我们知道golang对用户抽象了协程,协程要跑起来必然是需要系统线程来承载上下文,因为线程是最小的调度单元。golang的scheduler会帮你调度关联 PMG,这里的M是线程,G就是我们在golang里用go关键字spawn的协程。 对于用户来说,你是看不到也无法创建native thread原生线程的。 不管是golang nuts和golang issue里有人提过native thread feature的需求,但社区给出的论调是没必要,如果有必要那么可以用cgo,或者手动触发runtime.LockOSThread绑定。
golang抽象了pmg,我们通常不会特意的去关注某个golang线程数目,但上次就遇到了golang线程异常暴增, 最多的时候涨到1300多个线程。那我们知道线程过多有什么问题? 每个pthread的stack栈空间是8MB, 当然是virt, 这些线程也会增加kernel的调度成本,光上下文切换就不是闹的。当然golang 不会这么傻,不会让这么多的线程去轮询P上下文队列, 应该会有条件变量去控制调度。
什么问题会导致产生这么多的线程? 我先告诉大家答案,在我的这个场景下是 因为磁盘io问题引起的。 因为一些杂七杂八的程序都在这台主机,iops过高,又因为是阿里云磁盘性能低下,又又因为内存被占用的差不多了….
首先我们知道 golang写文件是阻塞,后面会说明原因。当我们写日志一般是先写到内核的page cache里,然后再由kernel通过阈值或定时刷新到磁盘,而不会像数据库那样调用fsync来磁盘落地。
既然先写到page cache内存里应该很快呀。 但这台服务器上有不少相关的服务在跑,在压测的场景下会产生大量的日志,而大量的日志都会扔到page cahe里,但刚才说了不少相关的服务都在一台阿里云主机上,虽然这台阿里云是高配,但相关服务都是吃内存不吐骨头的角色,导致page cache的内存明显少了。既然内存少了,那么kernel调用sync来持久化,但又因为阿里云主机的磁盘io吞吐很可悲,导致不能很快的flush到磁盘上。 那么就导致golang写日志的线程越来越多。
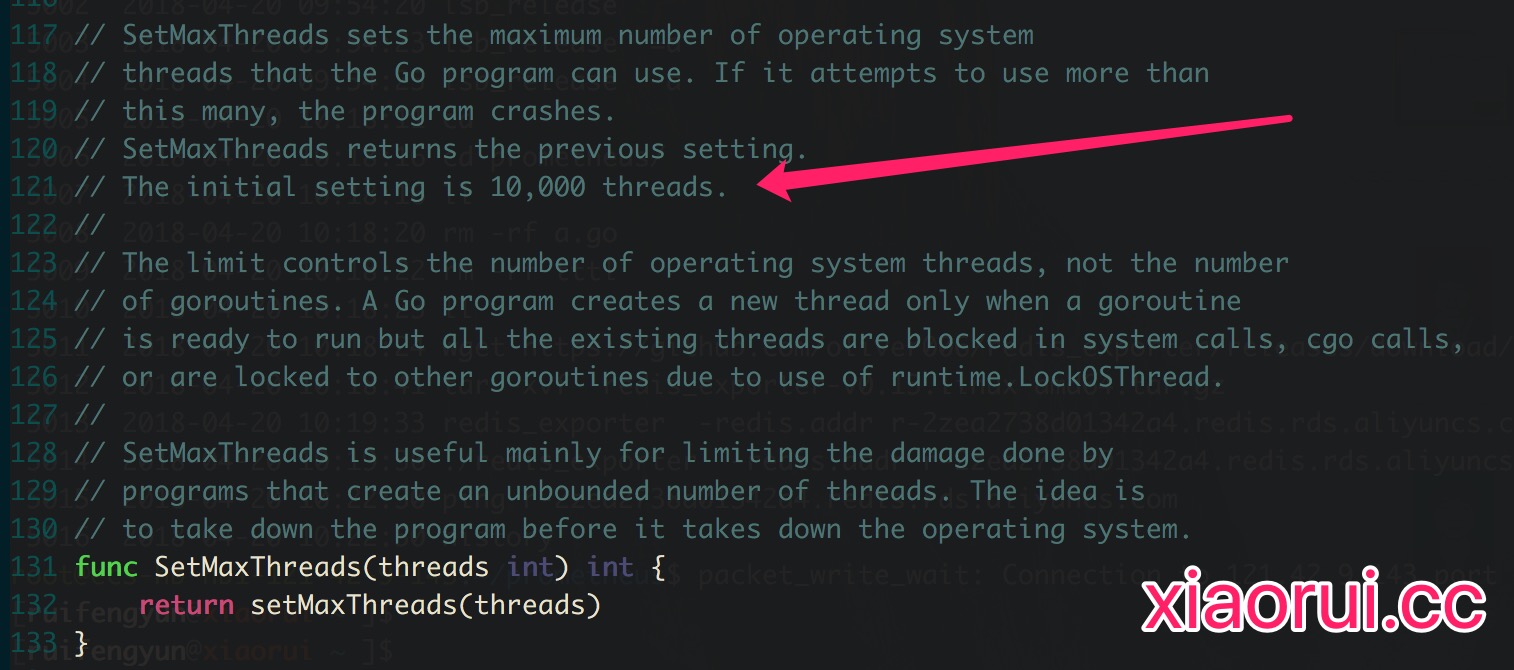
golang runtime是有个sysmon的协程,他会轮询的检测所有的P上下文队列,只要 G-M 的线程长时间在阻塞状态,那么就重新创建一个线程去从runtime P队列里获取任务。先前的阻塞的线程会被游离出去了,当他完成阻塞操作后会触发相关的callback回调,并加入回线程组里。简单说,如果你没有特意配置runtime.SetMaxThreads,那么在可没有复用的线程下会一直创建新线程。 golang默认的最大线程数10000个线程,这个是硬编码。 如果想要控制golang的pthread线程数可以使用 runtime.SetMaxThreads() 。
golang针对网络io使用了epoll事件机制来实现了同步非阻塞,但磁盘io用不了这套,首先 io fd 没有实现 Poll 接口,另外磁盘始终是就绪状态,而 epoll 是根据事件就绪通知,就绪 & 非就绪状态。
现在常见的一些高性能框架都没有直接的解决磁盘io异步非阻塞问题。 像nginx之前读写磁盘会阻塞worker进程,只有开启aio及线程池thread才会绕开阻塞问题。 可以说,整个linux下的 aio 不是很完善。新内核有个 io_uring 机制,不仅可监听常规的 net fd,也可监听文件 fd。
下面说下分析问题的过程, 首先通过ps和pprof看到golang的线程数,然后通过golang stack分析出当前的调用栈逻辑,继而通过strace来追踪系统调用情况。 golang stack没啥好说的,写日志阻塞那么调用栈里会显示不少log的调用情况。 那么我们主要来分析下,写日志和创建线程是怎么做的关联 ? 很简单就两个工具,一个是strace, 一个是 lsof 。
通过strace是可以看到write(8) fd的时候会mmap mprotect clone创建线程, 通过lsof 可以看到8是一个日志文件。配合Prometheus监控是可以看出iostat过高的时候,线程的数目也会跟着增长起来。 因为其他原因系统的内存也在减少,所以引起page cache不断刷盘。

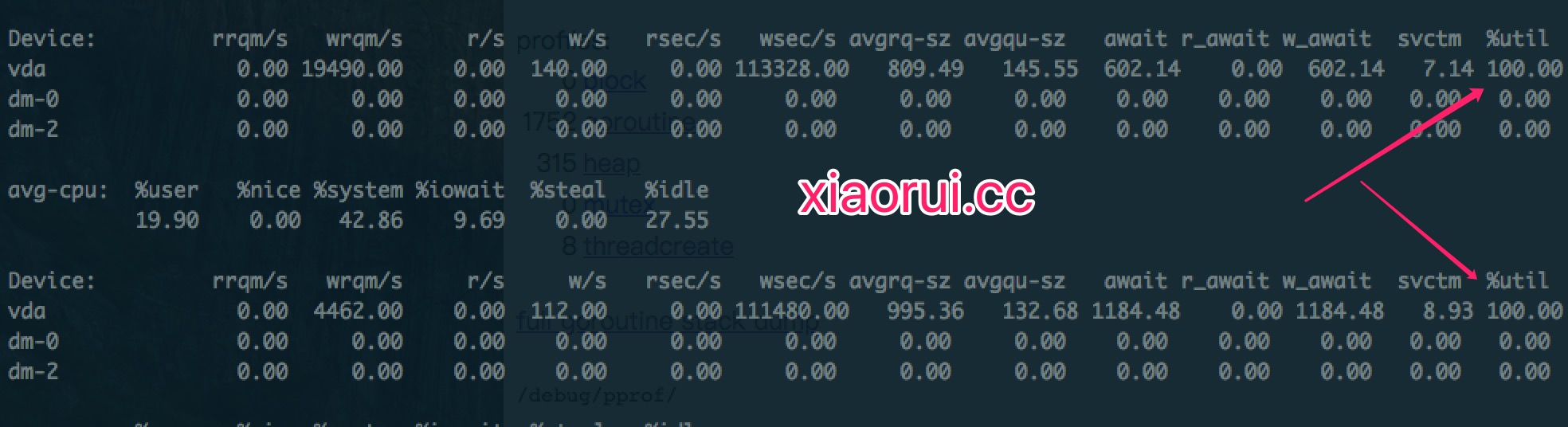
下面是用 golang pprof 观测到的数据,可以看到1009个线程.

当前的磁盘io使用情况, utils表示 长时间io吞吐 100%
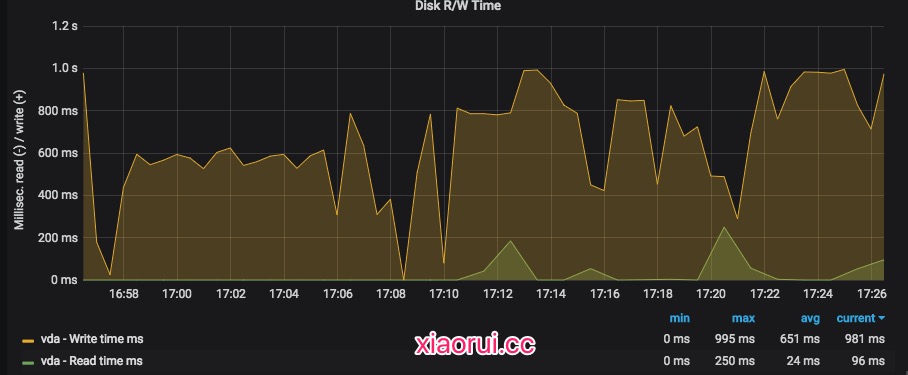
通过Prometheus查看io wait的趋势, 下面的图表可以看出io等待时间还是蛮高的。
上面说了,磁盘io造成golang线程暴涨是有很多原因的? 比如内存太小呀,日志输出太多呀,磁盘吞吐不行呀,各种各样的。
我们的解决方法是 首先限制runtime的线程数为200个 ( runtime.SetMaxThreads ),一般正常情况下都够用了。 通常24 core cpu的环境下,一个高频的proxy服务正常压测也才80多个线程。 这里主要还是为了避免预防各种未知诡异问题。
另外线上把服务的日志级别调高到warn警告,别整个debug level,导致io疯狂输出。
据我的测试,剩余的内存如果够大,也是可以减少线程的异常增长, 毕竟写日志O_APPEND按道理是速度很快的顺序io。
到此为止,golang线程暴增的问题差不多说完了。写这篇文章废了不少时间,其实发现问题 到 解决问题,一共也才十来分钟。当大家遇到一些性能问题时,使用golang pprof及性能工具来检查, 比较容易就可以定位问题。