This project is to parallelize Quick Hull algorithm for Convex Hull problem using CUDA and compare the performance between the serial (CPU) version of the algorithm.
The project is built using Nvidia GPU teaching kit.
CUDA-enabled GPU, CUDA Toolkit and CMake (CCMake) must be installed to run the project.
- Build libgputk
The following procedure will build
libgputk(the support library) that will be linked with your template file for processing command-line arguments, logging time, and checking the correctness of your solution.
Create the target build directory
mkdir build-dir
cd build-dir
We will use ccmake
ccmake ..
You will see the following screen
Pressing c would configure the build to your system (in the process detecting
the compiler, the CUDA Toolkit location, etc...).
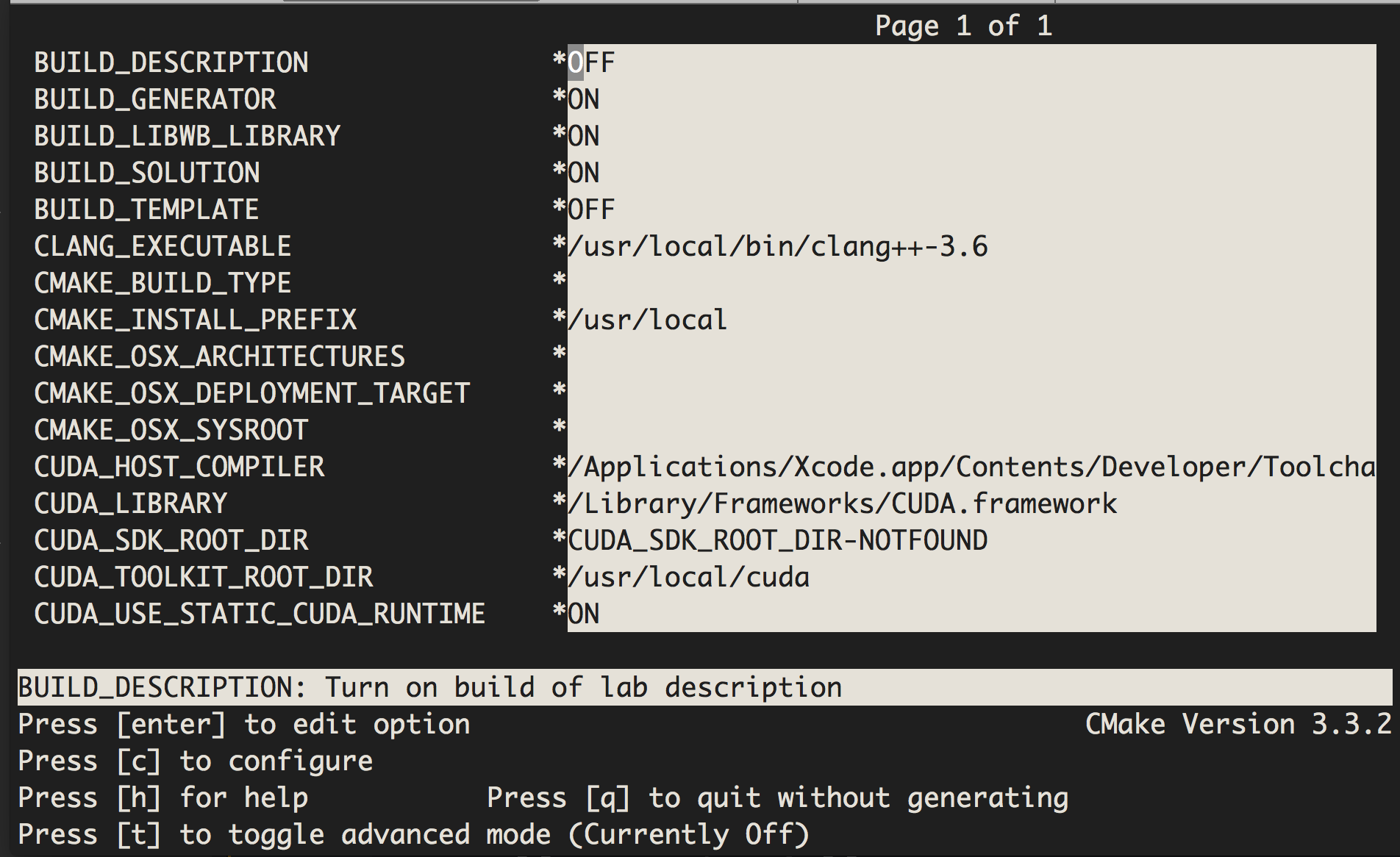
BUILD_LIBgpuTK_LIBRARY *ON
BUILD_LOGTIME *ON
If you have modified the above, then you should type g to regenerate the Makefile and then q to quit out of ccmake.
You can then use the make command to build the labs.
- Build the data generator and template
The following will compile the template file, and the data generator that will generate input files.
cd sources
make template
make daataset_generator
You can generate input data with
~~ ./dataset_generator ~~
This will create a directory that contains multiple pairs of input data. You can modify the file to generate input data of different sizes.
Change the file name in Makefile to change the template file version to the version that you want to build.
v1:
- initial version
v2:
- changed pt_idx structure
- Does not use pt_idx pointer vectors anymore (free from deep copy!!)
v3:
- Apply threshold to apply CUDA kernel
- Best perf at 32 * BLOCKSIZE
v4:
- Apply parallel reduction on the max dist calculation
- Best perf at 32 * BLOCKSIZE (85ms on 2M points)
v5:
- Apply Unified memory
- Does not work well
v6:
- Sort using thrust
- Works really well
Optimization flag includes -O3 -Xptxas -O3.

