![]()
jsonextract is a Go library for extracting JSON and JavaScript objects from any source. It can be used for data extraction tasks like web scraping.
If any text looks like a JavaScript object or is close to looking like JSON, it will be converted to it.
There's a small extractor program that uses this library to get data from URLs and files.
If you want to give it a try, you can just go-get it:
go install github.com/xarantolus/jsonextract/cmd/jsonx@latest
You can use it both on files and URLs like this:
jsonx reader_test.go
or like this:
jsonx "https://stackoverflow.com/users/5728357/xarantolus?tab=topactivity"
It is also possible to only extract objects with certain keys by passing them along:
jsonx "https://www.youtube.com/watch?v=ap-BkkrRg-o" videoId title channelId
Another example:
jsonx "https://www.youtube.com/playlist?list=PLBQ5P5txVQr9_jeZLGa0n5EIYvsOJFAnY" videoId title
There are examples in the examples subdirectory.
The string example shows how to use the package to get all JSON objects/arrays in a string, it uses a strings.Reader for that.
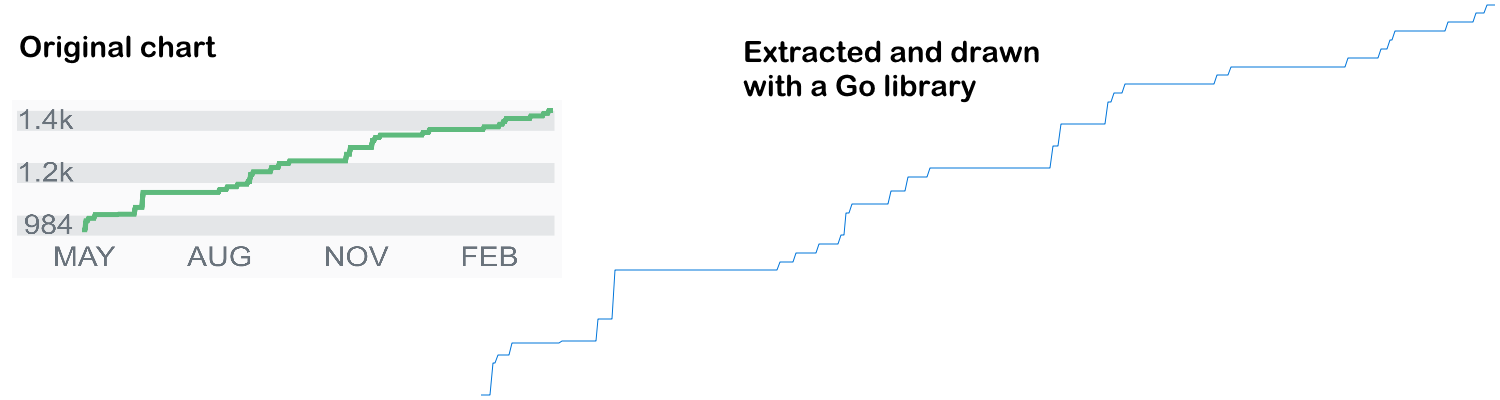
The stackoverflow-chart example shows how to extract the reputation chart data of a StackOverflow user. Extracted data is then used to draw the same chart using Go:
Another real-world use-case is the yt-live example which extracts video info about the current live stream of a YouTube channel. The example illustrates how simple and powerful this library can be.
Other examples for the Objects method can be found in the documentation.
This software supports not just extracting normal JSON, but also other JavaScript notation.
This means that text like the following, which is definitely not valid JSON, can also be extracted to an object:
<script>
var x = {
// Keys without quotes are valid in JavaScript, but not in JSON
key: "value",
num: 295.2,
// Comments are removed while processing
// Mixing normal and quoted keys is possible
"obj": {
"quoted": 325,
'other quotes': true,
unquoted: 'test', // This trailing comma will be removed
},
// JSON doesn't support all these number formats
"dec": +21,
"hex": 0x15,
"oct": 0o25,
"bin": 0b10101,
bigint: 21n,
// NaN will be converted to null. Infinity values are however not supported
"num2": NaN,
// No matter the sign, NaN becomes null
"num3": -NaN,
// Undefined will be interpreted as null
"udef": undefined,
`lastvalue`: `multiline strings are
no problem`
}
</script>results in
{"key":"value","num":295.2,"obj":{"quoted":325,"other quotes":true,"unquoted":"test"},"dec":21,"hex":21,"oct":21,"bin":21,"bigint":21,"num2":null,"num3":null,"udef":null,"lastvalue":"multiline strings are\nno problem"}- While the functions take an
io.Readerand stream data from it without buffering everything in memory, the underlying JS lexer usesioutil.ReadAll. That means that this won't work well on files that are larger than memory. - It is possible to craft input in a way that will require the parser to revert a lot, which will take more time. One such input is repeating opening braces for arrays
[without closing them, after more than a few thousand it gets noticeably slow. - When extracting objects from JavaScript files using
Reader, you can end up with many arrays that look like[0],[1],["i"], which is a result of indices being used in the script. You have to filter these out yourself. - While this package supports most number formats, there are some that don't work because the lexer doesn't support them. One of those is underscores in numbers. An example is that in JavaScript
2175can be written as2_175or0x8_7_f, but that doesn't work here (normal HEX numbers do however). Another example are numbers with a leading zero; they are rejected by the lexer because it's not clear if they should be interpreted as octal or decimal. - Another example of unsupported number types are the float values
Inf,+Inf,-Infand other infinity values. WhileNaNis converted tonull(asNaNis not valid JSON), infinity values don't have an appropriate JSON representation.
- v1.5.3: Support signed
+NaNand-NaNby converting them tonull, just like the normalNaN - v1.5.2:
Objectsnow behaves as documented and only matches the first option found. This is useful for cascading options from the most keys to the least keys you want, which is useful if there is some overlap. - v1.5.1:
Objectsnow also goes through all child elements of a matched element - v1.5.0:
Objectsnow terminates early if all callback functions are satisfied. To indicate this you can returnErrStopfrom anObjectOption's callback, which will make sure that this function is not called again. - v1.4.4:
Objects: AddRequiredfield that controls if an error should be returned if the object was not found. This makes it more convenient to use this function as no further checks are needed after extracting objects. - v1.4.3: Convert floats with trailing dots to valid JSON, e.g. a
1.is converted to1.0as the first one isn't valid JSON - v1.4.2: Fix crash found using go-fuzz
- v1.4.1: Transform
NaNinputs tonull - v1.4.0: Add
Objectsmethod for easily decoding smaller subsets of large nested structures - v1.3.1: Support more number formats by transforming them to decimal numbers, which are valid in JSON
- v1.3.0: Return to non-streaming version that worked with all objects, the streaming version seemed to skip certain parts and thus wasn't very great
- v1.2.0: Fork the JS lexer and make it use the underlying streaming lexer that was already in that package. That's a bit faster and prevents many unnecessary resets. This also makes it possible to extract from very large files with a small memory footprint.
- v1.1.11: No longer stop the lexer from reading too much, as that didn't work that good
- v1.1.10: Stops the JS lexer from reading all data from input at once, prevents expensive resets
- v1.1.9: JS Regex patterns are now returned as strings
- v1.1.8: Fix bug where template literals were interpreted the wrong way when certain escape sequences were present
- v1.1.7: More efficient extraction when a trailing comma is found
- v1.1.6: Always return the correct error
- v1.1.5: Small clarification on the callback
- v1.1.4: Support trailing commas in arrays and objects
- v1.1.3: Many small internal changes
- v1.1.2: Also support JS template strings
- v1.1.1: Also turn single-quoted strings into valid JSON
- v1.1.0: Now supports anything that looks like JSON, which also includes JavaScript object declarations
- v1.0.0: Initial version, supports only JSON
Thanks to everyone who made the parse package possible. Without it, creating this extractor would have been a lot harder.
Please feel free to open issues for anything that doesn't seem right, even small stuff.
This is free as in freedom software. Do whatever you like with it.