I recently had my first kid, to celebrate this I built Cry Baby, a small piece of software which provides a probability that your baby is crying by continuously recording audio, chunking it into 4-second clips, and feeding them into a Convolutional Neural Network (CNN).
Create a virtual environment and install the dependencies with Poetry using the command poetry install.
Depending on your hardware architecture, Poetry should automatically install the correct version of TensorFlow or TensorFlow Lite. This has been tested on a 2022 M1 MacBook Pro and an Intel NUC running Ubuntu 20.04.
You will need a hugging face account and an API token. Once you have the token copy example.env to .env and add your token there.
A Makefile is provided for running Cry Baby.
make runEvery 4 seconds, Cry Baby will print the probability of a baby crying in each audio clip it records. And saves the timestamp, a pointer to the audio file, and the probability to a CSV file.
The codebase for training the model is currently not included in this repository due to its preliminary state. If there is interest, I plan to refine and share it.
The model was trained on 1.2 GB of evenly distributed labeled audio files, consisting of both crying and non-crying samples.
Data sources include:
- Ubenwa CryCeleb2023
- ESC-50 Dataset for environmental sound classification, also featuring non-crying samples
- Audio clips downloaded from YouTube, such as this one
- Friends who were willing to record there babies crying
The raw audio files were processed into 4-second Mel Spectrogram clips using Librosa, which provides a two-dimensional representation of the sound based on the mel-scale frequencies.
The preprocessing routine is integral to Cry Baby's runtime operations and is available here.
The dataset underwent an initial split: 80% for training and the remaining 20% for validation and testing. The latter was further divided equally between validation and testing.
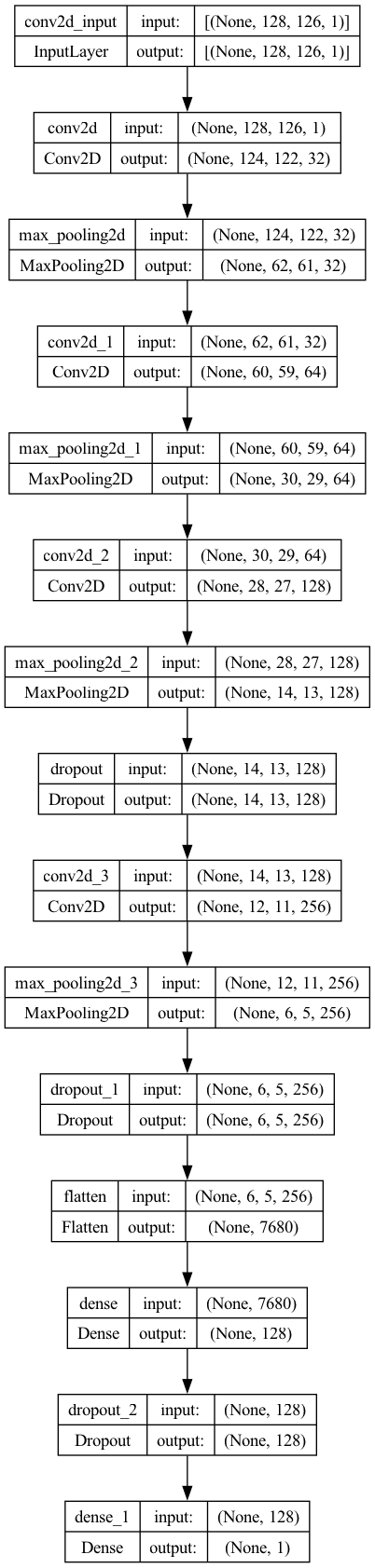
The model's architecture is inspired by the design presented in this research paper. Below is a visualization of the model structure:
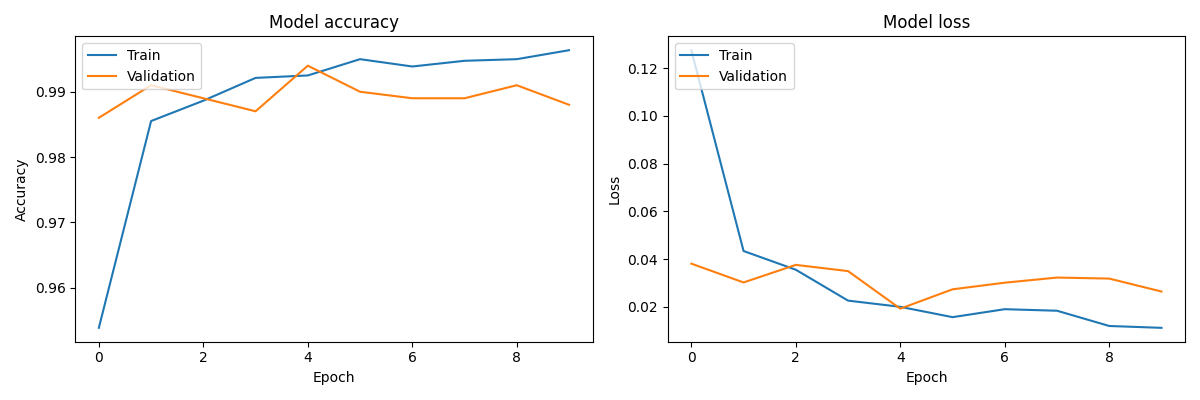
Training was conducted over 10 epochs with a batch size of 32. The corresponding training and validation loss and accuracy metrics are illustrated below.