
One can judge from experiment, or one can blindly accept authority.
Robert A. Heinlein
A "keep it simple" collection of many speech recognition engines focusing on inference only. We take the best and most well-known models, pick sensible defaults (if they don't already exist) and make them really easy to evaluate & use.
We've standardized some common ASR engines to make analysis of which speech recognition engine is the best for a given speech dataset. Selecting and discovering what ASR works well for a given scenario can be complicated since it depends on many factors. The standardization this repo provides should make it easier for researchers who want to compare their SoTA models to production systems, both cloud and local, or for people curious and are just getting started looking at speech recognition.
- Simple API to run an ASR, with CLI for quick testing with live mic or your chosen WAVs
- Supports a growing number of local and cloud ASRs
- Simple modular python interface using Pandas dataframes - easy to extend and change.
- Evaluation is driven by a line in the dataframe - want to evaluate more speech wavs? Add more lines.
- Automatic WER calculation with punctuation removal, word corrections (e.g. 1 -> one)
- Simple CSV output
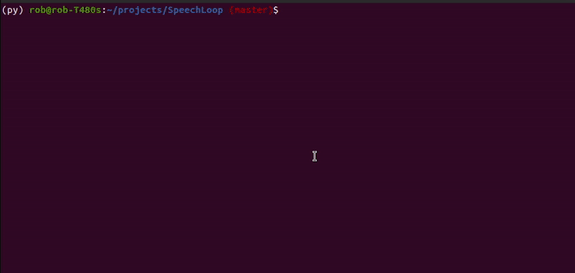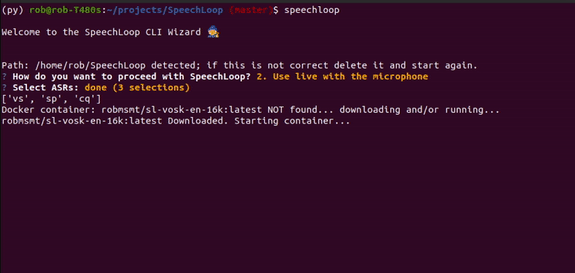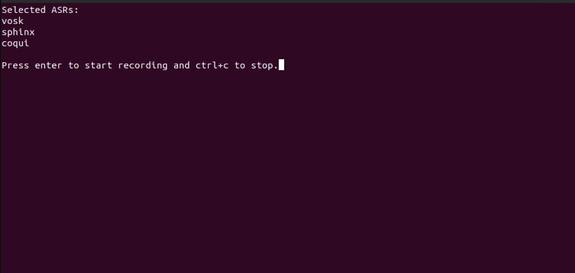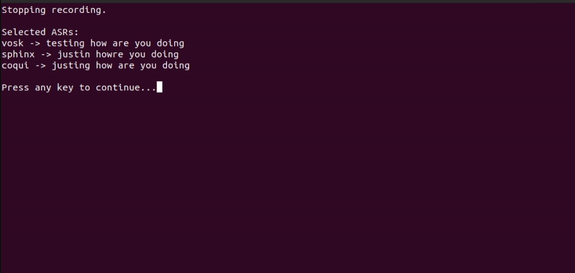
# make a virtualenv
python3 -m venv ~/venv/speechloop
# activate virtualenv
source ~/venv/speechloop/bin/activate
pip install speechloop
# cd to a directory with WAVs or use the examples!
speechloopWant to use a specific ASR in your own script? No problem
from speechloop.asr.vosk import Vosk
raw_audio_file = open("path/to/your/mono_16k.wav", "rb").read()
vs = Vosk()
print(f"{vs.longname} -> {vs.execute_with_audio(raw_audio_file)}")Using all as wanted_asr parameter to main.py will attempt to start all ASRs for testing.
| Short Code | Model | Licence | Type |
|---|---|---|---|
| ✅ sp | CMU Sphinx | Open Source | Offline - docker |
| ✅ vs | Alphacep Vosk | Open Source | Offline - docker |
| ✅ cq | Coqui | Open Source | Offline - docker |
| ❌ sb | Speech Brain | Open Source | Offline - docker |
| ❌ nm | Nvidia NeMo | Open Source | Offline - docker |
| ✅ gg | Proprietary | API set env:GOOGLE_APPLICATION_CREDENTIALS |
|
| ✅ az | Microsoft Azure | Proprietary | API set env:AZURE_KEY |
| ✅ aw | Amazon | Proprietary | API set env:AWS_ACCESS_KEY_ID+ AWS_SECRET_ACCESS_KEY or aws configure |
** In general, if there's a simple python API (that requires no extra compilation steps or heavy libs) then it'll be included as-is otherwise we build a docker container
The structure loosely follows the project:
├── docs
├── LICENSE
├── notebooks
│ └── eda.ipynb
├── README.md
├── requirements.txt
├── tests
└── speechloop
├── data
│ ├── simple_test
│ └── ...
├── output
├── asr.py
├── speechloop.py
├── audio.py
├── text.py
└── validate.py
- Python3.6+
- x86_64
- Recommend having approximately X GB storage space for each model
For developers - installation should be straight-forward and only take a number of minutes on most systems.
git clone https://github.com/robmsmt/SpeechLoop && cd SpeechLoop
python3 -m venv venv/py3
source venv/py3/bin/activate
pip install -r requirements-dev.txtSkip this step if it's already installed.
curl -fsSL https://get.docker.com -o get-docker.sh
sh get-docker.shNote it's important here that docker can run without root access. After this step has completed, you should check that you can type:
docker images and the list should be empty. If it requires that you type: sudo docker images then you should follow this step
Another good test is running: docker run hello-world
cd speechloop
python main.py --input_csv='data/simple_test/simple_test.csv' --wanted_asr=vs,sp,cqRun all tests with: python3 -m unittest discover .