Not Found
The requested item could not be located.
Perhaps you might want to check all posts or information pages.
The requested item could not be located.
Perhaps you might want to check all posts or information pages.
The requested item could not be located.
Perhaps you might want to check all posts or information pages.
| 2024-01-16 | Using udp-link to enhance TCP connections stability |
| 2020-05-13 | The zoo of binary-to-text encoding schemes |
| 2020-04-18 | Convert binary data to a text with the lowest overhead |
| 2020-01-18 | My notes for the "Pragmatic Thinking and Learning" book |
| 2019-12-20 | Computer Science vs Information Technology |
| 2019-12-19 | Who is an engineer |
| 2019-12-15 | Algorithm is... |
| 2019-12-15 | Turing: thesis, machine, completeness |
| 2019-08-21 | Organizing Unstructured Data |
| 2019-08-16 | Number Classification |
| 2019-08-08 | A converter of a character's case and Ascii codes |
| 2019-07-22 | Constraint Satisfaction Problem (CSP) |
| 2019-07-18 | How to remove a webpage from the Google index |
| 2019-07-02 | How to redirect a static website on the Github Pages |
| 2019-06-26 | Managing your plans in the S.M.A.R.T. way |
| 2019-06-21 | Dreyfus model of skill acquisition |
| 2019-06-15 | Maslow's hierarchy of needs |
| 2019-06-12 | Structured Programming Paradigm |
| 2019-06-10 | SQ3R |
| 2024-01-16 | Using udp-link to enhance TCP connections stability |
| 2020-05-13 | The zoo of binary-to-text encoding schemes |
| 2020-04-18 | Convert binary data to a text with the lowest overhead |
| 2020-01-18 | My notes for the "Pragmatic Thinking and Learning" book |
| 2019-12-20 | Computer Science vs Information Technology |
| 2019-12-19 | Who is an engineer |
| 2019-12-15 | Algorithm is... |
| 2019-12-15 | Turing: thesis, machine, completeness |
| 2019-08-21 | Organizing Unstructured Data |
| 2019-08-16 | Number Classification |
| 2019-08-08 | A converter of a character's case and Ascii codes |
| 2019-07-22 | Constraint Satisfaction Problem (CSP) |
| 2019-07-18 | How to remove a webpage from the Google index |
| 2019-07-02 | How to redirect a static website on the Github Pages |
| 2019-06-26 | Managing your plans in the S.M.A.R.T. way |
| 2019-06-21 | Dreyfus model of skill acquisition |
| 2019-06-15 | Maslow's hierarchy of needs |
| 2019-06-12 | Structured Programming Paradigm |
| 2019-06-10 | SQ3R |
| 2019-06-26 | Managing your plans in the S.M.A.R.T. way |
| 2019-06-21 | Dreyfus model of skill acquisition |
| 2019-06-15 | Maslow's hierarchy of needs |
| 2019-06-12 | Structured Programming Paradigm |
| 2019-06-10 | SQ3R |
| 2019-06-26 | Managing your plans in the S.M.A.R.T. way |
| 2019-06-21 | Dreyfus model of skill acquisition |
| 2019-06-15 | Maslow's hierarchy of needs |
| 2019-06-12 | Structured Programming Paradigm |
| 2019-06-10 | SQ3R |
| 2019-07-22 | Constraint Satisfaction Problem (CSP) |
| 2019-07-18 | How to remove a webpage from the Google index |
| 2019-07-02 | How to redirect a static website on the Github Pages |
| 2019-07-22 | Constraint Satisfaction Problem (CSP) |
| 2019-07-18 | How to remove a webpage from the Google index |
| 2019-07-02 | How to redirect a static website on the Github Pages |
| 2019-08-21 | Organizing Unstructured Data |
| 2019-08-16 | Number Classification |
| 2019-08-08 | A converter of a character's case and Ascii codes |
| 2019-08-21 | Organizing Unstructured Data |
| 2019-08-16 | Number Classification |
| 2019-08-08 | A converter of a character's case and Ascii codes |
| 2019-12-20 | Computer Science vs Information Technology |
| 2019-12-19 | Who is an engineer |
| 2019-12-15 | Algorithm is... |
| 2019-12-15 | Turing: thesis, machine, completeness |
| 2019-12-20 | Computer Science vs Information Technology |
| 2019-12-19 | Who is an engineer |
| 2019-12-15 | Algorithm is... |
| 2019-12-15 | Turing: thesis, machine, completeness |
| 2019-12-20 | Computer Science vs Information Technology |
| 2019-12-19 | Who is an engineer |
| 2019-12-15 | Algorithm is... |
| 2019-12-15 | Turing: thesis, machine, completeness |
| 2019-08-21 | Organizing Unstructured Data |
| 2019-08-16 | Number Classification |
| 2019-08-08 | A converter of a character's case and Ascii codes |
| 2019-07-22 | Constraint Satisfaction Problem (CSP) |
| 2019-07-18 | How to remove a webpage from the Google index |
| 2019-07-02 | How to redirect a static website on the Github Pages |
| 2019-06-26 | Managing your plans in the S.M.A.R.T. way |
| 2019-06-21 | Dreyfus model of skill acquisition |
| 2019-06-15 | Maslow's hierarchy of needs |
| 2019-06-12 | Structured Programming Paradigm |
| 2019-06-10 | SQ3R |
| 2019-12-20 | Computer Science vs Information Technology |
| 2019-12-19 | Who is an engineer |
| 2019-12-15 | Algorithm is... |
| 2019-12-15 | Turing: thesis, machine, completeness |
| 2019-08-21 | Organizing Unstructured Data |
| 2019-08-16 | Number Classification |
| 2019-08-08 | A converter of a character's case and Ascii codes |
| 2019-07-22 | Constraint Satisfaction Problem (CSP) |
| 2019-07-18 | How to remove a webpage from the Google index |
| 2019-07-02 | How to redirect a static website on the Github Pages |
| 2019-06-26 | Managing your plans in the S.M.A.R.T. way |
| 2019-06-21 | Dreyfus model of skill acquisition |
| 2019-06-15 | Maslow's hierarchy of needs |
| 2019-06-12 | Structured Programming Paradigm |
| 2019-06-10 | SQ3R |
| 2020-05-13 | The zoo of binary-to-text encoding schemes |
| 2020-05-13 | The zoo of binary-to-text encoding schemes |
Despite the obvious expectation to find some sort of a definition of the term "Algorithm" here, I have to disappoint you, as there isn't any general or well-accepted definition. But, it's not a unique situation! Take mathematics, for example. Although there are plenty of different "definitions" that can be found in the literature, they all are just oversimplified attempts to explain what an algorithm really means.
In general, an algorithm is a way of describing the logic. And that's why it's so hard to cover all possible forms of it in terms of common rules or definitions. Most prominent mathematicians began seriously thinking about computability and what can be computed at the beginning of the 20th century. But it was so hard to generalize all the cases that eventually they had to limit the consideration by functions defined only on the set of Natural numbers.
The most famous works were done by Alan Turing (related to algorithms) and Alonzo Church (related to computable functions). Alan Turing came up with the thesis which basically says, that if a function is computable then it has an algorithm, and if so, then it can be implemented on the Turing machine (TM). In other words, Turing's thesis makes it clear what can be computed and what is needed to get computed.
Turing machine is an abstract system that has a finite set of states and symbols, a few certain operations, and an endless tape (consisted of cells). The behavior of a TM is controlled by a program that defines a state transition and a next tape movement depending on a symbol that was read. Although, there is no a real-world analog of the TM as it is unlikely possible to have infinite memory. So, to get it more realistic, for a real analog of TM, it means two things:
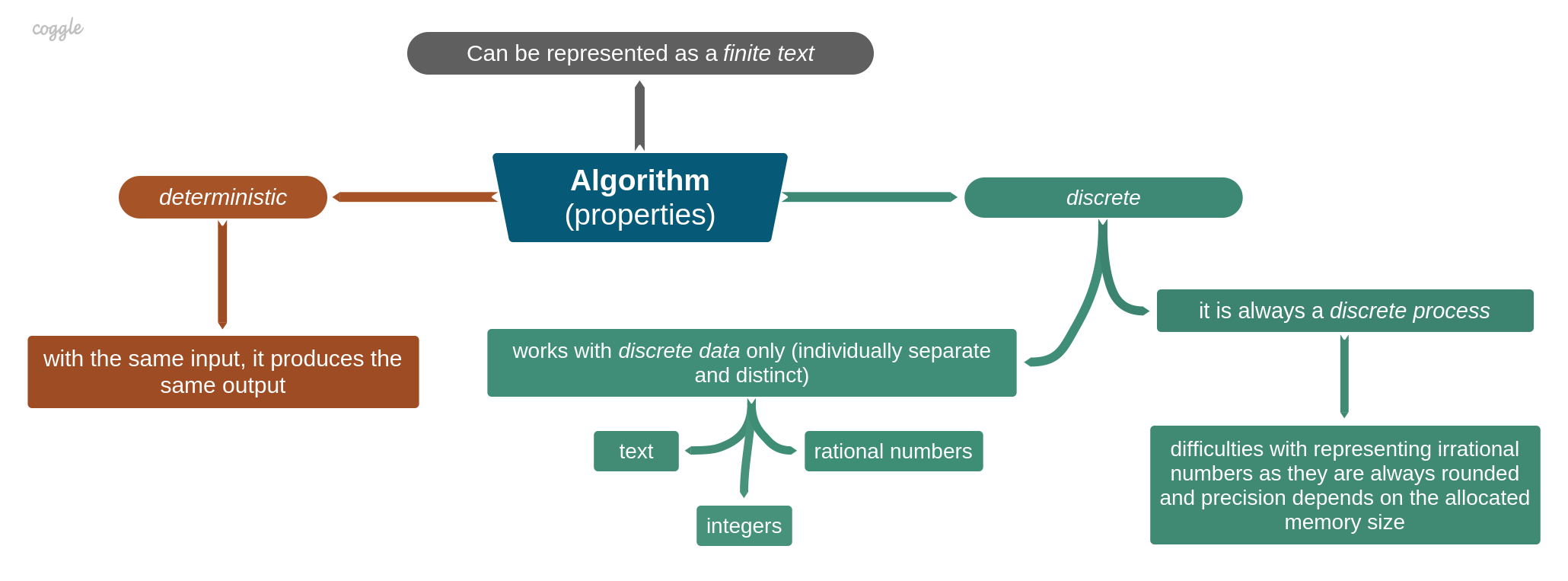
All algorithms share the same properties:
Despite the obvious expectation to find some sort of a definition of the term "Algorithm" here, I have to disappoint you, as there isn't any general or well-accepted definition. But, it's not a unique situation! Take mathematics, for example. Although there are plenty of different "definitions" that can be found in the literature, they all are just oversimplified attempts to explain what an algorithm really means.
In general, an algorithm is a way of describing the logic. And that's why it's so hard to cover all possible forms of it in terms of common rules or definitions. Most prominent mathematicians began seriously thinking about computability and what can be computed at the beginning of the 20th century. But it was so hard to generalize all the cases that eventually they had to limit the consideration by functions defined only on the set of Natural numbers.
The most famous works were done by Alan Turing (related to algorithms) and Alonzo Church (related to computable functions). Alan Turing came up with the thesis which basically says, that if a function is computable then it has an algorithm, and if so, then it can be implemented on the Turing machine (TM). In other words, Turing's thesis makes it clear what can be computed and what is needed to get computed.
Turing machine is an abstract system that has a finite set of states and symbols, a few certain operations, and an endless tape (consisted of cells). The behavior of a TM is controlled by a program that defines a state transition and a next tape movement depending on a symbol that was read. Although, there is no a real-world analog of the TM as it is unlikely possible to have infinite memory. So, to get it more realistic, for a real analog of TM, it means two things:
All algorithms share the same properties:
This article is about binary/text converters, the most popular implementations, and a non-standard approach that uses place-based single number encoding by representing a file as a big number and then converting it to another big number with any non-256 (1 byte/8 bit) radix. To make it practical, it makes sense to limit a radix (base) to 94 for matching numbers to all possible printable symbols within the 7-bit ASCII table. It is probably a theoretical prototype and has a purely academic flavor, as the time and space complexities make it applicable only to small files (up to a few tens of kilobytes), although it allows one to choose any base with no dependencies on powers of two, e.g. 7 or 77.
The main purpose of such converters is to convert a binary file represented by 256 different symbols (radix-256, 1 byte, 2^8) into a form suitable for transmission over a channel with a limited range of supported symbols. A good example is any text-based network protocol, such as HTTP (before ver. 2) or SMTP, where all transmitted binary data must be reversibly converted to a pure text form without control symbols. As you know, ASCII codes from 0 to 31 are considered control characters, and therefore they will definitely be lost during transmission over any logical channel that doesn't allow endpoints to transmit full 8-bit bytes (binary) with codes from 0 to 255. This limits the number of allowed symbols to less than 224 (256-32), but in fact it's limited only by the first 128 standardized symbols in the ASCII table, and even more.
The standard solution today is the Base64 algorithm defined in RFC 4648 (easy reading). It also describes Base32 and Base16 as possible variants. The key point here is that they all share the same property of being powers of two. The wider the range of supported symbols (codes), the more space-efficient the result of the conversion. It will be bigger anyway, the question is how much bigger. For example, Base64 encoding gives about 33% larger output, because 3 input bytes (8 valued bits) are translated into 4 output bytes (6 valued bits, 2^6=64). So the ratio is always 4/3, i.e. the output is larger by 1/3 or 33.(3)%. Practically speaking, Base32 is very inefficient because it means translating 5 input (8 valued bits) bytes to 8 output (5 valued bits, 2^5=32) bytes and the ratio is 8/5, i.e. the output is larger by 3/5 or 60%. In this context, it is hard to consider any kind of efficiency of Base16, since its output size is larger by 100% (each byte of 8 valued bits is represented by two bytes of 4 valued bits, also known as nibbles, 2^4=16). It is not even a translation, just a representation of an 8-bit byte in hexadecimal.
If you're curious how these input/output byte ratios were calculated for the Base64/32/16 encodings, the answer is LCM (Least Common Multiple). Let's calculate it ourselves, and for that we need another function, the GCD (Greatest Common Divisor)
The point is this. What if a channel is only able to transmit a few different symbols, like 9 or 17. That is, we have a file represented by a 256-symbol alphabet (a normal 8-bit byte), we are not limited by computing power or memory constraints on either side, but we are able to send only 7 different symbols instead of 256? Base64/32/16 are no solution here. Then Base7 is the only possible output format.
Another example, what if the amount of data transmitted is a concern for a channel? Base64, as it has been shown, increases the data by 33% no matter what is transmitted, always. Base94, for example, only increases the output by 22%.
It may seem that Base94 is not the limit. If the first 32 ASCII codes are control characters, and there are 256 codes in total, what stops you from using an alphabet of 256 - 32 = 224 symbols? There is a reason. Not all of the 224 ASCII codes are printable characters or have a standard representation. In general, only 7 bits (0..127) are standardized, and the rest (128..255) is used for the variety of locales, e.g. Koi8-R, Windows-1251, etc. This means that only 128 - 32 = 96 are available in the standardized range. In addition, the ASCII code 32 is the space character, and 127 doesn't have a visible character either. So 96 - 2 gives us the 94 printable characters that have the same association with their codes on most machines.
This solution is quite simple, but this simplicity also imposes a significant computational constraint. The entire input file can be treated as a big number with a base of 256. It could easily be a really big number, requiring thousands of bits. Then all we have to do is convert that big number to another base. That's it. And Python3 makes it even easier! Normally, conversions between different bases are done via an intermediate base10. The good news is that Python3 has built-in support for big number calculations (it is built into int). The int class has a method that reads any number of bytes and automatically represents them as a large Base10 number with a desired endian. So essentially all of this complexity can be implemented in just two lines of code, which is pretty amazing!
with open('inpit_file', 'rb') as f:
+ Convert binary data to a text with the lowest overhead :: Vorakl's notes Convert binary data to a text with the lowest overhead
A binary-to-text encoding with any radix from 2 to 94
This article is about binary/text converters, the most popular implementations, and a non-standard approach that uses place-based single number encoding by representing a file as a big number and then converting it to another big number with any non-256 (1 byte/8 bit) radix. To make it practical, it makes sense to limit a radix (base) to 94 for matching numbers to all possible printable symbols within the 7-bit ASCII table. It is probably a theoretical prototype and has a purely academic flavor, as the time and space complexities make it applicable only to small files (up to a few tens of kilobytes), although it allows one to choose any base with no dependencies on powers of two, e.g. 7 or 77.
Background
The main purpose of such converters is to convert a binary file represented by 256 different symbols (radix-256, 1 byte, 2^8) into a form suitable for transmission over a channel with a limited range of supported symbols. A good example is any text-based network protocol, such as HTTP (before ver. 2) or SMTP, where all transmitted binary data must be reversibly converted to a pure text form without control symbols. As you know, ASCII codes from 0 to 31 are considered control characters, and therefore they will definitely be lost during transmission over any logical channel that doesn't allow endpoints to transmit full 8-bit bytes (binary) with codes from 0 to 255. This limits the number of allowed symbols to less than 224 (256-32), but in fact it's limited only by the first 128 standardized symbols in the ASCII table, and even more.
The standard solution today is the Base64 algorithm defined in RFC 4648 (easy reading). It also describes Base32 and Base16 as possible variants. The key point here is that they all share the same property of being powers of two. The wider the range of supported symbols (codes), the more space-efficient the result of the conversion. It will be bigger anyway, the question is how much bigger. For example, Base64 encoding gives about 33% larger output, because 3 input bytes (8 valued bits) are translated into 4 output bytes (6 valued bits, 2^6=64). So the ratio is always 4/3, i.e. the output is larger by 1/3 or 33.(3)%. Practically speaking, Base32 is very inefficient because it means translating 5 input (8 valued bits) bytes to 8 output (5 valued bits, 2^5=32) bytes and the ratio is 8/5, i.e. the output is larger by 3/5 or 60%. In this context, it is hard to consider any kind of efficiency of Base16, since its output size is larger by 100% (each byte of 8 valued bits is represented by two bytes of 4 valued bits, also known as nibbles, 2^4=16). It is not even a translation, just a representation of an 8-bit byte in hexadecimal.
If you're curious how these input/output byte ratios were calculated for the Base64/32/16 encodings, the answer is LCM (Least Common Multiple). Let's calculate it ourselves, and for that we need another function, the GCD (Greatest Common Divisor)
- Base64 (Input: 8 bits, Output: 6 bits):
- LCM(8, 6) = 8*6/GCD(8,6) = 24 bit
- Input: 24 / 8 = 3 bytes
- Output: 24 / 6 = 4 bytes
- Ratio (Output/Input): 4/3
- Base32 (Input: 8 bits, Output: 5 bits):
- LCM(8, 5) = 8*5/GCD(8,5) = 40 bit
- Input: 40 / 8 = 5 bytes
- Output: 40 / 5 = 8 bytes
- Ratio (Output/Input): 8/5
- Base16 (Input: 8 bits, Output: 4 bits):
- LCM(8, 4) = 8*4/GCD(8,4) = 8 bit
- Input: 8 / 8 = 1 byte
- Output: 8 / 4 = 2 bytes
- Ratio (Output/Input): 2/1
What's the point?
The point is this. What if a channel is only able to transmit a few different symbols, like 9 or 17. That is, we have a file represented by a 256-symbol alphabet (a normal 8-bit byte), we are not limited by computing power or memory constraints on either side, but we are able to send only 7 different symbols instead of 256? Base64/32/16 are no solution here. Then Base7 is the only possible output format.
Another example, what if the amount of data transmitted is a concern for a channel? Base64, as it has been shown, increases the data by 33% no matter what is transmitted, always. Base94, for example, only increases the output by 22%.
It may seem that Base94 is not the limit. If the first 32 ASCII codes are control characters, and there are 256 codes in total, what stops you from using an alphabet of 256 - 32 = 224 symbols? There is a reason. Not all of the 224 ASCII codes are printable characters or have a standard representation. In general, only 7 bits (0..127) are standardized, and the rest (128..255) is used for the variety of locales, e.g. Koi8-R, Windows-1251, etc. This means that only 128 - 32 = 96 are available in the standardized range. In addition, the ASCII code 32 is the space character, and 127 doesn't have a visible character either. So 96 - 2 gives us the 94 printable characters that have the same association with their codes on most machines.
Solution
This solution is quite simple, but this simplicity also imposes a significant computational constraint. The entire input file can be treated as a big number with a base of 256. It could easily be a really big number, requiring thousands of bits. Then all we have to do is convert that big number to another base. That's it. And Python3 makes it even easier! Normally, conversions between different bases are done via an intermediate base10. The good news is that Python3 has built-in support for big number calculations (it is built into int). The int class has a method that reads any number of bytes and automatically represents them as a large Base10 number with a desired endian. So essentially all of this complexity can be implemented in just two lines of code, which is pretty amazing!
with open('inpit_file', 'rb') as f:
in_data = int.from_bytes(f.read(), 'big')
where in_data is our large Base10 number. This is only two lines, but this is where most of the math happens and most of the time is spent. So now convert it to any other base, as you'd normally do with normal small decimal numbers.
This is my personal blog. All ideas, opinions, examples, and other information that can be found here are my own and belong entirely to me. This is the result of my personal efforts and activities at my free time. It doesn't relate to any professional work I've done and doesn't have correlations with any companies I worked for, I'm currently working, or will work in the future.
\ No newline at end of file
diff --git a/articles/canonical/index.html b/articles/canonical/index.html
index 20c0ca2d..5be3fc53 100644
--- a/articles/canonical/index.html
+++ b/articles/canonical/index.html
@@ -1,4 +1,4 @@
- How to redirect a static website on the Github Pages :: Vorakl's notes How to redirect a static website on the Github Pages
The use case for a Temporary Redirect and the Canonical Link Element
I run a few static websites for my private projects on the Github Pages. I'm absolutely happy with the service, as it supports custom domains, automatically redirects to HTTPS, and transparently installs SSL certificates (with automatic issuing via Let's Encrypt). It is very fast (thanks to Fastly's content delivery network) and is extremely reliable (I haven't had any issues for years). Taking into account the fact that I get all of this for free, it perfectly matches my needs at the moment. It has, however, one important limitation: because it serves static websites only, this means no query parameters, no dynamic content generated on the server side, no options for injecting any server-side configuration (e.g., .htaccess), and the only things I can push to the website's root directory are static assets (e.g., HTML, CSS, JS, JPEG, etc.). In general, this is not a big issue. There are a lot of the open source static site generators available, such as Jekyll, which is available by default the dashboard, and Pelican, which I prefer in most cases. Nevertheless, when you need to implement something that is traditionally solved on the server side, a whole new level of challenge begins.
For example, I recently had to change a custom domain name for one of my websites. Keeping the old one was ridiculously expensive, and I wasn't willing to continue wasting money. I found a cheaper alternative and immediately faced a bigger problem: all the search engines have the old name in their indexes. Updating indexes takes time, and until that happens, I would have to redirect all requests to the new location. Ideally, I would redirect each indexed resource to the equivalent on the new site, but at minimum, I needed to redirect requests to the new start page. I had access to the old domain name for enough time, and therefore, I could run the site separately on both domain names at the same time.
There is one proper solution to this situation that should be used whenever possible: Permanent redirect, or the 301 Moved Permanently status code, is the way to redirect pages implemented in the HTTP protocol. The only issue is that it's supposed to happen on the server side within a server response's HTTP header. But the only solution I could implement resides on a client side; that is, either HTML code or JavaScript. I didn't consider the JS variant because I didn't want to rely on the script's support in web browsers. Once I defined the task, I recalled a solution: the HTML <meta> tag <meta http-equiv> with the 'refresh' HTTP header. Although it can be used to ask browsers to reload a page or jump to another URL after a specified number of seconds, after some research, I learned it is more complicated than I thought with some interesting facts and details.
The solution
TL;DR (for anyone who isn't interested in all the details): In brief, this solution configures two repositories to serve as static websites with custom domain names. On the site with the old domain, I reconstructed the website's entire directory structure and put the following index.html in each of them (including the root):
<!DOCTYPE HTML>
+ How to redirect a static website on the Github Pages :: Vorakl's notes How to redirect a static website on the Github Pages
The use case for a Temporary Redirect and the Canonical Link Element
I run a few static websites for my private projects on the Github Pages. I'm absolutely happy with the service, as it supports custom domains, automatically redirects to HTTPS, and transparently installs SSL certificates (with automatic issuing via Let's Encrypt). It is very fast (thanks to Fastly's content delivery network) and is extremely reliable (I haven't had any issues for years). Taking into account the fact that I get all of this for free, it perfectly matches my needs at the moment. It has, however, one important limitation: because it serves static websites only, this means no query parameters, no dynamic content generated on the server side, no options for injecting any server-side configuration (e.g., .htaccess), and the only things I can push to the website's root directory are static assets (e.g., HTML, CSS, JS, JPEG, etc.). In general, this is not a big issue. There are a lot of the open source static site generators available, such as Jekyll, which is available by default the dashboard, and Pelican, which I prefer in most cases. Nevertheless, when you need to implement something that is traditionally solved on the server side, a whole new level of challenge begins.
For example, I recently had to change a custom domain name for one of my websites. Keeping the old one was ridiculously expensive, and I wasn't willing to continue wasting money. I found a cheaper alternative and immediately faced a bigger problem: all the search engines have the old name in their indexes. Updating indexes takes time, and until that happens, I would have to redirect all requests to the new location. Ideally, I would redirect each indexed resource to the equivalent on the new site, but at minimum, I needed to redirect requests to the new start page. I had access to the old domain name for enough time, and therefore, I could run the site separately on both domain names at the same time.
There is one proper solution to this situation that should be used whenever possible: Permanent redirect, or the 301 Moved Permanently status code, is the way to redirect pages implemented in the HTTP protocol. The only issue is that it's supposed to happen on the server side within a server response's HTTP header. But the only solution I could implement resides on a client side; that is, either HTML code or JavaScript. I didn't consider the JS variant because I didn't want to rely on the script's support in web browsers. Once I defined the task, I recalled a solution: the HTML <meta> tag <meta http-equiv> with the 'refresh' HTTP header. Although it can be used to ask browsers to reload a page or jump to another URL after a specified number of seconds, after some research, I learned it is more complicated than I thought with some interesting facts and details.
The solution
TL;DR (for anyone who isn't interested in all the details): In brief, this solution configures two repositories to serve as static websites with custom domain names. On the site with the old domain, I reconstructed the website's entire directory structure and put the following index.html in each of them (including the root):
<!DOCTYPE HTML>
<html lang="en">
<head>
<meta charset="utf-8">
diff --git a/articles/char-converter/index.html b/articles/char-converter/index.html
index 650b7c7f..0ec22c0b 100644
--- a/articles/char-converter/index.html
+++ b/articles/char-converter/index.html
@@ -1,4 +1,4 @@
- A converter of a character's case and Ascii codes :: Vorakl's notes A converter of a character's case and Ascii codes
An example of using the Constraint Programming for calculating multiple but linked results
The constraint programming paradigm is effectively applied for solving a group of problems which can be translated to variables and constraints or represented as a mathematic equation, and so related to the CSP. Using declarative programming style it describes a general model with certain properties. In contrast to the imperative style, it doesn't tell how to achieve something, but rather what to achieve. Instead of defining a set of instructions with only one obvious way for computing values, the constraint programming declares relationships between variables within constraints. A final model makes it possible to compute the values of variables regardless of direction or changes. Thus, any change of the value of one variable affects the whole system (all other variables) and to satisfy defined constraints it leads to recomputing the other values.
Let's take, for example, Pythagoras' theorem: a² + b² = c². The constraint is represented by this equation, which has three variables (a, b, and c), and each has a domain (non-negative). Using the imperative programming style, to compute any of these variables having other two, we would need to create three different functions (because each variable is computed by a different equation):
- c = √(a² + b²)
- a = √(c² - b²)
- b = √(c² - a²)
These functions satisfy the main constraint and to check domains, each function should validate the input. Moreover, at least one more function would be needed for choosing an appropriate function accordingly to provided variables. This is one of possible solutions:
def pythagoras(*, a=None, b=None, c=None):
+ A converter of a character's case and Ascii codes :: Vorakl's notes A converter of a character's case and Ascii codes
An example of using the Constraint Programming for calculating multiple but linked results
The constraint programming paradigm is effectively applied for solving a group of problems which can be translated to variables and constraints or represented as a mathematic equation, and so related to the CSP. Using declarative programming style it describes a general model with certain properties. In contrast to the imperative style, it doesn't tell how to achieve something, but rather what to achieve. Instead of defining a set of instructions with only one obvious way for computing values, the constraint programming declares relationships between variables within constraints. A final model makes it possible to compute the values of variables regardless of direction or changes. Thus, any change of the value of one variable affects the whole system (all other variables) and to satisfy defined constraints it leads to recomputing the other values.
Let's take, for example, Pythagoras' theorem: a² + b² = c². The constraint is represented by this equation, which has three variables (a, b, and c), and each has a domain (non-negative). Using the imperative programming style, to compute any of these variables having other two, we would need to create three different functions (because each variable is computed by a different equation):
- c = √(a² + b²)
- a = √(c² - b²)
- b = √(c² - a²)
These functions satisfy the main constraint and to check domains, each function should validate the input. Moreover, at least one more function would be needed for choosing an appropriate function accordingly to provided variables. This is one of possible solutions:
def pythagoras(*, a=None, b=None, c=None):
''' Computes a side of a right triangle '''
# Validate
diff --git a/articles/cs-vs-it/index.html b/articles/cs-vs-it/index.html
index 4cb88a70..02677418 100644
--- a/articles/cs-vs-it/index.html
+++ b/articles/cs-vs-it/index.html
@@ -1 +1 @@
- Computer Science vs Information Technology :: Vorakl's notes Computer Science vs Information Technology
Differences between two computer-related studies
If you ever thought about getting a computer-related (graduated) education, you probably came across a variety of similar disciplines, more or less connected to each other, but grouped under two major fields of study: Computer Science (CS) and Information Technology (IT). The latest one sometimes comes in a broader meaning - Information Communications Technology (ICT), and Computer Science, in turn, is highly linked to Electrical Engineering. But what exactly makes them all different?
Briefly, Computer Science creates computer software technologies, Electrical Engineering creates hardware to run this software in an efficient way, while Information Technology uses them later to create Information Systems for storing, processing and transmitting data.
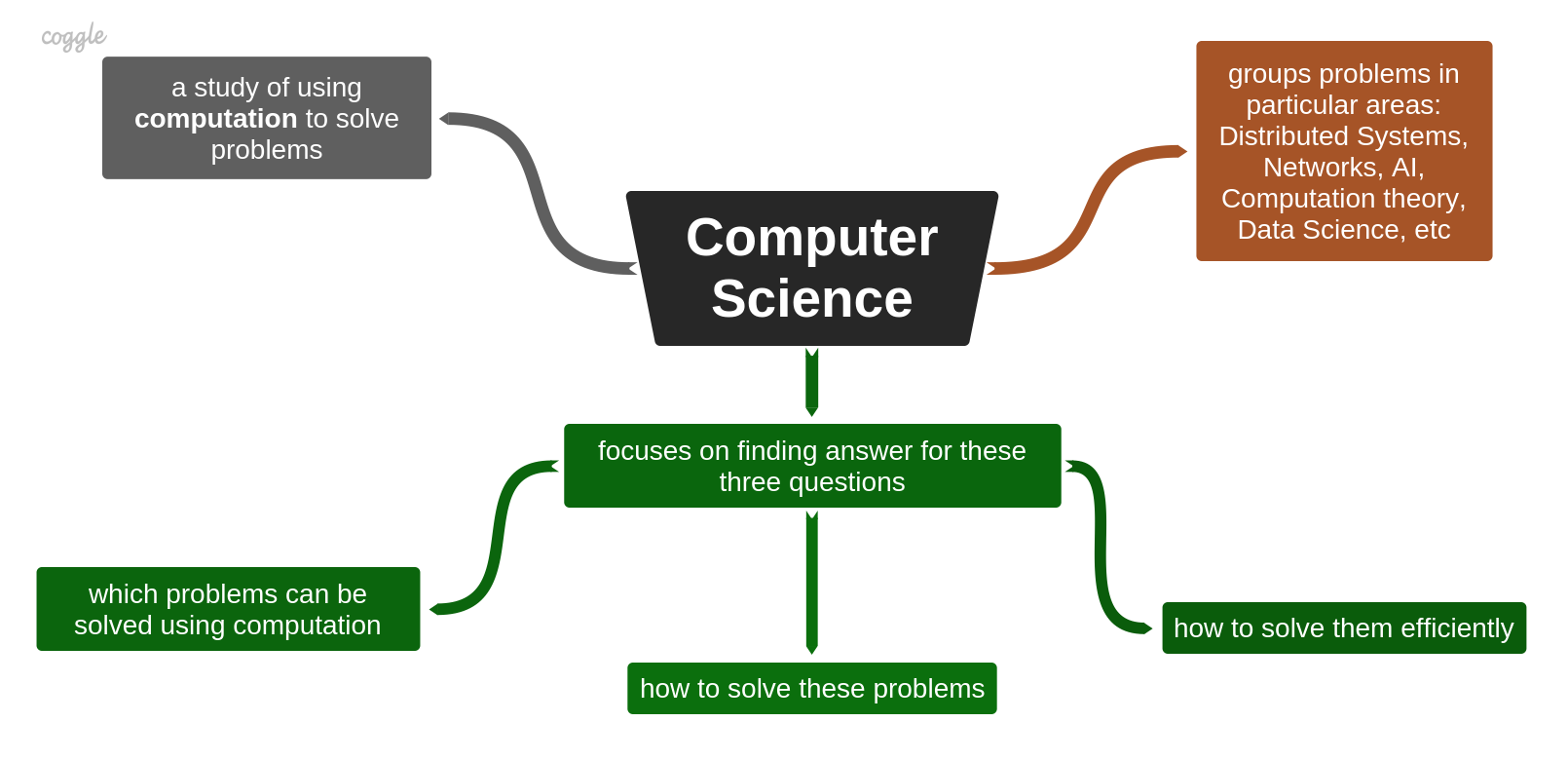
CS is a study of using computation and computer systems for solving real-world problems. Dealing mostly with software, the study includes the theory of computation and computer architecture, design, development, and application of software systems. The most common problems are organized in groups in particular areas, such as Distributed Systems, Artificial Intelligence, Data Science, Programming Languages and Compilers, Algorithms and Data Structures, etc. Summarizing, CS mainly focuses on finding answers to the following questions (by John DeNero, cs61a):
- which real-world problems can be solved using computation
- how to solve these problems
- how to solve them efficiently
The fact that CS is all about software, makes it tightly coupled to Electrical Engineering that deals with hardware and focuses on designing computer systems and electronic devices for running software in the most efficient way.
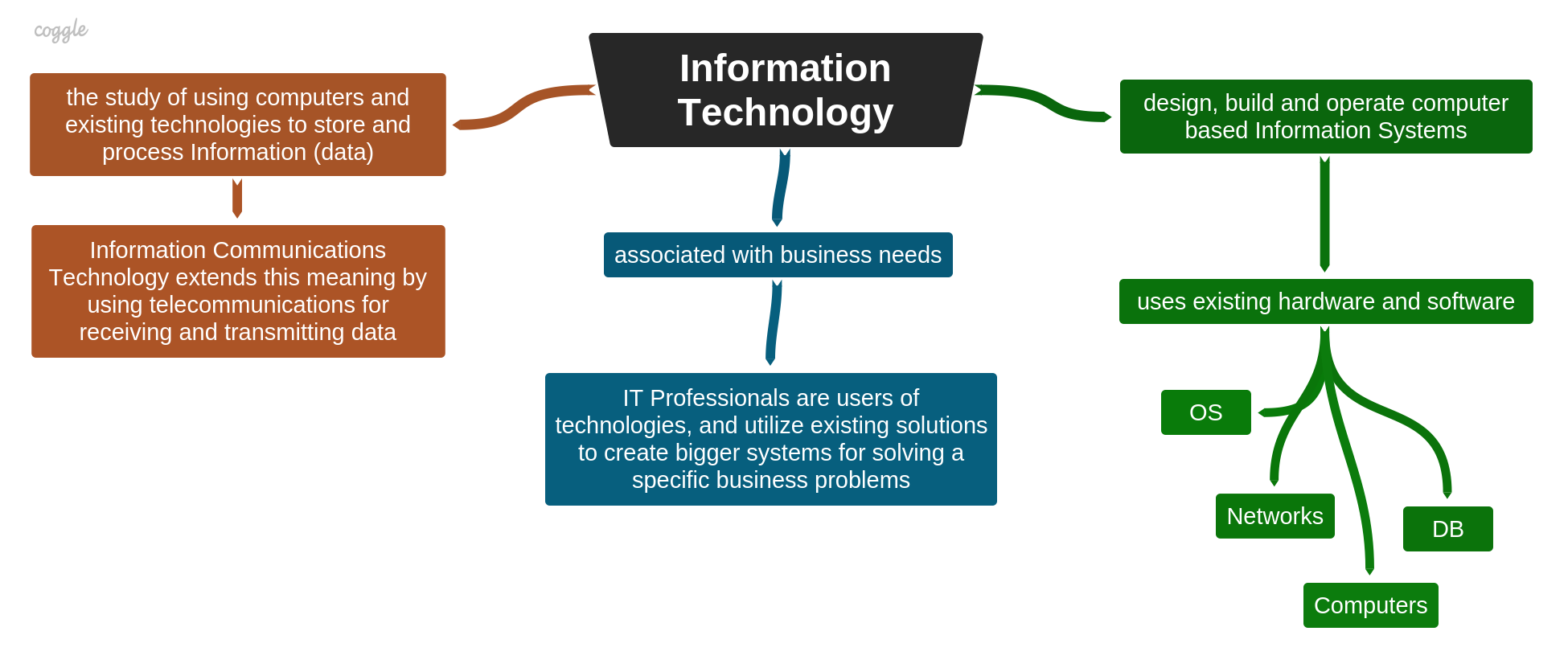
Unlike CS, IT is a study of using computers to design, build, and operate Information Systems which are used for storing and processing information (data). ICT extends it by applying telecommunications for receiving and transmitting data. It is crucial to notice, that IT apply existing technologies (e.g. hardware, operating systems, systems software, middleware applications, databases, networks) for creating Information Systems. Hence, IT professionals are users of technologies and utilize existing solutions (hardware and software) to create larger systems for solving a specific business need.
This is my personal blog. All ideas, opinions, examples, and other information that can be found here are my own and belong entirely to me. This is the result of my personal efforts and activities at my free time. It doesn't relate to any professional work I've done and doesn't have correlations with any companies I worked for, I'm currently working, or will work in the future.
\ No newline at end of file
+ Computer Science vs Information Technology :: Vorakl's notes Computer Science vs Information Technology
Differences between two computer-related studies
If you ever thought about getting a computer-related (graduated) education, you probably came across a variety of similar disciplines, more or less connected to each other, but grouped under two major fields of study: Computer Science (CS) and Information Technology (IT). The latest one sometimes comes in a broader meaning - Information Communications Technology (ICT), and Computer Science, in turn, is highly linked to Electrical Engineering. But what exactly makes them all different?
Briefly, Computer Science creates computer software technologies, Electrical Engineering creates hardware to run this software in an efficient way, while Information Technology uses them later to create Information Systems for storing, processing and transmitting data.
CS is a study of using computation and computer systems for solving real-world problems. Dealing mostly with software, the study includes the theory of computation and computer architecture, design, development, and application of software systems. The most common problems are organized in groups in particular areas, such as Distributed Systems, Artificial Intelligence, Data Science, Programming Languages and Compilers, Algorithms and Data Structures, etc. Summarizing, CS mainly focuses on finding answers to the following questions (by John DeNero, cs61a):
- which real-world problems can be solved using computation
- how to solve these problems
- how to solve them efficiently
The fact that CS is all about software, makes it tightly coupled to Electrical Engineering that deals with hardware and focuses on designing computer systems and electronic devices for running software in the most efficient way.
Unlike CS, IT is a study of using computers to design, build, and operate Information Systems which are used for storing and processing information (data). ICT extends it by applying telecommunications for receiving and transmitting data. It is crucial to notice, that IT apply existing technologies (e.g. hardware, operating systems, systems software, middleware applications, databases, networks) for creating Information Systems. Hence, IT professionals are users of technologies and utilize existing solutions (hardware and software) to create larger systems for solving a specific business need.
This is my personal blog. All ideas, opinions, examples, and other information that can be found here are my own and belong entirely to me. This is the result of my personal efforts and activities at my free time. It doesn't relate to any professional work I've done and doesn't have correlations with any companies I worked for, I'm currently working, or will work in the future.
\ No newline at end of file
diff --git a/articles/csp/index.html b/articles/csp/index.html
index 8ea4c1a4..06000625 100644
--- a/articles/csp/index.html
+++ b/articles/csp/index.html
@@ -1 +1 @@
- Constraint Satisfaction Problem (CSP) :: Vorakl's notes Constraint Satisfaction Problem (CSP)
A mathematical question that is defined by variables, domains, and constraints
Constraint Satisfaction Problem (CSP) is a class of problems that can be used to represent a large set of real-world problems. In particular, it is widely used in Artificial Intelligent (AI) as finding a solution for a formulated CSP may be used in decision making. There are a few adjacent areas in terms that for solving problems they all involve constraints: SAT (Boolean satisfiability problem), and the SMT (satisfiability modulo theories).
Generally speaking, the complexity of finding a solution for CSP is NP-Complete (takes exponential time), because a solution can be guessed and verified relatively fast (in polynomial time), and the SAT problem (NP-Hard) can be translated into a CSP problem. But, it also means, there is no known polynomial-time solution. Thus, the development of efficient algorithms and techniques for solving CSPs is crucial and appears as a subject in many scientific pieces of research.
The simplest kind of CSPs are defined by a set of discrete variables (e.g. X, Y), finite non-empty domains (e.g. 0<X<=4, Y<10), and a set of constraints (e.g. Y=X^2, X<>3) which involve some of the variables. There are distinguished two related terms: the Possible World (or the Complete Assignment) of a CSP is an assignment of values to all variables and the Model (or the Solution to a CSP) is a possible world that satisfies all the constraints.
Within the topic, there is a programming paradigm - Constraint Programming. It allows building a Constraint Based System where relations between variables are stated in a form of constraints. Hence, this defines certain specifics:
- the paradigm doesn't specify a sequence of steps to execute for finding a solution, but rather declares the solution's properties and desired result. This makes the paradigm a sort of Declarative Programming
- it's usually characterized by non-directional computation when to satisfy constraints, computations are propagated throughout a system accordingly to changed conditions or variables' values.
The example of using this paradigm can be seen in another my article "A converter of a character's case and Ascii codes".
A CSP can be effectively applied in a number of areas like mappings, assignments, planning and scheduling, games (e.g. sudoku), solving system of equations, etc. There are also a number of software frameworks which provide CSP solvers, like python-constraint and Google OR-Tools, just to name a few.
This is my personal blog. All ideas, opinions, examples, and other information that can be found here are my own and belong entirely to me. This is the result of my personal efforts and activities at my free time. It doesn't relate to any professional work I've done and doesn't have correlations with any companies I worked for, I'm currently working, or will work in the future.
\ No newline at end of file
+ Constraint Satisfaction Problem (CSP) :: Vorakl's notes Constraint Satisfaction Problem (CSP)
A mathematical question that is defined by variables, domains, and constraints
Constraint Satisfaction Problem (CSP) is a class of problems that can be used to represent a large set of real-world problems. In particular, it is widely used in Artificial Intelligent (AI) as finding a solution for a formulated CSP may be used in decision making. There are a few adjacent areas in terms that for solving problems they all involve constraints: SAT (Boolean satisfiability problem), and the SMT (satisfiability modulo theories).
Generally speaking, the complexity of finding a solution for CSP is NP-Complete (takes exponential time), because a solution can be guessed and verified relatively fast (in polynomial time), and the SAT problem (NP-Hard) can be translated into a CSP problem. But, it also means, there is no known polynomial-time solution. Thus, the development of efficient algorithms and techniques for solving CSPs is crucial and appears as a subject in many scientific pieces of research.
The simplest kind of CSPs are defined by a set of discrete variables (e.g. X, Y), finite non-empty domains (e.g. 0<X<=4, Y<10), and a set of constraints (e.g. Y=X^2, X<>3) which involve some of the variables. There are distinguished two related terms: the Possible World (or the Complete Assignment) of a CSP is an assignment of values to all variables and the Model (or the Solution to a CSP) is a possible world that satisfies all the constraints.
Within the topic, there is a programming paradigm - Constraint Programming. It allows building a Constraint Based System where relations between variables are stated in a form of constraints. Hence, this defines certain specifics:
- the paradigm doesn't specify a sequence of steps to execute for finding a solution, but rather declares the solution's properties and desired result. This makes the paradigm a sort of Declarative Programming
- it's usually characterized by non-directional computation when to satisfy constraints, computations are propagated throughout a system accordingly to changed conditions or variables' values.
The example of using this paradigm can be seen in another my article "A converter of a character's case and Ascii codes".
A CSP can be effectively applied in a number of areas like mappings, assignments, planning and scheduling, games (e.g. sudoku), solving system of equations, etc. There are also a number of software frameworks which provide CSP solvers, like python-constraint and Google OR-Tools, just to name a few.
This is my personal blog. All ideas, opinions, examples, and other information that can be found here are my own and belong entirely to me. This is the result of my personal efforts and activities at my free time. It doesn't relate to any professional work I've done and doesn't have correlations with any companies I worked for, I'm currently working, or will work in the future.
\ No newline at end of file
diff --git a/articles/data-structure/index.html b/articles/data-structure/index.html
index 4929b593..a74bd608 100644
--- a/articles/data-structure/index.html
+++ b/articles/data-structure/index.html
@@ -1 +1 @@
- Organizing Unstructured Data :: Vorakl's notes Organizing Unstructured Data
Managing data complexity using types, structures, ADTs, and objects
Topics
The main, if not the only, purpose of a computer is to compute information. It doesn't always have to be a computation of mathematical formulas. In general, it is a transformation of one piece of information into another. Computers only work with information that can be represented as discrete data. The input and output of a computer engine are always natural numbers or text (a sequence of symbols from a dictionary that correspond to certain natural numbers).

As long as data is unstructured, it's hard to make some sense of it. But once data is given a structured form, it becomes meaningful and suitable for further transformation.
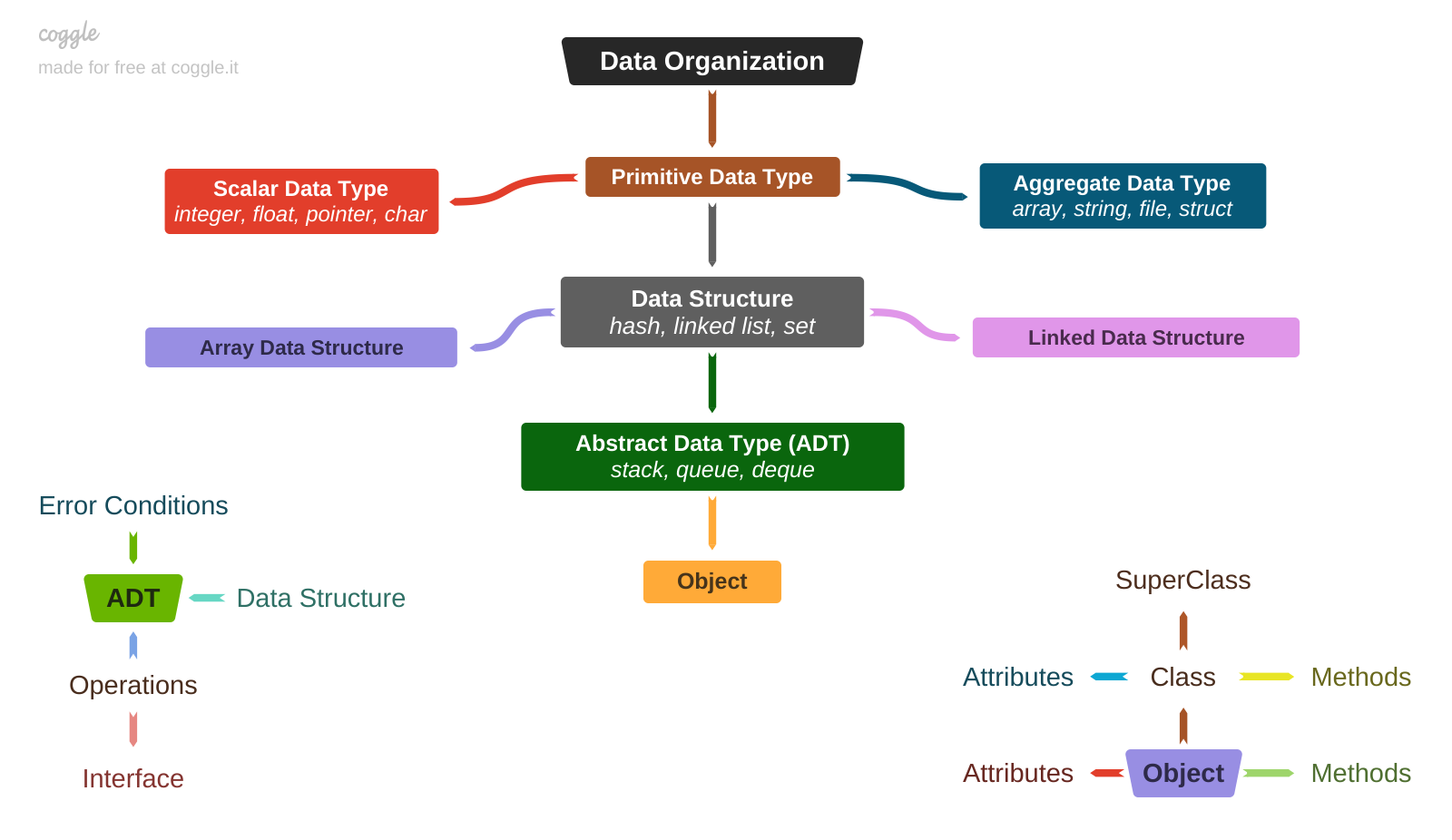
Type
The simplest form of data organization is Type. In general, a data type defines a set of values with certain properties. It usually defines a size in bytes. A primitive data type is an ordered set of bytes. When a variable of a primitive data type has only one value (holds only one piece of information), it's called a scalar and a type - scalar data type. Well-known examples are integer, float, pointer, and char. A collection of primitive (scalar) data types is called an aggregate data type, and it allows multiple values to be stored. This can be a homogeneous collection, where all elements are of the same type, such as an array, a string, or a file. Or it can be heterogeneous, where elements are of different types, such as a structure or a class. The main property is an ordered set of bytes. The internal organization is simple, straightforward, and all actions (e.g. reading or modifying) are performed directly on the data, according to a hardware architecture that defines the byte order in memory (little-/big-endian).
Data Structure
The next level of data abstraction is called Data Structure. It brings more complexity, but also more flexibility to make the right choice between access speed, ability to grow, modification speed, etc. Internally, it's represented by a collection of the scalar or aggregate data types. The main focus is on the details of the internal organization and a set of rules to control that organization. There are two types of data structures that result from a difference in the memory allocation of the underlying elements:
- Array Data Structures (static), based on physically contiguous elements in memory, with no gaps between them;
- Linked Data Structures (dynamic), based on elements, dynamically allocated in memory and linked in a linear structure using pointers (usually, one or two)
Well-known examples are linked list, hash (dictionary), set, list. These data structures are defined only by their physical organization in memory and a set of rules for data modifications that are performed directly. All internal implementation details are open. The actions performed on the data structures (add, remove, update, etc.) and the ways in which they are used can vary.
Abstract Data Type (ADT)
A higher level of data abstraction is represented by an Abstract Data Type (ADT), which shifts the focus from "how to store data" to "how to work with data". An ADT represents a logical organization, defined mainly by a list of predefined operations (functions) for manipulating data and controlling its consistency. Internally, data can be stored in any data structure or combination thereof. However, these internals are hidden and should not be directly accessible. All interactions with data are done through an interface (operations exposed to users). Most of ADTs share a common set of primitive operations, such as
- create - a constructor of a new instance
- destroy - a destructor of an existing instance
- add, get - the set-get functions for adding and removing elements of an instance
- is_empty, size - useful functions for managing existing data in an instance
The most common examples of ADTs are stack and queue. Both of these ADTs can be implemented using either array or linked data structures, and both have specific rules for adding and removing elements. All of these specifics are abstracted as functions, which in turn, perform appropriate actions on internal data. Dividing an ADT into operations and data structures creates an abstraction barrier that allows you to maintain a solid interface with the flexibility to change internals without side effects on the code using that ADT.
Object
A more comprehensive way of abstracting data is represented by Objects. An object can be thought of as a container for a piece of data that has certain properties. Similar to the ADT, this data is not directly accessible (known as encapsulation or isolation), but instead each object has a set of tightly bound methods that can be applied to operate on its data to produce an expected behavior for that object (known as polymorphism). All such methods are really just functions collected under a class. However, they become methods when called to operate on a particular object. Methods can also be inherited from another class, which is called a superclass. Unlike an ADT, an object doesn't represent a particular type of data, but rather a set of attributes, and it behaves as it should when its methods are invoked. Attributes are nothing more than variables of any type (including ADTs). Formally speaking, classes act as specifications of all of the object's attributes and the methods that can be invoked to deal with those attributes.
The Object-Oriented Programming (OOP) paradigm uses objects as the central elements of a program design. At program runtime, each object exists as an instance of a class. The class, in turn, plays a dual role: it defines the behavior (through a set of methods) of all objects instantiated from it, and it declares a prototype of data that will carry some state within the object once it's instantiated. As long as the state is isolated (incapsulated) in the objects, access to that state is organized by communication between the objects via message passing. It's usually implemented by calling a method of an object, which is equivalent to "passing" a message to that object.
This behavior is completely different from the Structured Programming Paradigm, which instead of maintaining a collection of interacting objects with an an embedded state, relies on dividing of a project's code into a sequence of mostly independent tasks (functions) that operate with an externally (to them) stored state.
This is my personal blog. All ideas, opinions, examples, and other information that can be found here are my own and belong entirely to me. This is the result of my personal efforts and activities at my free time. It doesn't relate to any professional work I've done and doesn't have correlations with any companies I worked for, I'm currently working, or will work in the future.
\ No newline at end of file
+ Organizing Unstructured Data :: Vorakl's notes Organizing Unstructured Data
Managing data complexity using types, structures, ADTs, and objects
Topics
The main, if not the only, purpose of a computer is to compute information. It doesn't always have to be a computation of mathematical formulas. In general, it is a transformation of one piece of information into another. Computers only work with information that can be represented as discrete data. The input and output of a computer engine are always natural numbers or text (a sequence of symbols from a dictionary that correspond to certain natural numbers).
As long as data is unstructured, it's hard to make some sense of it. But once data is given a structured form, it becomes meaningful and suitable for further transformation.
Type
The simplest form of data organization is Type. In general, a data type defines a set of values with certain properties. It usually defines a size in bytes. A primitive data type is an ordered set of bytes. When a variable of a primitive data type has only one value (holds only one piece of information), it's called a scalar and a type - scalar data type. Well-known examples are integer, float, pointer, and char. A collection of primitive (scalar) data types is called an aggregate data type, and it allows multiple values to be stored. This can be a homogeneous collection, where all elements are of the same type, such as an array, a string, or a file. Or it can be heterogeneous, where elements are of different types, such as a structure or a class. The main property is an ordered set of bytes. The internal organization is simple, straightforward, and all actions (e.g. reading or modifying) are performed directly on the data, according to a hardware architecture that defines the byte order in memory (little-/big-endian).
Data Structure
The next level of data abstraction is called Data Structure. It brings more complexity, but also more flexibility to make the right choice between access speed, ability to grow, modification speed, etc. Internally, it's represented by a collection of the scalar or aggregate data types. The main focus is on the details of the internal organization and a set of rules to control that organization. There are two types of data structures that result from a difference in the memory allocation of the underlying elements:
- Array Data Structures (static), based on physically contiguous elements in memory, with no gaps between them;
- Linked Data Structures (dynamic), based on elements, dynamically allocated in memory and linked in a linear structure using pointers (usually, one or two)
Well-known examples are linked list, hash (dictionary), set, list. These data structures are defined only by their physical organization in memory and a set of rules for data modifications that are performed directly. All internal implementation details are open. The actions performed on the data structures (add, remove, update, etc.) and the ways in which they are used can vary.
Abstract Data Type (ADT)
A higher level of data abstraction is represented by an Abstract Data Type (ADT), which shifts the focus from "how to store data" to "how to work with data". An ADT represents a logical organization, defined mainly by a list of predefined operations (functions) for manipulating data and controlling its consistency. Internally, data can be stored in any data structure or combination thereof. However, these internals are hidden and should not be directly accessible. All interactions with data are done through an interface (operations exposed to users). Most of ADTs share a common set of primitive operations, such as
- create - a constructor of a new instance
- destroy - a destructor of an existing instance
- add, get - the set-get functions for adding and removing elements of an instance
- is_empty, size - useful functions for managing existing data in an instance
The most common examples of ADTs are stack and queue. Both of these ADTs can be implemented using either array or linked data structures, and both have specific rules for adding and removing elements. All of these specifics are abstracted as functions, which in turn, perform appropriate actions on internal data. Dividing an ADT into operations and data structures creates an abstraction barrier that allows you to maintain a solid interface with the flexibility to change internals without side effects on the code using that ADT.
Object
A more comprehensive way of abstracting data is represented by Objects. An object can be thought of as a container for a piece of data that has certain properties. Similar to the ADT, this data is not directly accessible (known as encapsulation or isolation), but instead each object has a set of tightly bound methods that can be applied to operate on its data to produce an expected behavior for that object (known as polymorphism). All such methods are really just functions collected under a class. However, they become methods when called to operate on a particular object. Methods can also be inherited from another class, which is called a superclass. Unlike an ADT, an object doesn't represent a particular type of data, but rather a set of attributes, and it behaves as it should when its methods are invoked. Attributes are nothing more than variables of any type (including ADTs). Formally speaking, classes act as specifications of all of the object's attributes and the methods that can be invoked to deal with those attributes.
The Object-Oriented Programming (OOP) paradigm uses objects as the central elements of a program design. At program runtime, each object exists as an instance of a class. The class, in turn, plays a dual role: it defines the behavior (through a set of methods) of all objects instantiated from it, and it declares a prototype of data that will carry some state within the object once it's instantiated. As long as the state is isolated (incapsulated) in the objects, access to that state is organized by communication between the objects via message passing. It's usually implemented by calling a method of an object, which is equivalent to "passing" a message to that object.
This behavior is completely different from the Structured Programming Paradigm, which instead of maintaining a collection of interacting objects with an an embedded state, relies on dividing of a project's code into a sequence of mostly independent tasks (functions) that operate with an externally (to them) stored state.
This is my personal blog. All ideas, opinions, examples, and other information that can be found here are my own and belong entirely to me. This is the result of my personal efforts and activities at my free time. It doesn't relate to any professional work I've done and doesn't have correlations with any companies I worked for, I'm currently working, or will work in the future.
\ No newline at end of file
diff --git a/articles/dreyfus/index.html b/articles/dreyfus/index.html
index 066b4e9f..b07769a6 100644
--- a/articles/dreyfus/index.html
+++ b/articles/dreyfus/index.html
@@ -1 +1 @@
- Dreyfus model of skill acquisition :: Vorakl's notes Dreyfus model of skill acquisition
The power of the human mind over the reasoning machines
There is a special term to describe the intelligence of computers that actually mimics human intelligence only to a certain extent. It is called Artificial Intelligence (AI) to emphasize its synthetic nature. Going back to 1980, the U.S. military had been supporting AI research for more than 20 years, and it was time to ask why almost all efforts to build AI systems capable of "providing expert medical advice, exhibiting common sense, and functioning autonomously in critical military situations" had failed.
In February 1980, the Dreyfus brothers (Stuart E. and Hubert L.) presented their report on the research conducted at the University of California, Berkeley with the support of the US Air Force Office of Scientific Research - "A Five-Stage Model of the Mental Activities Involved in Directed Skill Acquisition". This model shows how humans acquire new skills through instruction and experience. After the publication, they continued to work on the model and with some modifications and extensions, the results were published in their book "Mind over Machine. The Power of Human Intuition and Expertise in the Era of the Computer" in 1986. As the brothers said in the book, "our intention is more modest, but more fundamental": "what we can reasonably expect from computer intelligence".
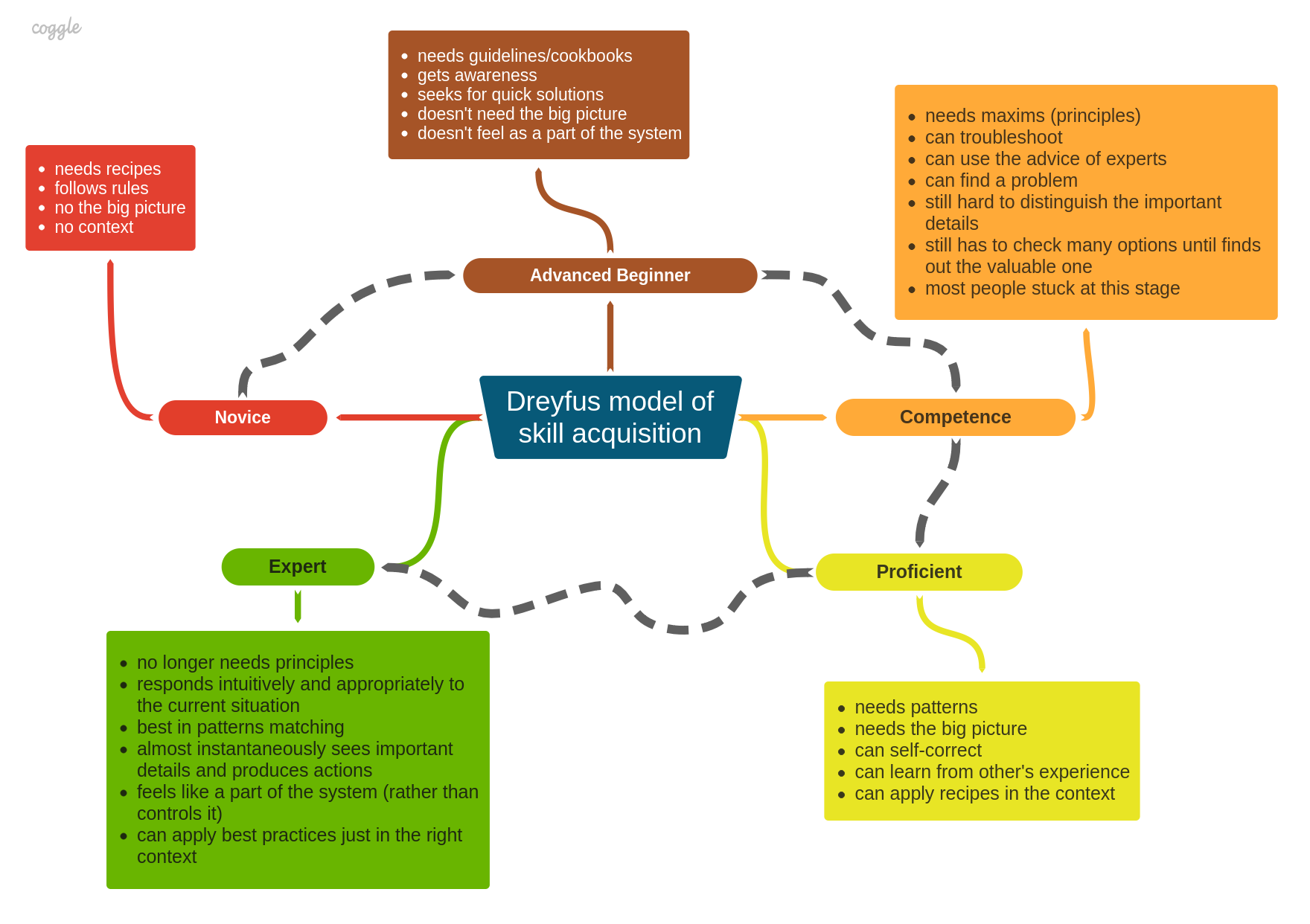
A process of skill acquisition typically goes through five developmental stages (novice, advanced beginner, competent, proficient, expert). Each stage characterizes a particular behavior and mental response to a situation. A successful transition from one stage to another is associated with the appropriate transformation of four mental functions: recall, recognition, decision, awareness. Understanding the stages of development is essential for any skill training procedure to facilitate the process of acquiring new skills and advancing to the next stage. For human beings, the entire journey from novice to expert usually takes an average of 10 years. Or, more realistically, 10,000 hours of learning and practice. Some research has also shown that there are only up to 5% of experts on the planet, regardless of their field of expertise.
The report also pointed out that "as the student becomes more skilled, he depends less on abstract principles and more on concrete experience" and that only "skill in its minimal form is produced by following abstract formal rules". Thus, the higher levels of performance depend on "everyday, concrete, experience in problem solving". By gaining experience, a student is able to start from scratch by following rules of action in context-free situations. Then, after gaining some experience, a student is able to use guidelines for responding to situational aspects. Further practice leads to being able to use maxims (principles) to determine an appropriate action. All of these three transformations correspond to the first three stages and always represent some kind of analytical decision-making process that is needed to "connect his understanding of the general situation with a specific action".
The significant change occurs at Stage 4, when the number of "experienced situations is so vast that normally each specific situation immediately dictates an intuitively appropriate action". The key point here is the shift "from analytical thinking to intuitive response". The highest level of expertise with masterful performance occurs only when the expert "no longer needs principles" and is able to "move almost instantaneously into the production of the appropriate perspective and its associated action". This is one of the most important observations: experts perform beyond the rules, and their performance degrades significantly when they are constrained by any kind of formal rules or processes. In 2008 the Pragmatic Bookshelf published an excellent book "Pragmatic Thinking and Learning" by Andy Hunt. It gives a lot of insight into the human brain and how it works, a number of tips on how to learn more and faster, including a detailed review of the Dreyfus model (ch.2). I also created mind maps for the entire book.
Understanding the difference between the human mind and how a reasoning machine "thinks" helps to set realistic expectations for the development of artificial intelligence systems. In trying to define what computers should do, it is first necessary to be clear about what computers can do. In this regard, the computer is an analytical engine, so it can apply rules and make logical inferences. Of course, it does this with extreme speed, high accuracy, and remarkable reproducibility, but it still follows a certain logic. It turns out that precisely this crucial difference between a reasoning machine, which is perhaps perpetually limited, and the intuitive expertise of the human mind, which cannot be reduced to rules, seems to be a good starting point for finding the balance between humans and computers.
This is my personal blog. All ideas, opinions, examples, and other information that can be found here are my own and belong entirely to me. This is the result of my personal efforts and activities at my free time. It doesn't relate to any professional work I've done and doesn't have correlations with any companies I worked for, I'm currently working, or will work in the future.
\ No newline at end of file
+ Dreyfus model of skill acquisition :: Vorakl's notes Dreyfus model of skill acquisition
The power of the human mind over the reasoning machines
There is a special term to describe the intelligence of computers that actually mimics human intelligence only to a certain extent. It is called Artificial Intelligence (AI) to emphasize its synthetic nature. Going back to 1980, the U.S. military had been supporting AI research for more than 20 years, and it was time to ask why almost all efforts to build AI systems capable of "providing expert medical advice, exhibiting common sense, and functioning autonomously in critical military situations" had failed.
In February 1980, the Dreyfus brothers (Stuart E. and Hubert L.) presented their report on the research conducted at the University of California, Berkeley with the support of the US Air Force Office of Scientific Research - "A Five-Stage Model of the Mental Activities Involved in Directed Skill Acquisition". This model shows how humans acquire new skills through instruction and experience. After the publication, they continued to work on the model and with some modifications and extensions, the results were published in their book "Mind over Machine. The Power of Human Intuition and Expertise in the Era of the Computer" in 1986. As the brothers said in the book, "our intention is more modest, but more fundamental": "what we can reasonably expect from computer intelligence".
A process of skill acquisition typically goes through five developmental stages (novice, advanced beginner, competent, proficient, expert). Each stage characterizes a particular behavior and mental response to a situation. A successful transition from one stage to another is associated with the appropriate transformation of four mental functions: recall, recognition, decision, awareness. Understanding the stages of development is essential for any skill training procedure to facilitate the process of acquiring new skills and advancing to the next stage. For human beings, the entire journey from novice to expert usually takes an average of 10 years. Or, more realistically, 10,000 hours of learning and practice. Some research has also shown that there are only up to 5% of experts on the planet, regardless of their field of expertise.
The report also pointed out that "as the student becomes more skilled, he depends less on abstract principles and more on concrete experience" and that only "skill in its minimal form is produced by following abstract formal rules". Thus, the higher levels of performance depend on "everyday, concrete, experience in problem solving". By gaining experience, a student is able to start from scratch by following rules of action in context-free situations. Then, after gaining some experience, a student is able to use guidelines for responding to situational aspects. Further practice leads to being able to use maxims (principles) to determine an appropriate action. All of these three transformations correspond to the first three stages and always represent some kind of analytical decision-making process that is needed to "connect his understanding of the general situation with a specific action".
The significant change occurs at Stage 4, when the number of "experienced situations is so vast that normally each specific situation immediately dictates an intuitively appropriate action". The key point here is the shift "from analytical thinking to intuitive response". The highest level of expertise with masterful performance occurs only when the expert "no longer needs principles" and is able to "move almost instantaneously into the production of the appropriate perspective and its associated action". This is one of the most important observations: experts perform beyond the rules, and their performance degrades significantly when they are constrained by any kind of formal rules or processes. In 2008 the Pragmatic Bookshelf published an excellent book "Pragmatic Thinking and Learning" by Andy Hunt. It gives a lot of insight into the human brain and how it works, a number of tips on how to learn more and faster, including a detailed review of the Dreyfus model (ch.2). I also created mind maps for the entire book.
Understanding the difference between the human mind and how a reasoning machine "thinks" helps to set realistic expectations for the development of artificial intelligence systems. In trying to define what computers should do, it is first necessary to be clear about what computers can do. In this regard, the computer is an analytical engine, so it can apply rules and make logical inferences. Of course, it does this with extreme speed, high accuracy, and remarkable reproducibility, but it still follows a certain logic. It turns out that precisely this crucial difference between a reasoning machine, which is perhaps perpetually limited, and the intuitive expertise of the human mind, which cannot be reduced to rules, seems to be a good starting point for finding the balance between humans and computers.
This is my personal blog. All ideas, opinions, examples, and other information that can be found here are my own and belong entirely to me. This is the result of my personal efforts and activities at my free time. It doesn't relate to any professional work I've done and doesn't have correlations with any companies I worked for, I'm currently working, or will work in the future.
\ No newline at end of file
diff --git a/articles/engineering/index.html b/articles/engineering/index.html
index 7453fadf..b8d0b02c 100644
--- a/articles/engineering/index.html
+++ b/articles/engineering/index.html
@@ -1 +1 @@
- Who is an engineer :: Vorakl's notes Who is an engineer
What's the crucial difference between engineers and scientists
With the coming of the Industrial Age (approx. 1760-1950), an agricultural society transitioned to an economy, based primarily on massive industrial production. It was the time of the rise of specialized educational centers, where people could get deep knowledge in many different fields of science and became either scientists or engineers.
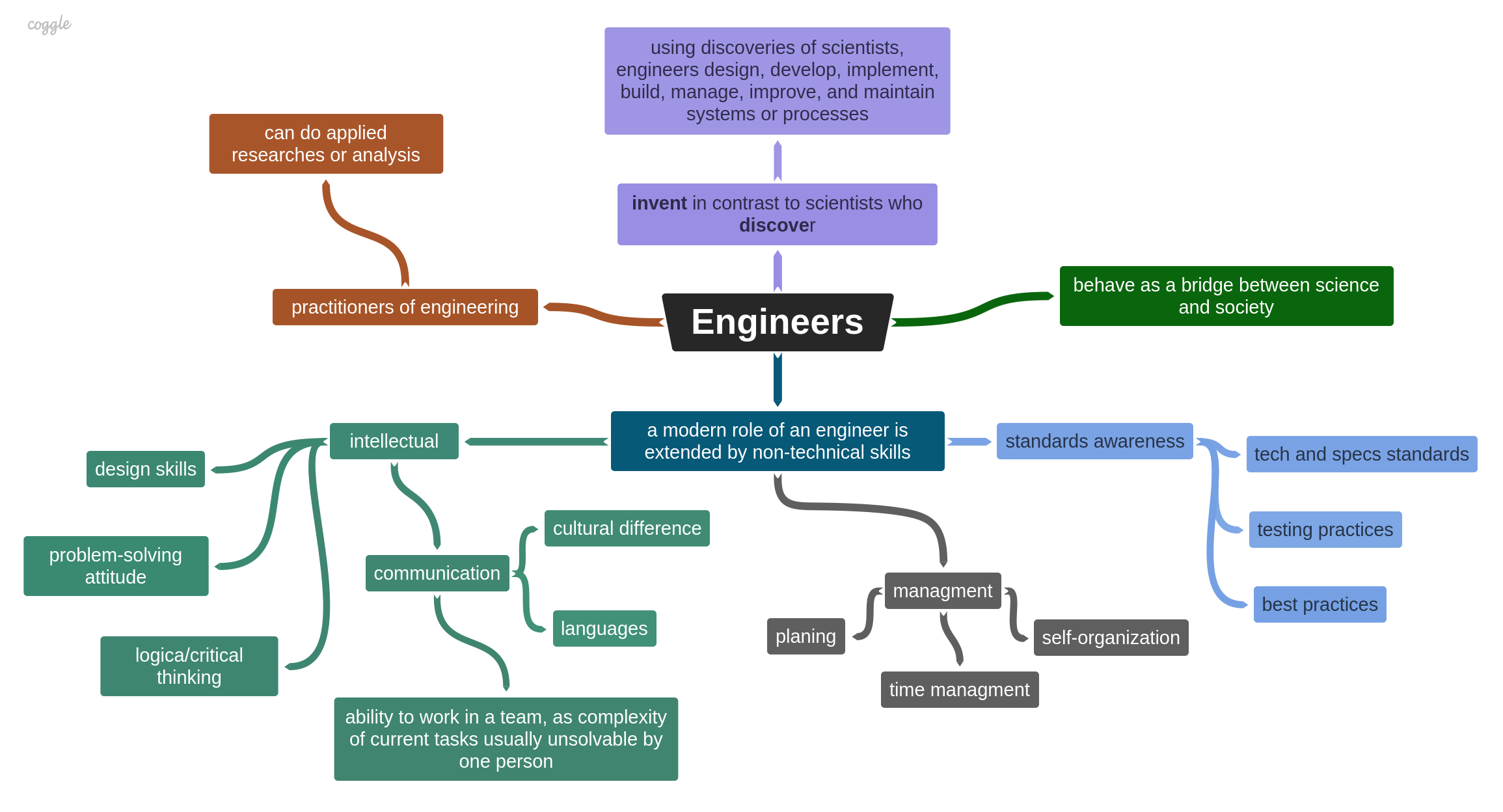
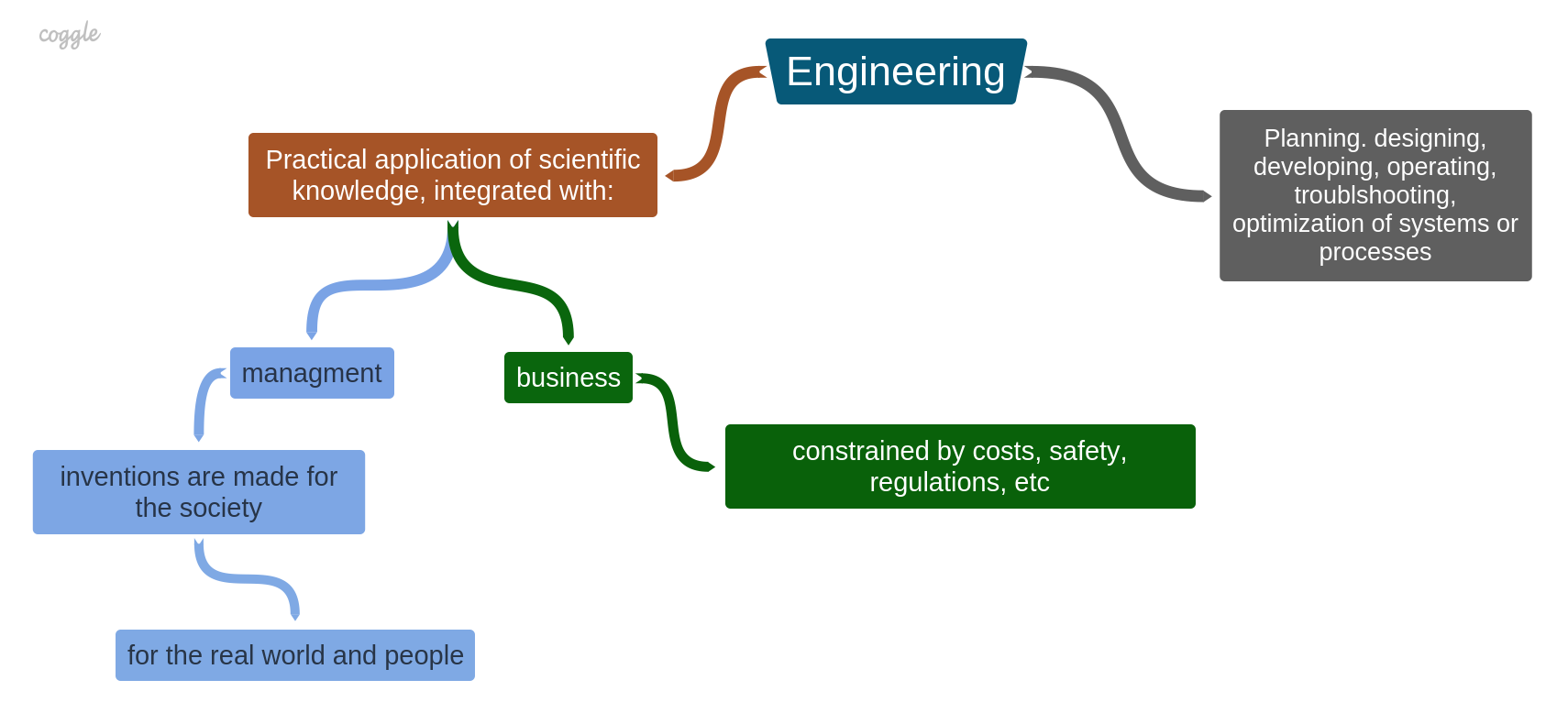
Briefly, the main difference between scientists and engineers is that scientists discover, but engineers invent. That is Engineers, using discoveries of scientists, invent systems, devices, processes, which they design, develop, implement, build, manage, maintain, and improve as different stages of the Engineering process. Engineering is a practical application of scientific knowledge, integrated with business and management. In other words, engineers act as a bridge between science and society by doing inventions for the real world and people.
In the modern time of the Information Age, the role of an engineer has been extended by non-technical skills, as a result of the globalization and spreading of trade relationships across the globe. These are skills such as intellectual (communication, foreign languages, critical thinking), management (time management, self-organization, planning), and standards awareness (tech certifications, best practices).
This is my personal blog. All ideas, opinions, examples, and other information that can be found here are my own and belong entirely to me. This is the result of my personal efforts and activities at my free time. It doesn't relate to any professional work I've done and doesn't have correlations with any companies I worked for, I'm currently working, or will work in the future.
\ No newline at end of file
+ Who is an engineer :: Vorakl's notes Who is an engineer
What's the crucial difference between engineers and scientists
With the coming of the Industrial Age (approx. 1760-1950), an agricultural society transitioned to an economy, based primarily on massive industrial production. It was the time of the rise of specialized educational centers, where people could get deep knowledge in many different fields of science and became either scientists or engineers.
Briefly, the main difference between scientists and engineers is that scientists discover, but engineers invent. That is Engineers, using discoveries of scientists, invent systems, devices, processes, which they design, develop, implement, build, manage, maintain, and improve as different stages of the Engineering process. Engineering is a practical application of scientific knowledge, integrated with business and management. In other words, engineers act as a bridge between science and society by doing inventions for the real world and people.
In the modern time of the Information Age, the role of an engineer has been extended by non-technical skills, as a result of the globalization and spreading of trade relationships across the globe. These are skills such as intellectual (communication, foreign languages, critical thinking), management (time management, self-organization, planning), and standards awareness (tech certifications, best practices).
This is my personal blog. All ideas, opinions, examples, and other information that can be found here are my own and belong entirely to me. This is the result of my personal efforts and activities at my free time. It doesn't relate to any professional work I've done and doesn't have correlations with any companies I worked for, I'm currently working, or will work in the future.
\ No newline at end of file
diff --git a/articles/goto/index.html b/articles/goto/index.html
index 841226d7..81e143c0 100644
--- a/articles/goto/index.html
+++ b/articles/goto/index.html
@@ -1 +1 @@
- Structured Programming Paradigm :: Vorakl's notes Structured Programming Paradigm
What can cause too much use of "goto statements"
There was a time when computer programs were so long and unstructured that only a few people could logically navigate the source code of huge software projects. With low-level programming languages, programmers used various equivalents of "goto" statements for conditional branching, which often resulted in decreased readability and difficulty maintaining logical context, especially when jumping too far into another subroutine.
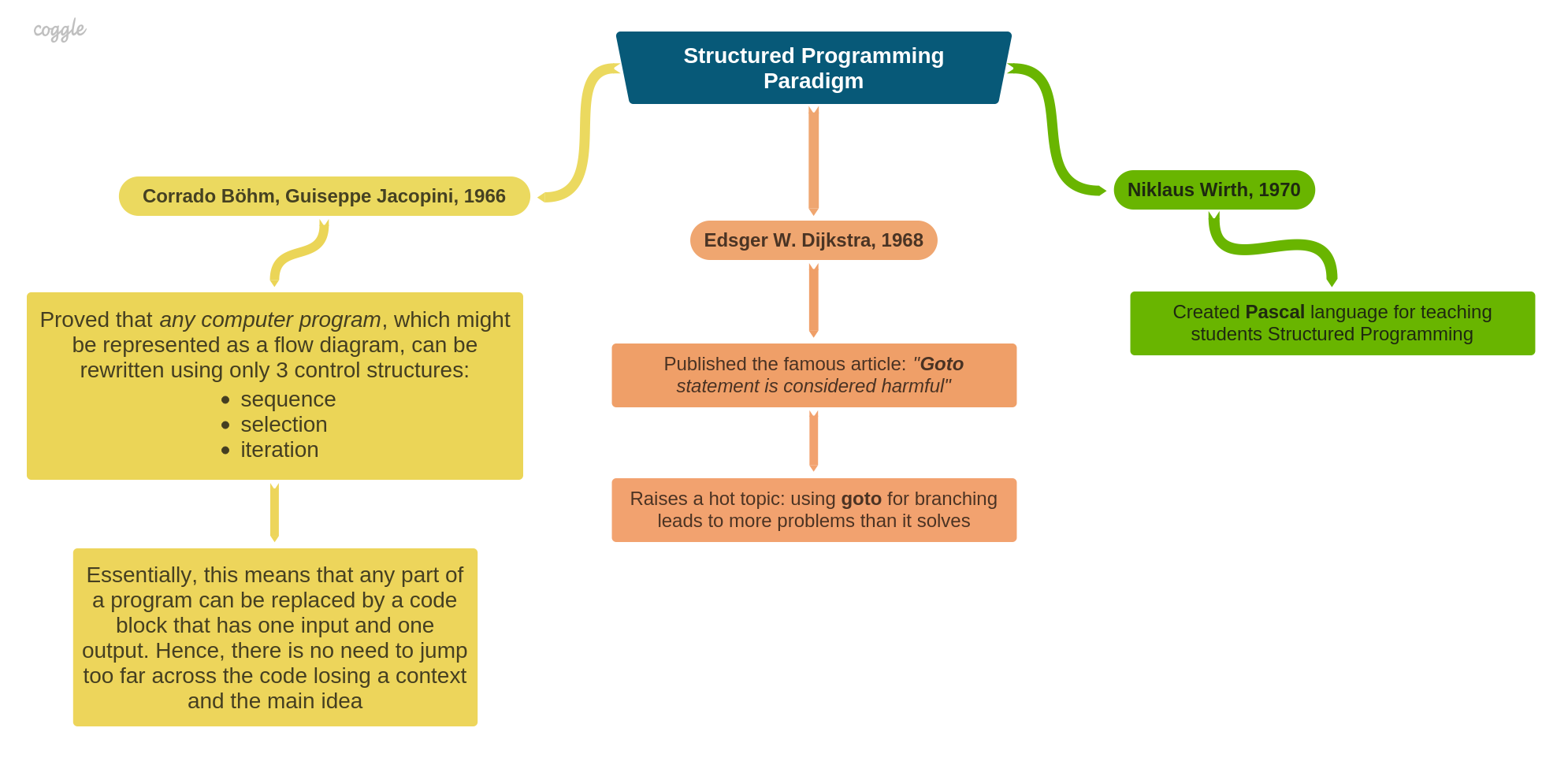
A few things happened on the way to a solution that eventually appeared in the form of the Structured Programming Paradigm. In 1966, Corrado Böhm and Guiseppe Jacopini proved a theorem that any computer program that can be represented as a flowchart can be rewritten using only 3 control structures (sequence, selection, and iteration).
In 1968, Edsger W. Dijkstra published the influential article "Go To Statement Considered Harmful", in which he pointed out that using too many goto statements would make computer programs harder to read and understand. However, his intention was unfortunately misunderstood and misused by the almost complete abandonment of the use of "goto" in high-level programming languages, even at the cost of less readable and vague code.
As a result of his work on improving ALGOL, Niklaus Wirth designed a new imperative programming language, Pascal, which was released in 1970. It has been widely used for teaching structured programming design to students for several decades since.
This is my personal blog. All ideas, opinions, examples, and other information that can be found here are my own and belong entirely to me. This is the result of my personal efforts and activities at my free time. It doesn't relate to any professional work I've done and doesn't have correlations with any companies I worked for, I'm currently working, or will work in the future.
\ No newline at end of file
+ Structured Programming Paradigm :: Vorakl's notes Structured Programming Paradigm
What can cause too much use of "goto statements"
There was a time when computer programs were so long and unstructured that only a few people could logically navigate the source code of huge software projects. With low-level programming languages, programmers used various equivalents of "goto" statements for conditional branching, which often resulted in decreased readability and difficulty maintaining logical context, especially when jumping too far into another subroutine.
A few things happened on the way to a solution that eventually appeared in the form of the Structured Programming Paradigm. In 1966, Corrado Böhm and Guiseppe Jacopini proved a theorem that any computer program that can be represented as a flowchart can be rewritten using only 3 control structures (sequence, selection, and iteration).
In 1968, Edsger W. Dijkstra published the influential article "Go To Statement Considered Harmful", in which he pointed out that using too many goto statements would make computer programs harder to read and understand. However, his intention was unfortunately misunderstood and misused by the almost complete abandonment of the use of "goto" in high-level programming languages, even at the cost of less readable and vague code.
As a result of his work on improving ALGOL, Niklaus Wirth designed a new imperative programming language, Pascal, which was released in 1970. It has been widely used for teaching structured programming design to students for several decades since.
This is my personal blog. All ideas, opinions, examples, and other information that can be found here are my own and belong entirely to me. This is the result of my personal efforts and activities at my free time. It doesn't relate to any professional work I've done and doesn't have correlations with any companies I worked for, I'm currently working, or will work in the future.
\ No newline at end of file
diff --git a/articles/index.html b/articles/index.html
index 9d4b891d..349419f5 100644
--- a/articles/index.html
+++ b/articles/index.html
@@ -1 +1 @@
- Archive :: Vorakl's notes
\ No newline at end of file
+ Archive :: Vorakl's notes
\ No newline at end of file
diff --git a/articles/learning/index.html b/articles/learning/index.html
index 36f0b30e..1803fed4 100644
--- a/articles/learning/index.html
+++ b/articles/learning/index.html
@@ -1 +1 @@
- My notes for the "Pragmatic Thinking and Learning" book :: Vorakl's notes My notes for the "Pragmatic Thinking and Learning" book
Notes in the form of mindmaps
New Skill Acquisition
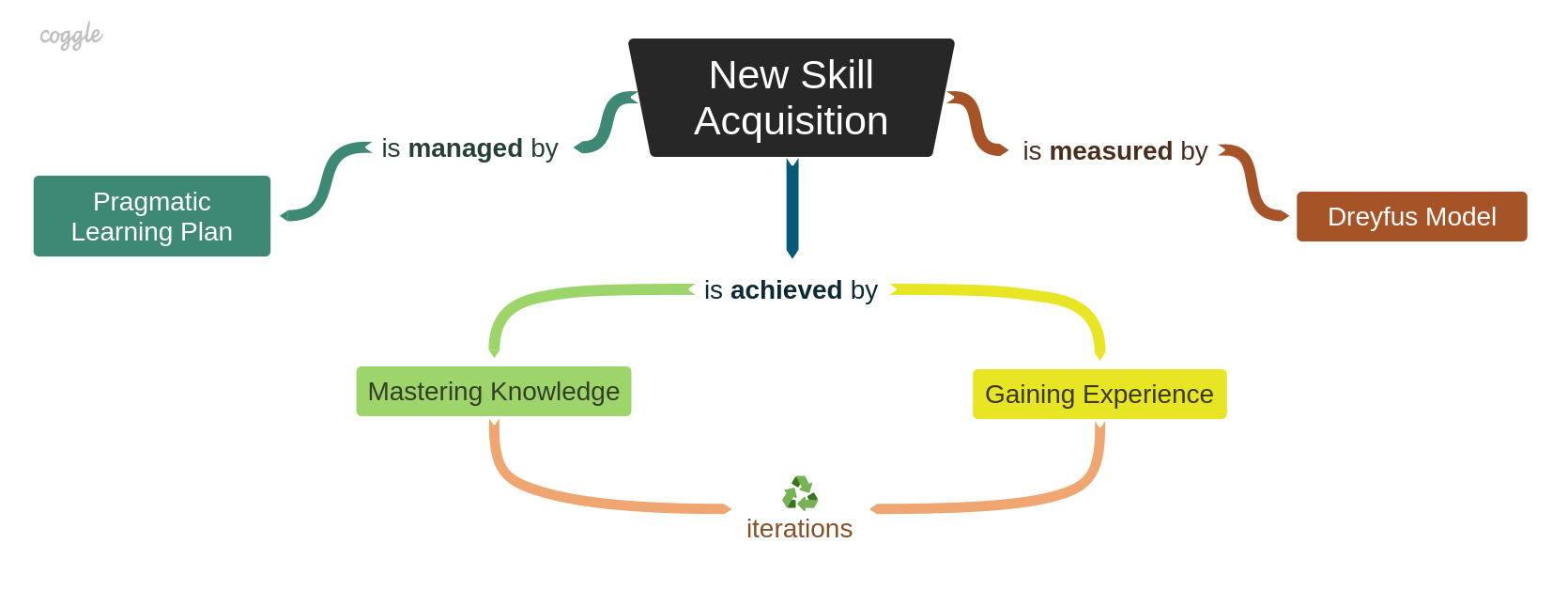
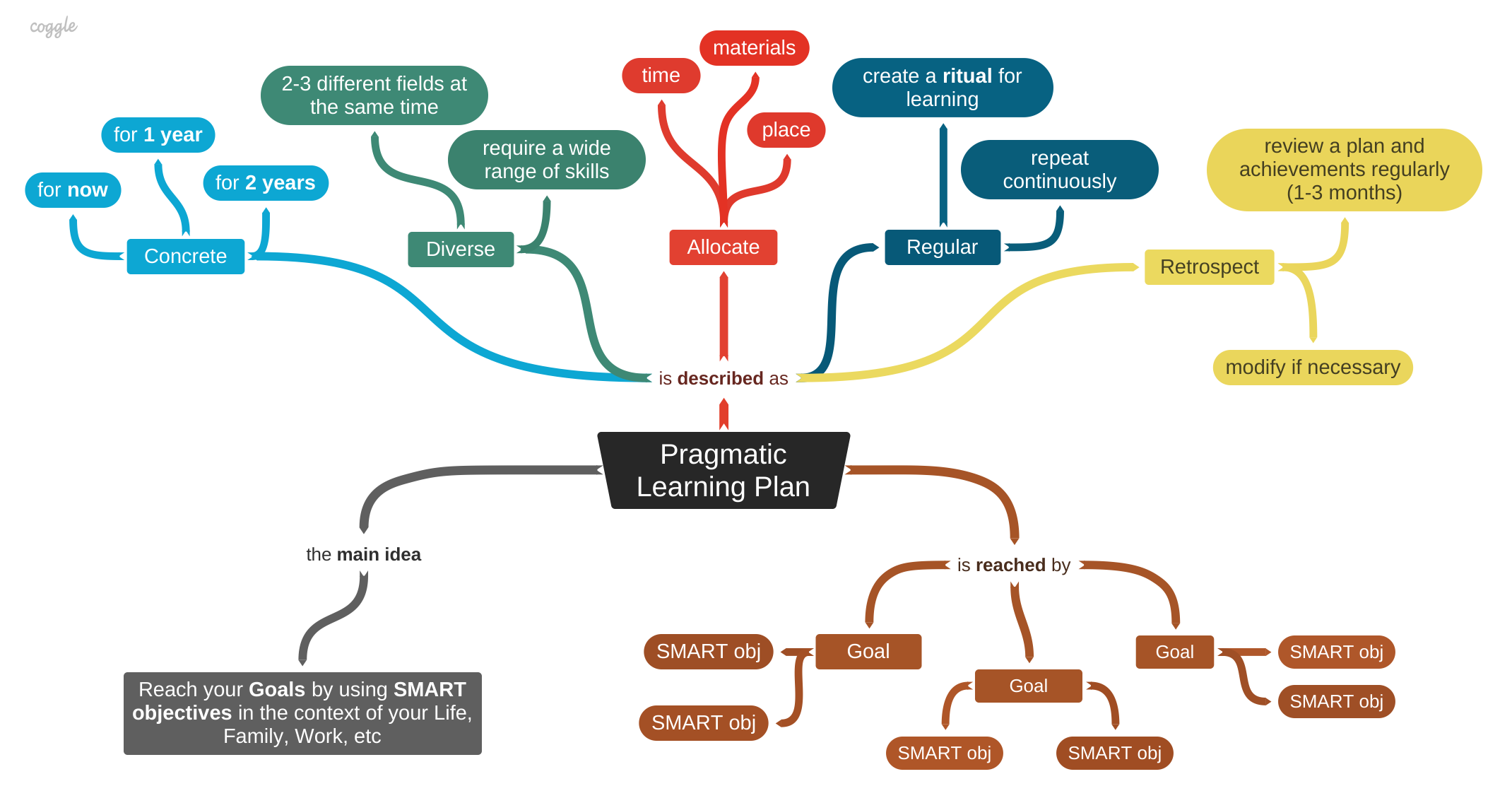
Pragmatic Learning Plan
Dreyfus model
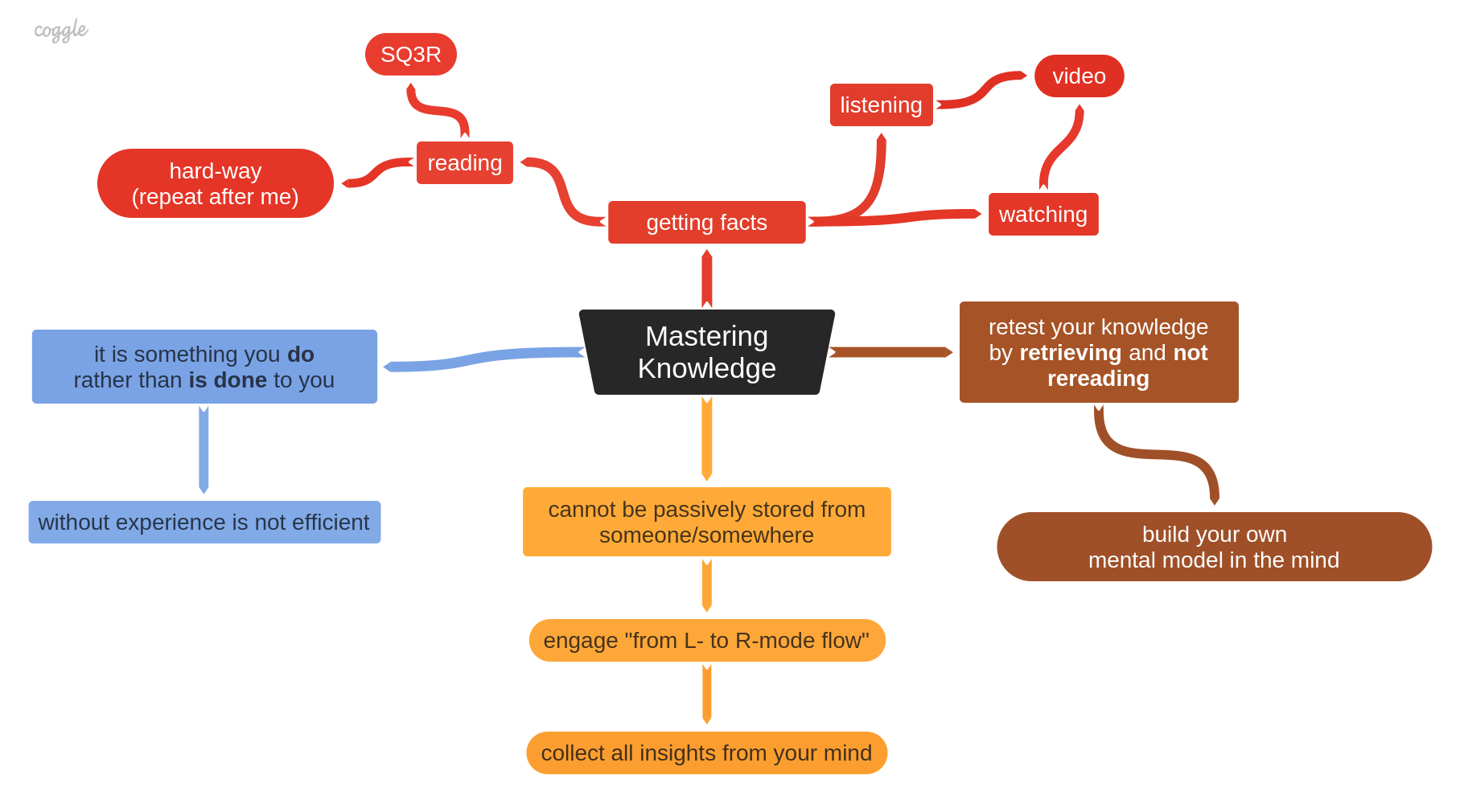
Mastering Knowledge
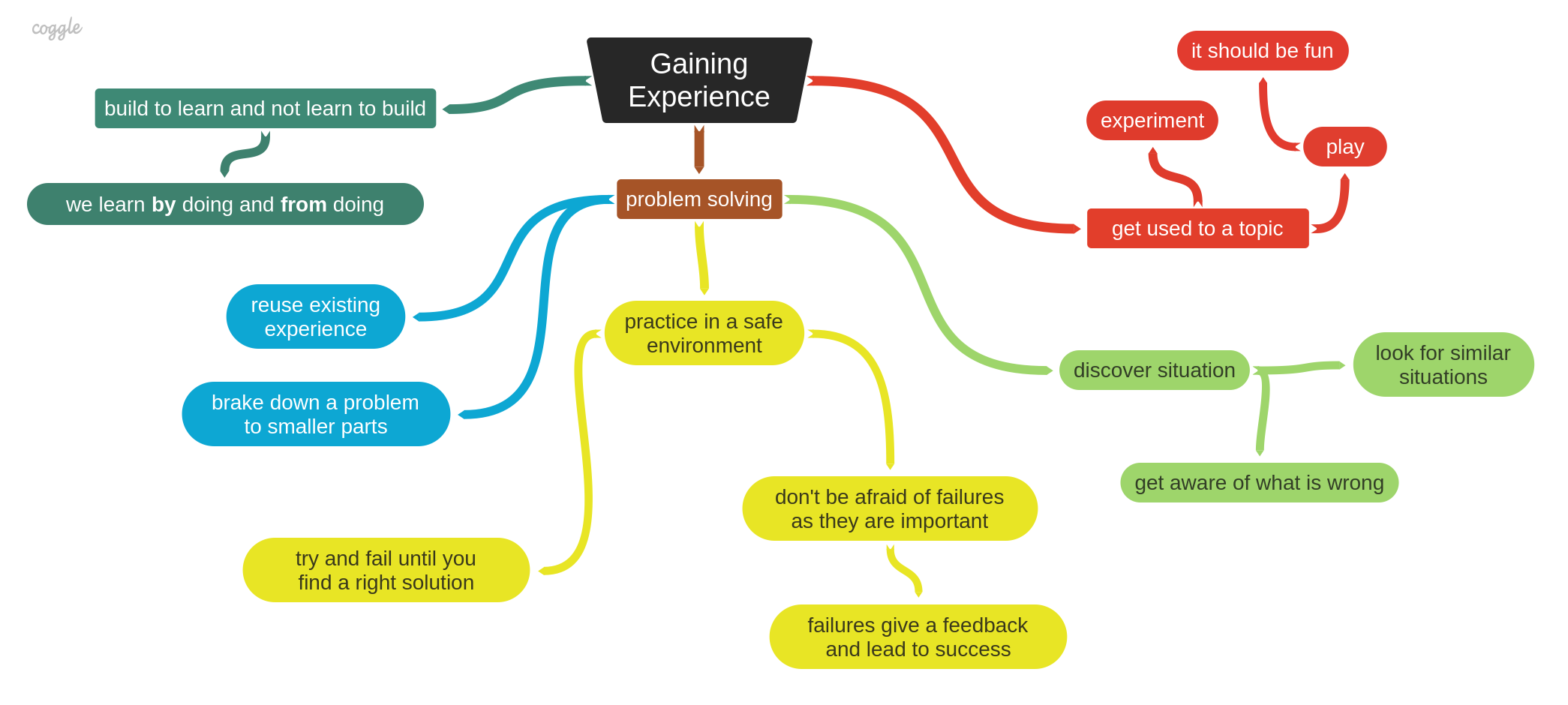
Gaining Experience
How to start learning
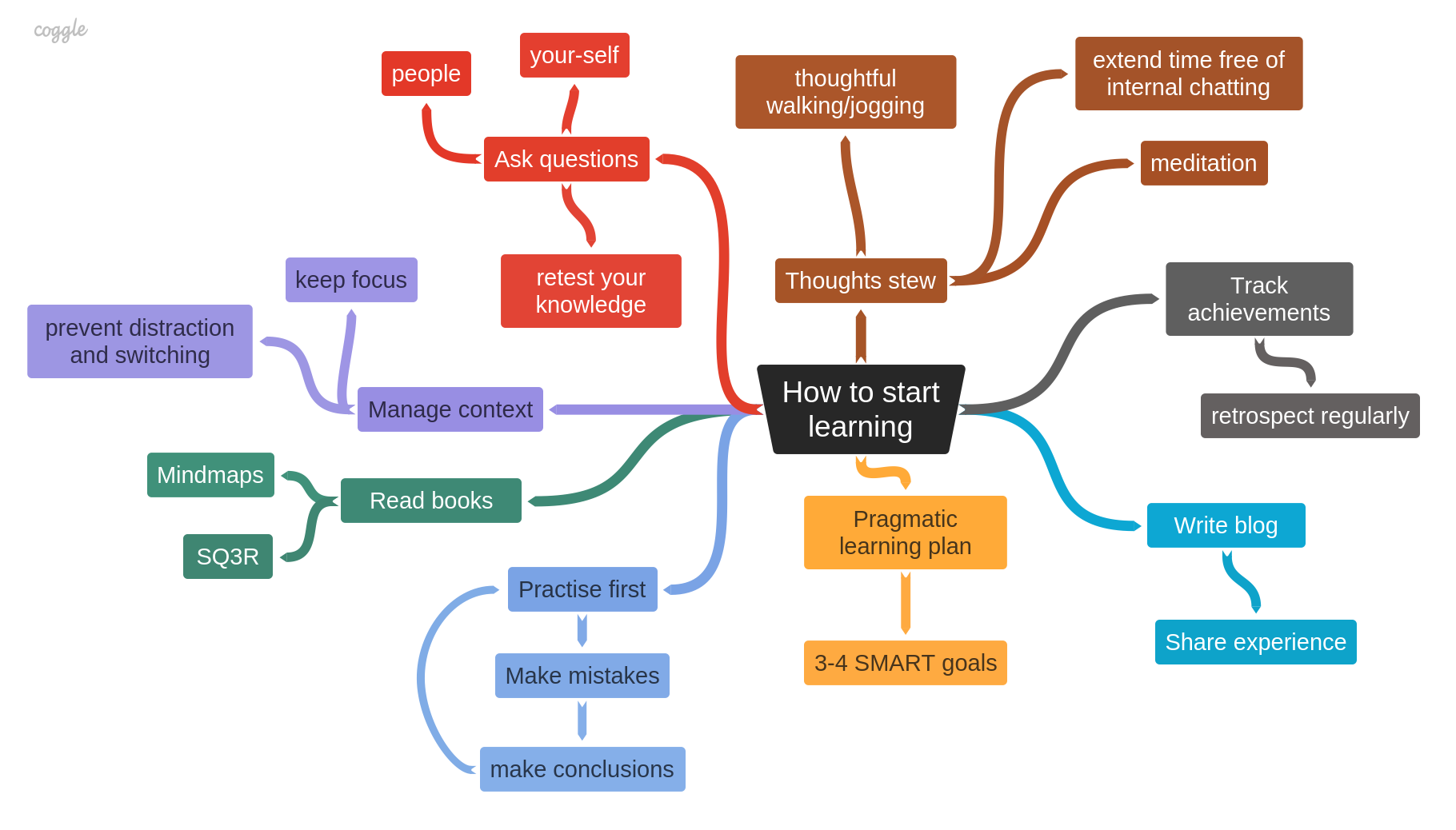
This is my personal blog. All ideas, opinions, examples, and other information that can be found here are my own and belong entirely to me. This is the result of my personal efforts and activities at my free time. It doesn't relate to any professional work I've done and doesn't have correlations with any companies I worked for, I'm currently working, or will work in the future.
\ No newline at end of file
+ My notes for the "Pragmatic Thinking and Learning" book :: Vorakl's notes My notes for the "Pragmatic Thinking and Learning" book
Notes in the form of mindmaps
New Skill Acquisition
Pragmatic Learning Plan
Dreyfus model
Mastering Knowledge
Gaining Experience
How to start learning
This is my personal blog. All ideas, opinions, examples, and other information that can be found here are my own and belong entirely to me. This is the result of my personal efforts and activities at my free time. It doesn't relate to any professional work I've done and doesn't have correlations with any companies I worked for, I'm currently working, or will work in the future.
\ No newline at end of file
diff --git a/articles/maslow/index.html b/articles/maslow/index.html
index df6a1062..39e59313 100644
--- a/articles/maslow/index.html
+++ b/articles/maslow/index.html
@@ -1 +1 @@
- Maslow's hierarchy of needs :: Vorakl's notes Maslow's hierarchy of needs
This theory describes the stages of growth in humans
Maslow's hierarchy of needs is a theory that shows a path of psychological development in humans through several hierarchical stages. Each stage characterizes a common set of motivations and needs. The important observation is that a certain motivation belongs to an appropriate stage and in order to occur, all previous stages must be well satisfied. The main goal of the Maslow's theory is to show all prerequisites which a human needs to meet for reaching the top level of psychological development - "self-actualization" - that can be achieved only when all basic and mental needs are fulfilled.
Self-actualization is the need that is perceived very specifically and is described as the desire to accomplish everything that one can, to become the most that one can be, to realize one's full potential. Maslow used this term to describe namely a desire, not a driving force. In his later theory, Maslow also noticed that the fullest realization can be found in giving oneself to something beyond oneself.
For me personally, this theory played an eye-opening role in understanding what was that implicit force which has been pushing me for many years to learn, to immigrate, and finally realize where I'm heading to.
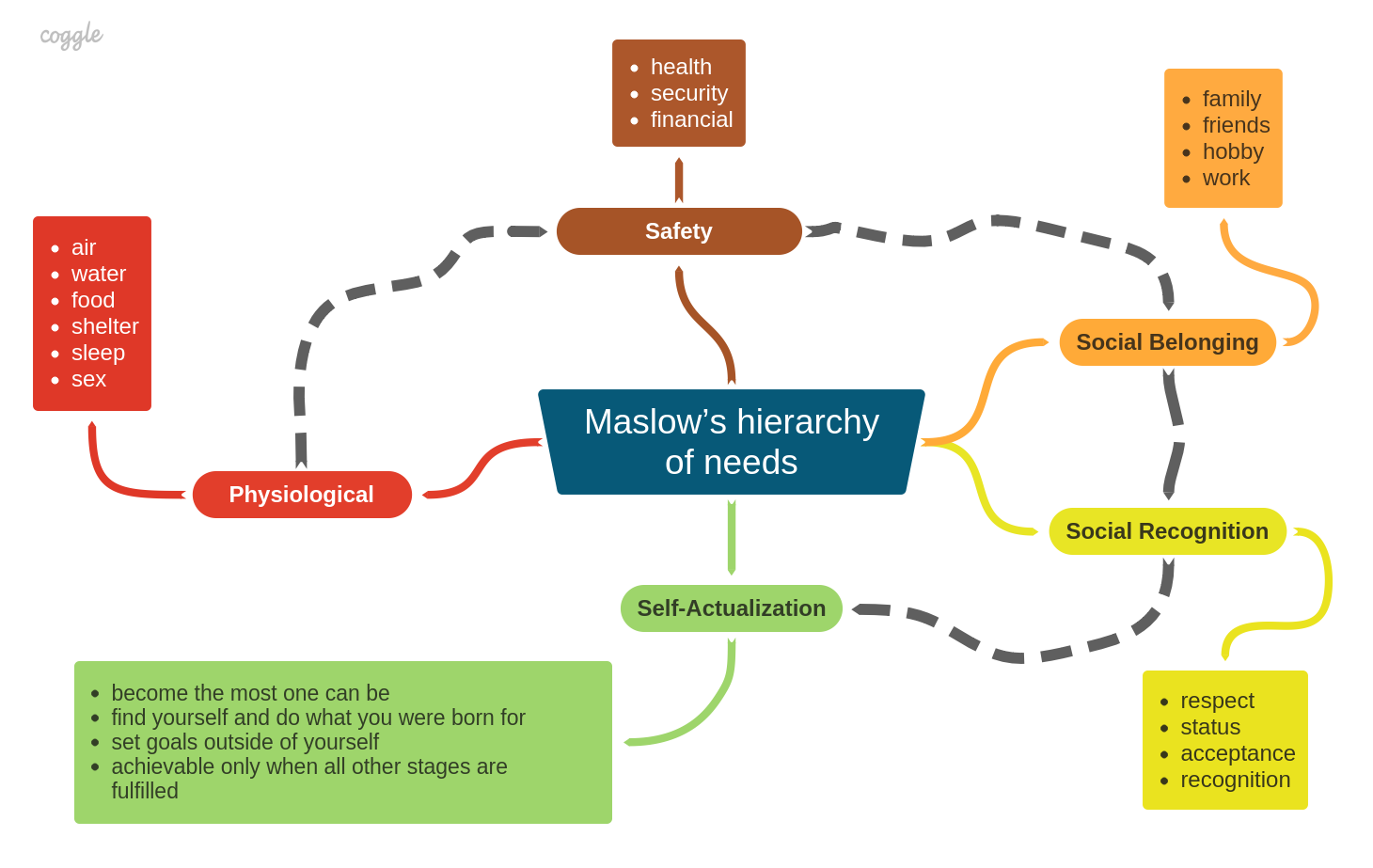
This is my personal blog. All ideas, opinions, examples, and other information that can be found here are my own and belong entirely to me. This is the result of my personal efforts and activities at my free time. It doesn't relate to any professional work I've done and doesn't have correlations with any companies I worked for, I'm currently working, or will work in the future.
\ No newline at end of file
+ Maslow's hierarchy of needs :: Vorakl's notes Maslow's hierarchy of needs
This theory describes the stages of growth in humans
Maslow's hierarchy of needs is a theory that shows a path of psychological development in humans through several hierarchical stages. Each stage characterizes a common set of motivations and needs. The important observation is that a certain motivation belongs to an appropriate stage and in order to occur, all previous stages must be well satisfied. The main goal of the Maslow's theory is to show all prerequisites which a human needs to meet for reaching the top level of psychological development - "self-actualization" - that can be achieved only when all basic and mental needs are fulfilled.
Self-actualization is the need that is perceived very specifically and is described as the desire to accomplish everything that one can, to become the most that one can be, to realize one's full potential. Maslow used this term to describe namely a desire, not a driving force. In his later theory, Maslow also noticed that the fullest realization can be found in giving oneself to something beyond oneself.
For me personally, this theory played an eye-opening role in understanding what was that implicit force which has been pushing me for many years to learn, to immigrate, and finally realize where I'm heading to.
This is my personal blog. All ideas, opinions, examples, and other information that can be found here are my own and belong entirely to me. This is the result of my personal efforts and activities at my free time. It doesn't relate to any professional work I've done and doesn't have correlations with any companies I worked for, I'm currently working, or will work in the future.
\ No newline at end of file
diff --git a/articles/numbers/index.html b/articles/numbers/index.html
index 40b30c89..ed04ed7a 100644
--- a/articles/numbers/index.html
+++ b/articles/numbers/index.html
@@ -1 +1 @@
- Number Classification :: Vorakl's notes Number Classification
All number categories, from Complex to Counting
Mathematics is unique. The unique science if everyone could agree that it is Science. But, it's also hard to argue that it is not Art. Math is absolutely certain, except the cases when it is not ("as far as the laws of mathematics refer to reality, they are not certain; and as far as they are certain, they do not refer to reality"). Still having no one general definition, math doesn't even bother to have one opinion on such the fundamental building block as Numbers. Nevertheless, math is an important part of almost every field of science, engineering, and human life.
Here is the most common and well-accepted number classification tree:
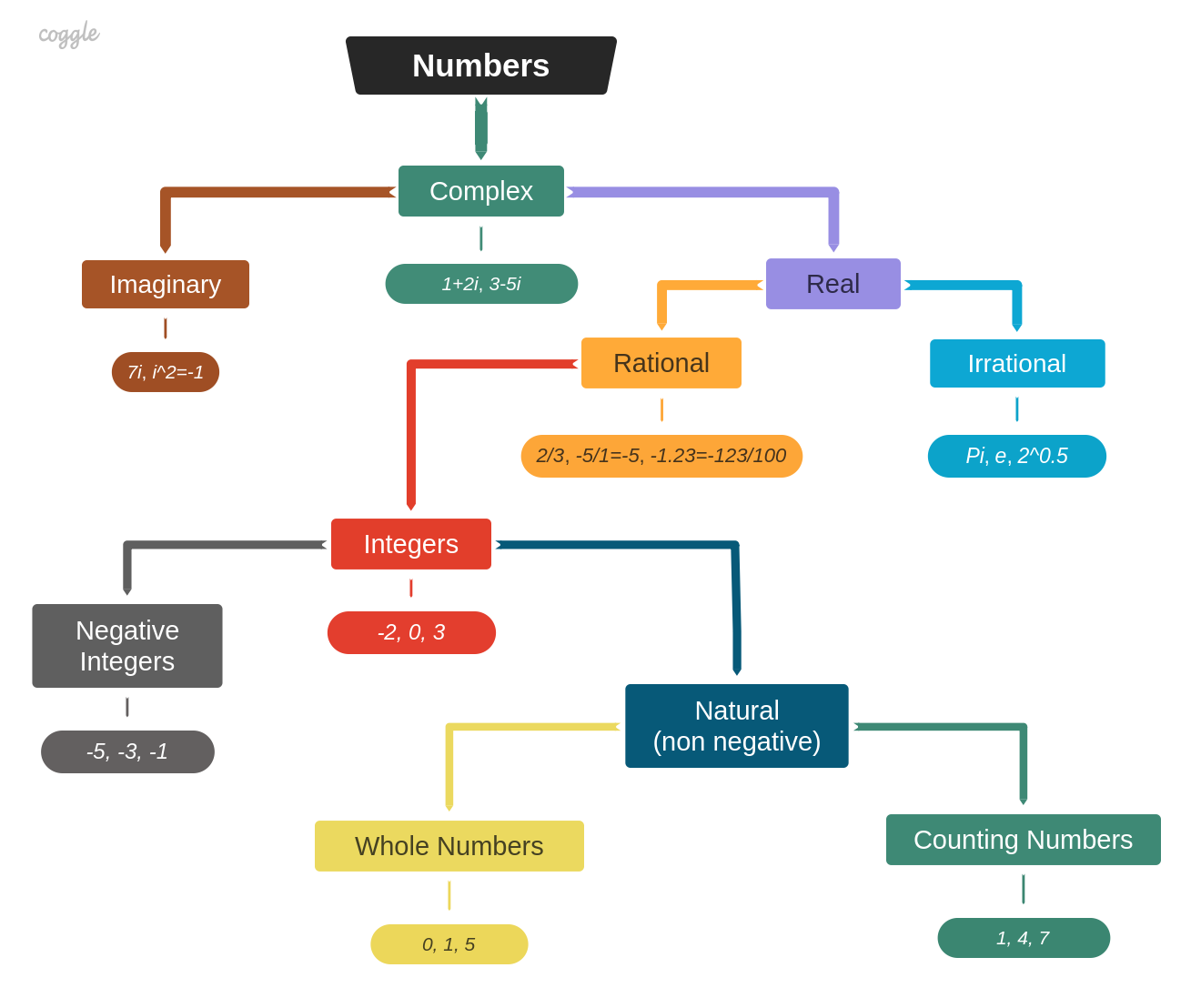
It also shouldn't be a surprise to find slight distinctions in the meaning of the same essences in Math and Computer Science (CS):
- Natural numbers. In Math, they are meant to be Positive Integers (1, 2, 3, ...), but in CS they are non-negative Integers which include Zero (0, 1, 2, 3 ...)
- Mantissa. In Math, it is a fractional part of the logarithm. In CS, it is significant digits of a floating-point number (thus, quite often are used other definitions in this case, like significand and coefficient)
There is a quite related topic in terms of the values which a variable can take on. In mathematics, a variable may be two different types: continuous and discrete:
- A variable is continuous when it can take on infinitely many, uncountable values. There is always another value in between two others in a non-empty range, no matter how close they are.
- A variable is discrete when there is always a positive minimum distance between two values in a non-empty range. The set of numbers is finite or countably infinite (e.g. Natural numbers)
The understanding of the discreteness is crucial in Computer Science as all real-world computers internally work only with discrete data (which makes it challenging to represent Irrational numbers). All existing computability theories (e.g. Turing thesis, Church thesis) are defined on discrete values, and the domain is the set of Natural numbers.
This is my personal blog. All ideas, opinions, examples, and other information that can be found here are my own and belong entirely to me. This is the result of my personal efforts and activities at my free time. It doesn't relate to any professional work I've done and doesn't have correlations with any companies I worked for, I'm currently working, or will work in the future.
\ No newline at end of file
+ Number Classification :: Vorakl's notes Number Classification
All number categories, from Complex to Counting
Mathematics is unique. The unique science if everyone could agree that it is Science. But, it's also hard to argue that it is not Art. Math is absolutely certain, except the cases when it is not ("as far as the laws of mathematics refer to reality, they are not certain; and as far as they are certain, they do not refer to reality"). Still having no one general definition, math doesn't even bother to have one opinion on such the fundamental building block as Numbers. Nevertheless, math is an important part of almost every field of science, engineering, and human life.
Here is the most common and well-accepted number classification tree:
It also shouldn't be a surprise to find slight distinctions in the meaning of the same essences in Math and Computer Science (CS):
- Natural numbers. In Math, they are meant to be Positive Integers (1, 2, 3, ...), but in CS they are non-negative Integers which include Zero (0, 1, 2, 3 ...)
- Mantissa. In Math, it is a fractional part of the logarithm. In CS, it is significant digits of a floating-point number (thus, quite often are used other definitions in this case, like significand and coefficient)
There is a quite related topic in terms of the values which a variable can take on. In mathematics, a variable may be two different types: continuous and discrete:
- A variable is continuous when it can take on infinitely many, uncountable values. There is always another value in between two others in a non-empty range, no matter how close they are.
- A variable is discrete when there is always a positive minimum distance between two values in a non-empty range. The set of numbers is finite or countably infinite (e.g. Natural numbers)
The understanding of the discreteness is crucial in Computer Science as all real-world computers internally work only with discrete data (which makes it challenging to represent Irrational numbers). All existing computability theories (e.g. Turing thesis, Church thesis) are defined on discrete values, and the domain is the set of Natural numbers.
This is my personal blog. All ideas, opinions, examples, and other information that can be found here are my own and belong entirely to me. This is the result of my personal efforts and activities at my free time. It doesn't relate to any professional work I've done and doesn't have correlations with any companies I worked for, I'm currently working, or will work in the future.
\ No newline at end of file
diff --git a/articles/remove-webpage-google/index.html b/articles/remove-webpage-google/index.html
index 656e57a2..734d7d46 100644
--- a/articles/remove-webpage-google/index.html
+++ b/articles/remove-webpage-google/index.html
@@ -1,4 +1,4 @@
- How to remove a webpage from the Google index :: Vorakl's notes How to remove a webpage from the Google index
The approach for removing outdated or deleted content from Google search results
It's important to keep in mind that search engines scan websites on periodic bases and these periods may vary depending on a number of factors. In general, websites' owners don't have full control over the behavior of search engines, but instead, they can define preferences in a form of instructions. Such instructions, for example, allow excluding certain web pages from showing up in search results or preventing search engines from digging into specific paths. There are two ways to declare preferences: tweaking parameters of robots.txt in the root of a website and HTML <meta> tag "robots" in the <head> block of web pages.
I've recently needed to move one of my static websites to another domain. It became a complex task as I'm not able to change a server-side configuration, and the redirection of HTTP-requests is only one part of the story. Once all users are being redirected to a new location, I had to initiate and speed up a process of cleaning up the search results from links to my old website.
There are basically a few common ways to remove web pages from search indexes:
- remove a page completely, so clients will be getting 404 Not Found HTTP response. It is clearly not my case, as the old website responses with valid and existing web pages
- restrict access to a page by asking clients to enter credentials. Then, the server will be sending 401 Unauthorized HTTP response. This also won't work for me, as requires changing the configuration on the server-side
- add an HTML <meta> tag robots with the value noindex. That's exactly what I needed and can be implemented on the client-side.
The last method allows setting different preferences per page right from the HTML code. That is, search engines must have access to a page to read it and find this instruction. This also means that all web pages with robots meta tag shouldn't be blocked even by a robots.txt file!
This solution will show a few steps for removing an entire website from Google's search results.
- check robots.txt (if it exists) and be sure that search bots are allowed to go through the site and read all indexed web pages. The file should either be empty or something like this (allows any bots read any webpage on a site):
User-agent: *
+ How to remove a webpage from the Google index :: Vorakl's notes How to remove a webpage from the Google index
The approach for removing outdated or deleted content from Google search results
It's important to keep in mind that search engines scan websites on periodic bases and these periods may vary depending on a number of factors. In general, websites' owners don't have full control over the behavior of search engines, but instead, they can define preferences in a form of instructions. Such instructions, for example, allow excluding certain web pages from showing up in search results or preventing search engines from digging into specific paths. There are two ways to declare preferences: tweaking parameters of robots.txt in the root of a website and HTML <meta> tag "robots" in the <head> block of web pages.
I've recently needed to move one of my static websites to another domain. It became a complex task as I'm not able to change a server-side configuration, and the redirection of HTTP-requests is only one part of the story. Once all users are being redirected to a new location, I had to initiate and speed up a process of cleaning up the search results from links to my old website.
There are basically a few common ways to remove web pages from search indexes:
- remove a page completely, so clients will be getting 404 Not Found HTTP response. It is clearly not my case, as the old website responses with valid and existing web pages
- restrict access to a page by asking clients to enter credentials. Then, the server will be sending 401 Unauthorized HTTP response. This also won't work for me, as requires changing the configuration on the server-side
- add an HTML <meta> tag robots with the value noindex. That's exactly what I needed and can be implemented on the client-side.
The last method allows setting different preferences per page right from the HTML code. That is, search engines must have access to a page to read it and find this instruction. This also means that all web pages with robots meta tag shouldn't be blocked even by a robots.txt file!
This solution will show a few steps for removing an entire website from Google's search results.
- check robots.txt (if it exists) and be sure that search bots are allowed to go through the site and read all indexed web pages. The file should either be empty or something like this (allows any bots read any webpage on a site):
User-agent: *
Disallow:
- add robots HTML <meta> tag in the <head> block with "noindex, nofollow" value in each indexed web page:
<meta name="robots" content="noindex, nofollow" />
- create a sitemap.xml file and define all indexed web pages with the <lastmod> section which points to some recent time. For example:
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
diff --git a/articles/smart/index.html b/articles/smart/index.html
index f76eb192..80763476 100644
--- a/articles/smart/index.html
+++ b/articles/smart/index.html
@@ -1 +1 @@
- Managing your plans in the S.M.A.R.T. way :: Vorakl's notes Managing your plans in the S.M.A.R.T. way
Reach your goals by setting SMART objectives within the action plan
The benefit of using SMART criteria in planning has been known for a few last decades. They were so widely applied, integrated as a proven technique in managing organizations' goals and objectives, and improved by so many contributors that currently is quite hard to name the only one certain definition of 'SMART'. For different people, this acronym means different things. Even the terms 'goal' and 'objective', in some cases, have either opposite or the same meaning. Nevertheless, the knowledge of the original ideas helps to get the most from the whole approach.
In 1981, the article of George T. Doran "There's a S.M.A.R.T. way to write management's goals and objectives" was published. He reasonably pointed out that despite all the available literature and seminars, "most managers still don't know what objectives are and how they can be written", that "the majority of U.S. corporations don't really have an effective objective setting/planning process", and that "the process of writing objectives is a major source of anxiety that many individuals would like to live without".
It was a frustrating reality caused by the lack of proper education across "corporate officers, managers, and supervisors", on all levels. George T. Doran has also mentioned, "objective setting must become a way of life" and suggested an effective way to tackle this problem. When it comes to define goals or write objectives, one has "to think of the acronym SMART" and be clear about a distinction between terms 'goal' and 'objective'.
"Goals represent unique executive beliefs and philosophies. They are usually of a form that is continuous and long-term". "Objectives , on the other hand, give quantitative support and expression to managements' beliefs", "enable an organization to focus on problems, and give the company a sense of direction", "a statement of results to be achieved".
The acronym itself, in the original form, had the following meaning:
- Specific, target a specific area for improvement
- Measurable, quantify or at least suggest an indicator of progress
- Assignable, specify who will do it
- Realistic, state what results can realistically be achieved, given available resources
- Time-Related, specify when the result(s) can be achieved
Taking into consideration the fact, that the proposed solution was targeted to organizations, it will not be a surprise that few "letters" changed their meaning to satisfy the needs of smaller groups or individuals. For instance, for personal use, as there are no others to whom it could be assigned, "A" and "R" change their meaning to Achievable (similar to Realistic) and Relevant (appropriate and related to the context).
There are two important observations to notice:
- the proposed technique doesn't require all objectives to be measurable or quantified. In some situations, it can lead to "lose the benefit of a more abstract objective in order to gain quantification"
- it is not required to have all five criteria set. "However, the closer we get to the SMART criteria as a guideline, the smarter our objectives will be".
One way to make goals and objectives working together is to join them in one Action Plan. The action plan makes it possible to reach long-term goals by using short-run objectives in the context of your real situation.

This is my personal blog. All ideas, opinions, examples, and other information that can be found here are my own and belong entirely to me. This is the result of my personal efforts and activities at my free time. It doesn't relate to any professional work I've done and doesn't have correlations with any companies I worked for, I'm currently working, or will work in the future.
\ No newline at end of file
+ Managing your plans in the S.M.A.R.T. way :: Vorakl's notes Managing your plans in the S.M.A.R.T. way
Reach your goals by setting SMART objectives within the action plan
The benefit of using SMART criteria in planning has been known for a few last decades. They were so widely applied, integrated as a proven technique in managing organizations' goals and objectives, and improved by so many contributors that currently is quite hard to name the only one certain definition of 'SMART'. For different people, this acronym means different things. Even the terms 'goal' and 'objective', in some cases, have either opposite or the same meaning. Nevertheless, the knowledge of the original ideas helps to get the most from the whole approach.
In 1981, the article of George T. Doran "There's a S.M.A.R.T. way to write management's goals and objectives" was published. He reasonably pointed out that despite all the available literature and seminars, "most managers still don't know what objectives are and how they can be written", that "the majority of U.S. corporations don't really have an effective objective setting/planning process", and that "the process of writing objectives is a major source of anxiety that many individuals would like to live without".
It was a frustrating reality caused by the lack of proper education across "corporate officers, managers, and supervisors", on all levels. George T. Doran has also mentioned, "objective setting must become a way of life" and suggested an effective way to tackle this problem. When it comes to define goals or write objectives, one has "to think of the acronym SMART" and be clear about a distinction between terms 'goal' and 'objective'.
"Goals represent unique executive beliefs and philosophies. They are usually of a form that is continuous and long-term". "Objectives , on the other hand, give quantitative support and expression to managements' beliefs", "enable an organization to focus on problems, and give the company a sense of direction", "a statement of results to be achieved".
The acronym itself, in the original form, had the following meaning:
- Specific, target a specific area for improvement
- Measurable, quantify or at least suggest an indicator of progress
- Assignable, specify who will do it
- Realistic, state what results can realistically be achieved, given available resources
- Time-Related, specify when the result(s) can be achieved
Taking into consideration the fact, that the proposed solution was targeted to organizations, it will not be a surprise that few "letters" changed their meaning to satisfy the needs of smaller groups or individuals. For instance, for personal use, as there are no others to whom it could be assigned, "A" and "R" change their meaning to Achievable (similar to Realistic) and Relevant (appropriate and related to the context).
There are two important observations to notice:
- the proposed technique doesn't require all objectives to be measurable or quantified. In some situations, it can lead to "lose the benefit of a more abstract objective in order to gain quantification"
- it is not required to have all five criteria set. "However, the closer we get to the SMART criteria as a guideline, the smarter our objectives will be".
One way to make goals and objectives working together is to join them in one Action Plan. The action plan makes it possible to reach long-term goals by using short-run objectives in the context of your real situation.
This is my personal blog. All ideas, opinions, examples, and other information that can be found here are my own and belong entirely to me. This is the result of my personal efforts and activities at my free time. It doesn't relate to any professional work I've done and doesn't have correlations with any companies I worked for, I'm currently working, or will work in the future.
\ No newline at end of file
diff --git a/articles/sq3r/index.html b/articles/sq3r/index.html
index 9e322f04..ec88039a 100644
--- a/articles/sq3r/index.html
+++ b/articles/sq3r/index.html
@@ -1 +1 @@
- SQ3R :: Vorakl's notes The SQ3R is a reading comprehension method of reading textbook materials named for its five steps: Survey, Question, Read, Recite, and Review. It provides an active and fairly efficient approach to acquiring information stored as text. A text form is far from the ideal or best source of meaningful data for our minds, but the SQ3R method makes it possible to remember, understand, and integrate new knowledge with what we already know.
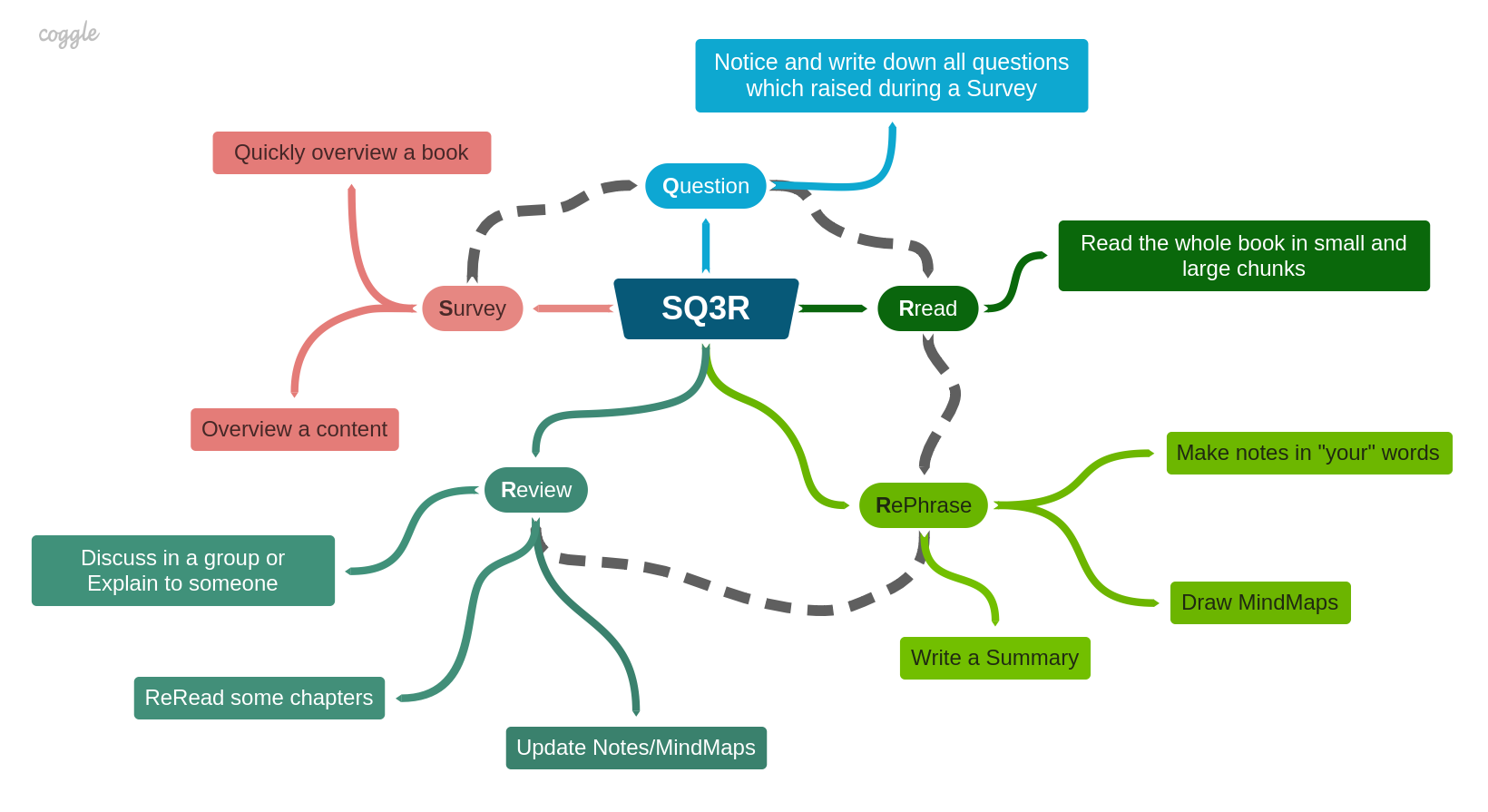
This is my personal blog. All ideas, opinions, examples, and other information that can be found here are my own and belong entirely to me. This is the result of my personal efforts and activities at my free time. It doesn't relate to any professional work I've done and doesn't have correlations with any companies I worked for, I'm currently working, or will work in the future.
\ No newline at end of file
+ SQ3R :: Vorakl's notes The SQ3R is a reading comprehension method of reading textbook materials named for its five steps: Survey, Question, Read, Recite, and Review. It provides an active and fairly efficient approach to acquiring information stored as text. A text form is far from the ideal or best source of meaningful data for our minds, but the SQ3R method makes it possible to remember, understand, and integrate new knowledge with what we already know.
This is my personal blog. All ideas, opinions, examples, and other information that can be found here are my own and belong entirely to me. This is the result of my personal efforts and activities at my free time. It doesn't relate to any professional work I've done and doesn't have correlations with any companies I worked for, I'm currently working, or will work in the future.
\ No newline at end of file
diff --git a/articles/stream-encoding/index.html b/articles/stream-encoding/index.html
index a29b9f66..a5796201 100644
--- a/articles/stream-encoding/index.html
+++ b/articles/stream-encoding/index.html
@@ -1,4 +1,4 @@
- The zoo of binary-to-text encoding schemes :: Vorakl's notes The zoo of binary-to-text encoding schemes
A stream encoding algorithm with a variable base (16, 32, 36, 64, 58, 85, 94)
In the previous article, I discussed the use of the positional numeral system for the purpose of binary-to-text translation. That method represents a binary file as a single big number with the radix 256 and then converts this big number to another one with an arbitrary radix (base) in a range from 2 to 94. Although this approach gives the minimum possible size overhead, unfortunately, it also has a number of downsides which make it hardly usable in a real-world situation. In this article, I'll show what is used in practice, which encodings could be found in the wild, and how to build your own encoder.
What's wrong with the positional single number encoding?
The main issue with converting a file as a big number in radix 256 to another big number with a smaller radix is that you need to read the whole file, load it to the memory and build actually that big number from each byte of the file. To construct a number, the Least Significant Byte (LSB), which is the last byte of a file, needs to be read and loaded. Although, there is not always enough memory to load a whole file as well as there is not always the whole file is available at any given time. For instance, if it's being transmitted over a network and only a small amount of bytes from the beginning (from the Most Significant Byte, MSB) has been loaded. This issue is usually addressed by processing a file as a stream of bytes, in chunks, which then are being converted in the same way (by converting a number from one base to another). These chunks are much smaller and, ideally, fit the CPU registers' size (up to 8 bytes). The only question here is how to find the best size and ratio of such chunks (input and output) to keep the size overhead as closely as possible to a minimum available by treating files as big numbers.
What's the essence of a positional numeral system?
In the positional numeral systems, everything turns around a radix (base) which shows how many different symbols are used to represent values. The actual glyph doesn't matter. Only their quantity. All these symbols are grouped in an alphabet (a table) where every symbol is defined by its own position, and this position represents its value. As long as counting starts from 0, the maximum symbol's value, in any numeral system, is always radix - 1. For instance, in the numeral system with a radix 10 (Decimal), the maximum value has a symbol '9'. But, for a system with a radix 2 (Binary), the maximum value has a symbol '1'. When symbols from an alphabet appear as a part of a number, they are called digits. A digit's position, in this case, is called index and defines the power of a radix while its value (position in the alphabet) defines a coefficient within the power of that radix.
The first crucial conclusion here is that any number, represented in some positional numeral system, gets its meaning only when is known its radix.
The second conclusion is not so obvious. Humans in most cases nowadays use the Decimal numeral system. Numbers gain more sense for them when they are represented as Decimal numbers and this is the system that is used the most for calculations. To any symbol in an alphabet is assigned its certain position which is a number with some radix. In most cases, this radix is 10 (Decimal). The Decimal numeral system is a temporary system that is used for converting one numeral system to another. Every time, when a number is defined by a radix, this radix is Decimal, no matter what's the radix of a number. Every time, when there is a need to convert a number X with radix M to a number Y with radix M, both numbers (X and Y) are represented by some certain alphabets (which define symbols with values), but their radixes (M and N) are always represented in Decimal system, thus, Decimal system is used as an intermediate numeral system to which a number X is converted first, and then the intermediate number is converted to a number Y. The intermediate numeral system could have been any radix, but radix 10 is what people use for calculations and that's what can be found in most converters implementations.
The third conclusion is even more important. Symbols don't bring any value, only their position in the alphabet. This means we need to know not only an actual number's representation but also its radix and an alphabet - the table that contains symbols assigned to values (position within the table). A good example is an alphabet of 16 symbols for Hexadecimal numbers (radix 16). There are first 10 digits linked to equivalent values, so the symbol '0' is linked to 0, '1' to 1, and so on up to the symbol '9' linked to 9. The rest 6 values (from 10 to 15) linked to English letter symbols (from 'A' to 'F'). And again, these values (positions in the table) are all Decimal numbers (radix 10). By the way, the table could have been different, but that's what is used by convention, so anyone is able to interpret Hexadecimal numbers in the same way.
Where does the overhead come from?
Let's take a look at a few examples. This is a number '123' that is represented by three symbols, but until we know a radix, it is not possible to understand its value. If the radix is 10 then it is 'one hundred twenty three' in the Decimal system and it can be calculated by the formula for converting a numeral system with any radix to radix 10 (because all numbers in this formula have radix 10): 1*10^2 + 2*10^1 + 3*10^0 = 123. If the radix is 8, then it is an Octal system and it is constructed as 1*8^2 + 2*8^1 + 3*8^0 which gives us a Decimal number 83. So, '123 base 8' equals to '83 base 10'. It is worth noticing that converting a number to a higher radix leads to lower a number of symbols needed for its representation. The converse is also true. If a number 83 with a radix 10 is converted to a radix 2, it gets a form '1010011'. Notice, the radix is changed from 10 to 2 and the number of symbols changed from 2 to 7! As lower a radix gets, as more symbols appear in representation.
Let's get back to binary files. What we can determine as 'symbol representation' or 'digits', 'alphabet', and 'radix' based on a structure of an ordinary file? Any file consists of bytes as it is the minimum addressable group of bits. It cannot be less than 8 bits. So, we can think about a number representation as of some amount of bytes. The chunks can vary from 1 byte to a file's size. For example, if there is only one byte, then the number consists of only one digit. One byte or 8 bits (binary digits with a radix 2) allows one to represent 2^8 = 256 different numbers. That means, we can persist 256 different symbols with their positions to build an alphabet. The good news, such a table has already been standardized many years ago and called ASCII. And the last thing, as the alphabet size is 256 symbols then a radix is also 256. Here is our number: a number of bytes in the chunk that we are going to process are the number of digits, a radix is 256, and the coefficient has a range from 0 to 255. For example, if a group of bytes to read from a stream and process at once consists of 4 bytes (from MSB to LSB): [13, 200, 3, 65] then our number can be represented as a Decimal number (radix 10) as 13*256^3 + 200*256^2 + 3*256^1 + 65*256^0 = 231211841
As it was discussed in the previous article, we can use no more than 94 different symbols to reliably represent texts. Thus, the desired radix lies somewhere in the range from 2 to 94. Even 94 is much less than 256, so a number's representation in a new radix is likely to have more symbols. This means, in turn, that the output group will have more bytes as it is a minimum amount of data we can operate on, even if a digit represented by a symbol needs fewer bits. You'll still need to allocate the whole byte for each symbol in the new radix number representation. Some amount of bits in such bytes will never be used. This is the root of inefficiency, and that's why it's highly important to find a good ratio of output to input byte groups. For instance, the most used nowadays Base64 encoding converts binary files to texts by reading 3-bytes groups from the input stream, represents them as a 3-digits number with a radix 256 (log[256^3, 2] = 24 bit), and then converts this number to a 4-digits number with a radix 64 (log[64^4, 2] = 24 bit), which in turn is written to the output stream as a group of 4 bytes. So, the ratio of output to input is 4/3 = 1.333333. In other words, the size overhead is 33.(3)%. There are a few considerations behind the logic of choosing the exact combination of input and output groups for a streaming conversion, which includes a target radix, a desirable/available alphabet, an ability to natively compute on a CPU, etc.
How to calculate a minimal overhead?
Let's calculate first, how many digits of a target base (radix) are needed to represent exactly the same number in the initial base. For instance, there is given a number 123 with a radix 10. How many bits (binary digits, a radix 2) are needed to represent the same decimal number? Every digit is a coefficient of power of a base. If it is not enough, one more base is added in power +1 to finally construct a number. Keeping in mind that counting starts from 0, if it's said that to represent some number 8 bit are needed, this means all bases in powers from 0 to 7 with their coefficients have to be summed up. Thus, to find out a number of digits needed to represent the number in some radix, we need to find an exponent, to which a new radix needs to be exponentiated. In our case, for a base-10 number 123, we need to calculate an exponent of a base-2 by using a logarithm function: log[123, 2] = 6.9425145. This means, to represent a number 123 with base 10, a little bit less than 7 bits will be enough. All computer systems operate on a set of natural numbers only. It is not possible to use 6.9425145 bits as this number is an approximated value of needed bits. 6 bits apparently won't be enough (2^6 = 64, which is much less than 123), so the only right approach is always to round up (by calling a ceil function) any non-integer values. Unfortunately, 7 bits are able to represent a bigger number (2^7 = 128) and this again contributes to a final overhead.
Let's have a look at the Base64 again. We know already (but not why is that, yet), that this streaming system uses 3 input bytes (a 3-digit number with a base 256) and converts them to a number with a base 64. How many base-64 digits will this number contain? The answer is log[256^3, 64] = 4, four digits, hence 4 symbols from the base64 alphabet.
While looking for the good input and output group sizes it's good to know a theoretically possible minimum of the overhead. To find it out, we need to do a similar calculation but take the minimally possible amount of input data, which is one byte (8 bits, decimal 2^8 = 256). For the Base64, it is log[256, 64] = 1.33(3), that is again 33.(3)%. For the Base32 it is log[256, 32] = 1.6, that is 60%. And for the Base16 it is log[256, 16] = 2, that is 100%. Wow! These theoretical numbers are exactly the same as practically used ratios of output bytes to input bytes give. Here are they: for the Base64 it is 4 / 3 = 1.33(3), for the Base32 it is 8 / 5 = 1.6, and for the Base16 it is 2 / 1 = 2. There is one interesting fact, all these three bases (16, 32, 64) have one thing in common - they all are powers of two! This leads us to the conclusion that converting numbers within the "power of two" bases allows one to get the best possible ratio and match precisely an input bits group to an output bits group. Although it is not always desirable or even possible. Sometimes there is a need to use a specific alphabet, e.g. in Base36, or the minimal overhead, e.g. in Base85 or Base94. All these bases are not the "powers of two", so a tradeoff has to be found to minimize the overhead.
How to calculate optimal input and output groups?
Alright, we've calculated a number of digits needed to represent some number in another base. But, why is that only a theoretical minimum? Why in practice it would need more? And, why would we still need to find a good ratio of output to input byte groups? To answer these questions, let's have a look at the Base85 encoding. To represent 1 byte (Base256) of information in Base85, it needs log[256, 85] = 1.24816852 digits. But, we can't use 1.248 digits. Only positive whole numbers are available! 1 digit is neither possible (too little). Then, 2 digits are the only way to go. In other words, to represent 1 byte (with a number in Base256), in fact, we'd need 2 bytes (with a number in Base85), where ~75% of space will be wasted, as the ratio is 2/1 = 2 and this is a 100% overhead, instead of a theoretical 24.8%. There is no point to use 1-byte input group and 2-bytes output group. Thus, there should be some good input and output groups so their ratio goes as close as possible to a calculated minimum or even match it!
The following approach starts from 1-byte group and using the same formula, every time checks a number of digits in the destination base. if it's not close enough, increments the input group by 1 byte and checks again. You can decide on your own, what is the applicable size of an input group and how close to the whole number up (ceil function) the output group needs to be.
This code goes through all bases, from 2 to 94, and prints a first found input/output group that has a delta between the number of digits and its rounded value less or equal 0.1, if any. That is, ceil(x) - x <=0.1. I limited an input group by 20 bytes but in reality, groups larger than 8 bytes (64bit) will require either a more complicated implementation still based on 64bit variable types or the big number mathematics which would bring it back to the solution from the previous article.
from math import log, ceil
+ The zoo of binary-to-text encoding schemes :: Vorakl's notes The zoo of binary-to-text encoding schemes
A stream encoding algorithm with a variable base (16, 32, 36, 64, 58, 85, 94)
In the previous article, I discussed the use of the positional numeral system for the purpose of binary-to-text translation. That method represents a binary file as a single big number with the radix 256 and then converts this big number to another one with an arbitrary radix (base) in a range from 2 to 94. Although this approach gives the minimum possible size overhead, unfortunately, it also has a number of downsides which make it hardly usable in a real-world situation. In this article, I'll show what is used in practice, which encodings could be found in the wild, and how to build your own encoder.
What's wrong with the positional single number encoding?
The main issue with converting a file as a big number in radix 256 to another big number with a smaller radix is that you need to read the whole file, load it to the memory and build actually that big number from each byte of the file. To construct a number, the Least Significant Byte (LSB), which is the last byte of a file, needs to be read and loaded. Although, there is not always enough memory to load a whole file as well as there is not always the whole file is available at any given time. For instance, if it's being transmitted over a network and only a small amount of bytes from the beginning (from the Most Significant Byte, MSB) has been loaded. This issue is usually addressed by processing a file as a stream of bytes, in chunks, which then are being converted in the same way (by converting a number from one base to another). These chunks are much smaller and, ideally, fit the CPU registers' size (up to 8 bytes). The only question here is how to find the best size and ratio of such chunks (input and output) to keep the size overhead as closely as possible to a minimum available by treating files as big numbers.
What's the essence of a positional numeral system?
In the positional numeral systems, everything turns around a radix (base) which shows how many different symbols are used to represent values. The actual glyph doesn't matter. Only their quantity. All these symbols are grouped in an alphabet (a table) where every symbol is defined by its own position, and this position represents its value. As long as counting starts from 0, the maximum symbol's value, in any numeral system, is always radix - 1. For instance, in the numeral system with a radix 10 (Decimal), the maximum value has a symbol '9'. But, for a system with a radix 2 (Binary), the maximum value has a symbol '1'. When symbols from an alphabet appear as a part of a number, they are called digits. A digit's position, in this case, is called index and defines the power of a radix while its value (position in the alphabet) defines a coefficient within the power of that radix.
The first crucial conclusion here is that any number, represented in some positional numeral system, gets its meaning only when is known its radix.
The second conclusion is not so obvious. Humans in most cases nowadays use the Decimal numeral system. Numbers gain more sense for them when they are represented as Decimal numbers and this is the system that is used the most for calculations. To any symbol in an alphabet is assigned its certain position which is a number with some radix. In most cases, this radix is 10 (Decimal). The Decimal numeral system is a temporary system that is used for converting one numeral system to another. Every time, when a number is defined by a radix, this radix is Decimal, no matter what's the radix of a number. Every time, when there is a need to convert a number X with radix M to a number Y with radix M, both numbers (X and Y) are represented by some certain alphabets (which define symbols with values), but their radixes (M and N) are always represented in Decimal system, thus, Decimal system is used as an intermediate numeral system to which a number X is converted first, and then the intermediate number is converted to a number Y. The intermediate numeral system could have been any radix, but radix 10 is what people use for calculations and that's what can be found in most converters implementations.
The third conclusion is even more important. Symbols don't bring any value, only their position in the alphabet. This means we need to know not only an actual number's representation but also its radix and an alphabet - the table that contains symbols assigned to values (position within the table). A good example is an alphabet of 16 symbols for Hexadecimal numbers (radix 16). There are first 10 digits linked to equivalent values, so the symbol '0' is linked to 0, '1' to 1, and so on up to the symbol '9' linked to 9. The rest 6 values (from 10 to 15) linked to English letter symbols (from 'A' to 'F'). And again, these values (positions in the table) are all Decimal numbers (radix 10). By the way, the table could have been different, but that's what is used by convention, so anyone is able to interpret Hexadecimal numbers in the same way.
Where does the overhead come from?
Let's take a look at a few examples. This is a number '123' that is represented by three symbols, but until we know a radix, it is not possible to understand its value. If the radix is 10 then it is 'one hundred twenty three' in the Decimal system and it can be calculated by the formula for converting a numeral system with any radix to radix 10 (because all numbers in this formula have radix 10): 1*10^2 + 2*10^1 + 3*10^0 = 123. If the radix is 8, then it is an Octal system and it is constructed as 1*8^2 + 2*8^1 + 3*8^0 which gives us a Decimal number 83. So, '123 base 8' equals to '83 base 10'. It is worth noticing that converting a number to a higher radix leads to lower a number of symbols needed for its representation. The converse is also true. If a number 83 with a radix 10 is converted to a radix 2, it gets a form '1010011'. Notice, the radix is changed from 10 to 2 and the number of symbols changed from 2 to 7! As lower a radix gets, as more symbols appear in representation.
Let's get back to binary files. What we can determine as 'symbol representation' or 'digits', 'alphabet', and 'radix' based on a structure of an ordinary file? Any file consists of bytes as it is the minimum addressable group of bits. It cannot be less than 8 bits. So, we can think about a number representation as of some amount of bytes. The chunks can vary from 1 byte to a file's size. For example, if there is only one byte, then the number consists of only one digit. One byte or 8 bits (binary digits with a radix 2) allows one to represent 2^8 = 256 different numbers. That means, we can persist 256 different symbols with their positions to build an alphabet. The good news, such a table has already been standardized many years ago and called ASCII. And the last thing, as the alphabet size is 256 symbols then a radix is also 256. Here is our number: a number of bytes in the chunk that we are going to process are the number of digits, a radix is 256, and the coefficient has a range from 0 to 255. For example, if a group of bytes to read from a stream and process at once consists of 4 bytes (from MSB to LSB): [13, 200, 3, 65] then our number can be represented as a Decimal number (radix 10) as 13*256^3 + 200*256^2 + 3*256^1 + 65*256^0 = 231211841
As it was discussed in the previous article, we can use no more than 94 different symbols to reliably represent texts. Thus, the desired radix lies somewhere in the range from 2 to 94. Even 94 is much less than 256, so a number's representation in a new radix is likely to have more symbols. This means, in turn, that the output group will have more bytes as it is a minimum amount of data we can operate on, even if a digit represented by a symbol needs fewer bits. You'll still need to allocate the whole byte for each symbol in the new radix number representation. Some amount of bits in such bytes will never be used. This is the root of inefficiency, and that's why it's highly important to find a good ratio of output to input byte groups. For instance, the most used nowadays Base64 encoding converts binary files to texts by reading 3-bytes groups from the input stream, represents them as a 3-digits number with a radix 256 (log[256^3, 2] = 24 bit), and then converts this number to a 4-digits number with a radix 64 (log[64^4, 2] = 24 bit), which in turn is written to the output stream as a group of 4 bytes. So, the ratio of output to input is 4/3 = 1.333333. In other words, the size overhead is 33.(3)%. There are a few considerations behind the logic of choosing the exact combination of input and output groups for a streaming conversion, which includes a target radix, a desirable/available alphabet, an ability to natively compute on a CPU, etc.
How to calculate a minimal overhead?
Let's calculate first, how many digits of a target base (radix) are needed to represent exactly the same number in the initial base. For instance, there is given a number 123 with a radix 10. How many bits (binary digits, a radix 2) are needed to represent the same decimal number? Every digit is a coefficient of power of a base. If it is not enough, one more base is added in power +1 to finally construct a number. Keeping in mind that counting starts from 0, if it's said that to represent some number 8 bit are needed, this means all bases in powers from 0 to 7 with their coefficients have to be summed up. Thus, to find out a number of digits needed to represent the number in some radix, we need to find an exponent, to which a new radix needs to be exponentiated. In our case, for a base-10 number 123, we need to calculate an exponent of a base-2 by using a logarithm function: log[123, 2] = 6.9425145. This means, to represent a number 123 with base 10, a little bit less than 7 bits will be enough. All computer systems operate on a set of natural numbers only. It is not possible to use 6.9425145 bits as this number is an approximated value of needed bits. 6 bits apparently won't be enough (2^6 = 64, which is much less than 123), so the only right approach is always to round up (by calling a ceil function) any non-integer values. Unfortunately, 7 bits are able to represent a bigger number (2^7 = 128) and this again contributes to a final overhead.
Let's have a look at the Base64 again. We know already (but not why is that, yet), that this streaming system uses 3 input bytes (a 3-digit number with a base 256) and converts them to a number with a base 64. How many base-64 digits will this number contain? The answer is log[256^3, 64] = 4, four digits, hence 4 symbols from the base64 alphabet.
While looking for the good input and output group sizes it's good to know a theoretically possible minimum of the overhead. To find it out, we need to do a similar calculation but take the minimally possible amount of input data, which is one byte (8 bits, decimal 2^8 = 256). For the Base64, it is log[256, 64] = 1.33(3), that is again 33.(3)%. For the Base32 it is log[256, 32] = 1.6, that is 60%. And for the Base16 it is log[256, 16] = 2, that is 100%. Wow! These theoretical numbers are exactly the same as practically used ratios of output bytes to input bytes give. Here are they: for the Base64 it is 4 / 3 = 1.33(3), for the Base32 it is 8 / 5 = 1.6, and for the Base16 it is 2 / 1 = 2. There is one interesting fact, all these three bases (16, 32, 64) have one thing in common - they all are powers of two! This leads us to the conclusion that converting numbers within the "power of two" bases allows one to get the best possible ratio and match precisely an input bits group to an output bits group. Although it is not always desirable or even possible. Sometimes there is a need to use a specific alphabet, e.g. in Base36, or the minimal overhead, e.g. in Base85 or Base94. All these bases are not the "powers of two", so a tradeoff has to be found to minimize the overhead.
How to calculate optimal input and output groups?
Alright, we've calculated a number of digits needed to represent some number in another base. But, why is that only a theoretical minimum? Why in practice it would need more? And, why would we still need to find a good ratio of output to input byte groups? To answer these questions, let's have a look at the Base85 encoding. To represent 1 byte (Base256) of information in Base85, it needs log[256, 85] = 1.24816852 digits. But, we can't use 1.248 digits. Only positive whole numbers are available! 1 digit is neither possible (too little). Then, 2 digits are the only way to go. In other words, to represent 1 byte (with a number in Base256), in fact, we'd need 2 bytes (with a number in Base85), where ~75% of space will be wasted, as the ratio is 2/1 = 2 and this is a 100% overhead, instead of a theoretical 24.8%. There is no point to use 1-byte input group and 2-bytes output group. Thus, there should be some good input and output groups so their ratio goes as close as possible to a calculated minimum or even match it!
The following approach starts from 1-byte group and using the same formula, every time checks a number of digits in the destination base. if it's not close enough, increments the input group by 1 byte and checks again. You can decide on your own, what is the applicable size of an input group and how close to the whole number up (ceil function) the output group needs to be.
This code goes through all bases, from 2 to 94, and prints a first found input/output group that has a delta between the number of digits and its rounded value less or equal 0.1, if any. That is, ceil(x) - x <=0.1. I limited an input group by 20 bytes but in reality, groups larger than 8 bytes (64bit) will require either a more complicated implementation still based on 64bit variable types or the big number mathematics which would bring it back to the solution from the previous article.
from math import log, ceil
def find_dec_fractions(num):
for i, k in [(i, log(256**i, num)) for i in range(1,20)]:
diff --git a/articles/turing/index.html b/articles/turing/index.html
index 60bfabae..b05cb608 100644
--- a/articles/turing/index.html
+++ b/articles/turing/index.html
@@ -1 +1 @@
- Turing: thesis, machine, completeness :: Vorakl's notes Turing: thesis, machine, completeness
A formal system in the computability theory
Alan Turing is one of the pioneers of the computability theory and logic formalization. He came up with the hypothesis of which algorithms can be implemented and computed by machines (Turing's thesis), created an abstract model of such machine (Turing machine), and described absolutely vital abilities of any system for being able to realize any logic that can be computed (Turing completeness).
Turing's thesis is only one of the existing formal systems in the computability theory. There are also λ-calculus, Markov algorithms, but they all were implemented on the Turing Machine that is used at this time as a general computational model to classify which real-world systems (mostly programming languages) are able to compute mathematical functions or implement algorithms.
All existing computability theories are defined on discrete values, and the domain is the set of Natural numbers.
I prepared several mindmaps to summarize basic ideas and statements:
- Turing's thesis:
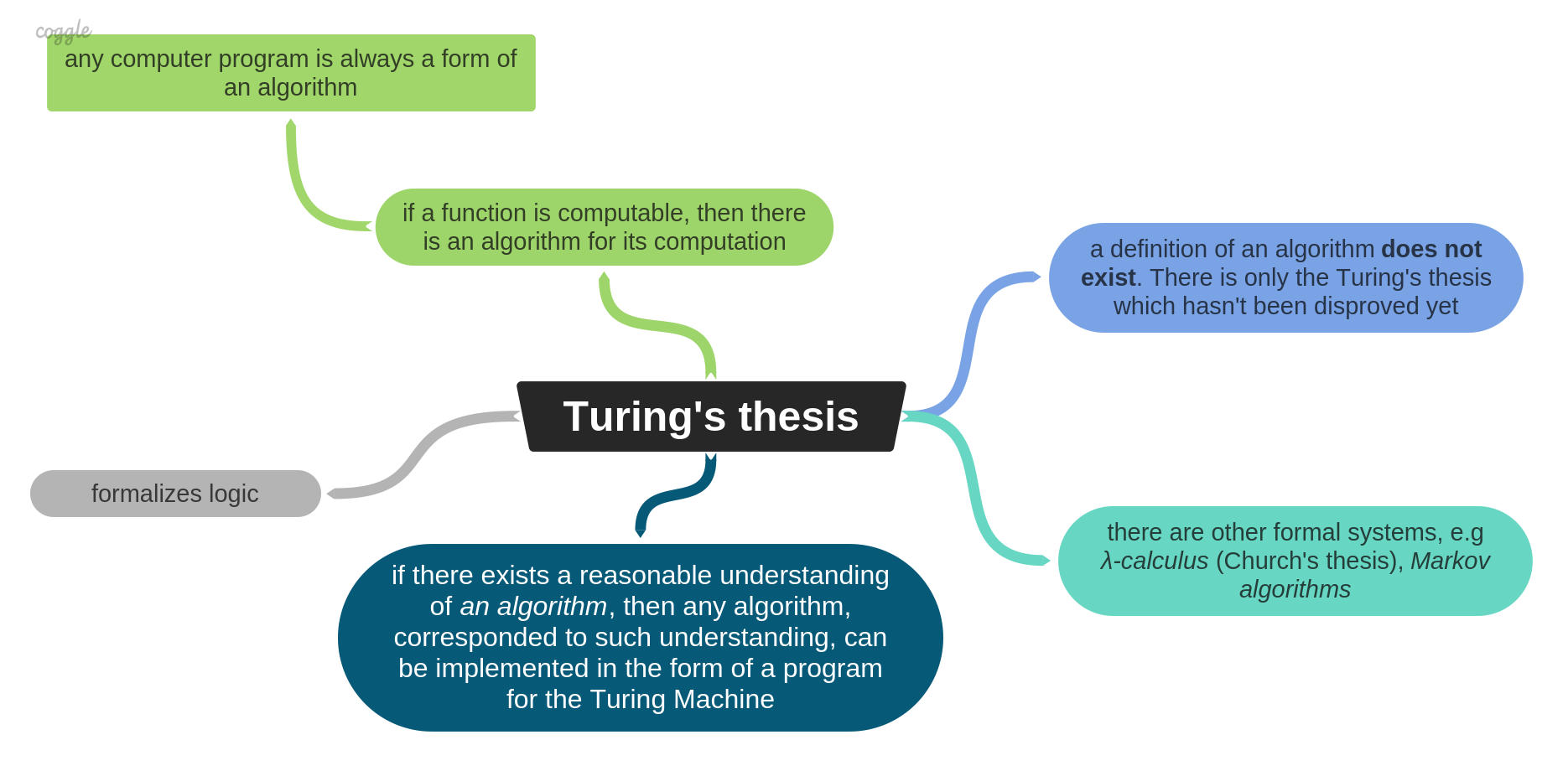
- Turing machine:
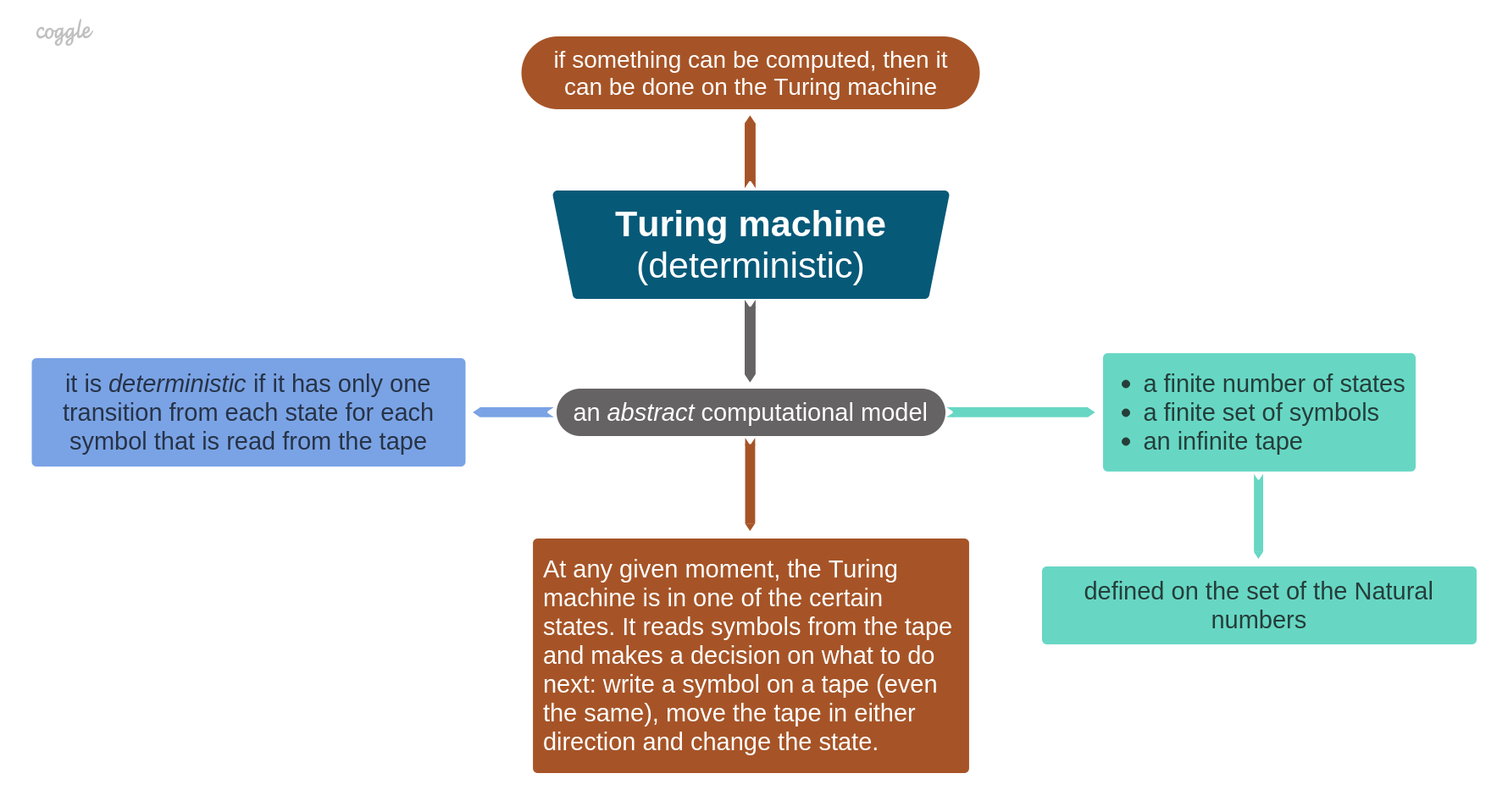
- Turing completeness:
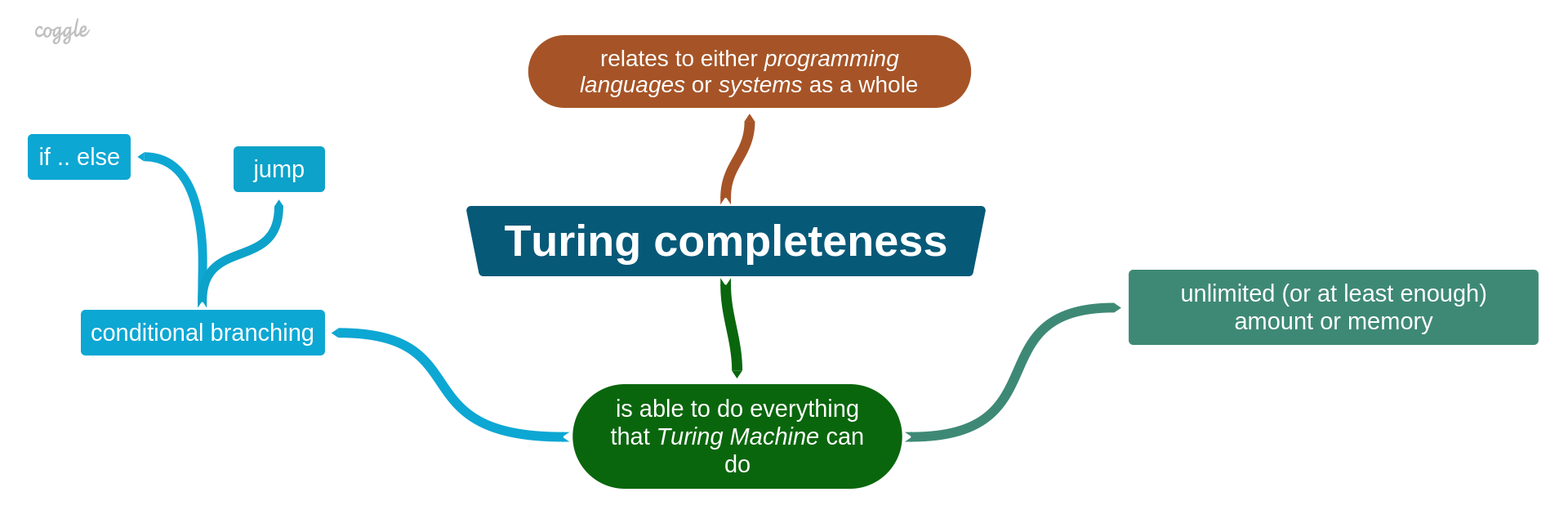
This is my personal blog. All ideas, opinions, examples, and other information that can be found here are my own and belong entirely to me. This is the result of my personal efforts and activities at my free time. It doesn't relate to any professional work I've done and doesn't have correlations with any companies I worked for, I'm currently working, or will work in the future.
\ No newline at end of file
+ Turing: thesis, machine, completeness :: Vorakl's notes Turing: thesis, machine, completeness
A formal system in the computability theory
Alan Turing is one of the pioneers of the computability theory and logic formalization. He came up with the hypothesis of which algorithms can be implemented and computed by machines (Turing's thesis), created an abstract model of such machine (Turing machine), and described absolutely vital abilities of any system for being able to realize any logic that can be computed (Turing completeness).
Turing's thesis is only one of the existing formal systems in the computability theory. There are also λ-calculus, Markov algorithms, but they all were implemented on the Turing Machine that is used at this time as a general computational model to classify which real-world systems (mostly programming languages) are able to compute mathematical functions or implement algorithms.
All existing computability theories are defined on discrete values, and the domain is the set of Natural numbers.
I prepared several mindmaps to summarize basic ideas and statements:
- Turing's thesis:
- Turing machine:
- Turing completeness:
This is my personal blog. All ideas, opinions, examples, and other information that can be found here are my own and belong entirely to me. This is the result of my personal efforts and activities at my free time. It doesn't relate to any professional work I've done and doesn't have correlations with any companies I worked for, I'm currently working, or will work in the future.
\ No newline at end of file
diff --git a/articles/udp-link/index.html b/articles/udp-link/index.html
index c227ce61..56cb0ac6 100644
--- a/articles/udp-link/index.html
+++ b/articles/udp-link/index.html
@@ -1,4 +1,4 @@
- Using udp-link to enhance TCP connections stability :: Vorakl's notes Using udp-link to enhance TCP connections stability
A UDP transport layer implementation for proxying TCP connections
I recently discovered udp-link, a very useful project for all those guys like me who spend most of their working time in terminals over ssh connections. The tool implements the UDP transport layer, which acts as a proxy for TCP connections. It's designed to be integrated into the OpenSSH configuration. However, with a little trick, it can also be used as a general-purpose TCP-over-UDP proxy. udp-link greatly improves the stability of connections over unreliable networks that experience packet loss and intermittent connectivity. It also includes an IP roaming, which allows TCP connections to remain alive even if an IP address changes.
udp-link is written in C by Pavel Gulchuk, who has a lot of experience in running unreliable networks. Despite being a young project, the version v0.4 shows pretty stable results. Once configured, you won't think about it anymore. Unless you're surprised every time when ssh connections don't brake, survive a laptop's sleep mode and connections to different Wi-Fi networks.
In the current architecture, the client-side tool takes data on the standard input and sends it to the server side via UDP. The same copy of the tool takes that data from the network on a specific UDP port and sends it to a TCP service (local or remote from a server-side perspective). The destination TCP service and a UDP listening port on the server side can be specified on the client at startup. Otherwise, a TCP connection will be established with 127.0.0.1:22 and a port is randomly chosen from a predefined port range. Note that the server firewall should allow the traffic to this port range on UDP. The TCP service can also reside on a different host, if the server side is used as a jumpbox. I consider it one of the greatest features that udp-link uses a zero server-side configuration, all configuration tweaks happen only on the client side.
udp-link on the server side does not run as a daemon or listen on a UDP port all the time. Instead, the client initiates the invocation of the tool on the on the server side in listening mode with a randomly generated key. This key is used to authenticate the client connection. This is done on demand by establishing a normal ssh connection over TCP with the server side, temporarily, just to run the tool in the background. The connection is then closed. This is where a secure client authentication comes into play. udp-link doesn't encrypt the transferred data, which is useful when is used together with ssh because it avoids a double encryption, but needs to be kept that in mind when used with other configurations.
To start using udp-link, you need to clone the repository, compile, and install the tool on both sides
git clone https://github.com/pgul/udp-link.git
+ Using udp-link to enhance TCP connections stability :: Vorakl's notes Using udp-link to enhance TCP connections stability
A UDP transport layer implementation for proxying TCP connections
I recently discovered udp-link, a very useful project for all those guys like me who spend most of their working time in terminals over ssh connections. The tool implements the UDP transport layer, which acts as a proxy for TCP connections. It's designed to be integrated into the OpenSSH configuration. However, with a little trick, it can also be used as a general-purpose TCP-over-UDP proxy. udp-link greatly improves the stability of connections over unreliable networks that experience packet loss and intermittent connectivity. It also includes an IP roaming, which allows TCP connections to remain alive even if an IP address changes.
udp-link is written in C by Pavel Gulchuk, who has a lot of experience in running unreliable networks. Despite being a young project, the version v0.4 shows pretty stable results. Once configured, you won't think about it anymore. Unless you're surprised every time when ssh connections don't brake, survive a laptop's sleep mode and connections to different Wi-Fi networks.
In the current architecture, the client-side tool takes data on the standard input and sends it to the server side via UDP. The same copy of the tool takes that data from the network on a specific UDP port and sends it to a TCP service (local or remote from a server-side perspective). The destination TCP service and a UDP listening port on the server side can be specified on the client at startup. Otherwise, a TCP connection will be established with 127.0.0.1:22 and a port is randomly chosen from a predefined port range. Note that the server firewall should allow the traffic to this port range on UDP. The TCP service can also reside on a different host, if the server side is used as a jumpbox. I consider it one of the greatest features that udp-link uses a zero server-side configuration, all configuration tweaks happen only on the client side.
udp-link on the server side does not run as a daemon or listen on a UDP port all the time. Instead, the client initiates the invocation of the tool on the on the server side in listening mode with a randomly generated key. This key is used to authenticate the client connection. This is done on demand by establishing a normal ssh connection over TCP with the server side, temporarily, just to run the tool in the background. The connection is then closed. This is where a secure client authentication comes into play. udp-link doesn't encrypt the transferred data, which is useful when is used together with ssh because it avoids a double encryption, but needs to be kept that in mind when used with other configurations.
To start using udp-link, you need to clone the repository, compile, and install the tool on both sides
git clone https://github.com/pgul/udp-link.git
cd udp-link
make
sudo make install
diff --git a/authors/index.html b/authors/index.html
index 519fcfc1..da83db36 100644
--- a/authors/index.html
+++ b/authors/index.html
@@ -1 +1 @@
- Authors :: Vorakl's notes
\ No newline at end of file
+ Authors :: Vorakl's notes
\ No newline at end of file
diff --git a/authors/vorakl/index.html b/authors/vorakl/index.html
index e8ce03d9..c9cc77e3 100644
--- a/authors/vorakl/index.html
+++ b/authors/vorakl/index.html
@@ -1 +1 @@
- Articles written by vorakl :: Vorakl's notes Articles written by vorakl
2024-01-16 Using udp-link to enhance TCP connections stability 2020-05-13 The zoo of binary-to-text encoding schemes 2020-04-18 Convert binary data to a text with the lowest overhead 2020-01-18 My notes for the "Pragmatic Thinking and Learning" book 2019-12-20 Computer Science vs Information Technology 2019-12-19 Who is an engineer 2019-12-15 Algorithm is... 2019-12-15 Turing: thesis, machine, completeness 2019-08-21 Organizing Unstructured Data 2019-08-16 Number Classification
\ No newline at end of file
+ Articles written by vorakl :: Vorakl's notes Articles written by vorakl
2024-01-16 Using udp-link to enhance TCP connections stability 2020-05-13 The zoo of binary-to-text encoding schemes 2020-04-18 Convert binary data to a text with the lowest overhead 2020-01-18 My notes for the "Pragmatic Thinking and Learning" book 2019-12-20 Computer Science vs Information Technology 2019-12-19 Who is an engineer 2019-12-15 Algorithm is... 2019-12-15 Turing: thesis, machine, completeness 2019-08-21 Organizing Unstructured Data 2019-08-16 Number Classification
\ No newline at end of file
diff --git a/authors/vorakl/p2/index.html b/authors/vorakl/p2/index.html
index 8da3c9d2..e5410920 100644
--- a/authors/vorakl/p2/index.html
+++ b/authors/vorakl/p2/index.html
@@ -1 +1 @@
- Articles written by vorakl :: Vorakl's notes Articles written by vorakl
2019-08-08 A converter of a character's case and Ascii codes 2019-07-22 Constraint Satisfaction Problem (CSP) 2019-07-18 How to remove a webpage from the Google index 2019-07-02 How to redirect a static website on the Github Pages 2019-06-26 Managing your plans in the S.M.A.R.T. way 2019-06-21 Dreyfus model of skill acquisition 2019-06-15 Maslow's hierarchy of needs 2019-06-12 Structured Programming Paradigm 2019-06-10 SQ3R
\ No newline at end of file
+ Articles written by vorakl :: Vorakl's notes Articles written by vorakl
2019-08-08 A converter of a character's case and Ascii codes 2019-07-22 Constraint Satisfaction Problem (CSP) 2019-07-18 How to remove a webpage from the Google index 2019-07-02 How to redirect a static website on the Github Pages 2019-06-26 Managing your plans in the S.M.A.R.T. way 2019-06-21 Dreyfus model of skill acquisition 2019-06-15 Maslow's hierarchy of needs 2019-06-12 Structured Programming Paradigm 2019-06-10 SQ3R
\ No newline at end of file
diff --git a/categories/article/index.html b/categories/article/index.html
index f0a94945..f271181e 100644
--- a/categories/article/index.html
+++ b/categories/article/index.html
@@ -1 +1 @@
- A full story about some specific topic :: Vorakl's notes A full story about some specific topic
\ No newline at end of file
+ A full story about some specific topic :: Vorakl's notes A full story about some specific topic
\ No newline at end of file
diff --git a/categories/howto/index.html b/categories/howto/index.html
index a1e16d28..34339ed1 100644
--- a/categories/howto/index.html
+++ b/categories/howto/index.html
@@ -1 +1 @@
- A practical guide how to make something :: Vorakl's notes A practical guide how to make something
2019-07-18 How to remove a webpage from the Google index 2019-07-02 How to redirect a static website on the Github Pages
\ No newline at end of file
+ A practical guide how to make something :: Vorakl's notes A practical guide how to make something
2019-07-18 How to remove a webpage from the Google index 2019-07-02 How to redirect a static website on the Github Pages
\ No newline at end of file
diff --git a/categories/index.html b/categories/index.html
index b857ff91..da263f43 100644
--- a/categories/index.html
+++ b/categories/index.html
@@ -1 +1 @@
- Categories :: Vorakl's notes
\ No newline at end of file
+ Categories :: Vorakl's notes
\ No newline at end of file
diff --git a/categories/note/index.html b/categories/note/index.html
index fa292a44..dd0ee419 100644
--- a/categories/note/index.html
+++ b/categories/note/index.html
@@ -1 +1 @@
- A brief record of thoughts :: Vorakl's notes A brief record of thoughts
2020-01-18 My notes for the "Pragmatic Thinking and Learning" book 2019-12-20 Computer Science vs Information Technology 2019-12-19 Who is an engineer 2019-12-15 Algorithm is... 2019-12-15 Turing: thesis, machine, completeness 2019-08-21 Organizing Unstructured Data 2019-08-16 Number Classification 2019-07-22 Constraint Satisfaction Problem (CSP) 2019-06-26 Managing your plans in the S.M.A.R.T. way 2019-06-21 Dreyfus model of skill acquisition
\ No newline at end of file
+ A brief record of thoughts :: Vorakl's notes A brief record of thoughts
2020-01-18 My notes for the "Pragmatic Thinking and Learning" book 2019-12-20 Computer Science vs Information Technology 2019-12-19 Who is an engineer 2019-12-15 Algorithm is... 2019-12-15 Turing: thesis, machine, completeness 2019-08-21 Organizing Unstructured Data 2019-08-16 Number Classification 2019-07-22 Constraint Satisfaction Problem (CSP) 2019-06-26 Managing your plans in the S.M.A.R.T. way 2019-06-21 Dreyfus model of skill acquisition
\ No newline at end of file
diff --git a/categories/note/p2/index.html b/categories/note/p2/index.html
index 3cd36363..58ac6f6a 100644
--- a/categories/note/p2/index.html
+++ b/categories/note/p2/index.html
@@ -1 +1 @@
- A brief record of thoughts :: Vorakl's notes A brief record of thoughts
2019-06-15 Maslow's hierarchy of needs 2019-06-12 Structured Programming Paradigm 2019-06-10 SQ3R
\ No newline at end of file
+ A brief record of thoughts :: Vorakl's notes A brief record of thoughts
2019-06-15 Maslow's hierarchy of needs 2019-06-12 Structured Programming Paradigm 2019-06-10 SQ3R
\ No newline at end of file
diff --git a/index.html b/index.html
index f8cc4fc2..254af672 100644
--- a/index.html
+++ b/index.html
@@ -1 +1 @@
- Notes on Systems and Software Engineering :: Vorakl's notes
\ No newline at end of file
+ Notes on Systems and Software Engineering :: Vorakl's notes
\ No newline at end of file
diff --git a/news/index.html b/news/index.html
index b3799e9a..e96177a1 100644
--- a/news/index.html
+++ b/news/index.html
@@ -1 +1 @@
- Notes on Systems and Software Engineering :: Vorakl's notes Notes on Systems and Software Engineering
2024-01-16 Using udp-link to enhance TCP connections stability 2020-05-13 The zoo of binary-to-text encoding schemes 2020-04-18 Convert binary data to a text with the lowest overhead 2020-01-18 My notes for the "Pragmatic Thinking and Learning" book 2019-12-20 Computer Science vs Information Technology 2019-12-19 Who is an engineer 2019-12-15 Algorithm is... 2019-12-15 Turing: thesis, machine, completeness 2019-08-21 Organizing Unstructured Data 2019-08-16 Number Classification
\ No newline at end of file
+ Notes on Systems and Software Engineering :: Vorakl's notes Notes on Systems and Software Engineering
2024-01-16 Using udp-link to enhance TCP connections stability 2020-05-13 The zoo of binary-to-text encoding schemes 2020-04-18 Convert binary data to a text with the lowest overhead 2020-01-18 My notes for the "Pragmatic Thinking and Learning" book 2019-12-20 Computer Science vs Information Technology 2019-12-19 Who is an engineer 2019-12-15 Algorithm is... 2019-12-15 Turing: thesis, machine, completeness 2019-08-21 Organizing Unstructured Data 2019-08-16 Number Classification
\ No newline at end of file
diff --git a/news/p2/index.html b/news/p2/index.html
index 5668d056..7e4223b5 100644
--- a/news/p2/index.html
+++ b/news/p2/index.html
@@ -1 +1 @@
- Notes on Systems and Software Engineering :: Vorakl's notes Notes on Systems and Software Engineering
2019-08-08 A converter of a character's case and Ascii codes 2019-07-22 Constraint Satisfaction Problem (CSP) 2019-07-18 How to remove a webpage from the Google index 2019-07-02 How to redirect a static website on the Github Pages 2019-06-26 Managing your plans in the S.M.A.R.T. way 2019-06-21 Dreyfus model of skill acquisition 2019-06-15 Maslow's hierarchy of needs 2019-06-12 Structured Programming Paradigm 2019-06-10 SQ3R
\ No newline at end of file
+ Notes on Systems and Software Engineering :: Vorakl's notes Notes on Systems and Software Engineering
2019-08-08 A converter of a character's case and Ascii codes 2019-07-22 Constraint Satisfaction Problem (CSP) 2019-07-18 How to remove a webpage from the Google index 2019-07-02 How to redirect a static website on the Github Pages 2019-06-26 Managing your plans in the S.M.A.R.T. way 2019-06-21 Dreyfus model of skill acquisition 2019-06-15 Maslow's hierarchy of needs 2019-06-12 Structured Programming Paradigm 2019-06-10 SQ3R
\ No newline at end of file
diff --git a/pages/about/index.html b/pages/about/index.html
index c234aca6..84fb5e35 100644
--- a/pages/about/index.html
+++ b/pages/about/index.html
@@ -1 +1 @@
- About me and my blog :: Vorakl's notes About me and my blog
A brief overview of my life path and a professional career I was born in Kiev, on a territory of UkrSSR, which later became an independent country. I lived in Ukraine for more than 30 years. When I was 11, I began learning programming in Sphere. Last 2 grades of an elementary school I was taking extra programming classes and got a certificate of assistant-programmer. First years at a high school, I got realy interested in administering a FidoNet node and digging into the Internet. I graduated from the National Technical University of Ukraine and got a Masters Degree in Radio and Television Engineering. In the last year at the university I applied to a Computer Academy Step and 2 years studied Computer Networks and Systems Engineering.
My career as a Computer Systems Engineer began in 2004. Since then, I worked in various fields, such as retail companies (Karavan, Fozzy Group) and internet service providers (Telesystems of Ukraine, Bramatelecom) in Ukraine, an IT consulting company (SoftServe) in Poland, an e-commerce company (ZooPlus) and american multinational technology company (IBM) in Germany. I was designing, building and maintaining computer networks, distributed infrastructures, and platforms for running high-available applications. In 2020, my family and I moved to the US and I was hired by Google.
\ No newline at end of file
+ About me and my blog :: Vorakl's notes About me and my blog
A brief overview of my life path and a professional career I was born in Kiev, on a territory of UkrSSR, which later became an independent country. I lived in Ukraine for more than 30 years. When I was 11, I began learning programming in Sphere. Last 2 grades of an elementary school I was taking extra programming classes and got a certificate of assistant-programmer. First years at a high school, I got realy interested in administering a FidoNet node and digging into the Internet. I graduated from the National Technical University of Ukraine and got a Masters Degree in Radio and Television Engineering. In the last year at the university I applied to a Computer Academy Step and 2 years studied Computer Networks and Systems Engineering.
My career as a Computer Systems Engineer began in 2004. Since then, I worked in various fields, such as retail companies (Karavan, Fozzy Group) and internet service providers (Telesystems of Ukraine, Bramatelecom) in Ukraine, an IT consulting company (SoftServe) in Poland, an e-commerce company (ZooPlus) and american multinational technology company (IBM) in Germany. I was designing, building and maintaining computer networks, distributed infrastructures, and platforms for running high-available applications. In 2020, my family and I moved to the US and I was hired by Google.
\ No newline at end of file
diff --git a/pages/contacts/index.html b/pages/contacts/index.html
index 18dea3a9..1d2b1651 100644
--- a/pages/contacts/index.html
+++ b/pages/contacts/index.html
@@ -1 +1 @@
- Contact information :: Vorakl's notes
\ No newline at end of file
+ Contact information :: Vorakl's notes
\ No newline at end of file
diff --git a/pages/feedback/index.html b/pages/feedback/index.html
index a33c783e..094e1dda 100644
--- a/pages/feedback/index.html
+++ b/pages/feedback/index.html
@@ -1 +1 @@
- Feedback :: Vorakl's notes Feedback
Send me a direct message
\ No newline at end of file
+ Feedback :: Vorakl's notes Feedback
Send me a direct message
\ No newline at end of file
diff --git a/pages/index.html b/pages/index.html
index cf71c272..f799f454 100644
--- a/pages/index.html
+++ b/pages/index.html
@@ -1 +1 @@
- Pages :: Vorakl's notes
\ No newline at end of file
+ Pages :: Vorakl's notes
\ No newline at end of file
diff --git a/pages/projects/index.html b/pages/projects/index.html
index 84516c9d..80649d67 100644
--- a/pages/projects/index.html
+++ b/pages/projects/index.html
@@ -1 +1 @@
- My projects :: Vorakl's notes My projects
Some of my projects which I'd like to show - Vorakl's Bash Library
- A collection of Bash Modules
- TrivialRC
- A minimalistic RC system and process manager for containers and applications
- Aves
- A theme for the Pelican (a static site generator)
\ No newline at end of file
+ My projects :: Vorakl's notes My projects
Some of my projects which I'd like to show - Vorakl's Bash Library
- A collection of Bash Modules
- TrivialRC
- A minimalistic RC system and process manager for containers and applications
- Aves
- A theme for the Pelican (a static site generator)
\ No newline at end of file
diff --git a/pages/reading/index.html b/pages/reading/index.html
index 0bdbd1fd..d6a17726 100644
--- a/pages/reading/index.html
+++ b/pages/reading/index.html
@@ -1 +1 @@
- Reading :: Vorakl's notes Reading
The most valuable and influential books I read This is a modest list of books I definitely recommend to read. The order in each category more or less matters, but categories them-selfs are up to the current interest.
Computer Science Fundamentals
- Understanding the Digital World, Brian Kernighan, 2017
- As it's perfectly said in the foreword: "What You Need to Know about Computers, the Internet, Privacy, and Security". Although the main reader of the book is a non-technical person with no previous IT background, anyone can benefit from reading it. The author describes very technical and hard topics using simple words and makes the understanding of the big picture easy and natural.
- Composing Programs, John DeNero
- This on-line resource focuses on various methods of organizing code, programming paradigms (functional, procedural, declarative), functional and data abstractions (ADT, Object-Oriented), and many other fundamental concepts of programming.
- (Russian) Программирование: введение в профессию, А.В.Столяров, 2016
- В первый том "вошли избранные сведения из истории вычислительной техники, обсуждение некоторых областей математики, непосредственно используемых программистами (таких как алгебра логики, комбинаторика, позиционные системы счисления), математических основ программирования (теория вычислимости и теория алгоритмов), принципы построения и функционирования вычислительных систем". Это одна из тех не многих книг, которая формирует фундамент, подкреплённый не только теоретическим материалом, но и полезными практическими примерами.
Software Development Practice
- Understanding Software, Max Kanat-Alexander, 2017
- The whole book is made of pure experience. It's absolutely practical work and brings not only the understanding of what it's like to build and maintain enormously large software but also how to be successful by avoiding pitfalls and doing things right.
- The DevOps Adoption Playbook, Sanjeev Sharma, 2017
- In my opinion, one of the most detailed and clear overview of the DevOps practice in software development. In contrast to many other books on this topic, the author digs into the roots, explains what it was like to develop software long before even Agile, what were the most crucial pitfalls in common Agile practice, and what exactly and how was addressed by the DevOps.
Soft Skills
- Pragmatic Thinking and Learning, Andy Hunt, 2008.
- The great example of work that anyone would benefit from, no matter what's the occupation or hobby, as it provides lots of insights into how our brain actually works, how we learn and remember, how we think and solve problems. Here is my notes in the form of mindmaps
- Soft Skills: The software developer's life manual, John Z. Sonmez, 2014.
- This book covers various non-technical but very important aspects of life any modern engineer, like career, productivity, communication, a setting of life goals, learning, etc.
Miscellaneous
- Python Interviews, Mike Driscoll, 2018.
- A collection of independent interviews of a dozen significant personalities from Python's world that helps to get the idea about the language's past, how it was developing from the very beginning, what's the current state and where it is going to...
\ No newline at end of file
+ Reading Recommendations :: Vorakl's notes Reading Recommendations
Books that I've read and recommend Even before I start reading a new technical book, I analyze it, read through the content, skim it, and even read a few paragraphs on a random page. It is usually pretty clear within the first few minutes whether a book is worth your time. Reading techniques like SQ3R make all this preparation and reading a thoughtful and organized process. When I read a book from cover to cover, there is no doubt that I found it to be a really good book and I can definitely recommend it.
These books are either technical or nearly technical. The order in each category is more or less important, but the categories themselves can be based on current interest.
Happy reading!
Computer Science Fundamentals
- Understanding the Digital World, Brian Kernighan, 2017
- As the preface perfectly puts it: "What you need to know about computers, the Internet, privacy, and security. Although the main reader of the book is a non-technical person with no previous IT background, everyone can benefit from reading it. The author describes very technical and difficult topics in simple terms and makes understanding the big picture easy and natural.
- (Russian) Программирование: введение в профессию, А.В.Столяров, 2016
- В первый том "вошли избранные сведения из истории вычислительной техники, обсуждение некоторых областей математики, непосредственно используемых программистами (таких как алгебра логики, комбинаторика, позиционные системы счисления), математических основ программирования (теория вычислимости и теория алгоритмов), принципы построения и функционирования вычислительных систем". Это одна из тех не многих книг, которая формирует фундамент, подкреплённый не только теоретическим материалом, но и полезными практическими примерами.
Software Development Practice
- Understanding Software, Max Kanat-Alexander, 2017
- The whole book is pure experience. It's completely practical, and not only gives you an understanding of what it's like to build and maintain enormously large software, but also how to succeed by avoiding pitfalls and doing things right.
- The DevOps Adoption Playbook, Sanjeev Sharma, 2017
- In my opinion, one of the most detailed and clear overviews of DevOps practice in software development. Unlike many other books on the subject, the author goes back to the roots, explaining what it was like to develop software long before Agile, what were the main pitfalls of common Agile practice, and what exactly and how was addressed by DevOps.
Soft Skills
- Pragmatic Thinking and Learning, Andy Hunt, 2008.
- The great example of work that everyone would benefit from, no matter what their profession or hobby, because it provides a lot of insight into how our brains actually work, how we learn and remember, how we think and solve problems. Here are my notes in the form of mind maps.
- Soft Skills: The software developer's life manual, John Z. Sonmez, 2014.
- This book covers various non-technical but very important aspects of the life of a modern software engineer, such as career, productivity, communication, setting life goals, learning, etc.
Miscellaneous
- Python Interviews, Mike Driscoll, 2018.
- A collection of independent interviews with a dozen major figures in the Python community, helping to understand the language's past, how it evolved from the beginning, where it's at now, and where it's going...
\ No newline at end of file
diff --git a/sitemap.xml b/sitemap.xml
index 610b15dc..72702024 100644
--- a/sitemap.xml
+++ b/sitemap.xml
@@ -125,6 +125,6 @@
https://vorakl.com/pages/reading/
weekly
- 2024-01-18
+ 2024-02-06
\ No newline at end of file
diff --git a/src.docs/content/pages/reading.rst b/src.docs/content/pages/reading.rst
index 28a7ab4f..e80536b6 100644
--- a/src.docs/content/pages/reading.rst
+++ b/src.docs/content/pages/reading.rst
@@ -1,10 +1,18 @@
-Reading
-#######
+Reading Recommendations
+#######################
:slug: reading
-:summary: The most valuable and influential books I read
+:summary: Books that I've read and recommend
-This is a modest list of books I definitely recommend to read. The order in each category more or less matters, but categories them-selfs are up to the current interest.
+Even before I start reading a new technical book, I analyze it, read through the content, skim it, and even read a few paragraphs on a random page. It is usually pretty clear within the first few minutes whether a book is worth your time. Reading techniques like SQ3R_ make all this preparation and reading a thoughtful and organized process. When I read a book from cover to cover, there is no doubt that I found it to be a really good book and I can definitely recommend it.
+
+|
+
+These books are either technical or nearly technical. The order in each category is more or less important, but the categories themselves can be based on current interest.
+
+|
+
+Happy reading!
|
@@ -22,40 +30,42 @@ Computer Science Fundamentals
-----------------------------
+ **Understanding the Digital World**, Brian Kernighan, 2017
- As it's perfectly said in the foreword: "What You Need to Know about Computers, the Internet, Privacy, and Security". Although the main reader of the book is a non-technical person with no previous IT background, anyone can benefit from reading it. The author describes very technical and hard topics using simple words and makes the understanding of the big picture easy and natural.
-
-+ `Composing Programs`_, John DeNero
- This on-line resource focuses on various methods of organizing code, programming paradigms (functional, procedural, declarative), functional and data abstractions (ADT, Object-Oriented), and many other fundamental concepts of programming.
+ As the preface perfectly puts it: "What you need to know about computers, the Internet, privacy, and security. Although the main reader of the book is a non-technical person with no previous IT background, everyone can benefit from reading it. The author describes very technical and difficult topics in simple terms and makes understanding the big picture easy and natural.
+ (Russian) `Программирование: введение в профессию`_, А.В.Столяров, 2016
В первый том *"вошли избранные сведения из истории вычислительной техники, обсуждение некоторых областей математики, непосредственно используемых программистами (таких как алгебра логики, комбинаторика, позиционные системы счисления), математических основ программирования (теория вычислимости и теория алгоритмов), принципы построения и функционирования вычислительных систем"*. Это одна из тех не многих книг, которая формирует фундамент, подкреплённый не только теоретическим материалом, но и полезными практическими примерами.
+
Software Development Practice
-----------------------------
+ **Understanding Software**, Max Kanat-Alexander, 2017
- The whole book is made of pure experience. It's absolutely practical work and brings not only the understanding of what it's like to build and maintain enormously large software but also how to be successful by avoiding pitfalls and doing things right.
+ The whole book is pure experience. It's completely practical, and not only gives you an understanding of what it's like to build and maintain enormously large software, but also how to succeed by avoiding pitfalls and doing things right.
+ **The DevOps Adoption Playbook**, Sanjeev Sharma, 2017
- In my opinion, one of the most detailed and clear overview of the DevOps practice in software development. In contrast to many other books on this topic, the author digs into the roots, explains what it was like to develop software long before even Agile, what were the most crucial pitfalls in common Agile practice, and what exactly and how was addressed by the DevOps.
+ In my opinion, one of the most detailed and clear overviews of DevOps practice in software development. Unlike many other books on the subject, the author goes back to the roots, explaining what it was like to develop software long before Agile, what were the main pitfalls of common Agile practice, and what exactly and how was addressed by DevOps.
+
Soft Skills
-----------
+ **Pragmatic Thinking and Learning**, Andy Hunt, 2008.
- The great example of work that anyone would benefit from, no matter what's the occupation or hobby, as it provides lots of insights into how our brain actually works, how we learn and remember, how we think and solve problems. Here is `my notes in the form of mindmaps`_
+ The great example of work that everyone would benefit from, no matter what their profession or hobby, because it provides a lot of insight into how our brains actually work, how we learn and remember, how we think and solve problems. Here are `my notes in the form of mind maps`_.
+
+ **Soft Skills: The software developer's life manual**, John Z. Sonmez, 2014.
- This book covers various non-technical but very important aspects of life any modern engineer, like career, productivity, communication, a setting of life goals, learning, etc.
+ This book covers various non-technical but very important aspects of the life of a modern software engineer, such as career, productivity, communication, setting life goals, learning, etc.
+
Miscellaneous
-------------
+ **Python Interviews**, Mike Driscoll, 2018.
- A collection of independent interviews of a dozen significant personalities from Python's world that helps to get the idea about the language's past, how it was developing from the very beginning, what's the current state and where it is going to...
+ A collection of independent interviews with a dozen major figures in the Python community, helping to understand the language's past, how it evolved from the beginning, where it's at now, and where it's going...
+
.. Links
-.. _`Composing Programs`: https://www.composingprograms.com/
.. _`Программирование: введение в профессию`: http://stolyarov.info/books/programming_intro/vol1
-.. _`my notes in the form of mindmaps`: {filename}/articles/learning.rst
+.. _`my notes in the form of mind maps`: {filename}/articles/learning.rst
+.. _SQ3R: {filename}/articles/sq3r.rst
diff --git a/src.docs/sitedev.py b/src.docs/sitedev.py
index 01d2c7ad..688531bc 100644
--- a/src.docs/sitedev.py
+++ b/src.docs/sitedev.py
@@ -14,7 +14,7 @@
ADD_DISCLAIMER_SHORT = False
DISCLAIMER_LONG = u"This is my personal blog. All ideas, opinions, examples, and other information that can be found here are my own and belong entirely to me. This is the result of my personal efforts and activities at my free time. It doesn't relate to any professional work I've done and doesn't have correlations with any companies I worked for, I'm currently working, or will work in the future."
ADD_DISCLAIMER_LONG = True
-SITE_VERSION = '1707178327'
+SITE_VERSION = '1707193688'
SITE_KEYWORDS = 'vorakl,blog,systems engineering,operations,software engineering'
PATH = 'content' # the location of all content
ARTICLE_PATHS = ['articles'] # a place for articles under the content location
diff --git a/tags/ai/index.html b/tags/ai/index.html
index 4683578e..ee6ea0be 100644
--- a/tags/ai/index.html
+++ b/tags/ai/index.html
@@ -1 +1 @@
- Artificial Intelligence :: Vorakl's notes Artificial Intelligence
2019-07-22 Constraint Satisfaction Problem (CSP) 2019-06-21 Dreyfus model of skill acquisition
\ No newline at end of file
+ Artificial Intelligence :: Vorakl's notes Artificial Intelligence
2019-07-22 Constraint Satisfaction Problem (CSP) 2019-06-21 Dreyfus model of skill acquisition
\ No newline at end of file
diff --git a/tags/binary-to-text/index.html b/tags/binary-to-text/index.html
index 8adbe6bc..d3092f43 100644
--- a/tags/binary-to-text/index.html
+++ b/tags/binary-to-text/index.html
@@ -1 +1 @@
- Translation between binary data and text :: Vorakl's notes Translation between binary data and text
2020-05-13 The zoo of binary-to-text encoding schemes 2020-04-18 Convert binary data to a text with the lowest overhead
\ No newline at end of file
+ Translation between binary data and text :: Vorakl's notes Translation between binary data and text
2020-05-13 The zoo of binary-to-text encoding schemes 2020-04-18 Convert binary data to a text with the lowest overhead
\ No newline at end of file
diff --git a/tags/cs/index.html b/tags/cs/index.html
index 14f02493..b6ca8879 100644
--- a/tags/cs/index.html
+++ b/tags/cs/index.html
@@ -1 +1 @@
- Computer Science :: Vorakl's notes Computer Science
2020-05-13 The zoo of binary-to-text encoding schemes 2020-04-18 Convert binary data to a text with the lowest overhead 2019-12-20 Computer Science vs Information Technology 2019-12-15 Algorithm is... 2019-12-15 Turing: thesis, machine, completeness 2019-08-21 Organizing Unstructured Data 2019-08-16 Number Classification 2019-08-08 A converter of a character's case and Ascii codes 2019-07-22 Constraint Satisfaction Problem (CSP) 2019-06-12 Structured Programming Paradigm
\ No newline at end of file
+ Computer Science :: Vorakl's notes Computer Science
2020-05-13 The zoo of binary-to-text encoding schemes 2020-04-18 Convert binary data to a text with the lowest overhead 2019-12-20 Computer Science vs Information Technology 2019-12-15 Algorithm is... 2019-12-15 Turing: thesis, machine, completeness 2019-08-21 Organizing Unstructured Data 2019-08-16 Number Classification 2019-08-08 A converter of a character's case and Ascii codes 2019-07-22 Constraint Satisfaction Problem (CSP) 2019-06-12 Structured Programming Paradigm
\ No newline at end of file
diff --git a/tags/encoding/index.html b/tags/encoding/index.html
index 766227ee..a41cde10 100644
--- a/tags/encoding/index.html
+++ b/tags/encoding/index.html
@@ -1 +1 @@
- Transformation one form of data to anoher :: Vorakl's notes Transformation one form of data to anoher
2020-05-13 The zoo of binary-to-text encoding schemes 2020-04-18 Convert binary data to a text with the lowest overhead 2019-08-08 A converter of a character's case and Ascii codes
\ No newline at end of file
+ Transformation one form of data to anoher :: Vorakl's notes Transformation one form of data to anoher
2020-05-13 The zoo of binary-to-text encoding schemes 2020-04-18 Convert binary data to a text with the lowest overhead 2019-08-08 A converter of a character's case and Ascii codes
\ No newline at end of file
diff --git a/tags/html/index.html b/tags/html/index.html
index bf7b37cb..b3e8bfdd 100644
--- a/tags/html/index.html
+++ b/tags/html/index.html
@@ -1 +1 @@
- The markup language for Web pages :: Vorakl's notes The markup language for Web pages
2019-07-18 How to remove a webpage from the Google index 2019-07-02 How to redirect a static website on the Github Pages
\ No newline at end of file
+ The markup language for Web pages :: Vorakl's notes The markup language for Web pages
2019-07-18 How to remove a webpage from the Google index 2019-07-02 How to redirect a static website on the Github Pages
\ No newline at end of file
diff --git a/tags/http/index.html b/tags/http/index.html
index 43de8812..fcff5e19 100644
--- a/tags/http/index.html
+++ b/tags/http/index.html
@@ -1 +1 @@
- The HyperText Transfer Protocol :: Vorakl's notes The HyperText Transfer Protocol
2019-07-02 How to redirect a static website on the Github Pages
\ No newline at end of file
+ The HyperText Transfer Protocol :: Vorakl's notes The HyperText Transfer Protocol
2019-07-02 How to redirect a static website on the Github Pages
\ No newline at end of file
diff --git a/tags/index.html b/tags/index.html
index 69ecfe87..c2a05cf6 100644
--- a/tags/index.html
+++ b/tags/index.html
@@ -1 +1 @@
- Tags :: Vorakl's notes Tags
networking Computer Networks and Protocols tools A variety of useful tools cs Computer Science programming Everything related to creating computer programs binary-to-text Translation between binary data and text encoding Transformation one form of data to anoher learning Materials about acquiring new skills mindmap Notes in hierarchically linked diagrams it Information Technology math Topics related to mathematics python A programming language ai Artificial Intelligence web The World Wide Web (hypertext system) html The markup language for Web pages http The HyperText Transfer Protocol management Management, Planning, Leading, etc psychology All about the human mind and behavior
\ No newline at end of file
+ Tags :: Vorakl's notes Tags
networking Computer Networks and Protocols tools A variety of useful tools cs Computer Science programming Everything related to creating computer programs binary-to-text Translation between binary data and text encoding Transformation one form of data to anoher learning Materials about acquiring new skills mindmap Notes in hierarchically linked diagrams it Information Technology math Topics related to mathematics python A programming language ai Artificial Intelligence web The World Wide Web (hypertext system) html The markup language for Web pages http The HyperText Transfer Protocol management Management, Planning, Leading, etc psychology All about the human mind and behavior
\ No newline at end of file
diff --git a/tags/it/index.html b/tags/it/index.html
index ef2178d2..e81d61ed 100644
--- a/tags/it/index.html
+++ b/tags/it/index.html
@@ -1 +1 @@
- Information Technology :: Vorakl's notes Information Technology
2019-12-20 Computer Science vs Information Technology 2019-07-18 How to remove a webpage from the Google index 2019-07-02 How to redirect a static website on the Github Pages
\ No newline at end of file
+ Information Technology :: Vorakl's notes Information Technology
2019-12-20 Computer Science vs Information Technology 2019-07-18 How to remove a webpage from the Google index 2019-07-02 How to redirect a static website on the Github Pages
\ No newline at end of file
diff --git a/tags/learning/index.html b/tags/learning/index.html
index dd354310..c1db0185 100644
--- a/tags/learning/index.html
+++ b/tags/learning/index.html
@@ -1 +1 @@
- Materials about acquiring new skills :: Vorakl's notes Materials about acquiring new skills
2020-01-18 My notes for the "Pragmatic Thinking and Learning" book 2019-06-21 Dreyfus model of skill acquisition 2019-06-10 SQ3R
\ No newline at end of file
+ Materials about acquiring new skills :: Vorakl's notes Materials about acquiring new skills
2020-01-18 My notes for the "Pragmatic Thinking and Learning" book 2019-06-21 Dreyfus model of skill acquisition 2019-06-10 SQ3R
\ No newline at end of file
diff --git a/tags/management/index.html b/tags/management/index.html
index 81b39798..2fcdaf02 100644
--- a/tags/management/index.html
+++ b/tags/management/index.html
@@ -1 +1 @@
- Management, Planning, Leading, etc :: Vorakl's notes
\ No newline at end of file
+ Management, Planning, Leading, etc :: Vorakl's notes
\ No newline at end of file
diff --git a/tags/math/index.html b/tags/math/index.html
index f9c2087b..44eecbe6 100644
--- a/tags/math/index.html
+++ b/tags/math/index.html
@@ -1 +1 @@
- Topics related to mathematics :: Vorakl's notes
\ No newline at end of file
+ Topics related to mathematics :: Vorakl's notes
\ No newline at end of file
diff --git a/tags/mindmap/index.html b/tags/mindmap/index.html
index 07e79e53..f117e8c6 100644
--- a/tags/mindmap/index.html
+++ b/tags/mindmap/index.html
@@ -1 +1 @@
- Notes in hierarchically linked diagrams :: Vorakl's notes Notes in hierarchically linked diagrams
2020-01-18 My notes for the "Pragmatic Thinking and Learning" book 2019-12-20 Computer Science vs Information Technology 2019-12-19 Who is an engineer 2019-12-15 Algorithm is... 2019-12-15 Turing: thesis, machine, completeness 2019-06-26 Managing your plans in the S.M.A.R.T. way 2019-06-21 Dreyfus model of skill acquisition 2019-06-15 Maslow's hierarchy of needs 2019-06-12 Structured Programming Paradigm 2019-06-10 SQ3R
\ No newline at end of file
+ Notes in hierarchically linked diagrams :: Vorakl's notes Notes in hierarchically linked diagrams
2020-01-18 My notes for the "Pragmatic Thinking and Learning" book 2019-12-20 Computer Science vs Information Technology 2019-12-19 Who is an engineer 2019-12-15 Algorithm is... 2019-12-15 Turing: thesis, machine, completeness 2019-06-26 Managing your plans in the S.M.A.R.T. way 2019-06-21 Dreyfus model of skill acquisition 2019-06-15 Maslow's hierarchy of needs 2019-06-12 Structured Programming Paradigm 2019-06-10 SQ3R
\ No newline at end of file
diff --git a/tags/networking/index.html b/tags/networking/index.html
index 7b3beb65..6d581be7 100644
--- a/tags/networking/index.html
+++ b/tags/networking/index.html
@@ -1 +1 @@
- Computer Networks and Protocols :: Vorakl's notes Computer Networks and Protocols
2024-01-16 Using udp-link to enhance TCP connections stability
\ No newline at end of file
+ Computer Networks and Protocols :: Vorakl's notes Computer Networks and Protocols
2024-01-16 Using udp-link to enhance TCP connections stability
\ No newline at end of file
diff --git a/tags/programming/index.html b/tags/programming/index.html
index 1b58db3d..f93d29e9 100644
--- a/tags/programming/index.html
+++ b/tags/programming/index.html
@@ -1 +1 @@
- Everything related to creating computer programs :: Vorakl's notes Everything related to creating computer programs
2020-05-13 The zoo of binary-to-text encoding schemes 2020-04-18 Convert binary data to a text with the lowest overhead 2019-08-21 Organizing Unstructured Data 2019-08-08 A converter of a character's case and Ascii codes 2019-07-22 Constraint Satisfaction Problem (CSP) 2019-06-12 Structured Programming Paradigm
\ No newline at end of file
+ Everything related to creating computer programs :: Vorakl's notes Everything related to creating computer programs
2020-05-13 The zoo of binary-to-text encoding schemes 2020-04-18 Convert binary data to a text with the lowest overhead 2019-08-21 Organizing Unstructured Data 2019-08-08 A converter of a character's case and Ascii codes 2019-07-22 Constraint Satisfaction Problem (CSP) 2019-06-12 Structured Programming Paradigm
\ No newline at end of file
diff --git a/tags/psychology/index.html b/tags/psychology/index.html
index a8b5cd33..134aabd0 100644
--- a/tags/psychology/index.html
+++ b/tags/psychology/index.html
@@ -1 +1 @@
- All about the human mind and behavior :: Vorakl's notes
\ No newline at end of file
+ All about the human mind and behavior :: Vorakl's notes
\ No newline at end of file
diff --git a/tags/python/index.html b/tags/python/index.html
index b59c8646..becf54a1 100644
--- a/tags/python/index.html
+++ b/tags/python/index.html
@@ -1 +1 @@
- A programming language :: Vorakl's notes
\ No newline at end of file
+ A programming language :: Vorakl's notes
\ No newline at end of file
diff --git a/tags/tools/index.html b/tags/tools/index.html
index e43b8625..7ee8b635 100644
--- a/tags/tools/index.html
+++ b/tags/tools/index.html
@@ -1 +1 @@
- A variety of useful tools :: Vorakl's notes
\ No newline at end of file
+ A variety of useful tools :: Vorakl's notes
\ No newline at end of file
diff --git a/tags/web/index.html b/tags/web/index.html
index 90497a04..c85f5071 100644
--- a/tags/web/index.html
+++ b/tags/web/index.html
@@ -1 +1 @@
- The World Wide Web (hypertext system) :: Vorakl's notes The World Wide Web (hypertext system)
2019-07-18 How to remove a webpage from the Google index 2019-07-02 How to redirect a static website on the Github Pages
\ No newline at end of file
+ The World Wide Web (hypertext system) :: Vorakl's notes The World Wide Web (hypertext system)
2019-07-18 How to remove a webpage from the Google index 2019-07-02 How to redirect a static website on the Github Pages
\ No newline at end of file
![[Archive]](data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAMAAAAoLQ9TAAAAn1BMVEVHcEzuQyFDqUP/dlSpu8z////d7v+pqanuQyHMIQCH7oeampqFhYVUu1S7dmWpqallmMz3XTv1WTfu7u6YzP/MzMzdMhDVh392dnbbMA7vRiTTe2/YLQvVKgjSaVnp9P/kORfk8f/RJgR3qt7u9v/QVD/g7/9votbOIwHWKwnz+f9/suXNLQ5pnNDPPyXMIQD4/P+Guu38/v+UyPuOwvXUfcTEAAAACnRSTlMA////////gL+/p4E1rgAAAJNJREFUeAFNygMOxAAUhOF6rdq2df+z7dT9i0m+PAJdPpfToIfw2Add9af05H8/HqNfAS79Vt80msYFZKTIfsm1DNCkvmVqsqyZlp82AJE9JQKGnqKoF15MPwDGlrrfX/NLtSOgy5m9vAMUIcOy6xsWgMA5LpwAkHjHhZcAqvi4iCvAlzv1BdzKOrINRTHsqC5vxB8wAwzldAteLAAAAABJRU5ErkJggg==) Archive
Archive![[categories]](data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAMAAAAoLQ9TAAAAflBMVEVHcEzMmGXKlmPy0bL/5czHk2Dvzqz84cfHk2DEkF353MDAjFn11re7h1Twzq7jvJe3g1Drx6Peto7Jm2+yf0zy0rLlv5jClWjgt42uekepdkPbsIOkcT7Wp3qgbTrSoXGdajfPnGqaZzSYZTKbaDWeaziibzyndEGreEWwfEnOm7M9AAAAJHRSTlMA/////////7///////////////////////////////////7/uB1ikAAAAW0lEQVR4AYXNpQEDURBF0fs+6pAP9F9TfLCCZeY9angEopDREEaCLEvbglc90YxY58RQ5sxKQSkVOas6z6hE56jYQCV19k/pSPvFXva/7BaeDN30UOXNJaswlQOK2Bmf70dgXAAAAABJRU5ErkJggg==) Categories
Categories![[tags]](data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAYAAAAf8/9hAAABaUlEQVR4AY2TA7IeQRRGexMpZxnZQryM2LZt27Zt27Ztc3TyTvymfk3Vufi+W6PuDtNOsbcKcuyt065hqIQw5URK/nr8IUO9ohtMPBqRZrDh1BMaTzuF2f7huwy9sjcYd+grcQpmhT+93Hub/tWLEUbv/8S3BA7ejbA224vcfp2gXvQGw3e/23vjZczniGowLSDW+lVzFLyBYfD2V1x9FvHhG0g0MZDtaYBYq+k7V/AG0n/zMy4++c6bL/BxVCDZ1QBONTbbq+vjXMEbSK91Dzn76BsvPsOLgYFobS3YXcdsr66PcwVvIN1W3uXk/a88/Qj3ewS+zqoBS2ua7dX1ca7gDaTT0pscu/uFR+/hWvvA5zH+0F/ZXl3fuaLr227hVQ7f/sz9d3C+RfA/iLWaHs44XJTW8y5x8OYn7r71fwaxVkMv9wmFaTH7PPtufOT2G8QatcI/sQhNZ5xh3/WPgnV+GSvCgyZ5/QeQVjev4io8YwAAAABJRU5ErkJggg==) Tags
Tags![[rss]](data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAYAAAAf8/9hAAAB2ElEQVR4AaWTA5AcURiE5y62bZtlOy7Gtm3btm3bPNu2ba0Hnengxby/qqt6//d17+5A6rtgUKkkTP72mg4Fu+qgaG99lBxqAuPR5jCfaAWKnjuekSH7TUHu1hoOpuOtgJu9/0pkmREFmRurQ7veEzjfETjR6rciQ5YZUZC2rhrUK92gHmsBqApQlAgt5hE0h2VQz/fi/huRZUYUJK6sAvliZ1j1/6n4HIQaeQdafiw4avxLyPeH80yILDOiIHZpZVjPdYBxX4NvZH29CGpOONQMf1huDxF7ssyIgogFFWE+1QaFO2sDihVKmjfMzltQfKInDHdGQMkOgy3mGYoOtwMZssyIguDZFWDS/1vu1uowue+FLf4tOJbQm8g/0hWGZ3PBKXk6G2TIMiMK/KaVg0H/bxkbKgkVv1j6MfRuPT9Dzo2GWS+kJ8uMKPCaVBbF+xsiZU05KAVJKHi2iB7mmNewJnvQwxh4BXJeHD1ZMCMKXMfao3BPPSSssANHLkikR6Hjdmiy5aN/twWaKtOTBTOiwGmUHQr0i5O+viLilkm/FRmyzIiCt8Mkh/D5FfmM/5XIMiMKqNdDJAeHERLcxtnDZ0pZBM0qj7B5FSl67ngGMmS/fRtLofdMUk3gzHxD5AAAAABJRU5ErkJggg==) RSS feed
RSS feed