贪心算法(Greedy Algorithm):一种在每次决策时,总是采取在当前状态下的最好选择,从而希望导致结果是最好或最优的算法。
贪心算法是一种改进的「分步解决算法」,其核心思想是:将求解过程分成「若干个步骤」,然后根据题意选择一种「度量标准」,每个步骤都应用「贪心原则」,选取当前状态下「最好 / 最优选择(局部最优解)」,并以此希望最后得出的结果也是「最好 / 最优结果(全局最优解)」。
换句话说,贪心算法不从整体最优上加以考虑,而是一步一步进行,每一步只以当前情况为基础,根据某个优化测度做出局部最优选择,从而省去了为找到最优解要穷举所有可能所必须耗费的大量时间。
对许多问题来说,可以使用贪心算法,通过局部最优解而得到整体最优解或者是整体最优解的近似解。但并不是所有问题,都可以使用贪心算法的。
一般来说,这些能够使用贪心算法解决的问题必须满足下面的两个特征:
- 贪⼼选择性质
- 最优子结构
贪心选择性质:指的是一个问题的全局最优解可以通过一系列局部最优解(贪心选择)来得到。
换句话说,当进行选择时,我们直接做出在当前问题中看来最优的选择,而不用去考虑子问题的解。在做出选择之后,才会去求解剩下的子问题,如下图所示。
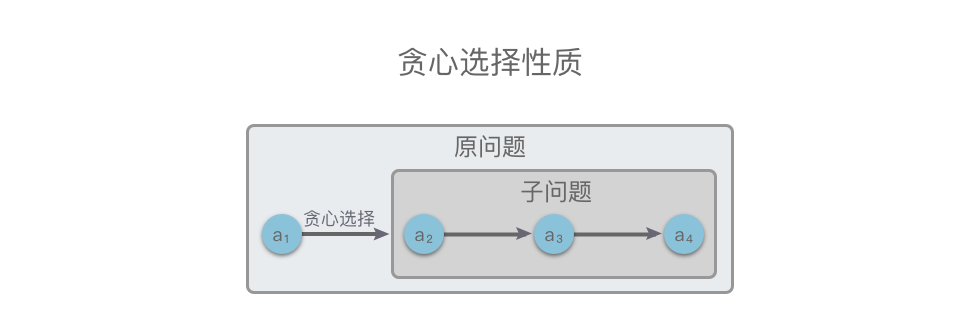
贪心算法在进行选择时,可能会依赖之前做出的选择,但不会依赖任何将来的选择或是子问题的解。运用贪心算法解决的问题在程序的运行过程中无回溯过程。
最优子结构性质:指的是一个问题的最优解包含其子问题的最优解。
问题的最优子结构性质是该问题能否用贪心算法求解的关键。
举个例子,如下图所示,原问题
也就是说,如果原问题的最优解包含子问题的最优解,则说明该问题满足最优子结构性质。
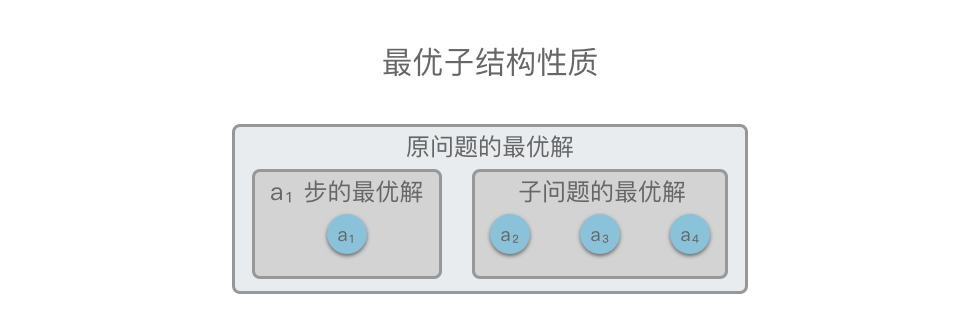
在做了贪心选择后,满足最优子结构性质的原问题可以分解成规模更小的类似子问题来解决,并且可以通过贪心选择和子问题的最优解推导出问题的最优解。
反之,如果不能利用子问题的最优解推导出整个问题的最优解,那么这种问题就不具有最优子结构。
贪心算法最难的部分不在于问题的求解,而在于是正确性的证明。我们常用的证明方法有「数学归纳法」和「交换论证法」。
数学归纳法:先计算出边界情况(例如
$n = 1$ )的最优解,然后再证明对于每个$n$ ,$F_{n + 1}$ 都可以由$F_n$ 推导出。交换论证法:从最优解出发,在保证全局最优不变的前提下,如果交换方案中任意两个元素 / 相邻的两个元素后,答案不会变得更好,则可以推定目前的解是最优解。
判断一个问题是否通过贪心算法求解,是需要进行严格的数学证明的。但是在日常写题或者算法面试中,不太会要求大家去证明贪心算法的正确性。
所以,当我们想要判断一个问题是否通过贪心算法求解时,我们可以:
- 凭直觉:如果感觉这道题可以通过「贪心算法」去做,就尝试找到局部最优解,再推导出全局最优解。
- 举反例:尝试一下,举出反例。也就是说找出一个局部最优解推不出全局最优解的例子,或者找出一个替换当前子问题的最优解,可以得到更优解的例子。如果举不出反例,大概率这道题是可以通过贪心算法求解的。
- 转换问题:将优化问题转换为具有贪心选择性质的问题,即先做出选择,再解决剩下的一个子问题。
- 贪心选择性质:根据题意选择一种度量标准,制定贪心策略,选取当前状态下「最好 / 最优选择」,从而得到局部最优解。
- 最优子结构性质:根据上一步制定的贪心策略,将贪心选择的局部最优解和子问题的最优解合并起来,得到原问题的最优解。
描述:一位很棒的家长为孩子们分发饼干。对于每个孩子
现在给定代表所有孩子胃口值的数组
要求:尽可能满足越多数量的孩子,并求出这个最大数值。
说明:
-
$1 \le g.length \le 3 * 10^4$ 。 -
$0 \le s.length \le 3 * 10^4$ 。 -
$1 \le g[i], s[j] \le 2^{31} - 1$ 。
示例:
- 示例 1:
输入:g = [1,2,3], s = [1,1]
输出:1
解释:你有三个孩子和两块小饼干,3 个孩子的胃口值分别是:1, 2, 3。虽然你有两块小饼干,由于他们的尺寸都是 1,你只能让胃口值是 1 的孩子满足。所以应该输出 1。- 示例 2:
输入: g = [1,2], s = [1,2,3]
输出: 2
解释: 你有两个孩子和三块小饼干,2个孩子的胃口值分别是1, 2。你拥有的饼干数量和尺寸都足以让所有孩子满足。所以你应该输出 2。为了尽可能的满⾜更多的⼩孩,而且一块饼干不能掰成两半,所以我们应该尽量让胃口小的孩子吃小块饼干,这样胃口大的孩子才有大块饼干吃。
所以,从贪心算法的角度来考虑,我们应该按照孩子的胃口从小到大对数组
下面我们使用贪心算法三步走的方法解决这道题。
- 转换问题:将原问题转变为,当胃口最小的孩子选择完满足这个孩子的胃口且尺寸最小的饼干之后,再解决剩下孩子的选择问题(子问题)。
- 贪心选择性质:对于当前孩子,用尺寸尽可能小的饼干满足这个孩子的胃口。
- 最优子结构性质:在上面的贪心策略下,当前孩子的贪心选择 + 剩下孩子的子问题最优解,就是全局最优解。也就是说在贪心选择的方案下,能够使得满足胃口的孩子数量达到最大。
使用贪心算法的代码解决步骤描述如下:
- 对数组
$g$ 、$s$ 进行从小到大排序,使用变量$index\underline{}g$ 和$index\underline{}s$ 分别指向$g$ 、$s$ 初始位置,使用变量$res$ 保存结果,初始化为$0$ 。 - 对比每个元素
$g[index\underline{}g]$ 和$s[index\underline{}s]$ :- 如果
$g[index\underline{}g] \le s[index\underline{}s]$ ,说明当前饼干满足当前孩子胃口,则答案数量加$1$ ,并且向右移动$index\underline{}g$ 和$index\underline{}s$ 。 - 如果
$g[index\underline{}g] > s[index\underline{}s]$ ,说明当前饼干无法满足当前孩子胃口,则向右移动$index_s$ ,判断下一块饼干是否可以满足当前孩子胃口。
- 如果
- 遍历完输出答案
$res$ 。
class Solution:
def findContentChildren(self, g: List[int], s: List[int]) -> int:
g.sort()
s.sort()
index_g, index_s = 0, 0
res = 0
while index_g < len(g) and index_s < len(s):
if g[index_g] <= s[index_s]:
res += 1
index_g += 1
index_s += 1
else:
index_s += 1
return res-
时间复杂度:$O(m \times \log m + n \times \log n)$,其中
$m$ 和$n$ 分别是数组$g$ 和$s$ 的长度。 - 空间复杂度:$O(\log m + \log n)$。
描述:给定一个区间的集合
要求:返回需要移除区间的最小数量。
说明:
-
$1 \le intervals.length \le 10^5$ 。 -
$intervals[i].length == 2$ 。 -
$-5 * 10^4 \le starti < endi \le 5 * 10^4$ 。
示例:
- 示例 1:
输入:intervals = [[1,2],[2,3],[3,4],[1,3]]
输出:1
解释:移除 [1,3] 后,剩下的区间没有重叠。- 示例 2:
输入: intervals = [ [1,2], [1,2], [1,2] ]
输出: 2
解释: 你需要移除两个 [1,2] 来使剩下的区间没有重叠。这道题我们可以转换一下思路。原题要求保证移除区间最少,使得剩下的区间互不重叠。换个角度就是:「如何使得剩下互不重叠区间的数目最多」。那么答案就变为了:「总区间个数 - 不重叠区间的最多个数」。我们的问题也变成了求所有区间中不重叠区间的最多个数。
从贪心算法的角度来考虑,我们应该将区间按照结束时间排序。每次选择结束时间最早的区间,然后再在剩下的时间内选出最多的区间。
我们用贪心三部曲来解决这道题。
- 转换问题:将原问题转变为,当选择结束时间最早的区间之后,再在剩下的时间内选出最多的区间(子问题)。
- 贪心选择性质:每次选择时,选择结束时间最早的区间。这样选出来的区间一定是原问题最优解的区间之一。
- 最优子结构性质:在上面的贪心策略下,贪心选择当前时间最早的区间 + 剩下的时间内选出最多区间的子问题最优解,就是全局最优解。也就是说在贪心选择的方案下,能够使所有区间中不重叠区间的个数最多。
使用贪心算法的代码解决步骤描述如下:
- 将区间集合按照结束坐标升序排列,然后维护两个变量,一个是当前不重叠区间的结束时间
$end\underline{}pos$ ,另一个是不重叠区间的个数$count$ 。初始情况下,结束坐标$end\underline{}pos$ 为第一个区间的结束坐标,$count$ 为$1$ 。 - 依次遍历每段区间。对于每段区间:$intervals[i]$:
- 如果
$end\underline{}pos \le intervals[i][0]$ ,即$end\underline{}pos$ 小于等于区间起始位置,则说明出现了不重叠区间,令不重叠区间数$count$ 加$1$ ,$end\underline{}pos$ 更新为新区间的结束位置。
- 如果
- 最终返回「总区间个数 - 不重叠区间的最多个数」即
$len(intervals) - count$ 作为答案。
class Solution:
def eraseOverlapIntervals(self, intervals: List[List[int]]) -> int:
if not intervals:
return 0
intervals.sort(key=lambda x: x[1])
end_pos = intervals[0][1]
count = 1
for i in range(1, len(intervals)):
if end_pos <= intervals[i][0]:
count += 1
end_pos = intervals[i][1]
return len(intervals) - count-
时间复杂度:$O(n \times \log n)$,其中
$n$ 是区间的数量。 - 空间复杂度:$O(\log n)$。
- 【博文】贪心 - OI Wiki
- 【博文】贪心算法 | 算法吧
- 【博文】贪心算法理论基础 - Carl - 代码随想录
- 【博文】小白带你学 贪心算法(Greedy Algorithm) - 知乎
- 【书籍】算法导论 第三版(中文版)- 殷建平等 译
- 【书籍】ACM-ICPC 程序设计系列 - 算法设计与实现 - 陈宇 吴昊 主编