This public repo houses most of the code from my horse race predictions app (missing are the complete scripts to do feature engineering and train the model, as well as some external service private API calls that I do not want to publicize - a model summary at a high level is provided here in the readme). Currently, there is no live demo that can be run, as I have not open-sourced any of my data, or my model. Yet, the backend and frontend code is here to review, and information about the model is written here in the readme.
The backend of this project is a flask webserver. The source of the data is The Daily Racing Form without which it is impossible to run a useful local version (TODO: add sample data files and sample prediction model so that backend can run as a demo).
The domain of horseracing data is fraught with issues. Horseracing data is sourced from a company like the aforementioned DRF, which all have very poor tooling for software bettors. Their primary business is tailored to readers and button-clickers. This leads to issues like trying to match a horse from a previous race with a name like Dan's Legacy with the same horse in the current race with a name like dans legacy. Simple things like this must be addressed by an app that wants to avoid garbage in garbage out. Thus, I use a robust ETL layer and store data in my own postgres database which I can then query for use in a machine learning model or an API and trust the output.
There is another interesting issue with horseracing, which is that there is a temporal element to them. The live odds at the time of racing are an input to my model, and to many horseracing prediction models. But you can only access the true live odds moments before the race begins. A horse may be entered into a race, then drop out as a "scratch" before the race begins. Or a race may be scheduled for a certain surface, then be changed due to rain. These variables are up in the air until the last minute, and are not adequately covered by the available data sources. So it introduces a requirement on this app to support user-input to quickly and ergonomically update the inputs to the model on the fly.
Pre-race info comes from DRF. I make use of an undocumented API to export files and upload them to S3. From S3, the files are downloaded and sent to processing via this script, which ultimately parses the files and stores the records in the DB.
On any given day, once the data has been processed into the DB, then the app will be able to render the data to inform the user about the day's upcoming races.
Diagram of the db models:
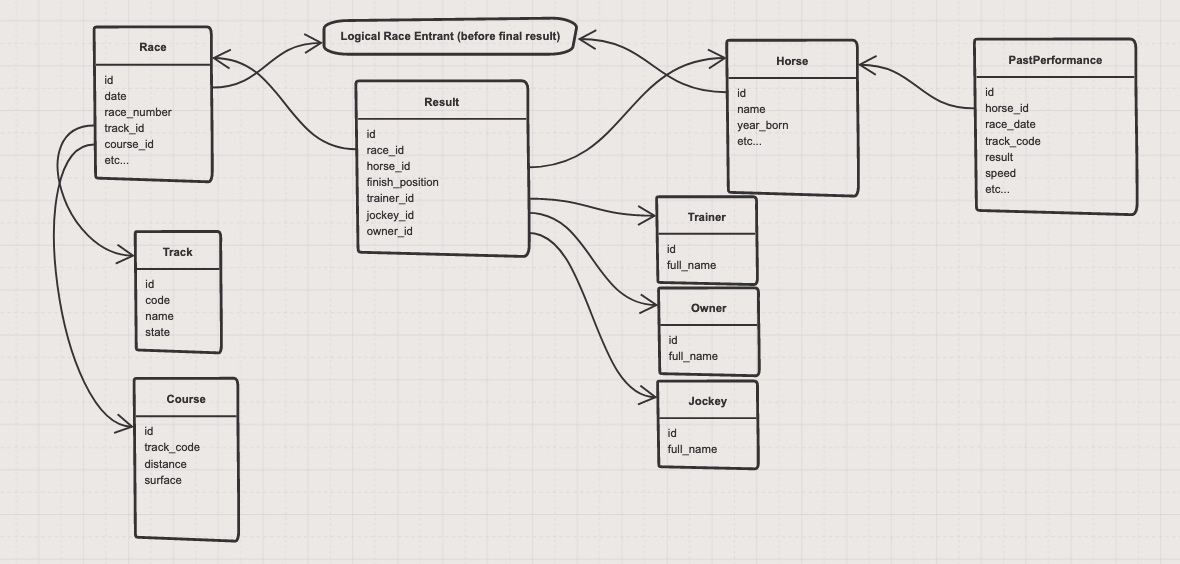
This app uses flask and sqlalchemy to serve a json API from the database. The routes are listed in main.py.
| Feature Name | Feature Description | Technical Details |
|---|---|---|
| Race Id | Identifier for a specific race | |
| Result Id | Identifier for an entrant in a race (that completed the race) | |
| Field Size | Count of entries in a race | |
| Track Tier | My own subjective ranking of track quality | One hot encoded as ['High Level', 'Decent Level', 'Other'] |
| Race Surface | What surface a race will be run ovr | One hot encoded as ['Dirt', 'Turf', 'Other'] |
| Quarter | Calendar quarter of the year | One hot encoded as 1-4 |
| Sprint | Is the race shorter than 7f? | |
| Route | Is the race as long as 9f or longer? | |
| Horse Sex | The sex of an individual entrant | One hot encoded as ['Filly', 'Mare', 'Colt', 'Horse', 'Other'] (yes, 'horse' is an official sex designation in horseacing, for a male horse older than 3 that has not been gelded) |
| Horse Age | Horse age, in years - horses are aged based soley on the year in which they were born | One hot encoded as ['2', '3', 'Other'] |
| Lifetime EPS | Lifetime earnings per previous start | LN() is taken on earnings, then the EPS is normalized to the particular race. Across the population of all races, this normalized variable has a standard normal dist. with a mean of 0 and StDev of 1 |
| Turf EPS | Lifetime earnings per previous start, only in turf races | Same procesing as Lifetime EPS |
| Past Performance Count | How many races has this horse previously run? | |
| Average Performance | Performance is a proprietary combination of elements in a given previous race | Performance is calculated for all previous races, and the weighted average is taken. Days since the previous race is the weights vector. This value is normalized within the particular race. |
| Average Performance at Similar | Performrance, but only from races at a similar distance, on the same surface | |
| Average Speed | Weighted average of speeds from previous races | Days since the race is the weights vector, and values are normalized within the race |
| Avereage Speed at Similar | Speed, but only from similar previous races | |
| Average First-Call Position | Weighted average of the position early in previous races | Similarly wieghted and normalized as the othr variables |
| Average First-Call Position at Similar | Average early position, but only from similar previous races | |
| DSLR | Days since last race | |
| Jockey Win % | Winning percentage of the horse's jockey | YTD |
| Trainer Win % | Winning percentage of the horse's trainer | YTD |
| Count120 | Number of races in which the horse ran in the past 120 days | |
| Implied Probability | The probability that the final odds of this horse imply | 1/odds - 1 * adj - where odds is the decimal odds, and adj is an adjustment for track takeout in the win pool |
# load raw data - preprocess as much as possible in the DB
statement = open('query.sql').read()
df = pd.read_sql(statement, engine)
# Prep the dependent variable "winner" to be a 0-indexed representation of the post position of the winning horse
race_winners = df[df.final_position == 1][['race_id',
'post_position',
'track_tier_TIER1',
'track_tier_TIER2',
'race_surface_d',
'race_surface_t',
'quarter_1.0',
'quarter_2.0',
'quarter_3.0',
'quarter_4.0',
'field_size',
'sprint',
'route'
]]
race_winners = race_winners.rename(
{'post_position': 'winner'}, axis='columns')
race_winners['winner'] = race_winners['winner'] - 1
# Select horse-specific attributes to pull into the model
model_data = df[[
'race_id',
'post_position',
'horse_sex_f',
'horse_sex_m',
'horse_sex_c',
'horse_sex_h',
'age_2.0',
'age_3.0',
'lifetime_eps',
'turf_eps',
'pp_count',
'total_perf',
'total_beyer',
'total_first_call',
'similar_perf',
'similar_beyer',
'similar_first_pos',
'dslr',
'jock',
'trainer',
'count120',
'implied_proba'
]]
# Pivot to the race level, and rejoin the race_winners df - already at the race level
model_data = model_data.pivot(
index='race_id', columns='post_position', values=model_data.columns[2:])
model_data = race_winners.join(
model_data, on='race_id', how='inner')
# Prepare to train the model
X = model_data[model_data.columns[2:]]
y = model_data['winner']
X_train, X_test, y_train, y_test = model_selection.train_test_split(
X, y, train_size=0.93, test_size=0.07, random_state=1)Previous implementations of this model have taught me to be very careful of overfitting the training data. After some testing, I settled on 3 hidden layers, with regularization on each, and dropout applied between them. The final layer ouputs a vector of 20 values which gets processed by softmax into a vector of win probabilites for the horse at each post position. 20 is the maximum number of horses we can allow in a race with this model.
Using the SparseCategoricalCrossentropy allows us to compare the output of softmax to the true winner value. Let's say in a 5-horse race, the 2nd horse wins, and the model predicted this with 50% accuracy. The true winner vector would be 1 (0-indexed) and the predicted vector would be something like [0.1, 0.5, 0.1, 0.2, 0.1].
We train the model to minimize loss of this fuction in a maximum of 500 epochs, or until 30 epochs provives no improvement on a validation set.
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(120, activation='tanh',
activity_regularizer=tf.keras.regularizers.L2(0.001)),
tf.keras.layers.Dropout(0.20),
tf.keras.layers.Dense(
80, activity_regularizer=tf.keras.regularizers.L2(0.001)),
tf.keras.layers.Dropout(0.20),
tf.keras.layers.Dense(
20, activity_regularizer=tf.keras.regularizers.L2(0.001)),
tf.keras.layers.Softmax()
])
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(),
optimizer='adam', metrics=['accuracy'])
model.fit(x=X_train, y=y_train, validation_split=0.12, epochs=500, callbacks=[
tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=30)])Results:
model.evaluate(X_train, y_train)
3524/3524 [==============================] - 4s 1ms/step - loss: 1.9756 - accuracy: 0.3527
[1.9755834341049194, 0.3526991307735443]
model.evaluate(X_test, y_test) 266/266 [==============================] - 0s 1ms/step - loss: 2.0323 - accuracy: 0.3366
[2.0323143005371094, 0.33659282326698303]
# example strategies using predictions on the test set
test_data[(test_data.pred_proba > 1.15 * test_data.implied_proba) & (test_data.pred_proba > 0.2)].groupby('win')['win_pay'].agg('sum')
win
False -305000.0
True 312920.0
test_data[(test_data.pred_proba > 1.15 * test_data.implied_proba) & (test_data.pred_proba > 0.25)].groupby('win')['win_pay'].agg('sum')
win
False -173200.0
True 200530.0
So in the long run, the model produces positive returns. The caveat is that "Implied Probability" is a post-hoc variable only available to us after a race. We can approximate this variable by using live odds close to race time as a substitute, but odds can change pretty quickly, and the slight edge of ~5% we might have erodes in realistic scenarios.