通过QQ导出的QQ群聊天记录进行一定的分析。
just a toy
2020-08-27 完成数据处理部分代码清洗,优化部分代码。
- QQ群聊天记录的数据清洗
- 构建简单用户画像
- 简单分析与统计
- 部分数据可视化
python版本:3.6.x
系统平台:windows
需要的第三方库:pymongo,pandas,jieba,seaborn,numpy
以上均可通过pip install 安装
需要的软件:MongoDB
-
read_chatlog.py
对导出的.txt聊天记录文件进行数据清洗。
注意:腾讯导出的聊天记录是UTF-8+bom的 需改成 -bom清洗后的数据存入mongo数据库中,具体数据如下:
数据项 说明 time 消息发送时间 ID QQ号或邮箱 name 发送该消息时所使用的马甲 text 发送消息的内容 -
user_profile.py
通过清洗好的数据构建用户画像,并保存到mongo数据库中。
用户基本画像数据如下:
数据项 说明 ID QQ号或邮箱 name_list 可统计得到的所有马甲 speak_num 发言次数 word_num 发言字数 photos_num 发送图片数 week_online 记录着周一到周日每天每小时的活跃数据 ban_time 被禁言时间(有待改进) -
seg_word.py
通过jieba分词工具将文本进行分析,统计词频并去停用词后保存。
-
chinese_stopword.txt
停用词典。
-
individual.py
个人数据统计,分析发言次数最多,发送字数最多,发送图片最多,被禁言时长最长的用户。
-
collecticity.py
总体数据分析,分析群活跃时间。
-
interesting.py
因吹斯听的分析。
- 马甲最长的聚聚
- 改名次数最多的聚聚
- 群内队形(+1)次数最多的内容,即使局部打断也可统计。
-
content.py
开发中
-
charts.py
将部分数据可视化。如下:
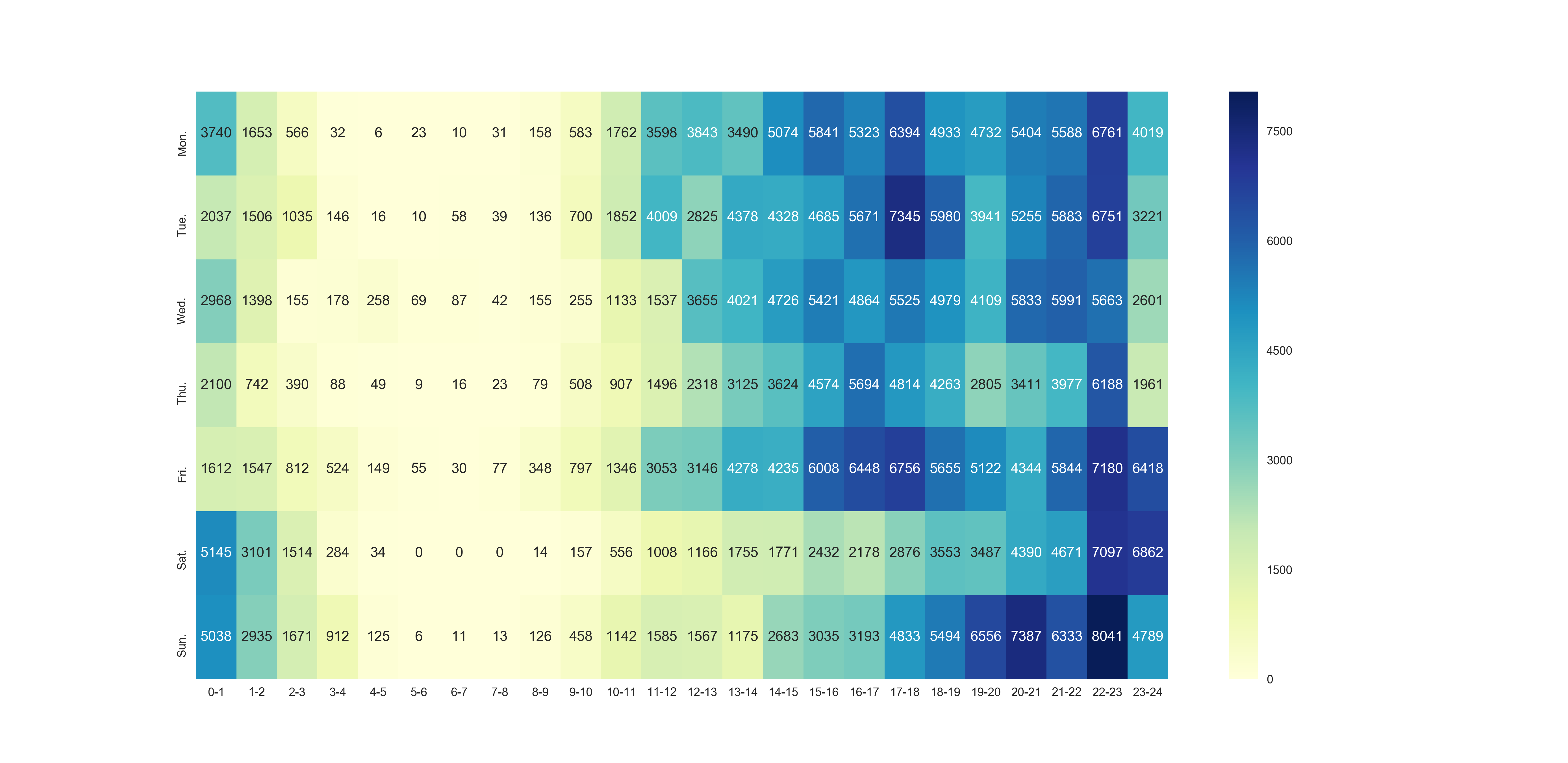
用户活跃时间heatmap,横轴为一天0-24时,纵轴为周一到周日。颜色越深的方块活跃程度越高。

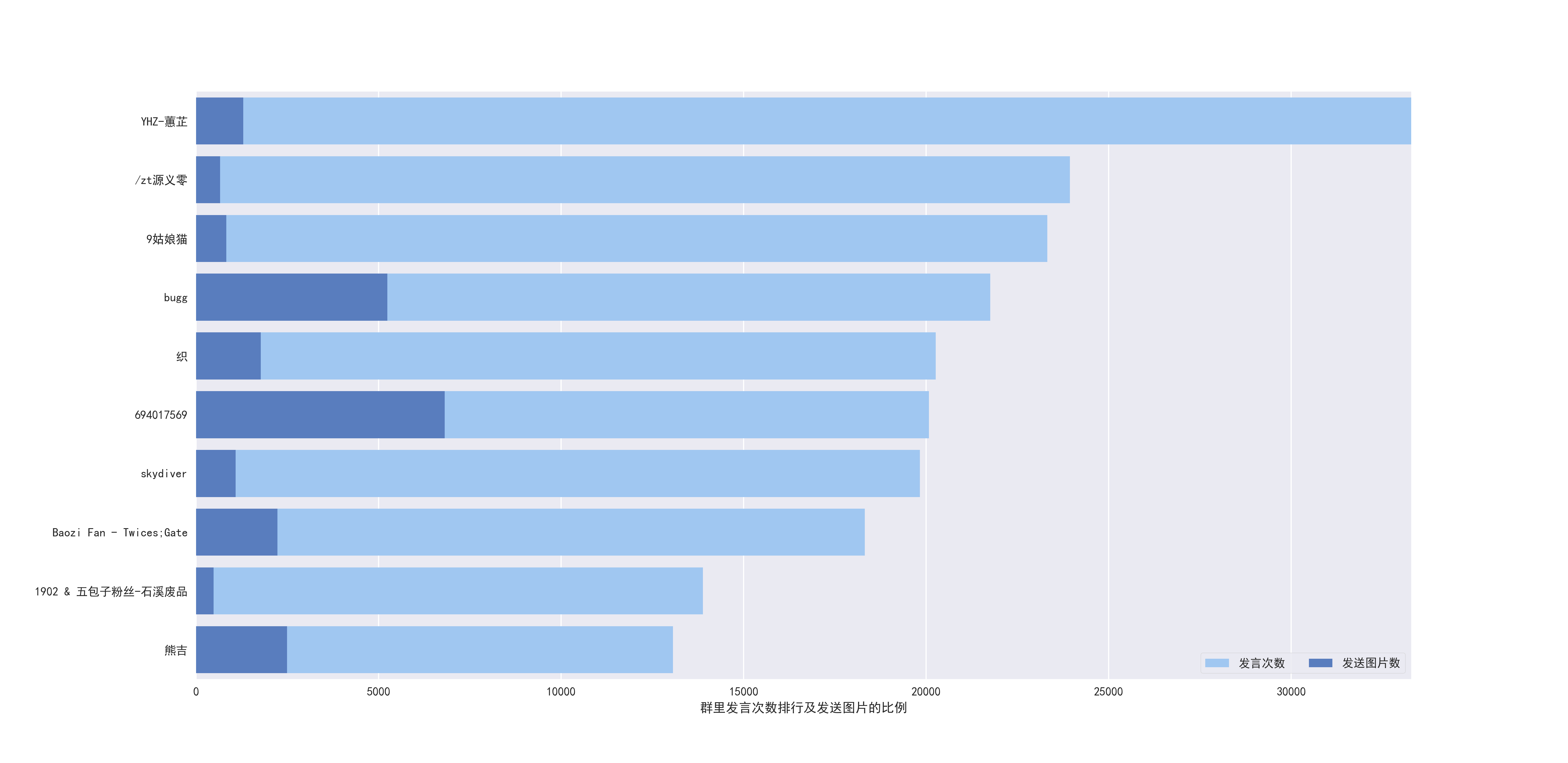
用户发言数TOP10及发表图片所占比例。

-
word_img.py
构建词云。分析群内常用词及部分话题,如下:
针对所有信息进行词云
- 构建词长度大于0:

- 词长度大于1:

- 词长度大于3:

针对群聊天记录构建的词云:
因为测试数据为技(zhuang)术(bi)群,所以本项不具有通用性。具体实现在此处
-
针对经常谈论的公司:

-
针对谈论的编程语言:






0.clone本项目到本地。
1.手动从QQ消息管理器中导出消息,注意改为UTF-8-BOM。并将其命名为chatlog.txt放置于run.py同级目录下。
2.开启mongodb服务,运行run.py
3.易于修改的参数有:
- 群等级标签:DataClean.py line83:根据不同群等级标签修改。不改无妨,影响用户名称显示
- 词云样式及背景图片:Wordcloud
- 词云屏蔽词:Wordcloud line45:此处已经屏蔽‘图片’,‘表情’,‘说’
填坑中,希望收到改进意见。