4장 #63
Replies: 4 comments
-
데이터베이스와 아키텍처 구성
아키텍처
가용성과 확장성의 확보
클러스터
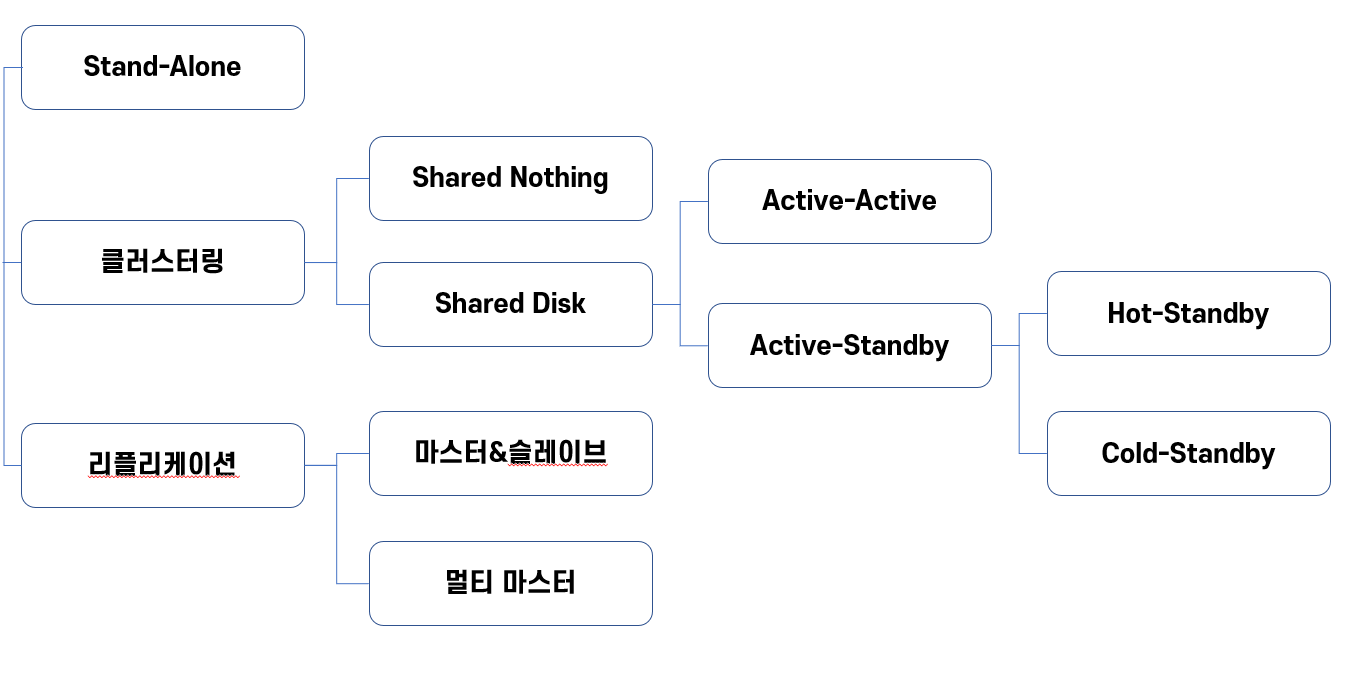
DB 서버 다중화 - 클러스터링
DB 서버 다중화 - 리플리케이션
Shared Nothing
|
Beta Was this translation helpful? Give feedback.
-
1. 다중화?__다중화(고가용성)__란 저장소를 복수로 준비해두는 것을 의미. 2. 아키텍처?시스템을 만들기 위한 물리 레벨의 조합. 3. 아키텍처의 역사(1) Stand-aloneDB만으로 시스템이 성립하는 가장 간단한 방법. 이 구성에서는 DB의 미들웨어(DBMS)와 어플리케이션의 SW는 같은 DB 서버에서 동작함. => DB를 사용하고 싶은 사용자는 DB 서버가 설치된 장소까지 물리적으로 접근하여 사용해야 함. 이는
따라서 매우 불편한 구조가 됨. 하지만 장점도 존재.
(2) 클라이언트/서버위의 단점을 해결하기 위해 DB를 네트워크에 연결한 구조. DB서버에선 DBMS가 동작하고, 클라이언트에선 업무 어플리케이션이 동작하는 "분업 체제"가 만들어짐. 해당 구조는 주로 기업이나 조직 내의 LAN에서 이용된다. 즉, 외부 네트워크를 거쳐 DB 서버에 접속할 방법이 없다는 것. 따라서 이 구조는 조직 내에서 제한된 용도의 시스템으로 이용되고 있음. 이 구조의 단점은 __어플리케이션 관리 비용__이다. 클라리언트/서버 시대에 연결되는 클라이언트는 스마트폰, 윈도우, 맥 등 다양한 종류가 존재. 인터넷을 통해 전세계 불특정 다수의 사용자가 어플리케이션을 이용하게 된다면, 각종 환경에 대응해 어플리케이션을 작성해야하고 각각에 대해 "버전 관리" 등을 진행하는데 비현실적인 비용이 소모. 이러한 부분에서 비즈니스 로직을 실행하는 어플리케이션을 서버에서 관리하자는 요구가 등장. (3) WEB 3계층그래서 등장한 것이 바로 이 WEB 3계층 구성. 해당 구성은 시스템을 다음 세 가지 계층의 조합으로 생각하는 모델이다.
즉, 클라이언트와 DB 사이에 웹 서버 계층 과어플리케이션 계층이 추가 된 것. 웹 서버는 클라이언트로부터 접속 요청을 직접 받아서 그 처리를 뒷단의 어플리케이션 계층에 넘기고 그 결과를 클라이언트에 반환. 어플리케이션 계층은 비즈니스 로직을 구현한 어플리케이션이 동작하는 층. 웹 서버로부터 연계된 요청을 처리하고 필요하면 DB 계층에 접속하여 이를 가공한 결과를 웹 서버로 반환한다. 이런 구조로 된다면 "웹 서버 계층"만 사용자의 직접적인 접속 요청을 받게 되어 보안이 강화된다. 또한 어플리케이션 관리 비용도 낮출 수 있다. 4. 가용성과 확장성 확보WEB 3계층에서 많은 문제가 해결되었지만 가용성이 낮고 확장성이 부족하다는 문제는 아직 남아 있게 됨. 하지만 시스템 장애의 당사자가 되지 않으려면 가용성을 담보해야만 함. (1) 가용성 향상 전략
현재는 신장전략이 주로 채택됨. (심장전략이 완전히 폐지된 것은 아님. 이를 채택하게 되면 전환시간이 짧아지고 무정지에 가까운 서비스를 계속하는 것이 가능) (2) 클러스터란?동일한 기능의 컴포넌트를 병렬화 하는 것. 즉, 동일한 기능의 컴포넌트를 복수 개 준비해서 한 개의 기능을 실현한다는 의미. 또한, 클러스터 구성으로 시스템의 가동률을 높이는 것을 여유도를 확보한다, 다중화라고 함. 같은 기능을 가진 서버가 많아지면 많아질 수록 좋을 것 같지지만, 전체적으로 봤을 때
(3) 단일 장애점이란?다중화되어있지 않아서 시스템 전체 서비스의 계속성에 영향을 주는 컴포넌트를 의미. 이때, 전체 시스템의 가용성은 이러한 단일 장애점에 의해 결정됨. 이때문에 단일 장애점을 없애기 위해 이중화를 해두지만, 이는 예산 제약과 직결된다.
즉, 시스템을 구성하는 컴포넌트에 대한 것이 신뢰성 5. DB 서버의 다중화 - 클러스터링(1) DB와 다른 서버의 차이DB 서버는 영속 계층의 사명이 부여되어 다중화 문제를 결정적으로 어렵게 하고 있다. 데이터는 항상 갱신되기 때문에 다중화를 유지하는 중에 데이터 정합성도 중요하게 의식해야 하기 때문에 (2) 가장 기본적인 다중화DB 서버만을 다중화하고 저장소는 하나만 두는 구성! 두 개의 DB 서버가 동시에 동작하는 것을 허락할지에 따라 모드가 나뉜다.
1번 구성 = Oracle, DB2 (3) Active-Active두 가지의 장점이 있다.
(4) Active-Standby보통 standby 상태의 DB 서버는 사용되지 않다가 active DB 서버에서 장애가 일어날 때만 사용된다.
구성의 종류
당연히 Hot standby가 전환시간이 짧음. 하지만 라이선스료가 비쌈. 6. DB 서버의 다중화 - 리플리케이션(1) 리플리케이션이란Active-Active와 Active-Standby 클러스터 구성에서는 서버 부분은 다중화할 수 있어도 저장소 부분은 다중화 할 수가 없음. 즉, 저장소가 망가지게 되면 데이터를 잃게 됨. 보통 저장소도 내부 컴포넌트가 다중화되어있지만, 데이터 센터 전체가 지진으로 붕괴되거나 화재가 난다면 손쓸 방법이 없음.
리플리케이션은 DB 서버와 저장소가 동시에 사용 불능일 때, 서비스를 지속할 수 있다는 점에서 매우 가용성이 높음. 이 견고함 덕분에 재해 대책으로 이용된다. (2) 리플리케이션에서 주의할 점Active측 저장소의 데이터는 항상 사용자로부터 갱신된다는 점. 이 갱신 주기를 얼마로 할 것인가와 성능 사이에 trade-off 관계가 생김. 👩💻 요기 어렵다. 다만, 그만큼 DB 서버의 라이선스료와 서버, 저장소 비용이 들고 시스템을 구성하는 노력도 증가. 7. 성능을 추구하기 위한 다중화 - Shared Nothing👩💻 Replication과 Clustering 그리고 아래 개념의 차이점? (1) Shared Disk와 Shared Nothing복수의 서버가 한 대의 Disk를 사용하는 구성 = Shared Disk Shared Disk 타입의 Active-Active 구성은 DB 서버를 늘려도 무한으로 처리율이 향상되지 않고 어딘가에서 한계점에 도달한다. DB 서버 간의 정보 공유를 위한 오버헤드가 크기 때문이다. 이 단점을 극복하기 위한 아키텍처로 고안된 것이 Shared Nothing Shared Nothing는 네트워크 이외의 자원을 모두 분리하는 방식.
Shared Nothing은 비용 대비 성능이 좋다. Shared Disk는 복잡한 동기화 구조가 필요해서 구축하려면 복잡. 하지만 Shared Nothing은 저장소를 공유하지 않기 때문에 각 DB 서버가 동일한 한 개의 데이터에 접근할 수 없다는 문제가 발생한다. 8. 아키텍처 종 정리 |
Beta Was this translation helpful? Give feedback.
-
데이터베이스와 아키텍처 구성다중화데이터베이스의 견고한 유지를 위해 중요한 개념, 고가용성이라고도 부른다. 아키텍처 설계하드웨어와 미들웨어의 구성, 어떤 서버? 어떤 저장소? 어떤 네트워크? → 총체적인 구성을 결정하는 것 → 시스템 요구조건을 충족하기 위해 어떤 아키텍처가 중요할까를 생각하자 아키텍처 변천사
가용성과 확정성 확보Web 3계층으로 물리적 거리문제, 동시작업 문제는 해결했으나, 가용성(서버가 1대면 그 서버 장애나면 서비스 죽음), 확장성(서버가 1대면 그 서버가 성능 한계 나면, 서버를 상위 기종 or 고성능 부품으로 교환) 문제는 해결 x 가용성 높이는 두 가지 전략
→ 현재는 대부분 신장전략(저품질 다수, 물량 중심)을 선택함 클러스터신장전략과 같이 컴포넌트(서버)를 병렬화하는 것. 클러스터는 “집합”을 의미한다. 클러스터링을 통해 시스템 가동률을 높이는 것을 “여유도(redundancy) 확보”라고 한다. 시스템 가동률
DB서버의 다중화 - 클러스터링네트워크, 애플리케이션 서버는 단순히 병렬화해서 다중화시키는 방법을 쓰면 되지만, DB서버는 데이터를 보존하는 영속 계층이므로 다중화에서 고민할 지점이 많다. 웹/애플리케이션 서버는 데이터를 일시적으로 처리하지만, db는 처리가 끝나고 데이터를 보존해야 하므로, 신뢰성이 중요하다. db서버의 아키텍처는 저장소와 묶어서 생각하자 데이터베이스는 두가지로 구성된다
데이터는 항상 갱신되므로 db서버가 다중화를 하려면 “데이터 정합성”을 의식해야 한다. DB서버를 다중화하고 저장소는 하나로 유지하는 경우DB서버가 두 개 존재하고, 저장소는 하나라고 가정하자. 이 때는 데이터를 보존하는 저장소가 1개라 정합성을 신경쓸 필요 없다. 그러나 두 개의 db서버를 동시에 동작할지 말지에 따라 두 방식으로 나뉜다
→ 대부분의 DBMS가 Active-StandBy 클러스터링 방식에 대응한다 Active-StandBy는 두 가지로 나뉜다
따라서 가격순으로 나열하면 Active-Active → hot- standby → cold-standby 순이다. DB서버와 데이터의 다중화 - 리플리케이션그러나 위의 방식은 저장소가 1개인데, 이 저장소가 없어지면 데이터를 잃게 된다(지진, 붕괴, 공격). 따라서 이에 대응을 위해 db 서버와 저장소를 세트로 묶어 복제한다. → 이를 리플리케이션(replication:복제) 라고 한다. 복제된 하드웨어 시설은 멀리 떨어진 지점에 두어 안정성을 높인다(재해복구센터) 주의할 점 결국 데이터의 정합성 유지다. 여러 저장소의 데이터가 함께 갱신되어 최신화되어야 active 측과 standby 측의 데이터 정합성을 유지할 수 있다. 일정 주기로 active의 데이터를 stanby 쪽에 써줘야 한다 리플리케이션 구성은 손자와 증손자 세트를 만들 수 있다. 이는 만약 오래된 데이터라도, 단순히 “참조”만 하게 할 경우에 해당 데이터를 손자나 증손자 세트에 두고 참조하게 한다 Mysql에서는 동기화하는 측의 부모를 “마스터”, 자식을 “슬레이브”라 부른다. → 이를 사용해 create, update, delete 요청이 아닌 단순 read 요청을 slave db로 분산해 성능을 높일 수 있다. 우리가 Spring에 @transactional(readOnly=true) 옵션을 거는 이유 중 하나임(이는 사용하는 해당 db 벤더사가 읽기 전용 트랜잭션을 적용할 때만 유효하고(h2는 안해줌), 추가적 설정이 필요하며, master-slave 구성일 때만 사용 가능) https://prolog.techcourse.co.kr/studylogs/3624 성능을 추구하기 위한 다중화 - Shared Nothing맨 위처럼 복수의 서버가 하나의 저장소를 공유하는 방식을 Shared Disk라 한다. 이 때 Active-Active 방식을 사용하면 db를 계속 늘려도 처리율이 무한으로 향상되지 않고 어디선가 한계점이 도달한다. 복수의 서버가 1대의 디스크를 사용하니 한 디스크에 정보가 몰려 병목 현상이 발생한다(좁은 페트병 뚜껑에 물이 많이 몰려듬). 저장소가 공유 자원이라 늘리기 어렵고, 서버 대수가 증가할 수록 db서버 간의 정보공유를 위한 오버헤드가 크기 때문이다. Shared Nothing 방식은 위 단점을 극복하기 위한 아키텍처로 고안됐다. 이는 네트워크 이외의 자원을 전혀 공유하지 않는 방식이다. DB 서버와 저장소의 세트를 한꺼번에 늘려서 저장소의 병목을 방지한다(서버만 늘리는 shared disk와 달리 저장소까지 늘림). db서버간의 정보를 공유할 필요가 없다. 구글이 자사에서 개발한 Shared Nothing 구조를 “샤딩(Sharding)”이라 부른다. 따라서 저장소의 병목이 줄어들어 처리율이 증가한다. Shared Nothing 방식은 같은 구성의 DB서버를 횡으로 나열하면 되기에 구조가 간단하고 구축이 쉽다. 그러나 저장소를 각 서버가 공유하지 않으므로, 각 서버가 동일한 데이터에 접근할 수 없다. 따라서 어떤 데이터가 필요한데, 그 데이터에 접근하는 서버가 죽으면 문제가 발생한다. 예를 들어 각 시별로 서버+저장소를 갖춘 shared nothing 구성이 있는데, 이 때 고양시의 저장소에 접근하는 서버가 죽으면 다른 서버에서 고양시 저장소로 접근이 불가능하다. 고양시와 부천시의 저장소-서버 세트들은 각각 분리되어 있기 때문이다. 따라서 db서버 하나가 다운될 때, 다른 서버가 이를 이어받아 처리할 수 있도록 해야 한다. 이를 “커버링(covering)”이라 한다. |
Beta Was this translation helpful? Give feedback.
-
|
찾아볼 것
|
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
4장 데이터베이스와 아키텍처 구성
💡목표
고속의 견고한 시스템을 구축하기 위해서는 아키텍처가 명확한 의도로 설계되어야 한다. 아키텍처가 중요한 이유와 어떤 식으로 접근해 검토하는지 파악
다중화
DB 서버가 2대(혹은 그 이상) 중에 1대가 고장이 난다고 하더라고 나머지 1대가 정상적으로 동작하면 서비스의 정지를 막는데 이를
다중화라고 합니다.아키텍처
아키텍처는
시스템의 목적과 기능을 나타내는 것이다. 즉, 아키텍처를 보았을 때 우리는 그 시스템이 어떤 용도로 이용되고 무엇을 목적으로 하는 것인지를 한 눈에 알아볼 수 있고 추측할 수 있습니다.아키텍처의 역사
데이터 베이스의 서버가 LAN이나 인터넷 등의 네트워크에 접속하지 않고 독립되어서 동작하는 구성방식 입니다.
장점
단점
stand-alone의 단점을 극복한 것으로 데이터베이스 서버 1대에 복수 사용자의 단말이 접속하는 구성을
클라이언트/서버라고 한다. 이는 클라이언트와 서버 2개의 레이어로 구성되어 있기 때문에2계층 구성이라고도 부릅니다.장점
단점
비즈니스 로직을 담당하는 애플리케이션을 서버에서 관리해 비용을 절감하기 위한 방식으로
웹서버 계층,애플리케이션 계층,데이터베이스 계층으로 관리하는 모델입니다.웹 서버 계층 : 웹 페이지가 들어 있는 파일을 사용자에게 제공하는 서버 프로그램 Ex) nginx, apache 등
애플레케이션 계층 : 비즈니스 로직을 구현한 애플리케이션이 동장하는 계층 Ex) tomcat
데이터베이스 계층 : 비즈니스 로직에 사용되는 데이터들을 저장하고 있는 계층
아키텍처에서 가용성 및 확장성 높이기
가용성을 높이는 2가지 전략
과거에는 두 방식 중 무엇이 더 효율적인지 판단하지 못해 두 방식 모두 고려했지만 현재에는
심장전략보다는 신장전략을 주 방식으로 택했으며 그 이유는 중앙으로 관리하는 것은 리스크가 크기 때문입니다. 그렇다고 심장전략을 아예 이용하지 않는 것은 아니며 FT(Fault Tolerant)서버에서는 심장전략을 택하고 있습니다. 단 내부의 CPU, 메모리 등의 부품의 경우에는 신장전략을 이용한 부분들이 있습니다. 즉, 두 방법 중 하나만을 고수하는 것이 아닌 이 둘을 조화롭게 이용해 나가고 있다는 것을 알 수 있습니다.신장전략(클러스터링)으로 시스템의 가동률을 높이게 되면 가동률(여유도)를 높일 수 있습니다. 그 이유는 같은 기능을 하는 시스템을 늘릴수록 전체에서 발생하는 에러 발생률을 줄일 수 있습니다. 시스템 대수와 가동률의 관계는 다음과 같습니다.
서버의 대수를 무작정 늘리는 것이 좋은 것이 아닌 적절하게 늘리는 것이 적은 비용으로 가동률을 높일 수 있는 방안입니다.
DB 서버의 다중화 - 클러스터링
클러스터링 : 동일한 기능의 컴포넌트를 병렬화하는 것 → 신장전략으로 동일한 기능을 하는 컴포넌트를 여러개 준비하는 것
DB에서의 다중화는 단순히 서버를 다중화하는 것보다는 고려해야할 부분이 많은데 그 이유는 DB는 영속 계층으로
데이터의 정합성을 보장해야하기 때문입니다.간단한 DB 다중화 방식(클러스터링)은 다음과 같습니다.
위의 아키텍처에서
Active-Active 방식과Active-Standby 방식2가지로 나뉘어집니다.Active-Active 방식은 두 DB서버를 동시에 가동시키는 것입니다.장점
단점
Active-Standby 방식은 하나만 동작을 하고 나머지 하나는 대기를 하는 상태입니다.장점
단점
Active-Standby 방식은 두가지 방식이 존재하는데
Cold-Standby와Hot-Standby로 나뉘는데Cold-Standby의 경우 여러대의 서버중에 하나만 활동을 하고 나머지는 대기 상태인 것이고Hot-Standby의 경우 대기 서버들도 활동을 하는 것입니다.DB서버와 데이터의 다중화 - 리플리케이션
리플리케이션 : 앞선 클러스터링의 경우 저장소는 하나로 고정하고 DB 서버들만 병렬화하는 방식이었다면 리플리케이션은 저장소도 병렬화하는 것입니다.
리플리케이션은 데이터도 병렬화하기 때문에 하드웨어(저장소)가 파괴되더라도 다른 하드웨어(저장소)가 살아있다면 시스템이 문제없이 동작할 수 있으므로 가용성이 매우 높은 기술입니다.
리플리케이션의 경우 데이터의 정합성이 중요한 사항입니다. 그래서 Active 측 저장소의 데이터가 변화하면 Standby 측의 저장소 역시 갱신이되어야합니다.
성능을 추구하기 위한 다중화 - Shared Nothing
shared-nothing VS shared-Disk
shared-Disk
shared-Nothing
Beta Was this translation helpful? Give feedback.
All reactions