ConditionalVAE is a project realized as part of the Deep Learning exam of the Master's degree in Artificial Intelligence, University of Bologna. The aim of this project is to build a Conditional Generative model and test it on the well known CelebA dataset.
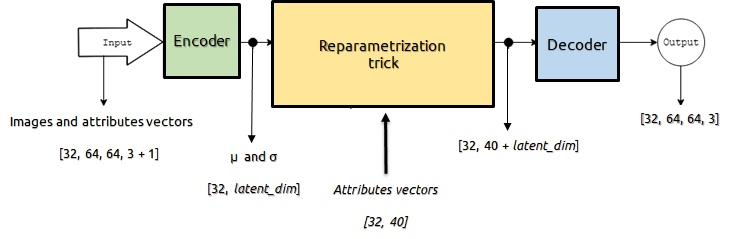
We implemented from scratch a Conditional Variational Autoencoder using Tensorflow 2.2 (in the figure below there is a diagram of our architecture).
We trained the model using Google Colab and we explored the conditioning ability of our model by generating new faces with specific attributes, and by performing attributes manipulation and latent vectors interpolation.
If you are interested, here you can find a brief report about this project.
- Download the repository.
- Open the Train_ConditionalVae notebook on Google Colab.
- Run the notebook with your own configuration.
- Train the model.
- Open the Image_Generation notebook on Google Colab.
- Run the notebook with your own configuration.
An example of new images generated with specific attributes (listed on the side):

The vector interpolation in the latent space is a method to generate new images which simulate the transition between two images.
In the figure below, we report 4 examples of images interpolation: in each row the first and the last images are the original ones, while the 6 images in the middle are the new ones.

Starting from a batch of images, we can reconstruct it modifying some face attributes.
For example, we can transform all the subjects into men with moustache:

- Python 3
- Jupyter Notebook
For more details: see our report
This project is licensed under the Apache License 2.0 - see the LICENSE.md file for details.
- Yaniv Benny, Tomer Galanti, Sagie Benaim, and Lior Wolf. Evaluation metrics for condi-tional image generation, 2020.D.C
- Dowson and B.V Landau. The frechet distance between multivariate normal distri-butions.Journal of Multivariate Analysis, 12(3):450 – 455, 1982. ISSN 0047-259X. doi:https://doi.org/10.1016/0047-259X(82)90077-X.URLhttp://www.sciencedirect.com/science/article/pii/0047259X8290077X.
- Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, SherjilOzair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Z. Ghahra-mani, M. Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger, editors,Advancesin Neural Information Processing Systems 27, pages 2672–2680. Curran Associates, Inc.,2014.URLhttp://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf.
- Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and SeppHochreiter. Gans trained by a two time-scale update rule converge to a local nash equi-librium, 2017.
- Irina Higgins, Lo ̈ıc Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew MBotvinick, Shakir Mohamed, and Alexander Lerchner. beta-vae: Learning basic visualconcepts with a constrained variational framework. InICLR, 2017.
- Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization, 2014.Diederik P Kingma and Max Welling. Auto-encoding variational bayes, 2013.
- Diederik P. Kingma, Tim Salimans, and Max Welling. Variational dropout and the localreparameterization trick, 2015.
- YannLeCunandCorinnaCortes.MNISThandwrittendigitdatabase.http://yann.lecun.com/exdb/mnist/, 2010.URLhttp://yann.lecun.com/exdb/mnist/.
- Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributesin the wild. InProceedings of International Conference on Computer Vision (ICCV),December 2015.
- Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks forbiomedical image segmentation, 2015.
- Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, andXi Chen. Improved techniques for training gans, 2016.
- Tim Salimans, Andrej Karpathy, Xi Chen, and Diederik P. Kingma. Pixelcnn++: Im-proving the pixelcnn with discretized logistic mixture likelihood and other modifications,2017.
- Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, DragomirAnguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeperwith convolutions, 2014.
- Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, and Zbigniew Wojna.Rethinking the inception architecture for computer vision, 2015.
- Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural discrete representationlearning, 2017.
- Biao Zhang, Deyi Xiong, Jinsong Su, Hong Duan, and Min Zhang. Variational neuralmachine translation, 2016