--by Sheldon Zhang
raft协议提供一个一致性场景,保证在raft集群可以正常工作的情况下集群的针对请求的响应是正确的
write ahead log: 在进行修改之前先进行Log(日志)记录,保证在数据丢失的情况下仍然可以根据Log得出正确的数据
正如论文中说的 "Raft is a consensus algorithm for managing a replicated log." raft集群通过复制Log进行容错,即所有的节点都从相同的状态出发,执行相同的Log最终得到相同的结果(deterministic),自然可以想到这中间最为困难的就是如何确保维护多个(日志)副本的一致性。
-
一致性
同一时间每个节点的某个值相同,即每个节点的共享内容相同。 -
节点状态 每个节点都会在Follower, Candidate, Leader中转移,在一个时刻中一个节点仅会处于一种状态。
-
节点结构 每个节点都包含以下三个组件 状态机:确保状态(数据)转移的一致性。状态机通过取出所有Log执行得出对外保证一致性的结果。 Log(日志):修改记录。 一致性组件:保证raft集群中所有的Log保持一致的组件。
-
Term(任期):在某个节点当选Leader时开始,并在其宕机时结束。
-
协议特点(对比Paxos)
- strong Leader: raft集群中节点的地位并不平等,Log仅能从Leader(同一时刻一个集群中仅有一个)向Follower写入,简化了Log的复制过程。
- Leader election: 通过随机等待时间简单地解决竞选 Leader 时的冲突。
- membership changes: 从协议层面保证在配置变化时这个集群仍然可以正常工作。
raft集群性质:容错性,保证在小部分副本宕机的时候集群仍然可以提供服务
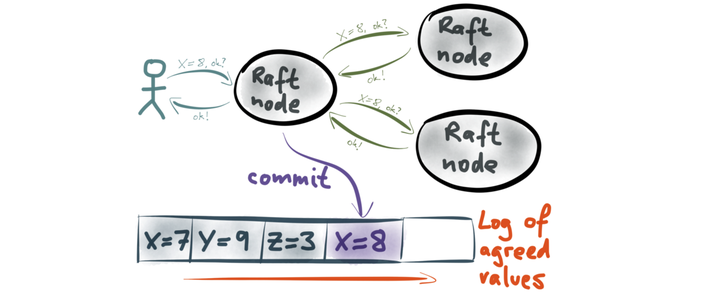
由图可知
-
在一个raft集群中仅存在一个Leader
-
用户能且只能和raft集群中的Leader交互(包括提交更改和查询)
-
处在Follower状态的节点能且仅能从Leader获取Log信息
-
当集群中超过半数的节点确认更改后才能正式提交(commit)更改,并向用户返回成功的状态
-
Leader会定时向Follower发送心跳包(不包含日志更改),确保Follower在线
设想当某个节点宕机了,那么它不会接受重新上线之前的Log,这就产生了Log的差异。而如何解决这个问题就是raft协议的核心。
那么很容易想到宕机的是处在Follower状态还是Leader状态,下面会分别进行讨论。
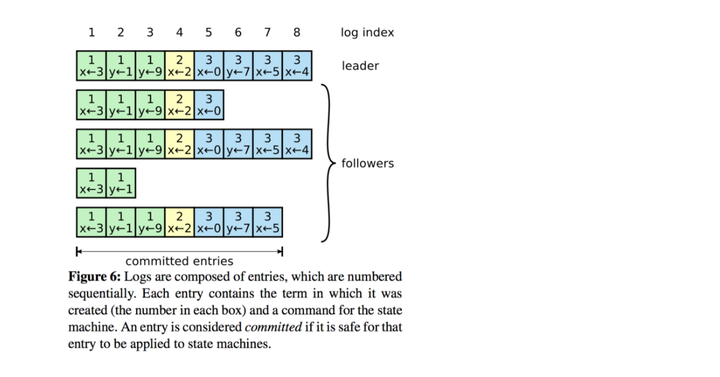
由图可知,在正常的任期内Leader的日志信息最完整,所以Leader会将其日志同步到Follower上。 在raft集群中存在Leader时即可接受客户的请求。在接受新的请求后,Leader会向Follower发送添加新的日志的请求。当超过半数的节点确认新的请求被写入日志,Leader会把这个请求标记为safe replicated,然后处理请求并返回结果。当某个节点的丢包或宕机时,Leader会持续给这个节点发送数据包直到日志一致。
但是需要考虑到新的Leader当选时日志信息不齐的状态,那么需要一个能保证一致性的算法来统一日志。假设新的Leader当选时的Log情况如下图

-
Leader针对每一个Follower维护一个NextIndex,表示Leader给当前Follower发送的下一条Log Entry在真个Log中所在的位置,初始化为Leader最后一条Log Entry的下一个位置
-
Leader向Follower发送的数据包包括两部分(Term, NextIndex-1) 其中Term表示对应的Log Entry是在哪个Term中产生的
-
当Follower收到数据包后会在自己的Log中查找是否有这条Log Entry,若没有则返回拒绝状态,Leader将NextIndex-1,如此循环直到Follower返回接受的状态
===> 得出Leader应该给这个Follower从哪里开始推送Log Entry
以上图中的 b 为例 NextIndex初始化为11 (Leader) => (6, 10) (Follower) <= False => (6, 9) <= False ··· => (4, 4) <= True 则Leader向Follower b从第五条Log Entry开始推送
当Follower宕机并重新上线时,Leader会通过这种方式进行日志同步
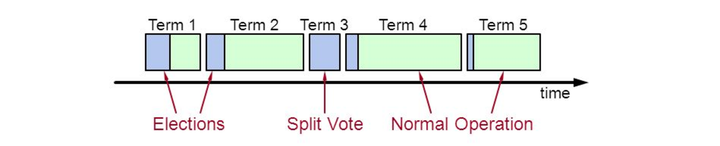
当Follower在一定时间内没有收到Leader的心跳包时认为Leader宕机,Follower进入Candidate状态开始竞选。
-
节点状态由Follower变为Candidate,同时设置参选的term为原term+1
-
每个参选的Candidate给自己投票,同时向其他的节点发送投票请求,在一个term中每个节点仅能投出一票。
-
每个节点等待投票结果,决定下面的状态
- Leader ==> 得到半数以上的选票,开始新的term
- Follower ==> 没有得到半数以上的选票,开始新的term
- Candidate ==> 平票或者其他情况,开始新的term进行下一轮竞选
如果Leader失效的超时时间固定会造成什么? 显然可能所有的Follower同时发现Leader宕机,同时进入Candidate状态,造成平票。如果设置为随机值就可以让先发现Leader宕机的节点优先当选。 如果投票的超时时间固定会发生什么? 如果所有的节点都是Candidate状态,那么他们会同时发送拉票申请,但是每个节点在一个term内仅能投出一票(都投给了自己),造成了平票,在进入下次竞选后仍会重复上述的局面。但是如果在150ms~300ms间随机选择投票的超时时间,那么就可以保证不会长时间保持僵局。
什么是安全性? 如果一个领导人已经在给定的索引值位置的日志条目应用到状态机中,那么其他任何的服务器在这个索引位置不会提交一个不同的日志
思考上述的竞选策略和日志同步策略,很容易发现在一个正常的Term内并没有从Follower到Leader的日志同步,所以我们需要对竞选策略进行一定的修改 在发送拉票请求时带上自己最后一条日志的Term和其index,其他节点在收到请求后比较自己的Log,首先比较Term,若自己最后一条Log Entry的Term大于请求的,则拒绝给它投票,在Term相同时比较index,若自己的index更大则拒绝投票
我们解决了在竞选中可能遇到的问题,但是下图的情况可能造成已经提交的日志丢失
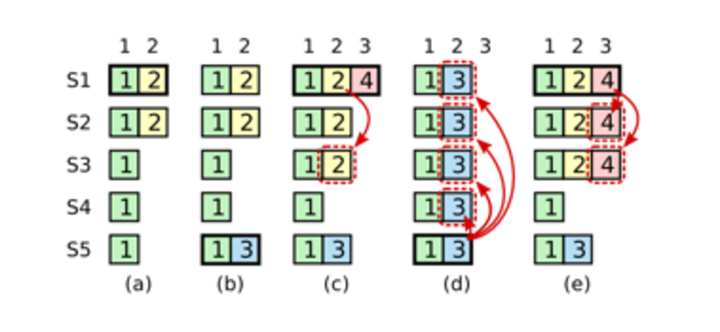
-
S1当选Leader,将(2, 2)写入日志并同步到S2,但是在commit之前不幸下线
-
S5当选Leader,此时系统Term为3,将(3, 2)写入日志,在同步之前下线
-
S1当选Leader,此时系统Term为4,S1向其他节点同步自己的日志,当在S3同步完成时,因为已经有超过半数的节点确认了,所以日志(2, 2)会被commit,然后S1再次下线
-
S5再次当选Leader,向其他节点同步自己的Log,于是显然已经commit的Log Entry(2, 2)被截断了,这个错误是不可接受的,因为一致性协议不允许已经commit的日志更改
所以我们只需要在commit时加上一点限制,只允许主节点提交包含当前Term的日志
这个规则下在阶段3,S1当选Leader也不能commit日志(2, 2)因为这不是这个Term内产生的日志。在阶段4中,S5不能当选Leader,因为S5没有(4, 3)这条日志
虽然主节点只能commit当前任期内的日志,但是可以通过日志匹配特性(Log Matching Property)提交之前的日志
我们可以注意到在Leader当选后会持续检查Follower的日志信息,如果不匹配的话会优先同步以前的日志,只有同步到与Leader的Log保持一致时才会添加最新的日志。这个机制就保证了在Leader提交最新的日志时也提交了旧的日志。