RealMySQL 4장 MySQL 아키텍쳐(1) #73
Replies: 3 comments
-
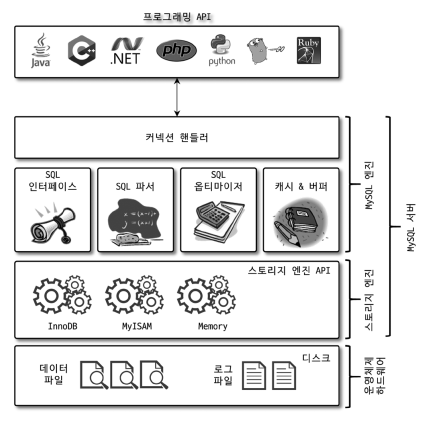
1. MySQL 엔진 아키텍처(1) 전체 구조MySQL 서버는 크게 MySQL 엔진과 스토리지 엔진으로 구분할 수 있다. <1> MySQL 엔진
클라이언트로부터의 접속 및 쿼리 요청을 처리하는 커넥션 핸들러와 SQL 파서 및 전처리기, 쿼리의 최적화된 실행을 위한 옵티마이저가 중심을 이룬다. <2> 스토리지 엔진
MySQL 서버에서 MySQL 엔진은 하나지만 스토리지 엔진은 여러 개를 동시에 사용할 수 있다. (테이블이 사용할 스토리지 엔진을 지정할 수도 있다.) <3> 핸들러 APIMySQL 엔진에서 스토리지 엔진에 요청을 할 때, 이 요청을 핸들러 요청이라 한다. 그리고 이때 사용되는 API가 바로 핸들러API이다. (2) MySQL 스레딩 구조
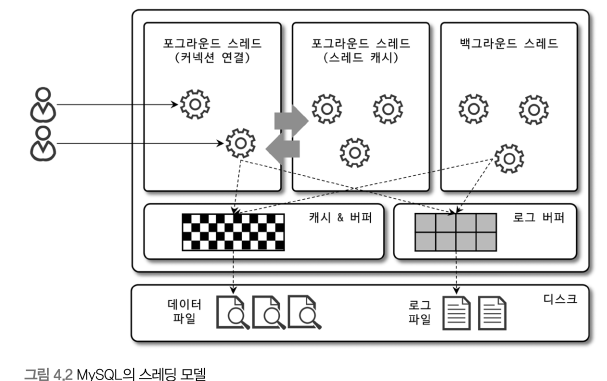
<1> 포그라운드 스레드(클라이언트 스레드)이는 최소한 MySQL 서버에 접속한 클라이언트의 수만큼 존재한다. 포그라운드 스레드는 데이터를 MySQL의 데이터 버퍼나 캐시로부터 가져오며, 버퍼나 캐시에 없는 경우에는 직접 디스크의 데이터나 인덱스 파일로부터 데이터를 읽어와서 작업을 처리한다.
<2> 백그라운드 스레드InnoDB에서 백그라운드 스레드가 하는 일 중 가장 중요한 것이 바로 로그 스레드와 버퍼의 데이터를 디스크로 내려쓰는 작업을 처리하는 쓰기 스레드이다. (3) 메모리 할당 및 사용 구조
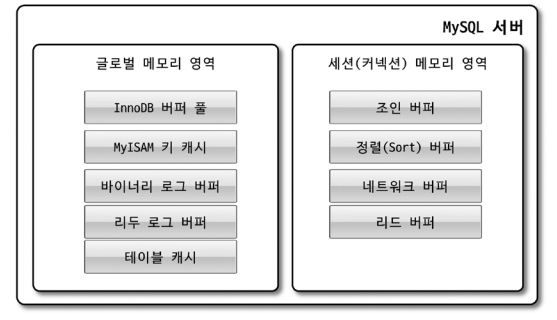
<1> 글로벌 메모리 영역일반적으로 클라이언트 스레드 수와 무관하게 하나의 메모리 공간만 할당된다. (2개 이상도 할당은 가능) 글로벌 메모리 영역은 모든 스레드에 의해 공유된다. <2> 로컬 메모리 영역세션 메모리 영역이라고도 한다. (4) 플러그인 스토리지 엔진 모델MySQL의 독특한 구조 중 대표적인 것이 플러그인 모델이다. (5) 컴포넌트MySQL 8.0부터는 기존의 플러그인 아키텍처를 대체하기 위해서 컴포넌트 아키텍처가 지원된다. 왜냐하면 플러그인은 아래와 같은 단점이 존재하기 때문이다.
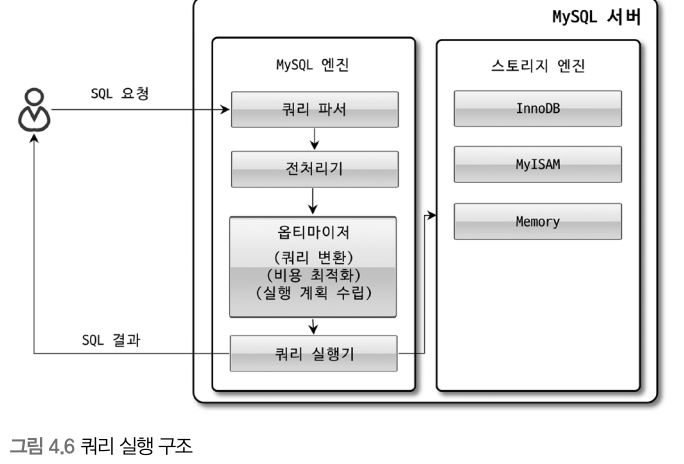
(6) 쿼리의 실행 구조<1> 쿼리 파서사용자 요청으로 들어온 쿼리 문장을 토큰으로 분리해 트리 형태의 구조로 만들어 내는 작업을 의미한다. <2> 전처리기파서 과정에서 만들어진 파서 트리를 기반으로 쿼리 문장에 구조적인 문제점이 있는지 확인한다. 실제 존재하지 않거나 권한상 사용할 수 없는 개체의 토큰은 이 단계에서 걸러진다. <3> 옵티마이저사용자의 요청으로 들어온 쿼리 문장을 저렴한 비용으로 가장 빠르게 처리할지를 결정하는 역할을 담당한다. (중요하고 영향 범위도 무지 넓다.) <4> 실행 엔진
옵티마이저가
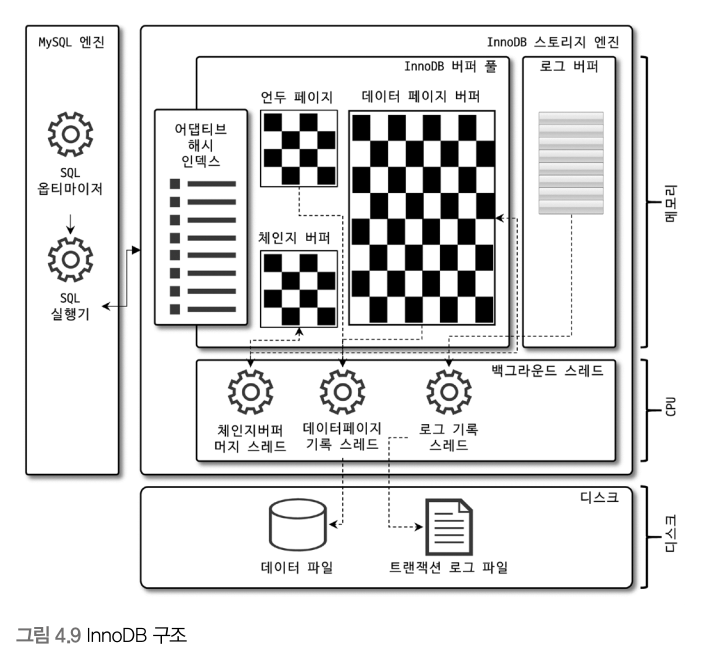
즉, 실행 엔진은 만들어진 계획대로 각 핸들러에게 요청해서 받은 결과를 또 다른 핸들러 요청의 입력으로 연결하는 역할을 수행한다. <5> 핸들러(스토리지 엔진)핸들러는 MySQL 서버의 가장 밑단에서 MySQL 실행 엔진의 요청에 따라 데이터를 디스크로 저장하고 디스크로부터 읽어 오는 역할을 담당한다. 핸들러는 결국 스토리지 엔진을 의미하는 것 (7) 복제다른 장에서 설명 예정 ~.. (8) 쿼리 캐시빠른 응답을 필요로하는 웹 기반의 응용 프로그램에서 매우 중요한 역할을 담당했다. (9) 스레드 풀스레드 풀은 내부적으로 사용자의 요청을 처리하는 스레드 개수를 줄여서 동시 처리되는 요청이 많다 하더라도 MySQL 서버의 CPU가 제한된 개수의 스레드 처리에만 집중할 수 있게 해서 서버의 자원 소모를 줄이는 것이 목적이다. 일반적으로는 CPU 코어의 개수와 스레드 풀 사이즈를 맞추는 것이 CPU 프로세서 친화도를 높이는데 좋다. (10) 트랜잭션 지원 메타데이터MySQL 서버는 5.7 버전까지 테이블의 구조를 FRM 파일에 저장하고, 일부 스토어드 프로그램 또한 파일 기반으로 관리했다. 그러니까 테이블의 생성 또는 변경 도중 서버가 비정상적으로 종료되면 일관되지 않는 상태로 남는 문제가 발생했다. MySQL8.0부턴 이를 해결하기 위해 테이블 구조 정보나 스토어드 프로그램의 코드 관련 정보들을 모두 InnoDB의 테이블에 저장하도록 했다. MySQL 서버가 동작하는데 기본적으로 필요한 테이블을 묶어서 시스템 테이블이라고 하는데, 이런 애들이 mysql DB에 저장하고 있다. mysql DB는 통째로 mysql.ibd라는 이름의 테이블스페이스에 저장된다(얘는 다른 .ibd 파일과 함께 특별히 주의해야 한다.) MySQL 8.0 버전부터 데이터 딕셔너리와 시스템 테이블이 모두 트랜잭션 기반의 InnoDB 스토리지 엔진에 저장되도록 개선되면서 이제 스키마 변경 작업 중간에 MySQL 서버가 비정상적으로 종료된다고 하더라도 스키마 변경이 완전한 성공 또는 완전한 실패로 정리된다. InnoDB 스토리지 엔진 아키텍처위에서는 MySQL 엔진의 전체적인 구조를 살펴봤다면, 이번 절에서는 MySQL의 스토리지 엔진 가운데 가장 많이 사용되는 InnoDB 스토리지 엔진을 간단히 살펴보자. InnoDB는 MySQL에서 사용할 수 있는 스토리지 엔진 중 거의 유일하게 레코드 기반의 잠금을 제공한다. 그리고 그 때문에 높은 동시성 처리가 가능하고 안정적이며 성능이 뛰어나다. (1) 프라이머리 키에 의한 클러스터링InnoDB의 모든 테이블은 프라이머리 키를 기준으로 클러스터링되어 저장된다. 즉, 프라이머리 키 값의 순서대로 디스크에 저장된다는 뜻이다. 모든 세컨더리 인덱스는 레코드의 주소 대신 프라이머리의 키 값을 논리적인 주소로 사용한다. 프라이머리 키가 클러스터링 인덱스이기 땜누에 프라이머리 키를 이요한 "레인지 스캔"은 상당히 빨리 처리될 수 있다. InnoDB 스토리지 엔진과는 달리 MyISAM 스토리지 엔진에서는 클러스터링 키를 지원하지 않는다. 그래서 MyISAM 테이블에서는 프라이머리 키와 세컨더리 인덱스는 구조적으로 아무런 차이가 없다.(걍 프라이머리 키는 unique 제약을 가진 세컨더리 인덱스일 뿐) 또한 MyISAM 테이블의 프라이머리 키를 포함한 모든 인덱스는 물리적인 레코드의 주소값(ROWID)을 가진다. (2) 외래 키 지원InnoDB 스토리지 엔진 레벨에서 지원하는 기능이다. (3) MVCC(Multi Version Concurrency Control)레코드 레베르이 트랜잭션을 지원하는 DBMS가 제공하는 기능. InnoDB는 Undo log를 이용해 이 기능을 구현한다. (4) 잠금 없는 일관된 읽기(Non-Locking Consistent Read)InnoDB 스토리지 엔진은 MVCC 기술을 이용해 잠금을 걸지 않고 읽기 작업을 수행한다. 잠금을 걸지 않기 때문에 읽기 작언은 다른 트랜잭션이 가지고 있는 잠금을 기다리지 않고 읽기 작업이 가능하다. (5) 자동 데드락 감지InnoDB 스토리지 엔진은 내부적으로 잠금이 교착 상태에 빠지지 않았는지 체크하기 위해 잠금 대기 목록을 그래프(Wait-for List) 형태로 관리한다. 일반적인 작업에서는 데드락 감지 스레드가 트랜잭션의 잠금 목록을 검사해서 데드락을 찾아내는 작업은 크게 부담되지 않는데, 동시 처리 스레드가 매우 많아지거나 각 트랜잭션이 가진 잠금의 개수가 많아지면 데드락 감지 스레드가 느려진다. (6) 자동화된 장애 복구InnoDB에는 손실이나 장애로부터 데이터를 보호하기 위한 여러 가지 메커니즘이 탑재되어 있다. 이를 활용해서 MySQL 서버가 시작될 때 완료되지 못한 트랜잭션이나 디스크에 일부만 기록된 데이터 페이지 등에 대한 일련의 복구 작업이 자동으로 진행된다. (7) InnoDB 버퍼 풀스토리지 엔진에서 가장 핵심적인 부분. 디스크의 데이터 파일이나 인덱스 정보를 메모리에 캐시해 두는 공간. 버퍼 풀이 변경된 데이터를 모아서 처리하면 랜덤한 디스크 작업의 횟수를 줄일 수 있다. <1> 버퍼 풀의 크기 설정OS와 각 클라이언트 스레드가 사용할 메모리를 충분히 고려해서 설정해야 한다. <2> 버퍼 풀의 구조InnoDB 스토리지 엔진은 버퍼 풀이라는 거대한 메모리 공간을 페이지 크기의 조각으로 쪼개어 InnoDB 스토리지 엔진이 데이터를 필요로 할 때 해당 데이터 페이지를 읽어서 각 조각에 저장한다. 프리 리스트는 InnoDB 버퍼 풀에서 실제 사용자 데이터로 채워지지 않은 비어 있는 페이지들의 목록.
<3> 버퍼 풀과 리두 로그둘은 매우 밀접한 관계를 맺고 있다. InnoDB 버퍼 풀의 더티 페이지는 특정 리두 로그 엔트리와 관계를 가지고, 체크포인트가 발생하면 체크포인트 LSN보다 작은 리두 로그 엔트리와 관련된 더티 페이지는 모두 디스크로 동기화 되어야 한다. <4> 버퍼 풀 플러시InnoDB 스토리지 엔진은 버퍼 풀에서 아직 디스크로 기록되지 않은 더티 페이지들을 성능상의 악영향 없이 디스크에 동기화 하기 위해 두 가지의 플래시 기능을 백그라운드로 실행한다. 플러시 리스트 플러시 LRU 리스트 플러시 <5> 버퍼 풀 상태 백업 및 복구InnoDB 스토리지 엔진은 MySQL 서버가 셧다운 되기 직전에 버퍼 풀의 백업을 실행하고, MySQL 서버가 시작되면 자동으로 백업된 버퍼 풀의 상태를 복구하 ㄹ수 있는 기능을 제공한다. <6> 버퍼 풀의 적재 내용 확인innodb_cached_indexes 테이블을 활용하면 테이블의 인덱스별로 데이터 페이지가 얼마나 InnoDB 버퍼 풀에 적재되어 있는지 확인할 수 있다. |

Beta Was this translation helpful? Give feedback.
-
아키텍처4.1 MySQL 엔진 아키텍처MySQL 엔진
스토리지 엔진
핸들러 API
4.1.2 MySQL 스레딩 구조
포그라운드 스레드 (클라이언트 스레드)
백그라운드 스레드
메모리 할당 및 사용 구조
쿼리 파서
전처리기
옵티마이저
4.2 InnoDB 스토리지 엔진 아키텍처
프라이머리 키에 의한 클러스터링외래 키 지원
MVCC(Multi Version Concurrency Control)
잠금 없는 일관된 읽기(Non-Locking Consistent Read)
자동 데드락 감지자동화된 장애 복구InnoDB 버퍼 풀
|


Beta Was this translation helpful? Give feedback.
-
구조mysql의 구조는 위와 같다. mysql 서버는 mysql 엔진과 스토리지 엔진으로 크게 구분할 수 있다. MySql 엔진클라이언트의 접속과 쿼리 요청을 처리하는 커넥션 핸들러, sql 파서 및 전처리, 옵티마이저가 존재한다. Mysql은 ansi 표준 sql 문법을 지원하므로 타 dbms와 호환되어 실행될 수 있다. 즉 문장분석 및 최적화와 같은 두뇌에 해당하는 처리를 한다. 스토리지 엔진실제 데이터를 디스크 스토리지에 저장하거나 스토리지로부터 데이터를 읽어들인다. InnoDb 등의 여러 가지 스토리지 엔진이 존재한다. 핸들러 APIMysql 엔진에서 스토리지 엔진과 읽기/쓰기 요청을 주고 받을 때 사용하는 api다.
MySql 스레딩 구조mysql 서버는 프로세스 기반이 아닌 스레드 기반으로 작동하며, 크게 포그라운드 스레드와 백그라운드 스레드로 구분할 수 있다. 포그라운드 스레드각 클라이언트 사용자가 요청하는 쿼리 문장을 처리한다. 최소 MYsql 서버에 접속된 클라이언트 수만큼 존재한다. 사용자가 작업 후 커넥션이 끝나면 해당 커넥션 스레드는 다시 스레드 캐시로 돌아간다. 그러나 스레드 캐시에 일정 수 이상의 스레드가 있으면 스레드 캐시에 돌아가는게 아닌 스레드를 종료시켜 일정 개수의 스레드만 스레드 캐시에 존재하게 한다. 포그라운드 스레드는 데이터를 먼저 Mysql의 데이터 버퍼나 캐시로부터 가져오며, 여기에 없으면 직접 디스크의 데이터나 인덱스 파일로부터 데이터를 읽어와 처리한다. MyISAM은 디스크 쓰기 작업까지 포그라운드 스레드가 처리하지만, INNODB는 데이터 버퍼나 캐시에 쓰는 작업까지만 포그라운드가 처리하고, 버퍼로부터 디스크로 쓰는 작업은 백그라운드 스레드가 처리한다.
백그라운드 스레드MYISAM에는 해당사항이 없는데, INNODB에서는 아래의 작업을 백그라운드에서 처리한다
가장 중요한 스레드는 로그 스레드의 버퍼의 데이터를 디스크로 내려쓰는 작업을 처리하는 쓰기 스레드이다. Mysql 5.5 버전부터 데이터 쓰기 스레드와 읽기 스레드의 개수를 2개 이상 지정할 수 있다. 데이터를 읽는 작업은 주로 포그라운드 스레드에서 처리되므로 많이 설정할 필요가 없으나, 쓰기 스레드는 대부분 백그라운드 스레드로 처리하므로 충분히 설정하는 것이 좋다. 사용자의 요청을 처리하는 도중 쓰기 작업은 지연되어 처리할 수 있으나, 읽기 작업은 절대 지연될 수 없다.(생각해보면 당연함, select를 요청했는데 좀따 알려줄게요 하면 안되지) 따라서 일반적인 dbms는 쓰기 작업을 버퍼링으로 일괄 처리하는 기능이 탑재되어 있다(innodb 역시). 그러나 myisam은 그렇지 않고 사용자 스레드가 쓰기 작업까지 함께 처리하도록 설계되어 있다. (이해안가는곳)따라서 innodb는 쓰기 쿼리가 일어나는 경우, 데이터가 디스크의 데이터 파일로 완전히 저장될 때 까지 기다리지 않아도 된다(이게 쓰기 지연이랑 무슨 관련??). 하지만 MyISAM에서 일반적인 쿼리는 쓰기 버퍼링 기능을 사용할 수 없다(사용자 스레드에 인서트 버퍼를 병합하는 처리 기능이 없으므로, 이건 이해함). 메모리 할당 및 사용 구조Mysql의 메모리 공간은 글로벌 메모리 영역과 로컬 메모리 영역으로 구분할 수 있다. 글로벌 메모리 영역일반적으로 클라이언트 수와 무관하게 하나의 메모리 공간만 할당된다. 2개 이상 할당되어도 사용자 스레드 수와는 무관하다. 또 모든 스레드에 의해 공유된다. 아래와 같은 것이 해당한다.
로컬 메모리 영역세션 메모리 영역이라고도 한다. 클라이언트 스레드가 쿼리를 처리하는데 사용하는 메모리 영역이다. 각 클라이언트 스레드별로 독립적으로 할당되며 공유되어 사용되지 않는다. 필요할 때만 공간이 할당되고 필요하지 않으면 Mysql이 공간을 할당조차 하지 않는 경우가 있다.(소트와 조인 버퍼와 같은 공간이 그러함) 커넥션 버퍼나 결과 버퍼는 커넥션이 열려 있는 동안 계속 할당된 상태로 남아있으며, 소트 버터나 조인 버터는 쿼리를 실행하는 순간에만 할당했다가 다시 해제한다. 아래와 같은 것이 해당한다
플러그인 스토리지 엔진 모델MYsql에는 핸들러라는 개념이 존재한다. Mysql 엔진이 스토리지 엔진을 조정하기 위해 핸들러라는 것을 사용하게 된다. 즉 스토리지 엔진에게 데이터를 읽어오거나 저장하도록 명령하기 위한 장치이다. Mysql의 상태 변수 중 따라서 Mysql의 처리 내용은 핸들러를 사용하므로, 어떤 스토리지 엔진(innodb,myisam)을 사용해도 처리 내용은 대부분 동일하다. 그러나 어떤 스토리지 엔진을 사용하느냐에 따라 데이터 읽기/쓰기 작업이 크게 다르므로, 가장 중요한 것은
라는 점이다. 예를 들어 group by나 order by는 쿼리 실행기에서 처리되는 것 처럼 말이다.
위 쿼리를 사용하면 mysql 서버의 스토리지 엔진을 확인할 수 있다.
그러나 플러그인은 아래와 같은 단점을 보유한다
컴포넌트Mysql 8.0 부터 기존의 플러그인 아키텍쳐를 대체하기 위해 컴포넌트 아키텍처가 지원된다. → 여기는 뭔 소리인지 모르겠음 쿼리 실행 구조위는 쿼리가 실행되는 구조이다 쿼리 파서요청에서 들어온 쿼리 문장은 토큰(Mysql이 인식하는 최소 단위의 어휘나 기호)로 분리해 트리 형태의 구조로 만드는 작업을 한다. 문법 오류를 여기서 발견함 전처리기파서가 만들어준 파서 트리를 기반으로 쿼리 문장의 구조적 문제점을 파악. 각 토큰을 테이블 이름, 칼럼 이름, 내장 함수와 같은 개체와 매핑해 해당 객체의 존재 여부와 객체 접근 권한을 확인한다. 실제 존재하지 않거나, 권한상 사용할 수 없는 개체의 토큰을 이 단계에서 걸러낸다. 옵티마이저쿼리 문장을 가장 저렴한 비용으로 빠르게 처리하기 위한 최적화 실행계획을 세운다. 실행 엔진옵티마이저(경영진)가 두뇌라면 실행 엔진(중간 관리자)과 핸들러(실무자)는 손과 발이다. 옵티마이저가 group by를 처리하기위해 임시 테이블을 사용하기로 결정했다고 해보자
핸들러Mysql 서버의 가장 밑단에서 실행 엔진의 요청에 따라 데이터를 디스크로 저장하고 디스크에서 읽어 옴. 띠라서 핸들러는 결국 스토리지 엔진을 의미한다. 따라서 InnoDB 테이블을 조작한다면 InnoDB가 핸들러가 된다. 복제16장에서 다룬다함 쿼리 캐시sql 실행 결과를 메모리에 캐시하고 동일 쿼리가 실행되면 테이블을 읽지 않고 메모리에서 즉시 반환 그러나 테이블 데이터가 변경되면 캐시 중 변경된 것들은 모두 삭제해야 함. 이 경우 동시 처리 성능 저하를 유발하는 경우가 많음. 따라서 Mysql 8.0으로 올라오면서 쿼리 캐시는 mysql 서버 기능에서 제외됐음 스레드 풀Mysql 커뮤니티 에디션에서는 지원하지 않음. 동시 처리되는 요청이 많더라도, MYsql서버의 cpu가 제한된 개수의 스레드 처리에만 집중할 수 있게 해서 서버의 자원 소모를 줄이는게 목적. 그러나 실제 서비스에서 큰 성능 향상을 보여주기는 힘들며, 동시 실행 스레드들을 cpu가 최대한 잘 처리할 수 있는 만큼 줄여서 빨리 처리하게 하는 기능이므로, 스케줄링 과정에서 cpu 시간을 제대로 확보하지 못하는 경우 쿼리 처리가 느려질 수도 있음 물론 제한된 수만의 스레드만으로 cpu가 처리할 수 있도록 적절히 유도되면 cpu의 프로세서 친화도(특정 프로세스가 어느 프로세서에서 실행되는지 결정→ 이게 높으면 왜 좋음?)도 높이고 운영체제 입장에서는 불필요한 컨텍스트 스위치를 줄여서 오버헤드를 낮춘다. 일반적으로 스레드 풀 사이즈는 cpu 코어 개수와 맞추는 것이 프로세서 친화도를 높이는데 좋음. 값이 너무 크면 스케줄링해야 할 스레드가 많아져서 비효율적으로 작동할 수 있음. 풀의 모든 스레드가 일을 하고 있다면 스레드 풀은 새 스레드를 추가할지, 기다릴지 여부를 판단. 풀의 타이머 스레드가 주기적으로 상태를 체크해 Percona Server의 스레드 풀은 선순위 큐와 후순위 큐를 이용해 특정 트랜잭션이나 쿼리를 우선적으로 처리하도록 재배치할 수 있음. 이를 통해 전체적인 처리 성능을 향상시킴. 트랜잭션 지원 메타데이터데이터베이스 서버에서 테이블의 구조 정보와 스토어드 프로그램 등의 정보를 데이터 딕셔너리 또는 메타데이터라 함. Mysql서버는 5.7버전까지 메타데이터를 파일에 저장했는데, 이는 생성 및 변경 작업이 트랜잭션을 지원하지 않아 생성/변경 도중 서버가 종료되면 일관성이 깨지는 문제가 생김. Mysql은 8.0 버전부터 이를 해결하기 위해 메타데이터를 모두 InnoDB의 테이블에 저장하도록 개선함. Mysql 서버가 작동하는데 기본적으로 필요한 테이블을 시스템 테이블이라 하는데, 이 시스템 테이블을 모두 innoDB 스토리지 엔진을 사용해 이 정보를 모두 모다 Mysql DB에 저장함. 이는 통째로 따라서 트랜잭션 기반의 innoDB 스토리지 엔진에 저장되므로 변경 작업 중간에 서버가 종료되어도 all or nothing을 보장함. 그러나 InnoDB 이외의 스토리지 엔진은 여전히 저장공간이 필요한데, 이 때는 SDI(Serialized Dictionary Information) 파일을 사용함. 이름 그대로 직렬화를 위한 포맷이므로, InnoDB 테이블의 구조도 SDI 파일로 변환 가능. InnoDB 스토리지 엔진 아키텍처InnoDb는 Mysql에서 사용하는 스토리지 엔진 중 거의 유일하게 레코드 기반의 잠금을 제공한다. 따라서 높은 동시성 처리 성능을 보유하고 있다. 프라이머리 키에 의한 클러스터링innodb의 모든 테이블은 기본적으로 프라이머리 키를 기준으로 클러스터링되어 저장된다. 즉 pk의 순서대로 디스크에 저장된다는 뜻이다. 모든 세컨더리인덱스는 레코드의 주소 대신, 프라이머리키의 값을 논리적인 주소로 사용한다. 따라서 pk를 이용한 레인지 스캔은 빨리 처리된다. 즉 실행 계획에서 pk가 다른인덱스에 비해 비중이 높다. Myisam에는 클러스터링 키를 지원하지 않아 pk와 세컨더리 인덱스가 차이가 없다. 외래 키 지원외래 키에 대한 지원은 innoDb에서만 지원한다. innoDb의 외래 키는 부모와자식 테이블 모두 해당 칼럼에 인덱스 생성이 필요하고, 변경 시 연관 테이블에 데이터가 있는지 체크 작업이 필요하므로, 잠금이 전파되고 데드락이발생할 수 있다. 따라서 외래키는 서버 운영의 불편함 때문에 쓰지 않는 경우도 있다.
MVCC(Multi Version Concurrency Control)레코드 레벨의 트랜잭션을 지원하는 dbms가 지원하는 기능이다. mvcc의 가장 큰 목적은 잠금을 사용하지 않는 일관된 읽기를 제공하는 데 있다. InnoDB는 언두 로그를 이용해 이 기능을 구현한다. 멀티버전은 하나의 레코드에 대해 여러 개의 버전이 동시에 관리된다는 뜻이다. 어떤 테이블에 위 데이터가 저장되어 있다고 생각해 보자
이는 격리 수준에 따라 다르다. 격리 수준이 최소 이러한 과정을 dbms에서는 mvcc라고 표현한다. 즉, 하나의 레코드에 대해 2개의 버전이 유지되고, 필요에 따라 어느 데이터가 보여지는지 상황에 따라 다르다. 여기서는 한 개의 데이터만 있지만, 상황에 따라 관리해야 하는 예전 버전의 데이터가 무한히 많아질 수 있다. 트랜잭션이 길어지만 언두에서 관리하는 예전 데이터가 삭제되지 못하고 오랫동안 관리돼야 하며, 따라서 테이블 저장공간이 늘어나는 상황이 발생 가능하다. 잠금 없는 일관된 읽기(Non-Locking Consistent Read)InnoDB 스토리지 엔진은 MVCC 엔진을 이용해 잠금을 걸지 않고 읽기 작업을 수행한다. 잠금을 걸지 않기 때문에 InnoDB에서 읽기 작업은 다른 트랜잭션이 가지고 있는 잠금을 기다리지 않고, 읽기 작업이 가능하다. 격리 수준이 innodb에서는 변경되기 전의 데이터를 읽기 위해 언두 로그를 사용한다. 자동 데드락 감지InnoDB 스토리지 엔진은 내부적으로 잠금이 교착 상태에 빠지지 않았느지 체크하기 위해 잠금 대기 목록을 그래프 형태로 관리한다. 데드락 감지 스레드가 주기적으로 잠금 대기 그래프를 검사해 교착 상태에 빠진 트랜잭션들을 찾아 그 중 하나를 강제 종료한다. 트랜잭션의 언두 로그를 적게 가진 트랜잭션이 롤백 대상 중 더 먼저 처리된다. 이는 롤백을 해도 언두 처리를 덜 하기 때문이고, 서버의 부하도 덜 유발해서이다. Innodb 테이블 엔진은 상위 레이어진 mysql엔진에서 관리되는 테이블 잠금은 볼수 없어서 데드락 감지가 불확실할 수 있다. 이 때 동시 처리 스레드가 많아지거나 잠금 개수가 많아지면 데드락 감지 스레드가 느려진다. 데드락 스레드가 잠금 목록을 검사하기 위해 잠금 상태가 변경되지 않도록 잠금 테이블에 새 잠금을 걸고 데드락을 찾기 때문이다. 따라서 서비스를 처리하는 스레드가 작업을 하지 못하고 대기하면서 cpu 자원을 더 많이 소모하고 서비스에 악영향이 생길 수 있다. 이 문제를 해결하기 위해 mysql 서버는 자동화된 장애 복구Mysql 서버와 무관하게 디스크나 서버 하드웨어 이슈로 innodb 스토리지 엔진이 자동으로 복구를 못하는 상황이 생길 수 있는데, innodb 데이터파일은 서버가 시작될 때 항상 자동 복구를 시행하며, 자동 복구가 안되는 손상이 있다면 자동 복구를 멈추고 서버를 종료한다. 이 때는 MYsql 서버의 설정 파일에 그러나 옵션을 걸어 진행해도 서버가 시작되지 않으면 백업을 이용해 다시 구축하는 방법밖에 없다. 백업이 있다면 마지막 백업으로 db를 새로 구축하고, 바이너리 로그를 사용해 장애 시점까지의 데이터를 복구할 수도 있다. 마지막 풀 백업 시점부터 장애 시점까지의 바이너리 로그가 있다면 innodb를 사용하는 것보다 풀 백업과 바이너리 로그로 백업하는게 데이터 손실이 더 적을 수도 있다. InnoDB 버퍼 풀InnoDB 스토리지 엔진에서 가장 핵심적인 부분이다. 디스크의 데이터 파일이나 인덱스 정보를 메모리에 캐시해 두는 공간이다. 쓰기 작업을 지연해 일괄 처리하는 버퍼 역할도 한다. 버퍼 풀은 데이터 변경 쿼리를 모아서 처리하므로 랜덤한 디스크 작업의 횟수를 줄일 수 있다. 버퍼 풀 크기 설정버퍼 풀의 크기는 운영체제와 각 클라이언트가 사용할 공간까지 고려해 걸정해야 한다. 만약 커넥션이 많다면 각 클라이언트 세션에서 테이블의 레코드를 읽고 쓸 때 사용하는 레코드 버퍼의 메모리 공간이 많이 필요해진다. 이 공간은 별도로 설정할 수 없고, 동적으로 해제되기도 해서 정확히 필요한 메모리 크기를 계산할 수 없다. Mysql 5.7 버전부터는 innodb 버퍼 풀의 크기를 동적으로 조절할 수 있다. 따라서 버퍼 풀의 크기를 적절히 작게 설정하고 조금씩 증가하는 방식이 최적이다. 보통 운영체제의 메모리 공간이 8gb 미만이면 50프로를 버퍼 풀로 설정 후 올리고, 50gb 이상이면 15~30gb 정도를 운영체제와 응용 프로그램에 할당하고 나머지를 버퍼 풀로 쓴다. 버퍼 풀의 크기 변경은 크리티컬한 변경이므로 서버가 한가한 시점에 진행한다. 그리고 버퍼 크기를 늘리는 것보다 줄이는 것이 크리티컬하다. innodb 버퍼 풀은 버퍼 풀 전체를 관리하는 잠금(세마포어)으로 인해 내부 잠금 경합(이게뭐지)을 많이 유발해왔는데, 이런 경합을 줄이기 위해 버퍼 풀을 여러 개로 쪼개 관리할 수 있게 개선됐다. 버퍼 풀이 쪼개지면서 잠금 자체도 경합이 분산되는 효과를 내는 것이다. 버퍼 풀의 구조innodb 스토리지 엔진은 버퍼 풀을 페이지 크기의 조각으로 쪼개어 스토리지 엔진이 데이터를 필요로 할 때 해당 데이터 페이지를 읽어서 각 조각에 저장한다. 버퍼 풀의 페이지 크기 조각을 관리하기 위해 innodb는 LRU(Least Recently Used)리스트와, 플러시 리스트, 프리 리스트라는 3개의 자료 구조를 관리한다. 프리 리스트는 실제 사용자 데이터로 채워지지 않은 비어 있는 페이지들의 목록이다. 사용게 디스크의 데이터 페이지를 읽어와야 하는 경우 사용된다. LRU 리스트는 LRU와 MRU(Most Recently Used)가 결합된 형태인데, old 서브리스트가 LRU, new 서브리스트가 MRU이다. LRU 리스트를 관리하는 목적은, 디스크로부터 한 번 읽어온 페이지를 최대한 오랫동안 InnoDB 버퍼 풀의 메모리에 유지해서 디스크 읽기를 최소화하는 것이다. InnoDB 스토리지 엔진에서 데이터를 찾아내는 과정은 다음과 같다
즉, 페이지가 읽히면 new(mru)로, 읽히지 않으면 old(lru)로 이동하는 구조이다. 플러시 리스트는 디스크로 동기화되지 않은, 더티 페이지의 변경 시점 기준의 페이지 목록을 관리한다. 일단 한 번 데이터 변경이가해진 데이터 페이지는 플러시 리스트에 관리되고 특정 시점이 되면 디스크로 기록돼야 한다. 데이터가 변경되면 innodb는 변경 내용을 리두 로그에 기록하고 버퍼 풀의 데이터 페이지에도 변경 내용을 반영한다. 따라서 리두 로그의 각 엔트리는 특정 데이터 페이지와 연결된다. 그러나 리두 로그가 디스크로 기록됐다고 해도 데이터 페이지가 디스크로 기록됨을 항상 보장하지 않는다. 따라서 innodb 스토리지 엔진은 체크포인트를 발생시켜 디스크의 리두 로그와 데이터 페이지의 상태를 동기화하게 된다. 체크포인트는 리두 로그의 어느 부분부터 복구를 시작할지 판단하는 기준점임 버퍼 풀과 리두 로그(뒤지게 어려움)버퍼 풀은 디스크 메모리가 모든 버퍼 풀에 적재되기 전까지 늘리면 늘릴수록 쿼리가 빨라짐. 그러나 버퍼 풀은 데이터 캐시와 쓰기 버퍼링(지연), 두 가지 용도가 있는데, 늘리는 것은 캐시만 이득은 보는 것임. 따라서 쓰기 버퍼링을 향샹시키려면 버퍼 풀과 리두 로그의 관계 파악이 필수. 버퍼 풀은 데이터의 변경이 없는 클린 페이지와 변경이 생긴 더티 페이지로 나뉨. 더티 페이지는 버퍼 풀에 무한정 머무를 수 없음. 데이터 수정이 계속 발생하면 리두 로그의 로그 엔트리는 새로운 로그 엔트리로 덮임. 따라서 재사용 가능한 공간과 재사용 불가능한 공간을 구분해야 한다. 이 때 재사용 불가능한 공간을 활성 리두 로그라 함. 리두 로그는 재사용되지만 기록될 때마다 로그 포지면은 계속 증가된 값을 가짐. 이를 LSM(log sequence number)라 함. 가장 최근 체크포인트 지점의 lsn이 활성 리두 로그 공간의 시작점이 됨. 그러나 활성 리두 로그 공간의 마지막은 계속해서 증가하기 때문에 체크포인트와 무관함. 가장 최근 체크포인트의 lsn과 마지막 리두 로그 엔트리의 lsn의 차이를 체크포인트 에이지라고 함. 즉 체크포인트 에이지는 활성 리두 로그 공간의 크기임. 체크포인트 lsn보다 작은 lsn값을 가진 더티 페이지와 리두 로그 엔트리는 모두 디스크로 동기화돼야 함. 버퍼 풀 플러시innodb는 버퍼 풀에서의 더티 페이지를 디스크로 동기화하기 위해 2개의 플러시 기능을 백그라운드로 실행한다.
버퍼 풀 상태 백업 및 복구디스크의 데이터가 버퍼 풀에 적재된 상황을 워밍업이라 한다. mysql 5.5에서는 서버를 셧다운하다가 다시 시작하는 경우, 강제 워밍업을 해 주요 테이블과 인덱스에 풀 스캔을 한번씩 실행한다. 5.6 버전부터는 버퍼 풀 덤프 및 적재 기능이 도입된다. 따라서 이 백업 파일은 제한적 크기를 두어 데이터 페이지의 메타 정보만 가져와 백업하도록 한다. 따라서 백업이 빠르게 완료된다. 버퍼 풀의 적재 내용 확인Mysql 8.0 버전부터는 information_schema 테이블에 innodb_cached_indexes 테이블을 새로 추가해, 테이블의 인덱스별로 데이터 페이지가 얼마나 innoDb 버퍼 풀에 적재돼 있는지 확인할 수 있다. |








Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
4장 아키텍처
MySQL의 전체 구조
MySQL 엔진
MySQL 엔진은 요청된 SQL 문장을 분석하거나 최적화와 같이 DBMS의 두뇌에 해당하는 처리를 수행한다.
스토리지 엔진
핸들러 API
핸들러 요청이라고 한다.MySQL 스레딩 구조
foreground thread(client thread)
background thread(InnoDB)
로그를 디스크로 기록하는 스레드innoDB 버퍼 풀의 데이터를 디스크에 기록하는 스레드이와 같이 다양한 thread 중에서도 데이터를 디스크에 쓰고 읽는 thread가 가장 중요하다. 데이터를 읽은 작업은 주로 client Thread에서 처리되며 쓰기 thread의 경우에는 background thread로 처리하기 때문에 여러개의 thread 개수를 가지는 것이 좋다.
InnoDB에서 쓰기 작업은 지연되어 처리가 가능하여 버퍼에서 디스크로의 변화가 적용되는 과정에서 다음 요청이 이를 기다릴 필요가 없지만 MyISAM의 경우 쓰기 작업까지 모두 client Thread에서 처리하기 때문에 쓰기 요청이 모두 마무리 되어야 다음 요청이 처리가 가능하다.
메모리 할당 및 사용구조
글로벌 메모리 영역
로컬 메모리 영역
쿼리 실행 구조
사용자의 요청으로 들어온 쿼리를 토큰으로 분리하여 트리 구조로 만들어 내는 작업을 의미한다. 이과정에서 쿼리문의
기본 문법 오류를 잡아내고 이를 사용자에게 오류메시지로 전달한다.예시
위의 쿼리문에서 SELECT, id, name, age, FROM, member, WHERE, id, = ,1의 토큰이 결정되며 아래와 같이 트리구조로 만든다.
쿼리 파서에서 만들어진 토큰 기반의 트리를 통해 구조적인 문제를 확인한다.(테이블이 존재하는지 혹은 테이블 내에 column이 존재하는지, 객체에 접근이 가능한지) 즉, 실제로 존재하지 않거나 권한상 사용할 수 없는 개체의 토큰을 걸러내는 작업을 하는 것이다.
옵티마이저는 사용자의 요청 쿼리를 가장 저렴한 비용으로 처리하는 방법을 결정하는 역할이다. MySQL 엔진의 두뇌라고 볼 수 있다.
옵티마이저에서 생성한 실행 계획을 실행하는 역할로 실행 계획에 맞게 핸들러에게 요청을 보내는 중간 다리 역할을 하는 엔진이다.
쿼리 캐시
스레드 풀
스레드 풀의 목적은 사용자의 요청을 처리하는 스레드 개수를 줄여서 MySQL 서버의 cpu가 제한된 개수의 스레드 처리에만 집중하게 하여 자원 소모를 줄이는 것이다.
thread_pool_oversubscribe에 정의된 개수만큼 추가로 작업을 받는다.)thread_pool_stall_limit에 정의된 밀리초만큼 작업을 쓰레드가 처리하지 못하면 새로운 스레드를 생성한다.thread_pool_max_thread를 넘어설 수 없다.InnoDB 스토리지 엔진 아키텍처
프라이머리 키에 의한 클러스터링
외래 키 지원
MVCC
예시: 데이터가 생성되고 변경되는 경우
잠금 없는 일관된 읽기
두명의 사용자가 하나의 자원에 대해 접근을 할 때 한 사용자는 데이터를 수정하고 나머지 한 사용자는 데이터를 조회한다고 하자
이 때 데이터가 수정중이 있더라도 undo를 통해서 조회하는 사용자도 데이터에 접근이 가능하다. 즉, 잠금없이 데이터를 조회가 가능하다.
자동 데드락 감지
자동화된 장애 복구
: undo 로그의 내용으로 트랜잭션 롤백이 실패한 문제이다.
InnoDB 버퍼 풀
버퍼 풀의 크기 설정
버퍼 풀의 구조
버퍼 풀과 리두 로그
버퍼 풀 플러시
플러시 리스트 플러시
LRU 리스트 플러시
버퍼 풀 상태 백업 및 복구
Beta Was this translation helpful? Give feedback.
All reactions