-
Notifications
You must be signed in to change notification settings - Fork 3.7k
New issue
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
Add sgd docs #5208
Merged
Merged
Add sgd docs #5208
Changes from 13 commits
Commits
Show all changes
21 commits
Select commit
Hold shift + click to select a range
dc2c740
Started documentation for Stochastic Gradient Descent
pratik305 4ee6162
correct some spelling mistake
pratik305 a0bb7a6
Merge branch 'main' into add-sgd-docs
pratik305 815613e
Merge branch 'main' into add-sgd-docs
pratik305 7fdbafd
Merge branch 'main' into add-sgd-docs
pratik305 d83729c
Merge branch 'main' into add-sgd-docs
pratik305 4ae857a
Add example and update documentation for SGD
pratik305 0b850ed
Merge branch 'main' into add-sgd-docs
pratik305 59535b0
Merge branch 'main' into add-sgd-docs
pratik305 8fbec8e
Merge branch 'main' into add-sgd-docs
pratik305 94ddb5b
added syntax
pratik305 b465efc
Merge branch 'add-sgd-docs' of https://github.com/pratik305/docs into…
pratik305 50bbdf4
Merge branch 'main' into add-sgd-docs
pratik305 3be99e8
corrected code
pratik305 a14f821
Merge branch 'add-sgd-docs' of https://github.com/pratik305/docs into…
pratik305 4fd729b
Merge branch 'main' into add-sgd-docs
pratik305 93d2bde
Merge branch 'main' into add-sgd-docs
pratik305 5a1fd51
Merge branch 'main' into add-sgd-docs
pratik305 8e18225
Merge branch 'main' into add-sgd-docs
pratik305 55a704b
updated the file
avdhoottt f57478f
Merge branch 'main' into add-sgd-docs
avdhoottt File filter
Filter by extension
Conversations
Failed to load comments.
Loading
Jump to
Jump to file
Failed to load files.
Loading
Diff view
Diff view
There are no files selected for viewing
119 changes: 119 additions & 0 deletions
119
...eural-networks/terms/stochastic-gradient-descent/stochastic-gradient-descent.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,119 @@ | ||
| --- | ||
| Title: 'Stochastic Gradient Descent' | ||
| Description: 'Stochastic Gradient Descent is an optimizer algorithm that minimizes the loss function in machine learning and deep learning models.' | ||
| Subjects: | ||
| - 'Machine Learning' | ||
| - 'Computer Science' | ||
| Tags: | ||
| - 'AI' | ||
| - 'Neural Networks' | ||
| CatalogContent: | ||
| - 'paths/computer-science' | ||
| - 'paths/data-science' | ||
| --- | ||
|
|
||
| **Stochastic Gradient Descent** (SGD) is an optimization algorithm. It is a variant of gradient descent optimizer. The SGD minimizes the loss function of machine learning algorithms and deep learning algorithms during backpropagation to update the weights and biases in Artificial Neural Networks. | ||
|
|
||
| The term `stochastic` means randomness on which the algorithm is based. In this algorithm, instead of taking whole datasets like `gradient descent`, we take single randomly selected data points or small batches of data. Suppose if the data set contains 500 rows SGD updates the model parameters 500 times in one cycle or one epoch. | ||
|
|
||
| This approach significantly reduces computation time, especially for large datasets, making SGD faster and more scalable.SGD is used for training models like neural networks, support vector machines (SVMs), and logistic regression. However, it introduces more noise into the learning process, which can lead to less stable convergence but also helps escape local minima, making it suitable for non-convex problems. | ||
|
|
||
|
|
||
| 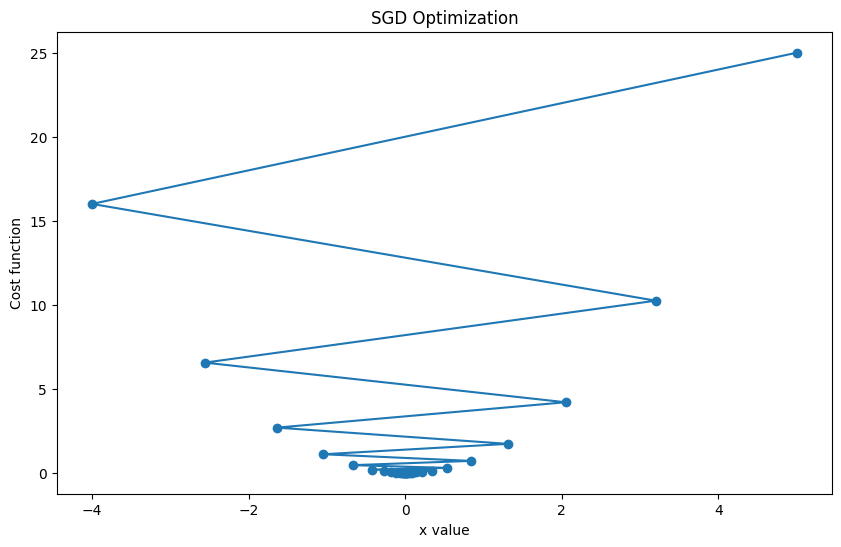 | ||
|
|
||
| ## Algorithms Step | ||
|
|
||
| - At each iteration, a random sample is selected from the training dataset. | ||
| - The gradient of the cost function with respect to the model parameters is computed based on the selected sample. | ||
| - The model parameters are updated using the computed gradient and the learning rate. | ||
| - The process is repeated for multiple iterations until convergence or a specified number of epochs. | ||
|
|
||
| ## Formula | ||
|
|
||
| $$ | ||
| \large \theta = \theta - \alpha \cdot \nabla J(\theta ; x_i, y_i) | ||
| $$ | ||
|
|
||
| Where: | ||
|
|
||
| - θ represents the model parameter (weight or bias) being updated. | ||
| - α is the learning rate, a hyperparameter that controls the step size of the update. | ||
| - ∇J(θ;xi,yi) is the gradient of the cost or loss function J with respect to the model parameter θ, computed based on a single training sample (xi,yi). | ||
|
|
||
| ## Advantages | ||
| - **Faster convergence:** SGD updates parameters more frequently hence it takes less time to converge especially for large datasets. | ||
| - **Reduced Computation Time:** SGD takes only a subset of dataset or batch for each update. This makes it easy to handle large datasets and compute faster. | ||
| - **Avoid Local Minima:** The noise introduced by updating parameters with individual data points or small batches can help escape local minima.This can potentially lead to better solutions in complex, non-convex optimization problems. | ||
| - **Online Learning:** SGD can be used in scenarios where data is arriving sequentially (online learning).- It allows models to be updated continuously as new data comes in. | ||
|
|
||
| ## Disadvantages | ||
| - **Noisy Updates:** Updates are based on a single data point or small batch, which introduces variability in the gradient estimates.This noise can cause the algorithm to converge more slowly or oscillate around the optimal solution. | ||
| - **Convergence Issues:** The noisy updates can lead to less stable convergence and might make it harder to reach the exact minimum of the loss function.Fine-tuning the learning rate and other hyperparameters becomes crucial to achieving good results. | ||
| - **Hyperparameter Sensitivity:** - SGD's performance is sensitive to the choice of learning rate and other hyperparameters.Finding the right set of hyperparameters often requires experimentation and tuning. | ||
|
|
||
| ## Practical Tips And Tricks When Using SGD | ||
| - Shuffle data before training | ||
| - Use mini batches(batch size 32) | ||
| - Normalize input | ||
| - Choose a suitable learning rate (0.01) | ||
|
|
||
| ## Syntax | ||
|
|
||
| ``SGD(learning_rate, n_iterations, loss_function, gradient_calculation)`` | ||
|
|
||
| - Learning Rate (α): A hyperparameter that controls the size of the update step. | ||
| - Number of Iterations: The number of times the algorithm will iterate over the dataset. | ||
| - Loss Function: The function that measures the error of the model predictions. | ||
| - Gradient Calculation: The method for computing gradients based on the loss function. | ||
|
|
||
| ## Example | ||
| ```python | ||
| def stochastic_gradient_descent(X, y, theta, learning_rate, n_iterations): | ||
| for iteration in range(n_iterations): | ||
| for i in range(len(y)): | ||
| gradient = compute_gradient(X[i], y[i], theta) | ||
| theta -= learning_rate * gradient | ||
| return theta | ||
| ``` | ||
|
|
||
| ## codebyte Example | ||
|
|
||
| Here’s a Python code snippet demonstrating how to implement SGD for linear regression: | ||
|
|
||
| ```codebyte/python | ||
| import numpy as np | ||
|
|
||
| # Generate synthetic data | ||
| np.random.seed(42) | ||
| X = 2 * np.random.rand(100, 1) | ||
| y = 4 + 3 * X + np.random.randn(100, 1) | ||
|
|
||
| # Initialize parameters | ||
| m, n = X.shape | ||
| theta = np.random.randn(n, 1) # Initial weights | ||
| learning_rate = 0.01 | ||
| n_iterations = 1000 | ||
|
|
||
| # Stochastic Gradient Descent function | ||
| def stochastic_gradient_descent(X, y, theta, learning_rate, n_iterations): | ||
| m = len(y) | ||
| for iteration in range(n_iterations): | ||
| # Shuffle the data | ||
| indices = np.random.permutation(m) | ||
| X_shuffled = X[indices] | ||
| y_shuffled = y[indices] | ||
|
|
||
| # Update weights for each sample | ||
| for i in range(m): | ||
| xi = X_shuffled[i:i+1] | ||
| yi = y_shuffled[i:i+1] | ||
| gradient = 2 * xi.T.dot(xi.dot(theta) - yi) | ||
| theta -= learning_rate * gradient | ||
|
|
||
| return theta | ||
|
|
||
| # Perform SGD | ||
| theta_final = stochastic_gradient_descent(X, y, theta, learning_rate, n_iterations) | ||
|
|
||
| print("Optimized weights:", theta_final) | ||
| ``` | ||
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Added some proper indentation.