LlamaTerm is a simple CLI utility that allows to use local LLM models easily and with some additional features.
⚠️ Currently this project supports models that use ChatML format or something similar. Use for example Gemma-2 or Phi-3 GGUFs.

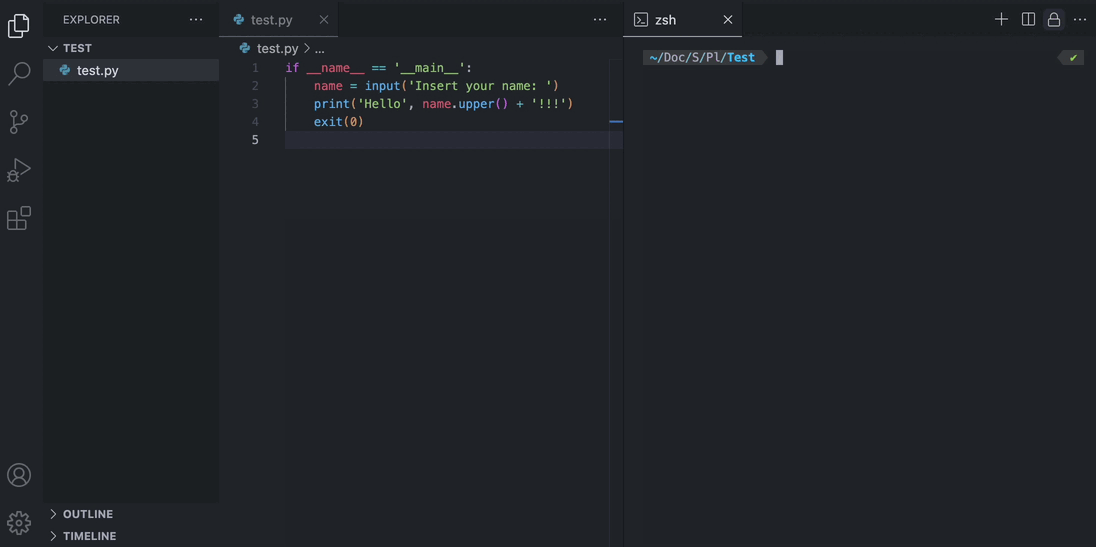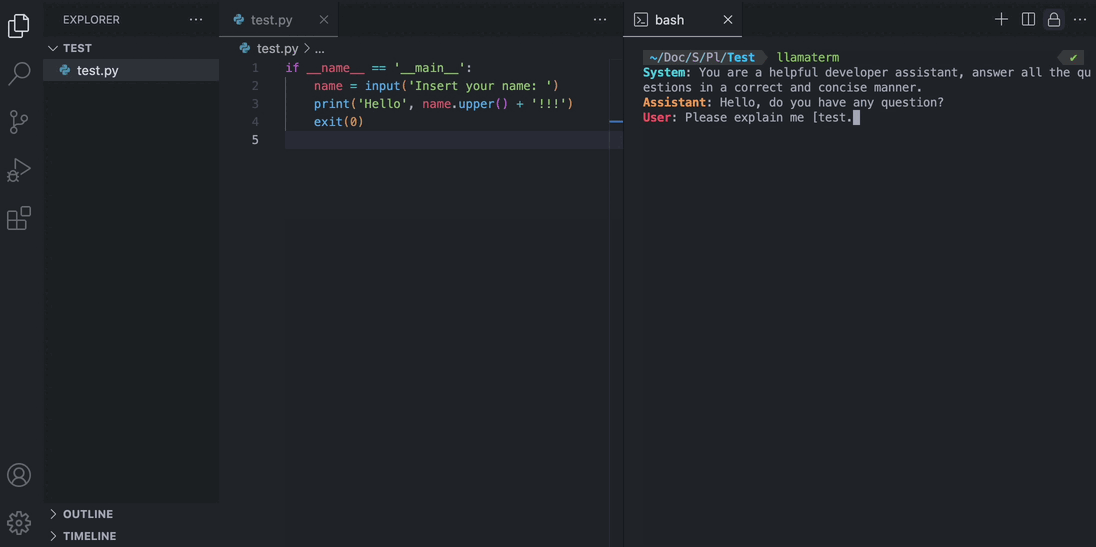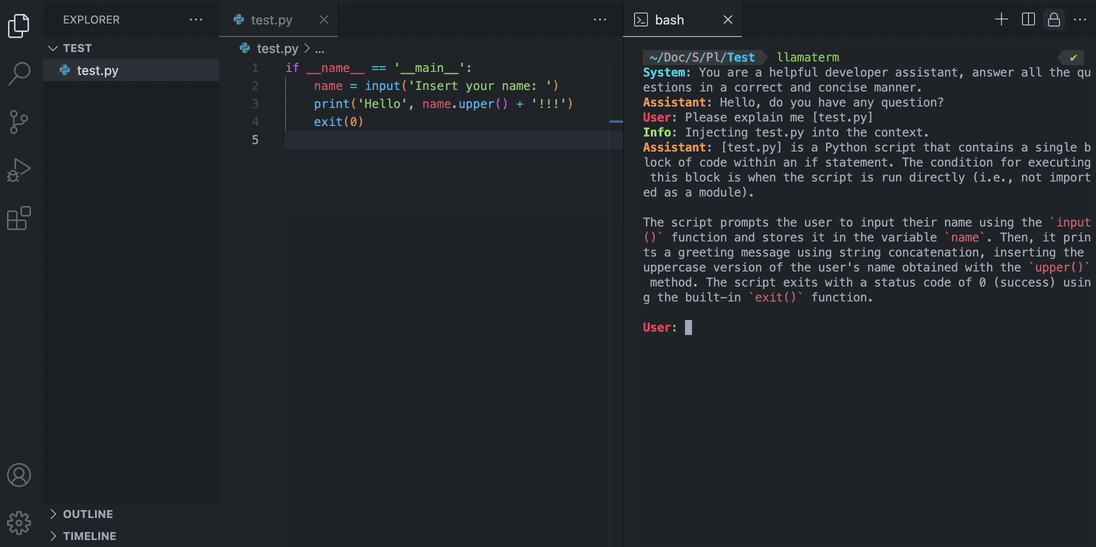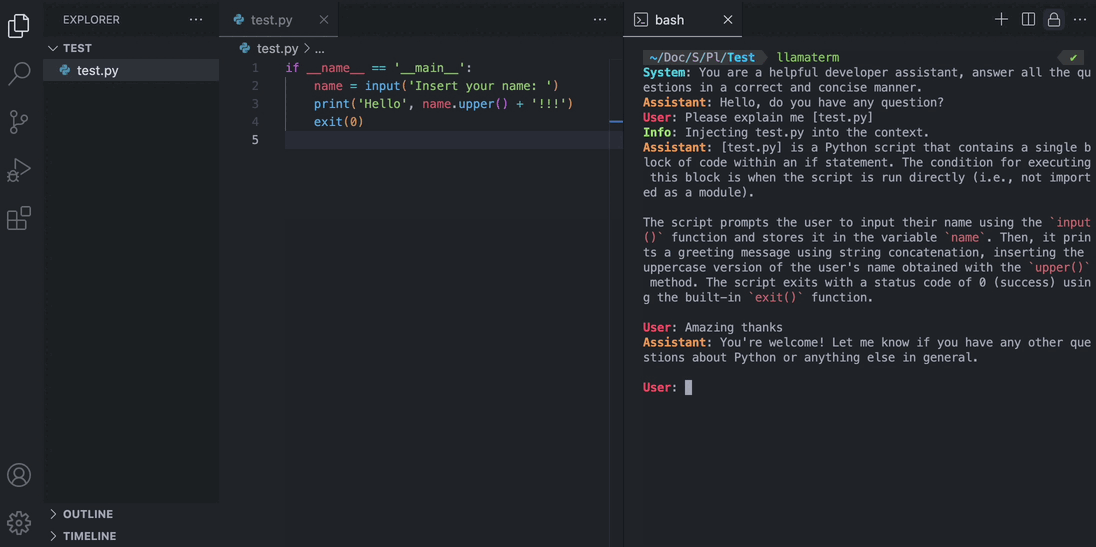
- Give local files to the model using square brackets
User: Can you explain the code in [helloworld.c] please? - More coming soon
You can setup LLamaTerm by:
- Rename
example-<model_name>.envto.env - Modify the
.envso that the model path corresponds (you may also need to editEOSandPREFIX_TEMPLATEif it's a non-standard model) - If you need syntax highlighting for code and markdown, then set
REAL_TIME=0in the.env. Note that you will lose real time output generation. - Install python dependencies with
pip install -r requirements.txt
Run LlamaTerm by adding the project directory to the PATH and then running llamaterm.
Alternatively you can just run ./llamaterm from the project directory.
For the following models you will just need to rename the corresponding example example-*.env file to .env and set the MODEL_PATH field in the .env:
- Gemma-2 Instruct 9B (🔥 BEST OVERALL)
- Phi-3 Instruct Mini (🍃 BEST EFFICIENCY)
- LLama-3 Instruct 8B
All the other models that have a prompt template similar to ChatML are supported but you will need to customize some fields like PREFIX_TEMPLATE, EOS etc... in the .env.