A Python-based Natural Language Processing project to predict how successful a movie will perform at the Box Office.
This project (named Caramel Popcorn) is a small-scale implementation of a Movie Analysis System. This means that upon being provided the details of a movie, the probability of it making a huge success can be accurately predicted.
The pipeline of the project includes three components as of now:
- Data Scraping [Modules Used: BeautifulSoup]
- Feature Exploration and Engineering [Languages Used: Python]
- NLP Classification [Modules Used: NLTK, MultinomialNB, SVC] [Corpus Used: WordNet]
As mentioned above, the model expects the Name and the complete Description of the movie to be analyzed, and classifies the movie into one of over 200 specific genres.
The data used to train this model was scraped from IMDB’s list of Top 1000 movies. This was done by parsing each webpage into an HTML document, and then extracting the useful bits of information using BeautifulSoup, a library offered by Python. The extracted data is then formatted into a Dataframe and then exported into a CSV file for further uses.
Once the required data is available in the form of a CSV file/Dataframe, it is then cleaned for our model to work with.
This cleaning process is conducted in a 2-step process:
- First, any redundant/garbage column is dropped
- Next, all the Null values, Garbage values and Outliers are handled
The cleaned data is then separated into two parts, one for our model to work with, and the other being unrelated with this phase of the project.
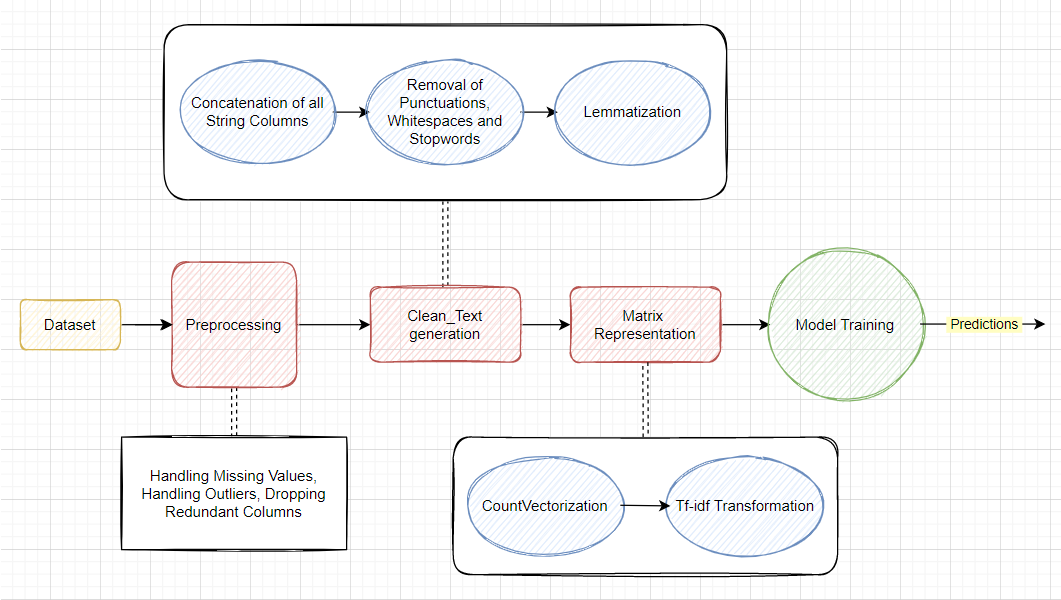
Once we have the data required for our model, we need to preprocess it and extract the features before we move onto the next step, i.e. NLP Classification.
The data preprocessing is conducted in a few steps.
First we obtain Clean_text from the provided textual columns. To do that:
- First, we add the contents of all the Textual Columns into one Column
- Next, for each row, we turn the whole string into lower case, strip any leading/trailing whitespaces, and substitute all Punctuation marks and Escape Sequence characters with a whitespace
- Next, we look for Stopwords, i.e. words that do not add much value, and remove them from the text
- Lastly, we Lemmatize all the words, i.e. change variant-forms into their root-words
Now we have obtained a Clean_text from the provided textual columns.
Next, we need to transform this string data into a numerical format.
To do that:
- First, we use CountVectorizer() to convert the collection of string data into token counts
- And then, we TfidfTransformer() to convert this count matrix into a tf-idf (term-frequency times inverse document-frequency) representation. This is done to scale down the impact of words that occur very frequently in the string collection/document.
Now we simply feed this tf-idf representation (in the form of a matrix) and the class-list, i.e. Genre List to our model for it to train.