist', left hand root
+ # 20: 'r_wrist', right hand root
+
+ # if root is not valid -> root-relative 3D pose is also not valid.
+ # Therefore, mark all joints as invalid
+ joint_valid[:20] *= joint_valid[20]
+ joint_valid[21:] *= joint_valid[41]
+
+ joints_3d_visible = np.minimum(1,
+ joint_valid.reshape(-1,
+ 1)).reshape(1, -1)
+ keypoints_img = camera_to_pixel(
+ keypoints_cam,
+ focal[0],
+ focal[1],
+ principal_pt[0],
+ principal_pt[1],
+ shift=True)[..., :2]
+ joints_3d = np.zeros((keypoints_cam.shape[-2], 3),
+ dtype=np.float32).reshape(1, -1, 3)
+ joints_3d[..., :2] = keypoints_img
+ joints_3d[..., :21,
+ 2] = keypoints_cam[..., :21, 2] - keypoints_cam[..., 20, 2]
+ joints_3d[..., 21:,
+ 2] = keypoints_cam[..., 21:, 2] - keypoints_cam[..., 41, 2]
+
+ data_info = {
+ 'img_id': ann['image_id'],
+ 'img_path': img['img_path'],
+ 'keypoints': joints_3d[:, :, :2],
+ 'keypoints_visible': joints_3d_visible,
+ 'hand_type': self.encode_handtype(ann['hand_type']),
+ 'hand_type_valid': np.array([ann['hand_type_valid']]),
+ 'dataset': self.metainfo['dataset_name'],
+ 'bbox': bbox,
+ 'bbox_score': np.ones(1, dtype=np.float32),
+ 'num_keypoints': num_keypoints,
+ 'iscrowd': ann.get('iscrowd', False),
+ 'id': ann['id'],
+ # store the raw annotation of the instance
+ # it is useful for evaluation without providing ann_file
+ 'raw_ann_info': copy.deepcopy(ann),
+ }
+
+ return data_info
+
+ @staticmethod
+ def encode_handtype(hand_type):
+ if hand_type == 'right':
+ return np.array([[1, 0]], dtype=np.float32)
+ elif hand_type == 'left':
+ return np.array([[0, 1]], dtype=np.float32)
+ elif hand_type == 'interacting':
+ return np.array([[1, 1]], dtype=np.float32)
+ else:
+ assert 0, f'Not support hand type: {hand_type}'
diff --git a/mmpose/datasets/datasets/hand3d/__init__.py b/mmpose/datasets/datasets/hand3d/__init__.py
new file mode 100644
index 0000000000..20d4049ef8
--- /dev/null
+++ b/mmpose/datasets/datasets/hand3d/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .interhand_3d_dataset import InterHand3DDataset
+
+__all__ = ['InterHand3DDataset']
diff --git a/mmpose/datasets/datasets/hand3d/interhand_3d_dataset.py b/mmpose/datasets/datasets/hand3d/interhand_3d_dataset.py
new file mode 100644
index 0000000000..13d0bd26b3
--- /dev/null
+++ b/mmpose/datasets/datasets/hand3d/interhand_3d_dataset.py
@@ -0,0 +1,347 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import json
+import os.path as osp
+from typing import Callable, List, Optional, Sequence, Tuple, Union
+
+import numpy as np
+from mmengine.fileio import exists, get_local_path
+from mmengine.utils import is_abs
+from xtcocotools.coco import COCO
+
+from mmpose.codecs.utils import camera_to_pixel
+from mmpose.datasets.datasets import BaseCocoStyleDataset
+from mmpose.registry import DATASETS
+from mmpose.structures.bbox import bbox_xywh2xyxy
+
+
+@DATASETS.register_module()
+class InterHand3DDataset(BaseCocoStyleDataset):
+ """InterHand2.6M dataset for 3d hand.
+
+ "InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose
+ Estimation from a Single RGB Image", ECCV'2020.
+ More details can be found in the `paper
+ `__ .
+
+ The dataset loads raw features and apply specified transforms
+ to return a dict containing the image tensors and other information.
+
+ InterHand2.6M keypoint indexes::
+
+ 0: 'r_thumb4',
+ 1: 'r_thumb3',
+ 2: 'r_thumb2',
+ 3: 'r_thumb1',
+ 4: 'r_index4',
+ 5: 'r_index3',
+ 6: 'r_index2',
+ 7: 'r_index1',
+ 8: 'r_middle4',
+ 9: 'r_middle3',
+ 10: 'r_middle2',
+ 11: 'r_middle1',
+ 12: 'r_ring4',
+ 13: 'r_ring3',
+ 14: 'r_ring2',
+ 15: 'r_ring1',
+ 16: 'r_pinky4',
+ 17: 'r_pinky3',
+ 18: 'r_pinky2',
+ 19: 'r_pinky1',
+ 20: 'r_wrist',
+ 21: 'l_thumb4',
+ 22: 'l_thumb3',
+ 23: 'l_thumb2',
+ 24: 'l_thumb1',
+ 25: 'l_index4',
+ 26: 'l_index3',
+ 27: 'l_index2',
+ 28: 'l_index1',
+ 29: 'l_middle4',
+ 30: 'l_middle3',
+ 31: 'l_middle2',
+ 32: 'l_middle1',
+ 33: 'l_ring4',
+ 34: 'l_ring3',
+ 35: 'l_ring2',
+ 36: 'l_ring1',
+ 37: 'l_pinky4',
+ 38: 'l_pinky3',
+ 39: 'l_pinky2',
+ 40: 'l_pinky1',
+ 41: 'l_wrist'
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ camera_param_file (str): Cameras' parameters file. Default: ''.
+ joint_file (str): Path to the joint file. Default: ''.
+ use_gt_root_depth (bool): Using the ground truth depth of the wrist
+ or given depth from rootnet_result_file. Default: ``True``.
+ rootnet_result_file (str): Path to the wrist depth file.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data.
+ Default: ``dict(img='')``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/interhand3d.py')
+
+ def __init__(self,
+ ann_file: str = '',
+ camera_param_file: str = '',
+ joint_file: str = '',
+ use_gt_root_depth: bool = True,
+ rootnet_result_file: Optional[str] = None,
+ data_mode: str = 'topdown',
+ metainfo: Optional[dict] = None,
+ data_root: Optional[str] = None,
+ data_prefix: dict = dict(img=''),
+ filter_cfg: Optional[dict] = None,
+ indices: Optional[Union[int, Sequence[int]]] = None,
+ serialize_data: bool = True,
+ pipeline: List[Union[dict, Callable]] = [],
+ test_mode: bool = False,
+ lazy_init: bool = False,
+ max_refetch: int = 1000):
+
+ _ann_file = ann_file
+ if not is_abs(_ann_file):
+ _ann_file = osp.join(data_root, _ann_file)
+ assert exists(_ann_file), 'Annotation file does not exist.'
+ self.ann_file = _ann_file
+
+ _camera_param_file = camera_param_file
+ if not is_abs(_camera_param_file):
+ _camera_param_file = osp.join(data_root, _camera_param_file)
+ assert exists(_camera_param_file), 'Camera file does not exist.'
+ self.camera_param_file = _camera_param_file
+
+ _joint_file = joint_file
+ if not is_abs(_joint_file):
+ _joint_file = osp.join(data_root, _joint_file)
+ assert exists(_joint_file), 'Joint file does not exist.'
+ self.joint_file = _joint_file
+
+ self.use_gt_root_depth = use_gt_root_depth
+ if not self.use_gt_root_depth:
+ assert rootnet_result_file is not None
+ _rootnet_result_file = rootnet_result_file
+ if not is_abs(_rootnet_result_file):
+ _rootnet_result_file = osp.join(data_root,
+ _rootnet_result_file)
+ assert exists(
+ _rootnet_result_file), 'Rootnet result file does not exist.'
+ self.rootnet_result_file = _rootnet_result_file
+
+ super().__init__(
+ ann_file=ann_file,
+ metainfo=metainfo,
+ data_mode=data_mode,
+ data_root=data_root,
+ data_prefix=data_prefix,
+ filter_cfg=filter_cfg,
+ indices=indices,
+ serialize_data=serialize_data,
+ pipeline=pipeline,
+ test_mode=test_mode,
+ lazy_init=lazy_init,
+ max_refetch=max_refetch)
+
+ def _load_annotations(self) -> Tuple[List[dict], List[dict]]:
+ """Load data from annotations in COCO format."""
+
+ assert exists(self.ann_file), 'Annotation file does not exist'
+
+ with get_local_path(self.ann_file) as local_path:
+ self.coco = COCO(local_path)
+ # set the metainfo about categories, which is a list of dict
+ # and each dict contains the 'id', 'name', etc. about this category
+ if 'categories' in self.coco.dataset:
+ self._metainfo['CLASSES'] = self.coco.loadCats(
+ self.coco.getCatIds())
+
+ with get_local_path(self.camera_param_file) as local_path:
+ with open(local_path, 'r') as f:
+ self.cameras = json.load(f)
+ with get_local_path(self.joint_file) as local_path:
+ with open(local_path, 'r') as f:
+ self.joints = json.load(f)
+
+ instance_list = []
+ image_list = []
+
+ for idx, img_id in enumerate(self.coco.getImgIds()):
+ img = self.coco.loadImgs(img_id)[0]
+ img.update({
+ 'img_id':
+ img_id,
+ 'img_path':
+ osp.join(self.data_prefix['img'], img['file_name']),
+ })
+ image_list.append(img)
+
+ ann_ids = self.coco.getAnnIds(imgIds=img_id)
+ ann = self.coco.loadAnns(ann_ids)[0]
+
+ instance_info = self.parse_data_info(
+ dict(raw_ann_info=ann, raw_img_info=img))
+
+ # skip invalid instance annotation.
+ if not instance_info:
+ continue
+
+ instance_list.append(instance_info)
+ return instance_list, image_list
+
+ def parse_data_info(self, raw_data_info: dict) -> Optional[dict]:
+ """Parse raw COCO annotation of an instance.
+
+ Args:
+ raw_data_info (dict): Raw data information loaded from
+ ``ann_file``. It should have following contents:
+
+ - ``'raw_ann_info'``: Raw annotation of an instance
+ - ``'raw_img_info'``: Raw information of the image that
+ contains the instance
+
+ Returns:
+ dict | None: Parsed instance annotation
+ """
+
+ ann = raw_data_info['raw_ann_info']
+ img = raw_data_info['raw_img_info']
+
+ if not self.use_gt_root_depth:
+ rootnet_result = {}
+ with get_local_path(self.rootnet_result_file) as local_path:
+ rootnet_annot = json.load(local_path)
+ for i in range(len(rootnet_annot)):
+ rootnet_result[str(
+ rootnet_annot[i]['annot_id'])] = rootnet_annot[i]
+
+ num_keypoints = self.metainfo['num_keypoints']
+
+ capture_id = str(img['capture'])
+ camera_name = img['camera']
+ frame_idx = str(img['frame_idx'])
+ camera_pos = np.array(
+ self.cameras[capture_id]['campos'][camera_name], dtype=np.float32)
+ camera_rot = np.array(
+ self.cameras[capture_id]['camrot'][camera_name], dtype=np.float32)
+ focal = np.array(
+ self.cameras[capture_id]['focal'][camera_name], dtype=np.float32)
+ principal_pt = np.array(
+ self.cameras[capture_id]['princpt'][camera_name], dtype=np.float32)
+ joint_world = np.array(
+ self.joints[capture_id][frame_idx]['world_coord'],
+ dtype=np.float32)
+ joint_valid = np.array(ann['joint_valid'], dtype=np.float32).flatten()
+
+ keypoints_cam = np.dot(
+ camera_rot,
+ joint_world.transpose(1, 0) -
+ camera_pos.reshape(3, 1)).transpose(1, 0)
+
+ if self.use_gt_root_depth:
+ bbox_xywh = np.array(ann['bbox'], dtype=np.float32).reshape(1, 4)
+ abs_depth = [keypoints_cam[20, 2], keypoints_cam[41, 2]]
+ else:
+ rootnet_ann_data = rootnet_result[str(ann['id'])]
+ bbox_xywh = np.array(
+ rootnet_ann_data['bbox'], dtype=np.float32).reshape(1, 4)
+ abs_depth = rootnet_ann_data['abs_depth']
+ bbox = bbox_xywh2xyxy(bbox_xywh)
+
+ # 41: 'l_wrist', left hand root
+ # 20: 'r_wrist', right hand root
+ rel_root_depth = keypoints_cam[41, 2] - keypoints_cam[20, 2]
+ # if root is not valid, root-relative 3D depth is also invalid.
+ rel_root_valid = joint_valid[20] * joint_valid[41]
+
+ # if root is not valid -> root-relative 3D pose is also not valid.
+ # Therefore, mark all joints as invalid
+ joint_valid[:20] *= joint_valid[20]
+ joint_valid[21:] *= joint_valid[41]
+
+ joints_3d_visible = np.minimum(1,
+ joint_valid.reshape(-1,
+ 1)).reshape(1, -1)
+ keypoints_img = camera_to_pixel(
+ keypoints_cam,
+ focal[0],
+ focal[1],
+ principal_pt[0],
+ principal_pt[1],
+ shift=True)[..., :2]
+ joints_3d = np.zeros((keypoints_cam.shape[-2], 3),
+ dtype=np.float32).reshape(1, -1, 3)
+ joints_3d[..., :2] = keypoints_img
+ joints_3d[..., :21,
+ 2] = keypoints_cam[..., :21, 2] - keypoints_cam[..., 20, 2]
+ joints_3d[..., 21:,
+ 2] = keypoints_cam[..., 21:, 2] - keypoints_cam[..., 41, 2]
+
+ data_info = {
+ 'img_id': ann['image_id'],
+ 'img_path': img['img_path'],
+ 'rotation': 0,
+ 'keypoints': joints_3d,
+ 'keypoints_cam': keypoints_cam.reshape(1, -1, 3),
+ 'keypoints_visible': joints_3d_visible,
+ 'hand_type': self.encode_handtype(ann['hand_type']),
+ 'hand_type_valid': np.array([ann['hand_type_valid']]),
+ 'rel_root_depth': rel_root_depth,
+ 'rel_root_valid': rel_root_valid,
+ 'abs_depth': abs_depth,
+ 'focal': focal,
+ 'principal_pt': principal_pt,
+ 'dataset': self.metainfo['dataset_name'],
+ 'bbox': bbox,
+ 'bbox_score': np.ones(1, dtype=np.float32),
+ 'num_keypoints': num_keypoints,
+ 'iscrowd': ann.get('iscrowd', False),
+ 'id': ann['id'],
+ # store the raw annotation of the instance
+ # it is useful for evaluation without providing ann_file
+ 'raw_ann_info': copy.deepcopy(ann),
+ }
+
+ return data_info
+
+ @staticmethod
+ def encode_handtype(hand_type):
+ if hand_type == 'right':
+ return np.array([[1, 0]], dtype=np.float32)
+ elif hand_type == 'left':
+ return np.array([[0, 1]], dtype=np.float32)
+ elif hand_type == 'interacting':
+ return np.array([[1, 1]], dtype=np.float32)
+ else:
+ assert 0, f'Not support hand type: {hand_type}'
diff --git a/mmpose/datasets/datasets/wholebody/__init__.py b/mmpose/datasets/datasets/wholebody/__init__.py
index 156094c2b0..b3934fc225 100644
--- a/mmpose/datasets/datasets/wholebody/__init__.py
+++ b/mmpose/datasets/datasets/wholebody/__init__.py
@@ -1,5 +1,6 @@
# Copyright (c) OpenMMLab. All rights reserved.
from .coco_wholebody_dataset import CocoWholeBodyDataset
from .halpe_dataset import HalpeDataset
+from .ubody2d_dataset import UBody2dDataset
-__all__ = ['CocoWholeBodyDataset', 'HalpeDataset']
+__all__ = ['CocoWholeBodyDataset', 'HalpeDataset', 'UBody2dDataset']
diff --git a/mmpose/datasets/datasets/wholebody/ubody2d_dataset.py b/mmpose/datasets/datasets/wholebody/ubody2d_dataset.py
new file mode 100644
index 0000000000..9a0cb1711a
--- /dev/null
+++ b/mmpose/datasets/datasets/wholebody/ubody2d_dataset.py
@@ -0,0 +1,63 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmpose.registry import DATASETS
+from .coco_wholebody_dataset import CocoWholeBodyDataset
+
+
+@DATASETS.register_module()
+class UBody2dDataset(CocoWholeBodyDataset):
+ """Ubody2d dataset for pose estimation.
+
+ "One-Stage 3D Whole-Body Mesh Recovery with Component Aware Transformer",
+ CVPR'2023. More details can be found in the `paper
+ `__ .
+
+ Ubody2D keypoints::
+
+ 0-16: 17 body keypoints,
+ 17-22: 6 foot keypoints,
+ 23-90: 68 face keypoints,
+ 91-132: 42 hand keypoints
+
+ In total, we have 133 keypoints for wholebody pose estimation.
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ bbox_file (str, optional): Detection result file path. If
+ ``bbox_file`` is set, detected bboxes loaded from this file will
+ be used instead of ground-truth bboxes. This setting is only for
+ evaluation, i.e., ignored when ``test_mode`` is ``False``.
+ Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data. Default:
+ ``dict(img=None, ann=None)``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ sample_interval (int, optional): The sample interval of the dataset.
+ Default: 1.
+ """
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/ubody2d.py')
diff --git a/mmpose/datasets/datasets/wholebody3d/__init__.py b/mmpose/datasets/datasets/wholebody3d/__init__.py
new file mode 100644
index 0000000000..db0e25b155
--- /dev/null
+++ b/mmpose/datasets/datasets/wholebody3d/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .ubody3d_dataset import UBody3dDataset
+
+__all__ = ['UBody3dDataset']
diff --git a/mmpose/datasets/datasets/wholebody3d/ubody3d_dataset.py b/mmpose/datasets/datasets/wholebody3d/ubody3d_dataset.py
new file mode 100644
index 0000000000..85b8d893e7
--- /dev/null
+++ b/mmpose/datasets/datasets/wholebody3d/ubody3d_dataset.py
@@ -0,0 +1,247 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from collections import defaultdict
+from typing import List, Tuple
+
+import numpy as np
+from mmengine.fileio import get_local_path
+from xtcocotools.coco import COCO
+
+from mmpose.datasets.datasets import BaseMocapDataset
+from mmpose.registry import DATASETS
+
+
+@DATASETS.register_module()
+class UBody3dDataset(BaseMocapDataset):
+ """Ubody3d dataset for 3D human pose estimation.
+
+ "One-Stage 3D Whole-Body Mesh Recovery with Component Aware Transformer",
+ CVPR'2023. More details can be found in the `paper
+ `__ .
+
+ Ubody3D keypoints::
+
+ 0-24: 25 body keypoints,
+ 25-64: 40 hand keypoints,
+ 65-136: 72 face keypoints,
+
+ In total, we have 137 keypoints for wholebody 3D pose estimation.
+
+ Args:
+ ann_file (str): Annotation file path. Default: ''.
+ seq_len (int): Number of frames in a sequence. Default: 1.
+ multiple_target (int): If larger than 0, merge every
+ ``multiple_target`` sequence together. Default: 0.
+ causal (bool): If set to ``True``, the rightmost input frame will be
+ the target frame. Otherwise, the middle input frame will be the
+ target frame. Default: ``True``.
+ subset_frac (float): The fraction to reduce dataset size. If set to 1,
+ the dataset size is not reduced. Default: 1.
+ camera_param_file (str): Cameras' parameters file. Default: ``None``.
+ data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
+ ``'bottomup'``. In ``'topdown'`` mode, each data sample contains
+ one instance; while in ``'bottomup'`` mode, each data sample
+ contains all instances in a image. Default: ``'topdown'``
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Default: ``None``.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Default: ``None``.
+ data_prefix (dict, optional): Prefix for training data.
+ Default: ``dict(img='')``.
+ filter_cfg (dict, optional): Config for filter data. Default: `None`.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Default: ``None`` which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy.
+ Default: ``True``.
+ pipeline (list, optional): Processing pipeline. Default: [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Default: ``False``.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Default: ``False``.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Default: 1000.
+ """
+
+ def __init__(self,
+ multiple_target: int = 0,
+ multiple_target_step: int = 0,
+ seq_step: int = 1,
+ pad_video_seq: bool = False,
+ **kwargs):
+ self.seq_step = seq_step
+ self.pad_video_seq = pad_video_seq
+
+ if multiple_target > 0 and multiple_target_step == 0:
+ multiple_target_step = multiple_target
+ self.multiple_target_step = multiple_target_step
+
+ super().__init__(multiple_target=multiple_target, **kwargs)
+
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/ubody3d.py')
+
+ def _load_ann_file(self, ann_file: str) -> dict:
+ """Load annotation file."""
+ with get_local_path(ann_file) as local_path:
+ self.ann_data = COCO(local_path)
+
+ def get_sequence_indices(self) -> List[List[int]]:
+ video_frames = defaultdict(list)
+ img_ids = self.ann_data.getImgIds()
+ for img_id in img_ids:
+ img_info = self.ann_data.loadImgs(img_id)[0]
+ subj, _, _ = self._parse_image_name(img_info['file_name'])
+ video_frames[subj].append(img_id)
+
+ sequence_indices = []
+ _len = (self.seq_len - 1) * self.seq_step + 1
+ _step = self.seq_step
+
+ if self.multiple_target:
+ for _, _img_ids in sorted(video_frames.items()):
+ n_frame = len(_img_ids)
+ _ann_ids = self.ann_data.getAnnIds(imgIds=_img_ids)
+ seqs_from_video = [
+ _ann_ids[i:(i + self.multiple_target):_step]
+ for i in range(0, n_frame, self.multiple_target_step)
+ ][:(n_frame + self.multiple_target_step -
+ self.multiple_target) // self.multiple_target_step]
+ sequence_indices.extend(seqs_from_video)
+ else:
+ for _, _img_ids in sorted(video_frames.items()):
+ n_frame = len(_img_ids)
+ _ann_ids = self.ann_data.getAnnIds(imgIds=_img_ids)
+ if self.pad_video_seq:
+ # Pad the sequence so that every frame in the sequence will
+ # be predicted.
+ if self.causal:
+ frames_left = self.seq_len - 1
+ frames_right = 0
+ else:
+ frames_left = (self.seq_len - 1) // 2
+ frames_right = frames_left
+ for i in range(n_frame):
+ pad_left = max(0, frames_left - i // _step)
+ pad_right = max(
+ 0, frames_right - (n_frame - 1 - i) // _step)
+ start = max(i % _step, i - frames_left * _step)
+ end = min(n_frame - (n_frame - 1 - i) % _step,
+ i + frames_right * _step + 1)
+ sequence_indices.append([_ann_ids[0]] * pad_left +
+ _ann_ids[start:end:_step] +
+ [_ann_ids[-1]] * pad_right)
+ else:
+ seqs_from_video = [
+ _ann_ids[i:(i + _len):_step]
+ for i in range(0, n_frame - _len + 1, _step)
+ ]
+ sequence_indices.extend(seqs_from_video)
+
+ # reduce dataset size if needed
+ subset_size = int(len(sequence_indices) * self.subset_frac)
+ start = np.random.randint(0, len(sequence_indices) - subset_size + 1)
+ end = start + subset_size
+
+ sequence_indices = sequence_indices[start:end]
+
+ return sequence_indices
+
+ def _parse_image_name(self, image_path: str) -> Tuple[str, int]:
+ """Parse image name to get video name and frame index.
+
+ Args:
+ image_name (str): Image name.
+
+ Returns:
+ tuple[str, int]: Video name and frame index.
+ """
+ trim, file_name = image_path.split('/')[-2:]
+ frame_id, suffix = file_name.split('.')
+ return trim, frame_id, suffix
+
+ def _load_annotations(self):
+ """Load data from annotations in COCO format."""
+ num_keypoints = self.metainfo['num_keypoints']
+ self._metainfo['CLASSES'] = self.ann_data.loadCats(
+ self.ann_data.getCatIds())
+
+ instance_list = []
+ image_list = []
+
+ for i, _ann_ids in enumerate(self.sequence_indices):
+ expected_num_frames = self.seq_len
+ if self.multiple_target:
+ expected_num_frames = self.multiple_target
+
+ assert len(_ann_ids) == (expected_num_frames), (
+ f'Expected `frame_ids` == {expected_num_frames}, but '
+ f'got {len(_ann_ids)} ')
+
+ anns = self.ann_data.loadAnns(_ann_ids)
+ img_ids = []
+ kpts = np.zeros((len(anns), num_keypoints, 2), dtype=np.float32)
+ kpts_3d = np.zeros((len(anns), num_keypoints, 3), dtype=np.float32)
+ keypoints_visible = np.zeros((len(anns), num_keypoints, 1),
+ dtype=np.float32)
+ for j, ann in enumerate(anns):
+ img_ids.append(ann['image_id'])
+ kpts[j] = np.array(ann['keypoints'], dtype=np.float32)
+ kpts_3d[j] = np.array(ann['keypoints_3d'], dtype=np.float32)
+ keypoints_visible[j] = np.array(
+ ann['keypoints_valid'], dtype=np.float32)
+ imgs = self.ann_data.loadImgs(img_ids)
+ keypoints_visible = keypoints_visible.squeeze(-1)
+
+ scales = np.zeros(len(imgs), dtype=np.float32)
+ centers = np.zeros((len(imgs), 2), dtype=np.float32)
+ img_paths = np.array([img['file_name'] for img in imgs])
+ factors = np.zeros((kpts_3d.shape[0], ), dtype=np.float32)
+
+ target_idx = [-1] if self.causal else [int(self.seq_len // 2)]
+ if self.multiple_target:
+ target_idx = list(range(self.multiple_target))
+
+ cam_param = anns[-1]['camera_param']
+ if 'w' not in cam_param or 'h' not in cam_param:
+ cam_param['w'] = 1000
+ cam_param['h'] = 1000
+
+ instance_info = {
+ 'num_keypoints': num_keypoints,
+ 'keypoints': kpts,
+ 'keypoints_3d': kpts_3d,
+ 'keypoints_visible': keypoints_visible,
+ 'scale': scales,
+ 'center': centers,
+ 'id': i,
+ 'category_id': 1,
+ 'iscrowd': 0,
+ 'img_paths': list(img_paths),
+ 'img_ids': [img['id'] for img in imgs],
+ 'lifting_target': kpts_3d[target_idx],
+ 'lifting_target_visible': keypoints_visible[target_idx],
+ 'target_img_paths': img_paths[target_idx],
+ 'camera_param': cam_param,
+ 'factor': factors,
+ 'target_idx': target_idx,
+ }
+
+ instance_list.append(instance_info)
+
+ for img_id in self.ann_data.getImgIds():
+ img = self.ann_data.loadImgs(img_id)[0]
+ img.update({
+ 'img_id':
+ img_id,
+ 'img_path':
+ osp.join(self.data_prefix['img'], img['file_name']),
+ })
+ image_list.append(img)
+
+ return instance_list, image_list
diff --git a/mmpose/datasets/transforms/__init__.py b/mmpose/datasets/transforms/__init__.py
index 7ccbf7dac2..54ad7f3159 100644
--- a/mmpose/datasets/transforms/__init__.py
+++ b/mmpose/datasets/transforms/__init__.py
@@ -1,13 +1,16 @@
# Copyright (c) OpenMMLab. All rights reserved.
from .bottomup_transforms import (BottomupGetHeatmapMask, BottomupRandomAffine,
- BottomupResize)
-from .common_transforms import (Albumentation, GenerateTarget,
- GetBBoxCenterScale, PhotometricDistortion,
- RandomBBoxTransform, RandomFlip,
- RandomHalfBody)
-from .converting import KeypointConverter
+ BottomupRandomChoiceResize,
+ BottomupRandomCrop, BottomupResize)
+from .common_transforms import (Albumentation, FilterAnnotations,
+ GenerateTarget, GetBBoxCenterScale,
+ PhotometricDistortion, RandomBBoxTransform,
+ RandomFlip, RandomHalfBody, YOLOXHSVRandomAug)
+from .converting import KeypointConverter, SingleHandConverter
from .formatting import PackPoseInputs
+from .hand_transforms import HandRandomFlip
from .loading import LoadImage
+from .mix_img_transforms import Mosaic, YOLOXMixUp
from .pose3d_transforms import RandomFlipAroundRoot
from .topdown_transforms import TopdownAffine
@@ -16,5 +19,8 @@
'RandomHalfBody', 'TopdownAffine', 'Albumentation',
'PhotometricDistortion', 'PackPoseInputs', 'LoadImage',
'BottomupGetHeatmapMask', 'BottomupRandomAffine', 'BottomupResize',
- 'GenerateTarget', 'KeypointConverter', 'RandomFlipAroundRoot'
+ 'GenerateTarget', 'KeypointConverter', 'RandomFlipAroundRoot',
+ 'FilterAnnotations', 'YOLOXHSVRandomAug', 'YOLOXMixUp', 'Mosaic',
+ 'BottomupRandomCrop', 'BottomupRandomChoiceResize', 'HandRandomFlip',
+ 'SingleHandConverter'
]
diff --git a/mmpose/datasets/transforms/bottomup_transforms.py b/mmpose/datasets/transforms/bottomup_transforms.py
index c31e0ae17d..0175e013dc 100644
--- a/mmpose/datasets/transforms/bottomup_transforms.py
+++ b/mmpose/datasets/transforms/bottomup_transforms.py
@@ -1,16 +1,21 @@
# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Dict, List, Optional, Tuple
+from functools import partial
+from typing import Dict, List, Optional, Sequence, Tuple, Union
import cv2
import numpy as np
import xtcocotools.mask as cocomask
from mmcv.image import imflip_, imresize
+from mmcv.image.geometric import imrescale
from mmcv.transforms import BaseTransform
from mmcv.transforms.utils import cache_randomness
from scipy.stats import truncnorm
from mmpose.registry import TRANSFORMS
-from mmpose.structures.bbox import get_udp_warp_matrix, get_warp_matrix
+from mmpose.structures.bbox import (bbox_clip_border, bbox_corner2xyxy,
+ bbox_xyxy2corner, get_pers_warp_matrix,
+ get_udp_warp_matrix, get_warp_matrix)
+from mmpose.structures.keypoint import keypoint_clip_border
@TRANSFORMS.register_module()
@@ -31,6 +36,10 @@ class BottomupGetHeatmapMask(BaseTransform):
- heatmap_mask
"""
+ def __init__(self, get_invalid: bool = False):
+ super().__init__()
+ self.get_invalid = get_invalid
+
def _segs_to_mask(self, segs: list, img_shape: Tuple[int,
int]) -> np.ndarray:
"""Calculate mask from object segmentations.
@@ -83,10 +92,12 @@ def transform(self, results: Dict) -> Optional[dict]:
invalid_segs = results.get('invalid_segs', [])
img_shape = results['img_shape'] # (img_h, img_w)
input_size = results['input_size']
+ mask = self._segs_to_mask(invalid_segs, img_shape)
- # Calculate the mask of the valid region by negating the segmentation
- # mask of invalid objects
- mask = 1 - self._segs_to_mask(invalid_segs, img_shape)
+ if not self.get_invalid:
+ # Calculate the mask of the valid region by negating the
+ # segmentation mask of invalid objects
+ mask = np.logical_not(mask)
# Apply an affine transform to the mask if the image has been
# transformed
@@ -176,7 +187,7 @@ class BottomupRandomAffine(BaseTransform):
"""
def __init__(self,
- input_size: Tuple[int, int],
+ input_size: Optional[Tuple[int, int]] = None,
shift_factor: float = 0.2,
shift_prob: float = 1.,
scale_factor: Tuple[float, float] = (0.75, 1.5),
@@ -184,9 +195,21 @@ def __init__(self,
scale_type: str = 'short',
rotate_factor: float = 30.,
rotate_prob: float = 1,
- use_udp: bool = False) -> None:
+ shear_factor: float = 2.0,
+ shear_prob: float = 1.0,
+ use_udp: bool = False,
+ pad_val: Union[float, Tuple[float]] = 0,
+ border: Tuple[int, int] = (0, 0),
+ distribution='trunc_norm',
+ transform_mode='affine',
+ bbox_keep_corner: bool = True,
+ clip_border: bool = False) -> None:
super().__init__()
+ assert transform_mode in ('affine', 'affine_udp', 'perspective'), \
+ f'the argument transform_mode should be either \'affine\', ' \
+ f'\'affine_udp\' or \'perspective\', but got \'{transform_mode}\''
+
self.input_size = input_size
self.shift_factor = shift_factor
self.shift_prob = shift_prob
@@ -195,14 +218,39 @@ def __init__(self,
self.scale_type = scale_type
self.rotate_factor = rotate_factor
self.rotate_prob = rotate_prob
+ self.shear_factor = shear_factor
+ self.shear_prob = shear_prob
+
self.use_udp = use_udp
+ self.distribution = distribution
+ self.clip_border = clip_border
+ self.bbox_keep_corner = bbox_keep_corner
- @staticmethod
- def _truncnorm(low: float = -1.,
- high: float = 1.,
- size: tuple = ()) -> np.ndarray:
- """Sample from a truncated normal distribution."""
- return truncnorm.rvs(low, high, size=size).astype(np.float32)
+ self.transform_mode = transform_mode
+
+ if isinstance(pad_val, (int, float)):
+ pad_val = (pad_val, pad_val, pad_val)
+
+ if 'affine' in transform_mode:
+ self._transform = partial(
+ cv2.warpAffine, flags=cv2.INTER_LINEAR, borderValue=pad_val)
+ else:
+ self._transform = partial(cv2.warpPerspective, borderValue=pad_val)
+
+ def _random(self,
+ low: float = -1.,
+ high: float = 1.,
+ size: tuple = ()) -> np.ndarray:
+ if self.distribution == 'trunc_norm':
+ """Sample from a truncated normal distribution."""
+ return truncnorm.rvs(low, high, size=size).astype(np.float32)
+ elif self.distribution == 'uniform':
+ x = np.random.rand(*size)
+ return x * (high - low) + low
+ else:
+ raise ValueError(f'the argument `distribution` should be either'
+ f'\'trunc_norn\' or \'uniform\', but got '
+ f'{self.distribution}.')
def _fix_aspect_ratio(self, scale: np.ndarray, aspect_ratio: float):
"""Extend the scale to match the given aspect ratio.
@@ -243,7 +291,7 @@ def _get_transform_params(self) -> Tuple:
"""
# get offset
if np.random.rand() < self.shift_prob:
- offset = self._truncnorm(size=(2, )) * self.shift_factor
+ offset = self._random(size=(2, )) * self.shift_factor
else:
offset = np.zeros((2, ), dtype=np.float32)
@@ -251,17 +299,24 @@ def _get_transform_params(self) -> Tuple:
if np.random.rand() < self.scale_prob:
scale_min, scale_max = self.scale_factor
scale = scale_min + (scale_max - scale_min) * (
- self._truncnorm(size=(1, )) + 1) / 2
+ self._random(size=(1, )) + 1) / 2
else:
scale = np.ones(1, dtype=np.float32)
# get rotation
if np.random.rand() < self.rotate_prob:
- rotate = self._truncnorm() * self.rotate_factor
+ rotate = self._random() * self.rotate_factor
else:
rotate = 0
- return offset, scale, rotate
+ # get shear
+ if 'perspective' in self.transform_mode and np.random.rand(
+ ) < self.shear_prob:
+ shear = self._random(size=(2, )) * self.shear_factor
+ else:
+ shear = np.zeros((2, ), dtype=np.float32)
+
+ return offset, scale, rotate, shear
def transform(self, results: Dict) -> Optional[dict]:
"""The transform function of :class:`BottomupRandomAffine` to perform
@@ -277,45 +332,77 @@ def transform(self, results: Dict) -> Optional[dict]:
dict: Result dict with images distorted.
"""
- img_h, img_w = results['img_shape']
+ img_h, img_w = results['img_shape'][:2]
w, h = self.input_size
- offset_rate, scale_rate, rotate = self._get_transform_params()
- offset = offset_rate * [img_w, img_h]
- scale = scale_rate * [img_w, img_h]
- # adjust the scale to match the target aspect ratio
- scale = self._fix_aspect_ratio(scale, aspect_ratio=w / h)
-
- if self.use_udp:
- center = np.array([(img_w - 1.0) / 2, (img_h - 1.0) / 2],
- dtype=np.float32)
- warp_mat = get_udp_warp_matrix(
- center=center + offset,
- scale=scale,
- rot=rotate,
- output_size=(w, h))
+ offset_rate, scale_rate, rotate, shear = self._get_transform_params()
+
+ if 'affine' in self.transform_mode:
+ offset = offset_rate * [img_w, img_h]
+ scale = scale_rate * [img_w, img_h]
+ # adjust the scale to match the target aspect ratio
+ scale = self._fix_aspect_ratio(scale, aspect_ratio=w / h)
+
+ if self.transform_mode == 'affine_udp':
+ center = np.array([(img_w - 1.0) / 2, (img_h - 1.0) / 2],
+ dtype=np.float32)
+ warp_mat = get_udp_warp_matrix(
+ center=center + offset,
+ scale=scale,
+ rot=rotate,
+ output_size=(w, h))
+ else:
+ center = np.array([img_w / 2, img_h / 2], dtype=np.float32)
+ warp_mat = get_warp_matrix(
+ center=center + offset,
+ scale=scale,
+ rot=rotate,
+ output_size=(w, h))
+
else:
- center = np.array([img_w / 2, img_h / 2], dtype=np.float32)
- warp_mat = get_warp_matrix(
- center=center + offset,
- scale=scale,
+ offset = offset_rate * [w, h]
+ center = np.array([w / 2, h / 2], dtype=np.float32)
+ warp_mat = get_pers_warp_matrix(
+ center=center,
+ translate=offset,
+ scale=scale_rate[0],
rot=rotate,
- output_size=(w, h))
+ shear=shear)
# warp image and keypoints
- results['img'] = cv2.warpAffine(
- results['img'], warp_mat, (int(w), int(h)), flags=cv2.INTER_LINEAR)
+ results['img'] = self._transform(results['img'], warp_mat,
+ (int(w), int(h)))
if 'keypoints' in results:
# Only transform (x, y) coordinates
- results['keypoints'][..., :2] = cv2.transform(
- results['keypoints'][..., :2], warp_mat)
+ kpts = cv2.transform(results['keypoints'], warp_mat)
+ if kpts.shape[-1] == 3:
+ kpts = kpts[..., :2] / kpts[..., 2:3]
+ results['keypoints'] = kpts
+
+ if self.clip_border:
+ results['keypoints'], results[
+ 'keypoints_visible'] = keypoint_clip_border(
+ results['keypoints'], results['keypoints_visible'],
+ (w, h))
if 'bbox' in results:
- bbox = np.tile(results['bbox'], 2).reshape(-1, 4, 2)
- # corner order: left_top, left_bottom, right_top, right_bottom
- bbox[:, 1:3, 0] = bbox[:, 0:2, 0]
- results['bbox'] = cv2.transform(bbox, warp_mat).reshape(-1, 8)
+ bbox = bbox_xyxy2corner(results['bbox'])
+ bbox = cv2.transform(bbox, warp_mat)
+ if bbox.shape[-1] == 3:
+ bbox = bbox[..., :2] / bbox[..., 2:3]
+ if not self.bbox_keep_corner:
+ bbox = bbox_corner2xyxy(bbox)
+ if self.clip_border:
+ bbox = bbox_clip_border(bbox, (w, h))
+ results['bbox'] = bbox
+
+ if 'area' in results:
+ warp_mat_for_area = warp_mat
+ if warp_mat.shape[0] == 2:
+ aux_row = np.array([[0.0, 0.0, 1.0]], dtype=warp_mat.dtype)
+ warp_mat_for_area = np.concatenate((warp_mat, aux_row))
+ results['area'] *= np.linalg.det(warp_mat_for_area)
results['input_size'] = self.input_size
results['warp_mat'] = warp_mat
@@ -380,6 +467,7 @@ def __init__(self,
aug_scales: Optional[List[float]] = None,
size_factor: int = 32,
resize_mode: str = 'fit',
+ pad_val: tuple = (0, 0, 0),
use_udp: bool = False):
super().__init__()
@@ -388,6 +476,7 @@ def __init__(self,
self.resize_mode = resize_mode
self.size_factor = size_factor
self.use_udp = use_udp
+ self.pad_val = pad_val
@staticmethod
def _ceil_to_multiple(size: Tuple[int, int], base: int):
@@ -496,7 +585,11 @@ def transform(self, results: Dict) -> Optional[dict]:
output_size=padded_input_size)
_img = cv2.warpAffine(
- img, warp_mat, padded_input_size, flags=cv2.INTER_LINEAR)
+ img,
+ warp_mat,
+ padded_input_size,
+ flags=cv2.INTER_LINEAR,
+ borderValue=self.pad_val)
imgs.append(_img)
@@ -515,3 +608,416 @@ def transform(self, results: Dict) -> Optional[dict]:
results['aug_scale'] = None
return results
+
+
+@TRANSFORMS.register_module()
+class BottomupRandomCrop(BaseTransform):
+ """Random crop the image & bboxes & masks.
+
+ The absolute ``crop_size`` is sampled based on ``crop_type`` and
+ ``image_size``, then the cropped results are generated.
+
+ Required Keys:
+
+ - img
+ - keypoints
+ - bbox (optional)
+ - masks (BitmapMasks | PolygonMasks) (optional)
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - keypoints
+ - keypoints_visible
+ - num_keypoints
+ - bbox (optional)
+ - bbox_score (optional)
+ - id (optional)
+ - category_id (optional)
+ - raw_ann_info (optional)
+ - iscrowd (optional)
+ - segmentation (optional)
+ - masks (optional)
+
+ Added Keys:
+
+ - warp_mat
+
+ Args:
+ crop_size (tuple): The relative ratio or absolute pixels of
+ (width, height).
+ crop_type (str, optional): One of "relative_range", "relative",
+ "absolute", "absolute_range". "relative" randomly crops
+ (h * crop_size[0], w * crop_size[1]) part from an input of size
+ (h, w). "relative_range" uniformly samples relative crop size from
+ range [crop_size[0], 1] and [crop_size[1], 1] for height and width
+ respectively. "absolute" crops from an input with absolute size
+ (crop_size[0], crop_size[1]). "absolute_range" uniformly samples
+ crop_h in range [crop_size[0], min(h, crop_size[1])] and crop_w
+ in range [crop_size[0], min(w, crop_size[1])].
+ Defaults to "absolute".
+ allow_negative_crop (bool, optional): Whether to allow a crop that does
+ not contain any bbox area. Defaults to False.
+ recompute_bbox (bool, optional): Whether to re-compute the boxes based
+ on cropped instance masks. Defaults to False.
+ bbox_clip_border (bool, optional): Whether clip the objects outside
+ the border of the image. Defaults to True.
+
+ Note:
+ - If the image is smaller than the absolute crop size, return the
+ original image.
+ - If the crop does not contain any gt-bbox region and
+ ``allow_negative_crop`` is set to False, skip this image.
+ """
+
+ def __init__(self,
+ crop_size: tuple,
+ crop_type: str = 'absolute',
+ allow_negative_crop: bool = False,
+ recompute_bbox: bool = False,
+ bbox_clip_border: bool = True) -> None:
+ if crop_type not in [
+ 'relative_range', 'relative', 'absolute', 'absolute_range'
+ ]:
+ raise ValueError(f'Invalid crop_type {crop_type}.')
+ if crop_type in ['absolute', 'absolute_range']:
+ assert crop_size[0] > 0 and crop_size[1] > 0
+ assert isinstance(crop_size[0], int) and isinstance(
+ crop_size[1], int)
+ if crop_type == 'absolute_range':
+ assert crop_size[0] <= crop_size[1]
+ else:
+ assert 0 < crop_size[0] <= 1 and 0 < crop_size[1] <= 1
+ self.crop_size = crop_size
+ self.crop_type = crop_type
+ self.allow_negative_crop = allow_negative_crop
+ self.bbox_clip_border = bbox_clip_border
+ self.recompute_bbox = recompute_bbox
+
+ def _crop_data(self, results: dict, crop_size: Tuple[int, int],
+ allow_negative_crop: bool) -> Union[dict, None]:
+ """Function to randomly crop images, bounding boxes, masks, semantic
+ segmentation maps.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+ crop_size (Tuple[int, int]): Expected absolute size after
+ cropping, (h, w).
+ allow_negative_crop (bool): Whether to allow a crop that does not
+ contain any bbox area.
+
+ Returns:
+ results (Union[dict, None]): Randomly cropped results, 'img_shape'
+ key in result dict is updated according to crop size. None will
+ be returned when there is no valid bbox after cropping.
+ """
+ assert crop_size[0] > 0 and crop_size[1] > 0
+ img = results['img']
+ margin_h = max(img.shape[0] - crop_size[0], 0)
+ margin_w = max(img.shape[1] - crop_size[1], 0)
+ offset_h, offset_w = self._rand_offset((margin_h, margin_w))
+ crop_y1, crop_y2 = offset_h, offset_h + crop_size[0]
+ crop_x1, crop_x2 = offset_w, offset_w + crop_size[1]
+
+ # Record the warp matrix for the RandomCrop
+ warp_mat = np.array([[1, 0, -offset_w], [0, 1, -offset_h], [0, 0, 1]],
+ dtype=np.float32)
+ if results.get('warp_mat', None) is None:
+ results['warp_mat'] = warp_mat
+ else:
+ results['warp_mat'] = warp_mat @ results['warp_mat']
+
+ # crop the image
+ img = img[crop_y1:crop_y2, crop_x1:crop_x2, ...]
+ img_shape = img.shape
+ results['img'] = img
+ results['img_shape'] = img_shape[:2]
+
+ # crop bboxes accordingly and clip to the image boundary
+ if results.get('bbox', None) is not None:
+ distances = (-offset_w, -offset_h)
+ bboxes = results['bbox']
+ bboxes = bboxes + np.tile(np.asarray(distances), 2)
+
+ if self.bbox_clip_border:
+ bboxes[..., 0::2] = bboxes[..., 0::2].clip(0, img_shape[1])
+ bboxes[..., 1::2] = bboxes[..., 1::2].clip(0, img_shape[0])
+
+ valid_inds = (bboxes[..., 0] < img_shape[1]) & \
+ (bboxes[..., 1] < img_shape[0]) & \
+ (bboxes[..., 2] > 0) & \
+ (bboxes[..., 3] > 0)
+
+ # If the crop does not contain any gt-bbox area and
+ # allow_negative_crop is False, skip this image.
+ if (not valid_inds.any() and not allow_negative_crop):
+ return None
+
+ results['bbox'] = bboxes[valid_inds]
+ meta_keys = [
+ 'bbox_score', 'id', 'category_id', 'raw_ann_info', 'iscrowd'
+ ]
+ for key in meta_keys:
+ if results.get(key):
+ if isinstance(results[key], list):
+ results[key] = np.asarray(
+ results[key])[valid_inds].tolist()
+ else:
+ results[key] = results[key][valid_inds]
+
+ if results.get('keypoints', None) is not None:
+ keypoints = results['keypoints']
+ distances = np.asarray(distances).reshape(1, 1, 2)
+ keypoints = keypoints + distances
+ if self.bbox_clip_border:
+ keypoints_outside_x = keypoints[:, :, 0] < 0
+ keypoints_outside_y = keypoints[:, :, 1] < 0
+ keypoints_outside_width = keypoints[:, :, 0] > img_shape[1]
+ keypoints_outside_height = keypoints[:, :,
+ 1] > img_shape[0]
+
+ kpt_outside = np.logical_or.reduce(
+ (keypoints_outside_x, keypoints_outside_y,
+ keypoints_outside_width, keypoints_outside_height))
+
+ results['keypoints_visible'][kpt_outside] *= 0
+ keypoints[:, :, 0] = keypoints[:, :, 0].clip(0, img_shape[1])
+ keypoints[:, :, 1] = keypoints[:, :, 1].clip(0, img_shape[0])
+ results['keypoints'] = keypoints[valid_inds]
+ results['keypoints_visible'] = results['keypoints_visible'][
+ valid_inds]
+
+ if results.get('segmentation', None) is not None:
+ results['segmentation'] = results['segmentation'][
+ crop_y1:crop_y2, crop_x1:crop_x2]
+
+ if results.get('masks', None) is not None:
+ results['masks'] = results['masks'][valid_inds.nonzero(
+ )[0]].crop(np.asarray([crop_x1, crop_y1, crop_x2, crop_y2]))
+ if self.recompute_bbox:
+ results['bbox'] = results['masks'].get_bboxes(
+ type(results['bbox']))
+
+ return results
+
+ @cache_randomness
+ def _rand_offset(self, margin: Tuple[int, int]) -> Tuple[int, int]:
+ """Randomly generate crop offset.
+
+ Args:
+ margin (Tuple[int, int]): The upper bound for the offset generated
+ randomly.
+
+ Returns:
+ Tuple[int, int]: The random offset for the crop.
+ """
+ margin_h, margin_w = margin
+ offset_h = np.random.randint(0, margin_h + 1)
+ offset_w = np.random.randint(0, margin_w + 1)
+
+ return offset_h, offset_w
+
+ @cache_randomness
+ def _get_crop_size(self, image_size: Tuple[int, int]) -> Tuple[int, int]:
+ """Randomly generates the absolute crop size based on `crop_type` and
+ `image_size`.
+
+ Args:
+ image_size (Tuple[int, int]): (h, w).
+
+ Returns:
+ crop_size (Tuple[int, int]): (crop_h, crop_w) in absolute pixels.
+ """
+ h, w = image_size
+ if self.crop_type == 'absolute':
+ return min(self.crop_size[1], h), min(self.crop_size[0], w)
+ elif self.crop_type == 'absolute_range':
+ crop_h = np.random.randint(
+ min(h, self.crop_size[0]),
+ min(h, self.crop_size[1]) + 1)
+ crop_w = np.random.randint(
+ min(w, self.crop_size[0]),
+ min(w, self.crop_size[1]) + 1)
+ return crop_h, crop_w
+ elif self.crop_type == 'relative':
+ crop_w, crop_h = self.crop_size
+ return int(h * crop_h + 0.5), int(w * crop_w + 0.5)
+ else:
+ # 'relative_range'
+ crop_size = np.asarray(self.crop_size, dtype=np.float32)
+ crop_h, crop_w = crop_size + np.random.rand(2) * (1 - crop_size)
+ return int(h * crop_h + 0.5), int(w * crop_w + 0.5)
+
+ def transform(self, results: dict) -> Union[dict, None]:
+ """Transform function to randomly crop images, bounding boxes, masks,
+ semantic segmentation maps.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ results (Union[dict, None]): Randomly cropped results, 'img_shape'
+ key in result dict is updated according to crop size. None will
+ be returned when there is no valid bbox after cropping.
+ """
+ image_size = results['img'].shape[:2]
+ crop_size = self._get_crop_size(image_size)
+ results = self._crop_data(results, crop_size, self.allow_negative_crop)
+ return results
+
+
+@TRANSFORMS.register_module()
+class BottomupRandomChoiceResize(BaseTransform):
+ """Resize images & bbox & mask from a list of multiple scales.
+
+ This transform resizes the input image to some scale. Bboxes and masks are
+ then resized with the same scale factor. Resize scale will be randomly
+ selected from ``scales``.
+
+ How to choose the target scale to resize the image will follow the rules
+ below:
+
+ - if `scale` is a list of tuple, the target scale is sampled from the list
+ uniformally.
+ - if `scale` is a tuple, the target scale will be set to the tuple.
+
+ Required Keys:
+
+ - img
+ - bbox
+ - keypoints
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - bbox
+ - keypoints
+
+ Added Keys:
+
+ - scale
+ - scale_factor
+ - scale_idx
+
+ Args:
+ scales (Union[list, Tuple]): Images scales for resizing.
+
+ **resize_kwargs: Other keyword arguments for the ``resize_type``.
+ """
+
+ def __init__(
+ self,
+ scales: Sequence[Union[int, Tuple]],
+ keep_ratio: bool = False,
+ clip_object_border: bool = True,
+ backend: str = 'cv2',
+ **resize_kwargs,
+ ) -> None:
+ super().__init__()
+ if isinstance(scales, list):
+ self.scales = scales
+ else:
+ self.scales = [scales]
+
+ self.keep_ratio = keep_ratio
+ self.clip_object_border = clip_object_border
+ self.backend = backend
+
+ @cache_randomness
+ def _random_select(self) -> Tuple[int, int]:
+ """Randomly select an scale from given candidates.
+
+ Returns:
+ (tuple, int): Returns a tuple ``(scale, scale_dix)``,
+ where ``scale`` is the selected image scale and
+ ``scale_idx`` is the selected index in the given candidates.
+ """
+
+ scale_idx = np.random.randint(len(self.scales))
+ scale = self.scales[scale_idx]
+ return scale, scale_idx
+
+ def _resize_img(self, results: dict) -> None:
+ """Resize images with ``self.scale``."""
+
+ if self.keep_ratio:
+
+ img, scale_factor = imrescale(
+ results['img'],
+ self.scale,
+ interpolation='bilinear',
+ return_scale=True,
+ backend=self.backend)
+ # the w_scale and h_scale has minor difference
+ # a real fix should be done in the mmcv.imrescale in the future
+ new_h, new_w = img.shape[:2]
+ h, w = results['img'].shape[:2]
+ w_scale = new_w / w
+ h_scale = new_h / h
+ else:
+ img, w_scale, h_scale = imresize(
+ results['img'],
+ self.scale,
+ interpolation='bilinear',
+ return_scale=True,
+ backend=self.backend)
+
+ results['img'] = img
+ results['img_shape'] = img.shape[:2]
+ results['scale_factor'] = (w_scale, h_scale)
+ results['input_size'] = img.shape[:2]
+ w, h = results['ori_shape']
+ center = np.array([w / 2, h / 2], dtype=np.float32)
+ scale = np.array([w, h], dtype=np.float32)
+ results['input_center'] = center
+ results['input_scale'] = scale
+
+ def _resize_bboxes(self, results: dict) -> None:
+ """Resize bounding boxes with ``self.scale``."""
+ if results.get('bbox', None) is not None:
+ bboxes = results['bbox'] * np.tile(
+ np.array(results['scale_factor']), 2)
+ if self.clip_object_border:
+ bboxes[:, 0::2] = np.clip(bboxes[:, 0::2], 0,
+ results['img_shape'][1])
+ bboxes[:, 1::2] = np.clip(bboxes[:, 1::2], 0,
+ results['img_shape'][0])
+ results['bbox'] = bboxes
+
+ def _resize_keypoints(self, results: dict) -> None:
+ """Resize keypoints with ``self.scale``."""
+ if results.get('keypoints', None) is not None:
+ keypoints = results['keypoints']
+
+ keypoints[:, :, :2] = keypoints[:, :, :2] * np.array(
+ results['scale_factor'])
+ if self.clip_object_border:
+ keypoints[:, :, 0] = np.clip(keypoints[:, :, 0], 0,
+ results['img_shape'][1])
+ keypoints[:, :, 1] = np.clip(keypoints[:, :, 1], 0,
+ results['img_shape'][0])
+ results['keypoints'] = keypoints
+
+ def transform(self, results: dict) -> dict:
+ """Apply resize transforms on results from a list of scales.
+
+ Args:
+ results (dict): Result dict contains the data to transform.
+
+ Returns:
+ dict: Resized results, 'img', 'bbox',
+ 'keypoints', 'scale', 'scale_factor', 'img_shape',
+ and 'keep_ratio' keys are updated in result dict.
+ """
+
+ target_scale, scale_idx = self._random_select()
+
+ self.scale = target_scale
+ self._resize_img(results)
+ self._resize_bboxes(results)
+ self._resize_keypoints(results)
+
+ results['scale_idx'] = scale_idx
+ return results
diff --git a/mmpose/datasets/transforms/common_transforms.py b/mmpose/datasets/transforms/common_transforms.py
index 87068246f8..33f9c560c0 100644
--- a/mmpose/datasets/transforms/common_transforms.py
+++ b/mmpose/datasets/transforms/common_transforms.py
@@ -3,6 +3,7 @@
from copy import deepcopy
from typing import Dict, List, Optional, Sequence, Tuple, Union
+import cv2
import mmcv
import mmengine
import numpy as np
@@ -69,7 +70,7 @@ def transform(self, results: Dict) -> Optional[dict]:
if rank == 0:
warnings.warn('Use the existing "bbox_center" and "bbox_scale"'
'. The padding will still be applied.')
- results['bbox_scale'] *= self.padding
+ results['bbox_scale'] = results['bbox_scale'] * self.padding
else:
bbox = results['bbox']
@@ -340,7 +341,7 @@ def _random_select_half_body(self, keypoints_visible: np.ndarray,
Args:
keypoints_visible (np.ndarray, optional): The visibility of
- keypoints in shape (N, K, 1).
+ keypoints in shape (N, K, 1) or (N, K, 2).
upper_body_ids (list): The list of upper body keypoint indices
lower_body_ids (list): The list of lower body keypoint indices
@@ -349,6 +350,9 @@ def _random_select_half_body(self, keypoints_visible: np.ndarray,
of each instance. ``None`` means not applying half-body transform.
"""
+ if keypoints_visible.ndim == 3:
+ keypoints_visible = keypoints_visible[..., 0]
+
half_body_ids = []
for visible in keypoints_visible:
@@ -390,7 +394,6 @@ def transform(self, results: Dict) -> Optional[dict]:
Returns:
dict: The result dict.
"""
-
half_body_ids = self._random_select_half_body(
keypoints_visible=results['keypoints_visible'],
upper_body_ids=results['upper_body_ids'],
@@ -500,8 +503,13 @@ def _get_transform_params(self, num_bboxes: int) -> Tuple:
- scale (np.ndarray): Scaling factor of each bbox in shape (n, 1)
- rotate (np.ndarray): Rotation degree of each bbox in shape (n,)
"""
+ random_v = self._truncnorm(size=(num_bboxes, 4))
+ offset_v = random_v[:, :2]
+ scale_v = random_v[:, 2:3]
+ rotate_v = random_v[:, 3]
+
# Get shift parameters
- offset = self._truncnorm(size=(num_bboxes, 2)) * self.shift_factor
+ offset = offset_v * self.shift_factor
offset = np.where(
np.random.rand(num_bboxes, 1) < self.shift_prob, offset, 0.)
@@ -509,12 +517,12 @@ def _get_transform_params(self, num_bboxes: int) -> Tuple:
scale_min, scale_max = self.scale_factor
mu = (scale_max + scale_min) * 0.5
sigma = (scale_max - scale_min) * 0.5
- scale = self._truncnorm(size=(num_bboxes, 1)) * sigma + mu
+ scale = scale_v * sigma + mu
scale = np.where(
np.random.rand(num_bboxes, 1) < self.scale_prob, scale, 1.)
# Get rotation parameters
- rotate = self._truncnorm(size=(num_bboxes, )) * self.rotate_factor
+ rotate = rotate_v * self.rotate_factor
rotate = np.where(
np.random.rand(num_bboxes) < self.rotate_prob, rotate, 0.)
@@ -536,8 +544,8 @@ def transform(self, results: Dict) -> Optional[dict]:
offset, scale, rotate = self._get_transform_params(num_bboxes)
- results['bbox_center'] += offset * bbox_scale
- results['bbox_scale'] *= scale
+ results['bbox_center'] = results['bbox_center'] + offset * bbox_scale
+ results['bbox_scale'] = results['bbox_scale'] * scale
results['bbox_rotation'] = rotate
return results
@@ -952,6 +960,11 @@ def transform(self, results: Dict) -> Optional[dict]:
' \'keypoints\' in the results.')
keypoints_visible = results['keypoints_visible']
+ if keypoints_visible.ndim == 3 and keypoints_visible.shape[2] == 2:
+ keypoints_visible, keypoints_visible_weights = \
+ keypoints_visible[..., 0], keypoints_visible[..., 1]
+ results['keypoints_visible'] = keypoints_visible
+ results['keypoints_visible_weights'] = keypoints_visible_weights
# Encoded items from the encoder(s) will be updated into the results.
# Please refer to the document of the specific codec for details about
@@ -968,8 +981,21 @@ def transform(self, results: Dict) -> Optional[dict]:
keypoints_visible=keypoints_visible,
**auxiliary_encode_kwargs)
+ if self.encoder.field_mapping_table:
+ encoded[
+ 'field_mapping_table'] = self.encoder.field_mapping_table
+ if self.encoder.instance_mapping_table:
+ encoded['instance_mapping_table'] = \
+ self.encoder.instance_mapping_table
+ if self.encoder.label_mapping_table:
+ encoded[
+ 'label_mapping_table'] = self.encoder.label_mapping_table
+
else:
encoded_list = []
+ _field_mapping_table = dict()
+ _instance_mapping_table = dict()
+ _label_mapping_table = dict()
for _encoder in self.encoder:
auxiliary_encode_kwargs = {
key: results[key]
@@ -981,6 +1007,10 @@ def transform(self, results: Dict) -> Optional[dict]:
keypoints_visible=keypoints_visible,
**auxiliary_encode_kwargs))
+ _field_mapping_table.update(_encoder.field_mapping_table)
+ _instance_mapping_table.update(_encoder.instance_mapping_table)
+ _label_mapping_table.update(_encoder.label_mapping_table)
+
if self.multilevel:
# For multilevel encoding, the encoded items from each encoder
# should have the same keys.
@@ -1021,26 +1051,23 @@ def transform(self, results: Dict) -> Optional[dict]:
if keypoint_weights:
encoded['keypoint_weights'] = keypoint_weights
+ if _field_mapping_table:
+ encoded['field_mapping_table'] = _field_mapping_table
+ if _instance_mapping_table:
+ encoded['instance_mapping_table'] = _instance_mapping_table
+ if _label_mapping_table:
+ encoded['label_mapping_table'] = _label_mapping_table
+
if self.use_dataset_keypoint_weights and 'keypoint_weights' in encoded:
if isinstance(encoded['keypoint_weights'], list):
for w in encoded['keypoint_weights']:
- w *= results['dataset_keypoint_weights']
+ w = w * results['dataset_keypoint_weights']
else:
- encoded['keypoint_weights'] *= results[
- 'dataset_keypoint_weights']
+ encoded['keypoint_weights'] = encoded[
+ 'keypoint_weights'] * results['dataset_keypoint_weights']
results.update(encoded)
- if results.get('keypoint_weights', None) is not None:
- results['transformed_keypoints_visible'] = results[
- 'keypoint_weights']
- elif results.get('keypoints', None) is not None:
- results['transformed_keypoints_visible'] = results[
- 'keypoints_visible']
- else:
- raise ValueError('GenerateTarget requires \'keypoint_weights\' or'
- ' \'keypoints_visible\' in the results.')
-
return results
def __repr__(self) -> str:
@@ -1054,3 +1081,178 @@ def __repr__(self) -> str:
repr_str += ('use_dataset_keypoint_weights='
f'{self.use_dataset_keypoint_weights})')
return repr_str
+
+
+@TRANSFORMS.register_module()
+class YOLOXHSVRandomAug(BaseTransform):
+ """Apply HSV augmentation to image sequentially. It is referenced from
+ https://github.com/Megvii-
+ BaseDetection/YOLOX/blob/main/yolox/data/data_augment.py#L21.
+
+ Required Keys:
+
+ - img
+
+ Modified Keys:
+
+ - img
+
+ Args:
+ hue_delta (int): delta of hue. Defaults to 5.
+ saturation_delta (int): delta of saturation. Defaults to 30.
+ value_delta (int): delat of value. Defaults to 30.
+ """
+
+ def __init__(self,
+ hue_delta: int = 5,
+ saturation_delta: int = 30,
+ value_delta: int = 30) -> None:
+ self.hue_delta = hue_delta
+ self.saturation_delta = saturation_delta
+ self.value_delta = value_delta
+
+ @cache_randomness
+ def _get_hsv_gains(self):
+ hsv_gains = np.random.uniform(-1, 1, 3) * [
+ self.hue_delta, self.saturation_delta, self.value_delta
+ ]
+ # random selection of h, s, v
+ hsv_gains *= np.random.randint(0, 2, 3)
+ # prevent overflow
+ hsv_gains = hsv_gains.astype(np.int16)
+ return hsv_gains
+
+ def transform(self, results: dict) -> dict:
+ img = results['img']
+ hsv_gains = self._get_hsv_gains()
+ img_hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV).astype(np.int16)
+
+ img_hsv[..., 0] = (img_hsv[..., 0] + hsv_gains[0]) % 180
+ img_hsv[..., 1] = np.clip(img_hsv[..., 1] + hsv_gains[1], 0, 255)
+ img_hsv[..., 2] = np.clip(img_hsv[..., 2] + hsv_gains[2], 0, 255)
+ cv2.cvtColor(img_hsv.astype(img.dtype), cv2.COLOR_HSV2BGR, dst=img)
+
+ results['img'] = img
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(hue_delta={self.hue_delta}, '
+ repr_str += f'saturation_delta={self.saturation_delta}, '
+ repr_str += f'value_delta={self.value_delta})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class FilterAnnotations(BaseTransform):
+ """Eliminate undesirable annotations based on specific conditions.
+
+ This class is designed to sift through annotations by examining multiple
+ factors such as the size of the bounding box, the visibility of keypoints,
+ and the overall area. Users can fine-tune the criteria to filter out
+ instances that have excessively small bounding boxes, insufficient area,
+ or an inadequate number of visible keypoints.
+
+ Required Keys:
+
+ - bbox (np.ndarray) (optional)
+ - area (np.int64) (optional)
+ - keypoints_visible (np.ndarray) (optional)
+
+ Modified Keys:
+
+ - bbox (optional)
+ - bbox_score (optional)
+ - category_id (optional)
+ - keypoints (optional)
+ - keypoints_visible (optional)
+ - area (optional)
+
+ Args:
+ min_gt_bbox_wh (tuple[float]): Minimum width and height of ground
+ truth boxes. Default: (1., 1.)
+ min_gt_area (int): Minimum foreground area of instances.
+ Default: 1
+ min_kpt_vis (int): Minimum number of visible keypoints. Default: 1
+ by_box (bool): Filter instances with bounding boxes not meeting the
+ min_gt_bbox_wh threshold. Default: False
+ by_area (bool): Filter instances with area less than min_gt_area
+ threshold. Default: False
+ by_kpt (bool): Filter instances with keypoints_visible not meeting the
+ min_kpt_vis threshold. Default: True
+ keep_empty (bool): Whether to return None when it
+ becomes an empty bbox after filtering. Defaults to True.
+ """
+
+ def __init__(self,
+ min_gt_bbox_wh: Tuple[int, int] = (1, 1),
+ min_gt_area: int = 1,
+ min_kpt_vis: int = 1,
+ by_box: bool = False,
+ by_area: bool = False,
+ by_kpt: bool = True,
+ keep_empty: bool = True) -> None:
+
+ assert by_box or by_kpt or by_area
+ self.min_gt_bbox_wh = min_gt_bbox_wh
+ self.min_gt_area = min_gt_area
+ self.min_kpt_vis = min_kpt_vis
+ self.by_box = by_box
+ self.by_area = by_area
+ self.by_kpt = by_kpt
+ self.keep_empty = keep_empty
+
+ def transform(self, results: dict) -> Union[dict, None]:
+ """Transform function to filter annotations.
+
+ Args:
+ results (dict): Result dict.
+
+ Returns:
+ dict: Updated result dict.
+ """
+ assert 'keypoints' in results
+ kpts = results['keypoints']
+ if kpts.shape[0] == 0:
+ return results
+
+ tests = []
+ if self.by_box and 'bbox' in results:
+ bbox = results['bbox']
+ tests.append(
+ ((bbox[..., 2] - bbox[..., 0] > self.min_gt_bbox_wh[0]) &
+ (bbox[..., 3] - bbox[..., 1] > self.min_gt_bbox_wh[1])))
+ if self.by_area and 'area' in results:
+ area = results['area']
+ tests.append(area >= self.min_gt_area)
+ if self.by_kpt:
+ kpts_vis = results['keypoints_visible']
+ if kpts_vis.ndim == 3:
+ kpts_vis = kpts_vis[..., 0]
+ tests.append(kpts_vis.sum(axis=1) >= self.min_kpt_vis)
+
+ keep = tests[0]
+ for t in tests[1:]:
+ keep = keep & t
+
+ if not keep.any():
+ if self.keep_empty:
+ return None
+
+ keys = ('bbox', 'bbox_score', 'category_id', 'keypoints',
+ 'keypoints_visible', 'area')
+ for key in keys:
+ if key in results:
+ results[key] = results[key][keep]
+
+ return results
+
+ def __repr__(self):
+ return (f'{self.__class__.__name__}('
+ f'min_gt_bbox_wh={self.min_gt_bbox_wh}, '
+ f'min_gt_area={self.min_gt_area}, '
+ f'min_kpt_vis={self.min_kpt_vis}, '
+ f'by_box={self.by_box}, '
+ f'by_area={self.by_area}, '
+ f'by_kpt={self.by_kpt}, '
+ f'keep_empty={self.keep_empty})')
diff --git a/mmpose/datasets/transforms/converting.py b/mmpose/datasets/transforms/converting.py
index 38dcea0994..bca000435a 100644
--- a/mmpose/datasets/transforms/converting.py
+++ b/mmpose/datasets/transforms/converting.py
@@ -62,7 +62,10 @@ def __init__(self, num_keypoints: int,
int]]]):
self.num_keypoints = num_keypoints
self.mapping = mapping
- source_index, target_index = zip(*mapping)
+ if len(mapping):
+ source_index, target_index = zip(*mapping)
+ else:
+ source_index, target_index = [], []
src1, src2 = [], []
interpolation = False
@@ -83,34 +86,62 @@ def __init__(self, num_keypoints: int,
self.source_index2 = src2
self.source_index = src1
- self.target_index = target_index
+ self.target_index = list(target_index)
self.interpolation = interpolation
def transform(self, results: dict) -> dict:
+ """Transforms the keypoint results to match the target keypoints."""
num_instances = results['keypoints'].shape[0]
+ if len(results['keypoints_visible'].shape) > 2:
+ results['keypoints_visible'] = results['keypoints_visible'][:, :,
+ 0]
- keypoints = np.zeros((num_instances, self.num_keypoints, 2))
+ # Initialize output arrays
+ keypoints = np.zeros((num_instances, self.num_keypoints, 3))
keypoints_visible = np.zeros((num_instances, self.num_keypoints))
+ key = 'keypoints_3d' if 'keypoints_3d' in results else 'keypoints'
+ c = results[key].shape[-1]
- # When paired source_indexes are input,
- # perform interpolation with self.source_index and self.source_index2
- if self.interpolation:
- keypoints[:, self.target_index] = 0.5 * (
- results['keypoints'][:, self.source_index] +
- results['keypoints'][:, self.source_index2])
+ flip_indices = results.get('flip_indices', None)
+ # Create a mask to weight visibility loss
+ keypoints_visible_weights = keypoints_visible.copy()
+ keypoints_visible_weights[:, self.target_index] = 1.0
+
+ # Interpolate keypoints if pairs of source indexes provided
+ if self.interpolation:
+ keypoints[:, self.target_index, :c] = 0.5 * (
+ results[key][:, self.source_index] +
+ results[key][:, self.source_index2])
keypoints_visible[:, self.target_index] = results[
- 'keypoints_visible'][:, self.source_index] * \
- results['keypoints_visible'][:, self.source_index2]
+ 'keypoints_visible'][:, self.source_index] * results[
+ 'keypoints_visible'][:, self.source_index2]
+ # Flip keypoints if flip_indices provided
+ if flip_indices is not None:
+ for i, (x1, x2) in enumerate(
+ zip(self.source_index, self.source_index2)):
+ idx = flip_indices[x1] if x1 == x2 else i
+ flip_indices[i] = idx if idx < self.num_keypoints else i
+ flip_indices = flip_indices[:len(self.source_index)]
+ # Otherwise just copy from the source index
else:
keypoints[:,
- self.target_index] = results['keypoints'][:, self.
- source_index]
+ self.target_index, :c] = results[key][:,
+ self.source_index]
keypoints_visible[:, self.target_index] = results[
'keypoints_visible'][:, self.source_index]
- results['keypoints'] = keypoints
- results['keypoints_visible'] = keypoints_visible
+ # Update the results dict
+ results['keypoints'] = keypoints[..., :2]
+ results['keypoints_visible'] = np.stack(
+ [keypoints_visible, keypoints_visible_weights], axis=2)
+ if 'keypoints_3d' in results:
+ results['keypoints_3d'] = keypoints
+ results['lifting_target'] = keypoints[results['target_idx']]
+ results['lifting_target_visible'] = keypoints_visible[
+ results['target_idx']]
+ results['flip_indices'] = flip_indices
+
return results
def __repr__(self) -> str:
@@ -123,3 +154,83 @@ def __repr__(self) -> str:
repr_str += f'(num_keypoints={self.num_keypoints}, '\
f'mapping={self.mapping})'
return repr_str
+
+
+@TRANSFORMS.register_module()
+class SingleHandConverter(BaseTransform):
+ """Mapping a single hand keypoints into double hands according to the given
+ mapping and hand type.
+
+ Required Keys:
+
+ - keypoints
+ - keypoints_visible
+ - hand_type
+
+ Modified Keys:
+
+ - keypoints
+ - keypoints_visible
+
+ Args:
+ num_keypoints (int): The number of keypoints in target dataset.
+ left_hand_mapping (list): A list containing mapping indexes. Each
+ element has format (source_index, target_index)
+ right_hand_mapping (list): A list containing mapping indexes. Each
+ element has format (source_index, target_index)
+
+ Example:
+ >>> import numpy as np
+ >>> self = SingleHandConverter(
+ >>> num_keypoints=42,
+ >>> left_hand_mapping=[
+ >>> (0, 0), (1, 1), (2, 2), (3, 3)
+ >>> ],
+ >>> right_hand_mapping=[
+ >>> (0, 21), (1, 22), (2, 23), (3, 24)
+ >>> ])
+ >>> results = dict(
+ >>> keypoints=np.arange(84).reshape(2, 21, 2),
+ >>> keypoints_visible=np.arange(84).reshape(2, 21, 2) % 2,
+ >>> hand_type=np.array([[0, 1], [1, 0]]))
+ >>> results = self(results)
+ """
+
+ def __init__(self, num_keypoints: int,
+ left_hand_mapping: Union[List[Tuple[int, int]],
+ List[Tuple[Tuple, int]]],
+ right_hand_mapping: Union[List[Tuple[int, int]],
+ List[Tuple[Tuple, int]]]):
+ self.num_keypoints = num_keypoints
+ self.left_hand_converter = KeypointConverter(num_keypoints,
+ left_hand_mapping)
+ self.right_hand_converter = KeypointConverter(num_keypoints,
+ right_hand_mapping)
+
+ def transform(self, results: dict) -> dict:
+ """Transforms the keypoint results to match the target keypoints."""
+ assert 'hand_type' in results, (
+ 'hand_type should be provided in results')
+ hand_type = results['hand_type']
+
+ if np.sum(hand_type - [[0, 1]]) <= 1e-6:
+ # left hand
+ results = self.left_hand_converter(results)
+ elif np.sum(hand_type - [[1, 0]]) <= 1e-6:
+ results = self.right_hand_converter(results)
+ else:
+ raise ValueError('hand_type should be left or right')
+
+ return results
+
+ def __repr__(self) -> str:
+ """print the basic information of the transform.
+
+ Returns:
+ str: Formatted string.
+ """
+ repr_str = self.__class__.__name__
+ repr_str += f'(num_keypoints={self.num_keypoints}, '\
+ f'left_hand_converter={self.left_hand_converter}, '\
+ f'right_hand_converter={self.right_hand_converter})'
+ return repr_str
diff --git a/mmpose/datasets/transforms/formatting.py b/mmpose/datasets/transforms/formatting.py
index 05aeef179f..d3f3ec04aa 100644
--- a/mmpose/datasets/transforms/formatting.py
+++ b/mmpose/datasets/transforms/formatting.py
@@ -51,8 +51,6 @@ def keypoints_to_tensor(keypoints: Union[np.ndarray, Sequence[np.ndarray]]
"""
if isinstance(keypoints, np.ndarray):
keypoints = np.ascontiguousarray(keypoints)
- N = keypoints.shape[0]
- keypoints = keypoints.transpose(1, 2, 0).reshape(-1, N)
tensor = torch.from_numpy(keypoints).contiguous()
else:
assert is_seq_of(keypoints, np.ndarray)
@@ -100,57 +98,52 @@ class PackPoseInputs(BaseTransform):
meta_keys (Sequence[str], optional): Meta keys which will be stored in
:obj: `PoseDataSample` as meta info. Defaults to ``('id',
'img_id', 'img_path', 'category_id', 'crowd_index, 'ori_shape',
- 'img_shape',, 'input_size', 'input_center', 'input_scale', 'flip',
+ 'img_shape', 'input_size', 'input_center', 'input_scale', 'flip',
'flip_direction', 'flip_indices', 'raw_ann_info')``
"""
# items in `instance_mapping_table` will be directly packed into
# PoseDataSample.gt_instances without converting to Tensor
- instance_mapping_table = {
- 'bbox': 'bboxes',
- 'head_size': 'head_size',
- 'bbox_center': 'bbox_centers',
- 'bbox_scale': 'bbox_scales',
- 'bbox_score': 'bbox_scores',
- 'keypoints': 'keypoints',
- 'keypoints_visible': 'keypoints_visible',
- 'lifting_target': 'lifting_target',
- 'lifting_target_visible': 'lifting_target_visible',
- }
-
- # items in `label_mapping_table` will be packed into
- # PoseDataSample.gt_instance_labels and converted to Tensor. These items
- # will be used for computing losses
- label_mapping_table = {
- 'keypoint_labels': 'keypoint_labels',
- 'lifting_target_label': 'lifting_target_label',
- 'lifting_target_weights': 'lifting_target_weights',
- 'trajectory_weights': 'trajectory_weights',
- 'keypoint_x_labels': 'keypoint_x_labels',
- 'keypoint_y_labels': 'keypoint_y_labels',
- 'keypoint_weights': 'keypoint_weights',
- 'instance_coords': 'instance_coords',
- 'transformed_keypoints_visible': 'keypoints_visible',
- }
+ instance_mapping_table = dict(
+ bbox='bboxes',
+ bbox_score='bbox_scores',
+ keypoints='keypoints',
+ keypoints_cam='keypoints_cam',
+ keypoints_visible='keypoints_visible',
+ # In CocoMetric, the area of predicted instances will be calculated
+ # using gt_instances.bbox_scales. To unsure correspondence with
+ # previous version, this key is preserved here.
+ bbox_scale='bbox_scales',
+ # `head_size` is used for computing MpiiPCKAccuracy metric,
+ # namely, PCKh
+ head_size='head_size',
+ )
# items in `field_mapping_table` will be packed into
# PoseDataSample.gt_fields and converted to Tensor. These items will be
# used for computing losses
- field_mapping_table = {
- 'heatmaps': 'heatmaps',
- 'instance_heatmaps': 'instance_heatmaps',
- 'heatmap_mask': 'heatmap_mask',
- 'heatmap_weights': 'heatmap_weights',
- 'displacements': 'displacements',
- 'displacement_weights': 'displacement_weights',
- }
+ field_mapping_table = dict(
+ heatmaps='heatmaps',
+ instance_heatmaps='instance_heatmaps',
+ heatmap_mask='heatmap_mask',
+ heatmap_weights='heatmap_weights',
+ displacements='displacements',
+ displacement_weights='displacement_weights')
+
+ # items in `label_mapping_table` will be packed into
+ # PoseDataSample.gt_instance_labels and converted to Tensor. These items
+ # will be used for computing losses
+ label_mapping_table = dict(
+ keypoint_labels='keypoint_labels',
+ keypoint_weights='keypoint_weights',
+ keypoints_visible_weights='keypoints_visible_weights')
def __init__(self,
meta_keys=('id', 'img_id', 'img_path', 'category_id',
'crowd_index', 'ori_shape', 'img_shape',
'input_size', 'input_center', 'input_scale',
'flip', 'flip_direction', 'flip_indices',
- 'raw_ann_info'),
+ 'raw_ann_info', 'dataset_name'),
pack_transformed=False):
self.meta_keys = meta_keys
self.pack_transformed = pack_transformed
@@ -184,12 +177,10 @@ def transform(self, results: dict) -> dict:
# pack instance data
gt_instances = InstanceData()
- for key, packed_key in self.instance_mapping_table.items():
+ _instance_mapping_table = results.get('instance_mapping_table',
+ self.instance_mapping_table)
+ for key, packed_key in _instance_mapping_table.items():
if key in results:
- if 'lifting_target' in results and key in {
- 'keypoints', 'keypoints_visible'
- }:
- continue
gt_instances.set_field(results[key], packed_key)
# pack `transformed_keypoints` for visualizing data transform
@@ -197,23 +188,15 @@ def transform(self, results: dict) -> dict:
if self.pack_transformed and 'transformed_keypoints' in results:
gt_instances.set_field(results['transformed_keypoints'],
'transformed_keypoints')
- if self.pack_transformed and \
- 'transformed_keypoints_visible' in results:
- gt_instances.set_field(results['transformed_keypoints_visible'],
- 'transformed_keypoints_visible')
data_sample.gt_instances = gt_instances
# pack instance labels
gt_instance_labels = InstanceData()
- for key, packed_key in self.label_mapping_table.items():
+ _label_mapping_table = results.get('label_mapping_table',
+ self.label_mapping_table)
+ for key, packed_key in _label_mapping_table.items():
if key in results:
- # For pose-lifting, store only target-related fields
- if 'lifting_target_label' in results and key in {
- 'keypoint_labels', 'keypoint_weights',
- 'transformed_keypoints_visible'
- }:
- continue
if isinstance(results[key], list):
# A list of labels is usually generated by combined
# multiple encoders (See ``GenerateTarget`` in
@@ -228,7 +211,9 @@ def transform(self, results: dict) -> dict:
# pack fields
gt_fields = None
- for key, packed_key in self.field_mapping_table.items():
+ _field_mapping_table = results.get('field_mapping_table',
+ self.field_mapping_table)
+ for key, packed_key in _field_mapping_table.items():
if key in results:
if isinstance(results[key], list):
if gt_fields is None:
diff --git a/mmpose/datasets/transforms/hand_transforms.py b/mmpose/datasets/transforms/hand_transforms.py
new file mode 100644
index 0000000000..cd43f860e5
--- /dev/null
+++ b/mmpose/datasets/transforms/hand_transforms.py
@@ -0,0 +1,67 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Union
+
+from mmpose.codecs import * # noqa: F401, F403
+from mmpose.registry import TRANSFORMS
+from .common_transforms import RandomFlip
+
+
+@TRANSFORMS.register_module()
+class HandRandomFlip(RandomFlip):
+ """Data augmentation with random image flip. A child class of
+ `TopDownRandomFlip`.
+
+ Required Keys:
+
+ - img
+ - joints_3d
+ - joints_3d_visible
+ - center
+ - hand_type
+ - rel_root_depth
+ - ann_info
+
+ Modified Keys:
+
+ - img
+ - joints_3d
+ - joints_3d_visible
+ - center
+ - hand_type
+ - rel_root_depth
+
+ Args:
+ prob (float | list[float]): The flipping probability. If a list is
+ given, the argument `direction` should be a list with the same
+ length. And each element in `prob` indicates the flipping
+ probability of the corresponding one in ``direction``. Defaults
+ to 0.5
+ """
+
+ def __init__(self, prob: Union[float, List[float]] = 0.5) -> None:
+ super().__init__(prob=prob, direction='horizontal')
+
+ def transform(self, results: dict) -> dict:
+ """The transform function of :class:`HandRandomFlip`.
+
+ See ``transform()`` method of :class:`BaseTransform` for details.
+
+ Args:
+ results (dict): The result dict
+
+ Returns:
+ dict: The result dict.
+ """
+ # base flip augmentation
+ results = super().transform(results)
+
+ # flip hand type and root depth
+ hand_type = results['hand_type']
+ rel_root_depth = results['rel_root_depth']
+ flipped = results['flip']
+ if flipped:
+ hand_type[..., [0, 1]] = hand_type[..., [1, 0]]
+ rel_root_depth = -rel_root_depth
+ results['hand_type'] = hand_type
+ results['rel_root_depth'] = rel_root_depth
+ return results
diff --git a/mmpose/datasets/transforms/loading.py b/mmpose/datasets/transforms/loading.py
index 28edcb4806..8501623e9a 100644
--- a/mmpose/datasets/transforms/loading.py
+++ b/mmpose/datasets/transforms/loading.py
@@ -48,19 +48,24 @@ def transform(self, results: dict) -> Optional[dict]:
Returns:
dict: The result dict.
"""
+ try:
+ if 'img' not in results:
+ # Load image from file by :meth:`LoadImageFromFile.transform`
+ results = super().transform(results)
+ else:
+ img = results['img']
+ assert isinstance(img, np.ndarray)
+ if self.to_float32:
+ img = img.astype(np.float32)
- if 'img' not in results:
- # Load image from file by :meth:`LoadImageFromFile.transform`
- results = super().transform(results)
- else:
- img = results['img']
- assert isinstance(img, np.ndarray)
- if self.to_float32:
- img = img.astype(np.float32)
-
- if 'img_path' not in results:
- results['img_path'] = None
- results['img_shape'] = img.shape[:2]
- results['ori_shape'] = img.shape[:2]
+ if 'img_path' not in results:
+ results['img_path'] = None
+ results['img_shape'] = img.shape[:2]
+ results['ori_shape'] = img.shape[:2]
+ except Exception as e:
+ e = type(e)(
+ f'`{str(e)}` occurs when loading `{results["img_path"]}`.'
+ 'Please check whether the file exists.')
+ raise e
return results
diff --git a/mmpose/datasets/transforms/mix_img_transforms.py b/mmpose/datasets/transforms/mix_img_transforms.py
new file mode 100644
index 0000000000..84d03ea5a2
--- /dev/null
+++ b/mmpose/datasets/transforms/mix_img_transforms.py
@@ -0,0 +1,501 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from abc import ABCMeta
+from collections import defaultdict
+from typing import Optional, Sequence, Tuple
+
+import mmcv
+import numpy as np
+from mmcv.transforms import BaseTransform
+from mmengine.dataset.base_dataset import Compose
+from numpy import random
+
+from mmpose.registry import TRANSFORMS
+from mmpose.structures import (bbox_clip_border, flip_bbox, flip_keypoints,
+ keypoint_clip_border)
+
+
+class MixImageTransform(BaseTransform, metaclass=ABCMeta):
+ """Abstract base class for mixup-style image data augmentation.
+
+ Args:
+ pre_transform (Optional[Sequence[str]]): A sequence of transform
+ to be applied before mixup. Defaults to None.
+ prob (float): Probability of applying the mixup transformation.
+ Defaults to 1.0.
+ """
+
+ def __init__(self,
+ pre_transform: Optional[Sequence[str]] = None,
+ prob: float = 1.0):
+
+ self.prob = prob
+
+ if pre_transform is None:
+ self.pre_transform = None
+ else:
+ self.pre_transform = Compose(pre_transform)
+
+ def transform(self, results: dict) -> dict:
+ """Transform the input data dictionary using mixup-style augmentation.
+
+ Args:
+ results (dict): A dictionary containing input data.
+ """
+
+ if random.uniform(0, 1) < self.prob:
+
+ dataset = results.pop('dataset', None)
+
+ results['mixed_data_list'] = self._get_mixed_data_list(dataset)
+ results = self.apply_mix(results)
+
+ if 'mixed_data_list' in results:
+ results.pop('mixed_data_list')
+
+ results['dataset'] = dataset
+
+ return results
+
+ def _get_mixed_data_list(self, dataset):
+ """Get a list of mixed data samples from the dataset.
+
+ Args:
+ dataset: The dataset from which to sample the mixed data.
+
+ Returns:
+ List[dict]: A list of dictionaries containing mixed data samples.
+ """
+ indexes = [
+ random.randint(0, len(dataset)) for _ in range(self.num_aux_image)
+ ]
+
+ mixed_data_list = [
+ copy.deepcopy(dataset.get_data_info(index)) for index in indexes
+ ]
+
+ if self.pre_transform is not None:
+ for i, data in enumerate(mixed_data_list):
+ data.update({'dataset': dataset})
+ _results = self.pre_transform(data)
+ _results.pop('dataset')
+ mixed_data_list[i] = _results
+
+ return mixed_data_list
+
+
+@TRANSFORMS.register_module()
+class Mosaic(MixImageTransform):
+ """Mosaic augmentation. This transformation takes four input images and
+ combines them into a single output image using the mosaic technique. The
+ resulting image is composed of parts from each of the four sub-images. The
+ mosaic transform steps are as follows:
+
+ 1. Choose the mosaic center as the intersection of the four images.
+ 2. Select the top-left image according to the index and randomly sample
+ three more images from the custom dataset.
+ 3. If an image is larger than the mosaic patch, it will be cropped.
+
+ .. code:: text
+
+ mosaic transform
+ center_x
+ +------------------------------+
+ | pad | |
+ | +-----------+ pad |
+ | | | |
+ | | image1 +-----------+
+ | | | |
+ | | | image2 |
+ center_y |----+-+-----------+-----------+
+ | | cropped | |
+ |pad | image3 | image4 |
+ | | | |
+ +----|-------------+-----------+
+ | |
+ +-------------+
+
+ Required Keys:
+
+ - img
+ - bbox (optional)
+ - bbox_score (optional)
+ - category_id (optional)
+ - keypoints (optional)
+ - keypoints_visible (optional)
+ - area (optional)
+
+ Modified Keys:
+
+ - img
+ - bbox (optional)
+ - bbox_score (optional)
+ - category_id (optional)
+ - keypoints (optional)
+ - keypoints_visible (optional)
+ - area (optional)
+
+ Args:
+ img_scale (Sequence[int]): Image size after mosaic pipeline of single
+ image. The shape order should be (width, height).
+ Defaults to (640, 640).
+ center_range (Sequence[float]): Center ratio range of mosaic
+ output. Defaults to (0.5, 1.5).
+ pad_val (int): Pad value. Defaults to 114.
+ pre_transform (Optional[Sequence[str]]): A sequence of transform
+ to be applied before mixup. Defaults to None.
+ prob (float): Probability of applying the mixup transformation.
+ Defaults to 1.0.
+ """
+
+ num_aux_image = 3
+
+ def __init__(
+ self,
+ img_scale: Tuple[int, int] = (640, 640),
+ center_range: Tuple[float, float] = (0.5, 1.5),
+ pad_val: float = 114.0,
+ pre_transform: Sequence[dict] = None,
+ prob: float = 1.0,
+ ):
+
+ super().__init__(pre_transform=pre_transform, prob=prob)
+
+ self.img_scale = img_scale
+ self.center_range = center_range
+ self.pad_val = pad_val
+
+ def apply_mix(self, results: dict) -> dict:
+ """Apply mosaic augmentation to the input data."""
+
+ assert 'mixed_data_list' in results
+ mixed_data_list = results.pop('mixed_data_list')
+ assert len(mixed_data_list) == self.num_aux_image
+
+ img, annos = self._create_mosaic_image(results, mixed_data_list)
+ bboxes = annos['bboxes']
+ kpts = annos['keypoints']
+ kpts_vis = annos['keypoints_visible']
+
+ bboxes = bbox_clip_border(bboxes, (2 * self.img_scale[0],
+ 2 * self.img_scale[1]))
+ kpts, kpts_vis = keypoint_clip_border(kpts, kpts_vis,
+ (2 * self.img_scale[0],
+ 2 * self.img_scale[1]))
+
+ results['img'] = img
+ results['img_shape'] = img.shape
+ results['bbox'] = bboxes
+ results['category_id'] = annos['category_id']
+ results['bbox_score'] = annos['bbox_scores']
+ results['keypoints'] = kpts
+ results['keypoints_visible'] = kpts_vis
+ results['area'] = annos['area']
+
+ return results
+
+ def _create_mosaic_image(self, results, mixed_data_list):
+ """Create the mosaic image and corresponding annotations by combining
+ four input images."""
+
+ # init mosaic image
+ img_scale_w, img_scale_h = self.img_scale
+ mosaic_img = np.full((int(img_scale_h * 2), int(img_scale_w * 2), 3),
+ self.pad_val,
+ dtype=results['img'].dtype)
+
+ # calculate mosaic center
+ center = (int(random.uniform(*self.center_range) * img_scale_w),
+ int(random.uniform(*self.center_range) * img_scale_h))
+
+ annos = defaultdict(list)
+ locs = ('top_left', 'top_right', 'bottom_left', 'bottom_right')
+ for loc, data in zip(locs, (results, *mixed_data_list)):
+
+ # process image
+ img = data['img']
+ h, w = img.shape[:2]
+ scale_ratio = min(img_scale_h / h, img_scale_w / w)
+ img = mmcv.imresize(img,
+ (int(w * scale_ratio), int(h * scale_ratio)))
+
+ # paste
+ paste_coord, crop_coord = self._mosaic_combine(
+ loc, center, img.shape[:2][::-1])
+ x1_p, y1_p, x2_p, y2_p = paste_coord
+ x1_c, y1_c, x2_c, y2_c = crop_coord
+
+ # crop and paste image
+ mosaic_img[y1_p:y2_p, x1_p:x2_p] = img[y1_c:y2_c, x1_c:x2_c]
+ padw = x1_p - x1_c
+ padh = y1_p - y1_c
+
+ # merge annotations
+ if 'bbox' in data:
+ bboxes = data['bbox']
+
+ # rescale & translate
+ bboxes *= scale_ratio
+ bboxes[..., ::2] += padw
+ bboxes[..., 1::2] += padh
+
+ annos['bboxes'].append(bboxes)
+ annos['bbox_scores'].append(data['bbox_score'])
+ annos['category_id'].append(data['category_id'])
+
+ if 'keypoints' in data:
+ kpts = data['keypoints']
+
+ # rescale & translate
+ kpts *= scale_ratio
+ kpts[..., 0] += padw
+ kpts[..., 1] += padh
+
+ annos['keypoints'].append(kpts)
+ annos['keypoints_visible'].append(data['keypoints_visible'])
+
+ if 'area' in data:
+ annos['area'].append(data['area'] * scale_ratio**2)
+
+ for key in annos:
+ annos[key] = np.concatenate(annos[key])
+ return mosaic_img, annos
+
+ def _mosaic_combine(
+ self, loc: str, center: Tuple[float, float], img_shape: Tuple[int, int]
+ ) -> Tuple[Tuple[int, int, int, int], Tuple[int, int, int, int]]:
+ """Determine the overall coordinates of the mosaic image and the
+ specific coordinates of the cropped sub-image."""
+
+ assert loc in ('top_left', 'top_right', 'bottom_left', 'bottom_right')
+
+ x1, y1, x2, y2 = 0, 0, 0, 0
+ cx, cy = center
+ w, h = img_shape
+
+ if loc == 'top_left':
+ x1, y1, x2, y2 = max(cx - w, 0), max(cy - h, 0), cx, cy
+ crop_coord = w - (x2 - x1), h - (y2 - y1), w, h
+ elif loc == 'top_right':
+ x1, y1, x2, y2 = cx, max(cy - h, 0), min(cx + w,
+ self.img_scale[0] * 2), cy
+ crop_coord = 0, h - (y2 - y1), min(w, x2 - x1), h
+ elif loc == 'bottom_left':
+ x1, y1, x2, y2 = max(cx - w,
+ 0), cy, cx, min(self.img_scale[1] * 2, cy + h)
+ crop_coord = w - (x2 - x1), 0, w, min(y2 - y1, h)
+ else:
+ x1, y1, x2, y2 = cx, cy, min(cx + w, self.img_scale[0] *
+ 2), min(self.img_scale[1] * 2, cy + h)
+ crop_coord = 0, 0, min(w, x2 - x1), min(y2 - y1, h)
+
+ return (x1, y1, x2, y2), crop_coord
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(img_scale={self.img_scale}, '
+ repr_str += f'center_range={self.center_range}, '
+ repr_str += f'pad_val={self.pad_val}, '
+ repr_str += f'prob={self.prob})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class YOLOXMixUp(MixImageTransform):
+ """MixUp data augmentation for YOLOX. This transform combines two images
+ through mixup to enhance the dataset's diversity.
+
+ Mixup Transform Steps:
+
+ 1. A random image is chosen from the dataset and placed in the
+ top-left corner of the target image (after padding and resizing).
+ 2. The target of the mixup transform is obtained by taking the
+ weighted average of the mixup image and the original image.
+
+ .. code:: text
+
+ mixup transform
+ +---------------+--------------+
+ | mixup image | |
+ | +--------|--------+ |
+ | | | | |
+ +---------------+ | |
+ | | | |
+ | | image | |
+ | | | |
+ | | | |
+ | +-----------------+ |
+ | pad |
+ +------------------------------+
+
+ Required Keys:
+
+ - img
+ - bbox (optional)
+ - bbox_score (optional)
+ - category_id (optional)
+ - keypoints (optional)
+ - keypoints_visible (optional)
+ - area (optional)
+
+ Modified Keys:
+
+ - img
+ - bbox (optional)
+ - bbox_score (optional)
+ - category_id (optional)
+ - keypoints (optional)
+ - keypoints_visible (optional)
+ - area (optional)
+
+ Args:
+ img_scale (Sequence[int]): Image output size after mixup pipeline.
+ The shape order should be (width, height). Defaults to (640, 640).
+ ratio_range (Sequence[float]): Scale ratio of mixup image.
+ Defaults to (0.5, 1.5).
+ flip_ratio (float): Horizontal flip ratio of mixup image.
+ Defaults to 0.5.
+ pad_val (int): Pad value. Defaults to 114.
+ pre_transform (Optional[Sequence[str]]): A sequence of transform
+ to be applied before mixup. Defaults to None.
+ prob (float): Probability of applying the mixup transformation.
+ Defaults to 1.0.
+ """
+ num_aux_image = 1
+
+ def __init__(self,
+ img_scale: Tuple[int, int] = (640, 640),
+ ratio_range: Tuple[float, float] = (0.5, 1.5),
+ flip_ratio: float = 0.5,
+ pad_val: float = 114.0,
+ bbox_clip_border: bool = True,
+ pre_transform: Sequence[dict] = None,
+ prob: float = 1.0):
+ assert isinstance(img_scale, tuple)
+ super().__init__(pre_transform=pre_transform, prob=prob)
+ self.img_scale = img_scale
+ self.ratio_range = ratio_range
+ self.flip_ratio = flip_ratio
+ self.pad_val = pad_val
+ self.bbox_clip_border = bbox_clip_border
+
+ def apply_mix(self, results: dict) -> dict:
+ """YOLOX MixUp transform function."""
+
+ assert 'mixed_data_list' in results
+ mixed_data_list = results.pop('mixed_data_list')
+ assert len(mixed_data_list) == self.num_aux_image
+
+ if mixed_data_list[0]['keypoints'].shape[0] == 0:
+ return results
+
+ img, annos = self._create_mixup_image(results, mixed_data_list)
+ bboxes = annos['bboxes']
+ kpts = annos['keypoints']
+ kpts_vis = annos['keypoints_visible']
+
+ h, w = img.shape[:2]
+ bboxes = bbox_clip_border(bboxes, (w, h))
+ kpts, kpts_vis = keypoint_clip_border(kpts, kpts_vis, (w, h))
+
+ results['img'] = img.astype(np.uint8)
+ results['img_shape'] = img.shape
+ results['bbox'] = bboxes
+ results['category_id'] = annos['category_id']
+ results['bbox_score'] = annos['bbox_scores']
+ results['keypoints'] = kpts
+ results['keypoints_visible'] = kpts_vis
+ results['area'] = annos['area']
+
+ return results
+
+ def _create_mixup_image(self, results, mixed_data_list):
+ """Create the mixup image and corresponding annotations by combining
+ two input images."""
+
+ aux_results = mixed_data_list[0]
+ aux_img = aux_results['img']
+
+ # init mixup image
+ out_img = np.ones((self.img_scale[1], self.img_scale[0], 3),
+ dtype=aux_img.dtype) * self.pad_val
+ annos = defaultdict(list)
+
+ # Calculate scale ratio and resize aux_img
+ scale_ratio = min(self.img_scale[1] / aux_img.shape[0],
+ self.img_scale[0] / aux_img.shape[1])
+ aux_img = mmcv.imresize(aux_img, (int(aux_img.shape[1] * scale_ratio),
+ int(aux_img.shape[0] * scale_ratio)))
+
+ # Set the resized aux_img in the top-left of out_img
+ out_img[:aux_img.shape[0], :aux_img.shape[1]] = aux_img
+
+ # random rescale
+ jit_factor = random.uniform(*self.ratio_range)
+ scale_ratio *= jit_factor
+ out_img = mmcv.imresize(out_img, (int(out_img.shape[1] * jit_factor),
+ int(out_img.shape[0] * jit_factor)))
+
+ # random flip
+ is_filp = random.uniform(0, 1) > self.flip_ratio
+ if is_filp:
+ out_img = out_img[:, ::-1, :]
+
+ # random crop
+ ori_img = results['img']
+ aux_h, aux_w = out_img.shape[:2]
+ h, w = ori_img.shape[:2]
+ padded_img = np.ones((max(aux_h, h), max(aux_w, w), 3)) * self.pad_val
+ padded_img = padded_img.astype(np.uint8)
+ padded_img[:aux_h, :aux_w] = out_img
+
+ dy = random.randint(0, max(0, padded_img.shape[0] - h) + 1)
+ dx = random.randint(0, max(0, padded_img.shape[1] - w) + 1)
+ padded_cropped_img = padded_img[dy:dy + h, dx:dx + w]
+
+ # mix up
+ mixup_img = 0.5 * ori_img + 0.5 * padded_cropped_img
+
+ # merge annotations
+ # bboxes
+ bboxes = aux_results['bbox'].copy()
+ bboxes *= scale_ratio
+ bboxes = bbox_clip_border(bboxes, (aux_w, aux_h))
+ if is_filp:
+ bboxes = flip_bbox(bboxes, [aux_w, aux_h], 'xyxy')
+ bboxes[..., ::2] -= dx
+ bboxes[..., 1::2] -= dy
+ annos['bboxes'] = [results['bbox'], bboxes]
+ annos['bbox_scores'] = [
+ results['bbox_score'], aux_results['bbox_score']
+ ]
+ annos['category_id'] = [
+ results['category_id'], aux_results['category_id']
+ ]
+
+ # keypoints
+ kpts = aux_results['keypoints'] * scale_ratio
+ kpts, kpts_vis = keypoint_clip_border(kpts,
+ aux_results['keypoints_visible'],
+ (aux_w, aux_h))
+ if is_filp:
+ kpts, kpts_vis = flip_keypoints(kpts, kpts_vis, (aux_w, aux_h),
+ aux_results['flip_indices'])
+ kpts[..., 0] -= dx
+ kpts[..., 1] -= dy
+ annos['keypoints'] = [results['keypoints'], kpts]
+ annos['keypoints_visible'] = [results['keypoints_visible'], kpts_vis]
+ annos['area'] = [results['area'], aux_results['area'] * scale_ratio**2]
+
+ for key in annos:
+ annos[key] = np.concatenate(annos[key])
+
+ return mixup_img, annos
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(img_scale={self.img_scale}, '
+ repr_str += f'ratio_range={self.ratio_range}, '
+ repr_str += f'flip_ratio={self.flip_ratio}, '
+ repr_str += f'pad_val={self.pad_val})'
+ return repr_str
diff --git a/mmpose/datasets/transforms/pose3d_transforms.py b/mmpose/datasets/transforms/pose3d_transforms.py
index e6559fa398..5831692000 100644
--- a/mmpose/datasets/transforms/pose3d_transforms.py
+++ b/mmpose/datasets/transforms/pose3d_transforms.py
@@ -25,28 +25,38 @@ class RandomFlipAroundRoot(BaseTransform):
flip_prob (float): Probability of flip. Default: 0.5.
flip_camera (bool): Whether to flip horizontal distortion coefficients.
Default: ``False``.
+ flip_label (bool): Whether to flip labels instead of data.
+ Default: ``False``.
Required keys:
- keypoints
- lifting_target
+ - keypoints or keypoint_labels
+ - lifting_target or lifting_target_label
+ - keypoints_visible or keypoint_labels_visible (optional)
+ - lifting_target_visible (optional)
+ - flip_indices (optional)
Modified keys:
- (keypoints, keypoints_visible, lifting_target, lifting_target_visible,
- camera_param)
+ - keypoints or keypoint_labels (optional)
+ - keypoints_visible or keypoint_labels_visible (optional)
+ - lifting_target or lifting_target_label (optional)
+ - lifting_target_visible (optional)
+ - camera_param (optional)
"""
def __init__(self,
keypoints_flip_cfg,
target_flip_cfg,
flip_prob=0.5,
- flip_camera=False):
+ flip_camera=False,
+ flip_label=False):
self.keypoints_flip_cfg = keypoints_flip_cfg
self.target_flip_cfg = target_flip_cfg
self.flip_prob = flip_prob
self.flip_camera = flip_camera
+ self.flip_label = flip_label
def transform(self, results: Dict) -> dict:
- """The transform function of :class:`ZeroCenterPose`.
+ """The transform function of :class:`RandomFlipAroundRoot`.
See ``transform()`` method of :class:`BaseTransform` for details.
@@ -57,25 +67,42 @@ def transform(self, results: Dict) -> dict:
dict: The result dict.
"""
- keypoints = results['keypoints']
- if 'keypoints_visible' in results:
- keypoints_visible = results['keypoints_visible']
- else:
- keypoints_visible = np.ones(keypoints.shape[:-1], dtype=np.float32)
- lifting_target = results['lifting_target']
- if 'lifting_target_visible' in results:
- lifting_target_visible = results['lifting_target_visible']
- else:
- lifting_target_visible = np.ones(
- lifting_target.shape[:-1], dtype=np.float32)
-
if np.random.rand() <= self.flip_prob:
+ if self.flip_label:
+ assert 'keypoint_labels' in results
+ assert 'lifting_target_label' in results
+ keypoints_key = 'keypoint_labels'
+ keypoints_visible_key = 'keypoint_labels_visible'
+ target_key = 'lifting_target_label'
+ else:
+ assert 'keypoints' in results
+ assert 'lifting_target' in results
+ keypoints_key = 'keypoints'
+ keypoints_visible_key = 'keypoints_visible'
+ target_key = 'lifting_target'
+
+ keypoints = results[keypoints_key]
+ if keypoints_visible_key in results:
+ keypoints_visible = results[keypoints_visible_key]
+ else:
+ keypoints_visible = np.ones(
+ keypoints.shape[:-1], dtype=np.float32)
+
+ lifting_target = results[target_key]
+ if 'lifting_target_visible' in results:
+ lifting_target_visible = results['lifting_target_visible']
+ else:
+ lifting_target_visible = np.ones(
+ lifting_target.shape[:-1], dtype=np.float32)
+
if 'flip_indices' not in results:
flip_indices = list(range(self.num_keypoints))
else:
flip_indices = results['flip_indices']
# flip joint coordinates
+ _camera_param = deepcopy(results['camera_param'])
+
keypoints, keypoints_visible = flip_keypoints_custom_center(
keypoints, keypoints_visible, flip_indices,
**self.keypoints_flip_cfg)
@@ -83,16 +110,15 @@ def transform(self, results: Dict) -> dict:
lifting_target, lifting_target_visible, flip_indices,
**self.target_flip_cfg)
- results['keypoints'] = keypoints
- results['keypoints_visible'] = keypoints_visible
- results['lifting_target'] = lifting_target
+ results[keypoints_key] = keypoints
+ results[keypoints_visible_key] = keypoints_visible
+ results[target_key] = lifting_target
results['lifting_target_visible'] = lifting_target_visible
# flip horizontal distortion coefficients
if self.flip_camera:
assert 'camera_param' in results, \
'Camera parameters are missing.'
- _camera_param = deepcopy(results['camera_param'])
assert 'c' in _camera_param
_camera_param['c'][0] *= -1
diff --git a/mmpose/datasets/transforms/topdown_transforms.py b/mmpose/datasets/transforms/topdown_transforms.py
index 29aa48eb06..18e85d9664 100644
--- a/mmpose/datasets/transforms/topdown_transforms.py
+++ b/mmpose/datasets/transforms/topdown_transforms.py
@@ -125,6 +125,8 @@ def transform(self, results: Dict) -> Optional[dict]:
results['transformed_keypoints'] = transformed_keypoints
results['input_size'] = (w, h)
+ results['input_center'] = center
+ results['input_scale'] = scale
return results
diff --git a/mmpose/engine/__init__.py b/mmpose/engine/__init__.py
index ac85928986..44f7fa17bc 100644
--- a/mmpose/engine/__init__.py
+++ b/mmpose/engine/__init__.py
@@ -1,3 +1,4 @@
# Copyright (c) OpenMMLab. All rights reserved.
from .hooks import * # noqa: F401, F403
from .optim_wrappers import * # noqa: F401, F403
+from .schedulers import * # noqa: F401, F403
diff --git a/mmpose/engine/hooks/__init__.py b/mmpose/engine/hooks/__init__.py
index dadb9c5f91..2c31ca081c 100644
--- a/mmpose/engine/hooks/__init__.py
+++ b/mmpose/engine/hooks/__init__.py
@@ -1,5 +1,11 @@
# Copyright (c) OpenMMLab. All rights reserved.
+from .badcase_hook import BadCaseAnalysisHook
from .ema_hook import ExpMomentumEMA
+from .mode_switch_hooks import YOLOXPoseModeSwitchHook
+from .sync_norm_hook import SyncNormHook
from .visualization_hook import PoseVisualizationHook
-__all__ = ['PoseVisualizationHook', 'ExpMomentumEMA']
+__all__ = [
+ 'PoseVisualizationHook', 'ExpMomentumEMA', 'BadCaseAnalysisHook',
+ 'YOLOXPoseModeSwitchHook', 'SyncNormHook'
+]
diff --git a/mmpose/engine/hooks/badcase_hook.py b/mmpose/engine/hooks/badcase_hook.py
new file mode 100644
index 0000000000..a06ef5af53
--- /dev/null
+++ b/mmpose/engine/hooks/badcase_hook.py
@@ -0,0 +1,239 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+import logging
+import os
+import warnings
+from typing import Dict, Optional, Sequence
+
+import mmcv
+import mmengine
+import mmengine.fileio as fileio
+import torch
+from mmengine.config import ConfigDict
+from mmengine.hooks import Hook
+from mmengine.logging import print_log
+from mmengine.runner import Runner
+from mmengine.visualization import Visualizer
+
+from mmpose.registry import HOOKS, METRICS, MODELS
+from mmpose.structures import PoseDataSample, merge_data_samples
+
+
+@HOOKS.register_module()
+class BadCaseAnalysisHook(Hook):
+ """Bad Case Analyze Hook. Used to visualize validation and testing process
+ prediction results.
+
+ In the testing phase:
+
+ 1. If ``show`` is True, it means that only the prediction results are
+ visualized without storing data, so ``vis_backends`` needs to
+ be excluded.
+ 2. If ``out_dir`` is specified, it means that the prediction results
+ need to be saved to ``out_dir``. In order to avoid vis_backends
+ also storing data, so ``vis_backends`` needs to be excluded.
+ 3. ``vis_backends`` takes effect if the user does not specify ``show``
+ and `out_dir``. You can set ``vis_backends`` to WandbVisBackend or
+ TensorboardVisBackend to store the prediction result in Wandb or
+ Tensorboard.
+
+ Args:
+ enable (bool): whether to draw prediction results. If it is False,
+ it means that no drawing will be done. Defaults to False.
+ show (bool): Whether to display the drawn image. Default to False.
+ wait_time (float): The interval of show (s). Defaults to 0.
+ interval (int): The interval of visualization. Defaults to 50.
+ kpt_thr (float): The threshold to visualize the keypoints.
+ Defaults to 0.3.
+ out_dir (str, optional): directory where painted images
+ will be saved in testing process.
+ backend_args (dict, optional): Arguments to instantiate the preifx of
+ uri corresponding backend. Defaults to None.
+ metric_type (str): the mretic type to decide a badcase,
+ loss or accuracy.
+ metric (ConfigDict): The config of metric.
+ metric_key (str): key of needed metric value in the return dict
+ from class 'metric'.
+ badcase_thr (float): min loss or max accuracy for a badcase.
+ """
+
+ def __init__(
+ self,
+ enable: bool = False,
+ show: bool = False,
+ wait_time: float = 0.,
+ interval: int = 50,
+ kpt_thr: float = 0.3,
+ out_dir: Optional[str] = None,
+ backend_args: Optional[dict] = None,
+ metric_type: str = 'loss',
+ metric: ConfigDict = ConfigDict(type='KeypointMSELoss'),
+ metric_key: str = 'PCK',
+ badcase_thr: float = 5,
+ ):
+ self._visualizer: Visualizer = Visualizer.get_current_instance()
+ self.interval = interval
+ self.kpt_thr = kpt_thr
+ self.show = show
+ if self.show:
+ # No need to think about vis backends.
+ self._visualizer._vis_backends = {}
+ warnings.warn('The show is True, it means that only '
+ 'the prediction results are visualized '
+ 'without storing data, so vis_backends '
+ 'needs to be excluded.')
+
+ self.wait_time = wait_time
+ self.enable = enable
+ self.out_dir = out_dir
+ self._test_index = 0
+ self.backend_args = backend_args
+
+ self.metric_type = metric_type
+ if metric_type not in ['loss', 'accuracy']:
+ raise KeyError(
+ f'The badcase metric type {metric_type} is not supported by '
+ f"{self.__class__.__name__}. Should be one of 'loss', "
+ f"'accuracy', but got {metric_type}.")
+ self.metric = MODELS.build(metric) if metric_type == 'loss'\
+ else METRICS.build(metric)
+ self.metric_name = metric.type if metric_type == 'loss'\
+ else metric_key
+ self.metric_key = metric_key
+ self.badcase_thr = badcase_thr
+ self.results = []
+
+ def check_badcase(self, data_batch, data_sample):
+ """Check whether the sample is a badcase.
+
+ Args:
+ data_batch (Sequence[dict]): A batch of data
+ from the dataloader.
+ data_samples (Sequence[dict]): A batch of outputs from
+ the model.
+ Return:
+ is_badcase (bool): whether the sample is a badcase or not
+ metric_value (float)
+ """
+ if self.metric_type == 'loss':
+ gts = data_sample.gt_instances.keypoints
+ preds = data_sample.pred_instances.keypoints
+ weights = data_sample.gt_instances.keypoints_visible
+ with torch.no_grad():
+ metric_value = self.metric(
+ torch.from_numpy(preds), torch.from_numpy(gts),
+ torch.from_numpy(weights)).item()
+ is_badcase = metric_value >= self.badcase_thr
+ else:
+ self.metric.process([data_batch], [data_sample.to_dict()])
+ metric_value = self.metric.evaluate(1)[self.metric_key]
+ is_badcase = metric_value <= self.badcase_thr
+ return is_badcase, metric_value
+
+ def after_test_iter(self, runner: Runner, batch_idx: int, data_batch: dict,
+ outputs: Sequence[PoseDataSample]) -> None:
+ """Run after every testing iterations.
+
+ Args:
+ runner (:obj:`Runner`): The runner of the testing process.
+ batch_idx (int): The index of the current batch in the test loop.
+ data_batch (dict): Data from dataloader.
+ outputs (Sequence[:obj:`PoseDataSample`]): Outputs from model.
+ """
+ if not self.enable:
+ return
+
+ if self.out_dir is not None:
+ self.out_dir = os.path.join(runner.work_dir, runner.timestamp,
+ self.out_dir)
+ mmengine.mkdir_or_exist(self.out_dir)
+
+ self._visualizer.set_dataset_meta(runner.test_evaluator.dataset_meta)
+
+ for data_sample in outputs:
+ self._test_index += 1
+
+ img_path = data_sample.get('img_path')
+ img_bytes = fileio.get(img_path, backend_args=self.backend_args)
+ img = mmcv.imfrombytes(img_bytes, channel_order='rgb')
+ data_sample = merge_data_samples([data_sample])
+
+ is_badcase, metric_value = self.check_badcase(
+ data_batch, data_sample)
+
+ if is_badcase:
+ img_name, postfix = os.path.basename(img_path).rsplit('.', 1)
+ bboxes = data_sample.gt_instances.bboxes.astype(int).tolist()
+ bbox_info = 'bbox' + str(bboxes)
+ metric_postfix = self.metric_name + str(round(metric_value, 2))
+
+ self.results.append({
+ 'img': img_name,
+ 'bbox': bboxes,
+ self.metric_name: metric_value
+ })
+
+ badcase_name = f'{img_name}_{bbox_info}_{metric_postfix}'
+
+ out_file = None
+ if self.out_dir is not None:
+ out_file = f'{badcase_name}.{postfix}'
+ out_file = os.path.join(self.out_dir, out_file)
+
+ # draw gt keypoints in blue color
+ self._visualizer.kpt_color = 'blue'
+ self._visualizer.link_color = 'blue'
+ img_gt_drawn = self._visualizer.add_datasample(
+ badcase_name if self.show else 'test_img',
+ img,
+ data_sample=data_sample,
+ show=False,
+ draw_pred=False,
+ draw_gt=True,
+ draw_bbox=False,
+ draw_heatmap=False,
+ wait_time=self.wait_time,
+ kpt_thr=self.kpt_thr,
+ out_file=None,
+ step=self._test_index)
+ # draw pred keypoints in red color
+ self._visualizer.kpt_color = 'red'
+ self._visualizer.link_color = 'red'
+ self._visualizer.add_datasample(
+ badcase_name if self.show else 'test_img',
+ img_gt_drawn,
+ data_sample=data_sample,
+ show=self.show,
+ draw_pred=True,
+ draw_gt=False,
+ draw_bbox=True,
+ draw_heatmap=False,
+ wait_time=self.wait_time,
+ kpt_thr=self.kpt_thr,
+ out_file=out_file,
+ step=self._test_index)
+
+ def after_test_epoch(self,
+ runner,
+ metrics: Optional[Dict[str, float]] = None) -> None:
+ """All subclasses should override this method, if they need any
+ operations after each test epoch.
+
+ Args:
+ runner (Runner): The runner of the testing process.
+ metrics (Dict[str, float], optional): Evaluation results of all
+ metrics on test dataset. The keys are the names of the
+ metrics, and the values are corresponding results.
+ """
+ if not self.enable or not self.results:
+ return
+
+ mmengine.mkdir_or_exist(self.out_dir)
+ out_file = os.path.join(self.out_dir, 'results.json')
+ with open(out_file, 'w') as f:
+ json.dump(self.results, f)
+
+ print_log(
+ f'the bad cases are saved under {self.out_dir}',
+ logger='current',
+ level=logging.INFO)
diff --git a/mmpose/engine/hooks/mode_switch_hooks.py b/mmpose/engine/hooks/mode_switch_hooks.py
new file mode 100644
index 0000000000..862e36dc0b
--- /dev/null
+++ b/mmpose/engine/hooks/mode_switch_hooks.py
@@ -0,0 +1,65 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import Sequence
+
+from mmengine.hooks import Hook
+from mmengine.model import is_model_wrapper
+from mmengine.runner import Runner
+
+from mmpose.registry import HOOKS
+
+
+@HOOKS.register_module()
+class YOLOXPoseModeSwitchHook(Hook):
+ """Switch the mode of YOLOX-Pose during training.
+
+ This hook:
+ 1) Turns off mosaic and mixup data augmentation.
+ 2) Uses instance mask to assist positive anchor selection.
+ 3) Uses auxiliary L1 loss in the head.
+
+ Args:
+ num_last_epochs (int): The number of last epochs at the end of
+ training to close the data augmentation and switch to L1 loss.
+ Defaults to 20.
+ new_train_dataset (dict): New training dataset configuration that
+ will be used in place of the original training dataset. Defaults
+ to None.
+ new_train_pipeline (Sequence[dict]): New data augmentation pipeline
+ configuration that will be used in place of the original pipeline
+ during training. Defaults to None.
+ """
+
+ def __init__(self,
+ num_last_epochs: int = 20,
+ new_train_dataset: dict = None,
+ new_train_pipeline: Sequence[dict] = None):
+ self.num_last_epochs = num_last_epochs
+ self.new_train_dataset = new_train_dataset
+ self.new_train_pipeline = new_train_pipeline
+
+ def _modify_dataloader(self, runner: Runner):
+ """Modify dataloader with new dataset and pipeline configurations."""
+ runner.logger.info(f'New Pipeline: {self.new_train_pipeline}')
+
+ train_dataloader_cfg = copy.deepcopy(runner.cfg.train_dataloader)
+ if self.new_train_dataset:
+ train_dataloader_cfg.dataset = self.new_train_dataset
+ if self.new_train_pipeline:
+ train_dataloader_cfg.dataset.pipeline = self.new_train_pipeline
+
+ new_train_dataloader = Runner.build_dataloader(train_dataloader_cfg)
+ runner.train_loop.dataloader = new_train_dataloader
+ runner.logger.info('Recreated the dataloader!')
+
+ def before_train_epoch(self, runner: Runner):
+ """Close mosaic and mixup augmentation, switch to use L1 loss."""
+ epoch = runner.epoch
+ model = runner.model
+ if is_model_wrapper(model):
+ model = model.module
+
+ if epoch + 1 == runner.max_epochs - self.num_last_epochs:
+ self._modify_dataloader(runner)
+ runner.logger.info('Added additional reg loss now!')
+ model.head.use_aux_loss = True
diff --git a/mmpose/engine/hooks/sync_norm_hook.py b/mmpose/engine/hooks/sync_norm_hook.py
new file mode 100644
index 0000000000..053e4f92af
--- /dev/null
+++ b/mmpose/engine/hooks/sync_norm_hook.py
@@ -0,0 +1,41 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from collections import OrderedDict
+
+from mmengine.dist import all_reduce_dict, get_dist_info
+from mmengine.hooks import Hook
+from torch import nn
+
+from mmpose.registry import HOOKS
+
+
+def get_norm_states(module: nn.Module) -> OrderedDict:
+ """Get the state_dict of batch norms in the module."""
+ async_norm_states = OrderedDict()
+ for name, child in module.named_modules():
+ if isinstance(child, nn.modules.batchnorm._NormBase):
+ for k, v in child.state_dict().items():
+ async_norm_states['.'.join([name, k])] = v
+ return async_norm_states
+
+
+@HOOKS.register_module()
+class SyncNormHook(Hook):
+ """Synchronize Norm states before validation."""
+
+ def before_val_epoch(self, runner):
+ """Synchronize normalization statistics."""
+ module = runner.model
+ rank, world_size = get_dist_info()
+
+ if world_size == 1:
+ return
+
+ norm_states = get_norm_states(module)
+ if len(norm_states) == 0:
+ return
+
+ try:
+ norm_states = all_reduce_dict(norm_states, op='mean')
+ module.load_state_dict(norm_states, strict=True)
+ except Exception as e:
+ runner.logger.warn(f'SyncNormHook failed: {str(e)}')
diff --git a/mmpose/engine/schedulers/__init__.py b/mmpose/engine/schedulers/__init__.py
new file mode 100644
index 0000000000..01261646fa
--- /dev/null
+++ b/mmpose/engine/schedulers/__init__.py
@@ -0,0 +1,8 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .quadratic_warmup import (QuadraticWarmupLR, QuadraticWarmupMomentum,
+ QuadraticWarmupParamScheduler)
+
+__all__ = [
+ 'QuadraticWarmupParamScheduler', 'QuadraticWarmupMomentum',
+ 'QuadraticWarmupLR'
+]
diff --git a/mmpose/engine/schedulers/quadratic_warmup.py b/mmpose/engine/schedulers/quadratic_warmup.py
new file mode 100644
index 0000000000..1021797217
--- /dev/null
+++ b/mmpose/engine/schedulers/quadratic_warmup.py
@@ -0,0 +1,131 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.optim.scheduler.lr_scheduler import LRSchedulerMixin
+from mmengine.optim.scheduler.momentum_scheduler import MomentumSchedulerMixin
+from mmengine.optim.scheduler.param_scheduler import INF, _ParamScheduler
+from torch.optim import Optimizer
+
+from mmpose.registry import PARAM_SCHEDULERS
+
+
+@PARAM_SCHEDULERS.register_module()
+class QuadraticWarmupParamScheduler(_ParamScheduler):
+ r"""Warm up the parameter value of each parameter group by quadratic
+ formula:
+
+ .. math::
+
+ X_{t} = X_{t-1} + \frac{2t+1}{{(end-begin)}^{2}} \times X_{base}
+
+ Args:
+ optimizer (Optimizer): Wrapped optimizer.
+ param_name (str): Name of the parameter to be adjusted, such as
+ ``lr``, ``momentum``.
+ begin (int): Step at which to start updating the parameters.
+ Defaults to 0.
+ end (int): Step at which to stop updating the parameters.
+ Defaults to INF.
+ last_step (int): The index of last step. Used for resume without
+ state dict. Defaults to -1.
+ by_epoch (bool): Whether the scheduled parameters are updated by
+ epochs. Defaults to True.
+ verbose (bool): Whether to print the value for each update.
+ Defaults to False.
+ """
+
+ def __init__(self,
+ optimizer: Optimizer,
+ param_name: str,
+ begin: int = 0,
+ end: int = INF,
+ last_step: int = -1,
+ by_epoch: bool = True,
+ verbose: bool = False):
+ if end >= INF:
+ raise ValueError('``end`` must be less than infinity,'
+ 'Please set ``end`` parameter of '
+ '``QuadraticWarmupScheduler`` as the '
+ 'number of warmup end.')
+ self.total_iters = end - begin
+ super().__init__(
+ optimizer=optimizer,
+ param_name=param_name,
+ begin=begin,
+ end=end,
+ last_step=last_step,
+ by_epoch=by_epoch,
+ verbose=verbose)
+
+ @classmethod
+ def build_iter_from_epoch(cls,
+ *args,
+ begin=0,
+ end=INF,
+ by_epoch=True,
+ epoch_length=None,
+ **kwargs):
+ """Build an iter-based instance of this scheduler from an epoch-based
+ config."""
+ assert by_epoch, 'Only epoch-based kwargs whose `by_epoch=True` can ' \
+ 'be converted to iter-based.'
+ assert epoch_length is not None and epoch_length > 0, \
+ f'`epoch_length` must be a positive integer, ' \
+ f'but got {epoch_length}.'
+ by_epoch = False
+ begin = begin * epoch_length
+ if end != INF:
+ end = end * epoch_length
+ return cls(*args, begin=begin, end=end, by_epoch=by_epoch, **kwargs)
+
+ def _get_value(self):
+ """Compute value using chainable form of the scheduler."""
+ if self.last_step == 0:
+ return [
+ base_value * (2 * self.last_step + 1) / self.total_iters**2
+ for base_value in self.base_values
+ ]
+
+ return [
+ group[self.param_name] + base_value *
+ (2 * self.last_step + 1) / self.total_iters**2
+ for base_value, group in zip(self.base_values,
+ self.optimizer.param_groups)
+ ]
+
+
+@PARAM_SCHEDULERS.register_module()
+class QuadraticWarmupLR(LRSchedulerMixin, QuadraticWarmupParamScheduler):
+ """Warm up the learning rate of each parameter group by quadratic formula.
+
+ Args:
+ optimizer (Optimizer): Wrapped optimizer.
+ begin (int): Step at which to start updating the parameters.
+ Defaults to 0.
+ end (int): Step at which to stop updating the parameters.
+ Defaults to INF.
+ last_step (int): The index of last step. Used for resume without
+ state dict. Defaults to -1.
+ by_epoch (bool): Whether the scheduled parameters are updated by
+ epochs. Defaults to True.
+ verbose (bool): Whether to print the value for each update.
+ Defaults to False.
+ """
+
+
+@PARAM_SCHEDULERS.register_module()
+class QuadraticWarmupMomentum(MomentumSchedulerMixin,
+ QuadraticWarmupParamScheduler):
+ """Warm up the momentum value of each parameter group by quadratic formula.
+
+ Args:
+ optimizer (Optimizer): Wrapped optimizer.
+ begin (int): Step at which to start updating the parameters.
+ Defaults to 0.
+ end (int): Step at which to stop updating the parameters.
+ Defaults to INF.
+ last_step (int): The index of last step. Used for resume without
+ state dict. Defaults to -1.
+ by_epoch (bool): Whether the scheduled parameters are updated by
+ epochs. Defaults to True.
+ verbose (bool): Whether to print the value for each update.
+ Defaults to False.
+ """
diff --git a/mmpose/evaluation/__init__.py b/mmpose/evaluation/__init__.py
index f70dc226d3..a758ba7c1b 100644
--- a/mmpose/evaluation/__init__.py
+++ b/mmpose/evaluation/__init__.py
@@ -1,3 +1,4 @@
# Copyright (c) OpenMMLab. All rights reserved.
+from .evaluators import * # noqa: F401,F403
from .functional import * # noqa: F401,F403
from .metrics import * # noqa: F401,F403
diff --git a/mmpose/evaluation/evaluators/__init__.py b/mmpose/evaluation/evaluators/__init__.py
new file mode 100644
index 0000000000..ae2d79d514
--- /dev/null
+++ b/mmpose/evaluation/evaluators/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .mutli_dataset_evaluator import MultiDatasetEvaluator
+
+__all__ = ['MultiDatasetEvaluator']
diff --git a/mmpose/evaluation/evaluators/mutli_dataset_evaluator.py b/mmpose/evaluation/evaluators/mutli_dataset_evaluator.py
new file mode 100644
index 0000000000..96c5971f24
--- /dev/null
+++ b/mmpose/evaluation/evaluators/mutli_dataset_evaluator.py
@@ -0,0 +1,88 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from collections import defaultdict
+from typing import Any, Optional, Sequence, Union
+
+from mmengine.evaluator.evaluator import Evaluator
+from mmengine.evaluator.metric import BaseMetric
+from mmengine.structures import BaseDataElement
+
+from mmpose.datasets.datasets.utils import parse_pose_metainfo
+from mmpose.registry import DATASETS, EVALUATORS
+
+
+@EVALUATORS.register_module()
+class MultiDatasetEvaluator(Evaluator):
+ """Wrapper class to compose multiple :class:`BaseMetric` instances.
+
+ Args:
+ metrics (dict or BaseMetric or Sequence): The configs of metrics.
+ datasets (Sequence[str]): The configs of datasets.
+ """
+
+ def __init__(
+ self,
+ metrics: Union[dict, BaseMetric, Sequence],
+ datasets: Sequence[dict],
+ ):
+
+ assert len(metrics) == len(datasets), 'the argument ' \
+ 'datasets should have same length as metrics'
+
+ super().__init__(metrics)
+
+ # Initialize metrics for each dataset
+ metrics_dict = dict()
+ for dataset, metric in zip(datasets, self.metrics):
+ metainfo_file = DATASETS.module_dict[dataset['type']].METAINFO
+ dataset_meta = parse_pose_metainfo(metainfo_file)
+ metric.dataset_meta = dataset_meta
+ metrics_dict[dataset_meta['dataset_name']] = metric
+ self.metrics_dict = metrics_dict
+
+ @property
+ def dataset_meta(self) -> Optional[dict]:
+ """Optional[dict]: Meta info of the dataset."""
+ return self._dataset_meta
+
+ @dataset_meta.setter
+ def dataset_meta(self, dataset_meta: dict) -> None:
+ """Set the dataset meta info to the evaluator and it's metrics."""
+ self._dataset_meta = dataset_meta
+
+ def process(self,
+ data_samples: Sequence[BaseDataElement],
+ data_batch: Optional[Any] = None):
+ """Convert ``BaseDataSample`` to dict and invoke process method of each
+ metric.
+
+ Args:
+ data_samples (Sequence[BaseDataElement]): predictions of the model,
+ and the ground truth of the validation set.
+ data_batch (Any, optional): A batch of data from the dataloader.
+ """
+ _data_samples = defaultdict(list)
+ _data_batch = dict(
+ inputs=defaultdict(list),
+ data_samples=defaultdict(list),
+ )
+
+ for inputs, data_ds, data_sample in zip(data_batch['inputs'],
+ data_batch['data_samples'],
+ data_samples):
+ if isinstance(data_sample, BaseDataElement):
+ data_sample = data_sample.to_dict()
+ assert isinstance(data_sample, dict)
+ dataset_name = data_sample.get('dataset_name',
+ self.dataset_meta['dataset_name'])
+ _data_samples[dataset_name].append(data_sample)
+ _data_batch['inputs'][dataset_name].append(inputs)
+ _data_batch['data_samples'][dataset_name].append(data_ds)
+
+ for dataset_name, metric in self.metrics_dict.items():
+ if dataset_name in _data_samples:
+ data_batch = dict(
+ inputs=_data_batch['inputs'][dataset_name],
+ data_samples=_data_batch['data_samples'][dataset_name])
+ metric.process(data_batch, _data_samples[dataset_name])
+ else:
+ continue
diff --git a/mmpose/evaluation/functional/__init__.py b/mmpose/evaluation/functional/__init__.py
index 49f243163c..47255fc394 100644
--- a/mmpose/evaluation/functional/__init__.py
+++ b/mmpose/evaluation/functional/__init__.py
@@ -3,10 +3,12 @@
keypoint_nme, keypoint_pck_accuracy,
multilabel_classification_accuracy,
pose_pck_accuracy, simcc_pck_accuracy)
-from .nms import nms, oks_nms, soft_oks_nms
+from .nms import nms, nms_torch, oks_nms, soft_oks_nms
+from .transforms import transform_ann, transform_pred, transform_sigmas
__all__ = [
'keypoint_pck_accuracy', 'keypoint_auc', 'keypoint_nme', 'keypoint_epe',
'pose_pck_accuracy', 'multilabel_classification_accuracy',
- 'simcc_pck_accuracy', 'nms', 'oks_nms', 'soft_oks_nms', 'keypoint_mpjpe'
+ 'simcc_pck_accuracy', 'nms', 'oks_nms', 'soft_oks_nms', 'keypoint_mpjpe',
+ 'nms_torch', 'transform_ann', 'transform_sigmas', 'transform_pred'
]
diff --git a/mmpose/evaluation/functional/nms.py b/mmpose/evaluation/functional/nms.py
index eed4e5cf73..7f669c89cb 100644
--- a/mmpose/evaluation/functional/nms.py
+++ b/mmpose/evaluation/functional/nms.py
@@ -7,6 +7,10 @@
from typing import List, Optional
import numpy as np
+import torch
+from torch import Tensor
+
+from mmpose.structures.bbox import bbox_overlaps
def nms(dets: np.ndarray, thr: float) -> List[int]:
@@ -325,3 +329,40 @@ def nearby_joints_nms(
keep_pose_inds = [keep_pose_inds[i] for i in sub_inds]
return keep_pose_inds
+
+
+def nms_torch(bboxes: Tensor,
+ scores: Tensor,
+ threshold: float = 0.65,
+ iou_calculator=bbox_overlaps,
+ return_group: bool = False):
+ """Perform Non-Maximum Suppression (NMS) on a set of bounding boxes using
+ their corresponding scores.
+
+ Args:
+
+ bboxes (Tensor): list of bounding boxes (each containing 4 elements
+ for x1, y1, x2, y2).
+ scores (Tensor): scores associated with each bounding box.
+ threshold (float): IoU threshold to determine overlap.
+ iou_calculator (function): method to calculate IoU.
+ return_group (bool): if True, returns groups of overlapping bounding
+ boxes, otherwise returns the main bounding boxes.
+ """
+
+ _, indices = scores.sort(descending=True)
+ groups = []
+ while len(indices):
+ idx, indices = indices[0], indices[1:]
+ bbox = bboxes[idx]
+ ious = iou_calculator(bbox, bboxes[indices])
+ close_indices = torch.where(ious > threshold)[1]
+ keep_indices = torch.ones_like(indices, dtype=torch.bool)
+ keep_indices[close_indices] = 0
+ groups.append(torch.cat((idx[None], indices[close_indices])))
+ indices = indices[keep_indices]
+
+ if return_group:
+ return groups
+ else:
+ return torch.cat([g[:1] for g in groups])
diff --git a/mmpose/evaluation/functional/transforms.py b/mmpose/evaluation/functional/transforms.py
new file mode 100644
index 0000000000..56873b389c
--- /dev/null
+++ b/mmpose/evaluation/functional/transforms.py
@@ -0,0 +1,99 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple, Union
+
+import numpy as np
+
+
+def transform_sigmas(sigmas: Union[List, np.ndarray], num_keypoints: int,
+ mapping: Union[List[Tuple[int, int]], List[Tuple[Tuple,
+ int]]]):
+ """Transforms the sigmas based on the mapping."""
+ if len(mapping):
+ source_index, target_index = map(list, zip(*mapping))
+ else:
+ source_index, target_index = [], []
+
+ list_input = False
+ if isinstance(sigmas, list):
+ sigmas = np.array(sigmas)
+ list_input = True
+
+ new_sigmas = np.ones(num_keypoints, dtype=sigmas.dtype)
+ new_sigmas[target_index] = sigmas[source_index]
+
+ if list_input:
+ new_sigmas = new_sigmas.tolist()
+
+ return new_sigmas
+
+
+def transform_ann(ann_info: Union[dict, list], num_keypoints: int,
+ mapping: Union[List[Tuple[int, int]], List[Tuple[Tuple,
+ int]]]):
+ """Transforms COCO-format annotations based on the mapping."""
+ if len(mapping):
+ source_index, target_index = map(list, zip(*mapping))
+ else:
+ source_index, target_index = [], []
+
+ list_input = True
+ if not isinstance(ann_info, list):
+ ann_info = [ann_info]
+ list_input = False
+
+ for each in ann_info:
+ if 'keypoints' in each:
+ keypoints = np.array(each['keypoints'])
+
+ C = 3 # COCO-format: x, y, score
+ keypoints = keypoints.reshape(-1, C)
+ new_keypoints = np.zeros((num_keypoints, C), dtype=keypoints.dtype)
+ new_keypoints[target_index] = keypoints[source_index]
+ each['keypoints'] = new_keypoints.reshape(-1).tolist()
+
+ if 'num_keypoints' in each:
+ each['num_keypoints'] = num_keypoints
+
+ if not list_input:
+ ann_info = ann_info[0]
+
+ return ann_info
+
+
+def transform_pred(pred_info: Union[dict, list], num_keypoints: int,
+ mapping: Union[List[Tuple[int, int]], List[Tuple[Tuple,
+ int]]]):
+ """Transforms predictions based on the mapping."""
+ if len(mapping):
+ source_index, target_index = map(list, zip(*mapping))
+ else:
+ source_index, target_index = [], []
+
+ list_input = True
+ if not isinstance(pred_info, list):
+ pred_info = [pred_info]
+ list_input = False
+
+ for each in pred_info:
+ if 'keypoints' in each:
+ keypoints = np.array(each['keypoints'])
+
+ N, _, C = keypoints.shape
+ new_keypoints = np.zeros((N, num_keypoints, C),
+ dtype=keypoints.dtype)
+ new_keypoints[:, target_index] = keypoints[:, source_index]
+ each['keypoints'] = new_keypoints
+
+ keypoint_scores = np.array(each['keypoint_scores'])
+ new_scores = np.zeros((N, num_keypoints),
+ dtype=keypoint_scores.dtype)
+ new_scores[:, target_index] = keypoint_scores[:, source_index]
+ each['keypoint_scores'] = new_scores
+
+ if 'num_keypoints' in each:
+ each['num_keypoints'] = num_keypoints
+
+ if not list_input:
+ pred_info = pred_info[0]
+
+ return pred_info
diff --git a/mmpose/evaluation/metrics/__init__.py b/mmpose/evaluation/metrics/__init__.py
index ac7e21b5cc..9e82356a49 100644
--- a/mmpose/evaluation/metrics/__init__.py
+++ b/mmpose/evaluation/metrics/__init__.py
@@ -1,14 +1,16 @@
# Copyright (c) OpenMMLab. All rights reserved.
from .coco_metric import CocoMetric
from .coco_wholebody_metric import CocoWholeBodyMetric
+from .hand_metric import InterHandMetric
from .keypoint_2d_metrics import (AUC, EPE, NME, JhmdbPCKAccuracy,
MpiiPCKAccuracy, PCKAccuracy)
from .keypoint_3d_metrics import MPJPE
from .keypoint_partition_metric import KeypointPartitionMetric
from .posetrack18_metric import PoseTrack18Metric
+from .simple_keypoint_3d_metrics import SimpleMPJPE
__all__ = [
'CocoMetric', 'PCKAccuracy', 'MpiiPCKAccuracy', 'JhmdbPCKAccuracy', 'AUC',
'EPE', 'NME', 'PoseTrack18Metric', 'CocoWholeBodyMetric',
- 'KeypointPartitionMetric', 'MPJPE'
+ 'KeypointPartitionMetric', 'MPJPE', 'InterHandMetric', 'SimpleMPJPE'
]
diff --git a/mmpose/evaluation/metrics/coco_metric.py b/mmpose/evaluation/metrics/coco_metric.py
index 8327e2eca7..84528041e7 100644
--- a/mmpose/evaluation/metrics/coco_metric.py
+++ b/mmpose/evaluation/metrics/coco_metric.py
@@ -8,12 +8,14 @@
import numpy as np
from mmengine.evaluator import BaseMetric
from mmengine.fileio import dump, get_local_path, load
-from mmengine.logging import MMLogger
+from mmengine.logging import MessageHub, MMLogger, print_log
from xtcocotools.coco import COCO
from xtcocotools.cocoeval import COCOeval
from mmpose.registry import METRICS
-from ..functional import oks_nms, soft_oks_nms
+from mmpose.structures.bbox import bbox_xyxy2xywh
+from ..functional import (oks_nms, soft_oks_nms, transform_ann, transform_pred,
+ transform_sigmas)
@METRICS.register_module()
@@ -72,6 +74,12 @@ class CocoMetric(BaseMetric):
test submission when the ground truth annotations are absent. If
set to ``True``, ``outfile_prefix`` should specify the path to
store the output results. Defaults to ``False``
+ pred_converter (dict, optional): Config dictionary for the prediction
+ converter. The dictionary has the same parameters as
+ 'KeypointConverter'. Defaults to None.
+ gt_converter (dict, optional): Config dictionary for the ground truth
+ converter. The dictionary has the same parameters as
+ 'KeypointConverter'. Defaults to None.
outfile_prefix (str | None): The prefix of json files. It includes
the file path and the prefix of filename, e.g., ``'a/b/prefix'``.
If not specified, a temp file will be created. Defaults to ``None``
@@ -94,6 +102,8 @@ def __init__(self,
nms_mode: str = 'oks_nms',
nms_thr: float = 0.9,
format_only: bool = False,
+ pred_converter: Dict = None,
+ gt_converter: Dict = None,
outfile_prefix: Optional[str] = None,
collect_device: str = 'cpu',
prefix: Optional[str] = None) -> None:
@@ -139,6 +149,35 @@ def __init__(self,
self.format_only = format_only
self.outfile_prefix = outfile_prefix
+ self.pred_converter = pred_converter
+ self.gt_converter = gt_converter
+
+ @property
+ def dataset_meta(self) -> Optional[dict]:
+ """Optional[dict]: Meta info of the dataset."""
+ return self._dataset_meta
+
+ @dataset_meta.setter
+ def dataset_meta(self, dataset_meta: dict) -> None:
+ """Set the dataset meta info to the metric."""
+ if self.gt_converter is not None:
+ dataset_meta['sigmas'] = transform_sigmas(
+ dataset_meta['sigmas'], self.gt_converter['num_keypoints'],
+ self.gt_converter['mapping'])
+ dataset_meta['num_keypoints'] = len(dataset_meta['sigmas'])
+ self._dataset_meta = dataset_meta
+
+ if self.coco is None:
+ message = MessageHub.get_current_instance()
+ ann_file = message.get_info(
+ f"{dataset_meta['dataset_name']}_ann_file", None)
+ if ann_file is not None:
+ with get_local_path(ann_file) as local_path:
+ self.coco = COCO(local_path)
+ print_log(
+ f'CocoMetric for dataset '
+ f"{dataset_meta['dataset_name']} has successfully "
+ f'loaded the annotation file from {ann_file}', 'current')
def process(self, data_batch: Sequence[dict],
data_samples: Sequence[dict]) -> None:
@@ -175,9 +214,13 @@ def process(self, data_batch: Sequence[dict],
pred = dict()
pred['id'] = data_sample['id']
pred['img_id'] = data_sample['img_id']
+
pred['keypoints'] = keypoints
pred['keypoint_scores'] = keypoint_scores
pred['category_id'] = data_sample.get('category_id', 1)
+ if 'bboxes' in data_sample['pred_instances']:
+ pred['bbox'] = bbox_xyxy2xywh(
+ data_sample['pred_instances']['bboxes'])
if 'bbox_scores' in data_sample['pred_instances']:
# some one-stage models will predict bboxes and scores
@@ -349,27 +392,40 @@ def compute_metrics(self, results: list) -> Dict[str, float]:
coco_json_path = self.gt_to_coco_json(
gt_dicts=gts, outfile_prefix=outfile_prefix)
self.coco = COCO(coco_json_path)
+ if self.gt_converter is not None:
+ for id_, ann in self.coco.anns.items():
+ self.coco.anns[id_] = transform_ann(
+ ann, self.gt_converter['num_keypoints'],
+ self.gt_converter['mapping'])
kpts = defaultdict(list)
# group the preds by img_id
for pred in preds:
img_id = pred['img_id']
- for idx in range(len(pred['keypoints'])):
+
+ if self.pred_converter is not None:
+ pred = transform_pred(pred,
+ self.pred_converter['num_keypoints'],
+ self.pred_converter['mapping'])
+
+ for idx, keypoints in enumerate(pred['keypoints']):
+
instance = {
'id': pred['id'],
'img_id': pred['img_id'],
'category_id': pred['category_id'],
- 'keypoints': pred['keypoints'][idx],
+ 'keypoints': keypoints,
'keypoint_scores': pred['keypoint_scores'][idx],
'bbox_score': pred['bbox_scores'][idx],
}
+ if 'bbox' in pred:
+ instance['bbox'] = pred['bbox'][idx]
if 'areas' in pred:
instance['area'] = pred['areas'][idx]
else:
# use keypoint to calculate bbox and get area
- keypoints = pred['keypoints'][idx]
area = (
np.max(keypoints[:, 0]) - np.min(keypoints[:, 0])) * (
np.max(keypoints[:, 1]) - np.min(keypoints[:, 1]))
@@ -383,7 +439,10 @@ def compute_metrics(self, results: list) -> Dict[str, float]:
# score the prediction results according to `score_mode`
# and perform NMS according to `nms_mode`
valid_kpts = defaultdict(list)
- num_keypoints = self.dataset_meta['num_keypoints']
+ if self.pred_converter is not None:
+ num_keypoints = self.pred_converter['num_keypoints']
+ else:
+ num_keypoints = self.dataset_meta['num_keypoints']
for img_id, instances in kpts.items():
for instance in instances:
# concatenate the keypoint coordinates and scores
@@ -469,12 +528,17 @@ def results2json(self, keypoints: Dict[int, list],
# collect all the person keypoints in current image
_keypoints = _keypoints.reshape(-1, num_keypoints * 3)
- result = [{
- 'image_id': img_kpt['img_id'],
- 'category_id': img_kpt['category_id'],
- 'keypoints': keypoint.tolist(),
- 'score': float(img_kpt['score']),
- } for img_kpt, keypoint in zip(img_kpts, _keypoints)]
+ result = []
+ for img_kpt, keypoint in zip(img_kpts, _keypoints):
+ res = {
+ 'image_id': img_kpt['img_id'],
+ 'category_id': img_kpt['category_id'],
+ 'keypoints': keypoint.tolist(),
+ 'score': float(img_kpt['score']),
+ }
+ if 'bbox' in img_kpt:
+ res['bbox'] = img_kpt['bbox'].tolist()
+ result.append(res)
cat_results.extend(result)
diff --git a/mmpose/evaluation/metrics/coco_wholebody_metric.py b/mmpose/evaluation/metrics/coco_wholebody_metric.py
index c5675f54c8..74dc52c2ad 100644
--- a/mmpose/evaluation/metrics/coco_wholebody_metric.py
+++ b/mmpose/evaluation/metrics/coco_wholebody_metric.py
@@ -245,7 +245,7 @@ def _do_python_keypoint_eval(self, outfile_prefix: str) -> list:
coco_det,
'keypoints_body',
sigmas[cuts[0]:cuts[1]],
- use_area=True)
+ use_area=self.use_area)
coco_eval.params.useSegm = None
coco_eval.evaluate()
coco_eval.accumulate()
@@ -256,7 +256,7 @@ def _do_python_keypoint_eval(self, outfile_prefix: str) -> list:
coco_det,
'keypoints_foot',
sigmas[cuts[1]:cuts[2]],
- use_area=True)
+ use_area=self.use_area)
coco_eval.params.useSegm = None
coco_eval.evaluate()
coco_eval.accumulate()
@@ -267,7 +267,7 @@ def _do_python_keypoint_eval(self, outfile_prefix: str) -> list:
coco_det,
'keypoints_face',
sigmas[cuts[2]:cuts[3]],
- use_area=True)
+ use_area=self.use_area)
coco_eval.params.useSegm = None
coco_eval.evaluate()
coco_eval.accumulate()
@@ -278,7 +278,7 @@ def _do_python_keypoint_eval(self, outfile_prefix: str) -> list:
coco_det,
'keypoints_lefthand',
sigmas[cuts[3]:cuts[4]],
- use_area=True)
+ use_area=self.use_area)
coco_eval.params.useSegm = None
coco_eval.evaluate()
coco_eval.accumulate()
@@ -289,14 +289,18 @@ def _do_python_keypoint_eval(self, outfile_prefix: str) -> list:
coco_det,
'keypoints_righthand',
sigmas[cuts[4]:cuts[5]],
- use_area=True)
+ use_area=self.use_area)
coco_eval.params.useSegm = None
coco_eval.evaluate()
coco_eval.accumulate()
coco_eval.summarize()
coco_eval = COCOeval(
- self.coco, coco_det, 'keypoints_wholebody', sigmas, use_area=True)
+ self.coco,
+ coco_det,
+ 'keypoints_wholebody',
+ sigmas,
+ use_area=self.use_area)
coco_eval.params.useSegm = None
coco_eval.evaluate()
coco_eval.accumulate()
diff --git a/mmpose/evaluation/metrics/hand_metric.py b/mmpose/evaluation/metrics/hand_metric.py
new file mode 100644
index 0000000000..004e168a7d
--- /dev/null
+++ b/mmpose/evaluation/metrics/hand_metric.py
@@ -0,0 +1,200 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Sequence
+
+import numpy as np
+from mmengine.evaluator import BaseMetric
+from mmengine.logging import MMLogger
+
+from mmpose.codecs.utils import pixel_to_camera
+from mmpose.registry import METRICS
+from ..functional import keypoint_epe
+
+
+@METRICS.register_module()
+class InterHandMetric(BaseMetric):
+
+ METRICS = {'MPJPE', 'MRRPE', 'HandednessAcc'}
+
+ def __init__(self,
+ modes: List[str] = ['MPJPE', 'MRRPE', 'HandednessAcc'],
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None) -> None:
+ super().__init__(collect_device=collect_device, prefix=prefix)
+ for mode in modes:
+ if mode not in self.METRICS:
+ raise ValueError("`mode` should be 'MPJPE', 'MRRPE', or "
+ f"'HandednessAcc', but got '{mode}'.")
+
+ self.modes = modes
+
+ def process(self, data_batch: Sequence[dict],
+ data_samples: Sequence[dict]) -> None:
+ """Process one batch of data samples and predictions. The processed
+ results should be stored in ``self.results``, which will be used to
+ compute the metrics when all batches have been processed.
+
+ Args:
+ data_batch (Sequence[dict]): A batch of data
+ from the dataloader.
+ data_samples (Sequence[dict]): A batch of outputs from
+ the model.
+ """
+ for data_sample in data_samples:
+ # predicted keypoints coordinates, [1, K, D]
+ pred_coords = data_sample['pred_instances']['keypoints']
+ _, K, _ = pred_coords.shape
+ pred_coords_cam = pred_coords.copy()
+ # ground truth data_info
+ gt = data_sample['gt_instances']
+ # ground truth keypoints coordinates, [1, K, D]
+ gt_coords = gt['keypoints_cam']
+
+ keypoints_cam = gt_coords.copy()
+ # ground truth keypoints_visible, [1, K, 1]
+ mask = gt['keypoints_visible'].astype(bool).reshape(1, -1)
+
+ pred_hand_type = data_sample['pred_instances']['hand_type']
+ gt_hand_type = data_sample['hand_type']
+ if pred_hand_type is None and 'HandednessAcc' in self.modes:
+ raise KeyError('metric HandednessAcc is not supported')
+
+ pred_root_depth = data_sample['pred_instances']['rel_root_depth']
+ if pred_root_depth is None and 'MRRPE' in self.modes:
+ raise KeyError('metric MRRPE is not supported')
+
+ abs_depth = data_sample['abs_depth']
+ focal = data_sample['focal']
+ principal_pt = data_sample['principal_pt']
+
+ result = {}
+
+ if 'MPJPE' in self.modes:
+ keypoints_cam[..., :21, :] -= keypoints_cam[..., 20, :]
+ keypoints_cam[..., 21:, :] -= keypoints_cam[..., 41, :]
+
+ pred_coords_cam[..., :21, 2] += abs_depth[0]
+ pred_coords_cam[..., 21:, 2] += abs_depth[1]
+ pred_coords_cam = pixel_to_camera(pred_coords_cam, focal[0],
+ focal[1], principal_pt[0],
+ principal_pt[1])
+
+ pred_coords_cam[..., :21, :] -= pred_coords_cam[..., 20, :]
+ pred_coords_cam[..., 21:, :] -= pred_coords_cam[..., 41, :]
+
+ if gt_hand_type.all():
+ single_mask = np.zeros((1, K), dtype=bool)
+ interacting_mask = mask
+ else:
+ single_mask = mask
+ interacting_mask = np.zeros((1, K), dtype=bool)
+
+ result['pred_coords'] = pred_coords_cam
+ result['gt_coords'] = keypoints_cam
+ result['mask'] = mask
+ result['single_mask'] = single_mask
+ result['interacting_mask'] = interacting_mask
+
+ if 'HandednessAcc' in self.modes:
+ hand_type_mask = data_sample['hand_type_valid'] > 0
+ result['pred_hand_type'] = pred_hand_type
+ result['gt_hand_type'] = gt_hand_type
+ result['hand_type_mask'] = hand_type_mask
+
+ if 'MRRPE' in self.modes:
+ keypoints_visible = gt['keypoints_visible']
+ if gt_hand_type.all() and keypoints_visible[
+ ..., 20] and keypoints_visible[..., 41]:
+ rel_root_mask = np.array([True])
+
+ pred_left_root_coords = np.array(
+ pred_coords[..., 41, :], dtype=np.float32)
+ pred_left_root_coords[...,
+ 2] += abs_depth[0] + pred_root_depth
+ pred_left_root_coords = pixel_to_camera(
+ pred_left_root_coords, focal[0], focal[1],
+ principal_pt[0], principal_pt[1])
+
+ pred_right_root_coords = np.array(
+ pred_coords[..., 20, :], dtype=np.float32)
+ pred_right_root_coords[..., 2] += abs_depth[0]
+ pred_right_root_coords = pixel_to_camera(
+ pred_right_root_coords, focal[0], focal[1],
+ principal_pt[0], principal_pt[1])
+ pred_rel_root_coords = pred_left_root_coords - \
+ pred_right_root_coords
+ pred_rel_root_coords = np.expand_dims(
+ pred_rel_root_coords, axis=0)
+ gt_rel_root_coords = gt_coords[...,
+ 41, :] - gt_coords[...,
+ 20, :]
+ gt_rel_root_coords = np.expand_dims(
+ gt_rel_root_coords, axis=0)
+ else:
+ rel_root_mask = np.array([False])
+ pred_rel_root_coords = np.array([[0, 0, 0]])
+ pred_rel_root_coords = pred_rel_root_coords.reshape(
+ 1, 1, 3)
+ gt_rel_root_coords = np.array([[0, 0, 0]]).reshape(1, 1, 3)
+
+ result['pred_rel_root_coords'] = pred_rel_root_coords
+ result['gt_rel_root_coords'] = gt_rel_root_coords
+ result['rel_root_mask'] = rel_root_mask
+
+ self.results.append(result)
+
+ def compute_metrics(self, results: list) -> Dict[str, float]:
+ """Compute the metrics from processed results.
+
+ Args:
+ results (list): The processed results of each batch.
+
+ Returns:
+ Dict[str, float]: The computed metrics. The keys are the names of
+ the metrics, and the values are corresponding results.
+ """
+ logger: MMLogger = MMLogger.get_current_instance()
+
+ metrics = dict()
+
+ logger.info(f'Evaluating {self.__class__.__name__}...')
+
+ if 'MPJPE' in self.modes:
+ # pred_coords: [N, K, D]
+ pred_coords = np.concatenate(
+ [result['pred_coords'] for result in results])
+ # gt_coords: [N, K, D]
+ gt_coords = np.concatenate(
+ [result['gt_coords'] for result in results])
+ # mask: [N, K]
+ mask = np.concatenate([result['mask'] for result in results])
+ single_mask = np.concatenate(
+ [result['single_mask'] for result in results])
+ interacting_mask = np.concatenate(
+ [result['interacting_mask'] for result in results])
+
+ metrics['MPJPE_all'] = keypoint_epe(pred_coords, gt_coords, mask)
+ metrics['MPJPE_single'] = keypoint_epe(pred_coords, gt_coords,
+ single_mask)
+ metrics['MPJPE_interacting'] = keypoint_epe(
+ pred_coords, gt_coords, interacting_mask)
+
+ if 'HandednessAcc' in self.modes:
+ pred_hand_type = np.concatenate(
+ [result['pred_hand_type'] for result in results])
+ gt_hand_type = np.concatenate(
+ [result['gt_hand_type'] for result in results])
+ hand_type_mask = np.concatenate(
+ [result['hand_type_mask'] for result in results])
+ acc = (pred_hand_type == gt_hand_type).all(axis=-1)
+ metrics['HandednessAcc'] = np.mean(acc[hand_type_mask])
+
+ if 'MRRPE' in self.modes:
+ pred_rel_root_coords = np.concatenate(
+ [result['pred_rel_root_coords'] for result in results])
+ gt_rel_root_coords = np.concatenate(
+ [result['gt_rel_root_coords'] for result in results])
+ rel_root_mask = np.array(
+ [result['rel_root_mask'] for result in results])
+ metrics['MRRPE'] = keypoint_epe(pred_rel_root_coords,
+ gt_rel_root_coords, rel_root_mask)
+ return metrics
diff --git a/mmpose/evaluation/metrics/keypoint_2d_metrics.py b/mmpose/evaluation/metrics/keypoint_2d_metrics.py
index 5c8d23ac08..c0be4b398f 100644
--- a/mmpose/evaluation/metrics/keypoint_2d_metrics.py
+++ b/mmpose/evaluation/metrics/keypoint_2d_metrics.py
@@ -106,7 +106,10 @@ def process(self, data_batch: Sequence[dict],
# ground truth keypoints coordinates, [1, K, D]
gt_coords = gt['keypoints']
# ground truth keypoints_visible, [1, K, 1]
- mask = gt['keypoints_visible'].astype(bool).reshape(1, -1)
+ mask = gt['keypoints_visible'].astype(bool)
+ if mask.ndim == 3:
+ mask = mask[:, :, 0]
+ mask = mask.reshape(1, -1)
result = {
'pred_coords': pred_coords,
@@ -587,7 +590,10 @@ def process(self, data_batch: Sequence[dict],
# ground truth keypoints coordinates, [1, K, D]
gt_coords = gt['keypoints']
# ground truth keypoints_visible, [1, K, 1]
- mask = gt['keypoints_visible'].astype(bool).reshape(1, -1)
+ mask = gt['keypoints_visible'].astype(bool)
+ if mask.ndim == 3:
+ mask = mask[:, :, 0]
+ mask = mask.reshape(1, -1)
result = {
'pred_coords': pred_coords,
@@ -669,7 +675,10 @@ def process(self, data_batch: Sequence[dict],
# ground truth keypoints coordinates, [1, K, D]
gt_coords = gt['keypoints']
# ground truth keypoints_visible, [1, K, 1]
- mask = gt['keypoints_visible'].astype(bool).reshape(1, -1)
+ mask = gt['keypoints_visible'].astype(bool)
+ if mask.ndim == 3:
+ mask = mask[:, :, 0]
+ mask = mask.reshape(1, -1)
result = {
'pred_coords': pred_coords,
@@ -805,7 +814,10 @@ def process(self, data_batch: Sequence[dict],
# ground truth keypoints coordinates, [1, K, D]
gt_coords = gt['keypoints']
# ground truth keypoints_visible, [1, K, 1]
- mask = gt['keypoints_visible'].astype(bool).reshape(1, -1)
+ mask = gt['keypoints_visible'].astype(bool)
+ if mask.ndim == 3:
+ mask = mask[:, :, 0]
+ mask = mask.reshape(1, -1)
result = {
'pred_coords': pred_coords,
diff --git a/mmpose/evaluation/metrics/keypoint_3d_metrics.py b/mmpose/evaluation/metrics/keypoint_3d_metrics.py
index e945650c30..fb3447bb3f 100644
--- a/mmpose/evaluation/metrics/keypoint_3d_metrics.py
+++ b/mmpose/evaluation/metrics/keypoint_3d_metrics.py
@@ -1,7 +1,7 @@
# Copyright (c) OpenMMLab. All rights reserved.
from collections import defaultdict
from os import path as osp
-from typing import Dict, Optional, Sequence
+from typing import Dict, List, Optional, Sequence
import numpy as np
from mmengine.evaluator import BaseMetric
@@ -38,6 +38,8 @@ class MPJPE(BaseMetric):
names to disambiguate homonymous metrics of different evaluators.
If prefix is not provided in the argument, ``self.default_prefix``
will be used instead. Default: ``None``.
+ skip_list (list, optional): The list of subject and action combinations
+ to be skipped. Default: [].
"""
ALIGNMENT = {'mpjpe': 'none', 'p-mpjpe': 'procrustes', 'n-mpjpe': 'scale'}
@@ -45,7 +47,8 @@ class MPJPE(BaseMetric):
def __init__(self,
mode: str = 'mpjpe',
collect_device: str = 'cpu',
- prefix: Optional[str] = None) -> None:
+ prefix: Optional[str] = None,
+ skip_list: List[str] = []) -> None:
super().__init__(collect_device=collect_device, prefix=prefix)
allowed_modes = self.ALIGNMENT.keys()
if mode not in allowed_modes:
@@ -53,6 +56,7 @@ def __init__(self,
f"'n-mpjpe', but got '{mode}'.")
self.mode = mode
+ self.skip_list = skip_list
def process(self, data_batch: Sequence[dict],
data_samples: Sequence[dict]) -> None:
@@ -67,24 +71,32 @@ def process(self, data_batch: Sequence[dict],
the model.
"""
for data_sample in data_samples:
- # predicted keypoints coordinates, [1, K, D]
+ # predicted keypoints coordinates, [T, K, D]
pred_coords = data_sample['pred_instances']['keypoints']
+ if pred_coords.ndim == 4:
+ pred_coords = np.squeeze(pred_coords, axis=0)
# ground truth data_info
gt = data_sample['gt_instances']
- # ground truth keypoints coordinates, [1, K, D]
+ # ground truth keypoints coordinates, [T, K, D]
gt_coords = gt['lifting_target']
- # ground truth keypoints_visible, [1, K, 1]
- mask = gt['lifting_target_visible'].astype(bool).reshape(1, -1)
+ # ground truth keypoints_visible, [T, K, 1]
+ mask = gt['lifting_target_visible'].astype(bool).reshape(
+ gt_coords.shape[0], -1)
# instance action
- img_path = data_sample['target_img_path']
+ img_path = data_sample['target_img_path'][0]
_, rest = osp.basename(img_path).split('_', 1)
action, _ = rest.split('.', 1)
+ actions = np.array([action] * gt_coords.shape[0])
+
+ subj_act = osp.basename(img_path).split('.')[0]
+ if subj_act in self.skip_list:
+ continue
result = {
'pred_coords': pred_coords,
'gt_coords': gt_coords,
'mask': mask,
- 'action': action
+ 'actions': actions
}
self.results.append(result)
@@ -104,16 +116,15 @@ def compute_metrics(self, results: list) -> Dict[str, float]:
# pred_coords: [N, K, D]
pred_coords = np.concatenate(
[result['pred_coords'] for result in results])
- if pred_coords.ndim == 4 and pred_coords.shape[1] == 1:
- pred_coords = np.squeeze(pred_coords, axis=1)
# gt_coords: [N, K, D]
- gt_coords = np.stack([result['gt_coords'] for result in results])
+ gt_coords = np.concatenate([result['gt_coords'] for result in results])
# mask: [N, K]
mask = np.concatenate([result['mask'] for result in results])
# action_category_indices: Dict[List[int]]
action_category_indices = defaultdict(list)
- for idx, result in enumerate(results):
- action_category = result['action'].split('_')[0]
+ actions = np.concatenate([result['actions'] for result in results])
+ for idx, action in enumerate(actions):
+ action_category = action.split('_')[0]
action_category_indices[action_category].append(idx)
error_name = self.mode.upper()
@@ -126,6 +137,7 @@ def compute_metrics(self, results: list) -> Dict[str, float]:
for action_category, indices in action_category_indices.items():
metrics[f'{error_name}_{action_category}'] = keypoint_mpjpe(
- pred_coords[indices], gt_coords[indices], mask[indices])
+ pred_coords[indices], gt_coords[indices], mask[indices],
+ self.ALIGNMENT[self.mode])
return metrics
diff --git a/mmpose/evaluation/metrics/simple_keypoint_3d_metrics.py b/mmpose/evaluation/metrics/simple_keypoint_3d_metrics.py
new file mode 100644
index 0000000000..dc0065d5b9
--- /dev/null
+++ b/mmpose/evaluation/metrics/simple_keypoint_3d_metrics.py
@@ -0,0 +1,119 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Sequence
+
+import numpy as np
+from mmengine.evaluator import BaseMetric
+from mmengine.logging import MMLogger
+
+from mmpose.registry import METRICS
+from ..functional import keypoint_mpjpe
+
+
+@METRICS.register_module()
+class SimpleMPJPE(BaseMetric):
+ """MPJPE evaluation metric.
+
+ Calculate the mean per-joint position error (MPJPE) of keypoints.
+
+ Note:
+ - length of dataset: N
+ - num_keypoints: K
+ - number of keypoint dimensions: D (typically D = 2)
+
+ Args:
+ mode (str): Method to align the prediction with the
+ ground truth. Supported options are:
+
+ - ``'mpjpe'``: no alignment will be applied
+ - ``'p-mpjpe'``: align in the least-square sense in scale
+ - ``'n-mpjpe'``: align in the least-square sense in
+ scale, rotation, and translation.
+
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be ``'cpu'`` or
+ ``'gpu'``. Default: ``'cpu'``.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, ``self.default_prefix``
+ will be used instead. Default: ``None``.
+ skip_list (list, optional): The list of subject and action combinations
+ to be skipped. Default: [].
+ """
+
+ ALIGNMENT = {'mpjpe': 'none', 'p-mpjpe': 'procrustes', 'n-mpjpe': 'scale'}
+
+ def __init__(self,
+ mode: str = 'mpjpe',
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None,
+ skip_list: List[str] = []) -> None:
+ super().__init__(collect_device=collect_device, prefix=prefix)
+ allowed_modes = self.ALIGNMENT.keys()
+ if mode not in allowed_modes:
+ raise KeyError("`mode` should be 'mpjpe', 'p-mpjpe', or "
+ f"'n-mpjpe', but got '{mode}'.")
+
+ self.mode = mode
+ self.skip_list = skip_list
+
+ def process(self, data_batch: Sequence[dict],
+ data_samples: Sequence[dict]) -> None:
+ """Process one batch of data samples and predictions. The processed
+ results should be stored in ``self.results``, which will be used to
+ compute the metrics when all batches have been processed.
+
+ Args:
+ data_batch (Sequence[dict]): A batch of data
+ from the dataloader.
+ data_samples (Sequence[dict]): A batch of outputs from
+ the model.
+ """
+ for data_sample in data_samples:
+ # predicted keypoints coordinates, [T, K, D]
+ pred_coords = data_sample['pred_instances']['keypoints']
+ if pred_coords.ndim == 4:
+ pred_coords = np.squeeze(pred_coords, axis=0)
+ # ground truth data_info
+ gt = data_sample['gt_instances']
+ # ground truth keypoints coordinates, [T, K, D]
+ gt_coords = gt['lifting_target']
+ # ground truth keypoints_visible, [T, K, 1]
+ mask = gt['lifting_target_visible'].astype(bool).reshape(
+ gt_coords.shape[0], -1)
+
+ result = {
+ 'pred_coords': pred_coords,
+ 'gt_coords': gt_coords,
+ 'mask': mask,
+ }
+
+ self.results.append(result)
+
+ def compute_metrics(self, results: list) -> Dict[str, float]:
+ """Compute the metrics from processed results.
+
+ Args:
+ results (list): The processed results of each batch.
+
+ Returns:
+ Dict[str, float]: The computed metrics. The keys are the names of
+ the metrics, and the values are the corresponding results.
+ """
+ logger: MMLogger = MMLogger.get_current_instance()
+
+ # pred_coords: [N, K, D]
+ pred_coords = np.concatenate(
+ [result['pred_coords'] for result in results])
+ # gt_coords: [N, K, D]
+ gt_coords = np.concatenate([result['gt_coords'] for result in results])
+ # mask: [N, K]
+ mask = np.concatenate([result['mask'] for result in results])
+
+ error_name = self.mode.upper()
+
+ logger.info(f'Evaluating {self.mode.upper()}...')
+ return {
+ error_name:
+ keypoint_mpjpe(pred_coords, gt_coords, mask,
+ self.ALIGNMENT[self.mode])
+ }
diff --git a/mmpose/models/__init__.py b/mmpose/models/__init__.py
index 4e236f9928..7e7b386b92 100644
--- a/mmpose/models/__init__.py
+++ b/mmpose/models/__init__.py
@@ -4,12 +4,21 @@
build_head, build_loss, build_neck, build_pose_estimator,
build_posenet)
from .data_preprocessors import * # noqa
+from .distillers import * # noqa
from .heads import * # noqa
from .losses import * # noqa
from .necks import * # noqa
from .pose_estimators import * # noqa
__all__ = [
- 'BACKBONES', 'HEADS', 'NECKS', 'LOSSES', 'build_backbone', 'build_head',
- 'build_loss', 'build_posenet', 'build_neck', 'build_pose_estimator'
+ 'BACKBONES',
+ 'HEADS',
+ 'NECKS',
+ 'LOSSES',
+ 'build_backbone',
+ 'build_head',
+ 'build_loss',
+ 'build_posenet',
+ 'build_neck',
+ 'build_pose_estimator',
]
diff --git a/mmpose/models/backbones/__init__.py b/mmpose/models/backbones/__init__.py
index cb2498560a..1559b6288b 100644
--- a/mmpose/models/backbones/__init__.py
+++ b/mmpose/models/backbones/__init__.py
@@ -1,6 +1,9 @@
# Copyright (c) OpenMMLab. All rights reserved.
from .alexnet import AlexNet
from .cpm import CPM
+from .csp_darknet import CSPDarknet
+from .cspnext import CSPNeXt
+from .dstformer import DSTFormer
from .hourglass import HourglassNet
from .hourglass_ae import HourglassAENet
from .hrformer import HRFormer
@@ -33,5 +36,6 @@
'SEResNet', 'SEResNeXt', 'ShuffleNetV1', 'ShuffleNetV2', 'CPM', 'RSN',
'MSPN', 'ResNeSt', 'VGG', 'TCN', 'ViPNAS_ResNet', 'ViPNAS_MobileNetV3',
'LiteHRNet', 'V2VNet', 'HRFormer', 'PyramidVisionTransformer',
- 'PyramidVisionTransformerV2', 'SwinTransformer'
+ 'PyramidVisionTransformerV2', 'SwinTransformer', 'DSTFormer', 'CSPDarknet',
+ 'CSPNeXt'
]
diff --git a/mmpose/models/backbones/csp_darknet.py b/mmpose/models/backbones/csp_darknet.py
new file mode 100644
index 0000000000..dbaba0cfd9
--- /dev/null
+++ b/mmpose/models/backbones/csp_darknet.py
@@ -0,0 +1,286 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
+from mmengine.model import BaseModule
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmpose.registry import MODELS
+from ..utils import CSPLayer
+
+
+class Focus(nn.Module):
+ """Focus width and height information into channel space.
+
+ Args:
+ in_channels (int): The input channels of this Module.
+ out_channels (int): The output channels of this Module.
+ kernel_size (int): The kernel size of the convolution. Default: 1
+ stride (int): The stride of the convolution. Default: 1
+ conv_cfg (dict): Config dict for convolution layer. Default: None,
+ which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN', momentum=0.03, eps=0.001).
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='Swish').
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size=1,
+ stride=1,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg=dict(type='Swish')):
+ super().__init__()
+ self.conv = ConvModule(
+ in_channels * 4,
+ out_channels,
+ kernel_size,
+ stride,
+ padding=(kernel_size - 1) // 2,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def forward(self, x):
+ # shape of x (b,c,w,h) -> y(b,4c,w/2,h/2)
+ patch_top_left = x[..., ::2, ::2]
+ patch_top_right = x[..., ::2, 1::2]
+ patch_bot_left = x[..., 1::2, ::2]
+ patch_bot_right = x[..., 1::2, 1::2]
+ x = torch.cat(
+ (
+ patch_top_left,
+ patch_bot_left,
+ patch_top_right,
+ patch_bot_right,
+ ),
+ dim=1,
+ )
+ return self.conv(x)
+
+
+class SPPBottleneck(BaseModule):
+ """Spatial pyramid pooling layer used in YOLOv3-SPP.
+
+ Args:
+ in_channels (int): The input channels of this Module.
+ out_channels (int): The output channels of this Module.
+ kernel_sizes (tuple[int]): Sequential of kernel sizes of pooling
+ layers. Default: (5, 9, 13).
+ conv_cfg (dict): Config dict for convolution layer. Default: None,
+ which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='Swish').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_sizes=(5, 9, 13),
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg=dict(type='Swish'),
+ init_cfg=None):
+ super().__init__(init_cfg)
+ mid_channels = in_channels // 2
+ self.conv1 = ConvModule(
+ in_channels,
+ mid_channels,
+ 1,
+ stride=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.poolings = nn.ModuleList([
+ nn.MaxPool2d(kernel_size=ks, stride=1, padding=ks // 2)
+ for ks in kernel_sizes
+ ])
+ conv2_channels = mid_channels * (len(kernel_sizes) + 1)
+ self.conv2 = ConvModule(
+ conv2_channels,
+ out_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def forward(self, x):
+ x = self.conv1(x)
+ with torch.cuda.amp.autocast(enabled=False):
+ x = torch.cat(
+ [x] + [pooling(x) for pooling in self.poolings], dim=1)
+ x = self.conv2(x)
+ return x
+
+
+@MODELS.register_module()
+class CSPDarknet(BaseModule):
+ """CSP-Darknet backbone used in YOLOv5 and YOLOX.
+
+ Args:
+ arch (str): Architecture of CSP-Darknet, from {P5, P6}.
+ Default: P5.
+ deepen_factor (float): Depth multiplier, multiply number of
+ blocks in CSP layer by this amount. Default: 1.0.
+ widen_factor (float): Width multiplier, multiply number of
+ channels in each layer by this amount. Default: 1.0.
+ out_indices (Sequence[int]): Output from which stages.
+ Default: (2, 3, 4).
+ frozen_stages (int): Stages to be frozen (stop grad and set eval
+ mode). -1 means not freezing any parameters. Default: -1.
+ use_depthwise (bool): Whether to use depthwise separable convolution.
+ Default: False.
+ arch_ovewrite(list): Overwrite default arch settings. Default: None.
+ spp_kernal_sizes: (tuple[int]): Sequential of kernel sizes of SPP
+ layers. Default: (5, 9, 13).
+ conv_cfg (dict): Config dict for convolution layer. Default: None.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ Default: dict(type='BN', requires_grad=True).
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='LeakyReLU', negative_slope=0.1).
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ Example:
+ >>> from mmpose.models import CSPDarknet
+ >>> import torch
+ >>> self = CSPDarknet(depth=53)
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 3, 416, 416)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ ...
+ (1, 256, 52, 52)
+ (1, 512, 26, 26)
+ (1, 1024, 13, 13)
+ """
+ # From left to right:
+ # in_channels, out_channels, num_blocks, add_identity, use_spp
+ arch_settings = {
+ 'P5': [[64, 128, 3, True, False], [128, 256, 9, True, False],
+ [256, 512, 9, True, False], [512, 1024, 3, False, True]],
+ 'P6': [[64, 128, 3, True, False], [128, 256, 9, True, False],
+ [256, 512, 9, True, False], [512, 768, 3, True, False],
+ [768, 1024, 3, False, True]]
+ }
+
+ def __init__(self,
+ arch='P5',
+ deepen_factor=1.0,
+ widen_factor=1.0,
+ out_indices=(2, 3, 4),
+ frozen_stages=-1,
+ use_depthwise=False,
+ arch_ovewrite=None,
+ spp_kernal_sizes=(5, 9, 13),
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg=dict(type='Swish'),
+ norm_eval=False,
+ init_cfg=dict(
+ type='Kaiming',
+ layer='Conv2d',
+ a=math.sqrt(5),
+ distribution='uniform',
+ mode='fan_in',
+ nonlinearity='leaky_relu')):
+ super().__init__(init_cfg)
+ arch_setting = self.arch_settings[arch]
+ if arch_ovewrite:
+ arch_setting = arch_ovewrite
+ assert set(out_indices).issubset(
+ i for i in range(len(arch_setting) + 1))
+ if frozen_stages not in range(-1, len(arch_setting) + 1):
+ raise ValueError('frozen_stages must be in range(-1, '
+ 'len(arch_setting) + 1). But received '
+ f'{frozen_stages}')
+
+ self.out_indices = out_indices
+ self.frozen_stages = frozen_stages
+ self.use_depthwise = use_depthwise
+ self.norm_eval = norm_eval
+ conv = DepthwiseSeparableConvModule if use_depthwise else ConvModule
+
+ self.stem = Focus(
+ 3,
+ int(arch_setting[0][0] * widen_factor),
+ kernel_size=3,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.layers = ['stem']
+
+ for i, (in_channels, out_channels, num_blocks, add_identity,
+ use_spp) in enumerate(arch_setting):
+ in_channels = int(in_channels * widen_factor)
+ out_channels = int(out_channels * widen_factor)
+ num_blocks = max(round(num_blocks * deepen_factor), 1)
+ stage = []
+ conv_layer = conv(
+ in_channels,
+ out_channels,
+ 3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ stage.append(conv_layer)
+ if use_spp:
+ spp = SPPBottleneck(
+ out_channels,
+ out_channels,
+ kernel_sizes=spp_kernal_sizes,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ stage.append(spp)
+ csp_layer = CSPLayer(
+ out_channels,
+ out_channels,
+ num_blocks=num_blocks,
+ add_identity=add_identity,
+ use_depthwise=use_depthwise,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ stage.append(csp_layer)
+ self.add_module(f'stage{i + 1}', nn.Sequential(*stage))
+ self.layers.append(f'stage{i + 1}')
+
+ def _freeze_stages(self):
+ if self.frozen_stages >= 0:
+ for i in range(self.frozen_stages + 1):
+ m = getattr(self, self.layers[i])
+ m.eval()
+ for param in m.parameters():
+ param.requires_grad = False
+
+ def train(self, mode=True):
+ super(CSPDarknet, self).train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ if isinstance(m, _BatchNorm):
+ m.eval()
+
+ def forward(self, x):
+ outs = []
+ for i, layer_name in enumerate(self.layers):
+ layer = getattr(self, layer_name)
+ x = layer(x)
+ if i in self.out_indices:
+ outs.append(x)
+ return tuple(outs)
diff --git a/mmpose/models/backbones/cspnext.py b/mmpose/models/backbones/cspnext.py
new file mode 100644
index 0000000000..5275bb255a
--- /dev/null
+++ b/mmpose/models/backbones/cspnext.py
@@ -0,0 +1,195 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Optional, Sequence, Tuple
+
+import torch.nn as nn
+from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
+from mmengine.model import BaseModule
+from torch import Tensor
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmpose.registry import MODELS
+from mmpose.utils.typing import ConfigType
+from ..utils import CSPLayer
+from .csp_darknet import SPPBottleneck
+
+
+@MODELS.register_module()
+class CSPNeXt(BaseModule):
+ """CSPNeXt backbone used in RTMDet.
+
+ Args:
+ arch (str): Architecture of CSPNeXt, from {P5, P6}.
+ Defaults to P5.
+ expand_ratio (float): Ratio to adjust the number of channels of the
+ hidden layer. Defaults to 0.5.
+ deepen_factor (float): Depth multiplier, multiply number of
+ blocks in CSP layer by this amount. Defaults to 1.0.
+ widen_factor (float): Width multiplier, multiply number of
+ channels in each layer by this amount. Defaults to 1.0.
+ out_indices (Sequence[int]): Output from which stages.
+ Defaults to (2, 3, 4).
+ frozen_stages (int): Stages to be frozen (stop grad and set eval
+ mode). -1 means not freezing any parameters. Defaults to -1.
+ use_depthwise (bool): Whether to use depthwise separable convolution.
+ Defaults to False.
+ arch_ovewrite (list): Overwrite default arch settings.
+ Defaults to None.
+ spp_kernel_sizes: (tuple[int]): Sequential of kernel sizes of SPP
+ layers. Defaults to (5, 9, 13).
+ channel_attention (bool): Whether to add channel attention in each
+ stage. Defaults to True.
+ conv_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ convolution layer. Defaults to None.
+ norm_cfg (:obj:`ConfigDict` or dict): Dictionary to construct and
+ config norm layer. Defaults to dict(type='BN', requires_grad=True).
+ act_cfg (:obj:`ConfigDict` or dict): Config dict for activation layer.
+ Defaults to dict(type='SiLU').
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only.
+ init_cfg (:obj:`ConfigDict` or dict or list[dict] or
+ list[:obj:`ConfigDict`]): Initialization config dict.
+ """
+ # From left to right:
+ # in_channels, out_channels, num_blocks, add_identity, use_spp
+ arch_settings = {
+ 'P5': [[64, 128, 3, True, False], [128, 256, 6, True, False],
+ [256, 512, 6, True, False], [512, 1024, 3, False, True]],
+ 'P6': [[64, 128, 3, True, False], [128, 256, 6, True, False],
+ [256, 512, 6, True, False], [512, 768, 3, True, False],
+ [768, 1024, 3, False, True]]
+ }
+
+ def __init__(
+ self,
+ arch: str = 'P5',
+ deepen_factor: float = 1.0,
+ widen_factor: float = 1.0,
+ out_indices: Sequence[int] = (2, 3, 4),
+ frozen_stages: int = -1,
+ use_depthwise: bool = False,
+ expand_ratio: float = 0.5,
+ arch_ovewrite: dict = None,
+ spp_kernel_sizes: Sequence[int] = (5, 9, 13),
+ channel_attention: bool = True,
+ conv_cfg: Optional[ConfigType] = None,
+ norm_cfg: ConfigType = dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg: ConfigType = dict(type='SiLU'),
+ norm_eval: bool = False,
+ init_cfg: Optional[ConfigType] = dict(
+ type='Kaiming',
+ layer='Conv2d',
+ a=math.sqrt(5),
+ distribution='uniform',
+ mode='fan_in',
+ nonlinearity='leaky_relu')
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ arch_setting = self.arch_settings[arch]
+ if arch_ovewrite:
+ arch_setting = arch_ovewrite
+ assert set(out_indices).issubset(
+ i for i in range(len(arch_setting) + 1))
+ if frozen_stages not in range(-1, len(arch_setting) + 1):
+ raise ValueError('frozen_stages must be in range(-1, '
+ 'len(arch_setting) + 1). But received '
+ f'{frozen_stages}')
+
+ self.out_indices = out_indices
+ self.frozen_stages = frozen_stages
+ self.use_depthwise = use_depthwise
+ self.norm_eval = norm_eval
+ conv = DepthwiseSeparableConvModule if use_depthwise else ConvModule
+ self.stem = nn.Sequential(
+ ConvModule(
+ 3,
+ int(arch_setting[0][0] * widen_factor // 2),
+ 3,
+ padding=1,
+ stride=2,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ ConvModule(
+ int(arch_setting[0][0] * widen_factor // 2),
+ int(arch_setting[0][0] * widen_factor // 2),
+ 3,
+ padding=1,
+ stride=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ ConvModule(
+ int(arch_setting[0][0] * widen_factor // 2),
+ int(arch_setting[0][0] * widen_factor),
+ 3,
+ padding=1,
+ stride=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.layers = ['stem']
+
+ for i, (in_channels, out_channels, num_blocks, add_identity,
+ use_spp) in enumerate(arch_setting):
+ in_channels = int(in_channels * widen_factor)
+ out_channels = int(out_channels * widen_factor)
+ num_blocks = max(round(num_blocks * deepen_factor), 1)
+ stage = []
+ conv_layer = conv(
+ in_channels,
+ out_channels,
+ 3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ stage.append(conv_layer)
+ if use_spp:
+ spp = SPPBottleneck(
+ out_channels,
+ out_channels,
+ kernel_sizes=spp_kernel_sizes,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ stage.append(spp)
+ csp_layer = CSPLayer(
+ out_channels,
+ out_channels,
+ num_blocks=num_blocks,
+ add_identity=add_identity,
+ use_depthwise=use_depthwise,
+ use_cspnext_block=True,
+ expand_ratio=expand_ratio,
+ channel_attention=channel_attention,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ stage.append(csp_layer)
+ self.add_module(f'stage{i + 1}', nn.Sequential(*stage))
+ self.layers.append(f'stage{i + 1}')
+
+ def _freeze_stages(self) -> None:
+ if self.frozen_stages >= 0:
+ for i in range(self.frozen_stages + 1):
+ m = getattr(self, self.layers[i])
+ m.eval()
+ for param in m.parameters():
+ param.requires_grad = False
+
+ def train(self, mode=True) -> None:
+ super().train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ if isinstance(m, _BatchNorm):
+ m.eval()
+
+ def forward(self, x: Tuple[Tensor, ...]) -> Tuple[Tensor, ...]:
+ outs = []
+ for i, layer_name in enumerate(self.layers):
+ layer = getattr(self, layer_name)
+ x = layer(x)
+ if i in self.out_indices:
+ outs.append(x)
+ return tuple(outs)
diff --git a/mmpose/models/backbones/dstformer.py b/mmpose/models/backbones/dstformer.py
new file mode 100644
index 0000000000..2ef13bdb02
--- /dev/null
+++ b/mmpose/models/backbones/dstformer.py
@@ -0,0 +1,304 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn.bricks import DropPath
+from mmengine.model import BaseModule, constant_init
+from mmengine.model.weight_init import trunc_normal_
+
+from mmpose.registry import MODELS
+from .base_backbone import BaseBackbone
+
+
+class Attention(BaseModule):
+
+ def __init__(self,
+ dim,
+ num_heads=8,
+ qkv_bias=False,
+ qk_scale=None,
+ attn_drop=0.,
+ proj_drop=0.,
+ mode='spatial'):
+ super().__init__()
+ self.num_heads = num_heads
+ head_dim = dim // num_heads
+ self.scale = qk_scale or head_dim**-0.5
+
+ self.attn_drop = nn.Dropout(attn_drop)
+ self.proj = nn.Linear(dim, dim)
+ self.mode = mode
+
+ self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
+ self.proj_drop = nn.Dropout(proj_drop)
+
+ self.attn_count_s = None
+ self.attn_count_t = None
+
+ def forward(self, x, seq_len=1):
+ B, N, C = x.shape
+
+ if self.mode == 'temporal':
+ qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C //
+ self.num_heads).permute(2, 0, 3, 1, 4)
+ q, k, v = qkv[0], qkv[1], qkv[
+ 2] # make torchscript happy (cannot use tensor as tuple)
+ x = self.forward_temporal(q, k, v, seq_len=seq_len)
+ elif self.mode == 'spatial':
+ qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C //
+ self.num_heads).permute(2, 0, 3, 1, 4)
+ q, k, v = qkv[0], qkv[1], qkv[
+ 2] # make torchscript happy (cannot use tensor as tuple)
+ x = self.forward_spatial(q, k, v)
+ else:
+ raise NotImplementedError(self.mode)
+ x = self.proj(x)
+ x = self.proj_drop(x)
+ return x
+
+ def forward_spatial(self, q, k, v):
+ B, _, N, C = q.shape
+ attn = (q @ k.transpose(-2, -1)) * self.scale
+ attn = attn.softmax(dim=-1)
+ attn = self.attn_drop(attn)
+
+ x = attn @ v
+ x = x.transpose(1, 2).reshape(B, N, C * self.num_heads)
+ return x
+
+ def forward_temporal(self, q, k, v, seq_len=8):
+ B, _, N, C = q.shape
+ qt = q.reshape(-1, seq_len, self.num_heads, N,
+ C).permute(0, 2, 3, 1, 4) # (B, H, N, T, C)
+ kt = k.reshape(-1, seq_len, self.num_heads, N,
+ C).permute(0, 2, 3, 1, 4) # (B, H, N, T, C)
+ vt = v.reshape(-1, seq_len, self.num_heads, N,
+ C).permute(0, 2, 3, 1, 4) # (B, H, N, T, C)
+
+ attn = (qt @ kt.transpose(-2, -1)) * self.scale
+ attn = attn.softmax(dim=-1)
+ attn = self.attn_drop(attn)
+
+ x = attn @ vt # (B, H, N, T, C)
+ x = x.permute(0, 3, 2, 1, 4).reshape(B, N, C * self.num_heads)
+ return x
+
+
+class AttentionBlock(BaseModule):
+
+ def __init__(self,
+ dim,
+ num_heads,
+ mlp_ratio=4.,
+ mlp_out_ratio=1.,
+ qkv_bias=True,
+ qk_scale=None,
+ drop=0.,
+ attn_drop=0.,
+ drop_path=0.,
+ st_mode='st'):
+ super().__init__()
+
+ self.st_mode = st_mode
+ self.norm1_s = nn.LayerNorm(dim, eps=1e-06)
+ self.norm1_t = nn.LayerNorm(dim, eps=1e-06)
+
+ self.attn_s = Attention(
+ dim,
+ num_heads=num_heads,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ attn_drop=attn_drop,
+ proj_drop=drop,
+ mode='spatial')
+ self.attn_t = Attention(
+ dim,
+ num_heads=num_heads,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ attn_drop=attn_drop,
+ proj_drop=drop,
+ mode='temporal')
+
+ self.drop_path = DropPath(
+ drop_path) if drop_path > 0. else nn.Identity()
+ self.norm2_s = nn.LayerNorm(dim, eps=1e-06)
+ self.norm2_t = nn.LayerNorm(dim, eps=1e-06)
+
+ mlp_hidden_dim = int(dim * mlp_ratio)
+ mlp_out_dim = int(dim * mlp_out_ratio)
+ self.mlp_s = nn.Sequential(
+ nn.Linear(dim, mlp_hidden_dim), nn.GELU(),
+ nn.Linear(mlp_hidden_dim, mlp_out_dim), nn.Dropout(drop))
+ self.mlp_t = nn.Sequential(
+ nn.Linear(dim, mlp_hidden_dim), nn.GELU(),
+ nn.Linear(mlp_hidden_dim, mlp_out_dim), nn.Dropout(drop))
+
+ def forward(self, x, seq_len=1):
+ if self.st_mode == 'st':
+ x = x + self.drop_path(self.attn_s(self.norm1_s(x), seq_len))
+ x = x + self.drop_path(self.mlp_s(self.norm2_s(x)))
+ x = x + self.drop_path(self.attn_t(self.norm1_t(x), seq_len))
+ x = x + self.drop_path(self.mlp_t(self.norm2_t(x)))
+ elif self.st_mode == 'ts':
+ x = x + self.drop_path(self.attn_t(self.norm1_t(x), seq_len))
+ x = x + self.drop_path(self.mlp_t(self.norm2_t(x)))
+ x = x + self.drop_path(self.attn_s(self.norm1_s(x), seq_len))
+ x = x + self.drop_path(self.mlp_s(self.norm2_s(x)))
+ else:
+ raise NotImplementedError(self.st_mode)
+ return x
+
+
+@MODELS.register_module()
+class DSTFormer(BaseBackbone):
+ """Dual-stream Spatio-temporal Transformer Module.
+
+ Args:
+ in_channels (int): Number of input channels.
+ feat_size: Number of feature channels. Default: 256.
+ depth: The network depth. Default: 5.
+ num_heads: Number of heads in multi-Head self-attention blocks.
+ Default: 8.
+ mlp_ratio (int, optional): The expansion ratio of FFN. Default: 4.
+ num_keypoints: num_keypoints (int): Number of keypoints. Default: 17.
+ seq_len: The sequence length. Default: 243.
+ qkv_bias (bool, optional): If True, add a learnable bias to q, k, v.
+ Default: True.
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Default: None.
+ drop_rate (float, optional): Dropout ratio of input. Default: 0.
+ attn_drop_rate (float, optional): Dropout ratio of attention weight.
+ Default: 0.
+ drop_path_rate (float, optional): Stochastic depth rate. Default: 0.
+ att_fuse: Whether to fuse the results of attention blocks.
+ Default: True.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+
+ Example:
+ >>> from mmpose.models import DSTFormer
+ >>> import torch
+ >>> self = DSTFormer(in_channels=3)
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 2, 17, 3)
+ >>> level_outputs = self.forward(inputs)
+ >>> print(tuple(level_outputs.shape))
+ (1, 2, 17, 512)
+ """
+
+ def __init__(self,
+ in_channels,
+ feat_size=256,
+ depth=5,
+ num_heads=8,
+ mlp_ratio=4,
+ num_keypoints=17,
+ seq_len=243,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ att_fuse=True,
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+
+ self.in_channels = in_channels
+ self.feat_size = feat_size
+
+ self.joints_embed = nn.Linear(in_channels, feat_size)
+ self.pos_drop = nn.Dropout(p=drop_rate)
+
+ dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)
+ ] # stochastic depth decay rule
+
+ self.blocks_st = nn.ModuleList([
+ AttentionBlock(
+ dim=feat_size,
+ num_heads=num_heads,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop_rate,
+ attn_drop=attn_drop_rate,
+ drop_path=dpr[i],
+ st_mode='st') for i in range(depth)
+ ])
+ self.blocks_ts = nn.ModuleList([
+ AttentionBlock(
+ dim=feat_size,
+ num_heads=num_heads,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop_rate,
+ attn_drop=attn_drop_rate,
+ drop_path=dpr[i],
+ st_mode='ts') for i in range(depth)
+ ])
+
+ self.norm = nn.LayerNorm(feat_size, eps=1e-06)
+
+ self.temp_embed = nn.Parameter(torch.zeros(1, seq_len, 1, feat_size))
+ self.spat_embed = nn.Parameter(
+ torch.zeros(1, num_keypoints, feat_size))
+
+ trunc_normal_(self.temp_embed, std=.02)
+ trunc_normal_(self.spat_embed, std=.02)
+
+ self.att_fuse = att_fuse
+ if self.att_fuse:
+ self.attn_regress = nn.ModuleList(
+ [nn.Linear(feat_size * 2, 2) for i in range(depth)])
+ for i in range(depth):
+ self.attn_regress[i].weight.data.fill_(0)
+ self.attn_regress[i].bias.data.fill_(0.5)
+
+ def forward(self, x):
+ if len(x.shape) == 3:
+ x = x[None, :]
+ assert len(x.shape) == 4
+
+ B, F, K, C = x.shape
+ x = x.reshape(-1, K, C)
+ BF = x.shape[0]
+ x = self.joints_embed(x) # (BF, K, feat_size)
+ x = x + self.spat_embed
+ _, K, C = x.shape
+ x = x.reshape(-1, F, K, C) + self.temp_embed[:, :F, :, :]
+ x = x.reshape(BF, K, C) # (BF, K, feat_size)
+ x = self.pos_drop(x)
+
+ for idx, (blk_st,
+ blk_ts) in enumerate(zip(self.blocks_st, self.blocks_ts)):
+ x_st = blk_st(x, F)
+ x_ts = blk_ts(x, F)
+ if self.att_fuse:
+ att = self.attn_regress[idx]
+ alpha = torch.cat([x_st, x_ts], dim=-1)
+ BF, K = alpha.shape[:2]
+ alpha = att(alpha)
+ alpha = alpha.softmax(dim=-1)
+ x = x_st * alpha[:, :, 0:1] + x_ts * alpha[:, :, 1:2]
+ else:
+ x = (x_st + x_ts) * 0.5
+ x = self.norm(x) # (BF, K, feat_size)
+ x = x.reshape(B, F, K, -1)
+ return x
+
+ def init_weights(self):
+ """Initialize the weights in backbone."""
+ super(DSTFormer, self).init_weights()
+
+ if (isinstance(self.init_cfg, dict)
+ and self.init_cfg['type'] == 'Pretrained'):
+ return
+
+ for m in self.modules():
+ if isinstance(m, nn.Linear):
+ trunc_normal_(m.weight, std=.02)
+ if isinstance(m, nn.Linear) and m.bias is not None:
+ constant_init(m.bias, 0)
+ elif isinstance(m, nn.LayerNorm):
+ constant_init(m.bias, 0)
+ constant_init(m.weight, 1.0)
diff --git a/mmpose/models/data_preprocessors/__init__.py b/mmpose/models/data_preprocessors/__init__.py
index 7c9bd22e2b..89980f1f6e 100644
--- a/mmpose/models/data_preprocessors/__init__.py
+++ b/mmpose/models/data_preprocessors/__init__.py
@@ -1,4 +1,8 @@
# Copyright (c) OpenMMLab. All rights reserved.
+from .batch_augmentation import BatchSyncRandomResize
from .data_preprocessor import PoseDataPreprocessor
-__all__ = ['PoseDataPreprocessor']
+__all__ = [
+ 'PoseDataPreprocessor',
+ 'BatchSyncRandomResize',
+]
diff --git a/mmpose/models/data_preprocessors/batch_augmentation.py b/mmpose/models/data_preprocessors/batch_augmentation.py
new file mode 100644
index 0000000000..e4dcd568e5
--- /dev/null
+++ b/mmpose/models/data_preprocessors/batch_augmentation.py
@@ -0,0 +1,115 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import random
+from typing import List, Tuple
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmengine import MessageHub
+from mmengine.dist import barrier, broadcast, get_dist_info
+from mmengine.structures import PixelData
+from torch import Tensor
+
+from mmpose.registry import MODELS
+from mmpose.structures import PoseDataSample
+
+
+@MODELS.register_module()
+class BatchSyncRandomResize(nn.Module):
+ """Batch random resize which synchronizes the random size across ranks.
+
+ Args:
+ random_size_range (tuple): The multi-scale random range during
+ multi-scale training.
+ interval (int): The iter interval of change
+ image size. Defaults to 10.
+ size_divisor (int): Image size divisible factor.
+ Defaults to 32.
+ """
+
+ def __init__(self,
+ random_size_range: Tuple[int, int],
+ interval: int = 10,
+ size_divisor: int = 32) -> None:
+ super().__init__()
+ self.rank, self.world_size = get_dist_info()
+ self._input_size = None
+ self._random_size_range = (round(random_size_range[0] / size_divisor),
+ round(random_size_range[1] / size_divisor))
+ self._interval = interval
+ self._size_divisor = size_divisor
+
+ def forward(self, inputs: Tensor, data_samples: List[PoseDataSample]
+ ) -> Tuple[Tensor, List[PoseDataSample]]:
+ """resize a batch of images and bboxes to shape ``self._input_size``"""
+ h, w = inputs.shape[-2:]
+ if self._input_size is None:
+ self._input_size = (h, w)
+ scale_y = self._input_size[0] / h
+ scale_x = self._input_size[1] / w
+ if scale_x != 1 or scale_y != 1:
+ inputs = F.interpolate(
+ inputs,
+ size=self._input_size,
+ mode='bilinear',
+ align_corners=False)
+ for data_sample in data_samples:
+ img_shape = (int(data_sample.img_shape[0] * scale_y),
+ int(data_sample.img_shape[1] * scale_x))
+ pad_shape = (int(data_sample.pad_shape[0] * scale_y),
+ int(data_sample.pad_shape[1] * scale_x))
+ data_sample.set_metainfo({
+ 'img_shape': img_shape,
+ 'pad_shape': pad_shape,
+ 'batch_input_shape': self._input_size
+ })
+
+ if 'gt_instance_labels' not in data_sample:
+ continue
+
+ if 'bboxes' in data_sample.gt_instance_labels:
+ data_sample.gt_instance_labels.bboxes[..., 0::2] *= scale_x
+ data_sample.gt_instance_labels.bboxes[..., 1::2] *= scale_y
+
+ if 'keypoints' in data_sample.gt_instance_labels:
+ data_sample.gt_instance_labels.keypoints[..., 0] *= scale_x
+ data_sample.gt_instance_labels.keypoints[..., 1] *= scale_y
+
+ if 'areas' in data_sample.gt_instance_labels:
+ data_sample.gt_instance_labels.areas *= scale_x * scale_y
+
+ if 'gt_fields' in data_sample \
+ and 'heatmap_mask' in data_sample.gt_fields:
+
+ mask = data_sample.gt_fields.heatmap_mask.unsqueeze(0)
+ gt_fields = PixelData()
+ gt_fields.set_field(
+ F.interpolate(
+ mask.float(),
+ size=self._input_size,
+ mode='bilinear',
+ align_corners=False).squeeze(0), 'heatmap_mask')
+
+ data_sample.gt_fields = gt_fields
+
+ message_hub = MessageHub.get_current_instance()
+ if (message_hub.get_info('iter') + 1) % self._interval == 0:
+ self._input_size = self._get_random_size(
+ aspect_ratio=float(w / h), device=inputs.device)
+ return inputs, data_samples
+
+ def _get_random_size(self, aspect_ratio: float,
+ device: torch.device) -> Tuple[int, int]:
+ """Randomly generate a shape in ``_random_size_range`` and broadcast to
+ all ranks."""
+ tensor = torch.LongTensor(2).to(device)
+ if self.rank == 0:
+ size = random.randint(*self._random_size_range)
+ size = (self._size_divisor * size,
+ self._size_divisor * int(aspect_ratio * size))
+ tensor[0] = size[0]
+ tensor[1] = size[1]
+ barrier()
+ broadcast(tensor, 0)
+ input_size = (tensor[0].item(), tensor[1].item())
+ return input_size
diff --git a/mmpose/models/data_preprocessors/data_preprocessor.py b/mmpose/models/data_preprocessors/data_preprocessor.py
index bcfe54ab59..9442d0ed50 100644
--- a/mmpose/models/data_preprocessors/data_preprocessor.py
+++ b/mmpose/models/data_preprocessors/data_preprocessor.py
@@ -1,9 +1,139 @@
# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Sequence, Union
+
+import numpy as np
+import torch
+import torch.nn as nn
from mmengine.model import ImgDataPreprocessor
+from mmengine.utils import is_seq_of
from mmpose.registry import MODELS
@MODELS.register_module()
class PoseDataPreprocessor(ImgDataPreprocessor):
- """Image pre-processor for pose estimation tasks."""
+ """Image pre-processor for pose estimation tasks.
+
+ Comparing with the :class:`ImgDataPreprocessor`,
+
+ 1. It will additionally append batch_input_shape
+ to data_samples considering the DETR-based pose estimation tasks.
+
+ 2. Support image augmentation transforms on batched data.
+
+ It provides the data pre-processing as follows
+
+ - Collate and move data to the target device.
+ - Pad inputs to the maximum size of current batch with defined
+ ``pad_value``. The padding size can be divisible by a defined
+ ``pad_size_divisor``
+ - Stack inputs to batch_inputs.
+ - Convert inputs from bgr to rgb if the shape of input is (3, H, W).
+ - Normalize image with defined std and mean.
+ - Apply batch augmentation transforms.
+
+ Args:
+ mean (sequence of float, optional): The pixel mean of R, G, B
+ channels. Defaults to None.
+ std (sequence of float, optional): The pixel standard deviation
+ of R, G, B channels. Defaults to None.
+ pad_size_divisor (int): The size of padded image should be
+ divisible by ``pad_size_divisor``. Defaults to 1.
+ pad_value (float or int): The padded pixel value. Defaults to 0.
+ bgr_to_rgb (bool): whether to convert image from BGR to RGB.
+ Defaults to False.
+ rgb_to_bgr (bool): whether to convert image from RGB to BGR.
+ Defaults to False.
+ non_blocking (bool): Whether block current process
+ when transferring data to device. Defaults to False.
+ batch_augments: (list of dict, optional): Configs of augmentation
+ transforms on batched data. Defaults to None.
+ """
+
+ def __init__(self,
+ mean: Sequence[float] = None,
+ std: Sequence[float] = None,
+ pad_size_divisor: int = 1,
+ pad_value: Union[float, int] = 0,
+ bgr_to_rgb: bool = False,
+ rgb_to_bgr: bool = False,
+ non_blocking: Optional[bool] = False,
+ batch_augments: Optional[List[dict]] = None):
+ super().__init__(
+ mean=mean,
+ std=std,
+ pad_size_divisor=pad_size_divisor,
+ pad_value=pad_value,
+ bgr_to_rgb=bgr_to_rgb,
+ rgb_to_bgr=rgb_to_bgr,
+ non_blocking=non_blocking)
+
+ if batch_augments is not None:
+ self.batch_augments = nn.ModuleList(
+ [MODELS.build(aug) for aug in batch_augments])
+ else:
+ self.batch_augments = None
+
+ def forward(self, data: dict, training: bool = False) -> dict:
+ """Perform normalization, padding and bgr2rgb conversion based on
+ ``BaseDataPreprocessor``.
+
+ Args:
+ data (dict): Data sampled from dataloader.
+ training (bool): Whether to enable training time augmentation.
+
+ Returns:
+ dict: Data in the same format as the model input.
+ """
+ batch_pad_shape = self._get_pad_shape(data)
+ data = super().forward(data=data, training=training)
+ inputs, data_samples = data['inputs'], data['data_samples']
+
+ # update metainfo since the image shape might change
+ batch_input_shape = tuple(inputs[0].size()[-2:])
+ for data_sample, pad_shape in zip(data_samples, batch_pad_shape):
+ data_sample.set_metainfo({
+ 'batch_input_shape': batch_input_shape,
+ 'pad_shape': pad_shape
+ })
+
+ # apply batch augmentations
+ if training and self.batch_augments is not None:
+ for batch_aug in self.batch_augments:
+ inputs, data_samples = batch_aug(inputs, data_samples)
+
+ return {'inputs': inputs, 'data_samples': data_samples}
+
+ def _get_pad_shape(self, data: dict) -> List[tuple]:
+ """Get the pad_shape of each image based on data and
+ pad_size_divisor."""
+ _batch_inputs = data['inputs']
+ # Process data with `pseudo_collate`.
+ if is_seq_of(_batch_inputs, torch.Tensor):
+ batch_pad_shape = []
+ for ori_input in _batch_inputs:
+ pad_h = int(
+ np.ceil(ori_input.shape[1] /
+ self.pad_size_divisor)) * self.pad_size_divisor
+ pad_w = int(
+ np.ceil(ori_input.shape[2] /
+ self.pad_size_divisor)) * self.pad_size_divisor
+ batch_pad_shape.append((pad_h, pad_w))
+ # Process data with `default_collate`.
+ elif isinstance(_batch_inputs, torch.Tensor):
+ assert _batch_inputs.dim() == 4, (
+ 'The input of `ImgDataPreprocessor` should be a NCHW tensor '
+ 'or a list of tensor, but got a tensor with shape: '
+ f'{_batch_inputs.shape}')
+ pad_h = int(
+ np.ceil(_batch_inputs.shape[1] /
+ self.pad_size_divisor)) * self.pad_size_divisor
+ pad_w = int(
+ np.ceil(_batch_inputs.shape[2] /
+ self.pad_size_divisor)) * self.pad_size_divisor
+ batch_pad_shape = [(pad_h, pad_w)] * _batch_inputs.shape[0]
+ else:
+ raise TypeError('Output of `cast_data` should be a dict '
+ 'or a tuple with inputs and data_samples, but got'
+ f'{type(data)}: {data}')
+ return batch_pad_shape
diff --git a/mmpose/models/distillers/__init__.py b/mmpose/models/distillers/__init__.py
new file mode 100644
index 0000000000..4cc22a6110
--- /dev/null
+++ b/mmpose/models/distillers/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .dwpose_distiller import DWPoseDistiller
+
+__all__ = ['DWPoseDistiller']
diff --git a/mmpose/models/distillers/dwpose_distiller.py b/mmpose/models/distillers/dwpose_distiller.py
new file mode 100644
index 0000000000..d267951cd5
--- /dev/null
+++ b/mmpose/models/distillers/dwpose_distiller.py
@@ -0,0 +1,290 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta
+from typing import Tuple
+
+import torch
+import torch.nn as nn
+from mmengine.config import Config
+from mmengine.logging import MessageHub
+from mmengine.model import BaseModel
+from mmengine.runner.checkpoint import load_checkpoint
+from torch import Tensor
+
+from mmpose.evaluation.functional import simcc_pck_accuracy
+from mmpose.models import build_pose_estimator
+from mmpose.registry import MODELS
+from mmpose.utils.tensor_utils import to_numpy
+from mmpose.utils.typing import (ForwardResults, OptConfigType, OptMultiConfig,
+ OptSampleList, SampleList)
+
+
+@MODELS.register_module()
+class DWPoseDistiller(BaseModel, metaclass=ABCMeta):
+ """Distiller introduced in `DWPose`_ by Yang et al (2023). This distiller
+ is designed for distillation of RTMPose.
+
+ It typically consists of teacher_model and student_model. Please use the
+ script `tools/misc/pth_transfer.py` to transfer the distilled model to the
+ original RTMPose model.
+
+ Args:
+ teacher_cfg (str): Config file of the teacher model.
+ student_cfg (str): Config file of the student model.
+ two_dis (bool): Whether this is the second stage of distillation.
+ Defaults to False.
+ distill_cfg (dict): Config for distillation. Defaults to None.
+ teacher_pretrained (str): Path of the pretrained teacher model.
+ Defaults to None.
+ train_cfg (dict, optional): The runtime config for training process.
+ Defaults to ``None``
+ data_preprocessor (dict, optional): The data preprocessing config to
+ build the instance of :class:`BaseDataPreprocessor`. Defaults to
+ ``None``
+ init_cfg (dict, optional): The config to control the initialization.
+ Defaults to ``None``
+
+ .. _`DWPose`: https://arxiv.org/abs/2307.15880
+ """
+
+ def __init__(self,
+ teacher_cfg,
+ student_cfg,
+ two_dis=False,
+ distill_cfg=None,
+ teacher_pretrained=None,
+ train_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None):
+ super().__init__(
+ data_preprocessor=data_preprocessor, init_cfg=init_cfg)
+
+ self.teacher = build_pose_estimator(
+ (Config.fromfile(teacher_cfg)).model)
+ self.teacher_pretrained = teacher_pretrained
+ self.teacher.eval()
+ for param in self.teacher.parameters():
+ param.requires_grad = False
+
+ self.student = build_pose_estimator(
+ (Config.fromfile(student_cfg)).model)
+
+ self.distill_cfg = distill_cfg
+ self.distill_losses = nn.ModuleDict()
+ if self.distill_cfg is not None:
+ for item_loc in distill_cfg:
+ for item_loss in item_loc.methods:
+ loss_name = item_loss.name
+ use_this = item_loss.use_this
+ if use_this:
+ self.distill_losses[loss_name] = MODELS.build(
+ item_loss)
+
+ self.two_dis = two_dis
+ self.train_cfg = train_cfg if train_cfg else self.student.train_cfg
+ self.test_cfg = self.student.test_cfg
+ self.metainfo = self.student.metainfo
+
+ def init_weights(self):
+ if self.teacher_pretrained is not None:
+ load_checkpoint(
+ self.teacher, self.teacher_pretrained, map_location='cpu')
+ self.student.init_weights()
+
+ def set_epoch(self):
+ """Set epoch for distiller.
+
+ Used for the decay of distillation loss.
+ """
+ self.message_hub = MessageHub.get_current_instance()
+ self.epoch = self.message_hub.get_info('epoch')
+ self.max_epochs = self.message_hub.get_info('max_epochs')
+
+ def forward(self,
+ inputs: torch.Tensor,
+ data_samples: OptSampleList,
+ mode: str = 'tensor') -> ForwardResults:
+ if mode == 'loss':
+ return self.loss(inputs, data_samples)
+ elif mode == 'predict':
+ # use customed metainfo to override the default metainfo
+ if self.metainfo is not None:
+ for data_sample in data_samples:
+ data_sample.set_metainfo(self.metainfo)
+ return self.predict(inputs, data_samples)
+ elif mode == 'tensor':
+ return self._forward(inputs)
+ else:
+ raise RuntimeError(f'Invalid mode "{mode}". '
+ 'Only supports loss, predict and tensor mode.')
+
+ def loss(self, inputs: Tensor, data_samples: SampleList) -> dict:
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ inputs (Tensor): Inputs with shape (N, C, H, W).
+ data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples.
+
+ Returns:
+ dict: A dictionary of losses.
+ """
+ self.set_epoch()
+
+ losses = dict()
+
+ with torch.no_grad():
+ fea_t = self.teacher.extract_feat(inputs)
+ lt_x, lt_y = self.teacher.head(fea_t)
+ pred_t = (lt_x, lt_y)
+
+ if not self.two_dis:
+ fea_s = self.student.extract_feat(inputs)
+ ori_loss, pred, gt, target_weight = self.head_loss(
+ fea_s, data_samples, train_cfg=self.train_cfg)
+ losses.update(ori_loss)
+ else:
+ ori_loss, pred, gt, target_weight = self.head_loss(
+ fea_t, data_samples, train_cfg=self.train_cfg)
+
+ all_keys = self.distill_losses.keys()
+
+ if 'loss_fea' in all_keys:
+ loss_name = 'loss_fea'
+ losses[loss_name] = self.distill_losses[loss_name](fea_s[-1],
+ fea_t[-1])
+ if not self.two_dis:
+ losses[loss_name] = (
+ 1 - self.epoch / self.max_epochs) * losses[loss_name]
+
+ if 'loss_logit' in all_keys:
+ loss_name = 'loss_logit'
+ losses[loss_name] = self.distill_losses[loss_name](
+ pred, pred_t, self.student.head.loss_module.beta,
+ target_weight)
+ if not self.two_dis:
+ losses[loss_name] = (
+ 1 - self.epoch / self.max_epochs) * losses[loss_name]
+
+ return losses
+
+ def predict(self, inputs, data_samples):
+ """Predict results from a batch of inputs and data samples with post-
+ processing.
+
+ Args:
+ inputs (Tensor): Inputs with shape (N, C, H, W)
+ data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples
+
+ Returns:
+ list[:obj:`PoseDataSample`]: The pose estimation results of the
+ input images. The return value is `PoseDataSample` instances with
+ ``pred_instances`` and ``pred_fields``(optional) field , and
+ ``pred_instances`` usually contains the following keys:
+
+ - keypoints (Tensor): predicted keypoint coordinates in shape
+ (num_instances, K, D) where K is the keypoint number and D
+ is the keypoint dimension
+ - keypoint_scores (Tensor): predicted keypoint scores in shape
+ (num_instances, K)
+ """
+ if self.two_dis:
+ assert self.student.with_head, (
+ 'The model must have head to perform prediction.')
+
+ if self.test_cfg.get('flip_test', False):
+ _feats = self.extract_feat(inputs)
+ _feats_flip = self.extract_feat(inputs.flip(-1))
+ feats = [_feats, _feats_flip]
+ else:
+ feats = self.extract_feat(inputs)
+
+ preds = self.student.head.predict(
+ feats, data_samples, test_cfg=self.student.test_cfg)
+
+ if isinstance(preds, tuple):
+ batch_pred_instances, batch_pred_fields = preds
+ else:
+ batch_pred_instances = preds
+ batch_pred_fields = None
+
+ results = self.student.add_pred_to_datasample(
+ batch_pred_instances, batch_pred_fields, data_samples)
+
+ return results
+ else:
+ return self.student.predict(inputs, data_samples)
+
+ def extract_feat(self, inputs: Tensor) -> Tuple[Tensor]:
+ """Extract features.
+
+ Args:
+ inputs (Tensor): Image tensor with shape (N, C, H ,W).
+
+ Returns:
+ tuple[Tensor]: Multi-level features that may have various
+ resolutions.
+ """
+ x = self.teacher.extract_feat(inputs)
+ return x
+
+ def head_loss(
+ self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ train_cfg: OptConfigType = {},
+ ) -> dict:
+ """Calculate losses from a batch of inputs and data samples."""
+
+ pred_x, pred_y = self.student.head.forward(feats)
+
+ gt_x = torch.cat([
+ d.gt_instance_labels.keypoint_x_labels for d in batch_data_samples
+ ],
+ dim=0)
+ gt_y = torch.cat([
+ d.gt_instance_labels.keypoint_y_labels for d in batch_data_samples
+ ],
+ dim=0)
+ keypoint_weights = torch.cat(
+ [
+ d.gt_instance_labels.keypoint_weights
+ for d in batch_data_samples
+ ],
+ dim=0,
+ )
+
+ pred_simcc = (pred_x, pred_y)
+ gt_simcc = (gt_x, gt_y)
+
+ # calculate losses
+ losses = dict()
+ loss = self.student.head.loss_module(pred_simcc, gt_simcc,
+ keypoint_weights)
+
+ losses.update(loss_kpt=loss)
+
+ # calculate accuracy
+ _, avg_acc, _ = simcc_pck_accuracy(
+ output=to_numpy(pred_simcc),
+ target=to_numpy(gt_simcc),
+ simcc_split_ratio=self.student.head.simcc_split_ratio,
+ mask=to_numpy(keypoint_weights) > 0,
+ )
+
+ acc_pose = torch.tensor(avg_acc, device=gt_x.device)
+ losses.update(acc_pose=acc_pose)
+
+ return losses, pred_simcc, gt_simcc, keypoint_weights
+
+ def _forward(self, inputs: Tensor):
+ """Network forward process. Usually includes backbone, neck and head
+ forward without any post-processing.
+
+ Args:
+ inputs (Tensor): Inputs with shape (N, C, H, W).
+
+ Returns:
+ Union[Tensor | Tuple[Tensor]]: forward output of the network.
+ """
+ return self.student._forward(inputs)
diff --git a/mmpose/models/heads/__init__.py b/mmpose/models/heads/__init__.py
index e01f2269e3..e4b499ad2b 100644
--- a/mmpose/models/heads/__init__.py
+++ b/mmpose/models/heads/__init__.py
@@ -1,17 +1,20 @@
# Copyright (c) OpenMMLab. All rights reserved.
from .base_head import BaseHead
-from .coord_cls_heads import RTMCCHead, SimCCHead
+from .coord_cls_heads import RTMCCHead, RTMWHead, SimCCHead
from .heatmap_heads import (AssociativeEmbeddingHead, CIDHead, CPMHead,
- HeatmapHead, MSPNHead, ViPNASHead)
+ HeatmapHead, InternetHead, MSPNHead, ViPNASHead)
from .hybrid_heads import DEKRHead, VisPredictHead
from .regression_heads import (DSNTHead, IntegralRegressionHead,
- RegressionHead, RLEHead, TemporalRegressionHead,
+ MotionRegressionHead, RegressionHead, RLEHead,
+ TemporalRegressionHead,
TrajectoryRegressionHead)
+from .transformer_heads import EDPoseHead
__all__ = [
'BaseHead', 'HeatmapHead', 'CPMHead', 'MSPNHead', 'ViPNASHead',
'RegressionHead', 'IntegralRegressionHead', 'SimCCHead', 'RLEHead',
'DSNTHead', 'AssociativeEmbeddingHead', 'DEKRHead', 'VisPredictHead',
'CIDHead', 'RTMCCHead', 'TemporalRegressionHead',
- 'TrajectoryRegressionHead'
+ 'TrajectoryRegressionHead', 'MotionRegressionHead', 'EDPoseHead',
+ 'InternetHead', 'RTMWHead'
]
diff --git a/mmpose/models/heads/coord_cls_heads/__init__.py b/mmpose/models/heads/coord_cls_heads/__init__.py
index 104ff91308..6a4e51c4d7 100644
--- a/mmpose/models/heads/coord_cls_heads/__init__.py
+++ b/mmpose/models/heads/coord_cls_heads/__init__.py
@@ -1,5 +1,6 @@
# Copyright (c) OpenMMLab. All rights reserved.
from .rtmcc_head import RTMCCHead
+from .rtmw_head import RTMWHead
from .simcc_head import SimCCHead
-__all__ = ['SimCCHead', 'RTMCCHead']
+__all__ = ['SimCCHead', 'RTMCCHead', 'RTMWHead']
diff --git a/mmpose/models/heads/coord_cls_heads/rtmw_head.py b/mmpose/models/heads/coord_cls_heads/rtmw_head.py
new file mode 100644
index 0000000000..7111f90446
--- /dev/null
+++ b/mmpose/models/heads/coord_cls_heads/rtmw_head.py
@@ -0,0 +1,337 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import Optional, Sequence, Tuple, Union
+
+import torch
+from mmcv.cnn import ConvModule
+from mmengine.dist import get_dist_info
+from mmengine.structures import PixelData
+from torch import Tensor, nn
+
+from mmpose.codecs.utils import get_simcc_normalized
+from mmpose.evaluation.functional import simcc_pck_accuracy
+from mmpose.models.utils.rtmcc_block import RTMCCBlock, ScaleNorm
+from mmpose.models.utils.tta import flip_vectors
+from mmpose.registry import KEYPOINT_CODECS, MODELS
+from mmpose.utils.tensor_utils import to_numpy
+from mmpose.utils.typing import (ConfigType, InstanceList, OptConfigType,
+ OptSampleList)
+from ..base_head import BaseHead
+
+OptIntSeq = Optional[Sequence[int]]
+
+
+@MODELS.register_module()
+class RTMWHead(BaseHead):
+ """Top-down head introduced in RTMPose-Wholebody (2023).
+
+ Args:
+ in_channels (int | sequence[int]): Number of channels in the input
+ feature map.
+ out_channels (int): Number of channels in the output heatmap.
+ input_size (tuple): Size of input image in shape [w, h].
+ in_featuremap_size (int | sequence[int]): Size of input feature map.
+ simcc_split_ratio (float): Split ratio of pixels.
+ Default: 2.0.
+ final_layer_kernel_size (int): Kernel size of the convolutional layer.
+ Default: 1.
+ gau_cfg (Config): Config dict for the Gated Attention Unit.
+ Default: dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='ReLU',
+ use_rel_bias=False,
+ pos_enc=False).
+ loss (Config): Config of the keypoint loss. Defaults to use
+ :class:`KLDiscretLoss`
+ decoder (Config, optional): The decoder config that controls decoding
+ keypoint coordinates from the network output. Defaults to ``None``
+ init_cfg (Config, optional): Config to control the initialization. See
+ :attr:`default_init_cfg` for default settings
+ """
+
+ def __init__(
+ self,
+ in_channels: Union[int, Sequence[int]],
+ out_channels: int,
+ input_size: Tuple[int, int],
+ in_featuremap_size: Tuple[int, int],
+ simcc_split_ratio: float = 2.0,
+ final_layer_kernel_size: int = 1,
+ gau_cfg: ConfigType = dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='ReLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss: ConfigType = dict(type='KLDiscretLoss', use_target_weight=True),
+ decoder: OptConfigType = None,
+ init_cfg: OptConfigType = None,
+ ):
+
+ if init_cfg is None:
+ init_cfg = self.default_init_cfg
+
+ super().__init__(init_cfg)
+
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.input_size = input_size
+ self.in_featuremap_size = in_featuremap_size
+ self.simcc_split_ratio = simcc_split_ratio
+
+ self.loss_module = MODELS.build(loss)
+ if decoder is not None:
+ self.decoder = KEYPOINT_CODECS.build(decoder)
+ else:
+ self.decoder = None
+
+ if isinstance(in_channels, (tuple, list)):
+ raise ValueError(
+ f'{self.__class__.__name__} does not support selecting '
+ 'multiple input features.')
+
+ # Define SimCC layers
+ flatten_dims = self.in_featuremap_size[0] * self.in_featuremap_size[1]
+
+ ps = 2
+ self.ps = nn.PixelShuffle(ps)
+ self.conv_dec = ConvModule(
+ in_channels // ps**2,
+ in_channels // 4,
+ kernel_size=final_layer_kernel_size,
+ stride=1,
+ padding=final_layer_kernel_size // 2,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='ReLU'))
+
+ self.final_layer = ConvModule(
+ in_channels,
+ out_channels,
+ kernel_size=final_layer_kernel_size,
+ stride=1,
+ padding=final_layer_kernel_size // 2,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='ReLU'))
+ self.final_layer2 = ConvModule(
+ in_channels // ps + in_channels // 4,
+ out_channels,
+ kernel_size=final_layer_kernel_size,
+ stride=1,
+ padding=final_layer_kernel_size // 2,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='ReLU'))
+
+ self.mlp = nn.Sequential(
+ ScaleNorm(flatten_dims),
+ nn.Linear(flatten_dims, gau_cfg['hidden_dims'] // 2, bias=False))
+
+ self.mlp2 = nn.Sequential(
+ ScaleNorm(flatten_dims * ps**2),
+ nn.Linear(
+ flatten_dims * ps**2, gau_cfg['hidden_dims'] // 2, bias=False))
+
+ W = int(self.input_size[0] * self.simcc_split_ratio)
+ H = int(self.input_size[1] * self.simcc_split_ratio)
+
+ self.gau = RTMCCBlock(
+ self.out_channels,
+ gau_cfg['hidden_dims'],
+ gau_cfg['hidden_dims'],
+ s=gau_cfg['s'],
+ expansion_factor=gau_cfg['expansion_factor'],
+ dropout_rate=gau_cfg['dropout_rate'],
+ drop_path=gau_cfg['drop_path'],
+ attn_type='self-attn',
+ act_fn=gau_cfg['act_fn'],
+ use_rel_bias=gau_cfg['use_rel_bias'],
+ pos_enc=gau_cfg['pos_enc'])
+
+ self.cls_x = nn.Linear(gau_cfg['hidden_dims'], W, bias=False)
+ self.cls_y = nn.Linear(gau_cfg['hidden_dims'], H, bias=False)
+
+ def forward(self, feats: Tuple[Tensor]) -> Tuple[Tensor, Tensor]:
+ """Forward the network.
+
+ The input is the featuremap extracted by backbone and the
+ output is the simcc representation.
+
+ Args:
+ feats (Tuple[Tensor]): Multi scale feature maps.
+
+ Returns:
+ pred_x (Tensor): 1d representation of x.
+ pred_y (Tensor): 1d representation of y.
+ """
+ # enc_b n / 2, h, w
+ # enc_t n, h, w
+ enc_b, enc_t = feats
+
+ feats_t = self.final_layer(enc_t)
+ feats_t = torch.flatten(feats_t, 2)
+ feats_t = self.mlp(feats_t)
+
+ dec_t = self.ps(enc_t)
+ dec_t = self.conv_dec(dec_t)
+ enc_b = torch.cat([dec_t, enc_b], dim=1)
+
+ feats_b = self.final_layer2(enc_b)
+ feats_b = torch.flatten(feats_b, 2)
+ feats_b = self.mlp2(feats_b)
+
+ feats = torch.cat([feats_t, feats_b], dim=2)
+
+ feats = self.gau(feats)
+
+ pred_x = self.cls_x(feats)
+ pred_y = self.cls_y(feats)
+
+ return pred_x, pred_y
+
+ def predict(
+ self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ test_cfg: OptConfigType = {},
+ ) -> InstanceList:
+ """Predict results from features.
+
+ Args:
+ feats (Tuple[Tensor] | List[Tuple[Tensor]]): The multi-stage
+ features (or multiple multi-stage features in TTA)
+ batch_data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples
+ test_cfg (dict): The runtime config for testing process. Defaults
+ to {}
+
+ Returns:
+ List[InstanceData]: The pose predictions, each contains
+ the following fields:
+ - keypoints (np.ndarray): predicted keypoint coordinates in
+ shape (num_instances, K, D) where K is the keypoint number
+ and D is the keypoint dimension
+ - keypoint_scores (np.ndarray): predicted keypoint scores in
+ shape (num_instances, K)
+ - keypoint_x_labels (np.ndarray, optional): The predicted 1-D
+ intensity distribution in the x direction
+ - keypoint_y_labels (np.ndarray, optional): The predicted 1-D
+ intensity distribution in the y direction
+ """
+
+ if test_cfg.get('flip_test', False):
+ # TTA: flip test -> feats = [orig, flipped]
+ assert isinstance(feats, list) and len(feats) == 2
+ flip_indices = batch_data_samples[0].metainfo['flip_indices']
+ _feats, _feats_flip = feats
+
+ _batch_pred_x, _batch_pred_y = self.forward(_feats)
+
+ _batch_pred_x_flip, _batch_pred_y_flip = self.forward(_feats_flip)
+ _batch_pred_x_flip, _batch_pred_y_flip = flip_vectors(
+ _batch_pred_x_flip,
+ _batch_pred_y_flip,
+ flip_indices=flip_indices)
+
+ batch_pred_x = (_batch_pred_x + _batch_pred_x_flip) * 0.5
+ batch_pred_y = (_batch_pred_y + _batch_pred_y_flip) * 0.5
+ else:
+ batch_pred_x, batch_pred_y = self.forward(feats)
+
+ preds = self.decode((batch_pred_x, batch_pred_y))
+
+ if test_cfg.get('output_heatmaps', False):
+ rank, _ = get_dist_info()
+ if rank == 0:
+ warnings.warn('The predicted simcc values are normalized for '
+ 'visualization. This may cause discrepancy '
+ 'between the keypoint scores and the 1D heatmaps'
+ '.')
+
+ # normalize the predicted 1d distribution
+ batch_pred_x = get_simcc_normalized(batch_pred_x)
+ batch_pred_y = get_simcc_normalized(batch_pred_y)
+
+ B, K, _ = batch_pred_x.shape
+ # B, K, Wx -> B, K, Wx, 1
+ x = batch_pred_x.reshape(B, K, 1, -1)
+ # B, K, Wy -> B, K, 1, Wy
+ y = batch_pred_y.reshape(B, K, -1, 1)
+ # B, K, Wx, Wy
+ batch_heatmaps = torch.matmul(y, x)
+ pred_fields = [
+ PixelData(heatmaps=hm) for hm in batch_heatmaps.detach()
+ ]
+
+ for pred_instances, pred_x, pred_y in zip(preds,
+ to_numpy(batch_pred_x),
+ to_numpy(batch_pred_y)):
+
+ pred_instances.keypoint_x_labels = pred_x[None]
+ pred_instances.keypoint_y_labels = pred_y[None]
+
+ return preds, pred_fields
+ else:
+ return preds
+
+ def loss(
+ self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ train_cfg: OptConfigType = {},
+ ) -> dict:
+ """Calculate losses from a batch of inputs and data samples."""
+
+ pred_x, pred_y = self.forward(feats)
+
+ gt_x = torch.cat([
+ d.gt_instance_labels.keypoint_x_labels for d in batch_data_samples
+ ],
+ dim=0)
+ gt_y = torch.cat([
+ d.gt_instance_labels.keypoint_y_labels for d in batch_data_samples
+ ],
+ dim=0)
+ keypoint_weights = torch.cat(
+ [
+ d.gt_instance_labels.keypoint_weights
+ for d in batch_data_samples
+ ],
+ dim=0,
+ )
+
+ pred_simcc = (pred_x, pred_y)
+ gt_simcc = (gt_x, gt_y)
+
+ # calculate losses
+ losses = dict()
+ loss = self.loss_module(pred_simcc, gt_simcc, keypoint_weights)
+
+ losses.update(loss_kpt=loss)
+
+ # calculate accuracy
+ _, avg_acc, _ = simcc_pck_accuracy(
+ output=to_numpy(pred_simcc),
+ target=to_numpy(gt_simcc),
+ simcc_split_ratio=self.simcc_split_ratio,
+ mask=to_numpy(keypoint_weights) > 0,
+ )
+
+ acc_pose = torch.tensor(avg_acc, device=gt_x.device)
+ losses.update(acc_pose=acc_pose)
+
+ return losses
+
+ @property
+ def default_init_cfg(self):
+ init_cfg = [
+ dict(type='Normal', layer=['Conv2d'], std=0.001),
+ dict(type='Constant', layer='BatchNorm2d', val=1),
+ dict(type='Normal', layer=['Linear'], std=0.01, bias=0),
+ ]
+ return init_cfg
diff --git a/mmpose/models/heads/heatmap_heads/__init__.py b/mmpose/models/heads/heatmap_heads/__init__.py
index b482216b36..c629455c19 100644
--- a/mmpose/models/heads/heatmap_heads/__init__.py
+++ b/mmpose/models/heads/heatmap_heads/__init__.py
@@ -3,10 +3,11 @@
from .cid_head import CIDHead
from .cpm_head import CPMHead
from .heatmap_head import HeatmapHead
+from .internet_head import InternetHead
from .mspn_head import MSPNHead
from .vipnas_head import ViPNASHead
__all__ = [
'HeatmapHead', 'CPMHead', 'MSPNHead', 'ViPNASHead',
- 'AssociativeEmbeddingHead', 'CIDHead'
+ 'AssociativeEmbeddingHead', 'CIDHead', 'InternetHead'
]
diff --git a/mmpose/models/heads/heatmap_heads/ae_head.py b/mmpose/models/heads/heatmap_heads/ae_head.py
index bd12d57a33..c9559eebc2 100644
--- a/mmpose/models/heads/heatmap_heads/ae_head.py
+++ b/mmpose/models/heads/heatmap_heads/ae_head.py
@@ -2,14 +2,15 @@
from typing import List, Optional, Sequence, Tuple, Union
import torch
-from mmengine.structures import PixelData
+from mmengine.structures import InstanceData, PixelData
from mmengine.utils import is_list_of
from torch import Tensor
from mmpose.models.utils.tta import aggregate_heatmaps, flip_heatmaps
from mmpose.registry import MODELS
-from mmpose.utils.typing import (ConfigType, Features, OptConfigType,
- OptSampleList, Predictions)
+from mmpose.utils.tensor_utils import to_numpy
+from mmpose.utils.typing import (ConfigType, Features, InstanceList,
+ OptConfigType, OptSampleList, Predictions)
from .heatmap_head import HeatmapHead
OptIntSeq = Optional[Sequence[int]]
@@ -226,6 +227,57 @@ def _flip_tags(self,
return tags
+ def decode(self, batch_outputs: Union[Tensor,
+ Tuple[Tensor]]) -> InstanceList:
+ """Decode keypoints from outputs.
+
+ Args:
+ batch_outputs (Tensor | Tuple[Tensor]): The network outputs of
+ a data batch
+
+ Returns:
+ List[InstanceData]: A list of InstanceData, each contains the
+ decoded pose information of the instances of one data sample.
+ """
+
+ def _pack_and_call(args, func):
+ if not isinstance(args, tuple):
+ args = (args, )
+ return func(*args)
+
+ if self.decoder is None:
+ raise RuntimeError(
+ f'The decoder has not been set in {self.__class__.__name__}. '
+ 'Please set the decoder configs in the init parameters to '
+ 'enable head methods `head.predict()` and `head.decode()`')
+
+ if self.decoder.support_batch_decoding:
+ batch_keypoints, batch_scores, batch_instance_scores = \
+ _pack_and_call(batch_outputs, self.decoder.batch_decode)
+
+ else:
+ batch_output_np = to_numpy(batch_outputs, unzip=True)
+ batch_keypoints = []
+ batch_scores = []
+ batch_instance_scores = []
+ for outputs in batch_output_np:
+ keypoints, scores, instance_scores = _pack_and_call(
+ outputs, self.decoder.decode)
+ batch_keypoints.append(keypoints)
+ batch_scores.append(scores)
+ batch_instance_scores.append(instance_scores)
+
+ preds = [
+ InstanceData(
+ bbox_scores=instance_scores,
+ keypoints=keypoints,
+ keypoint_scores=scores)
+ for keypoints, scores, instance_scores in zip(
+ batch_keypoints, batch_scores, batch_instance_scores)
+ ]
+
+ return preds
+
def forward(self, feats: Tuple[Tensor]) -> Tuple[Tensor, Tensor]:
"""Forward the network. The input is multi scale feature maps and the
output is the heatmaps and tags.
diff --git a/mmpose/models/heads/heatmap_heads/heatmap_head.py b/mmpose/models/heads/heatmap_heads/heatmap_head.py
index 0b0fa3f475..ccb10fcf54 100644
--- a/mmpose/models/heads/heatmap_heads/heatmap_head.py
+++ b/mmpose/models/heads/heatmap_heads/heatmap_head.py
@@ -48,8 +48,6 @@ class HeatmapHead(BaseHead):
keypoint coordinates from the network output. Defaults to ``None``
init_cfg (Config, optional): Config to control the initialization. See
:attr:`default_init_cfg` for default settings
- extra (dict, optional): Extra configurations.
- Defaults to ``None``
.. _`Simple Baselines`: https://arxiv.org/abs/1804.06208
"""
@@ -321,8 +319,8 @@ def loss(self,
def _load_state_dict_pre_hook(self, state_dict, prefix, local_meta, *args,
**kwargs):
"""A hook function to convert old-version state dict of
- :class:`DeepposeRegressionHead` (before MMPose v1.0.0) to a
- compatible format of :class:`RegressionHead`.
+ :class:`TopdownHeatmapSimpleHead` (before MMPose v1.0.0) to a
+ compatible format of :class:`HeatmapHead`.
The hook will be automatically registered during initialization.
"""
diff --git a/mmpose/models/heads/heatmap_heads/internet_head.py b/mmpose/models/heads/heatmap_heads/internet_head.py
new file mode 100644
index 0000000000..62de8e96db
--- /dev/null
+++ b/mmpose/models/heads/heatmap_heads/internet_head.py
@@ -0,0 +1,443 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Sequence, Tuple, Union
+
+import torch
+import torch.nn.functional as F
+from mmengine.model import normal_init
+from mmengine.structures import InstanceData
+from torch import Tensor, nn
+
+from mmpose.evaluation.functional import multilabel_classification_accuracy
+from mmpose.models.necks import GlobalAveragePooling
+from mmpose.models.utils.tta import flip_heatmaps
+from mmpose.registry import KEYPOINT_CODECS, MODELS
+from mmpose.utils.tensor_utils import to_numpy
+from mmpose.utils.typing import (ConfigType, Features, InstanceList,
+ OptConfigType, OptSampleList, Predictions)
+from ..base_head import BaseHead
+from .heatmap_head import HeatmapHead
+
+OptIntSeq = Optional[Sequence[int]]
+
+
+def make_linear_layers(feat_dims, relu_final=False):
+ """Make linear layers."""
+ layers = []
+ for i in range(len(feat_dims) - 1):
+ layers.append(nn.Linear(feat_dims[i], feat_dims[i + 1]))
+ if i < len(feat_dims) - 2 or \
+ (i == len(feat_dims) - 2 and relu_final):
+ layers.append(nn.ReLU(inplace=True))
+ return nn.Sequential(*layers)
+
+
+class Heatmap3DHead(HeatmapHead):
+ """Heatmap3DHead is a sub-module of Interhand3DHead, and outputs 3D
+ heatmaps. Heatmap3DHead is composed of (>=0) number of deconv layers and a
+ simple conv2d layer.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ depth_size (int): Number of depth discretization size. Defaults to 64.
+ deconv_out_channels (Sequence[int], optional): The output channel
+ number of each deconv layer. Defaults to ``(256, 256, 256)``
+ deconv_kernel_sizes (Sequence[int | tuple], optional): The kernel size
+ of each deconv layer. Each element should be either an integer for
+ both height and width dimensions, or a tuple of two integers for
+ the height and the width dimension respectively.Defaults to
+ ``(4, 4, 4)``.
+ final_layer (dict): Arguments of the final Conv2d layer.
+ Defaults to ``dict(kernel_size=1)``.
+ init_cfg (Config, optional): Config to control the initialization. See
+ :attr:`default_init_cfg` for default settings.
+ """
+
+ def __init__(self,
+ in_channels: Union[int, Sequence[int]],
+ out_channels: int,
+ depth_size: int = 64,
+ deconv_out_channels: OptIntSeq = (256, 256, 256),
+ deconv_kernel_sizes: OptIntSeq = (4, 4, 4),
+ final_layer: dict = dict(kernel_size=1),
+ init_cfg: OptConfigType = None):
+
+ super().__init__(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ deconv_out_channels=deconv_out_channels,
+ deconv_kernel_sizes=deconv_kernel_sizes,
+ final_layer=final_layer,
+ init_cfg=init_cfg)
+
+ assert out_channels % depth_size == 0
+ self.depth_size = depth_size
+
+ def forward(self, feats: Tensor) -> Tensor:
+ """Forward the network. The input is multi scale feature maps and the
+ output is the heatmap.
+
+ Args:
+ feats (Tensor): Feature map.
+
+ Returns:
+ Tensor: output heatmap.
+ """
+
+ x = self.deconv_layers(feats)
+ x = self.final_layer(x)
+ N, C, H, W = x.shape
+ # reshape the 2D heatmap to 3D heatmap
+ x = x.reshape(N, C // self.depth_size, self.depth_size, H, W)
+
+ return x
+
+
+class Heatmap1DHead(nn.Module):
+ """Heatmap1DHead is a sub-module of Interhand3DHead, and outputs 1D
+ heatmaps.
+
+ Args:
+ in_channels (int): Number of input channels. Defaults to 2048.
+ heatmap_size (int): Heatmap size. Defaults to 64.
+ hidden_dims (Sequence[int]): Number of feature dimension of FC layers.
+ Defaults to ``(512, )``.
+ """
+
+ def __init__(self,
+ in_channels: int = 2048,
+ heatmap_size: int = 64,
+ hidden_dims: Sequence[int] = (512, )):
+
+ super().__init__()
+
+ self.in_channels = in_channels
+ self.heatmap_size = heatmap_size
+
+ feature_dims = [in_channels, *hidden_dims, heatmap_size]
+ self.fc = make_linear_layers(feature_dims, relu_final=False)
+
+ def soft_argmax_1d(self, heatmap1d):
+ heatmap1d = F.softmax(heatmap1d, 1)
+ accu = heatmap1d * torch.arange(
+ self.heatmap_size, dtype=heatmap1d.dtype,
+ device=heatmap1d.device)[None, :]
+ coord = accu.sum(dim=1)
+ return coord
+
+ def forward(self, feats: Tuple[Tensor]) -> Tensor:
+ """Forward the network.
+
+ Args:
+ feats (Tuple[Tensor]): Multi scale feature maps.
+
+ Returns:
+ Tensor: output heatmap.
+ """
+ x = self.fc(feats)
+ x = self.soft_argmax_1d(x).view(-1, 1)
+ return x
+
+ def init_weights(self):
+ """Initialize model weights."""
+ for m in self.fc.modules():
+ if isinstance(m, nn.Linear):
+ normal_init(m, mean=0, std=0.01, bias=0)
+
+
+class MultilabelClassificationHead(nn.Module):
+ """MultilabelClassificationHead is a sub-module of Interhand3DHead, and
+ outputs hand type classification.
+
+ Args:
+ in_channels (int): Number of input channels. Defaults to 2048.
+ num_labels (int): Number of labels. Defaults to 2.
+ hidden_dims (Sequence[int]): Number of hidden dimension of FC layers.
+ Defaults to ``(512, )``.
+ """
+
+ def __init__(self,
+ in_channels: int = 2048,
+ num_labels: int = 2,
+ hidden_dims: Sequence[int] = (512, )):
+
+ super().__init__()
+
+ self.in_channels = in_channels
+
+ feature_dims = [in_channels, *hidden_dims, num_labels]
+ self.fc = make_linear_layers(feature_dims, relu_final=False)
+
+ def init_weights(self):
+ for m in self.fc.modules():
+ if isinstance(m, nn.Linear):
+ normal_init(m, mean=0, std=0.01, bias=0)
+
+ def forward(self, x):
+ """Forward function."""
+ labels = self.fc(x)
+ return labels
+
+
+@MODELS.register_module()
+class InternetHead(BaseHead):
+ """Internet head introduced in `Interhand 2.6M`_ by Moon et al (2020).
+
+ Args:
+ keypoint_head_cfg (dict): Configs of Heatmap3DHead for hand
+ keypoint estimation.
+ root_head_cfg (dict): Configs of Heatmap1DHead for relative
+ hand root depth estimation.
+ hand_type_head_cfg (dict): Configs of ``MultilabelClassificationHead``
+ for hand type classification.
+ loss (Config): Config of the keypoint loss.
+ Default: :class:`KeypointMSELoss`.
+ loss_root_depth (dict): Config for relative root depth loss.
+ Default: :class:`SmoothL1Loss`.
+ loss_hand_type (dict): Config for hand type classification
+ loss. Default: :class:`BCELoss`.
+ decoder (Config, optional): The decoder config that controls decoding
+ keypoint coordinates from the network output. Default: ``None``.
+ init_cfg (Config, optional): Config to control the initialization. See
+ :attr:`default_init_cfg` for default settings
+
+ .. _`Interhand 2.6M`: https://arxiv.org/abs/2008.09309
+ """
+
+ _version = 2
+
+ def __init__(self,
+ keypoint_head_cfg: ConfigType,
+ root_head_cfg: ConfigType,
+ hand_type_head_cfg: ConfigType,
+ loss: ConfigType = dict(
+ type='KeypointMSELoss', use_target_weight=True),
+ loss_root_depth: ConfigType = dict(
+ type='L1Loss', use_target_weight=True),
+ loss_hand_type: ConfigType = dict(
+ type='BCELoss', use_target_weight=True),
+ decoder: OptConfigType = None,
+ init_cfg: OptConfigType = None):
+
+ super().__init__()
+
+ # build sub-module heads
+ self.right_hand_head = Heatmap3DHead(**keypoint_head_cfg)
+ self.left_hand_head = Heatmap3DHead(**keypoint_head_cfg)
+ self.root_head = Heatmap1DHead(**root_head_cfg)
+ self.hand_type_head = MultilabelClassificationHead(
+ **hand_type_head_cfg)
+ self.neck = GlobalAveragePooling()
+
+ self.loss_module = MODELS.build(loss)
+ self.root_loss_module = MODELS.build(loss_root_depth)
+ self.hand_loss_module = MODELS.build(loss_hand_type)
+
+ if decoder is not None:
+ self.decoder = KEYPOINT_CODECS.build(decoder)
+ else:
+ self.decoder = None
+
+ def forward(self, feats: Tuple[Tensor]) -> Tensor:
+ """Forward the network. The input is multi scale feature maps and the
+ output is the heatmap.
+
+ Args:
+ feats (Tuple[Tensor]): Multi scale feature maps.
+
+ Returns:
+ Tuple[Tensor]: Output heatmap, root depth estimation and hand type
+ classification.
+ """
+ x = feats[-1]
+ outputs = []
+ outputs.append(
+ torch.cat([self.right_hand_head(x),
+ self.left_hand_head(x)], dim=1))
+ x = self.neck(x)
+ outputs.append(self.root_head(x))
+ outputs.append(self.hand_type_head(x))
+ return outputs
+
+ def predict(self,
+ feats: Features,
+ batch_data_samples: OptSampleList,
+ test_cfg: ConfigType = {}) -> Predictions:
+ """Predict results from features.
+
+ Args:
+ feats (Tuple[Tensor] | List[Tuple[Tensor]]): The multi-stage
+ features (or multiple multi-stage features in TTA)
+ batch_data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples
+ test_cfg (dict): The runtime config for testing process. Defaults
+ to {}
+
+ Returns:
+ InstanceList: Return the pose prediction.
+
+ The pose prediction is a list of ``InstanceData``, each contains
+ the following fields:
+
+ - keypoints (np.ndarray): predicted keypoint coordinates in
+ shape (num_instances, K, D) where K is the keypoint number
+ and D is the keypoint dimension
+ - keypoint_scores (np.ndarray): predicted keypoint scores in
+ shape (num_instances, K)
+ """
+
+ if test_cfg.get('flip_test', False):
+ # TTA: flip test -> feats = [orig, flipped]
+ assert isinstance(feats, list) and len(feats) == 2
+ flip_indices = batch_data_samples[0].metainfo['flip_indices']
+ _feats, _feats_flip = feats
+ _batch_outputs = self.forward(_feats)
+ _batch_heatmaps = _batch_outputs[0]
+
+ _batch_outputs_flip = self.forward(_feats_flip)
+ _batch_heatmaps_flip = flip_heatmaps(
+ _batch_outputs_flip[0],
+ flip_mode=test_cfg.get('flip_mode', 'heatmap'),
+ flip_indices=flip_indices,
+ shift_heatmap=test_cfg.get('shift_heatmap', False))
+
+ batch_heatmaps = (_batch_heatmaps + _batch_heatmaps_flip) * 0.5
+
+ # flip relative hand root depth
+ _batch_root = _batch_outputs[1]
+ _batch_root_flip = -_batch_outputs_flip[1]
+ batch_root = (_batch_root + _batch_root_flip) * 0.5
+
+ # flip hand type
+ _batch_type = _batch_outputs[2]
+ _batch_type_flip = torch.empty_like(_batch_outputs_flip[2])
+ _batch_type_flip[:, 0] = _batch_type[:, 1]
+ _batch_type_flip[:, 1] = _batch_type[:, 0]
+ batch_type = (_batch_type + _batch_type_flip) * 0.5
+
+ batch_outputs = [batch_heatmaps, batch_root, batch_type]
+
+ else:
+ batch_outputs = self.forward(feats)
+
+ preds = self.decode(tuple(batch_outputs))
+
+ return preds
+
+ def loss(self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ train_cfg: ConfigType = {}) -> dict:
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ feats (Tuple[Tensor]): The multi-stage features
+ batch_data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples
+ train_cfg (dict): The runtime config for training process.
+ Defaults to {}
+
+ Returns:
+ dict: A dictionary of losses.
+ """
+ pred_fields = self.forward(feats)
+ pred_heatmaps = pred_fields[0]
+ _, K, D, W, H = pred_heatmaps.shape
+ gt_heatmaps = torch.stack([
+ d.gt_fields.heatmaps.reshape(K, D, W, H)
+ for d in batch_data_samples
+ ])
+ keypoint_weights = torch.cat([
+ d.gt_instance_labels.keypoint_weights for d in batch_data_samples
+ ])
+
+ # calculate losses
+ losses = dict()
+
+ # hand keypoint loss
+ loss = self.loss_module(pred_heatmaps, gt_heatmaps, keypoint_weights)
+ losses.update(loss_kpt=loss)
+
+ # relative root depth loss
+ gt_roots = torch.stack(
+ [d.gt_instance_labels.root_depth for d in batch_data_samples])
+ root_weights = torch.stack([
+ d.gt_instance_labels.root_depth_weight for d in batch_data_samples
+ ])
+ loss_root = self.root_loss_module(pred_fields[1], gt_roots,
+ root_weights)
+ losses.update(loss_rel_root=loss_root)
+
+ # hand type loss
+ gt_types = torch.stack([
+ d.gt_instance_labels.type.reshape(-1) for d in batch_data_samples
+ ])
+ type_weights = torch.stack(
+ [d.gt_instance_labels.type_weight for d in batch_data_samples])
+ loss_type = self.hand_loss_module(pred_fields[2], gt_types,
+ type_weights)
+ losses.update(loss_hand_type=loss_type)
+
+ # calculate accuracy
+ if train_cfg.get('compute_acc', True):
+ acc = multilabel_classification_accuracy(
+ pred=to_numpy(pred_fields[2]),
+ gt=to_numpy(gt_types),
+ mask=to_numpy(type_weights))
+
+ acc_pose = torch.tensor(acc, device=gt_types.device)
+ losses.update(acc_pose=acc_pose)
+
+ return losses
+
+ def decode(self, batch_outputs: Union[Tensor,
+ Tuple[Tensor]]) -> InstanceList:
+ """Decode keypoints from outputs.
+
+ Args:
+ batch_outputs (Tensor | Tuple[Tensor]): The network outputs of
+ a data batch
+
+ Returns:
+ List[InstanceData]: A list of InstanceData, each contains the
+ decoded pose information of the instances of one data sample.
+ """
+
+ def _pack_and_call(args, func):
+ if not isinstance(args, tuple):
+ args = (args, )
+ return func(*args)
+
+ if self.decoder is None:
+ raise RuntimeError(
+ f'The decoder has not been set in {self.__class__.__name__}. '
+ 'Please set the decoder configs in the init parameters to '
+ 'enable head methods `head.predict()` and `head.decode()`')
+
+ batch_output_np = to_numpy(batch_outputs[0], unzip=True)
+ batch_root_np = to_numpy(batch_outputs[1], unzip=True)
+ batch_type_np = to_numpy(batch_outputs[2], unzip=True)
+ batch_keypoints = []
+ batch_scores = []
+ batch_roots = []
+ batch_types = []
+ for outputs, roots, types in zip(batch_output_np, batch_root_np,
+ batch_type_np):
+ keypoints, scores, rel_root_depth, hand_type = _pack_and_call(
+ tuple([outputs, roots, types]), self.decoder.decode)
+ batch_keypoints.append(keypoints)
+ batch_scores.append(scores)
+ batch_roots.append(rel_root_depth)
+ batch_types.append(hand_type)
+
+ preds = [
+ InstanceData(
+ keypoints=keypoints,
+ keypoint_scores=scores,
+ rel_root_depth=rel_root_depth,
+ hand_type=hand_type)
+ for keypoints, scores, rel_root_depth, hand_type in zip(
+ batch_keypoints, batch_scores, batch_roots, batch_types)
+ ]
+
+ return preds
diff --git a/mmpose/models/heads/hybrid_heads/__init__.py b/mmpose/models/heads/hybrid_heads/__init__.py
index 6431b6a2c2..ff026ce855 100644
--- a/mmpose/models/heads/hybrid_heads/__init__.py
+++ b/mmpose/models/heads/hybrid_heads/__init__.py
@@ -1,5 +1,6 @@
# Copyright (c) OpenMMLab. All rights reserved.
from .dekr_head import DEKRHead
from .vis_head import VisPredictHead
+from .yoloxpose_head import YOLOXPoseHead
-__all__ = ['DEKRHead', 'VisPredictHead']
+__all__ = ['DEKRHead', 'VisPredictHead', 'YOLOXPoseHead']
diff --git a/mmpose/models/heads/hybrid_heads/vis_head.py b/mmpose/models/heads/hybrid_heads/vis_head.py
index e9ea271ac5..f95634541b 100644
--- a/mmpose/models/heads/hybrid_heads/vis_head.py
+++ b/mmpose/models/heads/hybrid_heads/vis_head.py
@@ -31,8 +31,7 @@ def __init__(self,
pose_cfg: ConfigType,
loss: ConfigType = dict(
type='BCELoss', use_target_weight=False,
- with_logits=True),
- use_sigmoid: bool = False,
+ use_sigmoid=True),
init_cfg: OptConfigType = None):
if init_cfg is None:
@@ -54,14 +53,14 @@ def __init__(self,
self.pose_head = MODELS.build(pose_cfg)
self.pose_cfg = pose_cfg
- self.use_sigmoid = use_sigmoid
+ self.use_sigmoid = loss.get('use_sigmoid', False)
modules = [
nn.AdaptiveAvgPool2d(1),
nn.Flatten(),
nn.Linear(self.in_channels, self.out_channels)
]
- if use_sigmoid:
+ if self.use_sigmoid:
modules.append(nn.Sigmoid())
self.vis_head = nn.Sequential(*modules)
@@ -113,7 +112,7 @@ def integrate(self, batch_vis: Tensor,
assert len(pose_pred_instances) == len(batch_vis_np)
for index, _ in enumerate(pose_pred_instances):
- pose_pred_instances[index].keypoint_scores = batch_vis_np[index]
+ pose_pred_instances[index].keypoints_visible = batch_vis_np[index]
return pose_pred_instances, pose_pred_fields
@@ -176,15 +175,20 @@ def predict(self,
return self.integrate(batch_vis, batch_pose)
- def vis_accuracy(self, vis_pred_outputs, vis_labels):
+ @torch.no_grad()
+ def vis_accuracy(self, vis_pred_outputs, vis_labels, vis_weights=None):
"""Calculate visibility prediction accuracy."""
- probabilities = torch.sigmoid(torch.flatten(vis_pred_outputs))
+ if not self.use_sigmoid:
+ vis_pred_outputs = torch.sigmoid(vis_pred_outputs)
threshold = 0.5
- predictions = (probabilities >= threshold).int()
- labels = torch.flatten(vis_labels)
- correct = torch.sum(predictions == labels).item()
- accuracy = correct / len(labels)
- return torch.tensor(accuracy)
+ predictions = (vis_pred_outputs >= threshold).float()
+ correct = (predictions == vis_labels).float()
+ if vis_weights is not None:
+ accuracy = (correct * vis_weights).sum(dim=1) / (
+ vis_weights.sum(dim=1, keepdims=True) + 1e-6)
+ else:
+ accuracy = correct.mean(dim=1)
+ return accuracy.mean()
def loss(self,
feats: Tuple[Tensor],
@@ -203,18 +207,26 @@ def loss(self,
dict: A dictionary of losses.
"""
vis_pred_outputs = self.vis_forward(feats)
- vis_labels = torch.cat([
- d.gt_instance_labels.keypoint_weights for d in batch_data_samples
- ])
+ vis_labels = []
+ vis_weights = [] if self.loss_module.use_target_weight else None
+ for d in batch_data_samples:
+ vis_label = d.gt_instance_labels.keypoint_weights.float()
+ vis_labels.append(vis_label)
+ if vis_weights is not None:
+ vis_weights.append(
+ getattr(d.gt_instance_labels, 'keypoints_visible_weights',
+ vis_label.new_ones(vis_label.shape)))
+ vis_labels = torch.cat(vis_labels)
+ vis_weights = torch.cat(vis_weights) if vis_weights else None
# calculate vis losses
losses = dict()
- loss_vis = self.loss_module(vis_pred_outputs, vis_labels)
+ loss_vis = self.loss_module(vis_pred_outputs, vis_labels, vis_weights)
losses.update(loss_vis=loss_vis)
# calculate vis accuracy
- acc_vis = self.vis_accuracy(vis_pred_outputs, vis_labels)
+ acc_vis = self.vis_accuracy(vis_pred_outputs, vis_labels, vis_weights)
losses.update(acc_vis=acc_vis)
# calculate keypoints losses
diff --git a/mmpose/models/heads/hybrid_heads/yoloxpose_head.py b/mmpose/models/heads/hybrid_heads/yoloxpose_head.py
new file mode 100644
index 0000000000..bdd25f7851
--- /dev/null
+++ b/mmpose/models/heads/hybrid_heads/yoloxpose_head.py
@@ -0,0 +1,752 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import List, Optional, Sequence, Tuple, Union
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule, bias_init_with_prob
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmpose.evaluation.functional import nms_torch
+from mmpose.models.utils import filter_scores_and_topk
+from mmpose.registry import MODELS, TASK_UTILS
+from mmpose.structures import PoseDataSample
+from mmpose.utils import reduce_mean
+from mmpose.utils.typing import (ConfigType, Features, OptSampleList,
+ Predictions, SampleList)
+
+
+class YOLOXPoseHeadModule(BaseModule):
+ """YOLOXPose head module for one-stage human pose estimation.
+
+ This module predicts classification scores, bounding boxes, keypoint
+ offsets and visibilities from multi-level feature maps.
+
+ Args:
+ num_classes (int): Number of categories excluding the background
+ category.
+ num_keypoints (int): Number of keypoints defined for one instance.
+ in_channels (Union[int, Sequence]): Number of channels in the input
+ feature map.
+ feat_channels (int): Number of channels in the classification score
+ and objectness prediction branch. Defaults to 256.
+ widen_factor (float): Width multiplier, multiply number of
+ channels in each layer by this amount. Defaults to 1.0.
+ num_groups (int): Group number of group convolution layers in keypoint
+ regression branch. Defaults to 8.
+ channels_per_group (int): Number of channels for each group of group
+ convolution layers in keypoint regression branch. Defaults to 32.
+ featmap_strides (Sequence[int]): Downsample factor of each feature
+ map. Defaults to [8, 16, 32].
+ conv_bias (bool or str): If specified as `auto`, it will be decided
+ by the norm_cfg. Bias of conv will be set as True if `norm_cfg`
+ is None, otherwise False. Defaults to "auto".
+ conv_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ convolution layer. Defaults to None.
+ norm_cfg (:obj:`ConfigDict` or dict): Config dict for normalization
+ layer. Defaults to dict(type='BN', momentum=0.03, eps=0.001).
+ act_cfg (:obj:`ConfigDict` or dict): Config dict for activation layer.
+ Defaults to None.
+ init_cfg (:obj:`ConfigDict` or list[:obj:`ConfigDict`] or dict or
+ list[dict], optional): Initialization config dict.
+ Defaults to None.
+ """
+
+ def __init__(
+ self,
+ num_keypoints: int,
+ in_channels: Union[int, Sequence],
+ num_classes: int = 1,
+ widen_factor: float = 1.0,
+ feat_channels: int = 256,
+ stacked_convs: int = 2,
+ featmap_strides: Sequence[int] = [8, 16, 32],
+ conv_bias: Union[bool, str] = 'auto',
+ conv_cfg: Optional[ConfigType] = None,
+ norm_cfg: ConfigType = dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg: ConfigType = dict(type='SiLU', inplace=True),
+ init_cfg: Optional[ConfigType] = None,
+ ):
+ super().__init__(init_cfg=init_cfg)
+ self.num_classes = num_classes
+ self.feat_channels = int(feat_channels * widen_factor)
+ self.stacked_convs = stacked_convs
+ assert conv_bias == 'auto' or isinstance(conv_bias, bool)
+ self.conv_bias = conv_bias
+
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.featmap_strides = featmap_strides
+
+ if isinstance(in_channels, int):
+ in_channels = int(in_channels * widen_factor)
+ self.in_channels = in_channels
+ self.num_keypoints = num_keypoints
+
+ self._init_layers()
+
+ def _init_layers(self):
+ """Initialize heads for all level feature maps."""
+ self._init_cls_branch()
+ self._init_reg_branch()
+ self._init_pose_branch()
+
+ def _init_cls_branch(self):
+ """Initialize classification branch for all level feature maps."""
+ self.conv_cls = nn.ModuleList()
+ for _ in self.featmap_strides:
+ stacked_convs = []
+ for i in range(self.stacked_convs):
+ chn = self.in_channels if i == 0 else self.feat_channels
+ stacked_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ bias=self.conv_bias))
+ self.conv_cls.append(nn.Sequential(*stacked_convs))
+
+ # output layers
+ self.out_cls = nn.ModuleList()
+ self.out_obj = nn.ModuleList()
+ for _ in self.featmap_strides:
+ self.out_cls.append(
+ nn.Conv2d(self.feat_channels, self.num_classes, 1))
+
+ def _init_reg_branch(self):
+ """Initialize classification branch for all level feature maps."""
+ self.conv_reg = nn.ModuleList()
+ for _ in self.featmap_strides:
+ stacked_convs = []
+ for i in range(self.stacked_convs):
+ chn = self.in_channels if i == 0 else self.feat_channels
+ stacked_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ bias=self.conv_bias))
+ self.conv_reg.append(nn.Sequential(*stacked_convs))
+
+ # output layers
+ self.out_bbox = nn.ModuleList()
+ self.out_obj = nn.ModuleList()
+ for _ in self.featmap_strides:
+ self.out_bbox.append(nn.Conv2d(self.feat_channels, 4, 1))
+ self.out_obj.append(nn.Conv2d(self.feat_channels, 1, 1))
+
+ def _init_pose_branch(self):
+ self.conv_pose = nn.ModuleList()
+
+ for _ in self.featmap_strides:
+ stacked_convs = []
+ for i in range(self.stacked_convs * 2):
+ in_chn = self.in_channels if i == 0 else self.feat_channels
+ stacked_convs.append(
+ ConvModule(
+ in_chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ bias=self.conv_bias))
+ self.conv_pose.append(nn.Sequential(*stacked_convs))
+
+ # output layers
+ self.out_kpt = nn.ModuleList()
+ self.out_kpt_vis = nn.ModuleList()
+ for _ in self.featmap_strides:
+ self.out_kpt.append(
+ nn.Conv2d(self.feat_channels, self.num_keypoints * 2, 1))
+ self.out_kpt_vis.append(
+ nn.Conv2d(self.feat_channels, self.num_keypoints, 1))
+
+ def init_weights(self):
+ """Initialize weights of the head."""
+ # Use prior in model initialization to improve stability
+ super().init_weights()
+ bias_init = bias_init_with_prob(0.01)
+ for conv_cls, conv_obj in zip(self.out_cls, self.out_obj):
+ conv_cls.bias.data.fill_(bias_init)
+ conv_obj.bias.data.fill_(bias_init)
+
+ def forward(self, x: Tuple[Tensor]) -> Tuple[List]:
+ """Forward features from the upstream network.
+
+ Args:
+ x (Tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ cls_scores (List[Tensor]): Classification scores for each level.
+ objectnesses (List[Tensor]): Objectness scores for each level.
+ bbox_preds (List[Tensor]): Bounding box predictions for each level.
+ kpt_offsets (List[Tensor]): Keypoint offsets for each level.
+ kpt_vis (List[Tensor]): Keypoint visibilities for each level.
+ """
+
+ cls_scores, bbox_preds, objectnesses = [], [], []
+ kpt_offsets, kpt_vis = [], []
+
+ for i in range(len(x)):
+
+ cls_feat = self.conv_cls[i](x[i])
+ reg_feat = self.conv_reg[i](x[i])
+ pose_feat = self.conv_pose[i](x[i])
+
+ cls_scores.append(self.out_cls[i](cls_feat))
+ objectnesses.append(self.out_obj[i](reg_feat))
+ bbox_preds.append(self.out_bbox[i](reg_feat))
+ kpt_offsets.append(self.out_kpt[i](pose_feat))
+ kpt_vis.append(self.out_kpt_vis[i](pose_feat))
+
+ return cls_scores, objectnesses, bbox_preds, kpt_offsets, kpt_vis
+
+
+@MODELS.register_module()
+class YOLOXPoseHead(BaseModule):
+
+ def __init__(
+ self,
+ num_keypoints: int,
+ head_module_cfg: Optional[ConfigType] = None,
+ featmap_strides: Sequence[int] = [8, 16, 32],
+ num_classes: int = 1,
+ use_aux_loss: bool = False,
+ assigner: ConfigType = None,
+ prior_generator: ConfigType = None,
+ loss_cls: Optional[ConfigType] = None,
+ loss_obj: Optional[ConfigType] = None,
+ loss_bbox: Optional[ConfigType] = None,
+ loss_oks: Optional[ConfigType] = None,
+ loss_vis: Optional[ConfigType] = None,
+ loss_bbox_aux: Optional[ConfigType] = None,
+ loss_kpt_aux: Optional[ConfigType] = None,
+ overlaps_power: float = 1.0,
+ ):
+ super().__init__()
+
+ self.featmap_sizes = None
+ self.num_classes = num_classes
+ self.featmap_strides = featmap_strides
+ self.use_aux_loss = use_aux_loss
+ self.num_keypoints = num_keypoints
+ self.overlaps_power = overlaps_power
+
+ self.prior_generator = TASK_UTILS.build(prior_generator)
+ if head_module_cfg is not None:
+ head_module_cfg['featmap_strides'] = featmap_strides
+ head_module_cfg['num_keypoints'] = num_keypoints
+ self.head_module = YOLOXPoseHeadModule(**head_module_cfg)
+ self.assigner = TASK_UTILS.build(assigner)
+
+ # build losses
+ self.loss_cls = MODELS.build(loss_cls)
+ self.loss_obj = MODELS.build(loss_obj)
+ self.loss_bbox = MODELS.build(loss_bbox)
+ self.loss_oks = MODELS.build(loss_oks)
+ self.loss_vis = MODELS.build(loss_vis)
+ if loss_bbox_aux is not None:
+ self.loss_bbox_aux = MODELS.build(loss_bbox_aux)
+ if loss_kpt_aux is not None:
+ self.loss_kpt_aux = MODELS.build(loss_kpt_aux)
+
+ def forward(self, feats: Features):
+ assert isinstance(feats, (tuple, list))
+ return self.head_module(feats)
+
+ def loss(self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ train_cfg: ConfigType = {}) -> dict:
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ feats (Tuple[Tensor]): The multi-stage features
+ batch_data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples
+ train_cfg (dict): The runtime config for training process.
+ Defaults to {}
+
+ Returns:
+ dict: A dictionary of losses.
+ """
+
+ # 1. collect & reform predictions
+ cls_scores, objectnesses, bbox_preds, kpt_offsets, \
+ kpt_vis = self.forward(feats)
+
+ featmap_sizes = [cls_score.shape[2:] for cls_score in cls_scores]
+ mlvl_priors = self.prior_generator.grid_priors(
+ featmap_sizes,
+ dtype=cls_scores[0].dtype,
+ device=cls_scores[0].device,
+ with_stride=True)
+ flatten_priors = torch.cat(mlvl_priors)
+
+ # flatten cls_scores, bbox_preds and objectness
+ flatten_cls_scores = self._flatten_predictions(cls_scores)
+ flatten_bbox_preds = self._flatten_predictions(bbox_preds)
+ flatten_objectness = self._flatten_predictions(objectnesses)
+ flatten_kpt_offsets = self._flatten_predictions(kpt_offsets)
+ flatten_kpt_vis = self._flatten_predictions(kpt_vis)
+ flatten_bbox_decoded = self.decode_bbox(flatten_bbox_preds,
+ flatten_priors[..., :2],
+ flatten_priors[..., -1])
+ flatten_kpt_decoded = self.decode_kpt_reg(flatten_kpt_offsets,
+ flatten_priors[..., :2],
+ flatten_priors[..., -1])
+
+ # 2. generate targets
+ targets = self._get_targets(flatten_priors,
+ flatten_cls_scores.detach(),
+ flatten_objectness.detach(),
+ flatten_bbox_decoded.detach(),
+ flatten_kpt_decoded.detach(),
+ flatten_kpt_vis.detach(),
+ batch_data_samples)
+ pos_masks, cls_targets, obj_targets, obj_weights, \
+ bbox_targets, bbox_aux_targets, kpt_targets, kpt_aux_targets, \
+ vis_targets, vis_weights, pos_areas, pos_priors, group_indices, \
+ num_fg_imgs = targets
+
+ num_pos = torch.tensor(
+ sum(num_fg_imgs),
+ dtype=torch.float,
+ device=flatten_cls_scores.device)
+ num_total_samples = max(reduce_mean(num_pos), 1.0)
+
+ # 3. calculate loss
+ # 3.1 objectness loss
+ losses = dict()
+
+ obj_preds = flatten_objectness.view(-1, 1)
+ losses['loss_obj'] = self.loss_obj(obj_preds, obj_targets,
+ obj_weights) / num_total_samples
+
+ if num_pos > 0:
+ # 3.2 bbox loss
+ bbox_preds = flatten_bbox_decoded.view(-1, 4)[pos_masks]
+ losses['loss_bbox'] = self.loss_bbox(
+ bbox_preds, bbox_targets) / num_total_samples
+
+ # 3.3 keypoint loss
+ kpt_preds = flatten_kpt_decoded.view(-1, self.num_keypoints,
+ 2)[pos_masks]
+ losses['loss_kpt'] = self.loss_oks(kpt_preds, kpt_targets,
+ vis_targets, pos_areas)
+
+ # 3.4 keypoint visibility loss
+ kpt_vis_preds = flatten_kpt_vis.view(-1,
+ self.num_keypoints)[pos_masks]
+ losses['loss_vis'] = self.loss_vis(kpt_vis_preds, vis_targets,
+ vis_weights)
+
+ # 3.5 classification loss
+ cls_preds = flatten_cls_scores.view(-1,
+ self.num_classes)[pos_masks]
+ cls_targets = cls_targets.pow(self.overlaps_power).detach()
+ losses['loss_cls'] = self.loss_cls(cls_preds,
+ cls_targets) / num_total_samples
+
+ if self.use_aux_loss:
+ if hasattr(self, 'loss_bbox_aux'):
+ # 3.6 auxiliary bbox regression loss
+ bbox_preds_raw = flatten_bbox_preds.view(-1, 4)[pos_masks]
+ losses['loss_bbox_aux'] = self.loss_bbox_aux(
+ bbox_preds_raw, bbox_aux_targets) / num_total_samples
+
+ if hasattr(self, 'loss_kpt_aux'):
+ # 3.7 auxiliary keypoint regression loss
+ kpt_preds_raw = flatten_kpt_offsets.view(
+ -1, self.num_keypoints, 2)[pos_masks]
+ kpt_weights = vis_targets / vis_targets.size(-1)
+ losses['loss_kpt_aux'] = self.loss_kpt_aux(
+ kpt_preds_raw, kpt_aux_targets, kpt_weights)
+
+ return losses
+
+ @torch.no_grad()
+ def _get_targets(
+ self,
+ priors: Tensor,
+ batch_cls_scores: Tensor,
+ batch_objectness: Tensor,
+ batch_decoded_bboxes: Tensor,
+ batch_decoded_kpts: Tensor,
+ batch_kpt_vis: Tensor,
+ batch_data_samples: SampleList,
+ ):
+ num_imgs = len(batch_data_samples)
+
+ # use clip to avoid nan
+ batch_cls_scores = batch_cls_scores.clip(min=-1e4, max=1e4).sigmoid()
+ batch_objectness = batch_objectness.clip(min=-1e4, max=1e4).sigmoid()
+ batch_kpt_vis = batch_kpt_vis.clip(min=-1e4, max=1e4).sigmoid()
+ batch_cls_scores[torch.isnan(batch_cls_scores)] = 0
+ batch_objectness[torch.isnan(batch_objectness)] = 0
+
+ targets_each = []
+ for i in range(num_imgs):
+ target = self._get_targets_single(priors, batch_cls_scores[i],
+ batch_objectness[i],
+ batch_decoded_bboxes[i],
+ batch_decoded_kpts[i],
+ batch_kpt_vis[i],
+ batch_data_samples[i])
+ targets_each.append(target)
+
+ targets = list(zip(*targets_each))
+ for i, target in enumerate(targets):
+ if torch.is_tensor(target[0]):
+ target = tuple(filter(lambda x: x.size(0) > 0, target))
+ targets[i] = torch.cat(target)
+
+ foreground_masks, cls_targets, obj_targets, obj_weights, \
+ bbox_targets, kpt_targets, vis_targets, vis_weights, pos_areas, \
+ pos_priors, group_indices, num_pos_per_img = targets
+
+ # post-processing for targets
+ if self.use_aux_loss:
+ bbox_cxcy = (bbox_targets[:, :2] + bbox_targets[:, 2:]) / 2.0
+ bbox_wh = bbox_targets[:, 2:] - bbox_targets[:, :2]
+ bbox_aux_targets = torch.cat([
+ (bbox_cxcy - pos_priors[:, :2]) / pos_priors[:, 2:],
+ torch.log(bbox_wh / pos_priors[:, 2:] + 1e-8)
+ ],
+ dim=-1)
+
+ kpt_aux_targets = (kpt_targets - pos_priors[:, None, :2]) \
+ / pos_priors[:, None, 2:]
+ else:
+ bbox_aux_targets, kpt_aux_targets = None, None
+
+ return (foreground_masks, cls_targets, obj_targets, obj_weights,
+ bbox_targets, bbox_aux_targets, kpt_targets, kpt_aux_targets,
+ vis_targets, vis_weights, pos_areas, pos_priors, group_indices,
+ num_pos_per_img)
+
+ @torch.no_grad()
+ def _get_targets_single(
+ self,
+ priors: Tensor,
+ cls_scores: Tensor,
+ objectness: Tensor,
+ decoded_bboxes: Tensor,
+ decoded_kpts: Tensor,
+ kpt_vis: Tensor,
+ data_sample: PoseDataSample,
+ ) -> tuple:
+ """Compute classification, bbox, keypoints and objectness targets for
+ priors in a single image.
+
+ Args:
+ priors (Tensor): All priors of one image, a 2D-Tensor with shape
+ [num_priors, 4] in [cx, xy, stride_w, stride_y] format.
+ cls_scores (Tensor): Classification predictions of one image,
+ a 2D-Tensor with shape [num_priors, num_classes]
+ objectness (Tensor): Objectness predictions of one image,
+ a 1D-Tensor with shape [num_priors]
+ decoded_bboxes (Tensor): Decoded bboxes predictions of one image,
+ a 2D-Tensor with shape [num_priors, 4] in xyxy format.
+ decoded_kpts (Tensor): Decoded keypoints predictions of one image,
+ a 3D-Tensor with shape [num_priors, num_keypoints, 2].
+ kpt_vis (Tensor): Keypoints visibility predictions of one image,
+ a 2D-Tensor with shape [num_priors, num_keypoints].
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ data_sample (PoseDataSample): Data sample that contains the ground
+ truth annotations for current image.
+
+ Returns:
+ # TODO: modify the description of returned values
+ tuple:
+ foreground_mask (list[Tensor]): Binary mask of foreground
+ targets.
+ cls_target (list[Tensor]): Classification targets of an image.
+ obj_target (list[Tensor]): Objectness targets of an image.
+ bbox_target (list[Tensor]): BBox targets of an image.
+ bbox_aux_target (int): BBox aux targets of an image.
+ num_pos_per_img (int): Number of positive samples in an image.
+ """
+ # TODO: change the shape of objectness to [num_priors]
+ num_priors = priors.size(0)
+ gt_instances = data_sample.gt_instance_labels
+ num_gts = len(gt_instances)
+
+ # No target
+ if num_gts == 0:
+ cls_target = cls_scores.new_zeros((0, self.num_classes))
+ bbox_target = cls_scores.new_zeros((0, 4))
+ obj_target = cls_scores.new_zeros((num_priors, 1))
+ obj_weight = cls_scores.new_ones((num_priors, 1))
+ kpt_target = cls_scores.new_zeros((0, self.num_keypoints, 2))
+ vis_target = cls_scores.new_zeros((0, self.num_keypoints))
+ vis_weight = cls_scores.new_zeros((0, self.num_keypoints))
+ pos_areas = cls_scores.new_zeros((0, ))
+ pos_priors = priors[:0]
+ foreground_mask = cls_scores.new_zeros(num_priors).bool()
+ return (foreground_mask, cls_target, obj_target, obj_weight,
+ bbox_target, kpt_target, vis_target, vis_weight, pos_areas,
+ pos_priors, [], 0)
+
+ # assign positive samples
+ scores = cls_scores * objectness
+ pred_instances = InstanceData(
+ bboxes=decoded_bboxes,
+ scores=scores.sqrt_(),
+ priors=priors,
+ keypoints=decoded_kpts,
+ keypoints_visible=kpt_vis,
+ )
+ assign_result = self.assigner.assign(
+ pred_instances=pred_instances, gt_instances=gt_instances)
+
+ # sampling
+ pos_inds = torch.nonzero(
+ assign_result['gt_inds'] > 0, as_tuple=False).squeeze(-1).unique()
+ num_pos_per_img = pos_inds.size(0)
+ pos_gt_labels = assign_result['labels'][pos_inds]
+ pos_assigned_gt_inds = assign_result['gt_inds'][pos_inds] - 1
+
+ # bbox target
+ bbox_target = gt_instances.bboxes[pos_assigned_gt_inds.long()]
+
+ # cls target
+ max_overlaps = assign_result['max_overlaps'][pos_inds]
+ cls_target = F.one_hot(pos_gt_labels,
+ self.num_classes) * max_overlaps.unsqueeze(-1)
+
+ # pose targets
+ kpt_target = gt_instances.keypoints[pos_assigned_gt_inds]
+ vis_target = gt_instances.keypoints_visible[pos_assigned_gt_inds]
+ if 'keypoints_visible_weights' in gt_instances:
+ vis_weight = gt_instances.keypoints_visible_weights[
+ pos_assigned_gt_inds]
+ else:
+ vis_weight = vis_target.new_ones(vis_target.shape)
+ pos_areas = gt_instances.areas[pos_assigned_gt_inds]
+
+ # obj target
+ obj_target = torch.zeros_like(objectness)
+ obj_target[pos_inds] = 1
+ obj_weight = obj_target.new_ones(obj_target.shape)
+
+ # misc
+ foreground_mask = torch.zeros_like(objectness.squeeze()).to(torch.bool)
+ foreground_mask[pos_inds] = 1
+ pos_priors = priors[pos_inds]
+ group_index = [
+ torch.where(pos_assigned_gt_inds == num)[0]
+ for num in torch.unique(pos_assigned_gt_inds)
+ ]
+
+ return (foreground_mask, cls_target, obj_target, obj_weight,
+ bbox_target, kpt_target, vis_target, vis_weight, pos_areas,
+ pos_priors, group_index, num_pos_per_img)
+
+ def predict(self,
+ feats: Features,
+ batch_data_samples: OptSampleList,
+ test_cfg: ConfigType = {}) -> Predictions:
+ """Predict results from features.
+
+ Args:
+ feats (Tuple[Tensor] | List[Tuple[Tensor]]): The multi-stage
+ features (or multiple multi-scale features in TTA)
+ batch_data_samples (List[:obj:`PoseDataSample`]): The batch
+ data samples
+ test_cfg (dict): The runtime config for testing process. Defaults
+ to {}
+
+ Returns:
+ Union[InstanceList | Tuple[InstanceList | PixelDataList]]: If
+ ``test_cfg['output_heatmap']==True``, return both pose and heatmap
+ prediction; otherwise only return the pose prediction.
+
+ The pose prediction is a list of ``InstanceData``, each contains
+ the following fields:
+
+ - keypoints (np.ndarray): predicted keypoint coordinates in
+ shape (num_instances, K, D) where K is the keypoint number
+ and D is the keypoint dimension
+ - keypoint_scores (np.ndarray): predicted keypoint scores in
+ shape (num_instances, K)
+
+ The heatmap prediction is a list of ``PixelData``, each contains
+ the following fields:
+
+ - heatmaps (Tensor): The predicted heatmaps in shape (1, h, w)
+ or (K+1, h, w) if keypoint heatmaps are predicted
+ - displacements (Tensor): The predicted displacement fields
+ in shape (K*2, h, w)
+ """
+
+ cls_scores, objectnesses, bbox_preds, kpt_offsets, \
+ kpt_vis = self.forward(feats)
+
+ cfg = copy.deepcopy(test_cfg)
+
+ batch_img_metas = [d.metainfo for d in batch_data_samples]
+ featmap_sizes = [cls_score.shape[2:] for cls_score in cls_scores]
+
+ # If the shape does not change, use the previous mlvl_priors
+ if featmap_sizes != self.featmap_sizes:
+ self.mlvl_priors = self.prior_generator.grid_priors(
+ featmap_sizes,
+ dtype=cls_scores[0].dtype,
+ device=cls_scores[0].device)
+ self.featmap_sizes = featmap_sizes
+ flatten_priors = torch.cat(self.mlvl_priors)
+
+ mlvl_strides = [
+ flatten_priors.new_full((featmap_size.numel(), ),
+ stride) for featmap_size, stride in zip(
+ featmap_sizes, self.featmap_strides)
+ ]
+ flatten_stride = torch.cat(mlvl_strides)
+
+ # flatten cls_scores, bbox_preds and objectness
+ flatten_cls_scores = self._flatten_predictions(cls_scores).sigmoid()
+ flatten_bbox_preds = self._flatten_predictions(bbox_preds)
+ flatten_objectness = self._flatten_predictions(objectnesses).sigmoid()
+ flatten_kpt_offsets = self._flatten_predictions(kpt_offsets)
+ flatten_kpt_vis = self._flatten_predictions(kpt_vis).sigmoid()
+ flatten_bbox_preds = self.decode_bbox(flatten_bbox_preds,
+ flatten_priors, flatten_stride)
+ flatten_kpt_reg = self.decode_kpt_reg(flatten_kpt_offsets,
+ flatten_priors, flatten_stride)
+
+ results_list = []
+ for (bboxes, scores, objectness, kpt_reg, kpt_vis,
+ img_meta) in zip(flatten_bbox_preds, flatten_cls_scores,
+ flatten_objectness, flatten_kpt_reg,
+ flatten_kpt_vis, batch_img_metas):
+
+ score_thr = cfg.get('score_thr', 0.01)
+ scores *= objectness
+
+ nms_pre = cfg.get('nms_pre', 100000)
+ scores, labels = scores.max(1, keepdim=True)
+ scores, _, keep_idxs_score, results = filter_scores_and_topk(
+ scores, score_thr, nms_pre, results=dict(labels=labels[:, 0]))
+ labels = results['labels']
+
+ bboxes = bboxes[keep_idxs_score]
+ kpt_vis = kpt_vis[keep_idxs_score]
+ stride = flatten_stride[keep_idxs_score]
+ keypoints = kpt_reg[keep_idxs_score]
+
+ if bboxes.numel() > 0:
+ nms_thr = cfg.get('nms_thr', 1.0)
+ if nms_thr < 1.0:
+ keep_idxs_nms = nms_torch(bboxes, scores, nms_thr)
+ bboxes = bboxes[keep_idxs_nms]
+ stride = stride[keep_idxs_nms]
+ labels = labels[keep_idxs_nms]
+ kpt_vis = kpt_vis[keep_idxs_nms]
+ keypoints = keypoints[keep_idxs_nms]
+ scores = scores[keep_idxs_nms]
+
+ results = InstanceData(
+ scores=scores,
+ labels=labels,
+ bboxes=bboxes,
+ bbox_scores=scores,
+ keypoints=keypoints,
+ keypoint_scores=kpt_vis,
+ keypoints_visible=kpt_vis)
+
+ input_size = img_meta['input_size']
+ results.bboxes[:, 0::2].clamp_(0, input_size[0])
+ results.bboxes[:, 1::2].clamp_(0, input_size[1])
+
+ results_list.append(results.numpy())
+
+ return results_list
+
+ def decode_bbox(self, pred_bboxes: torch.Tensor, priors: torch.Tensor,
+ stride: Union[torch.Tensor, int]) -> torch.Tensor:
+ """Decode regression results (delta_x, delta_y, log_w, log_h) to
+ bounding boxes (tl_x, tl_y, br_x, br_y).
+
+ Note:
+ - batch size: B
+ - token number: N
+
+ Args:
+ pred_bboxes (torch.Tensor): Encoded boxes with shape (B, N, 4),
+ representing (delta_x, delta_y, log_w, log_h) for each box.
+ priors (torch.Tensor): Anchors coordinates, with shape (N, 2).
+ stride (torch.Tensor | int): Strides of the bboxes. It can be a
+ single value if the same stride applies to all boxes, or it
+ can be a tensor of shape (N, ) if different strides are used
+ for each box.
+
+ Returns:
+ torch.Tensor: Decoded bounding boxes with shape (N, 4),
+ representing (tl_x, tl_y, br_x, br_y) for each box.
+ """
+ stride = stride.view(1, stride.size(0), 1)
+ priors = priors.view(1, priors.size(0), 2)
+
+ xys = (pred_bboxes[..., :2] * stride) + priors
+ whs = pred_bboxes[..., 2:].exp() * stride
+
+ # Calculate bounding box corners
+ tl_x = xys[..., 0] - whs[..., 0] / 2
+ tl_y = xys[..., 1] - whs[..., 1] / 2
+ br_x = xys[..., 0] + whs[..., 0] / 2
+ br_y = xys[..., 1] + whs[..., 1] / 2
+
+ decoded_bboxes = torch.stack([tl_x, tl_y, br_x, br_y], -1)
+ return decoded_bboxes
+
+ def decode_kpt_reg(self, pred_kpt_offsets: torch.Tensor,
+ priors: torch.Tensor,
+ stride: torch.Tensor) -> torch.Tensor:
+ """Decode regression results (delta_x, delta_y) to keypoints
+ coordinates (x, y).
+
+ Args:
+ pred_kpt_offsets (torch.Tensor): Encoded keypoints offsets with
+ shape (batch_size, num_anchors, num_keypoints, 2).
+ priors (torch.Tensor): Anchors coordinates with shape
+ (num_anchors, 2).
+ stride (torch.Tensor): Strides of the anchors.
+
+ Returns:
+ torch.Tensor: Decoded keypoints coordinates with shape
+ (batch_size, num_boxes, num_keypoints, 2).
+ """
+ stride = stride.view(1, stride.size(0), 1, 1)
+ priors = priors.view(1, priors.size(0), 1, 2)
+ pred_kpt_offsets = pred_kpt_offsets.reshape(
+ *pred_kpt_offsets.shape[:-1], self.num_keypoints, 2)
+
+ decoded_kpts = pred_kpt_offsets * stride + priors
+ return decoded_kpts
+
+ def _flatten_predictions(self, preds: List[Tensor]):
+ """Flattens the predictions from a list of tensors to a single
+ tensor."""
+ preds = [x.permute(0, 2, 3, 1).flatten(1, 2) for x in preds]
+ return torch.cat(preds, dim=1)
diff --git a/mmpose/models/heads/regression_heads/__init__.py b/mmpose/models/heads/regression_heads/__init__.py
index ce9cd5e1b0..729d193b51 100644
--- a/mmpose/models/heads/regression_heads/__init__.py
+++ b/mmpose/models/heads/regression_heads/__init__.py
@@ -1,16 +1,14 @@
# Copyright (c) OpenMMLab. All rights reserved.
from .dsnt_head import DSNTHead
from .integral_regression_head import IntegralRegressionHead
+from .motion_regression_head import MotionRegressionHead
from .regression_head import RegressionHead
from .rle_head import RLEHead
from .temporal_regression_head import TemporalRegressionHead
from .trajectory_regression_head import TrajectoryRegressionHead
__all__ = [
- 'RegressionHead',
- 'IntegralRegressionHead',
- 'DSNTHead',
- 'RLEHead',
- 'TemporalRegressionHead',
- 'TrajectoryRegressionHead',
+ 'RegressionHead', 'IntegralRegressionHead', 'DSNTHead', 'RLEHead',
+ 'TemporalRegressionHead', 'TrajectoryRegressionHead',
+ 'MotionRegressionHead'
]
diff --git a/mmpose/models/heads/regression_heads/motion_regression_head.py b/mmpose/models/heads/regression_heads/motion_regression_head.py
new file mode 100644
index 0000000000..2ad9497345
--- /dev/null
+++ b/mmpose/models/heads/regression_heads/motion_regression_head.py
@@ -0,0 +1,194 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from collections import OrderedDict
+from typing import Tuple
+
+import numpy as np
+import torch
+from torch import Tensor, nn
+
+from mmpose.evaluation.functional import keypoint_mpjpe
+from mmpose.models.utils.tta import flip_coordinates
+from mmpose.registry import KEYPOINT_CODECS, MODELS
+from mmpose.utils.tensor_utils import to_numpy
+from mmpose.utils.typing import (ConfigType, OptConfigType, OptSampleList,
+ Predictions)
+from ..base_head import BaseHead
+
+
+@MODELS.register_module()
+class MotionRegressionHead(BaseHead):
+ """Regression head of `MotionBERT`_ by Zhu et al (2022).
+
+ Args:
+ in_channels (int): Number of input channels. Default: 256.
+ out_channels (int): Number of output channels. Default: 3.
+ embedding_size (int): Number of embedding channels. Default: 512.
+ loss (Config): Config for keypoint loss. Defaults to use
+ :class:`MSELoss`
+ decoder (Config, optional): The decoder config that controls decoding
+ keypoint coordinates from the network output. Defaults to ``None``
+ init_cfg (Config, optional): Config to control the initialization. See
+ :attr:`default_init_cfg` for default settings
+
+ .. _`MotionBERT`: https://arxiv.org/abs/2210.06551
+ """
+
+ _version = 2
+
+ def __init__(self,
+ in_channels: int = 256,
+ out_channels: int = 3,
+ embedding_size: int = 512,
+ loss: ConfigType = dict(
+ type='MSELoss', use_target_weight=True),
+ decoder: OptConfigType = None,
+ init_cfg: OptConfigType = None):
+
+ if init_cfg is None:
+ init_cfg = self.default_init_cfg
+
+ super().__init__(init_cfg)
+
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.loss_module = MODELS.build(loss)
+ if decoder is not None:
+ self.decoder = KEYPOINT_CODECS.build(decoder)
+ else:
+ self.decoder = None
+
+ # Define fully-connected layers
+ self.pre_logits = nn.Sequential(
+ OrderedDict([('fc', nn.Linear(in_channels, embedding_size)),
+ ('act', nn.Tanh())]))
+ self.fc = nn.Linear(
+ embedding_size,
+ out_channels) if embedding_size > 0 else nn.Identity()
+
+ def forward(self, feats: Tuple[Tensor]) -> Tensor:
+ """Forward the network. The input is multi scale feature maps and the
+ output is the coordinates.
+
+ Args:
+ feats (Tuple[Tensor]): Multi scale feature maps.
+
+ Returns:
+ Tensor: Output coordinates (and sigmas[optional]).
+ """
+ x = feats # (B, F, K, in_channels)
+ x = self.pre_logits(x) # (B, F, K, embedding_size)
+ x = self.fc(x) # (B, F, K, out_channels)
+
+ return x
+
+ def predict(self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ test_cfg: ConfigType = {}) -> Predictions:
+ """Predict results from outputs.
+
+ Returns:
+ preds (sequence[InstanceData]): Prediction results.
+ Each contains the following fields:
+
+ - keypoints: Predicted keypoints of shape (B, N, K, D).
+ - keypoint_scores: Scores of predicted keypoints of shape
+ (B, N, K).
+ """
+
+ if test_cfg.get('flip_test', False):
+ # TTA: flip test -> feats = [orig, flipped]
+ assert isinstance(feats, list) and len(feats) == 2
+ flip_indices = batch_data_samples[0].metainfo['flip_indices']
+ _feats, _feats_flip = feats
+ _batch_coords = self.forward(_feats)
+ _batch_coords_flip = torch.stack([
+ flip_coordinates(
+ _batch_coord_flip,
+ flip_indices=flip_indices,
+ shift_coords=test_cfg.get('shift_coords', True),
+ input_size=(1, 1))
+ for _batch_coord_flip in self.forward(_feats_flip)
+ ],
+ dim=0)
+ batch_coords = (_batch_coords + _batch_coords_flip) * 0.5
+ else:
+ batch_coords = self.forward(feats)
+
+ # Restore global position with camera_param and factor
+ camera_param = batch_data_samples[0].metainfo.get('camera_param', None)
+ if camera_param is not None:
+ w = torch.stack([
+ torch.from_numpy(np.array([b.metainfo['camera_param']['w']]))
+ for b in batch_data_samples
+ ])
+ h = torch.stack([
+ torch.from_numpy(np.array([b.metainfo['camera_param']['h']]))
+ for b in batch_data_samples
+ ])
+ else:
+ w = torch.stack([
+ torch.empty((0), dtype=torch.float32)
+ for _ in batch_data_samples
+ ])
+ h = torch.stack([
+ torch.empty((0), dtype=torch.float32)
+ for _ in batch_data_samples
+ ])
+
+ factor = batch_data_samples[0].metainfo.get('factor', None)
+ if factor is not None:
+ factor = torch.stack([
+ torch.from_numpy(b.metainfo['factor'])
+ for b in batch_data_samples
+ ])
+ else:
+ factor = torch.stack([
+ torch.empty((0), dtype=torch.float32)
+ for _ in batch_data_samples
+ ])
+
+ preds = self.decode((batch_coords, w, h, factor))
+
+ return preds
+
+ def loss(self,
+ inputs: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ train_cfg: ConfigType = {}) -> dict:
+ """Calculate losses from a batch of inputs and data samples."""
+
+ pred_outputs = self.forward(inputs)
+
+ lifting_target_label = torch.stack([
+ d.gt_instance_labels.lifting_target_label
+ for d in batch_data_samples
+ ])
+ lifting_target_weight = torch.stack([
+ d.gt_instance_labels.lifting_target_weight
+ for d in batch_data_samples
+ ])
+
+ # calculate losses
+ losses = dict()
+ loss = self.loss_module(pred_outputs, lifting_target_label,
+ lifting_target_weight.unsqueeze(-1))
+
+ losses.update(loss_pose3d=loss)
+
+ # calculate accuracy
+ mpjpe_err = keypoint_mpjpe(
+ pred=to_numpy(pred_outputs),
+ gt=to_numpy(lifting_target_label),
+ mask=to_numpy(lifting_target_weight) > 0)
+
+ mpjpe_pose = torch.tensor(
+ mpjpe_err, device=lifting_target_label.device)
+ losses.update(mpjpe=mpjpe_pose)
+
+ return losses
+
+ @property
+ def default_init_cfg(self):
+ init_cfg = [dict(type='TruncNormal', layer=['Linear'], std=0.02)]
+ return init_cfg
diff --git a/mmpose/models/heads/regression_heads/rle_head.py b/mmpose/models/heads/regression_heads/rle_head.py
index ef62d7d9ac..ef696dffa6 100644
--- a/mmpose/models/heads/regression_heads/rle_head.py
+++ b/mmpose/models/heads/regression_heads/rle_head.py
@@ -155,8 +155,8 @@ def loss(self,
def _load_state_dict_pre_hook(self, state_dict, prefix, local_meta, *args,
**kwargs):
"""A hook function to convert old-version state dict of
- :class:`TopdownHeatmapSimpleHead` (before MMPose v1.0.0) to a
- compatible format of :class:`HeatmapHead`.
+ :class:`DeepposeRegressionHead` (before MMPose v1.0.0) to a
+ compatible format of :class:`RegressionHead`.
The hook will be automatically registered during initialization.
"""
diff --git a/mmpose/models/heads/regression_heads/temporal_regression_head.py b/mmpose/models/heads/regression_heads/temporal_regression_head.py
index ac76316842..61e585103f 100644
--- a/mmpose/models/heads/regression_heads/temporal_regression_head.py
+++ b/mmpose/models/heads/regression_heads/temporal_regression_head.py
@@ -101,7 +101,7 @@ def predict(self,
else:
target_root = torch.stack([
torch.empty((0), dtype=torch.float32)
- for _ in batch_data_samples[0].metainfo
+ for _ in batch_data_samples
])
preds = self.decode((batch_coords, target_root))
@@ -120,15 +120,15 @@ def loss(self,
d.gt_instance_labels.lifting_target_label
for d in batch_data_samples
])
- lifting_target_weights = torch.cat([
- d.gt_instance_labels.lifting_target_weights
+ lifting_target_weight = torch.cat([
+ d.gt_instance_labels.lifting_target_weight
for d in batch_data_samples
])
# calculate losses
losses = dict()
loss = self.loss_module(pred_outputs, lifting_target_label,
- lifting_target_weights.unsqueeze(-1))
+ lifting_target_weight.unsqueeze(-1))
losses.update(loss_pose3d=loss)
@@ -136,7 +136,7 @@ def loss(self,
_, avg_acc, _ = keypoint_pck_accuracy(
pred=to_numpy(pred_outputs),
gt=to_numpy(lifting_target_label),
- mask=to_numpy(lifting_target_weights) > 0,
+ mask=to_numpy(lifting_target_weight) > 0,
thr=0.05,
norm_factor=np.ones((pred_outputs.size(0), 3), dtype=np.float32))
diff --git a/mmpose/models/heads/regression_heads/trajectory_regression_head.py b/mmpose/models/heads/regression_heads/trajectory_regression_head.py
index adfd7353d3..a1608aaae7 100644
--- a/mmpose/models/heads/regression_heads/trajectory_regression_head.py
+++ b/mmpose/models/heads/regression_heads/trajectory_regression_head.py
@@ -101,7 +101,7 @@ def predict(self,
else:
target_root = torch.stack([
torch.empty((0), dtype=torch.float32)
- for _ in batch_data_samples[0].metainfo
+ for _ in batch_data_samples
])
preds = self.decode((batch_coords, target_root))
diff --git a/mmpose/models/heads/transformer_heads/__init__.py b/mmpose/models/heads/transformer_heads/__init__.py
new file mode 100644
index 0000000000..bb16484ff8
--- /dev/null
+++ b/mmpose/models/heads/transformer_heads/__init__.py
@@ -0,0 +1,17 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .edpose_head import EDPoseHead
+from .transformers import (FFN, DeformableDetrTransformerDecoder,
+ DeformableDetrTransformerDecoderLayer,
+ DeformableDetrTransformerEncoder,
+ DeformableDetrTransformerEncoderLayer,
+ DetrTransformerDecoder, DetrTransformerDecoderLayer,
+ DetrTransformerEncoder, DetrTransformerEncoderLayer,
+ PositionEmbeddingSineHW)
+
+__all__ = [
+ 'EDPoseHead', 'DetrTransformerEncoder', 'DetrTransformerDecoder',
+ 'DetrTransformerEncoderLayer', 'DetrTransformerDecoderLayer',
+ 'DeformableDetrTransformerEncoder', 'DeformableDetrTransformerDecoder',
+ 'DeformableDetrTransformerEncoderLayer',
+ 'DeformableDetrTransformerDecoderLayer', 'PositionEmbeddingSineHW', 'FFN'
+]
diff --git a/mmpose/models/heads/transformer_heads/base_transformer_head.py b/mmpose/models/heads/transformer_heads/base_transformer_head.py
new file mode 100644
index 0000000000..96855e186d
--- /dev/null
+++ b/mmpose/models/heads/transformer_heads/base_transformer_head.py
@@ -0,0 +1,136 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import abstractmethod
+from typing import Dict, Tuple
+
+import torch
+from torch import Tensor
+
+from mmpose.registry import MODELS
+from mmpose.utils.typing import (Features, OptConfigType, OptMultiConfig,
+ OptSampleList, Predictions)
+from ..base_head import BaseHead
+
+
+@MODELS.register_module()
+class TransformerHead(BaseHead):
+ r"""Implementation of `Deformable DETR: Deformable Transformers for
+ End-to-End Object Detection `_
+
+ Code is modified from the `official github repo
+ `_.
+
+ Args:
+ encoder (ConfigDict, optional): Config of the
+ Transformer encoder. Defaults to None.
+ decoder (ConfigDict, optional): Config of the
+ Transformer decoder. Defaults to None.
+ out_head (ConfigDict, optional): Config for the
+ bounding final out head module. Defaults to None.
+ positional_encoding (ConfigDict, optional): Config for
+ transformer position encoding. Defaults to None.
+ num_queries (int): Number of query in Transformer.
+ loss (ConfigDict, optional): Config for loss functions.
+ Defaults to None.
+ init_cfg (ConfigDict, optional): Config to control the initialization.
+ """
+
+ def __init__(self,
+ encoder: OptConfigType = None,
+ decoder: OptConfigType = None,
+ out_head: OptConfigType = None,
+ positional_encoding: OptConfigType = None,
+ num_queries: int = 100,
+ loss: OptConfigType = None,
+ init_cfg: OptMultiConfig = None):
+
+ if init_cfg is None:
+ init_cfg = self.default_init_cfg
+
+ super().__init__(init_cfg)
+
+ self.encoder_cfg = encoder
+ self.decoder_cfg = decoder
+ self.out_head_cfg = out_head
+ self.positional_encoding_cfg = positional_encoding
+ self.num_queries = num_queries
+
+ def forward(self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList = None) -> Dict:
+ """Forward the network."""
+ encoder_outputs_dict = self.forward_encoder(feats, batch_data_samples)
+
+ decoder_outputs_dict = self.forward_decoder(**encoder_outputs_dict)
+
+ head_outputs_dict = self.forward_out_head(batch_data_samples,
+ **decoder_outputs_dict)
+ return head_outputs_dict
+
+ @abstractmethod
+ def predict(self,
+ feats: Features,
+ batch_data_samples: OptSampleList,
+ test_cfg: OptConfigType = {}) -> Predictions:
+ """Predict results from features."""
+ pass
+
+ def loss(self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ train_cfg: OptConfigType = {}) -> dict:
+ """Calculate losses from a batch of inputs and data samples."""
+ pass
+
+ @abstractmethod
+ def forward_encoder(self, feat: Tensor, feat_mask: Tensor,
+ feat_pos: Tensor, **kwargs) -> Dict:
+ pass
+
+ @abstractmethod
+ def forward_decoder(self, query: Tensor, query_pos: Tensor, memory: Tensor,
+ **kwargs) -> Dict:
+ pass
+
+ @abstractmethod
+ def forward_out_head(self, query: Tensor, query_pos: Tensor,
+ memory: Tensor, **kwargs) -> Dict:
+ pass
+
+ @staticmethod
+ def get_valid_ratio(mask: Tensor) -> Tensor:
+ """Get the valid radios of feature map in a level.
+
+ .. code:: text
+
+ |---> valid_W <---|
+ ---+-----------------+-----+---
+ A | | | A
+ | | | | |
+ | | | | |
+ valid_H | | | |
+ | | | | H
+ | | | | |
+ V | | | |
+ ---+-----------------+ | |
+ | | V
+ +-----------------------+---
+ |---------> W <---------|
+
+ The valid_ratios are defined as:
+ r_h = valid_H / H, r_w = valid_W / W
+ They are the factors to re-normalize the relative coordinates of the
+ image to the relative coordinates of the current level feature map.
+
+ Args:
+ mask (Tensor): Binary mask of a feature map, has shape (bs, H, W).
+
+ Returns:
+ Tensor: valid ratios [r_w, r_h] of a feature map, has shape (1, 2).
+ """
+ _, H, W = mask.shape
+ valid_H = torch.sum(~mask[:, :, 0], 1)
+ valid_W = torch.sum(~mask[:, 0, :], 1)
+ valid_ratio_h = valid_H.float() / H
+ valid_ratio_w = valid_W.float() / W
+ valid_ratio = torch.stack([valid_ratio_w, valid_ratio_h], -1)
+ return valid_ratio
diff --git a/mmpose/models/heads/transformer_heads/edpose_head.py b/mmpose/models/heads/transformer_heads/edpose_head.py
new file mode 100644
index 0000000000..d864f8fadd
--- /dev/null
+++ b/mmpose/models/heads/transformer_heads/edpose_head.py
@@ -0,0 +1,1346 @@
+# ----------------------------------------------------------------------------
+# Adapted from https://github.com/IDEA-Research/ED-Pose/ \
+# tree/master/models/edpose
+# Original licence: IDEA License 1.0
+# ----------------------------------------------------------------------------
+
+import copy
+import math
+from typing import Dict, List, Tuple
+
+import numpy as np
+import torch
+import torch.nn.functional as F
+from mmcv.ops import MultiScaleDeformableAttention
+from mmengine.model import BaseModule, ModuleList, constant_init
+from mmengine.structures import InstanceData
+from torch import Tensor, nn
+
+from mmpose.models.utils import inverse_sigmoid
+from mmpose.registry import KEYPOINT_CODECS, MODELS
+from mmpose.utils.tensor_utils import to_numpy
+from mmpose.utils.typing import (ConfigType, Features, OptConfigType,
+ OptSampleList, Predictions)
+from .base_transformer_head import TransformerHead
+from .transformers.deformable_detr_layers import (
+ DeformableDetrTransformerDecoderLayer, DeformableDetrTransformerEncoder)
+from .transformers.utils import FFN, PositionEmbeddingSineHW
+
+
+class EDPoseDecoder(BaseModule):
+ """Transformer decoder of EDPose: `Explicit Box Detection Unifies End-to-
+ End Multi-Person Pose Estimation.
+
+ Args:
+ layer_cfg (ConfigDict): the config of each encoder
+ layer. All the layers will share the same config.
+ num_layers (int): Number of decoder layers.
+ return_intermediate (bool, optional): Whether to return outputs of
+ intermediate layers. Defaults to `True`.
+ embed_dims (int): Dims of embed.
+ query_dim (int): Dims of queries.
+ num_feature_levels (int): Number of feature levels.
+ num_box_decoder_layers (int): Number of box decoder layers.
+ num_keypoints (int): Number of datasets' body keypoints.
+ num_dn (int): Number of denosing points.
+ num_group (int): Number of decoder layers.
+ """
+
+ def __init__(self,
+ layer_cfg,
+ num_layers,
+ return_intermediate,
+ embed_dims: int = 256,
+ query_dim=4,
+ num_feature_levels=1,
+ num_box_decoder_layers=2,
+ num_keypoints=17,
+ num_dn=100,
+ num_group=100):
+ super().__init__()
+
+ self.layer_cfg = layer_cfg
+ self.num_layers = num_layers
+ self.embed_dims = embed_dims
+
+ assert return_intermediate, 'support return_intermediate only'
+ self.return_intermediate = return_intermediate
+
+ assert query_dim in [
+ 2, 4
+ ], 'query_dim should be 2/4 but {}'.format(query_dim)
+ self.query_dim = query_dim
+
+ self.num_feature_levels = num_feature_levels
+
+ self.layers = ModuleList([
+ DeformableDetrTransformerDecoderLayer(**self.layer_cfg)
+ for _ in range(self.num_layers)
+ ])
+ self.norm = nn.LayerNorm(self.embed_dims)
+
+ self.ref_point_head = FFN(self.query_dim // 2 * self.embed_dims,
+ self.embed_dims, self.embed_dims, 2)
+
+ self.num_keypoints = num_keypoints
+ self.query_scale = None
+ self.bbox_embed = None
+ self.class_embed = None
+ self.pose_embed = None
+ self.pose_hw_embed = None
+ self.num_box_decoder_layers = num_box_decoder_layers
+ self.box_pred_damping = None
+ self.num_group = num_group
+ self.rm_detach = None
+ self.num_dn = num_dn
+ self.hw = nn.Embedding(self.num_keypoints, 2)
+ self.keypoint_embed = nn.Embedding(self.num_keypoints, embed_dims)
+ self.kpt_index = [
+ x for x in range(self.num_group * (self.num_keypoints + 1))
+ if x % (self.num_keypoints + 1) != 0
+ ]
+
+ def forward(self, query: Tensor, value: Tensor, key_padding_mask: Tensor,
+ reference_points: Tensor, spatial_shapes: Tensor,
+ level_start_index: Tensor, valid_ratios: Tensor,
+ humandet_attn_mask: Tensor, human2pose_attn_mask: Tensor,
+ **kwargs) -> Tuple[Tensor]:
+ """Forward function of decoder
+ Args:
+ query (Tensor): The input queries, has shape (bs, num_queries,
+ dim).
+ value (Tensor): The input values, has shape (bs, num_value, dim).
+ key_padding_mask (Tensor): The `key_padding_mask` of `cross_attn`
+ input. ByteTensor, has shape (bs, num_value).
+ reference_points (Tensor): The initial reference, has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h) when `as_two_stage` is `True`, otherwise has
+ shape (bs, num_queries, 2) with the last dimension arranged
+ as (cx, cy).
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+ level_start_index (Tensor): The start index of each level.
+ A tensor has shape (num_levels, ) and can be represented
+ as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
+ valid_ratios (Tensor): The ratios of the valid width and the valid
+ height relative to the width and the height of features in all
+ levels, has shape (bs, num_levels, 2).
+ reg_branches: (obj:`nn.ModuleList`, optional): Used for refining
+ the regression results.
+
+ Returns:
+ Tuple[Tuple[Tensor]]: Outputs of Deformable Transformer Decoder.
+
+ - output (Tuple[Tensor]): Output embeddings of the last decoder,
+ each has shape (num_decoder_layers, num_queries, bs, embed_dims)
+ - reference_points (Tensor): The reference of the last decoder
+ layer, each has shape (num_decoder_layers, bs, num_queries, 4).
+ The coordinates are arranged as (cx, cy, w, h)
+ """
+ output = query
+ attn_mask = humandet_attn_mask
+ intermediate = []
+ intermediate_reference_points = [reference_points]
+ effect_num_dn = self.num_dn if self.training else 0
+ inter_select_number = self.num_group
+ for layer_id, layer in enumerate(self.layers):
+ if reference_points.shape[-1] == 4:
+ reference_points_input = \
+ reference_points[:, :, None] * \
+ torch.cat([valid_ratios, valid_ratios], -1)[None, :]
+ else:
+ assert reference_points.shape[-1] == 2
+ reference_points_input = \
+ reference_points[:, :, None] * \
+ valid_ratios[None, :]
+
+ query_sine_embed = self.get_proposal_pos_embed(
+ reference_points_input[:, :, 0, :]) # nq, bs, 256*2
+ query_pos = self.ref_point_head(query_sine_embed) # nq, bs, 256
+
+ output = layer(
+ output.transpose(0, 1),
+ query_pos=query_pos.transpose(0, 1),
+ value=value.transpose(0, 1),
+ key_padding_mask=key_padding_mask,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios,
+ reference_points=reference_points_input.transpose(
+ 0, 1).contiguous(),
+ self_attn_mask=attn_mask,
+ **kwargs)
+ output = output.transpose(0, 1)
+ intermediate.append(self.norm(output))
+
+ # human update
+ if layer_id < self.num_box_decoder_layers:
+ delta_unsig = self.bbox_embed[layer_id](output)
+ new_reference_points = delta_unsig + inverse_sigmoid(
+ reference_points)
+ new_reference_points = new_reference_points.sigmoid()
+
+ # query expansion
+ if layer_id == self.num_box_decoder_layers - 1:
+ dn_output = output[:effect_num_dn]
+ dn_new_reference_points = new_reference_points[:effect_num_dn]
+ class_unselected = self.class_embed[layer_id](
+ output)[effect_num_dn:]
+ topk_proposals = torch.topk(
+ class_unselected.max(-1)[0], inter_select_number, dim=0)[1]
+ new_reference_points_for_box = torch.gather(
+ new_reference_points[effect_num_dn:], 0,
+ topk_proposals.unsqueeze(-1).repeat(1, 1, 4))
+ new_output_for_box = torch.gather(
+ output[effect_num_dn:], 0,
+ topk_proposals.unsqueeze(-1).repeat(1, 1, self.embed_dims))
+ bs = new_output_for_box.shape[1]
+ new_output_for_keypoint = new_output_for_box[:, None, :, :] \
+ + self.keypoint_embed.weight[None, :, None, :]
+ if self.num_keypoints == 17:
+ delta_xy = self.pose_embed[-1](new_output_for_keypoint)[
+ ..., :2]
+ else:
+ delta_xy = self.pose_embed[0](new_output_for_keypoint)[
+ ..., :2]
+ keypoint_xy = (inverse_sigmoid(
+ new_reference_points_for_box[..., :2][:, None]) +
+ delta_xy).sigmoid()
+ num_queries, _, bs, _ = keypoint_xy.shape
+ keypoint_wh_weight = self.hw.weight.unsqueeze(0).unsqueeze(
+ -2).repeat(num_queries, 1, bs, 1).sigmoid()
+ keypoint_wh = keypoint_wh_weight * \
+ new_reference_points_for_box[..., 2:][:, None]
+ new_reference_points_for_keypoint = torch.cat(
+ (keypoint_xy, keypoint_wh), dim=-1)
+ new_reference_points = torch.cat(
+ (new_reference_points_for_box.unsqueeze(1),
+ new_reference_points_for_keypoint),
+ dim=1).flatten(0, 1)
+ output = torch.cat(
+ (new_output_for_box.unsqueeze(1), new_output_for_keypoint),
+ dim=1).flatten(0, 1)
+ new_reference_points = torch.cat(
+ (dn_new_reference_points, new_reference_points), dim=0)
+ output = torch.cat((dn_output, output), dim=0)
+ attn_mask = human2pose_attn_mask
+
+ # human-to-keypoints update
+ if layer_id >= self.num_box_decoder_layers:
+ effect_num_dn = self.num_dn if self.training else 0
+ inter_select_number = self.num_group
+ ref_before_sigmoid = inverse_sigmoid(reference_points)
+ output_bbox_dn = output[:effect_num_dn]
+ output_bbox_norm = output[effect_num_dn:][0::(
+ self.num_keypoints + 1)]
+ ref_before_sigmoid_bbox_dn = \
+ ref_before_sigmoid[:effect_num_dn]
+ ref_before_sigmoid_bbox_norm = \
+ ref_before_sigmoid[effect_num_dn:][0::(
+ self.num_keypoints + 1)]
+ delta_unsig_dn = self.bbox_embed[layer_id](output_bbox_dn)
+ delta_unsig_norm = self.bbox_embed[layer_id](output_bbox_norm)
+ outputs_unsig_dn = delta_unsig_dn + ref_before_sigmoid_bbox_dn
+ outputs_unsig_norm = delta_unsig_norm + \
+ ref_before_sigmoid_bbox_norm
+ new_reference_points_for_box_dn = outputs_unsig_dn.sigmoid()
+ new_reference_points_for_box_norm = outputs_unsig_norm.sigmoid(
+ )
+ output_kpt = output[effect_num_dn:].index_select(
+ 0, torch.tensor(self.kpt_index, device=output.device))
+ delta_xy_unsig = self.pose_embed[layer_id -
+ self.num_box_decoder_layers](
+ output_kpt)
+ outputs_unsig = ref_before_sigmoid[
+ effect_num_dn:].index_select(
+ 0, torch.tensor(self.kpt_index,
+ device=output.device)).clone()
+ delta_hw_unsig = self.pose_hw_embed[
+ layer_id - self.num_box_decoder_layers](
+ output_kpt)
+ outputs_unsig[..., :2] += delta_xy_unsig[..., :2]
+ outputs_unsig[..., 2:] += delta_hw_unsig
+ new_reference_points_for_keypoint = outputs_unsig.sigmoid()
+ bs = new_reference_points_for_box_norm.shape[1]
+ new_reference_points_norm = torch.cat(
+ (new_reference_points_for_box_norm.unsqueeze(1),
+ new_reference_points_for_keypoint.view(
+ -1, self.num_keypoints, bs, 4)),
+ dim=1).flatten(0, 1)
+ new_reference_points = torch.cat(
+ (new_reference_points_for_box_dn,
+ new_reference_points_norm),
+ dim=0)
+
+ reference_points = new_reference_points.detach()
+ intermediate_reference_points.append(reference_points)
+
+ decoder_outputs = [itm_out.transpose(0, 1) for itm_out in intermediate]
+ reference_points = [
+ itm_refpoint.transpose(0, 1)
+ for itm_refpoint in intermediate_reference_points
+ ]
+
+ return decoder_outputs, reference_points
+
+ @staticmethod
+ def get_proposal_pos_embed(pos_tensor: Tensor,
+ temperature: int = 10000,
+ num_pos_feats: int = 128) -> Tensor:
+ """Get the position embedding of the proposal.
+
+ Args:
+ pos_tensor (Tensor): Not normalized proposals, has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h).
+ temperature (int, optional): The temperature used for scaling the
+ position embedding. Defaults to 10000.
+ num_pos_feats (int, optional): The feature dimension for each
+ position along x, y, w, and h-axis. Note the final returned
+ dimension for each position is 4 times of num_pos_feats.
+ Default to 128.
+
+ Returns:
+ Tensor: The position embedding of proposal, has shape
+ (bs, num_queries, num_pos_feats * 4), with the last dimension
+ arranged as (cx, cy, w, h)
+ """
+
+ scale = 2 * math.pi
+ dim_t = torch.arange(
+ num_pos_feats, dtype=torch.float32, device=pos_tensor.device)
+ dim_t = temperature**(2 * (dim_t // 2) / num_pos_feats)
+ x_embed = pos_tensor[:, :, 0] * scale
+ y_embed = pos_tensor[:, :, 1] * scale
+ pos_x = x_embed[:, :, None] / dim_t
+ pos_y = y_embed[:, :, None] / dim_t
+ pos_x = torch.stack((pos_x[:, :, 0::2].sin(), pos_x[:, :, 1::2].cos()),
+ dim=3).flatten(2)
+ pos_y = torch.stack((pos_y[:, :, 0::2].sin(), pos_y[:, :, 1::2].cos()),
+ dim=3).flatten(2)
+ if pos_tensor.size(-1) == 2:
+ pos = torch.cat((pos_y, pos_x), dim=2)
+ elif pos_tensor.size(-1) == 4:
+ w_embed = pos_tensor[:, :, 2] * scale
+ pos_w = w_embed[:, :, None] / dim_t
+ pos_w = torch.stack(
+ (pos_w[:, :, 0::2].sin(), pos_w[:, :, 1::2].cos()),
+ dim=3).flatten(2)
+
+ h_embed = pos_tensor[:, :, 3] * scale
+ pos_h = h_embed[:, :, None] / dim_t
+ pos_h = torch.stack(
+ (pos_h[:, :, 0::2].sin(), pos_h[:, :, 1::2].cos()),
+ dim=3).flatten(2)
+
+ pos = torch.cat((pos_y, pos_x, pos_w, pos_h), dim=2)
+ else:
+ raise ValueError('Unknown pos_tensor shape(-1):{}'.format(
+ pos_tensor.size(-1)))
+ return pos
+
+
+class EDPoseOutHead(BaseModule):
+ """Final Head of EDPose: `Explicit Box Detection Unifies End-to-End Multi-
+ Person Pose Estimation.
+
+ Args:
+ num_classes (int): The number of classes.
+ num_keypoints (int): The number of datasets' body keypoints.
+ num_queries (int): The number of queries.
+ cls_no_bias (bool): Weather add the bias to class embed.
+ embed_dims (int): The dims of embed.
+ as_two_stage (bool, optional): Whether to generate the proposal
+ from the outputs of encoder. Defaults to `False`.
+ refine_queries_num (int): The number of refines queries after
+ decoders.
+ num_box_decoder_layers (int): The number of bbox decoder layer.
+ num_group (int): The number of groups.
+ num_pred_layer (int): The number of the prediction layers.
+ Defaults to 6.
+ dec_pred_class_embed_share (bool): Whether to share parameters
+ for all the class prediction layers. Defaults to `False`.
+ dec_pred_bbox_embed_share (bool): Whether to share parameters
+ for all the bbox prediction layers. Defaults to `False`.
+ dec_pred_pose_embed_share (bool): Whether to share parameters
+ for all the pose prediction layers. Defaults to `False`.
+ """
+
+ def __init__(self,
+ num_classes,
+ num_keypoints: int = 17,
+ num_queries: int = 900,
+ cls_no_bias: bool = False,
+ embed_dims: int = 256,
+ as_two_stage: bool = False,
+ refine_queries_num: int = 100,
+ num_box_decoder_layers: int = 2,
+ num_group: int = 100,
+ num_pred_layer: int = 6,
+ dec_pred_class_embed_share: bool = False,
+ dec_pred_bbox_embed_share: bool = False,
+ dec_pred_pose_embed_share: bool = False,
+ **kwargs):
+ super().__init__()
+ self.embed_dims = embed_dims
+ self.as_two_stage = as_two_stage
+ self.num_classes = num_classes
+ self.refine_queries_num = refine_queries_num
+ self.num_box_decoder_layers = num_box_decoder_layers
+ self.num_keypoints = num_keypoints
+ self.num_queries = num_queries
+
+ # prepare pred layers
+ self.dec_pred_class_embed_share = dec_pred_class_embed_share
+ self.dec_pred_bbox_embed_share = dec_pred_bbox_embed_share
+ self.dec_pred_pose_embed_share = dec_pred_pose_embed_share
+ # prepare class & box embed
+ _class_embed = nn.Linear(
+ self.embed_dims, self.num_classes, bias=(not cls_no_bias))
+ if not cls_no_bias:
+ prior_prob = 0.01
+ bias_value = -math.log((1 - prior_prob) / prior_prob)
+ _class_embed.bias.data = torch.ones(self.num_classes) * bias_value
+
+ _bbox_embed = FFN(self.embed_dims, self.embed_dims, 4, 3)
+ _pose_embed = FFN(self.embed_dims, self.embed_dims, 2, 3)
+ _pose_hw_embed = FFN(self.embed_dims, self.embed_dims, 2, 3)
+
+ self.num_group = num_group
+ if dec_pred_bbox_embed_share:
+ box_embed_layerlist = [_bbox_embed for i in range(num_pred_layer)]
+ else:
+ box_embed_layerlist = [
+ copy.deepcopy(_bbox_embed) for i in range(num_pred_layer)
+ ]
+ if dec_pred_class_embed_share:
+ class_embed_layerlist = [
+ _class_embed for i in range(num_pred_layer)
+ ]
+ else:
+ class_embed_layerlist = [
+ copy.deepcopy(_class_embed) for i in range(num_pred_layer)
+ ]
+
+ if num_keypoints == 17:
+ if dec_pred_pose_embed_share:
+ pose_embed_layerlist = [
+ _pose_embed
+ for i in range(num_pred_layer - num_box_decoder_layers + 1)
+ ]
+ else:
+ pose_embed_layerlist = [
+ copy.deepcopy(_pose_embed)
+ for i in range(num_pred_layer - num_box_decoder_layers + 1)
+ ]
+ else:
+ if dec_pred_pose_embed_share:
+ pose_embed_layerlist = [
+ _pose_embed
+ for i in range(num_pred_layer - num_box_decoder_layers)
+ ]
+ else:
+ pose_embed_layerlist = [
+ copy.deepcopy(_pose_embed)
+ for i in range(num_pred_layer - num_box_decoder_layers)
+ ]
+
+ pose_hw_embed_layerlist = [
+ _pose_hw_embed
+ for i in range(num_pred_layer - num_box_decoder_layers)
+ ]
+ self.bbox_embed = nn.ModuleList(box_embed_layerlist)
+ self.class_embed = nn.ModuleList(class_embed_layerlist)
+ self.pose_embed = nn.ModuleList(pose_embed_layerlist)
+ self.pose_hw_embed = nn.ModuleList(pose_hw_embed_layerlist)
+
+ def init_weights(self) -> None:
+ """Initialize weights of the Deformable DETR head."""
+
+ for m in self.bbox_embed:
+ constant_init(m[-1], 0, bias=0)
+ for m in self.pose_embed:
+ constant_init(m[-1], 0, bias=0)
+
+ def forward(self, hidden_states: List[Tensor], references: List[Tensor],
+ mask_dict: Dict, hidden_states_enc: Tensor,
+ referens_enc: Tensor, batch_data_samples) -> Dict:
+ """Forward function.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries, dim).
+ references (list[Tensor]): List of the reference from the decoder.
+
+ Returns:
+ tuple[Tensor]: results of head containing the following tensor.
+
+ - pred_logits (Tensor): Outputs from the
+ classification head, the socres of every bboxes.
+ - pred_boxes (Tensor): The output boxes.
+ - pred_keypoints (Tensor): The output keypoints.
+ """
+ # update human boxes
+ effec_dn_num = self.refine_queries_num if self.training else 0
+ outputs_coord_list = []
+ outputs_class = []
+ for dec_lid, (layer_ref_sig, layer_bbox_embed, layer_cls_embed,
+ layer_hs) in enumerate(
+ zip(references[:-1], self.bbox_embed,
+ self.class_embed, hidden_states)):
+ if dec_lid < self.num_box_decoder_layers:
+ layer_delta_unsig = layer_bbox_embed(layer_hs)
+ layer_outputs_unsig = layer_delta_unsig + inverse_sigmoid(
+ layer_ref_sig)
+ layer_outputs_unsig = layer_outputs_unsig.sigmoid()
+ layer_cls = layer_cls_embed(layer_hs)
+ outputs_coord_list.append(layer_outputs_unsig)
+ outputs_class.append(layer_cls)
+ else:
+ layer_hs_bbox_dn = layer_hs[:, :effec_dn_num, :]
+ layer_hs_bbox_norm = \
+ layer_hs[:, effec_dn_num:, :][:, 0::(
+ self.num_keypoints + 1), :]
+ bs = layer_ref_sig.shape[0]
+ ref_before_sigmoid_bbox_dn = \
+ layer_ref_sig[:, : effec_dn_num, :]
+ ref_before_sigmoid_bbox_norm = \
+ layer_ref_sig[:, effec_dn_num:, :][:, 0::(
+ self.num_keypoints + 1), :]
+ layer_delta_unsig_dn = layer_bbox_embed(layer_hs_bbox_dn)
+ layer_delta_unsig_norm = layer_bbox_embed(layer_hs_bbox_norm)
+ layer_outputs_unsig_dn = layer_delta_unsig_dn + \
+ inverse_sigmoid(ref_before_sigmoid_bbox_dn)
+ layer_outputs_unsig_dn = layer_outputs_unsig_dn.sigmoid()
+ layer_outputs_unsig_norm = layer_delta_unsig_norm + \
+ inverse_sigmoid(ref_before_sigmoid_bbox_norm)
+ layer_outputs_unsig_norm = layer_outputs_unsig_norm.sigmoid()
+ layer_outputs_unsig = torch.cat(
+ (layer_outputs_unsig_dn, layer_outputs_unsig_norm), dim=1)
+ layer_cls_dn = layer_cls_embed(layer_hs_bbox_dn)
+ layer_cls_norm = layer_cls_embed(layer_hs_bbox_norm)
+ layer_cls = torch.cat((layer_cls_dn, layer_cls_norm), dim=1)
+ outputs_class.append(layer_cls)
+ outputs_coord_list.append(layer_outputs_unsig)
+
+ # update keypoints boxes
+ outputs_keypoints_list = []
+ kpt_index = [
+ x for x in range(self.num_group * (self.num_keypoints + 1))
+ if x % (self.num_keypoints + 1) != 0
+ ]
+ for dec_lid, (layer_ref_sig, layer_hs) in enumerate(
+ zip(references[:-1], hidden_states)):
+ if dec_lid < self.num_box_decoder_layers:
+ assert isinstance(layer_hs, torch.Tensor)
+ bs = layer_hs.shape[0]
+ layer_res = layer_hs.new_zeros(
+ (bs, self.num_queries, self.num_keypoints * 3))
+ outputs_keypoints_list.append(layer_res)
+ else:
+ bs = layer_ref_sig.shape[0]
+ layer_hs_kpt = \
+ layer_hs[:, effec_dn_num:, :].index_select(
+ 1, torch.tensor(kpt_index, device=layer_hs.device))
+ delta_xy_unsig = self.pose_embed[dec_lid -
+ self.num_box_decoder_layers](
+ layer_hs_kpt)
+ layer_ref_sig_kpt = \
+ layer_ref_sig[:, effec_dn_num:, :].index_select(
+ 1, torch.tensor(kpt_index, device=layer_hs.device))
+ layer_outputs_unsig_keypoints = delta_xy_unsig + \
+ inverse_sigmoid(layer_ref_sig_kpt[..., :2])
+ vis_xy_unsig = torch.ones_like(
+ layer_outputs_unsig_keypoints,
+ device=layer_outputs_unsig_keypoints.device)
+ xyv = torch.cat((layer_outputs_unsig_keypoints,
+ vis_xy_unsig[:, :, 0].unsqueeze(-1)),
+ dim=-1)
+ xyv = xyv.sigmoid()
+ layer_res = xyv.reshape(
+ (bs, self.num_group, self.num_keypoints, 3)).flatten(2, 3)
+ layer_res = self.keypoint_xyzxyz_to_xyxyzz(layer_res)
+ outputs_keypoints_list.append(layer_res)
+
+ dn_mask_dict = mask_dict
+ if self.refine_queries_num > 0 and dn_mask_dict is not None:
+ outputs_class, outputs_coord_list, outputs_keypoints_list = \
+ self.dn_post_process2(
+ outputs_class, outputs_coord_list,
+ outputs_keypoints_list, dn_mask_dict
+ )
+
+ for _out_class, _out_bbox, _out_keypoint in zip(
+ outputs_class, outputs_coord_list, outputs_keypoints_list):
+ assert _out_class.shape[1] == \
+ _out_bbox.shape[1] == _out_keypoint.shape[1]
+
+ return outputs_class[-1], outputs_coord_list[
+ -1], outputs_keypoints_list[-1]
+
+ def keypoint_xyzxyz_to_xyxyzz(self, keypoints: torch.Tensor):
+ """
+ Args:
+ keypoints (torch.Tensor): ..., 51
+ """
+ res = torch.zeros_like(keypoints)
+ num_points = keypoints.shape[-1] // 3
+ res[..., 0:2 * num_points:2] = keypoints[..., 0::3]
+ res[..., 1:2 * num_points:2] = keypoints[..., 1::3]
+ res[..., 2 * num_points:] = keypoints[..., 2::3]
+ return res
+
+
+@MODELS.register_module()
+class EDPoseHead(TransformerHead):
+ """Head introduced in `Explicit Box Detection Unifies End-to-End Multi-
+ Person Pose Estimation`_ by J Yang1 et al (2023). The head is composed of
+ Encoder, Decoder and Out_head.
+
+ Code is modified from the `official github repo
+ `_.
+
+ More details can be found in the `paper
+ `_ .
+
+ Args:
+ num_queries (int): Number of query in Transformer.
+ num_feature_levels (int): Number of feature levels. Defaults to 4.
+ num_keypoints (int): Number of keypoints. Defaults to 4.
+ as_two_stage (bool, optional): Whether to generate the proposal
+ from the outputs of encoder. Defaults to `False`.
+ encoder (:obj:`ConfigDict` or dict, optional): Config of the
+ Transformer encoder. Defaults to None.
+ decoder (:obj:`ConfigDict` or dict, optional): Config of the
+ Transformer decoder. Defaults to None.
+ out_head (:obj:`ConfigDict` or dict, optional): Config for the
+ bounding final out head module. Defaults to None.
+ positional_encoding (:obj:`ConfigDict` or dict): Config for
+ transformer position encoding. Defaults None.
+ denosing_cfg (:obj:`ConfigDict` or dict, optional): Config of the
+ human query denoising training strategy.
+ data_decoder (:obj:`ConfigDict` or dict, optional): Config of the
+ data decoder which transform the results from output space to
+ input space.
+ dec_pred_class_embed_share (bool): Whether to share the class embed
+ layer. Default False.
+ dec_pred_bbox_embed_share (bool): Whether to share the bbox embed
+ layer. Default False.
+ refine_queries_num (int): Number of refined human content queries
+ and their position queries .
+ two_stage_keep_all_tokens (bool): Whether to keep all tokens.
+ """
+
+ def __init__(self,
+ num_queries: int = 100,
+ num_feature_levels: int = 4,
+ num_keypoints: int = 17,
+ as_two_stage: bool = False,
+ encoder: OptConfigType = None,
+ decoder: OptConfigType = None,
+ out_head: OptConfigType = None,
+ positional_encoding: OptConfigType = None,
+ data_decoder: OptConfigType = None,
+ denosing_cfg: OptConfigType = None,
+ dec_pred_class_embed_share: bool = False,
+ dec_pred_bbox_embed_share: bool = False,
+ refine_queries_num: int = 100,
+ two_stage_keep_all_tokens: bool = False) -> None:
+
+ self.as_two_stage = as_two_stage
+ self.num_feature_levels = num_feature_levels
+ self.refine_queries_num = refine_queries_num
+ self.dec_pred_class_embed_share = dec_pred_class_embed_share
+ self.dec_pred_bbox_embed_share = dec_pred_bbox_embed_share
+ self.two_stage_keep_all_tokens = two_stage_keep_all_tokens
+ self.num_heads = decoder['layer_cfg']['self_attn_cfg']['num_heads']
+ self.num_group = decoder['num_group']
+ self.num_keypoints = num_keypoints
+ self.denosing_cfg = denosing_cfg
+ if data_decoder is not None:
+ self.data_decoder = KEYPOINT_CODECS.build(data_decoder)
+ else:
+ self.data_decoder = None
+
+ super().__init__(
+ encoder=encoder,
+ decoder=decoder,
+ out_head=out_head,
+ positional_encoding=positional_encoding,
+ num_queries=num_queries)
+
+ self.positional_encoding = PositionEmbeddingSineHW(
+ **self.positional_encoding_cfg)
+ self.encoder = DeformableDetrTransformerEncoder(**self.encoder_cfg)
+ self.decoder = EDPoseDecoder(
+ num_keypoints=num_keypoints, **self.decoder_cfg)
+ self.out_head = EDPoseOutHead(
+ num_keypoints=num_keypoints,
+ as_two_stage=as_two_stage,
+ refine_queries_num=refine_queries_num,
+ **self.out_head_cfg,
+ **self.decoder_cfg)
+
+ self.embed_dims = self.encoder.embed_dims
+ self.label_enc = nn.Embedding(
+ self.denosing_cfg['dn_labelbook_size'] + 1, self.embed_dims)
+
+ if not self.as_two_stage:
+ self.query_embedding = nn.Embedding(self.num_queries,
+ self.embed_dims)
+ self.refpoint_embedding = nn.Embedding(self.num_queries, 4)
+
+ self.level_embed = nn.Parameter(
+ torch.Tensor(self.num_feature_levels, self.embed_dims))
+
+ self.decoder.bbox_embed = self.out_head.bbox_embed
+ self.decoder.pose_embed = self.out_head.pose_embed
+ self.decoder.pose_hw_embed = self.out_head.pose_hw_embed
+ self.decoder.class_embed = self.out_head.class_embed
+
+ if self.as_two_stage:
+ self.memory_trans_fc = nn.Linear(self.embed_dims, self.embed_dims)
+ self.memory_trans_norm = nn.LayerNorm(self.embed_dims)
+ if dec_pred_class_embed_share and dec_pred_bbox_embed_share:
+ self.enc_out_bbox_embed = self.out_head.bbox_embed[0]
+ else:
+ self.enc_out_bbox_embed = copy.deepcopy(
+ self.out_head.bbox_embed[0])
+
+ if dec_pred_class_embed_share and dec_pred_bbox_embed_share:
+ self.enc_out_class_embed = self.out_head.class_embed[0]
+ else:
+ self.enc_out_class_embed = copy.deepcopy(
+ self.out_head.class_embed[0])
+
+ def init_weights(self) -> None:
+ """Initialize weights for Transformer and other components."""
+ super().init_weights()
+ for coder in self.encoder, self.decoder:
+ for p in coder.parameters():
+ if p.dim() > 1:
+ nn.init.xavier_uniform_(p)
+ for m in self.modules():
+ if isinstance(m, MultiScaleDeformableAttention):
+ m.init_weights()
+ if self.as_two_stage:
+ nn.init.xavier_uniform_(self.memory_trans_fc.weight)
+
+ nn.init.normal_(self.level_embed)
+
+ def pre_transformer(self,
+ img_feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList = None
+ ) -> Tuple[Dict]:
+ """Process image features before feeding them to the transformer.
+
+ Args:
+ img_feats (tuple[Tensor]): Multi-level features that may have
+ different resolutions, output from neck. Each feature has
+ shape (bs, dim, h_lvl, w_lvl), where 'lvl' means 'layer'.
+ batch_data_samples (list[:obj:`DetDataSample`], optional): The
+ batch data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+ Defaults to None.
+
+ Returns:
+ tuple[dict]: The first dict contains the inputs of encoder and the
+ second dict contains the inputs of decoder.
+
+ - encoder_inputs_dict (dict): The keyword args dictionary of
+ `self.encoder()`.
+ - decoder_inputs_dict (dict): The keyword args dictionary of
+ `self.forward_decoder()`, which includes 'memory_mask'.
+ """
+ batch_size = img_feats[0].size(0)
+ # construct binary masks for the transformer.
+ assert batch_data_samples is not None
+ batch_input_shape = batch_data_samples[0].batch_input_shape
+ img_shape_list = [sample.img_shape for sample in batch_data_samples]
+ input_img_h, input_img_w = batch_input_shape
+ masks = img_feats[0].new_ones((batch_size, input_img_h, input_img_w))
+ for img_id in range(batch_size):
+ img_h, img_w = img_shape_list[img_id]
+ masks[img_id, :img_h, :img_w] = 0
+ # NOTE following the official DETR repo, non-zero values representing
+ # ignored positions, while zero values means valid positions.
+
+ mlvl_masks = []
+ mlvl_pos_embeds = []
+ for feat in img_feats:
+ mlvl_masks.append(
+ F.interpolate(masks[None],
+ size=feat.shape[-2:]).to(torch.bool).squeeze(0))
+ mlvl_pos_embeds.append(self.positional_encoding(mlvl_masks[-1]))
+
+ feat_flatten = []
+ lvl_pos_embed_flatten = []
+ mask_flatten = []
+ spatial_shapes = []
+ for lvl, (feat, mask, pos_embed) in enumerate(
+ zip(img_feats, mlvl_masks, mlvl_pos_embeds)):
+ batch_size, c, h, w = feat.shape
+ # [bs, c, h_lvl, w_lvl] -> [bs, h_lvl*w_lvl, c]
+ feat = feat.view(batch_size, c, -1).permute(0, 2, 1)
+ pos_embed = pos_embed.view(batch_size, c, -1).permute(0, 2, 1)
+ lvl_pos_embed = pos_embed + self.level_embed[lvl].view(1, 1, -1)
+ # [bs, h_lvl, w_lvl] -> [bs, h_lvl*w_lvl]
+ mask = mask.flatten(1)
+ spatial_shape = (h, w)
+
+ feat_flatten.append(feat)
+ lvl_pos_embed_flatten.append(lvl_pos_embed)
+ mask_flatten.append(mask)
+ spatial_shapes.append(spatial_shape)
+
+ # (bs, num_feat_points, dim)
+ feat_flatten = torch.cat(feat_flatten, 1)
+ lvl_pos_embed_flatten = torch.cat(lvl_pos_embed_flatten, 1)
+ # (bs, num_feat_points), where num_feat_points = sum_lvl(h_lvl*w_lvl)
+ mask_flatten = torch.cat(mask_flatten, 1)
+
+ spatial_shapes = torch.as_tensor( # (num_level, 2)
+ spatial_shapes,
+ dtype=torch.long,
+ device=feat_flatten.device)
+ level_start_index = torch.cat((
+ spatial_shapes.new_zeros((1, )), # (num_level)
+ spatial_shapes.prod(1).cumsum(0)[:-1]))
+ valid_ratios = torch.stack( # (bs, num_level, 2)
+ [self.get_valid_ratio(m) for m in mlvl_masks], 1)
+
+ if self.refine_queries_num > 0 or batch_data_samples is not None:
+ input_query_label, input_query_bbox, humandet_attn_mask, \
+ human2pose_attn_mask, mask_dict =\
+ self.prepare_for_denosing(
+ batch_data_samples,
+ device=img_feats[0].device)
+ else:
+ assert batch_data_samples is None
+ input_query_bbox = input_query_label = \
+ humandet_attn_mask = human2pose_attn_mask = mask_dict = None
+
+ encoder_inputs_dict = dict(
+ query=feat_flatten,
+ query_pos=lvl_pos_embed_flatten,
+ key_padding_mask=mask_flatten,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios)
+ decoder_inputs_dict = dict(
+ memory_mask=mask_flatten,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios,
+ humandet_attn_mask=humandet_attn_mask,
+ human2pose_attn_mask=human2pose_attn_mask,
+ input_query_bbox=input_query_bbox,
+ input_query_label=input_query_label,
+ mask_dict=mask_dict)
+ return encoder_inputs_dict, decoder_inputs_dict
+
+ def forward_encoder(self,
+ img_feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList = None) -> Dict:
+ """Forward with Transformer encoder.
+
+ The forward procedure is defined as:
+ 'pre_transformer' -> 'encoder'
+
+ Args:
+ img_feats (tuple[Tensor]): Multi-level features that may have
+ different resolutions, output from neck. Each feature has
+ shape (bs, dim, h_lvl, w_lvl), where 'lvl' means 'layer'.
+ batch_data_samples (list[:obj:`DetDataSample`], optional): The
+ batch data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+ Defaults to None.
+
+ Returns:
+ dict: The dictionary of encoder outputs, which includes the
+ `memory` of the encoder output.
+ """
+ encoder_inputs_dict, decoder_inputs_dict = self.pre_transformer(
+ img_feats, batch_data_samples)
+
+ memory = self.encoder(**encoder_inputs_dict)
+ encoder_outputs_dict = dict(memory=memory, **decoder_inputs_dict)
+ return encoder_outputs_dict
+
+ def pre_decoder(self, memory: Tensor, memory_mask: Tensor,
+ spatial_shapes: Tensor, input_query_bbox: Tensor,
+ input_query_label: Tensor) -> Tuple[Dict, Dict]:
+ """Prepare intermediate variables before entering Transformer decoder,
+ such as `query` and `reference_points`.
+
+ Args:
+ memory (Tensor): The output embeddings of the Transformer encoder,
+ has shape (bs, num_feat_points, dim).
+ memory_mask (Tensor): ByteTensor, the padding mask of the memory,
+ has shape (bs, num_feat_points). It will only be used when
+ `as_two_stage` is `True`.
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+ It will only be used when `as_two_stage` is `True`.
+ input_query_bbox (Tensor): Denosing bbox query for training.
+ input_query_label (Tensor): Denosing label query for training.
+
+ Returns:
+ tuple[dict, dict]: The decoder_inputs_dict and head_inputs_dict.
+
+ - decoder_inputs_dict (dict): The keyword dictionary args of
+ `self.decoder()`.
+ - head_inputs_dict (dict): The keyword dictionary args of the
+ bbox_head functions.
+ """
+ bs, _, c = memory.shape
+ if self.as_two_stage:
+ output_memory, output_proposals = \
+ self.gen_encoder_output_proposals(
+ memory, memory_mask, spatial_shapes)
+ enc_outputs_class = self.enc_out_class_embed(output_memory)
+ enc_outputs_coord_unact = self.enc_out_bbox_embed(
+ output_memory) + output_proposals
+
+ topk_proposals = torch.topk(
+ enc_outputs_class.max(-1)[0], self.num_queries, dim=1)[1]
+ topk_coords_undetach = torch.gather(
+ enc_outputs_coord_unact, 1,
+ topk_proposals.unsqueeze(-1).repeat(1, 1, 4))
+ topk_coords_unact = topk_coords_undetach.detach()
+ reference_points = topk_coords_unact.sigmoid()
+
+ query_undetach = torch.gather(
+ output_memory, 1,
+ topk_proposals.unsqueeze(-1).repeat(1, 1, self.embed_dims))
+ query = query_undetach.detach()
+
+ if input_query_bbox is not None:
+ reference_points = torch.cat(
+ [input_query_bbox, topk_coords_unact], dim=1).sigmoid()
+ query = torch.cat([input_query_label, query], dim=1)
+ if self.two_stage_keep_all_tokens:
+ hidden_states_enc = output_memory.unsqueeze(0)
+ referens_enc = enc_outputs_coord_unact.unsqueeze(0)
+ else:
+ hidden_states_enc = query_undetach.unsqueeze(0)
+ referens_enc = topk_coords_undetach.sigmoid().unsqueeze(0)
+ else:
+ hidden_states_enc, referens_enc = None, None
+ query = self.query_embedding.weight[:, None, :].repeat(
+ 1, bs, 1).transpose(0, 1)
+ reference_points = \
+ self.refpoint_embedding.weight[:, None, :].repeat(1, bs, 1)
+
+ if input_query_bbox is not None:
+ reference_points = torch.cat(
+ [input_query_bbox, reference_points], dim=1)
+ query = torch.cat([input_query_label, query], dim=1)
+ reference_points = reference_points.sigmoid()
+
+ decoder_inputs_dict = dict(
+ query=query, reference_points=reference_points)
+ head_inputs_dict = dict(
+ hidden_states_enc=hidden_states_enc, referens_enc=referens_enc)
+ return decoder_inputs_dict, head_inputs_dict
+
+ def forward_decoder(self, memory: Tensor, memory_mask: Tensor,
+ spatial_shapes: Tensor, level_start_index: Tensor,
+ valid_ratios: Tensor, humandet_attn_mask: Tensor,
+ human2pose_attn_mask: Tensor, input_query_bbox: Tensor,
+ input_query_label: Tensor, mask_dict: Dict) -> Dict:
+ """Forward with Transformer decoder.
+
+ The forward procedure is defined as:
+ 'pre_decoder' -> 'decoder'
+
+ Args:
+ memory (Tensor): The output embeddings of the Transformer encoder,
+ has shape (bs, num_feat_points, dim).
+ memory_mask (Tensor): ByteTensor, the padding mask of the memory,
+ has shape (bs, num_feat_points).
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+ level_start_index (Tensor): The start index of each level.
+ A tensor has shape (num_levels, ) and can be represented
+ as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
+ valid_ratios (Tensor): The ratios of the valid width and the valid
+ height relative to the width and the height of features in all
+ levels, has shape (bs, num_levels, 2).
+ humandet_attn_mask (Tensor): Human attention mask.
+ human2pose_attn_mask (Tensor): Human to pose attention mask.
+ input_query_bbox (Tensor): Denosing bbox query for training.
+ input_query_label (Tensor): Denosing label query for training.
+
+ Returns:
+ dict: The dictionary of decoder outputs, which includes the
+ `hidden_states` of the decoder output and `references` including
+ the initial and intermediate reference_points.
+ """
+ decoder_in, head_in = self.pre_decoder(memory, memory_mask,
+ spatial_shapes,
+ input_query_bbox,
+ input_query_label)
+
+ inter_states, inter_references = self.decoder(
+ query=decoder_in['query'].transpose(0, 1),
+ value=memory.transpose(0, 1),
+ key_padding_mask=memory_mask, # for cross_attn
+ reference_points=decoder_in['reference_points'].transpose(0, 1),
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios,
+ humandet_attn_mask=humandet_attn_mask,
+ human2pose_attn_mask=human2pose_attn_mask)
+ references = inter_references
+ decoder_outputs_dict = dict(
+ hidden_states=inter_states,
+ references=references,
+ mask_dict=mask_dict)
+ decoder_outputs_dict.update(head_in)
+ return decoder_outputs_dict
+
+ def forward_out_head(self, batch_data_samples: OptSampleList,
+ hidden_states: List[Tensor], references: List[Tensor],
+ mask_dict: Dict, hidden_states_enc: Tensor,
+ referens_enc: Tensor) -> Tuple[Tensor]:
+ """Forward function."""
+ out = self.out_head(hidden_states, references, mask_dict,
+ hidden_states_enc, referens_enc,
+ batch_data_samples)
+ return out
+
+ def predict(self,
+ feats: Features,
+ batch_data_samples: OptSampleList,
+ test_cfg: ConfigType = {}) -> Predictions:
+ """Predict results from features."""
+ input_shapes = np.array(
+ [d.metainfo['input_size'] for d in batch_data_samples])
+
+ if test_cfg.get('flip_test', False):
+ assert NotImplementedError(
+ 'flip_test is currently not supported '
+ 'for EDPose. Please set `model.test_cfg.flip_test=False`')
+ else:
+ pred_logits, pred_boxes, pred_keypoints = self.forward(
+ feats, batch_data_samples) # (B, K, D)
+
+ pred = self.decode(
+ input_shapes,
+ pred_logits=pred_logits,
+ pred_boxes=pred_boxes,
+ pred_keypoints=pred_keypoints)
+ return pred
+
+ def decode(self, input_shapes: np.ndarray, pred_logits: Tensor,
+ pred_boxes: Tensor, pred_keypoints: Tensor):
+ """Select the final top-k keypoints, and decode the results from
+ normalize size to origin input size.
+
+ Args:
+ input_shapes (Tensor): The size of input image.
+ pred_logits (Tensor): The result of score.
+ pred_boxes (Tensor): The result of bbox.
+ pred_keypoints (Tensor): The result of keypoints.
+
+ Returns:
+ """
+
+ if self.data_decoder is None:
+ raise RuntimeError(f'The data decoder has not been set in \
+ {self.__class__.__name__}. '
+ 'Please set the data decoder configs in \
+ the init parameters to '
+ 'enable head methods `head.predict()` and \
+ `head.decode()`')
+
+ preds = []
+
+ pred_logits = pred_logits.sigmoid()
+ pred_logits, pred_boxes, pred_keypoints = to_numpy(
+ [pred_logits, pred_boxes, pred_keypoints])
+
+ for input_shape, pred_logit, pred_bbox, pred_kpts in zip(
+ input_shapes, pred_logits, pred_boxes, pred_keypoints):
+
+ bboxes, keypoints, keypoint_scores = self.data_decoder.decode(
+ input_shape, pred_logit, pred_bbox, pred_kpts)
+
+ # pack outputs
+ preds.append(
+ InstanceData(
+ keypoints=keypoints,
+ keypoint_scores=keypoint_scores,
+ bboxes=bboxes))
+
+ return preds
+
+ def gen_encoder_output_proposals(self, memory: Tensor, memory_mask: Tensor,
+ spatial_shapes: Tensor
+ ) -> Tuple[Tensor, Tensor]:
+ """Generate proposals from encoded memory. The function will only be
+ used when `as_two_stage` is `True`.
+
+ Args:
+ memory (Tensor): The output embeddings of the Transformer encoder,
+ has shape (bs, num_feat_points, dim).
+ memory_mask (Tensor): ByteTensor, the padding mask of the memory,
+ has shape (bs, num_feat_points).
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+
+ Returns:
+ tuple: A tuple of transformed memory and proposals.
+
+ - output_memory (Tensor): The transformed memory for obtaining
+ top-k proposals, has shape (bs, num_feat_points, dim).
+ - output_proposals (Tensor): The inverse-normalized proposal, has
+ shape (batch_size, num_keys, 4) with the last dimension arranged
+ as (cx, cy, w, h).
+ """
+ bs = memory.size(0)
+ proposals = []
+ _cur = 0 # start index in the sequence of the current level
+ for lvl, (H, W) in enumerate(spatial_shapes):
+ mask_flatten_ = memory_mask[:,
+ _cur:(_cur + H * W)].view(bs, H, W, 1)
+ valid_H = torch.sum(~mask_flatten_[:, :, 0, 0], 1).unsqueeze(-1)
+ valid_W = torch.sum(~mask_flatten_[:, 0, :, 0], 1).unsqueeze(-1)
+
+ grid_y, grid_x = torch.meshgrid(
+ torch.linspace(
+ 0, H - 1, H, dtype=torch.float32, device=memory.device),
+ torch.linspace(
+ 0, W - 1, W, dtype=torch.float32, device=memory.device))
+ grid = torch.cat([grid_x.unsqueeze(-1), grid_y.unsqueeze(-1)], -1)
+
+ scale = torch.cat([valid_W, valid_H], 1).view(bs, 1, 1, 2)
+ grid = (grid.unsqueeze(0).expand(bs, -1, -1, -1) + 0.5) / scale
+ wh = torch.ones_like(grid) * 0.05 * (2.0**lvl)
+ proposal = torch.cat((grid, wh), -1).view(bs, -1, 4)
+ proposals.append(proposal)
+ _cur += (H * W)
+ output_proposals = torch.cat(proposals, 1)
+ output_proposals_valid = ((output_proposals > 0.01) &
+ (output_proposals < 0.99)).all(
+ -1, keepdim=True)
+
+ output_proposals = inverse_sigmoid(output_proposals)
+ output_proposals = output_proposals.masked_fill(
+ memory_mask.unsqueeze(-1), float('inf'))
+ output_proposals = output_proposals.masked_fill(
+ ~output_proposals_valid, float('inf'))
+
+ output_memory = memory
+ output_memory = output_memory.masked_fill(
+ memory_mask.unsqueeze(-1), float(0))
+ output_memory = output_memory.masked_fill(~output_proposals_valid,
+ float(0))
+ output_memory = self.memory_trans_fc(output_memory)
+ output_memory = self.memory_trans_norm(output_memory)
+ # [bs, sum(hw), 2]
+ return output_memory, output_proposals
+
+ @property
+ def default_init_cfg(self):
+ init_cfg = [dict(type='Normal', layer=['Linear'], std=0.01, bias=0)]
+ return init_cfg
+
+ def prepare_for_denosing(self, targets: OptSampleList, device):
+ """prepare for dn components in forward function."""
+ if not self.training:
+ bs = len(targets)
+ attn_mask_infere = torch.zeros(
+ bs,
+ self.num_heads,
+ self.num_group * (self.num_keypoints + 1),
+ self.num_group * (self.num_keypoints + 1),
+ device=device,
+ dtype=torch.bool)
+ group_bbox_kpt = (self.num_keypoints + 1)
+ kpt_index = [
+ x for x in range(self.num_group * (self.num_keypoints + 1))
+ if x % (self.num_keypoints + 1) == 0
+ ]
+ for matchj in range(self.num_group * (self.num_keypoints + 1)):
+ sj = (matchj // group_bbox_kpt) * group_bbox_kpt
+ ej = (matchj // group_bbox_kpt + 1) * group_bbox_kpt
+ if sj > 0:
+ attn_mask_infere[:, :, matchj, :sj] = True
+ if ej < self.num_group * (self.num_keypoints + 1):
+ attn_mask_infere[:, :, matchj, ej:] = True
+ for match_x in range(self.num_group * (self.num_keypoints + 1)):
+ if match_x % group_bbox_kpt == 0:
+ attn_mask_infere[:, :, match_x, kpt_index] = False
+
+ attn_mask_infere = attn_mask_infere.flatten(0, 1)
+ return None, None, None, attn_mask_infere, None
+
+ # targets, dn_scalar, noise_scale = dn_args
+ device = targets[0]['boxes'].device
+ bs = len(targets)
+ refine_queries_num = self.refine_queries_num
+
+ # gather gt boxes and labels
+ gt_boxes = [t['boxes'] for t in targets]
+ gt_labels = [t['labels'] for t in targets]
+ gt_keypoints = [t['keypoints'] for t in targets]
+
+ # repeat them
+ def get_indices_for_repeat(now_num, target_num, device='cuda'):
+ """
+ Input:
+ - now_num: int
+ - target_num: int
+ Output:
+ - indices: tensor[target_num]
+ """
+ out_indice = []
+ base_indice = torch.arange(now_num).to(device)
+ multiplier = target_num // now_num
+ out_indice.append(base_indice.repeat(multiplier))
+ residue = target_num % now_num
+ out_indice.append(base_indice[torch.randint(
+ 0, now_num, (residue, ), device=device)])
+ return torch.cat(out_indice)
+
+ gt_boxes_expand = []
+ gt_labels_expand = []
+ gt_keypoints_expand = []
+ for idx, (gt_boxes_i, gt_labels_i, gt_keypoint_i) in enumerate(
+ zip(gt_boxes, gt_labels, gt_keypoints)):
+ num_gt_i = gt_boxes_i.shape[0]
+ if num_gt_i > 0:
+ indices = get_indices_for_repeat(num_gt_i, refine_queries_num,
+ device)
+ gt_boxes_expand_i = gt_boxes_i[indices] # num_dn, 4
+ gt_labels_expand_i = gt_labels_i[indices]
+ gt_keypoints_expand_i = gt_keypoint_i[indices]
+ else:
+ # all negative samples when no gt boxes
+ gt_boxes_expand_i = torch.rand(
+ refine_queries_num, 4, device=device)
+ gt_labels_expand_i = torch.ones(
+ refine_queries_num, dtype=torch.int64,
+ device=device) * int(self.num_classes)
+ gt_keypoints_expand_i = torch.rand(
+ refine_queries_num, self.num_keypoints * 3, device=device)
+ gt_boxes_expand.append(gt_boxes_expand_i)
+ gt_labels_expand.append(gt_labels_expand_i)
+ gt_keypoints_expand.append(gt_keypoints_expand_i)
+ gt_boxes_expand = torch.stack(gt_boxes_expand)
+ gt_labels_expand = torch.stack(gt_labels_expand)
+ gt_keypoints_expand = torch.stack(gt_keypoints_expand)
+ knwon_boxes_expand = gt_boxes_expand.clone()
+ knwon_labels_expand = gt_labels_expand.clone()
+
+ # add noise
+ if self.denosing_cfg['dn_label_noise_ratio'] > 0:
+ prob = torch.rand_like(knwon_labels_expand.float())
+ chosen_indice = prob < self.denosing_cfg['dn_label_noise_ratio']
+ new_label = torch.randint_like(
+ knwon_labels_expand[chosen_indice], 0,
+ self.dn_labelbook_size) # randomly put a new one here
+ knwon_labels_expand[chosen_indice] = new_label
+
+ if self.denosing_cfg['dn_box_noise_scale'] > 0:
+ diff = torch.zeros_like(knwon_boxes_expand)
+ diff[..., :2] = knwon_boxes_expand[..., 2:] / 2
+ diff[..., 2:] = knwon_boxes_expand[..., 2:]
+ knwon_boxes_expand += torch.mul(
+ (torch.rand_like(knwon_boxes_expand) * 2 - 1.0),
+ diff) * self.denosing_cfg['dn_box_noise_scale']
+ knwon_boxes_expand = knwon_boxes_expand.clamp(min=0.0, max=1.0)
+
+ input_query_label = self.label_enc(knwon_labels_expand)
+ input_query_bbox = inverse_sigmoid(knwon_boxes_expand)
+
+ # prepare mask
+ if 'group2group' in self.denosing_cfg['dn_attn_mask_type_list']:
+ attn_mask = torch.zeros(
+ bs,
+ self.num_heads,
+ refine_queries_num + self.num_queries,
+ refine_queries_num + self.num_queries,
+ device=device,
+ dtype=torch.bool)
+ attn_mask[:, :, refine_queries_num:, :refine_queries_num] = True
+ for idx, (gt_boxes_i,
+ gt_labels_i) in enumerate(zip(gt_boxes, gt_labels)):
+ num_gt_i = gt_boxes_i.shape[0]
+ if num_gt_i == 0:
+ continue
+ for matchi in range(refine_queries_num):
+ si = (matchi // num_gt_i) * num_gt_i
+ ei = (matchi // num_gt_i + 1) * num_gt_i
+ if si > 0:
+ attn_mask[idx, :, matchi, :si] = True
+ if ei < refine_queries_num:
+ attn_mask[idx, :, matchi, ei:refine_queries_num] = True
+ attn_mask = attn_mask.flatten(0, 1)
+
+ if 'group2group' in self.denosing_cfg['dn_attn_mask_type_list']:
+ attn_mask2 = torch.zeros(
+ bs,
+ self.num_heads,
+ refine_queries_num + self.num_group * (self.num_keypoints + 1),
+ refine_queries_num + self.num_group * (self.num_keypoints + 1),
+ device=device,
+ dtype=torch.bool)
+ attn_mask2[:, :, refine_queries_num:, :refine_queries_num] = True
+ group_bbox_kpt = (self.num_keypoints + 1)
+ kpt_index = [
+ x for x in range(self.num_group * (self.num_keypoints + 1))
+ if x % (self.num_keypoints + 1) == 0
+ ]
+ for matchj in range(self.num_group * (self.num_keypoints + 1)):
+ sj = (matchj // group_bbox_kpt) * group_bbox_kpt
+ ej = (matchj // group_bbox_kpt + 1) * group_bbox_kpt
+ if sj > 0:
+ attn_mask2[:, :, refine_queries_num:,
+ refine_queries_num:][:, :, matchj, :sj] = True
+ if ej < self.num_group * (self.num_keypoints + 1):
+ attn_mask2[:, :, refine_queries_num:,
+ refine_queries_num:][:, :, matchj, ej:] = True
+
+ for match_x in range(self.num_group * (self.num_keypoints + 1)):
+ if match_x % group_bbox_kpt == 0:
+ attn_mask2[:, :, refine_queries_num:,
+ refine_queries_num:][:, :, match_x,
+ kpt_index] = False
+
+ for idx, (gt_boxes_i,
+ gt_labels_i) in enumerate(zip(gt_boxes, gt_labels)):
+ num_gt_i = gt_boxes_i.shape[0]
+ if num_gt_i == 0:
+ continue
+ for matchi in range(refine_queries_num):
+ si = (matchi // num_gt_i) * num_gt_i
+ ei = (matchi // num_gt_i + 1) * num_gt_i
+ if si > 0:
+ attn_mask2[idx, :, matchi, :si] = True
+ if ei < refine_queries_num:
+ attn_mask2[idx, :, matchi,
+ ei:refine_queries_num] = True
+ attn_mask2 = attn_mask2.flatten(0, 1)
+
+ mask_dict = {
+ 'pad_size': refine_queries_num,
+ 'known_bboxs': gt_boxes_expand,
+ 'known_labels': gt_labels_expand,
+ 'known_keypoints': gt_keypoints_expand
+ }
+
+ return input_query_label, input_query_bbox, \
+ attn_mask, attn_mask2, mask_dict
+
+ def loss(self,
+ feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ train_cfg: OptConfigType = {}) -> dict:
+ """Calculate losses from a batch of inputs and data samples."""
+
+ assert NotImplementedError(
+ 'the training of EDPose has not been '
+ 'supported. Please stay tuned for further update.')
diff --git a/mmpose/models/heads/transformer_heads/transformers/__init__.py b/mmpose/models/heads/transformer_heads/transformers/__init__.py
new file mode 100644
index 0000000000..0e9f115cd1
--- /dev/null
+++ b/mmpose/models/heads/transformer_heads/transformers/__init__.py
@@ -0,0 +1,16 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .deformable_detr_layers import (DeformableDetrTransformerDecoder,
+ DeformableDetrTransformerDecoderLayer,
+ DeformableDetrTransformerEncoder,
+ DeformableDetrTransformerEncoderLayer)
+from .detr_layers import (DetrTransformerDecoder, DetrTransformerDecoderLayer,
+ DetrTransformerEncoder, DetrTransformerEncoderLayer)
+from .utils import FFN, PositionEmbeddingSineHW
+
+__all__ = [
+ 'DetrTransformerEncoder', 'DetrTransformerDecoder',
+ 'DetrTransformerEncoderLayer', 'DetrTransformerDecoderLayer',
+ 'DeformableDetrTransformerEncoder', 'DeformableDetrTransformerDecoder',
+ 'DeformableDetrTransformerEncoderLayer',
+ 'DeformableDetrTransformerDecoderLayer', 'PositionEmbeddingSineHW', 'FFN'
+]
diff --git a/mmpose/models/heads/transformer_heads/transformers/deformable_detr_layers.py b/mmpose/models/heads/transformer_heads/transformers/deformable_detr_layers.py
new file mode 100644
index 0000000000..149f04e469
--- /dev/null
+++ b/mmpose/models/heads/transformer_heads/transformers/deformable_detr_layers.py
@@ -0,0 +1,251 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple, Union
+
+import torch
+from mmcv.cnn import build_norm_layer
+from mmcv.cnn.bricks.transformer import FFN, MultiheadAttention
+from mmcv.ops import MultiScaleDeformableAttention
+from mmengine.model import ModuleList
+from torch import Tensor, nn
+
+from mmpose.models.utils import inverse_sigmoid
+from .detr_layers import (DetrTransformerDecoder, DetrTransformerDecoderLayer,
+ DetrTransformerEncoder, DetrTransformerEncoderLayer)
+
+
+class DeformableDetrTransformerEncoder(DetrTransformerEncoder):
+ """Transformer encoder of Deformable DETR."""
+
+ def _init_layers(self) -> None:
+ """Initialize encoder layers."""
+ self.layers = ModuleList([
+ DeformableDetrTransformerEncoderLayer(**self.layer_cfg)
+ for _ in range(self.num_layers)
+ ])
+ self.embed_dims = self.layers[0].embed_dims
+
+ def forward(self, query: Tensor, query_pos: Tensor,
+ key_padding_mask: Tensor, spatial_shapes: Tensor,
+ level_start_index: Tensor, valid_ratios: Tensor,
+ **kwargs) -> Tensor:
+ """Forward function of Transformer encoder.
+
+ Args:
+ query (Tensor): The input query, has shape (bs, num_queries, dim).
+ query_pos (Tensor): The positional encoding for query, has shape
+ (bs, num_queries, dim).
+ key_padding_mask (Tensor): The `key_padding_mask` of `self_attn`
+ input. ByteTensor, has shape (bs, num_queries).
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+ level_start_index (Tensor): The start index of each level.
+ A tensor has shape (num_levels, ) and can be represented
+ as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
+ valid_ratios (Tensor): The ratios of the valid width and the valid
+ height relative to the width and the height of features in all
+ levels, has shape (bs, num_levels, 2).
+
+ Returns:
+ Tensor: Output queries of Transformer encoder, which is also
+ called 'encoder output embeddings' or 'memory', has shape
+ (bs, num_queries, dim)
+ """
+ reference_points = self.get_encoder_reference_points(
+ spatial_shapes, valid_ratios, device=query.device)
+ for layer in self.layers:
+ query = layer(
+ query=query,
+ query_pos=query_pos,
+ key_padding_mask=key_padding_mask,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios,
+ reference_points=reference_points,
+ **kwargs)
+ return query
+
+ @staticmethod
+ def get_encoder_reference_points(spatial_shapes: Tensor,
+ valid_ratios: Tensor,
+ device: Union[torch.device,
+ str]) -> Tensor:
+ """Get the reference points used in encoder.
+
+ Args:
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+ valid_ratios (Tensor): The ratios of the valid width and the valid
+ height relative to the width and the height of features in all
+ levels, has shape (bs, num_levels, 2).
+ device (obj:`device` or str): The device acquired by the
+ `reference_points`.
+
+ Returns:
+ Tensor: Reference points used in decoder, has shape (bs, length,
+ num_levels, 2).
+ """
+
+ reference_points_list = []
+ for lvl, (H, W) in enumerate(spatial_shapes):
+ ref_y, ref_x = torch.meshgrid(
+ torch.linspace(
+ 0.5, H - 0.5, H, dtype=torch.float32, device=device),
+ torch.linspace(
+ 0.5, W - 0.5, W, dtype=torch.float32, device=device))
+ ref_y = ref_y.reshape(-1)[None] / (
+ valid_ratios[:, None, lvl, 1] * H)
+ ref_x = ref_x.reshape(-1)[None] / (
+ valid_ratios[:, None, lvl, 0] * W)
+ ref = torch.stack((ref_x, ref_y), -1)
+ reference_points_list.append(ref)
+ reference_points = torch.cat(reference_points_list, 1)
+ # [bs, sum(hw), num_level, 2]
+ reference_points = reference_points[:, :, None] * valid_ratios[:, None]
+ return reference_points
+
+
+class DeformableDetrTransformerDecoder(DetrTransformerDecoder):
+ """Transformer Decoder of Deformable DETR."""
+
+ def _init_layers(self) -> None:
+ """Initialize decoder layers."""
+ self.layers = ModuleList([
+ DeformableDetrTransformerDecoderLayer(**self.layer_cfg)
+ for _ in range(self.num_layers)
+ ])
+ self.embed_dims = self.layers[0].embed_dims
+ if self.post_norm_cfg is not None:
+ raise ValueError('There is not post_norm in '
+ f'{self._get_name()}')
+
+ def forward(self,
+ query: Tensor,
+ query_pos: Tensor,
+ value: Tensor,
+ key_padding_mask: Tensor,
+ reference_points: Tensor,
+ spatial_shapes: Tensor,
+ level_start_index: Tensor,
+ valid_ratios: Tensor,
+ reg_branches: Optional[nn.Module] = None,
+ **kwargs) -> Tuple[Tensor]:
+ """Forward function of Transformer decoder.
+
+ Args:
+ query (Tensor): The input queries, has shape (bs, num_queries,
+ dim).
+ query_pos (Tensor): The input positional query, has shape
+ (bs, num_queries, dim). It will be added to `query` before
+ forward function.
+ value (Tensor): The input values, has shape (bs, num_value, dim).
+ key_padding_mask (Tensor): The `key_padding_mask` of `cross_attn`
+ input. ByteTensor, has shape (bs, num_value).
+ reference_points (Tensor): The initial reference, has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h) when `as_two_stage` is `True`, otherwise has
+ shape (bs, num_queries, 2) with the last dimension arranged
+ as (cx, cy).
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+ level_start_index (Tensor): The start index of each level.
+ A tensor has shape (num_levels, ) and can be represented
+ as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
+ valid_ratios (Tensor): The ratios of the valid width and the valid
+ height relative to the width and the height of features in all
+ levels, has shape (bs, num_levels, 2).
+ reg_branches: (obj:`nn.ModuleList`, optional): Used for refining
+ the regression results. Only would be passed when
+ `with_box_refine` is `True`, otherwise would be `None`.
+
+ Returns:
+ tuple[Tensor]: Outputs of Deformable Transformer Decoder.
+
+ - output (Tensor): Output embeddings of the last decoder, has
+ shape (num_queries, bs, embed_dims) when `return_intermediate`
+ is `False`. Otherwise, Intermediate output embeddings of all
+ decoder layers, has shape (num_decoder_layers, num_queries, bs,
+ embed_dims).
+ - reference_points (Tensor): The reference of the last decoder
+ layer, has shape (bs, num_queries, 4) when `return_intermediate`
+ is `False`. Otherwise, Intermediate references of all decoder
+ layers, has shape (num_decoder_layers, bs, num_queries, 4). The
+ coordinates are arranged as (cx, cy, w, h)
+ """
+ output = query
+ intermediate = []
+ intermediate_reference_points = []
+ for layer_id, layer in enumerate(self.layers):
+ if reference_points.shape[-1] == 4:
+ reference_points_input = \
+ reference_points[:, :, None] * \
+ torch.cat([valid_ratios, valid_ratios], -1)[:, None]
+ else:
+ assert reference_points.shape[-1] == 2
+ reference_points_input = \
+ reference_points[:, :, None] * \
+ valid_ratios[:, None]
+ output = layer(
+ output,
+ query_pos=query_pos,
+ value=value,
+ key_padding_mask=key_padding_mask,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios,
+ reference_points=reference_points_input,
+ **kwargs)
+
+ if reg_branches is not None:
+ tmp_reg_preds = reg_branches[layer_id](output)
+ if reference_points.shape[-1] == 4:
+ new_reference_points = tmp_reg_preds + inverse_sigmoid(
+ reference_points)
+ new_reference_points = new_reference_points.sigmoid()
+ else:
+ assert reference_points.shape[-1] == 2
+ new_reference_points = tmp_reg_preds
+ new_reference_points[..., :2] = tmp_reg_preds[
+ ..., :2] + inverse_sigmoid(reference_points)
+ new_reference_points = new_reference_points.sigmoid()
+ reference_points = new_reference_points.detach()
+
+ if self.return_intermediate:
+ intermediate.append(output)
+ intermediate_reference_points.append(reference_points)
+
+ if self.return_intermediate:
+ return torch.stack(intermediate), torch.stack(
+ intermediate_reference_points)
+
+ return output, reference_points
+
+
+class DeformableDetrTransformerEncoderLayer(DetrTransformerEncoderLayer):
+ """Encoder layer of Deformable DETR."""
+
+ def _init_layers(self) -> None:
+ """Initialize self_attn, ffn, and norms."""
+ self.self_attn = MultiScaleDeformableAttention(**self.self_attn_cfg)
+ self.embed_dims = self.self_attn.embed_dims
+ self.ffn = FFN(**self.ffn_cfg)
+ norms_list = [
+ build_norm_layer(self.norm_cfg, self.embed_dims)[1]
+ for _ in range(2)
+ ]
+ self.norms = ModuleList(norms_list)
+
+
+class DeformableDetrTransformerDecoderLayer(DetrTransformerDecoderLayer):
+ """Decoder layer of Deformable DETR."""
+
+ def _init_layers(self) -> None:
+ """Initialize self_attn, cross-attn, ffn, and norms."""
+ self.self_attn = MultiheadAttention(**self.self_attn_cfg)
+ self.cross_attn = MultiScaleDeformableAttention(**self.cross_attn_cfg)
+ self.embed_dims = self.self_attn.embed_dims
+ self.ffn = FFN(**self.ffn_cfg)
+ norms_list = [
+ build_norm_layer(self.norm_cfg, self.embed_dims)[1]
+ for _ in range(3)
+ ]
+ self.norms = ModuleList(norms_list)
diff --git a/mmpose/models/heads/transformer_heads/transformers/detr_layers.py b/mmpose/models/heads/transformer_heads/transformers/detr_layers.py
new file mode 100644
index 0000000000..a669c5dda6
--- /dev/null
+++ b/mmpose/models/heads/transformer_heads/transformers/detr_layers.py
@@ -0,0 +1,354 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Union
+
+import torch
+from mmcv.cnn import build_norm_layer
+from mmcv.cnn.bricks.transformer import FFN, MultiheadAttention
+from mmengine import ConfigDict
+from mmengine.model import BaseModule, ModuleList
+from torch import Tensor
+
+from mmpose.utils.typing import ConfigType, OptConfigType
+
+
+class DetrTransformerEncoder(BaseModule):
+ """Encoder of DETR.
+
+ Args:
+ num_layers (int): Number of encoder layers.
+ layer_cfg (:obj:`ConfigDict` or dict): the config of each encoder
+ layer. All the layers will share the same config.
+ init_cfg (:obj:`ConfigDict` or dict, optional): the config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ num_layers: int,
+ layer_cfg: ConfigType,
+ init_cfg: OptConfigType = None) -> None:
+
+ super().__init__(init_cfg=init_cfg)
+ self.num_layers = num_layers
+ self.layer_cfg = layer_cfg
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ """Initialize encoder layers."""
+ self.layers = ModuleList([
+ DetrTransformerEncoderLayer(**self.layer_cfg)
+ for _ in range(self.num_layers)
+ ])
+ self.embed_dims = self.layers[0].embed_dims
+
+ def forward(self, query: Tensor, query_pos: Tensor,
+ key_padding_mask: Tensor, **kwargs) -> Tensor:
+ """Forward function of encoder.
+
+ Args:
+ query (Tensor): Input queries of encoder, has shape
+ (bs, num_queries, dim).
+ query_pos (Tensor): The positional embeddings of the queries, has
+ shape (bs, num_queries, dim).
+ key_padding_mask (Tensor): The `key_padding_mask` of `self_attn`
+ input. ByteTensor, has shape (bs, num_queries).
+
+ Returns:
+ Tensor: Has shape (bs, num_queries, dim) if `batch_first` is
+ `True`, otherwise (num_queries, bs, dim).
+ """
+ for layer in self.layers:
+ query = layer(query, query_pos, key_padding_mask, **kwargs)
+ return query
+
+
+class DetrTransformerDecoder(BaseModule):
+ """Decoder of DETR.
+
+ Args:
+ num_layers (int): Number of decoder layers.
+ layer_cfg (:obj:`ConfigDict` or dict): the config of each encoder
+ layer. All the layers will share the same config.
+ post_norm_cfg (:obj:`ConfigDict` or dict, optional): Config of the
+ post normalization layer. Defaults to `LN`.
+ return_intermediate (bool, optional): Whether to return outputs of
+ intermediate layers. Defaults to `True`,
+ init_cfg (:obj:`ConfigDict` or dict, optional): the config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ num_layers: int,
+ layer_cfg: ConfigType,
+ post_norm_cfg: OptConfigType = dict(type='LN'),
+ return_intermediate: bool = True,
+ init_cfg: Union[dict, ConfigDict] = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.layer_cfg = layer_cfg
+ self.num_layers = num_layers
+ self.post_norm_cfg = post_norm_cfg
+ self.return_intermediate = return_intermediate
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ """Initialize decoder layers."""
+ self.layers = ModuleList([
+ DetrTransformerDecoderLayer(**self.layer_cfg)
+ for _ in range(self.num_layers)
+ ])
+ self.embed_dims = self.layers[0].embed_dims
+ self.post_norm = build_norm_layer(self.post_norm_cfg,
+ self.embed_dims)[1]
+
+ def forward(self, query: Tensor, key: Tensor, value: Tensor,
+ query_pos: Tensor, key_pos: Tensor, key_padding_mask: Tensor,
+ **kwargs) -> Tensor:
+ """Forward function of decoder
+ Args:
+ query (Tensor): The input query, has shape (bs, num_queries, dim).
+ key (Tensor): The input key, has shape (bs, num_keys, dim).
+ value (Tensor): The input value with the same shape as `key`.
+ query_pos (Tensor): The positional encoding for `query`, with the
+ same shape as `query`.
+ key_pos (Tensor): The positional encoding for `key`, with the
+ same shape as `key`.
+ key_padding_mask (Tensor): The `key_padding_mask` of `cross_attn`
+ input. ByteTensor, has shape (bs, num_value).
+
+ Returns:
+ Tensor: The forwarded results will have shape
+ (num_decoder_layers, bs, num_queries, dim) if
+ `return_intermediate` is `True` else (1, bs, num_queries, dim).
+ """
+ intermediate = []
+ for layer in self.layers:
+ query = layer(
+ query,
+ key=key,
+ value=value,
+ query_pos=query_pos,
+ key_pos=key_pos,
+ key_padding_mask=key_padding_mask,
+ **kwargs)
+ if self.return_intermediate:
+ intermediate.append(self.post_norm(query))
+ query = self.post_norm(query)
+
+ if self.return_intermediate:
+ return torch.stack(intermediate)
+
+ return query.unsqueeze(0)
+
+
+class DetrTransformerEncoderLayer(BaseModule):
+ """Implements encoder layer in DETR transformer.
+
+ Args:
+ self_attn_cfg (:obj:`ConfigDict` or dict, optional): Config for self
+ attention.
+ ffn_cfg (:obj:`ConfigDict` or dict, optional): Config for FFN.
+ norm_cfg (:obj:`ConfigDict` or dict, optional): Config for
+ normalization layers. All the layers will share the same
+ config. Defaults to `LN`.
+ init_cfg (:obj:`ConfigDict` or dict, optional): Config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ self_attn_cfg: OptConfigType = dict(
+ embed_dims=256, num_heads=8, dropout=0.0),
+ ffn_cfg: OptConfigType = dict(
+ embed_dims=256,
+ feedforward_channels=1024,
+ num_fcs=2,
+ ffn_drop=0.,
+ act_cfg=dict(type='ReLU', inplace=True)),
+ norm_cfg: OptConfigType = dict(type='LN'),
+ init_cfg: OptConfigType = None) -> None:
+
+ super().__init__(init_cfg=init_cfg)
+
+ self.self_attn_cfg = self_attn_cfg
+ if 'batch_first' not in self.self_attn_cfg:
+ self.self_attn_cfg['batch_first'] = True
+ else:
+ assert self.self_attn_cfg['batch_first'] is True, 'First \
+ dimension of all DETRs in mmdet is `batch`, \
+ please set `batch_first` flag.'
+
+ self.ffn_cfg = ffn_cfg
+ self.norm_cfg = norm_cfg
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ """Initialize self-attention, FFN, and normalization."""
+ self.self_attn = MultiheadAttention(**self.self_attn_cfg)
+ self.embed_dims = self.self_attn.embed_dims
+ self.ffn = FFN(**self.ffn_cfg)
+ norms_list = [
+ build_norm_layer(self.norm_cfg, self.embed_dims)[1]
+ for _ in range(2)
+ ]
+ self.norms = ModuleList(norms_list)
+
+ def forward(self, query: Tensor, query_pos: Tensor,
+ key_padding_mask: Tensor, **kwargs) -> Tensor:
+ """Forward function of an encoder layer.
+
+ Args:
+ query (Tensor): The input query, has shape (bs, num_queries, dim).
+ query_pos (Tensor): The positional encoding for query, with
+ the same shape as `query`.
+ key_padding_mask (Tensor): The `key_padding_mask` of `self_attn`
+ input. ByteTensor. has shape (bs, num_queries).
+ Returns:
+ Tensor: forwarded results, has shape (bs, num_queries, dim).
+ """
+ query = self.self_attn(
+ query=query,
+ key=query,
+ value=query,
+ query_pos=query_pos,
+ key_pos=query_pos,
+ key_padding_mask=key_padding_mask,
+ **kwargs)
+ query = self.norms[0](query)
+ query = self.ffn(query)
+ query = self.norms[1](query)
+
+ return query
+
+
+class DetrTransformerDecoderLayer(BaseModule):
+ """Implements decoder layer in DETR transformer.
+
+ Args:
+ self_attn_cfg (:obj:`ConfigDict` or dict, optional): Config for self
+ attention.
+ cross_attn_cfg (:obj:`ConfigDict` or dict, optional): Config for cross
+ attention.
+ ffn_cfg (:obj:`ConfigDict` or dict, optional): Config for FFN.
+ norm_cfg (:obj:`ConfigDict` or dict, optional): Config for
+ normalization layers. All the layers will share the same
+ config. Defaults to `LN`.
+ init_cfg (:obj:`ConfigDict` or dict, optional): Config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ self_attn_cfg: OptConfigType = dict(
+ embed_dims=256,
+ num_heads=8,
+ dropout=0.0,
+ batch_first=True),
+ cross_attn_cfg: OptConfigType = dict(
+ embed_dims=256,
+ num_heads=8,
+ dropout=0.0,
+ batch_first=True),
+ ffn_cfg: OptConfigType = dict(
+ embed_dims=256,
+ feedforward_channels=1024,
+ num_fcs=2,
+ ffn_drop=0.,
+ act_cfg=dict(type='ReLU', inplace=True),
+ ),
+ norm_cfg: OptConfigType = dict(type='LN'),
+ init_cfg: OptConfigType = None) -> None:
+
+ super().__init__(init_cfg=init_cfg)
+
+ self.self_attn_cfg = self_attn_cfg
+ self.cross_attn_cfg = cross_attn_cfg
+ if 'batch_first' not in self.self_attn_cfg:
+ self.self_attn_cfg['batch_first'] = True
+ else:
+ assert self.self_attn_cfg['batch_first'] is True, 'First \
+ dimension of all DETRs in mmdet is `batch`, \
+ please set `batch_first` flag.'
+
+ if 'batch_first' not in self.cross_attn_cfg:
+ self.cross_attn_cfg['batch_first'] = True
+ else:
+ assert self.cross_attn_cfg['batch_first'] is True, 'First \
+ dimension of all DETRs in mmdet is `batch`, \
+ please set `batch_first` flag.'
+
+ self.ffn_cfg = ffn_cfg
+ self.norm_cfg = norm_cfg
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ """Initialize self-attention, FFN, and normalization."""
+ self.self_attn = MultiheadAttention(**self.self_attn_cfg)
+ self.cross_attn = MultiheadAttention(**self.cross_attn_cfg)
+ self.embed_dims = self.self_attn.embed_dims
+ self.ffn = FFN(**self.ffn_cfg)
+ norms_list = [
+ build_norm_layer(self.norm_cfg, self.embed_dims)[1]
+ for _ in range(3)
+ ]
+ self.norms = ModuleList(norms_list)
+
+ def forward(self,
+ query: Tensor,
+ key: Tensor = None,
+ value: Tensor = None,
+ query_pos: Tensor = None,
+ key_pos: Tensor = None,
+ self_attn_mask: Tensor = None,
+ cross_attn_mask: Tensor = None,
+ key_padding_mask: Tensor = None,
+ **kwargs) -> Tensor:
+ """
+ Args:
+ query (Tensor): The input query, has shape (bs, num_queries, dim).
+ key (Tensor, optional): The input key, has shape (bs, num_keys,
+ dim). If `None`, the `query` will be used. Defaults to `None`.
+ value (Tensor, optional): The input value, has the same shape as
+ `key`, as in `nn.MultiheadAttention.forward`. If `None`, the
+ `key` will be used. Defaults to `None`.
+ query_pos (Tensor, optional): The positional encoding for `query`,
+ has the same shape as `query`. If not `None`, it will be added
+ to `query` before forward function. Defaults to `None`.
+ key_pos (Tensor, optional): The positional encoding for `key`, has
+ the same shape as `key`. If not `None`, it will be added to
+ `key` before forward function. If None, and `query_pos` has the
+ same shape as `key`, then `query_pos` will be used for
+ `key_pos`. Defaults to None.
+ self_attn_mask (Tensor, optional): ByteTensor mask, has shape
+ (num_queries, num_keys), as in `nn.MultiheadAttention.forward`.
+ Defaults to None.
+ cross_attn_mask (Tensor, optional): ByteTensor mask, has shape
+ (num_queries, num_keys), as in `nn.MultiheadAttention.forward`.
+ Defaults to None.
+ key_padding_mask (Tensor, optional): The `key_padding_mask` of
+ `self_attn` input. ByteTensor, has shape (bs, num_value).
+ Defaults to None.
+
+ Returns:
+ Tensor: forwarded results, has shape (bs, num_queries, dim).
+ """
+
+ query = self.self_attn(
+ query=query,
+ key=query,
+ value=query,
+ query_pos=query_pos,
+ key_pos=query_pos,
+ attn_mask=self_attn_mask,
+ **kwargs)
+ query = self.norms[0](query)
+ query = self.cross_attn(
+ query=query,
+ key=key,
+ value=value,
+ query_pos=query_pos,
+ key_pos=key_pos,
+ attn_mask=cross_attn_mask,
+ key_padding_mask=key_padding_mask,
+ **kwargs)
+ query = self.norms[1](query)
+ query = self.ffn(query)
+ query = self.norms[2](query)
+
+ return query
diff --git a/mmpose/models/heads/transformer_heads/transformers/utils.py b/mmpose/models/heads/transformer_heads/transformers/utils.py
new file mode 100644
index 0000000000..7d7c086dc8
--- /dev/null
+++ b/mmpose/models/heads/transformer_heads/transformers/utils.py
@@ -0,0 +1,103 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import torch
+import torch.nn.functional as F
+from mmcv.cnn import Linear
+from mmengine.model import BaseModule, ModuleList
+from torch import Tensor
+
+
+class FFN(BaseModule):
+ """Very simple multi-layer perceptron with relu. Mostly used in DETR series
+ detectors.
+
+ Args:
+ input_dim (int): Feature dim of the input tensor.
+ hidden_dim (int): Feature dim of the hidden layer.
+ output_dim (int): Feature dim of the output tensor.
+ num_layers (int): Number of FFN layers..
+ """
+
+ def __init__(self, input_dim: int, hidden_dim: int, output_dim: int,
+ num_layers: int) -> None:
+ super().__init__()
+
+ self.num_layers = num_layers
+
+ self.layers = ModuleList()
+ self.layers.append(Linear(input_dim, hidden_dim))
+ for _ in range(num_layers - 2):
+ self.layers.append(Linear(hidden_dim, hidden_dim))
+ self.layers.append(Linear(hidden_dim, output_dim))
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward function of FFN.
+
+ Args:
+ x (Tensor): The input feature, has shape
+ (num_queries, bs, input_dim).
+ Returns:
+ Tensor: The output feature, has shape
+ (num_queries, bs, output_dim).
+ """
+ for i, layer in enumerate(self.layers):
+ x = layer(x)
+ if i < self.num_layers - 1:
+ x = F.relu(x)
+ return x
+
+
+class PositionEmbeddingSineHW(BaseModule):
+ """This is a more standard version of the position embedding, very similar
+ to the one used by the Attention is all you need paper, generalized to work
+ on images."""
+
+ def __init__(self,
+ num_pos_feats=64,
+ temperatureH=10000,
+ temperatureW=10000,
+ normalize=False,
+ scale=None):
+ super().__init__()
+ self.num_pos_feats = num_pos_feats
+ self.temperatureH = temperatureH
+ self.temperatureW = temperatureW
+ self.normalize = normalize
+ if scale is not None and normalize is False:
+ raise ValueError('normalize should be True if scale is passed')
+ if scale is None:
+ scale = 2 * math.pi
+ self.scale = scale
+
+ def forward(self, mask: Tensor):
+
+ assert mask is not None
+ not_mask = ~mask
+ y_embed = not_mask.cumsum(1, dtype=torch.float32)
+ x_embed = not_mask.cumsum(2, dtype=torch.float32)
+
+ if self.normalize:
+ eps = 1e-6
+ y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
+ x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
+
+ dim_tx = torch.arange(
+ self.num_pos_feats, dtype=torch.float32, device=mask.device)
+ dim_tx = self.temperatureW**(2 * (dim_tx // 2) / self.num_pos_feats)
+ pos_x = x_embed[:, :, :, None] / dim_tx
+
+ dim_ty = torch.arange(
+ self.num_pos_feats, dtype=torch.float32, device=mask.device)
+ dim_ty = self.temperatureH**(2 * (dim_ty // 2) / self.num_pos_feats)
+ pos_y = y_embed[:, :, :, None] / dim_ty
+
+ pos_x = torch.stack(
+ (pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()),
+ dim=4).flatten(3)
+ pos_y = torch.stack(
+ (pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()),
+ dim=4).flatten(3)
+ pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
+
+ return pos
diff --git a/mmpose/models/losses/__init__.py b/mmpose/models/losses/__init__.py
index f21071e156..92ed569bab 100644
--- a/mmpose/models/losses/__init__.py
+++ b/mmpose/models/losses/__init__.py
@@ -1,11 +1,15 @@
# Copyright (c) OpenMMLab. All rights reserved.
from .ae_loss import AssociativeEmbeddingLoss
+from .bbox_loss import IoULoss
from .classification_loss import BCELoss, JSDiscretLoss, KLDiscretLoss
+from .fea_dis_loss import FeaLoss
from .heatmap_loss import (AdaptiveWingLoss, KeypointMSELoss,
KeypointOHKMMSELoss)
+from .logit_dis_loss import KDLoss
from .loss_wrappers import CombinedLoss, MultipleLossWrapper
-from .regression_loss import (BoneLoss, L1Loss, MPJPELoss, MSELoss, RLELoss,
- SemiSupervisionLoss, SmoothL1Loss,
+from .regression_loss import (BoneLoss, L1Loss, MPJPELoss,
+ MPJPEVelocityJointLoss, MSELoss, OKSLoss,
+ RLELoss, SemiSupervisionLoss, SmoothL1Loss,
SoftWeightSmoothL1Loss, SoftWingLoss, WingLoss)
__all__ = [
@@ -13,5 +17,6 @@
'MPJPELoss', 'MSELoss', 'L1Loss', 'BCELoss', 'BoneLoss',
'SemiSupervisionLoss', 'SoftWingLoss', 'AdaptiveWingLoss', 'RLELoss',
'KLDiscretLoss', 'MultipleLossWrapper', 'JSDiscretLoss', 'CombinedLoss',
- 'AssociativeEmbeddingLoss', 'SoftWeightSmoothL1Loss'
+ 'AssociativeEmbeddingLoss', 'SoftWeightSmoothL1Loss',
+ 'MPJPEVelocityJointLoss', 'FeaLoss', 'KDLoss', 'OKSLoss', 'IoULoss'
]
diff --git a/mmpose/models/losses/bbox_loss.py b/mmpose/models/losses/bbox_loss.py
new file mode 100644
index 0000000000..b216dcdb4a
--- /dev/null
+++ b/mmpose/models/losses/bbox_loss.py
@@ -0,0 +1,72 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from functools import partial
+
+import torch.nn as nn
+import torch.nn.functional as F
+
+from mmpose.registry import MODELS
+from mmpose.structures.bbox import bbox_overlaps
+
+
+@MODELS.register_module()
+class IoULoss(nn.Module):
+ """Binary Cross Entropy loss.
+
+ Args:
+ reduction (str): Options are "none", "mean" and "sum".
+ eps (float): Epsilon to avoid log(0).
+ loss_weight (float): Weight of the loss. Default: 1.0.
+ mode (str): Loss scaling mode, including "linear", "square", and "log".
+ Default: 'log'
+ """
+
+ def __init__(self,
+ reduction='mean',
+ mode='log',
+ eps: float = 1e-16,
+ loss_weight=1.):
+ super().__init__()
+
+ assert reduction in ('mean', 'sum', 'none'), f'the argument ' \
+ f'`reduction` should be either \'mean\', \'sum\' or \'none\', ' \
+ f'but got {reduction}'
+
+ assert mode in ('linear', 'square', 'log'), f'the argument ' \
+ f'`reduction` should be either \'linear\', \'square\' or ' \
+ f'\'log\', but got {mode}'
+
+ self.reduction = reduction
+ self.criterion = partial(F.cross_entropy, reduction='none')
+ self.loss_weight = loss_weight
+ self.mode = mode
+ self.eps = eps
+
+ def forward(self, output, target):
+ """Forward function.
+
+ Note:
+ - batch_size: N
+ - num_labels: K
+
+ Args:
+ output (torch.Tensor[N, K]): Output classification.
+ target (torch.Tensor[N, K]): Target classification.
+ """
+ ious = bbox_overlaps(
+ output, target, is_aligned=True).clamp(min=self.eps)
+
+ if self.mode == 'linear':
+ loss = 1 - ious
+ elif self.mode == 'square':
+ loss = 1 - ious.pow(2)
+ elif self.mode == 'log':
+ loss = -ious.log()
+ else:
+ raise NotImplementedError
+
+ if self.reduction == 'sum':
+ loss = loss.sum()
+ elif self.reduction == 'mean':
+ loss = loss.mean()
+
+ return loss * self.loss_weight
diff --git a/mmpose/models/losses/classification_loss.py b/mmpose/models/losses/classification_loss.py
index 4605acabd3..2421e74819 100644
--- a/mmpose/models/losses/classification_loss.py
+++ b/mmpose/models/losses/classification_loss.py
@@ -1,4 +1,6 @@
# Copyright (c) OpenMMLab. All rights reserved.
+from functools import partial
+
import torch
import torch.nn as nn
import torch.nn.functional as F
@@ -13,17 +15,28 @@ class BCELoss(nn.Module):
Args:
use_target_weight (bool): Option to use weighted loss.
Different joint types may have different target weights.
+ reduction (str): Options are "none", "mean" and "sum".
loss_weight (float): Weight of the loss. Default: 1.0.
- with_logits (bool): Whether to use BCEWithLogitsLoss. Default: False.
+ use_sigmoid (bool, optional): Whether the prediction uses sigmoid
+ before output. Defaults to False.
"""
def __init__(self,
use_target_weight=False,
loss_weight=1.,
- with_logits=False):
+ reduction='mean',
+ use_sigmoid=False):
super().__init__()
- self.criterion = F.binary_cross_entropy if not with_logits\
+
+ assert reduction in ('mean', 'sum', 'none'), f'the argument ' \
+ f'`reduction` should be either \'mean\', \'sum\' or \'none\', ' \
+ f'but got {reduction}'
+
+ self.reduction = reduction
+ self.use_sigmoid = use_sigmoid
+ criterion = F.binary_cross_entropy if use_sigmoid \
else F.binary_cross_entropy_with_logits
+ self.criterion = partial(criterion, reduction='none')
self.use_target_weight = use_target_weight
self.loss_weight = loss_weight
@@ -43,13 +56,18 @@ def forward(self, output, target, target_weight=None):
if self.use_target_weight:
assert target_weight is not None
- loss = self.criterion(output, target, reduction='none')
+ loss = self.criterion(output, target)
if target_weight.dim() == 1:
target_weight = target_weight[:, None]
- loss = (loss * target_weight).mean()
+ loss = (loss * target_weight)
else:
loss = self.criterion(output, target)
+ if self.reduction == 'sum':
+ loss = loss.sum()
+ elif self.reduction == 'mean':
+ loss = loss.mean()
+
return loss * self.loss_weight
diff --git a/mmpose/models/losses/fea_dis_loss.py b/mmpose/models/losses/fea_dis_loss.py
new file mode 100644
index 0000000000..b90ca9d24f
--- /dev/null
+++ b/mmpose/models/losses/fea_dis_loss.py
@@ -0,0 +1,63 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+
+from mmpose.registry import MODELS
+
+
+@MODELS.register_module()
+class FeaLoss(nn.Module):
+ """PyTorch version of feature-based distillation from DWPose Modified from
+ the official implementation.
+
+
+ Args:
+ student_channels(int): Number of channels in the student's feature map.
+ teacher_channels(int): Number of channels in the teacher's feature map.
+ alpha_fea (float, optional): Weight of dis_loss. Defaults to 0.00007
+ """
+
+ def __init__(
+ self,
+ name,
+ use_this,
+ student_channels,
+ teacher_channels,
+ alpha_fea=0.00007,
+ ):
+ super(FeaLoss, self).__init__()
+ self.alpha_fea = alpha_fea
+
+ if teacher_channels != student_channels:
+ self.align = nn.Conv2d(
+ student_channels,
+ teacher_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0)
+ else:
+ self.align = None
+
+ def forward(self, preds_S, preds_T):
+ """Forward function.
+
+ Args:
+ preds_S(Tensor): Bs*C*H*W, student's feature map
+ preds_T(Tensor): Bs*C*H*W, teacher's feature map
+ """
+
+ if self.align is not None:
+ outs = self.align(preds_S)
+ else:
+ outs = preds_S
+
+ loss = self.get_dis_loss(outs, preds_T)
+
+ return loss
+
+ def get_dis_loss(self, preds_S, preds_T):
+ loss_mse = nn.MSELoss(reduction='sum')
+ N, C, H, W = preds_T.shape
+
+ dis_loss = loss_mse(preds_S, preds_T) / N * self.alpha_fea
+
+ return dis_loss
diff --git a/mmpose/models/losses/logit_dis_loss.py b/mmpose/models/losses/logit_dis_loss.py
new file mode 100644
index 0000000000..32906a1c3f
--- /dev/null
+++ b/mmpose/models/losses/logit_dis_loss.py
@@ -0,0 +1,64 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from mmpose.registry import MODELS
+
+
+@MODELS.register_module()
+class KDLoss(nn.Module):
+ """PyTorch version of logit-based distillation from DWPose Modified from
+ the official implementation.
+
+
+ Args:
+ weight (float, optional): Weight of dis_loss. Defaults to 1.0
+ """
+
+ def __init__(
+ self,
+ name,
+ use_this,
+ weight=1.0,
+ ):
+ super(KDLoss, self).__init__()
+
+ self.log_softmax = nn.LogSoftmax(dim=1)
+ self.kl_loss = nn.KLDivLoss(reduction='none')
+ self.weight = weight
+
+ def forward(self, pred, pred_t, beta, target_weight):
+ ls_x, ls_y = pred
+ lt_x, lt_y = pred_t
+
+ lt_x = lt_x.detach()
+ lt_y = lt_y.detach()
+
+ num_joints = ls_x.size(1)
+ loss = 0
+
+ loss += (self.loss(ls_x, lt_x, beta, target_weight))
+ loss += (self.loss(ls_y, lt_y, beta, target_weight))
+
+ return loss / num_joints
+
+ def loss(self, logit_s, logit_t, beta, weight):
+
+ N = logit_s.shape[0]
+
+ if len(logit_s.shape) == 3:
+ K = logit_s.shape[1]
+ logit_s = logit_s.reshape(N * K, -1)
+ logit_t = logit_t.reshape(N * K, -1)
+
+ # N*W(H)
+ s_i = self.log_softmax(logit_s * beta)
+ t_i = F.softmax(logit_t * beta, dim=1)
+
+ # kd
+ loss_all = torch.sum(self.kl_loss(s_i, t_i), dim=1)
+ loss_all = loss_all.reshape(N, K).sum(dim=1).mean()
+ loss_all = self.weight * loss_all
+
+ return loss_all
diff --git a/mmpose/models/losses/regression_loss.py b/mmpose/models/losses/regression_loss.py
index 9a64a4adfe..948d65bae7 100644
--- a/mmpose/models/losses/regression_loss.py
+++ b/mmpose/models/losses/regression_loss.py
@@ -1,11 +1,13 @@
# Copyright (c) OpenMMLab. All rights reserved.
import math
from functools import partial
+from typing import Optional
import torch
import torch.nn as nn
import torch.nn.functional as F
+from mmpose.datasets.datasets.utils import parse_pose_metainfo
from mmpose.registry import MODELS
from ..utils.realnvp import RealNVP
@@ -365,6 +367,84 @@ def forward(self, output, target, target_weight=None):
return loss * self.loss_weight
+@MODELS.register_module()
+class MPJPEVelocityJointLoss(nn.Module):
+ """MPJPE (Mean Per Joint Position Error) loss.
+
+ Args:
+ loss_weight (float): Weight of the loss. Default: 1.0.
+ lambda_scale (float): Factor of the N-MPJPE loss. Default: 0.5.
+ lambda_3d_velocity (float): Factor of the velocity loss. Default: 20.0.
+ """
+
+ def __init__(self,
+ use_target_weight=False,
+ loss_weight=1.,
+ lambda_scale=0.5,
+ lambda_3d_velocity=20.0):
+ super().__init__()
+ self.use_target_weight = use_target_weight
+ self.loss_weight = loss_weight
+ self.lambda_scale = lambda_scale
+ self.lambda_3d_velocity = lambda_3d_velocity
+
+ def forward(self, output, target, target_weight=None):
+ """Forward function.
+
+ Note:
+ - batch_size: N
+ - num_keypoints: K
+ - dimension of keypoints: D (D=2 or D=3)
+
+ Args:
+ output (torch.Tensor[N, K, D]): Output regression.
+ target (torch.Tensor[N, K, D]): Target regression.
+ target_weight (torch.Tensor[N,K,D]):
+ Weights across different joint types.
+ """
+ norm_output = torch.mean(
+ torch.sum(torch.square(output), dim=-1, keepdim=True),
+ dim=-2,
+ keepdim=True)
+ norm_target = torch.mean(
+ torch.sum(target * output, dim=-1, keepdim=True),
+ dim=-2,
+ keepdim=True)
+
+ velocity_output = output[..., 1:, :, :] - output[..., :-1, :, :]
+ velocity_target = target[..., 1:, :, :] - target[..., :-1, :, :]
+
+ if self.use_target_weight:
+ assert target_weight is not None
+ mpjpe = torch.mean(
+ torch.norm((output - target) * target_weight, dim=-1))
+
+ nmpjpe = torch.mean(
+ torch.norm(
+ (norm_target / norm_output * output - target) *
+ target_weight,
+ dim=-1))
+
+ loss_3d_velocity = torch.mean(
+ torch.norm(
+ (velocity_output - velocity_target) * target_weight,
+ dim=-1))
+ else:
+ mpjpe = torch.mean(torch.norm(output - target, dim=-1))
+
+ nmpjpe = torch.mean(
+ torch.norm(
+ norm_target / norm_output * output - target, dim=-1))
+
+ loss_3d_velocity = torch.mean(
+ torch.norm(velocity_output - velocity_target, dim=-1))
+
+ loss = mpjpe + nmpjpe * self.lambda_scale + \
+ loss_3d_velocity * self.lambda_3d_velocity
+
+ return loss * self.loss_weight
+
+
@MODELS.register_module()
class MPJPELoss(nn.Module):
"""MPJPE (Mean Per Joint Position Error) loss.
@@ -407,11 +487,19 @@ def forward(self, output, target, target_weight=None):
@MODELS.register_module()
class L1Loss(nn.Module):
- """L1Loss loss ."""
+ """L1Loss loss."""
- def __init__(self, use_target_weight=False, loss_weight=1.):
+ def __init__(self,
+ reduction='mean',
+ use_target_weight=False,
+ loss_weight=1.):
super().__init__()
- self.criterion = F.l1_loss
+
+ assert reduction in ('mean', 'sum', 'none'), f'the argument ' \
+ f'`reduction` should be either \'mean\', \'sum\' or \'none\', ' \
+ f'but got {reduction}'
+
+ self.criterion = partial(F.l1_loss, reduction=reduction)
self.use_target_weight = use_target_weight
self.loss_weight = loss_weight
@@ -430,6 +518,8 @@ def forward(self, output, target, target_weight=None):
"""
if self.use_target_weight:
assert target_weight is not None
+ for _ in range(target.ndim - target_weight.ndim):
+ target_weight = target_weight.unsqueeze(-1)
loss = self.criterion(output * target_weight,
target * target_weight)
else:
@@ -616,3 +706,108 @@ def forward(self, output, target):
losses['bone_loss'] = loss_bone
return losses
+
+
+@MODELS.register_module()
+class OKSLoss(nn.Module):
+ """A PyTorch implementation of the Object Keypoint Similarity (OKS) loss as
+ described in the paper "YOLO-Pose: Enhancing YOLO for Multi Person Pose
+ Estimation Using Object Keypoint Similarity Loss" by Debapriya et al.
+ (2022).
+
+ The OKS loss is used for keypoint-based object recognition and consists
+ of a measure of the similarity between predicted and ground truth
+ keypoint locations, adjusted by the size of the object in the image.
+
+ The loss function takes as input the predicted keypoint locations, the
+ ground truth keypoint locations, a mask indicating which keypoints are
+ valid, and bounding boxes for the objects.
+
+ Args:
+ metainfo (Optional[str]): Path to a JSON file containing information
+ about the dataset's annotations.
+ reduction (str): Options are "none", "mean" and "sum".
+ eps (float): Epsilon to avoid log(0).
+ loss_weight (float): Weight of the loss. Default: 1.0.
+ mode (str): Loss scaling mode, including "linear", "square", and "log".
+ Default: 'linear'
+ norm_target_weight (bool): whether to normalize the target weight
+ with number of visible keypoints. Defaults to False.
+ """
+
+ def __init__(self,
+ metainfo: Optional[str] = None,
+ reduction='mean',
+ mode='linear',
+ eps=1e-8,
+ norm_target_weight=False,
+ loss_weight=1.):
+ super().__init__()
+
+ assert reduction in ('mean', 'sum', 'none'), f'the argument ' \
+ f'`reduction` should be either \'mean\', \'sum\' or \'none\', ' \
+ f'but got {reduction}'
+
+ assert mode in ('linear', 'square', 'log'), f'the argument ' \
+ f'`reduction` should be either \'linear\', \'square\' or ' \
+ f'\'log\', but got {mode}'
+
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+ self.mode = mode
+ self.norm_target_weight = norm_target_weight
+ self.eps = eps
+
+ if metainfo is not None:
+ metainfo = parse_pose_metainfo(dict(from_file=metainfo))
+ sigmas = metainfo.get('sigmas', None)
+ if sigmas is not None:
+ self.register_buffer('sigmas', torch.as_tensor(sigmas))
+
+ def forward(self, output, target, target_weight=None, areas=None):
+ """Forward function.
+
+ Note:
+ - batch_size: N
+ - num_labels: K
+
+ Args:
+ output (torch.Tensor[N, K, 2]): Output keypoints coordinates.
+ target (torch.Tensor[N, K, 2]): Target keypoints coordinates..
+ target_weight (torch.Tensor[N, K]): Loss weight for each keypoint.
+ areas (torch.Tensor[N]): Instance size which is adopted as
+ normalization factor.
+ """
+ dist = torch.norm(output - target, dim=-1)
+ if areas is not None:
+ dist = dist / areas.pow(0.5).clip(min=self.eps).unsqueeze(-1)
+ if hasattr(self, 'sigmas'):
+ sigmas = self.sigmas.reshape(*((1, ) * (dist.ndim - 1)), -1)
+ dist = dist / (sigmas * 2)
+
+ oks = torch.exp(-dist.pow(2) / 2)
+
+ if target_weight is not None:
+ if self.norm_target_weight:
+ target_weight = target_weight / target_weight.sum(
+ dim=-1, keepdims=True).clip(min=self.eps)
+ else:
+ target_weight = target_weight / target_weight.size(-1)
+ oks = oks * target_weight
+ oks = oks.sum(dim=-1)
+
+ if self.mode == 'linear':
+ loss = 1 - oks
+ elif self.mode == 'square':
+ loss = 1 - oks.pow(2)
+ elif self.mode == 'log':
+ loss = -oks.log()
+ else:
+ raise NotImplementedError()
+
+ if self.reduction == 'sum':
+ loss = loss.sum()
+ elif self.reduction == 'mean':
+ loss = loss.mean()
+
+ return loss * self.loss_weight
diff --git a/mmpose/models/necks/__init__.py b/mmpose/models/necks/__init__.py
index b4f9105cb3..d4b4f51308 100644
--- a/mmpose/models/necks/__init__.py
+++ b/mmpose/models/necks/__init__.py
@@ -1,9 +1,13 @@
# Copyright (c) OpenMMLab. All rights reserved.
+from .channel_mapper import ChannelMapper
+from .cspnext_pafpn import CSPNeXtPAFPN
from .fmap_proc_neck import FeatureMapProcessor
from .fpn import FPN
from .gap_neck import GlobalAveragePooling
from .posewarper_neck import PoseWarperNeck
+from .yolox_pafpn import YOLOXPAFPN
__all__ = [
- 'GlobalAveragePooling', 'PoseWarperNeck', 'FPN', 'FeatureMapProcessor'
+ 'GlobalAveragePooling', 'PoseWarperNeck', 'FPN', 'FeatureMapProcessor',
+ 'ChannelMapper', 'YOLOXPAFPN', 'CSPNeXtPAFPN'
]
diff --git a/mmpose/models/necks/channel_mapper.py b/mmpose/models/necks/channel_mapper.py
new file mode 100644
index 0000000000..4d4148a089
--- /dev/null
+++ b/mmpose/models/necks/channel_mapper.py
@@ -0,0 +1,109 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple, Union
+
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule
+from torch import Tensor
+
+from mmpose.registry import MODELS
+from mmpose.utils.typing import OptConfigType, OptMultiConfig
+
+
+@MODELS.register_module()
+class ChannelMapper(BaseModule):
+ """Channel Mapper to reduce/increase channels of backbone features.
+
+ This is used to reduce/increase channels of backbone features.
+
+ Args:
+ in_channels (List[int]): Number of input channels per scale.
+ out_channels (int): Number of output channels (used at each scale).
+ kernel_size (int, optional): kernel_size for reducing channels (used
+ at each scale). Default: 3.
+ conv_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ convolution layer. Default: None.
+ norm_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ normalization layer. Default: None.
+ act_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ activation layer in ConvModule. Default: dict(type='ReLU').
+ num_outs (int, optional): Number of output feature maps. There would
+ be extra_convs when num_outs larger than the length of in_channels.
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or dict],
+ optional): Initialization config dict.
+ Example:
+ >>> import torch
+ >>> in_channels = [2, 3, 5, 7]
+ >>> scales = [340, 170, 84, 43]
+ >>> inputs = [torch.rand(1, c, s, s)
+ ... for c, s in zip(in_channels, scales)]
+ >>> self = ChannelMapper(in_channels, 11, 3).eval()
+ >>> outputs = self.forward(inputs)
+ >>> for i in range(len(outputs)):
+ ... print(f'outputs[{i}].shape = {outputs[i].shape}')
+ outputs[0].shape = torch.Size([1, 11, 340, 340])
+ outputs[1].shape = torch.Size([1, 11, 170, 170])
+ outputs[2].shape = torch.Size([1, 11, 84, 84])
+ outputs[3].shape = torch.Size([1, 11, 43, 43])
+ """
+
+ def __init__(
+ self,
+ in_channels: List[int],
+ out_channels: int,
+ kernel_size: int = 3,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: OptConfigType = None,
+ act_cfg: OptConfigType = dict(type='ReLU'),
+ num_outs: int = None,
+ bias: Union[bool, str] = 'auto',
+ init_cfg: OptMultiConfig = dict(
+ type='Xavier', layer='Conv2d', distribution='uniform')
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ assert isinstance(in_channels, list)
+ self.extra_convs = None
+ if num_outs is None:
+ num_outs = len(in_channels)
+ self.convs = nn.ModuleList()
+ for in_channel in in_channels:
+ self.convs.append(
+ ConvModule(
+ in_channel,
+ out_channels,
+ kernel_size,
+ bias=bias,
+ padding=(kernel_size - 1) // 2,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ if num_outs > len(in_channels):
+ self.extra_convs = nn.ModuleList()
+ for i in range(len(in_channels), num_outs):
+ if i == len(in_channels):
+ in_channel = in_channels[-1]
+ else:
+ in_channel = out_channels
+ self.extra_convs.append(
+ ConvModule(
+ in_channel,
+ out_channels,
+ 3,
+ stride=2,
+ padding=1,
+ bias=bias,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ def forward(self, inputs: Tuple[Tensor]) -> Tuple[Tensor]:
+ """Forward function."""
+ assert len(inputs) == len(self.convs)
+ outs = [self.convs[i](inputs[i]) for i in range(len(inputs))]
+ if self.extra_convs:
+ for i in range(len(self.extra_convs)):
+ if i == 0:
+ outs.append(self.extra_convs[0](inputs[-1]))
+ else:
+ outs.append(self.extra_convs[i](outs[-1]))
+ return tuple(outs)
diff --git a/mmpose/models/necks/cspnext_pafpn.py b/mmpose/models/necks/cspnext_pafpn.py
new file mode 100644
index 0000000000..35f4dc2f10
--- /dev/null
+++ b/mmpose/models/necks/cspnext_pafpn.py
@@ -0,0 +1,187 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Sequence, Tuple
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
+from mmengine.model import BaseModule
+from torch import Tensor
+
+from mmpose.registry import MODELS
+from mmpose.utils.typing import ConfigType, OptMultiConfig
+from ..utils import CSPLayer
+
+
+@MODELS.register_module()
+class CSPNeXtPAFPN(BaseModule):
+ """Path Aggregation Network with CSPNeXt blocks. Modified from RTMDet.
+
+ Args:
+ in_channels (Sequence[int]): Number of input channels per scale.
+ out_channels (int): Number of output channels (used at each scale)
+ out_indices (Sequence[int]): Output from which stages.
+ num_csp_blocks (int): Number of bottlenecks in CSPLayer.
+ Defaults to 3.
+ use_depthwise (bool): Whether to use depthwise separable convolution in
+ blocks. Defaults to False.
+ expand_ratio (float): Ratio to adjust the number of channels of the
+ hidden layer. Default: 0.5
+ upsample_cfg (dict): Config dict for interpolate layer.
+ Default: `dict(scale_factor=2, mode='nearest')`
+ conv_cfg (dict, optional): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN')
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='Swish')
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(
+ self,
+ in_channels: Sequence[int],
+ out_channels: int,
+ out_indices=(
+ 0,
+ 1,
+ 2,
+ ),
+ num_csp_blocks: int = 3,
+ use_depthwise: bool = False,
+ expand_ratio: float = 0.5,
+ upsample_cfg: ConfigType = dict(scale_factor=2, mode='nearest'),
+ conv_cfg: bool = None,
+ norm_cfg: ConfigType = dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg: ConfigType = dict(type='Swish'),
+ init_cfg: OptMultiConfig = dict(
+ type='Kaiming',
+ layer='Conv2d',
+ a=math.sqrt(5),
+ distribution='uniform',
+ mode='fan_in',
+ nonlinearity='leaky_relu')
+ ) -> None:
+ super().__init__(init_cfg)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.out_indices = out_indices
+
+ conv = DepthwiseSeparableConvModule if use_depthwise else ConvModule
+
+ # build top-down blocks
+ self.upsample = nn.Upsample(**upsample_cfg)
+ self.reduce_layers = nn.ModuleList()
+ self.top_down_blocks = nn.ModuleList()
+ for idx in range(len(in_channels) - 1, 0, -1):
+ self.reduce_layers.append(
+ ConvModule(
+ in_channels[idx],
+ in_channels[idx - 1],
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.top_down_blocks.append(
+ CSPLayer(
+ in_channels[idx - 1] * 2,
+ in_channels[idx - 1],
+ num_blocks=num_csp_blocks,
+ add_identity=False,
+ use_depthwise=use_depthwise,
+ use_cspnext_block=True,
+ expand_ratio=expand_ratio,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ # build bottom-up blocks
+ self.downsamples = nn.ModuleList()
+ self.bottom_up_blocks = nn.ModuleList()
+ for idx in range(len(in_channels) - 1):
+ self.downsamples.append(
+ conv(
+ in_channels[idx],
+ in_channels[idx],
+ 3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.bottom_up_blocks.append(
+ CSPLayer(
+ in_channels[idx] * 2,
+ in_channels[idx + 1],
+ num_blocks=num_csp_blocks,
+ add_identity=False,
+ use_depthwise=use_depthwise,
+ use_cspnext_block=True,
+ expand_ratio=expand_ratio,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ if self.out_channels is not None:
+ self.out_convs = nn.ModuleList()
+ for i in range(len(in_channels)):
+ self.out_convs.append(
+ conv(
+ in_channels[i],
+ out_channels,
+ 3,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.out_convs = conv(
+ in_channels[-1],
+ out_channels,
+ 3,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def forward(self, inputs: Tuple[Tensor, ...]) -> Tuple[Tensor, ...]:
+ """
+ Args:
+ inputs (tuple[Tensor]): input features.
+
+ Returns:
+ tuple[Tensor]: YOLOXPAFPN features.
+ """
+ assert len(inputs) == len(self.in_channels)
+
+ # top-down path
+ inner_outs = [inputs[-1]]
+ for idx in range(len(self.in_channels) - 1, 0, -1):
+ feat_high = inner_outs[0]
+ feat_low = inputs[idx - 1]
+ feat_high = self.reduce_layers[len(self.in_channels) - 1 - idx](
+ feat_high)
+ inner_outs[0] = feat_high
+
+ upsample_feat = self.upsample(feat_high)
+
+ inner_out = self.top_down_blocks[len(self.in_channels) - 1 - idx](
+ torch.cat([upsample_feat, feat_low], 1))
+ inner_outs.insert(0, inner_out)
+
+ # bottom-up path
+ outs = [inner_outs[0]]
+ for idx in range(len(self.in_channels) - 1):
+ feat_low = outs[-1]
+ feat_high = inner_outs[idx + 1]
+ downsample_feat = self.downsamples[idx](feat_low)
+ out = self.bottom_up_blocks[idx](
+ torch.cat([downsample_feat, feat_high], 1))
+ outs.append(out)
+
+ if self.out_channels is not None:
+ # out convs
+ for idx, conv in enumerate(self.out_convs):
+ outs[idx] = conv(outs[idx])
+
+ return tuple([outs[i] for i in self.out_indices])
diff --git a/mmpose/models/necks/yolox_pafpn.py b/mmpose/models/necks/yolox_pafpn.py
new file mode 100644
index 0000000000..adc4cfffa3
--- /dev/null
+++ b/mmpose/models/necks/yolox_pafpn.py
@@ -0,0 +1,156 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
+from mmengine.model import BaseModule
+
+from mmpose.registry import MODELS
+from ..utils import CSPLayer
+
+
+@MODELS.register_module()
+class YOLOXPAFPN(BaseModule):
+ """Path Aggregation Network used in YOLOX.
+
+ Args:
+ in_channels (List[int]): Number of input channels per scale.
+ out_channels (int): Number of output channels (used at each scale)
+ num_csp_blocks (int): Number of bottlenecks in CSPLayer. Default: 3
+ use_depthwise (bool): Whether to depthwise separable convolution in
+ blocks. Default: False
+ upsample_cfg (dict): Config dict for interpolate layer.
+ Default: `dict(scale_factor=2, mode='nearest')`
+ conv_cfg (dict, optional): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN')
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='Swish')
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ num_csp_blocks=3,
+ use_depthwise=False,
+ upsample_cfg=dict(scale_factor=2, mode='nearest'),
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg=dict(type='Swish'),
+ init_cfg=dict(
+ type='Kaiming',
+ layer='Conv2d',
+ a=math.sqrt(5),
+ distribution='uniform',
+ mode='fan_in',
+ nonlinearity='leaky_relu')):
+ super(YOLOXPAFPN, self).__init__(init_cfg)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+
+ conv = DepthwiseSeparableConvModule if use_depthwise else ConvModule
+
+ # build top-down blocks
+ self.upsample = nn.Upsample(**upsample_cfg)
+ self.reduce_layers = nn.ModuleList()
+ self.top_down_blocks = nn.ModuleList()
+ for idx in range(len(in_channels) - 1, 0, -1):
+ self.reduce_layers.append(
+ ConvModule(
+ in_channels[idx],
+ in_channels[idx - 1],
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.top_down_blocks.append(
+ CSPLayer(
+ in_channels[idx - 1] * 2,
+ in_channels[idx - 1],
+ num_blocks=num_csp_blocks,
+ add_identity=False,
+ use_depthwise=use_depthwise,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ # build bottom-up blocks
+ self.downsamples = nn.ModuleList()
+ self.bottom_up_blocks = nn.ModuleList()
+ for idx in range(len(in_channels) - 1):
+ self.downsamples.append(
+ conv(
+ in_channels[idx],
+ in_channels[idx],
+ 3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.bottom_up_blocks.append(
+ CSPLayer(
+ in_channels[idx] * 2,
+ in_channels[idx + 1],
+ num_blocks=num_csp_blocks,
+ add_identity=False,
+ use_depthwise=use_depthwise,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ self.out_convs = nn.ModuleList()
+ for i in range(len(in_channels)):
+ self.out_convs.append(
+ ConvModule(
+ in_channels[i],
+ out_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ def forward(self, inputs):
+ """
+ Args:
+ inputs (tuple[Tensor]): input features.
+
+ Returns:
+ tuple[Tensor]: YOLOXPAFPN features.
+ """
+ assert len(inputs) == len(self.in_channels)
+
+ # top-down path
+ inner_outs = [inputs[-1]]
+ for idx in range(len(self.in_channels) - 1, 0, -1):
+ feat_heigh = inner_outs[0]
+ feat_low = inputs[idx - 1]
+ feat_heigh = self.reduce_layers[len(self.in_channels) - 1 - idx](
+ feat_heigh)
+ inner_outs[0] = feat_heigh
+
+ upsample_feat = self.upsample(feat_heigh)
+
+ inner_out = self.top_down_blocks[len(self.in_channels) - 1 - idx](
+ torch.cat([upsample_feat, feat_low], 1))
+ inner_outs.insert(0, inner_out)
+
+ # bottom-up path
+ outs = [inner_outs[0]]
+ for idx in range(len(self.in_channels) - 1):
+ feat_low = outs[-1]
+ feat_height = inner_outs[idx + 1]
+ downsample_feat = self.downsamples[idx](feat_low)
+ out = self.bottom_up_blocks[idx](
+ torch.cat([downsample_feat, feat_height], 1))
+ outs.append(out)
+
+ # out convs
+ for idx, conv in enumerate(self.out_convs):
+ outs[idx] = conv(outs[idx])
+
+ return tuple(outs)
diff --git a/mmpose/models/pose_estimators/base.py b/mmpose/models/pose_estimators/base.py
index 0ae921d0ec..474e0a49d6 100644
--- a/mmpose/models/pose_estimators/base.py
+++ b/mmpose/models/pose_estimators/base.py
@@ -3,6 +3,8 @@
from typing import Tuple, Union
import torch
+from mmengine.dist import get_world_size
+from mmengine.logging import print_log
from mmengine.model import BaseModel
from torch import Tensor
@@ -22,6 +24,7 @@ class BasePoseEstimator(BaseModel, metaclass=ABCMeta):
config of :class:`BaseDataPreprocessor`. Defaults to ``None``
init_cfg (dict | ConfigDict): The model initialization config.
Defaults to ``None``
+ use_syncbn (bool): whether to use SyncBatchNorm. Defaults to False.
metainfo (dict): Meta information for dataset, such as keypoints
definition and properties. If set, the metainfo of the input data
batch will be overridden. For more details, please refer to
@@ -38,11 +41,14 @@ def __init__(self,
train_cfg: OptConfigType = None,
test_cfg: OptConfigType = None,
data_preprocessor: OptConfigType = None,
+ use_syncbn: bool = False,
init_cfg: OptMultiConfig = None,
metainfo: Optional[dict] = None):
super().__init__(
data_preprocessor=data_preprocessor, init_cfg=init_cfg)
self.metainfo = self._load_metainfo(metainfo)
+ self.train_cfg = train_cfg if train_cfg else {}
+ self.test_cfg = test_cfg if test_cfg else {}
self.backbone = MODELS.build(backbone)
@@ -57,13 +63,16 @@ def __init__(self,
if head is not None:
self.head = MODELS.build(head)
-
- self.train_cfg = train_cfg if train_cfg else {}
- self.test_cfg = test_cfg if test_cfg else {}
+ self.head.test_cfg = self.test_cfg.copy()
# Register the hook to automatically convert old version state dicts
self._register_load_state_dict_pre_hook(self._load_state_dict_pre_hook)
+ # TODO: Waiting for mmengine support
+ if use_syncbn and get_world_size() > 1:
+ torch.nn.SyncBatchNorm.convert_sync_batchnorm(self)
+ print_log('Using SyncBatchNorm()', 'current')
+
@property
def with_neck(self) -> bool:
"""bool: whether the pose estimator has a neck."""
@@ -193,18 +202,32 @@ def extract_feat(self, inputs: Tensor) -> Tuple[Tensor]:
def _load_state_dict_pre_hook(self, state_dict, prefix, local_meta, *args,
**kwargs):
- """A hook function to convert old-version state dict of
+ """A hook function to.
+
+ 1) convert old-version state dict of
:class:`TopdownHeatmapSimpleHead` (before MMPose v1.0.0) to a
compatible format of :class:`HeatmapHead`.
+ 2) remove the weights in data_preprocessor to avoid warning
+ `unexpected key in source state_dict: ...`. These weights are
+ initialized with given arguments and remain same during training
+ and inference.
+
The hook will be automatically registered during initialization.
"""
+
+ keys = list(state_dict.keys())
+
+ # remove the keys in data_preprocessor to avoid warning
+ for k in keys:
+ if k in ('data_preprocessor.mean', 'data_preprocessor.std'):
+ del state_dict[k]
+
version = local_meta.get('version', None)
if version and version >= self._version:
return
# convert old-version state dict
- keys = list(state_dict.keys())
for k in keys:
if 'keypoint_head' in k:
v = state_dict.pop(k)
diff --git a/mmpose/models/pose_estimators/bottomup.py b/mmpose/models/pose_estimators/bottomup.py
index 5400f2478e..7b82980a13 100644
--- a/mmpose/models/pose_estimators/bottomup.py
+++ b/mmpose/models/pose_estimators/bottomup.py
@@ -23,6 +23,7 @@ class BottomupPoseEstimator(BasePoseEstimator):
Defaults to ``None``
test_cfg (dict, optional): The runtime config for testing process.
Defaults to ``None``
+ use_syncbn (bool): whether to use SyncBatchNorm. Defaults to False.
data_preprocessor (dict, optional): The data preprocessing config to
build the instance of :class:`BaseDataPreprocessor`. Defaults to
``None``.
@@ -36,6 +37,7 @@ def __init__(self,
head: OptConfigType = None,
train_cfg: OptConfigType = None,
test_cfg: OptConfigType = None,
+ use_syncbn: bool = False,
data_preprocessor: OptConfigType = None,
init_cfg: OptMultiConfig = None):
super().__init__(
@@ -44,6 +46,7 @@ def __init__(self,
head=head,
train_cfg=train_cfg,
test_cfg=test_cfg,
+ use_syncbn=use_syncbn,
data_preprocessor=data_preprocessor,
init_cfg=init_cfg)
@@ -162,13 +165,24 @@ def add_pred_to_datasample(self, batch_pred_instances: InstanceList,
for pred_instances, pred_fields, data_sample in zip_longest(
batch_pred_instances, batch_pred_fields, batch_data_samples):
- # convert keypoint coordinates from input space to image space
input_size = data_sample.metainfo['input_size']
input_center = data_sample.metainfo['input_center']
input_scale = data_sample.metainfo['input_scale']
+ # convert keypoint coordinates from input space to image space
pred_instances.keypoints = pred_instances.keypoints / input_size \
* input_scale + input_center - 0.5 * input_scale
+ if 'keypoints_visible' not in pred_instances:
+ pred_instances.keypoints_visible = \
+ pred_instances.keypoint_scores
+
+ # convert bbox coordinates from input space to image space
+ if 'bboxes' in pred_instances:
+ bboxes = pred_instances.bboxes.reshape(
+ pred_instances.bboxes.shape[0], 2, 2)
+ bboxes = bboxes / input_size * input_scale + input_center \
+ - 0.5 * input_scale
+ pred_instances.bboxes = bboxes.reshape(bboxes.shape[0], 4)
data_sample.pred_instances = pred_instances
diff --git a/mmpose/models/pose_estimators/pose_lifter.py b/mmpose/models/pose_estimators/pose_lifter.py
index 5bad3dde3c..ec8401d1a2 100644
--- a/mmpose/models/pose_estimators/pose_lifter.py
+++ b/mmpose/models/pose_estimators/pose_lifter.py
@@ -2,9 +2,11 @@
from itertools import zip_longest
from typing import Tuple, Union
+import torch
from torch import Tensor
from mmpose.models.utils import check_and_update_config
+from mmpose.models.utils.tta import flip_coordinates
from mmpose.registry import MODELS
from mmpose.utils.typing import (ConfigType, InstanceList, OptConfigType,
Optional, OptMultiConfig, OptSampleList,
@@ -244,7 +246,22 @@ def predict(self, inputs: Tensor, data_samples: SampleList) -> SampleList:
assert self.with_head, (
'The model must have head to perform prediction.')
- feats = self.extract_feat(inputs)
+ if self.test_cfg.get('flip_test', False):
+ flip_indices = data_samples[0].metainfo['flip_indices']
+ _feats = self.extract_feat(inputs)
+ _feats_flip = self.extract_feat(
+ torch.stack([
+ flip_coordinates(
+ _input,
+ flip_indices=flip_indices,
+ shift_coords=self.test_cfg.get('shift_coords', True),
+ input_size=(1, 1)) for _input in inputs
+ ],
+ dim=0))
+
+ feats = [_feats, _feats_flip]
+ else:
+ feats = self.extract_feat(inputs)
pose_preds, batch_pred_instances, batch_pred_fields = None, None, None
traj_preds, batch_traj_instances, batch_traj_fields = None, None, None
diff --git a/mmpose/models/pose_estimators/topdown.py b/mmpose/models/pose_estimators/topdown.py
index 89b332893f..f5bb90273e 100644
--- a/mmpose/models/pose_estimators/topdown.py
+++ b/mmpose/models/pose_estimators/topdown.py
@@ -147,12 +147,16 @@ def add_pred_to_datasample(self, batch_pred_instances: InstanceList,
gt_instances = data_sample.gt_instances
# convert keypoint coordinates from input space to image space
- bbox_centers = gt_instances.bbox_centers
- bbox_scales = gt_instances.bbox_scales
+ input_center = data_sample.metainfo['input_center']
+ input_scale = data_sample.metainfo['input_scale']
input_size = data_sample.metainfo['input_size']
- pred_instances.keypoints = pred_instances.keypoints / input_size \
- * bbox_scales + bbox_centers - 0.5 * bbox_scales
+ pred_instances.keypoints[..., :2] = \
+ pred_instances.keypoints[..., :2] / input_size * input_scale \
+ + input_center - 0.5 * input_scale
+ if 'keypoints_visible' not in pred_instances:
+ pred_instances.keypoints_visible = \
+ pred_instances.keypoint_scores
if output_keypoint_indices is not None:
# select output keypoints with given indices
diff --git a/mmpose/models/task_modules/__init__.py b/mmpose/models/task_modules/__init__.py
new file mode 100644
index 0000000000..caecfb9d33
--- /dev/null
+++ b/mmpose/models/task_modules/__init__.py
@@ -0,0 +1,3 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .assigners import * # noqa
+from .prior_generators import * # noqa
diff --git a/mmpose/models/task_modules/assigners/__init__.py b/mmpose/models/task_modules/assigners/__init__.py
new file mode 100644
index 0000000000..7b6b006e38
--- /dev/null
+++ b/mmpose/models/task_modules/assigners/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .metric_calculators import BBoxOverlaps2D, PoseOKS
+from .sim_ota_assigner import SimOTAAssigner
+
+__all__ = ['SimOTAAssigner', 'PoseOKS', 'BBoxOverlaps2D']
diff --git a/mmpose/models/task_modules/assigners/metric_calculators.py b/mmpose/models/task_modules/assigners/metric_calculators.py
new file mode 100644
index 0000000000..ebf4333b66
--- /dev/null
+++ b/mmpose/models/task_modules/assigners/metric_calculators.py
@@ -0,0 +1,108 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch
+from torch import Tensor
+
+from mmpose.datasets.datasets.utils import parse_pose_metainfo
+from mmpose.registry import TASK_UTILS
+from mmpose.structures.bbox import bbox_overlaps
+
+
+def cast_tensor_type(x, scale=1., dtype=None):
+ if dtype == 'fp16':
+ # scale is for preventing overflows
+ x = (x / scale).half()
+ return x
+
+
+@TASK_UTILS.register_module()
+class BBoxOverlaps2D:
+ """2D Overlaps (e.g. IoUs, GIoUs) Calculator."""
+
+ def __init__(self, scale=1., dtype=None):
+ self.scale = scale
+ self.dtype = dtype
+
+ @torch.no_grad()
+ def __call__(self, bboxes1, bboxes2, mode='iou', is_aligned=False):
+ """Calculate IoU between 2D bboxes.
+
+ Args:
+ bboxes1 (Tensor or :obj:`BaseBoxes`): bboxes have shape (m, 4)
+ in format, or shape (m, 5) in format.
+ bboxes2 (Tensor or :obj:`BaseBoxes`): bboxes have shape (m, 4)
+ in format, shape (m, 5) in format, or be empty. If ``is_aligned `` is ``True``,
+ then m and n must be equal.
+ mode (str): "iou" (intersection over union), "iof" (intersection
+ over foreground), or "giou" (generalized intersection over
+ union).
+ is_aligned (bool, optional): If True, then m and n must be equal.
+ Default False.
+
+ Returns:
+ Tensor: shape (m, n) if ``is_aligned `` is False else shape (m,)
+ """
+ assert bboxes1.size(-1) in [0, 4, 5]
+ assert bboxes2.size(-1) in [0, 4, 5]
+ if bboxes2.size(-1) == 5:
+ bboxes2 = bboxes2[..., :4]
+ if bboxes1.size(-1) == 5:
+ bboxes1 = bboxes1[..., :4]
+
+ if self.dtype == 'fp16':
+ # change tensor type to save cpu and cuda memory and keep speed
+ bboxes1 = cast_tensor_type(bboxes1, self.scale, self.dtype)
+ bboxes2 = cast_tensor_type(bboxes2, self.scale, self.dtype)
+ overlaps = bbox_overlaps(bboxes1, bboxes2, mode, is_aligned)
+ if not overlaps.is_cuda and overlaps.dtype == torch.float16:
+ # resume cpu float32
+ overlaps = overlaps.float()
+ return overlaps
+
+ return bbox_overlaps(bboxes1, bboxes2, mode, is_aligned)
+
+ def __repr__(self):
+ """str: a string describing the module"""
+ repr_str = self.__class__.__name__ + f'(' \
+ f'scale={self.scale}, dtype={self.dtype})'
+ return repr_str
+
+
+@TASK_UTILS.register_module()
+class PoseOKS:
+ """OKS score Calculator."""
+
+ def __init__(self,
+ metainfo: Optional[str] = 'configs/_base_/datasets/coco.py'):
+
+ if metainfo is not None:
+ metainfo = parse_pose_metainfo(dict(from_file=metainfo))
+ sigmas = metainfo.get('sigmas', None)
+ if sigmas is not None:
+ self.sigmas = torch.as_tensor(sigmas)
+
+ @torch.no_grad()
+ def __call__(self,
+ output: Tensor,
+ target: Tensor,
+ target_weights: Tensor,
+ areas: Tensor,
+ eps: float = 1e-8) -> Tensor:
+
+ dist = torch.norm(output - target, dim=-1)
+ areas = areas.reshape(*((1, ) * (dist.ndim - 2)), -1, 1)
+ dist = dist / areas.pow(0.5).clip(min=eps)
+
+ if hasattr(self, 'sigmas'):
+ if self.sigmas.device != dist.device:
+ self.sigmas = self.sigmas.to(dist.device)
+ sigmas = self.sigmas.reshape(*((1, ) * (dist.ndim - 1)), -1)
+ dist = dist / (sigmas * 2)
+
+ target_weights = target_weights / target_weights.sum(
+ dim=-1, keepdims=True).clip(min=eps)
+ oks = (torch.exp(-dist.pow(2) / 2) * target_weights).sum(dim=-1)
+ return oks
diff --git a/mmpose/models/task_modules/assigners/sim_ota_assigner.py b/mmpose/models/task_modules/assigners/sim_ota_assigner.py
new file mode 100644
index 0000000000..69c7ed677e
--- /dev/null
+++ b/mmpose/models/task_modules/assigners/sim_ota_assigner.py
@@ -0,0 +1,284 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Tuple
+
+import torch
+import torch.nn.functional as F
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmpose.registry import TASK_UTILS
+from mmpose.utils.typing import ConfigType
+
+INF = 100000.0
+EPS = 1.0e-7
+
+
+@TASK_UTILS.register_module()
+class SimOTAAssigner:
+ """Computes matching between predictions and ground truth.
+
+ Args:
+ center_radius (float): Radius of center area to determine
+ if a prior is in the center of a gt. Defaults to 2.5.
+ candidate_topk (int): Top-k ious candidates to calculate dynamic-k.
+ Defaults to 10.
+ iou_weight (float): Weight of bbox iou cost. Defaults to 3.0.
+ cls_weight (float): Weight of classification cost. Defaults to 1.0.
+ oks_weight (float): Weight of keypoint OKS cost. Defaults to 3.0.
+ vis_weight (float): Weight of keypoint visibility cost. Defaults to 0.0
+ dynamic_k_indicator (str): Cost type for calculating dynamic-k,
+ either 'iou' or 'oks'. Defaults to 'iou'.
+ iou_calculator (dict): Config of IoU calculation method.
+ Defaults to dict(type='BBoxOverlaps2D').
+ oks_calculator (dict): Config of OKS calculation method.
+ Defaults to dict(type='PoseOKS').
+ """
+
+ def __init__(self,
+ center_radius: float = 2.5,
+ candidate_topk: int = 10,
+ iou_weight: float = 3.0,
+ cls_weight: float = 1.0,
+ oks_weight: float = 3.0,
+ vis_weight: float = 0.0,
+ dynamic_k_indicator: str = 'iou',
+ iou_calculator: ConfigType = dict(type='BBoxOverlaps2D'),
+ oks_calculator: ConfigType = dict(type='PoseOKS')):
+ self.center_radius = center_radius
+ self.candidate_topk = candidate_topk
+ self.iou_weight = iou_weight
+ self.cls_weight = cls_weight
+ self.oks_weight = oks_weight
+ self.vis_weight = vis_weight
+ assert dynamic_k_indicator in ('iou', 'oks'), f'the argument ' \
+ f'`dynamic_k_indicator` should be either \'iou\' or \'oks\', ' \
+ f'but got {dynamic_k_indicator}'
+ self.dynamic_k_indicator = dynamic_k_indicator
+
+ self.iou_calculator = TASK_UTILS.build(iou_calculator)
+ self.oks_calculator = TASK_UTILS.build(oks_calculator)
+
+ def assign(self, pred_instances: InstanceData, gt_instances: InstanceData,
+ **kwargs) -> dict:
+ """Assign gt to priors using SimOTA.
+
+ Args:
+ pred_instances (:obj:`InstanceData`): Instances of model
+ predictions. It includes ``priors``, and the priors can
+ be anchors or points, or the bboxes predicted by the
+ previous stage, has shape (n, 4). The bboxes predicted by
+ the current model or stage will be named ``bboxes``,
+ ``labels``, and ``scores``, the same as the ``InstanceData``
+ in other places.
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes``, with shape (k, 4),
+ and ``labels``, with shape (k, ).
+ Returns:
+ dict: Assignment result containing assigned gt indices,
+ max iou overlaps, assigned labels, etc.
+ """
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ gt_keypoints = gt_instances.keypoints
+ gt_keypoints_visible = gt_instances.keypoints_visible
+ gt_areas = gt_instances.areas
+ num_gt = gt_bboxes.size(0)
+
+ decoded_bboxes = pred_instances.bboxes
+ pred_scores = pred_instances.scores
+ priors = pred_instances.priors
+ keypoints = pred_instances.keypoints
+ keypoints_visible = pred_instances.keypoints_visible
+ num_bboxes = decoded_bboxes.size(0)
+
+ # assign 0 by default
+ assigned_gt_inds = decoded_bboxes.new_full((num_bboxes, ),
+ 0,
+ dtype=torch.long)
+ if num_gt == 0 or num_bboxes == 0:
+ # No ground truth or boxes, return empty assignment
+ max_overlaps = decoded_bboxes.new_zeros((num_bboxes, ))
+ assigned_labels = decoded_bboxes.new_full((num_bboxes, ),
+ -1,
+ dtype=torch.long)
+ return dict(
+ num_gts=num_gt,
+ gt_inds=assigned_gt_inds,
+ max_overlaps=max_overlaps,
+ labels=assigned_labels)
+
+ valid_mask, is_in_boxes_and_center = self.get_in_gt_and_in_center_info(
+ priors, gt_bboxes)
+ valid_decoded_bbox = decoded_bboxes[valid_mask]
+ valid_pred_scores = pred_scores[valid_mask]
+ valid_pred_kpts = keypoints[valid_mask]
+ valid_pred_kpts_vis = keypoints_visible[valid_mask]
+
+ num_valid = valid_decoded_bbox.size(0)
+ if num_valid == 0:
+ # No valid bboxes, return empty assignment
+ max_overlaps = decoded_bboxes.new_zeros((num_bboxes, ))
+ assigned_labels = decoded_bboxes.new_full((num_bboxes, ),
+ -1,
+ dtype=torch.long)
+ return dict(
+ num_gts=num_gt,
+ gt_inds=assigned_gt_inds,
+ max_overlaps=max_overlaps,
+ labels=assigned_labels)
+
+ cost_matrix = (~is_in_boxes_and_center) * INF
+
+ # calculate iou
+ pairwise_ious = self.iou_calculator(valid_decoded_bbox, gt_bboxes)
+ if self.iou_weight > 0:
+ iou_cost = -torch.log(pairwise_ious + EPS)
+ cost_matrix = cost_matrix + iou_cost * self.iou_weight
+
+ # calculate oks
+ if self.oks_weight > 0 or self.dynamic_k_indicator == 'oks':
+ pairwise_oks = self.oks_calculator(
+ valid_pred_kpts.unsqueeze(1), # [num_valid, 1, k, 2]
+ target=gt_keypoints.unsqueeze(0), # [1, num_gt, k, 2]
+ target_weights=gt_keypoints_visible.unsqueeze(
+ 0), # [1, num_gt, k]
+ areas=gt_areas.unsqueeze(0), # [1, num_gt]
+ ) # -> [num_valid, num_gt]
+
+ oks_cost = -torch.log(pairwise_oks + EPS)
+ cost_matrix = cost_matrix + oks_cost * self.oks_weight
+
+ # calculate cls
+ if self.cls_weight > 0:
+ gt_onehot_label = (
+ F.one_hot(gt_labels.to(torch.int64),
+ pred_scores.shape[-1]).float().unsqueeze(0).repeat(
+ num_valid, 1, 1))
+ valid_pred_scores = valid_pred_scores.unsqueeze(1).repeat(
+ 1, num_gt, 1)
+ # disable AMP autocast to avoid overflow
+ with torch.cuda.amp.autocast(enabled=False):
+ cls_cost = (
+ F.binary_cross_entropy(
+ valid_pred_scores.to(dtype=torch.float32),
+ gt_onehot_label,
+ reduction='none',
+ ).sum(-1).to(dtype=valid_pred_scores.dtype))
+ cost_matrix = cost_matrix + cls_cost * self.cls_weight
+ # calculate vis
+ if self.vis_weight > 0:
+ valid_pred_kpts_vis = valid_pred_kpts_vis.unsqueeze(1).repeat(
+ 1, num_gt, 1) # [num_valid, 1, k]
+ gt_kpt_vis = gt_keypoints_visible.unsqueeze(
+ 0).float() # [1, num_gt, k]
+ with torch.cuda.amp.autocast(enabled=False):
+ vis_cost = (
+ F.binary_cross_entropy(
+ valid_pred_kpts_vis.to(dtype=torch.float32),
+ gt_kpt_vis.repeat(num_valid, 1, 1),
+ reduction='none',
+ ).sum(-1).to(dtype=valid_pred_kpts_vis.dtype))
+ cost_matrix = cost_matrix + vis_cost * self.vis_weight
+
+ if self.dynamic_k_indicator == 'iou':
+ matched_pred_ious, matched_gt_inds = \
+ self.dynamic_k_matching(
+ cost_matrix, pairwise_ious, num_gt, valid_mask)
+ elif self.dynamic_k_indicator == 'oks':
+ matched_pred_ious, matched_gt_inds = \
+ self.dynamic_k_matching(
+ cost_matrix, pairwise_oks, num_gt, valid_mask)
+
+ # convert to AssignResult format
+ assigned_gt_inds[valid_mask] = matched_gt_inds + 1
+ assigned_labels = assigned_gt_inds.new_full((num_bboxes, ), -1)
+ assigned_labels[valid_mask] = gt_labels[matched_gt_inds].long()
+ max_overlaps = assigned_gt_inds.new_full((num_bboxes, ),
+ -INF,
+ dtype=torch.float32)
+ max_overlaps[valid_mask] = matched_pred_ious.to(max_overlaps)
+ return dict(
+ num_gts=num_gt,
+ gt_inds=assigned_gt_inds,
+ max_overlaps=max_overlaps,
+ labels=assigned_labels)
+
+ def get_in_gt_and_in_center_info(self, priors: Tensor, gt_bboxes: Tensor
+ ) -> Tuple[Tensor, Tensor]:
+ """Get the information of which prior is in gt bboxes and gt center
+ priors."""
+ num_gt = gt_bboxes.size(0)
+
+ repeated_x = priors[:, 0].unsqueeze(1).repeat(1, num_gt)
+ repeated_y = priors[:, 1].unsqueeze(1).repeat(1, num_gt)
+ repeated_stride_x = priors[:, 2].unsqueeze(1).repeat(1, num_gt)
+ repeated_stride_y = priors[:, 3].unsqueeze(1).repeat(1, num_gt)
+
+ # is prior centers in gt bboxes, shape: [n_prior, n_gt]
+ l_ = repeated_x - gt_bboxes[:, 0]
+ t_ = repeated_y - gt_bboxes[:, 1]
+ r_ = gt_bboxes[:, 2] - repeated_x
+ b_ = gt_bboxes[:, 3] - repeated_y
+
+ deltas = torch.stack([l_, t_, r_, b_], dim=1)
+ is_in_gts = deltas.min(dim=1).values > 0
+ is_in_gts_all = is_in_gts.sum(dim=1) > 0
+
+ # is prior centers in gt centers
+ gt_cxs = (gt_bboxes[:, 0] + gt_bboxes[:, 2]) / 2.0
+ gt_cys = (gt_bboxes[:, 1] + gt_bboxes[:, 3]) / 2.0
+ ct_box_l = gt_cxs - self.center_radius * repeated_stride_x
+ ct_box_t = gt_cys - self.center_radius * repeated_stride_y
+ ct_box_r = gt_cxs + self.center_radius * repeated_stride_x
+ ct_box_b = gt_cys + self.center_radius * repeated_stride_y
+
+ cl_ = repeated_x - ct_box_l
+ ct_ = repeated_y - ct_box_t
+ cr_ = ct_box_r - repeated_x
+ cb_ = ct_box_b - repeated_y
+
+ ct_deltas = torch.stack([cl_, ct_, cr_, cb_], dim=1)
+ is_in_cts = ct_deltas.min(dim=1).values > 0
+ is_in_cts_all = is_in_cts.sum(dim=1) > 0
+
+ # in boxes or in centers, shape: [num_priors]
+ is_in_gts_or_centers = is_in_gts_all | is_in_cts_all
+
+ # both in boxes and centers, shape: [num_fg, num_gt]
+ is_in_boxes_and_centers = (
+ is_in_gts[is_in_gts_or_centers, :]
+ & is_in_cts[is_in_gts_or_centers, :])
+ return is_in_gts_or_centers, is_in_boxes_and_centers
+
+ def dynamic_k_matching(self, cost: Tensor, pairwise_ious: Tensor,
+ num_gt: int,
+ valid_mask: Tensor) -> Tuple[Tensor, Tensor]:
+ """Use IoU and matching cost to calculate the dynamic top-k positive
+ targets."""
+ matching_matrix = torch.zeros_like(cost, dtype=torch.uint8)
+ # select candidate topk ious for dynamic-k calculation
+ candidate_topk = min(self.candidate_topk, pairwise_ious.size(0))
+ topk_ious, _ = torch.topk(pairwise_ious, candidate_topk, dim=0)
+ # calculate dynamic k for each gt
+ dynamic_ks = torch.clamp(topk_ious.sum(0).int(), min=1)
+ for gt_idx in range(num_gt):
+ _, pos_idx = torch.topk(
+ cost[:, gt_idx], k=dynamic_ks[gt_idx], largest=False)
+ matching_matrix[:, gt_idx][pos_idx] = 1
+
+ del topk_ious, dynamic_ks, pos_idx
+
+ prior_match_gt_mask = matching_matrix.sum(1) > 1
+ if prior_match_gt_mask.sum() > 0:
+ cost_min, cost_argmin = torch.min(
+ cost[prior_match_gt_mask, :], dim=1)
+ matching_matrix[prior_match_gt_mask, :] *= 0
+ matching_matrix[prior_match_gt_mask, cost_argmin] = 1
+ # get foreground mask inside box and center prior
+ fg_mask_inboxes = matching_matrix.sum(1) > 0
+ valid_mask[valid_mask.clone()] = fg_mask_inboxes
+
+ matched_gt_inds = matching_matrix[fg_mask_inboxes, :].argmax(1)
+ matched_pred_ious = (matching_matrix *
+ pairwise_ious).sum(1)[fg_mask_inboxes]
+ return matched_pred_ious, matched_gt_inds
diff --git a/mmpose/models/task_modules/prior_generators/__init__.py b/mmpose/models/task_modules/prior_generators/__init__.py
new file mode 100644
index 0000000000..e153da8447
--- /dev/null
+++ b/mmpose/models/task_modules/prior_generators/__init__.py
@@ -0,0 +1,2 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .mlvl_point_generator import MlvlPointGenerator # noqa
diff --git a/mmpose/models/task_modules/prior_generators/mlvl_point_generator.py b/mmpose/models/task_modules/prior_generators/mlvl_point_generator.py
new file mode 100644
index 0000000000..7dc6a6199b
--- /dev/null
+++ b/mmpose/models/task_modules/prior_generators/mlvl_point_generator.py
@@ -0,0 +1,245 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple, Union
+
+import numpy as np
+import torch
+from torch import Tensor
+from torch.nn.modules.utils import _pair
+
+from mmpose.registry import TASK_UTILS
+
+DeviceType = Union[str, torch.device]
+
+
+@TASK_UTILS.register_module()
+class MlvlPointGenerator:
+ """Standard points generator for multi-level (Mlvl) feature maps in 2D
+ points-based detectors.
+
+ Args:
+ strides (list[int] | list[tuple[int, int]]): Strides of anchors
+ in multiple feature levels in order (w, h).
+ offset (float): The offset of points, the value is normalized with
+ corresponding stride. Defaults to 0.5.
+ """
+
+ def __init__(self,
+ strides: Union[List[int], List[Tuple[int, int]]],
+ offset: float = 0.5) -> None:
+ self.strides = [_pair(stride) for stride in strides]
+ self.offset = offset
+
+ @property
+ def num_levels(self) -> int:
+ """int: number of feature levels that the generator will be applied"""
+ return len(self.strides)
+
+ @property
+ def num_base_priors(self) -> List[int]:
+ """list[int]: The number of priors (points) at a point
+ on the feature grid"""
+ return [1 for _ in range(len(self.strides))]
+
+ def _meshgrid(self,
+ x: Tensor,
+ y: Tensor,
+ row_major: bool = True) -> Tuple[Tensor, Tensor]:
+ yy, xx = torch.meshgrid(y, x)
+ if row_major:
+ # warning .flatten() would cause error in ONNX exporting
+ # have to use reshape here
+ return xx.reshape(-1), yy.reshape(-1)
+
+ else:
+ return yy.reshape(-1), xx.reshape(-1)
+
+ def grid_priors(self,
+ featmap_sizes: List[Tuple],
+ dtype: torch.dtype = torch.float32,
+ device: DeviceType = 'cuda',
+ with_stride: bool = False) -> List[Tensor]:
+ """Generate grid points of multiple feature levels.
+
+ Args:
+ featmap_sizes (list[tuple]): List of feature map sizes in
+ multiple feature levels, each size arrange as
+ as (h, w).
+ dtype (:obj:`dtype`): Dtype of priors. Defaults to torch.float32.
+ device (str | torch.device): The device where the anchors will be
+ put on.
+ with_stride (bool): Whether to concatenate the stride to
+ the last dimension of points.
+
+ Return:
+ list[torch.Tensor]: Points of multiple feature levels.
+ The sizes of each tensor should be (N, 2) when with stride is
+ ``False``, where N = width * height, width and height
+ are the sizes of the corresponding feature level,
+ and the last dimension 2 represent (coord_x, coord_y),
+ otherwise the shape should be (N, 4),
+ and the last dimension 4 represent
+ (coord_x, coord_y, stride_w, stride_h).
+ """
+
+ assert self.num_levels == len(featmap_sizes)
+ multi_level_priors = []
+ for i in range(self.num_levels):
+ priors = self.single_level_grid_priors(
+ featmap_sizes[i],
+ level_idx=i,
+ dtype=dtype,
+ device=device,
+ with_stride=with_stride)
+ multi_level_priors.append(priors)
+ return multi_level_priors
+
+ def single_level_grid_priors(self,
+ featmap_size: Tuple[int],
+ level_idx: int,
+ dtype: torch.dtype = torch.float32,
+ device: DeviceType = 'cuda',
+ with_stride: bool = False) -> Tensor:
+ """Generate grid Points of a single level.
+
+ Note:
+ This function is usually called by method ``self.grid_priors``.
+
+ Args:
+ featmap_size (tuple[int]): Size of the feature maps, arrange as
+ (h, w).
+ level_idx (int): The index of corresponding feature map level.
+ dtype (:obj:`dtype`): Dtype of priors. Defaults to torch.float32.
+ device (str | torch.device): The device the tensor will be put on.
+ Defaults to 'cuda'.
+ with_stride (bool): Concatenate the stride to the last dimension
+ of points.
+
+ Return:
+ Tensor: Points of single feature levels.
+ The shape of tensor should be (N, 2) when with stride is
+ ``False``, where N = width * height, width and height
+ are the sizes of the corresponding feature level,
+ and the last dimension 2 represent (coord_x, coord_y),
+ otherwise the shape should be (N, 4),
+ and the last dimension 4 represent
+ (coord_x, coord_y, stride_w, stride_h).
+ """
+ feat_h, feat_w = featmap_size
+ stride_w, stride_h = self.strides[level_idx]
+ shift_x = (torch.arange(0, feat_w, device=device) +
+ self.offset) * stride_w
+ # keep featmap_size as Tensor instead of int, so that we
+ # can convert to ONNX correctly
+ shift_x = shift_x.to(dtype)
+
+ shift_y = (torch.arange(0, feat_h, device=device) +
+ self.offset) * stride_h
+ # keep featmap_size as Tensor instead of int, so that we
+ # can convert to ONNX correctly
+ shift_y = shift_y.to(dtype)
+
+ shift_xx, shift_yy = self._meshgrid(shift_x, shift_y)
+ if not with_stride:
+ shifts = torch.stack([shift_xx, shift_yy], dim=-1)
+ else:
+ # use `shape[0]` instead of `len(shift_xx)` for ONNX export
+ stride_w = shift_xx.new_full((shift_xx.shape[0], ),
+ stride_w).to(dtype)
+ stride_h = shift_xx.new_full((shift_yy.shape[0], ),
+ stride_h).to(dtype)
+ shifts = torch.stack([shift_xx, shift_yy, stride_w, stride_h],
+ dim=-1)
+ all_points = shifts.to(device)
+ return all_points
+
+ def valid_flags(self,
+ featmap_sizes: List[Tuple[int, int]],
+ pad_shape: Tuple[int],
+ device: DeviceType = 'cuda') -> List[Tensor]:
+ """Generate valid flags of points of multiple feature levels.
+
+ Args:
+ featmap_sizes (list(tuple)): List of feature map sizes in
+ multiple feature levels, each size arrange as
+ as (h, w).
+ pad_shape (tuple(int)): The padded shape of the image,
+ arrange as (h, w).
+ device (str | torch.device): The device where the anchors will be
+ put on.
+
+ Return:
+ list(torch.Tensor): Valid flags of points of multiple levels.
+ """
+ assert self.num_levels == len(featmap_sizes)
+ multi_level_flags = []
+ for i in range(self.num_levels):
+ point_stride = self.strides[i]
+ feat_h, feat_w = featmap_sizes[i]
+ h, w = pad_shape[:2]
+ valid_feat_h = min(int(np.ceil(h / point_stride[1])), feat_h)
+ valid_feat_w = min(int(np.ceil(w / point_stride[0])), feat_w)
+ flags = self.single_level_valid_flags((feat_h, feat_w),
+ (valid_feat_h, valid_feat_w),
+ device=device)
+ multi_level_flags.append(flags)
+ return multi_level_flags
+
+ def single_level_valid_flags(self,
+ featmap_size: Tuple[int, int],
+ valid_size: Tuple[int, int],
+ device: DeviceType = 'cuda') -> Tensor:
+ """Generate the valid flags of points of a single feature map.
+
+ Args:
+ featmap_size (tuple[int]): The size of feature maps, arrange as
+ as (h, w).
+ valid_size (tuple[int]): The valid size of the feature maps.
+ The size arrange as as (h, w).
+ device (str | torch.device): The device where the flags will be
+ put on. Defaults to 'cuda'.
+
+ Returns:
+ torch.Tensor: The valid flags of each points in a single level \
+ feature map.
+ """
+ feat_h, feat_w = featmap_size
+ valid_h, valid_w = valid_size
+ assert valid_h <= feat_h and valid_w <= feat_w
+ valid_x = torch.zeros(feat_w, dtype=torch.bool, device=device)
+ valid_y = torch.zeros(feat_h, dtype=torch.bool, device=device)
+ valid_x[:valid_w] = 1
+ valid_y[:valid_h] = 1
+ valid_xx, valid_yy = self._meshgrid(valid_x, valid_y)
+ valid = valid_xx & valid_yy
+ return valid
+
+ def sparse_priors(self,
+ prior_idxs: Tensor,
+ featmap_size: Tuple[int],
+ level_idx: int,
+ dtype: torch.dtype = torch.float32,
+ device: DeviceType = 'cuda') -> Tensor:
+ """Generate sparse points according to the ``prior_idxs``.
+
+ Args:
+ prior_idxs (Tensor): The index of corresponding anchors
+ in the feature map.
+ featmap_size (tuple[int]): feature map size arrange as (w, h).
+ level_idx (int): The level index of corresponding feature
+ map.
+ dtype (obj:`torch.dtype`): Date type of points. Defaults to
+ ``torch.float32``.
+ device (str | torch.device): The device where the points is
+ located.
+ Returns:
+ Tensor: Anchor with shape (N, 2), N should be equal to
+ the length of ``prior_idxs``. And last dimension
+ 2 represent (coord_x, coord_y).
+ """
+ height, width = featmap_size
+ x = (prior_idxs % width + self.offset) * self.strides[level_idx][0]
+ y = ((prior_idxs // width) % height +
+ self.offset) * self.strides[level_idx][1]
+ prioris = torch.stack([x, y], 1).to(dtype)
+ prioris = prioris.to(device)
+ return prioris
diff --git a/mmpose/models/utils/__init__.py b/mmpose/models/utils/__init__.py
index 22d8a89b41..539da6ea2f 100644
--- a/mmpose/models/utils/__init__.py
+++ b/mmpose/models/utils/__init__.py
@@ -1,10 +1,14 @@
# Copyright (c) OpenMMLab. All rights reserved.
from .check_and_update_config import check_and_update_config
from .ckpt_convert import pvt_convert
+from .csp_layer import CSPLayer
+from .misc import filter_scores_and_topk
+from .ops import FrozenBatchNorm2d, inverse_sigmoid
from .rtmcc_block import RTMCCBlock, rope
from .transformer import PatchEmbed, nchw_to_nlc, nlc_to_nchw
__all__ = [
'PatchEmbed', 'nchw_to_nlc', 'nlc_to_nchw', 'pvt_convert', 'RTMCCBlock',
- 'rope', 'check_and_update_config'
+ 'rope', 'check_and_update_config', 'filter_scores_and_topk', 'CSPLayer',
+ 'FrozenBatchNorm2d', 'inverse_sigmoid'
]
diff --git a/mmpose/models/utils/csp_layer.py b/mmpose/models/utils/csp_layer.py
new file mode 100644
index 0000000000..071e1209a2
--- /dev/null
+++ b/mmpose/models/utils/csp_layer.py
@@ -0,0 +1,273 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
+from mmengine.model import BaseModule
+from mmengine.utils import digit_version
+from torch import Tensor
+
+from mmpose.utils.typing import ConfigType, OptConfigType, OptMultiConfig
+
+
+class ChannelAttention(BaseModule):
+ """Channel attention Module.
+
+ Args:
+ channels (int): The input (and output) channels of the attention layer.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Defaults to None
+ """
+
+ def __init__(self, channels: int, init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.global_avgpool = nn.AdaptiveAvgPool2d(1)
+ self.fc = nn.Conv2d(channels, channels, 1, 1, 0, bias=True)
+ if digit_version(torch.__version__) < (1, 7, 0):
+ self.act = nn.Hardsigmoid()
+ else:
+ self.act = nn.Hardsigmoid(inplace=True)
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward function for ChannelAttention."""
+ with torch.cuda.amp.autocast(enabled=False):
+ out = self.global_avgpool(x)
+ out = self.fc(out)
+ out = self.act(out)
+ return x * out
+
+
+class DarknetBottleneck(BaseModule):
+ """The basic bottleneck block used in Darknet.
+
+ Each ResBlock consists of two ConvModules and the input is added to the
+ final output. Each ConvModule is composed of Conv, BN, and LeakyReLU.
+ The first convLayer has filter size of 1x1 and the second one has the
+ filter size of 3x3.
+
+ Args:
+ in_channels (int): The input channels of this Module.
+ out_channels (int): The output channels of this Module.
+ expansion (float): The kernel size of the convolution.
+ Defaults to 0.5.
+ add_identity (bool): Whether to add identity to the out.
+ Defaults to True.
+ use_depthwise (bool): Whether to use depthwise separable convolution.
+ Defaults to False.
+ conv_cfg (dict): Config dict for convolution layer. Defaults to None,
+ which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Defaults to dict(type='BN').
+ act_cfg (dict): Config dict for activation layer.
+ Defaults to dict(type='Swish').
+ """
+
+ def __init__(self,
+ in_channels: int,
+ out_channels: int,
+ expansion: float = 0.5,
+ add_identity: bool = True,
+ use_depthwise: bool = False,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: ConfigType = dict(
+ type='BN', momentum=0.03, eps=0.001),
+ act_cfg: ConfigType = dict(type='Swish'),
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ hidden_channels = int(out_channels * expansion)
+ conv = DepthwiseSeparableConvModule if use_depthwise else ConvModule
+ self.conv1 = ConvModule(
+ in_channels,
+ hidden_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.conv2 = conv(
+ hidden_channels,
+ out_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.add_identity = \
+ add_identity and in_channels == out_channels
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward function."""
+ identity = x
+ out = self.conv1(x)
+ out = self.conv2(out)
+
+ if self.add_identity:
+ return out + identity
+ else:
+ return out
+
+
+class CSPNeXtBlock(BaseModule):
+ """The basic bottleneck block used in CSPNeXt.
+
+ Args:
+ in_channels (int): The input channels of this Module.
+ out_channels (int): The output channels of this Module.
+ expansion (float): Expand ratio of the hidden channel. Defaults to 0.5.
+ add_identity (bool): Whether to add identity to the out. Only works
+ when in_channels == out_channels. Defaults to True.
+ use_depthwise (bool): Whether to use depthwise separable convolution.
+ Defaults to False.
+ kernel_size (int): The kernel size of the second convolution layer.
+ Defaults to 5.
+ conv_cfg (dict): Config dict for convolution layer. Defaults to None,
+ which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Defaults to dict(type='BN', momentum=0.03, eps=0.001).
+ act_cfg (dict): Config dict for activation layer.
+ Defaults to dict(type='SiLU').
+ init_cfg (:obj:`ConfigDict` or dict or list[dict] or
+ list[:obj:`ConfigDict`], optional): Initialization config dict.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels: int,
+ out_channels: int,
+ expansion: float = 0.5,
+ add_identity: bool = True,
+ use_depthwise: bool = False,
+ kernel_size: int = 5,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: ConfigType = dict(
+ type='BN', momentum=0.03, eps=0.001),
+ act_cfg: ConfigType = dict(type='SiLU'),
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ hidden_channels = int(out_channels * expansion)
+ conv = DepthwiseSeparableConvModule if use_depthwise else ConvModule
+ self.conv1 = conv(
+ in_channels,
+ hidden_channels,
+ 3,
+ stride=1,
+ padding=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.conv2 = DepthwiseSeparableConvModule(
+ hidden_channels,
+ out_channels,
+ kernel_size,
+ stride=1,
+ padding=kernel_size // 2,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.add_identity = \
+ add_identity and in_channels == out_channels
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward function."""
+ identity = x
+ out = self.conv1(x)
+ out = self.conv2(out)
+
+ if self.add_identity:
+ return out + identity
+ else:
+ return out
+
+
+class CSPLayer(BaseModule):
+ """Cross Stage Partial Layer.
+
+ Args:
+ in_channels (int): The input channels of the CSP layer.
+ out_channels (int): The output channels of the CSP layer.
+ expand_ratio (float): Ratio to adjust the number of channels of the
+ hidden layer. Defaults to 0.5.
+ num_blocks (int): Number of blocks. Defaults to 1.
+ add_identity (bool): Whether to add identity in blocks.
+ Defaults to True.
+ use_cspnext_block (bool): Whether to use CSPNeXt block.
+ Defaults to False.
+ use_depthwise (bool): Whether to use depthwise separable convolution in
+ blocks. Defaults to False.
+ channel_attention (bool): Whether to add channel attention in each
+ stage. Defaults to True.
+ conv_cfg (dict, optional): Config dict for convolution layer.
+ Defaults to None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Defaults to dict(type='BN')
+ act_cfg (dict): Config dict for activation layer.
+ Defaults to dict(type='Swish')
+ init_cfg (:obj:`ConfigDict` or dict or list[dict] or
+ list[:obj:`ConfigDict`], optional): Initialization config dict.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels: int,
+ out_channels: int,
+ expand_ratio: float = 0.5,
+ num_blocks: int = 1,
+ add_identity: bool = True,
+ use_depthwise: bool = False,
+ use_cspnext_block: bool = False,
+ channel_attention: bool = False,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: ConfigType = dict(
+ type='BN', momentum=0.03, eps=0.001),
+ act_cfg: ConfigType = dict(type='Swish'),
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ block = CSPNeXtBlock if use_cspnext_block else DarknetBottleneck
+ mid_channels = int(out_channels * expand_ratio)
+ self.channel_attention = channel_attention
+ self.main_conv = ConvModule(
+ in_channels,
+ mid_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.short_conv = ConvModule(
+ in_channels,
+ mid_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.final_conv = ConvModule(
+ 2 * mid_channels,
+ out_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ self.blocks = nn.Sequential(*[
+ block(
+ mid_channels,
+ mid_channels,
+ 1.0,
+ add_identity,
+ use_depthwise,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg) for _ in range(num_blocks)
+ ])
+ if channel_attention:
+ self.attention = ChannelAttention(2 * mid_channels)
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward function."""
+ x_short = self.short_conv(x)
+
+ x_main = self.main_conv(x)
+ x_main = self.blocks(x_main)
+
+ x_final = torch.cat((x_main, x_short), dim=1)
+
+ if self.channel_attention:
+ x_final = self.attention(x_final)
+ return self.final_conv(x_final)
diff --git a/mmpose/models/utils/misc.py b/mmpose/models/utils/misc.py
new file mode 100644
index 0000000000..347c521709
--- /dev/null
+++ b/mmpose/models/utils/misc.py
@@ -0,0 +1,76 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from functools import partial
+
+import torch
+from six.moves import map, zip
+
+
+def multi_apply(func, *args, **kwargs):
+ """Apply function to a list of arguments.
+
+ Note:
+ This function applies the ``func`` to multiple inputs and
+ map the multiple outputs of the ``func`` into different
+ list. Each list contains the same type of outputs corresponding
+ to different inputs.
+
+ Args:
+ func (Function): A function that will be applied to a list of
+ arguments
+
+ Returns:
+ tuple(list): A tuple containing multiple list, each list contains
+ a kind of returned results by the function
+ """
+ pfunc = partial(func, **kwargs) if kwargs else func
+ map_results = map(pfunc, *args)
+ return tuple(map(list, zip(*map_results)))
+
+
+def filter_scores_and_topk(scores, score_thr, topk, results=None):
+ """Filter results using score threshold and topk candidates.
+
+ Args:
+ scores (Tensor): The scores, shape (num_bboxes, K).
+ score_thr (float): The score filter threshold.
+ topk (int): The number of topk candidates.
+ results (dict or list or Tensor, Optional): The results to
+ which the filtering rule is to be applied. The shape
+ of each item is (num_bboxes, N).
+
+ Returns:
+ tuple: Filtered results
+
+ - scores (Tensor): The scores after being filtered, \
+ shape (num_bboxes_filtered, ).
+ - labels (Tensor): The class labels, shape \
+ (num_bboxes_filtered, ).
+ - anchor_idxs (Tensor): The anchor indexes, shape \
+ (num_bboxes_filtered, ).
+ - filtered_results (dict or list or Tensor, Optional): \
+ The filtered results. The shape of each item is \
+ (num_bboxes_filtered, N).
+ """
+ valid_mask = scores > score_thr
+ scores = scores[valid_mask]
+ valid_idxs = torch.nonzero(valid_mask)
+
+ num_topk = min(topk, valid_idxs.size(0))
+ # torch.sort is actually faster than .topk (at least on GPUs)
+ scores, idxs = scores.sort(descending=True)
+ scores = scores[:num_topk]
+ topk_idxs = valid_idxs[idxs[:num_topk]]
+ keep_idxs, labels = topk_idxs.unbind(dim=1)
+
+ filtered_results = None
+ if results is not None:
+ if isinstance(results, dict):
+ filtered_results = {k: v[keep_idxs] for k, v in results.items()}
+ elif isinstance(results, list):
+ filtered_results = [result[keep_idxs] for result in results]
+ elif isinstance(results, torch.Tensor):
+ filtered_results = results[keep_idxs]
+ else:
+ raise NotImplementedError(f'Only supports dict or list or Tensor, '
+ f'but get {type(results)}.')
+ return scores, labels, keep_idxs, filtered_results
diff --git a/mmpose/models/utils/ops.py b/mmpose/models/utils/ops.py
index 0c94352647..d1ba0cf37c 100644
--- a/mmpose/models/utils/ops.py
+++ b/mmpose/models/utils/ops.py
@@ -3,8 +3,11 @@
from typing import Optional, Tuple, Union
import torch
+from torch import Tensor
from torch.nn import functional as F
+from mmpose.registry import MODELS
+
def resize(input: torch.Tensor,
size: Optional[Union[Tuple[int, int], torch.Size]] = None,
@@ -50,3 +53,58 @@ def resize(input: torch.Tensor,
# Perform the resizing operation
return F.interpolate(input, size, scale_factor, mode, align_corners)
+
+
+@MODELS.register_module()
+class FrozenBatchNorm2d(torch.nn.Module):
+ """BatchNorm2d where the batch statistics and the affine parameters are
+ fixed.
+
+ Copy-paste from torchvision.misc.ops with added eps before rqsrt, without
+ which any other models than torchvision.models.resnet[18,34,50,101] produce
+ nans.
+ """
+
+ def __init__(self, n, eps: int = 1e-5):
+ super(FrozenBatchNorm2d, self).__init__()
+ self.register_buffer('weight', torch.ones(n))
+ self.register_buffer('bias', torch.zeros(n))
+ self.register_buffer('running_mean', torch.zeros(n))
+ self.register_buffer('running_var', torch.ones(n))
+ self.eps = eps
+
+ def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict,
+ missing_keys, unexpected_keys, error_msgs):
+ num_batches_tracked_key = prefix + 'num_batches_tracked'
+ if num_batches_tracked_key in state_dict:
+ del state_dict[num_batches_tracked_key]
+
+ super(FrozenBatchNorm2d,
+ self)._load_from_state_dict(state_dict, prefix, local_metadata,
+ strict, missing_keys,
+ unexpected_keys, error_msgs)
+
+ def forward(self, x):
+ w = self.weight.reshape(1, -1, 1, 1)
+ b = self.bias.reshape(1, -1, 1, 1)
+ rv = self.running_var.reshape(1, -1, 1, 1)
+ rm = self.running_mean.reshape(1, -1, 1, 1)
+ scale = w * (rv + self.eps).rsqrt()
+ bias = b - rm * scale
+ return x * scale + bias
+
+
+def inverse_sigmoid(x: Tensor, eps: float = 1e-3) -> Tensor:
+ """Inverse function of sigmoid.
+
+ Args:
+ x (Tensor): The tensor to do the inverse.
+ eps (float): EPS avoid numerical overflow. Defaults 1e-5.
+ Returns:
+ Tensor: The x has passed the inverse function of sigmoid, has the same
+ shape with input.
+ """
+ x = x.clamp(min=0, max=1)
+ x1 = x.clamp(min=eps)
+ x2 = (1 - x).clamp(min=eps)
+ return torch.log(x1 / x2)
diff --git a/mmpose/registry.py b/mmpose/registry.py
index e3b8d17c4c..84903eaf2d 100644
--- a/mmpose/registry.py
+++ b/mmpose/registry.py
@@ -91,18 +91,22 @@
PARAM_SCHEDULERS = Registry(
'parameter scheduler',
parent=MMENGINE_PARAM_SCHEDULERS,
- locations=['mmpose.engine'])
+ locations=['mmpose.engine.schedulers'])
# manage all kinds of metrics
METRICS = Registry(
'metric', parent=MMENGINE_METRICS, locations=['mmpose.evaluation.metrics'])
# manage all kinds of evaluators
EVALUATORS = Registry(
- 'evaluator', parent=MMENGINE_EVALUATOR, locations=['mmpose.evaluation'])
+ 'evaluator',
+ parent=MMENGINE_EVALUATOR,
+ locations=['mmpose.evaluation.evaluators'])
# manage task-specific modules like anchor generators and box coders
TASK_UTILS = Registry(
- 'task util', parent=MMENGINE_TASK_UTILS, locations=['mmpose.models'])
+ 'task util',
+ parent=MMENGINE_TASK_UTILS,
+ locations=['mmpose.models.task_modules'])
# Registries For Visualizer and the related
# manage visualizer
diff --git a/mmpose/structures/__init__.py b/mmpose/structures/__init__.py
index e4384af1cd..15c3e2d278 100644
--- a/mmpose/structures/__init__.py
+++ b/mmpose/structures/__init__.py
@@ -1,8 +1,9 @@
# Copyright (c) OpenMMLab. All rights reserved.
-from .bbox import (bbox_cs2xywh, bbox_cs2xyxy, bbox_xywh2cs, bbox_xywh2xyxy,
- bbox_xyxy2cs, bbox_xyxy2xywh, flip_bbox,
- get_udp_warp_matrix, get_warp_matrix)
-from .keypoint import flip_keypoints
+from .bbox import (bbox_clip_border, bbox_corner2xyxy, bbox_cs2xywh,
+ bbox_cs2xyxy, bbox_xywh2cs, bbox_xywh2xyxy,
+ bbox_xyxy2corner, bbox_xyxy2cs, bbox_xyxy2xywh, flip_bbox,
+ get_pers_warp_matrix, get_udp_warp_matrix, get_warp_matrix)
+from .keypoint import flip_keypoints, keypoint_clip_border
from .multilevel_pixel_data import MultilevelPixelData
from .pose_data_sample import PoseDataSample
from .utils import merge_data_samples, revert_heatmap, split_instances
@@ -11,5 +12,7 @@
'PoseDataSample', 'MultilevelPixelData', 'bbox_cs2xywh', 'bbox_cs2xyxy',
'bbox_xywh2cs', 'bbox_xywh2xyxy', 'bbox_xyxy2cs', 'bbox_xyxy2xywh',
'flip_bbox', 'get_udp_warp_matrix', 'get_warp_matrix', 'flip_keypoints',
- 'merge_data_samples', 'revert_heatmap', 'split_instances'
+ 'merge_data_samples', 'revert_heatmap', 'split_instances',
+ 'keypoint_clip_border', 'bbox_clip_border', 'bbox_xyxy2corner',
+ 'bbox_corner2xyxy', 'get_pers_warp_matrix'
]
diff --git a/mmpose/structures/bbox/__init__.py b/mmpose/structures/bbox/__init__.py
index a3e723918c..abd3d5f2d9 100644
--- a/mmpose/structures/bbox/__init__.py
+++ b/mmpose/structures/bbox/__init__.py
@@ -1,10 +1,14 @@
# Copyright (c) OpenMMLab. All rights reserved.
-from .transforms import (bbox_cs2xywh, bbox_cs2xyxy, bbox_xywh2cs,
- bbox_xywh2xyxy, bbox_xyxy2cs, bbox_xyxy2xywh,
- flip_bbox, get_udp_warp_matrix, get_warp_matrix)
+from .bbox_overlaps import bbox_overlaps
+from .transforms import (bbox_clip_border, bbox_corner2xyxy, bbox_cs2xywh,
+ bbox_cs2xyxy, bbox_xywh2cs, bbox_xywh2xyxy,
+ bbox_xyxy2corner, bbox_xyxy2cs, bbox_xyxy2xywh,
+ flip_bbox, get_pers_warp_matrix, get_udp_warp_matrix,
+ get_warp_matrix)
__all__ = [
'bbox_cs2xywh', 'bbox_cs2xyxy', 'bbox_xywh2cs', 'bbox_xywh2xyxy',
'bbox_xyxy2cs', 'bbox_xyxy2xywh', 'flip_bbox', 'get_udp_warp_matrix',
- 'get_warp_matrix'
+ 'get_warp_matrix', 'bbox_overlaps', 'bbox_clip_border', 'bbox_xyxy2corner',
+ 'bbox_corner2xyxy', 'get_pers_warp_matrix'
]
diff --git a/mmpose/structures/bbox/bbox_overlaps.py b/mmpose/structures/bbox/bbox_overlaps.py
new file mode 100644
index 0000000000..682008c337
--- /dev/null
+++ b/mmpose/structures/bbox/bbox_overlaps.py
@@ -0,0 +1,117 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+
+def fp16_clamp(x, min_val=None, max_val=None):
+ if not x.is_cuda and x.dtype == torch.float16:
+ return x.float().clamp(min_val, max_val).half()
+ return x.clamp(min_val, max_val)
+
+
+def bbox_overlaps(bboxes1,
+ bboxes2,
+ mode='iou',
+ is_aligned=False,
+ eps=1e-6) -> torch.Tensor:
+ """Calculate overlap between two sets of bounding boxes.
+
+ Args:
+ bboxes1 (torch.Tensor): Bounding boxes of shape (..., m, 4) or empty.
+ bboxes2 (torch.Tensor): Bounding boxes of shape (..., n, 4) or empty.
+ mode (str): "iou" (intersection over union),
+ "iof" (intersection over foreground),
+ or "giou" (generalized intersection over union).
+ Defaults to "iou".
+ is_aligned (bool, optional): If True, then m and n must be equal.
+ Default False.
+ eps (float, optional): A small constant added to the denominator for
+ numerical stability. Default 1e-6.
+
+ Returns:
+ torch.Tensor: Overlap values of shape (..., m, n) if is_aligned is
+ False, else shape (..., m).
+
+ Example:
+ >>> bboxes1 = torch.FloatTensor([
+ >>> [0, 0, 10, 10],
+ >>> [10, 10, 20, 20],
+ >>> [32, 32, 38, 42],
+ >>> ])
+ >>> bboxes2 = torch.FloatTensor([
+ >>> [0, 0, 10, 20],
+ >>> [0, 10, 10, 19],
+ >>> [10, 10, 20, 20],
+ >>> ])
+ >>> overlaps = bbox_overlaps(bboxes1, bboxes2)
+ >>> assert overlaps.shape == (3, 3)
+ >>> overlaps = bbox_overlaps(bboxes1, bboxes2, is_aligned=True)
+ >>> assert overlaps.shape == (3, )
+ """
+ assert mode in ['iou', 'iof', 'giou'], f'Unsupported mode {mode}'
+ assert (bboxes1.size(-1) == 4 or bboxes1.size(0) == 0)
+ assert (bboxes2.size(-1) == 4 or bboxes2.size(0) == 0)
+
+ if bboxes1.ndim == 1:
+ bboxes1 = bboxes1.unsqueeze(0)
+ if bboxes2.ndim == 1:
+ bboxes2 = bboxes2.unsqueeze(0)
+
+ assert bboxes1.shape[:-2] == bboxes2.shape[:-2]
+ batch_shape = bboxes1.shape[:-2]
+
+ rows = bboxes1.size(-2)
+ cols = bboxes2.size(-2)
+ if is_aligned:
+ assert rows == cols
+
+ if rows * cols == 0:
+ if is_aligned:
+ return bboxes1.new(batch_shape + (rows, ))
+ else:
+ return bboxes1.new(batch_shape + (rows, cols))
+
+ area1 = (bboxes1[..., 2] - bboxes1[..., 0]) * (
+ bboxes1[..., 3] - bboxes1[..., 1])
+ area2 = (bboxes2[..., 2] - bboxes2[..., 0]) * (
+ bboxes2[..., 3] - bboxes2[..., 1])
+
+ if is_aligned:
+ lt = torch.max(bboxes1[..., :2], bboxes2[..., :2])
+ rb = torch.min(bboxes1[..., 2:], bboxes2[..., 2:])
+ wh = fp16_clamp(rb - lt, min_val=0)
+ overlap = wh[..., 0] * wh[..., 1]
+
+ if mode in ['iou', 'giou']:
+ union = area1 + area2 - overlap
+ else:
+ union = area1
+ if mode == 'giou':
+ enclosed_lt = torch.min(bboxes1[..., :2], bboxes2[..., :2])
+ enclosed_rb = torch.max(bboxes1[..., 2:], bboxes2[..., 2:])
+ else:
+ lt = torch.max(bboxes1[..., :, None, :2], bboxes2[..., None, :, :2])
+ rb = torch.min(bboxes1[..., :, None, 2:], bboxes2[..., None, :, 2:])
+ wh = fp16_clamp(rb - lt, min_val=0)
+ overlap = wh[..., 0] * wh[..., 1]
+
+ if mode in ['iou', 'giou']:
+ union = area1[..., None] + area2[..., None, :] - overlap
+ else:
+ union = area1[..., None]
+ if mode == 'giou':
+ enclosed_lt = torch.min(bboxes1[..., :, None, :2],
+ bboxes2[..., None, :, :2])
+ enclosed_rb = torch.max(bboxes1[..., :, None, 2:],
+ bboxes2[..., None, :, 2:])
+
+ eps_tensor = union.new_tensor([eps])
+ union = torch.max(union, eps_tensor)
+ ious = overlap / union
+ if mode in ['iou', 'iof']:
+ return ious
+ elif mode == 'giou':
+ enclose_wh = fp16_clamp(enclosed_rb - enclosed_lt, min_val=0)
+ enclose_area = enclose_wh[..., 0] * enclose_wh[..., 1]
+ enclose_area = torch.max(enclose_area, eps_tensor)
+ gious = ious - (enclose_area - union) / enclose_area
+ return gious
diff --git a/mmpose/structures/bbox/transforms.py b/mmpose/structures/bbox/transforms.py
index c0c8e73395..7ddd821ace 100644
--- a/mmpose/structures/bbox/transforms.py
+++ b/mmpose/structures/bbox/transforms.py
@@ -63,9 +63,8 @@ def bbox_xyxy2cs(bbox: np.ndarray,
if dim == 1:
bbox = bbox[None, :]
- x1, y1, x2, y2 = np.hsplit(bbox, [1, 2, 3])
- center = np.hstack([x1 + x2, y1 + y2]) * 0.5
- scale = np.hstack([x2 - x1, y2 - y1]) * padding
+ scale = (bbox[..., 2:] - bbox[..., :2]) * padding
+ center = (bbox[..., 2:] + bbox[..., :2]) * 0.5
if dim == 1:
center = center[0]
@@ -172,6 +171,103 @@ def bbox_cs2xywh(center: np.ndarray,
return bbox
+def bbox_xyxy2corner(bbox: np.ndarray):
+ """Convert bounding boxes from xyxy format to corner format.
+
+ Given a numpy array containing bounding boxes in the format
+ (xmin, ymin, xmax, ymax), this function converts the bounding
+ boxes to the corner format, where each box is represented by four
+ corner points (top-left, top-right, bottom-right, bottom-left).
+
+ Args:
+ bbox (numpy.ndarray): Input array of shape (N, 4) representing
+ N bounding boxes.
+
+ Returns:
+ numpy.ndarray: An array of shape (N, 4, 2) containing the corner
+ points of the bounding boxes.
+
+ Example:
+ bbox = np.array([[0, 0, 100, 50], [10, 20, 200, 150]])
+ corners = bbox_xyxy2corner(bbox)
+ """
+ dim = bbox.ndim
+ if dim == 1:
+ bbox = bbox[None]
+
+ bbox = np.tile(bbox, 2).reshape(-1, 4, 2)
+ bbox[:, 1:3, 0] = bbox[:, 0:2, 0]
+
+ if dim == 1:
+ bbox = bbox[0]
+
+ return bbox
+
+
+def bbox_corner2xyxy(bbox: np.ndarray):
+ """Convert bounding boxes from corner format to xyxy format.
+
+ Given a numpy array containing bounding boxes in the corner
+ format (four corner points for each box), this function converts
+ the bounding boxes to the (xmin, ymin, xmax, ymax) format.
+
+ Args:
+ bbox (numpy.ndarray): Input array of shape (N, 4, 2) representing
+ N bounding boxes.
+
+ Returns:
+ numpy.ndarray: An array of shape (N, 4) containing the bounding
+ boxes in xyxy format.
+
+ Example:
+ corners = np.array([[[0, 0], [100, 0], [100, 50], [0, 50]],
+ [[10, 20], [200, 20], [200, 150], [10, 150]]])
+ bbox = bbox_corner2xyxy(corners)
+ """
+ if bbox.shape[-1] == 8:
+ bbox = bbox.reshape(*bbox.shape[:-1], 4, 2)
+
+ dim = bbox.ndim
+ if dim == 2:
+ bbox = bbox[None]
+
+ bbox = np.concatenate((bbox.min(axis=1), bbox.max(axis=1)), axis=1)
+
+ if dim == 2:
+ bbox = bbox[0]
+
+ return bbox
+
+
+def bbox_clip_border(bbox: np.ndarray, shape: Tuple[int, int]) -> np.ndarray:
+ """Clip bounding box coordinates to fit within a specified shape.
+
+ Args:
+ bbox (np.ndarray): Bounding box coordinates of shape (..., 4)
+ or (..., 2).
+ shape (Tuple[int, int]): Shape of the image to which bounding
+ boxes are being clipped in the format of (w, h)
+
+ Returns:
+ np.ndarray: Clipped bounding box coordinates.
+
+ Example:
+ >>> bbox = np.array([[10, 20, 30, 40], [40, 50, 80, 90]])
+ >>> shape = (50, 50) # Example image shape
+ >>> clipped_bbox = bbox_clip_border(bbox, shape)
+ """
+ width, height = shape[:2]
+
+ if bbox.shape[-1] == 2:
+ bbox[..., 0] = np.clip(bbox[..., 0], a_min=0, a_max=width)
+ bbox[..., 1] = np.clip(bbox[..., 1], a_min=0, a_max=height)
+ else:
+ bbox[..., ::2] = np.clip(bbox[..., ::2], a_min=0, a_max=width)
+ bbox[..., 1::2] = np.clip(bbox[..., 1::2], a_min=0, a_max=height)
+
+ return bbox
+
+
def flip_bbox(bbox: np.ndarray,
image_size: Tuple[int, int],
bbox_format: str = 'xywh',
@@ -209,17 +305,19 @@ def flip_bbox(bbox: np.ndarray,
if bbox_format == 'xywh' or bbox_format == 'center':
bbox_flipped[..., 0] = w - bbox[..., 0] - 1
elif bbox_format == 'xyxy':
- bbox_flipped[..., ::2] = w - bbox[..., ::2] - 1
+ bbox_flipped[..., ::2] = w - bbox[..., -2::-2] - 1
elif direction == 'vertical':
if bbox_format == 'xywh' or bbox_format == 'center':
bbox_flipped[..., 1] = h - bbox[..., 1] - 1
elif bbox_format == 'xyxy':
- bbox_flipped[..., 1::2] = h - bbox[..., 1::2] - 1
+ bbox_flipped[..., 1::2] = h - bbox[..., ::-2] - 1
elif direction == 'diagonal':
if bbox_format == 'xywh' or bbox_format == 'center':
bbox_flipped[..., :2] = [w, h] - bbox[..., :2] - 1
elif bbox_format == 'xyxy':
bbox_flipped[...] = [w, h, w, h] - bbox - 1
+ bbox_flipped = np.concatenate(
+ (bbox_flipped[..., 2:], bbox_flipped[..., :2]), axis=-1)
return bbox_flipped
@@ -326,6 +424,61 @@ def get_warp_matrix(center: np.ndarray,
return warp_mat
+def get_pers_warp_matrix(center: np.ndarray, translate: np.ndarray,
+ scale: float, rot: float,
+ shear: np.ndarray) -> np.ndarray:
+ """Compute a perspective warp matrix based on specified transformations.
+
+ Args:
+ center (np.ndarray): Center of the transformation.
+ translate (np.ndarray): Translation vector.
+ scale (float): Scaling factor.
+ rot (float): Rotation angle in degrees.
+ shear (np.ndarray): Shearing angles in degrees along x and y axes.
+
+ Returns:
+ np.ndarray: Perspective warp matrix.
+
+ Example:
+ >>> center = np.array([0, 0])
+ >>> translate = np.array([10, 20])
+ >>> scale = 1.2
+ >>> rot = 30.0
+ >>> shear = np.array([15.0, 0.0])
+ >>> warp_matrix = get_pers_warp_matrix(center, translate,
+ scale, rot, shear)
+ """
+ translate_mat = np.array([[1, 0, translate[0] + center[0]],
+ [0, 1, translate[1] + center[1]], [0, 0, 1]],
+ dtype=np.float32)
+
+ shear_x = math.radians(shear[0])
+ shear_y = math.radians(shear[1])
+ shear_mat = np.array([[1, np.tan(shear_x), 0], [np.tan(shear_y), 1, 0],
+ [0, 0, 1]],
+ dtype=np.float32)
+
+ rotate_angle = math.radians(rot)
+ rotate_mat = np.array([[np.cos(rotate_angle), -np.sin(rotate_angle), 0],
+ [np.sin(rotate_angle),
+ np.cos(rotate_angle), 0], [0, 0, 1]],
+ dtype=np.float32)
+
+ scale_mat = np.array([[scale, 0, 0], [0, scale, 0], [0, 0, 1]],
+ dtype=np.float32)
+
+ recover_center_mat = np.array([[1, 0, -center[0]], [0, 1, -center[1]],
+ [0, 0, 1]],
+ dtype=np.float32)
+
+ warp_matrix = np.dot(
+ np.dot(
+ np.dot(np.dot(translate_mat, shear_mat), rotate_mat), scale_mat),
+ recover_center_mat)
+
+ return warp_matrix
+
+
def _rotate_point(pt: np.ndarray, angle_rad: float) -> np.ndarray:
"""Rotate a point by an angle.
diff --git a/mmpose/structures/keypoint/__init__.py b/mmpose/structures/keypoint/__init__.py
index 12ee96cf7c..f4969d3283 100644
--- a/mmpose/structures/keypoint/__init__.py
+++ b/mmpose/structures/keypoint/__init__.py
@@ -1,5 +1,8 @@
# Copyright (c) OpenMMLab. All rights reserved.
-from .transforms import flip_keypoints, flip_keypoints_custom_center
+from .transforms import (flip_keypoints, flip_keypoints_custom_center,
+ keypoint_clip_border)
-__all__ = ['flip_keypoints', 'flip_keypoints_custom_center']
+__all__ = [
+ 'flip_keypoints', 'flip_keypoints_custom_center', 'keypoint_clip_border'
+]
diff --git a/mmpose/structures/keypoint/transforms.py b/mmpose/structures/keypoint/transforms.py
index b50da4f8fe..b4a2aff925 100644
--- a/mmpose/structures/keypoint/transforms.py
+++ b/mmpose/structures/keypoint/transforms.py
@@ -20,8 +20,8 @@ def flip_keypoints(keypoints: np.ndarray,
Args:
keypoints (np.ndarray): Keypoints in shape (..., K, D)
keypoints_visible (np.ndarray, optional): The visibility of keypoints
- in shape (..., K, 1). Set ``None`` if the keypoint visibility is
- unavailable
+ in shape (..., K, 1) or (..., K, 2). Set ``None`` if the keypoint
+ visibility is unavailable
image_size (tuple): The image shape in [w, h]
flip_indices (List[int]): The indices of each keypoint's symmetric
keypoint
@@ -33,11 +33,12 @@ def flip_keypoints(keypoints: np.ndarray,
- keypoints_flipped (np.ndarray): Flipped keypoints in shape
(..., K, D)
- keypoints_visible_flipped (np.ndarray, optional): Flipped keypoints'
- visibility in shape (..., K, 1). Return ``None`` if the input
- ``keypoints_visible`` is ``None``
+ visibility in shape (..., K, 1) or (..., K, 2). Return ``None`` if
+ the input ``keypoints_visible`` is ``None``
"""
- assert keypoints.shape[:-1] == keypoints_visible.shape, (
+ ndim = keypoints.ndim
+ assert keypoints.shape[:-1] == keypoints_visible.shape[:ndim - 1], (
f'Mismatched shapes of keypoints {keypoints.shape} and '
f'keypoints_visible {keypoints_visible.shape}')
@@ -48,9 +49,10 @@ def flip_keypoints(keypoints: np.ndarray,
# swap the symmetric keypoint pairs
if direction == 'horizontal' or direction == 'vertical':
- keypoints = keypoints[..., flip_indices, :]
+ keypoints = keypoints.take(flip_indices, axis=ndim - 2)
if keypoints_visible is not None:
- keypoints_visible = keypoints_visible[..., flip_indices]
+ keypoints_visible = keypoints_visible.take(
+ flip_indices, axis=ndim - 2)
# flip the keypoints
w, h = image_size
@@ -119,3 +121,33 @@ def flip_keypoints_custom_center(keypoints: np.ndarray,
# Flip horizontally
keypoints_flipped[..., 0] = x_c * 2 - keypoints_flipped[..., 0]
return keypoints_flipped, keypoints_visible_flipped
+
+
+def keypoint_clip_border(keypoints: np.ndarray, keypoints_visible: np.ndarray,
+ shape: Tuple[int,
+ int]) -> Tuple[np.ndarray, np.ndarray]:
+ """Set the visibility values for keypoints outside the image border.
+
+ Args:
+ keypoints (np.ndarray): Input keypoints coordinates.
+ keypoints_visible (np.ndarray): Visibility values of keypoints.
+ shape (Tuple[int, int]): Shape of the image to which keypoints are
+ being clipped in the format of (w, h).
+
+ Note:
+ This function sets the visibility values of keypoints that fall outside
+ the specified frame border to zero (0.0).
+ """
+ width, height = shape[:2]
+
+ # Create a mask for keypoints outside the frame
+ outside_mask = ((keypoints[..., 0] > width) | (keypoints[..., 0] < 0) |
+ (keypoints[..., 1] > height) | (keypoints[..., 1] < 0))
+
+ # Update visibility values for keypoints outside the frame
+ if keypoints_visible.ndim == 2:
+ keypoints_visible[outside_mask] = 0.0
+ elif keypoints_visible.ndim == 3:
+ keypoints_visible[outside_mask, 0] = 0.0
+
+ return keypoints, keypoints_visible
diff --git a/mmpose/structures/utils.py b/mmpose/structures/utils.py
index 882cda8603..616b139c54 100644
--- a/mmpose/structures/utils.py
+++ b/mmpose/structures/utils.py
@@ -50,8 +50,7 @@ def merge_data_samples(data_samples: List[PoseDataSample]) -> PoseDataSample:
0].pred_fields:
reverted_heatmaps = [
revert_heatmap(data_sample.pred_fields.heatmaps,
- data_sample.gt_instances.bbox_centers,
- data_sample.gt_instances.bbox_scales,
+ data_sample.input_center, data_sample.input_scale,
data_sample.ori_shape)
for data_sample in data_samples
]
@@ -65,8 +64,7 @@ def merge_data_samples(data_samples: List[PoseDataSample]) -> PoseDataSample:
0].gt_fields:
reverted_heatmaps = [
revert_heatmap(data_sample.gt_fields.heatmaps,
- data_sample.gt_instances.bbox_centers,
- data_sample.gt_instances.bbox_scales,
+ data_sample.input_center, data_sample.input_scale,
data_sample.ori_shape)
for data_sample in data_samples
]
@@ -79,13 +77,13 @@ def merge_data_samples(data_samples: List[PoseDataSample]) -> PoseDataSample:
return merged
-def revert_heatmap(heatmap, bbox_center, bbox_scale, img_shape):
+def revert_heatmap(heatmap, input_center, input_scale, img_shape):
"""Revert predicted heatmap on the original image.
Args:
heatmap (np.ndarray or torch.tensor): predicted heatmap.
- bbox_center (np.ndarray): bounding box center coordinate.
- bbox_scale (np.ndarray): bounding box scale.
+ input_center (np.ndarray): bounding box center coordinate.
+ input_scale (np.ndarray): bounding box scale.
img_shape (tuple or list): size of original image.
"""
if torch.is_tensor(heatmap):
@@ -99,8 +97,8 @@ def revert_heatmap(heatmap, bbox_center, bbox_scale, img_shape):
hm_h, hm_w = heatmap.shape[:2]
img_h, img_w = img_shape
warp_mat = get_warp_matrix(
- bbox_center.reshape((2, )),
- bbox_scale.reshape((2, )),
+ input_center.reshape((2, )),
+ input_scale.reshape((2, )),
rot=0,
output_size=(hm_w, hm_h),
inv=True)
diff --git a/mmpose/testing/_utils.py b/mmpose/testing/_utils.py
index 1908129be8..2a2dd02348 100644
--- a/mmpose/testing/_utils.py
+++ b/mmpose/testing/_utils.py
@@ -101,6 +101,14 @@ def get_packed_inputs(batch_size=2,
image = rng.randint(0, 255, size=(3, h, w), dtype=np.uint8)
inputs['inputs'] = torch.from_numpy(image)
+ # attributes
+ bboxes = _rand_bboxes(rng, num_instances, w, h)
+ bbox_centers, bbox_scales = bbox_xyxy2cs(bboxes)
+
+ keypoints = _rand_keypoints(rng, bboxes, num_keypoints)
+ keypoints_visible = np.ones((num_instances, num_keypoints),
+ dtype=np.float32)
+
# meta
img_meta = {
'id': idx,
@@ -108,6 +116,8 @@ def get_packed_inputs(batch_size=2,
'img_path': '.png',
'img_shape': img_shape,
'input_size': input_size,
+ 'input_center': bbox_centers,
+ 'input_scale': bbox_scales,
'flip': False,
'flip_direction': None,
'flip_indices': list(range(num_keypoints))
@@ -119,12 +129,6 @@ def get_packed_inputs(batch_size=2,
# gt_instance
gt_instances = InstanceData()
gt_instance_labels = InstanceData()
- bboxes = _rand_bboxes(rng, num_instances, w, h)
- bbox_centers, bbox_scales = bbox_xyxy2cs(bboxes)
-
- keypoints = _rand_keypoints(rng, bboxes, num_keypoints)
- keypoints_visible = np.ones((num_instances, num_keypoints),
- dtype=np.float32)
# [N, K] -> [N, num_levels, K]
# keep the first dimension as the num_instances
diff --git a/mmpose/utils/__init__.py b/mmpose/utils/__init__.py
index c48ca01cea..fb9c018ed0 100644
--- a/mmpose/utils/__init__.py
+++ b/mmpose/utils/__init__.py
@@ -2,6 +2,7 @@
from .camera import SimpleCamera, SimpleCameraTorch
from .collect_env import collect_env
from .config_utils import adapt_mmdet_pipeline
+from .dist_utils import reduce_mean
from .logger import get_root_logger
from .setup_env import register_all_modules, setup_multi_processes
from .timer import StopWatch
@@ -9,5 +10,5 @@
__all__ = [
'get_root_logger', 'collect_env', 'StopWatch', 'setup_multi_processes',
'register_all_modules', 'SimpleCamera', 'SimpleCameraTorch',
- 'adapt_mmdet_pipeline'
+ 'adapt_mmdet_pipeline', 'reduce_mean'
]
diff --git a/mmpose/utils/dist_utils.py b/mmpose/utils/dist_utils.py
new file mode 100644
index 0000000000..915f92585a
--- /dev/null
+++ b/mmpose/utils/dist_utils.py
@@ -0,0 +1,11 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.distributed as dist
+
+
+def reduce_mean(tensor):
+ """"Obtain the mean of tensor on different GPUs."""
+ if not (dist.is_available() and dist.is_initialized()):
+ return tensor
+ tensor = tensor.clone()
+ dist.all_reduce(tensor.div_(dist.get_world_size()), op=dist.ReduceOp.SUM)
+ return tensor
diff --git a/mmpose/utils/tensor_utils.py b/mmpose/utils/tensor_utils.py
index 1be73f8991..755e26854c 100644
--- a/mmpose/utils/tensor_utils.py
+++ b/mmpose/utils/tensor_utils.py
@@ -29,6 +29,9 @@ def to_numpy(x: Union[Tensor, Sequence[Tensor]],
if isinstance(x, Tensor):
arrays = x.detach().cpu().numpy()
device = x.device
+ elif isinstance(x, np.ndarray) or is_seq_of(x, np.ndarray):
+ arrays = x
+ device = 'cpu'
elif is_seq_of(x, Tensor):
if unzip:
# convert (A, B) -> [(A[0], B[0]), (A[1], B[1]), ...]
diff --git a/mmpose/version.py b/mmpose/version.py
index bf58664b39..8a6d7e40d5 100644
--- a/mmpose/version.py
+++ b/mmpose/version.py
@@ -1,6 +1,6 @@
# Copyright (c) Open-MMLab. All rights reserved.
-__version__ = '1.1.0'
+__version__ = '1.2.0'
short_version = __version__
diff --git a/mmpose/visualization/local_visualizer.py b/mmpose/visualization/local_visualizer.py
index 080e628e33..2c2664cf86 100644
--- a/mmpose/visualization/local_visualizer.py
+++ b/mmpose/visualization/local_visualizer.py
@@ -1,5 +1,6 @@
# Copyright (c) OpenMMLab. All rights reserved.
import math
+import warnings
from typing import Dict, List, Optional, Tuple, Union
import cv2
@@ -117,6 +118,12 @@ def __init__(self,
show_keypoint_weight: bool = False,
backend: str = 'opencv',
alpha: float = 1.0):
+
+ warnings.filterwarnings(
+ 'ignore',
+ message='.*please provide the `save_dir` argument.*',
+ category=UserWarning)
+
super().__init__(
name=name,
image=image,
@@ -147,10 +154,19 @@ def set_dataset_meta(self,
Args:
dataset_meta (dict): meta information of dataset.
"""
- if dataset_meta.get(
- 'dataset_name') == 'coco' and skeleton_style == 'openpose':
- dataset_meta = parse_pose_metainfo(
- dict(from_file='configs/_base_/datasets/coco_openpose.py'))
+ if skeleton_style == 'openpose':
+ dataset_name = dataset_meta['dataset_name']
+ if dataset_name == 'coco':
+ dataset_meta = parse_pose_metainfo(
+ dict(from_file='configs/_base_/datasets/coco_openpose.py'))
+ elif dataset_name == 'coco_wholebody':
+ dataset_meta = parse_pose_metainfo(
+ dict(from_file='configs/_base_/datasets/'
+ 'coco_wholebody_openpose.py'))
+ else:
+ raise NotImplementedError(
+ f'openpose style has not been '
+ f'supported for {dataset_name} dataset')
if isinstance(dataset_meta, dict):
self.dataset_meta = dataset_meta.copy()
@@ -246,6 +262,10 @@ def _draw_instances_kpts(self,
np.ndarray: the drawn image which channel is RGB.
"""
+ if skeleton_style == 'openpose':
+ return self._draw_instances_kpts_openpose(image, instances,
+ kpt_thr)
+
self.set_image(image)
img_h, img_w, _ = image.shape
@@ -253,45 +273,146 @@ def _draw_instances_kpts(self,
keypoints = instances.get('transformed_keypoints',
instances.keypoints)
- if 'keypoint_scores' in instances:
- scores = instances.keypoint_scores
+ if 'keypoints_visible' in instances:
+ keypoints_visible = instances.keypoints_visible
else:
- scores = np.ones(keypoints.shape[:-1])
+ keypoints_visible = np.ones(keypoints.shape[:-1])
+
+ for kpts, visible in zip(keypoints, keypoints_visible):
+ kpts = np.array(kpts, copy=False)
+
+ if self.kpt_color is None or isinstance(self.kpt_color, str):
+ kpt_color = [self.kpt_color] * len(kpts)
+ elif len(self.kpt_color) == len(kpts):
+ kpt_color = self.kpt_color
+ else:
+ raise ValueError(
+ f'the length of kpt_color '
+ f'({len(self.kpt_color)}) does not matches '
+ f'that of keypoints ({len(kpts)})')
+
+ # draw links
+ if self.skeleton is not None and self.link_color is not None:
+ if self.link_color is None or isinstance(
+ self.link_color, str):
+ link_color = [self.link_color] * len(self.skeleton)
+ elif len(self.link_color) == len(self.skeleton):
+ link_color = self.link_color
+ else:
+ raise ValueError(
+ f'the length of link_color '
+ f'({len(self.link_color)}) does not matches '
+ f'that of skeleton ({len(self.skeleton)})')
+
+ for sk_id, sk in enumerate(self.skeleton):
+ pos1 = (int(kpts[sk[0], 0]), int(kpts[sk[0], 1]))
+ pos2 = (int(kpts[sk[1], 0]), int(kpts[sk[1], 1]))
+
+ if (pos1[0] <= 0 or pos1[0] >= img_w or pos1[1] <= 0
+ or pos1[1] >= img_h or pos2[0] <= 0
+ or pos2[0] >= img_w or pos2[1] <= 0
+ or pos2[1] >= img_h or visible[sk[0]] < kpt_thr
+ or visible[sk[1]] < kpt_thr
+ or link_color[sk_id] is None):
+ # skip the link that should not be drawn
+ continue
+
+ X = np.array((pos1[0], pos2[0]))
+ Y = np.array((pos1[1], pos2[1]))
+ color = link_color[sk_id]
+ if not isinstance(color, str):
+ color = tuple(int(c) for c in color)
+ transparency = self.alpha
+ if self.show_keypoint_weight:
+ transparency *= max(
+ 0,
+ min(1,
+ 0.5 * (visible[sk[0]] + visible[sk[1]])))
+
+ self.draw_lines(
+ X, Y, color, line_widths=self.line_width)
+
+ # draw each point on image
+ for kid, kpt in enumerate(kpts):
+ if visible[kid] < kpt_thr or kpt_color[kid] is None:
+ # skip the point that should not be drawn
+ continue
+
+ color = kpt_color[kid]
+ if not isinstance(color, str):
+ color = tuple(int(c) for c in color)
+ transparency = self.alpha
+ if self.show_keypoint_weight:
+ transparency *= max(0, min(1, visible[kid]))
+ self.draw_circles(
+ kpt,
+ radius=np.array([self.radius]),
+ face_colors=color,
+ edge_colors=color,
+ alpha=transparency,
+ line_widths=self.radius)
+ if show_kpt_idx:
+ kpt_idx_coords = kpt + [self.radius, -self.radius]
+ self.draw_texts(
+ str(kid),
+ kpt_idx_coords,
+ colors=color,
+ font_sizes=self.radius * 3,
+ vertical_alignments='bottom',
+ horizontal_alignments='center')
+
+ return self.get_image()
+
+ def _draw_instances_kpts_openpose(self,
+ image: np.ndarray,
+ instances: InstanceData,
+ kpt_thr: float = 0.3):
+ """Draw keypoints and skeletons (optional) of GT or prediction in
+ openpose style.
+
+ Args:
+ image (np.ndarray): The image to draw.
+ instances (:obj:`InstanceData`): Data structure for
+ instance-level annotations or predictions.
+ kpt_thr (float, optional): Minimum threshold of keypoints
+ to be shown. Default: 0.3.
+
+ Returns:
+ np.ndarray: the drawn image which channel is RGB.
+ """
+
+ self.set_image(image)
+ img_h, img_w, _ = image.shape
+
+ if 'keypoints' in instances:
+ keypoints = instances.get('transformed_keypoints',
+ instances.keypoints)
if 'keypoints_visible' in instances:
keypoints_visible = instances.keypoints_visible
else:
keypoints_visible = np.ones(keypoints.shape[:-1])
- if skeleton_style == 'openpose':
- keypoints_info = np.concatenate(
- (keypoints, scores[..., None], keypoints_visible[...,
- None]),
- axis=-1)
- # compute neck joint
- neck = np.mean(keypoints_info[:, [5, 6]], axis=1)
- # neck score when visualizing pred
- neck[:, 2:4] = np.logical_and(
- keypoints_info[:, 5, 2:4] > kpt_thr,
- keypoints_info[:, 6, 2:4] > kpt_thr).astype(int)
- new_keypoints_info = np.insert(
- keypoints_info, 17, neck, axis=1)
-
- mmpose_idx = [
- 17, 6, 8, 10, 7, 9, 12, 14, 16, 13, 15, 2, 1, 4, 3
- ]
- openpose_idx = [
- 1, 2, 3, 4, 6, 7, 8, 9, 10, 12, 13, 14, 15, 16, 17
- ]
- new_keypoints_info[:, openpose_idx] = \
- new_keypoints_info[:, mmpose_idx]
- keypoints_info = new_keypoints_info
-
- keypoints, scores, keypoints_visible = keypoints_info[
- ..., :2], keypoints_info[..., 2], keypoints_info[..., 3]
-
- for kpts, score, visible in zip(keypoints, scores,
- keypoints_visible):
+ keypoints_info = np.concatenate(
+ (keypoints, keypoints_visible[..., None]), axis=-1)
+ # compute neck joint
+ neck = np.mean(keypoints_info[:, [5, 6]], axis=1)
+ # neck score when visualizing pred
+ neck[:, 2:3] = np.logical_and(
+ keypoints_info[:, 5, 2:3] > kpt_thr,
+ keypoints_info[:, 6, 2:3] > kpt_thr).astype(int)
+ new_keypoints_info = np.insert(keypoints_info, 17, neck, axis=1)
+
+ mmpose_idx = [17, 6, 8, 10, 7, 9, 12, 14, 16, 13, 15, 2, 1, 4, 3]
+ openpose_idx = [1, 2, 3, 4, 6, 7, 8, 9, 10, 12, 13, 14, 15, 16, 17]
+ new_keypoints_info[:, openpose_idx] = \
+ new_keypoints_info[:, mmpose_idx]
+ keypoints_info = new_keypoints_info
+
+ keypoints, keypoints_visible = keypoints_info[
+ ..., :2], keypoints_info[..., 2]
+
+ for kpts, visible in zip(keypoints, keypoints_visible):
kpts = np.array(kpts, copy=False)
if self.kpt_color is None or isinstance(self.kpt_color, str):
@@ -320,17 +441,16 @@ def _draw_instances_kpts(self,
for sk_id, sk in enumerate(self.skeleton):
pos1 = (int(kpts[sk[0], 0]), int(kpts[sk[0], 1]))
pos2 = (int(kpts[sk[1], 0]), int(kpts[sk[1], 1]))
- if not (visible[sk[0]] and visible[sk[1]]):
- continue
if (pos1[0] <= 0 or pos1[0] >= img_w or pos1[1] <= 0
or pos1[1] >= img_h or pos2[0] <= 0
or pos2[0] >= img_w or pos2[1] <= 0
- or pos2[1] >= img_h or score[sk[0]] < kpt_thr
- or score[sk[1]] < kpt_thr
+ or pos2[1] >= img_h or visible[sk[0]] < kpt_thr
+ or visible[sk[1]] < kpt_thr
or link_color[sk_id] is None):
# skip the link that should not be drawn
continue
+
X = np.array((pos1[0], pos2[0]))
Y = np.array((pos1[1], pos2[1]))
color = link_color[sk_id]
@@ -339,9 +459,12 @@ def _draw_instances_kpts(self,
transparency = self.alpha
if self.show_keypoint_weight:
transparency *= max(
- 0, min(1, 0.5 * (score[sk[0]] + score[sk[1]])))
+ 0,
+ min(1,
+ 0.5 * (visible[sk[0]] + visible[sk[1]])))
- if skeleton_style == 'openpose':
+ if sk_id <= 16:
+ # body part
mX = np.mean(X)
mY = np.mean(Y)
length = ((Y[0] - Y[1])**2 + (X[0] - X[1])**2)**0.5
@@ -360,13 +483,13 @@ def _draw_instances_kpts(self,
alpha=transparency)
else:
- self.draw_lines(
- X, Y, color, line_widths=self.line_width)
+ # hand part
+ self.draw_lines(X, Y, color, line_widths=2)
# draw each point on image
for kid, kpt in enumerate(kpts):
- if score[kid] < kpt_thr or not visible[
- kid] or kpt_color[kid] is None:
+ if visible[kid] < kpt_thr or kpt_color[
+ kid] is None or kpt_color[kid].sum() == 0:
# skip the point that should not be drawn
continue
@@ -375,24 +498,18 @@ def _draw_instances_kpts(self,
color = tuple(int(c) for c in color)
transparency = self.alpha
if self.show_keypoint_weight:
- transparency *= max(0, min(1, score[kid]))
+ transparency *= max(0, min(1, visible[kid]))
+
+ # draw smaller dots for face & hand keypoints
+ radius = self.radius // 2 if kid > 17 else self.radius
+
self.draw_circles(
kpt,
- radius=np.array([self.radius]),
+ radius=np.array([radius]),
face_colors=color,
edge_colors=color,
alpha=transparency,
- line_widths=self.radius)
- if show_kpt_idx:
- kpt[0] += self.radius
- kpt[1] -= self.radius
- self.draw_texts(
- str(kid),
- kpt,
- colors=color,
- font_sizes=self.radius * 3,
- vertical_alignments='bottom',
- horizontal_alignments='center')
+ line_widths=radius)
return self.get_image()
diff --git a/mmpose/visualization/local_visualizer_3d.py b/mmpose/visualization/local_visualizer_3d.py
index 7e3462ce79..1b757a84e5 100644
--- a/mmpose/visualization/local_visualizer_3d.py
+++ b/mmpose/visualization/local_visualizer_3d.py
@@ -9,6 +9,7 @@
from mmengine.dist import master_only
from mmengine.structures import InstanceData
+from mmpose.apis import convert_keypoint_definition
from mmpose.registry import VISUALIZERS
from mmpose.structures import PoseDataSample
from . import PoseLocalVisualizer
@@ -74,18 +75,18 @@ def __init__(
self.det_dataset_skeleton = det_dataset_skeleton
self.det_dataset_link_color = det_dataset_link_color
- def _draw_3d_data_samples(
- self,
- image: np.ndarray,
- pose_samples: PoseDataSample,
- draw_gt: bool = True,
- kpt_thr: float = 0.3,
- num_instances=-1,
- axis_azimuth: float = 70,
- axis_limit: float = 1.7,
- axis_dist: float = 10.0,
- axis_elev: float = 15.0,
- ):
+ def _draw_3d_data_samples(self,
+ image: np.ndarray,
+ pose_samples: PoseDataSample,
+ draw_gt: bool = True,
+ kpt_thr: float = 0.3,
+ num_instances=-1,
+ axis_azimuth: float = 70,
+ axis_limit: float = 1.7,
+ axis_dist: float = 10.0,
+ axis_elev: float = 15.0,
+ show_kpt_idx: bool = False,
+ scores_2d: Optional[np.ndarray] = None):
"""Draw keypoints and skeletons (optional) of GT or prediction.
Args:
@@ -109,11 +110,16 @@ def _draw_3d_data_samples(
- y: [y_c - axis_limit/2, y_c + axis_limit/2]
- z: [0, axis_limit]
Where x_c, y_c is the mean value of x and y coordinates
+ show_kpt_idx (bool): Whether to show the index of keypoints.
+ Defaults to ``False``
+ scores_2d (np.ndarray, optional): Keypoint scores of 2d estimation
+ that will be used to filter 3d instances.
Returns:
Tuple(np.ndarray): the drawn image which channel is RGB.
"""
- vis_height, vis_width, _ = image.shape
+ vis_width = max(image.shape)
+ vis_height = vis_width
if 'pred_instances' in pose_samples:
pred_instances = pose_samples.pred_instances
@@ -145,20 +151,22 @@ def _draw_3d_data_samples(
def _draw_3d_instances_kpts(keypoints,
scores,
+ scores_2d,
keypoints_visible,
fig_idx,
+ show_kpt_idx,
title=None):
- for idx, (kpts, score, visible) in enumerate(
- zip(keypoints, scores, keypoints_visible)):
+ for idx, (kpts, score, score_2d) in enumerate(
+ zip(keypoints, scores, scores_2d)):
- valid = np.logical_and(score >= kpt_thr,
+ valid = np.logical_and(score >= kpt_thr, score_2d >= kpt_thr,
np.any(~np.isnan(kpts), axis=-1))
+ kpts_valid = kpts[valid]
ax = fig.add_subplot(
1, num_fig, fig_idx * (idx + 1), projection='3d')
ax.view_init(elev=axis_elev, azim=axis_azimuth)
- ax.set_zlim3d([0, axis_limit])
ax.set_aspect('auto')
ax.set_xticks([])
ax.set_yticks([])
@@ -166,18 +174,18 @@ def _draw_3d_instances_kpts(keypoints,
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.set_zticklabels([])
- ax.scatter([0], [0], [0], marker='o', color='red')
if title:
ax.set_title(f'{title} ({idx})')
ax.dist = axis_dist
- x_c = np.mean(kpts[valid, 0]) if valid.any() else 0
- y_c = np.mean(kpts[valid, 1]) if valid.any() else 0
+ x_c = np.mean(kpts_valid[:, 0]) if valid.any() else 0
+ y_c = np.mean(kpts_valid[:, 1]) if valid.any() else 0
+ z_c = np.mean(kpts_valid[:, 2]) if valid.any() else 0
ax.set_xlim3d([x_c - axis_limit / 2, x_c + axis_limit / 2])
ax.set_ylim3d([y_c - axis_limit / 2, y_c + axis_limit / 2])
-
- kpts = np.array(kpts, copy=False)
+ ax.set_zlim3d(
+ [min(0, z_c - axis_limit / 2), z_c + axis_limit / 2])
if self.kpt_color is None or isinstance(self.kpt_color, str):
kpt_color = [self.kpt_color] * len(kpts)
@@ -189,16 +197,16 @@ def _draw_3d_instances_kpts(keypoints,
f'({len(self.kpt_color)}) does not matches '
f'that of keypoints ({len(kpts)})')
- kpts = kpts[valid]
- x_3d, y_3d, z_3d = np.split(kpts[:, :3], [1, 2], axis=1)
+ x_3d, y_3d, z_3d = np.split(kpts_valid[:, :3], [1, 2], axis=1)
- kpt_color = kpt_color[valid][..., ::-1] / 255.
+ kpt_color = kpt_color[valid] / 255.
- ax.scatter(x_3d, y_3d, z_3d, marker='o', color=kpt_color)
+ ax.scatter(x_3d, y_3d, z_3d, marker='o', c=kpt_color)
- for kpt_idx in range(len(x_3d)):
- ax.text(x_3d[kpt_idx][0], y_3d[kpt_idx][0],
- z_3d[kpt_idx][0], str(kpt_idx))
+ if show_kpt_idx:
+ for kpt_idx in range(len(x_3d)):
+ ax.text(x_3d[kpt_idx][0], y_3d[kpt_idx][0],
+ z_3d[kpt_idx][0], str(kpt_idx))
if self.skeleton is not None and self.link_color is not None:
if self.link_color is None or isinstance(
@@ -218,9 +226,11 @@ def _draw_3d_instances_kpts(keypoints,
ys_3d = kpts[sk_indices, 1]
zs_3d = kpts[sk_indices, 2]
kpt_score = score[sk_indices]
- if kpt_score.min() > kpt_thr:
+ kpt_score_2d = score_2d[sk_indices]
+ if kpt_score.min() > kpt_thr and kpt_score_2d.min(
+ ) > kpt_thr:
# matplotlib uses RGB color in [0, 1] value range
- _color = link_color[sk_id][::-1] / 255.
+ _color = link_color[sk_id] / 255.
ax.plot(
xs_3d, ys_3d, zs_3d, color=_color, zdir='z')
@@ -233,12 +243,16 @@ def _draw_3d_instances_kpts(keypoints,
else:
scores = np.ones(keypoints.shape[:-1])
+ if scores_2d is None:
+ scores_2d = np.ones(keypoints.shape[:-1])
+
if 'keypoints_visible' in pred_instances:
keypoints_visible = pred_instances.keypoints_visible
else:
keypoints_visible = np.ones(keypoints.shape[:-1])
- _draw_3d_instances_kpts(keypoints, scores, keypoints_visible, 1,
+ _draw_3d_instances_kpts(keypoints, scores, scores_2d,
+ keypoints_visible, 1, show_kpt_idx,
'Prediction')
if draw_gt and 'gt_instances' in pose_samples:
@@ -252,9 +266,22 @@ def _draw_3d_instances_kpts(keypoints,
keypoints_visible = gt_instances.lifting_target_visible
else:
keypoints_visible = np.ones(keypoints.shape[:-1])
+ elif 'keypoints_gt' in gt_instances:
+ keypoints = gt_instances.get('keypoints_gt',
+ gt_instances.keypoints_gt)
+ scores = np.ones(keypoints.shape[:-1])
- _draw_3d_instances_kpts(keypoints, scores, keypoints_visible,
- 2, 'Ground Truth')
+ if 'keypoints_visible' in gt_instances:
+ keypoints_visible = gt_instances.keypoints_visible
+ else:
+ keypoints_visible = np.ones(keypoints.shape[:-1])
+ else:
+ raise ValueError('to visualize ground truth results, '
+ 'data sample must contain '
+ '"lifting_target" or "keypoints_gt"')
+
+ _draw_3d_instances_kpts(keypoints, scores, keypoints_visible, 2,
+ show_kpt_idx, 'Ground Truth')
# convert figure to numpy array
fig.tight_layout()
@@ -300,6 +327,7 @@ def _draw_instances_kpts(self,
self.set_image(image)
img_h, img_w, _ = image.shape
+ scores = None
if 'keypoints' in instances:
keypoints = instances.get('transformed_keypoints',
@@ -348,7 +376,7 @@ def _draw_instances_kpts(self,
for kpts, score, visible in zip(keypoints, scores,
keypoints_visible):
- kpts = np.array(kpts, copy=False)
+ kpts = np.array(kpts[..., :2], copy=False)
if kpt_color is None or isinstance(kpt_color, str):
kpt_color = [kpt_color] * len(kpts)
@@ -452,7 +480,7 @@ def _draw_instances_kpts(self,
self.draw_lines(
X, Y, color, line_widths=self.line_width)
- return self.get_image()
+ return self.get_image(), scores
@master_only
def add_datasample(self,
@@ -466,6 +494,13 @@ def add_datasample(self,
draw_bbox: bool = False,
show_kpt_idx: bool = False,
skeleton_style: str = 'mmpose',
+ dataset_2d: str = 'coco',
+ dataset_3d: str = 'h36m',
+ convert_keypoint: bool = True,
+ axis_azimuth: float = 70,
+ axis_limit: float = 1.7,
+ axis_dist: float = 10.0,
+ axis_elev: float = 15.0,
num_instances: int = -1,
show: bool = False,
wait_time: float = 0,
@@ -502,6 +537,21 @@ def add_datasample(self,
Defaults to ``False``
skeleton_style (str): Skeleton style selection. Defaults to
``'mmpose'``
+ dataset_2d (str): Name of 2d keypoint dataset. Defaults to
+ ``'CocoDataset'``
+ dataset_3d (str): Name of 3d keypoint dataset. Defaults to
+ ``'Human36mDataset'``
+ convert_keypoint (bool): Whether to convert keypoint definition.
+ Defaults to ``True``
+ axis_azimuth (float): axis azimuth angle for 3D visualizations.
+ axis_dist (float): axis distance for 3D visualizations.
+ axis_elev (float): axis elevation view angle for 3D visualizations.
+ axis_limit (float): The axis limit to visualize 3d pose. The xyz
+ range will be set as:
+ - x: [x_c - axis_limit/2, x_c + axis_limit/2]
+ - y: [y_c - axis_limit/2, y_c + axis_limit/2]
+ - z: [0, axis_limit]
+ Where x_c, y_c is the mean value of x and y coordinates
num_instances (int): Number of instances to be shown in 3D. If
smaller than 0, all the instances in the pose_result will be
shown. Otherwise, pad or truncate the pose_result to a length
@@ -516,34 +566,53 @@ def add_datasample(self,
"""
det_img_data = None
- gt_img_data = None
+ scores_2d = None
if draw_2d:
det_img_data = image.copy()
# draw bboxes & keypoints
- if 'pred_instances' in det_data_sample:
- det_img_data = self._draw_instances_kpts(
- det_img_data, det_data_sample.pred_instances, kpt_thr,
- show_kpt_idx, skeleton_style)
+ if (det_data_sample is not None
+ and 'pred_instances' in det_data_sample):
+ det_img_data, scores_2d = self._draw_instances_kpts(
+ image=det_img_data,
+ instances=det_data_sample.pred_instances,
+ kpt_thr=kpt_thr,
+ show_kpt_idx=show_kpt_idx,
+ skeleton_style=skeleton_style)
if draw_bbox:
det_img_data = self._draw_instances_bbox(
det_img_data, det_data_sample.pred_instances)
-
+ if scores_2d is not None and convert_keypoint:
+ if scores_2d.ndim == 2:
+ scores_2d = scores_2d[..., None]
+ scores_2d = np.squeeze(
+ convert_keypoint_definition(scores_2d, dataset_2d, dataset_3d),
+ axis=-1)
pred_img_data = self._draw_3d_data_samples(
image.copy(),
data_sample,
draw_gt=draw_gt,
- num_instances=num_instances)
+ num_instances=num_instances,
+ axis_azimuth=axis_azimuth,
+ axis_limit=axis_limit,
+ show_kpt_idx=show_kpt_idx,
+ axis_dist=axis_dist,
+ axis_elev=axis_elev,
+ scores_2d=scores_2d)
# merge visualization results
- if det_img_data is not None and gt_img_data is not None:
- drawn_img = np.concatenate(
- (det_img_data, pred_img_data, gt_img_data), axis=1)
- elif det_img_data is not None:
+ if det_img_data is not None:
+ width = max(pred_img_data.shape[1] - det_img_data.shape[1], 0)
+ height = max(pred_img_data.shape[0] - det_img_data.shape[0], 0)
+ det_img_data = cv2.copyMakeBorder(
+ det_img_data,
+ height // 2,
+ (height // 2 + 1) if height % 2 == 1 else height // 2,
+ width // 2, (width // 2 + 1) if width % 2 == 1 else width // 2,
+ cv2.BORDER_CONSTANT,
+ value=(255, 255, 255))
drawn_img = np.concatenate((det_img_data, pred_img_data), axis=1)
- elif gt_img_data is not None:
- drawn_img = np.concatenate((det_img_data, gt_img_data), axis=1)
else:
drawn_img = pred_img_data
diff --git a/mmpose/visualization/opencv_backend_visualizer.py b/mmpose/visualization/opencv_backend_visualizer.py
index 1c17506640..9604d07fea 100644
--- a/mmpose/visualization/opencv_backend_visualizer.py
+++ b/mmpose/visualization/opencv_backend_visualizer.py
@@ -129,7 +129,7 @@ def draw_circles(self,
**kwargs)
elif self.backend == 'opencv':
if isinstance(face_colors, str):
- face_colors = mmcv.color_val(face_colors)
+ face_colors = mmcv.color_val(face_colors)[::-1]
if alpha == 1.0:
self._image = cv2.circle(self._image,
@@ -247,7 +247,7 @@ def draw_texts(
if bboxes is not None:
bbox_color = bboxes[0]['facecolor']
if isinstance(bbox_color, str):
- bbox_color = mmcv.color_val(bbox_color)
+ bbox_color = mmcv.color_val(bbox_color)[::-1]
y = y - text_baseline // 2
self._image = cv2.rectangle(
@@ -358,7 +358,8 @@ def draw_lines(self,
**kwargs)
elif self.backend == 'opencv':
-
+ if isinstance(colors, str):
+ colors = mmcv.color_val(colors)[::-1]
self._image = cv2.line(
self._image, (x_datas[0], y_datas[0]),
(x_datas[1], y_datas[1]),
diff --git a/model-index.yml b/model-index.yml
index 498e5bc743..0ed87b91af 100644
--- a/model-index.yml
+++ b/model-index.yml
@@ -9,13 +9,17 @@ Import:
- configs/animal_2d_keypoint/topdown_heatmap/zebra/resnet_zebra.yml
- configs/body_2d_keypoint/cid/coco/hrnet_coco.yml
- configs/body_2d_keypoint/dekr/coco/hrnet_coco.yml
+- configs/body_2d_keypoint/rtmpose/body8/rtmpose_body8-coco.yml
+- configs/body_2d_keypoint/rtmpose/body8/rtmpose_body8-halpe26.yml
- configs/body_2d_keypoint/dekr/crowdpose/hrnet_crowdpose.yml
+- configs/body_2d_keypoint/edpose/coco/edpose_coco.yml
- configs/body_2d_keypoint/integral_regression/coco/resnet_ipr_coco.yml
- configs/body_2d_keypoint/integral_regression/coco/resnet_dsnt_coco.yml
- configs/body_2d_keypoint/integral_regression/coco/resnet_debias_coco.yml
- configs/body_2d_keypoint/rtmpose/coco/rtmpose_coco.yml
- configs/body_2d_keypoint/rtmpose/crowdpose/rtmpose_crowdpose.yml
- configs/body_2d_keypoint/rtmpose/mpii/rtmpose_mpii.yml
+- configs/body_2d_keypoint/rtmpose/humanart/rtmpose_humanart.yml
- configs/body_2d_keypoint/simcc/coco/mobilenetv2_coco.yml
- configs/body_2d_keypoint/simcc/coco/resnet_coco.yml
- configs/body_2d_keypoint/simcc/coco/vipnas_coco.yml
@@ -74,8 +78,12 @@ Import:
- configs/body_2d_keypoint/topdown_regression/coco/mobilenetv2_rle_coco.yml
- configs/body_2d_keypoint/topdown_regression/mpii/resnet_mpii.yml
- configs/body_2d_keypoint/topdown_regression/mpii/resnet_rle_mpii.yml
-- configs/body_3d_keypoint/pose_lift/h36m/videopose3d_h36m.yml
+- configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_coco.yml
+- configs/body_3d_keypoint/image_pose_lift/h36m/simplebaseline3d_h36m.yml
+- configs/body_3d_keypoint/video_pose_lift/h36m/videopose3d_h36m.yml
+- configs/body_3d_keypoint/motionbert/h36m/motionbert_h36m.yml
- configs/face_2d_keypoint/rtmpose/coco_wholebody_face/rtmpose_coco_wholebody_face.yml
+- configs/face_2d_keypoint/rtmpose/face6/rtmpose_face6.yml
- configs/face_2d_keypoint/rtmpose/wflw/rtmpose_wflw.yml
- configs/face_2d_keypoint/topdown_heatmap/300w/hrnetv2_300w.yml
- configs/face_2d_keypoint/topdown_heatmap/aflw/hrnetv2_aflw.yml
@@ -91,6 +99,7 @@ Import:
- configs/face_2d_keypoint/topdown_heatmap/wflw/hrnetv2_dark_wflw.yml
- configs/face_2d_keypoint/topdown_heatmap/wflw/hrnetv2_awing_wflw.yml
- configs/hand_2d_keypoint/rtmpose/coco_wholebody_hand/rtmpose_coco_wholebody_hand.yml
+- configs/hand_2d_keypoint/rtmpose/hand5/rtmpose_hand5.yml
- configs/hand_2d_keypoint/topdown_heatmap/coco_wholebody_hand/hourglass_coco_wholebody_hand.yml
- configs/hand_2d_keypoint/topdown_heatmap/coco_wholebody_hand/hrnetv2_coco_wholebody_hand.yml
- configs/hand_2d_keypoint/topdown_heatmap/coco_wholebody_hand/hrnetv2_dark_coco_wholebody_hand.yml
@@ -111,6 +120,7 @@ Import:
- configs/hand_2d_keypoint/topdown_heatmap/rhd2d/resnet_rhd2d.yml
- configs/hand_2d_keypoint/topdown_regression/onehand10k/resnet_onehand10k.yml
- configs/hand_2d_keypoint/topdown_regression/rhd2d/resnet_rhd2d.yml
+- configs/hand_3d_keypoint/internet/interhand3d/internet_interhand3d.yml
- configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/rtmpose_coco-wholebody.yml
- configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/hrnet_coco-wholebody.yml
- configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/hrnet_dark_coco-wholebody.yml
@@ -119,3 +129,5 @@ Import:
- configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/vipnas_dark_coco-wholebody.yml
- configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/cspnext_udp_coco-wholebody.yml
- configs/fashion_2d_keypoint/topdown_heatmap/deepfashion2/res50_deepfasion2.yml
+- configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/hrnet_deepfashion.yml
+- configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/resnet_deepfashion.yml
diff --git a/projects/README.md b/projects/README.md
index a10ccad65a..4bdc500e48 100644
--- a/projects/README.md
+++ b/projects/README.md
@@ -30,7 +30,11 @@ We also provide some documentation listed below to help you get started:
## Project List
-- **[:zap:RTMPose](./rtmpose)**: Real-Time Multi-Person Pose Estimation toolkit based on MMPose
+- **[:zap:RTMPose](./rtmpose)**: Real-Time Multi-Person Pose Estimation toolkit based on MMPose
+
+ TRY IT NOW
+
+
 @@ -42,7 +46,7 @@ We also provide some documentation listed below to help you get started:
@@ -42,7 +46,7 @@ We also provide some documentation listed below to help you get started:

-- **[:bulb:YOLOX-Pose](./yolox-pose)**: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss +- **[:bulb:YOLOX-Pose](./yolox_pose)**: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss
 @@ -54,4 +58,14 @@ We also provide some documentation listed below to help you get started:
@@ -54,4 +58,14 @@ We also provide some documentation listed below to help you get started:

+- **[💃Just-Dance](./just_dance)**: Enhancing Dance scoring system for comparing dance performances in videos. + + TRY IT NOW + + + +
+ - **What's next? Join the rank of *MMPose contributors* by creating a new project**! diff --git a/projects/just_dance/README.md b/projects/just_dance/README.md new file mode 100644 index 0000000000..385ef03005 --- /dev/null +++ b/projects/just_dance/README.md @@ -0,0 +1,42 @@ +# Just Dance - A Simple Implementation + + + + Try it on OpenXLab + + + +This project presents a dance scoring system based on RTMPose. Users can compare the similarity between two dancers in different videos: one referred to as the "teacher video" and the other as the "student video." + +Here are examples of the output dance comparison: + + +
+
+
+ +
+## Usage
+
+### Jupyter Notebook
+
+We provide a Jupyter Notebook [`just_dance_demo.ipynb`](./just_dance_demo.ipynb) that contains the complete process of dance comparison. It includes steps such as video FPS adjustment, pose estimation, snippet alignment, scoring, and the generation of the merged video.
+
+### CLI tool
+
+Users can simply run the following command to generate the comparison video:
+
+```shell
+python process_video.py ${TEACHER_VIDEO} ${STUDENT_VIDEO}
+```
+
+### Gradio
+
+Users can also utilize Gradio to build an application using this system. We provide the script [`app.py`](./app.py). This application supports webcam input in addition to existing videos. To build this application, please follow these two steps:
+
+1. Install Gradio
+ ```shell
+ pip install gradio
+ ```
+2. Run the script [`app.py`](./app.py)
+ ```shell
+ python app.py
+ ```
diff --git a/projects/just_dance/app.py b/projects/just_dance/app.py
new file mode 100644
index 0000000000..6213ed3663
--- /dev/null
+++ b/projects/just_dance/app.py
@@ -0,0 +1,117 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import sys
+from functools import partial
+from typing import Optional
+
+project_path = os.path.join(os.path.dirname(os.path.abspath(__file__)))
+mmpose_path = project_path.split('/projects', 1)[0]
+
+os.system('python -m pip install Openmim')
+os.system('python -m mim install "mmcv>=2.0.0"')
+os.system('python -m mim install mmengine')
+os.system('python -m mim install "mmdet>=3.0.0"')
+os.system(f'python -m mim install -e {mmpose_path}')
+
+os.environ['PATH'] = f"{os.environ['PATH']}:{project_path}"
+os.environ[
+ 'PYTHONPATH'] = f"{os.environ.get('PYTHONPATH', '.')}:{project_path}"
+sys.path.append(project_path)
+
+import gradio as gr # noqa
+from mmengine.utils import mkdir_or_exist # noqa
+from process_video import VideoProcessor # noqa
+
+
+def process_video(
+ teacher_video: Optional[str] = None,
+ student_video: Optional[str] = None,
+):
+ print(teacher_video)
+ print(student_video)
+
+ video_processor = VideoProcessor()
+ if student_video is None and teacher_video is not None:
+ # Pre-process the teacher video when users record the student video
+ # using a webcam. This allows users to view the teacher video and
+ # follow the dance moves while recording the student video.
+ _ = video_processor.get_keypoints_from_video(teacher_video)
+ return teacher_video
+ elif teacher_video is None and student_video is not None:
+ _ = video_processor.get_keypoints_from_video(student_video)
+ return student_video
+ elif teacher_video is None and student_video is None:
+ return None
+
+ return video_processor.run(teacher_video, student_video)
+
+
+# download video resources
+mkdir_or_exist(os.path.join(project_path, 'resources'))
+os.system(
+ f'wget -O {project_path}/resources/tom.mp4 https://download.openmmlab.com/mmpose/v1/projects/just_dance/tom.mp4' # noqa
+)
+os.system(
+ f'wget -O {project_path}/resources/idol_producer.mp4 https://download.openmmlab.com/mmpose/v1/projects/just_dance/idol_producer.mp4' # noqa
+)
+os.system(
+ f'wget -O {project_path}/resources/tsinghua_30fps.mp4 https://download.openmmlab.com/mmpose/v1/projects/just_dance/tsinghua_30fps.mp4' # noqa
+)
+os.system(
+ f'wget -O {project_path}/resources/student1.mp4 https://download.openmmlab.com/mmpose/v1/projects/just_dance/student1.mp4' # noqa
+)
+os.system(
+ f'wget -O {project_path}/resources/bear_teacher.mp4 https://download.openmmlab.com/mmpose/v1/projects/just_dance/bear_teacher.mp4' # noqa
+)
+
+with gr.Blocks() as demo:
+ with gr.Tab('Upload-Video'):
+ with gr.Row():
+ with gr.Column():
+ gr.Markdown('Student Video')
+ student_video = gr.Video(type='mp4')
+ gr.Examples([
+ os.path.join(project_path, 'resources/tom.mp4'),
+ os.path.join(project_path, 'resources/tsinghua_30fps.mp4'),
+ os.path.join(project_path, 'resources/student1.mp4')
+ ], student_video)
+ with gr.Column():
+ gr.Markdown('Teacher Video')
+ teacher_video = gr.Video(type='mp4')
+ gr.Examples([
+ os.path.join(project_path, 'resources/idol_producer.mp4'),
+ os.path.join(project_path, 'resources/bear_teacher.mp4')
+ ], teacher_video)
+
+ button = gr.Button('Grading', variant='primary')
+ gr.Markdown('## Display')
+ out_video = gr.Video()
+
+ button.click(
+ partial(process_video), [teacher_video, student_video], out_video)
+
+ with gr.Tab('Webcam-Video'):
+ with gr.Row():
+ with gr.Column():
+ gr.Markdown('Student Video')
+ student_video = gr.Video(source='webcam', type='mp4')
+ with gr.Column():
+ gr.Markdown('Teacher Video')
+ teacher_video = gr.Video(type='mp4')
+ gr.Examples([
+ os.path.join(project_path, 'resources/idol_producer.mp4')
+ ], teacher_video)
+ button_upload = gr.Button('Upload', variant='primary')
+
+ button = gr.Button('Grading', variant='primary')
+ gr.Markdown('## Display')
+ out_video = gr.Video()
+
+ button_upload.click(
+ partial(process_video), [teacher_video, student_video], out_video)
+ button.click(
+ partial(process_video), [teacher_video, student_video], out_video)
+
+gr.close_all()
+demo.queue()
+demo.launch()
diff --git a/projects/just_dance/calculate_similarity.py b/projects/just_dance/calculate_similarity.py
new file mode 100644
index 0000000000..0465dbffaa
--- /dev/null
+++ b/projects/just_dance/calculate_similarity.py
@@ -0,0 +1,105 @@
+import numpy as np
+import torch
+
+flip_indices = np.array(
+ [0, 2, 1, 4, 3, 6, 5, 8, 7, 10, 9, 12, 11, 14, 13, 16, 15])
+valid_indices = np.array([0] + list(range(5, 17)))
+
+
+@torch.no_grad()
+def _calculate_similarity(tch_kpts: np.ndarray, stu_kpts: np.ndarray):
+
+ stu_kpts = torch.from_numpy(stu_kpts[:, None, valid_indices])
+ tch_kpts = torch.from_numpy(tch_kpts[None, :, valid_indices])
+ stu_kpts = stu_kpts.expand(stu_kpts.shape[0], tch_kpts.shape[1],
+ stu_kpts.shape[2], 3)
+ tch_kpts = tch_kpts.expand(stu_kpts.shape[0], tch_kpts.shape[1],
+ stu_kpts.shape[2], 3)
+
+ matrix = torch.stack((stu_kpts, tch_kpts), dim=4)
+ if torch.cuda.is_available():
+ matrix = matrix.cuda()
+ mask = torch.logical_and(matrix[:, :, :, 2, 0] > 0.3,
+ matrix[:, :, :, 2, 1] > 0.3)
+ matrix[~mask] = 0.0
+
+ matrix_ = matrix.clone()
+ matrix_[matrix == 0] = 256
+ x_min = matrix_.narrow(3, 0, 1).min(dim=2).values
+ y_min = matrix_.narrow(3, 1, 1).min(dim=2).values
+ matrix_ = matrix.clone()
+ # matrix_[matrix == 0] = 0
+ x_max = matrix_.narrow(3, 0, 1).max(dim=2).values
+ y_max = matrix_.narrow(3, 1, 1).max(dim=2).values
+
+ matrix_ = matrix.clone()
+ matrix_[:, :, :, 0] = (matrix_[:, :, :, 0] - x_min) / (
+ x_max - x_min + 1e-4)
+ matrix_[:, :, :, 1] = (matrix_[:, :, :, 1] - y_min) / (
+ y_max - y_min + 1e-4)
+ matrix_[:, :, :, 2] = (matrix_[:, :, :, 2] > 0.3).float()
+ xy_dist = matrix_[..., :2, 0] - matrix_[..., :2, 1]
+ score = matrix_[..., 2, 0] * matrix_[..., 2, 1]
+
+ similarity = (torch.exp(-50 * xy_dist.pow(2).sum(dim=-1)) *
+ score).sum(dim=-1) / (
+ score.sum(dim=-1) + 1e-6)
+ num_visible_kpts = score.sum(dim=-1)
+ similarity = similarity * torch.log(
+ (1 + (num_visible_kpts - 1) * 10).clamp(min=1)) / np.log(161)
+
+ similarity[similarity.isnan()] = 0
+
+ return similarity
+
+
+@torch.no_grad()
+def calculate_similarity(tch_kpts: np.ndarray, stu_kpts: np.ndarray):
+ assert tch_kpts.shape[1] == 17
+ assert tch_kpts.shape[2] == 3
+ assert stu_kpts.shape[1] == 17
+ assert stu_kpts.shape[2] == 3
+
+ similarity1 = _calculate_similarity(tch_kpts, stu_kpts)
+
+ stu_kpts_flip = stu_kpts[:, flip_indices]
+ stu_kpts_flip[..., 0] = 191.5 - stu_kpts_flip[..., 0]
+ similarity2 = _calculate_similarity(tch_kpts, stu_kpts_flip)
+
+ similarity = torch.stack((similarity1, similarity2)).max(dim=0).values
+
+ return similarity
+
+
+@torch.no_grad()
+def select_piece_from_similarity(similarity):
+ m, n = similarity.size()
+ row_indices = torch.arange(m).view(-1, 1).expand(m, n).to(similarity)
+ col_indices = torch.arange(n).view(1, -1).expand(m, n).to(similarity)
+ diagonal_indices = similarity.size(0) - 1 - row_indices + col_indices
+ unique_diagonal_indices, inverse_indices = torch.unique(
+ diagonal_indices, return_inverse=True)
+
+ diagonal_sums_list = torch.zeros(
+ unique_diagonal_indices.size(0),
+ dtype=similarity.dtype,
+ device=similarity.device)
+ diagonal_sums_list.scatter_add_(0, inverse_indices.view(-1),
+ similarity.view(-1))
+ diagonal_sums_list[:min(m, n) // 4] = 0
+ diagonal_sums_list[-min(m, n) // 4:] = 0
+ index = diagonal_sums_list.argmax().item()
+
+ similarity_smooth = torch.nn.functional.max_pool2d(
+ similarity[None], (1, 11), stride=(1, 1), padding=(0, 5))[0]
+ similarity_vec = similarity_smooth.diagonal(offset=index - m +
+ 1).cpu().numpy()
+
+ stu_start = max(0, m - 1 - index)
+ tch_start = max(0, index - m + 1)
+
+ return dict(
+ stu_start=stu_start,
+ tch_start=tch_start,
+ length=len(similarity_vec),
+ similarity=similarity_vec)
diff --git a/projects/just_dance/configs/_base_ b/projects/just_dance/configs/_base_
new file mode 120000
index 0000000000..17b4ad5121
--- /dev/null
+++ b/projects/just_dance/configs/_base_
@@ -0,0 +1 @@
+../../../configs/_base_
diff --git a/projects/just_dance/configs/rtmdet-nano_one-person.py b/projects/just_dance/configs/rtmdet-nano_one-person.py
new file mode 100644
index 0000000000..a838522918
--- /dev/null
+++ b/projects/just_dance/configs/rtmdet-nano_one-person.py
@@ -0,0 +1,3 @@
+_base_ = '../../rtmpose/rtmdet/person/rtmdet_nano_320-8xb32_coco-person.py'
+
+model = dict(test_cfg=dict(nms_pre=1, score_thr=0.0, max_per_img=1))
diff --git a/projects/just_dance/just_dance_demo.ipynb b/projects/just_dance/just_dance_demo.ipynb
new file mode 100644
index 0000000000..45a16e4b8c
--- /dev/null
+++ b/projects/just_dance/just_dance_demo.ipynb
@@ -0,0 +1,712 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6d999c38-2087-4250-b6a4-a30cf8b44ec0",
+ "metadata": {
+ "ExecutionIndicator": {
+ "show": true
+ },
+ "execution": {
+ "iopub.execute_input": "2023-07-05T13:11:38.997916Z",
+ "iopub.status.busy": "2023-07-05T13:11:38.997587Z",
+ "iopub.status.idle": "2023-07-05T13:11:39.001928Z",
+ "shell.execute_reply": "2023-07-05T13:11:39.001429Z",
+ "shell.execute_reply.started": "2023-07-05T13:11:38.997898Z"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "%matplotlib inline\n",
+ "import matplotlib.pyplot as plt\n",
+ "import os.path as osp\n",
+ "import torch\n",
+ "import numpy as np\n",
+ "import mmcv\n",
+ "import cv2\n",
+ "from mmengine.utils import track_iter_progress"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "bfa9bf9b-dc2c-4803-a034-8ae8778113e0",
+ "metadata": {
+ "ExecutionIndicator": {
+ "show": true
+ },
+ "execution": {
+ "iopub.execute_input": "2023-07-05T12:42:15.884465Z",
+ "iopub.status.busy": "2023-07-05T12:42:15.884167Z",
+ "iopub.status.idle": "2023-07-05T12:42:19.774569Z",
+ "shell.execute_reply": "2023-07-05T12:42:19.774020Z",
+ "shell.execute_reply.started": "2023-07-05T12:42:15.884448Z"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# download example videos\n",
+ "from mmengine.utils import mkdir_or_exist\n",
+ "mkdir_or_exist('resources')\n",
+ "! wget -O resources/student_video.mp4 https://download.openmmlab.com/mmpose/v1/projects/just_dance/tom.mp4 \n",
+ "! wget -O resources/teacher_video.mp4 https://download.openmmlab.com/mmpose/v1/projects/just_dance/idol_producer.mp4 \n",
+ "# ! wget -O resources/student_video.mp4 https://download.openmmlab.com/mmpose/v1/projects/just_dance/tsinghua_30fps.mp4 \n",
+ "\n",
+ "student_video = 'resources/student_video.mp4'\n",
+ "teacher_video = 'resources/teacher_video.mp4'"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "652b6b91-e1c0-461b-90e5-653bc35ec380",
+ "metadata": {
+ "ExecutionIndicator": {
+ "show": true
+ },
+ "execution": {
+ "iopub.execute_input": "2023-07-05T12:42:20.693931Z",
+ "iopub.status.busy": "2023-07-05T12:42:20.693353Z",
+ "iopub.status.idle": "2023-07-05T12:43:14.533985Z",
+ "shell.execute_reply": "2023-07-05T12:43:14.533431Z",
+ "shell.execute_reply.started": "2023-07-05T12:42:20.693910Z"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# convert the fps of videos to 30\n",
+ "from mmcv import VideoReader\n",
+ "\n",
+ "if VideoReader(student_video) != 30:\n",
+ " # ffmpeg is required to convert the video fps\n",
+ " # which can be installed via `sudo apt install ffmpeg` on ubuntu\n",
+ " student_video_30fps = student_video.replace(\n",
+ " f\".{student_video.rsplit('.', 1)[1]}\",\n",
+ " f\"_30fps.{student_video.rsplit('.', 1)[1]}\"\n",
+ " )\n",
+ " !ffmpeg -i {student_video} -vf \"minterpolate='fps=30'\" {student_video_30fps}\n",
+ " student_video = student_video_30fps\n",
+ " \n",
+ "if VideoReader(teacher_video) != 30:\n",
+ " teacher_video_30fps = teacher_video.replace(\n",
+ " f\".{teacher_video.rsplit('.', 1)[1]}\",\n",
+ " f\"_30fps.{teacher_video.rsplit('.', 1)[1]}\"\n",
+ " )\n",
+ " !ffmpeg -i {teacher_video} -vf \"minterpolate='fps=30'\" {teacher_video_30fps}\n",
+ " teacher_video = teacher_video_30fps "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6a4e141d-ee4a-4e06-a380-230418c9b936",
+ "metadata": {
+ "ExecutionIndicator": {
+ "show": true
+ },
+ "execution": {
+ "iopub.execute_input": "2023-07-05T12:45:01.672054Z",
+ "iopub.status.busy": "2023-07-05T12:45:01.671727Z",
+ "iopub.status.idle": "2023-07-05T12:45:02.417026Z",
+ "shell.execute_reply": "2023-07-05T12:45:02.416567Z",
+ "shell.execute_reply.started": "2023-07-05T12:45:01.672035Z"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# init pose estimator\n",
+ "from mmpose.apis.inferencers import Pose2DInferencer\n",
+ "pose_estimator = Pose2DInferencer(\n",
+ " 'rtmpose-t_8xb256-420e_aic-coco-256x192',\n",
+ " det_model='configs/rtmdet-nano_one-person.py',\n",
+ " det_weights='https://download.openmmlab.com/mmpose/v1/projects/' \n",
+ " 'rtmpose/rtmdet_nano_8xb32-100e_coco-obj365-person-05d8511e.pth'\n",
+ ")\n",
+ "pose_estimator.model.test_cfg['flip_test'] = False"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "879ba5c0-4d2d-4cca-92d7-d4f94e04a821",
+ "metadata": {
+ "ExecutionIndicator": {
+ "show": true
+ },
+ "execution": {
+ "iopub.execute_input": "2023-07-05T12:45:05.192437Z",
+ "iopub.status.busy": "2023-07-05T12:45:05.191982Z",
+ "iopub.status.idle": "2023-07-05T12:45:05.197379Z",
+ "shell.execute_reply": "2023-07-05T12:45:05.196780Z",
+ "shell.execute_reply.started": "2023-07-05T12:45:05.192417Z"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "@torch.no_grad()\n",
+ "def get_keypoints_from_frame(image, pose_estimator):\n",
+ " \"\"\"Extract keypoints from a single video frame.\"\"\"\n",
+ "\n",
+ " det_results = pose_estimator.detector(\n",
+ " image, return_datasample=True)['predictions']\n",
+ " pred_instance = det_results[0].pred_instances.numpy()\n",
+ "\n",
+ " if len(pred_instance) == 0 or pred_instance.scores[0] < 0.2:\n",
+ " return np.zeros((1, 17, 3), dtype=np.float32)\n",
+ "\n",
+ " data_info = dict(\n",
+ " img=image,\n",
+ " bbox=pred_instance.bboxes[:1],\n",
+ " bbox_score=pred_instance.scores[:1])\n",
+ "\n",
+ " data_info.update(pose_estimator.model.dataset_meta)\n",
+ " data = pose_estimator.collate_fn(\n",
+ " [pose_estimator.pipeline(data_info)])\n",
+ "\n",
+ " # custom forward\n",
+ " data = pose_estimator.model.data_preprocessor(data, False)\n",
+ " feats = pose_estimator.model.extract_feat(data['inputs'])\n",
+ " pred_instances = pose_estimator.model.head.predict(\n",
+ " feats,\n",
+ " data['data_samples'],\n",
+ " test_cfg=pose_estimator.model.test_cfg)[0]\n",
+ " keypoints = np.concatenate(\n",
+ " (pred_instances.keypoints, pred_instances.keypoint_scores[...,\n",
+ " None]),\n",
+ " axis=-1)\n",
+ "\n",
+ " return keypoints "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "31e5bd4c-4c2b-4fe0-b64c-1afed67b7688",
+ "metadata": {
+ "ExecutionIndicator": {
+ "show": true
+ },
+ "execution": {
+ "iopub.execute_input": "2023-07-05T12:47:55.564788Z",
+ "iopub.status.busy": "2023-07-05T12:47:55.564450Z",
+ "iopub.status.idle": "2023-07-05T12:49:37.222662Z",
+ "shell.execute_reply": "2023-07-05T12:49:37.222028Z",
+ "shell.execute_reply.started": "2023-07-05T12:47:55.564770Z"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# pose estimation in two videos\n",
+ "student_poses, teacher_poses = [], []\n",
+ "for frame in VideoReader(student_video):\n",
+ " student_poses.append(get_keypoints_from_frame(frame, pose_estimator))\n",
+ "for frame in VideoReader(teacher_video):\n",
+ " teacher_poses.append(get_keypoints_from_frame(frame, pose_estimator))\n",
+ " \n",
+ "student_poses = np.concatenate(student_poses)\n",
+ "teacher_poses = np.concatenate(teacher_poses)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "38a8d7a5-17ed-4ce2-bb8b-d1637cb49578",
+ "metadata": {
+ "ExecutionIndicator": {
+ "show": true
+ },
+ "execution": {
+ "iopub.execute_input": "2023-07-05T12:55:09.342432Z",
+ "iopub.status.busy": "2023-07-05T12:55:09.342185Z",
+ "iopub.status.idle": "2023-07-05T12:55:09.350522Z",
+ "shell.execute_reply": "2023-07-05T12:55:09.350099Z",
+ "shell.execute_reply.started": "2023-07-05T12:55:09.342416Z"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "valid_indices = np.array([0] + list(range(5, 17)))\n",
+ "\n",
+ "@torch.no_grad()\n",
+ "def _calculate_similarity(tch_kpts: np.ndarray, stu_kpts: np.ndarray):\n",
+ "\n",
+ " stu_kpts = torch.from_numpy(stu_kpts[:, None, valid_indices])\n",
+ " tch_kpts = torch.from_numpy(tch_kpts[None, :, valid_indices])\n",
+ " stu_kpts = stu_kpts.expand(stu_kpts.shape[0], tch_kpts.shape[1],\n",
+ " stu_kpts.shape[2], 3)\n",
+ " tch_kpts = tch_kpts.expand(stu_kpts.shape[0], tch_kpts.shape[1],\n",
+ " stu_kpts.shape[2], 3)\n",
+ "\n",
+ " matrix = torch.stack((stu_kpts, tch_kpts), dim=4)\n",
+ " if torch.cuda.is_available():\n",
+ " matrix = matrix.cuda()\n",
+ " # only consider visible keypoints\n",
+ " mask = torch.logical_and(matrix[:, :, :, 2, 0] > 0.3,\n",
+ " matrix[:, :, :, 2, 1] > 0.3)\n",
+ " matrix[~mask] = 0.0\n",
+ "\n",
+ " matrix_ = matrix.clone()\n",
+ " matrix_[matrix == 0] = 256\n",
+ " x_min = matrix_.narrow(3, 0, 1).min(dim=2).values\n",
+ " y_min = matrix_.narrow(3, 1, 1).min(dim=2).values\n",
+ " matrix_ = matrix.clone()\n",
+ " x_max = matrix_.narrow(3, 0, 1).max(dim=2).values\n",
+ " y_max = matrix_.narrow(3, 1, 1).max(dim=2).values\n",
+ "\n",
+ " matrix_ = matrix.clone()\n",
+ " matrix_[:, :, :, 0] = (matrix_[:, :, :, 0] - x_min) / (\n",
+ " x_max - x_min + 1e-4)\n",
+ " matrix_[:, :, :, 1] = (matrix_[:, :, :, 1] - y_min) / (\n",
+ " y_max - y_min + 1e-4)\n",
+ " matrix_[:, :, :, 2] = (matrix_[:, :, :, 2] > 0.3).float()\n",
+ " xy_dist = matrix_[..., :2, 0] - matrix_[..., :2, 1]\n",
+ " score = matrix_[..., 2, 0] * matrix_[..., 2, 1]\n",
+ "\n",
+ " similarity = (torch.exp(-50 * xy_dist.pow(2).sum(dim=-1)) *\n",
+ " score).sum(dim=-1) / (\n",
+ " score.sum(dim=-1) + 1e-6)\n",
+ " num_visible_kpts = score.sum(dim=-1)\n",
+ " similarity = similarity * torch.log(\n",
+ " (1 + (num_visible_kpts - 1) * 10).clamp(min=1)) / np.log(161)\n",
+ "\n",
+ " similarity[similarity.isnan()] = 0\n",
+ "\n",
+ " return similarity"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "658bcf89-df06-4c73-9323-8973a49c14c3",
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2023-07-05T12:55:31.978675Z",
+ "iopub.status.busy": "2023-07-05T12:55:31.978219Z",
+ "iopub.status.idle": "2023-07-05T12:55:32.149624Z",
+ "shell.execute_reply": "2023-07-05T12:55:32.148568Z",
+ "shell.execute_reply.started": "2023-07-05T12:55:31.978657Z"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# compute similarity without flip\n",
+ "similarity1 = _calculate_similarity(teacher_poses, student_poses)\n",
+ "\n",
+ "# compute similarity with flip\n",
+ "flip_indices = np.array(\n",
+ " [0, 2, 1, 4, 3, 6, 5, 8, 7, 10, 9, 12, 11, 14, 13, 16, 15])\n",
+ "student_poses_flip = student_poses[:, flip_indices]\n",
+ "student_poses_flip[..., 0] = 191.5 - student_poses_flip[..., 0]\n",
+ "similarity2 = _calculate_similarity(teacher_poses, student_poses_flip)\n",
+ "\n",
+ "# select the larger similarity\n",
+ "similarity = torch.stack((similarity1, similarity2)).max(dim=0).values"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f981410d-4585-47c1-98c0-6946f948487d",
+ "metadata": {
+ "ExecutionIndicator": {
+ "show": false
+ },
+ "execution": {
+ "iopub.execute_input": "2023-07-05T12:55:57.321845Z",
+ "iopub.status.busy": "2023-07-05T12:55:57.321530Z",
+ "iopub.status.idle": "2023-07-05T12:55:57.582879Z",
+ "shell.execute_reply": "2023-07-05T12:55:57.582425Z",
+ "shell.execute_reply.started": "2023-07-05T12:55:57.321826Z"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# visualize the similarity\n",
+ "plt.imshow(similarity.cpu().numpy())\n",
+ "\n",
+ "# there is an apparent diagonal in the figure\n",
+ "# we can select matched video snippets with this diagonal"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "13c189e5-fc53-46a2-9057-f0f2ffc1f46d",
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2023-07-05T12:58:16.913855Z",
+ "iopub.status.busy": "2023-07-05T12:58:16.913529Z",
+ "iopub.status.idle": "2023-07-05T12:58:16.919972Z",
+ "shell.execute_reply": "2023-07-05T12:58:16.919005Z",
+ "shell.execute_reply.started": "2023-07-05T12:58:16.913837Z"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "@torch.no_grad()\n",
+ "def select_piece_from_similarity(similarity):\n",
+ " m, n = similarity.size()\n",
+ " row_indices = torch.arange(m).view(-1, 1).expand(m, n).to(similarity)\n",
+ " col_indices = torch.arange(n).view(1, -1).expand(m, n).to(similarity)\n",
+ " diagonal_indices = similarity.size(0) - 1 - row_indices + col_indices\n",
+ " unique_diagonal_indices, inverse_indices = torch.unique(\n",
+ " diagonal_indices, return_inverse=True)\n",
+ "\n",
+ " diagonal_sums_list = torch.zeros(\n",
+ " unique_diagonal_indices.size(0),\n",
+ " dtype=similarity.dtype,\n",
+ " device=similarity.device)\n",
+ " diagonal_sums_list.scatter_add_(0, inverse_indices.view(-1),\n",
+ " similarity.view(-1))\n",
+ " diagonal_sums_list[:min(m, n) // 4] = 0\n",
+ " diagonal_sums_list[-min(m, n) // 4:] = 0\n",
+ " index = diagonal_sums_list.argmax().item()\n",
+ "\n",
+ " similarity_smooth = torch.nn.functional.max_pool2d(\n",
+ " similarity[None], (1, 11), stride=(1, 1), padding=(0, 5))[0]\n",
+ " similarity_vec = similarity_smooth.diagonal(offset=index - m +\n",
+ " 1).cpu().numpy()\n",
+ "\n",
+ " stu_start = max(0, m - 1 - index)\n",
+ " tch_start = max(0, index - m + 1)\n",
+ "\n",
+ " return dict(\n",
+ " stu_start=stu_start,\n",
+ " tch_start=tch_start,\n",
+ " length=len(similarity_vec),\n",
+ " similarity=similarity_vec)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7c0e19df-949d-471d-804d-409b3b9ddf7d",
+ "metadata": {
+ "ExecutionIndicator": {
+ "show": true
+ },
+ "execution": {
+ "iopub.execute_input": "2023-07-05T12:58:44.860190Z",
+ "iopub.status.busy": "2023-07-05T12:58:44.859878Z",
+ "iopub.status.idle": "2023-07-05T12:58:44.888465Z",
+ "shell.execute_reply": "2023-07-05T12:58:44.887917Z",
+ "shell.execute_reply.started": "2023-07-05T12:58:44.860173Z"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "matched_piece_info = select_piece_from_similarity(similarity)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "51b0a2bd-253c-4a8f-a82a-263e18a4703e",
+ "metadata": {
+ "ExecutionIndicator": {
+ "show": true
+ },
+ "execution": {
+ "iopub.execute_input": "2023-07-05T13:01:19.061408Z",
+ "iopub.status.busy": "2023-07-05T13:01:19.060857Z",
+ "iopub.status.idle": "2023-07-05T13:01:19.293742Z",
+ "shell.execute_reply": "2023-07-05T13:01:19.293298Z",
+ "shell.execute_reply.started": "2023-07-05T13:01:19.061378Z"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "plt.imshow(similarity.cpu().numpy())\n",
+ "plt.plot((matched_piece_info['tch_start'], \n",
+ " matched_piece_info['tch_start']+matched_piece_info['length']-1),\n",
+ " (matched_piece_info['stu_start'],\n",
+ " matched_piece_info['stu_start']+matched_piece_info['length']-1), 'r')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ffcde4e7-ff50-483a-b515-604c1d8f121a",
+ "metadata": {},
+ "source": [
+ "# Generate Output Video"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "72171a0c-ab33-45bb-b84c-b15f0816ed3a",
+ "metadata": {
+ "ExecutionIndicator": {
+ "show": true
+ },
+ "execution": {
+ "iopub.execute_input": "2023-07-05T13:11:50.063595Z",
+ "iopub.status.busy": "2023-07-05T13:11:50.063259Z",
+ "iopub.status.idle": "2023-07-05T13:11:50.070929Z",
+ "shell.execute_reply": "2023-07-05T13:11:50.070411Z",
+ "shell.execute_reply.started": "2023-07-05T13:11:50.063574Z"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "from typing import Tuple\n",
+ "\n",
+ "def resize_image_to_fixed_height(image: np.ndarray,\n",
+ " fixed_height: int) -> np.ndarray:\n",
+ " \"\"\"Resizes an input image to a specified fixed height while maintaining its\n",
+ " aspect ratio.\n",
+ "\n",
+ " Args:\n",
+ " image (np.ndarray): Input image as a numpy array [H, W, C]\n",
+ " fixed_height (int): Desired fixed height of the output image.\n",
+ "\n",
+ " Returns:\n",
+ " Resized image as a numpy array (fixed_height, new_width, channels).\n",
+ " \"\"\"\n",
+ " original_height, original_width = image.shape[:2]\n",
+ "\n",
+ " scale_ratio = fixed_height / original_height\n",
+ " new_width = int(original_width * scale_ratio)\n",
+ " resized_image = cv2.resize(image, (new_width, fixed_height))\n",
+ "\n",
+ " return resized_image\n",
+ "\n",
+ "def blend_images(img1: np.ndarray,\n",
+ " img2: np.ndarray,\n",
+ " blend_ratios: Tuple[float, float] = (1, 1)) -> np.ndarray:\n",
+ " \"\"\"Blends two input images with specified blend ratios.\n",
+ "\n",
+ " Args:\n",
+ " img1 (np.ndarray): First input image as a numpy array [H, W, C].\n",
+ " img2 (np.ndarray): Second input image as a numpy array [H, W, C]\n",
+ " blend_ratios (tuple): A tuple of two floats representing the blend\n",
+ " ratios for the two input images.\n",
+ "\n",
+ " Returns:\n",
+ " Blended image as a numpy array [H, W, C]\n",
+ " \"\"\"\n",
+ "\n",
+ " def normalize_image(image: np.ndarray) -> np.ndarray:\n",
+ " if image.dtype == np.uint8:\n",
+ " return image.astype(np.float32) / 255.0\n",
+ " return image\n",
+ "\n",
+ " img1 = normalize_image(img1)\n",
+ " img2 = normalize_image(img2)\n",
+ "\n",
+ " blended_image = img1 * blend_ratios[0] + img2 * blend_ratios[1]\n",
+ " blended_image = blended_image.clip(min=0, max=1)\n",
+ " blended_image = (blended_image * 255).astype(np.uint8)\n",
+ "\n",
+ " return blended_image\n",
+ "\n",
+ "def get_smoothed_kpt(kpts, index, sigma=5):\n",
+ " \"\"\"Smooths keypoints using a Gaussian filter.\"\"\"\n",
+ " assert kpts.shape[1] == 17\n",
+ " assert kpts.shape[2] == 3\n",
+ " assert sigma % 2 == 1\n",
+ "\n",
+ " num_kpts = len(kpts)\n",
+ "\n",
+ " start_idx = max(0, index - sigma // 2)\n",
+ " end_idx = min(num_kpts, index + sigma // 2 + 1)\n",
+ "\n",
+ " # Extract a piece of the keypoints array to apply the filter\n",
+ " piece = kpts[start_idx:end_idx].copy()\n",
+ " original_kpt = kpts[index]\n",
+ "\n",
+ " # Split the piece into coordinates and scores\n",
+ " coords, scores = piece[..., :2], piece[..., 2]\n",
+ "\n",
+ " # Calculate the Gaussian ratio for each keypoint\n",
+ " gaussian_ratio = np.arange(len(scores)) + start_idx - index\n",
+ " gaussian_ratio = np.exp(-gaussian_ratio**2 / 2)\n",
+ "\n",
+ " # Update scores using the Gaussian ratio\n",
+ " scores *= gaussian_ratio[:, None]\n",
+ "\n",
+ " # Compute the smoothed coordinates\n",
+ " smoothed_coords = (coords * scores[..., None]).sum(axis=0) / (\n",
+ " scores[..., None].sum(axis=0) + 1e-4)\n",
+ "\n",
+ " original_kpt[..., :2] = smoothed_coords\n",
+ "\n",
+ " return original_kpt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "609b5adc-e176-4bf9-b9a4-506f72440017",
+ "metadata": {
+ "ExecutionIndicator": {
+ "show": true
+ },
+ "execution": {
+ "iopub.execute_input": "2023-07-05T13:12:46.198835Z",
+ "iopub.status.busy": "2023-07-05T13:12:46.198268Z",
+ "iopub.status.idle": "2023-07-05T13:12:46.202273Z",
+ "shell.execute_reply": "2023-07-05T13:12:46.200881Z",
+ "shell.execute_reply.started": "2023-07-05T13:12:46.198815Z"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "score, last_vis_score = 0, 0\n",
+ "video_writer = None\n",
+ "output_file = 'output.mp4'\n",
+ "stu_kpts = student_poses\n",
+ "tch_kpts = teacher_poses"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a264405a-5d50-49de-8637-2d1f67cb0a70",
+ "metadata": {
+ "ExecutionIndicator": {
+ "show": true
+ },
+ "execution": {
+ "iopub.execute_input": "2023-07-05T13:13:11.334760Z",
+ "iopub.status.busy": "2023-07-05T13:13:11.334433Z",
+ "iopub.status.idle": "2023-07-05T13:13:17.264181Z",
+ "shell.execute_reply": "2023-07-05T13:13:17.262931Z",
+ "shell.execute_reply.started": "2023-07-05T13:13:11.334742Z"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "from mmengine.structures import InstanceData\n",
+ "\n",
+ "tch_video_reader = VideoReader(teacher_video)\n",
+ "stu_video_reader = VideoReader(student_video)\n",
+ "for _ in range(matched_piece_info['tch_start']):\n",
+ " _ = next(tch_video_reader)\n",
+ "for _ in range(matched_piece_info['stu_start']):\n",
+ " _ = next(stu_video_reader)\n",
+ " \n",
+ "for i in track_iter_progress(range(matched_piece_info['length'])):\n",
+ " tch_frame = mmcv.bgr2rgb(next(tch_video_reader))\n",
+ " stu_frame = mmcv.bgr2rgb(next(stu_video_reader))\n",
+ " tch_frame = resize_image_to_fixed_height(tch_frame, 300)\n",
+ " stu_frame = resize_image_to_fixed_height(stu_frame, 300)\n",
+ "\n",
+ " stu_kpt = get_smoothed_kpt(stu_kpts, matched_piece_info['stu_start'] + i,\n",
+ " 5)\n",
+ " tch_kpt = get_smoothed_kpt(tch_kpts, matched_piece_info['tch_start'] + i,\n",
+ " 5)\n",
+ "\n",
+ " # draw pose\n",
+ " stu_kpt[..., 1] += (300 - 256)\n",
+ " tch_kpt[..., 0] += (256 - 192)\n",
+ " tch_kpt[..., 1] += (300 - 256)\n",
+ " stu_inst = InstanceData(\n",
+ " keypoints=stu_kpt[None, :, :2],\n",
+ " keypoint_scores=stu_kpt[None, :, 2])\n",
+ " tch_inst = InstanceData(\n",
+ " keypoints=tch_kpt[None, :, :2],\n",
+ " keypoint_scores=tch_kpt[None, :, 2])\n",
+ " \n",
+ " stu_out_img = pose_estimator.visualizer._draw_instances_kpts(\n",
+ " np.zeros((300, 256, 3)), stu_inst)\n",
+ " tch_out_img = pose_estimator.visualizer._draw_instances_kpts(\n",
+ " np.zeros((300, 256, 3)), tch_inst)\n",
+ " out_img = blend_images(\n",
+ " stu_out_img, tch_out_img, blend_ratios=(1, 0.3))\n",
+ "\n",
+ " # draw score\n",
+ " score_frame = matched_piece_info['similarity'][i]\n",
+ " score += score_frame * 1000\n",
+ " if score - last_vis_score > 1500:\n",
+ " last_vis_score = score\n",
+ " pose_estimator.visualizer.set_image(out_img)\n",
+ " pose_estimator.visualizer.draw_texts(\n",
+ " 'score: ', (60, 30),\n",
+ " font_sizes=15,\n",
+ " colors=(255, 255, 255),\n",
+ " vertical_alignments='bottom')\n",
+ " pose_estimator.visualizer.draw_texts(\n",
+ " f'{int(last_vis_score)}', (115, 30),\n",
+ " font_sizes=30 * max(0.4, score_frame),\n",
+ " colors=(255, 255, 255),\n",
+ " vertical_alignments='bottom')\n",
+ " out_img = pose_estimator.visualizer.get_image() \n",
+ " \n",
+ " # concatenate\n",
+ " concatenated_image = np.hstack((stu_frame, out_img, tch_frame))\n",
+ " if video_writer is None:\n",
+ " video_writer = cv2.VideoWriter(output_file,\n",
+ " cv2.VideoWriter_fourcc(*'mp4v'),\n",
+ " 30,\n",
+ " (concatenated_image.shape[1],\n",
+ " concatenated_image.shape[0]))\n",
+ " video_writer.write(mmcv.rgb2bgr(concatenated_image))\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "745fdd75-6ed4-4cae-9f21-c2cd486ee918",
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2023-07-05T13:13:18.704492Z",
+ "iopub.status.busy": "2023-07-05T13:13:18.704179Z",
+ "iopub.status.idle": "2023-07-05T13:13:18.714843Z",
+ "shell.execute_reply": "2023-07-05T13:13:18.713866Z",
+ "shell.execute_reply.started": "2023-07-05T13:13:18.704472Z"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "if video_writer is not None:\n",
+ " video_writer.release() "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7cb0bc99-ca19-44f1-bc0a-38e14afa980f",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.15"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/projects/just_dance/process_video.py b/projects/just_dance/process_video.py
new file mode 100644
index 0000000000..9efb41f5af
--- /dev/null
+++ b/projects/just_dance/process_video.py
@@ -0,0 +1,259 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import tempfile
+from typing import Optional
+
+import cv2
+import mmcv
+import numpy as np
+import torch
+from mmengine.structures import InstanceData
+from mmengine.utils import track_iter_progress
+
+from mmpose.apis import Pose2DInferencer
+from mmpose.datasets.datasets.utils import parse_pose_metainfo
+from mmpose.visualization import PoseLocalVisualizer
+
+try:
+ from .calculate_similarity import (calculate_similarity,
+ select_piece_from_similarity)
+ from .utils import (blend_images, convert_video_fps, get_smoothed_kpt,
+ resize_image_to_fixed_height)
+except ImportError:
+ from calculate_similarity import (calculate_similarity,
+ select_piece_from_similarity)
+ from utils import (blend_images, convert_video_fps, get_smoothed_kpt,
+ resize_image_to_fixed_height)
+
+model_cfg = dict(
+ human=dict(
+ model='rtmpose-t_8xb256-420e_aic-coco-256x192',
+ det_model=os.path.join(
+ os.path.dirname(os.path.abspath(__file__)),
+ 'configs/rtmdet-nano_one-person.py'),
+ det_weights='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmpose/rtmdet_nano_8xb32-100e_coco-obj365-person-05d8511e.pth',
+ ),
+ bear=dict(
+ model='rtmpose-l_8xb256-420e_humanart-256x192',
+ det_model='rtmdet-m',
+ det_cat_ids=77,
+ ),
+)
+
+
+class VideoProcessor:
+ """A class to process videos for pose estimation and visualization."""
+
+ def __init__(self):
+ self.category = 'human'
+
+ def _set_category(self, category):
+ assert category in model_cfg
+ self.category = category
+
+ @property
+ def pose_estimator(self) -> Pose2DInferencer:
+ if not hasattr(self, '_pose_estimator'):
+ self._pose_estimator = dict()
+ if self.category not in self._pose_estimator:
+ self._pose_estimator[self.category] = Pose2DInferencer(
+ **(model_cfg[self.category]))
+ self._pose_estimator[
+ self.category].model.test_cfg['flip_test'] = False
+ return self._pose_estimator[self.category]
+
+ @property
+ def visualizer(self) -> PoseLocalVisualizer:
+ if hasattr(self, '_visualizer'):
+ return self._visualizer
+ elif hasattr(self, '_pose_estimator'):
+ return self.pose_estimator.visualizer
+
+ # init visualizer
+ self._visualizer = PoseLocalVisualizer()
+ metainfo_file = os.path.join(
+ os.path.dirname(os.path.abspath(__file__)).rsplit(os.sep, 1)[0],
+ 'configs/_base_/datasets/coco.py')
+ metainfo = parse_pose_metainfo(dict(from_file=metainfo_file))
+ self._visualizer.set_dataset_meta(metainfo)
+ return self._visualizer
+
+ @torch.no_grad()
+ def get_keypoints_from_frame(self, image: np.ndarray) -> np.ndarray:
+ """Extract keypoints from a single video frame."""
+
+ det_results = self.pose_estimator.detector(
+ image, return_datasamples=True)['predictions']
+ pred_instance = det_results[0].pred_instances
+
+ if len(pred_instance) == 0:
+ return np.zeros((1, 17, 3), dtype=np.float32)
+
+ # only select the most significant person
+ data_info = dict(
+ img=image,
+ bbox=pred_instance.bboxes.cpu().numpy()[:1],
+ bbox_score=pred_instance.scores.cpu().numpy()[:1])
+
+ if data_info['bbox_score'] < 0.2:
+ return np.zeros((1, 17, 3), dtype=np.float32)
+
+ data_info.update(self.pose_estimator.model.dataset_meta)
+ data = self.pose_estimator.collate_fn(
+ [self.pose_estimator.pipeline(data_info)])
+
+ # custom forward
+ data = self.pose_estimator.model.data_preprocessor(data, False)
+ feats = self.pose_estimator.model.extract_feat(data['inputs'])
+ pred_instances = self.pose_estimator.model.head.predict(
+ feats,
+ data['data_samples'],
+ test_cfg=self.pose_estimator.model.test_cfg)[0]
+ keypoints = np.concatenate(
+ (pred_instances.keypoints, pred_instances.keypoint_scores[...,
+ None]),
+ axis=-1)
+
+ return keypoints
+
+ @torch.no_grad()
+ def get_keypoints_from_video(self, video: str) -> np.ndarray:
+ """Extract keypoints from a video."""
+
+ video_fname = video.rsplit('.', 1)[0]
+ if os.path.exists(f'{video_fname}_kpts.pth'):
+ keypoints = torch.load(f'{video_fname}_kpts.pth')
+ return keypoints
+
+ video_reader = mmcv.VideoReader(video)
+
+ if abs(video_reader.fps - 30) > 0.1:
+ video_reader = mmcv.VideoReader(convert_video_fps(video))
+
+ assert abs(video_reader.fps - 30) < 0.1, f'only support videos with ' \
+ f'30 FPS, but the video {video_fname} has {video_reader.fps} fps'
+
+ if os.path.basename(video_fname).startswith('bear'):
+ self._set_category('bear')
+ else:
+ self._set_category('human')
+ keypoints_list = []
+ for i, frame in enumerate(video_reader):
+ keypoints = self.get_keypoints_from_frame(frame)
+ keypoints_list.append(keypoints)
+ keypoints = np.concatenate(keypoints_list)
+ torch.save(keypoints, f'{video_fname}_kpts.pth')
+ return keypoints
+
+ @torch.no_grad()
+ def run(self,
+ tch_video: str,
+ stu_video: str,
+ output_file: Optional[str] = None):
+ # extract human poses
+ tch_kpts = self.get_keypoints_from_video(tch_video)
+ stu_kpts = self.get_keypoints_from_video(stu_video)
+
+ # compute similarity
+ similarity = calculate_similarity(tch_kpts, stu_kpts)
+
+ # select piece
+ piece_info = select_piece_from_similarity(similarity)
+
+ # output
+ tch_name = os.path.basename(tch_video).rsplit('.', 1)[0]
+ stu_name = os.path.basename(stu_video).rsplit('.', 1)[0]
+ if output_file is None:
+ fname = f'{tch_name}-{stu_name}.mp4'
+ output_file = os.path.join(tempfile.mkdtemp(), fname)
+ return self.generate_output_video(tch_video, stu_video, output_file,
+ tch_kpts, stu_kpts, piece_info)
+
+ def generate_output_video(self, tch_video: str, stu_video: str,
+ output_file: str, tch_kpts: np.ndarray,
+ stu_kpts: np.ndarray, piece_info: dict) -> str:
+ """Generate an output video with keypoints overlay."""
+
+ tch_video_reader = mmcv.VideoReader(tch_video)
+ stu_video_reader = mmcv.VideoReader(stu_video)
+ for _ in range(piece_info['tch_start']):
+ _ = next(tch_video_reader)
+ for _ in range(piece_info['stu_start']):
+ _ = next(stu_video_reader)
+
+ score, last_vis_score = 0, 0
+ video_writer = None
+ for i in track_iter_progress(range(piece_info['length'])):
+ tch_frame = mmcv.bgr2rgb(next(tch_video_reader))
+ stu_frame = mmcv.bgr2rgb(next(stu_video_reader))
+ tch_frame = resize_image_to_fixed_height(tch_frame, 300)
+ stu_frame = resize_image_to_fixed_height(stu_frame, 300)
+
+ stu_kpt = get_smoothed_kpt(stu_kpts, piece_info['stu_start'] + i,
+ 5)
+ tch_kpt = get_smoothed_kpt(tch_kpts, piece_info['tch_start'] + i,
+ 5)
+
+ # draw pose
+ stu_kpt[..., 1] += (300 - 256)
+ tch_kpt[..., 0] += (256 - 192)
+ tch_kpt[..., 1] += (300 - 256)
+ stu_inst = InstanceData(
+ keypoints=stu_kpt[None, :, :2],
+ keypoint_scores=stu_kpt[None, :, 2])
+ tch_inst = InstanceData(
+ keypoints=tch_kpt[None, :, :2],
+ keypoint_scores=tch_kpt[None, :, 2])
+
+ stu_out_img = self.visualizer._draw_instances_kpts(
+ np.zeros((300, 256, 3)), stu_inst)
+ tch_out_img = self.visualizer._draw_instances_kpts(
+ np.zeros((300, 256, 3)), tch_inst)
+ out_img = blend_images(
+ stu_out_img, tch_out_img, blend_ratios=(1, 0.3))
+
+ # draw score
+ score_frame = piece_info['similarity'][i]
+ score += score_frame * 1000
+ if score - last_vis_score > 1500:
+ last_vis_score = score
+ self.visualizer.set_image(out_img)
+ self.visualizer.draw_texts(
+ 'score: ', (60, 30),
+ font_sizes=15,
+ colors=(255, 255, 255),
+ vertical_alignments='bottom')
+ self.visualizer.draw_texts(
+ f'{int(last_vis_score)}', (115, 30),
+ font_sizes=30 * max(0.4, score_frame),
+ colors=(255, 255, 255),
+ vertical_alignments='bottom')
+ out_img = self.visualizer.get_image()
+
+ # concatenate
+ concatenated_image = np.hstack((stu_frame, out_img, tch_frame))
+ if video_writer is None:
+ video_writer = cv2.VideoWriter(output_file,
+ cv2.VideoWriter_fourcc(*'mp4v'),
+ 30,
+ (concatenated_image.shape[1],
+ concatenated_image.shape[0]))
+ video_writer.write(mmcv.rgb2bgr(concatenated_image))
+
+ if video_writer is not None:
+ video_writer.release()
+ return output_file
+
+
+if __name__ == '__main__':
+ from argparse import ArgumentParser
+ parser = ArgumentParser()
+ parser.add_argument('teacher_video', help='Path to the Teacher Video')
+ parser.add_argument('student_video', help='Path to the Student Video')
+ parser.add_argument(
+ '--output-file', help='Path to save the output Video', default=None)
+ args = parser.parse_args()
+
+ processor = VideoProcessor()
+ processor.run(args.teacher_video, args.student_video, args.output_file)
diff --git a/projects/just_dance/utils.py b/projects/just_dance/utils.py
new file mode 100644
index 0000000000..cd150bb1be
--- /dev/null
+++ b/projects/just_dance/utils.py
@@ -0,0 +1,106 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+from typing import Tuple
+
+import cv2
+import numpy as np
+
+
+def resize_image_to_fixed_height(image: np.ndarray,
+ fixed_height: int) -> np.ndarray:
+ """Resizes an input image to a specified fixed height while maintaining its
+ aspect ratio.
+
+ Args:
+ image (np.ndarray): Input image as a numpy array [H, W, C]
+ fixed_height (int): Desired fixed height of the output image.
+
+ Returns:
+ Resized image as a numpy array (fixed_height, new_width, channels).
+ """
+ original_height, original_width = image.shape[:2]
+
+ scale_ratio = fixed_height / original_height
+ new_width = int(original_width * scale_ratio)
+ resized_image = cv2.resize(image, (new_width, fixed_height))
+
+ return resized_image
+
+
+def blend_images(img1: np.ndarray,
+ img2: np.ndarray,
+ blend_ratios: Tuple[float, float] = (1, 1)) -> np.ndarray:
+ """Blends two input images with specified blend ratios.
+
+ Args:
+ img1 (np.ndarray): First input image as a numpy array [H, W, C].
+ img2 (np.ndarray): Second input image as a numpy array [H, W, C]
+ blend_ratios (tuple): A tuple of two floats representing the blend
+ ratios for the two input images.
+
+ Returns:
+ Blended image as a numpy array [H, W, C]
+ """
+
+ def normalize_image(image: np.ndarray) -> np.ndarray:
+ if image.dtype == np.uint8:
+ return image.astype(np.float32) / 255.0
+ return image
+
+ img1 = normalize_image(img1)
+ img2 = normalize_image(img2)
+
+ blended_image = img1 * blend_ratios[0] + img2 * blend_ratios[1]
+ blended_image = blended_image.clip(min=0, max=1)
+ blended_image = (blended_image * 255).astype(np.uint8)
+
+ return blended_image
+
+
+def convert_video_fps(video):
+
+ input_video = video
+ video_name, post_fix = input_video.rsplit('.', 1)
+ output_video = f'{video_name}_30fps.{post_fix}'
+ if os.path.exists(output_video):
+ return output_video
+
+ os.system(
+ f"ffmpeg -i {input_video} -vf \"minterpolate='fps=30'\" {output_video}"
+ )
+
+ return output_video
+
+
+def get_smoothed_kpt(kpts, index, sigma=5):
+ """Smooths keypoints using a Gaussian filter."""
+ assert kpts.shape[1] == 17
+ assert kpts.shape[2] == 3
+ assert sigma % 2 == 1
+
+ num_kpts = len(kpts)
+
+ start_idx = max(0, index - sigma // 2)
+ end_idx = min(num_kpts, index + sigma // 2 + 1)
+
+ # Extract a piece of the keypoints array to apply the filter
+ piece = kpts[start_idx:end_idx].copy()
+ original_kpt = kpts[index]
+
+ # Split the piece into coordinates and scores
+ coords, scores = piece[..., :2], piece[..., 2]
+
+ # Calculate the Gaussian ratio for each keypoint
+ gaussian_ratio = np.arange(len(scores)) + start_idx - index
+ gaussian_ratio = np.exp(-gaussian_ratio**2 / 2)
+
+ # Update scores using the Gaussian ratio
+ scores *= gaussian_ratio[:, None]
+
+ # Compute the smoothed coordinates
+ smoothed_coords = (coords * scores[..., None]).sum(axis=0) / (
+ scores[..., None].sum(axis=0) + 1e-4)
+
+ original_kpt[..., :2] = smoothed_coords
+
+ return original_kpt
diff --git a/projects/rtmpose/README.md b/projects/rtmpose/README.md
index dc5b0dbe23..a304a69b0d 100644
--- a/projects/rtmpose/README.md
+++ b/projects/rtmpose/README.md
@@ -44,10 +44,25 @@ ______________________________________________________________________
## 🥳 🚀 What's New [🔝](#-table-of-contents)
+- Sep. 2023:
+ - Add RTMW models trained on combined datasets. The alpha version of RTMW-x model achieves 70.2 mAP on COCO-Wholebody val set. You can try it [Here](https://openxlab.org.cn/apps/detail/mmpose/RTMPose). The technical report will be released soon.
+ - Add YOLOX and RTMDet models trained on HumanArt dataset.
+- Aug. 2023:
+ - Support distilled 133-keypoint WholeBody models powered by [DWPose](https://github.com/IDEA-Research/DWPose/tree/main).
+ - You can try DWPose/RTMPose with [sd-webui-controlnet](https://github.com/Mikubill/sd-webui-controlnet) now! Just update your sd-webui-controlnet >= v1.1237, then choose `dw_openpose_full` as preprocessor.
+ - You can try our DWPose with this [Demo](https://openxlab.org.cn/apps/detail/mmpose/RTMPose) by choosing `wholebody`!
+- Jul. 2023:
+ - Add [Online RTMPose Demo](https://openxlab.org.cn/apps/detail/mmpose/RTMPose).
+ - Support 17-keypoint Body models trained on Human-Art.
- Jun. 2023:
- Release 26-keypoint Body models trained on combined datasets.
- May. 2023:
- - Add [code examples](./examples/) of RTMPose.
+ - Exported SDK models (ONNX, TRT, ncnn, etc.) can be downloaded from [OpenMMLab Deploee](https://platform.openmmlab.com/deploee).
+ - [Online Conversion](https://platform.openmmlab.com/deploee/task-convert-list) of `.pth` models into SDK models (ONNX, TensorRT, ncnn, etc.).
+ - Add [code examples](./examples/) of RTMPose, such as:
+ - Pure Python inference without MMDeploy, MMCV etc.
+ - C++ examples with ONNXRuntime and TensorRT backends.
+ - Android examples with ncnn backend.
- Release Hand, Face, Body models trained on combined datasets.
- Mar. 2023: RTMPose is released. RTMPose-m runs at 430+ FPS and achieves 75.8 mAP on COCO val set.
@@ -134,6 +149,7 @@ Feel free to join our community group for more help:
- ncnn 20221128
- cuDNN 8.3.2
- CUDA 11.3
+- **Updates**: We recommend you to try `Body8` models trained on combined datasets, see [here](#body-2d).
| Detection Config | Pose Config | Input Size
+
+## Usage
+
+### Jupyter Notebook
+
+We provide a Jupyter Notebook [`just_dance_demo.ipynb`](./just_dance_demo.ipynb) that contains the complete process of dance comparison. It includes steps such as video FPS adjustment, pose estimation, snippet alignment, scoring, and the generation of the merged video.
+
+### CLI tool
+
+Users can simply run the following command to generate the comparison video:
+
+```shell
+python process_video.py ${TEACHER_VIDEO} ${STUDENT_VIDEO}
+```
+
+### Gradio
+
+Users can also utilize Gradio to build an application using this system. We provide the script [`app.py`](./app.py). This application supports webcam input in addition to existing videos. To build this application, please follow these two steps:
+
+1. Install Gradio
+ ```shell
+ pip install gradio
+ ```
+2. Run the script [`app.py`](./app.py)
+ ```shell
+ python app.py
+ ```
diff --git a/projects/just_dance/app.py b/projects/just_dance/app.py
new file mode 100644
index 0000000000..6213ed3663
--- /dev/null
+++ b/projects/just_dance/app.py
@@ -0,0 +1,117 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import sys
+from functools import partial
+from typing import Optional
+
+project_path = os.path.join(os.path.dirname(os.path.abspath(__file__)))
+mmpose_path = project_path.split('/projects', 1)[0]
+
+os.system('python -m pip install Openmim')
+os.system('python -m mim install "mmcv>=2.0.0"')
+os.system('python -m mim install mmengine')
+os.system('python -m mim install "mmdet>=3.0.0"')
+os.system(f'python -m mim install -e {mmpose_path}')
+
+os.environ['PATH'] = f"{os.environ['PATH']}:{project_path}"
+os.environ[
+ 'PYTHONPATH'] = f"{os.environ.get('PYTHONPATH', '.')}:{project_path}"
+sys.path.append(project_path)
+
+import gradio as gr # noqa
+from mmengine.utils import mkdir_or_exist # noqa
+from process_video import VideoProcessor # noqa
+
+
+def process_video(
+ teacher_video: Optional[str] = None,
+ student_video: Optional[str] = None,
+):
+ print(teacher_video)
+ print(student_video)
+
+ video_processor = VideoProcessor()
+ if student_video is None and teacher_video is not None:
+ # Pre-process the teacher video when users record the student video
+ # using a webcam. This allows users to view the teacher video and
+ # follow the dance moves while recording the student video.
+ _ = video_processor.get_keypoints_from_video(teacher_video)
+ return teacher_video
+ elif teacher_video is None and student_video is not None:
+ _ = video_processor.get_keypoints_from_video(student_video)
+ return student_video
+ elif teacher_video is None and student_video is None:
+ return None
+
+ return video_processor.run(teacher_video, student_video)
+
+
+# download video resources
+mkdir_or_exist(os.path.join(project_path, 'resources'))
+os.system(
+ f'wget -O {project_path}/resources/tom.mp4 https://download.openmmlab.com/mmpose/v1/projects/just_dance/tom.mp4' # noqa
+)
+os.system(
+ f'wget -O {project_path}/resources/idol_producer.mp4 https://download.openmmlab.com/mmpose/v1/projects/just_dance/idol_producer.mp4' # noqa
+)
+os.system(
+ f'wget -O {project_path}/resources/tsinghua_30fps.mp4 https://download.openmmlab.com/mmpose/v1/projects/just_dance/tsinghua_30fps.mp4' # noqa
+)
+os.system(
+ f'wget -O {project_path}/resources/student1.mp4 https://download.openmmlab.com/mmpose/v1/projects/just_dance/student1.mp4' # noqa
+)
+os.system(
+ f'wget -O {project_path}/resources/bear_teacher.mp4 https://download.openmmlab.com/mmpose/v1/projects/just_dance/bear_teacher.mp4' # noqa
+)
+
+with gr.Blocks() as demo:
+ with gr.Tab('Upload-Video'):
+ with gr.Row():
+ with gr.Column():
+ gr.Markdown('Student Video')
+ student_video = gr.Video(type='mp4')
+ gr.Examples([
+ os.path.join(project_path, 'resources/tom.mp4'),
+ os.path.join(project_path, 'resources/tsinghua_30fps.mp4'),
+ os.path.join(project_path, 'resources/student1.mp4')
+ ], student_video)
+ with gr.Column():
+ gr.Markdown('Teacher Video')
+ teacher_video = gr.Video(type='mp4')
+ gr.Examples([
+ os.path.join(project_path, 'resources/idol_producer.mp4'),
+ os.path.join(project_path, 'resources/bear_teacher.mp4')
+ ], teacher_video)
+
+ button = gr.Button('Grading', variant='primary')
+ gr.Markdown('## Display')
+ out_video = gr.Video()
+
+ button.click(
+ partial(process_video), [teacher_video, student_video], out_video)
+
+ with gr.Tab('Webcam-Video'):
+ with gr.Row():
+ with gr.Column():
+ gr.Markdown('Student Video')
+ student_video = gr.Video(source='webcam', type='mp4')
+ with gr.Column():
+ gr.Markdown('Teacher Video')
+ teacher_video = gr.Video(type='mp4')
+ gr.Examples([
+ os.path.join(project_path, 'resources/idol_producer.mp4')
+ ], teacher_video)
+ button_upload = gr.Button('Upload', variant='primary')
+
+ button = gr.Button('Grading', variant='primary')
+ gr.Markdown('## Display')
+ out_video = gr.Video()
+
+ button_upload.click(
+ partial(process_video), [teacher_video, student_video], out_video)
+ button.click(
+ partial(process_video), [teacher_video, student_video], out_video)
+
+gr.close_all()
+demo.queue()
+demo.launch()
diff --git a/projects/just_dance/calculate_similarity.py b/projects/just_dance/calculate_similarity.py
new file mode 100644
index 0000000000..0465dbffaa
--- /dev/null
+++ b/projects/just_dance/calculate_similarity.py
@@ -0,0 +1,105 @@
+import numpy as np
+import torch
+
+flip_indices = np.array(
+ [0, 2, 1, 4, 3, 6, 5, 8, 7, 10, 9, 12, 11, 14, 13, 16, 15])
+valid_indices = np.array([0] + list(range(5, 17)))
+
+
+@torch.no_grad()
+def _calculate_similarity(tch_kpts: np.ndarray, stu_kpts: np.ndarray):
+
+ stu_kpts = torch.from_numpy(stu_kpts[:, None, valid_indices])
+ tch_kpts = torch.from_numpy(tch_kpts[None, :, valid_indices])
+ stu_kpts = stu_kpts.expand(stu_kpts.shape[0], tch_kpts.shape[1],
+ stu_kpts.shape[2], 3)
+ tch_kpts = tch_kpts.expand(stu_kpts.shape[0], tch_kpts.shape[1],
+ stu_kpts.shape[2], 3)
+
+ matrix = torch.stack((stu_kpts, tch_kpts), dim=4)
+ if torch.cuda.is_available():
+ matrix = matrix.cuda()
+ mask = torch.logical_and(matrix[:, :, :, 2, 0] > 0.3,
+ matrix[:, :, :, 2, 1] > 0.3)
+ matrix[~mask] = 0.0
+
+ matrix_ = matrix.clone()
+ matrix_[matrix == 0] = 256
+ x_min = matrix_.narrow(3, 0, 1).min(dim=2).values
+ y_min = matrix_.narrow(3, 1, 1).min(dim=2).values
+ matrix_ = matrix.clone()
+ # matrix_[matrix == 0] = 0
+ x_max = matrix_.narrow(3, 0, 1).max(dim=2).values
+ y_max = matrix_.narrow(3, 1, 1).max(dim=2).values
+
+ matrix_ = matrix.clone()
+ matrix_[:, :, :, 0] = (matrix_[:, :, :, 0] - x_min) / (
+ x_max - x_min + 1e-4)
+ matrix_[:, :, :, 1] = (matrix_[:, :, :, 1] - y_min) / (
+ y_max - y_min + 1e-4)
+ matrix_[:, :, :, 2] = (matrix_[:, :, :, 2] > 0.3).float()
+ xy_dist = matrix_[..., :2, 0] - matrix_[..., :2, 1]
+ score = matrix_[..., 2, 0] * matrix_[..., 2, 1]
+
+ similarity = (torch.exp(-50 * xy_dist.pow(2).sum(dim=-1)) *
+ score).sum(dim=-1) / (
+ score.sum(dim=-1) + 1e-6)
+ num_visible_kpts = score.sum(dim=-1)
+ similarity = similarity * torch.log(
+ (1 + (num_visible_kpts - 1) * 10).clamp(min=1)) / np.log(161)
+
+ similarity[similarity.isnan()] = 0
+
+ return similarity
+
+
+@torch.no_grad()
+def calculate_similarity(tch_kpts: np.ndarray, stu_kpts: np.ndarray):
+ assert tch_kpts.shape[1] == 17
+ assert tch_kpts.shape[2] == 3
+ assert stu_kpts.shape[1] == 17
+ assert stu_kpts.shape[2] == 3
+
+ similarity1 = _calculate_similarity(tch_kpts, stu_kpts)
+
+ stu_kpts_flip = stu_kpts[:, flip_indices]
+ stu_kpts_flip[..., 0] = 191.5 - stu_kpts_flip[..., 0]
+ similarity2 = _calculate_similarity(tch_kpts, stu_kpts_flip)
+
+ similarity = torch.stack((similarity1, similarity2)).max(dim=0).values
+
+ return similarity
+
+
+@torch.no_grad()
+def select_piece_from_similarity(similarity):
+ m, n = similarity.size()
+ row_indices = torch.arange(m).view(-1, 1).expand(m, n).to(similarity)
+ col_indices = torch.arange(n).view(1, -1).expand(m, n).to(similarity)
+ diagonal_indices = similarity.size(0) - 1 - row_indices + col_indices
+ unique_diagonal_indices, inverse_indices = torch.unique(
+ diagonal_indices, return_inverse=True)
+
+ diagonal_sums_list = torch.zeros(
+ unique_diagonal_indices.size(0),
+ dtype=similarity.dtype,
+ device=similarity.device)
+ diagonal_sums_list.scatter_add_(0, inverse_indices.view(-1),
+ similarity.view(-1))
+ diagonal_sums_list[:min(m, n) // 4] = 0
+ diagonal_sums_list[-min(m, n) // 4:] = 0
+ index = diagonal_sums_list.argmax().item()
+
+ similarity_smooth = torch.nn.functional.max_pool2d(
+ similarity[None], (1, 11), stride=(1, 1), padding=(0, 5))[0]
+ similarity_vec = similarity_smooth.diagonal(offset=index - m +
+ 1).cpu().numpy()
+
+ stu_start = max(0, m - 1 - index)
+ tch_start = max(0, index - m + 1)
+
+ return dict(
+ stu_start=stu_start,
+ tch_start=tch_start,
+ length=len(similarity_vec),
+ similarity=similarity_vec)
diff --git a/projects/just_dance/configs/_base_ b/projects/just_dance/configs/_base_
new file mode 120000
index 0000000000..17b4ad5121
--- /dev/null
+++ b/projects/just_dance/configs/_base_
@@ -0,0 +1 @@
+../../../configs/_base_
diff --git a/projects/just_dance/configs/rtmdet-nano_one-person.py b/projects/just_dance/configs/rtmdet-nano_one-person.py
new file mode 100644
index 0000000000..a838522918
--- /dev/null
+++ b/projects/just_dance/configs/rtmdet-nano_one-person.py
@@ -0,0 +1,3 @@
+_base_ = '../../rtmpose/rtmdet/person/rtmdet_nano_320-8xb32_coco-person.py'
+
+model = dict(test_cfg=dict(nms_pre=1, score_thr=0.0, max_per_img=1))
diff --git a/projects/just_dance/just_dance_demo.ipynb b/projects/just_dance/just_dance_demo.ipynb
new file mode 100644
index 0000000000..45a16e4b8c
--- /dev/null
+++ b/projects/just_dance/just_dance_demo.ipynb
@@ -0,0 +1,712 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6d999c38-2087-4250-b6a4-a30cf8b44ec0",
+ "metadata": {
+ "ExecutionIndicator": {
+ "show": true
+ },
+ "execution": {
+ "iopub.execute_input": "2023-07-05T13:11:38.997916Z",
+ "iopub.status.busy": "2023-07-05T13:11:38.997587Z",
+ "iopub.status.idle": "2023-07-05T13:11:39.001928Z",
+ "shell.execute_reply": "2023-07-05T13:11:39.001429Z",
+ "shell.execute_reply.started": "2023-07-05T13:11:38.997898Z"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "%matplotlib inline\n",
+ "import matplotlib.pyplot as plt\n",
+ "import os.path as osp\n",
+ "import torch\n",
+ "import numpy as np\n",
+ "import mmcv\n",
+ "import cv2\n",
+ "from mmengine.utils import track_iter_progress"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "bfa9bf9b-dc2c-4803-a034-8ae8778113e0",
+ "metadata": {
+ "ExecutionIndicator": {
+ "show": true
+ },
+ "execution": {
+ "iopub.execute_input": "2023-07-05T12:42:15.884465Z",
+ "iopub.status.busy": "2023-07-05T12:42:15.884167Z",
+ "iopub.status.idle": "2023-07-05T12:42:19.774569Z",
+ "shell.execute_reply": "2023-07-05T12:42:19.774020Z",
+ "shell.execute_reply.started": "2023-07-05T12:42:15.884448Z"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# download example videos\n",
+ "from mmengine.utils import mkdir_or_exist\n",
+ "mkdir_or_exist('resources')\n",
+ "! wget -O resources/student_video.mp4 https://download.openmmlab.com/mmpose/v1/projects/just_dance/tom.mp4 \n",
+ "! wget -O resources/teacher_video.mp4 https://download.openmmlab.com/mmpose/v1/projects/just_dance/idol_producer.mp4 \n",
+ "# ! wget -O resources/student_video.mp4 https://download.openmmlab.com/mmpose/v1/projects/just_dance/tsinghua_30fps.mp4 \n",
+ "\n",
+ "student_video = 'resources/student_video.mp4'\n",
+ "teacher_video = 'resources/teacher_video.mp4'"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "652b6b91-e1c0-461b-90e5-653bc35ec380",
+ "metadata": {
+ "ExecutionIndicator": {
+ "show": true
+ },
+ "execution": {
+ "iopub.execute_input": "2023-07-05T12:42:20.693931Z",
+ "iopub.status.busy": "2023-07-05T12:42:20.693353Z",
+ "iopub.status.idle": "2023-07-05T12:43:14.533985Z",
+ "shell.execute_reply": "2023-07-05T12:43:14.533431Z",
+ "shell.execute_reply.started": "2023-07-05T12:42:20.693910Z"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# convert the fps of videos to 30\n",
+ "from mmcv import VideoReader\n",
+ "\n",
+ "if VideoReader(student_video) != 30:\n",
+ " # ffmpeg is required to convert the video fps\n",
+ " # which can be installed via `sudo apt install ffmpeg` on ubuntu\n",
+ " student_video_30fps = student_video.replace(\n",
+ " f\".{student_video.rsplit('.', 1)[1]}\",\n",
+ " f\"_30fps.{student_video.rsplit('.', 1)[1]}\"\n",
+ " )\n",
+ " !ffmpeg -i {student_video} -vf \"minterpolate='fps=30'\" {student_video_30fps}\n",
+ " student_video = student_video_30fps\n",
+ " \n",
+ "if VideoReader(teacher_video) != 30:\n",
+ " teacher_video_30fps = teacher_video.replace(\n",
+ " f\".{teacher_video.rsplit('.', 1)[1]}\",\n",
+ " f\"_30fps.{teacher_video.rsplit('.', 1)[1]}\"\n",
+ " )\n",
+ " !ffmpeg -i {teacher_video} -vf \"minterpolate='fps=30'\" {teacher_video_30fps}\n",
+ " teacher_video = teacher_video_30fps "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6a4e141d-ee4a-4e06-a380-230418c9b936",
+ "metadata": {
+ "ExecutionIndicator": {
+ "show": true
+ },
+ "execution": {
+ "iopub.execute_input": "2023-07-05T12:45:01.672054Z",
+ "iopub.status.busy": "2023-07-05T12:45:01.671727Z",
+ "iopub.status.idle": "2023-07-05T12:45:02.417026Z",
+ "shell.execute_reply": "2023-07-05T12:45:02.416567Z",
+ "shell.execute_reply.started": "2023-07-05T12:45:01.672035Z"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# init pose estimator\n",
+ "from mmpose.apis.inferencers import Pose2DInferencer\n",
+ "pose_estimator = Pose2DInferencer(\n",
+ " 'rtmpose-t_8xb256-420e_aic-coco-256x192',\n",
+ " det_model='configs/rtmdet-nano_one-person.py',\n",
+ " det_weights='https://download.openmmlab.com/mmpose/v1/projects/' \n",
+ " 'rtmpose/rtmdet_nano_8xb32-100e_coco-obj365-person-05d8511e.pth'\n",
+ ")\n",
+ "pose_estimator.model.test_cfg['flip_test'] = False"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "879ba5c0-4d2d-4cca-92d7-d4f94e04a821",
+ "metadata": {
+ "ExecutionIndicator": {
+ "show": true
+ },
+ "execution": {
+ "iopub.execute_input": "2023-07-05T12:45:05.192437Z",
+ "iopub.status.busy": "2023-07-05T12:45:05.191982Z",
+ "iopub.status.idle": "2023-07-05T12:45:05.197379Z",
+ "shell.execute_reply": "2023-07-05T12:45:05.196780Z",
+ "shell.execute_reply.started": "2023-07-05T12:45:05.192417Z"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "@torch.no_grad()\n",
+ "def get_keypoints_from_frame(image, pose_estimator):\n",
+ " \"\"\"Extract keypoints from a single video frame.\"\"\"\n",
+ "\n",
+ " det_results = pose_estimator.detector(\n",
+ " image, return_datasample=True)['predictions']\n",
+ " pred_instance = det_results[0].pred_instances.numpy()\n",
+ "\n",
+ " if len(pred_instance) == 0 or pred_instance.scores[0] < 0.2:\n",
+ " return np.zeros((1, 17, 3), dtype=np.float32)\n",
+ "\n",
+ " data_info = dict(\n",
+ " img=image,\n",
+ " bbox=pred_instance.bboxes[:1],\n",
+ " bbox_score=pred_instance.scores[:1])\n",
+ "\n",
+ " data_info.update(pose_estimator.model.dataset_meta)\n",
+ " data = pose_estimator.collate_fn(\n",
+ " [pose_estimator.pipeline(data_info)])\n",
+ "\n",
+ " # custom forward\n",
+ " data = pose_estimator.model.data_preprocessor(data, False)\n",
+ " feats = pose_estimator.model.extract_feat(data['inputs'])\n",
+ " pred_instances = pose_estimator.model.head.predict(\n",
+ " feats,\n",
+ " data['data_samples'],\n",
+ " test_cfg=pose_estimator.model.test_cfg)[0]\n",
+ " keypoints = np.concatenate(\n",
+ " (pred_instances.keypoints, pred_instances.keypoint_scores[...,\n",
+ " None]),\n",
+ " axis=-1)\n",
+ "\n",
+ " return keypoints "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "31e5bd4c-4c2b-4fe0-b64c-1afed67b7688",
+ "metadata": {
+ "ExecutionIndicator": {
+ "show": true
+ },
+ "execution": {
+ "iopub.execute_input": "2023-07-05T12:47:55.564788Z",
+ "iopub.status.busy": "2023-07-05T12:47:55.564450Z",
+ "iopub.status.idle": "2023-07-05T12:49:37.222662Z",
+ "shell.execute_reply": "2023-07-05T12:49:37.222028Z",
+ "shell.execute_reply.started": "2023-07-05T12:47:55.564770Z"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# pose estimation in two videos\n",
+ "student_poses, teacher_poses = [], []\n",
+ "for frame in VideoReader(student_video):\n",
+ " student_poses.append(get_keypoints_from_frame(frame, pose_estimator))\n",
+ "for frame in VideoReader(teacher_video):\n",
+ " teacher_poses.append(get_keypoints_from_frame(frame, pose_estimator))\n",
+ " \n",
+ "student_poses = np.concatenate(student_poses)\n",
+ "teacher_poses = np.concatenate(teacher_poses)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "38a8d7a5-17ed-4ce2-bb8b-d1637cb49578",
+ "metadata": {
+ "ExecutionIndicator": {
+ "show": true
+ },
+ "execution": {
+ "iopub.execute_input": "2023-07-05T12:55:09.342432Z",
+ "iopub.status.busy": "2023-07-05T12:55:09.342185Z",
+ "iopub.status.idle": "2023-07-05T12:55:09.350522Z",
+ "shell.execute_reply": "2023-07-05T12:55:09.350099Z",
+ "shell.execute_reply.started": "2023-07-05T12:55:09.342416Z"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "valid_indices = np.array([0] + list(range(5, 17)))\n",
+ "\n",
+ "@torch.no_grad()\n",
+ "def _calculate_similarity(tch_kpts: np.ndarray, stu_kpts: np.ndarray):\n",
+ "\n",
+ " stu_kpts = torch.from_numpy(stu_kpts[:, None, valid_indices])\n",
+ " tch_kpts = torch.from_numpy(tch_kpts[None, :, valid_indices])\n",
+ " stu_kpts = stu_kpts.expand(stu_kpts.shape[0], tch_kpts.shape[1],\n",
+ " stu_kpts.shape[2], 3)\n",
+ " tch_kpts = tch_kpts.expand(stu_kpts.shape[0], tch_kpts.shape[1],\n",
+ " stu_kpts.shape[2], 3)\n",
+ "\n",
+ " matrix = torch.stack((stu_kpts, tch_kpts), dim=4)\n",
+ " if torch.cuda.is_available():\n",
+ " matrix = matrix.cuda()\n",
+ " # only consider visible keypoints\n",
+ " mask = torch.logical_and(matrix[:, :, :, 2, 0] > 0.3,\n",
+ " matrix[:, :, :, 2, 1] > 0.3)\n",
+ " matrix[~mask] = 0.0\n",
+ "\n",
+ " matrix_ = matrix.clone()\n",
+ " matrix_[matrix == 0] = 256\n",
+ " x_min = matrix_.narrow(3, 0, 1).min(dim=2).values\n",
+ " y_min = matrix_.narrow(3, 1, 1).min(dim=2).values\n",
+ " matrix_ = matrix.clone()\n",
+ " x_max = matrix_.narrow(3, 0, 1).max(dim=2).values\n",
+ " y_max = matrix_.narrow(3, 1, 1).max(dim=2).values\n",
+ "\n",
+ " matrix_ = matrix.clone()\n",
+ " matrix_[:, :, :, 0] = (matrix_[:, :, :, 0] - x_min) / (\n",
+ " x_max - x_min + 1e-4)\n",
+ " matrix_[:, :, :, 1] = (matrix_[:, :, :, 1] - y_min) / (\n",
+ " y_max - y_min + 1e-4)\n",
+ " matrix_[:, :, :, 2] = (matrix_[:, :, :, 2] > 0.3).float()\n",
+ " xy_dist = matrix_[..., :2, 0] - matrix_[..., :2, 1]\n",
+ " score = matrix_[..., 2, 0] * matrix_[..., 2, 1]\n",
+ "\n",
+ " similarity = (torch.exp(-50 * xy_dist.pow(2).sum(dim=-1)) *\n",
+ " score).sum(dim=-1) / (\n",
+ " score.sum(dim=-1) + 1e-6)\n",
+ " num_visible_kpts = score.sum(dim=-1)\n",
+ " similarity = similarity * torch.log(\n",
+ " (1 + (num_visible_kpts - 1) * 10).clamp(min=1)) / np.log(161)\n",
+ "\n",
+ " similarity[similarity.isnan()] = 0\n",
+ "\n",
+ " return similarity"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "658bcf89-df06-4c73-9323-8973a49c14c3",
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2023-07-05T12:55:31.978675Z",
+ "iopub.status.busy": "2023-07-05T12:55:31.978219Z",
+ "iopub.status.idle": "2023-07-05T12:55:32.149624Z",
+ "shell.execute_reply": "2023-07-05T12:55:32.148568Z",
+ "shell.execute_reply.started": "2023-07-05T12:55:31.978657Z"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# compute similarity without flip\n",
+ "similarity1 = _calculate_similarity(teacher_poses, student_poses)\n",
+ "\n",
+ "# compute similarity with flip\n",
+ "flip_indices = np.array(\n",
+ " [0, 2, 1, 4, 3, 6, 5, 8, 7, 10, 9, 12, 11, 14, 13, 16, 15])\n",
+ "student_poses_flip = student_poses[:, flip_indices]\n",
+ "student_poses_flip[..., 0] = 191.5 - student_poses_flip[..., 0]\n",
+ "similarity2 = _calculate_similarity(teacher_poses, student_poses_flip)\n",
+ "\n",
+ "# select the larger similarity\n",
+ "similarity = torch.stack((similarity1, similarity2)).max(dim=0).values"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f981410d-4585-47c1-98c0-6946f948487d",
+ "metadata": {
+ "ExecutionIndicator": {
+ "show": false
+ },
+ "execution": {
+ "iopub.execute_input": "2023-07-05T12:55:57.321845Z",
+ "iopub.status.busy": "2023-07-05T12:55:57.321530Z",
+ "iopub.status.idle": "2023-07-05T12:55:57.582879Z",
+ "shell.execute_reply": "2023-07-05T12:55:57.582425Z",
+ "shell.execute_reply.started": "2023-07-05T12:55:57.321826Z"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# visualize the similarity\n",
+ "plt.imshow(similarity.cpu().numpy())\n",
+ "\n",
+ "# there is an apparent diagonal in the figure\n",
+ "# we can select matched video snippets with this diagonal"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "13c189e5-fc53-46a2-9057-f0f2ffc1f46d",
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2023-07-05T12:58:16.913855Z",
+ "iopub.status.busy": "2023-07-05T12:58:16.913529Z",
+ "iopub.status.idle": "2023-07-05T12:58:16.919972Z",
+ "shell.execute_reply": "2023-07-05T12:58:16.919005Z",
+ "shell.execute_reply.started": "2023-07-05T12:58:16.913837Z"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "@torch.no_grad()\n",
+ "def select_piece_from_similarity(similarity):\n",
+ " m, n = similarity.size()\n",
+ " row_indices = torch.arange(m).view(-1, 1).expand(m, n).to(similarity)\n",
+ " col_indices = torch.arange(n).view(1, -1).expand(m, n).to(similarity)\n",
+ " diagonal_indices = similarity.size(0) - 1 - row_indices + col_indices\n",
+ " unique_diagonal_indices, inverse_indices = torch.unique(\n",
+ " diagonal_indices, return_inverse=True)\n",
+ "\n",
+ " diagonal_sums_list = torch.zeros(\n",
+ " unique_diagonal_indices.size(0),\n",
+ " dtype=similarity.dtype,\n",
+ " device=similarity.device)\n",
+ " diagonal_sums_list.scatter_add_(0, inverse_indices.view(-1),\n",
+ " similarity.view(-1))\n",
+ " diagonal_sums_list[:min(m, n) // 4] = 0\n",
+ " diagonal_sums_list[-min(m, n) // 4:] = 0\n",
+ " index = diagonal_sums_list.argmax().item()\n",
+ "\n",
+ " similarity_smooth = torch.nn.functional.max_pool2d(\n",
+ " similarity[None], (1, 11), stride=(1, 1), padding=(0, 5))[0]\n",
+ " similarity_vec = similarity_smooth.diagonal(offset=index - m +\n",
+ " 1).cpu().numpy()\n",
+ "\n",
+ " stu_start = max(0, m - 1 - index)\n",
+ " tch_start = max(0, index - m + 1)\n",
+ "\n",
+ " return dict(\n",
+ " stu_start=stu_start,\n",
+ " tch_start=tch_start,\n",
+ " length=len(similarity_vec),\n",
+ " similarity=similarity_vec)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7c0e19df-949d-471d-804d-409b3b9ddf7d",
+ "metadata": {
+ "ExecutionIndicator": {
+ "show": true
+ },
+ "execution": {
+ "iopub.execute_input": "2023-07-05T12:58:44.860190Z",
+ "iopub.status.busy": "2023-07-05T12:58:44.859878Z",
+ "iopub.status.idle": "2023-07-05T12:58:44.888465Z",
+ "shell.execute_reply": "2023-07-05T12:58:44.887917Z",
+ "shell.execute_reply.started": "2023-07-05T12:58:44.860173Z"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "matched_piece_info = select_piece_from_similarity(similarity)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "51b0a2bd-253c-4a8f-a82a-263e18a4703e",
+ "metadata": {
+ "ExecutionIndicator": {
+ "show": true
+ },
+ "execution": {
+ "iopub.execute_input": "2023-07-05T13:01:19.061408Z",
+ "iopub.status.busy": "2023-07-05T13:01:19.060857Z",
+ "iopub.status.idle": "2023-07-05T13:01:19.293742Z",
+ "shell.execute_reply": "2023-07-05T13:01:19.293298Z",
+ "shell.execute_reply.started": "2023-07-05T13:01:19.061378Z"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "plt.imshow(similarity.cpu().numpy())\n",
+ "plt.plot((matched_piece_info['tch_start'], \n",
+ " matched_piece_info['tch_start']+matched_piece_info['length']-1),\n",
+ " (matched_piece_info['stu_start'],\n",
+ " matched_piece_info['stu_start']+matched_piece_info['length']-1), 'r')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ffcde4e7-ff50-483a-b515-604c1d8f121a",
+ "metadata": {},
+ "source": [
+ "# Generate Output Video"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "72171a0c-ab33-45bb-b84c-b15f0816ed3a",
+ "metadata": {
+ "ExecutionIndicator": {
+ "show": true
+ },
+ "execution": {
+ "iopub.execute_input": "2023-07-05T13:11:50.063595Z",
+ "iopub.status.busy": "2023-07-05T13:11:50.063259Z",
+ "iopub.status.idle": "2023-07-05T13:11:50.070929Z",
+ "shell.execute_reply": "2023-07-05T13:11:50.070411Z",
+ "shell.execute_reply.started": "2023-07-05T13:11:50.063574Z"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "from typing import Tuple\n",
+ "\n",
+ "def resize_image_to_fixed_height(image: np.ndarray,\n",
+ " fixed_height: int) -> np.ndarray:\n",
+ " \"\"\"Resizes an input image to a specified fixed height while maintaining its\n",
+ " aspect ratio.\n",
+ "\n",
+ " Args:\n",
+ " image (np.ndarray): Input image as a numpy array [H, W, C]\n",
+ " fixed_height (int): Desired fixed height of the output image.\n",
+ "\n",
+ " Returns:\n",
+ " Resized image as a numpy array (fixed_height, new_width, channels).\n",
+ " \"\"\"\n",
+ " original_height, original_width = image.shape[:2]\n",
+ "\n",
+ " scale_ratio = fixed_height / original_height\n",
+ " new_width = int(original_width * scale_ratio)\n",
+ " resized_image = cv2.resize(image, (new_width, fixed_height))\n",
+ "\n",
+ " return resized_image\n",
+ "\n",
+ "def blend_images(img1: np.ndarray,\n",
+ " img2: np.ndarray,\n",
+ " blend_ratios: Tuple[float, float] = (1, 1)) -> np.ndarray:\n",
+ " \"\"\"Blends two input images with specified blend ratios.\n",
+ "\n",
+ " Args:\n",
+ " img1 (np.ndarray): First input image as a numpy array [H, W, C].\n",
+ " img2 (np.ndarray): Second input image as a numpy array [H, W, C]\n",
+ " blend_ratios (tuple): A tuple of two floats representing the blend\n",
+ " ratios for the two input images.\n",
+ "\n",
+ " Returns:\n",
+ " Blended image as a numpy array [H, W, C]\n",
+ " \"\"\"\n",
+ "\n",
+ " def normalize_image(image: np.ndarray) -> np.ndarray:\n",
+ " if image.dtype == np.uint8:\n",
+ " return image.astype(np.float32) / 255.0\n",
+ " return image\n",
+ "\n",
+ " img1 = normalize_image(img1)\n",
+ " img2 = normalize_image(img2)\n",
+ "\n",
+ " blended_image = img1 * blend_ratios[0] + img2 * blend_ratios[1]\n",
+ " blended_image = blended_image.clip(min=0, max=1)\n",
+ " blended_image = (blended_image * 255).astype(np.uint8)\n",
+ "\n",
+ " return blended_image\n",
+ "\n",
+ "def get_smoothed_kpt(kpts, index, sigma=5):\n",
+ " \"\"\"Smooths keypoints using a Gaussian filter.\"\"\"\n",
+ " assert kpts.shape[1] == 17\n",
+ " assert kpts.shape[2] == 3\n",
+ " assert sigma % 2 == 1\n",
+ "\n",
+ " num_kpts = len(kpts)\n",
+ "\n",
+ " start_idx = max(0, index - sigma // 2)\n",
+ " end_idx = min(num_kpts, index + sigma // 2 + 1)\n",
+ "\n",
+ " # Extract a piece of the keypoints array to apply the filter\n",
+ " piece = kpts[start_idx:end_idx].copy()\n",
+ " original_kpt = kpts[index]\n",
+ "\n",
+ " # Split the piece into coordinates and scores\n",
+ " coords, scores = piece[..., :2], piece[..., 2]\n",
+ "\n",
+ " # Calculate the Gaussian ratio for each keypoint\n",
+ " gaussian_ratio = np.arange(len(scores)) + start_idx - index\n",
+ " gaussian_ratio = np.exp(-gaussian_ratio**2 / 2)\n",
+ "\n",
+ " # Update scores using the Gaussian ratio\n",
+ " scores *= gaussian_ratio[:, None]\n",
+ "\n",
+ " # Compute the smoothed coordinates\n",
+ " smoothed_coords = (coords * scores[..., None]).sum(axis=0) / (\n",
+ " scores[..., None].sum(axis=0) + 1e-4)\n",
+ "\n",
+ " original_kpt[..., :2] = smoothed_coords\n",
+ "\n",
+ " return original_kpt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "609b5adc-e176-4bf9-b9a4-506f72440017",
+ "metadata": {
+ "ExecutionIndicator": {
+ "show": true
+ },
+ "execution": {
+ "iopub.execute_input": "2023-07-05T13:12:46.198835Z",
+ "iopub.status.busy": "2023-07-05T13:12:46.198268Z",
+ "iopub.status.idle": "2023-07-05T13:12:46.202273Z",
+ "shell.execute_reply": "2023-07-05T13:12:46.200881Z",
+ "shell.execute_reply.started": "2023-07-05T13:12:46.198815Z"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "score, last_vis_score = 0, 0\n",
+ "video_writer = None\n",
+ "output_file = 'output.mp4'\n",
+ "stu_kpts = student_poses\n",
+ "tch_kpts = teacher_poses"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a264405a-5d50-49de-8637-2d1f67cb0a70",
+ "metadata": {
+ "ExecutionIndicator": {
+ "show": true
+ },
+ "execution": {
+ "iopub.execute_input": "2023-07-05T13:13:11.334760Z",
+ "iopub.status.busy": "2023-07-05T13:13:11.334433Z",
+ "iopub.status.idle": "2023-07-05T13:13:17.264181Z",
+ "shell.execute_reply": "2023-07-05T13:13:17.262931Z",
+ "shell.execute_reply.started": "2023-07-05T13:13:11.334742Z"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "from mmengine.structures import InstanceData\n",
+ "\n",
+ "tch_video_reader = VideoReader(teacher_video)\n",
+ "stu_video_reader = VideoReader(student_video)\n",
+ "for _ in range(matched_piece_info['tch_start']):\n",
+ " _ = next(tch_video_reader)\n",
+ "for _ in range(matched_piece_info['stu_start']):\n",
+ " _ = next(stu_video_reader)\n",
+ " \n",
+ "for i in track_iter_progress(range(matched_piece_info['length'])):\n",
+ " tch_frame = mmcv.bgr2rgb(next(tch_video_reader))\n",
+ " stu_frame = mmcv.bgr2rgb(next(stu_video_reader))\n",
+ " tch_frame = resize_image_to_fixed_height(tch_frame, 300)\n",
+ " stu_frame = resize_image_to_fixed_height(stu_frame, 300)\n",
+ "\n",
+ " stu_kpt = get_smoothed_kpt(stu_kpts, matched_piece_info['stu_start'] + i,\n",
+ " 5)\n",
+ " tch_kpt = get_smoothed_kpt(tch_kpts, matched_piece_info['tch_start'] + i,\n",
+ " 5)\n",
+ "\n",
+ " # draw pose\n",
+ " stu_kpt[..., 1] += (300 - 256)\n",
+ " tch_kpt[..., 0] += (256 - 192)\n",
+ " tch_kpt[..., 1] += (300 - 256)\n",
+ " stu_inst = InstanceData(\n",
+ " keypoints=stu_kpt[None, :, :2],\n",
+ " keypoint_scores=stu_kpt[None, :, 2])\n",
+ " tch_inst = InstanceData(\n",
+ " keypoints=tch_kpt[None, :, :2],\n",
+ " keypoint_scores=tch_kpt[None, :, 2])\n",
+ " \n",
+ " stu_out_img = pose_estimator.visualizer._draw_instances_kpts(\n",
+ " np.zeros((300, 256, 3)), stu_inst)\n",
+ " tch_out_img = pose_estimator.visualizer._draw_instances_kpts(\n",
+ " np.zeros((300, 256, 3)), tch_inst)\n",
+ " out_img = blend_images(\n",
+ " stu_out_img, tch_out_img, blend_ratios=(1, 0.3))\n",
+ "\n",
+ " # draw score\n",
+ " score_frame = matched_piece_info['similarity'][i]\n",
+ " score += score_frame * 1000\n",
+ " if score - last_vis_score > 1500:\n",
+ " last_vis_score = score\n",
+ " pose_estimator.visualizer.set_image(out_img)\n",
+ " pose_estimator.visualizer.draw_texts(\n",
+ " 'score: ', (60, 30),\n",
+ " font_sizes=15,\n",
+ " colors=(255, 255, 255),\n",
+ " vertical_alignments='bottom')\n",
+ " pose_estimator.visualizer.draw_texts(\n",
+ " f'{int(last_vis_score)}', (115, 30),\n",
+ " font_sizes=30 * max(0.4, score_frame),\n",
+ " colors=(255, 255, 255),\n",
+ " vertical_alignments='bottom')\n",
+ " out_img = pose_estimator.visualizer.get_image() \n",
+ " \n",
+ " # concatenate\n",
+ " concatenated_image = np.hstack((stu_frame, out_img, tch_frame))\n",
+ " if video_writer is None:\n",
+ " video_writer = cv2.VideoWriter(output_file,\n",
+ " cv2.VideoWriter_fourcc(*'mp4v'),\n",
+ " 30,\n",
+ " (concatenated_image.shape[1],\n",
+ " concatenated_image.shape[0]))\n",
+ " video_writer.write(mmcv.rgb2bgr(concatenated_image))\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "745fdd75-6ed4-4cae-9f21-c2cd486ee918",
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2023-07-05T13:13:18.704492Z",
+ "iopub.status.busy": "2023-07-05T13:13:18.704179Z",
+ "iopub.status.idle": "2023-07-05T13:13:18.714843Z",
+ "shell.execute_reply": "2023-07-05T13:13:18.713866Z",
+ "shell.execute_reply.started": "2023-07-05T13:13:18.704472Z"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "if video_writer is not None:\n",
+ " video_writer.release() "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7cb0bc99-ca19-44f1-bc0a-38e14afa980f",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.15"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/projects/just_dance/process_video.py b/projects/just_dance/process_video.py
new file mode 100644
index 0000000000..9efb41f5af
--- /dev/null
+++ b/projects/just_dance/process_video.py
@@ -0,0 +1,259 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import tempfile
+from typing import Optional
+
+import cv2
+import mmcv
+import numpy as np
+import torch
+from mmengine.structures import InstanceData
+from mmengine.utils import track_iter_progress
+
+from mmpose.apis import Pose2DInferencer
+from mmpose.datasets.datasets.utils import parse_pose_metainfo
+from mmpose.visualization import PoseLocalVisualizer
+
+try:
+ from .calculate_similarity import (calculate_similarity,
+ select_piece_from_similarity)
+ from .utils import (blend_images, convert_video_fps, get_smoothed_kpt,
+ resize_image_to_fixed_height)
+except ImportError:
+ from calculate_similarity import (calculate_similarity,
+ select_piece_from_similarity)
+ from utils import (blend_images, convert_video_fps, get_smoothed_kpt,
+ resize_image_to_fixed_height)
+
+model_cfg = dict(
+ human=dict(
+ model='rtmpose-t_8xb256-420e_aic-coco-256x192',
+ det_model=os.path.join(
+ os.path.dirname(os.path.abspath(__file__)),
+ 'configs/rtmdet-nano_one-person.py'),
+ det_weights='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmpose/rtmdet_nano_8xb32-100e_coco-obj365-person-05d8511e.pth',
+ ),
+ bear=dict(
+ model='rtmpose-l_8xb256-420e_humanart-256x192',
+ det_model='rtmdet-m',
+ det_cat_ids=77,
+ ),
+)
+
+
+class VideoProcessor:
+ """A class to process videos for pose estimation and visualization."""
+
+ def __init__(self):
+ self.category = 'human'
+
+ def _set_category(self, category):
+ assert category in model_cfg
+ self.category = category
+
+ @property
+ def pose_estimator(self) -> Pose2DInferencer:
+ if not hasattr(self, '_pose_estimator'):
+ self._pose_estimator = dict()
+ if self.category not in self._pose_estimator:
+ self._pose_estimator[self.category] = Pose2DInferencer(
+ **(model_cfg[self.category]))
+ self._pose_estimator[
+ self.category].model.test_cfg['flip_test'] = False
+ return self._pose_estimator[self.category]
+
+ @property
+ def visualizer(self) -> PoseLocalVisualizer:
+ if hasattr(self, '_visualizer'):
+ return self._visualizer
+ elif hasattr(self, '_pose_estimator'):
+ return self.pose_estimator.visualizer
+
+ # init visualizer
+ self._visualizer = PoseLocalVisualizer()
+ metainfo_file = os.path.join(
+ os.path.dirname(os.path.abspath(__file__)).rsplit(os.sep, 1)[0],
+ 'configs/_base_/datasets/coco.py')
+ metainfo = parse_pose_metainfo(dict(from_file=metainfo_file))
+ self._visualizer.set_dataset_meta(metainfo)
+ return self._visualizer
+
+ @torch.no_grad()
+ def get_keypoints_from_frame(self, image: np.ndarray) -> np.ndarray:
+ """Extract keypoints from a single video frame."""
+
+ det_results = self.pose_estimator.detector(
+ image, return_datasamples=True)['predictions']
+ pred_instance = det_results[0].pred_instances
+
+ if len(pred_instance) == 0:
+ return np.zeros((1, 17, 3), dtype=np.float32)
+
+ # only select the most significant person
+ data_info = dict(
+ img=image,
+ bbox=pred_instance.bboxes.cpu().numpy()[:1],
+ bbox_score=pred_instance.scores.cpu().numpy()[:1])
+
+ if data_info['bbox_score'] < 0.2:
+ return np.zeros((1, 17, 3), dtype=np.float32)
+
+ data_info.update(self.pose_estimator.model.dataset_meta)
+ data = self.pose_estimator.collate_fn(
+ [self.pose_estimator.pipeline(data_info)])
+
+ # custom forward
+ data = self.pose_estimator.model.data_preprocessor(data, False)
+ feats = self.pose_estimator.model.extract_feat(data['inputs'])
+ pred_instances = self.pose_estimator.model.head.predict(
+ feats,
+ data['data_samples'],
+ test_cfg=self.pose_estimator.model.test_cfg)[0]
+ keypoints = np.concatenate(
+ (pred_instances.keypoints, pred_instances.keypoint_scores[...,
+ None]),
+ axis=-1)
+
+ return keypoints
+
+ @torch.no_grad()
+ def get_keypoints_from_video(self, video: str) -> np.ndarray:
+ """Extract keypoints from a video."""
+
+ video_fname = video.rsplit('.', 1)[0]
+ if os.path.exists(f'{video_fname}_kpts.pth'):
+ keypoints = torch.load(f'{video_fname}_kpts.pth')
+ return keypoints
+
+ video_reader = mmcv.VideoReader(video)
+
+ if abs(video_reader.fps - 30) > 0.1:
+ video_reader = mmcv.VideoReader(convert_video_fps(video))
+
+ assert abs(video_reader.fps - 30) < 0.1, f'only support videos with ' \
+ f'30 FPS, but the video {video_fname} has {video_reader.fps} fps'
+
+ if os.path.basename(video_fname).startswith('bear'):
+ self._set_category('bear')
+ else:
+ self._set_category('human')
+ keypoints_list = []
+ for i, frame in enumerate(video_reader):
+ keypoints = self.get_keypoints_from_frame(frame)
+ keypoints_list.append(keypoints)
+ keypoints = np.concatenate(keypoints_list)
+ torch.save(keypoints, f'{video_fname}_kpts.pth')
+ return keypoints
+
+ @torch.no_grad()
+ def run(self,
+ tch_video: str,
+ stu_video: str,
+ output_file: Optional[str] = None):
+ # extract human poses
+ tch_kpts = self.get_keypoints_from_video(tch_video)
+ stu_kpts = self.get_keypoints_from_video(stu_video)
+
+ # compute similarity
+ similarity = calculate_similarity(tch_kpts, stu_kpts)
+
+ # select piece
+ piece_info = select_piece_from_similarity(similarity)
+
+ # output
+ tch_name = os.path.basename(tch_video).rsplit('.', 1)[0]
+ stu_name = os.path.basename(stu_video).rsplit('.', 1)[0]
+ if output_file is None:
+ fname = f'{tch_name}-{stu_name}.mp4'
+ output_file = os.path.join(tempfile.mkdtemp(), fname)
+ return self.generate_output_video(tch_video, stu_video, output_file,
+ tch_kpts, stu_kpts, piece_info)
+
+ def generate_output_video(self, tch_video: str, stu_video: str,
+ output_file: str, tch_kpts: np.ndarray,
+ stu_kpts: np.ndarray, piece_info: dict) -> str:
+ """Generate an output video with keypoints overlay."""
+
+ tch_video_reader = mmcv.VideoReader(tch_video)
+ stu_video_reader = mmcv.VideoReader(stu_video)
+ for _ in range(piece_info['tch_start']):
+ _ = next(tch_video_reader)
+ for _ in range(piece_info['stu_start']):
+ _ = next(stu_video_reader)
+
+ score, last_vis_score = 0, 0
+ video_writer = None
+ for i in track_iter_progress(range(piece_info['length'])):
+ tch_frame = mmcv.bgr2rgb(next(tch_video_reader))
+ stu_frame = mmcv.bgr2rgb(next(stu_video_reader))
+ tch_frame = resize_image_to_fixed_height(tch_frame, 300)
+ stu_frame = resize_image_to_fixed_height(stu_frame, 300)
+
+ stu_kpt = get_smoothed_kpt(stu_kpts, piece_info['stu_start'] + i,
+ 5)
+ tch_kpt = get_smoothed_kpt(tch_kpts, piece_info['tch_start'] + i,
+ 5)
+
+ # draw pose
+ stu_kpt[..., 1] += (300 - 256)
+ tch_kpt[..., 0] += (256 - 192)
+ tch_kpt[..., 1] += (300 - 256)
+ stu_inst = InstanceData(
+ keypoints=stu_kpt[None, :, :2],
+ keypoint_scores=stu_kpt[None, :, 2])
+ tch_inst = InstanceData(
+ keypoints=tch_kpt[None, :, :2],
+ keypoint_scores=tch_kpt[None, :, 2])
+
+ stu_out_img = self.visualizer._draw_instances_kpts(
+ np.zeros((300, 256, 3)), stu_inst)
+ tch_out_img = self.visualizer._draw_instances_kpts(
+ np.zeros((300, 256, 3)), tch_inst)
+ out_img = blend_images(
+ stu_out_img, tch_out_img, blend_ratios=(1, 0.3))
+
+ # draw score
+ score_frame = piece_info['similarity'][i]
+ score += score_frame * 1000
+ if score - last_vis_score > 1500:
+ last_vis_score = score
+ self.visualizer.set_image(out_img)
+ self.visualizer.draw_texts(
+ 'score: ', (60, 30),
+ font_sizes=15,
+ colors=(255, 255, 255),
+ vertical_alignments='bottom')
+ self.visualizer.draw_texts(
+ f'{int(last_vis_score)}', (115, 30),
+ font_sizes=30 * max(0.4, score_frame),
+ colors=(255, 255, 255),
+ vertical_alignments='bottom')
+ out_img = self.visualizer.get_image()
+
+ # concatenate
+ concatenated_image = np.hstack((stu_frame, out_img, tch_frame))
+ if video_writer is None:
+ video_writer = cv2.VideoWriter(output_file,
+ cv2.VideoWriter_fourcc(*'mp4v'),
+ 30,
+ (concatenated_image.shape[1],
+ concatenated_image.shape[0]))
+ video_writer.write(mmcv.rgb2bgr(concatenated_image))
+
+ if video_writer is not None:
+ video_writer.release()
+ return output_file
+
+
+if __name__ == '__main__':
+ from argparse import ArgumentParser
+ parser = ArgumentParser()
+ parser.add_argument('teacher_video', help='Path to the Teacher Video')
+ parser.add_argument('student_video', help='Path to the Student Video')
+ parser.add_argument(
+ '--output-file', help='Path to save the output Video', default=None)
+ args = parser.parse_args()
+
+ processor = VideoProcessor()
+ processor.run(args.teacher_video, args.student_video, args.output_file)
diff --git a/projects/just_dance/utils.py b/projects/just_dance/utils.py
new file mode 100644
index 0000000000..cd150bb1be
--- /dev/null
+++ b/projects/just_dance/utils.py
@@ -0,0 +1,106 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+from typing import Tuple
+
+import cv2
+import numpy as np
+
+
+def resize_image_to_fixed_height(image: np.ndarray,
+ fixed_height: int) -> np.ndarray:
+ """Resizes an input image to a specified fixed height while maintaining its
+ aspect ratio.
+
+ Args:
+ image (np.ndarray): Input image as a numpy array [H, W, C]
+ fixed_height (int): Desired fixed height of the output image.
+
+ Returns:
+ Resized image as a numpy array (fixed_height, new_width, channels).
+ """
+ original_height, original_width = image.shape[:2]
+
+ scale_ratio = fixed_height / original_height
+ new_width = int(original_width * scale_ratio)
+ resized_image = cv2.resize(image, (new_width, fixed_height))
+
+ return resized_image
+
+
+def blend_images(img1: np.ndarray,
+ img2: np.ndarray,
+ blend_ratios: Tuple[float, float] = (1, 1)) -> np.ndarray:
+ """Blends two input images with specified blend ratios.
+
+ Args:
+ img1 (np.ndarray): First input image as a numpy array [H, W, C].
+ img2 (np.ndarray): Second input image as a numpy array [H, W, C]
+ blend_ratios (tuple): A tuple of two floats representing the blend
+ ratios for the two input images.
+
+ Returns:
+ Blended image as a numpy array [H, W, C]
+ """
+
+ def normalize_image(image: np.ndarray) -> np.ndarray:
+ if image.dtype == np.uint8:
+ return image.astype(np.float32) / 255.0
+ return image
+
+ img1 = normalize_image(img1)
+ img2 = normalize_image(img2)
+
+ blended_image = img1 * blend_ratios[0] + img2 * blend_ratios[1]
+ blended_image = blended_image.clip(min=0, max=1)
+ blended_image = (blended_image * 255).astype(np.uint8)
+
+ return blended_image
+
+
+def convert_video_fps(video):
+
+ input_video = video
+ video_name, post_fix = input_video.rsplit('.', 1)
+ output_video = f'{video_name}_30fps.{post_fix}'
+ if os.path.exists(output_video):
+ return output_video
+
+ os.system(
+ f"ffmpeg -i {input_video} -vf \"minterpolate='fps=30'\" {output_video}"
+ )
+
+ return output_video
+
+
+def get_smoothed_kpt(kpts, index, sigma=5):
+ """Smooths keypoints using a Gaussian filter."""
+ assert kpts.shape[1] == 17
+ assert kpts.shape[2] == 3
+ assert sigma % 2 == 1
+
+ num_kpts = len(kpts)
+
+ start_idx = max(0, index - sigma // 2)
+ end_idx = min(num_kpts, index + sigma // 2 + 1)
+
+ # Extract a piece of the keypoints array to apply the filter
+ piece = kpts[start_idx:end_idx].copy()
+ original_kpt = kpts[index]
+
+ # Split the piece into coordinates and scores
+ coords, scores = piece[..., :2], piece[..., 2]
+
+ # Calculate the Gaussian ratio for each keypoint
+ gaussian_ratio = np.arange(len(scores)) + start_idx - index
+ gaussian_ratio = np.exp(-gaussian_ratio**2 / 2)
+
+ # Update scores using the Gaussian ratio
+ scores *= gaussian_ratio[:, None]
+
+ # Compute the smoothed coordinates
+ smoothed_coords = (coords * scores[..., None]).sum(axis=0) / (
+ scores[..., None].sum(axis=0) + 1e-4)
+
+ original_kpt[..., :2] = smoothed_coords
+
+ return original_kpt
diff --git a/projects/rtmpose/README.md b/projects/rtmpose/README.md
index dc5b0dbe23..a304a69b0d 100644
--- a/projects/rtmpose/README.md
+++ b/projects/rtmpose/README.md
@@ -44,10 +44,25 @@ ______________________________________________________________________
## 🥳 🚀 What's New [🔝](#-table-of-contents)
+- Sep. 2023:
+ - Add RTMW models trained on combined datasets. The alpha version of RTMW-x model achieves 70.2 mAP on COCO-Wholebody val set. You can try it [Here](https://openxlab.org.cn/apps/detail/mmpose/RTMPose). The technical report will be released soon.
+ - Add YOLOX and RTMDet models trained on HumanArt dataset.
+- Aug. 2023:
+ - Support distilled 133-keypoint WholeBody models powered by [DWPose](https://github.com/IDEA-Research/DWPose/tree/main).
+ - You can try DWPose/RTMPose with [sd-webui-controlnet](https://github.com/Mikubill/sd-webui-controlnet) now! Just update your sd-webui-controlnet >= v1.1237, then choose `dw_openpose_full` as preprocessor.
+ - You can try our DWPose with this [Demo](https://openxlab.org.cn/apps/detail/mmpose/RTMPose) by choosing `wholebody`!
+- Jul. 2023:
+ - Add [Online RTMPose Demo](https://openxlab.org.cn/apps/detail/mmpose/RTMPose).
+ - Support 17-keypoint Body models trained on Human-Art.
- Jun. 2023:
- Release 26-keypoint Body models trained on combined datasets.
- May. 2023:
- - Add [code examples](./examples/) of RTMPose.
+ - Exported SDK models (ONNX, TRT, ncnn, etc.) can be downloaded from [OpenMMLab Deploee](https://platform.openmmlab.com/deploee).
+ - [Online Conversion](https://platform.openmmlab.com/deploee/task-convert-list) of `.pth` models into SDK models (ONNX, TensorRT, ncnn, etc.).
+ - Add [code examples](./examples/) of RTMPose, such as:
+ - Pure Python inference without MMDeploy, MMCV etc.
+ - C++ examples with ONNXRuntime and TensorRT backends.
+ - Android examples with ncnn backend.
- Release Hand, Face, Body models trained on combined datasets.
- Mar. 2023: RTMPose is released. RTMPose-m runs at 430+ FPS and achieves 75.8 mAP on COCO val set.
@@ -134,6 +149,7 @@ Feel free to join our community group for more help:
- ncnn 20221128
- cuDNN 8.3.2
- CUDA 11.3
+- **Updates**: We recommend you to try `Body8` models trained on combined datasets, see [here](#body-2d).
| Detection Config | Pose Config | Input Size
(Det/Pose) | Model AP
(COCO) | Pipeline AP
(COCO) | Params (M)
(Det/Pose) | Flops (G)
(Det/Pose) | ORT-Latency(ms)
(i7-11700) | TRT-FP16-Latency(ms)
(GTX 1660Ti) | Download | | :------------------------------------------------------------------ | :---------------------------------------------------------------------------- | :---------------------------: | :---------------------: | :------------------------: | :---------------------------: | :--------------------------: | :--------------------------------: | :---------------------------------------: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | @@ -164,14 +180,14 @@ Feel free to join our community group for more help:
(COCO) | PCK@0.1
(Body8) | AUC
(Body8) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | -| :---------------------------------------------------------------------------: | :--------: | :---------------: | :---------------------: | :-----------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :---------------------------------------------------------------------------------------------------------------------------------------------: | -| [RTMPose-t](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 68.5 | 91.28 | 63.38 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-tiny_simcc-aic-coco_pt-aic-coco_420e-256x192-cfc8f33d_20230126.pth) | -| [RTMPose-s](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 72.2 | 92.95 | 66.19 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-aic-coco_pt-aic-coco_420e-256x192-fcb2599b_20230126.pth) | -| [RTMPose-m](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 75.8 | 94.13 | 68.53 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-256x192-63eb25f7_20230126.pth) | -| [RTMPose-l](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 76.5 | 94.35 | 68.98 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-aic-coco_pt-aic-coco_420e-256x192-f016ffe0_20230126.pth) | -| [RTMPose-m](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py) | 384x288 | 77.0 | 94.32 | 69.85 | 13.72 | 4.33 | 24.78 | 3.66 | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-384x288-a62a0b32_20230228.pth) | -| [RTMPose-l](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py) | 384x288 | 77.3 | 94.54 | 70.14 | 27.79 | 9.35 | - | 6.05 | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-aic-coco_pt-aic-coco_420e-384x288-97d6cb0f_20230228.pth) | +| Config | Input Size | AP
(COCO) | PCK@0.1
(Body8) | AUC
(Body8) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | +| :---------------------------------------------------------------------------: | :--------: | :---------------: | :---------------------: | :-----------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :-------------------------------------------------------------------------------------------------------------------------------------------: | +| [RTMPose-t](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 68.5 | 91.28 | 63.38 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-tiny_simcc-aic-coco_pt-aic-coco_420e-256x192-cfc8f33d_20230126.pth) | +| [RTMPose-s](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 72.2 | 92.95 | 66.19 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-aic-coco_pt-aic-coco_420e-256x192-fcb2599b_20230126.pth) | +| [RTMPose-m](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 75.8 | 94.13 | 68.53 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-256x192-63eb25f7_20230126.pth) | +| [RTMPose-l](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 76.5 | 94.35 | 68.98 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-aic-coco_pt-aic-coco_420e-256x192-f016ffe0_20230126.pth) | +| [RTMPose-m](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py) | 384x288 | 77.0 | 94.32 | 69.85 | 13.72 | 4.33 | 24.78 | 3.66 | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-384x288-a62a0b32_20230228.pth) | +| [RTMPose-l](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py) | 384x288 | 77.3 | 94.54 | 70.14 | 27.79 | 9.35 | - | 6.05 | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-aic-coco_pt-aic-coco_420e-384x288-97d6cb0f_20230228.pth) |
@@ -188,15 +204,45 @@ Feel free to join our community group for more help:
- [PoseTrack18](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#posetrack18)
- `Body8` denotes the addition of the [OCHuman](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#ochuman) dataset, in addition to the 7 datasets mentioned above, for evaluation.
-| Config | Input Size | AP
(COCO) | PCK@0.1
(Body8) | AUC
(Body8) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | -| :-----------------------------------------------------------------------------: | :--------: | :---------------: | :---------------------: | :-----------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :------------------------------------------------------------------------------------------------------------------------------------: | -| [RTMPose-t\*](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 65.9 | 91.44 | 63.18 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-body7_pt-body7_420e-256x192-026a1439_20230504.pth) | -| [RTMPose-s\*](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 69.7 | 92.45 | 65.15 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-body7_pt-body7_420e-256x192-acd4a1ef_20230504.pth) | -| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 74.9 | 94.25 | 68.59 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-256x192-e48f03d0_20230504.pth) | -| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 76.7 | 95.08 | 70.14 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7_420e-256x192-4dba18fc_20230504.pth) | -| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py) | 384x288 | 76.6 | 94.64 | 70.38 | 13.72 | 4.33 | 24.78 | 3.66 | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-384x288-65e718c4_20230504.pth) | -| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py) | 384x288 | 78.3 | 95.36 | 71.58 | 27.79 | 9.35 | - | 6.05 | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7_420e-384x288-3f5a1437_20230504.pth) | -| [RTMPose-x\*](./rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_coco-384x288.py) | 384x288 | 78.8 | - | - | 49.43 | 17.22 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-body7_pt-body7_700e-384x288-71d7b7e9_20230629.pth) | +| Config | Input Size | AP
(COCO) | PCK@0.1
(Body8) | AUC
(Body8) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | +| :-----------------------------------------------------------------------------: | :--------: | :---------------: | :---------------------: | :-----------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | +| [RTMPose-t\*](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 65.9 | 91.44 | 63.18 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-body7_pt-body7_420e-256x192-026a1439_20230504.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-t_simcc-body7_pt-body7_420e-256x192-026a1439_20230504.zip) | +| [RTMPose-s\*](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 69.7 | 92.45 | 65.15 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-body7_pt-body7_420e-256x192-acd4a1ef_20230504.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-s_simcc-body7_pt-body7_420e-256x192-acd4a1ef_20230504.zip) | +| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 74.9 | 94.25 | 68.59 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-256x192-e48f03d0_20230504.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-body7_pt-body7_420e-256x192-e48f03d0_20230504.zip) | +| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 76.7 | 95.08 | 70.14 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7_420e-256x192-4dba18fc_20230504.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_simcc-body7_pt-body7_420e-256x192-4dba18fc_20230504.zip) | +| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py) | 384x288 | 76.6 | 94.64 | 70.38 | 13.72 | 4.33 | 24.78 | 3.66 | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-384x288-65e718c4_20230504.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-body7_pt-body7_420e-384x288-65e718c4_20230504.zip) | +| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py) | 384x288 | 78.3 | 95.36 | 71.58 | 27.79 | 9.35 | - | 6.05 | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7_420e-384x288-3f5a1437_20230504.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_simcc-body7_pt-body7_420e-384x288-3f5a1437_20230504.zip) | +| [RTMPose-x\*](./rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_coco-384x288.py) | 384x288 | 78.8 | - | - | 49.43 | 17.22 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-body7_pt-body7_700e-384x288-71d7b7e9_20230629.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-x_simcc-body7_pt-body7_700e-384x288-71d7b7e9_20230629.zip) | + +
+
+ - Models are trained and evaluated on `Body8`.
-| Config | Input Size | PCK@0.1
- Models are trained and evaluated on `Body8`.
-| Config | Input Size | PCK@0.1
(Body8) | AUC
(Body8) | Params(M) | FLOPS(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | -| :---------------------------------------------------------------------------------------: | :--------: | :---------------------: | :-----------------: | :-------: | :------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------------------------------: | -| [RTMPose-t\*](./rtmpose/body_2d_keypoint/rtmpose-t_8xb1024-700e_body8-halpe26-256x192.py) | 256x192 | 91.89 | 66.35 | 3.51 | 0.37 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-body7_pt-body7-halpe26_700e-256x192-6020f8a6_20230605.pth) | -| [RTMPose-s\*](./rtmpose/body_2d_keypoint/rtmpose-s_8xb1024-700e_body8-halpe26-256x192.py) | 256x192 | 93.01 | 68.62 | 5.70 | 0.70 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-body7_pt-body7-halpe26_700e-256x192-7f134165_20230605.pth) | -| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb512-700e_body8-halpe26-256x192.py) | 256x192 | 94.75 | 71.91 | 13.93 | 1.95 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-256x192-4d3e73dd_20230605.pth) | -| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb512-700e_body8-halpe26-256x192.py) | 256x192 | 95.37 | 73.19 | 28.11 | 4.19 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-256x192-2abb7558_20230605.pth) | -| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb512-700e_body8-halpe26-384x288.py) | 384x288 | 95.15 | 73.56 | 14.06 | 4.37 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-384x288-89e6428b_20230605.pth) | -| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb512-700e_body8-halpe26-384x288.py) | 384x288 | 95.56 | 74.38 | 28.24 | 9.40 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-384x288-734182ce_20230605.pth) | -| [RTMPose-x\*](./rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_body8-halpe26-384x288.py) | 384x288 | 95.74 | 74.82 | 50.00 | 17.29 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-body7_pt-body7-halpe26_700e-384x288-7fb6e239_20230606.pth) | +| Config | Input Size | PCK@0.1
(Body8) | AUC
(Body8) | Params(M) | FLOPS(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | +| :---------------------------------------------------------------------------------------: | :--------: | :---------------------: | :-----------------: | :-------: | :------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | +| [RTMPose-t\*](./rtmpose/body_2d_keypoint/rtmpose-t_8xb1024-700e_body8-halpe26-256x192.py) | 256x192 | 91.89 | 66.35 | 3.51 | 0.37 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-body7_pt-body7-halpe26_700e-256x192-6020f8a6_20230605.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-t_simcc-body7_pt-body7-halpe26_700e-256x192-6020f8a6_20230605.zip) | +| [RTMPose-s\*](./rtmpose/body_2d_keypoint/rtmpose-s_8xb1024-700e_body8-halpe26-256x192.py) | 256x192 | 93.01 | 68.62 | 5.70 | 0.70 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-body7_pt-body7-halpe26_700e-256x192-7f134165_20230605.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-s_simcc-body7_pt-body7-halpe26_700e-256x192-7f134165_20230605.zip) | +| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb512-700e_body8-halpe26-256x192.py) | 256x192 | 94.75 | 71.91 | 13.93 | 1.95 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-256x192-4d3e73dd_20230605.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-256x192-4d3e73dd_20230605.zip) | +| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb512-700e_body8-halpe26-256x192.py) | 256x192 | 95.37 | 73.19 | 28.11 | 4.19 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-256x192-2abb7558_20230605.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-256x192-2abb7558_20230605.zip) | +| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb512-700e_body8-halpe26-384x288.py) | 384x288 | 95.15 | 73.56 | 14.06 | 4.37 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-384x288-89e6428b_20230605.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-384x288-89e6428b_20230605.zip) | +| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb512-700e_body8-halpe26-384x288.py) | 384x288 | 95.56 | 74.38 | 28.24 | 9.40 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-384x288-734182ce_20230605.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-384x288-734182ce_20230605.zip) | +| [RTMPose-x\*](./rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_body8-halpe26-384x288.py) | 384x288 | 95.74 | 74.82 | 50.00 | 17.29 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-body7_pt-body7-halpe26_700e-384x288-7fb6e239_20230606.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-x_simcc-body7_pt-body7-halpe26_700e-384x288-7fb6e239_20230606.zip) | #### Model Pruning @@ -222,9 +268,9 @@ Feel free to join our community group for more help: - Model pruning is supported by [MMRazor](https://github.com/open-mmlab/mmrazor) -| Config | Input Size | AP
(COCO) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | -| :-----------------------: | :--------: | :---------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :------------------------------------------------------------------------------------------------------------------------------------------------: | -| RTMPose-s-aic-coco-pruned | 256x192 | 69.4 | 3.43 | 0.35 | - | - | - | [Model](https://download.openmmlab.com/mmrazor/v1/pruning/group_fisher/rtmpose-s/group_fisher_finetune_rtmpose-s_8xb256-420e_aic-coco-256x192.pth) | +| Config | Input Size | AP
(COCO) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | +| :-----------------------: | :--------: | :---------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------: | +| RTMPose-s-aic-coco-pruned | 256x192 | 69.4 | 3.43 | 0.35 | - | - | - | [pth](https://download.openmmlab.com/mmrazor/v1/pruning/group_fisher/rtmpose-s/group_fisher_finetune_rtmpose-s_8xb256-420e_aic-coco-256x192.pth) | For more details, please refer to [GroupFisher Pruning for RTMPose](./rtmpose/pruning/README.md). @@ -233,12 +279,60 @@ For more details, please refer to [GroupFisher Pruning for RTMPose](./rtmpose/pr - Keypoints are defined as [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody/). For details please refer to the [meta info](/configs/_base_/datasets/coco_wholebody.py). - +
+
(AP10K) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | | :----------------------------: | :--------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :------------------------------: | -| [RTMPose-m](./rtmpose/animal_2d_keypoint/rtmpose-m_8xb64-210e_ap10k-256x256.py) | 256x256 | 72.2 | 2.57 | 14.157 | 2.404 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-ap10k_pt-aic-coco_210e-256x256-7a041aa1_20230206.pth) | +| [RTMPose-m](./rtmpose/animal_2d_keypoint/rtmpose-m_8xb64-210e_ap10k-256x256.py) | 256x256 | 72.2 | 2.57 | 14.157 | 2.404 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-ap10k_pt-aic-coco_210e-256x256-7a041aa1_20230206.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-ap10k_pt-aic-coco_210e-256x256-7a041aa1_20230206.zip) | ### Face 2d (106 Keypoints) @@ -267,9 +361,9 @@ For more details, please refer to [GroupFisher Pruning for RTMPose](./rtmpose/pr | Config | Input Size | NME
(LaPa) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | | :----------------------------: | :--------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :------------------------------: | -| [RTMPose-t\*](./rtmpose/face_2d_keypoint/rtmpose-t_8xb256-120e_lapa-256x256.py) | 256x256 | 1.67 | 0.652 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-face6_pt-in1k_120e-256x256-df79d9a5_20230529.pth) | -| [RTMPose-s\*](./rtmpose/face_2d_keypoint/rtmpose-s_8xb256-120e_lapa-256x256.py) | 256x256 | 1.59 | 1.119 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-face6_pt-in1k_120e-256x256-d779fdef_20230529.pth) | -| [RTMPose-m\*](./rtmpose/face_2d_keypoint/rtmpose-m_8xb256-120e_lapa-256x256.py) | 256x256 | 1.44 | 2.852 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.pth) | +| [RTMPose-t\*](./rtmpose/face_2d_keypoint/rtmpose-t_8xb256-120e_lapa-256x256.py) | 256x256 | 1.67 | 0.652 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-face6_pt-in1k_120e-256x256-df79d9a5_20230529.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-t_simcc-face6_pt-in1k_120e-256x256-df79d9a5_20230529.zip) | +| [RTMPose-s\*](./rtmpose/face_2d_keypoint/rtmpose-s_8xb256-120e_lapa-256x256.py) | 256x256 | 1.59 | 1.119 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-face6_pt-in1k_120e-256x256-d779fdef_20230529.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-s_simcc-face6_pt-in1k_120e-256x256-d779fdef_20230529.zip) | +| [RTMPose-m\*](./rtmpose/face_2d_keypoint/rtmpose-m_8xb256-120e_lapa-256x256.py) | 256x256 | 1.44 | 2.852 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.zip) |
@@ -280,7 +374,7 @@ For more details, please refer to [GroupFisher Pruning for RTMPose](./rtmpose/pr
| Detection Config | Input Size | Model AP
(OneHand10K) | Flops
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | | :---------------------------: | :--------: | :---------------------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :--------------------: | -| [RTMDet-nano
(alpha version)](./rtmdet/hand/rtmdet_nano_320-8xb32_hand.py) | 320x320 | 76.0 | 0.31 | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_nano_8xb32-300e_hand-267f9c8f.pth) | +| [RTMDet-nano
(alpha version)](./rtmdet/hand/rtmdet_nano_320-8xb32_hand.py) | 320x320 | 76.0 | 0.31 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_nano_8xb32-300e_hand-267f9c8f.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmdet_nano_8xb32-300e_hand-267f9c8f.zip) |
(COCO-Wholebody-Hand) | PCK@0.2
(Hand5) | AUC
(Hand5) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | -| :-------------------------------------------------------------------------------------------------------------------: | :--------: | :-----------------------------------: | :---------------------: | :-----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------------------------: | -| [RTMPose-m\*
(alpha version)](./rtmpose/hand_2d_keypoint/rtmpose-m_8xb32-210e_coco-wholebody-hand-256x256.py) | 256x256 | 81.5 | 96.4 | 83.9 | 2.581 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.pth) | +| Config | Input Size | PCK@0.2
(COCO-Wholebody-Hand) | PCK@0.2
(Hand5) | AUC
(Hand5) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | +| :-------------------------------------------------------------------------------------------------------------------: | :--------: | :-----------------------------------: | :---------------------: | :-----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | +| [RTMPose-m\*
(alpha version)](./rtmpose/hand_2d_keypoint/rtmpose-m_8xb32-210e_coco-wholebody-hand-256x256.py) | 256x256 | 81.5 | 96.4 | 83.9 | 2.581 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.zip) |
@@ -307,10 +401,10 @@ We provide the UDP pretraining configs of the CSPNeXt backbone. Find more detail
| Model | Input Size | Params
(M) | Flops
(G) | AP
(GT) | AR
(GT) | Download | | :----------: | :--------: | :----------------: | :---------------: | :-------------: | :-------------: | :---------------------------------------------------------------------------------------------------------------: | -| CSPNeXt-tiny | 256x192 | 6.03 | 1.43 | 65.5 | 68.9 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-tiny_udp-aic-coco_210e-256x192-cbed682d_20230130.pth) | -| CSPNeXt-s | 256x192 | 8.58 | 1.78 | 70.0 | 73.3 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-s_udp-aic-coco_210e-256x192-92f5a029_20230130.pth) | -| CSPNeXt-m | 256x192 | 17.53 | 3.05 | 74.8 | 77.7 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-m_udp-aic-coco_210e-256x192-f2f7d6f6_20230130.pth) | -| CSPNeXt-l | 256x192 | 32.44 | 5.32 | 77.2 | 79.9 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-l_udp-aic-coco_210e-256x192-273b7631_20230130.pth) | +| CSPNeXt-tiny | 256x192 | 6.03 | 1.43 | 65.5 | 68.9 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-tiny_udp-aic-coco_210e-256x192-cbed682d_20230130.pth) | +| CSPNeXt-s | 256x192 | 8.58 | 1.78 | 70.0 | 73.3 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-s_udp-aic-coco_210e-256x192-92f5a029_20230130.pth) | +| CSPNeXt-m | 256x192 | 17.53 | 3.05 | 74.8 | 77.7 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-m_udp-aic-coco_210e-256x192-f2f7d6f6_20230130.pth) | +| CSPNeXt-l | 256x192 | 32.44 | 5.32 | 77.2 | 79.9 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-l_udp-aic-coco_210e-256x192-273b7631_20230130.pth) |
@@ -329,13 +423,13 @@ We provide the UDP pretraining configs of the CSPNeXt backbone. Find more detail
| Model | Input Size | Params
(M) | Flops
(G) | AP
(COCO) | PCK@0.2
(Body8) | AUC
(Body8) | Download | | :------------: | :--------: | :----------------: | :---------------: | :---------------: | :---------------------: | :-----------------: | :--------------------------------------------------------------------------------: | -| CSPNeXt-tiny\* | 256x192 | 6.03 | 1.43 | 65.9 | 96.34 | 63.80 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-tiny_udp-body7_210e-256x192-a3775292_20230504.pth) | -| CSPNeXt-s\* | 256x192 | 8.58 | 1.78 | 68.7 | 96.59 | 64.92 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-s_udp-body7_210e-256x192-8c9ccbdb_20230504.pth) | -| CSPNeXt-m\* | 256x192 | 17.53 | 3.05 | 73.7 | 97.42 | 68.19 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-m_udp-body7_210e-256x192-e0c9327b_20230504.pth) | -| CSPNeXt-l\* | 256x192 | 32.44 | 5.32 | 75.7 | 97.76 | 69.57 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-l_udp-body7_210e-256x192-5e9558ef_20230504.pth) | -| CSPNeXt-m\* | 384x288 | 17.53 | 6.86 | 75.8 | 97.60 | 70.18 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-m_udp-body7_210e-384x288-b9bc2b57_20230504.pth) | -| CSPNeXt-l\* | 384x288 | 32.44 | 11.96 | 77.2 | 97.89 | 71.23 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-l_udp-body7_210e-384x288-b15bc30d_20230504.pth) | -| CSPNeXt-x\* | 384x288 | 54.92 | 19.96 | 78.1 | 98.00 | 71.79 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-x_udp-body7_210e-384x288-d28b58e6_20230529.pth) | +| CSPNeXt-tiny\* | 256x192 | 6.03 | 1.43 | 65.9 | 96.34 | 63.80 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-tiny_udp-body7_210e-256x192-a3775292_20230504.pth) | +| CSPNeXt-s\* | 256x192 | 8.58 | 1.78 | 68.7 | 96.59 | 64.92 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-s_udp-body7_210e-256x192-8c9ccbdb_20230504.pth) | +| CSPNeXt-m\* | 256x192 | 17.53 | 3.05 | 73.7 | 97.42 | 68.19 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-m_udp-body7_210e-256x192-e0c9327b_20230504.pth) | +| CSPNeXt-l\* | 256x192 | 32.44 | 5.32 | 75.7 | 97.76 | 69.57 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-l_udp-body7_210e-256x192-5e9558ef_20230504.pth) | +| CSPNeXt-m\* | 384x288 | 17.53 | 6.86 | 75.8 | 97.60 | 70.18 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-m_udp-body7_210e-384x288-b9bc2b57_20230504.pth) | +| CSPNeXt-l\* | 384x288 | 32.44 | 11.96 | 77.2 | 97.89 | 71.23 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-l_udp-body7_210e-384x288-b15bc30d_20230504.pth) | +| CSPNeXt-x\* | 384x288 | 54.92 | 19.96 | 78.1 | 98.00 | 71.79 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-x_udp-body7_210e-384x288-d28b58e6_20230529.pth) |
@@ -345,11 +439,11 @@ We also provide the ImageNet classification pre-trained weights of the CSPNeXt b
| Model | Input Size | Params
(M) | Flops
(G) | Top-1 (%) | Top-5 (%) | Download | | :----------: | :--------: | :----------------: | :---------------: | :-------: | :-------: | :---------------------------------------------------------------------------------------------------------------------------: | -| CSPNeXt-tiny | 224x224 | 2.73 | 0.34 | 69.44 | 89.45 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-tiny_imagenet_600e-3a2dd350.pth) | -| CSPNeXt-s | 224x224 | 4.89 | 0.66 | 74.41 | 92.23 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-s_imagenet_600e-ea671761.pth) | -| CSPNeXt-m | 224x224 | 13.05 | 1.93 | 79.27 | 94.79 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-m_8xb256-rsb-a1-600e_in1k-ecb3bbd9.pth) | -| CSPNeXt-l | 224x224 | 27.16 | 4.19 | 81.30 | 95.62 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-l_8xb256-rsb-a1-600e_in1k-6a760974.pth) | -| CSPNeXt-x | 224x224 | 48.85 | 7.76 | 82.10 | 95.69 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-x_8xb256-rsb-a1-600e_in1k-b3f78edd.pth) | +| CSPNeXt-tiny | 224x224 | 2.73 | 0.34 | 69.44 | 89.45 | [pth](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-tiny_imagenet_600e-3a2dd350.pth) | +| CSPNeXt-s | 224x224 | 4.89 | 0.66 | 74.41 | 92.23 | [pth](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-s_imagenet_600e-ea671761.pth) | +| CSPNeXt-m | 224x224 | 13.05 | 1.93 | 79.27 | 94.79 | [pth](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-m_8xb256-rsb-a1-600e_in1k-ecb3bbd9.pth) | +| CSPNeXt-l | 224x224 | 27.16 | 4.19 | 81.30 | 95.62 | [pth](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-l_8xb256-rsb-a1-600e_in1k-6a760974.pth) | +| CSPNeXt-x | 224x224 | 48.85 | 7.76 | 82.10 | 95.69 | [pth](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-x_8xb256-rsb-a1-600e_in1k-b3f78edd.pth) | ## 👀 Visualization [🔝](#-table-of-contents) @@ -362,8 +456,10 @@ We also provide the ImageNet classification pre-trained weights of the CSPNeXt b We provide two appoaches to try RTMPose: -- MMPose demo scripts -- Pre-compiled MMDeploy SDK (Recommend, 6-10 times faster) +- [Online RTMPose Demo](https://openxlab.org.cn/apps/detail/mmpose/RTMPose) +- [Examples](https://github.com/open-mmlab/mmpose/tree/dev-1.x/projects/rtmpose/examples/onnxruntime) based on Python and ONNXRuntime (without mmcv) +- MMPose demo scripts (based on Pytorch) +- Pre-compiled MMDeploy SDK (Recommended, 6-10 times faster) ### MMPose demo scripts @@ -689,9 +785,10 @@ Before starting the deployment, please make sure you install MMPose and MMDeploy Depending on the deployment backend, some backends require compilation of custom operators, so please refer to the corresponding document to ensure the environment is built correctly according to your needs: -- [ONNX RUNTIME SUPPORT](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/onnxruntime.html) -- [TENSORRT SUPPORT](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/tensorrt.html) -- [OPENVINO SUPPORT](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/openvino.html) +- [ONNX](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/onnxruntime.html) +- [TensorRT](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/tensorrt.html) +- [OpenVINO](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/openvino.html) +- [TorchScript](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/torchscript.html) - [More](https://github.com/open-mmlab/mmdeploy/tree/main/docs/en/05-supported-backends) ### 🛠️ Step2. Convert Model @@ -702,12 +799,20 @@ The detailed model conversion tutorial please refer to the [MMDeploy document](h Here we take converting RTMDet-nano and RTMPose-m to ONNX/TensorRT as an example. -- If you only want to use ONNX, please use: +- ONNX - [`detection_onnxruntime_static.py`](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmdet/detection/detection_onnxruntime_static.py) for RTMDet. - [`pose-detection_simcc_onnxruntime_dynamic.py`](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_onnxruntime_dynamic.py) for RTMPose. -- If you want to use TensorRT, please use: +- TensorRT - [`detection_tensorrt_static-320x320.py`](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmdet/detection/detection_tensorrt_static-320x320.py) for RTMDet. - [`pose-detection_simcc_tensorrt_dynamic-256x192.py`](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_tensorrt_dynamic-256x192.py) for RTMPose. +- More + | Backend | Config | + | :---------: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------: | + | ncnn-fp16 | [pose-detection_simcc_ncnn-fp16_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_ncnn-fp16_static-256x192.py) | + | CoreML | [pose-detection_simcc_coreml_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_coreml_static-256x192.py) | + | OpenVINO | [pose-detection_simcc_openvino_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_openvino_static-256x192.py) | + | RKNN | [pose-detection_simcc_rknn-fp16_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_rknn-fp16_static-256x192.py) | + | TorchScript | [pose-detection_torchscript.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_torchscript.py) | If you want to customize the settings in the deployment config for your requirements, please refer to [MMDeploy config tutorial](https://mmdeploy.readthedocs.io/en/latest/02-how-to-run/write_config.html). diff --git a/projects/rtmpose/README_CN.md b/projects/rtmpose/README_CN.md index 30bddf9ecd..859d0e9364 100644 --- a/projects/rtmpose/README_CN.md +++ b/projects/rtmpose/README_CN.md @@ -40,10 +40,25 @@ ______________________________________________________________________ ## 🥳 最新进展 [🔝](#-table-of-contents) +- 2023 年 9 月: + - 发布混合数据集上训练的 RTMW 模型。Alpha 版本的 RTMW-x 在 COCO-Wholebody 验证集上取得了 70.2 mAP。[在线 Demo](https://openxlab.org.cn/apps/detail/mmpose/RTMPose) 已支持 RTMW。技术报告正在撰写中。 + - 增加 HumanArt 上训练的 YOLOX 和 RTMDet 模型。 +- 2023 年 8 月: + - 支持基于 RTMPose 模型蒸馏的 133 点 WholeBody 模型(由 [DWPose](https://github.com/IDEA-Research/DWPose/tree/main) 提供)。 + - 你可以在 [sd-webui-controlnet](https://github.com/Mikubill/sd-webui-controlnet) 中使用 DWPose/RTMPose 作为姿态估计后端进行人物图像生成。升级 sd-webui-controlnet >= v1.1237 并选择 `dw_openpose_full` 即可使用。 + - [在线 Demo](https://openxlab.org.cn/apps/detail/mmpose/RTMPose) 已支持 DWPose,试玩请选择 `wholebody`。 +- 2023 年 7 月: + - 在线 RTMPose 试玩 [Demo](https://openxlab.org.cn/apps/detail/mmpose/RTMPose)。 + - 支持面向艺术图片人体姿态估计的 17 点 Body 模型。 - 2023 年 6 月: - 发布混合数据集训练的 26 点 Body 模型。 - 2023 年 5 月: - - 添加 [代码示例](./examples/) + - 已导出的 SDK 模型(ONNX、TRT、ncnn 等)可以从 [OpenMMLab Deploee](https://platform.openmmlab.com/deploee) 直接下载。 + - [在线导出](https://platform.openmmlab.com/deploee/task-convert-list) SDK 模型(ONNX、TRT、ncnn 等)。 + - 添加 [代码示例](./examples/),包括: + - 纯 Python 推理代码示例,无 MMDeploy、MMCV 依赖 + - C++ 代码示例:ONNXRuntime、TensorRT + - Android 项目示例:基于 ncnn - 发布混合数据集训练的 Hand, Face, Body 模型。 - 2023 年 3 月:发布 RTMPose。RTMPose-m 取得 COCO 验证集 75.8 mAP,推理速度达到 430+ FPS 。 @@ -125,6 +140,7 @@ RTMPose 是一个长期优化迭代的项目,致力于业务场景下的高性 - TensorRT 8.4.3.1 - cuDNN 8.3.2 - CUDA 11.3 +- **更新**:我们推荐你使用混合数据集训练的 `Body8` 模型,性能高于下表中提供的模型,[传送门](#人体-2d-关键点)。 | Detection Config | Pose Config | Input Size
(Det/Pose) | Model AP
(COCO) | Pipeline AP
(COCO) | Params (M)
(Det/Pose) | Flops (G)
(Det/Pose) | ORT-Latency(ms)
(i7-11700) | TRT-FP16-Latency(ms)
(GTX 1660Ti) | Download | | :------------------------------------------------------------------ | :---------------------------------------------------------------------------- | :---------------------------: | :---------------------: | :------------------------: | :---------------------------: | :--------------------------: | :--------------------------------: | :---------------------------------------: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | @@ -155,14 +171,14 @@ RTMPose 是一个长期优化迭代的项目,致力于业务场景下的高性
(COCO) | PCK@0.1
(Body8) | AUC
(Body8) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | -| :---------------------------------------------------------------------------: | :--------: | :---------------: | :---------------------: | :-----------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :---------------------------------------------------------------------------------------------------------------------------------------------: | -| [RTMPose-t](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 68.5 | 91.28 | 63.38 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-tiny_simcc-aic-coco_pt-aic-coco_420e-256x192-cfc8f33d_20230126.pth) | -| [RTMPose-s](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 72.2 | 92.95 | 66.19 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-aic-coco_pt-aic-coco_420e-256x192-fcb2599b_20230126.pth) | -| [RTMPose-m](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 75.8 | 94.13 | 68.53 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-256x192-63eb25f7_20230126.pth) | -| [RTMPose-l](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 76.5 | 94.35 | 68.98 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-aic-coco_pt-aic-coco_420e-256x192-f016ffe0_20230126.pth) | -| [RTMPose-m](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py) | 384x288 | 77.0 | 94.32 | 69.85 | 13.72 | 4.33 | 24.78 | 3.66 | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-384x288-a62a0b32_20230228.pth) | -| [RTMPose-l](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py) | 384x288 | 77.3 | 94.54 | 70.14 | 27.79 | 9.35 | - | 6.05 | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-aic-coco_pt-aic-coco_420e-384x288-97d6cb0f_20230228.pth) | +| Config | Input Size | AP
(COCO) | PCK@0.1
(Body8) | AUC
(Body8) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | +| :---------------------------------------------------------------------------: | :--------: | :---------------: | :---------------------: | :-----------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :-------------------------------------------------------------------------------------------------------------------------------------------: | +| [RTMPose-t](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 68.5 | 91.28 | 63.38 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-tiny_simcc-aic-coco_pt-aic-coco_420e-256x192-cfc8f33d_20230126.pth) | +| [RTMPose-s](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 72.2 | 92.95 | 66.19 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-aic-coco_pt-aic-coco_420e-256x192-fcb2599b_20230126.pth) | +| [RTMPose-m](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 75.8 | 94.13 | 68.53 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-256x192-63eb25f7_20230126.pth) | +| [RTMPose-l](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 76.5 | 94.35 | 68.98 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-aic-coco_pt-aic-coco_420e-256x192-f016ffe0_20230126.pth) | +| [RTMPose-m](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py) | 384x288 | 77.0 | 94.32 | 69.85 | 13.72 | 4.33 | 24.78 | 3.66 | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-384x288-a62a0b32_20230228.pth) | +| [RTMPose-l](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py) | 384x288 | 77.3 | 94.54 | 70.14 | 27.79 | 9.35 | - | 6.05 | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-aic-coco_pt-aic-coco_420e-384x288-97d6cb0f_20230228.pth) |
@@ -179,15 +195,45 @@ RTMPose 是一个长期优化迭代的项目,致力于业务场景下的高性
- [PoseTrack18](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#posetrack18)
- `Body8` 代表除了以上提到的 7 个数据集,再加上 [OCHuman](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#ochuman) 合并后一起进行评测得到的指标。
-| Config | Input Size | AP
(COCO) | PCK@0.1
(Body8) | AUC
(Body8) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | -| :-----------------------------------------------------------------------------: | :--------: | :---------------: | :---------------------: | :-----------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :------------------------------------------------------------------------------------------------------------------------------------: | -| [RTMPose-t\*](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 65.9 | 91.44 | 63.18 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-body7_pt-body7_420e-256x192-026a1439_20230504.pth) | -| [RTMPose-s\*](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 69.7 | 92.45 | 65.15 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-body7_pt-body7_420e-256x192-acd4a1ef_20230504.pth) | -| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 74.9 | 94.25 | 68.59 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-256x192-e48f03d0_20230504.pth) | -| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 76.7 | 95.08 | 70.14 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7_420e-256x192-4dba18fc_20230504.pth) | -| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py) | 384x288 | 76.6 | 94.64 | 70.38 | 13.72 | 4.33 | 24.78 | 3.66 | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-384x288-65e718c4_20230504.pth) | -| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py) | 384x288 | 78.3 | 95.36 | 71.58 | 27.79 | 9.35 | - | 6.05 | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7_420e-384x288-3f5a1437_20230504.pth) | -| [RTMPose-x\*](./rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_coco-384x288.py) | 384x288 | 78.8 | - | - | 49.43 | 17.22 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-body7_pt-body7_700e-384x288-71d7b7e9_20230629.pth) | +| Config | Input Size | AP
(COCO) | PCK@0.1
(Body8) | AUC
(Body8) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | +| :-----------------------------------------------------------------------------: | :--------: | :---------------: | :---------------------: | :-----------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | +| [RTMPose-t\*](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 65.9 | 91.44 | 63.18 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-body7_pt-body7_420e-256x192-026a1439_20230504.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-t_simcc-body7_pt-body7_420e-256x192-026a1439_20230504.zip) | +| [RTMPose-s\*](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 69.7 | 92.45 | 65.15 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-body7_pt-body7_420e-256x192-acd4a1ef_20230504.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-s_simcc-body7_pt-body7_420e-256x192-acd4a1ef_20230504.zip) | +| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 74.9 | 94.25 | 68.59 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-256x192-e48f03d0_20230504.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-body7_pt-body7_420e-256x192-e48f03d0_20230504.zip) | +| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 76.7 | 95.08 | 70.14 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7_420e-256x192-4dba18fc_20230504.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_simcc-body7_pt-body7_420e-256x192-4dba18fc_20230504.zip) | +| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py) | 384x288 | 76.6 | 94.64 | 70.38 | 13.72 | 4.33 | 24.78 | 3.66 | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-384x288-65e718c4_20230504.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-body7_pt-body7_420e-384x288-65e718c4_20230504.zip) | +| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py) | 384x288 | 78.3 | 95.36 | 71.58 | 27.79 | 9.35 | - | 6.05 | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7_420e-384x288-3f5a1437_20230504.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_simcc-body7_pt-body7_420e-384x288-3f5a1437_20230504.zip) | +| [RTMPose-x\*](./rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_coco-384x288.py) | 384x288 | 78.8 | - | - | 49.43 | 17.22 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-body7_pt-body7_700e-384x288-71d7b7e9_20230629.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-x_simcc-body7_pt-body7_700e-384x288-71d7b7e9_20230629.zip) | + +
+
+
- 模型在 `Body8` 上进行训练和评估。
-| Config | Input Size | PCK@0.1
(Body8) | AUC
(Body8) | Params(M) | FLOPS(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | -| :---------------------------------------------------------------------------------------: | :--------: | :---------------------: | :-----------------: | :-------: | :------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------------------------------: | -| [RTMPose-t\*](./rtmpose/body_2d_keypoint/rtmpose-t_8xb1024-700e_body8-halpe26-256x192.py) | 256x192 | 91.89 | 66.35 | 3.51 | 0.37 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-body7_pt-body7-halpe26_700e-256x192-6020f8a6_20230605.pth) | -| [RTMPose-s\*](./rtmpose/body_2d_keypoint/rtmpose-s_8xb1024-700e_body8-halpe26-256x192.py) | 256x192 | 93.01 | 68.62 | 5.70 | 0.70 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-body7_pt-body7-halpe26_700e-256x192-7f134165_20230605.pth) | -| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb512-700e_body8-halpe26-256x192.py) | 256x192 | 94.75 | 71.91 | 13.93 | 1.95 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-256x192-4d3e73dd_20230605.pth) | -| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb512-700e_body8-halpe26-256x192.py) | 256x192 | 95.37 | 73.19 | 28.11 | 4.19 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-256x192-2abb7558_20230605.pth) | -| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb512-700e_body8-halpe26-384x288.py) | 384x288 | 95.15 | 73.56 | 14.06 | 4.37 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-384x288-89e6428b_20230605.pth) | -| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb512-700e_body8-halpe26-384x288.py) | 384x288 | 95.56 | 74.38 | 28.24 | 9.40 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-384x288-734182ce_20230605.pth) | -| [RTMPose-x\*](./rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_body8-halpe26-384x288.py) | 384x288 | 95.74 | 74.82 | 50.00 | 17.29 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-body7_pt-body7-halpe26_700e-384x288-7fb6e239_20230606.pth) | +| Config | Input Size | PCK@0.1
(Body8) | AUC
(Body8) | Params(M) | FLOPS(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | +| :---------------------------------------------------------------------------------------: | :--------: | :---------------------: | :-----------------: | :-------: | :------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | +| [RTMPose-t\*](./rtmpose/body_2d_keypoint/rtmpose-t_8xb1024-700e_body8-halpe26-256x192.py) | 256x192 | 91.89 | 66.35 | 3.51 | 0.37 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-body7_pt-body7-halpe26_700e-256x192-6020f8a6_20230605.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-t_simcc-body7_pt-body7-halpe26_700e-256x192-6020f8a6_20230605.zip) | +| [RTMPose-s\*](./rtmpose/body_2d_keypoint/rtmpose-s_8xb1024-700e_body8-halpe26-256x192.py) | 256x192 | 93.01 | 68.62 | 5.70 | 0.70 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-body7_pt-body7-halpe26_700e-256x192-7f134165_20230605.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-s_simcc-body7_pt-body7-halpe26_700e-256x192-7f134165_20230605.zip) | +| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb512-700e_body8-halpe26-256x192.py) | 256x192 | 94.75 | 71.91 | 13.93 | 1.95 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-256x192-4d3e73dd_20230605.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-256x192-4d3e73dd_20230605.zip) | +| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb512-700e_body8-halpe26-256x192.py) | 256x192 | 95.37 | 73.19 | 28.11 | 4.19 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-256x192-2abb7558_20230605.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-256x192-2abb7558_20230605.zip) | +| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb512-700e_body8-halpe26-384x288.py) | 384x288 | 95.15 | 73.56 | 14.06 | 4.37 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-384x288-89e6428b_20230605.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-384x288-89e6428b_20230605.zip) | +| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb512-700e_body8-halpe26-384x288.py) | 384x288 | 95.56 | 74.38 | 28.24 | 9.40 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-384x288-734182ce_20230605.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-384x288-734182ce_20230605.zip) | +| [RTMPose-x\*](./rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_body8-halpe26-384x288.py) | 384x288 | 95.74 | 74.82 | 50.00 | 17.29 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-body7_pt-body7-halpe26_700e-384x288-7fb6e239_20230606.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-x_simcc-body7_pt-body7-halpe26_700e-384x288-7fb6e239_20230606.zip) | #### 模型剪枝 @@ -213,9 +259,9 @@ RTMPose 是一个长期优化迭代的项目,致力于业务场景下的高性 - 模型剪枝由 [MMRazor](https://github.com/open-mmlab/mmrazor) 提供 -| Config | Input Size | AP
(COCO) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | -| :-----------------------: | :--------: | :---------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :------------------------------------------------------------------------------------------------------------------------------------------------: | -| RTMPose-s-aic-coco-pruned | 256x192 | 69.4 | 3.43 | 0.35 | - | - | - | [Model](https://download.openmmlab.com/mmrazor/v1/pruning/group_fisher/rtmpose-s/group_fisher_finetune_rtmpose-s_8xb256-420e_aic-coco-256x192.pth) | +| Config | Input Size | AP
(COCO) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | +| :-----------------------: | :--------: | :---------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------: | +| RTMPose-s-aic-coco-pruned | 256x192 | 69.4 | 3.43 | 0.35 | - | - | - | [pth](https://download.openmmlab.com/mmrazor/v1/pruning/group_fisher/rtmpose-s/group_fisher_finetune_rtmpose-s_8xb256-420e_aic-coco-256x192.pth) | 更多信息,请参考 [GroupFisher Pruning for RTMPose](./rtmpose/pruning/README.md). @@ -224,12 +270,60 @@ RTMPose 是一个长期优化迭代的项目,致力于业务场景下的高性 - 关键点骨架定义遵循 [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody/),详情见 [meta info](/configs/_base_/datasets/coco_wholebody.py)。 -
+
(AP10K) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | | :----------------------------: | :--------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :------------------------------: | -| [RTMPose-m](./rtmpose/animal_2d_keypoint/rtmpose-m_8xb64-210e_ap10k-256x256.py) | 256x256 | 72.2 | 2.57 | 14.157 | 2.404 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-ap10k_pt-aic-coco_210e-256x256-7a041aa1_20230206.pth) | +| [RTMPose-m](./rtmpose/animal_2d_keypoint/rtmpose-m_8xb64-210e_ap10k-256x256.py) | 256x256 | 72.2 | 2.57 | 14.157 | 2.404 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-ap10k_pt-aic-coco_210e-256x256-7a041aa1_20230206.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-ap10k_pt-aic-coco_210e-256x256-7a041aa1_20230206.zip) | ### 脸部 2d 关键点 (106 Keypoints) @@ -258,9 +352,9 @@ RTMPose 是一个长期优化迭代的项目,致力于业务场景下的高性 | Config | Input Size | NME
(LaPa) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | | :----------------------------: | :--------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :------------------------------: | -| [RTMPose-t\*](./rtmpose/face_2d_keypoint/rtmpose-t_8xb256-120e_lapa-256x256.py) | 256x256 | 1.67 | 0.652 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-face6_pt-in1k_120e-256x256-df79d9a5_20230529.pth) | -| [RTMPose-s\*](./rtmpose/face_2d_keypoint/rtmpose-s_8xb256-120e_lapa-256x256.py) | 256x256 | 1.59 | 1.119 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-face6_pt-in1k_120e-256x256-d779fdef_20230529.pth) | -| [RTMPose-m\*](./rtmpose/face_2d_keypoint/rtmpose-m_8xb256-120e_lapa-256x256.py) | 256x256 | 1.44 | 2.852 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.pth) | +| [RTMPose-t\*](./rtmpose/face_2d_keypoint/rtmpose-t_8xb256-120e_lapa-256x256.py) | 256x256 | 1.67 | 0.652 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-face6_pt-in1k_120e-256x256-df79d9a5_20230529.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-t_simcc-face6_pt-in1k_120e-256x256-df79d9a5_20230529.zip) | +| [RTMPose-s\*](./rtmpose/face_2d_keypoint/rtmpose-s_8xb256-120e_lapa-256x256.py) | 256x256 | 1.59 | 1.119 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-face6_pt-in1k_120e-256x256-d779fdef_20230529.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-s_simcc-face6_pt-in1k_120e-256x256-d779fdef_20230529.zip) | +| [RTMPose-m\*](./rtmpose/face_2d_keypoint/rtmpose-m_8xb256-120e_lapa-256x256.py) | 256x256 | 1.44 | 2.852 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.zip) |
@@ -271,7 +365,7 @@ RTMPose 是一个长期优化迭代的项目,致力于业务场景下的高性
| Detection Config | Input Size | Model AP
(OneHand10K) | Flops
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | | :---------------------------: | :--------: | :---------------------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :--------------------: | -| [RTMDet-nano (试用)](./rtmdet/hand/rtmdet_nano_320-8xb32_hand.py) | 320x320 | 76.0 | 0.31 | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_nano_8xb32-300e_hand-267f9c8f.pth) | +| [RTMDet-nano
(alpha version)](./rtmdet/hand/rtmdet_nano_320-8xb32_hand.py) | 320x320 | 76.0 | 0.31 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_nano_8xb32-300e_hand-267f9c8f.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmdet_nano_8xb32-300e_hand-267f9c8f.zip) |
(COCO-Wholebody-Hand) | PCK@0.2
(Hand5) | AUC
(Hand5) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | -| :----------------------------------------------------------------------------------------------------------: | :--------: | :-----------------------------------: | :---------------------: | :-----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------------------------: | -| [RTMPose-m\*
(试用)](./rtmpose/hand_2d_keypoint/rtmpose-m_8xb32-210e_coco-wholebody-hand-256x256.py) | 256x256 | 81.5 | 96.4 | 83.9 | 2.581 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.pth) | +| Config | Input Size | PCK@0.2
(COCO-Wholebody-Hand) | PCK@0.2
(Hand5) | AUC
(Hand5) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | +| :-------------------------------------------------------------------------------------------------------------------: | :--------: | :-----------------------------------: | :---------------------: | :-----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | +| [RTMPose-m\*
(alpha version)](./rtmpose/hand_2d_keypoint/rtmpose-m_8xb32-210e_coco-wholebody-hand-256x256.py) | 256x256 | 81.5 | 96.4 | 83.9 | 2.581 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.zip) |
@@ -298,10 +392,10 @@ RTMPose 是一个长期优化迭代的项目,致力于业务场景下的高性
| Model | Input Size | Params
(M) | Flops
(G) | AP
(GT) | AR
(GT) | Download | | :----------: | :--------: | :----------------: | :---------------: | :-------------: | :-------------: | :---------------------------------------------------------------------------------------------------------------: | -| CSPNeXt-tiny | 256x192 | 6.03 | 1.43 | 65.5 | 68.9 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-tiny_udp-aic-coco_210e-256x192-cbed682d_20230130.pth) | -| CSPNeXt-s | 256x192 | 8.58 | 1.78 | 70.0 | 73.3 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-s_udp-aic-coco_210e-256x192-92f5a029_20230130.pth) | -| CSPNeXt-m | 256x192 | 17.53 | 3.05 | 74.8 | 77.7 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-m_udp-aic-coco_210e-256x192-f2f7d6f6_20230130.pth) | -| CSPNeXt-l | 256x192 | 32.44 | 5.32 | 77.2 | 79.9 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-l_udp-aic-coco_210e-256x192-273b7631_20230130.pth) | +| CSPNeXt-tiny | 256x192 | 6.03 | 1.43 | 65.5 | 68.9 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-tiny_udp-aic-coco_210e-256x192-cbed682d_20230130.pth) | +| CSPNeXt-s | 256x192 | 8.58 | 1.78 | 70.0 | 73.3 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-s_udp-aic-coco_210e-256x192-92f5a029_20230130.pth) | +| CSPNeXt-m | 256x192 | 17.53 | 3.05 | 74.8 | 77.7 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-m_udp-aic-coco_210e-256x192-f2f7d6f6_20230130.pth) | +| CSPNeXt-l | 256x192 | 32.44 | 5.32 | 77.2 | 79.9 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-l_udp-aic-coco_210e-256x192-273b7631_20230130.pth) |
@@ -320,13 +414,13 @@ RTMPose 是一个长期优化迭代的项目,致力于业务场景下的高性
| Model | Input Size | Params
(M) | Flops
(G) | AP
(COCO) | PCK@0.2
(Body8) | AUC
(Body8) | Download | | :------------: | :--------: | :----------------: | :---------------: | :---------------: | :---------------------: | :-----------------: | :--------------------------------------------------------------------------------: | -| CSPNeXt-tiny\* | 256x192 | 6.03 | 1.43 | 65.9 | 96.34 | 63.80 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-tiny_udp-body7_210e-256x192-a3775292_20230504.pth) | -| CSPNeXt-s\* | 256x192 | 8.58 | 1.78 | 68.7 | 96.59 | 64.92 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-s_udp-body7_210e-256x192-8c9ccbdb_20230504.pth) | -| CSPNeXt-m\* | 256x192 | 17.53 | 3.05 | 73.7 | 97.42 | 68.19 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-m_udp-body7_210e-256x192-e0c9327b_20230504.pth) | -| CSPNeXt-l\* | 256x192 | 32.44 | 5.32 | 75.7 | 97.76 | 69.57 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-l_udp-body7_210e-256x192-5e9558ef_20230504.pth) | -| CSPNeXt-m\* | 384x288 | 17.53 | 6.86 | 75.8 | 97.60 | 70.18 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-m_udp-body7_210e-384x288-b9bc2b57_20230504.pth) | -| CSPNeXt-l\* | 384x288 | 32.44 | 11.96 | 77.2 | 97.89 | 71.23 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-l_udp-body7_210e-384x288-b15bc30d_20230504.pth) | -| CSPNeXt-x\* | 384x288 | 54.92 | 19.96 | 78.1 | 98.00 | 71.79 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-x_udp-body7_210e-384x288-d28b58e6_20230529.pth) | +| CSPNeXt-tiny\* | 256x192 | 6.03 | 1.43 | 65.9 | 96.34 | 63.80 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-tiny_udp-body7_210e-256x192-a3775292_20230504.pth) | +| CSPNeXt-s\* | 256x192 | 8.58 | 1.78 | 68.7 | 96.59 | 64.92 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-s_udp-body7_210e-256x192-8c9ccbdb_20230504.pth) | +| CSPNeXt-m\* | 256x192 | 17.53 | 3.05 | 73.7 | 97.42 | 68.19 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-m_udp-body7_210e-256x192-e0c9327b_20230504.pth) | +| CSPNeXt-l\* | 256x192 | 32.44 | 5.32 | 75.7 | 97.76 | 69.57 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-l_udp-body7_210e-256x192-5e9558ef_20230504.pth) | +| CSPNeXt-m\* | 384x288 | 17.53 | 6.86 | 75.8 | 97.60 | 70.18 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-m_udp-body7_210e-384x288-b9bc2b57_20230504.pth) | +| CSPNeXt-l\* | 384x288 | 32.44 | 11.96 | 77.2 | 97.89 | 71.23 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-l_udp-body7_210e-384x288-b15bc30d_20230504.pth) | +| CSPNeXt-x\* | 384x288 | 54.92 | 19.96 | 78.1 | 98.00 | 71.79 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-x_udp-body7_210e-384x288-d28b58e6_20230529.pth) |
@@ -336,11 +430,11 @@ RTMPose 是一个长期优化迭代的项目,致力于业务场景下的高性
| Model | Input Size | Params
(M) | Flops
(G) | Top-1 (%) | Top-5 (%) | Download | | :----------: | :--------: | :----------------: | :---------------: | :-------: | :-------: | :---------------------------------------------------------------------------------------------------------------------------: | -| CSPNeXt-tiny | 224x224 | 2.73 | 0.34 | 69.44 | 89.45 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-tiny_imagenet_600e-3a2dd350.pth) | -| CSPNeXt-s | 224x224 | 4.89 | 0.66 | 74.41 | 92.23 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-s_imagenet_600e-ea671761.pth) | -| CSPNeXt-m | 224x224 | 13.05 | 1.93 | 79.27 | 94.79 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-m_8xb256-rsb-a1-600e_in1k-ecb3bbd9.pth) | -| CSPNeXt-l | 224x224 | 27.16 | 4.19 | 81.30 | 95.62 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-l_8xb256-rsb-a1-600e_in1k-6a760974.pth) | -| CSPNeXt-x | 224x224 | 48.85 | 7.76 | 82.10 | 95.69 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-x_8xb256-rsb-a1-600e_in1k-b3f78edd.pth) | +| CSPNeXt-tiny | 224x224 | 2.73 | 0.34 | 69.44 | 89.45 | [pth](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-tiny_imagenet_600e-3a2dd350.pth) | +| CSPNeXt-s | 224x224 | 4.89 | 0.66 | 74.41 | 92.23 | [pth](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-s_imagenet_600e-ea671761.pth) | +| CSPNeXt-m | 224x224 | 13.05 | 1.93 | 79.27 | 94.79 | [pth](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-m_8xb256-rsb-a1-600e_in1k-ecb3bbd9.pth) | +| CSPNeXt-l | 224x224 | 27.16 | 4.19 | 81.30 | 95.62 | [pth](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-l_8xb256-rsb-a1-600e_in1k-6a760974.pth) | +| CSPNeXt-x | 224x224 | 48.85 | 7.76 | 82.10 | 95.69 | [pth](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-x_8xb256-rsb-a1-600e_in1k-b3f78edd.pth) | ## 👀 可视化 [🔝](#-table-of-contents) @@ -353,7 +447,9 @@ RTMPose 是一个长期优化迭代的项目,致力于业务场景下的高性 我们提供了两种途径来让用户尝试 RTMPose 模型: -- MMPose demo 脚本 +- [在线 RTMPose Demo](https://openxlab.org.cn/apps/detail/mmpose/RTMPose) +- [Examples](https://github.com/open-mmlab/mmpose/tree/dev-1.x/projects/rtmpose/examples/onnxruntime) 基于 Python 和 ONNXRuntime (无 MMCV 依赖) +- MMPose demo 脚本 (基于 Pytorch) - MMDeploy SDK 预编译包 (推荐,速度提升6-10倍) ### MMPose demo 脚本 @@ -683,6 +779,7 @@ python demo/topdown_demo_with_mmdet.py \ - [ONNX](https://mmdeploy.readthedocs.io/zh_CN/latest/05-supported-backends/onnxruntime.html) - [TensorRT](https://mmdeploy.readthedocs.io/zh_CN/latest/05-supported-backends/tensorrt.html) - [OpenVINO](https://mmdeploy.readthedocs.io/zh_CN/latest/05-supported-backends/openvino.html) +- [TorchScript](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/torchscript.html) - [更多](https://github.com/open-mmlab/mmdeploy/tree/main/docs/en/05-supported-backends) ### 🛠️ 模型转换 @@ -703,6 +800,16 @@ python demo/topdown_demo_with_mmdet.py \ \- RTMPose:[`pose-detection_simcc_tensorrt_dynamic-256x192.py`](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_tensorrt_dynamic-256x192.py) +- 更多 + + | Backend | Config | + | :---------: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------: | + | ncnn-fp16 | [pose-detection_simcc_ncnn-fp16_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_ncnn-fp16_static-256x192.py) | + | CoreML | [pose-detection_simcc_coreml_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_coreml_static-256x192.py) | + | OpenVINO | [pose-detection_simcc_openvino_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_openvino_static-256x192.py) | + | RKNN | [pose-detection_simcc_rknn-fp16_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_rknn-fp16_static-256x192.py) | + | TorchScript | [pose-detection_torchscript.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_torchscript.py) | + 如果你需要对部署配置进行修改,请参考 [MMDeploy config tutorial](https://mmdeploy.readthedocs.io/zh_CN/latest/02-how-to-run/write_config.html). 本教程中使用的文件结构如下: diff --git a/projects/rtmpose/rtmdet/README.md b/projects/rtmpose/rtmdet/README.md new file mode 100644 index 0000000000..7c83f1d378 --- /dev/null +++ b/projects/rtmpose/rtmdet/README.md @@ -0,0 +1,3 @@ +# Welcome to RTMDet Project of MMPose + +**Highlight:** If you are deploy `projects/rtmpose/rtmdet` with [deploee](https://platform.openmmlab.com/deploee), please input [full http download link of train_config](https://raw.githubusercontent.com/open-mmlab/mmpose/main/projects/rtmpose/rtmdet/hand/rtmdet_nano_320-8xb32_hand.py) instead of relative path, deploee cannot parse mmdet config within mmpose repo. diff --git a/projects/rtmpose/rtmdet/person/humanart_detection.py b/projects/rtmpose/rtmdet/person/humanart_detection.py new file mode 100644 index 0000000000..a07a2499ce --- /dev/null +++ b/projects/rtmpose/rtmdet/person/humanart_detection.py @@ -0,0 +1,95 @@ +# dataset settings +dataset_type = 'CocoDataset' +data_root = 'data/' + +# Example to use different file client +# Method 1: simply set the data root and let the file I/O module +# automatically infer from prefix (not support LMDB and Memcache yet) + +# data_root = 's3://openmmlab/datasets/detection/coco/' + +# Method 2: Use `backend_args`, `file_client_args` in versions before 3.0.0rc6 +# backend_args = dict( +# backend='petrel', +# path_mapping=dict({ +# './data/': 's3://openmmlab/datasets/detection/', +# 'data/': 's3://openmmlab/datasets/detection/' +# })) +backend_args = None + +train_pipeline = [ + dict(type='LoadImageFromFile', backend_args=backend_args), + dict(type='LoadAnnotations', with_bbox=True), + dict(type='Resize', scale=(1333, 800), keep_ratio=True), + dict(type='RandomFlip', prob=0.5), + dict(type='PackDetInputs') +] +test_pipeline = [ + dict(type='LoadImageFromFile', backend_args=backend_args), + dict(type='Resize', scale=(1333, 800), keep_ratio=True), + # If you don't have a gt annotation, delete the pipeline + dict(type='LoadAnnotations', with_bbox=True), + dict( + type='PackDetInputs', + meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', + 'scale_factor')) +] +train_dataloader = dict( + batch_size=2, + num_workers=2, + persistent_workers=True, + sampler=dict(type='DefaultSampler', shuffle=True), + batch_sampler=dict(type='AspectRatioBatchSampler'), + dataset=dict( + type=dataset_type, + data_root=data_root, + ann_file='HumanArt/annotations/training_humanart_coco.json', + data_prefix=dict(img=''), + filter_cfg=dict(filter_empty_gt=True, min_size=32), + pipeline=train_pipeline, + backend_args=backend_args)) +val_dataloader = dict( + batch_size=1, + num_workers=2, + persistent_workers=True, + drop_last=False, + sampler=dict(type='DefaultSampler', shuffle=False), + dataset=dict( + type=dataset_type, + data_root=data_root, + ann_file='HumanArt/annotations/validation_humanart_coco.json', + data_prefix=dict(img=''), + test_mode=True, + pipeline=test_pipeline, + backend_args=backend_args)) +test_dataloader = val_dataloader + +val_evaluator = dict( + type='CocoMetric', + ann_file=data_root + 'HumanArt/annotations/validation_humanart_coco.json', + metric='bbox', + format_only=False, + backend_args=backend_args) +test_evaluator = val_evaluator + +# inference on test dataset and +# format the output results for submission. +# test_dataloader = dict( +# batch_size=1, +# num_workers=2, +# persistent_workers=True, +# drop_last=False, +# sampler=dict(type='DefaultSampler', shuffle=False), +# dataset=dict( +# type=dataset_type, +# data_root=data_root, +# ann_file=data_root + 'annotations/image_info_test-dev2017.json', +# data_prefix=dict(img='test2017/'), +# test_mode=True, +# pipeline=test_pipeline)) +# test_evaluator = dict( +# type='CocoMetric', +# metric='bbox', +# format_only=True, +# ann_file=data_root + 'annotations/image_info_test-dev2017.json', +# outfile_prefix='./work_dirs/coco_detection/test') diff --git a/projects/rtmpose/rtmdet/person/rtmdet_l_8xb32-300e_humanart.py b/projects/rtmpose/rtmdet/person/rtmdet_l_8xb32-300e_humanart.py new file mode 100644 index 0000000000..7b009072c6 --- /dev/null +++ b/projects/rtmpose/rtmdet/person/rtmdet_l_8xb32-300e_humanart.py @@ -0,0 +1,180 @@ +_base_ = [ + 'mmdet::_base_/default_runtime.py', + 'mmdet::_base_/schedules/schedule_1x.py', './humanart_detection.py', + 'mmdet::rtmdet_tta.py' +] +model = dict( + type='RTMDet', + data_preprocessor=dict( + type='DetDataPreprocessor', + mean=[103.53, 116.28, 123.675], + std=[57.375, 57.12, 58.395], + bgr_to_rgb=False, + batch_augments=None), + backbone=dict( + type='CSPNeXt', + arch='P5', + expand_ratio=0.5, + deepen_factor=1, + widen_factor=1, + channel_attention=True, + norm_cfg=dict(type='SyncBN'), + act_cfg=dict(type='SiLU', inplace=True)), + neck=dict( + type='CSPNeXtPAFPN', + in_channels=[256, 512, 1024], + out_channels=256, + num_csp_blocks=3, + expand_ratio=0.5, + norm_cfg=dict(type='SyncBN'), + act_cfg=dict(type='SiLU', inplace=True)), + bbox_head=dict( + type='RTMDetSepBNHead', + num_classes=80, + in_channels=256, + stacked_convs=2, + feat_channels=256, + anchor_generator=dict( + type='MlvlPointGenerator', offset=0, strides=[8, 16, 32]), + bbox_coder=dict(type='DistancePointBBoxCoder'), + loss_cls=dict( + type='QualityFocalLoss', + use_sigmoid=True, + beta=2.0, + loss_weight=1.0), + loss_bbox=dict(type='GIoULoss', loss_weight=2.0), + with_objectness=False, + exp_on_reg=True, + share_conv=True, + pred_kernel_size=1, + norm_cfg=dict(type='SyncBN'), + act_cfg=dict(type='SiLU', inplace=True)), + train_cfg=dict( + assigner=dict(type='DynamicSoftLabelAssigner', topk=13), + allowed_border=-1, + pos_weight=-1, + debug=False), + test_cfg=dict( + nms_pre=30000, + min_bbox_size=0, + score_thr=0.001, + nms=dict(type='nms', iou_threshold=0.65), + max_per_img=300), +) + +train_pipeline = [ + dict(type='LoadImageFromFile', backend_args={{_base_.backend_args}}), + dict(type='LoadAnnotations', with_bbox=True), + dict(type='CachedMosaic', img_scale=(640, 640), pad_val=114.0), + dict( + type='RandomResize', + scale=(1280, 1280), + ratio_range=(0.1, 2.0), + keep_ratio=True), + dict(type='RandomCrop', crop_size=(640, 640)), + dict(type='YOLOXHSVRandomAug'), + dict(type='RandomFlip', prob=0.5), + dict(type='Pad', size=(640, 640), pad_val=dict(img=(114, 114, 114))), + dict( + type='CachedMixUp', + img_scale=(640, 640), + ratio_range=(1.0, 1.0), + max_cached_images=20, + pad_val=(114, 114, 114)), + dict(type='PackDetInputs') +] + +train_pipeline_stage2 = [ + dict(type='LoadImageFromFile', backend_args={{_base_.backend_args}}), + dict(type='LoadAnnotations', with_bbox=True), + dict( + type='RandomResize', + scale=(640, 640), + ratio_range=(0.1, 2.0), + keep_ratio=True), + dict(type='RandomCrop', crop_size=(640, 640)), + dict(type='YOLOXHSVRandomAug'), + dict(type='RandomFlip', prob=0.5), + dict(type='Pad', size=(640, 640), pad_val=dict(img=(114, 114, 114))), + dict(type='PackDetInputs') +] + +test_pipeline = [ + dict(type='LoadImageFromFile', backend_args={{_base_.backend_args}}), + dict(type='Resize', scale=(640, 640), keep_ratio=True), + dict(type='Pad', size=(640, 640), pad_val=dict(img=(114, 114, 114))), + dict(type='LoadAnnotations', with_bbox=True), + dict( + type='PackDetInputs', + meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', + 'scale_factor')) +] + +train_dataloader = dict( + batch_size=32, + num_workers=10, + batch_sampler=None, + pin_memory=True, + dataset=dict(pipeline=train_pipeline)) +val_dataloader = dict( + batch_size=5, num_workers=10, dataset=dict(pipeline=test_pipeline)) +test_dataloader = val_dataloader + +max_epochs = 300 +stage2_num_epochs = 20 +base_lr = 0.0005 +interval = 10 + +train_cfg = dict( + max_epochs=max_epochs, + val_interval=interval, + dynamic_intervals=[(max_epochs - stage2_num_epochs, 1)]) + +val_evaluator = dict(proposal_nums=(100, 1, 10)) +test_evaluator = val_evaluator + +# optimizer +optim_wrapper = dict( + _delete_=True, + type='OptimWrapper', + optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05), + paramwise_cfg=dict( + norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True)) + +# learning rate +param_scheduler = [ + dict( + type='LinearLR', + start_factor=1.0e-5, + by_epoch=False, + begin=0, + end=1000), + dict( + # use cosine lr from 150 to 300 epoch + type='CosineAnnealingLR', + eta_min=base_lr * 0.05, + begin=max_epochs // 2, + end=max_epochs, + T_max=max_epochs // 2, + by_epoch=True, + convert_to_iter_based=True), +] + +# hooks +default_hooks = dict( + checkpoint=dict( + interval=interval, + max_keep_ckpts=3 # only keep latest 3 checkpoints + )) +custom_hooks = [ + dict( + type='EMAHook', + ema_type='ExpMomentumEMA', + momentum=0.0002, + update_buffers=True, + priority=49), + dict( + type='PipelineSwitchHook', + switch_epoch=max_epochs - stage2_num_epochs, + switch_pipeline=train_pipeline_stage2) +] diff --git a/projects/rtmpose/rtmdet/person/rtmdet_m_8xb32-300e_humanart.py b/projects/rtmpose/rtmdet/person/rtmdet_m_8xb32-300e_humanart.py new file mode 100644 index 0000000000..263ec89347 --- /dev/null +++ b/projects/rtmpose/rtmdet/person/rtmdet_m_8xb32-300e_humanart.py @@ -0,0 +1,6 @@ +_base_ = './rtmdet_l_8xb32-300e_humanart.py' + +model = dict( + backbone=dict(deepen_factor=0.67, widen_factor=0.75), + neck=dict(in_channels=[192, 384, 768], out_channels=192, num_csp_blocks=2), + bbox_head=dict(in_channels=192, feat_channels=192)) diff --git a/projects/rtmpose/rtmdet/person/rtmdet_s_8xb32-300e_humanart.py b/projects/rtmpose/rtmdet/person/rtmdet_s_8xb32-300e_humanart.py new file mode 100644 index 0000000000..927cbf7555 --- /dev/null +++ b/projects/rtmpose/rtmdet/person/rtmdet_s_8xb32-300e_humanart.py @@ -0,0 +1,62 @@ +_base_ = './rtmdet_l_8xb32-300e_humanart.py' +checkpoint = 'https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-s_imagenet_600e.pth' # noqa +model = dict( + backbone=dict( + deepen_factor=0.33, + widen_factor=0.5, + init_cfg=dict( + type='Pretrained', prefix='backbone.', checkpoint=checkpoint)), + neck=dict(in_channels=[128, 256, 512], out_channels=128, num_csp_blocks=1), + bbox_head=dict(in_channels=128, feat_channels=128, exp_on_reg=False)) + +train_pipeline = [ + dict(type='LoadImageFromFile', backend_args={{_base_.backend_args}}), + dict(type='LoadAnnotations', with_bbox=True), + dict(type='CachedMosaic', img_scale=(640, 640), pad_val=114.0), + dict( + type='RandomResize', + scale=(1280, 1280), + ratio_range=(0.5, 2.0), + keep_ratio=True), + dict(type='RandomCrop', crop_size=(640, 640)), + dict(type='YOLOXHSVRandomAug'), + dict(type='RandomFlip', prob=0.5), + dict(type='Pad', size=(640, 640), pad_val=dict(img=(114, 114, 114))), + dict( + type='CachedMixUp', + img_scale=(640, 640), + ratio_range=(1.0, 1.0), + max_cached_images=20, + pad_val=(114, 114, 114)), + dict(type='PackDetInputs') +] + +train_pipeline_stage2 = [ + dict(type='LoadImageFromFile', backend_args={{_base_.backend_args}}), + dict(type='LoadAnnotations', with_bbox=True), + dict( + type='RandomResize', + scale=(640, 640), + ratio_range=(0.5, 2.0), + keep_ratio=True), + dict(type='RandomCrop', crop_size=(640, 640)), + dict(type='YOLOXHSVRandomAug'), + dict(type='RandomFlip', prob=0.5), + dict(type='Pad', size=(640, 640), pad_val=dict(img=(114, 114, 114))), + dict(type='PackDetInputs') +] + +train_dataloader = dict(dataset=dict(pipeline=train_pipeline)) + +custom_hooks = [ + dict( + type='EMAHook', + ema_type='ExpMomentumEMA', + momentum=0.0002, + update_buffers=True, + priority=49), + dict( + type='PipelineSwitchHook', + switch_epoch=280, + switch_pipeline=train_pipeline_stage2) +] diff --git a/projects/rtmpose/rtmdet/person/rtmdet_tiny_8xb32-300e_humanart.py b/projects/rtmpose/rtmdet/person/rtmdet_tiny_8xb32-300e_humanart.py new file mode 100644 index 0000000000..c92442fa8d --- /dev/null +++ b/projects/rtmpose/rtmdet/person/rtmdet_tiny_8xb32-300e_humanart.py @@ -0,0 +1,43 @@ +_base_ = './rtmdet_s_8xb32-300e_humanart.py' + +checkpoint = 'https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-tiny_imagenet_600e.pth' # noqa + +model = dict( + backbone=dict( + deepen_factor=0.167, + widen_factor=0.375, + init_cfg=dict( + type='Pretrained', prefix='backbone.', checkpoint=checkpoint)), + neck=dict(in_channels=[96, 192, 384], out_channels=96, num_csp_blocks=1), + bbox_head=dict(in_channels=96, feat_channels=96, exp_on_reg=False)) + +train_pipeline = [ + dict(type='LoadImageFromFile', backend_args={{_base_.backend_args}}), + dict(type='LoadAnnotations', with_bbox=True), + dict( + type='CachedMosaic', + img_scale=(640, 640), + pad_val=114.0, + max_cached_images=20, + random_pop=False), + dict( + type='RandomResize', + scale=(1280, 1280), + ratio_range=(0.5, 2.0), + keep_ratio=True), + dict(type='RandomCrop', crop_size=(640, 640)), + dict(type='YOLOXHSVRandomAug'), + dict(type='RandomFlip', prob=0.5), + dict(type='Pad', size=(640, 640), pad_val=dict(img=(114, 114, 114))), + dict( + type='CachedMixUp', + img_scale=(640, 640), + ratio_range=(1.0, 1.0), + max_cached_images=10, + random_pop=False, + pad_val=(114, 114, 114), + prob=0.5), + dict(type='PackDetInputs') +] + +train_dataloader = dict(dataset=dict(pipeline=train_pipeline)) diff --git a/projects/rtmpose/rtmdet/person/rtmdet_x_8xb32-300e_humanart.py b/projects/rtmpose/rtmdet/person/rtmdet_x_8xb32-300e_humanart.py new file mode 100644 index 0000000000..60fd09c866 --- /dev/null +++ b/projects/rtmpose/rtmdet/person/rtmdet_x_8xb32-300e_humanart.py @@ -0,0 +1,7 @@ +_base_ = './rtmdet_l_8xb32-300e_humanart.py' + +model = dict( + backbone=dict(deepen_factor=1.33, widen_factor=1.25), + neck=dict( + in_channels=[320, 640, 1280], out_channels=320, num_csp_blocks=4), + bbox_head=dict(in_channels=320, feat_channels=320)) diff --git a/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_coco-384x288.py b/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_coco-384x288.py index 1441e07791..25da9aeeb1 100644 --- a/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_coco-384x288.py +++ b/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_coco-384x288.py @@ -66,7 +66,7 @@ arch='P5', expand_ratio=0.5, deepen_factor=1.33, - widen_factor=1.28, + widen_factor=1.25, out_indices=(4, ), channel_attention=True, norm_cfg=dict(type='SyncBN'), diff --git a/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmpose-s_8xb64-270e_coco-wholebody-256x192.py b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmpose-s_8xb64-270e_coco-wholebody-256x192.py new file mode 100644 index 0000000000..7afb493d6e --- /dev/null +++ b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmpose-s_8xb64-270e_coco-wholebody-256x192.py @@ -0,0 +1,233 @@ +_base_ = ['mmpose::_base_/default_runtime.py'] + +# common setting +num_keypoints = 133 +input_size = (192, 256) + +# runtime +max_epochs = 270 +stage2_num_epochs = 30 +base_lr = 4e-3 +train_batch_size = 64 +val_batch_size = 32 + +train_cfg = dict(max_epochs=max_epochs, val_interval=10) +randomness = dict(seed=21) + +# optimizer +optim_wrapper = dict( + type='OptimWrapper', + optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05), + clip_grad=dict(max_norm=35, norm_type=2), + paramwise_cfg=dict( + norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True)) + +# learning rate +param_scheduler = [ + dict( + type='LinearLR', + start_factor=1.0e-5, + by_epoch=False, + begin=0, + end=1000), + dict( + type='CosineAnnealingLR', + eta_min=base_lr * 0.05, + begin=max_epochs // 2, + end=max_epochs, + T_max=max_epochs // 2, + by_epoch=True, + convert_to_iter_based=True), +] + +# automatically scaling LR based on the actual training batch size +auto_scale_lr = dict(base_batch_size=512) + +# codec settings +codec = dict( + type='SimCCLabel', + input_size=input_size, + sigma=(4.9, 5.66), + simcc_split_ratio=2.0, + normalize=False, + use_dark=False) + +# model settings +model = dict( + type='TopdownPoseEstimator', + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + backbone=dict( + _scope_='mmdet', + type='CSPNeXt', + arch='P5', + expand_ratio=0.5, + deepen_factor=0.33, + widen_factor=0.5, + out_indices=(4, ), + channel_attention=True, + norm_cfg=dict(type='SyncBN'), + act_cfg=dict(type='SiLU'), + init_cfg=dict( + type='Pretrained', + prefix='backbone.', + checkpoint='https://download.openmmlab.com/mmpose/v1/projects/' + 'rtmposev1/cspnext-s_udp-aic-coco_210e-256x192-92f5a029_20230130.pth' # noqa + )), + head=dict( + type='RTMCCHead', + in_channels=512, + out_channels=num_keypoints, + input_size=codec['input_size'], + in_featuremap_size=tuple([s // 32 for s in codec['input_size']]), + simcc_split_ratio=codec['simcc_split_ratio'], + final_layer_kernel_size=7, + gau_cfg=dict( + hidden_dims=256, + s=128, + expansion_factor=2, + dropout_rate=0., + drop_path=0., + act_fn='SiLU', + use_rel_bias=False, + pos_enc=False), + loss=dict( + type='KLDiscretLoss', + use_target_weight=True, + beta=10., + label_softmax=True), + decoder=codec), + test_cfg=dict(flip_test=True, )) + +# base dataset settings +dataset_type = 'CocoWholeBodyDataset' +data_mode = 'topdown' +data_root = 'data/coco/' + +backend_args = dict(backend='local') + +# pipelines +train_pipeline = [ + dict(type='LoadImage', backend_args=backend_args), + dict(type='GetBBoxCenterScale'), + dict(type='RandomFlip', direction='horizontal'), + dict(type='RandomHalfBody'), + dict( + type='RandomBBoxTransform', scale_factor=[0.6, 1.4], rotate_factor=80), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='mmdet.YOLOXHSVRandomAug'), + dict( + type='Albumentation', + transforms=[ + dict(type='Blur', p=0.1), + dict(type='MedianBlur', p=0.1), + dict( + type='CoarseDropout', + max_holes=1, + max_height=0.4, + max_width=0.4, + min_holes=1, + min_height=0.2, + min_width=0.2, + p=1.0), + ]), + dict(type='GenerateTarget', encoder=codec), + dict(type='PackPoseInputs') +] +val_pipeline = [ + dict(type='LoadImage', backend_args=backend_args), + dict(type='GetBBoxCenterScale'), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='PackPoseInputs') +] + +train_pipeline_stage2 = [ + dict(type='LoadImage', backend_args=backend_args), + dict(type='GetBBoxCenterScale'), + dict(type='RandomFlip', direction='horizontal'), + dict(type='RandomHalfBody'), + dict( + type='RandomBBoxTransform', + shift_factor=0., + scale_factor=[0.75, 1.25], + rotate_factor=60), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='mmdet.YOLOXHSVRandomAug'), + dict( + type='Albumentation', + transforms=[ + dict(type='Blur', p=0.1), + dict(type='MedianBlur', p=0.1), + dict( + type='CoarseDropout', + max_holes=1, + max_height=0.4, + max_width=0.4, + min_holes=1, + min_height=0.2, + min_width=0.2, + p=0.5), + ]), + dict(type='GenerateTarget', encoder=codec), + dict(type='PackPoseInputs') +] + +# data loaders +train_dataloader = dict( + batch_size=train_batch_size, + num_workers=10, + persistent_workers=True, + sampler=dict(type='DefaultSampler', shuffle=True), + dataset=dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='annotations/coco_wholebody_train_v1.0.json', + data_prefix=dict(img='train2017/'), + pipeline=train_pipeline, + )) +val_dataloader = dict( + batch_size=val_batch_size, + num_workers=10, + persistent_workers=True, + drop_last=False, + sampler=dict(type='DefaultSampler', shuffle=False, round_up=False), + dataset=dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='annotations/coco_wholebody_val_v1.0.json', + data_prefix=dict(img='val2017/'), + test_mode=True, + bbox_file='data/coco/person_detection_results/' + 'COCO_val2017_detections_AP_H_56_person.json', + pipeline=val_pipeline, + )) +test_dataloader = val_dataloader + +# hooks +default_hooks = dict( + checkpoint=dict( + save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1)) + +custom_hooks = [ + dict( + type='EMAHook', + ema_type='ExpMomentumEMA', + momentum=0.0002, + update_buffers=True, + priority=49), + dict( + type='mmdet.PipelineSwitchHook', + switch_epoch=max_epochs - stage2_num_epochs, + switch_pipeline=train_pipeline_stage2) +] + +# evaluators +val_evaluator = dict( + type='CocoWholeBodyMetric', + ann_file=data_root + 'annotations/coco_wholebody_val_v1.0.json') +test_evaluator = val_evaluator diff --git a/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmpose-t_8xb64-270e_coco-wholebody-256x192.py b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmpose-t_8xb64-270e_coco-wholebody-256x192.py new file mode 100644 index 0000000000..3ea3de877b --- /dev/null +++ b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmpose-t_8xb64-270e_coco-wholebody-256x192.py @@ -0,0 +1,233 @@ +_base_ = ['mmpose::_base_/default_runtime.py'] + +# common setting +num_keypoints = 133 +input_size = (192, 256) + +# runtime +max_epochs = 270 +stage2_num_epochs = 30 +base_lr = 4e-3 +train_batch_size = 64 +val_batch_size = 32 + +train_cfg = dict(max_epochs=max_epochs, val_interval=10) +randomness = dict(seed=21) + +# optimizer +optim_wrapper = dict( + type='OptimWrapper', + optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05), + clip_grad=dict(max_norm=35, norm_type=2), + paramwise_cfg=dict( + norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True)) + +# learning rate +param_scheduler = [ + dict( + type='LinearLR', + start_factor=1.0e-5, + by_epoch=False, + begin=0, + end=1000), + dict( + type='CosineAnnealingLR', + eta_min=base_lr * 0.05, + begin=max_epochs // 2, + end=max_epochs, + T_max=max_epochs // 2, + by_epoch=True, + convert_to_iter_based=True), +] + +# automatically scaling LR based on the actual training batch size +auto_scale_lr = dict(base_batch_size=512) + +# codec settings +codec = dict( + type='SimCCLabel', + input_size=input_size, + sigma=(4.9, 5.66), + simcc_split_ratio=2.0, + normalize=False, + use_dark=False) + +# model settings +model = dict( + type='TopdownPoseEstimator', + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + backbone=dict( + _scope_='mmdet', + type='CSPNeXt', + arch='P5', + expand_ratio=0.5, + deepen_factor=0.167, + widen_factor=0.375, + out_indices=(4, ), + channel_attention=True, + norm_cfg=dict(type='SyncBN'), + act_cfg=dict(type='SiLU'), + init_cfg=dict( + type='Pretrained', + prefix='backbone.', + checkpoint='https://download.openmmlab.com/mmpose/v1/projects/' + 'rtmposev1/cspnext-tiny_udp-aic-coco_210e-256x192-cbed682d_20230130.pth' # noqa + )), + head=dict( + type='RTMCCHead', + in_channels=384, + out_channels=num_keypoints, + input_size=codec['input_size'], + in_featuremap_size=tuple([s // 32 for s in codec['input_size']]), + simcc_split_ratio=codec['simcc_split_ratio'], + final_layer_kernel_size=7, + gau_cfg=dict( + hidden_dims=256, + s=128, + expansion_factor=2, + dropout_rate=0., + drop_path=0., + act_fn='SiLU', + use_rel_bias=False, + pos_enc=False), + loss=dict( + type='KLDiscretLoss', + use_target_weight=True, + beta=10., + label_softmax=True), + decoder=codec), + test_cfg=dict(flip_test=True, )) + +# base dataset settings +dataset_type = 'CocoWholeBodyDataset' +data_mode = 'topdown' +data_root = 'data/coco/' + +backend_args = dict(backend='local') + +# pipelines +train_pipeline = [ + dict(type='LoadImage', backend_args=backend_args), + dict(type='GetBBoxCenterScale'), + dict(type='RandomFlip', direction='horizontal'), + dict(type='RandomHalfBody'), + dict( + type='RandomBBoxTransform', scale_factor=[0.6, 1.4], rotate_factor=80), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='mmdet.YOLOXHSVRandomAug'), + dict( + type='Albumentation', + transforms=[ + dict(type='Blur', p=0.1), + dict(type='MedianBlur', p=0.1), + dict( + type='CoarseDropout', + max_holes=1, + max_height=0.4, + max_width=0.4, + min_holes=1, + min_height=0.2, + min_width=0.2, + p=1.0), + ]), + dict(type='GenerateTarget', encoder=codec), + dict(type='PackPoseInputs') +] +val_pipeline = [ + dict(type='LoadImage', backend_args=backend_args), + dict(type='GetBBoxCenterScale'), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='PackPoseInputs') +] + +train_pipeline_stage2 = [ + dict(type='LoadImage', backend_args=backend_args), + dict(type='GetBBoxCenterScale'), + dict(type='RandomFlip', direction='horizontal'), + dict(type='RandomHalfBody'), + dict( + type='RandomBBoxTransform', + shift_factor=0., + scale_factor=[0.75, 1.25], + rotate_factor=60), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='mmdet.YOLOXHSVRandomAug'), + dict( + type='Albumentation', + transforms=[ + dict(type='Blur', p=0.1), + dict(type='MedianBlur', p=0.1), + dict( + type='CoarseDropout', + max_holes=1, + max_height=0.4, + max_width=0.4, + min_holes=1, + min_height=0.2, + min_width=0.2, + p=0.5), + ]), + dict(type='GenerateTarget', encoder=codec), + dict(type='PackPoseInputs') +] + +# data loaders +train_dataloader = dict( + batch_size=train_batch_size, + num_workers=10, + persistent_workers=True, + sampler=dict(type='DefaultSampler', shuffle=True), + dataset=dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='annotations/coco_wholebody_train_v1.0.json', + data_prefix=dict(img='train2017/'), + pipeline=train_pipeline, + )) +val_dataloader = dict( + batch_size=val_batch_size, + num_workers=10, + persistent_workers=True, + drop_last=False, + sampler=dict(type='DefaultSampler', shuffle=False, round_up=False), + dataset=dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='annotations/coco_wholebody_val_v1.0.json', + data_prefix=dict(img='val2017/'), + test_mode=True, + bbox_file='data/coco/person_detection_results/' + 'COCO_val2017_detections_AP_H_56_person.json', + pipeline=val_pipeline, + )) +test_dataloader = val_dataloader + +# hooks +default_hooks = dict( + checkpoint=dict( + save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1)) + +custom_hooks = [ + dict( + type='EMAHook', + ema_type='ExpMomentumEMA', + momentum=0.0002, + update_buffers=True, + priority=49), + dict( + type='mmdet.PipelineSwitchHook', + switch_epoch=max_epochs - stage2_num_epochs, + switch_pipeline=train_pipeline_stage2) +] + +# evaluators +val_evaluator = dict( + type='CocoWholeBodyMetric', + ann_file=data_root + 'annotations/coco_wholebody_val_v1.0.json') +test_evaluator = val_evaluator diff --git a/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb320-270e_cocktail13-384x288.py b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb320-270e_cocktail13-384x288.py new file mode 100644 index 0000000000..55d07b61a8 --- /dev/null +++ b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb320-270e_cocktail13-384x288.py @@ -0,0 +1,638 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from mmengine.config import read_base + +with read_base(): + from mmpose.configs._base_.default_runtime import * # noqa + +from albumentations.augmentations import Blur, CoarseDropout, MedianBlur +from mmdet.engine.hooks import PipelineSwitchHook +from mmengine.dataset import DefaultSampler +from mmengine.hooks import EMAHook +from mmengine.model import PretrainedInit +from mmengine.optim import CosineAnnealingLR, LinearLR, OptimWrapper +from torch.nn import SiLU, SyncBatchNorm +from torch.optim import AdamW + +from mmpose.codecs import SimCCLabel +from mmpose.datasets import (AicDataset, CocoWholeBodyDataset, COFWDataset, + CombinedDataset, CrowdPoseDataset, + Face300WDataset, GenerateTarget, + GetBBoxCenterScale, HalpeDataset, + HumanArt21Dataset, InterHand2DDoubleDataset, + JhmdbDataset, KeypointConverter, LapaDataset, + LoadImage, MpiiDataset, PackPoseInputs, + PoseTrack18Dataset, RandomFlip, RandomHalfBody, + TopdownAffine, UBody2dDataset, WFLWDataset) +from mmpose.datasets.transforms.common_transforms import ( + Albumentation, PhotometricDistortion, RandomBBoxTransform) +from mmpose.engine.hooks import ExpMomentumEMA +from mmpose.evaluation import CocoWholeBodyMetric +from mmpose.models import (CSPNeXt, CSPNeXtPAFPN, KLDiscretLoss, + PoseDataPreprocessor, RTMWHead, + TopdownPoseEstimator) + +# common setting +num_keypoints = 133 +input_size = (288, 384) + +# runtime +max_epochs = 270 +stage2_num_epochs = 10 +base_lr = 5e-4 +train_batch_size = 320 +val_batch_size = 32 + +train_cfg.update(max_epochs=max_epochs, val_interval=10) # noqa +randomness = dict(seed=21) + +# optimizer +optim_wrapper = dict( + type=OptimWrapper, + optimizer=dict(type=AdamW, lr=base_lr, weight_decay=0.05), + clip_grad=dict(max_norm=35, norm_type=2), + paramwise_cfg=dict( + norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True)) + +# learning rate +param_scheduler = [ + dict( + type=LinearLR, start_factor=1.0e-5, by_epoch=False, begin=0, end=1000), + dict( + type=CosineAnnealingLR, + eta_min=base_lr * 0.05, + begin=max_epochs // 2, + end=max_epochs, + T_max=max_epochs // 2, + by_epoch=True, + convert_to_iter_based=True), +] + +# automatically scaling LR based on the actual training batch size +auto_scale_lr = dict(base_batch_size=5632) + +# codec settings +codec = dict( + type=SimCCLabel, + input_size=input_size, + sigma=(6., 6.93), + simcc_split_ratio=2.0, + normalize=False, + use_dark=False) + +# model settings +model = dict( + type=TopdownPoseEstimator, + data_preprocessor=dict( + type=PoseDataPreprocessor, + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + backbone=dict( + type=CSPNeXt, + arch='P5', + expand_ratio=0.5, + deepen_factor=1.33, + widen_factor=1.25, + channel_attention=True, + norm_cfg=dict(type='BN'), + act_cfg=dict(type=SiLU), + init_cfg=dict( + type=PretrainedInit, + prefix='backbone.', + checkpoint='https://download.openmmlab.com/mmpose/v1/' + 'wholebody_2d_keypoint/rtmpose/ubody/rtmpose-x_simcc-ucoco_pt-aic-coco_270e-384x288-f5b50679_20230822.pth' # noqa + )), + neck=dict( + type=CSPNeXtPAFPN, + in_channels=[320, 640, 1280], + out_channels=None, + out_indices=( + 1, + 2, + ), + num_csp_blocks=2, + expand_ratio=0.5, + norm_cfg=dict(type=SyncBatchNorm), + act_cfg=dict(type=SiLU, inplace=True)), + head=dict( + type=RTMWHead, + in_channels=1280, + out_channels=num_keypoints, + input_size=input_size, + in_featuremap_size=tuple([s // 32 for s in input_size]), + simcc_split_ratio=codec['simcc_split_ratio'], + final_layer_kernel_size=7, + gau_cfg=dict( + hidden_dims=256, + s=128, + expansion_factor=2, + dropout_rate=0., + drop_path=0., + act_fn=SiLU, + use_rel_bias=False, + pos_enc=False), + loss=dict( + type=KLDiscretLoss, + use_target_weight=True, + beta=10., + label_softmax=True), + decoder=codec), + test_cfg=dict(flip_test=True)) + +# base dataset settings +dataset_type = CocoWholeBodyDataset +data_mode = 'topdown' +data_root = 'data/' + +backend_args = dict(backend='local') + +# pipelines +train_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict(type=RandomFlip, direction='horizontal'), + dict(type=RandomHalfBody), + dict(type=RandomBBoxTransform, scale_factor=[0.5, 1.5], rotate_factor=90), + dict(type=TopdownAffine, input_size=codec['input_size']), + dict(type=PhotometricDistortion), + dict( + type=Albumentation, + transforms=[ + dict(type=Blur, p=0.1), + dict(type=MedianBlur, p=0.1), + dict( + type=CoarseDropout, + max_holes=1, + max_height=0.4, + max_width=0.4, + min_holes=1, + min_height=0.2, + min_width=0.2, + p=1.0), + ]), + dict( + type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True), + dict(type=PackPoseInputs) +] +val_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict(type=TopdownAffine, input_size=codec['input_size']), + dict(type=PackPoseInputs) +] +train_pipeline_stage2 = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict(type=RandomFlip, direction='horizontal'), + dict(type=RandomHalfBody), + dict( + type=RandomBBoxTransform, + shift_factor=0., + scale_factor=[0.5, 1.5], + rotate_factor=90), + dict(type=TopdownAffine, input_size=codec['input_size']), + dict( + type=Albumentation, + transforms=[ + dict(type=Blur, p=0.1), + dict(type=MedianBlur, p=0.1), + ]), + dict( + type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True), + dict(type=PackPoseInputs) +] + +# mapping + +aic_coco133 = [(0, 6), (1, 8), (2, 10), (3, 5), (4, 7), (5, 9), (6, 12), + (7, 14), (8, 16), (9, 11), (10, 13), (11, 15)] + +crowdpose_coco133 = [(0, 5), (1, 6), (2, 7), (3, 8), (4, 9), (5, 10), (6, 11), + (7, 12), (8, 13), (9, 14), (10, 15), (11, 16)] + +mpii_coco133 = [ + (0, 16), + (1, 14), + (2, 12), + (3, 11), + (4, 13), + (5, 15), + (8, 18), + (9, 17), + (10, 10), + (11, 8), + (12, 6), + (13, 5), + (14, 7), + (15, 9), +] + +jhmdb_coco133 = [ + (0, 18), + (2, 17), + (3, 6), + (4, 5), + (5, 12), + (6, 11), + (7, 8), + (8, 7), + (9, 14), + (10, 13), + (11, 10), + (12, 9), + (13, 16), + (14, 15), +] + +halpe_coco133 = [(i, i) + for i in range(17)] + [(20, 17), (21, 20), (22, 18), (23, 21), + (24, 19), + (25, 22)] + [(i, i - 3) + for i in range(26, 136)] + +posetrack_coco133 = [ + (0, 0), + (2, 17), + (3, 3), + (4, 4), + (5, 5), + (6, 6), + (7, 7), + (8, 8), + (9, 9), + (10, 10), + (11, 11), + (12, 12), + (13, 13), + (14, 14), + (15, 15), + (16, 16), +] + +humanart_coco133 = [(i, i) for i in range(17)] + [(17, 99), (18, 120), + (19, 17), (20, 20)] + +# train datasets +dataset_coco = dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='coco/annotations/coco_wholebody_train_v1.0.json', + data_prefix=dict(img='detection/coco/train2017/'), + pipeline=[], +) + +dataset_aic = dict( + type=AicDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='aic/annotations/aic_train.json', + data_prefix=dict(img='pose/ai_challenge/ai_challenger_keypoint' + '_train_20170902/keypoint_train_images_20170902/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=aic_coco133) + ], +) + +dataset_crowdpose = dict( + type=CrowdPoseDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='crowdpose/annotations/mmpose_crowdpose_trainval.json', + data_prefix=dict(img='pose/CrowdPose/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=crowdpose_coco133) + ], +) + +dataset_mpii = dict( + type=MpiiDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='mpii/annotations/mpii_train.json', + data_prefix=dict(img='pose/MPI/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=mpii_coco133) + ], +) + +dataset_jhmdb = dict( + type=JhmdbDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='jhmdb/annotations/Sub1_train.json', + data_prefix=dict(img='pose/JHMDB/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=jhmdb_coco133) + ], +) + +dataset_halpe = dict( + type=HalpeDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='halpe/annotations/halpe_train_v1.json', + data_prefix=dict(img='pose/Halpe/hico_20160224_det/images/train2015'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=halpe_coco133) + ], +) + +dataset_posetrack = dict( + type=PoseTrack18Dataset, + data_root=data_root, + data_mode=data_mode, + ann_file='posetrack18/annotations/posetrack18_train.json', + data_prefix=dict(img='pose/PoseChallenge2018/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=posetrack_coco133) + ], +) + +dataset_humanart = dict( + type=HumanArt21Dataset, + data_root=data_root, + data_mode=data_mode, + ann_file='HumanArt/annotations/training_humanart.json', + filter_cfg=dict(scenes=['real_human']), + data_prefix=dict(img='pose/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=humanart_coco133) + ]) + +ubody_scenes = [ + 'Magic_show', 'Entertainment', 'ConductMusic', 'Online_class', 'TalkShow', + 'Speech', 'Fitness', 'Interview', 'Olympic', 'TVShow', 'Singing', + 'SignLanguage', 'Movie', 'LiveVlog', 'VideoConference' +] + +ubody_datasets = [] +for scene in ubody_scenes: + each = dict( + type=UBody2dDataset, + data_root=data_root, + data_mode=data_mode, + ann_file=f'Ubody/annotations/{scene}/train_annotations.json', + data_prefix=dict(img='pose/UBody/images/'), + pipeline=[], + sample_interval=10) + ubody_datasets.append(each) + +dataset_ubody = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/ubody2d.py'), + datasets=ubody_datasets, + pipeline=[], + test_mode=False, +) + +face_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale, padding=1.25), + dict( + type=RandomBBoxTransform, + shift_factor=0., + scale_factor=[1.5, 2.0], + rotate_factor=0), +] + +wflw_coco133 = [(i * 2, 23 + i) + for i in range(17)] + [(33 + i, 40 + i) for i in range(5)] + [ + (42 + i, 45 + i) for i in range(5) + ] + [(51 + i, 50 + i) + for i in range(9)] + [(60, 59), (61, 60), (63, 61), + (64, 62), (65, 63), (67, 64), + (68, 65), (69, 66), (71, 67), + (72, 68), (73, 69), + (75, 70)] + [(76 + i, 71 + i) + for i in range(20)] +dataset_wflw = dict( + type=WFLWDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='wflw/annotations/face_landmarks_wflw_train.json', + data_prefix=dict(img='pose/WFLW/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=wflw_coco133), *face_pipeline + ], +) + +mapping_300w_coco133 = [(i, 23 + i) for i in range(68)] +dataset_300w = dict( + type=Face300WDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='300w/annotations/face_landmarks_300w_train.json', + data_prefix=dict(img='pose/300w/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=mapping_300w_coco133), *face_pipeline + ], +) + +cofw_coco133 = [(0, 40), (2, 44), (4, 42), (1, 49), (3, 45), (6, 47), (8, 59), + (10, 62), (9, 68), (11, 65), (18, 54), (19, 58), (20, 53), + (21, 56), (22, 71), (23, 77), (24, 74), (25, 85), (26, 89), + (27, 80), (28, 31)] +dataset_cofw = dict( + type=COFWDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='cofw/annotations/cofw_train.json', + data_prefix=dict(img='pose/COFW/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=cofw_coco133), *face_pipeline + ], +) + +lapa_coco133 = [(i * 2, 23 + i) for i in range(17)] + [ + (33 + i, 40 + i) for i in range(5) +] + [(42 + i, 45 + i) for i in range(5)] + [ + (51 + i, 50 + i) for i in range(4) +] + [(58 + i, 54 + i) for i in range(5)] + [(66, 59), (67, 60), (69, 61), + (70, 62), (71, 63), (73, 64), + (75, 65), (76, 66), (78, 67), + (79, 68), (80, 69), + (82, 70)] + [(84 + i, 71 + i) + for i in range(20)] +dataset_lapa = dict( + type=LapaDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='LaPa/annotations/lapa_trainval.json', + data_prefix=dict(img='pose/LaPa/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=lapa_coco133), *face_pipeline + ], +) + +dataset_wb = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[dataset_coco, dataset_halpe, dataset_ubody], + pipeline=[], + test_mode=False, +) + +dataset_body = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[ + dataset_aic, + dataset_crowdpose, + dataset_mpii, + dataset_jhmdb, + dataset_posetrack, + dataset_humanart, + ], + pipeline=[], + test_mode=False, +) + +dataset_face = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[ + dataset_wflw, + dataset_300w, + dataset_cofw, + dataset_lapa, + ], + pipeline=[], + test_mode=False, +) + +hand_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict( + type=RandomBBoxTransform, + shift_factor=0., + scale_factor=[1.5, 2.0], + rotate_factor=0), +] + +interhand_left = [(21, 95), (22, 94), (23, 93), (24, 92), (25, 99), (26, 98), + (27, 97), (28, 96), (29, 103), (30, 102), (31, 101), + (32, 100), (33, 107), (34, 106), (35, 105), (36, 104), + (37, 111), (38, 110), (39, 109), (40, 108), (41, 91)] +interhand_right = [(i - 21, j + 21) for i, j in interhand_left] +interhand_coco133 = interhand_right + interhand_left + +dataset_interhand2d = dict( + type=InterHand2DDoubleDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='interhand26m/annotations/all/InterHand2.6M_train_data.json', + camera_param_file='interhand26m/annotations/all/' + 'InterHand2.6M_train_camera.json', + joint_file='interhand26m/annotations/all/' + 'InterHand2.6M_train_joint_3d.json', + data_prefix=dict(img='interhand2.6m/images/train/'), + sample_interval=10, + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=interhand_coco133, + ), *hand_pipeline + ], +) + +dataset_hand = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[dataset_interhand2d], + pipeline=[], + test_mode=False, +) + +train_datasets = [dataset_wb, dataset_body, dataset_face, dataset_hand] + +# data loaders +train_dataloader = dict( + batch_size=train_batch_size, + num_workers=4, + pin_memory=False, + persistent_workers=True, + sampler=dict(type=DefaultSampler, shuffle=True), + dataset=dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=train_datasets, + pipeline=train_pipeline, + test_mode=False, + )) + +val_dataloader = dict( + batch_size=val_batch_size, + num_workers=4, + persistent_workers=True, + drop_last=False, + sampler=dict(type=DefaultSampler, shuffle=False, round_up=False), + dataset=dict( + type=CocoWholeBodyDataset, + ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json', + data_prefix=dict(img='data/detection/coco/val2017/'), + pipeline=val_pipeline, + bbox_file='data/coco/person_detection_results/' + 'COCO_val2017_detections_AP_H_56_person.json', + test_mode=True)) + +test_dataloader = val_dataloader + +# hooks +default_hooks.update( # noqa + checkpoint=dict( + save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1)) + +custom_hooks = [ + dict( + type=EMAHook, + ema_type=ExpMomentumEMA, + momentum=0.0002, + update_buffers=True, + priority=49), + dict( + type=PipelineSwitchHook, + switch_epoch=max_epochs - stage2_num_epochs, + switch_pipeline=train_pipeline_stage2) +] + +# evaluators +val_evaluator = dict( + type=CocoWholeBodyMetric, + ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json') +test_evaluator = val_evaluator diff --git a/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb704-270e_cocktail13-256x192.py b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb704-270e_cocktail13-256x192.py new file mode 100644 index 0000000000..48275c3c11 --- /dev/null +++ b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb704-270e_cocktail13-256x192.py @@ -0,0 +1,639 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from mmengine.config import read_base + +with read_base(): + from mmpose.configs._base_.default_runtime import * # noqa + +from albumentations.augmentations import Blur, CoarseDropout, MedianBlur +from mmdet.engine.hooks import PipelineSwitchHook +from mmengine.dataset import DefaultSampler +from mmengine.hooks import EMAHook +from mmengine.model import PretrainedInit +from mmengine.optim import CosineAnnealingLR, LinearLR, OptimWrapper +from torch.nn import SiLU, SyncBatchNorm +from torch.optim import AdamW + +from mmpose.codecs import SimCCLabel +from mmpose.datasets import (AicDataset, CocoWholeBodyDataset, COFWDataset, + CombinedDataset, CrowdPoseDataset, + Face300WDataset, GenerateTarget, + GetBBoxCenterScale, HalpeDataset, + HumanArt21Dataset, InterHand2DDoubleDataset, + JhmdbDataset, KeypointConverter, LapaDataset, + LoadImage, MpiiDataset, PackPoseInputs, + PoseTrack18Dataset, RandomFlip, RandomHalfBody, + TopdownAffine, UBody2dDataset, WFLWDataset) +from mmpose.datasets.transforms.common_transforms import ( + Albumentation, PhotometricDistortion, RandomBBoxTransform) +from mmpose.engine.hooks import ExpMomentumEMA +from mmpose.evaluation import CocoWholeBodyMetric +from mmpose.models import (CSPNeXt, CSPNeXtPAFPN, KLDiscretLoss, + PoseDataPreprocessor, RTMWHead, + TopdownPoseEstimator) + +# common setting +num_keypoints = 133 +input_size = (192, 256) + +# runtime +max_epochs = 270 +stage2_num_epochs = 10 +base_lr = 5e-4 +train_batch_size = 704 +val_batch_size = 32 + +train_cfg.update(max_epochs=max_epochs, val_interval=10) # noqa +randomness = dict(seed=21) + +# optimizer +optim_wrapper = dict( + type=OptimWrapper, + optimizer=dict(type=AdamW, lr=base_lr, weight_decay=0.05), + clip_grad=dict(max_norm=35, norm_type=2), + paramwise_cfg=dict( + norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True)) + +# learning rate +param_scheduler = [ + dict( + type=LinearLR, start_factor=1.0e-5, by_epoch=False, begin=0, end=1000), + dict( + type=CosineAnnealingLR, + eta_min=base_lr * 0.05, + begin=max_epochs // 2, + end=max_epochs, + T_max=max_epochs // 2, + by_epoch=True, + convert_to_iter_based=True), +] + +# automatically scaling LR based on the actual training batch size +auto_scale_lr = dict(base_batch_size=5632) + +# codec settings +codec = dict( + type=SimCCLabel, + input_size=input_size, + sigma=(4.9, 5.66), + simcc_split_ratio=2.0, + normalize=False, + use_dark=False) + +# model settings +model = dict( + type=TopdownPoseEstimator, + data_preprocessor=dict( + type=PoseDataPreprocessor, + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + backbone=dict( + type=CSPNeXt, + arch='P5', + expand_ratio=0.5, + deepen_factor=1.33, + widen_factor=1.25, + channel_attention=True, + norm_cfg=dict(type='BN'), + act_cfg=dict(type=SiLU), + init_cfg=dict( + type=PretrainedInit, + prefix='backbone.', + checkpoint='https://download.openmmlab.com/mmpose/v1/' + 'wholebody_2d_keypoint/rtmpose/ubody/rtmpose-x_simcc-ucoco_pt-aic-coco_270e-256x192-05f5bcb7_20230822.pth' # noqa + )), + neck=dict( + type=CSPNeXtPAFPN, + in_channels=[320, 640, 1280], + out_channels=None, + out_indices=( + 1, + 2, + ), + num_csp_blocks=2, + expand_ratio=0.5, + norm_cfg=dict(type=SyncBatchNorm), + act_cfg=dict(type=SiLU, inplace=True)), + head=dict( + type=RTMWHead, + in_channels=1280, + out_channels=num_keypoints, + input_size=input_size, + in_featuremap_size=tuple([s // 32 for s in input_size]), + simcc_split_ratio=codec['simcc_split_ratio'], + final_layer_kernel_size=7, + gau_cfg=dict( + hidden_dims=256, + s=128, + expansion_factor=2, + dropout_rate=0., + drop_path=0., + act_fn=SiLU, + use_rel_bias=False, + pos_enc=False), + loss=dict( + type=KLDiscretLoss, + use_target_weight=True, + beta=10., + label_softmax=True), + decoder=codec), + test_cfg=dict(flip_test=True)) + +# base dataset settings +dataset_type = CocoWholeBodyDataset +data_mode = 'topdown' +data_root = 'data/' + +backend_args = dict(backend='local') + +# pipelines +train_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict(type=RandomFlip, direction='horizontal'), + dict(type=RandomHalfBody), + dict(type=RandomBBoxTransform, scale_factor=[0.5, 1.5], rotate_factor=90), + dict(type=TopdownAffine, input_size=codec['input_size']), + dict(type=PhotometricDistortion), + dict( + type=Albumentation, + transforms=[ + dict(type=Blur, p=0.1), + dict(type=MedianBlur, p=0.1), + dict( + type=CoarseDropout, + max_holes=1, + max_height=0.4, + max_width=0.4, + min_holes=1, + min_height=0.2, + min_width=0.2, + p=1.0), + ]), + dict( + type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True), + dict(type=PackPoseInputs) +] +val_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict(type=TopdownAffine, input_size=codec['input_size']), + dict(type=PackPoseInputs) +] + +train_pipeline_stage2 = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict(type=RandomFlip, direction='horizontal'), + dict(type=RandomHalfBody), + dict( + type=RandomBBoxTransform, + shift_factor=0., + scale_factor=[0.5, 1.5], + rotate_factor=90), + dict(type=TopdownAffine, input_size=codec['input_size']), + dict( + type=Albumentation, + transforms=[ + dict(type=Blur, p=0.1), + dict(type=MedianBlur, p=0.1), + ]), + dict( + type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True), + dict(type=PackPoseInputs) +] + +# mapping + +aic_coco133 = [(0, 6), (1, 8), (2, 10), (3, 5), (4, 7), (5, 9), (6, 12), + (7, 14), (8, 16), (9, 11), (10, 13), (11, 15)] + +crowdpose_coco133 = [(0, 5), (1, 6), (2, 7), (3, 8), (4, 9), (5, 10), (6, 11), + (7, 12), (8, 13), (9, 14), (10, 15), (11, 16)] + +mpii_coco133 = [ + (0, 16), + (1, 14), + (2, 12), + (3, 11), + (4, 13), + (5, 15), + (8, 18), + (9, 17), + (10, 10), + (11, 8), + (12, 6), + (13, 5), + (14, 7), + (15, 9), +] + +jhmdb_coco133 = [ + (0, 18), + (2, 17), + (3, 6), + (4, 5), + (5, 12), + (6, 11), + (7, 8), + (8, 7), + (9, 14), + (10, 13), + (11, 10), + (12, 9), + (13, 16), + (14, 15), +] + +halpe_coco133 = [(i, i) + for i in range(17)] + [(20, 17), (21, 20), (22, 18), (23, 21), + (24, 19), + (25, 22)] + [(i, i - 3) + for i in range(26, 136)] + +posetrack_coco133 = [ + (0, 0), + (2, 17), + (3, 3), + (4, 4), + (5, 5), + (6, 6), + (7, 7), + (8, 8), + (9, 9), + (10, 10), + (11, 11), + (12, 12), + (13, 13), + (14, 14), + (15, 15), + (16, 16), +] + +humanart_coco133 = [(i, i) for i in range(17)] + [(17, 99), (18, 120), + (19, 17), (20, 20)] + +# train datasets +dataset_coco = dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='coco/annotations/coco_wholebody_train_v1.0.json', + data_prefix=dict(img='detection/coco/train2017/'), + pipeline=[], +) + +dataset_aic = dict( + type=AicDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='aic/annotations/aic_train.json', + data_prefix=dict(img='pose/ai_challenge/ai_challenger_keypoint' + '_train_20170902/keypoint_train_images_20170902/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=aic_coco133) + ], +) + +dataset_crowdpose = dict( + type=CrowdPoseDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='crowdpose/annotations/mmpose_crowdpose_trainval.json', + data_prefix=dict(img='pose/CrowdPose/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=crowdpose_coco133) + ], +) + +dataset_mpii = dict( + type=MpiiDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='mpii/annotations/mpii_train.json', + data_prefix=dict(img='pose/MPI/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=mpii_coco133) + ], +) + +dataset_jhmdb = dict( + type=JhmdbDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='jhmdb/annotations/Sub1_train.json', + data_prefix=dict(img='pose/JHMDB/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=jhmdb_coco133) + ], +) + +dataset_halpe = dict( + type=HalpeDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='halpe/annotations/halpe_train_v1.json', + data_prefix=dict(img='pose/Halpe/hico_20160224_det/images/train2015'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=halpe_coco133) + ], +) + +dataset_posetrack = dict( + type=PoseTrack18Dataset, + data_root=data_root, + data_mode=data_mode, + ann_file='posetrack18/annotations/posetrack18_train.json', + data_prefix=dict(img='pose/PoseChallenge2018/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=posetrack_coco133) + ], +) + +dataset_humanart = dict( + type=HumanArt21Dataset, + data_root=data_root, + data_mode=data_mode, + ann_file='HumanArt/annotations/training_humanart.json', + filter_cfg=dict(scenes=['real_human']), + data_prefix=dict(img='pose/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=humanart_coco133) + ]) + +ubody_scenes = [ + 'Magic_show', 'Entertainment', 'ConductMusic', 'Online_class', 'TalkShow', + 'Speech', 'Fitness', 'Interview', 'Olympic', 'TVShow', 'Singing', + 'SignLanguage', 'Movie', 'LiveVlog', 'VideoConference' +] + +ubody_datasets = [] +for scene in ubody_scenes: + each = dict( + type=UBody2dDataset, + data_root=data_root, + data_mode=data_mode, + ann_file=f'Ubody/annotations/{scene}/train_annotations.json', + data_prefix=dict(img='pose/UBody/images/'), + pipeline=[], + sample_interval=10) + ubody_datasets.append(each) + +dataset_ubody = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/ubody2d.py'), + datasets=ubody_datasets, + pipeline=[], + test_mode=False, +) + +face_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale, padding=1.25), + dict( + type=RandomBBoxTransform, + shift_factor=0., + scale_factor=[1.5, 2.0], + rotate_factor=0), +] + +wflw_coco133 = [(i * 2, 23 + i) + for i in range(17)] + [(33 + i, 40 + i) for i in range(5)] + [ + (42 + i, 45 + i) for i in range(5) + ] + [(51 + i, 50 + i) + for i in range(9)] + [(60, 59), (61, 60), (63, 61), + (64, 62), (65, 63), (67, 64), + (68, 65), (69, 66), (71, 67), + (72, 68), (73, 69), + (75, 70)] + [(76 + i, 71 + i) + for i in range(20)] +dataset_wflw = dict( + type=WFLWDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='wflw/annotations/face_landmarks_wflw_train.json', + data_prefix=dict(img='pose/WFLW/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=wflw_coco133), *face_pipeline + ], +) + +mapping_300w_coco133 = [(i, 23 + i) for i in range(68)] +dataset_300w = dict( + type=Face300WDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='300w/annotations/face_landmarks_300w_train.json', + data_prefix=dict(img='pose/300w/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=mapping_300w_coco133), *face_pipeline + ], +) + +cofw_coco133 = [(0, 40), (2, 44), (4, 42), (1, 49), (3, 45), (6, 47), (8, 59), + (10, 62), (9, 68), (11, 65), (18, 54), (19, 58), (20, 53), + (21, 56), (22, 71), (23, 77), (24, 74), (25, 85), (26, 89), + (27, 80), (28, 31)] +dataset_cofw = dict( + type=COFWDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='cofw/annotations/cofw_train.json', + data_prefix=dict(img='pose/COFW/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=cofw_coco133), *face_pipeline + ], +) + +lapa_coco133 = [(i * 2, 23 + i) for i in range(17)] + [ + (33 + i, 40 + i) for i in range(5) +] + [(42 + i, 45 + i) for i in range(5)] + [ + (51 + i, 50 + i) for i in range(4) +] + [(58 + i, 54 + i) for i in range(5)] + [(66, 59), (67, 60), (69, 61), + (70, 62), (71, 63), (73, 64), + (75, 65), (76, 66), (78, 67), + (79, 68), (80, 69), + (82, 70)] + [(84 + i, 71 + i) + for i in range(20)] +dataset_lapa = dict( + type=LapaDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='LaPa/annotations/lapa_trainval.json', + data_prefix=dict(img='pose/LaPa/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=lapa_coco133), *face_pipeline + ], +) + +dataset_wb = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[dataset_coco, dataset_halpe, dataset_ubody], + pipeline=[], + test_mode=False, +) + +dataset_body = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[ + dataset_aic, + dataset_crowdpose, + dataset_mpii, + dataset_jhmdb, + dataset_posetrack, + dataset_humanart, + ], + pipeline=[], + test_mode=False, +) + +dataset_face = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[ + dataset_wflw, + dataset_300w, + dataset_cofw, + dataset_lapa, + ], + pipeline=[], + test_mode=False, +) + +hand_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict( + type=RandomBBoxTransform, + shift_factor=0., + scale_factor=[1.5, 2.0], + rotate_factor=0), +] + +interhand_left = [(21, 95), (22, 94), (23, 93), (24, 92), (25, 99), (26, 98), + (27, 97), (28, 96), (29, 103), (30, 102), (31, 101), + (32, 100), (33, 107), (34, 106), (35, 105), (36, 104), + (37, 111), (38, 110), (39, 109), (40, 108), (41, 91)] +interhand_right = [(i - 21, j + 21) for i, j in interhand_left] +interhand_coco133 = interhand_right + interhand_left + +dataset_interhand2d = dict( + type=InterHand2DDoubleDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='interhand26m/annotations/all/InterHand2.6M_train_data.json', + camera_param_file='interhand26m/annotations/all/' + 'InterHand2.6M_train_camera.json', + joint_file='interhand26m/annotations/all/' + 'InterHand2.6M_train_joint_3d.json', + data_prefix=dict(img='interhand2.6m/images/train/'), + sample_interval=10, + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=interhand_coco133, + ), *hand_pipeline + ], +) + +dataset_hand = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[dataset_interhand2d], + pipeline=[], + test_mode=False, +) + +train_datasets = [dataset_wb, dataset_body, dataset_face, dataset_hand] + +# data loaders +train_dataloader = dict( + batch_size=train_batch_size, + num_workers=4, + pin_memory=False, + persistent_workers=True, + sampler=dict(type=DefaultSampler, shuffle=True), + dataset=dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=train_datasets, + pipeline=train_pipeline, + test_mode=False, + )) + +val_dataloader = dict( + batch_size=val_batch_size, + num_workers=4, + persistent_workers=True, + drop_last=False, + sampler=dict(type=DefaultSampler, shuffle=False, round_up=False), + dataset=dict( + type=CocoWholeBodyDataset, + ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json', + data_prefix=dict(img='data/detection/coco/val2017/'), + pipeline=val_pipeline, + bbox_file='data/coco/person_detection_results/' + 'COCO_val2017_detections_AP_H_56_person.json', + test_mode=True)) + +test_dataloader = val_dataloader + +# hooks +default_hooks.update( # noqa + checkpoint=dict( + save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1)) + +custom_hooks = [ + dict( + type=EMAHook, + ema_type=ExpMomentumEMA, + momentum=0.0002, + update_buffers=True, + priority=49), + dict( + type=PipelineSwitchHook, + switch_epoch=max_epochs - stage2_num_epochs, + switch_pipeline=train_pipeline_stage2) +] + +# evaluators +val_evaluator = dict( + type=CocoWholeBodyMetric, + ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json') +test_evaluator = val_evaluator diff --git a/projects/rtmpose/yolox/humanart/yolox_l_8xb8-300e_humanart.py b/projects/rtmpose/yolox/humanart/yolox_l_8xb8-300e_humanart.py new file mode 100644 index 0000000000..6fd4354cec --- /dev/null +++ b/projects/rtmpose/yolox/humanart/yolox_l_8xb8-300e_humanart.py @@ -0,0 +1,8 @@ +_base_ = './yolox_s_8xb8-300e_humanart.py' + +# model settings +model = dict( + backbone=dict(deepen_factor=1.0, widen_factor=1.0), + neck=dict( + in_channels=[256, 512, 1024], out_channels=256, num_csp_blocks=3), + bbox_head=dict(in_channels=256, feat_channels=256)) diff --git a/projects/rtmpose/yolox/humanart/yolox_m_8xb8-300e_humanart.py b/projects/rtmpose/yolox/humanart/yolox_m_8xb8-300e_humanart.py new file mode 100644 index 0000000000..e74e2bb99c --- /dev/null +++ b/projects/rtmpose/yolox/humanart/yolox_m_8xb8-300e_humanart.py @@ -0,0 +1,8 @@ +_base_ = './yolox_s_8xb8-300e_humanart.py' + +# model settings +model = dict( + backbone=dict(deepen_factor=0.67, widen_factor=0.75), + neck=dict(in_channels=[192, 384, 768], out_channels=192, num_csp_blocks=2), + bbox_head=dict(in_channels=192, feat_channels=192), +) diff --git a/projects/rtmpose/yolox/humanart/yolox_nano_8xb8-300e_humanart.py b/projects/rtmpose/yolox/humanart/yolox_nano_8xb8-300e_humanart.py new file mode 100644 index 0000000000..96a363abec --- /dev/null +++ b/projects/rtmpose/yolox/humanart/yolox_nano_8xb8-300e_humanart.py @@ -0,0 +1,11 @@ +_base_ = './yolox_tiny_8xb8-300e_humanart.py' + +# model settings +model = dict( + backbone=dict(deepen_factor=0.33, widen_factor=0.25, use_depthwise=True), + neck=dict( + in_channels=[64, 128, 256], + out_channels=64, + num_csp_blocks=1, + use_depthwise=True), + bbox_head=dict(in_channels=64, feat_channels=64, use_depthwise=True)) diff --git a/projects/rtmpose/yolox/humanart/yolox_s_8xb8-300e_humanart.py b/projects/rtmpose/yolox/humanart/yolox_s_8xb8-300e_humanart.py new file mode 100644 index 0000000000..a7992b076d --- /dev/null +++ b/projects/rtmpose/yolox/humanart/yolox_s_8xb8-300e_humanart.py @@ -0,0 +1,250 @@ +_base_ = [ + 'mmdet::_base_/schedules/schedule_1x.py', + 'mmdet::_base_/default_runtime.py', 'mmdet::yolox/yolox_tta.py' +] + +img_scale = (640, 640) # width, height + +# model settings +model = dict( + type='YOLOX', + data_preprocessor=dict( + type='DetDataPreprocessor', + pad_size_divisor=32, + batch_augments=[ + dict( + type='BatchSyncRandomResize', + random_size_range=(480, 800), + size_divisor=32, + interval=10) + ]), + backbone=dict( + type='CSPDarknet', + deepen_factor=0.33, + widen_factor=0.5, + out_indices=(2, 3, 4), + use_depthwise=False, + spp_kernal_sizes=(5, 9, 13), + norm_cfg=dict(type='BN', momentum=0.03, eps=0.001), + act_cfg=dict(type='Swish'), + ), + neck=dict( + type='YOLOXPAFPN', + in_channels=[128, 256, 512], + out_channels=128, + num_csp_blocks=1, + use_depthwise=False, + upsample_cfg=dict(scale_factor=2, mode='nearest'), + norm_cfg=dict(type='BN', momentum=0.03, eps=0.001), + act_cfg=dict(type='Swish')), + bbox_head=dict( + type='YOLOXHead', + num_classes=80, + in_channels=128, + feat_channels=128, + stacked_convs=2, + strides=(8, 16, 32), + use_depthwise=False, + norm_cfg=dict(type='BN', momentum=0.03, eps=0.001), + act_cfg=dict(type='Swish'), + loss_cls=dict( + type='CrossEntropyLoss', + use_sigmoid=True, + reduction='sum', + loss_weight=1.0), + loss_bbox=dict( + type='IoULoss', + mode='square', + eps=1e-16, + reduction='sum', + loss_weight=5.0), + loss_obj=dict( + type='CrossEntropyLoss', + use_sigmoid=True, + reduction='sum', + loss_weight=1.0), + loss_l1=dict(type='L1Loss', reduction='sum', loss_weight=1.0)), + train_cfg=dict(assigner=dict(type='SimOTAAssigner', center_radius=2.5)), + # In order to align the source code, the threshold of the val phase is + # 0.01, and the threshold of the test phase is 0.001. + test_cfg=dict(score_thr=0.01, nms=dict(type='nms', iou_threshold=0.65))) + +# dataset settings +data_root = 'data/' +dataset_type = 'CocoDataset' + +# Example to use different file client +# Method 1: simply set the data root and let the file I/O module +# automatically infer from prefix (not support LMDB and Memcache yet) + +# data_root = 's3://openmmlab/datasets/detection/coco/' + +# Method 2: Use `backend_args`, `file_client_args` in versions before 3.0.0rc6 +# backend_args = dict( +# backend='petrel', +# path_mapping=dict({ +# './data/': 's3://openmmlab/datasets/detection/', +# 'data/': 's3://openmmlab/datasets/detection/' +# })) +backend_args = None + +train_pipeline = [ + dict(type='Mosaic', img_scale=img_scale, pad_val=114.0), + dict( + type='RandomAffine', + scaling_ratio_range=(0.1, 2), + # img_scale is (width, height) + border=(-img_scale[0] // 2, -img_scale[1] // 2)), + dict( + type='MixUp', + img_scale=img_scale, + ratio_range=(0.8, 1.6), + pad_val=114.0), + dict(type='YOLOXHSVRandomAug'), + dict(type='RandomFlip', prob=0.5), + # According to the official implementation, multi-scale + # training is not considered here but in the + # 'mmdet/models/detectors/yolox.py'. + # Resize and Pad are for the last 15 epochs when Mosaic, + # RandomAffine, and MixUp are closed by YOLOXModeSwitchHook. + dict(type='Resize', scale=img_scale, keep_ratio=True), + dict( + type='Pad', + pad_to_square=True, + # If the image is three-channel, the pad value needs + # to be set separately for each channel. + pad_val=dict(img=(114.0, 114.0, 114.0))), + dict(type='FilterAnnotations', min_gt_bbox_wh=(1, 1), keep_empty=False), + dict(type='PackDetInputs') +] + +train_dataset = dict( + # use MultiImageMixDataset wrapper to support mosaic and mixup + type='MultiImageMixDataset', + dataset=dict( + type=dataset_type, + data_root=data_root, + ann_file='HumanArt/annotations/training_humanart_coco.json', + data_prefix=dict(img=''), + pipeline=[ + dict(type='LoadImageFromFile', backend_args=backend_args), + dict(type='LoadAnnotations', with_bbox=True) + ], + filter_cfg=dict(filter_empty_gt=False, min_size=32), + backend_args=backend_args), + pipeline=train_pipeline) + +test_pipeline = [ + dict(type='LoadImageFromFile', backend_args=backend_args), + dict(type='Resize', scale=img_scale, keep_ratio=True), + dict( + type='Pad', + pad_to_square=True, + pad_val=dict(img=(114.0, 114.0, 114.0))), + dict(type='LoadAnnotations', with_bbox=True), + dict( + type='PackDetInputs', + meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', + 'scale_factor')) +] + +train_dataloader = dict( + batch_size=8, + num_workers=4, + persistent_workers=True, + sampler=dict(type='DefaultSampler', shuffle=True), + dataset=train_dataset) +val_dataloader = dict( + batch_size=8, + num_workers=4, + persistent_workers=True, + drop_last=False, + sampler=dict(type='DefaultSampler', shuffle=False), + dataset=dict( + type=dataset_type, + data_root=data_root, + ann_file='HumanArt/annotations/validation_humanart_coco.json', + data_prefix=dict(img=''), + test_mode=True, + pipeline=test_pipeline, + backend_args=backend_args)) +test_dataloader = val_dataloader + +val_evaluator = dict( + type='CocoMetric', + ann_file=data_root + 'HumanArt/annotations/validation_humanart_coco.json', + metric='bbox', + backend_args=backend_args) +test_evaluator = val_evaluator + +# training settings +max_epochs = 300 +num_last_epochs = 15 +interval = 10 + +train_cfg = dict(max_epochs=max_epochs, val_interval=interval) + +# optimizer +# default 8 gpu +base_lr = 0.01 +optim_wrapper = dict( + type='OptimWrapper', + optimizer=dict( + type='SGD', lr=base_lr, momentum=0.9, weight_decay=5e-4, + nesterov=True), + paramwise_cfg=dict(norm_decay_mult=0., bias_decay_mult=0.)) + +# learning rate +param_scheduler = [ + dict( + # use quadratic formula to warm up 5 epochs + # and lr is updated by iteration + # TODO: fix default scope in get function + type='mmdet.QuadraticWarmupLR', + by_epoch=True, + begin=0, + end=5, + convert_to_iter_based=True), + dict( + # use cosine lr from 5 to 285 epoch + type='CosineAnnealingLR', + eta_min=base_lr * 0.05, + begin=5, + T_max=max_epochs - num_last_epochs, + end=max_epochs - num_last_epochs, + by_epoch=True, + convert_to_iter_based=True), + dict( + # use fixed lr during last 15 epochs + type='ConstantLR', + by_epoch=True, + factor=1, + begin=max_epochs - num_last_epochs, + end=max_epochs, + ) +] + +default_hooks = dict( + checkpoint=dict( + interval=interval, + max_keep_ckpts=3 # only keep latest 3 checkpoints + )) + +custom_hooks = [ + dict( + type='YOLOXModeSwitchHook', + num_last_epochs=num_last_epochs, + priority=48), + dict(type='SyncNormHook', priority=48), + dict( + type='EMAHook', + ema_type='ExpMomentumEMA', + momentum=0.0001, + update_buffers=True, + priority=49) +] + +# NOTE: `auto_scale_lr` is for automatically scaling LR, +# USER SHOULD NOT CHANGE ITS VALUES. +# base_batch_size = (8 GPUs) x (8 samples per GPU) +auto_scale_lr = dict(base_batch_size=64) diff --git a/projects/rtmpose/yolox/humanart/yolox_tiny_8xb8-300e_humanart.py b/projects/rtmpose/yolox/humanart/yolox_tiny_8xb8-300e_humanart.py new file mode 100644 index 0000000000..71971e2ddc --- /dev/null +++ b/projects/rtmpose/yolox/humanart/yolox_tiny_8xb8-300e_humanart.py @@ -0,0 +1,54 @@ +_base_ = './yolox_s_8xb8-300e_humanart.py' + +# model settings +model = dict( + data_preprocessor=dict(batch_augments=[ + dict( + type='BatchSyncRandomResize', + random_size_range=(320, 640), + size_divisor=32, + interval=10) + ]), + backbone=dict(deepen_factor=0.33, widen_factor=0.375), + neck=dict(in_channels=[96, 192, 384], out_channels=96), + bbox_head=dict(in_channels=96, feat_channels=96)) + +img_scale = (640, 640) # width, height + +train_pipeline = [ + dict(type='Mosaic', img_scale=img_scale, pad_val=114.0), + dict( + type='RandomAffine', + scaling_ratio_range=(0.5, 1.5), + # img_scale is (width, height) + border=(-img_scale[0] // 2, -img_scale[1] // 2)), + dict(type='YOLOXHSVRandomAug'), + dict(type='RandomFlip', prob=0.5), + # Resize and Pad are for the last 15 epochs when Mosaic and + # RandomAffine are closed by YOLOXModeSwitchHook. + dict(type='Resize', scale=img_scale, keep_ratio=True), + dict( + type='Pad', + pad_to_square=True, + pad_val=dict(img=(114.0, 114.0, 114.0))), + dict(type='FilterAnnotations', min_gt_bbox_wh=(1, 1), keep_empty=False), + dict(type='PackDetInputs') +] + +test_pipeline = [ + dict(type='LoadImageFromFile', backend_args={{_base_.backend_args}}), + dict(type='Resize', scale=(416, 416), keep_ratio=True), + dict( + type='Pad', + pad_to_square=True, + pad_val=dict(img=(114.0, 114.0, 114.0))), + dict(type='LoadAnnotations', with_bbox=True), + dict( + type='PackDetInputs', + meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', + 'scale_factor')) +] + +train_dataloader = dict(dataset=dict(pipeline=train_pipeline)) +val_dataloader = dict(dataset=dict(pipeline=test_pipeline)) +test_dataloader = val_dataloader diff --git a/projects/rtmpose/yolox/humanart/yolox_x_8xb8-300e_humanart.py b/projects/rtmpose/yolox/humanart/yolox_x_8xb8-300e_humanart.py new file mode 100644 index 0000000000..6e03ffefb6 --- /dev/null +++ b/projects/rtmpose/yolox/humanart/yolox_x_8xb8-300e_humanart.py @@ -0,0 +1,8 @@ +_base_ = './yolox_s_8xb8-300e_humanart.py' + +# model settings +model = dict( + backbone=dict(deepen_factor=1.33, widen_factor=1.25), + neck=dict( + in_channels=[320, 640, 1280], out_channels=320, num_csp_blocks=4), + bbox_head=dict(in_channels=320, feat_channels=320)) diff --git a/projects/uniformer/README.md b/projects/uniformer/README.md new file mode 100644 index 0000000000..6f166f975e --- /dev/null +++ b/projects/uniformer/README.md @@ -0,0 +1,138 @@ +# Pose Estion with UniFormer + +This project implements a topdown heatmap based human pose estimator, utilizing the approach outlined in **UniFormer: Unifying Convolution and Self-attention for Visual Recognition** (TPAMI 2023) and **UniFormer: Unified Transformer for Efficient Spatiotemporal Representation Learning** (ICLR 2022). + +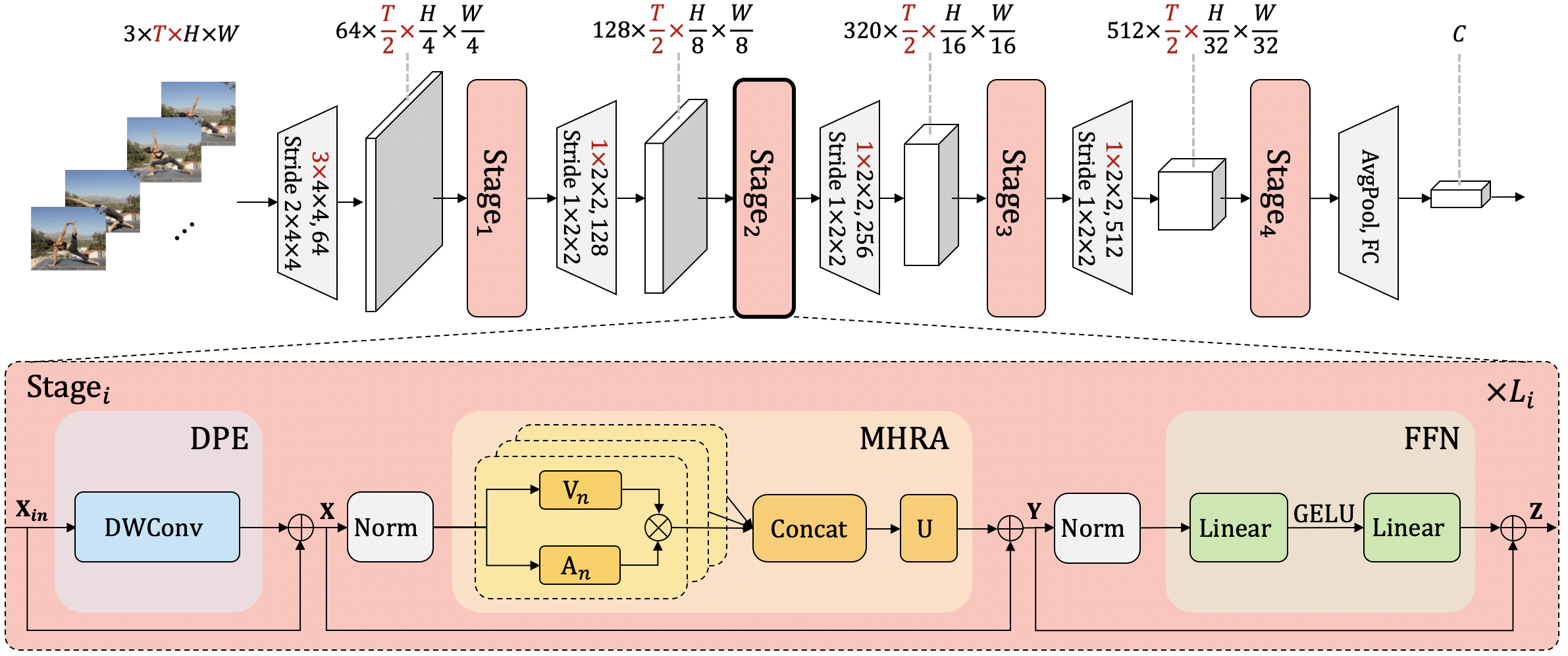
+ +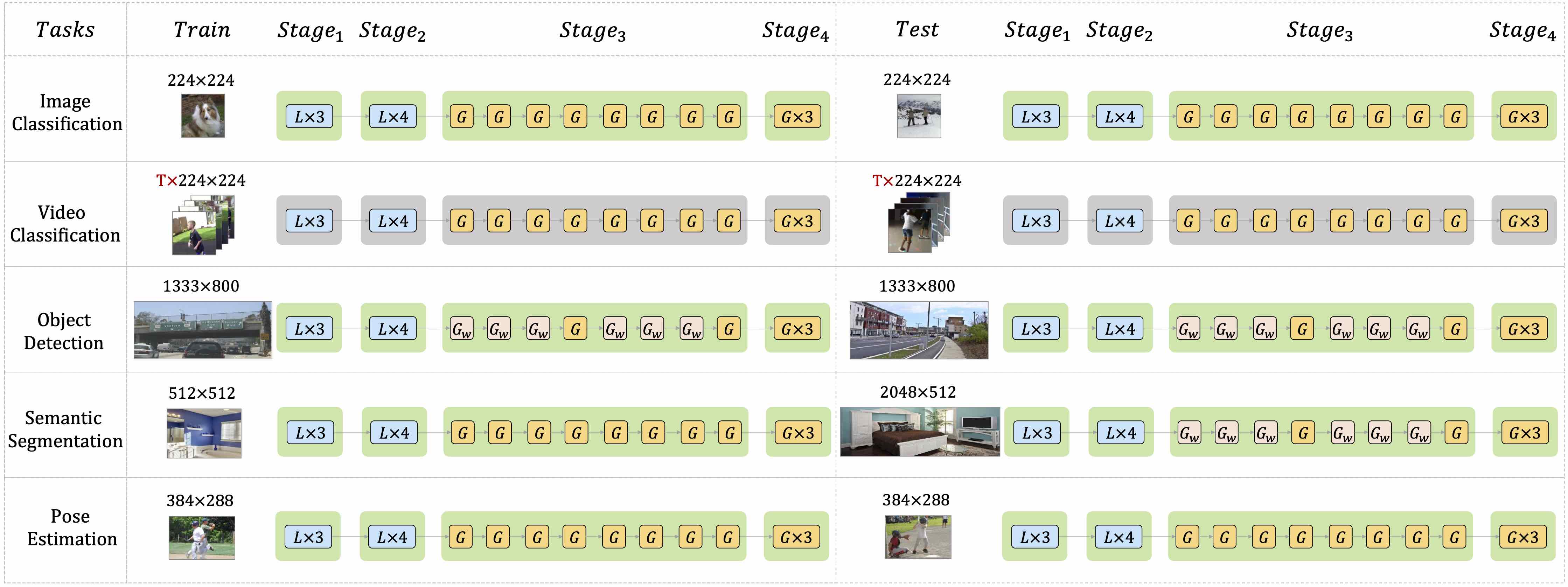
+ +## Usage + +### Preparation + +1. Setup Development Environment + +- Python 3.7 or higher +- PyTorch 1.6 or higher +- [MMEngine](https://github.com/open-mmlab/mmengine) v0.6.0 or higher +- [MMCV](https://github.com/open-mmlab/mmcv) v2.0.0rc4 or higher +- [MMDetection](https://github.com/open-mmlab/mmdetection) v3.0.0rc6 or higher +- [MMPose](https://github.com/open-mmlab/mmpose) v1.0.0rc1 or higher + +All the commands below rely on the correct configuration of `PYTHONPATH`, which should point to the project's directory so that Python can locate the module files. **In `uniformer/` root directory**, run the following line to add the current directory to `PYTHONPATH`: + +```shell +export PYTHONPATH=`pwd`:$PYTHONPATH +``` + +2. Download Pretrained Weights + +To either run inferences or train on the `uniformer pose estimation` project, you have to download the original Uniformer pretrained weights on the ImageNet1k dataset and the weights trained for the downstream pose estimation task. The original ImageNet1k weights are hosted on SenseTime's [huggingface repository](https://huggingface.co/Sense-X/uniformer_image), and the downstream pose estimation task weights are hosted either on Google Drive or Baiduyun. We have uploaded them to the OpenMMLab download URLs, allowing users to use them without burden. For example, you can take a look at [`td-hm_uniformer-b-8xb128-210e_coco-256x192.py`](./configs/td-hm_uniformer-b-8xb128-210e_coco-256x192.py#62), the corresponding pretrained weight URL is already here and when the training or testing process starts, the weight will be automatically downloaded to your device. For the downstream task weights, you can get their URLs from the [benchmark result table](#results). + +### Inference + +We have provided a [inferencer_demo.py](../../demo/inferencer_demo.py) with which developers can utilize to run quick inference demos. Here is a basic demonstration: + +```shell +python demo/inferencer_demo.py $INPUTS \ + --pose2d $CONFIG --pose2d-weights $CHECKPOINT \ + [--show] [--vis-out-dir $VIS_OUT_DIR] [--pred-out-dir $PRED_OUT_DIR] +``` + +For more information on using the inferencer, please see [this document](https://mmpose.readthedocs.io/en/latest/user_guides/inference.html#out-of-the-box-inferencer). + +Here's an example code: + +```shell +python demo/inferencer_demo.py tests/data/coco/000000000785.jpg \ + --pose2d projects/uniformer/configs/td-hm_uniformer-s-8xb128-210e_coco-256x192.py \ + --pose2d-weights https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_256x192_global_small-d4a7fdac_20230724.pth \ + --vis-out-dir vis_results +``` + +Then you will find the demo result in `vis_results` folder, and it may be similar to this: + +
+ +### Training and Testing + +1. Data Preparation + +Prepare the COCO dataset according to the [instruction](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#coco). + +2. To Train and Test with Single GPU: + +```shell +python tools/test.py $CONFIG --auto-scale-lr +``` + +```shell +python tools/test.py $CONFIG $CHECKPOINT +``` + +3. To Train and Test with Multiple GPUs: + +```shell +bash tools/dist_train.sh $CONFIG $NUM_GPUs --amp +``` + +```shell +bash tools/dist_test.sh $CONFIG $CHECKPOINT $NUM_GPUs --amp +``` + +## Results + +Here is the testing results on COCO val2017: + +| Model | Input Size | AP | AP50 | AP75 | AR | AR50 | Download | +| :-----------------------------------------------------------------: | :--------: | :--: | :-------------: | :-------------: | :--: | :-------------: | :--------------------------------------------------------------------: | +| [UniFormer-S](./configs/td-hm_uniformer-s-8xb128-210e_coco-256x192.py) | 256x192 | 74.0 | 90.2 | 82.1 | 79.5 | 94.1 | [model](https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_256x192_global_small-d4a7fdac_20230724.pth) \| [log](https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_256x192_global_small-d4a7fdac_20230724.log.json) | +| [UniFormer-S](./configs/td-hm_uniformer-s-8xb128-210e_coco-384x288.py) | 384x288 | 75.9 | 90.6 | 83.0 | 81.0 | 94.3 | [model](https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_384x288_global_small-7a613f78_20230724.pth) \| [log](https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_384x288_global_small-7a613f78_20230724.log.json) | +| [UniFormer-S](./configs/td-hm_uniformer-s-8xb64-210e_coco-448x320.py) | 448x320 | 76.2 | 90.6 | 83.2 | 81.4 | 94.4 | [model](https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_448x320_global_small-18b760de_20230724.pth) \| [log](https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_448x320_global_small-18b760de_20230724.log.json) | +| [UniFormer-B](./configs/td-hm_uniformer-b-8xb128-210e_coco-256x192.py) | 256x192 | 75.0 | 90.5 | 83.0 | 80.4 | 94.2 | [model](https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_256x192_global_base-1713bcd4_20230724.pth) \| [log](https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_256x192_global_base-1713bcd4_20230724.log.json) | +| [UniFormer-B](./configs/td-hm_uniformer-b-8xb32-210e_coco-384x288.py) | 384x288 | 76.7 | 90.8 | 84.1 | 81.9 | 94.6 | [model](https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_384x288_global_base-c650da38_20230724.pth) \| [log](https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_384x288_global_base-c650da38_20230724.log.json) | +| [UniFormer-B](./configs/td-hm_uniformer-b-8xb32-210e_coco-448x320.py) | 448x320 | 77.4 | 91.0 | 84.4 | 82.5 | 94.9 | [model](https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_448x320_global_base-a05c185f_20230724.pth) \| [log](https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_448x320_global_base-a05c185f_20230724.log.json) | + +Here is the testing results on COCO val 2017 from the official UniFormer Pose Estimation repository for comparison: + +| Backbone | Input Size | AP | AP50 | AP75 | ARM | ARL | AR | Model | Log | +| :---------- | :--------- | :--- | :-------------- | :-------------- | :------------- | :------------- | :--- | :-------------------------------------------------------- | :------------------------------------------------------- | +| UniFormer-S | 256x192 | 74.0 | 90.3 | 82.2 | 66.8 | 76.7 | 79.5 | [google](https://drive.google.com/file/d/162R0JuTpf3gpLe1IK6oxRoQK7JSj4ylx/view?usp=sharing) | [google](https://drive.google.com/file/d/15j40u97Db6TA2gMHdn0yFEsDFb5SMBy4/view?usp=sharing) | +| UniFormer-S | 384x288 | 75.9 | 90.6 | 83.4 | 68.6 | 79.0 | 81.4 | [google](https://drive.google.com/file/d/163vuFkpcgVOthC05jCwjGzo78Nr0eikW/view?usp=sharing) | [google](https://drive.google.com/file/d/15X9M_5cq9RQMgs64Yn9YvV5k5f0zOBHo/view?usp=sharing) | +| UniFormer-S | 448x320 | 76.2 | 90.6 | 83.2 | 68.6 | 79.4 | 81.4 | [google](https://drive.google.com/file/d/165nQRsT58SXJegcttksHwDn46Fme5dGX/view?usp=sharing) | [google](https://drive.google.com/file/d/15IJjSWp4R5OybMdV2CZEUx_TwXdTMOee/view?usp=sharing) | +| UniFormer-B | 256x192 | 75.0 | 90.6 | 83.0 | 67.8 | 77.7 | 80.4 | [google](https://drive.google.com/file/d/15tzJaRyEzyWp2mQhpjDbBzuGoyCaJJ-2/view?usp=sharing) | [google](https://drive.google.com/file/d/15jJyTPcJKj_id0PNdytloqt7yjH2M8UR/view?usp=sharing) | +| UniFormer-B | 384x288 | 76.7 | 90.8 | 84.0 | 69.3 | 79.7 | 81.4 | [google](https://drive.google.com/file/d/15qtUaOR_C7-vooheJE75mhA9oJQt3gSx/view?usp=sharing) | [google](https://drive.google.com/file/d/15L1Uxo_uRSMlGnOvWzAzkJLKX6Qh_xNw/view?usp=sharing) | +| UniFormer-B | 448x320 | 77.4 | 91.1 | 84.4 | 70.2 | 80.6 | 82.5 | [google](https://drive.google.com/file/d/156iNxetiCk8JJz41aFDmFh9cQbCaMk3D/view?usp=sharing) | [google](https://drive.google.com/file/d/15aRpZc2Tie5gsn3_l-aXto1MrC9wyzMC/view?usp=sharing) | + +Note: + +1. All the original models are pretrained on ImageNet-1K without Token Labeling and Layer Scale, as mentioned in the [official README](https://github.com/Sense-X/UniFormer/tree/main/pose_estimation) . The official team has confirmed that **Token labeling can largely improve the performance of the downstream tasks**. Developers can utilize the implementation by themselves. +2. The original implementation did not include the **freeze BN in the backbone**. The official team has confirmed that this can improve the performance as well. +3. To avoid running out of memory, developers can use `torch.utils.checkpoint` in the `config.py` by setting `use_checkpoint=True` and `checkpoint_num=[0, 0, 2, 0] # index for using checkpoint in every stage` +4. We warmly welcome any contributions if you can successfully reproduce the results from the paper! + +## Citation + +If this project benefits your work, please kindly consider citing the original papers: + +```bibtex +@misc{li2022uniformer, + title={UniFormer: Unifying Convolution and Self-attention for Visual Recognition}, + author={Kunchang Li and Yali Wang and Junhao Zhang and Peng Gao and Guanglu Song and Yu Liu and Hongsheng Li and Yu Qiao}, + year={2022}, + eprint={2201.09450}, + archivePrefix={arXiv}, + primaryClass={cs.CV} +} +``` + +```bibtex +@misc{li2022uniformer, + title={UniFormer: Unified Transformer for Efficient Spatiotemporal Representation Learning}, + author={Kunchang Li and Yali Wang and Peng Gao and Guanglu Song and Yu Liu and Hongsheng Li and Yu Qiao}, + year={2022}, + eprint={2201.04676}, + archivePrefix={arXiv}, + primaryClass={cs.CV} +} +``` diff --git a/projects/uniformer/configs/td-hm_uniformer-b-8xb128-210e_coco-256x192.py b/projects/uniformer/configs/td-hm_uniformer-b-8xb128-210e_coco-256x192.py new file mode 100644 index 0000000000..07f1377842 --- /dev/null +++ b/projects/uniformer/configs/td-hm_uniformer-b-8xb128-210e_coco-256x192.py @@ -0,0 +1,135 @@ +_base_ = ['mmpose::_base_/default_runtime.py'] + +custom_imports = dict(imports='projects.uniformer.models') + +# runtime +train_cfg = dict(max_epochs=210, val_interval=10) + +# enable DDP training when pretrained model is used +find_unused_parameters = True + +# optimizer +optim_wrapper = dict(optimizer=dict( + type='Adam', + lr=2e-3, +)) + +# learning policy +param_scheduler = [ + dict( + type='LinearLR', begin=0, end=500, start_factor=0.001, + by_epoch=False), # warm-up + dict( + type='MultiStepLR', + begin=0, + end=210, + milestones=[170, 200], + gamma=0.1, + by_epoch=True) +] + +# automatically scaling LR based on the actual training batch size +auto_scale_lr = dict(base_batch_size=1024) + +# hooks +default_hooks = dict( + checkpoint=dict(save_best='coco/AP', rule='greater', interval=5)) + +# codec settings +codec = dict( + type='MSRAHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2) + +# model settings +norm_cfg = dict(type='SyncBN', requires_grad=True) +model = dict( + type='TopdownPoseEstimator', + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + backbone=dict( + type='UniFormer', + embed_dims=[64, 128, 320, 512], + depths=[5, 8, 20, 7], + head_dim=64, + drop_path_rate=0.4, + use_checkpoint=False, # whether use torch.utils.checkpoint + use_window=False, # whether use window MHRA + use_hybrid=False, # whether use hybrid MHRA + init_cfg=dict( + # Set the path to pretrained backbone here + type='Pretrained', + checkpoint='https://download.openmmlab.com/mmpose/v1/projects/' + 'uniformer/uniformer_base_in1k.pth' # noqa + )), + head=dict( + type='HeatmapHead', + in_channels=512, + out_channels=17, + final_layer=dict(kernel_size=1), + loss=dict(type='KeypointMSELoss', use_target_weight=True), + decoder=codec), + test_cfg=dict(flip_test=True, flip_mode='heatmap', shift_heatmap=True)) + +# base dataset settings +dataset_type = 'CocoDataset' +data_mode = 'topdown' +data_root = 'data/coco/' + +# pipelines +train_pipeline = [ + dict(type='LoadImage'), + dict(type='GetBBoxCenterScale'), + dict(type='RandomFlip', direction='horizontal'), + dict(type='RandomHalfBody'), + dict(type='RandomBBoxTransform'), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='GenerateTarget', encoder=codec), + dict(type='PackPoseInputs') +] +val_pipeline = [ + dict(type='LoadImage'), + dict(type='GetBBoxCenterScale'), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='PackPoseInputs') +] + +# data loaders +train_dataloader = dict( + batch_size=128, + num_workers=2, + persistent_workers=True, + sampler=dict(type='DefaultSampler', shuffle=True), + dataset=dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='annotations/person_keypoints_train2017.json', + data_prefix=dict(img='train2017/'), + pipeline=train_pipeline, + )) +val_dataloader = dict( + batch_size=256, + num_workers=2, + persistent_workers=True, + drop_last=False, + sampler=dict(type='DefaultSampler', shuffle=False, round_up=False), + dataset=dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='annotations/person_keypoints_val2017.json', + bbox_file='data/coco/person_detection_results/' + 'COCO_val2017_detections_AP_H_56_person.json', + data_prefix=dict(img='val2017/'), + test_mode=True, + pipeline=val_pipeline, + )) +test_dataloader = val_dataloader + +# evaluators +val_evaluator = dict( + type='CocoMetric', + ann_file=data_root + 'annotations/person_keypoints_val2017.json') +test_evaluator = val_evaluator diff --git a/projects/uniformer/configs/td-hm_uniformer-b-8xb32-210e_coco-384x288.py b/projects/uniformer/configs/td-hm_uniformer-b-8xb32-210e_coco-384x288.py new file mode 100644 index 0000000000..d43061d0cd --- /dev/null +++ b/projects/uniformer/configs/td-hm_uniformer-b-8xb32-210e_coco-384x288.py @@ -0,0 +1,134 @@ +_base_ = ['mmpose::_base_/default_runtime.py'] + +custom_imports = dict(imports='projects.uniformer.models') + +# runtime +train_cfg = dict(max_epochs=210, val_interval=10) + +# enable DDP training when pretrained model is used +find_unused_parameters = True + +# optimizer +optim_wrapper = dict(optimizer=dict( + type='Adam', + lr=5e-4, +)) + +# learning policy +param_scheduler = [ + dict( + type='LinearLR', begin=0, end=500, start_factor=0.001, + by_epoch=False), # warm-up + dict( + type='MultiStepLR', + begin=0, + end=210, + milestones=[170, 200], + gamma=0.1, + by_epoch=True) +] + +# automatically scaling LR based on the actual training batch size +auto_scale_lr = dict(base_batch_size=512) + +# hooks +default_hooks = dict(checkpoint=dict(save_best='coco/AP', rule='greater')) + +# codec settings +codec = dict( + type='MSRAHeatmap', input_size=(288, 384), heatmap_size=(72, 96), sigma=3) + +# model settings +norm_cfg = dict(type='SyncBN', requires_grad=True) +model = dict( + type='TopdownPoseEstimator', + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + backbone=dict( + type='UniFormer', + embed_dims=[64, 128, 320, 512], + depths=[5, 8, 20, 7], + head_dim=64, + drop_path_rate=0.4, + use_checkpoint=False, # whether use torch.utils.checkpoint + use_window=False, # whether use window MHRA + use_hybrid=False, # whether use hybrid MHRA + init_cfg=dict( + # Set the path to pretrained backbone here + type='Pretrained', + checkpoint='https://download.openmmlab.com/mmpose/v1/projects/' + 'uniformer/uniformer_base_in1k.pth' # noqa + )), + head=dict( + type='HeatmapHead', + in_channels=512, + out_channels=17, + final_layer=dict(kernel_size=1), + loss=dict(type='KeypointMSELoss', use_target_weight=True), + decoder=codec), + test_cfg=dict(flip_test=True, flip_mode='heatmap', shift_heatmap=True)) + +# base dataset settings +dataset_type = 'CocoDataset' +data_mode = 'topdown' +data_root = 'data/coco/' + +# pipelines +train_pipeline = [ + dict(type='LoadImage'), + dict(type='GetBBoxCenterScale'), + dict(type='RandomFlip', direction='horizontal'), + dict(type='RandomHalfBody'), + dict(type='RandomBBoxTransform'), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='GenerateTarget', encoder=codec), + dict(type='PackPoseInputs') +] +val_pipeline = [ + dict(type='LoadImage'), + dict(type='GetBBoxCenterScale'), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='PackPoseInputs') +] + +# data loaders +train_dataloader = dict( + batch_size=128, + num_workers=2, + persistent_workers=True, + sampler=dict(type='DefaultSampler', shuffle=True), + dataset=dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='annotations/person_keypoints_train2017.json', + data_prefix=dict(img='train2017/'), + pipeline=train_pipeline, + )) +val_dataloader = dict( + batch_size=256, + num_workers=2, + persistent_workers=True, + drop_last=False, + sampler=dict(type='DefaultSampler', shuffle=False, round_up=False), + dataset=dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='annotations/person_keypoints_val2017.json', + bbox_file='data/coco/person_detection_results/' + 'COCO_val2017_detections_AP_H_56_person.json', + data_prefix=dict(img='val2017/'), + test_mode=True, + pipeline=val_pipeline, + )) +test_dataloader = val_dataloader + +# evaluators +val_evaluator = dict( + type='CocoMetric', + ann_file=data_root + 'annotations/person_keypoints_val2017.json') +test_evaluator = val_evaluator diff --git a/projects/uniformer/configs/td-hm_uniformer-b-8xb32-210e_coco-448x320.py b/projects/uniformer/configs/td-hm_uniformer-b-8xb32-210e_coco-448x320.py new file mode 100644 index 0000000000..81554ad27e --- /dev/null +++ b/projects/uniformer/configs/td-hm_uniformer-b-8xb32-210e_coco-448x320.py @@ -0,0 +1,134 @@ +_base_ = ['mmpose::_base_/default_runtime.py'] + +custom_imports = dict(imports='projects.uniformer.models') + +# runtime +train_cfg = dict(max_epochs=210, val_interval=10) + +# enable DDP training when pretrained model is used +find_unused_parameters = True + +# optimizer +optim_wrapper = dict(optimizer=dict( + type='Adam', + lr=5e-4, +)) + +# learning policy +param_scheduler = [ + dict( + type='LinearLR', begin=0, end=500, start_factor=0.001, + by_epoch=False), # warm-up + dict( + type='MultiStepLR', + begin=0, + end=210, + milestones=[170, 200], + gamma=0.1, + by_epoch=True) +] + +# automatically scaling LR based on the actual training batch size +auto_scale_lr = dict(base_batch_size=256) + +# hooks +default_hooks = dict(checkpoint=dict(save_best='coco/AP', rule='greater')) + +# codec settings +codec = dict( + type='MSRAHeatmap', input_size=(320, 448), heatmap_size=(80, 112), sigma=3) + +# model settings +norm_cfg = dict(type='SyncBN', requires_grad=True) +model = dict( + type='TopdownPoseEstimator', + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + backbone=dict( + type='UniFormer', + embed_dims=[64, 128, 320, 512], + depths=[5, 8, 20, 7], + head_dim=64, + drop_path_rate=0.55, + use_checkpoint=False, # whether use torch.utils.checkpoint + use_window=False, # whether use window MHRA + use_hybrid=False, # whether use hybrid MHRA + init_cfg=dict( + # Set the path to pretrained backbone here + type='Pretrained', + checkpoint='https://download.openmmlab.com/mmpose/v1/projects/' + 'uniformer/uniformer_base_in1k.pth' # noqa + )), + head=dict( + type='HeatmapHead', + in_channels=512, + out_channels=17, + final_layer=dict(kernel_size=1), + loss=dict(type='KeypointMSELoss', use_target_weight=True), + decoder=codec), + test_cfg=dict(flip_test=True, flip_mode='heatmap', shift_heatmap=True)) + +# base dataset settings +dataset_type = 'CocoDataset' +data_mode = 'topdown' +data_root = 'data/coco/' + +# pipelines +train_pipeline = [ + dict(type='LoadImage'), + dict(type='GetBBoxCenterScale'), + dict(type='RandomFlip', direction='horizontal'), + dict(type='RandomHalfBody'), + dict(type='RandomBBoxTransform'), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='GenerateTarget', encoder=codec), + dict(type='PackPoseInputs') +] +val_pipeline = [ + dict(type='LoadImage'), + dict(type='GetBBoxCenterScale'), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='PackPoseInputs') +] + +# data loaders +train_dataloader = dict( + batch_size=32, + num_workers=2, + persistent_workers=True, + sampler=dict(type='DefaultSampler', shuffle=True), + dataset=dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='annotations/person_keypoints_train2017.json', + data_prefix=dict(img='train2017/'), + pipeline=train_pipeline, + )) +val_dataloader = dict( + batch_size=256, + num_workers=2, + persistent_workers=True, + drop_last=False, + sampler=dict(type='DefaultSampler', shuffle=False, round_up=False), + dataset=dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='annotations/person_keypoints_val2017.json', + bbox_file='data/coco/person_detection_results/' + 'COCO_val2017_detections_AP_H_56_person.json', + data_prefix=dict(img='val2017/'), + test_mode=True, + pipeline=val_pipeline, + )) +test_dataloader = val_dataloader + +# evaluators +val_evaluator = dict( + type='CocoMetric', + ann_file=data_root + 'annotations/person_keypoints_val2017.json') +test_evaluator = val_evaluator diff --git a/projects/uniformer/configs/td-hm_uniformer-s-8xb128-210e_coco-256x192.py b/projects/uniformer/configs/td-hm_uniformer-s-8xb128-210e_coco-256x192.py new file mode 100644 index 0000000000..54994893dd --- /dev/null +++ b/projects/uniformer/configs/td-hm_uniformer-s-8xb128-210e_coco-256x192.py @@ -0,0 +1,17 @@ +_base_ = ['./td-hm_uniformer-b-8xb128-210e_coco-256x192.py'] + +# automatically scaling LR based on the actual training batch size +auto_scale_lr = dict(base_batch_size=1024) + +model = dict( + backbone=dict( + depths=[3, 4, 8, 3], + drop_path_rate=0.2, + init_cfg=dict( + type='Pretrained', + checkpoint='https://download.openmmlab.com/mmpose/v1/projects/' + 'uniformer/uniformer_small_in1k.pth' # noqa + ))) + +train_dataloader = dict(batch_size=32) +val_dataloader = dict(batch_size=256) diff --git a/projects/uniformer/configs/td-hm_uniformer-s-8xb128-210e_coco-384x288.py b/projects/uniformer/configs/td-hm_uniformer-s-8xb128-210e_coco-384x288.py new file mode 100644 index 0000000000..59f68946ef --- /dev/null +++ b/projects/uniformer/configs/td-hm_uniformer-s-8xb128-210e_coco-384x288.py @@ -0,0 +1,23 @@ +_base_ = ['./td-hm_uniformer-b-8xb32-210e_coco-384x288.py'] + +# optimizer +optim_wrapper = dict(optimizer=dict( + type='Adam', + lr=2e-3, +)) + +# automatically scaling LR based on the actual training batch size +auto_scale_lr = dict(base_batch_size=1024) + +model = dict( + backbone=dict( + depths=[3, 4, 8, 3], + drop_path_rate=0.2, + init_cfg=dict( + type='Pretrained', + checkpoint='https://download.openmmlab.com/mmpose/v1/projects/' + 'uniformer/uniformer_small_in1k.pth' # noqa + ))) + +train_dataloader = dict(batch_size=128) +val_dataloader = dict(batch_size=256) diff --git a/projects/uniformer/configs/td-hm_uniformer-s-8xb64-210e_coco-448x320.py b/projects/uniformer/configs/td-hm_uniformer-s-8xb64-210e_coco-448x320.py new file mode 100644 index 0000000000..0359ac6d63 --- /dev/null +++ b/projects/uniformer/configs/td-hm_uniformer-s-8xb64-210e_coco-448x320.py @@ -0,0 +1,22 @@ +_base_ = ['./td-hm_uniformer-b-8xb32-210e_coco-448x320.py'] + +# optimizer +optim_wrapper = dict(optimizer=dict( + type='Adam', + lr=1.0e-3, +)) + +# automatically scaling LR based on the actual training batch size +auto_scale_lr = dict(base_batch_size=512) + +model = dict( + backbone=dict( + depths=[3, 4, 8, 3], + drop_path_rate=0.2, + init_cfg=dict( + type='Pretrained', + checkpoint='https://download.openmmlab.com/mmpose/v1/projects/' + 'uniformer/uniformer_small_in1k.pth'))) + +train_dataloader = dict(batch_size=64) +val_dataloader = dict(batch_size=256) diff --git a/projects/uniformer/models/__init__.py b/projects/uniformer/models/__init__.py new file mode 100644 index 0000000000..6256db6f45 --- /dev/null +++ b/projects/uniformer/models/__init__.py @@ -0,0 +1 @@ +from .uniformer import * # noqa diff --git a/projects/uniformer/models/uniformer.py b/projects/uniformer/models/uniformer.py new file mode 100644 index 0000000000..cea36f061b --- /dev/null +++ b/projects/uniformer/models/uniformer.py @@ -0,0 +1,709 @@ +from collections import OrderedDict +from functools import partial +from typing import Dict, List, Optional, Union + +import torch +import torch.nn as nn +import torch.nn.functional as F +from mmcv.cnn.bricks.transformer import build_dropout +from mmengine.model import BaseModule +from mmengine.model.weight_init import trunc_normal_ +from mmengine.runner import checkpoint, load_checkpoint +from mmengine.utils import to_2tuple + +from mmpose.models.backbones.base_backbone import BaseBackbone +from mmpose.registry import MODELS +from mmpose.utils import get_root_logger + + +class Mlp(BaseModule): + """Multilayer perceptron. + + Args: + in_features (int): Number of input features. + hidden_features (int): Number of hidden features. + Defaults to None. + out_features (int): Number of output features. + Defaults to None. + drop (float): Dropout rate. Defaults to 0.0. + init_cfg (dict, optional): Config dict for initialization. + Defaults to None. + """ + + def __init__(self, + in_features: int, + hidden_features: int = None, + out_features: int = None, + drop_rate: float = 0., + init_cfg: Optional[dict] = None) -> None: + super().__init__(init_cfg=init_cfg) + out_features = out_features or in_features + hidden_features = hidden_features or in_features + self.fc1 = nn.Linear(in_features, hidden_features) + self.act = nn.GELU() + self.fc2 = nn.Linear(hidden_features, out_features) + self.drop = nn.Dropout(drop_rate) + + def forward(self, x): + x = self.act(self.fc1(x)) + x = self.fc2(self.drop(x)) + x = self.drop(x) + return x + + +class CMlp(BaseModule): + """Multilayer perceptron via convolution. + + Args: + in_features (int): Number of input features. + hidden_features (int): Number of hidden features. + Defaults to None. + out_features (int): Number of output features. + Defaults to None. + drop (float): Dropout rate. Defaults to 0.0. + init_cfg (dict, optional): Config dict for initialization. + Defaults to None. + """ + + def __init__(self, + in_features: int, + hidden_features: int = None, + out_features: int = None, + drop_rate: float = 0., + init_cfg: Optional[dict] = None) -> None: + super().__init__(init_cfg=init_cfg) + out_features = out_features or in_features + hidden_features = hidden_features or in_features + self.fc1 = nn.Conv2d(in_features, hidden_features, kernel_size=1) + self.act = nn.GELU() + self.fc2 = nn.Conv2d(hidden_features, out_features, kernel_size=1) + self.drop = nn.Dropout(drop_rate) + + def forward(self, x): + x = self.act(self.fc1(x)) + x = self.fc2(self.drop(x)) + x = self.drop(x) + return x + + +class CBlock(BaseModule): + """Convolution Block. + + Args: + embed_dim (int): Number of input features. + mlp_ratio (float): Ratio of mlp hidden dimension + to embedding dimension. Defaults to 4. + drop (float): Dropout rate. + Defaults to 0.0. + drop_paths (float): Stochastic depth rates. + Defaults to 0.0. + init_cfg (dict, optional): Config dict for initialization. + Defaults to None. + """ + + def __init__(self, + embed_dim: int, + mlp_ratio: float = 4., + drop_rate: float = 0., + drop_path_rate: float = 0., + init_cfg: Optional[dict] = None) -> None: + super().__init__(init_cfg=init_cfg) + self.pos_embed = nn.Conv2d( + embed_dim, embed_dim, 3, padding=1, groups=embed_dim) + self.norm1 = nn.BatchNorm2d(embed_dim) + self.conv1 = nn.Conv2d(embed_dim, embed_dim, 1) + self.conv2 = nn.Conv2d(embed_dim, embed_dim, 1) + self.attn = nn.Conv2d( + embed_dim, embed_dim, 5, padding=2, groups=embed_dim) + # NOTE: drop path for stochastic depth, we shall see if this is + # better than dropout here + self.drop_path = build_dropout( + dict(type='DropPath', drop_prob=drop_path_rate) + ) if drop_path_rate > 0. else nn.Identity() + self.norm2 = nn.BatchNorm2d(embed_dim) + mlp_hidden_dim = int(embed_dim * mlp_ratio) + self.mlp = CMlp( + in_features=embed_dim, + hidden_features=mlp_hidden_dim, + drop_rate=drop_rate) + + def forward(self, x): + x = x + self.pos_embed(x) + x = x + self.drop_path( + self.conv2(self.attn(self.conv1(self.norm1(x))))) + x = x + self.drop_path(self.mlp(self.norm2(x))) + return x + + +class Attention(BaseModule): + """Self-Attention. + + Args: + embed_dim (int): Number of input features. + num_heads (int): Number of attention heads. + Defaults to 8. + qkv_bias (bool): If True, add a learnable bias to query, key, value. + Defaults to True. + qk_scale (float, optional): Override default qk scale of + ``head_dim ** -0.5`` if set. Defaults to None. + attn_drop_rate (float): Attention dropout rate. + Defaults to 0.0. + proj_drop_rate (float): Dropout rate. + Defaults to 0.0. + init_cfg (dict, optional): Config dict for initialization. + Defaults to None. + init_cfg (dict, optional): The config of weight initialization. + Defaults to None. + """ + + def __init__(self, + embed_dim: int, + num_heads: int = 8, + qkv_bias: bool = True, + qk_scale: float = None, + attn_drop_rate: float = 0., + proj_drop_rate: float = 0., + init_cfg: Optional[dict] = None) -> None: + super().__init__(init_cfg=init_cfg) + self.num_heads = num_heads + head_dim = embed_dim // num_heads + # NOTE scale factor was wrong in my original version, can set manually + # to be compat with prev weights + self.scale = qk_scale or head_dim**-0.5 + + self.qkv = nn.Linear(embed_dim, embed_dim * 3, bias=qkv_bias) + self.attn_drop = nn.Dropout(attn_drop_rate) + self.proj = nn.Linear(embed_dim, embed_dim) + self.proj_drop = nn.Dropout(proj_drop_rate) + + def forward(self, x): + B, N, C = x.shape + qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, + C // self.num_heads).permute(2, 0, 3, 1, 4) + q, k, v = qkv[0], qkv[1], qkv[ + 2] # make torchscript happy (cannot use tensor as tuple) + + attn = (q @ k.transpose(-2, -1)) * self.scale + attn = attn.softmax(dim=-1) + attn = self.attn_drop(attn) + + x = (attn @ v).transpose(1, 2).reshape(B, N, C) + x = self.proj(x) + x = self.proj_drop(x) + return x + + +class PatchEmbed(BaseModule): + """Image to Patch Embedding. + + Args: + img_size (int): Number of input size. + Defaults to 224. + patch_size (int): Number of patch size. + Defaults to 16. + in_channels (int): Number of input features. + Defaults to 3. + embed_dims (int): Number of output features. + Defaults to 768. + init_cfg (dict, optional): Config dict for initialization. + Defaults to None. + """ + + def __init__(self, + img_size: int = 224, + patch_size: int = 16, + in_channels: int = 3, + embed_dim: int = 768, + init_cfg: Optional[dict] = None) -> None: + super().__init__(init_cfg=init_cfg) + img_size = to_2tuple(img_size) + patch_size = to_2tuple(patch_size) + num_patches = (img_size[1] // patch_size[1]) * ( + img_size[0] // patch_size[0]) + self.img_size = img_size + self.patch_size = patch_size + self.num_patches = num_patches + self.norm = nn.LayerNorm(embed_dim) + self.proj = nn.Conv2d( + in_channels, embed_dim, kernel_size=patch_size, stride=patch_size) + + def forward(self, x): + B, _, H, W = x.shape + x = self.proj(x) + B, _, H, W = x.shape + x = x.flatten(2).transpose(1, 2) + x = self.norm(x) + x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() + return x + + +class SABlock(BaseModule): + """Self-Attention Block. + + Args: + embed_dim (int): Number of input features. + num_heads (int): Number of attention heads. + mlp_ratio (float): Ratio of mlp hidden dimension + to embedding dimension. Defaults to 4. + qkv_bias (bool): If True, add a learnable bias to query, key, value. + Defaults to True. + qk_scale (float, optional): Override default qk scale of + ``head_dim ** -0.5`` if set. Defaults to None. + drop (float): Dropout rate. Defaults to 0.0. + attn_drop (float): Attention dropout rate. Defaults to 0.0. + drop_paths (float): Stochastic depth rates. + Defaults to 0.0. + init_cfg (dict, optional): Config dict for initialization. + Defaults to None. + """ + + def __init__(self, + embed_dim: int, + num_heads: int, + mlp_ratio: float = 4., + qkv_bias: bool = False, + qk_scale: float = None, + drop_rate: float = 0., + attn_drop_rate: float = 0., + drop_path_rate: float = 0., + init_cfg: Optional[dict] = None) -> None: + super().__init__(init_cfg=init_cfg) + + self.pos_embed = nn.Conv2d( + embed_dim, embed_dim, 3, padding=1, groups=embed_dim) + self.norm1 = nn.LayerNorm(embed_dim) + self.attn = Attention( + embed_dim, + num_heads=num_heads, + qkv_bias=qkv_bias, + qk_scale=qk_scale, + attn_drop_rate=attn_drop_rate, + proj_drop_rate=drop_rate) + # NOTE: drop path for stochastic depth, + # we shall see if this is better than dropout here + self.drop_path = build_dropout( + dict(type='DropPath', drop_prob=drop_path_rate) + ) if drop_path_rate > 0. else nn.Identity() + self.norm2 = nn.LayerNorm(embed_dim) + mlp_hidden_dim = int(embed_dim * mlp_ratio) + self.mlp = Mlp( + in_features=embed_dim, + hidden_features=mlp_hidden_dim, + drop_rate=drop_rate) + + def forward(self, x): + x = x + self.pos_embed(x) + B, N, H, W = x.shape + x = x.flatten(2).transpose(1, 2) + x = x + self.drop_path(self.attn(self.norm1(x))) + x = x + self.drop_path(self.mlp(self.norm2(x))) + x = x.transpose(1, 2).reshape(B, N, H, W) + return x + + +class WindowSABlock(BaseModule): + """Self-Attention Block. + + Args: + embed_dim (int): Number of input features. + num_heads (int): Number of attention heads. + window_size (int): Size of the partition window. Defaults to 14. + mlp_ratio (float): Ratio of mlp hidden dimension + to embedding dimension. Defaults to 4. + qkv_bias (bool): If True, add a learnable bias to query, key, value. + Defaults to True. + qk_scale (float, optional): Override default qk scale of + ``head_dim ** -0.5`` if set. Defaults to None. + drop (float): Dropout rate. Defaults to 0.0. + attn_drop (float): Attention dropout rate. Defaults to 0.0. + drop_paths (float): Stochastic depth rates. + Defaults to 0.0. + init_cfg (dict, optional): Config dict for initialization. + Defaults to None. + """ + + def __init__(self, + embed_dim: int, + num_heads: int, + window_size: int = 14, + mlp_ratio: float = 4., + qkv_bias: bool = False, + qk_scale: float = None, + drop_rate: float = 0., + attn_drop_rate: float = 0., + drop_path_rate: float = 0., + init_cfg: Optional[dict] = None) -> None: + super().__init__(init_cfg=init_cfg) + self.windows_size = window_size + self.pos_embed = nn.Conv2d( + embed_dim, embed_dim, 3, padding=1, groups=embed_dim) + self.norm1 = nn.LayerNorm(embed_dim) + self.attn = Attention( + embed_dim, + num_heads=num_heads, + qkv_bias=qkv_bias, + qk_scale=qk_scale, + attn_drop_rate=attn_drop_rate, + proj_drop_rate=drop_rate) + # NOTE: drop path for stochastic depth, + # we shall see if this is better than dropout here + self.drop_path = build_dropout( + dict(type='DropPath', drop_prob=drop_path_rate) + ) if drop_path_rate > 0. else nn.Identity() + # self.norm2 = build_dropout(norm_cfg, embed_dims)[1] + self.norm2 = nn.LayerNorm(embed_dim) + mlp_hidden_dim = int(embed_dim * mlp_ratio) + self.mlp = Mlp( + in_features=embed_dim, + hidden_features=mlp_hidden_dim, + drop_rate=drop_rate) + + def window_reverse(self, windows, H, W): + """ + Args: + windows: (num_windows*B, window_size, window_size, C) + H (int): Height of image + W (int): Width of image + Returns: + x: (B, H, W, C) + """ + window_size = self.window_size + B = int(windows.shape[0] / (H * W / window_size / window_size)) + x = windows.view(B, H // window_size, W // window_size, window_size, + window_size, -1) + x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1) + return x + + def window_partition(self, x): + """ + Args: + x: (B, H, W, C) + Returns: + windows: (num_windows*B, window_size, window_size, C) + """ + B, H, W, C = x.shape + window_size = self.window_size + x = x.view(B, H // window_size, window_size, W // window_size, + window_size, C) + windows = x.permute(0, 1, 3, 2, 4, + 5).contiguous().view(-1, window_size, window_size, + C) + return windows + + def forward(self, x): + x = x + self.pos_embed(x) + x = x.permute(0, 2, 3, 1) + B, H, W, C = x.shape + shortcut = x + x = self.norm1(x) + + pad_l = pad_t = 0 + pad_r = (self.window_size - W % self.window_size) % self.window_size + pad_b = (self.window_size - H % self.window_size) % self.window_size + x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b)) + _, H_pad, W_pad, _ = x.shape + + x_windows = self.window_partition( + x) # nW*B, window_size, window_size, C + x_windows = x_windows.view(-1, self.window_size * self.window_size, + C) # nW*B, window_size*window_size, C + + # W-MSA/SW-MSA + attn_windows = self.attn(x_windows) # nW*B, window_size*window_size, C + + # merge windows + attn_windows = attn_windows.view(-1, self.window_size, + self.window_size, C) + x = self.window_reverse(attn_windows, H_pad, W_pad) # B H' W' C + + # reverse cyclic shift + if pad_r > 0 or pad_b > 0: + x = x[:, :H, :W, :].contiguous() + + x = shortcut + self.drop_path(x) + x = x + self.drop_path(self.mlp(self.norm2(x))) + x = x.permute(0, 3, 1, 2).reshape(B, C, H, W) + return x + + +@MODELS.register_module() +class UniFormer(BaseBackbone): + """The implementation of Uniformer with downstream pose estimation task. + + UniFormer: Unifying Convolution and Self-attention for Visual Recognition + https://arxiv.org/abs/2201.09450 + UniFormer: Unified Transformer for Efficient Spatiotemporal Representation + Learning https://arxiv.org/abs/2201.04676 + + Args: + depths (List[int]): number of block in each layer. + Default to [3, 4, 8, 3]. + img_size (int, tuple): input image size. Default: 224. + in_channels (int): number of input channels. Default: 3. + num_classes (int): number of classes for classification head. Default + to 80. + embed_dims (List[int]): embedding dimensions. + Default to [64, 128, 320, 512]. + head_dim (int): dimension of attention heads + mlp_ratio (int): ratio of mlp hidden dim to embedding dim + qkv_bias (bool, optional): if True, add a learnable bias to query, key, + value. Default: True + qk_scale (float | None, optional): override default qk scale of + head_dim ** -0.5 if set. Default: None. + representation_size (Optional[int]): enable and set representation + layer (pre-logits) to this value if set + drop_rate (float): dropout rate. Default: 0. + attn_drop_rate (float): attention dropout rate. Default: 0. + drop_path_rate (float): stochastic depth rate. Default: 0. + norm_layer (nn.Module): normalization layer + use_checkpoint (bool): whether use torch.utils.checkpoint + checkpoint_num (list): index for using checkpoint in every stage + use_windows (bool): whether use window MHRA + use_hybrid (bool): whether use hybrid MHRA + window_size (int): size of window (>14). Default: 14. + init_cfg (dict, optional): Config dict for initialization. + Defaults to None. + """ + + def __init__( + self, + depths: List[int] = [3, 4, 8, 3], + img_size: int = 224, + in_channels: int = 3, + num_classes: int = 80, + embed_dims: List[int] = [64, 128, 320, 512], + head_dim: int = 64, + mlp_ratio: int = 4., + qkv_bias: bool = True, + qk_scale: float = None, + representation_size: Optional[int] = None, + drop_rate: float = 0., + attn_drop_rate: float = 0., + drop_path_rate: float = 0., + norm_layer=partial(nn.LayerNorm, eps=1e-6), + use_checkpoint: bool = False, + checkpoint_num=(0, 0, 0, 0), + use_window: bool = False, + use_hybrid: bool = False, + window_size: int = 14, + init_cfg: Optional[Union[Dict, List[Dict]]] = [ + dict(type='TruncNormal', layer='Linear', std=0.02, bias=0.), + dict(type='Constant', layer='LayerNorm', val=1., bias=0.) + ] + ) -> None: + super(UniFormer, self).__init__(init_cfg=init_cfg) + + self.num_classes = num_classes + self.use_checkpoint = use_checkpoint + self.checkpoint_num = checkpoint_num + self.use_window = use_window + self.logger = get_root_logger() + self.logger.info(f'Use torch.utils.checkpoint: {self.use_checkpoint}') + self.logger.info( + f'torch.utils.checkpoint number: {self.checkpoint_num}') + self.num_features = self.embed_dims = embed_dims + norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6) + + self.patch_embed1 = PatchEmbed( + img_size=img_size, + patch_size=4, + in_channels=in_channels, + embed_dim=embed_dims[0]) + self.patch_embed2 = PatchEmbed( + img_size=img_size // 4, + patch_size=2, + in_channels=embed_dims[0], + embed_dim=embed_dims[1]) + self.patch_embed3 = PatchEmbed( + img_size=img_size // 8, + patch_size=2, + in_channels=embed_dims[1], + embed_dim=embed_dims[2]) + self.patch_embed4 = PatchEmbed( + img_size=img_size // 16, + patch_size=2, + in_channels=embed_dims[2], + embed_dim=embed_dims[3]) + + self.drop_after_pos = nn.Dropout(drop_rate) + dpr = [ + x.item() for x in torch.linspace(0, drop_path_rate, sum(depths)) + ] # stochastic depth decay rule + num_heads = [dim // head_dim for dim in embed_dims] + self.blocks1 = nn.ModuleList([ + CBlock( + embed_dim=embed_dims[0], + mlp_ratio=mlp_ratio, + drop_rate=drop_rate, + drop_path_rate=dpr[i]) for i in range(depths[0]) + ]) + self.norm1 = norm_layer(embed_dims[0]) + self.blocks2 = nn.ModuleList([ + CBlock( + embed_dim=embed_dims[1], + mlp_ratio=mlp_ratio, + drop_rate=drop_rate, + drop_path_rate=dpr[i + depths[0]]) for i in range(depths[1]) + ]) + self.norm2 = norm_layer(embed_dims[1]) + if self.use_window: + self.logger.info('Use local window for all blocks in stage3') + self.blocks3 = nn.ModuleList([ + WindowSABlock( + embed_dim=embed_dims[2], + num_heads=num_heads[2], + window_size=window_size, + mlp_ratio=mlp_ratio, + qkv_bias=qkv_bias, + qk_scale=qk_scale, + drop_rate=drop_rate, + attn_drop_rate=attn_drop_rate, + drop_path_rate=dpr[i + depths[0] + depths[1]]) + for i in range(depths[2]) + ]) + elif use_hybrid: + self.logger.info('Use hybrid window for blocks in stage3') + block3 = [] + for i in range(depths[2]): + if (i + 1) % 4 == 0: + block3.append( + SABlock( + embed_dim=embed_dims[2], + num_heads=num_heads[2], + mlp_ratio=mlp_ratio, + qkv_bias=qkv_bias, + qk_scale=qk_scale, + drop_rate=drop_rate, + attn_drop_rate=attn_drop_rate, + drop_path_rate=dpr[i + depths[0] + depths[1]])) + else: + block3.append( + WindowSABlock( + embed_dim=embed_dims[2], + num_heads=num_heads[2], + window_size=window_size, + mlp_ratio=mlp_ratio, + qkv_bias=qkv_bias, + qk_scale=qk_scale, + drop_rate=drop_rate, + attn_drop_rate=attn_drop_rate, + drop_path_rate=dpr[i + depths[0] + depths[1]])) + self.blocks3 = nn.ModuleList(block3) + else: + self.logger.info('Use global window for all blocks in stage3') + self.blocks3 = nn.ModuleList([ + SABlock( + embed_dim=embed_dims[2], + num_heads=num_heads[2], + mlp_ratio=mlp_ratio, + qkv_bias=qkv_bias, + qk_scale=qk_scale, + drop_rate=drop_rate, + attn_drop_rate=attn_drop_rate, + drop_path_rate=dpr[i + depths[0] + depths[1]]) + for i in range(depths[2]) + ]) + self.norm3 = norm_layer(embed_dims[2]) + self.blocks4 = nn.ModuleList([ + SABlock( + embed_dim=embed_dims[3], + num_heads=num_heads[3], + mlp_ratio=mlp_ratio, + qkv_bias=qkv_bias, + qk_scale=qk_scale, + drop_rate=drop_rate, + attn_drop_rate=attn_drop_rate, + drop_path_rate=dpr[i + depths[0] + depths[1] + depths[2]]) + for i in range(depths[3]) + ]) + self.norm4 = norm_layer(embed_dims[3]) + + # Representation layer + if representation_size: + self.num_features = representation_size + self.pre_logits = nn.Sequential( + OrderedDict([('fc', nn.Linear(embed_dims, + representation_size)), + ('act', nn.Tanh())])) + else: + self.pre_logits = nn.Identity() + + self.apply(self._init_weights) + self.init_weights() + + def init_weights(self): + """Initialize the weights in backbone. + + Args: + pretrained (str, optional): Path to pre-trained weights. + Defaults to None. + """ + if (isinstance(self.init_cfg, dict) + and self.init_cfg['type'] == 'Pretrained'): + pretrained = self.init_cfg['checkpoint'] + load_checkpoint( + self, + pretrained, + map_location='cpu', + strict=False, + logger=self.logger) + self.logger.info(f'Load pretrained model from {pretrained}') + + def _init_weights(self, m): + if isinstance(m, nn.Linear): + trunc_normal_(m.weight, std=.02) + if isinstance(m, nn.Linear) and m.bias is not None: + nn.init.constant_(m.bias, 0) + elif isinstance(m, nn.LayerNorm): + nn.init.constant_(m.bias, 0) + nn.init.constant_(m.weight, 1.0) + + @torch.jit.ignore + def no_weight_decay(self): + return {'pos_embed', 'cls_token'} + + def get_classifier(self): + return self.head + + def reset_classifier(self, num_classes, global_pool=''): + self.num_classes = num_classes + self.head = nn.Linear( + self.embed_dims, + num_classes) if num_classes > 0 else nn.Identity() + + def forward(self, x): + out = [] + x = self.patch_embed1(x) + x = self.drop_after_pos(x) + for i, blk in enumerate(self.blocks1): + if self.use_checkpoint and i < self.checkpoint_num[0]: + x = checkpoint.checkpoint(blk, x) + else: + x = blk(x) + x_out = self.norm1(x.permute(0, 2, 3, 1)) + out.append(x_out.permute(0, 3, 1, 2).contiguous()) + x = self.patch_embed2(x) + for i, blk in enumerate(self.blocks2): + if self.use_checkpoint and i < self.checkpoint_num[1]: + x = checkpoint.checkpoint(blk, x) + else: + x = blk(x) + x_out = self.norm2(x.permute(0, 2, 3, 1)) + out.append(x_out.permute(0, 3, 1, 2).contiguous()) + x = self.patch_embed3(x) + for i, blk in enumerate(self.blocks3): + if self.use_checkpoint and i < self.checkpoint_num[2]: + x = checkpoint.checkpoint(blk, x) + else: + x = blk(x) + x_out = self.norm3(x.permute(0, 2, 3, 1)) + out.append(x_out.permute(0, 3, 1, 2).contiguous()) + x = self.patch_embed4(x) + for i, blk in enumerate(self.blocks4): + if self.use_checkpoint and i < self.checkpoint_num[3]: + x = checkpoint.checkpoint(blk, x) + else: + x = blk(x) + x_out = self.norm4(x.permute(0, 2, 3, 1)) + out.append(x_out.permute(0, 3, 1, 2).contiguous()) + return tuple(out) diff --git a/projects/yolox_pose/README.md b/projects/yolox_pose/README.md index 264b65fe9f..35a830487c 100644 --- a/projects/yolox_pose/README.md +++ b/projects/yolox_pose/README.md @@ -4,16 +4,24 @@ This project implements a YOLOX-based human pose estimator, utilizing the approa
+📌 For improved performance and compatibility, **consider using YOLOX-Pose which is built into MMPose**, which seamlessly integrates with MMPose's tools. To learn more about adopting YOLOX-Pose in your workflow, see the documentation: [YOLOX-Pose](/configs/body_2d_keypoint/yoloxpose/README.md). + ## Usage ### Prerequisites - Python 3.7 or higher + - PyTorch 1.6 or higher + - [MMEngine](https://github.com/open-mmlab/mmengine) v0.6.0 or higher + - [MMCV](https://github.com/open-mmlab/mmcv) v2.0.0rc4 or higher + - [MMDetection](https://github.com/open-mmlab/mmdetection) v3.0.0rc6 or higher -- [MMYOLO](https://github.com/open-mmlab/mmyolo) v0.5.0 or higher + +- [MMYOLO](https://github.com/open-mmlab/mmyolo) **v0.5.0** + - [MMPose](https://github.com/open-mmlab/mmpose) v1.0.0rc1 or higher All the commands below rely on the correct configuration of `PYTHONPATH`, which should point to the project's directory so that Python can locate the module files. **In `yolox-pose/` root directory**, run the following line to add the current directory to `PYTHONPATH`: diff --git a/projects/yolox_pose/datasets/__init__.py b/projects/yolox_pose/datasets/__init__.py index 69bae9de53..abf0d11d23 100644 --- a/projects/yolox_pose/datasets/__init__.py +++ b/projects/yolox_pose/datasets/__init__.py @@ -1,3 +1,13 @@ +import mmengine +import mmyolo + +compatible_version = '0.5.0' +if mmengine.digit_version(mmyolo.__version__)[1] > \ + mmengine.digit_version(compatible_version)[1]: + print(f'This project is only compatible with mmyolo {compatible_version} ' + f'or lower. Please install the required version via:' + f'pip install mmyolo=={compatible_version}') + from .bbox_keypoint_structure import * # noqa from .coco_dataset import * # noqa from .transforms import * # noqa diff --git a/projects/yolox_pose/models/__init__.py b/projects/yolox_pose/models/__init__.py index 0d4804e70a..c81450826d 100644 --- a/projects/yolox_pose/models/__init__.py +++ b/projects/yolox_pose/models/__init__.py @@ -1,3 +1,13 @@ +import mmengine +import mmyolo + +compatible_version = '0.5.0' +if mmengine.digit_version(mmyolo.__version__)[1] > \ + mmengine.digit_version(compatible_version)[1]: + print(f'This project is only compatible with mmyolo {compatible_version} ' + f'or lower. Please install the required version via:' + f'pip install mmyolo=={compatible_version}') + from .assigner import * # noqa from .data_preprocessor import * # noqa from .oks_loss import * # noqa diff --git a/requirements/mminstall.txt b/requirements/mminstall.txt index 30d8402a42..32eb00aceb 100644 --- a/requirements/mminstall.txt +++ b/requirements/mminstall.txt @@ -1,3 +1,3 @@ -mmcv>=2.0.0,<2.1.0 -mmdet>=3.0.0,<3.2.0 +mmcv>=2.0.0,<2.2.0 +mmdet>=3.0.0,<3.3.0 mmengine>=0.4.0,<1.0.0 diff --git a/tests/data/300wlp/AFW_134212_1_0.jpg b/tests/data/300wlp/AFW_134212_1_0.jpg new file mode 100644 index 0000000000..6e82cb47db Binary files /dev/null and b/tests/data/300wlp/AFW_134212_1_0.jpg differ diff --git a/tests/data/300wlp/AFW_134212_2_0.jpg b/tests/data/300wlp/AFW_134212_2_0.jpg new file mode 100644 index 0000000000..5640d2f0fb Binary files /dev/null and b/tests/data/300wlp/AFW_134212_2_0.jpg differ diff --git a/tests/data/300wlp/test_300wlp.json b/tests/data/300wlp/test_300wlp.json new file mode 100644 index 0000000000..1598d1fe17 --- /dev/null +++ b/tests/data/300wlp/test_300wlp.json @@ -0,0 +1 @@ +{"info": {"description": "LaPa Generated by MMPose Team", "version": 1.0, "year": "2023", "date_created": "2023/09/20"}, "images": [{"id": 1, "file_name": "AFW_134212_1_0.jpg", "height": 450, "width": 450}, {"id": 2, "file_name": "AFW_134212_2_0.jpg", "height": 450, "width": 450}], "annotations": [{"keypoints": [144.78085327148438, 253.39178466796875, 2.0, 143.70928955078125, 275.5905456542969, 2.0, 147.26495361328125, 292.55340576171875, 2.0, 154.74082946777344, 307.56976318359375, 2.0, 164.7685089111328, 325.37213134765625, 2.0, 175.56622314453125, 341.6143798828125, 2.0, 183.95713806152344, 350.2955322265625, 2.0, 191.24447631835938, 364.373291015625, 2.0, 212.22702026367188, 373.85772705078125, 2.0, 238.06739807128906, 365.5926513671875, 2.0, 262.0357971191406, 350.78265380859375, 2.0, 281.9491882324219, 335.1942138671875, 2.0, 297.3870849609375, 316.2213134765625, 2.0, 305.5174560546875, 296.20111083984375, 2.0, 310.0191650390625, 278.38665771484375, 2.0, 313.570556640625, 257.59332275390625, 2.0, 314.68060302734375, 234.81509399414062, 2.0, 141.07717895507812, 233.8748016357422, 2.0, 142.4314727783203, 231.93350219726562, 2.0, 149.53399658203125, 232.0662384033203, 2.0, 158.13735961914062, 234.31857299804688, 2.0, 167.29750061035156, 237.67184448242188, 2.0, 205.59320068359375, 234.99285888671875, 2.0, 216.04824829101562, 229.73251342773438, 2.0, 229.51547241210938, 225.43397521972656, 2.0, 245.78271484375, 224.81817626953125, 2.0, 261.8216552734375, 228.80909729003906, 2.0, 186.61602783203125, 257.0625, 2.0, 183.9759979248047, 273.16412353515625, 2.0, 180.80419921875, 288.9212646484375, 2.0, 181.61343383789062, 300.6891174316406, 2.0, 180.70370483398438, 302.4509582519531, 2.0, 184.2169189453125, 305.52349853515625, 2.0, 190.96376037597656, 307.95452880859375, 2.0, 199.12416076660156, 305.3871765136719, 2.0, 206.879150390625, 302.37335205078125, 2.0, 154.32986450195312, 249.83685302734375, 2.0, 156.83566284179688, 248.1170654296875, 2.0, 166.4077911376953, 247.8013916015625, 2.0, 177.58078002929688, 251.6158905029297, 2.0, 168.43463134765625, 254.5105743408203, 2.0, 159.2126007080078, 254.42872619628906, 2.0, 216.7241973876953, 250.81556701660156, 2.0, 224.13780212402344, 246.13824462890625, 2.0, 234.09474182128906, 245.99227905273438, 2.0, 245.9826202392578, 248.45945739746094, 2.0, 236.0019989013672, 253.0175323486328, 2.0, 224.37583923339844, 253.48345947265625, 2.0, 175.86959838867188, 319.50311279296875, 2.0, 179.09326171875, 319.59539794921875, 2.0, 187.91131591796875, 319.067138671875, 2.0, 193.9979248046875, 320.62445068359375, 2.0, 200.40106201171875, 319.33489990234375, 2.0, 217.08116149902344, 320.4862976074219, 2.0, 233.78671264648438, 322.4403076171875, 2.0, 219.32835388183594, 334.7911376953125, 2.0, 208.45263671875, 340.60760498046875, 2.0, 198.55410766601562, 341.6135559082031, 2.0, 189.62986755371094, 339.7992858886719, 2.0, 183.0074462890625, 332.94818115234375, 2.0, 178.17086791992188, 319.563232421875, 2.0, 188.85269165039062, 324.1929931640625, 2.0, 196.60971069335938, 325.0108642578125, 2.0, 205.92147827148438, 324.99169921875, 2.0, 231.7099609375, 322.35394287109375, 2.0, 206.32933044433594, 331.2320556640625, 2.0, 197.35250854492188, 331.98333740234375, 2.0, 189.53477478027344, 330.077392578125, 2.0], "image_id": 1, "id": 1, "num_keypoints": 68, "bbox": [141.07717895507812, 224.81817626953125, 173.60342407226562, 149.03955078125], "iscrowd": 0, "area": 25873, "category_id": 1}, {"keypoints": [135.04940795898438, 222.4427947998047, 2.0, 135.0158233642578, 245.55397033691406, 2.0, 136.51287841796875, 266.4256896972656, 2.0, 138.80328369140625, 286.6426086425781, 2.0, 144.32032775878906, 310.9339294433594, 2.0, 157.32864379882812, 334.45831298828125, 2.0, 174.5981903076172, 352.64923095703125, 2.0, 196.57693481445312, 368.895751953125, 2.0, 223.50587463378906, 378.31634521484375, 2.0, 251.17575073242188, 369.77850341796875, 2.0, 267.59075927734375, 355.8761901855469, 2.0, 280.4201965332031, 341.2083740234375, 2.0, 293.03106689453125, 321.76690673828125, 2.0, 301.7103576660156, 299.455078125, 2.0, 306.847412109375, 279.4398193359375, 2.0, 312.0267639160156, 260.4844970703125, 2.0, 314.9190673828125, 240.6781768798828, 2.0, 170.3564453125, 224.36227416992188, 2.0, 183.98776245117188, 220.8751220703125, 2.0, 199.30447387695312, 221.02830505371094, 2.0, 212.521484375, 223.36888122558594, 2.0, 223.74468994140625, 226.60350036621094, 2.0, 268.19195556640625, 228.3536376953125, 2.0, 278.82196044921875, 226.323486328125, 2.0, 289.98040771484375, 224.9724884033203, 2.0, 301.55609130859375, 226.1953887939453, 2.0, 308.71484375, 230.00015258789062, 2.0, 244.0289764404297, 256.7021484375, 2.0, 244.56097412109375, 275.8743896484375, 2.0, 244.62387084960938, 293.44793701171875, 2.0, 243.3439483642578, 305.9898376464844, 2.0, 222.41458129882812, 304.99017333984375, 2.0, 229.01458740234375, 308.64453125, 2.0, 237.42706298828125, 312.08013916015625, 2.0, 245.45481872558594, 310.38775634765625, 2.0, 250.5335693359375, 307.69195556640625, 2.0, 187.56089782714844, 246.6132049560547, 2.0, 197.1554412841797, 247.3951416015625, 2.0, 208.1782989501953, 248.00457763671875, 2.0, 217.29855346679688, 250.23162841796875, 2.0, 208.33084106445312, 253.25308227539062, 2.0, 196.66152954101562, 252.4826202392578, 2.0, 262.341064453125, 251.73179626464844, 2.0, 273.3721618652344, 250.15658569335938, 2.0, 284.34228515625, 250.62045288085938, 2.0, 290.07666015625, 250.62611389160156, 2.0, 282.4354248046875, 255.56341552734375, 2.0, 271.82550048828125, 255.81756591796875, 2.0, 199.1420135498047, 325.15618896484375, 2.0, 213.11370849609375, 323.486328125, 2.0, 227.83006286621094, 322.69268798828125, 2.0, 234.6953582763672, 325.06048583984375, 2.0, 241.50355529785156, 324.013916015625, 2.0, 252.42141723632812, 327.2342834472656, 2.0, 258.1256408691406, 331.502685546875, 2.0, 248.24850463867188, 341.65667724609375, 2.0, 238.77732849121094, 347.1531982421875, 2.0, 228.27822875976562, 347.7994384765625, 2.0, 218.2596435546875, 345.81182861328125, 2.0, 209.1992645263672, 338.6329345703125, 2.0, 202.04551696777344, 325.17730712890625, 2.0, 222.98101806640625, 328.13006591796875, 2.0, 232.16001892089844, 329.54791259765625, 2.0, 240.60108947753906, 329.82879638671875, 2.0, 256.0614929199219, 331.196044921875, 2.0, 238.20115661621094, 336.92901611328125, 2.0, 229.0829315185547, 337.291015625, 2.0, 220.1124267578125, 335.1085510253906, 2.0], "image_id": 2, "id": 2, "num_keypoints": 68, "bbox": [135.0158233642578, 220.8751220703125, 179.9032440185547, 157.44122314453125], "iscrowd": 0, "area": 28324, "category_id": 1}], "categories": [{"supercategory": "person", "id": 1, "name": "face", "keypoints": [], "skeleton": []}]} \ No newline at end of file diff --git a/tests/data/ubody3d/ubody3d_train.json b/tests/data/ubody3d/ubody3d_train.json new file mode 100644 index 0000000000..55a4ac5226 --- /dev/null +++ b/tests/data/ubody3d/ubody3d_train.json @@ -0,0 +1 @@ +{"images": [{"id": 15, "height": 720, "width": 1280, "file_name": "Magic_show/Magic_show_S1_Trim1/Magic_show_S1_Trim1/000016.png"}], "annotations": [{"id": 0, "image_id": 15, "bbox": [74.55498504638672, 8.571063995361328, 1062.4967727661133, 701.8491630554199], "segmentation": [[]], "area": 0, "iscrowd": 0, "category_id": 1, "score": 1, "person_id": 0, "hand_box1": [336.4236145019531, 321.40362548828125, 473.6637268066406, 452.62567138671875], "hand_box2": [699.218994140625, 50.335018157958984, 533.58251953125, 621.6577186584473], "keypoints": [[585.656005859375, 1398.5216064453125], [699.9061889648438, 1586.966064453125], [450.14288330078125, 1596.144775390625], [878.3228149414062, 2171.27783203125], [252.16543579101562, 2132.398681640625], [793.895263671875, 2988.90771484375], [232.56475830078125, 2939.503173828125], [588.2872314453125, 570.474365234375], [862.1456298828125, 514.33837890625], [373.89849853515625, 519.60888671875], [1073.739990234375, 765.0070190429688], [89.8785400390625, 775.919921875], [1000.2418212890625, 635.8955688476562], [189.44015502929688, 567.993408203125], [891.81298828125, 2948.2041015625], [1013.4824829101562, 3015.250732421875], [819.24658203125, 3122.821533203125], [172.14041137695312, 2868.272705078125], [31.46063232421875, 2937.01025390625], [244.37692260742188, 3111.135009765625], [760.2764282226562, 235.35623168945312], [469.04644775390625, 237.359130859375], [672.689453125, 216.68638610839844], [536.8645629882812, 215.08010864257812], [594.4747924804688, 302.86590576171875], [937.543212890625, 563.2012939453125], [877.2040405273438, 564.7064819335938], [826.8228759765625, 548.8115234375], [768.3922729492188, 532.2924194335938], [945.0330810546875, 433.25579833984375], [887.2977905273438, 411.39129638671875], [854.9716796875, 409.1885986328125], [812.5216064453125, 409.8503112792969], [993.1986083984375, 415.13519287109375], [983.431640625, 352.09503173828125], [976.8125610351562, 306.58990478515625], [967.6991577148438, 251.8966064453125], [1042.6788330078125, 439.2115783691406], [1061.695068359375, 382.62310791015625], [1078.3428955078125, 336.8554382324219], [1089.8707275390625, 288.113037109375], [1077.3145751953125, 467.8497009277344], [1113.5694580078125, 449.51904296875], [1147.91796875, 434.2681884765625], [1184.372314453125, 406.7205505371094], [262.0787048339844, 512.4108276367188], [314.8291320800781, 495.84429931640625], [355.2375183105469, 463.73870849609375], [400.5841064453125, 429.6348876953125], [290.11627197265625, 385.6371765136719], [334.016357421875, 356.7796325683594], [352.326904296875, 347.6751403808594], [379.92449951171875, 336.6559143066406], [248.99337768554688, 355.2509460449219], [270.441162109375, 294.56085205078125], [283.58990478515625, 247.07943725585938], [298.6072692871094, 191.95077514648438], [194.588623046875, 364.1822509765625], [197.89288330078125, 304.9277038574219], [198.94699096679688, 255.0223846435547], [207.83172607421875, 206.8009490966797], [152.69793701171875, 380.91925048828125], [126.07894897460938, 349.861083984375], [99.02603149414062, 320.67138671875], [75.35498046875, 280.7127380371094], [605.5189819335938, 258.36474609375], [636.6569213867188, 261.03448486328125], [672.689453125, 216.68638610839844], [536.8645629882812, 215.08010864257812], [480.609130859375, 193.2221221923828], [498.7352294921875, 169.0961151123047], [527.0252075195312, 168.48736572265625], [556.564453125, 174.32501220703125], [582.2213134765625, 183.7449188232422], [619.771728515625, 185.09783935546875], [646.1015625, 177.27572631835938], [678.3016357421875, 172.73214721679688], [709.5665283203125, 174.52818298339844], [730.6221313476562, 199.52928161621094], [600.2632446289062, 215.79234313964844], [598.0828247070312, 240.45635986328125], [596.2218627929688, 264.4862976074219], [594.4674072265625, 287.62481689453125], [572.7188110351562, 305.8975830078125], [583.9725341796875, 311.3199157714844], [596.401123046875, 315.5985107421875], [609.6165771484375, 311.5094909667969], [622.2186279296875, 306.6711120605469], [512.6423950195312, 211.75982666015625], [528.5633544921875, 204.07089233398438], [548.4610595703125, 205.9830780029297], [565.9568481445312, 217.66900634765625], [548.8089599609375, 222.94613647460938], [530.2134399414062, 222.75762939453125], [639.6070556640625, 219.82444763183594], [655.8860473632812, 209.6044158935547], [676.3201904296875, 208.3985595703125], [694.9487915039062, 217.1615753173828], [674.3418579101562, 226.85595703125], [655.4156494140625, 225.6745147705078], [551.7490234375, 353.2354736328125], [564.1500244140625, 346.4883728027344], [583.2034912109375, 344.99609375], [595.4065551757812, 347.21868896484375], [607.8397216796875, 345.721435546875], [629.6182250976562, 348.2886047363281], [648.6402587890625, 353.0809631347656], [634.0433349609375, 361.12738037109375], [612.543212890625, 365.1044921875], [598.9017333984375, 366.5699768066406], [585.4385375976562, 366.0231018066406], [566.12353515625, 362.2437744140625], [553.4495239257812, 352.7164001464844], [583.9151000976562, 355.8670654296875], [596.3876342773438, 356.340576171875], [608.99560546875, 356.22100830078125], [648.081787109375, 352.85076904296875], [612.7412719726562, 351.5333251953125], [598.9871215820312, 351.8242492675781], [585.3312377929688, 352.4969482421875], [464.1539001464844, 202.29954528808594], [465.8164978027344, 244.8143768310547], [469.96026611328125, 282.73333740234375], [474.998779296875, 318.5062255859375], [485.900390625, 354.82257080078125], [503.9440002441406, 389.1557922363281], [533.9607543945312, 420.1808776855469], [569.1990356445312, 439.69488525390625], [604.7715454101562, 445.1242370605469], [641.609130859375, 438.5807189941406], [677.1731567382812, 419.1774597167969], [709.558349609375, 390.3476867675781], [728.9358520507812, 358.6229553222656], [743.6824951171875, 323.7010192871094], [752.355224609375, 286.009033203125], [756.031494140625, 248.0742645263672], [756.6275634765625, 206.8378448486328]], "foot_kpts": [1166.72314453125, 38.096336364746094, 0, 1002.4937744140625, 109.48077392578125, 0, 1049.140869140625, 663.1453857421875, 0, 317.3815002441406, 32.0361328125, 0, 402.523681640625, 303.2774963378906, 0, 177.21731567382812, 665.190673828125, 0], "face_kpts": [482.1813659667969, 206.51531982421875, 0, 474.4501037597656, 248.23251342773438, 1, 482.5657043457031, 282.5651550292969, 1, 490.3671569824219, 326.8166198730469, 1, 498.9546813964844, 355.2204895019531, 1, 519.25634765625, 390.5085754394531, 1, 543.9222412109375, 417.4048156738281, 1, 574.4150390625, 437.6228332519531, 1, 614.6944580078125, 442.5209045410156, 1, 648.99267578125, 436.2539978027344, 1, 682.6341552734375, 416.4512023925781, 1, 702.5023193359375, 392.0824279785156, 1, 725.9093017578125, 358.3260803222656, 1, 739.4346923828125, 328.9374084472656, 1, 746.7598876953125, 285.0207824707031, 1, 748.8603515625, 251.59585571289062, 1, 755.915771484375, 212.4534149169922, 0, 496.4743957519531, 188.47494506835938, 1, 514.8231201171875, 177.99856567382812, 1, 535.214111328125, 176.0469970703125, 1, 556.4619140625, 177.9375, 1, 576.8843994140625, 183.35317993164062, 1, 631.4595947265625, 183.65673828125, 1, 652.4815673828125, 180.27340698242188, 1, 676.221923828125, 180.07711791992188, 1, 698.4794921875, 184.41073608398438, 1, 718.5443115234375, 196.21084594726562, 1, 604.396484375, 218.71194458007812, 1, 602.6702880859375, 245.68115234375, 1, 600.9422607421875, 271.4402770996094, 1, 599.4947509765625, 297.5359802246094, 1, 571.33203125, 313.3100891113281, 1, 586.1724853515625, 317.1542663574219, 1, 601.4893798828125, 320.0868835449219, 1, 617.738525390625, 316.9916687011719, 1, 632.822509765625, 313.9440002441406, 1, 524.906005859375, 216.0177001953125, 1, 542.880859375, 206.15841674804688, 1, 563.9365234375, 208.03213500976562, 1, 578.5321044921875, 222.44454956054688, 1, 559.7491455078125, 226.11843872070312, 1, 541.22607421875, 225.11203002929688, 1, 636.491943359375, 223.62353515625, 1, 652.7271728515625, 210.68789672851562, 1, 674.761474609375, 209.86370849609375, 1, 692.972900390625, 221.53323364257812, 1, 674.9864501953125, 228.75543212890625, 1, 656.0750732421875, 229.04306030273438, 1, 560.0743408203125, 351.4398498535156, 1, 577.081787109375, 347.0306091308594, 1, 594.04638671875, 345.2702941894531, 1, 604.1793212890625, 346.1555480957031, 1, 614.151611328125, 344.8525695800781, 1, 634.447509765625, 345.7118225097656, 1, 656.1597900390625, 347.9260559082031, 1, 640.6773681640625, 358.7562561035156, 1, 624.00732421875, 366.7438049316406, 1, 605.445556640625, 369.8896789550781, 1, 588.646484375, 367.5843811035156, 1, 573.5023193359375, 360.9281921386719, 1, 565.385498046875, 352.2278137207031, 1, 585.1085205078125, 353.1212463378906, 1, 604.616943359375, 355.0426330566406, 1, 626.8272705078125, 351.8833312988281, 1, 650.2919921875, 349.2644958496094, 1, 627.5924072265625, 353.0104675292969, 1, 604.7803955078125, 355.8074645996094, 1, 584.6986083984375, 354.2829284667969, 1], "lefthand_kpts": [942.7679443359375, 607.469482421875, 1, 888.291259765625, 539.277587890625, 1, 832.873291015625, 483.5708923339844, 1, 787.126953125, 436.6972351074219, 1, 710.735107421875, 413.7229309082031, 1, 888.9903564453125, 319.5710754394531, 1, 868.0140380859375, 280.7148742675781, 1, 830.3096923828125, 266.0387268066406, 1, 778.9337158203125, 271.2351379394531, 1, 962.7294921875, 272.7072448730469, 1, 955.781005859375, 187.65567016601562, 1, 953.9222412109375, 103.62838745117188, 1, 959.151611328125, 29.267608642578125, 1, 1047.009033203125, 294.3193664550781, 1, 1056.5989990234375, 215.84146118164062, 1, 1066.36865234375, 147.68014526367188, 1, 1081.0699462890625, 65.11972045898438, 1, 1107.0172119140625, 358.7002258300781, 1, 1159.4434814453125, 319.2156677246094, 1, 1206.9718017578125, 272.8797912597656, 1, 1261.1082763671875, 224.43637084960938, 1], "righthand_kpts": [233.142822265625, 582.3209228515625, 1, 300.6414794921875, 508.47479248046875, 1, 362.43896484375, 455.85186767578125, 1, 377.3603515625, 404.19744873046875, 1, 446.76416015625, 377.29241943359375, 1, 342.8802490234375, 310.6497802734375, 1, 368.6904296875, 284.673095703125, 1, 381.802734375, 251.73486328125, 1, 421.5467529296875, 225.363525390625, 1, 283.64288330078125, 254.122802734375, 1, 304.9996337890625, 170.8004150390625, 1, 320.6651611328125, 98.6851806640625, 1, 335.6553955078125, 28.2318115234375, 1, 199.05755615234375, 256.80859375, 1, 206.0360107421875, 177.01025390625, 1, 215.68804931640625, 106.7457275390625, 1, 224.53521728515625, 32.276611328125, 1, 128.827392578125, 294.99359130859375, 1, 99.0606689453125, 239.12982177734375, 1, 65.53125, 189.2431640625, 1, 37.63360595703125, 116.657958984375, 1], "center": [605.8033447265625, 359.4956359863281], "scale": [6.6406049728393555, 8.854140281677246], "keypoints_score": [0.9791078567504883, 0.9932481050491333, 1.0011144876480103, 0.973096489906311, 0.972457766532898, 0.866172194480896, 0.8760361671447754, 0.3526427149772644, 0.3903506398200989, 0.921836793422699, 0.9433825016021729, 0.20496317744255066, 0.2460474669933319, 0.20729553699493408, 0.17142903804779053, 0.18208564817905426, 0.22269707918167114], "face_kpts_score": [0.3680439293384552, 0.5355573892593384, 0.6418813467025757, 0.6644495725631714, 0.7590401768684387, 0.5538617372512817, 0.5907169580459595, 0.5878690481185913, 0.6348617076873779, 0.7361799478530884, 0.6556291580200195, 0.618322491645813, 0.6537319421768188, 0.5892513394355774, 0.7059171199798584, 0.645734429359436, 0.4574907422065735, 0.9639992713928223, 0.9263820648193359, 0.8876979351043701, 0.9284569621086121, 0.9739065170288086, 0.9502178430557251, 0.9174821376800537, 0.918608546257019, 0.9061530232429504, 0.862210750579834, 0.9776759147644043, 0.973875105381012, 0.974762499332428, 0.9565852880477905, 0.9716235399246216, 1.0059518814086914, 0.946382999420166, 0.9594531059265137, 0.9658107757568359, 1.0158061981201172, 0.9708306789398193, 0.9969902634620667, 0.9845597743988037, 0.9349627494812012, 0.9380444288253784, 0.9717998504638672, 0.9871775507926941, 0.9774664640426636, 0.9537898898124695, 0.9465979933738708, 0.9661000967025757, 0.9713011980056763, 0.9717509746551514, 0.956028938293457, 1.000832438468933, 0.9808722734451294, 0.9960898160934448, 0.9364079236984253, 1.0011546611785889, 0.9167187213897705, 0.9541155099868774, 0.9244742393493652, 0.988551139831543, 0.9954862594604492, 0.9832127094268799, 0.978826642036438, 0.9751479625701904, 0.956895112991333, 0.9974040985107422, 0.9864891767501831, 0.9898920655250549], "foot_kpts_score": [0.24755269289016724, 0.1599443256855011, 0.25949808955192566, 0.2688680589199066, 0.14811083674430847, 0.23364056646823883], "lefthand_kpts_score": [0.603957986831665, 0.46176729202270506, 0.5001004695892334, 0.6286116600036621, 0.7983541250228882, 0.7467568874359131, 0.7094749569892883, 0.7889106035232544, 0.8908322811126709, 0.8638974189758301, 1.0441084861755372, 0.9282500505447387, 0.9102095127105713, 0.7738837957382202, 0.94963458776474, 0.8981462478637695, 0.9926700949668884, 0.7828058958053589, 0.9498528003692627, 0.9387582302093506, 0.8471795082092285], "righthand_kpts_score": [0.6722876787185669, 0.60037282705307, 0.5398626983165741, 0.7077780723571777, 0.7050052642822265, 0.6411999225616455, 0.725990629196167, 0.758279001712799, 0.8829087972640991, 0.889958119392395, 0.9569337129592895, 0.9145335912704468, 0.9213766813278198, 0.8925279140472412, 0.9955486416816711, 1.0033048152923585, 1.0014301896095277, 0.9033888339996338, 0.9002806305885315, 0.8902452945709228, 0.888652241230011], "face_box": [445.3220458984375, 145.05938720703125, 348.63178710937495, 332.0302734375], "face_valid": true, "leftfoot_valid": false, "rightfoot_valid": false, "lefthand_valid": true, "righthand_valid": true, "lefthand_box": [699.218994140625, 50.335018157958984, 533.58251953125, 621.6577186584473], "righthand_box": [81.47227172851564, -7.12115478515625, 398.4362548828125, 664.060546875], "lefthand_update": true, "righthand_update": true, "lefthand_kpts_vitposehand": [942.7679443359375, 607.469482421875, 1, 888.291259765625, 539.277587890625, 1, 832.873291015625, 483.5708923339844, 1, 787.126953125, 436.6972351074219, 1, 710.735107421875, 413.7229309082031, 1, 888.9903564453125, 319.5710754394531, 1, 868.0140380859375, 280.7148742675781, 1, 830.3096923828125, 266.0387268066406, 1, 778.9337158203125, 271.2351379394531, 1, 962.7294921875, 272.7072448730469, 1, 955.781005859375, 187.65567016601562, 1, 953.9222412109375, 103.62838745117188, 1, 959.151611328125, 29.267608642578125, 1, 1047.009033203125, 294.3193664550781, 1, 1056.5989990234375, 215.84146118164062, 1, 1066.36865234375, 147.68014526367188, 1, 1081.0699462890625, 65.11972045898438, 1, 1107.0172119140625, 358.7002258300781, 1, 1159.4434814453125, 319.2156677246094, 1, 1206.9718017578125, 272.8797912597656, 1, 1261.1082763671875, 224.43637084960938, 1], "righthand_kpts_vitposehand": [233.142822265625, 582.3209228515625, 1, 300.6414794921875, 508.47479248046875, 1, 362.43896484375, 455.85186767578125, 1, 377.3603515625, 404.19744873046875, 1, 446.76416015625, 377.29241943359375, 1, 342.8802490234375, 310.6497802734375, 1, 368.6904296875, 284.673095703125, 1, 381.802734375, 251.73486328125, 1, 421.5467529296875, 225.363525390625, 1, 283.64288330078125, 254.122802734375, 1, 304.9996337890625, 170.8004150390625, 1, 320.6651611328125, 98.6851806640625, 1, 335.6553955078125, 28.2318115234375, 1, 199.05755615234375, 256.80859375, 1, 206.0360107421875, 177.01025390625, 1, 215.68804931640625, 106.7457275390625, 1, 224.53521728515625, 32.276611328125, 1, 128.827392578125, 294.99359130859375, 1, 99.0606689453125, 239.12982177734375, 1, 65.53125, 189.2431640625, 1, 37.63360595703125, 116.657958984375, 1], "num_keypoints": 9, "full_body": false, "valid_label": 2, "keypoints_3d": [[585.656005859375, 1398.5216064453125, 8.0], [699.9061889648438, 1586.966064453125, 7.7132415771484375], [450.14288330078125, 1596.144775390625, 7.6570892333984375], [878.3228149414062, 2171.27783203125, 5.664215087890625], [252.16543579101562, 2132.398681640625, 5.6501007080078125], [793.895263671875, 2988.90771484375, 4.6084747314453125], [232.56475830078125, 2939.503173828125, 4.28839111328125], [588.2872314453125, 570.474365234375, 9.544265747070312], [862.1456298828125, 514.33837890625, 8.8726806640625], [373.89849853515625, 519.60888671875, 9.171127319335938], [1073.739990234375, 765.0070190429688, 7.1384735107421875], [89.8785400390625, 775.919921875, 7.5379791259765625], [1000.2418212890625, 635.8955688476562, 5.19927978515625], [189.44015502929688, 567.993408203125, 5.757049560546875], [891.81298828125, 2948.2041015625, 3.0384368896484375], [1013.4824829101562, 3015.250732421875, 3.43035888671875], [819.24658203125, 3122.821533203125, 4.943603515625], [172.14041137695312, 2868.272705078125, 2.809112548828125], [31.46063232421875, 2937.01025390625, 3.1867828369140625], [244.37692260742188, 3111.135009765625, 4.5428619384765625], [760.2764282226562, 235.35623168945312, 9.170547485351562], [469.04644775390625, 237.359130859375, 9.270904541015625], [672.689453125, 216.68638610839844, 8.436477661132812], [536.8645629882812, 215.08010864257812, 8.477508544921875], [594.4747924804688, 302.86590576171875, 8.231826782226562], [937.543212890625, 563.2012939453125, 7.81884765625], [877.2040405273438, 564.7064819335938, 7.746490478515625], [826.8228759765625, 548.8115234375, 7.6898651123046875], [768.3922729492188, 532.2924194335938, 7.540069580078125], [945.0330810546875, 433.25579833984375, 7.78143310546875], [887.2977905273438, 411.39129638671875, 7.68023681640625], [854.9716796875, 409.1885986328125, 7.548248291015625], [812.5216064453125, 409.8503112792969, 7.41748046875], [993.1986083984375, 415.13519287109375, 7.762298583984375], [983.431640625, 352.09503173828125, 7.7212677001953125], [976.8125610351562, 306.58990478515625, 7.644317626953125], [967.6991577148438, 251.8966064453125, 7.58074951171875], [1042.6788330078125, 439.2115783691406, 7.7346954345703125], [1061.695068359375, 382.62310791015625, 7.7144622802734375], [1078.3428955078125, 336.8554382324219, 7.6671142578125], [1089.8707275390625, 288.113037109375, 7.64324951171875], [1077.3145751953125, 467.8497009277344, 7.6988525390625], [1113.5694580078125, 449.51904296875, 7.6714019775390625], [1147.91796875, 434.2681884765625, 7.6133880615234375], [1184.372314453125, 406.7205505371094, 7.566802978515625], [262.0787048339844, 512.4108276367188, 7.7939453125], [314.8291320800781, 495.84429931640625, 7.6787109375], [355.2375183105469, 463.73870849609375, 7.6097564697265625], [400.5841064453125, 429.6348876953125, 7.4446563720703125], [290.11627197265625, 385.6371765136719, 7.82208251953125], [334.016357421875, 356.7796325683594, 7.663116455078125], [352.326904296875, 347.6751403808594, 7.499725341796875], [379.92449951171875, 336.6559143066406, 7.330535888671875], [248.99337768554688, 355.2509460449219, 7.84161376953125], [270.441162109375, 294.56085205078125, 7.848602294921875], [283.58990478515625, 247.07943725585938, 7.8173370361328125], [298.6072692871094, 191.95077514648438, 7.8151092529296875], [194.588623046875, 364.1822509765625, 7.8341217041015625], [197.89288330078125, 304.9277038574219, 7.8556976318359375], [198.94699096679688, 255.0223846435547, 7.8529815673828125], [207.83172607421875, 206.8009490966797, 7.8715667724609375], [152.69793701171875, 380.91925048828125, 7.8072052001953125], [126.07894897460938, 349.861083984375, 7.8142547607421875], [99.02603149414062, 320.67138671875, 7.79296875], [75.35498046875, 280.7127380371094, 7.79833984375], [605.5189819335938, 258.36474609375, 7.6539459228515625], [636.6569213867188, 261.03448486328125, 7.6003265380859375], [672.689453125, 216.68638610839844, 6.8922119140625], [536.8645629882812, 215.08010864257812, 6.9332427978515625], [480.609130859375, 193.2221221923828, 7.156890869140625], [498.7352294921875, 169.0961151123047, 7.0008087158203125], [527.0252075195312, 168.48736572265625, 6.879364013671875], [556.564453125, 174.32501220703125, 6.8116912841796875], [582.2213134765625, 183.7449188232422, 6.796417236328125], [619.771728515625, 185.09783935546875, 6.7884368896484375], [646.1015625, 177.27572631835938, 6.788299560546875], [678.3016357421875, 172.73214721679688, 6.8334197998046875], [709.5665283203125, 174.52818298339844, 6.94036865234375], [730.6221313476562, 199.52928161621094, 7.08001708984375], [600.2632446289062, 215.79234313964844, 6.797698974609375], [598.0828247070312, 240.45635986328125, 6.753753662109375], [596.2218627929688, 264.4862976074219, 6.70782470703125], [594.4674072265625, 287.62481689453125, 6.66571044921875], [572.7188110351562, 305.8975830078125, 6.8535308837890625], [583.9725341796875, 311.3199157714844, 6.8229217529296875], [596.401123046875, 315.5985107421875, 6.804962158203125], [609.6165771484375, 311.5094909667969, 6.8159027099609375], [622.2186279296875, 306.6711120605469, 6.8405303955078125], [512.6423950195312, 211.75982666015625, 7.02471923828125], [528.5633544921875, 204.07089233398438, 6.9400634765625], [548.4610595703125, 205.9830780029297, 6.92816162109375], [565.9568481445312, 217.66900634765625, 6.9529266357421875], [548.8089599609375, 222.94613647460938, 6.9491424560546875], [530.2134399414062, 222.75762939453125, 6.9624176025390625], [639.6070556640625, 219.82444763183594, 6.930755615234375], [655.8860473632812, 209.6044158935547, 6.8970184326171875], [676.3201904296875, 208.3985595703125, 6.8957061767578125], [694.9487915039062, 217.1615753173828, 6.9696502685546875], [674.3418579101562, 226.85595703125, 6.9189300537109375], [655.4156494140625, 225.6745147705078, 6.91705322265625], [551.7490234375, 353.2354736328125, 6.971923828125], [564.1500244140625, 346.4883728027344, 6.88177490234375], [583.2034912109375, 344.99609375, 6.8333587646484375], [595.4065551757812, 347.21868896484375, 6.8253173828125], [607.8397216796875, 345.721435546875, 6.82666015625], [629.6182250976562, 348.2886047363281, 6.8668060302734375], [648.6402587890625, 353.0809631347656, 6.940582275390625], [634.0433349609375, 361.12738037109375, 6.8939056396484375], [612.543212890625, 365.1044921875, 6.8557891845703125], [598.9017333984375, 366.5699768066406, 6.8533477783203125], [585.4385375976562, 366.0231018066406, 6.8624725341796875], [566.12353515625, 362.2437744140625, 6.9132232666015625], [553.4495239257812, 352.7164001464844, 6.97503662109375], [583.9151000976562, 355.8670654296875, 6.8811187744140625], [596.3876342773438, 356.340576171875, 6.8712615966796875], [608.99560546875, 356.22100830078125, 6.8746795654296875], [648.081787109375, 352.85076904296875, 6.94110107421875], [612.7412719726562, 351.5333251953125, 6.865570068359375], [598.9871215820312, 351.8242492675781, 6.8616485595703125], [585.3312377929688, 352.4969482421875, 6.87408447265625], [464.1539001464844, 202.29954528808594, 7.4058380126953125], [465.8164978027344, 244.8143768310547, 7.313018798828125], [469.96026611328125, 282.73333740234375, 7.331451416015625], [474.998779296875, 318.5062255859375, 7.377685546875], [485.900390625, 354.82257080078125, 7.34814453125], [503.9440002441406, 389.1557922363281, 7.29644775390625], [533.9607543945312, 420.1808776855469, 7.2111968994140625], [569.1990356445312, 439.69488525390625, 7.0761260986328125], [604.7715454101562, 445.1242370605469, 7.0256805419921875], [641.609130859375, 438.5807189941406, 7.05670166015625], [677.1731567382812, 419.1774597167969, 7.1628265380859375], [709.558349609375, 390.3476867675781, 7.262908935546875], [728.9358520507812, 358.6229553222656, 7.3195648193359375], [743.6824951171875, 323.7010192871094, 7.3823699951171875], [752.355224609375, 286.009033203125, 7.3757171630859375], [756.031494140625, 248.0742645263672, 7.3575439453125], [756.6275634765625, 206.8378448486328, 7.39019775390625]], "keypoints_valid": [[1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0]], "camera_param": {"focal": [34553.93155415853, 34553.93075942993], "princpt": [605.3033752441406, 358.99560546875]}}], "categories": [{"supercategory": "person", "id": 1, "name": "person"}]} \ No newline at end of file diff --git a/tests/test_apis/test_inferencers/test_hand3d_inferencer.py b/tests/test_apis/test_inferencers/test_hand3d_inferencer.py new file mode 100644 index 0000000000..ccb467fb3c --- /dev/null +++ b/tests/test_apis/test_inferencers/test_hand3d_inferencer.py @@ -0,0 +1,69 @@ +# Copyright (c) OpenMMLab. All rights reserved. +import os +import os.path as osp +from collections import defaultdict +from tempfile import TemporaryDirectory +from unittest import TestCase + +import mmcv +import torch + +from mmpose.apis.inferencers import Hand3DInferencer +from mmpose.structures import PoseDataSample +from mmpose.utils import register_all_modules + + +class TestHand3DInferencer(TestCase): + + def tearDown(self) -> None: + register_all_modules(init_default_scope=True) + return super().tearDown() + + def test_init(self): + + inferencer = Hand3DInferencer(model='hand3d') + self.assertIsInstance(inferencer.model, torch.nn.Module) + + def test_call(self): + + inferencer = Hand3DInferencer(model='hand3d') + + img_path = 'tests/data/interhand2.6m/image29590.jpg' + img = mmcv.imread(img_path) + + # `inputs` is path to an image + inputs = img_path + results1 = next(inferencer(inputs, return_vis=True)) + self.assertIn('visualization', results1) + self.assertIn('predictions', results1) + self.assertIn('keypoints', results1['predictions'][0][0]) + self.assertEqual(len(results1['predictions'][0][0]['keypoints']), 42) + + # `inputs` is an image array + inputs = img + results2 = next(inferencer(inputs)) + self.assertEqual( + len(results1['predictions'][0]), len(results2['predictions'][0])) + self.assertSequenceEqual(results1['predictions'][0][0]['keypoints'], + results2['predictions'][0][0]['keypoints']) + results2 = next(inferencer(inputs, return_datasamples=True)) + self.assertIsInstance(results2['predictions'][0], PoseDataSample) + + # `inputs` is path to a directory + inputs = osp.dirname(img_path) + + with TemporaryDirectory() as tmp_dir: + # only save visualizations + for res in inferencer(inputs, vis_out_dir=tmp_dir): + pass + self.assertEqual(len(os.listdir(tmp_dir)), 4) + # save both visualizations and predictions + results3 = defaultdict(list) + for res in inferencer(inputs, out_dir=tmp_dir): + for key in res: + results3[key].extend(res[key]) + self.assertEqual(len(os.listdir(f'{tmp_dir}/visualizations')), 4) + self.assertEqual(len(os.listdir(f'{tmp_dir}/predictions')), 4) + self.assertEqual(len(results3['predictions']), 4) + self.assertSequenceEqual(results1['predictions'][0][0]['keypoints'], + results3['predictions'][1][0]['keypoints']) diff --git a/tests/test_apis/test_inferencers/test_mmpose_inferencer.py b/tests/test_apis/test_inferencers/test_mmpose_inferencer.py index 8b8a4744b8..c5c1a129ed 100644 --- a/tests/test_apis/test_inferencers/test_mmpose_inferencer.py +++ b/tests/test_apis/test_inferencers/test_mmpose_inferencer.py @@ -58,7 +58,7 @@ def test_pose2d_call(self): len(results1['predictions'][0]), len(results2['predictions'][0])) self.assertSequenceEqual(results1['predictions'][0][0]['keypoints'], results2['predictions'][0][0]['keypoints']) - results2 = next(inferencer(inputs, return_datasample=True)) + results2 = next(inferencer(inputs, return_datasamples=True)) self.assertIsInstance(results2['predictions'][0], PoseDataSample) # `inputs` is path to a directory @@ -127,3 +127,15 @@ def test_pose3d_call(self): '164970135-b14e424c-765a-4180-9bc8-fa8d6abc5510.json', os.listdir(f'{tmp_dir}/predictions')) self.assertTrue(inferencer._video_input) + + def test_hand3d_call(self): + + inferencer = MMPoseInferencer(pose3d='hand3d') + + # `inputs` is path to a video + inputs = 'tests/data/interhand2.6m/image29590.jpg' + results1 = next(inferencer(inputs, return_vis=True)) + self.assertIn('visualization', results1) + self.assertIn('predictions', results1) + self.assertIn('keypoints', results1['predictions'][0][0]) + self.assertEqual(len(results1['predictions'][0][0]['keypoints']), 42) diff --git a/tests/test_apis/test_inferencers/test_pose2d_inferencer.py b/tests/test_apis/test_inferencers/test_pose2d_inferencer.py index b59232efac..5663e425dc 100644 --- a/tests/test_apis/test_inferencers/test_pose2d_inferencer.py +++ b/tests/test_apis/test_inferencers/test_pose2d_inferencer.py @@ -122,7 +122,7 @@ def test_call(self): len(results1['predictions'][0]), len(results2['predictions'][0])) self.assertSequenceEqual(results1['predictions'][0][0]['keypoints'], results2['predictions'][0][0]['keypoints']) - results2 = next(inferencer(inputs, return_datasample=True)) + results2 = next(inferencer(inputs, return_datasamples=True)) self.assertIsInstance(results2['predictions'][0], PoseDataSample) # `inputs` is path to a directory @@ -144,6 +144,10 @@ def test_call(self): self.assertSequenceEqual(results1['predictions'][0][0]['keypoints'], results3['predictions'][3][0]['keypoints']) + with self.assertRaises(AssertionError): + for res in inferencer(inputs, vis_out_dir=f'{tmp_dir}/1.jpg'): + pass + # `inputs` is path to a video inputs = 'tests/data/posetrack18/videos/000001_mpiinew_test/' \ '000001_mpiinew_test.mp4' diff --git a/tests/test_apis/test_inferencers/test_pose3d_inferencer.py b/tests/test_apis/test_inferencers/test_pose3d_inferencer.py index da4a34b160..2ee56781c7 100644 --- a/tests/test_apis/test_inferencers/test_pose3d_inferencer.py +++ b/tests/test_apis/test_inferencers/test_pose3d_inferencer.py @@ -46,7 +46,7 @@ def test_init(self): # 1. init with config path and checkpoint inferencer = Pose3DInferencer( model= # noqa - 'configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-243frm-supv-cpn-ft_8xb128-200e_h36m.py', # noqa + 'configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-243frm-supv-cpn-ft_8xb128-200e_h36m.py', # noqa weights= # noqa 'https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_cpn_ft-88f5abbb_20210527.pth', # noqa pose2d_model='configs/body_2d_keypoint/simcc/coco/' @@ -62,8 +62,8 @@ def test_init(self): # 2. init with config name inferencer = Pose3DInferencer( - model='configs/body_3d_keypoint/pose_lift/h36m/pose-lift_' - 'videopose3d-243frm-supv-cpn-ft_8xb128-200e_h36m.py', + model='configs/body_3d_keypoint/video_pose_lift/h36m/' + 'video-pose-lift_tcn-243frm-supv-cpn-ft_8xb128-200e_h36m.py', pose2d_model='configs/body_2d_keypoint/simcc/coco/' 'simcc_res50_8xb64-210e_coco-256x192.py', det_model=det_model, @@ -114,7 +114,7 @@ def test_call(self): len(results1['predictions'][0]), len(results2['predictions'][0])) self.assertSequenceEqual(results1['predictions'][0][0]['keypoints'], results2['predictions'][0][0]['keypoints']) - results2 = next(inferencer(inputs, return_datasample=True)) + results2 = next(inferencer(inputs, return_datasamples=True)) self.assertIsInstance(results2['predictions'][0], PoseDataSample) # `inputs` is path to a directory diff --git a/tests/test_codecs/test_annotation_processors.py b/tests/test_codecs/test_annotation_processors.py new file mode 100644 index 0000000000..4b67cf4f1a --- /dev/null +++ b/tests/test_codecs/test_annotation_processors.py @@ -0,0 +1,35 @@ +# Copyright (c) OpenMMLab. All rights reserved. + +from unittest import TestCase + +import numpy as np + +from mmpose.codecs import YOLOXPoseAnnotationProcessor + + +class TestYOLOXPoseAnnotationProcessor(TestCase): + + def test_encode(self): + processor = YOLOXPoseAnnotationProcessor(expand_bbox=True) + + keypoints = np.array([[[0, 1], [2, 6], [4, 5]], [[5, 6], [7, 8], + [8, 9]]]) + keypoints_visible = np.array([[1, 1, 0], [1, 0, 1]]) + bbox = np.array([[0, 1, 3, 4], [1, 2, 5, 6]]) + category_id = [1, 2] + + encoded = processor.encode(keypoints, keypoints_visible, bbox, + category_id) + + self.assertTrue('bbox' in encoded) + self.assertTrue('bbox_labels' in encoded) + self.assertTrue( + np.array_equal(encoded['bbox'], + np.array([[0., 1., 3., 6.], [1., 2., 8., 9.]]))) + self.assertTrue( + np.array_equal(encoded['bbox_labels'], np.array([0, 1]))) + + def test_decode(self): + # make sure the `decode` method has been defined + processor = YOLOXPoseAnnotationProcessor() + _ = processor.decode(dict()) diff --git a/tests/test_codecs/test_associative_embedding.py b/tests/test_codecs/test_associative_embedding.py index 983fc93fb1..eae65dbedc 100644 --- a/tests/test_codecs/test_associative_embedding.py +++ b/tests/test_codecs/test_associative_embedding.py @@ -146,8 +146,8 @@ def test_decode(self): batch_heatmaps = torch.from_numpy(heatmaps[None]) batch_tags = torch.from_numpy(tags[None]) - batch_keypoints, batch_keypoint_scores = codec.batch_decode( - batch_heatmaps, batch_tags) + batch_keypoints, batch_keypoint_scores, batch_instance_scores = \ + codec.batch_decode(batch_heatmaps, batch_tags) self.assertIsInstance(batch_keypoints, list) self.assertIsInstance(batch_keypoint_scores, list) @@ -184,8 +184,8 @@ def test_decode(self): batch_heatmaps = torch.from_numpy(heatmaps[None]) batch_tags = torch.from_numpy(tags[None]) - batch_keypoints, batch_keypoint_scores = codec.batch_decode( - batch_heatmaps, batch_tags) + batch_keypoints, batch_keypoint_scores, batch_instance_scores = \ + codec.batch_decode(batch_heatmaps, batch_tags) self.assertIsInstance(batch_keypoints, list) self.assertIsInstance(batch_keypoint_scores, list) @@ -222,8 +222,8 @@ def test_decode(self): batch_heatmaps = torch.from_numpy(heatmaps[None]) batch_tags = torch.from_numpy(tags[None]) - batch_keypoints, batch_keypoint_scores = codec.batch_decode( - batch_heatmaps, batch_tags) + batch_keypoints, batch_keypoint_scores, batch_instance_scores = \ + codec.batch_decode(batch_heatmaps, batch_tags) self.assertIsInstance(batch_keypoints, list) self.assertIsInstance(batch_keypoint_scores, list) diff --git a/tests/test_codecs/test_edpose_label.py b/tests/test_codecs/test_edpose_label.py new file mode 100644 index 0000000000..79e4d3fe27 --- /dev/null +++ b/tests/test_codecs/test_edpose_label.py @@ -0,0 +1,58 @@ +# Copyright (c) OpenMMLab. All rights reserved. + +from unittest import TestCase + +import numpy as np + +from mmpose.codecs import EDPoseLabel + + +class TestEDPoseLabel(TestCase): + + def setUp(self): + self.encoder = EDPoseLabel(num_select=2, num_keypoints=2) + self.img_shape = (640, 480) + self.keypoints = np.array([[[100, 50], [200, 50]], + [[300, 400], [100, 200]]]) + self.area = np.array([5000, 8000]) + + def test_encode(self): + # Test encoding + encoded_data = self.encoder.encode( + img_shape=self.img_shape, keypoints=self.keypoints, area=self.area) + + self.assertEqual(encoded_data['keypoints'].shape, self.keypoints.shape) + self.assertEqual(encoded_data['area'].shape, self.area.shape) + + # Check if the keypoints were normalized correctly + expected_keypoints = self.keypoints / np.array( + self.img_shape, dtype=np.float32) + np.testing.assert_array_almost_equal(encoded_data['keypoints'], + expected_keypoints) + + # Check if the area was normalized correctly + expected_area = self.area / float( + self.img_shape[0] * self.img_shape[1]) + np.testing.assert_array_almost_equal(encoded_data['area'], + expected_area) + + def test_decode(self): + # Dummy predictions for logits, boxes, and keypoints + pred_logits = np.array([0.7, 0.6]).reshape(2, 1) + pred_boxes = np.array([[0.1, 0.1, 0.5, 0.5], [0.6, 0.6, 0.8, 0.8]]) + pred_keypoints = np.array([[0.2, 0.3, 1, 0.3, 0.4, 1], + [0.6, 0.7, 1, 0.7, 0.8, 1]]) + input_shapes = np.array(self.img_shape) + + # Test decoding + boxes, keypoints, scores = self.encoder.decode( + input_shapes=input_shapes, + pred_logits=pred_logits, + pred_boxes=pred_boxes, + pred_keypoints=pred_keypoints) + + self.assertEqual(boxes.shape, pred_boxes.shape) + self.assertEqual(keypoints.shape, (self.encoder.num_select, + self.encoder.num_keypoints, 2)) + self.assertEqual(scores.shape, + (self.encoder.num_select, self.encoder.num_keypoints)) diff --git a/tests/test_codecs/test_hand_3d_heatmap.py b/tests/test_codecs/test_hand_3d_heatmap.py new file mode 100644 index 0000000000..c357c3e6bc --- /dev/null +++ b/tests/test_codecs/test_hand_3d_heatmap.py @@ -0,0 +1,127 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import numpy as np + +from mmpose.registry import KEYPOINT_CODECS + + +class TestHand3DHeatmap(TestCase): + + def build_hand_3d_heatmap(self, **kwargs): + cfg = dict(type='Hand3DHeatmap') + cfg.update(kwargs) + return KEYPOINT_CODECS.build(cfg) + + def setUp(self) -> None: + # The bbox is usually padded so the keypoint will not be near the + # boundary + keypoints = (0.1 + 0.8 * np.random.rand(1, 42, 3)) + keypoints[..., :2] = keypoints[..., :2] * [256, 256] + keypoints = np.round(keypoints).astype(np.float32) + keypoints_visible = np.ones(( + 1, + 42, + ), dtype=np.float32) + heatmaps = np.random.rand(42, 64, 64, 64).astype(np.float32) + self.data = dict( + keypoints=keypoints, + keypoints_visible=keypoints_visible, + heatmaps=heatmaps) + + def test_encode(self): + keypoints = self.data['keypoints'] + keypoints_visible = self.data['keypoints_visible'] + + # test default settings + codec = self.build_hand_3d_heatmap() + + encoded = codec.encode( + keypoints, + keypoints_visible, + dataset_keypoint_weights=np.ones(42, ), + rel_root_depth=np.float32(1.), + rel_root_valid=0., + hand_type=np.array([[1, 0]]), + hand_type_valid=np.array([1]), + focal=np.array([1000., 1000.]), + principal_pt=np.array([200., 200.])) + + self.assertEqual(encoded['heatmaps'].shape, (42 * 64, 64, 64)) + self.assertEqual(encoded['keypoint_weights'].shape, ( + 1, + 42, + )) + + # test with different joint weights + codec = self.build_hand_3d_heatmap(use_different_joint_weights=True) + + encoded = codec.encode( + keypoints, + keypoints_visible, + dataset_keypoint_weights=np.ones(42, ), + rel_root_depth=np.float32(1.), + rel_root_valid=0., + hand_type=np.array([[1, 0]]), + hand_type_valid=np.array([1]), + focal=np.array([1000., 1000.]), + principal_pt=np.array([200., 200.])) + + self.assertEqual(encoded['heatmaps'].shape, (42 * 64, 64, 64)) + self.assertEqual(encoded['keypoint_weights'].shape, ( + 1, + 42, + )) + + # test joint_indices + codec = self.build_hand_3d_heatmap(joint_indices=[0, 8, 16]) + encoded = codec.encode( + keypoints, + keypoints_visible, + dataset_keypoint_weights=np.ones(42, ), + rel_root_depth=np.float32(1.), + rel_root_valid=0., + hand_type=np.array([[1, 0]]), + hand_type_valid=np.array([1]), + focal=np.array([1000., 1000.]), + principal_pt=np.array([200., 200.])) + self.assertEqual(encoded['heatmaps'].shape, (3 * 64, 64, 64)) + self.assertEqual(encoded['keypoint_weights'].shape, ( + 1, + 3, + )) + + def test_decode(self): + heatmaps = self.data['heatmaps'] + + # test default settings + codec = self.build_hand_3d_heatmap() + + keypoints, scores, _, _ = codec.decode(heatmaps, np.ones((1, )), + np.ones((1, 2))) + + self.assertEqual(keypoints.shape, (1, 42, 3)) + self.assertEqual(scores.shape, (1, 42)) + + def test_cicular_verification(self): + keypoints = self.data['keypoints'] + keypoints_visible = self.data['keypoints_visible'] + + codec = self.build_hand_3d_heatmap() + + encoded = codec.encode( + keypoints, + keypoints_visible, + dataset_keypoint_weights=np.ones(42, ), + rel_root_depth=np.float32(1.), + rel_root_valid=0., + hand_type=np.array([[1, 0]]), + hand_type_valid=np.array([1]), + focal=np.array([1000., 1000.]), + principal_pt=np.array([200., 200.])) + _keypoints, _, _, _ = codec.decode( + encoded['heatmaps'].reshape(42, 64, 64, 64), np.ones((1, )), + np.ones((1, 2))) + + self.assertTrue( + np.allclose(keypoints[..., :2], _keypoints[..., :2], atol=5.)) diff --git a/tests/test_codecs/test_image_pose_lifting.py b/tests/test_codecs/test_image_pose_lifting.py index bb94786c32..7033a3954c 100644 --- a/tests/test_codecs/test_image_pose_lifting.py +++ b/tests/test_codecs/test_image_pose_lifting.py @@ -13,14 +13,18 @@ def setUp(self) -> None: keypoints = (0.1 + 0.8 * np.random.rand(1, 17, 2)) * [192, 256] keypoints = np.round(keypoints).astype(np.float32) keypoints_visible = np.random.randint(2, size=(1, 17)) - lifting_target = (0.1 + 0.8 * np.random.rand(17, 3)) - lifting_target_visible = np.random.randint(2, size=(17, )) + lifting_target = (0.1 + 0.8 * np.random.rand(1, 17, 3)) + lifting_target_visible = np.random.randint( + 2, size=( + 1, + 17, + )) encoded_wo_sigma = np.random.rand(1, 17, 3) self.keypoints_mean = np.random.rand(17, 2).astype(np.float32) self.keypoints_std = np.random.rand(17, 2).astype(np.float32) + 1e-6 - self.target_mean = np.random.rand(17, 3).astype(np.float32) - self.target_std = np.random.rand(17, 3).astype(np.float32) + 1e-6 + self.target_mean = np.random.rand(1, 17, 3).astype(np.float32) + self.target_std = np.random.rand(1, 17, 3).astype(np.float32) + 1e-6 self.data = dict( keypoints=keypoints, @@ -30,7 +34,11 @@ def setUp(self) -> None: encoded_wo_sigma=encoded_wo_sigma) def build_pose_lifting_label(self, **kwargs): - cfg = dict(type='ImagePoseLifting', num_keypoints=17, root_index=0) + cfg = dict( + type='ImagePoseLifting', + num_keypoints=17, + root_index=0, + reshape_keypoints=False) cfg.update(kwargs) return KEYPOINT_CODECS.build(cfg) @@ -50,10 +58,19 @@ def test_encode(self): lifting_target_visible) self.assertEqual(encoded['keypoint_labels'].shape, (1, 17, 2)) - self.assertEqual(encoded['lifting_target_label'].shape, (17, 3)) - self.assertEqual(encoded['lifting_target_weights'].shape, (17, )) - self.assertEqual(encoded['trajectory_weights'].shape, (17, )) - self.assertEqual(encoded['target_root'].shape, (3, )) + self.assertEqual(encoded['lifting_target_label'].shape, (1, 17, 3)) + self.assertEqual(encoded['lifting_target_weight'].shape, ( + 1, + 17, + )) + self.assertEqual(encoded['trajectory_weights'].shape, ( + 1, + 17, + )) + self.assertEqual(encoded['target_root'].shape, ( + 1, + 3, + )) # test removing root codec = self.build_pose_lifting_label( @@ -63,10 +80,16 @@ def test_encode(self): self.assertTrue('target_root_removed' in encoded and 'target_root_index' in encoded) - self.assertEqual(encoded['lifting_target_weights'].shape, (16, )) + self.assertEqual(encoded['lifting_target_weight'].shape, ( + 1, + 16, + )) self.assertEqual(encoded['keypoint_labels'].shape, (1, 17, 2)) - self.assertEqual(encoded['lifting_target_label'].shape, (16, 3)) - self.assertEqual(encoded['target_root'].shape, (3, )) + self.assertEqual(encoded['lifting_target_label'].shape, (1, 16, 3)) + self.assertEqual(encoded['target_root'].shape, ( + 1, + 3, + )) # test normalization codec = self.build_pose_lifting_label( @@ -78,7 +101,7 @@ def test_encode(self): lifting_target_visible) self.assertEqual(encoded['keypoint_labels'].shape, (1, 17, 2)) - self.assertEqual(encoded['lifting_target_label'].shape, (17, 3)) + self.assertEqual(encoded['lifting_target_label'].shape, (1, 17, 3)) def test_decode(self): lifting_target = self.data['lifting_target'] @@ -112,12 +135,10 @@ def test_cicular_verification(self): lifting_target_visible) _keypoints, _ = codec.decode( - np.expand_dims(encoded['lifting_target_label'], axis=0), + encoded['lifting_target_label'], target_root=lifting_target[..., 0, :]) - self.assertTrue( - np.allclose( - np.expand_dims(lifting_target, axis=0), _keypoints, atol=5.)) + self.assertTrue(np.allclose(lifting_target, _keypoints, atol=5.)) # test removing root codec = self.build_pose_lifting_label(remove_root=True) @@ -125,12 +146,10 @@ def test_cicular_verification(self): lifting_target_visible) _keypoints, _ = codec.decode( - np.expand_dims(encoded['lifting_target_label'], axis=0), + encoded['lifting_target_label'], target_root=lifting_target[..., 0, :]) - self.assertTrue( - np.allclose( - np.expand_dims(lifting_target, axis=0), _keypoints, atol=5.)) + self.assertTrue(np.allclose(lifting_target, _keypoints, atol=5.)) # test normalization codec = self.build_pose_lifting_label( @@ -142,9 +161,7 @@ def test_cicular_verification(self): lifting_target_visible) _keypoints, _ = codec.decode( - np.expand_dims(encoded['lifting_target_label'], axis=0), + encoded['lifting_target_label'], target_root=lifting_target[..., 0, :]) - self.assertTrue( - np.allclose( - np.expand_dims(lifting_target, axis=0), _keypoints, atol=5.)) + self.assertTrue(np.allclose(lifting_target, _keypoints, atol=5.)) diff --git a/tests/test_codecs/test_motionbert_label.py b/tests/test_codecs/test_motionbert_label.py new file mode 100644 index 0000000000..596df463f7 --- /dev/null +++ b/tests/test_codecs/test_motionbert_label.py @@ -0,0 +1,155 @@ +# Copyright (c) OpenMMLab. All rights reserved. +import os.path as osp +from unittest import TestCase + +import numpy as np +from mmengine.fileio import load + +from mmpose.codecs import MotionBERTLabel +from mmpose.registry import KEYPOINT_CODECS + + +class TestMotionBERTLabel(TestCase): + + def get_camera_param(self, imgname, camera_param) -> dict: + """Get camera parameters of a frame by its image name.""" + subj, rest = osp.basename(imgname).split('_', 1) + action, rest = rest.split('.', 1) + camera, rest = rest.split('_', 1) + return camera_param[(subj, camera)] + + def build_pose_lifting_label(self, **kwargs): + cfg = dict(type='MotionBERTLabel', num_keypoints=17) + cfg.update(kwargs) + return KEYPOINT_CODECS.build(cfg) + + def setUp(self) -> None: + keypoints = (0.1 + 0.8 * np.random.rand(1, 17, 2)) * [1000, 1002] + keypoints = np.round(keypoints).astype(np.float32) + keypoints_visible = np.random.randint(2, size=(1, 17)) + lifting_target = (0.1 + 0.8 * np.random.rand(1, 17, 3)) + lifting_target_visible = np.random.randint( + 2, size=( + 1, + 17, + )) + encoded_wo_sigma = np.random.rand(1, 17, 3) + + camera_param = load('tests/data/h36m/cameras.pkl') + camera_param = self.get_camera_param( + 'S1/S1_Directions_1.54138969/S1_Directions_1.54138969_000001.jpg', + camera_param) + factor = 0.1 + 5 * np.random.rand(1, ) + + self.data = dict( + keypoints=keypoints, + keypoints_visible=keypoints_visible, + lifting_target=lifting_target, + lifting_target_visible=lifting_target_visible, + camera_param=camera_param, + factor=factor, + encoded_wo_sigma=encoded_wo_sigma) + + def test_build(self): + codec = self.build_pose_lifting_label() + self.assertIsInstance(codec, MotionBERTLabel) + + def test_encode(self): + keypoints = self.data['keypoints'] + keypoints_visible = self.data['keypoints_visible'] + lifting_target = self.data['lifting_target'] + lifting_target_visible = self.data['lifting_target_visible'] + camera_param = self.data['camera_param'] + factor = self.data['factor'] + + # test default settings + codec = self.build_pose_lifting_label() + encoded = codec.encode(keypoints, keypoints_visible, lifting_target, + lifting_target_visible, camera_param, factor) + + self.assertEqual(encoded['keypoint_labels'].shape, (1, 17, 2)) + self.assertEqual(encoded['lifting_target_label'].shape, (1, 17, 3)) + self.assertEqual(encoded['lifting_target_weight'].shape, ( + 1, + 17, + )) + + # test concatenating visibility + codec = self.build_pose_lifting_label(concat_vis=True) + encoded = codec.encode(keypoints, keypoints_visible, lifting_target, + lifting_target_visible, camera_param, factor) + + self.assertEqual(encoded['keypoint_labels'].shape, (1, 17, 3)) + self.assertEqual(encoded['lifting_target_label'].shape, (1, 17, 3)) + + def test_decode(self): + encoded_wo_sigma = self.data['encoded_wo_sigma'] + camera_param = self.data['camera_param'] + + # test default settings + codec = self.build_pose_lifting_label() + + decoded, scores = codec.decode(encoded_wo_sigma) + + self.assertEqual(decoded.shape, (1, 17, 3)) + self.assertEqual(scores.shape, (1, 17)) + + # test denormalize according to image shape + codec = self.build_pose_lifting_label() + + decoded, scores = codec.decode( + encoded_wo_sigma, + w=np.array([camera_param['w']]), + h=np.array([camera_param['h']])) + + self.assertEqual(decoded.shape, (1, 17, 3)) + self.assertEqual(scores.shape, (1, 17)) + + # test with factor + codec = self.build_pose_lifting_label() + + decoded, scores = codec.decode( + encoded_wo_sigma, factor=np.array([0.23])) + + self.assertEqual(decoded.shape, (1, 17, 3)) + self.assertEqual(scores.shape, (1, 17)) + + def test_cicular_verification(self): + keypoints_visible = self.data['keypoints_visible'] + lifting_target = self.data['lifting_target'] + lifting_target_visible = self.data['lifting_target_visible'] + camera_param = self.data['camera_param'] + + # test denormalize according to image shape + keypoints = (0.1 + 0.8 * np.random.rand(1, 17, 3)) + codec = self.build_pose_lifting_label() + encoded = codec.encode(keypoints, keypoints_visible, lifting_target, + lifting_target_visible, camera_param) + + _keypoints, _ = codec.decode( + encoded['keypoint_labels'], + w=np.array([camera_param['w']]), + h=np.array([camera_param['h']])) + + keypoints[..., :, :] = keypoints[..., :, :] - keypoints[..., 0, :] + + self.assertTrue( + np.allclose(keypoints[..., :2] / 1000, _keypoints[..., :2])) + + # test with factor + keypoints = (0.1 + 0.8 * np.random.rand(1, 17, 3)) + codec = self.build_pose_lifting_label() + encoded = codec.encode(keypoints, keypoints_visible, lifting_target, + lifting_target_visible, camera_param) + + _keypoints, _ = codec.decode( + encoded['keypoint_labels'], + w=np.array([camera_param['w']]), + h=np.array([camera_param['h']]), + factor=encoded['factor']) + + keypoints *= encoded['factor'] + keypoints[..., :, :] = keypoints[..., :, :] - keypoints[..., 0, :] + + self.assertTrue( + np.allclose(keypoints[..., :2] / 1000, _keypoints[..., :2])) diff --git a/tests/test_codecs/test_video_pose_lifting.py b/tests/test_codecs/test_video_pose_lifting.py index cc58292d0c..6ffd70cffe 100644 --- a/tests/test_codecs/test_video_pose_lifting.py +++ b/tests/test_codecs/test_video_pose_lifting.py @@ -19,7 +19,8 @@ def get_camera_param(self, imgname, camera_param) -> dict: return camera_param[(subj, camera)] def build_pose_lifting_label(self, **kwargs): - cfg = dict(type='VideoPoseLifting', num_keypoints=17) + cfg = dict( + type='VideoPoseLifting', num_keypoints=17, reshape_keypoints=False) cfg.update(kwargs) return KEYPOINT_CODECS.build(cfg) @@ -27,8 +28,12 @@ def setUp(self) -> None: keypoints = (0.1 + 0.8 * np.random.rand(1, 17, 2)) * [192, 256] keypoints = np.round(keypoints).astype(np.float32) keypoints_visible = np.random.randint(2, size=(1, 17)) - lifting_target = (0.1 + 0.8 * np.random.rand(17, 3)) - lifting_target_visible = np.random.randint(2, size=(17, )) + lifting_target = (0.1 + 0.8 * np.random.rand(1, 17, 3)) + lifting_target_visible = np.random.randint( + 2, size=( + 1, + 17, + )) encoded_wo_sigma = np.random.rand(1, 17, 3) camera_param = load('tests/data/h36m/cameras.pkl') @@ -61,10 +66,19 @@ def test_encode(self): lifting_target_visible, camera_param) self.assertEqual(encoded['keypoint_labels'].shape, (1, 17, 2)) - self.assertEqual(encoded['lifting_target_label'].shape, (17, 3)) - self.assertEqual(encoded['lifting_target_weights'].shape, (17, )) - self.assertEqual(encoded['trajectory_weights'].shape, (17, )) - self.assertEqual(encoded['target_root'].shape, (3, )) + self.assertEqual(encoded['lifting_target_label'].shape, (1, 17, 3)) + self.assertEqual(encoded['lifting_target_weight'].shape, ( + 1, + 17, + )) + self.assertEqual(encoded['trajectory_weights'].shape, ( + 1, + 17, + )) + self.assertEqual(encoded['target_root'].shape, ( + 1, + 3, + )) # test not zero-centering codec = self.build_pose_lifting_label(zero_center=False) @@ -72,9 +86,31 @@ def test_encode(self): lifting_target_visible, camera_param) self.assertEqual(encoded['keypoint_labels'].shape, (1, 17, 2)) - self.assertEqual(encoded['lifting_target_label'].shape, (17, 3)) - self.assertEqual(encoded['lifting_target_weights'].shape, (17, )) - self.assertEqual(encoded['trajectory_weights'].shape, (17, )) + self.assertEqual(encoded['lifting_target_label'].shape, (1, 17, 3)) + self.assertEqual(encoded['lifting_target_weight'].shape, ( + 1, + 17, + )) + self.assertEqual(encoded['trajectory_weights'].shape, ( + 1, + 17, + )) + + # test reshape_keypoints + codec = self.build_pose_lifting_label(reshape_keypoints=True) + encoded = codec.encode(keypoints, keypoints_visible, lifting_target, + lifting_target_visible, camera_param) + + self.assertEqual(encoded['keypoint_labels'].shape, (34, 1)) + self.assertEqual(encoded['lifting_target_label'].shape, (1, 17, 3)) + self.assertEqual(encoded['lifting_target_weight'].shape, ( + 1, + 17, + )) + self.assertEqual(encoded['trajectory_weights'].shape, ( + 1, + 17, + )) # test removing root codec = self.build_pose_lifting_label( @@ -84,10 +120,16 @@ def test_encode(self): self.assertTrue('target_root_removed' in encoded and 'target_root_index' in encoded) - self.assertEqual(encoded['lifting_target_weights'].shape, (16, )) + self.assertEqual(encoded['lifting_target_weight'].shape, ( + 1, + 16, + )) self.assertEqual(encoded['keypoint_labels'].shape, (1, 17, 2)) - self.assertEqual(encoded['lifting_target_label'].shape, (16, 3)) - self.assertEqual(encoded['target_root'].shape, (3, )) + self.assertEqual(encoded['lifting_target_label'].shape, (1, 16, 3)) + self.assertEqual(encoded['target_root'].shape, ( + 1, + 3, + )) # test normalizing camera codec = self.build_pose_lifting_label(normalize_camera=True) @@ -102,6 +144,35 @@ def test_encode(self): encoded['camera_param']['f'], atol=4.)) + # test with multiple targets + keypoints = (0.1 + 0.8 * np.random.rand(2, 17, 2)) * [192, 256] + keypoints = np.round(keypoints).astype(np.float32) + keypoints_visible = np.random.randint(2, size=(2, 17)) + lifting_target = (0.1 + 0.8 * np.random.rand(2, 17, 3)) + lifting_target_visible = np.random.randint( + 2, size=( + 2, + 17, + )) + codec = self.build_pose_lifting_label() + encoded = codec.encode(keypoints, keypoints_visible, lifting_target, + lifting_target_visible, camera_param) + + self.assertEqual(encoded['keypoint_labels'].shape, (2, 17, 2)) + self.assertEqual(encoded['lifting_target_label'].shape, (2, 17, 3)) + self.assertEqual(encoded['lifting_target_weight'].shape, ( + 2, + 17, + )) + self.assertEqual(encoded['trajectory_weights'].shape, ( + 2, + 17, + )) + self.assertEqual(encoded['target_root'].shape, ( + 2, + 3, + )) + def test_decode(self): lifting_target = self.data['lifting_target'] encoded_wo_sigma = self.data['encoded_wo_sigma'] @@ -135,12 +206,10 @@ def test_cicular_verification(self): lifting_target_visible, camera_param) _keypoints, _ = codec.decode( - np.expand_dims(encoded['lifting_target_label'], axis=0), + encoded['lifting_target_label'], target_root=lifting_target[..., 0, :]) - self.assertTrue( - np.allclose( - np.expand_dims(lifting_target, axis=0), _keypoints, atol=5.)) + self.assertTrue(np.allclose(lifting_target, _keypoints, atol=5.)) # test removing root codec = self.build_pose_lifting_label(remove_root=True) @@ -148,9 +217,7 @@ def test_cicular_verification(self): lifting_target_visible, camera_param) _keypoints, _ = codec.decode( - np.expand_dims(encoded['lifting_target_label'], axis=0), + encoded['lifting_target_label'], target_root=lifting_target[..., 0, :]) - self.assertTrue( - np.allclose( - np.expand_dims(lifting_target, axis=0), _keypoints, atol=5.)) + self.assertTrue(np.allclose(lifting_target, _keypoints, atol=5.)) diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_aic_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_aic_dataset.py index ae00a64393..57031cdacd 100644 --- a/tests/test_datasets/test_datasets/test_body_datasets/test_aic_dataset.py +++ b/tests/test_datasets/test_datasets/test_body_datasets/test_aic_dataset.py @@ -42,6 +42,7 @@ def check_data_info_keys(self, keypoints=np.ndarray, keypoints_visible=np.ndarray, invalid_segs=list, + area=(list, np.ndarray), id=list) else: raise ValueError(f'Invalid data_mode {data_mode}') diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_coco_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_coco_dataset.py index de78264dae..1706fba739 100644 --- a/tests/test_datasets/test_datasets/test_body_datasets/test_coco_dataset.py +++ b/tests/test_datasets/test_datasets/test_body_datasets/test_coco_dataset.py @@ -42,6 +42,7 @@ def check_data_info_keys(self, keypoints=np.ndarray, keypoints_visible=np.ndarray, invalid_segs=list, + area=(list, np.ndarray), id=list) else: raise ValueError(f'Invalid data_mode {data_mode}') diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_crowdpose_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_crowdpose_dataset.py index 8d63925257..0525e35d02 100644 --- a/tests/test_datasets/test_datasets/test_body_datasets/test_crowdpose_dataset.py +++ b/tests/test_datasets/test_datasets/test_body_datasets/test_crowdpose_dataset.py @@ -42,6 +42,7 @@ def check_data_info_keys(self, keypoints=np.ndarray, keypoints_visible=np.ndarray, invalid_segs=list, + area=(list, np.ndarray), id=list) else: raise ValueError(f'Invalid data_mode {data_mode}') diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_h36m_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_h36m_dataset.py index 88944dc11f..f86cafd1ab 100644 --- a/tests/test_datasets/test_datasets/test_body_datasets/test_h36m_dataset.py +++ b/tests/test_datasets/test_datasets/test_body_datasets/test_h36m_dataset.py @@ -116,6 +116,17 @@ def test_topdown(self): self.assertEqual(len(dataset), 4) self.check_data_info_keys(dataset[0]) + dataset = self.build_h36m_dataset( + data_mode='topdown', + seq_len=1, + seq_step=1, + multiple_target=1, + causal=False, + pad_video_seq=True, + camera_param_file='cameras.pkl') + self.assertEqual(len(dataset), 4) + self.check_data_info_keys(dataset[0]) + # test topdown testing with 2d keypoint detection file and # sequence config dataset = self.build_h36m_dataset( @@ -166,7 +177,7 @@ def test_exceptions_and_warnings(self): keypoint_2d_src='invalid') with self.assertRaisesRegex(AssertionError, - 'Annotation file does not exist'): + 'Annotation file `(.+?)` does not exist'): _ = self.build_h36m_dataset( data_mode='topdown', test_mode=False, ann_file='invalid') diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_humanart21_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_humanart21_dataset.py new file mode 100644 index 0000000000..dd51132f11 --- /dev/null +++ b/tests/test_datasets/test_datasets/test_body_datasets/test_humanart21_dataset.py @@ -0,0 +1,160 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import numpy as np + +from mmpose.datasets.datasets.body import HumanArt21Dataset + + +class TestHumanart21Dataset(TestCase): + + def build_humanart_dataset(self, **kwargs): + + cfg = dict( + ann_file='test_humanart.json', + bbox_file=None, + data_mode='topdown', + data_root='tests/data/humanart', + pipeline=[], + test_mode=False) + + cfg.update(kwargs) + return HumanArt21Dataset(**cfg) + + def check_data_info_keys(self, + data_info: dict, + data_mode: str = 'topdown'): + if data_mode == 'topdown': + expected_keys = dict( + img_id=int, + img_path=str, + bbox=np.ndarray, + bbox_score=np.ndarray, + keypoints=np.ndarray, + keypoints_visible=np.ndarray, + id=int) + elif data_mode == 'bottomup': + expected_keys = dict( + img_id=int, + img_path=str, + bbox=np.ndarray, + bbox_score=np.ndarray, + keypoints=np.ndarray, + keypoints_visible=np.ndarray, + invalid_segs=list, + id=list) + else: + raise ValueError(f'Invalid data_mode {data_mode}') + + for key, type_ in expected_keys.items(): + self.assertIn(key, data_info) + self.assertIsInstance(data_info[key], type_, key) + + def check_metainfo_keys(self, metainfo: dict): + expected_keys = dict( + dataset_name=str, + num_keypoints=int, + keypoint_id2name=dict, + keypoint_name2id=dict, + upper_body_ids=list, + lower_body_ids=list, + flip_indices=list, + flip_pairs=list, + keypoint_colors=np.ndarray, + num_skeleton_links=int, + skeleton_links=list, + skeleton_link_colors=np.ndarray, + dataset_keypoint_weights=np.ndarray) + + for key, type_ in expected_keys.items(): + self.assertIn(key, metainfo) + self.assertIsInstance(metainfo[key], type_, key) + + def test_metainfo(self): + dataset = self.build_humanart_dataset() + self.check_metainfo_keys(dataset.metainfo) + # test dataset_name + self.assertEqual(dataset.metainfo['dataset_name'], 'Human-Art') + + # test number of keypoints + num_keypoints = 21 + self.assertEqual(dataset.metainfo['num_keypoints'], num_keypoints) + self.assertEqual( + len(dataset.metainfo['keypoint_colors']), num_keypoints) + self.assertEqual( + len(dataset.metainfo['dataset_keypoint_weights']), num_keypoints) + # note that len(sigmas) may be zero if dataset.metainfo['sigmas'] = [] + self.assertEqual(len(dataset.metainfo['sigmas']), num_keypoints) + + # test some extra metainfo + self.assertEqual( + len(dataset.metainfo['skeleton_links']), + len(dataset.metainfo['skeleton_link_colors'])) + + def test_topdown(self): + # test topdown training + dataset = self.build_humanart_dataset(data_mode='topdown') + self.assertEqual(len(dataset), 4) + self.check_data_info_keys(dataset[0], data_mode='topdown') + + # test topdown testing + dataset = self.build_humanart_dataset( + data_mode='topdown', test_mode=True) + self.assertEqual(len(dataset), 4) + self.check_data_info_keys(dataset[0], data_mode='topdown') + + # test topdown testing with bbox file + dataset = self.build_humanart_dataset( + data_mode='topdown', + test_mode=True, + bbox_file='tests/data/humanart/test_humanart_det_AP_H_56.json') + self.assertEqual(len(dataset), 13) + self.check_data_info_keys(dataset[0], data_mode='topdown') + + # test topdown testing with filter config + dataset = self.build_humanart_dataset( + data_mode='topdown', + test_mode=True, + bbox_file='tests/data/humanart/test_humanart_det_AP_H_56.json', + filter_cfg=dict(bbox_score_thr=0.3)) + self.assertEqual(len(dataset), 8) + + def test_bottomup(self): + # test bottomup training + dataset = self.build_humanart_dataset(data_mode='bottomup') + self.assertEqual(len(dataset), 3) + self.check_data_info_keys(dataset[0], data_mode='bottomup') + + # test bottomup testing + dataset = self.build_humanart_dataset( + data_mode='bottomup', test_mode=True) + self.assertEqual(len(dataset), 3) + self.check_data_info_keys(dataset[0], data_mode='bottomup') + + def test_exceptions_and_warnings(self): + + with self.assertRaisesRegex(ValueError, 'got invalid data_mode'): + _ = self.build_humanart_dataset(data_mode='invalid') + + with self.assertRaisesRegex( + ValueError, + '"bbox_file" is only supported when `test_mode==True`'): + _ = self.build_humanart_dataset( + data_mode='topdown', + test_mode=False, + bbox_file='tests/data/humanart/test_humanart_det_AP_H_56.json') + + with self.assertRaisesRegex( + ValueError, '"bbox_file" is only supported in topdown mode'): + _ = self.build_humanart_dataset( + data_mode='bottomup', + test_mode=True, + bbox_file='tests/data/humanart/test_humanart_det_AP_H_56.json') + + with self.assertRaisesRegex( + ValueError, + '"bbox_score_thr" is only supported in topdown mode'): + _ = self.build_humanart_dataset( + data_mode='bottomup', + test_mode=True, + filter_cfg=dict(bbox_score_thr=0.3)) diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_jhmdb_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_jhmdb_dataset.py index d7aa46b067..2f27e06698 100644 --- a/tests/test_datasets/test_datasets/test_body_datasets/test_jhmdb_dataset.py +++ b/tests/test_datasets/test_datasets/test_body_datasets/test_jhmdb_dataset.py @@ -42,6 +42,7 @@ def check_data_info_keys(self, keypoints=np.ndarray, keypoints_visible=np.ndarray, invalid_segs=list, + area=(list, np.ndarray), id=list) else: raise ValueError(f'Invalid data_mode {data_mode}') diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_mhp_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_mhp_dataset.py index e93a524611..bdf5f3b807 100644 --- a/tests/test_datasets/test_datasets/test_body_datasets/test_mhp_dataset.py +++ b/tests/test_datasets/test_datasets/test_body_datasets/test_mhp_dataset.py @@ -45,6 +45,7 @@ def check_data_info_keys(self, keypoints=np.ndarray, keypoints_visible=np.ndarray, invalid_segs=list, + area=(list, np.ndarray), id=list) else: raise ValueError(f'Invalid data_mode {data_mode}') diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_mpii_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_mpii_dataset.py index f6431af429..2c35c4490a 100644 --- a/tests/test_datasets/test_datasets/test_body_datasets/test_mpii_dataset.py +++ b/tests/test_datasets/test_datasets/test_body_datasets/test_mpii_dataset.py @@ -44,6 +44,7 @@ def check_data_info_keys(self, keypoints=np.ndarray, keypoints_visible=np.ndarray, invalid_segs=list, + area=(list, np.ndarray), id=list) else: raise ValueError(f'Invalid data_mode {data_mode}') diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_posetrack18_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_posetrack18_dataset.py index ef3cd82dfb..8dabbaa0d5 100644 --- a/tests/test_datasets/test_datasets/test_body_datasets/test_posetrack18_dataset.py +++ b/tests/test_datasets/test_datasets/test_body_datasets/test_posetrack18_dataset.py @@ -42,6 +42,7 @@ def check_data_info_keys(self, keypoints=np.ndarray, keypoints_visible=np.ndarray, invalid_segs=list, + area=(list, np.ndarray), id=list) else: raise ValueError(f'Invalid data_mode {data_mode}') diff --git a/tests/test_datasets/test_datasets/test_dataset_wrappers/test_combined_dataset.py b/tests/test_datasets/test_datasets/test_dataset_wrappers/test_combined_dataset.py index 698f1f060d..ff2e8aaec2 100644 --- a/tests/test_datasets/test_datasets/test_dataset_wrappers/test_combined_dataset.py +++ b/tests/test_datasets/test_datasets/test_dataset_wrappers/test_combined_dataset.py @@ -81,6 +81,29 @@ def test_get_subset_index(self): self.assertEqual(subset_idx, 0) self.assertEqual(sample_idx, lens[0] - 1) + # combiend dataset with resampling ratio + dataset = self.build_combined_dataset(sample_ratio_factor=[1, 0.3]) + self.assertEqual( + len(dataset), + len(dataset.datasets[0]) + round(0.3 * len(dataset.datasets[1]))) + lens = dataset._lens + + index = lens[0] + subset_idx, sample_idx = dataset._get_subset_index(index) + self.assertEqual(subset_idx, 1) + self.assertIn(sample_idx, (0, 1, 2)) + + index = -lens[1] - 1 + subset_idx, sample_idx = dataset._get_subset_index(index) + self.assertEqual(subset_idx, 0) + self.assertEqual(sample_idx, lens[0] - 1) + + with self.assertRaises(AssertionError): + _ = self.build_combined_dataset(sample_ratio_factor=[1, 0.3, 0.1]) + + with self.assertRaises(AssertionError): + _ = self.build_combined_dataset(sample_ratio_factor=[1, -0.3]) + def test_prepare_data(self): dataset = self.build_combined_dataset() lens = dataset._lens diff --git a/tests/test_datasets/test_datasets/test_face_datasets/test_face_300wlp_dataset.py b/tests/test_datasets/test_datasets/test_face_datasets/test_face_300wlp_dataset.py new file mode 100644 index 0000000000..6462fe722f --- /dev/null +++ b/tests/test_datasets/test_datasets/test_face_datasets/test_face_300wlp_dataset.py @@ -0,0 +1,139 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import numpy as np + +from mmpose.datasets.datasets.face import Face300WLPDataset + + +class TestFace300WLPDataset(TestCase): + + def build_face_300wlp_dataset(self, **kwargs): + + cfg = dict( + ann_file='test_300wlp.json', + bbox_file=None, + data_mode='topdown', + data_root='tests/data/300wlp', + pipeline=[], + test_mode=False) + + cfg.update(kwargs) + return Face300WLPDataset(**cfg) + + def check_data_info_keys(self, + data_info: dict, + data_mode: str = 'topdown'): + if data_mode == 'topdown': + expected_keys = dict( + img_id=int, + img_path=str, + bbox_score=np.ndarray, + keypoints=np.ndarray, + keypoints_visible=np.ndarray, + id=int) + elif data_mode == 'bottomup': + expected_keys = dict( + img_id=int, + img_path=str, + bbox_score=np.ndarray, + keypoints=np.ndarray, + keypoints_visible=np.ndarray, + invalid_segs=list, + id=list) + else: + raise ValueError(f'Invalid data_mode {data_mode}') + + for key, type_ in expected_keys.items(): + self.assertIn(key, data_info) + self.assertIsInstance(data_info[key], type_, key) + + def check_metainfo_keys(self, metainfo: dict): + expected_keys = dict( + dataset_name=str, + num_keypoints=int, + keypoint_id2name=dict, + keypoint_name2id=dict, + upper_body_ids=list, + lower_body_ids=list, + flip_indices=list, + flip_pairs=list, + keypoint_colors=np.ndarray, + num_skeleton_links=int, + skeleton_links=list, + skeleton_link_colors=np.ndarray, + dataset_keypoint_weights=np.ndarray) + + for key, type_ in expected_keys.items(): + self.assertIn(key, metainfo) + self.assertIsInstance(metainfo[key], type_, key) + + def test_metainfo(self): + dataset = self.build_face_300wlp_dataset() + self.check_metainfo_keys(dataset.metainfo) + # test dataset_name + self.assertEqual(dataset.metainfo['dataset_name'], '300wlp') + + # test number of keypoints + num_keypoints = 68 + self.assertEqual(dataset.metainfo['num_keypoints'], num_keypoints) + self.assertEqual( + len(dataset.metainfo['keypoint_colors']), num_keypoints) + self.assertEqual( + len(dataset.metainfo['dataset_keypoint_weights']), num_keypoints) + + def test_topdown(self): + # test topdown training + dataset = self.build_face_300wlp_dataset(data_mode='topdown') + self.assertEqual(dataset.data_mode, 'topdown') + self.assertEqual(dataset.bbox_file, None) + self.assertEqual(len(dataset), 2) + self.check_data_info_keys(dataset[0]) + + # test topdown testing + dataset = self.build_face_300wlp_dataset( + data_mode='topdown', test_mode=True) + self.assertEqual(dataset.data_mode, 'topdown') + self.assertEqual(dataset.bbox_file, None) + self.assertEqual(len(dataset), 2) + self.check_data_info_keys(dataset[0]) + + def test_bottomup(self): + # test bottomup training + dataset = self.build_face_300wlp_dataset(data_mode='bottomup') + self.assertEqual(len(dataset), 2) + self.check_data_info_keys(dataset[0], data_mode='bottomup') + + # test bottomup testing + dataset = self.build_face_300wlp_dataset( + data_mode='bottomup', test_mode=True) + self.assertEqual(len(dataset), 2) + self.check_data_info_keys(dataset[0], data_mode='bottomup') + + def test_exceptions_and_warnings(self): + + with self.assertRaisesRegex(ValueError, 'got invalid data_mode'): + _ = self.build_face_300wlp_dataset(data_mode='invalid') + + with self.assertRaisesRegex( + ValueError, + '"bbox_file" is only supported when `test_mode==True`'): + _ = self.build_face_300wlp_dataset( + data_mode='topdown', + test_mode=False, + bbox_file='temp_bbox_file.json') + + with self.assertRaisesRegex( + ValueError, '"bbox_file" is only supported in topdown mode'): + _ = self.build_face_300wlp_dataset( + data_mode='bottomup', + test_mode=True, + bbox_file='temp_bbox_file.json') + + with self.assertRaisesRegex( + ValueError, + '"bbox_score_thr" is only supported in topdown mode'): + _ = self.build_face_300wlp_dataset( + data_mode='bottomup', + test_mode=True, + filter_cfg=dict(bbox_score_thr=0.3)) diff --git a/tests/test_datasets/test_datasets/test_hand_datasets/test_interhand2d_double_dataset.py b/tests/test_datasets/test_datasets/test_hand_datasets/test_interhand2d_double_dataset.py new file mode 100644 index 0000000000..3ed9f1cc92 --- /dev/null +++ b/tests/test_datasets/test_datasets/test_hand_datasets/test_interhand2d_double_dataset.py @@ -0,0 +1,132 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import numpy as np + +from mmpose.datasets.datasets.hand import InterHand2DDoubleDataset + + +class TestInterHand2DDoubleDataset(TestCase): + + def build_interhand2d_dataset(self, **kwargs): + + cfg = dict( + ann_file='test_interhand2.6m_data.json', + camera_param_file='test_interhand2.6m_camera.json', + joint_file='test_interhand2.6m_joint_3d.json', + data_mode='topdown', + data_root='tests/data/interhand2.6m', + pipeline=[], + test_mode=False) + + cfg.update(kwargs) + return InterHand2DDoubleDataset(**cfg) + + def check_metainfo_keys(self, metainfo: dict): + expected_keys = dict( + dataset_name=str, + num_keypoints=int, + keypoint_id2name=dict, + keypoint_name2id=dict, + upper_body_ids=list, + lower_body_ids=list, + flip_indices=list, + flip_pairs=list, + keypoint_colors=np.ndarray, + num_skeleton_links=int, + skeleton_links=list, + skeleton_link_colors=np.ndarray, + dataset_keypoint_weights=np.ndarray) + + for key, type_ in expected_keys.items(): + self.assertIn(key, metainfo) + self.assertIsInstance(metainfo[key], type_, key) + + def check_data_info_keys(self, + data_info: dict, + data_mode: str = 'topdown'): + if data_mode == 'topdown': + expected_keys = dict( + img_id=int, + img_path=str, + bbox=np.ndarray, + bbox_score=np.ndarray, + keypoints=np.ndarray, + keypoints_visible=np.ndarray, + hand_type=np.ndarray, + hand_type_valid=np.ndarray, + num_keypoints=int, + iscrowd=bool, + id=int) + elif data_mode == 'bottomup': + expected_keys = dict( + img_id=int, + img_path=str, + bbox=np.ndarray, + bbox_score=np.ndarray, + keypoints=np.ndarray, + keypoints_visible=np.ndarray, + hand_type=np.ndarray, + hand_type_valid=np.ndarray, + num_keypoints=list, + iscrowd=list, + invalid_segs=list, + id=list) + else: + raise ValueError(f'Invalid data_mode {data_mode}') + + for key, type_ in expected_keys.items(): + self.assertIn(key, data_info) + self.assertIsInstance(data_info[key], type_, key) + + def test_metainfo(self): + dataset = self.build_interhand2d_dataset() + self.check_metainfo_keys(dataset.metainfo) + # test dataset_name + self.assertEqual(dataset.metainfo['dataset_name'], 'interhand3d') + + # test number of keypoints + num_keypoints = 42 + self.assertEqual(dataset.metainfo['num_keypoints'], num_keypoints) + self.assertEqual( + len(dataset.metainfo['keypoint_colors']), num_keypoints) + self.assertEqual( + len(dataset.metainfo['dataset_keypoint_weights']), num_keypoints) + + # test some extra metainfo + self.assertEqual( + len(dataset.metainfo['skeleton_links']), + len(dataset.metainfo['skeleton_link_colors'])) + + def test_topdown(self): + # test topdown training + dataset = self.build_interhand2d_dataset(data_mode='topdown') + self.assertEqual(dataset.data_mode, 'topdown') + self.assertEqual(dataset.bbox_file, None) + self.assertEqual(len(dataset), 4) + self.check_data_info_keys(dataset[0]) + + # test topdown testing + dataset = self.build_interhand2d_dataset( + data_mode='topdown', test_mode=True) + self.assertEqual(dataset.data_mode, 'topdown') + self.assertEqual(dataset.bbox_file, None) + self.assertEqual(len(dataset), 4) + self.check_data_info_keys(dataset[0]) + + def test_bottomup(self): + # test bottomup training + dataset = self.build_interhand2d_dataset(data_mode='bottomup') + self.assertEqual(len(dataset), 4) + self.check_data_info_keys(dataset[0], data_mode='bottomup') + + # test bottomup testing + dataset = self.build_interhand2d_dataset( + data_mode='bottomup', test_mode=True) + self.assertEqual(len(dataset), 4) + self.check_data_info_keys(dataset[0], data_mode='bottomup') + + def test_exceptions_and_warnings(self): + + with self.assertRaisesRegex(ValueError, 'got invalid data_mode'): + _ = self.build_interhand2d_dataset(data_mode='invalid') diff --git a/tests/test_datasets/test_datasets/test_hand_datasets/test_interhand3d_dataset.py b/tests/test_datasets/test_datasets/test_hand_datasets/test_interhand3d_dataset.py new file mode 100644 index 0000000000..f9c4ac569e --- /dev/null +++ b/tests/test_datasets/test_datasets/test_hand_datasets/test_interhand3d_dataset.py @@ -0,0 +1,144 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import numpy as np + +from mmpose.datasets.datasets.hand3d import InterHand3DDataset + + +class TestInterHand3DDataset(TestCase): + + def build_interhand3d_dataset(self, **kwargs): + + cfg = dict( + ann_file='test_interhand2.6m_data.json', + camera_param_file='test_interhand2.6m_camera.json', + joint_file='test_interhand2.6m_joint_3d.json', + data_mode='topdown', + data_root='tests/data/interhand2.6m', + pipeline=[], + test_mode=False) + + cfg.update(kwargs) + return InterHand3DDataset(**cfg) + + def check_metainfo_keys(self, metainfo: dict): + expected_keys = dict( + dataset_name=str, + num_keypoints=int, + keypoint_id2name=dict, + keypoint_name2id=dict, + upper_body_ids=list, + lower_body_ids=list, + flip_indices=list, + flip_pairs=list, + keypoint_colors=np.ndarray, + num_skeleton_links=int, + skeleton_links=list, + skeleton_link_colors=np.ndarray, + dataset_keypoint_weights=np.ndarray) + + for key, type_ in expected_keys.items(): + self.assertIn(key, metainfo) + self.assertIsInstance(metainfo[key], type_, key) + + def check_data_info_keys(self, + data_info: dict, + data_mode: str = 'topdown'): + if data_mode == 'topdown': + expected_keys = dict( + img_id=int, + img_path=str, + bbox=np.ndarray, + bbox_score=np.ndarray, + rotation=int, + keypoints=np.ndarray, + keypoints_visible=np.ndarray, + hand_type=np.ndarray, + hand_type_valid=np.ndarray, + rel_root_depth=np.float32, + rel_root_valid=np.float32, + abs_depth=list, + focal=np.ndarray, + principal_pt=np.ndarray, + num_keypoints=int, + iscrowd=bool, + id=int) + elif data_mode == 'bottomup': + expected_keys = dict( + img_id=int, + img_path=str, + bbox=np.ndarray, + bbox_score=np.ndarray, + rotation=list, + keypoints=np.ndarray, + keypoints_visible=np.ndarray, + hand_type=np.ndarray, + hand_type_valid=np.ndarray, + rel_root_depth=list, + rel_root_valid=list, + abs_depth=list, + focal=np.ndarray, + principal_pt=np.ndarray, + num_keypoints=list, + iscrowd=list, + invalid_segs=list, + id=list) + else: + raise ValueError(f'Invalid data_mode {data_mode}') + + for key, type_ in expected_keys.items(): + self.assertIn(key, data_info) + self.assertIsInstance(data_info[key], type_, key) + + def test_metainfo(self): + dataset = self.build_interhand3d_dataset() + self.check_metainfo_keys(dataset.metainfo) + # test dataset_name + self.assertEqual(dataset.metainfo['dataset_name'], 'interhand3d') + + # test number of keypoints + num_keypoints = 42 + self.assertEqual(dataset.metainfo['num_keypoints'], num_keypoints) + self.assertEqual( + len(dataset.metainfo['keypoint_colors']), num_keypoints) + self.assertEqual( + len(dataset.metainfo['dataset_keypoint_weights']), num_keypoints) + + # test some extra metainfo + self.assertEqual( + len(dataset.metainfo['skeleton_links']), + len(dataset.metainfo['skeleton_link_colors'])) + + def test_topdown(self): + # test topdown training + dataset = self.build_interhand3d_dataset(data_mode='topdown') + self.assertEqual(dataset.data_mode, 'topdown') + self.assertEqual(dataset.bbox_file, None) + self.assertEqual(len(dataset), 4) + self.check_data_info_keys(dataset[0]) + + # test topdown testing + dataset = self.build_interhand3d_dataset( + data_mode='topdown', test_mode=True) + self.assertEqual(dataset.data_mode, 'topdown') + self.assertEqual(dataset.bbox_file, None) + self.assertEqual(len(dataset), 4) + self.check_data_info_keys(dataset[0]) + + def test_bottomup(self): + # test bottomup training + dataset = self.build_interhand3d_dataset(data_mode='bottomup') + self.assertEqual(len(dataset), 4) + self.check_data_info_keys(dataset[0], data_mode='bottomup') + + # test bottomup testing + dataset = self.build_interhand3d_dataset( + data_mode='bottomup', test_mode=True) + self.assertEqual(len(dataset), 4) + self.check_data_info_keys(dataset[0], data_mode='bottomup') + + def test_exceptions_and_warnings(self): + + with self.assertRaisesRegex(ValueError, 'got invalid data_mode'): + _ = self.build_interhand3d_dataset(data_mode='invalid') diff --git a/tests/test_datasets/test_datasets/test_wholebody_datasets/test_ubody_dataset.py b/tests/test_datasets/test_datasets/test_wholebody_datasets/test_ubody_dataset.py new file mode 100644 index 0000000000..77e01da5b1 --- /dev/null +++ b/tests/test_datasets/test_datasets/test_wholebody_datasets/test_ubody_dataset.py @@ -0,0 +1,77 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import numpy as np + +from mmpose.datasets.datasets.wholebody3d import UBody3dDataset + + +class TestUBody3dDataset(TestCase): + + def build_ubody3d_dataset(self, **kwargs): + + cfg = dict( + ann_file='ubody3d_train.json', + data_mode='topdown', + data_root='tests/data/ubody3d', + pipeline=[], + test_mode=False) + + cfg.update(kwargs) + return UBody3dDataset(**cfg) + + def check_data_info_keys(self, data_info: dict): + expected_keys = dict( + img_paths=list, + keypoints=np.ndarray, + keypoints_3d=np.ndarray, + scale=np.ndarray, + center=np.ndarray, + id=int) + + for key, type_ in expected_keys.items(): + self.assertIn(key, data_info) + self.assertIsInstance(data_info[key], type_, key) + + def test_metainfo(self): + dataset = self.build_ubody3d_dataset() + # test dataset_name + self.assertEqual(dataset.metainfo['dataset_name'], 'ubody3d') + + # test number of keypoints + num_keypoints = 137 + self.assertEqual(dataset.metainfo['num_keypoints'], num_keypoints) + self.assertEqual( + len(dataset.metainfo['keypoint_colors']), num_keypoints) + self.assertEqual( + len(dataset.metainfo['dataset_keypoint_weights']), num_keypoints) + + # test some extra metainfo + self.assertEqual( + len(dataset.metainfo['skeleton_links']), + len(dataset.metainfo['skeleton_link_colors'])) + + def test_topdown(self): + # test topdown training + dataset = self.build_ubody3d_dataset(data_mode='topdown') + dataset.full_init() + self.assertEqual(len(dataset), 1) + self.check_data_info_keys(dataset[0]) + + # test topdown testing + dataset = self.build_ubody3d_dataset( + data_mode='topdown', test_mode=True) + dataset.full_init() + self.assertEqual(len(dataset), 1) + self.check_data_info_keys(dataset[0]) + + # test topdown training with sequence config + dataset = self.build_ubody3d_dataset( + data_mode='topdown', + seq_len=1, + seq_step=1, + causal=False, + pad_video_seq=True) + dataset.full_init() + self.assertEqual(len(dataset), 1) + self.check_data_info_keys(dataset[0]) diff --git a/tests/test_datasets/test_transforms/test_bottomup_transforms.py b/tests/test_datasets/test_transforms/test_bottomup_transforms.py index cded7a6efb..8d9213c729 100644 --- a/tests/test_datasets/test_transforms/test_bottomup_transforms.py +++ b/tests/test_datasets/test_transforms/test_bottomup_transforms.py @@ -6,7 +6,9 @@ from mmcv.transforms import Compose from mmpose.datasets.transforms import (BottomupGetHeatmapMask, - BottomupRandomAffine, BottomupResize, + BottomupRandomAffine, + BottomupRandomChoiceResize, + BottomupRandomCrop, BottomupResize, RandomFlip) from mmpose.testing import get_coco_sample @@ -145,3 +147,166 @@ def test_transform(self): self.assertIsInstance(results['input_scale'], np.ndarray) self.assertEqual(results['img'][0].shape, (256, 256, 3)) self.assertEqual(results['img'][1].shape, (384, 384, 3)) + + +class TestBottomupRandomCrop(TestCase): + + def setUp(self): + # test invalid crop_type + with self.assertRaisesRegex(ValueError, 'Invalid crop_type'): + BottomupRandomCrop(crop_size=(10, 10), crop_type='unknown') + + crop_type_list = ['absolute', 'absolute_range'] + for crop_type in crop_type_list: + # test h > 0 and w > 0 + for crop_size in [(0, 0), (0, 1), (1, 0)]: + with self.assertRaises(AssertionError): + BottomupRandomCrop( + crop_size=crop_size, crop_type=crop_type) + # test type(h) = int and type(w) = int + for crop_size in [(1.0, 1), (1, 1.0), (1.0, 1.0)]: + with self.assertRaises(AssertionError): + BottomupRandomCrop( + crop_size=crop_size, crop_type=crop_type) + + # test crop_size[0] <= crop_size[1] + with self.assertRaises(AssertionError): + BottomupRandomCrop(crop_size=(10, 5), crop_type='absolute_range') + + # test h in (0, 1] and w in (0, 1] + crop_type_list = ['relative_range', 'relative'] + for crop_type in crop_type_list: + for crop_size in [(0, 1), (1, 0), (1.1, 0.5), (0.5, 1.1)]: + with self.assertRaises(AssertionError): + BottomupRandomCrop( + crop_size=crop_size, crop_type=crop_type) + + self.data_info = get_coco_sample(img_shape=(24, 32)) + + def test_transform(self): + # test relative and absolute crop + src_results = self.data_info + target_shape = (12, 16) + for crop_type, crop_size in zip(['relative', 'absolute'], [(0.5, 0.5), + (16, 12)]): + transform = BottomupRandomCrop( + crop_size=crop_size, crop_type=crop_type) + results = transform(deepcopy(src_results)) + self.assertEqual(results['img'].shape[:2], target_shape) + + # test absolute_range crop + transform = BottomupRandomCrop( + crop_size=(10, 20), crop_type='absolute_range') + results = transform(deepcopy(src_results)) + h, w = results['img'].shape[:2] + self.assertTrue(10 <= w <= 20) + self.assertTrue(10 <= h <= 20) + self.assertEqual(results['img_shape'], results['img'].shape[:2]) + # test relative_range crop + transform = BottomupRandomCrop( + crop_size=(0.5, 0.5), crop_type='relative_range') + results = transform(deepcopy(src_results)) + h, w = results['img'].shape[:2] + self.assertTrue(16 <= w <= 32) + self.assertTrue(12 <= h <= 24) + self.assertEqual(results['img_shape'], results['img'].shape[:2]) + + # test with keypoints, bbox, segmentation + src_results = get_coco_sample(img_shape=(10, 10), num_instances=2) + segmentation = np.random.randint(0, 255, size=(10, 10), dtype=np.uint8) + keypoints = np.ones_like(src_results['keypoints']) * 5 + src_results['segmentation'] = segmentation + src_results['keypoints'] = keypoints + transform = BottomupRandomCrop( + crop_size=(7, 5), + allow_negative_crop=False, + recompute_bbox=False, + bbox_clip_border=True) + results = transform(deepcopy(src_results)) + h, w = results['img'].shape[:2] + self.assertEqual(h, 5) + self.assertEqual(w, 7) + self.assertEqual(results['bbox'].shape[0], 2) + self.assertTrue(results['keypoints_visible'].all()) + self.assertTupleEqual(results['segmentation'].shape[:2], (5, 7)) + self.assertEqual(results['img_shape'], results['img'].shape[:2]) + + # test bbox_clip_border = False + transform = BottomupRandomCrop( + crop_size=(10, 11), + allow_negative_crop=False, + recompute_bbox=True, + bbox_clip_border=False) + results = transform(deepcopy(src_results)) + self.assertTrue((results['bbox'] == src_results['bbox']).all()) + + # test the crop does not contain any gt-bbox + # allow_negative_crop = False + img = np.random.randint(0, 255, size=(10, 10), dtype=np.uint8) + bbox = np.zeros((0, 4), dtype=np.float32) + src_results = {'img': img, 'bbox': bbox} + transform = BottomupRandomCrop( + crop_size=(5, 3), allow_negative_crop=False) + results = transform(deepcopy(src_results)) + self.assertIsNone(results) + + # allow_negative_crop = True + img = np.random.randint(0, 255, size=(10, 10), dtype=np.uint8) + bbox = np.zeros((0, 4), dtype=np.float32) + src_results = {'img': img, 'bbox': bbox} + transform = BottomupRandomCrop( + crop_size=(5, 3), allow_negative_crop=True) + results = transform(deepcopy(src_results)) + self.assertTrue(isinstance(results, dict)) + + +class TestBottomupRandomChoiceResize(TestCase): + + def setUp(self): + self.data_info = get_coco_sample(img_shape=(300, 400)) + + def test_transform(self): + results = dict() + # test with one scale + transform = BottomupRandomChoiceResize(scales=[(1333, 800)]) + results = deepcopy(self.data_info) + results = transform(results) + self.assertEqual(results['img'].shape, (800, 1333, 3)) + + # test with multi scales + _scale_choice = [(1333, 800), (1333, 600)] + transform = BottomupRandomChoiceResize(scales=_scale_choice) + results = deepcopy(self.data_info) + results = transform(results) + self.assertIn((results['img'].shape[1], results['img'].shape[0]), + _scale_choice) + + # test keep_ratio + transform = BottomupRandomChoiceResize( + scales=[(900, 600)], resize_type='Resize', keep_ratio=True) + results = deepcopy(self.data_info) + _input_ratio = results['img'].shape[0] / results['img'].shape[1] + results = transform(results) + _output_ratio = results['img'].shape[0] / results['img'].shape[1] + self.assertLess(abs(_input_ratio - _output_ratio), 1.5 * 1e-3) + + # test clip_object_border + bbox = [[200, 150, 600, 450]] + transform = BottomupRandomChoiceResize( + scales=[(200, 150)], resize_type='Resize', clip_object_border=True) + results = deepcopy(self.data_info) + results['bbox'] = np.array(bbox) + results = transform(results) + self.assertEqual(results['img'].shape, (150, 200, 3)) + self.assertTrue((results['bbox'] == np.array([[100, 75, 200, + 150]])).all()) + + transform = BottomupRandomChoiceResize( + scales=[(200, 150)], + resize_type='Resize', + clip_object_border=False) + results = self.data_info + results['bbox'] = np.array(bbox) + results = transform(results) + assert results['img'].shape == (150, 200, 3) + assert np.equal(results['bbox'], np.array([[100, 75, 300, 225]])).all() diff --git a/tests/test_datasets/test_transforms/test_common_transforms.py b/tests/test_datasets/test_transforms/test_common_transforms.py index 2818081dca..fe81b9a94c 100644 --- a/tests/test_datasets/test_transforms/test_common_transforms.py +++ b/tests/test_datasets/test_transforms/test_common_transforms.py @@ -4,15 +4,17 @@ from copy import deepcopy from unittest import TestCase +import mmcv import numpy as np from mmcv.transforms import Compose, LoadImageFromFile from mmengine.utils import is_list_of -from mmpose.datasets.transforms import (Albumentation, GenerateTarget, - GetBBoxCenterScale, +from mmpose.datasets.transforms import (Albumentation, FilterAnnotations, + GenerateTarget, GetBBoxCenterScale, PhotometricDistortion, RandomBBoxTransform, RandomFlip, - RandomHalfBody, TopdownAffine) + RandomHalfBody, TopdownAffine, + YOLOXHSVRandomAug) from mmpose.testing import get_coco_sample @@ -49,7 +51,7 @@ def test_transform(self): results.update(bbox_center=center, bbox_scale=scale) results = transform(results) self.assertTrue(np.allclose(results['bbox_center'], center)) - self.assertTrue(np.allclose(results['bbox_scale'], scale)) + self.assertTrue(np.allclose(results['bbox_scale'], scale * padding)) def test_repr(self): transform = GetBBoxCenterScale(padding=1.25) @@ -600,3 +602,134 @@ def test_errors(self): with self.assertWarnsRegex(DeprecationWarning, '`target_type` is deprecated'): _ = GenerateTarget(encoder=encoder, target_type='heatmap') + + +class TestFilterAnnotations(TestCase): + + def setUp(self): + """Setup the model and optimizer which are used in every test + method.""" + self.results = { + 'img': + np.random.random((224, 224, 3)), + 'img_shape': (224, 224), + 'bbox': + np.array([[10, 10, 20, 20], [20, 20, 40, 40], [40, 40, 80, 80]]), + 'bbox_score': + np.array([0.9, 0.8, 0.7]), + 'category_id': + np.array([1, 2, 3]), + 'keypoints': + np.array([[15, 15, 1], [25, 25, 1], [45, 45, 1]]), + 'keypoints_visible': + np.array([[1, 1, 0], [1, 1, 1], [1, 1, 1]]), + 'area': + np.array([300, 600, 1200]), + } + + def test_transform(self): + # Test keep_empty = True + transform = FilterAnnotations( + min_gt_bbox_wh=(50, 50), + keep_empty=True, + by_box=True, + ) + results = transform(copy.deepcopy(self.results)) + self.assertIsNone(results) + + # Test keep_empty = False + transform = FilterAnnotations( + min_gt_bbox_wh=(50, 50), + keep_empty=False, + ) + results = transform(copy.deepcopy(self.results)) + self.assertTrue(isinstance(results, dict)) + + # Test filter annotations by bbox + transform = FilterAnnotations(min_gt_bbox_wh=(15, 15), by_box=True) + results = transform(copy.deepcopy(self.results)) + print((results['bbox'] == np.array([[20, 20, 40, 40], [40, 40, 80, + 80]])).all()) + self.assertTrue((results['bbox'] == np.array([[20, 20, 40, 40], + [40, 40, 80, + 80]])).all()) + self.assertTrue((results['bbox_score'] == np.array([0.8, 0.7])).all()) + self.assertTrue((results['category_id'] == np.array([2, 3])).all()) + self.assertTrue((results['keypoints'] == np.array([[25, 25, 1], + [45, 45, + 1]])).all()) + self.assertTrue( + (results['keypoints_visible'] == np.array([[1, 1, 1], [1, 1, + 1]])).all()) + self.assertTrue((results['area'] == np.array([600, 1200])).all()) + + # Test filter annotations by area + transform = FilterAnnotations(min_gt_area=1000, by_area=True) + results = transform(copy.deepcopy(self.results)) + self.assertIsInstance(results, dict) + self.assertTrue((results['bbox'] == np.array([[40, 40, 80, + 80]])).all()) + self.assertTrue((results['bbox_score'] == np.array([0.7])).all()) + self.assertTrue((results['category_id'] == np.array([3])).all()) + self.assertTrue((results['keypoints'] == np.array([[45, 45, + 1]])).all()) + self.assertTrue( + (results['keypoints_visible'] == np.array([[1, 1, 1]])).all()) + self.assertTrue((results['area'] == np.array([1200])).all()) + + # Test filter annotations by keypoints visibility + transform = FilterAnnotations(min_kpt_vis=3, by_kpt=True) + results = transform(copy.deepcopy(self.results)) + self.assertIsInstance(results, dict) + self.assertTrue((results['bbox'] == np.array([[20, 20, 40, 40], + [40, 40, 80, + 80]])).all()) + self.assertTrue((results['bbox_score'] == np.array([0.8, 0.7])).all()) + self.assertTrue((results['category_id'] == np.array([2, 3])).all()) + self.assertTrue((results['keypoints'] == np.array([[25, 25, 1], + [45, 45, + 1]])).all()) + self.assertTrue( + (results['keypoints_visible'] == np.array([[1, 1, 1], [1, 1, + 1]])).all()) + self.assertTrue((results['area'] == np.array([600, 1200])).all()) + + +class TestYOLOXHSVRandomAug(TestCase): + + def setUp(self): + """Setup the model and optimizer which are used in every test method. + + TestCase calls functions in this order: setUp() -> testMethod() -> + tearDown() -> cleanUp() + """ + img = mmcv.imread( + osp.join( + osp.dirname(__file__), '../../data/coco/000000000785.jpg'), + 'color') + self.results = { + 'img': + img, + 'img_shape': (640, 425), + 'category_id': + np.array([1, 2, 3], dtype=np.int64), + 'bbox': + np.array([[10, 10, 20, 20], [20, 20, 40, 40], [40, 40, 80, 80]], + dtype=np.float32), + } + + def test_transform(self): + transform = YOLOXHSVRandomAug() + results = transform(copy.deepcopy(self.results)) + self.assertTrue( + results['img'].shape[:2] == self.results['img'].shape[:2]) + self.assertTrue( + results['category_id'].shape[0] == results['bbox'].shape[0]) + self.assertTrue(results['bbox'].dtype == np.float32) + + def test_repr(self): + transform = YOLOXHSVRandomAug() + self.assertEqual( + repr(transform), ('YOLOXHSVRandomAug(hue_delta=5, ' + 'saturation_delta=30, ' + 'value_delta=30)')) diff --git a/tests/test_datasets/test_transforms/test_converting.py b/tests/test_datasets/test_transforms/test_converting.py index 09f06e1e65..9f535b5126 100644 --- a/tests/test_datasets/test_transforms/test_converting.py +++ b/tests/test_datasets/test_transforms/test_converting.py @@ -1,6 +1,9 @@ # Copyright (c) OpenMMLab. All rights reserved. + from unittest import TestCase +import numpy as np + from mmpose.datasets.transforms import KeypointConverter from mmpose.testing import get_coco_sample @@ -32,8 +35,10 @@ def test_transform(self): self.assertTrue((results['keypoints'][:, target_index] == self.data_info['keypoints'][:, source_index]).all()) + self.assertEqual(results['keypoints_visible'].ndim, 3) + self.assertEqual(results['keypoints_visible'].shape[2], 2) self.assertTrue( - (results['keypoints_visible'][:, target_index] == + (results['keypoints_visible'][:, target_index, 0] == self.data_info['keypoints_visible'][:, source_index]).all()) # 2-to-1 mapping @@ -58,8 +63,10 @@ def test_transform(self): (results['keypoints'][:, target_index] == 0.5 * (self.data_info['keypoints'][:, source_index] + self.data_info['keypoints'][:, source_index2])).all()) + self.assertEqual(results['keypoints_visible'].ndim, 3) + self.assertEqual(results['keypoints_visible'].shape[2], 2) self.assertTrue( - (results['keypoints_visible'][:, target_index] == + (results['keypoints_visible'][:, target_index, 0] == self.data_info['keypoints_visible'][:, source_index] * self.data_info['keypoints_visible'][:, source_index2]).all()) @@ -67,7 +74,36 @@ def test_transform(self): self.assertTrue( (results['keypoints'][:, target_index] == self.data_info['keypoints'][:, source_index]).all()) + self.assertEqual(results['keypoints_visible'].ndim, 3) + self.assertEqual(results['keypoints_visible'].shape[2], 2) self.assertTrue( - (results['keypoints_visible'][:, target_index] == + (results['keypoints_visible'][:, target_index, 0] == self.data_info['keypoints_visible'][:, source_index]).all()) + + # check 3d keypoint + self.data_info['keypoints_3d'] = np.random.random((4, 17, 3)) + self.data_info['target_idx'] = [-1] + mapping = [(3, 0), (6, 1), (16, 2), (5, 3)] + transform = KeypointConverter(num_keypoints=5, mapping=mapping) + results = transform(self.data_info.copy()) + + # check shape + self.assertEqual(results['keypoints_3d'].shape[0], + self.data_info['keypoints_3d'].shape[0]) + self.assertEqual(results['keypoints_3d'].shape[1], 5) + self.assertEqual(results['keypoints_3d'].shape[2], 3) + self.assertEqual(results['keypoints_visible'].shape[0], + self.data_info['keypoints_visible'].shape[0]) + self.assertEqual(results['keypoints_visible'].shape[1], 5) + + # check value + for source_index, target_index in mapping: + self.assertTrue( + (results['keypoints_3d'][:, target_index] == + self.data_info['keypoints_3d'][:, source_index]).all()) + self.assertEqual(results['keypoints_visible'].ndim, 3) + self.assertEqual(results['keypoints_visible'].shape[2], 2) + self.assertTrue( + (results['keypoints_visible'][:, target_index, 0] == + self.data_info['keypoints_visible'][:, source_index]).all()) diff --git a/tests/test_datasets/test_transforms/test_mix_img_transform.py b/tests/test_datasets/test_transforms/test_mix_img_transform.py new file mode 100644 index 0000000000..bae26da83a --- /dev/null +++ b/tests/test_datasets/test_transforms/test_mix_img_transform.py @@ -0,0 +1,115 @@ +# Copyright (c) OpenMMLab. All rights reserved. + +from unittest import TestCase + +import numpy as np + +from mmpose.datasets.transforms import Mosaic, YOLOXMixUp + + +class TestMosaic(TestCase): + + def setUp(self): + # Create a sample data dictionary for testing + sample_data = { + 'img': + np.random.randint(0, 255, size=(480, 640, 3), dtype=np.uint8), + 'bbox': np.random.rand(2, 4), + 'bbox_score': np.random.rand(2, ), + 'category_id': [1, 2], + 'keypoints': np.random.rand(2, 3, 2), + 'keypoints_visible': np.random.rand(2, 3), + 'area': np.random.rand(2, ) + } + mixed_data_list = [sample_data.copy() for _ in range(3)] + sample_data.update({'mixed_data_list': mixed_data_list}) + + self.sample_data = sample_data + + def test_apply_mix(self): + mosaic = Mosaic() + transformed_data = mosaic.apply_mix(self.sample_data) + + # Check if the transformed data has the expected keys + self.assertTrue('img' in transformed_data) + self.assertTrue('img_shape' in transformed_data) + self.assertTrue('bbox' in transformed_data) + self.assertTrue('category_id' in transformed_data) + self.assertTrue('bbox_score' in transformed_data) + self.assertTrue('keypoints' in transformed_data) + self.assertTrue('keypoints_visible' in transformed_data) + self.assertTrue('area' in transformed_data) + + def test_create_mosaic_image(self): + mosaic = Mosaic() + mosaic_img, annos = mosaic._create_mosaic_image( + self.sample_data, self.sample_data['mixed_data_list']) + + # Check if the mosaic image and annotations are generated correctly + self.assertEqual(mosaic_img.shape, (1280, 1280, 3)) + self.assertTrue('bboxes' in annos) + self.assertTrue('bbox_scores' in annos) + self.assertTrue('category_id' in annos) + self.assertTrue('keypoints' in annos) + self.assertTrue('keypoints_visible' in annos) + self.assertTrue('area' in annos) + + def test_mosaic_combine(self): + mosaic = Mosaic() + center = (320, 240) + img_shape = (480, 640) + paste_coord, crop_coord = mosaic._mosaic_combine( + 'top_left', center, img_shape) + + # Check if the coordinates are calculated correctly + self.assertEqual(paste_coord, (0, 0, 320, 240)) + self.assertEqual(crop_coord, (160, 400, 480, 640)) + + +class TestYOLOXMixUp(TestCase): + + def setUp(self): + # Create a sample data dictionary for testing + sample_data = { + 'img': + np.random.randint(0, 255, size=(480, 640, 3), dtype=np.uint8), + 'bbox': np.random.rand(2, 4), + 'bbox_score': np.random.rand(2, ), + 'category_id': [1, 2], + 'keypoints': np.random.rand(2, 3, 2), + 'keypoints_visible': np.random.rand(2, 3), + 'area': np.random.rand(2, ), + 'flip_indices': [0, 2, 1] + } + mixed_data_list = [sample_data.copy() for _ in range(1)] + sample_data.update({'mixed_data_list': mixed_data_list}) + + self.sample_data = sample_data + + def test_apply_mix(self): + mixup = YOLOXMixUp() + transformed_data = mixup.apply_mix(self.sample_data) + + # Check if the transformed data has the expected keys + self.assertTrue('img' in transformed_data) + self.assertTrue('img_shape' in transformed_data) + self.assertTrue('bbox' in transformed_data) + self.assertTrue('category_id' in transformed_data) + self.assertTrue('bbox_score' in transformed_data) + self.assertTrue('keypoints' in transformed_data) + self.assertTrue('keypoints_visible' in transformed_data) + self.assertTrue('area' in transformed_data) + + def test_create_mixup_image(self): + mixup = YOLOXMixUp() + mixup_img, annos = mixup._create_mixup_image( + self.sample_data, self.sample_data['mixed_data_list']) + + # Check if the mosaic image and annotations are generated correctly + self.assertEqual(mixup_img.shape, (480, 640, 3)) + self.assertTrue('bboxes' in annos) + self.assertTrue('bbox_scores' in annos) + self.assertTrue('category_id' in annos) + self.assertTrue('keypoints' in annos) + self.assertTrue('keypoints_visible' in annos) + self.assertTrue('area' in annos) diff --git a/tests/test_datasets/test_transforms/test_pose3d_transforms.py b/tests/test_datasets/test_transforms/test_pose3d_transforms.py index 5f5d5aa096..c057dba4e7 100644 --- a/tests/test_datasets/test_transforms/test_pose3d_transforms.py +++ b/tests/test_datasets/test_transforms/test_pose3d_transforms.py @@ -35,7 +35,7 @@ def _parse_h36m_imgname(imgname): scales = data['scale'].astype(np.float32) idx = 0 - target_idx = 0 + target_idx = [0] data_info = { 'keypoints': keypoints[idx, :, :2].reshape(1, -1, 2), @@ -52,7 +52,6 @@ def _parse_h36m_imgname(imgname): 'sample_idx': idx, 'lifting_target': keypoints_3d[target_idx, :, :3], 'lifting_target_visible': keypoints_3d[target_idx, :, 3], - 'target_img_path': osp.join('tests/data/h36m', imgnames[target_idx]), } # add camera parameters @@ -108,9 +107,12 @@ def test_transform(self): tar_vis2 = results['lifting_target_visible'] self.assertEqual(kpts_vis2.shape, (1, 17)) - self.assertEqual(tar_vis2.shape, (17, )) + self.assertEqual(tar_vis2.shape, ( + 1, + 17, + )) self.assertEqual(kpts2.shape, (1, 17, 2)) - self.assertEqual(tar2.shape, (17, 3)) + self.assertEqual(tar2.shape, (1, 17, 3)) flip_indices = [ 0, 4, 5, 6, 1, 2, 3, 7, 8, 9, 10, 14, 15, 16, 11, 12, 13 @@ -121,12 +123,15 @@ def test_transform(self): self.assertTrue( np.allclose(kpts1[0][left][1:], kpts2[0][right][1:], atol=4.)) self.assertTrue( - np.allclose(tar1[left][1:], tar2[right][1:], atol=4.)) + np.allclose( + tar1[..., left, 1:], tar2[..., right, 1:], atol=4.)) self.assertTrue( - np.allclose(kpts_vis1[0][left], kpts_vis2[0][right], atol=4.)) + np.allclose( + kpts_vis1[..., left], kpts_vis2[..., right], atol=4.)) self.assertTrue( - np.allclose(tar_vis1[left], tar_vis2[right], atol=4.)) + np.allclose( + tar_vis1[..., left], tar_vis2[..., right], atol=4.)) # test camera flipping transform = RandomFlipAroundRoot( @@ -148,3 +153,47 @@ def test_transform(self): -self.data_info['camera_param']['p'][0], camera2['p'][0], atol=4.)) + + # test label flipping + self.data_info['keypoint_labels'] = kpts1 + self.data_info['keypoint_labels_visible'] = kpts_vis1 + self.data_info['lifting_target_label'] = tar1 + + transform = RandomFlipAroundRoot( + self.keypoints_flip_cfg, + self.target_flip_cfg, + flip_prob=1, + flip_label=True) + results = transform(deepcopy(self.data_info)) + + kpts2 = results['keypoint_labels'] + kpts_vis2 = results['keypoint_labels_visible'] + tar2 = results['lifting_target_label'] + tar_vis2 = results['lifting_target_visible'] + + self.assertEqual(kpts_vis2.shape, (1, 17)) + self.assertEqual(tar_vis2.shape, ( + 1, + 17, + )) + self.assertEqual(kpts2.shape, (1, 17, 2)) + self.assertEqual(tar2.shape, (1, 17, 3)) + + flip_indices = [ + 0, 4, 5, 6, 1, 2, 3, 7, 8, 9, 10, 14, 15, 16, 11, 12, 13 + ] + for left, right in enumerate(flip_indices): + self.assertTrue( + np.allclose(-kpts1[0][left][:1], kpts2[0][right][:1], atol=4.)) + self.assertTrue( + np.allclose(kpts1[0][left][1:], kpts2[0][right][1:], atol=4.)) + self.assertTrue( + np.allclose( + tar1[..., left, 1:], tar2[..., right, 1:], atol=4.)) + + self.assertTrue( + np.allclose( + kpts_vis1[..., left], kpts_vis2[..., right], atol=4.)) + self.assertTrue( + np.allclose( + tar_vis1[..., left], tar_vis2[..., right], atol=4.)) diff --git a/tests/test_engine/test_hooks/test_badcase_hook.py b/tests/test_engine/test_hooks/test_badcase_hook.py new file mode 100644 index 0000000000..4a84506fa8 --- /dev/null +++ b/tests/test_engine/test_hooks/test_badcase_hook.py @@ -0,0 +1,102 @@ +# Copyright (c) OpenMMLab. All rights reserved. +import os +import os.path as osp +import shutil +import time +from unittest import TestCase +from unittest.mock import MagicMock + +import numpy as np +from mmengine.config import ConfigDict +from mmengine.structures import InstanceData + +from mmpose.engine.hooks import BadCaseAnalysisHook +from mmpose.structures import PoseDataSample +from mmpose.visualization import PoseLocalVisualizer + + +def _rand_poses(num_boxes, kpt_num, h, w): + center = np.random.rand(num_boxes, 2) + offset = np.random.rand(num_boxes, kpt_num, 2) / 2.0 + + pose = center[:, None, :] + offset.clip(0, 1) + pose[:, :, 0] *= w + pose[:, :, 1] *= h + + return pose + + +class TestBadCaseHook(TestCase): + + def setUp(self) -> None: + kpt_num = 16 + PoseLocalVisualizer.get_instance('test_badcase_hook') + + data_sample = PoseDataSample() + data_sample.set_metainfo({ + 'img_path': + osp.join( + osp.dirname(__file__), '../../data/coco/000000000785.jpg') + }) + self.data_batch = {'data_samples': [data_sample] * 2} + + pred_det_data_sample = data_sample.clone() + pred_instances = InstanceData() + pred_instances.keypoints = _rand_poses(1, kpt_num, 10, 12) + pred_det_data_sample.pred_instances = pred_instances + + gt_instances = InstanceData() + gt_instances.keypoints = _rand_poses(1, kpt_num, 10, 12) + gt_instances.keypoints_visible = np.ones((1, kpt_num)) + gt_instances.head_size = np.random.rand(1, 1) + gt_instances.bboxes = np.random.rand(1, 4) + pred_det_data_sample.gt_instances = gt_instances + self.outputs = [pred_det_data_sample] * 2 + + def test_after_test_iter(self): + runner = MagicMock() + runner.iter = 1 + + # test + timestamp = time.strftime('%Y%m%d_%H%M%S', time.localtime()) + out_dir = timestamp + '1' + runner.work_dir = timestamp + runner.timestamp = '1' + hook = BadCaseAnalysisHook(enable=False, out_dir=out_dir) + hook.after_test_iter(runner, 1, self.data_batch, self.outputs) + self.assertTrue(not osp.exists(f'{timestamp}/1/{out_dir}')) + + hook = BadCaseAnalysisHook( + enable=True, + out_dir=out_dir, + metric_type='loss', + metric=ConfigDict(type='KeypointMSELoss'), + badcase_thr=-1, # is_badcase = True + ) + hook.after_test_iter(runner, 1, self.data_batch, self.outputs) + self.assertEqual(hook._test_index, 2) + self.assertTrue(osp.exists(f'{timestamp}/1/{out_dir}')) + # same image and preds/gts, so onlu one file + self.assertTrue(len(os.listdir(f'{timestamp}/1/{out_dir}')) == 1) + + hook.after_test_epoch(runner) + self.assertTrue(osp.exists(f'{timestamp}/1/{out_dir}/results.json')) + shutil.rmtree(f'{timestamp}') + + hook = BadCaseAnalysisHook( + enable=True, + out_dir=out_dir, + metric_type='accuracy', + metric=ConfigDict(type='MpiiPCKAccuracy'), + badcase_thr=-1, # is_badcase = False + ) + hook.after_test_iter(runner, 1, self.data_batch, self.outputs) + self.assertTrue(osp.exists(f'{timestamp}/1/{out_dir}')) + self.assertTrue(len(os.listdir(f'{timestamp}/1/{out_dir}')) == 0) + shutil.rmtree(f'{timestamp}') + + +if __name__ == '__main__': + test = TestBadCaseHook() + test.setUp() + test.test_after_test_iter() diff --git a/tests/test_engine/test_hooks/test_mode_switch_hooks.py b/tests/test_engine/test_hooks/test_mode_switch_hooks.py new file mode 100644 index 0000000000..fbf10bd3ef --- /dev/null +++ b/tests/test_engine/test_hooks/test_mode_switch_hooks.py @@ -0,0 +1,67 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase +from unittest.mock import Mock + +import torch +from mmengine.config import Config +from mmengine.runner import Runner +from torch.utils.data import Dataset + +from mmpose.engine.hooks import YOLOXPoseModeSwitchHook +from mmpose.utils import register_all_modules + + +class DummyDataset(Dataset): + METAINFO = dict() # type: ignore + data = torch.randn(12, 2) + label = torch.ones(12) + + @property + def metainfo(self): + return self.METAINFO + + def __len__(self): + return self.data.size(0) + + def __getitem__(self, index): + return dict(inputs=self.data[index], data_sample=self.label[index]) + + +pipeline1 = [ + dict(type='RandomHalfBody'), +] + +pipeline2 = [ + dict(type='RandomFlip'), +] +register_all_modules() + + +class TestYOLOXPoseModeSwitchHook(TestCase): + + def test(self): + train_dataloader = dict( + dataset=DummyDataset(), + sampler=dict(type='DefaultSampler', shuffle=True), + batch_size=3, + num_workers=0) + + runner = Mock() + runner.model = Mock() + runner.model.module = Mock() + + runner.model.head.use_aux_loss = False + runner.cfg.train_dataloader = Config(train_dataloader) + runner.train_dataloader = Runner.build_dataloader(train_dataloader) + runner.train_dataloader.dataset.pipeline = pipeline1 + + hook = YOLOXPoseModeSwitchHook( + num_last_epochs=15, new_train_pipeline=pipeline2) + + # test after change mode + runner.epoch = 284 + runner.max_epochs = 300 + hook.before_train_epoch(runner) + self.assertTrue(runner.model.bbox_head.use_aux_loss) + self.assertEqual(runner.train_loop.dataloader.dataset.pipeline, + pipeline2) diff --git a/tests/test_engine/test_hooks/test_sync_norm_hook.py b/tests/test_engine/test_hooks/test_sync_norm_hook.py new file mode 100644 index 0000000000..f256127fa1 --- /dev/null +++ b/tests/test_engine/test_hooks/test_sync_norm_hook.py @@ -0,0 +1,44 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase +from unittest.mock import Mock, patch + +import torch.nn as nn + +from mmpose.engine.hooks import SyncNormHook + + +class TestSyncNormHook(TestCase): + + @patch( + 'mmpose.engine.hooks.sync_norm_hook.get_dist_info', + return_value=(0, 1)) + def test_before_val_epoch_non_dist(self, mock): + model = nn.Sequential( + nn.Conv2d(1, 5, kernel_size=3), nn.BatchNorm2d(5, momentum=0.3), + nn.Linear(5, 10)) + runner = Mock() + runner.model = model + hook = SyncNormHook() + hook.before_val_epoch(runner) + + @patch( + 'mmpose.engine.hooks.sync_norm_hook.get_dist_info', + return_value=(0, 2)) + def test_before_val_epoch_dist(self, mock): + model = nn.Sequential( + nn.Conv2d(1, 5, kernel_size=3), nn.BatchNorm2d(5, momentum=0.3), + nn.Linear(5, 10)) + runner = Mock() + runner.model = model + hook = SyncNormHook() + hook.before_val_epoch(runner) + + @patch( + 'mmpose.engine.hooks.sync_norm_hook.get_dist_info', + return_value=(0, 2)) + def test_before_val_epoch_dist_no_norm(self, mock): + model = nn.Sequential(nn.Conv2d(1, 5, kernel_size=3), nn.Linear(5, 10)) + runner = Mock() + runner.model = model + hook = SyncNormHook() + hook.before_val_epoch(runner) diff --git a/tests/test_engine/test_schedulers/test_quadratic_warmup.py b/tests/test_engine/test_schedulers/test_quadratic_warmup.py new file mode 100644 index 0000000000..9f0650b0c2 --- /dev/null +++ b/tests/test_engine/test_schedulers/test_quadratic_warmup.py @@ -0,0 +1,108 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import torch +import torch.nn.functional as F +import torch.optim as optim +from mmengine.optim.scheduler import _ParamScheduler +from mmengine.testing import assert_allclose + +from mmpose.engine.schedulers import (QuadraticWarmupLR, + QuadraticWarmupMomentum, + QuadraticWarmupParamScheduler) + + +class ToyModel(torch.nn.Module): + + def __init__(self): + super().__init__() + self.conv1 = torch.nn.Conv2d(1, 1, 1) + self.conv2 = torch.nn.Conv2d(1, 1, 1) + + def forward(self, x): + return self.conv2(F.relu(self.conv1(x))) + + +class TestQuadraticWarmupScheduler(TestCase): + + def setUp(self): + """Setup the model and optimizer which are used in every test method. + + TestCase calls functions in this order: setUp() -> testMethod() -> + tearDown() -> cleanUp() + """ + self.model = ToyModel() + self.optimizer = optim.SGD( + self.model.parameters(), lr=0.05, momentum=0.01, weight_decay=5e-4) + + def _test_scheduler_value(self, + schedulers, + targets, + epochs=10, + param_name='lr'): + if isinstance(schedulers, _ParamScheduler): + schedulers = [schedulers] + for epoch in range(epochs): + for param_group, target in zip(self.optimizer.param_groups, + targets): + print(param_group[param_name]) + assert_allclose( + target[epoch], + param_group[param_name], + msg='{} is wrong in epoch {}: expected {}, got {}'.format( + param_name, epoch, target[epoch], + param_group[param_name]), + atol=1e-5, + rtol=0) + [scheduler.step() for scheduler in schedulers] + + def test_quadratic_warmup_scheduler(self): + with self.assertRaises(ValueError): + QuadraticWarmupParamScheduler(self.optimizer, param_name='lr') + epochs = 10 + iters = 5 + warmup_factor = [pow((i + 1) / float(iters), 2) for i in range(iters)] + single_targets = [x * 0.05 for x in warmup_factor] + [0.05] * ( + epochs - iters) + targets = [single_targets, [x * epochs for x in single_targets]] + scheduler = QuadraticWarmupParamScheduler( + self.optimizer, param_name='lr', end=iters) + self._test_scheduler_value(scheduler, targets, epochs) + + def test_quadratic_warmup_scheduler_convert_iterbased(self): + epochs = 10 + end = 5 + epoch_length = 11 + + iters = end * epoch_length + warmup_factor = [pow((i + 1) / float(iters), 2) for i in range(iters)] + single_targets = [x * 0.05 for x in warmup_factor] + [0.05] * ( + epochs * epoch_length - iters) + targets = [single_targets, [x * epochs for x in single_targets]] + scheduler = QuadraticWarmupParamScheduler.build_iter_from_epoch( + self.optimizer, + param_name='lr', + end=end, + epoch_length=epoch_length) + self._test_scheduler_value(scheduler, targets, epochs * epoch_length) + + def test_quadratic_warmup_lr(self): + epochs = 10 + iters = 5 + warmup_factor = [pow((i + 1) / float(iters), 2) for i in range(iters)] + single_targets = [x * 0.05 for x in warmup_factor] + [0.05] * ( + epochs - iters) + targets = [single_targets, [x * epochs for x in single_targets]] + scheduler = QuadraticWarmupLR(self.optimizer, end=iters) + self._test_scheduler_value(scheduler, targets, epochs) + + def test_quadratic_warmup_momentum(self): + epochs = 10 + iters = 5 + warmup_factor = [pow((i + 1) / float(iters), 2) for i in range(iters)] + single_targets = [x * 0.01 for x in warmup_factor] + [0.01] * ( + epochs - iters) + targets = [single_targets, [x * epochs for x in single_targets]] + scheduler = QuadraticWarmupMomentum(self.optimizer, end=iters) + self._test_scheduler_value( + scheduler, targets, epochs, param_name='momentum') diff --git a/tests/test_evaluation/test_evaluator/test_multi_dataset_evaluator.py b/tests/test_evaluation/test_evaluator/test_multi_dataset_evaluator.py new file mode 100644 index 0000000000..ef75d4332d --- /dev/null +++ b/tests/test_evaluation/test_evaluator/test_multi_dataset_evaluator.py @@ -0,0 +1,101 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import numpy as np + +from mmpose.evaluation.evaluators import MultiDatasetEvaluator +from mmpose.testing import get_coco_sample +from mmpose.utils import register_all_modules + + +class TestMultiDatasetEvaluator(TestCase): + + def setUp(self) -> None: + register_all_modules() + + aic_to_coco_converter = dict( + type='KeypointConverter', + num_keypoints=17, + mapping=[ + (0, 6), + (1, 8), + (2, 10), + (3, 5), + (4, 7), + (5, 9), + (6, 12), + (7, 14), + (8, 16), + (9, 11), + (10, 13), + (11, 15), + ]) + + # val datasets + dataset_coco_val = dict( + type='CocoDataset', + data_root='data/coco', + test_mode=True, + ) + + dataset_aic_val = dict( + type='AicDataset', + data_root='data/aic/', + test_mode=True, + ) + + self.datasets = [dataset_coco_val, dataset_aic_val] + + self.metrics = [ + dict(type='CocoMetric', ann_file='tests/data/coco/test_coco.json'), + dict( + type='CocoMetric', + ann_file='tests/data/aic/test_aic.json', + use_area=False, + gt_converter=aic_to_coco_converter, + prefix='aic') + ] + + data_sample1 = get_coco_sample( + img_shape=(240, 320), num_instances=2, with_bbox_cs=False) + data_sample1['dataset_name'] = 'coco' + data_sample1['id'] = 0 + data_sample1['img_id'] = 100 + data_sample1['gt_instances'] = dict(bbox_scores=np.ones(2), ) + data_sample1['pred_instances'] = dict( + keypoints=data_sample1['keypoints'], + keypoint_scores=data_sample1['keypoints_visible'], + ) + imgs1 = data_sample1.pop('img') + + data_sample2 = get_coco_sample( + img_shape=(240, 320), num_instances=3, with_bbox_cs=False) + data_sample2['dataset_name'] = 'aic' + data_sample2['id'] = 1 + data_sample2['img_id'] = 200 + data_sample2['gt_instances'] = dict(bbox_scores=np.ones(3), ) + data_sample2['pred_instances'] = dict( + keypoints=data_sample2['keypoints'], + keypoint_scores=data_sample2['keypoints_visible'], + ) + imgs2 = data_sample2.pop('img') + + self.data_batch = dict( + inputs=[imgs1, imgs2], data_samples=[data_sample1, data_sample2]) + self.data_samples = [data_sample1, data_sample2] + + def test_init(self): + evaluator = MultiDatasetEvaluator(self.metrics, self.datasets) + self.assertIn('metrics_dict', dir(evaluator)) + self.assertEqual(len(evaluator.metrics_dict), 2) + + with self.assertRaises(AssertionError): + evaluator = MultiDatasetEvaluator(self.metrics, self.datasets[:1]) + + def test_process(self): + evaluator = MultiDatasetEvaluator(self.metrics, self.datasets) + evaluator.dataset_meta = dict(dataset_name='default') + evaluator.process(self.data_samples, self.data_batch) + + for metric in evaluator.metrics: + self.assertGreater(len(metric.results), 0) diff --git a/tests/test_evaluation/test_functional/test_nms.py b/tests/test_evaluation/test_functional/test_nms.py index b29ed86ccb..34a2533b76 100644 --- a/tests/test_evaluation/test_functional/test_nms.py +++ b/tests/test_evaluation/test_functional/test_nms.py @@ -2,8 +2,9 @@ from unittest import TestCase import numpy as np +import torch -from mmpose.evaluation.functional.nms import nearby_joints_nms +from mmpose.evaluation.functional.nms import nearby_joints_nms, nms_torch class TestNearbyJointsNMS(TestCase): @@ -38,3 +39,21 @@ def test_nearby_joints_nms(self): with self.assertRaises(AssertionError): _ = nearby_joints_nms(kpts_db, 0.05, num_nearby_joints_thr=3) + + +class TestNMSTorch(TestCase): + + def test_nms_torch(self): + bboxes = torch.tensor([[0, 0, 3, 3], [1, 0, 3, 3], [4, 4, 6, 6]], + dtype=torch.float32) + + scores = torch.tensor([0.9, 0.8, 0.7]) + + expected_result = torch.tensor([0, 2]) + result = nms_torch(bboxes, scores, threshold=0.5) + self.assertTrue(torch.equal(result, expected_result)) + + expected_result = [torch.tensor([0, 1]), torch.tensor([2])] + result = nms_torch(bboxes, scores, threshold=0.5, return_group=True) + for res_out, res_expected in zip(result, expected_result): + self.assertTrue(torch.equal(res_out, res_expected)) diff --git a/tests/test_evaluation/test_functional/test_transforms.py b/tests/test_evaluation/test_functional/test_transforms.py new file mode 100644 index 0000000000..22ad39b604 --- /dev/null +++ b/tests/test_evaluation/test_functional/test_transforms.py @@ -0,0 +1,56 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from copy import deepcopy +from unittest import TestCase + +import numpy as np + +from mmpose.evaluation.functional import (transform_ann, transform_pred, + transform_sigmas) + + +class TestKeypointEval(TestCase): + + def test_transform_sigmas(self): + + mapping = [(3, 0), (6, 1), (16, 2), (5, 3)] + num_keypoints = 5 + sigmas = np.random.rand(17) + new_sigmas = transform_sigmas(sigmas, num_keypoints, mapping) + self.assertEqual(len(new_sigmas), 5) + for i, j in mapping: + self.assertEqual(sigmas[i], new_sigmas[j]) + + def test_transform_ann(self): + mapping = [(3, 0), (6, 1), (16, 2), (5, 3)] + num_keypoints = 5 + + kpt_info = dict( + num_keypoints=17, + keypoints=np.random.randint(3, size=(17 * 3, )).tolist()) + kpt_info_copy = deepcopy(kpt_info) + + _ = transform_ann(kpt_info, num_keypoints, mapping) + + self.assertEqual(kpt_info['num_keypoints'], 5) + self.assertEqual(len(kpt_info['keypoints']), 15) + for i, j in mapping: + self.assertListEqual(kpt_info_copy['keypoints'][i * 3:i * 3 + 3], + kpt_info['keypoints'][j * 3:j * 3 + 3]) + + def test_transform_pred(self): + mapping = [(3, 0), (6, 1), (16, 2), (5, 3)] + num_keypoints = 5 + + kpt_info = dict( + num_keypoints=17, + keypoints=np.random.randint(3, size=( + 1, + 17, + 3, + )), + keypoint_scores=np.ones((1, 17))) + + _ = transform_pred(kpt_info, num_keypoints, mapping) + + self.assertEqual(kpt_info['num_keypoints'], 5) + self.assertEqual(len(kpt_info['keypoints']), 1) diff --git a/tests/test_evaluation/test_metrics/test_coco_metric.py b/tests/test_evaluation/test_metrics/test_coco_metric.py index 82bf0bc572..9863f0ffe3 100644 --- a/tests/test_evaluation/test_metrics/test_coco_metric.py +++ b/tests/test_evaluation/test_metrics/test_coco_metric.py @@ -7,8 +7,10 @@ import numpy as np from mmengine.fileio import dump, load +from mmengine.logging import MessageHub from xtcocotools.coco import COCO +from mmpose.datasets.datasets import CocoDataset from mmpose.datasets.datasets.utils import parse_pose_metainfo from mmpose.evaluation.metrics import CocoMetric @@ -21,6 +23,12 @@ def setUp(self): TestCase calls functions in this order: setUp() -> testMethod() -> tearDown() -> cleanUp() """ + + # during CI on github, the unit tests for datasets will save ann_file + # into MessageHub, which will influence the unit tests for CocoMetric + msg = MessageHub.get_current_instance() + msg.runtime_info.clear() + self.tmp_dir = tempfile.TemporaryDirectory() self.ann_file_coco = 'tests/data/coco/test_coco.json' @@ -59,6 +67,10 @@ def setUp(self): self.topdown_data_crowdpose = self._convert_ann_to_topdown_batch_data( self.ann_file_crowdpose) + self.topdown_data_pseudo_coco = \ + self._convert_ann_to_topdown_batch_data( + self.ann_file_crowdpose, + num_pseudo_kpts=3) assert len(self.topdown_data_crowdpose) == 5 self.bottomup_data_crowdpose = \ self._convert_ann_to_bottomup_batch_data(self.ann_file_crowdpose) @@ -103,7 +115,9 @@ def setUp(self): 'coco/AR (L)': 1.0, } - def _convert_ann_to_topdown_batch_data(self, ann_file): + def _convert_ann_to_topdown_batch_data(self, + ann_file, + num_pseudo_kpts: int = 0): """Convert annotations to topdown-style batch data.""" topdown_data = [] db = load(ann_file) @@ -121,6 +135,12 @@ def _convert_ann_to_topdown_batch_data(self, ann_file): 'bbox_scores': np.ones((1, ), dtype=np.float32), 'bboxes': bboxes, } + + if num_pseudo_kpts > 0: + keypoints = np.concatenate( + (keypoints, *((keypoints[:, :1], ) * num_pseudo_kpts)), + axis=1) + pred_instances = { 'keypoints': keypoints[..., :2], 'keypoint_scores': keypoints[..., -1], @@ -610,3 +630,55 @@ def test_topdown_evaluate(self): osp.isfile(osp.join(self.tmp_dir.name, 'test8.gt.json'))) self.assertTrue( osp.isfile(osp.join(self.tmp_dir.name, 'test8.keypoints.json'))) + + def test_gt_converter(self): + + crowdpose_to_coco_converter = dict( + type='KeypointConverter', + num_keypoints=17, + mapping=[ + (0, 5), + (1, 6), + (2, 7), + (3, 8), + (4, 9), + (5, 10), + (6, 11), + (7, 12), + (8, 13), + (9, 14), + (10, 15), + (11, 16), + ]) + + metric_crowdpose = CocoMetric( + ann_file=self.ann_file_crowdpose, + outfile_prefix=f'{self.tmp_dir.name}/test_convert', + use_area=False, + gt_converter=crowdpose_to_coco_converter, + iou_type='keypoints_crowd', + prefix='crowdpose') + metric_crowdpose.dataset_meta = self.dataset_meta_crowdpose + + self.assertEqual(metric_crowdpose.dataset_meta['num_keypoints'], 17) + self.assertEqual(len(metric_crowdpose.dataset_meta['sigmas']), 17) + + # process samples + for data_batch, data_samples in self.topdown_data_pseudo_coco: + metric_crowdpose.process(data_batch, data_samples) + + _ = metric_crowdpose.evaluate(size=len(self.topdown_data_crowdpose)) + + self.assertTrue( + osp.isfile( + osp.join(self.tmp_dir.name, 'test_convert.keypoints.json'))) + + def test_get_ann_file_from_dataset(self): + _ = CocoDataset(ann_file=self.ann_file_coco, test_mode=True) + metric = CocoMetric(ann_file=None) + metric.dataset_meta = self.dataset_meta_coco + self.assertIsNotNone(metric.coco) + + # clear message to avoid disturbing other tests + message = MessageHub.get_current_instance() + message.pop_info('coco_ann_file') diff --git a/tests/test_evaluation/test_metrics/test_coco_wholebody_metric.py b/tests/test_evaluation/test_metrics/test_coco_wholebody_metric.py index 46e8498851..fa4c04fab3 100644 --- a/tests/test_evaluation/test_metrics/test_coco_wholebody_metric.py +++ b/tests/test_evaluation/test_metrics/test_coco_wholebody_metric.py @@ -7,6 +7,7 @@ import numpy as np from mmengine.fileio import dump, load +from mmengine.logging import MessageHub from xtcocotools.coco import COCO from mmpose.datasets.datasets.utils import parse_pose_metainfo @@ -21,6 +22,13 @@ def setUp(self): TestCase calls functions in this order: setUp() -> testMethod() -> tearDown() -> cleanUp() """ + + # during CI on github, the unit tests for datasets will save ann_file + # into MessageHub, which will influence the unit tests for + # CocoWholeBodyMetric + msg = MessageHub.get_current_instance() + msg.runtime_info.clear() + self.tmp_dir = tempfile.TemporaryDirectory() self.ann_file_coco = 'tests/data/coco/test_coco_wholebody.json' diff --git a/tests/test_evaluation/test_metrics/test_hand_metric.py b/tests/test_evaluation/test_metrics/test_hand_metric.py new file mode 100644 index 0000000000..4828484752 --- /dev/null +++ b/tests/test_evaluation/test_metrics/test_hand_metric.py @@ -0,0 +1,201 @@ +# Copyright (c) OpenMMLab. All rights reserved. +import json +import tempfile +from unittest import TestCase + +import numpy as np +from mmengine.fileio import load +from xtcocotools.coco import COCO + +from mmpose.codecs.utils import camera_to_pixel +from mmpose.datasets.datasets.utils import parse_pose_metainfo +from mmpose.evaluation import InterHandMetric + + +class TestInterHandMetric(TestCase): + + def setUp(self): + """Setup some variables which are used in every test method. + + TestCase calls functions in this order: setUp() -> testMethod() -> + tearDown() -> cleanUp() + """ + self.tmp_dir = tempfile.TemporaryDirectory() + + self.ann_file = 'tests/data/interhand2.6m/test_interhand2.6m_data.json' + meta_info = dict(from_file='configs/_base_/datasets/interhand3d.py') + self.dataset_meta = parse_pose_metainfo(meta_info) + self.coco = COCO(self.ann_file) + + self.joint_file = ('tests/data/interhand2.6m/' + 'test_interhand2.6m_joint_3d.json') + with open(self.joint_file, 'r') as f: + self.joints = json.load(f) + + self.camera_file = ('tests/data/interhand2.6m/' + 'test_interhand2.6m_camera.json') + with open(self.camera_file, 'r') as f: + self.cameras = json.load(f) + + self.topdown_data = self._convert_ann_to_topdown_batch_data( + self.ann_file) + assert len(self.topdown_data) == 4 + self.target = { + 'MPJPE_all': 0.0, + 'MPJPE_interacting': 0.0, + 'MPJPE_single': 0.0, + 'MRRPE': 0.0, + 'HandednessAcc': 1.0 + } + + def encode_handtype(self, hand_type): + if hand_type == 'right': + return np.array([[1, 0]], dtype=np.float32) + elif hand_type == 'left': + return np.array([[0, 1]], dtype=np.float32) + elif hand_type == 'interacting': + return np.array([[1, 1]], dtype=np.float32) + else: + assert 0, f'Not support hand type: {hand_type}' + + def _convert_ann_to_topdown_batch_data(self, ann_file): + """Convert annotations to topdown-style batch data.""" + topdown_data = [] + db = load(ann_file) + num_keypoints = 42 + imgid2info = dict() + for img in db['images']: + imgid2info[img['id']] = img + for ann in db['annotations']: + image_id = ann['image_id'] + img = imgid2info[image_id] + frame_idx = str(img['frame_idx']) + capture_id = str(img['capture']) + camera_name = img['camera'] + + camera_pos = np.array( + self.cameras[capture_id]['campos'][camera_name], + dtype=np.float32) + camera_rot = np.array( + self.cameras[capture_id]['camrot'][camera_name], + dtype=np.float32) + focal = np.array( + self.cameras[capture_id]['focal'][camera_name], + dtype=np.float32) + principal_pt = np.array( + self.cameras[capture_id]['princpt'][camera_name], + dtype=np.float32) + joint_world = np.array( + self.joints[capture_id][frame_idx]['world_coord'], + dtype=np.float32) + joint_valid = np.array( + ann['joint_valid'], dtype=np.float32).flatten() + + keypoints_cam = np.dot( + camera_rot, + joint_world.transpose(1, 0) - + camera_pos.reshape(3, 1)).transpose(1, 0) + joint_img = camera_to_pixel( + keypoints_cam, + focal[0], + focal[1], + principal_pt[0], + principal_pt[1], + shift=True)[:, :2] + + abs_depth = [keypoints_cam[20, 2], keypoints_cam[41, 2]] + + rel_root_depth = keypoints_cam[41, 2] - keypoints_cam[20, 2] + + joint_valid[:20] *= joint_valid[20] + joint_valid[21:] *= joint_valid[41] + + joints_3d = np.zeros((num_keypoints, 3), + dtype=np.float32).reshape(1, -1, 3) + joints_3d[..., :2] = joint_img + joints_3d[..., :21, + 2] = keypoints_cam[:21, 2] - keypoints_cam[20, 2] + joints_3d[..., 21:, + 2] = keypoints_cam[21:, 2] - keypoints_cam[41, 2] + joints_3d_visible = np.minimum(1, joint_valid.reshape(-1, 1)) + joints_3d_visible = joints_3d_visible.reshape(1, -1) + + gt_instances = { + 'keypoints_cam': keypoints_cam.reshape(1, -1, 3), + 'keypoints_visible': joints_3d_visible, + } + pred_instances = { + 'keypoints': joints_3d, + 'hand_type': self.encode_handtype(ann['hand_type']), + 'rel_root_depth': rel_root_depth, + } + + data = {'inputs': None} + data_sample = { + 'id': ann['id'], + 'img_id': ann['image_id'], + 'gt_instances': gt_instances, + 'pred_instances': pred_instances, + 'hand_type': self.encode_handtype(ann['hand_type']), + 'hand_type_valid': np.array([ann['hand_type_valid']]), + 'abs_depth': abs_depth, + 'focal': focal, + 'principal_pt': principal_pt, + } + + # batch size = 1 + data_batch = [data] + data_samples = [data_sample] + topdown_data.append((data_batch, data_samples)) + + return topdown_data + + def tearDown(self): + self.tmp_dir.cleanup() + + def test_init(self): + """test metric init method.""" + # test modes option + with self.assertRaisesRegex(ValueError, '`mode` should be'): + _ = InterHandMetric(modes=['invalid']) + + def test_topdown_evaluate(self): + """test topdown-style COCO metric evaluation.""" + # case 1: modes='MPJPE' + metric = InterHandMetric(modes=['MPJPE']) + metric.dataset_meta = self.dataset_meta + + # process samples + for data_batch, data_samples in self.topdown_data: + metric.process(data_batch, data_samples) + + eval_results = metric.evaluate(size=len(self.topdown_data)) + + for metric, err in eval_results.items(): + self.assertAlmostEqual(err, self.target[metric], places=4) + + # case 2: modes='MRRPE' + metric = InterHandMetric(modes=['MRRPE']) + metric.dataset_meta = self.dataset_meta + + # process samples + for data_batch, data_samples in self.topdown_data: + metric.process(data_batch, data_samples) + + eval_results = metric.evaluate(size=len(self.topdown_data)) + + for metric, err in eval_results.items(): + self.assertAlmostEqual(err, self.target[metric], places=4) + + # case 2: modes='HandednessAcc' + metric = InterHandMetric(modes=['HandednessAcc']) + metric.dataset_meta = self.dataset_meta + + # process samples + for data_batch, data_samples in self.topdown_data: + metric.process(data_batch, data_samples) + + eval_results = metric.evaluate(size=len(self.topdown_data)) + + for metric, err in eval_results.items(): + self.assertAlmostEqual(err, self.target[metric], places=4) diff --git a/tests/test_evaluation/test_metrics/test_keypoint_3d_metrics.py b/tests/test_evaluation/test_metrics/test_keypoint_3d_metrics.py index 8289b09d0f..391b7b194a 100644 --- a/tests/test_evaluation/test_metrics/test_keypoint_3d_metrics.py +++ b/tests/test_evaluation/test_metrics/test_keypoint_3d_metrics.py @@ -20,9 +20,10 @@ def setUp(self): for i in range(self.batch_size): gt_instances = InstanceData() keypoints = np.random.random((1, num_keypoints, 3)) - gt_instances.lifting_target = np.random.random((num_keypoints, 3)) + gt_instances.lifting_target = np.random.random( + (1, num_keypoints, 3)) gt_instances.lifting_target_visible = np.ones( - (num_keypoints, 1)).astype(bool) + (1, num_keypoints, 1)).astype(bool) pred_instances = InstanceData() pred_instances.keypoints = keypoints + np.random.normal( @@ -32,8 +33,10 @@ def setUp(self): data_sample = PoseDataSample( gt_instances=gt_instances, pred_instances=pred_instances) data_sample.set_metainfo( - dict(target_img_path='tests/data/h36m/S7/' - 'S7_Greeting.55011271/S7_Greeting.55011271_000396.jpg')) + dict(target_img_path=[ + 'tests/data/h36m/S7/' + 'S7_Greeting.55011271/S7_Greeting.55011271_000396.jpg' + ])) self.data_batch.append(data) self.data_samples.append(data_sample.to_dict()) diff --git a/tests/test_evaluation/test_metrics/test_keypoint_partition_metric.py b/tests/test_evaluation/test_metrics/test_keypoint_partition_metric.py index 2b1a60c113..0d11699097 100644 --- a/tests/test_evaluation/test_metrics/test_keypoint_partition_metric.py +++ b/tests/test_evaluation/test_metrics/test_keypoint_partition_metric.py @@ -7,6 +7,7 @@ import numpy as np from mmengine.fileio import load +from mmengine.logging import MessageHub from mmengine.structures import InstanceData from xtcocotools.coco import COCO @@ -22,6 +23,12 @@ def setUp(self): TestCase calls functions in this order: setUp() -> testMethod() -> tearDown() -> cleanUp() """ + + # during CI on github, the unit tests for datasets will save ann_file + # into MessageHub, which will influence the unit tests for CocoMetric + msg = MessageHub.get_current_instance() + msg.runtime_info.clear() + self.tmp_dir = tempfile.TemporaryDirectory() self.ann_file_coco = \ diff --git a/tests/test_models/test_backbones/test_csp_darknet.py b/tests/test_models/test_backbones/test_csp_darknet.py new file mode 100644 index 0000000000..61b200b749 --- /dev/null +++ b/tests/test_models/test_backbones/test_csp_darknet.py @@ -0,0 +1,125 @@ +# Copyright (c) OpenMMLab. All rights reserved. +import unittest + +import torch +from torch.nn.modules import GroupNorm +from torch.nn.modules.batchnorm import _BatchNorm + +from mmpose.models.backbones.csp_darknet import CSPDarknet + + +def is_norm(modules): + """Check if is one of the norms.""" + if isinstance(modules, (GroupNorm, _BatchNorm)): + return True + return False + + +def check_norm_state(modules, train_state): + """Check if norm layer is in correct train state.""" + for mod in modules: + if isinstance(mod, _BatchNorm): + if mod.training != train_state: + return False + return True + + +class TestCSPDarknetBackbone(unittest.TestCase): + + def test_invalid_frozen_stages(self): + with self.assertRaises(ValueError): + CSPDarknet(frozen_stages=6) + + def test_invalid_out_indices(self): + with self.assertRaises(AssertionError): + CSPDarknet(out_indices=[6]) + + def test_frozen_stages(self): + frozen_stages = 1 + model = CSPDarknet(frozen_stages=frozen_stages) + model.train() + + for mod in model.stem.modules(): + for param in mod.parameters(): + self.assertFalse(param.requires_grad) + for i in range(1, frozen_stages + 1): + layer = getattr(model, f'stage{i}') + for mod in layer.modules(): + if isinstance(mod, _BatchNorm): + self.assertFalse(mod.training) + for param in layer.parameters(): + self.assertFalse(param.requires_grad) + + def test_norm_eval(self): + model = CSPDarknet(norm_eval=True) + model.train() + + self.assertFalse(check_norm_state(model.modules(), True)) + + def test_csp_darknet_p5_forward(self): + model = CSPDarknet( + arch='P5', widen_factor=0.25, out_indices=range(0, 5)) + model.train() + + imgs = torch.randn(1, 3, 64, 64) + feat = model(imgs) + self.assertEqual(len(feat), 5) + self.assertEqual(feat[0].shape, torch.Size((1, 16, 32, 32))) + self.assertEqual(feat[1].shape, torch.Size((1, 32, 16, 16))) + self.assertEqual(feat[2].shape, torch.Size((1, 64, 8, 8))) + self.assertEqual(feat[3].shape, torch.Size((1, 128, 4, 4))) + self.assertEqual(feat[4].shape, torch.Size((1, 256, 2, 2))) + + def test_csp_darknet_p6_forward(self): + model = CSPDarknet( + arch='P6', + widen_factor=0.25, + out_indices=range(0, 6), + spp_kernal_sizes=(3, 5, 7)) + model.train() + + imgs = torch.randn(1, 3, 128, 128) + feat = model(imgs) + self.assertEqual(feat[0].shape, torch.Size((1, 16, 64, 64))) + self.assertEqual(feat[1].shape, torch.Size((1, 32, 32, 32))) + self.assertEqual(feat[2].shape, torch.Size((1, 64, 16, 16))) + self.assertEqual(feat[3].shape, torch.Size((1, 128, 8, 8))) + self.assertEqual(feat[4].shape, torch.Size((1, 192, 4, 4))) + self.assertEqual(feat[5].shape, torch.Size((1, 256, 2, 2))) + + def test_csp_darknet_custom_arch_forward(self): + arch_ovewrite = [[32, 56, 3, True, False], [56, 224, 2, True, False], + [224, 512, 1, True, False]] + model = CSPDarknet( + arch_ovewrite=arch_ovewrite, + widen_factor=0.25, + out_indices=(0, 1, 2, 3)) + model.train() + + imgs = torch.randn(1, 3, 32, 32) + feat = model(imgs) + self.assertEqual(len(feat), 4) + self.assertEqual(feat[0].shape, torch.Size((1, 8, 16, 16))) + self.assertEqual(feat[1].shape, torch.Size((1, 14, 8, 8))) + self.assertEqual(feat[2].shape, torch.Size((1, 56, 4, 4))) + self.assertEqual(feat[3].shape, torch.Size((1, 128, 2, 2))) + + def test_csp_darknet_custom_arch_norm(self): + model = CSPDarknet(widen_factor=0.125, out_indices=range(0, 5)) + for m in model.modules(): + if is_norm(m): + self.assertIsInstance(m, _BatchNorm) + model.train() + + imgs = torch.randn(1, 3, 64, 64) + feat = model(imgs) + self.assertEqual(len(feat), 5) + self.assertEqual(feat[0].shape, torch.Size((1, 8, 32, 32))) + self.assertEqual(feat[1].shape, torch.Size((1, 16, 16, 16))) + self.assertEqual(feat[2].shape, torch.Size((1, 32, 8, 8))) + self.assertEqual(feat[3].shape, torch.Size((1, 64, 4, 4))) + self.assertEqual(feat[4].shape, torch.Size((1, 128, 2, 2))) + + +if __name__ == '__main__': + unittest.main() diff --git a/tests/test_models/test_backbones/test_dstformer.py b/tests/test_models/test_backbones/test_dstformer.py new file mode 100644 index 0000000000..966ed6f49b --- /dev/null +++ b/tests/test_models/test_backbones/test_dstformer.py @@ -0,0 +1,36 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import torch + +from mmpose.models.backbones import DSTFormer +from mmpose.models.backbones.dstformer import AttentionBlock + + +class TestDSTFormer(TestCase): + + def test_attention_block(self): + # BasicTemporalBlock with causal == False + block = AttentionBlock(dim=256, num_heads=2) + x = torch.rand(2, 17, 256) + x_out = block(x) + self.assertEqual(x_out.shape, torch.Size([2, 17, 256])) + + def test_DSTFormer(self): + # Test DSTFormer with depth=2 + model = DSTFormer(in_channels=3, depth=2, seq_len=2) + pose3d = torch.rand((1, 2, 17, 3)) + feat = model(pose3d) + self.assertEqual(feat[0].shape, (2, 17, 256)) + + # Test DSTFormer with depth=4 and qkv_bias=False + model = DSTFormer(in_channels=3, depth=4, seq_len=2, qkv_bias=False) + pose3d = torch.rand((1, 2, 17, 3)) + feat = model(pose3d) + self.assertEqual(feat[0].shape, (2, 17, 256)) + + # Test DSTFormer with depth=4 and att_fuse=False + model = DSTFormer(in_channels=3, depth=4, seq_len=2, att_fuse=False) + pose3d = torch.rand((1, 2, 17, 3)) + feat = model(pose3d) + self.assertEqual(feat[0].shape, (2, 17, 256)) diff --git a/tests/test_models/test_data_preprocessors/test_data_preprocessor.py b/tests/test_models/test_data_preprocessors/test_data_preprocessor.py new file mode 100644 index 0000000000..6c669f55a2 --- /dev/null +++ b/tests/test_models/test_data_preprocessors/test_data_preprocessor.py @@ -0,0 +1,135 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import torch +from mmengine.logging import MessageHub + +from mmpose.models.data_preprocessors import (BatchSyncRandomResize, + PoseDataPreprocessor) +from mmpose.structures import PoseDataSample + + +class TestPoseDataPreprocessor(TestCase): + + def test_init(self): + # test mean is None + processor = PoseDataPreprocessor() + self.assertTrue(not hasattr(processor, 'mean')) + self.assertTrue(processor._enable_normalize is False) + + # test mean is not None + processor = PoseDataPreprocessor(mean=[0, 0, 0], std=[1, 1, 1]) + self.assertTrue(hasattr(processor, 'mean')) + self.assertTrue(hasattr(processor, 'std')) + self.assertTrue(processor._enable_normalize) + + # please specify both mean and std + with self.assertRaises(AssertionError): + PoseDataPreprocessor(mean=[0, 0, 0]) + + # bgr2rgb and rgb2bgr cannot be set to True at the same time + with self.assertRaises(AssertionError): + PoseDataPreprocessor(bgr_to_rgb=True, rgb_to_bgr=True) + + def test_forward(self): + processor = PoseDataPreprocessor(mean=[0, 0, 0], std=[1, 1, 1]) + + data = { + 'inputs': [torch.randint(0, 256, (3, 11, 10))], + 'data_samples': [PoseDataSample()] + } + out_data = processor(data) + batch_inputs, batch_data_samples = out_data['inputs'], out_data[ + 'data_samples'] + + self.assertEqual(batch_inputs.shape, (1, 3, 11, 10)) + self.assertEqual(len(batch_data_samples), 1) + + # test channel_conversion + processor = PoseDataPreprocessor( + mean=[0., 0., 0.], std=[1., 1., 1.], bgr_to_rgb=True) + out_data = processor(data) + batch_inputs, batch_data_samples = out_data['inputs'], out_data[ + 'data_samples'] + self.assertEqual(batch_inputs.shape, (1, 3, 11, 10)) + self.assertEqual(len(batch_data_samples), 1) + + # test padding + data = { + 'inputs': [ + torch.randint(0, 256, (3, 10, 11)), + torch.randint(0, 256, (3, 9, 14)) + ], + 'data_samples': [PoseDataSample()] * 2 + } + processor = PoseDataPreprocessor( + mean=[0., 0., 0.], std=[1., 1., 1.], bgr_to_rgb=True) + out_data = processor(data) + batch_inputs, batch_data_samples = out_data['inputs'], out_data[ + 'data_samples'] + self.assertEqual(batch_inputs.shape, (2, 3, 10, 14)) + self.assertEqual(len(batch_data_samples), 2) + + # test pad_size_divisor + data = { + 'inputs': [ + torch.randint(0, 256, (3, 10, 11)), + torch.randint(0, 256, (3, 9, 24)) + ], + 'data_samples': [PoseDataSample()] * 2 + } + processor = PoseDataPreprocessor( + mean=[0., 0., 0.], std=[1., 1., 1.], pad_size_divisor=5) + out_data = processor(data) + batch_inputs, batch_data_samples = out_data['inputs'], out_data[ + 'data_samples'] + self.assertEqual(batch_inputs.shape, (2, 3, 10, 25)) + self.assertEqual(len(batch_data_samples), 2) + for data_samples, expected_shape in zip(batch_data_samples, + [(10, 15), (10, 25)]): + self.assertEqual(data_samples.pad_shape, expected_shape) + + def test_batch_sync_random_resize(self): + processor = PoseDataPreprocessor(batch_augments=[ + dict( + type='BatchSyncRandomResize', + random_size_range=(320, 320), + size_divisor=32, + interval=1) + ]) + self.assertTrue( + isinstance(processor.batch_augments[0], BatchSyncRandomResize)) + message_hub = MessageHub.get_instance('test_batch_sync_random_resize') + message_hub.update_info('iter', 0) + packed_inputs = { + 'inputs': [ + torch.randint(0, 256, (3, 128, 128)), + torch.randint(0, 256, (3, 128, 128)) + ], + 'data_samples': [PoseDataSample()] * 2 + } + batch_inputs = processor(packed_inputs, training=True)['inputs'] + self.assertEqual(batch_inputs.shape, (2, 3, 128, 128)) + + # resize after one iter + message_hub.update_info('iter', 1) + packed_inputs = { + 'inputs': [ + torch.randint(0, 256, (3, 128, 128)), + torch.randint(0, 256, (3, 128, 128)) + ], + 'data_samples': + [PoseDataSample(metainfo=dict(img_shape=(128, 128)))] * 2 + } + batch_inputs = processor(packed_inputs, training=True)['inputs'] + self.assertEqual(batch_inputs.shape, (2, 3, 320, 320)) + + packed_inputs = { + 'inputs': [ + torch.randint(0, 256, (3, 128, 128)), + torch.randint(0, 256, (3, 128, 128)) + ], + 'data_samples': [PoseDataSample()] * 2 + } + batch_inputs = processor(packed_inputs, training=False)['inputs'] + self.assertEqual(batch_inputs.shape, (2, 3, 128, 128)) diff --git a/tests/test_models/test_distillers/test_dwpose_distiller.py b/tests/test_models/test_distillers/test_dwpose_distiller.py new file mode 100644 index 0000000000..60d2b231e5 --- /dev/null +++ b/tests/test_models/test_distillers/test_dwpose_distiller.py @@ -0,0 +1,113 @@ +# Copyright (c) OpenMMLab. All rights reserved. +import unittest +from unittest import TestCase + +import torch +from mmengine.model.utils import revert_sync_batchnorm +from parameterized import parameterized + +from mmpose.structures import PoseDataSample +from mmpose.testing import get_packed_inputs, get_pose_estimator_cfg +from mmpose.utils import register_all_modules + +configs = [ + 'wholebody_2d_keypoint/dwpose/ubody/' + 's1_dis/dwpose_l_dis_m_coco-ubody-256x192.py', + 'wholebody_2d_keypoint/dwpose/ubody/' + 's2_dis/dwpose_m-mm_coco-ubody-256x192.py', + 'wholebody_2d_keypoint/dwpose/coco-wholebody/' + 's1_dis/dwpose_l_dis_m_coco-256x192.py', + 'wholebody_2d_keypoint/dwpose/coco-wholebody/' + 's2_dis/dwpose_m-mm_coco-256x192.py', +] + +configs_with_devices = [(config, ('cpu', 'cuda')) for config in configs] + + +class TestDWPoseDistiller(TestCase): + + def setUp(self) -> None: + register_all_modules() + + @parameterized.expand(configs) + def test_init(self, config): + dis_cfg = get_pose_estimator_cfg(config) + model_cfg = get_pose_estimator_cfg(dis_cfg.student_cfg) + model_cfg.backbone.init_cfg = None + + from mmpose.models import build_pose_estimator + model = build_pose_estimator(model_cfg) + model = revert_sync_batchnorm(model) + self.assertTrue(model.backbone) + self.assertTrue(model.head) + if model_cfg.get('neck', None): + self.assertTrue(model.neck) + + @parameterized.expand(configs_with_devices) + def test_forward_loss(self, config, devices): + dis_cfg = get_pose_estimator_cfg(config) + model_cfg = get_pose_estimator_cfg(dis_cfg.student_cfg) + model_cfg.backbone.init_cfg = None + + from mmpose.models import build_pose_estimator + + for device in devices: + model = build_pose_estimator(model_cfg) + model = revert_sync_batchnorm(model) + + if device == 'cuda': + if not torch.cuda.is_available(): + return unittest.skip('test requires GPU and torch+cuda') + model = model.cuda() + + packed_inputs = get_packed_inputs(2, num_keypoints=133) + data = model.data_preprocessor(packed_inputs, training=True) + losses = model.forward(**data, mode='loss') + self.assertIsInstance(losses, dict) + + @parameterized.expand(configs_with_devices) + def test_forward_predict(self, config, devices): + dis_cfg = get_pose_estimator_cfg(config) + model_cfg = get_pose_estimator_cfg(dis_cfg.student_cfg) + model_cfg.backbone.init_cfg = None + + from mmpose.models import build_pose_estimator + + for device in devices: + model = build_pose_estimator(model_cfg) + model = revert_sync_batchnorm(model) + + if device == 'cuda': + if not torch.cuda.is_available(): + return unittest.skip('test requires GPU and torch+cuda') + model = model.cuda() + + packed_inputs = get_packed_inputs(2, num_keypoints=133) + model.eval() + with torch.no_grad(): + data = model.data_preprocessor(packed_inputs, training=True) + batch_results = model.forward(**data, mode='predict') + self.assertEqual(len(batch_results), 2) + self.assertIsInstance(batch_results[0], PoseDataSample) + + @parameterized.expand(configs_with_devices) + def test_forward_tensor(self, config, devices): + dis_cfg = get_pose_estimator_cfg(config) + model_cfg = get_pose_estimator_cfg(dis_cfg.student_cfg) + model_cfg.backbone.init_cfg = None + + from mmpose.models import build_pose_estimator + + for device in devices: + model = build_pose_estimator(model_cfg) + model = revert_sync_batchnorm(model) + + if device == 'cuda': + if not torch.cuda.is_available(): + return unittest.skip('test requires GPU and torch+cuda') + model = model.cuda() + + packed_inputs = get_packed_inputs(2, num_keypoints=133) + data = model.data_preprocessor(packed_inputs, training=True) + batch_results = model.forward(**data, mode='tensor') + self.assertIsInstance(batch_results, (tuple, torch.Tensor)) diff --git a/tests/test_models/test_necks/test_yolox_pafpn.py b/tests/test_models/test_necks/test_yolox_pafpn.py new file mode 100644 index 0000000000..89eae39a6c --- /dev/null +++ b/tests/test_models/test_necks/test_yolox_pafpn.py @@ -0,0 +1,30 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import torch + +from mmpose.models.necks import YOLOXPAFPN + + +class TestYOLOXPAFPN(TestCase): + + def test_forward(self): + in_channels = [128, 256, 512] + out_channels = 256 + num_csp_blocks = 3 + + model = YOLOXPAFPN( + in_channels=in_channels, + out_channels=out_channels, + num_csp_blocks=num_csp_blocks) + model.train() + + inputs = [ + torch.randn(1, c, 64 // (2**i), 64 // (2**i)) + for i, c in enumerate(in_channels) + ] + outputs = model(inputs) + + self.assertEqual(len(outputs), len(in_channels)) + for out in outputs: + self.assertEqual(out.shape[1], out_channels) diff --git a/tests/test_structures/test_bbox/test_bbox_overlaps.py b/tests/test_structures/test_bbox/test_bbox_overlaps.py new file mode 100644 index 0000000000..b3523c8af5 --- /dev/null +++ b/tests/test_structures/test_bbox/test_bbox_overlaps.py @@ -0,0 +1,75 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import torch + +from mmpose.structures.bbox import bbox_overlaps # Import your function here + + +class TestBBoxOverlaps(TestCase): + + def test_bbox_overlaps_iou(self): + bboxes1 = torch.FloatTensor([ + [0, 0, 10, 10], + [10, 10, 20, 20], + [32, 32, 38, 42], + ]) + bboxes2 = torch.FloatTensor([ + [0, 0, 10, 20], + [0, 10, 10, 19], + [10, 10, 20, 20], + ]) + overlaps = bbox_overlaps(bboxes1, bboxes2) + + expected_overlaps = torch.FloatTensor([ + [0.5000, 0.0000, 0.0000], + [0.0000, 0.0000, 1.0000], + [0.0000, 0.0000, 0.0000], + ]) + + self.assertTrue( + torch.allclose(overlaps, expected_overlaps, rtol=1e-4, atol=1e-4)) + + def test_bbox_overlaps_iof(self): + bboxes1 = torch.FloatTensor([ + [0, 0, 10, 10], + [10, 10, 20, 20], + [32, 32, 38, 42], + ]) + bboxes2 = torch.FloatTensor([ + [0, 0, 10, 20], + [0, 10, 10, 19], + [10, 10, 20, 20], + ]) + overlaps = bbox_overlaps(bboxes1, bboxes2, mode='iof') + + expected_overlaps = torch.FloatTensor([ + [1., 0., 0.], + [0., 0., 1.], + [0., 0., 0.], + ]) + + self.assertTrue( + torch.allclose(overlaps, expected_overlaps, rtol=1e-4, atol=1e-4)) + + def test_bbox_overlaps_giou(self): + bboxes1 = torch.FloatTensor([ + [0, 0, 10, 10], + [10, 10, 20, 20], + [32, 32, 38, 42], + ]) + bboxes2 = torch.FloatTensor([ + [0, 0, 10, 20], + [0, 10, 10, 19], + [10, 10, 20, 20], + ]) + overlaps = bbox_overlaps(bboxes1, bboxes2, mode='giou') + + expected_overlaps = torch.FloatTensor([ + [0.5000, 0.0000, -0.5000], + [-0.2500, -0.0500, 1.0000], + [-0.8371, -0.8766, -0.8214], + ]) + + self.assertTrue( + torch.allclose(overlaps, expected_overlaps, rtol=1e-4, atol=1e-4)) diff --git a/tests/test_structures/test_bbox/test_bbox_transforms.py b/tests/test_structures/test_bbox/test_bbox_transforms.py new file mode 100644 index 0000000000..b2eb3da683 --- /dev/null +++ b/tests/test_structures/test_bbox/test_bbox_transforms.py @@ -0,0 +1,126 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import numpy as np + +from mmpose.structures.bbox import (bbox_clip_border, bbox_corner2xyxy, + bbox_xyxy2corner, get_pers_warp_matrix) + + +class TestBBoxClipBorder(TestCase): + + def test_bbox_clip_border_2D(self): + bbox = np.array([[10, 20], [60, 80], [-5, 25], [100, 120]]) + shape = (50, 50) # Example image shape + clipped_bbox = bbox_clip_border(bbox, shape) + + expected_bbox = np.array([[10, 20], [50, 50], [0, 25], [50, 50]]) + + self.assertTrue(np.array_equal(clipped_bbox, expected_bbox)) + + def test_bbox_clip_border_4D(self): + bbox = np.array([ + [[10, 20, 30, 40], [40, 50, 80, 90]], + [[-5, 0, 30, 40], [70, 80, 120, 130]], + ]) + shape = (50, 60) # Example image shape + clipped_bbox = bbox_clip_border(bbox, shape) + + expected_bbox = np.array([ + [[10, 20, 30, 40], [40, 50, 50, 60]], + [[0, 0, 30, 40], [50, 60, 50, 60]], + ]) + + self.assertTrue(np.array_equal(clipped_bbox, expected_bbox)) + + +class TestBBoxXYXY2Corner(TestCase): + + def test_bbox_xyxy2corner_single(self): + bbox = np.array([0, 0, 100, 50]) + corners = bbox_xyxy2corner(bbox) + + expected_corners = np.array([[0, 0], [0, 50], [100, 0], [100, 50]]) + + self.assertTrue(np.array_equal(corners, expected_corners)) + + def test_bbox_xyxy2corner_multiple(self): + bboxes = np.array([[0, 0, 100, 50], [10, 20, 200, 150]]) + corners = bbox_xyxy2corner(bboxes) + + expected_corners = np.array([[[0, 0], [0, 50], [100, 0], [100, 50]], + [[10, 20], [10, 150], [200, 20], + [200, 150]]]) + + self.assertTrue(np.array_equal(corners, expected_corners)) + + +class TestBBoxCorner2XYXY(TestCase): + + def test_bbox_corner2xyxy_single(self): + + corners = np.array([[0, 0], [0, 50], [100, 0], [100, 50]]) + xyxy = bbox_corner2xyxy(corners) + expected_xyxy = np.array([0, 0, 100, 50]) + + self.assertTrue(np.array_equal(xyxy, expected_xyxy)) + + def test_bbox_corner2xyxy_multiple(self): + + corners = np.array([[[0, 0], [0, 50], [100, 0], [100, 50]], + [[10, 20], [10, 150], [200, 20], [200, 150]]]) + xyxy = bbox_corner2xyxy(corners) + expected_xyxy = np.array([[0, 0, 100, 50], [10, 20, 200, 150]]) + + self.assertTrue(np.array_equal(xyxy, expected_xyxy)) + + +class TestGetPersWarpMatrix(TestCase): + + def test_get_pers_warp_matrix_identity(self): + center = np.array([0, 0]) + translate = np.array([0, 0]) + scale = 1.0 + rot = 0.0 + shear = np.array([0.0, 0.0]) + warp_matrix = get_pers_warp_matrix(center, translate, scale, rot, + shear) + + expected_matrix = np.array([[1, 0, 0], [0, 1, 0], [0, 0, 1]], + dtype=np.float32) + + self.assertTrue(np.array_equal(warp_matrix, expected_matrix)) + + def test_get_pers_warp_matrix_translation(self): + center = np.array([0, 0]) + translate = np.array([10, 20]) + scale = 1.0 + rot = 0.0 + shear = np.array([0.0, 0.0]) + warp_matrix = get_pers_warp_matrix(center, translate, scale, rot, + shear) + + expected_matrix = np.array([[1, 0, 10], [0, 1, 20], [0, 0, 1]], + dtype=np.float32) + + self.assertTrue(np.array_equal(warp_matrix, expected_matrix)) + + def test_get_pers_warp_matrix_scale_rotation_shear(self): + center = np.array([0, 0]) + translate = np.array([0, 0]) + scale = 1.5 + rot = 45.0 + shear = np.array([15.0, 30.0]) + warp_matrix = get_pers_warp_matrix(center, translate, scale, rot, + shear) + + expected_matrix = np.array([ + [1.3448632, -0.77645713, 0.], + [1.6730325, 0.44828773, 0.], + [0., 0., 1.], + ], + dtype=np.float32) + + # Use np.allclose to compare floating-point arrays within a tolerance + self.assertTrue( + np.allclose(warp_matrix, expected_matrix, rtol=1e-3, atol=1e-3)) diff --git a/tests/test_structures/test_keypoint/test_keypoint_transforms.py b/tests/test_structures/test_keypoint/test_keypoint_transforms.py new file mode 100644 index 0000000000..5384ce2b14 --- /dev/null +++ b/tests/test_structures/test_keypoint/test_keypoint_transforms.py @@ -0,0 +1,57 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import numpy as np + +from mmpose.structures import keypoint_clip_border + + +class TestKeypointClipBorder(TestCase): + + def test_keypoint_clip_border(self): + keypoints = np.array([[[10, 20], [30, 40], [-5, 25], [50, 60]]]) + keypoints_visible = np.array([[1.0, 0.8, 0.5, 1.0]]) + shape = (50, 50) # Example frame shape + + clipped_keypoints, clipped_keypoints_visible = keypoint_clip_border( + keypoints, keypoints_visible, shape) + + # Check if keypoints outside the frame have visibility set to 0.0 + self.assertEqual(clipped_keypoints_visible[0, 2], 0.0) + self.assertEqual(clipped_keypoints_visible[0, 3], 0.0) + + # Check if keypoints inside the frame have unchanged visibility values + self.assertEqual(clipped_keypoints_visible[0, 0], 1.0) + self.assertEqual(clipped_keypoints_visible[0, 1], 0.8) + + # Check if keypoints array shapes remain unchanged + self.assertEqual(keypoints.shape, clipped_keypoints.shape) + self.assertEqual(keypoints_visible.shape, + clipped_keypoints_visible.shape) + + keypoints = np.array([[[10, 20], [30, 40], [-5, 25], [50, 60]]]) + keypoints_visible = np.array([[1.0, 0.8, 0.5, 1.0]]) + keypoints_visible_weight = np.array([[1.0, 0.0, 1.0, 1.0]]) + keypoints_visible = np.stack( + (keypoints_visible, keypoints_visible_weight), axis=-1) + shape = (50, 50) # Example frame shape + + clipped_keypoints, clipped_keypoints_visible = keypoint_clip_border( + keypoints, keypoints_visible, shape) + + # Check if keypoints array shapes remain unchanged + self.assertEqual(keypoints.shape, clipped_keypoints.shape) + self.assertEqual(keypoints_visible.shape, + clipped_keypoints_visible.shape) + + # Check if keypoints outside the frame have visibility set to 0.0 + self.assertEqual(clipped_keypoints_visible[0, 2, 0], 0.0) + self.assertEqual(clipped_keypoints_visible[0, 3, 0], 0.0) + + # Check if keypoints inside the frame have unchanged visibility values + self.assertEqual(clipped_keypoints_visible[0, 0, 0], 1.0) + self.assertEqual(clipped_keypoints_visible[0, 1, 0], 0.8) + + # Check if the visibility weights remain unchanged + self.assertSequenceEqual(clipped_keypoints_visible[..., 1].tolist(), + keypoints_visible[..., 1].tolist()) diff --git a/tools/dataset_converters/300wlp2coco.py b/tools/dataset_converters/300wlp2coco.py new file mode 100644 index 0000000000..1d9b563173 --- /dev/null +++ b/tools/dataset_converters/300wlp2coco.py @@ -0,0 +1,171 @@ +# Copyright (c) OpenMMLab. All rights reserved. +import json +import os +import os.path as osp +import shutil +import time + +import cv2 +import numpy as np +from scipy.io import loadmat + + +# Move all images to one folder +def move_img(img_path, save_img): + path_list = ['AFW', 'HELEN', 'IBUG', 'LFPW'] + # 保存路径 + if not os.path.isdir(save_img): + os.makedirs(save_img) + + for people_name in path_list: + # 读取文件夹中图片 + Image_dir = os.path.join(img_path, people_name) + img_list = os.listdir(Image_dir) + for img_name in img_list: + if 'jpg' in img_name: + old_img_path = Image_dir + '/' + img_name + shutil.move(old_img_path, save_img + '/' + img_name) + + +# split 300w-lp data +def split_data(file_img, + train_path, + val_path, + test_path, + shuffle=True, + ratio1=0.8, + ratio2=0.1): + img_list = os.listdir(file_img) + if shuffle: + np.random.shuffle(img_list) + + n_total = len(img_list) + offset_train = int(n_total * ratio1) + offset_val = int(n_total * ratio2) + offset_train + train_img = img_list[:offset_train] + val_img = img_list[offset_train:offset_val] + test_img = img_list[offset_val:] + for img in train_img: + shutil.move(file_img + '/' + img, train_path + '/' + img) + for img in val_img: + shutil.move(file_img + '/' + img, val_path + '/' + img) + for img in test_img: + shutil.move(file_img + '/' + img, test_path + '/' + img) + + +def default_dump(obj): + """Convert numpy classes to JSON serializable objects.""" + if isinstance(obj, (np.integer, np.floating, np.bool_)): + return obj.item() + elif isinstance(obj, np.ndarray): + return obj.tolist() + else: + return obj + + +def convert_300WLP_to_coco(root_path, img_pathDir, out_file): + annotations = [] + images = [] + cnt = 0 + if 'trainval' in img_pathDir: + img_dir_list = ['train', 'val'] + else: + img_dir_list = [img_pathDir] + + for tv in img_dir_list: + + img_dir = osp.join(root_path, tv) + landmark_dir = os.path.join(root_path, '300W_LP', 'landmarks') + img_list = os.listdir(img_dir) + + for idx, img_name in enumerate(img_list): + cnt += 1 + img_path = osp.join(img_dir, img_name) + type_name = img_name.split('_')[0] + ann_name = img_name.split('.')[0] + '_pts.mat' + ann_path = osp.join(landmark_dir, type_name, ann_name) + data_info = loadmat(ann_path) + + img = cv2.imread(img_path) + + keypoints = data_info['pts_2d'] + keypoints_all = [] + for i in range(keypoints.shape[0]): + x, y = keypoints[i][0], keypoints[i][1] + keypoints_all.append([x, y, 2]) + keypoints = np.array(keypoints_all) + + x1, y1, _ = np.amin(keypoints, axis=0) + x2, y2, _ = np.amax(keypoints, axis=0) + w, h = x2 - x1, y2 - y1 + bbox = [x1, y1, w, h] + + image = {} + image['id'] = cnt + image['file_name'] = img_name + image['height'] = img.shape[0] + image['width'] = img.shape[1] + images.append(image) + + ann = {} + ann['keypoints'] = keypoints.reshape(-1).tolist() + ann['image_id'] = cnt + ann['id'] = cnt + ann['num_keypoints'] = len(keypoints) + ann['bbox'] = bbox + ann['iscrowd'] = 0 + ann['area'] = int(ann['bbox'][2] * ann['bbox'][3]) + ann['category_id'] = 1 + + annotations.append(ann) + + cocotype = {} + + cocotype['info'] = {} + cocotype['info']['description'] = 'LaPa Generated by MMPose Team' + cocotype['info']['version'] = 1.0 + cocotype['info']['year'] = time.strftime('%Y', time.localtime()) + cocotype['info']['date_created'] = time.strftime('%Y/%m/%d', + time.localtime()) + + cocotype['images'] = images + cocotype['annotations'] = annotations + cocotype['categories'] = [{ + 'supercategory': 'person', + 'id': 1, + 'name': 'face', + 'keypoints': [], + 'skeleton': [] + }] + + json.dump( + cocotype, + open(out_file, 'w'), + ensure_ascii=False, + default=default_dump) + print(f'done {out_file}') + + +if __name__ == '__main__': + # 1.Move all images to one folder + # 2.split 300W-LP data + # 3.convert json + img_path = './300W-LP/300W-LP' + save_img = './300W-LP/images' + move_img(img_path, save_img) + + file_img = './300W-LP/images' + train_path = './300W-LP/train' + val_path = './300W-LP/val' + test_path = './300W-LP/test' + split_data(save_img, train_path, val_path, test_path) + + root_path = './300W-LP' + anno_path_json = osp.join(root_path, 'annotations') + if not osp.exists(anno_path_json): + os.makedirs(anno_path_json) + for tv in ['val', 'test', 'train']: + print(f'processing {tv}') + convert_300WLP_to_coco( + root_path, tv, + anno_path_json + '/' + f'face_landmarks_300wlp_{tv}.json') diff --git a/tools/dataset_converters/scripts/preprocess_300w.sh b/tools/dataset_converters/scripts/preprocess_300w.sh old mode 100644 new mode 100755 index bf405b5cc7..4ab1672f0f --- a/tools/dataset_converters/scripts/preprocess_300w.sh +++ b/tools/dataset_converters/scripts/preprocess_300w.sh @@ -3,6 +3,6 @@ DOWNLOAD_DIR=$1 DATA_ROOT=$2 -tar -zxvf $DOWNLOAD_DIR/300w/raw/300w.tar.gz.00 -C $DOWNLOAD_DIR/ +tar -zxvf $DOWNLOAD_DIR/OpenDataLab___300w/raw/300w.tar.gz.00 -C $DOWNLOAD_DIR/ tar -xvf $DOWNLOAD_DIR/300w/300w.tar.00 -C $DATA_ROOT/ -rm -rf $DOWNLOAD_DIR/300w +rm -rf $DOWNLOAD_DIR/300w $DOWNLOAD_DIR/OpenDataLab___300w diff --git a/tools/dataset_converters/scripts/preprocess_aic.sh b/tools/dataset_converters/scripts/preprocess_aic.sh index 726a61ca26..9cb27ccdfb 100644 --- a/tools/dataset_converters/scripts/preprocess_aic.sh +++ b/tools/dataset_converters/scripts/preprocess_aic.sh @@ -3,5 +3,5 @@ DOWNLOAD_DIR=$1 DATA_ROOT=$2 -tar -zxvf $DOWNLOAD_DIR/AI_Challenger/raw/AI_Challenger.tar.gz -C $DATA_ROOT -rm -rf $DOWNLOAD_DIR/AI_Challenger +tar -zxvf $DOWNLOAD_DIR/OpenDataLab___AI_Challenger/raw/AI_Challenger.tar.gz -C $DATA_ROOT +rm -rf $DOWNLOAD_DIR/OpenDataLab___AI_Challenger diff --git a/tools/dataset_converters/scripts/preprocess_ap10k.sh b/tools/dataset_converters/scripts/preprocess_ap10k.sh index a4c330157b..eed785e3d2 100644 --- a/tools/dataset_converters/scripts/preprocess_ap10k.sh +++ b/tools/dataset_converters/scripts/preprocess_ap10k.sh @@ -3,6 +3,6 @@ DOWNLOAD_DIR=$1 DATA_ROOT=$2 -tar -zxvf $DOWNLOAD_DIR/AP-10K/raw/AP-10K.tar.gz.00 -C $DOWNLOAD_DIR/ +tar -zxvf $DOWNLOAD_DIR/OpenDataLab___AP-10K/raw/AP-10K.tar.gz.00 -C $DOWNLOAD_DIR/ tar -xvf $DOWNLOAD_DIR/AP-10K/AP-10K.tar.00 -C $DATA_ROOT/ -rm -rf $DOWNLOAD_DIR/AP-10K +rm -rf $DOWNLOAD_DIR/AP-10K $DOWNLOAD_DIR/OpenDataLab___AP-10K diff --git a/tools/dataset_converters/scripts/preprocess_coco2017.sh b/tools/dataset_converters/scripts/preprocess_coco2017.sh index 853975e26b..6b09c8e501 100644 --- a/tools/dataset_converters/scripts/preprocess_coco2017.sh +++ b/tools/dataset_converters/scripts/preprocess_coco2017.sh @@ -3,7 +3,7 @@ DOWNLOAD_DIR=$1 DATA_ROOT=$2 -unzip $DOWNLOAD_DIR/COCO_2017/raw/Images/val2017.zip -d $DATA_ROOT -unzip $DOWNLOAD_DIR/COCO_2017/raw/Images/train2017.zip -d $DATA_ROOT -unzip $DOWNLOAD_DIR/COCO_2017/raw/Annotations/annotations_trainval2017.zip -d $DATA_ROOT -rm -rf $DOWNLOAD_DIR/COCO_2017 +unzip $DOWNLOAD_DIR/OpenDataLab___COCO_2017/raw/Images/val2017.zip -d $DATA_ROOT +unzip $DOWNLOAD_DIR/OpenDataLab___COCO_2017/raw/Images/train2017.zip -d $DATA_ROOT +unzip $DOWNLOAD_DIR/OpenDataLab___COCO_2017/raw/Annotations/annotations_trainval2017.zip -d $DATA_ROOT +rm -rf $DOWNLOAD_DIR/OpenDataLab___COCO_2017 diff --git a/tools/dataset_converters/scripts/preprocess_crowdpose.sh b/tools/dataset_converters/scripts/preprocess_crowdpose.sh index 3215239585..e85d5aeefb 100644 --- a/tools/dataset_converters/scripts/preprocess_crowdpose.sh +++ b/tools/dataset_converters/scripts/preprocess_crowdpose.sh @@ -3,5 +3,5 @@ DOWNLOAD_DIR=$1 DATA_ROOT=$2 -tar -zxvf $DOWNLOAD_DIR/CrowdPose/raw/CrowdPose.tar.gz -C $DATA_ROOT -rm -rf $DOWNLOAD_DIR/CrowdPose +tar -zxvf $DOWNLOAD_DIR/OpenDataLab___CrowdPose/raw/CrowdPose.tar.gz -C $DATA_ROOT +rm -rf $DOWNLOAD_DIR/OpenDataLab___CrowdPose diff --git a/tools/dataset_converters/scripts/preprocess_freihand.sh b/tools/dataset_converters/scripts/preprocess_freihand.sh index b3567cb5d7..bff275f42a 100644 --- a/tools/dataset_converters/scripts/preprocess_freihand.sh +++ b/tools/dataset_converters/scripts/preprocess_freihand.sh @@ -3,5 +3,5 @@ DOWNLOAD_DIR=$1 DATA_ROOT=$2 -tar -zxvf $DOWNLOAD_DIR/FreiHAND/raw/FreiHAND.tar.gz -C $DATA_ROOT -rm -rf $DOWNLOAD_DIR/FreiHAND +tar -zxvf $DOWNLOAD_DIR/OpenDataLab___FreiHAND/raw/FreiHAND.tar.gz -C $DATA_ROOT +rm -rf $DOWNLOAD_DIR/OpenDataLab___FreiHAND diff --git a/tools/dataset_converters/scripts/preprocess_hagrid.sh b/tools/dataset_converters/scripts/preprocess_hagrid.sh index de2356541c..129d27c9f1 100644 --- a/tools/dataset_converters/scripts/preprocess_hagrid.sh +++ b/tools/dataset_converters/scripts/preprocess_hagrid.sh @@ -3,6 +3,6 @@ DOWNLOAD_DIR=$1 DATA_ROOT=$2 -cat $DOWNLOAD_DIR/HaGRID/raw/*.tar.gz.* | tar -xvz -C $DATA_ROOT/.. +cat $DOWNLOAD_DIR/OpenDataLab___HaGRID/raw/*.tar.gz.* | tar -xvz -C $DATA_ROOT/.. tar -xvf $DATA_ROOT/HaGRID.tar -C $DATA_ROOT/.. -rm -rf $DOWNLOAD_DIR/HaGRID +rm -rf $DOWNLOAD_DIR/OpenDataLab___HaGRID diff --git a/tools/dataset_converters/scripts/preprocess_halpe.sh b/tools/dataset_converters/scripts/preprocess_halpe.sh index 103d6202f9..628de88ecc 100644 --- a/tools/dataset_converters/scripts/preprocess_halpe.sh +++ b/tools/dataset_converters/scripts/preprocess_halpe.sh @@ -3,6 +3,6 @@ DOWNLOAD_DIR=$1 DATA_ROOT=$2 -tar -zxvf $DOWNLOAD_DIR/Halpe/raw/Halpe.tar.gz.00 -C $DOWNLOAD_DIR/ +tar -zxvf $DOWNLOAD_DIR/OpenDataLab___Halpe/raw/Halpe.tar.gz.00 -C $DOWNLOAD_DIR/ tar -xvf $DOWNLOAD_DIR/Halpe/Halpe.tar.00 -C $DATA_ROOT/ -rm -rf $DOWNLOAD_DIR/Halpe +rm -rf $DOWNLOAD_DIR/Halpe $DOWNLOAD_DIR/OpenDataLab___Halpe diff --git a/tools/dataset_converters/scripts/preprocess_lapa.sh b/tools/dataset_converters/scripts/preprocess_lapa.sh index 977442c1b8..c7556ffc87 100644 --- a/tools/dataset_converters/scripts/preprocess_lapa.sh +++ b/tools/dataset_converters/scripts/preprocess_lapa.sh @@ -3,5 +3,5 @@ DOWNLOAD_DIR=$1 DATA_ROOT=$2 -tar -zxvf $DOWNLOAD_DIR/LaPa/raw/LaPa.tar.gz -C $DATA_ROOT -rm -rf $DOWNLOAD_DIR/LaPa +tar -zxvf $DOWNLOAD_DIR/OpenDataLab___LaPa/raw/LaPa.tar.gz -C $DATA_ROOT +rm -rf $DOWNLOAD_DIR/OpenDataLab___LaPa diff --git a/tools/dataset_converters/scripts/preprocess_mpii.sh b/tools/dataset_converters/scripts/preprocess_mpii.sh index 287b431897..c3027c23f6 100644 --- a/tools/dataset_converters/scripts/preprocess_mpii.sh +++ b/tools/dataset_converters/scripts/preprocess_mpii.sh @@ -3,5 +3,5 @@ DOWNLOAD_DIR=$1 DATA_ROOT=$2 -tar -zxvf $DOWNLOAD_DIR/MPII_Human_Pose/raw/MPII_Human_Pose.tar.gz -C $DATA_ROOT -rm -rf $DOWNLOAD_DIR/MPII_Human_Pose +tar -zxvf $DOWNLOAD_DIR/OpenDataLab___MPII_Human_Pose/raw/MPII_Human_Pose.tar.gz -C $DATA_ROOT +rm -rf $DOWNLOAD_DIR/OpenDataLab___MPII_Human_Pose diff --git a/tools/dataset_converters/scripts/preprocess_onehand10k.sh b/tools/dataset_converters/scripts/preprocess_onehand10k.sh index 47f6e8942c..07c0d083d3 100644 --- a/tools/dataset_converters/scripts/preprocess_onehand10k.sh +++ b/tools/dataset_converters/scripts/preprocess_onehand10k.sh @@ -3,6 +3,6 @@ DOWNLOAD_DIR=$1 DATA_ROOT=$2 -tar -zxvf $DOWNLOAD_DIR/OneHand10K/raw/OneHand10K.tar.gz.00 -C $DOWNLOAD_DIR/ +tar -zxvf $DOWNLOAD_DIR/OpenDataLab___OneHand10K/raw/OneHand10K.tar.gz.00 -C $DOWNLOAD_DIR/ tar -xvf $DOWNLOAD_DIR/OneHand10K/OneHand10K.tar.00 -C $DATA_ROOT/ -rm -rf $DOWNLOAD_DIR/OneHand10K +rm -rf $DOWNLOAD_DIR/OneHand10K $DOWNLOAD_DIR/OpenDataLab___OneHand10K diff --git a/tools/dataset_converters/scripts/preprocess_wflw.sh b/tools/dataset_converters/scripts/preprocess_wflw.sh index 723d1d158e..298ffc79d2 100644 --- a/tools/dataset_converters/scripts/preprocess_wflw.sh +++ b/tools/dataset_converters/scripts/preprocess_wflw.sh @@ -3,6 +3,6 @@ DOWNLOAD_DIR=$1 DATA_ROOT=$2 -tar -zxvf $DOWNLOAD_DIR/WFLW/raw/WFLW.tar.gz.00 -C $DOWNLOAD_DIR/ +tar -zxvf $DOWNLOAD_DIR/OpenDataLab___WFLW/raw/WFLW.tar.gz.00 -C $DOWNLOAD_DIR/ tar -xvf $DOWNLOAD_DIR/WFLW/WFLW.tar.00 -C $DATA_ROOT/ -rm -rf $DOWNLOAD_DIR/WFLW +rm -rf $DOWNLOAD_DIR/WFLW $DOWNLOAD_DIR/OpenDataLab___WFLW diff --git a/tools/dataset_converters/ubody_kpts_to_coco.py b/tools/dataset_converters/ubody_kpts_to_coco.py new file mode 100644 index 0000000000..9d927da7ca --- /dev/null +++ b/tools/dataset_converters/ubody_kpts_to_coco.py @@ -0,0 +1,138 @@ +# Copyright (c) OpenMMLab. All rights reserved. +import argparse +import os +from copy import deepcopy +from multiprocessing import Pool + +import mmengine +import numpy as np +from pycocotools.coco import COCO + + +def findAllFile(base): + file_path = [] + for root, ds, fs in os.walk(base): + for f in fs: + fullname = os.path.join(root, f) + file_path.append(fullname) + return file_path + + +def convert(video_path: str): + video_name = video_path.split('/')[-1] + image_path = video_path.replace(video_name, video_name.split('.')[0]) + image_path = image_path.replace('/videos/', '/images/') + os.makedirs(image_path, exist_ok=True) + print( + f'ffmpeg -i {video_path} -f image2 -r 30 -b:v 5626k {image_path}/%06d.png' # noqa + ) + os.system( + f'ffmpeg -i {video_path} -f image2 -r 30 -b:v 5626k {image_path}/%06d.png' # noqa + ) + + +def split_dataset(annotation_path: str, split_path: str): + folders = os.listdir(annotation_path) + splits = np.load(split_path) + train_annos = [] + val_annos = [] + train_imgs = [] + val_imgs = [] + t_id = 0 + v_id = 0 + categories = [{'supercategory': 'person', 'id': 1, 'name': 'person'}] + + for scene in folders: + scene_train_anns = [] + scene_val_anns = [] + scene_train_imgs = [] + scene_val_imgs = [] + data = COCO( + os.path.join(annotation_path, scene, 'keypoint_annotation.json')) + print(f'Processing {scene}.........') + progress_bar = mmengine.ProgressBar(len(data.anns.keys())) + for aid in data.anns.keys(): + ann = data.anns[aid] + img = data.loadImgs(ann['image_id'])[0] + + if img['file_name'].startswith('/'): + file_name = img['file_name'][1:] # [1:] means delete '/' + else: + file_name = img['file_name'] + video_name = file_name.split('/')[-2] + if 'Trim' in video_name: + video_name = video_name.split('_Trim')[0] + + img_path = os.path.join( + annotation_path.replace('annotations', 'images'), scene, + file_name) + if not os.path.exists(img_path): + progress_bar.update() + continue + + img['file_name'] = os.path.join(scene, file_name) + ann_ = deepcopy(ann) + img_ = deepcopy(img) + if video_name in splits: + scene_val_anns.append(ann) + scene_val_imgs.append(img) + ann_['id'] = v_id + ann_['image_id'] = v_id + img_['id'] = v_id + val_annos.append(ann_) + val_imgs.append(img_) + v_id += 1 + else: + scene_train_anns.append(ann) + scene_train_imgs.append(img) + ann_['id'] = t_id + ann_['image_id'] = t_id + img_['id'] = t_id + train_annos.append(ann_) + train_imgs.append(img_) + t_id += 1 + + progress_bar.update() + + scene_train_data = dict( + images=scene_train_imgs, + annotations=scene_train_anns, + categories=categories) + scene_val_data = dict( + images=scene_val_imgs, + annotations=scene_val_anns, + categories=categories) + + mmengine.dump( + scene_train_data, + os.path.join(annotation_path, scene, 'train_annotations.json')) + mmengine.dump( + scene_val_data, + os.path.join(annotation_path, scene, 'val_annotations.json')) + + train_data = dict( + images=train_imgs, annotations=train_annos, categories=categories) + val_data = dict( + images=val_imgs, annotations=val_annos, categories=categories) + + mmengine.dump(train_data, + os.path.join(annotation_path, 'train_annotations.json')) + mmengine.dump(val_data, + os.path.join(annotation_path, 'val_annotations.json')) + + +if __name__ == '__main__': + parser = argparse.ArgumentParser() + parser.add_argument('--data-root', type=str, default='data/UBody') + args = parser.parse_args() + video_root = f'{args.data_root}/videos' + split_path = f'{args.data_root}/splits/intra_scene_test_list.npy' + annotation_path = f'{args.data_root}/annotations' + + video_paths = findAllFile(video_root) + pool = Pool(processes=1) + pool.map(convert, video_paths) + pool.close() + pool.join() + + split_dataset(annotation_path, split_path) diff --git a/tools/dataset_converters/ubody_smplx_to_coco.py b/tools/dataset_converters/ubody_smplx_to_coco.py new file mode 100644 index 0000000000..16f827fce1 --- /dev/null +++ b/tools/dataset_converters/ubody_smplx_to_coco.py @@ -0,0 +1,430 @@ +# Copyright (c) OpenMMLab. All rights reserved. +import argparse +import json +import os +import os.path as osp +from functools import partial +from typing import Dict, List + +import mmengine +import numpy as np +import smplx +import torch +from pycocotools.coco import COCO + + +class SMPLX(object): + + def __init__(self, human_model_path): + self.human_model_path = human_model_path + self.layer_args = { + 'create_global_orient': False, + 'create_body_pose': False, + 'create_left_hand_pose': False, + 'create_right_hand_pose': False, + 'create_jaw_pose': False, + 'create_leye_pose': False, + 'create_reye_pose': False, + 'create_betas': False, + 'create_expression': False, + 'create_transl': False, + } + + self.neutral_model = smplx.create( + self.human_model_path, + 'smplx', + gender='NEUTRAL', + use_pca=False, + use_face_contour=True, + **self.layer_args) + if torch.cuda.is_available(): + self.neutral_model = self.neutral_model.to('cuda:0') + + self.vertex_num = 10475 + self.face = self.neutral_model.faces + self.shape_param_dim = 10 + self.expr_code_dim = 10 + # 22 (body joints) + 30 (hand joints) + 1 (face jaw joint) + self.orig_joint_num = 53 + + # yapf: disable + self.orig_joints_name = ( + # 22 body joints + 'Pelvis', 'L_Hip', 'R_Hip', 'Spine_1', 'L_Knee', 'R_Knee', + 'Spine2', 'L_Ankle', 'R_Ankle', 'Spine_3', 'L_Foot', 'R_Foot', + 'Neck', 'L_Collar', 'R_Collar', 'Head', 'L_Shoulder', + 'R_Shoulder', 'L_Elbow', 'R_Elbow', 'L_Wrist', 'R_Wrist', + # left hand joints + 'L_Index_1', 'L_Index_2', 'L_Index_3', 'L_Middle_1', 'L_Middle_2', + 'L_Middle_3', 'L_Pinky_1', 'L_Pinky_2', 'L_Pinky_3', 'L_Ring_1', + 'L_Ring_2', 'L_Ring_3', 'L_Thumb_1', 'L_Thumb_2', 'L_Thumb_3', + # right hand joints + 'R_Index_1', 'R_Index_2', 'R_Index_3', 'R_Middle_1', 'R_Middle_2', + 'R_Middle_3', 'R_Pinky_1', 'R_Pinky_2', 'R_Pinky_3', 'R_Ring_1', + 'R_Ring_2', 'R_Ring_3', 'R_Thumb_1', 'R_Thumb_2', 'R_Thumb_3', + # 1 face jaw joint + 'Jaw', + ) + self.orig_flip_pairs = ( + # body joints + (1, 2), (4, 5), (7, 8), (10, 11), (13, 14), (16, 17), (18, 19), + (20, 21), + # hand joints + (22, 37), (23, 38), (24, 39), (25, 40), (26, 41), (27, 42), + (28, 43), (29, 44), (30, 45), (31, 46), (32, 47), (33, 48), + (34, 49), (35, 50), (36, 51), + ) + # yapf: enable + self.orig_root_joint_idx = self.orig_joints_name.index('Pelvis') + self.orig_joint_part = { + 'body': + range( + self.orig_joints_name.index('Pelvis'), + self.orig_joints_name.index('R_Wrist') + 1), + 'lhand': + range( + self.orig_joints_name.index('L_Index_1'), + self.orig_joints_name.index('L_Thumb_3') + 1), + 'rhand': + range( + self.orig_joints_name.index('R_Index_1'), + self.orig_joints_name.index('R_Thumb_3') + 1), + 'face': + range( + self.orig_joints_name.index('Jaw'), + self.orig_joints_name.index('Jaw') + 1) + } + + # changed SMPLX joint set for the supervision + self.joint_num = ( + 137 # 25 (body joints) + 40 (hand joints) + 72 (face keypoints) + ) + # yapf: disable + self.joints_name = ( + # 25 body joints + 'Pelvis', 'L_Hip', 'R_Hip', 'L_Knee', 'R_Knee', 'L_Ankle', + 'R_Ankle', 'Neck', 'L_Shoulder', 'R_Shoulder', 'L_Elbow', + 'R_Elbow', 'L_Wrist', 'R_Wrist', 'L_Big_toe', 'L_Small_toe', + 'L_Heel', 'R_Big_toe', 'R_Small_toe', 'R_Heel', 'L_Ear', 'R_Ear', + 'L_Eye', 'R_Eye', 'Nose', + # left hand joints + 'L_Thumb_1', 'L_Thumb_2', 'L_Thumb_3', 'L_Thumb4', 'L_Index_1', + 'L_Index_2', 'L_Index_3', 'L_Index_4', 'L_Middle_1', 'L_Middle_2', + 'L_Middle_3', 'L_Middle_4', 'L_Ring_1', 'L_Ring_2', 'L_Ring_3', + 'L_Ring_4', 'L_Pinky_1', 'L_Pinky_2', 'L_Pinky_3', 'L_Pinky_4', + # right hand joints + 'R_Thumb_1', 'R_Thumb_2', 'R_Thumb_3', 'R_Thumb_4', 'R_Index_1', + 'R_Index_2', 'R_Index_3', 'R_Index_4', 'R_Middle_1', 'R_Middle_2', + 'R_Middle_3', 'R_Middle_4', 'R_Ring_1', 'R_Ring_2', 'R_Ring_3', + 'R_Ring_4', 'R_Pinky_1', 'R_Pinky_2', 'R_Pinky_3', 'R_Pinky_4', + # 72 face keypoints + *[ + f'Face_{i}' for i in range(1, 73) + ], + ) + + self.root_joint_idx = self.joints_name.index('Pelvis') + self.lwrist_idx = self.joints_name.index('L_Wrist') + self.rwrist_idx = self.joints_name.index('R_Wrist') + self.neck_idx = self.joints_name.index('Neck') + self.flip_pairs = ( + # body joints + (1, 2), (3, 4), (5, 6), (8, 9), (10, 11), (12, 13), (14, 17), + (15, 18), (16, 19), (20, 21), (22, 23), + # hand joints + (25, 45), (26, 46), (27, 47), (28, 48), (29, 49), (30, 50), + (31, 51), (32, 52), (33, 53), (34, 54), (35, 55), (36, 56), + (37, 57), (38, 58), (39, 59), (40, 60), (41, 61), (42, 62), + (43, 63), (44, 64), + # face eyebrow + (67, 68), (69, 78), (70, 77), (71, 76), (72, 75), (73, 74), + # face below nose + (83, 87), (84, 86), + # face eyes + (88, 97), (89, 96), (90, 95), (91, 94), (92, 99), (93, 98), + # face mouse + (100, 106), (101, 105), (102, 104), (107, 111), (108, 110), + # face lip + (112, 116), (113, 115), (117, 119), + # face contours + (120, 136), (121, 135), (122, 134), (123, 133), (124, 132), + (125, 131), (126, 130), (127, 129) + ) + self.joint_idx = ( + 0, 1, 2, 4, 5, 7, 8, 12, 16, 17, 18, 19, 20, 21, 60, 61, 62, 63, + 64, 65, 59, 58, 57, 56, 55, # body joints + 37, 38, 39, 66, 25, 26, 27, 67, 28, 29, 30, 68, 34, 35, 36, 69, 31, + 32, 33, 70, # left hand joints + 52, 53, 54, 71, 40, 41, 42, 72, 43, 44, 45, 73, 49, 50, 51, 74, 46, + 47, 48, 75, # right hand joints + 22, 15, # jaw, head + 57, 56, # eyeballs + 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, # eyebrow + 86, 87, 88, 89, # nose + 90, 91, 92, 93, 94, # below nose + 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, # eyes + 107, # right mouth + 108, 109, 110, 111, 112, # upper mouth + 113, # left mouth + 114, 115, 116, 117, 118, # lower mouth + 119, # right lip + 120, 121, 122, # upper lip + 123, # left lip + 124, 125, 126, # lower lip + 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, + 140, 141, 142, 143, # face contour + ) + # yapf: enable + + self.joint_part = { + 'body': + range( + self.joints_name.index('Pelvis'), + self.joints_name.index('Nose') + 1), + 'lhand': + range( + self.joints_name.index('L_Thumb_1'), + self.joints_name.index('L_Pinky_4') + 1), + 'rhand': + range( + self.joints_name.index('R_Thumb_1'), + self.joints_name.index('R_Pinky_4') + 1), + 'hand': + range( + self.joints_name.index('L_Thumb_1'), + self.joints_name.index('R_Pinky_4') + 1), + 'face': + range( + self.joints_name.index('Face_1'), + self.joints_name.index('Face_72') + 1) + } + + +def read_annotation_file(annotation_file: str) -> List[Dict]: + with open(annotation_file, 'r') as f: + annotations = json.load(f) + return annotations + + +def cam2pixel(cam_coord, f, c): + x = cam_coord[:, 0] / cam_coord[:, 2] * f[0] + c[0] + y = cam_coord[:, 1] / cam_coord[:, 2] * f[1] + c[1] + z = cam_coord[:, 2] + return np.stack((x, y, z), 1) + + +def process_scene_anno(scene: str, annotation_root: str, splits: np.array, + human_model_path: str): + annos = read_annotation_file( + osp.join(annotation_root, scene, 'smplx_annotation.json')) + keypoint_annos = COCO( + osp.join(annotation_root, scene, 'keypoint_annotation.json')) + human_model = SMPLX(human_model_path) + + train_annos = [] + val_annos = [] + train_imgs = [] + val_imgs = [] + + progress_bar = mmengine.ProgressBar(len(keypoint_annos.anns.keys())) + for aid in keypoint_annos.anns.keys(): + ann = keypoint_annos.anns[aid] + img = keypoint_annos.loadImgs(ann['image_id'])[0] + if img['file_name'].startswith('/'): + file_name = img['file_name'][1:] + else: + file_name = img['file_name'] + + video_name = file_name.split('/')[-2] + if 'Trim' in video_name: + video_name = video_name.split('_Trim')[0] + + img_path = os.path.join( + annotation_root.replace('annotations', 'images'), scene, file_name) + if not os.path.exists(img_path): + progress_bar.update() + continue + if str(aid) not in annos: + progress_bar.update() + continue + + smplx_param = annos[str(aid)] + human_model_param = smplx_param['smplx_param'] + cam_param = smplx_param['cam_param'] + if 'lhand_valid' not in human_model_param: + human_model_param['lhand_valid'] = ann['lefthand_valid'] + human_model_param['rhand_valid'] = ann['righthand_valid'] + human_model_param['face_valid'] = ann['face_valid'] + + rotation_valid = np.ones((human_model.orig_joint_num), + dtype=np.float32) + coord_valid = np.ones((human_model.joint_num), dtype=np.float32) + + root_pose = human_model_param['root_pose'] + body_pose = human_model_param['body_pose'] + shape = human_model_param['shape'] + trans = human_model_param['trans'] + + if 'lhand_pose' in human_model_param and human_model_param.get( + 'lhand_valid', False): + lhand_pose = human_model_param['lhand_pose'] + else: + lhand_pose = np.zeros( + (3 * len(human_model.orig_joint_part['lhand'])), + dtype=np.float32) + rotation_valid[human_model.orig_joint_part['lhand']] = 0 + coord_valid[human_model.orig_joint_part['lhand']] = 0 + + if 'rhand_pose' in human_model_param and human_model_param.get( + 'rhand_valid', False): + rhand_pose = human_model_param['rhand_pose'] + else: + rhand_pose = np.zeros( + (3 * len(human_model.orig_joint_part['rhand'])), + dtype=np.float32) + rotation_valid[human_model.orig_joint_part['rhand']] = 0 + coord_valid[human_model.orig_joint_part['rhand']] = 0 + + if 'jaw_pose' in human_model_param and \ + 'expr' in human_model_param and \ + human_model_param.get('face_valid', False): + jaw_pose = human_model_param['jaw_pose'] + expr = human_model_param['expr'] + else: + jaw_pose = np.zeros((3), dtype=np.float32) + expr = np.zeros((human_model.expr_code_dim), dtype=np.float32) + rotation_valid[human_model.orig_joint_part['face']] = 0 + coord_valid[human_model.orig_joint_part['face']] = 0 + + # init human model inputs + device = torch.device( + 'cuda:0') if torch.cuda.is_available() else torch.device('cpu') + root_pose = torch.FloatTensor(root_pose).to(device).view(1, 3) + body_pose = torch.FloatTensor(body_pose).to(device).view(-1, 3) + lhand_pose = torch.FloatTensor(lhand_pose).to(device).view(-1, 3) + rhand_pose = torch.FloatTensor(rhand_pose).to(device).view(-1, 3) + jaw_pose = torch.FloatTensor(jaw_pose).to(device).view(-1, 3) + shape = torch.FloatTensor(shape).to(device).view(1, -1) + expr = torch.FloatTensor(expr).to(device).view(1, -1) + trans = torch.FloatTensor(trans).to(device).view(1, -1) + zero_pose = torch.zeros((1, 3), dtype=torch.float32, device=device) + + with torch.no_grad(): + output = human_model.neutral_model( + betas=shape, + body_pose=body_pose.view(1, -1), + global_orient=root_pose, + transl=trans, + left_hand_pose=lhand_pose.view(1, -1), + right_hand_pose=rhand_pose.view(1, -1), + jaw_pose=jaw_pose.view(1, -1), + leye_pose=zero_pose, + reye_pose=zero_pose, + expression=expr) + + joint_cam = output.joints[0].cpu().numpy()[human_model.joint_idx, :] + joint_img = cam2pixel(joint_cam, cam_param['focal'], + cam_param['princpt']) + + joint_cam = (joint_cam - joint_cam[human_model.root_joint_idx, None, :] + ) # root-relative + joint_cam[human_model.joint_part['lhand'], :] = ( + joint_cam[human_model.joint_part['lhand'], :] - + joint_cam[human_model.lwrist_idx, None, :] + ) # left hand root-relative + joint_cam[human_model.joint_part['rhand'], :] = ( + joint_cam[human_model.joint_part['rhand'], :] - + joint_cam[human_model.rwrist_idx, None, :] + ) # right hand root-relative + joint_cam[human_model.joint_part['face'], :] = ( + joint_cam[human_model.joint_part['face'], :] - + joint_cam[human_model.neck_idx, None, :]) # face root-relative + + body_3d_size = 2 + output_hm_shape = (16, 16, 12) + joint_img[human_model.joint_part['body'], + 2] = ((joint_cam[human_model.joint_part['body'], 2].copy() / + (body_3d_size / 2) + 1) / 2.0 * output_hm_shape[0]) + joint_img[human_model.joint_part['lhand'], + 2] = ((joint_cam[human_model.joint_part['lhand'], 2].copy() / + (body_3d_size / 2) + 1) / 2.0 * output_hm_shape[0]) + joint_img[human_model.joint_part['rhand'], + 2] = ((joint_cam[human_model.joint_part['rhand'], 2].copy() / + (body_3d_size / 2) + 1) / 2.0 * output_hm_shape[0]) + joint_img[human_model.joint_part['face'], + 2] = ((joint_cam[human_model.joint_part['face'], 2].copy() / + (body_3d_size / 2) + 1) / 2.0 * output_hm_shape[0]) + + keypoints_2d = joint_img[:, :2].copy() + keypoints_3d = joint_img.copy() + keypoints_valid = coord_valid.reshape((-1, 1)) + + ann['keypoints'] = keypoints_2d.tolist() + ann['keypoints_3d'] = keypoints_3d.tolist() + ann['keypoints_valid'] = keypoints_valid.tolist() + ann['camera_param'] = cam_param + img['file_name'] = os.path.join(scene, file_name) + if video_name in splits: + val_annos.append(ann) + val_imgs.append(img) + else: + train_annos.append(ann) + train_imgs.append(img) + progress_bar.update() + + categories = [{ + 'supercategory': 'person', + 'id': 1, + 'name': 'person', + 'keypoints': human_model.joints_name, + 'skeleton': human_model.flip_pairs + }] + train_data = { + 'images': train_imgs, + 'annotations': train_annos, + 'categories': categories + } + val_data = { + 'images': val_imgs, + 'annotations': val_annos, + 'categories': categories + } + + mmengine.dump( + train_data, + osp.join(annotation_root, scene, 'train_3dkeypoint_annotation.json')) + mmengine.dump( + val_data, + osp.join(annotation_root, scene, 'val_3dkeypoint_annotation.json')) + + +if __name__ == '__main__': + parser = argparse.ArgumentParser() + parser.add_argument('--data-root', type=str, default='data/UBody') + parser.add_argument('--human-model-path', type=str, default='data/SMPLX') + parser.add_argument( + '--nproc', default=8, type=int, help='number of process') + args = parser.parse_args() + + split_path = f'{args.data_root}/splits/intra_scene_test_list.npy' + annotation_path = f'{args.data_root}/annotations' + + folders = os.listdir(annotation_path) + folders = [f for f in folders if osp.isdir(osp.join(annotation_path, f))] + human_model_path = args.human_model_path + splits = np.load(split_path) + + if args.nproc > 1: + mmengine.track_parallel_progress( + partial( + process_scene_anno, + annotation_root=annotation_path, + splits=splits, + human_model_path=human_model_path), folders, args.nproc) + else: + mmengine.track_progress( + partial( + process_scene_anno, + annotation_root=annotation_path, + splits=splits, + human_model_path=human_model_path), folders) diff --git a/tools/misc/pth_transfer.py b/tools/misc/pth_transfer.py new file mode 100644 index 0000000000..7433c6771e --- /dev/null +++ b/tools/misc/pth_transfer.py @@ -0,0 +1,46 @@ +# Copyright (c) OpenMMLab. All rights reserved. +import argparse +from collections import OrderedDict + +import torch + + +def change_model(args): + dis_model = torch.load(args.dis_path, map_location='cpu') + all_name = [] + if args.two_dis: + for name, v in dis_model['state_dict'].items(): + if name.startswith('teacher.backbone'): + all_name.append((name[8:], v)) + elif name.startswith('distill_losses.loss_mgd.down'): + all_name.append(('head.' + name[24:], v)) + elif name.startswith('student.head'): + all_name.append((name[8:], v)) + else: + continue + else: + for name, v in dis_model['state_dict'].items(): + if name.startswith('student.'): + all_name.append((name[8:], v)) + else: + continue + state_dict = OrderedDict(all_name) + dis_model['state_dict'] = state_dict + + save_keys = ['meta', 'state_dict'] + ckpt_keys = list(dis_model.keys()) + for k in ckpt_keys: + if k not in save_keys: + dis_model.pop(k, None) + + torch.save(dis_model, args.output_path) + + +if __name__ == '__main__': + parser = argparse.ArgumentParser(description='Transfer CKPT') + parser.add_argument('dis_path', help='dis_model path') + parser.add_argument('output_path', help='output path') + parser.add_argument( + '--two_dis', action='store_true', default=False, help='if two dis') + args = parser.parse_args() + change_model(args) diff --git a/tools/test.py b/tools/test.py index 5dc0110260..12fd6b4423 100644 --- a/tools/test.py +++ b/tools/test.py @@ -51,7 +51,14 @@ def parse_args(): choices=['none', 'pytorch', 'slurm', 'mpi'], default='none', help='job launcher') - parser.add_argument('--local_rank', type=int, default=0) + # When using PyTorch version >= 2.0.0, the `torch.distributed.launch` + # will pass the `--local-rank` parameter to `tools/test.py` instead + # of `--local_rank`. + parser.add_argument('--local_rank', '--local-rank', type=int, default=0) + parser.add_argument( + '--badcase', + action='store_true', + help='whether analyze badcase in test') args = parser.parse_args() if 'LOCAL_RANK' not in os.environ: os.environ['LOCAL_RANK'] = str(args.local_rank) @@ -75,19 +82,45 @@ def merge_args(cfg, args): osp.splitext(osp.basename(args.config))[0]) # -------------------- visualization -------------------- - if args.show or (args.show_dir is not None): + if (args.show and not args.badcase) or (args.show_dir is not None): assert 'visualization' in cfg.default_hooks, \ 'PoseVisualizationHook is not set in the ' \ '`default_hooks` field of config. Please set ' \ '`visualization=dict(type="PoseVisualizationHook")`' cfg.default_hooks.visualization.enable = True - cfg.default_hooks.visualization.show = args.show + cfg.default_hooks.visualization.show = False \ + if args.badcase else args.show if args.show: cfg.default_hooks.visualization.wait_time = args.wait_time cfg.default_hooks.visualization.out_dir = args.show_dir cfg.default_hooks.visualization.interval = args.interval + # -------------------- badcase analyze -------------------- + if args.badcase: + assert 'badcase' in cfg.default_hooks, \ + 'BadcaseAnalyzeHook is not set in the ' \ + '`default_hooks` field of config. Please set ' \ + '`badcase=dict(type="BadcaseAnalyzeHook")`' + + cfg.default_hooks.badcase.enable = True + cfg.default_hooks.badcase.show = args.show + if args.show: + cfg.default_hooks.badcase.wait_time = args.wait_time + cfg.default_hooks.badcase.interval = args.interval + + metric_type = cfg.default_hooks.badcase.get('metric_type', 'loss') + if metric_type not in ['loss', 'accuracy']: + raise ValueError('Only support badcase metric type' + "in ['loss', 'accuracy']") + + if metric_type == 'loss': + if not cfg.default_hooks.badcase.get('metric'): + cfg.default_hooks.badcase.metric = cfg.model.head.loss + else: + if not cfg.default_hooks.badcase.get('metric'): + cfg.default_hooks.badcase.metric = cfg.test_evaluator + # -------------------- Dump predictions -------------------- if args.dump is not None: assert args.dump.endswith(('.pkl', '.pickle')), \ diff --git a/tools/train.py b/tools/train.py index 1fd423ad3f..84eec2d577 100644 --- a/tools/train.py +++ b/tools/train.py @@ -98,7 +98,8 @@ def merge_args(cfg, args): if args.amp is True: from mmengine.optim import AmpOptimWrapper, OptimWrapper optim_wrapper = cfg.optim_wrapper.get('type', OptimWrapper) - assert optim_wrapper in (OptimWrapper, AmpOptimWrapper), \ + assert optim_wrapper in (OptimWrapper, AmpOptimWrapper, + 'OptimWrapper', 'AmpOptimWrapper'), \ '`--amp` is not supported custom optimizer wrapper type ' \ f'`{optim_wrapper}.' cfg.optim_wrapper.type = 'AmpOptimWrapper'
支持的骨干网络
- [x] [AlexNet](https://mmpose.readthedocs.io/zh_CN/latest/model_zoo_papers/backbones.html#alexnet-neurips-2012) (NeurIPS'2012) @@ -366,10 +345,10 @@ MMPose 是一款由不同学校和公司共同贡献的开源项目。我们感 ## 欢迎加入 OpenMMLab 社区 -扫描下方的二维码可关注 OpenMMLab 团队的 [知乎官方账号](https://www.zhihu.com/people/openmmlab),联络 OpenMMLab [官方微信小助手](https://user-images.githubusercontent.com/25839884/205872898-e2e6009d-c6bb-4d27-8d07-117e697a3da8.jpg)或加入 OpenMMLab 团队的 [官方交流 QQ 群](https://jq.qq.com/?_wv=1027&k=K0QI8ByU) +扫描下方的二维码可关注 OpenMMLab 团队的 [知乎官方账号](https://www.zhihu.com/people/openmmlab),扫描下方微信二维码添加喵喵好友,进入 MMPose 微信交流社群。【加好友申请格式:研究方向+地区+学校/公司+姓名】
-

 +
+
我们会在 OpenMMLab 社区为大家
diff --git a/configs/_base_/datasets/300wlp.py b/configs/_base_/datasets/300wlp.py
new file mode 100644
index 0000000000..76eb4b70b1
--- /dev/null
+++ b/configs/_base_/datasets/300wlp.py
@@ -0,0 +1,86 @@
+dataset_info = dict(
+ dataset_name='300wlp',
+ paper_info=dict(
+ author='Xiangyu Zhu1, and Zhen Lei1 '
+ 'and Xiaoming Liu2, and Hailin Shi1 '
+ 'and Stan Z. Li1',
+ title='300 faces in-the-wild challenge: '
+ 'Database and results',
+ container='Image and vision computing',
+ year='2016',
+ homepage='http://www.cbsr.ia.ac.cn/users/xiangyuzhu/'
+ 'projects/3DDFA/main.htm',
+ ),
+ keypoint_info={
+ 0: dict(name='kpt-0', id=0, color=[255, 0, 0], type='', swap=''),
+ 1: dict(name='kpt-1', id=1, color=[255, 0, 0], type='', swap=''),
+ 2: dict(name='kpt-2', id=2, color=[255, 0, 0], type='', swap=''),
+ 3: dict(name='kpt-3', id=3, color=[255, 0, 0], type='', swap=''),
+ 4: dict(name='kpt-4', id=4, color=[255, 0, 0], type='', swap=''),
+ 5: dict(name='kpt-5', id=5, color=[255, 0, 0], type='', swap=''),
+ 6: dict(name='kpt-6', id=6, color=[255, 0, 0], type='', swap=''),
+ 7: dict(name='kpt-7', id=7, color=[255, 0, 0], type='', swap=''),
+ 8: dict(name='kpt-8', id=8, color=[255, 0, 0], type='', swap=''),
+ 9: dict(name='kpt-9', id=9, color=[255, 0, 0], type='', swap=''),
+ 10: dict(name='kpt-10', id=10, color=[255, 0, 0], type='', swap=''),
+ 11: dict(name='kpt-11', id=11, color=[255, 0, 0], type='', swap=''),
+ 12: dict(name='kpt-12', id=12, color=[255, 0, 0], type='', swap=''),
+ 13: dict(name='kpt-13', id=13, color=[255, 0, 0], type='', swap=''),
+ 14: dict(name='kpt-14', id=14, color=[255, 0, 0], type='', swap=''),
+ 15: dict(name='kpt-15', id=15, color=[255, 0, 0], type='', swap=''),
+ 16: dict(name='kpt-16', id=16, color=[255, 0, 0], type='', swap=''),
+ 17: dict(name='kpt-17', id=17, color=[255, 0, 0], type='', swap=''),
+ 18: dict(name='kpt-18', id=18, color=[255, 0, 0], type='', swap=''),
+ 19: dict(name='kpt-19', id=19, color=[255, 0, 0], type='', swap=''),
+ 20: dict(name='kpt-20', id=20, color=[255, 0, 0], type='', swap=''),
+ 21: dict(name='kpt-21', id=21, color=[255, 0, 0], type='', swap=''),
+ 22: dict(name='kpt-22', id=22, color=[255, 0, 0], type='', swap=''),
+ 23: dict(name='kpt-23', id=23, color=[255, 0, 0], type='', swap=''),
+ 24: dict(name='kpt-24', id=24, color=[255, 0, 0], type='', swap=''),
+ 25: dict(name='kpt-25', id=25, color=[255, 0, 0], type='', swap=''),
+ 26: dict(name='kpt-26', id=26, color=[255, 0, 0], type='', swap=''),
+ 27: dict(name='kpt-27', id=27, color=[255, 0, 0], type='', swap=''),
+ 28: dict(name='kpt-28', id=28, color=[255, 0, 0], type='', swap=''),
+ 29: dict(name='kpt-29', id=29, color=[255, 0, 0], type='', swap=''),
+ 30: dict(name='kpt-30', id=30, color=[255, 0, 0], type='', swap=''),
+ 31: dict(name='kpt-31', id=31, color=[255, 0, 0], type='', swap=''),
+ 32: dict(name='kpt-32', id=32, color=[255, 0, 0], type='', swap=''),
+ 33: dict(name='kpt-33', id=33, color=[255, 0, 0], type='', swap=''),
+ 34: dict(name='kpt-34', id=34, color=[255, 0, 0], type='', swap=''),
+ 35: dict(name='kpt-35', id=35, color=[255, 0, 0], type='', swap=''),
+ 36: dict(name='kpt-36', id=36, color=[255, 0, 0], type='', swap=''),
+ 37: dict(name='kpt-37', id=37, color=[255, 0, 0], type='', swap=''),
+ 38: dict(name='kpt-38', id=38, color=[255, 0, 0], type='', swap=''),
+ 39: dict(name='kpt-39', id=39, color=[255, 0, 0], type='', swap=''),
+ 40: dict(name='kpt-40', id=40, color=[255, 0, 0], type='', swap=''),
+ 41: dict(name='kpt-41', id=41, color=[255, 0, 0], type='', swap=''),
+ 42: dict(name='kpt-42', id=42, color=[255, 0, 0], type='', swap=''),
+ 43: dict(name='kpt-43', id=43, color=[255, 0, 0], type='', swap=''),
+ 44: dict(name='kpt-44', id=44, color=[255, 0, 0], type='', swap=''),
+ 45: dict(name='kpt-45', id=45, color=[255, 0, 0], type='', swap=''),
+ 46: dict(name='kpt-46', id=46, color=[255, 0, 0], type='', swap=''),
+ 47: dict(name='kpt-47', id=47, color=[255, 0, 0], type='', swap=''),
+ 48: dict(name='kpt-48', id=48, color=[255, 0, 0], type='', swap=''),
+ 49: dict(name='kpt-49', id=49, color=[255, 0, 0], type='', swap=''),
+ 50: dict(name='kpt-50', id=50, color=[255, 0, 0], type='', swap=''),
+ 51: dict(name='kpt-51', id=51, color=[255, 0, 0], type='', swap=''),
+ 52: dict(name='kpt-52', id=52, color=[255, 0, 0], type='', swap=''),
+ 53: dict(name='kpt-53', id=53, color=[255, 0, 0], type='', swap=''),
+ 54: dict(name='kpt-54', id=54, color=[255, 0, 0], type='', swap=''),
+ 55: dict(name='kpt-55', id=55, color=[255, 0, 0], type='', swap=''),
+ 56: dict(name='kpt-56', id=56, color=[255, 0, 0], type='', swap=''),
+ 57: dict(name='kpt-57', id=57, color=[255, 0, 0], type='', swap=''),
+ 58: dict(name='kpt-58', id=58, color=[255, 0, 0], type='', swap=''),
+ 59: dict(name='kpt-59', id=59, color=[255, 0, 0], type='', swap=''),
+ 60: dict(name='kpt-60', id=60, color=[255, 0, 0], type='', swap=''),
+ 61: dict(name='kpt-61', id=61, color=[255, 0, 0], type='', swap=''),
+ 62: dict(name='kpt-62', id=62, color=[255, 0, 0], type='', swap=''),
+ 63: dict(name='kpt-63', id=63, color=[255, 0, 0], type='', swap=''),
+ 64: dict(name='kpt-64', id=64, color=[255, 0, 0], type='', swap=''),
+ 65: dict(name='kpt-65', id=65, color=[255, 0, 0], type='', swap=''),
+ 66: dict(name='kpt-66', id=66, color=[255, 0, 0], type='', swap=''),
+ 67: dict(name='kpt-67', id=67, color=[255, 0, 0], type='', swap=''),
+ },
+ skeleton_info={},
+ joint_weights=[1.] * 68,
+ sigmas=[])
diff --git a/configs/_base_/datasets/coco_wholebody_openpose.py b/configs/_base_/datasets/coco_wholebody_openpose.py
new file mode 100644
index 0000000000..f05dda18ab
--- /dev/null
+++ b/configs/_base_/datasets/coco_wholebody_openpose.py
@@ -0,0 +1,1128 @@
+dataset_info = dict(
+ dataset_name='coco_wholebody_openpose',
+ paper_info=dict(
+ author='Jin, Sheng and Xu, Lumin and Xu, Jin and '
+ 'Wang, Can and Liu, Wentao and '
+ 'Qian, Chen and Ouyang, Wanli and Luo, Ping',
+ title='Whole-Body Human Pose Estimation in the Wild',
+ container='Proceedings of the European '
+ 'Conference on Computer Vision (ECCV)',
+ year='2020',
+ homepage='https://github.com/jin-s13/COCO-WholeBody/',
+ ),
+ keypoint_info={
+ 0:
+ dict(name='nose', id=0, color=[255, 0, 0], type='upper', swap=''),
+ 1:
+ dict(name='neck', id=1, color=[255, 85, 0], type='upper', swap=''),
+ 2:
+ dict(
+ name='right_shoulder',
+ id=2,
+ color=[255, 170, 0],
+ type='upper',
+ swap='left_shoulder'),
+ 3:
+ dict(
+ name='right_elbow',
+ id=3,
+ color=[255, 255, 0],
+ type='upper',
+ swap='left_elbow'),
+ 4:
+ dict(
+ name='right_wrist',
+ id=4,
+ color=[170, 255, 0],
+ type='upper',
+ swap='left_wrist'),
+ 5:
+ dict(
+ name='left_shoulder',
+ id=5,
+ color=[85, 255, 0],
+ type='upper',
+ swap='right_shoulder'),
+ 6:
+ dict(
+ name='left_elbow',
+ id=6,
+ color=[0, 255, 0],
+ type='upper',
+ swap='right_elbow'),
+ 7:
+ dict(
+ name='left_wrist',
+ id=7,
+ color=[0, 255, 85],
+ type='upper',
+ swap='right_wrist'),
+ 8:
+ dict(
+ name='right_hip',
+ id=8,
+ color=[0, 255, 170],
+ type='lower',
+ swap='left_hip'),
+ 9:
+ dict(
+ name='right_knee',
+ id=9,
+ color=[0, 255, 255],
+ type='lower',
+ swap='left_knee'),
+ 10:
+ dict(
+ name='right_ankle',
+ id=10,
+ color=[0, 170, 255],
+ type='lower',
+ swap='left_ankle'),
+ 11:
+ dict(
+ name='left_hip',
+ id=11,
+ color=[0, 85, 255],
+ type='lower',
+ swap='right_hip'),
+ 12:
+ dict(
+ name='left_knee',
+ id=12,
+ color=[0, 0, 255],
+ type='lower',
+ swap='right_knee'),
+ 13:
+ dict(
+ name='left_ankle',
+ id=13,
+ color=[85, 0, 255],
+ type='lower',
+ swap='right_ankle'),
+ 14:
+ dict(
+ name='right_eye',
+ id=14,
+ color=[170, 0, 255],
+ type='upper',
+ swap='left_eye'),
+ 15:
+ dict(
+ name='left_eye',
+ id=15,
+ color=[255, 0, 255],
+ type='upper',
+ swap='right_eye'),
+ 16:
+ dict(
+ name='right_ear',
+ id=16,
+ color=[255, 0, 170],
+ type='upper',
+ swap='left_ear'),
+ 17:
+ dict(
+ name='left_ear',
+ id=17,
+ color=[255, 0, 85],
+ type='upper',
+ swap='right_ear'),
+ 18:
+ dict(
+ name='left_big_toe',
+ id=17,
+ color=[0, 0, 0],
+ type='lower',
+ swap='right_big_toe'),
+ 19:
+ dict(
+ name='left_small_toe',
+ id=18,
+ color=[0, 0, 0],
+ type='lower',
+ swap='right_small_toe'),
+ 20:
+ dict(
+ name='left_heel',
+ id=19,
+ color=[0, 0, 0],
+ type='lower',
+ swap='right_heel'),
+ 21:
+ dict(
+ name='right_big_toe',
+ id=20,
+ color=[0, 0, 0],
+ type='lower',
+ swap='left_big_toe'),
+ 22:
+ dict(
+ name='right_small_toe',
+ id=21,
+ color=[0, 0, 0],
+ type='lower',
+ swap='left_small_toe'),
+ 23:
+ dict(
+ name='right_heel',
+ id=22,
+ color=[0, 0, 0],
+ type='lower',
+ swap='left_heel'),
+ 24:
+ dict(
+ name='face-0',
+ id=23,
+ color=[255, 255, 255],
+ type='',
+ swap='face-16'),
+ 25:
+ dict(
+ name='face-1',
+ id=24,
+ color=[255, 255, 255],
+ type='',
+ swap='face-15'),
+ 26:
+ dict(
+ name='face-2',
+ id=25,
+ color=[255, 255, 255],
+ type='',
+ swap='face-14'),
+ 27:
+ dict(
+ name='face-3',
+ id=26,
+ color=[255, 255, 255],
+ type='',
+ swap='face-13'),
+ 28:
+ dict(
+ name='face-4',
+ id=27,
+ color=[255, 255, 255],
+ type='',
+ swap='face-12'),
+ 29:
+ dict(
+ name='face-5',
+ id=28,
+ color=[255, 255, 255],
+ type='',
+ swap='face-11'),
+ 30:
+ dict(
+ name='face-6',
+ id=29,
+ color=[255, 255, 255],
+ type='',
+ swap='face-10'),
+ 31:
+ dict(
+ name='face-7',
+ id=30,
+ color=[255, 255, 255],
+ type='',
+ swap='face-9'),
+ 32:
+ dict(name='face-8', id=31, color=[255, 255, 255], type='', swap=''),
+ 33:
+ dict(
+ name='face-9',
+ id=32,
+ color=[255, 255, 255],
+ type='',
+ swap='face-7'),
+ 34:
+ dict(
+ name='face-10',
+ id=33,
+ color=[255, 255, 255],
+ type='',
+ swap='face-6'),
+ 35:
+ dict(
+ name='face-11',
+ id=34,
+ color=[255, 255, 255],
+ type='',
+ swap='face-5'),
+ 36:
+ dict(
+ name='face-12',
+ id=35,
+ color=[255, 255, 255],
+ type='',
+ swap='face-4'),
+ 37:
+ dict(
+ name='face-13',
+ id=36,
+ color=[255, 255, 255],
+ type='',
+ swap='face-3'),
+ 38:
+ dict(
+ name='face-14',
+ id=37,
+ color=[255, 255, 255],
+ type='',
+ swap='face-2'),
+ 39:
+ dict(
+ name='face-15',
+ id=38,
+ color=[255, 255, 255],
+ type='',
+ swap='face-1'),
+ 40:
+ dict(
+ name='face-16',
+ id=39,
+ color=[255, 255, 255],
+ type='',
+ swap='face-0'),
+ 41:
+ dict(
+ name='face-17',
+ id=40,
+ color=[255, 255, 255],
+ type='',
+ swap='face-26'),
+ 42:
+ dict(
+ name='face-18',
+ id=41,
+ color=[255, 255, 255],
+ type='',
+ swap='face-25'),
+ 43:
+ dict(
+ name='face-19',
+ id=42,
+ color=[255, 255, 255],
+ type='',
+ swap='face-24'),
+ 44:
+ dict(
+ name='face-20',
+ id=43,
+ color=[255, 255, 255],
+ type='',
+ swap='face-23'),
+ 45:
+ dict(
+ name='face-21',
+ id=44,
+ color=[255, 255, 255],
+ type='',
+ swap='face-22'),
+ 46:
+ dict(
+ name='face-22',
+ id=45,
+ color=[255, 255, 255],
+ type='',
+ swap='face-21'),
+ 47:
+ dict(
+ name='face-23',
+ id=46,
+ color=[255, 255, 255],
+ type='',
+ swap='face-20'),
+ 48:
+ dict(
+ name='face-24',
+ id=47,
+ color=[255, 255, 255],
+ type='',
+ swap='face-19'),
+ 49:
+ dict(
+ name='face-25',
+ id=48,
+ color=[255, 255, 255],
+ type='',
+ swap='face-18'),
+ 50:
+ dict(
+ name='face-26',
+ id=49,
+ color=[255, 255, 255],
+ type='',
+ swap='face-17'),
+ 51:
+ dict(name='face-27', id=50, color=[255, 255, 255], type='', swap=''),
+ 52:
+ dict(name='face-28', id=51, color=[255, 255, 255], type='', swap=''),
+ 53:
+ dict(name='face-29', id=52, color=[255, 255, 255], type='', swap=''),
+ 54:
+ dict(name='face-30', id=53, color=[255, 255, 255], type='', swap=''),
+ 55:
+ dict(
+ name='face-31',
+ id=54,
+ color=[255, 255, 255],
+ type='',
+ swap='face-35'),
+ 56:
+ dict(
+ name='face-32',
+ id=55,
+ color=[255, 255, 255],
+ type='',
+ swap='face-34'),
+ 57:
+ dict(name='face-33', id=56, color=[255, 255, 255], type='', swap=''),
+ 58:
+ dict(
+ name='face-34',
+ id=57,
+ color=[255, 255, 255],
+ type='',
+ swap='face-32'),
+ 59:
+ dict(
+ name='face-35',
+ id=58,
+ color=[255, 255, 255],
+ type='',
+ swap='face-31'),
+ 60:
+ dict(
+ name='face-36',
+ id=59,
+ color=[255, 255, 255],
+ type='',
+ swap='face-45'),
+ 61:
+ dict(
+ name='face-37',
+ id=60,
+ color=[255, 255, 255],
+ type='',
+ swap='face-44'),
+ 62:
+ dict(
+ name='face-38',
+ id=61,
+ color=[255, 255, 255],
+ type='',
+ swap='face-43'),
+ 63:
+ dict(
+ name='face-39',
+ id=62,
+ color=[255, 255, 255],
+ type='',
+ swap='face-42'),
+ 64:
+ dict(
+ name='face-40',
+ id=63,
+ color=[255, 255, 255],
+ type='',
+ swap='face-47'),
+ 65:
+ dict(
+ name='face-41',
+ id=64,
+ color=[255, 255, 255],
+ type='',
+ swap='face-46'),
+ 66:
+ dict(
+ name='face-42',
+ id=65,
+ color=[255, 255, 255],
+ type='',
+ swap='face-39'),
+ 67:
+ dict(
+ name='face-43',
+ id=66,
+ color=[255, 255, 255],
+ type='',
+ swap='face-38'),
+ 68:
+ dict(
+ name='face-44',
+ id=67,
+ color=[255, 255, 255],
+ type='',
+ swap='face-37'),
+ 69:
+ dict(
+ name='face-45',
+ id=68,
+ color=[255, 255, 255],
+ type='',
+ swap='face-36'),
+ 70:
+ dict(
+ name='face-46',
+ id=69,
+ color=[255, 255, 255],
+ type='',
+ swap='face-41'),
+ 71:
+ dict(
+ name='face-47',
+ id=70,
+ color=[255, 255, 255],
+ type='',
+ swap='face-40'),
+ 72:
+ dict(
+ name='face-48',
+ id=71,
+ color=[255, 255, 255],
+ type='',
+ swap='face-54'),
+ 73:
+ dict(
+ name='face-49',
+ id=72,
+ color=[255, 255, 255],
+ type='',
+ swap='face-53'),
+ 74:
+ dict(
+ name='face-50',
+ id=73,
+ color=[255, 255, 255],
+ type='',
+ swap='face-52'),
+ 75:
+ dict(name='face-51', id=74, color=[255, 255, 255], type='', swap=''),
+ 76:
+ dict(
+ name='face-52',
+ id=75,
+ color=[255, 255, 255],
+ type='',
+ swap='face-50'),
+ 77:
+ dict(
+ name='face-53',
+ id=76,
+ color=[255, 255, 255],
+ type='',
+ swap='face-49'),
+ 78:
+ dict(
+ name='face-54',
+ id=77,
+ color=[255, 255, 255],
+ type='',
+ swap='face-48'),
+ 79:
+ dict(
+ name='face-55',
+ id=78,
+ color=[255, 255, 255],
+ type='',
+ swap='face-59'),
+ 80:
+ dict(
+ name='face-56',
+ id=79,
+ color=[255, 255, 255],
+ type='',
+ swap='face-58'),
+ 81:
+ dict(name='face-57', id=80, color=[255, 255, 255], type='', swap=''),
+ 82:
+ dict(
+ name='face-58',
+ id=81,
+ color=[255, 255, 255],
+ type='',
+ swap='face-56'),
+ 83:
+ dict(
+ name='face-59',
+ id=82,
+ color=[255, 255, 255],
+ type='',
+ swap='face-55'),
+ 84:
+ dict(
+ name='face-60',
+ id=83,
+ color=[255, 255, 255],
+ type='',
+ swap='face-64'),
+ 85:
+ dict(
+ name='face-61',
+ id=84,
+ color=[255, 255, 255],
+ type='',
+ swap='face-63'),
+ 86:
+ dict(name='face-62', id=85, color=[255, 255, 255], type='', swap=''),
+ 87:
+ dict(
+ name='face-63',
+ id=86,
+ color=[255, 255, 255],
+ type='',
+ swap='face-61'),
+ 88:
+ dict(
+ name='face-64',
+ id=87,
+ color=[255, 255, 255],
+ type='',
+ swap='face-60'),
+ 89:
+ dict(
+ name='face-65',
+ id=88,
+ color=[255, 255, 255],
+ type='',
+ swap='face-67'),
+ 90:
+ dict(name='face-66', id=89, color=[255, 255, 255], type='', swap=''),
+ 91:
+ dict(
+ name='face-67',
+ id=90,
+ color=[255, 255, 255],
+ type='',
+ swap='face-65'),
+ 92:
+ dict(
+ name='left_hand_root',
+ id=92,
+ color=[0, 0, 255],
+ type='',
+ swap='right_hand_root'),
+ 93:
+ dict(
+ name='left_thumb1',
+ id=93,
+ color=[0, 0, 255],
+ type='',
+ swap='right_thumb1'),
+ 94:
+ dict(
+ name='left_thumb2',
+ id=94,
+ color=[0, 0, 255],
+ type='',
+ swap='right_thumb2'),
+ 95:
+ dict(
+ name='left_thumb3',
+ id=95,
+ color=[0, 0, 255],
+ type='',
+ swap='right_thumb3'),
+ 96:
+ dict(
+ name='left_thumb4',
+ id=96,
+ color=[0, 0, 255],
+ type='',
+ swap='right_thumb4'),
+ 97:
+ dict(
+ name='left_forefinger1',
+ id=97,
+ color=[0, 0, 255],
+ type='',
+ swap='right_forefinger1'),
+ 98:
+ dict(
+ name='left_forefinger2',
+ id=98,
+ color=[0, 0, 255],
+ type='',
+ swap='right_forefinger2'),
+ 99:
+ dict(
+ name='left_forefinger3',
+ id=99,
+ color=[0, 0, 255],
+ type='',
+ swap='right_forefinger3'),
+ 100:
+ dict(
+ name='left_forefinger4',
+ id=100,
+ color=[0, 0, 255],
+ type='',
+ swap='right_forefinger4'),
+ 101:
+ dict(
+ name='left_middle_finger1',
+ id=101,
+ color=[0, 0, 255],
+ type='',
+ swap='right_middle_finger1'),
+ 102:
+ dict(
+ name='left_middle_finger2',
+ id=102,
+ color=[0, 0, 255],
+ type='',
+ swap='right_middle_finger2'),
+ 103:
+ dict(
+ name='left_middle_finger3',
+ id=103,
+ color=[0, 0, 255],
+ type='',
+ swap='right_middle_finger3'),
+ 104:
+ dict(
+ name='left_middle_finger4',
+ id=104,
+ color=[0, 0, 255],
+ type='',
+ swap='right_middle_finger4'),
+ 105:
+ dict(
+ name='left_ring_finger1',
+ id=105,
+ color=[0, 0, 255],
+ type='',
+ swap='right_ring_finger1'),
+ 106:
+ dict(
+ name='left_ring_finger2',
+ id=106,
+ color=[0, 0, 255],
+ type='',
+ swap='right_ring_finger2'),
+ 107:
+ dict(
+ name='left_ring_finger3',
+ id=107,
+ color=[0, 0, 255],
+ type='',
+ swap='right_ring_finger3'),
+ 108:
+ dict(
+ name='left_ring_finger4',
+ id=108,
+ color=[0, 0, 255],
+ type='',
+ swap='right_ring_finger4'),
+ 109:
+ dict(
+ name='left_pinky_finger1',
+ id=109,
+ color=[0, 0, 255],
+ type='',
+ swap='right_pinky_finger1'),
+ 110:
+ dict(
+ name='left_pinky_finger2',
+ id=110,
+ color=[0, 0, 255],
+ type='',
+ swap='right_pinky_finger2'),
+ 111:
+ dict(
+ name='left_pinky_finger3',
+ id=111,
+ color=[0, 0, 255],
+ type='',
+ swap='right_pinky_finger3'),
+ 112:
+ dict(
+ name='left_pinky_finger4',
+ id=112,
+ color=[0, 0, 255],
+ type='',
+ swap='right_pinky_finger4'),
+ 113:
+ dict(
+ name='right_hand_root',
+ id=113,
+ color=[0, 0, 255],
+ type='',
+ swap='left_hand_root'),
+ 114:
+ dict(
+ name='right_thumb1',
+ id=114,
+ color=[0, 0, 255],
+ type='',
+ swap='left_thumb1'),
+ 115:
+ dict(
+ name='right_thumb2',
+ id=115,
+ color=[0, 0, 255],
+ type='',
+ swap='left_thumb2'),
+ 116:
+ dict(
+ name='right_thumb3',
+ id=116,
+ color=[0, 0, 255],
+ type='',
+ swap='left_thumb3'),
+ 117:
+ dict(
+ name='right_thumb4',
+ id=117,
+ color=[0, 0, 255],
+ type='',
+ swap='left_thumb4'),
+ 118:
+ dict(
+ name='right_forefinger1',
+ id=118,
+ color=[0, 0, 255],
+ type='',
+ swap='left_forefinger1'),
+ 119:
+ dict(
+ name='right_forefinger2',
+ id=119,
+ color=[0, 0, 255],
+ type='',
+ swap='left_forefinger2'),
+ 120:
+ dict(
+ name='right_forefinger3',
+ id=120,
+ color=[0, 0, 255],
+ type='',
+ swap='left_forefinger3'),
+ 121:
+ dict(
+ name='right_forefinger4',
+ id=121,
+ color=[0, 0, 255],
+ type='',
+ swap='left_forefinger4'),
+ 122:
+ dict(
+ name='right_middle_finger1',
+ id=122,
+ color=[0, 0, 255],
+ type='',
+ swap='left_middle_finger1'),
+ 123:
+ dict(
+ name='right_middle_finger2',
+ id=123,
+ color=[0, 0, 255],
+ type='',
+ swap='left_middle_finger2'),
+ 124:
+ dict(
+ name='right_middle_finger3',
+ id=124,
+ color=[0, 0, 255],
+ type='',
+ swap='left_middle_finger3'),
+ 125:
+ dict(
+ name='right_middle_finger4',
+ id=125,
+ color=[0, 0, 255],
+ type='',
+ swap='left_middle_finger4'),
+ 126:
+ dict(
+ name='right_ring_finger1',
+ id=126,
+ color=[0, 0, 255],
+ type='',
+ swap='left_ring_finger1'),
+ 127:
+ dict(
+ name='right_ring_finger2',
+ id=127,
+ color=[0, 0, 255],
+ type='',
+ swap='left_ring_finger2'),
+ 128:
+ dict(
+ name='right_ring_finger3',
+ id=128,
+ color=[0, 0, 255],
+ type='',
+ swap='left_ring_finger3'),
+ 129:
+ dict(
+ name='right_ring_finger4',
+ id=129,
+ color=[0, 0, 255],
+ type='',
+ swap='left_ring_finger4'),
+ 130:
+ dict(
+ name='right_pinky_finger1',
+ id=130,
+ color=[0, 0, 255],
+ type='',
+ swap='left_pinky_finger1'),
+ 131:
+ dict(
+ name='right_pinky_finger2',
+ id=131,
+ color=[0, 0, 255],
+ type='',
+ swap='left_pinky_finger2'),
+ 132:
+ dict(
+ name='right_pinky_finger3',
+ id=132,
+ color=[0, 0, 255],
+ type='',
+ swap='left_pinky_finger3'),
+ 133:
+ dict(
+ name='right_pinky_finger4',
+ id=133,
+ color=[0, 0, 255],
+ type='',
+ swap='left_pinky_finger4')
+ },
+ skeleton_info={
+ 0:
+ dict(link=('neck', 'right_shoulder'), id=0, color=[255, 0, 0]),
+ 1:
+ dict(link=('neck', 'left_shoulder'), id=1, color=[255, 85, 0]),
+ 2:
+ dict(
+ link=('right_shoulder', 'right_elbow'), id=2, color=[255, 170, 0]),
+ 3:
+ dict(link=('right_elbow', 'right_wrist'), id=3, color=[255, 255, 0]),
+ 4:
+ dict(link=('left_shoulder', 'left_elbow'), id=4, color=[170, 255, 0]),
+ 5:
+ dict(link=('left_elbow', 'left_wrist'), id=5, color=[85, 255, 0]),
+ 6:
+ dict(link=('neck', 'right_hip'), id=6, color=[0, 255, 0]),
+ 7:
+ dict(link=('right_hip', 'right_knee'), id=7, color=[0, 255, 85]),
+ 8:
+ dict(link=('right_knee', 'right_ankle'), id=8, color=[0, 255, 170]),
+ 9:
+ dict(link=('neck', 'left_hip'), id=9, color=[0, 255, 225]),
+ 10:
+ dict(link=('left_hip', 'left_knee'), id=10, color=[0, 170, 255]),
+ 11:
+ dict(link=('left_knee', 'left_ankle'), id=11, color=[0, 85, 255]),
+ 12:
+ dict(link=('neck', 'nose'), id=12, color=[0, 0, 255]),
+ 13:
+ dict(link=('nose', 'right_eye'), id=13, color=[255, 0, 170]),
+ 14:
+ dict(link=('right_eye', 'right_ear'), id=14, color=[170, 0, 255]),
+ 15:
+ dict(link=('nose', 'left_eye'), id=15, color=[255, 0, 255]),
+ 16:
+ dict(link=('left_eye', 'left_ear'), id=16, color=[255, 0, 170]),
+ 17:
+ dict(link=('left_hand_root', 'left_thumb1'), id=17, color=[255, 0, 0]),
+ 18:
+ dict(link=('left_thumb1', 'left_thumb2'), id=18, color=[255, 76, 0]),
+ 19:
+ dict(link=('left_thumb2', 'left_thumb3'), id=19, color=[255, 153, 0]),
+ 20:
+ dict(link=('left_thumb3', 'left_thumb4'), id=20, color=[255, 230, 0]),
+ 21:
+ dict(
+ link=('left_hand_root', 'left_forefinger1'),
+ id=21,
+ color=[204, 255, 0]),
+ 22:
+ dict(
+ link=('left_forefinger1', 'left_forefinger2'),
+ id=22,
+ color=[128, 255, 0]),
+ 23:
+ dict(
+ link=('left_forefinger2', 'left_forefinger3'),
+ id=23,
+ color=[51, 255, 0]),
+ 24:
+ dict(
+ link=('left_forefinger3', 'left_forefinger4'),
+ id=24,
+ color=[0, 255, 26]),
+ 25:
+ dict(
+ link=('left_hand_root', 'left_middle_finger1'),
+ id=25,
+ color=[0, 255, 102]),
+ 26:
+ dict(
+ link=('left_middle_finger1', 'left_middle_finger2'),
+ id=26,
+ color=[0, 255, 178]),
+ 27:
+ dict(
+ link=('left_middle_finger2', 'left_middle_finger3'),
+ id=27,
+ color=[0, 255, 255]),
+ 28:
+ dict(
+ link=('left_middle_finger3', 'left_middle_finger4'),
+ id=28,
+ color=[0, 178, 255]),
+ 29:
+ dict(
+ link=('left_hand_root', 'left_ring_finger1'),
+ id=29,
+ color=[0, 102, 255]),
+ 30:
+ dict(
+ link=('left_ring_finger1', 'left_ring_finger2'),
+ id=30,
+ color=[0, 26, 255]),
+ 31:
+ dict(
+ link=('left_ring_finger2', 'left_ring_finger3'),
+ id=31,
+ color=[51, 0, 255]),
+ 32:
+ dict(
+ link=('left_ring_finger3', 'left_ring_finger4'),
+ id=32,
+ color=[128, 0, 255]),
+ 33:
+ dict(
+ link=('left_hand_root', 'left_pinky_finger1'),
+ id=33,
+ color=[204, 0, 255]),
+ 34:
+ dict(
+ link=('left_pinky_finger1', 'left_pinky_finger2'),
+ id=34,
+ color=[255, 0, 230]),
+ 35:
+ dict(
+ link=('left_pinky_finger2', 'left_pinky_finger3'),
+ id=35,
+ color=[255, 0, 153]),
+ 36:
+ dict(
+ link=('left_pinky_finger3', 'left_pinky_finger4'),
+ id=36,
+ color=[255, 0, 76]),
+ 37:
+ dict(
+ link=('right_hand_root', 'right_thumb1'), id=37, color=[255, 0,
+ 0]),
+ 38:
+ dict(link=('right_thumb1', 'right_thumb2'), id=38, color=[255, 76, 0]),
+ 39:
+ dict(
+ link=('right_thumb2', 'right_thumb3'), id=39, color=[255, 153, 0]),
+ 40:
+ dict(
+ link=('right_thumb3', 'right_thumb4'), id=40, color=[255, 230, 0]),
+ 41:
+ dict(
+ link=('right_hand_root', 'right_forefinger1'),
+ id=41,
+ color=[204, 255, 0]),
+ 42:
+ dict(
+ link=('right_forefinger1', 'right_forefinger2'),
+ id=42,
+ color=[128, 255, 0]),
+ 43:
+ dict(
+ link=('right_forefinger2', 'right_forefinger3'),
+ id=43,
+ color=[51, 255, 0]),
+ 44:
+ dict(
+ link=('right_forefinger3', 'right_forefinger4'),
+ id=44,
+ color=[0, 255, 26]),
+ 45:
+ dict(
+ link=('right_hand_root', 'right_middle_finger1'),
+ id=45,
+ color=[0, 255, 102]),
+ 46:
+ dict(
+ link=('right_middle_finger1', 'right_middle_finger2'),
+ id=46,
+ color=[0, 255, 178]),
+ 47:
+ dict(
+ link=('right_middle_finger2', 'right_middle_finger3'),
+ id=47,
+ color=[255, 255, 255]),
+ 48:
+ dict(
+ link=('right_middle_finger3', 'right_middle_finger4'),
+ id=48,
+ color=[0, 178, 255]),
+ 49:
+ dict(
+ link=('right_hand_root', 'right_ring_finger1'),
+ id=49,
+ color=[0, 102, 255]),
+ 50:
+ dict(
+ link=('right_ring_finger1', 'right_ring_finger2'),
+ id=50,
+ color=[0, 26, 255]),
+ 51:
+ dict(
+ link=('right_ring_finger2', 'right_ring_finger3'),
+ id=51,
+ color=[51, 0, 255]),
+ 52:
+ dict(
+ link=('right_ring_finger3', 'right_ring_finger4'),
+ id=52,
+ color=[128, 0, 255]),
+ 53:
+ dict(
+ link=('right_hand_root', 'right_pinky_finger1'),
+ id=53,
+ color=[204, 0, 255]),
+ 54:
+ dict(
+ link=('right_pinky_finger1', 'right_pinky_finger2'),
+ id=54,
+ color=[255, 0, 230]),
+ 55:
+ dict(
+ link=('right_pinky_finger2', 'right_pinky_finger3'),
+ id=55,
+ color=[255, 0, 153]),
+ 56:
+ dict(
+ link=('right_pinky_finger3', 'right_pinky_finger4'),
+ id=56,
+ color=[255, 0, 76])
+ },
+ joint_weights=[1.] * 134,
+ # 'https://github.com/jin-s13/COCO-WholeBody/blob/master/'
+ # 'evaluation/myeval_wholebody.py#L175'
+ sigmas=[
+ 0.026, 0.026, 0.025, 0.025, 0.035, 0.035, 0.079, 0.079, 0.072, 0.072,
+ 0.062, 0.062, 0.107, 0.107, 0.087, 0.087, 0.089, 0.089, 0.068, 0.066,
+ 0.066, 0.092, 0.094, 0.094, 0.042, 0.043, 0.044, 0.043, 0.040, 0.035,
+ 0.031, 0.025, 0.020, 0.023, 0.029, 0.032, 0.037, 0.038, 0.043, 0.041,
+ 0.045, 0.013, 0.012, 0.011, 0.011, 0.012, 0.012, 0.011, 0.011, 0.013,
+ 0.015, 0.009, 0.007, 0.007, 0.007, 0.012, 0.009, 0.008, 0.016, 0.010,
+ 0.017, 0.011, 0.009, 0.011, 0.009, 0.007, 0.013, 0.008, 0.011, 0.012,
+ 0.010, 0.034, 0.008, 0.008, 0.009, 0.008, 0.008, 0.007, 0.010, 0.008,
+ 0.009, 0.009, 0.009, 0.007, 0.007, 0.008, 0.011, 0.008, 0.008, 0.008,
+ 0.01, 0.008, 0.029, 0.022, 0.035, 0.037, 0.047, 0.026, 0.025, 0.024,
+ 0.035, 0.018, 0.024, 0.022, 0.026, 0.017, 0.021, 0.021, 0.032, 0.02,
+ 0.019, 0.022, 0.031, 0.029, 0.022, 0.035, 0.037, 0.047, 0.026, 0.025,
+ 0.024, 0.035, 0.018, 0.024, 0.022, 0.026, 0.017, 0.021, 0.021, 0.032,
+ 0.02, 0.019, 0.022, 0.031
+ ])
diff --git a/configs/_base_/datasets/humanart21.py b/configs/_base_/datasets/humanart21.py
new file mode 100644
index 0000000000..e6d935d1a9
--- /dev/null
+++ b/configs/_base_/datasets/humanart21.py
@@ -0,0 +1,218 @@
+dataset_info = dict(
+ dataset_name='Human-Art',
+ paper_info=dict(
+ author='Ju, Xuan and Zeng, Ailing and '
+ 'Wang, Jianan and Xu, Qiang and Zhang, Lei',
+ title='Human-Art: A Versatile Human-Centric Dataset '
+ 'Bridging Natural and Artificial Scenes',
+ container='Proceedings of the IEEE/CVF Conference on '
+ 'Computer Vision and Pattern Recognition',
+ year='2023',
+ homepage='https://idea-research.github.io/HumanArt/',
+ ),
+ keypoint_info={
+ 0:
+ dict(name='nose', id=0, color=[51, 153, 255], type='upper', swap=''),
+ 1:
+ dict(
+ name='left_eye',
+ id=1,
+ color=[51, 153, 255],
+ type='upper',
+ swap='right_eye'),
+ 2:
+ dict(
+ name='right_eye',
+ id=2,
+ color=[51, 153, 255],
+ type='upper',
+ swap='left_eye'),
+ 3:
+ dict(
+ name='left_ear',
+ id=3,
+ color=[51, 153, 255],
+ type='upper',
+ swap='right_ear'),
+ 4:
+ dict(
+ name='right_ear',
+ id=4,
+ color=[51, 153, 255],
+ type='upper',
+ swap='left_ear'),
+ 5:
+ dict(
+ name='left_shoulder',
+ id=5,
+ color=[0, 255, 0],
+ type='upper',
+ swap='right_shoulder'),
+ 6:
+ dict(
+ name='right_shoulder',
+ id=6,
+ color=[255, 128, 0],
+ type='upper',
+ swap='left_shoulder'),
+ 7:
+ dict(
+ name='left_elbow',
+ id=7,
+ color=[0, 255, 0],
+ type='upper',
+ swap='right_elbow'),
+ 8:
+ dict(
+ name='right_elbow',
+ id=8,
+ color=[255, 128, 0],
+ type='upper',
+ swap='left_elbow'),
+ 9:
+ dict(
+ name='left_wrist',
+ id=9,
+ color=[0, 255, 0],
+ type='upper',
+ swap='right_wrist'),
+ 10:
+ dict(
+ name='right_wrist',
+ id=10,
+ color=[255, 128, 0],
+ type='upper',
+ swap='left_wrist'),
+ 11:
+ dict(
+ name='left_hip',
+ id=11,
+ color=[0, 255, 0],
+ type='lower',
+ swap='right_hip'),
+ 12:
+ dict(
+ name='right_hip',
+ id=12,
+ color=[255, 128, 0],
+ type='lower',
+ swap='left_hip'),
+ 13:
+ dict(
+ name='left_knee',
+ id=13,
+ color=[0, 255, 0],
+ type='lower',
+ swap='right_knee'),
+ 14:
+ dict(
+ name='right_knee',
+ id=14,
+ color=[255, 128, 0],
+ type='lower',
+ swap='left_knee'),
+ 15:
+ dict(
+ name='left_ankle',
+ id=15,
+ color=[0, 255, 0],
+ type='lower',
+ swap='right_ankle'),
+ 16:
+ dict(
+ name='right_ankle',
+ id=16,
+ color=[255, 128, 0],
+ type='lower',
+ swap='left_ankle'),
+ 17:
+ dict(
+ name='left_finger',
+ id=17,
+ color=[0, 255, 0],
+ type='lower',
+ swap='right_finger'),
+ 18:
+ dict(
+ name='right_finger',
+ id=18,
+ color=[255, 128, 0],
+ type='lower',
+ swap='left_finger'),
+ 19:
+ dict(
+ name='left_toe',
+ id=19,
+ color=[0, 255, 0],
+ type='lower',
+ swap='right_toe'),
+ 20:
+ dict(
+ name='right_toe',
+ id=20,
+ color=[255, 128, 0],
+ type='lower',
+ swap='left_toe'),
+ },
+ skeleton_info={
+ 0:
+ dict(link=('left_ankle', 'left_knee'), id=0, color=[0, 255, 0]),
+ 1:
+ dict(link=('left_knee', 'left_hip'), id=1, color=[0, 255, 0]),
+ 2:
+ dict(link=('right_ankle', 'right_knee'), id=2, color=[255, 128, 0]),
+ 3:
+ dict(link=('right_knee', 'right_hip'), id=3, color=[255, 128, 0]),
+ 4:
+ dict(link=('left_hip', 'right_hip'), id=4, color=[51, 153, 255]),
+ 5:
+ dict(link=('left_shoulder', 'left_hip'), id=5, color=[51, 153, 255]),
+ 6:
+ dict(link=('right_shoulder', 'right_hip'), id=6, color=[51, 153, 255]),
+ 7:
+ dict(
+ link=('left_shoulder', 'right_shoulder'),
+ id=7,
+ color=[51, 153, 255]),
+ 8:
+ dict(link=('left_shoulder', 'left_elbow'), id=8, color=[0, 255, 0]),
+ 9:
+ dict(
+ link=('right_shoulder', 'right_elbow'), id=9, color=[255, 128, 0]),
+ 10:
+ dict(link=('left_elbow', 'left_wrist'), id=10, color=[0, 255, 0]),
+ 11:
+ dict(link=('right_elbow', 'right_wrist'), id=11, color=[255, 128, 0]),
+ 12:
+ dict(link=('left_eye', 'right_eye'), id=12, color=[51, 153, 255]),
+ 13:
+ dict(link=('nose', 'left_eye'), id=13, color=[51, 153, 255]),
+ 14:
+ dict(link=('nose', 'right_eye'), id=14, color=[51, 153, 255]),
+ 15:
+ dict(link=('left_eye', 'left_ear'), id=15, color=[51, 153, 255]),
+ 16:
+ dict(link=('right_eye', 'right_ear'), id=16, color=[51, 153, 255]),
+ 17:
+ dict(link=('left_ear', 'left_shoulder'), id=17, color=[51, 153, 255]),
+ 18:
+ dict(
+ link=('right_ear', 'right_shoulder'), id=18, color=[51, 153, 255]),
+ 19:
+ dict(link=('left_ankle', 'left_toe'), id=19, color=[0, 255, 0]),
+ 20:
+ dict(link=('right_ankle', 'right_toe'), id=20, color=[255, 128, 0]),
+ 21:
+ dict(link=('left_wrist', 'left_finger'), id=21, color=[0, 255, 0]),
+ 22:
+ dict(link=('right_wrist', 'right_finger'), id=22, color=[255, 128, 0]),
+ },
+ joint_weights=[
+ 1., 1., 1., 1., 1., 1., 1., 1.2, 1.2, 1.5, 1.5, 1., 1., 1.2, 1.2, 1.5,
+ 1.5, 1., 1., 1., 1.
+ ],
+ sigmas=[
+ 0.026, 0.025, 0.025, 0.035, 0.035, 0.079, 0.079, 0.072, 0.072, 0.062,
+ 0.062, 0.107, 0.107, 0.087, 0.087, 0.089, 0.089, 0.089, 0.089, 0.089,
+ 0.089
+ ])
diff --git a/configs/_base_/datasets/lapa.py b/configs/_base_/datasets/lapa.py
index 26a0843404..3929edd90e 100644
--- a/configs/_base_/datasets/lapa.py
+++ b/configs/_base_/datasets/lapa.py
@@ -12,667 +12,225 @@
),
keypoint_info={
0:
- dict(
- name='kpt-0', id=0, color=[255, 0, 0], type='upper',
- swap='kpt-32'),
+ dict(name='kpt-0', id=0, color=[255, 0, 0], type='', swap='kpt-32'),
1:
- dict(
- name='kpt-1', id=1, color=[255, 0, 0], type='upper',
- swap='kpt-31'),
+ dict(name='kpt-1', id=1, color=[255, 0, 0], type='', swap='kpt-31'),
2:
- dict(
- name='kpt-2', id=2, color=[255, 0, 0], type='upper',
- swap='kpt-30'),
+ dict(name='kpt-2', id=2, color=[255, 0, 0], type='', swap='kpt-30'),
3:
- dict(
- name='kpt-3', id=3, color=[255, 0, 0], type='lower',
- swap='kpt-29'),
+ dict(name='kpt-3', id=3, color=[255, 0, 0], type='', swap='kpt-29'),
4:
- dict(
- name='kpt-4', id=4, color=[255, 0, 0], type='lower',
- swap='kpt-28'),
+ dict(name='kpt-4', id=4, color=[255, 0, 0], type='', swap='kpt-28'),
5:
- dict(
- name='kpt-5', id=5, color=[255, 0, 0], type='lower',
- swap='kpt-27'),
+ dict(name='kpt-5', id=5, color=[255, 0, 0], type='', swap='kpt-27'),
6:
- dict(
- name='kpt-6', id=6, color=[255, 0, 0], type='lower',
- swap='kpt-26'),
+ dict(name='kpt-6', id=6, color=[255, 0, 0], type='', swap='kpt-26'),
7:
- dict(
- name='kpt-7', id=7, color=[255, 0, 0], type='lower',
- swap='kpt-25'),
+ dict(name='kpt-7', id=7, color=[255, 0, 0], type='', swap='kpt-25'),
8:
- dict(
- name='kpt-8', id=8, color=[255, 0, 0], type='lower',
- swap='kpt-24'),
+ dict(name='kpt-8', id=8, color=[255, 0, 0], type='', swap='kpt-24'),
9:
- dict(
- name='kpt-9', id=9, color=[255, 0, 0], type='lower',
- swap='kpt-23'),
+ dict(name='kpt-9', id=9, color=[255, 0, 0], type='', swap='kpt-23'),
10:
- dict(
- name='kpt-10',
- id=10,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-22'),
+ dict(name='kpt-10', id=10, color=[255, 0, 0], type='', swap='kpt-22'),
11:
- dict(
- name='kpt-11',
- id=11,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-21'),
+ dict(name='kpt-11', id=11, color=[255, 0, 0], type='', swap='kpt-21'),
12:
- dict(
- name='kpt-12',
- id=12,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-20'),
+ dict(name='kpt-12', id=12, color=[255, 0, 0], type='', swap='kpt-20'),
13:
- dict(
- name='kpt-13',
- id=13,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-19'),
+ dict(name='kpt-13', id=13, color=[255, 0, 0], type='', swap='kpt-19'),
14:
- dict(
- name='kpt-14',
- id=14,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-18'),
+ dict(name='kpt-14', id=14, color=[255, 0, 0], type='', swap='kpt-18'),
15:
- dict(
- name='kpt-15',
- id=15,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-17'),
+ dict(name='kpt-15', id=15, color=[255, 0, 0], type='', swap='kpt-17'),
16:
- dict(name='kpt-16', id=16, color=[255, 0, 0], type='lower', swap=''),
+ dict(name='kpt-16', id=16, color=[255, 0, 0], type='', swap=''),
17:
- dict(
- name='kpt-17',
- id=17,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-15'),
+ dict(name='kpt-17', id=17, color=[255, 0, 0], type='', swap='kpt-15'),
18:
- dict(
- name='kpt-18',
- id=18,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-14'),
+ dict(name='kpt-18', id=18, color=[255, 0, 0], type='', swap='kpt-14'),
19:
- dict(
- name='kpt-19',
- id=19,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-13'),
+ dict(name='kpt-19', id=19, color=[255, 0, 0], type='', swap='kpt-13'),
20:
- dict(
- name='kpt-20',
- id=20,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-12'),
+ dict(name='kpt-20', id=20, color=[255, 0, 0], type='', swap='kpt-12'),
21:
- dict(
- name='kpt-21',
- id=21,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-11'),
+ dict(name='kpt-21', id=21, color=[255, 0, 0], type='', swap='kpt-11'),
22:
- dict(
- name='kpt-22',
- id=22,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-10'),
+ dict(name='kpt-22', id=22, color=[255, 0, 0], type='', swap='kpt-10'),
23:
- dict(
- name='kpt-23',
- id=23,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-9'),
+ dict(name='kpt-23', id=23, color=[255, 0, 0], type='', swap='kpt-9'),
24:
- dict(
- name='kpt-24',
- id=24,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-8'),
+ dict(name='kpt-24', id=24, color=[255, 0, 0], type='', swap='kpt-8'),
25:
- dict(
- name='kpt-25',
- id=25,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-7'),
+ dict(name='kpt-25', id=25, color=[255, 0, 0], type='', swap='kpt-7'),
26:
- dict(
- name='kpt-26',
- id=26,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-6'),
+ dict(name='kpt-26', id=26, color=[255, 0, 0], type='', swap='kpt-6'),
27:
- dict(
- name='kpt-27',
- id=27,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-5'),
+ dict(name='kpt-27', id=27, color=[255, 0, 0], type='', swap='kpt-5'),
28:
- dict(
- name='kpt-28',
- id=28,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-4'),
+ dict(name='kpt-28', id=28, color=[255, 0, 0], type='', swap='kpt-4'),
29:
- dict(
- name='kpt-29',
- id=29,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-3'),
+ dict(name='kpt-29', id=29, color=[255, 0, 0], type='', swap='kpt-3'),
30:
- dict(
- name='kpt-30',
- id=30,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-2'),
+ dict(name='kpt-30', id=30, color=[255, 0, 0], type='', swap='kpt-2'),
31:
- dict(
- name='kpt-31',
- id=31,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-1'),
+ dict(name='kpt-31', id=31, color=[255, 0, 0], type='', swap='kpt-1'),
32:
- dict(
- name='kpt-32',
- id=32,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-0'),
+ dict(name='kpt-32', id=32, color=[255, 0, 0], type='', swap='kpt-0'),
33:
- dict(
- name='kpt-33',
- id=33,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-46'),
+ dict(name='kpt-33', id=33, color=[255, 0, 0], type='', swap='kpt-46'),
34:
- dict(
- name='kpt-34',
- id=34,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-45'),
+ dict(name='kpt-34', id=34, color=[255, 0, 0], type='', swap='kpt-45'),
35:
- dict(
- name='kpt-35',
- id=35,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-44'),
+ dict(name='kpt-35', id=35, color=[255, 0, 0], type='', swap='kpt-44'),
36:
- dict(
- name='kpt-36',
- id=36,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-43'),
+ dict(name='kpt-36', id=36, color=[255, 0, 0], type='', swap='kpt-43'),
37:
- dict(
- name='kpt-37',
- id=37,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-42'),
+ dict(name='kpt-37', id=37, color=[255, 0, 0], type='', swap='kpt-42'),
38:
- dict(
- name='kpt-38',
- id=38,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-50'),
+ dict(name='kpt-38', id=38, color=[255, 0, 0], type='', swap='kpt-50'),
39:
- dict(
- name='kpt-39',
- id=39,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-49'),
+ dict(name='kpt-39', id=39, color=[255, 0, 0], type='', swap='kpt-49'),
40:
- dict(
- name='kpt-40',
- id=40,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-48'),
+ dict(name='kpt-40', id=40, color=[255, 0, 0], type='', swap='kpt-48'),
41:
- dict(
- name='kpt-41',
- id=41,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-47'),
+ dict(name='kpt-41', id=41, color=[255, 0, 0], type='', swap='kpt-47'),
42:
- dict(
- name='kpt-42',
- id=42,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-37'),
+ dict(name='kpt-42', id=42, color=[255, 0, 0], type='', swap='kpt-37'),
43:
- dict(
- name='kpt-43',
- id=43,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-36'),
+ dict(name='kpt-43', id=43, color=[255, 0, 0], type='', swap='kpt-36'),
44:
- dict(
- name='kpt-44',
- id=44,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-35'),
+ dict(name='kpt-44', id=44, color=[255, 0, 0], type='', swap='kpt-35'),
45:
- dict(
- name='kpt-45',
- id=45,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-34'),
+ dict(name='kpt-45', id=45, color=[255, 0, 0], type='', swap='kpt-34'),
46:
- dict(
- name='kpt-46',
- id=46,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-33'),
+ dict(name='kpt-46', id=46, color=[255, 0, 0], type='', swap='kpt-33'),
47:
- dict(
- name='kpt-47',
- id=47,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-41'),
+ dict(name='kpt-47', id=47, color=[255, 0, 0], type='', swap='kpt-41'),
48:
- dict(
- name='kpt-48',
- id=48,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-40'),
+ dict(name='kpt-48', id=48, color=[255, 0, 0], type='', swap='kpt-40'),
49:
- dict(
- name='kpt-49',
- id=49,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-39'),
+ dict(name='kpt-49', id=49, color=[255, 0, 0], type='', swap='kpt-39'),
50:
- dict(
- name='kpt-50',
- id=50,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-38'),
+ dict(name='kpt-50', id=50, color=[255, 0, 0], type='', swap='kpt-38'),
51:
- dict(name='kpt-51', id=51, color=[255, 0, 0], type='upper', swap=''),
+ dict(name='kpt-51', id=51, color=[255, 0, 0], type='', swap=''),
52:
- dict(name='kpt-52', id=52, color=[255, 0, 0], type='upper', swap=''),
+ dict(name='kpt-52', id=52, color=[255, 0, 0], type='', swap=''),
53:
- dict(name='kpt-53', id=53, color=[255, 0, 0], type='lower', swap=''),
+ dict(name='kpt-53', id=53, color=[255, 0, 0], type='', swap=''),
54:
- dict(name='kpt-54', id=54, color=[255, 0, 0], type='lower', swap=''),
+ dict(name='kpt-54', id=54, color=[255, 0, 0], type='', swap=''),
55:
- dict(
- name='kpt-55',
- id=55,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-65'),
+ dict(name='kpt-55', id=55, color=[255, 0, 0], type='', swap='kpt-65'),
56:
- dict(
- name='kpt-56',
- id=56,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-64'),
+ dict(name='kpt-56', id=56, color=[255, 0, 0], type='', swap='kpt-64'),
57:
- dict(
- name='kpt-57',
- id=57,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-63'),
+ dict(name='kpt-57', id=57, color=[255, 0, 0], type='', swap='kpt-63'),
58:
- dict(
- name='kpt-58',
- id=58,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-62'),
+ dict(name='kpt-58', id=58, color=[255, 0, 0], type='', swap='kpt-62'),
59:
- dict(
- name='kpt-59',
- id=59,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-61'),
+ dict(name='kpt-59', id=59, color=[255, 0, 0], type='', swap='kpt-61'),
60:
- dict(name='kpt-60', id=60, color=[255, 0, 0], type='lower', swap=''),
+ dict(name='kpt-60', id=60, color=[255, 0, 0], type='', swap=''),
61:
- dict(
- name='kpt-61',
- id=61,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-59'),
+ dict(name='kpt-61', id=61, color=[255, 0, 0], type='', swap='kpt-59'),
62:
- dict(
- name='kpt-62',
- id=62,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-58'),
+ dict(name='kpt-62', id=62, color=[255, 0, 0], type='', swap='kpt-58'),
63:
- dict(
- name='kpt-63',
- id=63,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-57'),
+ dict(name='kpt-63', id=63, color=[255, 0, 0], type='', swap='kpt-57'),
64:
- dict(
- name='kpt-64',
- id=64,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-56'),
+ dict(name='kpt-64', id=64, color=[255, 0, 0], type='', swap='kpt-56'),
65:
- dict(
- name='kpt-65',
- id=65,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-55'),
+ dict(name='kpt-65', id=65, color=[255, 0, 0], type='', swap='kpt-55'),
66:
- dict(
- name='kpt-66',
- id=66,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-79'),
+ dict(name='kpt-66', id=66, color=[255, 0, 0], type='', swap='kpt-79'),
67:
- dict(
- name='kpt-67',
- id=67,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-78'),
+ dict(name='kpt-67', id=67, color=[255, 0, 0], type='', swap='kpt-78'),
68:
- dict(
- name='kpt-68',
- id=68,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-77'),
+ dict(name='kpt-68', id=68, color=[255, 0, 0], type='', swap='kpt-77'),
69:
- dict(
- name='kpt-69',
- id=69,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-76'),
+ dict(name='kpt-69', id=69, color=[255, 0, 0], type='', swap='kpt-76'),
70:
- dict(
- name='kpt-70',
- id=70,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-75'),
+ dict(name='kpt-70', id=70, color=[255, 0, 0], type='', swap='kpt-75'),
71:
- dict(
- name='kpt-71',
- id=71,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-82'),
+ dict(name='kpt-71', id=71, color=[255, 0, 0], type='', swap='kpt-82'),
72:
- dict(
- name='kpt-72',
- id=72,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-81'),
+ dict(name='kpt-72', id=72, color=[255, 0, 0], type='', swap='kpt-81'),
73:
- dict(
- name='kpt-73',
- id=73,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-80'),
+ dict(name='kpt-73', id=73, color=[255, 0, 0], type='', swap='kpt-80'),
74:
- dict(
- name='kpt-74',
- id=74,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-83'),
+ dict(name='kpt-74', id=74, color=[255, 0, 0], type='', swap='kpt-83'),
75:
- dict(
- name='kpt-75',
- id=75,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-70'),
+ dict(name='kpt-75', id=75, color=[255, 0, 0], type='', swap='kpt-70'),
76:
- dict(
- name='kpt-76',
- id=76,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-69'),
+ dict(name='kpt-76', id=76, color=[255, 0, 0], type='', swap='kpt-69'),
77:
- dict(
- name='kpt-77',
- id=77,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-68'),
+ dict(name='kpt-77', id=77, color=[255, 0, 0], type='', swap='kpt-68'),
78:
- dict(
- name='kpt-78',
- id=78,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-67'),
+ dict(name='kpt-78', id=78, color=[255, 0, 0], type='', swap='kpt-67'),
79:
- dict(
- name='kpt-79',
- id=79,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-66'),
+ dict(name='kpt-79', id=79, color=[255, 0, 0], type='', swap='kpt-66'),
80:
- dict(
- name='kpt-80',
- id=80,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-73'),
+ dict(name='kpt-80', id=80, color=[255, 0, 0], type='', swap='kpt-73'),
81:
- dict(
- name='kpt-81',
- id=81,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-72'),
+ dict(name='kpt-81', id=81, color=[255, 0, 0], type='', swap='kpt-72'),
82:
- dict(
- name='kpt-82',
- id=82,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-71'),
+ dict(name='kpt-82', id=82, color=[255, 0, 0], type='', swap='kpt-71'),
83:
- dict(
- name='kpt-83',
- id=83,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-74'),
+ dict(name='kpt-83', id=83, color=[255, 0, 0], type='', swap='kpt-74'),
84:
- dict(
- name='kpt-84',
- id=84,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-90'),
+ dict(name='kpt-84', id=84, color=[255, 0, 0], type='', swap='kpt-90'),
85:
- dict(
- name='kpt-85',
- id=85,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-89'),
+ dict(name='kpt-85', id=85, color=[255, 0, 0], type='', swap='kpt-89'),
86:
- dict(
- name='kpt-86',
- id=86,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-88'),
+ dict(name='kpt-86', id=86, color=[255, 0, 0], type='', swap='kpt-88'),
87:
- dict(name='kpt-87', id=87, color=[255, 0, 0], type='lower', swap=''),
+ dict(name='kpt-87', id=87, color=[255, 0, 0], type='', swap=''),
88:
- dict(
- name='kpt-88',
- id=88,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-86'),
+ dict(name='kpt-88', id=88, color=[255, 0, 0], type='', swap='kpt-86'),
89:
- dict(
- name='kpt-89',
- id=89,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-85'),
+ dict(name='kpt-89', id=89, color=[255, 0, 0], type='', swap='kpt-85'),
90:
- dict(
- name='kpt-90',
- id=90,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-84'),
+ dict(name='kpt-90', id=90, color=[255, 0, 0], type='', swap='kpt-84'),
91:
- dict(
- name='kpt-91',
- id=91,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-95'),
+ dict(name='kpt-91', id=91, color=[255, 0, 0], type='', swap='kpt-95'),
92:
- dict(
- name='kpt-92',
- id=92,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-94'),
+ dict(name='kpt-92', id=92, color=[255, 0, 0], type='', swap='kpt-94'),
93:
- dict(name='kpt-93', id=93, color=[255, 0, 0], type='lower', swap=''),
+ dict(name='kpt-93', id=93, color=[255, 0, 0], type='', swap=''),
94:
- dict(
- name='kpt-94',
- id=94,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-92'),
+ dict(name='kpt-94', id=94, color=[255, 0, 0], type='', swap='kpt-92'),
95:
- dict(
- name='kpt-95',
- id=95,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-91'),
+ dict(name='kpt-95', id=95, color=[255, 0, 0], type='', swap='kpt-91'),
96:
- dict(
- name='kpt-96',
- id=96,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-100'),
+ dict(name='kpt-96', id=96, color=[255, 0, 0], type='', swap='kpt-100'),
97:
- dict(
- name='kpt-97',
- id=97,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-99'),
+ dict(name='kpt-97', id=97, color=[255, 0, 0], type='', swap='kpt-99'),
98:
- dict(name='kpt-98', id=98, color=[255, 0, 0], type='lower', swap=''),
+ dict(name='kpt-98', id=98, color=[255, 0, 0], type='', swap=''),
99:
- dict(
- name='kpt-99',
- id=99,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-97'),
+ dict(name='kpt-99', id=99, color=[255, 0, 0], type='', swap='kpt-97'),
100:
dict(
- name='kpt-100',
- id=100,
- color=[255, 0, 0],
- type='lower',
- swap='kpt-96'),
+ name='kpt-100', id=100, color=[255, 0, 0], type='', swap='kpt-96'),
101:
dict(
- name='kpt-101',
- id=101,
- color=[255, 0, 0],
- type='lower',
+ name='kpt-101', id=101, color=[255, 0, 0], type='',
swap='kpt-103'),
102:
- dict(name='kpt-102', id=102, color=[255, 0, 0], type='lower', swap=''),
+ dict(name='kpt-102', id=102, color=[255, 0, 0], type='', swap=''),
103:
dict(
- name='kpt-103',
- id=103,
- color=[255, 0, 0],
- type='lower',
+ name='kpt-103', id=103, color=[255, 0, 0], type='',
swap='kpt-101'),
104:
dict(
- name='kpt-104',
- id=104,
- color=[255, 0, 0],
- type='upper',
+ name='kpt-104', id=104, color=[255, 0, 0], type='',
swap='kpt-105'),
105:
dict(
- name='kpt-105',
- id=105,
- color=[255, 0, 0],
- type='upper',
- swap='kpt-104')
+ name='kpt-105', id=105, color=[255, 0, 0], type='', swap='kpt-104')
},
skeleton_info={},
joint_weights=[
diff --git a/configs/_base_/datasets/ubody2d.py b/configs/_base_/datasets/ubody2d.py
new file mode 100644
index 0000000000..8486db05ab
--- /dev/null
+++ b/configs/_base_/datasets/ubody2d.py
@@ -0,0 +1,1153 @@
+dataset_info = dict(
+ dataset_name='ubody2d',
+ paper_info=dict(
+ author='Jing Lin, Ailing Zeng, Haoqian Wang, Lei Zhang, Yu Li',
+ title='One-Stage 3D Whole-Body Mesh Recovery with Component Aware'
+ 'Transformer',
+ container='IEEE Computer Society Conference on Computer Vision and '
+ 'Pattern Recognition (CVPR)',
+ year='2023',
+ homepage='https://github.com/IDEA-Research/OSX',
+ ),
+ keypoint_info={
+ 0:
+ dict(name='nose', id=0, color=[51, 153, 255], type='upper', swap=''),
+ 1:
+ dict(
+ name='left_eye',
+ id=1,
+ color=[51, 153, 255],
+ type='upper',
+ swap='right_eye'),
+ 2:
+ dict(
+ name='right_eye',
+ id=2,
+ color=[51, 153, 255],
+ type='upper',
+ swap='left_eye'),
+ 3:
+ dict(
+ name='left_ear',
+ id=3,
+ color=[51, 153, 255],
+ type='upper',
+ swap='right_ear'),
+ 4:
+ dict(
+ name='right_ear',
+ id=4,
+ color=[51, 153, 255],
+ type='upper',
+ swap='left_ear'),
+ 5:
+ dict(
+ name='left_shoulder',
+ id=5,
+ color=[0, 255, 0],
+ type='upper',
+ swap='right_shoulder'),
+ 6:
+ dict(
+ name='right_shoulder',
+ id=6,
+ color=[255, 128, 0],
+ type='upper',
+ swap='left_shoulder'),
+ 7:
+ dict(
+ name='left_elbow',
+ id=7,
+ color=[0, 255, 0],
+ type='upper',
+ swap='right_elbow'),
+ 8:
+ dict(
+ name='right_elbow',
+ id=8,
+ color=[255, 128, 0],
+ type='upper',
+ swap='left_elbow'),
+ 9:
+ dict(
+ name='left_wrist',
+ id=9,
+ color=[0, 255, 0],
+ type='upper',
+ swap='right_wrist'),
+ 10:
+ dict(
+ name='right_wrist',
+ id=10,
+ color=[255, 128, 0],
+ type='upper',
+ swap='left_wrist'),
+ 11:
+ dict(
+ name='left_hip',
+ id=11,
+ color=[0, 255, 0],
+ type='lower',
+ swap='right_hip'),
+ 12:
+ dict(
+ name='right_hip',
+ id=12,
+ color=[255, 128, 0],
+ type='lower',
+ swap='left_hip'),
+ 13:
+ dict(
+ name='left_knee',
+ id=13,
+ color=[0, 255, 0],
+ type='lower',
+ swap='right_knee'),
+ 14:
+ dict(
+ name='right_knee',
+ id=14,
+ color=[255, 128, 0],
+ type='lower',
+ swap='left_knee'),
+ 15:
+ dict(
+ name='left_ankle',
+ id=15,
+ color=[0, 255, 0],
+ type='lower',
+ swap='right_ankle'),
+ 16:
+ dict(
+ name='right_ankle',
+ id=16,
+ color=[255, 128, 0],
+ type='lower',
+ swap='left_ankle'),
+ 17:
+ dict(
+ name='left_big_toe',
+ id=17,
+ color=[255, 128, 0],
+ type='lower',
+ swap='right_big_toe'),
+ 18:
+ dict(
+ name='left_small_toe',
+ id=18,
+ color=[255, 128, 0],
+ type='lower',
+ swap='right_small_toe'),
+ 19:
+ dict(
+ name='left_heel',
+ id=19,
+ color=[255, 128, 0],
+ type='lower',
+ swap='right_heel'),
+ 20:
+ dict(
+ name='right_big_toe',
+ id=20,
+ color=[255, 128, 0],
+ type='lower',
+ swap='left_big_toe'),
+ 21:
+ dict(
+ name='right_small_toe',
+ id=21,
+ color=[255, 128, 0],
+ type='lower',
+ swap='left_small_toe'),
+ 22:
+ dict(
+ name='right_heel',
+ id=22,
+ color=[255, 128, 0],
+ type='lower',
+ swap='left_heel'),
+ 23:
+ dict(
+ name='face-0',
+ id=23,
+ color=[255, 255, 255],
+ type='',
+ swap='face-16'),
+ 24:
+ dict(
+ name='face-1',
+ id=24,
+ color=[255, 255, 255],
+ type='',
+ swap='face-15'),
+ 25:
+ dict(
+ name='face-2',
+ id=25,
+ color=[255, 255, 255],
+ type='',
+ swap='face-14'),
+ 26:
+ dict(
+ name='face-3',
+ id=26,
+ color=[255, 255, 255],
+ type='',
+ swap='face-13'),
+ 27:
+ dict(
+ name='face-4',
+ id=27,
+ color=[255, 255, 255],
+ type='',
+ swap='face-12'),
+ 28:
+ dict(
+ name='face-5',
+ id=28,
+ color=[255, 255, 255],
+ type='',
+ swap='face-11'),
+ 29:
+ dict(
+ name='face-6',
+ id=29,
+ color=[255, 255, 255],
+ type='',
+ swap='face-10'),
+ 30:
+ dict(
+ name='face-7',
+ id=30,
+ color=[255, 255, 255],
+ type='',
+ swap='face-9'),
+ 31:
+ dict(name='face-8', id=31, color=[255, 255, 255], type='', swap=''),
+ 32:
+ dict(
+ name='face-9',
+ id=32,
+ color=[255, 255, 255],
+ type='',
+ swap='face-7'),
+ 33:
+ dict(
+ name='face-10',
+ id=33,
+ color=[255, 255, 255],
+ type='',
+ swap='face-6'),
+ 34:
+ dict(
+ name='face-11',
+ id=34,
+ color=[255, 255, 255],
+ type='',
+ swap='face-5'),
+ 35:
+ dict(
+ name='face-12',
+ id=35,
+ color=[255, 255, 255],
+ type='',
+ swap='face-4'),
+ 36:
+ dict(
+ name='face-13',
+ id=36,
+ color=[255, 255, 255],
+ type='',
+ swap='face-3'),
+ 37:
+ dict(
+ name='face-14',
+ id=37,
+ color=[255, 255, 255],
+ type='',
+ swap='face-2'),
+ 38:
+ dict(
+ name='face-15',
+ id=38,
+ color=[255, 255, 255],
+ type='',
+ swap='face-1'),
+ 39:
+ dict(
+ name='face-16',
+ id=39,
+ color=[255, 255, 255],
+ type='',
+ swap='face-0'),
+ 40:
+ dict(
+ name='face-17',
+ id=40,
+ color=[255, 255, 255],
+ type='',
+ swap='face-26'),
+ 41:
+ dict(
+ name='face-18',
+ id=41,
+ color=[255, 255, 255],
+ type='',
+ swap='face-25'),
+ 42:
+ dict(
+ name='face-19',
+ id=42,
+ color=[255, 255, 255],
+ type='',
+ swap='face-24'),
+ 43:
+ dict(
+ name='face-20',
+ id=43,
+ color=[255, 255, 255],
+ type='',
+ swap='face-23'),
+ 44:
+ dict(
+ name='face-21',
+ id=44,
+ color=[255, 255, 255],
+ type='',
+ swap='face-22'),
+ 45:
+ dict(
+ name='face-22',
+ id=45,
+ color=[255, 255, 255],
+ type='',
+ swap='face-21'),
+ 46:
+ dict(
+ name='face-23',
+ id=46,
+ color=[255, 255, 255],
+ type='',
+ swap='face-20'),
+ 47:
+ dict(
+ name='face-24',
+ id=47,
+ color=[255, 255, 255],
+ type='',
+ swap='face-19'),
+ 48:
+ dict(
+ name='face-25',
+ id=48,
+ color=[255, 255, 255],
+ type='',
+ swap='face-18'),
+ 49:
+ dict(
+ name='face-26',
+ id=49,
+ color=[255, 255, 255],
+ type='',
+ swap='face-17'),
+ 50:
+ dict(name='face-27', id=50, color=[255, 255, 255], type='', swap=''),
+ 51:
+ dict(name='face-28', id=51, color=[255, 255, 255], type='', swap=''),
+ 52:
+ dict(name='face-29', id=52, color=[255, 255, 255], type='', swap=''),
+ 53:
+ dict(name='face-30', id=53, color=[255, 255, 255], type='', swap=''),
+ 54:
+ dict(
+ name='face-31',
+ id=54,
+ color=[255, 255, 255],
+ type='',
+ swap='face-35'),
+ 55:
+ dict(
+ name='face-32',
+ id=55,
+ color=[255, 255, 255],
+ type='',
+ swap='face-34'),
+ 56:
+ dict(name='face-33', id=56, color=[255, 255, 255], type='', swap=''),
+ 57:
+ dict(
+ name='face-34',
+ id=57,
+ color=[255, 255, 255],
+ type='',
+ swap='face-32'),
+ 58:
+ dict(
+ name='face-35',
+ id=58,
+ color=[255, 255, 255],
+ type='',
+ swap='face-31'),
+ 59:
+ dict(
+ name='face-36',
+ id=59,
+ color=[255, 255, 255],
+ type='',
+ swap='face-45'),
+ 60:
+ dict(
+ name='face-37',
+ id=60,
+ color=[255, 255, 255],
+ type='',
+ swap='face-44'),
+ 61:
+ dict(
+ name='face-38',
+ id=61,
+ color=[255, 255, 255],
+ type='',
+ swap='face-43'),
+ 62:
+ dict(
+ name='face-39',
+ id=62,
+ color=[255, 255, 255],
+ type='',
+ swap='face-42'),
+ 63:
+ dict(
+ name='face-40',
+ id=63,
+ color=[255, 255, 255],
+ type='',
+ swap='face-47'),
+ 64:
+ dict(
+ name='face-41',
+ id=64,
+ color=[255, 255, 255],
+ type='',
+ swap='face-46'),
+ 65:
+ dict(
+ name='face-42',
+ id=65,
+ color=[255, 255, 255],
+ type='',
+ swap='face-39'),
+ 66:
+ dict(
+ name='face-43',
+ id=66,
+ color=[255, 255, 255],
+ type='',
+ swap='face-38'),
+ 67:
+ dict(
+ name='face-44',
+ id=67,
+ color=[255, 255, 255],
+ type='',
+ swap='face-37'),
+ 68:
+ dict(
+ name='face-45',
+ id=68,
+ color=[255, 255, 255],
+ type='',
+ swap='face-36'),
+ 69:
+ dict(
+ name='face-46',
+ id=69,
+ color=[255, 255, 255],
+ type='',
+ swap='face-41'),
+ 70:
+ dict(
+ name='face-47',
+ id=70,
+ color=[255, 255, 255],
+ type='',
+ swap='face-40'),
+ 71:
+ dict(
+ name='face-48',
+ id=71,
+ color=[255, 255, 255],
+ type='',
+ swap='face-54'),
+ 72:
+ dict(
+ name='face-49',
+ id=72,
+ color=[255, 255, 255],
+ type='',
+ swap='face-53'),
+ 73:
+ dict(
+ name='face-50',
+ id=73,
+ color=[255, 255, 255],
+ type='',
+ swap='face-52'),
+ 74:
+ dict(name='face-51', id=74, color=[255, 255, 255], type='', swap=''),
+ 75:
+ dict(
+ name='face-52',
+ id=75,
+ color=[255, 255, 255],
+ type='',
+ swap='face-50'),
+ 76:
+ dict(
+ name='face-53',
+ id=76,
+ color=[255, 255, 255],
+ type='',
+ swap='face-49'),
+ 77:
+ dict(
+ name='face-54',
+ id=77,
+ color=[255, 255, 255],
+ type='',
+ swap='face-48'),
+ 78:
+ dict(
+ name='face-55',
+ id=78,
+ color=[255, 255, 255],
+ type='',
+ swap='face-59'),
+ 79:
+ dict(
+ name='face-56',
+ id=79,
+ color=[255, 255, 255],
+ type='',
+ swap='face-58'),
+ 80:
+ dict(name='face-57', id=80, color=[255, 255, 255], type='', swap=''),
+ 81:
+ dict(
+ name='face-58',
+ id=81,
+ color=[255, 255, 255],
+ type='',
+ swap='face-56'),
+ 82:
+ dict(
+ name='face-59',
+ id=82,
+ color=[255, 255, 255],
+ type='',
+ swap='face-55'),
+ 83:
+ dict(
+ name='face-60',
+ id=83,
+ color=[255, 255, 255],
+ type='',
+ swap='face-64'),
+ 84:
+ dict(
+ name='face-61',
+ id=84,
+ color=[255, 255, 255],
+ type='',
+ swap='face-63'),
+ 85:
+ dict(name='face-62', id=85, color=[255, 255, 255], type='', swap=''),
+ 86:
+ dict(
+ name='face-63',
+ id=86,
+ color=[255, 255, 255],
+ type='',
+ swap='face-61'),
+ 87:
+ dict(
+ name='face-64',
+ id=87,
+ color=[255, 255, 255],
+ type='',
+ swap='face-60'),
+ 88:
+ dict(
+ name='face-65',
+ id=88,
+ color=[255, 255, 255],
+ type='',
+ swap='face-67'),
+ 89:
+ dict(name='face-66', id=89, color=[255, 255, 255], type='', swap=''),
+ 90:
+ dict(
+ name='face-67',
+ id=90,
+ color=[255, 255, 255],
+ type='',
+ swap='face-65'),
+ 91:
+ dict(
+ name='left_hand_root',
+ id=91,
+ color=[255, 255, 255],
+ type='',
+ swap='right_hand_root'),
+ 92:
+ dict(
+ name='left_thumb1',
+ id=92,
+ color=[255, 128, 0],
+ type='',
+ swap='right_thumb1'),
+ 93:
+ dict(
+ name='left_thumb2',
+ id=93,
+ color=[255, 128, 0],
+ type='',
+ swap='right_thumb2'),
+ 94:
+ dict(
+ name='left_thumb3',
+ id=94,
+ color=[255, 128, 0],
+ type='',
+ swap='right_thumb3'),
+ 95:
+ dict(
+ name='left_thumb4',
+ id=95,
+ color=[255, 128, 0],
+ type='',
+ swap='right_thumb4'),
+ 96:
+ dict(
+ name='left_forefinger1',
+ id=96,
+ color=[255, 153, 255],
+ type='',
+ swap='right_forefinger1'),
+ 97:
+ dict(
+ name='left_forefinger2',
+ id=97,
+ color=[255, 153, 255],
+ type='',
+ swap='right_forefinger2'),
+ 98:
+ dict(
+ name='left_forefinger3',
+ id=98,
+ color=[255, 153, 255],
+ type='',
+ swap='right_forefinger3'),
+ 99:
+ dict(
+ name='left_forefinger4',
+ id=99,
+ color=[255, 153, 255],
+ type='',
+ swap='right_forefinger4'),
+ 100:
+ dict(
+ name='left_middle_finger1',
+ id=100,
+ color=[102, 178, 255],
+ type='',
+ swap='right_middle_finger1'),
+ 101:
+ dict(
+ name='left_middle_finger2',
+ id=101,
+ color=[102, 178, 255],
+ type='',
+ swap='right_middle_finger2'),
+ 102:
+ dict(
+ name='left_middle_finger3',
+ id=102,
+ color=[102, 178, 255],
+ type='',
+ swap='right_middle_finger3'),
+ 103:
+ dict(
+ name='left_middle_finger4',
+ id=103,
+ color=[102, 178, 255],
+ type='',
+ swap='right_middle_finger4'),
+ 104:
+ dict(
+ name='left_ring_finger1',
+ id=104,
+ color=[255, 51, 51],
+ type='',
+ swap='right_ring_finger1'),
+ 105:
+ dict(
+ name='left_ring_finger2',
+ id=105,
+ color=[255, 51, 51],
+ type='',
+ swap='right_ring_finger2'),
+ 106:
+ dict(
+ name='left_ring_finger3',
+ id=106,
+ color=[255, 51, 51],
+ type='',
+ swap='right_ring_finger3'),
+ 107:
+ dict(
+ name='left_ring_finger4',
+ id=107,
+ color=[255, 51, 51],
+ type='',
+ swap='right_ring_finger4'),
+ 108:
+ dict(
+ name='left_pinky_finger1',
+ id=108,
+ color=[0, 255, 0],
+ type='',
+ swap='right_pinky_finger1'),
+ 109:
+ dict(
+ name='left_pinky_finger2',
+ id=109,
+ color=[0, 255, 0],
+ type='',
+ swap='right_pinky_finger2'),
+ 110:
+ dict(
+ name='left_pinky_finger3',
+ id=110,
+ color=[0, 255, 0],
+ type='',
+ swap='right_pinky_finger3'),
+ 111:
+ dict(
+ name='left_pinky_finger4',
+ id=111,
+ color=[0, 255, 0],
+ type='',
+ swap='right_pinky_finger4'),
+ 112:
+ dict(
+ name='right_hand_root',
+ id=112,
+ color=[255, 255, 255],
+ type='',
+ swap='left_hand_root'),
+ 113:
+ dict(
+ name='right_thumb1',
+ id=113,
+ color=[255, 128, 0],
+ type='',
+ swap='left_thumb1'),
+ 114:
+ dict(
+ name='right_thumb2',
+ id=114,
+ color=[255, 128, 0],
+ type='',
+ swap='left_thumb2'),
+ 115:
+ dict(
+ name='right_thumb3',
+ id=115,
+ color=[255, 128, 0],
+ type='',
+ swap='left_thumb3'),
+ 116:
+ dict(
+ name='right_thumb4',
+ id=116,
+ color=[255, 128, 0],
+ type='',
+ swap='left_thumb4'),
+ 117:
+ dict(
+ name='right_forefinger1',
+ id=117,
+ color=[255, 153, 255],
+ type='',
+ swap='left_forefinger1'),
+ 118:
+ dict(
+ name='right_forefinger2',
+ id=118,
+ color=[255, 153, 255],
+ type='',
+ swap='left_forefinger2'),
+ 119:
+ dict(
+ name='right_forefinger3',
+ id=119,
+ color=[255, 153, 255],
+ type='',
+ swap='left_forefinger3'),
+ 120:
+ dict(
+ name='right_forefinger4',
+ id=120,
+ color=[255, 153, 255],
+ type='',
+ swap='left_forefinger4'),
+ 121:
+ dict(
+ name='right_middle_finger1',
+ id=121,
+ color=[102, 178, 255],
+ type='',
+ swap='left_middle_finger1'),
+ 122:
+ dict(
+ name='right_middle_finger2',
+ id=122,
+ color=[102, 178, 255],
+ type='',
+ swap='left_middle_finger2'),
+ 123:
+ dict(
+ name='right_middle_finger3',
+ id=123,
+ color=[102, 178, 255],
+ type='',
+ swap='left_middle_finger3'),
+ 124:
+ dict(
+ name='right_middle_finger4',
+ id=124,
+ color=[102, 178, 255],
+ type='',
+ swap='left_middle_finger4'),
+ 125:
+ dict(
+ name='right_ring_finger1',
+ id=125,
+ color=[255, 51, 51],
+ type='',
+ swap='left_ring_finger1'),
+ 126:
+ dict(
+ name='right_ring_finger2',
+ id=126,
+ color=[255, 51, 51],
+ type='',
+ swap='left_ring_finger2'),
+ 127:
+ dict(
+ name='right_ring_finger3',
+ id=127,
+ color=[255, 51, 51],
+ type='',
+ swap='left_ring_finger3'),
+ 128:
+ dict(
+ name='right_ring_finger4',
+ id=128,
+ color=[255, 51, 51],
+ type='',
+ swap='left_ring_finger4'),
+ 129:
+ dict(
+ name='right_pinky_finger1',
+ id=129,
+ color=[0, 255, 0],
+ type='',
+ swap='left_pinky_finger1'),
+ 130:
+ dict(
+ name='right_pinky_finger2',
+ id=130,
+ color=[0, 255, 0],
+ type='',
+ swap='left_pinky_finger2'),
+ 131:
+ dict(
+ name='right_pinky_finger3',
+ id=131,
+ color=[0, 255, 0],
+ type='',
+ swap='left_pinky_finger3'),
+ 132:
+ dict(
+ name='right_pinky_finger4',
+ id=132,
+ color=[0, 255, 0],
+ type='',
+ swap='left_pinky_finger4')
+ },
+ skeleton_info={
+ 0:
+ dict(link=('left_ankle', 'left_knee'), id=0, color=[0, 255, 0]),
+ 1:
+ dict(link=('left_knee', 'left_hip'), id=1, color=[0, 255, 0]),
+ 2:
+ dict(link=('right_ankle', 'right_knee'), id=2, color=[255, 128, 0]),
+ 3:
+ dict(link=('right_knee', 'right_hip'), id=3, color=[255, 128, 0]),
+ 4:
+ dict(link=('left_hip', 'right_hip'), id=4, color=[51, 153, 255]),
+ 5:
+ dict(link=('left_shoulder', 'left_hip'), id=5, color=[51, 153, 255]),
+ 6:
+ dict(link=('right_shoulder', 'right_hip'), id=6, color=[51, 153, 255]),
+ 7:
+ dict(
+ link=('left_shoulder', 'right_shoulder'),
+ id=7,
+ color=[51, 153, 255]),
+ 8:
+ dict(link=('left_shoulder', 'left_elbow'), id=8, color=[0, 255, 0]),
+ 9:
+ dict(
+ link=('right_shoulder', 'right_elbow'), id=9, color=[255, 128, 0]),
+ 10:
+ dict(link=('left_elbow', 'left_wrist'), id=10, color=[0, 255, 0]),
+ 11:
+ dict(link=('right_elbow', 'right_wrist'), id=11, color=[255, 128, 0]),
+ 12:
+ dict(link=('left_eye', 'right_eye'), id=12, color=[51, 153, 255]),
+ 13:
+ dict(link=('nose', 'left_eye'), id=13, color=[51, 153, 255]),
+ 14:
+ dict(link=('nose', 'right_eye'), id=14, color=[51, 153, 255]),
+ 15:
+ dict(link=('left_eye', 'left_ear'), id=15, color=[51, 153, 255]),
+ 16:
+ dict(link=('right_eye', 'right_ear'), id=16, color=[51, 153, 255]),
+ 17:
+ dict(link=('left_ear', 'left_shoulder'), id=17, color=[51, 153, 255]),
+ 18:
+ dict(
+ link=('right_ear', 'right_shoulder'), id=18, color=[51, 153, 255]),
+ 19:
+ dict(link=('left_ankle', 'left_big_toe'), id=19, color=[0, 255, 0]),
+ 20:
+ dict(link=('left_ankle', 'left_small_toe'), id=20, color=[0, 255, 0]),
+ 21:
+ dict(link=('left_ankle', 'left_heel'), id=21, color=[0, 255, 0]),
+ 22:
+ dict(
+ link=('right_ankle', 'right_big_toe'), id=22, color=[255, 128, 0]),
+ 23:
+ dict(
+ link=('right_ankle', 'right_small_toe'),
+ id=23,
+ color=[255, 128, 0]),
+ 24:
+ dict(link=('right_ankle', 'right_heel'), id=24, color=[255, 128, 0]),
+ 25:
+ dict(
+ link=('left_hand_root', 'left_thumb1'), id=25, color=[255, 128,
+ 0]),
+ 26:
+ dict(link=('left_thumb1', 'left_thumb2'), id=26, color=[255, 128, 0]),
+ 27:
+ dict(link=('left_thumb2', 'left_thumb3'), id=27, color=[255, 128, 0]),
+ 28:
+ dict(link=('left_thumb3', 'left_thumb4'), id=28, color=[255, 128, 0]),
+ 29:
+ dict(
+ link=('left_hand_root', 'left_forefinger1'),
+ id=29,
+ color=[255, 153, 255]),
+ 30:
+ dict(
+ link=('left_forefinger1', 'left_forefinger2'),
+ id=30,
+ color=[255, 153, 255]),
+ 31:
+ dict(
+ link=('left_forefinger2', 'left_forefinger3'),
+ id=31,
+ color=[255, 153, 255]),
+ 32:
+ dict(
+ link=('left_forefinger3', 'left_forefinger4'),
+ id=32,
+ color=[255, 153, 255]),
+ 33:
+ dict(
+ link=('left_hand_root', 'left_middle_finger1'),
+ id=33,
+ color=[102, 178, 255]),
+ 34:
+ dict(
+ link=('left_middle_finger1', 'left_middle_finger2'),
+ id=34,
+ color=[102, 178, 255]),
+ 35:
+ dict(
+ link=('left_middle_finger2', 'left_middle_finger3'),
+ id=35,
+ color=[102, 178, 255]),
+ 36:
+ dict(
+ link=('left_middle_finger3', 'left_middle_finger4'),
+ id=36,
+ color=[102, 178, 255]),
+ 37:
+ dict(
+ link=('left_hand_root', 'left_ring_finger1'),
+ id=37,
+ color=[255, 51, 51]),
+ 38:
+ dict(
+ link=('left_ring_finger1', 'left_ring_finger2'),
+ id=38,
+ color=[255, 51, 51]),
+ 39:
+ dict(
+ link=('left_ring_finger2', 'left_ring_finger3'),
+ id=39,
+ color=[255, 51, 51]),
+ 40:
+ dict(
+ link=('left_ring_finger3', 'left_ring_finger4'),
+ id=40,
+ color=[255, 51, 51]),
+ 41:
+ dict(
+ link=('left_hand_root', 'left_pinky_finger1'),
+ id=41,
+ color=[0, 255, 0]),
+ 42:
+ dict(
+ link=('left_pinky_finger1', 'left_pinky_finger2'),
+ id=42,
+ color=[0, 255, 0]),
+ 43:
+ dict(
+ link=('left_pinky_finger2', 'left_pinky_finger3'),
+ id=43,
+ color=[0, 255, 0]),
+ 44:
+ dict(
+ link=('left_pinky_finger3', 'left_pinky_finger4'),
+ id=44,
+ color=[0, 255, 0]),
+ 45:
+ dict(
+ link=('right_hand_root', 'right_thumb1'),
+ id=45,
+ color=[255, 128, 0]),
+ 46:
+ dict(
+ link=('right_thumb1', 'right_thumb2'), id=46, color=[255, 128, 0]),
+ 47:
+ dict(
+ link=('right_thumb2', 'right_thumb3'), id=47, color=[255, 128, 0]),
+ 48:
+ dict(
+ link=('right_thumb3', 'right_thumb4'), id=48, color=[255, 128, 0]),
+ 49:
+ dict(
+ link=('right_hand_root', 'right_forefinger1'),
+ id=49,
+ color=[255, 153, 255]),
+ 50:
+ dict(
+ link=('right_forefinger1', 'right_forefinger2'),
+ id=50,
+ color=[255, 153, 255]),
+ 51:
+ dict(
+ link=('right_forefinger2', 'right_forefinger3'),
+ id=51,
+ color=[255, 153, 255]),
+ 52:
+ dict(
+ link=('right_forefinger3', 'right_forefinger4'),
+ id=52,
+ color=[255, 153, 255]),
+ 53:
+ dict(
+ link=('right_hand_root', 'right_middle_finger1'),
+ id=53,
+ color=[102, 178, 255]),
+ 54:
+ dict(
+ link=('right_middle_finger1', 'right_middle_finger2'),
+ id=54,
+ color=[102, 178, 255]),
+ 55:
+ dict(
+ link=('right_middle_finger2', 'right_middle_finger3'),
+ id=55,
+ color=[102, 178, 255]),
+ 56:
+ dict(
+ link=('right_middle_finger3', 'right_middle_finger4'),
+ id=56,
+ color=[102, 178, 255]),
+ 57:
+ dict(
+ link=('right_hand_root', 'right_ring_finger1'),
+ id=57,
+ color=[255, 51, 51]),
+ 58:
+ dict(
+ link=('right_ring_finger1', 'right_ring_finger2'),
+ id=58,
+ color=[255, 51, 51]),
+ 59:
+ dict(
+ link=('right_ring_finger2', 'right_ring_finger3'),
+ id=59,
+ color=[255, 51, 51]),
+ 60:
+ dict(
+ link=('right_ring_finger3', 'right_ring_finger4'),
+ id=60,
+ color=[255, 51, 51]),
+ 61:
+ dict(
+ link=('right_hand_root', 'right_pinky_finger1'),
+ id=61,
+ color=[0, 255, 0]),
+ 62:
+ dict(
+ link=('right_pinky_finger1', 'right_pinky_finger2'),
+ id=62,
+ color=[0, 255, 0]),
+ 63:
+ dict(
+ link=('right_pinky_finger2', 'right_pinky_finger3'),
+ id=63,
+ color=[0, 255, 0]),
+ 64:
+ dict(
+ link=('right_pinky_finger3', 'right_pinky_finger4'),
+ id=64,
+ color=[0, 255, 0])
+ },
+ joint_weights=[1.] * 133,
+ # 'https://github.com/jin-s13/COCO-WholeBody/blob/master/'
+ # 'evaluation/myeval_wholebody.py#L175'
+ sigmas=[
+ 0.026, 0.025, 0.025, 0.035, 0.035, 0.079, 0.079, 0.072, 0.072, 0.062,
+ 0.062, 0.107, 0.107, 0.087, 0.087, 0.089, 0.089, 0.068, 0.066, 0.066,
+ 0.092, 0.094, 0.094, 0.042, 0.043, 0.044, 0.043, 0.040, 0.035, 0.031,
+ 0.025, 0.020, 0.023, 0.029, 0.032, 0.037, 0.038, 0.043, 0.041, 0.045,
+ 0.013, 0.012, 0.011, 0.011, 0.012, 0.012, 0.011, 0.011, 0.013, 0.015,
+ 0.009, 0.007, 0.007, 0.007, 0.012, 0.009, 0.008, 0.016, 0.010, 0.017,
+ 0.011, 0.009, 0.011, 0.009, 0.007, 0.013, 0.008, 0.011, 0.012, 0.010,
+ 0.034, 0.008, 0.008, 0.009, 0.008, 0.008, 0.007, 0.010, 0.008, 0.009,
+ 0.009, 0.009, 0.007, 0.007, 0.008, 0.011, 0.008, 0.008, 0.008, 0.01,
+ 0.008, 0.029, 0.022, 0.035, 0.037, 0.047, 0.026, 0.025, 0.024, 0.035,
+ 0.018, 0.024, 0.022, 0.026, 0.017, 0.021, 0.021, 0.032, 0.02, 0.019,
+ 0.022, 0.031, 0.029, 0.022, 0.035, 0.037, 0.047, 0.026, 0.025, 0.024,
+ 0.035, 0.018, 0.024, 0.022, 0.026, 0.017, 0.021, 0.021, 0.032, 0.02,
+ 0.019, 0.022, 0.031
+ ])
diff --git a/configs/_base_/datasets/ubody3d.py b/configs/_base_/datasets/ubody3d.py
new file mode 100644
index 0000000000..9242559ea1
--- /dev/null
+++ b/configs/_base_/datasets/ubody3d.py
@@ -0,0 +1,958 @@
+dataset_info = dict(
+ dataset_name='ubody3d',
+ paper_info=dict(
+ author='Jing Lin, Ailing Zeng, Haoqian Wang, Lei Zhang, Yu Li',
+ title='One-Stage 3D Whole-Body Mesh Recovery with Component Aware'
+ 'Transformer',
+ container='IEEE Computer Society Conference on Computer Vision and '
+ 'Pattern Recognition (CVPR)',
+ year='2023',
+ homepage='https://github.com/IDEA-Research/OSX',
+ ),
+ keypoint_info={
+ 0:
+ dict(name='Pelvis', id=0, color=[0, 255, 0], type='', swap=''),
+ 1:
+ dict(
+ name='L_Hip', id=1, color=[0, 255, 0], type='lower', swap='R_Hip'),
+ 2:
+ dict(
+ name='R_Hip', id=2, color=[0, 255, 0], type='lower', swap='L_Hip'),
+ 3:
+ dict(
+ name='L_Knee',
+ id=3,
+ color=[0, 255, 0],
+ type='lower',
+ swap='R_Knee'),
+ 4:
+ dict(
+ name='R_Knee',
+ id=4,
+ color=[0, 255, 0],
+ type='lower',
+ swap='L_Knee'),
+ 5:
+ dict(
+ name='L_Ankle',
+ id=5,
+ color=[0, 255, 0],
+ type='lower',
+ swap='R_Ankle'),
+ 6:
+ dict(
+ name='R_Ankle',
+ id=6,
+ color=[0, 255, 0],
+ type='lower',
+ swap='L_Ankle'),
+ 7:
+ dict(name='Neck', id=7, color=[0, 255, 0], type='upper', swap=''),
+ 8:
+ dict(
+ name='L_Shoulder',
+ id=8,
+ color=[0, 255, 0],
+ type='upper',
+ swap='R_Shoulder'),
+ 9:
+ dict(
+ name='R_Shoulder',
+ id=9,
+ color=[0, 255, 0],
+ type='upper',
+ swap='L_Shoulder'),
+ 10:
+ dict(
+ name='L_Elbow',
+ id=10,
+ color=[0, 255, 0],
+ type='upper',
+ swap='R_Elbow'),
+ 11:
+ dict(
+ name='R_Elbow',
+ id=11,
+ color=[0, 255, 0],
+ type='upper',
+ swap='L_Elbow'),
+ 12:
+ dict(
+ name='L_Wrist',
+ id=12,
+ color=[0, 255, 0],
+ type='upper',
+ swap='R_Wrist'),
+ 13:
+ dict(
+ name='R_Wrist',
+ id=13,
+ color=[0, 255, 0],
+ type='upper',
+ swap='L_Wrist'),
+ 14:
+ dict(
+ name='L_Big_toe',
+ id=14,
+ color=[0, 255, 0],
+ type='lower',
+ swap='R_Big_toe'),
+ 15:
+ dict(
+ name='L_Small_toe',
+ id=15,
+ color=[0, 255, 0],
+ type='lower',
+ swap='R_Small_toe'),
+ 16:
+ dict(
+ name='L_Heel',
+ id=16,
+ color=[0, 255, 0],
+ type='lower',
+ swap='R_Heel'),
+ 17:
+ dict(
+ name='R_Big_toe',
+ id=17,
+ color=[0, 255, 0],
+ type='lower',
+ swap='L_Big_toe'),
+ 18:
+ dict(
+ name='R_Small_toe',
+ id=18,
+ color=[0, 255, 0],
+ type='lower',
+ swap='L_Small_toe'),
+ 19:
+ dict(
+ name='R_Heel',
+ id=19,
+ color=[0, 255, 0],
+ type='lower',
+ swap='L_Heel'),
+ 20:
+ dict(
+ name='L_Ear', id=20, color=[0, 255, 0], type='upper',
+ swap='R_Ear'),
+ 21:
+ dict(
+ name='R_Ear', id=21, color=[0, 255, 0], type='upper',
+ swap='L_Ear'),
+ 22:
+ dict(name='L_Eye', id=22, color=[0, 255, 0], type='', swap='R_Eye'),
+ 23:
+ dict(name='R_Eye', id=23, color=[0, 255, 0], type='', swap='L_Eye'),
+ 24:
+ dict(name='Nose', id=24, color=[0, 255, 0], type='upper', swap=''),
+ 25:
+ dict(
+ name='L_Thumb_1',
+ id=25,
+ color=[255, 128, 0],
+ type='',
+ swap='R_Thumb_1'),
+ 26:
+ dict(
+ name='L_Thumb_2',
+ id=26,
+ color=[255, 128, 0],
+ type='',
+ swap='R_Thumb_2'),
+ 27:
+ dict(
+ name='L_Thumb_3',
+ id=27,
+ color=[255, 128, 0],
+ type='',
+ swap='R_Thumb_3'),
+ 28:
+ dict(
+ name='L_Thumb_4',
+ id=28,
+ color=[255, 128, 0],
+ type='',
+ swap='R_Thumb_4'),
+ 29:
+ dict(
+ name='L_Index_1',
+ id=29,
+ color=[255, 128, 0],
+ type='',
+ swap='R_Index_1'),
+ 30:
+ dict(
+ name='L_Index_2',
+ id=30,
+ color=[255, 128, 0],
+ type='',
+ swap='R_Index_2'),
+ 31:
+ dict(
+ name='L_Index_3',
+ id=31,
+ color=[255, 128, 0],
+ type='',
+ swap='R_Index_3'),
+ 32:
+ dict(
+ name='L_Index_4',
+ id=32,
+ color=[255, 128, 0],
+ type='',
+ swap='R_Index_4'),
+ 33:
+ dict(
+ name='L_Middle_1',
+ id=33,
+ color=[255, 128, 0],
+ type='',
+ swap='R_Middle_1'),
+ 34:
+ dict(
+ name='L_Middle_2',
+ id=34,
+ color=[255, 128, 0],
+ type='',
+ swap='R_Middle_2'),
+ 35:
+ dict(
+ name='L_Middle_3',
+ id=35,
+ color=[255, 128, 0],
+ type='',
+ swap='R_Middle_3'),
+ 36:
+ dict(
+ name='L_Middle_4',
+ id=36,
+ color=[255, 128, 0],
+ type='',
+ swap='R_Middle_4'),
+ 37:
+ dict(
+ name='L_Ring_1',
+ id=37,
+ color=[255, 128, 0],
+ type='',
+ swap='R_Ring_1'),
+ 38:
+ dict(
+ name='L_Ring_2',
+ id=38,
+ color=[255, 128, 0],
+ type='',
+ swap='R_Ring_2'),
+ 39:
+ dict(
+ name='L_Ring_3',
+ id=39,
+ color=[255, 128, 0],
+ type='',
+ swap='R_Ring_3'),
+ 40:
+ dict(
+ name='L_Ring_4',
+ id=40,
+ color=[255, 128, 0],
+ type='',
+ swap='R_Ring_4'),
+ 41:
+ dict(
+ name='L_Pinky_1',
+ id=41,
+ color=[255, 128, 0],
+ type='',
+ swap='R_Pinky_1'),
+ 42:
+ dict(
+ name='L_Pinky_2',
+ id=42,
+ color=[255, 128, 0],
+ type='',
+ swap='R_Pinky_2'),
+ 43:
+ dict(
+ name='L_Pinky_3',
+ id=43,
+ color=[255, 128, 0],
+ type='',
+ swap='R_Pinky_3'),
+ 44:
+ dict(
+ name='L_Pinky_4',
+ id=44,
+ color=[255, 128, 0],
+ type='',
+ swap='R_Pinky_4'),
+ 45:
+ dict(
+ name='R_Thumb_1',
+ id=45,
+ color=[255, 128, 0],
+ type='',
+ swap='L_Thumb_1'),
+ 46:
+ dict(
+ name='R_Thumb_2',
+ id=46,
+ color=[255, 128, 0],
+ type='',
+ swap='L_Thumb_2'),
+ 47:
+ dict(
+ name='R_Thumb_3',
+ id=47,
+ color=[255, 128, 0],
+ type='',
+ swap='L_Thumb_3'),
+ 48:
+ dict(
+ name='R_Thumb_4',
+ id=48,
+ color=[255, 128, 0],
+ type='',
+ swap='L_Thumb_4'),
+ 49:
+ dict(
+ name='R_Index_1',
+ id=49,
+ color=[255, 128, 0],
+ type='',
+ swap='L_Index_1'),
+ 50:
+ dict(
+ name='R_Index_2',
+ id=50,
+ color=[255, 128, 0],
+ type='',
+ swap='L_Index_2'),
+ 51:
+ dict(
+ name='R_Index_3',
+ id=51,
+ color=[255, 128, 0],
+ type='',
+ swap='L_Index_3'),
+ 52:
+ dict(
+ name='R_Index_4',
+ id=52,
+ color=[255, 128, 0],
+ type='',
+ swap='L_Index_4'),
+ 53:
+ dict(
+ name='R_Middle_1',
+ id=53,
+ color=[255, 128, 0],
+ type='',
+ swap='L_Middle_1'),
+ 54:
+ dict(
+ name='R_Middle_2',
+ id=54,
+ color=[255, 128, 0],
+ type='',
+ swap='L_Middle_2'),
+ 55:
+ dict(
+ name='R_Middle_3',
+ id=55,
+ color=[255, 128, 0],
+ type='',
+ swap='L_Middle_3'),
+ 56:
+ dict(
+ name='R_Middle_4',
+ id=56,
+ color=[255, 128, 0],
+ type='',
+ swap='L_Middle_4'),
+ 57:
+ dict(
+ name='R_Ring_1',
+ id=57,
+ color=[255, 128, 0],
+ type='',
+ swap='L_Ring_1'),
+ 58:
+ dict(
+ name='R_Ring_2',
+ id=58,
+ color=[255, 128, 0],
+ type='',
+ swap='L_Ring_2'),
+ 59:
+ dict(
+ name='R_Ring_3',
+ id=59,
+ color=[255, 128, 0],
+ type='',
+ swap='L_Ring_3'),
+ 60:
+ dict(
+ name='R_Ring_4',
+ id=60,
+ color=[255, 128, 0],
+ type='',
+ swap='L_Ring_4'),
+ 61:
+ dict(
+ name='R_Pinky_1',
+ id=61,
+ color=[255, 128, 0],
+ type='',
+ swap='L_Pinky_1'),
+ 62:
+ dict(
+ name='R_Pinky_2',
+ id=62,
+ color=[255, 128, 0],
+ type='',
+ swap='L_Pinky_2'),
+ 63:
+ dict(
+ name='R_Pinky_3',
+ id=63,
+ color=[255, 128, 0],
+ type='',
+ swap='L_Pinky_3'),
+ 64:
+ dict(
+ name='R_Pinky_4',
+ id=64,
+ color=[255, 128, 0],
+ type='',
+ swap='L_Pinky_4'),
+ 65:
+ dict(name='Face_1', id=65, color=[255, 255, 255], type='', swap=''),
+ 66:
+ dict(name='Face_2', id=66, color=[255, 255, 255], type='', swap=''),
+ 67:
+ dict(
+ name='Face_3',
+ id=67,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_4'),
+ 68:
+ dict(
+ name='Face_4',
+ id=68,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_3'),
+ 69:
+ dict(
+ name='Face_5',
+ id=69,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_14'),
+ 70:
+ dict(
+ name='Face_6',
+ id=70,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_13'),
+ 71:
+ dict(
+ name='Face_7',
+ id=71,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_12'),
+ 72:
+ dict(
+ name='Face_8',
+ id=72,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_11'),
+ 73:
+ dict(
+ name='Face_9',
+ id=73,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_10'),
+ 74:
+ dict(
+ name='Face_10',
+ id=74,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_9'),
+ 75:
+ dict(
+ name='Face_11',
+ id=75,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_8'),
+ 76:
+ dict(
+ name='Face_12',
+ id=76,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_7'),
+ 77:
+ dict(
+ name='Face_13',
+ id=77,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_6'),
+ 78:
+ dict(
+ name='Face_14',
+ id=78,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_5'),
+ 79:
+ dict(name='Face_15', id=79, color=[255, 255, 255], type='', swap=''),
+ 80:
+ dict(name='Face_16', id=80, color=[255, 255, 255], type='', swap=''),
+ 81:
+ dict(name='Face_17', id=81, color=[255, 255, 255], type='', swap=''),
+ 82:
+ dict(name='Face_18', id=82, color=[255, 255, 255], type='', swap=''),
+ 83:
+ dict(
+ name='Face_19',
+ id=83,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_23'),
+ 84:
+ dict(
+ name='Face_20',
+ id=84,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_22'),
+ 85:
+ dict(name='Face_21', id=85, color=[255, 255, 255], type='', swap=''),
+ 86:
+ dict(
+ name='Face_22',
+ id=86,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_20'),
+ 87:
+ dict(
+ name='Face_23',
+ id=87,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_19'),
+ 88:
+ dict(
+ name='Face_24',
+ id=88,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_33'),
+ 89:
+ dict(
+ name='Face_25',
+ id=89,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_32'),
+ 90:
+ dict(
+ name='Face_26',
+ id=90,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_31'),
+ 91:
+ dict(
+ name='Face_27',
+ id=91,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_30'),
+ 92:
+ dict(
+ name='Face_28',
+ id=92,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_35'),
+ 93:
+ dict(
+ name='Face_29',
+ id=93,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_34'),
+ 94:
+ dict(
+ name='Face_30',
+ id=94,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_27'),
+ 95:
+ dict(
+ name='Face_31',
+ id=95,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_26'),
+ 96:
+ dict(
+ name='Face_32',
+ id=96,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_25'),
+ 97:
+ dict(
+ name='Face_33',
+ id=97,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_24'),
+ 98:
+ dict(
+ name='Face_34',
+ id=98,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_29'),
+ 99:
+ dict(
+ name='Face_35',
+ id=99,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_28'),
+ 100:
+ dict(
+ name='Face_36',
+ id=100,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_42'),
+ 101:
+ dict(
+ name='Face_37',
+ id=101,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_41'),
+ 102:
+ dict(
+ name='Face_38',
+ id=102,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_40'),
+ 103:
+ dict(name='Face_39', id=103, color=[255, 255, 255], type='', swap=''),
+ 104:
+ dict(
+ name='Face_40',
+ id=104,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_38'),
+ 105:
+ dict(
+ name='Face_41',
+ id=105,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_37'),
+ 106:
+ dict(
+ name='Face_42',
+ id=106,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_36'),
+ 107:
+ dict(
+ name='Face_43',
+ id=107,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_47'),
+ 108:
+ dict(
+ name='Face_44',
+ id=108,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_46'),
+ 109:
+ dict(name='Face_45', id=109, color=[255, 255, 255], type='', swap=''),
+ 110:
+ dict(
+ name='Face_46',
+ id=110,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_44'),
+ 111:
+ dict(
+ name='Face_47',
+ id=111,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_43'),
+ 112:
+ dict(
+ name='Face_48',
+ id=112,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_52'),
+ 113:
+ dict(
+ name='Face_49',
+ id=113,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_51'),
+ 114:
+ dict(name='Face_50', id=114, color=[255, 255, 255], type='', swap=''),
+ 115:
+ dict(
+ name='Face_51',
+ id=115,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_49'),
+ 116:
+ dict(
+ name='Face_52',
+ id=116,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_48'),
+ 117:
+ dict(
+ name='Face_53',
+ id=117,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_55'),
+ 118:
+ dict(name='Face_54', id=118, color=[255, 255, 255], type='', swap=''),
+ 119:
+ dict(
+ name='Face_55',
+ id=119,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_53'),
+ 120:
+ dict(
+ name='Face_56',
+ id=120,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_72'),
+ 121:
+ dict(
+ name='Face_57',
+ id=121,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_71'),
+ 122:
+ dict(
+ name='Face_58',
+ id=122,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_70'),
+ 123:
+ dict(
+ name='Face_59',
+ id=123,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_69'),
+ 124:
+ dict(
+ name='Face_60',
+ id=124,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_68'),
+ 125:
+ dict(
+ name='Face_61',
+ id=125,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_67'),
+ 126:
+ dict(
+ name='Face_62',
+ id=126,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_66'),
+ 127:
+ dict(
+ name='Face_63',
+ id=127,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_65'),
+ 128:
+ dict(name='Face_64', id=128, color=[255, 255, 255], type='', swap=''),
+ 129:
+ dict(
+ name='Face_65',
+ id=129,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_63'),
+ 130:
+ dict(
+ name='Face_66',
+ id=130,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_62'),
+ 131:
+ dict(
+ name='Face_67',
+ id=131,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_61'),
+ 132:
+ dict(
+ name='Face_68',
+ id=132,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_60'),
+ 133:
+ dict(
+ name='Face_69',
+ id=133,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_59'),
+ 134:
+ dict(
+ name='Face_70',
+ id=134,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_58'),
+ 135:
+ dict(
+ name='Face_71',
+ id=135,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_57'),
+ 136:
+ dict(
+ name='Face_72',
+ id=136,
+ color=[255, 255, 255],
+ type='',
+ swap='Face_56'),
+ },
+ skeleton_info={
+ 0: dict(link=('L_Ankle', 'L_Knee'), id=0, color=[0, 255, 0]),
+ 1: dict(link=('L_Knee', 'L_Hip'), id=1, color=[0, 255, 0]),
+ 2: dict(link=('R_Ankle', 'R_Knee'), id=2, color=[0, 255, 0]),
+ 3: dict(link=('R_Knee', 'R_Hip'), id=3, color=[0, 255, 0]),
+ 4: dict(link=('L_Hip', 'R_Hip'), id=4, color=[0, 255, 0]),
+ 5: dict(link=('L_Shoulder', 'L_Hip'), id=5, color=[0, 255, 0]),
+ 6: dict(link=('R_Shoulder', 'R_Hip'), id=6, color=[0, 255, 0]),
+ 7: dict(link=('L_Shoulder', 'R_Shoulder'), id=7, color=[0, 255, 0]),
+ 8: dict(link=('L_Shoulder', 'L_Elbow'), id=8, color=[0, 255, 0]),
+ 9: dict(link=('R_Shoulder', 'R_Elbow'), id=9, color=[0, 255, 0]),
+ 10: dict(link=('L_Elbow', 'L_Wrist'), id=10, color=[0, 255, 0]),
+ 11: dict(link=('R_Elbow', 'R_Wrist'), id=11, color=[255, 128, 0]),
+ 12: dict(link=('L_Eye', 'R_Eye'), id=12, color=[255, 128, 0]),
+ 13: dict(link=('Nose', 'L_Eye'), id=13, color=[255, 128, 0]),
+ 14: dict(link=('Nose', 'R_Eye'), id=14, color=[255, 128, 0]),
+ 15: dict(link=('L_Eye', 'L_Ear'), id=15, color=[255, 128, 0]),
+ 16: dict(link=('R_Eye', 'R_Ear'), id=16, color=[255, 128, 0]),
+ 17: dict(link=('L_Ear', 'L_Shoulder'), id=17, color=[255, 128, 0]),
+ 18: dict(link=('R_Ear', 'R_Shoulder'), id=18, color=[255, 128, 0]),
+ 19: dict(link=('L_Ankle', 'L_Big_toe'), id=19, color=[255, 128, 0]),
+ 20: dict(link=('L_Ankle', 'L_Small_toe'), id=20, color=[255, 128, 0]),
+ 21: dict(link=('L_Ankle', 'L_Heel'), id=21, color=[255, 128, 0]),
+ 22: dict(link=('R_Ankle', 'R_Big_toe'), id=22, color=[255, 128, 0]),
+ 23: dict(link=('R_Ankle', 'R_Small_toe'), id=23, color=[255, 128, 0]),
+ 24: dict(link=('R_Ankle', 'R_Heel'), id=24, color=[255, 128, 0]),
+ 25: dict(link=('L_Wrist', 'L_Thumb_1'), id=25, color=[255, 128, 0]),
+ 26: dict(link=('L_Thumb_1', 'L_Thumb_2'), id=26, color=[255, 128, 0]),
+ 27: dict(link=('L_Thumb_2', 'L_Thumb_3'), id=27, color=[255, 128, 0]),
+ 28: dict(link=('L_Thumb_3', 'L_Thumb_4'), id=28, color=[255, 128, 0]),
+ 29: dict(link=('L_Wrist', 'L_Index_1'), id=29, color=[255, 128, 0]),
+ 30: dict(link=('L_Index_1', 'L_Index_2'), id=30, color=[255, 128, 0]),
+ 31:
+ dict(link=('L_Index_2', 'L_Index_3'), id=31, color=[255, 255, 255]),
+ 32:
+ dict(link=('L_Index_3', 'L_Index_4'), id=32, color=[255, 255, 255]),
+ 33: dict(link=('L_Wrist', 'L_Middle_1'), id=33, color=[255, 255, 255]),
+ 34:
+ dict(link=('L_Middle_1', 'L_Middle_2'), id=34, color=[255, 255, 255]),
+ 35:
+ dict(link=('L_Middle_2', 'L_Middle_3'), id=35, color=[255, 255, 255]),
+ 36:
+ dict(link=('L_Middle_3', 'L_Middle_4'), id=36, color=[255, 255, 255]),
+ 37: dict(link=('L_Wrist', 'L_Ring_1'), id=37, color=[255, 255, 255]),
+ 38: dict(link=('L_Ring_1', 'L_Ring_2'), id=38, color=[255, 255, 255]),
+ 39: dict(link=('L_Ring_2', 'L_Ring_3'), id=39, color=[255, 255, 255]),
+ 40: dict(link=('L_Ring_3', 'L_Ring_4'), id=40, color=[255, 255, 255]),
+ 41: dict(link=('L_Wrist', 'L_Pinky_1'), id=41, color=[255, 255, 255]),
+ 42:
+ dict(link=('L_Pinky_1', 'L_Pinky_2'), id=42, color=[255, 255, 255]),
+ 43:
+ dict(link=('L_Pinky_2', 'L_Pinky_3'), id=43, color=[255, 255, 255]),
+ 44:
+ dict(link=('L_Pinky_3', 'L_Pinky_4'), id=44, color=[255, 255, 255]),
+ 45: dict(link=('R_Wrist', 'R_Thumb_1'), id=45, color=[255, 255, 255]),
+ 46:
+ dict(link=('R_Thumb_1', 'R_Thumb_2'), id=46, color=[255, 255, 255]),
+ 47:
+ dict(link=('R_Thumb_2', 'R_Thumb_3'), id=47, color=[255, 255, 255]),
+ 48:
+ dict(link=('R_Thumb_3', 'R_Thumb_4'), id=48, color=[255, 255, 255]),
+ 49: dict(link=('R_Wrist', 'R_Index_1'), id=49, color=[255, 255, 255]),
+ 50:
+ dict(link=('R_Index_1', 'R_Index_2'), id=50, color=[255, 255, 255]),
+ 51:
+ dict(link=('R_Index_2', 'R_Index_3'), id=51, color=[255, 255, 255]),
+ 52:
+ dict(link=('R_Index_3', 'R_Index_4'), id=52, color=[255, 255, 255]),
+ 53: dict(link=('R_Wrist', 'R_Middle_1'), id=53, color=[255, 255, 255]),
+ 54:
+ dict(link=('R_Middle_1', 'R_Middle_2'), id=54, color=[255, 255, 255]),
+ 55:
+ dict(link=('R_Middle_2', 'R_Middle_3'), id=55, color=[255, 255, 255]),
+ 56:
+ dict(link=('R_Middle_3', 'R_Middle_4'), id=56, color=[255, 255, 255]),
+ 57: dict(link=('R_Wrist', 'R_Pinky_1'), id=57, color=[255, 255, 255]),
+ 58:
+ dict(link=('R_Pinky_1', 'R_Pinky_2'), id=58, color=[255, 255, 255]),
+ 59:
+ dict(link=('R_Pinky_2', 'R_Pinky_3'), id=59, color=[255, 255, 255]),
+ 60:
+ dict(link=('R_Pinky_3', 'R_Pinky_4'), id=60, color=[255, 255, 255]),
+ },
+ joint_weights=[1.] * 137,
+ sigmas=[])
diff --git a/configs/_base_/default_runtime.py b/configs/_base_/default_runtime.py
index 561d574fa7..6f27c0345a 100644
--- a/configs/_base_/default_runtime.py
+++ b/configs/_base_/default_runtime.py
@@ -8,7 +8,12 @@
checkpoint=dict(type='CheckpointHook', interval=10),
sampler_seed=dict(type='DistSamplerSeedHook'),
visualization=dict(type='PoseVisualizationHook', enable=False),
-)
+ badcase=dict(
+ type='BadCaseAnalysisHook',
+ enable=False,
+ out_dir='badcase',
+ metric_type='loss',
+ badcase_thr=5))
# custom hooks
custom_hooks = [
diff --git a/configs/body_2d_keypoint/associative_embedding/coco/ae_hrnet-w32_8xb24-300e_coco-512x512.py b/configs/body_2d_keypoint/associative_embedding/coco/ae_hrnet-w32_8xb24-300e_coco-512x512.py
index 5adc1aac1a..a4804cbe37 100644
--- a/configs/body_2d_keypoint/associative_embedding/coco/ae_hrnet-w32_8xb24-300e_coco-512x512.py
+++ b/configs/body_2d_keypoint/associative_embedding/coco/ae_hrnet-w32_8xb24-300e_coco-512x512.py
@@ -36,6 +36,8 @@
input_size=(512, 512),
heatmap_size=(128, 128),
sigma=2,
+ decode_topk=30,
+ decode_center_shift=0.5,
decode_keypoint_order=[
0, 1, 2, 3, 4, 5, 6, 11, 12, 7, 8, 9, 10, 13, 14, 15, 16
],
@@ -97,7 +99,7 @@
test_cfg=dict(
multiscale_test=False,
flip_test=True,
- shift_heatmap=True,
+ shift_heatmap=False,
restore_heatmap_size=True,
align_corners=False))
@@ -113,9 +115,14 @@
dict(
type='BottomupResize',
input_size=codec['input_size'],
- size_factor=32,
+ size_factor=64,
resize_mode='expand'),
- dict(type='PackPoseInputs')
+ dict(
+ type='PackPoseInputs',
+ meta_keys=('id', 'img_id', 'img_path', 'crowd_index', 'ori_shape',
+ 'img_shape', 'input_size', 'input_center', 'input_scale',
+ 'flip', 'flip_direction', 'flip_indices', 'raw_ann_info',
+ 'skeleton_links'))
]
# data loaders
@@ -154,6 +161,6 @@
type='CocoMetric',
ann_file=data_root + 'annotations/person_keypoints_val2017.json',
nms_mode='none',
- score_mode='keypoint',
+ score_mode='bbox',
)
test_evaluator = val_evaluator
diff --git a/configs/body_2d_keypoint/associative_embedding/coco/hrnet_coco.md b/configs/body_2d_keypoint/associative_embedding/coco/hrnet_coco.md
new file mode 100644
index 0000000000..caae01d60d
--- /dev/null
+++ b/configs/body_2d_keypoint/associative_embedding/coco/hrnet_coco.md
@@ -0,0 +1,57 @@
+
+
+
+
+
+
+
+
+Associative Embedding (NIPS'2017)
+ +```bibtex +@inproceedings{newell2017associative, + title={Associative embedding: End-to-end learning for joint detection and grouping}, + author={Newell, Alejandro and Huang, Zhiao and Deng, Jia}, + booktitle={Advances in neural information processing systems}, + pages={2277--2287}, + year={2017} +} +``` + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+Results on COCO val2017 without multi-scale test
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :-------------------------------------------- | :--------: | :---: | :-------------: | :-------------: | :---: | :-------------: | :-------------------------------------------: | :-------------------------------------------: |
+| [HRNet-w32](/configs/body_2d_keypoint/associative_embedding/coco/ae_hrnet-w32_8xb24-300e_coco-512x512.py) | 512x512 | 0.656 | 0.864 | 0.719 | 0.711 | 0.893 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/hrnet_w32_coco_512x512-bcb8c247_20200816.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/hrnet_w32_coco_512x512_20200816.log.json) |
diff --git a/configs/body_2d_keypoint/associative_embedding/coco/hrnet_coco.yml b/configs/body_2d_keypoint/associative_embedding/coco/hrnet_coco.yml
new file mode 100644
index 0000000000..5fcd749f0f
--- /dev/null
+++ b/configs/body_2d_keypoint/associative_embedding/coco/hrnet_coco.yml
@@ -0,0 +1,25 @@
+Collections:
+- Name: AE
+ Paper:
+ Title: "Associative embedding: End-to-end learning for joint detection and grouping"
+ URL: https://arxiv.org/abs/1611.05424
+ README: https://github.com/open-mmlab/mmpose/blob/main/docs/src/papers/algorithms/associative_embedding.md
+Models:
+- Config: configs/body_2d_keypoint/associative_embedding/coco/ae_hrnet-w32_8xb24-300e_coco-512x512.py
+ In Collection: AE
+ Metadata:
+ Architecture:
+ - AE
+ - HRNet
+ Training Data: COCO
+ Name: ae_hrnet-w32_8xb24-300e_coco-512x512
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.656
+ AP@0.5: 0.864
+ AP@0.75: 0.719
+ AR: 0.711
+ AR@0.5: 0.893
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/hrnet_w32_coco_512x512-bcb8c247_20200816.pth
diff --git a/configs/body_2d_keypoint/dekr/coco/dekr_hrnet-w32_8xb10-140e_coco-512x512.py b/configs/body_2d_keypoint/dekr/coco/dekr_hrnet-w32_8xb10-140e_coco-512x512.py
index 6f2d03a82f..743de8882c 100644
--- a/configs/body_2d_keypoint/dekr/coco/dekr_hrnet-w32_8xb10-140e_coco-512x512.py
+++ b/configs/body_2d_keypoint/dekr/coco/dekr_hrnet-w32_8xb10-140e_coco-512x512.py
@@ -98,6 +98,9 @@
loss_weight=0.002,
),
decoder=codec,
+ # This rescore net is adapted from the official repo.
+ # If you are not using the original COCO dataset for training,
+ # please make sure to remove the `rescore_cfg` item
rescore_cfg=dict(
in_channels=74,
norm_indexes=(5, 6),
diff --git a/configs/body_2d_keypoint/dekr/coco/dekr_hrnet-w48_8xb10-140e_coco-640x640.py b/configs/body_2d_keypoint/dekr/coco/dekr_hrnet-w48_8xb10-140e_coco-640x640.py
index 776a6bb039..57f656fb4d 100644
--- a/configs/body_2d_keypoint/dekr/coco/dekr_hrnet-w48_8xb10-140e_coco-640x640.py
+++ b/configs/body_2d_keypoint/dekr/coco/dekr_hrnet-w48_8xb10-140e_coco-640x640.py
@@ -99,6 +99,9 @@
loss_weight=0.002,
),
decoder=codec,
+ # This rescore net is adapted from the official repo.
+ # If you are not using the original COCO dataset for training,
+ # please make sure to remove the `rescore_cfg` item
rescore_cfg=dict(
in_channels=74,
norm_indexes=(5, 6),
diff --git a/configs/body_2d_keypoint/dekr/crowdpose/dekr_hrnet-w32_8xb10-300e_crowdpose-512x512.py b/configs/body_2d_keypoint/dekr/crowdpose/dekr_hrnet-w32_8xb10-300e_crowdpose-512x512.py
index c00f0459de..c990eecdd0 100644
--- a/configs/body_2d_keypoint/dekr/crowdpose/dekr_hrnet-w32_8xb10-300e_crowdpose-512x512.py
+++ b/configs/body_2d_keypoint/dekr/crowdpose/dekr_hrnet-w32_8xb10-300e_crowdpose-512x512.py
@@ -98,6 +98,9 @@
loss_weight=0.004,
),
decoder=codec,
+ # This rescore net is adapted from the official repo.
+ # If you are not using the original CrowdPose dataset for training,
+ # please make sure to remove the `rescore_cfg` item
rescore_cfg=dict(
in_channels=59,
norm_indexes=(0, 1),
diff --git a/configs/body_2d_keypoint/dekr/crowdpose/dekr_hrnet-w48_8xb5-300e_crowdpose-640x640.py b/configs/body_2d_keypoint/dekr/crowdpose/dekr_hrnet-w48_8xb5-300e_crowdpose-640x640.py
index 31d637299a..7d88ee5d20 100644
--- a/configs/body_2d_keypoint/dekr/crowdpose/dekr_hrnet-w48_8xb5-300e_crowdpose-640x640.py
+++ b/configs/body_2d_keypoint/dekr/crowdpose/dekr_hrnet-w48_8xb5-300e_crowdpose-640x640.py
@@ -99,6 +99,9 @@
loss_weight=0.004,
),
decoder=codec,
+ # This rescore net is adapted from the official repo.
+ # If you are not using the original CrowdPose dataset for training,
+ # please make sure to remove the `rescore_cfg` item
rescore_cfg=dict(
in_channels=59,
norm_indexes=(0, 1),
diff --git a/configs/body_2d_keypoint/edpose/coco/edpose_coco.md b/configs/body_2d_keypoint/edpose/coco/edpose_coco.md
new file mode 100644
index 0000000000..4016bc87e0
--- /dev/null
+++ b/configs/body_2d_keypoint/edpose/coco/edpose_coco.md
@@ -0,0 +1,62 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+ED-Pose (ICLR'2023)
+ +```bibtex +@inproceedings{ +yang2023explicit, +title={Explicit Box Detection Unifies End-to-End Multi-Person Pose Estimation}, +author={Jie Yang and Ailing Zeng and Shilong Liu and Feng Li and Ruimao Zhang and Lei Zhang}, +booktitle={International Conference on Learning Representations}, +year={2023}, +url={https://openreview.net/forum?id=s4WVupnJjmX} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on COCO val2017.
+
+| Arch | BackBone | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :-------------------------------------------- | :-------: | :---: | :-------------: | :-------------: | :---: | :-------------: | :--------------------------------------------: | :-------------------------------------------: |
+| [edpose_res50_coco](/configs/body_2d_keypoint/edpose/coco/edpose_res50_8xb2-50e_coco-800x1333.py) | ResNet-50 | 0.716 | 0.897 | 0.783 | 0.793 | 0.943 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/edpose/coco/edpose_res50_coco_3rdparty.pth) | [log](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/edpose/coco/edpose_res50_coco_3rdparty.json) |
+
+The checkpoint is converted from the official repo. The training of EDPose is not supported yet. It will be supported in the future updates.
+
+The above config follows [Pure Python style](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/config.html#a-pure-python-style-configuration-file-beta). Please install `mmengine>=0.8.2` to use this config.
diff --git a/configs/body_2d_keypoint/edpose/coco/edpose_coco.yml b/configs/body_2d_keypoint/edpose/coco/edpose_coco.yml
new file mode 100644
index 0000000000..4d00ee4114
--- /dev/null
+++ b/configs/body_2d_keypoint/edpose/coco/edpose_coco.yml
@@ -0,0 +1,26 @@
+Collections:
+- Name: ED-Pose
+ Paper:
+ Title: Explicit Box Detection Unifies End-to-End Multi-Person Pose Estimation
+ URL: https://arxiv.org/pdf/2302.01593.pdf
+ README: https://github.com/open-mmlab/mmpose/blob/main/docs/src/papers/algorithms/edpose.md
+Models:
+- Config: configs/body_2d_keypoint/edpose/coco/edpose_res50_8xb2-50e_coco-800x1333.py
+ In Collection: ED-Pose
+ Alias: edpose
+ Metadata:
+ Architecture: &id001
+ - ED-Pose
+ - ResNet
+ Training Data: COCO
+ Name: edpose_res50_8xb2-50e_coco-800x1333
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.716
+ AP@0.5: 0.897
+ AP@0.75: 0.783
+ AR: 0.793
+ AR@0.5: 0.943
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/edpose/coco/edpose_res50_coco_3rdparty.pth
diff --git a/configs/body_2d_keypoint/edpose/coco/edpose_res50_8xb2-50e_coco-800x1333.py b/configs/body_2d_keypoint/edpose/coco/edpose_res50_8xb2-50e_coco-800x1333.py
new file mode 100644
index 0000000000..a1592538db
--- /dev/null
+++ b/configs/body_2d_keypoint/edpose/coco/edpose_res50_8xb2-50e_coco-800x1333.py
@@ -0,0 +1,236 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.config import read_base
+
+with read_base():
+ from mmpose.configs._base_.default_runtime import * # noqa
+
+from mmcv.transforms import RandomChoice, RandomChoiceResize
+from mmengine.dataset import DefaultSampler
+from mmengine.model import PretrainedInit
+from mmengine.optim import LinearLR, MultiStepLR
+from torch.nn import GroupNorm
+from torch.optim import Adam
+
+from mmpose.codecs import EDPoseLabel
+from mmpose.datasets import (BottomupRandomChoiceResize, BottomupRandomCrop,
+ CocoDataset, LoadImage, PackPoseInputs,
+ RandomFlip)
+from mmpose.evaluation import CocoMetric
+from mmpose.models import (BottomupPoseEstimator, ChannelMapper, EDPoseHead,
+ PoseDataPreprocessor, ResNet)
+from mmpose.models.utils import FrozenBatchNorm2d
+
+# runtime
+train_cfg.update(max_epochs=50, val_interval=10) # noqa
+
+# optimizer
+optim_wrapper = dict(optimizer=dict(
+ type=Adam,
+ lr=1e-3,
+))
+
+# learning policy
+param_scheduler = [
+ dict(type=LinearLR, begin=0, end=500, start_factor=0.001,
+ by_epoch=False), # warm-up
+ dict(
+ type=MultiStepLR,
+ begin=0,
+ end=140,
+ milestones=[33, 45],
+ gamma=0.1,
+ by_epoch=True)
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=80)
+
+# hooks
+default_hooks.update( # noqa
+ checkpoint=dict(save_best='coco/AP', rule='greater'))
+
+# codec settings
+codec = dict(type=EDPoseLabel, num_select=50, num_keypoints=17)
+
+# model settings
+model = dict(
+ type=BottomupPoseEstimator,
+ data_preprocessor=dict(
+ type=PoseDataPreprocessor,
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True,
+ pad_size_divisor=1),
+ backbone=dict(
+ type=ResNet,
+ depth=50,
+ num_stages=4,
+ out_indices=(1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type=FrozenBatchNorm2d, requires_grad=False),
+ norm_eval=True,
+ style='pytorch',
+ init_cfg=dict(
+ type=PretrainedInit, checkpoint='torchvision://resnet50')),
+ neck=dict(
+ type=ChannelMapper,
+ in_channels=[512, 1024, 2048],
+ kernel_size=1,
+ out_channels=256,
+ act_cfg=None,
+ norm_cfg=dict(type=GroupNorm, num_groups=32),
+ num_outs=4),
+ head=dict(
+ type=EDPoseHead,
+ num_queries=900,
+ num_feature_levels=4,
+ num_keypoints=17,
+ as_two_stage=True,
+ encoder=dict(
+ num_layers=6,
+ layer_cfg=dict( # DeformableDetrTransformerEncoderLayer
+ self_attn_cfg=dict( # MultiScaleDeformableAttention
+ embed_dims=256,
+ num_heads=8,
+ num_levels=4,
+ num_points=4,
+ batch_first=True),
+ ffn_cfg=dict(
+ embed_dims=256,
+ feedforward_channels=2048,
+ num_fcs=2,
+ ffn_drop=0.0))),
+ decoder=dict(
+ num_layers=6,
+ embed_dims=256,
+ layer_cfg=dict( # DeformableDetrTransformerDecoderLayer
+ self_attn_cfg=dict( # MultiheadAttention
+ embed_dims=256,
+ num_heads=8,
+ batch_first=True),
+ cross_attn_cfg=dict( # MultiScaleDeformableAttention
+ embed_dims=256,
+ batch_first=True),
+ ffn_cfg=dict(
+ embed_dims=256, feedforward_channels=2048, ffn_drop=0.1)),
+ query_dim=4,
+ num_feature_levels=4,
+ num_group=100,
+ num_dn=100,
+ num_box_decoder_layers=2,
+ return_intermediate=True),
+ out_head=dict(num_classes=2),
+ positional_encoding=dict(
+ num_pos_feats=128,
+ temperatureH=20,
+ temperatureW=20,
+ normalize=True),
+ denosing_cfg=dict(
+ dn_box_noise_scale=0.4,
+ dn_label_noise_ratio=0.5,
+ dn_labelbook_size=100,
+ dn_attn_mask_type_list=['match2dn', 'dn2dn', 'group2group']),
+ data_decoder=codec),
+ test_cfg=dict(Pmultiscale_test=False, flip_test=False, num_select=50),
+ train_cfg=dict())
+
+# enable DDP training when rescore net is used
+find_unused_parameters = True
+
+# base dataset settings
+dataset_type = CocoDataset
+data_mode = 'bottomup'
+data_root = 'data/coco/'
+
+# pipelines
+train_pipeline = [
+ dict(type=LoadImage),
+ dict(type=RandomFlip, direction='horizontal'),
+ dict(
+ type=RandomChoice,
+ transforms=[
+ [
+ dict(
+ type=RandomChoiceResize,
+ scales=[(480, 1333), (512, 1333), (544, 1333), (576, 1333),
+ (608, 1333), (640, 1333), (672, 1333), (704, 1333),
+ (736, 1333), (768, 1333), (800, 1333)],
+ keep_ratio=True)
+ ],
+ [
+ dict(
+ type=BottomupRandomChoiceResize,
+ # The radio of all image in train dataset < 7
+ # follow the original implement
+ scales=[(400, 4200), (500, 4200), (600, 4200)],
+ keep_ratio=True),
+ dict(
+ type=BottomupRandomCrop,
+ crop_type='absolute_range',
+ crop_size=(384, 600),
+ allow_negative_crop=True),
+ dict(
+ type=BottomupRandomChoiceResize,
+ scales=[(480, 1333), (512, 1333), (544, 1333), (576, 1333),
+ (608, 1333), (640, 1333), (672, 1333), (704, 1333),
+ (736, 1333), (768, 1333), (800, 1333)],
+ keep_ratio=True)
+ ]
+ ]),
+ dict(type=PackPoseInputs),
+]
+
+val_pipeline = [
+ dict(type=LoadImage),
+ dict(
+ type=BottomupRandomChoiceResize,
+ scales=[(800, 1333)],
+ keep_ratio=True,
+ backend='pillow'),
+ dict(
+ type=PackPoseInputs,
+ meta_keys=('id', 'img_id', 'img_path', 'crowd_index', 'ori_shape',
+ 'img_shape', 'input_size', 'input_center', 'input_scale',
+ 'flip', 'flip_direction', 'flip_indices', 'raw_ann_info',
+ 'skeleton_links'))
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=1,
+ num_workers=1,
+ persistent_workers=True,
+ sampler=dict(type=DefaultSampler, shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=train_pipeline,
+ ))
+
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=8,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type=DefaultSampler, shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_val2017.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# evaluators
+val_evaluator = dict(
+ type=CocoMetric,
+ nms_mode='none',
+ score_mode='keypoint',
+)
+test_evaluator = val_evaluator
diff --git a/configs/body_2d_keypoint/rtmpose/body8/rtmpose_body8-coco.yml b/configs/body_2d_keypoint/rtmpose/body8/rtmpose_body8-coco.yml
index 9299eccb77..10a16c61d6 100644
--- a/configs/body_2d_keypoint/rtmpose/body8/rtmpose_body8-coco.yml
+++ b/configs/body_2d_keypoint/rtmpose/body8/rtmpose_body8-coco.yml
@@ -41,6 +41,10 @@ Models:
Weights: https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-body7_pt-body7_420e-256x192-acd4a1ef_20230504.pth
- Config: configs/body_2d_keypoint/rtmpose/body8/rtmpose-m_8xb256-420e_body8-256x192.py
In Collection: RTMPose
+ Alias:
+ - human
+ - body
+ - body17
Metadata:
Architecture: *id001
Training Data: *id002
diff --git a/configs/body_2d_keypoint/rtmpose/body8/rtmpose_body8-halpe26.yml b/configs/body_2d_keypoint/rtmpose/body8/rtmpose_body8-halpe26.yml
index ceef6f9998..142918a594 100644
--- a/configs/body_2d_keypoint/rtmpose/body8/rtmpose_body8-halpe26.yml
+++ b/configs/body_2d_keypoint/rtmpose/body8/rtmpose_body8-halpe26.yml
@@ -41,6 +41,7 @@ Models:
Weights: https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-body7_pt-body7-halpe26_700e-256x192-7f134165_20230605.pth
- Config: configs/body_2d_keypoint/rtmpose/body8/rtmpose-m_8xb512-700e_body8-halpe26-256x192.py
In Collection: RTMPose
+ Alias: body26
Metadata:
Architecture: *id001
Training Data: *id002
diff --git a/configs/body_2d_keypoint/rtmpose/coco/rtmpose_coco.yml b/configs/body_2d_keypoint/rtmpose/coco/rtmpose_coco.yml
index bebe64b3b7..adb734073a 100644
--- a/configs/body_2d_keypoint/rtmpose/coco/rtmpose_coco.yml
+++ b/configs/body_2d_keypoint/rtmpose/coco/rtmpose_coco.yml
@@ -106,7 +106,6 @@ Models:
Weights: https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-aic-coco_pt-aic-coco_420e-256x192-fcb2599b_20230126.pth
- Config: configs/body_2d_keypoint/rtmpose/coco/rtmpose-m_8xb256-420e_aic-coco-256x192.py
In Collection: RTMPose
- Alias: human
Metadata:
Architecture: *id001
Training Data: *id002
diff --git a/configs/body_2d_keypoint/topdown_heatmap/coco/hrformer_coco.md b/configs/body_2d_keypoint/topdown_heatmap/coco/hrformer_coco.md
index 87309d2e7c..ef793f06fc 100644
--- a/configs/body_2d_keypoint/topdown_heatmap/coco/hrformer_coco.md
+++ b/configs/body_2d_keypoint/topdown_heatmap/coco/hrformer_coco.md
@@ -40,4 +40,4 @@ Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 da
| [pose_hrformer_small](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrformer-small_8xb32-210e_coco-256x192.py) | 256x192 | 0.738 | 0.904 | 0.812 | 0.793 | 0.941 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrformer/hrformer_small_coco_256x192-5310d898_20220316.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrformer/hrformer_small_coco_256x192_20220316.log.json) |
| [pose_hrformer_small](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrformer-small_8xb32-210e_coco-384x288.py) | 384x288 | 0.757 | 0.905 | 0.824 | 0.807 | 0.941 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrformer/hrformer_small_coco_384x288-98d237ed_20220316.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrformer/hrformer_small_coco_384x288_20220316.log.json) |
| [pose_hrformer_base](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrformer-base_8xb32-210e_coco-256x192.py) | 256x192 | 0.754 | 0.906 | 0.827 | 0.807 | 0.943 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrformer/hrformer_base_coco_256x192-6f5f1169_20220316.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrformer/hrformer_base_coco_256x192_20220316.log.json) |
-| [pose_hrformer_base](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrformer-base_8xb32-210e_coco-384x288.py) | 384x288 | 0.774 | 0.909 | 0.842 | 0.823 | 0.945 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrformer/hrformer_base_coco_384x288-ecf0758d_20220316.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrformer/hrformer_base_coco_256x192_20220316.log.json) |
+| [pose_hrformer_base](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrformer-base_8xb32-210e_coco-384x288.py) | 384x288 | 0.774 | 0.909 | 0.842 | 0.823 | 0.945 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrformer/hrformer_base_coco_384x288-ecf0758d_20220316.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrformer/hrformer_base_coco_384x288_20220316.log.json) |
diff --git a/configs/body_2d_keypoint/topdown_heatmap/coco/hrnet_coco_aic.md b/configs/body_2d_keypoint/topdown_heatmap/coco/hrnet_coco_aic.md
index fd88e25e64..1e066d563c 100644
--- a/configs/body_2d_keypoint/topdown_heatmap/coco/hrnet_coco_aic.md
+++ b/configs/body_2d_keypoint/topdown_heatmap/coco/hrnet_coco_aic.md
@@ -57,5 +57,5 @@ Evaluation results on COCO val2017 of models trained with solely COCO dataset an
| Train Set | Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
| :------------------------------------------- | :------------- | :--------: | :---: | :-------------: | :-------------: | :---: | :-------------: | :-------------------------------------: | :------------------------------------: |
| [coco](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py) | pose_hrnet_w32 | 256x192 | 0.749 | 0.906 | 0.821 | 0.804 | 0.945 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192-81c58e40_20220909.pth) | [log](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192_20220909.log) |
-| [coco-aic-merge](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-merge.py) | pose_hrnet_w32 | 256x192 | 0.757 | 0.907 | 0.829 | 0.809 | 0.944 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-merge-b05435b9_20221025.pth) | [log](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-merge_20221025.log) |
-| [coco-aic-combine](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-combine.py) | pose_hrnet_w32 | 256x192 | 0.756 | 0.906 | 0.826 | 0.807 | 0.943 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-combine-4ce66880_20221026.pth) | [log](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-combine_20221026.log) |
+| [coco-aic-merge](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-merge.py) | pose_hrnet_w32 | 256x192 | 0.756 | 0.907 | 0.828 | 0.809 | 0.944 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-merge-a9ea6d77_20230818.pth) | [log](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-merge_20230818.json) |
+| [coco-aic-combine](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-combine.py) | pose_hrnet_w32 | 256x192 | 0.755 | 0.904 | 0.825 | 0.807 | 0.942 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-combine-458125cc_20230818.pth) | [log](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-combine_20230818.json) |
diff --git a/configs/body_2d_keypoint/topdown_heatmap/coco/resnet_coco.md b/configs/body_2d_keypoint/topdown_heatmap/coco/resnet_coco.md
index 4ce6da38c6..dbe14267ed 100644
--- a/configs/body_2d_keypoint/topdown_heatmap/coco/resnet_coco.md
+++ b/configs/body_2d_keypoint/topdown_heatmap/coco/resnet_coco.md
@@ -60,3 +60,9 @@ Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 da
| [pose_resnet_101](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res101_8xb32-210e_coco-384x288.py) | 384x288 | 0.749 | 0.906 | 0.817 | 0.799 | 0.941 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_res101_8xb64-210e_coco-256x192-065d3625_20220926.pth) | [log](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_res101_8xb64-210e_coco-256x192_20220926.log) |
| [pose_resnet_152](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res152_8xb32-210e_coco-256x192.py) | 256x192 | 0.736 | 0.904 | 0.818 | 0.791 | 0.942 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_res152_8xb32-210e_coco-256x192-0345f330_20220928.pth) | [log](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_res152_8xb32-210e_coco-256x192_20220928.log) |
| [pose_resnet_152](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res152_8xb32-210e_coco-384x288.py) | 384x288 | 0.750 | 0.908 | 0.821 | 0.800 | 0.942 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_res152_8xb32-210e_coco-384x288-7fbb906f_20220927.pth) | [log](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_res152_8xb32-210e_coco-384x288_20220927.log) |
+
+The following model is equipped with a visibility prediction head and has been trained using COCO and AIC datasets.
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :-------------------------------------------- | :--------: | :---: | :-------------: | :-------------: | :---: | :-------------: | :-------------------------------------------: | :-------------------------------------------: |
+| [pose_resnet_50](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm-vis_res50_8xb64-210e_coco-aic-256x192-merge.py) | 256x192 | 0.729 | 0.900 | 0.807 | 0.783 | 0.938 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm-vis_res50_8xb64-210e_coco-aic-256x192-merge-21815b2c_20230726.pth) | [log](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192_20220923.log) |
diff --git a/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm-vis_res50_8xb64-210e_coco-aic-256x192-merge.py b/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm-vis_res50_8xb64-210e_coco-aic-256x192-merge.py
new file mode 100644
index 0000000000..f5def39ed9
--- /dev/null
+++ b/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm-vis_res50_8xb64-210e_coco-aic-256x192-merge.py
@@ -0,0 +1,167 @@
+_base_ = ['../../../_base_/default_runtime.py']
+
+# runtime
+train_cfg = dict(max_epochs=210, val_interval=10)
+
+# optimizer
+optim_wrapper = dict(optimizer=dict(
+ type='Adam',
+ lr=5e-4,
+))
+
+# learning policy
+param_scheduler = [
+ dict(
+ type='LinearLR', begin=0, end=500, start_factor=0.001,
+ by_epoch=False), # warm-up
+ dict(
+ type='MultiStepLR',
+ begin=0,
+ end=210,
+ milestones=[170, 200],
+ gamma=0.1,
+ by_epoch=True)
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=512)
+
+# hooks
+default_hooks = dict(checkpoint=dict(save_best='coco/AP', rule='greater'))
+
+# codec settings
+codec = dict(
+ type='MSRAHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50'),
+ ),
+ head=dict(
+ type='VisPredictHead',
+ loss=dict(
+ type='BCELoss',
+ use_target_weight=True,
+ use_sigmoid=True,
+ loss_weight=1e-3,
+ ),
+ pose_cfg=dict(
+ type='HeatmapHead',
+ in_channels=2048,
+ out_channels=17,
+ loss=dict(type='KeypointMSELoss', use_target_weight=True),
+ decoder=codec)),
+ test_cfg=dict(
+ flip_test=True,
+ flip_mode='heatmap',
+ shift_heatmap=True,
+ ))
+
+# base dataset settings
+dataset_type = 'CocoDataset'
+data_mode = 'topdown'
+data_root = 'data/coco/'
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(type='RandomBBoxTransform'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+
+# train datasets
+dataset_coco = dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=[],
+)
+
+dataset_aic = dict(
+ type='AicDataset',
+ data_root='data/aic/',
+ data_mode=data_mode,
+ ann_file='annotations/aic_train.json',
+ data_prefix=dict(img='ai_challenger_keypoint_train_20170902/'
+ 'keypoint_train_images_20170902/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=17,
+ mapping=[
+ (0, 6),
+ (1, 8),
+ (2, 10),
+ (3, 5),
+ (4, 7),
+ (5, 9),
+ (6, 12),
+ (7, 14),
+ (8, 16),
+ (9, 11),
+ (10, 13),
+ (11, 15),
+ ])
+ ],
+)
+
+# data loaders
+train_dataloader = dict(
+ batch_size=64,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco.py'),
+ datasets=[dataset_coco, dataset_aic],
+ pipeline=train_pipeline,
+ test_mode=False,
+ ))
+val_dataloader = dict(
+ batch_size=32,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_val2017.json',
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# evaluators
+val_evaluator = dict(
+ type='CocoMetric',
+ # score_mode='bbox',
+ ann_file=data_root + 'annotations/person_keypoints_val2017.json')
+test_evaluator = val_evaluator
diff --git a/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-base-simple_8xb64-210e_coco-256x192.py b/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-base-simple_8xb64-210e_coco-256x192.py
index 9732371787..5a55780505 100644
--- a/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-base-simple_8xb64-210e_coco-256x192.py
+++ b/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-base-simple_8xb64-210e_coco-256x192.py
@@ -71,7 +71,7 @@
init_cfg=dict(
type='Pretrained',
checkpoint='https://download.openmmlab.com/mmpose/'
- 'v1/pretrained_models/mae_pretrain_vit_base.pth'),
+ 'v1/pretrained_models/mae_pretrain_vit_base_20230913.pth'),
),
neck=dict(type='FeatureMapProcessor', scale_factor=4.0, apply_relu=True),
head=dict(
diff --git a/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-base_8xb64-210e_coco-256x192.py b/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-base_8xb64-210e_coco-256x192.py
index fc08c61dff..06522b7b91 100644
--- a/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-base_8xb64-210e_coco-256x192.py
+++ b/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-base_8xb64-210e_coco-256x192.py
@@ -71,7 +71,7 @@
init_cfg=dict(
type='Pretrained',
checkpoint='https://download.openmmlab.com/mmpose/'
- 'v1/pretrained_models/mae_pretrain_vit_base.pth'),
+ 'v1/pretrained_models/mae_pretrain_vit_base_20230913.pth'),
),
head=dict(
type='HeatmapHead',
diff --git a/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-huge-simple_8xb64-210e_coco-256x192.py b/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-huge-simple_8xb64-210e_coco-256x192.py
index 7d94f97c1b..03ae669807 100644
--- a/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-huge-simple_8xb64-210e_coco-256x192.py
+++ b/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-huge-simple_8xb64-210e_coco-256x192.py
@@ -71,7 +71,7 @@
init_cfg=dict(
type='Pretrained',
checkpoint='https://download.openmmlab.com/mmpose/'
- 'v1/pretrained_models/mae_pretrain_vit_huge.pth'),
+ 'v1/pretrained_models/mae_pretrain_vit_huge_20230913.pth'),
),
neck=dict(type='FeatureMapProcessor', scale_factor=4.0, apply_relu=True),
head=dict(
diff --git a/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-huge_8xb64-210e_coco-256x192.py b/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-huge_8xb64-210e_coco-256x192.py
index 4aa2c21c1f..6b8afcf0f4 100644
--- a/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-huge_8xb64-210e_coco-256x192.py
+++ b/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-huge_8xb64-210e_coco-256x192.py
@@ -71,7 +71,7 @@
init_cfg=dict(
type='Pretrained',
checkpoint='https://download.openmmlab.com/mmpose/'
- 'v1/pretrained_models/mae_pretrain_vit_huge.pth'),
+ 'v1/pretrained_models/mae_pretrain_vit_huge_20230913.pth'),
),
head=dict(
type='HeatmapHead',
diff --git a/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-large-simple_8xb64-210e_coco-256x192.py b/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-large-simple_8xb64-210e_coco-256x192.py
index cf875d5167..2035e786df 100644
--- a/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-large-simple_8xb64-210e_coco-256x192.py
+++ b/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-large-simple_8xb64-210e_coco-256x192.py
@@ -71,7 +71,7 @@
init_cfg=dict(
type='Pretrained',
checkpoint='https://download.openmmlab.com/mmpose/'
- 'v1/pretrained_models/mae_pretrain_vit_large.pth'),
+ 'v1/pretrained_models/mae_pretrain_vit_large_20230913.pth'),
),
neck=dict(type='FeatureMapProcessor', scale_factor=4.0, apply_relu=True),
head=dict(
diff --git a/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-large_8xb64-210e_coco-256x192.py b/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-large_8xb64-210e_coco-256x192.py
index 5ba6eafb4b..f1d0e90578 100644
--- a/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-large_8xb64-210e_coco-256x192.py
+++ b/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-large_8xb64-210e_coco-256x192.py
@@ -71,7 +71,7 @@
init_cfg=dict(
type='Pretrained',
checkpoint='https://download.openmmlab.com/mmpose/'
- 'v1/pretrained_models/mae_pretrain_vit_large.pth'),
+ 'v1/pretrained_models/mae_pretrain_vit_large_20230913.pth'),
),
head=dict(
type='HeatmapHead',
diff --git a/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-small-simple_8xb64-210e_coco-256x192.py b/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-small-simple_8xb64-210e_coco-256x192.py
index 88bd3e43e3..d8216089b7 100644
--- a/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-small-simple_8xb64-210e_coco-256x192.py
+++ b/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-small-simple_8xb64-210e_coco-256x192.py
@@ -76,7 +76,7 @@
init_cfg=dict(
type='Pretrained',
checkpoint='https://download.openmmlab.com/mmpose/'
- 'v1/pretrained_models/mae_pretrain_vit_small.pth'),
+ 'v1/pretrained_models/mae_pretrain_vit_small_20230913.pth'),
),
neck=dict(type='FeatureMapProcessor', scale_factor=4.0, apply_relu=True),
head=dict(
diff --git a/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-small_8xb64-210e_coco-256x192.py b/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-small_8xb64-210e_coco-256x192.py
index 791f9b5945..5b77da96eb 100644
--- a/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-small_8xb64-210e_coco-256x192.py
+++ b/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-small_8xb64-210e_coco-256x192.py
@@ -76,7 +76,7 @@
init_cfg=dict(
type='Pretrained',
checkpoint='https://download.openmmlab.com/mmpose/'
- 'v1/pretrained_models/mae_pretrain_vit_small.pth'),
+ 'v1/pretrained_models/mae_pretrain_vit_small_20230913.pth'),
),
head=dict(
type='HeatmapHead',
diff --git a/configs/body_2d_keypoint/topdown_heatmap/coco/vitpose_coco.md b/configs/body_2d_keypoint/topdown_heatmap/coco/vitpose_coco.md
index 68baf35aec..054a7b0f6f 100644
--- a/configs/body_2d_keypoint/topdown_heatmap/coco/vitpose_coco.md
+++ b/configs/body_2d_keypoint/topdown_heatmap/coco/vitpose_coco.md
@@ -47,7 +47,7 @@ Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 da
| [ViTPose-B](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-base_8xb64-210e_coco-256x192.py) | 256x192 | 0.757 | 0.905 | 0.829 | 0.810 | 0.946 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-base_8xb64-210e_coco-256x192-216eae50_20230314.pth) | [log](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-base_8xb64-210e_coco-256x192-216eae50_20230314.json) |
| [ViTPose-L](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-large_8xb64-210e_coco-256x192.py) | 256x192 | 0.782 | 0.914 | 0.850 | 0.834 | 0.952 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-large_8xb64-210e_coco-256x192-53609f55_20230314.pth) | [log](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-large_8xb64-210e_coco-256x192-53609f55_20230314.json) |
| [ViTPose-H](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-huge_8xb64-210e_coco-256x192.py) | 256x192 | 0.788 | 0.917 | 0.855 | 0.839 | 0.954 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-huge_8xb64-210e_coco-256x192-e32adcd4_20230314.pth) | [log](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-huge_8xb64-210e_coco-256x192-e32adcd4_20230314.json) |
-| [ViTPose-H\*](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-huge_8xb64-210e_coco-256x192.py) | 256x192 | 0.790 | 0.916 | 0.857 | 0.840 | 0.953 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-huge_3rdparty_coco-256x192-5b738c8e_20230314) | - |
+| [ViTPose-H\*](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-huge_8xb64-210e_coco-256x192.py) | 256x192 | 0.790 | 0.916 | 0.857 | 0.840 | 0.953 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_ViTPose-huge_3rdparty_coco-256x192-5b738c8e_20230314.pth) | - |
*Models with * are converted from the [official repo](https://github.com/ViTAE-Transformer/ViTPose). The config files of these models are only for validation.*
diff --git a/configs/body_2d_keypoint/yoloxpose/README.md b/configs/body_2d_keypoint/yoloxpose/README.md
new file mode 100644
index 0000000000..8195b1e236
--- /dev/null
+++ b/configs/body_2d_keypoint/yoloxpose/README.md
@@ -0,0 +1,22 @@
+# YOLO-Pose: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss
+
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+YOLO-Pose is a bottom-up pose estimation approach that simultaneously detects all person instances and regresses keypoint locations in a single pass.
+
+We implement **YOLOX-Pose** based on the **YOLOX** object detection framework and inherits the benefits of unified pose estimation and object detection from YOLO-pose. To predict keypoint locations more accurately, separate branches with adaptive convolutions are used to regress the offsets for different joints. This allows optimizing the feature extraction for each keypoint.
diff --git a/configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_coco.md b/configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_coco.md
new file mode 100644
index 0000000000..fc98239e13
--- /dev/null
+++ b/configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_coco.md
@@ -0,0 +1,59 @@
+
+
+YOLO-Pose (CVPRW'2022)
+ +```bibtex +@inproceedings{maji2022yolo, + title={Yolo-pose: Enhancing yolo for multi person pose estimation using object keypoint similarity loss}, + author={Maji, Debapriya and Nagori, Soyeb and Mathew, Manu and Poddar, Deepak}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={2637--2646}, + year={2022} +} +``` + +
+
+
+
+
+YOLO-Pose (CVPRW'2022)
+ +```bibtex +@inproceedings{maji2022yolo, + title={Yolo-pose: Enhancing yolo for multi person pose estimation using object keypoint similarity loss}, + author={Maji, Debapriya and Nagori, Soyeb and Mathew, Manu and Poddar, Deepak}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={2637--2646}, + year={2022} +} +``` + +
+
+
+
+
+YOLOX
+ +```bibtex +@article{ge2021yolox, + title={Yolox: Exceeding yolo series in 2021}, + author={Ge, Zheng and Liu, Songtao and Wang, Feng and Li, Zeming and Sun, Jian}, + journal={arXiv preprint arXiv:2107.08430}, + year={2021} +} +``` + +
+
+
+Results on COCO val2017
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :-------------------------------------------- | :--------: | :---: | :-------------: | :-------------: | :---: | :-------------: | :-------------------------------------------: | :-------------------------------------------: |
+| [yoloxpose_tiny](/configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_tiny_4xb64-300e_coco-416.py) | 416x416 | 0.526 | 0.793 | 0.556 | 0.571 | 0.833 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/yolox_pose/yoloxpose_tiny_4xb64-300e_coco-416-76eb44ca_20230829.pth) | [log](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/yolox_pose/yoloxpose_tiny_4xb64-300e_coco-416-20230829.json) |
+| [yoloxpose_s](/configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_s_8xb32-300e_coco-640.py) | 640x640 | 0.641 | 0.872 | 0.702 | 0.682 | 0.902 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/yolox_pose/yoloxpose_s_8xb32-300e_coco-640-56c79c1f_20230829.pth) | [log](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/yolox_pose/yoloxpose_s_8xb32-300e_coco-640-20230829.json) |
+| [yoloxpose_m](/configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_m_8xb32-300e_coco-640.py) | 640x640 | 0.695 | 0.899 | 0.766 | 0.733 | 0.926 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/yolox_pose/yoloxpose_m_8xb32-300e_coco-640-84e9a538_20230829.pth) | [log](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/yolox_pose/yoloxpose_m_8xb32-300e_coco-640-20230829.json) |
+| [yoloxpose_l](/configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_l_8xb32-300e_coco-640.py) | 640x640 | 0.712 | 0.901 | 0.782 | 0.749 | 0.926 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/yolox_pose/yoloxpose_l_8xb32-300e_coco-640-de0f8dee_20230829.pth) | [log](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/yolox_pose/yoloxpose_l_8xb32-300e_coco-640-20230829.json) |
diff --git a/configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_coco.yml b/configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_coco.yml
new file mode 100644
index 0000000000..378ae5dbfe
--- /dev/null
+++ b/configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_coco.yml
@@ -0,0 +1,72 @@
+Collections:
+- Name: YOLOXPose
+ Paper:
+ Title: 'YOLO-Pose: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss'
+ URL: https://arxiv.org/abs/2204.06806
+ README: https://github.com/open-mmlab/mmpose/blob/main/docs/src/papers/algorithms/yolopose.md
+Models:
+- Config: configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_tiny_4xb64-300e_coco-416.py
+ In Collection: YOLOXPose
+ Metadata:
+ Architecture: &id001
+ - YOLOXPose
+ Training Data: COCO
+ Name: yoloxpose_tiny_4xb64-300e_coco-416
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.526
+ AP@0.5: 0.793
+ AP@0.75: 0.556
+ AR: 0.571
+ AR@0.5: 0.833
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/yolox_pose/yoloxpose_tiny_4xb64-300e_coco-416-76eb44ca_20230829.pth
+- Config: configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_s_8xb32-300e_coco-640.py
+ In Collection: YOLOXPose
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: yoloxpose_s_8xb32-300e_coco-640
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.641
+ AP@0.5: 0.872
+ AP@0.75: 0.702
+ AR: 0.682
+ AR@0.5: 0.902
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/yolox_pose/yoloxpose_s_8xb32-300e_coco-640-56c79c1f_20230829.pth
+- Config: configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_m_8xb32-300e_coco-640.py
+ In Collection: YOLOXPose
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: yoloxpose_m_8xb32-300e_coco-640
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.695
+ AP@0.5: 0.899
+ AP@0.75: 0.766
+ AR: 0.733
+ AR@0.5: 0.926
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/yolox_pose/yoloxpose_m_8xb32-300e_coco-640-84e9a538_20230829.pth
+- Config: configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_l_8xb32-300e_coco-640.py
+ In Collection: YOLOXPose
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: yoloxpose_l_8xb32-300e_coco-640
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.712
+ AP@0.5: 0.901
+ AP@0.75: 0.782
+ AR: 0.749
+ AR@0.5: 0.926
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/yolox_pose/yoloxpose_l_8xb32-300e_coco-640-de0f8dee_20230829.pth
diff --git a/configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_l_8xb32-300e_coco-640.py b/configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_l_8xb32-300e_coco-640.py
new file mode 100644
index 0000000000..db61ea854a
--- /dev/null
+++ b/configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_l_8xb32-300e_coco-640.py
@@ -0,0 +1,17 @@
+_base_ = './yoloxpose_s_8xb32-300e_coco-640.py'
+
+widen_factor = 1
+deepen_factor = 1
+checkpoint = 'https://download.openmmlab.com/mmdetection/v2.0/yolox/yolox_' \
+ 'l_8x8_300e_coco/yolox_l_8x8_300e_coco_20211126_140236-d3bd2b23.pth'
+
+# model settings
+model = dict(
+ backbone=dict(
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ init_cfg=dict(checkpoint=checkpoint),
+ ),
+ neck=dict(
+ in_channels=[256, 512, 1024], out_channels=256, num_csp_blocks=3),
+ head=dict(head_module_cfg=dict(widen_factor=widen_factor)))
diff --git a/configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_m_8xb32-300e_coco-640.py b/configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_m_8xb32-300e_coco-640.py
new file mode 100644
index 0000000000..1fa895bc54
--- /dev/null
+++ b/configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_m_8xb32-300e_coco-640.py
@@ -0,0 +1,16 @@
+_base_ = './yoloxpose_s_8xb32-300e_coco-640.py'
+
+widen_factor = 0.75
+deepen_factor = 0.67
+checkpoint = 'https://download.openmmlab.com/mmpose/v1/pretrained_models/' \
+ 'yolox_m_8x8_300e_coco_20230829.pth'
+
+# model settings
+model = dict(
+ backbone=dict(
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ init_cfg=dict(checkpoint=checkpoint),
+ ),
+ neck=dict(in_channels=[192, 384, 768], out_channels=192, num_csp_blocks=2),
+ head=dict(head_module_cfg=dict(widen_factor=widen_factor)))
diff --git a/configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_s_8xb32-300e_coco-640.py b/configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_s_8xb32-300e_coco-640.py
new file mode 100644
index 0000000000..948a916b06
--- /dev/null
+++ b/configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_s_8xb32-300e_coco-640.py
@@ -0,0 +1,266 @@
+_base_ = '../../../_base_/default_runtime.py'
+
+# runtime
+train_cfg = dict(
+ _delete_=True,
+ type='EpochBasedTrainLoop',
+ max_epochs=300,
+ val_interval=10,
+ dynamic_intervals=[(280, 1)])
+
+auto_scale_lr = dict(base_batch_size=256)
+
+default_hooks = dict(
+ checkpoint=dict(type='CheckpointHook', interval=10, max_keep_ckpts=3))
+
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=0.004, weight_decay=0.05),
+ paramwise_cfg=dict(
+ norm_decay_mult=0,
+ bias_decay_mult=0,
+ bypass_duplicate=True,
+ ),
+ clip_grad=dict(max_norm=0.1, norm_type=2))
+
+param_scheduler = [
+ dict(
+ type='QuadraticWarmupLR',
+ by_epoch=True,
+ begin=0,
+ end=5,
+ convert_to_iter_based=True),
+ dict(
+ type='CosineAnnealingLR',
+ eta_min=0.0002,
+ begin=5,
+ T_max=280,
+ end=280,
+ by_epoch=True,
+ convert_to_iter_based=True),
+ dict(type='ConstantLR', by_epoch=True, factor=1, begin=280, end=300),
+]
+
+# model
+widen_factor = 0.5
+deepen_factor = 0.33
+
+model = dict(
+ type='BottomupPoseEstimator',
+ init_cfg=dict(
+ type='Kaiming',
+ layer='Conv2d',
+ a=2.23606797749979,
+ distribution='uniform',
+ mode='fan_in',
+ nonlinearity='leaky_relu'),
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ pad_size_divisor=32,
+ mean=[0, 0, 0],
+ std=[1, 1, 1],
+ batch_augments=[
+ dict(
+ type='BatchSyncRandomResize',
+ random_size_range=(480, 800),
+ size_divisor=32,
+ interval=1),
+ ]),
+ backbone=dict(
+ type='CSPDarknet',
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ out_indices=(2, 3, 4),
+ spp_kernal_sizes=(5, 9, 13),
+ norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg=dict(type='Swish'),
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='https://download.openmmlab.com/mmdetection/v2.0/'
+ 'yolox/yolox_s_8x8_300e_coco/yolox_s_8x8_300e_coco_'
+ '20211121_095711-4592a793.pth',
+ prefix='backbone.',
+ )),
+ neck=dict(
+ type='YOLOXPAFPN',
+ in_channels=[128, 256, 512],
+ out_channels=128,
+ num_csp_blocks=1,
+ use_depthwise=False,
+ upsample_cfg=dict(scale_factor=2, mode='nearest'),
+ norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg=dict(type='Swish')),
+ head=dict(
+ type='YOLOXPoseHead',
+ num_keypoints=17,
+ featmap_strides=(8, 16, 32),
+ head_module_cfg=dict(
+ num_classes=1,
+ in_channels=256,
+ feat_channels=256,
+ widen_factor=widen_factor,
+ stacked_convs=2,
+ norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg=dict(type='Swish')),
+ prior_generator=dict(
+ type='MlvlPointGenerator', offset=0, strides=[8, 16, 32]),
+ assigner=dict(type='SimOTAAssigner', dynamic_k_indicator='oks'),
+ overlaps_power=0.5,
+ loss_cls=dict(type='BCELoss', reduction='sum', loss_weight=1.0),
+ loss_bbox=dict(
+ type='IoULoss',
+ mode='square',
+ eps=1e-16,
+ reduction='sum',
+ loss_weight=5.0),
+ loss_obj=dict(
+ type='BCELoss',
+ use_target_weight=True,
+ reduction='sum',
+ loss_weight=1.0),
+ loss_oks=dict(
+ type='OKSLoss',
+ reduction='none',
+ metainfo='configs/_base_/datasets/coco.py',
+ norm_target_weight=True,
+ loss_weight=30.0),
+ loss_vis=dict(
+ type='BCELoss',
+ use_target_weight=True,
+ reduction='mean',
+ loss_weight=1.0),
+ loss_bbox_aux=dict(type='L1Loss', reduction='sum', loss_weight=1.0),
+ ),
+ test_cfg=dict(
+ score_thr=0.01,
+ nms_thr=0.65,
+ ))
+
+# data
+input_size = (640, 640)
+codec = dict(type='YOLOXPoseAnnotationProcessor', input_size=input_size)
+
+train_pipeline_stage1 = [
+ dict(type='LoadImage', backend_args=None),
+ dict(
+ type='Mosaic',
+ img_scale=(640, 640),
+ pad_val=114.0,
+ pre_transform=[dict(type='LoadImage', backend_args=None)]),
+ dict(
+ type='BottomupRandomAffine',
+ input_size=(640, 640),
+ shift_factor=0.1,
+ rotate_factor=10,
+ scale_factor=(0.75, 1.0),
+ pad_val=114,
+ distribution='uniform',
+ transform_mode='perspective',
+ bbox_keep_corner=False,
+ clip_border=True,
+ ),
+ dict(
+ type='YOLOXMixUp',
+ img_scale=(640, 640),
+ ratio_range=(0.8, 1.6),
+ pad_val=114.0,
+ pre_transform=[dict(type='LoadImage', backend_args=None)]),
+ dict(type='YOLOXHSVRandomAug'),
+ dict(type='RandomFlip'),
+ dict(type='FilterAnnotations', by_kpt=True, by_box=True, keep_empty=False),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs'),
+]
+train_pipeline_stage2 = [
+ dict(type='LoadImage'),
+ dict(
+ type='BottomupRandomAffine',
+ input_size=(640, 640),
+ shift_prob=0,
+ rotate_prob=0,
+ scale_prob=0,
+ scale_type='long',
+ pad_val=(114, 114, 114),
+ bbox_keep_corner=False,
+ clip_border=True,
+ ),
+ dict(type='YOLOXHSVRandomAug'),
+ dict(type='RandomFlip'),
+ dict(type='FilterAnnotations', by_kpt=True, by_box=True, keep_empty=False),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs'),
+]
+
+data_mode = 'bottomup'
+data_root = 'data/'
+
+dataset_coco = dict(
+ type='CocoDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ filter_cfg=dict(filter_empty_gt=False, min_size=32),
+ ann_file='coco/annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='coco/train2017/'),
+ pipeline=train_pipeline_stage1,
+)
+
+train_dataloader = dict(
+ batch_size=32,
+ num_workers=8,
+ persistent_workers=True,
+ pin_memory=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dataset_coco)
+
+val_pipeline = [
+ dict(type='LoadImage'),
+ dict(
+ type='BottomupResize', input_size=input_size, pad_val=(114, 114, 114)),
+ dict(
+ type='PackPoseInputs',
+ meta_keys=('id', 'img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'input_size', 'input_center', 'input_scale'))
+]
+
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=2,
+ persistent_workers=True,
+ pin_memory=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type='CocoDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='coco/annotations/person_keypoints_val2017.json',
+ data_prefix=dict(img='coco/val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# evaluators
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'coco/annotations/person_keypoints_val2017.json',
+ score_mode='bbox',
+ nms_mode='none',
+)
+test_evaluator = val_evaluator
+
+custom_hooks = [
+ dict(
+ type='YOLOXPoseModeSwitchHook',
+ num_last_epochs=20,
+ new_train_pipeline=train_pipeline_stage2,
+ priority=48),
+ dict(type='SyncNormHook', priority=48),
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ strict_load=False,
+ priority=49),
+]
diff --git a/configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_tiny_4xb64-300e_coco-416.py b/configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_tiny_4xb64-300e_coco-416.py
new file mode 100644
index 0000000000..d13d104e02
--- /dev/null
+++ b/configs/body_2d_keypoint/yoloxpose/coco/yoloxpose_tiny_4xb64-300e_coco-416.py
@@ -0,0 +1,77 @@
+_base_ = './yoloxpose_s_8xb32-300e_coco-640.py'
+
+# model settings
+widen_factor = 0.375
+deepen_factor = 0.33
+checkpoint = 'https://download.openmmlab.com/mmdetection/v2.0/yolox/yolox_' \
+ 'tiny_8x8_300e_coco/yolox_tiny_8x8_300e_coco_20211124_171234-b4047906.pth'
+
+model = dict(
+ data_preprocessor=dict(batch_augments=[
+ dict(
+ type='BatchSyncRandomResize',
+ random_size_range=(320, 640),
+ size_divisor=32,
+ interval=1),
+ ]),
+ backbone=dict(
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ init_cfg=dict(checkpoint=checkpoint),
+ ),
+ neck=dict(
+ in_channels=[96, 192, 384],
+ out_channels=96,
+ ),
+ head=dict(head_module_cfg=dict(widen_factor=widen_factor), ))
+
+# dataset settings
+train_pipeline_stage1 = [
+ dict(type='LoadImage', backend_args=None),
+ dict(
+ type='Mosaic',
+ img_scale=_base_.input_size,
+ pad_val=114.0,
+ pre_transform=[dict(type='LoadImage', backend_args=None)]),
+ dict(
+ type='BottomupRandomAffine',
+ input_size=_base_.input_size,
+ shift_factor=0.1,
+ rotate_factor=10,
+ scale_factor=(0.75, 1.0),
+ pad_val=114,
+ distribution='uniform',
+ transform_mode='perspective',
+ bbox_keep_corner=False,
+ clip_border=True,
+ ),
+ dict(type='YOLOXHSVRandomAug'),
+ dict(type='RandomFlip'),
+ dict(type='FilterAnnotations', by_kpt=True, by_box=True, keep_empty=False),
+ dict(type='GenerateTarget', encoder=_base_.codec),
+ dict(
+ type='PackPoseInputs',
+ extra_mapping_labels={
+ 'bbox': 'bboxes',
+ 'bbox_labels': 'labels',
+ 'keypoints': 'keypoints',
+ 'keypoints_visible': 'keypoints_visible',
+ 'area': 'areas'
+ }),
+]
+train_dataloader = dict(
+ batch_size=64, dataset=dict(pipeline=train_pipeline_stage1))
+
+input_size = (416, 416)
+val_pipeline = [
+ dict(type='LoadImage'),
+ dict(
+ type='BottomupResize', input_size=input_size, pad_val=(114, 114, 114)),
+ dict(
+ type='PackPoseInputs',
+ meta_keys=('id', 'img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'input_size', 'input_center', 'input_scale'))
+]
+
+val_dataloader = dict(dataset=dict(pipeline=val_pipeline, ))
+test_dataloader = val_dataloader
diff --git a/configs/body_3d_keypoint/README.md b/configs/body_3d_keypoint/README.md
index b67f7ce7ac..61cacfb94f 100644
--- a/configs/body_3d_keypoint/README.md
+++ b/configs/body_3d_keypoint/README.md
@@ -1,6 +1,6 @@
# Human Body 3D Pose Estimation
-3D human body pose estimation aims at predicting the X, Y, Z coordinates of human body joints. Based on the camera number to capture the images or videos, existing works can be further divided into multi-view methods and single-view (monocular) methods.
+3D pose estimation is the detection and analysis of X, Y, Z coordinates of human body joints from RGB images. For single-person 3D pose estimation from a monocular camera, existing works can be classified into three categories: (1) from 2D poses to 3D poses (2D-to-3D pose lifting) (2) jointly learning 2D and 3D poses, and (3) directly regressing 3D poses from images.
## Data preparation
diff --git a/configs/body_3d_keypoint/image_pose_lift/README.md b/configs/body_3d_keypoint/image_pose_lift/README.md
new file mode 100644
index 0000000000..36b8bfe486
--- /dev/null
+++ b/configs/body_3d_keypoint/image_pose_lift/README.md
@@ -0,0 +1,13 @@
+# A simple yet effective baseline for 3d human pose estimation
+
+Simple 3D baseline proposes to break down the task of 3d human pose estimation into 2 stages: (1) Image → 2D pose (2) 2D pose → 3D pose.
+
+The authors find that "lifting" ground truth 2D joint locations to 3D space is a task that can be solved with a low error rate. Based on the success of 2d human pose estimation, it directly "lifts" 2d joint locations to 3d space.
+
+## Results and Models
+
+### Human3.6m Dataset
+
+| Arch | MPJPE | P-MPJPE | ckpt | log | Details and Download |
+| :------------------------------------------ | :---: | :-----: | :-----------------------------------------: | :-----------------------------------------: | :---------------------------------------------------------: |
+| [SimpleBaseline3D](/configs/body_3d_keypoint/image_pose_lift/h36m/image-pose-lift_tcn_8xb64-200e_h36m.py) | 43.4 | 34.3 | [ckpt](https://download.openmmlab.com/mmpose/body3d/simple_baseline/simple3Dbaseline_h36m-f0ad73a4_20210419.pth) | [log](https://download.openmmlab.com/mmpose/body3d/simple_baseline/20210415_065056.log.json) | [simplebaseline3d_h36m.md](./h36m/simplebaseline3d_h36m.md) |
diff --git a/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_simplebaseline3d_8xb64-200e_h36m.py b/configs/body_3d_keypoint/image_pose_lift/h36m/image-pose-lift_tcn_8xb64-200e_h36m.py
similarity index 100%
rename from configs/body_3d_keypoint/pose_lift/h36m/pose-lift_simplebaseline3d_8xb64-200e_h36m.py
rename to configs/body_3d_keypoint/image_pose_lift/h36m/image-pose-lift_tcn_8xb64-200e_h36m.py
diff --git a/configs/body_3d_keypoint/pose_lift/h36m/simplebaseline3d_h36m.md b/configs/body_3d_keypoint/image_pose_lift/h36m/simplebaseline3d_h36m.md
similarity index 83%
rename from configs/body_3d_keypoint/pose_lift/h36m/simplebaseline3d_h36m.md
rename to configs/body_3d_keypoint/image_pose_lift/h36m/simplebaseline3d_h36m.md
index 9bc1876315..0f741b90e3 100644
--- a/configs/body_3d_keypoint/pose_lift/h36m/simplebaseline3d_h36m.md
+++ b/configs/body_3d_keypoint/image_pose_lift/h36m/simplebaseline3d_h36m.md
@@ -39,6 +39,6 @@ Results on Human3.6M dataset with ground truth 2D detections
| Arch | MPJPE | P-MPJPE | ckpt | log |
| :-------------------------------------------------------------- | :---: | :-----: | :-------------------------------------------------------------: | :------------------------------------------------------------: |
-| [SimpleBaseline3D-tcn1](/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_simplebaseline3d_8xb64-200e_h36m.py) | 43.4 | 34.3 | [ckpt](https://download.openmmlab.com/mmpose/body3d/simple_baseline/simple3Dbaseline_h36m-f0ad73a4_20210419.pth) | [log](https://download.openmmlab.com/mmpose/body3d/simple_baseline/20210415_065056.log.json) |
+| [SimpleBaseline3D1](/configs/body_3d_keypoint/image_pose_lift/h36m/image-pose-lift_tcn_8xb64-200e_h36m.py) | 43.4 | 34.3 | [ckpt](https://download.openmmlab.com/mmpose/body3d/simple_baseline/simple3Dbaseline_h36m-f0ad73a4_20210419.pth) | [log](https://download.openmmlab.com/mmpose/body3d/simple_baseline/20210415_065056.log.json) |
1 Differing from the original paper, we didn't apply the `max-norm constraint` because we found this led to a better convergence and performance.
diff --git a/configs/body_3d_keypoint/pose_lift/h36m/simplebaseline3d_h36m.yml b/configs/body_3d_keypoint/image_pose_lift/h36m/simplebaseline3d_h36m.yml
similarity index 82%
rename from configs/body_3d_keypoint/pose_lift/h36m/simplebaseline3d_h36m.yml
rename to configs/body_3d_keypoint/image_pose_lift/h36m/simplebaseline3d_h36m.yml
index 1a8f32f82c..17894ee3b1 100644
--- a/configs/body_3d_keypoint/pose_lift/h36m/simplebaseline3d_h36m.yml
+++ b/configs/body_3d_keypoint/image_pose_lift/h36m/simplebaseline3d_h36m.yml
@@ -5,13 +5,13 @@ Collections:
URL: http://openaccess.thecvf.com/content_iccv_2017/html/Martinez_A_Simple_yet_ICCV_2017_paper.html
README: https://github.com/open-mmlab/mmpose/blob/main/docs/en/papers/algorithms/simplebaseline3d.md
Models:
-- Config: configs/body_3d_keypoint/pose_lift/h36m/pose-lift_simplebaseline3d_8xb64-200e_h36m.py
+- Config: configs/body_3d_keypoint/image_pose_lift/h36m/image-pose-lift_tcn_8xb64-200e_h36m.py
In Collection: SimpleBaseline3D
Metadata:
Architecture: &id001
- SimpleBaseline3D
Training Data: Human3.6M
- Name: pose-lift_simplebaseline3d_8xb64-200e_h36m
+ Name: image-pose-lift_tcn_8xb64-200e_h36m
Results:
- Dataset: Human3.6M
Metrics:
diff --git a/configs/body_3d_keypoint/motionbert/README.md b/configs/body_3d_keypoint/motionbert/README.md
new file mode 100644
index 0000000000..562ce7612a
--- /dev/null
+++ b/configs/body_3d_keypoint/motionbert/README.md
@@ -0,0 +1,23 @@
+# MotionBERT: A Unified Perspective on Learning Human Motion Representations
+
+Motionbert proposes a pretraining stage in which a motion encoder is trained to recover the underlying 3D motion from noisy partial 2D observations. The motion representations acquired in this way incorporate geometric, kinematic, and physical knowledge about human motion, which can be easily transferred to multiple downstream tasks.
+
+## Results and Models
+
+### Human3.6m Dataset
+
+| Arch | MPJPE | P-MPJPE | ckpt | log | Details and Download |
+| :-------------------------------------------------------------------- | :---: | :-----: | :-------------------------------------------------------------------: | :-: | :---------------------------------------------: |
+| [MotionBERT\*](/configs/body_3d_keypoint/motionbert/h36m/motionbert_dstformer-243frm_8xb32-240e_h36m.py) | 35.3 | 27.7 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_3d_keypoint/pose_lift/h36m/motionbert_h36m-f554954f_20230531.pth) | / | [motionbert_h36m.md](./h36m/motionbert_h36m.md) |
+| [MotionBERT-finetuned\*](/configs/body_3d_keypoint/motionbert/h36m/motionbert_dstformer-ft-243frm_8xb32-120e_h36m.py) | 27.5 | 21.6 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_3d_keypoint/pose_lift/h36m/motionbert_ft_h36m-d80af323_20230531.pth) | / | [motionbert_h36m.md](./h36m/motionbert_h36m.md) |
+
+### Human3.6m Dataset from official repo 1
+
+| Arch | MPJPE | Average MPJPE | P-MPJPE | ckpt | log | Details and Download |
+| :------------------------------------------------------------- | :---: | :-----------: | :-----: | :-------------------------------------------------------------: | :-: | :---------------------------------------------: |
+| [MotionBERT\*](/configs/body_3d_keypoint/motionbert/h36m/motionbert_dstformer-243frm_8xb32-240e_h36m-original.py) | 39.8 | 39.2 | 33.4 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_3d_keypoint/pose_lift/h36m/motionbert_h36m-f554954f_20230531.pth) | / | [motionbert_h36m.md](./h36m/motionbert_h36m.md) |
+| [MotionBERT-finetuned\*](/configs/body_3d_keypoint/motionbert/h36m/motionbert_dstformer-ft-243frm_8xb32-120e_h36m-original.py) | 37.7 | 37.2 | 32.2 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_3d_keypoint/pose_lift/h36m/motionbert_ft_h36m-d80af323_20230531.pth) | / | [motionbert_h36m.md](./h36m/motionbert_h36m.md) |
+
+1 Please refer to the [doc](./h36m/motionbert_h36m.md) for more details.
+
+*Models with * are converted from the official repo. The config files of these models are only for validation. We don't ensure these config files' training accuracy and welcome you to contribute your reproduction results.*
diff --git a/configs/body_3d_keypoint/motionbert/h36m/motionbert_dstformer-243frm_8xb32-240e_h36m-original.py b/configs/body_3d_keypoint/motionbert/h36m/motionbert_dstformer-243frm_8xb32-240e_h36m-original.py
new file mode 100644
index 0000000000..caf2e56530
--- /dev/null
+++ b/configs/body_3d_keypoint/motionbert/h36m/motionbert_dstformer-243frm_8xb32-240e_h36m-original.py
@@ -0,0 +1,137 @@
+_base_ = ['../../../_base_/default_runtime.py']
+
+vis_backends = [
+ dict(type='LocalVisBackend'),
+]
+visualizer = dict(
+ type='Pose3dLocalVisualizer', vis_backends=vis_backends, name='visualizer')
+
+# runtime
+train_cfg = dict(max_epochs=240, val_interval=10)
+
+# optimizer
+optim_wrapper = dict(
+ optimizer=dict(type='AdamW', lr=0.0002, weight_decay=0.01))
+
+# learning policy
+param_scheduler = [
+ dict(type='ExponentialLR', gamma=0.99, end=120, by_epoch=True)
+]
+
+auto_scale_lr = dict(base_batch_size=512)
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(
+ type='CheckpointHook',
+ save_best='MPJPE',
+ rule='less',
+ max_keep_ckpts=1),
+ logger=dict(type='LoggerHook', interval=20),
+)
+
+# codec settings
+train_codec = dict(
+ type='MotionBERTLabel', num_keypoints=17, concat_vis=True, mode='train')
+val_codec = dict(
+ type='MotionBERTLabel', num_keypoints=17, concat_vis=True, rootrel=True)
+
+# model settings
+model = dict(
+ type='PoseLifter',
+ backbone=dict(
+ type='DSTFormer',
+ in_channels=3,
+ feat_size=512,
+ depth=5,
+ num_heads=8,
+ mlp_ratio=2,
+ seq_len=243,
+ att_fuse=True,
+ ),
+ head=dict(
+ type='MotionRegressionHead',
+ in_channels=512,
+ out_channels=3,
+ embedding_size=512,
+ loss=dict(type='MPJPEVelocityJointLoss'),
+ decoder=val_codec,
+ ),
+ test_cfg=dict(flip_test=True))
+
+# base dataset settings
+dataset_type = 'Human36mDataset'
+data_root = 'data/h36m/'
+
+# pipelines
+train_pipeline = [
+ dict(type='GenerateTarget', encoder=train_codec),
+ dict(
+ type='RandomFlipAroundRoot',
+ keypoints_flip_cfg=dict(center_mode='static', center_x=0.),
+ target_flip_cfg=dict(center_mode='static', center_x=0.),
+ flip_label=True),
+ dict(
+ type='PackPoseInputs',
+ meta_keys=('id', 'category_id', 'target_img_path', 'flip_indices',
+ 'factor', 'camera_param'))
+]
+val_pipeline = [
+ dict(type='GenerateTarget', encoder=val_codec),
+ dict(
+ type='PackPoseInputs',
+ meta_keys=('id', 'category_id', 'target_img_path', 'flip_indices',
+ 'factor', 'camera_param'))
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=32,
+ prefetch_factor=4,
+ pin_memory=True,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ ann_file='annotation_body3d/fps50/h36m_train_original.npz',
+ seq_len=1,
+ multiple_target=243,
+ multiple_target_step=81,
+ camera_param_file='annotation_body3d/cameras.pkl',
+ data_root=data_root,
+ data_prefix=dict(img='images/'),
+ pipeline=train_pipeline,
+ ))
+
+val_dataloader = dict(
+ batch_size=32,
+ prefetch_factor=4,
+ pin_memory=True,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ ann_file='annotation_body3d/fps50/h36m_test_original.npz',
+ factor_file='annotation_body3d/fps50/h36m_factors.npy',
+ seq_len=1,
+ seq_step=1,
+ multiple_target=243,
+ camera_param_file='annotation_body3d/cameras.pkl',
+ data_root=data_root,
+ data_prefix=dict(img='images/'),
+ pipeline=val_pipeline,
+ test_mode=True,
+ ))
+test_dataloader = val_dataloader
+
+# evaluators
+skip_list = [
+ 'S9_Greet', 'S9_SittingDown', 'S9_Wait_1', 'S9_Greeting', 'S9_Waiting_1'
+]
+val_evaluator = [
+ dict(type='MPJPE', mode='mpjpe', skip_list=skip_list),
+ dict(type='MPJPE', mode='p-mpjpe', skip_list=skip_list)
+]
+test_evaluator = val_evaluator
diff --git a/configs/body_3d_keypoint/motionbert/h36m/motionbert_dstformer-243frm_8xb32-240e_h36m.py b/configs/body_3d_keypoint/motionbert/h36m/motionbert_dstformer-243frm_8xb32-240e_h36m.py
new file mode 100644
index 0000000000..ea91556198
--- /dev/null
+++ b/configs/body_3d_keypoint/motionbert/h36m/motionbert_dstformer-243frm_8xb32-240e_h36m.py
@@ -0,0 +1,136 @@
+_base_ = ['../../../_base_/default_runtime.py']
+
+vis_backends = [
+ dict(type='LocalVisBackend'),
+]
+visualizer = dict(
+ type='Pose3dLocalVisualizer', vis_backends=vis_backends, name='visualizer')
+
+# runtime
+train_cfg = dict(max_epochs=240, val_interval=10)
+
+# optimizer
+optim_wrapper = dict(
+ optimizer=dict(type='AdamW', lr=0.0002, weight_decay=0.01))
+
+# learning policy
+param_scheduler = [
+ dict(type='ExponentialLR', gamma=0.99, end=120, by_epoch=True)
+]
+
+auto_scale_lr = dict(base_batch_size=512)
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(
+ type='CheckpointHook',
+ save_best='MPJPE',
+ rule='less',
+ max_keep_ckpts=1),
+ logger=dict(type='LoggerHook', interval=20),
+)
+
+# codec settings
+train_codec = dict(
+ type='MotionBERTLabel', num_keypoints=17, concat_vis=True, mode='train')
+val_codec = dict(
+ type='MotionBERTLabel', num_keypoints=17, concat_vis=True, rootrel=True)
+
+# model settings
+model = dict(
+ type='PoseLifter',
+ backbone=dict(
+ type='DSTFormer',
+ in_channels=3,
+ feat_size=512,
+ depth=5,
+ num_heads=8,
+ mlp_ratio=2,
+ seq_len=243,
+ att_fuse=True,
+ ),
+ head=dict(
+ type='MotionRegressionHead',
+ in_channels=512,
+ out_channels=3,
+ embedding_size=512,
+ loss=dict(type='MPJPEVelocityJointLoss'),
+ decoder=val_codec,
+ ),
+ test_cfg=dict(flip_test=True))
+
+# base dataset settings
+dataset_type = 'Human36mDataset'
+data_root = 'data/h36m/'
+
+# pipelines
+train_pipeline = [
+ dict(type='GenerateTarget', encoder=train_codec),
+ dict(
+ type='RandomFlipAroundRoot',
+ keypoints_flip_cfg=dict(center_mode='static', center_x=0.),
+ target_flip_cfg=dict(center_mode='static', center_x=0.),
+ flip_label=True),
+ dict(
+ type='PackPoseInputs',
+ meta_keys=('id', 'category_id', 'target_img_path', 'flip_indices',
+ 'factor', 'camera_param'))
+]
+val_pipeline = [
+ dict(type='GenerateTarget', encoder=val_codec),
+ dict(
+ type='PackPoseInputs',
+ meta_keys=('id', 'category_id', 'target_img_path', 'flip_indices',
+ 'factor', 'camera_param'))
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=32,
+ prefetch_factor=4,
+ pin_memory=True,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ ann_file='annotation_body3d/fps50/h36m_train.npz',
+ seq_len=1,
+ multiple_target=243,
+ multiple_target_step=81,
+ camera_param_file='annotation_body3d/cameras.pkl',
+ data_root=data_root,
+ data_prefix=dict(img='images/'),
+ pipeline=train_pipeline,
+ ))
+
+val_dataloader = dict(
+ batch_size=32,
+ prefetch_factor=4,
+ pin_memory=True,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ ann_file='annotation_body3d/fps50/h36m_test.npz',
+ seq_len=1,
+ seq_step=1,
+ multiple_target=243,
+ camera_param_file='annotation_body3d/cameras.pkl',
+ data_root=data_root,
+ data_prefix=dict(img='images/'),
+ pipeline=val_pipeline,
+ test_mode=True,
+ ))
+test_dataloader = val_dataloader
+
+# evaluators
+skip_list = [
+ 'S9_Greet', 'S9_SittingDown', 'S9_Wait_1', 'S9_Greeting', 'S9_Waiting_1'
+]
+val_evaluator = [
+ dict(type='MPJPE', mode='mpjpe', skip_list=skip_list),
+ dict(type='MPJPE', mode='p-mpjpe', skip_list=skip_list)
+]
+test_evaluator = val_evaluator
diff --git a/configs/body_3d_keypoint/motionbert/h36m/motionbert_dstformer-ft-243frm_8xb32-120e_h36m-original.py b/configs/body_3d_keypoint/motionbert/h36m/motionbert_dstformer-ft-243frm_8xb32-120e_h36m-original.py
new file mode 100644
index 0000000000..555fd8ae0e
--- /dev/null
+++ b/configs/body_3d_keypoint/motionbert/h36m/motionbert_dstformer-ft-243frm_8xb32-120e_h36m-original.py
@@ -0,0 +1,142 @@
+_base_ = ['../../../_base_/default_runtime.py']
+
+vis_backends = [
+ dict(type='LocalVisBackend'),
+]
+visualizer = dict(
+ type='Pose3dLocalVisualizer', vis_backends=vis_backends, name='visualizer')
+
+# runtime
+train_cfg = dict(max_epochs=120, val_interval=10)
+
+# optimizer
+optim_wrapper = dict(
+ optimizer=dict(type='AdamW', lr=0.0002, weight_decay=0.01))
+
+# learning policy
+param_scheduler = [
+ dict(type='ExponentialLR', gamma=0.99, end=60, by_epoch=True)
+]
+
+auto_scale_lr = dict(base_batch_size=512)
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(
+ type='CheckpointHook',
+ save_best='MPJPE',
+ rule='less',
+ max_keep_ckpts=1),
+ logger=dict(type='LoggerHook', interval=20),
+)
+
+# codec settings
+train_codec = dict(
+ type='MotionBERTLabel', num_keypoints=17, concat_vis=True, mode='train')
+val_codec = dict(
+ type='MotionBERTLabel', num_keypoints=17, concat_vis=True, rootrel=True)
+
+# model settings
+model = dict(
+ type='PoseLifter',
+ backbone=dict(
+ type='DSTFormer',
+ in_channels=3,
+ feat_size=512,
+ depth=5,
+ num_heads=8,
+ mlp_ratio=2,
+ seq_len=243,
+ att_fuse=True,
+ ),
+ head=dict(
+ type='MotionRegressionHead',
+ in_channels=512,
+ out_channels=3,
+ embedding_size=512,
+ loss=dict(type='MPJPEVelocityJointLoss'),
+ decoder=val_codec,
+ ),
+ test_cfg=dict(flip_test=True),
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/body_3d_keypoint/'
+ 'pose_lift/h36m/motionbert_pretrain_h36m-29ffebf5_20230719.pth'),
+)
+
+# base dataset settings
+dataset_type = 'Human36mDataset'
+data_root = 'data/h36m/'
+
+# pipelines
+train_pipeline = [
+ dict(type='GenerateTarget', encoder=train_codec),
+ dict(
+ type='RandomFlipAroundRoot',
+ keypoints_flip_cfg=dict(center_mode='static', center_x=0.),
+ target_flip_cfg=dict(center_mode='static', center_x=0.),
+ flip_label=True),
+ dict(
+ type='PackPoseInputs',
+ meta_keys=('id', 'category_id', 'target_img_path', 'flip_indices',
+ 'factor', 'camera_param'))
+]
+val_pipeline = [
+ dict(type='GenerateTarget', encoder=val_codec),
+ dict(
+ type='PackPoseInputs',
+ meta_keys=('id', 'category_id', 'target_img_path', 'flip_indices',
+ 'factor', 'camera_param'))
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=32,
+ prefetch_factor=4,
+ pin_memory=True,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ ann_file='annotation_body3d/fps50/h36m_train_original.npz',
+ seq_len=1,
+ multiple_target=243,
+ multiple_target_step=81,
+ camera_param_file='annotation_body3d/cameras.pkl',
+ data_root=data_root,
+ data_prefix=dict(img='images/'),
+ pipeline=train_pipeline,
+ ))
+
+val_dataloader = dict(
+ batch_size=32,
+ prefetch_factor=4,
+ pin_memory=True,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ ann_file='annotation_body3d/fps50/h36m_test_original.npz',
+ factor_file='annotation_body3d/fps50/h36m_factors.npy',
+ seq_len=1,
+ seq_step=1,
+ multiple_target=243,
+ camera_param_file='annotation_body3d/cameras.pkl',
+ data_root=data_root,
+ data_prefix=dict(img='images/'),
+ pipeline=val_pipeline,
+ test_mode=True,
+ ))
+test_dataloader = val_dataloader
+
+# evaluators
+skip_list = [
+ 'S9_Greet', 'S9_SittingDown', 'S9_Wait_1', 'S9_Greeting', 'S9_Waiting_1'
+]
+val_evaluator = [
+ dict(type='MPJPE', mode='mpjpe', skip_list=skip_list),
+ dict(type='MPJPE', mode='p-mpjpe', skip_list=skip_list)
+]
+test_evaluator = val_evaluator
diff --git a/configs/body_3d_keypoint/motionbert/h36m/motionbert_dstformer-ft-243frm_8xb32-120e_h36m.py b/configs/body_3d_keypoint/motionbert/h36m/motionbert_dstformer-ft-243frm_8xb32-120e_h36m.py
new file mode 100644
index 0000000000..256a765539
--- /dev/null
+++ b/configs/body_3d_keypoint/motionbert/h36m/motionbert_dstformer-ft-243frm_8xb32-120e_h36m.py
@@ -0,0 +1,141 @@
+_base_ = ['../../../_base_/default_runtime.py']
+
+vis_backends = [
+ dict(type='LocalVisBackend'),
+]
+visualizer = dict(
+ type='Pose3dLocalVisualizer', vis_backends=vis_backends, name='visualizer')
+
+# runtime
+train_cfg = dict(max_epochs=120, val_interval=10)
+
+# optimizer
+optim_wrapper = dict(
+ optimizer=dict(type='AdamW', lr=0.0002, weight_decay=0.01))
+
+# learning policy
+param_scheduler = [
+ dict(type='ExponentialLR', gamma=0.99, end=60, by_epoch=True)
+]
+
+auto_scale_lr = dict(base_batch_size=512)
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(
+ type='CheckpointHook',
+ save_best='MPJPE',
+ rule='less',
+ max_keep_ckpts=1),
+ logger=dict(type='LoggerHook', interval=20),
+)
+
+# codec settings
+train_codec = dict(
+ type='MotionBERTLabel', num_keypoints=17, concat_vis=True, mode='train')
+val_codec = dict(
+ type='MotionBERTLabel', num_keypoints=17, concat_vis=True, rootrel=True)
+
+# model settings
+model = dict(
+ type='PoseLifter',
+ backbone=dict(
+ type='DSTFormer',
+ in_channels=3,
+ feat_size=512,
+ depth=5,
+ num_heads=8,
+ mlp_ratio=2,
+ seq_len=243,
+ att_fuse=True,
+ ),
+ head=dict(
+ type='MotionRegressionHead',
+ in_channels=512,
+ out_channels=3,
+ embedding_size=512,
+ loss=dict(type='MPJPEVelocityJointLoss'),
+ decoder=val_codec,
+ ),
+ test_cfg=dict(flip_test=True),
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/body_3d_keypoint/'
+ 'pose_lift/h36m/motionbert_pretrain_h36m-29ffebf5_20230719.pth'),
+)
+
+# base dataset settings
+dataset_type = 'Human36mDataset'
+data_root = 'data/h36m/'
+
+# pipelines
+train_pipeline = [
+ dict(type='GenerateTarget', encoder=train_codec),
+ dict(
+ type='RandomFlipAroundRoot',
+ keypoints_flip_cfg=dict(center_mode='static', center_x=0.),
+ target_flip_cfg=dict(center_mode='static', center_x=0.),
+ flip_label=True),
+ dict(
+ type='PackPoseInputs',
+ meta_keys=('id', 'category_id', 'target_img_path', 'flip_indices',
+ 'factor', 'camera_param'))
+]
+val_pipeline = [
+ dict(type='GenerateTarget', encoder=val_codec),
+ dict(
+ type='PackPoseInputs',
+ meta_keys=('id', 'category_id', 'target_img_path', 'flip_indices',
+ 'factor', 'camera_param'))
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=32,
+ prefetch_factor=4,
+ pin_memory=True,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ ann_file='annotation_body3d/fps50/h36m_train.npz',
+ seq_len=1,
+ multiple_target=243,
+ multiple_target_step=81,
+ camera_param_file='annotation_body3d/cameras.pkl',
+ data_root=data_root,
+ data_prefix=dict(img='images/'),
+ pipeline=train_pipeline,
+ ))
+
+val_dataloader = dict(
+ batch_size=32,
+ prefetch_factor=4,
+ pin_memory=True,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ ann_file='annotation_body3d/fps50/h36m_test.npz',
+ seq_len=1,
+ seq_step=1,
+ multiple_target=243,
+ camera_param_file='annotation_body3d/cameras.pkl',
+ data_root=data_root,
+ data_prefix=dict(img='images/'),
+ pipeline=val_pipeline,
+ test_mode=True,
+ ))
+test_dataloader = val_dataloader
+
+# evaluators
+skip_list = [
+ 'S9_Greet', 'S9_SittingDown', 'S9_Wait_1', 'S9_Greeting', 'S9_Waiting_1'
+]
+val_evaluator = [
+ dict(type='MPJPE', mode='mpjpe', skip_list=skip_list),
+ dict(type='MPJPE', mode='p-mpjpe', skip_list=skip_list)
+]
+test_evaluator = val_evaluator
diff --git a/configs/body_3d_keypoint/motionbert/h36m/motionbert_h36m.md b/configs/body_3d_keypoint/motionbert/h36m/motionbert_h36m.md
new file mode 100644
index 0000000000..8d8f1b5784
--- /dev/null
+++ b/configs/body_3d_keypoint/motionbert/h36m/motionbert_h36m.md
@@ -0,0 +1,55 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+MotionBERT (2022)
+ +```bibtex + @misc{Zhu_Ma_Liu_Liu_Wu_Wang_2022, + title={Learning Human Motion Representations: A Unified Perspective}, + author={Zhu, Wentao and Ma, Xiaoxuan and Liu, Zhaoyang and Liu, Libin and Wu, Wayne and Wang, Yizhou}, + year={2022}, + month={Oct}, + language={en-US} + } +``` + +
+
+
+Results on Human3.6M dataset with ground truth 2D detections
+
+| Arch | MPJPE | average MPJPE | P-MPJPE | ckpt |
+| :-------------------------------------------------------------------------------------- | :---: | :-----------: | :-----: | :--------------------------------------------------------------------------------------: |
+| [MotionBERT\*](/configs/body_3d_keypoint/motionbert/h36m/motionbert_dstformer-243frm_8xb32-240e_h36m.py) | 34.5 | 34.6 | 27.1 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_3d_keypoint/pose_lift/h36m/motionbert_h36m-f554954f_20230531.pth) |
+| [MotionBERT-finetuned\*](/configs/body_3d_keypoint/motionbert/h36m/motionbert_dstformer-ft-243frm_8xb32-120e_h36m.py) | 26.9 | 26.8 | 21.0 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_3d_keypoint/pose_lift/h36m/motionbert_ft_h36m-d80af323_20230531.pth) |
+
+Results on Human3.6M dataset converted from the [official repo](https://github.com/Walter0807/MotionBERT)1 with ground truth 2D detections
+
+| Arch | MPJPE | average MPJPE | P-MPJPE | ckpt | log |
+| :------------------------------------------------------------------------------------- | :---: | :-----------: | :-----: | :------------------------------------------------------------------------------------: | :-: |
+| [MotionBERT\*](/configs/body_3d_keypoint/motionbert/h36m/motionbert_dstformer-243frm_8xb32-240e_h36m-original.py) | 39.8 | 39.2 | 33.4 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_3d_keypoint/pose_lift/h36m/motionbert_h36m-f554954f_20230531.pth) | / |
+| [MotionBERT-finetuned\*](/configs/body_3d_keypoint/motionbert/h36m/motionbert_dstformer-ft-243frm_8xb32-120e_h36m-original.py) | 37.7 | 37.2 | 32.2 | [ckpt](https://download.openmmlab.com/mmpose/v1/body_3d_keypoint/pose_lift/h36m/motionbert_ft_h36m-d80af323_20230531.pth) | / |
+
+1 By default, we test models with [Human 3.6m dataset](/docs/en/dataset_zoo/3d_body_keypoint.md#human3-6m) processed by MMPose. The official repo's dataset includes more data and applies a different pre-processing technique. To achieve the same result with the official repo, please download the [test annotation file](https://download.openmmlab.com/mmpose/v1/body_3d_keypoint/pose_lift/h36m/h36m_test_original.npz), [train annotation file](https://download.openmmlab.com/mmpose/v1/body_3d_keypoint/pose_lift/h36m/h36m_train_original.npz) and [factors](https://download.openmmlab.com/mmpose/v1/body_3d_keypoint/pose_lift/h36m/h36m_factors.npy) under `$MMPOSE/data/h36m/annotation_body3d/fps50` and test with the configs we provided.
+
+*Models with * are converted from the [official repo](https://github.com/Walter0807/MotionBERT). The config files of these models are only for validation. We don't ensure these config files' training accuracy and welcome you to contribute your reproduction results.*
diff --git a/configs/body_3d_keypoint/motionbert/h36m/motionbert_h36m.yml b/configs/body_3d_keypoint/motionbert/h36m/motionbert_h36m.yml
new file mode 100644
index 0000000000..2dc285426c
--- /dev/null
+++ b/configs/body_3d_keypoint/motionbert/h36m/motionbert_h36m.yml
@@ -0,0 +1,45 @@
+Collections:
+- Name: MotionBERT
+ Paper:
+ Title: "Learning Human Motion Representations: A Unified Perspective"
+ URL: https://arxiv.org/abs/2210.06551
+ README: https://github.com/open-mmlab/mmpose/blob/main/docs/en/papers/algorithms/motionbert.md
+Models:
+- Config: configs/body_3d_keypoint/motionbert/h36m/motionbert_dstformer-243frm_8xb32-240e_h36m.py
+ In Collection: MotionBERT
+ Metadata:
+ Architecture: &id001
+ - MotionBERT
+ Training Data: Human3.6M (MotionBERT)
+ Name: motionbert_dstformer-243frm_8xb32-240e_h36m
+ Results:
+ - Dataset: Human3.6M
+ Metrics:
+ MPJPE: 34.5
+ P-MPJPE: 27.1
+ Task: Body 3D Keypoint
+ - Dataset: Human3.6M (MotionBERT)
+ Metrics:
+ MPJPE: 39.8
+ P-MPJPE: 33.4
+ Task: Body 3D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/v1/body_3d_keypoint/pose_lift/h36m/motionbert_h36m-f554954f_20230531.pth
+- Config: configs/body_3d_keypoint/motionbert/h36m/motionbert_dstformer-ft-243frm_8xb32-120e_h36m.py
+ In Collection: MotionBERT
+ Alias: human3d
+ Metadata:
+ Architecture: *id001
+ Training Data: Human3.6M (MotionBERT)
+ Name: motionbert_dstformer-ft-243frm_8xb32-120e_h36m
+ Results:
+ - Dataset: Human3.6M
+ Metrics:
+ MPJPE: 26.9
+ P-MPJPE: 21.0
+ Task: Body 3D Keypoint
+ - Dataset: Human3.6M (MotionBERT)
+ Metrics:
+ MPJPE: 37.7
+ P-MPJPE: 32.2
+ Task: Body 3D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/v1/body_3d_keypoint/pose_lift/h36m/motionbert_ft_h36m-d80af323_20230531.pth
diff --git a/configs/body_3d_keypoint/pose_lift/README.md b/configs/body_3d_keypoint/pose_lift/README.md
deleted file mode 100644
index 7e5f9f7e2a..0000000000
--- a/configs/body_3d_keypoint/pose_lift/README.md
+++ /dev/null
@@ -1,51 +0,0 @@
-# Single-view 3D Human Body Pose Estimation
-
-## Video-based Single-view 3D Human Body Pose Estimation
-
-Video-based 3D pose estimation is the detection and analysis of X, Y, Z coordinates of human body joints from a sequence of RGB images.
-
-For single-person 3D pose estimation from a monocular camera, existing works can be classified into three categories:
-
-(1) from 2D poses to 3D poses (2D-to-3D pose lifting)
-
-(2) jointly learning 2D and 3D poses, and
-
-(3) directly regressing 3D poses from images.
-
-### Results and Models
-
-#### Human3.6m Dataset
-
-| Arch | Receptive Field | MPJPE | P-MPJPE | N-MPJPE | ckpt | log |
-
-| :------------------------------------------------------ | :-------------: | :---: | :-----: | :-----: | :------------------------------------------------------: | :-----------------------------------------------------: |
-
-| [VideoPose3D-supervised](/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-27frm-supv_8xb128-80e_h36m.py) | 27 | 40.1 | 30.1 | / | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_supervised-fe8fbba9_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_supervised_20210527.log.json) |
-
-| [VideoPose3D-supervised](/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-81frm-supv_8xb128-80e_h36m.py) | 81 | 39.1 | 29.3 | / | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_81frames_fullconv_supervised-1f2d1104_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_81frames_fullconv_supervised_20210527.log.json) |
-
-| [VideoPose3D-supervised](/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-243frm-supv_8xb128-80e_h36m.py) | 243 | | | / | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised-880bea25_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_20210527.log.json) |
-
-| [VideoPose3D-supervised-CPN](/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-1frm-supv-cpn-ft_8xb128-80e_h36m.py) | 1 | 53.0 | 41.3 | / | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_1frame_fullconv_supervised_cpn_ft-5c3afaed_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_1frame_fullconv_supervised_cpn_ft_20210527.log.json) |
-
-| [VideoPose3D-supervised-CPN](/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-243frm-supv-cpn-ft_8xb128-200e_h36m.py) | 243 | | | / | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_cpn_ft-88f5abbb_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_cpn_ft_20210527.log.json) |
-
-| [VideoPose3D-semi-supervised](/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-27frm-semi-supv_8xb64-200e_h36m.py) | 27 | 57.2 | 42.4 | 54.2 | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_semi-supervised-54aef83b_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_semi-supervised_20210527.log.json) |
-
-| [VideoPose3D-semi-supervised-CPN](/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-27frm-semi-supv-cpn-ft_8xb64-200e_h36m.py) | 27 | 67.3 | 50.4 | 63.6 | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_semi-supervised_cpn_ft-71be9cde_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_semi-supervised_cpn_ft_20210527.log.json) |
-
-## Image-based Single-view 3D Human Body Pose Estimation
-
-3D pose estimation is the detection and analysis of X, Y, Z coordinates of human body joints from an RGB image.
-For single-person 3D pose estimation from a monocular camera, existing works can be classified into three categories:
-(1) from 2D poses to 3D poses (2D-to-3D pose lifting)
-(2) jointly learning 2D and 3D poses, and
-(3) directly regressing 3D poses from images.
-
-### Results and Models
-
-#### Human3.6m Dataset
-
-| Arch | MPJPE | P-MPJPE | N-MPJPE | ckpt | log |
-| :------------------------------------------------------ | :-------------: | :---: | :-----: | :-----: | :------------------------------------------------------: | :-----------------------------------------------------: |
-| [SimpleBaseline3D-tcn](/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_simplebaseline3d_8xb64-200e_h36m.py) | 43.4 | 34.3 | /|[ckpt](https://download.openmmlab.com/mmpose/body3d/simple_baseline/simple3Dbaseline_h36m-f0ad73a4_20210419.pth) | [log](https://download.openmmlab.com/mmpose/body3d/simple_baseline/20210415_065056.log.json) |
diff --git a/configs/body_3d_keypoint/video_pose_lift/README.md b/configs/body_3d_keypoint/video_pose_lift/README.md
new file mode 100644
index 0000000000..faf92b7899
--- /dev/null
+++ b/configs/body_3d_keypoint/video_pose_lift/README.md
@@ -0,0 +1,17 @@
+# 3D human pose estimation in video with temporal convolutions and semi-supervised training
+
+Based on the success of 2d human pose estimation, it directly "lifts" a sequence of 2d keypoints to 3d keypoints.
+
+## Results and Models
+
+### Human3.6m Dataset
+
+| Arch | MPJPE | P-MPJPE | N-MPJPE | ckpt | log | Details and Download |
+| :-------------------------------------------- | :---: | :-----: | :-----: | :-------------------------------------------: | :------------------------------------------: | :---------------------------------------------: |
+| [VideoPose3D-supervised-27frm](/configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-27frm-supv_8xb128-160e_h36m.py) | 40.1 | 30.1 | / | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_supervised-fe8fbba9_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_supervised_20210527.log.json) | [videpose3d_h36m.md](./h36m/videpose3d_h36m.md) |
+| [VideoPose3D-supervised-81frm](/configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-81frm-supv_8xb128-160e_h36m.py) | 39.1 | 29.3 | / | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_81frames_fullconv_supervised-1f2d1104_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_81frames_fullconv_supervised_20210527.log.json) | [videpose3d_h36m.md](./h36m/videpose3d_h36m.md) |
+| [VideoPose3D-supervised-243frm](/configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-243frm-supv_8xb128-160e_h36m.py) | 37.6 | 28.3 | / | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised-880bea25_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_20210527.log.json) | [videpose3d_h36m.md](./h36m/videpose3d_h36m.md) |
+| [VideoPose3D-supervised-CPN-1frm](/configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-1frm-supv-cpn-ft_8xb128-160e_h36m.py) | 53.0 | 41.3 | / | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_1frame_fullconv_supervised_cpn_ft-5c3afaed_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_1frame_fullconv_supervised_cpn_ft_20210527.log.json) | [videpose3d_h36m.md](./h36m/videpose3d_h36m.md) |
+| [VideoPose3D-supervised-CPN-243frm](/configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-243frm-supv-cpn-ft_8xb128-200e_h36m.py) | 47.9 | 38.0 | / | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_cpn_ft-88f5abbb_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_cpn_ft_20210527.log.json) | [videpose3d_h36m.md](./h36m/videpose3d_h36m.md) |
+| [VideoPose3D-semi-supervised-27frm](/configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-27frm-semi-supv_8xb64-200e_h36m.py) | 57.2 | 42.4 | 54.2 | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_semi-supervised-54aef83b_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_semi-supervised_20210527.log.json) | [videpose3d_h36m.md](./h36m/videpose3d_h36m.md) |
+| [VideoPose3D-semi-supervised-CPN-27frm](/configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-27frm-semi-supv-cpn-ft_8xb64-200e_h36m.py) | 67.3 | 50.4 | 63.6 | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_semi-supervised_cpn_ft-71be9cde_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_semi-supervised_cpn_ft_20210527.log.json) | [videpose3d_h36m.md](./h36m/videpose3d_h36m.md) |
diff --git a/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-1frm-supv-cpn-ft_8xb128-80e_h36m.py b/configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-1frm-supv-cpn-ft_8xb128-160e_h36m.py
similarity index 98%
rename from configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-1frm-supv-cpn-ft_8xb128-80e_h36m.py
rename to configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-1frm-supv-cpn-ft_8xb128-160e_h36m.py
index 0cbf89142d..c1190fe83e 100644
--- a/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-1frm-supv-cpn-ft_8xb128-80e_h36m.py
+++ b/configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-1frm-supv-cpn-ft_8xb128-160e_h36m.py
@@ -7,7 +7,7 @@
type='Pose3dLocalVisualizer', vis_backends=vis_backends, name='visualizer')
# runtime
-train_cfg = dict(max_epochs=80, val_interval=10)
+train_cfg = dict(max_epochs=160, val_interval=10)
# optimizer
optim_wrapper = dict(optimizer=dict(type='Adam', lr=1e-4))
diff --git a/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-243frm-supv-cpn-ft_8xb128-200e_h36m.py b/configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-243frm-supv-cpn-ft_8xb128-200e_h36m.py
similarity index 100%
rename from configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-243frm-supv-cpn-ft_8xb128-200e_h36m.py
rename to configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-243frm-supv-cpn-ft_8xb128-200e_h36m.py
diff --git a/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-243frm-supv_8xb128-80e_h36m.py b/configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-243frm-supv_8xb128-160e_h36m.py
similarity index 98%
rename from configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-243frm-supv_8xb128-80e_h36m.py
rename to configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-243frm-supv_8xb128-160e_h36m.py
index 0f311ac5cf..0d241c498f 100644
--- a/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-243frm-supv_8xb128-80e_h36m.py
+++ b/configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-243frm-supv_8xb128-160e_h36m.py
@@ -7,7 +7,7 @@
type='Pose3dLocalVisualizer', vis_backends=vis_backends, name='visualizer')
# runtime
-train_cfg = dict(max_epochs=80, val_interval=10)
+train_cfg = dict(max_epochs=160, val_interval=10)
# optimizer
optim_wrapper = dict(optimizer=dict(type='Adam', lr=1e-3))
diff --git a/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-27frm-semi-supv-cpn-ft_8xb64-200e_h36m.py b/configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-27frm-semi-supv-cpn-ft_8xb64-200e_h36m.py
similarity index 100%
rename from configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-27frm-semi-supv-cpn-ft_8xb64-200e_h36m.py
rename to configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-27frm-semi-supv-cpn-ft_8xb64-200e_h36m.py
diff --git a/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-27frm-semi-supv_8xb64-200e_h36m.py b/configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-27frm-semi-supv_8xb64-200e_h36m.py
similarity index 100%
rename from configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-27frm-semi-supv_8xb64-200e_h36m.py
rename to configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-27frm-semi-supv_8xb64-200e_h36m.py
diff --git a/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-27frm-supv_8xb128-80e_h36m.py b/configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-27frm-supv_8xb128-160e_h36m.py
similarity index 98%
rename from configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-27frm-supv_8xb128-80e_h36m.py
rename to configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-27frm-supv_8xb128-160e_h36m.py
index 2589b493a6..803f907b7b 100644
--- a/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-27frm-supv_8xb128-80e_h36m.py
+++ b/configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-27frm-supv_8xb128-160e_h36m.py
@@ -7,7 +7,7 @@
type='Pose3dLocalVisualizer', vis_backends=vis_backends, name='visualizer')
# runtime
-train_cfg = dict(max_epochs=80, val_interval=10)
+train_cfg = dict(max_epochs=160, val_interval=10)
# optimizer
optim_wrapper = dict(optimizer=dict(type='Adam', lr=1e-3))
diff --git a/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-81frm-supv_8xb128-80e_h36m.py b/configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-81frm-supv_8xb128-160e_h36m.py
similarity index 98%
rename from configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-81frm-supv_8xb128-80e_h36m.py
rename to configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-81frm-supv_8xb128-160e_h36m.py
index f2c27e423d..4b370fe76e 100644
--- a/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-81frm-supv_8xb128-80e_h36m.py
+++ b/configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-81frm-supv_8xb128-160e_h36m.py
@@ -7,7 +7,7 @@
type='Pose3dLocalVisualizer', vis_backends=vis_backends, name='visualizer')
# runtime
-train_cfg = dict(max_epochs=80, val_interval=10)
+train_cfg = dict(max_epochs=160, val_interval=10)
# optimizer
optim_wrapper = dict(optimizer=dict(type='Adam', lr=1e-3))
diff --git a/configs/body_3d_keypoint/pose_lift/h36m/videopose3d_h36m.md b/configs/body_3d_keypoint/video_pose_lift/h36m/videopose3d_h36m.md
similarity index 50%
rename from configs/body_3d_keypoint/pose_lift/h36m/videopose3d_h36m.md
rename to configs/body_3d_keypoint/video_pose_lift/h36m/videopose3d_h36m.md
index f1c75d786a..069b8de2da 100644
--- a/configs/body_3d_keypoint/pose_lift/h36m/videopose3d_h36m.md
+++ b/configs/body_3d_keypoint/video_pose_lift/h36m/videopose3d_h36m.md
@@ -41,27 +41,27 @@ Testing results on Human3.6M dataset with ground truth 2D detections, supervised
| Arch | Receptive Field | MPJPE | P-MPJPE | ckpt | log |
| :--------------------------------------------------------- | :-------------: | :---: | :-----: | :--------------------------------------------------------: | :-------------------------------------------------------: |
-| [VideoPose3D](/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-27frm-supv_8xb128-80e_h36m.py) | 27 | 40.1 | 30.1 | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_supervised-fe8fbba9_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_supervised_20210527.log.json) |
-| [VideoPose3D](/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-81frm-supv_8xb128-80e_h36m.py) | 81 | 39.1 | 29.3 | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_81frames_fullconv_supervised-1f2d1104_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_81frames_fullconv_supervised_20210527.log.json) |
-| [VideoPose3D](/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-243frm-supv_8xb128-80e_h36m.py) | 243 | | | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised-880bea25_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_20210527.log.json) |
+| [VideoPose3D-supervised-27frm](/configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-27frm-supv_8xb128-160e_h36m.py) | 27 | 40.1 | 30.1 | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_supervised-fe8fbba9_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_supervised_20210527.log.json) |
+| [VideoPose3D-supervised-81frm](/configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-81frm-supv_8xb128-160e_h36m.py) | 81 | 39.1 | 29.3 | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_81frames_fullconv_supervised-1f2d1104_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_81frames_fullconv_supervised_20210527.log.json) |
+| [VideoPose3D-supervised-243frm](/configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-243frm-supv_8xb128-160e_h36m.py) | 243 | 37.6 | 28.3 | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised-880bea25_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_20210527.log.json) |
Testing results on Human3.6M dataset with CPN 2D detections1, supervised training
| Arch | Receptive Field | MPJPE | P-MPJPE | ckpt | log |
| :--------------------------------------------------------- | :-------------: | :---: | :-----: | :--------------------------------------------------------: | :-------------------------------------------------------: |
-| [VideoPose3D](/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-1frm-supv-cpn-ft_8xb128-80e_h36m.py) | 1 | 53.0 | 41.3 | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_1frame_fullconv_supervised_cpn_ft-5c3afaed_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_1frame_fullconv_supervised_cpn_ft_20210527.log.json) |
-| [VideoPose3D](/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-243frm-supv-cpn-ft_8xb128-200e_h36m.py) | 243 | | | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_cpn_ft-88f5abbb_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_cpn_ft_20210527.log.json) |
+| [VideoPose3D-supervised-CPN-1frm](/configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-1frm-supv-cpn-ft_8xb128-160e_h36m.py) | 1 | 53.0 | 41.3 | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_1frame_fullconv_supervised_cpn_ft-5c3afaed_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_1frame_fullconv_supervised_cpn_ft_20210527.log.json) |
+| [VideoPose3D-supervised-CPN-243frm](/configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-243frm-supv-cpn-ft_8xb128-200e_h36m.py) | 243 | 47.9 | 38.0 | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_cpn_ft-88f5abbb_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_cpn_ft_20210527.log.json) |
Testing results on Human3.6M dataset with ground truth 2D detections, semi-supervised training
| Training Data | Arch | Receptive Field | MPJPE | P-MPJPE | N-MPJPE | ckpt | log |
| :------------ | :-------------------------------------------------: | :-------------: | :---: | :-----: | :-----: | :-------------------------------------------------: | :-------------------------------------------------: |
-| 10% S1 | [VideoPose3D](/configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-27frm-semi-supv_8xb64-200e_h36m.py) | 27 | 57.2 | 42.4 | 54.2 | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_semi-supervised-54aef83b_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_semi-supervised_20210527.log.json) |
+| 10% S1 | [VideoPose3D-semi-supervised-27frm](/configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-27frm-semi-supv_8xb64-200e_h36m.py) | 27 | 57.2 | 42.4 | 54.2 | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_semi-supervised-54aef83b_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_semi-supervised_20210527.log.json) |
Testing results on Human3.6M dataset with CPN 2D detections1, semi-supervised training
-| Training Data | Arch | Receptive Field | MPJPE | P-MPJPE | N-MPJPE | ckpt | log |
-| :------------ | :----------------------------: | :-------------: | :---: | :-----: | :-----: | :------------------------------------------------------------: | :-----------------------------------------------------------: |
-| 10% S1 | [VideoPose3D](/configs/xxx.py) | 27 | 67.3 | 50.4 | 63.6 | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_semi-supervised_cpn_ft-71be9cde_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_semi-supervised_cpn_ft_20210527.log.json) |
+| Training Data | Arch | Receptive Field | MPJPE | P-MPJPE | N-MPJPE | ckpt | log |
+| :------------ | :-------------------------------------------------: | :-------------: | :---: | :-----: | :-----: | :-------------------------------------------------: | :-------------------------------------------------: |
+| 10% S1 | [VideoPose3D-semi-supervised-CPN-27frm](/configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-27frm-semi-supv-cpn-ft_8xb64-200e_h36m.py) | 27 | 67.3 | 50.4 | 63.6 | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_semi-supervised_cpn_ft-71be9cde_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_semi-supervised_cpn_ft_20210527.log.json) |
1 CPN 2D detections are provided by [official repo](https://github.com/facebookresearch/VideoPose3D/blob/master/DATASETS.md). The reformatted version used in this repository can be downloaded from [train_detection](https://download.openmmlab.com/mmpose/body3d/videopose/cpn_ft_h36m_dbb_train.npy) and [test_detection](https://download.openmmlab.com/mmpose/body3d/videopose/cpn_ft_h36m_dbb_test.npy).
diff --git a/configs/body_3d_keypoint/pose_lift/h36m/videopose3d_h36m.yml b/configs/body_3d_keypoint/video_pose_lift/h36m/videopose3d_h36m.yml
similarity index 70%
rename from configs/body_3d_keypoint/pose_lift/h36m/videopose3d_h36m.yml
rename to configs/body_3d_keypoint/video_pose_lift/h36m/videopose3d_h36m.yml
index 6b9d92c115..818fe0483b 100644
--- a/configs/body_3d_keypoint/pose_lift/h36m/videopose3d_h36m.yml
+++ b/configs/body_3d_keypoint/video_pose_lift/h36m/videopose3d_h36m.yml
@@ -6,13 +6,13 @@ Collections:
URL: http://openaccess.thecvf.com/content_CVPR_2019/html/Pavllo_3D_Human_Pose_Estimation_in_Video_With_Temporal_Convolutions_and_CVPR_2019_paper.html
README: https://github.com/open-mmlab/mmpose/blob/main/docs/en/papers/algorithms/videopose3d.md
Models:
-- Config: configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-243frm-supv_8xb128-80e_h36m.py
+- Config: configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-27frm-supv_8xb128-160e_h36m.py
In Collection: VideoPose3D
Metadata:
Architecture: &id001
- VideoPose3D
Training Data: Human3.6M
- Name: pose-lift_videopose3d-243frm-supv_8xb128-80e_h36m
+ Name: video-pose-lift_tcn-27frm-supv_8xb128-160e_h36m
Results:
- Dataset: Human3.6M
Metrics:
@@ -20,12 +20,12 @@ Models:
P-MPJPE: 30.1
Task: Body 3D Keypoint
Weights: https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_supervised-fe8fbba9_20210527.pth
-- Config: configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-81frm-supv_8xb128-80e_h36m.py
+- Config: configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-81frm-supv_8xb128-160e_h36m.py
In Collection: VideoPose3D
Metadata:
Architecture: *id001
Training Data: Human3.6M
- Name: pose-lift_videopose3d-81frm-supv_8xb128-80e_h36m
+ Name: video-pose-lift_tcn-81frm-supv_8xb128-160e_h36m
Results:
- Dataset: Human3.6M
Metrics:
@@ -33,12 +33,12 @@ Models:
P-MPJPE: 29.2
Task: Body 3D Keypoint
Weights: https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_81frames_fullconv_supervised-1f2d1104_20210527.pth
-- Config: configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-243frm-supv_8xb128-80e_h36m.py
+- Config: configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-243frm-supv_8xb128-160e_h36m.py
In Collection: VideoPose3D
Metadata:
Architecture: *id001
Training Data: Human3.6M
- Name: pose-lift_videopose3d-243frm-supv_8xb128-80e_h36m
+ Name: video-pose-lift_tcn-243frm-supv_8xb128-160e_h36m
Results:
- Dataset: Human3.6M
Metrics:
@@ -46,12 +46,12 @@ Models:
P-MPJPE: 28.3
Task: Body 3D Keypoint
Weights: https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised-880bea25_20210527.pth
-- Config: configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-1frm-supv-cpn-ft_8xb128-80e_h36m.py
+- Config: configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-1frm-supv-cpn-ft_8xb128-160e_h36m.py
In Collection: VideoPose3D
Metadata:
Architecture: *id001
Training Data: Human3.6M
- Name: pose-lift_videopose3d-1frm-supv-cpn-ft_8xb128-80e_h36m
+ Name: video-pose-lift_tcn-1frm-supv-cpn-ft_8xb128-160e_h36m
Results:
- Dataset: Human3.6M
Metrics:
@@ -59,13 +59,12 @@ Models:
P-MPJPE: 41.3
Task: Body 3D Keypoint
Weights: https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_1frame_fullconv_supervised_cpn_ft-5c3afaed_20210527.pth
-- Config: configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-243frm-supv-cpn-ft_8xb128-200e_h36m.py
+- Config: configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-243frm-supv-cpn-ft_8xb128-200e_h36m.py
In Collection: VideoPose3D
- Alias: human3d
Metadata:
Architecture: *id001
Training Data: Human3.6M
- Name: pose-lift_videopose3d-243frm-supv-cpn-ft_8xb128-200e_h36m
+ Name: video-pose-lift_tcn-243frm-supv-cpn-ft_8xb128-200e_h36m
Results:
- Dataset: Human3.6M
Metrics:
@@ -73,12 +72,12 @@ Models:
P-MPJPE: 38.0
Task: Body 3D Keypoint
Weights: https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_cpn_ft-88f5abbb_20210527.pth
-- Config: configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-27frm-semi-supv_8xb64-200e_h36m.py
+- Config: configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-27frm-semi-supv_8xb64-200e_h36m.py
In Collection: VideoPose3D
Metadata:
Architecture: *id001
Training Data: Human3.6M
- Name: pose-lift_videopose3d-27frm-semi-supv_8xb64-200e_h36m
+ Name: video-pose-lift_tcn-27frm-semi-supv_8xb64-200e_h36m
Results:
- Dataset: Human3.6M
Metrics:
@@ -87,12 +86,12 @@ Models:
P-MPJPE: 42.8
Task: Body 3D Keypoint
Weights: https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_semi-supervised-54aef83b_20210527.pth
-- Config: configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-27frm-semi-supv-cpn-ft_8xb64-200e_h36m.py
+- Config: configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-27frm-semi-supv-cpn-ft_8xb64-200e_h36m.py
In Collection: VideoPose3D
Metadata:
Architecture: *id001
Training Data: Human3.6M
- Name: pose-lift_videopose3d-27frm-semi-supv-cpn-ft_8xb64-200e_h36m
+ Name: video-pose-lift_tcn-27frm-semi-supv-cpn-ft_8xb64-200e_h36m
Results:
- Dataset: Human3.6M
Metrics:
diff --git a/configs/face_2d_keypoint/rtmpose/face6/rtmpose_face6.md b/configs/face_2d_keypoint/rtmpose/face6/rtmpose_face6.md
index 254633e42c..5f989fa783 100644
--- a/configs/face_2d_keypoint/rtmpose/face6/rtmpose_face6.md
+++ b/configs/face_2d_keypoint/rtmpose/face6/rtmpose_face6.md
@@ -66,6 +66,6 @@
| Config | Input Size | NMEHuman3.6M (TPAMI'2014)
+ +```bibtex +@article{h36m_pami, +author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian}, +title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments}, +journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence}, +publisher = {IEEE Computer Society}, +volume = {36}, +number = {7}, +pages = {1325-1339}, +month = {jul}, +year = {2014} +} +``` + +(LaPa) | FLOPS
(G) | Download | | :--------------------------------------------------------------------------: | :--------: | :----------------: | :---------------: | :-----------------------------------------------------------------------------: | -| [RTMPose-t\*](./rtmpose/face_2d_keypoint/rtmpose-t_8xb256-120e_lapa-256x256.py) | 256x256 | 1.67 | 0.652 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-face6_pt-in1k_120e-256x256-df79d9a5_20230529.pth) | -| [RTMPose-s\*](./rtmpose/face_2d_keypoint/rtmpose-m_8xb256-120e_lapa-256x256.py) | 256x256 | 1.59 | 1.119 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-face6_pt-in1k_120e-256x256-d779fdef_20230529.pth) | -| [RTMPose-m\*](./rtmpose/face_2d_keypoint/rtmpose-m_8xb256-120e_lapa-256x256.py) | 256x256 | 1.44 | 2.852 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.pth) | +| [RTMPose-t\*](./rtmpose/face_2d_keypoint/rtmpose-t_8xb256-120e_face6-256x256.py) | 256x256 | 1.67 | 0.652 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-face6_pt-in1k_120e-256x256-df79d9a5_20230529.pth) | +| [RTMPose-s\*](./rtmpose/face_2d_keypoint/rtmpose-s_8xb256-120e_face6-256x256.py) | 256x256 | 1.59 | 1.119 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-face6_pt-in1k_120e-256x256-d779fdef_20230529.pth) | +| [RTMPose-m\*](./rtmpose/face_2d_keypoint/rtmpose-m_8xb256-120e_face6-256x256.py) | 256x256 | 1.44 | 2.852 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.pth) | diff --git a/configs/face_2d_keypoint/rtmpose/face6/rtmpose_face6.yml b/configs/face_2d_keypoint/rtmpose/face6/rtmpose_face6.yml index 2cd822a337..38b8395bd9 100644 --- a/configs/face_2d_keypoint/rtmpose/face6/rtmpose_face6.yml +++ b/configs/face_2d_keypoint/rtmpose/face6/rtmpose_face6.yml @@ -42,6 +42,7 @@ Models: Architecture: *id001 Training Data: *id002 Name: rtmpose-m_8xb256-120e_face6-256x256 + Alias: face Results: - Dataset: Face6 Metrics: diff --git a/configs/face_2d_keypoint/rtmpose/wflw/rtmpose_wflw.yml b/configs/face_2d_keypoint/rtmpose/wflw/rtmpose_wflw.yml index deee03a7dd..1112fdf69d 100644 --- a/configs/face_2d_keypoint/rtmpose/wflw/rtmpose_wflw.yml +++ b/configs/face_2d_keypoint/rtmpose/wflw/rtmpose_wflw.yml @@ -1,7 +1,6 @@ Models: - Config: configs/face_2d_keypoint/rtmpose/wflw/rtmpose-m_8xb64-60e_wflw-256x256.py In Collection: RTMPose - Alias: face Metadata: Architecture: - RTMPose diff --git a/configs/face_2d_keypoint/topdown_heatmap/300wlp/hrnetv2_300wlp.md b/configs/face_2d_keypoint/topdown_heatmap/300wlp/hrnetv2_300wlp.md new file mode 100644 index 0000000000..773bc602ae --- /dev/null +++ b/configs/face_2d_keypoint/topdown_heatmap/300wlp/hrnetv2_300wlp.md @@ -0,0 +1,42 @@ + + +
+
+
+
+
+HRNetv2 (TPAMI'2019)
+ +```bibtex +@article{WangSCJDZLMTWLX19, + title={Deep High-Resolution Representation Learning for Visual Recognition}, + author={Jingdong Wang and Ke Sun and Tianheng Cheng and + Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and + Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao}, + journal={TPAMI}, + year={2019} +} +``` + +
+
+
+Results on 300W-LP dataset
+
+The model is trained on 300W-LP train.
+
+| Arch | Input Size | NME*full* | NME*test* | ckpt | log |
+| :------------------------------------------------- | :--------: | :------------------: | :------------------: | :------------------------------------------------: | :------------------------------------------------: |
+| [pose_hrnetv2_w18](/configs/face_2d_keypoint/topdown_heatmap/300wlp/td-hm_hrnetv2-w18_8xb64-60e_300wlp-256x256.py) | 256x256 | 0.0413 | 0.04125 | [ckpt](https://download.openmmlab.com/mmpose/v1/face_2d_keypoint/topdown_heatmap/300wlp/hrnetv2_w18_300wlp_256x256-fb433d21_20230922.pth) | [log](https://download.openmmlab.com/mmpose/v1/face_2d_keypoint/topdown_heatmap/300wlp/hrnetv2_w18_300wlp_256x256-fb433d21_20230922.json) |
diff --git a/configs/face_2d_keypoint/topdown_heatmap/300wlp/hrnetv2_300wlp.yml b/configs/face_2d_keypoint/topdown_heatmap/300wlp/hrnetv2_300wlp.yml
new file mode 100644
index 0000000000..844c15df6d
--- /dev/null
+++ b/configs/face_2d_keypoint/topdown_heatmap/300wlp/hrnetv2_300wlp.yml
@@ -0,0 +1,20 @@
+Collections:
+- Name: HRNetv2
+ Paper:
+ Title: Deep High-Resolution Representation Learning for Visual Recognition
+ URL: https://ieeexplore.ieee.org/abstract/document/9052469/
+ README: https://github.com/open-mmlab/mmpose/blob/main/docs/src/papers/backbones/hrnetv2.md
+Models:
+- Config: configs/face_2d_keypoint/topdown_heatmap/300wlp/td-hm_hrnetv2-w18_8xb64-60e_300wlp-256x256.py
+ In Collection: HRNetv2
+ Metadata:
+ Architecture:
+ - HRNetv2
+ Training Data: 300W-LP
+ Name: td-hm_hrnetv2-w18_8xb64-60e_300wlp-256x256
+ Results:
+ - Dataset: 300W-LP
+ Metrics:
+ NME full: 0.0413
+ Task: Face 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/v1/face_2d_keypoint/topdown_heatmap/300wlp/hrnetv2_w18_300wlp_256x256-fb433d21_20230922.pth
diff --git a/configs/face_2d_keypoint/topdown_heatmap/300wlp/td-hm_hrnetv2-w18_8xb64-60e_300wlp-256x256.py b/configs/face_2d_keypoint/topdown_heatmap/300wlp/td-hm_hrnetv2-w18_8xb64-60e_300wlp-256x256.py
new file mode 100644
index 0000000000..e96a6bf0eb
--- /dev/null
+++ b/configs/face_2d_keypoint/topdown_heatmap/300wlp/td-hm_hrnetv2-w18_8xb64-60e_300wlp-256x256.py
@@ -0,0 +1,160 @@
+_base_ = ['../../../_base_/default_runtime.py']
+
+# runtime
+train_cfg = dict(max_epochs=60, val_interval=1)
+
+# optimizer
+optim_wrapper = dict(optimizer=dict(
+ type='Adam',
+ lr=2e-3,
+))
+
+# learning policy
+param_scheduler = [
+ dict(
+ type='LinearLR', begin=0, end=500, start_factor=0.001,
+ by_epoch=False), # warm-up
+ dict(
+ type='MultiStepLR',
+ begin=0,
+ end=60,
+ milestones=[40, 55],
+ gamma=0.1,
+ by_epoch=True)
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=512)
+
+# hooks
+default_hooks = dict(checkpoint=dict(save_best='NME', rule='less', interval=1))
+
+# codec settings
+codec = dict(
+ type='MSRAHeatmap',
+ input_size=(256, 256),
+ heatmap_size=(64, 64),
+ sigma=1.5)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(18, 36)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(18, 36, 72)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(18, 36, 72, 144),
+ multiscale_output=True),
+ upsample=dict(mode='bilinear', align_corners=False)),
+ init_cfg=dict(
+ type='Pretrained', checkpoint='open-mmlab://msra/hrnetv2_w18'),
+ ),
+ neck=dict(
+ type='FeatureMapProcessor',
+ concat=True,
+ ),
+ head=dict(
+ type='HeatmapHead',
+ in_channels=270,
+ out_channels=68,
+ deconv_out_channels=None,
+ conv_out_channels=(270, ),
+ conv_kernel_sizes=(1, ),
+ loss=dict(type='KeypointMSELoss', use_target_weight=True),
+ decoder=codec),
+ test_cfg=dict(
+ flip_test=True,
+ flip_mode='heatmap',
+ shift_heatmap=True,
+ ))
+
+# base dataset settings
+dataset_type = 'Face300WLPDataset'
+data_mode = 'topdown'
+data_root = 'data/300wlp/'
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_prob=0,
+ rotate_factor=60,
+ scale_factor=(0.75, 1.25)),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=2,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/face_landmarks_300wlp_train.json',
+ data_prefix=dict(img='train/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=32,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/face_landmarks_300wlp_valid.json',
+ data_prefix=dict(img='val/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# evaluators
+val_evaluator = dict(
+ type='NME',
+ norm_mode='keypoint_distance',
+)
+test_evaluator = val_evaluator
diff --git a/configs/fashion_2d_keypoint/topdown_heatmap/README.md b/configs/fashion_2d_keypoint/topdown_heatmap/README.md
new file mode 100644
index 0000000000..865a3b823e
--- /dev/null
+++ b/configs/fashion_2d_keypoint/topdown_heatmap/README.md
@@ -0,0 +1,42 @@
+# Top-down heatmap-based pose estimation
+
+Top-down methods divide the task into two stages: object detection, followed by single-object pose estimation given object bounding boxes. Instead of estimating keypoint coordinates directly, the pose estimator will produce heatmaps which represent the likelihood of being a keypoint, following the paradigm introduced in [Simple Baselines for Human Pose Estimation and Tracking](http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html).
+
+300WLP (IEEE'2017)
+ +```bibtex +@article{zhu2017face, + title={Face alignment in full pose range: A 3d total solution}, + author={Zhu, Xiangyu and Liu, Xiaoming and Lei, Zhen and Li, Stan Z}, + journal={IEEE transactions on pattern analysis and machine intelligence}, + year={2017}, + publisher={IEEE} +} +``` + +
+ +
+
+
+## Results and Models
+
+### DeepFashion Dataset
+
+Results on DeepFashion dataset with ResNet backbones:
+
+| Model | Input Size | PCK@0.2 | AUC | EPE | Details and Download |
+| :-----------------: | :--------: | :-----: | :--: | :--: | :----------------------------------------------------------: |
+| HRNet-w48-UDP-Upper | 256x192 | 96.1 | 60.9 | 15.1 | [hrnet_deepfashion.md](./deepfashion/hrnet_deepfashion.md) |
+| HRNet-w48-UDP-Lower | 256x192 | 97.8 | 76.1 | 8.9 | [hrnet_deepfashion.md](./deepfashion/hrnet_deepfashion.md) |
+| HRNet-w48-UDP-Full | 256x192 | 98.3 | 67.3 | 11.7 | [hrnet_deepfashion.md](./deepfashion/hrnet_deepfashion.md) |
+| ResNet-50-Upper | 256x192 | 95.4 | 57.8 | 16.8 | [resnet_deepfashion.md](./deepfashion/resnet_deepfashion.md) |
+| ResNet-50-Lower | 256x192 | 96.5 | 74.4 | 10.5 | [resnet_deepfashion.md](./deepfashion/resnet_deepfashion.md) |
+| ResNet-50-Full | 256x192 | 97.7 | 66.4 | 12.7 | [resnet_deepfashion.md](./deepfashion/resnet_deepfashion.md) |
+
+### DeepFashion2 Dataset
+
+Results on DeepFashion2 dataset
+
+| Model | Input Size | PCK@0.2 | AUC | EPE | Details and Download |
+| :-----------------------------: | :--------: | :-----: | :---: | :--: | :-----------------------------------------------------------: |
+| ResNet-50-Short-Sleeved-Shirt | 256x192 | 0.988 | 0.703 | 10.2 | [res50_deepfashion2.md](./deepfashion2/res50_deepfashion2.md) |
+| ResNet-50-Long-Sleeved-Shirt | 256x192 | 0.973 | 0.587 | 16.6 | [res50_deepfashion2.md](./deepfashion2/res50_deepfashion2.md) |
+| ResNet-50-Short-Sleeved-Outwear | 256x192 | 0.966 | 0.408 | 24.0 | [res50_deepfashion2.md](./deepfashion2/res50_deepfashion2.md) |
+| ResNet-50-Long-Sleeved-Outwear | 256x192 | 0.987 | 0.517 | 18.1 | [res50_deepfashion2.md](./deepfashion2/res50_deepfashion2.md) |
+| ResNet-50-Vest | 256x192 | 0.981 | 0.643 | 12.7 | [res50_deepfashion2.md](./deepfashion2/res50_deepfashion2.md) |
+| ResNet-50-Sling | 256x192 | 0.940 | 0.557 | 21.6 | [res50_deepfashion2.md](./deepfashion2/res50_deepfashion2.md) |
+| ResNet-50-Shorts | 256x192 | 0.975 | 0.682 | 12.4 | [res50_deepfashion2.md](./deepfashion2/res50_deepfashion2.md) |
+| ResNet-50-Trousers | 256x192 | 0.973 | 0.625 | 14.8 | [res50_deepfashion2.md](./deepfashion2/res50_deepfashion2.md) |
+| ResNet-50-Skirt | 256x192 | 0.952 | 0.653 | 16.6 | [res50_deepfashion2.md](./deepfashion2/res50_deepfashion2.md) |
+| ResNet-50-Short-Sleeved-Dress | 256x192 | 0.980 | 0.603 | 15.6 | [res50_deepfashion2.md](./deepfashion2/res50_deepfashion2.md) |
+| ResNet-50-Long-Sleeved-Dress | 256x192 | 0.976 | 0.518 | 20.1 | [res50_deepfashion2.md](./deepfashion2/res50_deepfashion2.md) |
+| ResNet-50-Vest-Dress | 256x192 | 0.980 | 0.600 | 16.0 | [res50_deepfashion2.md](./deepfashion2/res50_deepfashion2.md) |
+| ResNet-50-Sling-Dress | 256x192 | 0.967 | 0.544 | 19.5 | [res50_deepfashion2.md](./deepfashion2/res50_deepfashion2.md) |
diff --git a/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/hrnet_deepfashion.md b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/hrnet_deepfashion.md
new file mode 100644
index 0000000000..2d5e382c92
--- /dev/null
+++ b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/hrnet_deepfashion.md
@@ -0,0 +1,77 @@
+
+
+
+
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+
+
+UDP (CVPR'2020)
+ +```bibtex +@InProceedings{Huang_2020_CVPR, + author = {Huang, Junjie and Zhu, Zheng and Guo, Feng and Huang, Guan}, + title = {The Devil Is in the Details: Delving Into Unbiased Data Processing for Human Pose Estimation}, + booktitle = {The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, + month = {June}, + year = {2020} +} +``` + +
+
+
+
+
+DeepFashion (CVPR'2016)
+ +```bibtex +@inproceedings{liuLQWTcvpr16DeepFashion, + author = {Liu, Ziwei and Luo, Ping and Qiu, Shi and Wang, Xiaogang and Tang, Xiaoou}, + title = {DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations}, + booktitle = {Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + month = {June}, + year = {2016} +} +``` + +
+
+
+Results on DeepFashion val set
+
+| Set | Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :---- | :-------------------------------------------------------: | :--------: | :-----: | :--: | :--: | :-------------------------------------------------------: | :------------------------------------------------------: |
+| upper | [pose_hrnet_w48_udp](td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_uppder-256x192.py) | 256x192 | 96.1 | 60.9 | 15.1 | [ckpt](https://download.openmmlab.com/mmpose/v1/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_upper-256x192-de7c0eb1_20230810.pth) | [log](https://download.openmmlab.com/mmpose/v1/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_upper-256x192-de7c0eb1_20230810.log) |
+| lower | [pose_hrnet_w48_udp](td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_lower-256x192.py) | 256x192 | 97.8 | 76.1 | 8.9 | [ckpt](https://download.openmmlab.com/mmpose/v1/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_lower-256x192-ddaf747d_20230810.pth) | [log](https://download.openmmlab.com/mmpose/v1/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_lower-256x192-ddaf747d_20230810.log) |
+| full | [pose_hrnet_w48_udp](td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_full-256x192.py) | 256x192 | 98.3 | 67.3 | 11.7 | [ckpt](https://download.openmmlab.com/mmpose/v1/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_full-256x192-7ab504c7_20230810.pth) | [log](https://download.openmmlab.com/mmpose/v1/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_full-256x192-7ab504c7_20230810.log) |
+
+Note: Due to the time constraints, we have only trained resnet50 models. We warmly welcome any contributions if you can successfully reproduce the results from the paper!
diff --git a/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/hrnet_deepfashion.yml b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/hrnet_deepfashion.yml
new file mode 100644
index 0000000000..06c297ef8e
--- /dev/null
+++ b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/hrnet_deepfashion.yml
@@ -0,0 +1,45 @@
+Models:
+- Config: configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_lower-256x192.py
+ In Collection: UDP
+ Metadata:
+ Architecture: &id001
+ - HRNet
+ - UDP
+ Training Data: DeepFashion
+ Name: td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_lower-256x192
+ Results:
+ - Dataset: DeepFashion
+ Metrics:
+ AUC: 76.1
+ EPE: 8.9
+ PCK@0.2: 97.8
+ Task: Fashion 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/v1/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_lower-256x192-ddaf747d_20230810.pth
+- Config: configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_upper-256x192.py
+ In Collection: UDP
+ Metadata:
+ Architecture: *id001
+ Training Data: DeepFashion
+ Name: td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_upper-256x192
+ Results:
+ - Dataset: DeepFashion
+ Metrics:
+ AUC: 60.9
+ EPE: 15.1
+ PCK@0.2: 96.1
+ Task: Fashion 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/v1/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_upper-256x192-de7c0eb1_20230810.pth
+- Config: configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_full-256x192.py
+ In Collection: UDP
+ Metadata:
+ Architecture: *id001
+ Training Data: DeepFashion
+ Name: td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_full-256x192
+ Results:
+ - Dataset: DeepFashion
+ Metrics:
+ AUC: 67.3
+ EPE: 11.7
+ PCK@0.2: 98.3
+ Task: Fashion 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/v1/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_full-256x192-7ab504c7_20230810.pth
diff --git a/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/resnet_deepfashion.md b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/resnet_deepfashion.md
new file mode 100644
index 0000000000..cb5c3c1c84
--- /dev/null
+++ b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/resnet_deepfashion.md
@@ -0,0 +1,77 @@
+
+
+DeepFashion (ECCV'2016)
+ +```bibtex +@inproceedings{liuYLWTeccv16FashionLandmark, + author = {Liu, Ziwei and Yan, Sijie and Luo, Ping and Wang, Xiaogang and Tang, Xiaoou}, + title = {Fashion Landmark Detection in the Wild}, + booktitle = {European Conference on Computer Vision (ECCV)}, + month = {October}, + year = {2016} + } +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+
+
+DeepFashion (CVPR'2016)
+ +```bibtex +@inproceedings{liuLQWTcvpr16DeepFashion, + author = {Liu, Ziwei and Luo, Ping and Qiu, Shi and Wang, Xiaogang and Tang, Xiaoou}, + title = {DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations}, + booktitle = {Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + month = {June}, + year = {2016} +} +``` + +
+
+
+Results on DeepFashion val set
+
+| Set | Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :---- | :-------------------------------------------------------: | :--------: | :-----: | :--: | :--: | :-------------------------------------------------------: | :------------------------------------------------------: |
+| upper | [pose_resnet_50](td-hm_res50_8xb64-210e_deepfashion_upper-256x192.py) | 256x192 | 95.4 | 57.8 | 16.8 | [ckpt](https://download.openmmlab.com/mmpose/fashion/resnet/res50_deepfashion_upper_256x192-41794f03_20210124.pth) | [log](https://download.openmmlab.com/mmpose/fashion/resnet/res50_deepfashion_upper_256x192_20210124.log.json) |
+| lower | [pose_resnet_50](td-hm_res50_8xb64-210e_deepfashion_lower-256x192.py) | 256x192 | 96.5 | 74.4 | 10.5 | [ckpt](https://download.openmmlab.com/mmpose/fashion/resnet/res50_deepfashion_lower_256x192-1292a839_20210124.pth) | [log](https://download.openmmlab.com/mmpose/fashion/resnet/res50_deepfashion_lower_256x192_20210124.log.json) |
+| full | [pose_resnet_50](td-hm_res50_8xb64-210e_deepfashion_full-256x192.py) | 256x192 | 97.7 | 66.4 | 12.7 | [ckpt](https://download.openmmlab.com/mmpose/fashion/resnet/res50_deepfashion_full_256x192-0dbd6e42_20210124.pth) | [log](https://download.openmmlab.com/mmpose/fashion/resnet/res50_deepfashion_full_256x192_20210124.log.json) |
+
+Note: Due to the time constraints, we have only trained resnet50 models. We warmly welcome any contributions if you can successfully reproduce the results from the paper!
diff --git a/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/resnet_deepfashion.yml b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/resnet_deepfashion.yml
new file mode 100644
index 0000000000..1c382ee2d5
--- /dev/null
+++ b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/resnet_deepfashion.yml
@@ -0,0 +1,51 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res50_8xb64-210e_deepfashion_upper-256x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: &id001
+ - SimpleBaseline2D
+ - ResNet
+ Training Data: DeepFashion
+ Name: td-hm_res50_8xb64-210e_deepfashion_upper-256x192
+ Results:
+ - Dataset: DeepFashion
+ Metrics:
+ AUC: 57.8
+ EPE: 16.8
+ PCK@0.2: 95.4
+ Task: Fashion 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/fashion/resnet/res50_deepfashion_upper_256x192-41794f03_20210124.pth
+- Config: configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res50_8xb64-210e_deepfashion_lower-256x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: DeepFashion
+ Name: td-hm_res50_8xb64-210e_deepfashion_lower-256x192
+ Results:
+ - Dataset: DeepFashion
+ Metrics:
+ AUC: 74.4
+ EPE: 96.5
+ PCK@0.2: 10.5
+ Task: Fashion 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/fashion/resnet/res50_deepfashion_lower_256x192-1292a839_20210124.pth
+- Config: configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res50_8xb64-210e_deepfashion_full-256x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: DeepFashion
+ Name: td-hm_res50_8xb64-210e_deepfashion_full-256x192
+ Results:
+ - Dataset: DeepFashion
+ Metrics:
+ AUC: 66.4
+ EPE: 12.7
+ PCK@0.2: 97.7
+ Task: Fashion 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/fashion/resnet/res50_deepfashion_full_256x192-0dbd6e42_20210124.pth
diff --git a/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w32_8xb64-210e_deepfashion_full-256x192.py b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w32_8xb64-210e_deepfashion_full-256x192.py
new file mode 100644
index 0000000000..4a30ead782
--- /dev/null
+++ b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w32_8xb64-210e_deepfashion_full-256x192.py
@@ -0,0 +1,169 @@
+_base_ = '../../../_base_/default_runtime.py'
+
+# runtime
+train_cfg = dict(max_epochs=210, val_interval=10)
+
+# optimizer
+optim_wrapper = dict(optimizer=dict(
+ type='Adam',
+ lr=5e-4,
+))
+
+# learning policy
+param_scheduler = [
+ dict(
+ type='LinearLR', begin=0, end=500, start_factor=0.001,
+ by_epoch=False), # warm-up
+ dict(
+ type='MultiStepLR',
+ begin=0,
+ end=210,
+ milestones=[170, 200],
+ gamma=0.1,
+ by_epoch=True)
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=512)
+
+# hooks
+default_hooks = dict(
+ logger=dict(type='LoggerHook', interval=10),
+ checkpoint=dict(save_best='AUC', rule='greater'))
+
+# codec settings
+codec = dict(
+ type='MSRAHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth'),
+ ),
+ head=dict(
+ type='HeatmapHead',
+ in_channels=32,
+ out_channels=8,
+ deconv_out_channels=None,
+ loss=dict(type='KeypointMSELoss', use_target_weight=True),
+ decoder=codec),
+ test_cfg=dict(
+ flip_test=True,
+ flip_mode='heatmap',
+ shift_heatmap=True,
+ ))
+
+# base dataset settings
+dataset_type = 'DeepFashionDataset'
+data_mode = 'topdown'
+data_root = 'data/fld/'
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomBBoxTransform'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+test_pipeline = val_pipeline
+
+# data loaders
+train_dataloader = dict(
+ batch_size=64,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ subset='full',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/fld_full_train.json',
+ data_prefix=dict(img='img/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=32,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ subset='full',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/fld_full_val.json',
+ data_prefix=dict(img='img/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = dict(
+ batch_size=32,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ subset='full',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/fld_full_test.json',
+ data_prefix=dict(img='img/'),
+ test_mode=True,
+ pipeline=test_pipeline,
+ ))
+
+# evaluators
+val_evaluator = [
+ dict(type='PCKAccuracy', thr=0.2),
+ dict(type='AUC'),
+ dict(type='EPE'),
+]
+test_evaluator = val_evaluator
diff --git a/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w32_8xb64-210e_deepfashion_lower-256x192.py b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w32_8xb64-210e_deepfashion_lower-256x192.py
new file mode 100644
index 0000000000..0a86c38ba8
--- /dev/null
+++ b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w32_8xb64-210e_deepfashion_lower-256x192.py
@@ -0,0 +1,169 @@
+_base_ = '../../../_base_/default_runtime.py'
+
+# runtime
+train_cfg = dict(max_epochs=210, val_interval=10)
+
+# optimizer
+optim_wrapper = dict(optimizer=dict(
+ type='Adam',
+ lr=5e-4,
+))
+
+# learning policy
+param_scheduler = [
+ dict(
+ type='LinearLR', begin=0, end=500, start_factor=0.001,
+ by_epoch=False), # warm-up
+ dict(
+ type='MultiStepLR',
+ begin=0,
+ end=210,
+ milestones=[170, 200],
+ gamma=0.1,
+ by_epoch=True)
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=512)
+
+# hooks
+default_hooks = dict(
+ logger=dict(type='LoggerHook', interval=10),
+ checkpoint=dict(save_best='AUC', rule='greater'))
+
+# codec settings
+codec = dict(
+ type='MSRAHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth'),
+ ),
+ head=dict(
+ type='HeatmapHead',
+ in_channels=32,
+ out_channels=4,
+ deconv_out_channels=None,
+ loss=dict(type='KeypointMSELoss', use_target_weight=True),
+ decoder=codec),
+ test_cfg=dict(
+ flip_test=True,
+ flip_mode='heatmap',
+ shift_heatmap=True,
+ ))
+
+# base dataset settings
+dataset_type = 'DeepFashionDataset'
+data_mode = 'topdown'
+data_root = 'data/fld/'
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomBBoxTransform'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+test_pipeline = val_pipeline
+
+# data loaders
+train_dataloader = dict(
+ batch_size=64,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ subset='lower',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/fld_lower_train.json',
+ data_prefix=dict(img='img/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=32,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ subset='lower',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/fld_lower_val.json',
+ data_prefix=dict(img='img/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = dict(
+ batch_size=32,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ subset='lower',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/fld_lower_test.json',
+ data_prefix=dict(img='img/'),
+ test_mode=True,
+ pipeline=test_pipeline,
+ ))
+
+# evaluators
+val_evaluator = [
+ dict(type='PCKAccuracy', thr=0.2),
+ dict(type='AUC'),
+ dict(type='EPE'),
+]
+test_evaluator = val_evaluator
diff --git a/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w32_8xb64-210e_deepfashion_upper-256x192.py b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w32_8xb64-210e_deepfashion_upper-256x192.py
new file mode 100644
index 0000000000..7d6af18fd9
--- /dev/null
+++ b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w32_8xb64-210e_deepfashion_upper-256x192.py
@@ -0,0 +1,169 @@
+_base_ = '../../../_base_/default_runtime.py'
+
+# runtime
+train_cfg = dict(max_epochs=210, val_interval=10)
+
+# optimizer
+optim_wrapper = dict(optimizer=dict(
+ type='Adam',
+ lr=5e-4,
+))
+
+# learning policy
+param_scheduler = [
+ dict(
+ type='LinearLR', begin=0, end=500, start_factor=0.001,
+ by_epoch=False), # warm-up
+ dict(
+ type='MultiStepLR',
+ begin=0,
+ end=210,
+ milestones=[170, 200],
+ gamma=0.1,
+ by_epoch=True)
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=512)
+
+# hooks
+default_hooks = dict(
+ logger=dict(type='LoggerHook', interval=10),
+ checkpoint=dict(save_best='AUC', rule='greater'))
+
+# codec settings
+codec = dict(
+ type='MSRAHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth'),
+ ),
+ head=dict(
+ type='HeatmapHead',
+ in_channels=32,
+ out_channels=6,
+ deconv_out_channels=None,
+ loss=dict(type='KeypointMSELoss', use_target_weight=True),
+ decoder=codec),
+ test_cfg=dict(
+ flip_test=True,
+ flip_mode='heatmap',
+ shift_heatmap=True,
+ ))
+
+# base dataset settings
+dataset_type = 'DeepFashionDataset'
+data_mode = 'topdown'
+data_root = 'data/fld/'
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomBBoxTransform'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+test_pipeline = val_pipeline
+
+# data loaders
+train_dataloader = dict(
+ batch_size=64,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ subset='upper',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/fld_upper_train.json',
+ data_prefix=dict(img='img/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=32,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ subset='upper',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/fld_upper_val.json',
+ data_prefix=dict(img='img/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = dict(
+ batch_size=32,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ subset='upper',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/fld_upper_test.json',
+ data_prefix=dict(img='img/'),
+ test_mode=True,
+ pipeline=test_pipeline,
+ ))
+
+# evaluators
+val_evaluator = [
+ dict(type='PCKAccuracy', thr=0.2),
+ dict(type='AUC'),
+ dict(type='EPE'),
+]
+test_evaluator = val_evaluator
diff --git a/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w32_udp_8xb64-210e_deepfashion_full-256x192.py b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w32_udp_8xb64-210e_deepfashion_full-256x192.py
new file mode 100644
index 0000000000..8977c25b56
--- /dev/null
+++ b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w32_udp_8xb64-210e_deepfashion_full-256x192.py
@@ -0,0 +1,26 @@
+_base_ = './td-hm_hrnet-w32_8xb64-210e_deepfashion_full-256x192.py'
+
+# codec settings
+codec = dict(
+ type='UDPHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+
+model = dict(
+ test_cfg=dict(flip_test=True, flip_mode='heatmap', shift_heatmap=False))
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(type='RandomBBoxTransform'),
+ dict(type='TopdownAffine', input_size=codec['input_size'], use_udp=True),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size'], use_udp=True),
+ dict(type='PackPoseInputs')
+]
diff --git a/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w32_udp_8xb64-210e_deepfashion_lower-256x192.py b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w32_udp_8xb64-210e_deepfashion_lower-256x192.py
new file mode 100644
index 0000000000..595035b132
--- /dev/null
+++ b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w32_udp_8xb64-210e_deepfashion_lower-256x192.py
@@ -0,0 +1,26 @@
+_base_ = './td-hm_hrnet-w32_8xb64-210e_deepfashion_lower-256x192.py'
+
+# codec settings
+codec = dict(
+ type='UDPHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+
+model = dict(
+ test_cfg=dict(flip_test=True, flip_mode='heatmap', shift_heatmap=False))
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(type='RandomBBoxTransform'),
+ dict(type='TopdownAffine', input_size=codec['input_size'], use_udp=True),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size'], use_udp=True),
+ dict(type='PackPoseInputs')
+]
diff --git a/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w32_udp_8xb64-210e_deepfashion_upper-256x192.py b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w32_udp_8xb64-210e_deepfashion_upper-256x192.py
new file mode 100644
index 0000000000..777ffddb22
--- /dev/null
+++ b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w32_udp_8xb64-210e_deepfashion_upper-256x192.py
@@ -0,0 +1,26 @@
+_base_ = './td-hm_hrnet-w32_8xb64-210e_deepfashion_upper-256x192.py'
+
+# codec settings
+codec = dict(
+ type='UDPHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+
+model = dict(
+ test_cfg=dict(flip_test=True, flip_mode='heatmap', shift_heatmap=False))
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(type='RandomBBoxTransform'),
+ dict(type='TopdownAffine', input_size=codec['input_size'], use_udp=True),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size'], use_udp=True),
+ dict(type='PackPoseInputs')
+]
diff --git a/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_8xb32-210e_deepfashion_full-256x192.py b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_8xb32-210e_deepfashion_full-256x192.py
new file mode 100644
index 0000000000..bf7a80d59f
--- /dev/null
+++ b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_8xb32-210e_deepfashion_full-256x192.py
@@ -0,0 +1,42 @@
+_base_ = './td-hm_hrnet-w32_8xb64-210e_deepfashion_full-256x192.py'
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=256)
+
+model = dict(
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth'),
+ ),
+ head=dict(in_channels=48))
+
+train_dataloader = dict(batch_size=32)
diff --git a/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_8xb32-210e_deepfashion_lower-256x192.py b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_8xb32-210e_deepfashion_lower-256x192.py
new file mode 100644
index 0000000000..a26e3f0cd4
--- /dev/null
+++ b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_8xb32-210e_deepfashion_lower-256x192.py
@@ -0,0 +1,42 @@
+_base_ = './td-hm_hrnet-w32_8xb64-210e_deepfashion_lower-256x192.py' # noqa
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=256)
+
+model = dict(
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth'),
+ ),
+ head=dict(in_channels=48))
+
+train_dataloader = dict(batch_size=32)
diff --git a/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_8xb32-210e_deepfashion_upper-256x192.py b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_8xb32-210e_deepfashion_upper-256x192.py
new file mode 100644
index 0000000000..cd619bd963
--- /dev/null
+++ b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_8xb32-210e_deepfashion_upper-256x192.py
@@ -0,0 +1,42 @@
+_base_ = './td-hm_hrnet-w32_8xb64-210e_deepfashion_upper-256x192.py' # noqa
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=256)
+
+model = dict(
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth'),
+ ),
+ head=dict(in_channels=48))
+
+train_dataloader = dict(batch_size=32)
diff --git a/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_full-256x192.py b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_full-256x192.py
new file mode 100644
index 0000000000..5445d7d377
--- /dev/null
+++ b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_full-256x192.py
@@ -0,0 +1,31 @@
+_base_ = './td-hm_hrnet-w48_8xb32-210e_deepfashion_full-256x192.py'
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=256)
+
+# codec settings
+codec = dict(
+ type='UDPHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+
+model = dict(
+ test_cfg=dict(flip_test=True, flip_mode='heatmap', shift_heatmap=False))
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(type='RandomBBoxTransform'),
+ dict(type='TopdownAffine', input_size=codec['input_size'], use_udp=True),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size'], use_udp=True),
+ dict(type='PackPoseInputs')
+]
+
+train_dataloader = dict(batch_size=32)
diff --git a/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_lower-256x192.py b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_lower-256x192.py
new file mode 100644
index 0000000000..c7c5c09666
--- /dev/null
+++ b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_lower-256x192.py
@@ -0,0 +1,31 @@
+_base_ = './td-hm_hrnet-w48_8xb32-210e_deepfashion_lower-256x192.py'
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=256)
+
+# codec settings
+codec = dict(
+ type='UDPHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+
+model = dict(
+ test_cfg=dict(flip_test=True, flip_mode='heatmap', shift_heatmap=False))
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(type='RandomBBoxTransform'),
+ dict(type='TopdownAffine', input_size=codec['input_size'], use_udp=True),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size'], use_udp=True),
+ dict(type='PackPoseInputs')
+]
+
+train_dataloader = dict(batch_size=32)
diff --git a/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_upper-256x192.py b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_upper-256x192.py
new file mode 100644
index 0000000000..706a87da84
--- /dev/null
+++ b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_hrnet-w48_udp_8xb32-210e_deepfashion_upper-256x192.py
@@ -0,0 +1,31 @@
+_base_ = './td-hm_hrnet-w48_8xb32-210e_deepfashion_upper-256x192.py'
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=256)
+
+# codec settings
+codec = dict(
+ type='UDPHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+
+model = dict(
+ test_cfg=dict(flip_test=True, flip_mode='heatmap', shift_heatmap=False))
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(type='RandomBBoxTransform'),
+ dict(type='TopdownAffine', input_size=codec['input_size'], use_udp=True),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size'], use_udp=True),
+ dict(type='PackPoseInputs')
+]
+
+train_dataloader = dict(batch_size=32)
diff --git a/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res101_8xb64-210e_deepfashion_full-256x192.py b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res101_8xb64-210e_deepfashion_full-256x192.py
new file mode 100644
index 0000000000..57e9558f76
--- /dev/null
+++ b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res101_8xb64-210e_deepfashion_full-256x192.py
@@ -0,0 +1,8 @@
+_base_ = './td-hm_res50_8xb64-210e_deepfashion_full-256x192.py'
+
+model = dict(
+ backbone=dict(
+ type='ResNet',
+ depth=101,
+ init_cfg=dict(type='Pretrained',
+ checkpoint='torchvision://resnet101')))
diff --git a/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res101_8xb64-210e_deepfashion_lower-256x192.py b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res101_8xb64-210e_deepfashion_lower-256x192.py
new file mode 100644
index 0000000000..0073adfdfb
--- /dev/null
+++ b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res101_8xb64-210e_deepfashion_lower-256x192.py
@@ -0,0 +1,8 @@
+_base_ = './td-hm_res50_8xb64-210e_deepfashion_lower-256x192.py'
+
+model = dict(
+ backbone=dict(
+ type='ResNet',
+ depth=101,
+ init_cfg=dict(type='Pretrained',
+ checkpoint='torchvision://resnet101')))
diff --git a/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res101_8xb64-210e_deepfashion_upper-256x192.py b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res101_8xb64-210e_deepfashion_upper-256x192.py
new file mode 100644
index 0000000000..cf2198fa28
--- /dev/null
+++ b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res101_8xb64-210e_deepfashion_upper-256x192.py
@@ -0,0 +1,8 @@
+_base_ = './td-hm_res50_8xb64-210e_deepfashion_upper-256x192.py'
+
+model = dict(
+ backbone=dict(
+ type='ResNet',
+ depth=101,
+ init_cfg=dict(type='Pretrained',
+ checkpoint='torchvision://resnet101')))
diff --git a/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res152_8xb32-210e_deepfashion_full-256x192.py b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res152_8xb32-210e_deepfashion_full-256x192.py
new file mode 100644
index 0000000000..04dee6d3a5
--- /dev/null
+++ b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res152_8xb32-210e_deepfashion_full-256x192.py
@@ -0,0 +1,13 @@
+_base_ = './td-hm_res50_8xb64-210e_deepfashion_full-256x192.py'
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=256)
+
+model = dict(
+ backbone=dict(
+ type='ResNet',
+ depth=152,
+ init_cfg=dict(type='Pretrained',
+ checkpoint='torchvision://resnet152')))
+
+train_dataloader = dict(batch_size=32)
diff --git a/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res152_8xb32-210e_deepfashion_lower-256x192.py b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res152_8xb32-210e_deepfashion_lower-256x192.py
new file mode 100644
index 0000000000..ef4b3d57d3
--- /dev/null
+++ b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res152_8xb32-210e_deepfashion_lower-256x192.py
@@ -0,0 +1,13 @@
+_base_ = './td-hm_res50_8xb64-210e_deepfashion_lower-256x192.py'
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=256)
+
+model = dict(
+ backbone=dict(
+ type='ResNet',
+ depth=152,
+ init_cfg=dict(type='Pretrained',
+ checkpoint='torchvision://resnet152')))
+
+train_dataloader = dict(batch_size=32)
diff --git a/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res152_8xb32-210e_deepfashion_upper-256x192.py b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res152_8xb32-210e_deepfashion_upper-256x192.py
new file mode 100644
index 0000000000..122ad6817a
--- /dev/null
+++ b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res152_8xb32-210e_deepfashion_upper-256x192.py
@@ -0,0 +1,13 @@
+_base_ = './td-hm_res50_8xb64-210e_deepfashion_upper-256x192.py'
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=256)
+
+model = dict(
+ backbone=dict(
+ type='ResNet',
+ depth=152,
+ init_cfg=dict(type='Pretrained',
+ checkpoint='torchvision://resnet152')))
+
+train_dataloader = dict(batch_size=32)
diff --git a/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res50_8xb64-210e_deepfashion_full-256x192.py b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res50_8xb64-210e_deepfashion_full-256x192.py
new file mode 100644
index 0000000000..292e83cb12
--- /dev/null
+++ b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res50_8xb64-210e_deepfashion_full-256x192.py
@@ -0,0 +1,140 @@
+_base_ = '../../../_base_/default_runtime.py'
+
+# runtime
+train_cfg = dict(max_epochs=210, val_interval=10)
+
+# optimizer
+optim_wrapper = dict(optimizer=dict(
+ type='Adam',
+ lr=5e-4,
+))
+
+# learning policy
+param_scheduler = [
+ dict(
+ type='LinearLR', begin=0, end=500, start_factor=0.001,
+ by_epoch=False), # warm-up
+ dict(
+ type='MultiStepLR',
+ begin=0,
+ end=210,
+ milestones=[170, 200],
+ gamma=0.1,
+ by_epoch=True)
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=512)
+
+# hooks
+default_hooks = dict(
+ logger=dict(type='LoggerHook', interval=10),
+ checkpoint=dict(save_best='AUC', rule='greater'))
+
+# codec settings
+codec = dict(
+ type='MSRAHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50'),
+ ),
+ head=dict(
+ type='HeatmapHead',
+ in_channels=2048,
+ out_channels=8,
+ loss=dict(type='KeypointMSELoss', use_target_weight=True),
+ decoder=codec),
+ test_cfg=dict(
+ flip_test=True,
+ flip_mode='heatmap',
+ shift_heatmap=True,
+ ))
+
+# base dataset settings
+dataset_type = 'DeepFashionDataset'
+data_mode = 'topdown'
+data_root = 'data/fld/'
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomBBoxTransform'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+test_pipeline = val_pipeline
+
+# data loaders
+train_dataloader = dict(
+ batch_size=64,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ subset='full',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/fld_full_train.json',
+ data_prefix=dict(img='img/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=32,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ subset='full',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/fld_full_val.json',
+ data_prefix=dict(img='img/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = dict(
+ batch_size=32,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ subset='full',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/fld_full_test.json',
+ data_prefix=dict(img='img/'),
+ test_mode=True,
+ pipeline=test_pipeline,
+ ))
+
+# evaluators
+val_evaluator = [
+ dict(type='PCKAccuracy', thr=0.2),
+ dict(type='AUC'),
+ dict(type='EPE'),
+]
+test_evaluator = val_evaluator
diff --git a/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res50_8xb64-210e_deepfashion_lower-256x192.py b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res50_8xb64-210e_deepfashion_lower-256x192.py
new file mode 100644
index 0000000000..51e4ddfcbd
--- /dev/null
+++ b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res50_8xb64-210e_deepfashion_lower-256x192.py
@@ -0,0 +1,140 @@
+_base_ = '../../../_base_/default_runtime.py'
+
+# runtime
+train_cfg = dict(max_epochs=210, val_interval=10)
+
+# optimizer
+optim_wrapper = dict(optimizer=dict(
+ type='Adam',
+ lr=5e-4,
+))
+
+# learning policy
+param_scheduler = [
+ dict(
+ type='LinearLR', begin=0, end=500, start_factor=0.001,
+ by_epoch=False), # warm-up
+ dict(
+ type='MultiStepLR',
+ begin=0,
+ end=210,
+ milestones=[170, 200],
+ gamma=0.1,
+ by_epoch=True)
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=64)
+
+# hooks
+default_hooks = dict(
+ logger=dict(type='LoggerHook', interval=10),
+ checkpoint=dict(save_best='AUC', rule='greater'))
+
+# codec settings
+codec = dict(
+ type='MSRAHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50'),
+ ),
+ head=dict(
+ type='HeatmapHead',
+ in_channels=2048,
+ out_channels=4,
+ loss=dict(type='KeypointMSELoss', use_target_weight=True),
+ decoder=codec),
+ test_cfg=dict(
+ flip_test=True,
+ flip_mode='heatmap',
+ shift_heatmap=True,
+ ))
+
+# base dataset settings
+dataset_type = 'DeepFashionDataset'
+data_mode = 'topdown'
+data_root = 'data/fld/'
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomBBoxTransform'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+test_pipeline = val_pipeline
+
+# data loaders
+train_dataloader = dict(
+ batch_size=64,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ subset='lower',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/fld_lower_train.json',
+ data_prefix=dict(img='img/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=32,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ subset='lower',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/fld_lower_val.json',
+ data_prefix=dict(img='img/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = dict(
+ batch_size=32,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ subset='lower',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/fld_lower_test.json',
+ data_prefix=dict(img='img/'),
+ test_mode=True,
+ pipeline=test_pipeline,
+ ))
+
+# evaluators
+val_evaluator = [
+ dict(type='PCKAccuracy', thr=0.2),
+ dict(type='AUC'),
+ dict(type='EPE'),
+]
+test_evaluator = val_evaluator
diff --git a/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res50_8xb64-210e_deepfashion_upper-256x192.py b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res50_8xb64-210e_deepfashion_upper-256x192.py
new file mode 100644
index 0000000000..2966396690
--- /dev/null
+++ b/configs/fashion_2d_keypoint/topdown_heatmap/deepfashion/td-hm_res50_8xb64-210e_deepfashion_upper-256x192.py
@@ -0,0 +1,140 @@
+_base_ = '../../../_base_/default_runtime.py'
+
+# runtime
+train_cfg = dict(max_epochs=210, val_interval=10)
+
+# optimizer
+optim_wrapper = dict(optimizer=dict(
+ type='Adam',
+ lr=5e-4,
+))
+
+# learning policy
+param_scheduler = [
+ dict(
+ type='LinearLR', begin=0, end=500, start_factor=0.001,
+ by_epoch=False), # warm-up
+ dict(
+ type='MultiStepLR',
+ begin=0,
+ end=210,
+ milestones=[170, 200],
+ gamma=0.1,
+ by_epoch=True)
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=64)
+
+# hooks
+default_hooks = dict(
+ logger=dict(type='LoggerHook', interval=10),
+ checkpoint=dict(save_best='AUC', rule='greater'))
+
+# codec settings
+codec = dict(
+ type='MSRAHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50'),
+ ),
+ head=dict(
+ type='HeatmapHead',
+ in_channels=2048,
+ out_channels=6,
+ loss=dict(type='KeypointMSELoss', use_target_weight=True),
+ decoder=codec),
+ test_cfg=dict(
+ flip_test=True,
+ flip_mode='heatmap',
+ shift_heatmap=True,
+ ))
+
+# base dataset settings
+dataset_type = 'DeepFashionDataset'
+data_mode = 'topdown'
+data_root = 'data/fld/'
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomBBoxTransform'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+test_pipeline = val_pipeline
+
+# data loaders
+train_dataloader = dict(
+ batch_size=64,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ subset='upper',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/fld_upper_train.json',
+ data_prefix=dict(img='img/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=32,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ subset='upper',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/fld_upper_val.json',
+ data_prefix=dict(img='img/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = dict(
+ batch_size=32,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ subset='upper',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/fld_upper_test.json',
+ data_prefix=dict(img='img/'),
+ test_mode=True,
+ pipeline=test_pipeline,
+ ))
+
+# evaluators
+val_evaluator = [
+ dict(type='PCKAccuracy', thr=0.2),
+ dict(type='AUC'),
+ dict(type='EPE'),
+]
+test_evaluator = val_evaluator
diff --git a/configs/hand_2d_keypoint/rtmpose/coco_wholebody_hand/rtmpose_coco_wholebody_hand.yml b/configs/hand_2d_keypoint/rtmpose/coco_wholebody_hand/rtmpose_coco_wholebody_hand.yml
index 2f87733605..b0f9d9ac3c 100644
--- a/configs/hand_2d_keypoint/rtmpose/coco_wholebody_hand/rtmpose_coco_wholebody_hand.yml
+++ b/configs/hand_2d_keypoint/rtmpose/coco_wholebody_hand/rtmpose_coco_wholebody_hand.yml
@@ -1,7 +1,6 @@
Models:
- Config: configs/hand_2d_keypoint/rtmpose/coco_wholebody_hand/rtmpose-m_8xb32-210e_coco-wholebody-hand-256x256.py
In Collection: RTMPose
- Alias: hand
Metadata:
Architecture:
- RTMPose
diff --git a/configs/hand_2d_keypoint/rtmpose/hand5/rtmpose_hand5.yml b/configs/hand_2d_keypoint/rtmpose/hand5/rtmpose_hand5.yml
index a8dfd42e39..c32aa4a61c 100644
--- a/configs/hand_2d_keypoint/rtmpose/hand5/rtmpose_hand5.yml
+++ b/configs/hand_2d_keypoint/rtmpose/hand5/rtmpose_hand5.yml
@@ -7,6 +7,7 @@ Collections:
Models:
- Config: configs/hand_2d_keypoint/rtmpose/hand5/rtmpose-m_8xb256-210e_hand5-256x256.py
In Collection: RTMPose
+ Alias: hand
Metadata:
Architecture: &id001
- RTMPose
diff --git a/configs/hand_3d_keypoint/internet/README.md b/configs/hand_3d_keypoint/internet/README.md
new file mode 100644
index 0000000000..8d913e0767
--- /dev/null
+++ b/configs/hand_3d_keypoint/internet/README.md
@@ -0,0 +1,10 @@
+# InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image
+
+## Results and Models
+
+### InterHand2.6m 3D Dataset
+
+| Arch | Set | MPJPE-single | MPJPE-interacting | MPJPE-all | MRRPE | APh | ckpt | log | Details and Download |
+| :------------------------------- | :-------: | :----------: | :---------------: | :-------: | :---: | :--: | :------------------------------: | :-----------------------------: | :-----------------------------------------------: |
+| [InterNet_resnet_50](/configs/hand/3d_kpt_sview_rgb_img/internet/interhand3d/res50_interhand3d_all_256x256.py) | test(H+M) | 9.47 | 13.40 | 11.59 | 29.28 | 0.99 | [ckpt](https://download.openmmlab.com/mmpose/hand3d/internet/res50_intehand3dv1.0_all_256x256-42b7f2ac_20210702.pth) | [log](https://download.openmmlab.com/mmpose/hand3d/internet/res50_intehand3dv1.0_all_256x256_20210702.log.json) | [internet_interhand3d.md](./interhand3d/internet_interhand3d.md) |
+| [InterNet_resnet_50](/configs/hand/3d_kpt_sview_rgb_img/internet/interhand3d/res50_interhand3d_all_256x256.py) | val(M) | 11.22 | 15.23 | 13.16 | 31.73 | 0.98 | [ckpt](https://download.openmmlab.com/mmpose/hand3d/internet/res50_intehand3dv1.0_all_256x256-42b7f2ac_20210702.pth) | [log](https://download.openmmlab.com/mmpose/hand3d/internet/res50_intehand3dv1.0_all_256x256_20210702.log.json) | [internet_interhand3d.md](./interhand3d/internet_interhand3d.md) |
diff --git a/configs/hand_3d_keypoint/internet/interhand3d/internet_interhand3d.md b/configs/hand_3d_keypoint/internet/interhand3d/internet_interhand3d.md
new file mode 100644
index 0000000000..eb775d7439
--- /dev/null
+++ b/configs/hand_3d_keypoint/internet/interhand3d/internet_interhand3d.md
@@ -0,0 +1,59 @@
+
+
+DeepFashion (ECCV'2016)
+ +```bibtex +@inproceedings{liuYLWTeccv16FashionLandmark, + author = {Liu, Ziwei and Yan, Sijie and Luo, Ping and Wang, Xiaogang and Tang, Xiaoou}, + title = {Fashion Landmark Detection in the Wild}, + booktitle = {European Conference on Computer Vision (ECCV)}, + month = {October}, + year = {2016} + } +``` + +
+
+
+
+
+InterNet (ECCV'2020)
+ +```bibtex +@InProceedings{Moon_2020_ECCV_InterHand2.6M, +author = {Moon, Gyeongsik and Yu, Shoou-I and Wen, He and Shiratori, Takaaki and Lee, Kyoung Mu}, +title = {InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image}, +booktitle = {European Conference on Computer Vision (ECCV)}, +year = {2020} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on InterHand2.6M val & test set
+
+| Train Set | Set | Arch | Input Size | MPJPE-single | MPJPE-interacting | MPJPE-all | MRRPE | APh | ckpt | log |
+| :-------- | :-------- | :----------------------------------------: | :--------: | :----------: | :---------------: | :-------: | :---: | :--: | :----------------------------------------: | :---------------------------------------: |
+| All | test(H+M) | [InterNet_resnet_50](/configs/hand/3d_kpt_sview_rgb_img/internet/interhand3d/res50_interhand3d_all_256x256.py) | 256x256 | 9.69 | 13.72 | 11.86 | 29.27 | 0.99 | [ckpt](https://download.openmmlab.com/mmpose/v1/hand_3d_keypoint/internet/interhand3d/internet_res50_interhand3d-d6ff20d6_20230913.pth) | [log](https://download.openmmlab.com/mmpose/v1/hand_3d_keypoint/internet/interhand3d/internet_res50_interhand3d-d6ff20d6_20230913.json) |
+| All | val(M) | [InterNet_resnet_50](/configs/hand/3d_kpt_sview_rgb_img/internet/interhand3d/res50_interhand3d_all_256x256.py) | 256x256 | 11.30 | 15.57 | 13.36 | 32.15 | 0.98 | [ckpt](https://download.openmmlab.com/mmpose/v1/hand_3d_keypoint/internet/interhand3d/internet_res50_interhand3d-d6ff20d6_20230913.pth) | [log](https://download.openmmlab.com/mmpose/v1/hand_3d_keypoint/internet/interhand3d/internet_res50_interhand3d-d6ff20d6_20230913.json) |
+| All | test(H+M) | [InterNet_resnet_50\*](/configs/hand/3d_kpt_sview_rgb_img/internet/interhand3d/res50_interhand3d_all_256x256.py) | 256x256 | 9.47 | 13.40 | 11.59 | 29.28 | 0.99 | [ckpt](https://download.openmmlab.com/mmpose/hand3d/internet/res50_intehand3dv1.0_all_256x256-42b7f2ac_20210702.pth) | [log](https://download.openmmlab.com/mmpose/hand3d/internet/res50_intehand3dv1.0_all_256x256_20210702.log.json) |
+| All | val(M) | [InterNet_resnet_50\*](/configs/hand/3d_kpt_sview_rgb_img/internet/interhand3d/res50_interhand3d_all_256x256.py) | 256x256 | 11.22 | 15.23 | 13.16 | 31.73 | 0.98 | [ckpt](https://download.openmmlab.com/mmpose/hand3d/internet/res50_intehand3dv1.0_all_256x256-42b7f2ac_20210702.pth) | [log](https://download.openmmlab.com/mmpose/hand3d/internet/res50_intehand3dv1.0_all_256x256_20210702.log.json) |
+
+*Models with * are trained in [MMPose 0.x](https://github.com/open-mmlab/mmpose/tree/0.x). The checkpoints and logs are only for validation.*
diff --git a/configs/hand_3d_keypoint/internet/interhand3d/internet_interhand3d.yml b/configs/hand_3d_keypoint/internet/interhand3d/internet_interhand3d.yml
new file mode 100644
index 0000000000..778e436272
--- /dev/null
+++ b/configs/hand_3d_keypoint/internet/interhand3d/internet_interhand3d.yml
@@ -0,0 +1,35 @@
+Collections:
+- Name: InterNet
+ Paper:
+ Title: 'InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation
+ from a Single RGB Image'
+ URL: https://link.springer.com/content/pdf/10.1007/978-3-030-58565-5_33.pdf
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/internet.md
+Models:
+- Config: configs/hand_3d_keypoint/internet/interhand3d/internet_res50_4xb16-20e_interhand3d-256x256.py
+ In Collection: InterNet
+ Alias: hand3d
+ Metadata:
+ Architecture: &id001
+ - InterNet
+ - ResNet
+ Training Data: InterHand2.6M
+ Name: internet_res50_4xb16-20e_interhand3d-256x256
+ Results:
+ - Dataset: InterHand2.6M (H+M)
+ Metrics:
+ APh: 0.99
+ MPJPE-all: 11.86
+ MPJPE-interacting: 13.72
+ MPJPE-single: 9.69
+ MRRPE: 29.27
+ Task: Hand 3D Keypoint
+ - Dataset: InterHand2.6M (M)
+ Metrics:
+ APh: 0.98
+ MPJPE-all: 13.36
+ MPJPE-interacting: 15.57
+ MPJPE-single: 11.30
+ MRRPE: 32.15
+ Task: Hand 3D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand3d/internet/res50_intehand3dv1.0_all_256x256-42b7f2ac_20210702.pth
diff --git a/configs/hand_3d_keypoint/internet/interhand3d/internet_res50_4xb16-20e_interhand3d-256x256.py b/configs/hand_3d_keypoint/internet/interhand3d/internet_res50_4xb16-20e_interhand3d-256x256.py
new file mode 100644
index 0000000000..ffe9f0f051
--- /dev/null
+++ b/configs/hand_3d_keypoint/internet/interhand3d/internet_res50_4xb16-20e_interhand3d-256x256.py
@@ -0,0 +1,182 @@
+_base_ = ['../../../_base_/default_runtime.py']
+
+# visualization
+vis_backends = [
+ dict(type='LocalVisBackend'),
+]
+visualizer = dict(
+ type='Pose3dLocalVisualizer', vis_backends=vis_backends, name='visualizer')
+
+# runtime
+train_cfg = dict(max_epochs=20, val_interval=1)
+
+# optimizer
+optim_wrapper = dict(optimizer=dict(type='Adam', lr=0.0002))
+
+# learning policy
+param_scheduler = [
+ dict(
+ type='MultiStepLR',
+ begin=0,
+ end=20,
+ milestones=[15, 17],
+ gamma=0.1,
+ by_epoch=True)
+]
+
+auto_scale_lr = dict(base_batch_size=128)
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(
+ type='CheckpointHook',
+ interval=1,
+ save_best='MPJPE_all',
+ rule='less',
+ max_keep_ckpts=1),
+ logger=dict(type='LoggerHook', interval=20),
+)
+
+# codec settings
+codec = dict(
+ type='Hand3DHeatmap',
+ image_size=[256, 256],
+ root_heatmap_size=64,
+ heatmap_size=[64, 64, 64],
+ sigma=2.5,
+ max_bound=255,
+ depth_size=64)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
+ head=dict(
+ type='InternetHead',
+ keypoint_head_cfg=dict(
+ in_channels=2048,
+ out_channels=21 * 64,
+ depth_size=codec['depth_size'],
+ deconv_out_channels=(256, 256, 256),
+ deconv_kernel_sizes=(4, 4, 4),
+ ),
+ root_head_cfg=dict(
+ in_channels=2048,
+ heatmap_size=codec['root_heatmap_size'],
+ hidden_dims=(512, ),
+ ),
+ hand_type_head_cfg=dict(
+ in_channels=2048,
+ num_labels=2,
+ hidden_dims=(512, ),
+ ),
+ decoder=codec),
+ test_cfg=dict(flip_test=False))
+
+# base dataset settings
+dataset_type = 'InterHand3DDataset'
+data_mode = 'topdown'
+data_root = 'data/interhand2.6m/'
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='HandRandomFlip', prob=0.5),
+ dict(type='RandomBBoxTransform', rotate_factor=90.0),
+ dict(type='TopdownAffine', input_size=codec['image_size']),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(
+ type='PackPoseInputs',
+ meta_keys=('id', 'img_id', 'img_path', 'rotation', 'img_shape',
+ 'focal', 'principal_pt', 'input_size', 'input_center',
+ 'input_scale', 'hand_type', 'hand_type_valid', 'flip',
+ 'flip_indices', 'abs_depth'))
+]
+val_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['image_size']),
+ dict(
+ type='PackPoseInputs',
+ meta_keys=('id', 'img_id', 'img_path', 'rotation', 'img_shape',
+ 'focal', 'principal_pt', 'input_size', 'input_center',
+ 'input_scale', 'hand_type', 'hand_type_valid', 'flip',
+ 'flip_indices', 'abs_depth'))
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=16,
+ num_workers=1,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ ann_file='annotations/all/InterHand2.6M_train_data.json',
+ camera_param_file='annotations/all/InterHand2.6M_train_camera.json',
+ joint_file='annotations/all/InterHand2.6M_train_joint_3d.json',
+ use_gt_root_depth=True,
+ rootnet_result_file=None,
+ data_mode=data_mode,
+ data_root=data_root,
+ data_prefix=dict(img='images/train/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=16,
+ num_workers=1,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ ann_file='annotations/machine_annot/InterHand2.6M_val_data.json',
+ camera_param_file='annotations/machine_annot/'
+ 'InterHand2.6M_val_camera.json',
+ joint_file='annotations/machine_annot/InterHand2.6M_val_joint_3d.json',
+ use_gt_root_depth=True,
+ rootnet_result_file=None,
+ data_mode=data_mode,
+ data_root=data_root,
+ data_prefix=dict(img='images/val/'),
+ pipeline=val_pipeline,
+ test_mode=True,
+ ))
+test_dataloader = dict(
+ batch_size=16,
+ num_workers=1,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ ann_file='annotations/all/'
+ 'InterHand2.6M_test_data.json',
+ camera_param_file='annotations/all/'
+ 'InterHand2.6M_test_camera.json',
+ joint_file='annotations/all/'
+ 'InterHand2.6M_test_joint_3d.json',
+ use_gt_root_depth=True,
+ rootnet_result_file=None,
+ data_mode=data_mode,
+ data_root=data_root,
+ data_prefix=dict(img='images/test/'),
+ pipeline=val_pipeline,
+ test_mode=True,
+ ))
+
+# evaluators
+val_evaluator = [
+ dict(type='InterHandMetric', modes=['MPJPE', 'MRRPE', 'HandednessAcc'])
+]
+test_evaluator = val_evaluator
diff --git a/configs/wholebody_2d_keypoint/dwpose/README.md b/configs/wholebody_2d_keypoint/dwpose/README.md
new file mode 100644
index 0000000000..d85cb48c53
--- /dev/null
+++ b/configs/wholebody_2d_keypoint/dwpose/README.md
@@ -0,0 +1,63 @@
+# DWPose
+
+Whole-body pose estimation localizes the human body, hand, face, and foot keypoints in an image. This task is challenging due to multi-scale body parts, fine-grained localization for low-resolution regions, and data scarcity. Meanwhile, applying a highly efficient and accurate pose estimator to widely human-centric understanding and generation tasks is urgent. In this work, we present a two-stage pose **D**istillation for **W**hole-body **P**ose estimators, named **DWPose**, to improve their effectiveness and efficiency. The first-stage distillation designs a weight-decay strategy while utilizing a teacher's intermediate feature and final logits with both visible and invisible keypoints to supervise the student from scratch. The second stage distills the student model itself to further improve performance. Different from the previous self-knowledge distillation, this stage finetunes the student's head with only 20% training time as a plug-and-play training strategy. For data limitations, we explore the UBody dataset that contains diverse facial expressions and hand gestures for real-life applications. Comprehensive experiments show the superiority of our proposed simple yet effective methods. We achieve new state-of-the-art performance on COCO-WholeBody, significantly boosting the whole-body AP of RTMPose-l from 64.8% to 66.5%, even surpassing RTMPose-x teacher with 65.3% AP. We release a series of models with different sizes, from tiny to large, for satisfying various downstream tasks.
+
+## Results and Models
+
+### COCO-WholeBody Dataset
+
+Results on COCO-WholeBody v1.0 val with detector having human AP of 56.4 on COCO val2017 dataset
+
+- DWPose Models are supported by [DWPose](https://github.com/IDEA-Research/DWPose)
+- Models are trained and distilled on the following datasets:
+ - [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody/)
+ - [UBody](https://github.com/IDEA-Research/OSX)
+
+| Config | S1 Dis_config | S2 Dis_config | Input Size | Whole AP | Whole AR | FLOPSInterHand2.6M (ECCV'2020)
+ +```bibtex +@InProceedings{Moon_2020_ECCV_InterHand2.6M, +author = {Moon, Gyeongsik and Yu, Shoou-I and Wen, He and Shiratori, Takaaki and Lee, Kyoung Mu}, +title = {InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image}, +booktitle = {European Conference on Computer Vision (ECCV)}, +year = {2020} +} +``` + +(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | +| :----------- | :-----------------: | :-----------------: | :--------: | :------: | :------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :------------: | +| [DWPose-t](../rtmpose/ubody/rtmpose-t_8xb64-270e_coco-ubody-wholebody-256x192.py) | [DW l-t](../dwpose/ubody/s1_dis/dwpose_l_dis_t_coco-ubody-256x192.py) | [DW t-t](../dwpose/ubody/s2_dis/dwpose_t-tt_coco-ubody-256x192.py) | 256x192 | 48.5 | 58.4 | 0.5 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-ucoco_dw-ucoco_270e-256x192-dcf277bf_20230728.pth) | +| [DWPose-s](../rtmpose/ubody/rtmpose-s_8xb64-270e_coco-ubody-wholebody-256x192.py) | [DW l-s](../dwpose/ubody/s1_dis/dwpose_l_dis_s_coco-ubody-256x192.py) | [DW s-s](../dwpose/ubody/s2_dis/dwpose_s-ss_coco-ubody-256x192.py) | 256x192 | 53.8 | 63.2 | 0.9 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-ucoco_dw-ucoco_270e-256x192-3fd922c8_20230728.pth) | +| [DWPose-m](../rtmpose/ubody/rtmpose-m_8xb64-270e_coco-ubody-wholebody-256x192.py) | [DW l-m](../dwpose/ubody/s1_dis/dwpose_l_dis_m_coco-ubody-256x192.py) | [DW m-m](../dwpose/ubody/s2_dis/dwpose_m-mm_coco-ubody-256x192.py) | 256x192 | 60.6 | 69.5 | 2.22 | 13.50 | 4.00 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-ucoco_dw-ucoco_270e-256x192-c8b76419_20230728.pth) | +| [DWPose-l](../rtmpose/ubody/rtmpose-l_8xb64-270e_coco-ubody-wholebody-256x192.py) | [DW x-l](../dwpose/ubody/s1_dis/dwpose_x_dis_l_coco-ubody-256x192.py) | [DW l-l](../dwpose/ubody/s2_dis/dwpose_l-ll_coco-ubody-256x192.py) | 256x192 | 63.1 | 71.7 | 4.52 | 23.41 | 5.67 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-ucoco_dw-ucoco_270e-256x192-4d6dfc62_20230728.pth) | +| [DWPose-l](../rtmpose/ubody/rtmpose-l_8xb32-270e_coco-ubody-wholebody-384x288.py) | [DW x-l](../dwpose/ubody/s1_dis/dwpose_x_dis_l_coco-ubody-384x288.py) | [DW l-l](../dwpose/ubody/s2_dis/dwpose_l-ll_coco-ubody-384x288.py) | 384x288 | 66.5 | 74.3 | 10.07 | 44.58 | 7.68 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-ucoco_dw-ucoco_270e-384x288-2438fd99_20230728.pth) | + +## Train a model + +### Train DWPose with the first stage distillation + +``` +bash tools/dist_train.sh configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/rtmpose_x_dis_l_coco-ubody-384x288.py 8 +``` + +### Tansfer the S1 distillation models into regular models + +``` +# first stage distillation +python pth_transfer.py $dis_ckpt $new_pose_ckpt +``` + +⭐Before S2 distillation, you should add your model path into 'teacher_pretrained' of your S2 dis_config. + +### Train DWPose with the second stage distillation + +``` +bash tools/dist_train.sh configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_l-ll_coco-ubody-384x288.py 8 +``` + +### Tansfer the S2 distillation models into regular models + +``` +# second stage distillation +python pth_transfer.py $dis_ckpt $new_pose_ckpt --two_dis +``` + +## Citation + +``` +@article{yang2023effective, + title={Effective Whole-body Pose Estimation with Two-stages Distillation}, + author={Yang, Zhendong and Zeng, Ailing and Yuan, Chun and Li, Yu}, + journal={arXiv preprint arXiv:2307.15880}, + year={2023} +} +``` diff --git a/configs/wholebody_2d_keypoint/dwpose/coco-wholebody/s1_dis/dwpose_l_dis_m_coco-256x192.py b/configs/wholebody_2d_keypoint/dwpose/coco-wholebody/s1_dis/dwpose_l_dis_m_coco-256x192.py new file mode 100644 index 0000000000..422871acbb --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/coco-wholebody/s1_dis/dwpose_l_dis_m_coco-256x192.py @@ -0,0 +1,48 @@ +_base_ = [ + '../../../rtmpose/coco-wholebody/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py' # noqa: E501 +] + +# model settings +find_unused_parameters = False + +# config settings +fea = True +logit = True + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + teacher_pretrained='https://download.openmmlab.com/mmpose/v1/projects/' + 'rtmpose/rtmpose-l_simcc-coco-wholebody_pt-aic-coco_270e-256x192-6f206314_20230124.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/' + 'rtmpose-l_8xb64-270e_coco-wholebody-256x192.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/' + 'rtmpose-m_8xb64-270e_coco-wholebody-256x192.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='FeaLoss', + name='loss_fea', + use_this=fea, + student_channels=768, + teacher_channels=1024, + alpha_fea=0.00007, + ) + ]), + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=0.1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), +) +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/dwpose/coco-wholebody/s1_dis/dwpose_x_dis_l_coco-384x288.py b/configs/wholebody_2d_keypoint/dwpose/coco-wholebody/s1_dis/dwpose_x_dis_l_coco-384x288.py new file mode 100644 index 0000000000..150cb2bbe6 --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/coco-wholebody/s1_dis/dwpose_x_dis_l_coco-384x288.py @@ -0,0 +1,48 @@ +_base_ = [ + '../../../rtmpose/coco-wholebody/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py' # noqa: E501 +] + +# model settings +find_unused_parameters = False + +# config settings +fea = True +logit = True + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + teacher_pretrained='https://download.openmmlab.com/mmpose/v1/projects/' + 'rtmposev1/rtmpose-x_simcc-coco-wholebody_pt-body7_270e-384x288-401dfc90_20230629.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/' + 'rtmpose-x_8xb32-270e_coco-wholebody-384x288.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/' + 'rtmpose-l_8xb32-270e_coco-wholebody-384x288.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='FeaLoss', + name='loss_fea', + use_this=fea, + student_channels=1024, + teacher_channels=1280, + alpha_fea=0.00007, + ) + ]), + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=0.1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), +) +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/dwpose/coco-wholebody/s2_dis/dwpose_l-ll_coco-384x288.py b/configs/wholebody_2d_keypoint/dwpose/coco-wholebody/s2_dis/dwpose_l-ll_coco-384x288.py new file mode 100644 index 0000000000..6c63f99b0c --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/coco-wholebody/s2_dis/dwpose_l-ll_coco-384x288.py @@ -0,0 +1,45 @@ +_base_ = [ + '../../../rtmpose/coco-wholebody/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py' # noqa: E501 +] + +# model settings +find_unused_parameters = True + +# dis settings +second_dis = True + +# config settings +logit = True + +train_cfg = dict(max_epochs=60, val_interval=10) + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + two_dis=second_dis, + teacher_pretrained='work_dirs/' + 'dwpose_x_dis_l_coco-384x288/dw-x-l_coco_384.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/' + 'rtmpose-l_8xb32-270e_coco-wholebody-384x288.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/' + 'rtmpose-l_8xb32-270e_coco-wholebody-384x288.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + train_cfg=train_cfg, +) + +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/dwpose/coco-wholebody/s2_dis/dwpose_m-mm_coco-256x192.py b/configs/wholebody_2d_keypoint/dwpose/coco-wholebody/s2_dis/dwpose_m-mm_coco-256x192.py new file mode 100644 index 0000000000..943ec60184 --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/coco-wholebody/s2_dis/dwpose_m-mm_coco-256x192.py @@ -0,0 +1,45 @@ +_base_ = [ + '../../../rtmpose/coco-wholebody/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py' # noqa: E501 +] + +# model settings +find_unused_parameters = True + +# dis settings +second_dis = True + +# config settings +logit = True + +train_cfg = dict(max_epochs=60, val_interval=10) + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + two_dis=second_dis, + teacher_pretrained='work_dirs/' + 'dwpose_l_dis_m_coco-256x192/dw-l-m_coco_256.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/' + 'rtmpose-m_8xb64-270e_coco-wholebody-256x192.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/' + 'rtmpose-m_8xb64-270e_coco-wholebody-256x192.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + train_cfg=train_cfg, +) + +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/dwpose_l_dis_m_coco-ubody-256x192.py b/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/dwpose_l_dis_m_coco-ubody-256x192.py new file mode 100644 index 0000000000..b3a917b96e --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/dwpose_l_dis_m_coco-ubody-256x192.py @@ -0,0 +1,48 @@ +_base_ = [ + '../../../rtmpose/ubody/rtmpose-m_8xb64-270e_coco-ubody-wholebody-256x192.py' # noqa: E501 +] + +# model settings +find_unused_parameters = False + +# config settings +fea = True +logit = True + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + teacher_pretrained='https://download.openmmlab.com/mmpose/v1/projects/' + 'rtmposev1/rtmpose-l_ucoco_256x192-95bb32f5_20230822.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-l_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-m_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='FeaLoss', + name='loss_fea', + use_this=fea, + student_channels=768, + teacher_channels=1024, + alpha_fea=0.00007, + ) + ]), + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=0.1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), +) +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/dwpose_l_dis_s_coco-ubody-256x192.py b/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/dwpose_l_dis_s_coco-ubody-256x192.py new file mode 100644 index 0000000000..c90a0ea6a7 --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/dwpose_l_dis_s_coco-ubody-256x192.py @@ -0,0 +1,48 @@ +_base_ = [ + '../../../rtmpose/ubody/rtmpose-s_8xb64-270e_coco-ubody-wholebody-256x192.py' # noqa: E501 +] + +# model settings +find_unused_parameters = False + +# config settings +fea = True +logit = True + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + teacher_pretrained='https://download.openmmlab.com/mmpose/v1/projects/' + 'rtmposev1/rtmpose-l_ucoco_256x192-95bb32f5_20230822.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-l_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-s_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='FeaLoss', + name='loss_fea', + use_this=fea, + student_channels=512, + teacher_channels=1024, + alpha_fea=0.00007, + ) + ]), + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=0.1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), +) +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/dwpose_l_dis_t_coco-ubody-256x192.py b/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/dwpose_l_dis_t_coco-ubody-256x192.py new file mode 100644 index 0000000000..01618f146a --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/dwpose_l_dis_t_coco-ubody-256x192.py @@ -0,0 +1,48 @@ +_base_ = [ + '../../../rtmpose/ubody/rtmpose-s_8xb64-270e_coco-ubody-wholebody-256x192.py' # noqa: E501 +] + +# model settings +find_unused_parameters = False + +# config settings +fea = True +logit = True + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + teacher_pretrained='https://download.openmmlab.com/mmpose/v1/projects/' + 'rtmposev1/rtmpose-l_ucoco_256x192-95bb32f5_20230822.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-l_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-t_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='FeaLoss', + name='loss_fea', + use_this=fea, + student_channels=384, + teacher_channels=1024, + alpha_fea=0.00007, + ) + ]), + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=0.1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), +) +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/dwpose_x_dis_l_coco-ubody-256x192.py b/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/dwpose_x_dis_l_coco-ubody-256x192.py new file mode 100644 index 0000000000..85a287324b --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/dwpose_x_dis_l_coco-ubody-256x192.py @@ -0,0 +1,48 @@ +_base_ = [ + '../../../rtmpose/ubody/rtmpose-l_8xb64-270e_coco-ubody-wholebody-256x192.py' # noqa: E501 +] + +# model settings +find_unused_parameters = False + +# config settings +fea = True +logit = True + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + teacher_pretrained='https://download.openmmlab.com/mmpose/v1/projects/' + 'rtmposev1/rtmpose-x_ucoco_256x192-05f5bcb7_20230822.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-x_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-l_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='FeaLoss', + name='loss_fea', + use_this=fea, + student_channels=1024, + teacher_channels=1280, + alpha_fea=0.00007, + ) + ]), + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=0.1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), +) +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/rtmpose_x_dis_l_coco-ubody-384x288.py b/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/rtmpose_x_dis_l_coco-ubody-384x288.py new file mode 100644 index 0000000000..acde64a03a --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/ubody/s1_dis/rtmpose_x_dis_l_coco-ubody-384x288.py @@ -0,0 +1,48 @@ +_base_ = [ + '../../../rtmpose/ubody/rtmpose-l_8xb32-270e_coco-ubody-wholebody-384x288.py' # noqa: E501 +] + +# model settings +find_unused_parameters = False + +# config settings +fea = True +logit = True + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + teacher_pretrained='https://download.openmmlab.com/mmpose/v1/projects/' + 'rtmposev1/rtmpose-x_ucoco_384x288-f5b50679_20230822.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-x_8xb32-270e_coco-ubody-wholebody-384x288.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-l_8xb32-270e_coco-ubody-wholebody-384x288.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='FeaLoss', + name='loss_fea', + use_this=fea, + student_channels=1024, + teacher_channels=1280, + alpha_fea=0.00007, + ) + ]), + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=0.1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), +) +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_l-ll_coco-ubody-256x192.py b/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_l-ll_coco-ubody-256x192.py new file mode 100644 index 0000000000..e3f456a2b9 --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_l-ll_coco-ubody-256x192.py @@ -0,0 +1,45 @@ +_base_ = [ + '../../../rtmpose/ubody/rtmpose-l_8xb64-270e_coco-ubody-wholebody-256x192.py' # noqa: E501 +] + +# model settings +find_unused_parameters = True + +# dis settings +second_dis = True + +# config settings +logit = True + +train_cfg = dict(max_epochs=60, val_interval=10) + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + two_dis=second_dis, + teacher_pretrained='work_dirs/' + 'dwpose_x_dis_l_coco-ubody-256x192/dw-x-l_ucoco_256.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-l_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-l_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + train_cfg=train_cfg, +) + +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_l-ll_coco-ubody-384x288.py b/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_l-ll_coco-ubody-384x288.py new file mode 100644 index 0000000000..3815fad1e2 --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_l-ll_coco-ubody-384x288.py @@ -0,0 +1,45 @@ +_base_ = [ + '../../../rtmpose/ubody/rtmpose-l_8xb32-270e_coco-ubody-wholebody-384x288.py' # noqa: E501 +] + +# model settings +find_unused_parameters = True + +# dis settings +second_dis = True + +# config settings +logit = True + +train_cfg = dict(max_epochs=60, val_interval=10) + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + two_dis=second_dis, + teacher_pretrained='work_dirs/' + 'dwpose_x_dis_l_coco-ubody-384x288/dw-x-l_ucoco_384.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-l_8xb32-270e_coco-ubody-wholebody-384x288.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-l_8xb32-270e_coco-ubody-wholebody-384x288.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + train_cfg=train_cfg, +) + +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_m-mm_coco-ubody-256x192.py b/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_m-mm_coco-ubody-256x192.py new file mode 100644 index 0000000000..1e6834ffca --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_m-mm_coco-ubody-256x192.py @@ -0,0 +1,45 @@ +_base_ = [ + '../../../rtmpose/ubody/rtmpose-m_8xb64-270e_coco-ubody-wholebody-256x192.py' # noqa: E501 +] + +# model settings +find_unused_parameters = True + +# dis settings +second_dis = True + +# config settings +logit = True + +train_cfg = dict(max_epochs=60, val_interval=10) + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + two_dis=second_dis, + teacher_pretrained='work_dirs/' + 'dwpose_l_dis_m_coco-ubody-256x192/dw-l-m_ucoco_256.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-m_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-m_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + train_cfg=train_cfg, +) + +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_s-ss_coco-ubody-256x192.py b/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_s-ss_coco-ubody-256x192.py new file mode 100644 index 0000000000..24a4a94642 --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_s-ss_coco-ubody-256x192.py @@ -0,0 +1,45 @@ +_base_ = [ + '../../../rtmpose/ubody/rtmpose-s_8xb64-270e_coco-ubody-wholebody-256x192.py' # noqa: E501 +] + +# model settings +find_unused_parameters = True + +# dis settings +second_dis = True + +# config settings +logit = True + +train_cfg = dict(max_epochs=60, val_interval=10) + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + two_dis=second_dis, + teacher_pretrained='work_dirs/' + 'dwpose_l_dis_s_coco-ubody-256x192/dw-l-s_ucoco_256.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-s_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-s_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + train_cfg=train_cfg, +) + +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_t-tt_coco-ubody-256x192.py b/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_t-tt_coco-ubody-256x192.py new file mode 100644 index 0000000000..c7c322ece2 --- /dev/null +++ b/configs/wholebody_2d_keypoint/dwpose/ubody/s2_dis/dwpose_t-tt_coco-ubody-256x192.py @@ -0,0 +1,45 @@ +_base_ = [ + '../../../rtmpose/ubody/rtmpose-t_8xb64-270e_coco-ubody-wholebody-256x192.py' # noqa: E501 +] + +# model settings +find_unused_parameters = True + +# dis settings +second_dis = True + +# config settings +logit = True + +train_cfg = dict(max_epochs=60, val_interval=10) + +# method details +model = dict( + _delete_=True, + type='DWPoseDistiller', + two_dis=second_dis, + teacher_pretrained='work_dirs/' + 'dwpose_l_dis_t_coco-ubody-256x192/dw-l-t_ucoco_256.pth', # noqa: E501 + teacher_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-t_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + student_cfg='configs/wholebody_2d_keypoint/rtmpose/ubody/' + 'rtmpose-t_8xb64-270e_coco-ubody-wholebody-256x192.py', # noqa: E501 + distill_cfg=[ + dict(methods=[ + dict( + type='KDLoss', + name='loss_logit', + use_this=logit, + weight=1, + ) + ]), + ], + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + train_cfg=train_cfg, +) + +optim_wrapper = dict(clip_grad=dict(max_norm=1., norm_type=2)) diff --git a/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb320-270e_cocktail13-384x288.py b/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb320-270e_cocktail13-384x288.py new file mode 100644 index 0000000000..55d07b61a8 --- /dev/null +++ b/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb320-270e_cocktail13-384x288.py @@ -0,0 +1,638 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from mmengine.config import read_base + +with read_base(): + from mmpose.configs._base_.default_runtime import * # noqa + +from albumentations.augmentations import Blur, CoarseDropout, MedianBlur +from mmdet.engine.hooks import PipelineSwitchHook +from mmengine.dataset import DefaultSampler +from mmengine.hooks import EMAHook +from mmengine.model import PretrainedInit +from mmengine.optim import CosineAnnealingLR, LinearLR, OptimWrapper +from torch.nn import SiLU, SyncBatchNorm +from torch.optim import AdamW + +from mmpose.codecs import SimCCLabel +from mmpose.datasets import (AicDataset, CocoWholeBodyDataset, COFWDataset, + CombinedDataset, CrowdPoseDataset, + Face300WDataset, GenerateTarget, + GetBBoxCenterScale, HalpeDataset, + HumanArt21Dataset, InterHand2DDoubleDataset, + JhmdbDataset, KeypointConverter, LapaDataset, + LoadImage, MpiiDataset, PackPoseInputs, + PoseTrack18Dataset, RandomFlip, RandomHalfBody, + TopdownAffine, UBody2dDataset, WFLWDataset) +from mmpose.datasets.transforms.common_transforms import ( + Albumentation, PhotometricDistortion, RandomBBoxTransform) +from mmpose.engine.hooks import ExpMomentumEMA +from mmpose.evaluation import CocoWholeBodyMetric +from mmpose.models import (CSPNeXt, CSPNeXtPAFPN, KLDiscretLoss, + PoseDataPreprocessor, RTMWHead, + TopdownPoseEstimator) + +# common setting +num_keypoints = 133 +input_size = (288, 384) + +# runtime +max_epochs = 270 +stage2_num_epochs = 10 +base_lr = 5e-4 +train_batch_size = 320 +val_batch_size = 32 + +train_cfg.update(max_epochs=max_epochs, val_interval=10) # noqa +randomness = dict(seed=21) + +# optimizer +optim_wrapper = dict( + type=OptimWrapper, + optimizer=dict(type=AdamW, lr=base_lr, weight_decay=0.05), + clip_grad=dict(max_norm=35, norm_type=2), + paramwise_cfg=dict( + norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True)) + +# learning rate +param_scheduler = [ + dict( + type=LinearLR, start_factor=1.0e-5, by_epoch=False, begin=0, end=1000), + dict( + type=CosineAnnealingLR, + eta_min=base_lr * 0.05, + begin=max_epochs // 2, + end=max_epochs, + T_max=max_epochs // 2, + by_epoch=True, + convert_to_iter_based=True), +] + +# automatically scaling LR based on the actual training batch size +auto_scale_lr = dict(base_batch_size=5632) + +# codec settings +codec = dict( + type=SimCCLabel, + input_size=input_size, + sigma=(6., 6.93), + simcc_split_ratio=2.0, + normalize=False, + use_dark=False) + +# model settings +model = dict( + type=TopdownPoseEstimator, + data_preprocessor=dict( + type=PoseDataPreprocessor, + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + backbone=dict( + type=CSPNeXt, + arch='P5', + expand_ratio=0.5, + deepen_factor=1.33, + widen_factor=1.25, + channel_attention=True, + norm_cfg=dict(type='BN'), + act_cfg=dict(type=SiLU), + init_cfg=dict( + type=PretrainedInit, + prefix='backbone.', + checkpoint='https://download.openmmlab.com/mmpose/v1/' + 'wholebody_2d_keypoint/rtmpose/ubody/rtmpose-x_simcc-ucoco_pt-aic-coco_270e-384x288-f5b50679_20230822.pth' # noqa + )), + neck=dict( + type=CSPNeXtPAFPN, + in_channels=[320, 640, 1280], + out_channels=None, + out_indices=( + 1, + 2, + ), + num_csp_blocks=2, + expand_ratio=0.5, + norm_cfg=dict(type=SyncBatchNorm), + act_cfg=dict(type=SiLU, inplace=True)), + head=dict( + type=RTMWHead, + in_channels=1280, + out_channels=num_keypoints, + input_size=input_size, + in_featuremap_size=tuple([s // 32 for s in input_size]), + simcc_split_ratio=codec['simcc_split_ratio'], + final_layer_kernel_size=7, + gau_cfg=dict( + hidden_dims=256, + s=128, + expansion_factor=2, + dropout_rate=0., + drop_path=0., + act_fn=SiLU, + use_rel_bias=False, + pos_enc=False), + loss=dict( + type=KLDiscretLoss, + use_target_weight=True, + beta=10., + label_softmax=True), + decoder=codec), + test_cfg=dict(flip_test=True)) + +# base dataset settings +dataset_type = CocoWholeBodyDataset +data_mode = 'topdown' +data_root = 'data/' + +backend_args = dict(backend='local') + +# pipelines +train_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict(type=RandomFlip, direction='horizontal'), + dict(type=RandomHalfBody), + dict(type=RandomBBoxTransform, scale_factor=[0.5, 1.5], rotate_factor=90), + dict(type=TopdownAffine, input_size=codec['input_size']), + dict(type=PhotometricDistortion), + dict( + type=Albumentation, + transforms=[ + dict(type=Blur, p=0.1), + dict(type=MedianBlur, p=0.1), + dict( + type=CoarseDropout, + max_holes=1, + max_height=0.4, + max_width=0.4, + min_holes=1, + min_height=0.2, + min_width=0.2, + p=1.0), + ]), + dict( + type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True), + dict(type=PackPoseInputs) +] +val_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict(type=TopdownAffine, input_size=codec['input_size']), + dict(type=PackPoseInputs) +] +train_pipeline_stage2 = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict(type=RandomFlip, direction='horizontal'), + dict(type=RandomHalfBody), + dict( + type=RandomBBoxTransform, + shift_factor=0., + scale_factor=[0.5, 1.5], + rotate_factor=90), + dict(type=TopdownAffine, input_size=codec['input_size']), + dict( + type=Albumentation, + transforms=[ + dict(type=Blur, p=0.1), + dict(type=MedianBlur, p=0.1), + ]), + dict( + type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True), + dict(type=PackPoseInputs) +] + +# mapping + +aic_coco133 = [(0, 6), (1, 8), (2, 10), (3, 5), (4, 7), (5, 9), (6, 12), + (7, 14), (8, 16), (9, 11), (10, 13), (11, 15)] + +crowdpose_coco133 = [(0, 5), (1, 6), (2, 7), (3, 8), (4, 9), (5, 10), (6, 11), + (7, 12), (8, 13), (9, 14), (10, 15), (11, 16)] + +mpii_coco133 = [ + (0, 16), + (1, 14), + (2, 12), + (3, 11), + (4, 13), + (5, 15), + (8, 18), + (9, 17), + (10, 10), + (11, 8), + (12, 6), + (13, 5), + (14, 7), + (15, 9), +] + +jhmdb_coco133 = [ + (0, 18), + (2, 17), + (3, 6), + (4, 5), + (5, 12), + (6, 11), + (7, 8), + (8, 7), + (9, 14), + (10, 13), + (11, 10), + (12, 9), + (13, 16), + (14, 15), +] + +halpe_coco133 = [(i, i) + for i in range(17)] + [(20, 17), (21, 20), (22, 18), (23, 21), + (24, 19), + (25, 22)] + [(i, i - 3) + for i in range(26, 136)] + +posetrack_coco133 = [ + (0, 0), + (2, 17), + (3, 3), + (4, 4), + (5, 5), + (6, 6), + (7, 7), + (8, 8), + (9, 9), + (10, 10), + (11, 11), + (12, 12), + (13, 13), + (14, 14), + (15, 15), + (16, 16), +] + +humanart_coco133 = [(i, i) for i in range(17)] + [(17, 99), (18, 120), + (19, 17), (20, 20)] + +# train datasets +dataset_coco = dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='coco/annotations/coco_wholebody_train_v1.0.json', + data_prefix=dict(img='detection/coco/train2017/'), + pipeline=[], +) + +dataset_aic = dict( + type=AicDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='aic/annotations/aic_train.json', + data_prefix=dict(img='pose/ai_challenge/ai_challenger_keypoint' + '_train_20170902/keypoint_train_images_20170902/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=aic_coco133) + ], +) + +dataset_crowdpose = dict( + type=CrowdPoseDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='crowdpose/annotations/mmpose_crowdpose_trainval.json', + data_prefix=dict(img='pose/CrowdPose/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=crowdpose_coco133) + ], +) + +dataset_mpii = dict( + type=MpiiDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='mpii/annotations/mpii_train.json', + data_prefix=dict(img='pose/MPI/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=mpii_coco133) + ], +) + +dataset_jhmdb = dict( + type=JhmdbDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='jhmdb/annotations/Sub1_train.json', + data_prefix=dict(img='pose/JHMDB/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=jhmdb_coco133) + ], +) + +dataset_halpe = dict( + type=HalpeDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='halpe/annotations/halpe_train_v1.json', + data_prefix=dict(img='pose/Halpe/hico_20160224_det/images/train2015'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=halpe_coco133) + ], +) + +dataset_posetrack = dict( + type=PoseTrack18Dataset, + data_root=data_root, + data_mode=data_mode, + ann_file='posetrack18/annotations/posetrack18_train.json', + data_prefix=dict(img='pose/PoseChallenge2018/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=posetrack_coco133) + ], +) + +dataset_humanart = dict( + type=HumanArt21Dataset, + data_root=data_root, + data_mode=data_mode, + ann_file='HumanArt/annotations/training_humanart.json', + filter_cfg=dict(scenes=['real_human']), + data_prefix=dict(img='pose/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=humanart_coco133) + ]) + +ubody_scenes = [ + 'Magic_show', 'Entertainment', 'ConductMusic', 'Online_class', 'TalkShow', + 'Speech', 'Fitness', 'Interview', 'Olympic', 'TVShow', 'Singing', + 'SignLanguage', 'Movie', 'LiveVlog', 'VideoConference' +] + +ubody_datasets = [] +for scene in ubody_scenes: + each = dict( + type=UBody2dDataset, + data_root=data_root, + data_mode=data_mode, + ann_file=f'Ubody/annotations/{scene}/train_annotations.json', + data_prefix=dict(img='pose/UBody/images/'), + pipeline=[], + sample_interval=10) + ubody_datasets.append(each) + +dataset_ubody = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/ubody2d.py'), + datasets=ubody_datasets, + pipeline=[], + test_mode=False, +) + +face_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale, padding=1.25), + dict( + type=RandomBBoxTransform, + shift_factor=0., + scale_factor=[1.5, 2.0], + rotate_factor=0), +] + +wflw_coco133 = [(i * 2, 23 + i) + for i in range(17)] + [(33 + i, 40 + i) for i in range(5)] + [ + (42 + i, 45 + i) for i in range(5) + ] + [(51 + i, 50 + i) + for i in range(9)] + [(60, 59), (61, 60), (63, 61), + (64, 62), (65, 63), (67, 64), + (68, 65), (69, 66), (71, 67), + (72, 68), (73, 69), + (75, 70)] + [(76 + i, 71 + i) + for i in range(20)] +dataset_wflw = dict( + type=WFLWDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='wflw/annotations/face_landmarks_wflw_train.json', + data_prefix=dict(img='pose/WFLW/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=wflw_coco133), *face_pipeline + ], +) + +mapping_300w_coco133 = [(i, 23 + i) for i in range(68)] +dataset_300w = dict( + type=Face300WDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='300w/annotations/face_landmarks_300w_train.json', + data_prefix=dict(img='pose/300w/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=mapping_300w_coco133), *face_pipeline + ], +) + +cofw_coco133 = [(0, 40), (2, 44), (4, 42), (1, 49), (3, 45), (6, 47), (8, 59), + (10, 62), (9, 68), (11, 65), (18, 54), (19, 58), (20, 53), + (21, 56), (22, 71), (23, 77), (24, 74), (25, 85), (26, 89), + (27, 80), (28, 31)] +dataset_cofw = dict( + type=COFWDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='cofw/annotations/cofw_train.json', + data_prefix=dict(img='pose/COFW/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=cofw_coco133), *face_pipeline + ], +) + +lapa_coco133 = [(i * 2, 23 + i) for i in range(17)] + [ + (33 + i, 40 + i) for i in range(5) +] + [(42 + i, 45 + i) for i in range(5)] + [ + (51 + i, 50 + i) for i in range(4) +] + [(58 + i, 54 + i) for i in range(5)] + [(66, 59), (67, 60), (69, 61), + (70, 62), (71, 63), (73, 64), + (75, 65), (76, 66), (78, 67), + (79, 68), (80, 69), + (82, 70)] + [(84 + i, 71 + i) + for i in range(20)] +dataset_lapa = dict( + type=LapaDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='LaPa/annotations/lapa_trainval.json', + data_prefix=dict(img='pose/LaPa/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=lapa_coco133), *face_pipeline + ], +) + +dataset_wb = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[dataset_coco, dataset_halpe, dataset_ubody], + pipeline=[], + test_mode=False, +) + +dataset_body = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[ + dataset_aic, + dataset_crowdpose, + dataset_mpii, + dataset_jhmdb, + dataset_posetrack, + dataset_humanart, + ], + pipeline=[], + test_mode=False, +) + +dataset_face = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[ + dataset_wflw, + dataset_300w, + dataset_cofw, + dataset_lapa, + ], + pipeline=[], + test_mode=False, +) + +hand_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict( + type=RandomBBoxTransform, + shift_factor=0., + scale_factor=[1.5, 2.0], + rotate_factor=0), +] + +interhand_left = [(21, 95), (22, 94), (23, 93), (24, 92), (25, 99), (26, 98), + (27, 97), (28, 96), (29, 103), (30, 102), (31, 101), + (32, 100), (33, 107), (34, 106), (35, 105), (36, 104), + (37, 111), (38, 110), (39, 109), (40, 108), (41, 91)] +interhand_right = [(i - 21, j + 21) for i, j in interhand_left] +interhand_coco133 = interhand_right + interhand_left + +dataset_interhand2d = dict( + type=InterHand2DDoubleDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='interhand26m/annotations/all/InterHand2.6M_train_data.json', + camera_param_file='interhand26m/annotations/all/' + 'InterHand2.6M_train_camera.json', + joint_file='interhand26m/annotations/all/' + 'InterHand2.6M_train_joint_3d.json', + data_prefix=dict(img='interhand2.6m/images/train/'), + sample_interval=10, + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=interhand_coco133, + ), *hand_pipeline + ], +) + +dataset_hand = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[dataset_interhand2d], + pipeline=[], + test_mode=False, +) + +train_datasets = [dataset_wb, dataset_body, dataset_face, dataset_hand] + +# data loaders +train_dataloader = dict( + batch_size=train_batch_size, + num_workers=4, + pin_memory=False, + persistent_workers=True, + sampler=dict(type=DefaultSampler, shuffle=True), + dataset=dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=train_datasets, + pipeline=train_pipeline, + test_mode=False, + )) + +val_dataloader = dict( + batch_size=val_batch_size, + num_workers=4, + persistent_workers=True, + drop_last=False, + sampler=dict(type=DefaultSampler, shuffle=False, round_up=False), + dataset=dict( + type=CocoWholeBodyDataset, + ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json', + data_prefix=dict(img='data/detection/coco/val2017/'), + pipeline=val_pipeline, + bbox_file='data/coco/person_detection_results/' + 'COCO_val2017_detections_AP_H_56_person.json', + test_mode=True)) + +test_dataloader = val_dataloader + +# hooks +default_hooks.update( # noqa + checkpoint=dict( + save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1)) + +custom_hooks = [ + dict( + type=EMAHook, + ema_type=ExpMomentumEMA, + momentum=0.0002, + update_buffers=True, + priority=49), + dict( + type=PipelineSwitchHook, + switch_epoch=max_epochs - stage2_num_epochs, + switch_pipeline=train_pipeline_stage2) +] + +# evaluators +val_evaluator = dict( + type=CocoWholeBodyMetric, + ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json') +test_evaluator = val_evaluator diff --git a/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb704-270e_cocktail13-256x192.py b/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb704-270e_cocktail13-256x192.py new file mode 100644 index 0000000000..48275c3c11 --- /dev/null +++ b/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb704-270e_cocktail13-256x192.py @@ -0,0 +1,639 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from mmengine.config import read_base + +with read_base(): + from mmpose.configs._base_.default_runtime import * # noqa + +from albumentations.augmentations import Blur, CoarseDropout, MedianBlur +from mmdet.engine.hooks import PipelineSwitchHook +from mmengine.dataset import DefaultSampler +from mmengine.hooks import EMAHook +from mmengine.model import PretrainedInit +from mmengine.optim import CosineAnnealingLR, LinearLR, OptimWrapper +from torch.nn import SiLU, SyncBatchNorm +from torch.optim import AdamW + +from mmpose.codecs import SimCCLabel +from mmpose.datasets import (AicDataset, CocoWholeBodyDataset, COFWDataset, + CombinedDataset, CrowdPoseDataset, + Face300WDataset, GenerateTarget, + GetBBoxCenterScale, HalpeDataset, + HumanArt21Dataset, InterHand2DDoubleDataset, + JhmdbDataset, KeypointConverter, LapaDataset, + LoadImage, MpiiDataset, PackPoseInputs, + PoseTrack18Dataset, RandomFlip, RandomHalfBody, + TopdownAffine, UBody2dDataset, WFLWDataset) +from mmpose.datasets.transforms.common_transforms import ( + Albumentation, PhotometricDistortion, RandomBBoxTransform) +from mmpose.engine.hooks import ExpMomentumEMA +from mmpose.evaluation import CocoWholeBodyMetric +from mmpose.models import (CSPNeXt, CSPNeXtPAFPN, KLDiscretLoss, + PoseDataPreprocessor, RTMWHead, + TopdownPoseEstimator) + +# common setting +num_keypoints = 133 +input_size = (192, 256) + +# runtime +max_epochs = 270 +stage2_num_epochs = 10 +base_lr = 5e-4 +train_batch_size = 704 +val_batch_size = 32 + +train_cfg.update(max_epochs=max_epochs, val_interval=10) # noqa +randomness = dict(seed=21) + +# optimizer +optim_wrapper = dict( + type=OptimWrapper, + optimizer=dict(type=AdamW, lr=base_lr, weight_decay=0.05), + clip_grad=dict(max_norm=35, norm_type=2), + paramwise_cfg=dict( + norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True)) + +# learning rate +param_scheduler = [ + dict( + type=LinearLR, start_factor=1.0e-5, by_epoch=False, begin=0, end=1000), + dict( + type=CosineAnnealingLR, + eta_min=base_lr * 0.05, + begin=max_epochs // 2, + end=max_epochs, + T_max=max_epochs // 2, + by_epoch=True, + convert_to_iter_based=True), +] + +# automatically scaling LR based on the actual training batch size +auto_scale_lr = dict(base_batch_size=5632) + +# codec settings +codec = dict( + type=SimCCLabel, + input_size=input_size, + sigma=(4.9, 5.66), + simcc_split_ratio=2.0, + normalize=False, + use_dark=False) + +# model settings +model = dict( + type=TopdownPoseEstimator, + data_preprocessor=dict( + type=PoseDataPreprocessor, + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + backbone=dict( + type=CSPNeXt, + arch='P5', + expand_ratio=0.5, + deepen_factor=1.33, + widen_factor=1.25, + channel_attention=True, + norm_cfg=dict(type='BN'), + act_cfg=dict(type=SiLU), + init_cfg=dict( + type=PretrainedInit, + prefix='backbone.', + checkpoint='https://download.openmmlab.com/mmpose/v1/' + 'wholebody_2d_keypoint/rtmpose/ubody/rtmpose-x_simcc-ucoco_pt-aic-coco_270e-256x192-05f5bcb7_20230822.pth' # noqa + )), + neck=dict( + type=CSPNeXtPAFPN, + in_channels=[320, 640, 1280], + out_channels=None, + out_indices=( + 1, + 2, + ), + num_csp_blocks=2, + expand_ratio=0.5, + norm_cfg=dict(type=SyncBatchNorm), + act_cfg=dict(type=SiLU, inplace=True)), + head=dict( + type=RTMWHead, + in_channels=1280, + out_channels=num_keypoints, + input_size=input_size, + in_featuremap_size=tuple([s // 32 for s in input_size]), + simcc_split_ratio=codec['simcc_split_ratio'], + final_layer_kernel_size=7, + gau_cfg=dict( + hidden_dims=256, + s=128, + expansion_factor=2, + dropout_rate=0., + drop_path=0., + act_fn=SiLU, + use_rel_bias=False, + pos_enc=False), + loss=dict( + type=KLDiscretLoss, + use_target_weight=True, + beta=10., + label_softmax=True), + decoder=codec), + test_cfg=dict(flip_test=True)) + +# base dataset settings +dataset_type = CocoWholeBodyDataset +data_mode = 'topdown' +data_root = 'data/' + +backend_args = dict(backend='local') + +# pipelines +train_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict(type=RandomFlip, direction='horizontal'), + dict(type=RandomHalfBody), + dict(type=RandomBBoxTransform, scale_factor=[0.5, 1.5], rotate_factor=90), + dict(type=TopdownAffine, input_size=codec['input_size']), + dict(type=PhotometricDistortion), + dict( + type=Albumentation, + transforms=[ + dict(type=Blur, p=0.1), + dict(type=MedianBlur, p=0.1), + dict( + type=CoarseDropout, + max_holes=1, + max_height=0.4, + max_width=0.4, + min_holes=1, + min_height=0.2, + min_width=0.2, + p=1.0), + ]), + dict( + type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True), + dict(type=PackPoseInputs) +] +val_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict(type=TopdownAffine, input_size=codec['input_size']), + dict(type=PackPoseInputs) +] + +train_pipeline_stage2 = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict(type=RandomFlip, direction='horizontal'), + dict(type=RandomHalfBody), + dict( + type=RandomBBoxTransform, + shift_factor=0., + scale_factor=[0.5, 1.5], + rotate_factor=90), + dict(type=TopdownAffine, input_size=codec['input_size']), + dict( + type=Albumentation, + transforms=[ + dict(type=Blur, p=0.1), + dict(type=MedianBlur, p=0.1), + ]), + dict( + type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True), + dict(type=PackPoseInputs) +] + +# mapping + +aic_coco133 = [(0, 6), (1, 8), (2, 10), (3, 5), (4, 7), (5, 9), (6, 12), + (7, 14), (8, 16), (9, 11), (10, 13), (11, 15)] + +crowdpose_coco133 = [(0, 5), (1, 6), (2, 7), (3, 8), (4, 9), (5, 10), (6, 11), + (7, 12), (8, 13), (9, 14), (10, 15), (11, 16)] + +mpii_coco133 = [ + (0, 16), + (1, 14), + (2, 12), + (3, 11), + (4, 13), + (5, 15), + (8, 18), + (9, 17), + (10, 10), + (11, 8), + (12, 6), + (13, 5), + (14, 7), + (15, 9), +] + +jhmdb_coco133 = [ + (0, 18), + (2, 17), + (3, 6), + (4, 5), + (5, 12), + (6, 11), + (7, 8), + (8, 7), + (9, 14), + (10, 13), + (11, 10), + (12, 9), + (13, 16), + (14, 15), +] + +halpe_coco133 = [(i, i) + for i in range(17)] + [(20, 17), (21, 20), (22, 18), (23, 21), + (24, 19), + (25, 22)] + [(i, i - 3) + for i in range(26, 136)] + +posetrack_coco133 = [ + (0, 0), + (2, 17), + (3, 3), + (4, 4), + (5, 5), + (6, 6), + (7, 7), + (8, 8), + (9, 9), + (10, 10), + (11, 11), + (12, 12), + (13, 13), + (14, 14), + (15, 15), + (16, 16), +] + +humanart_coco133 = [(i, i) for i in range(17)] + [(17, 99), (18, 120), + (19, 17), (20, 20)] + +# train datasets +dataset_coco = dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='coco/annotations/coco_wholebody_train_v1.0.json', + data_prefix=dict(img='detection/coco/train2017/'), + pipeline=[], +) + +dataset_aic = dict( + type=AicDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='aic/annotations/aic_train.json', + data_prefix=dict(img='pose/ai_challenge/ai_challenger_keypoint' + '_train_20170902/keypoint_train_images_20170902/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=aic_coco133) + ], +) + +dataset_crowdpose = dict( + type=CrowdPoseDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='crowdpose/annotations/mmpose_crowdpose_trainval.json', + data_prefix=dict(img='pose/CrowdPose/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=crowdpose_coco133) + ], +) + +dataset_mpii = dict( + type=MpiiDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='mpii/annotations/mpii_train.json', + data_prefix=dict(img='pose/MPI/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=mpii_coco133) + ], +) + +dataset_jhmdb = dict( + type=JhmdbDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='jhmdb/annotations/Sub1_train.json', + data_prefix=dict(img='pose/JHMDB/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=jhmdb_coco133) + ], +) + +dataset_halpe = dict( + type=HalpeDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='halpe/annotations/halpe_train_v1.json', + data_prefix=dict(img='pose/Halpe/hico_20160224_det/images/train2015'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=halpe_coco133) + ], +) + +dataset_posetrack = dict( + type=PoseTrack18Dataset, + data_root=data_root, + data_mode=data_mode, + ann_file='posetrack18/annotations/posetrack18_train.json', + data_prefix=dict(img='pose/PoseChallenge2018/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=posetrack_coco133) + ], +) + +dataset_humanart = dict( + type=HumanArt21Dataset, + data_root=data_root, + data_mode=data_mode, + ann_file='HumanArt/annotations/training_humanart.json', + filter_cfg=dict(scenes=['real_human']), + data_prefix=dict(img='pose/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=humanart_coco133) + ]) + +ubody_scenes = [ + 'Magic_show', 'Entertainment', 'ConductMusic', 'Online_class', 'TalkShow', + 'Speech', 'Fitness', 'Interview', 'Olympic', 'TVShow', 'Singing', + 'SignLanguage', 'Movie', 'LiveVlog', 'VideoConference' +] + +ubody_datasets = [] +for scene in ubody_scenes: + each = dict( + type=UBody2dDataset, + data_root=data_root, + data_mode=data_mode, + ann_file=f'Ubody/annotations/{scene}/train_annotations.json', + data_prefix=dict(img='pose/UBody/images/'), + pipeline=[], + sample_interval=10) + ubody_datasets.append(each) + +dataset_ubody = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/ubody2d.py'), + datasets=ubody_datasets, + pipeline=[], + test_mode=False, +) + +face_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale, padding=1.25), + dict( + type=RandomBBoxTransform, + shift_factor=0., + scale_factor=[1.5, 2.0], + rotate_factor=0), +] + +wflw_coco133 = [(i * 2, 23 + i) + for i in range(17)] + [(33 + i, 40 + i) for i in range(5)] + [ + (42 + i, 45 + i) for i in range(5) + ] + [(51 + i, 50 + i) + for i in range(9)] + [(60, 59), (61, 60), (63, 61), + (64, 62), (65, 63), (67, 64), + (68, 65), (69, 66), (71, 67), + (72, 68), (73, 69), + (75, 70)] + [(76 + i, 71 + i) + for i in range(20)] +dataset_wflw = dict( + type=WFLWDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='wflw/annotations/face_landmarks_wflw_train.json', + data_prefix=dict(img='pose/WFLW/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=wflw_coco133), *face_pipeline + ], +) + +mapping_300w_coco133 = [(i, 23 + i) for i in range(68)] +dataset_300w = dict( + type=Face300WDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='300w/annotations/face_landmarks_300w_train.json', + data_prefix=dict(img='pose/300w/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=mapping_300w_coco133), *face_pipeline + ], +) + +cofw_coco133 = [(0, 40), (2, 44), (4, 42), (1, 49), (3, 45), (6, 47), (8, 59), + (10, 62), (9, 68), (11, 65), (18, 54), (19, 58), (20, 53), + (21, 56), (22, 71), (23, 77), (24, 74), (25, 85), (26, 89), + (27, 80), (28, 31)] +dataset_cofw = dict( + type=COFWDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='cofw/annotations/cofw_train.json', + data_prefix=dict(img='pose/COFW/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=cofw_coco133), *face_pipeline + ], +) + +lapa_coco133 = [(i * 2, 23 + i) for i in range(17)] + [ + (33 + i, 40 + i) for i in range(5) +] + [(42 + i, 45 + i) for i in range(5)] + [ + (51 + i, 50 + i) for i in range(4) +] + [(58 + i, 54 + i) for i in range(5)] + [(66, 59), (67, 60), (69, 61), + (70, 62), (71, 63), (73, 64), + (75, 65), (76, 66), (78, 67), + (79, 68), (80, 69), + (82, 70)] + [(84 + i, 71 + i) + for i in range(20)] +dataset_lapa = dict( + type=LapaDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='LaPa/annotations/lapa_trainval.json', + data_prefix=dict(img='pose/LaPa/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=lapa_coco133), *face_pipeline + ], +) + +dataset_wb = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[dataset_coco, dataset_halpe, dataset_ubody], + pipeline=[], + test_mode=False, +) + +dataset_body = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[ + dataset_aic, + dataset_crowdpose, + dataset_mpii, + dataset_jhmdb, + dataset_posetrack, + dataset_humanart, + ], + pipeline=[], + test_mode=False, +) + +dataset_face = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[ + dataset_wflw, + dataset_300w, + dataset_cofw, + dataset_lapa, + ], + pipeline=[], + test_mode=False, +) + +hand_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict( + type=RandomBBoxTransform, + shift_factor=0., + scale_factor=[1.5, 2.0], + rotate_factor=0), +] + +interhand_left = [(21, 95), (22, 94), (23, 93), (24, 92), (25, 99), (26, 98), + (27, 97), (28, 96), (29, 103), (30, 102), (31, 101), + (32, 100), (33, 107), (34, 106), (35, 105), (36, 104), + (37, 111), (38, 110), (39, 109), (40, 108), (41, 91)] +interhand_right = [(i - 21, j + 21) for i, j in interhand_left] +interhand_coco133 = interhand_right + interhand_left + +dataset_interhand2d = dict( + type=InterHand2DDoubleDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='interhand26m/annotations/all/InterHand2.6M_train_data.json', + camera_param_file='interhand26m/annotations/all/' + 'InterHand2.6M_train_camera.json', + joint_file='interhand26m/annotations/all/' + 'InterHand2.6M_train_joint_3d.json', + data_prefix=dict(img='interhand2.6m/images/train/'), + sample_interval=10, + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=interhand_coco133, + ), *hand_pipeline + ], +) + +dataset_hand = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[dataset_interhand2d], + pipeline=[], + test_mode=False, +) + +train_datasets = [dataset_wb, dataset_body, dataset_face, dataset_hand] + +# data loaders +train_dataloader = dict( + batch_size=train_batch_size, + num_workers=4, + pin_memory=False, + persistent_workers=True, + sampler=dict(type=DefaultSampler, shuffle=True), + dataset=dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=train_datasets, + pipeline=train_pipeline, + test_mode=False, + )) + +val_dataloader = dict( + batch_size=val_batch_size, + num_workers=4, + persistent_workers=True, + drop_last=False, + sampler=dict(type=DefaultSampler, shuffle=False, round_up=False), + dataset=dict( + type=CocoWholeBodyDataset, + ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json', + data_prefix=dict(img='data/detection/coco/val2017/'), + pipeline=val_pipeline, + bbox_file='data/coco/person_detection_results/' + 'COCO_val2017_detections_AP_H_56_person.json', + test_mode=True)) + +test_dataloader = val_dataloader + +# hooks +default_hooks.update( # noqa + checkpoint=dict( + save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1)) + +custom_hooks = [ + dict( + type=EMAHook, + ema_type=ExpMomentumEMA, + momentum=0.0002, + update_buffers=True, + priority=49), + dict( + type=PipelineSwitchHook, + switch_epoch=max_epochs - stage2_num_epochs, + switch_pipeline=train_pipeline_stage2) +] + +# evaluators +val_evaluator = dict( + type=CocoWholeBodyMetric, + ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json') +test_evaluator = val_evaluator diff --git a/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw_cocktail13.md b/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw_cocktail13.md new file mode 100644 index 0000000000..54e75383ba --- /dev/null +++ b/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw_cocktail13.md @@ -0,0 +1,76 @@ + + +
+
+
+
+
+RTMPose (arXiv'2023)
+ +```bibtex +@misc{https://doi.org/10.48550/arxiv.2303.07399, + doi = {10.48550/ARXIV.2303.07399}, + url = {https://arxiv.org/abs/2303.07399}, + author = {Jiang, Tao and Lu, Peng and Zhang, Li and Ma, Ningsheng and Han, Rui and Lyu, Chengqi and Li, Yining and Chen, Kai}, + keywords = {Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences}, + title = {RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose}, + publisher = {arXiv}, + year = {2023}, + copyright = {Creative Commons Attribution 4.0 International} +} + +``` + +
+
+
+
+
+RTMDet (arXiv'2022)
+ +```bibtex +@misc{lyu2022rtmdet, + title={RTMDet: An Empirical Study of Designing Real-Time Object Detectors}, + author={Chengqi Lyu and Wenwei Zhang and Haian Huang and Yue Zhou and Yudong Wang and Yanyi Liu and Shilong Zhang and Kai Chen}, + year={2022}, + eprint={2212.07784}, + archivePrefix={arXiv}, + primaryClass={cs.CV} +} +``` + +
+
+
+- `Cocktail13` denotes model trained on 13 public datasets:
+ - [AI Challenger](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#aic)
+ - [CrowdPose](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#crowdpose)
+ - [MPII](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#mpii)
+ - [sub-JHMDB](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#sub-jhmdb-dataset)
+ - [Halpe](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_wholebody_keypoint.html#halpe)
+ - [PoseTrack18](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#posetrack18)
+ - [COCO-Wholebody](https://github.com/jin-s13/COCO-WholeBody/)
+ - [UBody](https://github.com/IDEA-Research/OSX)
+ - [Human-Art](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#human-art-dataset)
+ - [WFLW](https://wywu.github.io/projects/LAB/WFLW.html)
+ - [300W](https://ibug.doc.ic.ac.uk/resources/300-W/)
+ - [COFW](http://www.vision.caltech.edu/xpburgos/ICCV13/)
+ - [LaPa](https://github.com/JDAI-CV/lapa-dataset)
+
+Results on COCO-WholeBody v1.0 val with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | Body AP | Body AR | Foot AP | Foot AR | Face AP | Face AR | Hand AP | Hand AR | Whole AP | Whole AR | ckpt | log |
+| :-------------------------------------- | :--------: | :-----: | :-----: | :-----: | :-----: | :-----: | :-----: | :-----: | :-----: | :------: | :------: | :--------------------------------------: | :-------------------------------------: |
+| [rtmw-x](/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb320-270e_cocktail13-256x192.py) | 256x192 | 0.753 | 0.815 | 0.773 | 0.869 | 0.843 | 0.894 | 0.602 | 0.703 | 0.672 | 0.754 | [ckpt](https://download.openmmlab.com/mmpose/v1/projects/rtmw/rtmw-x_simcc-cocktail13_pt-ucoco_270e-256x192-fbef0d61_20230925.pth) | [log](https://download.openmmlab.com/mmpose/v1/projects/rtmw/rtmw-x_simcc-cocktail13_pt-ucoco_270e-256x192-fbef0d61_20230925.json) |
+| [rtmw-x](/configs/wholebody_2d_keypoint/rtmpose/cocktail13/rtmw-x_8xb320-270e_cocktail13-384x288.py) | 384x288 | 0.764 | 0.825 | 0.791 | 0.883 | 0.882 | 0.922 | 0.654 | 0.744 | 0.702 | 0.779 | [ckpt](https://download.openmmlab.com/mmpose/v1/projects/rtmw/rtmw-x_simcc-cocktail13_pt-ucoco_270e-384x288-0949e3a9_20230925.pth) | [log](https://download.openmmlab.com/mmpose/v1/projects/rtmw/rtmw-x_simcc-cocktail13_pt-ucoco_270e-384x288-0949e3a9_20230925.json) |
diff --git a/configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py b/configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py
index af2c133f22..39a6ff79d7 100644
--- a/configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py
+++ b/configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py
@@ -68,7 +68,7 @@
type='Pretrained',
prefix='backbone.',
checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
- 'rtmposev1/cspnext-l_udp-aic-coco_210e-256x192-273b7631_20230130.pth' # noqa
+ 'rtmposev1/cspnext-l_udp-aic-coco_210e-256x192-273b7631_20230130.pth' # noqa: E501
)),
head=dict(
type='RTMCCHead',
diff --git a/configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py b/configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py
index 7765c9ec44..9f32f25777 100644
--- a/configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py
+++ b/configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py
@@ -68,7 +68,7 @@
type='Pretrained',
prefix='backbone.',
checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
- 'rtmposev1/cspnext-l_udp-aic-coco_210e-256x192-273b7631_20230130.pth' # noqa
+ 'rtmposev1/cspnext-l_udp-aic-coco_210e-256x192-273b7631_20230130.pth' # noqa: E501
)),
head=dict(
type='RTMCCHead',
diff --git a/configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py b/configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py
index 1e2afc518d..8c8c92d5f7 100644
--- a/configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py
+++ b/configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py
@@ -68,7 +68,7 @@
type='Pretrained',
prefix='backbone.',
checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
- 'rtmposev1/cspnext-m_udp-aic-coco_210e-256x192-f2f7d6f6_20230130.pth' # noqa
+ 'rtmposev1/cspnext-m_udp-aic-coco_210e-256x192-f2f7d6f6_20230130.pth' # noqa: E501
)),
head=dict(
type='RTMCCHead',
diff --git a/configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/rtmpose-x_8xb32-270e_coco-wholebody-384x288.py b/configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/rtmpose-x_8xb32-270e_coco-wholebody-384x288.py
new file mode 100644
index 0000000000..55b11c419a
--- /dev/null
+++ b/configs/wholebody_2d_keypoint/rtmpose/coco-wholebody/rtmpose-x_8xb32-270e_coco-wholebody-384x288.py
@@ -0,0 +1,233 @@
+_base_ = ['mmpose::_base_/default_runtime.py']
+
+# common setting
+num_keypoints = 133
+input_size = (288, 384)
+
+# runtime
+max_epochs = 270
+stage2_num_epochs = 30
+base_lr = 4e-3
+train_batch_size = 32
+val_batch_size = 32
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
+ clip_grad=dict(max_norm=35, norm_type=2),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=512)
+
+# codec settings
+codec = dict(
+ type='SimCCLabel',
+ input_size=input_size,
+ sigma=(6., 6.93),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ _scope_='mmdet',
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=1.33,
+ widen_factor=1.25,
+ out_indices=(4, ),
+ channel_attention=True,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmposev1/cspnext-x_udp-body7_210e-384x288-d28b58e6_20230529.pth' # noqa: E501
+ )),
+ head=dict(
+ type='RTMCCHead',
+ in_channels=1280,
+ out_channels=num_keypoints,
+ input_size=codec['input_size'],
+ in_featuremap_size=tuple([s // 32 for s in codec['input_size']]),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=10.,
+ label_softmax=True),
+ decoder=codec),
+ test_cfg=dict(flip_test=True, ))
+
+# base dataset settings
+dataset_type = 'CocoWholeBodyDataset'
+data_mode = 'topdown'
+data_root = 'data/coco/'
+
+backend_args = dict(backend='local')
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.5, 1.5], rotate_factor=90),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=1.0),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.5, 1.5],
+ rotate_factor=90),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=train_batch_size,
+ num_workers=10,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/coco_wholebody_train_v1.0.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=val_batch_size,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/coco_wholebody_val_v1.0.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(
+ save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoWholeBodyMetric',
+ ann_file=data_root + 'annotations/coco_wholebody_val_v1.0.json')
+test_evaluator = val_evaluator
diff --git a/configs/wholebody_2d_keypoint/rtmpose/ubody/rtmpose-l_8xb32-270e_coco-ubody-wholebody-384x288.py b/configs/wholebody_2d_keypoint/rtmpose/ubody/rtmpose-l_8xb32-270e_coco-ubody-wholebody-384x288.py
new file mode 100644
index 0000000000..203766402c
--- /dev/null
+++ b/configs/wholebody_2d_keypoint/rtmpose/ubody/rtmpose-l_8xb32-270e_coco-ubody-wholebody-384x288.py
@@ -0,0 +1,256 @@
+_base_ = ['../../../_base_/default_runtime.py']
+
+# runtime
+max_epochs = 270
+stage2_num_epochs = 30
+base_lr = 4e-3
+train_batch_size = 32
+val_batch_size = 32
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ # use cosine lr from 150 to 300 epoch
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=512)
+
+# codec settings
+codec = dict(
+ type='SimCCLabel',
+ input_size=(288, 384),
+ sigma=(6., 6.93),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ _scope_='mmdet',
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=1.,
+ widen_factor=1.,
+ out_indices=(4, ),
+ channel_attention=True,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmpose/cspnext-l_udp-aic-coco_210e-256x192-273b7631_20230130.pth' # noqa: E501
+ )),
+ head=dict(
+ type='RTMCCHead',
+ in_channels=1024,
+ out_channels=133,
+ input_size=codec['input_size'],
+ in_featuremap_size=(9, 12),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=10.,
+ label_softmax=True),
+ decoder=codec),
+ test_cfg=dict(flip_test=True, ))
+
+# base dataset settings
+dataset_type = 'UBody2dDataset'
+data_mode = 'topdown'
+data_root = 'data/UBody/'
+
+backend_args = dict(backend='local')
+
+scenes = [
+ 'Magic_show', 'Entertainment', 'ConductMusic', 'Online_class', 'TalkShow',
+ 'Speech', 'Fitness', 'Interview', 'Olympic', 'TVShow', 'Singing',
+ 'SignLanguage', 'Movie', 'LiveVlog', 'VideoConference'
+]
+
+train_datasets = [
+ dict(
+ type='CocoWholeBodyDataset',
+ data_root='data/coco/',
+ data_mode=data_mode,
+ ann_file='annotations/coco_wholebody_train_v1.0.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=[])
+]
+
+for scene in scenes:
+ train_dataset = dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file=f'annotations/{scene}/train_annotations.json',
+ data_prefix=dict(img='images/'),
+ pipeline=[],
+ sample_interval=10)
+ train_datasets.append(train_dataset)
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.5, 1.5], rotate_factor=90),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=1.0),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.5, 1.5],
+ rotate_factor=90),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=train_batch_size,
+ num_workers=10,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=train_datasets,
+ pipeline=train_pipeline,
+ test_mode=False,
+ ))
+
+val_dataloader = dict(
+ batch_size=val_batch_size,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type='CocoWholeBodyDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json',
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ data_prefix=dict(img='coco/val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(
+ save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoWholeBodyMetric',
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json')
+test_evaluator = val_evaluator
diff --git a/configs/wholebody_2d_keypoint/rtmpose/ubody/rtmpose-l_8xb64-270e_coco-ubody-wholebody-256x192.py b/configs/wholebody_2d_keypoint/rtmpose/ubody/rtmpose-l_8xb64-270e_coco-ubody-wholebody-256x192.py
new file mode 100644
index 0000000000..66c42ad8a8
--- /dev/null
+++ b/configs/wholebody_2d_keypoint/rtmpose/ubody/rtmpose-l_8xb64-270e_coco-ubody-wholebody-256x192.py
@@ -0,0 +1,256 @@
+_base_ = ['../../../_base_/default_runtime.py']
+
+# runtime
+max_epochs = 270
+stage2_num_epochs = 30
+base_lr = 4e-3
+train_batch_size = 64
+val_batch_size = 32
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ # use cosine lr from 150 to 300 epoch
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=512)
+
+# codec settings
+codec = dict(
+ type='SimCCLabel',
+ input_size=(192, 256),
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ _scope_='mmdet',
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=1.,
+ widen_factor=1.,
+ out_indices=(4, ),
+ channel_attention=True,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmpose/cspnext-l_udp-aic-coco_210e-256x192-273b7631_20230130.pth' # noqa: E501
+ )),
+ head=dict(
+ type='RTMCCHead',
+ in_channels=1024,
+ out_channels=133,
+ input_size=codec['input_size'],
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=10.,
+ label_softmax=True),
+ decoder=codec),
+ test_cfg=dict(flip_test=True, ))
+
+# base dataset settings
+dataset_type = 'UBody2dDataset'
+data_mode = 'topdown'
+data_root = 'data/UBody/'
+
+backend_args = dict(backend='local')
+
+scenes = [
+ 'Magic_show', 'Entertainment', 'ConductMusic', 'Online_class', 'TalkShow',
+ 'Speech', 'Fitness', 'Interview', 'Olympic', 'TVShow', 'Singing',
+ 'SignLanguage', 'Movie', 'LiveVlog', 'VideoConference'
+]
+
+train_datasets = [
+ dict(
+ type='CocoWholeBodyDataset',
+ data_root='data/coco/',
+ data_mode=data_mode,
+ ann_file='annotations/coco_wholebody_train_v1.0.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=[])
+]
+
+for scene in scenes:
+ train_dataset = dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file=f'annotations/{scene}/train_annotations.json',
+ data_prefix=dict(img='images/'),
+ pipeline=[],
+ sample_interval=10)
+ train_datasets.append(train_dataset)
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.5, 1.5], rotate_factor=90),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=1.0),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.5, 1.5],
+ rotate_factor=90),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=train_batch_size,
+ num_workers=10,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=train_datasets,
+ pipeline=train_pipeline,
+ test_mode=False,
+ ))
+
+val_dataloader = dict(
+ batch_size=val_batch_size,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type='CocoWholeBodyDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json',
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ data_prefix=dict(img='coco/val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(
+ save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoWholeBodyMetric',
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json')
+test_evaluator = val_evaluator
diff --git a/configs/wholebody_2d_keypoint/rtmpose/ubody/rtmpose-m_8xb64-270e_coco-ubody-wholebody-256x192.py b/configs/wholebody_2d_keypoint/rtmpose/ubody/rtmpose-m_8xb64-270e_coco-ubody-wholebody-256x192.py
new file mode 100644
index 0000000000..0856fbbe9b
--- /dev/null
+++ b/configs/wholebody_2d_keypoint/rtmpose/ubody/rtmpose-m_8xb64-270e_coco-ubody-wholebody-256x192.py
@@ -0,0 +1,256 @@
+_base_ = ['../../../_base_/default_runtime.py']
+
+# runtime
+max_epochs = 270
+stage2_num_epochs = 30
+base_lr = 4e-3
+train_batch_size = 64
+val_batch_size = 32
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ # use cosine lr from 150 to 300 epoch
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=512)
+
+# codec settings
+codec = dict(
+ type='SimCCLabel',
+ input_size=(192, 256),
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ _scope_='mmdet',
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=0.67,
+ widen_factor=0.75,
+ out_indices=(4, ),
+ channel_attention=True,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmpose/cspnext-m_udp-aic-coco_210e-256x192-f2f7d6f6_20230130.pth' # noqa: E501
+ )),
+ head=dict(
+ type='RTMCCHead',
+ in_channels=768,
+ out_channels=133,
+ input_size=codec['input_size'],
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=10.,
+ label_softmax=True),
+ decoder=codec),
+ test_cfg=dict(flip_test=True, ))
+
+# base dataset settings
+dataset_type = 'UBody2dDataset'
+data_mode = 'topdown'
+data_root = 'data/UBody/'
+
+backend_args = dict(backend='local')
+
+scenes = [
+ 'Magic_show', 'Entertainment', 'ConductMusic', 'Online_class', 'TalkShow',
+ 'Speech', 'Fitness', 'Interview', 'Olympic', 'TVShow', 'Singing',
+ 'SignLanguage', 'Movie', 'LiveVlog', 'VideoConference'
+]
+
+train_datasets = [
+ dict(
+ type='CocoWholeBodyDataset',
+ data_root='data/coco/',
+ data_mode=data_mode,
+ ann_file='annotations/coco_wholebody_train_v1.0.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=[])
+]
+
+for scene in scenes:
+ train_dataset = dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file=f'annotations/{scene}/train_annotations.json',
+ data_prefix=dict(img='images/'),
+ pipeline=[],
+ sample_interval=10)
+ train_datasets.append(train_dataset)
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.5, 1.5], rotate_factor=90),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=1.0),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.5, 1.5],
+ rotate_factor=90),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=train_batch_size,
+ num_workers=10,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=train_datasets,
+ pipeline=train_pipeline,
+ test_mode=False,
+ ))
+
+val_dataloader = dict(
+ batch_size=val_batch_size,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type='CocoWholeBodyDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json',
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ data_prefix=dict(img='coco/val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(
+ save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoWholeBodyMetric',
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json')
+test_evaluator = val_evaluator
diff --git a/configs/wholebody_2d_keypoint/rtmpose/ubody/rtmpose-s_8xb64-270e_coco-ubody-wholebody-256x192.py b/configs/wholebody_2d_keypoint/rtmpose/ubody/rtmpose-s_8xb64-270e_coco-ubody-wholebody-256x192.py
new file mode 100644
index 0000000000..66562ee867
--- /dev/null
+++ b/configs/wholebody_2d_keypoint/rtmpose/ubody/rtmpose-s_8xb64-270e_coco-ubody-wholebody-256x192.py
@@ -0,0 +1,256 @@
+_base_ = ['../../../_base_/default_runtime.py']
+
+# runtime
+max_epochs = 270
+stage2_num_epochs = 30
+base_lr = 4e-3
+train_batch_size = 64
+val_batch_size = 32
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ # use cosine lr from 150 to 300 epoch
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=512)
+
+# codec settings
+codec = dict(
+ type='SimCCLabel',
+ input_size=(192, 256),
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ _scope_='mmdet',
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=0.33,
+ widen_factor=0.5,
+ out_indices=(4, ),
+ channel_attention=True,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmpose/cspnext-s_udp-aic-coco_210e-256x192-92f5a029_20230130.pth' # noqa: E501
+ )),
+ head=dict(
+ type='RTMCCHead',
+ in_channels=512,
+ out_channels=133,
+ input_size=codec['input_size'],
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=10.,
+ label_softmax=True),
+ decoder=codec),
+ test_cfg=dict(flip_test=True, ))
+
+# base dataset settings
+dataset_type = 'UBody2dDataset'
+data_mode = 'topdown'
+data_root = 'data/UBody/'
+
+backend_args = dict(backend='local')
+
+scenes = [
+ 'Magic_show', 'Entertainment', 'ConductMusic', 'Online_class', 'TalkShow',
+ 'Speech', 'Fitness', 'Interview', 'Olympic', 'TVShow', 'Singing',
+ 'SignLanguage', 'Movie', 'LiveVlog', 'VideoConference'
+]
+
+train_datasets = [
+ dict(
+ type='CocoWholeBodyDataset',
+ data_root='data/coco/',
+ data_mode=data_mode,
+ ann_file='annotations/coco_wholebody_train_v1.0.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=[])
+]
+
+for scene in scenes:
+ train_dataset = dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file=f'annotations/{scene}/train_annotations.json',
+ data_prefix=dict(img='images/'),
+ pipeline=[],
+ sample_interval=10)
+ train_datasets.append(train_dataset)
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.5, 1.5], rotate_factor=90),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=1.0),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.5, 1.5],
+ rotate_factor=90),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=train_batch_size,
+ num_workers=10,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=train_datasets,
+ pipeline=train_pipeline,
+ test_mode=False,
+ ))
+
+val_dataloader = dict(
+ batch_size=val_batch_size,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type='CocoWholeBodyDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json',
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ data_prefix=dict(img='coco/val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(
+ save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoWholeBodyMetric',
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json')
+test_evaluator = val_evaluator
diff --git a/configs/wholebody_2d_keypoint/rtmpose/ubody/rtmpose-t_8xb64-270e_coco-ubody-wholebody-256x192.py b/configs/wholebody_2d_keypoint/rtmpose/ubody/rtmpose-t_8xb64-270e_coco-ubody-wholebody-256x192.py
new file mode 100644
index 0000000000..beb10b16f3
--- /dev/null
+++ b/configs/wholebody_2d_keypoint/rtmpose/ubody/rtmpose-t_8xb64-270e_coco-ubody-wholebody-256x192.py
@@ -0,0 +1,256 @@
+_base_ = ['../../../_base_/default_runtime.py']
+
+# runtime
+max_epochs = 270
+stage2_num_epochs = 30
+base_lr = 4e-3
+train_batch_size = 64
+val_batch_size = 32
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ # use cosine lr from 150 to 300 epoch
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=512)
+
+# codec settings
+codec = dict(
+ type='SimCCLabel',
+ input_size=(192, 256),
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ _scope_='mmdet',
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=0.167,
+ widen_factor=0.375,
+ out_indices=(4, ),
+ channel_attention=True,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmpose/cspnext-tiny_udp-aic-coco_210e-256x192-cbed682d_20230130.pth' # noqa: E501
+ )),
+ head=dict(
+ type='RTMCCHead',
+ in_channels=384,
+ out_channels=133,
+ input_size=codec['input_size'],
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=10.,
+ label_softmax=True),
+ decoder=codec),
+ test_cfg=dict(flip_test=True, ))
+
+# base dataset settings
+dataset_type = 'UBody2dDataset'
+data_mode = 'topdown'
+data_root = 'data/UBody/'
+
+backend_args = dict(backend='local')
+
+scenes = [
+ 'Magic_show', 'Entertainment', 'ConductMusic', 'Online_class', 'TalkShow',
+ 'Speech', 'Fitness', 'Interview', 'Olympic', 'TVShow', 'Singing',
+ 'SignLanguage', 'Movie', 'LiveVlog', 'VideoConference'
+]
+
+train_datasets = [
+ dict(
+ type='CocoWholeBodyDataset',
+ data_root='data/coco/',
+ data_mode=data_mode,
+ ann_file='annotations/coco_wholebody_train_v1.0.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=[])
+]
+
+for scene in scenes:
+ train_dataset = dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file=f'annotations/{scene}/train_annotations.json',
+ data_prefix=dict(img='images/'),
+ pipeline=[],
+ sample_interval=10)
+ train_datasets.append(train_dataset)
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.5, 1.5], rotate_factor=90),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=1.0),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.5, 1.5],
+ rotate_factor=90),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=train_batch_size,
+ num_workers=10,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=train_datasets,
+ pipeline=train_pipeline,
+ test_mode=False,
+ ))
+
+val_dataloader = dict(
+ batch_size=val_batch_size,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type='CocoWholeBodyDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json',
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ data_prefix=dict(img='coco/val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(
+ save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoWholeBodyMetric',
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json')
+test_evaluator = val_evaluator
diff --git a/configs/wholebody_2d_keypoint/rtmpose/ubody/rtmpose-x_8xb32-270e_coco-ubody-wholebody-384x288.py b/configs/wholebody_2d_keypoint/rtmpose/ubody/rtmpose-x_8xb32-270e_coco-ubody-wholebody-384x288.py
new file mode 100644
index 0000000000..695f640897
--- /dev/null
+++ b/configs/wholebody_2d_keypoint/rtmpose/ubody/rtmpose-x_8xb32-270e_coco-ubody-wholebody-384x288.py
@@ -0,0 +1,260 @@
+_base_ = ['../../../_base_/default_runtime.py']
+
+# common setting
+num_keypoints = 133
+input_size = (288, 384)
+
+# runtime
+max_epochs = 270
+stage2_num_epochs = 30
+base_lr = 4e-3
+train_batch_size = 32
+val_batch_size = 32
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
+ clip_grad=dict(max_norm=35, norm_type=2),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=512)
+
+# codec settings
+codec = dict(
+ type='SimCCLabel',
+ input_size=input_size,
+ sigma=(6., 6.93),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ _scope_='mmdet',
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=1.33,
+ widen_factor=1.25,
+ out_indices=(4, ),
+ channel_attention=True,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmposev1/cspnext-x_udp-body7_210e-384x288-d28b58e6_20230529.pth' # noqa: E501
+ )),
+ head=dict(
+ type='RTMCCHead',
+ in_channels=1280,
+ out_channels=num_keypoints,
+ input_size=codec['input_size'],
+ in_featuremap_size=tuple([s // 32 for s in codec['input_size']]),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=10.,
+ label_softmax=True),
+ decoder=codec),
+ test_cfg=dict(flip_test=True, ))
+
+# base dataset settings
+dataset_type = 'UBody2dDataset'
+data_mode = 'topdown'
+data_root = 'data/UBody/'
+
+backend_args = dict(backend='local')
+
+scenes = [
+ 'Magic_show', 'Entertainment', 'ConductMusic', 'Online_class', 'TalkShow',
+ 'Speech', 'Fitness', 'Interview', 'Olympic', 'TVShow', 'Singing',
+ 'SignLanguage', 'Movie', 'LiveVlog', 'VideoConference'
+]
+
+train_datasets = [
+ dict(
+ type='CocoWholeBodyDataset',
+ data_root='data/coco/',
+ data_mode=data_mode,
+ ann_file='annotations/coco_wholebody_train_v1.0.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=[])
+]
+
+for scene in scenes:
+ train_dataset = dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file=f'annotations/{scene}/train_annotations.json',
+ data_prefix=dict(img='images/'),
+ pipeline=[],
+ sample_interval=10)
+ train_datasets.append(train_dataset)
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.5, 1.5], rotate_factor=90),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=1.0),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.5, 1.5],
+ rotate_factor=90),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=train_batch_size,
+ num_workers=10,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=train_datasets,
+ pipeline=train_pipeline,
+ test_mode=False,
+ ))
+
+val_dataloader = dict(
+ batch_size=val_batch_size,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type='CocoWholeBodyDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json',
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ data_prefix=dict(img='coco/val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(
+ save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoWholeBodyMetric',
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json')
+test_evaluator = val_evaluator
diff --git a/configs/wholebody_2d_keypoint/rtmpose/ubody/rtmpose-x_8xb64-270e_coco-ubody-wholebody-256x192.py b/configs/wholebody_2d_keypoint/rtmpose/ubody/rtmpose-x_8xb64-270e_coco-ubody-wholebody-256x192.py
new file mode 100644
index 0000000000..30f1015394
--- /dev/null
+++ b/configs/wholebody_2d_keypoint/rtmpose/ubody/rtmpose-x_8xb64-270e_coco-ubody-wholebody-256x192.py
@@ -0,0 +1,260 @@
+_base_ = ['../../../_base_/default_runtime.py']
+
+# common setting
+num_keypoints = 133
+input_size = (192, 256)
+
+# runtime
+max_epochs = 270
+stage2_num_epochs = 30
+base_lr = 4e-3
+train_batch_size = 64
+val_batch_size = 32
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
+ clip_grad=dict(max_norm=35, norm_type=2),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=512)
+
+# codec settings
+codec = dict(
+ type='SimCCLabel',
+ input_size=(192, 256),
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ _scope_='mmdet',
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=1.33,
+ widen_factor=1.25,
+ out_indices=(4, ),
+ channel_attention=True,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmposev1/cspnext-x_udp-body7_210e-384x288-d28b58e6_20230529.pth' # noqa: E501
+ )),
+ head=dict(
+ type='RTMCCHead',
+ in_channels=1280,
+ out_channels=num_keypoints,
+ input_size=codec['input_size'],
+ in_featuremap_size=tuple([s // 32 for s in codec['input_size']]),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=10.,
+ label_softmax=True),
+ decoder=codec),
+ test_cfg=dict(flip_test=True, ))
+
+# base dataset settings
+dataset_type = 'UBody2dDataset'
+data_mode = 'topdown'
+data_root = 'data/UBody/'
+
+backend_args = dict(backend='local')
+
+scenes = [
+ 'Magic_show', 'Entertainment', 'ConductMusic', 'Online_class', 'TalkShow',
+ 'Speech', 'Fitness', 'Interview', 'Olympic', 'TVShow', 'Singing',
+ 'SignLanguage', 'Movie', 'LiveVlog', 'VideoConference'
+]
+
+train_datasets = [
+ dict(
+ type='CocoWholeBodyDataset',
+ data_root='data/coco/',
+ data_mode=data_mode,
+ ann_file='annotations/coco_wholebody_train_v1.0.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=[])
+]
+
+for scene in scenes:
+ train_dataset = dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file=f'annotations/{scene}/train_annotations.json',
+ data_prefix=dict(img='images/'),
+ pipeline=[],
+ sample_interval=10)
+ train_datasets.append(train_dataset)
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.5, 1.5], rotate_factor=90),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=1.0),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.5, 1.5],
+ rotate_factor=90),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=train_batch_size,
+ num_workers=10,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=train_datasets,
+ pipeline=train_pipeline,
+ test_mode=False,
+ ))
+
+val_dataloader = dict(
+ batch_size=val_batch_size,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type='CocoWholeBodyDataset',
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json',
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ data_prefix=dict(img='coco/val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(
+ save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoWholeBodyMetric',
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json')
+test_evaluator = val_evaluator
diff --git a/configs/wholebody_2d_keypoint/topdown_heatmap/README.md b/configs/wholebody_2d_keypoint/topdown_heatmap/README.md
index 23ee1ed315..71837c998b 100644
--- a/configs/wholebody_2d_keypoint/topdown_heatmap/README.md
+++ b/configs/wholebody_2d_keypoint/topdown_heatmap/README.md
@@ -18,9 +18,18 @@ Results on COCO-WholeBody v1.0 val with detector having human AP of 56.4 on COCO
| HRNet-w32+Dark | 256x192 | 0.582 | 0.671 | [hrnet_dark_coco-wholebody.md](./coco-wholebody/hrnet_dark_coco-wholebody.md) |
| HRNet-w48 | 256x192 | 0.579 | 0.681 | [hrnet_coco-wholebody.md](./coco-wholebody/hrnet_coco-wholebody.md) |
| CSPNeXt-m | 256x192 | 0.567 | 0.641 | [cspnext_udp_coco-wholebody.md](./coco-wholebody/cspnext_udp_coco-wholebody.md) |
+| HRNet-w32 | 256x192 | 0.549 | 0.646 | [hrnet_ubody-coco-wholebody.md](./ubody2d/hrnet_ubody-coco-wholebody.md) |
| ResNet-152 | 256x192 | 0.548 | 0.661 | [resnet_coco-wholebody.md](./coco-wholebody/resnet_coco-wholebody.md) |
| HRNet-w32 | 256x192 | 0.536 | 0.636 | [hrnet_coco-wholebody.md](./coco-wholebody/hrnet_coco-wholebody.md) |
| ResNet-101 | 256x192 | 0.531 | 0.645 | [resnet_coco-wholebody.md](./coco-wholebody/resnet_coco-wholebody.md) |
| S-ViPNAS-Res50+Dark | 256x192 | 0.528 | 0.632 | [vipnas_dark_coco-wholebody.md](./coco-wholebody/vipnas_dark_coco-wholebody.md) |
| ResNet-50 | 256x192 | 0.521 | 0.633 | [resnet_coco-wholebody.md](./coco-wholebody/resnet_coco-wholebody.md) |
| S-ViPNAS-Res50 | 256x192 | 0.495 | 0.607 | [vipnas_coco-wholebody.md](./coco-wholebody/vipnas_coco-wholebody.md) |
+
+### UBody2D Dataset
+
+Result on UBody val set, computed with gt keypoints.
+
+| Model | Input Size | Whole AP | Whole AR | Details and Download |
+| :-------: | :--------: | :------: | :------: | :----------------------------------------------------------------------: |
+| HRNet-w32 | 256x192 | 0.690 | 0.729 | [hrnet_ubody-coco-wholebody.md](./ubody2d/hrnet_ubody-coco-wholebody.md) |
diff --git a/configs/wholebody_2d_keypoint/topdown_heatmap/ubody2d/hrnet_coco-wholebody.yml b/configs/wholebody_2d_keypoint/topdown_heatmap/ubody2d/hrnet_coco-wholebody.yml
new file mode 100644
index 0000000000..d51126cab8
--- /dev/null
+++ b/configs/wholebody_2d_keypoint/topdown_heatmap/ubody2d/hrnet_coco-wholebody.yml
@@ -0,0 +1,23 @@
+Models:
+- Config: configs/wholebody_2d_keypoint/topdown_heatmap/ubody2d/td-hm_hrnet-w32_8xb64-210e_ubody-256x192.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: &id001
+ - HRNet
+ Training Data: UBody-COCO-WholeBody
+ Name: td-hm_hrnet-w32_8xb64-210e_ubody-256x192
+ Results:
+ - Dataset: COCO-WholeBody
+ Metrics:
+ Body AP: 0.678
+ Body AR: 0.755
+ Face AP: 0.630
+ Face AR: 0.708
+ Foot AP: 0.543
+ Foot AR: 0.661
+ Hand AP: 0.467
+ Hand AR: 0.566
+ Whole AP: 0.536
+ Whole AR: 0.636
+ Task: Wholebody 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/v1/wholebody_2d_keypoint/ubody/td-hm_hrnet-w32_8xb64-210e_ubody-coco-256x192-7c227391_20230807.pth
diff --git a/configs/wholebody_2d_keypoint/topdown_heatmap/ubody2d/hrnet_ubody-coco-wholebody.md b/configs/wholebody_2d_keypoint/topdown_heatmap/ubody2d/hrnet_ubody-coco-wholebody.md
new file mode 100644
index 0000000000..bd62073847
--- /dev/null
+++ b/configs/wholebody_2d_keypoint/topdown_heatmap/ubody2d/hrnet_ubody-coco-wholebody.md
@@ -0,0 +1,38 @@
+
+
+COCO-WholeBody (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+Results on COCO-WholeBody v1.0 val with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | Body AP | Body AR | Foot AP | Foot AR | Face AP | Face AR | Hand AP | Hand AR | Whole AP | Whole AR | ckpt | log |
+| :-------------------------------------- | :--------: | :-----: | :-----: | :-----: | :-----: | :-----: | :-----: | :-----: | :-----: | :------: | :------: | :--------------------------------------: | :-------------------------------------: |
+| [pose_hrnet_w32](/configs/wholebody_2d_keypoint/topdown_heatmap/ubody/td-hm_hrnet-w32_8xb64-210e_coco-wholebody-256x192.py) | 256x192 | 0.685 | 0.759 | 0.564 | 0.675 | 0.625 | 0.705 | 0.516 | 0.609 | 0.549 | 0.646 | [ckpt](https://download.openmmlab.com/mmpose/v1/wholebody_2d_keypoint/ubody/td-hm_hrnet-w32_8xb64-210e_ubody-coco-256x192-7c227391_20230807.pth) | [log](https://download.openmmlab.com/mmpose/v1/wholebody_2d_keypoint/ubody/td-hm_hrnet-w32_8xb64-210e_ubody-coco-256x192-7c227391_20230807.json) |
diff --git a/configs/wholebody_2d_keypoint/topdown_heatmap/ubody2d/td-hm_hrnet-w32_8xb64-210e_ubody-256x192.py b/configs/wholebody_2d_keypoint/topdown_heatmap/ubody2d/td-hm_hrnet-w32_8xb64-210e_ubody-256x192.py
new file mode 100644
index 0000000000..055484d009
--- /dev/null
+++ b/configs/wholebody_2d_keypoint/topdown_heatmap/ubody2d/td-hm_hrnet-w32_8xb64-210e_ubody-256x192.py
@@ -0,0 +1,173 @@
+_base_ = ['../../../_base_/default_runtime.py']
+
+# runtime
+train_cfg = dict(max_epochs=210, val_interval=10)
+
+# optimizer
+optim_wrapper = dict(optimizer=dict(
+ type='Adam',
+ lr=5e-4,
+))
+
+# learning policy
+param_scheduler = [
+ dict(
+ type='LinearLR', begin=0, end=500, start_factor=0.001,
+ by_epoch=False), # warm-up
+ dict(
+ type='MultiStepLR',
+ begin=0,
+ end=210,
+ milestones=[170, 200],
+ gamma=0.1,
+ by_epoch=True)
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=512)
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(save_best='coco-wholebody/AP', rule='greater'))
+
+# codec settings
+codec = dict(
+ type='MSRAHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth'),
+ ),
+ head=dict(
+ type='HeatmapHead',
+ in_channels=32,
+ out_channels=133,
+ deconv_out_channels=None,
+ loss=dict(type='KeypointMSELoss', use_target_weight=True),
+ decoder=codec),
+ test_cfg=dict(
+ flip_test=True,
+ flip_mode='heatmap',
+ shift_heatmap=True,
+ ))
+
+# base dataset settings
+dataset_type = 'UBody2dDataset'
+data_mode = 'topdown'
+data_root = 'data/UBody/'
+
+scenes = [
+ 'Magic_show', 'Entertainment', 'ConductMusic', 'Online_class', 'TalkShow',
+ 'Speech', 'Fitness', 'Interview', 'Olympic', 'TVShow', 'Singing',
+ 'SignLanguage', 'Movie', 'LiveVlog', 'VideoConference'
+]
+
+train_datasets = [
+ dict(
+ type='CocoWholeBodyDataset',
+ data_root='data/coco/',
+ data_mode=data_mode,
+ ann_file='annotations/coco_wholebody_train_v1.0.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=[])
+]
+
+for scene in scenes:
+ train_dataset = dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file=f'annotations/{scene}/train_annotations.json',
+ data_prefix=dict(img='images/'),
+ pipeline=[],
+ sample_interval=10)
+ train_datasets.append(train_dataset)
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(type='RandomBBoxTransform'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=64,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
+ datasets=train_datasets,
+ pipeline=train_pipeline,
+ test_mode=False,
+ ))
+val_dataloader = dict(
+ batch_size=32,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type='CocoWholeBodyDataset',
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json',
+ data_prefix=dict(img='data/coco/val2017/'),
+ pipeline=val_pipeline,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ test_mode=True))
+test_dataloader = val_dataloader
+
+val_evaluator = dict(
+ type='CocoWholeBodyMetric',
+ ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json')
+test_evaluator = val_evaluator
diff --git a/dataset-index.yml b/dataset-index.yml
index a6acc57cc4..b27e3fffef 100644
--- a/dataset-index.yml
+++ b/dataset-index.yml
@@ -1,71 +1,72 @@
+openxlab: true
coco2017:
- dataset: COCO_2017
+ dataset: OpenDataLab/COCO_2017
download_root: data
data_root: data/pose
script: tools/dataset_converters/scripts/preprocess_coco2017.sh
mpii:
- dataset: MPII_Human_Pose
+ dataset: OpenDataLab/MPII_Human_Pose
download_root: data
data_root: data/pose
script: tools/dataset_converters/scripts/preprocess_mpii.sh
aic:
- dataset: AI_Challenger
+ dataset: OpenDataLab/AI_Challenger
download_root: data
data_root: data/pose
script: tools/dataset_converters/scripts/preprocess_aic.sh
crowdpose:
- dataset: CrowdPose
+ dataset: OpenDataLab/CrowdPose
download_root: data
data_root: data/pose
script: tools/dataset_converters/scripts/preprocess_crowdpose.sh
halpe:
- dataset: Halpe
+ dataset: OpenDataLab/Halpe
download_root: data
data_root: data/pose
script: tools/dataset_converters/scripts/preprocess_halpe.sh
lapa:
- dataset: LaPa
+ dataset: OpenDataLab/LaPa
download_root: data
data_root: data/pose
script: tools/dataset_converters/scripts/preprocess_lapa.sh
300w:
- dataset: 300w
+ dataset: OpenDataLab/300w
download_root: data
data_root: data/pose
script: tools/dataset_converters/scripts/preprocess_300w.sh
wflw:
- dataset: WFLW
+ dataset: OpenDataLab/WFLW
download_root: data
data_root: data/pose
script: tools/dataset_converters/scripts/preprocess_wflw.sh
onehand10k:
- dataset: OneHand10K
+ dataset: OpenDataLab/OneHand10K
download_root: data
data_root: data/pose
script: tools/dataset_converters/scripts/preprocess_onehand10k.sh
freihand:
- dataset: FreiHAND
+ dataset: OpenDataLab/FreiHAND
download_root: data
data_root: data/pose
script: tools/dataset_converters/scripts/preprocess_freihand.sh
ap10k:
- dataset: AP-10K
+ dataset: OpenDataLab/AP-10K
download_root: data
data_root: data/pose
script: tools/dataset_converters/scripts/preprocess_ap10k.sh
hagrid:
- dataset: HaGRID
+ dataset: OpenDataLab/HaGRID
download_root: data
data_root: data/pose
script: tools/dataset_converters/scripts/preprocess_hagrid.sh
diff --git a/demo/body3d_pose_lifter_demo.py b/demo/body3d_pose_lifter_demo.py
index 840cd4edc9..a6c1d394e9 100644
--- a/demo/body3d_pose_lifter_demo.py
+++ b/demo/body3d_pose_lifter_demo.py
@@ -1,4 +1,5 @@
# Copyright (c) OpenMMLab. All rights reserved.
+import logging
import mimetypes
import os
import time
@@ -10,9 +11,9 @@
import mmcv
import mmengine
import numpy as np
-from mmengine.structures import InstanceData
+from mmengine.logging import print_log
-from mmpose.apis import (_track_by_iou, _track_by_oks, collect_multi_frames,
+from mmpose.apis import (_track_by_iou, _track_by_oks,
convert_keypoint_definition, extract_pose_sequence,
inference_pose_lifter_model, inference_topdown,
init_model)
@@ -57,23 +58,25 @@ def parse_args():
default=False,
help='Whether to show visualizations')
parser.add_argument(
- '--rebase-keypoint-height',
+ '--disable-rebase-keypoint',
action='store_true',
- help='Rebase the predicted 3D pose so its lowest keypoint has a '
- 'height of 0 (landing on the ground). This is useful for '
- 'visualization when the model do not predict the global position '
- 'of the 3D pose.')
+ default=False,
+ help='Whether to disable rebasing the predicted 3D pose so its '
+ 'lowest keypoint has a height of 0 (landing on the ground). Rebase '
+ 'is useful for visualization when the model do not predict the '
+ 'global position of the 3D pose.')
parser.add_argument(
- '--norm-pose-2d',
+ '--disable-norm-pose-2d',
action='store_true',
- help='Scale the bbox (along with the 2D pose) to the average bbox '
- 'scale of the dataset, and move the bbox (along with the 2D pose) to '
- 'the average bbox center of the dataset. This is useful when bbox '
- 'is small, especially in multi-person scenarios.')
+ default=False,
+ help='Whether to scale the bbox (along with the 2D pose) to the '
+ 'average bbox scale of the dataset, and move the bbox (along with the '
+ '2D pose) to the average bbox center of the dataset. This is useful '
+ 'when bbox is small, especially in multi-person scenarios.')
parser.add_argument(
'--num-instances',
type=int,
- default=-1,
+ default=1,
help='The number of 3D poses to be visualized in every frame. If '
'less than 0, it will be set to the number of pose results in the '
'first frame.')
@@ -87,7 +90,7 @@ def parse_args():
'--save-predictions',
action='store_true',
default=False,
- help='whether to save predicted results')
+ help='Whether to save predicted results')
parser.add_argument(
'--device', default='cuda:0', help='Device used for inference')
parser.add_argument(
@@ -118,60 +121,144 @@ def parse_args():
default=3,
help='Keypoint radius for visualization')
parser.add_argument(
- '--use-multi-frames',
+ '--online',
action='store_true',
default=False,
- help='whether to use multi frames for inference in the 2D pose'
+ help='Inference mode. If set to True, can not use future frame'
+ 'information when using multi frames for inference in the 2D pose'
'detection stage. Default: False.')
args = parser.parse_args()
return args
-def get_area(results):
- for i, data_sample in enumerate(results):
- pred_instance = data_sample.pred_instances.cpu().numpy()
- if 'bboxes' in pred_instance:
- bboxes = pred_instance.bboxes
- results[i].pred_instances.set_field(
- np.array([(bbox[2] - bbox[0]) * (bbox[3] - bbox[1])
- for bbox in bboxes]), 'areas')
- else:
- keypoints = pred_instance.keypoints
- areas, bboxes = [], []
- for keypoint in keypoints:
- xmin = np.min(keypoint[:, 0][keypoint[:, 0] > 0], initial=1e10)
- xmax = np.max(keypoint[:, 0])
- ymin = np.min(keypoint[:, 1][keypoint[:, 1] > 0], initial=1e10)
- ymax = np.max(keypoint[:, 1])
- areas.append((xmax - xmin) * (ymax - ymin))
- bboxes.append([xmin, ymin, xmax, ymax])
- results[i].pred_instances.areas = np.array(areas)
- results[i].pred_instances.bboxes = np.array(bboxes)
- return results
+def process_one_image(args, detector, frame, frame_idx, pose_estimator,
+ pose_est_results_last, pose_est_results_list, next_id,
+ pose_lifter, visualize_frame, visualizer):
+ """Visualize detected and predicted keypoints of one image.
+
+ Pipeline of this function:
+
+ frame
+ |
+ V
+ +-----------------+
+ | detector |
+ +-----------------+
+ | det_result
+ V
+ +-----------------+
+ | pose_estimator |
+ +-----------------+
+ | pose_est_results
+ V
+ +--------------------------------------------+
+ | convert 2d kpts into pose-lifting format |
+ +--------------------------------------------+
+ | pose_est_results_list
+ V
+ +-----------------------+
+ | extract_pose_sequence |
+ +-----------------------+
+ | pose_seq_2d
+ V
+ +-------------+
+ | pose_lifter |
+ +-------------+
+ | pose_lift_results
+ V
+ +-----------------+
+ | post-processing |
+ +-----------------+
+ | pred_3d_data_samples
+ V
+ +------------+
+ | visualizer |
+ +------------+
+
+ Args:
+ args (Argument): Custom command-line arguments.
+ detector (mmdet.BaseDetector): The mmdet detector.
+ frame (np.ndarray): The image frame read from input image or video.
+ frame_idx (int): The index of current frame.
+ pose_estimator (TopdownPoseEstimator): The pose estimator for 2d pose.
+ pose_est_results_last (list(PoseDataSample)): The results of pose
+ estimation from the last frame for tracking instances.
+ pose_est_results_list (list(list(PoseDataSample))): The list of all
+ pose estimation results converted by
+ ``convert_keypoint_definition`` from previous frames. In
+ pose-lifting stage it is used to obtain the 2d estimation sequence.
+ next_id (int): The next track id to be used.
+ pose_lifter (PoseLifter): The pose-lifter for estimating 3d pose.
+ visualize_frame (np.ndarray): The image for drawing the results on.
+ visualizer (Visualizer): The visualizer for visualizing the 2d and 3d
+ pose estimation results.
+
+ Returns:
+ pose_est_results (list(PoseDataSample)): The pose estimation result of
+ the current frame.
+ pose_est_results_list (list(list(PoseDataSample))): The list of all
+ converted pose estimation results until the current frame.
+ pred_3d_instances (InstanceData): The result of pose-lifting.
+ Specifically, the predicted keypoints and scores are saved at
+ ``pred_3d_instances.keypoints`` and
+ ``pred_3d_instances.keypoint_scores``.
+ next_id (int): The next track id to be used.
+ """
+ pose_lift_dataset = pose_lifter.cfg.test_dataloader.dataset
+ pose_lift_dataset_name = pose_lifter.dataset_meta['dataset_name']
+ # First stage: conduct 2D pose detection in a Topdown manner
+ # use detector to obtain person bounding boxes
+ det_result = inference_detector(detector, frame)
+ pred_instance = det_result.pred_instances.cpu().numpy()
-def get_pose_est_results(args, pose_estimator, frame, bboxes,
- pose_est_results_last, next_id, pose_lift_dataset):
- pose_det_dataset = pose_estimator.cfg.test_dataloader.dataset
+ # filter out the person instances with category and bbox threshold
+ # e.g. 0 for person in COCO
+ bboxes = pred_instance.bboxes
+ bboxes = bboxes[np.logical_and(pred_instance.labels == args.det_cat_id,
+ pred_instance.scores > args.bbox_thr)]
- # make person results for current image
+ # estimate pose results for current image
pose_est_results = inference_topdown(pose_estimator, frame, bboxes)
- pose_est_results = get_area(pose_est_results)
if args.use_oks_tracking:
_track = partial(_track_by_oks)
else:
_track = _track_by_iou
- for i, result in enumerate(pose_est_results):
- track_id, pose_est_results_last, match_result = _track(
- result, pose_est_results_last, args.tracking_thr)
+ pose_det_dataset_name = pose_estimator.dataset_meta['dataset_name']
+ pose_est_results_converted = []
+
+ # convert 2d pose estimation results into the format for pose-lifting
+ # such as changing the keypoint order, flipping the keypoint, etc.
+ for i, data_sample in enumerate(pose_est_results):
+ pred_instances = data_sample.pred_instances.cpu().numpy()
+ keypoints = pred_instances.keypoints
+ # calculate area and bbox
+ if 'bboxes' in pred_instances:
+ areas = np.array([(bbox[2] - bbox[0]) * (bbox[3] - bbox[1])
+ for bbox in pred_instances.bboxes])
+ pose_est_results[i].pred_instances.set_field(areas, 'areas')
+ else:
+ areas, bboxes = [], []
+ for keypoint in keypoints:
+ xmin = np.min(keypoint[:, 0][keypoint[:, 0] > 0], initial=1e10)
+ xmax = np.max(keypoint[:, 0])
+ ymin = np.min(keypoint[:, 1][keypoint[:, 1] > 0], initial=1e10)
+ ymax = np.max(keypoint[:, 1])
+ areas.append((xmax - xmin) * (ymax - ymin))
+ bboxes.append([xmin, ymin, xmax, ymax])
+ pose_est_results[i].pred_instances.areas = np.array(areas)
+ pose_est_results[i].pred_instances.bboxes = np.array(bboxes)
+
+ # track id
+ track_id, pose_est_results_last, _ = _track(data_sample,
+ pose_est_results_last,
+ args.tracking_thr)
if track_id == -1:
- pred_instances = result.pred_instances.cpu().numpy()
- keypoints = pred_instances.keypoints
if np.count_nonzero(keypoints[:, :, 1]) >= 3:
- pose_est_results[i].set_field(next_id, 'track_id')
+ track_id = next_id
next_id += 1
else:
# If the number of keypoints detected is small,
@@ -179,39 +266,30 @@ def get_pose_est_results(args, pose_estimator, frame, bboxes,
keypoints[:, :, 1] = -10
pose_est_results[i].pred_instances.set_field(
keypoints, 'keypoints')
- bboxes = pred_instances.bboxes * 0
- pose_est_results[i].pred_instances.set_field(bboxes, 'bboxes')
- pose_est_results[i].set_field(-1, 'track_id')
+ pose_est_results[i].pred_instances.set_field(
+ pred_instances.bboxes * 0, 'bboxes')
pose_est_results[i].set_field(pred_instances, 'pred_instances')
- else:
- pose_est_results[i].set_field(track_id, 'track_id')
+ track_id = -1
+ pose_est_results[i].set_field(track_id, 'track_id')
- del match_result
-
- pose_est_results_converted = []
- for pose_est_result in pose_est_results:
+ # convert keypoints for pose-lifting
pose_est_result_converted = PoseDataSample()
- gt_instances = InstanceData()
- pred_instances = InstanceData()
- for k in pose_est_result.gt_instances.keys():
- gt_instances.set_field(pose_est_result.gt_instances[k], k)
- for k in pose_est_result.pred_instances.keys():
- pred_instances.set_field(pose_est_result.pred_instances[k], k)
- pose_est_result_converted.gt_instances = gt_instances
- pose_est_result_converted.pred_instances = pred_instances
- pose_est_result_converted.track_id = pose_est_result.track_id
-
- keypoints = convert_keypoint_definition(pred_instances.keypoints,
- pose_det_dataset['type'],
- pose_lift_dataset['type'])
- pose_est_result_converted.pred_instances.keypoints = keypoints
+ pose_est_result_converted.set_field(
+ pose_est_results[i].pred_instances.clone(), 'pred_instances')
+ pose_est_result_converted.set_field(
+ pose_est_results[i].gt_instances.clone(), 'gt_instances')
+ keypoints = convert_keypoint_definition(keypoints,
+ pose_det_dataset_name,
+ pose_lift_dataset_name)
+ pose_est_result_converted.pred_instances.set_field(
+ keypoints, 'keypoints')
+ pose_est_result_converted.set_field(pose_est_results[i].track_id,
+ 'track_id')
pose_est_results_converted.append(pose_est_result_converted)
- return pose_est_results, pose_est_results_converted, next_id
+ pose_est_results_list.append(pose_est_results_converted.copy())
-def get_pose_lift_results(args, visualizer, pose_lifter, pose_est_results_list,
- frame, frame_idx, pose_est_results):
- pose_lift_dataset = pose_lifter.cfg.test_dataloader.dataset
+ # Second stage: Pose lifting
# extract and pad input pose2d sequence
pose_seq_2d = extract_pose_sequence(
pose_est_results_list,
@@ -220,19 +298,19 @@ def get_pose_lift_results(args, visualizer, pose_lifter, pose_est_results_list,
seq_len=pose_lift_dataset.get('seq_len', 1),
step=pose_lift_dataset.get('seq_step', 1))
- # 2D-to-3D pose lifting
- width, height = frame.shape[:2]
+ # conduct 2D-to-3D pose lifting
+ norm_pose_2d = not args.disable_norm_pose_2d
pose_lift_results = inference_pose_lifter_model(
pose_lifter,
pose_seq_2d,
- image_size=(width, height),
- norm_pose_2d=args.norm_pose_2d)
+ image_size=visualize_frame.shape[:2],
+ norm_pose_2d=norm_pose_2d)
- # Pose processing
- for idx, pose_lift_res in enumerate(pose_lift_results):
- pose_lift_res.track_id = pose_est_results[idx].get('track_id', 1e4)
+ # post-processing
+ for idx, pose_lift_result in enumerate(pose_lift_results):
+ pose_lift_result.track_id = pose_est_results[idx].get('track_id', 1e4)
- pred_instances = pose_lift_res.pred_instances
+ pred_instances = pose_lift_result.pred_instances
keypoints = pred_instances.keypoints
keypoint_scores = pred_instances.keypoint_scores
if keypoint_scores.ndim == 3:
@@ -247,7 +325,7 @@ def get_pose_lift_results(args, visualizer, pose_lifter, pose_est_results_list,
keypoints[..., 2] = -keypoints[..., 2]
# rebase height (z-axis)
- if args.rebase_keypoint_height:
+ if not args.disable_rebase_keypoint:
keypoints[..., 2] -= np.min(
keypoints[..., 2], axis=-1, keepdims=True)
@@ -258,6 +336,7 @@ def get_pose_lift_results(args, visualizer, pose_lifter, pose_est_results_list,
pred_3d_data_samples = merge_data_samples(pose_lift_results)
det_data_sample = merge_data_samples(pose_est_results)
+ pred_3d_instances = pred_3d_data_samples.get('pred_instances', None)
if args.num_instances < 0:
args.num_instances = len(pose_lift_results)
@@ -266,27 +345,19 @@ def get_pose_lift_results(args, visualizer, pose_lifter, pose_est_results_list,
if visualizer is not None:
visualizer.add_datasample(
'result',
- frame,
+ visualize_frame,
data_sample=pred_3d_data_samples,
det_data_sample=det_data_sample,
draw_gt=False,
+ dataset_2d=pose_det_dataset_name,
+ dataset_3d=pose_lift_dataset_name,
show=args.show,
draw_bbox=True,
kpt_thr=args.kpt_thr,
num_instances=args.num_instances,
wait_time=args.show_interval)
- return pred_3d_data_samples.get('pred_instances', None)
-
-
-def get_bbox(args, detector, frame):
- det_result = inference_detector(detector, frame)
- pred_instance = det_result.pred_instances.cpu().numpy()
-
- bboxes = pred_instance.bboxes
- bboxes = bboxes[np.logical_and(pred_instance.labels == args.det_cat_id,
- pred_instance.scores > args.bbox_thr)]
- return bboxes
+ return pose_est_results, pose_est_results_list, pred_3d_instances, next_id
def main():
@@ -317,12 +388,6 @@ def main():
det_dataset_link_color = pose_estimator.dataset_meta.get(
'skeleton_link_colors', None)
- # frame index offsets for inference, used in multi-frame inference setting
- if args.use_multi_frames:
- assert 'frame_indices' in pose_estimator.cfg.test_dataloader.dataset
- indices = pose_estimator.cfg.test_dataloader.dataset[
- 'frame_indices_test']
-
pose_lifter = init_model(
args.pose_lifter_config,
args.pose_lifter_checkpoint,
@@ -331,7 +396,6 @@ def main():
assert isinstance(pose_lifter, PoseLifter), \
'Only "PoseLifter" model is supported for the 2nd stage ' \
'(2D-to-3D lifting)'
- pose_lift_dataset = pose_lifter.cfg.test_dataloader.dataset
pose_lifter.cfg.visualizer.radius = args.radius
pose_lifter.cfg.visualizer.line_width = args.thickness
@@ -370,19 +434,22 @@ def main():
pred_instances_list = []
if input_type == 'image':
frame = mmcv.imread(args.input, channel_order='rgb')
-
- # First stage: 2D pose detection
- bboxes = get_bbox(args, detector, frame)
- pose_est_results, pose_est_results_converted, _ = get_pose_est_results(
- args, pose_estimator, frame, bboxes, [], 0, pose_lift_dataset)
- pose_est_results_list.append(pose_est_results_converted.copy())
- pred_3d_pred = get_pose_lift_results(args, visualizer, pose_lifter,
- pose_est_results_list, frame, 0,
- pose_est_results)
+ _, _, pred_3d_instances, _ = process_one_image(
+ args=args,
+ detector=detector,
+ frame=frame,
+ frame_idx=0,
+ pose_estimator=pose_estimator,
+ pose_est_results_last=[],
+ pose_est_results_list=pose_est_results_list,
+ next_id=0,
+ pose_lifter=pose_lifter,
+ visualize_frame=frame,
+ visualizer=visualizer)
if args.save_predictions:
# save prediction results
- pred_instances_list = split_instances(pred_3d_pred)
+ pred_instances_list = split_instances(pred_3d_instances)
if save_output:
frame_vis = visualizer.get_image()
@@ -390,7 +457,7 @@ def main():
elif input_type in ['webcam', 'video']:
next_id = 0
- pose_est_results_converted = []
+ pose_est_results = []
if args.input == 'webcam':
video = cv2.VideoCapture(0)
@@ -413,33 +480,30 @@ def main():
if not success:
break
- pose_est_results_last = pose_est_results_converted
+ pose_est_results_last = pose_est_results
# First stage: 2D pose detection
- if args.use_multi_frames:
- frames = collect_multi_frames(video, frame_idx, indices,
- args.online)
-
# make person results for current image
- bboxes = get_bbox(args, detector, frame)
- pose_est_results, pose_est_results_converted, next_id = get_pose_est_results( # noqa: E501
- args, pose_estimator,
- frames if args.use_multi_frames else frame, bboxes,
- pose_est_results_last, next_id, pose_lift_dataset)
- pose_est_results_list.append(pose_est_results_converted.copy())
-
- # Second stage: Pose lifting
- pred_3d_pred = get_pose_lift_results(args, visualizer, pose_lifter,
- pose_est_results_list,
- mmcv.bgr2rgb(frame),
- frame_idx, pose_est_results)
+ (pose_est_results, pose_est_results_list, pred_3d_instances,
+ next_id) = process_one_image(
+ args=args,
+ detector=detector,
+ frame=frame,
+ frame_idx=frame_idx,
+ pose_estimator=pose_estimator,
+ pose_est_results_last=pose_est_results_last,
+ pose_est_results_list=pose_est_results_list,
+ next_id=next_id,
+ pose_lifter=pose_lifter,
+ visualize_frame=mmcv.bgr2rgb(frame),
+ visualizer=visualizer)
if args.save_predictions:
# save prediction results
pred_instances_list.append(
dict(
frame_id=frame_idx,
- instances=split_instances(pred_3d_pred)))
+ instances=split_instances(pred_3d_instances)))
if save_output:
frame_vis = visualizer.get_image()
@@ -452,10 +516,11 @@ def main():
video_writer.write(mmcv.rgb2bgr(frame_vis))
- # press ESC to exit
- if cv2.waitKey(5) & 0xFF == 27:
- break
- time.sleep(args.show_interval)
+ if args.show:
+ # press ESC to exit
+ if cv2.waitKey(5) & 0xFF == 27:
+ break
+ time.sleep(args.show_interval)
video.release()
@@ -476,6 +541,13 @@ def main():
indent='\t')
print(f'predictions have been saved at {args.pred_save_path}')
+ if save_output:
+ input_type = input_type.replace('webcam', 'video')
+ print_log(
+ f'the output {input_type} has been saved at {output_file}',
+ logger='current',
+ level=logging.INFO)
+
if __name__ == '__main__':
main()
diff --git a/demo/bottomup_demo.py b/demo/bottomup_demo.py
index 3d6fee7a03..b493e4c4a1 100644
--- a/demo/bottomup_demo.py
+++ b/demo/bottomup_demo.py
@@ -1,4 +1,5 @@
# Copyright (c) OpenMMLab. All rights reserved.
+import logging
import mimetypes
import os
import time
@@ -9,6 +10,7 @@
import mmcv
import mmengine
import numpy as np
+from mmengine.logging import print_log
from mmpose.apis import inference_bottomup, init_model
from mmpose.registry import VISUALIZERS
@@ -196,11 +198,12 @@ def main():
video_writer.write(mmcv.rgb2bgr(frame_vis))
- # press ESC to exit
- if cv2.waitKey(5) & 0xFF == 27:
- break
+ if args.show:
+ # press ESC to exit
+ if cv2.waitKey(5) & 0xFF == 27:
+ break
- time.sleep(args.show_interval)
+ time.sleep(args.show_interval)
if video_writer:
video_writer.release()
@@ -222,6 +225,13 @@ def main():
indent='\t')
print(f'predictions have been saved at {args.pred_save_path}')
+ if output_file:
+ input_type = input_type.replace('webcam', 'video')
+ print_log(
+ f'the output {input_type} has been saved at {output_file}',
+ logger='current',
+ level=logging.INFO)
+
if __name__ == '__main__':
main()
diff --git a/demo/docs/en/2d_animal_demo.md b/demo/docs/en/2d_animal_demo.md
index aa9970395b..0680e5a6ed 100644
--- a/demo/docs/en/2d_animal_demo.md
+++ b/demo/docs/en/2d_animal_demo.md
@@ -20,8 +20,8 @@ Take [animalpose model](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet
```shell
python demo/topdown_demo_with_mmdet.py \
- demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
- https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ demo/mmdetection_cfg/rtmdet_m_8xb32-300e_coco.py \
+ https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_m_8xb32-300e_coco/rtmdet_m_8xb32-300e_coco_20220719_112220-229f527c.pth \
configs/animal_2d_keypoint/topdown_heatmap/animalpose/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256.py \
https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_animalpose_256x256-1aa7f075_20210426.pth \
--input tests/data/animalpose/ca110.jpeg \
@@ -39,14 +39,14 @@ The augement `--det-cat-id=15` selected detected bounding boxes with label 'cat'
**COCO-animals**
In COCO dataset, there are 80 object categories, including 10 common `animal` categories (14: 'bird', 15: 'cat', 16: 'dog', 17: 'horse', 18: 'sheep', 19: 'cow', 20: 'elephant', 21: 'bear', 22: 'zebra', 23: 'giraffe').
-For other animals, we have also provided some pre-trained animal detection models (1-class models). Supported models can be found in [detection model zoo](/demo/docs/en/mmdet_modelzoo.md).
+For other animals, we have also provided some pre-trained animal detection models. Supported models can be found in [detection model zoo](/demo/docs/en/mmdet_modelzoo.md).
To save visualized results on disk:
```shell
python demo/topdown_demo_with_mmdet.py \
- demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
- https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ demo/mmdetection_cfg/rtmdet_m_8xb32-300e_coco.py \
+ https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_m_8xb32-300e_coco/rtmdet_m_8xb32-300e_coco_20220719_112220-229f527c.pth \
configs/animal_2d_keypoint/topdown_heatmap/animalpose/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256.py \
https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_animalpose_256x256-1aa7f075_20210426.pth \
--input tests/data/animalpose/ca110.jpeg \
@@ -57,8 +57,8 @@ To save predicted results on disk:
```shell
python demo/topdown_demo_with_mmdet.py \
- demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
- https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ demo/mmdetection_cfg/rtmdet_m_8xb32-300e_coco.py \
+ https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_m_8xb32-300e_coco/rtmdet_m_8xb32-300e_coco_20220719_112220-229f527c.pth \
configs/animal_2d_keypoint/topdown_heatmap/animalpose/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256.py \
https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_animalpose_256x256-1aa7f075_20210426.pth \
--input tests/data/animalpose/ca110.jpeg \
@@ -69,8 +69,8 @@ To run demos on CPU:
```shell
python demo/topdown_demo_with_mmdet.py \
- demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
- https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ demo/mmdetection_cfg/rtmdet_tiny_8xb32-300e_coco.py \
+ https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_tiny_8xb32-300e_coco/rtmdet_tiny_8xb32-300e_coco_20220902_112414-78e30dcc.pth \
configs/animal_2d_keypoint/topdown_heatmap/animalpose/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256.py \
https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_animalpose_256x256-1aa7f075_20210426.pth \
--input tests/data/animalpose/ca110.jpeg \
@@ -85,8 +85,8 @@ For example,
```shell
python demo/topdown_demo_with_mmdet.py \
- demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
- https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ demo/mmdetection_cfg/rtmdet_m_8xb32-300e_coco.py \
+ https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_m_8xb32-300e_coco/rtmdet_m_8xb32-300e_coco_20220719_112220-229f527c.pth \
configs/animal_2d_keypoint/topdown_heatmap/animalpose/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256.py \
https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_animalpose_256x256-1aa7f075_20210426.pth \
--input demo/resources/UBody (CVPR'2023)
+ +```bibtex +@article{lin2023one, + title={One-Stage 3D Whole-Body Mesh Recovery with Component Aware Transformer}, + author={Lin, Jing and Zeng, Ailing and Wang, Haoqian and Zhang, Lei and Li, Yu}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + year={2023}, +} +``` + ++
If you use a heatmap-based model and set argument `--draw-heatmap`, the predicted heatmap will be visualized together with the keypoints. @@ -41,8 +41,8 @@ To save visualized results on disk: python demo/topdown_demo_with_mmdet.py \ demo/mmdetection_cfg/yolox-s_8xb8-300e_coco-face.py \ https://download.openmmlab.com/mmpose/mmdet_pretrained/yolo-x_8xb8-300e_coco-face_13274d7c.pth \ - configs/face_2d_keypoint/topdown_heatmap/aflw/td-hm_hrnetv2-w18_8xb64-60e_aflw-256x256.py \ - https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_aflw_256x256-f2bbc62b_20210125.pth \ + configs/face_2d_keypoint/rtmpose/face6/rtmpose-m_8xb256-120e_face6-256x256.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.pth \ --input tests/data/cofw/001766.jpg \ --draw-heatmap --output-root vis_results ``` @@ -55,8 +55,8 @@ To run demos on CPU: python demo/topdown_demo_with_mmdet.py \ demo/mmdetection_cfg/yolox-s_8xb8-300e_coco-face.py \ https://download.openmmlab.com/mmpose/mmdet_pretrained/yolo-x_8xb8-300e_coco-face_13274d7c.pth \ - configs/face_2d_keypoint/topdown_heatmap/aflw/td-hm_hrnetv2-w18_8xb64-60e_aflw-256x256.py \ - https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_aflw_256x256-f2bbc62b_20210125.pth \ + configs/face_2d_keypoint/rtmpose/face6/rtmpose-m_8xb256-120e_face6-256x256.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.pth \ --input tests/data/cofw/001766.jpg \ --show --draw-heatmap --device=cpu ``` @@ -69,13 +69,13 @@ Videos share the same interface with images. The difference is that the `${INPUT python demo/topdown_demo_with_mmdet.py \ demo/mmdetection_cfg/yolox-s_8xb8-300e_coco-face.py \ https://download.openmmlab.com/mmpose/mmdet_pretrained/yolo-x_8xb8-300e_coco-face_13274d7c.pth \ - configs/face_2d_keypoint/topdown_heatmap/aflw/td-hm_hrnetv2-w18_8xb64-60e_aflw-256x256.py \ - https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_aflw_256x256-f2bbc62b_20210125.pth \ + configs/face_2d_keypoint/rtmpose/face6/rtmpose-m_8xb256-120e_face6-256x256.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.pth \ --input demo/resources/
+
The original video can be downloaded from [Google Drive](https://drive.google.com/file/d/1kQt80t6w802b_vgVcmiV_QfcSJ3RWzmb/view?usp=sharing). diff --git a/demo/docs/en/2d_hand_demo.md b/demo/docs/en/2d_hand_demo.md index f47b3695e3..cea74e2be4 100644 --- a/demo/docs/en/2d_hand_demo.md +++ b/demo/docs/en/2d_hand_demo.md @@ -21,17 +21,17 @@ Take [onehand10k model](https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnet ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \ - https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth \ - configs/hand_2d_keypoint/topdown_heatmap/onehand10k/td-hm_hrnetv2-w18_8xb64-210e_onehand10k-256x256.py \ - https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_onehand10k_256x256-30bc9c6b_20210330.pth \ + demo/mmdetection_cfg/rtmdet_nano_320-8xb32_hand.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_nano_8xb32-300e_hand-267f9c8f.pth \ + configs/hand_2d_keypoint/rtmpose/hand5/rtmpose-m_8xb256-210e_hand5-256x256.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.pth \ --input tests/data/onehand10k/9.jpg \ --show --draw-heatmap ``` Visualization result: -
+
If you use a heatmap-based model and set argument `--draw-heatmap`, the predicted heatmap will be visualized together with the keypoints. @@ -39,10 +39,10 @@ To save visualized results on disk: ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \ - https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth \ - configs/hand_2d_keypoint/topdown_heatmap/onehand10k/td-hm_hrnetv2-w18_8xb64-210e_onehand10k-256x256.py \ - https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_onehand10k_256x256-30bc9c6b_20210330.pth \ + demo/mmdetection_cfg/rtmdet_nano_320-8xb32_hand.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_nano_8xb32-300e_hand-267f9c8f.pth \ + configs/hand_2d_keypoint/rtmpose/hand5/rtmpose-m_8xb256-210e_hand5-256x256.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.pth \ --input tests/data/onehand10k/9.jpg \ --output-root vis_results --show --draw-heatmap ``` @@ -53,10 +53,10 @@ To run demos on CPU: ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \ - https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth \ - configs/hand_2d_keypoint/topdown_heatmap/onehand10k/td-hm_hrnetv2-w18_8xb64-210e_onehand10k-256x256.py \ - https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_onehand10k_256x256-30bc9c6b_20210330.pth \ + demo/mmdetection_cfg/rtmdet_nano_320-8xb32_hand.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_nano_8xb32-300e_hand-267f9c8f.pth \ + configs/hand_2d_keypoint/rtmpose/hand5/rtmpose-m_8xb256-210e_hand5-256x256.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.pth \ --input tests/data/onehand10k/9.jpg \ --show --draw-heatmap --device cpu ``` @@ -67,15 +67,15 @@ Videos share the same interface with images. The difference is that the `${INPUT ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \ - https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth \ - configs/hand_2d_keypoint/topdown_heatmap/onehand10k/td-hm_hrnetv2-w18_8xb64-210e_onehand10k-256x256.py \ - https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_onehand10k_256x256-30bc9c6b_20210330.pth \ - --input demo/resources/
+
The original video can be downloaded from [Github](https://raw.githubusercontent.com/open-mmlab/mmpose/master/tests/data/nvgesture/sk_color.avi). diff --git a/demo/docs/en/2d_human_pose_demo.md b/demo/docs/en/2d_human_pose_demo.md index a2e3cf59dd..4e682cc8ff 100644 --- a/demo/docs/en/2d_human_pose_demo.md +++ b/demo/docs/en/2d_human_pose_demo.md @@ -66,17 +66,17 @@ Example: ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ - https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ - configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py \ - https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_256x192-c78dce93_20200708.pth \ + demo/mmdetection_cfg/rtmdet_m_640-8xb32_coco-person.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_m_8xb32-100e_coco-obj365-person-235e8209.pth \ + configs/body_2d_keypoint/rtmpose/body8/rtmpose-m_8xb256-420e_body8-256x192.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-256x192-e48f03d0_20230504.pth \ --input tests/data/coco/000000197388.jpg --show --draw-heatmap \ --output-root vis_results/ ``` Visualization result: -
+
To save the predicted results on disk, please specify `--save-predictions`. @@ -90,10 +90,10 @@ Example: ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ - https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ - configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py \ - https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192-81c58e40_20220909.pth \ + demo/mmdetection_cfg/rtmdet_m_640-8xb32_coco-person.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_m_8xb32-100e_coco-obj365-person-235e8209.pth \ + configs/body_2d_keypoint/rtmpose/body8/rtmpose-m_8xb256-420e_body8-256x192.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-256x192-e48f03d0_20230504.pth \ --input tests/data/posetrack18/videos/000001_mpiinew_test/000001_mpiinew_test.mp4 \ --output-root=vis_results/demo --show --draw-heatmap ``` diff --git a/demo/docs/en/2d_wholebody_pose_demo.md b/demo/docs/en/2d_wholebody_pose_demo.md index ddd4cbd13d..a4f9ace061 100644 --- a/demo/docs/en/2d_wholebody_pose_demo.md +++ b/demo/docs/en/2d_wholebody_pose_demo.md @@ -56,8 +56,8 @@ Examples: ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ - https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ + demo/mmdetection_cfg/rtmdet_m_640-8xb32_coco-person.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_m_8xb32-100e_coco-obj365-person-235e8209.pth \ configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/td-hm_hrnet-w48_dark-8xb32-210e_coco-wholebody-384x288.py \ https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_384x288_dark-f5726563_20200918.pth \ --input tests/data/coco/000000196141.jpg \ @@ -76,8 +76,8 @@ Examples: ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ - https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ + demo/mmdetection_cfg/rtmdet_m_640-8xb32_coco-person.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_m_8xb32-100e_coco-obj365-person-235e8209.pth \ configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/td-hm_hrnet-w48_dark-8xb32-210e_coco-wholebody-384x288.py \ https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_384x288_dark-f5726563_20200918.pth \ --input https://user-images.githubusercontent.com/87690686/137440639-fb08603d-9a35-474e-b65f-46b5c06b68d6.mp4 \ diff --git a/demo/docs/en/3d_hand_demo.md b/demo/docs/en/3d_hand_demo.md new file mode 100644 index 0000000000..edd1a4fa6e --- /dev/null +++ b/demo/docs/en/3d_hand_demo.md @@ -0,0 +1,52 @@ +## 3D Hand Demo + +
+ +### 3D Hand Estimation Image Demo + +#### Using gt hand bounding boxes as input + +We provide a demo script to test a single image, given gt json file. + +```shell +python demo/hand3d_internet_demo.py \ + ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \ + --input ${INPUT_FILE} \ + --output-root ${OUTPUT_ROOT} \ + [--save-predictions] \ + [--gt-joints-file ${GT_JOINTS_FILE}]\ + [--disable-rebase-keypoint] \ + [--show] \ + [--device ${GPU_ID or CPU}] \ + [--kpt-thr ${KPT_THR}] \ + [--show-kpt-idx] \ + [--show-interval] \ + [--radius ${RADIUS}] \ + [--thickness ${THICKNESS}] +``` + +The pre-trained hand pose estimation model can be downloaded from [model zoo](https://mmpose.readthedocs.io/en/latest/model_zoo/hand_3d_keypoint.html). +Take [internet model](https://download.openmmlab.com/mmpose/hand3d/internet/res50_intehand3dv1.0_all_256x256-42b7f2ac_20210702.pth) as an example: + +```shell +python demo/hand3d_internet_demo.py \ + configs/hand_3d_keypoint/internet/interhand3d/internet_res50_4xb16-20e_interhand3d-256x256.py \ + https://download.openmmlab.com/mmpose/hand3d/internet/res50_intehand3dv1.0_all_256x256-42b7f2ac_20210702.pth \ + --input tests/data/interhand2.6m/image69148.jpg \ + --save-predictions \ + --output-root vis_results +``` + +### 3D Hand Pose Estimation with Inferencer + +The Inferencer provides a convenient interface for inference, allowing customization using model aliases instead of configuration files and checkpoint paths. It supports various input formats, including image paths, video paths, image folder paths, and webcams. Below is an example command: + +```shell +python demo/inferencer_demo.py tests/data/interhand2.6m/image29590.jpg --pose3d hand3d --vis-out-dir vis_results/hand3d +``` + +This command infers the image and saves the visualization results in the `vis_results/hand3d` directory. + +
+
如果使用了 heatmap-based 模型同时设置了 `--draw-heatmap` ,预测的热图也会跟随关键点一同可视化出来。 @@ -42,8 +42,8 @@ python demo/topdown_demo_with_mmdet.py \ python demo/topdown_demo_with_mmdet.py \ demo/mmdetection_cfg/yolox-s_8xb8-300e_coco-face.py \ https://download.openmmlab.com/mmpose/mmdet_pretrained/yolo-x_8xb8-300e_coco-face_13274d7c.pth \ - configs/face_2d_keypoint/topdown_heatmap/aflw/td-hm_hrnetv2-w18_8xb64-60e_aflw-256x256.py \ - https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_aflw_256x256-f2bbc62b_20210125.pth \ + configs/face_2d_keypoint/rtmpose/face6/rtmpose-m_8xb256-120e_face6-256x256.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.pth \ --input tests/data/cofw/001766.jpg \ --draw-heatmap --output-root vis_results ``` @@ -56,13 +56,13 @@ python demo/topdown_demo_with_mmdet.py \ python demo/topdown_demo_with_mmdet.py \ demo/mmdetection_cfg/yolox-s_8xb8-300e_coco-face.py \ https://download.openmmlab.com/mmpose/mmdet_pretrained/yolo-x_8xb8-300e_coco-face_13274d7c.pth \ - configs/face_2d_keypoint/topdown_heatmap/aflw/td-hm_hrnetv2-w18_8xb64-60e_aflw-256x256.py \ - https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_aflw_256x256-f2bbc62b_20210125.pth \ + configs/face_2d_keypoint/rtmpose/face6/rtmpose-m_8xb256-120e_face6-256x256.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.pth \ --input demo/resources/
+
这段视频可以在 [Google Drive](https://drive.google.com/file/d/1kQt80t6w802b_vgVcmiV_QfcSJ3RWzmb/view?usp=sharing) 下载。 diff --git a/demo/docs/zh_cn/2d_hand_demo.md b/demo/docs/zh_cn/2d_hand_demo.md index c2d80edd4e..886aace38e 100644 --- a/demo/docs/zh_cn/2d_hand_demo.md +++ b/demo/docs/zh_cn/2d_hand_demo.md @@ -22,17 +22,17 @@ python demo/topdown_demo_with_mmdet.py \ ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \ - https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth \ - configs/hand_2d_keypoint/topdown_heatmap/onehand10k/td-hm_hrnetv2-w18_8xb64-210e_onehand10k-256x256.py \ - https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_onehand10k_256x256-30bc9c6b_20210330.pth \ + demo/mmdetection_cfg/rtmdet_nano_320-8xb32_hand.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_nano_8xb32-300e_hand-267f9c8f.pth \ + configs/hand_2d_keypoint/rtmpose/hand5/rtmpose-m_8xb256-210e_hand5-256x256.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.pth \ --input tests/data/onehand10k/9.jpg \ --show --draw-heatmap ``` 可视化结果如下: -
+
如果使用了 heatmap-based 模型同时设置了 `--draw-heatmap` ,预测的热图也会跟随关键点一同可视化出来。 @@ -40,10 +40,10 @@ python demo/topdown_demo_with_mmdet.py \ ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \ - https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth \ - configs/hand_2d_keypoint/topdown_heatmap/onehand10k/td-hm_hrnetv2-w18_8xb64-210e_onehand10k-256x256.py \ - https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_onehand10k_256x256-30bc9c6b_20210330.pth \ + demo/mmdetection_cfg/rtmdet_nano_320-8xb32_hand.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_nano_8xb32-300e_hand-267f9c8f.pth \ + configs/hand_2d_keypoint/rtmpose/hand5/rtmpose-m_8xb256-210e_hand5-256x256.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.pth \ --input tests/data/onehand10k/9.jpg \ --output-root vis_results --show --draw-heatmap ``` @@ -54,10 +54,10 @@ python demo/topdown_demo_with_mmdet.py \ ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \ - https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth \ - configs/hand_2d_keypoint/topdown_heatmap/onehand10k/td-hm_hrnetv2-w18_8xb64-210e_onehand10k-256x256.py \ - https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_onehand10k_256x256-30bc9c6b_20210330.pth \ + demo/mmdetection_cfg/rtmdet_nano_320-8xb32_hand.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_nano_8xb32-300e_hand-267f9c8f.pth \ + configs/hand_2d_keypoint/rtmpose/hand5/rtmpose-m_8xb256-210e_hand5-256x256.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.pth \ --input tests/data/onehand10k/9.jpg \ --show --draw-heatmap --device cpu ``` @@ -68,14 +68,16 @@ python demo/topdown_demo_with_mmdet.py \ ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \ - https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth \ - configs/hand_2d_keypoint/topdown_heatmap/onehand10k/td-hm_hrnetv2-w18_8xb64-210e_onehand10k-256x256.py \ - https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_onehand10k_256x256-30bc9c6b_20210330.pth \ - --input demo/resources/
+
这段视频可以在 [Google Drive](https://raw.githubusercontent.com/open-mmlab/mmpose/master/tests/data/nvgesture/sk_color.avi) 下载到。 diff --git a/demo/docs/zh_cn/2d_human_pose_demo.md b/demo/docs/zh_cn/2d_human_pose_demo.md index ff6484301a..b39e510891 100644 --- a/demo/docs/zh_cn/2d_human_pose_demo.md +++ b/demo/docs/zh_cn/2d_human_pose_demo.md @@ -65,17 +65,17 @@ python demo/topdown_demo_with_mmdet.py \ ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ - https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ - configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py \ - https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_256x192-c78dce93_20200708.pth \ + demo/mmdetection_cfg/rtmdet_m_640-8xb32_coco-person.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_m_8xb32-100e_coco-obj365-person-235e8209.pth \ + configs/body_2d_keypoint/rtmpose/body8/rtmpose-m_8xb256-420e_body8-256x192.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-256x192-e48f03d0_20230504.pth \ --input tests/data/coco/000000197388.jpg --show --draw-heatmap \ --output-root vis_results/ ``` 可视化结果如下: -
+
想要本地保存识别结果,用户需要加上 `--save-predictions` 。 @@ -87,10 +87,10 @@ python demo/topdown_demo_with_mmdet.py \ ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ - https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ - configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py \ - https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192-81c58e40_20220909.pth \ + demo/mmdetection_cfg/rtmdet_m_640-8xb32_coco-person.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_m_8xb32-100e_coco-obj365-person-235e8209.pth \ + configs/body_2d_keypoint/rtmpose/body8/rtmpose-m_8xb256-420e_body8-256x192.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-256x192-e48f03d0_20230504.pth \ --input tests/data/posetrack18/videos/000001_mpiinew_test/000001_mpiinew_test.mp4 \ --output-root=vis_results/demo --show --draw-heatmap ``` diff --git a/demo/docs/zh_cn/2d_wholebody_pose_demo.md b/demo/docs/zh_cn/2d_wholebody_pose_demo.md index 8c901d47fa..6c4d77e3df 100644 --- a/demo/docs/zh_cn/2d_wholebody_pose_demo.md +++ b/demo/docs/zh_cn/2d_wholebody_pose_demo.md @@ -55,8 +55,8 @@ python demo/topdown_demo_with_mmdet.py \ ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ - https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ + demo/mmdetection_cfg/rtmdet_m_640-8xb32_coco-person.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_m_8xb32-100e_coco-obj365-person-235e8209.pth \ configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/td-hm_hrnet-w48_dark-8xb32-210e_coco-wholebody-384x288.py \ https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_384x288_dark-f5726563_20200918.pth \ --input tests/data/coco/000000196141.jpg \ @@ -73,8 +73,8 @@ python demo/topdown_demo_with_mmdet.py \ ```shell python demo/topdown_demo_with_mmdet.py \ - demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ - https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ + demo/mmdetection_cfg/rtmdet_m_640-8xb32_coco-person.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_m_8xb32-100e_coco-obj365-person-235e8209.pth \ configs/wholebody_2d_keypoint/topdown_heatmap/coco-wholebody/td-hm_hrnet-w48_dark-8xb32-210e_coco-wholebody-384x288.py \ https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_384x288_dark-f5726563_20200918.pth \ --input https://user-images.githubusercontent.com/87690686/137440639-fb08603d-9a35-474e-b65f-46b5c06b68d6.mp4 \ diff --git a/demo/docs/zh_cn/mmdet_modelzoo.md b/demo/docs/zh_cn/mmdet_modelzoo.md index aabfb1768d..1cb12358a3 100644 --- a/demo/docs/zh_cn/mmdet_modelzoo.md +++ b/demo/docs/zh_cn/mmdet_modelzoo.md @@ -13,6 +13,7 @@ MMDetection 提供了基于 COCO 的包括 `person` 在内的 80 个类别的预 | Arch | Box AP | ckpt | log | | :---------------------------------------------------------------- | :----: | :---------------------------------------------------------------: | :--------------------------------------------------------------: | | [Cascade_R-CNN X-101-64x4d-FPN-1class](/demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py) | 0.817 | [ckpt](https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth) | [log](https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k_20201030.log.json) | +| [RTMDet-nano](/demo/mmdetection_cfg/rtmdet_nano_320-8xb32_hand.py) | 0.760 | [ckpt](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_nano_8xb32-300e_hand-267f9c8f.pth) | - | ### 脸部 Bounding Box 检测模型 diff --git a/demo/hand3d_internet_demo.py b/demo/hand3d_internet_demo.py new file mode 100644 index 0000000000..1cb10a820a --- /dev/null +++ b/demo/hand3d_internet_demo.py @@ -0,0 +1,285 @@ +# Copyright (c) OpenMMLab. All rights reserved. +import logging +import mimetypes +import os +import time +from argparse import ArgumentParser + +import cv2 +import json_tricks as json +import mmcv +import mmengine +import numpy as np +from mmengine.logging import print_log + +from mmpose.apis import inference_topdown, init_model +from mmpose.registry import VISUALIZERS +from mmpose.structures import (PoseDataSample, merge_data_samples, + split_instances) + + +def parse_args(): + parser = ArgumentParser() + parser.add_argument('config', help='Config file') + parser.add_argument('checkpoint', help='Checkpoint file') + parser.add_argument( + '--input', type=str, default='', help='Image/Video file') + parser.add_argument( + '--output-root', + type=str, + default='', + help='root of the output img file. ' + 'Default not saving the visualization images.') + parser.add_argument( + '--save-predictions', + action='store_true', + default=False, + help='whether to save predicted results') + parser.add_argument( + '--disable-rebase-keypoint', + action='store_true', + default=False, + help='Whether to disable rebasing the predicted 3D pose so its ' + 'lowest keypoint has a height of 0 (landing on the ground). Rebase ' + 'is useful for visualization when the model do not predict the ' + 'global position of the 3D pose.') + parser.add_argument( + '--show', + action='store_true', + default=False, + help='whether to show result') + parser.add_argument('--device', default='cpu', help='Device for inference') + parser.add_argument( + '--kpt-thr', + type=float, + default=0.3, + help='Visualizing keypoint thresholds') + parser.add_argument( + '--show-kpt-idx', + action='store_true', + default=False, + help='Whether to show the index of keypoints') + parser.add_argument( + '--show-interval', type=int, default=0, help='Sleep seconds per frame') + parser.add_argument( + '--radius', + type=int, + default=3, + help='Keypoint radius for visualization') + parser.add_argument( + '--thickness', + type=int, + default=1, + help='Link thickness for visualization') + + args = parser.parse_args() + return args + + +def process_one_image(args, img, model, visualizer=None, show_interval=0): + """Visualize predicted keypoints of one image.""" + # inference a single image + pose_results = inference_topdown(model, img) + # post-processing + pose_results_2d = [] + for idx, res in enumerate(pose_results): + pred_instances = res.pred_instances + keypoints = pred_instances.keypoints + rel_root_depth = pred_instances.rel_root_depth + scores = pred_instances.keypoint_scores + hand_type = pred_instances.hand_type + + res_2d = PoseDataSample() + gt_instances = res.gt_instances.clone() + pred_instances = pred_instances.clone() + res_2d.gt_instances = gt_instances + res_2d.pred_instances = pred_instances + + # add relative root depth to left hand joints + keypoints[:, 21:, 2] += rel_root_depth + + # set joint scores according to hand type + scores[:, :21] *= hand_type[:, [0]] + scores[:, 21:] *= hand_type[:, [1]] + # normalize kpt score + if scores.max() > 1: + scores /= 255 + + res_2d.pred_instances.set_field(keypoints[..., :2].copy(), 'keypoints') + + # rotate the keypoint to make z-axis correspondent to height + # for better visualization + vis_R = np.array([[1, 0, 0], [0, 0, -1], [0, 1, 0]]) + keypoints[..., :3] = keypoints[..., :3] @ vis_R + + # rebase height (z-axis) + if not args.disable_rebase_keypoint: + valid = scores > 0 + keypoints[..., 2] -= np.min( + keypoints[valid, 2], axis=-1, keepdims=True) + + pose_results[idx].pred_instances.keypoints = keypoints + pose_results[idx].pred_instances.keypoint_scores = scores + pose_results_2d.append(res_2d) + + data_samples = merge_data_samples(pose_results) + data_samples_2d = merge_data_samples(pose_results_2d) + + # show the results + if isinstance(img, str): + img = mmcv.imread(img, channel_order='rgb') + elif isinstance(img, np.ndarray): + img = mmcv.bgr2rgb(img) + + if visualizer is not None: + visualizer.add_datasample( + 'result', + img, + data_sample=data_samples, + det_data_sample=data_samples_2d, + draw_gt=False, + draw_bbox=True, + kpt_thr=args.kpt_thr, + convert_keypoint=False, + axis_azimuth=-115, + axis_limit=200, + axis_elev=15, + show_kpt_idx=args.show_kpt_idx, + show=args.show, + wait_time=show_interval) + + # if there is no instance detected, return None + return data_samples.get('pred_instances', None) + + +def main(): + args = parse_args() + + assert args.input != '' + assert args.show or (args.output_root != '') + + output_file = None + if args.output_root: + mmengine.mkdir_or_exist(args.output_root) + output_file = os.path.join(args.output_root, + os.path.basename(args.input)) + if args.input == 'webcam': + output_file += '.mp4' + + if args.save_predictions: + assert args.output_root != '' + args.pred_save_path = f'{args.output_root}/results_' \ + f'{os.path.splitext(os.path.basename(args.input))[0]}.json' + + # build the model from a config file and a checkpoint file + model = init_model( + args.config, args.checkpoint, device=args.device.lower()) + + # init visualizer + model.cfg.visualizer.radius = args.radius + model.cfg.visualizer.line_width = args.thickness + + visualizer = VISUALIZERS.build(model.cfg.visualizer) + visualizer.set_dataset_meta(model.dataset_meta) + + if args.input == 'webcam': + input_type = 'webcam' + else: + input_type = mimetypes.guess_type(args.input)[0].split('/')[0] + + if input_type == 'image': + # inference + pred_instances = process_one_image(args, args.input, model, visualizer) + + if args.save_predictions: + pred_instances_list = split_instances(pred_instances) + + if output_file: + img_vis = visualizer.get_image() + mmcv.imwrite(mmcv.rgb2bgr(img_vis), output_file) + + elif input_type in ['webcam', 'video']: + + if args.input == 'webcam': + cap = cv2.VideoCapture(0) + else: + cap = cv2.VideoCapture(args.input) + + video_writer = None + pred_instances_list = [] + frame_idx = 0 + + while cap.isOpened(): + success, frame = cap.read() + frame_idx += 1 + + if not success: + break + + # topdown pose estimation + pred_instances = process_one_image(args, frame, model, visualizer, + 0.001) + + if args.save_predictions: + # save prediction results + pred_instances_list.append( + dict( + frame_id=frame_idx, + instances=split_instances(pred_instances))) + + # output videos + if output_file: + frame_vis = visualizer.get_image() + + if video_writer is None: + fourcc = cv2.VideoWriter_fourcc(*'mp4v') + # the size of the image with visualization may vary + # depending on the presence of heatmaps + video_writer = cv2.VideoWriter( + output_file, + fourcc, + 25, # saved fps + (frame_vis.shape[1], frame_vis.shape[0])) + + video_writer.write(mmcv.rgb2bgr(frame_vis)) + + if args.show: + # press ESC to exit + if cv2.waitKey(5) & 0xFF == 27: + break + + time.sleep(args.show_interval) + + if video_writer: + video_writer.release() + + cap.release() + + else: + args.save_predictions = False + raise ValueError( + f'file {os.path.basename(args.input)} has invalid format.') + + if args.save_predictions: + with open(args.pred_save_path, 'w') as f: + json.dump( + dict( + meta_info=model.dataset_meta, + instance_info=pred_instances_list), + f, + indent='\t') + print_log( + f'predictions have been saved at {args.pred_save_path}', + logger='current', + level=logging.INFO) + + if output_file is not None: + input_type = input_type.replace('webcam', 'video') + print_log( + f'the output {input_type} has been saved at {output_file}', + logger='current', + level=logging.INFO) + + +if __name__ == '__main__': + main() diff --git a/demo/image_demo.py b/demo/image_demo.py index bfbc808b1e..6a408d1760 100644 --- a/demo/image_demo.py +++ b/demo/image_demo.py @@ -1,7 +1,9 @@ # Copyright (c) OpenMMLab. All rights reserved. +import logging from argparse import ArgumentParser from mmcv.image import imread +from mmengine.logging import print_log from mmpose.apis import inference_topdown, init_model from mmpose.registry import VISUALIZERS @@ -100,6 +102,12 @@ def main(): show=args.show, out_file=args.out_file) + if args.out_file is not None: + print_log( + f'the output image has been saved at {args.out_file}', + logger='current', + level=logging.INFO) + if __name__ == '__main__': main() diff --git a/demo/inferencer_demo.py b/demo/inferencer_demo.py index b91e91f74b..0ab816e9fb 100644 --- a/demo/inferencer_demo.py +++ b/demo/inferencer_demo.py @@ -97,19 +97,27 @@ def parse_args(): action='store_true', help='Whether to use OKS as similarity in tracking') parser.add_argument( - '--norm-pose-2d', + '--disable-norm-pose-2d', action='store_true', - help='Scale the bbox (along with the 2D pose) to the average bbox ' - 'scale of the dataset, and move the bbox (along with the 2D pose) to ' - 'the average bbox center of the dataset. This is useful when bbox ' - 'is small, especially in multi-person scenarios.') + help='Whether to scale the bbox (along with the 2D pose) to the ' + 'average bbox scale of the dataset, and move the bbox (along with the ' + '2D pose) to the average bbox center of the dataset. This is useful ' + 'when bbox is small, especially in multi-person scenarios.') parser.add_argument( - '--rebase-keypoint-height', + '--disable-rebase-keypoint', action='store_true', - help='Rebase the predicted 3D pose so its lowest keypoint has a ' - 'height of 0 (landing on the ground). This is useful for ' - 'visualization when the model do not predict the global position ' - 'of the 3D pose.') + default=False, + help='Whether to disable rebasing the predicted 3D pose so its ' + 'lowest keypoint has a height of 0 (landing on the ground). Rebase ' + 'is useful for visualization when the model do not predict the ' + 'global position of the 3D pose.') + parser.add_argument( + '--num-instances', + type=int, + default=1, + help='The number of 3D poses to be visualized in every frame. If ' + 'less than 0, it will be set to the number of pose results in the ' + 'first frame.') parser.add_argument( '--radius', type=int, diff --git a/demo/mmdetection_cfg/rtmdet_m_640-8xb32_coco-person.py b/demo/mmdetection_cfg/rtmdet_m_640-8xb32_coco-person.py new file mode 100644 index 0000000000..620de8dc8f --- /dev/null +++ b/demo/mmdetection_cfg/rtmdet_m_640-8xb32_coco-person.py @@ -0,0 +1,20 @@ +_base_ = 'mmdet::rtmdet/rtmdet_m_8xb32-300e_coco.py' + +checkpoint = 'https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-m_8xb256-rsb-a1-600e_in1k-ecb3bbd9.pth' # noqa + +model = dict( + backbone=dict( + init_cfg=dict( + type='Pretrained', prefix='backbone.', checkpoint=checkpoint)), + bbox_head=dict(num_classes=1), + test_cfg=dict( + nms_pre=1000, + min_bbox_size=0, + score_thr=0.05, + nms=dict(type='nms', iou_threshold=0.6), + max_per_img=100)) + +train_dataloader = dict(dataset=dict(metainfo=dict(classes=('person', )))) + +val_dataloader = dict(dataset=dict(metainfo=dict(classes=('person', )))) +test_dataloader = val_dataloader diff --git a/demo/mmdetection_cfg/rtmdet_m_8xb32-300e_coco.py b/demo/mmdetection_cfg/rtmdet_m_8xb32-300e_coco.py new file mode 100644 index 0000000000..6d0d3dfef1 --- /dev/null +++ b/demo/mmdetection_cfg/rtmdet_m_8xb32-300e_coco.py @@ -0,0 +1 @@ +_base_ = 'mmdet::rtmdet/rtmdet_m_8xb32-300e_coco.py' diff --git a/demo/mmdetection_cfg/rtmdet_nano_320-8xb32_coco-person.py b/demo/mmdetection_cfg/rtmdet_nano_320-8xb32_coco-person.py new file mode 100644 index 0000000000..c2f1b64e4a --- /dev/null +++ b/demo/mmdetection_cfg/rtmdet_nano_320-8xb32_coco-person.py @@ -0,0 +1,104 @@ +_base_ = 'mmdet::rtmdet/rtmdet_l_8xb32-300e_coco.py' + +input_shape = 320 + +model = dict( + backbone=dict( + deepen_factor=0.33, + widen_factor=0.25, + use_depthwise=True, + ), + neck=dict( + in_channels=[64, 128, 256], + out_channels=64, + num_csp_blocks=1, + use_depthwise=True, + ), + bbox_head=dict( + in_channels=64, + feat_channels=64, + share_conv=False, + exp_on_reg=False, + use_depthwise=True, + num_classes=1), + test_cfg=dict( + nms_pre=1000, + min_bbox_size=0, + score_thr=0.05, + nms=dict(type='nms', iou_threshold=0.6), + max_per_img=100)) + +train_pipeline = [ + dict(type='LoadImageFromFile'), + dict(type='LoadAnnotations', with_bbox=True), + dict( + type='CachedMosaic', + img_scale=(input_shape, input_shape), + pad_val=114.0, + max_cached_images=20, + random_pop=False), + dict( + type='RandomResize', + scale=(input_shape * 2, input_shape * 2), + ratio_range=(0.5, 1.5), + keep_ratio=True), + dict(type='RandomCrop', crop_size=(input_shape, input_shape)), + dict(type='YOLOXHSVRandomAug'), + dict(type='RandomFlip', prob=0.5), + dict( + type='Pad', + size=(input_shape, input_shape), + pad_val=dict(img=(114, 114, 114))), + dict(type='PackDetInputs') +] + +train_pipeline_stage2 = [ + dict(type='LoadImageFromFile'), + dict(type='LoadAnnotations', with_bbox=True), + dict( + type='RandomResize', + scale=(input_shape, input_shape), + ratio_range=(0.5, 1.5), + keep_ratio=True), + dict(type='RandomCrop', crop_size=(input_shape, input_shape)), + dict(type='YOLOXHSVRandomAug'), + dict(type='RandomFlip', prob=0.5), + dict( + type='Pad', + size=(input_shape, input_shape), + pad_val=dict(img=(114, 114, 114))), + dict(type='PackDetInputs') +] + +test_pipeline = [ + dict(type='LoadImageFromFile'), + dict(type='Resize', scale=(input_shape, input_shape), keep_ratio=True), + dict( + type='Pad', + size=(input_shape, input_shape), + pad_val=dict(img=(114, 114, 114))), + dict( + type='PackDetInputs', + meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', + 'scale_factor')) +] + +train_dataloader = dict( + dataset=dict(pipeline=train_pipeline, metainfo=dict(classes=('person', )))) + +val_dataloader = dict( + dataset=dict(pipeline=test_pipeline, metainfo=dict(classes=('person', )))) +test_dataloader = val_dataloader + +custom_hooks = [ + dict( + type='EMAHook', + ema_type='ExpMomentumEMA', + momentum=0.0002, + update_buffers=True, + priority=49), + dict( + type='PipelineSwitchHook', + switch_epoch=280, + switch_pipeline=train_pipeline_stage2) +] diff --git a/demo/mmdetection_cfg/rtmdet_nano_320-8xb32_hand.py b/demo/mmdetection_cfg/rtmdet_nano_320-8xb32_hand.py new file mode 100644 index 0000000000..278cc0bfe8 --- /dev/null +++ b/demo/mmdetection_cfg/rtmdet_nano_320-8xb32_hand.py @@ -0,0 +1,171 @@ +_base_ = 'mmdet::rtmdet/rtmdet_l_8xb32-300e_coco.py' + +input_shape = 320 + +model = dict( + backbone=dict( + deepen_factor=0.33, + widen_factor=0.25, + use_depthwise=True, + ), + neck=dict( + in_channels=[64, 128, 256], + out_channels=64, + num_csp_blocks=1, + use_depthwise=True, + ), + bbox_head=dict( + in_channels=64, + feat_channels=64, + share_conv=False, + exp_on_reg=False, + use_depthwise=True, + num_classes=1), + test_cfg=dict( + nms_pre=1000, + min_bbox_size=0, + score_thr=0.05, + nms=dict(type='nms', iou_threshold=0.6), + max_per_img=100)) + +# file_client_args = dict( +# backend='petrel', +# path_mapping=dict({'data/': 's3://openmmlab/datasets/'})) + +train_pipeline = [ + dict(type='LoadImageFromFile'), + dict(type='LoadAnnotations', with_bbox=True), + dict( + type='CachedMosaic', + img_scale=(input_shape, input_shape), + pad_val=114.0, + max_cached_images=20, + random_pop=False), + dict( + type='RandomResize', + scale=(input_shape * 2, input_shape * 2), + ratio_range=(0.5, 1.5), + keep_ratio=True), + dict(type='RandomCrop', crop_size=(input_shape, input_shape)), + dict(type='YOLOXHSVRandomAug'), + dict(type='RandomFlip', prob=0.5), + dict( + type='Pad', + size=(input_shape, input_shape), + pad_val=dict(img=(114, 114, 114))), + dict(type='PackDetInputs') +] + +train_pipeline_stage2 = [ + dict(type='LoadImageFromFile'), + dict(type='LoadAnnotations', with_bbox=True), + dict( + type='RandomResize', + scale=(input_shape, input_shape), + ratio_range=(0.5, 1.5), + keep_ratio=True), + dict(type='RandomCrop', crop_size=(input_shape, input_shape)), + dict(type='YOLOXHSVRandomAug'), + dict(type='RandomFlip', prob=0.5), + dict( + type='Pad', + size=(input_shape, input_shape), + pad_val=dict(img=(114, 114, 114))), + dict(type='PackDetInputs') +] + +test_pipeline = [ + dict(type='LoadImageFromFile'), + dict(type='Resize', scale=(input_shape, input_shape), keep_ratio=True), + dict( + type='Pad', + size=(input_shape, input_shape), + pad_val=dict(img=(114, 114, 114))), + dict( + type='PackDetInputs', + meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', + 'scale_factor')) +] + +data_mode = 'topdown' +data_root = 'data/' + +train_dataset = dict( + _delete_=True, + type='ConcatDataset', + datasets=[ + dict( + type='mmpose.OneHand10KDataset', + data_root=data_root, + data_mode=data_mode, + pipeline=train_pipeline, + ann_file='onehand10k/annotations/onehand10k_train.json', + data_prefix=dict(img='pose/OneHand10K/')), + dict( + type='mmpose.FreiHandDataset', + data_root=data_root, + data_mode=data_mode, + pipeline=train_pipeline, + ann_file='freihand/annotations/freihand_train.json', + data_prefix=dict(img='pose/FreiHand/')), + dict( + type='mmpose.Rhd2DDataset', + data_root=data_root, + data_mode=data_mode, + pipeline=train_pipeline, + ann_file='rhd/annotations/rhd_train.json', + data_prefix=dict(img='pose/RHD/')), + dict( + type='mmpose.HalpeHandDataset', + data_root=data_root, + data_mode=data_mode, + pipeline=train_pipeline, + ann_file='halpe/annotations/halpe_train_v1.json', + data_prefix=dict( + img='pose/Halpe/hico_20160224_det/images/train2015/') # noqa + ) + ], + ignore_keys=[ + 'CLASSES', 'dataset_keypoint_weights', 'dataset_name', 'flip_indices', + 'flip_pairs', 'keypoint_colors', 'keypoint_id2name', + 'keypoint_name2id', 'lower_body_ids', 'num_keypoints', + 'num_skeleton_links', 'sigmas', 'skeleton_link_colors', + 'skeleton_links', 'upper_body_ids' + ], +) + +test_dataset = dict( + _delete_=True, + type='mmpose.OneHand10KDataset', + data_root=data_root, + data_mode=data_mode, + pipeline=test_pipeline, + ann_file='onehand10k/annotations/onehand10k_test.json', + data_prefix=dict(img='pose/OneHand10K/'), +) + +train_dataloader = dict(dataset=train_dataset) +val_dataloader = dict(dataset=test_dataset) +test_dataloader = val_dataloader + +custom_hooks = [ + dict( + type='EMAHook', + ema_type='ExpMomentumEMA', + momentum=0.0002, + update_buffers=True, + priority=49), + dict( + type='PipelineSwitchHook', + switch_epoch=280, + switch_pipeline=train_pipeline_stage2) +] + +val_evaluator = dict( + type='CocoMetric', + ann_file=data_root + 'onehand10k/annotations/onehand10k_test.json', + metric='bbox', + format_only=False) +test_evaluator = val_evaluator + +train_cfg = dict(val_interval=1) diff --git a/demo/mmdetection_cfg/rtmdet_tiny_8xb32-300e_coco.py b/demo/mmdetection_cfg/rtmdet_tiny_8xb32-300e_coco.py new file mode 100644 index 0000000000..db26ca8338 --- /dev/null +++ b/demo/mmdetection_cfg/rtmdet_tiny_8xb32-300e_coco.py @@ -0,0 +1 @@ +_base_ = 'mmdet::rtmdet/rtmdet_tiny_8xb32-300e_coco.py' diff --git a/demo/topdown_demo_with_mmdet.py b/demo/topdown_demo_with_mmdet.py index 38f4e92e4e..4e39c36207 100644 --- a/demo/topdown_demo_with_mmdet.py +++ b/demo/topdown_demo_with_mmdet.py @@ -1,4 +1,5 @@ # Copyright (c) OpenMMLab. All rights reserved. +import logging import mimetypes import os import time @@ -9,6 +10,7 @@ import mmcv import mmengine import numpy as np +from mmengine.logging import print_log from mmpose.apis import inference_topdown from mmpose.apis import init_model as init_pose_estimator @@ -261,11 +263,12 @@ def main(): video_writer.write(mmcv.rgb2bgr(frame_vis)) - # press ESC to exit - if cv2.waitKey(5) & 0xFF == 27: - break + if args.show: + # press ESC to exit + if cv2.waitKey(5) & 0xFF == 27: + break - time.sleep(args.show_interval) + time.sleep(args.show_interval) if video_writer: video_writer.release() @@ -287,6 +290,13 @@ def main(): indent='\t') print(f'predictions have been saved at {args.pred_save_path}') + if output_file: + input_type = input_type.replace('webcam', 'video') + print_log( + f'the output {input_type} has been saved at {output_file}', + logger='current', + level=logging.INFO) + if __name__ == '__main__': main() diff --git a/docs/en/advanced_guides/codecs.md b/docs/en/advanced_guides/codecs.md index 610bd83a57..e874f389d3 100644 --- a/docs/en/advanced_guides/codecs.md +++ b/docs/en/advanced_guides/codecs.md @@ -8,7 +8,9 @@ MMPose 1.0 introduced a new module **Codec** to integrate the encoding and decod Here is a diagram to show where the `Codec` is: - + + +## Basic Concepts A typical codec consists of two parts: @@ -60,7 +62,23 @@ def encode(self, return encoded ``` -The encoded data is converted to Tensor format in `PackPoseInputs` and packed in `data_sample.gt_instance_labels` for model calls, which is generally used for loss calculation, as demonstrated by `loss()` in `RegressionHead`. +The encoded data is converted to Tensor format in `PackPoseInputs` and packed in `data_sample.gt_instance_labels` for model calls. By default it will consist of the following encoded fields: + +- `keypoint_labels` +- `keypoint_weights` +- `keypoints_visible_weights` + +To specify data fields to be packed, you can define the `label_mapping_table` attribute in the codec. For example, in `VideoPoseLifting`: + +```Python +label_mapping_table = dict( + trajectory_weights='trajectory_weights', + lifting_target_label='lifting_target_label', + lifting_target_weight='lifting_target_weight', +) +``` + +`data_sample.gt_instance_labels` are generally used for loss calculation, as demonstrated by `loss()` in `RegressionHead`. ```Python def loss(self, @@ -86,6 +104,10 @@ def loss(self, ### Omitted ### ``` +```{note} +Encoder also defines data to be packed in `data_sample.gt_instances` and `data_sample.gt_fields`. Modify `instance_mapping_table` and `field_mapping_table` in the codec will specify values to be packed respectively. For default values, please check [BaseKeypointCodec](https://github.com/open-mmlab/mmpose/blob/main/mmpose/codecs/base.py). +``` + ### Decoder The decoder transforms the model outputs into coordinates in the input image space, which is the opposite processing of the encoder. @@ -225,3 +247,225 @@ test_pipeline = [ dict(type='PackPoseInputs') ] ``` + +## Supported Codecs + +Supported codecs are in [$MMPOSE/mmpose/codecs/](https://github.com/open-mmlab/mmpose/tree/dev-1.x/mmpose/codecs). Here is a list: + +- [RegressionLabel](#RegressionLabel) +- [IntegralRegressionLabel](#IntegralRegressionLabel) +- [MSRAHeatmap](#MSRAHeatmap) +- [UDPHeatmap](#UDPHeatmap) +- [MegviiHeatmap](#MegviiHeatmap) +- [SPR](#SPR) +- [SimCC](#SimCC) +- [DecoupledHeatmap](#DecoupledHeatmap) +- [ImagePoseLifting](#ImagePoseLifting) +- [VideoPoseLifting](#VideoPoseLifting) +- [MotionBERTLabel](#MotionBERTLabel) + +### RegressionLabel + +[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/regression_label.py#L12) + +The `RegressionLabel` codec is used to generate normalized coordinates as the regression targets. + +**Input** + +- Encoding keypoints from input image space to normalized space. + +**Output** + +- Decoding normalized coordinates from normalized space to input image space. + +Related works: + +- [DeepPose](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#deeppose-cvpr-2014) +- [RLE](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#rle-iccv-2021) + +### IntegralRegressionLabel + +[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/integral_regression_label.py) + +The `IntegralRegressionLabel` codec is used to generate normalized coordinates as the regression targets. + +**Input** + +- Encoding keypoints from input image space to normalized space, and generate Gaussian heatmaps as well. + +**Output** + +- Decoding normalized coordinates from normalized space to input image space. + +Related works: + +- [IPR](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#ipr-eccv-2018) +- [DSNT](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#dsnt-2018) +- [Debias IPR](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#debias-ipr-iccv-2021) + +### MSRAHeatmap + +[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/msra_heatmap.py) + +The `MSRAHeatmap` codec is used to generate Gaussian heatmaps as the targets. + +**Input** + +- Encoding keypoints from input image space to output space as 2D Gaussian heatmaps. + +**Output** + +- Decoding 2D Gaussian heatmaps from output space to input image space as coordinates. + +Related works: + +- [SimpleBaseline2D](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#simplebaseline2d-eccv-2018) +- [CPM](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#cpm-cvpr-2016) +- [HRNet](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#hrnet-cvpr-2019) +- [DARK](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#darkpose-cvpr-2020) + +### UDPHeatmap + +[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/udp_heatmap.py) + +The `UDPHeatmap` codec is used to generate Gaussian heatmaps as the targets. + +**Input** + +- Encoding keypoints from input image space to output space as 2D Gaussian heatmaps. + +**Output** + +- Decoding 2D Gaussian heatmaps from output space to input image space as coordinates. + +Related works: + +- [UDP](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#udp-cvpr-2020) + +### MegviiHeatmap + +[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/megvii_heatmap.py) + +The `MegviiHeatmap` codec is used to generate Gaussian heatmaps as the targets, which is usually used in Megvii's works. + +**Input** + +- Encoding keypoints from input image space to output space as 2D Gaussian heatmaps. + +**Output** + +- Decoding 2D Gaussian heatmaps from output space to input image space as coordinates. + +Related works: + +- [MSPN](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#mspn-arxiv-2019) +- [RSN](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#rsn-eccv-2020) + +### SPR + +[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/spr.py) + +The `SPR` codec is used to generate Gaussian heatmaps of instances' center, and offsets as the targets. + +**Input** + +- Encoding keypoints from input image space to output space as 2D Gaussian heatmaps and offsets. + +**Output** + +- Decoding 2D Gaussian heatmaps and offsets from output space to input image space as coordinates. + +Related works: + +- [DEKR](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#dekr-cvpr-2021) + +### SimCC + +[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/simcc_label.py) + +The `SimCC` codec is used to generate 1D Gaussian representations as the targets. + +**Input** + +- Encoding keypoints from input image space to output space as 1D Gaussian representations. + +**Output** + +- Decoding 1D Gaussian representations from output space to input image space as coordinates. + +Related works: + +- [SimCC](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#simcc-eccv-2022) +- [RTMPose](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#rtmpose-arxiv-2023) + +### DecoupledHeatmap + +[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/decoupled_heatmap.py) + +The `DecoupledHeatmap` codec is used to generate Gaussian heatmaps as the targets. + +**Input** + +- Encoding human center points and keypoints from input image space to output space as 2D Gaussian heatmaps. + +**Output** + +- Decoding 2D Gaussian heatmaps from output space to input image space as coordinates. + +Related works: + +- [CID](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#cid-cvpr-2022) + +### ImagePoseLifting + +[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/image_pose_lifting.py) + +The `ImagePoseLifting` codec is used for image 2D-to-3D pose lifting. + +**Input** + +- Encoding 2d keypoints from input image space to normalized 3d space. + +**Output** + +- Decoding 3d keypoints from normalized space to input image space. + +Related works: + +- [SimpleBaseline3D](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#simplebaseline3d-iccv-2017) + +### VideoPoseLifting + +[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/video_pose_lifting.py) + +The `VideoPoseLifting` codec is used for video 2D-to-3D pose lifting. + +**Input** + +- Encoding 2d keypoints from input image space to normalized 3d space. + +**Output** + +- Decoding 3d keypoints from normalized space to input image space. + +Related works: + +- [VideoPose3D](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#videopose3d-cvpr-2019) + +### MotionBERTLabel + +[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/motionbert_label.py) + +The `MotionBERTLabel` codec is used for video 2D-to-3D pose lifting. + +**Input** + +- Encoding 2d keypoints from input image space to normalized 3d space. + +**Output** + +- Decoding 3d keypoints from normalized space to input image space. + +Related works: + +- [MotionBERT](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo/body_3d_keypoint.html#pose-lift-motionbert-on-h36m) diff --git a/docs/en/advanced_guides/customize_datasets.md b/docs/en/advanced_guides/customize_datasets.md index 1aac418812..aec7520a30 100644 --- a/docs/en/advanced_guides/customize_datasets.md +++ b/docs/en/advanced_guides/customize_datasets.md @@ -72,19 +72,15 @@ configs/_base_/datasets/custom.py An example of the dataset config is as follows. -`keypoint_info` contains the information about each keypoint. - -1. `name`: the keypoint name. The keypoint name must be unique. -2. `id`: the keypoint id. -3. `color`: (\[B, G, R\]) is used for keypoint visualization. -4. `type`: 'upper' or 'lower', will be used in data augmentation. -5. `swap`: indicates the 'swap pair' (also known as 'flip pair'). When applying image horizontal flip, the left part will become the right part. We need to flip the keypoints accordingly. - -`skeleton_info` contains information about the keypoint connectivity, which is used for visualization. - -`joint_weights` assigns different loss weights to different keypoints. - -`sigmas` is used to calculate the OKS score. You can read [keypoints-eval](https://cocodataset.org/#keypoints-eval) to learn more about it. +- `keypoint_info` contains the information about each keypoint. + 1. `name`: the keypoint name. The keypoint name must be unique. + 2. `id`: the keypoint id. + 3. `color`: (\[B, G, R\]) is used for keypoint visualization. + 4. `type`: 'upper' or 'lower', will be used in data augmentation [RandomHalfBody](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/transforms/common_transforms.py#L263). + 5. `swap`: indicates the 'swap pair' (also known as 'flip pair'). When applying image horizontal flip, the left part will become the right part, used in data augmentation [RandomFlip](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/transforms/common_transforms.py#L94). We need to flip the keypoints accordingly. +- `skeleton_info` contains information about the keypoint connectivity, which is used for visualization. +- `joint_weights` assigns different loss weights to different keypoints. +- `sigmas` is used to calculate the OKS score. You can read [keypoints-eval](https://cocodataset.org/#keypoints-eval) to learn more about it. Here is an simplified example of dataset_info config file ([full text](/configs/_base_/datasets/coco.py)). @@ -217,7 +213,7 @@ The following dataset wrappers are supported in [MMEngine](https://github.com/op ### CombinedDataset -MMPose provides `CombinedDataset` to combine multiple datasets with different annotations. A combined dataset can be defined in config files as: +MMPose provides [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) to combine multiple datasets with different annotations. A combined dataset can be defined in config files as: ```python dataset_1 = dict( @@ -254,6 +250,6 @@ combined_dataset = dict( - **MetaInfo of combined dataset** determines the annotation format. Either metainfo of a sub-dataset or a customed dataset metainfo is valid here. To custom a dataset metainfo, please refer to [Create a custom dataset_info config file for the dataset](#create-a-custom-datasetinfo-config-file-for-the-dataset). -- **Converter transforms of sub-datasets** are applied when there exist mismatches of annotation format between sub-datasets and the combined dataset. For example, the number and order of keypoints might be different in the combined dataset and the sub-datasets. Then `KeypointConverter` can be used to unify the keypoints number and order. +- **Converter transforms of sub-datasets** are applied when there exist mismatches of annotation format between sub-datasets and the combined dataset. For example, the number and order of keypoints might be different in the combined dataset and the sub-datasets. Then [KeypointConverter](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/converting.py#L11) can be used to unify the keypoints number and order. -- More details about `CombinedDataset` and `KeypointConverter` can be found in Advanced Guides-[Training with Mixed Datasets](../user_guides/mixed_datasets.md). +- More details about [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) and [KeypointConverter](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/converting.py#L11) can be found in [Advanced Guides - Training with Mixed Datasets](../user_guides/mixed_datasets.md). diff --git a/docs/en/advanced_guides/customize_evaluation.md b/docs/en/advanced_guides/customize_evaluation.md new file mode 100644 index 0000000000..95effaf9ca --- /dev/null +++ b/docs/en/advanced_guides/customize_evaluation.md @@ -0,0 +1,5 @@ +# Customize Evaluation + +Coming soon. + +Currently, you can refer to [Evaluation Tutorial of MMEngine](https://mmengine.readthedocs.io/en/latest/tutorials/evaluation.html) to customize your own evaluation. diff --git a/docs/en/advanced_guides/customize_transforms.md b/docs/en/advanced_guides/customize_transforms.md index 154413994b..b8e13459f9 100644 --- a/docs/en/advanced_guides/customize_transforms.md +++ b/docs/en/advanced_guides/customize_transforms.md @@ -1,3 +1,212 @@ # Customize Data Transformation and Augmentation -Coming soon. +## DATA TRANSFORM + +In the OpenMMLab algorithm library, the construction of the dataset and the preparation of the data are decoupled from each other. Usually, the construction of the dataset only analyzes the dataset and records the basic information of each sample, while the preparation of the data is through a series of According to the basic information of the sample, perform data loading, preprocessing, formatting and other operations. + +### The use of data transformation + +The **data transformation** and **data augmentation** classes in **MMPose** are defined in the [$MMPose/datasets/transforms](https://github.com/open-mmlab/mmpose/tree/dev-1.x/mmpose/datasets/transforms) directory, and the corresponding file structure is as follows: + +```txt +mmpose +|----datasets + |----transforms + |----bottomup_transforms # Button-Up transforms + |----common_transforms # Common Transforms + |----converting # Keypoint converting + |----formatting # Input data formatting + |----loading # Raw data loading + |----pose3d_transforms # Pose3d-transforms + |----topdown_transforms # Top-Down transforms +``` + +In **MMPose**, **data augmentation** and **data transformation** is a stage that users often need to consider. You can refer to the following process to design related stages: + +[](https://mermaid-js.github.io/mermaid-live-editor/edit#pako:eNp9UbFOwzAQ_ZXIczuQbBkYKAKKOlRpJ5TlGp8TC9sX2WdVpeq_Y0cClahl8rv3nt_d2WfRkURRC2Xo2A3gudg0rSuKEA-9h3Eo9h5cUORteMj8i9FjPt_AqCeSp4wbYmBNLuPdoBVPJAb9hRmtyJB_18zkc4lO3mlQZv4VHXpg3IPvkf-_UGV-C93nlgKu3Riv_Q0c1xZ6LJbLx_kWSdvAAc0t7aqc5Cl3Srqrroi81C5NHbJnzs26lH9zyplc_UbcGr8SC2HRW9Ay_do5e1vBA1psRZ2gRAXRcCtad0lWiEy7k-tEzT7iQsRRpomeNaSntKJWYEJiR3AfRD_15RuTF7md) + +The `common_transforms` component provides commonly used `RandomFlip`, `RandomHalfBody` **data augmentation**. + +- Operations such as `Shift`, `Rotate`, and `Resize` in the `Top-Down` method are reflected in the [RandomBBoxTransform](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/common_transforms.py#L435) method. +- The [BottomupResize](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/bottomup_transforms.py#L327) method is embodied in the `Buttom-Up` algorithm. +- `pose-3d` is the [RandomFlipAroundRoot](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/pose3d_transforms.py#L13) method. + +**MMPose** provides corresponding data conversion interfaces for `Top-Down`, `Button-Up`, and `pose-3d`. Transform the image and coordinate labels from the `original_image_space` to the `input_image_space` by using an affine transformation. + +- The `Top-Down` method is manifested as [TopdownAffine](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/topdown_transforms.py#L14). +- The `Bottom-Up` method is embodied as [BottomupRandomAffine](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/bottomup_transforms.py#L134). + +Taking `RandomFlip` as an example, this method randomly transforms the `original_image` and converts it into an `input_image` or an `intermediate_image`. To define a data transformation process, you need to inherit the [BaseTransform](https://github.com/open-mmlab/mmcv/blob/main/mmcv/transforms/base.py) class and register with `TRANSFORM`: + +```python +from mmcv.transforms import BaseTransform +from mmpose.registry import TRANSFORMS + +@TRANSFORMS.register_module() +class RandomFlip(BaseTransform): + """Randomly flip the image, bbox and keypoints. + + Required Keys: + + - img + - img_shape + - flip_indices + - input_size (optional) + - bbox (optional) + - bbox_center (optional) + - keypoints (optional) + - keypoints_visible (optional) + - img_mask (optional) + + Modified Keys: + + - img + - bbox (optional) + - bbox_center (optional) + - keypoints (optional) + - keypoints_visible (optional) + - img_mask (optional) + + Added Keys: + + - flip + - flip_direction + + Args: + prob (float | list[float]): The flipping probability. If a list is + given, the argument `direction` should be a list with the same + length. And each element in `prob` indicates the flipping + probability of the corresponding one in ``direction``. Defaults + to 0.5 + direction (str | list[str]): The flipping direction. Options are + ``'horizontal'``, ``'vertical'`` and ``'diagonal'``. If a list is + is given, each data sample's flipping direction will be sampled + from a distribution determined by the argument ``prob``. Defaults + to ``'horizontal'``. + """ + def __init__(self, + prob: Union[float, List[float]] = 0.5, + direction: Union[str, List[str]] = 'horizontal') -> None: + if isinstance(prob, list): + assert is_list_of(prob, float) + assert 0 <= sum(prob) <= 1 + elif isinstance(prob, float): + assert 0 <= prob <= 1 + else: + raise ValueError(f'probs must be float or list of float, but \ + got `{type(prob)}`.') + self.prob = prob + + valid_directions = ['horizontal', 'vertical', 'diagonal'] + if isinstance(direction, str): + assert direction in valid_directions + elif isinstance(direction, list): + assert is_list_of(direction, str) + assert set(direction).issubset(set(valid_directions)) + else: + raise ValueError(f'direction must be either str or list of str, \ + but got `{type(direction)}`.') + self.direction = direction + + if isinstance(prob, list): + assert len(prob) == len(self.direction) +``` + +**Input**: + +- `prob` specifies the probability of transformation in horizontal, vertical, diagonal, etc., and is a `list` of floating-point numbers in the range \[0,1\]. +- `direction` specifies the direction of data transformation: + - `horizontal` + - `vertical` + - `diagonal` + +**Output**: + +- Return a `dict` data after data transformation. + +Here is a simple example of using `diagonal RandomFlip`: + +```python +from mmpose.datasets.transforms import LoadImage, RandomFlip +import mmcv + +# Load the original image from the path +results = dict( + img_path='data/test/multi-person.jpeg' + ) +transform = LoadImage() +results = transform(results) +# At this point, the original image loaded is a `dict` +# that contains the following attributes`: +# - `img_path`: Absolute path of image +# - `img`: Pixel points of the image +# - `img_shape`: The shape of the image +# - `ori_shape`: The original shape of the image + +# Perform diagonal flip transformation on the original image +transform = RandomFlip(prob=1., direction='diagonal') +results = transform(results) +# At this point, the original image loaded is a `dict` +# that contains the following attributes`: +# - `img_path`: Absolute path of image +# - `img`: Pixel points of the image +# - `img_shape`: The shape of the image +# - `ori_shape`: The original shape of the image +# - `flip`: Is the image flipped and transformed +# - `flip_direction`: The direction in which +# the image is flipped and transformed + +# Get the image after flipping and transformation +mmcv.imshow(results['img']) +``` + +For more information on using custom data transformations and enhancements, please refer to [$MMPose/test/test_datasets/test_transforms/test_common_transforms](https://github.com/open-mmlab/mmpose/blob/main/tests/test_datasets/test_transforms/test_common_transforms.py#L59)。 + +#### RandomHalfBody + +The [RandomHalfBody](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/common_transforms.py#L263) **data augmentation** algorithm probabilistically transforms the data of the upper or lower body. + +**Input**: + +- `min_total_keypoints` minimum total keypoints +- `min_half_keypoints` minimum half-body keypoints +- `padding` The filling ratio of the bbox +- `prob` accepts the probability of half-body transformation when the number of key points meets the requirements + +**Output**: + +- Return a `dict` data after data transformation. + +#### Topdown Affine + +The [TopdownAffine](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/topdown_transforms.py#L14) data transformation algorithm transforms the `original image` into an `input image` through affine transformation + +- `input_size` The bbox area will be cropped and corrected to the \[w,h\] size +- `use_udp` whether to use fair data process [UDP](https://arxiv.org/abs/1911.07524). + +**Output**: + +- Return a `dict` data after data transformation. + +### Using Data Augmentation and Transformation in the Pipeline + +The **data augmentation** and **data transformation** process in the configuration file can be the following example: + +```python +train_pipeline_stage2 = [ + ... + dict(type='RandomFlip', direction='horizontal'), + dict(type='RandomHalfBody'), + dict( + type='RandomBBoxTransform', + shift_factor=0., + scale_factor=[0.75, 1.25], + rotate_factor=60), + dict( + type='TopdownAffine', + input_size=codec['input_size']), + ... +] +``` + +The pipeline in the example performs **data enhancement** on the `input data`, performs random horizontal transformation and half-body transformation, and performs `Top-Down` `Shift`, `Rotate`, and `Resize` operations, and implements affine transformation through `TopdownAffine` operations to transform to the `input_image_space`. diff --git a/docs/en/advanced_guides/how_to_deploy.md b/docs/en/advanced_guides/how_to_deploy.md deleted file mode 100644 index b4fead876c..0000000000 --- a/docs/en/advanced_guides/how_to_deploy.md +++ /dev/null @@ -1,3 +0,0 @@ -# How to Deploy MMPose Models - -Coming soon. diff --git a/docs/en/advanced_guides/implement_new_models.md b/docs/en/advanced_guides/implement_new_models.md index 4a10b0c3c9..7e73cfcbf4 100644 --- a/docs/en/advanced_guides/implement_new_models.md +++ b/docs/en/advanced_guides/implement_new_models.md @@ -1,3 +1,164 @@ # Implement New Models -Coming soon. +This tutorial will introduce how to implement your own models in MMPose. After summarizing, we split the need to implement new models into two categories: + +1. Based on the algorithm paradigm supported by MMPose, customize the modules (backbone, neck, head, codec, etc.) in the model +2. Implement new algorithm paradigm + +## Basic Concepts + +What you want to implement is one of the above, and this section is important to you because it is the basic principle of building models in the OpenMMLab. + +In MMPose, all the code related to the implementation of the model structure is stored in the [models directory](https://github.com/open-mmlab/mmpose/tree/main/mmpose/models) : + +```shell +mmpose +|----models + |----backbones # + |----data_preprocessors # image normalization + |----heads # + |----losses # loss functions + |----necks # + |----pose_estimators # algorithm paradigm + |----utils # +``` + +You can refer to the following flow chart to locate the module you need to implement: + + + +## Pose Estimatiors + +In pose estimatiors, we will define the inference process of a model, and decode the model output results in `predict()`, first transform it from `output space` to `input image space` using the [codec](./codecs.md), and then combine the meta information to transform to `original image space`. + + + +Currently, MMPose supports the following types of pose estimator: + +1. [Top-down](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/pose_estimators/topdown.py): The input of the pose model is a cropped single target (animal, human body, human face, human hand, plant, clothes, etc.) image, and the output is the key point prediction result of the target +2. [Bottom-up](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/pose_estimators/bottomup.py): The input of the pose model is an image containing any number of targets, and the output is the key point prediction result of all targets in the image +3. [Pose Lifting](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/pose_estimators/pose_lifter.py): The input of the pose model is a 2D keypoint coordinate array, and the output is a 3D keypoint coordinate array + +If the model you want to implement does not belong to the above algorithm paradigm, then you need to inherit the [BasePoseEstimator](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/pose_estimators/base.py) class to define your own algorithm paradigm. + +## Backbones + +If you want to implement a new backbone network, you need to create a new file in the [backbones directory](https://github.com/open-mmlab/mmpose/tree/main/mmpose/models/backbones) to define it. + +The new backbone network needs to inherit the [BaseBackbone](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/backbones/base_backbone.py) class, and there is no difference in other aspects from inheriting `nn.Module` to create. + +After completing the implementation of the backbone network, you need to use `MODELS` to register it: + +```Python3 +from mmpose.registry import MODELS +from .base_backbone import BaseBackbone + + +@MODELS.register_module() +class YourNewBackbone(BaseBackbone): +``` + +Finally, please remember to import your new backbone network in [\_\_init\_\_.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/backbones/__init__.py) . + +## Heads + +The addition of a new prediction head is similar to the backbone network process. You need to create a new file in the [heads directory](https://github.com/open-mmlab/mmpose/tree/main/mmpose/models/heads) to define it, and then inherit [BaseHead](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/heads/base_head.py) . + +One thing to note is that in MMPose, the loss function is calculated in the Head. According to the different training and evaluation stages, `loss()` and `predict()` are executed respectively. + +In `predict()`, the model will call the `decode()` method of the corresponding codec to transform the model output result from `output space` to `input image space`. + +After completing the implementation of the prediction head, you need to use `MODELS` to register it: + +```Python3 +from mmpose.registry import MODELS +from ..base_head import BaseHead + +@MODELS.register_module() +class YourNewHead(BaseHead): +``` + +Finally, please remember to import your new prediction head in [\_\_init\_\_.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/heads/__init__.py). + +### Head with Keypoints Visibility Prediction + +Many models predict keypoint visibility based on confidence in coordinate predictions. However, this approach is suboptimal. Our [VisPredictHead](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/models/heads/hybrid_heads/vis_head.py) wrapper enables heads to directly predict keypoint visibility from ground truth training data, improving reliability. To add visibility prediction, wrap your head module with VisPredictHead in the config file. + +```python +model=dict( + ... + head=dict( + type='VisPredictHead', + loss=dict( + type='BCELoss', + use_target_weight=True, + use_sigmoid=True, + loss_weight=1e-3), + pose_cfg=dict( + type='HeatmapHead', + in_channels=2048, + out_channels=17, + loss=dict(type='KeypointMSELoss', use_target_weight=True), + decoder=codec)), + ... +) +``` + +To implement such a head module wrapper, we only need to inherit [BaseHead](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/heads/base_head.py), then pass the pose head configuration in `__init__()` and instantiate it through `MODELS.build()`. As shown below: + +```python +@MODELS.register_module() +class VisPredictHead(BaseHead): + """VisPredictHead must be used together with other heads. It can predict + keypoints coordinates of and their visibility simultaneously. In the + current version, it only supports top-down approaches. + + Args: + pose_cfg (Config): Config to construct keypoints prediction head + loss (Config): Config for visibility loss. Defaults to use + :class:`BCELoss` + use_sigmoid (bool): Whether to use sigmoid activation function + init_cfg (Config, optional): Config to control the initialization. See + :attr:`default_init_cfg` for default settings + """ + + def __init__(self, + pose_cfg: ConfigType, + loss: ConfigType = dict( + type='BCELoss', use_target_weight=False, + use_sigmoid=True), + init_cfg: OptConfigType = None): + + if init_cfg is None: + init_cfg = self.default_init_cfg + + super().__init__(init_cfg) + + self.in_channels = pose_cfg['in_channels'] + if pose_cfg.get('num_joints', None) is not None: + self.out_channels = pose_cfg['num_joints'] + elif pose_cfg.get('out_channels', None) is not None: + self.out_channels = pose_cfg['out_channels'] + else: + raise ValueError('VisPredictHead requires \'num_joints\' or' + ' \'out_channels\' in the pose_cfg.') + + self.loss_module = MODELS.build(loss) + + self.pose_head = MODELS.build(pose_cfg) + self.pose_cfg = pose_cfg + + self.use_sigmoid = loss.get('use_sigmoid', False) + + modules = [ + nn.AdaptiveAvgPool2d(1), + nn.Flatten(), + nn.Linear(self.in_channels, self.out_channels) + ] + if self.use_sigmoid: + modules.append(nn.Sigmoid()) + + self.vis_head = nn.Sequential(*modules) +``` + +Then you can implement other parts of the code as a normal head. diff --git a/docs/en/dataset_zoo/2d_wholebody_keypoint.md b/docs/en/dataset_zoo/2d_wholebody_keypoint.md index a082c657c6..1c1e9f75d1 100644 --- a/docs/en/dataset_zoo/2d_wholebody_keypoint.md +++ b/docs/en/dataset_zoo/2d_wholebody_keypoint.md @@ -131,3 +131,85 @@ mmpose Please also install the latest version of [Extended COCO API](https://github.com/jin-s13/xtcocoapi) (version>=1.5) to support Halpe evaluation: `pip install xtcocotools` + +## UBody + + + +
+
+
+UBody (CVPR'2023)
+ +```bibtex +@article{lin2023one, + title={One-Stage 3D Whole-Body Mesh Recovery with Component Aware Transformer}, + author={Lin, Jing and Zeng, Ailing and Wang, Haoqian and Zhang, Lei and Li, Yu}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + year={2023}, +} +``` + +
+  +
+
+
+For [Ubody](https://github.com/IDEA-Research/OSX) dataset, videos and annotations can be downloaded from [OSX homepage](https://github.com/IDEA-Research/OSX).
+
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── UBody
+ ├── annotations
+ │ ├── ConductMusic
+ │ ├── Entertainment
+ │ ├── Fitness
+ │ ├── Interview
+ │ ├── LiveVlog
+ │ ├── Magic_show
+ │ ├── Movie
+ │ ├── Olympic
+ │ ├── Online_class
+ │ ├── SignLanguage
+ │ ├── Singing
+ │ ├── Speech
+ │ ├── TVShow
+ │ ├── TalkShow
+ │ └── VideoConference
+ ├── splits
+ │ ├── inter_scene_test_list.npy
+ │ └── intra_scene_test_list.npy
+ ├── videos
+ │ ├── ConductMusic
+ │ ├── Entertainment
+ │ ├── Fitness
+ │ ├── Interview
+ │ ├── LiveVlog
+ │ ├── Magic_show
+ │ ├── Movie
+ │ ├── Olympic
+ │ ├── Online_class
+ │ ├── SignLanguage
+ │ ├── Singing
+ │ ├── Speech
+ │ ├── TVShow
+ │ ├── TalkShow
+ │ └── VideoConference
+```
+
+Convert videos to images then split them into train/val set:
+
+```shell
+python tools/dataset_converters/ubody_kpts_to_coco.py
+```
+
+Please also install the latest version of [Extended COCO API](https://github.com/jin-s13/xtcocoapi) (version>=1.5) to support COCO-WholeBody evaluation:
+
+`pip install xtcocotools`
diff --git a/docs/en/dataset_zoo/3d_body_keypoint.md b/docs/en/dataset_zoo/3d_body_keypoint.md
index 82e21010fc..3a35e2443b 100644
--- a/docs/en/dataset_zoo/3d_body_keypoint.md
+++ b/docs/en/dataset_zoo/3d_body_keypoint.md
@@ -8,6 +8,7 @@ MMPose supported datasets:
- [Human3.6M](#human36m) \[ [Homepage](http://vision.imar.ro/human3.6m/description.php) \]
- [CMU Panoptic](#cmu-panoptic) \[ [Homepage](http://domedb.perception.cs.cmu.edu/) \]
- [Campus/Shelf](#campus-and-shelf) \[ [Homepage](http://campar.in.tum.de/Chair/MultiHumanPose) \]
+- [UBody](#ubody3d) \[ [Homepage](https://osx-ubody.github.io/) \]
## Human3.6M
@@ -197,3 +198,100 @@ mmpose
| ├── pred_shelf_maskrcnn_hrnet_coco.pkl
| ├── actorsGT.mat
```
+
+## UBody3d
+
+
+
+
+UBody (CVPR'2023)
+ +```bibtex +@article{lin2023one, + title={One-Stage 3D Whole-Body Mesh Recovery with Component Aware Transformer}, + author={Lin, Jing and Zeng, Ailing and Wang, Haoqian and Zhang, Lei and Li, Yu}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + year={2023}, +} +``` + +
+
+
+
+For [Ubody](https://github.com/IDEA-Research/OSX) dataset, videos and annotations can be downloaded from [OSX homepage](https://github.com/IDEA-Research/OSX).
+
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── UBody
+ ├── annotations
+ │ ├── ConductMusic
+ │ ├── Entertainment
+ │ ├── Fitness
+ │ ├── Interview
+ │ ├── LiveVlog
+ │ ├── Magic_show
+ │ ├── Movie
+ │ ├── Olympic
+ │ ├── Online_class
+ │ ├── SignLanguage
+ │ ├── Singing
+ │ ├── Speech
+ │ ├── TVShow
+ │ ├── TalkShow
+ │ └── VideoConference
+ ├── splits
+ │ ├── inter_scene_test_list.npy
+ │ └── intra_scene_test_list.npy
+ ├── videos
+ │ ├── ConductMusic
+ │ ├── Entertainment
+ │ ├── Fitness
+ │ ├── Interview
+ │ ├── LiveVlog
+ │ ├── Magic_show
+ │ ├── Movie
+ │ ├── Olympic
+ │ ├── Online_class
+ │ ├── SignLanguage
+ │ ├── Singing
+ │ ├── Speech
+ │ ├── TVShow
+ │ ├── TalkShow
+ │ └── VideoConference
+```
+
+Convert videos to images then split them into train/val set:
+
+```shell
+python tools/dataset_converters/ubody_kpts_to_coco.py
+```
+
+Before generating 3D keypoints, you need to install SMPLX tools and download human models, please refer to [Github](https://github.com/vchoutas/smplx#installation) and [SMPLX](https://smpl-x.is.tue.mpg.de/download.php).
+
+```shell
+pip install smplx
+```
+
+The directory tree of human models should be like this:
+
+```text
+human_model_path
+|── smplx
+ ├── SMPLX_NEUTRAL.npz
+ ├── SMPLX_NEUTRAL.pkl
+```
+
+After the above preparations are finished, execute the following script:
+
+```shell
+python tools/dataset_converters/ubody_smplx_to_coco.py --data-root {$MMPOSE/data/UBody} --human-model-path {$MMPOSE/data/human_model_path/}
+```
diff --git a/docs/en/guide_to_framework.md b/docs/en/guide_to_framework.md
index 1bfe7d3b59..167a65d949 100644
--- a/docs/en/guide_to_framework.md
+++ b/docs/en/guide_to_framework.md
@@ -17,6 +17,7 @@ This tutorial covers what developers will concern when using MMPose 1.0:
The content of this tutorial is organized as follows:
- [A 20 Minute Guide to MMPose Framework](#a-20-minute-guide-to-mmpose-framework)
+ - [Structure](#structure)
- [Overview](#overview)
- [Step1: Configs](#step1-configs)
- [Step2: Data](#step2-data)
@@ -33,6 +34,47 @@ The content of this tutorial is organized as follows:
- [Neck](#neck)
- [Head](#head)
+## Structure
+
+The file structure of MMPose 1.0 is as follows:
+
+```shell
+mmpose
+|----apis
+|----structures
+|----datasets
+ |----transforms
+|----codecs
+|----models
+ |----pose_estimators
+ |----data_preprocessors
+ |----backbones
+ |----necks
+ |----heads
+ |----losses
+|----engine
+ |----hooks
+|----evaluation
+|----visualization
+```
+
+- **apis** provides high-level APIs for model inference
+- **structures** provides data structures like bbox, keypoint and PoseDataSample
+- **datasets** supports various datasets for pose estimation
+ - **transforms** contains a lot of useful data augmentation transforms
+- **codecs** provides pose encoders and decoders: an encoder encodes poses (mostly keypoints) into learning targets (e.g. heatmaps), and a decoder decodes model outputs into pose predictions
+- **models** provides all components of pose estimation models in a modular structure
+ - **pose_estimators** defines all pose estimation model classes
+ - **data_preprocessors** is for preprocessing the input data of the model
+ - **backbones** provides a collection of backbone networks
+ - **necks** contains various neck modules
+ - **heads** contains various prediction heads that perform pose estimation
+ - **losses** contains various loss functions
+- **engine** provides runtime components related to pose estimation
+ - **hooks** provides various hooks of the runner
+- **evaluation** provides metrics for evaluating model performance
+- **visualization** is for visualizing skeletons, heatmaps and other information
+
## Overview

@@ -62,16 +104,14 @@ Note that all new modules need to be registered using `Registry` and imported in
The organization of data in MMPose contains:
- Dataset Meta Information
-
- Dataset
-
- Pipeline
### Dataset Meta Information
-The meta information of a pose dataset usually includes the definition of keypoints and skeleton, symmetrical characteristic, and keypoint properties (e.g. belonging to upper or lower body, weights and sigmas). These information is important in data preprocessing, model training and evaluation. In MMpose, the dataset meta information is stored in configs files under `$MMPOSE/configs/_base_/datasets/`.
+The meta information of a pose dataset usually includes the definition of keypoints and skeleton, symmetrical characteristic, and keypoint properties (e.g. belonging to upper or lower body, weights and sigmas). These information is important in data preprocessing, model training and evaluation. In MMpose, the dataset meta information is stored in configs files under [$MMPOSE/configs/\_base\_/datasets](https://github.com/open-mmlab/mmpose/tree/main/configs/_base_/datasets).
-To use a custom dataset in MMPose, you need to add a new config file of the dataset meta information. Take the MPII dataset (`$MMPOSE/configs/_base_/datasets/mpii.py`) as an example. Here is its dataset information:
+To use a custom dataset in MMPose, you need to add a new config file of the dataset meta information. Take the MPII dataset ([$MMPOSE/configs/\_base\_/datasets/mpii.py](https://github.com/open-mmlab/mmpose/blob/main/configs/_base_/datasets/mpii.py)) as an example. Here is its dataset information:
```Python
dataset_info = dict(
@@ -111,7 +151,17 @@ dataset_info = dict(
])
```
-In the model config, the user needs to specify the metainfo path of the custom dataset (e.g. `$MMPOSE/configs/_base_/datasets/custom.py`) as follows:\`\`\`
+- `keypoint_info` contains the information about each keypoint.
+ 1. `name`: the keypoint name. The keypoint name must be unique.
+ 2. `id`: the keypoint id.
+ 3. `color`: (\[B, G, R\]) is used for keypoint visualization.
+ 4. `type`: 'upper' or 'lower', will be used in data augmentation [RandomHalfBody](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/transforms/common_transforms.py#L263).
+ 5. `swap`: indicates the 'swap pair' (also known as 'flip pair'). When applying image horizontal flip, the left part will become the right part, used in data augmentation [RandomFlip](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/transforms/common_transforms.py#L94). We need to flip the keypoints accordingly.
+- `skeleton_info` contains information about the keypoint connectivity, which is used for visualization.
+- `joint_weights` assigns different loss weights to different keypoints.
+- `sigmas` is used to calculate the OKS score. You can read [keypoints-eval](https://cocodataset.org/#keypoints-eval) to learn more about it.
+
+In the model config, the user needs to specify the metainfo path of the custom dataset (e.g. `$MMPOSE/configs/_base_/datasets/{your_dataset}.py`) as follows:
```python
# dataset and dataloader settings
@@ -121,9 +171,9 @@ train_dataloader = dict(
batch_size=2,
dataset=dict(
type=dataset_type,
- data_root='root/of/your/train/data',
- ann_file='path/to/your/train/json',
- data_prefix=dict(img='path/to/your/train/img'),
+ data_root='root of your train data',
+ ann_file='path to your json file',
+ data_prefix=dict(img='path to your train img'),
# specify the new dataset meta information config file
metainfo=dict(from_file='configs/_base_/datasets/custom.py'),
...),
@@ -133,9 +183,9 @@ val_dataloader = dict(
batch_size=2,
dataset=dict(
type=dataset_type,
- data_root='root/of/your/val/data',
- ann_file='path/to/your/val/json',
- data_prefix=dict(img='path/to/your/val/img'),
+ data_root='root of your val data',
+ ann_file='path to your val json',
+ data_prefix=dict(img='path to your val img'),
# specify the new dataset meta information config file
metainfo=dict(from_file='configs/_base_/datasets/custom.py'),
...),
@@ -144,127 +194,127 @@ val_dataloader = dict(
test_dataloader = val_dataloader
```
+More specifically speaking, if you organize your data as follows:
+
+```shell
+data
+├── annotations
+│ ├── train.json
+│ ├── val.json
+├── train
+│ ├── images
+│ │ ├── 000001.jpg
+├── val
+│ ├── images
+│ │ ├── 000002.jpg
+```
+
+You need to set your config as follows:
+
+```
+dataset=dict(
+ ...
+ data_root='data/',
+ ann_file='annotations/train.json',
+ data_prefix=dict(img='train/images/'),
+ ...),
+```
+
### Dataset
To use custom dataset in MMPose, we recommend converting the annotations into a supported format (e.g. COCO or MPII) and directly using our implementation of the corresponding dataset. If this is not applicable, you may need to implement your own dataset class.
-Most 2D keypoint datasets in MMPose **organize the annotations in a COCO-like style**. Thus we provide a base class [BaseCocoStyleDataset](mmpose/datasets/datasets/base/base_coco_style_dataset.py) for these datasets. We recommend that users subclass `BaseCocoStyleDataset` and override the methods as needed (usually `__init__()` and `_load_annotations()`) to extend to a new custom 2D keypoint dataset.
+More details about using custom datasets can be found in [Customize Datasets](./advanced_guides/customize_datasets.md).
```{note}
-Please refer to [COCO](./dataset_zoo/2d_body_keypoint.md) for more details about the COCO data format.
+If you wish to inherit from the `BaseDataset` provided by [MMEngine](https://github.com/open-mmlab/mmengine). Please refer to this [documents](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/basedataset.html) for details.
```
+#### 2D Dataset
+
+Most 2D keypoint datasets in MMPose **organize the annotations in a COCO-like style**. Thus we provide a base class [BaseCocoStyleDataset](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/datasets/base/base_coco_style_dataset.py) for these datasets. We recommend that users subclass [BaseCocoStyleDataset](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/datasets/base/base_coco_style_dataset.py) and override the methods as needed (usually `__init__()` and `_load_annotations()`) to extend to a new custom 2D keypoint dataset.
+
```{note}
-The bbox format in MMPose is in `xyxy` instead of `xywh`, which is consistent with the format used in other OpenMMLab projects like [MMDetection](https://github.com/open-mmlab/mmdetection). We provide useful utils for bbox format conversion, such as `bbox_xyxy2xywh`, `bbox_xywh2xyxy`, `bbox_xyxy2cs`, etc., which are defined in `$MMPOSE/mmpose/structures/bbox/transforms.py`.
+Please refer to [COCO](./dataset_zoo/2d_body_keypoint.md) for more details about the COCO data format.
```
-Let's take the implementation of the MPII dataset (`$MMPOSE/mmpose/datasets/datasets/body/mpii_dataset.py`) as an example.
+The bbox format in MMPose is in `xyxy` instead of `xywh`, which is consistent with the format used in other OpenMMLab projects like [MMDetection](https://github.com/open-mmlab/mmdetection). We provide useful utils for bbox format conversion, such as `bbox_xyxy2xywh`, `bbox_xywh2xyxy`, `bbox_xyxy2cs`, etc., which are defined in [$MMPOSE/mmpose/structures/bbox/transforms.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/structures/bbox/transforms.py).
+
+Let's take the implementation of the CrowPose dataset ([$MMPOSE/mmpose/datasets/datasets/body/crowdpose_dataset.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/datasets/body/crowdpose_dataset.py)) in COCO format as an example.
```Python
@DATASETS.register_module()
-class MpiiDataset(BaseCocoStyleDataset):
- METAINFO: dict = dict(from_file='configs/_base_/datasets/mpii.py')
-
- def __init__(self,
- ## omitted
- headbox_file: Optional[str] = None,
- ## omitted
- ):
-
- if headbox_file:
- if data_mode != 'topdown':
- raise ValueError(
- f'{self.__class__.__name__} is set to {data_mode}: '
- 'mode, while "headbox_file" is only '
- 'supported in topdown mode.')
-
- if not test_mode:
- raise ValueError(
- f'{self.__class__.__name__} has `test_mode==False` '
- 'while "headbox_file" is only '
- 'supported when `test_mode==True`.')
-
- headbox_file_type = headbox_file[-3:]
- allow_headbox_file_type = ['mat']
- if headbox_file_type not in allow_headbox_file_type:
- raise KeyError(
- f'The head boxes file type {headbox_file_type} is not '
- f'supported. Should be `mat` but got {headbox_file_type}.')
- self.headbox_file = headbox_file
-
- super().__init__(
- ## omitted
- )
-
- def _load_annotations(self) -> List[dict]:
- """Load data from annotations in MPII format."""
- check_file_exist(self.ann_file)
- with open(self.ann_file) as anno_file:
- anns = json.load(anno_file)
-
- if self.headbox_file:
- check_file_exist(self.headbox_file)
- headbox_dict = loadmat(self.headbox_file)
- headboxes_src = np.transpose(headbox_dict['headboxes_src'],
- [2, 0, 1])
- SC_BIAS = 0.6
-
- data_list = []
- ann_id = 0
-
- # mpii bbox scales are normalized with factor 200.
- pixel_std = 200.
-
- for idx, ann in enumerate(anns):
- center = np.array(ann['center'], dtype=np.float32)
- scale = np.array([ann['scale'], ann['scale']],
- dtype=np.float32) * pixel_std
-
- # Adjust center/scale slightly to avoid cropping limbs
- if center[0] != -1:
- center[1] = center[1] + 15. / pixel_std * scale[1]
-
- # MPII uses matlab format, index is 1-based,
- # we should first convert to 0-based index
- center = center - 1
-
- # unify shape with coco datasets
- center = center.reshape(1, -1)
- scale = scale.reshape(1, -1)
- bbox = bbox_cs2xyxy(center, scale)
-
- # load keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
- keypoints = np.array(ann['joints']).reshape(1, -1, 2)
- keypoints_visible = np.array(ann['joints_vis']).reshape(1, -1)
-
- data_info = {
- 'id': ann_id,
- 'img_id': int(ann['image'].split('.')[0]),
- 'img_path': osp.join(self.data_prefix['img'], ann['image']),
- 'bbox_center': center,
- 'bbox_scale': scale,
- 'bbox': bbox,
- 'bbox_score': np.ones(1, dtype=np.float32),
- 'keypoints': keypoints,
- 'keypoints_visible': keypoints_visible,
- }
-
- if self.headbox_file:
- # calculate the diagonal length of head box as norm_factor
- headbox = headboxes_src[idx]
- head_size = np.linalg.norm(headbox[1] - headbox[0], axis=0)
- head_size *= SC_BIAS
- data_info['head_size'] = head_size.reshape(1, -1)
-
- data_list.append(data_info)
- ann_id = ann_id + 1
-
- return data_list
+class CrowdPoseDataset(BaseCocoStyleDataset):
+ """CrowdPose dataset for pose estimation.
+
+ "CrowdPose: Efficient Crowded Scenes Pose Estimation and
+ A New Benchmark", CVPR'2019.
+ More details can be found in the `paper
+ Animal-Pose (ICCV'2019)
@@ -79,7 +105,7 @@ We choose the images from PascalVOC for train & val. In total, we have 3608 imag 2798 images with 4000 annotations are used for training, and 810 images with 1117 annotations are used for validation. Those images from other sources (1000 images with 1000 annotations) are used for testing. -## COFW +### COFWCOFW (ICCV'2013)
@@ -139,7 +165,7 @@ mmpose |── 000002.jpg ``` -## DeepposeKit +### DeepposeKitDesert Locust (Elife'2019)
@@ -207,7 +233,7 @@ For [Vinegar Fly](https://github.com/jgraving/DeepPoseKit-Data), [Desert Locust] Since the official dataset does not provide the test set, we randomly select 90% images for training, and the rest (10%) for evaluation. -## Macaque +### MacaqueMacaquePose (bioRxiv'2020)
@@ -257,7 +283,7 @@ For [MacaquePose](http://www2.ehub.kyoto-u.ac.jp/datasets/macaquepose/index.html Since the official dataset does not provide the test set, we randomly select 12500 images for training, and the rest for evaluation. -## Human3.6M +### Human3.6MHuman3.6M (TPAMI'2014)
@@ -333,7 +359,7 @@ After that, the annotations need to be transformed into COCO format which is com python tools/dataset_converters/h36m_to_coco.py ``` -## MPII +### MPIIMPII (CVPR'2014)
@@ -396,3 +422,81 @@ For example, ```shell python tools/dataset_converters/labelstudio2coco.py config.xml project-1-at-2023-05-13-09-22-91b53efa.json output/result.json ``` + +### UBody2D + +
+
+
+For [Ubody](https://github.com/IDEA-Research/OSX) dataset, videos and annotations can be downloaded from [OSX homepage](https://github.com/IDEA-Research/OSX).
+
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── UBody
+ ├── annotations
+ │ ├── ConductMusic
+ │ ├── Entertainment
+ │ ├── Fitness
+ │ ├── Interview
+ │ ├── LiveVlog
+ │ ├── Magic_show
+ │ ├── Movie
+ │ ├── Olympic
+ │ ├── Online_class
+ │ ├── SignLanguage
+ │ ├── Singing
+ │ ├── Speech
+ │ ├── TVShow
+ │ ├── TalkShow
+ │ └── VideoConference
+ ├── splits
+ │ ├── inter_scene_test_list.npy
+ │ └── intra_scene_test_list.npy
+ ├── videos
+ │ ├── ConductMusic
+ │ ├── Entertainment
+ │ ├── Fitness
+ │ ├── Interview
+ │ ├── LiveVlog
+ │ ├── Magic_show
+ │ ├── Movie
+ │ ├── Olympic
+ │ ├── Online_class
+ │ ├── SignLanguage
+ │ ├── Singing
+ │ ├── Speech
+ │ ├── TVShow
+ │ ├── TalkShow
+ │ └── VideoConference
+```
+
+We provide a script to convert vidoes to images and split annotations to train/val sets. It can be used by running the following command:
+
+```shell
+python tools/dataset_converters/ubody_kpts_to_coco.py --data-root ${UBODY_DATA_ROOT}
+```
+
+For example,
+
+```shell
+python tools/dataset_converters/ubody_kpts_to_coco.py --data-root data/UBody
+```
diff --git a/docs/en/user_guides/how_to_deploy.md b/docs/en/user_guides/how_to_deploy.md
new file mode 100644
index 0000000000..0b8e31a395
--- /dev/null
+++ b/docs/en/user_guides/how_to_deploy.md
@@ -0,0 +1,294 @@
+# Publish Model and Deployment
+
+This chapter will introduce how to export and deploy models trained with MMPose. It includes the following sections:
+
+- [Model Simplification](#model-simplification)
+- [Deployment with MMDeploy](#deployment-with-mmdeploy)
+ - [Introduction to MMDeploy](#introduction-to-mmdeploy)
+ - [Supported Models](#supported-models)
+ - [Installation](#installation)
+ - [Model Conversion](#model-conversion)
+ - [How to Find the Deployment Configuration File for an MMPose Model](#how-to-find-the-deployment-configuration-file-for-an-mmpose-model)
+ - [RTMPose Model Export Example](#rtmpose-model-export-example)
+ - [ONNX](#onnx)
+ - [TensorRT](#tensorrt)
+ - [Advanced Settings](#advanced-settings)
+ - [Model Profiling](#model-profiling)
+ - [Accuracy Validation](#accuracy-validation)
+
+## Publish Model
+
+By default, the checkpoint file saved during MMPose training contains all the information about the model, including the model structure, weights, optimizer states, etc. This information is redundant for model deployment. Therefore, we need to simplify the model. The simplified `.pth` file can even be less than half the size of the original.
+
+MMPose provides the [tools/misc/publish_model.py](https://github.com/open-mmlab/mmpose/blob/dev-1.x/tools/misc/publish_model.py) script for model simplification, which can be used as follows:
+
+```shell
+python tools/misc/publish_model.py ${IN_FILE} ${OUT_FILE}
+```
+
+For example:
+
+```shell
+python tools/misc/publish_model.py ./epoch_10.pth ./epoch_10_publish.pth
+```
+
+The script will automatically simplify the model, save the simplified model to the specified path, and add a timestamp to the filename, for example, `./epoch_10_publish-21815b2c_20230726.pth`.
+
+## Deployment with MMDeploy
+
+### Introduction to MMDeploy
+
+MMDeploy is the OpenMMLab model deployment toolbox, providing a unified deployment experience for various algorithm libraries. With MMDeploy, developers can easily generate SDKs tailored to specific hardware from MMPose, saving a lot of adaptation time.
+
+- You can directly download SDK versions of models (ONNX, TensorRT, ncnn, etc.) from the [ OpenMMLab Deploee](https://platform.openmmlab.com/deploee).
+- We also support [Online Model Conversion](https://platform.openmmlab.com/deploee/task-convert-list), so you don't need to install MMDeploy locally.
+
+For more information and usage guidelines, see the [MMDeploy documentation](https://mmdeploy.readthedocs.io/en/latest/get_started.html).
+
+### Supported Models
+
+| Model | Task | ONNX Runtime | TensorRT | ncnn | PPLNN | OpenVINO | CoreML | TorchScript |
+| :-------------------------------------------------------------------------------------------------------- | :------------ | :----------: | :------: | :--: | :---: | :------: | :----: | :---------: |
+| [HRNet](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#hrnet-cvpr-2019) | PoseDetection | Y | Y | Y | N | Y | Y | Y |
+| [MSPN](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#mspn-arxiv-2019) | PoseDetection | Y | Y | Y | N | Y | Y | Y |
+| [LiteHRNet](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#litehrnet-cvpr-2021) | PoseDetection | Y | Y | Y | N | Y | Y | Y |
+| [Hourglass](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#hourglass-eccv-2016) | PoseDetection | Y | Y | Y | N | Y | Y | Y |
+| [SimCC](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#simcc-eccv-2022) | PoseDetection | Y | Y | Y | N | Y | Y | Y |
+| [RTMPose](https://github.com/open-mmlab/mmpose/tree/main/projects/rtmpose) | PoseDetection | Y | Y | Y | N | Y | Y | Y |
+| [YoloX-Pose](https://github.com/open-mmlab/mmpose/tree/main/projects/yolox_pose) | PoseDetection | Y | Y | N | N | Y | Y | Y |
+
+### Installation
+
+Before starting the deployment, you need to make sure that MMPose, MMDetection, and MMDeploy are correctly installed. Please follow the installation instructions below:
+
+- [Installation of MMPose and MMDetection](../installation.md)
+- [Installation of MMDeploy](https://mmdeploy.readthedocs.io/en/latest/04-supported-codebases/mmpose.html)
+
+Depending on the backend you choose for deployment, some backends require **compilation of custom operators** supported by MMDeploy. Please refer to the corresponding documentation to ensure that the environment is set up correctly:
+
+- [ONNX](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/onnxruntime.html)
+- [TensorRT](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/tensorrt.html)
+- [OpenVINO](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/openvino.html)
+- [ncnn](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/ncnn.html)
+- [TorchScript](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/torchscript.html)
+- [More](https://github.com/open-mmlab/mmdeploy/tree/main/docs/en/05-supported-backends)
+
+### Model Conversion
+
+After completing the installation, you can start model deployment. You can use the provided [tools/deploy.py](https://github.com/open-mmlab/mmdeploy/blob/main/tools/deploy.py) script in MMDeploy to easily convert MMPose models to different deployment backends.
+
+Here's how you can use it:
+
+```shell
+python ./tools/deploy.py \
+ ${DEPLOY_CFG_PATH} \
+ ${MODEL_CFG_PATH} \
+ ${MODEL_CHECKPOINT_PATH} \
+ ${INPUT_IMG} \
+ --test-img ${TEST_IMG} \
+ --work-dir ${WORK_DIR} \
+ --calib-dataset-cfg ${CALIB_DATA_CFG} \
+ --device ${DEVICE} \
+ --log-level INFO \
+ --show \
+ --dump-info
+```
+
+Parameter descriptions:
+
+- `deploy_cfg`: Deployment configuration specific to mmdeploy, including inference framework type, quantization, and whether the input shape is dynamic or static. The configuration files may have reference relationships, and `configs/mmpose/pose-detection_simcc_onnxruntime_dynamic.py` is an example.
+
+- `model_cfg`: Model configuration specific to the mm algorithm library, e.g., `mmpose/configs/body_2d_keypoint/rtmpose/coco/rtmpose-m_8xb256-420e_aic-coco-256x192.py`, independent of mmdeploy path.
+
+- `checkpoint`: Path to the torch model. It can be a local file path or a download link (e.g., `http/https`).
+
+- `img`: Path to the test image or point cloud file used for model conversion.
+
+- `--test-img`: Path to the image file used to test the model. Default is set to `None`.
+
+- `--work-dir`: Working directory to save logs and model files.
+
+- `--calib-dataset-cfg`: This parameter only takes effect in `int8` mode and is used for the calibration dataset configuration file. If not provided in `int8` mode, the script will automatically use the 'val' dataset from the model configuration file for calibration.
+
+- `--device`: Device used for model conversion. Default is `cpu`, but for trt, you can use `cuda:0`, for example.
+
+- `--log-level`: Set the log level, with options including 'CRITICAL', 'FATAL', 'ERROR', 'WARN', 'WARNING', 'INFO', 'DEBUG', and 'NOTSET'. Default is `INFO`.
+
+- `--show`: Whether to display the detection results.
+
+- `--dump-info`: Whether to output SDK information.
+
+#### How to Find the Deployment Configuration File for an MMPose Model
+
+1. All deployment configuration files related to MMPose are stored in the [configs/mmpose/](https://github.com/open-mmlab/mmdeploy/tree/main/configs/mmpose) directory.
+2. The naming convention for deployment configuration files is `{Task}_{Algorithm}_{Backend}_{Dynamic/Static}_{Input Size}`.
+
+#### RTMPose Model Export Example
+
+In this section, we demonstrate how to export the RTMPose model in ONNX and TensorRT formats. For more information, refer to the [MMDeploy documentation](https://mmdeploy.readthedocs.io/en/latest/02-how-to-run/convert_model.html).
+
+- ONNX Configuration
+
+ - [pose-detection_simcc_onnxruntime_dynamic.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_onnxruntime_dynamic.py)
+
+- TensorRT Configuration
+
+ - [pose-detection_simcc_tensorrt_dynamic-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_tensorrt_dynamic-256x192.py)
+
+- More
+
+ | Backend | Config |
+ | :-------: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+ | ncnn-fp16 | [pose-detection_simcc_ncnn-fp16_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_ncnn-fp16_static-256x192.py) |
+ | CoreML | [pose-detection_simcc_coreml_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_coreml_static-256x192.py) |
+ | OpenVINO | [pose-detection_simcc_openvino_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_openvino_static-256x192.py) |
+ | RKNN | [pose-detection_simcc_rknn-fp16_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_rknn-fp16_static-256x192.py) |
+
+If you need to modify the deployment configuration, please refer to the [MMDeploy config tutorial](https://mmdeploy.readthedocs.io/en/latest/02-how-to-run/write_config.html).
+
+The file structure used in this tutorial is as follows:
+
+```shell
+|----mmdeploy
+|----mmpose
+```
+
+##### ONNX
+
+Run the following command:
+
+```shell
+# Go to the mmdeploy directory
+cd ${PATH_TO_MMDEPLOY}
+
+# Convert RTMPose
+# The input model path can be a local path or a download link.
+python tools/deploy.py \
+ configs/mmpose/pose-detection_simcc_onnxruntime_dynamic.py \
+ ../mmpose/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py \
+ https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-256x192-63eb25f7_20230126.pth \
+ demo/resources/human-pose.jpg \
+ --work-dir rtmpose-ort/rtmpose-m \
+ --device cpu \
+ --show \
+ --dump-info # Export SDK info
+```
+
+The default exported model file is `{work-dir}/end2end.onnx`
+
+##### TensorRT
+
+Run the following command:
+
+```shell
+# Go to the mmdeploy directory
+cd ${PATH_TO_MMDEPLOY}
+
+# Convert RTMPose
+# The input model path can be a local path or a download link.
+python tools/deploy.py \
+ configs/mmpose/pose-detection_simcc_tensorrt_dynamic-256x192.py \
+ ../mmpose/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py \
+ https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-256x192-63eb25f7_20230126.pth \
+ demo/resources/human-pose.jpg \
+ --work-dir rtmpose-trt/rtmpose-m \
+ --device cuda:0 \
+ --show \
+ --dump-info # Export SDK info
+```
+
+The default exported model file is `{work-dir}/end2end.engine`
+
+If the model is successfully exported, you will see the detection results on the sample image:
+
+
+
+###### Advanced Settings
+
+If you want to use TensorRT-FP16, you can enable it by modifying the following MMDeploy configuration:
+
+```Python
+# in MMDeploy config
+backend_config = dict(
+ type='tensorrt',
+ common_config=dict(
+ fp16_mode=True # Enable FP16
+ ))
+```
+
+### Model Profiling
+
+If you want to test the inference speed of the model in the deployment framework, MMDeploy provides a convenient script called `tools/profiler.py`.
+
+You need to prepare a folder containing test images named `./test_images`, and the profiler will randomly extract images from this directory for model profiling.
+
+```shell
+# Go to the mmdeploy directory
+cd ${PATH_TO_MMDEPLOY}
+
+python tools/profiler.py \
+ configs/mmpose/pose-detection_simcc_onnxruntime_dynamic.py \
+ ../mmpose/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py \
+ ../test_images \
+ --model {WORK_DIR}/end2end.onnx \
+ --shape 256x192 \
+ --device cpu \
+ --warmup 50 \
+ --num-iter 200
+```
+
+The profiling results will be displayed as follows:
+
+```shell
+01/30 15:06:35 - mmengine - INFO - [onnxruntime]-70 times per count: 8.73 ms, 114.50 FPS
+01/30 15:06:36 - mmengine - INFO - [onnxruntime]-90 times per count: 9.05 ms, 110.48 FPS
+01/30 15:06:37 - mmengine - INFO - [onnxruntime]-110 times per count: 9.87 ms, 101.32 FPS
+01/30 15:06:37 - mmengine - INFO - [onnxruntime]-130 times per count: 9.99 ms, 100.10 FPS
+01/30 15:06:38 - mmengine - INFO - [onnxruntime]-150 times per count: 10.39 ms, 96.29 FPS
+01/30 15:06:39 - mmengine - INFO - [onnxruntime]-170 times per count: 10.77 ms, 92.86 FPS
+01/30 15:06:40 - mmengine - INFO - [onnxruntime]-190 times per count: 10.98 ms, 91.05 FPS
+01/30 15:06:40 - mmengine - INFO - [onnxruntime]-210 times per count: 11.19 ms, 89.33 FPS
+01/30 15:06:41 - mmengine - INFO - [onnxruntime]-230 times per count: 11.16 ms, 89.58 FPS
+01/30 15:06:42 - mmengine - INFO - [onnxruntime]-250 times per count: 11.06 ms, 90.41 FPS
+----- Settings:
++------------+---------+
+| batch size | 1 |
+| shape | 256x192 |
+| iterations | 200 |
+| warmup | 50 |
++------------+---------+
+----- Results:
++--------+------------+---------+
+| Stats | Latency/ms | FPS |
++--------+------------+---------+
+| Mean | 11.060 | 90.412 |
+| Median | 11.852 | 84.375 |
+| Min | 7.812 | 128.007 |
+| Max | 13.690 | 73.044 |
++--------+------------+---------+
+```
+
+```{note}
+If you want to learn more about profiler and its more parameter settings and functionality, you can refer to the [Profiler documentation](https://mmdeploy.readthedocs.io/en/main/02-how-to-run/useful_tools.html#profiler).
+```
+
+### Model Accuracy Testing
+
+If you want to test the inference accuracy of the model in the deployment framework, MMDeploy provides a convenient script called `tools/test.py`.
+
+```shell
+# Go to the mmdeploy directory
+cd ${PATH_TO_MMDEPLOY}
+
+python tools/test.py \
+ configs/mmpose/pose-detection_simcc_onnxruntime_dynamic.py \
+ ./mmpose/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py \
+ --model {PATH_TO_MODEL}/rtmpose_m.pth \
+ --device cpu
+```
+
+```{note}
+For more detailed content, please refer to the [MMDeploy documentation](https://github.com/open-mmlab/mmdeploy/blob/main/docs/en/02-how-to-run/profile_model.md).
+```
+
+With this, you have covered the steps for model simplification and deployment using MMDeploy for MMPose models. It includes converting models to different formats (ONNX, TensorRT, etc.), testing inference speed, and accuracy in the deployment framework.
diff --git a/docs/en/user_guides/inference.md b/docs/en/user_guides/inference.md
index fa51aa20fa..3263b392e2 100644
--- a/docs/en/user_guides/inference.md
+++ b/docs/en/user_guides/inference.md
@@ -5,15 +5,18 @@ This guide will demonstrate **how to perform inference**, or running pose estima
For instructions on testing existing models on standard datasets, refer to this [guide](./train_and_test.md#test).
-In MMPose, a model is defined by a configuration file, while its pre-existing parameters are stored in a checkpoint file. You can find the model configuration files and corresponding checkpoint URLs in the [Model Zoo](https://mmpose.readthedocs.io/en/latest/modelzoo.html). We recommend starting with the HRNet model, using [this configuration file](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py) and [this checkpoint file](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192-81c58e40_20220909.pth).
+In MMPose, we provide two ways to perform inference:
+
+1. Inferencer: a Unified Inference Interface
+2. Python API: more flexible and customizable
## Inferencer: a Unified Inference Interface
-MMPose offers a comprehensive API for inference, known as `MMPoseInferencer`. This API enables users to perform inference on both images and videos using all the models supported by MMPose. Furthermore, the API provides automatic visualization of inference results and allows for the convenient saving of predictions.
+MMPose offers a comprehensive API for inference, known as [MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24). This API enables users to perform inference on both images and videos using all the models supported by MMPose. Furthermore, the API provides automatic visualization of inference results and allows for the convenient saving of predictions.
### Basic Usage
-The `MMPoseInferencer` can be used in any Python program to perform pose estimation. Below is an example of inference on a given image using the pre-trained human pose estimator within the Python shell.
+The [MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) can be used in any Python program to perform pose estimation. Below is an example of inference on a given image using the pre-trained human pose estimator within the Python shell.
```python
from mmpose.apis import MMPoseInferencer
@@ -80,7 +83,7 @@ python demo/inferencer_demo.py 'tests/data/coco/000000000785.jpg' \
--pose2d 'human' --show --pred-out-dir 'predictions'
```
-The predictions will be save in `predictions/000000000785.json`. The argument names correspond with the `MMPoseInferencer`, which serves as an API.
+The predictions will be save in `predictions/000000000785.json`. The argument names correspond with the [MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24), which serves as an API.
The inferencer is capable of processing a range of input types, which includes the following:
@@ -219,7 +222,7 @@ result = next(result_generator)
### Arguments of Inferencer
-The `MMPoseInferencer` offers a variety of arguments for customizing pose estimation, visualization, and saving predictions. Below is a list of the arguments available when initializing the inferencer and their descriptions:
+The [MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) offers a variety of arguments for customizing pose estimation, visualization, and saving predictions. Below is a list of the arguments available when initializing the inferencer and their descriptions:
| Argument | Description |
| ---------------- | ---------------------------------------------------------------------------------------------------------------- |
@@ -233,38 +236,40 @@ The `MMPoseInferencer` offers a variety of arguments for customizing pose estima
| `device` | The device to perform the inference. If left `None`, the Inferencer will select the most suitable one. |
| `scope` | The namespace where the model modules are defined. |
-The inferencer is designed for both visualization and saving predictions. The table below presents the list of arguments available when using the `MMPoseInferencer` for inference, along with their compatibility with 2D and 3D inferencing:
-
-| Argument | Description | 2D | 3D |
-| ------------------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------------------- | --- | --- |
-| `show` | Controls the display of the image or video in a pop-up window. | ✔️ | ✔️ |
-| `radius` | Sets the visualization keypoint radius. | ✔️ | ✔️ |
-| `thickness` | Determines the link thickness for visualization. | ✔️ | ✔️ |
-| `kpt_thr` | Sets the keypoint score threshold. Keypoints with scores exceeding this threshold will be displayed. | ✔️ | ✔️ |
-| `draw_bbox` | Decides whether to display the bounding boxes of instances. | ✔️ | ✔️ |
-| `draw_heatmap` | Decides if the predicted heatmaps should be drawn. | ✔️ | ❌ |
-| `black_background` | Decides whether the estimated poses should be displayed on a black background. | ✔️ | ❌ |
-| `skeleton_style` | Sets the skeleton style. Options include 'mmpose' (default) and 'openpose'. | ✔️ | ❌ |
-| `use_oks_tracking` | Decides whether to use OKS as a similarity measure in tracking. | ❌ | ✔️ |
-| `tracking_thr` | Sets the similarity threshold for tracking. | ❌ | ✔️ |
-| `norm_pose_2d` | Decides whether to scale the bounding box to the dataset's average bounding box scale and relocate the bounding box to the dataset's average bounding box center. | ❌ | ✔️ |
-| `rebase_keypoint_height` | Decides whether to set the lowest keypoint with height 0. | ❌ | ✔️ |
-| `return_vis` | Decides whether to include visualization images in the results. | ✔️ | ✔️ |
-| `vis_out_dir` | Defines the folder path to save the visualization images. If unset, the visualization images will not be saved. | ✔️ | ✔️ |
-| `return_datasample` | Determines if the prediction should be returned in the `PoseDataSample` format. | ✔️ | ✔️ |
-| `pred_out_dir` | Specifies the folder path to save the predictions. If unset, the predictions will not be saved. | ✔️ | ✔️ |
-| `out_dir` | If `vis_out_dir` or `pred_out_dir` is unset, these will be set to `f'{out_dir}/visualization'` or `f'{out_dir}/predictions'`, respectively. | ✔️ | ✔️ |
+The inferencer is designed for both visualization and saving predictions. The table below presents the list of arguments available when using the [MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) for inference, along with their compatibility with 2D and 3D inferencing:
+
+| Argument | Description | 2D | 3D |
+| ------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------- | --- | --- |
+| `show` | Controls the display of the image or video in a pop-up window. | ✔️ | ✔️ |
+| `radius` | Sets the visualization keypoint radius. | ✔️ | ✔️ |
+| `thickness` | Determines the link thickness for visualization. | ✔️ | ✔️ |
+| `kpt_thr` | Sets the keypoint score threshold. Keypoints with scores exceeding this threshold will be displayed. | ✔️ | ✔️ |
+| `draw_bbox` | Decides whether to display the bounding boxes of instances. | ✔️ | ✔️ |
+| `draw_heatmap` | Decides if the predicted heatmaps should be drawn. | ✔️ | ❌ |
+| `black_background` | Decides whether the estimated poses should be displayed on a black background. | ✔️ | ❌ |
+| `skeleton_style` | Sets the skeleton style. Options include 'mmpose' (default) and 'openpose'. | ✔️ | ❌ |
+| `use_oks_tracking` | Decides whether to use OKS as a similarity measure in tracking. | ❌ | ✔️ |
+| `tracking_thr` | Sets the similarity threshold for tracking. | ❌ | ✔️ |
+| `disable_norm_pose_2d` | Decides whether to scale the bounding box to the dataset's average bounding box scale and relocate the bounding box to the dataset's average bounding box center. | ❌ | ✔️ |
+| `disable_rebase_keypoint` | Decides whether to set the lowest keypoint with height 0. | ❌ | ✔️ |
+| `num_instances` | Sets the number of instances to visualize in the results. If set to a negative number, all detected instances will be visualized. | ❌ | ✔️ |
+| `return_vis` | Decides whether to include visualization images in the results. | ✔️ | ✔️ |
+| `vis_out_dir` | Defines the folder path to save the visualization images. If unset, the visualization images will not be saved. | ✔️ | ✔️ |
+| `return_datasamples` | Determines if the prediction should be returned in the `PoseDataSample` format. | ✔️ | ✔️ |
+| `pred_out_dir` | Specifies the folder path to save the predictions. If unset, the predictions will not be saved. | ✔️ | ✔️ |
+| `out_dir` | If `vis_out_dir` or `pred_out_dir` is unset, these will be set to `f'{out_dir}/visualization'` or `f'{out_dir}/predictions'`, respectively. | ✔️ | ✔️ |
### Model Alias
-The MMPose library has predefined aliases for several frequently used models. These aliases can be utilized as a shortcut when initializing the `MMPoseInferencer`, as an alternative to providing the full model configuration name. Here are the available 2D model aliases and their corresponding configuration names:
+The MMPose library has predefined aliases for several frequently used models. These aliases can be utilized as a shortcut when initializing the [MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24), as an alternative to providing the full model configuration name. Here are the available 2D model aliases and their corresponding configuration names:
| Alias | Configuration Name | Task | Pose Estimator | Detector |
| --------- | -------------------------------------------------- | ------------------------------- | -------------- | ------------------- |
| animal | rtmpose-m_8xb64-210e_ap10k-256x256 | Animal pose estimation | RTMPose-m | RTMDet-m |
-| human | rtmpose-m_8xb256-420e_aic-coco-256x192 | Human pose estimation | RTMPose-m | RTMDet-m |
-| face | rtmpose-m_8xb64-60e_wflw-256x256 | Face keypoint detection | RTMPose-m | yolox-s |
-| hand | rtmpose-m_8xb32-210e_coco-wholebody-hand-256x256 | Hand keypoint detection | RTMPose-m | ssdlite_mobilenetv2 |
+| human | rtmpose-m_8xb256-420e_body8-256x192 | Human pose estimation | RTMPose-m | RTMDet-m |
+| body26 | rtmpose-m_8xb512-700e_body8-halpe26-256x192 | Human pose estimation | RTMPose-m | RTMDet-m |
+| face | rtmpose-m_8xb256-120e_face6-256x256 | Face keypoint detection | RTMPose-m | yolox-s |
+| hand | rtmpose-m_8xb256-210e_hand5-256x256 | Hand keypoint detection | RTMPose-m | ssdlite_mobilenetv2 |
| wholebody | rtmpose-m_8xb64-270e_coco-wholebody-256x192 | Human wholebody pose estimation | RTMPose-m | RTMDet-m |
| vitpose | td-hm_ViTPose-base-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-base | RTMDet-m |
| vitpose-s | td-hm_ViTPose-small-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-small | RTMDet-m |
@@ -274,12 +279,172 @@ The MMPose library has predefined aliases for several frequently used models. Th
The following table lists the available 3D model aliases and their corresponding configuration names:
-| Alias | Configuration Name | Task | 3D Pose Estimator | 2D Pose Estimator | Detector |
-| ------- | --------------------------------------------------------- | ------------------------ | ----------------- | ----------------- | -------- |
-| human3d | pose-lift_videopose3d-243frm-supv-cpn-ft_8xb128-200e_h36m | Human 3D pose estimation | VideoPose3D | RTMPose-m | RTMDet-m |
+| Alias | Configuration Name | Task | 3D Pose Estimator | 2D Pose Estimator | Detector |
+| ------- | -------------------------------------------- | ------------------------ | ----------------- | ----------------- | ----------- |
+| human3d | vid_pl_motionbert_8xb32-120e_h36m | Human 3D pose estimation | MotionBert | RTMPose-m | RTMDet-m |
+| hand3d | internet_res50_4xb16-20e_interhand3d-256x256 | Hand 3D pose estimation | InterNet | - | whole image |
In addition, users can utilize the CLI tool to display all available aliases with the following command:
```shell
python demo/inferencer_demo.py --show-alias
```
+
+## Python API: more flexible and customizable
+
+MMPose provides a separate Python API for inference, which is more flexible but requires users to handle inputs and outputs themselves. Therefore, this API is suitable for users who are **familiar with MMPose**.
+
+The Python inference interface provided by MMPose is located in [$MMPOSE/mmpose/apis](https://github.com/open-mmlab/mmpose/tree/dev-1.x/mmpose/apis) directory. Here is an example of building a topdown model and performing inference:
+
+### Build a model
+
+```python
+from mmcv.image import imread
+
+from mmpose.apis import inference_topdown, init_model
+from mmpose.registry import VISUALIZERS
+from mmpose.structures import merge_data_samples
+
+model_cfg = 'configs/body_2d_keypoint/rtmpose/coco/rtmpose-m_8xb256-420e_coco-256x192.py'
+
+ckpt = 'https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-256x192-4d3e73dd_20230605.pth'
+
+device = 'cuda'
+
+# init model
+model = init_model(model_cfg, ckpt, device=device)
+```
+
+### Inference
+
+```python
+img_path = 'tests/data/coco/000000000785.jpg'
+
+# inference on a single image
+batch_results = inference_topdown(model, img_path)
+```
+
+The inference interface returns a list of PoseDataSample, each of which corresponds to the inference result of an image. The structure of PoseDataSample is as follows:
+
+```python
+[
+ UBody (CVPR'2023)
+ +```bibtex +@article{lin2023one, + title={One-Stage 3D Whole-Body Mesh Recovery with Component Aware Transformer}, + author={Lin, Jing and Zeng, Ailing and Wang, Haoqian and Zhang, Lei and Li, Yu}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + year={2023}, +} +``` + +-In this scenario, both COCO and AIC datasets need to adjust the keypoint indices using `KeypointConverter`: +In this scenario, both COCO and AIC datasets need to adjust the keypoint indices using [KeypointConverter](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/converting.py#L11): ```python dataset_coco = dict( @@ -157,3 +162,53 @@ dataset = dict( ``` Additionally, the output channel number of the model should be adjusted as the number of keypoints changes. If the users aim to evaluate the model on the COCO dataset, a subset of model outputs must be chosen. This subset can be customized using the `output_keypoint_indices` argument in `test_cfg`. Users can refer to the [config file](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-combine.py), which combines the COCO and AIC dataset, for more details and use it as a template to create their custom dataset. + +## Sampling Strategy for Mixed Datasets + +When training with mixed datasets, users often encounter the problem of inconsistent data distributions between different datasets. To address this issue, we provide two different sampling strategies: + +1. Adjust the sampling ratio of each sub dataset +2. Adjust the ratio of each sub dataset in each batch + +### Adjust the sampling ratio of each sub dataset + +In [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15), we provide the `sample_ratio_factor` argument to adjust the sampling ratio of each sub dataset. + +For example: + +- If `sample_ratio_factor` is `[1.0, 0.5]`, then all data from the first sub dataset will be included in the training, and the second sub dataset will be sampled at a ratio of 0.5. +- If `sample_ratio_factor` is `[1.0, 2.0]`, then all data from the first sub dataset will be included in the training, and the second sub dataset will be sampled at a ratio of 2 times its total number. + +### Adjust the ratio of each sub dataset in each batch + +In [$MMPOSE/datasets/samplers.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/samplers.py) we provide [MultiSourceSampler](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/samplers.py#L15) to adjust the ratio of each sub dataset in each batch. + +For example: + +- If `sample_ratio_factor` is `[1.0, 0.5]`, then the data volume of the first sub dataset in each batch will be `1.0 / (1.0 + 0.5) = 66.7%`, and the data volume of the second sub dataset will be `0.5 / (1.0 + 0.5) = 33.3%`. That is, the first sub dataset will be twice as large as the second sub dataset in each batch. + +Users can set the `sampler` argument in the configuration file: + +```python +# data loaders +train_bs = 256 +train_dataloader = dict( + batch_size=train_bs, + num_workers=4, + persistent_workers=True, + sampler=dict( + type='MultiSourceSampler', + batch_size=train_bs, + # ratio of sub datasets in each batch + source_ratio=[1.0, 0.5], + shuffle=True, + round_up=True), + dataset=dict( + type='CombinedDataset', + metainfo=dict(from_file='configs/_base_/datasets/coco.py'), + # set sub datasets + datasets=[sub_dataset1, sub_dataset2], + pipeline=train_pipeline, + test_mode=False, + )) +``` diff --git a/docs/en/advanced_guides/model_analysis.md b/docs/en/user_guides/model_analysis.md similarity index 84% rename from docs/en/advanced_guides/model_analysis.md rename to docs/en/user_guides/model_analysis.md index e10bb634a6..2050c01a1a 100644 --- a/docs/en/advanced_guides/model_analysis.md +++ b/docs/en/user_guides/model_analysis.md @@ -2,7 +2,7 @@ ## Get Model Params & FLOPs -MMPose provides `tools/analysis_tools/get_flops.py` to get model parameters and FLOPs. +MMPose provides [tools/analysis_tools/get_flops.py](https://github.com/open-mmlab/mmpose/blob/dev-1.x/tools/analysis_tools/get_flops.py) to get model parameters and FLOPs. ```shell python tools/analysis_tools/get_flops.py ${CONFIG_FILE} [--shape ${INPUT_SHAPE}] [--cfg-options ${CFG_OPTIONS}] @@ -42,7 +42,7 @@ This tool is still experimental and we do not guarantee that the number is absol ## Log Analysis -MMPose provides `tools/analysis_tools/analyze_logs.py` to analyze the training log. The log file can be either a json file or a text file. The json file is recommended, because it is more convenient to parse and visualize. +MMPose provides [tools/analysis_tools/analyze_logs.py](https://github.com/open-mmlab/mmpose/blob/dev-1.x/tools/analysis_tools/analyze_logs.py) to analyze the training log. The log file can be either a json file or a text file. The json file is recommended, because it is more convenient to parse and visualize. Currently, the following functions are supported: diff --git a/docs/en/user_guides/prepare_datasets.md b/docs/en/user_guides/prepare_datasets.md index 2f8ddcbc32..be47e07b8f 100644 --- a/docs/en/user_guides/prepare_datasets.md +++ b/docs/en/user_guides/prepare_datasets.md @@ -158,7 +158,7 @@ The heatmap target will be visualized together if it is generated in the pipelin ## Download dataset via MIM -By using [OpenDataLab](https://opendatalab.com/), you can obtain free formatted datasets in various fields. Through the search function of the platform, you may address the dataset they look for quickly and easily. Using the formatted datasets from the platform, you can efficiently conduct tasks across datasets. +By using [OpenXLab](https://openxlab.org.cn/datasets), you can obtain free formatted datasets in various fields. Through the search function of the platform, you may address the dataset they look for quickly and easily. Using the formatted datasets from the platform, you can efficiently conduct tasks across datasets. If you use MIM to download, make sure that the version is greater than v0.3.8. You can use the following command to update, install, login and download the dataset: @@ -166,10 +166,10 @@ If you use MIM to download, make sure that the version is greater than v0.3.8. Y # upgrade your MIM pip install -U openmim -# install OpenDataLab CLI tools -pip install -U opendatalab -# log in OpenDataLab, registry -odl login +# install OpenXLab CLI tools +pip install -U openxlab +# log in OpenXLab +openxlab login # download coco2017 and preprocess by MIM mim download mmpose --dataset coco2017 diff --git a/docs/en/user_guides/train_and_test.md b/docs/en/user_guides/train_and_test.md index 6bcc88fc3b..8b40ff9f57 100644 --- a/docs/en/user_guides/train_and_test.md +++ b/docs/en/user_guides/train_and_test.md @@ -14,7 +14,6 @@ python tools/train.py ${CONFIG_FILE} [ARGS] ```{note} By default, MMPose prefers GPU to CPU. If you want to train a model on CPU, please empty `CUDA_VISIBLE_DEVICES` or set it to -1 to make GPU invisible to the program. - ``` ```shell @@ -214,6 +213,31 @@ python ./tools/train.py \ - `randomness.deterministic=True`, set the deterministic option for `cuDNN` backend, i.e., set `torch.backends.cudnn.deterministic` to `True` and `torch.backends.cudnn.benchmark` to `False`. Defaults to `False`. See [Pytorch Randomness](https://pytorch.org/docs/stable/notes/randomness.html) for more details. +## Training Log + +During training, the training log will be printed in the console as follows: + +```shell +07/14 08:26:50 - mmengine - INFO - Epoch(train) [38][ 6/38] base_lr: 5.148343e-04 lr: 5.148343e-04 eta: 0:15:34 time: 0.540754 data_time: 0.394292 memory: 3141 loss: 0.006220 loss_kpt: 0.006220 acc_pose: 1.000000 +``` + +The training log contains the following information: + +- `07/14 08:26:50`: The current time. +- `mmengine`: The name of the program. +- `INFO` or `WARNING`: The log level. +- `Epoch(train)`: The current training stage. `train` means the training stage, `val` means the validation stage. +- `[38][ 6/38]`: The current epoch and the current iteration. +- `base_lr`: The base learning rate. +- `lr`: The current (real) learning rate. +- `eta`: The estimated time of arrival. +- `time`: The elapsed time (minutes) of the current iteration. +- `data_time`: The elapsed time (minutes) of data processing (i/o and transforms). +- `memory`: The GPU memory (MB) allocated by the program. +- `loss`: The total loss value of the current iteration. +- `loss_kpt`: The loss value you passed in head module. +- `acc_pose`: The accuracy value you passed in head module. + ## Visualize training process Monitoring the training process is essential for understanding the performance of your model and making necessary adjustments. In this section, we will introduce two methods to visualize the training process of your MMPose model: TensorBoard and the MMEngine Visualizer. @@ -261,7 +285,6 @@ python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [ARGS] ```{note} By default, MMPose prefers GPU to CPU. If you want to test a model on CPU, please empty `CUDA_VISIBLE_DEVICES` or set it to -1 to make GPU invisible to the program. - ``` ```shell @@ -367,3 +390,121 @@ Here are the environment variables that can be used to configure the slurm job. | `GPUS_PER_NODE` | The number of GPUs to be allocated per node. Defaults to 8. | | `CPUS_PER_TASK` | The number of CPUs to be allocated per task (Usually one GPU corresponds to one task). Defaults to 5. | | `SRUN_ARGS` | The other arguments of `srun`. Available options can be found [here](https://slurm.schedmd.com/srun.html). | + +## Custom Testing Features + +### Test with Custom Metrics + +If you're looking to assess models using unique metrics not already supported by MMPose, you'll need to code these metrics yourself and include them in your config file. For guidance on how to accomplish this, check out our [customized evaluation guide](https://mmpose.readthedocs.io/en/latest/advanced_guides/customize_evaluation.html). + +### Evaluating Across Multiple Datasets + +MMPose offers a handy tool known as `MultiDatasetEvaluator` for streamlined assessment across multiple datasets. Setting up this evaluator in your config file is a breeze. Below is a quick example demonstrating how to evaluate a model using both the COCO and AIC datasets: + +```python +# Set up validation datasets +coco_val = dict(type='CocoDataset', ...) +aic_val = dict(type='AicDataset', ...) +val_dataset = dict( + type='CombinedDataset', + datasets=[coco_val, aic_val], + pipeline=val_pipeline, + ...) + +# configurate the evaluator +val_evaluator = dict( + type='MultiDatasetEvaluator', + metrics=[ # metrics for each dataset + dict(type='CocoMetric', + ann_file='data/coco/annotations/person_keypoints_val2017.json'), + dict(type='CocoMetric', + ann_file='data/aic/annotations/aic_val.json', + use_area=False, + prefix='aic') + ], + # the number and order of datasets must align with metrics + datasets=[coco_val, aic_val], + ) +``` + +Keep in mind that different datasets, like COCO and AIC, have various keypoint definitions. Yet, the model's output keypoints are standardized. This results in a discrepancy between the model outputs and the actual ground truth. To address this, you can employ `KeypointConverter` to align the keypoint configurations between different datasets. Here’s a full example that shows how to leverage `KeypointConverter` to align AIC keypoints with COCO keypoints: + +```python +aic_to_coco_converter = dict( + type='KeypointConverter', + num_keypoints=17, + mapping=[ + (0, 6), + (1, 8), + (2, 10), + (3, 5), + (4, 7), + (5, 9), + (6, 12), + (7, 14), + (8, 16), + (9, 11), + (10, 13), + (11, 15), + ]) + +# val datasets +coco_val = dict( + type='CocoDataset', + data_root='data/coco/', + data_mode='topdown', + ann_file='annotations/person_keypoints_val2017.json', + bbox_file='data/coco/person_detection_results/' + 'COCO_val2017_detections_AP_H_56_person.json', + data_prefix=dict(img='val2017/'), + test_mode=True, + pipeline=[], +) + +aic_val = dict( + type='AicDataset', + data_root='data/aic/', + data_mode=data_mode, + ann_file='annotations/aic_val.json', + data_prefix=dict(img='ai_challenger_keypoint_validation_20170911/' + 'keypoint_validation_images_20170911/'), + test_mode=True, + pipeline=[], + ) + +val_dataset = dict( + type='CombinedDataset', + metainfo=dict(from_file='configs/_base_/datasets/coco.py'), + datasets=[coco_val, aic_val], + pipeline=val_pipeline, + test_mode=True, + ) + +val_dataloader = dict( + batch_size=32, + num_workers=2, + persistent_workers=True, + drop_last=False, + sampler=dict(type='DefaultSampler', shuffle=False, round_up=False), + dataset=val_dataset) + +test_dataloader = val_dataloader + +val_evaluator = dict( + type='MultiDatasetEvaluator', + metrics=[ + dict(type='CocoMetric', + ann_file=data_root + 'annotations/person_keypoints_val2017.json'), + dict(type='CocoMetric', + ann_file='data/aic/annotations/aic_val.json', + use_area=False, + gt_converter=aic_to_coco_converter, + prefix='aic') + ], + datasets=val_dataset['datasets'], + ) + +test_evaluator = val_evaluator +``` + +For further clarification on converting AIC keypoints to COCO keypoints, please consult [this guide](https://mmpose.readthedocs.io/en/latest/user_guides/mixed_datasets.html#merge-aic-into-coco). diff --git a/docs/src/papers/algorithms/dwpose.md b/docs/src/papers/algorithms/dwpose.md new file mode 100644 index 0000000000..4fd23effdc --- /dev/null +++ b/docs/src/papers/algorithms/dwpose.md @@ -0,0 +1,30 @@ +# Effective Whole-body Pose Estimation with Two-stages Distillation + + + +
+
+
+## Abstract
+
+
+
+Whole-body pose estimation localizes the human body, hand, face, and foot keypoints in an image. This task is challenging due to multi-scale body parts, fine-grained localization for low-resolution regions, and data scarcity. Meanwhile, applying a highly efficient and accurate pose estimator to widely human-centric understanding and generation tasks is urgent. In this work, we present a two-stage pose **D**istillation for **W**hole-body **P**ose estimators, named **DWPose**, to improve their effectiveness and efficiency. The first-stage distillation designs a weight-decay strategy while utilizing a teacher's intermediate feature and final logits with both visible and invisible keypoints to supervise the student from scratch. The second stage distills the student model itself to further improve performance. Different from the previous self-knowledge distillation, this stage finetunes the student's head with only 20% training time as a plug-and-play training strategy. For data limitations, we explore the UBody dataset that contains diverse facial expressions and hand gestures for real-life applications. Comprehensive experiments show the superiority of our proposed simple yet effective methods. We achieve new state-of-the-art performance on COCO-WholeBody, significantly boosting the whole-body AP of RTMPose-l from 64.8% to 66.5%, even surpassing RTMPose-x teacher with 65.3% AP. We release a series of models with different sizes, from tiny to large, for satisfying various downstream tasks. Our code and models are available at https://github.com/IDEA-Research/DWPose.
+
+
+
+RTMPose (arXiv'2023)
+ +```bibtex +@article{yang2023effective, + title={Effective Whole-body Pose Estimation with Two-stages Distillation}, + author={Yang, Zhendong and Zeng, Ailing and Yuan, Chun and Li, Yu}, + journal={arXiv preprint arXiv:2307.15880}, + year={2023} +} + +``` + +
+ +
+
diff --git a/docs/src/papers/algorithms/edpose.md b/docs/src/papers/algorithms/edpose.md
new file mode 100644
index 0000000000..07acf2edb5
--- /dev/null
+++ b/docs/src/papers/algorithms/edpose.md
@@ -0,0 +1,31 @@
+# Explicit Box Detection Unifies End-to-End Multi-Person Pose Estimation
+
+
+
+
+
+
+
+## Abstract
+
+
+
+This paper presents a novel end-to-end framework with Explicit box Detection for multi-person Pose estimation, called ED-Pose, where it unifies the contextual learning between human-level (global) and keypoint-level (local) information. Different from previous one-stage methods, ED-Pose re-considers this task as two explicit box detection processes with a unified representation and regression supervision. First, we introduce a human detection decoder from encoded tokens to extract global features. It can provide a good initialization for the latter keypoint detection, making the training process converge fast. Second, to bring in contextual information near keypoints, we regard pose estimation as a keypoint box detection problem to learn both box positions and contents for each keypoint. A human-to-keypoint detection decoder adopts an interactive learning strategy between human and keypoint features to further enhance global and local feature aggregation. In general, ED-Pose is conceptually simple without post-processing and dense heatmap supervision. It demonstrates its effectiveness and efficiency compared with both two-stage and one-stage methods. Notably, explicit box detection boosts the pose estimation performance by 4.5 AP on COCO and 9.9 AP on CrowdPose. For the first time, as a fully end-to-end framework with a L1 regression loss, ED-Pose surpasses heatmap-based Top-down methods under the same backbone by 1.2 AP on COCO and achieves the state-of-the-art with 76.6 AP on CrowdPose without bells and whistles. Code is available at https://github.com/IDEA-Research/ED-Pose.
+
+
+
+ED-Pose (ICLR'2023)
+ +```bibtex +@inproceedings{ +yang2023explicit, +title={Explicit Box Detection Unifies End-to-End Multi-Person Pose Estimation}, +author={Jie Yang and Ailing Zeng and Shilong Liu and Feng Li and Ruimao Zhang and Lei Zhang}, +booktitle={International Conference on Learning Representations}, +year={2023}, +url={https://openreview.net/forum?id=s4WVupnJjmX} +} +``` + +
+ +
+
diff --git a/docs/src/papers/algorithms/motionbert.md b/docs/src/papers/algorithms/motionbert.md
new file mode 100644
index 0000000000..9ebe9ae010
--- /dev/null
+++ b/docs/src/papers/algorithms/motionbert.md
@@ -0,0 +1,30 @@
+# MotionBERT: Unified Pretraining for Human Motion Analysis
+
+
+
+
+
+
+
+## Abstract
+
+
+
+We present MotionBERT, a unified pretraining framework, to tackle different sub-tasks of human motion analysis including 3D pose estimation, skeleton-based action recognition, and mesh recovery. The proposed framework is capable of utilizing all kinds of human motion data resources, including motion capture data and in-the-wild videos. During pretraining, the pretext task requires the motion encoder to recover the underlying 3D motion from noisy partial 2D observations. The pretrained motion representation thus acquires geometric, kinematic, and physical knowledge about human motion and therefore can be easily transferred to multiple downstream tasks. We implement the motion encoder with a novel Dual-stream Spatio-temporal Transformer (DSTformer) neural network. It could capture long-range spatio-temporal relationships among the skeletal joints comprehensively and adaptively, exemplified by the lowest 3D pose estimation error so far when trained from scratch. More importantly, the proposed framework achieves state-of-the-art performance on all three downstream tasks by simply finetuning the pretrained motion encoder with 1-2 linear layers, which demonstrates the versatility of the learned motion representations.
+
+
+
+MotionBERT (ICCV'2023)
+ +```bibtex + @misc{Zhu_Ma_Liu_Liu_Wu_Wang_2022, + title={Learning Human Motion Representations: A Unified Perspective}, + author={Zhu, Wentao and Ma, Xiaoxuan and Liu, Zhaoyang and Liu, Libin and Wu, Wayne and Wang, Yizhou}, + year={2022}, + month={Oct}, + language={en-US} + } +``` + +
+ +
+
diff --git a/docs/src/papers/algorithms/yolopose.md b/docs/src/papers/algorithms/yolopose.md
new file mode 100644
index 0000000000..fe1f41a804
--- /dev/null
+++ b/docs/src/papers/algorithms/yolopose.md
@@ -0,0 +1,30 @@
+# YOLO-Pose: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss
+
+
+
+
+
+
+## Abstract
+
+
+
+We introduce YOLO-pose, a novel heatmap-free approach for joint detection, and 2D multi-person pose estimation in an image based on the popular YOLO object detection framework. Existing heatmap based two-stage approaches are sub-optimal as they are not end-to-end trainable and training relies on a surrogate L1 loss that is not equivalent to maximizing the evaluation metric, i.e. Object Keypoint Similarity (OKS). Our framework allows us to train the model end-to-end and optimize the OKS metric itself. The proposed model learns to jointly detect bounding boxes for multiple persons and their corresponding 2D poses in a single forward pass and thus bringing in the best of both top-down and bottom-up approaches. Proposed approach doesn't require the postprocessing of bottom-up approaches to group detected keypoints into a skeleton as each bounding box has an associated pose, resulting in an inherent grouping of the keypoints. Unlike top-down approaches, multiple forward passes are done away with since all persons are localized along with their pose in a single inference. YOLO-pose achieves new state-of-the-art results on COCO validation (90.2% AP50) and test-dev set (90.3% AP50), surpassing all existing bottom-up approaches in a single forward pass without flip test, multi-scale testing, or any other test time augmentation. All experiments and results reported in this paper are without any test time augmentation, unlike traditional approaches that use flip-test and multi-scale testing to boost performance.
+
+
+
+YOLO-Pose (CVPRW'2022)
+ +```bibtex +@inproceedings{maji2022yolo, + title={Yolo-pose: Enhancing yolo for multi person pose estimation using object keypoint similarity loss}, + author={Maji, Debapriya and Nagori, Soyeb and Mathew, Manu and Poddar, Deepak}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={2637--2646}, + year={2022} +} +``` + +
+ +
+
diff --git a/docs/src/papers/datasets/ubody.md b/docs/src/papers/datasets/ubody.md
new file mode 100644
index 0000000000..319eabe2b4
--- /dev/null
+++ b/docs/src/papers/datasets/ubody.md
@@ -0,0 +1,17 @@
+# One-Stage 3D Whole-Body Mesh Recovery with Component Aware Transformer
+
+
+
+
+
diff --git a/docs/zh_cn/advanced_guides/codecs.md b/docs/zh_cn/advanced_guides/codecs.md
index 85d4d2e54b..62d5e3089b 100644
--- a/docs/zh_cn/advanced_guides/codecs.md
+++ b/docs/zh_cn/advanced_guides/codecs.md
@@ -8,7 +8,9 @@ MMPose 1.0 中引入了新模块 **编解码器(Codec)** ,将关键点数
编解码器在工作流程中所处的位置如下所示:
-
+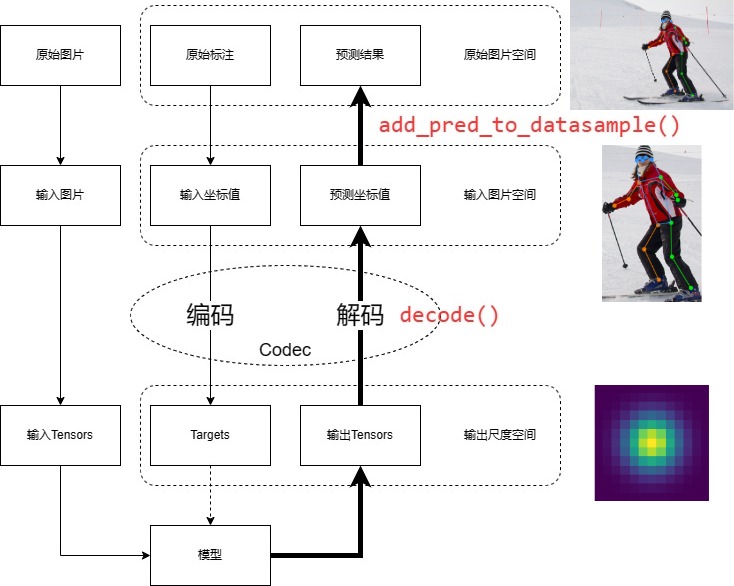
+
+## 基本概念
一个编解码器主要包含两个部分:
@@ -60,7 +62,23 @@ def encode(self,
return encoded
```
-编码后的数据会在 `PackPoseInputs` 中被转换为 Tensor 格式,并封装到 `data_sample.gt_instance_labels` 中供模型调用,一般主要用于 loss 计算,下面以 `RegressionHead` 中的 `loss()` 为例:
+编码后的数据会在 `PackPoseInputs` 中被转换为 Tensor 格式,并封装到 `data_sample.gt_instance_labels` 中供模型调用,默认包含以下的字段:
+
+- `keypoint_labels`
+- `keypoint_weights`
+- `keypoints_visible_weights`
+
+如要指定要打包的数据字段,可以在编解码器中定义 `label_mapping_table` 属性。例如,在 `VideoPoseLifting` 中:
+
+```Python
+label_mapping_table = dict(
+ trajectory_weights='trajectory_weights',
+ lifting_target_label='lifting_target_label',
+ lifting_target_weight='lifting_target_weight',
+)
+```
+
+`data_sample.gt_instance_labels` 一般主要用于 loss 计算,下面以 `RegressionHead` 中的 `loss()` 为例:
```Python
def loss(self,
@@ -86,6 +104,10 @@ def loss(self,
### 后续内容省略 ###
```
+```{note}
+解码器亦会定义封装在 `data_sample.gt_instances` 和 `data_sample.gt_fields` 中的字段。修改编码器中的 `instance_mapping_table` 和 `field_mapping_table` 的值将分别指定封装的字段,其中默认值定义在 [BaseKeypointCodec](https://github.com/open-mmlab/mmpose/blob/main/mmpose/codecs/base.py) 中。
+```
+
### 解码器
解码器主要负责将模型的输出解码为输入图片尺度的坐标值,处理过程与编码器相反。
@@ -225,3 +247,225 @@ test_pipeline = [
dict(type='PackPoseInputs')
]
```
+
+## 已支持编解码器列表
+
+编解码器相关的代码位于 [$MMPOSE/mmpose/codecs/](https://github.com/open-mmlab/mmpose/tree/dev-1.x/mmpose/codecs)。目前 MMPose 已支持的编解码器如下所示:
+
+- [RegressionLabel](#RegressionLabel)
+- [IntegralRegressionLabel](#IntegralRegressionLabel)
+- [MSRAHeatmap](#MSRAHeatmap)
+- [UDPHeatmap](#UDPHeatmap)
+- [MegviiHeatmap](#MegviiHeatmap)
+- [SPR](#SPR)
+- [SimCC](#SimCC)
+- [DecoupledHeatmap](#DecoupledHeatmap)
+- [ImagePoseLifting](#ImagePoseLifting)
+- [VideoPoseLifting](#VideoPoseLifting)
+- [MotionBERTLabel](#MotionBERTLabel)
+
+### RegressionLabel
+
+[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/regression_label.py#L12)
+
+RegressionLabel 编解码器主要用于 Regression-based 方法,适用于直接把坐标值作为训练目标的场景。
+
+**输入:**
+
+- 将**输入图片尺度**的坐标值编码为**归一化**的坐标值,用于训练目标的生成。
+
+**输出:**
+
+- 将模型输出的归一化坐标值解码为**输入图片尺度**的坐标值。
+
+常见的使用此编解码器的算法有:
+
+- [DeepPose](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#deeppose-cvpr-2014)
+- [RLE](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#rle-iccv-2021)
+
+### IntegralRegressionLabel
+
+[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/integral_regression_label.py)
+
+IntegralRegressionLabel 编解码器主要用于 Integral Regression-based 方法,适用于把坐标值作为训练目标的场景。
+
+**输入:**
+
+- 将**输入图片尺度**的坐标值编码为**归一化**的坐标值,用于训练目标的生成。
+
+**输出:**
+
+- 将模型输出的归一化坐标值解码为**输入图片尺度**的坐标值。
+
+常见的使用此编解码器的算法有:
+
+- [IPR](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#ipr-eccv-2018)
+- [DSNT](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#dsnt-2018)
+- [Debias IPR](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#debias-ipr-iccv-2021)
+
+### MSRAHeatmap
+
+[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/msra_heatmap.py)
+
+MSRAHeatmap 编解码器主要用于 Heatmap-based 方法,适用于把高斯热图作为训练目标的场景。
+
+**输入:**
+
+- 将**输入图片尺度**的坐标值编码为 2D 离散高斯分布,用于训练目标的生成。
+
+**输出:**
+
+- 将模型输出的 2D 高斯分布解码为**输入图片尺度**的坐标值。
+
+常见的使用此编解码器的算法有:
+
+- [SimpleBaseline2D](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#simplebaseline2d-eccv-2018)
+- [CPM](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#cpm-cvpr-2016)
+- [HRNet](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#hrnet-cvpr-2019)
+- [DARK](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#darkpose-cvpr-2020)
+
+### UDPHeatmap
+
+[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/udp_heatmap.py)
+
+UDPHeatmap 编解码器主要用于 Heatmap-based 方法,适用于把高斯热图作为训练目标的场景。
+
+**输入:**
+
+- 将**输入图片尺度**的坐标值编码为 2D 离散高斯分布,用于训练目标的生成。
+
+**输出:**
+
+- 将模型输出的 2D 高斯分布解码为**输入图片尺度**的坐标值。
+
+常见的使用此编解码器的算法有:
+
+- [UDP](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#udp-cvpr-2020)
+
+### MegviiHeatmap
+
+[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/megvii_heatmap.py)
+
+MegviiHeatmap 编解码器主要用于 Megvii 提出的 Heatmap-based 方法,适用于把高斯热图作为训练目标的场景。
+
+**输入:**
+
+- 将**输入图片尺度**的坐标值编码为 2D 离散高斯分布,用于训练目标的生成。
+
+**输出:**
+
+- 将模型输出的 2D 高斯分布解码为**输入图片尺度**的坐标值。
+
+常见的使用此编解码器的算法有:
+
+- [MSPN](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#mspn-arxiv-2019)
+- [RSN](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#rsn-eccv-2020)
+
+### SPR
+
+[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/spr.py)
+
+SPR 编解码器主要用于 DEKR 方法,适用于同时使用中心 Heatmap 和偏移坐标值作为训练目标的场景。
+
+**输入:**
+
+- 将**输入图片尺度**的中心关键点坐标值编码为 2D 离散高斯分布,以及相对于中心的偏移,用于训练目标的生成。
+
+**输出:**
+
+- 将模型输出的 2D 高斯分布与偏移进行组合,解码为**输入图片尺度**的坐标值。
+
+常见的使用此编解码器的算法有:
+
+- [DEKR](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#dekr-cvpr-2021)
+
+### SimCC
+
+[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/simcc_label.py)
+
+SimCC 编解码器主要用于 SimCC-based 方法,适用于两个 1D 离散分布表征的 x 和 y 坐标作为训练目标的场景。
+
+**输入:**
+
+- 将**输入图片尺度**的坐标值编码为水平和竖直方向 1D 离散分布,用于训练目标的生成。
+
+**输出:**
+
+- 将模型输出的 1D 离散分布解码为**输入图片尺度**的坐标值。
+
+常见的使用此编解码器的算法有:
+
+- [SimCC](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#simcc-eccv-2022)
+- [RTMPose](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#rtmpose-arxiv-2023)
+
+### DecoupledHeatmap
+
+[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/decoupled_heatmap.py)
+
+DecoupledHeatmap 编解码器主要用于 CID 方法,适用于把高斯热图作为训练目标的场景。
+
+**输入:**
+
+- 将**输入图片尺度**的人体中心坐标值和关键点坐标值编码为 2D 离散高斯分布,用于训练目标的生成。
+
+**输出:**
+
+- 将模型输出的人体中心与关键点 2D 高斯分布解码为**输入图片尺度**的坐标值。
+
+常见的使用此编解码器的算法有:
+
+- [CID](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#cid-cvpr-2022)
+
+### ImagePoseLifting
+
+[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/image_pose_lifting.py)
+
+ImagePoseLifting 编解码器主要用于 2D-to-3D pose lifting 方法,适用于把单张图片的 2D 坐标值作为训练目标的场景。
+
+**输入:**
+
+- 将**输入图片尺度**的坐标值编码为 3D 坐标空间归一化的坐标值,用于训练目标的生成。
+
+**输出:**
+
+- 将模型输出的 3D 坐标空间归一化的坐标值解码为**输入图片尺度**的坐标值。
+
+常见的使用此编解码器的算法有:
+
+- [SimpleBaseline3D](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#simplebaseline3d-iccv-2017)
+
+### VideoPoseLifting
+
+[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/video_pose_lifting.py)
+
+VideoPoseLifting 编解码器主要用于 2D-to-3D pose lifting 方法,适用于把视频中一组 2D 坐标值作为训练目标的场景。
+
+**输入:**
+
+- 将**输入图片尺度**的坐标值编码为 3D 坐标空间归一化的坐标值,用于训练目标的生成。
+
+**输出:**
+
+- 将模型输出的 3D 坐标空间归一化的坐标值解码为**输入图片尺度**的坐标值。
+
+常见的使用此编解码器的算法有:
+
+- [VideoPose3D](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#videopose3d-cvpr-2019)
+
+### MotionBERTLabel
+
+[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/motionbert_label.py)
+
+MotionBERTLabel 编解码器主要用于 2D-to-3D pose lifting 方法,适用于把视频中一组 2D 坐标值作为训练目标的场景。
+
+**输入:**
+
+- 将**输入图片尺度**的坐标值编码为 3D 坐标空间归一化的坐标值,用于训练目标的生成。
+
+**输出:**
+
+- 将模型输出的 3D 坐标空间归一化的坐标值解码为**输入图片尺度**的坐标值。
+
+常见的使用此编解码器的算法有:
+
+- [MotionBERT](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo/body_3d_keypoint.html#pose-lift-motionbert-on-h36m)
diff --git a/docs/zh_cn/advanced_guides/customize_datasets.md b/docs/zh_cn/advanced_guides/customize_datasets.md
index 61b58dc929..9d1db35ceb 100644
--- a/docs/zh_cn/advanced_guides/customize_datasets.md
+++ b/docs/zh_cn/advanced_guides/customize_datasets.md
@@ -88,8 +88,8 @@ config/_base_/datasets/custom.py
1. `name`: 关键点名称,必须是唯一的,例如 `nose`、`left_eye` 等。
2. `id`: 关键点 ID,必须是唯一的,从 0 开始。
3. `color`: 关键点可视化时的颜色,以 (\[B, G, R\]) 格式组织起来,用于可视化。
- 4. `type`: 关键点类型,可以是 `upper`、`lower` 或 \`\`,用于数据增强。
- 5. `swap`: 关键点交换关系,用于水平翻转数据增强。
+ 4. `type`: 关键点类型,可以是 `upper`、`lower` 或 `''`,用于数据增强 [RandomHalfBody](https://github.com/open-mmlab/mmpose/blob/b225a773d168fc2afd48cde5f76c0202d1ba2f52/mmpose/datasets/transforms/common_transforms.py#L263)。
+ 5. `swap`: 关键点交换关系,用于水平翻转数据增强 [RandomFlip](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/common_transforms.py#L94)。
- `skeleton_info`:骨架连接关系,用于可视化。
- `joint_weights`:每个关键点的权重,用于损失函数计算。
- `sigma`:标准差,用于计算 OKS 分数,详细信息请参考 [keypoints-eval](https://cocodataset.org/#keypoints-eval)。
@@ -217,14 +217,14 @@ test_dataloader = dict(
## 数据集封装
-目前 [MMEngine](https://github.com/open-mmlab/mmengine) 支持以下数据集封装:
+在 MMPose 中,支持使用 MMPose 实现的数据集封装和 [MMEngine](https://github.com/open-mmlab/mmengine) 实现的数据集封装。目前 [MMEngine](https://github.com/open-mmlab/mmengine) 支持以下数据集封装:
- [ConcatDataset](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/basedataset.html#concatdataset)
- [RepeatDataset](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/basedataset.html#repeatdataset)
### CombinedDataset
-MMPose 提供了一个 `CombinedDataset` 类,它可以将多个数据集封装成一个数据集。它的使用方法如下:
+MMPose 提供了一个 [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) 类,它可以将多个数据集封装成一个数据集。它的使用方法如下:
```python
dataset_1 = dict(
diff --git a/docs/zh_cn/advanced_guides/customize_evaluation.md b/docs/zh_cn/advanced_guides/customize_evaluation.md
new file mode 100644
index 0000000000..95effaf9ca
--- /dev/null
+++ b/docs/zh_cn/advanced_guides/customize_evaluation.md
@@ -0,0 +1,5 @@
+# Customize Evaluation
+
+Coming soon.
+
+Currently, you can refer to [Evaluation Tutorial of MMEngine](https://mmengine.readthedocs.io/en/latest/tutorials/evaluation.html) to customize your own evaluation.
diff --git a/docs/zh_cn/advanced_guides/customize_transforms.md b/docs/zh_cn/advanced_guides/customize_transforms.md
index 154413994b..0da83597c3 100644
--- a/docs/zh_cn/advanced_guides/customize_transforms.md
+++ b/docs/zh_cn/advanced_guides/customize_transforms.md
@@ -1,3 +1,213 @@
-# Customize Data Transformation and Augmentation
+# 自定义数据变换和数据增强
-Coming soon.
+### 数据变换
+
+在**OpenMMLab**算法库中,数据集的构建和数据的准备是相互解耦的,通常,数据集的构建只对数据集进行解析,记录每个样本的基本信息,而数据的准备则是通过一系列的数据变换,根据样本的基本信息进行数据加载、预处理、格式化等操作。
+
+### 数据变换的使用
+
+**MMPose**中的`数据变换`和`数据增强`类定义在[$MMPose/datasets/transforms](https://github.com/open-mmlab/mmpose/tree/dev-1.x/mmpose/datasets/transforms)目录中,对应的文件结构如下:
+
+```txt
+mmpose
+|----datasets
+ |----transforms
+ |----bottomup_transforms # 自底向上
+ |----common_transforms # 常用变换
+ |----converting # 关键点转换
+ |----formatting # 输入数据格式化
+ |----loading # 原始数据加载
+ |----pose3d_transforms # 三维变换
+ |----topdown_transforms # 自顶向下
+```
+
+在**MMPose**中,**数据增强**和**数据变换**是使用者经常需要考虑的一个阶段,可参考如下流程进行相关阶段的设计:
+
+[](https://mermaid-js.github.io/mermaid-live-editor/edit#pako:eNp9UT1LA0EQ_SvH1knhXXeFhYpfWIQklVwz3s7mFvd2jr09JIaAjQQRRLAU0Ua0t5X8m4v-DHcThPOIqfbNe2_fMDMTlhJHFjOh6CLNwNjgpJ_oICirs5GBIguGBnQpyOTlluf3lSz8ewhK7BAfe9wnC1aS9niQSWGXJJbyEj3aJUXmWFpLxpeo-T8NQs8foEYDFodgRmg3f4g834P0vEclHumiavrru-f67bZ-nH_dzIJud7s9yUpfvMwWH-_r9Ea5lL_nD_X16ypvg_507yLrq09vaVGtLuHflLAlR42EdUNErMNyNDlI7u438e6E2QxzTFjsIEcBlbIJS_TUWaGyNBjrlMXWVNhhVcHdlvckuKXmLBagSscWoE-JfuvpD2uI1Wk)
+
+[common_transforms](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/common_transforms.py)组件提供了常用的`RandomFlip`,`RandomHalfBody`数据增强算法。
+
+- `Top-Down`方法中`Shift`,`Rotate`,`Resize`等操作体现为[RandomBBoxTransform](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/common_transforms.py#L435)方法。
+- `Buttom-Up`算法中体现为[BottomupResize](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/bottomup_transforms.py#L327)方法。
+- `pose-3d`则为[RandomFlipAroundRoot](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/pose3d_transforms.py#L13)方法。
+
+**MMPose**对于`Top-Down`、`Buttom-Up`,`pose-3d`都提供了对应的数据变换接口。通过采用仿射变换,将图像和坐标标注从`原始图片空间`变换到`输入图片空间`。
+
+- `Top-Down`方法中体现为[TopdownAffine](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/topdown_transforms.py#L14)。
+- `Buttom-Up`方法体现为[BottomupRandomAffine](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/bottomup_transforms.py#L134)。
+
+以[RandomFlip](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/transforms/common_transforms.py)为例,该方法随机的对`原始图片`进行变换,并转换为`输入图像`或`中间图像`。要定义一个数据变换的过程,需要继承[BaseTransform](https://github.com/open-mmlab/mmcv/blob/main/mmcv/transforms/base.py)类,并进行`TRANSFORM`注册:
+
+```python
+from mmcv.transforms import BaseTransform
+from mmpose.registry import TRANSFORMS
+
+@TRANSFORMS.register_module()
+class RandomFlip(BaseTransform):
+ """Randomly flip the image, bbox and keypoints.
+
+ Required Keys:
+
+ - img
+ - img_shape
+ - flip_indices
+ - input_size (optional)
+ - bbox (optional)
+ - bbox_center (optional)
+ - keypoints (optional)
+ - keypoints_visible (optional)
+ - img_mask (optional)
+
+ Modified Keys:
+
+ - img
+ - bbox (optional)
+ - bbox_center (optional)
+ - keypoints (optional)
+ - keypoints_visible (optional)
+ - img_mask (optional)
+
+ Added Keys:
+
+ - flip
+ - flip_direction
+
+ Args:
+ prob (float | list[float]): The flipping probability. If a list is
+ given, the argument `direction` should be a list with the same
+ length. And each element in `prob` indicates the flipping
+ probability of the corresponding one in ``direction``. Defaults
+ to 0.5
+ direction (str | list[str]): The flipping direction. Options are
+ ``'horizontal'``, ``'vertical'`` and ``'diagonal'``. If a list is
+ is given, each data sample's flipping direction will be sampled
+ from a distribution determined by the argument ``prob``. Defaults
+ to ``'horizontal'``.
+ """
+ def __init__(self,
+ prob: Union[float, List[float]] = 0.5,
+ direction: Union[str, List[str]] = 'horizontal') -> None:
+ if isinstance(prob, list):
+ assert is_list_of(prob, float)
+ assert 0 <= sum(prob) <= 1
+ elif isinstance(prob, float):
+ assert 0 <= prob <= 1
+ else:
+ raise ValueError(f'probs must be float or list of float, but \
+ got `{type(prob)}`.')
+ self.prob = prob
+
+ valid_directions = ['horizontal', 'vertical', 'diagonal']
+ if isinstance(direction, str):
+ assert direction in valid_directions
+ elif isinstance(direction, list):
+ assert is_list_of(direction, str)
+ assert set(direction).issubset(set(valid_directions))
+ else:
+ raise ValueError(f'direction must be either str or list of str, \
+ but got `{type(direction)}`.')
+ self.direction = direction
+
+ if isinstance(prob, list):
+ assert len(prob) == len(self.direction)
+```
+
+**输入**:
+
+- `prob`指定了在水平,垂直,斜向等变换的概率,是一个范围在\[0,1\]之间的浮点数`list`。
+- `direction`指定了数据变换的方向:
+ - `horizontal`水平变换
+ - `vertical`垂直变换
+ - `diagonal`对角变换
+
+**输出**:
+
+- 输出一个经过**数据变换**后的`dict`数据
+
+`RandomFlip`的[transform](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/transforms/common_transforms.py#L187)实现了对输入图像的以给定的`prob`概率进行水平、垂直或是对角方向的数据翻转,并返回输出图像。
+
+以下是使用`对角翻转变换`的一个简单示例:
+
+```python
+from mmpose.datasets.transforms import LoadImage, RandomFlip
+import mmcv
+
+# 从路径中加载原始图片
+results = dict(
+ img_path='data/test/multi-person.jpeg'
+ )
+transform = LoadImage()
+results = transform(results)
+# 此时,加载的原始图片是一个包含以下属性的`dict`:
+# - `img_path`: 图片的绝对路径
+# - `img`: 图片的像素点
+# - `img_shape`: 图片的形状
+# - `ori_shape`: 图片的原始形状
+
+# 对原始图像进行对角翻转变换
+transform = RandomFlip(prob=1., direction='diagonal')
+results = transform(results)
+# 此时,加载的原始图片是一个包含以下属性的`dict`:
+# - `img_path`: 图片的绝对路径
+# - `img`: 图片的像素点
+# - `img_shape`: 图片的形状
+# - `ori_shape`: 图片的原始形状
+# - `flip`: 图片是否进行翻转变换
+# - `flip_direction`: 图片进行翻转变换的方向
+
+# 取出经过翻转变换后的图片
+mmcv.imshow(results['img'])
+```
+
+更多有关自定义数据变换和增强的使用方法,可以参考[$MMPose/test/test_datasets/test_transforms/test_common_transforms](https://github.com/open-mmlab/mmpose/blob/main/tests/test_datasets/test_transforms/test_common_transforms.py#L59)等。
+
+#### RandomHalfBody
+
+[RandomHalfBody](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/common_transforms.py#L263)**数据增强**算法概率的进行上半身或下半身的**数据变换**。
+**输入**:
+
+- `min_total_keypoints`最小总关键点数
+- `min_half_keypoints`最小半身关键点数
+- `padding`bbox的填充比例
+- `prob`在关键点数目符合要求下,接受半身变换的概率
+
+**输出**:
+
+- 输出一个经过**数据变换**后的`dict`数据
+
+#### TopdownAffine
+
+[TopdownAffine](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/topdown_transforms.py#L14)**数据变换**算法通过仿射变换将`原始图片`变换为`输入图片`。
+
+**输入**:
+
+- `input_size`bbox区域将会被裁剪和修正到的\[w,h\]大小
+- `use_udp`是否使用公正的数据过程[UDP](https://arxiv.org/abs/1911.07524)
+
+**输出**:
+
+- 输出一个经过**数据变换**后的`dict`数据
+
+### 在流水线中使用数据增强和变换
+
+配置文件中的**数据增强**和**数据变换**过程可以是如下示例:
+
+```python
+train_pipeline_stage2 = [
+ ...
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.75, 1.25],
+ rotate_factor=60),
+ dict(
+ type='TopdownAffine',
+ input_size=codec['input_size']),
+ ...
+]
+```
+
+示例中的流水线对输入数据进行**数据增强**,进行随机的水平增强和半身增强,
+并进行`Top-Down`的`Shift`、`Rotate`、`Resize`操作,通过`TopdownAffine`操作实现仿射变换,变换至`输入图片空间`。
diff --git a/docs/zh_cn/advanced_guides/how_to_deploy.md b/docs/zh_cn/advanced_guides/how_to_deploy.md
deleted file mode 100644
index b4fead876c..0000000000
--- a/docs/zh_cn/advanced_guides/how_to_deploy.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# How to Deploy MMPose Models
-
-Coming soon.
diff --git a/docs/zh_cn/advanced_guides/implement_new_models.md b/docs/zh_cn/advanced_guides/implement_new_models.md
index 4a10b0c3c9..34fe2ba128 100644
--- a/docs/zh_cn/advanced_guides/implement_new_models.md
+++ b/docs/zh_cn/advanced_guides/implement_new_models.md
@@ -1,3 +1,163 @@
-# Implement New Models
+# 实现新模型
-Coming soon.
+本教程将介绍如何在 MMPose 中实现你自己的模型。我们经过总结,将实现新模型这一需求拆分为两类:
+
+1. 基于 MMPose 中已支持的算法范式,对模型中的模块(骨干网络、颈部、预测头、编解码器等)进行自定义
+2. 实现新的算法范式
+
+## 基础知识
+
+不论你想实现的模型是以上哪一种,这一节的内容都对你很重要,因为它是 OpenMMLab 系列算法库构建模型的基本原则。
+在 MMPose 中,所有与模型结构实现相关的代码都存放在 [models 目录](https://github.com/open-mmlab/mmpose/tree/main/mmpose/models)下:
+
+```shell
+mmpose
+|----models
+ |----backbones # 骨干网络
+ |----data_preprocessors # 数据预处理,如:图片归一化
+ |----heads # 预测头
+ |----losses # 损失函数
+ |----necks # 颈部
+ |----pose_estimators # 姿态估计算法范式
+ |----utils # 工具方法
+```
+
+你可以参考以下流程图来定位你所需要实现的模块:
+
+
+
+## 姿态估计算法范式
+
+在姿态估计范式中,我们会定义一个模型的推理流程,并在 `predict()` 中对模型输出结果进行解码,先将其从 `输出尺度空间` 用 [编解码器](./codecs.md) 变换到 `输入图片空间`,然后再结合元信息变换到 `原始图片空间`。
+
+
+
+当前 MMPose 已支持以下几类算法范式:
+
+1. [Top-down](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/pose_estimators/topdown.py):Pose 模型的输入为经过裁剪的单个目标(动物、人体、人脸、人手、植物、衣服等)图片,输出为这个目标的关键点预测结果
+2. [Bottom-up](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/pose_estimators/bottomup.py):Pose 模型的输入为包含任意个目标的图片,输出为图片中所有目标的关键点预测结果
+3. [Pose Lifting](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/pose_estimators/pose_lifter.py):Pose 模型的输入为 2D 关键点坐标数组,输出为 3D 关键点坐标数组
+
+如果你要实现的模型不属于以上算法范式,那么你需要继承 [BasePoseEstimator](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/pose_estimators/base.py) 类来定义你自己的算法范式。
+
+## 骨干网络
+
+如果希望实现一个新的骨干网络,你需要在 [backbones 目录](https://github.com/open-mmlab/mmpose/tree/main/mmpose/models/backbones) 下新建一个文件进行定义。
+
+新建的骨干网络需要继承 [BaseBackbone](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/backbones/base_backbone.py) 类,其他方面与你继承 nn.Module 来创建没有任何不同。
+
+在完成骨干网络的实现后,你需要使用 `MODELS` 来对其进行注册:
+
+```Python3
+from mmpose.registry import MODELS
+from .base_backbone import BaseBackbone
+
+
+@MODELS.register_module()
+class YourNewBackbone(BaseBackbone):
+```
+
+最后,请记得在 [backbones/\_\_init\_\_.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/backbones/__init__.py) 中导入你的新骨干网络。
+
+## 预测头部
+
+新的预测头部的加入与骨干网络流程类似,你需要在 [heads 目录](https://github.com/open-mmlab/mmpose/tree/main/mmpose/models/heads) 下新建一个文件进行定义,然后继承 [BaseHead](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/heads/base_head.py)。
+
+需要特别注意的一点是,在 MMPose 中会在 Head 里进行损失函数的计算。根据训练与评测阶段的不同,分别执行 `loss()` 和 `predict()`。
+
+在 `predict()` 中,模型会调用对应编解码器的 `decode()` 方法,将模型输出的结果从 `输出尺度空间` 转换到 `输入图片空间` 。
+
+在完成预测头部的实现后,你需要使用 `MODELS` 来对其进行注册:
+
+```Python3
+from mmpose.registry import MODELS
+from ..base_head import BaseHead
+
+@MODELS.register_module()
+class YourNewHead(BaseHead):
+```
+
+最后,请记得在 [heads/\_\_init\_\_.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/heads/__init__.py) 中导入你的新预测头部。
+
+### 关键点可见性预测头部
+
+许多模型都是通过对关键点坐标预测的置信度来判断关键点的可见性的。然而,这种解决方案并非最优。我们提供了一个叫做 [VisPredictHead](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/models/heads/hybrid_heads/vis_head.py) 的头部模块包装器,使得头部模块能够直接预测关键点的可见性。这个包装器是用训练数据中关键点可见性真值来训练的。因此,其预测会更加可靠。用户可以通过修改配置文件来对自己的头部模块加上这个包装器。下面是一个例子:
+
+```python
+model=dict(
+ ...
+ head=dict(
+ type='VisPredictHead',
+ loss=dict(
+ type='BCELoss',
+ use_target_weight=True,
+ use_sigmoid=True,
+ loss_weight=1e-3),
+ pose_cfg=dict(
+ type='HeatmapHead',
+ in_channels=2048,
+ out_channels=17,
+ loss=dict(type='KeypointMSELoss', use_target_weight=True),
+ decoder=codec)),
+ ...
+)
+```
+
+要实现这样一个预测头部模块包装器,我们只需要像定义正常的预测头部一样,继承 [BaseHead](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/heads/base_head.py),然后在 `__init__()` 中传入关键点定位的头部配置,并通过 `MODELS.build()` 进行实例化。如下所示:
+
+```python
+@MODELS.register_module()
+class VisPredictHead(BaseHead):
+ """VisPredictHead must be used together with other heads. It can predict
+ keypoints coordinates of and their visibility simultaneously. In the
+ current version, it only supports top-down approaches.
+
+ Args:
+ pose_cfg (Config): Config to construct keypoints prediction head
+ loss (Config): Config for visibility loss. Defaults to use
+ :class:`BCELoss`
+ use_sigmoid (bool): Whether to use sigmoid activation function
+ init_cfg (Config, optional): Config to control the initialization. See
+ :attr:`default_init_cfg` for default settings
+ """
+
+ def __init__(self,
+ pose_cfg: ConfigType,
+ loss: ConfigType = dict(
+ type='BCELoss', use_target_weight=False,
+ use_sigmoid=True),
+ init_cfg: OptConfigType = None):
+
+ if init_cfg is None:
+ init_cfg = self.default_init_cfg
+
+ super().__init__(init_cfg)
+
+ self.in_channels = pose_cfg['in_channels']
+ if pose_cfg.get('num_joints', None) is not None:
+ self.out_channels = pose_cfg['num_joints']
+ elif pose_cfg.get('out_channels', None) is not None:
+ self.out_channels = pose_cfg['out_channels']
+ else:
+ raise ValueError('VisPredictHead requires \'num_joints\' or'
+ ' \'out_channels\' in the pose_cfg.')
+
+ self.loss_module = MODELS.build(loss)
+
+ self.pose_head = MODELS.build(pose_cfg)
+ self.pose_cfg = pose_cfg
+
+ self.use_sigmoid = loss.get('use_sigmoid', False)
+
+ modules = [
+ nn.AdaptiveAvgPool2d(1),
+ nn.Flatten(),
+ nn.Linear(self.in_channels, self.out_channels)
+ ]
+ if self.use_sigmoid:
+ modules.append(nn.Sigmoid())
+
+ self.vis_head = nn.Sequential(*modules)
+```
+
+然后你只需要像一个普通的预测头一样继续实现其余部分即可。
diff --git a/docs/zh_cn/dataset_zoo/2d_fashion_landmark.md b/docs/zh_cn/dataset_zoo/2d_fashion_landmark.md
index 25b7fd7c64..b1146b47b6 100644
--- a/docs/zh_cn/dataset_zoo/2d_fashion_landmark.md
+++ b/docs/zh_cn/dataset_zoo/2d_fashion_landmark.md
@@ -1,3 +1,142 @@
-# 2D服装关键点数据集
+# 2D Fashion Landmark Dataset
-内容建设中……
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- [DeepFashion](#deepfashion) \[ [Homepage](http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion/LandmarkDetection.html) \]
+- [DeepFashion2](#deepfashion2) \[ [Homepage](https://github.com/switchablenorms/DeepFashion2) \]
+
+## DeepFashion (Fashion Landmark Detection, FLD)
+
+
+
+UBody (CVPR'2023)
+ +```bibtex +@article{lin2023one, + title={One-Stage 3D Whole-Body Mesh Recovery with Component Aware Transformer}, + author={Lin, Jing and Zeng, Ailing and Wang, Haoqian and Zhang, Lei and Li, Yu}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + year={2023}, +} +``` + +
+
+
+
+
+DeepFashion (CVPR'2016)
+ +```bibtex +@inproceedings{liuLQWTcvpr16DeepFashion, + author = {Liu, Ziwei and Luo, Ping and Qiu, Shi and Wang, Xiaogang and Tang, Xiaoou}, + title = {DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations}, + booktitle = {Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + month = {June}, + year = {2016} +} +``` + +
+
+
+DeepFashion (ECCV'2016)
+ +```bibtex +@inproceedings{liuYLWTeccv16FashionLandmark, + author = {Liu, Ziwei and Yan, Sijie and Luo, Ping and Wang, Xiaogang and Tang, Xiaoou}, + title = {Fashion Landmark Detection in the Wild}, + booktitle = {European Conference on Computer Vision (ECCV)}, + month = {October}, + year = {2016} + } +``` + +
+  +
+
+
+For [DeepFashion](http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion/LandmarkDetection.html) dataset, images can be downloaded from [download](http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion/LandmarkDetection.html).
+Please download the annotation files from [fld_annotations](https://download.openmmlab.com/mmpose/datasets/fld_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── fld
+ │-- annotations
+ │ │-- fld_upper_train.json
+ │ |-- fld_upper_val.json
+ │ |-- fld_upper_test.json
+ │ │-- fld_lower_train.json
+ │ |-- fld_lower_val.json
+ │ |-- fld_lower_test.json
+ │ │-- fld_full_train.json
+ │ |-- fld_full_val.json
+ │ |-- fld_full_test.json
+ │-- img
+ │ │-- img_00000001.jpg
+ │ │-- img_00000002.jpg
+ │ │-- img_00000003.jpg
+ │ │-- img_00000004.jpg
+ │ │-- img_00000005.jpg
+ │ │-- ...
+```
+
+## DeepFashion2
+
+
+
+
+
+
+
+
+
+For [DeepFashion2](https://github.com/switchablenorms/DeepFashion2) dataset, images can be downloaded from [download](https://drive.google.com/drive/folders/125F48fsMBz2EF0Cpqk6aaHet5VH399Ok?usp=sharing).
+Please download the [annotation files](https://drive.google.com/file/d/1RM9l9EaB9ULRXhoCS72PkCXtJ4Cn4i6O/view?usp=share_link). These annotation files are converted by [deepfashion2_to_coco.py](https://github.com/switchablenorms/DeepFashion2/blob/master/evaluation/deepfashion2_to_coco.py).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── deepfashion2
+ │── train
+ │-- deepfashion2_short_sleeved_outwear_train.json
+ │-- deepfashion2_short_sleeved_dress_train.json
+ │-- deepfashion2_skirt_train.json
+ │-- deepfashion2_sling_dress_train.json
+ │-- ...
+ │-- image
+ │ │-- 000001.jpg
+ │ │-- 000002.jpg
+ │ │-- 000003.jpg
+ │ │-- 000004.jpg
+ │ │-- 000005.jpg
+ │ │-- ...
+ │── validation
+ │-- deepfashion2_short_sleeved_dress_validation.json
+ │-- deepfashion2_long_sleeved_shirt_validation.json
+ │-- deepfashion2_trousers_validation.json
+ │-- deepfashion2_skirt_validation.json
+ │-- ...
+ │-- image
+ │ │-- 000001.jpg
+ │ │-- 000002.jpg
+ │ │-- 000003.jpg
+ │ │-- 000004.jpg
+ │ │-- 000005.jpg
+ │ │-- ...
+```
diff --git a/docs/zh_cn/guide_to_framework.md b/docs/zh_cn/guide_to_framework.md
index 349abf2358..df86f8634f 100644
--- a/docs/zh_cn/guide_to_framework.md
+++ b/docs/zh_cn/guide_to_framework.md
@@ -1,4 +1,4 @@
-# 20 分钟了解 MMPose 架构设计
+# 20 分钟上手 MMPose
MMPose 1.0 与之前的版本有较大改动,对部分模块进行了重新设计和组织,降低代码冗余度,提升运行效率,降低学习难度。
@@ -18,7 +18,8 @@ MMPose 1.0 采用了全新的模块结构设计以精简代码,提升运行效
以下是这篇教程的目录:
-- [20 分钟了解 MMPose 架构设计](#20-分钟了解-mmpose-架构设计)
+- [20 分钟上手 MMPose](#20-分钟上手-mmpose)
+ - [文件结构](#文件结构)
- [总览](#总览)
- [Step1:配置文件](#step1配置文件)
- [Step2:数据](#step2数据)
@@ -35,6 +36,47 @@ MMPose 1.0 采用了全新的模块结构设计以精简代码,提升运行效
- [颈部模块(Neck)](#颈部模块neck)
- [预测头(Head)](#预测头head)
+## 文件结构
+
+MMPose 1.0 的文件结构如下所示:
+
+```shell
+mmpose
+|----apis
+|----structures
+|----datasets
+ |----transforms
+|----codecs
+|----models
+ |----pose_estimators
+ |----data_preprocessors
+ |----backbones
+ |----necks
+ |----heads
+ |----losses
+|----engine
+ |----hooks
+|----evaluation
+|----visualization
+```
+
+- **apis** 提供用于模型推理的高级 API
+- **structures** 提供 bbox、keypoint 和 PoseDataSample 等数据结构
+- **datasets** 支持用于姿态估计的各种数据集
+ - **transforms** 包含各种数据增强变换
+- **codecs** 提供姿态编解码器:编码器用于将姿态信息(通常为关键点坐标)编码为模型学习目标(如热力图),解码器则用于将模型输出解码为姿态估计结果
+- **models** 以模块化结构提供了姿态估计模型的各类组件
+ - **pose_estimators** 定义了所有姿态估计模型类
+ - **data_preprocessors** 用于预处理模型的输入数据
+ - **backbones** 包含各种骨干网络
+ - **necks** 包含各种模型颈部组件
+ - **heads** 包含各种模型头部
+ - **losses** 包含各种损失函数
+- **engine** 包含与姿态估计任务相关的运行时组件
+ - **hooks** 提供运行时的各种钩子
+- **evaluation** 提供各种评估模型性能的指标
+- **visualization** 用于可视化关键点骨架和热力图等信息
+
## 总览

@@ -55,25 +97,25 @@ MMPose 1.0 采用了全新的模块结构设计以精简代码,提升运行效
## Step1:配置文件
-在MMPose中,我们通常 python 格式的配置文件,用于整个项目的定义、参数管理,因此我们强烈建议第一次接触 MMPose 的开发者,查阅 [配置文件](./user_guides/configs.md) 学习配置文件的定义。
+在MMPose中,我们通常 python 格式的配置文件,用于整个项目的定义、参数管理,因此我们强烈建议第一次接触 MMPose 的开发者,查阅 [【用户教程 - 如何看懂配置文件】](./user_guides/configs.md) 学习配置文件的定义。
-需要注意的是,所有新增的模块都需要使用注册器(Registry)进行注册,并在对应目录的 `__init__.py` 中进行 `import`,以便能够使用配置文件构建其实例。
+需要注意的是,所有新增的模块都需要使用注册器进行注册,并在对应目录的 `__init__.py` 中进行 `import`,以便能够使用配置文件构建其实例。
## Step2:数据
MMPose 数据的组织主要包含三个方面:
-- 数据集元信息
+- 数据集元信息(meta info)
-- 数据集
+- 数据集(dataset)
-- 数据流水线
+- 数据流水线(pipeline)
### 数据集元信息
-元信息指具体标注之外的数据集信息。姿态估计数据集的元信息通常包括:关键点和骨骼连接的定义、对称性、关键点性质(如关键点权重、标注标准差、所属上下半身)等。这些信息在数据在数据处理、模型训练和测试中有重要作用。在 MMPose 中,数据集的元信息使用 python 格式的配置文件保存,位于 `$MMPOSE/configs/_base_/datasets` 目录下。
+元信息指具体标注之外的数据集信息。姿态估计数据集的元信息通常包括:关键点和骨骼连接的定义、对称性、关键点性质(如关键点权重、标注标准差、所属上下半身)等。这些信息在数据在数据处理、模型训练和测试中有重要作用。在 MMPose 中,数据集的元信息使用 python 格式的配置文件保存,位于 [$MMPOSE/configs/_base_/datasets](https://github.com/open-mmlab/mmpose/tree/main/configs/_base_/datasets) 目录下。
-在 MMPose 中使用自定义数据集时,你需要增加对应的元信息配置文件。以 MPII 数据集(`$MMPOSE/configs/_base_/datasets/mpii.py`)为例:
+在 MMPose 中使用自定义数据集时,你需要增加对应的元信息配置文件。以 MPII 数据集([$MMPOSE/configs/\_base\_/datasets/mpii.py](https://github.com/open-mmlab/mmpose/blob/main/configs/_base_/datasets/mpii.py))为例:
```Python
dataset_info = dict(
@@ -113,7 +155,19 @@ dataset_info = dict(
])
```
-在模型配置文件中,你需要为自定义数据集指定对应的元信息配置文件。假如该元信息配置文件路径为 `$MMPOSE/configs/_base_/datasets/custom.py`,指定方式如下:
+在这份元信息配置文件中:
+
+- `keypoint_info`:每个关键点的信息:
+ 1. `name`: 关键点名称,必须是唯一的,例如 `nose`、`left_eye` 等。
+ 2. `id`: 关键点 ID,必须是唯一的,从 0 开始。
+ 3. `color`: 关键点可视化时的颜色,以 (\[B, G, R\]) 格式组织起来,用于可视化。
+ 4. `type`: 关键点类型,可以是 `upper`、`lower` 或 `''`,用于数据增强 [RandomHalfBody](https://github.com/open-mmlab/mmpose/blob/b225a773d168fc2afd48cde5f76c0202d1ba2f52/mmpose/datasets/transforms/common_transforms.py#L263)。
+ 5. `swap`: 关键点交换关系,用于水平翻转数据增强 [RandomFlip](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/common_transforms.py#L94)。
+- `skeleton_info`:骨架连接关系,用于可视化。
+- `joint_weights`:每个关键点的权重,用于损失函数计算。
+- `sigma`:标准差,用于计算 OKS 分数,详细信息请参考 [keypoints-eval](https://cocodataset.org/#keypoints-eval)。
+
+在模型配置文件中,你需要为自定义数据集指定对应的元信息配置文件。假如该元信息配置文件路径为 `$MMPOSE/configs/_base_/datasets/{your_dataset}.py`,指定方式如下:
```python
# dataset and dataloader settings
@@ -122,9 +176,9 @@ train_dataloader = dict(
batch_size=2,
dataset=dict(
type=dataset_type,
- data_root='root/of/your/train/data',
- ann_file='path/to/your/train/json',
- data_prefix=dict(img='path/to/your/train/img'),
+ data_root='root of your train data',
+ ann_file='path to your json file',
+ data_prefix=dict(img='path to your train img'),
# 指定对应的元信息配置文件
metainfo=dict(from_file='configs/_base_/datasets/custom.py'),
...),
@@ -133,9 +187,9 @@ val_dataloader = dict(
batch_size=2,
dataset=dict(
type=dataset_type,
- data_root='root/of/your/val/data',
- ann_file='path/to/your/val/json',
- data_prefix=dict(img='path/to/your/val/img'),
+ data_root='root of your val data',
+ ann_file='path to your val json',
+ data_prefix=dict(img='path to your val img'),
# 指定对应的元信息配置文件
metainfo=dict(from_file='configs/_base_/datasets/custom.py'),
...),
@@ -143,126 +197,128 @@ val_dataloader = dict(
test_dataloader = val_dataloader
```
+下面是一个更加具体的例子,假设你的数据集按照以下结构进行组织:
+
+```shell
+data
+├── annotations
+│ ├── train.json
+│ ├── val.json
+├── train
+│ ├── images
+│ │ ├── 000001.jpg
+├── val
+│ ├── images
+│ │ ├── 000002.jpg
+```
+
+你的数据集路径应该如下所示:
+
+```
+dataset=dict(
+ ...
+ data_root='data/',
+ ann_file='annotations/train.json',
+ data_prefix=dict(img='train/images/'),
+ ...),
+```
+
### 数据集
在 MMPose 中使用自定义数据集时,我们推荐将数据转化为已支持的格式(如 COCO 或 MPII),并直接使用我们提供的对应数据集实现。如果这种方式不可行,则用户需要实现自己的数据集类。
-MMPose 中的大部分 2D 关键点数据集**以 COCO 形式组织**,为此我们提供了基类 [BaseCocoStyleDataset](/mmpose/datasets/datasets/base/base_coco_style_dataset.py)。我们推荐用户继承该基类,并按需重写它的方法(通常是 `__init__()` 和 `_load_annotations()` 方法),以扩展到新的 2D 关键点数据集。
+更多自定义数据集的使用方式,请前往 [【进阶教程 - 自定义数据集】](./advanced_guides/customize_datasets.md)。
+
+````{note}
+如果你需要直接继承 [MMEngine](https://github.com/open-mmlab/mmengine) 中提供的 `BaseDataset` 基类。具体方法请参考相关[文档](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/basedataset.html)
+
+
+#### 2D 数据集
+MMPose 中的大部分 2D 关键点数据集**以 COCO 形式组织**,为此我们提供了基类 [BaseCocoStyleDataset](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/datasets/base/base_coco_style_dataset.py)。我们推荐用户继承该基类,并按需重写它的方法(通常是 `__init__()` 和 `_load_annotations()` 方法),以扩展到新的 2D 关键点数据集。
```{note}
关于COCO数据格式的详细说明请参考 [COCO](./dataset_zoo/2d_body_keypoint.md) 。
-```
+````
-```{note}
-在 MMPose 中 bbox 的数据格式采用 `xyxy`,而不是 `xywh`,这与 [MMDetection](https://github.com/open-mmlab/mmdetection) 等其他 OpenMMLab 成员保持一致。为了实现不同 bbox 格式之间的转换,我们提供了丰富的函数:`bbox_xyxy2xywh`、`bbox_xywh2xyxy`、`bbox_xyxy2cs`等。这些函数定义在`$MMPOSE/mmpose/structures/bbox/transforms.py`。
-```
+在 MMPose 中 bbox 的数据格式采用 `xyxy`,而不是 `xywh`,这与 [MMDetection](https://github.com/open-mmlab/mmdetection) 等其他 OpenMMLab 成员保持一致。为了实现不同 bbox 格式之间的转换,我们提供了丰富的函数:`bbox_xyxy2xywh`、`bbox_xywh2xyxy`、`bbox_xyxy2cs`等。这些函数定义在 [$MMPOSE/mmpose/structures/bbox/transforms.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/structures/bbox/transforms.py)。
-下面我们以MPII数据集的实现(`$MMPOSE/mmpose/datasets/datasets/body/mpii_dataset.py`)为例:
+下面我们以 COCO 格式标注的 CrowdPose 数据集的实现([$MMPOSE/mmpose/datasets/datasets/body/crowdpose_dataset.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/datasets/body/crowdpose_dataset.py))为例:
```Python
@DATASETS.register_module()
-class MpiiDataset(BaseCocoStyleDataset):
- METAINFO: dict = dict(from_file='configs/_base_/datasets/mpii.py')
+class CrowdPoseDataset(BaseCocoStyleDataset):
+ """CrowdPose dataset for pose estimation.
+
+ "CrowdPose: Efficient Crowded Scenes Pose Estimation and
+ A New Benchmark", CVPR'2019.
+ More details can be found in the `paper
+ DeepFashion2 (CVPR'2019)
+ +```bibtex +@article{DeepFashion2, + author = {Yuying Ge and Ruimao Zhang and Lingyun Wu and Xiaogang Wang and Xiaoou Tang and Ping Luo}, + title={A Versatile Benchmark for Detection, Pose Estimation, Segmentation and Re-Identification of Clothing Images}, + journal={CVPR}, + year={2019} +} +``` + +Animal-Pose (ICCV'2019)
@@ -78,7 +102,7 @@ MMPose 提供了一些工具来帮助用户处理数据集。 开源作者没有提供官方的 train/val/test 划分,我们选择来自 PascalVOC 的图片作为 train & val,train+val 一共 3600 张图片,5117 个标注。其中 2798 张图片,4000 个标注用于训练,810 张图片,1117 个标注用于验证。测试集包含 1000 张图片,1000 个标注用于评估。 -## COFW 数据集 +### COFW 数据集COFW (ICCV'2013)
@@ -139,7 +163,7 @@ mmpose |── 000002.jpg ``` -## DeepposeKit 数据集 +### DeepposeKit 数据集Desert Locust (Elife'2019)
@@ -215,7 +239,7 @@ mmpose 由于官方数据集中没有提供测试集,我们随机选择了 90% 的图片用于训练,剩下的 10% 用于测试。 -## Macaque 数据集 +### Macaque 数据集MacaquePose (bioRxiv'2020)
@@ -269,7 +293,7 @@ mmpose 由于官方数据集中没有提供测试集,我们随机选择了 90% 的图片用于训练,剩下的 10% 用于测试。 -## Human3.6M 数据集 +### Human3.6M 数据集Human3.6M (TPAMI'2014)
@@ -346,7 +370,7 @@ mmpose python tools/dataset_converters/h36m_to_coco.py ``` -## MPII 数据集 +### MPII 数据集MPII (CVPR'2014)
@@ -377,7 +401,7 @@ python tools/dataset_converters/mat2json ${PRED_MAT_FILE} ${GT_JSON_FILE} ${OUTP python tools/dataset/mat2json work_dirs/res50_mpii_256x256/pred.mat data/mpii/annotations/mpii_val.json pred.json ``` -## Label Studio 数据集 +### Label Studio 数据集Label Studio
diff --git a/docs/zh_cn/user_guides/how_to_deploy.md b/docs/zh_cn/user_guides/how_to_deploy.md new file mode 100644 index 0000000000..2349fcca09 --- /dev/null +++ b/docs/zh_cn/user_guides/how_to_deploy.md @@ -0,0 +1,292 @@ +# 模型精简与部署 + +本章将介绍如何导出与部署 MMPose 训练得到的模型,包含以下内容: + +- [模型精简](#模型精简) +- [使用 MMDeploy 部署](#使用-mmdeploy-部署) + - [MMDeploy 介绍](#mmdeploy-介绍) + - [模型支持列表](#模型支持列表) + - [安装](#安装) + - [模型转换](#模型转换) + - [如何查找 MMPose 模型对应的部署配置文件](#如何查找-mmpose-模型对应的部署配置文件) + - [RTMPose 模型导出示例](#rtmpose-模型导出示例) + - [ONNX](#onnx) + - [TensorRT](#tensorrt) + - [高级设置](#高级设置) + - [模型测速](#模型测速) + - [精度验证](#精度验证) + +## 模型精简 + +在默认状态下,MMPose 训练过程中保存的 checkpoint 文件包含了模型的所有信息,包括模型结构、权重、优化器状态等。这些信息对于模型的部署来说是冗余的,因此我们需要对模型进行精简,精简后的 `.pth` 文件大小甚至能够缩小一半以上。 + +MMPose 提供了 [tools/misc/publish_model.py](https://github.com/open-mmlab/mmpose/blob/dev-1.x/tools/misc/publish_model.py) 来进行模型精简,使用方式如下: + +```shell +python tools/misc/publish_model.py ${IN_FILE} ${OUT_FILE} +``` + +例如: + +```shell +python tools/misc/publish_model.py ./epoch_10.pth ./epoch_10_publish.pth +``` + +脚本会自动对模型进行精简,并将精简后的模型保存到制定路径,并在文件名的最后加上时间戳,例如 `./epoch_10_publish-21815b2c_20230726.pth`。 + +## 使用 MMDeploy 部署 + +### MMDeploy 介绍 + +MMDeploy 是 OpenMMLab 模型部署工具箱,为各算法库提供统一的部署体验。基于 MMDeploy,开发者可以轻松从 MMPose 生成指定硬件所需 SDK,省去大量适配时间。 + +- 你可以从 [【硬件模型库】](https://platform.openmmlab.com/deploee) 直接下载 SDK 版模型(ONNX、TensorRT、ncnn 等)。 +- 同时我们也支持 [在线模型转换](https://platform.openmmlab.com/deploee/task-convert-list),从而无需本地安装 MMDeploy。 + +更多介绍和使用指南见 [MMDeploy 文档](https://mmdeploy.readthedocs.io/zh_CN/latest/get_started.html)。 + +### 模型支持列表 + +| Model | Task | ONNX Runtime | TensorRT | ncnn | PPLNN | OpenVINO | CoreML | TorchScript | +| :-------------------------------------------------------------------------------------------------------- | :------------ | :----------: | :------: | :--: | :---: | :------: | :----: | :---------: | +| [HRNet](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#hrnet-cvpr-2019) | PoseDetection | Y | Y | Y | N | Y | Y | Y | +| [MSPN](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#mspn-arxiv-2019) | PoseDetection | Y | Y | Y | N | Y | Y | Y | +| [LiteHRNet](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#litehrnet-cvpr-2021) | PoseDetection | Y | Y | Y | N | Y | Y | Y | +| [Hourglass](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#hourglass-eccv-2016) | PoseDetection | Y | Y | Y | N | Y | Y | Y | +| [SimCC](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/algorithms.html#simcc-eccv-2022) | PoseDetection | Y | Y | Y | N | Y | Y | Y | +| [RTMPose](https://github.com/open-mmlab/mmpose/tree/main/projects/rtmpose) | PoseDetection | Y | Y | Y | N | Y | Y | Y | +| [YoloX-Pose](https://github.com/open-mmlab/mmpose/tree/main/projects/yolox_pose) | PoseDetection | Y | Y | N | N | Y | Y | Y | + +### 安装 + +在开始部署之前,首先你需要确保正确安装了 MMPose, MMDetection, MMDeploy,相关安装教程如下: + +- [安装 MMPose 与 MMDetection](../installation.md) +- [安装 MMDeploy](https://mmdeploy.readthedocs.io/zh_CN/latest/04-supported-codebases/mmpose.html) + +根据部署后端的不同,有的后端需要对 MMDeploy 支持的**自定义算子进行编译**,请根据需求前往对应的文档确保环境搭建正确: + +- [ONNX](https://mmdeploy.readthedocs.io/zh_CN/latest/05-supported-backends/onnxruntime.html) +- [TensorRT](https://mmdeploy.readthedocs.io/zh_CN/latest/05-supported-backends/tensorrt.html) +- [OpenVINO](https://mmdeploy.readthedocs.io/zh_CN/latest/05-supported-backends/openvino.html) +- [ncnn](https://mmdeploy.readthedocs.io/zh_CN/latest/05-supported-backends/ncnn.html) +- [TorchScript](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/torchscript.html) +- [更多](https://github.com/open-mmlab/mmdeploy/tree/main/docs/zh_cn/05-supported-backends) + +### 模型转换 + +在完成安装之后,你就可以开始模型部署了。通过 MMDeploy 提供的 [tools/deploy.py](https://github.com/open-mmlab/mmdeploy/blob/main/tools/deploy.py) 可以方便地将 MMPose 模型转换到不同的部署后端。 + +使用方法如下: + +```shell +python ./tools/deploy.py \ + ${DEPLOY_CFG_PATH} \ + ${MODEL_CFG_PATH} \ + ${MODEL_CHECKPOINT_PATH} \ + ${INPUT_IMG} \ + --test-img ${TEST_IMG} \ + --work-dir ${WORK_DIR} \ + --calib-dataset-cfg ${CALIB_DATA_CFG} \ + --device ${DEVICE} \ + --log-level INFO \ + --show \ + --dump-info +``` + +参数描述: + +- `deploy_cfg` : mmdeploy 针对此模型的部署配置,包含推理框架类型、是否量化、输入 shape 是否动态等。配置文件之间可能有引用关系,`configs/mmpose/pose-detection_simcc_onnxruntime_dynamic.py` 是一个示例。 + +- `model_cfg` : mm 算法库的模型配置,例如 `mmpose/configs/body_2d_keypoint/rtmpose/coco/rtmpose-m_8xb256-420e_aic-coco-256x192.py`,与 mmdeploy 的路径无关。 + +- `checkpoint` : torch 模型路径。可以 http/https 开头,详见 mmcv.FileClient 的实现。 + +- `img` : 模型转换时,用做测试的图像或点云文件路径。 + +- `--test-img` : 用于测试模型的图像文件路径。默认设置成None。 + +- `--work-dir` : 工作目录,用来保存日志和模型文件。 + +- `--calib-dataset-cfg` : 此参数只有int8模式下生效,用于校准数据集配置文件。若在int8模式下未传入参数,则会自动使用模型配置文件中的’val’数据集进行校准。 + +- `--device` : 用于模型转换的设备。 默认是cpu,对于 trt 可使用 cuda:0 这种形式。 + +- `--log-level` : 设置日记的等级,选项包括'CRITICAL', 'FATAL', 'ERROR', 'WARN', 'WARNING', 'INFO', 'DEBUG', 'NOTSET'。 默认是INFO。 + +- `--show` : 是否显示检测的结果。 + +- `--dump-info` : 是否输出 SDK 信息。 + +#### 如何查找 MMPose 模型对应的部署配置文件 + +1. 所有与 MMPose 相关的部署配置文件都存放在 [configs/mmpose/](https://github.com/open-mmlab/mmdeploy/tree/main/configs/mmpose) 目录下。 +2. 部署配置文件命名遵循 `{任务}_{算法}_{部署后端}_{动态/静态}_{输入尺寸}` 。 + +#### RTMPose 模型导出示例 + +我们本节演示将 RTMPose 模型导出为 ONNX 和 TensorRT 格式,如果你希望了解更多内容请前往 [MMDeploy 文档](https://mmdeploy.readthedocs.io/zh_CN/latest/02-how-to-run/convert_model.html)。 + +- ONNX 配置 + + - [pose-detection_simcc_onnxruntime_dynamic.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_onnxruntime_dynamic.py) + +- TensorRT 配置 + + - [pose-detection_simcc_tensorrt_dynamic-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_tensorrt_dynamic-256x192.py) + +- 更多 + + | Backend | Config | + | :-------: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------: | + | ncnn-fp16 | [pose-detection_simcc_ncnn-fp16_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_ncnn-fp16_static-256x192.py) | + | CoreML | [pose-detection_simcc_coreml_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_coreml_static-256x192.py) | + | OpenVINO | [pose-detection_simcc_openvino_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_openvino_static-256x192.py) | + | RKNN | [pose-detection_simcc_rknn-fp16_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_rknn-fp16_static-256x192.py) | + +如果你需要对部署配置进行修改,请参考 [MMDeploy config tutorial](https://mmdeploy.readthedocs.io/zh_CN/latest/02-how-to-run/write_config.html). + +本教程中使用的文件结构如下: + +```shell +|----mmdeploy +|----mmpose +``` + +##### ONNX + +运行如下命令: + +```shell +# 前往 mmdeploy 目录 +cd ${PATH_TO_MMDEPLOY} + +# 转换 RTMPose +# 输入模型路径可以是本地路径,也可以是下载链接。 +python tools/deploy.py \ + configs/mmpose/pose-detection_simcc_onnxruntime_dynamic.py \ + ../mmpose/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-256x192-63eb25f7_20230126.pth \ + demo/resources/human-pose.jpg \ + --work-dir rtmpose-ort/rtmpose-m \ + --device cpu \ + --show \ + --dump-info # 导出 sdk info +``` + +默认导出模型文件为 `{work-dir}/end2end.onnx` + +##### TensorRT + +运行如下命令: + +```shell +# 前往 mmdeploy 目录 +cd ${PATH_TO_MMDEPLOY} + +# 转换 RTMPose +# 输入模型路径可以是本地路径,也可以是下载链接。 +python tools/deploy.py \ + configs/mmpose/pose-detection_simcc_tensorrt_dynamic-256x192.py \ + ../mmpose/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py \ + https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-256x192-63eb25f7_20230126.pth \ + demo/resources/human-pose.jpg \ + --work-dir rtmpose-trt/rtmpose-m \ + --device cuda:0 \ + --show \ + --dump-info # 导出 sdk info +``` + +默认导出模型文件为 `{work-dir}/end2end.engine` + +如果模型顺利导出,你将会看到样例图片上的检测结果: + + + +###### 高级设置 + +如果需要使用 TensorRT-FP16,你可以通过修改 MMDeploy config 中以下配置开启: + +```Python +# in MMDeploy config +backend_config = dict( + type='tensorrt', + common_config=dict( + fp16_mode=True # 打开 fp16 + )) +``` + +### 模型测速 + +如果需要测试模型在部署框架下的推理速度,MMDeploy 提供了方便的 [tools/profiler.py](https://github.com/open-mmlab/mmdeploy/blob/main/tools/profiler.py) 脚本。 + +用户需要准备一个存放测试图片的文件夹`./test_images`,profiler 将随机从该目录下抽取图片用于模型测速。 + +```shell +# 前往 mmdeploy 目录 +cd ${PATH_TO_MMDEPLOY} + +python tools/profiler.py \ + configs/mmpose/pose-detection_simcc_onnxruntime_dynamic.py \ + ../mmpose/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py \ + ../test_images \ + --model {WORK_DIR}/end2end.onnx \ + --shape 256x192 \ + --device cpu \ + --warmup 50 \ + --num-iter 200 +``` + +测试结果如下: + +```shell +01/30 15:06:35 - mmengine - INFO - [onnxruntime]-70 times per count: 8.73 ms, 114.50 FPS +01/30 15:06:36 - mmengine - INFO - [onnxruntime]-90 times per count: 9.05 ms, 110.48 FPS +01/30 15:06:37 - mmengine - INFO - [onnxruntime]-110 times per count: 9.87 ms, 101.32 FPS +01/30 15:06:37 - mmengine - INFO - [onnxruntime]-130 times per count: 9.99 ms, 100.10 FPS +01/30 15:06:38 - mmengine - INFO - [onnxruntime]-150 times per count: 10.39 ms, 96.29 FPS +01/30 15:06:39 - mmengine - INFO - [onnxruntime]-170 times per count: 10.77 ms, 92.86 FPS +01/30 15:06:40 - mmengine - INFO - [onnxruntime]-190 times per count: 10.98 ms, 91.05 FPS +01/30 15:06:40 - mmengine - INFO - [onnxruntime]-210 times per count: 11.19 ms, 89.33 FPS +01/30 15:06:41 - mmengine - INFO - [onnxruntime]-230 times per count: 11.16 ms, 89.58 FPS +01/30 15:06:42 - mmengine - INFO - [onnxruntime]-250 times per count: 11.06 ms, 90.41 FPS +----- Settings: ++------------+---------+ +| batch size | 1 | +| shape | 256x192 | +| iterations | 200 | +| warmup | 50 | ++------------+---------+ +----- Results: ++--------+------------+---------+ +| Stats | Latency/ms | FPS | ++--------+------------+---------+ +| Mean | 11.060 | 90.412 | +| Median | 11.852 | 84.375 | +| Min | 7.812 | 128.007 | +| Max | 13.690 | 73.044 | ++--------+------------+---------+ +``` + +```{note} +如果你希望详细了解 profiler 的更多参数设置与功能,可以前往 [Profiler 文档](https://mmdeploy.readthedocs.io/en/main/02-how-to-run/useful_tools.html#profiler)。 +``` + +### 精度验证 + +如果需要测试模型在部署框架下的推理精度,MMDeploy 提供了方便的 `tools/test.py` 脚本。 + +```shell +# 前往 mmdeploy 目录 +cd ${PATH_TO_MMDEPLOY} + +python tools/test.py \ + configs/mmpose/pose-detection_simcc_onnxruntime_dynamic.py \ + ./mmpose/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py \ + --model {PATH_TO_MODEL}/rtmpose_m.pth \ + --device cpu +``` + +```{note} +详细内容请参考 [MMDeploy 文档](https://github.com/open-mmlab/mmdeploy/blob/main/docs/zh_cn/02-how-to-run/profile_model.md) +``` diff --git a/docs/zh_cn/user_guides/inference.md b/docs/zh_cn/user_guides/inference.md index 0844bc611f..24ba42974b 100644 --- a/docs/zh_cn/user_guides/inference.md +++ b/docs/zh_cn/user_guides/inference.md @@ -1,18 +1,21 @@ # 使用现有模型进行推理 -MMPose为姿态估计提供了大量可以从[模型库](https://mmpose.readthedocs.io/en/latest/model_zoo.html)中找到的预测训练模型。本指南将演示**如何执行推理**,或使用训练过的模型对提供的图像或视频运行姿态估计。 +MMPose 为姿态估计提供了大量可以从 [模型库](https://mmpose.readthedocs.io/en/latest/model_zoo.html) 中找到的预测训练模型。 -有关在标准数据集上测试现有模型的说明,请参阅本指南。 +本指南将演示**如何执行推理**,或使用训练过的模型对提供的图像或视频运行姿态估计。 -在MMPose,模型由配置文件定义,而其已计算好的参数存储在权重文件(checkpoint file)中。您可以在[模型库](https://mmpose.readthedocs.io/en/latest/model_zoo.html)中找到模型配置文件和相应的权重文件的URL。我们建议从使用HRNet模型的[配置文件](https://github.com/open-mmlab/mmpose/blob/main/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py)和[权重文件](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192-81c58e40_20220909.pth)开始。 +MMPose 提供了两种推理接口: + +1. 推理器:统一的推理接口 +2. 推理 API:用于更加灵活的自定义推理 ## 推理器:统一的推理接口 -MMPose提供了一个被称为`MMPoseInferencer`的、全面的推理API。这个API使得用户得以使用所有MMPose支持的模型来对图像和视频进行模型推理。此外,该API可以完成推理结果自动化,并方便用户保存预测结果。 +MMPose 提供了一个被称为 [MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) 的、全面的推理 API。这个 API 使得用户得以使用所有 MMPose 支持的模型来对图像和视频进行模型推理。此外,该API可以完成推理结果自动化,并方便用户保存预测结果。 ### 基本用法 -`MMPoseInferencer`可以在任何Python程序中被用来执行姿态估计任务。以下是在一个在Python Shell中使用预训练的人体姿态模型对给定图像进行推理的示例。 +[MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) 可以在任何 Python 程序中被用来执行姿态估计任务。以下是在一个在 Python Shell 中使用预训练的人体姿态模型对给定图像进行推理的示例。 ```python from mmpose.apis import MMPoseInferencer @@ -75,7 +78,7 @@ python demo/inferencer_demo.py 'tests/data/coco/000000000785.jpg' \ --pose2d 'human' --show --pred-out-dir 'predictions' ``` -预测结果将被保存在路径`predictions/000000000785.json`。作为一个API,`inferencer_demo.py`的输入参数与`MMPoseInferencer`的相同。前者能够处理一系列输入类型,包括以下内容: +预测结果将被保存在路径 `predictions/000000000785.json` 。作为一个API,`inferencer_demo.py` 的输入参数与 [MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) 的相同。前者能够处理一系列输入类型,包括以下内容: - 图像路径 @@ -87,7 +90,7 @@ python demo/inferencer_demo.py 'tests/data/coco/000000000785.jpg' \ - 表示图像的 numpy array 列表 (在命令行界面工具中未支持) -- 摄像头(在这种情况下,输入参数应该设置为`webcam`或`webcam:{CAMERA_ID}`) +- 摄像头(在这种情况下,输入参数应该设置为 `webcam` 或 `webcam:{CAMERA_ID}`) 当输入对应于多个图像时,例如输入为**视频**或**文件夹**路径时,推理生成器必须被遍历,以便推理器对视频/文件夹中的所有帧/图像进行推理。以下是一个示例: @@ -102,7 +105,7 @@ results = [result for result in result_generator] ### 自定义姿态估计模型 -`MMPoseInferencer`提供了几种可用于自定义所使用的模型的方法: +[MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) 提供了几种可用于自定义所使用的模型的方法: ```python # 使用模型别名构建推断器 @@ -122,7 +125,7 @@ inferencer = MMPoseInferencer( 模型别名的完整列表可以在模型别名部分中找到。 -此外,自顶向下的姿态估计器还需要一个对象检测模型。`MMPoseInferencer`能够推断用MMPose支持的数据集训练的模型的实例类型,然后构建必要的对象检测模型。用户也可以通过以下方式手动指定检测模型: +此外,自顶向下的姿态估计器还需要一个对象检测模型。[MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) 能够推断用 MMPose 支持的数据集训练的模型的实例类型,然后构建必要的对象检测模型。用户也可以通过以下方式手动指定检测模型: ```python # 通过别名指定检测模型 @@ -157,29 +160,29 @@ inferencer = MMPoseInferencer( 在执行姿态估计推理任务之后,您可能希望保存结果以供进一步分析或处理。本节将指导您将预测的关键点和可视化结果保存到本地。 -要将预测保存在JSON文件中,在运行`MMPoseInferencer`的实例`inferencer`时使用`pred_out_dir`参数: +要将预测保存在JSON文件中,在运行 [MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) 的实例 `inferencer` 时使用 `pred_out_dir` 参数: ```python result_generator = inferencer(img_path, pred_out_dir='predictions') result = next(result_generator) ``` -预测结果将以JSON格式保存在`predictions/`文件夹中,每个文件以相应的输入图像或视频的名称命名。 +预测结果将以 JSON 格式保存在 `predictions/` 文件夹中,每个文件以相应的输入图像或视频的名称命名。 -对于更高级的场景,还可以直接从`inferencer`返回的`result`字典中访问预测结果。其中,`predictions`包含输入图像或视频中每个单独实例的预测关键点列表。然后,您可以使用您喜欢的方法操作或存储这些结果。 +对于更高级的场景,还可以直接从 `inferencer` 返回的 `result` 字典中访问预测结果。其中,`predictions` 包含输入图像或视频中每个单独实例的预测关键点列表。然后,您可以使用您喜欢的方法操作或存储这些结果。 -请记住,如果你想将可视化图像和预测文件保存在一个文件夹中,你可以使用`out_dir`参数: +请记住,如果你想将可视化图像和预测文件保存在一个文件夹中,你可以使用 `out_dir` 参数: ```python result_generator = inferencer(img_path, out_dir='output') result = next(result_generator) ``` -在这种情况下,可视化图像将保存在`output/visualization/`文件夹中,而预测将存储在`output/forecasts/`文件夹中。 +在这种情况下,可视化图像将保存在 `output/visualization/` 文件夹中,而预测将存储在 `output/forecasts/` 文件夹中。 ### 可视化 -推理器`inferencer`可以自动对输入的图像或视频进行预测。可视化结果可以显示在一个新的窗口中,并保存在本地。 +推理器 `inferencer` 可以自动对输入的图像或视频进行预测。可视化结果可以显示在一个新的窗口中,并保存在本地。 要在新窗口中查看可视化结果,请使用以下代码: @@ -187,7 +190,7 @@ result = next(result_generator) - 如果输入视频来自网络摄像头,默认情况下将在新窗口中显示可视化结果,以此让用户看到输入 -- 如果平台上没有GUI,这个步骤可能会卡住 +- 如果平台上没有 GUI,这个步骤可能会卡住 要将可视化结果保存在本地,可以像这样指定`vis_out_dir`参数: @@ -196,9 +199,9 @@ result_generator = inferencer(img_path, vis_out_dir='vis_results') result = next(result_generator) ``` -输入图片或视频的可视化预测结果将保存在`vis_results/`文件夹中 +输入图片或视频的可视化预测结果将保存在 `vis_results/` 文件夹中 -在开头展示的滑雪图中,姿态的可视化估计结果由关键点(用实心圆描绘)和骨架(用线条表示)组成。这些视觉元素的默认大小可能不会产生令人满意的结果。用户可以使用`radius`和`thickness`参数来调整圆的大小和线的粗细,如下所示: +在开头展示的滑雪图中,姿态的可视化估计结果由关键点(用实心圆描绘)和骨架(用线条表示)组成。这些视觉元素的默认大小可能不会产生令人满意的结果。用户可以使用 `radius` 和 `thickness` 参数来调整圆的大小和线的粗细,如下所示: ```python result_generator = inferencer(img_path, show=True, radius=4, thickness=2) @@ -207,7 +210,7 @@ result = next(result_generator) ### 推理器参数 -`MMPoseInferencer`提供了各种自定义姿态估计、可视化和保存预测结果的参数。下面是初始化推断器时可用的参数列表及对这些参数的描述: +[MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) 提供了各种自定义姿态估计、可视化和保存预测结果的参数。下面是初始化推断器时可用的参数列表及对这些参数的描述: | Argument | Description | | ---------------- | ------------------------------------------------------------ | @@ -221,47 +224,213 @@ result = next(result_generator) | `device` | 执行推理的设备。如果为 `None`,推理器将选择最合适的一个。 | | `scope` | 定义模型模块的名称空间 | -推理器被设计用于可视化和保存预测。以下表格列出了在使用 `MMPoseInferencer` 进行推断时可用的参数列表,以及它们与 2D 和 3D 推理器的兼容性: - -| 参数 | 描述 | 2D | 3D | -| ------------------------ | -------------------------------------------------------------------------------------------------------------------------- | --- | --- | -| `show` | 控制是否在弹出窗口中显示图像或视频。 | ✔️ | ✔️ | -| `radius` | 设置可视化关键点的半径。 | ✔️ | ✔️ | -| `thickness` | 确定可视化链接的厚度。 | ✔️ | ✔️ | -| `kpt_thr` | 设置关键点分数阈值。分数超过此阈值的关键点将被显示。 | ✔️ | ✔️ | -| `draw_bbox` | 决定是否显示实例的边界框。 | ✔️ | ✔️ | -| `draw_heatmap` | 决定是否绘制预测的热图。 | ✔️ | ❌ | -| `black_background` | 决定是否在黑色背景上显示预估的姿势。 | ✔️ | ❌ | -| `skeleton_style` | 设置骨架样式。可选项包括 'mmpose'(默认)和 'openpose'。 | ✔️ | ❌ | -| `use_oks_tracking` | 决定是否在追踪中使用OKS作为相似度测量。 | ❌ | ✔️ | -| `tracking_thr` | 设置追踪的相似度阈值。 | ❌ | ✔️ | -| `norm_pose_2d` | 决定是否将边界框缩放至数据集的平均边界框尺寸,并将边界框移至数据集的平均边界框中心。 | ❌ | ✔️ | -| `rebase_keypoint_height` | 决定是否将最低关键点的高度置为 0。 | ❌ | ✔️ | -| `return_vis` | 决定是否在结果中包含可视化图像。 | ✔️ | ✔️ | -| `vis_out_dir` | 定义保存可视化图像的文件夹路径。如果未设置,将不保存可视化图像。 | ✔️ | ✔️ | -| `return_datasample` | 决定是否以 `PoseDataSample` 格式返回预测。 | ✔️ | ✔️ | -| `pred_out_dir` | 指定保存预测的文件夹路径。如果未设置,将不保存预测。 | ✔️ | ✔️ | -| `out_dir` | 如果 `vis_out_dir` 或 `pred_out_dir` 未设置,它们将分别设置为 `f'{out_dir}/visualization'` 或 `f'{out_dir}/predictions'`。 | ✔️ | ✔️ | +推理器被设计用于可视化和保存预测。以下表格列出了在使用 [MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) 进行推断时可用的参数列表,以及它们与 2D 和 3D 推理器的兼容性: + +| 参数 | 描述 | 2D | 3D | +| ------------------------- | -------------------------------------------------------------------------------------------------------------------------- | --- | --- | +| `show` | 控制是否在弹出窗口中显示图像或视频。 | ✔️ | ✔️ | +| `radius` | 设置可视化关键点的半径。 | ✔️ | ✔️ | +| `thickness` | 确定可视化链接的厚度。 | ✔️ | ✔️ | +| `kpt_thr` | 设置关键点分数阈值。分数超过此阈值的关键点将被显示。 | ✔️ | ✔️ | +| `draw_bbox` | 决定是否显示实例的边界框。 | ✔️ | ✔️ | +| `draw_heatmap` | 决定是否绘制预测的热图。 | ✔️ | ❌ | +| `black_background` | 决定是否在黑色背景上显示预估的姿势。 | ✔️ | ❌ | +| `skeleton_style` | 设置骨架样式。可选项包括 'mmpose'(默认)和 'openpose'。 | ✔️ | ❌ | +| `use_oks_tracking` | 决定是否在追踪中使用OKS作为相似度测量。 | ❌ | ✔️ | +| `tracking_thr` | 设置追踪的相似度阈值。 | ❌ | ✔️ | +| `disable_norm_pose_2d` | 决定是否将边界框缩放至数据集的平均边界框尺寸,并将边界框移至数据集的平均边界框中心。 | ❌ | ✔️ | +| `disable_rebase_keypoint` | 决定是否将最低关键点的高度置为 0。 | ❌ | ✔️ | +| `num_instances` | 设置可视化结果中显示的实例数量。如果设置为负数,则所有实例的结果都会可视化。 | ❌ | ✔️ | +| `return_vis` | 决定是否在结果中包含可视化图像。 | ✔️ | ✔️ | +| `vis_out_dir` | 定义保存可视化图像的文件夹路径。如果未设置,将不保存可视化图像。 | ✔️ | ✔️ | +| `return_datasamples` | 决定是否以 `PoseDataSample` 格式返回预测。 | ✔️ | ✔️ | +| `pred_out_dir` | 指定保存预测的文件夹路径。如果未设置,将不保存预测。 | ✔️ | ✔️ | +| `out_dir` | 如果 `vis_out_dir` 或 `pred_out_dir` 未设置,它们将分别设置为 `f'{out_dir}/visualization'` 或 `f'{out_dir}/predictions'`。 | ✔️ | ✔️ | ### 模型别名 -MMPose为常用模型提供了一组预定义的别名。在初始化 `MMPoseInferencer` 时,这些别名可以用作简略的表达方式,而不是指定完整的模型配置名称。下面是可用的模型别名及其对应的配置名称的列表: - -| 别名 | 配置文件名称 | 对应任务 | 姿态估计模型 | 检测模型 | -| --------- | -------------------------------------------------- | ------------------------------- | ------------- | ------------------- | -| animal | rtmpose-m_8xb64-210e_ap10k-256x256 | Animal pose estimation | RTMPose-m | RTMDet-m | -| human | rtmpose-m_8xb256-420e_aic-coco-256x192 | Human pose estimation | RTMPose-m | RTMDet-m | -| face | rtmpose-m_8xb64-60e_wflw-256x256 | Face keypoint detection | RTMPose-m | yolox-s | -| hand | rtmpose-m_8xb32-210e_coco-wholebody-hand-256x256 | Hand keypoint detection | RTMPose-m | ssdlite_mobilenetv2 | -| wholebody | rtmpose-m_8xb64-270e_coco-wholebody-256x192 | Human wholebody pose estimation | RTMPose-m | RTMDet-m | -| vitpose | td-hm_ViTPose-base-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-base | RTMDet-m | -| vitpose-s | td-hm_ViTPose-small-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-small | RTMDet-m | -| vitpose-b | td-hm_ViTPose-base-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-base | RTMDet-m | -| vitpose-l | td-hm_ViTPose-large-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-large | RTMDet-m | -| vitpose-h | td-hm_ViTPose-huge-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-huge | RTMDet-m | +MMPose 为常用模型提供了一组预定义的别名。在初始化 [MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) 时,这些别名可以用作简略的表达方式,而不是指定完整的模型配置名称。下面是可用的模型别名及其对应的配置名称的列表: + +| 别名 | 配置文件名称 | 对应任务 | 姿态估计模型 | 检测模型 | +| --------- | -------------------------------------------------- | ---------------- | ------------- | ------------------- | +| animal | rtmpose-m_8xb64-210e_ap10k-256x256 | 动物姿态估计 | RTMPose-m | RTMDet-m | +| human | rtmpose-m_8xb256-420e_body8-256x192 | 人体姿态估计 | RTMPose-m | RTMDet-m | +| body26 | rtmpose-m_8xb512-700e_body8-halpe26-256x192 | 人体姿态估计 | RTMPose-m | RTMDet-m | +| face | rtmpose-m_8xb256-120e_face6-256x256 | 人脸关键点检测 | RTMPose-m | yolox-s | +| hand | rtmpose-m_8xb256-210e_hand5-256x256 | 手部关键点检测 | RTMPose-m | ssdlite_mobilenetv2 | +| wholebody | rtmpose-m_8xb64-270e_coco-wholebody-256x192 | 人体全身姿态估计 | RTMPose-m | RTMDet-m | +| vitpose | td-hm_ViTPose-base-simple_8xb64-210e_coco-256x192 | 人体姿态估计 | ViTPose-base | RTMDet-m | +| vitpose-s | td-hm_ViTPose-small-simple_8xb64-210e_coco-256x192 | 人体姿态估计 | ViTPose-small | RTMDet-m | +| vitpose-b | td-hm_ViTPose-base-simple_8xb64-210e_coco-256x192 | 人体姿态估计 | ViTPose-base | RTMDet-m | +| vitpose-l | td-hm_ViTPose-large-simple_8xb64-210e_coco-256x192 | 人体姿态估计 | ViTPose-large | RTMDet-m | +| vitpose-h | td-hm_ViTPose-huge-simple_8xb64-210e_coco-256x192 | 人体姿态估计 | ViTPose-huge | RTMDet-m | + +下表列出了可用的 3D 姿态估计模型别名及其对应的配置文件: + +| 别名 | 配置文件名称 | 对应任务 | 3D 姿态估计模型 | 2D 姿态估计模型 | 检测模型 | +| ------- | -------------------------------------------- | ----------------- | --------------- | --------------- | -------- | +| human3d | vid_pl_motionbert_8xb32-120e_h36m | 3D 人体姿态估计 | MotionBert | RTMPose-m | RTMDet-m | +| hand3d | internet_res50_4xb16-20e_interhand3d-256x256 | 3D 手部关键点检测 | InterNet | - | 全图 | 此外,用户可以使用命令行界面工具显示所有可用的别名,使用以下命令: ```shell python demo/inferencer_demo.py --show-alias ``` + +## 推理 API:用于更加灵活的自定义推理 + +MMPose 提供了单独的 Python API 用于不同模型的推理,这种推理方式更加灵活,但是需要用户自己处理输入和输出,因此适合于**熟悉 MMPose** 的用户。 + +MMPose 提供的 Python 推理接口存放于 [$MMPOSE/mmpose/apis](https://github.com/open-mmlab/mmpose/tree/dev-1.x/mmpose/apis) 目录下,以下是一个构建 topdown 模型并进行推理的示例: + +### 构建模型 + +```python +from mmcv.image import imread + +from mmpose.apis import inference_topdown, init_model +from mmpose.registry import VISUALIZERS +from mmpose.structures import merge_data_samples + +model_cfg = 'configs/body_2d_keypoint/rtmpose/coco/rtmpose-m_8xb256-420e_coco-256x192.py' + +ckpt = 'https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-256x192-4d3e73dd_20230605.pth' + +device = 'cuda' + +# 使用初始化接口构建模型 +model = init_model(model_cfg, ckpt, device=device) +``` + +### 推理 + +```python +img_path = 'tests/data/coco/000000000785.jpg' + +# 单张图片推理 +batch_results = inference_topdown(model, img_path) +``` + +推理接口返回的结果是一个 PoseDataSample 列表,每个 PoseDataSample 对应一张图片的推理结果。PoseDataSample 的结构如下所示: + +```python +[ +-在这种情况下,COCO 和 AIC 数据集都需要使用 `KeypointConverter` 来调整它们关键点的顺序: +在这种情况下,COCO 和 AIC 数据集都需要使用 [KeypointConverter](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/converting.py#L11) 来调整它们关键点的顺序: ```python dataset_coco = dict( @@ -142,7 +145,7 @@ dataset_aic = dict( - 在 `skeleton_info` 中添加了“头顶”和“颈部”间的连线; - 拓展 `joint_weights` 和 `sigmas` 以添加新增关键点的信息。 -完成以上步骤后,合并数据集 `CombinedDataset` 可以通过以下方式配置: +完成以上步骤后,合并数据集 [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) 可以通过以下方式配置: ```python dataset = dict( @@ -157,3 +160,53 @@ dataset = dict( ``` 此外,在使用混合数据集时,由于关键点数量的变化,模型的输出通道数也要做相应调整。如果用户用混合数据集训练了模型,但是要在 COCO 数据集上评估模型,就需要从模型输出的关键点中取出一个子集来匹配 COCO 中的关键点格式。可以通过 `test_cfg` 中的 `output_keypoint_indices` 参数自定义此子集。这个 [配置文件](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-combine.py) 展示了如何用 AIC 和 COCO 合并后的数据集训练模型并在 COCO 数据集上进行测试。用户可以查阅这个文件以获取更多细节,或者参考这个文件来构建新的混合数据集。 + +## 调整混合数据集采样策略 + +在混合数据集训练中,常常面临着不同数据集的数据分布不统一问题,对此我们提供了两种不同的采样策略: + +1. 调整每个子数据集的采样比例 +2. 调整每个 batch 中每个子数据集的比例 + +### 调整每个子数据集的采样比例 + +在 [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) 中,我们提供了 `sample_ratio_factor` 参数来调整每个子数据集的采样比例。 + +例如: + +- 如果 `sample_ratio_factor` 为 `[1.0, 0.5]`,则第一个子数据集全部数据加入训练,第二个子数据集抽样出 0.5 加入训练。 +- 如果 `sample_ratio_factor` 为 `[1.0, 2.0]`,则第一个子数据集全部数据加入训练,第二个子数据集抽样出其总数的 2 倍加入训练。 + +### 调整每个 batch 中每个子数据集的比例 + +在 [$MMPOSE/datasets/samplers.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/samplers.py) 中,我们提供了 [MultiSourceSampler](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/samplers.py#L15) 来调整每个 batch 中每个子数据集的比例。 + +例如: + +- 如果 `sample_ratio_factor` 为 `[1.0, 0.5]`,则每个 batch 中第一个子数据集的数据量为 `1.0 / (1.0 + 0.5) = 66.7%`,第二个子数据集的数据量为 `0.5 / (1.0 + 0.5) = 33.3%`。即,第一个子数据集在 batch 中的占比为第二个子数据集的 2 倍。 + +用户可以在配置文件中通过 `sampler` 参数来进行设置: + +```python +# data loaders +train_bs = 256 +train_dataloader = dict( + batch_size=train_bs, + num_workers=4, + persistent_workers=True, + sampler=dict( + type='MultiSourceSampler', + batch_size=train_bs, + # 设置子数据集比例 + source_ratio=[1.0, 0.5], + shuffle=True, + round_up=True), + dataset=dict( + type='CombinedDataset', + metainfo=dict(from_file='configs/_base_/datasets/coco.py'), + # 子数据集 + datasets=[sub_dataset1, sub_dataset2], + pipeline=train_pipeline, + test_mode=False, + )) +``` diff --git a/docs/zh_cn/advanced_guides/model_analysis.md b/docs/zh_cn/user_guides/model_analysis.md similarity index 86% rename from docs/zh_cn/advanced_guides/model_analysis.md rename to docs/zh_cn/user_guides/model_analysis.md index 234dc5be85..b88755620e 100644 --- a/docs/zh_cn/advanced_guides/model_analysis.md +++ b/docs/zh_cn/user_guides/model_analysis.md @@ -1,8 +1,8 @@ -# Model Analysis +# 模型统计与分析 ## 统计模型参数量与计算量 -MMPose 提供了 `tools/analysis_tools/get_flops.py` 来统计模型的参数量与计算量。 +MMPose 提供了 [tools/analysis_tools/get_flops.py](https://github.com/open-mmlab/mmpose/blob/dev-1.x/tools/analysis_tools/get_flops.py) 来统计模型的参数量与计算量。 ```shell python tools/analysis_tools/get_flops.py ${CONFIG_FILE} [--shape ${INPUT_SHAPE}] [--cfg-options ${CFG_OPTIONS}] @@ -42,7 +42,7 @@ Params: 28.54 M ## 分析训练日志 -MMPose 提供了 `tools/analysis_tools/analyze_logs.py` 来对训练日志进行简单的分析,包括: +MMPose 提供了 [tools/analysis_tools/analyze_logs.py](https://github.com/open-mmlab/mmpose/blob/dev-1.x/tools/analysis_tools/analyze_logs.py) 来对训练日志进行简单的分析,包括: - 将日志绘制成损失和精度曲线图 - 统计训练速度 diff --git a/docs/zh_cn/user_guides/prepare_datasets.md b/docs/zh_cn/user_guides/prepare_datasets.md index 8b7d651e88..4452405819 100644 --- a/docs/zh_cn/user_guides/prepare_datasets.md +++ b/docs/zh_cn/user_guides/prepare_datasets.md @@ -158,7 +158,7 @@ python tools/misc/browse_dataset.py configs/body_2d_keypoint/topdown_heatmap/coc ## 用 MIM 下载数据集 -通过使用 [OpenDataLab](https://opendatalab.com/),您可以直接下载开源数据集。通过平台的搜索功能,您可以快速轻松地找到他们正在寻找的数据集。使用平台上的格式化数据集,您可以高效地跨数据集执行任务。 +通过使用 [OpenXLab](https://openxlab.org.cn/datasets),您可以直接下载开源数据集。通过平台的搜索功能,您可以快速轻松地找到他们正在寻找的数据集。使用平台上的格式化数据集,您可以高效地跨数据集执行任务。 如果您使用 MIM 下载,请确保版本大于 v0.3.8。您可以使用以下命令进行更新、安装、登录和数据集下载: @@ -166,10 +166,10 @@ python tools/misc/browse_dataset.py configs/body_2d_keypoint/topdown_heatmap/coc # upgrade your MIM pip install -U openmim -# install OpenDataLab CLI tools -pip install -U opendatalab -# log in OpenDataLab, registry -odl login +# install OpenXLab CLI tools +pip install -U openxlab +# log in OpenXLab +openxlab login # download coco2017 and preprocess by MIM mim download mmpose --dataset coco2017 diff --git a/docs/zh_cn/user_guides/train_and_test.md b/docs/zh_cn/user_guides/train_and_test.md index 452eddc928..6cadeab0a3 100644 --- a/docs/zh_cn/user_guides/train_and_test.md +++ b/docs/zh_cn/user_guides/train_and_test.md @@ -1,5 +1,498 @@ # 训练与测试 -中文内容建设中,暂时请查阅[英文版文档](../../en/user_guides/train_and_test.md) +## 启动训练 -如果您愿意参与中文文档的翻译与维护,我们团队将十分感谢您的贡献!欢迎加入我们的社区群与我们取得联系,或直接按照 [如何给 MMPose 贡献代码](../contribution_guide.md) 在 GitHub 上提交 Pull Request。 +### 本地训练 + +你可以使用 `tools/train.py` 在单机上使用 CPU 或单个 GPU 训练模型。 + +```shell +python tools/train.py ${CONFIG_FILE} [ARGS] +``` + +```{note} +默认情况下,MMPose 会优先使用 GPU 而不是 CPU。如果你想在 CPU 上训练模型,请清空 `CUDA_VISIBLE_DEVICES` 或将其设置为 -1,使 GPU 对程序不可见。 +``` + +```shell +CUDA_VISIBLE_DEVICES=-1 python tools/train.py ${CONFIG_FILE} [ARGS] +``` + +| ARGS | Description | +| ------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- | +| `CONFIG_FILE` | 配置文件路径 | +| `--work-dir WORK_DIR` | 训练日志与 checkpoint 存放目录,默认使用配置文件名作为目录存放在 `./work_dirs` 下 | +| `--resume [RESUME]` | 恢复训练,可以从指定 checkpoint 进行重启,不指定则会使用最近一次的 checkpoint | +| `--amp` | 开启混合精度训练 | +| `--no-validate` | **不建议新手开启**。 训练中不进行评测 | +| `--auto-scale-lr` | 自动根据当前设置的实际 batch size 和配置文件中的标准 batch size 进行学习率缩放 | +| `--cfg-options CFG_OPTIONS` | 对当前配置文件中的一些设置进行临时覆盖,字典 key-value 格式为 xxx=yyy。如果需要覆盖的值是一个数组,格式应当为 `key="[a,b]"` 或 `key=a,b`。也允许使用元组,如 `key="[(a,b),(c,d)]"`。注意双引号是**必须的**,且**不允许**使用空格。 | +| `--show-dir SHOW_DIR` | 验证阶段生成的可视化图片存放路径 | +| `--show` | 使用窗口显示预测的可视化结果 | +| `--interval INTERVAL` | 进行可视化的间隔(每隔多少张图可视化一张) | +| `--wait-time WAIT_TIME` | 可视化显示时每张图片的持续时间(单位:秒),默认为 1 | +| `--launcher {none,pytorch,slurm,mpi}` | 可选的启动器 | + +### 多卡训练 + +我们提供了一个脚本来使用 `torch.distributed.launch` 启动多卡训练。 + +```shell +bash ./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [PY_ARGS] +``` + +| ARGS | Description | +| ------------- | -------------------------------------------------- | +| `CONFIG_FILE` | 配置文件路径 | +| `GPU_NUM` | 使用 GPU 数量 | +| `[PYARGS]` | 其他配置项 `tools/train.py`, 见 [这里](#本地训练). | + +你也可以通过环境变量来指定启动器的额外参数。例如,通过以下命令将启动器的通信端口改为 29666: + +```shell +PORT=29666 bash ./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [PY_ARGS] +``` + +如果你想同时启动多个训练任务并使用不同的 GPU,你可以通过指定不同的端口和可见设备来启动它们。 + +```shell +CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 bash ./tools/dist_train.sh ${CONFIG_FILE1} 4 [PY_ARGS] +CUDA_VISIBLE_DEVICES=4,5,6,7 GPUS=29501 bash ./tools/dist_train.sh ${CONFIG_FILE2} 4 [PY_ARGS] +``` + +### 分布式训练 + +#### 局域网多机训练 + +如果你使用以太网连接的多台机器启动训练任务,你可以运行以下命令: + +在第一台机器上: + +```shell +NNODES=2 NODE_RANK=1 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_train.sh $CONFIG $GPUS +``` + +相比于单机多卡,你需要指定一些额外的环境变量: + +| 环境变量 | 描述 | +| ------------- | -------------------------- | +| `NNODES` | 机器总数 | +| `NODE_RANK` | 当前机器序号 | +| `PORT` | 通信端口,所有机器必须相同 | +| `MASTER_ADDR` | 主机地址,所有机器必须相同 | + +通常情况下,如果你没有像 InfiniBand 这样的高速网络,那么训练速度会很慢。 + +#### Slurm 多机训练 + +如果你在一个使用 [slurm](https://slurm.schedmd.com/) 管理的集群上运行 MMPose,你可以使用 `slurm_train.sh` 脚本。 + +```shell +[ENV_VARS] ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${WORK_DIR} [PY_ARGS] +``` + +脚本参数说明: + +| 参数 | 描述 | +| ------------- | -------------------------------------------------- | +| `PARTITION` | 指定集群分区 | +| `JOB_NAME` | 任务名,可以任取 | +| `CONFIG_FILE` | 配置文件路径 | +| `WORK_DIR` | 训练日志存储路径 | +| `[PYARGS]` | 其他配置项 `tools/train.py`, 见 [这里](#本地训练). | + +以下是可以用来配置 slurm 任务的环境变量: + +| 环境变量 | 描述 | +| --------------- | ------------------------------------------------------------------------ | +| `GPUS` | GPU 总数,默认为 8 | +| `GPUS_PER_NODE` | 每台机器使用的 GPU 总数,默认为 8 | +| `CPUS_PER_TASK` | 每个任务分配的 CPU 总数(通常为 1 张 GPU 对应 1 个任务进程),默认为 5 | +| `SRUN_ARGS` | `srun` 的其他参数,可选项见 [这里](https://slurm.schedmd.com/srun.html). | + +## 恢复训练 + +恢复训练意味着从之前的训练中保存的状态继续训练,其中状态包括模型权重、优化器状态和优化器参数调整策略的状态。 + +### 自动恢复 + +用户可以在训练命令的末尾添加 `--resume` 来恢复训练。程序会自动从 `work_dirs` 中加载最新的权重文件来恢复训练。如果 `work_dirs` 中有最新的 `checkpoint`(例如在之前的训练中中断了训练),则会从 `checkpoint` 处恢复训练。否则(例如之前的训练没有及时保存 `checkpoint` 或者启动了一个新的训练任务),则会重新开始训练。 + +以下是一个恢复训练的例子: + +```shell +python tools/train.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192.py --resume +``` + +### 指定 checkpoint 恢复 + +你可以在 `load_from` 中指定 `checkpoint` 的路径,MMPose 会自动读取 `checkpoint` 并从中恢复训练。命令如下: + +```shell +python tools/train.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192.py \ + --resume work_dirs/td-hm_res50_8xb64-210e_coco-256x192/latest.pth +``` + +如果你希望在配置文件中手动指定 `checkpoint` 路径,除了设置 `resume=True`,还需要设置 `load_from`。 + +需要注意的是,如果只设置了 `load_from` 而没有设置 `resume=True`,那么只会加载 `checkpoint` 中的权重,而不会从之前的状态继续训练。 + +以下的例子与上面指定 `--resume` 参数的例子等价: + +```Python +resume = True +load_from = 'work_dirs/td-hm_res50_8xb64-210e_coco-256x192/latest.pth' +# model settings +model = dict( + ## omitted ## + ) +``` + +## 在训练中冻结部分参数 + +在某些场景下,我们可能希望在训练过程中冻结模型的某些参数,以便微调特定部分或防止过拟合。在 MMPose 中,你可以通过在 `paramwise_cfg` 中设置 `custom_keys` 来为模型中的任何模块设置不同的超参数。这样可以让你控制模型特定部分的学习率和衰减系数。 + +例如,如果你想冻结 `backbone.layer0` 和 `backbone.layer1` 的所有参数,你可以在配置文件中添加以下内容: + +```Python +optim_wrapper = dict( + optimizer=dict(...), + paramwise_cfg=dict( + custom_keys={ + 'backbone.layer0': dict(lr_mult=0, decay_mult=0), + 'backbone.layer0': dict(lr_mult=0, decay_mult=0), + })) +``` + +以上配置将会通过将学习率和衰减系数设置为 0 来冻结 `backbone.layer0` 和 `backbone.layer1` 中的参数。通过这种方式,你可以有效地控制训练过程,并根据需要微调模型的特定部分。 + +## 自动混合精度训练(AMP) + +混合精度训练可以减少训练时间和存储需求,而不改变模型或降低模型训练精度,从而支持更大的 batch size、更大的模型和更大的输入尺寸。 + +要启用自动混合精度(AMP)训练,请在训练命令的末尾添加 `--amp`,如下所示: + +```shell +python tools/train.py ${CONFIG_FILE} --amp +``` + +具体例子如下: + +```shell +python tools/train.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192.py --amp +``` + +## 设置随机种子 + +如果你想指定随机种子,你可以通过如下命令: + +```shell +python ./tools/train.py \ + ${CONFIG} \ # 配置文件 + --cfg-options randomness.seed=2023 \ # 设置 random seed = 2023 + [randomness.diff_rank_seed=True] \ # 不同 rank 的进程使用不同的随机种子 + [randomness.deterministic=True] # 设置 cudnn.deterministic=True +# `[]` 表示可选的参数,你不需要输入 `[]` +``` + +`randomness` 还有三个参数可以设置,具体含义如下。 + +- `randomness.seed=2023`,将随机种子设置为 `2023`。 + +- `randomness.diff_rank_seed=True`,根据全局 `rank` 设置不同的随机种子。默认为 `False`。 + +- `randomness.deterministic=True`,设置 `cuDNN` 后端的确定性选项,即将 `torch.backends.cudnn.deterministic` 设置为 `True`,将 `torch.backends.cudnn.benchmark` 设置为 `False`。默认为 `False`。更多细节请参考 [Pytorch Randomness](https://pytorch.org/docs/stable/notes/randomness.html)。 + +## 训练日志说明 + +在训练中,命令行会实时打印训练日志如下: + +```shell +07/14 08:26:50 - mmengine - INFO - Epoch(train) [38][ 6/38] base_lr: 5.148343e-04 lr: 5.148343e-04 eta: 0:15:34 time: 0.540754 data_time: 0.394292 memory: 3141 loss: 0.006220 loss_kpt: 0.006220 acc_pose: 1.000000 +``` + +以上训练日志包括如下内容: + +- `07/14 08:26:50`:当前时间 +- `mmengine`:日志前缀,表示日志来自 MMEngine +- `INFO` or `WARNING`:日志级别,表示该日志为普通信息 +- `Epoch(train)`:当前处于训练阶段,如果处于验证阶段,则为 `Epoch(val)` +- `[38][ 6/38]`:当前处于第 38 个 epoch,当前 batch 为第 6 个 batch,总共有 38 个 batch +- `base_lr`:基础学习率 +- `lr`:当前实际使用的学习率 +- `eta`:预计训练剩余时间 +- `time`:当前 batch 的训练时间(单位:分钟) +- `data_time`:当前 batch 的数据加载(i/o,数据增强)时间(单位:分钟) +- `memory`:当前进程占用的显存(单位:MB) +- `loss`:当前 batch 的总 loss +- `loss_kpt`:当前 batch 的关键点 loss +- `acc_pose`:当前 batch 的姿态准确率 + +## 可视化训练进程 + +监视训练过程对于了解模型的性能并进行必要的调整至关重要。在本节中,我们将介绍两种可视化训练过程的方法:TensorBoard 和 MMEngine Visualizer。 + +### TensorBoard + +TensorBoard 是一个强大的工具,可以让你可视化训练过程中的 loss 变化。要启用 TensorBoard 可视化,你可能需要: + +1. 安装 TensorBoard + + ```shell + pip install tensorboard + ``` + +2. 在配置文件中开启 TensorBoard 作为可视化后端: + + ```python + visualizer = dict(vis_backends=[ + dict(type='LocalVisBackend'), + dict(type='TensorboardVisBackend'), + ]) + ``` + +Tensorboard 生成的 event 文件会保存在实验日志文件夹 `${WORK_DIR}` 下,该文件夹默认为 `work_dir/${CONFIG}`,你也可以通过 `--work-dir` 参数指定。要可视化训练过程,请使用以下命令: + +```shell +tensorboard --logdir ${WORK_DIR}/${TIMESTAMP}/vis_data +``` + +### MMEngine Visualizer + +MMPose 还支持在验证过程中可视化模型的推理结果。要启用此功能,请在启动训练时使用 `--show` 选项或设置 `--show-dir`。这个功能提供了一种有效的方法来分析模型在特定示例上的性能并进行必要的调整。 + +## 测试 + +### 本地测试 + +你可以使用 `tools/test.py` 在单机上使用 CPU 或单个 GPU 测试模型。 + +```shell +python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [ARGS] +``` + +```{note} +默认情况下,MMPose 会优先使用 GPU 而不是 CPU。如果你想在 CPU 上测试模型,请清空 `CUDA_VISIBLE_DEVICES` 或将其设置为 -1,使 GPU 对程序不可见。 +``` + +```shell +CUDA_VISIBLE_DEVICES=-1 python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [ARGS] +``` + +| ARGS | Description | +| ------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- | +| `CONFIG_FILE` | 配置文件路径file. | +| `CHECKPOINT_FILE` | checkpoint 文件路径,可以是本地文件,也可以是网络链接。 [这里](https://MMPose.readthedocs.io/en/latest/model_zoo.html) 是 MMPose 提供的 checkpoint 列表. | +| `--work-dir WORK_DIR` | 评测结果存储目录 | +| `--out OUT` | 评测结果存放文件 | +| `--dump DUMP` | 导出评测时的模型输出,用于用户自行离线评测 | +| `--cfg-options CFG_OPTIONS` | 对当前配置文件中的一些设置进行临时覆盖,字典 key-value 格式为 xxx=yyy。如果需要覆盖的值是一个数组,格式应当为 `key="[a,b]"` 或 `key=a,b`。也允许使用元组,如 `key="[(a,b),(c,d)]"`。注意双引号是**必须的**,且**不允许**使用空格。 | +| `--show-dir SHOW_DIR` | T验证阶段生成的可视化图片存放路径 | +| `--show` | 使用窗口显示预测的可视化结果 | +| `--interval INTERVAL` | 进行可视化的间隔(每隔多少张图可视化一张) | +| `--wait-time WAIT_TIME` | 可视化显示时每张图片的持续时间(单位:秒),默认为 1 | +| `--launcher {none,pytorch,slurm,mpi}` | 可选的启动器 | + +### 多卡测试 + +我们提供了一个脚本来使用 `torch.distributed.launch` 启动多卡测试。 + +```shell +bash ./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [PY_ARGS] +``` + +| ARGS | Description | +| ----------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------- | +| `CONFIG_FILE` | 配置文件路径 | +| `CHECKPOINT_FILE` | checkpoint 文件路径,可以是本地文件,也可以是网络链接。 [这里](https://MMPose.readthedocs.io/en/latest/model_zoo.html) 是 MMPose 提供的 checkpoint 列表 | +| `GPU_NUM` | 使用 GPU 数量 | +| `[PYARGS]` | 其他配置项 `tools/test.py`, 见 [这里](#本地测试) | + +你也可以通过环境变量来指定启动器的额外参数。例如,通过以下命令将启动器的通信端口改为 29666: + +```shell +PORT=29666 bash ./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [PY_ARGS] +``` + +如果你想同时启动多个测试任务并使用不同的 GPU,你可以通过指定不同的端口和可见设备来启动它们。 + +```shell +CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 bash ./tools/dist_test.sh ${CONFIG_FILE1} ${CHECKPOINT_FILE} 4 [PY_ARGS] +CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 bash ./tools/dist_test.sh ${CONFIG_FILE2} ${CHECKPOINT_FILE} 4 [PY_ARGS] +``` + +### 分布式测试 + +#### 局域网多机测试 + +如果你使用以太网连接的多台机器启动测试任务,你可以运行以下命令: + +在第一台机器上: + +```shell +NNODES=2 NODE_RANK=0 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_test.sh $CONFIG $CHECKPOINT_FILE $GPUS +``` + +在第二台机器上: + +```shell +NNODES=2 NODE_RANK=1 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_test.sh $CONFIG $CHECKPOINT_FILE $GPUS +``` + +相比于单机多卡,你需要指定一些额外的环境变量: + +| 环境变量 | 描述 | +| ------------- | -------------------------- | +| `NNODES` | 机器总数 | +| `NODE_RANK` | 当前机器序号 | +| `PORT` | 通信端口,所有机器必须相同 | +| `MASTER_ADDR` | 主机地址,所有机器必须相同 | + +通常情况下,如果你没有像 InfiniBand 这样的高速网络,那么测试速度会很慢。 + +#### Slurm 多机测试 + +如果你在一个使用 [slurm](https://slurm.schedmd.com/) 管理的集群上运行 MMPose,你可以使用 `slurm_test.sh` 脚本。 + +```shell +[ENV_VARS] ./tools/slurm_test.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${CHECKPOINT_FILE} [PY_ARGS] +``` + +脚本参数说明: + +| 参数 | 描述 | +| ----------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------- | +| `PARTITION` | 指定集群分区 | +| `JOB_NAME` | 任务名,可以任取 | +| `CONFIG_FILE` | 配置文件路径 | +| `CHECKPOINT_FILE` | checkpoint 文件路径,可以是本地文件,也可以是网络链接。 [这里](https://MMPose.readthedocs.io/en/latest/model_zoo.html) 是 MMPose 提供的 checkpoint 列表 | +| `[PYARGS]` | 其他配置项 `tools/test.py`, 见 [这里](#本地测试) | + +以下是可以用来配置 slurm 任务的环境变量: + +| 环境变量 | 描述 | +| --------------- | ------------------------------------------------------------------------ | +| `GPUS` | GPU 总数,默认为 8 | +| `GPUS_PER_NODE` | 每台机器使用的 GPU 总数,默认为 8 | +| `CPUS_PER_TASK` | 每个任务分配的 CPU 总数(通常为 1 张 GPU 对应 1 个任务进程),默认为 5 | +| `SRUN_ARGS` | `srun` 的其他参数,可选项见 [这里](https://slurm.schedmd.com/srun.html). | + +## 自定义测试 + +### 用自定义度量进行测试 + +如果您希望使用 MMPose 中尚未支持的独特度量来评估模型,您将需要自己编写这些度量并将它们包含在您的配置文件中。关于如何实现这一点的指导,请查看我们的 [自定义评估指南](https://mmpose.readthedocs.io/zh_CN/dev-1.x/advanced_guides/customize_evaluation.html)。 + +### 在多个数据集上进行评估 + +MMPose 提供了一个名为 `MultiDatasetEvaluator` 的便捷工具,用于在多个数据集上进行简化评估。在配置文件中设置此评估器非常简单。下面是一个快速示例,演示如何使用 COCO 和 AIC 数据集评估模型: + +```python +# 设置验证数据集 +coco_val = dict(type='CocoDataset', ...) + +aic_val = dict(type='AicDataset', ...) + +val_dataset = dict( + type='CombinedDataset', + datasets=[coco_val, aic_val], + pipeline=val_pipeline, + ...) + +# 配置评估器 +val_evaluator = dict( + type='MultiDatasetEvaluator', + metrics=[ # 为每个数据集配置度量 + dict(type='CocoMetric', + ann_file='data/coco/annotations/person_keypoints_val2017.json'), + dict(type='CocoMetric', + ann_file='data/aic/annotations/aic_val.json', + use_area=False, + prefix='aic') + ], + # 数据集个数和顺序与度量必须匹配 + datasets=[coco_val, aic_val], + ) +``` + +同的数据集(如 COCO 和 AIC)具有不同的关键点定义。然而,模型的输出关键点是标准化的。这导致了模型输出与真值之间关键点顺序的差异。为解决这一问题,您可以使用 `KeypointConverter` 来对齐不同数据集之间的关键点顺序。下面是一个完整示例,展示了如何利用 `KeypointConverter` 来对齐 AIC 关键点与 COCO 关键点: + +```python +aic_to_coco_converter = dict( + type='KeypointConverter', + num_keypoints=17, + mapping=[ + (0, 6), + (1, 8), + (2, 10), + (3, 5), + (4, 7), + (5, 9), + (6, 12), + (7, 14), + (8, 16), + (9, 11), + (10, 13), + (11, 15), + ]) + +# val datasets +coco_val = dict( + type='CocoDataset', + data_root='data/coco/', + data_mode='topdown', + ann_file='annotations/person_keypoints_val2017.json', + bbox_file='data/coco/person_detection_results/' + 'COCO_val2017_detections_AP_H_56_person.json', + data_prefix=dict(img='val2017/'), + test_mode=True, + pipeline=[], +) + +aic_val = dict( + type='AicDataset', + data_root='data/aic/', + data_mode=data_mode, + ann_file='annotations/aic_val.json', + data_prefix=dict(img='ai_challenger_keypoint_validation_20170911/' + 'keypoint_validation_images_20170911/'), + test_mode=True, + pipeline=[], + ) + +val_dataset = dict( + type='CombinedDataset', + metainfo=dict(from_file='configs/_base_/datasets/coco.py'), + datasets=[coco_val, aic_val], + pipeline=val_pipeline, + test_mode=True, + ) + +val_dataloader = dict( + batch_size=32, + num_workers=2, + persistent_workers=True, + drop_last=False, + sampler=dict(type='DefaultSampler', shuffle=False, round_up=False), + dataset=val_dataset) + +test_dataloader = val_dataloader + +val_evaluator = dict( + type='MultiDatasetEvaluator', + metrics=[ + dict(type='CocoMetric', + ann_file=data_root + 'annotations/person_keypoints_val2017.json'), + dict(type='CocoMetric', + ann_file='data/aic/annotations/aic_val.json', + use_area=False, + gt_converter=aic_to_coco_converter, + prefix='aic') + ], + datasets=val_dataset['datasets'], + ) + +test_evaluator = val_evaluator +``` + +如需进一步了解如何将 AIC 关键点转换为 COCO 关键点,请查阅 [该指南](https://mmpose.readthedocs.io/zh_CN/dev-1.x/user_guides/mixed_datasets.html#aic-coco)。 diff --git a/docs/zh_cn/user_guides/useful_tools.md b/docs/zh_cn/user_guides/useful_tools.md deleted file mode 100644 index f2ceb771b7..0000000000 --- a/docs/zh_cn/user_guides/useful_tools.md +++ /dev/null @@ -1,5 +0,0 @@ -# 常用工具 - -中文内容建设中,暂时请查阅[英文版文档](../../en/user_guides/useful_tools.md) - -如果您愿意参与中文文档的翻译与维护,我们团队将十分感谢您的贡献!欢迎加入我们的社区群与我们取得联系,或直接按照 [如何给 MMPose 贡献代码](../contribution_guide.md) 在 GitHub 上提交 Pull Request。 diff --git a/docs/zh_cn/user_guides/visualization.md b/docs/zh_cn/user_guides/visualization.md deleted file mode 100644 index a584eb450e..0000000000 --- a/docs/zh_cn/user_guides/visualization.md +++ /dev/null @@ -1,5 +0,0 @@ -# 可视化 - -中文内容建设中,暂时请查阅[英文版文档](../../en/user_guides/visualization.md) - -如果您愿意参与中文文档的翻译与维护,我们团队将十分感谢您的贡献!欢迎加入我们的社区群与我们取得联系,或直接按照 [如何给 MMPose 贡献代码](../contribution_guide.md) 在 GitHub 上提交 Pull Request。 diff --git a/mmpose/__init__.py b/mmpose/__init__.py index ad7946470d..583ede0a4d 100644 --- a/mmpose/__init__.py +++ b/mmpose/__init__.py @@ -6,7 +6,7 @@ from .version import __version__, short_version mmcv_minimum_version = '2.0.0rc4' -mmcv_maximum_version = '2.1.0' +mmcv_maximum_version = '2.2.0' mmcv_version = digit_version(mmcv.__version__) mmengine_minimum_version = '0.6.0' diff --git a/mmpose/apis/__init__.py b/mmpose/apis/__init__.py index 0c44f7a3f8..322ee9cf73 100644 --- a/mmpose/apis/__init__.py +++ b/mmpose/apis/__init__.py @@ -5,11 +5,12 @@ extract_pose_sequence, inference_pose_lifter_model) from .inference_tracking import _compute_iou, _track_by_iou, _track_by_oks from .inferencers import MMPoseInferencer, Pose2DInferencer +from .visualization import visualize __all__ = [ 'init_model', 'inference_topdown', 'inference_bottomup', 'collect_multi_frames', 'Pose2DInferencer', 'MMPoseInferencer', '_track_by_iou', '_track_by_oks', '_compute_iou', 'inference_pose_lifter_model', 'extract_pose_sequence', - 'convert_keypoint_definition', 'collate_pose_sequence' + 'convert_keypoint_definition', 'collate_pose_sequence', 'visualize' ] diff --git a/mmpose/apis/inference.py b/mmpose/apis/inference.py index 772ef17b7c..5662d6f30b 100644 --- a/mmpose/apis/inference.py +++ b/mmpose/apis/inference.py @@ -53,7 +53,8 @@ def dataset_meta_from_config(config: Config, import mmpose.datasets.datasets # noqa: F401, F403 from mmpose.registry import DATASETS - dataset_class = DATASETS.get(dataset_cfg.type) + dataset_class = dataset_cfg.type if isinstance( + dataset_cfg.type, type) else DATASETS.get(dataset_cfg.type) metainfo = dataset_class.METAINFO metainfo = parse_pose_metainfo(metainfo) diff --git a/mmpose/apis/inference_3d.py b/mmpose/apis/inference_3d.py index d5bb753945..ae6428f187 100644 --- a/mmpose/apis/inference_3d.py +++ b/mmpose/apis/inference_3d.py @@ -23,18 +23,15 @@ def convert_keypoint_definition(keypoints, pose_det_dataset, ndarray[K, 2 or 3]: the transformed 2D keypoints. """ assert pose_lift_dataset in [ - 'Human36mDataset'], '`pose_lift_dataset` should be ' \ - f'`Human36mDataset`, but got {pose_lift_dataset}.' + 'h36m'], '`pose_lift_dataset` should be ' \ + f'`h36m`, but got {pose_lift_dataset}.' - coco_style_datasets = [ - 'CocoDataset', 'PoseTrack18VideoDataset', 'PoseTrack18Dataset' - ] keypoints_new = np.zeros((keypoints.shape[0], 17, keypoints.shape[2]), dtype=keypoints.dtype) - if pose_lift_dataset == 'Human36mDataset': - if pose_det_dataset in ['Human36mDataset']: + if pose_lift_dataset == 'h36m': + if pose_det_dataset in ['h36m']: keypoints_new = keypoints - elif pose_det_dataset in coco_style_datasets: + elif pose_det_dataset in ['coco', 'posetrack18']: # pelvis (root) is in the middle of l_hip and r_hip keypoints_new[:, 0] = (keypoints[:, 11] + keypoints[:, 12]) / 2 # thorax is in the middle of l_shoulder and r_shoulder @@ -48,7 +45,7 @@ def convert_keypoint_definition(keypoints, pose_det_dataset, # rearrange other keypoints keypoints_new[:, [1, 2, 3, 4, 5, 6, 9, 11, 12, 13, 14, 15, 16]] = \ keypoints[:, [12, 14, 16, 11, 13, 15, 0, 5, 7, 9, 6, 8, 10]] - elif pose_det_dataset in ['AicDataset']: + elif pose_det_dataset in ['aic']: # pelvis (root) is in the middle of l_hip and r_hip keypoints_new[:, 0] = (keypoints[:, 9] + keypoints[:, 6]) / 2 # thorax is in the middle of l_shoulder and r_shoulder @@ -66,7 +63,7 @@ def convert_keypoint_definition(keypoints, pose_det_dataset, keypoints_new[:, [1, 2, 3, 4, 5, 6, 11, 12, 13, 14, 15, 16]] = \ keypoints[:, [6, 7, 8, 9, 10, 11, 3, 4, 5, 0, 1, 2]] - elif pose_det_dataset in ['CrowdPoseDataset']: + elif pose_det_dataset in ['crowdpose']: # pelvis (root) is in the middle of l_hip and r_hip keypoints_new[:, 0] = (keypoints[:, 6] + keypoints[:, 7]) / 2 # thorax is in the middle of l_shoulder and r_shoulder @@ -181,16 +178,11 @@ def collate_pose_sequence(pose_results_2d, pose_sequences = [] for idx in range(N): pose_seq = PoseDataSample() - gt_instances = InstanceData() pred_instances = InstanceData() - for k in pose_results_2d[target_frame][idx].gt_instances.keys(): - gt_instances.set_field( - pose_results_2d[target_frame][idx].gt_instances[k], k) - for k in pose_results_2d[target_frame][idx].pred_instances.keys(): - if k != 'keypoints': - pred_instances.set_field( - pose_results_2d[target_frame][idx].pred_instances[k], k) + gt_instances = pose_results_2d[target_frame][idx].gt_instances.clone() + pred_instances = pose_results_2d[target_frame][ + idx].pred_instances.clone() pose_seq.pred_instances = pred_instances pose_seq.gt_instances = gt_instances @@ -228,7 +220,7 @@ def collate_pose_sequence(pose_results_2d, # replicate the right most frame keypoints[:, frame_idx + 1:] = keypoints[:, frame_idx] break - pose_seq.pred_instances.keypoints = keypoints + pose_seq.pred_instances.set_field(keypoints, 'keypoints') pose_sequences.append(pose_seq) return pose_sequences @@ -276,8 +268,15 @@ def inference_pose_lifter_model(model, bbox_center = None bbox_scale = None + pose_results_2d_copy = [] for i, pose_res in enumerate(pose_results_2d): + pose_res_copy = [] for j, data_sample in enumerate(pose_res): + data_sample_copy = PoseDataSample() + data_sample_copy.gt_instances = data_sample.gt_instances.clone() + data_sample_copy.pred_instances = data_sample.pred_instances.clone( + ) + data_sample_copy.track_id = data_sample.track_id kpts = data_sample.pred_instances.keypoints bboxes = data_sample.pred_instances.bboxes keypoints = [] @@ -292,11 +291,13 @@ def inference_pose_lifter_model(model, bbox_scale + bbox_center) else: keypoints.append(kpt[:, :2]) - pose_results_2d[i][j].pred_instances.keypoints = np.array( - keypoints) + data_sample_copy.pred_instances.set_field( + np.array(keypoints), 'keypoints') + pose_res_copy.append(data_sample_copy) + pose_results_2d_copy.append(pose_res_copy) - pose_sequences_2d = collate_pose_sequence(pose_results_2d, with_track_id, - target_idx) + pose_sequences_2d = collate_pose_sequence(pose_results_2d_copy, + with_track_id, target_idx) if not pose_sequences_2d: return [] @@ -316,8 +317,10 @@ def inference_pose_lifter_model(model, T, K, ), dtype=np.float32) - data_info['lifting_target'] = np.zeros((K, 3), dtype=np.float32) - data_info['lifting_target_visible'] = np.ones((K, 1), dtype=np.float32) + data_info['lifting_target'] = np.zeros((1, K, 3), dtype=np.float32) + data_info['factor'] = np.zeros((T, ), dtype=np.float32) + data_info['lifting_target_visible'] = np.ones((1, K, 1), + dtype=np.float32) if image_size is not None: assert len(image_size) == 2 diff --git a/mmpose/apis/inferencers/__init__.py b/mmpose/apis/inferencers/__init__.py index 5955d79da9..0e2b5c8293 100644 --- a/mmpose/apis/inferencers/__init__.py +++ b/mmpose/apis/inferencers/__init__.py @@ -1,4 +1,5 @@ # Copyright (c) OpenMMLab. All rights reserved. +from .hand3d_inferencer import Hand3DInferencer from .mmpose_inferencer import MMPoseInferencer from .pose2d_inferencer import Pose2DInferencer from .pose3d_inferencer import Pose3DInferencer @@ -6,5 +7,5 @@ __all__ = [ 'Pose2DInferencer', 'MMPoseInferencer', 'get_model_aliases', - 'Pose3DInferencer' + 'Pose3DInferencer', 'Hand3DInferencer' ] diff --git a/mmpose/apis/inferencers/base_mmpose_inferencer.py b/mmpose/apis/inferencers/base_mmpose_inferencer.py index bed28b90d7..d7d5eb8c19 100644 --- a/mmpose/apis/inferencers/base_mmpose_inferencer.py +++ b/mmpose/apis/inferencers/base_mmpose_inferencer.py @@ -1,10 +1,10 @@ # Copyright (c) OpenMMLab. All rights reserved. +import logging import mimetypes import os -import warnings from collections import defaultdict from typing import (Callable, Dict, Generator, Iterable, List, Optional, - Sequence, Union) + Sequence, Tuple, Union) import cv2 import mmcv @@ -15,14 +15,23 @@ from mmengine.dataset import Compose from mmengine.fileio import (get_file_backend, isdir, join_path, list_dir_or_file) -from mmengine.infer.infer import BaseInferencer +from mmengine.infer.infer import BaseInferencer, ModelType +from mmengine.logging import print_log from mmengine.registry import init_default_scope from mmengine.runner.checkpoint import _load_checkpoint_to_model from mmengine.structures import InstanceData from mmengine.utils import mkdir_or_exist from mmpose.apis.inference import dataset_meta_from_config +from mmpose.registry import DATASETS from mmpose.structures import PoseDataSample, split_instances +from .utils import default_det_models + +try: + from mmdet.apis.det_inferencer import DetInferencer + has_mmdet = True +except (ImportError, ModuleNotFoundError): + has_mmdet = False InstanceList = List[InstanceData] InputType = Union[str, np.ndarray] @@ -42,7 +51,45 @@ class BaseMMPoseInferencer(BaseInferencer): 'return_vis', 'show', 'wait_time', 'draw_bbox', 'radius', 'thickness', 'kpt_thr', 'vis_out_dir', 'black_background' } - postprocess_kwargs: set = {'pred_out_dir'} + postprocess_kwargs: set = {'pred_out_dir', 'return_datasample'} + + def _init_detector( + self, + det_model: Optional[Union[ModelType, str]] = None, + det_weights: Optional[str] = None, + det_cat_ids: Optional[Union[int, Tuple]] = None, + device: Optional[str] = None, + ): + object_type = DATASETS.get(self.cfg.dataset_type).__module__.split( + 'datasets.')[-1].split('.')[0].lower() + + if det_model in ('whole_image', 'whole-image') or \ + (det_model is None and + object_type not in default_det_models): + self.detector = None + + else: + det_scope = 'mmdet' + if det_model is None: + det_info = default_det_models[object_type] + det_model, det_weights, det_cat_ids = det_info[ + 'model'], det_info['weights'], det_info['cat_ids'] + elif os.path.exists(det_model): + det_cfg = Config.fromfile(det_model) + det_scope = det_cfg.default_scope + + if has_mmdet: + self.detector = DetInferencer( + det_model, det_weights, device=device, scope=det_scope) + else: + raise RuntimeError( + 'MMDetection (v3.0.0 or above) is required to build ' + 'inferencers for top-down pose estimation models.') + + if isinstance(det_cat_ids, (tuple, list)): + self.det_cat_ids = det_cat_ids + else: + self.det_cat_ids = (det_cat_ids, ) def _load_weights_to_model(self, model: nn.Module, checkpoint: Optional[dict], @@ -65,15 +112,20 @@ def _load_weights_to_model(self, model: nn.Module, # mmpose 1.x model.dataset_meta = checkpoint_meta['dataset_meta'] else: - warnings.warn( + print_log( 'dataset_meta are not saved in the checkpoint\'s ' - 'meta data, load via config.') + 'meta data, load via config.', + logger='current', + level=logging.WARNING) model.dataset_meta = dataset_meta_from_config( cfg, dataset_mode='train') else: - warnings.warn('Checkpoint is not loaded, and the inference ' - 'result is calculated by the randomly initialized ' - 'model!') + print_log( + 'Checkpoint is not loaded, and the inference ' + 'result is calculated by the randomly initialized ' + 'model!', + logger='current', + level=logging.WARNING) model.dataset_meta = dataset_meta_from_config( cfg, dataset_mode='train') @@ -176,7 +228,10 @@ def _get_webcam_inputs(self, inputs: str) -> Generator: # Attempt to open the video capture object. vcap = cv2.VideoCapture(camera_id) if not vcap.isOpened(): - warnings.warn(f'Cannot open camera (ID={camera_id})') + print_log( + f'Cannot open camera (ID={camera_id})', + logger='current', + level=logging.WARNING) return [] # Set video input flag and metadata. @@ -257,6 +312,101 @@ def preprocess(self, # only supports inference with batch size 1 yield self.collate_fn(data_infos), [input] + def __call__( + self, + inputs: InputsType, + return_datasamples: bool = False, + batch_size: int = 1, + out_dir: Optional[str] = None, + **kwargs, + ) -> dict: + """Call the inferencer. + + Args: + inputs (InputsType): Inputs for the inferencer. + return_datasamples (bool): Whether to return results as + :obj:`BaseDataElement`. Defaults to False. + batch_size (int): Batch size. Defaults to 1. + out_dir (str, optional): directory to save visualization + results and predictions. Will be overoden if vis_out_dir or + pred_out_dir are given. Defaults to None + **kwargs: Key words arguments passed to :meth:`preprocess`, + :meth:`forward`, :meth:`visualize` and :meth:`postprocess`. + Each key in kwargs should be in the corresponding set of + ``preprocess_kwargs``, ``forward_kwargs``, + ``visualize_kwargs`` and ``postprocess_kwargs``. + + Returns: + dict: Inference and visualization results. + """ + if out_dir is not None: + if 'vis_out_dir' not in kwargs: + kwargs['vis_out_dir'] = f'{out_dir}/visualizations' + if 'pred_out_dir' not in kwargs: + kwargs['pred_out_dir'] = f'{out_dir}/predictions' + + ( + preprocess_kwargs, + forward_kwargs, + visualize_kwargs, + postprocess_kwargs, + ) = self._dispatch_kwargs(**kwargs) + + self.update_model_visualizer_settings(**kwargs) + + # preprocessing + if isinstance(inputs, str) and inputs.startswith('webcam'): + inputs = self._get_webcam_inputs(inputs) + batch_size = 1 + if not visualize_kwargs.get('show', False): + print_log( + 'The display mode is closed when using webcam ' + 'input. It will be turned on automatically.', + logger='current', + level=logging.WARNING) + visualize_kwargs['show'] = True + else: + inputs = self._inputs_to_list(inputs) + + # check the compatibility between inputs/outputs + if not self._video_input and len(inputs) > 0: + vis_out_dir = visualize_kwargs.get('vis_out_dir', None) + if vis_out_dir is not None: + _, file_extension = os.path.splitext(vis_out_dir) + assert not file_extension, f'the argument `vis_out_dir` ' \ + f'should be a folder while the input contains multiple ' \ + f'images, but got {vis_out_dir}' + + if 'bbox_thr' in self.forward_kwargs: + forward_kwargs['bbox_thr'] = preprocess_kwargs.get('bbox_thr', -1) + inputs = self.preprocess( + inputs, batch_size=batch_size, **preprocess_kwargs) + + preds = [] + + for proc_inputs, ori_inputs in inputs: + preds = self.forward(proc_inputs, **forward_kwargs) + + visualization = self.visualize(ori_inputs, preds, + **visualize_kwargs) + results = self.postprocess( + preds, + visualization, + return_datasamples=return_datasamples, + **postprocess_kwargs) + yield results + + if self._video_input: + self._finalize_video_processing( + postprocess_kwargs.get('pred_out_dir', '')) + + # In 3D Inferencers, some intermediate results (e.g. 2d keypoints) + # will be temporarily stored in `self._buffer`. It's essential to + # clear this information to prevent any interference with subsequent + # inferences. + if hasattr(self, '_buffer'): + self._buffer.clear() + def visualize(self, inputs: list, preds: List[PoseDataSample], @@ -340,44 +490,58 @@ def visualize(self, results.append(visualization) if vis_out_dir: - out_img = mmcv.rgb2bgr(visualization) - _, file_extension = os.path.splitext(vis_out_dir) - if file_extension: - dir_name = os.path.dirname(vis_out_dir) - file_name = os.path.basename(vis_out_dir) - else: - dir_name = vis_out_dir - file_name = None - mkdir_or_exist(dir_name) - - if self._video_input: - - if self.video_info['writer'] is None: - fourcc = cv2.VideoWriter_fourcc(*'mp4v') - if file_name is None: - file_name = os.path.basename( - self.video_info['name']) - out_file = join_path(dir_name, file_name) - self.video_info['writer'] = cv2.VideoWriter( - out_file, fourcc, self.video_info['fps'], - (visualization.shape[1], visualization.shape[0])) - self.video_info['writer'].write(out_img) - - else: - file_name = file_name if file_name else img_name - out_file = join_path(dir_name, file_name) - mmcv.imwrite(out_img, out_file) + self.save_visualization( + visualization, + vis_out_dir, + img_name=img_name, + ) if return_vis: return results else: return [] + def save_visualization(self, visualization, vis_out_dir, img_name=None): + out_img = mmcv.rgb2bgr(visualization) + _, file_extension = os.path.splitext(vis_out_dir) + if file_extension: + dir_name = os.path.dirname(vis_out_dir) + file_name = os.path.basename(vis_out_dir) + else: + dir_name = vis_out_dir + file_name = None + mkdir_or_exist(dir_name) + + if self._video_input: + + if self.video_info['writer'] is None: + fourcc = cv2.VideoWriter_fourcc(*'mp4v') + if file_name is None: + file_name = os.path.basename(self.video_info['name']) + out_file = join_path(dir_name, file_name) + self.video_info['output_file'] = out_file + self.video_info['writer'] = cv2.VideoWriter( + out_file, fourcc, self.video_info['fps'], + (visualization.shape[1], visualization.shape[0])) + self.video_info['writer'].write(out_img) + + else: + if file_name is None: + file_name = img_name if img_name else 'visualization.jpg' + + out_file = join_path(dir_name, file_name) + mmcv.imwrite(out_img, out_file) + print_log( + f'the output image has been saved at {out_file}', + logger='current', + level=logging.INFO) + def postprocess( self, preds: List[PoseDataSample], visualization: List[np.ndarray], - return_datasample=False, + return_datasample=None, + return_datasamples=False, pred_out_dir: str = '', ) -> dict: """Process the predictions and visualization results from ``forward`` @@ -392,7 +556,7 @@ def postprocess( Args: preds (List[Dict]): Predictions of the model. visualization (np.ndarray): Visualized predictions. - return_datasample (bool): Whether to return results as + return_datasamples (bool): Whether to return results as datasamples. Defaults to False. pred_out_dir (str): Directory to save the inference results w/o visualization. If left as empty, no file will be saved. @@ -405,16 +569,24 @@ def postprocess( - ``visualization (Any)``: Returned by :meth:`visualize` - ``predictions`` (dict or DataSample): Returned by :meth:`forward` and processed in :meth:`postprocess`. - If ``return_datasample=False``, it usually should be a + If ``return_datasamples=False``, it usually should be a json-serializable dict containing only basic data elements such as strings and numbers. """ + if return_datasample is not None: + print_log( + 'The `return_datasample` argument is deprecated ' + 'and will be removed in future versions. Please ' + 'use `return_datasamples`.', + logger='current', + level=logging.WARNING) + return_datasamples = return_datasample result_dict = defaultdict(list) result_dict['visualization'] = visualization for pred in preds: - if not return_datasample: + if not return_datasamples: # convert datasamples to list of instance predictions pred = split_instances(pred.pred_instances) result_dict['predictions'].append(pred) @@ -454,6 +626,11 @@ def _finalize_video_processing( # Release the video writer if it exists if self.video_info['writer'] is not None: + out_file = self.video_info['output_file'] + print_log( + f'the output video has been saved at {out_file}', + logger='current', + level=logging.INFO) self.video_info['writer'].release() # Save predictions diff --git a/mmpose/apis/inferencers/hand3d_inferencer.py b/mmpose/apis/inferencers/hand3d_inferencer.py new file mode 100644 index 0000000000..57f1eb06eb --- /dev/null +++ b/mmpose/apis/inferencers/hand3d_inferencer.py @@ -0,0 +1,339 @@ +# Copyright (c) OpenMMLab. All rights reserved. +import logging +import os +from collections import defaultdict +from typing import Dict, List, Optional, Sequence, Tuple, Union + +import mmcv +import numpy as np +import torch +from mmengine.config import Config, ConfigDict +from mmengine.infer.infer import ModelType +from mmengine.logging import print_log +from mmengine.model import revert_sync_batchnorm +from mmengine.registry import init_default_scope +from mmengine.structures import InstanceData + +from mmpose.evaluation.functional import nms +from mmpose.registry import INFERENCERS +from mmpose.structures import PoseDataSample, merge_data_samples +from .base_mmpose_inferencer import BaseMMPoseInferencer + +InstanceList = List[InstanceData] +InputType = Union[str, np.ndarray] +InputsType = Union[InputType, Sequence[InputType]] +PredType = Union[InstanceData, InstanceList] +ImgType = Union[np.ndarray, Sequence[np.ndarray]] +ConfigType = Union[Config, ConfigDict] +ResType = Union[Dict, List[Dict], InstanceData, List[InstanceData]] + + +@INFERENCERS.register_module() +class Hand3DInferencer(BaseMMPoseInferencer): + """The inferencer for 3D hand pose estimation. + + Args: + model (str, optional): Pretrained 2D pose estimation algorithm. + It's the path to the config file or the model name defined in + metafile. For example, it could be: + + - model alias, e.g. ``'body'``, + - config name, e.g. ``'simcc_res50_8xb64-210e_coco-256x192'``, + - config path + + Defaults to ``None``. + weights (str, optional): Path to the checkpoint. If it is not + specified and "model" is a model name of metafile, the weights + will be loaded from metafile. Defaults to None. + device (str, optional): Device to run inference. If None, the + available device will be automatically used. Defaults to None. + scope (str, optional): The scope of the model. Defaults to "mmpose". + det_model (str, optional): Config path or alias of detection model. + Defaults to None. + det_weights (str, optional): Path to the checkpoints of detection + model. Defaults to None. + det_cat_ids (int or list[int], optional): Category id for + detection model. Defaults to None. + """ + + preprocess_kwargs: set = {'bbox_thr', 'nms_thr', 'bboxes'} + forward_kwargs: set = {'disable_rebase_keypoint'} + visualize_kwargs: set = { + 'return_vis', + 'show', + 'wait_time', + 'draw_bbox', + 'radius', + 'thickness', + 'kpt_thr', + 'vis_out_dir', + 'num_instances', + } + postprocess_kwargs: set = {'pred_out_dir', 'return_datasample'} + + def __init__(self, + model: Union[ModelType, str], + weights: Optional[str] = None, + device: Optional[str] = None, + scope: Optional[str] = 'mmpose', + det_model: Optional[Union[ModelType, str]] = None, + det_weights: Optional[str] = None, + det_cat_ids: Optional[Union[int, Tuple]] = None) -> None: + + init_default_scope(scope) + super().__init__( + model=model, weights=weights, device=device, scope=scope) + self.model = revert_sync_batchnorm(self.model) + + # assign dataset metainfo to self.visualizer + self.visualizer.set_dataset_meta(self.model.dataset_meta) + + # initialize hand detector + self._init_detector( + det_model=det_model, + det_weights=det_weights, + det_cat_ids=det_cat_ids, + device=device, + ) + + self._video_input = False + self._buffer = defaultdict(list) + + def preprocess_single(self, + input: InputType, + index: int, + bbox_thr: float = 0.3, + nms_thr: float = 0.3, + bboxes: Union[List[List], List[np.ndarray], + np.ndarray] = []): + """Process a single input into a model-feedable format. + + Args: + input (InputType): Input given by user. + index (int): index of the input + bbox_thr (float): threshold for bounding box detection. + Defaults to 0.3. + nms_thr (float): IoU threshold for bounding box NMS. + Defaults to 0.3. + + Yields: + Any: Data processed by the ``pipeline`` and ``collate_fn``. + """ + + if isinstance(input, str): + data_info = dict(img_path=input) + else: + data_info = dict(img=input, img_path=f'{index}.jpg'.rjust(10, '0')) + data_info.update(self.model.dataset_meta) + + if self.detector is not None: + try: + det_results = self.detector( + input, return_datasamples=True)['predictions'] + except ValueError: + print_log( + 'Support for mmpose and mmdet versions up to 3.1.0 ' + 'will be discontinued in upcoming releases. To ' + 'ensure ongoing compatibility, please upgrade to ' + 'mmdet version 3.2.0 or later.', + logger='current', + level=logging.WARNING) + det_results = self.detector( + input, return_datasample=True)['predictions'] + pred_instance = det_results[0].pred_instances.cpu().numpy() + bboxes = np.concatenate( + (pred_instance.bboxes, pred_instance.scores[:, None]), axis=1) + + label_mask = np.zeros(len(bboxes), dtype=np.uint8) + for cat_id in self.det_cat_ids: + label_mask = np.logical_or(label_mask, + pred_instance.labels == cat_id) + + bboxes = bboxes[np.logical_and(label_mask, + pred_instance.scores > bbox_thr)] + bboxes = bboxes[nms(bboxes, nms_thr)] + + data_infos = [] + if len(bboxes) > 0: + for bbox in bboxes: + inst = data_info.copy() + inst['bbox'] = bbox[None, :4] + inst['bbox_score'] = bbox[4:5] + data_infos.append(self.pipeline(inst)) + else: + inst = data_info.copy() + + # get bbox from the image size + if isinstance(input, str): + input = mmcv.imread(input) + h, w = input.shape[:2] + + inst['bbox'] = np.array([[0, 0, w, h]], dtype=np.float32) + inst['bbox_score'] = np.ones(1, dtype=np.float32) + data_infos.append(self.pipeline(inst)) + + return data_infos + + @torch.no_grad() + def forward(self, + inputs: Union[dict, tuple], + disable_rebase_keypoint: bool = False): + """Performs a forward pass through the model. + + Args: + inputs (Union[dict, tuple]): The input data to be processed. Can + be either a dictionary or a tuple. + disable_rebase_keypoint (bool, optional): Flag to disable rebasing + the height of the keypoints. Defaults to False. + + Returns: + A list of data samples with prediction instances. + """ + data_samples = self.model.test_step(inputs) + data_samples_2d = [] + + for idx, res in enumerate(data_samples): + pred_instances = res.pred_instances + keypoints = pred_instances.keypoints + rel_root_depth = pred_instances.rel_root_depth + scores = pred_instances.keypoint_scores + hand_type = pred_instances.hand_type + + res_2d = PoseDataSample() + gt_instances = res.gt_instances.clone() + pred_instances = pred_instances.clone() + res_2d.gt_instances = gt_instances + res_2d.pred_instances = pred_instances + + # add relative root depth to left hand joints + keypoints[:, 21:, 2] += rel_root_depth + + # set joint scores according to hand type + scores[:, :21] *= hand_type[:, [0]] + scores[:, 21:] *= hand_type[:, [1]] + # normalize kpt score + if scores.max() > 1: + scores /= 255 + + res_2d.pred_instances.set_field(keypoints[..., :2].copy(), + 'keypoints') + + # rotate the keypoint to make z-axis correspondent to height + # for better visualization + vis_R = np.array([[1, 0, 0], [0, 0, -1], [0, 1, 0]]) + keypoints[..., :3] = keypoints[..., :3] @ vis_R + + # rebase height (z-axis) + if not disable_rebase_keypoint: + valid = scores > 0 + keypoints[..., 2] -= np.min( + keypoints[valid, 2], axis=-1, keepdims=True) + + data_samples[idx].pred_instances.keypoints = keypoints + data_samples[idx].pred_instances.keypoint_scores = scores + data_samples_2d.append(res_2d) + + data_samples = [merge_data_samples(data_samples)] + data_samples_2d = merge_data_samples(data_samples_2d) + + self._buffer['pose2d_results'] = data_samples_2d + + return data_samples + + def visualize( + self, + inputs: list, + preds: List[PoseDataSample], + return_vis: bool = False, + show: bool = False, + draw_bbox: bool = False, + wait_time: float = 0, + radius: int = 3, + thickness: int = 1, + kpt_thr: float = 0.3, + num_instances: int = 1, + vis_out_dir: str = '', + window_name: str = '', + ) -> List[np.ndarray]: + """Visualize predictions. + + Args: + inputs (list): Inputs preprocessed by :meth:`_inputs_to_list`. + preds (Any): Predictions of the model. + return_vis (bool): Whether to return images with predicted results. + show (bool): Whether to display the image in a popup window. + Defaults to False. + wait_time (float): The interval of show (ms). Defaults to 0 + draw_bbox (bool): Whether to draw the bounding boxes. + Defaults to False + radius (int): Keypoint radius for visualization. Defaults to 3 + thickness (int): Link thickness for visualization. Defaults to 1 + kpt_thr (float): The threshold to visualize the keypoints. + Defaults to 0.3 + vis_out_dir (str, optional): Directory to save visualization + results w/o predictions. If left as empty, no file will + be saved. Defaults to ''. + window_name (str, optional): Title of display window. + window_close_event_handler (callable, optional): + + Returns: + List[np.ndarray]: Visualization results. + """ + if (not return_vis) and (not show) and (not vis_out_dir): + return + + if getattr(self, 'visualizer', None) is None: + raise ValueError('Visualization needs the "visualizer" term' + 'defined in the config, but got None.') + + self.visualizer.radius = radius + self.visualizer.line_width = thickness + + results = [] + + for single_input, pred in zip(inputs, preds): + if isinstance(single_input, str): + img = mmcv.imread(single_input, channel_order='rgb') + elif isinstance(single_input, np.ndarray): + img = mmcv.bgr2rgb(single_input) + else: + raise ValueError('Unsupported input type: ' + f'{type(single_input)}') + img_name = os.path.basename(pred.metainfo['img_path']) + + # since visualization and inference utilize the same process, + # the wait time is reduced when a video input is utilized, + # thereby eliminating the issue of inference getting stuck. + wait_time = 1e-5 if self._video_input else wait_time + + if num_instances < 0: + num_instances = len(pred.pred_instances) + + visualization = self.visualizer.add_datasample( + window_name, + img, + data_sample=pred, + det_data_sample=self._buffer['pose2d_results'], + draw_gt=False, + draw_bbox=draw_bbox, + show=show, + wait_time=wait_time, + convert_keypoint=False, + axis_azimuth=-115, + axis_limit=200, + axis_elev=15, + kpt_thr=kpt_thr, + num_instances=num_instances) + results.append(visualization) + + if vis_out_dir: + self.save_visualization( + visualization, + vis_out_dir, + img_name=img_name, + ) + + if return_vis: + return results + else: + return [] diff --git a/mmpose/apis/inferencers/mmpose_inferencer.py b/mmpose/apis/inferencers/mmpose_inferencer.py index b44361bba8..cd08d8f6cb 100644 --- a/mmpose/apis/inferencers/mmpose_inferencer.py +++ b/mmpose/apis/inferencers/mmpose_inferencer.py @@ -9,6 +9,7 @@ from mmengine.structures import InstanceData from .base_mmpose_inferencer import BaseMMPoseInferencer +from .hand3d_inferencer import Hand3DInferencer from .pose2d_inferencer import Pose2DInferencer from .pose3d_inferencer import Pose3DInferencer @@ -56,15 +57,15 @@ class MMPoseInferencer(BaseMMPoseInferencer): preprocess_kwargs: set = { 'bbox_thr', 'nms_thr', 'bboxes', 'use_oks_tracking', 'tracking_thr', - 'norm_pose_2d' + 'disable_norm_pose_2d' } - forward_kwargs: set = {'rebase_keypoint_height'} + forward_kwargs: set = {'disable_rebase_keypoint'} visualize_kwargs: set = { 'return_vis', 'show', 'wait_time', 'draw_bbox', 'radius', 'thickness', 'kpt_thr', 'vis_out_dir', 'skeleton_style', 'draw_heatmap', - 'black_background' + 'black_background', 'num_instances' } - postprocess_kwargs: set = {'pred_out_dir'} + postprocess_kwargs: set = {'pred_out_dir', 'return_datasample'} def __init__(self, pose2d: Optional[str] = None, @@ -79,10 +80,15 @@ def __init__(self, self.visualizer = None if pose3d is not None: - self.inferencer = Pose3DInferencer(pose3d, pose3d_weights, pose2d, - pose2d_weights, device, scope, - det_model, det_weights, - det_cat_ids) + if 'hand3d' in pose3d: + self.inferencer = Hand3DInferencer(pose3d, pose3d_weights, + device, scope, det_model, + det_weights, det_cat_ids) + else: + self.inferencer = Pose3DInferencer(pose3d, pose3d_weights, + pose2d, pose2d_weights, + device, scope, det_model, + det_weights, det_cat_ids) elif pose2d is not None: self.inferencer = Pose2DInferencer(pose2d, pose2d_weights, device, scope, det_model, det_weights, @@ -126,7 +132,7 @@ def forward(self, inputs: InputType, **forward_kwargs) -> PredType: def __call__( self, inputs: InputsType, - return_datasample: bool = False, + return_datasamples: bool = False, batch_size: int = 1, out_dir: Optional[str] = None, **kwargs, @@ -135,7 +141,7 @@ def __call__( Args: inputs (InputsType): Inputs for the inferencer. - return_datasample (bool): Whether to return results as + return_datasamples (bool): Whether to return results as :obj:`BaseDataElement`. Defaults to False. batch_size (int): Batch size. Defaults to 1. out_dir (str, optional): directory to save visualization @@ -201,8 +207,11 @@ def __call__( visualization = self.visualize(ori_inputs, preds, **visualize_kwargs) - results = self.postprocess(preds, visualization, return_datasample, - **postprocess_kwargs) + results = self.postprocess( + preds, + visualization, + return_datasamples=return_datasamples, + **postprocess_kwargs) yield results if self._video_input: diff --git a/mmpose/apis/inferencers/pose2d_inferencer.py b/mmpose/apis/inferencers/pose2d_inferencer.py index 3f1f20fdc0..5a0bbad004 100644 --- a/mmpose/apis/inferencers/pose2d_inferencer.py +++ b/mmpose/apis/inferencers/pose2d_inferencer.py @@ -1,6 +1,5 @@ # Copyright (c) OpenMMLab. All rights reserved. -import os -import warnings +import logging from typing import Dict, List, Optional, Sequence, Tuple, Union import mmcv @@ -8,21 +7,15 @@ import torch from mmengine.config import Config, ConfigDict from mmengine.infer.infer import ModelType +from mmengine.logging import print_log from mmengine.model import revert_sync_batchnorm from mmengine.registry import init_default_scope from mmengine.structures import InstanceData from mmpose.evaluation.functional import nms -from mmpose.registry import DATASETS, INFERENCERS +from mmpose.registry import INFERENCERS from mmpose.structures import merge_data_samples from .base_mmpose_inferencer import BaseMMPoseInferencer -from .utils import default_det_models - -try: - from mmdet.apis.det_inferencer import DetInferencer - has_mmdet = True -except (ImportError, ModuleNotFoundError): - has_mmdet = False InstanceList = List[InstanceData] InputType = Union[str, np.ndarray] @@ -77,7 +70,7 @@ class Pose2DInferencer(BaseMMPoseInferencer): 'draw_heatmap', 'black_background', } - postprocess_kwargs: set = {'pred_out_dir'} + postprocess_kwargs: set = {'pred_out_dir', 'return_datasample'} def __init__(self, model: Union[ModelType, str], @@ -98,36 +91,12 @@ def __init__(self, # initialize detector for top-down models if self.cfg.data_mode == 'topdown': - object_type = DATASETS.get(self.cfg.dataset_type).__module__.split( - 'datasets.')[-1].split('.')[0].lower() - - if det_model in ('whole_image', 'whole-image') or \ - (det_model is None and - object_type not in default_det_models): - self.detector = None - - else: - det_scope = 'mmdet' - if det_model is None: - det_info = default_det_models[object_type] - det_model, det_weights, det_cat_ids = det_info[ - 'model'], det_info['weights'], det_info['cat_ids'] - elif os.path.exists(det_model): - det_cfg = Config.fromfile(det_model) - det_scope = det_cfg.default_scope - - if has_mmdet: - self.detector = DetInferencer( - det_model, det_weights, device=device, scope=det_scope) - else: - raise RuntimeError( - 'MMDetection (v3.0.0 or above) is required to build ' - 'inferencers for top-down pose estimation models.') - - if isinstance(det_cat_ids, (tuple, list)): - self.det_cat_ids = det_cat_ids - else: - self.det_cat_ids = (det_cat_ids, ) + self._init_detector( + det_model=det_model, + det_weights=det_weights, + det_cat_ids=det_cat_ids, + device=device, + ) self._video_input = False @@ -182,9 +151,21 @@ def preprocess_single(self, data_info.update(self.model.dataset_meta) if self.cfg.data_mode == 'topdown': + bboxes = [] if self.detector is not None: - det_results = self.detector( - input, return_datasample=True)['predictions'] + try: + det_results = self.detector( + input, return_datasamples=True)['predictions'] + except ValueError: + print_log( + 'Support for mmpose and mmdet versions up to 3.1.0 ' + 'will be discontinued in upcoming releases. To ' + 'ensure ongoing compatibility, please upgrade to ' + 'mmdet version 3.2.0 or later.', + logger='current', + level=logging.WARNING) + det_results = self.detector( + input, return_datasample=True)['predictions'] pred_instance = det_results[0].pred_instances.cpu().numpy() bboxes = np.concatenate( (pred_instance.bboxes, pred_instance.scores[:, None]), @@ -253,75 +234,3 @@ def forward(self, ds.pred_instances = ds.pred_instances[ ds.pred_instances.bbox_scores > bbox_thr] return data_samples - - def __call__( - self, - inputs: InputsType, - return_datasample: bool = False, - batch_size: int = 1, - out_dir: Optional[str] = None, - **kwargs, - ) -> dict: - """Call the inferencer. - - Args: - inputs (InputsType): Inputs for the inferencer. - return_datasample (bool): Whether to return results as - :obj:`BaseDataElement`. Defaults to False. - batch_size (int): Batch size. Defaults to 1. - out_dir (str, optional): directory to save visualization - results and predictions. Will be overoden if vis_out_dir or - pred_out_dir are given. Defaults to None - **kwargs: Key words arguments passed to :meth:`preprocess`, - :meth:`forward`, :meth:`visualize` and :meth:`postprocess`. - Each key in kwargs should be in the corresponding set of - ``preprocess_kwargs``, ``forward_kwargs``, - ``visualize_kwargs`` and ``postprocess_kwargs``. - - Returns: - dict: Inference and visualization results. - """ - if out_dir is not None: - if 'vis_out_dir' not in kwargs: - kwargs['vis_out_dir'] = f'{out_dir}/visualizations' - if 'pred_out_dir' not in kwargs: - kwargs['pred_out_dir'] = f'{out_dir}/predictions' - - ( - preprocess_kwargs, - forward_kwargs, - visualize_kwargs, - postprocess_kwargs, - ) = self._dispatch_kwargs(**kwargs) - - self.update_model_visualizer_settings(**kwargs) - - # preprocessing - if isinstance(inputs, str) and inputs.startswith('webcam'): - inputs = self._get_webcam_inputs(inputs) - batch_size = 1 - if not visualize_kwargs.get('show', False): - warnings.warn('The display mode is closed when using webcam ' - 'input. It will be turned on automatically.') - visualize_kwargs['show'] = True - else: - inputs = self._inputs_to_list(inputs) - - forward_kwargs['bbox_thr'] = preprocess_kwargs.get('bbox_thr', -1) - inputs = self.preprocess( - inputs, batch_size=batch_size, **preprocess_kwargs) - - preds = [] - - for proc_inputs, ori_inputs in inputs: - preds = self.forward(proc_inputs, **forward_kwargs) - - visualization = self.visualize(ori_inputs, preds, - **visualize_kwargs) - results = self.postprocess(preds, visualization, return_datasample, - **postprocess_kwargs) - yield results - - if self._video_input: - self._finalize_video_processing( - postprocess_kwargs.get('pred_out_dir', '')) diff --git a/mmpose/apis/inferencers/pose3d_inferencer.py b/mmpose/apis/inferencers/pose3d_inferencer.py index 0fe66ac72b..b0c88c4e7d 100644 --- a/mmpose/apis/inferencers/pose3d_inferencer.py +++ b/mmpose/apis/inferencers/pose3d_inferencer.py @@ -1,21 +1,17 @@ # Copyright (c) OpenMMLab. All rights reserved. import os -import warnings from collections import defaultdict from functools import partial from typing import Callable, Dict, List, Optional, Sequence, Tuple, Union -import cv2 import mmcv import numpy as np import torch from mmengine.config import Config, ConfigDict -from mmengine.fileio import join_path from mmengine.infer.infer import ModelType from mmengine.model import revert_sync_batchnorm from mmengine.registry import init_default_scope from mmengine.structures import InstanceData -from mmengine.utils import mkdir_or_exist from mmpose.apis import (_track_by_iou, _track_by_oks, collate_pose_sequence, convert_keypoint_definition, extract_pose_sequence) @@ -67,9 +63,9 @@ class Pose3DInferencer(BaseMMPoseInferencer): preprocess_kwargs: set = { 'bbox_thr', 'nms_thr', 'bboxes', 'use_oks_tracking', 'tracking_thr', - 'norm_pose_2d' + 'disable_norm_pose_2d' } - forward_kwargs: set = {'rebase_keypoint_height'} + forward_kwargs: set = {'disable_rebase_keypoint'} visualize_kwargs: set = { 'return_vis', 'show', @@ -77,10 +73,11 @@ class Pose3DInferencer(BaseMMPoseInferencer): 'draw_bbox', 'radius', 'thickness', + 'num_instances', 'kpt_thr', 'vis_out_dir', } - postprocess_kwargs: set = {'pred_out_dir'} + postprocess_kwargs: set = {'pred_out_dir', 'return_datasample'} def __init__(self, model: Union[ModelType, str], @@ -109,9 +106,9 @@ def __init__(self, # helper functions self._keypoint_converter = partial( convert_keypoint_definition, - pose_det_dataset=self.pose2d_model.cfg.test_dataloader. - dataset['type'], - pose_lift_dataset=self.cfg.test_dataloader.dataset['type'], + pose_det_dataset=self.pose2d_model.model. + dataset_meta['dataset_name'], + pose_lift_dataset=self.model.dataset_meta['dataset_name'], ) self._pose_seq_extractor = partial( @@ -132,7 +129,7 @@ def preprocess_single(self, np.ndarray] = [], use_oks_tracking: bool = False, tracking_thr: float = 0.3, - norm_pose_2d: bool = False): + disable_norm_pose_2d: bool = False): """Process a single input into a model-feedable format. Args: @@ -149,8 +146,9 @@ def preprocess_single(self, whether OKS-based tracking should be used. Defaults to False. tracking_thr (float, optional): The threshold for tracking. Defaults to 0.3. - norm_pose_2d (bool, optional): A flag that indicates whether 2D - pose normalization should be used. Defaults to False. + disable_norm_pose_2d (bool, optional): A flag that indicates + whether 2D pose normalization should be used. + Defaults to False. Yields: Any: The data processed by the pipeline and collate_fn. @@ -168,7 +166,7 @@ def preprocess_single(self, nms_thr=nms_thr, bboxes=bboxes, merge_results=False, - return_datasample=True))['predictions'] + return_datasamples=True))['predictions'] for ds in results_pose2d: ds.pred_instances.set_field( @@ -231,14 +229,24 @@ def preprocess_single(self, bbox_center = stats_info.get('bbox_center', None) bbox_scale = stats_info.get('bbox_scale', None) - for i, pose_res in enumerate(pose_results_2d): - for j, data_sample in enumerate(pose_res): + pose_results_2d_copy = [] + for pose_res in pose_results_2d: + pose_res_copy = [] + for data_sample in pose_res: + + data_sample_copy = PoseDataSample() + data_sample_copy.gt_instances = \ + data_sample.gt_instances.clone() + data_sample_copy.pred_instances = \ + data_sample.pred_instances.clone() + data_sample_copy.track_id = data_sample.track_id + kpts = data_sample.pred_instances.keypoints bboxes = data_sample.pred_instances.bboxes keypoints = [] for k in range(len(kpts)): kpt = kpts[k] - if norm_pose_2d: + if not disable_norm_pose_2d: bbox = bboxes[k] center = np.array([[(bbox[0] + bbox[2]) / 2, (bbox[1] + bbox[3]) / 2]]) @@ -247,9 +255,12 @@ def preprocess_single(self, bbox_scale + bbox_center) else: keypoints.append(kpt[:, :2]) - pose_results_2d[i][j].pred_instances.keypoints = np.array( - keypoints) - pose_sequences_2d = collate_pose_sequence(pose_results_2d, True, + data_sample_copy.pred_instances.set_field( + np.array(keypoints), 'keypoints') + pose_res_copy.append(data_sample_copy) + + pose_results_2d_copy.append(pose_res_copy) + pose_sequences_2d = collate_pose_sequence(pose_results_2d_copy, True, target_idx) if not pose_sequences_2d: return [] @@ -271,8 +282,9 @@ def preprocess_single(self, K, ), dtype=np.float32) - data_info['lifting_target'] = np.zeros((K, 3), dtype=np.float32) - data_info['lifting_target_visible'] = np.ones((K, 1), + data_info['lifting_target'] = np.zeros((1, K, 3), dtype=np.float32) + data_info['factor'] = np.zeros((T, ), dtype=np.float32) + data_info['lifting_target_visible'] = np.ones((1, K, 1), dtype=np.float32) data_info['camera_param'] = dict(w=width, h=height) @@ -287,19 +299,18 @@ def preprocess_single(self, @torch.no_grad() def forward(self, inputs: Union[dict, tuple], - rebase_keypoint_height: bool = False): + disable_rebase_keypoint: bool = False): """Perform forward pass through the model and process the results. Args: inputs (Union[dict, tuple]): The inputs for the model. - rebase_keypoint_height (bool, optional): Flag to rebase the - height of the keypoints (z-axis). Defaults to False. + disable_rebase_keypoint (bool, optional): Flag to disable rebasing + the height of the keypoints. Defaults to False. Returns: list: A list of data samples, each containing the model's output results. """ - pose_lift_results = self.model.test_step(inputs) # Post-processing of pose estimation results @@ -309,14 +320,22 @@ def forward(self, pose_lift_res.track_id = pose_est_results_converted[idx].get( 'track_id', 1e4) - # Invert x and z values of the keypoints + # align the shape of output keypoints coordinates and scores keypoints = pose_lift_res.pred_instances.keypoints + keypoint_scores = pose_lift_res.pred_instances.keypoint_scores + if keypoint_scores.ndim == 3: + pose_lift_results[idx].pred_instances.keypoint_scores = \ + np.squeeze(keypoint_scores, axis=1) + if keypoints.ndim == 4: + keypoints = np.squeeze(keypoints, axis=1) + + # Invert x and z values of the keypoints keypoints = keypoints[..., [0, 2, 1]] keypoints[..., 0] = -keypoints[..., 0] keypoints[..., 2] = -keypoints[..., 2] # If rebase_keypoint_height is True, adjust z-axis values - if rebase_keypoint_height: + if not disable_rebase_keypoint: keypoints[..., 2] -= np.min( keypoints[..., 2], axis=-1, keepdims=True) @@ -328,78 +347,6 @@ def forward(self, data_samples = [merge_data_samples(pose_lift_results)] return data_samples - def __call__( - self, - inputs: InputsType, - return_datasample: bool = False, - batch_size: int = 1, - out_dir: Optional[str] = None, - **kwargs, - ) -> dict: - """Call the inferencer. - - Args: - inputs (InputsType): Inputs for the inferencer. - return_datasample (bool): Whether to return results as - :obj:`BaseDataElement`. Defaults to False. - batch_size (int): Batch size. Defaults to 1. - out_dir (str, optional): directory to save visualization - results and predictions. Will be overoden if vis_out_dir or - pred_out_dir are given. Defaults to None - **kwargs: Key words arguments passed to :meth:`preprocess`, - :meth:`forward`, :meth:`visualize` and :meth:`postprocess`. - Each key in kwargs should be in the corresponding set of - ``preprocess_kwargs``, ``forward_kwargs``, - ``visualize_kwargs`` and ``postprocess_kwargs``. - - Returns: - dict: Inference and visualization results. - """ - if out_dir is not None: - if 'vis_out_dir' not in kwargs: - kwargs['vis_out_dir'] = f'{out_dir}/visualizations' - if 'pred_out_dir' not in kwargs: - kwargs['pred_out_dir'] = f'{out_dir}/predictions' - - ( - preprocess_kwargs, - forward_kwargs, - visualize_kwargs, - postprocess_kwargs, - ) = self._dispatch_kwargs(**kwargs) - - self.update_model_visualizer_settings(**kwargs) - - # preprocessing - if isinstance(inputs, str) and inputs.startswith('webcam'): - inputs = self._get_webcam_inputs(inputs) - batch_size = 1 - if not visualize_kwargs.get('show', False): - warnings.warn('The display mode is closed when using webcam ' - 'input. It will be turned on automatically.') - visualize_kwargs['show'] = True - else: - inputs = self._inputs_to_list(inputs) - - inputs = self.preprocess( - inputs, batch_size=batch_size, **preprocess_kwargs) - - preds = [] - - for proc_inputs, ori_inputs in inputs: - preds = self.forward(proc_inputs, **forward_kwargs) - - visualization = self.visualize(ori_inputs, preds, - **visualize_kwargs) - results = self.postprocess(preds, visualization, return_datasample, - **postprocess_kwargs) - yield results - - if self._video_input: - self._finalize_video_processing( - postprocess_kwargs.get('pred_out_dir', '')) - self._buffer.clear() - def visualize(self, inputs: list, preds: List[PoseDataSample], @@ -410,6 +357,7 @@ def visualize(self, radius: int = 3, thickness: int = 1, kpt_thr: float = 0.3, + num_instances: int = 1, vis_out_dir: str = '', window_name: str = '', window_close_event_handler: Optional[Callable] = None @@ -470,6 +418,9 @@ def visualize(self, # thereby eliminating the issue of inference getting stuck. wait_time = 1e-5 if self._video_input else wait_time + if num_instances < 0: + num_instances = len(pred.pred_instances) + visualization = self.visualizer.add_datasample( window_name, img, @@ -479,38 +430,21 @@ def visualize(self, draw_bbox=draw_bbox, show=show, wait_time=wait_time, - kpt_thr=kpt_thr) + dataset_2d=self.pose2d_model.model. + dataset_meta['dataset_name'], + dataset_3d=self.model.dataset_meta['dataset_name'], + kpt_thr=kpt_thr, + num_instances=num_instances) results.append(visualization) if vis_out_dir: - out_img = mmcv.rgb2bgr(visualization) - _, file_extension = os.path.splitext(vis_out_dir) - if file_extension: - dir_name = os.path.dirname(vis_out_dir) - file_name = os.path.basename(vis_out_dir) - else: - dir_name = vis_out_dir - file_name = None - mkdir_or_exist(dir_name) - - if self._video_input: - - if self.video_info['writer'] is None: - fourcc = cv2.VideoWriter_fourcc(*'mp4v') - if file_name is None: - file_name = os.path.basename( - self.video_info['name']) - out_file = join_path(dir_name, file_name) - self.video_info['writer'] = cv2.VideoWriter( - out_file, fourcc, self.video_info['fps'], - (visualization.shape[1], visualization.shape[0])) - self.video_info['writer'].write(out_img) - - else: - img_name = os.path.basename(pred.metainfo['img_path']) - file_name = file_name if file_name else img_name - out_file = join_path(dir_name, file_name) - mmcv.imwrite(out_img, out_file) + img_name = os.path.basename(pred.metainfo['img_path']) \ + if 'img_path' in pred.metainfo else None + self.save_visualization( + visualization, + vis_out_dir, + img_name=img_name, + ) if return_vis: return results diff --git a/mmpose/apis/inferencers/utils/default_det_models.py b/mmpose/apis/inferencers/utils/default_det_models.py index 93b759c879..ea02097be0 100644 --- a/mmpose/apis/inferencers/utils/default_det_models.py +++ b/mmpose/apis/inferencers/utils/default_det_models.py @@ -15,11 +15,10 @@ 'yolo-x_8xb8-300e_coco-face_13274d7c.pth', cat_ids=(0, )), hand=dict( - model=osp.join( - mmpose_path, '.mim', 'demo/mmdetection_cfg/' - 'ssdlite_mobilenetv2_scratch_600e_onehand.py'), - weights='https://download.openmmlab.com/mmpose/mmdet_pretrained/' - 'ssdlite_mobilenetv2_scratch_600e_onehand-4f9f8686_20220523.pth', + model=osp.join(mmpose_path, '.mim', 'demo/mmdetection_cfg/' + 'rtmdet_nano_320-8xb32_hand.py'), + weights='https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/' + 'rtmdet_nano_8xb32-300e_hand-267f9c8f.pth', cat_ids=(0, )), animal=dict( model='rtmdet-m', diff --git a/mmpose/apis/visualization.py b/mmpose/apis/visualization.py new file mode 100644 index 0000000000..3ba96401d2 --- /dev/null +++ b/mmpose/apis/visualization.py @@ -0,0 +1,82 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from copy import deepcopy +from typing import Union + +import mmcv +import numpy as np +from mmengine.structures import InstanceData + +from mmpose.datasets.datasets.utils import parse_pose_metainfo +from mmpose.structures import PoseDataSample +from mmpose.visualization import PoseLocalVisualizer + + +def visualize( + img: Union[np.ndarray, str], + keypoints: np.ndarray, + keypoint_score: np.ndarray = None, + metainfo: Union[str, dict] = None, + visualizer: PoseLocalVisualizer = None, + show_kpt_idx: bool = False, + skeleton_style: str = 'mmpose', + show: bool = False, + kpt_thr: float = 0.3, +): + """Visualize 2d keypoints on an image. + + Args: + img (str | np.ndarray): The image to be displayed. + keypoints (np.ndarray): The keypoint to be displayed. + keypoint_score (np.ndarray): The score of each keypoint. + metainfo (str | dict): The metainfo of dataset. + visualizer (PoseLocalVisualizer): The visualizer. + show_kpt_idx (bool): Whether to show the index of keypoints. + skeleton_style (str): Skeleton style. Options are 'mmpose' and + 'openpose'. + show (bool): Whether to show the image. + wait_time (int): Value of waitKey param. + kpt_thr (float): Keypoint threshold. + """ + assert skeleton_style in [ + 'mmpose', 'openpose' + ], (f'Only support skeleton style in {["mmpose", "openpose"]}, ') + + if visualizer is None: + visualizer = PoseLocalVisualizer() + else: + visualizer = deepcopy(visualizer) + + if isinstance(metainfo, str): + metainfo = parse_pose_metainfo(dict(from_file=metainfo)) + elif isinstance(metainfo, dict): + metainfo = parse_pose_metainfo(metainfo) + + if metainfo is not None: + visualizer.set_dataset_meta(metainfo, skeleton_style=skeleton_style) + + if isinstance(img, str): + img = mmcv.imread(img, channel_order='rgb') + elif isinstance(img, np.ndarray): + img = mmcv.bgr2rgb(img) + + if keypoint_score is None: + keypoint_score = np.ones(keypoints.shape[0]) + + tmp_instances = InstanceData() + tmp_instances.keypoints = keypoints + tmp_instances.keypoint_score = keypoint_score + + tmp_datasample = PoseDataSample() + tmp_datasample.pred_instances = tmp_instances + + visualizer.add_datasample( + 'visualization', + img, + tmp_datasample, + show_kpt_idx=show_kpt_idx, + skeleton_style=skeleton_style, + show=show, + wait_time=0, + kpt_thr=kpt_thr) + + return visualizer.get_image() diff --git a/mmpose/codecs/__init__.py b/mmpose/codecs/__init__.py index cdbd8feb0c..4250949a4e 100644 --- a/mmpose/codecs/__init__.py +++ b/mmpose/codecs/__init__.py @@ -1,9 +1,13 @@ # Copyright (c) OpenMMLab. All rights reserved. +from .annotation_processors import YOLOXPoseAnnotationProcessor from .associative_embedding import AssociativeEmbedding from .decoupled_heatmap import DecoupledHeatmap +from .edpose_label import EDPoseLabel +from .hand_3d_heatmap import Hand3DHeatmap from .image_pose_lifting import ImagePoseLifting from .integral_regression_label import IntegralRegressionLabel from .megvii_heatmap import MegviiHeatmap +from .motionbert_label import MotionBERTLabel from .msra_heatmap import MSRAHeatmap from .regression_label import RegressionLabel from .simcc_label import SimCCLabel @@ -14,5 +18,7 @@ __all__ = [ 'MSRAHeatmap', 'MegviiHeatmap', 'UDPHeatmap', 'RegressionLabel', 'SimCCLabel', 'IntegralRegressionLabel', 'AssociativeEmbedding', 'SPR', - 'DecoupledHeatmap', 'VideoPoseLifting', 'ImagePoseLifting' + 'DecoupledHeatmap', 'VideoPoseLifting', 'ImagePoseLifting', + 'MotionBERTLabel', 'YOLOXPoseAnnotationProcessor', 'EDPoseLabel', + 'Hand3DHeatmap' ] diff --git a/mmpose/codecs/annotation_processors.py b/mmpose/codecs/annotation_processors.py new file mode 100644 index 0000000000..e857cdc0e4 --- /dev/null +++ b/mmpose/codecs/annotation_processors.py @@ -0,0 +1,92 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from typing import Dict, List, Optional, Tuple + +import numpy as np + +from mmpose.registry import KEYPOINT_CODECS +from .base import BaseKeypointCodec + +INF = 1e6 +NEG_INF = -1e6 + + +class BaseAnnotationProcessor(BaseKeypointCodec): + """Base class for annotation processors.""" + + def decode(self, *args, **kwargs): + pass + + +@KEYPOINT_CODECS.register_module() +class YOLOXPoseAnnotationProcessor(BaseAnnotationProcessor): + """Convert dataset annotations to the input format of YOLOX-Pose. + + This processor expands bounding boxes and converts category IDs to labels. + + Args: + expand_bbox (bool, optional): Whether to expand the bounding box + to include all keypoints. Defaults to False. + input_size (tuple, optional): The size of the input image for the + model, formatted as (h, w). This argument is necessary for the + codec in deployment but is not used indeed. + """ + + auxiliary_encode_keys = {'category_id', 'bbox'} + label_mapping_table = dict( + bbox='bboxes', + bbox_labels='labels', + keypoints='keypoints', + keypoints_visible='keypoints_visible', + area='areas', + ) + + def __init__(self, + expand_bbox: bool = False, + input_size: Optional[Tuple] = None): + super().__init__() + self.expand_bbox = expand_bbox + + def encode(self, + keypoints: Optional[np.ndarray] = None, + keypoints_visible: Optional[np.ndarray] = None, + bbox: Optional[np.ndarray] = None, + category_id: Optional[List[int]] = None + ) -> Dict[str, np.ndarray]: + """Encode keypoints, bounding boxes, and category IDs. + + Args: + keypoints (np.ndarray, optional): Keypoints array. Defaults + to None. + keypoints_visible (np.ndarray, optional): Visibility array for + keypoints. Defaults to None. + bbox (np.ndarray, optional): Bounding box array. Defaults to None. + category_id (List[int], optional): List of category IDs. Defaults + to None. + + Returns: + Dict[str, np.ndarray]: Encoded annotations. + """ + results = {} + + if self.expand_bbox and bbox is not None: + # Handle keypoints visibility + if keypoints_visible.ndim == 3: + keypoints_visible = keypoints_visible[..., 0] + + # Expand bounding box to include keypoints + kpts_min = keypoints.copy() + kpts_min[keypoints_visible == 0] = INF + bbox[..., :2] = np.minimum(bbox[..., :2], kpts_min.min(axis=1)) + + kpts_max = keypoints.copy() + kpts_max[keypoints_visible == 0] = NEG_INF + bbox[..., 2:] = np.maximum(bbox[..., 2:], kpts_max.max(axis=1)) + + results['bbox'] = bbox + + if category_id is not None: + # Convert category IDs to labels + bbox_labels = np.array(category_id).astype(np.int8) - 1 + results['bbox_labels'] = bbox_labels + + return results diff --git a/mmpose/codecs/associative_embedding.py b/mmpose/codecs/associative_embedding.py index 7e080f1657..def9bfd89e 100644 --- a/mmpose/codecs/associative_embedding.py +++ b/mmpose/codecs/associative_embedding.py @@ -1,5 +1,4 @@ # Copyright (c) OpenMMLab. All rights reserved. -from collections import namedtuple from itertools import product from typing import Any, List, Optional, Tuple @@ -16,6 +15,21 @@ refine_keypoints_dark_udp) +def _py_max_match(scores): + """Apply munkres algorithm to get the best match. + + Args: + scores(np.ndarray): cost matrix. + + Returns: + np.ndarray: best match. + """ + m = Munkres() + tmp = m.compute(scores) + tmp = np.array(tmp).astype(int) + return tmp + + def _group_keypoints_by_tags(vals: np.ndarray, tags: np.ndarray, locs: np.ndarray, @@ -54,89 +68,78 @@ def _group_keypoints_by_tags(vals: np.ndarray, np.ndarray: grouped keypoints in shape (G, K, D+1), where the last dimenssion is the concatenated keypoint coordinates and scores. """ + + tag_k, loc_k, val_k = tags, locs, vals K, M, D = locs.shape assert vals.shape == tags.shape[:2] == (K, M) assert len(keypoint_order) == K - # Build Munkres instance - munkres = Munkres() - - # Build a group pool, each group contains the keypoints of an instance - groups = [] + default_ = np.zeros((K, 3 + tag_k.shape[2]), dtype=np.float32) - Group = namedtuple('Group', field_names=['kpts', 'scores', 'tag_list']) + joint_dict = {} + tag_dict = {} + for i in range(K): + idx = keypoint_order[i] - def _init_group(): - """Initialize a group, which is composed of the keypoints, keypoint - scores and the tag of each keypoint.""" - _group = Group( - kpts=np.zeros((K, D), dtype=np.float32), - scores=np.zeros(K, dtype=np.float32), - tag_list=[]) - return _group + tags = tag_k[idx] + joints = np.concatenate((loc_k[idx], val_k[idx, :, None], tags), 1) + mask = joints[:, 2] > val_thr + tags = tags[mask] # shape: [M, L] + joints = joints[mask] # shape: [M, 3 + L], 3: x, y, val - for i in keypoint_order: - # Get all valid candidate of the i-th keypoints - valid = vals[i] > val_thr - if not valid.any(): + if joints.shape[0] == 0: continue - tags_i = tags[i, valid] # (M', L) - vals_i = vals[i, valid] # (M',) - locs_i = locs[i, valid] # (M', D) - - if len(groups) == 0: # Initialize the group pool - for tag, val, loc in zip(tags_i, vals_i, locs_i): - group = _init_group() - group.kpts[i] = loc - group.scores[i] = val - group.tag_list.append(tag) - - groups.append(group) - - else: # Match keypoints to existing groups - groups = groups[:max_groups] - group_tags = [np.mean(g.tag_list, axis=0) for g in groups] - - # Calculate distance matrix between group tags and tag candidates - # of the i-th keypoint - # Shape: (M', 1, L) , (1, G, L) -> (M', G, L) - diff = tags_i[:, None] - np.array(group_tags)[None] - dists = np.linalg.norm(diff, ord=2, axis=2) - num_kpts, num_groups = dists.shape[:2] - - # Experimental cost function for keypoint-group matching - costs = np.round(dists) * 100 - vals_i[..., None] - if num_kpts > num_groups: - padding = np.full((num_kpts, num_kpts - num_groups), - 1e10, - dtype=np.float32) - costs = np.concatenate((costs, padding), axis=1) - - # Match keypoints and groups by Munkres algorithm - matches = munkres.compute(costs) - for kpt_idx, group_idx in matches: - if group_idx < num_groups and dists[kpt_idx, - group_idx] < tag_thr: - # Add the keypoint to the matched group - group = groups[group_idx] + if i == 0 or len(joint_dict) == 0: + for tag, joint in zip(tags, joints): + key = tag[0] + joint_dict.setdefault(key, np.copy(default_))[idx] = joint + tag_dict[key] = [tag] + else: + # shape: [M] + grouped_keys = list(joint_dict.keys()) + # shape: [M, L] + grouped_tags = [np.mean(tag_dict[i], axis=0) for i in grouped_keys] + + # shape: [M, M, L] + diff = joints[:, None, 3:] - np.array(grouped_tags)[None, :, :] + # shape: [M, M] + diff_normed = np.linalg.norm(diff, ord=2, axis=2) + diff_saved = np.copy(diff_normed) + diff_normed = np.round(diff_normed) * 100 - joints[:, 2:3] + + num_added = diff.shape[0] + num_grouped = diff.shape[1] + + if num_added > num_grouped: + diff_normed = np.concatenate( + (diff_normed, + np.zeros((num_added, num_added - num_grouped), + dtype=np.float32) + 1e10), + axis=1) + + pairs = _py_max_match(diff_normed) + for row, col in pairs: + if (row < num_added and col < num_grouped + and diff_saved[row][col] < tag_thr): + key = grouped_keys[col] + joint_dict[key][idx] = joints[row] + tag_dict[key].append(tags[row]) else: - # Initialize a new group with unmatched keypoint - group = _init_group() - groups.append(group) - - group.kpts[i] = locs_i[kpt_idx] - group.scores[i] = vals_i[kpt_idx] - group.tag_list.append(tags_i[kpt_idx]) - - groups = groups[:max_groups] - if groups: - grouped_keypoints = np.stack( - [np.r_['1', g.kpts, g.scores[:, None]] for g in groups]) - else: - grouped_keypoints = np.empty((0, K, D + 1)) + key = tags[row][0] + joint_dict.setdefault(key, np.copy(default_))[idx] = \ + joints[row] + tag_dict[key] = [tags[row]] - return grouped_keypoints + joint_dict_keys = list(joint_dict.keys())[:max_groups] + + if joint_dict_keys: + results = np.array([joint_dict[i] + for i in joint_dict_keys]).astype(np.float32) + results = results[..., :D + 1] + else: + results = np.empty((0, K, D + 1), dtype=np.float32) + return results @KEYPOINT_CODECS.register_module() @@ -210,7 +213,8 @@ def __init__( decode_gaussian_kernel: int = 3, decode_keypoint_thr: float = 0.1, decode_tag_thr: float = 1.0, - decode_topk: int = 20, + decode_topk: int = 30, + decode_center_shift=0.0, decode_max_instances: Optional[int] = None, ) -> None: super().__init__() @@ -222,8 +226,9 @@ def __init__( self.decode_keypoint_thr = decode_keypoint_thr self.decode_tag_thr = decode_tag_thr self.decode_topk = decode_topk + self.decode_center_shift = decode_center_shift self.decode_max_instances = decode_max_instances - self.dedecode_keypoint_order = decode_keypoint_order.copy() + self.decode_keypoint_order = decode_keypoint_order.copy() if self.use_udp: self.scale_factor = ((np.array(input_size) - 1) / @@ -376,7 +381,7 @@ def _group_func(inputs: Tuple): vals, tags, locs, - keypoint_order=self.dedecode_keypoint_order, + keypoint_order=self.decode_keypoint_order, val_thr=self.decode_keypoint_thr, tag_thr=self.decode_tag_thr, max_groups=self.decode_max_instances) @@ -463,13 +468,13 @@ def batch_decode(self, batch_heatmaps: Tensor, batch_tags: Tensor f'tagging map ({batch_tags.shape})') # Heatmap NMS - batch_heatmaps = batch_heatmap_nms(batch_heatmaps, - self.decode_nms_kernel) + batch_heatmaps_peak = batch_heatmap_nms(batch_heatmaps, + self.decode_nms_kernel) # Get top-k in each heatmap and and convert to numpy batch_topk_vals, batch_topk_tags, batch_topk_locs = to_numpy( self._get_batch_topk( - batch_heatmaps, batch_tags, k=self.decode_topk)) + batch_heatmaps_peak, batch_tags, k=self.decode_topk)) # Group keypoint candidates into groups (instances) batch_groups = self._group_keypoints(batch_topk_vals, batch_topk_tags, @@ -482,16 +487,14 @@ def batch_decode(self, batch_heatmaps: Tensor, batch_tags: Tensor # Refine the keypoint prediction batch_keypoints = [] batch_keypoint_scores = [] + batch_instance_scores = [] for i, (groups, heatmaps, tags) in enumerate( zip(batch_groups, batch_heatmaps_np, batch_tags_np)): keypoints, scores = groups[..., :-1], groups[..., -1] + instance_scores = scores.mean(axis=-1) if keypoints.size > 0: - # identify missing keypoints - keypoints, scores = self._fill_missing_keypoints( - keypoints, scores, heatmaps, tags) - # refine keypoint coordinates according to heatmap distribution if self.use_udp: keypoints = refine_keypoints_dark_udp( @@ -500,13 +503,20 @@ def batch_decode(self, batch_heatmaps: Tensor, batch_tags: Tensor blur_kernel_size=self.decode_gaussian_kernel) else: keypoints = refine_keypoints(keypoints, heatmaps) + keypoints += self.decode_center_shift * \ + (scores > 0).astype(keypoints.dtype)[..., None] + + # identify missing keypoints + keypoints, scores = self._fill_missing_keypoints( + keypoints, scores, heatmaps, tags) batch_keypoints.append(keypoints) batch_keypoint_scores.append(scores) + batch_instance_scores.append(instance_scores) # restore keypoint scale batch_keypoints = [ kpts * self.scale_factor for kpts in batch_keypoints ] - return batch_keypoints, batch_keypoint_scores + return batch_keypoints, batch_keypoint_scores, batch_instance_scores diff --git a/mmpose/codecs/base.py b/mmpose/codecs/base.py index d8479fdf1e..b01e8c4b2c 100644 --- a/mmpose/codecs/base.py +++ b/mmpose/codecs/base.py @@ -18,6 +18,10 @@ class BaseKeypointCodec(metaclass=ABCMeta): # mandatory `keypoints` and `keypoints_visible` arguments. auxiliary_encode_keys = set() + field_mapping_table = dict() + instance_mapping_table = dict() + label_mapping_table = dict() + @abstractmethod def encode(self, keypoints: np.ndarray, diff --git a/mmpose/codecs/decoupled_heatmap.py b/mmpose/codecs/decoupled_heatmap.py index da38a4ce2c..b5929e3dcf 100644 --- a/mmpose/codecs/decoupled_heatmap.py +++ b/mmpose/codecs/decoupled_heatmap.py @@ -65,6 +65,15 @@ class DecoupledHeatmap(BaseKeypointCodec): # instance, so that it can assign varying sigmas based on their size auxiliary_encode_keys = {'bbox'} + label_mapping_table = dict( + keypoint_weights='keypoint_weights', + instance_coords='instance_coords', + ) + field_mapping_table = dict( + heatmaps='heatmaps', + instance_heatmaps='instance_heatmaps', + ) + def __init__( self, input_size: Tuple[int, int], diff --git a/mmpose/codecs/edpose_label.py b/mmpose/codecs/edpose_label.py new file mode 100644 index 0000000000..0433784886 --- /dev/null +++ b/mmpose/codecs/edpose_label.py @@ -0,0 +1,153 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from typing import Optional + +import numpy as np + +from mmpose.registry import KEYPOINT_CODECS +from mmpose.structures import bbox_cs2xyxy, bbox_xyxy2cs +from .base import BaseKeypointCodec + + +@KEYPOINT_CODECS.register_module() +class EDPoseLabel(BaseKeypointCodec): + r"""Generate keypoint and label coordinates for `ED-Pose`_ by + Yang J. et al (2023). + + Note: + + - instance number: N + - keypoint number: K + - keypoint dimension: D + - image size: [w, h] + + Encoded: + + - keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D) + - keypoints_visible (np.ndarray): Keypoint visibility in shape + (N, K, D) + - area (np.ndarray): Area in shape (N) + - bbox (np.ndarray): Bbox in shape (N, 4) + + Args: + num_select (int): The number of candidate instances + num_keypoints (int): The Number of keypoints + """ + + auxiliary_encode_keys = {'area', 'bboxes', 'img_shape'} + instance_mapping_table = dict( + bbox='bboxes', + keypoints='keypoints', + keypoints_visible='keypoints_visible', + area='areas', + ) + + def __init__(self, num_select: int = 100, num_keypoints: int = 17): + super().__init__() + + self.num_select = num_select + self.num_keypoints = num_keypoints + + def encode( + self, + img_shape, + keypoints: np.ndarray, + keypoints_visible: Optional[np.ndarray] = None, + area: Optional[np.ndarray] = None, + bboxes: Optional[np.ndarray] = None, + ) -> dict: + """Encoding keypoints, area and bbox from input image space to + normalized space. + + Args: + - img_shape (Sequence[int]): The shape of image in the format + of (width, height). + - keypoints (np.ndarray): Keypoint coordinates in + shape (N, K, D). + - keypoints_visible (np.ndarray): Keypoint visibility in shape + (N, K) + - area (np.ndarray): + - bboxes (np.ndarray): + + Returns: + encoded (dict): Contains the following items: + + - keypoint_labels (np.ndarray): The processed keypoints in + shape like (N, K, D). + - keypoints_visible (np.ndarray): Keypoint visibility in shape + (N, K, D) + - area_labels (np.ndarray): The processed target + area in shape (N). + - bboxes_labels: The processed target bbox in + shape (N, 4). + """ + w, h = img_shape + + if keypoints_visible is None: + keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32) + + if bboxes is not None: + bboxes = np.concatenate(bbox_xyxy2cs(bboxes), axis=-1) + bboxes = bboxes / np.array([w, h, w, h], dtype=np.float32) + + if area is not None: + area = area / float(w * h) + + if keypoints is not None: + keypoints = keypoints / np.array([w, h], dtype=np.float32) + + encoded = dict( + keypoints=keypoints, + area=area, + bbox=bboxes, + keypoints_visible=keypoints_visible) + + return encoded + + def decode(self, input_shapes: np.ndarray, pred_logits: np.ndarray, + pred_boxes: np.ndarray, pred_keypoints: np.ndarray): + """Select the final top-k keypoints, and decode the results from + normalize size to origin input size. + + Args: + input_shapes (Tensor): The size of input image resize. + test_cfg (ConfigType): Config of testing. + pred_logits (Tensor): The result of score. + pred_boxes (Tensor): The result of bbox. + pred_keypoints (Tensor): The result of keypoints. + + Returns: + tuple: Decoded boxes, keypoints, and keypoint scores. + """ + + # Initialization + num_keypoints = self.num_keypoints + prob = pred_logits.reshape(-1) + + # Select top-k instances based on prediction scores + topk_indexes = np.argsort(-prob)[:self.num_select] + topk_values = np.take_along_axis(prob, topk_indexes, axis=0) + scores = np.tile(topk_values[:, np.newaxis], [1, num_keypoints]) + + # Decode bounding boxes + topk_boxes = topk_indexes // pred_logits.shape[1] + boxes = bbox_cs2xyxy(*np.split(pred_boxes, [2], axis=-1)) + boxes = np.take_along_axis( + boxes, np.tile(topk_boxes[:, np.newaxis], [1, 4]), axis=0) + + # Convert from relative to absolute coordinates + img_h, img_w = np.split(input_shapes, 2, axis=0) + scale_fct = np.hstack([img_w, img_h, img_w, img_h]) + boxes = boxes * scale_fct[np.newaxis, :] + + # Decode keypoints + topk_keypoints = topk_indexes // pred_logits.shape[1] + keypoints = np.take_along_axis( + pred_keypoints, + np.tile(topk_keypoints[:, np.newaxis], [1, num_keypoints * 3]), + axis=0) + keypoints = keypoints[:, :(num_keypoints * 2)] + keypoints = keypoints * np.tile( + np.hstack([img_w, img_h]), [num_keypoints])[np.newaxis, :] + keypoints = keypoints.reshape(-1, num_keypoints, 2) + + return boxes, keypoints, scores diff --git a/mmpose/codecs/hand_3d_heatmap.py b/mmpose/codecs/hand_3d_heatmap.py new file mode 100644 index 0000000000..b088e0d7fa --- /dev/null +++ b/mmpose/codecs/hand_3d_heatmap.py @@ -0,0 +1,202 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from typing import Optional, Tuple + +import numpy as np + +from mmpose.registry import KEYPOINT_CODECS +from .base import BaseKeypointCodec +from .utils.gaussian_heatmap import generate_3d_gaussian_heatmaps +from .utils.post_processing import get_heatmap_3d_maximum + + +@KEYPOINT_CODECS.register_module() +class Hand3DHeatmap(BaseKeypointCodec): + r"""Generate target 3d heatmap and relative root depth for hand datasets. + + Note: + + - instance number: N + - keypoint number: K + - keypoint dimension: D + + Args: + image_size (tuple): Size of image. Default: ``[256, 256]``. + root_heatmap_size (int): Size of heatmap of root head. + Default: 64. + heatmap_size (tuple): Size of heatmap. Default: ``[64, 64, 64]``. + heatmap3d_depth_bound (float): Boundary for 3d heatmap depth. + Default: 400.0. + heatmap_size_root (int): Size of 3d heatmap root. Default: 64. + depth_size (int): Number of depth discretization size, used for + decoding. Defaults to 64. + root_depth_bound (float): Boundary for 3d heatmap root depth. + Default: 400.0. + use_different_joint_weights (bool): Whether to use different joint + weights. Default: ``False``. + sigma (int): Sigma of heatmap gaussian. Default: 2. + joint_indices (list, optional): Indices of joints used for heatmap + generation. If None (default) is given, all joints will be used. + Default: ``None``. + max_bound (float): The maximal value of heatmap. Default: 1.0. + """ + + auxiliary_encode_keys = { + 'dataset_keypoint_weights', 'rel_root_depth', 'rel_root_valid', + 'hand_type', 'hand_type_valid', 'focal', 'principal_pt' + } + + instance_mapping_table = { + 'keypoints': 'keypoints', + 'keypoints_visible': 'keypoints_visible', + 'keypoints_cam': 'keypoints_cam', + } + + label_mapping_table = { + 'keypoint_weights': 'keypoint_weights', + 'root_depth_weight': 'root_depth_weight', + 'type_weight': 'type_weight', + 'root_depth': 'root_depth', + 'type': 'type' + } + + def __init__(self, + image_size: Tuple[int, int] = [256, 256], + root_heatmap_size: int = 64, + heatmap_size: Tuple[int, int, int] = [64, 64, 64], + heatmap3d_depth_bound: float = 400.0, + heatmap_size_root: int = 64, + root_depth_bound: float = 400.0, + depth_size: int = 64, + use_different_joint_weights: bool = False, + sigma: int = 2, + joint_indices: Optional[list] = None, + max_bound: float = 1.0): + super().__init__() + + self.image_size = np.array(image_size) + self.root_heatmap_size = root_heatmap_size + self.heatmap_size = np.array(heatmap_size) + self.heatmap3d_depth_bound = heatmap3d_depth_bound + self.heatmap_size_root = heatmap_size_root + self.root_depth_bound = root_depth_bound + self.depth_size = depth_size + self.use_different_joint_weights = use_different_joint_weights + + self.sigma = sigma + self.joint_indices = joint_indices + self.max_bound = max_bound + self.scale_factor = (np.array(image_size) / + heatmap_size[:-1]).astype(np.float32) + + def encode( + self, + keypoints: np.ndarray, + keypoints_visible: Optional[np.ndarray], + dataset_keypoint_weights: Optional[np.ndarray], + rel_root_depth: np.float32, + rel_root_valid: np.float32, + hand_type: np.ndarray, + hand_type_valid: np.ndarray, + focal: np.ndarray, + principal_pt: np.ndarray, + ) -> dict: + """Encoding keypoints from input image space to input image space. + + Args: + keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D). + keypoints_visible (np.ndarray, optional): Keypoint visibilities in + shape (N, K). + dataset_keypoint_weights (np.ndarray, optional): Keypoints weight + in shape (K, ). + rel_root_depth (np.float32): Relative root depth. + rel_root_valid (float): Validity of relative root depth. + hand_type (np.ndarray): Type of hand encoded as a array. + hand_type_valid (np.ndarray): Validity of hand type. + focal (np.ndarray): Focal length of camera. + principal_pt (np.ndarray): Principal point of camera. + + Returns: + encoded (dict): Contains the following items: + + - heatmaps (np.ndarray): The generated heatmap in shape + (K * D, H, W) where [W, H, D] is the `heatmap_size` + - keypoint_weights (np.ndarray): The target weights in shape + (N, K) + - root_depth (np.ndarray): Encoded relative root depth + - root_depth_weight (np.ndarray): The weights of relative root + depth + - type (np.ndarray): Encoded hand type + - type_weight (np.ndarray): The weights of hand type + """ + if keypoints_visible is None: + keypoints_visible = np.ones(keypoints.shape[:-1], dtype=np.float32) + + if self.use_different_joint_weights: + assert dataset_keypoint_weights is not None, 'To use different ' \ + 'joint weights,`dataset_keypoint_weights` cannot be None.' + + heatmaps, keypoint_weights = generate_3d_gaussian_heatmaps( + heatmap_size=self.heatmap_size, + keypoints=keypoints, + keypoints_visible=keypoints_visible, + sigma=self.sigma, + image_size=self.image_size, + heatmap3d_depth_bound=self.heatmap3d_depth_bound, + joint_indices=self.joint_indices, + max_bound=self.max_bound, + use_different_joint_weights=self.use_different_joint_weights, + dataset_keypoint_weights=dataset_keypoint_weights) + + rel_root_depth = (rel_root_depth / self.root_depth_bound + + 0.5) * self.heatmap_size_root + rel_root_valid = rel_root_valid * (rel_root_depth >= 0) * ( + rel_root_depth <= self.heatmap_size_root) + + encoded = dict( + heatmaps=heatmaps, + keypoint_weights=keypoint_weights, + root_depth=rel_root_depth * np.ones(1, dtype=np.float32), + type=hand_type, + type_weight=hand_type_valid, + root_depth_weight=rel_root_valid * np.ones(1, dtype=np.float32)) + return encoded + + def decode(self, heatmaps: np.ndarray, root_depth: np.ndarray, + hand_type: np.ndarray) -> Tuple[np.ndarray, np.ndarray]: + """Decode keypoint coordinates from heatmaps. The decoded keypoint + coordinates are in the input image space. + + Args: + heatmaps (np.ndarray): Heatmaps in shape (K, D, H, W) + root_depth (np.ndarray): Root depth prediction. + hand_type (np.ndarray): Hand type prediction. + + Returns: + tuple: + - keypoints (np.ndarray): Decoded keypoint coordinates in shape + (N, K, D) + - scores (np.ndarray): The keypoint scores in shape (N, K). It + usually represents the confidence of the keypoint prediction + """ + heatmap3d = heatmaps.copy() + + keypoints, scores = get_heatmap_3d_maximum(heatmap3d) + + # transform keypoint depth to camera space + keypoints[..., 2] = (keypoints[..., 2] / self.depth_size - + 0.5) * self.heatmap3d_depth_bound + + # Unsqueeze the instance dimension for single-instance results + keypoints, scores = keypoints[None], scores[None] + + # Restore the keypoint scale + keypoints[..., :2] = keypoints[..., :2] * self.scale_factor + + # decode relative hand root depth + # transform relative root depth to camera space + rel_root_depth = ((root_depth / self.root_heatmap_size - 0.5) * + self.root_depth_bound) + + hand_type = (hand_type > 0).reshape(1, -1).astype(int) + + return keypoints, scores, rel_root_depth, hand_type diff --git a/mmpose/codecs/image_pose_lifting.py b/mmpose/codecs/image_pose_lifting.py index 64bf925997..81bd192eb3 100644 --- a/mmpose/codecs/image_pose_lifting.py +++ b/mmpose/codecs/image_pose_lifting.py @@ -25,6 +25,10 @@ class ImagePoseLifting(BaseKeypointCodec): Default: ``False``. save_index (bool): If true, store the root position separated from the original pose. Default: ``False``. + reshape_keypoints (bool): If true, reshape the keypoints into shape + (-1, N). Default: ``True``. + concat_vis (bool): If true, concat the visibility item of keypoints. + Default: ``False``. keypoints_mean (np.ndarray, optional): Mean values of keypoints coordinates in shape (K, D). keypoints_std (np.ndarray, optional): Std values of keypoints @@ -37,11 +41,22 @@ class ImagePoseLifting(BaseKeypointCodec): auxiliary_encode_keys = {'lifting_target', 'lifting_target_visible'} + instance_mapping_table = dict( + lifting_target='lifting_target', + lifting_target_visible='lifting_target_visible', + ) + label_mapping_table = dict( + trajectory_weights='trajectory_weights', + lifting_target_label='lifting_target_label', + lifting_target_weight='lifting_target_weight') + def __init__(self, num_keypoints: int, root_index: int, remove_root: bool = False, save_index: bool = False, + reshape_keypoints: bool = True, + concat_vis: bool = False, keypoints_mean: Optional[np.ndarray] = None, keypoints_std: Optional[np.ndarray] = None, target_mean: Optional[np.ndarray] = None, @@ -52,10 +67,30 @@ def __init__(self, self.root_index = root_index self.remove_root = remove_root self.save_index = save_index - if keypoints_mean is not None and keypoints_std is not None: - assert keypoints_mean.shape == keypoints_std.shape - if target_mean is not None and target_std is not None: - assert target_mean.shape == target_std.shape + self.reshape_keypoints = reshape_keypoints + self.concat_vis = concat_vis + if keypoints_mean is not None: + assert keypoints_std is not None, 'keypoints_std is None' + keypoints_mean = np.array( + keypoints_mean, + dtype=np.float32).reshape(1, num_keypoints, -1) + keypoints_std = np.array( + keypoints_std, dtype=np.float32).reshape(1, num_keypoints, -1) + + assert keypoints_mean.shape == keypoints_std.shape, ( + f'keypoints_mean.shape {keypoints_mean.shape} != ' + f'keypoints_std.shape {keypoints_std.shape}') + if target_mean is not None: + assert target_std is not None, 'target_std is None' + target_dim = num_keypoints - 1 if remove_root else num_keypoints + target_mean = np.array( + target_mean, dtype=np.float32).reshape(1, target_dim, -1) + target_std = np.array( + target_std, dtype=np.float32).reshape(1, target_dim, -1) + + assert target_mean.shape == target_std.shape, ( + f'target_mean.shape {target_mean.shape} != ' + f'target_std.shape {target_std.shape}') self.keypoints_mean = keypoints_mean self.keypoints_std = keypoints_std self.target_mean = target_mean @@ -73,18 +108,20 @@ def encode(self, keypoints_visible (np.ndarray, optional): Keypoint visibilities in shape (N, K). lifting_target (np.ndarray, optional): 3d target coordinate in - shape (K, C). + shape (T, K, C). lifting_target_visible (np.ndarray, optional): Target coordinate in - shape (K, ). + shape (T, K, ). Returns: encoded (dict): Contains the following items: - keypoint_labels (np.ndarray): The processed keypoints in - shape (K * D, N) where D is 2 for 2d coordinates. + shape like (N, K, D) or (K * D, N). + - keypoint_labels_visible (np.ndarray): The processed + keypoints' weights in shape (N, K, ) or (N-1, K, ). - lifting_target_label: The processed target coordinate in shape (K, C) or (K-1, C). - - lifting_target_weights (np.ndarray): The target weights in + - lifting_target_weight (np.ndarray): The target weights in shape (K, ) or (K-1, ). - trajectory_weights (np.ndarray): The trajectory weights in shape (K, ). @@ -93,30 +130,32 @@ def encode(self, In addition, there are some optional items it may contain: + - target_root (np.ndarray): The root coordinate of target in + shape (C, ). Exists if ``zero_center`` is ``True``. - target_root_removed (bool): Indicate whether the root of - pose lifting target is removed. Added if ``self.remove_root`` - is ``True``. + pose-lifitng target is removed. Exists if + ``remove_root`` is ``True``. - target_root_index (int): An integer indicating the index of - root. Added if ``self.remove_root`` and ``self.save_index`` + root. Exists if ``remove_root`` and ``save_index`` are ``True``. """ if keypoints_visible is None: keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32) if lifting_target is None: - lifting_target = keypoints[0] + lifting_target = [keypoints[0]] - # set initial value for `lifting_target_weights` + # set initial value for `lifting_target_weight` # and `trajectory_weights` if lifting_target_visible is None: lifting_target_visible = np.ones( lifting_target.shape[:-1], dtype=np.float32) - lifting_target_weights = lifting_target_visible + lifting_target_weight = lifting_target_visible trajectory_weights = (1 / lifting_target[:, 2]) else: valid = lifting_target_visible > 0.5 - lifting_target_weights = np.where(valid, 1., 0.).astype(np.float32) - trajectory_weights = lifting_target_weights + lifting_target_weight = np.where(valid, 1., 0.).astype(np.float32) + trajectory_weights = lifting_target_weight encoded = dict() @@ -126,15 +165,22 @@ def encode(self, f'Got invalid joint shape {lifting_target.shape}' root = lifting_target[..., self.root_index, :] - lifting_target_label = lifting_target - root + lifting_target_label = lifting_target - lifting_target[ + ..., self.root_index:self.root_index + 1, :] if self.remove_root: lifting_target_label = np.delete( lifting_target_label, self.root_index, axis=-2) - assert lifting_target_weights.ndim in {1, 2} - axis_to_remove = -2 if lifting_target_weights.ndim == 2 else -1 - lifting_target_weights = np.delete( - lifting_target_weights, self.root_index, axis=axis_to_remove) + lifting_target_visible = np.delete( + lifting_target_visible, self.root_index, axis=-2) + assert lifting_target_weight.ndim in { + 2, 3 + }, (f'lifting_target_weight.ndim {lifting_target_weight.ndim} ' + 'is not in {2, 3}') + + axis_to_remove = -2 if lifting_target_weight.ndim == 3 else -1 + lifting_target_weight = np.delete( + lifting_target_weight, self.root_index, axis=axis_to_remove) # Add a flag to avoid latter transforms that rely on the root # joint or the original joint index encoded['target_root_removed'] = True @@ -145,27 +191,47 @@ def encode(self, # Normalize the 2D keypoint coordinate with mean and std keypoint_labels = keypoints.copy() - if self.keypoints_mean is not None and self.keypoints_std is not None: - keypoints_shape = keypoints.shape - assert self.keypoints_mean.shape == keypoints_shape[1:] + if self.keypoints_mean is not None: + assert self.keypoints_mean.shape[1:] == keypoints.shape[1:], ( + f'self.keypoints_mean.shape[1:] {self.keypoints_mean.shape[1:]} ' # noqa + f'!= keypoints.shape[1:] {keypoints.shape[1:]}') + encoded['keypoints_mean'] = self.keypoints_mean.copy() + encoded['keypoints_std'] = self.keypoints_std.copy() keypoint_labels = (keypoint_labels - self.keypoints_mean) / self.keypoints_std - if self.target_mean is not None and self.target_std is not None: - target_shape = lifting_target_label.shape - assert self.target_mean.shape == target_shape + if self.target_mean is not None: + assert self.target_mean.shape == lifting_target_label.shape, ( + f'self.target_mean.shape {self.target_mean.shape} ' + f'!= lifting_target_label.shape {lifting_target_label.shape}') + encoded['target_mean'] = self.target_mean.copy() + encoded['target_std'] = self.target_std.copy() lifting_target_label = (lifting_target_label - self.target_mean) / self.target_std # Generate reshaped keypoint coordinates - assert keypoint_labels.ndim in {2, 3} + assert keypoint_labels.ndim in { + 2, 3 + }, (f'keypoint_labels.ndim {keypoint_labels.ndim} is not in {2, 3}') if keypoint_labels.ndim == 2: keypoint_labels = keypoint_labels[None, ...] + if self.concat_vis: + keypoints_visible_ = keypoints_visible + if keypoints_visible.ndim == 2: + keypoints_visible_ = keypoints_visible[..., None] + keypoint_labels = np.concatenate( + (keypoint_labels, keypoints_visible_), axis=2) + + if self.reshape_keypoints: + N = keypoint_labels.shape[0] + keypoint_labels = keypoint_labels.transpose(1, 2, 0).reshape(-1, N) + encoded['keypoint_labels'] = keypoint_labels + encoded['keypoint_labels_visible'] = keypoints_visible encoded['lifting_target_label'] = lifting_target_label - encoded['lifting_target_weights'] = lifting_target_weights + encoded['lifting_target_weight'] = lifting_target_weight encoded['trajectory_weights'] = trajectory_weights encoded['target_root'] = root @@ -190,11 +256,13 @@ def decode(self, keypoints = encoded.copy() if self.target_mean is not None and self.target_std is not None: - assert self.target_mean.shape == keypoints.shape[1:] + assert self.target_mean.shape == keypoints.shape, ( + f'self.target_mean.shape {self.target_mean.shape} ' + f'!= keypoints.shape {keypoints.shape}') keypoints = keypoints * self.target_std + self.target_mean - if target_root.size > 0: - keypoints = keypoints + np.expand_dims(target_root, axis=0) + if target_root is not None and target_root.size > 0: + keypoints = keypoints + target_root if self.remove_root: keypoints = np.insert( keypoints, self.root_index, target_root, axis=1) diff --git a/mmpose/codecs/integral_regression_label.py b/mmpose/codecs/integral_regression_label.py index ed8e72cb10..a3ded1f00b 100644 --- a/mmpose/codecs/integral_regression_label.py +++ b/mmpose/codecs/integral_regression_label.py @@ -45,6 +45,12 @@ class IntegralRegressionLabel(BaseKeypointCodec): .. _`DSNT`: https://arxiv.org/abs/1801.07372 """ + label_mapping_table = dict( + keypoint_labels='keypoint_labels', + keypoint_weights='keypoint_weights', + ) + field_mapping_table = dict(heatmaps='heatmaps', ) + def __init__(self, input_size: Tuple[int, int], heatmap_size: Tuple[int, int], diff --git a/mmpose/codecs/megvii_heatmap.py b/mmpose/codecs/megvii_heatmap.py index e898004637..3af0a54ff8 100644 --- a/mmpose/codecs/megvii_heatmap.py +++ b/mmpose/codecs/megvii_heatmap.py @@ -39,6 +39,9 @@ class MegviiHeatmap(BaseKeypointCodec): .. _`CPN`: https://arxiv.org/abs/1711.07319 """ + label_mapping_table = dict(keypoint_weights='keypoint_weights', ) + field_mapping_table = dict(heatmaps='heatmaps', ) + def __init__( self, input_size: Tuple[int, int], diff --git a/mmpose/codecs/motionbert_label.py b/mmpose/codecs/motionbert_label.py new file mode 100644 index 0000000000..98024ea4e6 --- /dev/null +++ b/mmpose/codecs/motionbert_label.py @@ -0,0 +1,240 @@ +# Copyright (c) OpenMMLab. All rights reserved. + +from copy import deepcopy +from typing import Optional, Tuple + +import numpy as np + +from mmpose.registry import KEYPOINT_CODECS +from .base import BaseKeypointCodec +from .utils import camera_to_image_coord + + +@KEYPOINT_CODECS.register_module() +class MotionBERTLabel(BaseKeypointCodec): + r"""Generate keypoint and label coordinates for `MotionBERT`_ by Zhu et al + (2022). + + Note: + + - instance number: N + - keypoint number: K + - keypoint dimension: D + - pose-lifitng target dimension: C + + Args: + num_keypoints (int): The number of keypoints in the dataset. + root_index (int): Root keypoint index in the pose. Default: 0. + remove_root (bool): If true, remove the root keypoint from the pose. + Default: ``False``. + save_index (bool): If true, store the root position separated from the + original pose, only takes effect if ``remove_root`` is ``True``. + Default: ``False``. + concat_vis (bool): If true, concat the visibility item of keypoints. + Default: ``False``. + rootrel (bool): If true, the root keypoint will be set to the + coordinate origin. Default: ``False``. + mode (str): Indicating whether the current mode is 'train' or 'test'. + Default: ``'test'``. + """ + + auxiliary_encode_keys = { + 'lifting_target', 'lifting_target_visible', 'camera_param', 'factor' + } + + instance_mapping_table = dict( + lifting_target='lifting_target', + lifting_target_visible='lifting_target_visible', + ) + label_mapping_table = dict( + trajectory_weights='trajectory_weights', + lifting_target_label='lifting_target_label', + lifting_target_weight='lifting_target_weight') + + def __init__(self, + num_keypoints: int, + root_index: int = 0, + remove_root: bool = False, + save_index: bool = False, + concat_vis: bool = False, + rootrel: bool = False, + mode: str = 'test'): + super().__init__() + + self.num_keypoints = num_keypoints + self.root_index = root_index + self.remove_root = remove_root + self.save_index = save_index + self.concat_vis = concat_vis + self.rootrel = rootrel + assert mode.lower() in {'train', 'test' + }, (f'Unsupported mode {mode}, ' + 'mode should be one of ("train", "test").') + self.mode = mode.lower() + + def encode(self, + keypoints: np.ndarray, + keypoints_visible: Optional[np.ndarray] = None, + lifting_target: Optional[np.ndarray] = None, + lifting_target_visible: Optional[np.ndarray] = None, + camera_param: Optional[dict] = None, + factor: Optional[np.ndarray] = None) -> dict: + """Encoding keypoints from input image space to normalized space. + + Args: + keypoints (np.ndarray): Keypoint coordinates in shape (B, T, K, D). + keypoints_visible (np.ndarray, optional): Keypoint visibilities in + shape (B, T, K). + lifting_target (np.ndarray, optional): 3d target coordinate in + shape (T, K, C). + lifting_target_visible (np.ndarray, optional): Target coordinate in + shape (T, K, ). + camera_param (dict, optional): The camera parameter dictionary. + factor (np.ndarray, optional): The factor mapping camera and image + coordinate in shape (T, ). + + Returns: + encoded (dict): Contains the following items: + + - keypoint_labels (np.ndarray): The processed keypoints in + shape like (N, K, D). + - keypoint_labels_visible (np.ndarray): The processed + keypoints' weights in shape (N, K, ) or (N, K-1, ). + - lifting_target_label: The processed target coordinate in + shape (K, C) or (K-1, C). + - lifting_target_weight (np.ndarray): The target weights in + shape (K, ) or (K-1, ). + - factor (np.ndarray): The factor mapping camera and image + coordinate in shape (T, 1). + """ + if keypoints_visible is None: + keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32) + + # set initial value for `lifting_target_weight` + if lifting_target_visible is None: + lifting_target_visible = np.ones( + lifting_target.shape[:-1], dtype=np.float32) + lifting_target_weight = lifting_target_visible + else: + valid = lifting_target_visible > 0.5 + lifting_target_weight = np.where(valid, 1., 0.).astype(np.float32) + + if camera_param is None: + camera_param = dict() + + encoded = dict() + + assert lifting_target is not None + lifting_target_label = lifting_target.copy() + keypoint_labels = keypoints.copy() + + assert keypoint_labels.ndim in { + 2, 3 + }, (f'Keypoint labels should have 2 or 3 dimensions, ' + f'but got {keypoint_labels.ndim}.') + if keypoint_labels.ndim == 2: + keypoint_labels = keypoint_labels[None, ...] + + # Normalize the 2D keypoint coordinate with image width and height + _camera_param = deepcopy(camera_param) + assert 'w' in _camera_param and 'h' in _camera_param, ( + 'Camera parameters should contain "w" and "h".') + w, h = _camera_param['w'], _camera_param['h'] + keypoint_labels[ + ..., :2] = keypoint_labels[..., :2] / w * 2 - [1, h / w] + + # convert target to image coordinate + T = keypoint_labels.shape[0] + factor_ = np.array([4] * T, dtype=np.float32).reshape(T, ) + if 'f' in _camera_param and 'c' in _camera_param: + lifting_target_label, factor_ = camera_to_image_coord( + self.root_index, lifting_target_label, _camera_param) + if self.mode == 'train': + w, h = w / 1000, h / 1000 + lifting_target_label[ + ..., :2] = lifting_target_label[..., :2] / w * 2 - [1, h / w] + lifting_target_label[..., 2] = lifting_target_label[..., 2] / w * 2 + lifting_target_label[..., :, :] = lifting_target_label[ + ..., :, :] - lifting_target_label[..., + self.root_index:self.root_index + + 1, :] + if factor is None or factor[0] == 0: + factor = factor_ + if factor.ndim == 1: + factor = factor[:, None] + if self.mode == 'test': + lifting_target_label *= factor[..., None] + + if self.concat_vis: + keypoints_visible_ = keypoints_visible + if keypoints_visible.ndim == 2: + keypoints_visible_ = keypoints_visible[..., None] + keypoint_labels = np.concatenate( + (keypoint_labels, keypoints_visible_), axis=2) + + encoded['keypoint_labels'] = keypoint_labels + encoded['keypoint_labels_visible'] = keypoints_visible + encoded['lifting_target_label'] = lifting_target_label + encoded['lifting_target_weight'] = lifting_target_weight + encoded['lifting_target'] = lifting_target_label + encoded['lifting_target_visible'] = lifting_target_visible + encoded['factor'] = factor + + return encoded + + def decode( + self, + encoded: np.ndarray, + w: Optional[np.ndarray] = None, + h: Optional[np.ndarray] = None, + factor: Optional[np.ndarray] = None, + ) -> Tuple[np.ndarray, np.ndarray]: + """Decode keypoint coordinates from normalized space to input image + space. + + Args: + encoded (np.ndarray): Coordinates in shape (N, K, C). + w (np.ndarray, optional): The image widths in shape (N, ). + Default: ``None``. + h (np.ndarray, optional): The image heights in shape (N, ). + Default: ``None``. + factor (np.ndarray, optional): The factor for projection in shape + (N, ). Default: ``None``. + + Returns: + keypoints (np.ndarray): Decoded coordinates in shape (N, K, C). + scores (np.ndarray): The keypoint scores in shape (N, K). + """ + keypoints = encoded.copy() + scores = np.ones(keypoints.shape[:-1], dtype=np.float32) + + if self.rootrel: + keypoints[..., 0, :] = 0 + + if w is not None and w.size > 0: + assert w.shape == h.shape, (f'w and h should have the same shape, ' + f'but got {w.shape} and {h.shape}.') + assert w.shape[0] == keypoints.shape[0], ( + f'w and h should have the same batch size, ' + f'but got {w.shape[0]} and {keypoints.shape[0]}.') + assert w.ndim in {1, + 2}, (f'w and h should have 1 or 2 dimensions, ' + f'but got {w.ndim}.') + if w.ndim == 1: + w = w[:, None] + h = h[:, None] + trans = np.append( + np.ones((w.shape[0], 1)), h / w, axis=1)[:, None, :] + keypoints[..., :2] = (keypoints[..., :2] + trans) * w[:, None] / 2 + keypoints[..., 2:] = keypoints[..., 2:] * w[:, None] / 2 + + if factor is not None and factor.size > 0: + assert factor.shape[0] == keypoints.shape[0], ( + f'factor should have the same batch size, ' + f'but got {factor.shape[0]} and {keypoints.shape[0]}.') + keypoints *= factor[..., None] + + keypoints[..., :, :] = keypoints[..., :, :] - keypoints[ + ..., self.root_index:self.root_index + 1, :] + keypoints /= 1000. + return keypoints, scores diff --git a/mmpose/codecs/msra_heatmap.py b/mmpose/codecs/msra_heatmap.py index 63ba292e4d..15742555b4 100644 --- a/mmpose/codecs/msra_heatmap.py +++ b/mmpose/codecs/msra_heatmap.py @@ -47,6 +47,9 @@ class MSRAHeatmap(BaseKeypointCodec): .. _`Dark Pose`: https://arxiv.org/abs/1910.06278 """ + label_mapping_table = dict(keypoint_weights='keypoint_weights', ) + field_mapping_table = dict(heatmaps='heatmaps', ) + def __init__(self, input_size: Tuple[int, int], heatmap_size: Tuple[int, int], diff --git a/mmpose/codecs/regression_label.py b/mmpose/codecs/regression_label.py index f79195beb4..74cd21b73d 100644 --- a/mmpose/codecs/regression_label.py +++ b/mmpose/codecs/regression_label.py @@ -30,6 +30,11 @@ class RegressionLabel(BaseKeypointCodec): """ + label_mapping_table = dict( + keypoint_labels='keypoint_labels', + keypoint_weights='keypoint_weights', + ) + def __init__(self, input_size: Tuple[int, int]) -> None: super().__init__() diff --git a/mmpose/codecs/simcc_label.py b/mmpose/codecs/simcc_label.py index a22498c352..6183e2be73 100644 --- a/mmpose/codecs/simcc_label.py +++ b/mmpose/codecs/simcc_label.py @@ -52,6 +52,12 @@ class SimCCLabel(BaseKeypointCodec): Estimation`: https://arxiv.org/abs/2107.03332 """ + label_mapping_table = dict( + keypoint_x_labels='keypoint_x_labels', + keypoint_y_labels='keypoint_y_labels', + keypoint_weights='keypoint_weights', + ) + def __init__(self, input_size: Tuple[int, int], smoothing_type: str = 'gaussian', diff --git a/mmpose/codecs/spr.py b/mmpose/codecs/spr.py index add6f5715b..8e09b185c7 100644 --- a/mmpose/codecs/spr.py +++ b/mmpose/codecs/spr.py @@ -73,6 +73,13 @@ class SPR(BaseKeypointCodec): https://arxiv.org/abs/1908.09220 """ + field_mapping_table = dict( + heatmaps='heatmaps', + heatmap_weights='heatmap_weights', + displacements='displacements', + displacement_weights='displacement_weights', + ) + def __init__( self, input_size: Tuple[int, int], diff --git a/mmpose/codecs/udp_heatmap.py b/mmpose/codecs/udp_heatmap.py index c38ea17be4..7e7e341e19 100644 --- a/mmpose/codecs/udp_heatmap.py +++ b/mmpose/codecs/udp_heatmap.py @@ -57,6 +57,9 @@ class UDPHeatmap(BaseKeypointCodec): Human Pose Estimation`: https://arxiv.org/abs/1911.07524 """ + label_mapping_table = dict(keypoint_weights='keypoint_weights', ) + field_mapping_table = dict(heatmaps='heatmaps', ) + def __init__(self, input_size: Tuple[int, int], heatmap_size: Tuple[int, int], diff --git a/mmpose/codecs/utils/__init__.py b/mmpose/codecs/utils/__init__.py index eaa093f12b..b5b19588b9 100644 --- a/mmpose/codecs/utils/__init__.py +++ b/mmpose/codecs/utils/__init__.py @@ -1,5 +1,8 @@ # Copyright (c) OpenMMLab. All rights reserved. -from .gaussian_heatmap import (generate_gaussian_heatmaps, +from .camera_image_projection import (camera_to_image_coord, camera_to_pixel, + pixel_to_camera) +from .gaussian_heatmap import (generate_3d_gaussian_heatmaps, + generate_gaussian_heatmaps, generate_udp_gaussian_heatmaps, generate_unbiased_gaussian_heatmaps) from .instance_property import (get_diagonal_lengths, get_instance_bbox, @@ -7,8 +10,9 @@ from .offset_heatmap import (generate_displacement_heatmap, generate_offset_heatmap) from .post_processing import (batch_heatmap_nms, gaussian_blur, - gaussian_blur1d, get_heatmap_maximum, - get_simcc_maximum, get_simcc_normalized) + gaussian_blur1d, get_heatmap_3d_maximum, + get_heatmap_maximum, get_simcc_maximum, + get_simcc_normalized) from .refinement import (refine_keypoints, refine_keypoints_dark, refine_keypoints_dark_udp, refine_simcc_dark) @@ -19,5 +23,7 @@ 'batch_heatmap_nms', 'refine_keypoints', 'refine_keypoints_dark', 'refine_keypoints_dark_udp', 'generate_displacement_heatmap', 'refine_simcc_dark', 'gaussian_blur1d', 'get_diagonal_lengths', - 'get_instance_root', 'get_instance_bbox', 'get_simcc_normalized' + 'get_instance_root', 'get_instance_bbox', 'get_simcc_normalized', + 'camera_to_image_coord', 'camera_to_pixel', 'pixel_to_camera', + 'get_heatmap_3d_maximum', 'generate_3d_gaussian_heatmaps' ] diff --git a/mmpose/codecs/utils/camera_image_projection.py b/mmpose/codecs/utils/camera_image_projection.py new file mode 100644 index 0000000000..b26d1396f1 --- /dev/null +++ b/mmpose/codecs/utils/camera_image_projection.py @@ -0,0 +1,102 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from typing import Dict, Tuple + +import numpy as np + + +def camera_to_image_coord(root_index: int, kpts_3d_cam: np.ndarray, + camera_param: Dict) -> Tuple[np.ndarray, np.ndarray]: + """Project keypoints from camera space to image space and calculate factor. + + Args: + root_index (int): Index for root keypoint. + kpts_3d_cam (np.ndarray): Keypoint coordinates in camera space in + shape (N, K, D). + camera_param (dict): Parameters for the camera. + + Returns: + tuple: + - kpts_3d_image (np.ndarray): Keypoint coordinates in image space in + shape (N, K, D). + - factor (np.ndarray): The scaling factor that maps keypoints from + image space to camera space in shape (N, ). + """ + + root = kpts_3d_cam[..., root_index, :] + tl_kpt = root.copy() + tl_kpt[..., :2] -= 1.0 + br_kpt = root.copy() + br_kpt[..., :2] += 1.0 + tl_kpt = np.reshape(tl_kpt, (-1, 3)) + br_kpt = np.reshape(br_kpt, (-1, 3)) + fx, fy = camera_param['f'] / 1000. + cx, cy = camera_param['c'] / 1000. + + tl2d = camera_to_pixel(tl_kpt, fx, fy, cx, cy) + br2d = camera_to_pixel(br_kpt, fx, fy, cx, cy) + + rectangle_3d_size = 2.0 + kpts_3d_image = np.zeros_like(kpts_3d_cam) + kpts_3d_image[..., :2] = camera_to_pixel(kpts_3d_cam.copy(), fx, fy, cx, + cy) + ratio = (br2d[..., 0] - tl2d[..., 0] + 0.001) / rectangle_3d_size + factor = rectangle_3d_size / (br2d[..., 0] - tl2d[..., 0] + 0.001) + kpts_3d_depth = ratio[:, None] * ( + kpts_3d_cam[..., 2] - kpts_3d_cam[..., root_index:root_index + 1, 2]) + kpts_3d_image[..., 2] = kpts_3d_depth + return kpts_3d_image, factor + + +def camera_to_pixel(kpts_3d: np.ndarray, + fx: float, + fy: float, + cx: float, + cy: float, + shift: bool = False) -> np.ndarray: + """Project keypoints from camera space to image space. + + Args: + kpts_3d (np.ndarray): Keypoint coordinates in camera space. + fx (float): x-coordinate of camera's focal length. + fy (float): y-coordinate of camera's focal length. + cx (float): x-coordinate of image center. + cy (float): y-coordinate of image center. + shift (bool): Whether to shift the coordinates by 1e-8. + + Returns: + pose_2d (np.ndarray): Projected keypoint coordinates in image space. + """ + if not shift: + pose_2d = kpts_3d[..., :2] / kpts_3d[..., 2:3] + else: + pose_2d = kpts_3d[..., :2] / (kpts_3d[..., 2:3] + 1e-8) + pose_2d[..., 0] *= fx + pose_2d[..., 1] *= fy + pose_2d[..., 0] += cx + pose_2d[..., 1] += cy + return pose_2d + + +def pixel_to_camera(kpts_3d: np.ndarray, fx: float, fy: float, cx: float, + cy: float) -> np.ndarray: + """Project keypoints from camera space to image space. + + Args: + kpts_3d (np.ndarray): Keypoint coordinates in camera space. + fx (float): x-coordinate of camera's focal length. + fy (float): y-coordinate of camera's focal length. + cx (float): x-coordinate of image center. + cy (float): y-coordinate of image center. + shift (bool): Whether to shift the coordinates by 1e-8. + + Returns: + pose_2d (np.ndarray): Projected keypoint coordinates in image space. + """ + pose_2d = kpts_3d.copy() + pose_2d[..., 0] -= cx + pose_2d[..., 1] -= cy + pose_2d[..., 0] /= fx + pose_2d[..., 1] /= fy + pose_2d[..., 0] *= kpts_3d[..., 2] + pose_2d[..., 1] *= kpts_3d[..., 2] + return pose_2d diff --git a/mmpose/codecs/utils/gaussian_heatmap.py b/mmpose/codecs/utils/gaussian_heatmap.py index 91e08c2cdd..f8deeb8d9d 100644 --- a/mmpose/codecs/utils/gaussian_heatmap.py +++ b/mmpose/codecs/utils/gaussian_heatmap.py @@ -1,10 +1,122 @@ # Copyright (c) OpenMMLab. All rights reserved. from itertools import product -from typing import Tuple, Union +from typing import Optional, Tuple, Union import numpy as np +def generate_3d_gaussian_heatmaps( + heatmap_size: Tuple[int, int, int], + keypoints: np.ndarray, + keypoints_visible: np.ndarray, + sigma: Union[float, Tuple[float], np.ndarray], + image_size: Tuple[int, int], + heatmap3d_depth_bound: float = 400.0, + joint_indices: Optional[list] = None, + max_bound: float = 1.0, + use_different_joint_weights: bool = False, + dataset_keypoint_weights: Optional[np.ndarray] = None +) -> Tuple[np.ndarray, np.ndarray]: + """Generate 3d gaussian heatmaps of keypoints. + + Args: + heatmap_size (Tuple[int, int]): Heatmap size in [W, H, D] + keypoints (np.ndarray): Keypoint coordinates in shape (N, K, C) + keypoints_visible (np.ndarray): Keypoint visibilities in shape + (N, K) + sigma (float or List[float]): A list of sigma values of the Gaussian + heatmap for each instance. If sigma is given as a single float + value, it will be expanded into a tuple + image_size (Tuple[int, int]): Size of input image. + heatmap3d_depth_bound (float): Boundary for 3d heatmap depth. + Default: 400.0. + joint_indices (List[int], optional): Indices of joints used for heatmap + generation. If None (default) is given, all joints will be used. + Default: ``None``. + max_bound (float): The maximal value of heatmap. Default: 1.0. + use_different_joint_weights (bool): Whether to use different joint + weights. Default: ``False``. + dataset_keypoint_weights (np.ndarray, optional): Keypoints weight in + shape (K, ). + + Returns: + tuple: + - heatmaps (np.ndarray): The generated heatmap in shape + (K * D, H, W) where [W, H, D] is the `heatmap_size` + - keypoint_weights (np.ndarray): The target weights in shape + (N, K) + """ + + W, H, D = heatmap_size + + # select the joints used for target generation + if joint_indices is not None: + keypoints = keypoints[:, joint_indices, ...] + keypoints_visible = keypoints_visible[:, joint_indices, ...] + N, K, _ = keypoints.shape + + heatmaps = np.zeros([K, D, H, W], dtype=np.float32) + keypoint_weights = keypoints_visible.copy() + + if isinstance(sigma, (int, float)): + sigma = (sigma, ) * N + + for n in range(N): + # 3-sigma rule + radius = sigma[n] * 3 + + # joint location in heatmap coordinates + mu_x = keypoints[n, :, 0] * W / image_size[0] # (K, ) + mu_y = keypoints[n, :, 1] * H / image_size[1] + mu_z = (keypoints[n, :, 2] / heatmap3d_depth_bound + 0.5) * D + + keypoint_weights[n, ...] = keypoint_weights[n, ...] * (mu_z >= 0) * ( + mu_z < D) + if use_different_joint_weights: + keypoint_weights[ + n] = keypoint_weights[n] * dataset_keypoint_weights + # xy grid + gaussian_size = 2 * radius + 1 + + # get neighboring voxels coordinates + x = y = z = np.arange(gaussian_size, dtype=np.float32) - radius + zz, yy, xx = np.meshgrid(z, y, x) + + xx = np.expand_dims(xx, axis=0) + yy = np.expand_dims(yy, axis=0) + zz = np.expand_dims(zz, axis=0) + mu_x = np.expand_dims(mu_x, axis=(-1, -2, -3)) + mu_y = np.expand_dims(mu_y, axis=(-1, -2, -3)) + mu_z = np.expand_dims(mu_z, axis=(-1, -2, -3)) + + xx, yy, zz = xx + mu_x, yy + mu_y, zz + mu_z + local_size = xx.shape[1] + + # round the coordinates + xx = xx.round().clip(0, W - 1) + yy = yy.round().clip(0, H - 1) + zz = zz.round().clip(0, D - 1) + + # compute the target value near joints + gaussian = np.exp(-((xx - mu_x)**2 + (yy - mu_y)**2 + (zz - mu_z)**2) / + (2 * sigma[n]**2)) + + # put the local target value to the full target heatmap + idx_joints = np.tile( + np.expand_dims(np.arange(K), axis=(-1, -2, -3)), + [1, local_size, local_size, local_size]) + idx = np.stack([idx_joints, zz, yy, xx], + axis=-1).astype(int).reshape(-1, 4) + + heatmaps[idx[:, 0], idx[:, 1], idx[:, 2], idx[:, 3]] = np.maximum( + heatmaps[idx[:, 0], idx[:, 1], idx[:, 2], idx[:, 3]], + gaussian.reshape(-1)) + + heatmaps = (heatmaps * max_bound).reshape(-1, H, W) + + return heatmaps, keypoint_weights + + def generate_gaussian_heatmaps( heatmap_size: Tuple[int, int], keypoints: np.ndarray, diff --git a/mmpose/codecs/utils/post_processing.py b/mmpose/codecs/utils/post_processing.py index 75356388dc..7bb447e199 100644 --- a/mmpose/codecs/utils/post_processing.py +++ b/mmpose/codecs/utils/post_processing.py @@ -94,6 +94,54 @@ def get_simcc_maximum(simcc_x: np.ndarray, return locs, vals +def get_heatmap_3d_maximum(heatmaps: np.ndarray + ) -> Tuple[np.ndarray, np.ndarray]: + """Get maximum response location and value from heatmaps. + + Note: + batch_size: B + num_keypoints: K + heatmap dimension: D + heatmap height: H + heatmap width: W + + Args: + heatmaps (np.ndarray): Heatmaps in shape (K, D, H, W) or + (B, K, D, H, W) + + Returns: + tuple: + - locs (np.ndarray): locations of maximum heatmap responses in shape + (K, 3) or (B, K, 3) + - vals (np.ndarray): values of maximum heatmap responses in shape + (K,) or (B, K) + """ + assert isinstance(heatmaps, + np.ndarray), ('heatmaps should be numpy.ndarray') + assert heatmaps.ndim == 4 or heatmaps.ndim == 5, ( + f'Invalid shape {heatmaps.shape}') + + if heatmaps.ndim == 4: + K, D, H, W = heatmaps.shape + B = None + heatmaps_flatten = heatmaps.reshape(K, -1) + else: + B, K, D, H, W = heatmaps.shape + heatmaps_flatten = heatmaps.reshape(B * K, -1) + + z_locs, y_locs, x_locs = np.unravel_index( + np.argmax(heatmaps_flatten, axis=1), shape=(D, H, W)) + locs = np.stack((x_locs, y_locs, z_locs), axis=-1).astype(np.float32) + vals = np.amax(heatmaps_flatten, axis=1) + locs[vals <= 0.] = -1 + + if B: + locs = locs.reshape(B, K, 3) + vals = vals.reshape(B, K) + + return locs, vals + + def get_heatmap_maximum(heatmaps: np.ndarray) -> Tuple[np.ndarray, np.ndarray]: """Get maximum response location and value from heatmaps. diff --git a/mmpose/codecs/video_pose_lifting.py b/mmpose/codecs/video_pose_lifting.py index 56cf35fa2d..2b08b4da85 100644 --- a/mmpose/codecs/video_pose_lifting.py +++ b/mmpose/codecs/video_pose_lifting.py @@ -30,6 +30,10 @@ class VideoPoseLifting(BaseKeypointCodec): save_index (bool): If true, store the root position separated from the original pose, only takes effect if ``remove_root`` is ``True``. Default: ``False``. + reshape_keypoints (bool): If true, reshape the keypoints into shape + (-1, N). Default: ``True``. + concat_vis (bool): If true, concat the visibility item of keypoints. + Default: ``False``. normalize_camera (bool): Whether to normalize camera intrinsics. Default: ``False``. """ @@ -38,12 +42,23 @@ class VideoPoseLifting(BaseKeypointCodec): 'lifting_target', 'lifting_target_visible', 'camera_param' } + instance_mapping_table = dict( + lifting_target='lifting_target', + lifting_target_visible='lifting_target_visible', + ) + label_mapping_table = dict( + trajectory_weights='trajectory_weights', + lifting_target_label='lifting_target_label', + lifting_target_weight='lifting_target_weight') + def __init__(self, num_keypoints: int, zero_center: bool = True, root_index: int = 0, remove_root: bool = False, save_index: bool = False, + reshape_keypoints: bool = True, + concat_vis: bool = False, normalize_camera: bool = False): super().__init__() @@ -52,6 +67,8 @@ def __init__(self, self.root_index = root_index self.remove_root = remove_root self.save_index = save_index + self.reshape_keypoints = reshape_keypoints + self.concat_vis = concat_vis self.normalize_camera = normalize_camera def encode(self, @@ -67,19 +84,21 @@ def encode(self, keypoints_visible (np.ndarray, optional): Keypoint visibilities in shape (N, K). lifting_target (np.ndarray, optional): 3d target coordinate in - shape (K, C). + shape (T, K, C). lifting_target_visible (np.ndarray, optional): Target coordinate in - shape (K, ). + shape (T, K, ). camera_param (dict, optional): The camera parameter dictionary. Returns: encoded (dict): Contains the following items: - keypoint_labels (np.ndarray): The processed keypoints in - shape (K * D, N) where D is 2 for 2d coordinates. + shape like (N, K, D) or (K * D, N). + - keypoint_labels_visible (np.ndarray): The processed + keypoints' weights in shape (N, K, ) or (N-1, K, ). - lifting_target_label: The processed target coordinate in shape (K, C) or (K-1, C). - - lifting_target_weights (np.ndarray): The target weights in + - lifting_target_weight (np.ndarray): The target weights in shape (K, ) or (K-1, ). - trajectory_weights (np.ndarray): The trajectory weights in shape (K, ). @@ -87,33 +106,33 @@ def encode(self, In addition, there are some optional items it may contain: - target_root (np.ndarray): The root coordinate of target in - shape (C, ). Exists if ``self.zero_center`` is ``True``. + shape (C, ). Exists if ``zero_center`` is ``True``. - target_root_removed (bool): Indicate whether the root of pose-lifitng target is removed. Exists if - ``self.remove_root`` is ``True``. + ``remove_root`` is ``True``. - target_root_index (int): An integer indicating the index of - root. Exists if ``self.remove_root`` and ``self.save_index`` + root. Exists if ``remove_root`` and ``save_index`` are ``True``. - camera_param (dict): The updated camera parameter dictionary. - Exists if ``self.normalize_camera`` is ``True``. + Exists if ``normalize_camera`` is ``True``. """ if keypoints_visible is None: keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32) if lifting_target is None: - lifting_target = keypoints[0] + lifting_target = [keypoints[0]] - # set initial value for `lifting_target_weights` + # set initial value for `lifting_target_weight` # and `trajectory_weights` if lifting_target_visible is None: lifting_target_visible = np.ones( lifting_target.shape[:-1], dtype=np.float32) - lifting_target_weights = lifting_target_visible + lifting_target_weight = lifting_target_visible trajectory_weights = (1 / lifting_target[:, 2]) else: valid = lifting_target_visible > 0.5 - lifting_target_weights = np.where(valid, 1., 0.).astype(np.float32) - trajectory_weights = lifting_target_weights + lifting_target_weight = np.where(valid, 1., 0.).astype(np.float32) + trajectory_weights = lifting_target_weight if camera_param is None: camera_param = dict() @@ -128,16 +147,23 @@ def encode(self, f'Got invalid joint shape {lifting_target.shape}' root = lifting_target[..., self.root_index, :] - lifting_target_label = lifting_target_label - root + lifting_target_label -= lifting_target_label[ + ..., self.root_index:self.root_index + 1, :] encoded['target_root'] = root if self.remove_root: lifting_target_label = np.delete( lifting_target_label, self.root_index, axis=-2) - assert lifting_target_weights.ndim in {1, 2} - axis_to_remove = -2 if lifting_target_weights.ndim == 2 else -1 - lifting_target_weights = np.delete( - lifting_target_weights, + lifting_target_visible = np.delete( + lifting_target_visible, self.root_index, axis=-2) + assert lifting_target_weight.ndim in { + 2, 3 + }, (f'Got invalid lifting target weights shape ' + f'{lifting_target_weight.shape}') + + axis_to_remove = -2 if lifting_target_weight.ndim == 3 else -1 + lifting_target_weight = np.delete( + lifting_target_weight, self.root_index, axis=axis_to_remove) # Add a flag to avoid latter transforms that rely on the root @@ -150,26 +176,43 @@ def encode(self, # Normalize the 2D keypoint coordinate with image width and height _camera_param = deepcopy(camera_param) - assert 'w' in _camera_param and 'h' in _camera_param + assert 'w' in _camera_param and 'h' in _camera_param, ( + 'Camera parameter `w` and `h` should be provided.') + center = np.array([0.5 * _camera_param['w'], 0.5 * _camera_param['h']], dtype=np.float32) scale = np.array(0.5 * _camera_param['w'], dtype=np.float32) keypoint_labels = (keypoints - center) / scale - assert keypoint_labels.ndim in {2, 3} + assert keypoint_labels.ndim in { + 2, 3 + }, (f'Got invalid keypoint labels shape {keypoint_labels.shape}') if keypoint_labels.ndim == 2: keypoint_labels = keypoint_labels[None, ...] if self.normalize_camera: - assert 'f' in _camera_param and 'c' in _camera_param + assert 'f' in _camera_param and 'c' in _camera_param, ( + 'Camera parameter `f` and `c` should be provided.') _camera_param['f'] = _camera_param['f'] / scale _camera_param['c'] = (_camera_param['c'] - center[:, None]) / scale encoded['camera_param'] = _camera_param + if self.concat_vis: + keypoints_visible_ = keypoints_visible + if keypoints_visible.ndim == 2: + keypoints_visible_ = keypoints_visible[..., None] + keypoint_labels = np.concatenate( + (keypoint_labels, keypoints_visible_), axis=2) + + if self.reshape_keypoints: + N = keypoint_labels.shape[0] + keypoint_labels = keypoint_labels.transpose(1, 2, 0).reshape(-1, N) + encoded['keypoint_labels'] = keypoint_labels + encoded['keypoints_visible'] = keypoints_visible encoded['lifting_target_label'] = lifting_target_label - encoded['lifting_target_weights'] = lifting_target_weights + encoded['lifting_target_weight'] = lifting_target_weight encoded['trajectory_weights'] = trajectory_weights return encoded @@ -192,8 +235,8 @@ def decode(self, """ keypoints = encoded.copy() - if target_root.size > 0: - keypoints = keypoints + np.expand_dims(target_root, axis=0) + if target_root is not None and target_root.size > 0: + keypoints = keypoints + target_root if self.remove_root: keypoints = np.insert( keypoints, self.root_index, target_root, axis=1) diff --git a/mmpose/datasets/dataset_wrappers.py b/mmpose/datasets/dataset_wrappers.py index 28eeac9945..48bb3fc2a4 100644 --- a/mmpose/datasets/dataset_wrappers.py +++ b/mmpose/datasets/dataset_wrappers.py @@ -1,8 +1,9 @@ # Copyright (c) OpenMMLab. All rights reserved. from copy import deepcopy -from typing import Any, Callable, List, Tuple, Union +from typing import Any, Callable, List, Optional, Tuple, Union +import numpy as np from mmengine.dataset import BaseDataset from mmengine.registry import build_from_cfg @@ -18,21 +19,37 @@ class CombinedDataset(BaseDataset): metainfo (dict): The meta information of combined dataset. datasets (list): The configs of datasets to be combined. pipeline (list, optional): Processing pipeline. Defaults to []. + sample_ratio_factor (list, optional): A list of sampling ratio + factors for each dataset. Defaults to None """ def __init__(self, metainfo: dict, datasets: list, pipeline: List[Union[dict, Callable]] = [], + sample_ratio_factor: Optional[List[float]] = None, **kwargs): self.datasets = [] + self.resample = sample_ratio_factor is not None for cfg in datasets: dataset = build_from_cfg(cfg, DATASETS) self.datasets.append(dataset) self._lens = [len(dataset) for dataset in self.datasets] + if self.resample: + assert len(sample_ratio_factor) == len(datasets), f'the length ' \ + f'of `sample_ratio_factor` {len(sample_ratio_factor)} does ' \ + f'not match the length of `datasets` {len(datasets)}' + assert min(sample_ratio_factor) >= 0.0, 'the ratio values in ' \ + '`sample_ratio_factor` should not be negative.' + self._lens_ori = self._lens + self._lens = [ + round(l * sample_ratio_factor[i]) + for i, l in enumerate(self._lens_ori) + ] + self._len = sum(self._lens) super(CombinedDataset, self).__init__(pipeline=pipeline, **kwargs) @@ -71,6 +88,12 @@ def _get_subset_index(self, index: int) -> Tuple[int, int]: while index >= self._lens[subset_index]: index -= self._lens[subset_index] subset_index += 1 + + if self.resample: + gap = (self._lens_ori[subset_index] - + 1e-4) / self._lens[subset_index] + index = round(gap * index + np.random.rand() * gap - 0.5) + return subset_index, index def prepare_data(self, idx: int) -> Any: @@ -86,6 +109,11 @@ def prepare_data(self, idx: int) -> Any: data_info = self.get_data_info(idx) + # the assignment of 'dataset' should not be performed within the + # `get_data_info` function. Otherwise, it can lead to the mixed + # data augmentation process getting stuck. + data_info['dataset'] = self + return self.pipeline(data_info) def get_data_info(self, idx: int) -> dict: @@ -100,6 +128,9 @@ def get_data_info(self, idx: int) -> dict: # Get data sample processed by ``subset.pipeline`` data_info = self.datasets[subset_idx][sample_idx] + if 'dataset' in data_info: + data_info.pop('dataset') + # Add metainfo items that are required in the pipeline and the model metainfo_keys = [ 'upper_body_ids', 'lower_body_ids', 'flip_pairs', diff --git a/mmpose/datasets/datasets/__init__.py b/mmpose/datasets/datasets/__init__.py index 9f5801753f..f0709ab32f 100644 --- a/mmpose/datasets/datasets/__init__.py +++ b/mmpose/datasets/datasets/__init__.py @@ -6,4 +6,6 @@ from .face import * # noqa: F401, F403 from .fashion import * # noqa: F401, F403 from .hand import * # noqa: F401, F403 +from .hand3d import * # noqa: F401, F403 from .wholebody import * # noqa: F401, F403 +from .wholebody3d import * # noqa: F401, F403 diff --git a/mmpose/datasets/datasets/base/base_coco_style_dataset.py b/mmpose/datasets/datasets/base/base_coco_style_dataset.py index 3b592813d8..ac94961f2c 100644 --- a/mmpose/datasets/datasets/base/base_coco_style_dataset.py +++ b/mmpose/datasets/datasets/base/base_coco_style_dataset.py @@ -2,12 +2,13 @@ import copy import os.path as osp from copy import deepcopy -from itertools import filterfalse, groupby +from itertools import chain, filterfalse, groupby from typing import Any, Callable, Dict, List, Optional, Sequence, Tuple, Union import numpy as np from mmengine.dataset import BaseDataset, force_full_init from mmengine.fileio import exists, get_local_path, load +from mmengine.logging import MessageHub from mmengine.utils import is_list_of from xtcocotools.coco import COCO @@ -56,6 +57,8 @@ class BaseCocoStyleDataset(BaseDataset): max_refetch (int, optional): If ``Basedataset.prepare_data`` get a None img. The maximum extra number of cycles to get a valid image. Default: 1000. + sample_interval (int, optional): The sample interval of the dataset. + Default: 1. """ METAINFO: dict = dict() @@ -73,7 +76,8 @@ def __init__(self, pipeline: List[Union[dict, Callable]] = [], test_mode: bool = False, lazy_init: bool = False, - max_refetch: int = 1000): + max_refetch: int = 1000, + sample_interval: int = 1): if data_mode not in {'topdown', 'bottomup'}: raise ValueError( @@ -94,6 +98,7 @@ def __init__(self, 'while "bbox_file" is only ' 'supported when `test_mode==True`.') self.bbox_file = bbox_file + self.sample_interval = sample_interval super().__init__( ann_file=ann_file, @@ -108,6 +113,13 @@ def __init__(self, lazy_init=lazy_init, max_refetch=max_refetch) + if self.test_mode: + # save the ann_file into MessageHub for CocoMetric + message = MessageHub.get_current_instance() + dataset_name = self.metainfo['dataset_name'] + message.update_info_dict( + {f'{dataset_name}_ann_file': self.ann_file}) + @classmethod def _load_metainfo(cls, metainfo: dict = None) -> dict: """Collect meta information from the dictionary of meta. @@ -147,6 +159,14 @@ def prepare_data(self, idx) -> Any: """ data_info = self.get_data_info(idx) + # Mixed image transformations require multiple source images for + # effective blending. Therefore, we assign the 'dataset' field in + # `data_info` to provide these auxiliary images. + # Note: The 'dataset' assignment should not occur within the + # `get_data_info` function, as doing so may cause the mixed image + # transformations to stall or hang. + data_info['dataset'] = self + return self.pipeline(data_info) def get_data_info(self, idx: int) -> dict: @@ -162,7 +182,7 @@ def get_data_info(self, idx: int) -> dict: # Add metainfo items that are required in the pipeline and the model metainfo_keys = [ - 'upper_body_ids', 'lower_body_ids', 'flip_pairs', + 'dataset_name', 'upper_body_ids', 'lower_body_ids', 'flip_pairs', 'dataset_keypoint_weights', 'flip_indices', 'skeleton_links' ] @@ -195,18 +215,23 @@ def load_data_list(self) -> List[dict]: def _load_annotations(self) -> Tuple[List[dict], List[dict]]: """Load data from annotations in COCO format.""" - assert exists(self.ann_file), 'Annotation file does not exist' + assert exists(self.ann_file), ( + f'Annotation file `{self.ann_file}`does not exist') with get_local_path(self.ann_file) as local_path: self.coco = COCO(local_path) # set the metainfo about categories, which is a list of dict # and each dict contains the 'id', 'name', etc. about this category - self._metainfo['CLASSES'] = self.coco.loadCats(self.coco.getCatIds()) + if 'categories' in self.coco.dataset: + self._metainfo['CLASSES'] = self.coco.loadCats( + self.coco.getCatIds()) instance_list = [] image_list = [] for img_id in self.coco.getImgIds(): + if img_id % self.sample_interval != 0: + continue img = self.coco.loadImgs(img_id)[0] img.update({ 'img_id': @@ -273,6 +298,12 @@ def parse_data_info(self, raw_data_info: dict) -> Optional[dict]: else: num_keypoints = np.count_nonzero(keypoints.max(axis=2)) + if 'area' in ann: + area = np.array(ann['area'], dtype=np.float32) + else: + area = np.clip((x2 - x1) * (y2 - y1) * 0.53, a_min=1.0, a_max=None) + area = np.array(area, dtype=np.float32) + data_info = { 'img_id': ann['image_id'], 'img_path': img['img_path'], @@ -281,10 +312,11 @@ def parse_data_info(self, raw_data_info: dict) -> Optional[dict]: 'num_keypoints': num_keypoints, 'keypoints': keypoints, 'keypoints_visible': keypoints_visible, + 'area': area, 'iscrowd': ann.get('iscrowd', 0), 'segmentation': ann.get('segmentation', None), 'id': ann['id'], - 'category_id': ann['category_id'], + 'category_id': np.array(ann['category_id']), # store the raw annotation of the instance # it is useful for evaluation without providing ann_file 'raw_ann_info': copy.deepcopy(ann), @@ -350,7 +382,13 @@ def _get_bottomup_data_infos(self, instance_list: List[Dict], if key not in data_info_bu: seq = [d[key] for d in data_infos] if isinstance(seq[0], np.ndarray): - seq = np.concatenate(seq, axis=0) + if seq[0].ndim > 0: + seq = np.concatenate(seq, axis=0) + else: + seq = np.stack(seq, axis=0) + elif isinstance(seq[0], (tuple, list)): + seq = list(chain.from_iterable(seq)) + data_info_bu[key] = seq # The segmentation annotation of invalid objects will be used @@ -381,11 +419,16 @@ def _get_bottomup_data_infos(self, instance_list: List[Dict], def _load_detection_results(self) -> List[dict]: """Load data from detection results with dummy keypoint annotations.""" - assert exists(self.ann_file), 'Annotation file does not exist' - assert exists(self.bbox_file), 'Bbox file does not exist' + assert exists(self.ann_file), ( + f'Annotation file `{self.ann_file}` does not exist') + assert exists( + self.bbox_file), (f'Bbox file `{self.bbox_file}` does not exist') # load detection results det_results = load(self.bbox_file) - assert is_list_of(det_results, dict) + assert is_list_of( + det_results, + dict), (f'BBox file `{self.bbox_file}` should be a list of dict, ' + f'but got {type(det_results)}') # load coco annotations to build image id-to-name index with get_local_path(self.ann_file) as local_path: diff --git a/mmpose/datasets/datasets/base/base_mocap_dataset.py b/mmpose/datasets/datasets/base/base_mocap_dataset.py index d671a6ae94..f9cea2987c 100644 --- a/mmpose/datasets/datasets/base/base_mocap_dataset.py +++ b/mmpose/datasets/datasets/base/base_mocap_dataset.py @@ -1,14 +1,17 @@ # Copyright (c) OpenMMLab. All rights reserved. +import itertools +import logging import os.path as osp from copy import deepcopy from itertools import filterfalse, groupby from typing import Any, Callable, Dict, List, Optional, Sequence, Tuple, Union +import cv2 import numpy as np from mmengine.dataset import BaseDataset, force_full_init from mmengine.fileio import exists, get_local_path, load +from mmengine.logging import print_log from mmengine.utils import is_abs -from PIL import Image from mmpose.registry import DATASETS from ..utils import parse_pose_metainfo @@ -21,6 +24,8 @@ class BaseMocapDataset(BaseDataset): Args: ann_file (str): Annotation file path. Default: ''. seq_len (int): Number of frames in a sequence. Default: 1. + multiple_target (int): If larger than 0, merge every + ``multiple_target`` sequence together. Default: 0. causal (bool): If set to ``True``, the rightmost input frame will be the target frame. Otherwise, the middle input frame will be the target frame. Default: ``True``. @@ -63,6 +68,7 @@ class BaseMocapDataset(BaseDataset): def __init__(self, ann_file: str = '', seq_len: int = 1, + multiple_target: int = 0, causal: bool = True, subset_frac: float = 1.0, camera_param_file: Optional[str] = None, @@ -87,21 +93,29 @@ def __init__(self, _ann_file = ann_file if not is_abs(_ann_file): _ann_file = osp.join(data_root, _ann_file) - assert exists(_ann_file), 'Annotation file does not exist.' - with get_local_path(_ann_file) as local_path: - self.ann_data = np.load(local_path) + assert exists(_ann_file), ( + f'Annotation file `{_ann_file}` does not exist.') + + self._load_ann_file(_ann_file) self.camera_param_file = camera_param_file if self.camera_param_file: if not is_abs(self.camera_param_file): self.camera_param_file = osp.join(data_root, self.camera_param_file) - assert exists(self.camera_param_file) + assert exists(self.camera_param_file), ( + f'Camera parameters file `{self.camera_param_file}` does not ' + 'exist.') self.camera_param = load(self.camera_param_file) self.seq_len = seq_len self.causal = causal + self.multiple_target = multiple_target + if self.multiple_target: + assert (self.seq_len == 1), ( + 'Multi-target data sample only supports seq_len=1.') + assert 0 < subset_frac <= 1, ( f'Unsupported `subset_frac` {subset_frac}. Supported range ' 'is (0, 1].') @@ -122,6 +136,19 @@ def __init__(self, lazy_init=lazy_init, max_refetch=max_refetch) + def _load_ann_file(self, ann_file: str) -> dict: + """Load annotation file to get image information. + + Args: + ann_file (str): Annotation file path. + + Returns: + dict: Annotation information. + """ + + with get_local_path(ann_file) as local_path: + self.ann_data = np.load(local_path) + @classmethod def _load_metainfo(cls, metainfo: dict = None) -> dict: """Collect meta information from the dictionary of meta. @@ -207,10 +234,13 @@ def get_img_info(self, img_idx, img_name): try: with get_local_path(osp.join(self.data_prefix['img'], img_name)) as local_path: - im = Image.open(local_path) - w, h = im.size - im.close() + im = cv2.imread(local_path) + h, w, _ = im.shape except: # noqa: E722 + print_log( + f'Failed to read image {img_name}.', + logger='current', + level=logging.DEBUG) return None img = { @@ -241,6 +271,17 @@ def get_sequence_indices(self) -> List[List[int]]: sequence_indices = [[idx] for idx in range(num_imgs)] else: raise NotImplementedError('Multi-frame data sample unsupported!') + + if self.multiple_target > 0: + sequence_indices_merged = [] + for i in range(0, len(sequence_indices), self.multiple_target): + if i + self.multiple_target > len(sequence_indices): + break + sequence_indices_merged.append( + list( + itertools.chain.from_iterable( + sequence_indices[i:i + self.multiple_target]))) + sequence_indices = sequence_indices_merged return sequence_indices def _load_annotations(self) -> Tuple[List[dict], List[dict]]: @@ -274,7 +315,13 @@ def _load_annotations(self) -> Tuple[List[dict], List[dict]]: image_list = [] for idx, frame_ids in enumerate(self.sequence_indices): - assert len(frame_ids) == self.seq_len + expected_num_frames = self.seq_len + if self.multiple_target: + expected_num_frames = self.multiple_target + + assert len(frame_ids) == (expected_num_frames), ( + f'Expected `frame_ids` == {expected_num_frames}, but ' + f'got {len(frame_ids)} ') _img_names = img_names[frame_ids] @@ -286,7 +333,9 @@ def _load_annotations(self) -> Tuple[List[dict], List[dict]]: keypoints_3d = _keypoints_3d[..., :3] keypoints_3d_visible = _keypoints_3d[..., 3] - target_idx = -1 if self.causal else int(self.seq_len) // 2 + target_idx = [-1] if self.causal else [int(self.seq_len) // 2] + if self.multiple_target: + target_idx = list(range(self.multiple_target)) instance_info = { 'num_keypoints': num_keypoints, @@ -312,9 +361,10 @@ def _load_annotations(self) -> Tuple[List[dict], List[dict]]: instance_list.append(instance_info) - for idx, imgname in enumerate(img_names): - img_info = self.get_img_info(idx, imgname) - image_list.append(img_info) + if self.data_mode == 'bottomup': + for idx, imgname in enumerate(img_names): + img_info = self.get_img_info(idx, imgname) + image_list.append(img_info) return instance_list, image_list diff --git a/mmpose/datasets/datasets/body/__init__.py b/mmpose/datasets/datasets/body/__init__.py index 1405b0d675..3ae05a3856 100644 --- a/mmpose/datasets/datasets/body/__init__.py +++ b/mmpose/datasets/datasets/body/__init__.py @@ -2,6 +2,7 @@ from .aic_dataset import AicDataset from .coco_dataset import CocoDataset from .crowdpose_dataset import CrowdPoseDataset +from .humanart21_dataset import HumanArt21Dataset from .humanart_dataset import HumanArtDataset from .jhmdb_dataset import JhmdbDataset from .mhp_dataset import MhpDataset @@ -14,5 +15,6 @@ __all__ = [ 'CocoDataset', 'MpiiDataset', 'MpiiTrbDataset', 'AicDataset', 'CrowdPoseDataset', 'OCHumanDataset', 'MhpDataset', 'PoseTrack18Dataset', - 'JhmdbDataset', 'PoseTrack18VideoDataset', 'HumanArtDataset' + 'JhmdbDataset', 'PoseTrack18VideoDataset', 'HumanArtDataset', + 'HumanArt21Dataset' ] diff --git a/mmpose/datasets/datasets/body/humanart21_dataset.py b/mmpose/datasets/datasets/body/humanart21_dataset.py new file mode 100644 index 0000000000..e4b5695261 --- /dev/null +++ b/mmpose/datasets/datasets/body/humanart21_dataset.py @@ -0,0 +1,148 @@ +# Copyright (c) OpenMMLab. All rights reserved. +import copy +from typing import Optional + +import numpy as np + +from mmpose.registry import DATASETS +from .humanart_dataset import HumanArtDataset + + +@DATASETS.register_module() +class HumanArt21Dataset(HumanArtDataset): + """Human-Art dataset for pose estimation with 21 kpts. + + "Human-Art: A Versatile Human-Centric Dataset + Bridging Natural and Artificial Scenes", CVPR'2023. + More details can be found in the `paper +
-- **[:bulb:YOLOX-Pose](./yolox-pose)**: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss +- **[:bulb:YOLOX-Pose](./yolox_pose)**: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss
@@ -54,4 +58,14 @@ We also provide some documentation listed below to help you get started:
+- **[💃Just-Dance](./just_dance)**: Enhancing Dance scoring system for comparing dance performances in videos. + + TRY IT NOW + + + +
+  +
+
+ - **What's next? Join the rank of *MMPose contributors* by creating a new project**! diff --git a/projects/just_dance/README.md b/projects/just_dance/README.md new file mode 100644 index 0000000000..385ef03005 --- /dev/null +++ b/projects/just_dance/README.md @@ -0,0 +1,42 @@ +# Just Dance - A Simple Implementation + + + + Try it on OpenXLab + + + +This project presents a dance scoring system based on RTMPose. Users can compare the similarity between two dancers in different videos: one referred to as the "teacher video" and the other as the "student video." + +Here are examples of the output dance comparison: + +
(Det/Pose) | Model AP
(COCO) | Pipeline AP
(COCO) | Params (M)
(Det/Pose) | Flops (G)
(Det/Pose) | ORT-Latency(ms)
(i7-11700) | TRT-FP16-Latency(ms)
(GTX 1660Ti) | Download | | :------------------------------------------------------------------ | :---------------------------------------------------------------------------- | :---------------------------: | :---------------------: | :------------------------: | :---------------------------: | :--------------------------: | :--------------------------------: | :---------------------------------------: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | @@ -164,14 +180,14 @@ Feel free to join our community group for more help:
AIC+COCO
-| Config | Input Size | AP(COCO) | PCK@0.1
(Body8) | AUC
(Body8) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | -| :---------------------------------------------------------------------------: | :--------: | :---------------: | :---------------------: | :-----------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :---------------------------------------------------------------------------------------------------------------------------------------------: | -| [RTMPose-t](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 68.5 | 91.28 | 63.38 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-tiny_simcc-aic-coco_pt-aic-coco_420e-256x192-cfc8f33d_20230126.pth) | -| [RTMPose-s](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 72.2 | 92.95 | 66.19 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-aic-coco_pt-aic-coco_420e-256x192-fcb2599b_20230126.pth) | -| [RTMPose-m](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 75.8 | 94.13 | 68.53 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-256x192-63eb25f7_20230126.pth) | -| [RTMPose-l](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 76.5 | 94.35 | 68.98 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-aic-coco_pt-aic-coco_420e-256x192-f016ffe0_20230126.pth) | -| [RTMPose-m](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py) | 384x288 | 77.0 | 94.32 | 69.85 | 13.72 | 4.33 | 24.78 | 3.66 | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-384x288-a62a0b32_20230228.pth) | -| [RTMPose-l](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py) | 384x288 | 77.3 | 94.54 | 70.14 | 27.79 | 9.35 | - | 6.05 | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-aic-coco_pt-aic-coco_420e-384x288-97d6cb0f_20230228.pth) | +| Config | Input Size | AP
(COCO) | PCK@0.1
(Body8) | AUC
(Body8) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | +| :---------------------------------------------------------------------------: | :--------: | :---------------: | :---------------------: | :-----------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :-------------------------------------------------------------------------------------------------------------------------------------------: | +| [RTMPose-t](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 68.5 | 91.28 | 63.38 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-tiny_simcc-aic-coco_pt-aic-coco_420e-256x192-cfc8f33d_20230126.pth) | +| [RTMPose-s](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 72.2 | 92.95 | 66.19 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-aic-coco_pt-aic-coco_420e-256x192-fcb2599b_20230126.pth) | +| [RTMPose-m](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 75.8 | 94.13 | 68.53 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-256x192-63eb25f7_20230126.pth) | +| [RTMPose-l](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 76.5 | 94.35 | 68.98 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-aic-coco_pt-aic-coco_420e-256x192-f016ffe0_20230126.pth) | +| [RTMPose-m](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py) | 384x288 | 77.0 | 94.32 | 69.85 | 13.72 | 4.33 | 24.78 | 3.66 | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-384x288-a62a0b32_20230228.pth) | +| [RTMPose-l](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py) | 384x288 | 77.3 | 94.54 | 70.14 | 27.79 | 9.35 | - | 6.05 | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-aic-coco_pt-aic-coco_420e-384x288-97d6cb0f_20230228.pth) |
(COCO) | PCK@0.1
(Body8) | AUC
(Body8) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | -| :-----------------------------------------------------------------------------: | :--------: | :---------------: | :---------------------: | :-----------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :------------------------------------------------------------------------------------------------------------------------------------: | -| [RTMPose-t\*](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 65.9 | 91.44 | 63.18 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-body7_pt-body7_420e-256x192-026a1439_20230504.pth) | -| [RTMPose-s\*](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 69.7 | 92.45 | 65.15 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-body7_pt-body7_420e-256x192-acd4a1ef_20230504.pth) | -| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 74.9 | 94.25 | 68.59 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-256x192-e48f03d0_20230504.pth) | -| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 76.7 | 95.08 | 70.14 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7_420e-256x192-4dba18fc_20230504.pth) | -| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py) | 384x288 | 76.6 | 94.64 | 70.38 | 13.72 | 4.33 | 24.78 | 3.66 | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-384x288-65e718c4_20230504.pth) | -| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py) | 384x288 | 78.3 | 95.36 | 71.58 | 27.79 | 9.35 | - | 6.05 | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7_420e-384x288-3f5a1437_20230504.pth) | -| [RTMPose-x\*](./rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_coco-384x288.py) | 384x288 | 78.8 | - | - | 49.43 | 17.22 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-body7_pt-body7_700e-384x288-71d7b7e9_20230629.pth) | +| Config | Input Size | AP
(COCO) | PCK@0.1
(Body8) | AUC
(Body8) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | +| :-----------------------------------------------------------------------------: | :--------: | :---------------: | :---------------------: | :-----------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | +| [RTMPose-t\*](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 65.9 | 91.44 | 63.18 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-body7_pt-body7_420e-256x192-026a1439_20230504.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-t_simcc-body7_pt-body7_420e-256x192-026a1439_20230504.zip) | +| [RTMPose-s\*](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 69.7 | 92.45 | 65.15 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-body7_pt-body7_420e-256x192-acd4a1ef_20230504.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-s_simcc-body7_pt-body7_420e-256x192-acd4a1ef_20230504.zip) | +| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 74.9 | 94.25 | 68.59 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-256x192-e48f03d0_20230504.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-body7_pt-body7_420e-256x192-e48f03d0_20230504.zip) | +| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 76.7 | 95.08 | 70.14 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7_420e-256x192-4dba18fc_20230504.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_simcc-body7_pt-body7_420e-256x192-4dba18fc_20230504.zip) | +| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py) | 384x288 | 76.6 | 94.64 | 70.38 | 13.72 | 4.33 | 24.78 | 3.66 | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-384x288-65e718c4_20230504.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-body7_pt-body7_420e-384x288-65e718c4_20230504.zip) | +| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py) | 384x288 | 78.3 | 95.36 | 71.58 | 27.79 | 9.35 | - | 6.05 | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7_420e-384x288-3f5a1437_20230504.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_simcc-body7_pt-body7_420e-384x288-3f5a1437_20230504.zip) | +| [RTMPose-x\*](./rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_coco-384x288.py) | 384x288 | 78.8 | - | - | 49.43 | 17.22 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-body7_pt-body7_700e-384x288-71d7b7e9_20230629.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-x_simcc-body7_pt-body7_700e-384x288-71d7b7e9_20230629.zip) | + +
+ +
+Detetors:
+
+| Detection Config | Input Size | Model AP
+
+Detetors:
+
+| Detection Config | Input Size | Model AP
(OneHand10K) | Flops
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | +| :---------------------------: | :--------: | :---------------------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :--------------------: | +| [RTMDet-tiny](./rtmdet/person/rtmdet_tiny_8xb32-300e_humanart.py) | 640x640 | 46.6 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_tiny_8xb32-300e_humanart-7da5554e.pth) | +| [RTMDet-s](./rtmdet/person/rtmdet_s_8xb32-300e_humanart.py) | 640x640 | 50.6 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_s_8xb32-300e_humanart-af5bd52d.pth) | +| [YOLOX-nano](./yolox/humanart/yolox_nano_8xb8-300e_humanart.py) | 640x640 | 38.9 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/yolox_nano_8xb8-300e_humanart-40f6f0d0.pth) | +| [YOLOX-tiny](./yolox/humanart/yolox_tiny_8xb8-300e_humanart.py) | 640x640 | 47.7 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/yolox_tiny_8xb8-300e_humanart-6f3252f9.pth) | +| [YOLOX-s](./yolox/humanart/yolox_s_8xb8-300e_humanart.py) | 640x640 | 54.6 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/yolox_s_8xb8-300e_humanart-3ef259a7.pth) | +| [YOLOX-m](./yolox/humanart/yolox_m_8xb8-300e_humanart.py) | 640x640 | 59.1 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/yolox_m_8xb8-300e_humanart-c2c7a14a.pth) | +| [YOLOX-l](./yolox/humanart/yolox_l_8xb8-300e_humanart.py) | 640x640 | 60.2 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/yolox_l_8xb8-300e_humanart-ce1d7a62.pth) | +| [YOLOX-x](./yolox/humanart/yolox_x_8xb8-300e_humanart.py) | 640x640 | 61.3 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/yolox_x_8xb8-300e_humanart-a39d44ed.pth) | + +Pose Estimators: + +| Config | Input Size | AP
(Human-Art GT) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | +| :-----------------------------------------------------------------------------: | :--------: | :-----------------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | +| [RTMPose-t\*](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 65.5 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_8xb256-420e_humanart-256x192-60b68c98_20230612.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-t_8xb256-420e_humanart-256x192-60b68c98_20230612.zip) | +| [RTMPose-s\*](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 69.8 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_8xb256-420e_humanart-256x192-5a3ac943_20230611.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-s_8xb256-420e_humanart-256x192-5a3ac943_20230611.zip) | +| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 72.8 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_8xb256-420e_humanart-256x192-8430627b_20230611.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_8xb256-420e_humanart-256x192-8430627b_20230611.zip) | +| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 75.3 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_8xb256-420e_humanart-256x192-389f2cb0_20230611.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_8xb256-420e_humanart-256x192-389f2cb0_20230611.zip) |
@@ -206,15 +252,15 @@ Feel free to join our community group for more help:
- Human-Art
+ +- RTMPose for Human-Centric Artificial Scenes is supported by [Human-Art](https://github.com/IDEA-Research/HumanArt) +-(OneHand10K) | Flops
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | +| :---------------------------: | :--------: | :---------------------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :--------------------: | +| [RTMDet-tiny](./rtmdet/person/rtmdet_tiny_8xb32-300e_humanart.py) | 640x640 | 46.6 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_tiny_8xb32-300e_humanart-7da5554e.pth) | +| [RTMDet-s](./rtmdet/person/rtmdet_s_8xb32-300e_humanart.py) | 640x640 | 50.6 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_s_8xb32-300e_humanart-af5bd52d.pth) | +| [YOLOX-nano](./yolox/humanart/yolox_nano_8xb8-300e_humanart.py) | 640x640 | 38.9 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/yolox_nano_8xb8-300e_humanart-40f6f0d0.pth) | +| [YOLOX-tiny](./yolox/humanart/yolox_tiny_8xb8-300e_humanart.py) | 640x640 | 47.7 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/yolox_tiny_8xb8-300e_humanart-6f3252f9.pth) | +| [YOLOX-s](./yolox/humanart/yolox_s_8xb8-300e_humanart.py) | 640x640 | 54.6 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/yolox_s_8xb8-300e_humanart-3ef259a7.pth) | +| [YOLOX-m](./yolox/humanart/yolox_m_8xb8-300e_humanart.py) | 640x640 | 59.1 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/yolox_m_8xb8-300e_humanart-c2c7a14a.pth) | +| [YOLOX-l](./yolox/humanart/yolox_l_8xb8-300e_humanart.py) | 640x640 | 60.2 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/yolox_l_8xb8-300e_humanart-ce1d7a62.pth) | +| [YOLOX-x](./yolox/humanart/yolox_x_8xb8-300e_humanart.py) | 640x640 | 61.3 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/yolox_x_8xb8-300e_humanart-a39d44ed.pth) | + +Pose Estimators: + +| Config | Input Size | AP
(Human-Art GT) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | +| :-----------------------------------------------------------------------------: | :--------: | :-----------------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | +| [RTMPose-t\*](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 65.5 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_8xb256-420e_humanart-256x192-60b68c98_20230612.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-t_8xb256-420e_humanart-256x192-60b68c98_20230612.zip) | +| [RTMPose-s\*](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 69.8 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_8xb256-420e_humanart-256x192-5a3ac943_20230611.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-s_8xb256-420e_humanart-256x192-5a3ac943_20230611.zip) | +| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 72.8 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_8xb256-420e_humanart-256x192-8430627b_20230611.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_8xb256-420e_humanart-256x192-8430627b_20230611.zip) | +| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 75.3 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_8xb256-420e_humanart-256x192-389f2cb0_20230611.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_8xb256-420e_humanart-256x192-389f2cb0_20230611.zip) |
(Body8) | AUC
(Body8) | Params(M) | FLOPS(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | -| :---------------------------------------------------------------------------------------: | :--------: | :---------------------: | :-----------------: | :-------: | :------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------------------------------: | -| [RTMPose-t\*](./rtmpose/body_2d_keypoint/rtmpose-t_8xb1024-700e_body8-halpe26-256x192.py) | 256x192 | 91.89 | 66.35 | 3.51 | 0.37 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-body7_pt-body7-halpe26_700e-256x192-6020f8a6_20230605.pth) | -| [RTMPose-s\*](./rtmpose/body_2d_keypoint/rtmpose-s_8xb1024-700e_body8-halpe26-256x192.py) | 256x192 | 93.01 | 68.62 | 5.70 | 0.70 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-body7_pt-body7-halpe26_700e-256x192-7f134165_20230605.pth) | -| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb512-700e_body8-halpe26-256x192.py) | 256x192 | 94.75 | 71.91 | 13.93 | 1.95 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-256x192-4d3e73dd_20230605.pth) | -| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb512-700e_body8-halpe26-256x192.py) | 256x192 | 95.37 | 73.19 | 28.11 | 4.19 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-256x192-2abb7558_20230605.pth) | -| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb512-700e_body8-halpe26-384x288.py) | 384x288 | 95.15 | 73.56 | 14.06 | 4.37 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-384x288-89e6428b_20230605.pth) | -| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb512-700e_body8-halpe26-384x288.py) | 384x288 | 95.56 | 74.38 | 28.24 | 9.40 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-384x288-734182ce_20230605.pth) | -| [RTMPose-x\*](./rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_body8-halpe26-384x288.py) | 384x288 | 95.74 | 74.82 | 50.00 | 17.29 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-body7_pt-body7-halpe26_700e-384x288-7fb6e239_20230606.pth) | +| Config | Input Size | PCK@0.1
(Body8) | AUC
(Body8) | Params(M) | FLOPS(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | +| :---------------------------------------------------------------------------------------: | :--------: | :---------------------: | :-----------------: | :-------: | :------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | +| [RTMPose-t\*](./rtmpose/body_2d_keypoint/rtmpose-t_8xb1024-700e_body8-halpe26-256x192.py) | 256x192 | 91.89 | 66.35 | 3.51 | 0.37 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-body7_pt-body7-halpe26_700e-256x192-6020f8a6_20230605.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-t_simcc-body7_pt-body7-halpe26_700e-256x192-6020f8a6_20230605.zip) | +| [RTMPose-s\*](./rtmpose/body_2d_keypoint/rtmpose-s_8xb1024-700e_body8-halpe26-256x192.py) | 256x192 | 93.01 | 68.62 | 5.70 | 0.70 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-body7_pt-body7-halpe26_700e-256x192-7f134165_20230605.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-s_simcc-body7_pt-body7-halpe26_700e-256x192-7f134165_20230605.zip) | +| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb512-700e_body8-halpe26-256x192.py) | 256x192 | 94.75 | 71.91 | 13.93 | 1.95 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-256x192-4d3e73dd_20230605.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-256x192-4d3e73dd_20230605.zip) | +| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb512-700e_body8-halpe26-256x192.py) | 256x192 | 95.37 | 73.19 | 28.11 | 4.19 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-256x192-2abb7558_20230605.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-256x192-2abb7558_20230605.zip) | +| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb512-700e_body8-halpe26-384x288.py) | 384x288 | 95.15 | 73.56 | 14.06 | 4.37 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-384x288-89e6428b_20230605.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-384x288-89e6428b_20230605.zip) | +| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb512-700e_body8-halpe26-384x288.py) | 384x288 | 95.56 | 74.38 | 28.24 | 9.40 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-384x288-734182ce_20230605.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-384x288-734182ce_20230605.zip) | +| [RTMPose-x\*](./rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_body8-halpe26-384x288.py) | 384x288 | 95.74 | 74.82 | 50.00 | 17.29 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-body7_pt-body7-halpe26_700e-384x288-7fb6e239_20230606.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-x_simcc-body7_pt-body7-halpe26_700e-384x288-7fb6e239_20230606.zip) | #### Model Pruning @@ -222,9 +268,9 @@ Feel free to join our community group for more help: - Model pruning is supported by [MMRazor](https://github.com/open-mmlab/mmrazor) -| Config | Input Size | AP
(COCO) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | -| :-----------------------: | :--------: | :---------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :------------------------------------------------------------------------------------------------------------------------------------------------: | -| RTMPose-s-aic-coco-pruned | 256x192 | 69.4 | 3.43 | 0.35 | - | - | - | [Model](https://download.openmmlab.com/mmrazor/v1/pruning/group_fisher/rtmpose-s/group_fisher_finetune_rtmpose-s_8xb256-420e_aic-coco-256x192.pth) | +| Config | Input Size | AP
(COCO) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | +| :-----------------------: | :--------: | :---------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------: | +| RTMPose-s-aic-coco-pruned | 256x192 | 69.4 | 3.43 | 0.35 | - | - | - | [pth](https://download.openmmlab.com/mmrazor/v1/pruning/group_fisher/rtmpose-s/group_fisher_finetune_rtmpose-s_8xb256-420e_aic-coco-256x192.pth) | For more details, please refer to [GroupFisher Pruning for RTMPose](./rtmpose/pruning/README.md). @@ -233,12 +279,60 @@ For more details, please refer to [GroupFisher Pruning for RTMPose](./rtmpose/pr - Keypoints are defined as [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody/). For details please refer to the [meta info](/configs/_base_/datasets/coco_wholebody.py). -
+
+
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | | :------------------------------ | :--------: | :------: | :------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-------------------------------: | -| [RTMPose-m](./rtmpose/wholebody_2d_keypoint/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 58.2 | 67.4 | 2.22 | 13.50 | 4.00 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-coco-wholebody_pt-aic-coco_270e-256x192-cd5e845c_20230123.pth) | -| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 61.1 | 70.0 | 4.52 | 23.41 | 5.67 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-coco-wholebody_pt-aic-coco_270e-256x192-6f206314_20230124.pth) | -| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 64.8 | 73.0 | 10.07 | 44.58 | 7.68 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-coco-wholebody_pt-aic-coco_270e-384x288-eaeb96c8_20230125.pth) | -| [RTMPose-x](./rtmpose/wholebody_2d_keypoint/rtmpose-x_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 65.3 | 73.3 | 18.1 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-coco-wholebody_pt-body7_270e-384x288-401dfc90_20230629.pth) | +| [RTMPose-m](./rtmpose/wholebody_2d_keypoint/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 58.2 | 67.4 | 2.22 | 13.50 | 4.00 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-coco-wholebody_pt-aic-coco_270e-256x192-cd5e845c_20230123.pth) | +| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 61.1 | 70.0 | 4.52 | 23.41 | 5.67 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-coco-wholebody_pt-aic-coco_270e-256x192-6f206314_20230124.pth) | +| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 64.8 | 73.0 | 10.07 | 44.58 | 7.68 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-coco-wholebody_pt-aic-coco_270e-384x288-eaeb96c8_20230125.pth) | +| [RTMPose-x](./rtmpose/wholebody_2d_keypoint/rtmpose-x_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 65.3 | 73.3 | 18.1 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-coco-wholebody_pt-body7_270e-384x288-401dfc90_20230629.pth) | + +
+
+COCO-WholeBody
+ | Config | Input Size | Whole AP | Whole AR | FLOPS(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | | :------------------------------ | :--------: | :------: | :------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-------------------------------: | -| [RTMPose-m](./rtmpose/wholebody_2d_keypoint/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 58.2 | 67.4 | 2.22 | 13.50 | 4.00 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-coco-wholebody_pt-aic-coco_270e-256x192-cd5e845c_20230123.pth) | -| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 61.1 | 70.0 | 4.52 | 23.41 | 5.67 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-coco-wholebody_pt-aic-coco_270e-256x192-6f206314_20230124.pth) | -| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 64.8 | 73.0 | 10.07 | 44.58 | 7.68 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-coco-wholebody_pt-aic-coco_270e-384x288-eaeb96c8_20230125.pth) | -| [RTMPose-x](./rtmpose/wholebody_2d_keypoint/rtmpose-x_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 65.3 | 73.3 | 18.1 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-coco-wholebody_pt-body7_270e-384x288-401dfc90_20230629.pth) | +| [RTMPose-m](./rtmpose/wholebody_2d_keypoint/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 58.2 | 67.4 | 2.22 | 13.50 | 4.00 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-coco-wholebody_pt-aic-coco_270e-256x192-cd5e845c_20230123.pth) | +| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 61.1 | 70.0 | 4.52 | 23.41 | 5.67 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-coco-wholebody_pt-aic-coco_270e-256x192-6f206314_20230124.pth) | +| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 64.8 | 73.0 | 10.07 | 44.58 | 7.68 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-coco-wholebody_pt-aic-coco_270e-384x288-eaeb96c8_20230125.pth) | +| [RTMPose-x](./rtmpose/wholebody_2d_keypoint/rtmpose-x_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 65.3 | 73.3 | 18.1 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-coco-wholebody_pt-body7_270e-384x288-401dfc90_20230629.pth) | + +
+
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | +| :------------------------------ | :--------: | :------: | :------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-------------------------------: | +| [RTMW-x
(alpha version)](./rtmpose/wholebody_2d_keypoint/rtmw-x_8xb704-270e_cocktail13-256x192.py) | 256x192 | 67.2 | 75.4 | 13.1 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmw/rtmw-x_simcc-cocktail13_pt-ucoco_270e-256x192-fbef0d61_20230925.pth) | +| [RTMW-x
(alpha version)](./rtmpose/wholebody_2d_keypoint/rtmw-x_8xb320-270e_cocktail13-384x288.py) | 384x288 | 70.2 | 77.9 | 29.3 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmw/rtmw-x_simcc-cocktail13_pt-ucoco_270e-384x288-0949e3a9_20230925.pth) | + +
+
+Cocktail13
+ +- `Cocktail13` denotes model trained on 13 public datasets: + - [AI Challenger](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#aic) + - [CrowdPose](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#crowdpose) + - [MPII](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#mpii) + - [sub-JHMDB](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#sub-jhmdb-dataset) + - [Halpe](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_wholebody_keypoint.html#halpe) + - [PoseTrack18](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#posetrack18) + - [COCO-Wholebody](https://github.com/jin-s13/COCO-WholeBody/) + - [UBody](https://github.com/IDEA-Research/OSX) + - [Human-Art](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#human-art-dataset) + - [WFLW](https://wywu.github.io/projects/LAB/WFLW.html) + - [300W](https://ibug.doc.ic.ac.uk/resources/300-W/) + - [COFW](http://www.vision.caltech.edu/xpburgos/ICCV13/) + - [LaPa](https://github.com/JDAI-CV/lapa-dataset) + +| Config | Input Size | Whole AP | Whole AR | FLOPS(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | +| :------------------------------ | :--------: | :------: | :------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-------------------------------: | +| [RTMW-x
(alpha version)](./rtmpose/wholebody_2d_keypoint/rtmw-x_8xb704-270e_cocktail13-256x192.py) | 256x192 | 67.2 | 75.4 | 13.1 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmw/rtmw-x_simcc-cocktail13_pt-ucoco_270e-256x192-fbef0d61_20230925.pth) | +| [RTMW-x
(alpha version)](./rtmpose/wholebody_2d_keypoint/rtmw-x_8xb320-270e_cocktail13-384x288.py) | 384x288 | 70.2 | 77.9 | 29.3 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmw/rtmw-x_simcc-cocktail13_pt-ucoco_270e-384x288-0949e3a9_20230925.pth) | + +
+
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | +| :------------------------------ | :--------: | :------: | :------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-------------------------------: | +| [RTMPose-t](./rtmpose/wholebody_2d_keypoint/rtmpose-t_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 48.5 | 58.4 | 0.5 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-ucoco_dw-ucoco_270e-256x192-dcf277bf_20230728.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-t_simcc-ucoco_dw-ucoco_270e-256x192-dcf277bf_20230728.pth) | +| [RTMPose-s](./rtmpose/wholebody_2d_keypoint/rtmpose-s_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 53.8 | 63.2 | 0.9 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-ucoco_dw-ucoco_270e-256x192-3fd922c8_20230728.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-s_simcc-ucoco_dw-ucoco_270e-256x192-3fd922c8_20230728.zip) | +| [RTMPose-m](./rtmpose/wholebody_2d_keypoint/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 60.6 | 69.5 | 2.22 | 13.50 | 4.00 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-ucoco_dw-ucoco_270e-256x192-c8b76419_20230728.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-ucoco_dw-ucoco_270e-256x192-c8b76419_20230728.zip) | +| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 63.1 | 71.7 | 4.52 | 23.41 | 5.67 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-ucoco_dw-ucoco_270e-256x192-4d6dfc62_20230728.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_simcc-ucoco_dw-ucoco_270e-256x192-4d6dfc62_20230728.zip) | +| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 66.5 | 74.3 | 10.07 | 44.58 | 7.68 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-ucoco_dw-ucoco_270e-384x288-2438fd99_20230728.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_simcc-ucoco_dw-ucoco_270e-384x288-2438fd99_20230728.zip) | + +
### Animal 2d (17 Keypoints)
@@ -247,7 +341,7 @@ For more details, please refer to [GroupFisher Pruning for RTMPose](./rtmpose/pr
| Config | Input Size | APCOCO+UBody
+ +- DWPose Models are supported by [DWPose](https://github.com/IDEA-Research/DWPose) +- Models are trained and distilled on: + - [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody/) + - [UBody](https://github.com/IDEA-Research/OSX) + +| Config | Input Size | Whole AP | Whole AR | FLOPS(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | +| :------------------------------ | :--------: | :------: | :------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-------------------------------: | +| [RTMPose-t](./rtmpose/wholebody_2d_keypoint/rtmpose-t_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 48.5 | 58.4 | 0.5 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-ucoco_dw-ucoco_270e-256x192-dcf277bf_20230728.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-t_simcc-ucoco_dw-ucoco_270e-256x192-dcf277bf_20230728.pth) | +| [RTMPose-s](./rtmpose/wholebody_2d_keypoint/rtmpose-s_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 53.8 | 63.2 | 0.9 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-ucoco_dw-ucoco_270e-256x192-3fd922c8_20230728.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-s_simcc-ucoco_dw-ucoco_270e-256x192-3fd922c8_20230728.zip) | +| [RTMPose-m](./rtmpose/wholebody_2d_keypoint/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 60.6 | 69.5 | 2.22 | 13.50 | 4.00 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-ucoco_dw-ucoco_270e-256x192-c8b76419_20230728.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-ucoco_dw-ucoco_270e-256x192-c8b76419_20230728.zip) | +| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 63.1 | 71.7 | 4.52 | 23.41 | 5.67 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-ucoco_dw-ucoco_270e-256x192-4d6dfc62_20230728.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_simcc-ucoco_dw-ucoco_270e-256x192-4d6dfc62_20230728.zip) | +| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 66.5 | 74.3 | 10.07 | 44.58 | 7.68 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-ucoco_dw-ucoco_270e-384x288-2438fd99_20230728.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_simcc-ucoco_dw-ucoco_270e-384x288-2438fd99_20230728.zip) | + +
(AP10K) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | | :----------------------------: | :--------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :------------------------------: | -| [RTMPose-m](./rtmpose/animal_2d_keypoint/rtmpose-m_8xb64-210e_ap10k-256x256.py) | 256x256 | 72.2 | 2.57 | 14.157 | 2.404 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-ap10k_pt-aic-coco_210e-256x256-7a041aa1_20230206.pth) | +| [RTMPose-m](./rtmpose/animal_2d_keypoint/rtmpose-m_8xb64-210e_ap10k-256x256.py) | 256x256 | 72.2 | 2.57 | 14.157 | 2.404 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-ap10k_pt-aic-coco_210e-256x256-7a041aa1_20230206.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-ap10k_pt-aic-coco_210e-256x256-7a041aa1_20230206.zip) | ### Face 2d (106 Keypoints) @@ -267,9 +361,9 @@ For more details, please refer to [GroupFisher Pruning for RTMPose](./rtmpose/pr | Config | Input Size | NME
(LaPa) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | | :----------------------------: | :--------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :------------------------------: | -| [RTMPose-t\*](./rtmpose/face_2d_keypoint/rtmpose-t_8xb256-120e_lapa-256x256.py) | 256x256 | 1.67 | 0.652 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-face6_pt-in1k_120e-256x256-df79d9a5_20230529.pth) | -| [RTMPose-s\*](./rtmpose/face_2d_keypoint/rtmpose-s_8xb256-120e_lapa-256x256.py) | 256x256 | 1.59 | 1.119 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-face6_pt-in1k_120e-256x256-d779fdef_20230529.pth) | -| [RTMPose-m\*](./rtmpose/face_2d_keypoint/rtmpose-m_8xb256-120e_lapa-256x256.py) | 256x256 | 1.44 | 2.852 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.pth) | +| [RTMPose-t\*](./rtmpose/face_2d_keypoint/rtmpose-t_8xb256-120e_lapa-256x256.py) | 256x256 | 1.67 | 0.652 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-face6_pt-in1k_120e-256x256-df79d9a5_20230529.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-t_simcc-face6_pt-in1k_120e-256x256-df79d9a5_20230529.zip) | +| [RTMPose-s\*](./rtmpose/face_2d_keypoint/rtmpose-s_8xb256-120e_lapa-256x256.py) | 256x256 | 1.59 | 1.119 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-face6_pt-in1k_120e-256x256-d779fdef_20230529.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-s_simcc-face6_pt-in1k_120e-256x256-d779fdef_20230529.zip) | +| [RTMPose-m\*](./rtmpose/face_2d_keypoint/rtmpose-m_8xb256-120e_lapa-256x256.py) | 256x256 | 1.44 | 2.852 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.zip) |
(OneHand10K) | Flops
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | | :---------------------------: | :--------: | :---------------------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :--------------------: | -| [RTMDet-nano
(alpha version)](./rtmdet/hand/rtmdet_nano_320-8xb32_hand.py) | 320x320 | 76.0 | 0.31 | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_nano_8xb32-300e_hand-267f9c8f.pth) | +| [RTMDet-nano
(alpha version)](./rtmdet/hand/rtmdet_nano_320-8xb32_hand.py) | 320x320 | 76.0 | 0.31 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_nano_8xb32-300e_hand-267f9c8f.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmdet_nano_8xb32-300e_hand-267f9c8f.zip) |
Hand5
@@ -292,9 +386,9 @@ For more details, please refer to [GroupFisher Pruning for RTMPose](./rtmpose/pr - [RHD2d](https://lmb.informatik.uni-freiburg.de/resources/datasets/RenderedHandposeDataset.en.html) - [Halpe](https://github.com/Fang-Haoshu/Halpe-FullBody/) -| Config | Input Size | PCK@0.2(COCO-Wholebody-Hand) | PCK@0.2
(Hand5) | AUC
(Hand5) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | -| :-------------------------------------------------------------------------------------------------------------------: | :--------: | :-----------------------------------: | :---------------------: | :-----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------------------------: | -| [RTMPose-m\*
(alpha version)](./rtmpose/hand_2d_keypoint/rtmpose-m_8xb32-210e_coco-wholebody-hand-256x256.py) | 256x256 | 81.5 | 96.4 | 83.9 | 2.581 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.pth) | +| Config | Input Size | PCK@0.2
(COCO-Wholebody-Hand) | PCK@0.2
(Hand5) | AUC
(Hand5) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | +| :-------------------------------------------------------------------------------------------------------------------: | :--------: | :-----------------------------------: | :---------------------: | :-----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | +| [RTMPose-m\*
(alpha version)](./rtmpose/hand_2d_keypoint/rtmpose-m_8xb32-210e_coco-wholebody-hand-256x256.py) | 256x256 | 81.5 | 96.4 | 83.9 | 2.581 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.zip) |
(M) | Flops
(G) | AP
(GT) | AR
(GT) | Download | | :----------: | :--------: | :----------------: | :---------------: | :-------------: | :-------------: | :---------------------------------------------------------------------------------------------------------------: | -| CSPNeXt-tiny | 256x192 | 6.03 | 1.43 | 65.5 | 68.9 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-tiny_udp-aic-coco_210e-256x192-cbed682d_20230130.pth) | -| CSPNeXt-s | 256x192 | 8.58 | 1.78 | 70.0 | 73.3 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-s_udp-aic-coco_210e-256x192-92f5a029_20230130.pth) | -| CSPNeXt-m | 256x192 | 17.53 | 3.05 | 74.8 | 77.7 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-m_udp-aic-coco_210e-256x192-f2f7d6f6_20230130.pth) | -| CSPNeXt-l | 256x192 | 32.44 | 5.32 | 77.2 | 79.9 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-l_udp-aic-coco_210e-256x192-273b7631_20230130.pth) | +| CSPNeXt-tiny | 256x192 | 6.03 | 1.43 | 65.5 | 68.9 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-tiny_udp-aic-coco_210e-256x192-cbed682d_20230130.pth) | +| CSPNeXt-s | 256x192 | 8.58 | 1.78 | 70.0 | 73.3 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-s_udp-aic-coco_210e-256x192-92f5a029_20230130.pth) | +| CSPNeXt-m | 256x192 | 17.53 | 3.05 | 74.8 | 77.7 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-m_udp-aic-coco_210e-256x192-f2f7d6f6_20230130.pth) | +| CSPNeXt-l | 256x192 | 32.44 | 5.32 | 77.2 | 79.9 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-l_udp-aic-coco_210e-256x192-273b7631_20230130.pth) |
(M) | Flops
(G) | AP
(COCO) | PCK@0.2
(Body8) | AUC
(Body8) | Download | | :------------: | :--------: | :----------------: | :---------------: | :---------------: | :---------------------: | :-----------------: | :--------------------------------------------------------------------------------: | -| CSPNeXt-tiny\* | 256x192 | 6.03 | 1.43 | 65.9 | 96.34 | 63.80 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-tiny_udp-body7_210e-256x192-a3775292_20230504.pth) | -| CSPNeXt-s\* | 256x192 | 8.58 | 1.78 | 68.7 | 96.59 | 64.92 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-s_udp-body7_210e-256x192-8c9ccbdb_20230504.pth) | -| CSPNeXt-m\* | 256x192 | 17.53 | 3.05 | 73.7 | 97.42 | 68.19 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-m_udp-body7_210e-256x192-e0c9327b_20230504.pth) | -| CSPNeXt-l\* | 256x192 | 32.44 | 5.32 | 75.7 | 97.76 | 69.57 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-l_udp-body7_210e-256x192-5e9558ef_20230504.pth) | -| CSPNeXt-m\* | 384x288 | 17.53 | 6.86 | 75.8 | 97.60 | 70.18 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-m_udp-body7_210e-384x288-b9bc2b57_20230504.pth) | -| CSPNeXt-l\* | 384x288 | 32.44 | 11.96 | 77.2 | 97.89 | 71.23 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-l_udp-body7_210e-384x288-b15bc30d_20230504.pth) | -| CSPNeXt-x\* | 384x288 | 54.92 | 19.96 | 78.1 | 98.00 | 71.79 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-x_udp-body7_210e-384x288-d28b58e6_20230529.pth) | +| CSPNeXt-tiny\* | 256x192 | 6.03 | 1.43 | 65.9 | 96.34 | 63.80 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-tiny_udp-body7_210e-256x192-a3775292_20230504.pth) | +| CSPNeXt-s\* | 256x192 | 8.58 | 1.78 | 68.7 | 96.59 | 64.92 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-s_udp-body7_210e-256x192-8c9ccbdb_20230504.pth) | +| CSPNeXt-m\* | 256x192 | 17.53 | 3.05 | 73.7 | 97.42 | 68.19 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-m_udp-body7_210e-256x192-e0c9327b_20230504.pth) | +| CSPNeXt-l\* | 256x192 | 32.44 | 5.32 | 75.7 | 97.76 | 69.57 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-l_udp-body7_210e-256x192-5e9558ef_20230504.pth) | +| CSPNeXt-m\* | 384x288 | 17.53 | 6.86 | 75.8 | 97.60 | 70.18 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-m_udp-body7_210e-384x288-b9bc2b57_20230504.pth) | +| CSPNeXt-l\* | 384x288 | 32.44 | 11.96 | 77.2 | 97.89 | 71.23 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-l_udp-body7_210e-384x288-b15bc30d_20230504.pth) | +| CSPNeXt-x\* | 384x288 | 54.92 | 19.96 | 78.1 | 98.00 | 71.79 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-x_udp-body7_210e-384x288-d28b58e6_20230529.pth) |
(M) | Flops
(G) | Top-1 (%) | Top-5 (%) | Download | | :----------: | :--------: | :----------------: | :---------------: | :-------: | :-------: | :---------------------------------------------------------------------------------------------------------------------------: | -| CSPNeXt-tiny | 224x224 | 2.73 | 0.34 | 69.44 | 89.45 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-tiny_imagenet_600e-3a2dd350.pth) | -| CSPNeXt-s | 224x224 | 4.89 | 0.66 | 74.41 | 92.23 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-s_imagenet_600e-ea671761.pth) | -| CSPNeXt-m | 224x224 | 13.05 | 1.93 | 79.27 | 94.79 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-m_8xb256-rsb-a1-600e_in1k-ecb3bbd9.pth) | -| CSPNeXt-l | 224x224 | 27.16 | 4.19 | 81.30 | 95.62 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-l_8xb256-rsb-a1-600e_in1k-6a760974.pth) | -| CSPNeXt-x | 224x224 | 48.85 | 7.76 | 82.10 | 95.69 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-x_8xb256-rsb-a1-600e_in1k-b3f78edd.pth) | +| CSPNeXt-tiny | 224x224 | 2.73 | 0.34 | 69.44 | 89.45 | [pth](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-tiny_imagenet_600e-3a2dd350.pth) | +| CSPNeXt-s | 224x224 | 4.89 | 0.66 | 74.41 | 92.23 | [pth](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-s_imagenet_600e-ea671761.pth) | +| CSPNeXt-m | 224x224 | 13.05 | 1.93 | 79.27 | 94.79 | [pth](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-m_8xb256-rsb-a1-600e_in1k-ecb3bbd9.pth) | +| CSPNeXt-l | 224x224 | 27.16 | 4.19 | 81.30 | 95.62 | [pth](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-l_8xb256-rsb-a1-600e_in1k-6a760974.pth) | +| CSPNeXt-x | 224x224 | 48.85 | 7.76 | 82.10 | 95.69 | [pth](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-x_8xb256-rsb-a1-600e_in1k-b3f78edd.pth) | ## 👀 Visualization [🔝](#-table-of-contents) @@ -362,8 +456,10 @@ We also provide the ImageNet classification pre-trained weights of the CSPNeXt b We provide two appoaches to try RTMPose: -- MMPose demo scripts -- Pre-compiled MMDeploy SDK (Recommend, 6-10 times faster) +- [Online RTMPose Demo](https://openxlab.org.cn/apps/detail/mmpose/RTMPose) +- [Examples](https://github.com/open-mmlab/mmpose/tree/dev-1.x/projects/rtmpose/examples/onnxruntime) based on Python and ONNXRuntime (without mmcv) +- MMPose demo scripts (based on Pytorch) +- Pre-compiled MMDeploy SDK (Recommended, 6-10 times faster) ### MMPose demo scripts @@ -689,9 +785,10 @@ Before starting the deployment, please make sure you install MMPose and MMDeploy Depending on the deployment backend, some backends require compilation of custom operators, so please refer to the corresponding document to ensure the environment is built correctly according to your needs: -- [ONNX RUNTIME SUPPORT](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/onnxruntime.html) -- [TENSORRT SUPPORT](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/tensorrt.html) -- [OPENVINO SUPPORT](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/openvino.html) +- [ONNX](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/onnxruntime.html) +- [TensorRT](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/tensorrt.html) +- [OpenVINO](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/openvino.html) +- [TorchScript](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/torchscript.html) - [More](https://github.com/open-mmlab/mmdeploy/tree/main/docs/en/05-supported-backends) ### 🛠️ Step2. Convert Model @@ -702,12 +799,20 @@ The detailed model conversion tutorial please refer to the [MMDeploy document](h Here we take converting RTMDet-nano and RTMPose-m to ONNX/TensorRT as an example. -- If you only want to use ONNX, please use: +- ONNX - [`detection_onnxruntime_static.py`](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmdet/detection/detection_onnxruntime_static.py) for RTMDet. - [`pose-detection_simcc_onnxruntime_dynamic.py`](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_onnxruntime_dynamic.py) for RTMPose. -- If you want to use TensorRT, please use: +- TensorRT - [`detection_tensorrt_static-320x320.py`](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmdet/detection/detection_tensorrt_static-320x320.py) for RTMDet. - [`pose-detection_simcc_tensorrt_dynamic-256x192.py`](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_tensorrt_dynamic-256x192.py) for RTMPose. +- More + | Backend | Config | + | :---------: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------: | + | ncnn-fp16 | [pose-detection_simcc_ncnn-fp16_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_ncnn-fp16_static-256x192.py) | + | CoreML | [pose-detection_simcc_coreml_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_coreml_static-256x192.py) | + | OpenVINO | [pose-detection_simcc_openvino_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_openvino_static-256x192.py) | + | RKNN | [pose-detection_simcc_rknn-fp16_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_rknn-fp16_static-256x192.py) | + | TorchScript | [pose-detection_torchscript.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_torchscript.py) | If you want to customize the settings in the deployment config for your requirements, please refer to [MMDeploy config tutorial](https://mmdeploy.readthedocs.io/en/latest/02-how-to-run/write_config.html). diff --git a/projects/rtmpose/README_CN.md b/projects/rtmpose/README_CN.md index 30bddf9ecd..859d0e9364 100644 --- a/projects/rtmpose/README_CN.md +++ b/projects/rtmpose/README_CN.md @@ -40,10 +40,25 @@ ______________________________________________________________________ ## 🥳 最新进展 [🔝](#-table-of-contents) +- 2023 年 9 月: + - 发布混合数据集上训练的 RTMW 模型。Alpha 版本的 RTMW-x 在 COCO-Wholebody 验证集上取得了 70.2 mAP。[在线 Demo](https://openxlab.org.cn/apps/detail/mmpose/RTMPose) 已支持 RTMW。技术报告正在撰写中。 + - 增加 HumanArt 上训练的 YOLOX 和 RTMDet 模型。 +- 2023 年 8 月: + - 支持基于 RTMPose 模型蒸馏的 133 点 WholeBody 模型(由 [DWPose](https://github.com/IDEA-Research/DWPose/tree/main) 提供)。 + - 你可以在 [sd-webui-controlnet](https://github.com/Mikubill/sd-webui-controlnet) 中使用 DWPose/RTMPose 作为姿态估计后端进行人物图像生成。升级 sd-webui-controlnet >= v1.1237 并选择 `dw_openpose_full` 即可使用。 + - [在线 Demo](https://openxlab.org.cn/apps/detail/mmpose/RTMPose) 已支持 DWPose,试玩请选择 `wholebody`。 +- 2023 年 7 月: + - 在线 RTMPose 试玩 [Demo](https://openxlab.org.cn/apps/detail/mmpose/RTMPose)。 + - 支持面向艺术图片人体姿态估计的 17 点 Body 模型。 - 2023 年 6 月: - 发布混合数据集训练的 26 点 Body 模型。 - 2023 年 5 月: - - 添加 [代码示例](./examples/) + - 已导出的 SDK 模型(ONNX、TRT、ncnn 等)可以从 [OpenMMLab Deploee](https://platform.openmmlab.com/deploee) 直接下载。 + - [在线导出](https://platform.openmmlab.com/deploee/task-convert-list) SDK 模型(ONNX、TRT、ncnn 等)。 + - 添加 [代码示例](./examples/),包括: + - 纯 Python 推理代码示例,无 MMDeploy、MMCV 依赖 + - C++ 代码示例:ONNXRuntime、TensorRT + - Android 项目示例:基于 ncnn - 发布混合数据集训练的 Hand, Face, Body 模型。 - 2023 年 3 月:发布 RTMPose。RTMPose-m 取得 COCO 验证集 75.8 mAP,推理速度达到 430+ FPS 。 @@ -125,6 +140,7 @@ RTMPose 是一个长期优化迭代的项目,致力于业务场景下的高性 - TensorRT 8.4.3.1 - cuDNN 8.3.2 - CUDA 11.3 +- **更新**:我们推荐你使用混合数据集训练的 `Body8` 模型,性能高于下表中提供的模型,[传送门](#人体-2d-关键点)。 | Detection Config | Pose Config | Input Size
(Det/Pose) | Model AP
(COCO) | Pipeline AP
(COCO) | Params (M)
(Det/Pose) | Flops (G)
(Det/Pose) | ORT-Latency(ms)
(i7-11700) | TRT-FP16-Latency(ms)
(GTX 1660Ti) | Download | | :------------------------------------------------------------------ | :---------------------------------------------------------------------------- | :---------------------------: | :---------------------: | :------------------------: | :---------------------------: | :--------------------------: | :--------------------------------: | :---------------------------------------: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | @@ -155,14 +171,14 @@ RTMPose 是一个长期优化迭代的项目,致力于业务场景下的高性
AIC+COCO
-| Config | Input Size | AP(COCO) | PCK@0.1
(Body8) | AUC
(Body8) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | -| :---------------------------------------------------------------------------: | :--------: | :---------------: | :---------------------: | :-----------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :---------------------------------------------------------------------------------------------------------------------------------------------: | -| [RTMPose-t](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 68.5 | 91.28 | 63.38 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-tiny_simcc-aic-coco_pt-aic-coco_420e-256x192-cfc8f33d_20230126.pth) | -| [RTMPose-s](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 72.2 | 92.95 | 66.19 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-aic-coco_pt-aic-coco_420e-256x192-fcb2599b_20230126.pth) | -| [RTMPose-m](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 75.8 | 94.13 | 68.53 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-256x192-63eb25f7_20230126.pth) | -| [RTMPose-l](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 76.5 | 94.35 | 68.98 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-aic-coco_pt-aic-coco_420e-256x192-f016ffe0_20230126.pth) | -| [RTMPose-m](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py) | 384x288 | 77.0 | 94.32 | 69.85 | 13.72 | 4.33 | 24.78 | 3.66 | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-384x288-a62a0b32_20230228.pth) | -| [RTMPose-l](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py) | 384x288 | 77.3 | 94.54 | 70.14 | 27.79 | 9.35 | - | 6.05 | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-aic-coco_pt-aic-coco_420e-384x288-97d6cb0f_20230228.pth) | +| Config | Input Size | AP
(COCO) | PCK@0.1
(Body8) | AUC
(Body8) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | +| :---------------------------------------------------------------------------: | :--------: | :---------------: | :---------------------: | :-----------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :-------------------------------------------------------------------------------------------------------------------------------------------: | +| [RTMPose-t](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 68.5 | 91.28 | 63.38 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-tiny_simcc-aic-coco_pt-aic-coco_420e-256x192-cfc8f33d_20230126.pth) | +| [RTMPose-s](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 72.2 | 92.95 | 66.19 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-aic-coco_pt-aic-coco_420e-256x192-fcb2599b_20230126.pth) | +| [RTMPose-m](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 75.8 | 94.13 | 68.53 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-256x192-63eb25f7_20230126.pth) | +| [RTMPose-l](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 76.5 | 94.35 | 68.98 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-aic-coco_pt-aic-coco_420e-256x192-f016ffe0_20230126.pth) | +| [RTMPose-m](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py) | 384x288 | 77.0 | 94.32 | 69.85 | 13.72 | 4.33 | 24.78 | 3.66 | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-384x288-a62a0b32_20230228.pth) | +| [RTMPose-l](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py) | 384x288 | 77.3 | 94.54 | 70.14 | 27.79 | 9.35 | - | 6.05 | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-aic-coco_pt-aic-coco_420e-384x288-97d6cb0f_20230228.pth) |
(COCO) | PCK@0.1
(Body8) | AUC
(Body8) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | -| :-----------------------------------------------------------------------------: | :--------: | :---------------: | :---------------------: | :-----------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :------------------------------------------------------------------------------------------------------------------------------------: | -| [RTMPose-t\*](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 65.9 | 91.44 | 63.18 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-body7_pt-body7_420e-256x192-026a1439_20230504.pth) | -| [RTMPose-s\*](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 69.7 | 92.45 | 65.15 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-body7_pt-body7_420e-256x192-acd4a1ef_20230504.pth) | -| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 74.9 | 94.25 | 68.59 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-256x192-e48f03d0_20230504.pth) | -| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 76.7 | 95.08 | 70.14 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7_420e-256x192-4dba18fc_20230504.pth) | -| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py) | 384x288 | 76.6 | 94.64 | 70.38 | 13.72 | 4.33 | 24.78 | 3.66 | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-384x288-65e718c4_20230504.pth) | -| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py) | 384x288 | 78.3 | 95.36 | 71.58 | 27.79 | 9.35 | - | 6.05 | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7_420e-384x288-3f5a1437_20230504.pth) | -| [RTMPose-x\*](./rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_coco-384x288.py) | 384x288 | 78.8 | - | - | 49.43 | 17.22 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-body7_pt-body7_700e-384x288-71d7b7e9_20230629.pth) | +| Config | Input Size | AP
(COCO) | PCK@0.1
(Body8) | AUC
(Body8) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | +| :-----------------------------------------------------------------------------: | :--------: | :---------------: | :---------------------: | :-----------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | +| [RTMPose-t\*](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 65.9 | 91.44 | 63.18 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-body7_pt-body7_420e-256x192-026a1439_20230504.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-t_simcc-body7_pt-body7_420e-256x192-026a1439_20230504.zip) | +| [RTMPose-s\*](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 69.7 | 92.45 | 65.15 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-body7_pt-body7_420e-256x192-acd4a1ef_20230504.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-s_simcc-body7_pt-body7_420e-256x192-acd4a1ef_20230504.zip) | +| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 74.9 | 94.25 | 68.59 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-256x192-e48f03d0_20230504.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-body7_pt-body7_420e-256x192-e48f03d0_20230504.zip) | +| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 76.7 | 95.08 | 70.14 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7_420e-256x192-4dba18fc_20230504.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_simcc-body7_pt-body7_420e-256x192-4dba18fc_20230504.zip) | +| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py) | 384x288 | 76.6 | 94.64 | 70.38 | 13.72 | 4.33 | 24.78 | 3.66 | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-384x288-65e718c4_20230504.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-body7_pt-body7_420e-384x288-65e718c4_20230504.zip) | +| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py) | 384x288 | 78.3 | 95.36 | 71.58 | 27.79 | 9.35 | - | 6.05 | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7_420e-384x288-3f5a1437_20230504.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_simcc-body7_pt-body7_420e-384x288-3f5a1437_20230504.zip) | +| [RTMPose-x\*](./rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_coco-384x288.py) | 384x288 | 78.8 | - | - | 49.43 | 17.22 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-body7_pt-body7_700e-384x288-71d7b7e9_20230629.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-x_simcc-body7_pt-body7_700e-384x288-71d7b7e9_20230629.zip) | + +
+
+
+人体检测模型:
+
+| Detection Config | Input Size | Model AP
(OneHand10K) | Flops
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | +| :---------------------------: | :--------: | :---------------------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :--------------------: | +| [RTMDet-tiny](./rtmdet/person/rtmdet_tiny_8xb32-300e_humanart.py) | 640x640 | 46.6 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_tiny_8xb32-300e_humanart-7da5554e.pth) | +| [RTMDet-s](./rtmdet/person/rtmdet_s_8xb32-300e_humanart.py) | 640x640 | 50.6 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_s_8xb32-300e_humanart-af5bd52d.pth) | +| [YOLOX-nano](./yolox/humanart/yolox_nano_8xb8-300e_humanart.py) | 640x640 | 38.9 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/yolox_nano_8xb8-300e_humanart-40f6f0d0.pth) | +| [YOLOX-tiny](./yolox/humanart/yolox_tiny_8xb8-300e_humanart.py) | 640x640 | 47.7 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/yolox_tiny_8xb8-300e_humanart-6f3252f9.pth) | +| [YOLOX-s](./yolox/humanart/yolox_s_8xb8-300e_humanart.py) | 640x640 | 54.6 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/yolox_s_8xb8-300e_humanart-3ef259a7.pth) | +| [YOLOX-m](./yolox/humanart/yolox_m_8xb8-300e_humanart.py) | 640x640 | 59.1 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/yolox_m_8xb8-300e_humanart-c2c7a14a.pth) | +| [YOLOX-l](./yolox/humanart/yolox_l_8xb8-300e_humanart.py) | 640x640 | 60.2 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/yolox_l_8xb8-300e_humanart-ce1d7a62.pth) | +| [YOLOX-x](./yolox/humanart/yolox_x_8xb8-300e_humanart.py) | 640x640 | 61.3 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/yolox_x_8xb8-300e_humanart-a39d44ed.pth) | + +人体姿态估计模型: + +| Config | Input Size | AP
(Human-Art GT) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | +| :-----------------------------------------------------------------------------: | :--------: | :-----------------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | +| [RTMPose-t\*](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 65.5 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_8xb256-420e_humanart-256x192-60b68c98_20230612.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-t_8xb256-420e_humanart-256x192-60b68c98_20230612.zip) | +| [RTMPose-s\*](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 69.8 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_8xb256-420e_humanart-256x192-5a3ac943_20230611.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-s_8xb256-420e_humanart-256x192-5a3ac943_20230611.zip) | +| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 72.8 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_8xb256-420e_humanart-256x192-8430627b_20230611.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_8xb256-420e_humanart-256x192-8430627b_20230611.zip) | +| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 75.3 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_8xb256-420e_humanart-256x192-389f2cb0_20230611.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_8xb256-420e_humanart-256x192-389f2cb0_20230611.zip) |
@@ -197,15 +243,15 @@ RTMPose 是一个长期优化迭代的项目,致力于业务场景下的高性
- Human-Art
+ +- 面向艺术图片的人体姿态估计 RTMPose 模型由 [Human-Art](https://github.com/IDEA-Research/HumanArt) 提供。 +-(OneHand10K) | Flops
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | +| :---------------------------: | :--------: | :---------------------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :--------------------: | +| [RTMDet-tiny](./rtmdet/person/rtmdet_tiny_8xb32-300e_humanart.py) | 640x640 | 46.6 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_tiny_8xb32-300e_humanart-7da5554e.pth) | +| [RTMDet-s](./rtmdet/person/rtmdet_s_8xb32-300e_humanart.py) | 640x640 | 50.6 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_s_8xb32-300e_humanart-af5bd52d.pth) | +| [YOLOX-nano](./yolox/humanart/yolox_nano_8xb8-300e_humanart.py) | 640x640 | 38.9 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/yolox_nano_8xb8-300e_humanart-40f6f0d0.pth) | +| [YOLOX-tiny](./yolox/humanart/yolox_tiny_8xb8-300e_humanart.py) | 640x640 | 47.7 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/yolox_tiny_8xb8-300e_humanart-6f3252f9.pth) | +| [YOLOX-s](./yolox/humanart/yolox_s_8xb8-300e_humanart.py) | 640x640 | 54.6 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/yolox_s_8xb8-300e_humanart-3ef259a7.pth) | +| [YOLOX-m](./yolox/humanart/yolox_m_8xb8-300e_humanart.py) | 640x640 | 59.1 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/yolox_m_8xb8-300e_humanart-c2c7a14a.pth) | +| [YOLOX-l](./yolox/humanart/yolox_l_8xb8-300e_humanart.py) | 640x640 | 60.2 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/yolox_l_8xb8-300e_humanart-ce1d7a62.pth) | +| [YOLOX-x](./yolox/humanart/yolox_x_8xb8-300e_humanart.py) | 640x640 | 61.3 | - | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/yolox_x_8xb8-300e_humanart-a39d44ed.pth) | + +人体姿态估计模型: + +| Config | Input Size | AP
(Human-Art GT) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | +| :-----------------------------------------------------------------------------: | :--------: | :-----------------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | +| [RTMPose-t\*](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 65.5 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_8xb256-420e_humanart-256x192-60b68c98_20230612.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-t_8xb256-420e_humanart-256x192-60b68c98_20230612.zip) | +| [RTMPose-s\*](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 69.8 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_8xb256-420e_humanart-256x192-5a3ac943_20230611.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-s_8xb256-420e_humanart-256x192-5a3ac943_20230611.zip) | +| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 72.8 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_8xb256-420e_humanart-256x192-8430627b_20230611.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_8xb256-420e_humanart-256x192-8430627b_20230611.zip) | +| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 75.3 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_8xb256-420e_humanart-256x192-389f2cb0_20230611.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_8xb256-420e_humanart-256x192-389f2cb0_20230611.zip) |
(Body8) | AUC
(Body8) | Params(M) | FLOPS(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | -| :---------------------------------------------------------------------------------------: | :--------: | :---------------------: | :-----------------: | :-------: | :------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------------------------------: | -| [RTMPose-t\*](./rtmpose/body_2d_keypoint/rtmpose-t_8xb1024-700e_body8-halpe26-256x192.py) | 256x192 | 91.89 | 66.35 | 3.51 | 0.37 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-body7_pt-body7-halpe26_700e-256x192-6020f8a6_20230605.pth) | -| [RTMPose-s\*](./rtmpose/body_2d_keypoint/rtmpose-s_8xb1024-700e_body8-halpe26-256x192.py) | 256x192 | 93.01 | 68.62 | 5.70 | 0.70 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-body7_pt-body7-halpe26_700e-256x192-7f134165_20230605.pth) | -| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb512-700e_body8-halpe26-256x192.py) | 256x192 | 94.75 | 71.91 | 13.93 | 1.95 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-256x192-4d3e73dd_20230605.pth) | -| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb512-700e_body8-halpe26-256x192.py) | 256x192 | 95.37 | 73.19 | 28.11 | 4.19 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-256x192-2abb7558_20230605.pth) | -| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb512-700e_body8-halpe26-384x288.py) | 384x288 | 95.15 | 73.56 | 14.06 | 4.37 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-384x288-89e6428b_20230605.pth) | -| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb512-700e_body8-halpe26-384x288.py) | 384x288 | 95.56 | 74.38 | 28.24 | 9.40 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-384x288-734182ce_20230605.pth) | -| [RTMPose-x\*](./rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_body8-halpe26-384x288.py) | 384x288 | 95.74 | 74.82 | 50.00 | 17.29 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-body7_pt-body7-halpe26_700e-384x288-7fb6e239_20230606.pth) | +| Config | Input Size | PCK@0.1
(Body8) | AUC
(Body8) | Params(M) | FLOPS(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | +| :---------------------------------------------------------------------------------------: | :--------: | :---------------------: | :-----------------: | :-------: | :------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | +| [RTMPose-t\*](./rtmpose/body_2d_keypoint/rtmpose-t_8xb1024-700e_body8-halpe26-256x192.py) | 256x192 | 91.89 | 66.35 | 3.51 | 0.37 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-body7_pt-body7-halpe26_700e-256x192-6020f8a6_20230605.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-t_simcc-body7_pt-body7-halpe26_700e-256x192-6020f8a6_20230605.zip) | +| [RTMPose-s\*](./rtmpose/body_2d_keypoint/rtmpose-s_8xb1024-700e_body8-halpe26-256x192.py) | 256x192 | 93.01 | 68.62 | 5.70 | 0.70 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-body7_pt-body7-halpe26_700e-256x192-7f134165_20230605.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-s_simcc-body7_pt-body7-halpe26_700e-256x192-7f134165_20230605.zip) | +| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb512-700e_body8-halpe26-256x192.py) | 256x192 | 94.75 | 71.91 | 13.93 | 1.95 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-256x192-4d3e73dd_20230605.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-256x192-4d3e73dd_20230605.zip) | +| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb512-700e_body8-halpe26-256x192.py) | 256x192 | 95.37 | 73.19 | 28.11 | 4.19 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-256x192-2abb7558_20230605.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-256x192-2abb7558_20230605.zip) | +| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb512-700e_body8-halpe26-384x288.py) | 384x288 | 95.15 | 73.56 | 14.06 | 4.37 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-384x288-89e6428b_20230605.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-384x288-89e6428b_20230605.zip) | +| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb512-700e_body8-halpe26-384x288.py) | 384x288 | 95.56 | 74.38 | 28.24 | 9.40 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-384x288-734182ce_20230605.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-384x288-734182ce_20230605.zip) | +| [RTMPose-x\*](./rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_body8-halpe26-384x288.py) | 384x288 | 95.74 | 74.82 | 50.00 | 17.29 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-body7_pt-body7-halpe26_700e-384x288-7fb6e239_20230606.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-x_simcc-body7_pt-body7-halpe26_700e-384x288-7fb6e239_20230606.zip) | #### 模型剪枝 @@ -213,9 +259,9 @@ RTMPose 是一个长期优化迭代的项目,致力于业务场景下的高性 - 模型剪枝由 [MMRazor](https://github.com/open-mmlab/mmrazor) 提供 -| Config | Input Size | AP
(COCO) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | -| :-----------------------: | :--------: | :---------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :------------------------------------------------------------------------------------------------------------------------------------------------: | -| RTMPose-s-aic-coco-pruned | 256x192 | 69.4 | 3.43 | 0.35 | - | - | - | [Model](https://download.openmmlab.com/mmrazor/v1/pruning/group_fisher/rtmpose-s/group_fisher_finetune_rtmpose-s_8xb256-420e_aic-coco-256x192.pth) | +| Config | Input Size | AP
(COCO) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download | +| :-----------------------: | :--------: | :---------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------: | +| RTMPose-s-aic-coco-pruned | 256x192 | 69.4 | 3.43 | 0.35 | - | - | - | [pth](https://download.openmmlab.com/mmrazor/v1/pruning/group_fisher/rtmpose-s/group_fisher_finetune_rtmpose-s_8xb256-420e_aic-coco-256x192.pth) | 更多信息,请参考 [GroupFisher Pruning for RTMPose](./rtmpose/pruning/README.md). @@ -224,12 +270,60 @@ RTMPose 是一个长期优化迭代的项目,致力于业务场景下的高性 - 关键点骨架定义遵循 [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody/),详情见 [meta info](/configs/_base_/datasets/coco_wholebody.py)。 -
+
+
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | | :------------------------------ | :--------: | :------: | :------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-------------------------------: | -| [RTMPose-m](./rtmpose/wholebody_2d_keypoint/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 58.2 | 67.4 | 2.22 | 13.50 | 4.00 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-coco-wholebody_pt-aic-coco_270e-256x192-cd5e845c_20230123.pth) | -| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 61.1 | 70.0 | 4.52 | 23.41 | 5.67 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-coco-wholebody_pt-aic-coco_270e-256x192-6f206314_20230124.pth) | -| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 64.8 | 73.0 | 10.07 | 44.58 | 7.68 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-coco-wholebody_pt-aic-coco_270e-384x288-eaeb96c8_20230125.pth) | -| [RTMPose-x](./rtmpose/wholebody_2d_keypoint/rtmpose-x_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 65.3 | 73.3 | 18.1 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-coco-wholebody_pt-body7_270e-384x288-401dfc90_20230629.pth) | +| [RTMPose-m](./rtmpose/wholebody_2d_keypoint/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 58.2 | 67.4 | 2.22 | 13.50 | 4.00 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-coco-wholebody_pt-aic-coco_270e-256x192-cd5e845c_20230123.pth) | +| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 61.1 | 70.0 | 4.52 | 23.41 | 5.67 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-coco-wholebody_pt-aic-coco_270e-256x192-6f206314_20230124.pth) | +| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 64.8 | 73.0 | 10.07 | 44.58 | 7.68 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-coco-wholebody_pt-aic-coco_270e-384x288-eaeb96c8_20230125.pth) | +| [RTMPose-x](./rtmpose/wholebody_2d_keypoint/rtmpose-x_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 65.3 | 73.3 | 18.1 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-coco-wholebody_pt-body7_270e-384x288-401dfc90_20230629.pth) | + +
+
+COCO-WholeBody
+ | Config | Input Size | Whole AP | Whole AR | FLOPS(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | | :------------------------------ | :--------: | :------: | :------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-------------------------------: | -| [RTMPose-m](./rtmpose/wholebody_2d_keypoint/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 58.2 | 67.4 | 2.22 | 13.50 | 4.00 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-coco-wholebody_pt-aic-coco_270e-256x192-cd5e845c_20230123.pth) | -| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 61.1 | 70.0 | 4.52 | 23.41 | 5.67 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-coco-wholebody_pt-aic-coco_270e-256x192-6f206314_20230124.pth) | -| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 64.8 | 73.0 | 10.07 | 44.58 | 7.68 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-coco-wholebody_pt-aic-coco_270e-384x288-eaeb96c8_20230125.pth) | -| [RTMPose-x](./rtmpose/wholebody_2d_keypoint/rtmpose-x_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 65.3 | 73.3 | 18.1 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-coco-wholebody_pt-body7_270e-384x288-401dfc90_20230629.pth) | +| [RTMPose-m](./rtmpose/wholebody_2d_keypoint/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 58.2 | 67.4 | 2.22 | 13.50 | 4.00 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-coco-wholebody_pt-aic-coco_270e-256x192-cd5e845c_20230123.pth) | +| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 61.1 | 70.0 | 4.52 | 23.41 | 5.67 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-coco-wholebody_pt-aic-coco_270e-256x192-6f206314_20230124.pth) | +| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 64.8 | 73.0 | 10.07 | 44.58 | 7.68 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-coco-wholebody_pt-aic-coco_270e-384x288-eaeb96c8_20230125.pth) | +| [RTMPose-x](./rtmpose/wholebody_2d_keypoint/rtmpose-x_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 65.3 | 73.3 | 18.1 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-coco-wholebody_pt-body7_270e-384x288-401dfc90_20230629.pth) | + +
+
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | +| :------------------------------ | :--------: | :------: | :------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-------------------------------: | +| [RTMW-x
(alpha version)](./rtmpose/wholebody_2d_keypoint/rtmw-x_8xb704-270e_cocktail13-256x192.py) | 256x192 | 67.2 | 75.4 | 13.1 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmw/rtmw-x_simcc-cocktail13_pt-ucoco_270e-256x192-fbef0d61_20230925.pth) | +| [RTMW-x
(alpha version)](./rtmpose/wholebody_2d_keypoint/rtmw-x_8xb320-270e_cocktail13-384x288.py) | 384x288 | 70.2 | 77.9 | 29.3 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmw/rtmw-x_simcc-cocktail13_pt-ucoco_270e-384x288-0949e3a9_20230925.pth) | + +
+
+Cocktail13
+ +- `Cocktail13` 代表模型在 13 个开源数据集上训练得到: + - [AI Challenger](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#aic) + - [CrowdPose](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#crowdpose) + - [MPII](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#mpii) + - [sub-JHMDB](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#sub-jhmdb-dataset) + - [Halpe](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_wholebody_keypoint.html#halpe) + - [PoseTrack18](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#posetrack18) + - [COCO-Wholebody](https://github.com/jin-s13/COCO-WholeBody/) + - [UBody](https://github.com/IDEA-Research/OSX) + - [Human-Art](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#human-art-dataset) + - [WFLW](https://wywu.github.io/projects/LAB/WFLW.html) + - [300W](https://ibug.doc.ic.ac.uk/resources/300-W/) + - [COFW](http://www.vision.caltech.edu/xpburgos/ICCV13/) + - [LaPa](https://github.com/JDAI-CV/lapa-dataset) + +| Config | Input Size | Whole AP | Whole AR | FLOPS(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | +| :------------------------------ | :--------: | :------: | :------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-------------------------------: | +| [RTMW-x
(alpha version)](./rtmpose/wholebody_2d_keypoint/rtmw-x_8xb704-270e_cocktail13-256x192.py) | 256x192 | 67.2 | 75.4 | 13.1 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmw/rtmw-x_simcc-cocktail13_pt-ucoco_270e-256x192-fbef0d61_20230925.pth) | +| [RTMW-x
(alpha version)](./rtmpose/wholebody_2d_keypoint/rtmw-x_8xb320-270e_cocktail13-384x288.py) | 384x288 | 70.2 | 77.9 | 29.3 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmw/rtmw-x_simcc-cocktail13_pt-ucoco_270e-384x288-0949e3a9_20230925.pth) | + +
+
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | +| :------------------------------ | :--------: | :------: | :------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-------------------------------: | +| [RTMPose-t](./rtmpose/wholebody_2d_keypoint/rtmpose-t_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 48.5 | 58.4 | 0.5 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-ucoco_dw-ucoco_270e-256x192-dcf277bf_20230728.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-t_simcc-ucoco_dw-ucoco_270e-256x192-dcf277bf_20230728.pth) | +| [RTMPose-s](./rtmpose/wholebody_2d_keypoint/rtmpose-s_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 53.8 | 63.2 | 0.9 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-ucoco_dw-ucoco_270e-256x192-3fd922c8_20230728.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-s_simcc-ucoco_dw-ucoco_270e-256x192-3fd922c8_20230728.zip) | +| [RTMPose-m](./rtmpose/wholebody_2d_keypoint/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 60.6 | 69.5 | 2.22 | 13.50 | 4.00 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-ucoco_dw-ucoco_270e-256x192-c8b76419_20230728.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-ucoco_dw-ucoco_270e-256x192-c8b76419_20230728.zip) | +| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 63.1 | 71.7 | 4.52 | 23.41 | 5.67 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-ucoco_dw-ucoco_270e-256x192-4d6dfc62_20230728.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_simcc-ucoco_dw-ucoco_270e-256x192-4d6dfc62_20230728.zip) | +| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 66.5 | 74.3 | 10.07 | 44.58 | 7.68 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-ucoco_dw-ucoco_270e-384x288-2438fd99_20230728.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_simcc-ucoco_dw-ucoco_270e-384x288-2438fd99_20230728.zip) | + +
### 动物 2d 关键点 (17 Keypoints)
@@ -238,7 +332,7 @@ RTMPose 是一个长期优化迭代的项目,致力于业务场景下的高性
| Config | Input Size | APCOCO+UBody
+ +- DWPose 模型由 [DWPose](https://github.com/IDEA-Research/DWPose) 项目提供 +- 模型在以下数据集上训练并蒸馏: + - [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody/) + - [UBody](https://github.com/IDEA-Research/OSX) + +| Config | Input Size | Whole AP | Whole AR | FLOPS(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | +| :------------------------------ | :--------: | :------: | :------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-------------------------------: | +| [RTMPose-t](./rtmpose/wholebody_2d_keypoint/rtmpose-t_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 48.5 | 58.4 | 0.5 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-ucoco_dw-ucoco_270e-256x192-dcf277bf_20230728.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-t_simcc-ucoco_dw-ucoco_270e-256x192-dcf277bf_20230728.pth) | +| [RTMPose-s](./rtmpose/wholebody_2d_keypoint/rtmpose-s_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 53.8 | 63.2 | 0.9 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-ucoco_dw-ucoco_270e-256x192-3fd922c8_20230728.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-s_simcc-ucoco_dw-ucoco_270e-256x192-3fd922c8_20230728.zip) | +| [RTMPose-m](./rtmpose/wholebody_2d_keypoint/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 60.6 | 69.5 | 2.22 | 13.50 | 4.00 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-ucoco_dw-ucoco_270e-256x192-c8b76419_20230728.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-ucoco_dw-ucoco_270e-256x192-c8b76419_20230728.zip) | +| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 63.1 | 71.7 | 4.52 | 23.41 | 5.67 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-ucoco_dw-ucoco_270e-256x192-4d6dfc62_20230728.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_simcc-ucoco_dw-ucoco_270e-256x192-4d6dfc62_20230728.zip) | +| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 66.5 | 74.3 | 10.07 | 44.58 | 7.68 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-ucoco_dw-ucoco_270e-384x288-2438fd99_20230728.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-l_simcc-ucoco_dw-ucoco_270e-384x288-2438fd99_20230728.zip) | + +
(AP10K) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | | :----------------------------: | :--------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :------------------------------: | -| [RTMPose-m](./rtmpose/animal_2d_keypoint/rtmpose-m_8xb64-210e_ap10k-256x256.py) | 256x256 | 72.2 | 2.57 | 14.157 | 2.404 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-ap10k_pt-aic-coco_210e-256x256-7a041aa1_20230206.pth) | +| [RTMPose-m](./rtmpose/animal_2d_keypoint/rtmpose-m_8xb64-210e_ap10k-256x256.py) | 256x256 | 72.2 | 2.57 | 14.157 | 2.404 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-ap10k_pt-aic-coco_210e-256x256-7a041aa1_20230206.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-ap10k_pt-aic-coco_210e-256x256-7a041aa1_20230206.zip) | ### 脸部 2d 关键点 (106 Keypoints) @@ -258,9 +352,9 @@ RTMPose 是一个长期优化迭代的项目,致力于业务场景下的高性 | Config | Input Size | NME
(LaPa) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | | :----------------------------: | :--------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :------------------------------: | -| [RTMPose-t\*](./rtmpose/face_2d_keypoint/rtmpose-t_8xb256-120e_lapa-256x256.py) | 256x256 | 1.67 | 0.652 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-face6_pt-in1k_120e-256x256-df79d9a5_20230529.pth) | -| [RTMPose-s\*](./rtmpose/face_2d_keypoint/rtmpose-s_8xb256-120e_lapa-256x256.py) | 256x256 | 1.59 | 1.119 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-face6_pt-in1k_120e-256x256-d779fdef_20230529.pth) | -| [RTMPose-m\*](./rtmpose/face_2d_keypoint/rtmpose-m_8xb256-120e_lapa-256x256.py) | 256x256 | 1.44 | 2.852 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.pth) | +| [RTMPose-t\*](./rtmpose/face_2d_keypoint/rtmpose-t_8xb256-120e_lapa-256x256.py) | 256x256 | 1.67 | 0.652 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-face6_pt-in1k_120e-256x256-df79d9a5_20230529.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-t_simcc-face6_pt-in1k_120e-256x256-df79d9a5_20230529.zip) | +| [RTMPose-s\*](./rtmpose/face_2d_keypoint/rtmpose-s_8xb256-120e_lapa-256x256.py) | 256x256 | 1.59 | 1.119 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-face6_pt-in1k_120e-256x256-d779fdef_20230529.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-s_simcc-face6_pt-in1k_120e-256x256-d779fdef_20230529.zip) | +| [RTMPose-m\*](./rtmpose/face_2d_keypoint/rtmpose-m_8xb256-120e_lapa-256x256.py) | 256x256 | 1.44 | 2.852 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.zip) |
(OneHand10K) | Flops
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | | :---------------------------: | :--------: | :---------------------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :--------------------: | -| [RTMDet-nano (试用)](./rtmdet/hand/rtmdet_nano_320-8xb32_hand.py) | 320x320 | 76.0 | 0.31 | - | - | [Det Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_nano_8xb32-300e_hand-267f9c8f.pth) | +| [RTMDet-nano
(alpha version)](./rtmdet/hand/rtmdet_nano_320-8xb32_hand.py) | 320x320 | 76.0 | 0.31 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmdet_nano_8xb32-300e_hand-267f9c8f.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmdet_nano_8xb32-300e_hand-267f9c8f.zip) |
Hand5
@@ -283,9 +377,9 @@ RTMPose 是一个长期优化迭代的项目,致力于业务场景下的高性 - [RHD2d](https://lmb.informatik.uni-freiburg.de/resources/datasets/RenderedHandposeDataset.en.html) - [Halpe](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_wholebody_keypoint.html#halpe) -| Config | Input Size | PCK@0.2(COCO-Wholebody-Hand) | PCK@0.2
(Hand5) | AUC
(Hand5) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | -| :----------------------------------------------------------------------------------------------------------: | :--------: | :-----------------------------------: | :---------------------: | :-----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------------------------: | -| [RTMPose-m\*
(试用)](./rtmpose/hand_2d_keypoint/rtmpose-m_8xb32-210e_coco-wholebody-hand-256x256.py) | 256x256 | 81.5 | 96.4 | 83.9 | 2.581 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.pth) | +| Config | Input Size | PCK@0.2
(COCO-Wholebody-Hand) | PCK@0.2
(Hand5) | AUC
(Hand5) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download | +| :-------------------------------------------------------------------------------------------------------------------: | :--------: | :-----------------------------------: | :---------------------: | :-----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | +| [RTMPose-m\*
(alpha version)](./rtmpose/hand_2d_keypoint/rtmpose-m_8xb32-210e_coco-wholebody-hand-256x256.py) | 256x256 | 81.5 | 96.4 | 83.9 | 2.581 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.pth)
[onnx](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/onnx_sdk/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.zip) |
(M) | Flops
(G) | AP
(GT) | AR
(GT) | Download | | :----------: | :--------: | :----------------: | :---------------: | :-------------: | :-------------: | :---------------------------------------------------------------------------------------------------------------: | -| CSPNeXt-tiny | 256x192 | 6.03 | 1.43 | 65.5 | 68.9 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-tiny_udp-aic-coco_210e-256x192-cbed682d_20230130.pth) | -| CSPNeXt-s | 256x192 | 8.58 | 1.78 | 70.0 | 73.3 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-s_udp-aic-coco_210e-256x192-92f5a029_20230130.pth) | -| CSPNeXt-m | 256x192 | 17.53 | 3.05 | 74.8 | 77.7 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-m_udp-aic-coco_210e-256x192-f2f7d6f6_20230130.pth) | -| CSPNeXt-l | 256x192 | 32.44 | 5.32 | 77.2 | 79.9 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-l_udp-aic-coco_210e-256x192-273b7631_20230130.pth) | +| CSPNeXt-tiny | 256x192 | 6.03 | 1.43 | 65.5 | 68.9 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-tiny_udp-aic-coco_210e-256x192-cbed682d_20230130.pth) | +| CSPNeXt-s | 256x192 | 8.58 | 1.78 | 70.0 | 73.3 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-s_udp-aic-coco_210e-256x192-92f5a029_20230130.pth) | +| CSPNeXt-m | 256x192 | 17.53 | 3.05 | 74.8 | 77.7 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-m_udp-aic-coco_210e-256x192-f2f7d6f6_20230130.pth) | +| CSPNeXt-l | 256x192 | 32.44 | 5.32 | 77.2 | 79.9 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-l_udp-aic-coco_210e-256x192-273b7631_20230130.pth) |
(M) | Flops
(G) | AP
(COCO) | PCK@0.2
(Body8) | AUC
(Body8) | Download | | :------------: | :--------: | :----------------: | :---------------: | :---------------: | :---------------------: | :-----------------: | :--------------------------------------------------------------------------------: | -| CSPNeXt-tiny\* | 256x192 | 6.03 | 1.43 | 65.9 | 96.34 | 63.80 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-tiny_udp-body7_210e-256x192-a3775292_20230504.pth) | -| CSPNeXt-s\* | 256x192 | 8.58 | 1.78 | 68.7 | 96.59 | 64.92 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-s_udp-body7_210e-256x192-8c9ccbdb_20230504.pth) | -| CSPNeXt-m\* | 256x192 | 17.53 | 3.05 | 73.7 | 97.42 | 68.19 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-m_udp-body7_210e-256x192-e0c9327b_20230504.pth) | -| CSPNeXt-l\* | 256x192 | 32.44 | 5.32 | 75.7 | 97.76 | 69.57 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-l_udp-body7_210e-256x192-5e9558ef_20230504.pth) | -| CSPNeXt-m\* | 384x288 | 17.53 | 6.86 | 75.8 | 97.60 | 70.18 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-m_udp-body7_210e-384x288-b9bc2b57_20230504.pth) | -| CSPNeXt-l\* | 384x288 | 32.44 | 11.96 | 77.2 | 97.89 | 71.23 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-l_udp-body7_210e-384x288-b15bc30d_20230504.pth) | -| CSPNeXt-x\* | 384x288 | 54.92 | 19.96 | 78.1 | 98.00 | 71.79 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-x_udp-body7_210e-384x288-d28b58e6_20230529.pth) | +| CSPNeXt-tiny\* | 256x192 | 6.03 | 1.43 | 65.9 | 96.34 | 63.80 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-tiny_udp-body7_210e-256x192-a3775292_20230504.pth) | +| CSPNeXt-s\* | 256x192 | 8.58 | 1.78 | 68.7 | 96.59 | 64.92 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-s_udp-body7_210e-256x192-8c9ccbdb_20230504.pth) | +| CSPNeXt-m\* | 256x192 | 17.53 | 3.05 | 73.7 | 97.42 | 68.19 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-m_udp-body7_210e-256x192-e0c9327b_20230504.pth) | +| CSPNeXt-l\* | 256x192 | 32.44 | 5.32 | 75.7 | 97.76 | 69.57 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-l_udp-body7_210e-256x192-5e9558ef_20230504.pth) | +| CSPNeXt-m\* | 384x288 | 17.53 | 6.86 | 75.8 | 97.60 | 70.18 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-m_udp-body7_210e-384x288-b9bc2b57_20230504.pth) | +| CSPNeXt-l\* | 384x288 | 32.44 | 11.96 | 77.2 | 97.89 | 71.23 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-l_udp-body7_210e-384x288-b15bc30d_20230504.pth) | +| CSPNeXt-x\* | 384x288 | 54.92 | 19.96 | 78.1 | 98.00 | 71.79 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-x_udp-body7_210e-384x288-d28b58e6_20230529.pth) |
(M) | Flops
(G) | Top-1 (%) | Top-5 (%) | Download | | :----------: | :--------: | :----------------: | :---------------: | :-------: | :-------: | :---------------------------------------------------------------------------------------------------------------------------: | -| CSPNeXt-tiny | 224x224 | 2.73 | 0.34 | 69.44 | 89.45 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-tiny_imagenet_600e-3a2dd350.pth) | -| CSPNeXt-s | 224x224 | 4.89 | 0.66 | 74.41 | 92.23 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-s_imagenet_600e-ea671761.pth) | -| CSPNeXt-m | 224x224 | 13.05 | 1.93 | 79.27 | 94.79 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-m_8xb256-rsb-a1-600e_in1k-ecb3bbd9.pth) | -| CSPNeXt-l | 224x224 | 27.16 | 4.19 | 81.30 | 95.62 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-l_8xb256-rsb-a1-600e_in1k-6a760974.pth) | -| CSPNeXt-x | 224x224 | 48.85 | 7.76 | 82.10 | 95.69 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-x_8xb256-rsb-a1-600e_in1k-b3f78edd.pth) | +| CSPNeXt-tiny | 224x224 | 2.73 | 0.34 | 69.44 | 89.45 | [pth](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-tiny_imagenet_600e-3a2dd350.pth) | +| CSPNeXt-s | 224x224 | 4.89 | 0.66 | 74.41 | 92.23 | [pth](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-s_imagenet_600e-ea671761.pth) | +| CSPNeXt-m | 224x224 | 13.05 | 1.93 | 79.27 | 94.79 | [pth](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-m_8xb256-rsb-a1-600e_in1k-ecb3bbd9.pth) | +| CSPNeXt-l | 224x224 | 27.16 | 4.19 | 81.30 | 95.62 | [pth](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-l_8xb256-rsb-a1-600e_in1k-6a760974.pth) | +| CSPNeXt-x | 224x224 | 48.85 | 7.76 | 82.10 | 95.69 | [pth](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-x_8xb256-rsb-a1-600e_in1k-b3f78edd.pth) | ## 👀 可视化 [🔝](#-table-of-contents) @@ -353,7 +447,9 @@ RTMPose 是一个长期优化迭代的项目,致力于业务场景下的高性 我们提供了两种途径来让用户尝试 RTMPose 模型: -- MMPose demo 脚本 +- [在线 RTMPose Demo](https://openxlab.org.cn/apps/detail/mmpose/RTMPose) +- [Examples](https://github.com/open-mmlab/mmpose/tree/dev-1.x/projects/rtmpose/examples/onnxruntime) 基于 Python 和 ONNXRuntime (无 MMCV 依赖) +- MMPose demo 脚本 (基于 Pytorch) - MMDeploy SDK 预编译包 (推荐,速度提升6-10倍) ### MMPose demo 脚本 @@ -683,6 +779,7 @@ python demo/topdown_demo_with_mmdet.py \ - [ONNX](https://mmdeploy.readthedocs.io/zh_CN/latest/05-supported-backends/onnxruntime.html) - [TensorRT](https://mmdeploy.readthedocs.io/zh_CN/latest/05-supported-backends/tensorrt.html) - [OpenVINO](https://mmdeploy.readthedocs.io/zh_CN/latest/05-supported-backends/openvino.html) +- [TorchScript](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/torchscript.html) - [更多](https://github.com/open-mmlab/mmdeploy/tree/main/docs/en/05-supported-backends) ### 🛠️ 模型转换 @@ -703,6 +800,16 @@ python demo/topdown_demo_with_mmdet.py \ \- RTMPose:[`pose-detection_simcc_tensorrt_dynamic-256x192.py`](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_tensorrt_dynamic-256x192.py) +- 更多 + + | Backend | Config | + | :---------: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------: | + | ncnn-fp16 | [pose-detection_simcc_ncnn-fp16_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_ncnn-fp16_static-256x192.py) | + | CoreML | [pose-detection_simcc_coreml_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_coreml_static-256x192.py) | + | OpenVINO | [pose-detection_simcc_openvino_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_openvino_static-256x192.py) | + | RKNN | [pose-detection_simcc_rknn-fp16_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_rknn-fp16_static-256x192.py) | + | TorchScript | [pose-detection_torchscript.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_torchscript.py) | + 如果你需要对部署配置进行修改,请参考 [MMDeploy config tutorial](https://mmdeploy.readthedocs.io/zh_CN/latest/02-how-to-run/write_config.html). 本教程中使用的文件结构如下: diff --git a/projects/rtmpose/rtmdet/README.md b/projects/rtmpose/rtmdet/README.md new file mode 100644 index 0000000000..7c83f1d378 --- /dev/null +++ b/projects/rtmpose/rtmdet/README.md @@ -0,0 +1,3 @@ +# Welcome to RTMDet Project of MMPose + +**Highlight:** If you are deploy `projects/rtmpose/rtmdet` with [deploee](https://platform.openmmlab.com/deploee), please input [full http download link of train_config](https://raw.githubusercontent.com/open-mmlab/mmpose/main/projects/rtmpose/rtmdet/hand/rtmdet_nano_320-8xb32_hand.py) instead of relative path, deploee cannot parse mmdet config within mmpose repo. diff --git a/projects/rtmpose/rtmdet/person/humanart_detection.py b/projects/rtmpose/rtmdet/person/humanart_detection.py new file mode 100644 index 0000000000..a07a2499ce --- /dev/null +++ b/projects/rtmpose/rtmdet/person/humanart_detection.py @@ -0,0 +1,95 @@ +# dataset settings +dataset_type = 'CocoDataset' +data_root = 'data/' + +# Example to use different file client +# Method 1: simply set the data root and let the file I/O module +# automatically infer from prefix (not support LMDB and Memcache yet) + +# data_root = 's3://openmmlab/datasets/detection/coco/' + +# Method 2: Use `backend_args`, `file_client_args` in versions before 3.0.0rc6 +# backend_args = dict( +# backend='petrel', +# path_mapping=dict({ +# './data/': 's3://openmmlab/datasets/detection/', +# 'data/': 's3://openmmlab/datasets/detection/' +# })) +backend_args = None + +train_pipeline = [ + dict(type='LoadImageFromFile', backend_args=backend_args), + dict(type='LoadAnnotations', with_bbox=True), + dict(type='Resize', scale=(1333, 800), keep_ratio=True), + dict(type='RandomFlip', prob=0.5), + dict(type='PackDetInputs') +] +test_pipeline = [ + dict(type='LoadImageFromFile', backend_args=backend_args), + dict(type='Resize', scale=(1333, 800), keep_ratio=True), + # If you don't have a gt annotation, delete the pipeline + dict(type='LoadAnnotations', with_bbox=True), + dict( + type='PackDetInputs', + meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', + 'scale_factor')) +] +train_dataloader = dict( + batch_size=2, + num_workers=2, + persistent_workers=True, + sampler=dict(type='DefaultSampler', shuffle=True), + batch_sampler=dict(type='AspectRatioBatchSampler'), + dataset=dict( + type=dataset_type, + data_root=data_root, + ann_file='HumanArt/annotations/training_humanart_coco.json', + data_prefix=dict(img=''), + filter_cfg=dict(filter_empty_gt=True, min_size=32), + pipeline=train_pipeline, + backend_args=backend_args)) +val_dataloader = dict( + batch_size=1, + num_workers=2, + persistent_workers=True, + drop_last=False, + sampler=dict(type='DefaultSampler', shuffle=False), + dataset=dict( + type=dataset_type, + data_root=data_root, + ann_file='HumanArt/annotations/validation_humanart_coco.json', + data_prefix=dict(img=''), + test_mode=True, + pipeline=test_pipeline, + backend_args=backend_args)) +test_dataloader = val_dataloader + +val_evaluator = dict( + type='CocoMetric', + ann_file=data_root + 'HumanArt/annotations/validation_humanart_coco.json', + metric='bbox', + format_only=False, + backend_args=backend_args) +test_evaluator = val_evaluator + +# inference on test dataset and +# format the output results for submission. +# test_dataloader = dict( +# batch_size=1, +# num_workers=2, +# persistent_workers=True, +# drop_last=False, +# sampler=dict(type='DefaultSampler', shuffle=False), +# dataset=dict( +# type=dataset_type, +# data_root=data_root, +# ann_file=data_root + 'annotations/image_info_test-dev2017.json', +# data_prefix=dict(img='test2017/'), +# test_mode=True, +# pipeline=test_pipeline)) +# test_evaluator = dict( +# type='CocoMetric', +# metric='bbox', +# format_only=True, +# ann_file=data_root + 'annotations/image_info_test-dev2017.json', +# outfile_prefix='./work_dirs/coco_detection/test') diff --git a/projects/rtmpose/rtmdet/person/rtmdet_l_8xb32-300e_humanart.py b/projects/rtmpose/rtmdet/person/rtmdet_l_8xb32-300e_humanart.py new file mode 100644 index 0000000000..7b009072c6 --- /dev/null +++ b/projects/rtmpose/rtmdet/person/rtmdet_l_8xb32-300e_humanart.py @@ -0,0 +1,180 @@ +_base_ = [ + 'mmdet::_base_/default_runtime.py', + 'mmdet::_base_/schedules/schedule_1x.py', './humanart_detection.py', + 'mmdet::rtmdet_tta.py' +] +model = dict( + type='RTMDet', + data_preprocessor=dict( + type='DetDataPreprocessor', + mean=[103.53, 116.28, 123.675], + std=[57.375, 57.12, 58.395], + bgr_to_rgb=False, + batch_augments=None), + backbone=dict( + type='CSPNeXt', + arch='P5', + expand_ratio=0.5, + deepen_factor=1, + widen_factor=1, + channel_attention=True, + norm_cfg=dict(type='SyncBN'), + act_cfg=dict(type='SiLU', inplace=True)), + neck=dict( + type='CSPNeXtPAFPN', + in_channels=[256, 512, 1024], + out_channels=256, + num_csp_blocks=3, + expand_ratio=0.5, + norm_cfg=dict(type='SyncBN'), + act_cfg=dict(type='SiLU', inplace=True)), + bbox_head=dict( + type='RTMDetSepBNHead', + num_classes=80, + in_channels=256, + stacked_convs=2, + feat_channels=256, + anchor_generator=dict( + type='MlvlPointGenerator', offset=0, strides=[8, 16, 32]), + bbox_coder=dict(type='DistancePointBBoxCoder'), + loss_cls=dict( + type='QualityFocalLoss', + use_sigmoid=True, + beta=2.0, + loss_weight=1.0), + loss_bbox=dict(type='GIoULoss', loss_weight=2.0), + with_objectness=False, + exp_on_reg=True, + share_conv=True, + pred_kernel_size=1, + norm_cfg=dict(type='SyncBN'), + act_cfg=dict(type='SiLU', inplace=True)), + train_cfg=dict( + assigner=dict(type='DynamicSoftLabelAssigner', topk=13), + allowed_border=-1, + pos_weight=-1, + debug=False), + test_cfg=dict( + nms_pre=30000, + min_bbox_size=0, + score_thr=0.001, + nms=dict(type='nms', iou_threshold=0.65), + max_per_img=300), +) + +train_pipeline = [ + dict(type='LoadImageFromFile', backend_args={{_base_.backend_args}}), + dict(type='LoadAnnotations', with_bbox=True), + dict(type='CachedMosaic', img_scale=(640, 640), pad_val=114.0), + dict( + type='RandomResize', + scale=(1280, 1280), + ratio_range=(0.1, 2.0), + keep_ratio=True), + dict(type='RandomCrop', crop_size=(640, 640)), + dict(type='YOLOXHSVRandomAug'), + dict(type='RandomFlip', prob=0.5), + dict(type='Pad', size=(640, 640), pad_val=dict(img=(114, 114, 114))), + dict( + type='CachedMixUp', + img_scale=(640, 640), + ratio_range=(1.0, 1.0), + max_cached_images=20, + pad_val=(114, 114, 114)), + dict(type='PackDetInputs') +] + +train_pipeline_stage2 = [ + dict(type='LoadImageFromFile', backend_args={{_base_.backend_args}}), + dict(type='LoadAnnotations', with_bbox=True), + dict( + type='RandomResize', + scale=(640, 640), + ratio_range=(0.1, 2.0), + keep_ratio=True), + dict(type='RandomCrop', crop_size=(640, 640)), + dict(type='YOLOXHSVRandomAug'), + dict(type='RandomFlip', prob=0.5), + dict(type='Pad', size=(640, 640), pad_val=dict(img=(114, 114, 114))), + dict(type='PackDetInputs') +] + +test_pipeline = [ + dict(type='LoadImageFromFile', backend_args={{_base_.backend_args}}), + dict(type='Resize', scale=(640, 640), keep_ratio=True), + dict(type='Pad', size=(640, 640), pad_val=dict(img=(114, 114, 114))), + dict(type='LoadAnnotations', with_bbox=True), + dict( + type='PackDetInputs', + meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', + 'scale_factor')) +] + +train_dataloader = dict( + batch_size=32, + num_workers=10, + batch_sampler=None, + pin_memory=True, + dataset=dict(pipeline=train_pipeline)) +val_dataloader = dict( + batch_size=5, num_workers=10, dataset=dict(pipeline=test_pipeline)) +test_dataloader = val_dataloader + +max_epochs = 300 +stage2_num_epochs = 20 +base_lr = 0.0005 +interval = 10 + +train_cfg = dict( + max_epochs=max_epochs, + val_interval=interval, + dynamic_intervals=[(max_epochs - stage2_num_epochs, 1)]) + +val_evaluator = dict(proposal_nums=(100, 1, 10)) +test_evaluator = val_evaluator + +# optimizer +optim_wrapper = dict( + _delete_=True, + type='OptimWrapper', + optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05), + paramwise_cfg=dict( + norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True)) + +# learning rate +param_scheduler = [ + dict( + type='LinearLR', + start_factor=1.0e-5, + by_epoch=False, + begin=0, + end=1000), + dict( + # use cosine lr from 150 to 300 epoch + type='CosineAnnealingLR', + eta_min=base_lr * 0.05, + begin=max_epochs // 2, + end=max_epochs, + T_max=max_epochs // 2, + by_epoch=True, + convert_to_iter_based=True), +] + +# hooks +default_hooks = dict( + checkpoint=dict( + interval=interval, + max_keep_ckpts=3 # only keep latest 3 checkpoints + )) +custom_hooks = [ + dict( + type='EMAHook', + ema_type='ExpMomentumEMA', + momentum=0.0002, + update_buffers=True, + priority=49), + dict( + type='PipelineSwitchHook', + switch_epoch=max_epochs - stage2_num_epochs, + switch_pipeline=train_pipeline_stage2) +] diff --git a/projects/rtmpose/rtmdet/person/rtmdet_m_8xb32-300e_humanart.py b/projects/rtmpose/rtmdet/person/rtmdet_m_8xb32-300e_humanart.py new file mode 100644 index 0000000000..263ec89347 --- /dev/null +++ b/projects/rtmpose/rtmdet/person/rtmdet_m_8xb32-300e_humanart.py @@ -0,0 +1,6 @@ +_base_ = './rtmdet_l_8xb32-300e_humanart.py' + +model = dict( + backbone=dict(deepen_factor=0.67, widen_factor=0.75), + neck=dict(in_channels=[192, 384, 768], out_channels=192, num_csp_blocks=2), + bbox_head=dict(in_channels=192, feat_channels=192)) diff --git a/projects/rtmpose/rtmdet/person/rtmdet_s_8xb32-300e_humanart.py b/projects/rtmpose/rtmdet/person/rtmdet_s_8xb32-300e_humanart.py new file mode 100644 index 0000000000..927cbf7555 --- /dev/null +++ b/projects/rtmpose/rtmdet/person/rtmdet_s_8xb32-300e_humanart.py @@ -0,0 +1,62 @@ +_base_ = './rtmdet_l_8xb32-300e_humanart.py' +checkpoint = 'https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-s_imagenet_600e.pth' # noqa +model = dict( + backbone=dict( + deepen_factor=0.33, + widen_factor=0.5, + init_cfg=dict( + type='Pretrained', prefix='backbone.', checkpoint=checkpoint)), + neck=dict(in_channels=[128, 256, 512], out_channels=128, num_csp_blocks=1), + bbox_head=dict(in_channels=128, feat_channels=128, exp_on_reg=False)) + +train_pipeline = [ + dict(type='LoadImageFromFile', backend_args={{_base_.backend_args}}), + dict(type='LoadAnnotations', with_bbox=True), + dict(type='CachedMosaic', img_scale=(640, 640), pad_val=114.0), + dict( + type='RandomResize', + scale=(1280, 1280), + ratio_range=(0.5, 2.0), + keep_ratio=True), + dict(type='RandomCrop', crop_size=(640, 640)), + dict(type='YOLOXHSVRandomAug'), + dict(type='RandomFlip', prob=0.5), + dict(type='Pad', size=(640, 640), pad_val=dict(img=(114, 114, 114))), + dict( + type='CachedMixUp', + img_scale=(640, 640), + ratio_range=(1.0, 1.0), + max_cached_images=20, + pad_val=(114, 114, 114)), + dict(type='PackDetInputs') +] + +train_pipeline_stage2 = [ + dict(type='LoadImageFromFile', backend_args={{_base_.backend_args}}), + dict(type='LoadAnnotations', with_bbox=True), + dict( + type='RandomResize', + scale=(640, 640), + ratio_range=(0.5, 2.0), + keep_ratio=True), + dict(type='RandomCrop', crop_size=(640, 640)), + dict(type='YOLOXHSVRandomAug'), + dict(type='RandomFlip', prob=0.5), + dict(type='Pad', size=(640, 640), pad_val=dict(img=(114, 114, 114))), + dict(type='PackDetInputs') +] + +train_dataloader = dict(dataset=dict(pipeline=train_pipeline)) + +custom_hooks = [ + dict( + type='EMAHook', + ema_type='ExpMomentumEMA', + momentum=0.0002, + update_buffers=True, + priority=49), + dict( + type='PipelineSwitchHook', + switch_epoch=280, + switch_pipeline=train_pipeline_stage2) +] diff --git a/projects/rtmpose/rtmdet/person/rtmdet_tiny_8xb32-300e_humanart.py b/projects/rtmpose/rtmdet/person/rtmdet_tiny_8xb32-300e_humanart.py new file mode 100644 index 0000000000..c92442fa8d --- /dev/null +++ b/projects/rtmpose/rtmdet/person/rtmdet_tiny_8xb32-300e_humanart.py @@ -0,0 +1,43 @@ +_base_ = './rtmdet_s_8xb32-300e_humanart.py' + +checkpoint = 'https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-tiny_imagenet_600e.pth' # noqa + +model = dict( + backbone=dict( + deepen_factor=0.167, + widen_factor=0.375, + init_cfg=dict( + type='Pretrained', prefix='backbone.', checkpoint=checkpoint)), + neck=dict(in_channels=[96, 192, 384], out_channels=96, num_csp_blocks=1), + bbox_head=dict(in_channels=96, feat_channels=96, exp_on_reg=False)) + +train_pipeline = [ + dict(type='LoadImageFromFile', backend_args={{_base_.backend_args}}), + dict(type='LoadAnnotations', with_bbox=True), + dict( + type='CachedMosaic', + img_scale=(640, 640), + pad_val=114.0, + max_cached_images=20, + random_pop=False), + dict( + type='RandomResize', + scale=(1280, 1280), + ratio_range=(0.5, 2.0), + keep_ratio=True), + dict(type='RandomCrop', crop_size=(640, 640)), + dict(type='YOLOXHSVRandomAug'), + dict(type='RandomFlip', prob=0.5), + dict(type='Pad', size=(640, 640), pad_val=dict(img=(114, 114, 114))), + dict( + type='CachedMixUp', + img_scale=(640, 640), + ratio_range=(1.0, 1.0), + max_cached_images=10, + random_pop=False, + pad_val=(114, 114, 114), + prob=0.5), + dict(type='PackDetInputs') +] + +train_dataloader = dict(dataset=dict(pipeline=train_pipeline)) diff --git a/projects/rtmpose/rtmdet/person/rtmdet_x_8xb32-300e_humanart.py b/projects/rtmpose/rtmdet/person/rtmdet_x_8xb32-300e_humanart.py new file mode 100644 index 0000000000..60fd09c866 --- /dev/null +++ b/projects/rtmpose/rtmdet/person/rtmdet_x_8xb32-300e_humanart.py @@ -0,0 +1,7 @@ +_base_ = './rtmdet_l_8xb32-300e_humanart.py' + +model = dict( + backbone=dict(deepen_factor=1.33, widen_factor=1.25), + neck=dict( + in_channels=[320, 640, 1280], out_channels=320, num_csp_blocks=4), + bbox_head=dict(in_channels=320, feat_channels=320)) diff --git a/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_coco-384x288.py b/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_coco-384x288.py index 1441e07791..25da9aeeb1 100644 --- a/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_coco-384x288.py +++ b/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_coco-384x288.py @@ -66,7 +66,7 @@ arch='P5', expand_ratio=0.5, deepen_factor=1.33, - widen_factor=1.28, + widen_factor=1.25, out_indices=(4, ), channel_attention=True, norm_cfg=dict(type='SyncBN'), diff --git a/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmpose-s_8xb64-270e_coco-wholebody-256x192.py b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmpose-s_8xb64-270e_coco-wholebody-256x192.py new file mode 100644 index 0000000000..7afb493d6e --- /dev/null +++ b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmpose-s_8xb64-270e_coco-wholebody-256x192.py @@ -0,0 +1,233 @@ +_base_ = ['mmpose::_base_/default_runtime.py'] + +# common setting +num_keypoints = 133 +input_size = (192, 256) + +# runtime +max_epochs = 270 +stage2_num_epochs = 30 +base_lr = 4e-3 +train_batch_size = 64 +val_batch_size = 32 + +train_cfg = dict(max_epochs=max_epochs, val_interval=10) +randomness = dict(seed=21) + +# optimizer +optim_wrapper = dict( + type='OptimWrapper', + optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05), + clip_grad=dict(max_norm=35, norm_type=2), + paramwise_cfg=dict( + norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True)) + +# learning rate +param_scheduler = [ + dict( + type='LinearLR', + start_factor=1.0e-5, + by_epoch=False, + begin=0, + end=1000), + dict( + type='CosineAnnealingLR', + eta_min=base_lr * 0.05, + begin=max_epochs // 2, + end=max_epochs, + T_max=max_epochs // 2, + by_epoch=True, + convert_to_iter_based=True), +] + +# automatically scaling LR based on the actual training batch size +auto_scale_lr = dict(base_batch_size=512) + +# codec settings +codec = dict( + type='SimCCLabel', + input_size=input_size, + sigma=(4.9, 5.66), + simcc_split_ratio=2.0, + normalize=False, + use_dark=False) + +# model settings +model = dict( + type='TopdownPoseEstimator', + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + backbone=dict( + _scope_='mmdet', + type='CSPNeXt', + arch='P5', + expand_ratio=0.5, + deepen_factor=0.33, + widen_factor=0.5, + out_indices=(4, ), + channel_attention=True, + norm_cfg=dict(type='SyncBN'), + act_cfg=dict(type='SiLU'), + init_cfg=dict( + type='Pretrained', + prefix='backbone.', + checkpoint='https://download.openmmlab.com/mmpose/v1/projects/' + 'rtmposev1/cspnext-s_udp-aic-coco_210e-256x192-92f5a029_20230130.pth' # noqa + )), + head=dict( + type='RTMCCHead', + in_channels=512, + out_channels=num_keypoints, + input_size=codec['input_size'], + in_featuremap_size=tuple([s // 32 for s in codec['input_size']]), + simcc_split_ratio=codec['simcc_split_ratio'], + final_layer_kernel_size=7, + gau_cfg=dict( + hidden_dims=256, + s=128, + expansion_factor=2, + dropout_rate=0., + drop_path=0., + act_fn='SiLU', + use_rel_bias=False, + pos_enc=False), + loss=dict( + type='KLDiscretLoss', + use_target_weight=True, + beta=10., + label_softmax=True), + decoder=codec), + test_cfg=dict(flip_test=True, )) + +# base dataset settings +dataset_type = 'CocoWholeBodyDataset' +data_mode = 'topdown' +data_root = 'data/coco/' + +backend_args = dict(backend='local') + +# pipelines +train_pipeline = [ + dict(type='LoadImage', backend_args=backend_args), + dict(type='GetBBoxCenterScale'), + dict(type='RandomFlip', direction='horizontal'), + dict(type='RandomHalfBody'), + dict( + type='RandomBBoxTransform', scale_factor=[0.6, 1.4], rotate_factor=80), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='mmdet.YOLOXHSVRandomAug'), + dict( + type='Albumentation', + transforms=[ + dict(type='Blur', p=0.1), + dict(type='MedianBlur', p=0.1), + dict( + type='CoarseDropout', + max_holes=1, + max_height=0.4, + max_width=0.4, + min_holes=1, + min_height=0.2, + min_width=0.2, + p=1.0), + ]), + dict(type='GenerateTarget', encoder=codec), + dict(type='PackPoseInputs') +] +val_pipeline = [ + dict(type='LoadImage', backend_args=backend_args), + dict(type='GetBBoxCenterScale'), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='PackPoseInputs') +] + +train_pipeline_stage2 = [ + dict(type='LoadImage', backend_args=backend_args), + dict(type='GetBBoxCenterScale'), + dict(type='RandomFlip', direction='horizontal'), + dict(type='RandomHalfBody'), + dict( + type='RandomBBoxTransform', + shift_factor=0., + scale_factor=[0.75, 1.25], + rotate_factor=60), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='mmdet.YOLOXHSVRandomAug'), + dict( + type='Albumentation', + transforms=[ + dict(type='Blur', p=0.1), + dict(type='MedianBlur', p=0.1), + dict( + type='CoarseDropout', + max_holes=1, + max_height=0.4, + max_width=0.4, + min_holes=1, + min_height=0.2, + min_width=0.2, + p=0.5), + ]), + dict(type='GenerateTarget', encoder=codec), + dict(type='PackPoseInputs') +] + +# data loaders +train_dataloader = dict( + batch_size=train_batch_size, + num_workers=10, + persistent_workers=True, + sampler=dict(type='DefaultSampler', shuffle=True), + dataset=dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='annotations/coco_wholebody_train_v1.0.json', + data_prefix=dict(img='train2017/'), + pipeline=train_pipeline, + )) +val_dataloader = dict( + batch_size=val_batch_size, + num_workers=10, + persistent_workers=True, + drop_last=False, + sampler=dict(type='DefaultSampler', shuffle=False, round_up=False), + dataset=dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='annotations/coco_wholebody_val_v1.0.json', + data_prefix=dict(img='val2017/'), + test_mode=True, + bbox_file='data/coco/person_detection_results/' + 'COCO_val2017_detections_AP_H_56_person.json', + pipeline=val_pipeline, + )) +test_dataloader = val_dataloader + +# hooks +default_hooks = dict( + checkpoint=dict( + save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1)) + +custom_hooks = [ + dict( + type='EMAHook', + ema_type='ExpMomentumEMA', + momentum=0.0002, + update_buffers=True, + priority=49), + dict( + type='mmdet.PipelineSwitchHook', + switch_epoch=max_epochs - stage2_num_epochs, + switch_pipeline=train_pipeline_stage2) +] + +# evaluators +val_evaluator = dict( + type='CocoWholeBodyMetric', + ann_file=data_root + 'annotations/coco_wholebody_val_v1.0.json') +test_evaluator = val_evaluator diff --git a/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmpose-t_8xb64-270e_coco-wholebody-256x192.py b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmpose-t_8xb64-270e_coco-wholebody-256x192.py new file mode 100644 index 0000000000..3ea3de877b --- /dev/null +++ b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmpose-t_8xb64-270e_coco-wholebody-256x192.py @@ -0,0 +1,233 @@ +_base_ = ['mmpose::_base_/default_runtime.py'] + +# common setting +num_keypoints = 133 +input_size = (192, 256) + +# runtime +max_epochs = 270 +stage2_num_epochs = 30 +base_lr = 4e-3 +train_batch_size = 64 +val_batch_size = 32 + +train_cfg = dict(max_epochs=max_epochs, val_interval=10) +randomness = dict(seed=21) + +# optimizer +optim_wrapper = dict( + type='OptimWrapper', + optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05), + clip_grad=dict(max_norm=35, norm_type=2), + paramwise_cfg=dict( + norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True)) + +# learning rate +param_scheduler = [ + dict( + type='LinearLR', + start_factor=1.0e-5, + by_epoch=False, + begin=0, + end=1000), + dict( + type='CosineAnnealingLR', + eta_min=base_lr * 0.05, + begin=max_epochs // 2, + end=max_epochs, + T_max=max_epochs // 2, + by_epoch=True, + convert_to_iter_based=True), +] + +# automatically scaling LR based on the actual training batch size +auto_scale_lr = dict(base_batch_size=512) + +# codec settings +codec = dict( + type='SimCCLabel', + input_size=input_size, + sigma=(4.9, 5.66), + simcc_split_ratio=2.0, + normalize=False, + use_dark=False) + +# model settings +model = dict( + type='TopdownPoseEstimator', + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + backbone=dict( + _scope_='mmdet', + type='CSPNeXt', + arch='P5', + expand_ratio=0.5, + deepen_factor=0.167, + widen_factor=0.375, + out_indices=(4, ), + channel_attention=True, + norm_cfg=dict(type='SyncBN'), + act_cfg=dict(type='SiLU'), + init_cfg=dict( + type='Pretrained', + prefix='backbone.', + checkpoint='https://download.openmmlab.com/mmpose/v1/projects/' + 'rtmposev1/cspnext-tiny_udp-aic-coco_210e-256x192-cbed682d_20230130.pth' # noqa + )), + head=dict( + type='RTMCCHead', + in_channels=384, + out_channels=num_keypoints, + input_size=codec['input_size'], + in_featuremap_size=tuple([s // 32 for s in codec['input_size']]), + simcc_split_ratio=codec['simcc_split_ratio'], + final_layer_kernel_size=7, + gau_cfg=dict( + hidden_dims=256, + s=128, + expansion_factor=2, + dropout_rate=0., + drop_path=0., + act_fn='SiLU', + use_rel_bias=False, + pos_enc=False), + loss=dict( + type='KLDiscretLoss', + use_target_weight=True, + beta=10., + label_softmax=True), + decoder=codec), + test_cfg=dict(flip_test=True, )) + +# base dataset settings +dataset_type = 'CocoWholeBodyDataset' +data_mode = 'topdown' +data_root = 'data/coco/' + +backend_args = dict(backend='local') + +# pipelines +train_pipeline = [ + dict(type='LoadImage', backend_args=backend_args), + dict(type='GetBBoxCenterScale'), + dict(type='RandomFlip', direction='horizontal'), + dict(type='RandomHalfBody'), + dict( + type='RandomBBoxTransform', scale_factor=[0.6, 1.4], rotate_factor=80), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='mmdet.YOLOXHSVRandomAug'), + dict( + type='Albumentation', + transforms=[ + dict(type='Blur', p=0.1), + dict(type='MedianBlur', p=0.1), + dict( + type='CoarseDropout', + max_holes=1, + max_height=0.4, + max_width=0.4, + min_holes=1, + min_height=0.2, + min_width=0.2, + p=1.0), + ]), + dict(type='GenerateTarget', encoder=codec), + dict(type='PackPoseInputs') +] +val_pipeline = [ + dict(type='LoadImage', backend_args=backend_args), + dict(type='GetBBoxCenterScale'), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='PackPoseInputs') +] + +train_pipeline_stage2 = [ + dict(type='LoadImage', backend_args=backend_args), + dict(type='GetBBoxCenterScale'), + dict(type='RandomFlip', direction='horizontal'), + dict(type='RandomHalfBody'), + dict( + type='RandomBBoxTransform', + shift_factor=0., + scale_factor=[0.75, 1.25], + rotate_factor=60), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='mmdet.YOLOXHSVRandomAug'), + dict( + type='Albumentation', + transforms=[ + dict(type='Blur', p=0.1), + dict(type='MedianBlur', p=0.1), + dict( + type='CoarseDropout', + max_holes=1, + max_height=0.4, + max_width=0.4, + min_holes=1, + min_height=0.2, + min_width=0.2, + p=0.5), + ]), + dict(type='GenerateTarget', encoder=codec), + dict(type='PackPoseInputs') +] + +# data loaders +train_dataloader = dict( + batch_size=train_batch_size, + num_workers=10, + persistent_workers=True, + sampler=dict(type='DefaultSampler', shuffle=True), + dataset=dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='annotations/coco_wholebody_train_v1.0.json', + data_prefix=dict(img='train2017/'), + pipeline=train_pipeline, + )) +val_dataloader = dict( + batch_size=val_batch_size, + num_workers=10, + persistent_workers=True, + drop_last=False, + sampler=dict(type='DefaultSampler', shuffle=False, round_up=False), + dataset=dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='annotations/coco_wholebody_val_v1.0.json', + data_prefix=dict(img='val2017/'), + test_mode=True, + bbox_file='data/coco/person_detection_results/' + 'COCO_val2017_detections_AP_H_56_person.json', + pipeline=val_pipeline, + )) +test_dataloader = val_dataloader + +# hooks +default_hooks = dict( + checkpoint=dict( + save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1)) + +custom_hooks = [ + dict( + type='EMAHook', + ema_type='ExpMomentumEMA', + momentum=0.0002, + update_buffers=True, + priority=49), + dict( + type='mmdet.PipelineSwitchHook', + switch_epoch=max_epochs - stage2_num_epochs, + switch_pipeline=train_pipeline_stage2) +] + +# evaluators +val_evaluator = dict( + type='CocoWholeBodyMetric', + ann_file=data_root + 'annotations/coco_wholebody_val_v1.0.json') +test_evaluator = val_evaluator diff --git a/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb320-270e_cocktail13-384x288.py b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb320-270e_cocktail13-384x288.py new file mode 100644 index 0000000000..55d07b61a8 --- /dev/null +++ b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb320-270e_cocktail13-384x288.py @@ -0,0 +1,638 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from mmengine.config import read_base + +with read_base(): + from mmpose.configs._base_.default_runtime import * # noqa + +from albumentations.augmentations import Blur, CoarseDropout, MedianBlur +from mmdet.engine.hooks import PipelineSwitchHook +from mmengine.dataset import DefaultSampler +from mmengine.hooks import EMAHook +from mmengine.model import PretrainedInit +from mmengine.optim import CosineAnnealingLR, LinearLR, OptimWrapper +from torch.nn import SiLU, SyncBatchNorm +from torch.optim import AdamW + +from mmpose.codecs import SimCCLabel +from mmpose.datasets import (AicDataset, CocoWholeBodyDataset, COFWDataset, + CombinedDataset, CrowdPoseDataset, + Face300WDataset, GenerateTarget, + GetBBoxCenterScale, HalpeDataset, + HumanArt21Dataset, InterHand2DDoubleDataset, + JhmdbDataset, KeypointConverter, LapaDataset, + LoadImage, MpiiDataset, PackPoseInputs, + PoseTrack18Dataset, RandomFlip, RandomHalfBody, + TopdownAffine, UBody2dDataset, WFLWDataset) +from mmpose.datasets.transforms.common_transforms import ( + Albumentation, PhotometricDistortion, RandomBBoxTransform) +from mmpose.engine.hooks import ExpMomentumEMA +from mmpose.evaluation import CocoWholeBodyMetric +from mmpose.models import (CSPNeXt, CSPNeXtPAFPN, KLDiscretLoss, + PoseDataPreprocessor, RTMWHead, + TopdownPoseEstimator) + +# common setting +num_keypoints = 133 +input_size = (288, 384) + +# runtime +max_epochs = 270 +stage2_num_epochs = 10 +base_lr = 5e-4 +train_batch_size = 320 +val_batch_size = 32 + +train_cfg.update(max_epochs=max_epochs, val_interval=10) # noqa +randomness = dict(seed=21) + +# optimizer +optim_wrapper = dict( + type=OptimWrapper, + optimizer=dict(type=AdamW, lr=base_lr, weight_decay=0.05), + clip_grad=dict(max_norm=35, norm_type=2), + paramwise_cfg=dict( + norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True)) + +# learning rate +param_scheduler = [ + dict( + type=LinearLR, start_factor=1.0e-5, by_epoch=False, begin=0, end=1000), + dict( + type=CosineAnnealingLR, + eta_min=base_lr * 0.05, + begin=max_epochs // 2, + end=max_epochs, + T_max=max_epochs // 2, + by_epoch=True, + convert_to_iter_based=True), +] + +# automatically scaling LR based on the actual training batch size +auto_scale_lr = dict(base_batch_size=5632) + +# codec settings +codec = dict( + type=SimCCLabel, + input_size=input_size, + sigma=(6., 6.93), + simcc_split_ratio=2.0, + normalize=False, + use_dark=False) + +# model settings +model = dict( + type=TopdownPoseEstimator, + data_preprocessor=dict( + type=PoseDataPreprocessor, + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + backbone=dict( + type=CSPNeXt, + arch='P5', + expand_ratio=0.5, + deepen_factor=1.33, + widen_factor=1.25, + channel_attention=True, + norm_cfg=dict(type='BN'), + act_cfg=dict(type=SiLU), + init_cfg=dict( + type=PretrainedInit, + prefix='backbone.', + checkpoint='https://download.openmmlab.com/mmpose/v1/' + 'wholebody_2d_keypoint/rtmpose/ubody/rtmpose-x_simcc-ucoco_pt-aic-coco_270e-384x288-f5b50679_20230822.pth' # noqa + )), + neck=dict( + type=CSPNeXtPAFPN, + in_channels=[320, 640, 1280], + out_channels=None, + out_indices=( + 1, + 2, + ), + num_csp_blocks=2, + expand_ratio=0.5, + norm_cfg=dict(type=SyncBatchNorm), + act_cfg=dict(type=SiLU, inplace=True)), + head=dict( + type=RTMWHead, + in_channels=1280, + out_channels=num_keypoints, + input_size=input_size, + in_featuremap_size=tuple([s // 32 for s in input_size]), + simcc_split_ratio=codec['simcc_split_ratio'], + final_layer_kernel_size=7, + gau_cfg=dict( + hidden_dims=256, + s=128, + expansion_factor=2, + dropout_rate=0., + drop_path=0., + act_fn=SiLU, + use_rel_bias=False, + pos_enc=False), + loss=dict( + type=KLDiscretLoss, + use_target_weight=True, + beta=10., + label_softmax=True), + decoder=codec), + test_cfg=dict(flip_test=True)) + +# base dataset settings +dataset_type = CocoWholeBodyDataset +data_mode = 'topdown' +data_root = 'data/' + +backend_args = dict(backend='local') + +# pipelines +train_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict(type=RandomFlip, direction='horizontal'), + dict(type=RandomHalfBody), + dict(type=RandomBBoxTransform, scale_factor=[0.5, 1.5], rotate_factor=90), + dict(type=TopdownAffine, input_size=codec['input_size']), + dict(type=PhotometricDistortion), + dict( + type=Albumentation, + transforms=[ + dict(type=Blur, p=0.1), + dict(type=MedianBlur, p=0.1), + dict( + type=CoarseDropout, + max_holes=1, + max_height=0.4, + max_width=0.4, + min_holes=1, + min_height=0.2, + min_width=0.2, + p=1.0), + ]), + dict( + type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True), + dict(type=PackPoseInputs) +] +val_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict(type=TopdownAffine, input_size=codec['input_size']), + dict(type=PackPoseInputs) +] +train_pipeline_stage2 = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict(type=RandomFlip, direction='horizontal'), + dict(type=RandomHalfBody), + dict( + type=RandomBBoxTransform, + shift_factor=0., + scale_factor=[0.5, 1.5], + rotate_factor=90), + dict(type=TopdownAffine, input_size=codec['input_size']), + dict( + type=Albumentation, + transforms=[ + dict(type=Blur, p=0.1), + dict(type=MedianBlur, p=0.1), + ]), + dict( + type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True), + dict(type=PackPoseInputs) +] + +# mapping + +aic_coco133 = [(0, 6), (1, 8), (2, 10), (3, 5), (4, 7), (5, 9), (6, 12), + (7, 14), (8, 16), (9, 11), (10, 13), (11, 15)] + +crowdpose_coco133 = [(0, 5), (1, 6), (2, 7), (3, 8), (4, 9), (5, 10), (6, 11), + (7, 12), (8, 13), (9, 14), (10, 15), (11, 16)] + +mpii_coco133 = [ + (0, 16), + (1, 14), + (2, 12), + (3, 11), + (4, 13), + (5, 15), + (8, 18), + (9, 17), + (10, 10), + (11, 8), + (12, 6), + (13, 5), + (14, 7), + (15, 9), +] + +jhmdb_coco133 = [ + (0, 18), + (2, 17), + (3, 6), + (4, 5), + (5, 12), + (6, 11), + (7, 8), + (8, 7), + (9, 14), + (10, 13), + (11, 10), + (12, 9), + (13, 16), + (14, 15), +] + +halpe_coco133 = [(i, i) + for i in range(17)] + [(20, 17), (21, 20), (22, 18), (23, 21), + (24, 19), + (25, 22)] + [(i, i - 3) + for i in range(26, 136)] + +posetrack_coco133 = [ + (0, 0), + (2, 17), + (3, 3), + (4, 4), + (5, 5), + (6, 6), + (7, 7), + (8, 8), + (9, 9), + (10, 10), + (11, 11), + (12, 12), + (13, 13), + (14, 14), + (15, 15), + (16, 16), +] + +humanart_coco133 = [(i, i) for i in range(17)] + [(17, 99), (18, 120), + (19, 17), (20, 20)] + +# train datasets +dataset_coco = dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='coco/annotations/coco_wholebody_train_v1.0.json', + data_prefix=dict(img='detection/coco/train2017/'), + pipeline=[], +) + +dataset_aic = dict( + type=AicDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='aic/annotations/aic_train.json', + data_prefix=dict(img='pose/ai_challenge/ai_challenger_keypoint' + '_train_20170902/keypoint_train_images_20170902/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=aic_coco133) + ], +) + +dataset_crowdpose = dict( + type=CrowdPoseDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='crowdpose/annotations/mmpose_crowdpose_trainval.json', + data_prefix=dict(img='pose/CrowdPose/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=crowdpose_coco133) + ], +) + +dataset_mpii = dict( + type=MpiiDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='mpii/annotations/mpii_train.json', + data_prefix=dict(img='pose/MPI/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=mpii_coco133) + ], +) + +dataset_jhmdb = dict( + type=JhmdbDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='jhmdb/annotations/Sub1_train.json', + data_prefix=dict(img='pose/JHMDB/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=jhmdb_coco133) + ], +) + +dataset_halpe = dict( + type=HalpeDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='halpe/annotations/halpe_train_v1.json', + data_prefix=dict(img='pose/Halpe/hico_20160224_det/images/train2015'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=halpe_coco133) + ], +) + +dataset_posetrack = dict( + type=PoseTrack18Dataset, + data_root=data_root, + data_mode=data_mode, + ann_file='posetrack18/annotations/posetrack18_train.json', + data_prefix=dict(img='pose/PoseChallenge2018/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=posetrack_coco133) + ], +) + +dataset_humanart = dict( + type=HumanArt21Dataset, + data_root=data_root, + data_mode=data_mode, + ann_file='HumanArt/annotations/training_humanart.json', + filter_cfg=dict(scenes=['real_human']), + data_prefix=dict(img='pose/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=humanart_coco133) + ]) + +ubody_scenes = [ + 'Magic_show', 'Entertainment', 'ConductMusic', 'Online_class', 'TalkShow', + 'Speech', 'Fitness', 'Interview', 'Olympic', 'TVShow', 'Singing', + 'SignLanguage', 'Movie', 'LiveVlog', 'VideoConference' +] + +ubody_datasets = [] +for scene in ubody_scenes: + each = dict( + type=UBody2dDataset, + data_root=data_root, + data_mode=data_mode, + ann_file=f'Ubody/annotations/{scene}/train_annotations.json', + data_prefix=dict(img='pose/UBody/images/'), + pipeline=[], + sample_interval=10) + ubody_datasets.append(each) + +dataset_ubody = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/ubody2d.py'), + datasets=ubody_datasets, + pipeline=[], + test_mode=False, +) + +face_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale, padding=1.25), + dict( + type=RandomBBoxTransform, + shift_factor=0., + scale_factor=[1.5, 2.0], + rotate_factor=0), +] + +wflw_coco133 = [(i * 2, 23 + i) + for i in range(17)] + [(33 + i, 40 + i) for i in range(5)] + [ + (42 + i, 45 + i) for i in range(5) + ] + [(51 + i, 50 + i) + for i in range(9)] + [(60, 59), (61, 60), (63, 61), + (64, 62), (65, 63), (67, 64), + (68, 65), (69, 66), (71, 67), + (72, 68), (73, 69), + (75, 70)] + [(76 + i, 71 + i) + for i in range(20)] +dataset_wflw = dict( + type=WFLWDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='wflw/annotations/face_landmarks_wflw_train.json', + data_prefix=dict(img='pose/WFLW/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=wflw_coco133), *face_pipeline + ], +) + +mapping_300w_coco133 = [(i, 23 + i) for i in range(68)] +dataset_300w = dict( + type=Face300WDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='300w/annotations/face_landmarks_300w_train.json', + data_prefix=dict(img='pose/300w/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=mapping_300w_coco133), *face_pipeline + ], +) + +cofw_coco133 = [(0, 40), (2, 44), (4, 42), (1, 49), (3, 45), (6, 47), (8, 59), + (10, 62), (9, 68), (11, 65), (18, 54), (19, 58), (20, 53), + (21, 56), (22, 71), (23, 77), (24, 74), (25, 85), (26, 89), + (27, 80), (28, 31)] +dataset_cofw = dict( + type=COFWDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='cofw/annotations/cofw_train.json', + data_prefix=dict(img='pose/COFW/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=cofw_coco133), *face_pipeline + ], +) + +lapa_coco133 = [(i * 2, 23 + i) for i in range(17)] + [ + (33 + i, 40 + i) for i in range(5) +] + [(42 + i, 45 + i) for i in range(5)] + [ + (51 + i, 50 + i) for i in range(4) +] + [(58 + i, 54 + i) for i in range(5)] + [(66, 59), (67, 60), (69, 61), + (70, 62), (71, 63), (73, 64), + (75, 65), (76, 66), (78, 67), + (79, 68), (80, 69), + (82, 70)] + [(84 + i, 71 + i) + for i in range(20)] +dataset_lapa = dict( + type=LapaDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='LaPa/annotations/lapa_trainval.json', + data_prefix=dict(img='pose/LaPa/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=lapa_coco133), *face_pipeline + ], +) + +dataset_wb = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[dataset_coco, dataset_halpe, dataset_ubody], + pipeline=[], + test_mode=False, +) + +dataset_body = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[ + dataset_aic, + dataset_crowdpose, + dataset_mpii, + dataset_jhmdb, + dataset_posetrack, + dataset_humanart, + ], + pipeline=[], + test_mode=False, +) + +dataset_face = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[ + dataset_wflw, + dataset_300w, + dataset_cofw, + dataset_lapa, + ], + pipeline=[], + test_mode=False, +) + +hand_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict( + type=RandomBBoxTransform, + shift_factor=0., + scale_factor=[1.5, 2.0], + rotate_factor=0), +] + +interhand_left = [(21, 95), (22, 94), (23, 93), (24, 92), (25, 99), (26, 98), + (27, 97), (28, 96), (29, 103), (30, 102), (31, 101), + (32, 100), (33, 107), (34, 106), (35, 105), (36, 104), + (37, 111), (38, 110), (39, 109), (40, 108), (41, 91)] +interhand_right = [(i - 21, j + 21) for i, j in interhand_left] +interhand_coco133 = interhand_right + interhand_left + +dataset_interhand2d = dict( + type=InterHand2DDoubleDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='interhand26m/annotations/all/InterHand2.6M_train_data.json', + camera_param_file='interhand26m/annotations/all/' + 'InterHand2.6M_train_camera.json', + joint_file='interhand26m/annotations/all/' + 'InterHand2.6M_train_joint_3d.json', + data_prefix=dict(img='interhand2.6m/images/train/'), + sample_interval=10, + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=interhand_coco133, + ), *hand_pipeline + ], +) + +dataset_hand = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[dataset_interhand2d], + pipeline=[], + test_mode=False, +) + +train_datasets = [dataset_wb, dataset_body, dataset_face, dataset_hand] + +# data loaders +train_dataloader = dict( + batch_size=train_batch_size, + num_workers=4, + pin_memory=False, + persistent_workers=True, + sampler=dict(type=DefaultSampler, shuffle=True), + dataset=dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=train_datasets, + pipeline=train_pipeline, + test_mode=False, + )) + +val_dataloader = dict( + batch_size=val_batch_size, + num_workers=4, + persistent_workers=True, + drop_last=False, + sampler=dict(type=DefaultSampler, shuffle=False, round_up=False), + dataset=dict( + type=CocoWholeBodyDataset, + ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json', + data_prefix=dict(img='data/detection/coco/val2017/'), + pipeline=val_pipeline, + bbox_file='data/coco/person_detection_results/' + 'COCO_val2017_detections_AP_H_56_person.json', + test_mode=True)) + +test_dataloader = val_dataloader + +# hooks +default_hooks.update( # noqa + checkpoint=dict( + save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1)) + +custom_hooks = [ + dict( + type=EMAHook, + ema_type=ExpMomentumEMA, + momentum=0.0002, + update_buffers=True, + priority=49), + dict( + type=PipelineSwitchHook, + switch_epoch=max_epochs - stage2_num_epochs, + switch_pipeline=train_pipeline_stage2) +] + +# evaluators +val_evaluator = dict( + type=CocoWholeBodyMetric, + ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json') +test_evaluator = val_evaluator diff --git a/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb704-270e_cocktail13-256x192.py b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb704-270e_cocktail13-256x192.py new file mode 100644 index 0000000000..48275c3c11 --- /dev/null +++ b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb704-270e_cocktail13-256x192.py @@ -0,0 +1,639 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from mmengine.config import read_base + +with read_base(): + from mmpose.configs._base_.default_runtime import * # noqa + +from albumentations.augmentations import Blur, CoarseDropout, MedianBlur +from mmdet.engine.hooks import PipelineSwitchHook +from mmengine.dataset import DefaultSampler +from mmengine.hooks import EMAHook +from mmengine.model import PretrainedInit +from mmengine.optim import CosineAnnealingLR, LinearLR, OptimWrapper +from torch.nn import SiLU, SyncBatchNorm +from torch.optim import AdamW + +from mmpose.codecs import SimCCLabel +from mmpose.datasets import (AicDataset, CocoWholeBodyDataset, COFWDataset, + CombinedDataset, CrowdPoseDataset, + Face300WDataset, GenerateTarget, + GetBBoxCenterScale, HalpeDataset, + HumanArt21Dataset, InterHand2DDoubleDataset, + JhmdbDataset, KeypointConverter, LapaDataset, + LoadImage, MpiiDataset, PackPoseInputs, + PoseTrack18Dataset, RandomFlip, RandomHalfBody, + TopdownAffine, UBody2dDataset, WFLWDataset) +from mmpose.datasets.transforms.common_transforms import ( + Albumentation, PhotometricDistortion, RandomBBoxTransform) +from mmpose.engine.hooks import ExpMomentumEMA +from mmpose.evaluation import CocoWholeBodyMetric +from mmpose.models import (CSPNeXt, CSPNeXtPAFPN, KLDiscretLoss, + PoseDataPreprocessor, RTMWHead, + TopdownPoseEstimator) + +# common setting +num_keypoints = 133 +input_size = (192, 256) + +# runtime +max_epochs = 270 +stage2_num_epochs = 10 +base_lr = 5e-4 +train_batch_size = 704 +val_batch_size = 32 + +train_cfg.update(max_epochs=max_epochs, val_interval=10) # noqa +randomness = dict(seed=21) + +# optimizer +optim_wrapper = dict( + type=OptimWrapper, + optimizer=dict(type=AdamW, lr=base_lr, weight_decay=0.05), + clip_grad=dict(max_norm=35, norm_type=2), + paramwise_cfg=dict( + norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True)) + +# learning rate +param_scheduler = [ + dict( + type=LinearLR, start_factor=1.0e-5, by_epoch=False, begin=0, end=1000), + dict( + type=CosineAnnealingLR, + eta_min=base_lr * 0.05, + begin=max_epochs // 2, + end=max_epochs, + T_max=max_epochs // 2, + by_epoch=True, + convert_to_iter_based=True), +] + +# automatically scaling LR based on the actual training batch size +auto_scale_lr = dict(base_batch_size=5632) + +# codec settings +codec = dict( + type=SimCCLabel, + input_size=input_size, + sigma=(4.9, 5.66), + simcc_split_ratio=2.0, + normalize=False, + use_dark=False) + +# model settings +model = dict( + type=TopdownPoseEstimator, + data_preprocessor=dict( + type=PoseDataPreprocessor, + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + backbone=dict( + type=CSPNeXt, + arch='P5', + expand_ratio=0.5, + deepen_factor=1.33, + widen_factor=1.25, + channel_attention=True, + norm_cfg=dict(type='BN'), + act_cfg=dict(type=SiLU), + init_cfg=dict( + type=PretrainedInit, + prefix='backbone.', + checkpoint='https://download.openmmlab.com/mmpose/v1/' + 'wholebody_2d_keypoint/rtmpose/ubody/rtmpose-x_simcc-ucoco_pt-aic-coco_270e-256x192-05f5bcb7_20230822.pth' # noqa + )), + neck=dict( + type=CSPNeXtPAFPN, + in_channels=[320, 640, 1280], + out_channels=None, + out_indices=( + 1, + 2, + ), + num_csp_blocks=2, + expand_ratio=0.5, + norm_cfg=dict(type=SyncBatchNorm), + act_cfg=dict(type=SiLU, inplace=True)), + head=dict( + type=RTMWHead, + in_channels=1280, + out_channels=num_keypoints, + input_size=input_size, + in_featuremap_size=tuple([s // 32 for s in input_size]), + simcc_split_ratio=codec['simcc_split_ratio'], + final_layer_kernel_size=7, + gau_cfg=dict( + hidden_dims=256, + s=128, + expansion_factor=2, + dropout_rate=0., + drop_path=0., + act_fn=SiLU, + use_rel_bias=False, + pos_enc=False), + loss=dict( + type=KLDiscretLoss, + use_target_weight=True, + beta=10., + label_softmax=True), + decoder=codec), + test_cfg=dict(flip_test=True)) + +# base dataset settings +dataset_type = CocoWholeBodyDataset +data_mode = 'topdown' +data_root = 'data/' + +backend_args = dict(backend='local') + +# pipelines +train_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict(type=RandomFlip, direction='horizontal'), + dict(type=RandomHalfBody), + dict(type=RandomBBoxTransform, scale_factor=[0.5, 1.5], rotate_factor=90), + dict(type=TopdownAffine, input_size=codec['input_size']), + dict(type=PhotometricDistortion), + dict( + type=Albumentation, + transforms=[ + dict(type=Blur, p=0.1), + dict(type=MedianBlur, p=0.1), + dict( + type=CoarseDropout, + max_holes=1, + max_height=0.4, + max_width=0.4, + min_holes=1, + min_height=0.2, + min_width=0.2, + p=1.0), + ]), + dict( + type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True), + dict(type=PackPoseInputs) +] +val_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict(type=TopdownAffine, input_size=codec['input_size']), + dict(type=PackPoseInputs) +] + +train_pipeline_stage2 = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict(type=RandomFlip, direction='horizontal'), + dict(type=RandomHalfBody), + dict( + type=RandomBBoxTransform, + shift_factor=0., + scale_factor=[0.5, 1.5], + rotate_factor=90), + dict(type=TopdownAffine, input_size=codec['input_size']), + dict( + type=Albumentation, + transforms=[ + dict(type=Blur, p=0.1), + dict(type=MedianBlur, p=0.1), + ]), + dict( + type=GenerateTarget, encoder=codec, use_dataset_keypoint_weights=True), + dict(type=PackPoseInputs) +] + +# mapping + +aic_coco133 = [(0, 6), (1, 8), (2, 10), (3, 5), (4, 7), (5, 9), (6, 12), + (7, 14), (8, 16), (9, 11), (10, 13), (11, 15)] + +crowdpose_coco133 = [(0, 5), (1, 6), (2, 7), (3, 8), (4, 9), (5, 10), (6, 11), + (7, 12), (8, 13), (9, 14), (10, 15), (11, 16)] + +mpii_coco133 = [ + (0, 16), + (1, 14), + (2, 12), + (3, 11), + (4, 13), + (5, 15), + (8, 18), + (9, 17), + (10, 10), + (11, 8), + (12, 6), + (13, 5), + (14, 7), + (15, 9), +] + +jhmdb_coco133 = [ + (0, 18), + (2, 17), + (3, 6), + (4, 5), + (5, 12), + (6, 11), + (7, 8), + (8, 7), + (9, 14), + (10, 13), + (11, 10), + (12, 9), + (13, 16), + (14, 15), +] + +halpe_coco133 = [(i, i) + for i in range(17)] + [(20, 17), (21, 20), (22, 18), (23, 21), + (24, 19), + (25, 22)] + [(i, i - 3) + for i in range(26, 136)] + +posetrack_coco133 = [ + (0, 0), + (2, 17), + (3, 3), + (4, 4), + (5, 5), + (6, 6), + (7, 7), + (8, 8), + (9, 9), + (10, 10), + (11, 11), + (12, 12), + (13, 13), + (14, 14), + (15, 15), + (16, 16), +] + +humanart_coco133 = [(i, i) for i in range(17)] + [(17, 99), (18, 120), + (19, 17), (20, 20)] + +# train datasets +dataset_coco = dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='coco/annotations/coco_wholebody_train_v1.0.json', + data_prefix=dict(img='detection/coco/train2017/'), + pipeline=[], +) + +dataset_aic = dict( + type=AicDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='aic/annotations/aic_train.json', + data_prefix=dict(img='pose/ai_challenge/ai_challenger_keypoint' + '_train_20170902/keypoint_train_images_20170902/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=aic_coco133) + ], +) + +dataset_crowdpose = dict( + type=CrowdPoseDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='crowdpose/annotations/mmpose_crowdpose_trainval.json', + data_prefix=dict(img='pose/CrowdPose/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=crowdpose_coco133) + ], +) + +dataset_mpii = dict( + type=MpiiDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='mpii/annotations/mpii_train.json', + data_prefix=dict(img='pose/MPI/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=mpii_coco133) + ], +) + +dataset_jhmdb = dict( + type=JhmdbDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='jhmdb/annotations/Sub1_train.json', + data_prefix=dict(img='pose/JHMDB/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=jhmdb_coco133) + ], +) + +dataset_halpe = dict( + type=HalpeDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='halpe/annotations/halpe_train_v1.json', + data_prefix=dict(img='pose/Halpe/hico_20160224_det/images/train2015'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=halpe_coco133) + ], +) + +dataset_posetrack = dict( + type=PoseTrack18Dataset, + data_root=data_root, + data_mode=data_mode, + ann_file='posetrack18/annotations/posetrack18_train.json', + data_prefix=dict(img='pose/PoseChallenge2018/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=posetrack_coco133) + ], +) + +dataset_humanart = dict( + type=HumanArt21Dataset, + data_root=data_root, + data_mode=data_mode, + ann_file='HumanArt/annotations/training_humanart.json', + filter_cfg=dict(scenes=['real_human']), + data_prefix=dict(img='pose/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=humanart_coco133) + ]) + +ubody_scenes = [ + 'Magic_show', 'Entertainment', 'ConductMusic', 'Online_class', 'TalkShow', + 'Speech', 'Fitness', 'Interview', 'Olympic', 'TVShow', 'Singing', + 'SignLanguage', 'Movie', 'LiveVlog', 'VideoConference' +] + +ubody_datasets = [] +for scene in ubody_scenes: + each = dict( + type=UBody2dDataset, + data_root=data_root, + data_mode=data_mode, + ann_file=f'Ubody/annotations/{scene}/train_annotations.json', + data_prefix=dict(img='pose/UBody/images/'), + pipeline=[], + sample_interval=10) + ubody_datasets.append(each) + +dataset_ubody = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/ubody2d.py'), + datasets=ubody_datasets, + pipeline=[], + test_mode=False, +) + +face_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale, padding=1.25), + dict( + type=RandomBBoxTransform, + shift_factor=0., + scale_factor=[1.5, 2.0], + rotate_factor=0), +] + +wflw_coco133 = [(i * 2, 23 + i) + for i in range(17)] + [(33 + i, 40 + i) for i in range(5)] + [ + (42 + i, 45 + i) for i in range(5) + ] + [(51 + i, 50 + i) + for i in range(9)] + [(60, 59), (61, 60), (63, 61), + (64, 62), (65, 63), (67, 64), + (68, 65), (69, 66), (71, 67), + (72, 68), (73, 69), + (75, 70)] + [(76 + i, 71 + i) + for i in range(20)] +dataset_wflw = dict( + type=WFLWDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='wflw/annotations/face_landmarks_wflw_train.json', + data_prefix=dict(img='pose/WFLW/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=wflw_coco133), *face_pipeline + ], +) + +mapping_300w_coco133 = [(i, 23 + i) for i in range(68)] +dataset_300w = dict( + type=Face300WDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='300w/annotations/face_landmarks_300w_train.json', + data_prefix=dict(img='pose/300w/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=mapping_300w_coco133), *face_pipeline + ], +) + +cofw_coco133 = [(0, 40), (2, 44), (4, 42), (1, 49), (3, 45), (6, 47), (8, 59), + (10, 62), (9, 68), (11, 65), (18, 54), (19, 58), (20, 53), + (21, 56), (22, 71), (23, 77), (24, 74), (25, 85), (26, 89), + (27, 80), (28, 31)] +dataset_cofw = dict( + type=COFWDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='cofw/annotations/cofw_train.json', + data_prefix=dict(img='pose/COFW/images/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=cofw_coco133), *face_pipeline + ], +) + +lapa_coco133 = [(i * 2, 23 + i) for i in range(17)] + [ + (33 + i, 40 + i) for i in range(5) +] + [(42 + i, 45 + i) for i in range(5)] + [ + (51 + i, 50 + i) for i in range(4) +] + [(58 + i, 54 + i) for i in range(5)] + [(66, 59), (67, 60), (69, 61), + (70, 62), (71, 63), (73, 64), + (75, 65), (76, 66), (78, 67), + (79, 68), (80, 69), + (82, 70)] + [(84 + i, 71 + i) + for i in range(20)] +dataset_lapa = dict( + type=LapaDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='LaPa/annotations/lapa_trainval.json', + data_prefix=dict(img='pose/LaPa/'), + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=lapa_coco133), *face_pipeline + ], +) + +dataset_wb = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[dataset_coco, dataset_halpe, dataset_ubody], + pipeline=[], + test_mode=False, +) + +dataset_body = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[ + dataset_aic, + dataset_crowdpose, + dataset_mpii, + dataset_jhmdb, + dataset_posetrack, + dataset_humanart, + ], + pipeline=[], + test_mode=False, +) + +dataset_face = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[ + dataset_wflw, + dataset_300w, + dataset_cofw, + dataset_lapa, + ], + pipeline=[], + test_mode=False, +) + +hand_pipeline = [ + dict(type=LoadImage, backend_args=backend_args), + dict(type=GetBBoxCenterScale), + dict( + type=RandomBBoxTransform, + shift_factor=0., + scale_factor=[1.5, 2.0], + rotate_factor=0), +] + +interhand_left = [(21, 95), (22, 94), (23, 93), (24, 92), (25, 99), (26, 98), + (27, 97), (28, 96), (29, 103), (30, 102), (31, 101), + (32, 100), (33, 107), (34, 106), (35, 105), (36, 104), + (37, 111), (38, 110), (39, 109), (40, 108), (41, 91)] +interhand_right = [(i - 21, j + 21) for i, j in interhand_left] +interhand_coco133 = interhand_right + interhand_left + +dataset_interhand2d = dict( + type=InterHand2DDoubleDataset, + data_root=data_root, + data_mode=data_mode, + ann_file='interhand26m/annotations/all/InterHand2.6M_train_data.json', + camera_param_file='interhand26m/annotations/all/' + 'InterHand2.6M_train_camera.json', + joint_file='interhand26m/annotations/all/' + 'InterHand2.6M_train_joint_3d.json', + data_prefix=dict(img='interhand2.6m/images/train/'), + sample_interval=10, + pipeline=[ + dict( + type=KeypointConverter, + num_keypoints=num_keypoints, + mapping=interhand_coco133, + ), *hand_pipeline + ], +) + +dataset_hand = dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=[dataset_interhand2d], + pipeline=[], + test_mode=False, +) + +train_datasets = [dataset_wb, dataset_body, dataset_face, dataset_hand] + +# data loaders +train_dataloader = dict( + batch_size=train_batch_size, + num_workers=4, + pin_memory=False, + persistent_workers=True, + sampler=dict(type=DefaultSampler, shuffle=True), + dataset=dict( + type=CombinedDataset, + metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'), + datasets=train_datasets, + pipeline=train_pipeline, + test_mode=False, + )) + +val_dataloader = dict( + batch_size=val_batch_size, + num_workers=4, + persistent_workers=True, + drop_last=False, + sampler=dict(type=DefaultSampler, shuffle=False, round_up=False), + dataset=dict( + type=CocoWholeBodyDataset, + ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json', + data_prefix=dict(img='data/detection/coco/val2017/'), + pipeline=val_pipeline, + bbox_file='data/coco/person_detection_results/' + 'COCO_val2017_detections_AP_H_56_person.json', + test_mode=True)) + +test_dataloader = val_dataloader + +# hooks +default_hooks.update( # noqa + checkpoint=dict( + save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1)) + +custom_hooks = [ + dict( + type=EMAHook, + ema_type=ExpMomentumEMA, + momentum=0.0002, + update_buffers=True, + priority=49), + dict( + type=PipelineSwitchHook, + switch_epoch=max_epochs - stage2_num_epochs, + switch_pipeline=train_pipeline_stage2) +] + +# evaluators +val_evaluator = dict( + type=CocoWholeBodyMetric, + ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json') +test_evaluator = val_evaluator diff --git a/projects/rtmpose/yolox/humanart/yolox_l_8xb8-300e_humanart.py b/projects/rtmpose/yolox/humanart/yolox_l_8xb8-300e_humanart.py new file mode 100644 index 0000000000..6fd4354cec --- /dev/null +++ b/projects/rtmpose/yolox/humanart/yolox_l_8xb8-300e_humanart.py @@ -0,0 +1,8 @@ +_base_ = './yolox_s_8xb8-300e_humanart.py' + +# model settings +model = dict( + backbone=dict(deepen_factor=1.0, widen_factor=1.0), + neck=dict( + in_channels=[256, 512, 1024], out_channels=256, num_csp_blocks=3), + bbox_head=dict(in_channels=256, feat_channels=256)) diff --git a/projects/rtmpose/yolox/humanart/yolox_m_8xb8-300e_humanart.py b/projects/rtmpose/yolox/humanart/yolox_m_8xb8-300e_humanart.py new file mode 100644 index 0000000000..e74e2bb99c --- /dev/null +++ b/projects/rtmpose/yolox/humanart/yolox_m_8xb8-300e_humanart.py @@ -0,0 +1,8 @@ +_base_ = './yolox_s_8xb8-300e_humanart.py' + +# model settings +model = dict( + backbone=dict(deepen_factor=0.67, widen_factor=0.75), + neck=dict(in_channels=[192, 384, 768], out_channels=192, num_csp_blocks=2), + bbox_head=dict(in_channels=192, feat_channels=192), +) diff --git a/projects/rtmpose/yolox/humanart/yolox_nano_8xb8-300e_humanart.py b/projects/rtmpose/yolox/humanart/yolox_nano_8xb8-300e_humanart.py new file mode 100644 index 0000000000..96a363abec --- /dev/null +++ b/projects/rtmpose/yolox/humanart/yolox_nano_8xb8-300e_humanart.py @@ -0,0 +1,11 @@ +_base_ = './yolox_tiny_8xb8-300e_humanart.py' + +# model settings +model = dict( + backbone=dict(deepen_factor=0.33, widen_factor=0.25, use_depthwise=True), + neck=dict( + in_channels=[64, 128, 256], + out_channels=64, + num_csp_blocks=1, + use_depthwise=True), + bbox_head=dict(in_channels=64, feat_channels=64, use_depthwise=True)) diff --git a/projects/rtmpose/yolox/humanart/yolox_s_8xb8-300e_humanart.py b/projects/rtmpose/yolox/humanart/yolox_s_8xb8-300e_humanart.py new file mode 100644 index 0000000000..a7992b076d --- /dev/null +++ b/projects/rtmpose/yolox/humanart/yolox_s_8xb8-300e_humanart.py @@ -0,0 +1,250 @@ +_base_ = [ + 'mmdet::_base_/schedules/schedule_1x.py', + 'mmdet::_base_/default_runtime.py', 'mmdet::yolox/yolox_tta.py' +] + +img_scale = (640, 640) # width, height + +# model settings +model = dict( + type='YOLOX', + data_preprocessor=dict( + type='DetDataPreprocessor', + pad_size_divisor=32, + batch_augments=[ + dict( + type='BatchSyncRandomResize', + random_size_range=(480, 800), + size_divisor=32, + interval=10) + ]), + backbone=dict( + type='CSPDarknet', + deepen_factor=0.33, + widen_factor=0.5, + out_indices=(2, 3, 4), + use_depthwise=False, + spp_kernal_sizes=(5, 9, 13), + norm_cfg=dict(type='BN', momentum=0.03, eps=0.001), + act_cfg=dict(type='Swish'), + ), + neck=dict( + type='YOLOXPAFPN', + in_channels=[128, 256, 512], + out_channels=128, + num_csp_blocks=1, + use_depthwise=False, + upsample_cfg=dict(scale_factor=2, mode='nearest'), + norm_cfg=dict(type='BN', momentum=0.03, eps=0.001), + act_cfg=dict(type='Swish')), + bbox_head=dict( + type='YOLOXHead', + num_classes=80, + in_channels=128, + feat_channels=128, + stacked_convs=2, + strides=(8, 16, 32), + use_depthwise=False, + norm_cfg=dict(type='BN', momentum=0.03, eps=0.001), + act_cfg=dict(type='Swish'), + loss_cls=dict( + type='CrossEntropyLoss', + use_sigmoid=True, + reduction='sum', + loss_weight=1.0), + loss_bbox=dict( + type='IoULoss', + mode='square', + eps=1e-16, + reduction='sum', + loss_weight=5.0), + loss_obj=dict( + type='CrossEntropyLoss', + use_sigmoid=True, + reduction='sum', + loss_weight=1.0), + loss_l1=dict(type='L1Loss', reduction='sum', loss_weight=1.0)), + train_cfg=dict(assigner=dict(type='SimOTAAssigner', center_radius=2.5)), + # In order to align the source code, the threshold of the val phase is + # 0.01, and the threshold of the test phase is 0.001. + test_cfg=dict(score_thr=0.01, nms=dict(type='nms', iou_threshold=0.65))) + +# dataset settings +data_root = 'data/' +dataset_type = 'CocoDataset' + +# Example to use different file client +# Method 1: simply set the data root and let the file I/O module +# automatically infer from prefix (not support LMDB and Memcache yet) + +# data_root = 's3://openmmlab/datasets/detection/coco/' + +# Method 2: Use `backend_args`, `file_client_args` in versions before 3.0.0rc6 +# backend_args = dict( +# backend='petrel', +# path_mapping=dict({ +# './data/': 's3://openmmlab/datasets/detection/', +# 'data/': 's3://openmmlab/datasets/detection/' +# })) +backend_args = None + +train_pipeline = [ + dict(type='Mosaic', img_scale=img_scale, pad_val=114.0), + dict( + type='RandomAffine', + scaling_ratio_range=(0.1, 2), + # img_scale is (width, height) + border=(-img_scale[0] // 2, -img_scale[1] // 2)), + dict( + type='MixUp', + img_scale=img_scale, + ratio_range=(0.8, 1.6), + pad_val=114.0), + dict(type='YOLOXHSVRandomAug'), + dict(type='RandomFlip', prob=0.5), + # According to the official implementation, multi-scale + # training is not considered here but in the + # 'mmdet/models/detectors/yolox.py'. + # Resize and Pad are for the last 15 epochs when Mosaic, + # RandomAffine, and MixUp are closed by YOLOXModeSwitchHook. + dict(type='Resize', scale=img_scale, keep_ratio=True), + dict( + type='Pad', + pad_to_square=True, + # If the image is three-channel, the pad value needs + # to be set separately for each channel. + pad_val=dict(img=(114.0, 114.0, 114.0))), + dict(type='FilterAnnotations', min_gt_bbox_wh=(1, 1), keep_empty=False), + dict(type='PackDetInputs') +] + +train_dataset = dict( + # use MultiImageMixDataset wrapper to support mosaic and mixup + type='MultiImageMixDataset', + dataset=dict( + type=dataset_type, + data_root=data_root, + ann_file='HumanArt/annotations/training_humanart_coco.json', + data_prefix=dict(img=''), + pipeline=[ + dict(type='LoadImageFromFile', backend_args=backend_args), + dict(type='LoadAnnotations', with_bbox=True) + ], + filter_cfg=dict(filter_empty_gt=False, min_size=32), + backend_args=backend_args), + pipeline=train_pipeline) + +test_pipeline = [ + dict(type='LoadImageFromFile', backend_args=backend_args), + dict(type='Resize', scale=img_scale, keep_ratio=True), + dict( + type='Pad', + pad_to_square=True, + pad_val=dict(img=(114.0, 114.0, 114.0))), + dict(type='LoadAnnotations', with_bbox=True), + dict( + type='PackDetInputs', + meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', + 'scale_factor')) +] + +train_dataloader = dict( + batch_size=8, + num_workers=4, + persistent_workers=True, + sampler=dict(type='DefaultSampler', shuffle=True), + dataset=train_dataset) +val_dataloader = dict( + batch_size=8, + num_workers=4, + persistent_workers=True, + drop_last=False, + sampler=dict(type='DefaultSampler', shuffle=False), + dataset=dict( + type=dataset_type, + data_root=data_root, + ann_file='HumanArt/annotations/validation_humanart_coco.json', + data_prefix=dict(img=''), + test_mode=True, + pipeline=test_pipeline, + backend_args=backend_args)) +test_dataloader = val_dataloader + +val_evaluator = dict( + type='CocoMetric', + ann_file=data_root + 'HumanArt/annotations/validation_humanart_coco.json', + metric='bbox', + backend_args=backend_args) +test_evaluator = val_evaluator + +# training settings +max_epochs = 300 +num_last_epochs = 15 +interval = 10 + +train_cfg = dict(max_epochs=max_epochs, val_interval=interval) + +# optimizer +# default 8 gpu +base_lr = 0.01 +optim_wrapper = dict( + type='OptimWrapper', + optimizer=dict( + type='SGD', lr=base_lr, momentum=0.9, weight_decay=5e-4, + nesterov=True), + paramwise_cfg=dict(norm_decay_mult=0., bias_decay_mult=0.)) + +# learning rate +param_scheduler = [ + dict( + # use quadratic formula to warm up 5 epochs + # and lr is updated by iteration + # TODO: fix default scope in get function + type='mmdet.QuadraticWarmupLR', + by_epoch=True, + begin=0, + end=5, + convert_to_iter_based=True), + dict( + # use cosine lr from 5 to 285 epoch + type='CosineAnnealingLR', + eta_min=base_lr * 0.05, + begin=5, + T_max=max_epochs - num_last_epochs, + end=max_epochs - num_last_epochs, + by_epoch=True, + convert_to_iter_based=True), + dict( + # use fixed lr during last 15 epochs + type='ConstantLR', + by_epoch=True, + factor=1, + begin=max_epochs - num_last_epochs, + end=max_epochs, + ) +] + +default_hooks = dict( + checkpoint=dict( + interval=interval, + max_keep_ckpts=3 # only keep latest 3 checkpoints + )) + +custom_hooks = [ + dict( + type='YOLOXModeSwitchHook', + num_last_epochs=num_last_epochs, + priority=48), + dict(type='SyncNormHook', priority=48), + dict( + type='EMAHook', + ema_type='ExpMomentumEMA', + momentum=0.0001, + update_buffers=True, + priority=49) +] + +# NOTE: `auto_scale_lr` is for automatically scaling LR, +# USER SHOULD NOT CHANGE ITS VALUES. +# base_batch_size = (8 GPUs) x (8 samples per GPU) +auto_scale_lr = dict(base_batch_size=64) diff --git a/projects/rtmpose/yolox/humanart/yolox_tiny_8xb8-300e_humanart.py b/projects/rtmpose/yolox/humanart/yolox_tiny_8xb8-300e_humanart.py new file mode 100644 index 0000000000..71971e2ddc --- /dev/null +++ b/projects/rtmpose/yolox/humanart/yolox_tiny_8xb8-300e_humanart.py @@ -0,0 +1,54 @@ +_base_ = './yolox_s_8xb8-300e_humanart.py' + +# model settings +model = dict( + data_preprocessor=dict(batch_augments=[ + dict( + type='BatchSyncRandomResize', + random_size_range=(320, 640), + size_divisor=32, + interval=10) + ]), + backbone=dict(deepen_factor=0.33, widen_factor=0.375), + neck=dict(in_channels=[96, 192, 384], out_channels=96), + bbox_head=dict(in_channels=96, feat_channels=96)) + +img_scale = (640, 640) # width, height + +train_pipeline = [ + dict(type='Mosaic', img_scale=img_scale, pad_val=114.0), + dict( + type='RandomAffine', + scaling_ratio_range=(0.5, 1.5), + # img_scale is (width, height) + border=(-img_scale[0] // 2, -img_scale[1] // 2)), + dict(type='YOLOXHSVRandomAug'), + dict(type='RandomFlip', prob=0.5), + # Resize and Pad are for the last 15 epochs when Mosaic and + # RandomAffine are closed by YOLOXModeSwitchHook. + dict(type='Resize', scale=img_scale, keep_ratio=True), + dict( + type='Pad', + pad_to_square=True, + pad_val=dict(img=(114.0, 114.0, 114.0))), + dict(type='FilterAnnotations', min_gt_bbox_wh=(1, 1), keep_empty=False), + dict(type='PackDetInputs') +] + +test_pipeline = [ + dict(type='LoadImageFromFile', backend_args={{_base_.backend_args}}), + dict(type='Resize', scale=(416, 416), keep_ratio=True), + dict( + type='Pad', + pad_to_square=True, + pad_val=dict(img=(114.0, 114.0, 114.0))), + dict(type='LoadAnnotations', with_bbox=True), + dict( + type='PackDetInputs', + meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', + 'scale_factor')) +] + +train_dataloader = dict(dataset=dict(pipeline=train_pipeline)) +val_dataloader = dict(dataset=dict(pipeline=test_pipeline)) +test_dataloader = val_dataloader diff --git a/projects/rtmpose/yolox/humanart/yolox_x_8xb8-300e_humanart.py b/projects/rtmpose/yolox/humanart/yolox_x_8xb8-300e_humanart.py new file mode 100644 index 0000000000..6e03ffefb6 --- /dev/null +++ b/projects/rtmpose/yolox/humanart/yolox_x_8xb8-300e_humanart.py @@ -0,0 +1,8 @@ +_base_ = './yolox_s_8xb8-300e_humanart.py' + +# model settings +model = dict( + backbone=dict(deepen_factor=1.33, widen_factor=1.25), + neck=dict( + in_channels=[320, 640, 1280], out_channels=320, num_csp_blocks=4), + bbox_head=dict(in_channels=320, feat_channels=320)) diff --git a/projects/uniformer/README.md b/projects/uniformer/README.md new file mode 100644 index 0000000000..6f166f975e --- /dev/null +++ b/projects/uniformer/README.md @@ -0,0 +1,138 @@ +# Pose Estion with UniFormer + +This project implements a topdown heatmap based human pose estimator, utilizing the approach outlined in **UniFormer: Unifying Convolution and Self-attention for Visual Recognition** (TPAMI 2023) and **UniFormer: Unified Transformer for Efficient Spatiotemporal Representation Learning** (ICLR 2022). + +
+ +
+ +## Usage + +### Preparation + +1. Setup Development Environment + +- Python 3.7 or higher +- PyTorch 1.6 or higher +- [MMEngine](https://github.com/open-mmlab/mmengine) v0.6.0 or higher +- [MMCV](https://github.com/open-mmlab/mmcv) v2.0.0rc4 or higher +- [MMDetection](https://github.com/open-mmlab/mmdetection) v3.0.0rc6 or higher +- [MMPose](https://github.com/open-mmlab/mmpose) v1.0.0rc1 or higher + +All the commands below rely on the correct configuration of `PYTHONPATH`, which should point to the project's directory so that Python can locate the module files. **In `uniformer/` root directory**, run the following line to add the current directory to `PYTHONPATH`: + +```shell +export PYTHONPATH=`pwd`:$PYTHONPATH +``` + +2. Download Pretrained Weights + +To either run inferences or train on the `uniformer pose estimation` project, you have to download the original Uniformer pretrained weights on the ImageNet1k dataset and the weights trained for the downstream pose estimation task. The original ImageNet1k weights are hosted on SenseTime's [huggingface repository](https://huggingface.co/Sense-X/uniformer_image), and the downstream pose estimation task weights are hosted either on Google Drive or Baiduyun. We have uploaded them to the OpenMMLab download URLs, allowing users to use them without burden. For example, you can take a look at [`td-hm_uniformer-b-8xb128-210e_coco-256x192.py`](./configs/td-hm_uniformer-b-8xb128-210e_coco-256x192.py#62), the corresponding pretrained weight URL is already here and when the training or testing process starts, the weight will be automatically downloaded to your device. For the downstream task weights, you can get their URLs from the [benchmark result table](#results). + +### Inference + +We have provided a [inferencer_demo.py](../../demo/inferencer_demo.py) with which developers can utilize to run quick inference demos. Here is a basic demonstration: + +```shell +python demo/inferencer_demo.py $INPUTS \ + --pose2d $CONFIG --pose2d-weights $CHECKPOINT \ + [--show] [--vis-out-dir $VIS_OUT_DIR] [--pred-out-dir $PRED_OUT_DIR] +``` + +For more information on using the inferencer, please see [this document](https://mmpose.readthedocs.io/en/latest/user_guides/inference.html#out-of-the-box-inferencer). + +Here's an example code: + +```shell +python demo/inferencer_demo.py tests/data/coco/000000000785.jpg \ + --pose2d projects/uniformer/configs/td-hm_uniformer-s-8xb128-210e_coco-256x192.py \ + --pose2d-weights https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_256x192_global_small-d4a7fdac_20230724.pth \ + --vis-out-dir vis_results +``` + +Then you will find the demo result in `vis_results` folder, and it may be similar to this: + +
+ +### Training and Testing + +1. Data Preparation + +Prepare the COCO dataset according to the [instruction](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#coco). + +2. To Train and Test with Single GPU: + +```shell +python tools/test.py $CONFIG --auto-scale-lr +``` + +```shell +python tools/test.py $CONFIG $CHECKPOINT +``` + +3. To Train and Test with Multiple GPUs: + +```shell +bash tools/dist_train.sh $CONFIG $NUM_GPUs --amp +``` + +```shell +bash tools/dist_test.sh $CONFIG $CHECKPOINT $NUM_GPUs --amp +``` + +## Results + +Here is the testing results on COCO val2017: + +| Model | Input Size | AP | AP50 | AP75 | AR | AR50 | Download | +| :-----------------------------------------------------------------: | :--------: | :--: | :-------------: | :-------------: | :--: | :-------------: | :--------------------------------------------------------------------: | +| [UniFormer-S](./configs/td-hm_uniformer-s-8xb128-210e_coco-256x192.py) | 256x192 | 74.0 | 90.2 | 82.1 | 79.5 | 94.1 | [model](https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_256x192_global_small-d4a7fdac_20230724.pth) \| [log](https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_256x192_global_small-d4a7fdac_20230724.log.json) | +| [UniFormer-S](./configs/td-hm_uniformer-s-8xb128-210e_coco-384x288.py) | 384x288 | 75.9 | 90.6 | 83.0 | 81.0 | 94.3 | [model](https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_384x288_global_small-7a613f78_20230724.pth) \| [log](https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_384x288_global_small-7a613f78_20230724.log.json) | +| [UniFormer-S](./configs/td-hm_uniformer-s-8xb64-210e_coco-448x320.py) | 448x320 | 76.2 | 90.6 | 83.2 | 81.4 | 94.4 | [model](https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_448x320_global_small-18b760de_20230724.pth) \| [log](https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_448x320_global_small-18b760de_20230724.log.json) | +| [UniFormer-B](./configs/td-hm_uniformer-b-8xb128-210e_coco-256x192.py) | 256x192 | 75.0 | 90.5 | 83.0 | 80.4 | 94.2 | [model](https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_256x192_global_base-1713bcd4_20230724.pth) \| [log](https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_256x192_global_base-1713bcd4_20230724.log.json) | +| [UniFormer-B](./configs/td-hm_uniformer-b-8xb32-210e_coco-384x288.py) | 384x288 | 76.7 | 90.8 | 84.1 | 81.9 | 94.6 | [model](https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_384x288_global_base-c650da38_20230724.pth) \| [log](https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_384x288_global_base-c650da38_20230724.log.json) | +| [UniFormer-B](./configs/td-hm_uniformer-b-8xb32-210e_coco-448x320.py) | 448x320 | 77.4 | 91.0 | 84.4 | 82.5 | 94.9 | [model](https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_448x320_global_base-a05c185f_20230724.pth) \| [log](https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_448x320_global_base-a05c185f_20230724.log.json) | + +Here is the testing results on COCO val 2017 from the official UniFormer Pose Estimation repository for comparison: + +| Backbone | Input Size | AP | AP50 | AP75 | ARM | ARL | AR | Model | Log | +| :---------- | :--------- | :--- | :-------------- | :-------------- | :------------- | :------------- | :--- | :-------------------------------------------------------- | :------------------------------------------------------- | +| UniFormer-S | 256x192 | 74.0 | 90.3 | 82.2 | 66.8 | 76.7 | 79.5 | [google](https://drive.google.com/file/d/162R0JuTpf3gpLe1IK6oxRoQK7JSj4ylx/view?usp=sharing) | [google](https://drive.google.com/file/d/15j40u97Db6TA2gMHdn0yFEsDFb5SMBy4/view?usp=sharing) | +| UniFormer-S | 384x288 | 75.9 | 90.6 | 83.4 | 68.6 | 79.0 | 81.4 | [google](https://drive.google.com/file/d/163vuFkpcgVOthC05jCwjGzo78Nr0eikW/view?usp=sharing) | [google](https://drive.google.com/file/d/15X9M_5cq9RQMgs64Yn9YvV5k5f0zOBHo/view?usp=sharing) | +| UniFormer-S | 448x320 | 76.2 | 90.6 | 83.2 | 68.6 | 79.4 | 81.4 | [google](https://drive.google.com/file/d/165nQRsT58SXJegcttksHwDn46Fme5dGX/view?usp=sharing) | [google](https://drive.google.com/file/d/15IJjSWp4R5OybMdV2CZEUx_TwXdTMOee/view?usp=sharing) | +| UniFormer-B | 256x192 | 75.0 | 90.6 | 83.0 | 67.8 | 77.7 | 80.4 | [google](https://drive.google.com/file/d/15tzJaRyEzyWp2mQhpjDbBzuGoyCaJJ-2/view?usp=sharing) | [google](https://drive.google.com/file/d/15jJyTPcJKj_id0PNdytloqt7yjH2M8UR/view?usp=sharing) | +| UniFormer-B | 384x288 | 76.7 | 90.8 | 84.0 | 69.3 | 79.7 | 81.4 | [google](https://drive.google.com/file/d/15qtUaOR_C7-vooheJE75mhA9oJQt3gSx/view?usp=sharing) | [google](https://drive.google.com/file/d/15L1Uxo_uRSMlGnOvWzAzkJLKX6Qh_xNw/view?usp=sharing) | +| UniFormer-B | 448x320 | 77.4 | 91.1 | 84.4 | 70.2 | 80.6 | 82.5 | [google](https://drive.google.com/file/d/156iNxetiCk8JJz41aFDmFh9cQbCaMk3D/view?usp=sharing) | [google](https://drive.google.com/file/d/15aRpZc2Tie5gsn3_l-aXto1MrC9wyzMC/view?usp=sharing) | + +Note: + +1. All the original models are pretrained on ImageNet-1K without Token Labeling and Layer Scale, as mentioned in the [official README](https://github.com/Sense-X/UniFormer/tree/main/pose_estimation) . The official team has confirmed that **Token labeling can largely improve the performance of the downstream tasks**. Developers can utilize the implementation by themselves. +2. The original implementation did not include the **freeze BN in the backbone**. The official team has confirmed that this can improve the performance as well. +3. To avoid running out of memory, developers can use `torch.utils.checkpoint` in the `config.py` by setting `use_checkpoint=True` and `checkpoint_num=[0, 0, 2, 0] # index for using checkpoint in every stage` +4. We warmly welcome any contributions if you can successfully reproduce the results from the paper! + +## Citation + +If this project benefits your work, please kindly consider citing the original papers: + +```bibtex +@misc{li2022uniformer, + title={UniFormer: Unifying Convolution and Self-attention for Visual Recognition}, + author={Kunchang Li and Yali Wang and Junhao Zhang and Peng Gao and Guanglu Song and Yu Liu and Hongsheng Li and Yu Qiao}, + year={2022}, + eprint={2201.09450}, + archivePrefix={arXiv}, + primaryClass={cs.CV} +} +``` + +```bibtex +@misc{li2022uniformer, + title={UniFormer: Unified Transformer for Efficient Spatiotemporal Representation Learning}, + author={Kunchang Li and Yali Wang and Peng Gao and Guanglu Song and Yu Liu and Hongsheng Li and Yu Qiao}, + year={2022}, + eprint={2201.04676}, + archivePrefix={arXiv}, + primaryClass={cs.CV} +} +``` diff --git a/projects/uniformer/configs/td-hm_uniformer-b-8xb128-210e_coco-256x192.py b/projects/uniformer/configs/td-hm_uniformer-b-8xb128-210e_coco-256x192.py new file mode 100644 index 0000000000..07f1377842 --- /dev/null +++ b/projects/uniformer/configs/td-hm_uniformer-b-8xb128-210e_coco-256x192.py @@ -0,0 +1,135 @@ +_base_ = ['mmpose::_base_/default_runtime.py'] + +custom_imports = dict(imports='projects.uniformer.models') + +# runtime +train_cfg = dict(max_epochs=210, val_interval=10) + +# enable DDP training when pretrained model is used +find_unused_parameters = True + +# optimizer +optim_wrapper = dict(optimizer=dict( + type='Adam', + lr=2e-3, +)) + +# learning policy +param_scheduler = [ + dict( + type='LinearLR', begin=0, end=500, start_factor=0.001, + by_epoch=False), # warm-up + dict( + type='MultiStepLR', + begin=0, + end=210, + milestones=[170, 200], + gamma=0.1, + by_epoch=True) +] + +# automatically scaling LR based on the actual training batch size +auto_scale_lr = dict(base_batch_size=1024) + +# hooks +default_hooks = dict( + checkpoint=dict(save_best='coco/AP', rule='greater', interval=5)) + +# codec settings +codec = dict( + type='MSRAHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2) + +# model settings +norm_cfg = dict(type='SyncBN', requires_grad=True) +model = dict( + type='TopdownPoseEstimator', + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + backbone=dict( + type='UniFormer', + embed_dims=[64, 128, 320, 512], + depths=[5, 8, 20, 7], + head_dim=64, + drop_path_rate=0.4, + use_checkpoint=False, # whether use torch.utils.checkpoint + use_window=False, # whether use window MHRA + use_hybrid=False, # whether use hybrid MHRA + init_cfg=dict( + # Set the path to pretrained backbone here + type='Pretrained', + checkpoint='https://download.openmmlab.com/mmpose/v1/projects/' + 'uniformer/uniformer_base_in1k.pth' # noqa + )), + head=dict( + type='HeatmapHead', + in_channels=512, + out_channels=17, + final_layer=dict(kernel_size=1), + loss=dict(type='KeypointMSELoss', use_target_weight=True), + decoder=codec), + test_cfg=dict(flip_test=True, flip_mode='heatmap', shift_heatmap=True)) + +# base dataset settings +dataset_type = 'CocoDataset' +data_mode = 'topdown' +data_root = 'data/coco/' + +# pipelines +train_pipeline = [ + dict(type='LoadImage'), + dict(type='GetBBoxCenterScale'), + dict(type='RandomFlip', direction='horizontal'), + dict(type='RandomHalfBody'), + dict(type='RandomBBoxTransform'), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='GenerateTarget', encoder=codec), + dict(type='PackPoseInputs') +] +val_pipeline = [ + dict(type='LoadImage'), + dict(type='GetBBoxCenterScale'), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='PackPoseInputs') +] + +# data loaders +train_dataloader = dict( + batch_size=128, + num_workers=2, + persistent_workers=True, + sampler=dict(type='DefaultSampler', shuffle=True), + dataset=dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='annotations/person_keypoints_train2017.json', + data_prefix=dict(img='train2017/'), + pipeline=train_pipeline, + )) +val_dataloader = dict( + batch_size=256, + num_workers=2, + persistent_workers=True, + drop_last=False, + sampler=dict(type='DefaultSampler', shuffle=False, round_up=False), + dataset=dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='annotations/person_keypoints_val2017.json', + bbox_file='data/coco/person_detection_results/' + 'COCO_val2017_detections_AP_H_56_person.json', + data_prefix=dict(img='val2017/'), + test_mode=True, + pipeline=val_pipeline, + )) +test_dataloader = val_dataloader + +# evaluators +val_evaluator = dict( + type='CocoMetric', + ann_file=data_root + 'annotations/person_keypoints_val2017.json') +test_evaluator = val_evaluator diff --git a/projects/uniformer/configs/td-hm_uniformer-b-8xb32-210e_coco-384x288.py b/projects/uniformer/configs/td-hm_uniformer-b-8xb32-210e_coco-384x288.py new file mode 100644 index 0000000000..d43061d0cd --- /dev/null +++ b/projects/uniformer/configs/td-hm_uniformer-b-8xb32-210e_coco-384x288.py @@ -0,0 +1,134 @@ +_base_ = ['mmpose::_base_/default_runtime.py'] + +custom_imports = dict(imports='projects.uniformer.models') + +# runtime +train_cfg = dict(max_epochs=210, val_interval=10) + +# enable DDP training when pretrained model is used +find_unused_parameters = True + +# optimizer +optim_wrapper = dict(optimizer=dict( + type='Adam', + lr=5e-4, +)) + +# learning policy +param_scheduler = [ + dict( + type='LinearLR', begin=0, end=500, start_factor=0.001, + by_epoch=False), # warm-up + dict( + type='MultiStepLR', + begin=0, + end=210, + milestones=[170, 200], + gamma=0.1, + by_epoch=True) +] + +# automatically scaling LR based on the actual training batch size +auto_scale_lr = dict(base_batch_size=512) + +# hooks +default_hooks = dict(checkpoint=dict(save_best='coco/AP', rule='greater')) + +# codec settings +codec = dict( + type='MSRAHeatmap', input_size=(288, 384), heatmap_size=(72, 96), sigma=3) + +# model settings +norm_cfg = dict(type='SyncBN', requires_grad=True) +model = dict( + type='TopdownPoseEstimator', + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + backbone=dict( + type='UniFormer', + embed_dims=[64, 128, 320, 512], + depths=[5, 8, 20, 7], + head_dim=64, + drop_path_rate=0.4, + use_checkpoint=False, # whether use torch.utils.checkpoint + use_window=False, # whether use window MHRA + use_hybrid=False, # whether use hybrid MHRA + init_cfg=dict( + # Set the path to pretrained backbone here + type='Pretrained', + checkpoint='https://download.openmmlab.com/mmpose/v1/projects/' + 'uniformer/uniformer_base_in1k.pth' # noqa + )), + head=dict( + type='HeatmapHead', + in_channels=512, + out_channels=17, + final_layer=dict(kernel_size=1), + loss=dict(type='KeypointMSELoss', use_target_weight=True), + decoder=codec), + test_cfg=dict(flip_test=True, flip_mode='heatmap', shift_heatmap=True)) + +# base dataset settings +dataset_type = 'CocoDataset' +data_mode = 'topdown' +data_root = 'data/coco/' + +# pipelines +train_pipeline = [ + dict(type='LoadImage'), + dict(type='GetBBoxCenterScale'), + dict(type='RandomFlip', direction='horizontal'), + dict(type='RandomHalfBody'), + dict(type='RandomBBoxTransform'), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='GenerateTarget', encoder=codec), + dict(type='PackPoseInputs') +] +val_pipeline = [ + dict(type='LoadImage'), + dict(type='GetBBoxCenterScale'), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='PackPoseInputs') +] + +# data loaders +train_dataloader = dict( + batch_size=128, + num_workers=2, + persistent_workers=True, + sampler=dict(type='DefaultSampler', shuffle=True), + dataset=dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='annotations/person_keypoints_train2017.json', + data_prefix=dict(img='train2017/'), + pipeline=train_pipeline, + )) +val_dataloader = dict( + batch_size=256, + num_workers=2, + persistent_workers=True, + drop_last=False, + sampler=dict(type='DefaultSampler', shuffle=False, round_up=False), + dataset=dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='annotations/person_keypoints_val2017.json', + bbox_file='data/coco/person_detection_results/' + 'COCO_val2017_detections_AP_H_56_person.json', + data_prefix=dict(img='val2017/'), + test_mode=True, + pipeline=val_pipeline, + )) +test_dataloader = val_dataloader + +# evaluators +val_evaluator = dict( + type='CocoMetric', + ann_file=data_root + 'annotations/person_keypoints_val2017.json') +test_evaluator = val_evaluator diff --git a/projects/uniformer/configs/td-hm_uniformer-b-8xb32-210e_coco-448x320.py b/projects/uniformer/configs/td-hm_uniformer-b-8xb32-210e_coco-448x320.py new file mode 100644 index 0000000000..81554ad27e --- /dev/null +++ b/projects/uniformer/configs/td-hm_uniformer-b-8xb32-210e_coco-448x320.py @@ -0,0 +1,134 @@ +_base_ = ['mmpose::_base_/default_runtime.py'] + +custom_imports = dict(imports='projects.uniformer.models') + +# runtime +train_cfg = dict(max_epochs=210, val_interval=10) + +# enable DDP training when pretrained model is used +find_unused_parameters = True + +# optimizer +optim_wrapper = dict(optimizer=dict( + type='Adam', + lr=5e-4, +)) + +# learning policy +param_scheduler = [ + dict( + type='LinearLR', begin=0, end=500, start_factor=0.001, + by_epoch=False), # warm-up + dict( + type='MultiStepLR', + begin=0, + end=210, + milestones=[170, 200], + gamma=0.1, + by_epoch=True) +] + +# automatically scaling LR based on the actual training batch size +auto_scale_lr = dict(base_batch_size=256) + +# hooks +default_hooks = dict(checkpoint=dict(save_best='coco/AP', rule='greater')) + +# codec settings +codec = dict( + type='MSRAHeatmap', input_size=(320, 448), heatmap_size=(80, 112), sigma=3) + +# model settings +norm_cfg = dict(type='SyncBN', requires_grad=True) +model = dict( + type='TopdownPoseEstimator', + data_preprocessor=dict( + type='PoseDataPreprocessor', + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True), + backbone=dict( + type='UniFormer', + embed_dims=[64, 128, 320, 512], + depths=[5, 8, 20, 7], + head_dim=64, + drop_path_rate=0.55, + use_checkpoint=False, # whether use torch.utils.checkpoint + use_window=False, # whether use window MHRA + use_hybrid=False, # whether use hybrid MHRA + init_cfg=dict( + # Set the path to pretrained backbone here + type='Pretrained', + checkpoint='https://download.openmmlab.com/mmpose/v1/projects/' + 'uniformer/uniformer_base_in1k.pth' # noqa + )), + head=dict( + type='HeatmapHead', + in_channels=512, + out_channels=17, + final_layer=dict(kernel_size=1), + loss=dict(type='KeypointMSELoss', use_target_weight=True), + decoder=codec), + test_cfg=dict(flip_test=True, flip_mode='heatmap', shift_heatmap=True)) + +# base dataset settings +dataset_type = 'CocoDataset' +data_mode = 'topdown' +data_root = 'data/coco/' + +# pipelines +train_pipeline = [ + dict(type='LoadImage'), + dict(type='GetBBoxCenterScale'), + dict(type='RandomFlip', direction='horizontal'), + dict(type='RandomHalfBody'), + dict(type='RandomBBoxTransform'), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='GenerateTarget', encoder=codec), + dict(type='PackPoseInputs') +] +val_pipeline = [ + dict(type='LoadImage'), + dict(type='GetBBoxCenterScale'), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='PackPoseInputs') +] + +# data loaders +train_dataloader = dict( + batch_size=32, + num_workers=2, + persistent_workers=True, + sampler=dict(type='DefaultSampler', shuffle=True), + dataset=dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='annotations/person_keypoints_train2017.json', + data_prefix=dict(img='train2017/'), + pipeline=train_pipeline, + )) +val_dataloader = dict( + batch_size=256, + num_workers=2, + persistent_workers=True, + drop_last=False, + sampler=dict(type='DefaultSampler', shuffle=False, round_up=False), + dataset=dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='annotations/person_keypoints_val2017.json', + bbox_file='data/coco/person_detection_results/' + 'COCO_val2017_detections_AP_H_56_person.json', + data_prefix=dict(img='val2017/'), + test_mode=True, + pipeline=val_pipeline, + )) +test_dataloader = val_dataloader + +# evaluators +val_evaluator = dict( + type='CocoMetric', + ann_file=data_root + 'annotations/person_keypoints_val2017.json') +test_evaluator = val_evaluator diff --git a/projects/uniformer/configs/td-hm_uniformer-s-8xb128-210e_coco-256x192.py b/projects/uniformer/configs/td-hm_uniformer-s-8xb128-210e_coco-256x192.py new file mode 100644 index 0000000000..54994893dd --- /dev/null +++ b/projects/uniformer/configs/td-hm_uniformer-s-8xb128-210e_coco-256x192.py @@ -0,0 +1,17 @@ +_base_ = ['./td-hm_uniformer-b-8xb128-210e_coco-256x192.py'] + +# automatically scaling LR based on the actual training batch size +auto_scale_lr = dict(base_batch_size=1024) + +model = dict( + backbone=dict( + depths=[3, 4, 8, 3], + drop_path_rate=0.2, + init_cfg=dict( + type='Pretrained', + checkpoint='https://download.openmmlab.com/mmpose/v1/projects/' + 'uniformer/uniformer_small_in1k.pth' # noqa + ))) + +train_dataloader = dict(batch_size=32) +val_dataloader = dict(batch_size=256) diff --git a/projects/uniformer/configs/td-hm_uniformer-s-8xb128-210e_coco-384x288.py b/projects/uniformer/configs/td-hm_uniformer-s-8xb128-210e_coco-384x288.py new file mode 100644 index 0000000000..59f68946ef --- /dev/null +++ b/projects/uniformer/configs/td-hm_uniformer-s-8xb128-210e_coco-384x288.py @@ -0,0 +1,23 @@ +_base_ = ['./td-hm_uniformer-b-8xb32-210e_coco-384x288.py'] + +# optimizer +optim_wrapper = dict(optimizer=dict( + type='Adam', + lr=2e-3, +)) + +# automatically scaling LR based on the actual training batch size +auto_scale_lr = dict(base_batch_size=1024) + +model = dict( + backbone=dict( + depths=[3, 4, 8, 3], + drop_path_rate=0.2, + init_cfg=dict( + type='Pretrained', + checkpoint='https://download.openmmlab.com/mmpose/v1/projects/' + 'uniformer/uniformer_small_in1k.pth' # noqa + ))) + +train_dataloader = dict(batch_size=128) +val_dataloader = dict(batch_size=256) diff --git a/projects/uniformer/configs/td-hm_uniformer-s-8xb64-210e_coco-448x320.py b/projects/uniformer/configs/td-hm_uniformer-s-8xb64-210e_coco-448x320.py new file mode 100644 index 0000000000..0359ac6d63 --- /dev/null +++ b/projects/uniformer/configs/td-hm_uniformer-s-8xb64-210e_coco-448x320.py @@ -0,0 +1,22 @@ +_base_ = ['./td-hm_uniformer-b-8xb32-210e_coco-448x320.py'] + +# optimizer +optim_wrapper = dict(optimizer=dict( + type='Adam', + lr=1.0e-3, +)) + +# automatically scaling LR based on the actual training batch size +auto_scale_lr = dict(base_batch_size=512) + +model = dict( + backbone=dict( + depths=[3, 4, 8, 3], + drop_path_rate=0.2, + init_cfg=dict( + type='Pretrained', + checkpoint='https://download.openmmlab.com/mmpose/v1/projects/' + 'uniformer/uniformer_small_in1k.pth'))) + +train_dataloader = dict(batch_size=64) +val_dataloader = dict(batch_size=256) diff --git a/projects/uniformer/models/__init__.py b/projects/uniformer/models/__init__.py new file mode 100644 index 0000000000..6256db6f45 --- /dev/null +++ b/projects/uniformer/models/__init__.py @@ -0,0 +1 @@ +from .uniformer import * # noqa diff --git a/projects/uniformer/models/uniformer.py b/projects/uniformer/models/uniformer.py new file mode 100644 index 0000000000..cea36f061b --- /dev/null +++ b/projects/uniformer/models/uniformer.py @@ -0,0 +1,709 @@ +from collections import OrderedDict +from functools import partial +from typing import Dict, List, Optional, Union + +import torch +import torch.nn as nn +import torch.nn.functional as F +from mmcv.cnn.bricks.transformer import build_dropout +from mmengine.model import BaseModule +from mmengine.model.weight_init import trunc_normal_ +from mmengine.runner import checkpoint, load_checkpoint +from mmengine.utils import to_2tuple + +from mmpose.models.backbones.base_backbone import BaseBackbone +from mmpose.registry import MODELS +from mmpose.utils import get_root_logger + + +class Mlp(BaseModule): + """Multilayer perceptron. + + Args: + in_features (int): Number of input features. + hidden_features (int): Number of hidden features. + Defaults to None. + out_features (int): Number of output features. + Defaults to None. + drop (float): Dropout rate. Defaults to 0.0. + init_cfg (dict, optional): Config dict for initialization. + Defaults to None. + """ + + def __init__(self, + in_features: int, + hidden_features: int = None, + out_features: int = None, + drop_rate: float = 0., + init_cfg: Optional[dict] = None) -> None: + super().__init__(init_cfg=init_cfg) + out_features = out_features or in_features + hidden_features = hidden_features or in_features + self.fc1 = nn.Linear(in_features, hidden_features) + self.act = nn.GELU() + self.fc2 = nn.Linear(hidden_features, out_features) + self.drop = nn.Dropout(drop_rate) + + def forward(self, x): + x = self.act(self.fc1(x)) + x = self.fc2(self.drop(x)) + x = self.drop(x) + return x + + +class CMlp(BaseModule): + """Multilayer perceptron via convolution. + + Args: + in_features (int): Number of input features. + hidden_features (int): Number of hidden features. + Defaults to None. + out_features (int): Number of output features. + Defaults to None. + drop (float): Dropout rate. Defaults to 0.0. + init_cfg (dict, optional): Config dict for initialization. + Defaults to None. + """ + + def __init__(self, + in_features: int, + hidden_features: int = None, + out_features: int = None, + drop_rate: float = 0., + init_cfg: Optional[dict] = None) -> None: + super().__init__(init_cfg=init_cfg) + out_features = out_features or in_features + hidden_features = hidden_features or in_features + self.fc1 = nn.Conv2d(in_features, hidden_features, kernel_size=1) + self.act = nn.GELU() + self.fc2 = nn.Conv2d(hidden_features, out_features, kernel_size=1) + self.drop = nn.Dropout(drop_rate) + + def forward(self, x): + x = self.act(self.fc1(x)) + x = self.fc2(self.drop(x)) + x = self.drop(x) + return x + + +class CBlock(BaseModule): + """Convolution Block. + + Args: + embed_dim (int): Number of input features. + mlp_ratio (float): Ratio of mlp hidden dimension + to embedding dimension. Defaults to 4. + drop (float): Dropout rate. + Defaults to 0.0. + drop_paths (float): Stochastic depth rates. + Defaults to 0.0. + init_cfg (dict, optional): Config dict for initialization. + Defaults to None. + """ + + def __init__(self, + embed_dim: int, + mlp_ratio: float = 4., + drop_rate: float = 0., + drop_path_rate: float = 0., + init_cfg: Optional[dict] = None) -> None: + super().__init__(init_cfg=init_cfg) + self.pos_embed = nn.Conv2d( + embed_dim, embed_dim, 3, padding=1, groups=embed_dim) + self.norm1 = nn.BatchNorm2d(embed_dim) + self.conv1 = nn.Conv2d(embed_dim, embed_dim, 1) + self.conv2 = nn.Conv2d(embed_dim, embed_dim, 1) + self.attn = nn.Conv2d( + embed_dim, embed_dim, 5, padding=2, groups=embed_dim) + # NOTE: drop path for stochastic depth, we shall see if this is + # better than dropout here + self.drop_path = build_dropout( + dict(type='DropPath', drop_prob=drop_path_rate) + ) if drop_path_rate > 0. else nn.Identity() + self.norm2 = nn.BatchNorm2d(embed_dim) + mlp_hidden_dim = int(embed_dim * mlp_ratio) + self.mlp = CMlp( + in_features=embed_dim, + hidden_features=mlp_hidden_dim, + drop_rate=drop_rate) + + def forward(self, x): + x = x + self.pos_embed(x) + x = x + self.drop_path( + self.conv2(self.attn(self.conv1(self.norm1(x))))) + x = x + self.drop_path(self.mlp(self.norm2(x))) + return x + + +class Attention(BaseModule): + """Self-Attention. + + Args: + embed_dim (int): Number of input features. + num_heads (int): Number of attention heads. + Defaults to 8. + qkv_bias (bool): If True, add a learnable bias to query, key, value. + Defaults to True. + qk_scale (float, optional): Override default qk scale of + ``head_dim ** -0.5`` if set. Defaults to None. + attn_drop_rate (float): Attention dropout rate. + Defaults to 0.0. + proj_drop_rate (float): Dropout rate. + Defaults to 0.0. + init_cfg (dict, optional): Config dict for initialization. + Defaults to None. + init_cfg (dict, optional): The config of weight initialization. + Defaults to None. + """ + + def __init__(self, + embed_dim: int, + num_heads: int = 8, + qkv_bias: bool = True, + qk_scale: float = None, + attn_drop_rate: float = 0., + proj_drop_rate: float = 0., + init_cfg: Optional[dict] = None) -> None: + super().__init__(init_cfg=init_cfg) + self.num_heads = num_heads + head_dim = embed_dim // num_heads + # NOTE scale factor was wrong in my original version, can set manually + # to be compat with prev weights + self.scale = qk_scale or head_dim**-0.5 + + self.qkv = nn.Linear(embed_dim, embed_dim * 3, bias=qkv_bias) + self.attn_drop = nn.Dropout(attn_drop_rate) + self.proj = nn.Linear(embed_dim, embed_dim) + self.proj_drop = nn.Dropout(proj_drop_rate) + + def forward(self, x): + B, N, C = x.shape + qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, + C // self.num_heads).permute(2, 0, 3, 1, 4) + q, k, v = qkv[0], qkv[1], qkv[ + 2] # make torchscript happy (cannot use tensor as tuple) + + attn = (q @ k.transpose(-2, -1)) * self.scale + attn = attn.softmax(dim=-1) + attn = self.attn_drop(attn) + + x = (attn @ v).transpose(1, 2).reshape(B, N, C) + x = self.proj(x) + x = self.proj_drop(x) + return x + + +class PatchEmbed(BaseModule): + """Image to Patch Embedding. + + Args: + img_size (int): Number of input size. + Defaults to 224. + patch_size (int): Number of patch size. + Defaults to 16. + in_channels (int): Number of input features. + Defaults to 3. + embed_dims (int): Number of output features. + Defaults to 768. + init_cfg (dict, optional): Config dict for initialization. + Defaults to None. + """ + + def __init__(self, + img_size: int = 224, + patch_size: int = 16, + in_channels: int = 3, + embed_dim: int = 768, + init_cfg: Optional[dict] = None) -> None: + super().__init__(init_cfg=init_cfg) + img_size = to_2tuple(img_size) + patch_size = to_2tuple(patch_size) + num_patches = (img_size[1] // patch_size[1]) * ( + img_size[0] // patch_size[0]) + self.img_size = img_size + self.patch_size = patch_size + self.num_patches = num_patches + self.norm = nn.LayerNorm(embed_dim) + self.proj = nn.Conv2d( + in_channels, embed_dim, kernel_size=patch_size, stride=patch_size) + + def forward(self, x): + B, _, H, W = x.shape + x = self.proj(x) + B, _, H, W = x.shape + x = x.flatten(2).transpose(1, 2) + x = self.norm(x) + x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() + return x + + +class SABlock(BaseModule): + """Self-Attention Block. + + Args: + embed_dim (int): Number of input features. + num_heads (int): Number of attention heads. + mlp_ratio (float): Ratio of mlp hidden dimension + to embedding dimension. Defaults to 4. + qkv_bias (bool): If True, add a learnable bias to query, key, value. + Defaults to True. + qk_scale (float, optional): Override default qk scale of + ``head_dim ** -0.5`` if set. Defaults to None. + drop (float): Dropout rate. Defaults to 0.0. + attn_drop (float): Attention dropout rate. Defaults to 0.0. + drop_paths (float): Stochastic depth rates. + Defaults to 0.0. + init_cfg (dict, optional): Config dict for initialization. + Defaults to None. + """ + + def __init__(self, + embed_dim: int, + num_heads: int, + mlp_ratio: float = 4., + qkv_bias: bool = False, + qk_scale: float = None, + drop_rate: float = 0., + attn_drop_rate: float = 0., + drop_path_rate: float = 0., + init_cfg: Optional[dict] = None) -> None: + super().__init__(init_cfg=init_cfg) + + self.pos_embed = nn.Conv2d( + embed_dim, embed_dim, 3, padding=1, groups=embed_dim) + self.norm1 = nn.LayerNorm(embed_dim) + self.attn = Attention( + embed_dim, + num_heads=num_heads, + qkv_bias=qkv_bias, + qk_scale=qk_scale, + attn_drop_rate=attn_drop_rate, + proj_drop_rate=drop_rate) + # NOTE: drop path for stochastic depth, + # we shall see if this is better than dropout here + self.drop_path = build_dropout( + dict(type='DropPath', drop_prob=drop_path_rate) + ) if drop_path_rate > 0. else nn.Identity() + self.norm2 = nn.LayerNorm(embed_dim) + mlp_hidden_dim = int(embed_dim * mlp_ratio) + self.mlp = Mlp( + in_features=embed_dim, + hidden_features=mlp_hidden_dim, + drop_rate=drop_rate) + + def forward(self, x): + x = x + self.pos_embed(x) + B, N, H, W = x.shape + x = x.flatten(2).transpose(1, 2) + x = x + self.drop_path(self.attn(self.norm1(x))) + x = x + self.drop_path(self.mlp(self.norm2(x))) + x = x.transpose(1, 2).reshape(B, N, H, W) + return x + + +class WindowSABlock(BaseModule): + """Self-Attention Block. + + Args: + embed_dim (int): Number of input features. + num_heads (int): Number of attention heads. + window_size (int): Size of the partition window. Defaults to 14. + mlp_ratio (float): Ratio of mlp hidden dimension + to embedding dimension. Defaults to 4. + qkv_bias (bool): If True, add a learnable bias to query, key, value. + Defaults to True. + qk_scale (float, optional): Override default qk scale of + ``head_dim ** -0.5`` if set. Defaults to None. + drop (float): Dropout rate. Defaults to 0.0. + attn_drop (float): Attention dropout rate. Defaults to 0.0. + drop_paths (float): Stochastic depth rates. + Defaults to 0.0. + init_cfg (dict, optional): Config dict for initialization. + Defaults to None. + """ + + def __init__(self, + embed_dim: int, + num_heads: int, + window_size: int = 14, + mlp_ratio: float = 4., + qkv_bias: bool = False, + qk_scale: float = None, + drop_rate: float = 0., + attn_drop_rate: float = 0., + drop_path_rate: float = 0., + init_cfg: Optional[dict] = None) -> None: + super().__init__(init_cfg=init_cfg) + self.windows_size = window_size + self.pos_embed = nn.Conv2d( + embed_dim, embed_dim, 3, padding=1, groups=embed_dim) + self.norm1 = nn.LayerNorm(embed_dim) + self.attn = Attention( + embed_dim, + num_heads=num_heads, + qkv_bias=qkv_bias, + qk_scale=qk_scale, + attn_drop_rate=attn_drop_rate, + proj_drop_rate=drop_rate) + # NOTE: drop path for stochastic depth, + # we shall see if this is better than dropout here + self.drop_path = build_dropout( + dict(type='DropPath', drop_prob=drop_path_rate) + ) if drop_path_rate > 0. else nn.Identity() + # self.norm2 = build_dropout(norm_cfg, embed_dims)[1] + self.norm2 = nn.LayerNorm(embed_dim) + mlp_hidden_dim = int(embed_dim * mlp_ratio) + self.mlp = Mlp( + in_features=embed_dim, + hidden_features=mlp_hidden_dim, + drop_rate=drop_rate) + + def window_reverse(self, windows, H, W): + """ + Args: + windows: (num_windows*B, window_size, window_size, C) + H (int): Height of image + W (int): Width of image + Returns: + x: (B, H, W, C) + """ + window_size = self.window_size + B = int(windows.shape[0] / (H * W / window_size / window_size)) + x = windows.view(B, H // window_size, W // window_size, window_size, + window_size, -1) + x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1) + return x + + def window_partition(self, x): + """ + Args: + x: (B, H, W, C) + Returns: + windows: (num_windows*B, window_size, window_size, C) + """ + B, H, W, C = x.shape + window_size = self.window_size + x = x.view(B, H // window_size, window_size, W // window_size, + window_size, C) + windows = x.permute(0, 1, 3, 2, 4, + 5).contiguous().view(-1, window_size, window_size, + C) + return windows + + def forward(self, x): + x = x + self.pos_embed(x) + x = x.permute(0, 2, 3, 1) + B, H, W, C = x.shape + shortcut = x + x = self.norm1(x) + + pad_l = pad_t = 0 + pad_r = (self.window_size - W % self.window_size) % self.window_size + pad_b = (self.window_size - H % self.window_size) % self.window_size + x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b)) + _, H_pad, W_pad, _ = x.shape + + x_windows = self.window_partition( + x) # nW*B, window_size, window_size, C + x_windows = x_windows.view(-1, self.window_size * self.window_size, + C) # nW*B, window_size*window_size, C + + # W-MSA/SW-MSA + attn_windows = self.attn(x_windows) # nW*B, window_size*window_size, C + + # merge windows + attn_windows = attn_windows.view(-1, self.window_size, + self.window_size, C) + x = self.window_reverse(attn_windows, H_pad, W_pad) # B H' W' C + + # reverse cyclic shift + if pad_r > 0 or pad_b > 0: + x = x[:, :H, :W, :].contiguous() + + x = shortcut + self.drop_path(x) + x = x + self.drop_path(self.mlp(self.norm2(x))) + x = x.permute(0, 3, 1, 2).reshape(B, C, H, W) + return x + + +@MODELS.register_module() +class UniFormer(BaseBackbone): + """The implementation of Uniformer with downstream pose estimation task. + + UniFormer: Unifying Convolution and Self-attention for Visual Recognition + https://arxiv.org/abs/2201.09450 + UniFormer: Unified Transformer for Efficient Spatiotemporal Representation + Learning https://arxiv.org/abs/2201.04676 + + Args: + depths (List[int]): number of block in each layer. + Default to [3, 4, 8, 3]. + img_size (int, tuple): input image size. Default: 224. + in_channels (int): number of input channels. Default: 3. + num_classes (int): number of classes for classification head. Default + to 80. + embed_dims (List[int]): embedding dimensions. + Default to [64, 128, 320, 512]. + head_dim (int): dimension of attention heads + mlp_ratio (int): ratio of mlp hidden dim to embedding dim + qkv_bias (bool, optional): if True, add a learnable bias to query, key, + value. Default: True + qk_scale (float | None, optional): override default qk scale of + head_dim ** -0.5 if set. Default: None. + representation_size (Optional[int]): enable and set representation + layer (pre-logits) to this value if set + drop_rate (float): dropout rate. Default: 0. + attn_drop_rate (float): attention dropout rate. Default: 0. + drop_path_rate (float): stochastic depth rate. Default: 0. + norm_layer (nn.Module): normalization layer + use_checkpoint (bool): whether use torch.utils.checkpoint + checkpoint_num (list): index for using checkpoint in every stage + use_windows (bool): whether use window MHRA + use_hybrid (bool): whether use hybrid MHRA + window_size (int): size of window (>14). Default: 14. + init_cfg (dict, optional): Config dict for initialization. + Defaults to None. + """ + + def __init__( + self, + depths: List[int] = [3, 4, 8, 3], + img_size: int = 224, + in_channels: int = 3, + num_classes: int = 80, + embed_dims: List[int] = [64, 128, 320, 512], + head_dim: int = 64, + mlp_ratio: int = 4., + qkv_bias: bool = True, + qk_scale: float = None, + representation_size: Optional[int] = None, + drop_rate: float = 0., + attn_drop_rate: float = 0., + drop_path_rate: float = 0., + norm_layer=partial(nn.LayerNorm, eps=1e-6), + use_checkpoint: bool = False, + checkpoint_num=(0, 0, 0, 0), + use_window: bool = False, + use_hybrid: bool = False, + window_size: int = 14, + init_cfg: Optional[Union[Dict, List[Dict]]] = [ + dict(type='TruncNormal', layer='Linear', std=0.02, bias=0.), + dict(type='Constant', layer='LayerNorm', val=1., bias=0.) + ] + ) -> None: + super(UniFormer, self).__init__(init_cfg=init_cfg) + + self.num_classes = num_classes + self.use_checkpoint = use_checkpoint + self.checkpoint_num = checkpoint_num + self.use_window = use_window + self.logger = get_root_logger() + self.logger.info(f'Use torch.utils.checkpoint: {self.use_checkpoint}') + self.logger.info( + f'torch.utils.checkpoint number: {self.checkpoint_num}') + self.num_features = self.embed_dims = embed_dims + norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6) + + self.patch_embed1 = PatchEmbed( + img_size=img_size, + patch_size=4, + in_channels=in_channels, + embed_dim=embed_dims[0]) + self.patch_embed2 = PatchEmbed( + img_size=img_size // 4, + patch_size=2, + in_channels=embed_dims[0], + embed_dim=embed_dims[1]) + self.patch_embed3 = PatchEmbed( + img_size=img_size // 8, + patch_size=2, + in_channels=embed_dims[1], + embed_dim=embed_dims[2]) + self.patch_embed4 = PatchEmbed( + img_size=img_size // 16, + patch_size=2, + in_channels=embed_dims[2], + embed_dim=embed_dims[3]) + + self.drop_after_pos = nn.Dropout(drop_rate) + dpr = [ + x.item() for x in torch.linspace(0, drop_path_rate, sum(depths)) + ] # stochastic depth decay rule + num_heads = [dim // head_dim for dim in embed_dims] + self.blocks1 = nn.ModuleList([ + CBlock( + embed_dim=embed_dims[0], + mlp_ratio=mlp_ratio, + drop_rate=drop_rate, + drop_path_rate=dpr[i]) for i in range(depths[0]) + ]) + self.norm1 = norm_layer(embed_dims[0]) + self.blocks2 = nn.ModuleList([ + CBlock( + embed_dim=embed_dims[1], + mlp_ratio=mlp_ratio, + drop_rate=drop_rate, + drop_path_rate=dpr[i + depths[0]]) for i in range(depths[1]) + ]) + self.norm2 = norm_layer(embed_dims[1]) + if self.use_window: + self.logger.info('Use local window for all blocks in stage3') + self.blocks3 = nn.ModuleList([ + WindowSABlock( + embed_dim=embed_dims[2], + num_heads=num_heads[2], + window_size=window_size, + mlp_ratio=mlp_ratio, + qkv_bias=qkv_bias, + qk_scale=qk_scale, + drop_rate=drop_rate, + attn_drop_rate=attn_drop_rate, + drop_path_rate=dpr[i + depths[0] + depths[1]]) + for i in range(depths[2]) + ]) + elif use_hybrid: + self.logger.info('Use hybrid window for blocks in stage3') + block3 = [] + for i in range(depths[2]): + if (i + 1) % 4 == 0: + block3.append( + SABlock( + embed_dim=embed_dims[2], + num_heads=num_heads[2], + mlp_ratio=mlp_ratio, + qkv_bias=qkv_bias, + qk_scale=qk_scale, + drop_rate=drop_rate, + attn_drop_rate=attn_drop_rate, + drop_path_rate=dpr[i + depths[0] + depths[1]])) + else: + block3.append( + WindowSABlock( + embed_dim=embed_dims[2], + num_heads=num_heads[2], + window_size=window_size, + mlp_ratio=mlp_ratio, + qkv_bias=qkv_bias, + qk_scale=qk_scale, + drop_rate=drop_rate, + attn_drop_rate=attn_drop_rate, + drop_path_rate=dpr[i + depths[0] + depths[1]])) + self.blocks3 = nn.ModuleList(block3) + else: + self.logger.info('Use global window for all blocks in stage3') + self.blocks3 = nn.ModuleList([ + SABlock( + embed_dim=embed_dims[2], + num_heads=num_heads[2], + mlp_ratio=mlp_ratio, + qkv_bias=qkv_bias, + qk_scale=qk_scale, + drop_rate=drop_rate, + attn_drop_rate=attn_drop_rate, + drop_path_rate=dpr[i + depths[0] + depths[1]]) + for i in range(depths[2]) + ]) + self.norm3 = norm_layer(embed_dims[2]) + self.blocks4 = nn.ModuleList([ + SABlock( + embed_dim=embed_dims[3], + num_heads=num_heads[3], + mlp_ratio=mlp_ratio, + qkv_bias=qkv_bias, + qk_scale=qk_scale, + drop_rate=drop_rate, + attn_drop_rate=attn_drop_rate, + drop_path_rate=dpr[i + depths[0] + depths[1] + depths[2]]) + for i in range(depths[3]) + ]) + self.norm4 = norm_layer(embed_dims[3]) + + # Representation layer + if representation_size: + self.num_features = representation_size + self.pre_logits = nn.Sequential( + OrderedDict([('fc', nn.Linear(embed_dims, + representation_size)), + ('act', nn.Tanh())])) + else: + self.pre_logits = nn.Identity() + + self.apply(self._init_weights) + self.init_weights() + + def init_weights(self): + """Initialize the weights in backbone. + + Args: + pretrained (str, optional): Path to pre-trained weights. + Defaults to None. + """ + if (isinstance(self.init_cfg, dict) + and self.init_cfg['type'] == 'Pretrained'): + pretrained = self.init_cfg['checkpoint'] + load_checkpoint( + self, + pretrained, + map_location='cpu', + strict=False, + logger=self.logger) + self.logger.info(f'Load pretrained model from {pretrained}') + + def _init_weights(self, m): + if isinstance(m, nn.Linear): + trunc_normal_(m.weight, std=.02) + if isinstance(m, nn.Linear) and m.bias is not None: + nn.init.constant_(m.bias, 0) + elif isinstance(m, nn.LayerNorm): + nn.init.constant_(m.bias, 0) + nn.init.constant_(m.weight, 1.0) + + @torch.jit.ignore + def no_weight_decay(self): + return {'pos_embed', 'cls_token'} + + def get_classifier(self): + return self.head + + def reset_classifier(self, num_classes, global_pool=''): + self.num_classes = num_classes + self.head = nn.Linear( + self.embed_dims, + num_classes) if num_classes > 0 else nn.Identity() + + def forward(self, x): + out = [] + x = self.patch_embed1(x) + x = self.drop_after_pos(x) + for i, blk in enumerate(self.blocks1): + if self.use_checkpoint and i < self.checkpoint_num[0]: + x = checkpoint.checkpoint(blk, x) + else: + x = blk(x) + x_out = self.norm1(x.permute(0, 2, 3, 1)) + out.append(x_out.permute(0, 3, 1, 2).contiguous()) + x = self.patch_embed2(x) + for i, blk in enumerate(self.blocks2): + if self.use_checkpoint and i < self.checkpoint_num[1]: + x = checkpoint.checkpoint(blk, x) + else: + x = blk(x) + x_out = self.norm2(x.permute(0, 2, 3, 1)) + out.append(x_out.permute(0, 3, 1, 2).contiguous()) + x = self.patch_embed3(x) + for i, blk in enumerate(self.blocks3): + if self.use_checkpoint and i < self.checkpoint_num[2]: + x = checkpoint.checkpoint(blk, x) + else: + x = blk(x) + x_out = self.norm3(x.permute(0, 2, 3, 1)) + out.append(x_out.permute(0, 3, 1, 2).contiguous()) + x = self.patch_embed4(x) + for i, blk in enumerate(self.blocks4): + if self.use_checkpoint and i < self.checkpoint_num[3]: + x = checkpoint.checkpoint(blk, x) + else: + x = blk(x) + x_out = self.norm4(x.permute(0, 2, 3, 1)) + out.append(x_out.permute(0, 3, 1, 2).contiguous()) + return tuple(out) diff --git a/projects/yolox_pose/README.md b/projects/yolox_pose/README.md index 264b65fe9f..35a830487c 100644 --- a/projects/yolox_pose/README.md +++ b/projects/yolox_pose/README.md @@ -4,16 +4,24 @@ This project implements a YOLOX-based human pose estimator, utilizing the approa
+📌 For improved performance and compatibility, **consider using YOLOX-Pose which is built into MMPose**, which seamlessly integrates with MMPose's tools. To learn more about adopting YOLOX-Pose in your workflow, see the documentation: [YOLOX-Pose](/configs/body_2d_keypoint/yoloxpose/README.md). + ## Usage ### Prerequisites - Python 3.7 or higher + - PyTorch 1.6 or higher + - [MMEngine](https://github.com/open-mmlab/mmengine) v0.6.0 or higher + - [MMCV](https://github.com/open-mmlab/mmcv) v2.0.0rc4 or higher + - [MMDetection](https://github.com/open-mmlab/mmdetection) v3.0.0rc6 or higher -- [MMYOLO](https://github.com/open-mmlab/mmyolo) v0.5.0 or higher + +- [MMYOLO](https://github.com/open-mmlab/mmyolo) **v0.5.0** + - [MMPose](https://github.com/open-mmlab/mmpose) v1.0.0rc1 or higher All the commands below rely on the correct configuration of `PYTHONPATH`, which should point to the project's directory so that Python can locate the module files. **In `yolox-pose/` root directory**, run the following line to add the current directory to `PYTHONPATH`: diff --git a/projects/yolox_pose/datasets/__init__.py b/projects/yolox_pose/datasets/__init__.py index 69bae9de53..abf0d11d23 100644 --- a/projects/yolox_pose/datasets/__init__.py +++ b/projects/yolox_pose/datasets/__init__.py @@ -1,3 +1,13 @@ +import mmengine +import mmyolo + +compatible_version = '0.5.0' +if mmengine.digit_version(mmyolo.__version__)[1] > \ + mmengine.digit_version(compatible_version)[1]: + print(f'This project is only compatible with mmyolo {compatible_version} ' + f'or lower. Please install the required version via:' + f'pip install mmyolo=={compatible_version}') + from .bbox_keypoint_structure import * # noqa from .coco_dataset import * # noqa from .transforms import * # noqa diff --git a/projects/yolox_pose/models/__init__.py b/projects/yolox_pose/models/__init__.py index 0d4804e70a..c81450826d 100644 --- a/projects/yolox_pose/models/__init__.py +++ b/projects/yolox_pose/models/__init__.py @@ -1,3 +1,13 @@ +import mmengine +import mmyolo + +compatible_version = '0.5.0' +if mmengine.digit_version(mmyolo.__version__)[1] > \ + mmengine.digit_version(compatible_version)[1]: + print(f'This project is only compatible with mmyolo {compatible_version} ' + f'or lower. Please install the required version via:' + f'pip install mmyolo=={compatible_version}') + from .assigner import * # noqa from .data_preprocessor import * # noqa from .oks_loss import * # noqa diff --git a/requirements/mminstall.txt b/requirements/mminstall.txt index 30d8402a42..32eb00aceb 100644 --- a/requirements/mminstall.txt +++ b/requirements/mminstall.txt @@ -1,3 +1,3 @@ -mmcv>=2.0.0,<2.1.0 -mmdet>=3.0.0,<3.2.0 +mmcv>=2.0.0,<2.2.0 +mmdet>=3.0.0,<3.3.0 mmengine>=0.4.0,<1.0.0 diff --git a/tests/data/300wlp/AFW_134212_1_0.jpg b/tests/data/300wlp/AFW_134212_1_0.jpg new file mode 100644 index 0000000000..6e82cb47db Binary files /dev/null and b/tests/data/300wlp/AFW_134212_1_0.jpg differ diff --git a/tests/data/300wlp/AFW_134212_2_0.jpg b/tests/data/300wlp/AFW_134212_2_0.jpg new file mode 100644 index 0000000000..5640d2f0fb Binary files /dev/null and b/tests/data/300wlp/AFW_134212_2_0.jpg differ diff --git a/tests/data/300wlp/test_300wlp.json b/tests/data/300wlp/test_300wlp.json new file mode 100644 index 0000000000..1598d1fe17 --- /dev/null +++ b/tests/data/300wlp/test_300wlp.json @@ -0,0 +1 @@ +{"info": {"description": "LaPa Generated by MMPose Team", "version": 1.0, "year": "2023", "date_created": "2023/09/20"}, "images": [{"id": 1, "file_name": "AFW_134212_1_0.jpg", "height": 450, "width": 450}, {"id": 2, "file_name": "AFW_134212_2_0.jpg", "height": 450, "width": 450}], "annotations": [{"keypoints": [144.78085327148438, 253.39178466796875, 2.0, 143.70928955078125, 275.5905456542969, 2.0, 147.26495361328125, 292.55340576171875, 2.0, 154.74082946777344, 307.56976318359375, 2.0, 164.7685089111328, 325.37213134765625, 2.0, 175.56622314453125, 341.6143798828125, 2.0, 183.95713806152344, 350.2955322265625, 2.0, 191.24447631835938, 364.373291015625, 2.0, 212.22702026367188, 373.85772705078125, 2.0, 238.06739807128906, 365.5926513671875, 2.0, 262.0357971191406, 350.78265380859375, 2.0, 281.9491882324219, 335.1942138671875, 2.0, 297.3870849609375, 316.2213134765625, 2.0, 305.5174560546875, 296.20111083984375, 2.0, 310.0191650390625, 278.38665771484375, 2.0, 313.570556640625, 257.59332275390625, 2.0, 314.68060302734375, 234.81509399414062, 2.0, 141.07717895507812, 233.8748016357422, 2.0, 142.4314727783203, 231.93350219726562, 2.0, 149.53399658203125, 232.0662384033203, 2.0, 158.13735961914062, 234.31857299804688, 2.0, 167.29750061035156, 237.67184448242188, 2.0, 205.59320068359375, 234.99285888671875, 2.0, 216.04824829101562, 229.73251342773438, 2.0, 229.51547241210938, 225.43397521972656, 2.0, 245.78271484375, 224.81817626953125, 2.0, 261.8216552734375, 228.80909729003906, 2.0, 186.61602783203125, 257.0625, 2.0, 183.9759979248047, 273.16412353515625, 2.0, 180.80419921875, 288.9212646484375, 2.0, 181.61343383789062, 300.6891174316406, 2.0, 180.70370483398438, 302.4509582519531, 2.0, 184.2169189453125, 305.52349853515625, 2.0, 190.96376037597656, 307.95452880859375, 2.0, 199.12416076660156, 305.3871765136719, 2.0, 206.879150390625, 302.37335205078125, 2.0, 154.32986450195312, 249.83685302734375, 2.0, 156.83566284179688, 248.1170654296875, 2.0, 166.4077911376953, 247.8013916015625, 2.0, 177.58078002929688, 251.6158905029297, 2.0, 168.43463134765625, 254.5105743408203, 2.0, 159.2126007080078, 254.42872619628906, 2.0, 216.7241973876953, 250.81556701660156, 2.0, 224.13780212402344, 246.13824462890625, 2.0, 234.09474182128906, 245.99227905273438, 2.0, 245.9826202392578, 248.45945739746094, 2.0, 236.0019989013672, 253.0175323486328, 2.0, 224.37583923339844, 253.48345947265625, 2.0, 175.86959838867188, 319.50311279296875, 2.0, 179.09326171875, 319.59539794921875, 2.0, 187.91131591796875, 319.067138671875, 2.0, 193.9979248046875, 320.62445068359375, 2.0, 200.40106201171875, 319.33489990234375, 2.0, 217.08116149902344, 320.4862976074219, 2.0, 233.78671264648438, 322.4403076171875, 2.0, 219.32835388183594, 334.7911376953125, 2.0, 208.45263671875, 340.60760498046875, 2.0, 198.55410766601562, 341.6135559082031, 2.0, 189.62986755371094, 339.7992858886719, 2.0, 183.0074462890625, 332.94818115234375, 2.0, 178.17086791992188, 319.563232421875, 2.0, 188.85269165039062, 324.1929931640625, 2.0, 196.60971069335938, 325.0108642578125, 2.0, 205.92147827148438, 324.99169921875, 2.0, 231.7099609375, 322.35394287109375, 2.0, 206.32933044433594, 331.2320556640625, 2.0, 197.35250854492188, 331.98333740234375, 2.0, 189.53477478027344, 330.077392578125, 2.0], "image_id": 1, "id": 1, "num_keypoints": 68, "bbox": [141.07717895507812, 224.81817626953125, 173.60342407226562, 149.03955078125], "iscrowd": 0, "area": 25873, "category_id": 1}, {"keypoints": [135.04940795898438, 222.4427947998047, 2.0, 135.0158233642578, 245.55397033691406, 2.0, 136.51287841796875, 266.4256896972656, 2.0, 138.80328369140625, 286.6426086425781, 2.0, 144.32032775878906, 310.9339294433594, 2.0, 157.32864379882812, 334.45831298828125, 2.0, 174.5981903076172, 352.64923095703125, 2.0, 196.57693481445312, 368.895751953125, 2.0, 223.50587463378906, 378.31634521484375, 2.0, 251.17575073242188, 369.77850341796875, 2.0, 267.59075927734375, 355.8761901855469, 2.0, 280.4201965332031, 341.2083740234375, 2.0, 293.03106689453125, 321.76690673828125, 2.0, 301.7103576660156, 299.455078125, 2.0, 306.847412109375, 279.4398193359375, 2.0, 312.0267639160156, 260.4844970703125, 2.0, 314.9190673828125, 240.6781768798828, 2.0, 170.3564453125, 224.36227416992188, 2.0, 183.98776245117188, 220.8751220703125, 2.0, 199.30447387695312, 221.02830505371094, 2.0, 212.521484375, 223.36888122558594, 2.0, 223.74468994140625, 226.60350036621094, 2.0, 268.19195556640625, 228.3536376953125, 2.0, 278.82196044921875, 226.323486328125, 2.0, 289.98040771484375, 224.9724884033203, 2.0, 301.55609130859375, 226.1953887939453, 2.0, 308.71484375, 230.00015258789062, 2.0, 244.0289764404297, 256.7021484375, 2.0, 244.56097412109375, 275.8743896484375, 2.0, 244.62387084960938, 293.44793701171875, 2.0, 243.3439483642578, 305.9898376464844, 2.0, 222.41458129882812, 304.99017333984375, 2.0, 229.01458740234375, 308.64453125, 2.0, 237.42706298828125, 312.08013916015625, 2.0, 245.45481872558594, 310.38775634765625, 2.0, 250.5335693359375, 307.69195556640625, 2.0, 187.56089782714844, 246.6132049560547, 2.0, 197.1554412841797, 247.3951416015625, 2.0, 208.1782989501953, 248.00457763671875, 2.0, 217.29855346679688, 250.23162841796875, 2.0, 208.33084106445312, 253.25308227539062, 2.0, 196.66152954101562, 252.4826202392578, 2.0, 262.341064453125, 251.73179626464844, 2.0, 273.3721618652344, 250.15658569335938, 2.0, 284.34228515625, 250.62045288085938, 2.0, 290.07666015625, 250.62611389160156, 2.0, 282.4354248046875, 255.56341552734375, 2.0, 271.82550048828125, 255.81756591796875, 2.0, 199.1420135498047, 325.15618896484375, 2.0, 213.11370849609375, 323.486328125, 2.0, 227.83006286621094, 322.69268798828125, 2.0, 234.6953582763672, 325.06048583984375, 2.0, 241.50355529785156, 324.013916015625, 2.0, 252.42141723632812, 327.2342834472656, 2.0, 258.1256408691406, 331.502685546875, 2.0, 248.24850463867188, 341.65667724609375, 2.0, 238.77732849121094, 347.1531982421875, 2.0, 228.27822875976562, 347.7994384765625, 2.0, 218.2596435546875, 345.81182861328125, 2.0, 209.1992645263672, 338.6329345703125, 2.0, 202.04551696777344, 325.17730712890625, 2.0, 222.98101806640625, 328.13006591796875, 2.0, 232.16001892089844, 329.54791259765625, 2.0, 240.60108947753906, 329.82879638671875, 2.0, 256.0614929199219, 331.196044921875, 2.0, 238.20115661621094, 336.92901611328125, 2.0, 229.0829315185547, 337.291015625, 2.0, 220.1124267578125, 335.1085510253906, 2.0], "image_id": 2, "id": 2, "num_keypoints": 68, "bbox": [135.0158233642578, 220.8751220703125, 179.9032440185547, 157.44122314453125], "iscrowd": 0, "area": 28324, "category_id": 1}], "categories": [{"supercategory": "person", "id": 1, "name": "face", "keypoints": [], "skeleton": []}]} \ No newline at end of file diff --git a/tests/data/ubody3d/ubody3d_train.json b/tests/data/ubody3d/ubody3d_train.json new file mode 100644 index 0000000000..55a4ac5226 --- /dev/null +++ b/tests/data/ubody3d/ubody3d_train.json @@ -0,0 +1 @@ +{"images": [{"id": 15, "height": 720, "width": 1280, "file_name": "Magic_show/Magic_show_S1_Trim1/Magic_show_S1_Trim1/000016.png"}], "annotations": [{"id": 0, "image_id": 15, "bbox": [74.55498504638672, 8.571063995361328, 1062.4967727661133, 701.8491630554199], "segmentation": [[]], "area": 0, "iscrowd": 0, "category_id": 1, "score": 1, "person_id": 0, "hand_box1": [336.4236145019531, 321.40362548828125, 473.6637268066406, 452.62567138671875], "hand_box2": [699.218994140625, 50.335018157958984, 533.58251953125, 621.6577186584473], "keypoints": [[585.656005859375, 1398.5216064453125], [699.9061889648438, 1586.966064453125], [450.14288330078125, 1596.144775390625], [878.3228149414062, 2171.27783203125], [252.16543579101562, 2132.398681640625], [793.895263671875, 2988.90771484375], [232.56475830078125, 2939.503173828125], [588.2872314453125, 570.474365234375], [862.1456298828125, 514.33837890625], [373.89849853515625, 519.60888671875], [1073.739990234375, 765.0070190429688], [89.8785400390625, 775.919921875], [1000.2418212890625, 635.8955688476562], [189.44015502929688, 567.993408203125], [891.81298828125, 2948.2041015625], [1013.4824829101562, 3015.250732421875], [819.24658203125, 3122.821533203125], [172.14041137695312, 2868.272705078125], [31.46063232421875, 2937.01025390625], [244.37692260742188, 3111.135009765625], [760.2764282226562, 235.35623168945312], [469.04644775390625, 237.359130859375], [672.689453125, 216.68638610839844], [536.8645629882812, 215.08010864257812], [594.4747924804688, 302.86590576171875], [937.543212890625, 563.2012939453125], [877.2040405273438, 564.7064819335938], [826.8228759765625, 548.8115234375], [768.3922729492188, 532.2924194335938], [945.0330810546875, 433.25579833984375], [887.2977905273438, 411.39129638671875], [854.9716796875, 409.1885986328125], [812.5216064453125, 409.8503112792969], [993.1986083984375, 415.13519287109375], [983.431640625, 352.09503173828125], [976.8125610351562, 306.58990478515625], [967.6991577148438, 251.8966064453125], [1042.6788330078125, 439.2115783691406], [1061.695068359375, 382.62310791015625], [1078.3428955078125, 336.8554382324219], [1089.8707275390625, 288.113037109375], [1077.3145751953125, 467.8497009277344], [1113.5694580078125, 449.51904296875], [1147.91796875, 434.2681884765625], [1184.372314453125, 406.7205505371094], [262.0787048339844, 512.4108276367188], [314.8291320800781, 495.84429931640625], [355.2375183105469, 463.73870849609375], [400.5841064453125, 429.6348876953125], [290.11627197265625, 385.6371765136719], [334.016357421875, 356.7796325683594], [352.326904296875, 347.6751403808594], [379.92449951171875, 336.6559143066406], [248.99337768554688, 355.2509460449219], [270.441162109375, 294.56085205078125], [283.58990478515625, 247.07943725585938], [298.6072692871094, 191.95077514648438], [194.588623046875, 364.1822509765625], [197.89288330078125, 304.9277038574219], [198.94699096679688, 255.0223846435547], [207.83172607421875, 206.8009490966797], [152.69793701171875, 380.91925048828125], [126.07894897460938, 349.861083984375], [99.02603149414062, 320.67138671875], [75.35498046875, 280.7127380371094], [605.5189819335938, 258.36474609375], [636.6569213867188, 261.03448486328125], [672.689453125, 216.68638610839844], [536.8645629882812, 215.08010864257812], [480.609130859375, 193.2221221923828], [498.7352294921875, 169.0961151123047], [527.0252075195312, 168.48736572265625], [556.564453125, 174.32501220703125], [582.2213134765625, 183.7449188232422], [619.771728515625, 185.09783935546875], [646.1015625, 177.27572631835938], [678.3016357421875, 172.73214721679688], [709.5665283203125, 174.52818298339844], [730.6221313476562, 199.52928161621094], [600.2632446289062, 215.79234313964844], [598.0828247070312, 240.45635986328125], [596.2218627929688, 264.4862976074219], [594.4674072265625, 287.62481689453125], [572.7188110351562, 305.8975830078125], [583.9725341796875, 311.3199157714844], [596.401123046875, 315.5985107421875], [609.6165771484375, 311.5094909667969], [622.2186279296875, 306.6711120605469], [512.6423950195312, 211.75982666015625], [528.5633544921875, 204.07089233398438], [548.4610595703125, 205.9830780029297], [565.9568481445312, 217.66900634765625], [548.8089599609375, 222.94613647460938], [530.2134399414062, 222.75762939453125], [639.6070556640625, 219.82444763183594], [655.8860473632812, 209.6044158935547], [676.3201904296875, 208.3985595703125], [694.9487915039062, 217.1615753173828], [674.3418579101562, 226.85595703125], [655.4156494140625, 225.6745147705078], [551.7490234375, 353.2354736328125], [564.1500244140625, 346.4883728027344], [583.2034912109375, 344.99609375], [595.4065551757812, 347.21868896484375], [607.8397216796875, 345.721435546875], [629.6182250976562, 348.2886047363281], [648.6402587890625, 353.0809631347656], [634.0433349609375, 361.12738037109375], [612.543212890625, 365.1044921875], [598.9017333984375, 366.5699768066406], [585.4385375976562, 366.0231018066406], [566.12353515625, 362.2437744140625], [553.4495239257812, 352.7164001464844], [583.9151000976562, 355.8670654296875], [596.3876342773438, 356.340576171875], [608.99560546875, 356.22100830078125], [648.081787109375, 352.85076904296875], [612.7412719726562, 351.5333251953125], [598.9871215820312, 351.8242492675781], [585.3312377929688, 352.4969482421875], [464.1539001464844, 202.29954528808594], [465.8164978027344, 244.8143768310547], [469.96026611328125, 282.73333740234375], [474.998779296875, 318.5062255859375], [485.900390625, 354.82257080078125], [503.9440002441406, 389.1557922363281], [533.9607543945312, 420.1808776855469], [569.1990356445312, 439.69488525390625], [604.7715454101562, 445.1242370605469], [641.609130859375, 438.5807189941406], [677.1731567382812, 419.1774597167969], [709.558349609375, 390.3476867675781], [728.9358520507812, 358.6229553222656], [743.6824951171875, 323.7010192871094], [752.355224609375, 286.009033203125], [756.031494140625, 248.0742645263672], [756.6275634765625, 206.8378448486328]], "foot_kpts": [1166.72314453125, 38.096336364746094, 0, 1002.4937744140625, 109.48077392578125, 0, 1049.140869140625, 663.1453857421875, 0, 317.3815002441406, 32.0361328125, 0, 402.523681640625, 303.2774963378906, 0, 177.21731567382812, 665.190673828125, 0], "face_kpts": [482.1813659667969, 206.51531982421875, 0, 474.4501037597656, 248.23251342773438, 1, 482.5657043457031, 282.5651550292969, 1, 490.3671569824219, 326.8166198730469, 1, 498.9546813964844, 355.2204895019531, 1, 519.25634765625, 390.5085754394531, 1, 543.9222412109375, 417.4048156738281, 1, 574.4150390625, 437.6228332519531, 1, 614.6944580078125, 442.5209045410156, 1, 648.99267578125, 436.2539978027344, 1, 682.6341552734375, 416.4512023925781, 1, 702.5023193359375, 392.0824279785156, 1, 725.9093017578125, 358.3260803222656, 1, 739.4346923828125, 328.9374084472656, 1, 746.7598876953125, 285.0207824707031, 1, 748.8603515625, 251.59585571289062, 1, 755.915771484375, 212.4534149169922, 0, 496.4743957519531, 188.47494506835938, 1, 514.8231201171875, 177.99856567382812, 1, 535.214111328125, 176.0469970703125, 1, 556.4619140625, 177.9375, 1, 576.8843994140625, 183.35317993164062, 1, 631.4595947265625, 183.65673828125, 1, 652.4815673828125, 180.27340698242188, 1, 676.221923828125, 180.07711791992188, 1, 698.4794921875, 184.41073608398438, 1, 718.5443115234375, 196.21084594726562, 1, 604.396484375, 218.71194458007812, 1, 602.6702880859375, 245.68115234375, 1, 600.9422607421875, 271.4402770996094, 1, 599.4947509765625, 297.5359802246094, 1, 571.33203125, 313.3100891113281, 1, 586.1724853515625, 317.1542663574219, 1, 601.4893798828125, 320.0868835449219, 1, 617.738525390625, 316.9916687011719, 1, 632.822509765625, 313.9440002441406, 1, 524.906005859375, 216.0177001953125, 1, 542.880859375, 206.15841674804688, 1, 563.9365234375, 208.03213500976562, 1, 578.5321044921875, 222.44454956054688, 1, 559.7491455078125, 226.11843872070312, 1, 541.22607421875, 225.11203002929688, 1, 636.491943359375, 223.62353515625, 1, 652.7271728515625, 210.68789672851562, 1, 674.761474609375, 209.86370849609375, 1, 692.972900390625, 221.53323364257812, 1, 674.9864501953125, 228.75543212890625, 1, 656.0750732421875, 229.04306030273438, 1, 560.0743408203125, 351.4398498535156, 1, 577.081787109375, 347.0306091308594, 1, 594.04638671875, 345.2702941894531, 1, 604.1793212890625, 346.1555480957031, 1, 614.151611328125, 344.8525695800781, 1, 634.447509765625, 345.7118225097656, 1, 656.1597900390625, 347.9260559082031, 1, 640.6773681640625, 358.7562561035156, 1, 624.00732421875, 366.7438049316406, 1, 605.445556640625, 369.8896789550781, 1, 588.646484375, 367.5843811035156, 1, 573.5023193359375, 360.9281921386719, 1, 565.385498046875, 352.2278137207031, 1, 585.1085205078125, 353.1212463378906, 1, 604.616943359375, 355.0426330566406, 1, 626.8272705078125, 351.8833312988281, 1, 650.2919921875, 349.2644958496094, 1, 627.5924072265625, 353.0104675292969, 1, 604.7803955078125, 355.8074645996094, 1, 584.6986083984375, 354.2829284667969, 1], "lefthand_kpts": [942.7679443359375, 607.469482421875, 1, 888.291259765625, 539.277587890625, 1, 832.873291015625, 483.5708923339844, 1, 787.126953125, 436.6972351074219, 1, 710.735107421875, 413.7229309082031, 1, 888.9903564453125, 319.5710754394531, 1, 868.0140380859375, 280.7148742675781, 1, 830.3096923828125, 266.0387268066406, 1, 778.9337158203125, 271.2351379394531, 1, 962.7294921875, 272.7072448730469, 1, 955.781005859375, 187.65567016601562, 1, 953.9222412109375, 103.62838745117188, 1, 959.151611328125, 29.267608642578125, 1, 1047.009033203125, 294.3193664550781, 1, 1056.5989990234375, 215.84146118164062, 1, 1066.36865234375, 147.68014526367188, 1, 1081.0699462890625, 65.11972045898438, 1, 1107.0172119140625, 358.7002258300781, 1, 1159.4434814453125, 319.2156677246094, 1, 1206.9718017578125, 272.8797912597656, 1, 1261.1082763671875, 224.43637084960938, 1], "righthand_kpts": [233.142822265625, 582.3209228515625, 1, 300.6414794921875, 508.47479248046875, 1, 362.43896484375, 455.85186767578125, 1, 377.3603515625, 404.19744873046875, 1, 446.76416015625, 377.29241943359375, 1, 342.8802490234375, 310.6497802734375, 1, 368.6904296875, 284.673095703125, 1, 381.802734375, 251.73486328125, 1, 421.5467529296875, 225.363525390625, 1, 283.64288330078125, 254.122802734375, 1, 304.9996337890625, 170.8004150390625, 1, 320.6651611328125, 98.6851806640625, 1, 335.6553955078125, 28.2318115234375, 1, 199.05755615234375, 256.80859375, 1, 206.0360107421875, 177.01025390625, 1, 215.68804931640625, 106.7457275390625, 1, 224.53521728515625, 32.276611328125, 1, 128.827392578125, 294.99359130859375, 1, 99.0606689453125, 239.12982177734375, 1, 65.53125, 189.2431640625, 1, 37.63360595703125, 116.657958984375, 1], "center": [605.8033447265625, 359.4956359863281], "scale": [6.6406049728393555, 8.854140281677246], "keypoints_score": [0.9791078567504883, 0.9932481050491333, 1.0011144876480103, 0.973096489906311, 0.972457766532898, 0.866172194480896, 0.8760361671447754, 0.3526427149772644, 0.3903506398200989, 0.921836793422699, 0.9433825016021729, 0.20496317744255066, 0.2460474669933319, 0.20729553699493408, 0.17142903804779053, 0.18208564817905426, 0.22269707918167114], "face_kpts_score": [0.3680439293384552, 0.5355573892593384, 0.6418813467025757, 0.6644495725631714, 0.7590401768684387, 0.5538617372512817, 0.5907169580459595, 0.5878690481185913, 0.6348617076873779, 0.7361799478530884, 0.6556291580200195, 0.618322491645813, 0.6537319421768188, 0.5892513394355774, 0.7059171199798584, 0.645734429359436, 0.4574907422065735, 0.9639992713928223, 0.9263820648193359, 0.8876979351043701, 0.9284569621086121, 0.9739065170288086, 0.9502178430557251, 0.9174821376800537, 0.918608546257019, 0.9061530232429504, 0.862210750579834, 0.9776759147644043, 0.973875105381012, 0.974762499332428, 0.9565852880477905, 0.9716235399246216, 1.0059518814086914, 0.946382999420166, 0.9594531059265137, 0.9658107757568359, 1.0158061981201172, 0.9708306789398193, 0.9969902634620667, 0.9845597743988037, 0.9349627494812012, 0.9380444288253784, 0.9717998504638672, 0.9871775507926941, 0.9774664640426636, 0.9537898898124695, 0.9465979933738708, 0.9661000967025757, 0.9713011980056763, 0.9717509746551514, 0.956028938293457, 1.000832438468933, 0.9808722734451294, 0.9960898160934448, 0.9364079236984253, 1.0011546611785889, 0.9167187213897705, 0.9541155099868774, 0.9244742393493652, 0.988551139831543, 0.9954862594604492, 0.9832127094268799, 0.978826642036438, 0.9751479625701904, 0.956895112991333, 0.9974040985107422, 0.9864891767501831, 0.9898920655250549], "foot_kpts_score": [0.24755269289016724, 0.1599443256855011, 0.25949808955192566, 0.2688680589199066, 0.14811083674430847, 0.23364056646823883], "lefthand_kpts_score": [0.603957986831665, 0.46176729202270506, 0.5001004695892334, 0.6286116600036621, 0.7983541250228882, 0.7467568874359131, 0.7094749569892883, 0.7889106035232544, 0.8908322811126709, 0.8638974189758301, 1.0441084861755372, 0.9282500505447387, 0.9102095127105713, 0.7738837957382202, 0.94963458776474, 0.8981462478637695, 0.9926700949668884, 0.7828058958053589, 0.9498528003692627, 0.9387582302093506, 0.8471795082092285], "righthand_kpts_score": [0.6722876787185669, 0.60037282705307, 0.5398626983165741, 0.7077780723571777, 0.7050052642822265, 0.6411999225616455, 0.725990629196167, 0.758279001712799, 0.8829087972640991, 0.889958119392395, 0.9569337129592895, 0.9145335912704468, 0.9213766813278198, 0.8925279140472412, 0.9955486416816711, 1.0033048152923585, 1.0014301896095277, 0.9033888339996338, 0.9002806305885315, 0.8902452945709228, 0.888652241230011], "face_box": [445.3220458984375, 145.05938720703125, 348.63178710937495, 332.0302734375], "face_valid": true, "leftfoot_valid": false, "rightfoot_valid": false, "lefthand_valid": true, "righthand_valid": true, "lefthand_box": [699.218994140625, 50.335018157958984, 533.58251953125, 621.6577186584473], "righthand_box": [81.47227172851564, -7.12115478515625, 398.4362548828125, 664.060546875], "lefthand_update": true, "righthand_update": true, "lefthand_kpts_vitposehand": [942.7679443359375, 607.469482421875, 1, 888.291259765625, 539.277587890625, 1, 832.873291015625, 483.5708923339844, 1, 787.126953125, 436.6972351074219, 1, 710.735107421875, 413.7229309082031, 1, 888.9903564453125, 319.5710754394531, 1, 868.0140380859375, 280.7148742675781, 1, 830.3096923828125, 266.0387268066406, 1, 778.9337158203125, 271.2351379394531, 1, 962.7294921875, 272.7072448730469, 1, 955.781005859375, 187.65567016601562, 1, 953.9222412109375, 103.62838745117188, 1, 959.151611328125, 29.267608642578125, 1, 1047.009033203125, 294.3193664550781, 1, 1056.5989990234375, 215.84146118164062, 1, 1066.36865234375, 147.68014526367188, 1, 1081.0699462890625, 65.11972045898438, 1, 1107.0172119140625, 358.7002258300781, 1, 1159.4434814453125, 319.2156677246094, 1, 1206.9718017578125, 272.8797912597656, 1, 1261.1082763671875, 224.43637084960938, 1], "righthand_kpts_vitposehand": [233.142822265625, 582.3209228515625, 1, 300.6414794921875, 508.47479248046875, 1, 362.43896484375, 455.85186767578125, 1, 377.3603515625, 404.19744873046875, 1, 446.76416015625, 377.29241943359375, 1, 342.8802490234375, 310.6497802734375, 1, 368.6904296875, 284.673095703125, 1, 381.802734375, 251.73486328125, 1, 421.5467529296875, 225.363525390625, 1, 283.64288330078125, 254.122802734375, 1, 304.9996337890625, 170.8004150390625, 1, 320.6651611328125, 98.6851806640625, 1, 335.6553955078125, 28.2318115234375, 1, 199.05755615234375, 256.80859375, 1, 206.0360107421875, 177.01025390625, 1, 215.68804931640625, 106.7457275390625, 1, 224.53521728515625, 32.276611328125, 1, 128.827392578125, 294.99359130859375, 1, 99.0606689453125, 239.12982177734375, 1, 65.53125, 189.2431640625, 1, 37.63360595703125, 116.657958984375, 1], "num_keypoints": 9, "full_body": false, "valid_label": 2, "keypoints_3d": [[585.656005859375, 1398.5216064453125, 8.0], [699.9061889648438, 1586.966064453125, 7.7132415771484375], [450.14288330078125, 1596.144775390625, 7.6570892333984375], [878.3228149414062, 2171.27783203125, 5.664215087890625], [252.16543579101562, 2132.398681640625, 5.6501007080078125], [793.895263671875, 2988.90771484375, 4.6084747314453125], [232.56475830078125, 2939.503173828125, 4.28839111328125], [588.2872314453125, 570.474365234375, 9.544265747070312], [862.1456298828125, 514.33837890625, 8.8726806640625], [373.89849853515625, 519.60888671875, 9.171127319335938], [1073.739990234375, 765.0070190429688, 7.1384735107421875], [89.8785400390625, 775.919921875, 7.5379791259765625], [1000.2418212890625, 635.8955688476562, 5.19927978515625], [189.44015502929688, 567.993408203125, 5.757049560546875], [891.81298828125, 2948.2041015625, 3.0384368896484375], [1013.4824829101562, 3015.250732421875, 3.43035888671875], [819.24658203125, 3122.821533203125, 4.943603515625], [172.14041137695312, 2868.272705078125, 2.809112548828125], [31.46063232421875, 2937.01025390625, 3.1867828369140625], [244.37692260742188, 3111.135009765625, 4.5428619384765625], [760.2764282226562, 235.35623168945312, 9.170547485351562], [469.04644775390625, 237.359130859375, 9.270904541015625], [672.689453125, 216.68638610839844, 8.436477661132812], [536.8645629882812, 215.08010864257812, 8.477508544921875], [594.4747924804688, 302.86590576171875, 8.231826782226562], [937.543212890625, 563.2012939453125, 7.81884765625], [877.2040405273438, 564.7064819335938, 7.746490478515625], [826.8228759765625, 548.8115234375, 7.6898651123046875], [768.3922729492188, 532.2924194335938, 7.540069580078125], [945.0330810546875, 433.25579833984375, 7.78143310546875], [887.2977905273438, 411.39129638671875, 7.68023681640625], [854.9716796875, 409.1885986328125, 7.548248291015625], [812.5216064453125, 409.8503112792969, 7.41748046875], [993.1986083984375, 415.13519287109375, 7.762298583984375], [983.431640625, 352.09503173828125, 7.7212677001953125], [976.8125610351562, 306.58990478515625, 7.644317626953125], [967.6991577148438, 251.8966064453125, 7.58074951171875], [1042.6788330078125, 439.2115783691406, 7.7346954345703125], [1061.695068359375, 382.62310791015625, 7.7144622802734375], [1078.3428955078125, 336.8554382324219, 7.6671142578125], [1089.8707275390625, 288.113037109375, 7.64324951171875], [1077.3145751953125, 467.8497009277344, 7.6988525390625], [1113.5694580078125, 449.51904296875, 7.6714019775390625], [1147.91796875, 434.2681884765625, 7.6133880615234375], [1184.372314453125, 406.7205505371094, 7.566802978515625], [262.0787048339844, 512.4108276367188, 7.7939453125], [314.8291320800781, 495.84429931640625, 7.6787109375], [355.2375183105469, 463.73870849609375, 7.6097564697265625], [400.5841064453125, 429.6348876953125, 7.4446563720703125], [290.11627197265625, 385.6371765136719, 7.82208251953125], [334.016357421875, 356.7796325683594, 7.663116455078125], [352.326904296875, 347.6751403808594, 7.499725341796875], [379.92449951171875, 336.6559143066406, 7.330535888671875], [248.99337768554688, 355.2509460449219, 7.84161376953125], [270.441162109375, 294.56085205078125, 7.848602294921875], [283.58990478515625, 247.07943725585938, 7.8173370361328125], [298.6072692871094, 191.95077514648438, 7.8151092529296875], [194.588623046875, 364.1822509765625, 7.8341217041015625], [197.89288330078125, 304.9277038574219, 7.8556976318359375], [198.94699096679688, 255.0223846435547, 7.8529815673828125], [207.83172607421875, 206.8009490966797, 7.8715667724609375], [152.69793701171875, 380.91925048828125, 7.8072052001953125], [126.07894897460938, 349.861083984375, 7.8142547607421875], [99.02603149414062, 320.67138671875, 7.79296875], [75.35498046875, 280.7127380371094, 7.79833984375], [605.5189819335938, 258.36474609375, 7.6539459228515625], [636.6569213867188, 261.03448486328125, 7.6003265380859375], [672.689453125, 216.68638610839844, 6.8922119140625], [536.8645629882812, 215.08010864257812, 6.9332427978515625], [480.609130859375, 193.2221221923828, 7.156890869140625], [498.7352294921875, 169.0961151123047, 7.0008087158203125], [527.0252075195312, 168.48736572265625, 6.879364013671875], [556.564453125, 174.32501220703125, 6.8116912841796875], [582.2213134765625, 183.7449188232422, 6.796417236328125], [619.771728515625, 185.09783935546875, 6.7884368896484375], [646.1015625, 177.27572631835938, 6.788299560546875], [678.3016357421875, 172.73214721679688, 6.8334197998046875], [709.5665283203125, 174.52818298339844, 6.94036865234375], [730.6221313476562, 199.52928161621094, 7.08001708984375], [600.2632446289062, 215.79234313964844, 6.797698974609375], [598.0828247070312, 240.45635986328125, 6.753753662109375], [596.2218627929688, 264.4862976074219, 6.70782470703125], [594.4674072265625, 287.62481689453125, 6.66571044921875], [572.7188110351562, 305.8975830078125, 6.8535308837890625], [583.9725341796875, 311.3199157714844, 6.8229217529296875], [596.401123046875, 315.5985107421875, 6.804962158203125], [609.6165771484375, 311.5094909667969, 6.8159027099609375], [622.2186279296875, 306.6711120605469, 6.8405303955078125], [512.6423950195312, 211.75982666015625, 7.02471923828125], [528.5633544921875, 204.07089233398438, 6.9400634765625], [548.4610595703125, 205.9830780029297, 6.92816162109375], [565.9568481445312, 217.66900634765625, 6.9529266357421875], [548.8089599609375, 222.94613647460938, 6.9491424560546875], [530.2134399414062, 222.75762939453125, 6.9624176025390625], [639.6070556640625, 219.82444763183594, 6.930755615234375], [655.8860473632812, 209.6044158935547, 6.8970184326171875], [676.3201904296875, 208.3985595703125, 6.8957061767578125], [694.9487915039062, 217.1615753173828, 6.9696502685546875], [674.3418579101562, 226.85595703125, 6.9189300537109375], [655.4156494140625, 225.6745147705078, 6.91705322265625], [551.7490234375, 353.2354736328125, 6.971923828125], [564.1500244140625, 346.4883728027344, 6.88177490234375], [583.2034912109375, 344.99609375, 6.8333587646484375], [595.4065551757812, 347.21868896484375, 6.8253173828125], [607.8397216796875, 345.721435546875, 6.82666015625], [629.6182250976562, 348.2886047363281, 6.8668060302734375], [648.6402587890625, 353.0809631347656, 6.940582275390625], [634.0433349609375, 361.12738037109375, 6.8939056396484375], [612.543212890625, 365.1044921875, 6.8557891845703125], [598.9017333984375, 366.5699768066406, 6.8533477783203125], [585.4385375976562, 366.0231018066406, 6.8624725341796875], [566.12353515625, 362.2437744140625, 6.9132232666015625], [553.4495239257812, 352.7164001464844, 6.97503662109375], [583.9151000976562, 355.8670654296875, 6.8811187744140625], [596.3876342773438, 356.340576171875, 6.8712615966796875], [608.99560546875, 356.22100830078125, 6.8746795654296875], [648.081787109375, 352.85076904296875, 6.94110107421875], [612.7412719726562, 351.5333251953125, 6.865570068359375], [598.9871215820312, 351.8242492675781, 6.8616485595703125], [585.3312377929688, 352.4969482421875, 6.87408447265625], [464.1539001464844, 202.29954528808594, 7.4058380126953125], [465.8164978027344, 244.8143768310547, 7.313018798828125], [469.96026611328125, 282.73333740234375, 7.331451416015625], [474.998779296875, 318.5062255859375, 7.377685546875], [485.900390625, 354.82257080078125, 7.34814453125], [503.9440002441406, 389.1557922363281, 7.29644775390625], [533.9607543945312, 420.1808776855469, 7.2111968994140625], [569.1990356445312, 439.69488525390625, 7.0761260986328125], [604.7715454101562, 445.1242370605469, 7.0256805419921875], [641.609130859375, 438.5807189941406, 7.05670166015625], [677.1731567382812, 419.1774597167969, 7.1628265380859375], [709.558349609375, 390.3476867675781, 7.262908935546875], [728.9358520507812, 358.6229553222656, 7.3195648193359375], [743.6824951171875, 323.7010192871094, 7.3823699951171875], [752.355224609375, 286.009033203125, 7.3757171630859375], [756.031494140625, 248.0742645263672, 7.3575439453125], [756.6275634765625, 206.8378448486328, 7.39019775390625]], "keypoints_valid": [[1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0]], "camera_param": {"focal": [34553.93155415853, 34553.93075942993], "princpt": [605.3033752441406, 358.99560546875]}}], "categories": [{"supercategory": "person", "id": 1, "name": "person"}]} \ No newline at end of file diff --git a/tests/test_apis/test_inferencers/test_hand3d_inferencer.py b/tests/test_apis/test_inferencers/test_hand3d_inferencer.py new file mode 100644 index 0000000000..ccb467fb3c --- /dev/null +++ b/tests/test_apis/test_inferencers/test_hand3d_inferencer.py @@ -0,0 +1,69 @@ +# Copyright (c) OpenMMLab. All rights reserved. +import os +import os.path as osp +from collections import defaultdict +from tempfile import TemporaryDirectory +from unittest import TestCase + +import mmcv +import torch + +from mmpose.apis.inferencers import Hand3DInferencer +from mmpose.structures import PoseDataSample +from mmpose.utils import register_all_modules + + +class TestHand3DInferencer(TestCase): + + def tearDown(self) -> None: + register_all_modules(init_default_scope=True) + return super().tearDown() + + def test_init(self): + + inferencer = Hand3DInferencer(model='hand3d') + self.assertIsInstance(inferencer.model, torch.nn.Module) + + def test_call(self): + + inferencer = Hand3DInferencer(model='hand3d') + + img_path = 'tests/data/interhand2.6m/image29590.jpg' + img = mmcv.imread(img_path) + + # `inputs` is path to an image + inputs = img_path + results1 = next(inferencer(inputs, return_vis=True)) + self.assertIn('visualization', results1) + self.assertIn('predictions', results1) + self.assertIn('keypoints', results1['predictions'][0][0]) + self.assertEqual(len(results1['predictions'][0][0]['keypoints']), 42) + + # `inputs` is an image array + inputs = img + results2 = next(inferencer(inputs)) + self.assertEqual( + len(results1['predictions'][0]), len(results2['predictions'][0])) + self.assertSequenceEqual(results1['predictions'][0][0]['keypoints'], + results2['predictions'][0][0]['keypoints']) + results2 = next(inferencer(inputs, return_datasamples=True)) + self.assertIsInstance(results2['predictions'][0], PoseDataSample) + + # `inputs` is path to a directory + inputs = osp.dirname(img_path) + + with TemporaryDirectory() as tmp_dir: + # only save visualizations + for res in inferencer(inputs, vis_out_dir=tmp_dir): + pass + self.assertEqual(len(os.listdir(tmp_dir)), 4) + # save both visualizations and predictions + results3 = defaultdict(list) + for res in inferencer(inputs, out_dir=tmp_dir): + for key in res: + results3[key].extend(res[key]) + self.assertEqual(len(os.listdir(f'{tmp_dir}/visualizations')), 4) + self.assertEqual(len(os.listdir(f'{tmp_dir}/predictions')), 4) + self.assertEqual(len(results3['predictions']), 4) + self.assertSequenceEqual(results1['predictions'][0][0]['keypoints'], + results3['predictions'][1][0]['keypoints']) diff --git a/tests/test_apis/test_inferencers/test_mmpose_inferencer.py b/tests/test_apis/test_inferencers/test_mmpose_inferencer.py index 8b8a4744b8..c5c1a129ed 100644 --- a/tests/test_apis/test_inferencers/test_mmpose_inferencer.py +++ b/tests/test_apis/test_inferencers/test_mmpose_inferencer.py @@ -58,7 +58,7 @@ def test_pose2d_call(self): len(results1['predictions'][0]), len(results2['predictions'][0])) self.assertSequenceEqual(results1['predictions'][0][0]['keypoints'], results2['predictions'][0][0]['keypoints']) - results2 = next(inferencer(inputs, return_datasample=True)) + results2 = next(inferencer(inputs, return_datasamples=True)) self.assertIsInstance(results2['predictions'][0], PoseDataSample) # `inputs` is path to a directory @@ -127,3 +127,15 @@ def test_pose3d_call(self): '164970135-b14e424c-765a-4180-9bc8-fa8d6abc5510.json', os.listdir(f'{tmp_dir}/predictions')) self.assertTrue(inferencer._video_input) + + def test_hand3d_call(self): + + inferencer = MMPoseInferencer(pose3d='hand3d') + + # `inputs` is path to a video + inputs = 'tests/data/interhand2.6m/image29590.jpg' + results1 = next(inferencer(inputs, return_vis=True)) + self.assertIn('visualization', results1) + self.assertIn('predictions', results1) + self.assertIn('keypoints', results1['predictions'][0][0]) + self.assertEqual(len(results1['predictions'][0][0]['keypoints']), 42) diff --git a/tests/test_apis/test_inferencers/test_pose2d_inferencer.py b/tests/test_apis/test_inferencers/test_pose2d_inferencer.py index b59232efac..5663e425dc 100644 --- a/tests/test_apis/test_inferencers/test_pose2d_inferencer.py +++ b/tests/test_apis/test_inferencers/test_pose2d_inferencer.py @@ -122,7 +122,7 @@ def test_call(self): len(results1['predictions'][0]), len(results2['predictions'][0])) self.assertSequenceEqual(results1['predictions'][0][0]['keypoints'], results2['predictions'][0][0]['keypoints']) - results2 = next(inferencer(inputs, return_datasample=True)) + results2 = next(inferencer(inputs, return_datasamples=True)) self.assertIsInstance(results2['predictions'][0], PoseDataSample) # `inputs` is path to a directory @@ -144,6 +144,10 @@ def test_call(self): self.assertSequenceEqual(results1['predictions'][0][0]['keypoints'], results3['predictions'][3][0]['keypoints']) + with self.assertRaises(AssertionError): + for res in inferencer(inputs, vis_out_dir=f'{tmp_dir}/1.jpg'): + pass + # `inputs` is path to a video inputs = 'tests/data/posetrack18/videos/000001_mpiinew_test/' \ '000001_mpiinew_test.mp4' diff --git a/tests/test_apis/test_inferencers/test_pose3d_inferencer.py b/tests/test_apis/test_inferencers/test_pose3d_inferencer.py index da4a34b160..2ee56781c7 100644 --- a/tests/test_apis/test_inferencers/test_pose3d_inferencer.py +++ b/tests/test_apis/test_inferencers/test_pose3d_inferencer.py @@ -46,7 +46,7 @@ def test_init(self): # 1. init with config path and checkpoint inferencer = Pose3DInferencer( model= # noqa - 'configs/body_3d_keypoint/pose_lift/h36m/pose-lift_videopose3d-243frm-supv-cpn-ft_8xb128-200e_h36m.py', # noqa + 'configs/body_3d_keypoint/video_pose_lift/h36m/video-pose-lift_tcn-243frm-supv-cpn-ft_8xb128-200e_h36m.py', # noqa weights= # noqa 'https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_cpn_ft-88f5abbb_20210527.pth', # noqa pose2d_model='configs/body_2d_keypoint/simcc/coco/' @@ -62,8 +62,8 @@ def test_init(self): # 2. init with config name inferencer = Pose3DInferencer( - model='configs/body_3d_keypoint/pose_lift/h36m/pose-lift_' - 'videopose3d-243frm-supv-cpn-ft_8xb128-200e_h36m.py', + model='configs/body_3d_keypoint/video_pose_lift/h36m/' + 'video-pose-lift_tcn-243frm-supv-cpn-ft_8xb128-200e_h36m.py', pose2d_model='configs/body_2d_keypoint/simcc/coco/' 'simcc_res50_8xb64-210e_coco-256x192.py', det_model=det_model, @@ -114,7 +114,7 @@ def test_call(self): len(results1['predictions'][0]), len(results2['predictions'][0])) self.assertSequenceEqual(results1['predictions'][0][0]['keypoints'], results2['predictions'][0][0]['keypoints']) - results2 = next(inferencer(inputs, return_datasample=True)) + results2 = next(inferencer(inputs, return_datasamples=True)) self.assertIsInstance(results2['predictions'][0], PoseDataSample) # `inputs` is path to a directory diff --git a/tests/test_codecs/test_annotation_processors.py b/tests/test_codecs/test_annotation_processors.py new file mode 100644 index 0000000000..4b67cf4f1a --- /dev/null +++ b/tests/test_codecs/test_annotation_processors.py @@ -0,0 +1,35 @@ +# Copyright (c) OpenMMLab. All rights reserved. + +from unittest import TestCase + +import numpy as np + +from mmpose.codecs import YOLOXPoseAnnotationProcessor + + +class TestYOLOXPoseAnnotationProcessor(TestCase): + + def test_encode(self): + processor = YOLOXPoseAnnotationProcessor(expand_bbox=True) + + keypoints = np.array([[[0, 1], [2, 6], [4, 5]], [[5, 6], [7, 8], + [8, 9]]]) + keypoints_visible = np.array([[1, 1, 0], [1, 0, 1]]) + bbox = np.array([[0, 1, 3, 4], [1, 2, 5, 6]]) + category_id = [1, 2] + + encoded = processor.encode(keypoints, keypoints_visible, bbox, + category_id) + + self.assertTrue('bbox' in encoded) + self.assertTrue('bbox_labels' in encoded) + self.assertTrue( + np.array_equal(encoded['bbox'], + np.array([[0., 1., 3., 6.], [1., 2., 8., 9.]]))) + self.assertTrue( + np.array_equal(encoded['bbox_labels'], np.array([0, 1]))) + + def test_decode(self): + # make sure the `decode` method has been defined + processor = YOLOXPoseAnnotationProcessor() + _ = processor.decode(dict()) diff --git a/tests/test_codecs/test_associative_embedding.py b/tests/test_codecs/test_associative_embedding.py index 983fc93fb1..eae65dbedc 100644 --- a/tests/test_codecs/test_associative_embedding.py +++ b/tests/test_codecs/test_associative_embedding.py @@ -146,8 +146,8 @@ def test_decode(self): batch_heatmaps = torch.from_numpy(heatmaps[None]) batch_tags = torch.from_numpy(tags[None]) - batch_keypoints, batch_keypoint_scores = codec.batch_decode( - batch_heatmaps, batch_tags) + batch_keypoints, batch_keypoint_scores, batch_instance_scores = \ + codec.batch_decode(batch_heatmaps, batch_tags) self.assertIsInstance(batch_keypoints, list) self.assertIsInstance(batch_keypoint_scores, list) @@ -184,8 +184,8 @@ def test_decode(self): batch_heatmaps = torch.from_numpy(heatmaps[None]) batch_tags = torch.from_numpy(tags[None]) - batch_keypoints, batch_keypoint_scores = codec.batch_decode( - batch_heatmaps, batch_tags) + batch_keypoints, batch_keypoint_scores, batch_instance_scores = \ + codec.batch_decode(batch_heatmaps, batch_tags) self.assertIsInstance(batch_keypoints, list) self.assertIsInstance(batch_keypoint_scores, list) @@ -222,8 +222,8 @@ def test_decode(self): batch_heatmaps = torch.from_numpy(heatmaps[None]) batch_tags = torch.from_numpy(tags[None]) - batch_keypoints, batch_keypoint_scores = codec.batch_decode( - batch_heatmaps, batch_tags) + batch_keypoints, batch_keypoint_scores, batch_instance_scores = \ + codec.batch_decode(batch_heatmaps, batch_tags) self.assertIsInstance(batch_keypoints, list) self.assertIsInstance(batch_keypoint_scores, list) diff --git a/tests/test_codecs/test_edpose_label.py b/tests/test_codecs/test_edpose_label.py new file mode 100644 index 0000000000..79e4d3fe27 --- /dev/null +++ b/tests/test_codecs/test_edpose_label.py @@ -0,0 +1,58 @@ +# Copyright (c) OpenMMLab. All rights reserved. + +from unittest import TestCase + +import numpy as np + +from mmpose.codecs import EDPoseLabel + + +class TestEDPoseLabel(TestCase): + + def setUp(self): + self.encoder = EDPoseLabel(num_select=2, num_keypoints=2) + self.img_shape = (640, 480) + self.keypoints = np.array([[[100, 50], [200, 50]], + [[300, 400], [100, 200]]]) + self.area = np.array([5000, 8000]) + + def test_encode(self): + # Test encoding + encoded_data = self.encoder.encode( + img_shape=self.img_shape, keypoints=self.keypoints, area=self.area) + + self.assertEqual(encoded_data['keypoints'].shape, self.keypoints.shape) + self.assertEqual(encoded_data['area'].shape, self.area.shape) + + # Check if the keypoints were normalized correctly + expected_keypoints = self.keypoints / np.array( + self.img_shape, dtype=np.float32) + np.testing.assert_array_almost_equal(encoded_data['keypoints'], + expected_keypoints) + + # Check if the area was normalized correctly + expected_area = self.area / float( + self.img_shape[0] * self.img_shape[1]) + np.testing.assert_array_almost_equal(encoded_data['area'], + expected_area) + + def test_decode(self): + # Dummy predictions for logits, boxes, and keypoints + pred_logits = np.array([0.7, 0.6]).reshape(2, 1) + pred_boxes = np.array([[0.1, 0.1, 0.5, 0.5], [0.6, 0.6, 0.8, 0.8]]) + pred_keypoints = np.array([[0.2, 0.3, 1, 0.3, 0.4, 1], + [0.6, 0.7, 1, 0.7, 0.8, 1]]) + input_shapes = np.array(self.img_shape) + + # Test decoding + boxes, keypoints, scores = self.encoder.decode( + input_shapes=input_shapes, + pred_logits=pred_logits, + pred_boxes=pred_boxes, + pred_keypoints=pred_keypoints) + + self.assertEqual(boxes.shape, pred_boxes.shape) + self.assertEqual(keypoints.shape, (self.encoder.num_select, + self.encoder.num_keypoints, 2)) + self.assertEqual(scores.shape, + (self.encoder.num_select, self.encoder.num_keypoints)) diff --git a/tests/test_codecs/test_hand_3d_heatmap.py b/tests/test_codecs/test_hand_3d_heatmap.py new file mode 100644 index 0000000000..c357c3e6bc --- /dev/null +++ b/tests/test_codecs/test_hand_3d_heatmap.py @@ -0,0 +1,127 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import numpy as np + +from mmpose.registry import KEYPOINT_CODECS + + +class TestHand3DHeatmap(TestCase): + + def build_hand_3d_heatmap(self, **kwargs): + cfg = dict(type='Hand3DHeatmap') + cfg.update(kwargs) + return KEYPOINT_CODECS.build(cfg) + + def setUp(self) -> None: + # The bbox is usually padded so the keypoint will not be near the + # boundary + keypoints = (0.1 + 0.8 * np.random.rand(1, 42, 3)) + keypoints[..., :2] = keypoints[..., :2] * [256, 256] + keypoints = np.round(keypoints).astype(np.float32) + keypoints_visible = np.ones(( + 1, + 42, + ), dtype=np.float32) + heatmaps = np.random.rand(42, 64, 64, 64).astype(np.float32) + self.data = dict( + keypoints=keypoints, + keypoints_visible=keypoints_visible, + heatmaps=heatmaps) + + def test_encode(self): + keypoints = self.data['keypoints'] + keypoints_visible = self.data['keypoints_visible'] + + # test default settings + codec = self.build_hand_3d_heatmap() + + encoded = codec.encode( + keypoints, + keypoints_visible, + dataset_keypoint_weights=np.ones(42, ), + rel_root_depth=np.float32(1.), + rel_root_valid=0., + hand_type=np.array([[1, 0]]), + hand_type_valid=np.array([1]), + focal=np.array([1000., 1000.]), + principal_pt=np.array([200., 200.])) + + self.assertEqual(encoded['heatmaps'].shape, (42 * 64, 64, 64)) + self.assertEqual(encoded['keypoint_weights'].shape, ( + 1, + 42, + )) + + # test with different joint weights + codec = self.build_hand_3d_heatmap(use_different_joint_weights=True) + + encoded = codec.encode( + keypoints, + keypoints_visible, + dataset_keypoint_weights=np.ones(42, ), + rel_root_depth=np.float32(1.), + rel_root_valid=0., + hand_type=np.array([[1, 0]]), + hand_type_valid=np.array([1]), + focal=np.array([1000., 1000.]), + principal_pt=np.array([200., 200.])) + + self.assertEqual(encoded['heatmaps'].shape, (42 * 64, 64, 64)) + self.assertEqual(encoded['keypoint_weights'].shape, ( + 1, + 42, + )) + + # test joint_indices + codec = self.build_hand_3d_heatmap(joint_indices=[0, 8, 16]) + encoded = codec.encode( + keypoints, + keypoints_visible, + dataset_keypoint_weights=np.ones(42, ), + rel_root_depth=np.float32(1.), + rel_root_valid=0., + hand_type=np.array([[1, 0]]), + hand_type_valid=np.array([1]), + focal=np.array([1000., 1000.]), + principal_pt=np.array([200., 200.])) + self.assertEqual(encoded['heatmaps'].shape, (3 * 64, 64, 64)) + self.assertEqual(encoded['keypoint_weights'].shape, ( + 1, + 3, + )) + + def test_decode(self): + heatmaps = self.data['heatmaps'] + + # test default settings + codec = self.build_hand_3d_heatmap() + + keypoints, scores, _, _ = codec.decode(heatmaps, np.ones((1, )), + np.ones((1, 2))) + + self.assertEqual(keypoints.shape, (1, 42, 3)) + self.assertEqual(scores.shape, (1, 42)) + + def test_cicular_verification(self): + keypoints = self.data['keypoints'] + keypoints_visible = self.data['keypoints_visible'] + + codec = self.build_hand_3d_heatmap() + + encoded = codec.encode( + keypoints, + keypoints_visible, + dataset_keypoint_weights=np.ones(42, ), + rel_root_depth=np.float32(1.), + rel_root_valid=0., + hand_type=np.array([[1, 0]]), + hand_type_valid=np.array([1]), + focal=np.array([1000., 1000.]), + principal_pt=np.array([200., 200.])) + _keypoints, _, _, _ = codec.decode( + encoded['heatmaps'].reshape(42, 64, 64, 64), np.ones((1, )), + np.ones((1, 2))) + + self.assertTrue( + np.allclose(keypoints[..., :2], _keypoints[..., :2], atol=5.)) diff --git a/tests/test_codecs/test_image_pose_lifting.py b/tests/test_codecs/test_image_pose_lifting.py index bb94786c32..7033a3954c 100644 --- a/tests/test_codecs/test_image_pose_lifting.py +++ b/tests/test_codecs/test_image_pose_lifting.py @@ -13,14 +13,18 @@ def setUp(self) -> None: keypoints = (0.1 + 0.8 * np.random.rand(1, 17, 2)) * [192, 256] keypoints = np.round(keypoints).astype(np.float32) keypoints_visible = np.random.randint(2, size=(1, 17)) - lifting_target = (0.1 + 0.8 * np.random.rand(17, 3)) - lifting_target_visible = np.random.randint(2, size=(17, )) + lifting_target = (0.1 + 0.8 * np.random.rand(1, 17, 3)) + lifting_target_visible = np.random.randint( + 2, size=( + 1, + 17, + )) encoded_wo_sigma = np.random.rand(1, 17, 3) self.keypoints_mean = np.random.rand(17, 2).astype(np.float32) self.keypoints_std = np.random.rand(17, 2).astype(np.float32) + 1e-6 - self.target_mean = np.random.rand(17, 3).astype(np.float32) - self.target_std = np.random.rand(17, 3).astype(np.float32) + 1e-6 + self.target_mean = np.random.rand(1, 17, 3).astype(np.float32) + self.target_std = np.random.rand(1, 17, 3).astype(np.float32) + 1e-6 self.data = dict( keypoints=keypoints, @@ -30,7 +34,11 @@ def setUp(self) -> None: encoded_wo_sigma=encoded_wo_sigma) def build_pose_lifting_label(self, **kwargs): - cfg = dict(type='ImagePoseLifting', num_keypoints=17, root_index=0) + cfg = dict( + type='ImagePoseLifting', + num_keypoints=17, + root_index=0, + reshape_keypoints=False) cfg.update(kwargs) return KEYPOINT_CODECS.build(cfg) @@ -50,10 +58,19 @@ def test_encode(self): lifting_target_visible) self.assertEqual(encoded['keypoint_labels'].shape, (1, 17, 2)) - self.assertEqual(encoded['lifting_target_label'].shape, (17, 3)) - self.assertEqual(encoded['lifting_target_weights'].shape, (17, )) - self.assertEqual(encoded['trajectory_weights'].shape, (17, )) - self.assertEqual(encoded['target_root'].shape, (3, )) + self.assertEqual(encoded['lifting_target_label'].shape, (1, 17, 3)) + self.assertEqual(encoded['lifting_target_weight'].shape, ( + 1, + 17, + )) + self.assertEqual(encoded['trajectory_weights'].shape, ( + 1, + 17, + )) + self.assertEqual(encoded['target_root'].shape, ( + 1, + 3, + )) # test removing root codec = self.build_pose_lifting_label( @@ -63,10 +80,16 @@ def test_encode(self): self.assertTrue('target_root_removed' in encoded and 'target_root_index' in encoded) - self.assertEqual(encoded['lifting_target_weights'].shape, (16, )) + self.assertEqual(encoded['lifting_target_weight'].shape, ( + 1, + 16, + )) self.assertEqual(encoded['keypoint_labels'].shape, (1, 17, 2)) - self.assertEqual(encoded['lifting_target_label'].shape, (16, 3)) - self.assertEqual(encoded['target_root'].shape, (3, )) + self.assertEqual(encoded['lifting_target_label'].shape, (1, 16, 3)) + self.assertEqual(encoded['target_root'].shape, ( + 1, + 3, + )) # test normalization codec = self.build_pose_lifting_label( @@ -78,7 +101,7 @@ def test_encode(self): lifting_target_visible) self.assertEqual(encoded['keypoint_labels'].shape, (1, 17, 2)) - self.assertEqual(encoded['lifting_target_label'].shape, (17, 3)) + self.assertEqual(encoded['lifting_target_label'].shape, (1, 17, 3)) def test_decode(self): lifting_target = self.data['lifting_target'] @@ -112,12 +135,10 @@ def test_cicular_verification(self): lifting_target_visible) _keypoints, _ = codec.decode( - np.expand_dims(encoded['lifting_target_label'], axis=0), + encoded['lifting_target_label'], target_root=lifting_target[..., 0, :]) - self.assertTrue( - np.allclose( - np.expand_dims(lifting_target, axis=0), _keypoints, atol=5.)) + self.assertTrue(np.allclose(lifting_target, _keypoints, atol=5.)) # test removing root codec = self.build_pose_lifting_label(remove_root=True) @@ -125,12 +146,10 @@ def test_cicular_verification(self): lifting_target_visible) _keypoints, _ = codec.decode( - np.expand_dims(encoded['lifting_target_label'], axis=0), + encoded['lifting_target_label'], target_root=lifting_target[..., 0, :]) - self.assertTrue( - np.allclose( - np.expand_dims(lifting_target, axis=0), _keypoints, atol=5.)) + self.assertTrue(np.allclose(lifting_target, _keypoints, atol=5.)) # test normalization codec = self.build_pose_lifting_label( @@ -142,9 +161,7 @@ def test_cicular_verification(self): lifting_target_visible) _keypoints, _ = codec.decode( - np.expand_dims(encoded['lifting_target_label'], axis=0), + encoded['lifting_target_label'], target_root=lifting_target[..., 0, :]) - self.assertTrue( - np.allclose( - np.expand_dims(lifting_target, axis=0), _keypoints, atol=5.)) + self.assertTrue(np.allclose(lifting_target, _keypoints, atol=5.)) diff --git a/tests/test_codecs/test_motionbert_label.py b/tests/test_codecs/test_motionbert_label.py new file mode 100644 index 0000000000..596df463f7 --- /dev/null +++ b/tests/test_codecs/test_motionbert_label.py @@ -0,0 +1,155 @@ +# Copyright (c) OpenMMLab. All rights reserved. +import os.path as osp +from unittest import TestCase + +import numpy as np +from mmengine.fileio import load + +from mmpose.codecs import MotionBERTLabel +from mmpose.registry import KEYPOINT_CODECS + + +class TestMotionBERTLabel(TestCase): + + def get_camera_param(self, imgname, camera_param) -> dict: + """Get camera parameters of a frame by its image name.""" + subj, rest = osp.basename(imgname).split('_', 1) + action, rest = rest.split('.', 1) + camera, rest = rest.split('_', 1) + return camera_param[(subj, camera)] + + def build_pose_lifting_label(self, **kwargs): + cfg = dict(type='MotionBERTLabel', num_keypoints=17) + cfg.update(kwargs) + return KEYPOINT_CODECS.build(cfg) + + def setUp(self) -> None: + keypoints = (0.1 + 0.8 * np.random.rand(1, 17, 2)) * [1000, 1002] + keypoints = np.round(keypoints).astype(np.float32) + keypoints_visible = np.random.randint(2, size=(1, 17)) + lifting_target = (0.1 + 0.8 * np.random.rand(1, 17, 3)) + lifting_target_visible = np.random.randint( + 2, size=( + 1, + 17, + )) + encoded_wo_sigma = np.random.rand(1, 17, 3) + + camera_param = load('tests/data/h36m/cameras.pkl') + camera_param = self.get_camera_param( + 'S1/S1_Directions_1.54138969/S1_Directions_1.54138969_000001.jpg', + camera_param) + factor = 0.1 + 5 * np.random.rand(1, ) + + self.data = dict( + keypoints=keypoints, + keypoints_visible=keypoints_visible, + lifting_target=lifting_target, + lifting_target_visible=lifting_target_visible, + camera_param=camera_param, + factor=factor, + encoded_wo_sigma=encoded_wo_sigma) + + def test_build(self): + codec = self.build_pose_lifting_label() + self.assertIsInstance(codec, MotionBERTLabel) + + def test_encode(self): + keypoints = self.data['keypoints'] + keypoints_visible = self.data['keypoints_visible'] + lifting_target = self.data['lifting_target'] + lifting_target_visible = self.data['lifting_target_visible'] + camera_param = self.data['camera_param'] + factor = self.data['factor'] + + # test default settings + codec = self.build_pose_lifting_label() + encoded = codec.encode(keypoints, keypoints_visible, lifting_target, + lifting_target_visible, camera_param, factor) + + self.assertEqual(encoded['keypoint_labels'].shape, (1, 17, 2)) + self.assertEqual(encoded['lifting_target_label'].shape, (1, 17, 3)) + self.assertEqual(encoded['lifting_target_weight'].shape, ( + 1, + 17, + )) + + # test concatenating visibility + codec = self.build_pose_lifting_label(concat_vis=True) + encoded = codec.encode(keypoints, keypoints_visible, lifting_target, + lifting_target_visible, camera_param, factor) + + self.assertEqual(encoded['keypoint_labels'].shape, (1, 17, 3)) + self.assertEqual(encoded['lifting_target_label'].shape, (1, 17, 3)) + + def test_decode(self): + encoded_wo_sigma = self.data['encoded_wo_sigma'] + camera_param = self.data['camera_param'] + + # test default settings + codec = self.build_pose_lifting_label() + + decoded, scores = codec.decode(encoded_wo_sigma) + + self.assertEqual(decoded.shape, (1, 17, 3)) + self.assertEqual(scores.shape, (1, 17)) + + # test denormalize according to image shape + codec = self.build_pose_lifting_label() + + decoded, scores = codec.decode( + encoded_wo_sigma, + w=np.array([camera_param['w']]), + h=np.array([camera_param['h']])) + + self.assertEqual(decoded.shape, (1, 17, 3)) + self.assertEqual(scores.shape, (1, 17)) + + # test with factor + codec = self.build_pose_lifting_label() + + decoded, scores = codec.decode( + encoded_wo_sigma, factor=np.array([0.23])) + + self.assertEqual(decoded.shape, (1, 17, 3)) + self.assertEqual(scores.shape, (1, 17)) + + def test_cicular_verification(self): + keypoints_visible = self.data['keypoints_visible'] + lifting_target = self.data['lifting_target'] + lifting_target_visible = self.data['lifting_target_visible'] + camera_param = self.data['camera_param'] + + # test denormalize according to image shape + keypoints = (0.1 + 0.8 * np.random.rand(1, 17, 3)) + codec = self.build_pose_lifting_label() + encoded = codec.encode(keypoints, keypoints_visible, lifting_target, + lifting_target_visible, camera_param) + + _keypoints, _ = codec.decode( + encoded['keypoint_labels'], + w=np.array([camera_param['w']]), + h=np.array([camera_param['h']])) + + keypoints[..., :, :] = keypoints[..., :, :] - keypoints[..., 0, :] + + self.assertTrue( + np.allclose(keypoints[..., :2] / 1000, _keypoints[..., :2])) + + # test with factor + keypoints = (0.1 + 0.8 * np.random.rand(1, 17, 3)) + codec = self.build_pose_lifting_label() + encoded = codec.encode(keypoints, keypoints_visible, lifting_target, + lifting_target_visible, camera_param) + + _keypoints, _ = codec.decode( + encoded['keypoint_labels'], + w=np.array([camera_param['w']]), + h=np.array([camera_param['h']]), + factor=encoded['factor']) + + keypoints *= encoded['factor'] + keypoints[..., :, :] = keypoints[..., :, :] - keypoints[..., 0, :] + + self.assertTrue( + np.allclose(keypoints[..., :2] / 1000, _keypoints[..., :2])) diff --git a/tests/test_codecs/test_video_pose_lifting.py b/tests/test_codecs/test_video_pose_lifting.py index cc58292d0c..6ffd70cffe 100644 --- a/tests/test_codecs/test_video_pose_lifting.py +++ b/tests/test_codecs/test_video_pose_lifting.py @@ -19,7 +19,8 @@ def get_camera_param(self, imgname, camera_param) -> dict: return camera_param[(subj, camera)] def build_pose_lifting_label(self, **kwargs): - cfg = dict(type='VideoPoseLifting', num_keypoints=17) + cfg = dict( + type='VideoPoseLifting', num_keypoints=17, reshape_keypoints=False) cfg.update(kwargs) return KEYPOINT_CODECS.build(cfg) @@ -27,8 +28,12 @@ def setUp(self) -> None: keypoints = (0.1 + 0.8 * np.random.rand(1, 17, 2)) * [192, 256] keypoints = np.round(keypoints).astype(np.float32) keypoints_visible = np.random.randint(2, size=(1, 17)) - lifting_target = (0.1 + 0.8 * np.random.rand(17, 3)) - lifting_target_visible = np.random.randint(2, size=(17, )) + lifting_target = (0.1 + 0.8 * np.random.rand(1, 17, 3)) + lifting_target_visible = np.random.randint( + 2, size=( + 1, + 17, + )) encoded_wo_sigma = np.random.rand(1, 17, 3) camera_param = load('tests/data/h36m/cameras.pkl') @@ -61,10 +66,19 @@ def test_encode(self): lifting_target_visible, camera_param) self.assertEqual(encoded['keypoint_labels'].shape, (1, 17, 2)) - self.assertEqual(encoded['lifting_target_label'].shape, (17, 3)) - self.assertEqual(encoded['lifting_target_weights'].shape, (17, )) - self.assertEqual(encoded['trajectory_weights'].shape, (17, )) - self.assertEqual(encoded['target_root'].shape, (3, )) + self.assertEqual(encoded['lifting_target_label'].shape, (1, 17, 3)) + self.assertEqual(encoded['lifting_target_weight'].shape, ( + 1, + 17, + )) + self.assertEqual(encoded['trajectory_weights'].shape, ( + 1, + 17, + )) + self.assertEqual(encoded['target_root'].shape, ( + 1, + 3, + )) # test not zero-centering codec = self.build_pose_lifting_label(zero_center=False) @@ -72,9 +86,31 @@ def test_encode(self): lifting_target_visible, camera_param) self.assertEqual(encoded['keypoint_labels'].shape, (1, 17, 2)) - self.assertEqual(encoded['lifting_target_label'].shape, (17, 3)) - self.assertEqual(encoded['lifting_target_weights'].shape, (17, )) - self.assertEqual(encoded['trajectory_weights'].shape, (17, )) + self.assertEqual(encoded['lifting_target_label'].shape, (1, 17, 3)) + self.assertEqual(encoded['lifting_target_weight'].shape, ( + 1, + 17, + )) + self.assertEqual(encoded['trajectory_weights'].shape, ( + 1, + 17, + )) + + # test reshape_keypoints + codec = self.build_pose_lifting_label(reshape_keypoints=True) + encoded = codec.encode(keypoints, keypoints_visible, lifting_target, + lifting_target_visible, camera_param) + + self.assertEqual(encoded['keypoint_labels'].shape, (34, 1)) + self.assertEqual(encoded['lifting_target_label'].shape, (1, 17, 3)) + self.assertEqual(encoded['lifting_target_weight'].shape, ( + 1, + 17, + )) + self.assertEqual(encoded['trajectory_weights'].shape, ( + 1, + 17, + )) # test removing root codec = self.build_pose_lifting_label( @@ -84,10 +120,16 @@ def test_encode(self): self.assertTrue('target_root_removed' in encoded and 'target_root_index' in encoded) - self.assertEqual(encoded['lifting_target_weights'].shape, (16, )) + self.assertEqual(encoded['lifting_target_weight'].shape, ( + 1, + 16, + )) self.assertEqual(encoded['keypoint_labels'].shape, (1, 17, 2)) - self.assertEqual(encoded['lifting_target_label'].shape, (16, 3)) - self.assertEqual(encoded['target_root'].shape, (3, )) + self.assertEqual(encoded['lifting_target_label'].shape, (1, 16, 3)) + self.assertEqual(encoded['target_root'].shape, ( + 1, + 3, + )) # test normalizing camera codec = self.build_pose_lifting_label(normalize_camera=True) @@ -102,6 +144,35 @@ def test_encode(self): encoded['camera_param']['f'], atol=4.)) + # test with multiple targets + keypoints = (0.1 + 0.8 * np.random.rand(2, 17, 2)) * [192, 256] + keypoints = np.round(keypoints).astype(np.float32) + keypoints_visible = np.random.randint(2, size=(2, 17)) + lifting_target = (0.1 + 0.8 * np.random.rand(2, 17, 3)) + lifting_target_visible = np.random.randint( + 2, size=( + 2, + 17, + )) + codec = self.build_pose_lifting_label() + encoded = codec.encode(keypoints, keypoints_visible, lifting_target, + lifting_target_visible, camera_param) + + self.assertEqual(encoded['keypoint_labels'].shape, (2, 17, 2)) + self.assertEqual(encoded['lifting_target_label'].shape, (2, 17, 3)) + self.assertEqual(encoded['lifting_target_weight'].shape, ( + 2, + 17, + )) + self.assertEqual(encoded['trajectory_weights'].shape, ( + 2, + 17, + )) + self.assertEqual(encoded['target_root'].shape, ( + 2, + 3, + )) + def test_decode(self): lifting_target = self.data['lifting_target'] encoded_wo_sigma = self.data['encoded_wo_sigma'] @@ -135,12 +206,10 @@ def test_cicular_verification(self): lifting_target_visible, camera_param) _keypoints, _ = codec.decode( - np.expand_dims(encoded['lifting_target_label'], axis=0), + encoded['lifting_target_label'], target_root=lifting_target[..., 0, :]) - self.assertTrue( - np.allclose( - np.expand_dims(lifting_target, axis=0), _keypoints, atol=5.)) + self.assertTrue(np.allclose(lifting_target, _keypoints, atol=5.)) # test removing root codec = self.build_pose_lifting_label(remove_root=True) @@ -148,9 +217,7 @@ def test_cicular_verification(self): lifting_target_visible, camera_param) _keypoints, _ = codec.decode( - np.expand_dims(encoded['lifting_target_label'], axis=0), + encoded['lifting_target_label'], target_root=lifting_target[..., 0, :]) - self.assertTrue( - np.allclose( - np.expand_dims(lifting_target, axis=0), _keypoints, atol=5.)) + self.assertTrue(np.allclose(lifting_target, _keypoints, atol=5.)) diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_aic_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_aic_dataset.py index ae00a64393..57031cdacd 100644 --- a/tests/test_datasets/test_datasets/test_body_datasets/test_aic_dataset.py +++ b/tests/test_datasets/test_datasets/test_body_datasets/test_aic_dataset.py @@ -42,6 +42,7 @@ def check_data_info_keys(self, keypoints=np.ndarray, keypoints_visible=np.ndarray, invalid_segs=list, + area=(list, np.ndarray), id=list) else: raise ValueError(f'Invalid data_mode {data_mode}') diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_coco_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_coco_dataset.py index de78264dae..1706fba739 100644 --- a/tests/test_datasets/test_datasets/test_body_datasets/test_coco_dataset.py +++ b/tests/test_datasets/test_datasets/test_body_datasets/test_coco_dataset.py @@ -42,6 +42,7 @@ def check_data_info_keys(self, keypoints=np.ndarray, keypoints_visible=np.ndarray, invalid_segs=list, + area=(list, np.ndarray), id=list) else: raise ValueError(f'Invalid data_mode {data_mode}') diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_crowdpose_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_crowdpose_dataset.py index 8d63925257..0525e35d02 100644 --- a/tests/test_datasets/test_datasets/test_body_datasets/test_crowdpose_dataset.py +++ b/tests/test_datasets/test_datasets/test_body_datasets/test_crowdpose_dataset.py @@ -42,6 +42,7 @@ def check_data_info_keys(self, keypoints=np.ndarray, keypoints_visible=np.ndarray, invalid_segs=list, + area=(list, np.ndarray), id=list) else: raise ValueError(f'Invalid data_mode {data_mode}') diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_h36m_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_h36m_dataset.py index 88944dc11f..f86cafd1ab 100644 --- a/tests/test_datasets/test_datasets/test_body_datasets/test_h36m_dataset.py +++ b/tests/test_datasets/test_datasets/test_body_datasets/test_h36m_dataset.py @@ -116,6 +116,17 @@ def test_topdown(self): self.assertEqual(len(dataset), 4) self.check_data_info_keys(dataset[0]) + dataset = self.build_h36m_dataset( + data_mode='topdown', + seq_len=1, + seq_step=1, + multiple_target=1, + causal=False, + pad_video_seq=True, + camera_param_file='cameras.pkl') + self.assertEqual(len(dataset), 4) + self.check_data_info_keys(dataset[0]) + # test topdown testing with 2d keypoint detection file and # sequence config dataset = self.build_h36m_dataset( @@ -166,7 +177,7 @@ def test_exceptions_and_warnings(self): keypoint_2d_src='invalid') with self.assertRaisesRegex(AssertionError, - 'Annotation file does not exist'): + 'Annotation file `(.+?)` does not exist'): _ = self.build_h36m_dataset( data_mode='topdown', test_mode=False, ann_file='invalid') diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_humanart21_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_humanart21_dataset.py new file mode 100644 index 0000000000..dd51132f11 --- /dev/null +++ b/tests/test_datasets/test_datasets/test_body_datasets/test_humanart21_dataset.py @@ -0,0 +1,160 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import numpy as np + +from mmpose.datasets.datasets.body import HumanArt21Dataset + + +class TestHumanart21Dataset(TestCase): + + def build_humanart_dataset(self, **kwargs): + + cfg = dict( + ann_file='test_humanart.json', + bbox_file=None, + data_mode='topdown', + data_root='tests/data/humanart', + pipeline=[], + test_mode=False) + + cfg.update(kwargs) + return HumanArt21Dataset(**cfg) + + def check_data_info_keys(self, + data_info: dict, + data_mode: str = 'topdown'): + if data_mode == 'topdown': + expected_keys = dict( + img_id=int, + img_path=str, + bbox=np.ndarray, + bbox_score=np.ndarray, + keypoints=np.ndarray, + keypoints_visible=np.ndarray, + id=int) + elif data_mode == 'bottomup': + expected_keys = dict( + img_id=int, + img_path=str, + bbox=np.ndarray, + bbox_score=np.ndarray, + keypoints=np.ndarray, + keypoints_visible=np.ndarray, + invalid_segs=list, + id=list) + else: + raise ValueError(f'Invalid data_mode {data_mode}') + + for key, type_ in expected_keys.items(): + self.assertIn(key, data_info) + self.assertIsInstance(data_info[key], type_, key) + + def check_metainfo_keys(self, metainfo: dict): + expected_keys = dict( + dataset_name=str, + num_keypoints=int, + keypoint_id2name=dict, + keypoint_name2id=dict, + upper_body_ids=list, + lower_body_ids=list, + flip_indices=list, + flip_pairs=list, + keypoint_colors=np.ndarray, + num_skeleton_links=int, + skeleton_links=list, + skeleton_link_colors=np.ndarray, + dataset_keypoint_weights=np.ndarray) + + for key, type_ in expected_keys.items(): + self.assertIn(key, metainfo) + self.assertIsInstance(metainfo[key], type_, key) + + def test_metainfo(self): + dataset = self.build_humanart_dataset() + self.check_metainfo_keys(dataset.metainfo) + # test dataset_name + self.assertEqual(dataset.metainfo['dataset_name'], 'Human-Art') + + # test number of keypoints + num_keypoints = 21 + self.assertEqual(dataset.metainfo['num_keypoints'], num_keypoints) + self.assertEqual( + len(dataset.metainfo['keypoint_colors']), num_keypoints) + self.assertEqual( + len(dataset.metainfo['dataset_keypoint_weights']), num_keypoints) + # note that len(sigmas) may be zero if dataset.metainfo['sigmas'] = [] + self.assertEqual(len(dataset.metainfo['sigmas']), num_keypoints) + + # test some extra metainfo + self.assertEqual( + len(dataset.metainfo['skeleton_links']), + len(dataset.metainfo['skeleton_link_colors'])) + + def test_topdown(self): + # test topdown training + dataset = self.build_humanart_dataset(data_mode='topdown') + self.assertEqual(len(dataset), 4) + self.check_data_info_keys(dataset[0], data_mode='topdown') + + # test topdown testing + dataset = self.build_humanart_dataset( + data_mode='topdown', test_mode=True) + self.assertEqual(len(dataset), 4) + self.check_data_info_keys(dataset[0], data_mode='topdown') + + # test topdown testing with bbox file + dataset = self.build_humanart_dataset( + data_mode='topdown', + test_mode=True, + bbox_file='tests/data/humanart/test_humanart_det_AP_H_56.json') + self.assertEqual(len(dataset), 13) + self.check_data_info_keys(dataset[0], data_mode='topdown') + + # test topdown testing with filter config + dataset = self.build_humanart_dataset( + data_mode='topdown', + test_mode=True, + bbox_file='tests/data/humanart/test_humanart_det_AP_H_56.json', + filter_cfg=dict(bbox_score_thr=0.3)) + self.assertEqual(len(dataset), 8) + + def test_bottomup(self): + # test bottomup training + dataset = self.build_humanart_dataset(data_mode='bottomup') + self.assertEqual(len(dataset), 3) + self.check_data_info_keys(dataset[0], data_mode='bottomup') + + # test bottomup testing + dataset = self.build_humanart_dataset( + data_mode='bottomup', test_mode=True) + self.assertEqual(len(dataset), 3) + self.check_data_info_keys(dataset[0], data_mode='bottomup') + + def test_exceptions_and_warnings(self): + + with self.assertRaisesRegex(ValueError, 'got invalid data_mode'): + _ = self.build_humanart_dataset(data_mode='invalid') + + with self.assertRaisesRegex( + ValueError, + '"bbox_file" is only supported when `test_mode==True`'): + _ = self.build_humanart_dataset( + data_mode='topdown', + test_mode=False, + bbox_file='tests/data/humanart/test_humanart_det_AP_H_56.json') + + with self.assertRaisesRegex( + ValueError, '"bbox_file" is only supported in topdown mode'): + _ = self.build_humanart_dataset( + data_mode='bottomup', + test_mode=True, + bbox_file='tests/data/humanart/test_humanart_det_AP_H_56.json') + + with self.assertRaisesRegex( + ValueError, + '"bbox_score_thr" is only supported in topdown mode'): + _ = self.build_humanart_dataset( + data_mode='bottomup', + test_mode=True, + filter_cfg=dict(bbox_score_thr=0.3)) diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_jhmdb_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_jhmdb_dataset.py index d7aa46b067..2f27e06698 100644 --- a/tests/test_datasets/test_datasets/test_body_datasets/test_jhmdb_dataset.py +++ b/tests/test_datasets/test_datasets/test_body_datasets/test_jhmdb_dataset.py @@ -42,6 +42,7 @@ def check_data_info_keys(self, keypoints=np.ndarray, keypoints_visible=np.ndarray, invalid_segs=list, + area=(list, np.ndarray), id=list) else: raise ValueError(f'Invalid data_mode {data_mode}') diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_mhp_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_mhp_dataset.py index e93a524611..bdf5f3b807 100644 --- a/tests/test_datasets/test_datasets/test_body_datasets/test_mhp_dataset.py +++ b/tests/test_datasets/test_datasets/test_body_datasets/test_mhp_dataset.py @@ -45,6 +45,7 @@ def check_data_info_keys(self, keypoints=np.ndarray, keypoints_visible=np.ndarray, invalid_segs=list, + area=(list, np.ndarray), id=list) else: raise ValueError(f'Invalid data_mode {data_mode}') diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_mpii_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_mpii_dataset.py index f6431af429..2c35c4490a 100644 --- a/tests/test_datasets/test_datasets/test_body_datasets/test_mpii_dataset.py +++ b/tests/test_datasets/test_datasets/test_body_datasets/test_mpii_dataset.py @@ -44,6 +44,7 @@ def check_data_info_keys(self, keypoints=np.ndarray, keypoints_visible=np.ndarray, invalid_segs=list, + area=(list, np.ndarray), id=list) else: raise ValueError(f'Invalid data_mode {data_mode}') diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_posetrack18_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_posetrack18_dataset.py index ef3cd82dfb..8dabbaa0d5 100644 --- a/tests/test_datasets/test_datasets/test_body_datasets/test_posetrack18_dataset.py +++ b/tests/test_datasets/test_datasets/test_body_datasets/test_posetrack18_dataset.py @@ -42,6 +42,7 @@ def check_data_info_keys(self, keypoints=np.ndarray, keypoints_visible=np.ndarray, invalid_segs=list, + area=(list, np.ndarray), id=list) else: raise ValueError(f'Invalid data_mode {data_mode}') diff --git a/tests/test_datasets/test_datasets/test_dataset_wrappers/test_combined_dataset.py b/tests/test_datasets/test_datasets/test_dataset_wrappers/test_combined_dataset.py index 698f1f060d..ff2e8aaec2 100644 --- a/tests/test_datasets/test_datasets/test_dataset_wrappers/test_combined_dataset.py +++ b/tests/test_datasets/test_datasets/test_dataset_wrappers/test_combined_dataset.py @@ -81,6 +81,29 @@ def test_get_subset_index(self): self.assertEqual(subset_idx, 0) self.assertEqual(sample_idx, lens[0] - 1) + # combiend dataset with resampling ratio + dataset = self.build_combined_dataset(sample_ratio_factor=[1, 0.3]) + self.assertEqual( + len(dataset), + len(dataset.datasets[0]) + round(0.3 * len(dataset.datasets[1]))) + lens = dataset._lens + + index = lens[0] + subset_idx, sample_idx = dataset._get_subset_index(index) + self.assertEqual(subset_idx, 1) + self.assertIn(sample_idx, (0, 1, 2)) + + index = -lens[1] - 1 + subset_idx, sample_idx = dataset._get_subset_index(index) + self.assertEqual(subset_idx, 0) + self.assertEqual(sample_idx, lens[0] - 1) + + with self.assertRaises(AssertionError): + _ = self.build_combined_dataset(sample_ratio_factor=[1, 0.3, 0.1]) + + with self.assertRaises(AssertionError): + _ = self.build_combined_dataset(sample_ratio_factor=[1, -0.3]) + def test_prepare_data(self): dataset = self.build_combined_dataset() lens = dataset._lens diff --git a/tests/test_datasets/test_datasets/test_face_datasets/test_face_300wlp_dataset.py b/tests/test_datasets/test_datasets/test_face_datasets/test_face_300wlp_dataset.py new file mode 100644 index 0000000000..6462fe722f --- /dev/null +++ b/tests/test_datasets/test_datasets/test_face_datasets/test_face_300wlp_dataset.py @@ -0,0 +1,139 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import numpy as np + +from mmpose.datasets.datasets.face import Face300WLPDataset + + +class TestFace300WLPDataset(TestCase): + + def build_face_300wlp_dataset(self, **kwargs): + + cfg = dict( + ann_file='test_300wlp.json', + bbox_file=None, + data_mode='topdown', + data_root='tests/data/300wlp', + pipeline=[], + test_mode=False) + + cfg.update(kwargs) + return Face300WLPDataset(**cfg) + + def check_data_info_keys(self, + data_info: dict, + data_mode: str = 'topdown'): + if data_mode == 'topdown': + expected_keys = dict( + img_id=int, + img_path=str, + bbox_score=np.ndarray, + keypoints=np.ndarray, + keypoints_visible=np.ndarray, + id=int) + elif data_mode == 'bottomup': + expected_keys = dict( + img_id=int, + img_path=str, + bbox_score=np.ndarray, + keypoints=np.ndarray, + keypoints_visible=np.ndarray, + invalid_segs=list, + id=list) + else: + raise ValueError(f'Invalid data_mode {data_mode}') + + for key, type_ in expected_keys.items(): + self.assertIn(key, data_info) + self.assertIsInstance(data_info[key], type_, key) + + def check_metainfo_keys(self, metainfo: dict): + expected_keys = dict( + dataset_name=str, + num_keypoints=int, + keypoint_id2name=dict, + keypoint_name2id=dict, + upper_body_ids=list, + lower_body_ids=list, + flip_indices=list, + flip_pairs=list, + keypoint_colors=np.ndarray, + num_skeleton_links=int, + skeleton_links=list, + skeleton_link_colors=np.ndarray, + dataset_keypoint_weights=np.ndarray) + + for key, type_ in expected_keys.items(): + self.assertIn(key, metainfo) + self.assertIsInstance(metainfo[key], type_, key) + + def test_metainfo(self): + dataset = self.build_face_300wlp_dataset() + self.check_metainfo_keys(dataset.metainfo) + # test dataset_name + self.assertEqual(dataset.metainfo['dataset_name'], '300wlp') + + # test number of keypoints + num_keypoints = 68 + self.assertEqual(dataset.metainfo['num_keypoints'], num_keypoints) + self.assertEqual( + len(dataset.metainfo['keypoint_colors']), num_keypoints) + self.assertEqual( + len(dataset.metainfo['dataset_keypoint_weights']), num_keypoints) + + def test_topdown(self): + # test topdown training + dataset = self.build_face_300wlp_dataset(data_mode='topdown') + self.assertEqual(dataset.data_mode, 'topdown') + self.assertEqual(dataset.bbox_file, None) + self.assertEqual(len(dataset), 2) + self.check_data_info_keys(dataset[0]) + + # test topdown testing + dataset = self.build_face_300wlp_dataset( + data_mode='topdown', test_mode=True) + self.assertEqual(dataset.data_mode, 'topdown') + self.assertEqual(dataset.bbox_file, None) + self.assertEqual(len(dataset), 2) + self.check_data_info_keys(dataset[0]) + + def test_bottomup(self): + # test bottomup training + dataset = self.build_face_300wlp_dataset(data_mode='bottomup') + self.assertEqual(len(dataset), 2) + self.check_data_info_keys(dataset[0], data_mode='bottomup') + + # test bottomup testing + dataset = self.build_face_300wlp_dataset( + data_mode='bottomup', test_mode=True) + self.assertEqual(len(dataset), 2) + self.check_data_info_keys(dataset[0], data_mode='bottomup') + + def test_exceptions_and_warnings(self): + + with self.assertRaisesRegex(ValueError, 'got invalid data_mode'): + _ = self.build_face_300wlp_dataset(data_mode='invalid') + + with self.assertRaisesRegex( + ValueError, + '"bbox_file" is only supported when `test_mode==True`'): + _ = self.build_face_300wlp_dataset( + data_mode='topdown', + test_mode=False, + bbox_file='temp_bbox_file.json') + + with self.assertRaisesRegex( + ValueError, '"bbox_file" is only supported in topdown mode'): + _ = self.build_face_300wlp_dataset( + data_mode='bottomup', + test_mode=True, + bbox_file='temp_bbox_file.json') + + with self.assertRaisesRegex( + ValueError, + '"bbox_score_thr" is only supported in topdown mode'): + _ = self.build_face_300wlp_dataset( + data_mode='bottomup', + test_mode=True, + filter_cfg=dict(bbox_score_thr=0.3)) diff --git a/tests/test_datasets/test_datasets/test_hand_datasets/test_interhand2d_double_dataset.py b/tests/test_datasets/test_datasets/test_hand_datasets/test_interhand2d_double_dataset.py new file mode 100644 index 0000000000..3ed9f1cc92 --- /dev/null +++ b/tests/test_datasets/test_datasets/test_hand_datasets/test_interhand2d_double_dataset.py @@ -0,0 +1,132 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import numpy as np + +from mmpose.datasets.datasets.hand import InterHand2DDoubleDataset + + +class TestInterHand2DDoubleDataset(TestCase): + + def build_interhand2d_dataset(self, **kwargs): + + cfg = dict( + ann_file='test_interhand2.6m_data.json', + camera_param_file='test_interhand2.6m_camera.json', + joint_file='test_interhand2.6m_joint_3d.json', + data_mode='topdown', + data_root='tests/data/interhand2.6m', + pipeline=[], + test_mode=False) + + cfg.update(kwargs) + return InterHand2DDoubleDataset(**cfg) + + def check_metainfo_keys(self, metainfo: dict): + expected_keys = dict( + dataset_name=str, + num_keypoints=int, + keypoint_id2name=dict, + keypoint_name2id=dict, + upper_body_ids=list, + lower_body_ids=list, + flip_indices=list, + flip_pairs=list, + keypoint_colors=np.ndarray, + num_skeleton_links=int, + skeleton_links=list, + skeleton_link_colors=np.ndarray, + dataset_keypoint_weights=np.ndarray) + + for key, type_ in expected_keys.items(): + self.assertIn(key, metainfo) + self.assertIsInstance(metainfo[key], type_, key) + + def check_data_info_keys(self, + data_info: dict, + data_mode: str = 'topdown'): + if data_mode == 'topdown': + expected_keys = dict( + img_id=int, + img_path=str, + bbox=np.ndarray, + bbox_score=np.ndarray, + keypoints=np.ndarray, + keypoints_visible=np.ndarray, + hand_type=np.ndarray, + hand_type_valid=np.ndarray, + num_keypoints=int, + iscrowd=bool, + id=int) + elif data_mode == 'bottomup': + expected_keys = dict( + img_id=int, + img_path=str, + bbox=np.ndarray, + bbox_score=np.ndarray, + keypoints=np.ndarray, + keypoints_visible=np.ndarray, + hand_type=np.ndarray, + hand_type_valid=np.ndarray, + num_keypoints=list, + iscrowd=list, + invalid_segs=list, + id=list) + else: + raise ValueError(f'Invalid data_mode {data_mode}') + + for key, type_ in expected_keys.items(): + self.assertIn(key, data_info) + self.assertIsInstance(data_info[key], type_, key) + + def test_metainfo(self): + dataset = self.build_interhand2d_dataset() + self.check_metainfo_keys(dataset.metainfo) + # test dataset_name + self.assertEqual(dataset.metainfo['dataset_name'], 'interhand3d') + + # test number of keypoints + num_keypoints = 42 + self.assertEqual(dataset.metainfo['num_keypoints'], num_keypoints) + self.assertEqual( + len(dataset.metainfo['keypoint_colors']), num_keypoints) + self.assertEqual( + len(dataset.metainfo['dataset_keypoint_weights']), num_keypoints) + + # test some extra metainfo + self.assertEqual( + len(dataset.metainfo['skeleton_links']), + len(dataset.metainfo['skeleton_link_colors'])) + + def test_topdown(self): + # test topdown training + dataset = self.build_interhand2d_dataset(data_mode='topdown') + self.assertEqual(dataset.data_mode, 'topdown') + self.assertEqual(dataset.bbox_file, None) + self.assertEqual(len(dataset), 4) + self.check_data_info_keys(dataset[0]) + + # test topdown testing + dataset = self.build_interhand2d_dataset( + data_mode='topdown', test_mode=True) + self.assertEqual(dataset.data_mode, 'topdown') + self.assertEqual(dataset.bbox_file, None) + self.assertEqual(len(dataset), 4) + self.check_data_info_keys(dataset[0]) + + def test_bottomup(self): + # test bottomup training + dataset = self.build_interhand2d_dataset(data_mode='bottomup') + self.assertEqual(len(dataset), 4) + self.check_data_info_keys(dataset[0], data_mode='bottomup') + + # test bottomup testing + dataset = self.build_interhand2d_dataset( + data_mode='bottomup', test_mode=True) + self.assertEqual(len(dataset), 4) + self.check_data_info_keys(dataset[0], data_mode='bottomup') + + def test_exceptions_and_warnings(self): + + with self.assertRaisesRegex(ValueError, 'got invalid data_mode'): + _ = self.build_interhand2d_dataset(data_mode='invalid') diff --git a/tests/test_datasets/test_datasets/test_hand_datasets/test_interhand3d_dataset.py b/tests/test_datasets/test_datasets/test_hand_datasets/test_interhand3d_dataset.py new file mode 100644 index 0000000000..f9c4ac569e --- /dev/null +++ b/tests/test_datasets/test_datasets/test_hand_datasets/test_interhand3d_dataset.py @@ -0,0 +1,144 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import numpy as np + +from mmpose.datasets.datasets.hand3d import InterHand3DDataset + + +class TestInterHand3DDataset(TestCase): + + def build_interhand3d_dataset(self, **kwargs): + + cfg = dict( + ann_file='test_interhand2.6m_data.json', + camera_param_file='test_interhand2.6m_camera.json', + joint_file='test_interhand2.6m_joint_3d.json', + data_mode='topdown', + data_root='tests/data/interhand2.6m', + pipeline=[], + test_mode=False) + + cfg.update(kwargs) + return InterHand3DDataset(**cfg) + + def check_metainfo_keys(self, metainfo: dict): + expected_keys = dict( + dataset_name=str, + num_keypoints=int, + keypoint_id2name=dict, + keypoint_name2id=dict, + upper_body_ids=list, + lower_body_ids=list, + flip_indices=list, + flip_pairs=list, + keypoint_colors=np.ndarray, + num_skeleton_links=int, + skeleton_links=list, + skeleton_link_colors=np.ndarray, + dataset_keypoint_weights=np.ndarray) + + for key, type_ in expected_keys.items(): + self.assertIn(key, metainfo) + self.assertIsInstance(metainfo[key], type_, key) + + def check_data_info_keys(self, + data_info: dict, + data_mode: str = 'topdown'): + if data_mode == 'topdown': + expected_keys = dict( + img_id=int, + img_path=str, + bbox=np.ndarray, + bbox_score=np.ndarray, + rotation=int, + keypoints=np.ndarray, + keypoints_visible=np.ndarray, + hand_type=np.ndarray, + hand_type_valid=np.ndarray, + rel_root_depth=np.float32, + rel_root_valid=np.float32, + abs_depth=list, + focal=np.ndarray, + principal_pt=np.ndarray, + num_keypoints=int, + iscrowd=bool, + id=int) + elif data_mode == 'bottomup': + expected_keys = dict( + img_id=int, + img_path=str, + bbox=np.ndarray, + bbox_score=np.ndarray, + rotation=list, + keypoints=np.ndarray, + keypoints_visible=np.ndarray, + hand_type=np.ndarray, + hand_type_valid=np.ndarray, + rel_root_depth=list, + rel_root_valid=list, + abs_depth=list, + focal=np.ndarray, + principal_pt=np.ndarray, + num_keypoints=list, + iscrowd=list, + invalid_segs=list, + id=list) + else: + raise ValueError(f'Invalid data_mode {data_mode}') + + for key, type_ in expected_keys.items(): + self.assertIn(key, data_info) + self.assertIsInstance(data_info[key], type_, key) + + def test_metainfo(self): + dataset = self.build_interhand3d_dataset() + self.check_metainfo_keys(dataset.metainfo) + # test dataset_name + self.assertEqual(dataset.metainfo['dataset_name'], 'interhand3d') + + # test number of keypoints + num_keypoints = 42 + self.assertEqual(dataset.metainfo['num_keypoints'], num_keypoints) + self.assertEqual( + len(dataset.metainfo['keypoint_colors']), num_keypoints) + self.assertEqual( + len(dataset.metainfo['dataset_keypoint_weights']), num_keypoints) + + # test some extra metainfo + self.assertEqual( + len(dataset.metainfo['skeleton_links']), + len(dataset.metainfo['skeleton_link_colors'])) + + def test_topdown(self): + # test topdown training + dataset = self.build_interhand3d_dataset(data_mode='topdown') + self.assertEqual(dataset.data_mode, 'topdown') + self.assertEqual(dataset.bbox_file, None) + self.assertEqual(len(dataset), 4) + self.check_data_info_keys(dataset[0]) + + # test topdown testing + dataset = self.build_interhand3d_dataset( + data_mode='topdown', test_mode=True) + self.assertEqual(dataset.data_mode, 'topdown') + self.assertEqual(dataset.bbox_file, None) + self.assertEqual(len(dataset), 4) + self.check_data_info_keys(dataset[0]) + + def test_bottomup(self): + # test bottomup training + dataset = self.build_interhand3d_dataset(data_mode='bottomup') + self.assertEqual(len(dataset), 4) + self.check_data_info_keys(dataset[0], data_mode='bottomup') + + # test bottomup testing + dataset = self.build_interhand3d_dataset( + data_mode='bottomup', test_mode=True) + self.assertEqual(len(dataset), 4) + self.check_data_info_keys(dataset[0], data_mode='bottomup') + + def test_exceptions_and_warnings(self): + + with self.assertRaisesRegex(ValueError, 'got invalid data_mode'): + _ = self.build_interhand3d_dataset(data_mode='invalid') diff --git a/tests/test_datasets/test_datasets/test_wholebody_datasets/test_ubody_dataset.py b/tests/test_datasets/test_datasets/test_wholebody_datasets/test_ubody_dataset.py new file mode 100644 index 0000000000..77e01da5b1 --- /dev/null +++ b/tests/test_datasets/test_datasets/test_wholebody_datasets/test_ubody_dataset.py @@ -0,0 +1,77 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import numpy as np + +from mmpose.datasets.datasets.wholebody3d import UBody3dDataset + + +class TestUBody3dDataset(TestCase): + + def build_ubody3d_dataset(self, **kwargs): + + cfg = dict( + ann_file='ubody3d_train.json', + data_mode='topdown', + data_root='tests/data/ubody3d', + pipeline=[], + test_mode=False) + + cfg.update(kwargs) + return UBody3dDataset(**cfg) + + def check_data_info_keys(self, data_info: dict): + expected_keys = dict( + img_paths=list, + keypoints=np.ndarray, + keypoints_3d=np.ndarray, + scale=np.ndarray, + center=np.ndarray, + id=int) + + for key, type_ in expected_keys.items(): + self.assertIn(key, data_info) + self.assertIsInstance(data_info[key], type_, key) + + def test_metainfo(self): + dataset = self.build_ubody3d_dataset() + # test dataset_name + self.assertEqual(dataset.metainfo['dataset_name'], 'ubody3d') + + # test number of keypoints + num_keypoints = 137 + self.assertEqual(dataset.metainfo['num_keypoints'], num_keypoints) + self.assertEqual( + len(dataset.metainfo['keypoint_colors']), num_keypoints) + self.assertEqual( + len(dataset.metainfo['dataset_keypoint_weights']), num_keypoints) + + # test some extra metainfo + self.assertEqual( + len(dataset.metainfo['skeleton_links']), + len(dataset.metainfo['skeleton_link_colors'])) + + def test_topdown(self): + # test topdown training + dataset = self.build_ubody3d_dataset(data_mode='topdown') + dataset.full_init() + self.assertEqual(len(dataset), 1) + self.check_data_info_keys(dataset[0]) + + # test topdown testing + dataset = self.build_ubody3d_dataset( + data_mode='topdown', test_mode=True) + dataset.full_init() + self.assertEqual(len(dataset), 1) + self.check_data_info_keys(dataset[0]) + + # test topdown training with sequence config + dataset = self.build_ubody3d_dataset( + data_mode='topdown', + seq_len=1, + seq_step=1, + causal=False, + pad_video_seq=True) + dataset.full_init() + self.assertEqual(len(dataset), 1) + self.check_data_info_keys(dataset[0]) diff --git a/tests/test_datasets/test_transforms/test_bottomup_transforms.py b/tests/test_datasets/test_transforms/test_bottomup_transforms.py index cded7a6efb..8d9213c729 100644 --- a/tests/test_datasets/test_transforms/test_bottomup_transforms.py +++ b/tests/test_datasets/test_transforms/test_bottomup_transforms.py @@ -6,7 +6,9 @@ from mmcv.transforms import Compose from mmpose.datasets.transforms import (BottomupGetHeatmapMask, - BottomupRandomAffine, BottomupResize, + BottomupRandomAffine, + BottomupRandomChoiceResize, + BottomupRandomCrop, BottomupResize, RandomFlip) from mmpose.testing import get_coco_sample @@ -145,3 +147,166 @@ def test_transform(self): self.assertIsInstance(results['input_scale'], np.ndarray) self.assertEqual(results['img'][0].shape, (256, 256, 3)) self.assertEqual(results['img'][1].shape, (384, 384, 3)) + + +class TestBottomupRandomCrop(TestCase): + + def setUp(self): + # test invalid crop_type + with self.assertRaisesRegex(ValueError, 'Invalid crop_type'): + BottomupRandomCrop(crop_size=(10, 10), crop_type='unknown') + + crop_type_list = ['absolute', 'absolute_range'] + for crop_type in crop_type_list: + # test h > 0 and w > 0 + for crop_size in [(0, 0), (0, 1), (1, 0)]: + with self.assertRaises(AssertionError): + BottomupRandomCrop( + crop_size=crop_size, crop_type=crop_type) + # test type(h) = int and type(w) = int + for crop_size in [(1.0, 1), (1, 1.0), (1.0, 1.0)]: + with self.assertRaises(AssertionError): + BottomupRandomCrop( + crop_size=crop_size, crop_type=crop_type) + + # test crop_size[0] <= crop_size[1] + with self.assertRaises(AssertionError): + BottomupRandomCrop(crop_size=(10, 5), crop_type='absolute_range') + + # test h in (0, 1] and w in (0, 1] + crop_type_list = ['relative_range', 'relative'] + for crop_type in crop_type_list: + for crop_size in [(0, 1), (1, 0), (1.1, 0.5), (0.5, 1.1)]: + with self.assertRaises(AssertionError): + BottomupRandomCrop( + crop_size=crop_size, crop_type=crop_type) + + self.data_info = get_coco_sample(img_shape=(24, 32)) + + def test_transform(self): + # test relative and absolute crop + src_results = self.data_info + target_shape = (12, 16) + for crop_type, crop_size in zip(['relative', 'absolute'], [(0.5, 0.5), + (16, 12)]): + transform = BottomupRandomCrop( + crop_size=crop_size, crop_type=crop_type) + results = transform(deepcopy(src_results)) + self.assertEqual(results['img'].shape[:2], target_shape) + + # test absolute_range crop + transform = BottomupRandomCrop( + crop_size=(10, 20), crop_type='absolute_range') + results = transform(deepcopy(src_results)) + h, w = results['img'].shape[:2] + self.assertTrue(10 <= w <= 20) + self.assertTrue(10 <= h <= 20) + self.assertEqual(results['img_shape'], results['img'].shape[:2]) + # test relative_range crop + transform = BottomupRandomCrop( + crop_size=(0.5, 0.5), crop_type='relative_range') + results = transform(deepcopy(src_results)) + h, w = results['img'].shape[:2] + self.assertTrue(16 <= w <= 32) + self.assertTrue(12 <= h <= 24) + self.assertEqual(results['img_shape'], results['img'].shape[:2]) + + # test with keypoints, bbox, segmentation + src_results = get_coco_sample(img_shape=(10, 10), num_instances=2) + segmentation = np.random.randint(0, 255, size=(10, 10), dtype=np.uint8) + keypoints = np.ones_like(src_results['keypoints']) * 5 + src_results['segmentation'] = segmentation + src_results['keypoints'] = keypoints + transform = BottomupRandomCrop( + crop_size=(7, 5), + allow_negative_crop=False, + recompute_bbox=False, + bbox_clip_border=True) + results = transform(deepcopy(src_results)) + h, w = results['img'].shape[:2] + self.assertEqual(h, 5) + self.assertEqual(w, 7) + self.assertEqual(results['bbox'].shape[0], 2) + self.assertTrue(results['keypoints_visible'].all()) + self.assertTupleEqual(results['segmentation'].shape[:2], (5, 7)) + self.assertEqual(results['img_shape'], results['img'].shape[:2]) + + # test bbox_clip_border = False + transform = BottomupRandomCrop( + crop_size=(10, 11), + allow_negative_crop=False, + recompute_bbox=True, + bbox_clip_border=False) + results = transform(deepcopy(src_results)) + self.assertTrue((results['bbox'] == src_results['bbox']).all()) + + # test the crop does not contain any gt-bbox + # allow_negative_crop = False + img = np.random.randint(0, 255, size=(10, 10), dtype=np.uint8) + bbox = np.zeros((0, 4), dtype=np.float32) + src_results = {'img': img, 'bbox': bbox} + transform = BottomupRandomCrop( + crop_size=(5, 3), allow_negative_crop=False) + results = transform(deepcopy(src_results)) + self.assertIsNone(results) + + # allow_negative_crop = True + img = np.random.randint(0, 255, size=(10, 10), dtype=np.uint8) + bbox = np.zeros((0, 4), dtype=np.float32) + src_results = {'img': img, 'bbox': bbox} + transform = BottomupRandomCrop( + crop_size=(5, 3), allow_negative_crop=True) + results = transform(deepcopy(src_results)) + self.assertTrue(isinstance(results, dict)) + + +class TestBottomupRandomChoiceResize(TestCase): + + def setUp(self): + self.data_info = get_coco_sample(img_shape=(300, 400)) + + def test_transform(self): + results = dict() + # test with one scale + transform = BottomupRandomChoiceResize(scales=[(1333, 800)]) + results = deepcopy(self.data_info) + results = transform(results) + self.assertEqual(results['img'].shape, (800, 1333, 3)) + + # test with multi scales + _scale_choice = [(1333, 800), (1333, 600)] + transform = BottomupRandomChoiceResize(scales=_scale_choice) + results = deepcopy(self.data_info) + results = transform(results) + self.assertIn((results['img'].shape[1], results['img'].shape[0]), + _scale_choice) + + # test keep_ratio + transform = BottomupRandomChoiceResize( + scales=[(900, 600)], resize_type='Resize', keep_ratio=True) + results = deepcopy(self.data_info) + _input_ratio = results['img'].shape[0] / results['img'].shape[1] + results = transform(results) + _output_ratio = results['img'].shape[0] / results['img'].shape[1] + self.assertLess(abs(_input_ratio - _output_ratio), 1.5 * 1e-3) + + # test clip_object_border + bbox = [[200, 150, 600, 450]] + transform = BottomupRandomChoiceResize( + scales=[(200, 150)], resize_type='Resize', clip_object_border=True) + results = deepcopy(self.data_info) + results['bbox'] = np.array(bbox) + results = transform(results) + self.assertEqual(results['img'].shape, (150, 200, 3)) + self.assertTrue((results['bbox'] == np.array([[100, 75, 200, + 150]])).all()) + + transform = BottomupRandomChoiceResize( + scales=[(200, 150)], + resize_type='Resize', + clip_object_border=False) + results = self.data_info + results['bbox'] = np.array(bbox) + results = transform(results) + assert results['img'].shape == (150, 200, 3) + assert np.equal(results['bbox'], np.array([[100, 75, 300, 225]])).all() diff --git a/tests/test_datasets/test_transforms/test_common_transforms.py b/tests/test_datasets/test_transforms/test_common_transforms.py index 2818081dca..fe81b9a94c 100644 --- a/tests/test_datasets/test_transforms/test_common_transforms.py +++ b/tests/test_datasets/test_transforms/test_common_transforms.py @@ -4,15 +4,17 @@ from copy import deepcopy from unittest import TestCase +import mmcv import numpy as np from mmcv.transforms import Compose, LoadImageFromFile from mmengine.utils import is_list_of -from mmpose.datasets.transforms import (Albumentation, GenerateTarget, - GetBBoxCenterScale, +from mmpose.datasets.transforms import (Albumentation, FilterAnnotations, + GenerateTarget, GetBBoxCenterScale, PhotometricDistortion, RandomBBoxTransform, RandomFlip, - RandomHalfBody, TopdownAffine) + RandomHalfBody, TopdownAffine, + YOLOXHSVRandomAug) from mmpose.testing import get_coco_sample @@ -49,7 +51,7 @@ def test_transform(self): results.update(bbox_center=center, bbox_scale=scale) results = transform(results) self.assertTrue(np.allclose(results['bbox_center'], center)) - self.assertTrue(np.allclose(results['bbox_scale'], scale)) + self.assertTrue(np.allclose(results['bbox_scale'], scale * padding)) def test_repr(self): transform = GetBBoxCenterScale(padding=1.25) @@ -600,3 +602,134 @@ def test_errors(self): with self.assertWarnsRegex(DeprecationWarning, '`target_type` is deprecated'): _ = GenerateTarget(encoder=encoder, target_type='heatmap') + + +class TestFilterAnnotations(TestCase): + + def setUp(self): + """Setup the model and optimizer which are used in every test + method.""" + self.results = { + 'img': + np.random.random((224, 224, 3)), + 'img_shape': (224, 224), + 'bbox': + np.array([[10, 10, 20, 20], [20, 20, 40, 40], [40, 40, 80, 80]]), + 'bbox_score': + np.array([0.9, 0.8, 0.7]), + 'category_id': + np.array([1, 2, 3]), + 'keypoints': + np.array([[15, 15, 1], [25, 25, 1], [45, 45, 1]]), + 'keypoints_visible': + np.array([[1, 1, 0], [1, 1, 1], [1, 1, 1]]), + 'area': + np.array([300, 600, 1200]), + } + + def test_transform(self): + # Test keep_empty = True + transform = FilterAnnotations( + min_gt_bbox_wh=(50, 50), + keep_empty=True, + by_box=True, + ) + results = transform(copy.deepcopy(self.results)) + self.assertIsNone(results) + + # Test keep_empty = False + transform = FilterAnnotations( + min_gt_bbox_wh=(50, 50), + keep_empty=False, + ) + results = transform(copy.deepcopy(self.results)) + self.assertTrue(isinstance(results, dict)) + + # Test filter annotations by bbox + transform = FilterAnnotations(min_gt_bbox_wh=(15, 15), by_box=True) + results = transform(copy.deepcopy(self.results)) + print((results['bbox'] == np.array([[20, 20, 40, 40], [40, 40, 80, + 80]])).all()) + self.assertTrue((results['bbox'] == np.array([[20, 20, 40, 40], + [40, 40, 80, + 80]])).all()) + self.assertTrue((results['bbox_score'] == np.array([0.8, 0.7])).all()) + self.assertTrue((results['category_id'] == np.array([2, 3])).all()) + self.assertTrue((results['keypoints'] == np.array([[25, 25, 1], + [45, 45, + 1]])).all()) + self.assertTrue( + (results['keypoints_visible'] == np.array([[1, 1, 1], [1, 1, + 1]])).all()) + self.assertTrue((results['area'] == np.array([600, 1200])).all()) + + # Test filter annotations by area + transform = FilterAnnotations(min_gt_area=1000, by_area=True) + results = transform(copy.deepcopy(self.results)) + self.assertIsInstance(results, dict) + self.assertTrue((results['bbox'] == np.array([[40, 40, 80, + 80]])).all()) + self.assertTrue((results['bbox_score'] == np.array([0.7])).all()) + self.assertTrue((results['category_id'] == np.array([3])).all()) + self.assertTrue((results['keypoints'] == np.array([[45, 45, + 1]])).all()) + self.assertTrue( + (results['keypoints_visible'] == np.array([[1, 1, 1]])).all()) + self.assertTrue((results['area'] == np.array([1200])).all()) + + # Test filter annotations by keypoints visibility + transform = FilterAnnotations(min_kpt_vis=3, by_kpt=True) + results = transform(copy.deepcopy(self.results)) + self.assertIsInstance(results, dict) + self.assertTrue((results['bbox'] == np.array([[20, 20, 40, 40], + [40, 40, 80, + 80]])).all()) + self.assertTrue((results['bbox_score'] == np.array([0.8, 0.7])).all()) + self.assertTrue((results['category_id'] == np.array([2, 3])).all()) + self.assertTrue((results['keypoints'] == np.array([[25, 25, 1], + [45, 45, + 1]])).all()) + self.assertTrue( + (results['keypoints_visible'] == np.array([[1, 1, 1], [1, 1, + 1]])).all()) + self.assertTrue((results['area'] == np.array([600, 1200])).all()) + + +class TestYOLOXHSVRandomAug(TestCase): + + def setUp(self): + """Setup the model and optimizer which are used in every test method. + + TestCase calls functions in this order: setUp() -> testMethod() -> + tearDown() -> cleanUp() + """ + img = mmcv.imread( + osp.join( + osp.dirname(__file__), '../../data/coco/000000000785.jpg'), + 'color') + self.results = { + 'img': + img, + 'img_shape': (640, 425), + 'category_id': + np.array([1, 2, 3], dtype=np.int64), + 'bbox': + np.array([[10, 10, 20, 20], [20, 20, 40, 40], [40, 40, 80, 80]], + dtype=np.float32), + } + + def test_transform(self): + transform = YOLOXHSVRandomAug() + results = transform(copy.deepcopy(self.results)) + self.assertTrue( + results['img'].shape[:2] == self.results['img'].shape[:2]) + self.assertTrue( + results['category_id'].shape[0] == results['bbox'].shape[0]) + self.assertTrue(results['bbox'].dtype == np.float32) + + def test_repr(self): + transform = YOLOXHSVRandomAug() + self.assertEqual( + repr(transform), ('YOLOXHSVRandomAug(hue_delta=5, ' + 'saturation_delta=30, ' + 'value_delta=30)')) diff --git a/tests/test_datasets/test_transforms/test_converting.py b/tests/test_datasets/test_transforms/test_converting.py index 09f06e1e65..9f535b5126 100644 --- a/tests/test_datasets/test_transforms/test_converting.py +++ b/tests/test_datasets/test_transforms/test_converting.py @@ -1,6 +1,9 @@ # Copyright (c) OpenMMLab. All rights reserved. + from unittest import TestCase +import numpy as np + from mmpose.datasets.transforms import KeypointConverter from mmpose.testing import get_coco_sample @@ -32,8 +35,10 @@ def test_transform(self): self.assertTrue((results['keypoints'][:, target_index] == self.data_info['keypoints'][:, source_index]).all()) + self.assertEqual(results['keypoints_visible'].ndim, 3) + self.assertEqual(results['keypoints_visible'].shape[2], 2) self.assertTrue( - (results['keypoints_visible'][:, target_index] == + (results['keypoints_visible'][:, target_index, 0] == self.data_info['keypoints_visible'][:, source_index]).all()) # 2-to-1 mapping @@ -58,8 +63,10 @@ def test_transform(self): (results['keypoints'][:, target_index] == 0.5 * (self.data_info['keypoints'][:, source_index] + self.data_info['keypoints'][:, source_index2])).all()) + self.assertEqual(results['keypoints_visible'].ndim, 3) + self.assertEqual(results['keypoints_visible'].shape[2], 2) self.assertTrue( - (results['keypoints_visible'][:, target_index] == + (results['keypoints_visible'][:, target_index, 0] == self.data_info['keypoints_visible'][:, source_index] * self.data_info['keypoints_visible'][:, source_index2]).all()) @@ -67,7 +74,36 @@ def test_transform(self): self.assertTrue( (results['keypoints'][:, target_index] == self.data_info['keypoints'][:, source_index]).all()) + self.assertEqual(results['keypoints_visible'].ndim, 3) + self.assertEqual(results['keypoints_visible'].shape[2], 2) self.assertTrue( - (results['keypoints_visible'][:, target_index] == + (results['keypoints_visible'][:, target_index, 0] == self.data_info['keypoints_visible'][:, source_index]).all()) + + # check 3d keypoint + self.data_info['keypoints_3d'] = np.random.random((4, 17, 3)) + self.data_info['target_idx'] = [-1] + mapping = [(3, 0), (6, 1), (16, 2), (5, 3)] + transform = KeypointConverter(num_keypoints=5, mapping=mapping) + results = transform(self.data_info.copy()) + + # check shape + self.assertEqual(results['keypoints_3d'].shape[0], + self.data_info['keypoints_3d'].shape[0]) + self.assertEqual(results['keypoints_3d'].shape[1], 5) + self.assertEqual(results['keypoints_3d'].shape[2], 3) + self.assertEqual(results['keypoints_visible'].shape[0], + self.data_info['keypoints_visible'].shape[0]) + self.assertEqual(results['keypoints_visible'].shape[1], 5) + + # check value + for source_index, target_index in mapping: + self.assertTrue( + (results['keypoints_3d'][:, target_index] == + self.data_info['keypoints_3d'][:, source_index]).all()) + self.assertEqual(results['keypoints_visible'].ndim, 3) + self.assertEqual(results['keypoints_visible'].shape[2], 2) + self.assertTrue( + (results['keypoints_visible'][:, target_index, 0] == + self.data_info['keypoints_visible'][:, source_index]).all()) diff --git a/tests/test_datasets/test_transforms/test_mix_img_transform.py b/tests/test_datasets/test_transforms/test_mix_img_transform.py new file mode 100644 index 0000000000..bae26da83a --- /dev/null +++ b/tests/test_datasets/test_transforms/test_mix_img_transform.py @@ -0,0 +1,115 @@ +# Copyright (c) OpenMMLab. All rights reserved. + +from unittest import TestCase + +import numpy as np + +from mmpose.datasets.transforms import Mosaic, YOLOXMixUp + + +class TestMosaic(TestCase): + + def setUp(self): + # Create a sample data dictionary for testing + sample_data = { + 'img': + np.random.randint(0, 255, size=(480, 640, 3), dtype=np.uint8), + 'bbox': np.random.rand(2, 4), + 'bbox_score': np.random.rand(2, ), + 'category_id': [1, 2], + 'keypoints': np.random.rand(2, 3, 2), + 'keypoints_visible': np.random.rand(2, 3), + 'area': np.random.rand(2, ) + } + mixed_data_list = [sample_data.copy() for _ in range(3)] + sample_data.update({'mixed_data_list': mixed_data_list}) + + self.sample_data = sample_data + + def test_apply_mix(self): + mosaic = Mosaic() + transformed_data = mosaic.apply_mix(self.sample_data) + + # Check if the transformed data has the expected keys + self.assertTrue('img' in transformed_data) + self.assertTrue('img_shape' in transformed_data) + self.assertTrue('bbox' in transformed_data) + self.assertTrue('category_id' in transformed_data) + self.assertTrue('bbox_score' in transformed_data) + self.assertTrue('keypoints' in transformed_data) + self.assertTrue('keypoints_visible' in transformed_data) + self.assertTrue('area' in transformed_data) + + def test_create_mosaic_image(self): + mosaic = Mosaic() + mosaic_img, annos = mosaic._create_mosaic_image( + self.sample_data, self.sample_data['mixed_data_list']) + + # Check if the mosaic image and annotations are generated correctly + self.assertEqual(mosaic_img.shape, (1280, 1280, 3)) + self.assertTrue('bboxes' in annos) + self.assertTrue('bbox_scores' in annos) + self.assertTrue('category_id' in annos) + self.assertTrue('keypoints' in annos) + self.assertTrue('keypoints_visible' in annos) + self.assertTrue('area' in annos) + + def test_mosaic_combine(self): + mosaic = Mosaic() + center = (320, 240) + img_shape = (480, 640) + paste_coord, crop_coord = mosaic._mosaic_combine( + 'top_left', center, img_shape) + + # Check if the coordinates are calculated correctly + self.assertEqual(paste_coord, (0, 0, 320, 240)) + self.assertEqual(crop_coord, (160, 400, 480, 640)) + + +class TestYOLOXMixUp(TestCase): + + def setUp(self): + # Create a sample data dictionary for testing + sample_data = { + 'img': + np.random.randint(0, 255, size=(480, 640, 3), dtype=np.uint8), + 'bbox': np.random.rand(2, 4), + 'bbox_score': np.random.rand(2, ), + 'category_id': [1, 2], + 'keypoints': np.random.rand(2, 3, 2), + 'keypoints_visible': np.random.rand(2, 3), + 'area': np.random.rand(2, ), + 'flip_indices': [0, 2, 1] + } + mixed_data_list = [sample_data.copy() for _ in range(1)] + sample_data.update({'mixed_data_list': mixed_data_list}) + + self.sample_data = sample_data + + def test_apply_mix(self): + mixup = YOLOXMixUp() + transformed_data = mixup.apply_mix(self.sample_data) + + # Check if the transformed data has the expected keys + self.assertTrue('img' in transformed_data) + self.assertTrue('img_shape' in transformed_data) + self.assertTrue('bbox' in transformed_data) + self.assertTrue('category_id' in transformed_data) + self.assertTrue('bbox_score' in transformed_data) + self.assertTrue('keypoints' in transformed_data) + self.assertTrue('keypoints_visible' in transformed_data) + self.assertTrue('area' in transformed_data) + + def test_create_mixup_image(self): + mixup = YOLOXMixUp() + mixup_img, annos = mixup._create_mixup_image( + self.sample_data, self.sample_data['mixed_data_list']) + + # Check if the mosaic image and annotations are generated correctly + self.assertEqual(mixup_img.shape, (480, 640, 3)) + self.assertTrue('bboxes' in annos) + self.assertTrue('bbox_scores' in annos) + self.assertTrue('category_id' in annos) + self.assertTrue('keypoints' in annos) + self.assertTrue('keypoints_visible' in annos) + self.assertTrue('area' in annos) diff --git a/tests/test_datasets/test_transforms/test_pose3d_transforms.py b/tests/test_datasets/test_transforms/test_pose3d_transforms.py index 5f5d5aa096..c057dba4e7 100644 --- a/tests/test_datasets/test_transforms/test_pose3d_transforms.py +++ b/tests/test_datasets/test_transforms/test_pose3d_transforms.py @@ -35,7 +35,7 @@ def _parse_h36m_imgname(imgname): scales = data['scale'].astype(np.float32) idx = 0 - target_idx = 0 + target_idx = [0] data_info = { 'keypoints': keypoints[idx, :, :2].reshape(1, -1, 2), @@ -52,7 +52,6 @@ def _parse_h36m_imgname(imgname): 'sample_idx': idx, 'lifting_target': keypoints_3d[target_idx, :, :3], 'lifting_target_visible': keypoints_3d[target_idx, :, 3], - 'target_img_path': osp.join('tests/data/h36m', imgnames[target_idx]), } # add camera parameters @@ -108,9 +107,12 @@ def test_transform(self): tar_vis2 = results['lifting_target_visible'] self.assertEqual(kpts_vis2.shape, (1, 17)) - self.assertEqual(tar_vis2.shape, (17, )) + self.assertEqual(tar_vis2.shape, ( + 1, + 17, + )) self.assertEqual(kpts2.shape, (1, 17, 2)) - self.assertEqual(tar2.shape, (17, 3)) + self.assertEqual(tar2.shape, (1, 17, 3)) flip_indices = [ 0, 4, 5, 6, 1, 2, 3, 7, 8, 9, 10, 14, 15, 16, 11, 12, 13 @@ -121,12 +123,15 @@ def test_transform(self): self.assertTrue( np.allclose(kpts1[0][left][1:], kpts2[0][right][1:], atol=4.)) self.assertTrue( - np.allclose(tar1[left][1:], tar2[right][1:], atol=4.)) + np.allclose( + tar1[..., left, 1:], tar2[..., right, 1:], atol=4.)) self.assertTrue( - np.allclose(kpts_vis1[0][left], kpts_vis2[0][right], atol=4.)) + np.allclose( + kpts_vis1[..., left], kpts_vis2[..., right], atol=4.)) self.assertTrue( - np.allclose(tar_vis1[left], tar_vis2[right], atol=4.)) + np.allclose( + tar_vis1[..., left], tar_vis2[..., right], atol=4.)) # test camera flipping transform = RandomFlipAroundRoot( @@ -148,3 +153,47 @@ def test_transform(self): -self.data_info['camera_param']['p'][0], camera2['p'][0], atol=4.)) + + # test label flipping + self.data_info['keypoint_labels'] = kpts1 + self.data_info['keypoint_labels_visible'] = kpts_vis1 + self.data_info['lifting_target_label'] = tar1 + + transform = RandomFlipAroundRoot( + self.keypoints_flip_cfg, + self.target_flip_cfg, + flip_prob=1, + flip_label=True) + results = transform(deepcopy(self.data_info)) + + kpts2 = results['keypoint_labels'] + kpts_vis2 = results['keypoint_labels_visible'] + tar2 = results['lifting_target_label'] + tar_vis2 = results['lifting_target_visible'] + + self.assertEqual(kpts_vis2.shape, (1, 17)) + self.assertEqual(tar_vis2.shape, ( + 1, + 17, + )) + self.assertEqual(kpts2.shape, (1, 17, 2)) + self.assertEqual(tar2.shape, (1, 17, 3)) + + flip_indices = [ + 0, 4, 5, 6, 1, 2, 3, 7, 8, 9, 10, 14, 15, 16, 11, 12, 13 + ] + for left, right in enumerate(flip_indices): + self.assertTrue( + np.allclose(-kpts1[0][left][:1], kpts2[0][right][:1], atol=4.)) + self.assertTrue( + np.allclose(kpts1[0][left][1:], kpts2[0][right][1:], atol=4.)) + self.assertTrue( + np.allclose( + tar1[..., left, 1:], tar2[..., right, 1:], atol=4.)) + + self.assertTrue( + np.allclose( + kpts_vis1[..., left], kpts_vis2[..., right], atol=4.)) + self.assertTrue( + np.allclose( + tar_vis1[..., left], tar_vis2[..., right], atol=4.)) diff --git a/tests/test_engine/test_hooks/test_badcase_hook.py b/tests/test_engine/test_hooks/test_badcase_hook.py new file mode 100644 index 0000000000..4a84506fa8 --- /dev/null +++ b/tests/test_engine/test_hooks/test_badcase_hook.py @@ -0,0 +1,102 @@ +# Copyright (c) OpenMMLab. All rights reserved. +import os +import os.path as osp +import shutil +import time +from unittest import TestCase +from unittest.mock import MagicMock + +import numpy as np +from mmengine.config import ConfigDict +from mmengine.structures import InstanceData + +from mmpose.engine.hooks import BadCaseAnalysisHook +from mmpose.structures import PoseDataSample +from mmpose.visualization import PoseLocalVisualizer + + +def _rand_poses(num_boxes, kpt_num, h, w): + center = np.random.rand(num_boxes, 2) + offset = np.random.rand(num_boxes, kpt_num, 2) / 2.0 + + pose = center[:, None, :] + offset.clip(0, 1) + pose[:, :, 0] *= w + pose[:, :, 1] *= h + + return pose + + +class TestBadCaseHook(TestCase): + + def setUp(self) -> None: + kpt_num = 16 + PoseLocalVisualizer.get_instance('test_badcase_hook') + + data_sample = PoseDataSample() + data_sample.set_metainfo({ + 'img_path': + osp.join( + osp.dirname(__file__), '../../data/coco/000000000785.jpg') + }) + self.data_batch = {'data_samples': [data_sample] * 2} + + pred_det_data_sample = data_sample.clone() + pred_instances = InstanceData() + pred_instances.keypoints = _rand_poses(1, kpt_num, 10, 12) + pred_det_data_sample.pred_instances = pred_instances + + gt_instances = InstanceData() + gt_instances.keypoints = _rand_poses(1, kpt_num, 10, 12) + gt_instances.keypoints_visible = np.ones((1, kpt_num)) + gt_instances.head_size = np.random.rand(1, 1) + gt_instances.bboxes = np.random.rand(1, 4) + pred_det_data_sample.gt_instances = gt_instances + self.outputs = [pred_det_data_sample] * 2 + + def test_after_test_iter(self): + runner = MagicMock() + runner.iter = 1 + + # test + timestamp = time.strftime('%Y%m%d_%H%M%S', time.localtime()) + out_dir = timestamp + '1' + runner.work_dir = timestamp + runner.timestamp = '1' + hook = BadCaseAnalysisHook(enable=False, out_dir=out_dir) + hook.after_test_iter(runner, 1, self.data_batch, self.outputs) + self.assertTrue(not osp.exists(f'{timestamp}/1/{out_dir}')) + + hook = BadCaseAnalysisHook( + enable=True, + out_dir=out_dir, + metric_type='loss', + metric=ConfigDict(type='KeypointMSELoss'), + badcase_thr=-1, # is_badcase = True + ) + hook.after_test_iter(runner, 1, self.data_batch, self.outputs) + self.assertEqual(hook._test_index, 2) + self.assertTrue(osp.exists(f'{timestamp}/1/{out_dir}')) + # same image and preds/gts, so onlu one file + self.assertTrue(len(os.listdir(f'{timestamp}/1/{out_dir}')) == 1) + + hook.after_test_epoch(runner) + self.assertTrue(osp.exists(f'{timestamp}/1/{out_dir}/results.json')) + shutil.rmtree(f'{timestamp}') + + hook = BadCaseAnalysisHook( + enable=True, + out_dir=out_dir, + metric_type='accuracy', + metric=ConfigDict(type='MpiiPCKAccuracy'), + badcase_thr=-1, # is_badcase = False + ) + hook.after_test_iter(runner, 1, self.data_batch, self.outputs) + self.assertTrue(osp.exists(f'{timestamp}/1/{out_dir}')) + self.assertTrue(len(os.listdir(f'{timestamp}/1/{out_dir}')) == 0) + shutil.rmtree(f'{timestamp}') + + +if __name__ == '__main__': + test = TestBadCaseHook() + test.setUp() + test.test_after_test_iter() diff --git a/tests/test_engine/test_hooks/test_mode_switch_hooks.py b/tests/test_engine/test_hooks/test_mode_switch_hooks.py new file mode 100644 index 0000000000..fbf10bd3ef --- /dev/null +++ b/tests/test_engine/test_hooks/test_mode_switch_hooks.py @@ -0,0 +1,67 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase +from unittest.mock import Mock + +import torch +from mmengine.config import Config +from mmengine.runner import Runner +from torch.utils.data import Dataset + +from mmpose.engine.hooks import YOLOXPoseModeSwitchHook +from mmpose.utils import register_all_modules + + +class DummyDataset(Dataset): + METAINFO = dict() # type: ignore + data = torch.randn(12, 2) + label = torch.ones(12) + + @property + def metainfo(self): + return self.METAINFO + + def __len__(self): + return self.data.size(0) + + def __getitem__(self, index): + return dict(inputs=self.data[index], data_sample=self.label[index]) + + +pipeline1 = [ + dict(type='RandomHalfBody'), +] + +pipeline2 = [ + dict(type='RandomFlip'), +] +register_all_modules() + + +class TestYOLOXPoseModeSwitchHook(TestCase): + + def test(self): + train_dataloader = dict( + dataset=DummyDataset(), + sampler=dict(type='DefaultSampler', shuffle=True), + batch_size=3, + num_workers=0) + + runner = Mock() + runner.model = Mock() + runner.model.module = Mock() + + runner.model.head.use_aux_loss = False + runner.cfg.train_dataloader = Config(train_dataloader) + runner.train_dataloader = Runner.build_dataloader(train_dataloader) + runner.train_dataloader.dataset.pipeline = pipeline1 + + hook = YOLOXPoseModeSwitchHook( + num_last_epochs=15, new_train_pipeline=pipeline2) + + # test after change mode + runner.epoch = 284 + runner.max_epochs = 300 + hook.before_train_epoch(runner) + self.assertTrue(runner.model.bbox_head.use_aux_loss) + self.assertEqual(runner.train_loop.dataloader.dataset.pipeline, + pipeline2) diff --git a/tests/test_engine/test_hooks/test_sync_norm_hook.py b/tests/test_engine/test_hooks/test_sync_norm_hook.py new file mode 100644 index 0000000000..f256127fa1 --- /dev/null +++ b/tests/test_engine/test_hooks/test_sync_norm_hook.py @@ -0,0 +1,44 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase +from unittest.mock import Mock, patch + +import torch.nn as nn + +from mmpose.engine.hooks import SyncNormHook + + +class TestSyncNormHook(TestCase): + + @patch( + 'mmpose.engine.hooks.sync_norm_hook.get_dist_info', + return_value=(0, 1)) + def test_before_val_epoch_non_dist(self, mock): + model = nn.Sequential( + nn.Conv2d(1, 5, kernel_size=3), nn.BatchNorm2d(5, momentum=0.3), + nn.Linear(5, 10)) + runner = Mock() + runner.model = model + hook = SyncNormHook() + hook.before_val_epoch(runner) + + @patch( + 'mmpose.engine.hooks.sync_norm_hook.get_dist_info', + return_value=(0, 2)) + def test_before_val_epoch_dist(self, mock): + model = nn.Sequential( + nn.Conv2d(1, 5, kernel_size=3), nn.BatchNorm2d(5, momentum=0.3), + nn.Linear(5, 10)) + runner = Mock() + runner.model = model + hook = SyncNormHook() + hook.before_val_epoch(runner) + + @patch( + 'mmpose.engine.hooks.sync_norm_hook.get_dist_info', + return_value=(0, 2)) + def test_before_val_epoch_dist_no_norm(self, mock): + model = nn.Sequential(nn.Conv2d(1, 5, kernel_size=3), nn.Linear(5, 10)) + runner = Mock() + runner.model = model + hook = SyncNormHook() + hook.before_val_epoch(runner) diff --git a/tests/test_engine/test_schedulers/test_quadratic_warmup.py b/tests/test_engine/test_schedulers/test_quadratic_warmup.py new file mode 100644 index 0000000000..9f0650b0c2 --- /dev/null +++ b/tests/test_engine/test_schedulers/test_quadratic_warmup.py @@ -0,0 +1,108 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import torch +import torch.nn.functional as F +import torch.optim as optim +from mmengine.optim.scheduler import _ParamScheduler +from mmengine.testing import assert_allclose + +from mmpose.engine.schedulers import (QuadraticWarmupLR, + QuadraticWarmupMomentum, + QuadraticWarmupParamScheduler) + + +class ToyModel(torch.nn.Module): + + def __init__(self): + super().__init__() + self.conv1 = torch.nn.Conv2d(1, 1, 1) + self.conv2 = torch.nn.Conv2d(1, 1, 1) + + def forward(self, x): + return self.conv2(F.relu(self.conv1(x))) + + +class TestQuadraticWarmupScheduler(TestCase): + + def setUp(self): + """Setup the model and optimizer which are used in every test method. + + TestCase calls functions in this order: setUp() -> testMethod() -> + tearDown() -> cleanUp() + """ + self.model = ToyModel() + self.optimizer = optim.SGD( + self.model.parameters(), lr=0.05, momentum=0.01, weight_decay=5e-4) + + def _test_scheduler_value(self, + schedulers, + targets, + epochs=10, + param_name='lr'): + if isinstance(schedulers, _ParamScheduler): + schedulers = [schedulers] + for epoch in range(epochs): + for param_group, target in zip(self.optimizer.param_groups, + targets): + print(param_group[param_name]) + assert_allclose( + target[epoch], + param_group[param_name], + msg='{} is wrong in epoch {}: expected {}, got {}'.format( + param_name, epoch, target[epoch], + param_group[param_name]), + atol=1e-5, + rtol=0) + [scheduler.step() for scheduler in schedulers] + + def test_quadratic_warmup_scheduler(self): + with self.assertRaises(ValueError): + QuadraticWarmupParamScheduler(self.optimizer, param_name='lr') + epochs = 10 + iters = 5 + warmup_factor = [pow((i + 1) / float(iters), 2) for i in range(iters)] + single_targets = [x * 0.05 for x in warmup_factor] + [0.05] * ( + epochs - iters) + targets = [single_targets, [x * epochs for x in single_targets]] + scheduler = QuadraticWarmupParamScheduler( + self.optimizer, param_name='lr', end=iters) + self._test_scheduler_value(scheduler, targets, epochs) + + def test_quadratic_warmup_scheduler_convert_iterbased(self): + epochs = 10 + end = 5 + epoch_length = 11 + + iters = end * epoch_length + warmup_factor = [pow((i + 1) / float(iters), 2) for i in range(iters)] + single_targets = [x * 0.05 for x in warmup_factor] + [0.05] * ( + epochs * epoch_length - iters) + targets = [single_targets, [x * epochs for x in single_targets]] + scheduler = QuadraticWarmupParamScheduler.build_iter_from_epoch( + self.optimizer, + param_name='lr', + end=end, + epoch_length=epoch_length) + self._test_scheduler_value(scheduler, targets, epochs * epoch_length) + + def test_quadratic_warmup_lr(self): + epochs = 10 + iters = 5 + warmup_factor = [pow((i + 1) / float(iters), 2) for i in range(iters)] + single_targets = [x * 0.05 for x in warmup_factor] + [0.05] * ( + epochs - iters) + targets = [single_targets, [x * epochs for x in single_targets]] + scheduler = QuadraticWarmupLR(self.optimizer, end=iters) + self._test_scheduler_value(scheduler, targets, epochs) + + def test_quadratic_warmup_momentum(self): + epochs = 10 + iters = 5 + warmup_factor = [pow((i + 1) / float(iters), 2) for i in range(iters)] + single_targets = [x * 0.01 for x in warmup_factor] + [0.01] * ( + epochs - iters) + targets = [single_targets, [x * epochs for x in single_targets]] + scheduler = QuadraticWarmupMomentum(self.optimizer, end=iters) + self._test_scheduler_value( + scheduler, targets, epochs, param_name='momentum') diff --git a/tests/test_evaluation/test_evaluator/test_multi_dataset_evaluator.py b/tests/test_evaluation/test_evaluator/test_multi_dataset_evaluator.py new file mode 100644 index 0000000000..ef75d4332d --- /dev/null +++ b/tests/test_evaluation/test_evaluator/test_multi_dataset_evaluator.py @@ -0,0 +1,101 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import numpy as np + +from mmpose.evaluation.evaluators import MultiDatasetEvaluator +from mmpose.testing import get_coco_sample +from mmpose.utils import register_all_modules + + +class TestMultiDatasetEvaluator(TestCase): + + def setUp(self) -> None: + register_all_modules() + + aic_to_coco_converter = dict( + type='KeypointConverter', + num_keypoints=17, + mapping=[ + (0, 6), + (1, 8), + (2, 10), + (3, 5), + (4, 7), + (5, 9), + (6, 12), + (7, 14), + (8, 16), + (9, 11), + (10, 13), + (11, 15), + ]) + + # val datasets + dataset_coco_val = dict( + type='CocoDataset', + data_root='data/coco', + test_mode=True, + ) + + dataset_aic_val = dict( + type='AicDataset', + data_root='data/aic/', + test_mode=True, + ) + + self.datasets = [dataset_coco_val, dataset_aic_val] + + self.metrics = [ + dict(type='CocoMetric', ann_file='tests/data/coco/test_coco.json'), + dict( + type='CocoMetric', + ann_file='tests/data/aic/test_aic.json', + use_area=False, + gt_converter=aic_to_coco_converter, + prefix='aic') + ] + + data_sample1 = get_coco_sample( + img_shape=(240, 320), num_instances=2, with_bbox_cs=False) + data_sample1['dataset_name'] = 'coco' + data_sample1['id'] = 0 + data_sample1['img_id'] = 100 + data_sample1['gt_instances'] = dict(bbox_scores=np.ones(2), ) + data_sample1['pred_instances'] = dict( + keypoints=data_sample1['keypoints'], + keypoint_scores=data_sample1['keypoints_visible'], + ) + imgs1 = data_sample1.pop('img') + + data_sample2 = get_coco_sample( + img_shape=(240, 320), num_instances=3, with_bbox_cs=False) + data_sample2['dataset_name'] = 'aic' + data_sample2['id'] = 1 + data_sample2['img_id'] = 200 + data_sample2['gt_instances'] = dict(bbox_scores=np.ones(3), ) + data_sample2['pred_instances'] = dict( + keypoints=data_sample2['keypoints'], + keypoint_scores=data_sample2['keypoints_visible'], + ) + imgs2 = data_sample2.pop('img') + + self.data_batch = dict( + inputs=[imgs1, imgs2], data_samples=[data_sample1, data_sample2]) + self.data_samples = [data_sample1, data_sample2] + + def test_init(self): + evaluator = MultiDatasetEvaluator(self.metrics, self.datasets) + self.assertIn('metrics_dict', dir(evaluator)) + self.assertEqual(len(evaluator.metrics_dict), 2) + + with self.assertRaises(AssertionError): + evaluator = MultiDatasetEvaluator(self.metrics, self.datasets[:1]) + + def test_process(self): + evaluator = MultiDatasetEvaluator(self.metrics, self.datasets) + evaluator.dataset_meta = dict(dataset_name='default') + evaluator.process(self.data_samples, self.data_batch) + + for metric in evaluator.metrics: + self.assertGreater(len(metric.results), 0) diff --git a/tests/test_evaluation/test_functional/test_nms.py b/tests/test_evaluation/test_functional/test_nms.py index b29ed86ccb..34a2533b76 100644 --- a/tests/test_evaluation/test_functional/test_nms.py +++ b/tests/test_evaluation/test_functional/test_nms.py @@ -2,8 +2,9 @@ from unittest import TestCase import numpy as np +import torch -from mmpose.evaluation.functional.nms import nearby_joints_nms +from mmpose.evaluation.functional.nms import nearby_joints_nms, nms_torch class TestNearbyJointsNMS(TestCase): @@ -38,3 +39,21 @@ def test_nearby_joints_nms(self): with self.assertRaises(AssertionError): _ = nearby_joints_nms(kpts_db, 0.05, num_nearby_joints_thr=3) + + +class TestNMSTorch(TestCase): + + def test_nms_torch(self): + bboxes = torch.tensor([[0, 0, 3, 3], [1, 0, 3, 3], [4, 4, 6, 6]], + dtype=torch.float32) + + scores = torch.tensor([0.9, 0.8, 0.7]) + + expected_result = torch.tensor([0, 2]) + result = nms_torch(bboxes, scores, threshold=0.5) + self.assertTrue(torch.equal(result, expected_result)) + + expected_result = [torch.tensor([0, 1]), torch.tensor([2])] + result = nms_torch(bboxes, scores, threshold=0.5, return_group=True) + for res_out, res_expected in zip(result, expected_result): + self.assertTrue(torch.equal(res_out, res_expected)) diff --git a/tests/test_evaluation/test_functional/test_transforms.py b/tests/test_evaluation/test_functional/test_transforms.py new file mode 100644 index 0000000000..22ad39b604 --- /dev/null +++ b/tests/test_evaluation/test_functional/test_transforms.py @@ -0,0 +1,56 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from copy import deepcopy +from unittest import TestCase + +import numpy as np + +from mmpose.evaluation.functional import (transform_ann, transform_pred, + transform_sigmas) + + +class TestKeypointEval(TestCase): + + def test_transform_sigmas(self): + + mapping = [(3, 0), (6, 1), (16, 2), (5, 3)] + num_keypoints = 5 + sigmas = np.random.rand(17) + new_sigmas = transform_sigmas(sigmas, num_keypoints, mapping) + self.assertEqual(len(new_sigmas), 5) + for i, j in mapping: + self.assertEqual(sigmas[i], new_sigmas[j]) + + def test_transform_ann(self): + mapping = [(3, 0), (6, 1), (16, 2), (5, 3)] + num_keypoints = 5 + + kpt_info = dict( + num_keypoints=17, + keypoints=np.random.randint(3, size=(17 * 3, )).tolist()) + kpt_info_copy = deepcopy(kpt_info) + + _ = transform_ann(kpt_info, num_keypoints, mapping) + + self.assertEqual(kpt_info['num_keypoints'], 5) + self.assertEqual(len(kpt_info['keypoints']), 15) + for i, j in mapping: + self.assertListEqual(kpt_info_copy['keypoints'][i * 3:i * 3 + 3], + kpt_info['keypoints'][j * 3:j * 3 + 3]) + + def test_transform_pred(self): + mapping = [(3, 0), (6, 1), (16, 2), (5, 3)] + num_keypoints = 5 + + kpt_info = dict( + num_keypoints=17, + keypoints=np.random.randint(3, size=( + 1, + 17, + 3, + )), + keypoint_scores=np.ones((1, 17))) + + _ = transform_pred(kpt_info, num_keypoints, mapping) + + self.assertEqual(kpt_info['num_keypoints'], 5) + self.assertEqual(len(kpt_info['keypoints']), 1) diff --git a/tests/test_evaluation/test_metrics/test_coco_metric.py b/tests/test_evaluation/test_metrics/test_coco_metric.py index 82bf0bc572..9863f0ffe3 100644 --- a/tests/test_evaluation/test_metrics/test_coco_metric.py +++ b/tests/test_evaluation/test_metrics/test_coco_metric.py @@ -7,8 +7,10 @@ import numpy as np from mmengine.fileio import dump, load +from mmengine.logging import MessageHub from xtcocotools.coco import COCO +from mmpose.datasets.datasets import CocoDataset from mmpose.datasets.datasets.utils import parse_pose_metainfo from mmpose.evaluation.metrics import CocoMetric @@ -21,6 +23,12 @@ def setUp(self): TestCase calls functions in this order: setUp() -> testMethod() -> tearDown() -> cleanUp() """ + + # during CI on github, the unit tests for datasets will save ann_file + # into MessageHub, which will influence the unit tests for CocoMetric + msg = MessageHub.get_current_instance() + msg.runtime_info.clear() + self.tmp_dir = tempfile.TemporaryDirectory() self.ann_file_coco = 'tests/data/coco/test_coco.json' @@ -59,6 +67,10 @@ def setUp(self): self.topdown_data_crowdpose = self._convert_ann_to_topdown_batch_data( self.ann_file_crowdpose) + self.topdown_data_pseudo_coco = \ + self._convert_ann_to_topdown_batch_data( + self.ann_file_crowdpose, + num_pseudo_kpts=3) assert len(self.topdown_data_crowdpose) == 5 self.bottomup_data_crowdpose = \ self._convert_ann_to_bottomup_batch_data(self.ann_file_crowdpose) @@ -103,7 +115,9 @@ def setUp(self): 'coco/AR (L)': 1.0, } - def _convert_ann_to_topdown_batch_data(self, ann_file): + def _convert_ann_to_topdown_batch_data(self, + ann_file, + num_pseudo_kpts: int = 0): """Convert annotations to topdown-style batch data.""" topdown_data = [] db = load(ann_file) @@ -121,6 +135,12 @@ def _convert_ann_to_topdown_batch_data(self, ann_file): 'bbox_scores': np.ones((1, ), dtype=np.float32), 'bboxes': bboxes, } + + if num_pseudo_kpts > 0: + keypoints = np.concatenate( + (keypoints, *((keypoints[:, :1], ) * num_pseudo_kpts)), + axis=1) + pred_instances = { 'keypoints': keypoints[..., :2], 'keypoint_scores': keypoints[..., -1], @@ -610,3 +630,55 @@ def test_topdown_evaluate(self): osp.isfile(osp.join(self.tmp_dir.name, 'test8.gt.json'))) self.assertTrue( osp.isfile(osp.join(self.tmp_dir.name, 'test8.keypoints.json'))) + + def test_gt_converter(self): + + crowdpose_to_coco_converter = dict( + type='KeypointConverter', + num_keypoints=17, + mapping=[ + (0, 5), + (1, 6), + (2, 7), + (3, 8), + (4, 9), + (5, 10), + (6, 11), + (7, 12), + (8, 13), + (9, 14), + (10, 15), + (11, 16), + ]) + + metric_crowdpose = CocoMetric( + ann_file=self.ann_file_crowdpose, + outfile_prefix=f'{self.tmp_dir.name}/test_convert', + use_area=False, + gt_converter=crowdpose_to_coco_converter, + iou_type='keypoints_crowd', + prefix='crowdpose') + metric_crowdpose.dataset_meta = self.dataset_meta_crowdpose + + self.assertEqual(metric_crowdpose.dataset_meta['num_keypoints'], 17) + self.assertEqual(len(metric_crowdpose.dataset_meta['sigmas']), 17) + + # process samples + for data_batch, data_samples in self.topdown_data_pseudo_coco: + metric_crowdpose.process(data_batch, data_samples) + + _ = metric_crowdpose.evaluate(size=len(self.topdown_data_crowdpose)) + + self.assertTrue( + osp.isfile( + osp.join(self.tmp_dir.name, 'test_convert.keypoints.json'))) + + def test_get_ann_file_from_dataset(self): + _ = CocoDataset(ann_file=self.ann_file_coco, test_mode=True) + metric = CocoMetric(ann_file=None) + metric.dataset_meta = self.dataset_meta_coco + self.assertIsNotNone(metric.coco) + + # clear message to avoid disturbing other tests + message = MessageHub.get_current_instance() + message.pop_info('coco_ann_file') diff --git a/tests/test_evaluation/test_metrics/test_coco_wholebody_metric.py b/tests/test_evaluation/test_metrics/test_coco_wholebody_metric.py index 46e8498851..fa4c04fab3 100644 --- a/tests/test_evaluation/test_metrics/test_coco_wholebody_metric.py +++ b/tests/test_evaluation/test_metrics/test_coco_wholebody_metric.py @@ -7,6 +7,7 @@ import numpy as np from mmengine.fileio import dump, load +from mmengine.logging import MessageHub from xtcocotools.coco import COCO from mmpose.datasets.datasets.utils import parse_pose_metainfo @@ -21,6 +22,13 @@ def setUp(self): TestCase calls functions in this order: setUp() -> testMethod() -> tearDown() -> cleanUp() """ + + # during CI on github, the unit tests for datasets will save ann_file + # into MessageHub, which will influence the unit tests for + # CocoWholeBodyMetric + msg = MessageHub.get_current_instance() + msg.runtime_info.clear() + self.tmp_dir = tempfile.TemporaryDirectory() self.ann_file_coco = 'tests/data/coco/test_coco_wholebody.json' diff --git a/tests/test_evaluation/test_metrics/test_hand_metric.py b/tests/test_evaluation/test_metrics/test_hand_metric.py new file mode 100644 index 0000000000..4828484752 --- /dev/null +++ b/tests/test_evaluation/test_metrics/test_hand_metric.py @@ -0,0 +1,201 @@ +# Copyright (c) OpenMMLab. All rights reserved. +import json +import tempfile +from unittest import TestCase + +import numpy as np +from mmengine.fileio import load +from xtcocotools.coco import COCO + +from mmpose.codecs.utils import camera_to_pixel +from mmpose.datasets.datasets.utils import parse_pose_metainfo +from mmpose.evaluation import InterHandMetric + + +class TestInterHandMetric(TestCase): + + def setUp(self): + """Setup some variables which are used in every test method. + + TestCase calls functions in this order: setUp() -> testMethod() -> + tearDown() -> cleanUp() + """ + self.tmp_dir = tempfile.TemporaryDirectory() + + self.ann_file = 'tests/data/interhand2.6m/test_interhand2.6m_data.json' + meta_info = dict(from_file='configs/_base_/datasets/interhand3d.py') + self.dataset_meta = parse_pose_metainfo(meta_info) + self.coco = COCO(self.ann_file) + + self.joint_file = ('tests/data/interhand2.6m/' + 'test_interhand2.6m_joint_3d.json') + with open(self.joint_file, 'r') as f: + self.joints = json.load(f) + + self.camera_file = ('tests/data/interhand2.6m/' + 'test_interhand2.6m_camera.json') + with open(self.camera_file, 'r') as f: + self.cameras = json.load(f) + + self.topdown_data = self._convert_ann_to_topdown_batch_data( + self.ann_file) + assert len(self.topdown_data) == 4 + self.target = { + 'MPJPE_all': 0.0, + 'MPJPE_interacting': 0.0, + 'MPJPE_single': 0.0, + 'MRRPE': 0.0, + 'HandednessAcc': 1.0 + } + + def encode_handtype(self, hand_type): + if hand_type == 'right': + return np.array([[1, 0]], dtype=np.float32) + elif hand_type == 'left': + return np.array([[0, 1]], dtype=np.float32) + elif hand_type == 'interacting': + return np.array([[1, 1]], dtype=np.float32) + else: + assert 0, f'Not support hand type: {hand_type}' + + def _convert_ann_to_topdown_batch_data(self, ann_file): + """Convert annotations to topdown-style batch data.""" + topdown_data = [] + db = load(ann_file) + num_keypoints = 42 + imgid2info = dict() + for img in db['images']: + imgid2info[img['id']] = img + for ann in db['annotations']: + image_id = ann['image_id'] + img = imgid2info[image_id] + frame_idx = str(img['frame_idx']) + capture_id = str(img['capture']) + camera_name = img['camera'] + + camera_pos = np.array( + self.cameras[capture_id]['campos'][camera_name], + dtype=np.float32) + camera_rot = np.array( + self.cameras[capture_id]['camrot'][camera_name], + dtype=np.float32) + focal = np.array( + self.cameras[capture_id]['focal'][camera_name], + dtype=np.float32) + principal_pt = np.array( + self.cameras[capture_id]['princpt'][camera_name], + dtype=np.float32) + joint_world = np.array( + self.joints[capture_id][frame_idx]['world_coord'], + dtype=np.float32) + joint_valid = np.array( + ann['joint_valid'], dtype=np.float32).flatten() + + keypoints_cam = np.dot( + camera_rot, + joint_world.transpose(1, 0) - + camera_pos.reshape(3, 1)).transpose(1, 0) + joint_img = camera_to_pixel( + keypoints_cam, + focal[0], + focal[1], + principal_pt[0], + principal_pt[1], + shift=True)[:, :2] + + abs_depth = [keypoints_cam[20, 2], keypoints_cam[41, 2]] + + rel_root_depth = keypoints_cam[41, 2] - keypoints_cam[20, 2] + + joint_valid[:20] *= joint_valid[20] + joint_valid[21:] *= joint_valid[41] + + joints_3d = np.zeros((num_keypoints, 3), + dtype=np.float32).reshape(1, -1, 3) + joints_3d[..., :2] = joint_img + joints_3d[..., :21, + 2] = keypoints_cam[:21, 2] - keypoints_cam[20, 2] + joints_3d[..., 21:, + 2] = keypoints_cam[21:, 2] - keypoints_cam[41, 2] + joints_3d_visible = np.minimum(1, joint_valid.reshape(-1, 1)) + joints_3d_visible = joints_3d_visible.reshape(1, -1) + + gt_instances = { + 'keypoints_cam': keypoints_cam.reshape(1, -1, 3), + 'keypoints_visible': joints_3d_visible, + } + pred_instances = { + 'keypoints': joints_3d, + 'hand_type': self.encode_handtype(ann['hand_type']), + 'rel_root_depth': rel_root_depth, + } + + data = {'inputs': None} + data_sample = { + 'id': ann['id'], + 'img_id': ann['image_id'], + 'gt_instances': gt_instances, + 'pred_instances': pred_instances, + 'hand_type': self.encode_handtype(ann['hand_type']), + 'hand_type_valid': np.array([ann['hand_type_valid']]), + 'abs_depth': abs_depth, + 'focal': focal, + 'principal_pt': principal_pt, + } + + # batch size = 1 + data_batch = [data] + data_samples = [data_sample] + topdown_data.append((data_batch, data_samples)) + + return topdown_data + + def tearDown(self): + self.tmp_dir.cleanup() + + def test_init(self): + """test metric init method.""" + # test modes option + with self.assertRaisesRegex(ValueError, '`mode` should be'): + _ = InterHandMetric(modes=['invalid']) + + def test_topdown_evaluate(self): + """test topdown-style COCO metric evaluation.""" + # case 1: modes='MPJPE' + metric = InterHandMetric(modes=['MPJPE']) + metric.dataset_meta = self.dataset_meta + + # process samples + for data_batch, data_samples in self.topdown_data: + metric.process(data_batch, data_samples) + + eval_results = metric.evaluate(size=len(self.topdown_data)) + + for metric, err in eval_results.items(): + self.assertAlmostEqual(err, self.target[metric], places=4) + + # case 2: modes='MRRPE' + metric = InterHandMetric(modes=['MRRPE']) + metric.dataset_meta = self.dataset_meta + + # process samples + for data_batch, data_samples in self.topdown_data: + metric.process(data_batch, data_samples) + + eval_results = metric.evaluate(size=len(self.topdown_data)) + + for metric, err in eval_results.items(): + self.assertAlmostEqual(err, self.target[metric], places=4) + + # case 2: modes='HandednessAcc' + metric = InterHandMetric(modes=['HandednessAcc']) + metric.dataset_meta = self.dataset_meta + + # process samples + for data_batch, data_samples in self.topdown_data: + metric.process(data_batch, data_samples) + + eval_results = metric.evaluate(size=len(self.topdown_data)) + + for metric, err in eval_results.items(): + self.assertAlmostEqual(err, self.target[metric], places=4) diff --git a/tests/test_evaluation/test_metrics/test_keypoint_3d_metrics.py b/tests/test_evaluation/test_metrics/test_keypoint_3d_metrics.py index 8289b09d0f..391b7b194a 100644 --- a/tests/test_evaluation/test_metrics/test_keypoint_3d_metrics.py +++ b/tests/test_evaluation/test_metrics/test_keypoint_3d_metrics.py @@ -20,9 +20,10 @@ def setUp(self): for i in range(self.batch_size): gt_instances = InstanceData() keypoints = np.random.random((1, num_keypoints, 3)) - gt_instances.lifting_target = np.random.random((num_keypoints, 3)) + gt_instances.lifting_target = np.random.random( + (1, num_keypoints, 3)) gt_instances.lifting_target_visible = np.ones( - (num_keypoints, 1)).astype(bool) + (1, num_keypoints, 1)).astype(bool) pred_instances = InstanceData() pred_instances.keypoints = keypoints + np.random.normal( @@ -32,8 +33,10 @@ def setUp(self): data_sample = PoseDataSample( gt_instances=gt_instances, pred_instances=pred_instances) data_sample.set_metainfo( - dict(target_img_path='tests/data/h36m/S7/' - 'S7_Greeting.55011271/S7_Greeting.55011271_000396.jpg')) + dict(target_img_path=[ + 'tests/data/h36m/S7/' + 'S7_Greeting.55011271/S7_Greeting.55011271_000396.jpg' + ])) self.data_batch.append(data) self.data_samples.append(data_sample.to_dict()) diff --git a/tests/test_evaluation/test_metrics/test_keypoint_partition_metric.py b/tests/test_evaluation/test_metrics/test_keypoint_partition_metric.py index 2b1a60c113..0d11699097 100644 --- a/tests/test_evaluation/test_metrics/test_keypoint_partition_metric.py +++ b/tests/test_evaluation/test_metrics/test_keypoint_partition_metric.py @@ -7,6 +7,7 @@ import numpy as np from mmengine.fileio import load +from mmengine.logging import MessageHub from mmengine.structures import InstanceData from xtcocotools.coco import COCO @@ -22,6 +23,12 @@ def setUp(self): TestCase calls functions in this order: setUp() -> testMethod() -> tearDown() -> cleanUp() """ + + # during CI on github, the unit tests for datasets will save ann_file + # into MessageHub, which will influence the unit tests for CocoMetric + msg = MessageHub.get_current_instance() + msg.runtime_info.clear() + self.tmp_dir = tempfile.TemporaryDirectory() self.ann_file_coco = \ diff --git a/tests/test_models/test_backbones/test_csp_darknet.py b/tests/test_models/test_backbones/test_csp_darknet.py new file mode 100644 index 0000000000..61b200b749 --- /dev/null +++ b/tests/test_models/test_backbones/test_csp_darknet.py @@ -0,0 +1,125 @@ +# Copyright (c) OpenMMLab. All rights reserved. +import unittest + +import torch +from torch.nn.modules import GroupNorm +from torch.nn.modules.batchnorm import _BatchNorm + +from mmpose.models.backbones.csp_darknet import CSPDarknet + + +def is_norm(modules): + """Check if is one of the norms.""" + if isinstance(modules, (GroupNorm, _BatchNorm)): + return True + return False + + +def check_norm_state(modules, train_state): + """Check if norm layer is in correct train state.""" + for mod in modules: + if isinstance(mod, _BatchNorm): + if mod.training != train_state: + return False + return True + + +class TestCSPDarknetBackbone(unittest.TestCase): + + def test_invalid_frozen_stages(self): + with self.assertRaises(ValueError): + CSPDarknet(frozen_stages=6) + + def test_invalid_out_indices(self): + with self.assertRaises(AssertionError): + CSPDarknet(out_indices=[6]) + + def test_frozen_stages(self): + frozen_stages = 1 + model = CSPDarknet(frozen_stages=frozen_stages) + model.train() + + for mod in model.stem.modules(): + for param in mod.parameters(): + self.assertFalse(param.requires_grad) + for i in range(1, frozen_stages + 1): + layer = getattr(model, f'stage{i}') + for mod in layer.modules(): + if isinstance(mod, _BatchNorm): + self.assertFalse(mod.training) + for param in layer.parameters(): + self.assertFalse(param.requires_grad) + + def test_norm_eval(self): + model = CSPDarknet(norm_eval=True) + model.train() + + self.assertFalse(check_norm_state(model.modules(), True)) + + def test_csp_darknet_p5_forward(self): + model = CSPDarknet( + arch='P5', widen_factor=0.25, out_indices=range(0, 5)) + model.train() + + imgs = torch.randn(1, 3, 64, 64) + feat = model(imgs) + self.assertEqual(len(feat), 5) + self.assertEqual(feat[0].shape, torch.Size((1, 16, 32, 32))) + self.assertEqual(feat[1].shape, torch.Size((1, 32, 16, 16))) + self.assertEqual(feat[2].shape, torch.Size((1, 64, 8, 8))) + self.assertEqual(feat[3].shape, torch.Size((1, 128, 4, 4))) + self.assertEqual(feat[4].shape, torch.Size((1, 256, 2, 2))) + + def test_csp_darknet_p6_forward(self): + model = CSPDarknet( + arch='P6', + widen_factor=0.25, + out_indices=range(0, 6), + spp_kernal_sizes=(3, 5, 7)) + model.train() + + imgs = torch.randn(1, 3, 128, 128) + feat = model(imgs) + self.assertEqual(feat[0].shape, torch.Size((1, 16, 64, 64))) + self.assertEqual(feat[1].shape, torch.Size((1, 32, 32, 32))) + self.assertEqual(feat[2].shape, torch.Size((1, 64, 16, 16))) + self.assertEqual(feat[3].shape, torch.Size((1, 128, 8, 8))) + self.assertEqual(feat[4].shape, torch.Size((1, 192, 4, 4))) + self.assertEqual(feat[5].shape, torch.Size((1, 256, 2, 2))) + + def test_csp_darknet_custom_arch_forward(self): + arch_ovewrite = [[32, 56, 3, True, False], [56, 224, 2, True, False], + [224, 512, 1, True, False]] + model = CSPDarknet( + arch_ovewrite=arch_ovewrite, + widen_factor=0.25, + out_indices=(0, 1, 2, 3)) + model.train() + + imgs = torch.randn(1, 3, 32, 32) + feat = model(imgs) + self.assertEqual(len(feat), 4) + self.assertEqual(feat[0].shape, torch.Size((1, 8, 16, 16))) + self.assertEqual(feat[1].shape, torch.Size((1, 14, 8, 8))) + self.assertEqual(feat[2].shape, torch.Size((1, 56, 4, 4))) + self.assertEqual(feat[3].shape, torch.Size((1, 128, 2, 2))) + + def test_csp_darknet_custom_arch_norm(self): + model = CSPDarknet(widen_factor=0.125, out_indices=range(0, 5)) + for m in model.modules(): + if is_norm(m): + self.assertIsInstance(m, _BatchNorm) + model.train() + + imgs = torch.randn(1, 3, 64, 64) + feat = model(imgs) + self.assertEqual(len(feat), 5) + self.assertEqual(feat[0].shape, torch.Size((1, 8, 32, 32))) + self.assertEqual(feat[1].shape, torch.Size((1, 16, 16, 16))) + self.assertEqual(feat[2].shape, torch.Size((1, 32, 8, 8))) + self.assertEqual(feat[3].shape, torch.Size((1, 64, 4, 4))) + self.assertEqual(feat[4].shape, torch.Size((1, 128, 2, 2))) + + +if __name__ == '__main__': + unittest.main() diff --git a/tests/test_models/test_backbones/test_dstformer.py b/tests/test_models/test_backbones/test_dstformer.py new file mode 100644 index 0000000000..966ed6f49b --- /dev/null +++ b/tests/test_models/test_backbones/test_dstformer.py @@ -0,0 +1,36 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import torch + +from mmpose.models.backbones import DSTFormer +from mmpose.models.backbones.dstformer import AttentionBlock + + +class TestDSTFormer(TestCase): + + def test_attention_block(self): + # BasicTemporalBlock with causal == False + block = AttentionBlock(dim=256, num_heads=2) + x = torch.rand(2, 17, 256) + x_out = block(x) + self.assertEqual(x_out.shape, torch.Size([2, 17, 256])) + + def test_DSTFormer(self): + # Test DSTFormer with depth=2 + model = DSTFormer(in_channels=3, depth=2, seq_len=2) + pose3d = torch.rand((1, 2, 17, 3)) + feat = model(pose3d) + self.assertEqual(feat[0].shape, (2, 17, 256)) + + # Test DSTFormer with depth=4 and qkv_bias=False + model = DSTFormer(in_channels=3, depth=4, seq_len=2, qkv_bias=False) + pose3d = torch.rand((1, 2, 17, 3)) + feat = model(pose3d) + self.assertEqual(feat[0].shape, (2, 17, 256)) + + # Test DSTFormer with depth=4 and att_fuse=False + model = DSTFormer(in_channels=3, depth=4, seq_len=2, att_fuse=False) + pose3d = torch.rand((1, 2, 17, 3)) + feat = model(pose3d) + self.assertEqual(feat[0].shape, (2, 17, 256)) diff --git a/tests/test_models/test_data_preprocessors/test_data_preprocessor.py b/tests/test_models/test_data_preprocessors/test_data_preprocessor.py new file mode 100644 index 0000000000..6c669f55a2 --- /dev/null +++ b/tests/test_models/test_data_preprocessors/test_data_preprocessor.py @@ -0,0 +1,135 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import torch +from mmengine.logging import MessageHub + +from mmpose.models.data_preprocessors import (BatchSyncRandomResize, + PoseDataPreprocessor) +from mmpose.structures import PoseDataSample + + +class TestPoseDataPreprocessor(TestCase): + + def test_init(self): + # test mean is None + processor = PoseDataPreprocessor() + self.assertTrue(not hasattr(processor, 'mean')) + self.assertTrue(processor._enable_normalize is False) + + # test mean is not None + processor = PoseDataPreprocessor(mean=[0, 0, 0], std=[1, 1, 1]) + self.assertTrue(hasattr(processor, 'mean')) + self.assertTrue(hasattr(processor, 'std')) + self.assertTrue(processor._enable_normalize) + + # please specify both mean and std + with self.assertRaises(AssertionError): + PoseDataPreprocessor(mean=[0, 0, 0]) + + # bgr2rgb and rgb2bgr cannot be set to True at the same time + with self.assertRaises(AssertionError): + PoseDataPreprocessor(bgr_to_rgb=True, rgb_to_bgr=True) + + def test_forward(self): + processor = PoseDataPreprocessor(mean=[0, 0, 0], std=[1, 1, 1]) + + data = { + 'inputs': [torch.randint(0, 256, (3, 11, 10))], + 'data_samples': [PoseDataSample()] + } + out_data = processor(data) + batch_inputs, batch_data_samples = out_data['inputs'], out_data[ + 'data_samples'] + + self.assertEqual(batch_inputs.shape, (1, 3, 11, 10)) + self.assertEqual(len(batch_data_samples), 1) + + # test channel_conversion + processor = PoseDataPreprocessor( + mean=[0., 0., 0.], std=[1., 1., 1.], bgr_to_rgb=True) + out_data = processor(data) + batch_inputs, batch_data_samples = out_data['inputs'], out_data[ + 'data_samples'] + self.assertEqual(batch_inputs.shape, (1, 3, 11, 10)) + self.assertEqual(len(batch_data_samples), 1) + + # test padding + data = { + 'inputs': [ + torch.randint(0, 256, (3, 10, 11)), + torch.randint(0, 256, (3, 9, 14)) + ], + 'data_samples': [PoseDataSample()] * 2 + } + processor = PoseDataPreprocessor( + mean=[0., 0., 0.], std=[1., 1., 1.], bgr_to_rgb=True) + out_data = processor(data) + batch_inputs, batch_data_samples = out_data['inputs'], out_data[ + 'data_samples'] + self.assertEqual(batch_inputs.shape, (2, 3, 10, 14)) + self.assertEqual(len(batch_data_samples), 2) + + # test pad_size_divisor + data = { + 'inputs': [ + torch.randint(0, 256, (3, 10, 11)), + torch.randint(0, 256, (3, 9, 24)) + ], + 'data_samples': [PoseDataSample()] * 2 + } + processor = PoseDataPreprocessor( + mean=[0., 0., 0.], std=[1., 1., 1.], pad_size_divisor=5) + out_data = processor(data) + batch_inputs, batch_data_samples = out_data['inputs'], out_data[ + 'data_samples'] + self.assertEqual(batch_inputs.shape, (2, 3, 10, 25)) + self.assertEqual(len(batch_data_samples), 2) + for data_samples, expected_shape in zip(batch_data_samples, + [(10, 15), (10, 25)]): + self.assertEqual(data_samples.pad_shape, expected_shape) + + def test_batch_sync_random_resize(self): + processor = PoseDataPreprocessor(batch_augments=[ + dict( + type='BatchSyncRandomResize', + random_size_range=(320, 320), + size_divisor=32, + interval=1) + ]) + self.assertTrue( + isinstance(processor.batch_augments[0], BatchSyncRandomResize)) + message_hub = MessageHub.get_instance('test_batch_sync_random_resize') + message_hub.update_info('iter', 0) + packed_inputs = { + 'inputs': [ + torch.randint(0, 256, (3, 128, 128)), + torch.randint(0, 256, (3, 128, 128)) + ], + 'data_samples': [PoseDataSample()] * 2 + } + batch_inputs = processor(packed_inputs, training=True)['inputs'] + self.assertEqual(batch_inputs.shape, (2, 3, 128, 128)) + + # resize after one iter + message_hub.update_info('iter', 1) + packed_inputs = { + 'inputs': [ + torch.randint(0, 256, (3, 128, 128)), + torch.randint(0, 256, (3, 128, 128)) + ], + 'data_samples': + [PoseDataSample(metainfo=dict(img_shape=(128, 128)))] * 2 + } + batch_inputs = processor(packed_inputs, training=True)['inputs'] + self.assertEqual(batch_inputs.shape, (2, 3, 320, 320)) + + packed_inputs = { + 'inputs': [ + torch.randint(0, 256, (3, 128, 128)), + torch.randint(0, 256, (3, 128, 128)) + ], + 'data_samples': [PoseDataSample()] * 2 + } + batch_inputs = processor(packed_inputs, training=False)['inputs'] + self.assertEqual(batch_inputs.shape, (2, 3, 128, 128)) diff --git a/tests/test_models/test_distillers/test_dwpose_distiller.py b/tests/test_models/test_distillers/test_dwpose_distiller.py new file mode 100644 index 0000000000..60d2b231e5 --- /dev/null +++ b/tests/test_models/test_distillers/test_dwpose_distiller.py @@ -0,0 +1,113 @@ +# Copyright (c) OpenMMLab. All rights reserved. +import unittest +from unittest import TestCase + +import torch +from mmengine.model.utils import revert_sync_batchnorm +from parameterized import parameterized + +from mmpose.structures import PoseDataSample +from mmpose.testing import get_packed_inputs, get_pose_estimator_cfg +from mmpose.utils import register_all_modules + +configs = [ + 'wholebody_2d_keypoint/dwpose/ubody/' + 's1_dis/dwpose_l_dis_m_coco-ubody-256x192.py', + 'wholebody_2d_keypoint/dwpose/ubody/' + 's2_dis/dwpose_m-mm_coco-ubody-256x192.py', + 'wholebody_2d_keypoint/dwpose/coco-wholebody/' + 's1_dis/dwpose_l_dis_m_coco-256x192.py', + 'wholebody_2d_keypoint/dwpose/coco-wholebody/' + 's2_dis/dwpose_m-mm_coco-256x192.py', +] + +configs_with_devices = [(config, ('cpu', 'cuda')) for config in configs] + + +class TestDWPoseDistiller(TestCase): + + def setUp(self) -> None: + register_all_modules() + + @parameterized.expand(configs) + def test_init(self, config): + dis_cfg = get_pose_estimator_cfg(config) + model_cfg = get_pose_estimator_cfg(dis_cfg.student_cfg) + model_cfg.backbone.init_cfg = None + + from mmpose.models import build_pose_estimator + model = build_pose_estimator(model_cfg) + model = revert_sync_batchnorm(model) + self.assertTrue(model.backbone) + self.assertTrue(model.head) + if model_cfg.get('neck', None): + self.assertTrue(model.neck) + + @parameterized.expand(configs_with_devices) + def test_forward_loss(self, config, devices): + dis_cfg = get_pose_estimator_cfg(config) + model_cfg = get_pose_estimator_cfg(dis_cfg.student_cfg) + model_cfg.backbone.init_cfg = None + + from mmpose.models import build_pose_estimator + + for device in devices: + model = build_pose_estimator(model_cfg) + model = revert_sync_batchnorm(model) + + if device == 'cuda': + if not torch.cuda.is_available(): + return unittest.skip('test requires GPU and torch+cuda') + model = model.cuda() + + packed_inputs = get_packed_inputs(2, num_keypoints=133) + data = model.data_preprocessor(packed_inputs, training=True) + losses = model.forward(**data, mode='loss') + self.assertIsInstance(losses, dict) + + @parameterized.expand(configs_with_devices) + def test_forward_predict(self, config, devices): + dis_cfg = get_pose_estimator_cfg(config) + model_cfg = get_pose_estimator_cfg(dis_cfg.student_cfg) + model_cfg.backbone.init_cfg = None + + from mmpose.models import build_pose_estimator + + for device in devices: + model = build_pose_estimator(model_cfg) + model = revert_sync_batchnorm(model) + + if device == 'cuda': + if not torch.cuda.is_available(): + return unittest.skip('test requires GPU and torch+cuda') + model = model.cuda() + + packed_inputs = get_packed_inputs(2, num_keypoints=133) + model.eval() + with torch.no_grad(): + data = model.data_preprocessor(packed_inputs, training=True) + batch_results = model.forward(**data, mode='predict') + self.assertEqual(len(batch_results), 2) + self.assertIsInstance(batch_results[0], PoseDataSample) + + @parameterized.expand(configs_with_devices) + def test_forward_tensor(self, config, devices): + dis_cfg = get_pose_estimator_cfg(config) + model_cfg = get_pose_estimator_cfg(dis_cfg.student_cfg) + model_cfg.backbone.init_cfg = None + + from mmpose.models import build_pose_estimator + + for device in devices: + model = build_pose_estimator(model_cfg) + model = revert_sync_batchnorm(model) + + if device == 'cuda': + if not torch.cuda.is_available(): + return unittest.skip('test requires GPU and torch+cuda') + model = model.cuda() + + packed_inputs = get_packed_inputs(2, num_keypoints=133) + data = model.data_preprocessor(packed_inputs, training=True) + batch_results = model.forward(**data, mode='tensor') + self.assertIsInstance(batch_results, (tuple, torch.Tensor)) diff --git a/tests/test_models/test_necks/test_yolox_pafpn.py b/tests/test_models/test_necks/test_yolox_pafpn.py new file mode 100644 index 0000000000..89eae39a6c --- /dev/null +++ b/tests/test_models/test_necks/test_yolox_pafpn.py @@ -0,0 +1,30 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import torch + +from mmpose.models.necks import YOLOXPAFPN + + +class TestYOLOXPAFPN(TestCase): + + def test_forward(self): + in_channels = [128, 256, 512] + out_channels = 256 + num_csp_blocks = 3 + + model = YOLOXPAFPN( + in_channels=in_channels, + out_channels=out_channels, + num_csp_blocks=num_csp_blocks) + model.train() + + inputs = [ + torch.randn(1, c, 64 // (2**i), 64 // (2**i)) + for i, c in enumerate(in_channels) + ] + outputs = model(inputs) + + self.assertEqual(len(outputs), len(in_channels)) + for out in outputs: + self.assertEqual(out.shape[1], out_channels) diff --git a/tests/test_structures/test_bbox/test_bbox_overlaps.py b/tests/test_structures/test_bbox/test_bbox_overlaps.py new file mode 100644 index 0000000000..b3523c8af5 --- /dev/null +++ b/tests/test_structures/test_bbox/test_bbox_overlaps.py @@ -0,0 +1,75 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import torch + +from mmpose.structures.bbox import bbox_overlaps # Import your function here + + +class TestBBoxOverlaps(TestCase): + + def test_bbox_overlaps_iou(self): + bboxes1 = torch.FloatTensor([ + [0, 0, 10, 10], + [10, 10, 20, 20], + [32, 32, 38, 42], + ]) + bboxes2 = torch.FloatTensor([ + [0, 0, 10, 20], + [0, 10, 10, 19], + [10, 10, 20, 20], + ]) + overlaps = bbox_overlaps(bboxes1, bboxes2) + + expected_overlaps = torch.FloatTensor([ + [0.5000, 0.0000, 0.0000], + [0.0000, 0.0000, 1.0000], + [0.0000, 0.0000, 0.0000], + ]) + + self.assertTrue( + torch.allclose(overlaps, expected_overlaps, rtol=1e-4, atol=1e-4)) + + def test_bbox_overlaps_iof(self): + bboxes1 = torch.FloatTensor([ + [0, 0, 10, 10], + [10, 10, 20, 20], + [32, 32, 38, 42], + ]) + bboxes2 = torch.FloatTensor([ + [0, 0, 10, 20], + [0, 10, 10, 19], + [10, 10, 20, 20], + ]) + overlaps = bbox_overlaps(bboxes1, bboxes2, mode='iof') + + expected_overlaps = torch.FloatTensor([ + [1., 0., 0.], + [0., 0., 1.], + [0., 0., 0.], + ]) + + self.assertTrue( + torch.allclose(overlaps, expected_overlaps, rtol=1e-4, atol=1e-4)) + + def test_bbox_overlaps_giou(self): + bboxes1 = torch.FloatTensor([ + [0, 0, 10, 10], + [10, 10, 20, 20], + [32, 32, 38, 42], + ]) + bboxes2 = torch.FloatTensor([ + [0, 0, 10, 20], + [0, 10, 10, 19], + [10, 10, 20, 20], + ]) + overlaps = bbox_overlaps(bboxes1, bboxes2, mode='giou') + + expected_overlaps = torch.FloatTensor([ + [0.5000, 0.0000, -0.5000], + [-0.2500, -0.0500, 1.0000], + [-0.8371, -0.8766, -0.8214], + ]) + + self.assertTrue( + torch.allclose(overlaps, expected_overlaps, rtol=1e-4, atol=1e-4)) diff --git a/tests/test_structures/test_bbox/test_bbox_transforms.py b/tests/test_structures/test_bbox/test_bbox_transforms.py new file mode 100644 index 0000000000..b2eb3da683 --- /dev/null +++ b/tests/test_structures/test_bbox/test_bbox_transforms.py @@ -0,0 +1,126 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import numpy as np + +from mmpose.structures.bbox import (bbox_clip_border, bbox_corner2xyxy, + bbox_xyxy2corner, get_pers_warp_matrix) + + +class TestBBoxClipBorder(TestCase): + + def test_bbox_clip_border_2D(self): + bbox = np.array([[10, 20], [60, 80], [-5, 25], [100, 120]]) + shape = (50, 50) # Example image shape + clipped_bbox = bbox_clip_border(bbox, shape) + + expected_bbox = np.array([[10, 20], [50, 50], [0, 25], [50, 50]]) + + self.assertTrue(np.array_equal(clipped_bbox, expected_bbox)) + + def test_bbox_clip_border_4D(self): + bbox = np.array([ + [[10, 20, 30, 40], [40, 50, 80, 90]], + [[-5, 0, 30, 40], [70, 80, 120, 130]], + ]) + shape = (50, 60) # Example image shape + clipped_bbox = bbox_clip_border(bbox, shape) + + expected_bbox = np.array([ + [[10, 20, 30, 40], [40, 50, 50, 60]], + [[0, 0, 30, 40], [50, 60, 50, 60]], + ]) + + self.assertTrue(np.array_equal(clipped_bbox, expected_bbox)) + + +class TestBBoxXYXY2Corner(TestCase): + + def test_bbox_xyxy2corner_single(self): + bbox = np.array([0, 0, 100, 50]) + corners = bbox_xyxy2corner(bbox) + + expected_corners = np.array([[0, 0], [0, 50], [100, 0], [100, 50]]) + + self.assertTrue(np.array_equal(corners, expected_corners)) + + def test_bbox_xyxy2corner_multiple(self): + bboxes = np.array([[0, 0, 100, 50], [10, 20, 200, 150]]) + corners = bbox_xyxy2corner(bboxes) + + expected_corners = np.array([[[0, 0], [0, 50], [100, 0], [100, 50]], + [[10, 20], [10, 150], [200, 20], + [200, 150]]]) + + self.assertTrue(np.array_equal(corners, expected_corners)) + + +class TestBBoxCorner2XYXY(TestCase): + + def test_bbox_corner2xyxy_single(self): + + corners = np.array([[0, 0], [0, 50], [100, 0], [100, 50]]) + xyxy = bbox_corner2xyxy(corners) + expected_xyxy = np.array([0, 0, 100, 50]) + + self.assertTrue(np.array_equal(xyxy, expected_xyxy)) + + def test_bbox_corner2xyxy_multiple(self): + + corners = np.array([[[0, 0], [0, 50], [100, 0], [100, 50]], + [[10, 20], [10, 150], [200, 20], [200, 150]]]) + xyxy = bbox_corner2xyxy(corners) + expected_xyxy = np.array([[0, 0, 100, 50], [10, 20, 200, 150]]) + + self.assertTrue(np.array_equal(xyxy, expected_xyxy)) + + +class TestGetPersWarpMatrix(TestCase): + + def test_get_pers_warp_matrix_identity(self): + center = np.array([0, 0]) + translate = np.array([0, 0]) + scale = 1.0 + rot = 0.0 + shear = np.array([0.0, 0.0]) + warp_matrix = get_pers_warp_matrix(center, translate, scale, rot, + shear) + + expected_matrix = np.array([[1, 0, 0], [0, 1, 0], [0, 0, 1]], + dtype=np.float32) + + self.assertTrue(np.array_equal(warp_matrix, expected_matrix)) + + def test_get_pers_warp_matrix_translation(self): + center = np.array([0, 0]) + translate = np.array([10, 20]) + scale = 1.0 + rot = 0.0 + shear = np.array([0.0, 0.0]) + warp_matrix = get_pers_warp_matrix(center, translate, scale, rot, + shear) + + expected_matrix = np.array([[1, 0, 10], [0, 1, 20], [0, 0, 1]], + dtype=np.float32) + + self.assertTrue(np.array_equal(warp_matrix, expected_matrix)) + + def test_get_pers_warp_matrix_scale_rotation_shear(self): + center = np.array([0, 0]) + translate = np.array([0, 0]) + scale = 1.5 + rot = 45.0 + shear = np.array([15.0, 30.0]) + warp_matrix = get_pers_warp_matrix(center, translate, scale, rot, + shear) + + expected_matrix = np.array([ + [1.3448632, -0.77645713, 0.], + [1.6730325, 0.44828773, 0.], + [0., 0., 1.], + ], + dtype=np.float32) + + # Use np.allclose to compare floating-point arrays within a tolerance + self.assertTrue( + np.allclose(warp_matrix, expected_matrix, rtol=1e-3, atol=1e-3)) diff --git a/tests/test_structures/test_keypoint/test_keypoint_transforms.py b/tests/test_structures/test_keypoint/test_keypoint_transforms.py new file mode 100644 index 0000000000..5384ce2b14 --- /dev/null +++ b/tests/test_structures/test_keypoint/test_keypoint_transforms.py @@ -0,0 +1,57 @@ +# Copyright (c) OpenMMLab. All rights reserved. +from unittest import TestCase + +import numpy as np + +from mmpose.structures import keypoint_clip_border + + +class TestKeypointClipBorder(TestCase): + + def test_keypoint_clip_border(self): + keypoints = np.array([[[10, 20], [30, 40], [-5, 25], [50, 60]]]) + keypoints_visible = np.array([[1.0, 0.8, 0.5, 1.0]]) + shape = (50, 50) # Example frame shape + + clipped_keypoints, clipped_keypoints_visible = keypoint_clip_border( + keypoints, keypoints_visible, shape) + + # Check if keypoints outside the frame have visibility set to 0.0 + self.assertEqual(clipped_keypoints_visible[0, 2], 0.0) + self.assertEqual(clipped_keypoints_visible[0, 3], 0.0) + + # Check if keypoints inside the frame have unchanged visibility values + self.assertEqual(clipped_keypoints_visible[0, 0], 1.0) + self.assertEqual(clipped_keypoints_visible[0, 1], 0.8) + + # Check if keypoints array shapes remain unchanged + self.assertEqual(keypoints.shape, clipped_keypoints.shape) + self.assertEqual(keypoints_visible.shape, + clipped_keypoints_visible.shape) + + keypoints = np.array([[[10, 20], [30, 40], [-5, 25], [50, 60]]]) + keypoints_visible = np.array([[1.0, 0.8, 0.5, 1.0]]) + keypoints_visible_weight = np.array([[1.0, 0.0, 1.0, 1.0]]) + keypoints_visible = np.stack( + (keypoints_visible, keypoints_visible_weight), axis=-1) + shape = (50, 50) # Example frame shape + + clipped_keypoints, clipped_keypoints_visible = keypoint_clip_border( + keypoints, keypoints_visible, shape) + + # Check if keypoints array shapes remain unchanged + self.assertEqual(keypoints.shape, clipped_keypoints.shape) + self.assertEqual(keypoints_visible.shape, + clipped_keypoints_visible.shape) + + # Check if keypoints outside the frame have visibility set to 0.0 + self.assertEqual(clipped_keypoints_visible[0, 2, 0], 0.0) + self.assertEqual(clipped_keypoints_visible[0, 3, 0], 0.0) + + # Check if keypoints inside the frame have unchanged visibility values + self.assertEqual(clipped_keypoints_visible[0, 0, 0], 1.0) + self.assertEqual(clipped_keypoints_visible[0, 1, 0], 0.8) + + # Check if the visibility weights remain unchanged + self.assertSequenceEqual(clipped_keypoints_visible[..., 1].tolist(), + keypoints_visible[..., 1].tolist()) diff --git a/tools/dataset_converters/300wlp2coco.py b/tools/dataset_converters/300wlp2coco.py new file mode 100644 index 0000000000..1d9b563173 --- /dev/null +++ b/tools/dataset_converters/300wlp2coco.py @@ -0,0 +1,171 @@ +# Copyright (c) OpenMMLab. All rights reserved. +import json +import os +import os.path as osp +import shutil +import time + +import cv2 +import numpy as np +from scipy.io import loadmat + + +# Move all images to one folder +def move_img(img_path, save_img): + path_list = ['AFW', 'HELEN', 'IBUG', 'LFPW'] + # 保存路径 + if not os.path.isdir(save_img): + os.makedirs(save_img) + + for people_name in path_list: + # 读取文件夹中图片 + Image_dir = os.path.join(img_path, people_name) + img_list = os.listdir(Image_dir) + for img_name in img_list: + if 'jpg' in img_name: + old_img_path = Image_dir + '/' + img_name + shutil.move(old_img_path, save_img + '/' + img_name) + + +# split 300w-lp data +def split_data(file_img, + train_path, + val_path, + test_path, + shuffle=True, + ratio1=0.8, + ratio2=0.1): + img_list = os.listdir(file_img) + if shuffle: + np.random.shuffle(img_list) + + n_total = len(img_list) + offset_train = int(n_total * ratio1) + offset_val = int(n_total * ratio2) + offset_train + train_img = img_list[:offset_train] + val_img = img_list[offset_train:offset_val] + test_img = img_list[offset_val:] + for img in train_img: + shutil.move(file_img + '/' + img, train_path + '/' + img) + for img in val_img: + shutil.move(file_img + '/' + img, val_path + '/' + img) + for img in test_img: + shutil.move(file_img + '/' + img, test_path + '/' + img) + + +def default_dump(obj): + """Convert numpy classes to JSON serializable objects.""" + if isinstance(obj, (np.integer, np.floating, np.bool_)): + return obj.item() + elif isinstance(obj, np.ndarray): + return obj.tolist() + else: + return obj + + +def convert_300WLP_to_coco(root_path, img_pathDir, out_file): + annotations = [] + images = [] + cnt = 0 + if 'trainval' in img_pathDir: + img_dir_list = ['train', 'val'] + else: + img_dir_list = [img_pathDir] + + for tv in img_dir_list: + + img_dir = osp.join(root_path, tv) + landmark_dir = os.path.join(root_path, '300W_LP', 'landmarks') + img_list = os.listdir(img_dir) + + for idx, img_name in enumerate(img_list): + cnt += 1 + img_path = osp.join(img_dir, img_name) + type_name = img_name.split('_')[0] + ann_name = img_name.split('.')[0] + '_pts.mat' + ann_path = osp.join(landmark_dir, type_name, ann_name) + data_info = loadmat(ann_path) + + img = cv2.imread(img_path) + + keypoints = data_info['pts_2d'] + keypoints_all = [] + for i in range(keypoints.shape[0]): + x, y = keypoints[i][0], keypoints[i][1] + keypoints_all.append([x, y, 2]) + keypoints = np.array(keypoints_all) + + x1, y1, _ = np.amin(keypoints, axis=0) + x2, y2, _ = np.amax(keypoints, axis=0) + w, h = x2 - x1, y2 - y1 + bbox = [x1, y1, w, h] + + image = {} + image['id'] = cnt + image['file_name'] = img_name + image['height'] = img.shape[0] + image['width'] = img.shape[1] + images.append(image) + + ann = {} + ann['keypoints'] = keypoints.reshape(-1).tolist() + ann['image_id'] = cnt + ann['id'] = cnt + ann['num_keypoints'] = len(keypoints) + ann['bbox'] = bbox + ann['iscrowd'] = 0 + ann['area'] = int(ann['bbox'][2] * ann['bbox'][3]) + ann['category_id'] = 1 + + annotations.append(ann) + + cocotype = {} + + cocotype['info'] = {} + cocotype['info']['description'] = 'LaPa Generated by MMPose Team' + cocotype['info']['version'] = 1.0 + cocotype['info']['year'] = time.strftime('%Y', time.localtime()) + cocotype['info']['date_created'] = time.strftime('%Y/%m/%d', + time.localtime()) + + cocotype['images'] = images + cocotype['annotations'] = annotations + cocotype['categories'] = [{ + 'supercategory': 'person', + 'id': 1, + 'name': 'face', + 'keypoints': [], + 'skeleton': [] + }] + + json.dump( + cocotype, + open(out_file, 'w'), + ensure_ascii=False, + default=default_dump) + print(f'done {out_file}') + + +if __name__ == '__main__': + # 1.Move all images to one folder + # 2.split 300W-LP data + # 3.convert json + img_path = './300W-LP/300W-LP' + save_img = './300W-LP/images' + move_img(img_path, save_img) + + file_img = './300W-LP/images' + train_path = './300W-LP/train' + val_path = './300W-LP/val' + test_path = './300W-LP/test' + split_data(save_img, train_path, val_path, test_path) + + root_path = './300W-LP' + anno_path_json = osp.join(root_path, 'annotations') + if not osp.exists(anno_path_json): + os.makedirs(anno_path_json) + for tv in ['val', 'test', 'train']: + print(f'processing {tv}') + convert_300WLP_to_coco( + root_path, tv, + anno_path_json + '/' + f'face_landmarks_300wlp_{tv}.json') diff --git a/tools/dataset_converters/scripts/preprocess_300w.sh b/tools/dataset_converters/scripts/preprocess_300w.sh old mode 100644 new mode 100755 index bf405b5cc7..4ab1672f0f --- a/tools/dataset_converters/scripts/preprocess_300w.sh +++ b/tools/dataset_converters/scripts/preprocess_300w.sh @@ -3,6 +3,6 @@ DOWNLOAD_DIR=$1 DATA_ROOT=$2 -tar -zxvf $DOWNLOAD_DIR/300w/raw/300w.tar.gz.00 -C $DOWNLOAD_DIR/ +tar -zxvf $DOWNLOAD_DIR/OpenDataLab___300w/raw/300w.tar.gz.00 -C $DOWNLOAD_DIR/ tar -xvf $DOWNLOAD_DIR/300w/300w.tar.00 -C $DATA_ROOT/ -rm -rf $DOWNLOAD_DIR/300w +rm -rf $DOWNLOAD_DIR/300w $DOWNLOAD_DIR/OpenDataLab___300w diff --git a/tools/dataset_converters/scripts/preprocess_aic.sh b/tools/dataset_converters/scripts/preprocess_aic.sh index 726a61ca26..9cb27ccdfb 100644 --- a/tools/dataset_converters/scripts/preprocess_aic.sh +++ b/tools/dataset_converters/scripts/preprocess_aic.sh @@ -3,5 +3,5 @@ DOWNLOAD_DIR=$1 DATA_ROOT=$2 -tar -zxvf $DOWNLOAD_DIR/AI_Challenger/raw/AI_Challenger.tar.gz -C $DATA_ROOT -rm -rf $DOWNLOAD_DIR/AI_Challenger +tar -zxvf $DOWNLOAD_DIR/OpenDataLab___AI_Challenger/raw/AI_Challenger.tar.gz -C $DATA_ROOT +rm -rf $DOWNLOAD_DIR/OpenDataLab___AI_Challenger diff --git a/tools/dataset_converters/scripts/preprocess_ap10k.sh b/tools/dataset_converters/scripts/preprocess_ap10k.sh index a4c330157b..eed785e3d2 100644 --- a/tools/dataset_converters/scripts/preprocess_ap10k.sh +++ b/tools/dataset_converters/scripts/preprocess_ap10k.sh @@ -3,6 +3,6 @@ DOWNLOAD_DIR=$1 DATA_ROOT=$2 -tar -zxvf $DOWNLOAD_DIR/AP-10K/raw/AP-10K.tar.gz.00 -C $DOWNLOAD_DIR/ +tar -zxvf $DOWNLOAD_DIR/OpenDataLab___AP-10K/raw/AP-10K.tar.gz.00 -C $DOWNLOAD_DIR/ tar -xvf $DOWNLOAD_DIR/AP-10K/AP-10K.tar.00 -C $DATA_ROOT/ -rm -rf $DOWNLOAD_DIR/AP-10K +rm -rf $DOWNLOAD_DIR/AP-10K $DOWNLOAD_DIR/OpenDataLab___AP-10K diff --git a/tools/dataset_converters/scripts/preprocess_coco2017.sh b/tools/dataset_converters/scripts/preprocess_coco2017.sh index 853975e26b..6b09c8e501 100644 --- a/tools/dataset_converters/scripts/preprocess_coco2017.sh +++ b/tools/dataset_converters/scripts/preprocess_coco2017.sh @@ -3,7 +3,7 @@ DOWNLOAD_DIR=$1 DATA_ROOT=$2 -unzip $DOWNLOAD_DIR/COCO_2017/raw/Images/val2017.zip -d $DATA_ROOT -unzip $DOWNLOAD_DIR/COCO_2017/raw/Images/train2017.zip -d $DATA_ROOT -unzip $DOWNLOAD_DIR/COCO_2017/raw/Annotations/annotations_trainval2017.zip -d $DATA_ROOT -rm -rf $DOWNLOAD_DIR/COCO_2017 +unzip $DOWNLOAD_DIR/OpenDataLab___COCO_2017/raw/Images/val2017.zip -d $DATA_ROOT +unzip $DOWNLOAD_DIR/OpenDataLab___COCO_2017/raw/Images/train2017.zip -d $DATA_ROOT +unzip $DOWNLOAD_DIR/OpenDataLab___COCO_2017/raw/Annotations/annotations_trainval2017.zip -d $DATA_ROOT +rm -rf $DOWNLOAD_DIR/OpenDataLab___COCO_2017 diff --git a/tools/dataset_converters/scripts/preprocess_crowdpose.sh b/tools/dataset_converters/scripts/preprocess_crowdpose.sh index 3215239585..e85d5aeefb 100644 --- a/tools/dataset_converters/scripts/preprocess_crowdpose.sh +++ b/tools/dataset_converters/scripts/preprocess_crowdpose.sh @@ -3,5 +3,5 @@ DOWNLOAD_DIR=$1 DATA_ROOT=$2 -tar -zxvf $DOWNLOAD_DIR/CrowdPose/raw/CrowdPose.tar.gz -C $DATA_ROOT -rm -rf $DOWNLOAD_DIR/CrowdPose +tar -zxvf $DOWNLOAD_DIR/OpenDataLab___CrowdPose/raw/CrowdPose.tar.gz -C $DATA_ROOT +rm -rf $DOWNLOAD_DIR/OpenDataLab___CrowdPose diff --git a/tools/dataset_converters/scripts/preprocess_freihand.sh b/tools/dataset_converters/scripts/preprocess_freihand.sh index b3567cb5d7..bff275f42a 100644 --- a/tools/dataset_converters/scripts/preprocess_freihand.sh +++ b/tools/dataset_converters/scripts/preprocess_freihand.sh @@ -3,5 +3,5 @@ DOWNLOAD_DIR=$1 DATA_ROOT=$2 -tar -zxvf $DOWNLOAD_DIR/FreiHAND/raw/FreiHAND.tar.gz -C $DATA_ROOT -rm -rf $DOWNLOAD_DIR/FreiHAND +tar -zxvf $DOWNLOAD_DIR/OpenDataLab___FreiHAND/raw/FreiHAND.tar.gz -C $DATA_ROOT +rm -rf $DOWNLOAD_DIR/OpenDataLab___FreiHAND diff --git a/tools/dataset_converters/scripts/preprocess_hagrid.sh b/tools/dataset_converters/scripts/preprocess_hagrid.sh index de2356541c..129d27c9f1 100644 --- a/tools/dataset_converters/scripts/preprocess_hagrid.sh +++ b/tools/dataset_converters/scripts/preprocess_hagrid.sh @@ -3,6 +3,6 @@ DOWNLOAD_DIR=$1 DATA_ROOT=$2 -cat $DOWNLOAD_DIR/HaGRID/raw/*.tar.gz.* | tar -xvz -C $DATA_ROOT/.. +cat $DOWNLOAD_DIR/OpenDataLab___HaGRID/raw/*.tar.gz.* | tar -xvz -C $DATA_ROOT/.. tar -xvf $DATA_ROOT/HaGRID.tar -C $DATA_ROOT/.. -rm -rf $DOWNLOAD_DIR/HaGRID +rm -rf $DOWNLOAD_DIR/OpenDataLab___HaGRID diff --git a/tools/dataset_converters/scripts/preprocess_halpe.sh b/tools/dataset_converters/scripts/preprocess_halpe.sh index 103d6202f9..628de88ecc 100644 --- a/tools/dataset_converters/scripts/preprocess_halpe.sh +++ b/tools/dataset_converters/scripts/preprocess_halpe.sh @@ -3,6 +3,6 @@ DOWNLOAD_DIR=$1 DATA_ROOT=$2 -tar -zxvf $DOWNLOAD_DIR/Halpe/raw/Halpe.tar.gz.00 -C $DOWNLOAD_DIR/ +tar -zxvf $DOWNLOAD_DIR/OpenDataLab___Halpe/raw/Halpe.tar.gz.00 -C $DOWNLOAD_DIR/ tar -xvf $DOWNLOAD_DIR/Halpe/Halpe.tar.00 -C $DATA_ROOT/ -rm -rf $DOWNLOAD_DIR/Halpe +rm -rf $DOWNLOAD_DIR/Halpe $DOWNLOAD_DIR/OpenDataLab___Halpe diff --git a/tools/dataset_converters/scripts/preprocess_lapa.sh b/tools/dataset_converters/scripts/preprocess_lapa.sh index 977442c1b8..c7556ffc87 100644 --- a/tools/dataset_converters/scripts/preprocess_lapa.sh +++ b/tools/dataset_converters/scripts/preprocess_lapa.sh @@ -3,5 +3,5 @@ DOWNLOAD_DIR=$1 DATA_ROOT=$2 -tar -zxvf $DOWNLOAD_DIR/LaPa/raw/LaPa.tar.gz -C $DATA_ROOT -rm -rf $DOWNLOAD_DIR/LaPa +tar -zxvf $DOWNLOAD_DIR/OpenDataLab___LaPa/raw/LaPa.tar.gz -C $DATA_ROOT +rm -rf $DOWNLOAD_DIR/OpenDataLab___LaPa diff --git a/tools/dataset_converters/scripts/preprocess_mpii.sh b/tools/dataset_converters/scripts/preprocess_mpii.sh index 287b431897..c3027c23f6 100644 --- a/tools/dataset_converters/scripts/preprocess_mpii.sh +++ b/tools/dataset_converters/scripts/preprocess_mpii.sh @@ -3,5 +3,5 @@ DOWNLOAD_DIR=$1 DATA_ROOT=$2 -tar -zxvf $DOWNLOAD_DIR/MPII_Human_Pose/raw/MPII_Human_Pose.tar.gz -C $DATA_ROOT -rm -rf $DOWNLOAD_DIR/MPII_Human_Pose +tar -zxvf $DOWNLOAD_DIR/OpenDataLab___MPII_Human_Pose/raw/MPII_Human_Pose.tar.gz -C $DATA_ROOT +rm -rf $DOWNLOAD_DIR/OpenDataLab___MPII_Human_Pose diff --git a/tools/dataset_converters/scripts/preprocess_onehand10k.sh b/tools/dataset_converters/scripts/preprocess_onehand10k.sh index 47f6e8942c..07c0d083d3 100644 --- a/tools/dataset_converters/scripts/preprocess_onehand10k.sh +++ b/tools/dataset_converters/scripts/preprocess_onehand10k.sh @@ -3,6 +3,6 @@ DOWNLOAD_DIR=$1 DATA_ROOT=$2 -tar -zxvf $DOWNLOAD_DIR/OneHand10K/raw/OneHand10K.tar.gz.00 -C $DOWNLOAD_DIR/ +tar -zxvf $DOWNLOAD_DIR/OpenDataLab___OneHand10K/raw/OneHand10K.tar.gz.00 -C $DOWNLOAD_DIR/ tar -xvf $DOWNLOAD_DIR/OneHand10K/OneHand10K.tar.00 -C $DATA_ROOT/ -rm -rf $DOWNLOAD_DIR/OneHand10K +rm -rf $DOWNLOAD_DIR/OneHand10K $DOWNLOAD_DIR/OpenDataLab___OneHand10K diff --git a/tools/dataset_converters/scripts/preprocess_wflw.sh b/tools/dataset_converters/scripts/preprocess_wflw.sh index 723d1d158e..298ffc79d2 100644 --- a/tools/dataset_converters/scripts/preprocess_wflw.sh +++ b/tools/dataset_converters/scripts/preprocess_wflw.sh @@ -3,6 +3,6 @@ DOWNLOAD_DIR=$1 DATA_ROOT=$2 -tar -zxvf $DOWNLOAD_DIR/WFLW/raw/WFLW.tar.gz.00 -C $DOWNLOAD_DIR/ +tar -zxvf $DOWNLOAD_DIR/OpenDataLab___WFLW/raw/WFLW.tar.gz.00 -C $DOWNLOAD_DIR/ tar -xvf $DOWNLOAD_DIR/WFLW/WFLW.tar.00 -C $DATA_ROOT/ -rm -rf $DOWNLOAD_DIR/WFLW +rm -rf $DOWNLOAD_DIR/WFLW $DOWNLOAD_DIR/OpenDataLab___WFLW diff --git a/tools/dataset_converters/ubody_kpts_to_coco.py b/tools/dataset_converters/ubody_kpts_to_coco.py new file mode 100644 index 0000000000..9d927da7ca --- /dev/null +++ b/tools/dataset_converters/ubody_kpts_to_coco.py @@ -0,0 +1,138 @@ +# Copyright (c) OpenMMLab. All rights reserved. +import argparse +import os +from copy import deepcopy +from multiprocessing import Pool + +import mmengine +import numpy as np +from pycocotools.coco import COCO + + +def findAllFile(base): + file_path = [] + for root, ds, fs in os.walk(base): + for f in fs: + fullname = os.path.join(root, f) + file_path.append(fullname) + return file_path + + +def convert(video_path: str): + video_name = video_path.split('/')[-1] + image_path = video_path.replace(video_name, video_name.split('.')[0]) + image_path = image_path.replace('/videos/', '/images/') + os.makedirs(image_path, exist_ok=True) + print( + f'ffmpeg -i {video_path} -f image2 -r 30 -b:v 5626k {image_path}/%06d.png' # noqa + ) + os.system( + f'ffmpeg -i {video_path} -f image2 -r 30 -b:v 5626k {image_path}/%06d.png' # noqa + ) + + +def split_dataset(annotation_path: str, split_path: str): + folders = os.listdir(annotation_path) + splits = np.load(split_path) + train_annos = [] + val_annos = [] + train_imgs = [] + val_imgs = [] + t_id = 0 + v_id = 0 + categories = [{'supercategory': 'person', 'id': 1, 'name': 'person'}] + + for scene in folders: + scene_train_anns = [] + scene_val_anns = [] + scene_train_imgs = [] + scene_val_imgs = [] + data = COCO( + os.path.join(annotation_path, scene, 'keypoint_annotation.json')) + print(f'Processing {scene}.........') + progress_bar = mmengine.ProgressBar(len(data.anns.keys())) + for aid in data.anns.keys(): + ann = data.anns[aid] + img = data.loadImgs(ann['image_id'])[0] + + if img['file_name'].startswith('/'): + file_name = img['file_name'][1:] # [1:] means delete '/' + else: + file_name = img['file_name'] + video_name = file_name.split('/')[-2] + if 'Trim' in video_name: + video_name = video_name.split('_Trim')[0] + + img_path = os.path.join( + annotation_path.replace('annotations', 'images'), scene, + file_name) + if not os.path.exists(img_path): + progress_bar.update() + continue + + img['file_name'] = os.path.join(scene, file_name) + ann_ = deepcopy(ann) + img_ = deepcopy(img) + if video_name in splits: + scene_val_anns.append(ann) + scene_val_imgs.append(img) + ann_['id'] = v_id + ann_['image_id'] = v_id + img_['id'] = v_id + val_annos.append(ann_) + val_imgs.append(img_) + v_id += 1 + else: + scene_train_anns.append(ann) + scene_train_imgs.append(img) + ann_['id'] = t_id + ann_['image_id'] = t_id + img_['id'] = t_id + train_annos.append(ann_) + train_imgs.append(img_) + t_id += 1 + + progress_bar.update() + + scene_train_data = dict( + images=scene_train_imgs, + annotations=scene_train_anns, + categories=categories) + scene_val_data = dict( + images=scene_val_imgs, + annotations=scene_val_anns, + categories=categories) + + mmengine.dump( + scene_train_data, + os.path.join(annotation_path, scene, 'train_annotations.json')) + mmengine.dump( + scene_val_data, + os.path.join(annotation_path, scene, 'val_annotations.json')) + + train_data = dict( + images=train_imgs, annotations=train_annos, categories=categories) + val_data = dict( + images=val_imgs, annotations=val_annos, categories=categories) + + mmengine.dump(train_data, + os.path.join(annotation_path, 'train_annotations.json')) + mmengine.dump(val_data, + os.path.join(annotation_path, 'val_annotations.json')) + + +if __name__ == '__main__': + parser = argparse.ArgumentParser() + parser.add_argument('--data-root', type=str, default='data/UBody') + args = parser.parse_args() + video_root = f'{args.data_root}/videos' + split_path = f'{args.data_root}/splits/intra_scene_test_list.npy' + annotation_path = f'{args.data_root}/annotations' + + video_paths = findAllFile(video_root) + pool = Pool(processes=1) + pool.map(convert, video_paths) + pool.close() + pool.join() + + split_dataset(annotation_path, split_path) diff --git a/tools/dataset_converters/ubody_smplx_to_coco.py b/tools/dataset_converters/ubody_smplx_to_coco.py new file mode 100644 index 0000000000..16f827fce1 --- /dev/null +++ b/tools/dataset_converters/ubody_smplx_to_coco.py @@ -0,0 +1,430 @@ +# Copyright (c) OpenMMLab. All rights reserved. +import argparse +import json +import os +import os.path as osp +from functools import partial +from typing import Dict, List + +import mmengine +import numpy as np +import smplx +import torch +from pycocotools.coco import COCO + + +class SMPLX(object): + + def __init__(self, human_model_path): + self.human_model_path = human_model_path + self.layer_args = { + 'create_global_orient': False, + 'create_body_pose': False, + 'create_left_hand_pose': False, + 'create_right_hand_pose': False, + 'create_jaw_pose': False, + 'create_leye_pose': False, + 'create_reye_pose': False, + 'create_betas': False, + 'create_expression': False, + 'create_transl': False, + } + + self.neutral_model = smplx.create( + self.human_model_path, + 'smplx', + gender='NEUTRAL', + use_pca=False, + use_face_contour=True, + **self.layer_args) + if torch.cuda.is_available(): + self.neutral_model = self.neutral_model.to('cuda:0') + + self.vertex_num = 10475 + self.face = self.neutral_model.faces + self.shape_param_dim = 10 + self.expr_code_dim = 10 + # 22 (body joints) + 30 (hand joints) + 1 (face jaw joint) + self.orig_joint_num = 53 + + # yapf: disable + self.orig_joints_name = ( + # 22 body joints + 'Pelvis', 'L_Hip', 'R_Hip', 'Spine_1', 'L_Knee', 'R_Knee', + 'Spine2', 'L_Ankle', 'R_Ankle', 'Spine_3', 'L_Foot', 'R_Foot', + 'Neck', 'L_Collar', 'R_Collar', 'Head', 'L_Shoulder', + 'R_Shoulder', 'L_Elbow', 'R_Elbow', 'L_Wrist', 'R_Wrist', + # left hand joints + 'L_Index_1', 'L_Index_2', 'L_Index_3', 'L_Middle_1', 'L_Middle_2', + 'L_Middle_3', 'L_Pinky_1', 'L_Pinky_2', 'L_Pinky_3', 'L_Ring_1', + 'L_Ring_2', 'L_Ring_3', 'L_Thumb_1', 'L_Thumb_2', 'L_Thumb_3', + # right hand joints + 'R_Index_1', 'R_Index_2', 'R_Index_3', 'R_Middle_1', 'R_Middle_2', + 'R_Middle_3', 'R_Pinky_1', 'R_Pinky_2', 'R_Pinky_3', 'R_Ring_1', + 'R_Ring_2', 'R_Ring_3', 'R_Thumb_1', 'R_Thumb_2', 'R_Thumb_3', + # 1 face jaw joint + 'Jaw', + ) + self.orig_flip_pairs = ( + # body joints + (1, 2), (4, 5), (7, 8), (10, 11), (13, 14), (16, 17), (18, 19), + (20, 21), + # hand joints + (22, 37), (23, 38), (24, 39), (25, 40), (26, 41), (27, 42), + (28, 43), (29, 44), (30, 45), (31, 46), (32, 47), (33, 48), + (34, 49), (35, 50), (36, 51), + ) + # yapf: enable + self.orig_root_joint_idx = self.orig_joints_name.index('Pelvis') + self.orig_joint_part = { + 'body': + range( + self.orig_joints_name.index('Pelvis'), + self.orig_joints_name.index('R_Wrist') + 1), + 'lhand': + range( + self.orig_joints_name.index('L_Index_1'), + self.orig_joints_name.index('L_Thumb_3') + 1), + 'rhand': + range( + self.orig_joints_name.index('R_Index_1'), + self.orig_joints_name.index('R_Thumb_3') + 1), + 'face': + range( + self.orig_joints_name.index('Jaw'), + self.orig_joints_name.index('Jaw') + 1) + } + + # changed SMPLX joint set for the supervision + self.joint_num = ( + 137 # 25 (body joints) + 40 (hand joints) + 72 (face keypoints) + ) + # yapf: disable + self.joints_name = ( + # 25 body joints + 'Pelvis', 'L_Hip', 'R_Hip', 'L_Knee', 'R_Knee', 'L_Ankle', + 'R_Ankle', 'Neck', 'L_Shoulder', 'R_Shoulder', 'L_Elbow', + 'R_Elbow', 'L_Wrist', 'R_Wrist', 'L_Big_toe', 'L_Small_toe', + 'L_Heel', 'R_Big_toe', 'R_Small_toe', 'R_Heel', 'L_Ear', 'R_Ear', + 'L_Eye', 'R_Eye', 'Nose', + # left hand joints + 'L_Thumb_1', 'L_Thumb_2', 'L_Thumb_3', 'L_Thumb4', 'L_Index_1', + 'L_Index_2', 'L_Index_3', 'L_Index_4', 'L_Middle_1', 'L_Middle_2', + 'L_Middle_3', 'L_Middle_4', 'L_Ring_1', 'L_Ring_2', 'L_Ring_3', + 'L_Ring_4', 'L_Pinky_1', 'L_Pinky_2', 'L_Pinky_3', 'L_Pinky_4', + # right hand joints + 'R_Thumb_1', 'R_Thumb_2', 'R_Thumb_3', 'R_Thumb_4', 'R_Index_1', + 'R_Index_2', 'R_Index_3', 'R_Index_4', 'R_Middle_1', 'R_Middle_2', + 'R_Middle_3', 'R_Middle_4', 'R_Ring_1', 'R_Ring_2', 'R_Ring_3', + 'R_Ring_4', 'R_Pinky_1', 'R_Pinky_2', 'R_Pinky_3', 'R_Pinky_4', + # 72 face keypoints + *[ + f'Face_{i}' for i in range(1, 73) + ], + ) + + self.root_joint_idx = self.joints_name.index('Pelvis') + self.lwrist_idx = self.joints_name.index('L_Wrist') + self.rwrist_idx = self.joints_name.index('R_Wrist') + self.neck_idx = self.joints_name.index('Neck') + self.flip_pairs = ( + # body joints + (1, 2), (3, 4), (5, 6), (8, 9), (10, 11), (12, 13), (14, 17), + (15, 18), (16, 19), (20, 21), (22, 23), + # hand joints + (25, 45), (26, 46), (27, 47), (28, 48), (29, 49), (30, 50), + (31, 51), (32, 52), (33, 53), (34, 54), (35, 55), (36, 56), + (37, 57), (38, 58), (39, 59), (40, 60), (41, 61), (42, 62), + (43, 63), (44, 64), + # face eyebrow + (67, 68), (69, 78), (70, 77), (71, 76), (72, 75), (73, 74), + # face below nose + (83, 87), (84, 86), + # face eyes + (88, 97), (89, 96), (90, 95), (91, 94), (92, 99), (93, 98), + # face mouse + (100, 106), (101, 105), (102, 104), (107, 111), (108, 110), + # face lip + (112, 116), (113, 115), (117, 119), + # face contours + (120, 136), (121, 135), (122, 134), (123, 133), (124, 132), + (125, 131), (126, 130), (127, 129) + ) + self.joint_idx = ( + 0, 1, 2, 4, 5, 7, 8, 12, 16, 17, 18, 19, 20, 21, 60, 61, 62, 63, + 64, 65, 59, 58, 57, 56, 55, # body joints + 37, 38, 39, 66, 25, 26, 27, 67, 28, 29, 30, 68, 34, 35, 36, 69, 31, + 32, 33, 70, # left hand joints + 52, 53, 54, 71, 40, 41, 42, 72, 43, 44, 45, 73, 49, 50, 51, 74, 46, + 47, 48, 75, # right hand joints + 22, 15, # jaw, head + 57, 56, # eyeballs + 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, # eyebrow + 86, 87, 88, 89, # nose + 90, 91, 92, 93, 94, # below nose + 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, # eyes + 107, # right mouth + 108, 109, 110, 111, 112, # upper mouth + 113, # left mouth + 114, 115, 116, 117, 118, # lower mouth + 119, # right lip + 120, 121, 122, # upper lip + 123, # left lip + 124, 125, 126, # lower lip + 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, + 140, 141, 142, 143, # face contour + ) + # yapf: enable + + self.joint_part = { + 'body': + range( + self.joints_name.index('Pelvis'), + self.joints_name.index('Nose') + 1), + 'lhand': + range( + self.joints_name.index('L_Thumb_1'), + self.joints_name.index('L_Pinky_4') + 1), + 'rhand': + range( + self.joints_name.index('R_Thumb_1'), + self.joints_name.index('R_Pinky_4') + 1), + 'hand': + range( + self.joints_name.index('L_Thumb_1'), + self.joints_name.index('R_Pinky_4') + 1), + 'face': + range( + self.joints_name.index('Face_1'), + self.joints_name.index('Face_72') + 1) + } + + +def read_annotation_file(annotation_file: str) -> List[Dict]: + with open(annotation_file, 'r') as f: + annotations = json.load(f) + return annotations + + +def cam2pixel(cam_coord, f, c): + x = cam_coord[:, 0] / cam_coord[:, 2] * f[0] + c[0] + y = cam_coord[:, 1] / cam_coord[:, 2] * f[1] + c[1] + z = cam_coord[:, 2] + return np.stack((x, y, z), 1) + + +def process_scene_anno(scene: str, annotation_root: str, splits: np.array, + human_model_path: str): + annos = read_annotation_file( + osp.join(annotation_root, scene, 'smplx_annotation.json')) + keypoint_annos = COCO( + osp.join(annotation_root, scene, 'keypoint_annotation.json')) + human_model = SMPLX(human_model_path) + + train_annos = [] + val_annos = [] + train_imgs = [] + val_imgs = [] + + progress_bar = mmengine.ProgressBar(len(keypoint_annos.anns.keys())) + for aid in keypoint_annos.anns.keys(): + ann = keypoint_annos.anns[aid] + img = keypoint_annos.loadImgs(ann['image_id'])[0] + if img['file_name'].startswith('/'): + file_name = img['file_name'][1:] + else: + file_name = img['file_name'] + + video_name = file_name.split('/')[-2] + if 'Trim' in video_name: + video_name = video_name.split('_Trim')[0] + + img_path = os.path.join( + annotation_root.replace('annotations', 'images'), scene, file_name) + if not os.path.exists(img_path): + progress_bar.update() + continue + if str(aid) not in annos: + progress_bar.update() + continue + + smplx_param = annos[str(aid)] + human_model_param = smplx_param['smplx_param'] + cam_param = smplx_param['cam_param'] + if 'lhand_valid' not in human_model_param: + human_model_param['lhand_valid'] = ann['lefthand_valid'] + human_model_param['rhand_valid'] = ann['righthand_valid'] + human_model_param['face_valid'] = ann['face_valid'] + + rotation_valid = np.ones((human_model.orig_joint_num), + dtype=np.float32) + coord_valid = np.ones((human_model.joint_num), dtype=np.float32) + + root_pose = human_model_param['root_pose'] + body_pose = human_model_param['body_pose'] + shape = human_model_param['shape'] + trans = human_model_param['trans'] + + if 'lhand_pose' in human_model_param and human_model_param.get( + 'lhand_valid', False): + lhand_pose = human_model_param['lhand_pose'] + else: + lhand_pose = np.zeros( + (3 * len(human_model.orig_joint_part['lhand'])), + dtype=np.float32) + rotation_valid[human_model.orig_joint_part['lhand']] = 0 + coord_valid[human_model.orig_joint_part['lhand']] = 0 + + if 'rhand_pose' in human_model_param and human_model_param.get( + 'rhand_valid', False): + rhand_pose = human_model_param['rhand_pose'] + else: + rhand_pose = np.zeros( + (3 * len(human_model.orig_joint_part['rhand'])), + dtype=np.float32) + rotation_valid[human_model.orig_joint_part['rhand']] = 0 + coord_valid[human_model.orig_joint_part['rhand']] = 0 + + if 'jaw_pose' in human_model_param and \ + 'expr' in human_model_param and \ + human_model_param.get('face_valid', False): + jaw_pose = human_model_param['jaw_pose'] + expr = human_model_param['expr'] + else: + jaw_pose = np.zeros((3), dtype=np.float32) + expr = np.zeros((human_model.expr_code_dim), dtype=np.float32) + rotation_valid[human_model.orig_joint_part['face']] = 0 + coord_valid[human_model.orig_joint_part['face']] = 0 + + # init human model inputs + device = torch.device( + 'cuda:0') if torch.cuda.is_available() else torch.device('cpu') + root_pose = torch.FloatTensor(root_pose).to(device).view(1, 3) + body_pose = torch.FloatTensor(body_pose).to(device).view(-1, 3) + lhand_pose = torch.FloatTensor(lhand_pose).to(device).view(-1, 3) + rhand_pose = torch.FloatTensor(rhand_pose).to(device).view(-1, 3) + jaw_pose = torch.FloatTensor(jaw_pose).to(device).view(-1, 3) + shape = torch.FloatTensor(shape).to(device).view(1, -1) + expr = torch.FloatTensor(expr).to(device).view(1, -1) + trans = torch.FloatTensor(trans).to(device).view(1, -1) + zero_pose = torch.zeros((1, 3), dtype=torch.float32, device=device) + + with torch.no_grad(): + output = human_model.neutral_model( + betas=shape, + body_pose=body_pose.view(1, -1), + global_orient=root_pose, + transl=trans, + left_hand_pose=lhand_pose.view(1, -1), + right_hand_pose=rhand_pose.view(1, -1), + jaw_pose=jaw_pose.view(1, -1), + leye_pose=zero_pose, + reye_pose=zero_pose, + expression=expr) + + joint_cam = output.joints[0].cpu().numpy()[human_model.joint_idx, :] + joint_img = cam2pixel(joint_cam, cam_param['focal'], + cam_param['princpt']) + + joint_cam = (joint_cam - joint_cam[human_model.root_joint_idx, None, :] + ) # root-relative + joint_cam[human_model.joint_part['lhand'], :] = ( + joint_cam[human_model.joint_part['lhand'], :] - + joint_cam[human_model.lwrist_idx, None, :] + ) # left hand root-relative + joint_cam[human_model.joint_part['rhand'], :] = ( + joint_cam[human_model.joint_part['rhand'], :] - + joint_cam[human_model.rwrist_idx, None, :] + ) # right hand root-relative + joint_cam[human_model.joint_part['face'], :] = ( + joint_cam[human_model.joint_part['face'], :] - + joint_cam[human_model.neck_idx, None, :]) # face root-relative + + body_3d_size = 2 + output_hm_shape = (16, 16, 12) + joint_img[human_model.joint_part['body'], + 2] = ((joint_cam[human_model.joint_part['body'], 2].copy() / + (body_3d_size / 2) + 1) / 2.0 * output_hm_shape[0]) + joint_img[human_model.joint_part['lhand'], + 2] = ((joint_cam[human_model.joint_part['lhand'], 2].copy() / + (body_3d_size / 2) + 1) / 2.0 * output_hm_shape[0]) + joint_img[human_model.joint_part['rhand'], + 2] = ((joint_cam[human_model.joint_part['rhand'], 2].copy() / + (body_3d_size / 2) + 1) / 2.0 * output_hm_shape[0]) + joint_img[human_model.joint_part['face'], + 2] = ((joint_cam[human_model.joint_part['face'], 2].copy() / + (body_3d_size / 2) + 1) / 2.0 * output_hm_shape[0]) + + keypoints_2d = joint_img[:, :2].copy() + keypoints_3d = joint_img.copy() + keypoints_valid = coord_valid.reshape((-1, 1)) + + ann['keypoints'] = keypoints_2d.tolist() + ann['keypoints_3d'] = keypoints_3d.tolist() + ann['keypoints_valid'] = keypoints_valid.tolist() + ann['camera_param'] = cam_param + img['file_name'] = os.path.join(scene, file_name) + if video_name in splits: + val_annos.append(ann) + val_imgs.append(img) + else: + train_annos.append(ann) + train_imgs.append(img) + progress_bar.update() + + categories = [{ + 'supercategory': 'person', + 'id': 1, + 'name': 'person', + 'keypoints': human_model.joints_name, + 'skeleton': human_model.flip_pairs + }] + train_data = { + 'images': train_imgs, + 'annotations': train_annos, + 'categories': categories + } + val_data = { + 'images': val_imgs, + 'annotations': val_annos, + 'categories': categories + } + + mmengine.dump( + train_data, + osp.join(annotation_root, scene, 'train_3dkeypoint_annotation.json')) + mmengine.dump( + val_data, + osp.join(annotation_root, scene, 'val_3dkeypoint_annotation.json')) + + +if __name__ == '__main__': + parser = argparse.ArgumentParser() + parser.add_argument('--data-root', type=str, default='data/UBody') + parser.add_argument('--human-model-path', type=str, default='data/SMPLX') + parser.add_argument( + '--nproc', default=8, type=int, help='number of process') + args = parser.parse_args() + + split_path = f'{args.data_root}/splits/intra_scene_test_list.npy' + annotation_path = f'{args.data_root}/annotations' + + folders = os.listdir(annotation_path) + folders = [f for f in folders if osp.isdir(osp.join(annotation_path, f))] + human_model_path = args.human_model_path + splits = np.load(split_path) + + if args.nproc > 1: + mmengine.track_parallel_progress( + partial( + process_scene_anno, + annotation_root=annotation_path, + splits=splits, + human_model_path=human_model_path), folders, args.nproc) + else: + mmengine.track_progress( + partial( + process_scene_anno, + annotation_root=annotation_path, + splits=splits, + human_model_path=human_model_path), folders) diff --git a/tools/misc/pth_transfer.py b/tools/misc/pth_transfer.py new file mode 100644 index 0000000000..7433c6771e --- /dev/null +++ b/tools/misc/pth_transfer.py @@ -0,0 +1,46 @@ +# Copyright (c) OpenMMLab. All rights reserved. +import argparse +from collections import OrderedDict + +import torch + + +def change_model(args): + dis_model = torch.load(args.dis_path, map_location='cpu') + all_name = [] + if args.two_dis: + for name, v in dis_model['state_dict'].items(): + if name.startswith('teacher.backbone'): + all_name.append((name[8:], v)) + elif name.startswith('distill_losses.loss_mgd.down'): + all_name.append(('head.' + name[24:], v)) + elif name.startswith('student.head'): + all_name.append((name[8:], v)) + else: + continue + else: + for name, v in dis_model['state_dict'].items(): + if name.startswith('student.'): + all_name.append((name[8:], v)) + else: + continue + state_dict = OrderedDict(all_name) + dis_model['state_dict'] = state_dict + + save_keys = ['meta', 'state_dict'] + ckpt_keys = list(dis_model.keys()) + for k in ckpt_keys: + if k not in save_keys: + dis_model.pop(k, None) + + torch.save(dis_model, args.output_path) + + +if __name__ == '__main__': + parser = argparse.ArgumentParser(description='Transfer CKPT') + parser.add_argument('dis_path', help='dis_model path') + parser.add_argument('output_path', help='output path') + parser.add_argument( + '--two_dis', action='store_true', default=False, help='if two dis') + args = parser.parse_args() + change_model(args) diff --git a/tools/test.py b/tools/test.py index 5dc0110260..12fd6b4423 100644 --- a/tools/test.py +++ b/tools/test.py @@ -51,7 +51,14 @@ def parse_args(): choices=['none', 'pytorch', 'slurm', 'mpi'], default='none', help='job launcher') - parser.add_argument('--local_rank', type=int, default=0) + # When using PyTorch version >= 2.0.0, the `torch.distributed.launch` + # will pass the `--local-rank` parameter to `tools/test.py` instead + # of `--local_rank`. + parser.add_argument('--local_rank', '--local-rank', type=int, default=0) + parser.add_argument( + '--badcase', + action='store_true', + help='whether analyze badcase in test') args = parser.parse_args() if 'LOCAL_RANK' not in os.environ: os.environ['LOCAL_RANK'] = str(args.local_rank) @@ -75,19 +82,45 @@ def merge_args(cfg, args): osp.splitext(osp.basename(args.config))[0]) # -------------------- visualization -------------------- - if args.show or (args.show_dir is not None): + if (args.show and not args.badcase) or (args.show_dir is not None): assert 'visualization' in cfg.default_hooks, \ 'PoseVisualizationHook is not set in the ' \ '`default_hooks` field of config. Please set ' \ '`visualization=dict(type="PoseVisualizationHook")`' cfg.default_hooks.visualization.enable = True - cfg.default_hooks.visualization.show = args.show + cfg.default_hooks.visualization.show = False \ + if args.badcase else args.show if args.show: cfg.default_hooks.visualization.wait_time = args.wait_time cfg.default_hooks.visualization.out_dir = args.show_dir cfg.default_hooks.visualization.interval = args.interval + # -------------------- badcase analyze -------------------- + if args.badcase: + assert 'badcase' in cfg.default_hooks, \ + 'BadcaseAnalyzeHook is not set in the ' \ + '`default_hooks` field of config. Please set ' \ + '`badcase=dict(type="BadcaseAnalyzeHook")`' + + cfg.default_hooks.badcase.enable = True + cfg.default_hooks.badcase.show = args.show + if args.show: + cfg.default_hooks.badcase.wait_time = args.wait_time + cfg.default_hooks.badcase.interval = args.interval + + metric_type = cfg.default_hooks.badcase.get('metric_type', 'loss') + if metric_type not in ['loss', 'accuracy']: + raise ValueError('Only support badcase metric type' + "in ['loss', 'accuracy']") + + if metric_type == 'loss': + if not cfg.default_hooks.badcase.get('metric'): + cfg.default_hooks.badcase.metric = cfg.model.head.loss + else: + if not cfg.default_hooks.badcase.get('metric'): + cfg.default_hooks.badcase.metric = cfg.test_evaluator + # -------------------- Dump predictions -------------------- if args.dump is not None: assert args.dump.endswith(('.pkl', '.pickle')), \ diff --git a/tools/train.py b/tools/train.py index 1fd423ad3f..84eec2d577 100644 --- a/tools/train.py +++ b/tools/train.py @@ -98,7 +98,8 @@ def merge_args(cfg, args): if args.amp is True: from mmengine.optim import AmpOptimWrapper, OptimWrapper optim_wrapper = cfg.optim_wrapper.get('type', OptimWrapper) - assert optim_wrapper in (OptimWrapper, AmpOptimWrapper), \ + assert optim_wrapper in (OptimWrapper, AmpOptimWrapper, + 'OptimWrapper', 'AmpOptimWrapper'), \ '`--amp` is not supported custom optimizer wrapper type ' \ f'`{optim_wrapper}.' cfg.optim_wrapper.type = 'AmpOptimWrapper'