We implemented some algorithms for partitioning on GraphX, and evaluated. And find the partitioning has space of improving. Seek opinion and advice.
- Graph in real world follow power law. Eg. On twitter 1% of the vertices are adjacent to nearly half of the edges.
- For high-degree vertex, one vertex concentrates vast resources. So the workload on few high-degree vertex should be decomposed by all machines
- For low-degree vertex, The computation on one vertex is quite small. Thus should exploit the locality of the computation on low-degree vertex.
- HybridCut
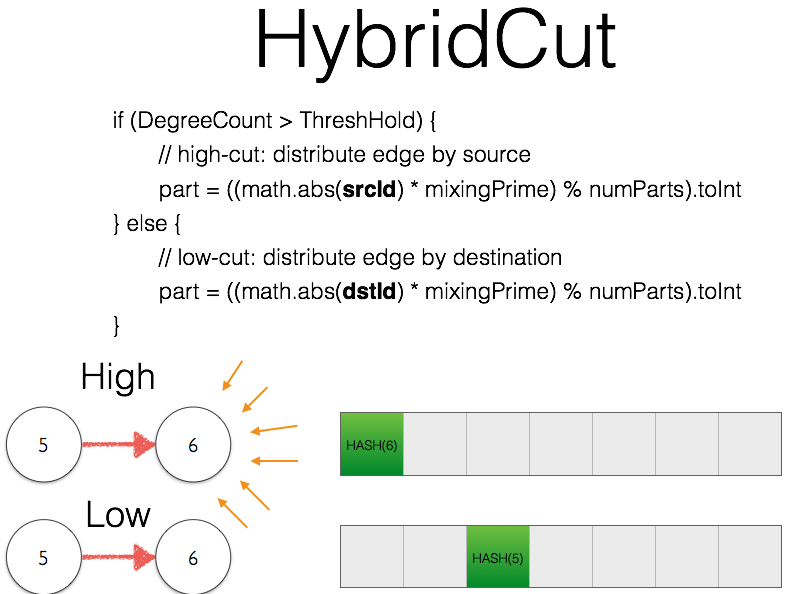
- HybridCutPlus

- Greedy BiCut
- a heuristic algorithm for bipartite
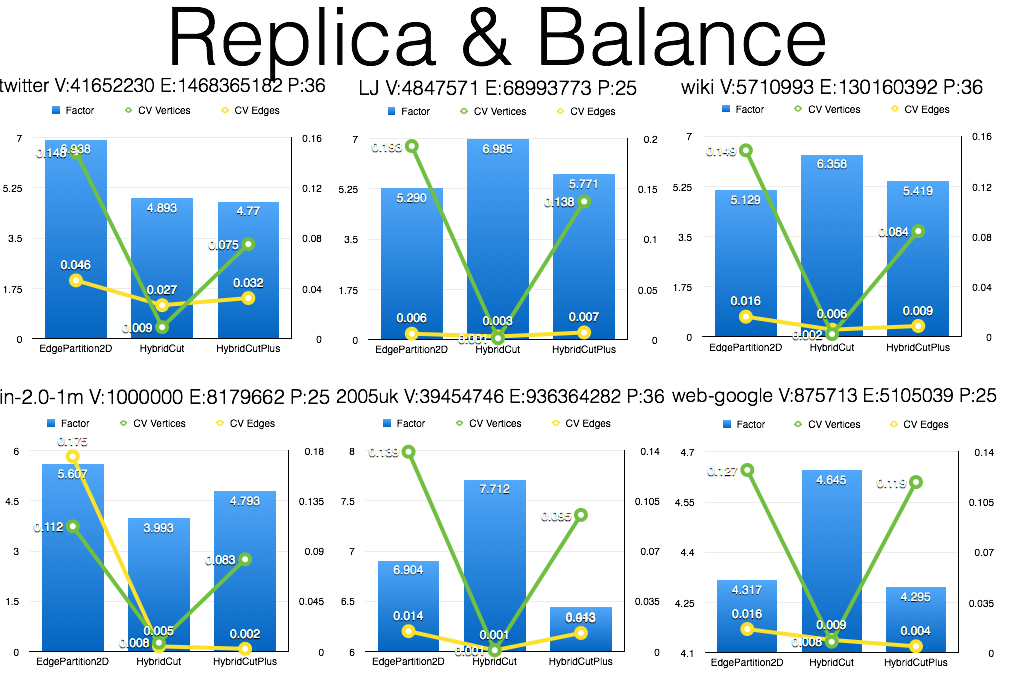
- The left Y axis is replication factor, right axis is the balance (measured using CV, coefficient of variation) of either vertices or edges of all partitions. The balance of edges can infer computation balance, and the balance of vertices can infer communication balance.
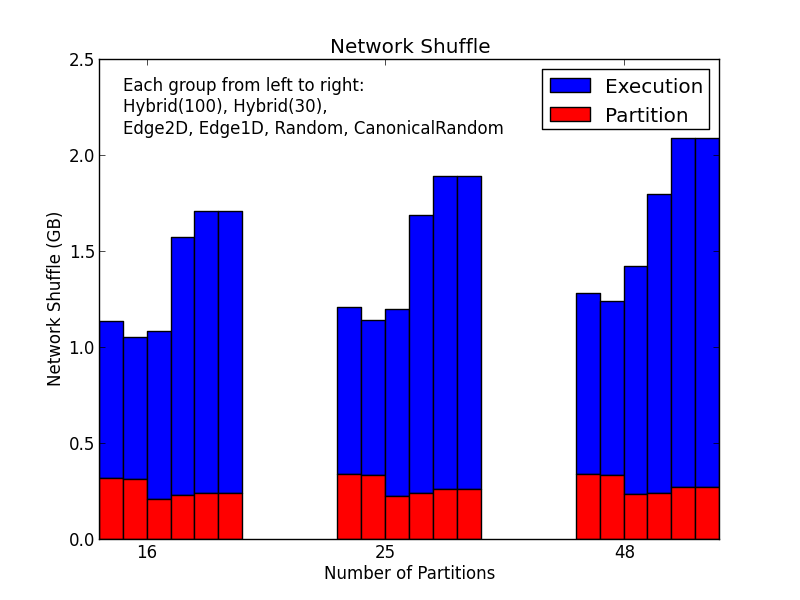
- This is an example of a balanced partitioning achieving 20% saving on communication.
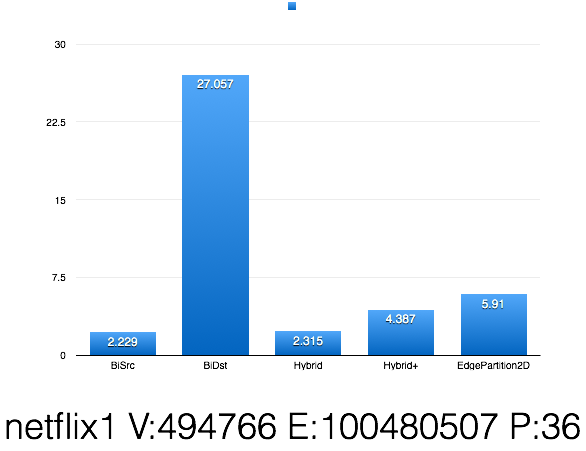
- This is a simple partitioning result of BiCut.
- in-2.0-1m is a generated power law graph with alpha equals 2.0
- https://github.com/larryxiao/spark/blob/GraphX/graphx/src/main/scala/org/apache/spark/graphx/impl/GraphImpl.scala#L173
- Because the implementation breaks the current separation with PartitionStrategy.scala, so need to think of a way to support access to graph.
- Bipartite-oriented Distributed Graph Partitioning for Big Learning.
- PowerLyra : Differentiated Graph Computation and Partitioning on Skewed Graphs