
W3C Xpath 1.0標準文法をサポートする純Javaで実装されたHTMLパーサー。JsoupとAntlr4を基にしたHTMLパーサーで、おそらくJavaの中では最高峰でしょう。試してみてください。
JsoupXpath は、HTMLデータをXPathを使用して解析・抽出する純Javaで開発されたパーサーです。HTML解析のためにW3C XPATH 1.0標準文法を完全に再実装しており、XPathのLexerとParserはAntlr4に基づいて構築され、HTMLのDOMツリー生成はJsoupを使用しています。そのため、JsoupXpathと名付けられました。 JavaでXPathの強力さと便利さを享受したいが、十分に使いやすいXPathパーサーが見つからないという問題を解決するため、JsoupXpathを開発しました。JsoupXpathの実装は論理が明確で拡張も容易で、W3C XPATH 1.0標準文法を完全にサポートしています。W3C規格:http://www.w3.org/TR/1999/REC-xpath-19991116、JsoupXpath文法記述ファイル[Xpath.g4](https://github.com/zhegexiaohuozi/JsoupXpath/blob/master/src/main/resources/Xpath.g4)
https://github.com/zhegexiaohuozi/JsoupXpath/releases
- Issue
https://github.com/zhegexiaohuozi/JsoupXpath/issues
- WeChatサブスクリプションアカウント

使い方の例や関連記事、Seimiシステム関連プロジェクトの最新アップデート情報などを発信しています。また、著者によるバックエンド技術に関する記事や感想も掲載されています。
Maven依存関係、全バージョンについてはリリース情報や中央Mavenリポジトリを参照してください。
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>JsoupXpath</artifactId>
<version>2.5.3</version>
</dependency>
例:
String html = "<html><body><script>console.log('aaaaa')</script><div class='test'>some body</div><div class='xiao'>Two</div></body></html>";
JXDocument underTest = JXDocument.create(html);
String xpath = "//div[contains(@class,'xiao')]/text()";
JXNode node = underTest.selNOne(xpath);
Assert.assertEquals("Two",node.asString());
その他の参照例は org.seimicrawler.xpath.JXDocumentTest、ここに多くのテストケースがあります
または、Issue中のより典型的な例も参照してください
W3C XPATH 1.0標準構文を完全にサポートしています。W3C規格:http://www.w3.org/TR/1999/REC-xpath-19991116
ここではJsoupXpathのAntlr4に基づく構文解析木の例を示します。JsoupXpathの構文処理能力と構文解析の実行過程を素早く把握できるようにするために提供しています。
-
//ul[@class='subject-list']/li[./div/div/span[@class='pl']/num()>(1000+90*(2*50))][last()][1]/div/h2/allText()これは主にいくつかの式のネストの解析例です。画像をクリックすると、大きな画像を表示します。 -
//ul[@class='subject-list']/li[not(contains(self::li/div/div/span[@class='pl']//text(),'14582'))]/div/h2//text()これはビルトイン関数のサポートの解析例です。画像をクリックすると、大きな画像を表示します。
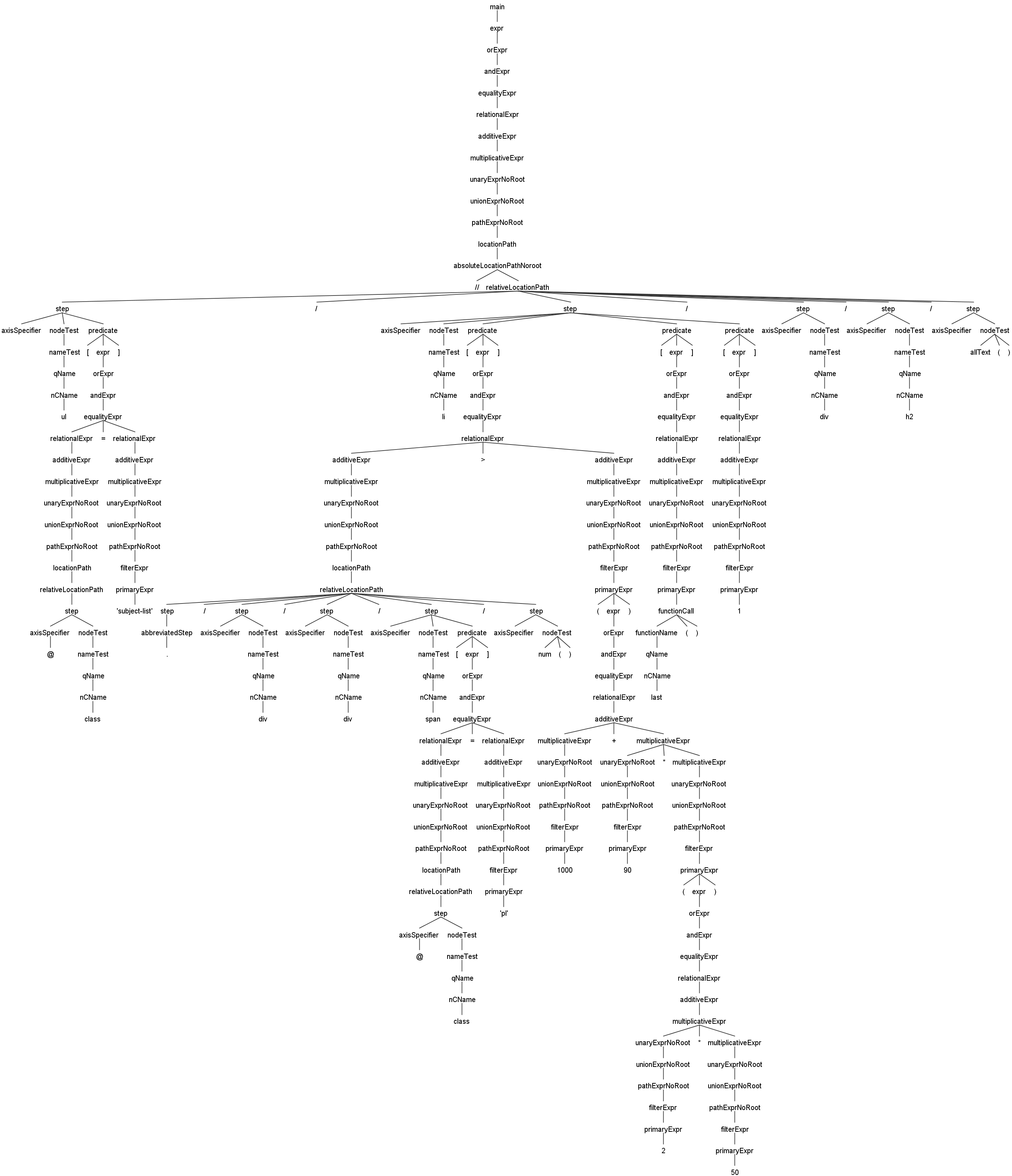
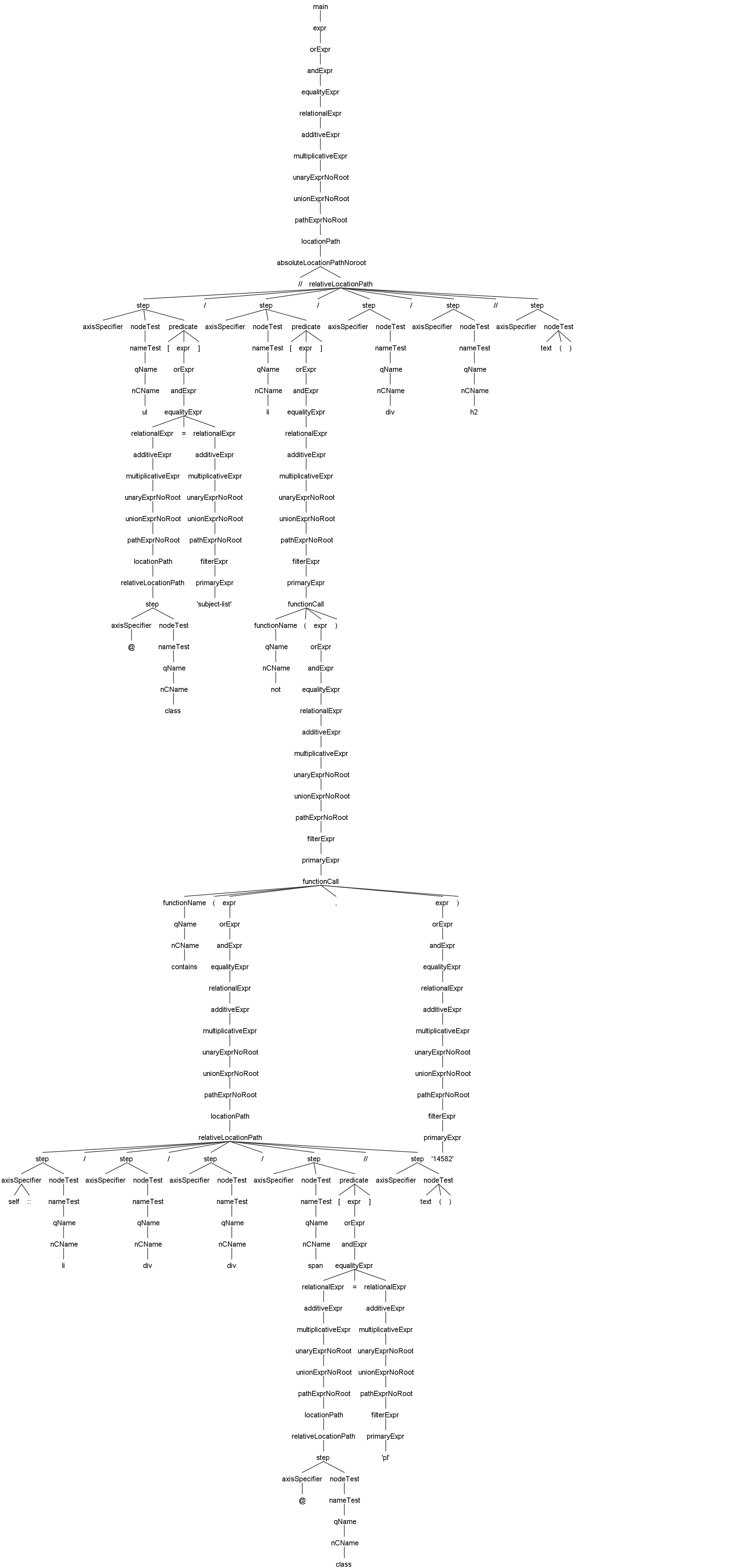
多くの場合、FirefoxやChromeで生成されたXPathを直接コピーすることをお勧めしません。これらのブラウザはページをレンダリングする際、 sue たとえば<table>タグには自動的に<tbody>タグを追加します。このようなballsはXPathのパスが一般化されていないため、値を取得できないことがあります。したがって、XPathの本質的な力を享受し、その有用性とエレガントさを味わうためには、XPathの標準構文を学ぶことが最善の方法です。これにより、様々な問題に対応し、XPathの真の力を享受することができます!
-
int position()現在のノードが存在するコンテキストでの位置を返します -
int last()コンテキストの最後のノード位置を返します -
int first()コンテキストの最初のノード位置を返します -
string concat(string, string, string*)複数の文字列を連結します -
boolean contains(string, string)最初の文字列が2番目の文字列を含むかどうかを判定します -
int count(node-set)指定されたノードセット内のノード数を計算します -
double/long sum(node-set)指定されたノードセット内の数値ノードの合計を計算します。計算範囲内に非数値の内容が含まれていると計算は失効します -
boolean starts-with(string, string)最初の文字列が2番目の文字列で始まるかどうかを判定します -
int string-length(string?)文字列が指定された場合、その長さを返します。指定されなかった場合、現在のノードを文字列に変換して長さを返します -
string substring(string, number, number?)最初のパラメーターは文字列、2つ目は開始位置(XPathのインデックスは1から始まる)、3つ目は切り出す長さを指定します。XPathの文法ではこの位置は終了位置ではありませんsubstring("12345", 1.5, 2.6) returns "234"
substring("12345", 2, 3) returns "234"
-
string substring-ex(string, number, number)最初のパラメーターは文字列、2つ目は開始位置(Javaの習慣に従い0から始まる)、3つ目は終了位置(負数もサポート)を指定します。これはJsoupXpathの拡張関数で、Javaの习惯を持つ開発者の使用を容易にします -
string substring-after(string, string)最初の文字列から2番目の文字列の後方部分を切り出します -
string substring-after-last(string, string)最初の文字列から2番目の文字列最後の出現位置の後方部分を切り出します -
string substring-before(string, string)最初の文字列から2番目の文字列の前方部分を切り出します -
string substring-before-last(string, string)最初の文字列から2番目の文字列最後の出現位置の前方部分を切り出します -
date format-date(string, string ,string)最初のパラメーターは式、2つ目のパラメーターは式の値の時間形式、3つ目のパラメーターはタイムゾーンのロケール(省略可能)です
上記はXPath 1.0標準の関数のみです。開発者は簡単に独自の関数を追加することができます。org.seimicrawler.xpath.core.Function.javaインターフェースを実装し、システム初期化時にScanner.registerFunction(Class<? extends Function> func)を呼び出すだけです。文法パターンを変更する必要はありません。JsoupXpathの実行時は自動的に認識してロードします。標準文法でJsoupXpathが未実装の関数については、メインリポジトリにPull requestを提出してOfWeekに貢献してください。
allText()ノードの下の全テキストを抽出します。//div/h3//text()のような再帰的なテキスト取得の代替ですhtml()全ノードの内部のHTMLを取得しますouterHtml()全ノードの、ノード自体を含む全HTMLを取得しますnum()ノードの固有のテキスト中の全数字を抽出します。ノードの固有のテキスト(子孫ノードが含まれるテキストではない)に数字が1つだけ存在する場合(例えば、読者数、コメント数、価格など)は、直接その数字を抽出できます。複数の数字がある場合は最初に一致する連続した数字を抽出しますtext()ノードの固有のテキストを抽出します。詳しくは https://github.com/zhegexiaohuozi/JsoupXpath/releases/tag/v2.4.1 を参照してくださいnode()全ノードを抽出します
AxisName: 'ancestor' // 現在のコンテキストにおけるノードの祖先を選択
| 'ancestor-or-self' // 現在のコンテキストにおけるノードの祖先と自身を選択
| 'attribute' // ノードの属性を抽出する演算をマーク
| 'child' // 現在のコンテキストにおけるノードの子ノードを選択 これはXPathのデフォルトの軸で、/div/li は /div/child::li の省略形
| 'descendant' // 現在のコンテキストにおけるノードの子孫を選択
| 'descendant-or-self' // 現在のコンテキストにおけるノードの子孫と自身を選択
| 'following' // 現在のコンテキストにおけるノードの後にある全ノードを選択
| 'following-sibling' // 現在のコンテキストにおけるノードの後にある全同胞ノードを選択
| 'parent' // 現在のコンテキストにおけるノードの親ノードを選択
| 'preceding' // 現在のコンテキストにおけるノードの前にある全ノードを選択
| 'preceding-sibling' // 現在のコンテキストにおけるノードの前にある全同胞ノードを選択
| 'self' // 現在のコンテキストにおける自身を選択
| 'following-sibling-one' // コンテキストにおけるノードの次の同胞ノードを選択(JsoupXpath拡張)
| 'preceding-sibling-one' // コンテキストにおけるノードの前の同胞ノードを選択(JsoupXpath拡張)
| 'sibling' // 全同胞(JsoupXpath拡張)(開発中。。。)
;
MINUS
: '-';
PLUS
: '+';
DOT
: '.';
MUL
: '*';
DIVISION
: '`div`';
MODULO
: '`mod`';
DOTDOT
: '..';
AT
: '@';
COMMA
: ',';
PIPE
: '|';
LESS
: '<';
MORE_
: '>';
LE
: '<=';
GE
: '>=';
START_WITH
: '^='; // `a^=b` 文字列aが文字列bで始まる a startwith b (JsoupXpath拡張)
END_WITH
: '$='; // `a*=b` aがbを含む, a contains b (JsoupXpath拡張)
CONTAIN_WITH
: '*='; // aがbを含む, a contains b (JsoupXpath拡張)
REGEXP_WITH
: '~='; // aの内容が正規表現bに符合する (JsoupXpath拡張)
REGEXP_NOT_WITH
: '!~'; //aの内容が正規表現bに符合しない (JsoupXpath拡張)
現在、JsoupXpathが幅広く使用されているプロジェクトや組織には、SeimiCrawler があります。 もし、あなたのプロジェクトでもJsoupXpathを使用していて、このリストに表示されることを希望する場合は、以下の連絡先を利用してご連絡ください。メールの形式は以下の通りです:
プロジェクトまたは組織名称:XX
プロジェクトまたは組織URL:http://xxx.xxx.cc