Introducing Scrappey, your comprehensive website scraping solution provided by Scrappey.com. With Scrappey's powerful and user-friendly API, you can effortlessly retrieve data from websites, including those protected by Cloudflare/Datadome. Join Scrappey today and revolutionize your data extraction process. 🚀 Now with caching!
Disclaimer: Please ensure that your web scraping activities comply with the website's terms of service and legal regulations. Scrappey is not responsible for any misuse or unethical use of the library. Use it responsibly and respect the website's policies.
Website: https://scrappey.com/ GitHub: https://github.com/
Use npm to install the Scrappey library. 💻
npm install scrappey-wrapperRequire the Scrappey library in your code. 📦
const Scrappey = require('scrappey-wrapper');Create an instance of Scrappey by providing your Scrappey API key. 🔑
const apiKey = 'YOUR_API_KEY';
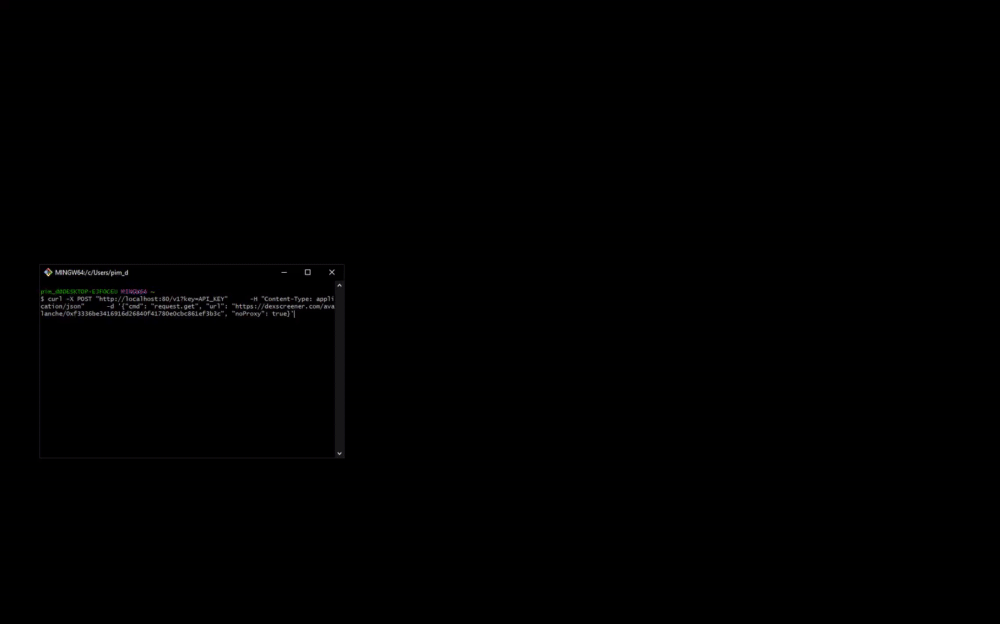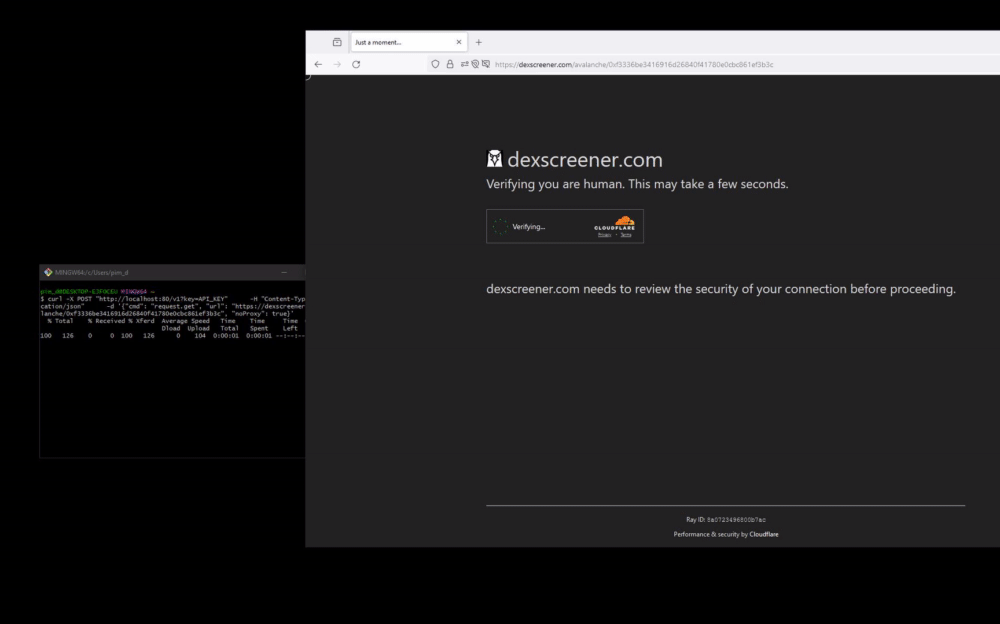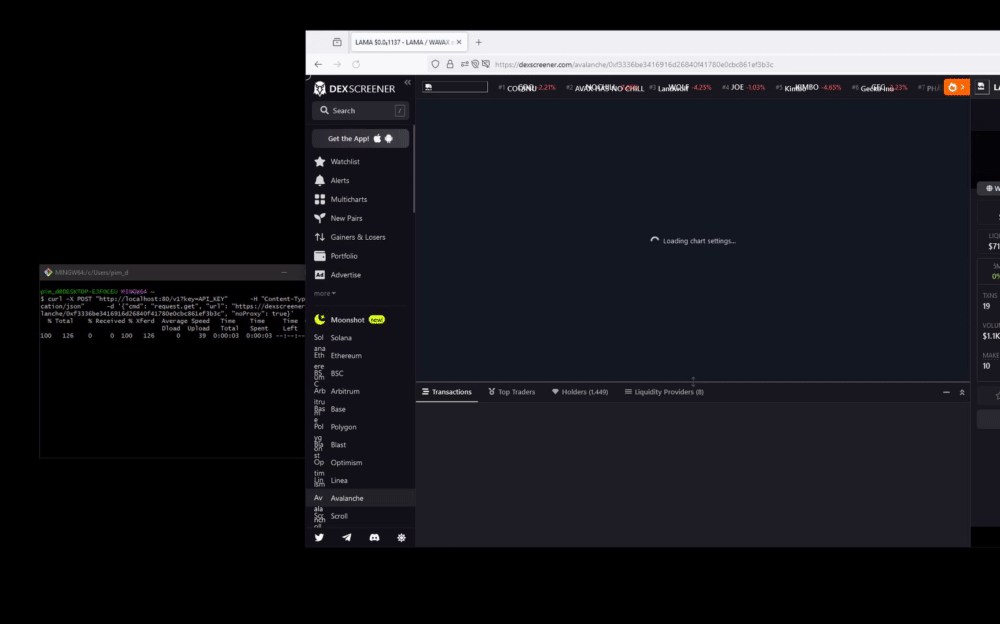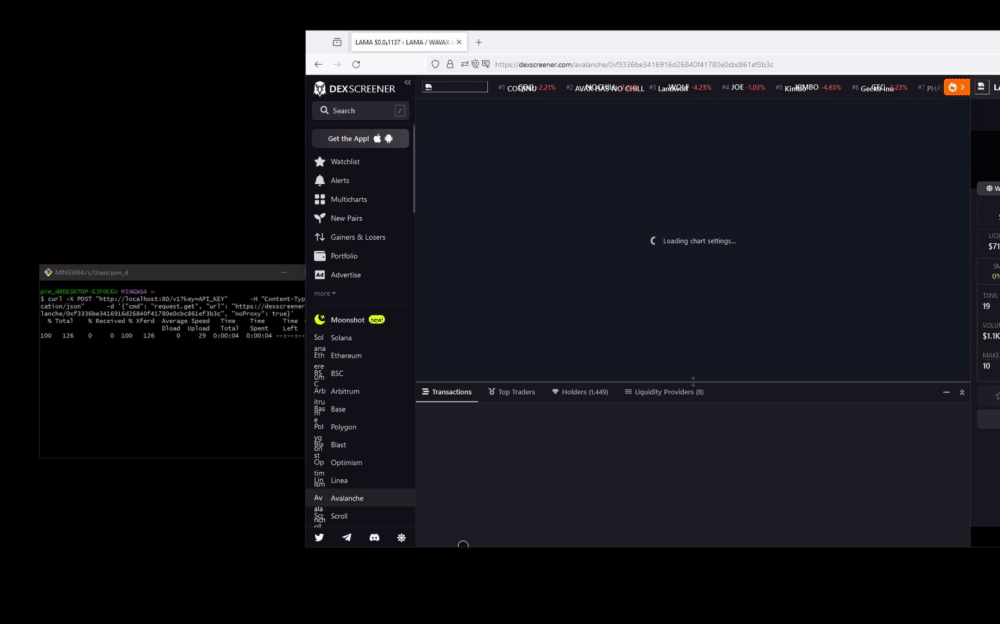
const scrappey = new Scrappey(apiKey);Here's an example of how Scrappey works. 🚀 This is an example using our development environment. Example is shown in Firefox, Chrome is also supported.
import Scrappey from "scrappey-wrapper";
const initialize = new Scrappey("API_KEY_HERE");
async function run() {
//Creates a session, this allows you to send multiple requests with the same browser tab open
//You can also choose to not create a session for temporary one time requests
//Setting a session string and proxy is optional, we automatically use our own residential proxies for you
//This is included in the request price
const createSession = await initialize.createSession({
"session": "test",
//"proxy": "http://username:password@ip:port"
})
//The unique session id that is used to identify the request for future use
// (the browser tab is kept open for 4 minutes)
const session = createSession.session
//The fingerprint that is used to identify the session
//This includes information like the user-agent, screen or language used
const fingerprint = createSession.fingerprint
console.log(`Found session ${session}`)
//Don't know what data to use in the request? Check out our Request Builder
//https://app.scrappey.com/#/builder
//It will auotmatically generate the data for you with the input you provided
const get = await initialize.get({
session: session,
url: 'https://httpbin.rs/get'
})
//Only successfull requests will take balance from your account
//This can verified by looking at the solution verified field
console.log(`Request was successful and took balance: ${get.solution.verified}`)
//To only get the text from a response use get.solution.innerText
//To also get all the HTML elements, use get.solution.response
const responseData = get.solution.response
console.log(`Found response`, responseData)
//Sending a POST with a=b&c=b data format
const post = await initialize.post({
session: session,
url: 'https://httpbin.rs/post',
postData: "test=test&test2=test2",
})
//Sending a post with JSON data
const jsonPost = await initialize.post({
session: session,
url: 'https://backend.scrappey.com/api/auth/login',
customHeaders: {
//HTTP1 is uppercase headers
//HTTP2 is lowercase headers
"content-type": "application/json"
},
postData: JSON.stringify({
email: "testtest@test.nl",
password: "password",
})
})
//To get the text from a JSON request, use innerText instead of response
console.log(jsonPost.solution.innerText)
await initialize.destroySession(session)
}
run().then((data) => console.log(data)).catch((err) => console.error(err))
/**
* Looking for more examples? Check out our examples below
*
* Cookiejar example with custom cookies and headers
* and using AI parse to get data from a website
*
* {
"cmd": "request.get",
"url": "https://httpbin.rs/get",
"customHeaders": {
"auth": "test"
},
"cookiejar": [
{
"key": "cookiekey",
"value": "cookievalue",
"domain": "httpbin.rs",
"path": "/"
}
],
"session": "86908d12-b225-446c-bb16-dc5c283e1d59",
"autoparse": true,
"properties": "parse using ai, product name",
"proxy": "http://proxystring"
}
*
Post example with cookiejar and custom headers
If you use a session, cookies are kept within the browser, then it's not needed
to add a cookiejar
{
"cmd": "request.post",
"url": "https://httpbin.rs/post",
"postData": "{\"happy\":\"true}",
"customHeaders": {
"content-type": "application/json",
"auth": "test"
},
"cookiejar": [
{
"key": "cookiekey",
"value": "cookievalue",
"domain": "httpbin.rs",
"path": "/"
}
],
"session": "86908d12-b225-446c-bb16-dc5c283e1d59",
"autoparse": true,
"properties": "parse using ai, product name",
"proxy": "http://proxystring"
}
*
*
*/Scrappey Wrapper Features:
- Easy session management with session creation and destruction
- Support for GET and POST requests
- Support for both FormData and JSON data formats
- Customizable headers for requests
- Robust and user-friendly
For more information, please visit the official Scrappey documentation. 📚
This project is licensed under the MIT License.
cloudflare anti bot bypass, cloudflare solver, scraper, scraping, cloudflare scraper, cloudflare turnstile solver, turnstile solver, data extraction, web scraping, website scraping, data scraping, scraping tool, API scraping, scraping solution, web data extraction, website data extraction, web scraping library, website scraping library, cloudflare bypass, scraping API, web scraping API, cloudflare protection, data scraping tool, scraping service, cloudflare challenge solver, web scraping solution, web scraping service, cloudflare scraping, cloudflare bot protection, scraping framework, scraping library, cloudflare bypass tool, cloudflare anti-bot, cloudflare protection bypass, cloudflare solver tool, web scraping tool, data extraction library, website scraping tool, cloudflare turnstile bypass, cloudflare anti-bot solver, turnstile solver tool, cloudflare scraping solution, website data scraper, cloudflare challenge bypass, web scraping framework, cloudflare challenge solver tool, web data scraping, data scraper, scraping data from websites, SEO, data mining, data harvesting, data crawling, web scraping software, website scraping tool, web scraping framework, data extraction tool, web data scraper, data scraping service, scraping automation, scraping tutorial, scraping code, scraping techniques, scraping best practices, scraping scripts, scraping tutorial, scraping examples, scraping challenges, scraping tricks, scraping tips, scraping tricks, scraping strategies, scraping methods, cloudflare protection bypass, cloudflare security bypass, web scraping Python, web scraping JavaScript, web scraping PHP, web scraping Ruby, web scraping Java, web scraping C#, web scraping Node.js, web scraping BeautifulSoup, web scraping Selenium, web scraping Scrapy, web scraping Puppeteer, web scraping requests, web scraping headless browser, web scraping dynamic content, web scraping AJAX, web scraping pagination, web scraping authentication, web scraping cookies, web scraping session management, web scraping data parsing, web scraping data cleaning, web scraping data analysis, web scraping data visualization, web scraping legal issues, web scraping ethics, web scraping compliance, web scraping regulations, web scraping IP blocking, web scraping anti-scraping measures, web scraping proxy, web scraping CAPTCHA solving, web scraping IP rotation, web scraping rate limiting, web scraping data privacy, web scraping consent, web scraping terms of service, web scraping robots.txt, web scraping data storage, web scraping database integration, web scraping data integration, web scraping API integration, web scraping data export, web scraping data processing, web scraping data transformation, web scraping data enrichment, web scraping data validation, web scraping error handling, web scraping scalability, web scraping performance optimization, web scraping distributed scraping, web scraping cloud-based scraping, web scraping serverless scraping, akamai, datadome, perimetex, shape, kasada, queue-it, incapsula.