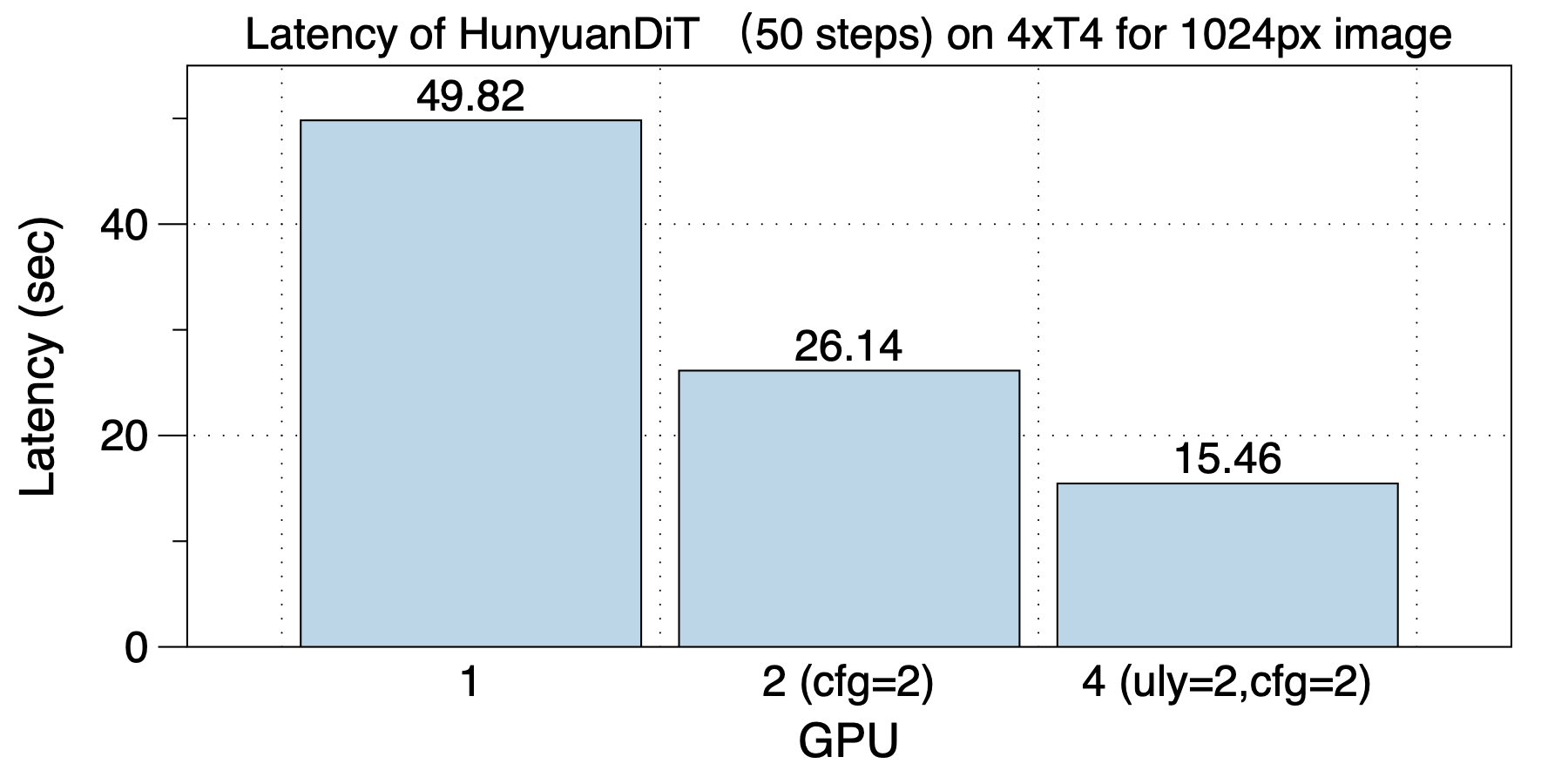
On an 8xA100 (NVLink) machine, the optimal parallel scheme varies with the number of GPUs used, highlighting the importance of hybrid parallelism. The best parallel strategies for different GPU scales are as follows: with 2 GPUs, use ulysses_degree=2; with 4 GPUs, use cfg_parallel=2, ulysses_degree=2; with 8 GPUs, use cfg_parallel=2, pipefusion_parallel=4.
The acceleration effect brought by torch.compile is quite impressive, with parallel schemes achieving a speedup of 1.26x to 1.76x. This enhancement is most pronounced in scenarios of 8 GPUs, where a speedup of 1.76x can be achieved.
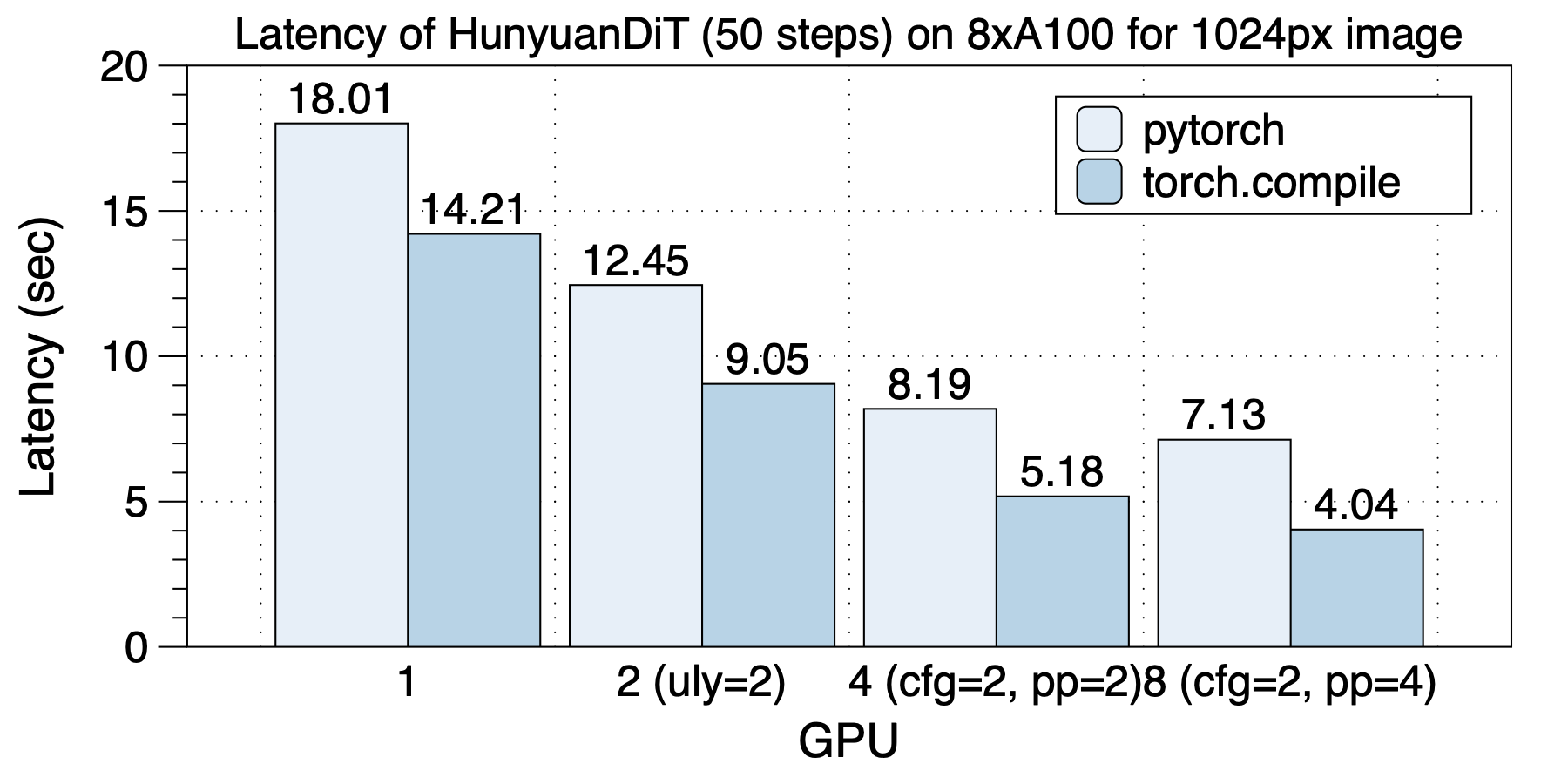
The latency situation on 8xL40 (PCIe) is depicted in the graph below. Similarly, the optimal parallel strategies vary with different GPU scales. Unlike on A100, there is no significant change in latency between 8 GPUs and 4 GPUs on L40. We attribute this to the low communication bandwidth across sockets due to PCIe limitations.
torch.compile provides a speedup ranging from 1.2x to 1.43x.
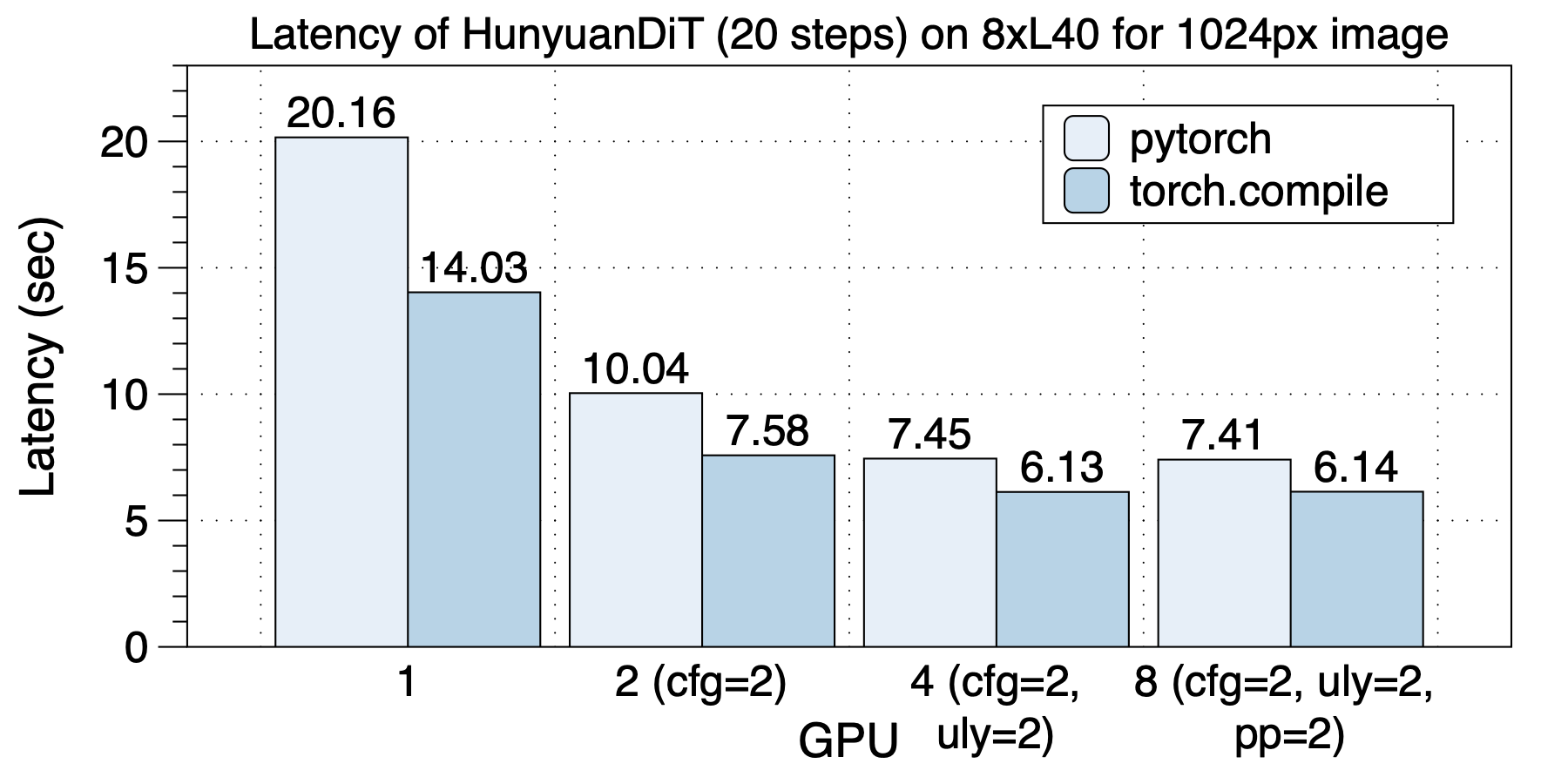
The acceleration on 8xV100 is shown in the figure below.
torch.compile offers a speedup ranging from 1.10x to 1.30x.
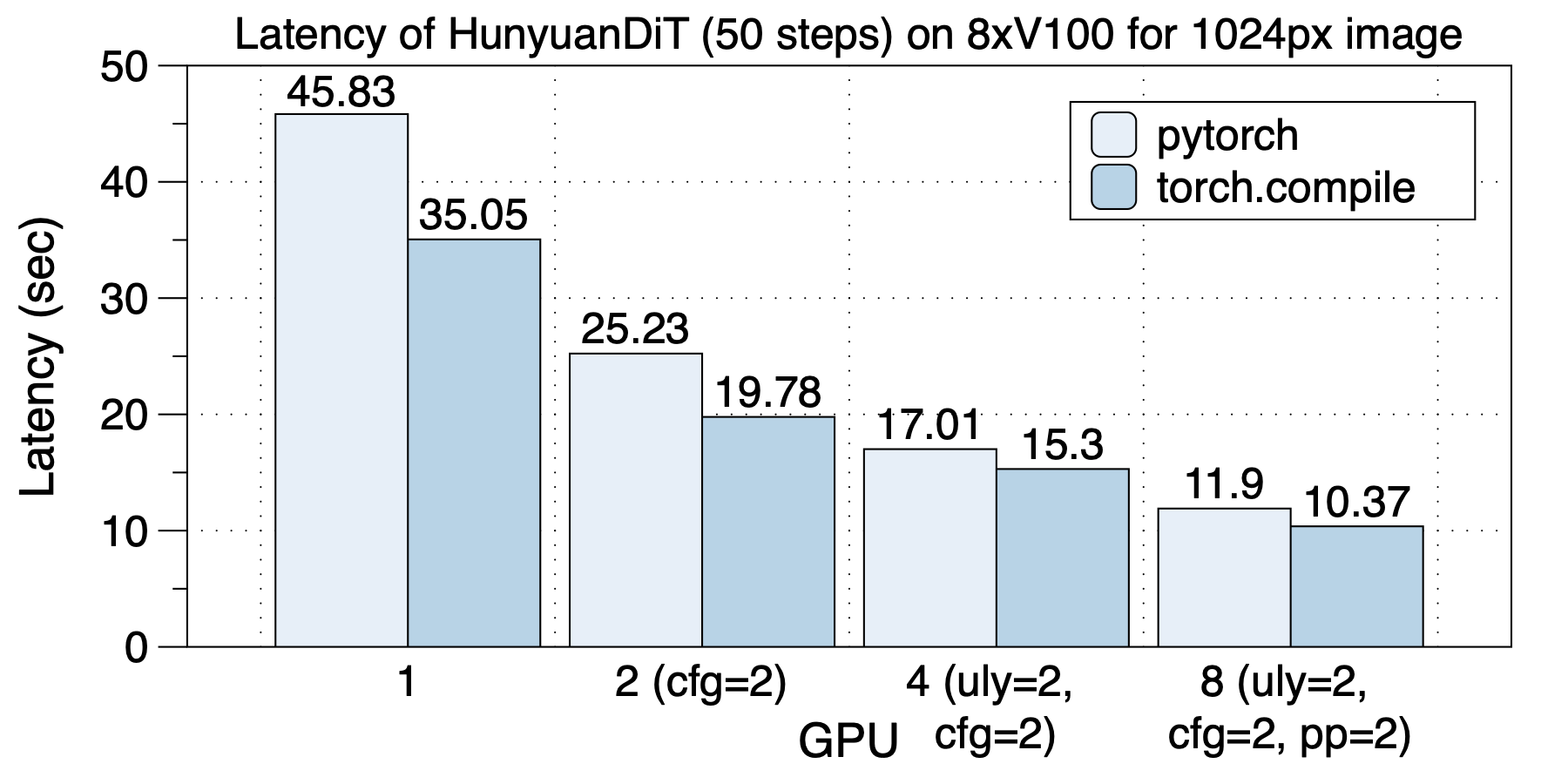
The acceleration on 4xT4 is shown in the figure below.