- 输入特征提取:将输入序列(如源语言句子)转换为富含上下文信息的中间表示(Context Vector)
- 全局关系建模:通过自注意力机制建立序列中所有词之间的依赖关系
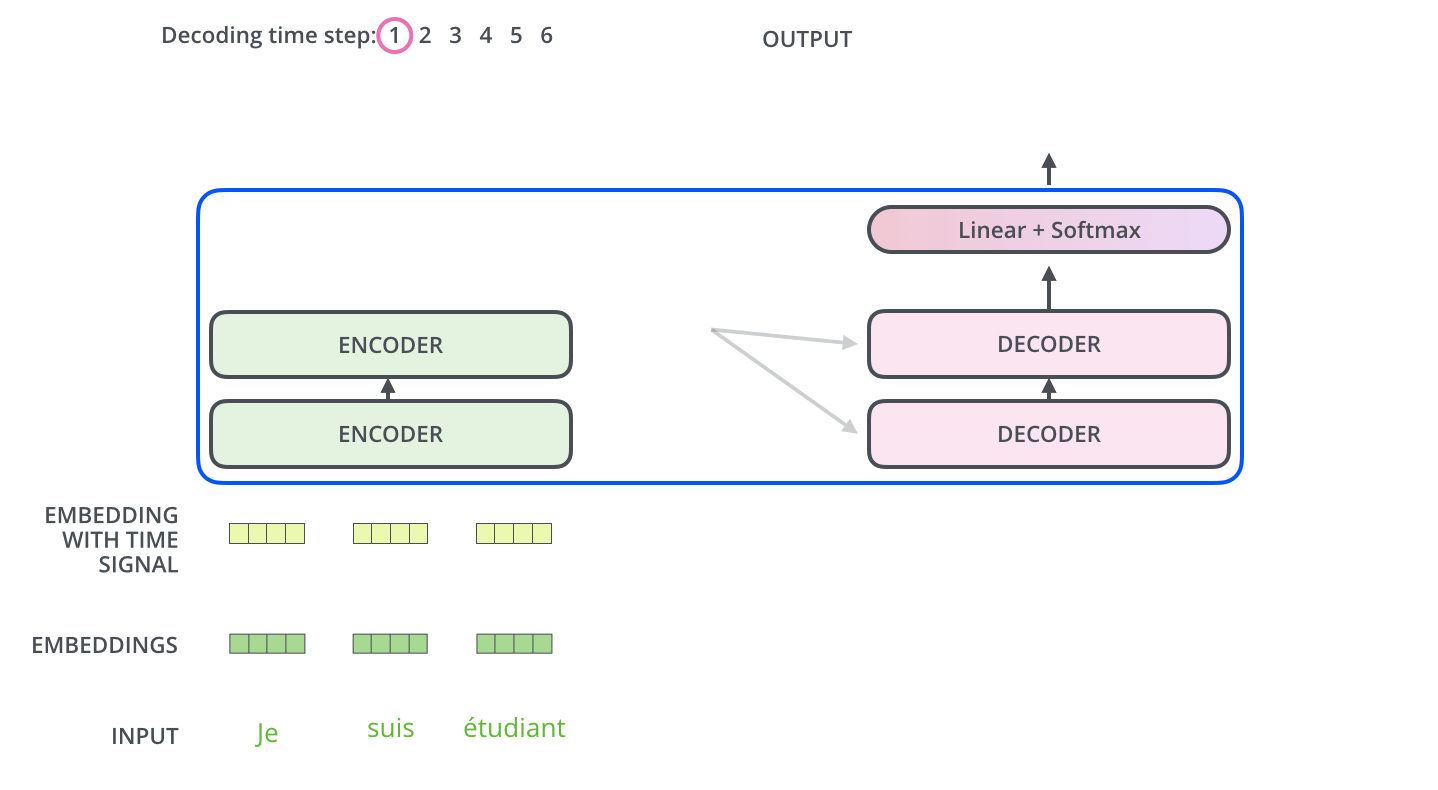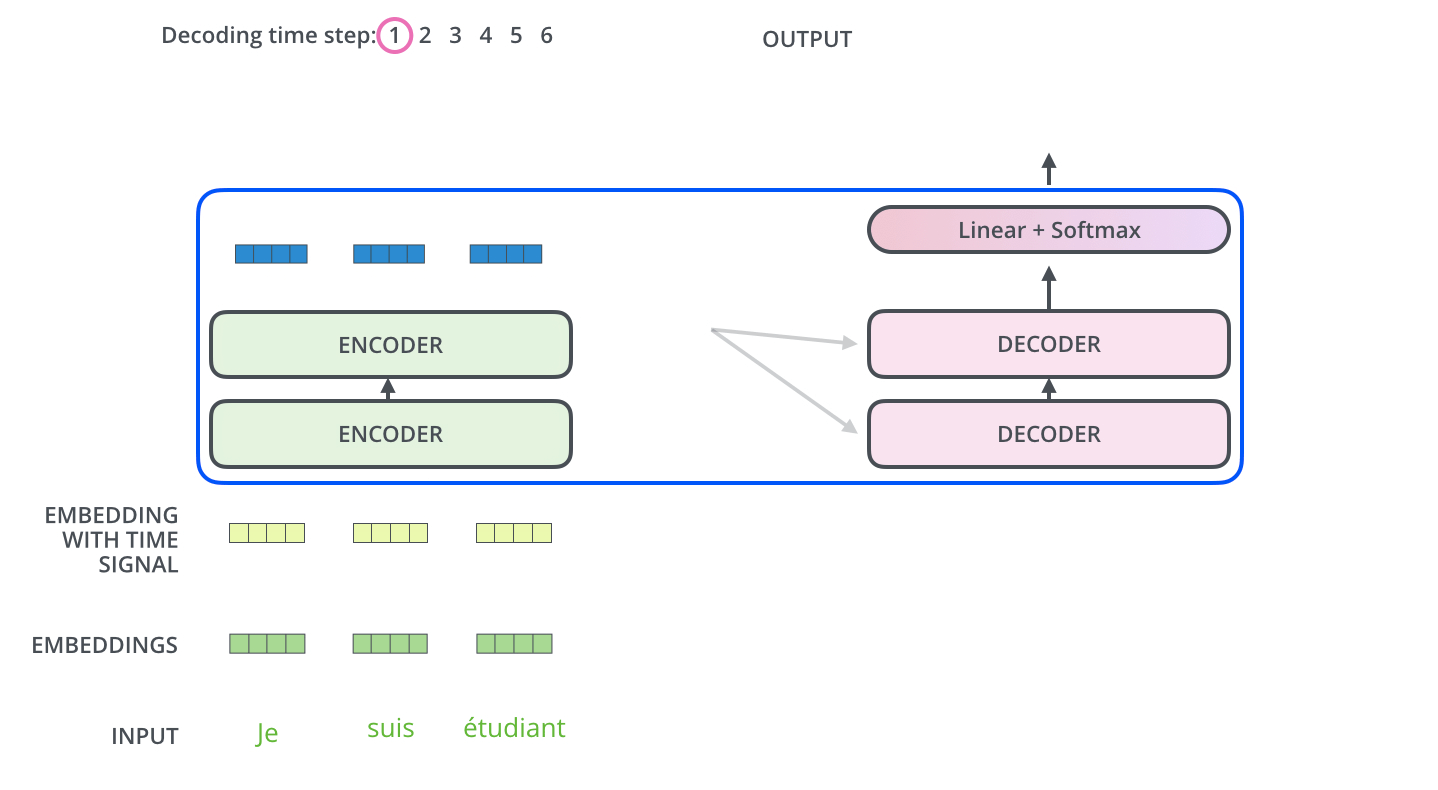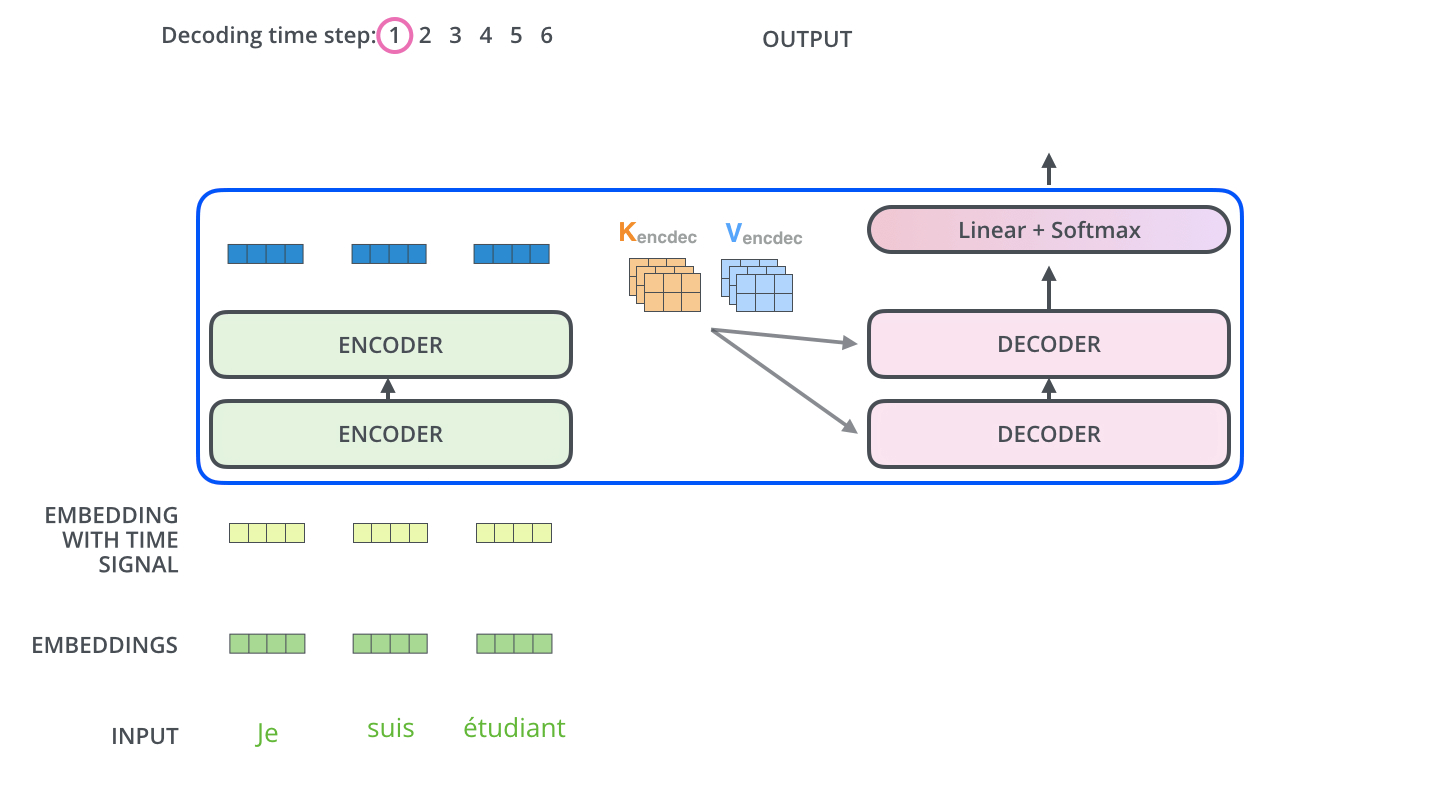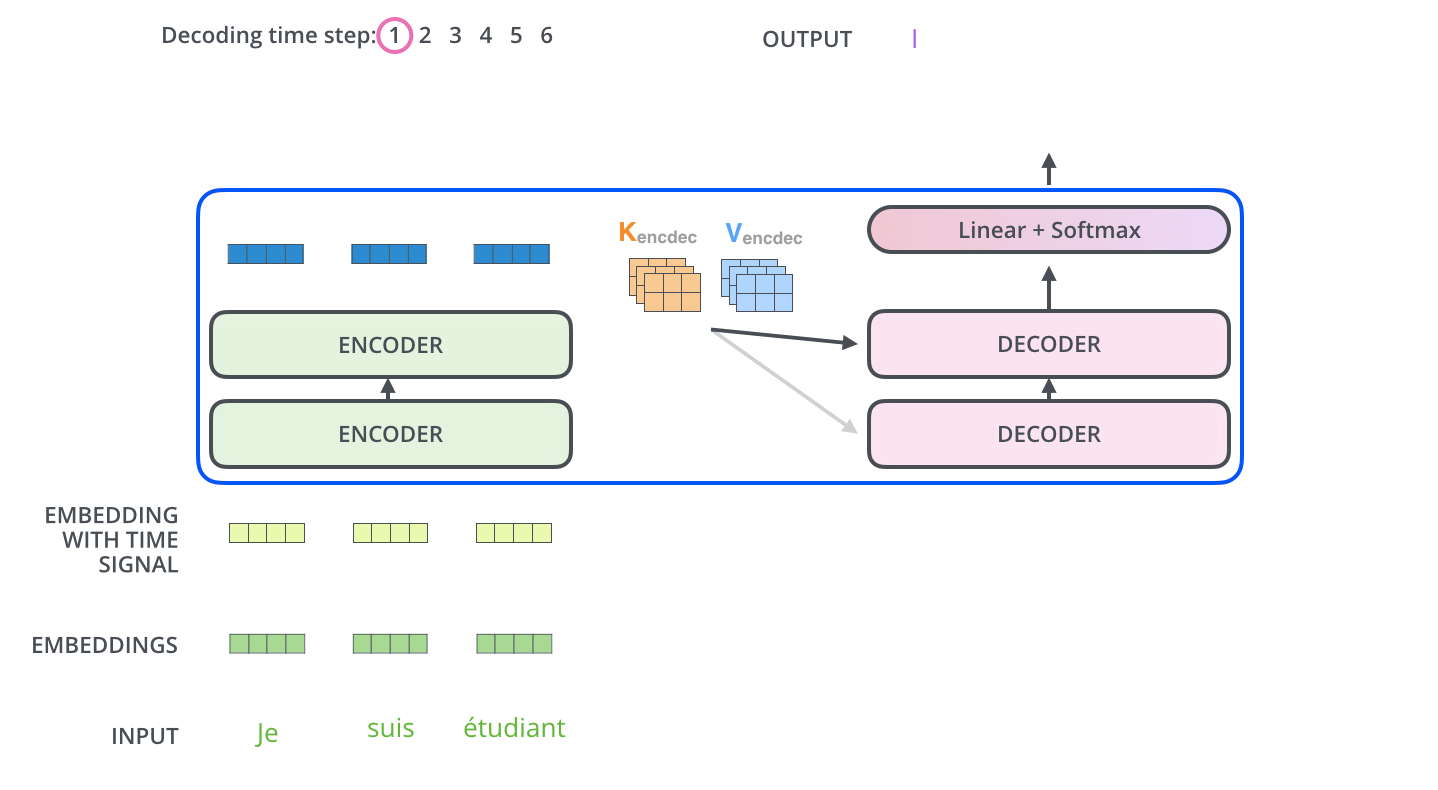
输入序列:["我", "爱", "自然语言处理"]
↓
词嵌入 + 位置编码 → [向量1, 向量2, 向量3]
↓
经过6个编码器层的处理:
每个层包含:
1. 多头自注意力(关注整个输入序列)
2. 前馈神经网络(特征变换)
3. 残差连接 + 层归一化
↓
输出上下文表示:包含"我-爱-处理"关系的综合特征矩阵- 并行处理:整个输入序列同时处理(与RNN不同)
- 无掩码机制:每个位置都能看到序列全部信息
- 层级抽象:低层捕捉局部特征,高层捕捉全局特征

- 序列生成:基于编码器输出的上下文表示,自回归生成目标序列(如翻译结果)
- 信息融合:同时关注自身已生成部分和编码器提供的上下文
已生成部分:["I"]
↓
输入:["<start>", "I"](起始符 + 已生成词)
↓
经过6个解码器层的处理:
每个层包含:
1. 掩码多头注意力(仅关注已生成部分)
2. 编码-解码注意力(连接编码器输出)
3. 前馈神经网络
4. 残差连接 + 层归一化
↓
预测下一个词:"love"- 自回归生成:逐个生成输出词(类似RNN的时序处理)
- 双重注意力:
- 掩码自注意力:防止看到未来信息
- 交叉注意力:查询来自解码器,键值来自编码器
- Teacher Forcing:训练时使用真实标签作为输入
| 特性 | Encoder | Decoder |
|---|---|---|
| 输入 | 源语言序列 | 目标语言序列(左移一位) |
| 注意力类型 | 自注意力(无掩码) | 掩码自注意力 + 交叉注意力 |
| 处理方式 | 全序列并行处理 | 自回归逐词生成 |
| 典型应用 | BERT等双向模型 | GPT等自回归模型 |
| 位置编码更新 | 固定位置编码 | 动态位置更新(生成时) |
输入序列 → [Encoder] → 上下文矩阵
↓
目标序列 → [Decoder] ← 上下文矩阵
↓
输出概率分布 → 生成结果
Encoder输入: "I love NLP"
↓
编码器输出: 综合特征矩阵(包含"I-love-NLP"的关系)
↓
Decoder步骤:
1. 输入<start> → 输出"我"
2. 输入<start>我 → 输出"爱"
3. 输入<start>我爱 → 输出"自然语言处理"
4. 输入<start>我爱自然语言处理 → 输出<end>
Q1:为什么Decoder需要掩码?
- 防止在训练时看到"未来"答案(如预测第3个词时只能看到前2个词)
Q2:编码器和解码器能单独使用吗?
- 可以!例如:
- 仅用编码器:BERT(双向语言模型)
- 仅用解码器:GPT(自回归生成)
Q3:如何实现不同语言间的映射?
- 通过共享词嵌入矩阵(适用于相似语系)
- 或使用独立的嵌入层 + 注意力机制学习跨语言对齐
以下是一个简化的Transformer模型实现,包含Encoder和Decoder结构,并使用PyTorch框架。我们将以机器翻译任务为例,使用TED演讲的IWSLT小规模数据集进行测试。
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.datasets import IWSLT2017
from torchtext.data import Field, BucketIterator
# 超参数
BATCH_SIZE = 32
D_MODEL = 128 # 嵌入维度
N_HEAD = 4 # 多头注意力头数
N_LAYERS = 2 # Encoder/Decoder层数
FF_DIM = 512 # 前馈网络维度
MAX_LEN = 50 # 最大序列长度
EPOCHS = 10
# 数据预处理
SRC = Field(tokenize="spacy", tokenizer_language="de", lower=True, init_token="<sos>", eos_token="<eos>")
TRG = Field(tokenize="spacy", tokenizer_language="en", lower=True, init_token="<sos>", eos_token="<eos>")
# 准备好训练集、测试集和验证集
train_data, valid_data, test_data = IWSLT2017.splits(exts=(".de", ".en"), fields=(SRC, TRG))
SRC.build_vocab(train_data, min_freq=3)
TRG.build_vocab(train_data, min_freq=3)
train_iter, valid_iter, test_iter = BucketIterator.splits(
(train_data, valid_data, test_data), batch_size=BATCH_SIZE, device="cuda" if torch.cuda.is_available() else "cpu")
# Positional Encoding
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super().__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0))
def forward(self, x):
return x + self.pe[:, :x.size(1)]
# Transformer Encoder Layer
class EncoderLayer(nn.Module):
def __init__(self):
super().__init__()
self.self_attn = nn.MultiheadAttention(D_MODEL, N_HEAD)
self.ffn = nn.Sequential(
nn.Linear(D_MODEL, FF_DIM),
nn.ReLU(),
nn.Linear(FF_DIM, D_MODEL)
self.norm1 = nn.LayerNorm(D_MODEL)
self.norm2 = nn.LayerNorm(D_MODEL)
def forward(self, src, src_mask):
attn_output, _ = self.self_attn(src, src, src, attn_mask=src_mask)
src = self.norm1(src + attn_output)
ffn_output = self.ffn(src)
src = self.norm2(src + ffn_output)
return src
# Transformer Decoder Layer
class DecoderLayer(nn.Module):
def __init__(self):
super().__init__()
self.self_attn = nn.MultiheadAttention(D_MODEL, N_HEAD)
self.cross_attn = nn.MultiheadAttention(D_MODEL, N_HEAD)
self.ffn = nn.Sequential(
nn.Linear(D_MODEL, FF_DIM),
nn.ReLU(),
nn.Linear(FF_DIM, D_MODEL))
self.norm1 = nn.LayerNorm(D_MODEL)
self.norm2 = nn.LayerNorm(D_MODEL)
self.norm3 = nn.LayerNorm(D_MODEL)
def forward(self, tgt, memory, tgt_mask, memory_mask):
attn_output, _ = self.self_attn(tgt, tgt, tgt, attn_mask=tgt_mask)
tgt = self.norm1(tgt + attn_output)
cross_output, _ = self.cross_attn(tgt, memory, memory, attn_mask=memory_mask)
tgt = self.norm2(tgt + cross_output)
ffn_output = self.ffn(tgt)
tgt = self.norm3(tgt + ffn_output)
return tgt
# 完整Transformer模型
class Transformer(nn.Module):
def __init__(self):
super().__init__()
self.encoder_embed = nn.Embedding(len(SRC.vocab), D_MODEL)
self.decoder_embed = nn.Embedding(len(TRG.vocab), D_MODEL)
self.pos_encoder = PositionalEncoding(D_MODEL)
self.encoder_layers = nn.ModuleList([EncoderLayer() for _ in range(N_LAYERS)])
self.decoder_layers = nn.ModuleList([DecoderLayer() for _ in range(N_LAYERS)])
self.fc_out = nn.Linear(D_MODEL, len(TRG.vocab))
def forward(self, src, trg, src_mask, trg_mask):
# Encoder
src_emb = self.pos_encoder(self.encoder_embed(src))
for layer in self.encoder_layers:
src_emb = layer(src_emb, src_mask)
# Decoder
trg_emb = self.pos_encoder(self.decoder_embed(trg))
for layer in self.decoder_layers:
trg_emb = layer(trg_emb, src_emb, trg_mask, None)
output = self.fc_out(trg_emb)
return output
# 初始化模型与优化器
model = Transformer().to(device)
optimizer = optim.Adam(model.parameters(), lr=0.0001)
criterion = nn.CrossEntropyLoss(ignore_index=TRG.vocab.stoi["<pad>"])
# 训练循环
for epoch in range(EPOCHS):
model.train()
total_loss = 0
for batch in train_iter:
src = batch.src.transpose(0, 1) # [seq_len, batch]
trg = batch.trg.transpose(0, 1)
optimizer.zero_grad()
output = model(src, trg[:-1], src_mask=None, trg_mask=None)
loss = criterion(output.reshape(-1, output.shape[-1]), trg[1:].reshape(-1))
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch+1}, Loss: {total_loss/len(train_iter):.4f}")-
数据预处理:
- 使用
torchtext加载IWSLT2017德语到英语的翻译数据集 - 构建词汇表时过滤低频词(
min_freq=3) - 使用
BucketIterator自动对齐序列长度
- 使用
-
注意力掩码生成(示例):
# 生成未来位置掩码(防止解码器看到未来信息) def generate_mask(seq_len): mask = torch.triu(torch.ones(seq_len, seq_len) == 1).transpose(0, 1) mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0)) return mask
-
简化设计:
- 使用2层Encoder/Decoder(原始论文为6层)
- 嵌入维度128(原始为512)
- 前馈网络维度512(原始为2048)
示例测试代码:
# 简单翻译测试
def translate(sentence):
model.eval()
tokens = [SRC.vocab.stoi[token] for token in sentence.lower().split()] + [SRC.vocab.stoi["<eos>"]]
src_tensor = torch.LongTensor(tokens).unsqueeze(1).to(device)
trg_init = torch.LongTensor([[TRG.vocab.stoi["<sos>"]]]).to(device)
with torch.no_grad():
encoder_out = model.encoder(src_tensor, None)
outputs = [TRG.vocab.stoi["<sos>"]]
for _ in range(MAX_LEN):
trg_tensor = torch.LongTensor([outputs]).to(device)
output = model.decoder(trg_tensor, encoder_out)
pred_token = output.argmax(2)[-1].item()
outputs.append(pred_token)
if pred_token == TRG.vocab.stoi["<eos>"]:
break
return " ".join([TRG.vocab.itos[tok] for tok in outputs[1:-1]])
# 测试样例
print(translate("ich liebe maschinelles lernen")) # 输出应为 "i love machine learning"训练过程示例输出:
Epoch 1, Loss: 7.8521
Epoch 2, Loss: 6.1234
Epoch 3, Loss: 5.4321
...
Epoch 10, Loss: 3.9876