This project is still under development. Some features may not be implemented yet, and documentation may be incomplete.
A tiny yet powerful LLM inference system tailored for researching purpose.
vLLM-equivalent performance with only 2k lines of code (2% of vLLM).
There are so many open source frameworks for LLM serving, including HuggingFace Transformers, vLLM, LightLLM, DistServe and DeepSpeed-MII. Why SwiftLLM?
The reason is that, those frameworks are tailored for production, instead of researching. They are equipped with numerous features, such as 100+ model supports, various hardward supports, LoRA, quantization, multimodal, prefix caching, beam search, and so on. While being an all-in-one solution for production, their codebase is too big and complex to understand and modify (for example, vLLM has 100k+ lines of code), making it hard to use them for researching purpose. Also, their historical burden is also a problem.
SwiftLLM is designed to be a tiny yet powerful LLM inference system tailored for researching purpose. "Tiny" means that it only keeps features that are essential for researching, "powerful" means that it has no compromise on performance, and finally "swift" means that it is easy to understand and modify. While supporting basic features (see the list below) and being able to achieve equivalent performance to vLLM, the codebase of SwiftLLM is less than 2k lines of code (~2% of vLLM), written in Python and OpenAI Triton (a DSL for writing CUDA kernels), making it easy to read, modify, debug, test, extend, and can be easily integrated with your novel and brilliant research ideas.
Currently, SwiftLLM supports the following features:
- Iterational Scheduling and Selective Batching (proposed in Orca)
- PagedAttenton (proposed in vLLM, paper)
- LLaMA / LLaMA2 / LLaMA3 models (link) and their variants
- Piggybacking prefill and decoding (proposed in SARATHI)
- Flash attention (proposed in FlashAttention and FlashAttention-2)
- Paged attention v2 (also called Flash-Decoding, proposed here)
And we plan to add support for the following features in the future:
- Tensor parallelism and pipeline parallelism
To keep the codebase tiny, we will not support the following features. If you want to use them in your research project, you may need to implement them by yourself:
- Quantization
- LoRA
- Multimodal
- Models that does not follow LLaMA's architecture
- Sampling methods other than greedy sampling
- Hardware supports other than NVIDIA GPU (but it should be easy to migrate to other hardwares as long as OpenAI Triton supports them)
Remember that SwiftLLM is NOT an all-in-one solution for production. It's advised to think it as a "foundation" for your research project, and you may need to implement some features by yourself. We encourage you, my dear researcher, to read the code, understand it, modify it, and extend it to fit your research needs.
SwiftLLM's architecture can be divided into two major parts: the control plane and the data plane.
Briefly speaking, the control plane decides "what to compute" or "how to schedule", while the data plane decides "how to compute" or "how to implement" and performs the concrete computation. They work in a master-worker manner: the control plane acts like a master, who performs the high-level scheduling and coordination and sends jobs to the data plane, which acts like a worker, who performs the low-level computation.
The code for the control plane resides in the swiftllm/server directory, including components like Engine, Scheduler, the API server, and TokenizationEngine. The code for the data plane resides in the swiftllm/worker directory, including descriptions of the computation graph (in swiftllm/worker/model.py), implementation of layers in the model (in swiftllm/layers), and the OpenAI Triton kernels (you can imagine "kernels" as functions executed on the GPU) (in swiftllm/kernels).
Let's take the toy API server (located in swiftllm/server/api_server.py) as an example:
- Upon launching, it uses an
EngineConfigto create anEngine. - After that, the engine is initialized via
Engine.initialize, where it creates theScheduler, theTokenizationEngine, and a set of (currently only one since Tensor Parallelism is not supported) workers. Then it commands the worker to executeprofile_num_blocksto calculate the number of GPU blocks, after which the engine commands all workers to allocate their KV cache and KV swap. - Finally, the event loop is activated via
Engine.start_all_event_loops. In each step of the loop, the engine queries the scheduler for the next batch of requests to compute, commands the worker to perform swap in/out, then sends the batch to the worker to compute. - The API server listens to user requests and interacts with the engine to fulfill them.
Currently the control plane (Engine) and the data plane (LlamaModel) resides on the same node. After Tensor Parallelism / Pipeline Parallelism is implemented, the data plane may be distributed to multiple nodes.
We offer two ways to use SwiftLLM: using both the control plane and the data plane, or using only the data plane.
If your idea is simple or elegant enough that can be seamlessly integrated into the existing control plane, you may use both the control plane and the data plane. In another case, where you would like to implement a splendid ide, you may only leverage the data plane, and implement a new control plane by yourself.
First let's set up the environment:
- You may start from a clean conda environment with Python >= 3.9, or use an existing one. Do not forget to activate the conda environment if you are using one.
- Install PyTorch. Pay attention to select the correct version based on your hardware.
- Install
packagingviapip install packaging
And then comes the installation:
- Clone this repo via
git clone https://github.com/interestingLSY/swiftLLM.git cdinto the repo (cd swiftLLM) and install other dependencies viapip install -r requirements.txt.- PyTorch may install a stable version of OpenAI Triton for you. If you like to use the nightly version for the cutting-edge performance but with potential issues, you may uninstall it and install the nightly version.
- Run
pip install -e .to install SwiftLLM into your environment. - Install some C-bindings via
pip install -e csrc
Here are some examples:
- Currently SwiftLLM does not support downloading weights from HuggingFace automatically. You may need to clone or download the model weights from HuggingFace first. Both
.binformat and.safetensorsformat are supported. Assume your model weight is stored at/data/to/weight/. - For an offline serving example, you can try
python3 examples/offline.py --model-path /data/to/weight. This example utilizes the data plane only. If you plan to use SwiftLLM without the control plane, this is a good starting point. - For an online serving example that uses the
Engine, you can trypython3 examples/online.py --model-path /data/to/weight. This is a great example if you plan to use both the control plane and the data plane. - For a more complex example, you can refer to
swiftllm/server/api_server.py. It launches an API server and provides a vLLM-like interface for online serving.
Despite being tiny (Tiny ones can be adorable too!), SwiftLLM has no compromise on performance. We have evaluated SwiftLLM on several scenarios, and demonstrate that SwiftLLM can achieve equivalent performance, or even better, compared to vLLM.
The first scenario is "a single forward operation", where we feed the model with a batch of inputs and let it generate one output token (equivelant to one "forward" operation). This is the basic operation of LLM inference (both online and offline) so its performance is crucial.
Here we use LLaMA-3 7B model with NVIDIA A100 80G PCIE / RTX 4090 GPU under FP16 precision. The results are shown below (lower is better):
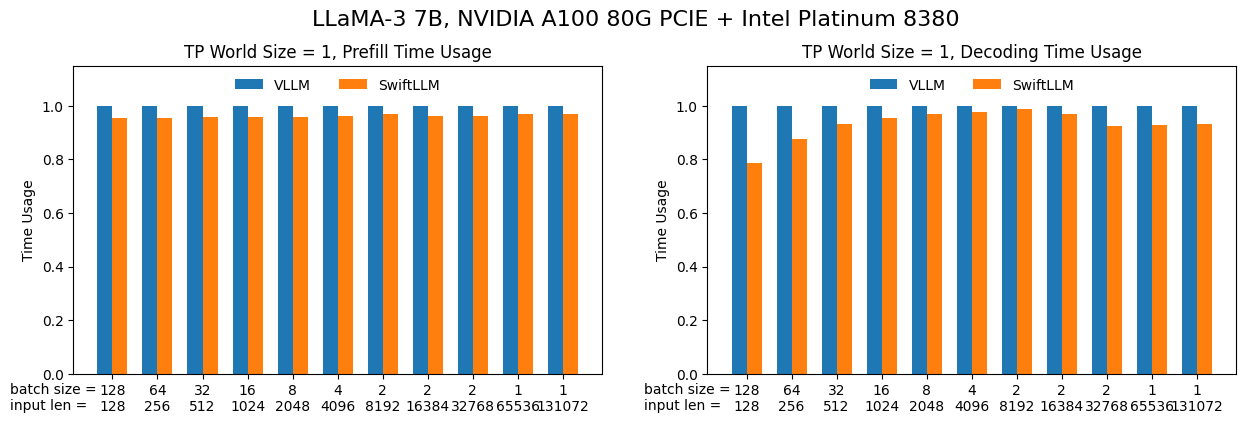
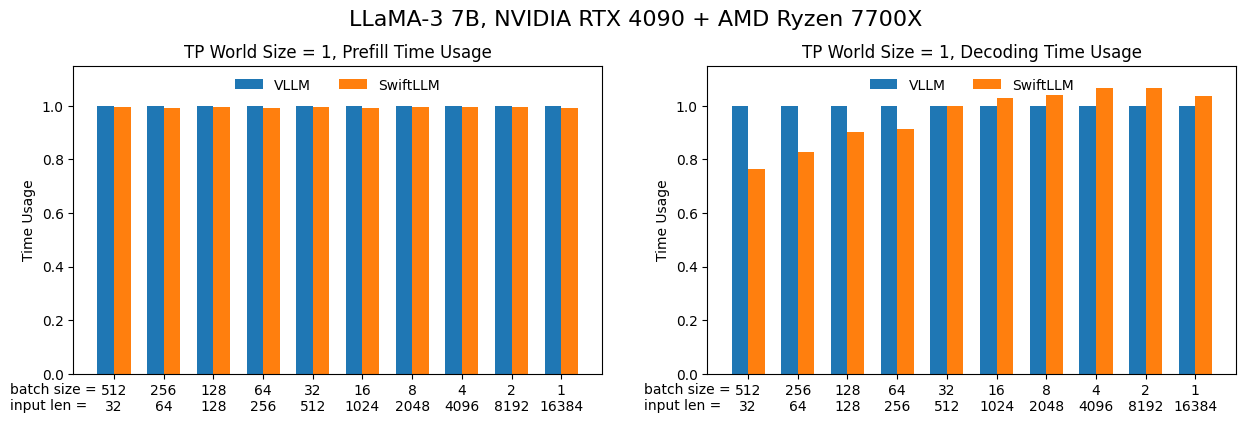
It can be seen that SwiftLLM can achieve equivalent performance (or even outperform) to vLLM under the same settings.
The second scenario is "online serving", where we start an API server, sample prompts from a real-world dataset, and let the model generate completions. This is the scenario where LLM is used in real-world applications like chatbots or code completions.
Here we use the ShareGPT dataset to sample prompts, and use a poisson process with different lambdas to simulate different request arrival rates. The results are shown below (lower is better):
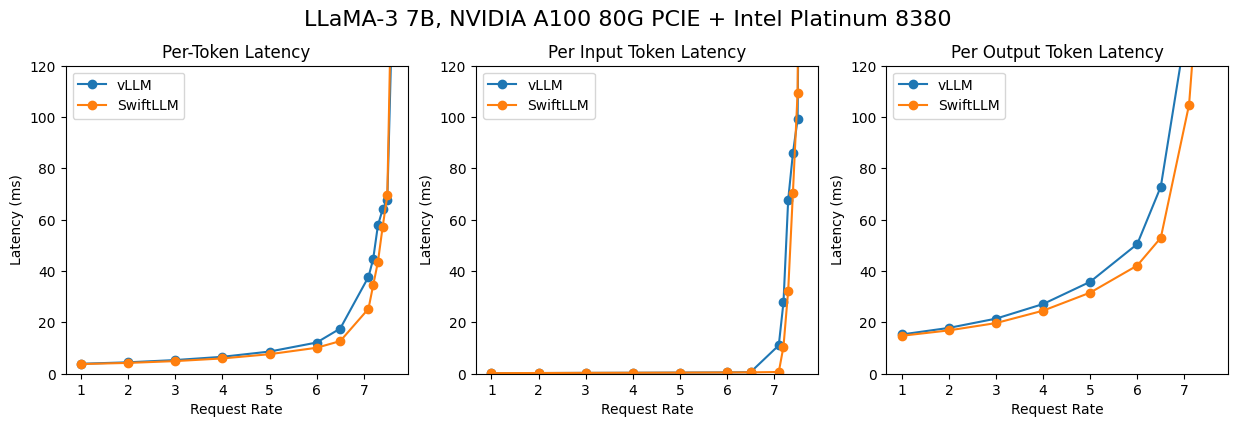
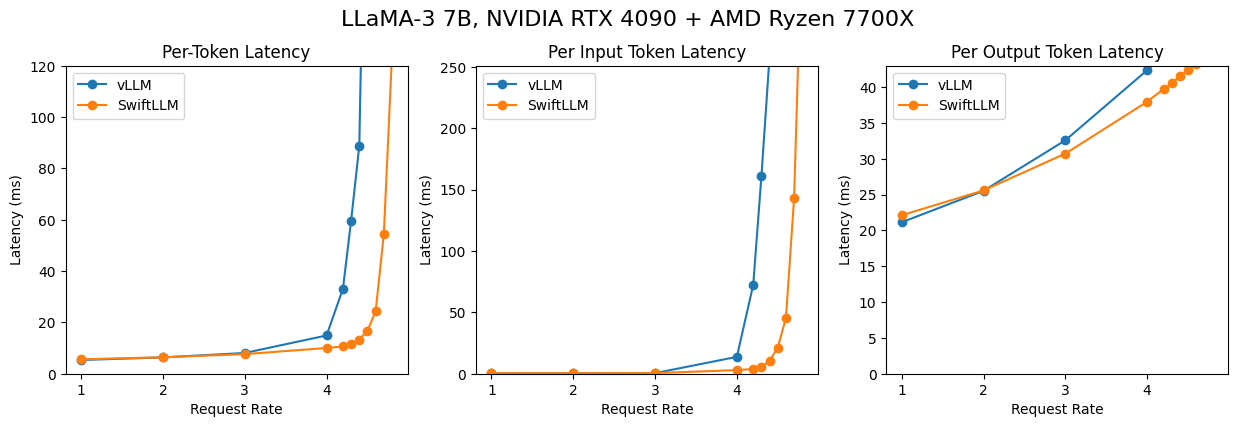
It can be seen that on A100 80G PCIE, SwiftLLM can achieve equivalent performance to vLLM, while on RTX 4090, SwiftLLM significantly outperforms vLLM (mainly because of that our control plane has a lower overhead).