@@ -12,7 +14,7 @@ MMYOLO 中,将使用 MMEngine 提供的 `Visualizer` 可视化器进行特征
- 支持基础绘图接口以及特征图可视化。
- 支持选择模型中的不同层来得到特征图,包含 `squeeze_mean` , `select_max` , `topk` 三种显示方式,用户还可以使用 `arrangement` 自定义特征图显示的布局方式。
-## 特征图绘制
+### 特征图绘制
你可以调用 `demo/featmap_vis_demo.py` 来简单快捷地得到可视化结果,为了方便理解,将其主要参数的功能梳理如下:
@@ -50,7 +52,7 @@ MMYOLO 中,将使用 MMEngine 提供的 `Visualizer` 可视化器进行特征
**注意:当图片和特征图尺度不一样时候,`draw_featmap` 函数会自动进行上采样对齐。如果你的图片在推理过程中前处理存在类似 Pad 的操作此时得到的特征图也是 Pad 过的,那么直接上采样就可能会出现不对齐问题。**
-## 用法示例
+### 用法示例
以预训练好的 YOLOv5-s 模型为例:
@@ -167,7 +169,7 @@ python demo/featmap_vis_demo.py demo/dog.jpg \
```
-

+
(5) 存储绘制后的图片,在绘制完成后,可以选择本地窗口显示,也可以存储到本地,只需要加入参数 `--out-file xxx.jpg`:
@@ -180,3 +182,113 @@ python demo/featmap_vis_demo.py demo/dog.jpg \
--channel-reduction select_max \
--out-file featmap_backbone.jpg
```
+
+## Grad-Based 和 Grad-Free CAM 可视化
+
+目标检测 CAM 可视化相比于分类 CAM 复杂很多且差异很大。本文只是简要说明用法,后续会单独开文档详细描述实现原理和注意事项。
+
+你可以调用 `demo/boxmap_vis_demo.py` 来简单快捷地得到 Box 级别的 AM 可视化结果,目前已经支持 `YOLOv5/YOLOv6/YOLOX/RTMDet`。
+
+以 YOLOv5 为例,和特征图可视化绘制一样,你需要先修改 `test_pipeline`,否则会出现特征图和原图不对齐问题。
+
+旧的 `test_pipeline` 为:
+
+```python
+test_pipeline = [
+ dict(
+ type='LoadImageFromFile',
+ file_client_args=_base_.file_client_args),
+ dict(type='YOLOv5KeepRatioResize', scale=img_scale),
+ dict(
+ type='LetterResize',
+ scale=img_scale,
+ allow_scale_up=False,
+ pad_val=dict(img=114)),
+ dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param'))
+]
+```
+
+修改为如下配置:
+
+```python
+test_pipeline = [
+ dict(
+ type='LoadImageFromFile',
+ file_client_args=_base_.file_client_args),
+ dict(type='mmdet.Resize', scale=img_scale, keep_ratio=False), # 这里将 LetterResize 修改成 mmdet.Resize
+ dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor'))
+]
+```
+
+(1) 使用 `GradCAM` 方法可视化 neck 模块的最后一个输出层的 AM 图
+
+```shell
+python demo/boxam_vis_demo.py \
+ demo/dog.jpg \
+ configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth
+
+```
+
+
+

+
+
+相对应的特征图 AM 图如下:
+
+
+
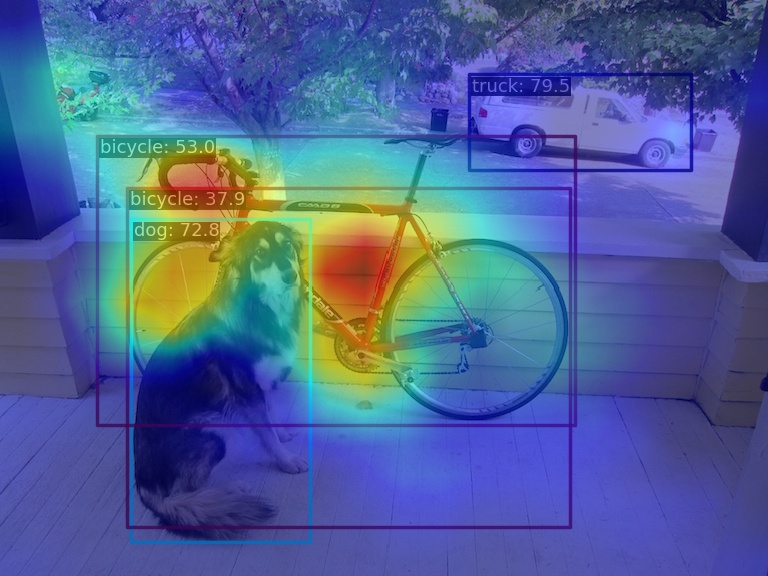
+
+
+可以看出 `GradCAM` 效果可以突出 box 级别的 AM 信息。
+
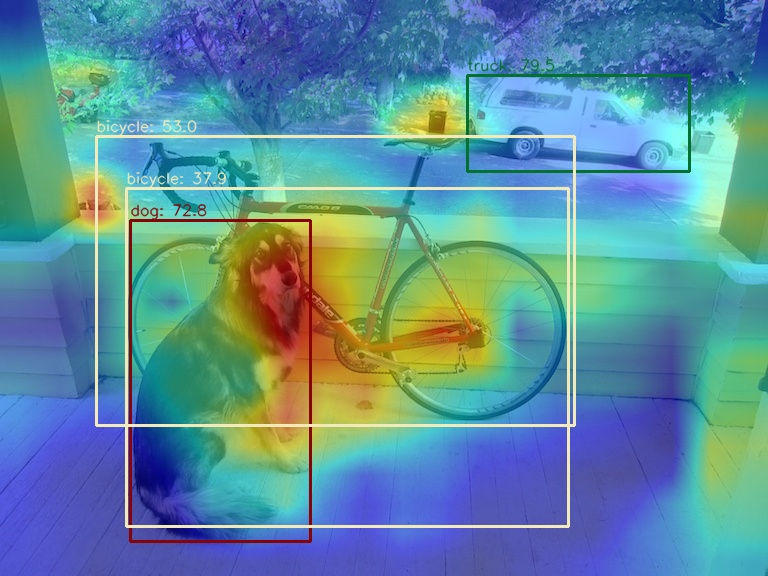
+你可以通过 `--topk` 参数选择仅仅可视化预测分值最高的前几个预测框
+
+```shell
+python demo/boxam_vis_demo.py \
+ demo/dog.jpg \
+ configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth \
+ --topk 2
+```
+
+
+

+
+
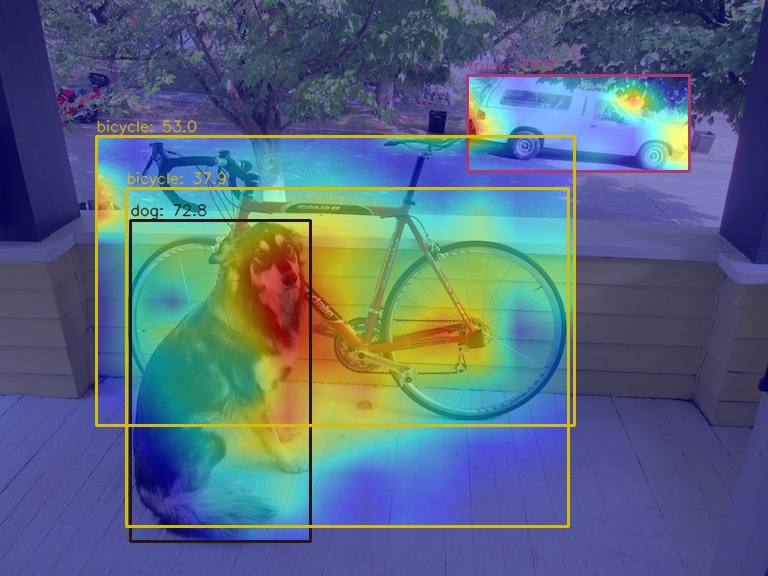
+(2) 使用 `AblationCAM` 方法可视化 neck 模块的最后一个输出层的 AM 图
+
+```shell
+python demo/boxam_vis_demo.py \
+ demo/dog.jpg \
+ configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth \
+ --method ablationcam
+```
+
+
+
+
+
+由于 `AblationCAM` 是通过每个通道对分值的贡献程度来加权,因此无法实现类似 `GradCAM` 的仅仅可视化 box 级别的 AM 信息, 但是你可以使用 `--norm-in-bbox` 来仅仅显示 bbox 内部 AM
+
+```shell
+python demo/boxam_vis_demo.py \
+ demo/dog.jpg \
+ configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth \
+ --method ablationcam \
+ --norm-in-bbox
+```
+
+
+
+
diff --git a/docs/zh_cn/user_guides/yolov5_tutorial.md b/docs/zh_cn/user_guides/yolov5_tutorial.md
index 2cd7ccf68..20a24cbd9 100644
--- a/docs/zh_cn/user_guides/yolov5_tutorial.md
+++ b/docs/zh_cn/user_guides/yolov5_tutorial.md
@@ -30,7 +30,7 @@ mim install -v -e .
本文选取不到 40MB 大小的 balloon 气球数据集作为 MMYOLO 的学习数据集。
```shell
-python tools/misc/download_dataset.py --dataset-name balloon --save-dir data --unzip
+python tools/misc/download_dataset.py --dataset-name balloon --save-dir data --unzip
python tools/dataset_converters/balloon2coco.py
```
diff --git a/mmyolo/datasets/transforms/__init__.py b/mmyolo/datasets/transforms/__init__.py
index 2ff6ad7b0..842ad641a 100644
--- a/mmyolo/datasets/transforms/__init__.py
+++ b/mmyolo/datasets/transforms/__init__.py
@@ -1,10 +1,10 @@
# Copyright (c) OpenMMLab. All rights reserved.
-from .mix_img_transforms import Mosaic, YOLOv5MixUp, YOLOXMixUp
+from .mix_img_transforms import Mosaic, Mosaic9, YOLOv5MixUp, YOLOXMixUp
from .transforms import (LetterResize, LoadAnnotations, YOLOv5HSVRandomAug,
YOLOv5KeepRatioResize, YOLOv5RandomAffine)
__all__ = [
'YOLOv5KeepRatioResize', 'LetterResize', 'Mosaic', 'YOLOXMixUp',
'YOLOv5MixUp', 'YOLOv5HSVRandomAug', 'LoadAnnotations',
- 'YOLOv5RandomAffine'
+ 'YOLOv5RandomAffine', 'Mosaic9'
]
diff --git a/mmyolo/datasets/transforms/mix_img_transforms.py b/mmyolo/datasets/transforms/mix_img_transforms.py
index 42b82318e..1b85ab2a5 100644
--- a/mmyolo/datasets/transforms/mix_img_transforms.py
+++ b/mmyolo/datasets/transforms/mix_img_transforms.py
@@ -195,15 +195,15 @@ class Mosaic(BaseMixImageTransform):
mosaic transform
center_x
+------------------------------+
- | pad | pad |
- | +-----------+ |
+ | pad | |
+ | +-----------+ pad |
| | | |
- | | image1 |--------+ |
- | | | | |
- | | | image2 | |
- center_y |----+-------------+-----------|
+ | | image1 +-----------+
+ | | | |
+ | | | image2 |
+ center_y |----+-+-----------+-----------+
| | cropped | |
- |pad | image3 | image4 |
+ |pad | image3 | image4 |
| | | |
+----|-------------+-----------+
| |
@@ -465,13 +465,306 @@ def __repr__(self) -> str:
return repr_str
+@TRANSFORMS.register_module()
+class Mosaic9(BaseMixImageTransform):
+ """Mosaic9 augmentation.
+
+ Given 9 images, mosaic transform combines them into
+ one output image. The output image is composed of the parts from each sub-
+ image.
+
+ +-------------------------------+------------+
+ | pad | pad | |
+ | +----------+ | |
+ | | +---------------+ top_right |
+ | | | top | image2 |
+ | | top_left | image1 | |
+ | | image8 o--------+------+--------+---+
+ | | | | | |
+ +----+----------+ | right |pad|
+ | | center | image3 | |
+ | left | image0 +---------------+---|
+ | image7 | | | |
+ +---+-----------+---+--------+ | |
+ | | cropped | | bottom_right |pad|
+ | |bottom_left| | image4 | |
+ | | image6 | bottom | | |
+ +---|-----------+ image5 +---------------+---|
+ | pad | | pad |
+ +-----------+------------+-------------------+
+
+ The mosaic transform steps are as follows:
+
+ 1. Get the center image according to the index, and randomly
+ sample another 8 images from the custom dataset.
+ 2. Randomly offset the image after Mosaic
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_bboxes_labels (np.int64) (optional)
+ - gt_ignore_flags (np.bool) (optional)
+ - mix_results (List[dict])
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - gt_bboxes (optional)
+ - gt_bboxes_labels (optional)
+ - gt_ignore_flags (optional)
+
+ Args:
+ img_scale (Sequence[int]): Image size after mosaic pipeline of single
+ image. The shape order should be (height, width).
+ Defaults to (640, 640).
+ bbox_clip_border (bool, optional): Whether to clip the objects outside
+ the border of the image. In some dataset like MOT17, the gt bboxes
+ are allowed to cross the border of images. Therefore, we don't
+ need to clip the gt bboxes in these cases. Defaults to True.
+ pad_val (int): Pad value. Defaults to 114.
+ pre_transform(Sequence[dict]): Sequence of transform object or
+ config dict to be composed.
+ prob (float): Probability of applying this transformation.
+ Defaults to 1.0.
+ use_cached (bool): Whether to use cache. Defaults to False.
+ max_cached_images (int): The maximum length of the cache. The larger
+ the cache, the stronger the randomness of this transform. As a
+ rule of thumb, providing 5 caches for each image suffices for
+ randomness. Defaults to 50.
+ random_pop (bool): Whether to randomly pop a result from the cache
+ when the cache is full. If set to False, use FIFO popping method.
+ Defaults to True.
+ max_refetch (int): The maximum number of retry iterations for getting
+ valid results from the pipeline. If the number of iterations is
+ greater than `max_refetch`, but results is still None, then the
+ iteration is terminated and raise the error. Defaults to 15.
+ """
+
+ def __init__(self,
+ img_scale: Tuple[int, int] = (640, 640),
+ bbox_clip_border: bool = True,
+ pad_val: Union[float, int] = 114.0,
+ pre_transform: Sequence[dict] = None,
+ prob: float = 1.0,
+ use_cached: bool = False,
+ max_cached_images: int = 50,
+ random_pop: bool = True,
+ max_refetch: int = 15):
+ assert isinstance(img_scale, tuple)
+ assert 0 <= prob <= 1.0, 'The probability should be in range [0,1]. ' \
+ f'got {prob}.'
+ if use_cached:
+ assert max_cached_images >= 9, 'The length of cache must >= 9, ' \
+ f'but got {max_cached_images}.'
+
+ super().__init__(
+ pre_transform=pre_transform,
+ prob=prob,
+ use_cached=use_cached,
+ max_cached_images=max_cached_images,
+ random_pop=random_pop,
+ max_refetch=max_refetch)
+
+ self.img_scale = img_scale
+ self.bbox_clip_border = bbox_clip_border
+ self.pad_val = pad_val
+
+ # intermediate variables
+ self._current_img_shape = [0, 0]
+ self._center_img_shape = [0, 0]
+ self._previous_img_shape = [0, 0]
+
+ def get_indexes(self, dataset: Union[BaseDataset, list]) -> list:
+ """Call function to collect indexes.
+
+ Args:
+ dataset (:obj:`Dataset` or list): The dataset or cached list.
+
+ Returns:
+ list: indexes.
+ """
+ indexes = [random.randint(0, len(dataset)) for _ in range(8)]
+ return indexes
+
+ def mix_img_transform(self, results: dict) -> dict:
+ """Mixed image data transformation.
+
+ Args:
+ results (dict): Result dict.
+
+ Returns:
+ results (dict): Updated result dict.
+ """
+ assert 'mix_results' in results
+
+ mosaic_bboxes = []
+ mosaic_bboxes_labels = []
+ mosaic_ignore_flags = []
+
+ img_scale_h, img_scale_w = self.img_scale
+
+ if len(results['img'].shape) == 3:
+ mosaic_img = np.full(
+ (int(img_scale_h * 3), int(img_scale_w * 3), 3),
+ self.pad_val,
+ dtype=results['img'].dtype)
+ else:
+ mosaic_img = np.full((int(img_scale_h * 3), int(img_scale_w * 3)),
+ self.pad_val,
+ dtype=results['img'].dtype)
+
+ # index = 0 is mean original image
+ # len(results['mix_results']) = 8
+ loc_strs = ('center', 'top', 'top_right', 'right', 'bottom_right',
+ 'bottom', 'bottom_left', 'left', 'top_left')
+
+ results_all = [results, *results['mix_results']]
+ for index, results_patch in enumerate(results_all):
+ img_i = results_patch['img']
+ # keep_ratio resize
+ img_i_h, img_i_w = img_i.shape[:2]
+ scale_ratio_i = min(img_scale_h / img_i_h, img_scale_w / img_i_w)
+ img_i = mmcv.imresize(
+ img_i,
+ (int(img_i_w * scale_ratio_i), int(img_i_h * scale_ratio_i)))
+
+ paste_coord = self._mosaic_combine(loc_strs[index],
+ img_i.shape[:2])
+
+ padw, padh = paste_coord[:2]
+ x1, y1, x2, y2 = (max(x, 0) for x in paste_coord)
+ mosaic_img[y1:y2, x1:x2] = img_i[y1 - padh:, x1 - padw:]
+
+ gt_bboxes_i = results_patch['gt_bboxes']
+ gt_bboxes_labels_i = results_patch['gt_bboxes_labels']
+ gt_ignore_flags_i = results_patch['gt_ignore_flags']
+ gt_bboxes_i.rescale_([scale_ratio_i, scale_ratio_i])
+ gt_bboxes_i.translate_([padw, padh])
+
+ mosaic_bboxes.append(gt_bboxes_i)
+ mosaic_bboxes_labels.append(gt_bboxes_labels_i)
+ mosaic_ignore_flags.append(gt_ignore_flags_i)
+
+ # Offset
+ offset_x = int(random.uniform(0, img_scale_w))
+ offset_y = int(random.uniform(0, img_scale_h))
+ mosaic_img = mosaic_img[offset_y:offset_y + 2 * img_scale_h,
+ offset_x:offset_x + 2 * img_scale_w]
+
+ mosaic_bboxes = mosaic_bboxes[0].cat(mosaic_bboxes, 0)
+ mosaic_bboxes.translate_([-offset_x, -offset_y])
+ mosaic_bboxes_labels = np.concatenate(mosaic_bboxes_labels, 0)
+ mosaic_ignore_flags = np.concatenate(mosaic_ignore_flags, 0)
+
+ if self.bbox_clip_border:
+ mosaic_bboxes.clip_([2 * img_scale_h, 2 * img_scale_w])
+ else:
+ # remove outside bboxes
+ inside_inds = mosaic_bboxes.is_inside(
+ [2 * img_scale_h, 2 * img_scale_w]).numpy()
+ mosaic_bboxes = mosaic_bboxes[inside_inds]
+ mosaic_bboxes_labels = mosaic_bboxes_labels[inside_inds]
+ mosaic_ignore_flags = mosaic_ignore_flags[inside_inds]
+
+ results['img'] = mosaic_img
+ results['img_shape'] = mosaic_img.shape
+ results['gt_bboxes'] = mosaic_bboxes
+ results['gt_bboxes_labels'] = mosaic_bboxes_labels
+ results['gt_ignore_flags'] = mosaic_ignore_flags
+ return results
+
+ def _mosaic_combine(self, loc: str,
+ img_shape_hw: Tuple[int, int]) -> Tuple[int, ...]:
+ """Calculate global coordinate of mosaic image.
+
+ Args:
+ loc (str): Index for the sub-image.
+ img_shape_hw (Sequence[int]): Height and width of sub-image
+
+ Returns:
+ paste_coord (tuple): paste corner coordinate in mosaic image.
+ """
+ assert loc in ('center', 'top', 'top_right', 'right', 'bottom_right',
+ 'bottom', 'bottom_left', 'left', 'top_left')
+
+ img_scale_h, img_scale_w = self.img_scale
+
+ self._current_img_shape = img_shape_hw
+ current_img_h, current_img_w = self._current_img_shape
+ previous_img_h, previous_img_w = self._previous_img_shape
+ center_img_h, center_img_w = self._center_img_shape
+
+ if loc == 'center':
+ self._center_img_shape = self._current_img_shape
+ # xmin, ymin, xmax, ymax
+ paste_coord = img_scale_w, \
+ img_scale_h, \
+ img_scale_w + current_img_w, \
+ img_scale_h + current_img_h
+ elif loc == 'top':
+ paste_coord = img_scale_w, \
+ img_scale_h - current_img_h, \
+ img_scale_w + current_img_w, \
+ img_scale_h
+ elif loc == 'top_right':
+ paste_coord = img_scale_w + previous_img_w, \
+ img_scale_h - current_img_h, \
+ img_scale_w + previous_img_w + current_img_w, \
+ img_scale_h
+ elif loc == 'right':
+ paste_coord = img_scale_w + center_img_w, \
+ img_scale_h, \
+ img_scale_w + center_img_w + current_img_w, \
+ img_scale_h + current_img_h
+ elif loc == 'bottom_right':
+ paste_coord = img_scale_w + center_img_w, \
+ img_scale_h + previous_img_h, \
+ img_scale_w + center_img_w + current_img_w, \
+ img_scale_h + previous_img_h + current_img_h
+ elif loc == 'bottom':
+ paste_coord = img_scale_w + center_img_w - current_img_w, \
+ img_scale_h + center_img_h, \
+ img_scale_w + center_img_w, \
+ img_scale_h + center_img_h + current_img_h
+ elif loc == 'bottom_left':
+ paste_coord = img_scale_w + center_img_w - \
+ previous_img_w - current_img_w, \
+ img_scale_h + center_img_h, \
+ img_scale_w + center_img_w - previous_img_w, \
+ img_scale_h + center_img_h + current_img_h
+ elif loc == 'left':
+ paste_coord = img_scale_w - current_img_w, \
+ img_scale_h + center_img_h - current_img_h, \
+ img_scale_w, \
+ img_scale_h + center_img_h
+ elif loc == 'top_left':
+ paste_coord = img_scale_w - current_img_w, \
+ img_scale_h + center_img_h - \
+ previous_img_h - current_img_h, \
+ img_scale_w, \
+ img_scale_h + center_img_h - previous_img_h
+
+ self._previous_img_shape = self._current_img_shape
+ # xmin, ymin, xmax, ymax
+ return paste_coord
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(img_scale={self.img_scale}, '
+ repr_str += f'pad_val={self.pad_val}, '
+ repr_str += f'prob={self.prob})'
+ return repr_str
+
+
@TRANSFORMS.register_module()
class YOLOv5MixUp(BaseMixImageTransform):
"""MixUp data augmentation for YOLOv5.
.. code:: text
- The mixup transform steps are as follows:
+ The mixup transform steps are as follows:
1. Another random image is picked by dataset.
2. Randomly obtain the fusion ratio from the beta distribution,
@@ -514,7 +807,7 @@ class YOLOv5MixUp(BaseMixImageTransform):
when the cache is full. If set to False, use FIFO popping method.
Defaults to True.
max_refetch (int): The maximum number of iterations. If the number of
- iterations is greater than `max_iters`, but gt_bbox is still
+ iterations is greater than `max_refetch`, but gt_bbox is still
empty, then the iteration is terminated. Defaults to 15.
"""
@@ -599,20 +892,20 @@ class YOLOXMixUp(BaseMixImageTransform):
.. code:: text
mixup transform
- +------------------------------+
+ +---------------+--------------+
| mixup image | |
| +--------|--------+ |
| | | | |
- |---------------+ | |
+ +---------------+ | |
| | | |
| | image | |
| | | |
| | | |
- | |-----------------+ |
+ | +-----------------+ |
| pad |
+------------------------------+
- The mixup transform steps are as follows:
+ The mixup transform steps are as follows:
1. Another random image is picked by dataset and embedded in
the top left patch(after padding and resizing)
@@ -662,7 +955,7 @@ class YOLOXMixUp(BaseMixImageTransform):
when the cache is full. If set to False, use FIFO popping method.
Defaults to True.
max_refetch (int): The maximum number of iterations. If the number of
- iterations is greater than `max_iters`, but gt_bbox is still
+ iterations is greater than `max_refetch`, but gt_bbox is still
empty, then the iteration is terminated. Defaults to 15.
"""
@@ -759,9 +1052,9 @@ def mix_img_transform(self, results: dict) -> dict:
ori_img = results['img']
origin_h, origin_w = out_img.shape[:2]
target_h, target_w = ori_img.shape[:2]
- padded_img = np.zeros(
- (max(origin_h, target_h), max(origin_w,
- target_w), 3)).astype(np.uint8)
+ padded_img = np.ones((max(origin_h, target_h), max(
+ origin_w, target_w), 3)) * self.pad_val
+ padded_img = padded_img.astype(np.uint8)
padded_img[:origin_h, :origin_w] = out_img
x_offset, y_offset = 0, 0
@@ -823,6 +1116,6 @@ def __repr__(self) -> str:
repr_str += f'ratio_range={self.ratio_range}, '
repr_str += f'flip_ratio={self.flip_ratio}, '
repr_str += f'pad_val={self.pad_val}, '
- repr_str += f'max_iters={self.max_iters}, '
+ repr_str += f'max_refetch={self.max_refetch}, '
repr_str += f'bbox_clip_border={self.bbox_clip_border})'
return repr_str
diff --git a/mmyolo/datasets/transforms/transforms.py b/mmyolo/datasets/transforms/transforms.py
index 17dc961db..890df8ac2 100644
--- a/mmyolo/datasets/transforms/transforms.py
+++ b/mmyolo/datasets/transforms/transforms.py
@@ -104,8 +104,7 @@ def _resize_img(self, results: dict):
resized_h, resized_w = image.shape[:2]
scale_ratio = resized_h / original_h
- scale_factor = np.array([scale_ratio, scale_ratio],
- dtype=np.float32)
+ scale_factor = (scale_ratio, scale_ratio)
results['img'] = image
results['img_shape'] = image.shape[:2]
@@ -208,10 +207,13 @@ def _resize_img(self, results: dict):
interpolation=self.interpolation,
backend=self.backend)
- scale_factor = np.array([ratio[0], ratio[1]], dtype=np.float32)
+ scale_factor = (ratio[1], ratio[0]) # mmcv scale factor is (w, h)
if 'scale_factor' in results:
- results['scale_factor'] = results['scale_factor'] * scale_factor
+ results['scale_factor'] = (results['scale_factor'][0] *
+ scale_factor[0],
+ results['scale_factor'][1] *
+ scale_factor[1])
else:
results['scale_factor'] = scale_factor
diff --git a/mmyolo/datasets/yolov5_coco.py b/mmyolo/datasets/yolov5_coco.py
index 048571186..55bc899ab 100644
--- a/mmyolo/datasets/yolov5_coco.py
+++ b/mmyolo/datasets/yolov5_coco.py
@@ -7,6 +7,9 @@
class BatchShapePolicyDataset(BaseDetDataset):
+ """Dataset with the batch shape policy that makes paddings with least
+ pixels during batch inference process, which does not require the image
+ scales of all batches to be the same throughout validation."""
def __init__(self,
*args,
@@ -17,7 +20,7 @@ def __init__(self,
def full_init(self):
"""rewrite full_init() to be compatible with serialize_data in
- BatchShapesPolicy."""
+ BatchShapePolicy."""
if self._fully_initialized:
return
# load data information
diff --git a/mmyolo/deploy/models/dense_heads/yolov5_head.py b/mmyolo/deploy/models/dense_heads/yolov5_head.py
index cf61fb3ca..ecbe24437 100644
--- a/mmyolo/deploy/models/dense_heads/yolov5_head.py
+++ b/mmyolo/deploy/models/dense_heads/yolov5_head.py
@@ -146,3 +146,34 @@ def yolov5_head__predict_by_feat(ctx,
return nms_func(bboxes, scores, max_output_boxes_per_class, iou_threshold,
score_threshold, pre_top_k, keep_top_k)
+
+
+@FUNCTION_REWRITER.register_rewriter(
+ func_name='mmyolo.models.dense_heads.yolov5_head.'
+ 'YOLOv5Head.predict',
+ backend='rknn')
+def yolov5_head__predict__rknn(ctx, self, x: Tuple[Tensor], *args,
+ **kwargs) -> Tuple[Tensor, Tensor, Tensor]:
+ """Perform forward propagation of the detection head and predict detection
+ results on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Multi-level features from the
+ upstream network, each is a 4D-tensor.
+ """
+ outs = self(x)
+ return outs
+
+
+@FUNCTION_REWRITER.register_rewriter(
+ func_name='mmyolo.models.dense_heads.yolov5_head.'
+ 'YOLOv5HeadModule.forward',
+ backend='rknn')
+def yolov5_head_module__forward__rknn(
+ ctx, self, x: Tensor, *args,
+ **kwargs) -> Tuple[Tensor, Tensor, Tensor]:
+ """Forward feature of a single scale level."""
+ out = []
+ for i, feat in enumerate(x):
+ out.append(self.convs_pred[i](feat))
+ return out
diff --git a/mmyolo/deploy/object_detection.py b/mmyolo/deploy/object_detection.py
index 2317ec915..ba8c69ea8 100644
--- a/mmyolo/deploy/object_detection.py
+++ b/mmyolo/deploy/object_detection.py
@@ -1,6 +1,7 @@
# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Callable
+from typing import Callable, Dict, Optional
+import torch
from mmdeploy.codebase.base import CODEBASE, MMCodebase
from mmdeploy.codebase.mmdet.deploy import ObjectDetection
from mmdeploy.utils import Codebase, Task
@@ -16,13 +17,23 @@ class MMYOLO(MMCodebase):
task_registry = MMYOLO_TASK
+ @classmethod
+ def register_deploy_modules(cls):
+ """register all rewriters for mmdet."""
+ import mmdeploy.codebase.mmdet.models # noqa: F401
+ import mmdeploy.codebase.mmdet.ops # noqa: F401
+ import mmdeploy.codebase.mmdet.structures # noqa: F401
+
@classmethod
def register_all_modules(cls):
+ """register all modules."""
from mmdet.utils.setup_env import \
register_all_modules as register_all_modules_mmdet
from mmyolo.utils.setup_env import \
register_all_modules as register_all_modules_mmyolo
+
+ cls.register_deploy_modules()
register_all_modules_mmyolo(True)
register_all_modules_mmdet(False)
@@ -72,3 +83,40 @@ def get_visualizer(self, name: str, save_dir: str):
if metainfo is not None:
visualizer.dataset_meta = metainfo
return visualizer
+
+ def build_pytorch_model(self,
+ model_checkpoint: Optional[str] = None,
+ cfg_options: Optional[Dict] = None,
+ **kwargs) -> torch.nn.Module:
+ """Initialize torch model.
+
+ Args:
+ model_checkpoint (str): The checkpoint file of torch model,
+ defaults to `None`.
+ cfg_options (dict): Optional config key-pair parameters.
+ Returns:
+ nn.Module: An initialized torch model generated by other OpenMMLab
+ codebases.
+ """
+ from copy import deepcopy
+
+ from mmengine.model import revert_sync_batchnorm
+ from mmengine.registry import MODELS
+
+ from mmyolo.utils import switch_to_deploy
+
+ model = deepcopy(self.model_cfg.model)
+ preprocess_cfg = deepcopy(self.model_cfg.get('preprocess_cfg', {}))
+ preprocess_cfg.update(
+ deepcopy(self.model_cfg.get('data_preprocessor', {})))
+ model.setdefault('data_preprocessor', preprocess_cfg)
+ model = MODELS.build(model)
+ if model_checkpoint is not None:
+ from mmengine.runner.checkpoint import load_checkpoint
+ load_checkpoint(model, model_checkpoint, map_location=self.device)
+
+ model = revert_sync_batchnorm(model)
+ switch_to_deploy(model)
+ model = model.to(self.device)
+ model.eval()
+ return model
diff --git a/mmyolo/engine/hooks/switch_to_deploy_hook.py b/mmyolo/engine/hooks/switch_to_deploy_hook.py
index e597eb22b..28ac345f4 100644
--- a/mmyolo/engine/hooks/switch_to_deploy_hook.py
+++ b/mmyolo/engine/hooks/switch_to_deploy_hook.py
@@ -17,4 +17,5 @@ class SwitchToDeployHook(Hook):
"""
def before_test_epoch(self, runner: Runner):
+ """Switch to deploy mode before testing."""
switch_to_deploy(runner.model)
diff --git a/mmyolo/engine/optimizers/__init__.py b/mmyolo/engine/optimizers/__init__.py
index 3ad91894a..b598020d0 100644
--- a/mmyolo/engine/optimizers/__init__.py
+++ b/mmyolo/engine/optimizers/__init__.py
@@ -1,4 +1,5 @@
# Copyright (c) OpenMMLab. All rights reserved.
from .yolov5_optim_constructor import YOLOv5OptimizerConstructor
+from .yolov7_optim_wrapper_constructor import YOLOv7OptimWrapperConstructor
-__all__ = ['YOLOv5OptimizerConstructor']
+__all__ = ['YOLOv5OptimizerConstructor', 'YOLOv7OptimWrapperConstructor']
diff --git a/mmyolo/engine/optimizers/yolov5_optim_constructor.py b/mmyolo/engine/optimizers/yolov5_optim_constructor.py
index 8abe5db89..5e5f42cb5 100644
--- a/mmyolo/engine/optimizers/yolov5_optim_constructor.py
+++ b/mmyolo/engine/optimizers/yolov5_optim_constructor.py
@@ -120,6 +120,10 @@ def __call__(self, model: nn.Module) -> OptimWrapper:
# bias
optimizer_cfg['params'].append({'params': params_groups[2]})
+ print_log(
+ 'Optimizer groups: %g .bias, %g conv.weight, %g other' %
+ (len(params_groups[2]), len(params_groups[0]), len(
+ params_groups[1])), 'current')
del params_groups
optimizer = OPTIMIZERS.build(optimizer_cfg)
diff --git a/mmyolo/engine/optimizers/yolov7_optim_wrapper_constructor.py b/mmyolo/engine/optimizers/yolov7_optim_wrapper_constructor.py
new file mode 100644
index 000000000..79ea8b699
--- /dev/null
+++ b/mmyolo/engine/optimizers/yolov7_optim_wrapper_constructor.py
@@ -0,0 +1,139 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch.nn as nn
+from mmengine.dist import get_world_size
+from mmengine.logging import print_log
+from mmengine.model import is_model_wrapper
+from mmengine.optim import OptimWrapper
+
+from mmyolo.models.dense_heads.yolov7_head import ImplicitA, ImplicitM
+from mmyolo.registry import (OPTIM_WRAPPER_CONSTRUCTORS, OPTIM_WRAPPERS,
+ OPTIMIZERS)
+
+
+# TODO: Consider merging into YOLOv5OptimizerConstructor
+@OPTIM_WRAPPER_CONSTRUCTORS.register_module()
+class YOLOv7OptimWrapperConstructor:
+ """YOLOv7 constructor for optimizer wrappers.
+
+ It has the following functions:
+
+ - divides the optimizer parameters into 3 groups:
+ Conv, Bias and BN/ImplicitA/ImplicitM
+
+ - support `weight_decay` parameter adaption based on
+ `batch_size_per_gpu`
+
+ Args:
+ optim_wrapper_cfg (dict): The config dict of the optimizer wrapper.
+ Positional fields are
+
+ - ``type``: class name of the OptimizerWrapper
+ - ``optimizer``: The configuration of optimizer.
+
+ Optional fields are
+
+ - any arguments of the corresponding optimizer wrapper type,
+ e.g., accumulative_counts, clip_grad, etc.
+
+ The positional fields of ``optimizer`` are
+
+ - `type`: class name of the optimizer.
+
+ Optional fields are
+
+ - any arguments of the corresponding optimizer type, e.g.,
+ lr, weight_decay, momentum, etc.
+
+ paramwise_cfg (dict, optional): Parameter-wise options. Must include
+ `base_total_batch_size` if not None. If the total input batch
+ is smaller than `base_total_batch_size`, the `weight_decay`
+ parameter will be kept unchanged, otherwise linear scaling.
+
+ Example:
+ >>> model = torch.nn.modules.Conv1d(1, 1, 1)
+ >>> optim_wrapper_cfg = dict(
+ >>> dict(type='OptimWrapper', optimizer=dict(type='SGD', lr=0.01,
+ >>> momentum=0.9, weight_decay=0.0001, batch_size_per_gpu=16))
+ >>> paramwise_cfg = dict(base_total_batch_size=64)
+ >>> optim_wrapper_builder = YOLOv7OptimWrapperConstructor(
+ >>> optim_wrapper_cfg, paramwise_cfg)
+ >>> optim_wrapper = optim_wrapper_builder(model)
+ """
+
+ def __init__(self,
+ optim_wrapper_cfg: dict,
+ paramwise_cfg: Optional[dict] = None):
+ if paramwise_cfg is None:
+ paramwise_cfg = {'base_total_batch_size': 64}
+ assert 'base_total_batch_size' in paramwise_cfg
+
+ if not isinstance(optim_wrapper_cfg, dict):
+ raise TypeError('optimizer_cfg should be a dict',
+ f'but got {type(optim_wrapper_cfg)}')
+ assert 'optimizer' in optim_wrapper_cfg, (
+ '`optim_wrapper_cfg` must contain "optimizer" config')
+
+ self.optim_wrapper_cfg = optim_wrapper_cfg
+ self.optimizer_cfg = self.optim_wrapper_cfg.pop('optimizer')
+ self.base_total_batch_size = paramwise_cfg['base_total_batch_size']
+
+ def __call__(self, model: nn.Module) -> OptimWrapper:
+ if is_model_wrapper(model):
+ model = model.module
+ optimizer_cfg = self.optimizer_cfg.copy()
+ weight_decay = optimizer_cfg.pop('weight_decay', 0)
+
+ if 'batch_size_per_gpu' in optimizer_cfg:
+ batch_size_per_gpu = optimizer_cfg.pop('batch_size_per_gpu')
+ # No scaling if total_batch_size is less than
+ # base_total_batch_size, otherwise linear scaling.
+ total_batch_size = get_world_size() * batch_size_per_gpu
+ accumulate = max(
+ round(self.base_total_batch_size / total_batch_size), 1)
+ scale_factor = total_batch_size * \
+ accumulate / self.base_total_batch_size
+
+ if scale_factor != 1:
+ weight_decay *= scale_factor
+ print_log(f'Scaled weight_decay to {weight_decay}', 'current')
+
+ params_groups = [], [], []
+ for v in model.modules():
+ # no decay
+ # Caution: Coupling with model
+ if isinstance(v, (ImplicitA, ImplicitM)):
+ params_groups[0].append(v.implicit)
+ elif isinstance(v, nn.modules.batchnorm._NormBase):
+ params_groups[0].append(v.weight)
+ # apply decay
+ elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter):
+ params_groups[1].append(v.weight) # apply decay
+
+ # biases, no decay
+ if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter):
+ params_groups[2].append(v.bias)
+
+ # Note: Make sure bias is in the last parameter group
+ optimizer_cfg['params'] = []
+ # conv
+ optimizer_cfg['params'].append({
+ 'params': params_groups[1],
+ 'weight_decay': weight_decay
+ })
+ # bn ...
+ optimizer_cfg['params'].append({'params': params_groups[0]})
+ # bias
+ optimizer_cfg['params'].append({'params': params_groups[2]})
+
+ print_log(
+ 'Optimizer groups: %g .bias, %g conv.weight, %g other' %
+ (len(params_groups[2]), len(params_groups[1]), len(
+ params_groups[0])), 'current')
+ del params_groups
+
+ optimizer = OPTIMIZERS.build(optimizer_cfg)
+ optim_wrapper = OPTIM_WRAPPERS.build(
+ self.optim_wrapper_cfg, default_args=dict(optimizer=optimizer))
+ return optim_wrapper
diff --git a/mmyolo/models/backbones/__init__.py b/mmyolo/models/backbones/__init__.py
index 851e8917c..0c5015376 100644
--- a/mmyolo/models/backbones/__init__.py
+++ b/mmyolo/models/backbones/__init__.py
@@ -3,10 +3,10 @@
from .csp_darknet import YOLOv5CSPDarknet, YOLOXCSPDarknet
from .csp_resnet import PPYOLOECSPResNet
from .cspnext import CSPNeXt
-from .efficient_rep import YOLOv6EfficientRep
+from .efficient_rep import YOLOv6CSPBep, YOLOv6EfficientRep
from .yolov7_backbone import YOLOv7Backbone
__all__ = [
- 'YOLOv5CSPDarknet', 'BaseBackbone', 'YOLOv6EfficientRep',
+ 'YOLOv5CSPDarknet', 'BaseBackbone', 'YOLOv6EfficientRep', 'YOLOv6CSPBep',
'YOLOXCSPDarknet', 'CSPNeXt', 'YOLOv7Backbone', 'PPYOLOECSPResNet'
]
diff --git a/mmyolo/models/backbones/base_backbone.py b/mmyolo/models/backbones/base_backbone.py
index 57a00eae0..730c7095e 100644
--- a/mmyolo/models/backbones/base_backbone.py
+++ b/mmyolo/models/backbones/base_backbone.py
@@ -48,7 +48,7 @@ class BaseBackbone(BaseModule, metaclass=ABCMeta):
In P6 model, n=5
Args:
- arch_setting (dict): Architecture of BaseBackbone.
+ arch_setting (list): Architecture of BaseBackbone.
plugins (list[dict]): List of plugins for stages, each dict contains:
- cfg (dict, required): Cfg dict to build plugin.
@@ -75,7 +75,7 @@ class BaseBackbone(BaseModule, metaclass=ABCMeta):
"""
def __init__(self,
- arch_setting: dict,
+ arch_setting: list,
deepen_factor: float = 1.0,
widen_factor: float = 1.0,
input_channels: int = 3,
@@ -87,7 +87,6 @@ def __init__(self,
norm_eval: bool = False,
init_cfg: OptMultiConfig = None):
super().__init__(init_cfg)
-
self.num_stages = len(arch_setting)
self.arch_setting = arch_setting
@@ -135,7 +134,7 @@ def build_stage_layer(self, stage_idx: int, setting: list):
"""
pass
- def make_stage_plugins(self, plugins, idx, setting):
+ def make_stage_plugins(self, plugins, stage_idx, setting):
"""Make plugins for backbone ``stage_idx`` th stage.
Currently we support to insert ``context_block``,
@@ -154,7 +153,7 @@ def make_stage_plugins(self, plugins, idx, setting):
... ]
>>> model = YOLOv5CSPDarknet()
>>> stage_plugins = model.make_stage_plugins(plugins, 0, setting)
- >>> assert len(stage_plugins) == 3
+ >>> assert len(stage_plugins) == 1
Suppose ``stage_idx=0``, the structure of blocks in the stage would be:
@@ -162,7 +161,7 @@ def make_stage_plugins(self, plugins, idx, setting):
conv1 -> conv2 -> conv3 -> yyy
- Suppose 'stage_idx=1', the structure of blocks in the stage would be:
+ Suppose ``stage_idx=1``, the structure of blocks in the stage would be:
.. code-block:: none
@@ -188,7 +187,7 @@ def make_stage_plugins(self, plugins, idx, setting):
plugin = plugin.copy()
stages = plugin.pop('stages', None)
assert stages is None or len(stages) == self.num_stages
- if stages is None or stages[idx]:
+ if stages is None or stages[stage_idx]:
name, layer = build_plugin_layer(
plugin['cfg'], in_channels=in_channels)
plugin_layers.append(layer)
diff --git a/mmyolo/models/backbones/csp_darknet.py b/mmyolo/models/backbones/csp_darknet.py
index 88d99c79d..2ce0fb669 100644
--- a/mmyolo/models/backbones/csp_darknet.py
+++ b/mmyolo/models/backbones/csp_darknet.py
@@ -3,7 +3,7 @@
import torch
import torch.nn as nn
-from mmcv.cnn import ConvModule
+from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
from mmdet.models.backbones.csp_darknet import CSPLayer, Focus
from mmdet.utils import ConfigType, OptMultiConfig
@@ -146,8 +146,8 @@ def build_stage_layer(self, stage_idx: int, setting: list) -> list:
return stage
def init_weights(self):
+ """Initialize the parameters."""
if self.init_cfg is None:
- """Initialize the parameters."""
for m in self.modules():
if isinstance(m, torch.nn.Conv2d):
# In order to be consistent with the source code,
@@ -178,6 +178,8 @@ class YOLOXCSPDarknet(BaseBackbone):
Defaults to (2, 3, 4).
frozen_stages (int): Stages to be frozen (stop grad and set eval
mode). -1 means not freezing any parameters. Defaults to -1.
+ use_depthwise (bool): Whether to use depthwise separable convolution.
+ Defaults to False.
spp_kernal_sizes: (tuple[int]): Sequential of kernel sizes of SPP
layers. Defaults to (5, 9, 13).
norm_cfg (dict): Dictionary to construct and config norm layer.
@@ -218,12 +220,14 @@ def __init__(self,
input_channels: int = 3,
out_indices: Tuple[int] = (2, 3, 4),
frozen_stages: int = -1,
+ use_depthwise: bool = False,
spp_kernal_sizes: Tuple[int] = (5, 9, 13),
norm_cfg: ConfigType = dict(
type='BN', momentum=0.03, eps=0.001),
act_cfg: ConfigType = dict(type='SiLU', inplace=True),
norm_eval: bool = False,
init_cfg: OptMultiConfig = None):
+ self.use_depthwise = use_depthwise
self.spp_kernal_sizes = spp_kernal_sizes
super().__init__(self.arch_settings[arch], deepen_factor, widen_factor,
input_channels, out_indices, frozen_stages, plugins,
@@ -251,7 +255,9 @@ def build_stage_layer(self, stage_idx: int, setting: list) -> list:
out_channels = make_divisible(out_channels, self.widen_factor)
num_blocks = make_round(num_blocks, self.deepen_factor)
stage = []
- conv_layer = ConvModule(
+ conv = DepthwiseSeparableConvModule \
+ if self.use_depthwise else ConvModule
+ conv_layer = conv(
in_channels,
out_channels,
kernel_size=3,
diff --git a/mmyolo/models/backbones/efficient_rep.py b/mmyolo/models/backbones/efficient_rep.py
index 9ac1b81be..691c5b846 100644
--- a/mmyolo/models/backbones/efficient_rep.py
+++ b/mmyolo/models/backbones/efficient_rep.py
@@ -8,20 +8,18 @@
from mmyolo.models.layers.yolo_bricks import SPPFBottleneck
from mmyolo.registry import MODELS
-from ..layers import RepStageBlock, RepVGGBlock
-from ..utils import make_divisible, make_round
+from ..layers import BepC3StageBlock, RepStageBlock
+from ..utils import make_round
from .base_backbone import BaseBackbone
@MODELS.register_module()
class YOLOv6EfficientRep(BaseBackbone):
"""EfficientRep backbone used in YOLOv6.
-
Args:
arch (str): Architecture of BaseDarknet, from {P5, P6}.
Defaults to P5.
plugins (list[dict]): List of plugins for stages, each dict contains:
-
- cfg (dict, required): Cfg dict to build plugin.
- stages (tuple[bool], optional): Stages to apply plugin, length
should be same as 'num_stages'.
@@ -41,10 +39,10 @@ class YOLOv6EfficientRep(BaseBackbone):
norm_eval (bool): Whether to set norm layers to eval mode, namely,
freeze running stats (mean and var). Note: Effect on Batch Norm
and its variants only. Defaults to False.
- block (nn.Module): block used to build each stage.
+ block_cfg (dict): Config dict for the block used to build each
+ layer. Defaults to dict(type='RepVGGBlock').
init_cfg (Union[dict, list[dict]], optional): Initialization config
dict. Defaults to None.
-
Example:
>>> from mmyolo.models import YOLOv6EfficientRep
>>> import torch
@@ -78,9 +76,9 @@ def __init__(self,
type='BN', momentum=0.03, eps=0.001),
act_cfg: ConfigType = dict(type='ReLU', inplace=True),
norm_eval: bool = False,
- block: nn.Module = RepVGGBlock,
+ block_cfg: ConfigType = dict(type='RepVGGBlock'),
init_cfg: OptMultiConfig = None):
- self.block = block
+ self.block_cfg = block_cfg
super().__init__(
self.arch_settings[arch],
deepen_factor,
@@ -96,12 +94,16 @@ def __init__(self,
def build_stem_layer(self) -> nn.Module:
"""Build a stem layer."""
- return self.block(
- in_channels=self.input_channels,
- out_channels=make_divisible(self.arch_setting[0][0],
- self.widen_factor),
- kernel_size=3,
- stride=2)
+
+ block_cfg = self.block_cfg.copy()
+ block_cfg.update(
+ dict(
+ in_channels=self.input_channels,
+ out_channels=int(self.arch_setting[0][0] * self.widen_factor),
+ kernel_size=3,
+ stride=2,
+ ))
+ return MODELS.build(block_cfg)
def build_stage_layer(self, stage_idx: int, setting: list) -> list:
"""Build a stage layer.
@@ -112,24 +114,28 @@ def build_stage_layer(self, stage_idx: int, setting: list) -> list:
"""
in_channels, out_channels, num_blocks, use_spp = setting
- in_channels = make_divisible(in_channels, self.widen_factor)
- out_channels = make_divisible(out_channels, self.widen_factor)
+ in_channels = int(in_channels * self.widen_factor)
+ out_channels = int(out_channels * self.widen_factor)
num_blocks = make_round(num_blocks, self.deepen_factor)
- stage = []
+ rep_stage_block = RepStageBlock(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ num_blocks=num_blocks,
+ block_cfg=self.block_cfg,
+ )
- ef_block = nn.Sequential(
- self.block(
+ block_cfg = self.block_cfg.copy()
+ block_cfg.update(
+ dict(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=3,
- stride=2),
- RepStageBlock(
- in_channels=out_channels,
- out_channels=out_channels,
- n=num_blocks,
- block=self.block,
- ))
+ stride=2))
+ stage = []
+
+ ef_block = nn.Sequential(MODELS.build(block_cfg), rep_stage_block)
+
stage.append(ef_block)
if use_spp:
@@ -152,3 +158,130 @@ def init_weights(self):
m.reset_parameters()
else:
super().init_weights()
+
+
+@MODELS.register_module()
+class YOLOv6CSPBep(YOLOv6EfficientRep):
+ """CSPBep backbone used in YOLOv6.
+ Args:
+ arch (str): Architecture of BaseDarknet, from {P5, P6}.
+ Defaults to P5.
+ plugins (list[dict]): List of plugins for stages, each dict contains:
+ - cfg (dict, required): Cfg dict to build plugin.
+ - stages (tuple[bool], optional): Stages to apply plugin, length
+ should be same as 'num_stages'.
+ deepen_factor (float): Depth multiplier, multiply number of
+ blocks in CSP layer by this amount. Defaults to 1.0.
+ widen_factor (float): Width multiplier, multiply number of
+ channels in each layer by this amount. Defaults to 1.0.
+ input_channels (int): Number of input image channels. Defaults to 3.
+ out_indices (Tuple[int]): Output from which stages.
+ Defaults to (2, 3, 4).
+ frozen_stages (int): Stages to be frozen (stop grad and set eval
+ mode). -1 means not freezing any parameters. Defaults to -1.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ Defaults to dict(type='BN', requires_grad=True).
+ act_cfg (dict): Config dict for activation layer.
+ Defaults to dict(type='LeakyReLU', negative_slope=0.1).
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Defaults to False.
+ block_cfg (dict): Config dict for the block used to build each
+ layer. Defaults to dict(type='RepVGGBlock').
+ block_act_cfg (dict): Config dict for activation layer used in each
+ stage. Defaults to dict(type='SiLU', inplace=True).
+ init_cfg (Union[dict, list[dict]], optional): Initialization config
+ dict. Defaults to None.
+ Example:
+ >>> from mmyolo.models import YOLOv6CSPBep
+ >>> import torch
+ >>> model = YOLOv6CSPBep()
+ >>> model.eval()
+ >>> inputs = torch.rand(1, 3, 416, 416)
+ >>> level_outputs = model(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ ...
+ (1, 256, 52, 52)
+ (1, 512, 26, 26)
+ (1, 1024, 13, 13)
+ """
+ # From left to right:
+ # in_channels, out_channels, num_blocks, use_spp
+ arch_settings = {
+ 'P5': [[64, 128, 6, False], [128, 256, 12, False],
+ [256, 512, 18, False], [512, 1024, 6, True]]
+ }
+
+ def __init__(self,
+ arch: str = 'P5',
+ plugins: Union[dict, List[dict]] = None,
+ deepen_factor: float = 1.0,
+ widen_factor: float = 1.0,
+ input_channels: int = 3,
+ hidden_ratio: float = 0.5,
+ out_indices: Tuple[int] = (2, 3, 4),
+ frozen_stages: int = -1,
+ norm_cfg: ConfigType = dict(
+ type='BN', momentum=0.03, eps=0.001),
+ act_cfg: ConfigType = dict(type='SiLU', inplace=True),
+ norm_eval: bool = False,
+ block_cfg: ConfigType = dict(type='ConvWrapper'),
+ init_cfg: OptMultiConfig = None):
+ self.hidden_ratio = hidden_ratio
+ super().__init__(
+ arch=arch,
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ input_channels=input_channels,
+ out_indices=out_indices,
+ plugins=plugins,
+ frozen_stages=frozen_stages,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ norm_eval=norm_eval,
+ block_cfg=block_cfg,
+ init_cfg=init_cfg)
+
+ def build_stage_layer(self, stage_idx: int, setting: list) -> list:
+ """Build a stage layer.
+
+ Args:
+ stage_idx (int): The index of a stage layer.
+ setting (list): The architecture setting of a stage layer.
+ """
+ in_channels, out_channels, num_blocks, use_spp = setting
+ in_channels = int(in_channels * self.widen_factor)
+ out_channels = int(out_channels * self.widen_factor)
+ num_blocks = make_round(num_blocks, self.deepen_factor)
+
+ rep_stage_block = BepC3StageBlock(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ num_blocks=num_blocks,
+ hidden_ratio=self.hidden_ratio,
+ block_cfg=self.block_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ block_cfg = self.block_cfg.copy()
+ block_cfg.update(
+ dict(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=3,
+ stride=2))
+ stage = []
+
+ ef_block = nn.Sequential(MODELS.build(block_cfg), rep_stage_block)
+
+ stage.append(ef_block)
+
+ if use_spp:
+ spp = SPPFBottleneck(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ kernel_sizes=5,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ stage.append(spp)
+ return stage
diff --git a/mmyolo/models/backbones/yolov7_backbone.py b/mmyolo/models/backbones/yolov7_backbone.py
index c016e277d..bb9a5eed8 100644
--- a/mmyolo/models/backbones/yolov7_backbone.py
+++ b/mmyolo/models/backbones/yolov7_backbone.py
@@ -1,12 +1,13 @@
# Copyright (c) OpenMMLab. All rights reserved.
-from typing import List, Tuple, Union
+from typing import List, Optional, Tuple, Union
import torch.nn as nn
from mmcv.cnn import ConvModule
+from mmdet.models.backbones.csp_darknet import Focus
from mmdet.utils import ConfigType, OptMultiConfig
from mmyolo.registry import MODELS
-from ..layers import ELANBlock, MaxPoolAndStrideConvBlock
+from ..layers import MaxPoolAndStrideConvBlock
from .base_backbone import BaseBackbone
@@ -15,8 +16,7 @@ class YOLOv7Backbone(BaseBackbone):
"""Backbone used in YOLOv7.
Args:
- arch (str): Architecture of YOLOv7, from {P5, P6}.
- Defaults to P5.
+ arch (str): Architecture of YOLOv7Defaults to L.
deepen_factor (float): Depth multiplier, multiply number of
blocks in CSP layer by this amount. Defaults to 1.0.
widen_factor (float): Width multiplier, multiply number of
@@ -40,28 +40,107 @@ class YOLOv7Backbone(BaseBackbone):
init_cfg (:obj:`ConfigDict` or dict or list[dict] or
list[:obj:`ConfigDict`]): Initialization config dict.
"""
+ _tiny_stage1_cfg = dict(type='TinyDownSampleBlock', middle_ratio=0.5)
+ _tiny_stage2_4_cfg = dict(type='TinyDownSampleBlock', middle_ratio=1.0)
+ _l_expand_channel_2x = dict(
+ type='ELANBlock',
+ middle_ratio=0.5,
+ block_ratio=0.5,
+ num_blocks=2,
+ num_convs_in_block=2)
+ _l_no_change_channel = dict(
+ type='ELANBlock',
+ middle_ratio=0.25,
+ block_ratio=0.25,
+ num_blocks=2,
+ num_convs_in_block=2)
+ _x_expand_channel_2x = dict(
+ type='ELANBlock',
+ middle_ratio=0.4,
+ block_ratio=0.4,
+ num_blocks=3,
+ num_convs_in_block=2)
+ _x_no_change_channel = dict(
+ type='ELANBlock',
+ middle_ratio=0.2,
+ block_ratio=0.2,
+ num_blocks=3,
+ num_convs_in_block=2)
+ _w_no_change_channel = dict(
+ type='ELANBlock',
+ middle_ratio=0.5,
+ block_ratio=0.5,
+ num_blocks=2,
+ num_convs_in_block=2)
+ _e_no_change_channel = dict(
+ type='ELANBlock',
+ middle_ratio=0.4,
+ block_ratio=0.4,
+ num_blocks=3,
+ num_convs_in_block=2)
+ _d_no_change_channel = dict(
+ type='ELANBlock',
+ middle_ratio=1 / 3,
+ block_ratio=1 / 3,
+ num_blocks=4,
+ num_convs_in_block=2)
+ _e2e_no_change_channel = dict(
+ type='EELANBlock',
+ num_elan_block=2,
+ middle_ratio=0.4,
+ block_ratio=0.4,
+ num_blocks=3,
+ num_convs_in_block=2)
# From left to right:
- # in_channels, out_channels, ELAN mode
+ # in_channels, out_channels, Block_params
arch_settings = {
- 'P5': [[64, 128, 'expand_channel_2x'], [256, 512, 'expand_channel_2x'],
- [512, 1024, 'expand_channel_2x'],
- [1024, 1024, 'no_change_channel']]
+ 'Tiny': [[64, 64, _tiny_stage1_cfg], [64, 128, _tiny_stage2_4_cfg],
+ [128, 256, _tiny_stage2_4_cfg],
+ [256, 512, _tiny_stage2_4_cfg]],
+ 'L': [[64, 256, _l_expand_channel_2x],
+ [256, 512, _l_expand_channel_2x],
+ [512, 1024, _l_expand_channel_2x],
+ [1024, 1024, _l_no_change_channel]],
+ 'X': [[80, 320, _x_expand_channel_2x],
+ [320, 640, _x_expand_channel_2x],
+ [640, 1280, _x_expand_channel_2x],
+ [1280, 1280, _x_no_change_channel]],
+ 'W':
+ [[64, 128, _w_no_change_channel], [128, 256, _w_no_change_channel],
+ [256, 512, _w_no_change_channel], [512, 768, _w_no_change_channel],
+ [768, 1024, _w_no_change_channel]],
+ 'E':
+ [[80, 160, _e_no_change_channel], [160, 320, _e_no_change_channel],
+ [320, 640, _e_no_change_channel], [640, 960, _e_no_change_channel],
+ [960, 1280, _e_no_change_channel]],
+ 'D': [[96, 192,
+ _d_no_change_channel], [192, 384, _d_no_change_channel],
+ [384, 768, _d_no_change_channel],
+ [768, 1152, _d_no_change_channel],
+ [1152, 1536, _d_no_change_channel]],
+ 'E2E': [[80, 160, _e2e_no_change_channel],
+ [160, 320, _e2e_no_change_channel],
+ [320, 640, _e2e_no_change_channel],
+ [640, 960, _e2e_no_change_channel],
+ [960, 1280, _e2e_no_change_channel]],
}
def __init__(self,
- arch: str = 'P5',
- plugins: Union[dict, List[dict]] = None,
+ arch: str = 'L',
deepen_factor: float = 1.0,
widen_factor: float = 1.0,
input_channels: int = 3,
out_indices: Tuple[int] = (2, 3, 4),
frozen_stages: int = -1,
+ plugins: Union[dict, List[dict]] = None,
norm_cfg: ConfigType = dict(
type='BN', momentum=0.03, eps=0.001),
act_cfg: ConfigType = dict(type='SiLU', inplace=True),
norm_eval: bool = False,
init_cfg: OptMultiConfig = None):
+ assert arch in self.arch_settings.keys()
+ self.arch = arch
super().__init__(
self.arch_settings[arch],
deepen_factor,
@@ -77,31 +156,57 @@ def __init__(self,
def build_stem_layer(self) -> nn.Module:
"""Build a stem layer."""
- stem = nn.Sequential(
- ConvModule(
- 3,
- int(self.arch_setting[0][0] * self.widen_factor // 2),
+ if self.arch in ['L', 'X']:
+ stem = nn.Sequential(
+ ConvModule(
+ 3,
+ int(self.arch_setting[0][0] * self.widen_factor // 2),
+ 3,
+ padding=1,
+ stride=1,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg),
+ ConvModule(
+ int(self.arch_setting[0][0] * self.widen_factor // 2),
+ int(self.arch_setting[0][0] * self.widen_factor),
+ 3,
+ padding=1,
+ stride=2,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg),
+ ConvModule(
+ int(self.arch_setting[0][0] * self.widen_factor),
+ int(self.arch_setting[0][0] * self.widen_factor),
+ 3,
+ padding=1,
+ stride=1,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ elif self.arch == 'Tiny':
+ stem = nn.Sequential(
+ ConvModule(
+ 3,
+ int(self.arch_setting[0][0] * self.widen_factor // 2),
+ 3,
+ padding=1,
+ stride=2,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg),
+ ConvModule(
+ int(self.arch_setting[0][0] * self.widen_factor // 2),
+ int(self.arch_setting[0][0] * self.widen_factor),
+ 3,
+ padding=1,
+ stride=2,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ elif self.arch in ['W', 'E', 'D', 'E2E']:
+ stem = Focus(
3,
- padding=1,
- stride=1,
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg),
- ConvModule(
- int(self.arch_setting[0][0] * self.widen_factor // 2),
int(self.arch_setting[0][0] * self.widen_factor),
- 3,
- padding=1,
- stride=2,
+ kernel_size=3,
norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg),
- ConvModule(
- int(self.arch_setting[0][0] * self.widen_factor),
- int(self.arch_setting[0][0] * self.widen_factor),
- 3,
- padding=1,
- stride=1,
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg))
+ act_cfg=self.act_cfg)
return stem
def build_stage_layer(self, stage_idx: int, setting: list) -> list:
@@ -111,39 +216,70 @@ def build_stage_layer(self, stage_idx: int, setting: list) -> list:
stage_idx (int): The index of a stage layer.
setting (list): The architecture setting of a stage layer.
"""
- in_channels, out_channels, elan_mode = setting
-
+ in_channels, out_channels, stage_block_cfg = setting
in_channels = int(in_channels * self.widen_factor)
out_channels = int(out_channels * self.widen_factor)
+ stage_block_cfg = stage_block_cfg.copy()
+ stage_block_cfg.setdefault('norm_cfg', self.norm_cfg)
+ stage_block_cfg.setdefault('act_cfg', self.act_cfg)
+
+ stage_block_cfg['in_channels'] = in_channels
+ stage_block_cfg['out_channels'] = out_channels
+
stage = []
- if stage_idx == 0:
- pre_layer = ConvModule(
+ if self.arch in ['W', 'E', 'D', 'E2E']:
+ stage_block_cfg['in_channels'] = out_channels
+ elif self.arch in ['L', 'X']:
+ if stage_idx == 0:
+ stage_block_cfg['in_channels'] = out_channels // 2
+
+ downsample_layer = self._build_downsample_layer(
+ stage_idx, in_channels, out_channels)
+ stage.append(MODELS.build(stage_block_cfg))
+ if downsample_layer is not None:
+ stage.insert(0, downsample_layer)
+ return stage
+
+ def _build_downsample_layer(self, stage_idx: int, in_channels: int,
+ out_channels: int) -> Optional[nn.Module]:
+ """Build a downsample layer pre stage."""
+ if self.arch in ['E', 'D', 'E2E']:
+ downsample_layer = MaxPoolAndStrideConvBlock(
in_channels,
out_channels,
- 3,
- stride=2,
- padding=1,
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg)
- elan_layer = ELANBlock(
- out_channels,
- mode=elan_mode,
- num_blocks=2,
+ use_in_channels_of_middle=True,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg)
- stage.extend([pre_layer, elan_layer])
- else:
- pre_layer = MaxPoolAndStrideConvBlock(
+ elif self.arch == 'W':
+ downsample_layer = ConvModule(
in_channels,
- mode='reduce_channel_2x',
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg)
- elan_layer = ELANBlock(
- in_channels,
- mode=elan_mode,
- num_blocks=2,
+ out_channels,
+ 3,
+ stride=2,
+ padding=1,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg)
- stage.extend([pre_layer, elan_layer])
- return stage
+ elif self.arch == 'Tiny':
+ if stage_idx != 0:
+ downsample_layer = nn.MaxPool2d(2, 2)
+ else:
+ downsample_layer = None
+ elif self.arch in ['L', 'X']:
+ if stage_idx == 0:
+ downsample_layer = ConvModule(
+ in_channels,
+ out_channels // 2,
+ 3,
+ stride=2,
+ padding=1,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ else:
+ downsample_layer = MaxPoolAndStrideConvBlock(
+ in_channels,
+ in_channels,
+ use_in_channels_of_middle=False,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ return downsample_layer
diff --git a/mmyolo/models/dense_heads/__init__.py b/mmyolo/models/dense_heads/__init__.py
index 469880688..57fd668c0 100644
--- a/mmyolo/models/dense_heads/__init__.py
+++ b/mmyolo/models/dense_heads/__init__.py
@@ -3,11 +3,12 @@
from .rtmdet_head import RTMDetHead, RTMDetSepBNHeadModule
from .yolov5_head import YOLOv5Head, YOLOv5HeadModule
from .yolov6_head import YOLOv6Head, YOLOv6HeadModule
-from .yolov7_head import YOLOv7Head
+from .yolov7_head import YOLOv7Head, YOLOv7HeadModule, YOLOv7p6HeadModule
from .yolox_head import YOLOXHead, YOLOXHeadModule
__all__ = [
'YOLOv5Head', 'YOLOv6Head', 'YOLOXHead', 'YOLOv5HeadModule',
'YOLOv6HeadModule', 'YOLOXHeadModule', 'RTMDetHead',
- 'RTMDetSepBNHeadModule', 'YOLOv7Head', 'PPYOLOEHead', 'PPYOLOEHeadModule'
+ 'RTMDetSepBNHeadModule', 'YOLOv7Head', 'PPYOLOEHead', 'PPYOLOEHeadModule',
+ 'YOLOv7HeadModule', 'YOLOv7p6HeadModule'
]
diff --git a/mmyolo/models/dense_heads/yolov5_head.py b/mmyolo/models/dense_heads/yolov5_head.py
index 50115bbab..57913ca6e 100644
--- a/mmyolo/models/dense_heads/yolov5_head.py
+++ b/mmyolo/models/dense_heads/yolov5_head.py
@@ -167,6 +167,7 @@ def __init__(self,
reduction='mean',
loss_weight=1.0),
prior_match_thr: float = 4.0,
+ near_neighbor_thr: float = 0.5,
obj_level_weights: List[float] = [4.0, 1.0, 0.4],
train_cfg: OptConfigType = None,
test_cfg: OptConfigType = None,
@@ -192,6 +193,7 @@ def __init__(self,
self.featmap_sizes = [torch.empty(1)] * self.num_levels
self.prior_match_thr = prior_match_thr
+ self.near_neighbor_thr = near_neighbor_thr
self.obj_level_weights = obj_level_weights
self.special_init()
@@ -231,7 +233,7 @@ def special_init(self):
[0, 1], # up
[-1, 0], # right
[0, -1], # bottom
- ]).float() * 0.5
+ ]).float()
self.register_buffer(
'grid_offset', grid_offset[:, None], persistent=False)
@@ -534,9 +536,10 @@ def loss_by_feat(
# them as positive samples as well.
batch_targets_cxcy = batch_targets_scaled[:, 2:4]
grid_xy = scaled_factor[[2, 3]] - batch_targets_cxcy
- left, up = ((batch_targets_cxcy % 1 < 0.5) &
+ left, up = ((batch_targets_cxcy % 1 < self.near_neighbor_thr) &
(batch_targets_cxcy > 1)).T
- right, bottom = ((grid_xy % 1 < 0.5) & (grid_xy > 1)).T
+ right, bottom = ((grid_xy % 1 < self.near_neighbor_thr) &
+ (grid_xy > 1)).T
offset_inds = torch.stack(
(torch.ones_like(left), left, up, right, bottom))
@@ -552,7 +555,8 @@ def loss_by_feat(
priors_inds, (img_inds, class_inds) = priors_inds.long().view(
-1), img_class_inds.long().T
- grid_xy_long = (grid_xy - retained_offsets).long()
+ grid_xy_long = (grid_xy -
+ retained_offsets * self.near_neighbor_thr).long()
grid_x_inds, grid_y_inds = grid_xy_long.T
bboxes_targets = torch.cat((grid_xy - grid_xy_long, grid_wh), 1)
diff --git a/mmyolo/models/dense_heads/yolov6_head.py b/mmyolo/models/dense_heads/yolov6_head.py
index cf56ea405..b2581ef5f 100644
--- a/mmyolo/models/dense_heads/yolov6_head.py
+++ b/mmyolo/models/dense_heads/yolov6_head.py
@@ -14,7 +14,6 @@
from torch import Tensor
from mmyolo.registry import MODELS, TASK_UTILS
-from ..utils import make_divisible
from .yolov5_head import YOLOv5Head
@@ -31,7 +30,7 @@ class YOLOv6HeadModule(BaseModule):
feature map.
widen_factor (float): Width multiplier, multiply number of
channels in each layer by this amount. Default: 1.0.
- num_base_priors:int: The number of priors (points) at a point
+ num_base_priors: (int): The number of priors (points) at a point
on the feature grid.
featmap_strides (Sequence[int]): Downsample factor of each feature map.
Defaults to [8, 16, 32].
@@ -65,12 +64,10 @@ def __init__(self,
self.act_cfg = act_cfg
if isinstance(in_channels, int):
- self.in_channels = [make_divisible(in_channels, widen_factor)
+ self.in_channels = [int(in_channels * widen_factor)
] * self.num_levels
else:
- self.in_channels = [
- make_divisible(i, widen_factor) for i in in_channels
- ]
+ self.in_channels = [int(i * widen_factor) for i in in_channels]
self._init_layers()
@@ -380,7 +377,7 @@ def loss_by_feat(
loss_cls=loss_cls * world_size, loss_bbox=loss_bbox * world_size)
@staticmethod
- def gt_instances_preprocess(batch_gt_instances: Tensor,
+ def gt_instances_preprocess(batch_gt_instances: Union[Tensor, Sequence],
batch_size: int) -> Tensor:
"""Split batch_gt_instances with batch size, from [all_gt_bboxes, 6]
to.
@@ -396,28 +393,51 @@ def gt_instances_preprocess(batch_gt_instances: Tensor,
Returns:
Tensor: batch gt instances data, shape [batch_size, number_gt, 5]
"""
-
- # sqlit batch gt instance [all_gt_bboxes, 6] ->
- # [batch_size, number_gt_each_batch, 5]
- batch_instance_list = []
- max_gt_bbox_len = 0
- for i in range(batch_size):
- single_batch_instance = \
- batch_gt_instances[batch_gt_instances[:, 0] == i, :]
- single_batch_instance = single_batch_instance[:, 1:]
- batch_instance_list.append(single_batch_instance)
- if len(single_batch_instance) > max_gt_bbox_len:
- max_gt_bbox_len = len(single_batch_instance)
-
- # fill [-1., 0., 0., 0., 0.] if some shape of
- # single batch not equal max_gt_bbox_len
- for index, gt_instance in enumerate(batch_instance_list):
- if gt_instance.shape[0] >= max_gt_bbox_len:
- continue
- fill_tensor = batch_gt_instances.new_full(
- [max_gt_bbox_len - gt_instance.shape[0], 5], 0)
- fill_tensor[:, 0] = -1.
- batch_instance_list[index] = torch.cat(
- (batch_instance_list[index], fill_tensor), dim=0)
-
- return torch.stack(batch_instance_list)
+ if isinstance(batch_gt_instances, Sequence):
+ max_gt_bbox_len = max(
+ [len(gt_instances) for gt_instances in batch_gt_instances])
+ # fill [-1., 0., 0., 0., 0.] if some shape of
+ # single batch not equal max_gt_bbox_len
+ batch_instance_list = []
+ for index, gt_instance in enumerate(batch_gt_instances):
+ bboxes = gt_instance.bboxes
+ labels = gt_instance.labels
+ batch_instance_list.append(
+ torch.cat((labels[:, None], bboxes), dim=-1))
+
+ if bboxes.shape[0] >= max_gt_bbox_len:
+ continue
+
+ fill_tensor = bboxes.new_full(
+ [max_gt_bbox_len - bboxes.shape[0], 5], 0)
+ fill_tensor[:, 0] = -1.
+ batch_instance_list[index] = torch.cat(
+ (batch_instance_list[-1], fill_tensor), dim=0)
+
+ return torch.stack(batch_instance_list)
+ else:
+ # faster version
+ # sqlit batch gt instance [all_gt_bboxes, 6] ->
+ # [batch_size, number_gt_each_batch, 5]
+ batch_instance_list = []
+ max_gt_bbox_len = 0
+ for i in range(batch_size):
+ single_batch_instance = \
+ batch_gt_instances[batch_gt_instances[:, 0] == i, :]
+ single_batch_instance = single_batch_instance[:, 1:]
+ batch_instance_list.append(single_batch_instance)
+ if len(single_batch_instance) > max_gt_bbox_len:
+ max_gt_bbox_len = len(single_batch_instance)
+
+ # fill [-1., 0., 0., 0., 0.] if some shape of
+ # single batch not equal max_gt_bbox_len
+ for index, gt_instance in enumerate(batch_instance_list):
+ if gt_instance.shape[0] >= max_gt_bbox_len:
+ continue
+ fill_tensor = batch_gt_instances.new_full(
+ [max_gt_bbox_len - gt_instance.shape[0], 5], 0)
+ fill_tensor[:, 0] = -1.
+ batch_instance_list[index] = torch.cat(
+ (batch_instance_list[index], fill_tensor), dim=0)
+
+ return torch.stack(batch_instance_list)
diff --git a/mmyolo/models/dense_heads/yolov7_head.py b/mmyolo/models/dense_heads/yolov7_head.py
index 532c86434..80e6aadd2 100644
--- a/mmyolo/models/dense_heads/yolov7_head.py
+++ b/mmyolo/models/dense_heads/yolov7_head.py
@@ -1,84 +1,210 @@
# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Sequence
+import math
+from typing import List, Optional, Sequence, Tuple, Union
+import torch
import torch.nn as nn
-from mmdet.utils import (ConfigType, OptConfigType, OptInstanceList,
- OptMultiConfig)
+from mmcv.cnn import ConvModule
+from mmdet.models.utils import multi_apply
+from mmdet.utils import ConfigType, OptInstanceList
+from mmengine.dist import get_dist_info
from mmengine.structures import InstanceData
from torch import Tensor
from mmyolo.registry import MODELS
-from .yolov5_head import YOLOv5Head
+from ..layers import ImplicitA, ImplicitM
+from ..task_modules.assigners.batch_yolov7_assigner import BatchYOLOv7Assigner
+from .yolov5_head import YOLOv5Head, YOLOv5HeadModule
+
+
+@MODELS.register_module()
+class YOLOv7HeadModule(YOLOv5HeadModule):
+ """YOLOv7Head head module used in YOLOv7."""
+
+ def _init_layers(self):
+ """initialize conv layers in YOLOv7 head."""
+ self.convs_pred = nn.ModuleList()
+ for i in range(self.num_levels):
+ conv_pred = nn.Sequential(
+ ImplicitA(self.in_channels[i]),
+ nn.Conv2d(self.in_channels[i],
+ self.num_base_priors * self.num_out_attrib, 1),
+ ImplicitM(self.num_base_priors * self.num_out_attrib),
+ )
+ self.convs_pred.append(conv_pred)
+
+ def init_weights(self):
+ """Initialize the bias of YOLOv7 head."""
+ super(YOLOv5HeadModule, self).init_weights()
+ for mi, s in zip(self.convs_pred, self.featmap_strides): # from
+ mi = mi[1] # nn.Conv2d
+
+ b = mi.bias.data.view(3, -1)
+ # obj (8 objects per 640 image)
+ b.data[:, 4] += math.log(8 / (640 / s)**2)
+ b.data[:, 5:] += math.log(0.6 / (self.num_classes - 0.99))
+
+ mi.bias.data = b.view(-1)
+
+
+@MODELS.register_module()
+class YOLOv7p6HeadModule(YOLOv5HeadModule):
+ """YOLOv7Head head module used in YOLOv7."""
+
+ def __init__(self,
+ *args,
+ main_out_channels: Sequence[int] = [256, 512, 768, 1024],
+ aux_out_channels: Sequence[int] = [320, 640, 960, 1280],
+ use_aux: bool = True,
+ norm_cfg: ConfigType = dict(
+ type='BN', momentum=0.03, eps=0.001),
+ act_cfg: ConfigType = dict(type='SiLU', inplace=True),
+ **kwargs):
+ self.main_out_channels = main_out_channels
+ self.aux_out_channels = aux_out_channels
+ self.use_aux = use_aux
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ super().__init__(*args, **kwargs)
+
+ def _init_layers(self):
+ """initialize conv layers in YOLOv7 head."""
+ self.main_convs_pred = nn.ModuleList()
+ for i in range(self.num_levels):
+ conv_pred = nn.Sequential(
+ ConvModule(
+ self.in_channels[i],
+ self.main_out_channels[i],
+ 3,
+ padding=1,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg),
+ ImplicitA(self.main_out_channels[i]),
+ nn.Conv2d(self.main_out_channels[i],
+ self.num_base_priors * self.num_out_attrib, 1),
+ ImplicitM(self.num_base_priors * self.num_out_attrib),
+ )
+ self.main_convs_pred.append(conv_pred)
+
+ if self.use_aux:
+ self.aux_convs_pred = nn.ModuleList()
+ for i in range(self.num_levels):
+ aux_pred = nn.Sequential(
+ ConvModule(
+ self.in_channels[i],
+ self.aux_out_channels[i],
+ 3,
+ padding=1,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg),
+ nn.Conv2d(self.aux_out_channels[i],
+ self.num_base_priors * self.num_out_attrib, 1))
+ self.aux_convs_pred.append(aux_pred)
+ else:
+ self.aux_convs_pred = [None] * len(self.main_convs_pred)
+
+ def init_weights(self):
+ """Initialize the bias of YOLOv5 head."""
+ super(YOLOv5HeadModule, self).init_weights()
+ for mi, aux, s in zip(self.main_convs_pred, self.aux_convs_pred,
+ self.featmap_strides): # from
+ mi = mi[2] # nn.Conv2d
+ b = mi.bias.data.view(3, -1)
+ # obj (8 objects per 640 image)
+ b.data[:, 4] += math.log(8 / (640 / s)**2)
+ b.data[:, 5:] += math.log(0.6 / (self.num_classes - 0.99))
+ mi.bias.data = b.view(-1)
+
+ if self.use_aux:
+ aux = aux[1] # nn.Conv2d
+ b = aux.bias.data.view(3, -1)
+ # obj (8 objects per 640 image)
+ b.data[:, 4] += math.log(8 / (640 / s)**2)
+ b.data[:, 5:] += math.log(0.6 / (self.num_classes - 0.99))
+ mi.bias.data = b.view(-1)
+
+ def forward(self, x: Tuple[Tensor]) -> Tuple[List]:
+ """Forward features from the upstream network.
+
+ Args:
+ x (Tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+ Returns:
+ Tuple[List]: A tuple of multi-level classification scores, bbox
+ predictions, and objectnesses.
+ """
+ assert len(x) == self.num_levels
+ return multi_apply(self.forward_single, x, self.main_convs_pred,
+ self.aux_convs_pred)
+
+ def forward_single(self, x: Tensor, convs: nn.Module,
+ aux_convs: Optional[nn.Module]) \
+ -> Tuple[Union[Tensor, List], Union[Tensor, List],
+ Union[Tensor, List]]:
+ """Forward feature of a single scale level."""
+
+ pred_map = convs(x)
+ bs, _, ny, nx = pred_map.shape
+ pred_map = pred_map.view(bs, self.num_base_priors, self.num_out_attrib,
+ ny, nx)
+
+ cls_score = pred_map[:, :, 5:, ...].reshape(bs, -1, ny, nx)
+ bbox_pred = pred_map[:, :, :4, ...].reshape(bs, -1, ny, nx)
+ objectness = pred_map[:, :, 4:5, ...].reshape(bs, -1, ny, nx)
+
+ if not self.training or not self.use_aux:
+ return cls_score, bbox_pred, objectness
+ else:
+ aux_pred_map = aux_convs(x)
+ aux_pred_map = aux_pred_map.view(bs, self.num_base_priors,
+ self.num_out_attrib, ny, nx)
+ aux_cls_score = aux_pred_map[:, :, 5:, ...].reshape(bs, -1, ny, nx)
+ aux_bbox_pred = aux_pred_map[:, :, :4, ...].reshape(bs, -1, ny, nx)
+ aux_objectness = aux_pred_map[:, :, 4:5,
+ ...].reshape(bs, -1, ny, nx)
+
+ return [cls_score,
+ aux_cls_score], [bbox_pred, aux_bbox_pred
+ ], [objectness, aux_objectness]
-# Training mode is currently not supported
@MODELS.register_module()
class YOLOv7Head(YOLOv5Head):
"""YOLOv7Head head used in `YOLOv7
`_.
Args:
- head_module(nn.Module): Base module used for YOLOv6Head
- prior_generator(dict): Points generator feature maps
- in 2D points-based detectors.
- loss_cls (:obj:`ConfigDict` or dict): Config of classification loss.
- loss_bbox (:obj:`ConfigDict` or dict): Config of localization loss.
- loss_obj (:obj:`ConfigDict` or dict): Config of objectness loss.
- train_cfg (:obj:`ConfigDict` or dict, optional): Training config of
- anchor head. Defaults to None.
- test_cfg (:obj:`ConfigDict` or dict, optional): Testing config of
- anchor head. Defaults to None.
- init_cfg (:obj:`ConfigDict` or list[:obj:`ConfigDict`] or dict or
- list[dict], optional): Initialization config dict.
- Defaults to None.
+ simota_candidate_topk (int): The candidate top-k which used to
+ get top-k ious to calculate dynamic-k in BatchYOLOv7Assigner.
+ Defaults to 10.
+ simota_iou_weight (float): The scale factor for regression
+ iou cost in BatchYOLOv7Assigner. Defaults to 3.0.
+ simota_cls_weight (float): The scale factor for classification
+ cost in BatchYOLOv7Assigner. Defaults to 1.0.
"""
def __init__(self,
- head_module: nn.Module,
- prior_generator: ConfigType = dict(
- type='mmdet.YOLOAnchorGenerator',
- base_sizes=[[(10, 13), (16, 30), (33, 23)],
- [(30, 61), (62, 45), (59, 119)],
- [(116, 90), (156, 198), (373, 326)]],
- strides=[8, 16, 32]),
- bbox_coder: ConfigType = dict(type='YOLOv5BBoxCoder'),
- loss_cls: ConfigType = dict(
- type='mmdet.CrossEntropyLoss',
- use_sigmoid=True,
- reduction='sum',
- loss_weight=1.0),
- loss_bbox: ConfigType = dict(
- type='mmdet.GIoULoss', reduction='sum', loss_weight=5.0),
- loss_obj: ConfigType = dict(
- type='mmdet.CrossEntropyLoss',
- use_sigmoid=True,
- reduction='sum',
- loss_weight=1.0),
- train_cfg: OptConfigType = None,
- test_cfg: OptConfigType = None,
- init_cfg: OptMultiConfig = None):
- super().__init__(
- head_module=head_module,
- prior_generator=prior_generator,
- bbox_coder=bbox_coder,
- loss_cls=loss_cls,
- loss_bbox=loss_bbox,
- loss_obj=loss_obj,
- train_cfg=train_cfg,
- test_cfg=test_cfg,
- init_cfg=init_cfg)
-
- def special_init(self):
- """Since YOLO series algorithms will inherit from YOLOv5Head, but
- different algorithms have special initialization process.
-
- The special_init function is designed to deal with this situation.
- """
- pass
+ *args,
+ simota_candidate_topk: int = 20,
+ simota_iou_weight: float = 3.0,
+ simota_cls_weight: float = 1.0,
+ aux_loss_weights: float = 0.25,
+ **kwargs):
+ super().__init__(*args, **kwargs)
+ self.aux_loss_weights = aux_loss_weights
+ self.assigner = BatchYOLOv7Assigner(
+ num_classes=self.num_classes,
+ num_base_priors=self.num_base_priors,
+ featmap_strides=self.featmap_strides,
+ prior_match_thr=self.prior_match_thr,
+ candidate_topk=simota_candidate_topk,
+ iou_weight=simota_iou_weight,
+ cls_weight=simota_cls_weight)
def loss_by_feat(
self,
- cls_scores: Sequence[Tensor],
- bbox_preds: Sequence[Tensor],
+ cls_scores: Sequence[Union[Tensor, List]],
+ bbox_preds: Sequence[Union[Tensor, List]],
+ objectnesses: Sequence[Union[Tensor, List]],
batch_gt_instances: Sequence[InstanceData],
batch_img_metas: Sequence[dict],
batch_gt_instances_ignore: OptInstanceList = None) -> dict:
@@ -92,6 +218,9 @@ def loss_by_feat(
bbox_preds (Sequence[Tensor]): Box energies / deltas for each scale
level, each is a 4D-tensor, the channel number is
num_priors * 4.
+ objectnesses (Sequence[Tensor]): Score factor for
+ all scale level, each is a 4D-tensor, has shape
+ (batch_size, 1, H, W).
batch_gt_instances (list[:obj:`InstanceData`]): Batch of
gt_instance. It usually includes ``bboxes`` and ``labels``
attributes.
@@ -104,4 +233,172 @@ def loss_by_feat(
Returns:
dict[str, Tensor]: A dictionary of losses.
"""
- raise NotImplementedError('Not implemented yet!')
+
+ if isinstance(cls_scores[0], Sequence):
+ with_aux = True
+ batch_size = cls_scores[0][0].shape[0]
+ device = cls_scores[0][0].device
+
+ bbox_preds_main, bbox_preds_aux = zip(*bbox_preds)
+ objectnesses_main, objectnesses_aux = zip(*objectnesses)
+ cls_scores_main, cls_scores_aux = zip(*cls_scores)
+
+ head_preds = self._merge_predict_results(bbox_preds_main,
+ objectnesses_main,
+ cls_scores_main)
+ head_preds_aux = self._merge_predict_results(
+ bbox_preds_aux, objectnesses_aux, cls_scores_aux)
+ else:
+ with_aux = False
+ batch_size = cls_scores[0].shape[0]
+ device = cls_scores[0].device
+
+ head_preds = self._merge_predict_results(bbox_preds, objectnesses,
+ cls_scores)
+
+ # Convert gt to norm xywh format
+ # (num_base_priors, num_batch_gt, 7)
+ # 7 is mean (batch_idx, cls_id, x_norm, y_norm,
+ # w_norm, h_norm, prior_idx)
+ batch_targets_normed = self._convert_gt_to_norm_format(
+ batch_gt_instances, batch_img_metas)
+
+ scaled_factors = [
+ torch.tensor(head_pred.shape, device=device)[[3, 2, 3, 2]]
+ for head_pred in head_preds
+ ]
+
+ loss_cls, loss_obj, loss_box = self._calc_loss(
+ head_preds=head_preds,
+ head_preds_aux=None,
+ batch_targets_normed=batch_targets_normed,
+ near_neighbor_thr=self.near_neighbor_thr,
+ scaled_factors=scaled_factors,
+ batch_img_metas=batch_img_metas,
+ device=device)
+
+ if with_aux:
+ loss_cls_aux, loss_obj_aux, loss_box_aux = self._calc_loss(
+ head_preds=head_preds,
+ head_preds_aux=head_preds_aux,
+ batch_targets_normed=batch_targets_normed,
+ near_neighbor_thr=self.near_neighbor_thr * 2,
+ scaled_factors=scaled_factors,
+ batch_img_metas=batch_img_metas,
+ device=device)
+ loss_cls += self.aux_loss_weights * loss_cls_aux
+ loss_obj += self.aux_loss_weights * loss_obj_aux
+ loss_box += self.aux_loss_weights * loss_box_aux
+
+ _, world_size = get_dist_info()
+ return dict(
+ loss_cls=loss_cls * batch_size * world_size,
+ loss_obj=loss_obj * batch_size * world_size,
+ loss_bbox=loss_box * batch_size * world_size)
+
+ def _calc_loss(self, head_preds, head_preds_aux, batch_targets_normed,
+ near_neighbor_thr, scaled_factors, batch_img_metas, device):
+ loss_cls = torch.zeros(1, device=device)
+ loss_box = torch.zeros(1, device=device)
+ loss_obj = torch.zeros(1, device=device)
+
+ assigner_results = self.assigner(
+ head_preds,
+ batch_targets_normed,
+ batch_img_metas[0]['batch_input_shape'],
+ self.priors_base_sizes,
+ self.grid_offset,
+ near_neighbor_thr=near_neighbor_thr)
+ # mlvl is mean multi_level
+ mlvl_positive_infos = assigner_results['mlvl_positive_infos']
+ mlvl_priors = assigner_results['mlvl_priors']
+ mlvl_targets_normed = assigner_results['mlvl_targets_normed']
+
+ if head_preds_aux is not None:
+ # This is mean calc aux branch loss
+ head_preds = head_preds_aux
+
+ for i, head_pred in enumerate(head_preds):
+ batch_inds, proir_idx, grid_x, grid_y = mlvl_positive_infos[i].T
+ num_pred_positive = batch_inds.shape[0]
+ target_obj = torch.zeros_like(head_pred[..., 0])
+ # empty positive sampler
+ if num_pred_positive == 0:
+ loss_box += head_pred[..., :4].sum() * 0
+ loss_cls += head_pred[..., 5:].sum() * 0
+ loss_obj += self.loss_obj(
+ head_pred[..., 4], target_obj) * self.obj_level_weights[i]
+ continue
+
+ priors = mlvl_priors[i]
+ targets_normed = mlvl_targets_normed[i]
+
+ head_pred_positive = head_pred[batch_inds, proir_idx, grid_y,
+ grid_x]
+
+ # calc bbox loss
+ grid_xy = torch.stack([grid_x, grid_y], dim=1)
+ decoded_pred_bbox = self._decode_bbox_to_xywh(
+ head_pred_positive[:, :4], priors, grid_xy)
+ target_bbox_scaled = targets_normed[:, 2:6] * scaled_factors[i]
+
+ loss_box_i, iou = self.loss_bbox(decoded_pred_bbox,
+ target_bbox_scaled)
+ loss_box += loss_box_i
+
+ # calc obj loss
+ target_obj[batch_inds, proir_idx, grid_y,
+ grid_x] = iou.detach().clamp(0).type(target_obj.dtype)
+ loss_obj += self.loss_obj(head_pred[..., 4],
+ target_obj) * self.obj_level_weights[i]
+
+ # calc cls loss
+ if self.num_classes > 1:
+ pred_cls_scores = targets_normed[:, 1].long()
+ target_class = torch.full_like(
+ head_pred_positive[:, 5:], 0., device=device)
+ target_class[range(num_pred_positive), pred_cls_scores] = 1.
+ loss_cls += self.loss_cls(head_pred_positive[:, 5:],
+ target_class)
+ else:
+ loss_cls += head_pred_positive[:, 5:].sum() * 0
+ return loss_cls, loss_obj, loss_box
+
+ def _merge_predict_results(self, bbox_preds: Sequence[Tensor],
+ objectnesses: Sequence[Tensor],
+ cls_scores: Sequence[Tensor]) -> List[Tensor]:
+ """Merge predict output from 3 heads.
+
+ Args:
+ cls_scores (Sequence[Tensor]): Box scores for each scale level,
+ each is a 4D-tensor, the channel number is
+ num_priors * num_classes.
+ bbox_preds (Sequence[Tensor]): Box energies / deltas for each scale
+ level, each is a 4D-tensor, the channel number is
+ num_priors * 4.
+ objectnesses (Sequence[Tensor]): Score factor for
+ all scale level, each is a 4D-tensor, has shape
+ (batch_size, 1, H, W).
+
+ Returns:
+ List[Tensor]: Merged output.
+ """
+ head_preds = []
+ for bbox_pred, objectness, cls_score in zip(bbox_preds, objectnesses,
+ cls_scores):
+ b, _, h, w = bbox_pred.shape
+ bbox_pred = bbox_pred.reshape(b, self.num_base_priors, -1, h, w)
+ objectness = objectness.reshape(b, self.num_base_priors, -1, h, w)
+ cls_score = cls_score.reshape(b, self.num_base_priors, -1, h, w)
+ head_pred = torch.cat([bbox_pred, objectness, cls_score],
+ dim=2).permute(0, 1, 3, 4, 2).contiguous()
+ head_preds.append(head_pred)
+ return head_preds
+
+ def _decode_bbox_to_xywh(self, bbox_pred, priors_base_sizes,
+ grid_xy) -> Tensor:
+ bbox_pred = bbox_pred.sigmoid()
+ pred_xy = bbox_pred[:, :2] * 2 - 0.5 + grid_xy
+ pred_wh = (bbox_pred[:, 2:] * 2)**2 * priors_base_sizes
+ decoded_bbox_pred = torch.cat((pred_xy, pred_wh), dim=-1)
+ return decoded_bbox_pred
diff --git a/mmyolo/models/layers/__init__.py b/mmyolo/models/layers/__init__.py
index 3c8a543bd..d8ef15154 100644
--- a/mmyolo/models/layers/__init__.py
+++ b/mmyolo/models/layers/__init__.py
@@ -1,12 +1,14 @@
# Copyright (c) OpenMMLab. All rights reserved.
from .ema import ExpMomentumEMA
-from .yolo_bricks import (EffectiveSELayer, ELANBlock,
+from .yolo_bricks import (BepC3StageBlock, EELANBlock, EffectiveSELayer,
+ ELANBlock, ImplicitA, ImplicitM,
MaxPoolAndStrideConvBlock, PPYOLOEBasicBlock,
RepStageBlock, RepVGGBlock, SPPFBottleneck,
- SPPFCSPBlock)
+ SPPFCSPBlock, TinyDownSampleBlock)
__all__ = [
'SPPFBottleneck', 'RepVGGBlock', 'RepStageBlock', 'ExpMomentumEMA',
'ELANBlock', 'MaxPoolAndStrideConvBlock', 'SPPFCSPBlock',
- 'PPYOLOEBasicBlock', 'EffectiveSELayer'
+ 'PPYOLOEBasicBlock', 'EffectiveSELayer', 'TinyDownSampleBlock',
+ 'EELANBlock', 'ImplicitA', 'ImplicitM', 'BepC3StageBlock'
]
diff --git a/mmyolo/models/layers/yolo_bricks.py b/mmyolo/models/layers/yolo_bricks.py
index c720c1a40..f284acfa3 100644
--- a/mmyolo/models/layers/yolo_bricks.py
+++ b/mmyolo/models/layers/yolo_bricks.py
@@ -22,7 +22,7 @@ class SiLU(nn.Module):
def __init__(self, inplace=True):
super().__init__()
- def forward(self, inputs) -> torch.Tensor:
+ def forward(self, inputs) -> Tensor:
return inputs * torch.sigmoid(inputs)
MODELS.register_module(module=SiLU, name='SiLU')
@@ -100,7 +100,7 @@ def __init__(self,
norm_cfg=norm_cfg,
act_cfg=act_cfg)
- def forward(self, x: torch.Tensor) -> torch.Tensor:
+ def forward(self, x: Tensor) -> Tensor:
"""Forward process
Args:
x (Tensor): The input tensor.
@@ -118,6 +118,7 @@ def forward(self, x: torch.Tensor) -> torch.Tensor:
return x
+@MODELS.register_module()
class RepVGGBlock(nn.Module):
"""RepVGGBlock is a basic rep-style block, including training and deploy
status This code is based on
@@ -227,7 +228,7 @@ def __init__(self,
norm_cfg=norm_cfg,
act_cfg=None)
- def forward(self, inputs: torch.Tensor) -> torch.Tensor:
+ def forward(self, inputs: Tensor) -> Tensor:
"""Forward process.
Args:
inputs (Tensor): The input tensor.
@@ -281,8 +282,7 @@ def _pad_1x1_to_3x3_tensor(self, kernel1x1):
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
- def _fuse_bn_tensor(self,
- branch: nn.Module) -> Tuple[np.ndarray, torch.Tensor]:
+ def _fuse_bn_tensor(self, branch: nn.Module) -> Tuple[np.ndarray, Tensor]:
"""Derives the equivalent kernel and bias of a specific branch layer.
Args:
@@ -348,38 +348,177 @@ def switch_to_deploy(self):
self.deploy = True
-class RepStageBlock(nn.Module):
- """RepStageBlock is a stage block with rep-style basic block.
+@MODELS.register_module()
+class BepC3StageBlock(nn.Module):
+ """Beer-mug RepC3 Block.
Args:
- in_channels (int): The input channels of this Module.
- out_channels (int): The output channels of this Module.
- n (int, tuple[int]): Number of blocks. Defaults to 1.
- block (nn.Module): Basic unit of RepStage. Defaults to RepVGGBlock.
+ in_channels (int): Number of channels in the input image
+ out_channels (int): Number of channels produced by the convolution
+ num_blocks (int): Number of blocks. Defaults to 1
+ hidden_ratio (float): Hidden channel expansion.
+ Default: 0.5
+ concat_all_layer (bool): Concat all layer when forward calculate.
+ Default: True
+ block_cfg (dict): Config dict for the block used to build each
+ layer. Defaults to dict(type='RepVGGBlock').
+ norm_cfg (ConfigType): Config dict for normalization layer.
+ Defaults to dict(type='BN', momentum=0.03, eps=0.001).
+ act_cfg (ConfigType): Config dict for activation layer.
+ Defaults to dict(type='ReLU', inplace=True).
"""
def __init__(self,
in_channels: int,
out_channels: int,
- n: int = 1,
- block: nn.Module = RepVGGBlock):
+ num_blocks: int = 1,
+ hidden_ratio: float = 0.5,
+ concat_all_layer: bool = True,
+ block_cfg: ConfigType = dict(type='RepVGGBlock'),
+ norm_cfg: ConfigType = dict(
+ type='BN', momentum=0.03, eps=0.001),
+ act_cfg: ConfigType = dict(type='ReLU', inplace=True)):
super().__init__()
- self.conv1 = block(in_channels, out_channels)
- self.block = nn.Sequential(*(block(out_channels, out_channels)
- for _ in range(n - 1))) if n > 1 else None
+ hidden_channels = int(out_channels * hidden_ratio)
- def forward(self, x: torch.Tensor) -> torch.Tensor:
- """Forward process.
- Args:
- inputs (Tensor): The input tensor.
+ self.conv1 = ConvModule(
+ in_channels,
+ hidden_channels,
+ kernel_size=1,
+ stride=1,
+ groups=1,
+ bias=False,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.conv2 = ConvModule(
+ in_channels,
+ hidden_channels,
+ kernel_size=1,
+ stride=1,
+ groups=1,
+ bias=False,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.conv3 = ConvModule(
+ 2 * hidden_channels,
+ out_channels,
+ kernel_size=1,
+ stride=1,
+ groups=1,
+ bias=False,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.block = RepStageBlock(
+ in_channels=hidden_channels,
+ out_channels=hidden_channels,
+ num_blocks=num_blocks,
+ block_cfg=block_cfg,
+ bottle_block=BottleRep)
+ self.concat_all_layer = concat_all_layer
+ if not concat_all_layer:
+ self.conv3 = ConvModule(
+ hidden_channels,
+ out_channels,
+ kernel_size=1,
+ stride=1,
+ groups=1,
+ bias=False,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
- Returns:
- Tensor: The output tensor.
- """
- x = self.conv1(x)
- if self.block is not None:
- x = self.block(x)
- return x
+ def forward(self, x):
+ if self.concat_all_layer is True:
+ return self.conv3(
+ torch.cat((self.block(self.conv1(x)), self.conv2(x)), dim=1))
+ else:
+ return self.conv3(self.block(self.conv1(x)))
+
+
+class BottleRep(nn.Module):
+ """Bottle Rep Block.
+
+ Args:
+ in_channels (int): Number of channels in the input image
+ out_channels (int): Number of channels produced by the convolution
+ block_cfg (dict): Config dict for the block used to build each
+ layer. Defaults to dict(type='RepVGGBlock').
+ adaptive_weight (bool): Add adaptive_weight when forward calculate.
+ Defaults False.
+ """
+
+ def __init__(self,
+ in_channels: int,
+ out_channels: int,
+ block_cfg: ConfigType = dict(type='RepVGGBlock'),
+ adaptive_weight: bool = False):
+ super().__init__()
+ conv1_cfg = block_cfg.copy()
+ conv2_cfg = block_cfg.copy()
+
+ conv1_cfg.update(
+ dict(in_channels=in_channels, out_channels=out_channels))
+ conv2_cfg.update(
+ dict(in_channels=out_channels, out_channels=out_channels))
+
+ self.conv1 = MODELS.build(conv1_cfg)
+ self.conv2 = MODELS.build(conv2_cfg)
+
+ if in_channels != out_channels:
+ self.shortcut = False
+ else:
+ self.shortcut = True
+ if adaptive_weight:
+ self.alpha = nn.Parameter(torch.ones(1))
+ else:
+ self.alpha = 1.0
+
+ def forward(self, x: Tensor) -> Tensor:
+ outputs = self.conv1(x)
+ outputs = self.conv2(outputs)
+ return outputs + self.alpha * x if self.shortcut else outputs
+
+
+@MODELS.register_module()
+class ConvWrapper(nn.Module):
+ """Wrapper for normal Conv with SiLU activation.
+
+ Args:
+ in_channels (int): Number of channels in the input image
+ out_channels (int): Number of channels produced by the convolution
+ kernel_size (int or tuple): Size of the convolving kernel
+ stride (int or tuple): Stride of the convolution. Default: 1
+ groups (int, optional): Number of blocked connections from input
+ channels to output channels. Default: 1
+ bias (bool, optional): Conv bias. Default: True.
+ norm_cfg (ConfigType): Config dict for normalization layer.
+ Defaults to dict(type='BN', momentum=0.03, eps=0.001).
+ act_cfg (ConfigType): Config dict for activation layer.
+ Defaults to dict(type='ReLU', inplace=True).
+ """
+
+ def __init__(self,
+ in_channels: int,
+ out_channels: int,
+ kernel_size: int = 3,
+ stride: int = 1,
+ groups: int = 1,
+ bias: bool = True,
+ norm_cfg: ConfigType = None,
+ act_cfg: ConfigType = dict(type='SiLU')):
+ super().__init__()
+ self.block = ConvModule(
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride,
+ padding=kernel_size // 2,
+ groups=groups,
+ bias=bias,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def forward(self, x: Tensor) -> Tensor:
+ return self.block(x)
@MODELS.register_module()
@@ -465,20 +604,21 @@ def forward(self, feat: Tensor, avg_feat: Tensor) -> Tensor:
return self.conv(feat * weight)
+@MODELS.register_module()
class ELANBlock(BaseModule):
"""Efficient layer aggregation networks for YOLOv7.
- - if mode is `reduce_channel_2x`, the output channel will be
- reduced by a factor of 2
- - if mode is `no_change_channel`, the output channel does not change.
- - if mode is `expand_channel_2x`, the output channel will be
- expanded by a factor of 2
-
Args:
in_channels (int): The input channels of this Module.
- mode (str): Output channel mode. Defaults to `expand_channel_2x`.
+ out_channels (int): The out channels of this Module.
+ middle_ratio (float): The scaling ratio of the middle layer
+ based on the in_channels.
+ block_ratio (float): The scaling ratio of the block layer
+ based on the in_channels.
num_blocks (int): The number of blocks in the main branch.
Defaults to 2.
+ num_convs_in_block (int): The number of convs pre block.
+ Defaults to 1.
conv_cfg (dict): Config dict for convolution layer. Defaults to None.
which means using conv2d. Defaults to None.
norm_cfg (dict): Config dict for normalization layer.
@@ -491,37 +631,28 @@ class ELANBlock(BaseModule):
def __init__(self,
in_channels: int,
- mode: str = 'expand_channel_2x',
+ out_channels: int,
+ middle_ratio: float,
+ block_ratio: float,
num_blocks: int = 2,
+ num_convs_in_block: int = 1,
conv_cfg: OptConfigType = None,
norm_cfg: ConfigType = dict(
type='BN', momentum=0.03, eps=0.001),
act_cfg: ConfigType = dict(type='SiLU', inplace=True),
init_cfg: OptMultiConfig = None):
super().__init__(init_cfg=init_cfg)
+ assert num_blocks >= 1
+ assert num_convs_in_block >= 1
- assert mode in ('expand_channel_2x', 'no_change_channel',
- 'reduce_channel_2x')
-
- if mode == 'expand_channel_2x':
- mid_channels = in_channels // 2
- block_channels = mid_channels
- final_conv_in_channels = 2 * in_channels
- final_conv_out_channels = 2 * in_channels
- elif mode == 'no_change_channel':
- mid_channels = in_channels // 4
- block_channels = mid_channels
- final_conv_in_channels = in_channels
- final_conv_out_channels = in_channels
- else:
- mid_channels = in_channels // 2
- block_channels = mid_channels // 2
- final_conv_in_channels = in_channels * 2
- final_conv_out_channels = in_channels // 2
+ middle_channels = int(in_channels * middle_ratio)
+ block_channels = int(in_channels * block_ratio)
+ final_conv_in_channels = int(
+ num_blocks * block_channels) + 2 * middle_channels
self.main_conv = ConvModule(
in_channels,
- mid_channels,
+ middle_channels,
1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
@@ -529,7 +660,7 @@ def __init__(self,
self.short_conv = ConvModule(
in_channels,
- mid_channels,
+ middle_channels,
1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
@@ -537,9 +668,9 @@ def __init__(self,
self.blocks = nn.ModuleList()
for _ in range(num_blocks):
- if mode == 'reduce_channel_2x':
+ if num_convs_in_block == 1:
internal_block = ConvModule(
- mid_channels,
+ middle_channels,
block_channels,
3,
padding=1,
@@ -547,29 +678,26 @@ def __init__(self,
norm_cfg=norm_cfg,
act_cfg=act_cfg)
else:
- internal_block = nn.Sequential(
- ConvModule(
- mid_channels,
- block_channels,
- 3,
- padding=1,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg),
- ConvModule(
- block_channels,
- block_channels,
- 3,
- padding=1,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg))
- mid_channels = block_channels
+ internal_block = []
+ for _ in range(num_convs_in_block):
+ internal_block.append(
+ ConvModule(
+ middle_channels,
+ block_channels,
+ 3,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ middle_channels = block_channels
+ internal_block = nn.Sequential(*internal_block)
+
+ middle_channels = block_channels
self.blocks.append(internal_block)
self.final_conv = ConvModule(
final_conv_in_channels,
- final_conv_out_channels,
+ out_channels,
1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
@@ -591,17 +719,38 @@ def forward(self, x: Tensor) -> Tensor:
return self.final_conv(x_final)
+@MODELS.register_module()
+class EELANBlock(BaseModule):
+ """Expand efficient layer aggregation networks for YOLOv7.
+
+ Args:
+ num_elan_block (int): The number of ELANBlock.
+ """
+
+ def __init__(self, num_elan_block: int, **kwargs):
+ super().__init__()
+ assert num_elan_block >= 1
+ self.e_elan_blocks = nn.ModuleList()
+ for _ in range(num_elan_block):
+ self.e_elan_blocks.append(ELANBlock(**kwargs))
+
+ def forward(self, x: Tensor) -> Tensor:
+ outs = []
+ for elan_blocks in self.e_elan_blocks:
+ outs.append(elan_blocks(x))
+ return sum(outs)
+
+
class MaxPoolAndStrideConvBlock(BaseModule):
"""Max pooling and stride conv layer for YOLOv7.
- - if mode is `reduce_channel_2x`, the output channel will
- be reduced by a factor of 2
- - if mode is `no_change_channel`, the output channel does not change.
-
Args:
in_channels (int): The input channels of this Module.
- mode (str): Output channel mode. `reduce_channel_2x` or
- `no_change_channel`. Defaults to `reduce_channel_2x`
+ out_channels (int): The out channels of this Module.
+ maxpool_kernel_sizes (int): kernel sizes of pooling layers.
+ Defaults to 2.
+ use_in_channels_of_middle (bool): Whether to calculate middle channels
+ based on in_channels. Defaults to False.
conv_cfg (dict): Config dict for convolution layer. Defaults to None.
which means using conv2d. Defaults to None.
norm_cfg (dict): Config dict for normalization layer.
@@ -614,7 +763,9 @@ class MaxPoolAndStrideConvBlock(BaseModule):
def __init__(self,
in_channels: int,
- mode: str = 'reduce_channel_2x',
+ out_channels: int,
+ maxpool_kernel_sizes: int = 2,
+ use_in_channels_of_middle: bool = False,
conv_cfg: OptConfigType = None,
norm_cfg: ConfigType = dict(
type='BN', momentum=0.03, eps=0.001),
@@ -622,33 +773,31 @@ def __init__(self,
init_cfg: OptMultiConfig = None):
super().__init__(init_cfg=init_cfg)
- assert mode in ('no_change_channel', 'reduce_channel_2x')
-
- if mode == 'reduce_channel_2x':
- out_channels = in_channels // 2
- else:
- out_channels = in_channels
+ middle_channels = in_channels if use_in_channels_of_middle \
+ else out_channels // 2
self.maxpool_branches = nn.Sequential(
- MaxPool2d(2, 2),
+ MaxPool2d(
+ kernel_size=maxpool_kernel_sizes, stride=maxpool_kernel_sizes),
ConvModule(
in_channels,
- out_channels,
+ out_channels // 2,
1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg))
+
self.stride_conv_branches = nn.Sequential(
ConvModule(
in_channels,
- out_channels,
+ middle_channels,
1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg),
ConvModule(
- out_channels,
- out_channels,
+ middle_channels,
+ out_channels // 2,
3,
stride=2,
padding=1,
@@ -666,6 +815,92 @@ def forward(self, x: Tensor) -> Tensor:
return torch.cat([stride_conv_out, maxpool_out], dim=1)
+@MODELS.register_module()
+class TinyDownSampleBlock(BaseModule):
+ """Down sample layer for YOLOv7-tiny.
+
+ Args:
+ in_channels (int): The input channels of this Module.
+ out_channels (int): The out channels of this Module.
+ middle_ratio (float): The scaling ratio of the middle layer
+ based on the in_channels. Defaults to 1.0.
+ kernel_sizes (int, tuple[int]): Sequential or number of kernel
+ sizes of pooling layers. Defaults to 3.
+ conv_cfg (dict): Config dict for convolution layer. Defaults to None.
+ which means using conv2d. Defaults to None.
+ norm_cfg (dict): Config dict for normalization layer.
+ Defaults to dict(type='BN', momentum=0.03, eps=0.001).
+ act_cfg (dict): Config dict for activation layer.
+ Defaults to dict(type='LeakyReLU', negative_slope=0.1).
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Defaults to None.
+ """
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ middle_ratio: float = 1.0,
+ kernel_sizes: Union[int, Sequence[int]] = 3,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: ConfigType = dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg: ConfigType = dict(type='LeakyReLU', negative_slope=0.1),
+ init_cfg: OptMultiConfig = None):
+ super().__init__(init_cfg)
+
+ middle_channels = int(in_channels * middle_ratio)
+
+ self.short_conv = ConvModule(
+ in_channels,
+ middle_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ self.main_convs = nn.ModuleList()
+ for i in range(3):
+ if i == 0:
+ self.main_convs.append(
+ ConvModule(
+ in_channels,
+ middle_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ else:
+ self.main_convs.append(
+ ConvModule(
+ middle_channels,
+ middle_channels,
+ kernel_sizes,
+ padding=(kernel_sizes - 1) // 2,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ self.final_conv = ConvModule(
+ middle_channels * 4,
+ out_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def forward(self, x) -> Tensor:
+ short_out = self.short_conv(x)
+
+ main_outs = []
+ for main_conv in self.main_convs:
+ main_out = main_conv(x)
+ main_outs.append(main_out)
+ x = main_out
+
+ return self.final_conv(torch.cat([*main_outs[::-1], short_out], dim=1))
+
+
+@MODELS.register_module()
class SPPFCSPBlock(BaseModule):
"""Spatial pyramid pooling - Fast (SPPF) layer with CSP for
YOLOv7
@@ -677,6 +912,8 @@ class SPPFCSPBlock(BaseModule):
Defaults to 0.5.
kernel_sizes (int, tuple[int]): Sequential or number of kernel
sizes of pooling layers. Defaults to 5.
+ is_tiny_version (bool): Is tiny version of SPPFCSPBlock. If True,
+ it means it is a yolov7 tiny model. Defaults to False.
conv_cfg (dict): Config dict for convolution layer. Defaults to None.
which means using conv2d. Defaults to None.
norm_cfg (dict): Config dict for normalization layer.
@@ -692,38 +929,50 @@ def __init__(self,
out_channels: int,
expand_ratio: float = 0.5,
kernel_sizes: Union[int, Sequence[int]] = 5,
+ is_tiny_version: bool = False,
conv_cfg: OptConfigType = None,
norm_cfg: ConfigType = dict(
type='BN', momentum=0.03, eps=0.001),
act_cfg: ConfigType = dict(type='SiLU', inplace=True),
init_cfg: OptMultiConfig = None):
super().__init__(init_cfg=init_cfg)
+ self.is_tiny_version = is_tiny_version
+
mid_channels = int(2 * out_channels * expand_ratio)
- self.main_layers = nn.Sequential(
- ConvModule(
+ if is_tiny_version:
+ self.main_layers = ConvModule(
in_channels,
mid_channels,
1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
- act_cfg=act_cfg),
- ConvModule(
- mid_channels,
- mid_channels,
- 3,
- padding=1,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg),
- ConvModule(
- mid_channels,
- mid_channels,
- 1,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg),
- )
+ act_cfg=act_cfg)
+ else:
+ self.main_layers = nn.Sequential(
+ ConvModule(
+ in_channels,
+ mid_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ ConvModule(
+ mid_channels,
+ mid_channels,
+ 3,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ ConvModule(
+ mid_channels,
+ mid_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ )
self.kernel_sizes = kernel_sizes
if isinstance(kernel_sizes, int):
@@ -735,24 +984,33 @@ def __init__(self,
for ks in kernel_sizes
])
- self.fuse_layers = nn.Sequential(
- ConvModule(
+ if is_tiny_version:
+ self.fuse_layers = ConvModule(
4 * mid_channels,
mid_channels,
1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
- act_cfg=act_cfg),
- ConvModule(
- mid_channels,
- mid_channels,
- 3,
- padding=1,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg))
+ act_cfg=act_cfg)
+ else:
+ self.fuse_layers = nn.Sequential(
+ ConvModule(
+ 4 * mid_channels,
+ mid_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ ConvModule(
+ mid_channels,
+ mid_channels,
+ 3,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
- self.short_layers = ConvModule(
+ self.short_layer = ConvModule(
in_channels,
mid_channels,
1,
@@ -777,15 +1035,66 @@ def forward(self, x) -> Tensor:
if isinstance(self.kernel_sizes, int):
y1 = self.poolings(x1)
y2 = self.poolings(y1)
- x1 = self.fuse_layers(
- torch.cat([x1] + [y1, y2, self.poolings(y2)], 1))
+ concat_list = [x1] + [y1, y2, self.poolings(y2)]
+ if self.is_tiny_version:
+ x1 = self.fuse_layers(torch.cat(concat_list[::-1], 1))
+ else:
+ x1 = self.fuse_layers(torch.cat(concat_list, 1))
else:
- x1 = self.fuse_layers(
- torch.cat([x1] + [m(x1) for m in self.poolings], 1))
- x2 = self.short_layers(x)
+ concat_list = [x1] + [m(x1) for m in self.poolings]
+ if self.is_tiny_version:
+ x1 = self.fuse_layers(torch.cat(concat_list[::-1], 1))
+ else:
+ x1 = self.fuse_layers(torch.cat(concat_list, 1))
+
+ x2 = self.short_layer(x)
return self.final_conv(torch.cat((x1, x2), dim=1))
+class ImplicitA(nn.Module):
+ """Implicit add layer in YOLOv7.
+
+ Args:
+ in_channels (int): The input channels of this Module.
+ mean (float): Mean value of implicit module. Defaults to 0.
+ std (float): Std value of implicit module. Defaults to 0.02
+ """
+
+ def __init__(self, in_channels: int, mean: float = 0., std: float = .02):
+ super().__init__()
+ self.implicit = nn.Parameter(torch.zeros(1, in_channels, 1, 1))
+ nn.init.normal_(self.implicit, mean=mean, std=std)
+
+ def forward(self, x):
+ """Forward process
+ Args:
+ x (Tensor): The input tensor.
+ """
+ return self.implicit + x
+
+
+class ImplicitM(nn.Module):
+ """Implicit multiplier layer in YOLOv7.
+
+ Args:
+ in_channels (int): The input channels of this Module.
+ mean (float): Mean value of implicit module. Defaults to 1.
+ std (float): Std value of implicit module. Defaults to 0.02.
+ """
+
+ def __init__(self, in_channels: int, mean: float = 1., std: float = .02):
+ super().__init__()
+ self.implicit = nn.Parameter(torch.ones(1, in_channels, 1, 1))
+ nn.init.normal_(self.implicit, mean=mean, std=std)
+
+ def forward(self, x):
+ """Forward process
+ Args:
+ x (Tensor): The input tensor.
+ """
+ return self.implicit * x
+
+
@MODELS.register_module()
class PPYOLOEBasicBlock(nn.Module):
"""PPYOLOE Backbone BasicBlock.
@@ -986,3 +1295,69 @@ def forward(self, x: Tensor) -> Tensor:
y = self.attn(y)
y = self.conv3(y)
return y
+
+
+@MODELS.register_module()
+class RepStageBlock(nn.Module):
+ """RepStageBlock is a stage block with rep-style basic block.
+
+ Args:
+ in_channels (int): The input channels of this Module.
+ out_channels (int): The output channels of this Module.
+ num_blocks (int, tuple[int]): Number of blocks. Defaults to 1.
+ bottle_block (nn.Module): Basic unit of RepStage.
+ Defaults to RepVGGBlock.
+ block_cfg (ConfigType): Config of RepStage.
+ Defaults to 'RepVGGBlock'.
+ """
+
+ def __init__(self,
+ in_channels: int,
+ out_channels: int,
+ num_blocks: int = 1,
+ bottle_block: nn.Module = RepVGGBlock,
+ block_cfg: ConfigType = dict(type='RepVGGBlock')):
+ super().__init__()
+ block_cfg = block_cfg.copy()
+
+ block_cfg.update(
+ dict(in_channels=in_channels, out_channels=out_channels))
+
+ self.conv1 = MODELS.build(block_cfg)
+
+ block_cfg.update(
+ dict(in_channels=out_channels, out_channels=out_channels))
+
+ self.block = None
+ if num_blocks > 1:
+ self.block = nn.Sequential(*(MODELS.build(block_cfg)
+ for _ in range(num_blocks - 1)))
+
+ if bottle_block == BottleRep:
+ self.conv1 = BottleRep(
+ in_channels,
+ out_channels,
+ block_cfg=block_cfg,
+ adaptive_weight=True)
+ num_blocks = num_blocks // 2
+ self.block = None
+ if num_blocks > 1:
+ self.block = nn.Sequential(*(BottleRep(
+ out_channels,
+ out_channels,
+ block_cfg=block_cfg,
+ adaptive_weight=True) for _ in range(num_blocks - 1)))
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward process.
+
+ Args:
+ inputs (Tensor): The input tensor.
+
+ Returns:
+ Tensor: The output tensor.
+ """
+ x = self.conv1(x)
+ if self.block is not None:
+ x = self.block(x)
+ return x
diff --git a/mmyolo/models/losses/iou_loss.py b/mmyolo/models/losses/iou_loss.py
index 579f26190..0e9ccc263 100644
--- a/mmyolo/models/losses/iou_loss.py
+++ b/mmyolo/models/losses/iou_loss.py
@@ -20,27 +20,31 @@ def bbox_overlaps(pred: torch.Tensor,
`Implementation of paper `Enhancing Geometric Factors into
Model Learning and Inference for Object Detection and Instance
Segmentation `_.
+
In the CIoU implementation of YOLOv5 and MMDetection, there is a slight
difference in the way the alpha parameter is computed.
+
mmdet version:
alpha = (ious > 0.5).float() * v / (1 - ious + v)
YOLOv5 version:
alpha = v / (v - ious + (1 + eps)
+
Args:
pred (Tensor): Predicted bboxes of format (x1, y1, x2, y2)
or (x, y, w, h),shape (n, 4).
target (Tensor): Corresponding gt bboxes, shape (n, 4).
- iou_mode (str): Options are "ciou".
+ iou_mode (str): Options are ('iou', 'ciou', 'giou', 'siou').
Defaults to "ciou".
bbox_format (str): Options are "xywh" and "xyxy".
Defaults to "xywh".
siou_theta (float): siou_theta for SIoU when calculate shape cost.
Defaults to 4.0.
eps (float): Eps to avoid log(0).
+
Returns:
- Tensor: shape (n,).
+ Tensor: shape (n, ).
"""
- assert iou_mode in ('ciou', 'giou', 'siou')
+ assert iou_mode in ('iou', 'ciou', 'giou', 'siou')
assert bbox_format in ('xyxy', 'xywh')
if bbox_format == 'xywh':
pred = HorizontalBoxes.cxcywh_to_xyxy(pred)
diff --git a/mmyolo/models/necks/__init__.py b/mmyolo/models/necks/__init__.py
index c6dd09554..7165327d4 100644
--- a/mmyolo/models/necks/__init__.py
+++ b/mmyolo/models/necks/__init__.py
@@ -3,11 +3,11 @@
from .cspnext_pafpn import CSPNeXtPAFPN
from .ppyoloe_csppan import PPYOLOECSPPAFPN
from .yolov5_pafpn import YOLOv5PAFPN
-from .yolov6_pafpn import YOLOv6RepPAFPN
+from .yolov6_pafpn import YOLOv6CSPRepPAFPN, YOLOv6RepPAFPN
from .yolov7_pafpn import YOLOv7PAFPN
from .yolox_pafpn import YOLOXPAFPN
__all__ = [
'YOLOv5PAFPN', 'BaseYOLONeck', 'YOLOv6RepPAFPN', 'YOLOXPAFPN',
- 'CSPNeXtPAFPN', 'YOLOv7PAFPN', 'PPYOLOECSPPAFPN'
+ 'CSPNeXtPAFPN', 'YOLOv7PAFPN', 'PPYOLOECSPPAFPN', 'YOLOv6CSPRepPAFPN'
]
diff --git a/mmyolo/models/necks/yolov5_pafpn.py b/mmyolo/models/necks/yolov5_pafpn.py
index cc7487e78..b95147fc5 100644
--- a/mmyolo/models/necks/yolov5_pafpn.py
+++ b/mmyolo/models/necks/yolov5_pafpn.py
@@ -56,12 +56,15 @@ def __init__(self,
init_cfg=init_cfg)
def init_weights(self):
- """Initialize the parameters."""
- for m in self.modules():
- if isinstance(m, torch.nn.Conv2d):
- # In order to be consistent with the source code,
- # reset the Conv2d initialization parameters
- m.reset_parameters()
+ if self.init_cfg is None:
+ """Initialize the parameters."""
+ for m in self.modules():
+ if isinstance(m, torch.nn.Conv2d):
+ # In order to be consistent with the source code,
+ # reset the Conv2d initialization parameters
+ m.reset_parameters()
+ else:
+ super().init_weights()
def build_reduce_layer(self, idx: int) -> nn.Module:
"""build reduce layer.
diff --git a/mmyolo/models/necks/yolov6_pafpn.py b/mmyolo/models/necks/yolov6_pafpn.py
index 54f22d0ab..74b7ce932 100644
--- a/mmyolo/models/necks/yolov6_pafpn.py
+++ b/mmyolo/models/necks/yolov6_pafpn.py
@@ -7,8 +7,8 @@
from mmdet.utils import ConfigType, OptMultiConfig
from mmyolo.registry import MODELS
-from ..layers import RepStageBlock, RepVGGBlock
-from ..utils import make_divisible, make_round
+from ..layers import BepC3StageBlock, RepStageBlock
+from ..utils import make_round
from .base_yolo_neck import BaseYOLONeck
@@ -29,8 +29,8 @@ class YOLOv6RepPAFPN(BaseYOLONeck):
Defaults to dict(type='BN', momentum=0.03, eps=0.001).
act_cfg (dict): Config dict for activation layer.
Defaults to dict(type='ReLU', inplace=True).
- block (nn.Module): block used to build each layer.
- Defaults to RepVGGBlock.
+ block_cfg (dict): Config dict for the block used to build each
+ layer. Defaults to dict(type='RepVGGBlock').
init_cfg (dict or list[dict], optional): Initialization config dict.
Defaults to None.
"""
@@ -45,10 +45,10 @@ def __init__(self,
norm_cfg: ConfigType = dict(
type='BN', momentum=0.03, eps=0.001),
act_cfg: ConfigType = dict(type='ReLU', inplace=True),
- block: nn.Module = RepVGGBlock,
+ block_cfg: ConfigType = dict(type='RepVGGBlock'),
init_cfg: OptMultiConfig = None):
self.num_csp_blocks = num_csp_blocks
- self.block = block
+ self.block_cfg = block_cfg
super().__init__(
in_channels=in_channels,
out_channels=out_channels,
@@ -64,16 +64,14 @@ def build_reduce_layer(self, idx: int) -> nn.Module:
Args:
idx (int): layer idx.
-
Returns:
nn.Module: The reduce layer.
"""
if idx == 2:
layer = ConvModule(
- in_channels=make_divisible(self.in_channels[idx],
- self.widen_factor),
- out_channels=make_divisible(self.out_channels[idx - 1],
- self.widen_factor),
+ in_channels=int(self.in_channels[idx] * self.widen_factor),
+ out_channels=int(self.out_channels[idx - 1] *
+ self.widen_factor),
kernel_size=1,
stride=1,
norm_cfg=self.norm_cfg,
@@ -88,15 +86,12 @@ def build_upsample_layer(self, idx: int) -> nn.Module:
Args:
idx (int): layer idx.
-
Returns:
nn.Module: The upsample layer.
"""
return nn.ConvTranspose2d(
- in_channels=make_divisible(self.out_channels[idx - 1],
- self.widen_factor),
- out_channels=make_divisible(self.out_channels[idx - 1],
- self.widen_factor),
+ in_channels=int(self.out_channels[idx - 1] * self.widen_factor),
+ out_channels=int(self.out_channels[idx - 1] * self.widen_factor),
kernel_size=2,
stride=2,
bias=True)
@@ -106,26 +101,27 @@ def build_top_down_layer(self, idx: int) -> nn.Module:
Args:
idx (int): layer idx.
-
Returns:
nn.Module: The top down layer.
"""
+ block_cfg = self.block_cfg.copy()
+
layer0 = RepStageBlock(
- in_channels=make_divisible(
- self.out_channels[idx - 1] + self.in_channels[idx - 1],
+ in_channels=int(
+ (self.out_channels[idx - 1] + self.in_channels[idx - 1]) *
self.widen_factor),
- out_channels=make_divisible(self.out_channels[idx - 1],
- self.widen_factor),
- n=make_round(self.num_csp_blocks, self.deepen_factor),
- block=self.block)
+ out_channels=int(self.out_channels[idx - 1] * self.widen_factor),
+ num_blocks=make_round(self.num_csp_blocks, self.deepen_factor),
+ block_cfg=block_cfg)
+
if idx == 1:
return layer0
elif idx == 2:
layer1 = ConvModule(
- in_channels=make_divisible(self.out_channels[idx - 1],
- self.widen_factor),
- out_channels=make_divisible(self.out_channels[idx - 2],
- self.widen_factor),
+ in_channels=int(self.out_channels[idx - 1] *
+ self.widen_factor),
+ out_channels=int(self.out_channels[idx - 2] *
+ self.widen_factor),
kernel_size=1,
stride=1,
norm_cfg=self.norm_cfg,
@@ -137,15 +133,12 @@ def build_downsample_layer(self, idx: int) -> nn.Module:
Args:
idx (int): layer idx.
-
Returns:
nn.Module: The downsample layer.
"""
return ConvModule(
- in_channels=make_divisible(self.out_channels[idx],
- self.widen_factor),
- out_channels=make_divisible(self.out_channels[idx],
- self.widen_factor),
+ in_channels=int(self.out_channels[idx] * self.widen_factor),
+ out_channels=int(self.out_channels[idx] * self.widen_factor),
kernel_size=3,
stride=2,
padding=3 // 2,
@@ -157,26 +150,136 @@ def build_bottom_up_layer(self, idx: int) -> nn.Module:
Args:
idx (int): layer idx.
-
Returns:
nn.Module: The bottom up layer.
"""
+ block_cfg = self.block_cfg.copy()
+
return RepStageBlock(
- in_channels=make_divisible(self.out_channels[idx] * 2,
- self.widen_factor),
- out_channels=make_divisible(self.out_channels[idx + 1],
- self.widen_factor),
- n=make_round(self.num_csp_blocks, self.deepen_factor),
- block=self.block)
+ in_channels=int(self.out_channels[idx] * 2 * self.widen_factor),
+ out_channels=int(self.out_channels[idx + 1] * self.widen_factor),
+ num_blocks=make_round(self.num_csp_blocks, self.deepen_factor),
+ block_cfg=block_cfg)
def build_out_layer(self, *args, **kwargs) -> nn.Module:
"""build out layer."""
return nn.Identity()
def init_weights(self):
- """Initialize the parameters."""
- for m in self.modules():
- if isinstance(m, torch.nn.Conv2d):
- # In order to be consistent with the source code,
- # reset the Conv2d initialization parameters
- m.reset_parameters()
+ if self.init_cfg is None:
+ """Initialize the parameters."""
+ for m in self.modules():
+ if isinstance(m, torch.nn.Conv2d):
+ # In order to be consistent with the source code,
+ # reset the Conv2d initialization parameters
+ m.reset_parameters()
+ else:
+ super().init_weights()
+
+
+@MODELS.register_module()
+class YOLOv6CSPRepPAFPN(YOLOv6RepPAFPN):
+ """Path Aggregation Network used in YOLOv6.
+
+ Args:
+ in_channels (List[int]): Number of input channels per scale.
+ out_channels (int): Number of output channels (used at each scale)
+ deepen_factor (float): Depth multiplier, multiply number of
+ blocks in CSP layer by this amount. Defaults to 1.0.
+ widen_factor (float): Width multiplier, multiply number of
+ channels in each layer by this amount. Defaults to 1.0.
+ num_csp_blocks (int): Number of bottlenecks in CSPLayer. Defaults to 1.
+ freeze_all(bool): Whether to freeze the model.
+ norm_cfg (dict): Config dict for normalization layer.
+ Defaults to dict(type='BN', momentum=0.03, eps=0.001).
+ act_cfg (dict): Config dict for activation layer.
+ Defaults to dict(type='ReLU', inplace=True).
+ block_cfg (dict): Config dict for the block used to build each
+ layer. Defaults to dict(type='RepVGGBlock').
+ block_act_cfg (dict): Config dict for activation layer used in each
+ stage. Defaults to dict(type='SiLU', inplace=True).
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels: List[int],
+ out_channels: int,
+ deepen_factor: float = 1.0,
+ widen_factor: float = 1.0,
+ hidden_ratio: float = 0.5,
+ num_csp_blocks: int = 12,
+ freeze_all: bool = False,
+ norm_cfg: ConfigType = dict(
+ type='BN', momentum=0.03, eps=0.001),
+ act_cfg: ConfigType = dict(type='ReLU', inplace=True),
+ block_act_cfg: ConfigType = dict(type='SiLU', inplace=True),
+ block_cfg: ConfigType = dict(type='RepVGGBlock'),
+ init_cfg: OptMultiConfig = None):
+ self.hidden_ratio = hidden_ratio
+ self.block_act_cfg = block_act_cfg
+ super().__init__(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ num_csp_blocks=num_csp_blocks,
+ freeze_all=freeze_all,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ block_cfg=block_cfg,
+ init_cfg=init_cfg)
+
+ def build_top_down_layer(self, idx: int) -> nn.Module:
+ """build top down layer.
+
+ Args:
+ idx (int): layer idx.
+ Returns:
+ nn.Module: The top down layer.
+ """
+ block_cfg = self.block_cfg.copy()
+
+ layer0 = BepC3StageBlock(
+ in_channels=int(
+ (self.out_channels[idx - 1] + self.in_channels[idx - 1]) *
+ self.widen_factor),
+ out_channels=int(self.out_channels[idx - 1] * self.widen_factor),
+ num_blocks=make_round(self.num_csp_blocks, self.deepen_factor),
+ block_cfg=block_cfg,
+ hidden_ratio=self.hidden_ratio,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.block_act_cfg)
+
+ if idx == 1:
+ return layer0
+ elif idx == 2:
+ layer1 = ConvModule(
+ in_channels=int(self.out_channels[idx - 1] *
+ self.widen_factor),
+ out_channels=int(self.out_channels[idx - 2] *
+ self.widen_factor),
+ kernel_size=1,
+ stride=1,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ return nn.Sequential(layer0, layer1)
+
+ def build_bottom_up_layer(self, idx: int) -> nn.Module:
+ """build bottom up layer.
+
+ Args:
+ idx (int): layer idx.
+ Returns:
+ nn.Module: The bottom up layer.
+ """
+ block_cfg = self.block_cfg.copy()
+
+ return BepC3StageBlock(
+ in_channels=int(self.out_channels[idx] * 2 * self.widen_factor),
+ out_channels=int(self.out_channels[idx + 1] * self.widen_factor),
+ num_blocks=make_round(self.num_csp_blocks, self.deepen_factor),
+ block_cfg=block_cfg,
+ hidden_ratio=self.hidden_ratio,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.block_act_cfg)
diff --git a/mmyolo/models/necks/yolov7_pafpn.py b/mmyolo/models/necks/yolov7_pafpn.py
index ec48663db..1d31f4623 100644
--- a/mmyolo/models/necks/yolov7_pafpn.py
+++ b/mmyolo/models/necks/yolov7_pafpn.py
@@ -6,8 +6,7 @@
from mmdet.utils import ConfigType, OptMultiConfig
from mmyolo.registry import MODELS
-from ..layers import (ELANBlock, MaxPoolAndStrideConvBlock, RepVGGBlock,
- SPPFCSPBlock)
+from ..layers import MaxPoolAndStrideConvBlock, RepVGGBlock, SPPFCSPBlock
from .base_yolo_neck import BaseYOLONeck
@@ -18,12 +17,21 @@ class YOLOv7PAFPN(BaseYOLONeck):
Args:
in_channels (List[int]): Number of input channels per scale.
out_channels (int): Number of output channels (used at each scale).
+ block_cfg (dict): Config dict for block.
deepen_factor (float): Depth multiplier, multiply number of
blocks in CSP layer by this amount. Defaults to 1.0.
widen_factor (float): Width multiplier, multiply number of
channels in each layer by this amount. Defaults to 1.0.
spp_expand_ratio (float): Expand ratio of SPPCSPBlock.
Defaults to 0.5.
+ is_tiny_version (bool): Is tiny version of neck. If True,
+ it means it is a yolov7 tiny model. Defaults to False.
+ use_maxpool_in_downsample (bool): Whether maxpooling is
+ used in downsample layers. Defaults to True.
+ use_in_channels_in_downsample (bool): MaxPoolAndStrideConvBlock
+ module input parameters. Defaults to False.
+ use_repconv_outs (bool): Whether to use `repconv` in the output
+ layer. Defaults to True.
upsample_feats_cat_first (bool): Whether the output features are
concat first after upsampling in the topdown module.
Defaults to True. Currently only YOLOv7 is false.
@@ -39,9 +47,19 @@ class YOLOv7PAFPN(BaseYOLONeck):
def __init__(self,
in_channels: List[int],
out_channels: List[int],
+ block_cfg: dict = dict(
+ type='ELANBlock',
+ middle_ratio=0.5,
+ block_ratio=0.25,
+ num_blocks=4,
+ num_convs_in_block=1),
deepen_factor: float = 1.0,
widen_factor: float = 1.0,
spp_expand_ratio: float = 0.5,
+ is_tiny_version: bool = False,
+ use_maxpool_in_downsample: bool = True,
+ use_in_channels_in_downsample: bool = False,
+ use_repconv_outs: bool = True,
upsample_feats_cat_first: bool = False,
freeze_all: bool = False,
norm_cfg: ConfigType = dict(
@@ -49,7 +67,15 @@ def __init__(self,
act_cfg: ConfigType = dict(type='SiLU', inplace=True),
init_cfg: OptMultiConfig = None):
+ self.is_tiny_version = is_tiny_version
+ self.use_maxpool_in_downsample = use_maxpool_in_downsample
+ self.use_in_channels_in_downsample = use_in_channels_in_downsample
self.spp_expand_ratio = spp_expand_ratio
+ self.use_repconv_outs = use_repconv_outs
+ self.block_cfg = block_cfg
+ self.block_cfg.setdefault('norm_cfg', norm_cfg)
+ self.block_cfg.setdefault('act_cfg', act_cfg)
+
super().__init__(
in_channels=[
int(channel * widen_factor) for channel in in_channels
@@ -74,11 +100,12 @@ def build_reduce_layer(self, idx: int) -> nn.Module:
Returns:
nn.Module: The reduce layer.
"""
- if idx == 2:
+ if idx == len(self.in_channels) - 1:
layer = SPPFCSPBlock(
self.in_channels[idx],
self.out_channels[idx],
expand_ratio=self.spp_expand_ratio,
+ is_tiny_version=self.is_tiny_version,
kernel_sizes=5,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg)
@@ -112,12 +139,10 @@ def build_top_down_layer(self, idx: int) -> nn.Module:
Returns:
nn.Module: The top down layer.
"""
- return ELANBlock(
- self.out_channels[idx - 1] * 2,
- mode='reduce_channel_2x',
- num_blocks=4,
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg)
+ block_cfg = self.block_cfg.copy()
+ block_cfg['in_channels'] = self.out_channels[idx - 1] * 2
+ block_cfg['out_channels'] = self.out_channels[idx - 1]
+ return MODELS.build(block_cfg)
def build_downsample_layer(self, idx: int) -> nn.Module:
"""build downsample layer.
@@ -128,11 +153,22 @@ def build_downsample_layer(self, idx: int) -> nn.Module:
Returns:
nn.Module: The downsample layer.
"""
- return MaxPoolAndStrideConvBlock(
- self.out_channels[idx],
- mode='no_change_channel',
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg)
+ if self.use_maxpool_in_downsample and not self.is_tiny_version:
+ return MaxPoolAndStrideConvBlock(
+ self.out_channels[idx],
+ self.out_channels[idx + 1],
+ use_in_channels_of_middle=self.use_in_channels_in_downsample,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ else:
+ return ConvModule(
+ self.out_channels[idx],
+ self.out_channels[idx + 1],
+ 3,
+ stride=2,
+ padding=1,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
def build_bottom_up_layer(self, idx: int) -> nn.Module:
"""build bottom up layer.
@@ -143,12 +179,10 @@ def build_bottom_up_layer(self, idx: int) -> nn.Module:
Returns:
nn.Module: The bottom up layer.
"""
- return ELANBlock(
- self.out_channels[idx + 1] * 2,
- mode='reduce_channel_2x',
- num_blocks=4,
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg)
+ block_cfg = self.block_cfg.copy()
+ block_cfg['in_channels'] = self.out_channels[idx + 1] * 2
+ block_cfg['out_channels'] = self.out_channels[idx + 1]
+ return MODELS.build(block_cfg)
def build_out_layer(self, idx: int) -> nn.Module:
"""build out layer.
@@ -159,9 +193,24 @@ def build_out_layer(self, idx: int) -> nn.Module:
Returns:
nn.Module: The out layer.
"""
- return RepVGGBlock(
- self.out_channels[idx],
- self.out_channels[idx] * 2,
- 3,
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg)
+ if len(self.in_channels) == 4:
+ # P6
+ return nn.Identity()
+
+ out_channels = self.out_channels[idx] * 2
+
+ if self.use_repconv_outs:
+ return RepVGGBlock(
+ self.out_channels[idx],
+ out_channels,
+ 3,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ else:
+ return ConvModule(
+ self.out_channels[idx],
+ out_channels,
+ 3,
+ padding=1,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
diff --git a/mmyolo/models/necks/yolox_pafpn.py b/mmyolo/models/necks/yolox_pafpn.py
index 765a1ba47..bd2595e70 100644
--- a/mmyolo/models/necks/yolox_pafpn.py
+++ b/mmyolo/models/necks/yolox_pafpn.py
@@ -2,7 +2,7 @@
from typing import List
import torch.nn as nn
-from mmcv.cnn import ConvModule
+from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
from mmdet.models.backbones.csp_darknet import CSPLayer
from mmdet.utils import ConfigType, OptMultiConfig
@@ -22,6 +22,8 @@ class YOLOXPAFPN(BaseYOLONeck):
widen_factor (float): Width multiplier, multiply number of
channels in each layer by this amount. Defaults to 1.0.
num_csp_blocks (int): Number of bottlenecks in CSPLayer. Defaults to 1.
+ use_depthwise (bool): Whether to use depthwise separable convolution.
+ Defaults to False.
freeze_all(bool): Whether to freeze the model. Defaults to False.
norm_cfg (dict): Config dict for normalization layer.
Defaults to dict(type='BN', momentum=0.03, eps=0.001).
@@ -37,12 +39,14 @@ def __init__(self,
deepen_factor: float = 1.0,
widen_factor: float = 1.0,
num_csp_blocks: int = 3,
+ use_depthwise: bool = False,
freeze_all: bool = False,
norm_cfg: ConfigType = dict(
type='BN', momentum=0.03, eps=0.001),
act_cfg: ConfigType = dict(type='SiLU', inplace=True),
init_cfg: OptMultiConfig = None):
self.num_csp_blocks = round(num_csp_blocks * deepen_factor)
+ self.use_depthwise = use_depthwise
super().__init__(
in_channels=[
@@ -123,7 +127,9 @@ def build_downsample_layer(self, idx: int) -> nn.Module:
Returns:
nn.Module: The downsample layer.
"""
- return ConvModule(
+ conv = DepthwiseSeparableConvModule \
+ if self.use_depthwise else ConvModule
+ return conv(
self.in_channels[idx],
self.in_channels[idx],
kernel_size=3,
diff --git a/mmyolo/models/plugins/cbam.py b/mmyolo/models/plugins/cbam.py
index 0741fe9f2..e9559f2e2 100644
--- a/mmyolo/models/plugins/cbam.py
+++ b/mmyolo/models/plugins/cbam.py
@@ -48,6 +48,7 @@ def __init__(self,
self.sigmoid = nn.Sigmoid()
def forward(self, x: torch.Tensor) -> torch.Tensor:
+ """Forward function."""
avgpool_out = self.fc(self.avg_pool(x))
maxpool_out = self.fc(self.max_pool(x))
out = self.sigmoid(avgpool_out + maxpool_out)
@@ -74,6 +75,7 @@ def __init__(self, kernel_size: int = 7):
act_cfg=dict(type='Sigmoid'))
def forward(self, x: torch.Tensor) -> torch.Tensor:
+ """Forward function."""
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avg_out, max_out], dim=1)
@@ -111,6 +113,7 @@ def __init__(self,
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x: torch.Tensor) -> torch.Tensor:
+ """Forward function."""
out = self.channel_attention(x) * x
out = self.spatial_attention(out) * out
return out
diff --git a/mmyolo/models/task_modules/assigners/batch_yolov7_assigner.py b/mmyolo/models/task_modules/assigners/batch_yolov7_assigner.py
new file mode 100644
index 000000000..7d59239ec
--- /dev/null
+++ b/mmyolo/models/task_modules/assigners/batch_yolov7_assigner.py
@@ -0,0 +1,325 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Sequence
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmdet.structures.bbox import bbox_cxcywh_to_xyxy, bbox_overlaps
+
+
+def _cat_multi_level_tensor_in_place(*multi_level_tensor, place_hold_var):
+ """concat multi-level tensor in place."""
+ for level_tensor in multi_level_tensor:
+ for i, var in enumerate(level_tensor):
+ if len(var) > 0:
+ level_tensor[i] = torch.cat(var, dim=0)
+ else:
+ level_tensor[i] = place_hold_var
+
+
+class BatchYOLOv7Assigner(nn.Module):
+ """Batch YOLOv7 Assigner.
+
+ It consists of two assigning steps:
+
+ 1. YOLOv5 cross-grid sample assigning
+ 2. SimOTA assigning
+
+ This code referenced to
+ https://github.com/WongKinYiu/yolov7/blob/main/utils/loss.py.
+ """
+
+ def __init__(self,
+ num_classes: int,
+ num_base_priors: int,
+ featmap_strides: Sequence[int],
+ prior_match_thr: float = 4.0,
+ candidate_topk: int = 10,
+ iou_weight: float = 3.0,
+ cls_weight: float = 1.0):
+ super().__init__()
+ self.num_classes = num_classes
+ self.num_base_priors = num_base_priors
+ self.featmap_strides = featmap_strides
+ # yolov5 param
+ self.prior_match_thr = prior_match_thr
+ # simota param
+ self.candidate_topk = candidate_topk
+ self.iou_weight = iou_weight
+ self.cls_weight = cls_weight
+
+ @torch.no_grad()
+ def forward(self,
+ pred_results,
+ batch_targets_normed,
+ batch_input_shape,
+ priors_base_sizes,
+ grid_offset,
+ near_neighbor_thr=0.5) -> dict:
+ # (num_base_priors, num_batch_gt, 7)
+ # 7 is mean (batch_idx, cls_id, x_norm, y_norm,
+ # w_norm, h_norm, prior_idx)
+
+ # mlvl is mean multi_level
+ if batch_targets_normed.shape[1] == 0:
+ # empty gt of batch
+ num_levels = len(pred_results)
+ return dict(
+ mlvl_positive_infos=[pred_results[0].new_empty(
+ (0, 4))] * num_levels,
+ mlvl_priors=[] * num_levels,
+ mlvl_targets_normed=[] * num_levels)
+
+ # if near_neighbor_thr = 0.5 are mean the nearest
+ # 3 neighbors are also considered positive samples.
+ # if near_neighbor_thr = 1.0 are mean the nearest
+ # 5 neighbors are also considered positive samples.
+ mlvl_positive_infos, mlvl_priors = self.yolov5_assigner(
+ pred_results,
+ batch_targets_normed,
+ priors_base_sizes,
+ grid_offset,
+ near_neighbor_thr=near_neighbor_thr)
+
+ mlvl_positive_infos, mlvl_priors, \
+ mlvl_targets_normed = self.simota_assigner(
+ pred_results, batch_targets_normed, mlvl_positive_infos,
+ mlvl_priors, batch_input_shape)
+
+ place_hold_var = batch_targets_normed.new_empty((0, 4))
+ _cat_multi_level_tensor_in_place(
+ mlvl_positive_infos,
+ mlvl_priors,
+ mlvl_targets_normed,
+ place_hold_var=place_hold_var)
+
+ return dict(
+ mlvl_positive_infos=mlvl_positive_infos,
+ mlvl_priors=mlvl_priors,
+ mlvl_targets_normed=mlvl_targets_normed)
+
+ def yolov5_assigner(self,
+ pred_results,
+ batch_targets_normed,
+ priors_base_sizes,
+ grid_offset,
+ near_neighbor_thr=0.5):
+ num_batch_gts = batch_targets_normed.shape[1]
+ assert num_batch_gts > 0
+
+ mlvl_positive_infos, mlvl_priors = [], []
+
+ scaled_factor = torch.ones(7, device=pred_results[0].device)
+ for i in range(len(pred_results)): # lever
+ priors_base_sizes_i = priors_base_sizes[i]
+ # (1, 1, feat_shape_w, feat_shape_h, feat_shape_w, feat_shape_h)
+ scaled_factor[2:6] = torch.tensor(
+ pred_results[i].shape)[[3, 2, 3, 2]]
+
+ # Scale batch_targets from range 0-1 to range 0-features_maps size.
+ # (num_base_priors, num_batch_gts, 7)
+ batch_targets_scaled = batch_targets_normed * scaled_factor
+
+ # Shape match
+ wh_ratio = batch_targets_scaled[...,
+ 4:6] / priors_base_sizes_i[:, None]
+ match_inds = torch.max(
+ wh_ratio, 1. / wh_ratio).max(2)[0] < self.prior_match_thr
+ batch_targets_scaled = batch_targets_scaled[
+ match_inds] # (num_matched_target, 7)
+
+ # no gt bbox matches anchor
+ if batch_targets_scaled.shape[0] == 0:
+ mlvl_positive_infos.append(
+ batch_targets_scaled.new_empty((0, 4)))
+ mlvl_priors.append([])
+ continue
+
+ # Positive samples with additional neighbors
+ batch_targets_cxcy = batch_targets_scaled[:, 2:4]
+ grid_xy = scaled_factor[[2, 3]] - batch_targets_cxcy
+ left, up = ((batch_targets_cxcy % 1 < near_neighbor_thr) &
+ (batch_targets_cxcy > 1)).T
+ right, bottom = ((grid_xy % 1 < near_neighbor_thr) &
+ (grid_xy > 1)).T
+ offset_inds = torch.stack(
+ (torch.ones_like(left), left, up, right, bottom))
+ batch_targets_scaled = batch_targets_scaled.repeat(
+ (5, 1, 1))[offset_inds] # ()
+ retained_offsets = grid_offset.repeat(1, offset_inds.shape[1],
+ 1)[offset_inds]
+
+ # batch_targets_scaled: (num_matched_target, 7)
+ # 7 is mean (batch_idx, cls_id, x_scaled,
+ # y_scaled, w_scaled, h_scaled, prior_idx)
+
+ # mlvl_positive_info: (num_matched_target, 4)
+ # 4 is mean (batch_idx, prior_idx, x_scaled, y_scaled)
+ mlvl_positive_info = batch_targets_scaled[:, [0, 6, 2, 3]]
+ retained_offsets = retained_offsets * near_neighbor_thr
+ mlvl_positive_info[:,
+ 2:] = mlvl_positive_info[:,
+ 2:] - retained_offsets
+ mlvl_positive_info[:, 2].clamp_(0, scaled_factor[2] - 1)
+ mlvl_positive_info[:, 3].clamp_(0, scaled_factor[3] - 1)
+ mlvl_positive_info = mlvl_positive_info.long()
+ priors_inds = mlvl_positive_info[:, 1]
+
+ mlvl_positive_infos.append(mlvl_positive_info)
+ mlvl_priors.append(priors_base_sizes_i[priors_inds])
+
+ return mlvl_positive_infos, mlvl_priors
+
+ def simota_assigner(self, pred_results, batch_targets_normed,
+ mlvl_positive_infos, mlvl_priors, batch_input_shape):
+ num_batch_gts = batch_targets_normed.shape[1]
+ assert num_batch_gts > 0
+ num_levels = len(mlvl_positive_infos)
+
+ mlvl_positive_infos_matched = [[] for _ in range(num_levels)]
+ mlvl_priors_matched = [[] for _ in range(num_levels)]
+ mlvl_targets_normed_matched = [[] for _ in range(num_levels)]
+
+ for batch_idx in range(pred_results[0].shape[0]):
+ # (num_batch_gt, 7)
+ # 7 is mean (batch_idx, cls_id, x_norm, y_norm,
+ # w_norm, h_norm, prior_idx)
+ targets_normed = batch_targets_normed[0]
+ # (num_gt, 7)
+ targets_normed = targets_normed[targets_normed[:, 0] == batch_idx]
+ num_gts = targets_normed.shape[0]
+
+ if num_gts == 0:
+ continue
+
+ _mlvl_decoderd_bboxes = []
+ _mlvl_obj_cls = []
+ _mlvl_priors = []
+ _mlvl_positive_infos = []
+ _from_which_layer = []
+
+ for i, head_pred in enumerate(pred_results):
+ # (num_matched_target, 4)
+ # 4 is mean (batch_idx, prior_idx, grid_x, grid_y)
+ _mlvl_positive_info = mlvl_positive_infos[i]
+ if _mlvl_positive_info.shape[0] == 0:
+ continue
+
+ idx = (_mlvl_positive_info[:, 0] == batch_idx)
+ _mlvl_positive_info = _mlvl_positive_info[idx]
+ _mlvl_positive_infos.append(_mlvl_positive_info)
+
+ priors = mlvl_priors[i][idx]
+ _mlvl_priors.append(priors)
+
+ _from_which_layer.append(
+ torch.ones(size=(_mlvl_positive_info.shape[0], )) * i)
+
+ # (n,85)
+ level_batch_idx, prior_ind, \
+ grid_x, grid_y = _mlvl_positive_info.T
+ pred_positive = head_pred[level_batch_idx, prior_ind, grid_y,
+ grid_x]
+ _mlvl_obj_cls.append(pred_positive[:, 4:])
+
+ # decoded
+ grid = torch.stack([grid_x, grid_y], dim=1)
+ pred_positive_cxcy = (pred_positive[:, :2].sigmoid() * 2. -
+ 0.5 + grid) * self.featmap_strides[i]
+ pred_positive_wh = (pred_positive[:, 2:4].sigmoid() * 2) ** 2 \
+ * priors * self.featmap_strides[i]
+ pred_positive_xywh = torch.cat(
+ [pred_positive_cxcy, pred_positive_wh], dim=-1)
+ _mlvl_decoderd_bboxes.append(pred_positive_xywh)
+
+ # 1 calc pair_wise_iou_loss
+ _mlvl_decoderd_bboxes = torch.cat(_mlvl_decoderd_bboxes, dim=0)
+ num_pred_positive = _mlvl_decoderd_bboxes.shape[0]
+ if num_pred_positive == 0:
+ continue
+
+ # scaled xywh
+ batch_input_shape_wh = pred_results[0].new_tensor(
+ batch_input_shape[::-1]).repeat((1, 2))
+ targets_scaled_bbox = targets_normed[:, 2:6] * batch_input_shape_wh
+
+ targets_scaled_bbox = bbox_cxcywh_to_xyxy(targets_scaled_bbox)
+ _mlvl_decoderd_bboxes = bbox_cxcywh_to_xyxy(_mlvl_decoderd_bboxes)
+ pair_wise_iou = bbox_overlaps(targets_scaled_bbox,
+ _mlvl_decoderd_bboxes)
+ pair_wise_iou_loss = -torch.log(pair_wise_iou + 1e-8)
+
+ # 2 calc pair_wise_cls_loss
+ _mlvl_obj_cls = torch.cat(_mlvl_obj_cls, dim=0).float().sigmoid()
+ _mlvl_positive_infos = torch.cat(_mlvl_positive_infos, dim=0)
+ _from_which_layer = torch.cat(_from_which_layer, dim=0)
+ _mlvl_priors = torch.cat(_mlvl_priors, dim=0)
+
+ gt_cls_per_image = (
+ F.one_hot(targets_normed[:, 1].to(torch.int64),
+ self.num_classes).float().unsqueeze(1).repeat(
+ 1, num_pred_positive, 1))
+ # cls_score * obj
+ cls_preds_ = _mlvl_obj_cls[:, 1:]\
+ .unsqueeze(0)\
+ .repeat(num_gts, 1, 1) \
+ * _mlvl_obj_cls[:, 0:1]\
+ .unsqueeze(0).repeat(num_gts, 1, 1)
+ y = cls_preds_.sqrt_()
+ pair_wise_cls_loss = F.binary_cross_entropy_with_logits(
+ torch.log(y / (1 - y)), gt_cls_per_image,
+ reduction='none').sum(-1)
+ del cls_preds_
+
+ # calc cost
+ cost = (
+ self.cls_weight * pair_wise_cls_loss +
+ self.iou_weight * pair_wise_iou_loss)
+
+ # num_gt, num_match_pred
+ matching_matrix = torch.zeros_like(cost)
+
+ top_k, _ = torch.topk(
+ pair_wise_iou,
+ min(self.candidate_topk, pair_wise_iou.shape[1]),
+ dim=1)
+ dynamic_ks = torch.clamp(top_k.sum(1).int(), min=1)
+
+ # Select only topk matches per gt
+ for gt_idx in range(num_gts):
+ _, pos_idx = torch.topk(
+ cost[gt_idx], k=dynamic_ks[gt_idx].item(), largest=False)
+ matching_matrix[gt_idx][pos_idx] = 1.0
+ del top_k, dynamic_ks
+
+ # Each prediction box can match at most one gt box,
+ # and if there are more than one,
+ # only the least costly one can be taken
+ anchor_matching_gt = matching_matrix.sum(0)
+ if (anchor_matching_gt > 1).sum() > 0:
+ _, cost_argmin = torch.min(
+ cost[:, anchor_matching_gt > 1], dim=0)
+ matching_matrix[:, anchor_matching_gt > 1] *= 0.0
+ matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1.0
+ fg_mask_inboxes = matching_matrix.sum(0) > 0.0
+ matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0)
+
+ targets_normed = targets_normed[matched_gt_inds]
+ _mlvl_positive_infos = _mlvl_positive_infos[fg_mask_inboxes]
+ _from_which_layer = _from_which_layer[fg_mask_inboxes]
+ _mlvl_priors = _mlvl_priors[fg_mask_inboxes]
+
+ # Rearranged in the order of the prediction layers
+ # to facilitate loss
+ for i in range(num_levels):
+ layer_idx = _from_which_layer == i
+ mlvl_positive_infos_matched[i].append(
+ _mlvl_positive_infos[layer_idx])
+ mlvl_priors_matched[i].append(_mlvl_priors[layer_idx])
+ mlvl_targets_normed_matched[i].append(
+ targets_normed[layer_idx])
+
+ results = mlvl_positive_infos_matched, \
+ mlvl_priors_matched, \
+ mlvl_targets_normed_matched
+ return results
diff --git a/mmyolo/utils/boxam_utils.py b/mmyolo/utils/boxam_utils.py
new file mode 100644
index 000000000..5e1ec9134
--- /dev/null
+++ b/mmyolo/utils/boxam_utils.py
@@ -0,0 +1,504 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import bisect
+import copy
+import warnings
+from pathlib import Path
+from typing import Callable, List, Optional, Tuple, Union
+
+import cv2
+import numpy as np
+import torch
+import torch.nn as nn
+import torchvision
+from mmcv.transforms import Compose
+from mmdet.evaluation import get_classes
+from mmdet.models import build_detector
+from mmdet.utils import ConfigType
+from mmengine.config import Config
+from mmengine.runner import load_checkpoint
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+try:
+ from pytorch_grad_cam import (AblationCAM, AblationLayer,
+ ActivationsAndGradients)
+ from pytorch_grad_cam import GradCAM as Base_GradCAM
+ from pytorch_grad_cam import GradCAMPlusPlus as Base_GradCAMPlusPlus
+ from pytorch_grad_cam.base_cam import BaseCAM
+ from pytorch_grad_cam.utils.image import scale_cam_image, show_cam_on_image
+ from pytorch_grad_cam.utils.svd_on_activations import get_2d_projection
+except ImportError:
+ pass
+
+
+def init_detector(
+ config: Union[str, Path, Config],
+ checkpoint: Optional[str] = None,
+ palette: str = 'coco',
+ device: str = 'cuda:0',
+ cfg_options: Optional[dict] = None,
+) -> nn.Module:
+ """Initialize a detector from config file.
+
+ Args:
+ config (str, :obj:`Path`, or :obj:`mmengine.Config`): Config file path,
+ :obj:`Path`, or the config object.
+ checkpoint (str, optional): Checkpoint path. If left as None, the model
+ will not load any weights.
+ palette (str): Color palette used for visualization. If palette
+ is stored in checkpoint, use checkpoint's palette first, otherwise
+ use externally passed palette. Currently, supports 'coco', 'voc',
+ 'citys' and 'random'. Defaults to coco.
+ device (str): The device where the anchors will be put on.
+ Defaults to cuda:0.
+ cfg_options (dict, optional): Options to override some settings in
+ the used config.
+
+ Returns:
+ nn.Module: The constructed detector.
+ """
+ if isinstance(config, (str, Path)):
+ config = Config.fromfile(config)
+ elif not isinstance(config, Config):
+ raise TypeError('config must be a filename or Config object, '
+ f'but got {type(config)}')
+ if cfg_options is not None:
+ config.merge_from_dict(cfg_options)
+ elif 'init_cfg' in config.model.backbone:
+ config.model.backbone.init_cfg = None
+
+ # only change this
+ # grad based method requires train_cfg
+ # config.model.train_cfg = None
+
+ model = build_detector(config.model)
+ if checkpoint is not None:
+ checkpoint = load_checkpoint(model, checkpoint, map_location='cpu')
+ # Weights converted from elsewhere may not have meta fields.
+ checkpoint_meta = checkpoint.get('meta', {})
+ # save the dataset_meta in the model for convenience
+ if 'dataset_meta' in checkpoint_meta:
+ # mmdet 3.x
+ model.dataset_meta = checkpoint_meta['dataset_meta']
+ elif 'CLASSES' in checkpoint_meta:
+ # < mmdet 3.x
+ classes = checkpoint_meta['CLASSES']
+ model.dataset_meta = {'CLASSES': classes, 'PALETTE': palette}
+ else:
+ warnings.simplefilter('once')
+ warnings.warn(
+ 'dataset_meta or class names are not saved in the '
+ 'checkpoint\'s meta data, use COCO classes by default.')
+ model.dataset_meta = {
+ 'CLASSES': get_classes('coco'),
+ 'PALETTE': palette
+ }
+
+ model.cfg = config # save the config in the model for convenience
+ model.to(device)
+ model.eval()
+ return model
+
+
+def reshape_transform(feats: Union[Tensor, List[Tensor]],
+ max_shape: Tuple[int, int] = (20, 20),
+ is_need_grad: bool = False):
+ """Reshape and aggregate feature maps when the input is a multi-layer
+ feature map.
+
+ Takes these tensors with different sizes, resizes them to a common shape,
+ and concatenates them.
+ """
+ if len(max_shape) == 1:
+ max_shape = max_shape * 2
+
+ if isinstance(feats, torch.Tensor):
+ feats = [feats]
+ else:
+ if is_need_grad:
+ raise NotImplementedError('The `grad_base` method does not '
+ 'support output multi-activation layers')
+
+ max_h = max([im.shape[-2] for im in feats])
+ max_w = max([im.shape[-1] for im in feats])
+ if -1 in max_shape:
+ max_shape = (max_h, max_w)
+ else:
+ max_shape = (min(max_h, max_shape[0]), min(max_w, max_shape[1]))
+
+ activations = []
+ for feat in feats:
+ activations.append(
+ torch.nn.functional.interpolate(
+ torch.abs(feat), max_shape, mode='bilinear'))
+
+ activations = torch.cat(activations, axis=1)
+ return activations
+
+
+class BoxAMDetectorWrapper(nn.Module):
+ """Wrap the mmdet model class to facilitate handling of non-tensor
+ situations during inference."""
+
+ def __init__(self,
+ cfg: ConfigType,
+ checkpoint: str,
+ score_thr: float,
+ device: str = 'cuda:0'):
+ super().__init__()
+ self.cfg = cfg
+ self.device = device
+ self.score_thr = score_thr
+ self.checkpoint = checkpoint
+ self.detector = init_detector(self.cfg, self.checkpoint, device=device)
+
+ pipeline_cfg = copy.deepcopy(self.cfg.test_dataloader.dataset.pipeline)
+ pipeline_cfg[0].type = 'mmdet.LoadImageFromNDArray'
+
+ new_test_pipeline = []
+ for pipeline in pipeline_cfg:
+ if not pipeline['type'].endswith('LoadAnnotations'):
+ new_test_pipeline.append(pipeline)
+ self.test_pipeline = Compose(new_test_pipeline)
+
+ self.is_need_loss = False
+ self.input_data = None
+ self.image = None
+
+ def need_loss(self, is_need_loss: bool):
+ """Grad-based methods require loss."""
+ self.is_need_loss = is_need_loss
+
+ def set_input_data(self,
+ image: np.ndarray,
+ pred_instances: Optional[InstanceData] = None):
+ """Set the input data to be used in the next step."""
+ self.image = image
+
+ if self.is_need_loss:
+ assert pred_instances is not None
+ pred_instances = pred_instances.numpy()
+ data = dict(
+ img=self.image,
+ img_id=0,
+ gt_bboxes=pred_instances.bboxes,
+ gt_bboxes_labels=pred_instances.labels)
+ data = self.test_pipeline(data)
+ else:
+ data = dict(img=self.image, img_id=0)
+ data = self.test_pipeline(data)
+ data['inputs'] = [data['inputs']]
+ data['data_samples'] = [data['data_samples']]
+ self.input_data = data
+
+ def __call__(self, *args, **kwargs):
+ assert self.input_data is not None
+ if self.is_need_loss:
+ # Maybe this is a direction that can be optimized
+ # self.detector.init_weights()
+
+ if hasattr(self.detector.bbox_head, 'featmap_sizes'):
+ # Prevent the model algorithm error when calculating loss
+ self.detector.bbox_head.featmap_sizes = None
+
+ data_ = {}
+ data_['inputs'] = [self.input_data['inputs']]
+ data_['data_samples'] = [self.input_data['data_samples']]
+ data = self.detector.data_preprocessor(data_, training=False)
+ loss = self.detector._run_forward(data, mode='loss')
+
+ if hasattr(self.detector.bbox_head, 'featmap_sizes'):
+ self.detector.bbox_head.featmap_sizes = None
+
+ return [loss]
+ else:
+ with torch.no_grad():
+ results = self.detector.test_step(self.input_data)
+ return results
+
+
+class BoxAMDetectorVisualizer:
+ """Box AM visualization class."""
+
+ def __init__(self,
+ method_class,
+ model: nn.Module,
+ target_layers: List,
+ reshape_transform: Optional[Callable] = None,
+ is_need_grad: bool = False,
+ extra_params: Optional[dict] = None):
+ self.target_layers = target_layers
+ self.reshape_transform = reshape_transform
+ self.is_need_grad = is_need_grad
+
+ if method_class.__name__ == 'AblationCAM':
+ batch_size = extra_params.get('batch_size', 1)
+ ratio_channels_to_ablate = extra_params.get(
+ 'ratio_channels_to_ablate', 1.)
+ self.cam = AblationCAM(
+ model,
+ target_layers,
+ use_cuda=True if 'cuda' in model.device else False,
+ reshape_transform=reshape_transform,
+ batch_size=batch_size,
+ ablation_layer=extra_params['ablation_layer'],
+ ratio_channels_to_ablate=ratio_channels_to_ablate)
+ else:
+ self.cam = method_class(
+ model,
+ target_layers,
+ use_cuda=True if 'cuda' in model.device else False,
+ reshape_transform=reshape_transform,
+ )
+ if self.is_need_grad:
+ self.cam.activations_and_grads.release()
+
+ self.classes = model.detector.dataset_meta['CLASSES']
+ self.COLORS = np.random.uniform(0, 255, size=(len(self.classes), 3))
+
+ def switch_activations_and_grads(self, model) -> None:
+ """In the grad-based method, we need to switch
+ ``ActivationsAndGradients`` layer, otherwise an error will occur."""
+ self.cam.model = model
+
+ if self.is_need_grad is True:
+ self.cam.activations_and_grads = ActivationsAndGradients(
+ model, self.target_layers, self.reshape_transform)
+ self.is_need_grad = False
+ else:
+ self.cam.activations_and_grads.release()
+ self.is_need_grad = True
+
+ def __call__(self, img, targets, aug_smooth=False, eigen_smooth=False):
+ img = torch.from_numpy(img)[None].permute(0, 3, 1, 2)
+ return self.cam(img, targets, aug_smooth, eigen_smooth)[0, :]
+
+ def show_am(self,
+ image: np.ndarray,
+ pred_instance: InstanceData,
+ grayscale_am: np.ndarray,
+ with_norm_in_bboxes: bool = False):
+ """Normalize the AM to be in the range [0, 1] inside every bounding
+ boxes, and zero outside of the bounding boxes."""
+
+ boxes = pred_instance.bboxes
+ labels = pred_instance.labels
+
+ if with_norm_in_bboxes is True:
+ boxes = boxes.astype(np.int32)
+ renormalized_am = np.zeros(grayscale_am.shape, dtype=np.float32)
+ images = []
+ for x1, y1, x2, y2 in boxes:
+ img = renormalized_am * 0
+ img[y1:y2, x1:x2] = scale_cam_image(
+ [grayscale_am[y1:y2, x1:x2].copy()])[0]
+ images.append(img)
+
+ renormalized_am = np.max(np.float32(images), axis=0)
+ renormalized_am = scale_cam_image([renormalized_am])[0]
+ else:
+ renormalized_am = grayscale_am
+
+ am_image_renormalized = show_cam_on_image(
+ image / 255, renormalized_am, use_rgb=False)
+
+ image_with_bounding_boxes = self._draw_boxes(
+ boxes, labels, am_image_renormalized, pred_instance.get('scores'))
+ return image_with_bounding_boxes
+
+ def _draw_boxes(self,
+ boxes: List,
+ labels: List,
+ image: np.ndarray,
+ scores: Optional[List] = None):
+ """draw boxes on image."""
+ for i, box in enumerate(boxes):
+ label = labels[i]
+ color = self.COLORS[label]
+ cv2.rectangle(image, (int(box[0]), int(box[1])),
+ (int(box[2]), int(box[3])), color, 2)
+ if scores is not None:
+ score = scores[i]
+ text = str(self.classes[label]) + ': ' + str(
+ round(score * 100, 1))
+ else:
+ text = self.classes[label]
+
+ cv2.putText(
+ image,
+ text, (int(box[0]), int(box[1] - 5)),
+ cv2.FONT_HERSHEY_SIMPLEX,
+ 0.5,
+ color,
+ 1,
+ lineType=cv2.LINE_AA)
+ return image
+
+
+class DetAblationLayer(AblationLayer):
+ """Det AblationLayer."""
+
+ def __init__(self):
+ super().__init__()
+ self.activations = None
+
+ def set_next_batch(self, input_batch_index, activations,
+ num_channels_to_ablate):
+ """Extract the next batch member from activations, and repeat it
+ num_channels_to_ablate times."""
+ if isinstance(activations, torch.Tensor):
+ return super().set_next_batch(input_batch_index, activations,
+ num_channels_to_ablate)
+
+ self.activations = []
+ for activation in activations:
+ activation = activation[
+ input_batch_index, :, :, :].clone().unsqueeze(0)
+ self.activations.append(
+ activation.repeat(num_channels_to_ablate, 1, 1, 1))
+
+ def __call__(self, x):
+ """Go over the activation indices to be ablated, stored in
+ self.indices."""
+ result = self.activations
+
+ if isinstance(result, torch.Tensor):
+ return super().__call__(x)
+
+ channel_cumsum = np.cumsum([r.shape[1] for r in result])
+ num_channels_to_ablate = result[0].size(0) # batch
+ for i in range(num_channels_to_ablate):
+ pyramid_layer = bisect.bisect_right(channel_cumsum,
+ self.indices[i])
+ if pyramid_layer > 0:
+ index_in_pyramid_layer = self.indices[i] - channel_cumsum[
+ pyramid_layer - 1]
+ else:
+ index_in_pyramid_layer = self.indices[i]
+ result[pyramid_layer][i, index_in_pyramid_layer, :, :] = -1000
+ return result
+
+
+class DetBoxScoreTarget:
+ """Det Score calculation class.
+
+ In the case of the grad-free method, the calculation method is that
+ for every original detected bounding box specified in "bboxes",
+ assign a score on how the current bounding boxes match it,
+
+ 1. In Bbox IoU
+ 2. In the classification score.
+ 3. In Mask IoU if ``segms`` exist.
+
+ If there is not a large enough overlap, or the category changed,
+ assign a score of 0. The total score is the sum of all the box scores.
+
+ In the case of the grad-based method, the calculation method is
+ the sum of losses after excluding a specific key.
+ """
+
+ def __init__(self,
+ pred_instance: InstanceData,
+ match_iou_thr: float = 0.5,
+ device: str = 'cuda:0',
+ ignore_loss_params: Optional[List] = None):
+ self.focal_bboxes = pred_instance.bboxes
+ self.focal_labels = pred_instance.labels
+ self.match_iou_thr = match_iou_thr
+ self.device = device
+ self.ignore_loss_params = ignore_loss_params
+ if ignore_loss_params is not None:
+ assert isinstance(self.ignore_loss_params, list)
+
+ def __call__(self, results):
+ output = torch.tensor([0.], device=self.device)
+
+ if 'loss_cls' in results:
+ # grad-based method
+ # results is dict
+ for loss_key, loss_value in results.items():
+ if 'loss' not in loss_key or \
+ loss_key in self.ignore_loss_params:
+ continue
+ if isinstance(loss_value, list):
+ output += sum(loss_value)
+ else:
+ output += loss_value
+ return output
+ else:
+ # grad-free method
+ # results is DetDataSample
+ pred_instances = results.pred_instances
+ if len(pred_instances) == 0:
+ return output
+
+ pred_bboxes = pred_instances.bboxes
+ pred_scores = pred_instances.scores
+ pred_labels = pred_instances.labels
+
+ for focal_box, focal_label in zip(self.focal_bboxes,
+ self.focal_labels):
+ ious = torchvision.ops.box_iou(focal_box[None],
+ pred_bboxes[..., :4])
+ index = ious.argmax()
+ if ious[0, index] > self.match_iou_thr and pred_labels[
+ index] == focal_label:
+ # TODO: Adaptive adjustment of weights based on algorithms
+ score = ious[0, index] + pred_scores[index]
+ output = output + score
+ return output
+
+
+class SpatialBaseCAM(BaseCAM):
+ """CAM that maintains spatial information.
+
+ Gradients are often averaged over the spatial dimension in CAM
+ visualization for classification, but this is unreasonable in detection
+ tasks. There is no need to average the gradients in the detection task.
+ """
+
+ def get_cam_image(self,
+ input_tensor: torch.Tensor,
+ target_layer: torch.nn.Module,
+ targets: List[torch.nn.Module],
+ activations: torch.Tensor,
+ grads: torch.Tensor,
+ eigen_smooth: bool = False) -> np.ndarray:
+
+ weights = self.get_cam_weights(input_tensor, target_layer, targets,
+ activations, grads)
+ weighted_activations = weights * activations
+ if eigen_smooth:
+ cam = get_2d_projection(weighted_activations)
+ else:
+ cam = weighted_activations.sum(axis=1)
+ return cam
+
+
+class GradCAM(SpatialBaseCAM, Base_GradCAM):
+ """Gradients are no longer averaged over the spatial dimension."""
+
+ def get_cam_weights(self, input_tensor, target_layer, target_category,
+ activations, grads):
+ return grads
+
+
+class GradCAMPlusPlus(SpatialBaseCAM, Base_GradCAMPlusPlus):
+ """Gradients are no longer averaged over the spatial dimension."""
+
+ def get_cam_weights(self, input_tensor, target_layers, target_category,
+ activations, grads):
+ grads_power_2 = grads**2
+ grads_power_3 = grads_power_2 * grads
+ # Equation 19 in https://arxiv.org/abs/1710.11063
+ sum_activations = np.sum(activations, axis=(2, 3))
+ eps = 0.000001
+ aij = grads_power_2 / (
+ 2 * grads_power_2 +
+ sum_activations[:, :, None, None] * grads_power_3 + eps)
+ # Now bring back the ReLU from eq.7 in the paper,
+ # And zero out aijs where the activations are 0
+ aij = np.where(grads != 0, aij, 0)
+
+ weights = np.maximum(grads, 0) * aij
+ return weights
diff --git a/mmyolo/utils/labelme_utils.py b/mmyolo/utils/labelme_utils.py
new file mode 100644
index 000000000..3bfc65029
--- /dev/null
+++ b/mmyolo/utils/labelme_utils.py
@@ -0,0 +1,91 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+
+from mmengine.structures import InstanceData
+
+
+class LabelmeFormat:
+ """Predict results save into labelme file.
+
+ Base on https://github.com/wkentaro/labelme/blob/main/labelme/label_file.py
+
+ Args:
+ classes (tuple): Model classes name.
+ """
+
+ def __init__(self, classes: tuple):
+ super().__init__()
+ self.classes = classes
+
+ def __call__(self, pred_instances: InstanceData, metainfo: dict,
+ output_path: str, selected_classes: list):
+ """Get image data field for labelme.
+
+ Args:
+ pred_instances (InstanceData): Candidate prediction info.
+ metainfo (dict): Meta info of prediction.
+ output_path (str): Image file path.
+ selected_classes (list): Selected class name.
+
+ Labelme file eg.
+ {
+ "version": "5.0.5",
+ "flags": {},
+ "imagePath": "/data/cat/1.jpg",
+ "imageData": null,
+ "imageHeight": 3000,
+ "imageWidth": 4000,
+ "shapes": [
+ {
+ "label": "cat",
+ "points": [
+ [
+ 1148.076923076923,
+ 1188.4615384615383
+ ],
+ [
+ 2471.1538461538457,
+ 2176.923076923077
+ ]
+ ],
+ "group_id": null,
+ "shape_type": "rectangle",
+ "flags": {}
+ },
+ {...}
+ ]
+ }
+ """
+
+ image_path = metainfo['img_path']
+
+ json_info = {
+ 'version': '5.0.5',
+ 'flags': {},
+ 'imagePath': image_path,
+ 'imageData': None,
+ 'imageHeight': metainfo['ori_shape'][0],
+ 'imageWidth': metainfo['ori_shape'][1],
+ 'shapes': []
+ }
+
+ for pred_instance in pred_instances:
+ pred_bbox = pred_instance.bboxes.cpu().numpy().tolist()[0]
+ pred_label = self.classes[pred_instance.labels]
+
+ if selected_classes is not None and \
+ pred_label not in selected_classes:
+ # filter class name
+ continue
+
+ sub_dict = {
+ 'label': pred_label,
+ 'points': [pred_bbox[:2], pred_bbox[2:]],
+ 'group_id': None,
+ 'shape_type': 'rectangle',
+ 'flags': {}
+ }
+ json_info['shapes'].append(sub_dict)
+
+ with open(output_path, 'w', encoding='utf-8') as f_json:
+ json.dump(json_info, f_json, ensure_ascii=False, indent=2)
diff --git a/mmyolo/utils/large_image.py b/mmyolo/utils/large_image.py
new file mode 100644
index 000000000..68c6938e5
--- /dev/null
+++ b/mmyolo/utils/large_image.py
@@ -0,0 +1,76 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Sequence, Tuple
+
+from mmcv.ops import batched_nms
+from mmdet.structures import DetDataSample, SampleList
+from mmengine.structures import InstanceData
+
+
+def shift_predictions(det_data_samples: SampleList,
+ offsets: Sequence[Tuple[int, int]],
+ src_image_shape: Tuple[int, int]) -> SampleList:
+ """Shift predictions to the original image.
+
+ Args:
+ det_data_samples (List[:obj:`DetDataSample`]): A list of patch results.
+ offsets (Sequence[Tuple[int, int]]): Positions of the left top points
+ of patches.
+ src_image_shape (Tuple[int, int]): A (height, width) tuple of the large
+ image's width and height.
+ Returns:
+ (List[:obj:`DetDataSample`]): shifted results.
+ """
+ try:
+ from sahi.slicing import shift_bboxes, shift_masks
+ except ImportError:
+ raise ImportError('Please run "pip install -U sahi" '
+ 'to install sahi first for large image inference.')
+
+ assert len(det_data_samples) == len(
+ offsets), 'The `results` should has the ' 'same length with `offsets`.'
+ shifted_predictions = []
+ for det_data_sample, offset in zip(det_data_samples, offsets):
+ pred_inst = det_data_sample.pred_instances.clone()
+
+ # shift bboxes and masks
+ pred_inst.bboxes = shift_bboxes(pred_inst.bboxes, offset)
+ if 'masks' in det_data_sample:
+ pred_inst.masks = shift_masks(pred_inst.masks, offset,
+ src_image_shape)
+
+ shifted_predictions.append(pred_inst.clone())
+
+ shifted_predictions = InstanceData.cat(shifted_predictions)
+
+ return shifted_predictions
+
+
+def merge_results_by_nms(results: SampleList, offsets: Sequence[Tuple[int,
+ int]],
+ src_image_shape: Tuple[int, int],
+ nms_cfg: dict) -> DetDataSample:
+ """Merge patch results by nms.
+
+ Args:
+ results (List[:obj:`DetDataSample`]): A list of patch results.
+ offsets (Sequence[Tuple[int, int]]): Positions of the left top points
+ of patches.
+ src_image_shape (Tuple[int, int]): A (height, width) tuple of the large
+ image's width and height.
+ nms_cfg (dict): it should specify nms type and other parameters
+ like `iou_threshold`.
+ Returns:
+ :obj:`DetDataSample`: merged results.
+ """
+ shifted_instances = shift_predictions(results, offsets, src_image_shape)
+
+ _, keeps = batched_nms(
+ boxes=shifted_instances.bboxes,
+ scores=shifted_instances.scores,
+ idxs=shifted_instances.labels,
+ nms_cfg=nms_cfg)
+ merged_instances = shifted_instances[keeps]
+
+ merged_result = results[0].clone()
+ merged_result.pred_instances = merged_instances
+ return merged_result
diff --git a/mmyolo/utils/misc.py b/mmyolo/utils/misc.py
index dbc2a62e7..5b5dd5d20 100644
--- a/mmyolo/utils/misc.py
+++ b/mmyolo/utils/misc.py
@@ -5,6 +5,7 @@
import numpy as np
import torch
from mmengine.utils import scandir
+from prettytable import PrettyTable
from mmyolo.models import RepVGGBlock
@@ -90,3 +91,26 @@ def get_file_list(source_root: str) -> [list, dict]:
source_type = dict(is_dir=is_dir, is_url=is_url, is_file=is_file)
return source_file_path_list, source_type
+
+
+def show_data_classes(data_classes):
+ """When printing an error, all class names of the dataset."""
+ print('\n\nThe name of the class contained in the dataset:')
+ data_classes_info = PrettyTable()
+ data_classes_info.title = 'Information of dataset class'
+ # List Print Settings
+ # If the quantity is too large, 25 rows will be displayed in each column
+ if len(data_classes) < 25:
+ data_classes_info.add_column('Class name', data_classes)
+ elif len(data_classes) % 25 != 0 and len(data_classes) > 25:
+ col_num = int(len(data_classes) / 25) + 1
+ data_name_list = list(data_classes)
+ for i in range(0, (col_num * 25) - len(data_classes)):
+ data_name_list.append('')
+ for i in range(0, len(data_name_list), 25):
+ data_classes_info.add_column('Class name',
+ data_name_list[i:i + 25])
+
+ # Align display data to the left
+ data_classes_info.align['Class name'] = 'l'
+ print(data_classes_info)
diff --git a/mmyolo/version.py b/mmyolo/version.py
index 3d43f2dfe..f823adabf 100644
--- a/mmyolo/version.py
+++ b/mmyolo/version.py
@@ -1,6 +1,6 @@
# Copyright (c) OpenMMLab. All rights reserved.
-__version__ = '0.1.3'
+__version__ = '0.2.0'
from typing import Tuple
diff --git a/model-index.yml b/model-index.yml
index 40ad558b3..de8794ca9 100644
--- a/model-index.yml
+++ b/model-index.yml
@@ -3,3 +3,4 @@ Import:
- configs/yolov6/metafile.yml
- configs/yolox/metafile.yml
- configs/rtmdet/metafile.yml
+ - configs/yolov7/metafile.yml
diff --git a/projects/easydeploy/README.md b/projects/easydeploy/README.md
new file mode 100644
index 000000000..1816e7ed9
--- /dev/null
+++ b/projects/easydeploy/README.md
@@ -0,0 +1,11 @@
+# MMYOLO Model Easy-Deployment
+
+## Introduction
+
+This project is developed for easily converting your MMYOLO models to other inference backends without the need of MMDeploy, which reduces the cost of both time and effort on getting familiar with MMDeploy.
+
+Currently we support converting to `ONNX` and `TensorRT` formats, other inference backends such `ncnn` will be added to this project as well.
+
+## Supported Backends
+
+- [Model Convert](docs/model_convert.md)
diff --git a/projects/easydeploy/README_zh-CN.md b/projects/easydeploy/README_zh-CN.md
new file mode 100644
index 000000000..4c6bc0cf4
--- /dev/null
+++ b/projects/easydeploy/README_zh-CN.md
@@ -0,0 +1,11 @@
+# MMYOLO 模型转换
+
+## 介绍
+
+本项目作为 MMYOLO 的部署 project 单独存在,意图剥离 MMDeploy 当前的体系,独自支持用户完成模型训练后的转换和部署功能,使用户的学习和工程成本下降。
+
+当前支持对 ONNX 格式和 TensorRT 格式的转换,后续对其他推理平台也会支持起来。
+
+## 转换教程
+
+- [Model Convert](docs/model_convert.md)
diff --git a/projects/easydeploy/backbone/__init__.py b/projects/easydeploy/backbone/__init__.py
new file mode 100644
index 000000000..46776f9b1
--- /dev/null
+++ b/projects/easydeploy/backbone/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .focus import DeployFocus, GConvFocus, NcnnFocus
+
+__all__ = ['DeployFocus', 'NcnnFocus', 'GConvFocus']
diff --git a/projects/easydeploy/backbone/focus.py b/projects/easydeploy/backbone/focus.py
new file mode 100644
index 000000000..2a19afcca
--- /dev/null
+++ b/projects/easydeploy/backbone/focus.py
@@ -0,0 +1,79 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from torch import Tensor
+
+
+class DeployFocus(nn.Module):
+
+ def __init__(self, orin_Focus: nn.Module):
+ super().__init__()
+ self.__dict__.update(orin_Focus.__dict__)
+
+ def forward(self, x: Tensor) -> Tensor:
+ batch_size, channel, height, width = x.shape
+ x = x.reshape(batch_size, channel, -1, 2, width)
+ x = x.reshape(batch_size, channel, x.shape[2], 2, -1, 2)
+ half_h = x.shape[2]
+ half_w = x.shape[4]
+ x = x.permute(0, 5, 3, 1, 2, 4)
+ x = x.reshape(batch_size, channel * 4, half_h, half_w)
+
+ return self.conv(x)
+
+
+class NcnnFocus(nn.Module):
+
+ def __init__(self, orin_Focus: nn.Module):
+ super().__init__()
+ self.__dict__.update(orin_Focus.__dict__)
+
+ def forward(self, x: Tensor) -> Tensor:
+ batch_size, c, h, w = x.shape
+ assert h % 2 == 0 and w % 2 == 0, f'focus for yolox needs even feature\
+ height and width, got {(h, w)}.'
+
+ x = x.reshape(batch_size, c * h, 1, w)
+ _b, _c, _h, _w = x.shape
+ g = _c // 2
+ # fuse to ncnn's shufflechannel
+ x = x.view(_b, g, 2, _h, _w)
+ x = torch.transpose(x, 1, 2).contiguous()
+ x = x.view(_b, -1, _h, _w)
+
+ x = x.reshape(_b, c * h * w, 1, 1)
+
+ _b, _c, _h, _w = x.shape
+ g = _c // 2
+ # fuse to ncnn's shufflechannel
+ x = x.view(_b, g, 2, _h, _w)
+ x = torch.transpose(x, 1, 2).contiguous()
+ x = x.view(_b, -1, _h, _w)
+
+ x = x.reshape(_b, c * 4, h // 2, w // 2)
+
+ return self.conv(x)
+
+
+class GConvFocus(nn.Module):
+
+ def __init__(self, orin_Focus: nn.Module):
+ super().__init__()
+ device = next(orin_Focus.parameters()).device
+ self.weight1 = torch.tensor([[1., 0], [0, 0]]).expand(3, 1, 2,
+ 2).to(device)
+ self.weight2 = torch.tensor([[0, 0], [1., 0]]).expand(3, 1, 2,
+ 2).to(device)
+ self.weight3 = torch.tensor([[0, 1.], [0, 0]]).expand(3, 1, 2,
+ 2).to(device)
+ self.weight4 = torch.tensor([[0, 0], [0, 1.]]).expand(3, 1, 2,
+ 2).to(device)
+ self.__dict__.update(orin_Focus.__dict__)
+
+ def forward(self, x: Tensor) -> Tensor:
+ conv1 = F.conv2d(x, self.weight1, stride=2, groups=3)
+ conv2 = F.conv2d(x, self.weight2, stride=2, groups=3)
+ conv3 = F.conv2d(x, self.weight3, stride=2, groups=3)
+ conv4 = F.conv2d(x, self.weight4, stride=2, groups=3)
+ return self.conv(torch.cat([conv1, conv2, conv3, conv4], dim=1))
diff --git a/projects/easydeploy/bbox_code/__init__.py b/projects/easydeploy/bbox_code/__init__.py
new file mode 100644
index 000000000..2a5c41da7
--- /dev/null
+++ b/projects/easydeploy/bbox_code/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .bbox_coder import rtmdet_bbox_decoder, yolov5_bbox_decoder
+
+__all__ = ['yolov5_bbox_decoder', 'rtmdet_bbox_decoder']
diff --git a/projects/easydeploy/bbox_code/bbox_coder.py b/projects/easydeploy/bbox_code/bbox_coder.py
new file mode 100644
index 000000000..153d7888e
--- /dev/null
+++ b/projects/easydeploy/bbox_code/bbox_coder.py
@@ -0,0 +1,35 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch
+from torch import Tensor
+
+
+def yolov5_bbox_decoder(priors: Tensor, bbox_preds: Tensor,
+ stride: Tensor) -> Tensor:
+ bbox_preds = bbox_preds.sigmoid()
+
+ x_center = (priors[..., 0] + priors[..., 2]) * 0.5
+ y_center = (priors[..., 1] + priors[..., 3]) * 0.5
+ w = priors[..., 2] - priors[..., 0]
+ h = priors[..., 3] - priors[..., 1]
+
+ x_center_pred = (bbox_preds[..., 0] - 0.5) * 2 * stride + x_center
+ y_center_pred = (bbox_preds[..., 1] - 0.5) * 2 * stride + y_center
+ w_pred = (bbox_preds[..., 2] * 2)**2 * w
+ h_pred = (bbox_preds[..., 3] * 2)**2 * h
+
+ decoded_bboxes = torch.stack(
+ [x_center_pred, y_center_pred, w_pred, h_pred], dim=-1)
+
+ return decoded_bboxes
+
+
+def rtmdet_bbox_decoder(priors: Tensor, bbox_preds: Tensor,
+ stride: Optional[Tensor]) -> Tensor:
+ tl_x = (priors[..., 0] - bbox_preds[..., 0])
+ tl_y = (priors[..., 1] - bbox_preds[..., 1])
+ br_x = (priors[..., 0] + bbox_preds[..., 2])
+ br_y = (priors[..., 1] + bbox_preds[..., 3])
+ decoded_bboxes = torch.stack([tl_x, tl_y, br_x, br_y], -1)
+ return decoded_bboxes
diff --git a/projects/easydeploy/docs/model_convert.md b/projects/easydeploy/docs/model_convert.md
new file mode 100644
index 000000000..062247fc4
--- /dev/null
+++ b/projects/easydeploy/docs/model_convert.md
@@ -0,0 +1,56 @@
+# MMYOLO 模型 ONNX 转换
+
+## 环境依赖
+
+- [onnx](https://github.com/onnx/onnx)
+
+ ```shell
+ pip install onnx
+ ```
+
+ [onnx-simplifier](https://github.com/daquexian/onnx-simplifier) (可选,用于简化模型)
+
+ ```shell
+ pip install onnx-simplifier
+ ```
+
+## 使用方法
+
+[模型导出脚本](./projects/easydeploy/tools/export.py)用于将 `MMYOLO` 模型转换为 `onnx` 。
+
+### 参数介绍:
+
+- `config` : 构建模型使用的配置文件,如 [`yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py`](./configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py) 。
+- `checkpoint` : 训练得到的权重文件,如 `yolov5s.pth` 。
+- `--work-dir` : 转换后的模型保存路径。
+- `--img-size`: 转换模型时输入的尺寸,如 `640 640`。
+- `--batch-size`: 转换后的模型输入 `batch size` 。
+- `--device`: 转换模型使用的设备,默认为 `cuda:0`。
+- `--simplify`: 是否简化导出的 `onnx` 模型,需要安装 [onnx-simplifier](https://github.com/daquexian/onnx-simplifier),默认关闭。
+- `--opset`: 指定导出 `onnx` 的 `opset`,默认为 `11` 。
+- `--backend`: 指定导出 `onnx` 用于的后端 id,`ONNXRuntime`: `1`, `TensorRT8`: `2`, `TensorRT7`: `3`,默认为`1`即 `ONNXRuntime`。
+- `--pre-topk`: 指定导出 `onnx` 的后处理筛选候选框个数阈值,默认为 `1000`。
+- `--keep-topk`: 指定导出 `onnx` 的非极大值抑制输出的候选框个数阈值,默认为 `100`。
+- `--iou-threshold`: 非极大值抑制中过滤重复候选框的 `iou` 阈值,默认为 `0.65`。
+- `--score-threshold`: 非极大值抑制中过滤候选框得分的阈值,默认为 `0.25`。
+
+例子:
+
+```shell
+python ./projects/easydeploy/tools/export.py \
+ configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
+ yolov5s.pth \
+ --work-dir work_dir \
+ --img-size 640 640 \
+ --batch 1 \
+ --device cpu \
+ --simplify \
+ --opset 11 \
+ --backend 1 \
+ --pre-topk 1000 \
+ --keep-topk 100 \
+ --iou-threshold 0.65 \
+ --score-threshold 0.25
+```
+
+然后利用后端支持的工具如 `TensorRT` 读取 `onnx` 再次转换为后端支持的模型格式如 `.engine/.plan` 等
diff --git a/projects/easydeploy/model/__init__.py b/projects/easydeploy/model/__init__.py
new file mode 100644
index 000000000..5ab73a82a
--- /dev/null
+++ b/projects/easydeploy/model/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .backendwrapper import BackendWrapper, EngineBuilder
+from .model import DeployModel
+
+__all__ = ['DeployModel', 'BackendWrapper', 'EngineBuilder']
diff --git a/projects/easydeploy/model/backendwrapper.py b/projects/easydeploy/model/backendwrapper.py
new file mode 100644
index 000000000..ddc10e90f
--- /dev/null
+++ b/projects/easydeploy/model/backendwrapper.py
@@ -0,0 +1,256 @@
+import warnings
+from collections import OrderedDict, namedtuple
+from functools import partial
+from pathlib import Path
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import onnxruntime
+import tensorrt as trt
+import torch
+from numpy import ndarray
+from torch import Tensor
+
+warnings.filterwarnings(action='ignore', category=DeprecationWarning)
+
+
+class BackendWrapper:
+
+ def __init__(
+ self,
+ weight: Union[str, Path],
+ device: Optional[Union[str, int, torch.device]] = None) -> None:
+ weight = Path(weight) if isinstance(weight, str) else weight
+ assert weight.exists() and weight.suffix in ('.onnx', '.engine',
+ '.plan')
+ if isinstance(device, str):
+ device = torch.device(device)
+ elif isinstance(device, int):
+ device = torch.device(f'cuda:{device}')
+ self.weight = weight
+ self.device = device
+ self.__build_model()
+ self.__init_runtime()
+ self.__warm_up(10)
+
+ def __build_model(self) -> None:
+ model_info = dict()
+ num_input = num_output = 0
+ names = []
+ is_dynamic = False
+ if self.weight.suffix == '.onnx':
+ model_info['backend'] = 'ONNXRuntime'
+ providers = ['CPUExecutionProvider']
+ if 'cuda' in self.device.type:
+ providers.insert(0, 'CUDAExecutionProvider')
+ model = onnxruntime.InferenceSession(
+ str(self.weight), providers=providers)
+ for i, tensor in enumerate(model.get_inputs()):
+ model_info[tensor.name] = dict(
+ shape=tensor.shape, dtype=tensor.type)
+ num_input += 1
+ names.append(tensor.name)
+ is_dynamic |= any(
+ map(lambda x: isinstance(x, str), tensor.shape))
+ for i, tensor in enumerate(model.get_outputs()):
+ model_info[tensor.name] = dict(
+ shape=tensor.shape, dtype=tensor.type)
+ num_output += 1
+ names.append(tensor.name)
+ else:
+ model_info['backend'] = 'TensorRT'
+ logger = trt.Logger(trt.Logger.ERROR)
+ trt.init_libnvinfer_plugins(logger, namespace='')
+ with trt.Runtime(logger) as runtime:
+ model = runtime.deserialize_cuda_engine(
+ self.weight.read_bytes())
+ profile_shape = []
+ for i in range(model.num_bindings):
+ name = model.get_binding_name(i)
+ shape = tuple(model.get_binding_shape(i))
+ dtype = trt.nptype(model.get_binding_dtype(i))
+ is_dynamic |= (-1 in shape)
+ if model.binding_is_input(i):
+ num_input += 1
+ profile_shape.append(model.get_profile_shape(i, 0))
+ else:
+ num_output += 1
+ model_info[name] = dict(shape=shape, dtype=dtype)
+ names.append(name)
+ model_info['profile_shape'] = profile_shape
+
+ self.num_input = num_input
+ self.num_output = num_output
+ self.names = names
+ self.is_dynamic = is_dynamic
+ self.model = model
+ self.model_info = model_info
+
+ def __init_runtime(self) -> None:
+ bindings = OrderedDict()
+ Binding = namedtuple('Binding',
+ ('name', 'dtype', 'shape', 'data', 'ptr'))
+ if self.model_info['backend'] == 'TensorRT':
+ context = self.model.create_execution_context()
+ for name in self.names:
+ shape, dtype = self.model_info[name].values()
+ if self.is_dynamic:
+ cpu_tensor, gpu_tensor, ptr = None, None, None
+ else:
+ cpu_tensor = np.empty(shape, dtype=np.dtype(dtype))
+ gpu_tensor = torch.from_numpy(cpu_tensor).to(self.device)
+ ptr = int(gpu_tensor.data_ptr())
+ bindings[name] = Binding(name, dtype, shape, gpu_tensor, ptr)
+ else:
+ output_names = []
+ for i, name in enumerate(self.names):
+ if i >= self.num_input:
+ output_names.append(name)
+ shape, dtype = self.model_info[name].values()
+ bindings[name] = Binding(name, dtype, shape, None, None)
+ context = partial(self.model.run, output_names)
+ self.addrs = OrderedDict((n, d.ptr) for n, d in bindings.items())
+ self.bindings = bindings
+ self.context = context
+
+ def __infer(
+ self, inputs: List[Union[ndarray,
+ Tensor]]) -> List[Union[ndarray, Tensor]]:
+ assert len(inputs) == self.num_input
+ if self.model_info['backend'] == 'TensorRT':
+ outputs = []
+ for i, (name, gpu_input) in enumerate(
+ zip(self.names[:self.num_input], inputs)):
+ if self.is_dynamic:
+ self.context.set_binding_shape(i, gpu_input.shape)
+ self.addrs[name] = gpu_input.data_ptr()
+
+ for i, name in enumerate(self.names[self.num_input:]):
+ i += self.num_input
+ if self.is_dynamic:
+ shape = tuple(self.context.get_binding_shape(i))
+ dtype = self.bindings[name].dtype
+ cpu_tensor = np.empty(shape, dtype=np.dtype(dtype))
+ out = torch.from_numpy(cpu_tensor).to(self.device)
+ self.addrs[name] = out.data_ptr()
+ else:
+ out = self.bindings[name].data
+ outputs.append(out)
+ assert self.context.execute_v2(list(
+ self.addrs.values())), 'Infer fault'
+ else:
+ input_feed = {
+ name: inputs[i]
+ for i, name in enumerate(self.names[:self.num_input])
+ }
+ outputs = self.context(input_feed)
+ return outputs
+
+ def __warm_up(self, n=10) -> None:
+ for _ in range(n):
+ _tmp = []
+ if self.model_info['backend'] == 'TensorRT':
+ for i, name in enumerate(self.names[:self.num_input]):
+ if self.is_dynamic:
+ shape = self.model_info['profile_shape'][i][1]
+ dtype = self.bindings[name].dtype
+ cpu_tensor = np.empty(shape, dtype=np.dtype(dtype))
+ _tmp.append(
+ torch.from_numpy(cpu_tensor).to(self.device))
+ else:
+ _tmp.append(self.bindings[name].data)
+ else:
+ print('Please warm up ONNXRuntime model by yourself')
+ print("So this model doesn't warm up")
+ return
+ _ = self.__infer(_tmp)
+
+ def __call__(
+ self, inputs: Union[List, Tensor,
+ ndarray]) -> List[Union[Tensor, ndarray]]:
+ if not isinstance(inputs, list):
+ inputs = [inputs]
+ outputs = self.__infer(inputs)
+ return outputs
+
+
+class EngineBuilder:
+
+ def __init__(
+ self,
+ checkpoint: Union[str, Path],
+ opt_shape: Union[Tuple, List] = (1, 3, 640, 640),
+ device: Optional[Union[str, int, torch.device]] = None) -> None:
+ checkpoint = Path(checkpoint) if isinstance(checkpoint,
+ str) else checkpoint
+ assert checkpoint.exists() and checkpoint.suffix == '.onnx'
+ if isinstance(device, str):
+ device = torch.device(device)
+ elif isinstance(device, int):
+ device = torch.device(f'cuda:{device}')
+
+ self.checkpoint = checkpoint
+ self.opt_shape = np.array(opt_shape, dtype=np.float32)
+ self.device = device
+
+ def __build_engine(self,
+ scale: Optional[List[List]] = None,
+ fp16: bool = True,
+ with_profiling: bool = True) -> None:
+ logger = trt.Logger(trt.Logger.WARNING)
+ trt.init_libnvinfer_plugins(logger, namespace='')
+ builder = trt.Builder(logger)
+ config = builder.create_builder_config()
+ config.max_workspace_size = torch.cuda.get_device_properties(
+ self.device).total_memory
+ flag = (1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
+ network = builder.create_network(flag)
+ parser = trt.OnnxParser(network, logger)
+ if not parser.parse_from_file(str(self.checkpoint)):
+ raise RuntimeError(
+ f'failed to load ONNX file: {str(self.checkpoint)}')
+ inputs = [network.get_input(i) for i in range(network.num_inputs)]
+ outputs = [network.get_output(i) for i in range(network.num_outputs)]
+ profile = None
+ dshape = -1 in network.get_input(0).shape
+ if dshape:
+ profile = builder.create_optimization_profile()
+ if scale is None:
+ scale = np.array(
+ [[1, 1, 0.5, 0.5], [1, 1, 1, 1], [4, 1, 1.5, 1.5]],
+ dtype=np.float32)
+ scale = (self.opt_shape * scale).astype(np.int32)
+ elif isinstance(scale, List):
+ scale = np.array(scale, dtype=np.int32)
+ assert scale.shape[0] == 3, 'Input a wrong scale list'
+ else:
+ raise NotImplementedError
+
+ for inp in inputs:
+ logger.log(
+ trt.Logger.WARNING,
+ f'input "{inp.name}" with shape{inp.shape} {inp.dtype}')
+ if dshape:
+ profile.set_shape(inp.name, *scale)
+ for out in outputs:
+ logger.log(
+ trt.Logger.WARNING,
+ f'output "{out.name}" with shape{out.shape} {out.dtype}')
+ if fp16 and builder.platform_has_fast_fp16:
+ config.set_flag(trt.BuilderFlag.FP16)
+ self.weight = self.checkpoint.with_suffix('.engine')
+ if dshape:
+ config.add_optimization_profile(profile)
+ if with_profiling:
+ config.profiling_verbosity = trt.ProfilingVerbosity.DETAILED
+ with builder.build_engine(network, config) as engine:
+ self.weight.write_bytes(engine.serialize())
+ logger.log(
+ trt.Logger.WARNING, f'Build tensorrt engine finish.\n'
+ f'Save in {str(self.weight.absolute())}')
+
+ def build(self,
+ scale: Optional[List[List]] = None,
+ fp16: bool = True,
+ with_profiling=True):
+ self.__build_engine(scale, fp16, with_profiling)
diff --git a/projects/easydeploy/model/model.py b/projects/easydeploy/model/model.py
new file mode 100644
index 000000000..c274dd831
--- /dev/null
+++ b/projects/easydeploy/model/model.py
@@ -0,0 +1,144 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from functools import partial
+from typing import List, Optional
+
+import torch
+import torch.nn as nn
+from mmdet.models.backbones.csp_darknet import Focus
+from mmengine.config import ConfigDict
+from torch import Tensor
+
+from mmyolo.models import RepVGGBlock
+from mmyolo.models.dense_heads import RTMDetHead, YOLOv5Head
+from ..backbone import DeployFocus, GConvFocus, NcnnFocus
+from ..bbox_code import rtmdet_bbox_decoder, yolov5_bbox_decoder
+from ..nms import batched_nms, efficient_nms, onnx_nms
+
+
+class DeployModel(nn.Module):
+
+ def __init__(self,
+ baseModel: nn.Module,
+ postprocess_cfg: Optional[ConfigDict] = None):
+ super().__init__()
+ self.baseModel = baseModel
+ self.baseHead = baseModel.bbox_head
+ self.__init_sub_attributes()
+ detector_type = type(self.baseHead)
+ if postprocess_cfg is None:
+ pre_top_k = 1000
+ keep_top_k = 100
+ iou_threshold = 0.65
+ score_threshold = 0.25
+ backend = 1
+ else:
+ pre_top_k = postprocess_cfg.get('pre_top_k', 1000)
+ keep_top_k = postprocess_cfg.get('keep_top_k', 100)
+ iou_threshold = postprocess_cfg.get('iou_threshold', 0.65)
+ score_threshold = postprocess_cfg.get('score_threshold', 0.25)
+ backend = postprocess_cfg.get('backend', 1)
+ self.__switch_deploy()
+ self.__dict__.update(locals())
+
+ def __init_sub_attributes(self):
+ self.bbox_decoder = self.baseHead.bbox_coder.decode
+ self.prior_generate = self.baseHead.prior_generator.grid_priors
+ self.num_base_priors = self.baseHead.num_base_priors
+ self.featmap_strides = self.baseHead.featmap_strides
+ self.num_classes = self.baseHead.num_classes
+
+ def __switch_deploy(self):
+ for layer in self.baseModel.modules():
+ if isinstance(layer, RepVGGBlock):
+ layer.switch_to_deploy()
+ if isinstance(layer, Focus):
+ # onnxruntime tensorrt8 tensorrt7
+ if self.backend in (1, 2, 3):
+ self.baseModel.backbone.stem = DeployFocus(layer)
+ # ncnn
+ elif self.backend == 4:
+ self.baseModel.backbone.stem = NcnnFocus(layer)
+ # switch focus to group conv
+ else:
+ self.baseModel.backbone.stem = GConvFocus(layer)
+
+ def pred_by_feat(self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ objectnesses: Optional[List[Tensor]] = None,
+ **kwargs):
+ assert len(cls_scores) == len(bbox_preds)
+ dtype = cls_scores[0].dtype
+ device = cls_scores[0].device
+
+ nms_func = self.select_nms()
+ if self.detector_type is YOLOv5Head:
+ bbox_decoder = yolov5_bbox_decoder
+ elif self.detector_type is RTMDetHead:
+ bbox_decoder = rtmdet_bbox_decoder
+ else:
+ bbox_decoder = self.bbox_decoder
+
+ num_imgs = cls_scores[0].shape[0]
+ featmap_sizes = [cls_score.shape[2:] for cls_score in cls_scores]
+
+ mlvl_priors = self.prior_generate(
+ featmap_sizes, dtype=dtype, device=device)
+
+ flatten_priors = torch.cat(mlvl_priors)
+
+ mlvl_strides = [
+ flatten_priors.new_full(
+ (featmap_size[0] * featmap_size[1] * self.num_base_priors, ),
+ stride) for featmap_size, stride in zip(
+ featmap_sizes, self.featmap_strides)
+ ]
+ flatten_stride = torch.cat(mlvl_strides)
+
+ # flatten cls_scores, bbox_preds and objectness
+ flatten_cls_scores = [
+ cls_score.permute(0, 2, 3, 1).reshape(num_imgs, -1,
+ self.num_classes)
+ for cls_score in cls_scores
+ ]
+ cls_scores = torch.cat(flatten_cls_scores, dim=1).sigmoid()
+
+ flatten_bbox_preds = [
+ bbox_pred.permute(0, 2, 3, 1).reshape(num_imgs, -1, 4)
+ for bbox_pred in bbox_preds
+ ]
+ flatten_bbox_preds = torch.cat(flatten_bbox_preds, dim=1)
+
+ if objectnesses is not None:
+ flatten_objectness = [
+ objectness.permute(0, 2, 3, 1).reshape(num_imgs, -1)
+ for objectness in objectnesses
+ ]
+ flatten_objectness = torch.cat(flatten_objectness, dim=1).sigmoid()
+ cls_scores = cls_scores * (flatten_objectness.unsqueeze(-1))
+
+ scores = cls_scores
+
+ bboxes = bbox_decoder(flatten_priors[None], flatten_bbox_preds,
+ flatten_stride)
+
+ return nms_func(bboxes, scores, self.keep_top_k, self.iou_threshold,
+ self.score_threshold, self.pre_top_k, self.keep_top_k)
+
+ def select_nms(self):
+ if self.backend == 1:
+ nms_func = onnx_nms
+ elif self.backend == 2:
+ nms_func = efficient_nms
+ elif self.backend == 3:
+ nms_func = batched_nms
+ else:
+ raise NotImplementedError
+ if type(self.baseHead) is YOLOv5Head:
+ nms_func = partial(nms_func, box_coding=1)
+ return nms_func
+
+ def forward(self, inputs: Tensor):
+ neck_outputs = self.baseModel(inputs)
+ outputs = self.pred_by_feat(*neck_outputs)
+ return outputs
diff --git a/projects/easydeploy/nms/__init__.py b/projects/easydeploy/nms/__init__.py
new file mode 100644
index 000000000..59c5cdbd2
--- /dev/null
+++ b/projects/easydeploy/nms/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .ort_nms import onnx_nms
+from .trt_nms import batched_nms, efficient_nms
+
+__all__ = ['efficient_nms', 'batched_nms', 'onnx_nms']
diff --git a/projects/easydeploy/nms/ort_nms.py b/projects/easydeploy/nms/ort_nms.py
new file mode 100644
index 000000000..aad93cf05
--- /dev/null
+++ b/projects/easydeploy/nms/ort_nms.py
@@ -0,0 +1,122 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from torch import Tensor
+
+_XYWH2XYXY = torch.tensor([[1.0, 0.0, 1.0, 0.0], [0.0, 1.0, 0.0, 1.0],
+ [-0.5, 0.0, 0.5, 0.0], [0.0, -0.5, 0.0, 0.5]],
+ dtype=torch.float32)
+
+
+def select_nms_index(scores: Tensor,
+ boxes: Tensor,
+ nms_index: Tensor,
+ batch_size: int,
+ keep_top_k: int = -1):
+ batch_inds, cls_inds = nms_index[:, 0], nms_index[:, 1]
+ box_inds = nms_index[:, 2]
+
+ scores = scores[batch_inds, cls_inds, box_inds].unsqueeze(1)
+ boxes = boxes[batch_inds, box_inds, ...]
+ dets = torch.cat([boxes, scores], dim=1)
+
+ batched_dets = dets.unsqueeze(0).repeat(batch_size, 1, 1)
+ batch_template = torch.arange(
+ 0, batch_size, dtype=batch_inds.dtype, device=batch_inds.device)
+ batched_dets = batched_dets.where(
+ (batch_inds == batch_template.unsqueeze(1)).unsqueeze(-1),
+ batched_dets.new_zeros(1))
+
+ batched_labels = cls_inds.unsqueeze(0).repeat(batch_size, 1)
+ batched_labels = batched_labels.where(
+ (batch_inds == batch_template.unsqueeze(1)),
+ batched_labels.new_ones(1) * -1)
+
+ N = batched_dets.shape[0]
+
+ batched_dets = torch.cat((batched_dets, batched_dets.new_zeros((N, 1, 5))),
+ 1)
+ batched_labels = torch.cat((batched_labels, -batched_labels.new_ones(
+ (N, 1))), 1)
+
+ _, topk_inds = batched_dets[:, :, -1].sort(dim=1, descending=True)
+ topk_batch_inds = torch.arange(
+ batch_size, dtype=topk_inds.dtype,
+ device=topk_inds.device).view(-1, 1)
+ batched_dets = batched_dets[topk_batch_inds, topk_inds, ...]
+ batched_labels = batched_labels[topk_batch_inds, topk_inds, ...]
+ batched_dets, batched_scores = batched_dets.split([4, 1], 2)
+ batched_scores = batched_scores.squeeze(-1)
+
+ num_dets = (batched_scores > 0).sum(1, keepdim=True)
+ return num_dets, batched_dets, batched_scores, batched_labels
+
+
+class ONNXNMSop(torch.autograd.Function):
+
+ @staticmethod
+ def forward(
+ ctx,
+ boxes: Tensor,
+ scores: Tensor,
+ max_output_boxes_per_class: Tensor = torch.tensor([100]),
+ iou_threshold: Tensor = torch.tensor([0.5]),
+ score_threshold: Tensor = torch.tensor([0.05])
+ ) -> Tensor:
+ device = boxes.device
+ batch = scores.shape[0]
+ num_det = 20
+ batches = torch.randint(0, batch, (num_det, )).sort()[0].to(device)
+ idxs = torch.arange(100, 100 + num_det).to(device)
+ zeros = torch.zeros((num_det, ), dtype=torch.int64).to(device)
+ selected_indices = torch.cat([batches[None], zeros[None], idxs[None]],
+ 0).T.contiguous()
+ selected_indices = selected_indices.to(torch.int64)
+
+ return selected_indices
+
+ @staticmethod
+ def symbolic(
+ g,
+ boxes: Tensor,
+ scores: Tensor,
+ max_output_boxes_per_class: Tensor = torch.tensor([100]),
+ iou_threshold: Tensor = torch.tensor([0.5]),
+ score_threshold: Tensor = torch.tensor([0.05]),
+ ):
+ return g.op(
+ 'NonMaxSuppression',
+ boxes,
+ scores,
+ max_output_boxes_per_class,
+ iou_threshold,
+ score_threshold,
+ outputs=1)
+
+
+def onnx_nms(
+ boxes: torch.Tensor,
+ scores: torch.Tensor,
+ max_output_boxes_per_class: int = 100,
+ iou_threshold: float = 0.5,
+ score_threshold: float = 0.05,
+ pre_top_k: int = -1,
+ keep_top_k: int = 100,
+ box_coding: int = 0,
+):
+ max_output_boxes_per_class = torch.tensor([max_output_boxes_per_class])
+ iou_threshold = torch.tensor([iou_threshold])
+ score_threshold = torch.tensor([score_threshold])
+
+ batch_size, _, _ = scores.shape
+ if box_coding == 1:
+ boxes = boxes @ (_XYWH2XYXY.to(boxes.device))
+ scores = scores.transpose(1, 2).contiguous()
+ selected_indices = ONNXNMSop.apply(boxes, scores,
+ max_output_boxes_per_class,
+ iou_threshold, score_threshold)
+
+ num_dets, batched_dets, batched_scores, batched_labels = select_nms_index(
+ scores, boxes, selected_indices, batch_size, keep_top_k=keep_top_k)
+
+ return num_dets, batched_dets, batched_scores, batched_labels.to(
+ torch.int32)
diff --git a/projects/easydeploy/nms/trt_nms.py b/projects/easydeploy/nms/trt_nms.py
new file mode 100644
index 000000000..5c837b406
--- /dev/null
+++ b/projects/easydeploy/nms/trt_nms.py
@@ -0,0 +1,220 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from torch import Tensor
+
+
+class TRTEfficientNMSop(torch.autograd.Function):
+
+ @staticmethod
+ def forward(
+ ctx,
+ boxes: Tensor,
+ scores: Tensor,
+ background_class: int = -1,
+ box_coding: int = 0,
+ iou_threshold: float = 0.45,
+ max_output_boxes: int = 100,
+ plugin_version: str = '1',
+ score_activation: int = 0,
+ score_threshold: float = 0.25,
+ ):
+ batch_size, _, num_classes = scores.shape
+ num_det = torch.randint(
+ 0, max_output_boxes, (batch_size, 1), dtype=torch.int32)
+ det_boxes = torch.randn(batch_size, max_output_boxes, 4)
+ det_scores = torch.randn(batch_size, max_output_boxes)
+ det_classes = torch.randint(
+ 0, num_classes, (batch_size, max_output_boxes), dtype=torch.int32)
+ return num_det, det_boxes, det_scores, det_classes
+
+ @staticmethod
+ def symbolic(g,
+ boxes: Tensor,
+ scores: Tensor,
+ background_class: int = -1,
+ box_coding: int = 0,
+ iou_threshold: float = 0.45,
+ max_output_boxes: int = 100,
+ plugin_version: str = '1',
+ score_activation: int = 0,
+ score_threshold: float = 0.25):
+ out = g.op(
+ 'TRT::EfficientNMS_TRT',
+ boxes,
+ scores,
+ background_class_i=background_class,
+ box_coding_i=box_coding,
+ iou_threshold_f=iou_threshold,
+ max_output_boxes_i=max_output_boxes,
+ plugin_version_s=plugin_version,
+ score_activation_i=score_activation,
+ score_threshold_f=score_threshold,
+ outputs=4)
+ num_det, det_boxes, det_scores, det_classes = out
+ return num_det, det_boxes, det_scores, det_classes
+
+
+class TRTbatchedNMSop(torch.autograd.Function):
+ """TensorRT NMS operation."""
+
+ @staticmethod
+ def forward(
+ ctx,
+ boxes: Tensor,
+ scores: Tensor,
+ plugin_version: str = '1',
+ shareLocation: int = 1,
+ backgroundLabelId: int = -1,
+ numClasses: int = 80,
+ topK: int = 1000,
+ keepTopK: int = 100,
+ scoreThreshold: float = 0.25,
+ iouThreshold: float = 0.45,
+ isNormalized: int = 0,
+ clipBoxes: int = 0,
+ scoreBits: int = 16,
+ caffeSemantics: int = 1,
+ ):
+ batch_size, _, numClasses = scores.shape
+ num_det = torch.randint(
+ 0, keepTopK, (batch_size, 1), dtype=torch.int32)
+ det_boxes = torch.randn(batch_size, keepTopK, 4)
+ det_scores = torch.randn(batch_size, keepTopK)
+ det_classes = torch.randint(0, numClasses,
+ (batch_size, keepTopK)).float()
+ return num_det, det_boxes, det_scores, det_classes
+
+ @staticmethod
+ def symbolic(
+ g,
+ boxes: Tensor,
+ scores: Tensor,
+ plugin_version: str = '1',
+ shareLocation: int = 1,
+ backgroundLabelId: int = -1,
+ numClasses: int = 80,
+ topK: int = 1000,
+ keepTopK: int = 100,
+ scoreThreshold: float = 0.25,
+ iouThreshold: float = 0.45,
+ isNormalized: int = 0,
+ clipBoxes: int = 0,
+ scoreBits: int = 16,
+ caffeSemantics: int = 1,
+ ):
+ out = g.op(
+ 'TRT::BatchedNMSDynamic_TRT',
+ boxes,
+ scores,
+ shareLocation_i=shareLocation,
+ plugin_version_s=plugin_version,
+ backgroundLabelId_i=backgroundLabelId,
+ numClasses_i=numClasses,
+ topK_i=topK,
+ keepTopK_i=keepTopK,
+ scoreThreshold_f=scoreThreshold,
+ iouThreshold_f=iouThreshold,
+ isNormalized_i=isNormalized,
+ clipBoxes_i=clipBoxes,
+ scoreBits_i=scoreBits,
+ caffeSemantics_i=caffeSemantics,
+ outputs=4)
+ num_det, det_boxes, det_scores, det_classes = out
+ return num_det, det_boxes, det_scores, det_classes
+
+
+def _efficient_nms(
+ boxes: Tensor,
+ scores: Tensor,
+ max_output_boxes_per_class: int = 1000,
+ iou_threshold: float = 0.5,
+ score_threshold: float = 0.05,
+ pre_top_k: int = -1,
+ keep_top_k: int = 100,
+ box_coding: int = 0,
+):
+ """Wrapper for `efficient_nms` with TensorRT.
+ Args:
+ boxes (Tensor): The bounding boxes of shape [N, num_boxes, 4].
+ scores (Tensor): The detection scores of shape
+ [N, num_boxes, num_classes].
+ max_output_boxes_per_class (int): Maximum number of output
+ boxes per class of nms. Defaults to 1000.
+ iou_threshold (float): IOU threshold of nms. Defaults to 0.5.
+ score_threshold (float): score threshold of nms.
+ Defaults to 0.05.
+ pre_top_k (int): Number of top K boxes to keep before nms.
+ Defaults to -1.
+ keep_top_k (int): Number of top K boxes to keep after nms.
+ Defaults to -1.
+ box_coding (int): Bounding boxes format for nms.
+ Defaults to 0 means [x1, y1 ,x2, y2].
+ Set to 1 means [x, y, w, h].
+ Returns:
+ tuple[Tensor, Tensor, Tensor, Tensor]:
+ (num_det, det_boxes, det_scores, det_classes),
+ `num_det` of shape [N, 1]
+ `det_boxes` of shape [N, num_det, 4]
+ `det_scores` of shape [N, num_det]
+ `det_classes` of shape [N, num_det]
+ """
+ num_det, det_boxes, det_scores, det_classes = TRTEfficientNMSop.apply(
+ boxes, scores, -1, box_coding, iou_threshold, keep_top_k, '1', 0,
+ score_threshold)
+ return num_det, det_boxes, det_scores, det_classes
+
+
+def _batched_nms(
+ boxes: Tensor,
+ scores: Tensor,
+ max_output_boxes_per_class: int = 1000,
+ iou_threshold: float = 0.5,
+ score_threshold: float = 0.05,
+ pre_top_k: int = -1,
+ keep_top_k: int = 100,
+ box_coding: int = 0,
+):
+ """Wrapper for `efficient_nms` with TensorRT.
+ Args:
+ boxes (Tensor): The bounding boxes of shape [N, num_boxes, 4].
+ scores (Tensor): The detection scores of shape
+ [N, num_boxes, num_classes].
+ max_output_boxes_per_class (int): Maximum number of output
+ boxes per class of nms. Defaults to 1000.
+ iou_threshold (float): IOU threshold of nms. Defaults to 0.5.
+ score_threshold (float): score threshold of nms.
+ Defaults to 0.05.
+ pre_top_k (int): Number of top K boxes to keep before nms.
+ Defaults to -1.
+ keep_top_k (int): Number of top K boxes to keep after nms.
+ Defaults to -1.
+ box_coding (int): Bounding boxes format for nms.
+ Defaults to 0 means [x1, y1 ,x2, y2].
+ Set to 1 means [x, y, w, h].
+ Returns:
+ tuple[Tensor, Tensor, Tensor, Tensor]:
+ (num_det, det_boxes, det_scores, det_classes),
+ `num_det` of shape [N, 1]
+ `det_boxes` of shape [N, num_det, 4]
+ `det_scores` of shape [N, num_det]
+ `det_classes` of shape [N, num_det]
+ """
+ boxes = boxes if boxes.dim() == 4 else boxes.unsqueeze(2)
+ _, _, numClasses = scores.shape
+
+ num_det, det_boxes, det_scores, det_classes = TRTbatchedNMSop.apply(
+ boxes, scores, '1', 1, -1, int(numClasses), min(pre_top_k, 4096),
+ keep_top_k, score_threshold, iou_threshold, 0, 0, 16, 1)
+
+ det_classes = det_classes.int()
+ return num_det, det_boxes, det_scores, det_classes
+
+
+def efficient_nms(*args, **kwargs):
+ """Wrapper function for `_efficient_nms`."""
+ return _efficient_nms(*args, **kwargs)
+
+
+def batched_nms(*args, **kwargs):
+ """Wrapper function for `_batched_nms`."""
+ return _batched_nms(*args, **kwargs)
diff --git a/projects/easydeploy/tools/build_engine.py b/projects/easydeploy/tools/build_engine.py
new file mode 100644
index 000000000..7b02e97b5
--- /dev/null
+++ b/projects/easydeploy/tools/build_engine.py
@@ -0,0 +1,43 @@
+import argparse
+
+from ..model import EngineBuilder
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('checkpoint', help='Checkpoint file')
+ parser.add_argument(
+ '--img-size',
+ nargs='+',
+ type=int,
+ default=[640, 640],
+ help='Image size of height and width')
+ parser.add_argument(
+ '--device', type=str, default='cuda:0', help='TensorRT builder device')
+ parser.add_argument(
+ '--scales',
+ type=str,
+ default='[[1,3,640,640],[1,3,640,640],[1,3,640,640]]',
+ help='Input scales for build dynamic input shape engine')
+ parser.add_argument(
+ '--fp16', action='store_true', help='Build model with fp16 mode')
+ args = parser.parse_args()
+ args.img_size *= 2 if len(args.img_size) == 1 else 1
+ return args
+
+
+def main(args):
+ img_size = (1, 3, *args.img_size)
+ try:
+ scales = eval(args.scales)
+ except Exception:
+ print('Input scales is not a python variable')
+ print('Set scales default None')
+ scales = None
+ builder = EngineBuilder(args.checkpoint, img_size, args.device)
+ builder.build(scales, fp16=args.fp16)
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ main(args)
diff --git a/projects/easydeploy/tools/export.py b/projects/easydeploy/tools/export.py
new file mode 100644
index 000000000..e1a33c381
--- /dev/null
+++ b/projects/easydeploy/tools/export.py
@@ -0,0 +1,135 @@
+import argparse
+import os
+import warnings
+from io import BytesIO
+
+import onnx
+import torch
+from mmdet.apis import init_detector
+from mmengine.config import ConfigDict
+
+from mmyolo.utils import register_all_modules
+from projects.easydeploy.model import DeployModel
+
+warnings.filterwarnings(action='ignore', category=torch.jit.TracerWarning)
+warnings.filterwarnings(action='ignore', category=torch.jit.ScriptWarning)
+warnings.filterwarnings(action='ignore', category=UserWarning)
+warnings.filterwarnings(action='ignore', category=FutureWarning)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('config', help='Config file')
+ parser.add_argument('checkpoint', help='Checkpoint file')
+ parser.add_argument(
+ '--work-dir', default='./work_dir', help='Path to save export model')
+ parser.add_argument(
+ '--img-size',
+ nargs='+',
+ type=int,
+ default=[640, 640],
+ help='Image size of height and width')
+ parser.add_argument('--batch-size', type=int, default=1, help='Batch size')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference')
+ parser.add_argument(
+ '--simplify',
+ action='store_true',
+ help='Simplify onnx model by onnx-sim')
+ parser.add_argument(
+ '--opset', type=int, default=11, help='ONNX opset version')
+ parser.add_argument(
+ '--backend', type=int, default=1, help='Backend for export onnx')
+ parser.add_argument(
+ '--pre-topk',
+ type=int,
+ default=1000,
+ help='Postprocess pre topk bboxes feed into NMS')
+ parser.add_argument(
+ '--keep-topk',
+ type=int,
+ default=100,
+ help='Postprocess keep topk bboxes out of NMS')
+ parser.add_argument(
+ '--iou-threshold',
+ type=float,
+ default=0.65,
+ help='IoU threshold for NMS')
+ parser.add_argument(
+ '--score-threshold',
+ type=float,
+ default=0.25,
+ help='Score threshold for NMS')
+ args = parser.parse_args()
+ args.img_size *= 2 if len(args.img_size) == 1 else 1
+ return args
+
+
+def build_model_from_cfg(config_path, checkpoint_path, device):
+ model = init_detector(config_path, checkpoint_path, device=device)
+ model.eval()
+ return model
+
+
+def main():
+ args = parse_args()
+ register_all_modules()
+
+ if not os.path.exists(args.work_dir):
+ os.mkdir(args.work_dir)
+
+ postprocess_cfg = ConfigDict(
+ pre_top_k=args.pre_topk,
+ keep_top_k=args.keep_topk,
+ iou_threshold=args.iou_threshold,
+ score_threshold=args.score_threshold,
+ backend=args.backend)
+
+ baseModel = build_model_from_cfg(args.config, args.checkpoint, args.device)
+
+ deploy_model = DeployModel(
+ baseModel=baseModel, postprocess_cfg=postprocess_cfg)
+ deploy_model.eval()
+
+ fake_input = torch.randn(args.batch_size, 3,
+ *args.img_size).to(args.device)
+ # dry run
+ deploy_model(fake_input)
+
+ save_onnx_path = os.path.join(args.work_dir, 'end2end.onnx')
+ # export onnx
+ with BytesIO() as f:
+ torch.onnx.export(
+ deploy_model,
+ fake_input,
+ f,
+ input_names=['images'],
+ output_names=['num_det', 'det_boxes', 'det_scores', 'det_classes'],
+ opset_version=args.opset)
+ f.seek(0)
+ onnx_model = onnx.load(f)
+ onnx.checker.check_model(onnx_model)
+
+ # Fix tensorrt onnx output shape, just for view
+ if args.backend in (2, 3):
+ shapes = [
+ args.batch_size, 1, args.batch_size, args.keep_topk, 4,
+ args.batch_size, args.keep_topk, args.batch_size,
+ args.keep_topk
+ ]
+ for i in onnx_model.graph.output:
+ for j in i.type.tensor_type.shape.dim:
+ j.dim_param = str(shapes.pop(0))
+ if args.simplify:
+ try:
+ import onnxsim
+ onnx_model, check = onnxsim.simplify(onnx_model)
+ assert check, 'assert check failed'
+ except Exception as e:
+ print(f'Simplify failure: {e}')
+ onnx.save(onnx_model, save_onnx_path)
+ print(f'ONNX export success, save into {save_onnx_path}')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/requirements/runtime.txt b/requirements/runtime.txt
index 24ce15ab7..794a9cab5 100644
--- a/requirements/runtime.txt
+++ b/requirements/runtime.txt
@@ -1 +1,2 @@
numpy
+prettytable
diff --git a/requirements/sahi.txt b/requirements/sahi.txt
new file mode 100644
index 000000000..0e7b7b842
--- /dev/null
+++ b/requirements/sahi.txt
@@ -0,0 +1 @@
+sahi>=0.11.4
diff --git a/tests/test_datasets/test_transforms/test_mix_img_transforms.py b/tests/test_datasets/test_transforms/test_mix_img_transforms.py
index d2855fb13..fa6ef7e58 100644
--- a/tests/test_datasets/test_transforms/test_mix_img_transforms.py
+++ b/tests/test_datasets/test_transforms/test_mix_img_transforms.py
@@ -9,7 +9,7 @@
from mmdet.structures.mask import BitmapMasks
from mmyolo.datasets import YOLOv5CocoDataset
-from mmyolo.datasets.transforms import Mosaic, YOLOv5MixUp, YOLOXMixUp
+from mmyolo.datasets.transforms import Mosaic, Mosaic9, YOLOv5MixUp, YOLOXMixUp
from mmyolo.utils import register_all_modules
register_all_modules()
@@ -108,6 +108,99 @@ def test_transform_with_box_list(self):
self.assertTrue(results['gt_ignore_flags'].dtype == bool)
+class TestMosaic9(unittest.TestCase):
+
+ def setUp(self):
+ """Setup the data info which are used in every test method.
+
+ TestCase calls functions in this order: setUp() -> testMethod() ->
+ tearDown() -> cleanUp()
+ """
+ rng = np.random.RandomState(0)
+ self.pre_transform = [
+ dict(
+ type='LoadImageFromFile',
+ file_client_args=dict(backend='disk')),
+ dict(type='LoadAnnotations', with_bbox=True)
+ ]
+
+ self.dataset = YOLOv5CocoDataset(
+ data_prefix=dict(
+ img=osp.join(osp.dirname(__file__), '../../data')),
+ ann_file=osp.join(
+ osp.dirname(__file__), '../../data/coco_sample_color.json'),
+ filter_cfg=dict(filter_empty_gt=False, min_size=32),
+ pipeline=[])
+ self.results = {
+ 'img':
+ np.random.random((224, 224, 3)),
+ 'img_shape': (224, 224),
+ 'gt_bboxes_labels':
+ np.array([1, 2, 3], dtype=np.int64),
+ 'gt_bboxes':
+ np.array([[10, 10, 20, 20], [20, 20, 40, 40], [40, 40, 80, 80]],
+ dtype=np.float32),
+ 'gt_ignore_flags':
+ np.array([0, 0, 1], dtype=bool),
+ 'gt_masks':
+ BitmapMasks(rng.rand(3, 224, 224), height=224, width=224),
+ 'dataset':
+ self.dataset
+ }
+
+ def test_transform(self):
+ # test assertion for invalid img_scale
+ with self.assertRaises(AssertionError):
+ transform = Mosaic9(img_scale=640)
+
+ # test assertion for invalid probability
+ with self.assertRaises(AssertionError):
+ transform = Mosaic9(prob=1.5)
+
+ # test assertion for invalid max_cached_images
+ with self.assertRaises(AssertionError):
+ transform = Mosaic9(use_cached=True, max_cached_images=1)
+
+ transform = Mosaic9(
+ img_scale=(10, 12), pre_transform=self.pre_transform)
+ results = transform(copy.deepcopy(self.results))
+ self.assertTrue(results['img'].shape[:2] == (20, 24))
+ self.assertTrue(results['gt_bboxes_labels'].shape[0] ==
+ results['gt_bboxes'].shape[0])
+ self.assertTrue(results['gt_bboxes_labels'].dtype == np.int64)
+ self.assertTrue(results['gt_bboxes'].dtype == np.float32)
+ self.assertTrue(results['gt_ignore_flags'].dtype == bool)
+
+ def test_transform_with_no_gt(self):
+ self.results['gt_bboxes'] = np.empty((0, 4), dtype=np.float32)
+ self.results['gt_bboxes_labels'] = np.empty((0, ), dtype=np.int64)
+ self.results['gt_ignore_flags'] = np.empty((0, ), dtype=bool)
+ transform = Mosaic9(
+ img_scale=(10, 12), pre_transform=self.pre_transform)
+ results = transform(copy.deepcopy(self.results))
+ self.assertIsInstance(results, dict)
+ self.assertTrue(results['img'].shape[:2] == (20, 24))
+ self.assertTrue(
+ results['gt_bboxes_labels'].shape[0] == results['gt_bboxes'].
+ shape[0] == results['gt_ignore_flags'].shape[0])
+ self.assertTrue(results['gt_bboxes_labels'].dtype == np.int64)
+ self.assertTrue(results['gt_bboxes'].dtype == np.float32)
+ self.assertTrue(results['gt_ignore_flags'].dtype == bool)
+
+ def test_transform_with_box_list(self):
+ transform = Mosaic9(
+ img_scale=(10, 12), pre_transform=self.pre_transform)
+ results = copy.deepcopy(self.results)
+ results['gt_bboxes'] = HorizontalBoxes(results['gt_bboxes'])
+ results = transform(results)
+ self.assertTrue(results['img'].shape[:2] == (20, 24))
+ self.assertTrue(results['gt_bboxes_labels'].shape[0] ==
+ results['gt_bboxes'].shape[0])
+ self.assertTrue(results['gt_bboxes_labels'].dtype == np.int64)
+ self.assertTrue(results['gt_bboxes'].dtype == torch.float32)
+ self.assertTrue(results['gt_ignore_flags'].dtype == bool)
+
+
class TestYOLOv5MixUp(unittest.TestCase):
def setUp(self):
diff --git a/tests/test_datasets/test_transforms/test_transforms.py b/tests/test_datasets/test_transforms/test_transforms.py
index 43012bcae..610c084ae 100644
--- a/tests/test_datasets/test_transforms/test_transforms.py
+++ b/tests/test_datasets/test_transforms/test_transforms.py
@@ -27,59 +27,62 @@ def setUp(self):
self.data_info1 = dict(
img=np.random.random((300, 400, 3)),
gt_bboxes=np.array([[0, 0, 150, 150]], dtype=np.float32),
- batch_shape=np.array([460, 672], dtype=np.int64),
+ batch_shape=np.array([192, 672], dtype=np.int64),
gt_masks=BitmapMasks(rng.rand(1, 300, 400), height=300, width=400))
self.data_info2 = dict(
img=np.random.random((300, 400, 3)),
gt_bboxes=np.array([[0, 0, 150, 150]], dtype=np.float32))
self.data_info3 = dict(
img=np.random.random((300, 400, 3)),
- batch_shape=np.array([460, 672], dtype=np.int64))
+ batch_shape=np.array([192, 672], dtype=np.int64))
self.data_info4 = dict(img=np.random.random((300, 400, 3)))
def test_letter_resize(self):
# Test allow_scale_up
transform = LetterResize(scale=(640, 640), allow_scale_up=False)
results = transform(copy.deepcopy(self.data_info1))
- self.assertEqual(results['img_shape'], (460, 672, 3))
+ self.assertEqual(results['img_shape'], (192, 672, 3))
self.assertTrue(
- (results['gt_bboxes'] == np.array([[136., 80., 286.,
- 230.]])).all())
- self.assertTrue((results['batch_shape'] == np.array([460, 672])).all())
+ (results['gt_bboxes'] == np.array([[208., 0., 304., 96.]])).all())
+ self.assertTrue((results['batch_shape'] == np.array([192, 672])).all())
+ self.assertTrue((results['pad_param'] == np.array([0., 0., 208.,
+ 208.])).all())
self.assertTrue(
- (results['pad_param'] == np.array([80., 80., 136., 136.])).all())
- self.assertTrue((results['scale_factor'] <= 1.).all())
+ (np.array(results['scale_factor'], dtype=np.float32) <= 1.).all())
# Test pad_val
transform = LetterResize(scale=(640, 640), pad_val=dict(img=144))
results = transform(copy.deepcopy(self.data_info1))
- self.assertEqual(results['img_shape'], (460, 672, 3))
+ self.assertEqual(results['img_shape'], (192, 672, 3))
self.assertTrue(
- (results['gt_bboxes'] == np.array([[29., 0., 259., 230.]])).all())
- self.assertTrue((results['batch_shape'] == np.array([460, 672])).all())
- self.assertTrue((results['pad_param'] == np.array([0., 0., 29.,
- 30.])).all())
- self.assertTrue((results['scale_factor'] > 1.).all())
+ (results['gt_bboxes'] == np.array([[208., 0., 304., 96.]])).all())
+ self.assertTrue((results['batch_shape'] == np.array([192, 672])).all())
+ self.assertTrue((results['pad_param'] == np.array([0., 0., 208.,
+ 208.])).all())
+ self.assertTrue(
+ (np.array(results['scale_factor'], dtype=np.float32) <= 1.).all())
# Test use_mini_pad
transform = LetterResize(scale=(640, 640), use_mini_pad=True)
results = transform(copy.deepcopy(self.data_info1))
- self.assertEqual(results['img_shape'], (460, 640, 3))
+ self.assertEqual(results['img_shape'], (192, 256, 3))
+ self.assertTrue((results['gt_bboxes'] == np.array([[0., 0., 96.,
+ 96.]])).all())
+ self.assertTrue((results['batch_shape'] == np.array([192, 672])).all())
+ self.assertTrue((results['pad_param'] == np.array([0., 0., 0.,
+ 0.])).all())
self.assertTrue(
- (results['gt_bboxes'] == np.array([[13., 0., 243., 230.]])).all())
- self.assertTrue((results['batch_shape'] == np.array([460, 672])).all())
- self.assertTrue((results['pad_param'] == np.array([0., 0., 13.,
- 14.])).all())
- self.assertTrue((results['scale_factor'] > 1.).all())
+ (np.array(results['scale_factor'], dtype=np.float32) <= 1.).all())
# Test stretch_only
transform = LetterResize(scale=(640, 640), stretch_only=True)
results = transform(copy.deepcopy(self.data_info1))
- self.assertEqual(results['img_shape'], (460, 672, 3))
+ self.assertEqual(results['img_shape'], (192, 672, 3))
self.assertTrue((results['gt_bboxes'] == np.array(
- [[0., 0., 230., 251.99998474121094]])).all())
- self.assertTrue((results['batch_shape'] == np.array([460, 672])).all())
- self.assertTrue((results['pad_param'] == np.array([0, 0, 0, 0])).all())
+ [[0., 0., 251.99998474121094, 96.]])).all())
+ self.assertTrue((results['batch_shape'] == np.array([192, 672])).all())
+ self.assertTrue((results['pad_param'] == np.array([0., 0., 0.,
+ 0.])).all())
# Test
transform = LetterResize(scale=(640, 640), pad_val=dict(img=144))
@@ -150,13 +153,15 @@ def test_yolov5_keep_ratio_resize(self):
self.assertEqual(results['img_shape'], (480, 640))
self.assertTrue(
(results['gt_bboxes'] == np.array([[0., 0., 240., 240.]])).all())
- self.assertTrue((results['scale_factor'] == 1.6).all())
+ self.assertTrue((np.array(results['scale_factor'],
+ dtype=np.float32) == 1.6).all())
# Test only img
transform = YOLOv5KeepRatioResize(scale=(640, 640))
results = transform(copy.deepcopy(self.data_info2))
self.assertEqual(results['img_shape'], (480, 640))
- self.assertTrue((results['scale_factor'] == 1.6).all())
+ self.assertTrue((np.array(results['scale_factor'],
+ dtype=np.float32) == 1.6).all())
class TestYOLOv5HSVRandomAug(unittest.TestCase):
diff --git a/tests/test_engine/test_optimizers/test_yolov7_optim_wrapper_constructor.py b/tests/test_engine/test_optimizers/test_yolov7_optim_wrapper_constructor.py
new file mode 100644
index 000000000..a2f445bed
--- /dev/null
+++ b/tests/test_engine/test_optimizers/test_yolov7_optim_wrapper_constructor.py
@@ -0,0 +1,81 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+import copy
+from unittest import TestCase
+
+import torch
+import torch.nn as nn
+from mmengine.optim import build_optim_wrapper
+
+from mmyolo.engine import YOLOv7OptimWrapperConstructor
+from mmyolo.utils import register_all_modules
+
+register_all_modules()
+
+
+class ExampleModel(nn.Module):
+
+ def __init__(self):
+ super().__init__()
+ self.param1 = nn.Parameter(torch.ones(1))
+ self.conv1 = nn.Conv2d(3, 4, kernel_size=1, bias=False)
+ self.conv2 = nn.Conv2d(4, 2, kernel_size=1)
+ self.bn = nn.BatchNorm2d(2)
+
+
+class TestYOLOv7OptimWrapperConstructor(TestCase):
+
+ def setUp(self):
+ self.model = ExampleModel()
+ self.base_lr = 0.01
+ self.weight_decay = 0.0001
+ self.optim_wrapper_cfg = dict(
+ type='OptimWrapper',
+ optimizer=dict(
+ type='SGD',
+ lr=self.base_lr,
+ momentum=0.9,
+ weight_decay=self.weight_decay,
+ batch_size_per_gpu=16))
+
+ def test_init(self):
+ YOLOv7OptimWrapperConstructor(copy.deepcopy(self.optim_wrapper_cfg))
+ YOLOv7OptimWrapperConstructor(
+ copy.deepcopy(self.optim_wrapper_cfg),
+ paramwise_cfg={'base_total_batch_size': 64})
+
+ # `paramwise_cfg` must include `base_total_batch_size` if not None.
+ with self.assertRaises(AssertionError):
+ YOLOv7OptimWrapperConstructor(
+ copy.deepcopy(self.optim_wrapper_cfg), paramwise_cfg={'a': 64})
+
+ def test_build(self):
+ optim_wrapper = YOLOv7OptimWrapperConstructor(
+ copy.deepcopy(self.optim_wrapper_cfg))(
+ self.model)
+ # test param_groups
+ assert len(optim_wrapper.optimizer.param_groups) == 3
+ for i in range(3):
+ param_groups_i = optim_wrapper.optimizer.param_groups[i]
+ assert param_groups_i['lr'] == self.base_lr
+ if i == 0:
+ assert param_groups_i['weight_decay'] == self.weight_decay
+ else:
+ assert param_groups_i['weight_decay'] == 0
+
+ # test weight_decay linear scaling
+ optim_wrapper_cfg = copy.deepcopy(self.optim_wrapper_cfg)
+ optim_wrapper_cfg['optimizer']['batch_size_per_gpu'] = 128
+ optim_wrapper = YOLOv7OptimWrapperConstructor(optim_wrapper_cfg)(
+ self.model)
+ assert optim_wrapper.optimizer.param_groups[0][
+ 'weight_decay'] == self.weight_decay * 2
+
+ # test without batch_size_per_gpu
+ optim_wrapper_cfg = copy.deepcopy(self.optim_wrapper_cfg)
+ optim_wrapper_cfg['optimizer'].pop('batch_size_per_gpu')
+ optim_wrapper = dict(
+ optim_wrapper_cfg, constructor='YOLOv7OptimWrapperConstructor')
+ optim_wrapper = build_optim_wrapper(self.model, optim_wrapper)
+ assert optim_wrapper.optimizer.param_groups[0][
+ 'weight_decay'] == self.weight_decay
diff --git a/tests/test_models/test_backbone/test_efficient_rep.py b/tests/test_models/test_backbone/test_efficient_rep.py
index 836ee739d..53af20294 100644
--- a/tests/test_models/test_backbone/test_efficient_rep.py
+++ b/tests/test_models/test_backbone/test_efficient_rep.py
@@ -5,7 +5,7 @@
import torch
from torch.nn.modules.batchnorm import _BatchNorm
-from mmyolo.models.backbones import YOLOv6EfficientRep
+from mmyolo.models.backbones import YOLOv6CSPBep, YOLOv6EfficientRep
from mmyolo.utils import register_all_modules
from .utils import check_norm_state, is_norm
@@ -23,7 +23,7 @@ def test_init(self):
# frozen_stages must in range(-1, len(arch_setting) + 1)
YOLOv6EfficientRep(frozen_stages=6)
- def test_forward(self):
+ def test_YOLOv6EfficientRep_forward(self):
# Test YOLOv6EfficientRep with first stage frozen
frozen_stages = 1
model = YOLOv6EfficientRep(frozen_stages=frozen_stages)
@@ -111,3 +111,92 @@ def test_forward(self):
assert feat[0].shape == torch.Size((1, 256, 32, 32))
assert feat[1].shape == torch.Size((1, 512, 16, 16))
assert feat[2].shape == torch.Size((1, 1024, 8, 8))
+
+ def test_YOLOv6CSPBep_forward(self):
+ # Test YOLOv6CSPBep with first stage frozen
+ frozen_stages = 1
+ model = YOLOv6CSPBep(frozen_stages=frozen_stages)
+ model.init_weights()
+ model.train()
+
+ for mod in model.stem.modules():
+ for param in mod.parameters():
+ assert param.requires_grad is False
+ for i in range(1, frozen_stages + 1):
+ layer = getattr(model, f'stage{i}')
+ for mod in layer.modules():
+ if isinstance(mod, _BatchNorm):
+ assert mod.training is False
+ for param in layer.parameters():
+ assert param.requires_grad is False
+
+ # Test YOLOv6CSPBep with norm_eval=True
+ model = YOLOv6CSPBep(norm_eval=True)
+ model.train()
+
+ assert check_norm_state(model.modules(), False)
+
+ # Test YOLOv6CSPBep forward with widen_factor=0.25
+ model = YOLOv6CSPBep(
+ arch='P5', widen_factor=0.25, out_indices=range(0, 5))
+ model.train()
+
+ imgs = torch.randn(1, 3, 64, 64)
+ feat = model(imgs)
+ assert len(feat) == 5
+ assert feat[0].shape == torch.Size((1, 16, 32, 32))
+ assert feat[1].shape == torch.Size((1, 32, 16, 16))
+ assert feat[2].shape == torch.Size((1, 64, 8, 8))
+ assert feat[3].shape == torch.Size((1, 128, 4, 4))
+ assert feat[4].shape == torch.Size((1, 256, 2, 2))
+
+ # Test YOLOv6CSPBep forward with dict(type='ReLU')
+ model = YOLOv6CSPBep(
+ widen_factor=0.125,
+ act_cfg=dict(type='ReLU'),
+ out_indices=range(0, 5))
+ model.train()
+
+ imgs = torch.randn(1, 3, 64, 64)
+ feat = model(imgs)
+ assert len(feat) == 5
+ assert feat[0].shape == torch.Size((1, 8, 32, 32))
+ assert feat[1].shape == torch.Size((1, 16, 16, 16))
+ assert feat[2].shape == torch.Size((1, 32, 8, 8))
+ assert feat[3].shape == torch.Size((1, 64, 4, 4))
+ assert feat[4].shape == torch.Size((1, 128, 2, 2))
+
+ # Test YOLOv6CSPBep with BatchNorm forward
+ model = YOLOv6CSPBep(widen_factor=0.125, out_indices=range(0, 5))
+ for m in model.modules():
+ if is_norm(m):
+ assert isinstance(m, _BatchNorm)
+ model.train()
+
+ imgs = torch.randn(1, 3, 64, 64)
+ feat = model(imgs)
+ assert len(feat) == 5
+ assert feat[0].shape == torch.Size((1, 8, 32, 32))
+ assert feat[1].shape == torch.Size((1, 16, 16, 16))
+ assert feat[2].shape == torch.Size((1, 32, 8, 8))
+ assert feat[3].shape == torch.Size((1, 64, 4, 4))
+ assert feat[4].shape == torch.Size((1, 128, 2, 2))
+
+ # Test YOLOv6CSPBep with BatchNorm forward
+ model = YOLOv6CSPBep(plugins=[
+ dict(
+ cfg=dict(type='mmdet.DropBlock', drop_prob=0.1, block_size=3),
+ stages=(False, False, True, True)),
+ ])
+
+ assert len(model.stage1) == 1
+ assert len(model.stage2) == 1
+ assert len(model.stage3) == 2 # +DropBlock
+ assert len(model.stage4) == 3 # +SPPF+DropBlock
+ model.train()
+ imgs = torch.randn(1, 3, 256, 256)
+ feat = model(imgs)
+ assert len(feat) == 3
+ assert feat[0].shape == torch.Size((1, 256, 32, 32))
+ assert feat[1].shape == torch.Size((1, 512, 16, 16))
+ assert feat[2].shape == torch.Size((1, 1024, 8, 8))
diff --git a/tests/test_models/test_backbone/test_yolov7_backbone.py b/tests/test_models/test_backbone/test_yolov7_backbone.py
new file mode 100644
index 000000000..76b40aa44
--- /dev/null
+++ b/tests/test_models/test_backbone/test_yolov7_backbone.py
@@ -0,0 +1,154 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from unittest import TestCase
+
+import pytest
+import torch
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmyolo.models.backbones import YOLOv7Backbone
+from mmyolo.utils import register_all_modules
+from .utils import check_norm_state
+
+register_all_modules()
+
+
+class TestYOLOv7Backbone(TestCase):
+
+ def test_init(self):
+ # out_indices in range(len(arch_setting) + 1)
+ with pytest.raises(AssertionError):
+ YOLOv7Backbone(out_indices=(6, ))
+
+ with pytest.raises(ValueError):
+ # frozen_stages must in range(-1, len(arch_setting) + 1)
+ YOLOv7Backbone(frozen_stages=6)
+
+ def test_forward(self):
+ # Test YOLOv7Backbone-L with first stage frozen
+ frozen_stages = 1
+ model = YOLOv7Backbone(frozen_stages=frozen_stages)
+ model.init_weights()
+ model.train()
+
+ for mod in model.stem.modules():
+ for param in mod.parameters():
+ assert param.requires_grad is False
+ for i in range(1, frozen_stages + 1):
+ layer = getattr(model, f'stage{i}')
+ for mod in layer.modules():
+ if isinstance(mod, _BatchNorm):
+ assert mod.training is False
+ for param in layer.parameters():
+ assert param.requires_grad is False
+
+ # Test YOLOv7Backbone-L with norm_eval=True
+ model = YOLOv7Backbone(norm_eval=True)
+ model.train()
+
+ assert check_norm_state(model.modules(), False)
+
+ # Test YOLOv7Backbone-L forward with widen_factor=0.25
+ model = YOLOv7Backbone(
+ widen_factor=0.25, out_indices=tuple(range(0, 5)))
+ model.train()
+
+ imgs = torch.randn(1, 3, 64, 64)
+ feat = model(imgs)
+ assert len(feat) == 5
+ assert feat[0].shape == torch.Size((1, 16, 32, 32))
+ assert feat[1].shape == torch.Size((1, 64, 16, 16))
+ assert feat[2].shape == torch.Size((1, 128, 8, 8))
+ assert feat[3].shape == torch.Size((1, 256, 4, 4))
+ assert feat[4].shape == torch.Size((1, 256, 2, 2))
+
+ # Test YOLOv7Backbone-L with plugins
+ model = YOLOv7Backbone(
+ widen_factor=0.25,
+ plugins=[
+ dict(
+ cfg=dict(
+ type='mmdet.DropBlock', drop_prob=0.1, block_size=3),
+ stages=(False, False, True, True)),
+ ])
+
+ assert len(model.stage1) == 2
+ assert len(model.stage2) == 2
+ assert len(model.stage3) == 3 # +DropBlock
+ assert len(model.stage4) == 3 # +DropBlock
+ model.train()
+ imgs = torch.randn(1, 3, 128, 128)
+ feat = model(imgs)
+ assert len(feat) == 3
+ assert feat[0].shape == torch.Size((1, 128, 16, 16))
+ assert feat[1].shape == torch.Size((1, 256, 8, 8))
+ assert feat[2].shape == torch.Size((1, 256, 4, 4))
+
+ # Test YOLOv7Backbone-X forward with widen_factor=0.25
+ model = YOLOv7Backbone(arch='X', widen_factor=0.25)
+ model.train()
+
+ imgs = torch.randn(1, 3, 64, 64)
+ feat = model(imgs)
+ assert len(feat) == 3
+ assert feat[0].shape == torch.Size((1, 160, 8, 8))
+ assert feat[1].shape == torch.Size((1, 320, 4, 4))
+ assert feat[2].shape == torch.Size((1, 320, 2, 2))
+
+ # Test YOLOv7Backbone-tiny forward with widen_factor=0.25
+ model = YOLOv7Backbone(arch='Tiny', widen_factor=0.25)
+ model.train()
+
+ feat = model(imgs)
+ assert len(feat) == 3
+ assert feat[0].shape == torch.Size((1, 32, 8, 8))
+ assert feat[1].shape == torch.Size((1, 64, 4, 4))
+ assert feat[2].shape == torch.Size((1, 128, 2, 2))
+
+ # Test YOLOv7Backbone-w forward with widen_factor=0.25
+ model = YOLOv7Backbone(
+ arch='W', widen_factor=0.25, out_indices=(2, 3, 4, 5))
+ model.train()
+
+ imgs = torch.randn(1, 3, 128, 128)
+ feat = model(imgs)
+ assert len(feat) == 4
+ assert feat[0].shape == torch.Size((1, 64, 16, 16))
+ assert feat[1].shape == torch.Size((1, 128, 8, 8))
+ assert feat[2].shape == torch.Size((1, 192, 4, 4))
+ assert feat[3].shape == torch.Size((1, 256, 2, 2))
+
+ # Test YOLOv7Backbone-w forward with widen_factor=0.25
+ model = YOLOv7Backbone(
+ arch='D', widen_factor=0.25, out_indices=(2, 3, 4, 5))
+ model.train()
+
+ feat = model(imgs)
+ assert len(feat) == 4
+ assert feat[0].shape == torch.Size((1, 96, 16, 16))
+ assert feat[1].shape == torch.Size((1, 192, 8, 8))
+ assert feat[2].shape == torch.Size((1, 288, 4, 4))
+ assert feat[3].shape == torch.Size((1, 384, 2, 2))
+
+ # Test YOLOv7Backbone-w forward with widen_factor=0.25
+ model = YOLOv7Backbone(
+ arch='E', widen_factor=0.25, out_indices=(2, 3, 4, 5))
+ model.train()
+
+ feat = model(imgs)
+ assert len(feat) == 4
+ assert feat[0].shape == torch.Size((1, 80, 16, 16))
+ assert feat[1].shape == torch.Size((1, 160, 8, 8))
+ assert feat[2].shape == torch.Size((1, 240, 4, 4))
+ assert feat[3].shape == torch.Size((1, 320, 2, 2))
+
+ # Test YOLOv7Backbone-w forward with widen_factor=0.25
+ model = YOLOv7Backbone(
+ arch='E2E', widen_factor=0.25, out_indices=(2, 3, 4, 5))
+ model.train()
+
+ feat = model(imgs)
+ assert len(feat) == 4
+ assert feat[0].shape == torch.Size((1, 80, 16, 16))
+ assert feat[1].shape == torch.Size((1, 160, 8, 8))
+ assert feat[2].shape == torch.Size((1, 240, 4, 4))
+ assert feat[3].shape == torch.Size((1, 320, 2, 2))
diff --git a/tests/test_models/test_dense_heads/test_yolov5_head.py b/tests/test_models/test_dense_heads/test_yolov5_head.py
index de31c1f31..18299e09b 100644
--- a/tests/test_models/test_dense_heads/test_yolov5_head.py
+++ b/tests/test_models/test_dense_heads/test_yolov5_head.py
@@ -127,7 +127,7 @@ def test_loss_by_feat(self):
head = YOLOv5Head(head_module=self.head_module)
gt_instances = InstanceData(
bboxes=torch.Tensor([[23.6667, 23.8757, 238.6326, 151.8874]]),
- labels=torch.LongTensor([1]))
+ labels=torch.LongTensor([0]))
one_gt_losses = head.loss_by_feat(cls_scores, bbox_preds, objectnesses,
[gt_instances], img_metas)
diff --git a/tests/test_models/test_dense_heads/test_yolov7_head.py b/tests/test_models/test_dense_heads/test_yolov7_head.py
new file mode 100644
index 000000000..5033f97e1
--- /dev/null
+++ b/tests/test_models/test_dense_heads/test_yolov7_head.py
@@ -0,0 +1,145 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from unittest import TestCase
+
+import torch
+from mmengine.config import Config
+from mmengine.structures import InstanceData
+
+from mmyolo.models.dense_heads import YOLOv7Head
+from mmyolo.utils import register_all_modules
+
+register_all_modules()
+
+
+# TODO: Test YOLOv7p6HeadModule
+class TestYOLOv7Head(TestCase):
+
+ def setUp(self):
+ self.head_module = dict(
+ type='YOLOv7HeadModule',
+ num_classes=2,
+ in_channels=[32, 64, 128],
+ featmap_strides=[8, 16, 32],
+ num_base_priors=3)
+
+ def test_predict_by_feat(self):
+ s = 256
+ img_metas = [{
+ 'img_shape': (s, s, 3),
+ 'ori_shape': (s, s, 3),
+ 'scale_factor': (1.0, 1.0),
+ }]
+ test_cfg = Config(
+ dict(
+ multi_label=True,
+ max_per_img=300,
+ score_thr=0.01,
+ nms=dict(type='nms', iou_threshold=0.65)))
+
+ head = YOLOv7Head(head_module=self.head_module, test_cfg=test_cfg)
+
+ feat = []
+ for i in range(len(self.head_module['in_channels'])):
+ in_channel = self.head_module['in_channels'][i]
+ feat_size = self.head_module['featmap_strides'][i]
+ feat.append(
+ torch.rand(1, in_channel, s // feat_size, s // feat_size))
+
+ cls_scores, bbox_preds, objectnesses = head.forward(feat)
+ head.predict_by_feat(
+ cls_scores,
+ bbox_preds,
+ objectnesses,
+ img_metas,
+ cfg=test_cfg,
+ rescale=True,
+ with_nms=True)
+ head.predict_by_feat(
+ cls_scores,
+ bbox_preds,
+ objectnesses,
+ img_metas,
+ cfg=test_cfg,
+ rescale=False,
+ with_nms=False)
+
+ def test_loss_by_feat(self):
+ s = 256
+ img_metas = [{
+ 'img_shape': (s, s, 3),
+ 'batch_input_shape': (s, s),
+ 'scale_factor': 1,
+ }]
+
+ head = YOLOv7Head(head_module=self.head_module)
+
+ feat = []
+ for i in range(len(self.head_module['in_channels'])):
+ in_channel = self.head_module['in_channels'][i]
+ feat_size = self.head_module['featmap_strides'][i]
+ feat.append(
+ torch.rand(1, in_channel, s // feat_size, s // feat_size))
+
+ cls_scores, bbox_preds, objectnesses = head.forward(feat)
+
+ # Test that empty ground truth encourages the network to predict
+ # background
+ gt_instances = InstanceData(
+ bboxes=torch.empty((0, 4)), labels=torch.LongTensor([]))
+
+ empty_gt_losses = head.loss_by_feat(cls_scores, bbox_preds,
+ objectnesses, [gt_instances],
+ img_metas)
+ # When there is no truth, the cls loss should be nonzero but there
+ # should be no box loss.
+ empty_cls_loss = empty_gt_losses['loss_cls'].sum()
+ empty_box_loss = empty_gt_losses['loss_bbox'].sum()
+ empty_obj_loss = empty_gt_losses['loss_obj'].sum()
+ self.assertEqual(
+ empty_cls_loss.item(), 0,
+ 'there should be no cls loss when there are no true boxes')
+ self.assertEqual(
+ empty_box_loss.item(), 0,
+ 'there should be no box loss when there are no true boxes')
+ self.assertGreater(empty_obj_loss.item(), 0,
+ 'objectness loss should be non-zero')
+
+ # When truth is non-empty then both cls and box loss should be nonzero
+ # for random inputs
+ head = YOLOv7Head(head_module=self.head_module)
+ gt_instances = InstanceData(
+ bboxes=torch.Tensor([[23.6667, 23.8757, 238.6326, 151.8874]]),
+ labels=torch.LongTensor([1]))
+
+ one_gt_losses = head.loss_by_feat(cls_scores, bbox_preds, objectnesses,
+ [gt_instances], img_metas)
+ onegt_cls_loss = one_gt_losses['loss_cls'].sum()
+ onegt_box_loss = one_gt_losses['loss_bbox'].sum()
+ onegt_obj_loss = one_gt_losses['loss_obj'].sum()
+ self.assertGreater(onegt_cls_loss.item(), 0,
+ 'cls loss should be non-zero')
+ self.assertGreater(onegt_box_loss.item(), 0,
+ 'box loss should be non-zero')
+ self.assertGreater(onegt_obj_loss.item(), 0,
+ 'obj loss should be non-zero')
+
+ # test num_class = 1
+ self.head_module['num_classes'] = 1
+ head = YOLOv7Head(head_module=self.head_module)
+ gt_instances = InstanceData(
+ bboxes=torch.Tensor([[23.6667, 23.8757, 238.6326, 151.8874]]),
+ labels=torch.LongTensor([0]))
+
+ cls_scores, bbox_preds, objectnesses = head.forward(feat)
+
+ one_gt_losses = head.loss_by_feat(cls_scores, bbox_preds, objectnesses,
+ [gt_instances], img_metas)
+ onegt_cls_loss = one_gt_losses['loss_cls'].sum()
+ onegt_box_loss = one_gt_losses['loss_bbox'].sum()
+ onegt_obj_loss = one_gt_losses['loss_obj'].sum()
+ self.assertEqual(onegt_cls_loss.item(), 0,
+ 'cls loss should be non-zero')
+ self.assertGreater(onegt_box_loss.item(), 0,
+ 'box loss should be non-zero')
+ self.assertGreater(onegt_obj_loss.item(), 0,
+ 'obj loss should be non-zero')
diff --git a/tests/test_models/test_detectors/test_yolo_detector.py b/tests/test_models/test_detectors/test_yolo_detector.py
index d8df3289d..906b2324b 100644
--- a/tests/test_models/test_detectors/test_yolo_detector.py
+++ b/tests/test_models/test_detectors/test_yolo_detector.py
@@ -22,7 +22,8 @@ def setUp(self):
'yolov5/yolov5_n-v61_syncbn_fast_8xb16-300e_coco.py',
'yolov6/yolov6_s_syncbn_fast_8xb32-400e_coco.py',
'yolox/yolox_tiny_8xb8-300e_coco.py',
- 'rtmdet/rtmdet_tiny_syncbn_8xb32-300e_coco.py'
+ 'rtmdet/rtmdet_tiny_syncbn_8xb32-300e_coco.py',
+ 'yolov7/yolov7_tiny_syncbn_fast_8x16b-300e_coco.py'
])
def test_init(self, cfg_file):
model = get_detector_cfg(cfg_file)
@@ -37,6 +38,7 @@ def test_init(self, cfg_file):
@parameterized.expand([
('yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py', ('cuda', 'cpu')),
('yolox/yolox_s_8xb8-300e_coco.py', ('cuda', 'cpu')),
+ ('yolov7/yolov7_tiny_syncbn_fast_8x16b-300e_coco.py', ('cuda', 'cpu')),
('rtmdet/rtmdet_tiny_syncbn_8xb32-300e_coco.py', ('cuda', 'cpu'))
])
def test_forward_loss_mode(self, cfg_file, devices):
@@ -47,6 +49,13 @@ def test_forward_loss_mode(self, cfg_file, devices):
model = get_detector_cfg(cfg_file)
model.backbone.init_cfg = None
+ if 'fast' in cfg_file:
+ model.data_preprocessor = dict(
+ type='mmdet.DetDataPreprocessor',
+ mean=[0., 0., 0.],
+ std=[255., 255., 255.],
+ bgr_to_rgb=True)
+
from mmdet.models import build_detector
assert all([device in ['cpu', 'cuda'] for device in devices])
@@ -69,6 +78,7 @@ def test_forward_loss_mode(self, cfg_file, devices):
'cpu')),
('yolov6/yolov6_s_syncbn_fast_8xb32-400e_coco.py', ('cuda', 'cpu')),
('yolox/yolox_tiny_8xb8-300e_coco.py', ('cuda', 'cpu')),
+ ('yolov7/yolov7_tiny_syncbn_fast_8x16b-300e_coco.py', ('cuda', 'cpu')),
('rtmdet/rtmdet_tiny_syncbn_8xb32-300e_coco.py', ('cuda', 'cpu'))
])
def test_forward_predict_mode(self, cfg_file, devices):
@@ -100,6 +110,7 @@ def test_forward_predict_mode(self, cfg_file, devices):
'cpu')),
('yolov6/yolov6_s_syncbn_fast_8xb32-400e_coco.py', ('cuda', 'cpu')),
('yolox/yolox_tiny_8xb8-300e_coco.py', ('cuda', 'cpu')),
+ ('yolov7/yolov7_tiny_syncbn_fast_8x16b-300e_coco.py', ('cuda', 'cpu')),
('rtmdet/rtmdet_tiny_syncbn_8xb32-300e_coco.py', ('cuda', 'cpu'))
])
def test_forward_tensor_mode(self, cfg_file, devices):
diff --git a/tests/test_models/test_necks/test_yolov6_pafpn.py b/tests/test_models/test_necks/test_yolov6_pafpn.py
index ae09f6ac1..bea49febe 100644
--- a/tests/test_models/test_necks/test_yolov6_pafpn.py
+++ b/tests/test_models/test_necks/test_yolov6_pafpn.py
@@ -3,15 +3,15 @@
import torch
-from mmyolo.models.necks import YOLOv6RepPAFPN
+from mmyolo.models.necks import YOLOv6CSPRepPAFPN, YOLOv6RepPAFPN
from mmyolo.utils import register_all_modules
register_all_modules()
-class TestYOLOv6RepPAFPN(TestCase):
+class TestYOLOv6PAFPN(TestCase):
- def test_forward(self):
+ def test_YOLOv6RepPAFP_forward(self):
s = 64
in_channels = [8, 16, 32]
feat_sizes = [s // 2**i for i in range(4)] # [32, 16, 8]
@@ -27,3 +27,20 @@ def test_forward(self):
for i in range(len(feats)):
assert outs[i].shape[1] == out_channels[i]
assert outs[i].shape[2] == outs[i].shape[3] == s // (2**i)
+
+ def test_YOLOv6CSPRepPAFPN_forward(self):
+ s = 64
+ in_channels = [8, 16, 32]
+ feat_sizes = [s // 2**i for i in range(4)] # [32, 16, 8]
+ out_channels = [8, 16, 32]
+ feats = [
+ torch.rand(1, in_channels[i], feat_sizes[i], feat_sizes[i])
+ for i in range(len(in_channels))
+ ]
+ neck = YOLOv6CSPRepPAFPN(
+ in_channels=in_channels, out_channels=out_channels)
+ outs = neck(feats)
+ assert len(outs) == len(feats)
+ for i in range(len(feats)):
+ assert outs[i].shape[1] == out_channels[i]
+ assert outs[i].shape[2] == outs[i].shape[3] == s // (2**i)
diff --git a/tests/test_models/test_necks/test_yolov7_pafpn.py b/tests/test_models/test_necks/test_yolov7_pafpn.py
new file mode 100644
index 000000000..17bf455c1
--- /dev/null
+++ b/tests/test_models/test_necks/test_yolov7_pafpn.py
@@ -0,0 +1,79 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from unittest import TestCase
+
+import torch
+from mmcv.cnn import ConvModule
+
+from mmyolo.models.necks import YOLOv7PAFPN
+from mmyolo.utils import register_all_modules
+
+register_all_modules()
+
+
+class TestYOLOv7PAFPN(TestCase):
+
+ def test_forward(self):
+ # test P5
+ s = 64
+ in_channels = [8, 16, 32]
+ feat_sizes = [s // 2**i for i in range(4)] # [32, 16, 8]
+ out_channels = [8, 16, 32]
+ feats = [
+ torch.rand(1, in_channels[i], feat_sizes[i], feat_sizes[i])
+ for i in range(len(in_channels))
+ ]
+ neck = YOLOv7PAFPN(in_channels=in_channels, out_channels=out_channels)
+ outs = neck(feats)
+ assert len(outs) == len(feats)
+ for i in range(len(feats)):
+ assert outs[i].shape[1] == out_channels[i] * 2
+ assert outs[i].shape[2] == outs[i].shape[3] == s // (2**i)
+
+ # test is_tiny_version
+ neck = YOLOv7PAFPN(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ is_tiny_version=True)
+ outs = neck(feats)
+ assert len(outs) == len(feats)
+ for i in range(len(feats)):
+ assert outs[i].shape[1] == out_channels[i] * 2
+ assert outs[i].shape[2] == outs[i].shape[3] == s // (2**i)
+
+ # test use_in_channels_in_downsample
+ neck = YOLOv7PAFPN(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ use_in_channels_in_downsample=True)
+ for f in feats:
+ print(f.shape)
+ outs = neck(feats)
+ for f in outs:
+ print(f.shape)
+ assert len(outs) == len(feats)
+ for i in range(len(feats)):
+ assert outs[i].shape[1] == out_channels[i] * 2
+ assert outs[i].shape[2] == outs[i].shape[3] == s // (2**i)
+
+ # test use_repconv_outs is False
+ neck = YOLOv7PAFPN(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ use_repconv_outs=False)
+ self.assertIsInstance(neck.out_layers[0], ConvModule)
+
+ # test P6
+ s = 64
+ in_channels = [8, 16, 32, 64]
+ feat_sizes = [s // 2**i for i in range(4)]
+ out_channels = [8, 16, 32, 64]
+ feats = [
+ torch.rand(1, in_channels[i], feat_sizes[i], feat_sizes[i])
+ for i in range(len(in_channels))
+ ]
+ neck = YOLOv7PAFPN(in_channels=in_channels, out_channels=out_channels)
+ outs = neck(feats)
+ assert len(outs) == len(feats)
+ for i in range(len(feats)):
+ assert outs[i].shape[1] == out_channels[i]
+ assert outs[i].shape[2] == outs[i].shape[3] == s // (2**i)
diff --git a/tools/analysis_tools/browse_coco_json.py b/tools/analysis_tools/browse_coco_json.py
index 4f16774ca..71a2fc2a9 100644
--- a/tools/analysis_tools/browse_coco_json.py
+++ b/tools/analysis_tools/browse_coco_json.py
@@ -10,7 +10,10 @@
def show_coco_json(args):
- coco = COCO(osp.join(args.data_root, args.ann_file))
+ if args.data_root is not None:
+ coco = COCO(osp.join(args.data_root, args.ann_file))
+ else:
+ coco = COCO(args.ann_file)
print(f'Total number of images:{len(coco.getImgIds())}')
categories = coco.loadCats(coco.getCatIds())
category_names = [category['name'] for category in categories]
@@ -30,8 +33,11 @@ def show_coco_json(args):
for i in range(len(image_ids)):
image_data = coco.loadImgs(image_ids[i])[0]
- image_path = osp.join(args.data_root, args.img_dir,
- image_data['file_name'])
+ if args.data_root is not None:
+ image_path = osp.join(args.data_root, args.img_dir,
+ image_data['file_name'])
+ else:
+ image_path = osp.join(args.img_dir, image_data['file_name'])
annotation_ids = coco.getAnnIds(
imgIds=image_data['id'], catIds=category_ids, iscrowd=0)
@@ -103,14 +109,13 @@ def show_bbox_only(coco, anns, show_label_bbox=True, is_filling=True):
def parse_args():
parser = argparse.ArgumentParser(description='Show coco json file')
+ parser.add_argument('--data-root', default=None, help='dataset root')
parser.add_argument(
- 'data_root', default='data/coco/', help='data root path')
+ '--img-dir', default='data/coco/train2017', help='image folder path')
parser.add_argument(
- '--ann_file',
- default='annotations/instances_train2017.json',
+ '--ann-file',
+ default='data/coco/annotations/instances_train2017.json',
help='ann file path')
- parser.add_argument(
- '--img_dir', default='train2017', help='image folder path')
parser.add_argument(
'--wait-time', type=float, default=2, help='the interval of show (s)')
parser.add_argument(
@@ -133,6 +138,10 @@ def parse_args():
return args
-if __name__ == '__main__':
+def main():
args = parse_args()
show_coco_json(args)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/analysis_tools/browse_dataset.py b/tools/analysis_tools/browse_dataset.py
index ee5e37929..5b45c25d3 100644
--- a/tools/analysis_tools/browse_dataset.py
+++ b/tools/analysis_tools/browse_dataset.py
@@ -1,28 +1,64 @@
# Copyright (c) OpenMMLab. All rights reserved.
import argparse
import os.path as osp
+import sys
+from typing import Tuple
+import cv2
+import mmcv
import numpy as np
from mmdet.models.utils import mask2ndarray
from mmdet.structures.bbox import BaseBoxes
from mmengine.config import Config, DictAction
+from mmengine.dataset import Compose
from mmengine.utils import ProgressBar
+from mmengine.visualization import Visualizer
from mmyolo.registry import DATASETS, VISUALIZERS
from mmyolo.utils import register_all_modules
+# TODO: Support for printing the change in key of results
def parse_args():
parser = argparse.ArgumentParser(description='Browse a dataset')
parser.add_argument('config', help='train config file path')
+ parser.add_argument(
+ '--phase',
+ '-p',
+ default='train',
+ type=str,
+ choices=['train', 'test', 'val'],
+ help='phase of dataset to visualize, accept "train" "test" and "val".'
+ ' Defaults to "train".')
+ parser.add_argument(
+ '--mode',
+ '-m',
+ default='transformed',
+ type=str,
+ choices=['original', 'transformed', 'pipeline'],
+ help='display mode; display original pictures or '
+ 'transformed pictures or comparison pictures. "original" '
+ 'means show images load from disk; "transformed" means '
+ 'to show images after transformed; "pipeline" means show all '
+ 'the intermediate images. Defaults to "transformed".')
parser.add_argument(
'--output-dir',
default=None,
type=str,
- help='If there is no display interface, you can save it')
+ help='If there is no display interface, you can save it.')
parser.add_argument('--not-show', default=False, action='store_true')
+ parser.add_argument(
+ '--show-number',
+ '-n',
+ type=int,
+ default=sys.maxsize,
+ help='number of images selected to visualize, '
+ 'must bigger than 0. if the number is bigger than length '
+ 'of dataset, show all the images in dataset; '
+ 'default "sys.maxsize", show all images in dataset')
parser.add_argument(
'--show-interval',
+ '-i',
type=float,
default=3,
help='the interval of show (s)')
@@ -40,49 +76,180 @@ def parse_args():
return args
+def _get_adaptive_scale(img_shape: Tuple[int, int],
+ min_scale: float = 0.3,
+ max_scale: float = 3.0) -> float:
+ """Get adaptive scale according to image shape.
+
+ The target scale depends on the the short edge length of the image. If the
+ short edge length equals 224, the output is 1.0. And output linear
+ scales according the short edge length. You can also specify the minimum
+ scale and the maximum scale to limit the linear scale.
+
+ Args:
+ img_shape (Tuple[int, int]): The shape of the canvas image.
+ min_scale (int): The minimum scale. Defaults to 0.3.
+ max_scale (int): The maximum scale. Defaults to 3.0.
+ Returns:
+ int: The adaptive scale.
+ """
+ short_edge_length = min(img_shape)
+ scale = short_edge_length / 224.
+ return min(max(scale, min_scale), max_scale)
+
+
+def make_grid(imgs, names):
+ """Concat list of pictures into a single big picture, align height here."""
+ visualizer = Visualizer.get_current_instance()
+ ori_shapes = [img.shape[:2] for img in imgs]
+ max_height = int(max(img.shape[0] for img in imgs) * 1.1)
+ min_width = min(img.shape[1] for img in imgs)
+ horizontal_gap = min_width // 10
+ img_scale = _get_adaptive_scale((max_height, min_width))
+
+ texts = []
+ text_positions = []
+ start_x = 0
+ for i, img in enumerate(imgs):
+ pad_height = (max_height - img.shape[0]) // 2
+ pad_width = horizontal_gap // 2
+ # make border
+ imgs[i] = cv2.copyMakeBorder(
+ img,
+ pad_height,
+ max_height - img.shape[0] - pad_height + int(img_scale * 30 * 2),
+ pad_width,
+ pad_width,
+ cv2.BORDER_CONSTANT,
+ value=(255, 255, 255))
+ texts.append(f'{"execution: "}{i}\n{names[i]}\n{ori_shapes[i]}')
+ text_positions.append(
+ [start_x + img.shape[1] // 2 + pad_width, max_height])
+ start_x += img.shape[1] + horizontal_gap
+
+ display_img = np.concatenate(imgs, axis=1)
+ visualizer.set_image(display_img)
+ img_scale = _get_adaptive_scale(display_img.shape[:2])
+ visualizer.draw_texts(
+ texts,
+ positions=np.array(text_positions),
+ font_sizes=img_scale * 7,
+ colors='black',
+ horizontal_alignments='center',
+ font_families='monospace')
+ return visualizer.get_image()
+
+
+class InspectCompose(Compose):
+ """Compose multiple transforms sequentially.
+
+ And record "img" field of all results in one list.
+ """
+
+ def __init__(self, transforms, intermediate_imgs):
+ super().__init__(transforms=transforms)
+ self.intermediate_imgs = intermediate_imgs
+
+ def __call__(self, data):
+ if 'img' in data:
+ self.intermediate_imgs.append({
+ 'name': 'original',
+ 'img': data['img'].copy()
+ })
+ self.ptransforms = [
+ self.transforms[i] for i in range(len(self.transforms) - 1)
+ ]
+ for t in self.ptransforms:
+ data = t(data)
+ # Keep the same meta_keys in the PackDetInputs
+ self.transforms[-1].meta_keys = [key for key in data]
+ data_sample = self.transforms[-1](data)
+ if data is None:
+ return None
+ if 'img' in data:
+ self.intermediate_imgs.append({
+ 'name':
+ t.__class__.__name__,
+ 'dataset_sample':
+ data_sample['data_samples']
+ })
+ return data
+
+
def main():
args = parse_args()
cfg = Config.fromfile(args.config)
if args.cfg_options is not None:
cfg.merge_from_dict(args.cfg_options)
- # register all modules in mmdet into the registries
+ # register all modules in mmyolo into the registries
register_all_modules()
- dataset = DATASETS.build(cfg.train_dataloader.dataset)
+ dataset_cfg = cfg.get(args.phase + '_dataloader').get('dataset')
+ dataset = DATASETS.build(dataset_cfg)
visualizer = VISUALIZERS.build(cfg.visualizer)
visualizer.dataset_meta = dataset.metainfo
- progress_bar = ProgressBar(len(dataset))
- for item in dataset:
- img = item['inputs'].permute(1, 2, 0).numpy()
- data_samples = item['data_samples'].numpy()
- gt_instances = data_samples.gt_instances
- img_path = osp.basename(item['data_samples'].img_path)
-
- out_file = osp.join(
- args.output_dir,
- osp.basename(img_path)) if args.output_dir is not None else None
-
- img = img[..., [2, 1, 0]] # bgr to rgb
- gt_bboxes = gt_instances.get('bboxes', None)
- if gt_bboxes is not None and isinstance(gt_bboxes, BaseBoxes):
- gt_instances.bboxes = gt_bboxes.tensor
- gt_masks = gt_instances.get('masks', None)
- if gt_masks is not None:
- masks = mask2ndarray(gt_masks)
- gt_instances.masks = masks.astype(np.bool)
- data_samples.gt_instances = gt_instances
-
- visualizer.add_datasample(
- osp.basename(img_path),
- img,
- data_samples,
- draw_pred=False,
- show=not args.not_show,
- wait_time=args.show_interval,
- out_file=out_file)
+ intermediate_imgs = []
+ # TODO: The dataset wrapper occasion is not considered here
+ dataset.pipeline = InspectCompose(dataset.pipeline.transforms,
+ intermediate_imgs)
+
+ # init visualization image number
+ assert args.show_number > 0
+ display_number = min(args.show_number, len(dataset))
+
+ progress_bar = ProgressBar(display_number)
+ for i, item in zip(range(display_number), dataset):
+ image_i = []
+ result_i = [result['dataset_sample'] for result in intermediate_imgs]
+ for k, datasample in enumerate(result_i):
+ image = datasample.img
+ gt_instances = datasample.gt_instances
+ image = image[..., [2, 1, 0]] # bgr to rgb
+ gt_bboxes = gt_instances.get('bboxes', None)
+ if gt_bboxes is not None and isinstance(gt_bboxes, BaseBoxes):
+ gt_instances.bboxes = gt_bboxes.tensor
+ gt_masks = gt_instances.get('masks', None)
+ if gt_masks is not None:
+ masks = mask2ndarray(gt_masks)
+ gt_instances.masks = masks.astype(np.bool)
+ datasample.gt_instances = gt_instances
+ # get filename from dataset or just use index as filename
+ visualizer.add_datasample(
+ 'result',
+ image,
+ datasample,
+ draw_pred=False,
+ draw_gt=True,
+ show=False)
+ image_show = visualizer.get_image()
+ image_i.append(image_show)
+
+ if args.mode == 'original':
+ image = image_i[0]
+ elif args.mode == 'transformed':
+ image = image_i[-1]
+ else:
+ image = make_grid([result for result in image_i],
+ [result['name'] for result in intermediate_imgs])
+
+ if hasattr(datasample, 'img_path'):
+ filename = osp.basename(datasample.img_path)
+ else:
+ # some dataset have not image path
+ filename = f'{i}.jpg'
+ out_file = osp.join(args.output_dir,
+ filename) if args.output_dir is not None else None
+
+ if out_file is not None:
+ mmcv.imwrite(image[..., ::-1], out_file)
+
+ if not args.not_show:
+ visualizer.show(
+ image, win_name=filename, wait_time=args.show_interval)
+ intermediate_imgs.clear()
progress_bar.update()
diff --git a/tools/analysis_tools/dataset_analysis.py b/tools/analysis_tools/dataset_analysis.py
index ae0bd1144..6e494677f 100644
--- a/tools/analysis_tools/dataset_analysis.py
+++ b/tools/analysis_tools/dataset_analysis.py
@@ -7,12 +7,12 @@
import matplotlib.pyplot as plt
import numpy as np
from mmengine.config import Config
-from mmengine.dataset.dataset_wrapper import ConcatDataset
from mmengine.utils import ProgressBar
from prettytable import PrettyTable
from mmyolo.registry import DATASETS
from mmyolo.utils import register_all_modules
+from mmyolo.utils.misc import show_data_classes
def parse_args():
@@ -348,29 +348,6 @@ def show_data_list(args, area_rule):
print(data_info)
-def show_data_classes(data_classes):
- """When printing an error, all class names of the dataset."""
- print('\n\nThe name of the class contained in the dataset:')
- data_classes_info = PrettyTable()
- data_classes_info.title = 'Information of dataset class'
- # List Print Settings
- # If the quantity is too large, 25 rows will be displayed in each column
- if len(data_classes) < 25:
- data_classes_info.add_column('Class name', data_classes)
- elif len(data_classes) % 25 != 0 and len(data_classes) > 25:
- col_num = int(len(data_classes) / 25) + 1
- data_name_list = list(data_classes)
- for i in range(0, (col_num * 25) - len(data_classes)):
- data_name_list.append('')
- for i in range(0, len(data_name_list), 25):
- data_classes_info.add_column('Class name',
- data_name_list[i:i + 25])
-
- # Align display data to the left
- data_classes_info.align['Class name'] = 'l'
- print(data_classes_info)
-
-
def main():
args = parse_args()
cfg = Config.fromfile(args.config)
@@ -378,21 +355,36 @@ def main():
# register all modules in mmdet into the registries
register_all_modules()
+ def replace_pipeline_to_none(cfg):
+ """Recursively iterate over all dataset(or datasets) and set their
+ pipelines to none.Datasets are mean ConcatDataset.
+
+ Recursively terminates only when all dataset(or datasets) have been
+ traversed
+ """
+
+ if cfg.get('dataset', None) is None and cfg.get('datasets',
+ None) is None:
+ return
+ dataset = cfg.dataset if cfg.get('dataset', None) else cfg.datasets
+ if isinstance(dataset, list):
+ for item in dataset:
+ item.pipeline = None
+ elif dataset.get('pipeline', None):
+ dataset.pipeline = None
+ else:
+ replace_pipeline_to_none(dataset)
+
# 1.Build Dataset
if args.val_dataset is False:
+ replace_pipeline_to_none(cfg.train_dataloader)
dataset = DATASETS.build(cfg.train_dataloader.dataset)
- elif args.val_dataset is True:
+ else:
+ replace_pipeline_to_none(cfg.val_dataloader)
dataset = DATASETS.build(cfg.val_dataloader.dataset)
- # Determine whether the dataset is ConcatDataset
- if isinstance(dataset, ConcatDataset):
- datasets = dataset.datasets
- data_list = []
- for idx in range(len(datasets)):
- datasets_list = datasets[idx].load_data_list()
- data_list += datasets_list
- else:
- data_list = dataset.load_data_list()
+ # Build lists to store data for all raw data
+ data_list = dataset
# 2.Prepare data
# Drawing settings
diff --git a/tools/dataset_converters/labelme2coco.py b/tools/dataset_converters/labelme2coco.py
new file mode 100644
index 000000000..94e46e166
--- /dev/null
+++ b/tools/dataset_converters/labelme2coco.py
@@ -0,0 +1,310 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""This script helps to convert labelme-style dataset to the coco format.
+
+Usage:
+ $ python labelme2coco.py \
+ --img-dir /path/to/images \
+ --labels-dir /path/to/labels \
+ --out /path/to/coco_instances.json \
+ [--class-id-txt /path/to/class_with_id.txt]
+
+Note:
+ Labels dir file structure:
+ .
+ └── PATH_TO_LABELS
+ ├── image1.json
+ ├── image2.json
+ └── ...
+
+ Images dir file structure:
+ .
+ └── PATH_TO_IMAGES
+ ├── image1.jpg
+ ├── image2.png
+ └── ...
+
+ If user set `--class-id-txt` then will use it in `categories` field,
+ if not set, then will generate auto base on the all labelme label
+ files to `class_with_id.json`.
+
+ class_with_id.txt example, each line is "id class_name":
+ ```text
+ 1 cat
+ 2 dog
+ 3 bicycle
+ 4 motorcycle
+
+ ```
+"""
+import argparse
+import json
+from pathlib import Path
+from typing import Optional
+
+import numpy as np
+from mmengine import track_iter_progress
+
+from mmyolo.utils.misc import IMG_EXTENSIONS
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--img-dir', type=str, help='Dataset image directory')
+ parser.add_argument(
+ '--labels-dir', type=str, help='Dataset labels directory')
+ parser.add_argument('--out', type=str, help='COCO label json output path')
+ parser.add_argument(
+ '--class-id-txt', default=None, type=str, help='All class id txt path')
+ args = parser.parse_args()
+ return args
+
+
+def format_coco_annotations(points: list, image_id: int, annotations_id: int,
+ category_id: int) -> dict:
+ """Gen COCO annotations format label from labelme format label.
+
+ Args:
+ points (list): Coordinates of four vertices of rectangle bbox.
+ image_id (int): Image id.
+ annotations_id (int): Annotations id.
+ category_id (int): Image dir path.
+
+ Return:
+ annotation_info (dict): COCO annotation data.
+ """
+ annotation_info = dict()
+ annotation_info['iscrowd'] = 0
+ annotation_info['category_id'] = category_id
+ annotation_info['id'] = annotations_id
+ annotation_info['image_id'] = image_id
+
+ # bbox is [x1, y1, w, h]
+ annotation_info['bbox'] = [
+ points[0][0], points[0][1], points[1][0] - points[0][0],
+ points[1][1] - points[0][1]
+ ]
+
+ annotation_info['area'] = annotation_info['bbox'][2] * annotation_info[
+ 'bbox'][3] # bbox w * h
+ segmentation_points = np.asarray(points).copy()
+ segmentation_points[1, :] = np.asarray(points)[2, :]
+ segmentation_points[2, :] = np.asarray(points)[1, :]
+ annotation_info['segmentation'] = [list(segmentation_points.flatten())]
+
+ return annotation_info
+
+
+def parse_labelme_to_coco(
+ image_dir: str,
+ labels_root: str,
+ all_classes_id: Optional[dict] = None) -> (dict, dict):
+ """Gen COCO json format label from labelme format label.
+
+ Args:
+ image_dir (str): Image dir path.
+ labels_root (str): Image label root path.
+ all_classes_id (Optional[dict]): All class with id. Default None.
+
+ Return:
+ coco_json (dict): COCO json data.
+ category_to_id (dict): category id and name.
+
+ COCO json example:
+
+ {
+ "images": [
+ {
+ "height": 3000,
+ "width": 4000,
+ "id": 1,
+ "file_name": "IMG_20210627_225110.jpg"
+ },
+ ...
+ ],
+ "categories": [
+ {
+ "id": 1,
+ "name": "cat"
+ },
+ ...
+ ],
+ "annotations": [
+ {
+ "iscrowd": 0,
+ "category_id": 1,
+ "id": 1,
+ "image_id": 1,
+ "bbox": [
+ 1183.7313232421875,
+ 1230.0509033203125,
+ 1270.9998779296875,
+ 927.0848388671875
+ ],
+ "area": 1178324.7170306593,
+ "segmentation": [
+ [
+ 1183.7313232421875,
+ 1230.0509033203125,
+ 1183.7313232421875,
+ 2157.1357421875,
+ 2454.731201171875,
+ 2157.1357421875,
+ 2454.731201171875,
+ 1230.0509033203125
+ ]
+ ]
+ },
+ ...
+ ]
+ }
+ """
+
+ # init coco json field
+ coco_json = {'images': [], 'categories': [], 'annotations': []}
+
+ image_id = 0
+ annotations_id = 0
+ if all_classes_id is None:
+ category_to_id = dict()
+ categories_labels = []
+ else:
+ category_to_id = all_classes_id
+ categories_labels = list(all_classes_id.keys())
+
+ # filter incorrect image file
+ img_file_list = [
+ img_file for img_file in Path(image_dir).iterdir()
+ if img_file.suffix.lower() in IMG_EXTENSIONS
+ ]
+
+ for img_file in track_iter_progress(img_file_list):
+
+ # get label file according to the image file name
+ label_path = Path(labels_root).joinpath(
+ img_file.stem).with_suffix('.json')
+ if not label_path.exists():
+ print(f'Can not find label file: {label_path}, skip...')
+ continue
+
+ # load labelme label
+ with open(label_path, encoding='utf-8') as f:
+ labelme_data = json.load(f)
+
+ image_id = image_id + 1 # coco id begin from 1
+
+ # update coco 'images' field
+ coco_json['images'].append({
+ 'height':
+ labelme_data['imageHeight'],
+ 'width':
+ labelme_data['imageWidth'],
+ 'id':
+ image_id,
+ 'file_name':
+ Path(labelme_data['imagePath']).name
+ })
+
+ for label_shapes in labelme_data['shapes']:
+
+ # Update coco 'categories' field
+ class_name = label_shapes['label']
+
+ if (all_classes_id is None) and (class_name
+ not in categories_labels):
+ # only update when not been added before
+ coco_json['categories'].append({
+ 'id':
+ len(categories_labels) + 1, # categories id start with 1
+ 'name': class_name
+ })
+ categories_labels.append(class_name)
+ category_to_id[class_name] = len(categories_labels)
+
+ elif (all_classes_id is not None) and (class_name
+ not in categories_labels):
+ # check class name
+ raise ValueError(f'Got unexpected class name {class_name}, '
+ 'which is not in your `--class-id-txt`.')
+
+ # get shape type and convert it to coco format
+ shape_type = label_shapes['shape_type']
+ if shape_type != 'rectangle':
+ print(f'not support `{shape_type}` yet, skip...')
+ continue
+
+ annotations_id = annotations_id + 1
+ # convert point from [xmin, ymin, xmax, ymax] to [x1, y1, w, h]
+ (x1, y1), (x2, y2) = label_shapes['points']
+ x1, x2 = sorted([x1, x2]) # xmin, xmax
+ y1, y2 = sorted([y1, y2]) # ymin, ymax
+ points = [[x1, y1], [x2, y2], [x1, y2], [x2, y1]]
+ coco_annotations = format_coco_annotations(
+ points, image_id, annotations_id, category_to_id[class_name])
+ coco_json['annotations'].append(coco_annotations)
+
+ print(f'Total image = {image_id}')
+ print(f'Total annotations = {annotations_id}')
+ print(f'Number of categories = {len(categories_labels)}, '
+ f'which is {categories_labels}')
+
+ return coco_json, category_to_id
+
+
+def convert_labelme_to_coco(image_dir: str,
+ labels_dir: str,
+ out_path: str,
+ class_id_txt: Optional[str] = None):
+ """Convert labelme format label to COCO json format label.
+
+ Args:
+ image_dir (str): Image dir path.
+ labels_dir (str): Image label path.
+ out_path (str): COCO json file save path.
+ class_id_txt (Optional[str]): All class id txt file path.
+ Default None.
+ """
+ assert Path(out_path).suffix == '.json'
+
+ if class_id_txt is not None:
+ assert Path(class_id_txt).suffix == '.txt'
+
+ all_classes_id = dict()
+ with open(class_id_txt, encoding='utf-8') as f:
+ txt_lines = f.read().splitlines()
+ assert len(txt_lines) > 0
+
+ for txt_line in txt_lines:
+ v, k = txt_line.split(' ')
+ all_classes_id.update({k: v})
+ else:
+ all_classes_id = None
+
+ # convert to coco json
+ coco_json_data, category_to_id = parse_labelme_to_coco(
+ image_dir, labels_dir, all_classes_id)
+
+ # save json result
+ Path(out_path).parent.mkdir(exist_ok=True, parents=True)
+ print(f'Saving json to {out_path}')
+ json.dump(coco_json_data, open(out_path, 'w'), indent=2)
+
+ if class_id_txt is None:
+ category_to_id_path = Path(out_path).with_name('class_with_id.txt')
+ print(f'Saving class id txt to {category_to_id_path}')
+ with open(category_to_id_path, 'w', encoding='utf-8') as f:
+ for k, v in category_to_id.items():
+ f.write(f'{v} {k}\n')
+ else:
+ print('Not Saving new class id txt, user should using '
+ f'{class_id_txt} for training config')
+
+
+def main():
+ args = parse_args()
+ convert_labelme_to_coco(args.img_dir, args.labels_dir, args.out,
+ args.class_id_txt)
+ print('All done!')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/misc/coco_split.py b/tools/misc/coco_split.py
new file mode 100644
index 000000000..8ce70349b
--- /dev/null
+++ b/tools/misc/coco_split.py
@@ -0,0 +1,122 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import json
+import random
+from pathlib import Path
+
+import numpy as np
+from pycocotools.coco import COCO
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ '--json', type=str, required=True, help='COCO json label path')
+ parser.add_argument(
+ '--out-dir', type=str, required=True, help='output path')
+ parser.add_argument(
+ '--ratios',
+ nargs='+',
+ type=float,
+ help='ratio for sub dataset, if set 2 number then will generate '
+ 'trainval + test (eg. "0.8 0.1 0.1" or "2 1 1"), if set 3 number '
+ 'then will generate train + val + test (eg. "0.85 0.15" or "2 1")')
+ parser.add_argument(
+ '--shuffle',
+ action='store_true',
+ help='Whether to display in disorder')
+ parser.add_argument('--seed', default=-1, type=int, help='seed')
+ args = parser.parse_args()
+ return args
+
+
+def split_coco_dataset(coco_json_path: str, save_dir: str, ratios: list,
+ shuffle: bool, seed: int):
+ if not Path(coco_json_path).exists():
+ raise FileNotFoundError(f'Can not not found {coco_json_path}')
+
+ if not Path(save_dir).exists():
+ Path(save_dir).mkdir(parents=True)
+
+ # ratio normalize
+ ratios = np.array(ratios) / np.array(ratios).sum()
+
+ if len(ratios) == 2:
+ ratio_train, ratio_test = ratios
+ ratio_val = 0
+ train_type = 'trainval'
+ elif len(ratios) == 3:
+ ratio_train, ratio_val, ratio_test = ratios
+ train_type = 'train'
+ else:
+ raise ValueError('ratios must set 2 or 3 group!')
+
+ # Read coco info
+ coco = COCO(coco_json_path)
+ coco_image_ids = coco.getImgIds()
+
+ # gen image number of each dataset
+ val_image_num = int(len(coco_image_ids) * ratio_val)
+ test_image_num = int(len(coco_image_ids) * ratio_test)
+ train_image_num = len(coco_image_ids) - val_image_num - test_image_num
+ print('Split info: ====== \n'
+ f'Train ratio = {ratio_train}, number = {train_image_num}\n'
+ f'Val ratio = {ratio_val}, number = {val_image_num}\n'
+ f'Test ratio = {ratio_test}, number = {test_image_num}')
+
+ seed = int(seed)
+ if seed != -1:
+ print(f'Set the global seed: {seed}')
+ np.random.seed(seed)
+
+ if shuffle:
+ print('shuffle dataset.')
+ random.shuffle(coco_image_ids)
+
+ # split each dataset
+ train_image_ids = coco_image_ids[:train_image_num]
+ if val_image_num != 0:
+ val_image_ids = coco_image_ids[train_image_num:train_image_num +
+ val_image_num]
+ else:
+ val_image_ids = None
+ test_image_ids = coco_image_ids[train_image_num + val_image_num:]
+
+ # Save new json
+ categories = coco.loadCats(coco.getCatIds())
+ for img_id_list in [train_image_ids, val_image_ids, test_image_ids]:
+ if img_id_list is None:
+ continue
+
+ # Gen new json
+ img_dict = {
+ 'images': coco.loadImgs(ids=img_id_list),
+ 'categories': categories,
+ 'annotations': coco.loadAnns(coco.getAnnIds(imgIds=img_id_list))
+ }
+
+ # save json
+ if img_id_list == train_image_ids:
+ json_file_path = Path(save_dir, f'{train_type}.json')
+ elif img_id_list == val_image_ids:
+ json_file_path = Path(save_dir, 'val.json')
+ elif img_id_list == test_image_ids:
+ json_file_path = Path(save_dir, 'test.json')
+ else:
+ raise ValueError('img_id_list ERROR!')
+
+ print(f'Saving json to {json_file_path}')
+ with open(json_file_path, 'w') as f_json:
+ json.dump(img_dict, f_json, ensure_ascii=False, indent=2)
+
+ print('All done!')
+
+
+def main():
+ args = parse_args()
+ split_coco_dataset(args.json, args.out_dir, args.ratios, args.shuffle,
+ args.seed)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/misc/download_dataset.py b/tools/misc/download_dataset.py
index 5d4776b09..7d1c64d82 100644
--- a/tools/misc/download_dataset.py
+++ b/tools/misc/download_dataset.py
@@ -91,10 +91,14 @@ def main():
balloon=[
# src link: https://github.com/matterport/Mask_RCNN/releases/download/v2.1/balloon_dataset.zip # noqa
'https://download.openmmlab.com/mmyolo/data/balloon_dataset.zip'
- ])
+ ],
+ cat=[
+ 'https://download.openmmlab.com/mmyolo/data/cat_dataset.zip' # noqa
+ ],
+ )
url = data2url.get(args.dataset_name, None)
if url is None:
- print('Only support COCO, VOC, balloon,and LVIS now!')
+ print('Only support COCO, VOC, balloon, cat and LVIS now!')
return
download(
url,
diff --git a/tools/misc/extract_subcoco.py b/tools/misc/extract_subcoco.py
index a797b580c..31528e0b3 100644
--- a/tools/misc/extract_subcoco.py
+++ b/tools/misc/extract_subcoco.py
@@ -49,23 +49,47 @@ def _process_data(args,
'annotations': []
}
- images = json_data['images']
+ area_dict = {
+ 'small': [0., 32 * 32],
+ 'medium': [32 * 32, 96 * 96],
+ 'large': [96 * 96, float('inf')]
+ }
+
coco = COCO(ann_path)
+ # filter annotations by category ids and area range
+ areaRng = area_dict[args.area_size] if args.area_size else []
+ catIds = coco.getCatIds(args.classes) if args.classes else []
+ ann_ids = coco.getAnnIds(catIds=catIds, areaRng=areaRng)
+ ann_info = coco.loadAnns(ann_ids)
+
+ # get image ids by anns set
+ filter_img_ids = {ann['image_id'] for ann in ann_info}
+ filter_img = coco.loadImgs(filter_img_ids)
+
# shuffle
- np.random.shuffle(images)
+ np.random.shuffle(filter_img)
- progress_bar = mmengine.ProgressBar(args.num_img)
+ num_img = args.num_img if args.num_img > 0 else len(filter_img)
+ if num_img > len(filter_img):
+ print(
+ f'num_img is too big, will be set to {len(filter_img)}, '
+ 'because of not enough image after filter by classes and area_size'
+ )
+ num_img = len(filter_img)
- for i in range(args.num_img):
- file_name = images[i]['file_name']
+ progress_bar = mmengine.ProgressBar(num_img)
+
+ for i in range(num_img):
+ file_name = filter_img[i]['file_name']
image_path = osp.join(args.root, in_dataset_type + year, file_name)
- ann_ids = coco.getAnnIds(imgIds=[images[i]['id']])
- ann_info = coco.loadAnns(ann_ids)
+ ann_ids = coco.getAnnIds(
+ imgIds=[filter_img[i]['id']], catIds=catIds, areaRng=areaRng)
+ img_ann_info = coco.loadAnns(ann_ids)
- new_json_data['images'].append(images[i])
- new_json_data['annotations'].extend(ann_info)
+ new_json_data['images'].append(filter_img[i])
+ new_json_data['annotations'].extend(img_ann_info)
shutil.copy(image_path, osp.join(args.out_dir,
out_dataset_type + year))
@@ -88,7 +112,16 @@ def parse_args():
parser.add_argument(
'out_dir', type=str, help='directory where subset coco will be saved.')
parser.add_argument(
- '--num-img', default=50, type=int, help='num of extract image')
+ '--num-img',
+ default=50,
+ type=int,
+ help='num of extract image, -1 means all images')
+ parser.add_argument(
+ '--area-size',
+ choices=['small', 'medium', 'large'],
+ help='filter ground-truth info by area size')
+ parser.add_argument(
+ '--classes', nargs='+', help='filter ground-truth by class name')
parser.add_argument(
'--use-training-set',
action='store_true',
diff --git a/tools/model_converters/yolov6_to_mmyolo.py b/tools/model_converters/yolov6_to_mmyolo.py
index c5385803a..e9e86ab46 100644
--- a/tools/model_converters/yolov6_to_mmyolo.py
+++ b/tools/model_converters/yolov6_to_mmyolo.py
@@ -28,12 +28,28 @@ def convert(src, dst):
if 'ERBlock_2' in k:
name = k.replace('ERBlock_2', 'stage1.0')
+ if '.cv' in k:
+ name = name.replace('.cv', '.conv')
+ if '.m.' in k:
+ name = name.replace('.m.', '.block.')
elif 'ERBlock_3' in k:
name = k.replace('ERBlock_3', 'stage2.0')
+ if '.cv' in k:
+ name = name.replace('.cv', '.conv')
+ if '.m.' in k:
+ name = name.replace('.m.', '.block.')
elif 'ERBlock_4' in k:
name = k.replace('ERBlock_4', 'stage3.0')
+ if '.cv' in k:
+ name = name.replace('.cv', '.conv')
+ if '.m.' in k:
+ name = name.replace('.m.', '.block.')
elif 'ERBlock_5' in k:
name = k.replace('ERBlock_5', 'stage4.0')
+ if '.cv' in k:
+ name = name.replace('.cv', '.conv')
+ if '.m.' in k:
+ name = name.replace('.m.', '.block.')
if 'stage4.0.2' in name:
name = name.replace('stage4.0.2', 'stage4.1')
name = name.replace('cv', 'conv')
@@ -41,10 +57,22 @@ def convert(src, dst):
name = k.replace('reduce_layer0', 'reduce_layers.2')
elif 'Rep_p4' in k:
name = k.replace('Rep_p4', 'top_down_layers.0.0')
+ if '.cv' in k:
+ name = name.replace('.cv', '.conv')
+ if '.m.' in k:
+ name = name.replace('.m.', '.block.')
elif 'reduce_layer1' in k:
name = k.replace('reduce_layer1', 'top_down_layers.0.1')
+ if '.cv' in k:
+ name = name.replace('.cv', '.conv')
+ if '.m.' in k:
+ name = name.replace('.m.', '.block.')
elif 'Rep_p3' in k:
name = k.replace('Rep_p3', 'top_down_layers.1')
+ if '.cv' in k:
+ name = name.replace('.cv', '.conv')
+ if '.m.' in k:
+ name = name.replace('.m.', '.block.')
elif 'upsample0' in k:
name = k.replace('upsample0.upsample_transpose',
'upsample_layers.0')
@@ -53,8 +81,16 @@ def convert(src, dst):
'upsample_layers.1')
elif 'Rep_n3' in k:
name = k.replace('Rep_n3', 'bottom_up_layers.0')
+ if '.cv' in k:
+ name = name.replace('.cv', '.conv')
+ if '.m.' in k:
+ name = name.replace('.m.', '.block.')
elif 'Rep_n4' in k:
name = k.replace('Rep_n4', 'bottom_up_layers.1')
+ if '.cv' in k:
+ name = name.replace('.cv', '.conv')
+ if '.m.' in k:
+ name = name.replace('.m.', '.block.')
elif 'downsample2' in k:
name = k.replace('downsample2', 'downsample_layers.0')
elif 'downsample1' in k:
diff --git a/tools/model_converters/yolov7_to_mmyolo.py b/tools/model_converters/yolov7_to_mmyolo.py
index ced4157b5..f8bff9472 100644
--- a/tools/model_converters/yolov7_to_mmyolo.py
+++ b/tools/model_converters/yolov7_to_mmyolo.py
@@ -1,10 +1,85 @@
# Copyright (c) OpenMMLab. All rights reserved.
import argparse
+import os.path as osp
from collections import OrderedDict
import torch
-convert_dict = {
+convert_dict_tiny = {
+ # stem
+ 'model.0': 'backbone.stem.0',
+ 'model.1': 'backbone.stem.1',
+
+ # stage1 TinyDownSampleBlock
+ 'model.2': 'backbone.stage1.0.short_conv',
+ 'model.3': 'backbone.stage1.0.main_convs.0',
+ 'model.4': 'backbone.stage1.0.main_convs.1',
+ 'model.5': 'backbone.stage1.0.main_convs.2',
+ 'model.7': 'backbone.stage1.0.final_conv',
+
+ # stage2 TinyDownSampleBlock
+ 'model.9': 'backbone.stage2.1.short_conv',
+ 'model.10': 'backbone.stage2.1.main_convs.0',
+ 'model.11': 'backbone.stage2.1.main_convs.1',
+ 'model.12': 'backbone.stage2.1.main_convs.2',
+ 'model.14': 'backbone.stage2.1.final_conv',
+
+ # stage3 TinyDownSampleBlock
+ 'model.16': 'backbone.stage3.1.short_conv',
+ 'model.17': 'backbone.stage3.1.main_convs.0',
+ 'model.18': 'backbone.stage3.1.main_convs.1',
+ 'model.19': 'backbone.stage3.1.main_convs.2',
+ 'model.21': 'backbone.stage3.1.final_conv',
+
+ # stage4 TinyDownSampleBlock
+ 'model.23': 'backbone.stage4.1.short_conv',
+ 'model.24': 'backbone.stage4.1.main_convs.0',
+ 'model.25': 'backbone.stage4.1.main_convs.1',
+ 'model.26': 'backbone.stage4.1.main_convs.2',
+ 'model.28': 'backbone.stage4.1.final_conv',
+
+ # neck SPPCSPBlock
+ 'model.29': 'neck.reduce_layers.2.short_layer',
+ 'model.30': 'neck.reduce_layers.2.main_layers',
+ 'model.35': 'neck.reduce_layers.2.fuse_layers',
+ 'model.37': 'neck.reduce_layers.2.final_conv',
+ 'model.38': 'neck.upsample_layers.0.0',
+ 'model.40': 'neck.reduce_layers.1',
+ 'model.42': 'neck.top_down_layers.0.short_conv',
+ 'model.43': 'neck.top_down_layers.0.main_convs.0',
+ 'model.44': 'neck.top_down_layers.0.main_convs.1',
+ 'model.45': 'neck.top_down_layers.0.main_convs.2',
+ 'model.47': 'neck.top_down_layers.0.final_conv',
+ 'model.48': 'neck.upsample_layers.1.0',
+ 'model.50': 'neck.reduce_layers.0',
+ 'model.52': 'neck.top_down_layers.1.short_conv',
+ 'model.53': 'neck.top_down_layers.1.main_convs.0',
+ 'model.54': 'neck.top_down_layers.1.main_convs.1',
+ 'model.55': 'neck.top_down_layers.1.main_convs.2',
+ 'model.57': 'neck.top_down_layers.1.final_conv',
+ 'model.58': 'neck.downsample_layers.0',
+ 'model.60': 'neck.bottom_up_layers.0.short_conv',
+ 'model.61': 'neck.bottom_up_layers.0.main_convs.0',
+ 'model.62': 'neck.bottom_up_layers.0.main_convs.1',
+ 'model.63': 'neck.bottom_up_layers.0.main_convs.2',
+ 'model.65': 'neck.bottom_up_layers.0.final_conv',
+ 'model.66': 'neck.downsample_layers.1',
+ 'model.68': 'neck.bottom_up_layers.1.short_conv',
+ 'model.69': 'neck.bottom_up_layers.1.main_convs.0',
+ 'model.70': 'neck.bottom_up_layers.1.main_convs.1',
+ 'model.71': 'neck.bottom_up_layers.1.main_convs.2',
+ 'model.73': 'neck.bottom_up_layers.1.final_conv',
+ 'model.74': 'neck.out_layers.0',
+ 'model.75': 'neck.out_layers.1',
+ 'model.76': 'neck.out_layers.2',
+
+ # head
+ 'model.77.m.0': 'bbox_head.head_module.convs_pred.0.1',
+ 'model.77.m.1': 'bbox_head.head_module.convs_pred.1.1',
+ 'model.77.m.2': 'bbox_head.head_module.convs_pred.2.1'
+}
+
+convert_dict_l = {
# stem
'model.0': 'backbone.stem.0',
'model.1': 'backbone.stem.1',
@@ -70,7 +145,7 @@
'model.51.cv4': 'neck.reduce_layers.2.main_layers.2',
'model.51.cv5': 'neck.reduce_layers.2.fuse_layers.0',
'model.51.cv6': 'neck.reduce_layers.2.fuse_layers.1',
- 'model.51.cv2': 'neck.reduce_layers.2.short_layers',
+ 'model.51.cv2': 'neck.reduce_layers.2.short_layer',
'model.51.cv7': 'neck.reduce_layers.2.final_conv',
# neck
@@ -140,11 +215,522 @@
'model.104.rbr_1x1.1': 'neck.out_layers.2.rbr_1x1.bn',
# head
- 'model.105.m': 'bbox_head.head_module.convs_pred'
+ 'model.105.m.0': 'bbox_head.head_module.convs_pred.0.1',
+ 'model.105.m.1': 'bbox_head.head_module.convs_pred.1.1',
+ 'model.105.m.2': 'bbox_head.head_module.convs_pred.2.1'
+}
+
+convert_dict_x = {
+ # stem
+ 'model.0': 'backbone.stem.0',
+ 'model.1': 'backbone.stem.1',
+ 'model.2': 'backbone.stem.2',
+
+ # stage1
+ # ConvModule
+ 'model.3': 'backbone.stage1.0',
+ # ELANBlock expand_channel_2x
+ 'model.4': 'backbone.stage1.1.short_conv',
+ 'model.5': 'backbone.stage1.1.main_conv',
+ 'model.6': 'backbone.stage1.1.blocks.0.0',
+ 'model.7': 'backbone.stage1.1.blocks.0.1',
+ 'model.8': 'backbone.stage1.1.blocks.1.0',
+ 'model.9': 'backbone.stage1.1.blocks.1.1',
+ 'model.10': 'backbone.stage1.1.blocks.2.0',
+ 'model.11': 'backbone.stage1.1.blocks.2.1',
+ 'model.13': 'backbone.stage1.1.final_conv',
+
+ # stage2
+ # MaxPoolBlock reduce_channel_2x
+ 'model.15': 'backbone.stage2.0.maxpool_branches.1',
+ 'model.16': 'backbone.stage2.0.stride_conv_branches.0',
+ 'model.17': 'backbone.stage2.0.stride_conv_branches.1',
+
+ # ELANBlock expand_channel_2x
+ 'model.19': 'backbone.stage2.1.short_conv',
+ 'model.20': 'backbone.stage2.1.main_conv',
+ 'model.21': 'backbone.stage2.1.blocks.0.0',
+ 'model.22': 'backbone.stage2.1.blocks.0.1',
+ 'model.23': 'backbone.stage2.1.blocks.1.0',
+ 'model.24': 'backbone.stage2.1.blocks.1.1',
+ 'model.25': 'backbone.stage2.1.blocks.2.0',
+ 'model.26': 'backbone.stage2.1.blocks.2.1',
+ 'model.28': 'backbone.stage2.1.final_conv',
+
+ # stage3
+ # MaxPoolBlock reduce_channel_2x
+ 'model.30': 'backbone.stage3.0.maxpool_branches.1',
+ 'model.31': 'backbone.stage3.0.stride_conv_branches.0',
+ 'model.32': 'backbone.stage3.0.stride_conv_branches.1',
+ # ELANBlock expand_channel_2x
+ 'model.34': 'backbone.stage3.1.short_conv',
+ 'model.35': 'backbone.stage3.1.main_conv',
+ 'model.36': 'backbone.stage3.1.blocks.0.0',
+ 'model.37': 'backbone.stage3.1.blocks.0.1',
+ 'model.38': 'backbone.stage3.1.blocks.1.0',
+ 'model.39': 'backbone.stage3.1.blocks.1.1',
+ 'model.40': 'backbone.stage3.1.blocks.2.0',
+ 'model.41': 'backbone.stage3.1.blocks.2.1',
+ 'model.43': 'backbone.stage3.1.final_conv',
+
+ # stage4
+ # MaxPoolBlock reduce_channel_2x
+ 'model.45': 'backbone.stage4.0.maxpool_branches.1',
+ 'model.46': 'backbone.stage4.0.stride_conv_branches.0',
+ 'model.47': 'backbone.stage4.0.stride_conv_branches.1',
+ # ELANBlock no_change_channel
+ 'model.49': 'backbone.stage4.1.short_conv',
+ 'model.50': 'backbone.stage4.1.main_conv',
+ 'model.51': 'backbone.stage4.1.blocks.0.0',
+ 'model.52': 'backbone.stage4.1.blocks.0.1',
+ 'model.53': 'backbone.stage4.1.blocks.1.0',
+ 'model.54': 'backbone.stage4.1.blocks.1.1',
+ 'model.55': 'backbone.stage4.1.blocks.2.0',
+ 'model.56': 'backbone.stage4.1.blocks.2.1',
+ 'model.58': 'backbone.stage4.1.final_conv',
+
+ # neck SPPCSPBlock
+ 'model.59.cv1': 'neck.reduce_layers.2.main_layers.0',
+ 'model.59.cv3': 'neck.reduce_layers.2.main_layers.1',
+ 'model.59.cv4': 'neck.reduce_layers.2.main_layers.2',
+ 'model.59.cv5': 'neck.reduce_layers.2.fuse_layers.0',
+ 'model.59.cv6': 'neck.reduce_layers.2.fuse_layers.1',
+ 'model.59.cv2': 'neck.reduce_layers.2.short_layer',
+ 'model.59.cv7': 'neck.reduce_layers.2.final_conv',
+
+ # neck
+ 'model.60': 'neck.upsample_layers.0.0',
+ 'model.62': 'neck.reduce_layers.1',
+
+ # neck ELANBlock reduce_channel_2x
+ 'model.64': 'neck.top_down_layers.0.short_conv',
+ 'model.65': 'neck.top_down_layers.0.main_conv',
+ 'model.66': 'neck.top_down_layers.0.blocks.0.0',
+ 'model.67': 'neck.top_down_layers.0.blocks.0.1',
+ 'model.68': 'neck.top_down_layers.0.blocks.1.0',
+ 'model.69': 'neck.top_down_layers.0.blocks.1.1',
+ 'model.70': 'neck.top_down_layers.0.blocks.2.0',
+ 'model.71': 'neck.top_down_layers.0.blocks.2.1',
+ 'model.73': 'neck.top_down_layers.0.final_conv',
+ 'model.74': 'neck.upsample_layers.1.0',
+ 'model.76': 'neck.reduce_layers.0',
+
+ # neck ELANBlock reduce_channel_2x
+ 'model.78': 'neck.top_down_layers.1.short_conv',
+ 'model.79': 'neck.top_down_layers.1.main_conv',
+ 'model.80': 'neck.top_down_layers.1.blocks.0.0',
+ 'model.81': 'neck.top_down_layers.1.blocks.0.1',
+ 'model.82': 'neck.top_down_layers.1.blocks.1.0',
+ 'model.83': 'neck.top_down_layers.1.blocks.1.1',
+ 'model.84': 'neck.top_down_layers.1.blocks.2.0',
+ 'model.85': 'neck.top_down_layers.1.blocks.2.1',
+ 'model.87': 'neck.top_down_layers.1.final_conv',
+
+ # neck MaxPoolBlock no_change_channel
+ 'model.89': 'neck.downsample_layers.0.maxpool_branches.1',
+ 'model.90': 'neck.downsample_layers.0.stride_conv_branches.0',
+ 'model.91': 'neck.downsample_layers.0.stride_conv_branches.1',
+
+ # neck ELANBlock reduce_channel_2x
+ 'model.93': 'neck.bottom_up_layers.0.short_conv',
+ 'model.94': 'neck.bottom_up_layers.0.main_conv',
+ 'model.95': 'neck.bottom_up_layers.0.blocks.0.0',
+ 'model.96': 'neck.bottom_up_layers.0.blocks.0.1',
+ 'model.97': 'neck.bottom_up_layers.0.blocks.1.0',
+ 'model.98': 'neck.bottom_up_layers.0.blocks.1.1',
+ 'model.99': 'neck.bottom_up_layers.0.blocks.2.0',
+ 'model.100': 'neck.bottom_up_layers.0.blocks.2.1',
+ 'model.102': 'neck.bottom_up_layers.0.final_conv',
+
+ # neck MaxPoolBlock no_change_channel
+ 'model.104': 'neck.downsample_layers.1.maxpool_branches.1',
+ 'model.105': 'neck.downsample_layers.1.stride_conv_branches.0',
+ 'model.106': 'neck.downsample_layers.1.stride_conv_branches.1',
+
+ # neck ELANBlock reduce_channel_2x
+ 'model.108': 'neck.bottom_up_layers.1.short_conv',
+ 'model.109': 'neck.bottom_up_layers.1.main_conv',
+ 'model.110': 'neck.bottom_up_layers.1.blocks.0.0',
+ 'model.111': 'neck.bottom_up_layers.1.blocks.0.1',
+ 'model.112': 'neck.bottom_up_layers.1.blocks.1.0',
+ 'model.113': 'neck.bottom_up_layers.1.blocks.1.1',
+ 'model.114': 'neck.bottom_up_layers.1.blocks.2.0',
+ 'model.115': 'neck.bottom_up_layers.1.blocks.2.1',
+ 'model.117': 'neck.bottom_up_layers.1.final_conv',
+
+ # Conv
+ 'model.118': 'neck.out_layers.0',
+ 'model.119': 'neck.out_layers.1',
+ 'model.120': 'neck.out_layers.2',
+
+ # head
+ 'model.121.m.0': 'bbox_head.head_module.convs_pred.0.1',
+ 'model.121.m.1': 'bbox_head.head_module.convs_pred.1.1',
+ 'model.121.m.2': 'bbox_head.head_module.convs_pred.2.1'
+}
+
+convert_dict_w = {
+ # stem
+ 'model.1': 'backbone.stem.conv',
+
+ # stage1
+ # ConvModule
+ 'model.2': 'backbone.stage1.0',
+ # ELANBlock
+ 'model.3': 'backbone.stage1.1.short_conv',
+ 'model.4': 'backbone.stage1.1.main_conv',
+ 'model.5': 'backbone.stage1.1.blocks.0.0',
+ 'model.6': 'backbone.stage1.1.blocks.0.1',
+ 'model.7': 'backbone.stage1.1.blocks.1.0',
+ 'model.8': 'backbone.stage1.1.blocks.1.1',
+ 'model.10': 'backbone.stage1.1.final_conv',
+
+ # stage2
+ 'model.11': 'backbone.stage2.0',
+ # ELANBlock
+ 'model.12': 'backbone.stage2.1.short_conv',
+ 'model.13': 'backbone.stage2.1.main_conv',
+ 'model.14': 'backbone.stage2.1.blocks.0.0',
+ 'model.15': 'backbone.stage2.1.blocks.0.1',
+ 'model.16': 'backbone.stage2.1.blocks.1.0',
+ 'model.17': 'backbone.stage2.1.blocks.1.1',
+ 'model.19': 'backbone.stage2.1.final_conv',
+
+ # stage3
+ 'model.20': 'backbone.stage3.0',
+ # ELANBlock
+ 'model.21': 'backbone.stage3.1.short_conv',
+ 'model.22': 'backbone.stage3.1.main_conv',
+ 'model.23': 'backbone.stage3.1.blocks.0.0',
+ 'model.24': 'backbone.stage3.1.blocks.0.1',
+ 'model.25': 'backbone.stage3.1.blocks.1.0',
+ 'model.26': 'backbone.stage3.1.blocks.1.1',
+ 'model.28': 'backbone.stage3.1.final_conv',
+
+ # stage4
+ 'model.29': 'backbone.stage4.0',
+ # ELANBlock
+ 'model.30': 'backbone.stage4.1.short_conv',
+ 'model.31': 'backbone.stage4.1.main_conv',
+ 'model.32': 'backbone.stage4.1.blocks.0.0',
+ 'model.33': 'backbone.stage4.1.blocks.0.1',
+ 'model.34': 'backbone.stage4.1.blocks.1.0',
+ 'model.35': 'backbone.stage4.1.blocks.1.1',
+ 'model.37': 'backbone.stage4.1.final_conv',
+
+ # stage5
+ 'model.38': 'backbone.stage5.0',
+ # ELANBlock
+ 'model.39': 'backbone.stage5.1.short_conv',
+ 'model.40': 'backbone.stage5.1.main_conv',
+ 'model.41': 'backbone.stage5.1.blocks.0.0',
+ 'model.42': 'backbone.stage5.1.blocks.0.1',
+ 'model.43': 'backbone.stage5.1.blocks.1.0',
+ 'model.44': 'backbone.stage5.1.blocks.1.1',
+ 'model.46': 'backbone.stage5.1.final_conv',
+
+ # neck SPPCSPBlock
+ 'model.47.cv1': 'neck.reduce_layers.3.main_layers.0',
+ 'model.47.cv3': 'neck.reduce_layers.3.main_layers.1',
+ 'model.47.cv4': 'neck.reduce_layers.3.main_layers.2',
+ 'model.47.cv5': 'neck.reduce_layers.3.fuse_layers.0',
+ 'model.47.cv6': 'neck.reduce_layers.3.fuse_layers.1',
+ 'model.47.cv2': 'neck.reduce_layers.3.short_layer',
+ 'model.47.cv7': 'neck.reduce_layers.3.final_conv',
+
+ # neck
+ 'model.48': 'neck.upsample_layers.0.0',
+ 'model.50': 'neck.reduce_layers.2',
+
+ # neck ELANBlock
+ 'model.52': 'neck.top_down_layers.0.short_conv',
+ 'model.53': 'neck.top_down_layers.0.main_conv',
+ 'model.54': 'neck.top_down_layers.0.blocks.0',
+ 'model.55': 'neck.top_down_layers.0.blocks.1',
+ 'model.56': 'neck.top_down_layers.0.blocks.2',
+ 'model.57': 'neck.top_down_layers.0.blocks.3',
+ 'model.59': 'neck.top_down_layers.0.final_conv',
+ 'model.60': 'neck.upsample_layers.1.0',
+ 'model.62': 'neck.reduce_layers.1',
+
+ # neck ELANBlock reduce_channel_2x
+ 'model.64': 'neck.top_down_layers.1.short_conv',
+ 'model.65': 'neck.top_down_layers.1.main_conv',
+ 'model.66': 'neck.top_down_layers.1.blocks.0',
+ 'model.67': 'neck.top_down_layers.1.blocks.1',
+ 'model.68': 'neck.top_down_layers.1.blocks.2',
+ 'model.69': 'neck.top_down_layers.1.blocks.3',
+ 'model.71': 'neck.top_down_layers.1.final_conv',
+ 'model.72': 'neck.upsample_layers.2.0',
+ 'model.74': 'neck.reduce_layers.0',
+ 'model.76': 'neck.top_down_layers.2.short_conv',
+ 'model.77': 'neck.top_down_layers.2.main_conv',
+ 'model.78': 'neck.top_down_layers.2.blocks.0',
+ 'model.79': 'neck.top_down_layers.2.blocks.1',
+ 'model.80': 'neck.top_down_layers.2.blocks.2',
+ 'model.81': 'neck.top_down_layers.2.blocks.3',
+ 'model.83': 'neck.top_down_layers.2.final_conv',
+ 'model.84': 'neck.downsample_layers.0',
+
+ # neck ELANBlock
+ 'model.86': 'neck.bottom_up_layers.0.short_conv',
+ 'model.87': 'neck.bottom_up_layers.0.main_conv',
+ 'model.88': 'neck.bottom_up_layers.0.blocks.0',
+ 'model.89': 'neck.bottom_up_layers.0.blocks.1',
+ 'model.90': 'neck.bottom_up_layers.0.blocks.2',
+ 'model.91': 'neck.bottom_up_layers.0.blocks.3',
+ 'model.93': 'neck.bottom_up_layers.0.final_conv',
+ 'model.94': 'neck.downsample_layers.1',
+
+ # neck ELANBlock reduce_channel_2x
+ 'model.96': 'neck.bottom_up_layers.1.short_conv',
+ 'model.97': 'neck.bottom_up_layers.1.main_conv',
+ 'model.98': 'neck.bottom_up_layers.1.blocks.0',
+ 'model.99': 'neck.bottom_up_layers.1.blocks.1',
+ 'model.100': 'neck.bottom_up_layers.1.blocks.2',
+ 'model.101': 'neck.bottom_up_layers.1.blocks.3',
+ 'model.103': 'neck.bottom_up_layers.1.final_conv',
+ 'model.104': 'neck.downsample_layers.2',
+
+ # neck ELANBlock reduce_channel_2x
+ 'model.106': 'neck.bottom_up_layers.2.short_conv',
+ 'model.107': 'neck.bottom_up_layers.2.main_conv',
+ 'model.108': 'neck.bottom_up_layers.2.blocks.0',
+ 'model.109': 'neck.bottom_up_layers.2.blocks.1',
+ 'model.110': 'neck.bottom_up_layers.2.blocks.2',
+ 'model.111': 'neck.bottom_up_layers.2.blocks.3',
+ 'model.113': 'neck.bottom_up_layers.2.final_conv',
+ 'model.114': 'bbox_head.head_module.main_convs_pred.0.0',
+ 'model.115': 'bbox_head.head_module.main_convs_pred.1.0',
+ 'model.116': 'bbox_head.head_module.main_convs_pred.2.0',
+ 'model.117': 'bbox_head.head_module.main_convs_pred.3.0',
+
+ # head
+ 'model.118.m.0': 'bbox_head.head_module.main_convs_pred.0.2',
+ 'model.118.m.1': 'bbox_head.head_module.main_convs_pred.1.2',
+ 'model.118.m.2': 'bbox_head.head_module.main_convs_pred.2.2',
+ 'model.118.m.3': 'bbox_head.head_module.main_convs_pred.3.2'
+}
+
+convert_dict_e = {
+ # stem
+ 'model.1': 'backbone.stem.conv',
+
+ # stage1
+ 'model.2.cv1': 'backbone.stage1.0.stride_conv_branches.0',
+ 'model.2.cv2': 'backbone.stage1.0.stride_conv_branches.1',
+ 'model.2.cv3': 'backbone.stage1.0.maxpool_branches.1',
+
+ # ELANBlock
+ 'model.3': 'backbone.stage1.1.short_conv',
+ 'model.4': 'backbone.stage1.1.main_conv',
+ 'model.5': 'backbone.stage1.1.blocks.0.0',
+ 'model.6': 'backbone.stage1.1.blocks.0.1',
+ 'model.7': 'backbone.stage1.1.blocks.1.0',
+ 'model.8': 'backbone.stage1.1.blocks.1.1',
+ 'model.9': 'backbone.stage1.1.blocks.2.0',
+ 'model.10': 'backbone.stage1.1.blocks.2.1',
+ 'model.12': 'backbone.stage1.1.final_conv',
+
+ # stage2
+ 'model.13.cv1': 'backbone.stage2.0.stride_conv_branches.0',
+ 'model.13.cv2': 'backbone.stage2.0.stride_conv_branches.1',
+ 'model.13.cv3': 'backbone.stage2.0.maxpool_branches.1',
+
+ # ELANBlock
+ 'model.14': 'backbone.stage2.1.short_conv',
+ 'model.15': 'backbone.stage2.1.main_conv',
+ 'model.16': 'backbone.stage2.1.blocks.0.0',
+ 'model.17': 'backbone.stage2.1.blocks.0.1',
+ 'model.18': 'backbone.stage2.1.blocks.1.0',
+ 'model.19': 'backbone.stage2.1.blocks.1.1',
+ 'model.20': 'backbone.stage2.1.blocks.2.0',
+ 'model.21': 'backbone.stage2.1.blocks.2.1',
+ 'model.23': 'backbone.stage2.1.final_conv',
+
+ # stage3
+ 'model.24.cv1': 'backbone.stage3.0.stride_conv_branches.0',
+ 'model.24.cv2': 'backbone.stage3.0.stride_conv_branches.1',
+ 'model.24.cv3': 'backbone.stage3.0.maxpool_branches.1',
+
+ # ELANBlock
+ 'model.25': 'backbone.stage3.1.short_conv',
+ 'model.26': 'backbone.stage3.1.main_conv',
+ 'model.27': 'backbone.stage3.1.blocks.0.0',
+ 'model.28': 'backbone.stage3.1.blocks.0.1',
+ 'model.29': 'backbone.stage3.1.blocks.1.0',
+ 'model.30': 'backbone.stage3.1.blocks.1.1',
+ 'model.31': 'backbone.stage3.1.blocks.2.0',
+ 'model.32': 'backbone.stage3.1.blocks.2.1',
+ 'model.34': 'backbone.stage3.1.final_conv',
+
+ # stage4
+ 'model.35.cv1': 'backbone.stage4.0.stride_conv_branches.0',
+ 'model.35.cv2': 'backbone.stage4.0.stride_conv_branches.1',
+ 'model.35.cv3': 'backbone.stage4.0.maxpool_branches.1',
+
+ # ELANBlock
+ 'model.36': 'backbone.stage4.1.short_conv',
+ 'model.37': 'backbone.stage4.1.main_conv',
+ 'model.38': 'backbone.stage4.1.blocks.0.0',
+ 'model.39': 'backbone.stage4.1.blocks.0.1',
+ 'model.40': 'backbone.stage4.1.blocks.1.0',
+ 'model.41': 'backbone.stage4.1.blocks.1.1',
+ 'model.42': 'backbone.stage4.1.blocks.2.0',
+ 'model.43': 'backbone.stage4.1.blocks.2.1',
+ 'model.45': 'backbone.stage4.1.final_conv',
+
+ # stage5
+ 'model.46.cv1': 'backbone.stage5.0.stride_conv_branches.0',
+ 'model.46.cv2': 'backbone.stage5.0.stride_conv_branches.1',
+ 'model.46.cv3': 'backbone.stage5.0.maxpool_branches.1',
+
+ # ELANBlock
+ 'model.47': 'backbone.stage5.1.short_conv',
+ 'model.48': 'backbone.stage5.1.main_conv',
+ 'model.49': 'backbone.stage5.1.blocks.0.0',
+ 'model.50': 'backbone.stage5.1.blocks.0.1',
+ 'model.51': 'backbone.stage5.1.blocks.1.0',
+ 'model.52': 'backbone.stage5.1.blocks.1.1',
+ 'model.53': 'backbone.stage5.1.blocks.2.0',
+ 'model.54': 'backbone.stage5.1.blocks.2.1',
+ 'model.56': 'backbone.stage5.1.final_conv',
+
+ # neck SPPCSPBlock
+ 'model.57.cv1': 'neck.reduce_layers.3.main_layers.0',
+ 'model.57.cv3': 'neck.reduce_layers.3.main_layers.1',
+ 'model.57.cv4': 'neck.reduce_layers.3.main_layers.2',
+ 'model.57.cv5': 'neck.reduce_layers.3.fuse_layers.0',
+ 'model.57.cv6': 'neck.reduce_layers.3.fuse_layers.1',
+ 'model.57.cv2': 'neck.reduce_layers.3.short_layer',
+ 'model.57.cv7': 'neck.reduce_layers.3.final_conv',
+
+ # neck
+ 'model.58': 'neck.upsample_layers.0.0',
+ 'model.60': 'neck.reduce_layers.2',
+
+ # neck ELANBlock
+ 'model.62': 'neck.top_down_layers.0.short_conv',
+ 'model.63': 'neck.top_down_layers.0.main_conv',
+ 'model.64': 'neck.top_down_layers.0.blocks.0',
+ 'model.65': 'neck.top_down_layers.0.blocks.1',
+ 'model.66': 'neck.top_down_layers.0.blocks.2',
+ 'model.67': 'neck.top_down_layers.0.blocks.3',
+ 'model.68': 'neck.top_down_layers.0.blocks.4',
+ 'model.69': 'neck.top_down_layers.0.blocks.5',
+ 'model.71': 'neck.top_down_layers.0.final_conv',
+ 'model.72': 'neck.upsample_layers.1.0',
+ 'model.74': 'neck.reduce_layers.1',
+
+ # neck ELANBlock
+ 'model.76': 'neck.top_down_layers.1.short_conv',
+ 'model.77': 'neck.top_down_layers.1.main_conv',
+ 'model.78': 'neck.top_down_layers.1.blocks.0',
+ 'model.79': 'neck.top_down_layers.1.blocks.1',
+ 'model.80': 'neck.top_down_layers.1.blocks.2',
+ 'model.81': 'neck.top_down_layers.1.blocks.3',
+ 'model.82': 'neck.top_down_layers.1.blocks.4',
+ 'model.83': 'neck.top_down_layers.1.blocks.5',
+ 'model.85': 'neck.top_down_layers.1.final_conv',
+ 'model.86': 'neck.upsample_layers.2.0',
+ 'model.88': 'neck.reduce_layers.0',
+ 'model.90': 'neck.top_down_layers.2.short_conv',
+ 'model.91': 'neck.top_down_layers.2.main_conv',
+ 'model.92': 'neck.top_down_layers.2.blocks.0',
+ 'model.93': 'neck.top_down_layers.2.blocks.1',
+ 'model.94': 'neck.top_down_layers.2.blocks.2',
+ 'model.95': 'neck.top_down_layers.2.blocks.3',
+ 'model.96': 'neck.top_down_layers.2.blocks.4',
+ 'model.97': 'neck.top_down_layers.2.blocks.5',
+ 'model.99': 'neck.top_down_layers.2.final_conv',
+ 'model.100.cv1': 'neck.downsample_layers.0.stride_conv_branches.0',
+ 'model.100.cv2': 'neck.downsample_layers.0.stride_conv_branches.1',
+ 'model.100.cv3': 'neck.downsample_layers.0.maxpool_branches.1',
+
+ # neck ELANBlock
+ 'model.102': 'neck.bottom_up_layers.0.short_conv',
+ 'model.103': 'neck.bottom_up_layers.0.main_conv',
+ 'model.104': 'neck.bottom_up_layers.0.blocks.0',
+ 'model.105': 'neck.bottom_up_layers.0.blocks.1',
+ 'model.106': 'neck.bottom_up_layers.0.blocks.2',
+ 'model.107': 'neck.bottom_up_layers.0.blocks.3',
+ 'model.108': 'neck.bottom_up_layers.0.blocks.4',
+ 'model.109': 'neck.bottom_up_layers.0.blocks.5',
+ 'model.111': 'neck.bottom_up_layers.0.final_conv',
+ 'model.112.cv1': 'neck.downsample_layers.1.stride_conv_branches.0',
+ 'model.112.cv2': 'neck.downsample_layers.1.stride_conv_branches.1',
+ 'model.112.cv3': 'neck.downsample_layers.1.maxpool_branches.1',
+
+ # neck ELANBlock
+ 'model.114': 'neck.bottom_up_layers.1.short_conv',
+ 'model.115': 'neck.bottom_up_layers.1.main_conv',
+ 'model.116': 'neck.bottom_up_layers.1.blocks.0',
+ 'model.117': 'neck.bottom_up_layers.1.blocks.1',
+ 'model.118': 'neck.bottom_up_layers.1.blocks.2',
+ 'model.119': 'neck.bottom_up_layers.1.blocks.3',
+ 'model.120': 'neck.bottom_up_layers.1.blocks.4',
+ 'model.121': 'neck.bottom_up_layers.1.blocks.5',
+ 'model.123': 'neck.bottom_up_layers.1.final_conv',
+ 'model.124.cv1': 'neck.downsample_layers.2.stride_conv_branches.0',
+ 'model.124.cv2': 'neck.downsample_layers.2.stride_conv_branches.1',
+ 'model.124.cv3': 'neck.downsample_layers.2.maxpool_branches.1',
+
+ # neck ELANBlock
+ 'model.126': 'neck.bottom_up_layers.2.short_conv',
+ 'model.127': 'neck.bottom_up_layers.2.main_conv',
+ 'model.128': 'neck.bottom_up_layers.2.blocks.0',
+ 'model.129': 'neck.bottom_up_layers.2.blocks.1',
+ 'model.130': 'neck.bottom_up_layers.2.blocks.2',
+ 'model.131': 'neck.bottom_up_layers.2.blocks.3',
+ 'model.132': 'neck.bottom_up_layers.2.blocks.4',
+ 'model.133': 'neck.bottom_up_layers.2.blocks.5',
+ 'model.135': 'neck.bottom_up_layers.2.final_conv',
+ 'model.136': 'bbox_head.head_module.main_convs_pred.0.0',
+ 'model.137': 'bbox_head.head_module.main_convs_pred.1.0',
+ 'model.138': 'bbox_head.head_module.main_convs_pred.2.0',
+ 'model.139': 'bbox_head.head_module.main_convs_pred.3.0',
+
+ # head
+ 'model.140.m.0': 'bbox_head.head_module.main_convs_pred.0.2',
+ 'model.140.m.1': 'bbox_head.head_module.main_convs_pred.1.2',
+ 'model.140.m.2': 'bbox_head.head_module.main_convs_pred.2.2',
+ 'model.140.m.3': 'bbox_head.head_module.main_convs_pred.3.2'
+}
+
+convert_dicts = {
+ 'yolov7-tiny.pt': convert_dict_tiny,
+ 'yolov7-w6.pt': convert_dict_w,
+ 'yolov7-e6.pt': convert_dict_e,
+ 'yolov7.pt': convert_dict_l,
+ 'yolov7x.pt': convert_dict_x
}
def convert(src, dst):
+ src_key = osp.basename(src)
+ convert_dict = convert_dicts[osp.basename(src)]
+
+ num_levels = 3
+ if src_key == 'yolov7.pt':
+ indexes = [102, 51]
+ in_channels = [256, 512, 1024]
+ elif src_key == 'yolov7x.pt':
+ indexes = [121, 59]
+ in_channels = [320, 640, 1280]
+ elif src_key == 'yolov7-tiny.pt':
+ indexes = [77, 1000]
+ in_channels = [128, 256, 512]
+ elif src_key == 'yolov7-w6.pt':
+ indexes = [118, 47]
+ in_channels = [256, 512, 768, 1024]
+ num_levels = 4
+ elif src_key == 'yolov7-e6.pt':
+ indexes = [140, [2, 13, 24, 35, 46, 57, 100, 112, 124]]
+ in_channels = 320, 640, 960, 1280
+ num_levels = 4
+
+ if isinstance(indexes[1], int):
+ indexes[1] = [indexes[1]]
"""Convert keys in detectron pretrained YOLOv7 models to mmyolo style."""
try:
yolov7_model = torch.load(src)['model'].float()
@@ -161,24 +747,41 @@ def convert(src, dst):
continue
num, module = key.split('.')[1:3]
- if int(num) < 102 and int(num) != 51:
+ if int(num) < indexes[0] and int(num) not in indexes[1]:
prefix = f'model.{num}'
new_key = key.replace(prefix, convert_dict[prefix])
state_dict[new_key] = weight
print(f'Convert {key} to {new_key}')
- elif int(num) < 105 and int(num) != 51:
- strs_key = key.split('.')[:4]
+ elif int(num) in indexes[1]:
+ strs_key = key.split('.')[:3]
new_key = key.replace('.'.join(strs_key),
convert_dict['.'.join(strs_key)])
state_dict[new_key] = weight
print(f'Convert {key} to {new_key}')
else:
- strs_key = key.split('.')[:3]
+ strs_key = key.split('.')[:4]
new_key = key.replace('.'.join(strs_key),
convert_dict['.'.join(strs_key)])
state_dict[new_key] = weight
print(f'Convert {key} to {new_key}')
+ # Add ImplicitA and ImplicitM
+ for i in range(num_levels):
+ if num_levels == 3:
+ implicit_a = f'bbox_head.head_module.' \
+ f'convs_pred.{i}.0.implicit'
+ state_dict[implicit_a] = torch.zeros((1, in_channels[i], 1, 1))
+ implicit_m = f'bbox_head.head_module.' \
+ f'convs_pred.{i}.2.implicit'
+ state_dict[implicit_m] = torch.ones((1, 3 * 85, 1, 1))
+ else:
+ implicit_a = f'bbox_head.head_module.' \
+ f'main_convs_pred.{i}.1.implicit'
+ state_dict[implicit_a] = torch.zeros((1, in_channels[i], 1, 1))
+ implicit_m = f'bbox_head.head_module.' \
+ f'main_convs_pred.{i}.3.implicit'
+ state_dict[implicit_m] = torch.ones((1, 3 * 85, 1, 1))
+
# save checkpoint
checkpoint = dict()
checkpoint['state_dict'] = state_dict
@@ -189,8 +792,8 @@ def convert(src, dst):
def main():
parser = argparse.ArgumentParser(description='Convert model keys')
parser.add_argument(
- '--src', default='yolov7.pt', help='src yolov7 model path')
- parser.add_argument('--dst', default='mm_yolov7l.pt', help='save path')
+ 'src', default='yolov7.pt', help='src yolov7 model path')
+ parser.add_argument('dst', default='mm_yolov7l.pt', help='save path')
args = parser.parse_args()
convert(args.src, args.dst)
diff --git a/tools/test.py b/tools/test.py
index fc80c887a..0c5b89b89 100644
--- a/tools/test.py
+++ b/tools/test.py
@@ -12,7 +12,7 @@
from mmyolo.utils import register_all_modules
-# TODO: support fuse_conv_bn and format_only
+# TODO: support fuse_conv_bn
def parse_args():
parser = argparse.ArgumentParser(
description='MMYOLO test (and eval) a model')
@@ -24,7 +24,13 @@ def parse_args():
parser.add_argument(
'--out',
type=str,
- help='dump predictions to a pickle file for offline evaluation')
+ help='output result file (must be a .pkl file) in pickle format')
+ parser.add_argument(
+ '--json-prefix',
+ type=str,
+ help='the prefix of the output json file without perform evaluation, '
+ 'which is useful when you want to format the result to a specific '
+ 'format and submit it to the test server')
parser.add_argument(
'--show', action='store_true', help='show prediction results')
parser.add_argument(
@@ -92,6 +98,14 @@ def main():
if args.deploy:
cfg.custom_hooks.append(dict(type='SwitchToDeployHook'))
+ # add `format_only` and `outfile_prefix` into cfg
+ if args.json_prefix is not None:
+ cfg_json = {
+ 'test_evaluator.format_only': True,
+ 'test_evaluator.outfile_prefix': args.json_prefix
+ }
+ cfg.merge_from_dict(cfg_json)
+
# build the runner from config
if 'runner_type' not in cfg:
# build the default runner
 +
+ +
+- Plot the classification and regression loss of some run, and save the figure to a pdf.
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ --keys loss_cls loss_bbox \
+ --legend loss_cls loss_bbox \
+ --out losses_yolov5_s.pdf
+ ```
+
+
+
+- Plot the classification and regression loss of some run, and save the figure to a pdf.
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ --keys loss_cls loss_bbox \
+ --legend loss_cls loss_bbox \
+ --out losses_yolov5_s.pdf
+ ```
+
+  +
+- Compare the bbox mAP of two runs in the same figure.
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ yolov5_n-v61_syncbn_fast_8xb16-300e_coco_20220919_090739.log.json \
+ --keys bbox_mAP \
+ --legend yolov5_s yolov5_n \
+ --eval-interval 10 # Note that the evaluation interval must be the same as during training. Otherwise, it will raise an error.
+ ```
+
+
+
+- Compare the bbox mAP of two runs in the same figure.
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ yolov5_n-v61_syncbn_fast_8xb16-300e_coco_20220919_090739.log.json \
+ --keys bbox_mAP \
+ --legend yolov5_s yolov5_n \
+ --eval-interval 10 # Note that the evaluation interval must be the same as during training. Otherwise, it will raise an error.
+ ```
+
+ +
+#### Compute the average training speed
+
+```shell
+mim run mmdet analyze_logs cal_train_time \
+ ${LOG} \ # path of train log in json format
+ [--include-outliers] # include the first value of every epoch when computing the average time
+```
+
+Examples:
+
+```shell
+mim run mmdet analyze_logs cal_train_time \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json
+```
+
+The output is expected to be like the following.
+
+```text
+-----Analyze train time of yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json-----
+slowest epoch 278, average time is 0.1705 s/iter
+fastest epoch 300, average time is 0.1510 s/iter
+time std over epochs is 0.0026
+average iter time: 0.1556 s/iter
+```
+
+### Print the whole config
+
+`print_config.py` in MMDetection prints the whole config verbatim, expanding all its imports. The command is as following.
+
+```shell
+mim run mmdet print_config \
+ ${CONFIG} \ # path of the config file
+ [--save-path] \ # save path of whole config, suffixed with .py, .json or .yml
+ [--cfg-options ${OPTIONS [OPTIONS...]}] # override some settings in the used config
+```
+
+Examples:
+
+```shell
+mim run mmdet print_config \
+ configs/yolov5/yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py \
+ --save-path ./work_dirs/yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py
+```
+
+Running the above command will save the `yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py` config file with the inheritance relationship expanded to \`\`yolov5_s-v61_syncbn_fast_1xb4-300e_balloon_whole.py`in the`./work_dirs\` folder.
diff --git a/docs/en/advanced_guides/plugins.md b/docs/en/advanced_guides/plugins.md
index 779d515c6..b488ab894 100644
--- a/docs/en/advanced_guides/plugins.md
+++ b/docs/en/advanced_guides/plugins.md
@@ -1 +1,34 @@
# Plugins
+
+MMYOLO supports adding plugins such as `none_local` and `dropblock` after different stages of Backbone. Users can directly manage plugins by modifying the plugins parameter of the backbone in the config. For example, add `GeneralizedAttention` plugins for `YOLOv5`. The configuration files are as follows:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+model = dict(
+ backbone=dict(
+ plugins=[
+ dict(
+ cfg=dict(
+ type='GeneralizedAttention',
+ spatial_range=-1,
+ num_heads=8,
+ attention_type='0011',
+ kv_stride=2),
+ stages=(False, False, True, True))
+ ]))
+```
+
+`cfg` parameter indicates the specific configuration of the plugin. The `stages` parameter indicates whether to add plug-ins after the corresponding stage of the backbone. The length of the list `stages` must be the same as the number of backbone stages.
+
+MMYOLO currently supports the following plugins:
+
+
+
+#### Compute the average training speed
+
+```shell
+mim run mmdet analyze_logs cal_train_time \
+ ${LOG} \ # path of train log in json format
+ [--include-outliers] # include the first value of every epoch when computing the average time
+```
+
+Examples:
+
+```shell
+mim run mmdet analyze_logs cal_train_time \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json
+```
+
+The output is expected to be like the following.
+
+```text
+-----Analyze train time of yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json-----
+slowest epoch 278, average time is 0.1705 s/iter
+fastest epoch 300, average time is 0.1510 s/iter
+time std over epochs is 0.0026
+average iter time: 0.1556 s/iter
+```
+
+### Print the whole config
+
+`print_config.py` in MMDetection prints the whole config verbatim, expanding all its imports. The command is as following.
+
+```shell
+mim run mmdet print_config \
+ ${CONFIG} \ # path of the config file
+ [--save-path] \ # save path of whole config, suffixed with .py, .json or .yml
+ [--cfg-options ${OPTIONS [OPTIONS...]}] # override some settings in the used config
+```
+
+Examples:
+
+```shell
+mim run mmdet print_config \
+ configs/yolov5/yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py \
+ --save-path ./work_dirs/yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py
+```
+
+Running the above command will save the `yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py` config file with the inheritance relationship expanded to \`\`yolov5_s-v61_syncbn_fast_1xb4-300e_balloon_whole.py`in the`./work_dirs\` folder.
diff --git a/docs/en/advanced_guides/plugins.md b/docs/en/advanced_guides/plugins.md
index 779d515c6..b488ab894 100644
--- a/docs/en/advanced_guides/plugins.md
+++ b/docs/en/advanced_guides/plugins.md
@@ -1 +1,34 @@
# Plugins
+
+MMYOLO supports adding plugins such as `none_local` and `dropblock` after different stages of Backbone. Users can directly manage plugins by modifying the plugins parameter of the backbone in the config. For example, add `GeneralizedAttention` plugins for `YOLOv5`. The configuration files are as follows:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+model = dict(
+ backbone=dict(
+ plugins=[
+ dict(
+ cfg=dict(
+ type='GeneralizedAttention',
+ spatial_range=-1,
+ num_heads=8,
+ attention_type='0011',
+ kv_stride=2),
+ stages=(False, False, True, True))
+ ]))
+```
+
+`cfg` parameter indicates the specific configuration of the plugin. The `stages` parameter indicates whether to add plug-ins after the corresponding stage of the backbone. The length of the list `stages` must be the same as the number of backbone stages.
+
+MMYOLO currently supports the following plugins:
+
+ +
+Then, you can clone the repositories to local:
+
+```shell
+git clone git@github.com:{username}/mmyolo.git
+```
+
+After that, you should add official repository as the upstream repository.
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmyolo
+```
+
+Check whether the remote repository has been added successfully by `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmyolo.git (fetch)
+origin git@github.com:{username}/mmyolo.git (push)
+upstream git@github.com:open-mmlab/mmyolo (fetch)
+upstream git@github.com:open-mmlab/mmyolo (push)
+```
+
+```{note}
+Here's a brief introduction to the origin and upstream. When we use "git clone", we create an "origin" remote by default, which points to the repository cloned from. As for "upstream", we add it ourselves to point to the target repository. Of course, if you don't like the name "upstream", you could name it as you wish. Usually, we'll push the code to "origin". If the pushed code conflicts with the latest code in official("upstream"), we should pull the latest code from upstream to resolve the conflicts, and then push to "origin" again. The posted Pull Request will be updated automatically.
+```
+
+#### 2. Configure pre-commit
+
+You should configure [pre-commit](https://pre-commit.com/#intro) in the local development environment to make sure the code style matches that of OpenMMLab. **Note**: The following code should be executed under the MMYOLO directory.
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+Check that pre-commit is configured successfully, and install the hooks defined in `.pre-commit-config.yaml`.
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+Then, you can clone the repositories to local:
+
+```shell
+git clone git@github.com:{username}/mmyolo.git
+```
+
+After that, you should add official repository as the upstream repository.
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmyolo
+```
+
+Check whether the remote repository has been added successfully by `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmyolo.git (fetch)
+origin git@github.com:{username}/mmyolo.git (push)
+upstream git@github.com:open-mmlab/mmyolo (fetch)
+upstream git@github.com:open-mmlab/mmyolo (push)
+```
+
+```{note}
+Here's a brief introduction to the origin and upstream. When we use "git clone", we create an "origin" remote by default, which points to the repository cloned from. As for "upstream", we add it ourselves to point to the target repository. Of course, if you don't like the name "upstream", you could name it as you wish. Usually, we'll push the code to "origin". If the pushed code conflicts with the latest code in official("upstream"), we should pull the latest code from upstream to resolve the conflicts, and then push to "origin" again. The posted Pull Request will be updated automatically.
+```
+
+#### 2. Configure pre-commit
+
+You should configure [pre-commit](https://pre-commit.com/#intro) in the local development environment to make sure the code style matches that of OpenMMLab. **Note**: The following code should be executed under the MMYOLO directory.
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+Check that pre-commit is configured successfully, and install the hooks defined in `.pre-commit-config.yaml`.
+
+```shell
+pre-commit run --all-files
+```
+
+ +
+
+
+ +
+```{note}
+Chinese users may fail to download the pre-commit hooks due to the network issue. In this case, you could download these hooks from gitee by setting the .pre-commit-config-zh-cn.yaml
+
+pre-commit install -c .pre-commit-config-zh-cn.yaml
+pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
+```
+
+If the installation process is interrupted, you can repeatedly run `pre-commit run ... ` to continue the installation.
+
+If the code does not conform to the code style specification, pre-commit will raise a warning and fixes some of the errors automatically.
+
+
+
+```{note}
+Chinese users may fail to download the pre-commit hooks due to the network issue. In this case, you could download these hooks from gitee by setting the .pre-commit-config-zh-cn.yaml
+
+pre-commit install -c .pre-commit-config-zh-cn.yaml
+pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
+```
+
+If the installation process is interrupted, you can repeatedly run `pre-commit run ... ` to continue the installation.
+
+If the code does not conform to the code style specification, pre-commit will raise a warning and fixes some of the errors automatically.
+
+ +
+If we want to commit our code bypassing the pre-commit hook, we can use the `--no-verify` option(**only for temporarily commit**.
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. Create a development branch
+
+After configuring the pre-commit, we should create a branch based on the dev branch to develop the new feature or fix the bug. The proposed branch name is `username/pr_name`
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+In subsequent development, if the dev branch of the local repository is behind the dev branch of "upstream", we need to pull the upstream for synchronization, and then execute the above command:
+
+```shell
+git pull upstream dev
+```
+
+#### 4. Commit the code and pass the unit test
+
+- MMYOLO introduces mypy to do static type checking to increase the robustness of the code. Therefore, we need to add Type Hints to our code and pass the mypy check. If you are not familiar with Type Hints, you can refer to [this tutorial](https://docs.python.org/3/library/typing.html).
+
+- The committed code should pass through the unit test
+
+ ```shell
+ # Pass all unit tests
+ pytest tests
+
+ # Pass the unit test of yolov5_coco dataset
+ pytest tests/test_datasets/test_yolov5_coco.py
+ ```
+
+ If the unit test fails for lack of dependencies, you can install the dependencies referring to the [guidance](#unit-test)
+
+- If the documents are modified/added, we should check the rendering result referring to [guidance](#document-rendering)
+
+#### 5. Push the code to remote
+
+We could push the local commits to remote after passing through the check of unit test and pre-commit. You can associate the local branch with remote branch by adding `-u` option.
+
+```shell
+git push -u origin {branch_name}
+```
+
+This will allow you to use the `git push` command to push code directly next time, without having to specify a branch or the remote repository.
+
+#### 6. Create a Pull Request
+
+(1) Create a pull request in GitHub's Pull request interface
+
+
+
+If we want to commit our code bypassing the pre-commit hook, we can use the `--no-verify` option(**only for temporarily commit**.
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. Create a development branch
+
+After configuring the pre-commit, we should create a branch based on the dev branch to develop the new feature or fix the bug. The proposed branch name is `username/pr_name`
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+In subsequent development, if the dev branch of the local repository is behind the dev branch of "upstream", we need to pull the upstream for synchronization, and then execute the above command:
+
+```shell
+git pull upstream dev
+```
+
+#### 4. Commit the code and pass the unit test
+
+- MMYOLO introduces mypy to do static type checking to increase the robustness of the code. Therefore, we need to add Type Hints to our code and pass the mypy check. If you are not familiar with Type Hints, you can refer to [this tutorial](https://docs.python.org/3/library/typing.html).
+
+- The committed code should pass through the unit test
+
+ ```shell
+ # Pass all unit tests
+ pytest tests
+
+ # Pass the unit test of yolov5_coco dataset
+ pytest tests/test_datasets/test_yolov5_coco.py
+ ```
+
+ If the unit test fails for lack of dependencies, you can install the dependencies referring to the [guidance](#unit-test)
+
+- If the documents are modified/added, we should check the rendering result referring to [guidance](#document-rendering)
+
+#### 5. Push the code to remote
+
+We could push the local commits to remote after passing through the check of unit test and pre-commit. You can associate the local branch with remote branch by adding `-u` option.
+
+```shell
+git push -u origin {branch_name}
+```
+
+This will allow you to use the `git push` command to push code directly next time, without having to specify a branch or the remote repository.
+
+#### 6. Create a Pull Request
+
+(1) Create a pull request in GitHub's Pull request interface
+
+ +
+(2) Modify the PR description according to the guidelines so that other developers can better understand your changes
+
+
+
+(2) Modify the PR description according to the guidelines so that other developers can better understand your changes
+
+ +
+Find more details about Pull Request description in [pull request guidelines](#pr-specs).
+
+**note**
+
+(a) The Pull Request description should contain the reason for the change, the content of the change, and the impact of the change, and be associated with the relevant Issue (see [documentation](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue)
+
+(b) If it is your first contribution, please sign the CLA
+
+
+
+Find more details about Pull Request description in [pull request guidelines](#pr-specs).
+
+**note**
+
+(a) The Pull Request description should contain the reason for the change, the content of the change, and the impact of the change, and be associated with the relevant Issue (see [documentation](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue)
+
+(b) If it is your first contribution, please sign the CLA
+
+ +
+(c) Check whether the Pull Request pass through the CI
+
+
+
+(c) Check whether the Pull Request pass through the CI
+
+ +
+MMYOLO will run unit test for the posted Pull Request on Linux, based on different versions of Python, and PyTorch to make sure the code is correct. We can see the specific test information by clicking `Details` in the above image so that we can modify the code.
+
+(3) If the Pull Request passes the CI, then you can wait for the review from other developers. You'll modify the code based on the reviewer's comments, and repeat the steps [4](#4-commit-the-code-and-pass-the-unit-test)-[5](#5-push-the-code-to-remote) until all reviewers approve it. Then, we will merge it ASAP.
+
+
+
+MMYOLO will run unit test for the posted Pull Request on Linux, based on different versions of Python, and PyTorch to make sure the code is correct. We can see the specific test information by clicking `Details` in the above image so that we can modify the code.
+
+(3) If the Pull Request passes the CI, then you can wait for the review from other developers. You'll modify the code based on the reviewer's comments, and repeat the steps [4](#4-commit-the-code-and-pass-the-unit-test)-[5](#5-push-the-code-to-remote) until all reviewers approve it. Then, we will merge it ASAP.
+
+ +
+#### 7. Resolve conflicts
+
+If your local branch conflicts with the latest dev branch of "upstream", you'll need to resolove them. There are two ways to do this:
+
+```shell
+git fetch --all --prune
+git rebase upstream/dev
+```
+
+or
+
+```shell
+git fetch --all --prune
+git merge upstream/dev
+```
+
+If you are very good at handling conflicts, then you can use rebase to resolve conflicts, as this will keep your commit logs tidy. If you are unfamiliar with `rebase`, you can use `merge` to resolve conflicts.
+
+### Guidance
+
+#### Unit test
+
+We should also make sure the committed code will not decrease the coverage of unit test, we could run the following command to check the coverage of unit test:
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### Document rendering
+
+If the documents are modified/added, we should check the rendering result. We could install the dependencies and run the following command to render the documents and check the results:
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### Code style
+
+#### Python
+
+We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
+
+We use the following tools for linting and formatting:
+
+- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
+- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
+- [yapf](https://github.com/google/yapf): A formatter for Python files.
+- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
+- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
+- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
+
+Style configurations of yapf and isort can be found in [setup.cfg](./setup.cfg).
+
+We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
+fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
+The config for a pre-commit hook is stored in [.pre-commit-config](./.pre-commit-config.yaml).
+
+#### C++ and CUDA
+
+We follow the [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html).
+
+### PR Specs
+
+1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
+
+2. One short-time branch should be matched with only one PR
+
+3. Accomplish a detailed change in one PR. Avoid large PR
+
+ - Bad: Support Faster R-CNN
+ - Acceptable: Add a box head to Faster R-CNN
+ - Good: Add a parameter to box head to support custom conv-layer number
+
+4. Provide clear and significant commit message
+
+5. Provide clear and meaningful PR description
+
+ - Task name should be clarified in title. The general format is: \[Prefix\] Short description of the PR (Suffix)
+ - Prefix: add new feature \[Feature\], fix bug \[Fix\], related to documents \[Docs\], in developing \[WIP\] (which will not be reviewed temporarily)
+ - Introduce main changes, results and influences on other modules in short description
+ - Associate related issues and pull requests with a milestone
diff --git a/docs/en/deploy/basic_deployment_guide.md b/docs/en/deploy/basic_deployment_guide.md
index 19e84788e..69258f540 100644
--- a/docs/en/deploy/basic_deployment_guide.md
+++ b/docs/en/deploy/basic_deployment_guide.md
@@ -1 +1,287 @@
# Basic Deployment Guide
+
+## Introduction of MMDeploy
+
+MMDeploy is an open-source deep learning model deployment toolset. It is a part of the [OpenMMLab](https://openmmlab.com/) project, and provides **a unified experience of exporting different models** to various platforms and devices of the OpenMMLab series libraries. Using MMDeploy, developers can easily export the specific compiled SDK they need from the training result, which saves a lot of effort.
+
+More detailed introduction and guides can be found [here](https://github.com/open-mmlab/mmdeploy/blob/dev-1.x/docs/en/get_started.md)
+
+## Supported Algorithms
+
+Currently our deployment kit supports on the following models and backends:
+
+| Model | Task | OnnxRuntime | TensorRT | Model config |
+| :----- | :-------------- | :---------: | :------: | :---------------------------------------------------------------------: |
+| YOLOv5 | ObjectDetection | Y | Y | [config](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov5) |
+| YOLOv6 | ObjectDetection | Y | Y | [config](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov6) |
+| YOLOX | ObjectDetection | Y | Y | [config](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolox) |
+| RTMDet | ObjectDetection | Y | Y | [config](https://github.com/open-mmlab/mmyolo/tree/main/configs/rtmdet) |
+
+Note: ncnn and other inference backends support are coming soon.
+
+## How to Write Config for MMYOLO
+
+All config files related to the deployment are located at [`configs/deploy`](../../../configs/deploy/).
+
+You only need to change the relative data processing part in the model config file to support either static or dynamic input for your model. Besides, MMDeploy integrates the post-processing parts as customized ops, you can modify the strategy in `post_processing` parameter in `codebase_config`.
+
+Here is the detail description:
+
+```python
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+```
+
+- `score_threshold`: set the score threshold to filter candidate bboxes before `nms`
+- `confidence_threshold`: set the confidence threshold to filter candidate bboxes before `nms`
+- `iou_threshold`: set the `iou` threshold for removing duplicates in `nums`
+- `max_output_boxes_per_class`: set the maximum number of bboxes for each class
+- `pre_top_k`: set the number of fixedcandidate bboxes before `nms`, sorted by scores
+- `keep_top_k`: set the number of output candidate bboxs after `nms`
+- `background_label_id`: set to `-1` as MMYOLO has no background class information
+
+### Configuration for Static Inputs
+
+#### 1. Model Config
+
+Taking `YOLOv5` of MMYOLO as an example, here are the details:
+
+```python
+_base_ = '../../yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+test_pipeline = [
+ dict(type='LoadImageFromFile', file_client_args=_base_.file_client_args),
+ dict(
+ type='LetterResize',
+ scale=_base_.img_scale,
+ allow_scale_up=False,
+ use_mini_pad=False,
+ ),
+ dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param'))
+]
+
+test_dataloader = dict(
+ dataset=dict(pipeline=test_pipeline, batch_shapes_cfg=None))
+```
+
+`_base_ = '../../yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'` inherits the model config in the training stage.
+
+`test_pipeline` adds the data processing piple for the deployment, `LetterResize` controls the size of the input images and the input for the converted model
+
+`test_dataloader` adds the dataloader config for the deployment, `batch_shapes_cfg` decides whether to use the `batch_shapes` strategy. More details can be found at [yolov5 configs](../user_guides/config.md)
+
+#### 2. Deployment Config
+
+Here we still use the `YOLOv5` in MMYOLO as the example. We can use [`detection_onnxruntime_static.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_onnxruntime_static.py) as the config to deploy \`YOLOv5\` to \`ONNXRuntim\` with static inputs.
+
+```python
+_base_ = ['./base_static.py']
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+backend_config = dict(type='onnxruntime')
+```
+
+`backend_config` indicates the deployment backend with `type='onnxruntime'`, other information can be referred from the third section.
+
+To deploy the `YOLOv5` to `TensorRT`, please refer to the [`detection_tensorrt_static-640x640.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_tensorrt_static-640x640.py) as follows.
+
+```python
+_base_ = ['./base_static.py']
+onnx_config = dict(input_shape=(640, 640))
+backend_config = dict(
+ type='tensorrt',
+ common_config=dict(fp16_mode=False, max_workspace_size=1 << 30),
+ model_inputs=[
+ dict(
+ input_shapes=dict(
+ input=dict(
+ min_shape=[1, 3, 640, 640],
+ opt_shape=[1, 3, 640, 640],
+ max_shape=[1, 3, 640, 640])))
+ ])
+use_efficientnms = False
+```
+
+`backend_config` indices the backend with `type=‘tensorrt’`.
+
+Different from `ONNXRuntime` deployment configuration, `TensorRT` needs to specify the input image size and the parameters required to build the engine file, including:
+
+- `onnx_config` specifies the input shape as `input_shape=(640, 640)`
+- `fp16_mode=False` and `max_workspace_size=1 << 30` in `backend_config['common_config']` indicates whether to build the engine in the parameter format of `fp16`, and the maximum video memory for the current `gpu` device, respectively. The unit is in `GB`. For detailed configuration of `fp16`, please refer to the [`detection_tensorrt-fp16_static-640x640.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_tensorrt-fp16_static-640x640.py)
+- The `min_shape`/`opt_shape`/`max_shape` in `backend_config['model_inputs']['input_shapes']['input']` should remain the same under static input, the default is `[1, 3, 640, 640]`.
+
+`use_efficientnms` is a new configuration introduced by the `MMYOLO` series, indicating whether to enable `Efficient NMS Plugin` to replace `TRTBatchedNMS plugin` in `MMDeploy` when exporting `onnx`.
+
+You can refer to the official [efficient NMS plugins](https://github.com/NVIDIA/TensorRT/blob/main/plugin/efficientNMSPlugin/README.md) by `TensorRT` for more details.
+
+Note: this out-of-box feature is **only available in TensorRT>=8.0**, no need to compile it by yourself.
+
+### Configuration for Dynamic Inputs
+
+#### 1. Model Config
+
+When you deploy a dynamic input model, you don't need to modify any model configuration files but the deployment configuration files.
+
+#### 2. Deployment Config
+
+To deploy the `YOLOv5` in MMYOLO to `ONNXRuntime`, please refer to the [`detection_onnxruntime_dynamic.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_onnxruntime_dynamic.py).
+
+```python
+_base_ = ['./base_dynamic.py']
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+backend_config = dict(type='onnxruntime')
+```
+
+`backend_config` indicates the backend with `type='onnxruntime'`. Other parameters stay the same as the static input section.
+
+To deploy the `YOLOv5` to `TensorRT`, please refer to the [`detection_tensorrt_dynamic-192x192-960x960.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_tensorrt_dynamic-192x192-960x960.py).
+
+```python
+_base_ = ['./base_dynamic.py']
+backend_config = dict(
+ type='tensorrt',
+ common_config=dict(fp16_mode=False, max_workspace_size=1 << 30),
+ model_inputs=[
+ dict(
+ input_shapes=dict(
+ input=dict(
+ min_shape=[1, 3, 192, 192],
+ opt_shape=[1, 3, 640, 640],
+ max_shape=[1, 3, 960, 960])))
+ ])
+use_efficientnms = False
+```
+
+`backend_config` indicates the backend with `type='tensorrt'`. Since the dynamic and static inputs are different in `TensorRT`, please check the details at [TensorRT dynamic input official introduction](https://docs.nvidia.com/deeplearning/tensorrt/archives/tensorrt-843/developer-guide/index.html#work_dynamic_shapes).
+
+`TensorRT` deployment requires you to specify `min_shape`, `opt_shape` , and `max_shape`. `TensorRT` limits the size of the input image between `min_shape` and `max_shape`.
+
+`min_shape` is the minimum size of the input image. `opt_shape` is the common size of the input image, inference performance is best under this size. `max_shape` is the maximum size of the input image.
+
+`use_efficientnms` configuration is the same as the `TensorRT` static input configuration in the previous section.
+
+### INT8 Quantization Support
+
+Note: Int8 quantization support will soon be released.
+
+## How to Convert Model
+
+### Usage
+
+Set the root directory of `MMDeploy` as an env parameter `MMDEPLOY_DIR` using `export MMDEPLOY_DIR=/the/root/path/of/MMDeploy` command.
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ ${DEPLOY_CFG_PATH} \
+ ${MODEL_CFG_PATH} \
+ ${MODEL_CHECKPOINT_PATH} \
+ ${INPUT_IMG} \
+ --test-img ${TEST_IMG} \
+ --work-dir ${WORK_DIR} \
+ --calib-dataset-cfg ${CALIB_DATA_CFG} \
+ --device ${DEVICE} \
+ --log-level INFO \
+ --show \
+ --dump-info
+```
+
+### Parameter Description
+
+- `deploy_cfg`: set the deployment config path of MMDeploy for the model, including the type of inference framework, whether quantize, whether the input shape is dynamic, etc. There may be a reference relationship between configuration files, e.g. `configs/deploy/detection_onnxruntime_static.py`
+- `model_cfg`: set the MMYOLO model config path, e.g. `configs/deploy/model/yolov5_s-deploy.py`, regardless of the path to MMDeploy
+- `checkpoint`: set the torch model path. It can start with `http/https`, more details are available in `mmengine.fileio` apis
+- `img`: set the path to the image or point cloud file used for testing during model conversion
+- `--test-img`: set the image file that used to test model. If not specified, it will be set to `None`
+- `--work-dir`: set the work directory that used to save logs and models
+- `--calib-dataset-cfg`: use for calibration only for INT8 mode. If not specified, it will be set to None and use “val” dataset in model config for calibration
+- `--device`: set the device used for model conversion. The default is `cpu`, for TensorRT used `cuda:0`
+- `--log-level`: set log level which in `'CRITICAL', 'FATAL', 'ERROR', 'WARN', 'WARNING', 'INFO', 'DEBUG', 'NOTSET'`. If not specified, it will be set to `INFO`
+- `--show`: show the result on screen or not
+- `--dump-info`: output SDK information or not
+
+## How to Evaluate Model
+
+### Usage
+
+After the model is converted to your backend, you can use `${MMDEPLOY_DIR}/tools/test.py` to evaluate the performance.
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ ${DEPLOY_CFG} \
+ ${MODEL_CFG} \
+ --model ${BACKEND_MODEL_FILES} \
+ [--out ${OUTPUT_PKL_FILE}] \
+ [--format-only] \
+ [--metrics ${METRICS}] \
+ [--show] \
+ [--show-dir ${OUTPUT_IMAGE_DIR}] \
+ [--show-score-thr ${SHOW_SCORE_THR}] \
+ --device ${DEVICE} \
+ [--cfg-options ${CFG_OPTIONS}] \
+ [--metric-options ${METRIC_OPTIONS}]
+ [--log2file work_dirs/output.txt]
+ [--batch-size ${BATCH_SIZE}]
+ [--speed-test] \
+ [--warmup ${WARM_UP}] \
+ [--log-interval ${LOG_INTERVERL}]
+```
+
+### Parameter Description
+
+- `deploy_cfg`: set the deployment config file path
+- `model_cfg`: set the MMYOLO model config file path
+- `--model`: set the converted model. For example, if we exported a TensorRT model, we need to pass in the file path with the suffix ".engine"
+- `--out`: save the output result in pickle format, use only when you need it
+- `--format-only`: format the output without evaluating it. It is useful when you want to format the result into a specific format and submit it to a test server
+- `--metrics`: use the specific metric supported in MMYOLO to evaluate, such as "proposal" in COCO format data.
+- `--show`: show the evaluation result on screen or not
+- `--show-dir`: save the evaluation result to this directory, valid only when specified
+- `--show-score-thr`: show the threshold for the detected bboxes or not
+- `--device`: indicate the device to run the model. Note that some backends limit the running devices. For example, TensorRT must run on CUDA
+- `--cfg-options`: pass in additional configs, which will override the current deployment configs
+- `--metric-options`: add custom options for metrics. The key-value pair format in xxx=yyy will be the kwargs of the dataset.evaluate() method
+- `--log2file`: save the evaluation results (with the speed) to a file
+- `--batch-size`: set the batch size for inference, which will override the `samples_per_gpu` in data config. The default value is `1`, however, not every model supports `batch_size > 1`
+- `--speed-test`: test the inference speed or not
+- `--warmup`: warm up before speed test or not, works only when `speed-test` is specified
+- `--log-interval`: set the interval between each log, works only when `speed-test` is specified
+
+Note: other parameters in `${MMDEPLOY_DIR}/tools/test.py` are used for speed test, they will not affect the evaluation results.
diff --git a/docs/en/deploy/yolov5_deployment.md b/docs/en/deploy/yolov5_deployment.md
index c2683d761..f0e319674 100644
--- a/docs/en/deploy/yolov5_deployment.md
+++ b/docs/en/deploy/yolov5_deployment.md
@@ -1 +1,432 @@
# YOLOv5 Deployment
+
+Please check the [basic_deployment_guide](basic_deployment_guide.md) to get familiar with the configurations.
+
+## Model Training and Validation
+
+The details of training and validation can be found at [yolov5_tutorial](../user_guides/yolov5_tutorial.md).
+
+## MMDeploy Environment Setup
+
+Please check the installation document of `MMDeploy` at [build_from_source](https://github.com/open-mmlab/mmdeploy/blob/dev-1.x/docs/en/01-how-to-build/build_from_source.md). Please build both `MMDeploy` and the customized Ops to your specific platform.
+
+Note: please check at `MMDeploy` [FAQ](https://github.com/open-mmlab/mmdeploy/blob/dev-1.x/docs/en/faq.md) or create new issues in `MMDeploy` when you come across any problems.
+
+## How to Prepare Configuration File
+
+This deployment guide uses the `YOLOv5` model trained on `COCO` dataset in MMYOLO to illustrate the whole process, including both static and dynamic inputs and different procedures for `TensorRT` and `ONNXRuntime`.
+
+### For Static Input
+
+#### 1. Model Config
+
+To deploy the model with static inputs, you need to ensure that the model inputs are in fixed size, e.g. the input size is set to `640x640` while uploading data in the test pipeline and test dataloader.
+
+Here is a example in [`yolov5_s-static.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/deploy/model/yolov5_s-static.py)
+
+```python
+_base_ = '../../yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+test_pipeline = [
+ dict(type='LoadImageFromFile', file_client_args=_base_.file_client_args),
+ dict(
+ type='LetterResize',
+ scale=_base_.img_scale,
+ allow_scale_up=False,
+ use_mini_pad=False,
+ ),
+ dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param'))
+]
+
+test_dataloader = dict(
+ dataset=dict(pipeline=test_pipeline, batch_shapes_cfg=None))
+```
+
+As the `YOLOv5` will turn on `allow_scale_up` and `use_mini_pad` during the test to change the size of the input image in order to achieve higher accuracy. However, it will cause the input size mismatch problem when deploying in the static input model.
+
+Compared with the original configuration file, this configuration has been modified as follows:
+
+- turn off the settings related to reshaping the image in `test_pipeline`, e.g. setting `allow_scale_up=False` and `use_mini_pad=False` in `LetterResize`
+- turn off the `batch_shapes` in `test_dataloader` as `batch_shapes_cfg=None`.
+
+#### 2. Deployment Cofnig
+
+To deploy the model to `ONNXRuntime`, please refer to the [`detection_onnxruntime_static.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/deploy/detection_onnxruntime_static.py) as follows:
+
+```python
+_base_ = ['./base_static.py']
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+backend_config = dict(type='onnxruntime')
+```
+
+The `post_processing` in the default configuration aligns the accuracy of the current model with the trained `pytorch` model. If you need to modify the relevant parameters, you can refer to the detailed introduction of [dasic_deployment_guide](basic_deployment_guide.md).
+
+To deploy the model to `TensorRT`, please refer to the [`detection_tensorrt_static-640x640.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/deploy/detection_tensorrt_static-640x640.p).
+
+```python
+_base_ = ['./base_static.py']
+onnx_config = dict(input_shape=(640, 640))
+backend_config = dict(
+ type='tensorrt',
+ common_config=dict(fp16_mode=False, max_workspace_size=1 << 30),
+ model_inputs=[
+ dict(
+ input_shapes=dict(
+ input=dict(
+ min_shape=[1, 3, 640, 640],
+ opt_shape=[1, 3, 640, 640],
+ max_shape=[1, 3, 640, 640])))
+ ])
+use_efficientnms = False
+```
+
+In this guide, we use the default settings such as `input_shape=(640, 640)` and `fp16_mode=False` to build in network in `fp32` mode. Moreover, we set `max_workspace_size=1 << 30` for the gpu memory which allows `TensorRT` to build the engine with maximum `1GB` memory.
+
+### For Dynamic Input
+
+#### 1. Model Confige
+
+As `TensorRT` limits the minimum and maximum input size, we can use any size for the inputs when deploy the model in dynamic mode. In this way, we can keep the default settings in [`yolov5_s-v61_syncbn_8xb16-300e_coco.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py). The data processing and dataloader parts are as follows.
+
+```python
+batch_shapes_cfg = dict(
+ type='BatchShapePolicy',
+ batch_size=val_batch_size_per_gpu,
+ img_size=img_scale[0],
+ size_divisor=32,
+ extra_pad_ratio=0.5)
+
+test_pipeline = [
+ dict(type='LoadImageFromFile', file_client_args=_base_.file_client_args),
+ dict(type='YOLOv5KeepRatioResize', scale=img_scale),
+ dict(
+ type='LetterResize',
+ scale=img_scale,
+ allow_scale_up=False,
+ pad_val=dict(img=114)),
+ dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param'))
+]
+
+val_dataloader = dict(
+ batch_size=val_batch_size_per_gpu,
+ num_workers=val_num_workers,
+ persistent_workers=persistent_workers,
+ pin_memory=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ test_mode=True,
+ data_prefix=dict(img='val2017/'),
+ ann_file='annotations/instances_val2017.json',
+ pipeline=test_pipeline,
+ batch_shapes_cfg=batch_shapes_cfg))
+```
+
+We use `allow_scale_up=False` to control when the input small images will be upsampled or not in the initialization of `LetterResize`. At the same time, the default `use_mini_pad=False` turns off the minimum padding strategy of the image, and `val_dataloader['dataset']` is passed in` batch_shapes_cfg=batch_shapes_cfg` to ensure that the minimum padding is performed according to the input size in `batch`. These configs will change the dimensions of the input image, so the converted model can support dynamic inputs according to the above dataset loader when testing.
+
+#### 2. Deployment Cofnig
+
+To deploy the model to `ONNXRuntime`, please refer to the [`detection_onnxruntime_dynamic.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_onnxruntime_dynamic.py) for more details.
+
+```python
+_base_ = ['./base_dynamic.py']
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+backend_config = dict(type='onnxruntime')
+```
+
+Differs from the static input config we introduced in previous section, dynamic input config additionally inherits the `dynamic_axes`. The rest of the configuration stays the same as the static inputs.
+
+To deploy the model to `TensorRT`, please refer to the [`detection_tensorrt_dynamic-192x192-960x960.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/deploy/detection_tensorrt_dynamic-192x192-960x960.py) for more details.
+
+```python
+_base_ = ['./base_dynamic.py']
+backend_config = dict(
+ type='tensorrt',
+ common_config=dict(fp16_mode=False, max_workspace_size=1 << 30),
+ model_inputs=[
+ dict(
+ input_shapes=dict(
+ input=dict(
+ min_shape=[1, 3, 192, 192],
+ opt_shape=[1, 3, 640, 640],
+ max_shape=[1, 3, 960, 960])))
+ ])
+use_efficientnms = False
+```
+
+In our example, the network is built in `fp32` mode as `fp16_mode=False`, and the maximum graphic memory is `1GB` for building the `TensorRT` engine as `max_workspace_size=1 << 30`.
+
+At the same time, `min_shape=[1, 3, 192, 192]`, `opt_shape=[1, 3, 640, 640]`, and `max_shape=[1, 3, 960, 960]` in the default setting set the model with minimum input size to `192x192`, the maximum size to `960x960`, and the most common size to `640x640`.
+
+When you deploy the model, it can adopt to the input image dimensions automatically.
+
+## How to Convert Model
+
+Note: The `MMDeploy` root directory used in this guide is `/home/openmmlab/dev/mmdeploy`, please modify it to your `MMDeploy` directory.
+
+Use the following command to download the pretrained YOLOv5 weight and save it to your device:
+
+```shell
+wget https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth -O /home/openmmlab/dev/mmdeploy/yolov5s.pth
+```
+
+Set the relevant env parameters using the following command as well:
+
+```shell
+export MMDEPLOY_DIR=/home/openmmlab/dev/mmdeploy
+export PATH_TO_CHECKPOINTS=/home/openmmlab/dev/mmdeploy/yolov5s.pth
+```
+
+### YOLOv5 Static Model Deployment
+
+#### ONNXRuntime
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir \
+ --show \
+ --device cpu
+```
+
+#### TensorRT
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir \
+ --show \
+ --device cuda:0
+```
+
+### YOLOv5 Dynamic Model Deployment
+
+#### ONNXRuntime
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_onnxruntime_dynamic.py \
+ configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir \
+ --show \
+ --device cpu
+```
+
+#### TensorRT
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_tensorrt_dynamic-192x192-960x960.py \
+ configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir \
+ --show \
+ --device cuda:0
+```
+
+When convert the model using the above commands, you will find the following files under the `work_dir` folder:
+
+
+
+or
+
+
+
+After exporting to `onnxruntime`, you will get three files as shown in Figure 1, where `end2end.onnx` represents the exported `onnxruntime` model.
+
+After exporting to `TensorRT`, you will get the four files as shown in Figure 2, where `end2end.onnx` represents the exported intermediate model. `MMDeploy` uses this model to automatically continue to convert the `end2end.engine` model for `TensorRT `Deployment.
+
+## How to Evaluate Model
+
+After successfully convert the model, you can use `${MMDEPLOY_DIR}/tools/test.py` to evaluate the converted model. The following part shows how to evaluate the static models of `ONNXRuntime` and `TensorRT`. For dynamic model evaluation, please modify the configuration of the inputs.
+
+#### ONNXRuntime
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ --model work_dir/end2end.onnx \
+ --device cpu \
+ --work-dir work_dir
+```
+
+Once the process is done, you can get the output results as this:
+
+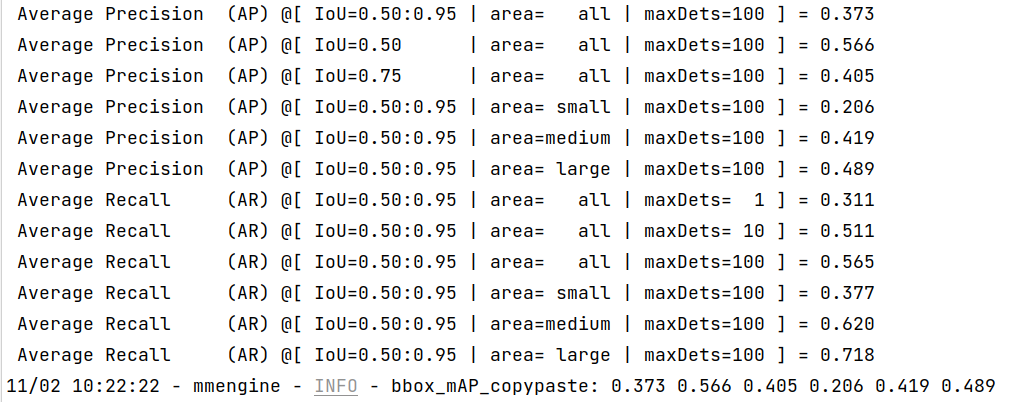
+
+#### TensorRT
+
+Note: `TensorRT` must run on `CUDA` devices!
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ --model work_dir/end2end.engine \
+ --device cuda:0 \
+ --work-dir work_dir
+```
+
+Once the process is done, you can get the output results as this:
+
+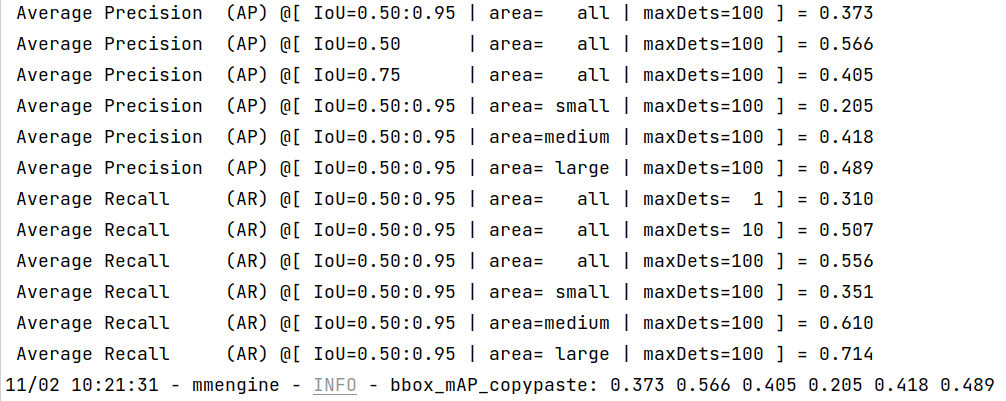
+
+More useful evaluation tools will be released in the future.
+
+# Deploy using Docker
+
+`MMYOLO` provides a deployment [`Dockerfile`](https://github.com/open-mmlab/mmyolo/blob/main/docker/Dockerfile_deployment) for deployment purpose. Please make sure your local docker version is greater than `19.03`.
+
+Note: users in mainland China can comment out the `Optional` part in the dockerfile for better experience.
+
+```dockerfile
+# (Optional)
+RUN sed -i 's/http:\/\/archive.ubuntu.com\/ubuntu\//http:\/\/mirrors.aliyun.com\/ubuntu\//g' /etc/apt/sources.list && \
+ pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
+```
+
+To build the docker image,
+
+```bash
+# build an image with PyTorch 1.12, CUDA 11.6, TensorRT 8.2.4 ONNXRuntime 1.8.1
+docker build -f docker/Dockerfile_deployment -t mmyolo:v1 .
+```
+
+To run the docker image,
+
+```bash
+export DATA_DIR=/path/to/your/dataset
+docker run --gpus all --shm-size=8g -it --name mmyolo -v ${DATA_DIR}:/openmmlab/mmyolo/data/coco mmyolo:v1
+```
+
+`DATA_DIR` is the path of your `COCO` dataset.
+
+We provide a `script.sh` file for you which runs the whole pipeline. Create the script under `/openmmlab/mmyolo` directory in your docker container using the following content.
+
+```bash
+#!/bin/bash
+wget -q https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth \
+ -O yolov5s.pth
+export MMDEPLOY_DIR=/openmmlab/mmdeploy
+export PATH_TO_CHECKPOINTS=/openmmlab/mmyolo/yolov5s.pth
+
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir_trt \
+ --device cuda:0
+
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ --model work_dir_trt/end2end.engine \
+ --device cuda:0 \
+ --work-dir work_dir_trt
+
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir_ort \
+ --device cpu
+
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ --model work_dir_ort/end2end.onnx \
+ --device cpu \
+ --work-dir work_dir_ort
+```
+
+Then run the script under `/openmmlab/mmyolo`.
+
+```bash
+sh script.sh
+```
+
+This script automatically downloads the `YOLOv5` pretrained weights in `MMYOLO` and convert the model using `MMDeploy`. You will get the output result as follows.
+
+- TensorRT:
+
+ 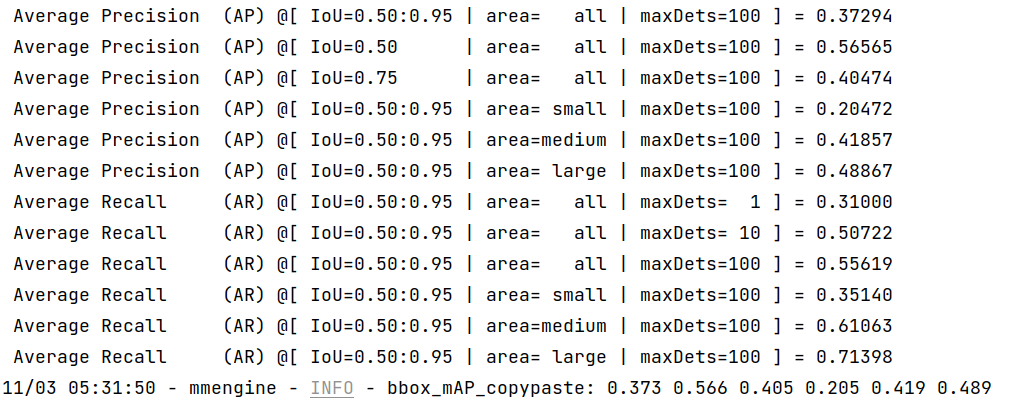
+
+- ONNXRuntime:
+
+ 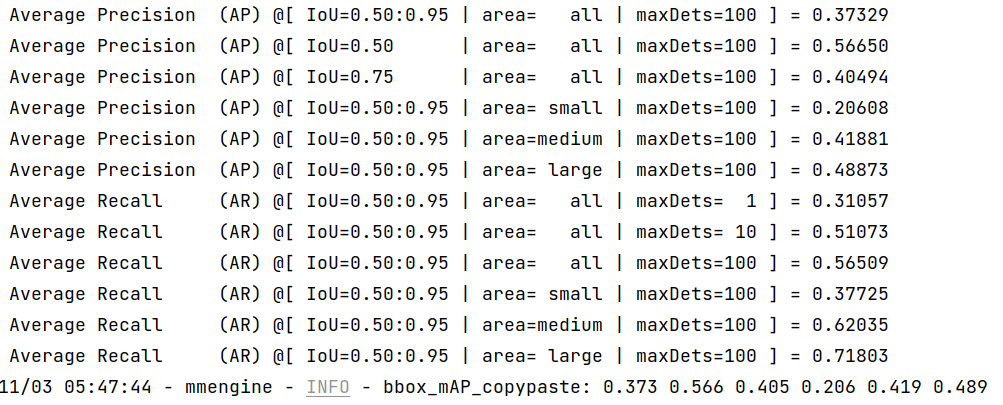
+
+We can see from the above images that the accuracy of converted models shrink within 1% compared with the pytorch [MMYOLO-YOLOv5](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov5#results-and-models) models.
+
+If you need to test the inference speed of the converted model, you can use the following commands.
+
+- TensorRT
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/profiler.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ data/coco/val2017 \
+ --model work_dir_trt/end2end.engine \
+ --device cuda:0
+```
+
+- ONNXRuntime
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/profiler.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ data/coco/val2017 \
+ --model work_dir_ort/end2end.onnx \
+ --device cpu
+```
+
+## Model Inference
+
+TODO
diff --git a/docs/en/get_started.md b/docs/en/get_started.md
index dd1028ace..ab04f5ba3 100644
--- a/docs/en/get_started.md
+++ b/docs/en/get_started.md
@@ -7,6 +7,7 @@ Compatible MMEngine, MMCV and MMDetection versions are shown as below. Please in
| MMYOLO version | MMDetection version | MMEngine version | MMCV version |
| :------------: | :----------------------: | :----------------------: | :---------------------: |
| main | mmdet>=3.0.0rc3, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+| 0.2.0 | mmdet>=3.0.0rc3, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
| 0.1.3 | mmdet>=3.0.0rc3, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
| 0.1.2 | mmdet>=3.0.0rc2, \<3.1.0 | mmengine>=0.3.0, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
| 0.1.1 | mmdet==3.0.0rc1 | mmengine>=0.1.0, \<0.2.0 | mmcv>=2.0.0rc0, \<2.1.0 |
diff --git a/docs/en/index.rst b/docs/en/index.rst
index 8c60978c4..5082b8427 100644
--- a/docs/en/index.rst
+++ b/docs/en/index.rst
@@ -51,6 +51,13 @@ Welcome to MMYOLO's documentation!
notes/changelog.md
notes/faq.md
+.. toctree::
+ :maxdepth: 2
+ :caption: Community
+
+ community/contributing.md
+ community/code_style.md
+
.. toctree::
:caption: Switch Languag
diff --git a/docs/en/notes/changelog.md b/docs/en/notes/changelog.md
index 90175b7b1..fc09f75d2 100644
--- a/docs/en/notes/changelog.md
+++ b/docs/en/notes/changelog.md
@@ -1,5 +1,55 @@
# Changelog
+## v0.2.0(1/12/2022)
+
+### Highlights
+
+1. Support [YOLOv7](https://github.com/open-mmlab/mmyolo/tree/dev/configs/yolov7) P5 and P6 model
+2. Support [YOLOv6](https://github.com/open-mmlab/mmyolo/blob/dev/configs/yolov6/README.md) ML model
+3. Support [Grad-Based CAM and Grad-Free CAM](https://github.com/open-mmlab/mmyolo/blob/dev/demo/boxam_vis_demo.py)
+4. Support [large image inference](https://github.com/open-mmlab/mmyolo/blob/dev/demo/large_image_demo.py) based on sahi
+5. Add [easydeploy](https://github.com/open-mmlab/mmyolo/blob/dev/projects/easydeploy/README.md) project under the projects folder
+6. Add [custom dataset guide](https://github.com/open-mmlab/mmyolo/blob/dev/docs/zh_cn/user_guides/custom_dataset.md)
+
+### New Features
+
+1. `browse_dataset.py` script supports visualization of original image, data augmentation and intermediate results (#304)
+2. Add flag to output labelme label file in `image_demo.py` (#288, #314)
+3. Add `labelme2coco` script (#308, #313)
+4. Add split COCO dataset script (#311)
+5. Add two examples of backbone replacement in `how-to.md` and update `plugin.md` (#291)
+6. Add `contributing.md` and `code_style.md` (#322)
+7. Add docs about how to use mim to run scripts across libraries (#321)
+8. Support `YOLOv5` deployment at RV1126 device (#262)
+
+### Bug Fixes
+
+1. Fix MixUp padding error (#319)
+2. Fix scale factor order error of `LetterResize` and `YOLOv5KeepRatioResize` (#305)
+3. Fix training errors of `YOLOX Nano` model (#285)
+4. Fix `RTMDet` deploy error (#287)
+5. Fix int8 deploy config (#315)
+6. Fix `make_stage_plugins` doc in `basebackbone` (#296)
+7. Enable switch to deploy when create pytorch model in deployment (#324)
+8. Fix some errors in `RTMDet` model graph (#317)
+
+### Improvements
+
+1. Add option of json output in `test.py` (#316)
+2. Add area condition in `extract_subcoco.py` script (#286)
+3. Deployment doc translation (#289)
+4. Add YOLOv6 description overview doc (#252)
+5. Improve `config.md` (#297, #303)
+ 6Add mosaic9 graph in docstring (#307)
+6. Improve `browse_coco_json.py` script args (#309)
+7. Refactor some functions in `dataset_analysis.py` to be more general (#294)
+
+#### Contributors
+
+A total of 14 developers contributed to this release.
+
+Thank @fcakyon, @matrixgame2018, @MambaWong, @imAzhou, @triple-Mu, @RangeKing, @PeterH0323, @xin-li-67, @kitecats, @hanrui1sensetime, @AllentDan, @Zheng-LinXiao, @hhaAndroid, @wanghonglie
+
## v0.1.3(10/11/2022)
### New Features
diff --git a/docs/en/user_guides/config.md b/docs/en/user_guides/config.md
index 56edadf5f..0e0aac446 100644
--- a/docs/en/user_guides/config.md
+++ b/docs/en/user_guides/config.md
@@ -198,7 +198,7 @@ val_dataloader = dict(
test_dataloader = val_dataloader
```
-[Evaluators](https://mmengine.readthedocs.io/en/latest/design/metric_and_evaluator.html) are used to compute the metrics of the trained model on the validation and testing datasets. The config of evaluators consists of one or a list of metric configs:
+[Evaluators](https://mmengine.readthedocs.io/en/latest/design/evaluation.html) are used to compute the metrics of the trained model on the validation and testing datasets. The config of evaluators consists of one or a list of metric configs:
```python
val_evaluator = dict( # Validation evaluator config
@@ -270,7 +270,7 @@ test_cfg = dict(type='TestLoop') # The testing loop type
### Optimization config
-`optim_wrapper` is the field to configure optimization-related settings. The optimizer wrapper not only provides the functions of the optimizer but also supports functions such as gradient clipping, mixed precision training, etc. Find out more in the [optimizer wrapper tutorial](https://mmengine.readthedocs.io/en/latest/tutorials/optimizer.html).
+`optim_wrapper` is the field to configure optimization-related settings. The optimizer wrapper not only provides the functions of the optimizer but also supports functions such as gradient clipping, mixed precision training, etc. Find out more in the [optimizer wrapper tutorial](https://mmengine.readthedocs.io/en/latest/tutorials/optim_wrapper.html).
```python
optim_wrapper = dict( # Optimizer wrapper config
@@ -282,7 +282,7 @@ optim_wrapper = dict( # Optimizer wrapper config
weight_decay=0.0005, # Weight decay of SGD
nesterov=True, # Enable Nesterov momentum, Refer to http://www.cs.toronto.edu/~hinton/absps/momentum.pdf
batch_size_pre_gpu=train_batch_size_pre_gpu), # Enable automatic learning rate scaling
- clip_grad=None, # Gradient clip option. Set None to disable gradient clip. Find usage in https://mmengine.readthedocs.io/en/latest/tutorials/optimizer.html
+ clip_grad=None, # Gradient clip option. Set None to disable gradient clip. Find usage in https://mmengine.readthedocs.io/en/latest/tutorials/optim_wrapper.html
constructor='YOLOv5OptimizerConstructor') # The constructor for YOLOv5 optimizer
```
@@ -545,7 +545,7 @@ When submitting jobs using `tools/train.py` or `tools/test.py`, you may specify
We follow the below style to name config files. Contributors are advised to follow the same style.
```
-{algorithm name}_{model component names [component1]_[component2]_[...]}-[version id]_[norm setting]_[data preprocessor type]_{training settings}_{training dataset information}_{testing dataset information}.py
+{algorithm name}_{model component names [component1]_[component2]_[...]}-[version id]_[norm setting]_[data preprocessor type]_{training settings}_{training dataset information}_[testing dataset information].py
```
The file name is divided into 8 name fields, which have 4 required parts and 4 optional parts. All parts and components are connected with `_` and words of each part or component should be connected with `-`. `{}` indicates the required name field, and `[]` indicates the optional name field.
diff --git a/docs/en/user_guides/custom_dataset.md b/docs/en/user_guides/custom_dataset.md
new file mode 100644
index 000000000..205564aaf
--- /dev/null
+++ b/docs/en/user_guides/custom_dataset.md
@@ -0,0 +1,4 @@
+# The whole process of custom dataset annotation+training+testing+deployment
+
+Coming soon.
+Please refer to [chinese documentation](../../zh_cn/user_guides/custom_dataset.md)
diff --git a/docs/en/user_guides/index.rst b/docs/en/user_guides/index.rst
index 830d6d93e..0981ae036 100644
--- a/docs/en/user_guides/index.rst
+++ b/docs/en/user_guides/index.rst
@@ -24,5 +24,6 @@ Useful Tools
.. toctree::
:maxdepth: 1
+ custom_dataset.md
visualization.md
useful_tools.md
diff --git a/docs/en/user_guides/useful_tools.md b/docs/en/user_guides/useful_tools.md
index a1ec5dfca..e9a5939fd 100644
--- a/docs/en/user_guides/useful_tools.md
+++ b/docs/en/user_guides/useful_tools.md
@@ -5,11 +5,9 @@ We provide lots of useful tools under the `tools/` directory. In addition, you c
Take MMDetection as an example. If you want to use [print_config.py](https://github.com/open-mmlab/mmdetection/blob/3.x/tools/misc/print_config.py), you can directly use the following commands without copying the source code to the MMYOLO library.
```shell
-mim run mmdet print_config [CONFIG]
+mim run mmdet print_config ${CONFIG}
```
-**Note**: The MMDetection library must be installed through the MIM before the above command can succeed.
-
## Visualization
### Visualize COCO labels
@@ -17,49 +15,60 @@ mim run mmdet print_config [CONFIG]
`tools/analysis_tools/browse_coco_json.py` is a script that can visualization to display the COCO label in the picture.
```shell
-python tools/analysis_tools/browse_coco_json.py ${DATA_ROOT} \
- [--ann_file ${ANN_FILE}] \
- [--img_dir ${IMG_DIR}] \
+python tools/analysis_tools/browse_coco_json.py [--data-root ${DATA_ROOT}] \
+ [--img-dir ${IMG_DIR}] \
+ [--ann-file ${ANN_FILE}] \
[--wait-time ${WAIT_TIME}] \
[--disp-all] [--category-names CATEGORY_NAMES [CATEGORY_NAMES ...]] \
[--shuffle]
```
+If images and labels are in the same folder, you can specify `--data-root` to the folder, and then `--img-dir` and `--ann-file` to specify the relative path of the folder. The code will be automatically spliced.
+If the image and label files are not in the same folder, you do not need to specify `--data-root`, but directly specify `--img-dir` and `--ann-file` of the absolute path.
+
E.g:
1. Visualize all categories of `COCO` and display all types of annotations such as `bbox` and `mask`:
```shell
-python tools/analysis_tools/browse_coco_json.py './data/coco/' \
- --ann_file 'annotations/instances_train2017.json' \
- --img_dir 'train2017' \
+python tools/analysis_tools/browse_coco_json.py --data-root './data/coco' \
+ --img-dir 'train2017' \
+ --ann-file 'annotations/instances_train2017.json' \
+ --disp-all
+```
+
+If images and labels are not in the same folder, you can use a absolutely path:
+
+```shell
+python tools/analysis_tools/browse_coco_json.py --img-dir '/dataset/image/coco/train2017' \
+ --ann-file '/label/instances_train2017.json' \
--disp-all
```
2. Visualize all categories of `COCO`, and display only the `bbox` type labels, and shuffle the image to show:
```shell
-python tools/analysis_tools/browse_coco_json.py './data/coco/' \
- --ann_file 'annotations/instances_train2017.json' \
- --img_dir 'train2017' \
+python tools/analysis_tools/browse_coco_json.py --data-root './data/coco' \
+ --img-dir 'train2017' \
+ --ann-file 'annotations/instances_train2017.json' \
--shuffle
```
3. Only visualize the `bicycle` and `person` categories of `COCO` and only the `bbox` type labels are displayed:
```shell
-python tools/analysis_tools/browse_coco_json.py './data/coco/' \
- --ann_file 'annotations/instances_train2017.json' \
- --img_dir 'train2017' \
+python tools/analysis_tools/browse_coco_json.py --data-root './data/coco' \
+ --img-dir 'train2017' \
+ --ann-file 'annotations/instances_train2017.json' \
--category-names 'bicycle' 'person'
```
4. Visualize all categories of `COCO`, and display all types of label such as `bbox`, `mask`, and shuffle the image to show:
```shell
-python tools/analysis_tools/browse_coco_json.py './data/coco/' \
- --ann_file 'annotations/instances_train2017.json' \
- --img_dir 'train2017' \
+python tools/analysis_tools/browse_coco_json.py --data-root './data/coco' \
+ --img-dir 'train2017' \
+ --ann-file 'annotations/instances_train2017.json' \
--disp-all \
--shuffle
```
@@ -350,10 +359,77 @@ python tools/analysis_tools/optimize_anchors.py ${CONFIG} \
--output-dir ${OUTPUT_DIR}
```
+## Perform inference on large images
+
+First install [`sahi`](https://github.com/obss/sahi) with:
+
+```shell
+pip install -U sahi>=0.11.4
+```
+
+Perform MMYOLO inference on large images (as satellite imagery) as:
+
+```shell
+wget -P checkpoint https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_m-v61_syncbn_fast_8xb16-300e_coco/yolov5_m-v61_syncbn_fast_8xb16-300e_coco_20220917_204944-516a710f.pth
+
+python demo/large_image_demo.py \
+ demo/large_image.jpg \
+ configs/yolov5/yolov5_m-v61_syncbn_fast_8xb16-300e_coco.py \
+ checkpoint/yolov5_m-v61_syncbn_fast_8xb16-300e_coco_20220917_204944-516a710f.pth \
+```
+
+Arrange slicing parameters as:
+
+```shell
+python demo/large_image_demo.py \
+ demo/large_image.jpg \
+ configs/yolov5/yolov5_m-v61_syncbn_fast_8xb16-300e_coco.py \
+ checkpoint/yolov5_m-v61_syncbn_fast_8xb16-300e_coco_20220917_204944-516a710f.pth \
+ --patch-size 512
+ --patch-overlap-ratio 0.25
+```
+
+Export debug visuals while performing inference on large images as:
+
+```shell
+python demo/large_image_demo.py \
+ demo/large_image.jpg \
+ configs/yolov5/yolov5_m-v61_syncbn_fast_8xb16-300e_coco.py \
+ checkpoint/yolov5_m-v61_syncbn_fast_8xb16-300e_coco_20220917_204944-516a710f.pth \
+ --debug
+```
+
+[`sahi`](https://github.com/obss/sahi) citation:
+
+```
+@article{akyon2022sahi,
+ title={Slicing Aided Hyper Inference and Fine-tuning for Small Object Detection},
+ author={Akyon, Fatih Cagatay and Altinuc, Sinan Onur and Temizel, Alptekin},
+ journal={2022 IEEE International Conference on Image Processing (ICIP)},
+ doi={10.1109/ICIP46576.2022.9897990},
+ pages={966-970},
+ year={2022}
+}
+```
+
## Extracts a subset of COCO
The training dataset of the COCO2017 dataset includes 118K images, and the validation set includes 5K images, which is a relatively large dataset. Loading JSON in debugging or quick verification scenarios will consume more resources and bring slower startup speed.
-The `extract_subcoco.py` script provides the ability to extract a specified number of images. The user can use the `--num-img` parameter to get a COCO subset of the specified number of images.
+
+The `extract_subcoco.py` script provides the ability to extract a specified number/classes/area-size of images. The user can use the `--num-img`, `--classes`, `--area-size` parameter to get a COCO subset of the specified condition of images.
+
+For example, extract images use scripts as follows:
+
+```shell
+python tools/misc/extract_subcoco.py \
+ ${ROOT} \
+ ${OUT_DIR} \
+ --num-img 20 \
+ --classes cat dog person \
+ --area-size small
+```
+
+It gone be extract 20 images, and only includes annotations which belongs to cat(or dog/person) and bbox area size is small, after filter by class and area size, the empty annotation images won't be chosen, guarantee the images be extracted definitely has annotation info.
Currently, only support COCO2017. In the future will support user-defined datasets of standard coco JSON format.
@@ -384,3 +460,15 @@ python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --num-img 20 --use-train
```shell
python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --num-img 20 --use-training-set --seed 1
```
+
+4. Extract images by specify classes
+
+```shell
+python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --classes cat dog person
+```
+
+5. Extract images by specify anchor size
+
+```shell
+python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --area-size small
+```
diff --git a/docs/en/user_guides/visualization.md b/docs/en/user_guides/visualization.md
index eb5a530cb..7835a434f 100644
--- a/docs/en/user_guides/visualization.md
+++ b/docs/en/user_guides/visualization.md
@@ -1,5 +1,7 @@
# Visualization
+This article includes feature map visualization and Grad-Based and Grad-Free CAM visualization
+
## Feature map visualization
+
+#### 7. Resolve conflicts
+
+If your local branch conflicts with the latest dev branch of "upstream", you'll need to resolove them. There are two ways to do this:
+
+```shell
+git fetch --all --prune
+git rebase upstream/dev
+```
+
+or
+
+```shell
+git fetch --all --prune
+git merge upstream/dev
+```
+
+If you are very good at handling conflicts, then you can use rebase to resolve conflicts, as this will keep your commit logs tidy. If you are unfamiliar with `rebase`, you can use `merge` to resolve conflicts.
+
+### Guidance
+
+#### Unit test
+
+We should also make sure the committed code will not decrease the coverage of unit test, we could run the following command to check the coverage of unit test:
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### Document rendering
+
+If the documents are modified/added, we should check the rendering result. We could install the dependencies and run the following command to render the documents and check the results:
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### Code style
+
+#### Python
+
+We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
+
+We use the following tools for linting and formatting:
+
+- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
+- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
+- [yapf](https://github.com/google/yapf): A formatter for Python files.
+- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
+- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
+- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
+
+Style configurations of yapf and isort can be found in [setup.cfg](./setup.cfg).
+
+We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
+fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
+The config for a pre-commit hook is stored in [.pre-commit-config](./.pre-commit-config.yaml).
+
+#### C++ and CUDA
+
+We follow the [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html).
+
+### PR Specs
+
+1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
+
+2. One short-time branch should be matched with only one PR
+
+3. Accomplish a detailed change in one PR. Avoid large PR
+
+ - Bad: Support Faster R-CNN
+ - Acceptable: Add a box head to Faster R-CNN
+ - Good: Add a parameter to box head to support custom conv-layer number
+
+4. Provide clear and significant commit message
+
+5. Provide clear and meaningful PR description
+
+ - Task name should be clarified in title. The general format is: \[Prefix\] Short description of the PR (Suffix)
+ - Prefix: add new feature \[Feature\], fix bug \[Fix\], related to documents \[Docs\], in developing \[WIP\] (which will not be reviewed temporarily)
+ - Introduce main changes, results and influences on other modules in short description
+ - Associate related issues and pull requests with a milestone
diff --git a/docs/en/deploy/basic_deployment_guide.md b/docs/en/deploy/basic_deployment_guide.md
index 19e84788e..69258f540 100644
--- a/docs/en/deploy/basic_deployment_guide.md
+++ b/docs/en/deploy/basic_deployment_guide.md
@@ -1 +1,287 @@
# Basic Deployment Guide
+
+## Introduction of MMDeploy
+
+MMDeploy is an open-source deep learning model deployment toolset. It is a part of the [OpenMMLab](https://openmmlab.com/) project, and provides **a unified experience of exporting different models** to various platforms and devices of the OpenMMLab series libraries. Using MMDeploy, developers can easily export the specific compiled SDK they need from the training result, which saves a lot of effort.
+
+More detailed introduction and guides can be found [here](https://github.com/open-mmlab/mmdeploy/blob/dev-1.x/docs/en/get_started.md)
+
+## Supported Algorithms
+
+Currently our deployment kit supports on the following models and backends:
+
+| Model | Task | OnnxRuntime | TensorRT | Model config |
+| :----- | :-------------- | :---------: | :------: | :---------------------------------------------------------------------: |
+| YOLOv5 | ObjectDetection | Y | Y | [config](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov5) |
+| YOLOv6 | ObjectDetection | Y | Y | [config](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov6) |
+| YOLOX | ObjectDetection | Y | Y | [config](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolox) |
+| RTMDet | ObjectDetection | Y | Y | [config](https://github.com/open-mmlab/mmyolo/tree/main/configs/rtmdet) |
+
+Note: ncnn and other inference backends support are coming soon.
+
+## How to Write Config for MMYOLO
+
+All config files related to the deployment are located at [`configs/deploy`](../../../configs/deploy/).
+
+You only need to change the relative data processing part in the model config file to support either static or dynamic input for your model. Besides, MMDeploy integrates the post-processing parts as customized ops, you can modify the strategy in `post_processing` parameter in `codebase_config`.
+
+Here is the detail description:
+
+```python
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+```
+
+- `score_threshold`: set the score threshold to filter candidate bboxes before `nms`
+- `confidence_threshold`: set the confidence threshold to filter candidate bboxes before `nms`
+- `iou_threshold`: set the `iou` threshold for removing duplicates in `nums`
+- `max_output_boxes_per_class`: set the maximum number of bboxes for each class
+- `pre_top_k`: set the number of fixedcandidate bboxes before `nms`, sorted by scores
+- `keep_top_k`: set the number of output candidate bboxs after `nms`
+- `background_label_id`: set to `-1` as MMYOLO has no background class information
+
+### Configuration for Static Inputs
+
+#### 1. Model Config
+
+Taking `YOLOv5` of MMYOLO as an example, here are the details:
+
+```python
+_base_ = '../../yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+test_pipeline = [
+ dict(type='LoadImageFromFile', file_client_args=_base_.file_client_args),
+ dict(
+ type='LetterResize',
+ scale=_base_.img_scale,
+ allow_scale_up=False,
+ use_mini_pad=False,
+ ),
+ dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param'))
+]
+
+test_dataloader = dict(
+ dataset=dict(pipeline=test_pipeline, batch_shapes_cfg=None))
+```
+
+`_base_ = '../../yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'` inherits the model config in the training stage.
+
+`test_pipeline` adds the data processing piple for the deployment, `LetterResize` controls the size of the input images and the input for the converted model
+
+`test_dataloader` adds the dataloader config for the deployment, `batch_shapes_cfg` decides whether to use the `batch_shapes` strategy. More details can be found at [yolov5 configs](../user_guides/config.md)
+
+#### 2. Deployment Config
+
+Here we still use the `YOLOv5` in MMYOLO as the example. We can use [`detection_onnxruntime_static.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_onnxruntime_static.py) as the config to deploy \`YOLOv5\` to \`ONNXRuntim\` with static inputs.
+
+```python
+_base_ = ['./base_static.py']
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+backend_config = dict(type='onnxruntime')
+```
+
+`backend_config` indicates the deployment backend with `type='onnxruntime'`, other information can be referred from the third section.
+
+To deploy the `YOLOv5` to `TensorRT`, please refer to the [`detection_tensorrt_static-640x640.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_tensorrt_static-640x640.py) as follows.
+
+```python
+_base_ = ['./base_static.py']
+onnx_config = dict(input_shape=(640, 640))
+backend_config = dict(
+ type='tensorrt',
+ common_config=dict(fp16_mode=False, max_workspace_size=1 << 30),
+ model_inputs=[
+ dict(
+ input_shapes=dict(
+ input=dict(
+ min_shape=[1, 3, 640, 640],
+ opt_shape=[1, 3, 640, 640],
+ max_shape=[1, 3, 640, 640])))
+ ])
+use_efficientnms = False
+```
+
+`backend_config` indices the backend with `type=‘tensorrt’`.
+
+Different from `ONNXRuntime` deployment configuration, `TensorRT` needs to specify the input image size and the parameters required to build the engine file, including:
+
+- `onnx_config` specifies the input shape as `input_shape=(640, 640)`
+- `fp16_mode=False` and `max_workspace_size=1 << 30` in `backend_config['common_config']` indicates whether to build the engine in the parameter format of `fp16`, and the maximum video memory for the current `gpu` device, respectively. The unit is in `GB`. For detailed configuration of `fp16`, please refer to the [`detection_tensorrt-fp16_static-640x640.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_tensorrt-fp16_static-640x640.py)
+- The `min_shape`/`opt_shape`/`max_shape` in `backend_config['model_inputs']['input_shapes']['input']` should remain the same under static input, the default is `[1, 3, 640, 640]`.
+
+`use_efficientnms` is a new configuration introduced by the `MMYOLO` series, indicating whether to enable `Efficient NMS Plugin` to replace `TRTBatchedNMS plugin` in `MMDeploy` when exporting `onnx`.
+
+You can refer to the official [efficient NMS plugins](https://github.com/NVIDIA/TensorRT/blob/main/plugin/efficientNMSPlugin/README.md) by `TensorRT` for more details.
+
+Note: this out-of-box feature is **only available in TensorRT>=8.0**, no need to compile it by yourself.
+
+### Configuration for Dynamic Inputs
+
+#### 1. Model Config
+
+When you deploy a dynamic input model, you don't need to modify any model configuration files but the deployment configuration files.
+
+#### 2. Deployment Config
+
+To deploy the `YOLOv5` in MMYOLO to `ONNXRuntime`, please refer to the [`detection_onnxruntime_dynamic.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_onnxruntime_dynamic.py).
+
+```python
+_base_ = ['./base_dynamic.py']
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+backend_config = dict(type='onnxruntime')
+```
+
+`backend_config` indicates the backend with `type='onnxruntime'`. Other parameters stay the same as the static input section.
+
+To deploy the `YOLOv5` to `TensorRT`, please refer to the [`detection_tensorrt_dynamic-192x192-960x960.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_tensorrt_dynamic-192x192-960x960.py).
+
+```python
+_base_ = ['./base_dynamic.py']
+backend_config = dict(
+ type='tensorrt',
+ common_config=dict(fp16_mode=False, max_workspace_size=1 << 30),
+ model_inputs=[
+ dict(
+ input_shapes=dict(
+ input=dict(
+ min_shape=[1, 3, 192, 192],
+ opt_shape=[1, 3, 640, 640],
+ max_shape=[1, 3, 960, 960])))
+ ])
+use_efficientnms = False
+```
+
+`backend_config` indicates the backend with `type='tensorrt'`. Since the dynamic and static inputs are different in `TensorRT`, please check the details at [TensorRT dynamic input official introduction](https://docs.nvidia.com/deeplearning/tensorrt/archives/tensorrt-843/developer-guide/index.html#work_dynamic_shapes).
+
+`TensorRT` deployment requires you to specify `min_shape`, `opt_shape` , and `max_shape`. `TensorRT` limits the size of the input image between `min_shape` and `max_shape`.
+
+`min_shape` is the minimum size of the input image. `opt_shape` is the common size of the input image, inference performance is best under this size. `max_shape` is the maximum size of the input image.
+
+`use_efficientnms` configuration is the same as the `TensorRT` static input configuration in the previous section.
+
+### INT8 Quantization Support
+
+Note: Int8 quantization support will soon be released.
+
+## How to Convert Model
+
+### Usage
+
+Set the root directory of `MMDeploy` as an env parameter `MMDEPLOY_DIR` using `export MMDEPLOY_DIR=/the/root/path/of/MMDeploy` command.
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ ${DEPLOY_CFG_PATH} \
+ ${MODEL_CFG_PATH} \
+ ${MODEL_CHECKPOINT_PATH} \
+ ${INPUT_IMG} \
+ --test-img ${TEST_IMG} \
+ --work-dir ${WORK_DIR} \
+ --calib-dataset-cfg ${CALIB_DATA_CFG} \
+ --device ${DEVICE} \
+ --log-level INFO \
+ --show \
+ --dump-info
+```
+
+### Parameter Description
+
+- `deploy_cfg`: set the deployment config path of MMDeploy for the model, including the type of inference framework, whether quantize, whether the input shape is dynamic, etc. There may be a reference relationship between configuration files, e.g. `configs/deploy/detection_onnxruntime_static.py`
+- `model_cfg`: set the MMYOLO model config path, e.g. `configs/deploy/model/yolov5_s-deploy.py`, regardless of the path to MMDeploy
+- `checkpoint`: set the torch model path. It can start with `http/https`, more details are available in `mmengine.fileio` apis
+- `img`: set the path to the image or point cloud file used for testing during model conversion
+- `--test-img`: set the image file that used to test model. If not specified, it will be set to `None`
+- `--work-dir`: set the work directory that used to save logs and models
+- `--calib-dataset-cfg`: use for calibration only for INT8 mode. If not specified, it will be set to None and use “val” dataset in model config for calibration
+- `--device`: set the device used for model conversion. The default is `cpu`, for TensorRT used `cuda:0`
+- `--log-level`: set log level which in `'CRITICAL', 'FATAL', 'ERROR', 'WARN', 'WARNING', 'INFO', 'DEBUG', 'NOTSET'`. If not specified, it will be set to `INFO`
+- `--show`: show the result on screen or not
+- `--dump-info`: output SDK information or not
+
+## How to Evaluate Model
+
+### Usage
+
+After the model is converted to your backend, you can use `${MMDEPLOY_DIR}/tools/test.py` to evaluate the performance.
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ ${DEPLOY_CFG} \
+ ${MODEL_CFG} \
+ --model ${BACKEND_MODEL_FILES} \
+ [--out ${OUTPUT_PKL_FILE}] \
+ [--format-only] \
+ [--metrics ${METRICS}] \
+ [--show] \
+ [--show-dir ${OUTPUT_IMAGE_DIR}] \
+ [--show-score-thr ${SHOW_SCORE_THR}] \
+ --device ${DEVICE} \
+ [--cfg-options ${CFG_OPTIONS}] \
+ [--metric-options ${METRIC_OPTIONS}]
+ [--log2file work_dirs/output.txt]
+ [--batch-size ${BATCH_SIZE}]
+ [--speed-test] \
+ [--warmup ${WARM_UP}] \
+ [--log-interval ${LOG_INTERVERL}]
+```
+
+### Parameter Description
+
+- `deploy_cfg`: set the deployment config file path
+- `model_cfg`: set the MMYOLO model config file path
+- `--model`: set the converted model. For example, if we exported a TensorRT model, we need to pass in the file path with the suffix ".engine"
+- `--out`: save the output result in pickle format, use only when you need it
+- `--format-only`: format the output without evaluating it. It is useful when you want to format the result into a specific format and submit it to a test server
+- `--metrics`: use the specific metric supported in MMYOLO to evaluate, such as "proposal" in COCO format data.
+- `--show`: show the evaluation result on screen or not
+- `--show-dir`: save the evaluation result to this directory, valid only when specified
+- `--show-score-thr`: show the threshold for the detected bboxes or not
+- `--device`: indicate the device to run the model. Note that some backends limit the running devices. For example, TensorRT must run on CUDA
+- `--cfg-options`: pass in additional configs, which will override the current deployment configs
+- `--metric-options`: add custom options for metrics. The key-value pair format in xxx=yyy will be the kwargs of the dataset.evaluate() method
+- `--log2file`: save the evaluation results (with the speed) to a file
+- `--batch-size`: set the batch size for inference, which will override the `samples_per_gpu` in data config. The default value is `1`, however, not every model supports `batch_size > 1`
+- `--speed-test`: test the inference speed or not
+- `--warmup`: warm up before speed test or not, works only when `speed-test` is specified
+- `--log-interval`: set the interval between each log, works only when `speed-test` is specified
+
+Note: other parameters in `${MMDEPLOY_DIR}/tools/test.py` are used for speed test, they will not affect the evaluation results.
diff --git a/docs/en/deploy/yolov5_deployment.md b/docs/en/deploy/yolov5_deployment.md
index c2683d761..f0e319674 100644
--- a/docs/en/deploy/yolov5_deployment.md
+++ b/docs/en/deploy/yolov5_deployment.md
@@ -1 +1,432 @@
# YOLOv5 Deployment
+
+Please check the [basic_deployment_guide](basic_deployment_guide.md) to get familiar with the configurations.
+
+## Model Training and Validation
+
+The details of training and validation can be found at [yolov5_tutorial](../user_guides/yolov5_tutorial.md).
+
+## MMDeploy Environment Setup
+
+Please check the installation document of `MMDeploy` at [build_from_source](https://github.com/open-mmlab/mmdeploy/blob/dev-1.x/docs/en/01-how-to-build/build_from_source.md). Please build both `MMDeploy` and the customized Ops to your specific platform.
+
+Note: please check at `MMDeploy` [FAQ](https://github.com/open-mmlab/mmdeploy/blob/dev-1.x/docs/en/faq.md) or create new issues in `MMDeploy` when you come across any problems.
+
+## How to Prepare Configuration File
+
+This deployment guide uses the `YOLOv5` model trained on `COCO` dataset in MMYOLO to illustrate the whole process, including both static and dynamic inputs and different procedures for `TensorRT` and `ONNXRuntime`.
+
+### For Static Input
+
+#### 1. Model Config
+
+To deploy the model with static inputs, you need to ensure that the model inputs are in fixed size, e.g. the input size is set to `640x640` while uploading data in the test pipeline and test dataloader.
+
+Here is a example in [`yolov5_s-static.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/deploy/model/yolov5_s-static.py)
+
+```python
+_base_ = '../../yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+test_pipeline = [
+ dict(type='LoadImageFromFile', file_client_args=_base_.file_client_args),
+ dict(
+ type='LetterResize',
+ scale=_base_.img_scale,
+ allow_scale_up=False,
+ use_mini_pad=False,
+ ),
+ dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param'))
+]
+
+test_dataloader = dict(
+ dataset=dict(pipeline=test_pipeline, batch_shapes_cfg=None))
+```
+
+As the `YOLOv5` will turn on `allow_scale_up` and `use_mini_pad` during the test to change the size of the input image in order to achieve higher accuracy. However, it will cause the input size mismatch problem when deploying in the static input model.
+
+Compared with the original configuration file, this configuration has been modified as follows:
+
+- turn off the settings related to reshaping the image in `test_pipeline`, e.g. setting `allow_scale_up=False` and `use_mini_pad=False` in `LetterResize`
+- turn off the `batch_shapes` in `test_dataloader` as `batch_shapes_cfg=None`.
+
+#### 2. Deployment Cofnig
+
+To deploy the model to `ONNXRuntime`, please refer to the [`detection_onnxruntime_static.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/deploy/detection_onnxruntime_static.py) as follows:
+
+```python
+_base_ = ['./base_static.py']
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+backend_config = dict(type='onnxruntime')
+```
+
+The `post_processing` in the default configuration aligns the accuracy of the current model with the trained `pytorch` model. If you need to modify the relevant parameters, you can refer to the detailed introduction of [dasic_deployment_guide](basic_deployment_guide.md).
+
+To deploy the model to `TensorRT`, please refer to the [`detection_tensorrt_static-640x640.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/deploy/detection_tensorrt_static-640x640.p).
+
+```python
+_base_ = ['./base_static.py']
+onnx_config = dict(input_shape=(640, 640))
+backend_config = dict(
+ type='tensorrt',
+ common_config=dict(fp16_mode=False, max_workspace_size=1 << 30),
+ model_inputs=[
+ dict(
+ input_shapes=dict(
+ input=dict(
+ min_shape=[1, 3, 640, 640],
+ opt_shape=[1, 3, 640, 640],
+ max_shape=[1, 3, 640, 640])))
+ ])
+use_efficientnms = False
+```
+
+In this guide, we use the default settings such as `input_shape=(640, 640)` and `fp16_mode=False` to build in network in `fp32` mode. Moreover, we set `max_workspace_size=1 << 30` for the gpu memory which allows `TensorRT` to build the engine with maximum `1GB` memory.
+
+### For Dynamic Input
+
+#### 1. Model Confige
+
+As `TensorRT` limits the minimum and maximum input size, we can use any size for the inputs when deploy the model in dynamic mode. In this way, we can keep the default settings in [`yolov5_s-v61_syncbn_8xb16-300e_coco.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py). The data processing and dataloader parts are as follows.
+
+```python
+batch_shapes_cfg = dict(
+ type='BatchShapePolicy',
+ batch_size=val_batch_size_per_gpu,
+ img_size=img_scale[0],
+ size_divisor=32,
+ extra_pad_ratio=0.5)
+
+test_pipeline = [
+ dict(type='LoadImageFromFile', file_client_args=_base_.file_client_args),
+ dict(type='YOLOv5KeepRatioResize', scale=img_scale),
+ dict(
+ type='LetterResize',
+ scale=img_scale,
+ allow_scale_up=False,
+ pad_val=dict(img=114)),
+ dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param'))
+]
+
+val_dataloader = dict(
+ batch_size=val_batch_size_per_gpu,
+ num_workers=val_num_workers,
+ persistent_workers=persistent_workers,
+ pin_memory=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ test_mode=True,
+ data_prefix=dict(img='val2017/'),
+ ann_file='annotations/instances_val2017.json',
+ pipeline=test_pipeline,
+ batch_shapes_cfg=batch_shapes_cfg))
+```
+
+We use `allow_scale_up=False` to control when the input small images will be upsampled or not in the initialization of `LetterResize`. At the same time, the default `use_mini_pad=False` turns off the minimum padding strategy of the image, and `val_dataloader['dataset']` is passed in` batch_shapes_cfg=batch_shapes_cfg` to ensure that the minimum padding is performed according to the input size in `batch`. These configs will change the dimensions of the input image, so the converted model can support dynamic inputs according to the above dataset loader when testing.
+
+#### 2. Deployment Cofnig
+
+To deploy the model to `ONNXRuntime`, please refer to the [`detection_onnxruntime_dynamic.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_onnxruntime_dynamic.py) for more details.
+
+```python
+_base_ = ['./base_dynamic.py']
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+backend_config = dict(type='onnxruntime')
+```
+
+Differs from the static input config we introduced in previous section, dynamic input config additionally inherits the `dynamic_axes`. The rest of the configuration stays the same as the static inputs.
+
+To deploy the model to `TensorRT`, please refer to the [`detection_tensorrt_dynamic-192x192-960x960.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/deploy/detection_tensorrt_dynamic-192x192-960x960.py) for more details.
+
+```python
+_base_ = ['./base_dynamic.py']
+backend_config = dict(
+ type='tensorrt',
+ common_config=dict(fp16_mode=False, max_workspace_size=1 << 30),
+ model_inputs=[
+ dict(
+ input_shapes=dict(
+ input=dict(
+ min_shape=[1, 3, 192, 192],
+ opt_shape=[1, 3, 640, 640],
+ max_shape=[1, 3, 960, 960])))
+ ])
+use_efficientnms = False
+```
+
+In our example, the network is built in `fp32` mode as `fp16_mode=False`, and the maximum graphic memory is `1GB` for building the `TensorRT` engine as `max_workspace_size=1 << 30`.
+
+At the same time, `min_shape=[1, 3, 192, 192]`, `opt_shape=[1, 3, 640, 640]`, and `max_shape=[1, 3, 960, 960]` in the default setting set the model with minimum input size to `192x192`, the maximum size to `960x960`, and the most common size to `640x640`.
+
+When you deploy the model, it can adopt to the input image dimensions automatically.
+
+## How to Convert Model
+
+Note: The `MMDeploy` root directory used in this guide is `/home/openmmlab/dev/mmdeploy`, please modify it to your `MMDeploy` directory.
+
+Use the following command to download the pretrained YOLOv5 weight and save it to your device:
+
+```shell
+wget https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth -O /home/openmmlab/dev/mmdeploy/yolov5s.pth
+```
+
+Set the relevant env parameters using the following command as well:
+
+```shell
+export MMDEPLOY_DIR=/home/openmmlab/dev/mmdeploy
+export PATH_TO_CHECKPOINTS=/home/openmmlab/dev/mmdeploy/yolov5s.pth
+```
+
+### YOLOv5 Static Model Deployment
+
+#### ONNXRuntime
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir \
+ --show \
+ --device cpu
+```
+
+#### TensorRT
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir \
+ --show \
+ --device cuda:0
+```
+
+### YOLOv5 Dynamic Model Deployment
+
+#### ONNXRuntime
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_onnxruntime_dynamic.py \
+ configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir \
+ --show \
+ --device cpu
+```
+
+#### TensorRT
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_tensorrt_dynamic-192x192-960x960.py \
+ configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir \
+ --show \
+ --device cuda:0
+```
+
+When convert the model using the above commands, you will find the following files under the `work_dir` folder:
+
+
+
+or
+
+
+
+After exporting to `onnxruntime`, you will get three files as shown in Figure 1, where `end2end.onnx` represents the exported `onnxruntime` model.
+
+After exporting to `TensorRT`, you will get the four files as shown in Figure 2, where `end2end.onnx` represents the exported intermediate model. `MMDeploy` uses this model to automatically continue to convert the `end2end.engine` model for `TensorRT `Deployment.
+
+## How to Evaluate Model
+
+After successfully convert the model, you can use `${MMDEPLOY_DIR}/tools/test.py` to evaluate the converted model. The following part shows how to evaluate the static models of `ONNXRuntime` and `TensorRT`. For dynamic model evaluation, please modify the configuration of the inputs.
+
+#### ONNXRuntime
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ --model work_dir/end2end.onnx \
+ --device cpu \
+ --work-dir work_dir
+```
+
+Once the process is done, you can get the output results as this:
+
+
+
+#### TensorRT
+
+Note: `TensorRT` must run on `CUDA` devices!
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ --model work_dir/end2end.engine \
+ --device cuda:0 \
+ --work-dir work_dir
+```
+
+Once the process is done, you can get the output results as this:
+
+
+
+More useful evaluation tools will be released in the future.
+
+# Deploy using Docker
+
+`MMYOLO` provides a deployment [`Dockerfile`](https://github.com/open-mmlab/mmyolo/blob/main/docker/Dockerfile_deployment) for deployment purpose. Please make sure your local docker version is greater than `19.03`.
+
+Note: users in mainland China can comment out the `Optional` part in the dockerfile for better experience.
+
+```dockerfile
+# (Optional)
+RUN sed -i 's/http:\/\/archive.ubuntu.com\/ubuntu\//http:\/\/mirrors.aliyun.com\/ubuntu\//g' /etc/apt/sources.list && \
+ pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
+```
+
+To build the docker image,
+
+```bash
+# build an image with PyTorch 1.12, CUDA 11.6, TensorRT 8.2.4 ONNXRuntime 1.8.1
+docker build -f docker/Dockerfile_deployment -t mmyolo:v1 .
+```
+
+To run the docker image,
+
+```bash
+export DATA_DIR=/path/to/your/dataset
+docker run --gpus all --shm-size=8g -it --name mmyolo -v ${DATA_DIR}:/openmmlab/mmyolo/data/coco mmyolo:v1
+```
+
+`DATA_DIR` is the path of your `COCO` dataset.
+
+We provide a `script.sh` file for you which runs the whole pipeline. Create the script under `/openmmlab/mmyolo` directory in your docker container using the following content.
+
+```bash
+#!/bin/bash
+wget -q https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth \
+ -O yolov5s.pth
+export MMDEPLOY_DIR=/openmmlab/mmdeploy
+export PATH_TO_CHECKPOINTS=/openmmlab/mmyolo/yolov5s.pth
+
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir_trt \
+ --device cuda:0
+
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ --model work_dir_trt/end2end.engine \
+ --device cuda:0 \
+ --work-dir work_dir_trt
+
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir_ort \
+ --device cpu
+
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ --model work_dir_ort/end2end.onnx \
+ --device cpu \
+ --work-dir work_dir_ort
+```
+
+Then run the script under `/openmmlab/mmyolo`.
+
+```bash
+sh script.sh
+```
+
+This script automatically downloads the `YOLOv5` pretrained weights in `MMYOLO` and convert the model using `MMDeploy`. You will get the output result as follows.
+
+- TensorRT:
+
+ 
+
+- ONNXRuntime:
+
+ 
+
+We can see from the above images that the accuracy of converted models shrink within 1% compared with the pytorch [MMYOLO-YOLOv5](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov5#results-and-models) models.
+
+If you need to test the inference speed of the converted model, you can use the following commands.
+
+- TensorRT
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/profiler.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ data/coco/val2017 \
+ --model work_dir_trt/end2end.engine \
+ --device cuda:0
+```
+
+- ONNXRuntime
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/profiler.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ data/coco/val2017 \
+ --model work_dir_ort/end2end.onnx \
+ --device cpu
+```
+
+## Model Inference
+
+TODO
diff --git a/docs/en/get_started.md b/docs/en/get_started.md
index dd1028ace..ab04f5ba3 100644
--- a/docs/en/get_started.md
+++ b/docs/en/get_started.md
@@ -7,6 +7,7 @@ Compatible MMEngine, MMCV and MMDetection versions are shown as below. Please in
| MMYOLO version | MMDetection version | MMEngine version | MMCV version |
| :------------: | :----------------------: | :----------------------: | :---------------------: |
| main | mmdet>=3.0.0rc3, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+| 0.2.0 | mmdet>=3.0.0rc3, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
| 0.1.3 | mmdet>=3.0.0rc3, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
| 0.1.2 | mmdet>=3.0.0rc2, \<3.1.0 | mmengine>=0.3.0, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
| 0.1.1 | mmdet==3.0.0rc1 | mmengine>=0.1.0, \<0.2.0 | mmcv>=2.0.0rc0, \<2.1.0 |
diff --git a/docs/en/index.rst b/docs/en/index.rst
index 8c60978c4..5082b8427 100644
--- a/docs/en/index.rst
+++ b/docs/en/index.rst
@@ -51,6 +51,13 @@ Welcome to MMYOLO's documentation!
notes/changelog.md
notes/faq.md
+.. toctree::
+ :maxdepth: 2
+ :caption: Community
+
+ community/contributing.md
+ community/code_style.md
+
.. toctree::
:caption: Switch Languag
diff --git a/docs/en/notes/changelog.md b/docs/en/notes/changelog.md
index 90175b7b1..fc09f75d2 100644
--- a/docs/en/notes/changelog.md
+++ b/docs/en/notes/changelog.md
@@ -1,5 +1,55 @@
# Changelog
+## v0.2.0(1/12/2022)
+
+### Highlights
+
+1. Support [YOLOv7](https://github.com/open-mmlab/mmyolo/tree/dev/configs/yolov7) P5 and P6 model
+2. Support [YOLOv6](https://github.com/open-mmlab/mmyolo/blob/dev/configs/yolov6/README.md) ML model
+3. Support [Grad-Based CAM and Grad-Free CAM](https://github.com/open-mmlab/mmyolo/blob/dev/demo/boxam_vis_demo.py)
+4. Support [large image inference](https://github.com/open-mmlab/mmyolo/blob/dev/demo/large_image_demo.py) based on sahi
+5. Add [easydeploy](https://github.com/open-mmlab/mmyolo/blob/dev/projects/easydeploy/README.md) project under the projects folder
+6. Add [custom dataset guide](https://github.com/open-mmlab/mmyolo/blob/dev/docs/zh_cn/user_guides/custom_dataset.md)
+
+### New Features
+
+1. `browse_dataset.py` script supports visualization of original image, data augmentation and intermediate results (#304)
+2. Add flag to output labelme label file in `image_demo.py` (#288, #314)
+3. Add `labelme2coco` script (#308, #313)
+4. Add split COCO dataset script (#311)
+5. Add two examples of backbone replacement in `how-to.md` and update `plugin.md` (#291)
+6. Add `contributing.md` and `code_style.md` (#322)
+7. Add docs about how to use mim to run scripts across libraries (#321)
+8. Support `YOLOv5` deployment at RV1126 device (#262)
+
+### Bug Fixes
+
+1. Fix MixUp padding error (#319)
+2. Fix scale factor order error of `LetterResize` and `YOLOv5KeepRatioResize` (#305)
+3. Fix training errors of `YOLOX Nano` model (#285)
+4. Fix `RTMDet` deploy error (#287)
+5. Fix int8 deploy config (#315)
+6. Fix `make_stage_plugins` doc in `basebackbone` (#296)
+7. Enable switch to deploy when create pytorch model in deployment (#324)
+8. Fix some errors in `RTMDet` model graph (#317)
+
+### Improvements
+
+1. Add option of json output in `test.py` (#316)
+2. Add area condition in `extract_subcoco.py` script (#286)
+3. Deployment doc translation (#289)
+4. Add YOLOv6 description overview doc (#252)
+5. Improve `config.md` (#297, #303)
+ 6Add mosaic9 graph in docstring (#307)
+6. Improve `browse_coco_json.py` script args (#309)
+7. Refactor some functions in `dataset_analysis.py` to be more general (#294)
+
+#### Contributors
+
+A total of 14 developers contributed to this release.
+
+Thank @fcakyon, @matrixgame2018, @MambaWong, @imAzhou, @triple-Mu, @RangeKing, @PeterH0323, @xin-li-67, @kitecats, @hanrui1sensetime, @AllentDan, @Zheng-LinXiao, @hhaAndroid, @wanghonglie
+
## v0.1.3(10/11/2022)
### New Features
diff --git a/docs/en/user_guides/config.md b/docs/en/user_guides/config.md
index 56edadf5f..0e0aac446 100644
--- a/docs/en/user_guides/config.md
+++ b/docs/en/user_guides/config.md
@@ -198,7 +198,7 @@ val_dataloader = dict(
test_dataloader = val_dataloader
```
-[Evaluators](https://mmengine.readthedocs.io/en/latest/design/metric_and_evaluator.html) are used to compute the metrics of the trained model on the validation and testing datasets. The config of evaluators consists of one or a list of metric configs:
+[Evaluators](https://mmengine.readthedocs.io/en/latest/design/evaluation.html) are used to compute the metrics of the trained model on the validation and testing datasets. The config of evaluators consists of one or a list of metric configs:
```python
val_evaluator = dict( # Validation evaluator config
@@ -270,7 +270,7 @@ test_cfg = dict(type='TestLoop') # The testing loop type
### Optimization config
-`optim_wrapper` is the field to configure optimization-related settings. The optimizer wrapper not only provides the functions of the optimizer but also supports functions such as gradient clipping, mixed precision training, etc. Find out more in the [optimizer wrapper tutorial](https://mmengine.readthedocs.io/en/latest/tutorials/optimizer.html).
+`optim_wrapper` is the field to configure optimization-related settings. The optimizer wrapper not only provides the functions of the optimizer but also supports functions such as gradient clipping, mixed precision training, etc. Find out more in the [optimizer wrapper tutorial](https://mmengine.readthedocs.io/en/latest/tutorials/optim_wrapper.html).
```python
optim_wrapper = dict( # Optimizer wrapper config
@@ -282,7 +282,7 @@ optim_wrapper = dict( # Optimizer wrapper config
weight_decay=0.0005, # Weight decay of SGD
nesterov=True, # Enable Nesterov momentum, Refer to http://www.cs.toronto.edu/~hinton/absps/momentum.pdf
batch_size_pre_gpu=train_batch_size_pre_gpu), # Enable automatic learning rate scaling
- clip_grad=None, # Gradient clip option. Set None to disable gradient clip. Find usage in https://mmengine.readthedocs.io/en/latest/tutorials/optimizer.html
+ clip_grad=None, # Gradient clip option. Set None to disable gradient clip. Find usage in https://mmengine.readthedocs.io/en/latest/tutorials/optim_wrapper.html
constructor='YOLOv5OptimizerConstructor') # The constructor for YOLOv5 optimizer
```
@@ -545,7 +545,7 @@ When submitting jobs using `tools/train.py` or `tools/test.py`, you may specify
We follow the below style to name config files. Contributors are advised to follow the same style.
```
-{algorithm name}_{model component names [component1]_[component2]_[...]}-[version id]_[norm setting]_[data preprocessor type]_{training settings}_{training dataset information}_{testing dataset information}.py
+{algorithm name}_{model component names [component1]_[component2]_[...]}-[version id]_[norm setting]_[data preprocessor type]_{training settings}_{training dataset information}_[testing dataset information].py
```
The file name is divided into 8 name fields, which have 4 required parts and 4 optional parts. All parts and components are connected with `_` and words of each part or component should be connected with `-`. `{}` indicates the required name field, and `[]` indicates the optional name field.
diff --git a/docs/en/user_guides/custom_dataset.md b/docs/en/user_guides/custom_dataset.md
new file mode 100644
index 000000000..205564aaf
--- /dev/null
+++ b/docs/en/user_guides/custom_dataset.md
@@ -0,0 +1,4 @@
+# The whole process of custom dataset annotation+training+testing+deployment
+
+Coming soon.
+Please refer to [chinese documentation](../../zh_cn/user_guides/custom_dataset.md)
diff --git a/docs/en/user_guides/index.rst b/docs/en/user_guides/index.rst
index 830d6d93e..0981ae036 100644
--- a/docs/en/user_guides/index.rst
+++ b/docs/en/user_guides/index.rst
@@ -24,5 +24,6 @@ Useful Tools
.. toctree::
:maxdepth: 1
+ custom_dataset.md
visualization.md
useful_tools.md
diff --git a/docs/en/user_guides/useful_tools.md b/docs/en/user_guides/useful_tools.md
index a1ec5dfca..e9a5939fd 100644
--- a/docs/en/user_guides/useful_tools.md
+++ b/docs/en/user_guides/useful_tools.md
@@ -5,11 +5,9 @@ We provide lots of useful tools under the `tools/` directory. In addition, you c
Take MMDetection as an example. If you want to use [print_config.py](https://github.com/open-mmlab/mmdetection/blob/3.x/tools/misc/print_config.py), you can directly use the following commands without copying the source code to the MMYOLO library.
```shell
-mim run mmdet print_config [CONFIG]
+mim run mmdet print_config ${CONFIG}
```
-**Note**: The MMDetection library must be installed through the MIM before the above command can succeed.
-
## Visualization
### Visualize COCO labels
@@ -17,49 +15,60 @@ mim run mmdet print_config [CONFIG]
`tools/analysis_tools/browse_coco_json.py` is a script that can visualization to display the COCO label in the picture.
```shell
-python tools/analysis_tools/browse_coco_json.py ${DATA_ROOT} \
- [--ann_file ${ANN_FILE}] \
- [--img_dir ${IMG_DIR}] \
+python tools/analysis_tools/browse_coco_json.py [--data-root ${DATA_ROOT}] \
+ [--img-dir ${IMG_DIR}] \
+ [--ann-file ${ANN_FILE}] \
[--wait-time ${WAIT_TIME}] \
[--disp-all] [--category-names CATEGORY_NAMES [CATEGORY_NAMES ...]] \
[--shuffle]
```
+If images and labels are in the same folder, you can specify `--data-root` to the folder, and then `--img-dir` and `--ann-file` to specify the relative path of the folder. The code will be automatically spliced.
+If the image and label files are not in the same folder, you do not need to specify `--data-root`, but directly specify `--img-dir` and `--ann-file` of the absolute path.
+
E.g:
1. Visualize all categories of `COCO` and display all types of annotations such as `bbox` and `mask`:
```shell
-python tools/analysis_tools/browse_coco_json.py './data/coco/' \
- --ann_file 'annotations/instances_train2017.json' \
- --img_dir 'train2017' \
+python tools/analysis_tools/browse_coco_json.py --data-root './data/coco' \
+ --img-dir 'train2017' \
+ --ann-file 'annotations/instances_train2017.json' \
+ --disp-all
+```
+
+If images and labels are not in the same folder, you can use a absolutely path:
+
+```shell
+python tools/analysis_tools/browse_coco_json.py --img-dir '/dataset/image/coco/train2017' \
+ --ann-file '/label/instances_train2017.json' \
--disp-all
```
2. Visualize all categories of `COCO`, and display only the `bbox` type labels, and shuffle the image to show:
```shell
-python tools/analysis_tools/browse_coco_json.py './data/coco/' \
- --ann_file 'annotations/instances_train2017.json' \
- --img_dir 'train2017' \
+python tools/analysis_tools/browse_coco_json.py --data-root './data/coco' \
+ --img-dir 'train2017' \
+ --ann-file 'annotations/instances_train2017.json' \
--shuffle
```
3. Only visualize the `bicycle` and `person` categories of `COCO` and only the `bbox` type labels are displayed:
```shell
-python tools/analysis_tools/browse_coco_json.py './data/coco/' \
- --ann_file 'annotations/instances_train2017.json' \
- --img_dir 'train2017' \
+python tools/analysis_tools/browse_coco_json.py --data-root './data/coco' \
+ --img-dir 'train2017' \
+ --ann-file 'annotations/instances_train2017.json' \
--category-names 'bicycle' 'person'
```
4. Visualize all categories of `COCO`, and display all types of label such as `bbox`, `mask`, and shuffle the image to show:
```shell
-python tools/analysis_tools/browse_coco_json.py './data/coco/' \
- --ann_file 'annotations/instances_train2017.json' \
- --img_dir 'train2017' \
+python tools/analysis_tools/browse_coco_json.py --data-root './data/coco' \
+ --img-dir 'train2017' \
+ --ann-file 'annotations/instances_train2017.json' \
--disp-all \
--shuffle
```
@@ -350,10 +359,77 @@ python tools/analysis_tools/optimize_anchors.py ${CONFIG} \
--output-dir ${OUTPUT_DIR}
```
+## Perform inference on large images
+
+First install [`sahi`](https://github.com/obss/sahi) with:
+
+```shell
+pip install -U sahi>=0.11.4
+```
+
+Perform MMYOLO inference on large images (as satellite imagery) as:
+
+```shell
+wget -P checkpoint https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_m-v61_syncbn_fast_8xb16-300e_coco/yolov5_m-v61_syncbn_fast_8xb16-300e_coco_20220917_204944-516a710f.pth
+
+python demo/large_image_demo.py \
+ demo/large_image.jpg \
+ configs/yolov5/yolov5_m-v61_syncbn_fast_8xb16-300e_coco.py \
+ checkpoint/yolov5_m-v61_syncbn_fast_8xb16-300e_coco_20220917_204944-516a710f.pth \
+```
+
+Arrange slicing parameters as:
+
+```shell
+python demo/large_image_demo.py \
+ demo/large_image.jpg \
+ configs/yolov5/yolov5_m-v61_syncbn_fast_8xb16-300e_coco.py \
+ checkpoint/yolov5_m-v61_syncbn_fast_8xb16-300e_coco_20220917_204944-516a710f.pth \
+ --patch-size 512
+ --patch-overlap-ratio 0.25
+```
+
+Export debug visuals while performing inference on large images as:
+
+```shell
+python demo/large_image_demo.py \
+ demo/large_image.jpg \
+ configs/yolov5/yolov5_m-v61_syncbn_fast_8xb16-300e_coco.py \
+ checkpoint/yolov5_m-v61_syncbn_fast_8xb16-300e_coco_20220917_204944-516a710f.pth \
+ --debug
+```
+
+[`sahi`](https://github.com/obss/sahi) citation:
+
+```
+@article{akyon2022sahi,
+ title={Slicing Aided Hyper Inference and Fine-tuning for Small Object Detection},
+ author={Akyon, Fatih Cagatay and Altinuc, Sinan Onur and Temizel, Alptekin},
+ journal={2022 IEEE International Conference on Image Processing (ICIP)},
+ doi={10.1109/ICIP46576.2022.9897990},
+ pages={966-970},
+ year={2022}
+}
+```
+
## Extracts a subset of COCO
The training dataset of the COCO2017 dataset includes 118K images, and the validation set includes 5K images, which is a relatively large dataset. Loading JSON in debugging or quick verification scenarios will consume more resources and bring slower startup speed.
-The `extract_subcoco.py` script provides the ability to extract a specified number of images. The user can use the `--num-img` parameter to get a COCO subset of the specified number of images.
+
+The `extract_subcoco.py` script provides the ability to extract a specified number/classes/area-size of images. The user can use the `--num-img`, `--classes`, `--area-size` parameter to get a COCO subset of the specified condition of images.
+
+For example, extract images use scripts as follows:
+
+```shell
+python tools/misc/extract_subcoco.py \
+ ${ROOT} \
+ ${OUT_DIR} \
+ --num-img 20 \
+ --classes cat dog person \
+ --area-size small
+```
+
+It gone be extract 20 images, and only includes annotations which belongs to cat(or dog/person) and bbox area size is small, after filter by class and area size, the empty annotation images won't be chosen, guarantee the images be extracted definitely has annotation info.
Currently, only support COCO2017. In the future will support user-defined datasets of standard coco JSON format.
@@ -384,3 +460,15 @@ python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --num-img 20 --use-train
```shell
python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --num-img 20 --use-training-set --seed 1
```
+
+4. Extract images by specify classes
+
+```shell
+python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --classes cat dog person
+```
+
+5. Extract images by specify anchor size
+
+```shell
+python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --area-size small
+```
diff --git a/docs/en/user_guides/visualization.md b/docs/en/user_guides/visualization.md
index eb5a530cb..7835a434f 100644
--- a/docs/en/user_guides/visualization.md
+++ b/docs/en/user_guides/visualization.md
@@ -1,5 +1,7 @@
# Visualization
+This article includes feature map visualization and Grad-Based and Grad-Free CAM visualization
+
## Feature map visualization
 +
+
 +
+ +
+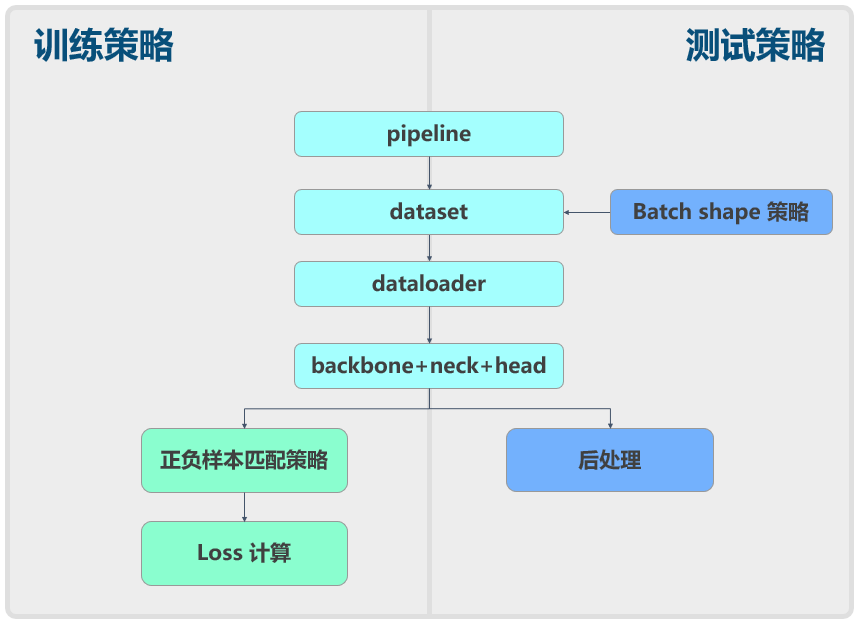 +
+ +
+ +
+