-[]
-
+Autocorrelation
+```{r}
+car::durbinWatsonTest(lm_ols)
+```
-# Version Control
-## Just a brief introduction{.columns-2 .build}
-
-----
+

-
-
+
+## See you then ~
-## Using Git with RStudio
+
-* RStudio has associate with the Git and SVN very well.
-* Process to use git:
- + Register a user account in https://github.com.
- + Connect your account with RStudio following [this instruction](http://www.molecularecologist.com/2013/11/using-github-with-r-and-rstudio/).
- + Create a version-control project in RStudio
- +

- + Commit, Pull and Push
+

+
## External Sources
+* My email: [yue-hu-1@uiowa.edu](mailto: yue-hu-1@uiowa.edu)
+
+* Workshops: http://ppc.uiowa.edu/node/3608
+* Consulting service: http://ppc.uiowa.edu/node/3385/
* Q&A Blogs:
+ http://stackoverflow.com/questions/tagged/r
+ https://stat.ethz.ch/mailman/listinfo/r-help
@@ -294,12 +336,4 @@ interplot(m = lm_in, var1 = "hp", var2 = "wt") +
+ http://www.cookbook-r.com/Graphs/
+ http://shiny.stat.ubc.ca/r-graph-catalog/
-* Workshops: http://ppc.uiowa.edu/node/3608
-* Consulting service: http://ppc.uiowa.edu/node/3385/
-
-----
-
-
-[]
-
diff --git a/RworkshopIV.Rmd b/RworkshopIV.Rmd
index 6ebfcf5..0e8193c 100644
--- a/RworkshopIV.Rmd
+++ b/RworkshopIV.Rmd
@@ -1,166 +1,351 @@
---
title: "Hello, R!"
-author: "Yue Hu's R Workshop Series IV"
+author: "Yue Hu's R Workshop Series III"
output:
ioslides_presentation:
+ self_contained: yes
incremental: yes
logo: image/logo.gif
slidy_presentation: null
transition: faster
widescreen: yes
---
+```{r setup, include=FALSE}
+knitr::opts_chunk$set(message = FALSE, warning = FALSE)
+```
-# Preface
-## What Are Covered in This Workshop Series
-* [A overview of R](https://rpubs.com/sammo3182/Rintro)
-* [Data manipulation (input/output, row/column selections, etc.)](https://rpubs.com/sammo3182/Rintro)
-* [Descriptive and binary hypotheses (summary, correlation, t-test, etc.)](http://rpubs.com/sammo3182/Rstat)
-* [Multiple regression (OLS, GLS, MLM, etc.)](http://rpubs.com/sammo3182/Rstat)
-* **Multilevel Regression**
-* [Presentation (table, graph)](https://rpubs.com/sammo3182/Rpresent)
+## Tabling
+There are over twenty packages for [table presentation](http://conjugateprior.org/2013/03/r-to-latex-packages-coverage/) in R. My favoriate three are `stargazer`, `xtable`, and `texreg`.
-# What's Multilevel Effects?{.hcenter}
-## An Example about Pizza
-How do cost/fuel affect pizza quality?
+(Sorry, but all of them are for **Latex** output)
-

+* `stargazer`: good for summary table and regular regression results
+* `texreg`: when some results can't be presented by `stargazer`, try `texreg` (e.g., MLM results.)
+* `xtable`: the most extensively compatible package, but need more settings to get a pretty output, most of which `stargazer` and `texreg` can automatically do for you.
+## An example {.smaller .columns-2}
-## An Example about Pizza{.hcenter}
-How do those factors vary by neighborhood?
+```{r message = F}
+lm_ols <- lm(mpg ~ cyl + hp + wt, data = mtcars)
+stargazer::stargazer(lm_ols, type = "text", align = T)
+```
-

+* For Word users, click [here](http://www.r-statistics.com/2010/05/exporting-r-output-to-ms-word-with-r2wd-an-example-session/).
+## Print out directly in the website or the manuscript{.smaler}
+```{r results='asis'}
+stargazer::stargazer(lm_ols, type = "html", align = T)
+```
-## Data
-(Based on Harris \& Lander's ["Predicting Pizza in Chinatown: An Intro to Multilevel Regression"(2010)](http://www.jaredlander.com/wordpress/wordpress-2.9.2/wordpress/wp-content/uploads/2010/10/NYC-PA-Meetup-Multilevel-Models.ppt))
+# But...why tabulating the results if you can plot it?
+## How do R plots look like
+
+
+
-```{r message=FALSE}
-library(RCurl);library(dplyr) # load package for reading url and manipulate data
-path <- getURL("https://raw.githubusercontent.com/HarlanH/nyc-pa-meetup-multilevel-pizza/master/Fake%20Pizza%20Data.csv")
-pizza <- read.csv(text = path) # read the csv data
-glimpse(pizza)
+----
+
+

+
+
+----
+
+

+
+
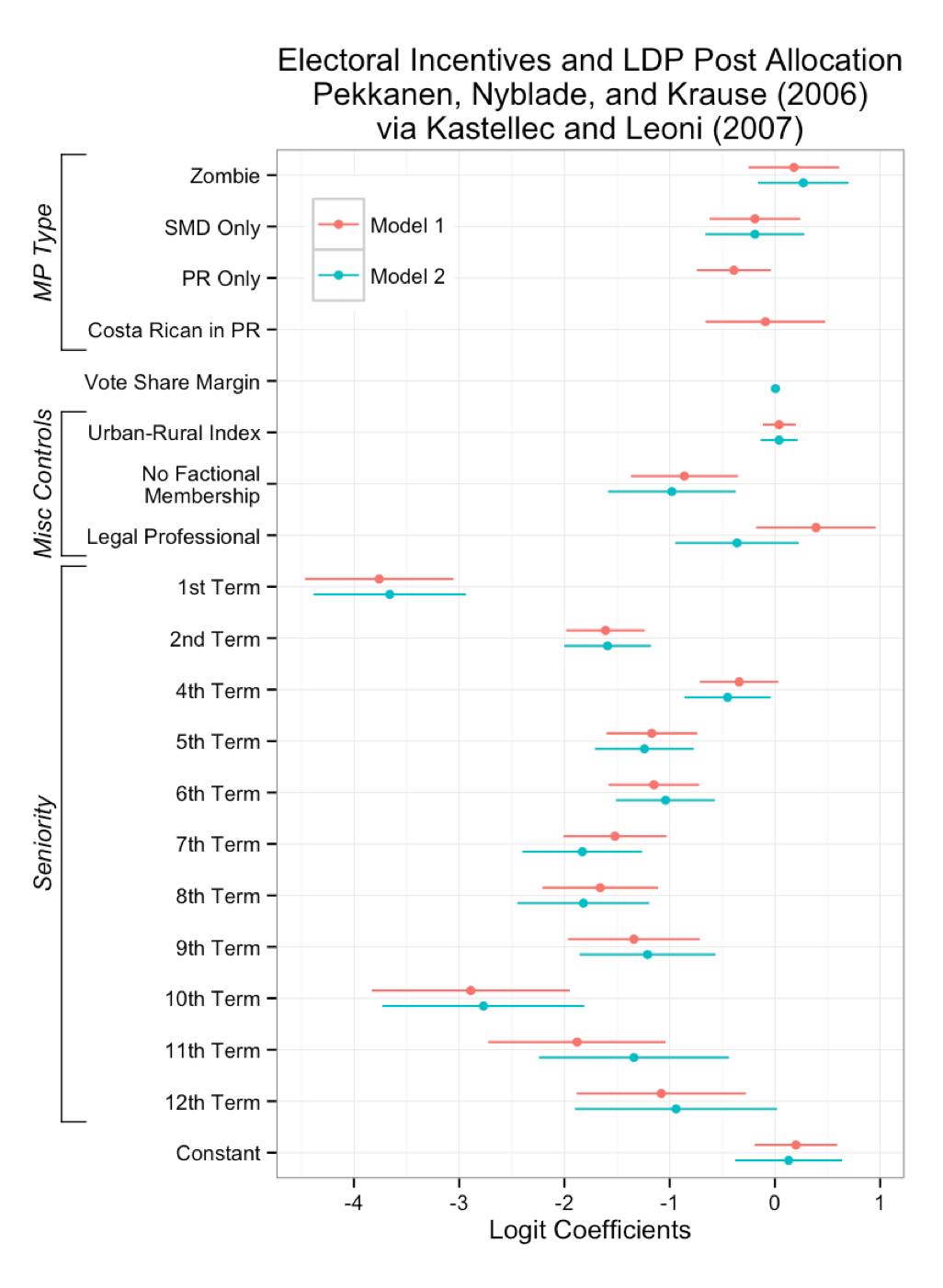
+## Too "fancy" for your research? Then...
+*
+
+
+
+----
+
+

+
+
+----
+
+

+
+
+## Let's Start!
+
+* Basic plots: `plot()`.
+* Lattice plots: e.g., `ggplot()`.
+* Interactive plots: `shiny()`. (save for later)
+ +
+

+
+
+## Basic plot
+Pro:
+
+* Embedded in R
+* Good tool for
data exploration.
+*
Spatial analysis and
3-D plots.
+
+Con:
+
+* Not very pretty
+* Not very flexible
+
+## An example: create a histogram
+
+```{r fig.align="center"}
+hist(mtcars$mpg)
+```
+
+## Saving the plot{.build}
+* Compatible format:`.jpg`, `.png`, `.wmf`, `.pdf`, `.bmp`, and `postscript`.
+* Process:
+ 1. call the graphic device
+ 2. plot
+ 3. close the device
+
+```{r eval = F}
+jpeg("histgraph.jpg")
+hist
+dev.off()
```
+
Tip
+
+Sometimes, RStudio may distort the graphic output. In this situation, try to zoom or use `windows()` function.
+
+
+----
+
+The device list:
+
+| Function | Output to |
+|----------------------------- |------------------ |
+| pdf("mygraph.pdf") | pdf file |
+| win.metafile("mygraph.wmf") | windows metafile |
+| png("mygraph.png") | png file |
+| jpeg("mygraph.jpg") | jpeg file |
+| bmp("mygraph.bmp") | bmp file |
+| postscript("mygraph.ps") | postscript file |
+
-## Neighborhood Variance{.smaller}
-(Multilevel Effects!!)
+## `ggplot`: the most popular graphic engine in R {.build}
-```{r message=FALSE, fig.align="center", fig.height = 3}
++ Built by Hadley Wickham based on Leland Wilkinson's *Grammar of Graphics*.
++ It breaks the plot into components as
scales and
layers---increase the flexibility.
++ To use `ggplot`, one needs to install the package `ggplot2` first.
+
+```{r message=FALSE}
library(ggplot2)
-lm_nei <- lm(Rating ~ CostPerSlice * Neighborhood, data=pizza)
-pizza$pre_nei <- predict(lm_nei)
-ggplot(pizza, aes(CostPerSlice, Rating, color=Neighborhood)) +
- geom_point() + theme_bw() +
- geom_smooth(aes(y = pre_nei), method='lm',se=FALSE) +
- xlab("Cost per Slice") + ylab("Quality")
```
-## Dig in
-```{r echo=FALSE, fig.align="center"}
-lm_sour <- lm(Rating ~ CostPerSlice * HeatSource, data=pizza)
-pizza$pre_sour <- predict(lm_sour)
-ggplot(pizza, aes(CostPerSlice, Rating, color=HeatSource)) +
- geom_point() + facet_wrap(~ Neighborhood) + theme_bw() +
- xlab("Cost per Slice") + ylab("Quality") +
- geom_smooth(aes(y=pre_sour), method='lm', se=FALSE)
+## Histogram in `ggplot`
+```{r fig.align="center", fig.height=2.7}
+ggplot(mtcars, aes(x=mpg)) +
+ geom_histogram(aes(y=..density..), binwidth=2, colour="black")
```
+## Decoration
+
+```{r fig.align="center", fig.height=2.7}
+ggplot(mtcars, aes(x=mpg)) +
+ geom_histogram(aes(y=..density..), binwidth=2, colour="black", fill="purple") +
+ geom_density(alpha=.2, fill="blue") + # Overlay with transparent density plot
+ theme_bw() + ggtitle("histogram with a Normal Curve") +
+ xlab("Miles Per Gallon") + ylab("Density")
+```
-## Multilevel Model (MLM)
-```{r message = F}
-library(lme4) # package for multilevel model
-# Allow intercept varying
-mlm_fix <- lmer(Rating ~ HeatSource + (1 | Neighborhood),data=pizza)
-# Allow slope varing
-mlm_ran <- lmer(Rating ~ HeatSource + CostPerSlice +
- (CostPerSlice | Neighborhood),data=pizza)
+## Break in Parts:{.smaller}
-# Slop varying but not correlate to intercept
-mlm_ur <- lmer(Rating ~ HeatSource + CostPerSlice +
- (CostPerSlice || Neighborhood),data=pizza)
-# Just for the purpose of instruction
+```{r eval=FALSE}
+ggplot(data = mtcars, aes(x=mpg)) +
+ geom_histogram(aes(y=..density..), binwidth=2, colour="black", fill="purple") +
+ geom_density(alpha=.2, fill="blue") + # Overlay with transparent density plot
+ theme_bw() + ggtitle("histogram with a Normal Curve") +
+ xlab("Miles Per Gallon") + ylab("Density")
```
+* `data`: The data that you want to visualise
+
+* `aes`: Aesthetic mappings
+describing how variables in the data are mapped to aesthetic attributes
+ + horizontal position (`x`)
+ + vertical position (`y`)
+ + colour
+ + size
+* `geoms`: Geometric objects that represent what you actually see on
+the plot
+ + points
+ + lines
+ + polygons
+ + bars
-## Result: Fixed Effect {.smaller .columns-2}
-```{r size = "tiny"}
-summary(mlm_fix)
+----
+
+* `theme`, `ggtitle`, `xlab`, `ylab`: decorations.
+* Other parts you may see in some developed template
+ + `stats`: Statistics transformations
+ + `scales`: relate the data to the aesthetic
+ + `coord`: a coordinate system that describes how data coordinates are
+mapped to the plane of the graphic.
+ + `facet`: a faceting specification describes how to break up the data into sets.
+
+## An advanced version:
+```{r fig.height=3}
+library(dplyr)
+df_desc <- select(mtcars, am, carb, cyl, gear,vs) %>% # select the variables
+ tidyr::gather(var, value) # reshape the wide data to long data
+
+ggplot(data = df_desc, aes(x = as.factor(value))) + geom_bar() +
+ facet_wrap(~ var, scales = "free", ncol = 5) + xlab("")
+```
+
+## Save `ggplot`
+* `ggsave(
, "")`:
+ + When the `` is omitted, R will save the last presented plot.
+ + There are additional arguments which users can use to adjust the size, path, scale, etc.
+
+
+
+## Plotting with packages: `dotwhisker`{.smaller}
+Plot the comparable coefficients or other estimates (margins, predicted probabilities, etc.).
+
+```{r message=FALSE}
+library(dotwhisker)
+library(broom)
+m1 <- lm(mpg ~ wt + cyl + disp + gear, data = mtcars)
```
-## Result: Fixed + Random Effect {.smaller .columns-2}
+----
```{r}
-summary(mlm_ran)
+summary(m1)
```
-## Result: Uncorrelated Random Effect {.smaller .columns-2}
+----
+
```{r}
-summary(mlm_ur) # Shouldn't do since cor between CostPerSlice and Interaction was - .3
+dwplot(m1)
```
-## About Covariance Matrix
-* Using Cholesky parameterization (which requires exchange matrix.):
- + Avoid uneccessary rising of asymptotically flat surface warning---**Easier to converge**.
- + Benefit **small- to medium-sized** data sets and complex variance-covariance models.
-* If you want to use log-Cholesky (unconstrained) parameterization, you want to use `nlme` package
+----
+
+```{r message=F, fig.align="center", fig.height=4}
+m2 <- update(m1, . ~ . + hp) # add another predictor
+m3 <- update(m2, . ~ . + am) # and another
-## Diagnosis
-Fitted vs. residual plot
-```{r, fig.align="center", fig.height=4}
-plot(mlm_ran, type = c("p", "smooth"))
+dwplot(list(m1, m2, m3))
```
----
-Quantile-Quantile plots
-```{r fig.align="center"}
-lattice::qqmath(mlm_ran)
+```{r eval = F}
+dwplot(list(m1, m2, m3)) +
+ relabel_y_axis(c("Weight", "Cylinders", "Displacement",
+ "Gears", "Horsepower", "Manual")) +
+ theme_bw() + xlab("Coefficient Estimate") + ylab("") +
+ geom_vline(xintercept = 0, colour = "grey60", linetype = 2) +
+ ggtitle("Predicting Gas Mileage") +
+ theme(plot.title = element_text(face="bold"),
+ legend.justification=c(0, 0), legend.position=c(0, 0),
+ legend.background = element_rect(colour="grey80"),
+ legend.title = element_blank())
```
-## Diagnosis: Posterior Predictive Simulation
+----
-```{r}
-iqrvec <- sapply(simulate(mlm_ran, 1000), IQR)
-obsval <- IQR(pizza$Rating)
-post_pred_p <- mean(obsval >= c(obsval, iqrvec))
-post_pred_p
+```{r echo = F}
+dwplot(list(m1, m2, m3)) +
+ relabel_y_axis(c("Weight", "Cylinders", "Displacement",
+ "Gears", "Horsepower", "Manual")) +
+ theme_bw() + xlab("Coefficient Estimate") + ylab("") +
+ geom_vline(xintercept = 0, colour = "grey60", linetype = 2) +
+ ggtitle("Predicting Gas Mileage") +
+ theme(plot.title = element_text(face="bold"),
+ legend.justification=c(0, 0), legend.position=c(0, 0),
+ legend.background = element_rect(colour="grey80"),
+ legend.title = element_blank())
```
-Warning: the above method does not allow for the uncertainty in the estimated parameters.
-## Present
-Fixed effect coefficients: `dotwhisker`
+## Plotting with packages: `interplot`{.smaller}
+
+
```{r message=FALSE}
-library(broom);library(dotwhisker)
-mlm_coef <- tidy(mlm_ran)
-delete <- grep("\\bsd_.*|cor_.*\\b", mlm_coef$term, value = T)
-mlm_sub <- filter(mlm_coef, term != delete) %>% filter(term != "(Intercept)")
+library(interplot)
+lm_in <- lm(mpg ~ cyl + hp * wt, data = mtcars)
```
-Only keep the substantive variables.
----
+```{r}
+summary(lm_in)
+```
+
+----
```{r fig.align="center"}
-dwplot(mlm_sub) + ylab("Fixed Effect") + xlab("Coefficient") +
- geom_vline(xintercept = 0, colour = "red", linetype = 2)
+interplot(m = lm_in, var1 = "hp", var2 = "wt", hist = TRUE) +
+ xlab("Automobile Weight (thousands lbs)") +
+ ylab("Estimated Coefficient for \nGross horsepower")
```
+## Wrap Up
+* R has a bunch of packages for creating publishing-like tables, e.g., `stargazer`, `xtable`, and `texreg`
-## Interaction{.smaller}
-Use `interplot` package:
-```{r message=FALSE, fig.align="center", fig.height=3.5, warning=FALSE}
-mlm_int <- lmer(Rating ~ HeatSource * CostPerSlice + (CostPerSlice | Neighborhood),data=pizza)
-library(interplot)
-interplot(mlm_int, var1 = "HeatSource", var2 = "CostPerSlice", hist = T) +
- xlab("Cost Per Slice") + ylab("Estimated Coefficient for Heat Source")
-```
+* There are three ways to visualize statistics in R: basic, lattice (`ggplot`), and interactive.
+ + basic: e.g., `hist()`
+ + `ggplot`: /n e.g., `ggplot(, aes(x=)) + geom_histogram()`.
+
+* Two special types of plot:
+ + Estimate plot with [`dotwhisker`](https://cran.r-project.org/web/packages/interplot/vignettes/interplot-vignette.html).
+ + Interaction plot with [`interplot`](https://cran.r-project.org/web/packages/dotwhisker/vignettes/dwplot-vignette.html).
+
+
+## Almost the end: one topic left
+
+
+[]
+
+
+
+# Version Control
+## Just a brief introduction{.columns-2 .build}
+
+

+
+
+
 + + Commit, Pull and Push
## External Sources
@@ -175,11 +360,11 @@ interplot(mlm_int, var1 = "HeatSource", var2 = "CostPerSlice", hist = T) +
+ http://shiny.stat.ubc.ca/r-graph-catalog/
* Workshops: http://ppc.uiowa.edu/node/3608
-* Consulting service: http://ppc.uiowa.edu/node/3385/
+* Consulting service: http://ppc.uiowa.edu/isrc/methods-consulting
+
----
+ + Commit, Pull and Push
## External Sources
@@ -175,11 +360,11 @@ interplot(mlm_int, var1 = "HeatSource", var2 = "CostPerSlice", hist = T) +
+ http://shiny.stat.ubc.ca/r-graph-catalog/
* Workshops: http://ppc.uiowa.edu/node/3608
-* Consulting service: http://ppc.uiowa.edu/node/3385/
+* Consulting service: http://ppc.uiowa.edu/isrc/methods-consulting
+
----
-

+[]
+
+
 +
+ 
 -
+ +
-
+ +  +
+ + +
+ +  + one-dimension array == vector
+ two-dimension array == matrix
-* **Function**: a process to handle the object
+* **Function**: a process to handle the object (`functionName(varLabel = varData)`)
## Do math with R: Basic Functions
@@ -136,8 +135,8 @@ x^2;sqrt(x);log(x);exp(x)
# matrix algebra
z <- matrix(1:4, ncol = 2)
z + z - z
-z %*% z # inner mulTiplication
-z %o% z # outter mulTiplication
+z %*% z # inner mulTiplication
+z %o% z # outter mulTiplication
# logical evaluation
x == z; x != Z
@@ -146,16 +145,17 @@ x > z; x <= z
```
-## Commen Data Type: Vector{.smaller}
+## Common Data Type: Vector{.smaller}
```{r}
1:10 # numeric (integer/double)
c("R", "workshop") # character
3 == 5 # logical
factor(1:3, levels = 1:3, labels = c("low", "medium", "high")) # factor
```
-(Tip)
+(Tip)
+
+ one-dimension array == vector
+ two-dimension array == matrix
-* **Function**: a process to handle the object
+* **Function**: a process to handle the object (`functionName(varLabel = varData)`)
## Do math with R: Basic Functions
@@ -136,8 +135,8 @@ x^2;sqrt(x);log(x);exp(x)
# matrix algebra
z <- matrix(1:4, ncol = 2)
z + z - z
-z %*% z # inner mulTiplication
-z %o% z # outter mulTiplication
+z %*% z # inner mulTiplication
+z %o% z # outter mulTiplication
# logical evaluation
x == z; x != Z
@@ -146,16 +145,17 @@ x > z; x <= z
```
-## Commen Data Type: Vector{.smaller}
+## Common Data Type: Vector{.smaller}
```{r}
1:10 # numeric (integer/double)
c("R", "workshop") # character
3 == 5 # logical
factor(1:3, levels = 1:3, labels = c("low", "medium", "high")) # factor
```
-(Tip)
+(Tip)
+
 -
-
-
-# Data Input and Manipulation
-## Input default data types{.build}
-
-* Default data types: .Rds, .Rdata(.Rda)
-
-```{r eval=FALSE}
-load("
-
-
-
-# Data Input and Manipulation
-## Input default data types{.build}
-
-* Default data types: .Rds, .Rdata(.Rda)
-
-```{r eval=FALSE}
-load(" +
+
+
+# Math and Basic Statistics with R
+## Set where to locate the data and store the results
+
+
+
+
+
+# Math and Basic Statistics with R
+## Set where to locate the data and store the results
+
+ -
-