
{kind=link}
BarkingGPT is our experiment with Whisper, LLMs & Bark to give LLMs the ability to be able to speak, sing & express emotions just the way a human would do. The technology still have a long way to go to be able to make this experience reliable & consistent.
Currently barkingGPT supports all the emotions bark supports, we use single shot Instruction prompting to create a BarkAgent with ChatGPT that can laugh, sigh, sing, gasp, show hesitation, clears thought & create a little bit of music (We are working on integrating other expert models to provide better music experience with BarkingGPT).
You can find a few of our results below:
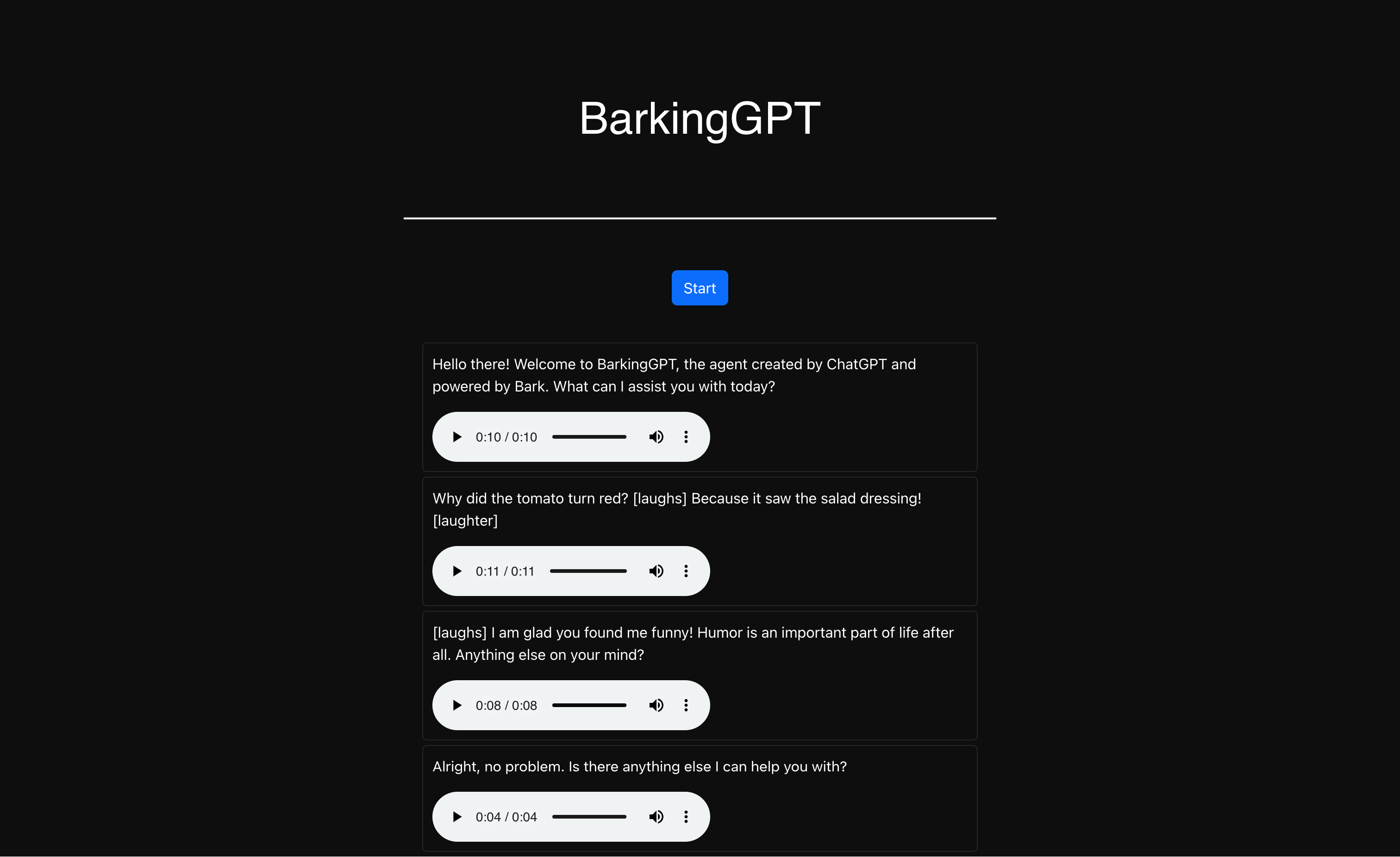
Currently the model takes around 2.30 mins on a 4 x A100, to be able to generate 1.15 secs clip on a single thread. We are trying to optimise it to make it suitable for Agent like scenarios with almost real-time Q&A.
- UI Improvements
- Support for other LLMs (Vicuna & Alpaca)
- Code refactoring
- Documentation
- JAX whisper
- Speaking & Barking Agents (Integration with AutoGPT)
- Consistent music generation with Diffusion
- Prompt collection
- Bark, the text-to-speech API, has a limit of 32 tokens per request. Therefore, we had to split long paragraphs into sentences with a maximum of 32 tokens, generate audio for each sentence, and then merge the audio together to create the final audio output.
- Non-speech sounds such as [laugh] do not work at the beginning of a sentence.
- GPU: 4 x 80 A100
- RAM: 460 GB RAM
- CPU: 64 vCPU
- OS: Ububtu 24
Setup Environment
python -m venv venv
source venv/bin/activate
Update config.py file with OpenAI Key
OPENAI_API_KEY=""
Setup Backend
cd backend
pip install -r requirements.txt
python app.py
Setup Web UI
cd ui
yarn install
yarn run