
Un analyseur HTML en pur Java qui soutient la syntaxe standard W3C Xpath 1.0. Il s'agit d'un analyseur HTML avec une base xpath basé sur Jsoup et Antlr4. Il pourrait être le meilleur en Java, essayez-le.
JsoupXpath est un analyseur HTML développé en pur Java, utilisant xpath pour analyser et extraire des données HTML. Il réimplémente complètement les normes de syntaxe W3C XPATH 1.0 pour l'analyse HTML. Le Lexer et le Parser de xpath sont construits sur Antlr4, et l'arbre DOM HTML est généré par Jsoup, d'où le nom JsoupXpath. Pour profiter de la puissance et de la facilité d'utilisation de xpath dans Java, mais sans trouver un analyseur xpath suffisamment pratique, JsoupXpath a été développé. La logique d'implémentation de JsoupXpath est claire et facile à étendre, il prend en charge la syntaxe W3C XPATH 1.0 complète. Norme W3C : http://www.w3.org/TR/1999/REC-xpath-19991116, Le fichier de description de la grammaire JsoupXpath Xpath.g4
https://github.com/zhegexiaohuozi/JsoupXpath/releases
- Issue
https://github.com/zhegexiaohuozi/JsoupXpath/issues
- Compte de messagerie WeChat

Il y sera publié des cas d'utilisation, des articles et les dernières mises à jour des projets liés au système seimi, ainsi que des articles et des réflexions de l'auteur sur les technologies backend de l'Internet.
Dépendance Maven, pour la version complète, consultez les informations de mise en production ou la base de données Maven centrale :
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>JsoupXpath</artifactId>
<version>2.5.3</version>
</dependency>
Exemple :
String html = "<html><body><script>console.log('aaaaa')</script><div class='test'>some body</div><div class='xiao'>Two</div></body></html>";
JXDocument underTest = JXDocument.create(html);
String xpath = "//div[contains(@class,'xiao')]/text()";
JXNode node = underTest.selNOne(xpath);
Assert.assertEquals("Two",node.asString());D'autres références peuvent être trouvées dans org.seimicrawler.xpath.JXDocumentTest, où il y a de nombreux cas de test.
Ou consultez des exemples typiques dans les issues.
Le support complet de la norme W3C XPATH 1.0 est assuré. Specification W3C : http://www.w3.org/TR/1999/REC-xpath-19991116
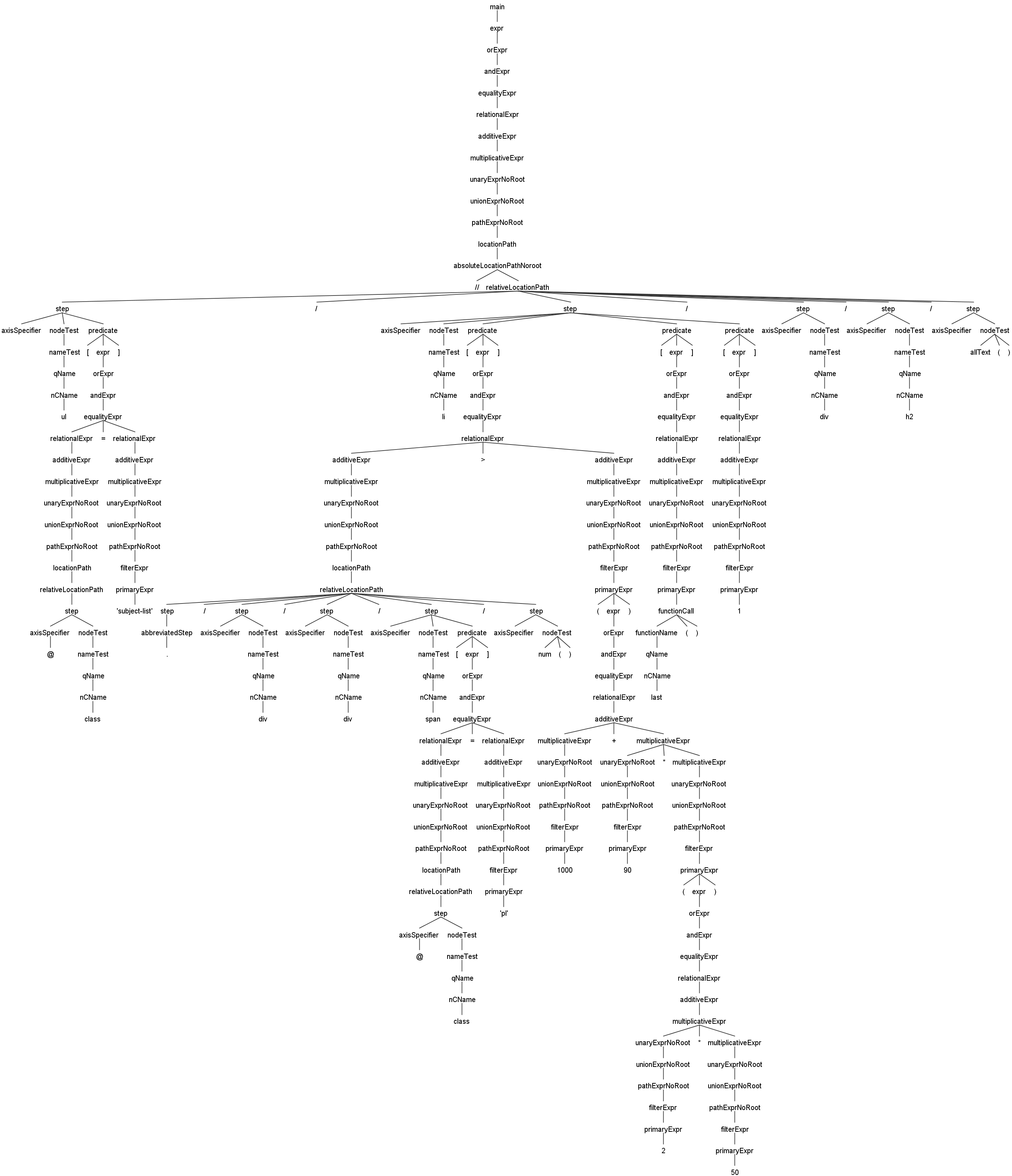
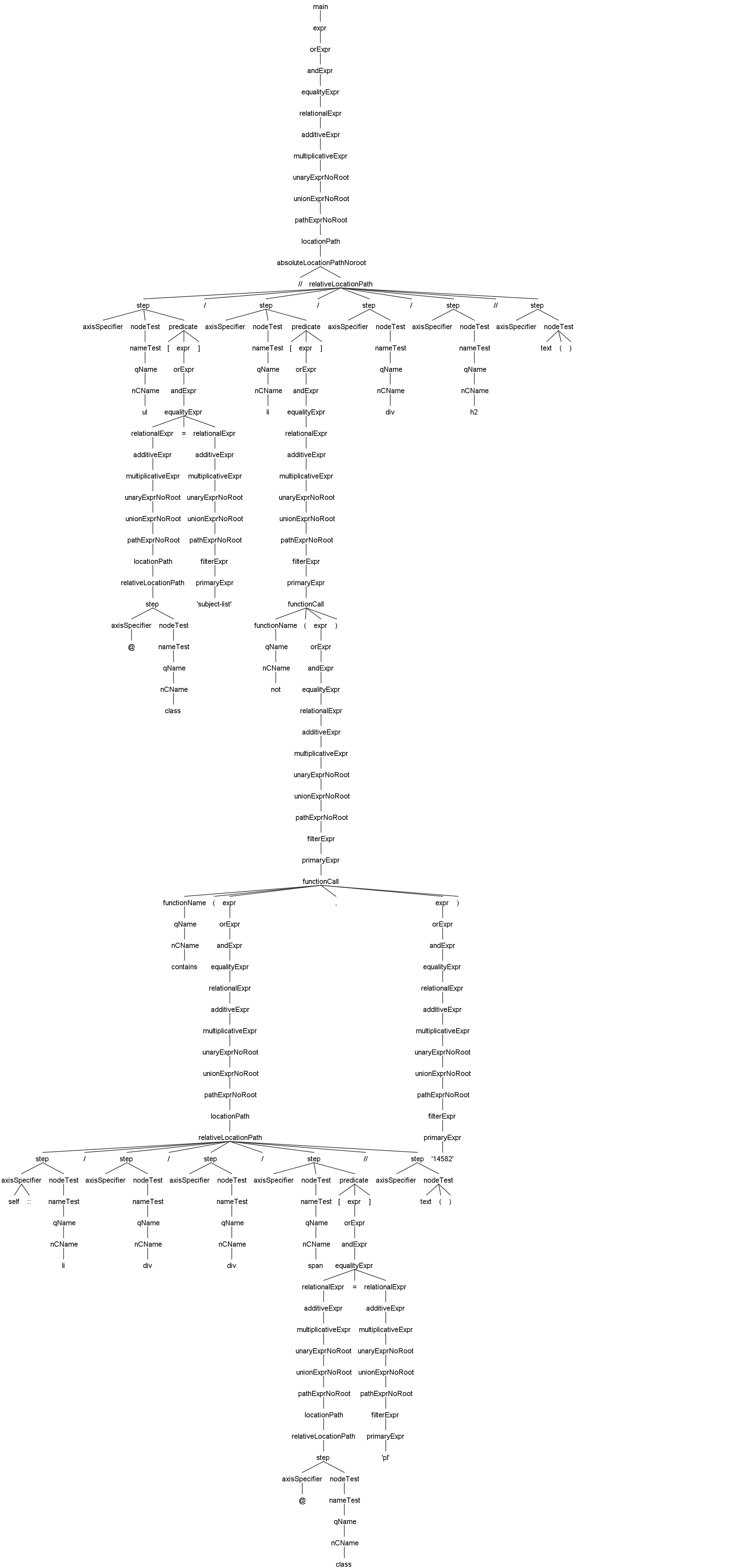
Voici un exemple d'arbre de syntaxe basé sur Antlr4 pour JsoupXpath, qui facilite une vue d'ensemble rapide des capacités de traitement syntaxique et du processus d'exécution d'analyse de JsoupXpath.
-
//ul[@class='subject-list']/li[./div/div/span[@class='pl']/num()>(1000+90*(2*50))][last()][1]/div/h2/allText()Cet exemple illustre principalement l'analyse de l'expression imbriquée. Cliquez sur l'image pour voir la version agrandie. -
//ul[@class='subject-list']/li[not(contains(self::li/div/div/span[@class='pl']//text(),'14582'))]/div/h2//text()Cet exemple illustre l'analyse en support des fonctions intégrées. Cliquez sur l'image pour voir la version agrandie.
Il est généralement déconseillé de copier directement les Xpath générés par Firefox ou Chrome. Ces navigateurs complètent automatiquement certaines balises lors du rendu des pages, comme l'ajout de la balise tbody à l'intérieur des balises table. Les Xpath générés de cette façon ne sont donc pas universellement applicables et peuvent ne pas retourner de valeur. Ainsi, pour utiliser Xpath et apprécier sa puissance ainsi que son élégance, il est préférable d'apprendre les bases de la syntaxe Xpath. Cela permet de résoudre efficacement une variété de problèmes et de pleinement profiter de la véritable puissance de Xpath !
-
int position()retourne la position du nœud courant dans son contexte -
int last()retourne la position du dernier nœud dans son contexte -
int first()retourne la position du premier nœud dans son contexte -
string concat(string, string, string*)concatène plusieurs chaînes de caractères -
boolean contains(string, string)détermine si la première chaîne contient la seconde -
int count(node-set)calcule le nombre de nœuds dans l'ensemble de nœuds donné -
double/long sum(node-set)calcule la somme des valeurs numériques des nœuds dans l'ensemble de nœuds donné ; si l'ensemble contient du contenu non numérique, le calcul est invalide -
boolean starts-with(string, string)détermine si la première chaîne commence par la seconde -
int string-length(string?)retourne la longueur de la chaîne donnée, ou, si aucune chaîne n'est fournie, la longueur de la chaîne représentant le nœud courant -
string substring(string, number, number?)le premier paramètre spécifie la chaîne, le deuxième la position de début (les index XPath commencent à 1), et le troisième la longueur de la sous-chaîne à extraire (ce n'est pas la position de fin dans la syntaxe XPath).substring("12345", 1.5, 2.6) retourne "234"
substring("12345", 2, 3) retourne "234"
-
string substring-ex(string, number, number)le premier paramètre spécifie la chaîne, le deuxième la position de début (comme en Java, commence à 0), et le troisième la position de fin (négatives autorisées) ; cette fonction est une extension de JsoupXpath pour faciliter l'utilisation par les développeurs habitués à Java. -
string substring-after(string, string)extrait la partie de la première chaîne après l'occurrence de la seconde -
string substring-after-last(string, string)extrait la partie de la première chaîne après la dernière occurrence de la seconde -
string substring-before(string, string)extrait la partie de la première chaîne avant l'occurrence de la seconde -
string substring-before-last(string, string)extrait la partie de la première chaîne avant la dernière occurrence de la seconde -
date format-date(string, string, string)le premier paramètre est l'expression, le deuxième est le format de date de l'expression, et le troisième est le fuseau horaire (optionnel)
Ce qui précède ne concerne que les fonctions de la norme Xpath 1.0. Les développeurs peuvent facilement ajouter des fonctions personnalisées en implémentant l'interface org.seimicrawler.xpath.core.Function.java et en appelant Scanner.registerFunction(Class<? extends Function> func) lors de l'initialisation de leur système. Aucune modification de la grammaire n'est nécessaire, et JsoupXpath détecte et charge ces fonctions au moment de l'exécution. Pour les fonctions de la grammaire standard qui ne sont pas encore implémentées dans JsoupXpath, nous encourageons les utilisateurs à soumettre des Pull Requests au dépôt principal pour améliorer ensemble le projet.
allText()extrait tout le texte sous un nœud, remplaçant des expressions récursives de type//div/h3//text()html()obtient le HTML interne de tous les nœudsouterHtml()obtient le HTML complet de tous les nœuds, y compris le nœud lui-mêmenum()extrait tous les chiffres du texte propre du nœud ; si le texte propre du nœud (c'est-à-dire excluant le texte des nœuds descendants) ne contient qu'un nombre, comme un nombre de lectures, de commentaires ou un prix, le nombre est directement extrait. Si plusieurs nombres sont présents, le premier nombre consécutif est extrait.text()extrait le texte propre du nœud. Pour plus de détails, voir https://github.com/zhegexiaohuozi/JsoupXpath/releases/tag/v2.4.1node()extrait tous les nœuds
AxisName: 'ancestor' // sélectionne les ancêtres du nœud dans le contexte actuel
| 'ancestor-or-self' // sélectionne les ancêtres et le nœud lui-même dans le contexte actuel
| 'attribute' // marque pour extraire les attributs du nœud
| 'child' // sélectionne les nœuds enfants du nœud dans le contexte actuel. C'est l'axe par défaut de XPath, par exemple, /div/li est une abréviation de /div/child::li
| 'descendant' // sélectionne les descendants du nœud dans le contexte actuel
| 'descendant-or-self' // sélectionne les descendants et le nœud lui-même dans le contexte actuel
| 'following' // sélectionne tous les nœuds qui suivent le nœud dans le contexte actuel
| 'following-sibling' // sélectionne tous les nœuds frères qui suivent le nœud dans le contexte actuel
| 'parent' // sélectionne le nœud parent du nœud dans le contexte actuel
| 'preceding' // sélectionne tous les nœuds qui précèdent le nœud dans le contexte actuel
| 'preceding-sibling' // sélectionne tous les nœuds frères qui précèdent le nœud dans le contexte actuel
| 'self' // sélectionne le nœud dans le contexte actuel
| 'following-sibling-one' // sélectionne le premier nœud frère suivant dans le contexte (extension JsoupXpath)
| 'preceding-sibling-one' // sélectionne le premier nœud frère précédent dans le contexte (extension JsoupXpath)
| 'sibling' // sélectionne tous les nœuds frères (extension JsoupXpath) (en développement..)
;
MINUS
: '-';
PLUS
: '+';
DOT
: '.';
MUL
: '*';
DIVISION
: '`div`';
MODULO
: '`mod`';
DOTDOT
: '..';
AT
: '@';
COMMA
: ',';
PIPE
: '|';
LESS
: '<';
MORE_
: '>';
LE
: '<=';
GE
: '>=';
START_WITH
: '^='; // `a^=b` la chaîne a commence par la chaîne b, a startwith b (extension JsoupXpath)
END_WITH
: '$='; // `a*=b` a contient b, a contains b (extension JsoupXpath)
CONTAIN_WITH
: '*='; // a contient b, a contains b (extension JsoupXpath)
REGEXP_WITH
: '~='; // le contenu de a correspond à l'expression régulière b (extension JsoupXpath)
REGEXP_NOT_WITH
: '!~'; // le contenu de a ne correspond pas à l'expression régulière b (extension JsoupXpath)
Actuellement, JsoupXpath est largement utilisé dans les projets ou organisations suivantes : SeimiCrawler. Si vous avez également un projet qui utilise JsoupXpath et souhaitez figurer dans cette liste, vous pouvez me contacter via les coordonnées suivantes. Le format de l'e-mail peut être le suivant :
Nom du projet ou de l'organisation : XX
URL du projet ou de l'organisation : http://xxx.xxx.cc