--by Sheldon Zhang
在巨大数据规模下的部分统计 -> example: word count
巨大的数据规模 -> 分布式系统
针对巨大的服务器集群如何有效的分配计算任务?
名词解释:
master: 进行任务分配,调度的机器
worker: 具体执行工作的机,包括mapper和reducer
mapper: 进行map操作的机器
reducer: 进行reduce操作的机器
GFS: 分布式系统下的文件管理系统,可以高效的传输文件
(组织元素)将杂乱的元素有序组织到一起
可以理解为创建映射(对应STL中的map),针对一个关键词创建一个对应的键值
可以理解为将原始数据转化为初始键值对
在word count中键值就是切分后的单词本身
并创建一个(word, "1")的元组为下面的reduce提供数据
在map的过程中会不断向主机发送心跳包,信息包含:当前任务和完成情况,
对map中产生的每一个key进行统计并输出结果,相当于分key处理的合并操作
将具有相同key值的value进行处理后产生新的键值作为结果输出
在有序的元素下进行运算
Our abstraction is inspired by the map and reduce primitives present in Lisp and many other functional languages
在函数式编程中map是对一个列表的每一个元素进行运算,reduce是对列表中的每一个元素进行迭代计算
迭代运算的前提是要求列表中的元素存在一定的关联,这对于无序的原始数据是不可能的,所以map的操作就是逐个组织元素,从而使一个key下的value存在关联
类比machine learning, map的过程相当于特征工程而reduce相当于在提取特征上进行的进一步的处理
- 数据切片
将大量的数据切成默认为64M的文件切片,有利于文件的传输
会在多个机器上创建不同切片的副本
- map操作
attention:
不是所有的机器都是等价的,类似主从配置,存在master进行任务分配和相关信息的统计
当worker完成某个任务时会通过master将对应的任务标记为完成
master进行任务的分配(FIFO),往往是在一个机器上一次分配多个任务,
因为不同的任务处理的时间不同,这样一来可以保证效率最大化,不间断的处理数据- map任务的分配也不是随机的(data local思想)
通过移动运算代替移动数据,将任务分配给有对应数据的worker
- map任务的分配也不是随机的(data local思想)
- shuffle操作(核心)

partition = hash(key) % num(reducer)
针对每一个key均会计算partition,表示有当前key的键值对要发送到哪个reducer进行操作,带来的问题就是reducer之间的负载不均衡,会拖延整个任务的进度
在完成这个操作之后,会将partition和原始的键值对(先被序列化为字节数组)一起写入内存的缓冲区(减少对磁盘IO的占用)
-
spill(溢写)
我们已经知道了哪个数据要发给哪个reducer,但是在这之前为了减少网络带宽的使用,需要对相应的数据进行一些合并(一个map task最终只会产生一个溢写文件)
spill的操作是将内存中的数据写到硬盘里,需要按照partition, key的顺序排序进行排列
在这里的排序效率比在reduce shuffle阶段的排序效率高,因为数据全部在内存当中,可以减少后面排序的时间消耗
需要注意的是spill是一个单独的线程,不会影响上一步中向缓冲区中写入数据
这样的操作如何实现?
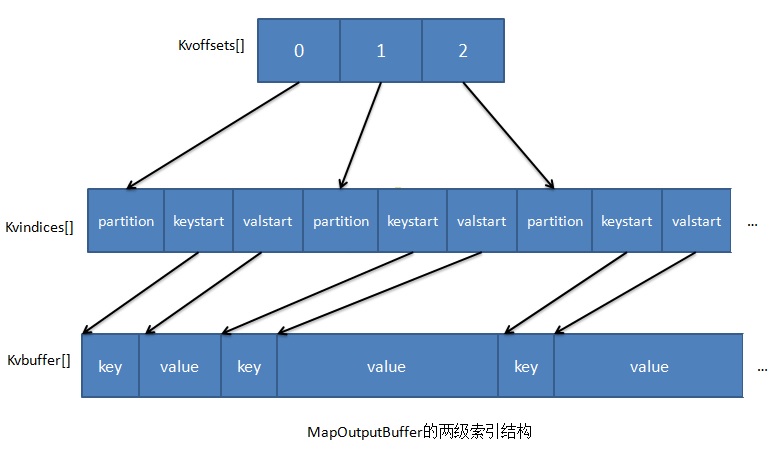
环形缓冲区 结构上相当于一个环形链表,在里面数据量达到一定的比例时触发spill线程,锁定此时内存中的数据,但是不影响继续写入缓冲区
现在缓冲区中的数据包含(key, value, partition) 先按照partition排序,再按照key排序,这样一来就保证了在磁盘中的文件是依照partition分区的,且在一个分区内key按照升序排列,这样带来的好处就在于我们可以按key进行高效的随机检索-
combine (optional)
可以理解为map操作中的reduce(优化中间结果)将有相同key值的元组合并,并把value相加(1, "1"), (1, "1"), (2, "1"), (4, "1") ----> (1, "2"), (2, "1"),(4, "1")
会有两个地方出现combine操作
1. 在上一步的排序完成之后,写入磁盘之前,这样一来可以减小文件的大小,减少文件传输时带宽的占用
2. 输出文件较大时溢写文件较多,在merge的同时会进行combine操作但是不是所有的任务都可以使用combine操作,需要reduce的输入输出类型一致(combine本身就是reduce),需要计算逻辑上combine不会影响结果
在求平均值时,使用combine操作会影响计算,但是在求和时不会影响结果- merge
在有多个溢写文件时,需要对他们进行多路归并排序,保证一个map task只会产生一个中间文件,同时产生一个index文件,记录每一个分区的起始位置,长度,压缩长度
-
- copy
reducer通过发起http请求向master获取对应map task输出文件的位置,通过GFS拉取文件到本地的内存中(没有排序),当达到一定的内存使用比例时溢写到自己的磁盘上
在map task被标记为完成时,master就开始分配reduce task,reducer就开始从mapper上拉取对应的数据
在溢写时会进行排序,如果没有这个步骤的话会造成reducer在分key处理的时候重复遍历,降低处理速度 - merge
当copy达到阈值将要写入硬盘时进行merge,在这个过程中如果设置combiner的话也会启用,这种方式一直运行直到拉取了所有的数据
然后通过磁盘到磁盘的merge合并产生的多个溢写文件为一个,产生reduce的输入文件
- reduce操作
进行最后的统计操作,输出最终的结果
需要注意的就是reduce的结果输出后立即被master回收
master会定时ping每一个worker,如果一个机器在一段时间内所有的数据包都没有回应,master就会把他标记为失效的主机
-
mapper错误
当前主机的所有的map操作需要重新执行,因为map产生的文件保存在主机本地,当主机下线这些文件也不可访问
同时需要在主机列表中删除当前节点,防止继续有任务分配给当前的节点
mapper节点的错误会通知到所有的节点,并且通知将要从当前节点A拉取数据的reducer需要从mapperB拉取数据 -
reducer错误
并没有什么关系,reduce操作完成后生成的文件立即被master回收,不会造成影响
只需要在主机列表中删除,并把未完成的任务重新分配即可 -
master错误
需要重新执行当前整个mapreduce任务
考虑到实际上单个机器出错可能性很小,这个代价可以接受 -
程序自身的bug导致长时间占用资源
在心跳包中包含当前任务的进度信息,如果没有新的进度则不汇报,当一个机器的没有汇报的时间超过阈值,master就控制worker杀掉当前的任务,并且将此任务重新进行分配
当缓冲区的使用率达到一定的阈值后触发一次spill操作,生成spill临时文件,当缓冲区使用率再次达到阈值时再次触发spill操作,会生成很多临时文件直到处理数据完毕
不会等到缓冲区全部写满时才触发spill
当触发spill操作时,mapper还可以想缓冲区中空的地方写数据,已经写数据的空间会被锁定,
经过排序后写入磁盘,缓冲区中这部分内存会被释放,可以继续使用
- 两节索引结构