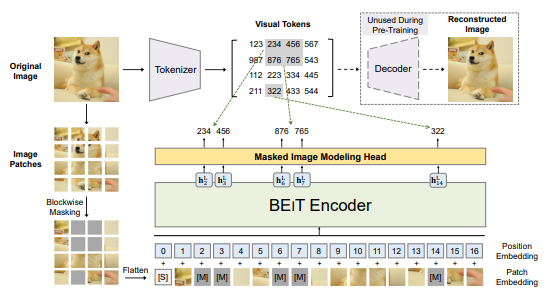
We introduce a self-supervised vision representation model BEiT, which stands for Bidirectional Encoder representation from Image Transformers. Following BERT developed in the natural language processing area, we propose a masked image modeling task to pretrain vision Transformers. Specifically, each image has two views in our pre-training, i.e, image patches (such as 16x16 pixels), and visual tokens (i.e., discrete tokens). We first "tokenize" the original image into visual tokens. Then we randomly mask some image patches and fed them into the backbone Transformer. The pre-training objective is to recover the original visual tokens based on the corrupted image patches. After pre-training BEiT, we directly fine-tune the model parameters on downstream tasks by appending task layers upon the pretrained encoder. Experimental results on image classification and semantic segmentation show that our model achieves competitive results with previous pre-training methods. For example, base-size BEiT achieves 83.2% top-1 accuracy on ImageNet-1K, significantly outperforming from-scratch DeiT training (81.8%) with the same setup. Moreover, large-size BEiT obtains 86.3% only using ImageNet-1K, even outperforming ViT-L with supervised pre-training on ImageNet-22K (85.2%). The code and pretrained models are available at this https URL.
To use other repositories' pre-trained models, it is necessary to convert keys.
We provide a script beit2mmseg.py in the tools directory to convert the key of models from the official repo to MMSegmentation style.
python tools/model_converters/beit2mmseg.py ${PRETRAIN_PATH} ${STORE_PATH}E.g.
python tools/model_converters/beit2mmseg.py https://conversationhub.blob.core.windows.net/beit-share-public/beit/beit_base_patch16_224_pt22k_ft22k.pth pretrain/beit_base_patch16_224_pt22k_ft22k.pthThis script convert model from PRETRAIN_PATH and store the converted model in STORE_PATH.
In our default setting, pretrained models could be defined below:
| pretrained models | original models |
|---|---|
| BEiT_base.pth | 'BEiT_base' |
| BEiT_large.pth | 'BEiT_large' |
Verify the single-scale results of the model:
sh tools/dist_test.sh \
configs/beit/upernet_beit-large_fp16_8x1_640x640_160k_ade20k.py \
upernet_beit-large_fp16_8x1_640x640_160k_ade20k-8fc0dd5d.pth $GPUS --eval mIoUSince relative position embedding requires the input length and width to be equal, the sliding window is adopted for multi-scale inference. So we set min_size=640, that is, the shortest edge is 640. So the multi-scale inference of config is performed separately, instead of '--aug-test'. For multi-scale inference:
sh tools/dist_test.sh \
configs/beit/upernet_beit-large_fp16_640x640_160k_ade20k_ms.py \
upernet_beit-large_fp16_8x1_640x640_160k_ade20k-8fc0dd5d.pth $GPUS --eval mIoU| Method | Backbone | Crop Size | pretrain | pretrain img size | Batch Size | Lr schd | Mem (GB) | Inf time (fps) | Device | mIoU | mIoU(ms+flip) | config | download |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| UPerNet | BEiT-B | 640x640 | ImageNet-22K | 224x224 | 16 | 160000 | 15.88 | 2.00 | V100 | 53.08 | 53.84 | config | model | log |
| UPerNet | BEiT-L | 640x640 | ImageNet-22K | 224x224 | 8 | 320000 | 22.64 | 0.96 | V100 | 56.33 | 56.84 | config | model | log |
@inproceedings{beit,
title={{BEiT}: {BERT} Pre-Training of Image Transformers},
author={Hangbo Bao and Li Dong and Songhao Piao and Furu Wei},
booktitle={International Conference on Learning Representations},
year={2022},
url={https://openreview.net/forum?id=p-BhZSz59o4}
}