Replicating data in Linked Data is able to improve data availability and performances of federated query engines. Existing replication-aware federated query engines mainly focused on source-selection and query decomposition in order to prune redundant sources and reduce intermediate results thanks to data-locality.
PeNeLoop is a novel parallel join operator that exploits replicated data to improve query execution time. Instead of pruning replicated data sources, PeNeLoop exploits these sources for parallel execution of join operators. We implement PeNeLoop in the federated query engine FedX[1] with the replicated-aware source selection Fedra[2].
Dataset and queries
We use one instance of the Waterloo SPARQL Diversity Test Suite (WatDiv)[3] synthetic dataset with 10^5 triples. We generate 50 000 queries, with subject and object unbounded and predicate bounded, from 500 templates. Then, 100 queries are randomly picked to be executed against our federations. Generated queries are STAR, PATH and SNOWFLAKE shaped queries, we use the DISTINCT modifier and include at least one join.
Queries used during the experiments are available here.
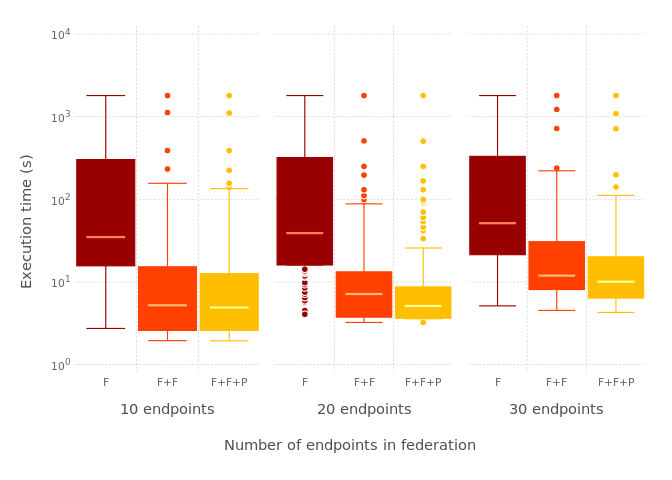
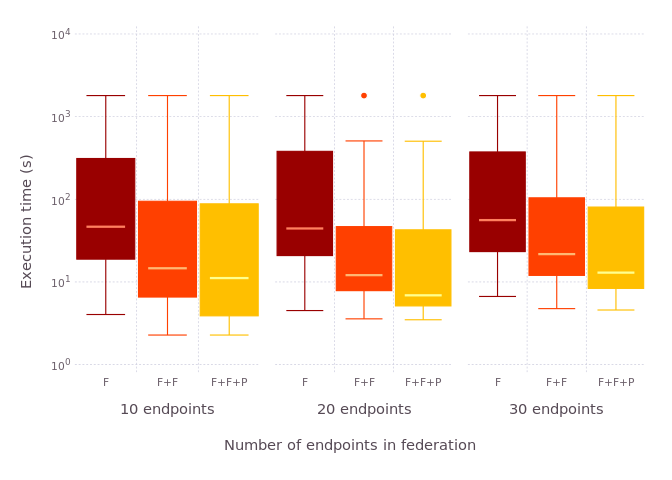
We compare the query execution time with FedX, FedX+Fedra and FedX+Fedra+PeNeLoop in federations of 10, 20 and 30 endpoints. We use a timeout of 1800s. Queries that failed to deliver an answer due to an error are excluded from the final results.
- All queries (PDF version)
- Queries with at least 1000 transferred tuples (PDF version)
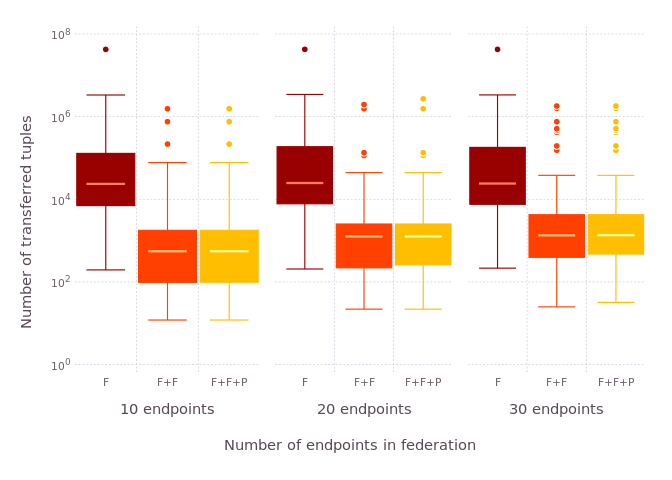
We compare the number of transferred tuples with FedX, FedX+Fedra and FedX+Fedra+PeNeLoop in federations of 10, 20 and 30 endpoints.
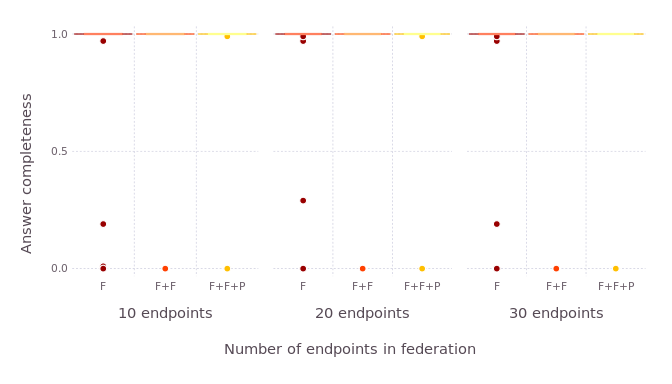
We compare the answer completeness with FedX, FedX+Fedra and FedX+Fedra+PeNeLoop in federations of 10, 20 and 30 endpoints.
- Schwarte, A., Haase, P., Hose, K., Schenkel, R., Schmidt, M.: Fedx: Optimization techniques for federated query processing on linked data. In: International Semantic Web Conference. pp. 601–616. Springer (2011)
- Montoya, G., Skaf-Molli, H., Molli, P., Vidal, M.E.: Federated sparql queries processing with replicated fragments. In: International Semantic Web Conference. pp. 36–51. Springer International Publishing (2015)
- Aluc, G., Hartig, O., Ozsu, M.T., Daudjee, K.: Diversified stress testing of rdf data management systems. In: International Semantic Web Conference. pp. 197–212. Springer (2014)
Requirements: you must have installed the FedX query engine with Fedra. Please follow the instructions for installing FedX + Fedra before installing this algorithm.
- Clone the repository or download it
git clone https://github.com/Callidon/FedraPBJ.git- Navigate into the project folder and execute the installation script. It takes in parameter the location of FedX's directory
cd FedraPBJ/
./install.sh <path-to-FedX-directory>- Compile FedX & use it as usual