《Attention Is All You Need》由Google团队于2017年发表,提出了一种全新的神经网络架构——Transformer,彻底改变了自然语言处理(NLP)领域。
1. 序列建模的困境
在Transformer出现前(2017年),RNN/LSTM是处理序列任务(如翻译、文本生成)的主流架构。但存在两大缺陷:
- 长距离依赖问题:随着序列长度增加,RNN难以保持早期信息的传递(梯度消失/爆炸)
- 顺序计算限制:无法并行化处理序列,训练速度慢
2. 注意力机制的崛起
Bahdanau等人(2014)首次在RNN中引入注意力机制,用于聚焦关键上下文信息。后续研究(如Google的ByteNet、ConvS2S)尝试用CNN替代RNN,但卷积的局部感知特性仍不理想。
3. Transformer的诞生
Google团队在2017年NIPS会议上提出完全基于注意力机制的Transformer架构,彻底抛弃循环和卷积结构,实现全局感知和并行计算。
1. 自注意力机制(Self-Attention)
- 允许序列中任意两个位置直接交互
- 计算复杂度:O(n²)(n为序列长度)
- 公式:
$\text{Attention}(Q,K,V) = \text{softmax}(\frac{QK^T}{\sqrt{d_k}})V$
2. 多头注意力(Multi-Head Attention)
- 并行多个注意力头,捕捉不同子空间的特征
- 拼接后线性变换:
$\text{MultiHead}(Q,K,V) = \text{Concat}(head_1,...,head_h)W^O$
3. 位置编码(Positional Encoding)
- 使用正弦/余弦函数注入位置信息:
$PE_{(pos,2i)} = \sin(pos/10000^{2i/d_{model}})$
$PE_{(pos,2i+1)} = \cos(pos/10000^{2i/d_{model}})$
4. 纯注意力架构
- 完全摒弃循环结构
- 编码器-解码器堆叠架构
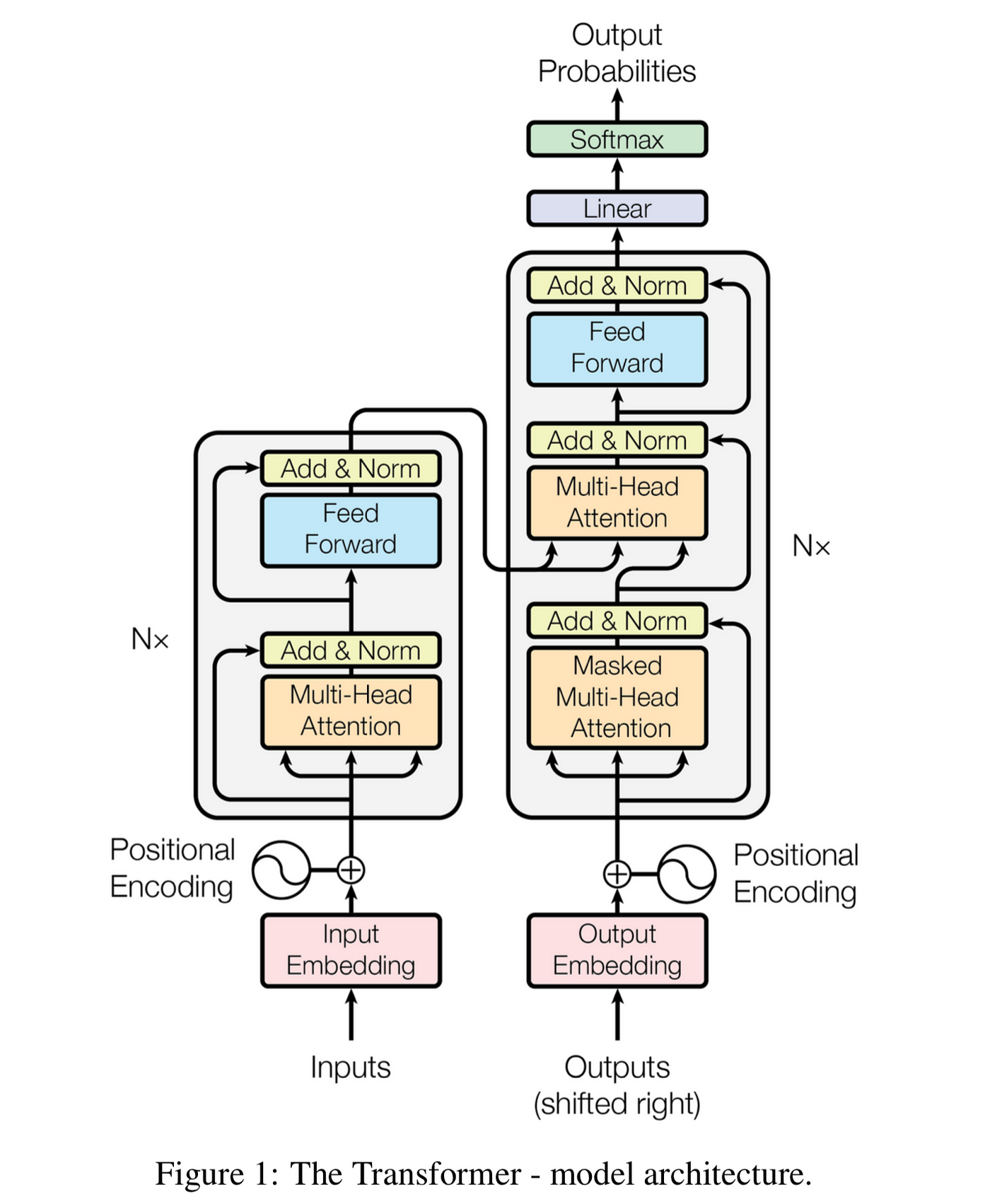
- 输入嵌入:词向量 + 位置编码
- 多头自注意力层:每个词关注整个序列
- 前馈网络:两个线性层+ReLU激活
- 残差连接 & LayerNorm:每个子层后应用
- 掩码多头注意力:防止未来信息泄露
- 编码-解码注意力:连接编码器输出
- 输出层:线性变换 + softmax
-
缩放点积注意力:
$\sqrt{d_k}$ 缩放防止梯度消失 - 位置前馈网络:同一线性变换应用于每个位置
-
训练技巧:
- Label Smoothing(ε=0.1)
- Adam优化器(β1=0.9, β2=0.98, ε=10^-9)
- 学习率warmup(4000步)
import torch
import torch.nn as nn
import math
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
# 线性变换矩阵
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask=None):
# 维度转换:[batch_size, seq_len, d_model] -> [batch_size, num_heads, seq_len, d_k]
batch_size = q.size(0)
q = self.W_q(q).view(batch_size, -1, self.num_heads, self.d_k).transpose(1,2)
k = self.W_k(k).view(batch_size, -1, self.num_heads, self.d_k).transpose(1,2)
v = self.W_v(v).view(batch_size, -1, self.num_heads, self.d_k).transpose(1,2)
# 计算缩放点积注意力
attn_scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.d_k)
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, -1e9)
attn_probs = torch.softmax(attn_scores, dim=-1)
output = torch.matmul(attn_probs, v)
# 拼接多头结果
output = output.transpose(1,2).contiguous().view(batch_size, -1, self.d_model)
return self.W_o(output)
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super().__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0))
def forward(self, x):
return x + self.pe[:, :x.size(1)]- BERT(2018):仅用编码器的双向预训练模型
- GPT系列(2018-2020):仅用解码器的自回归模型
- 模型压缩:
- DistilBERT(知识蒸馏)
- ALBERT(参数共享)
- 高效注意力:
- Sparse Transformer
- Linformer(低秩近似)
- 跨模态应用:
- Vision Transformer(图像分类)
- DALL-E(文本到图像生成)