| Topic | Description |
|---|---|
| LVLM Model | Large multimodal models / Foundation Model |
| Multimodal Benchmark & Dataset | 😍 Interesting Multimodal Benchmark and Dataset |
| LVLM Agent | Agent & Application of LVLM |
| LVLM Hallucination | Benchmark & Methods for Hallucination |





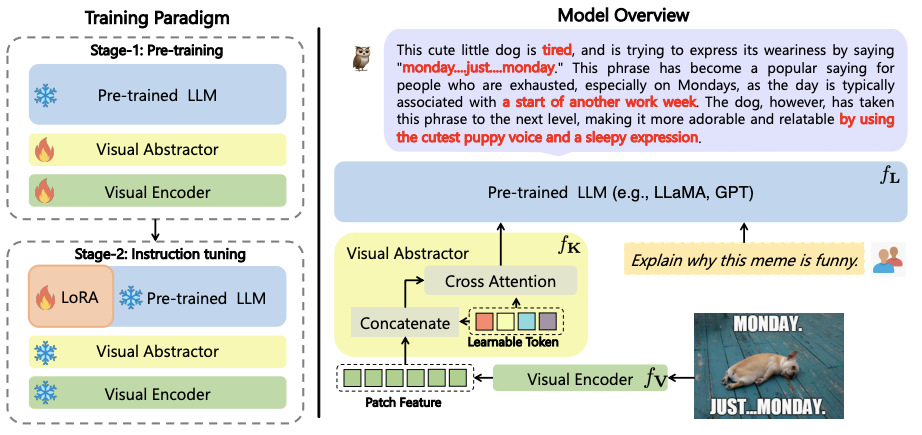

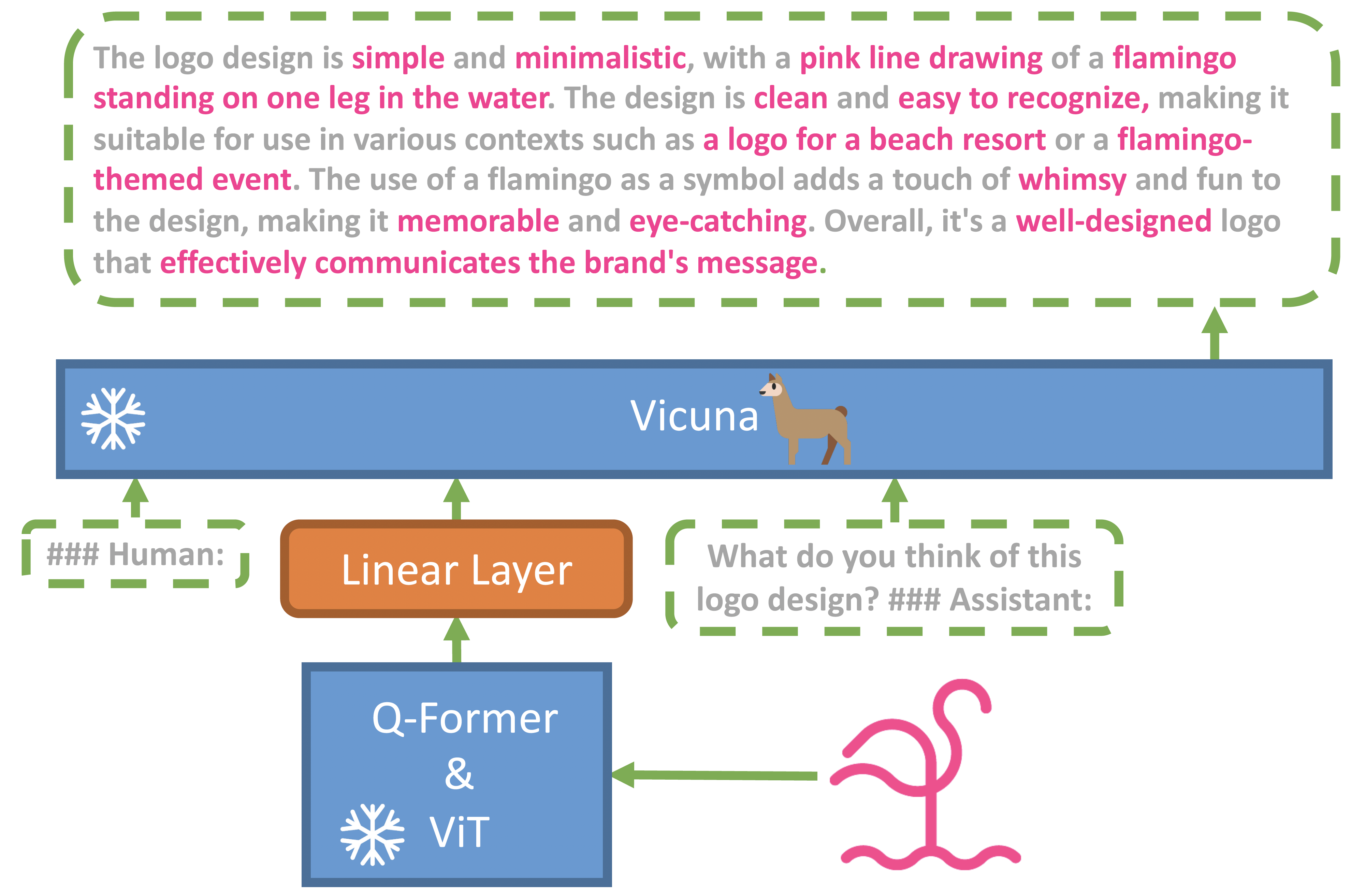

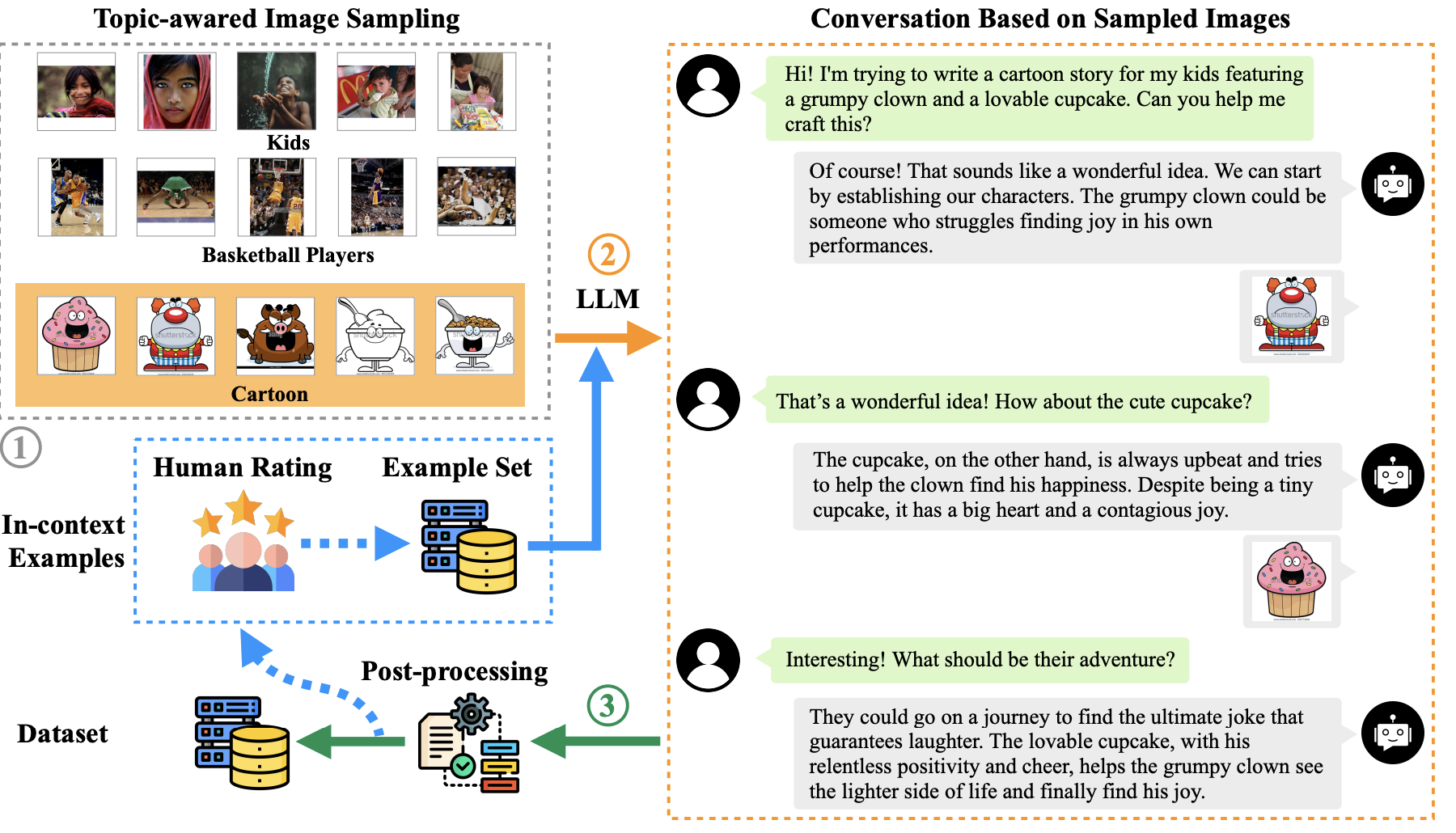
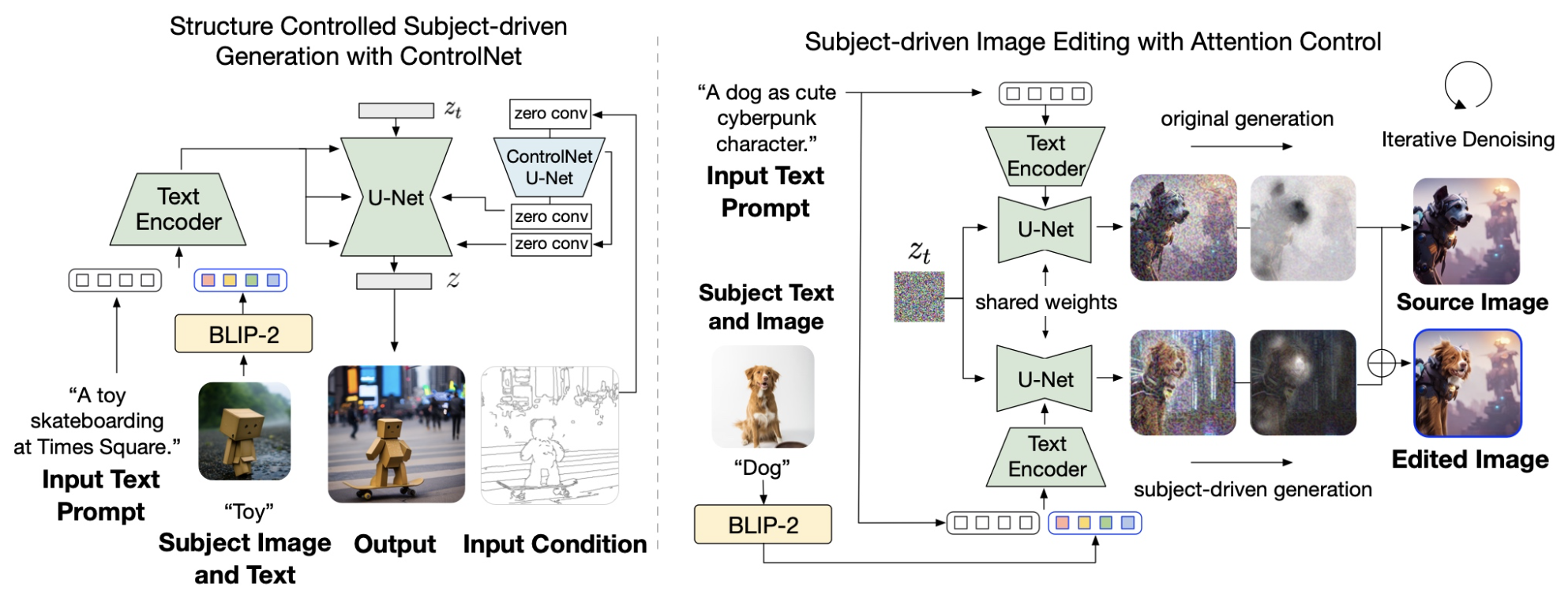







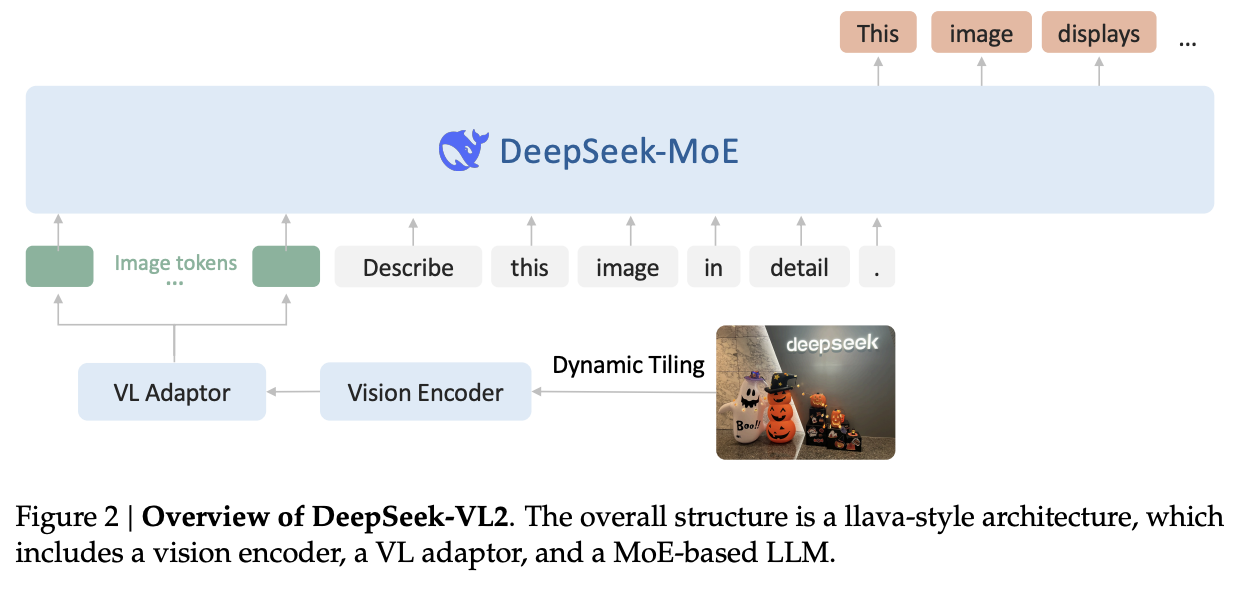

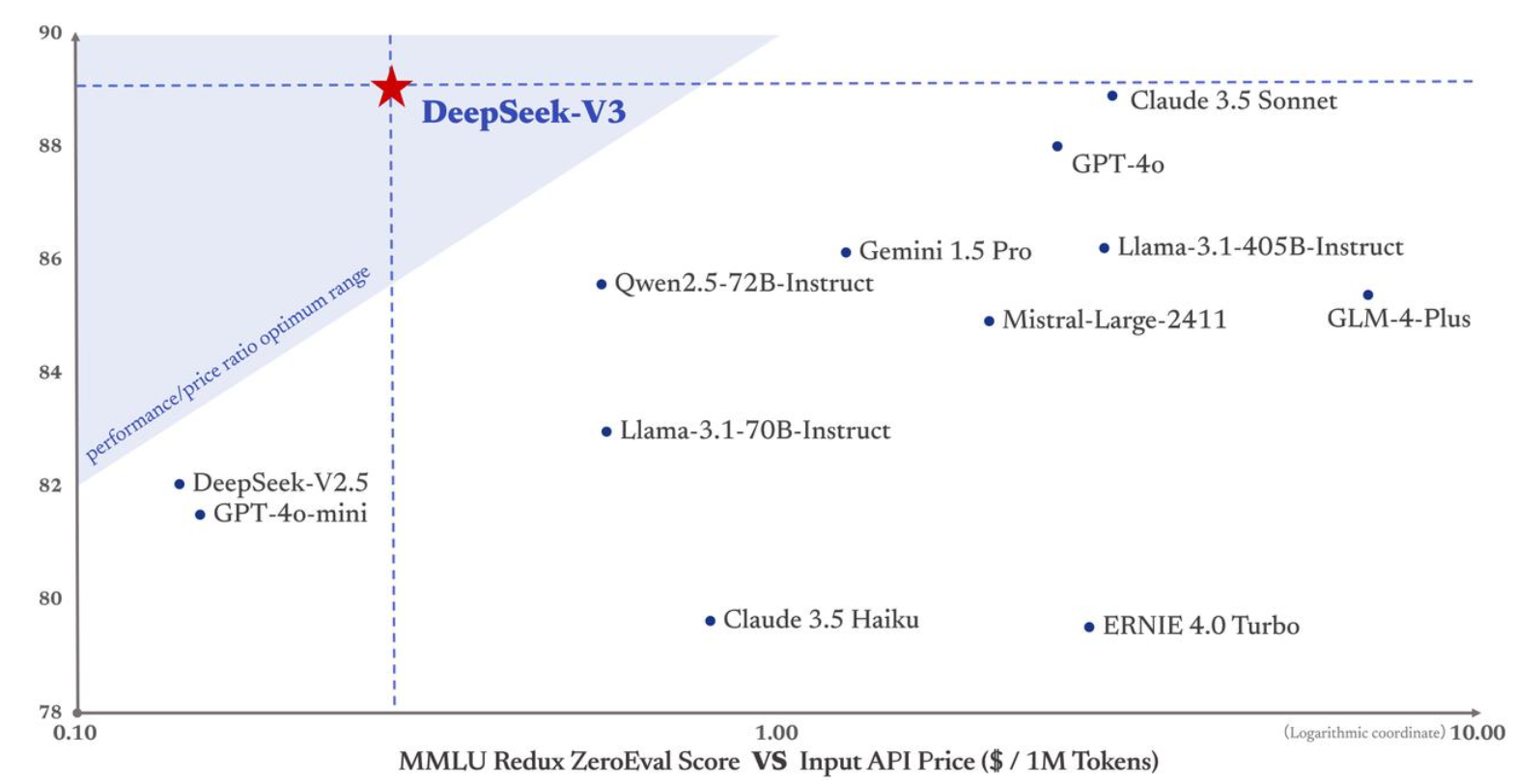

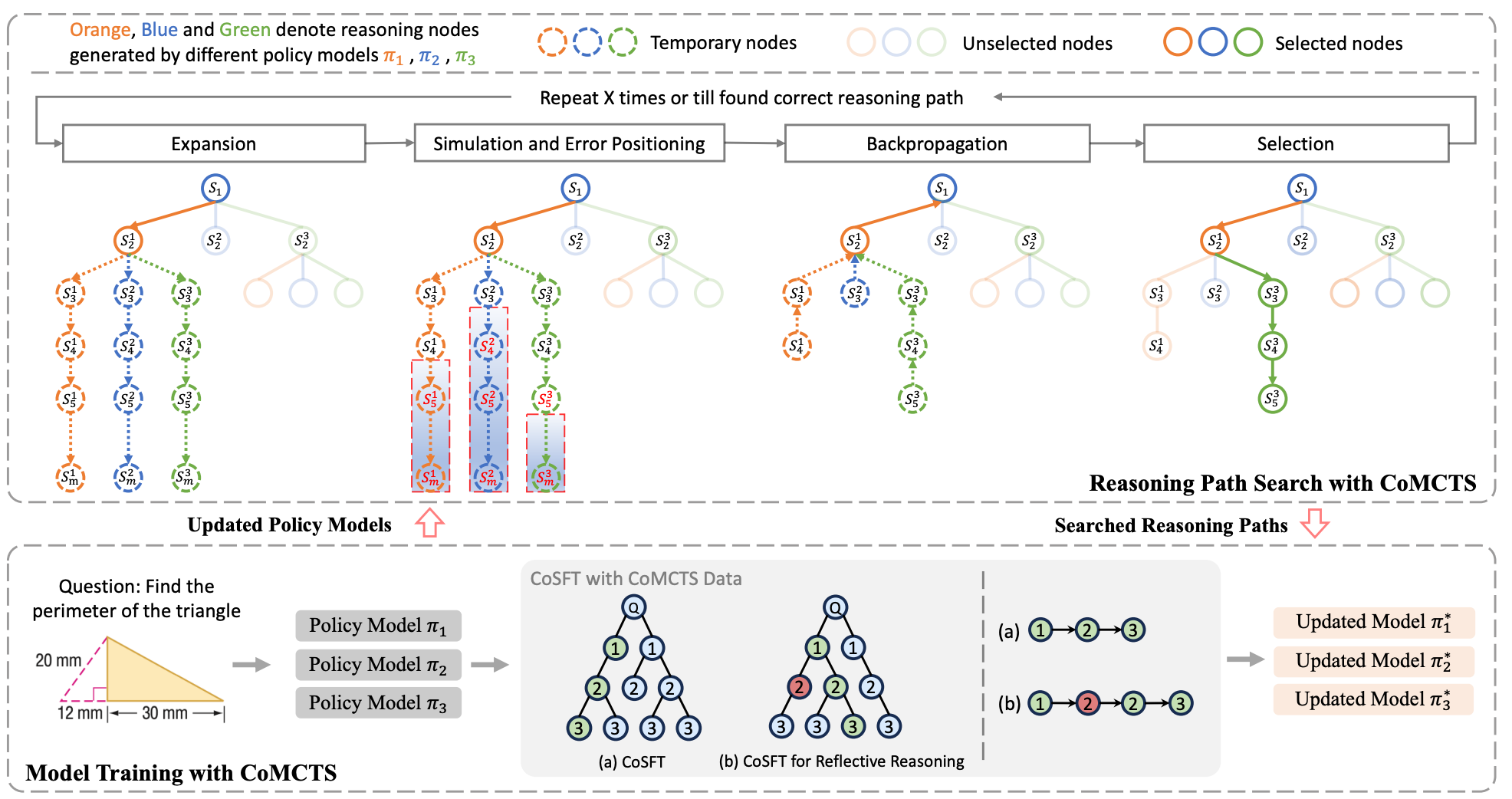
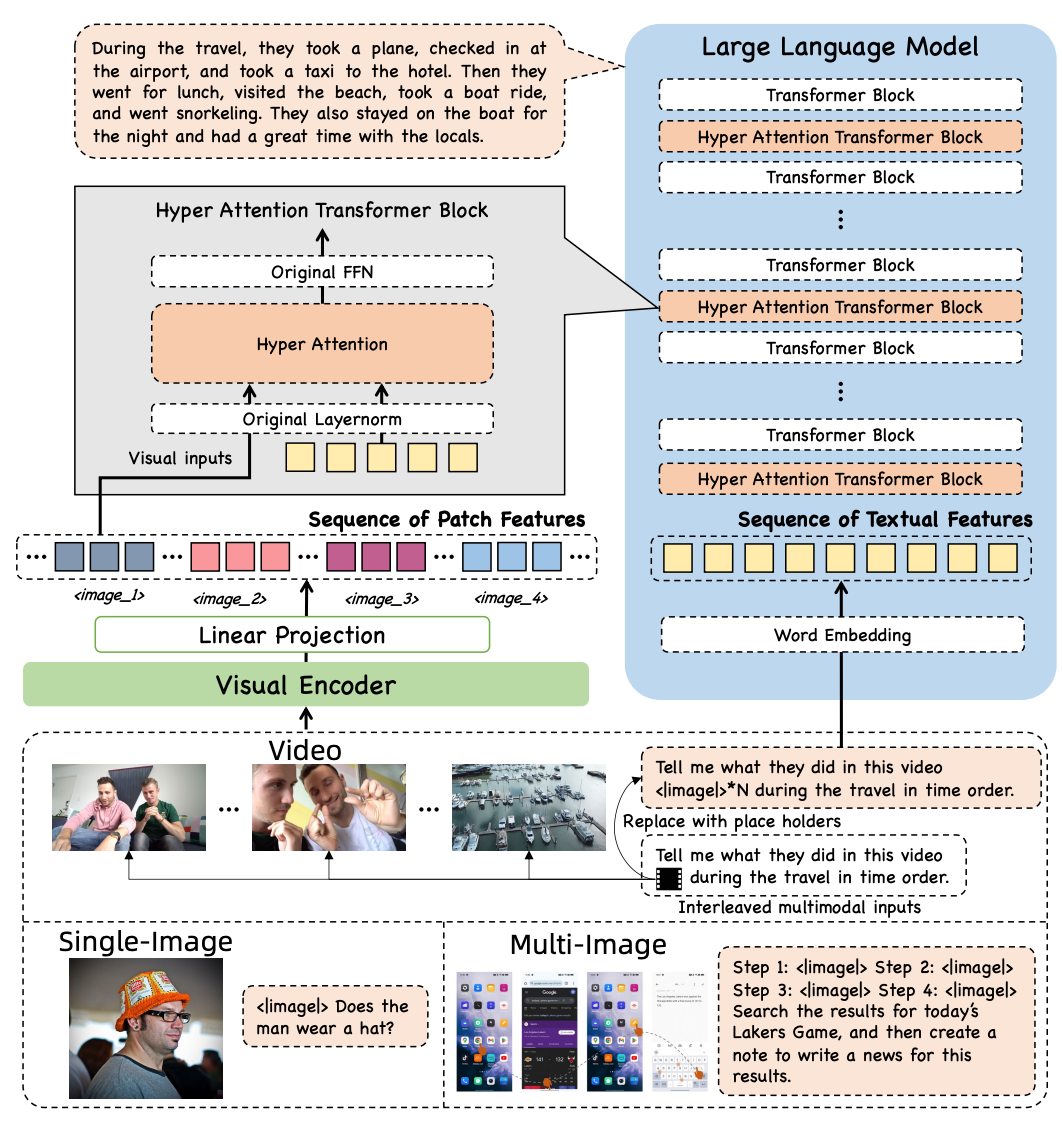



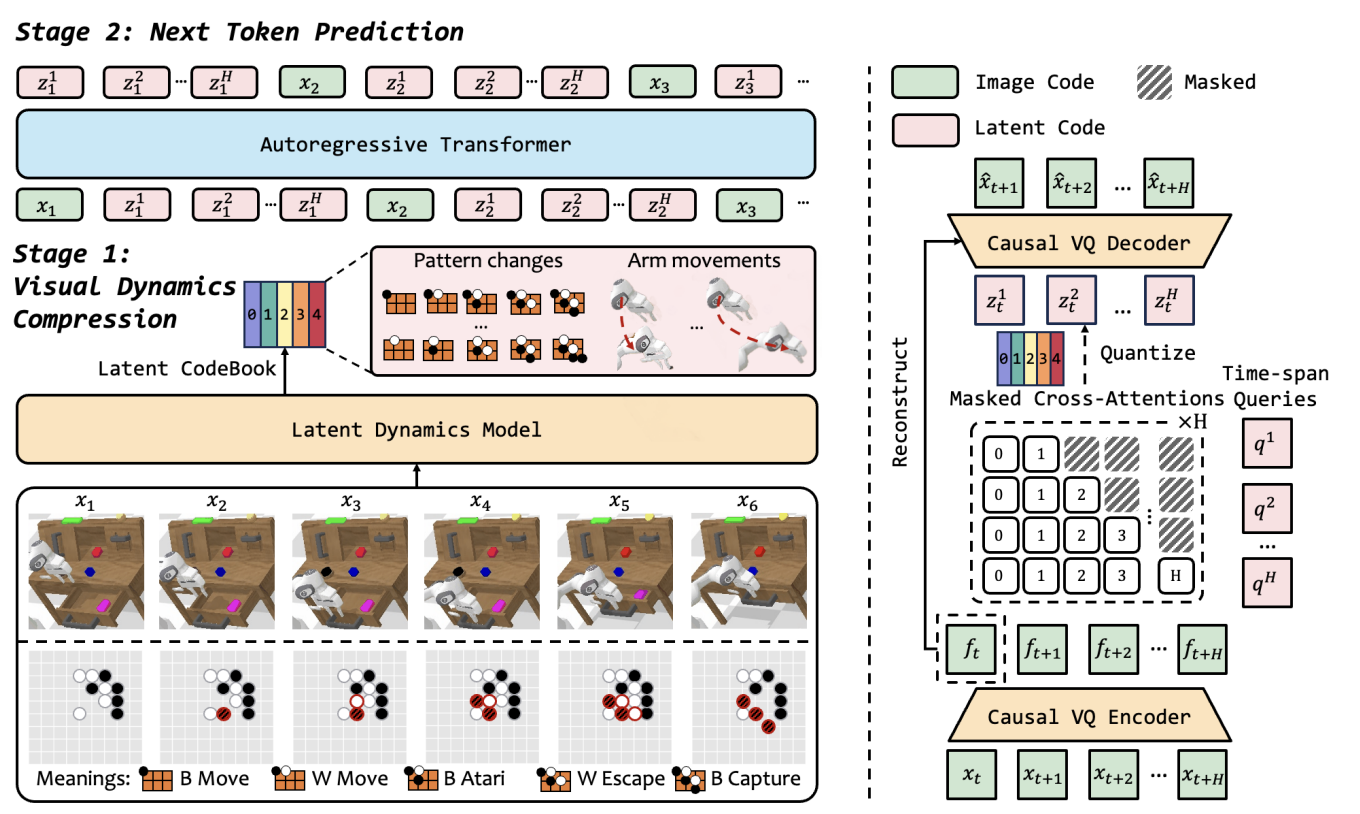

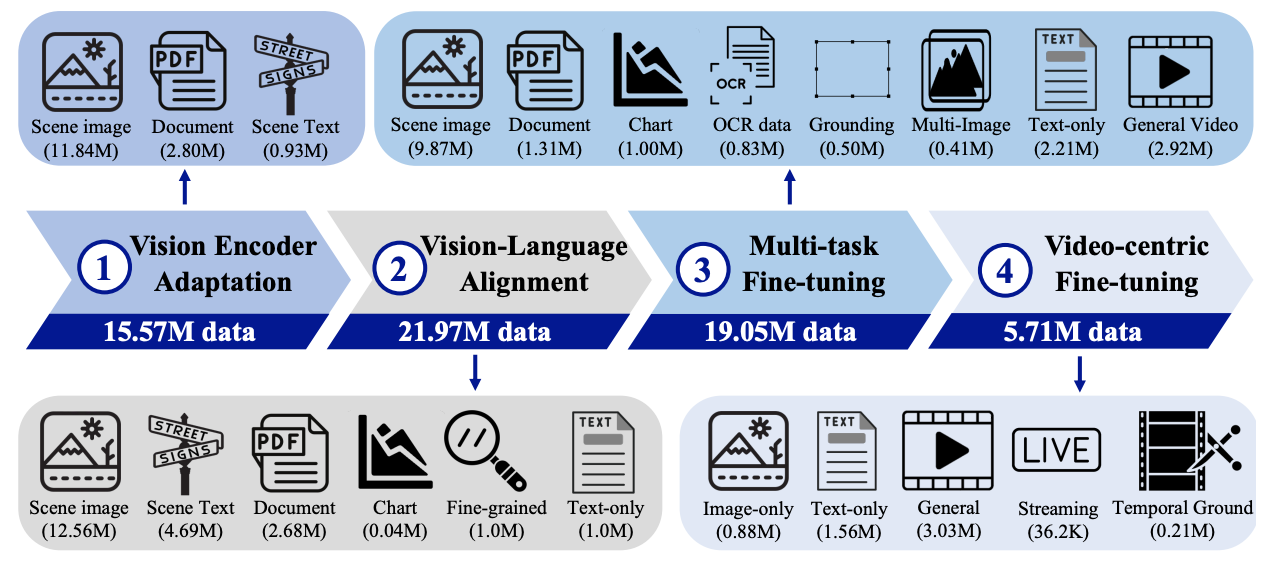



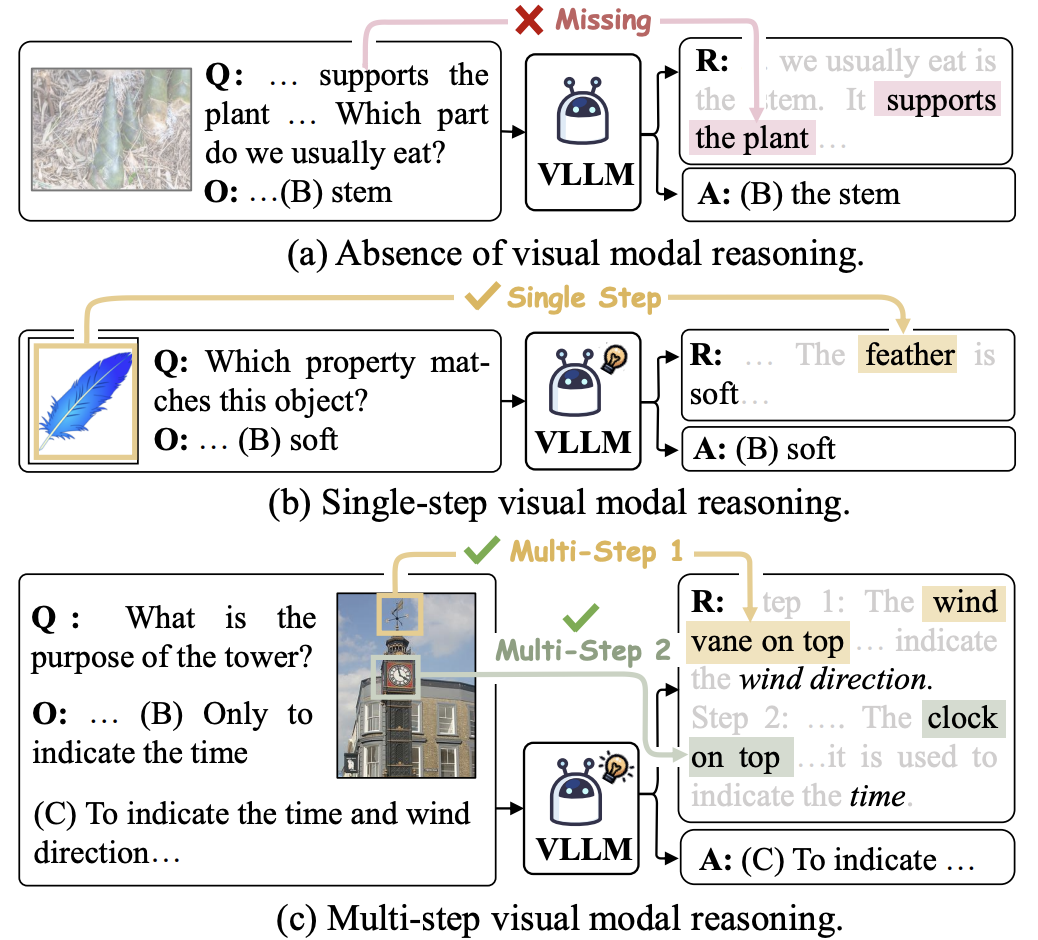





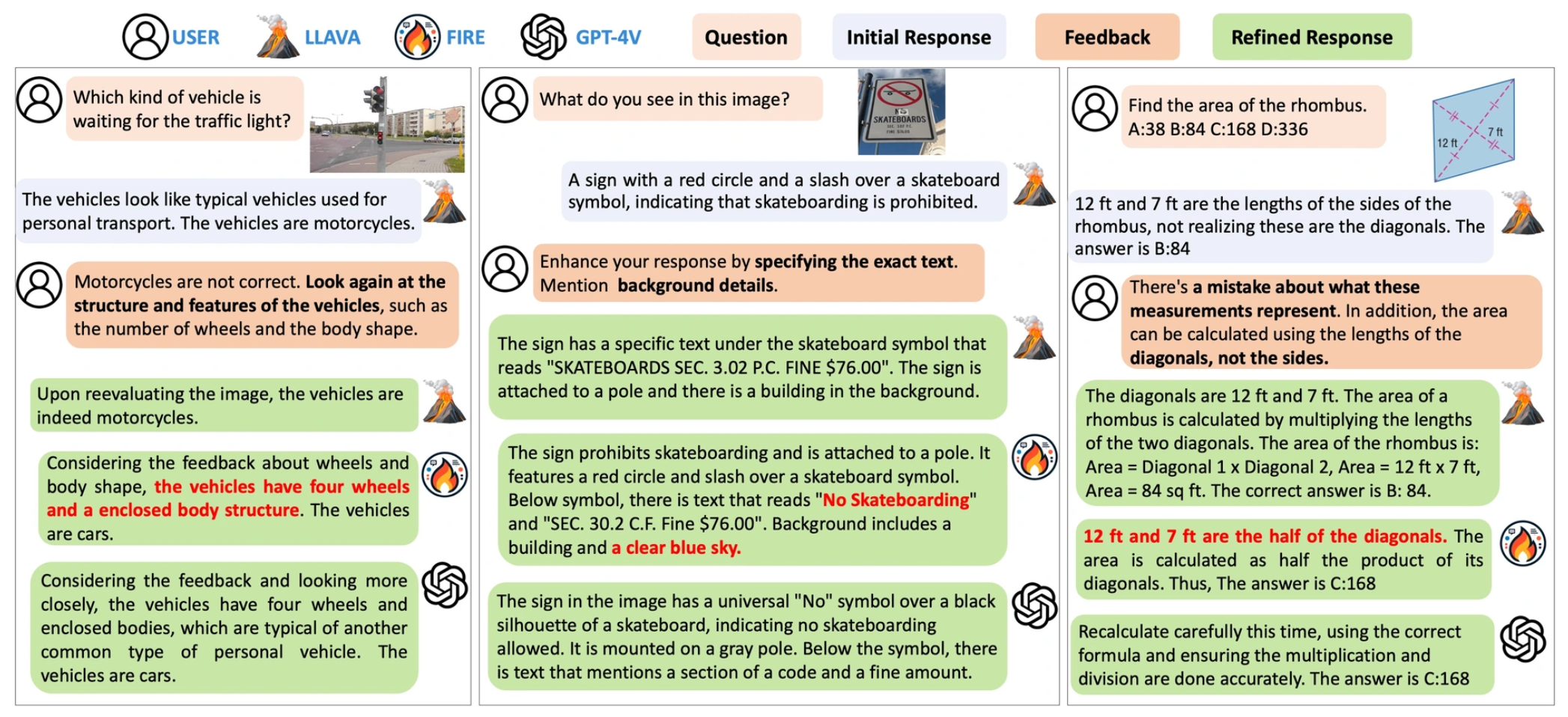













| Title | Venue/Date | Note | Code | Picture |
|---|---|---|---|---|
 MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action |
2023-03 | MM-REACT | Github |  |
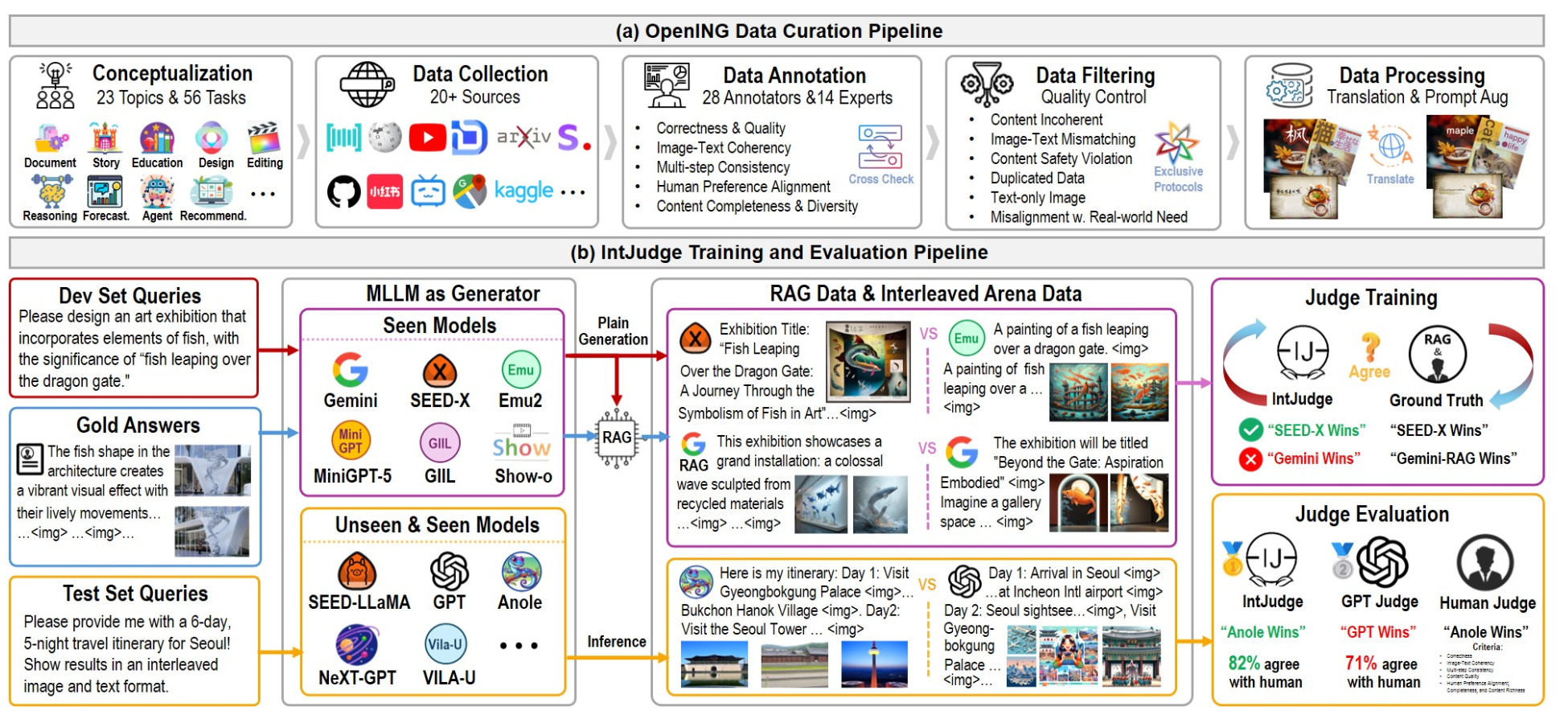
 Visual Programming: Compositional visual reasoning without training |
CVPR 2023 Best Paper | VISPROG (Similar to ViperGPT) | Github | 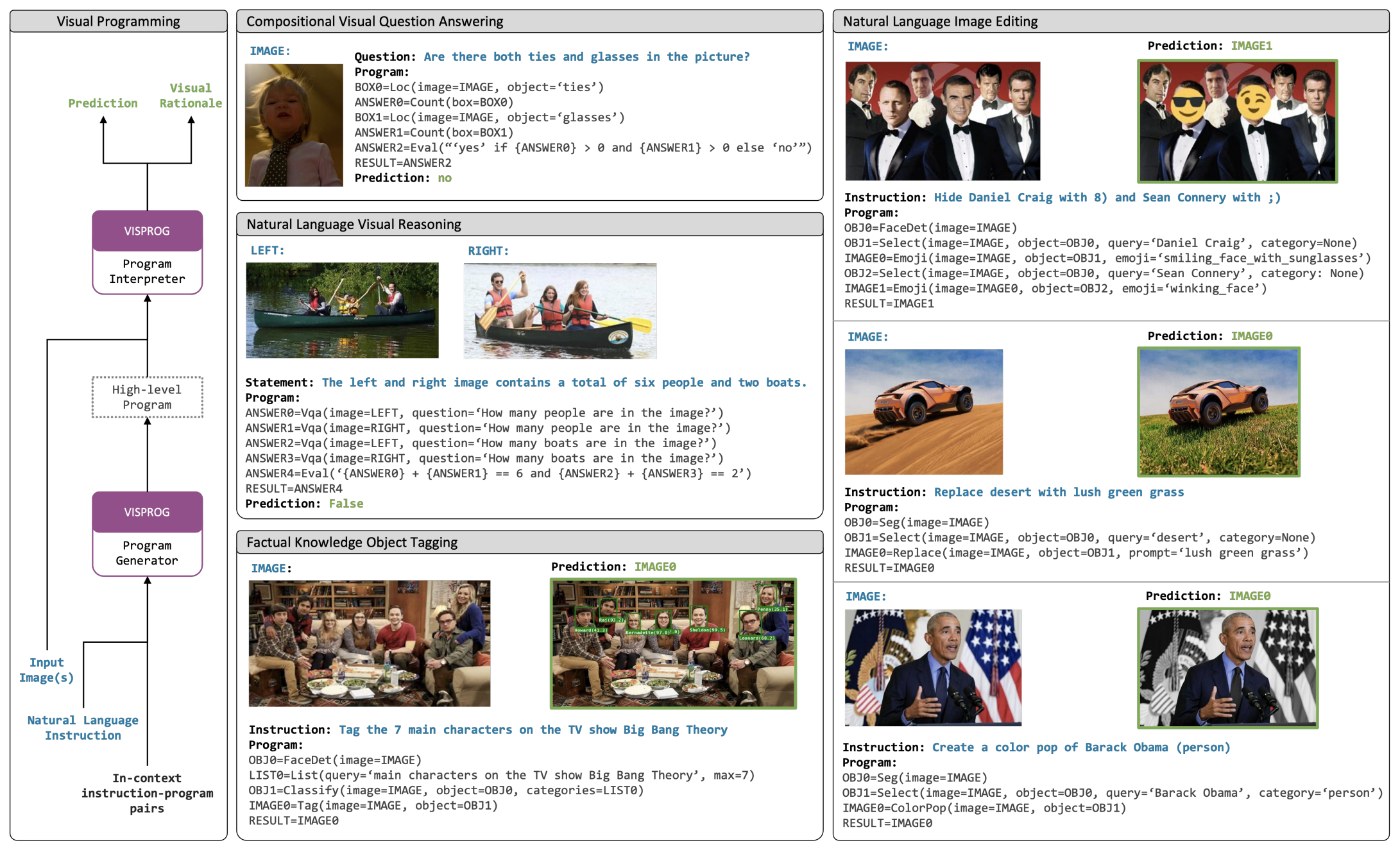 |
 HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in HuggingFace |
2023-03 | HuggingfaceGPT | Github | 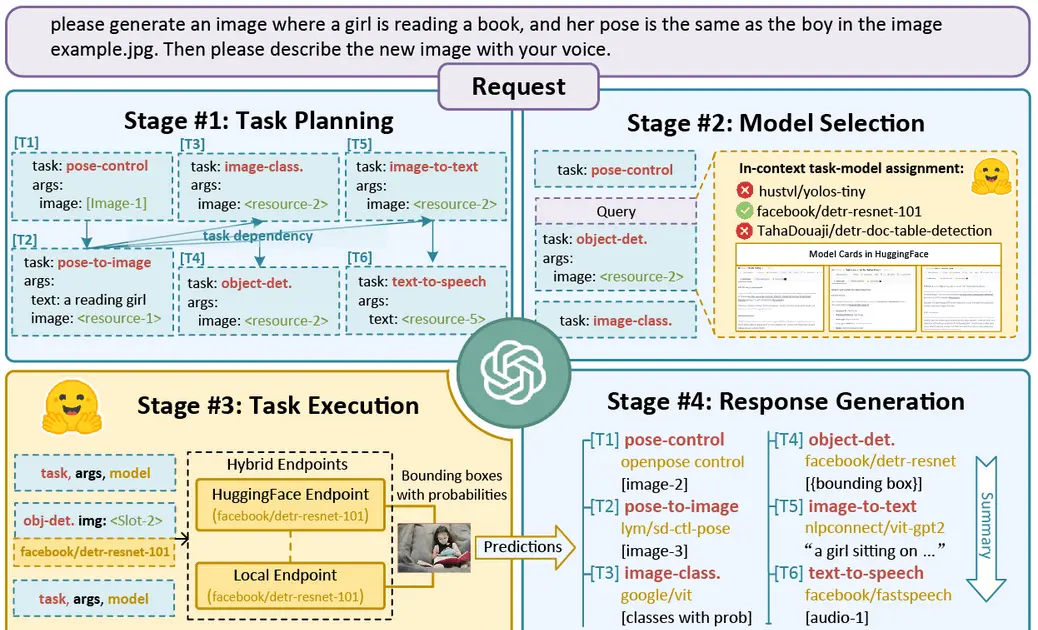 |
 Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models |
2023-04 | Chameleon | Github | 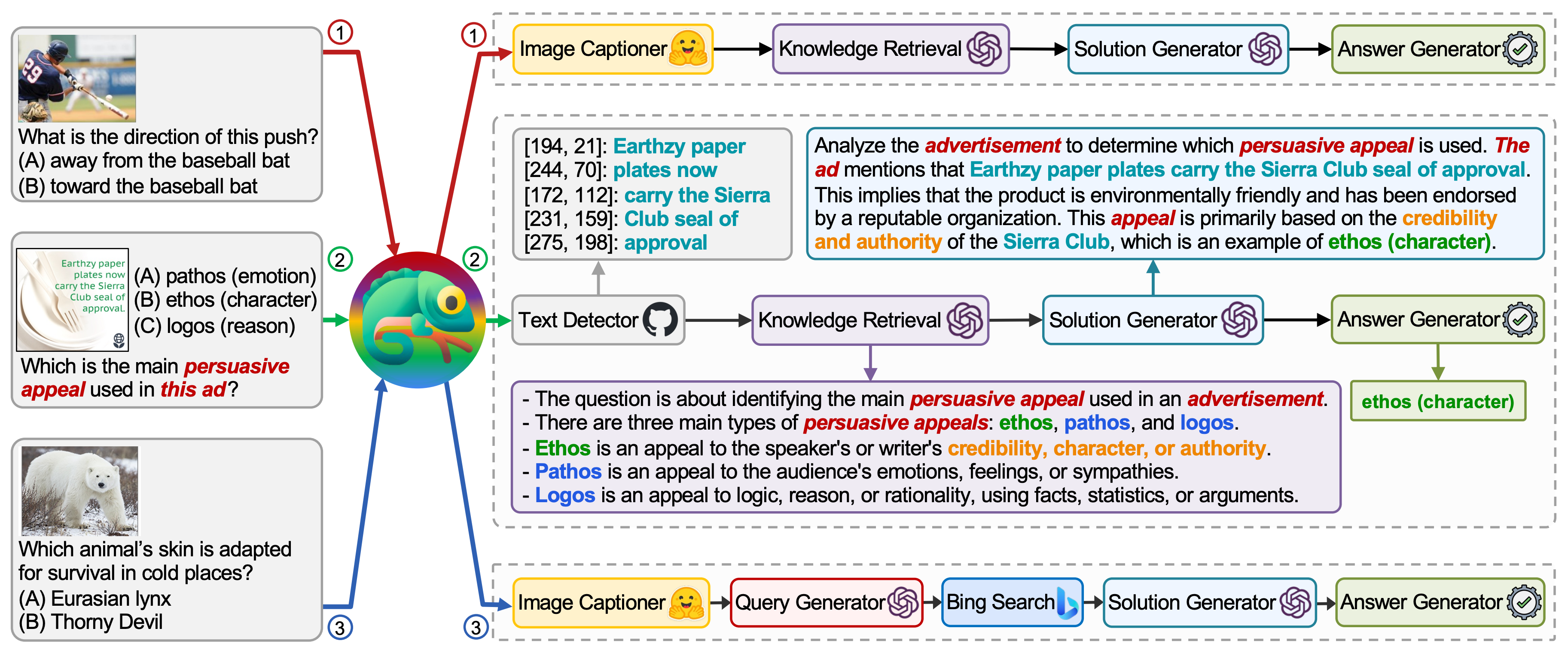 |
 IdealGPT: Iteratively Decomposing Vision and Language Reasoning via Large Language Models |
2023-05 | IdealGPT | Github |  |
 AssistGPT: A General Multi-modal Assistant that can Plan, Execute, Inspect, and Learn |
2023-06 | AssistGPT | Github | 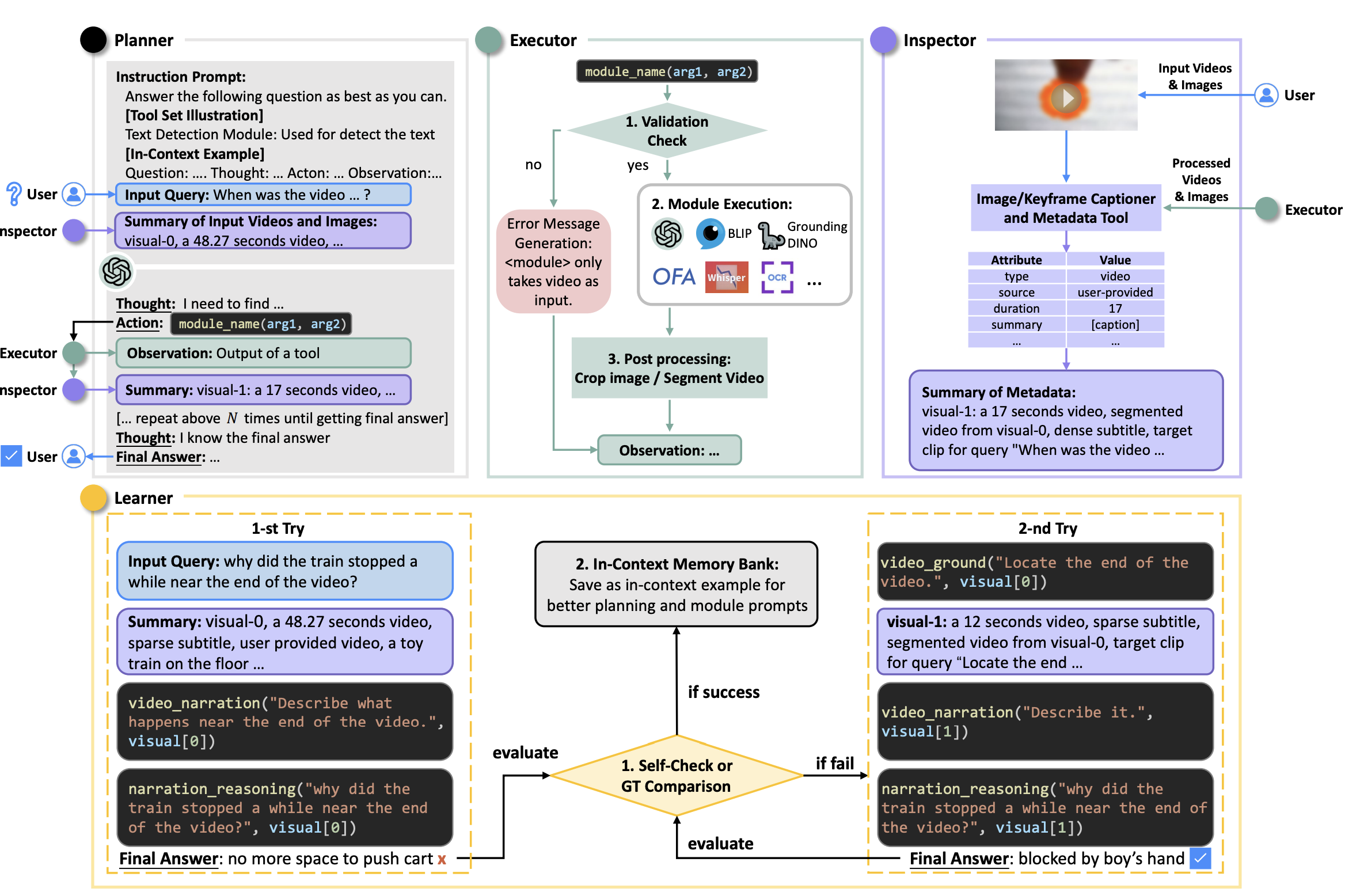 |
 A Picture Is Worth a Graph: A Blueprint Debate Paradigm for Multimodal Reasoning |
ACM MM 2024 | Multi-Agent Debate | Github | 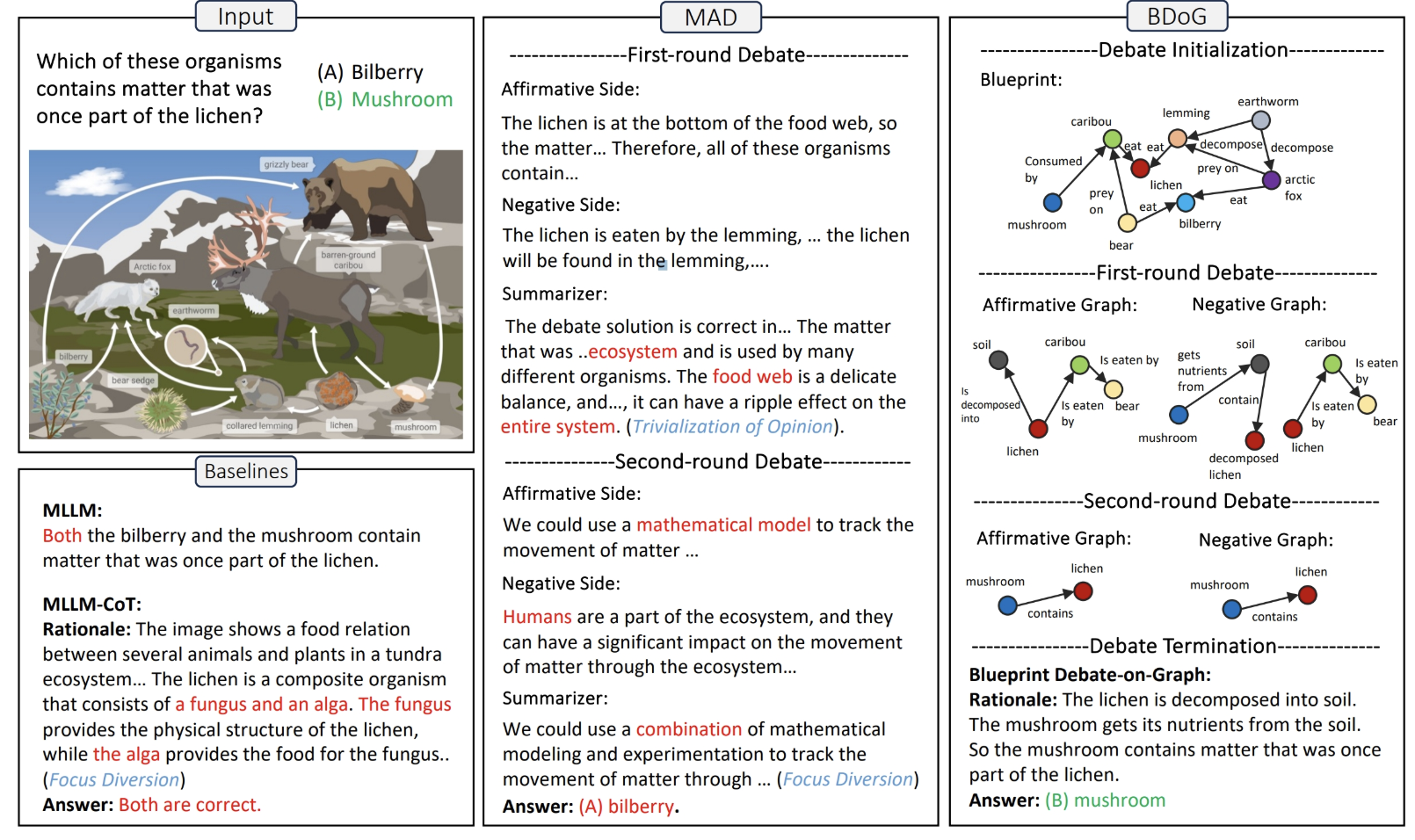 |
 Visual Sketchpad: Sketching as a Visual Chain of Thought for Multimodal Language Models |
NeurIPS 2024 | Draw to facilitate reasoning | Project | 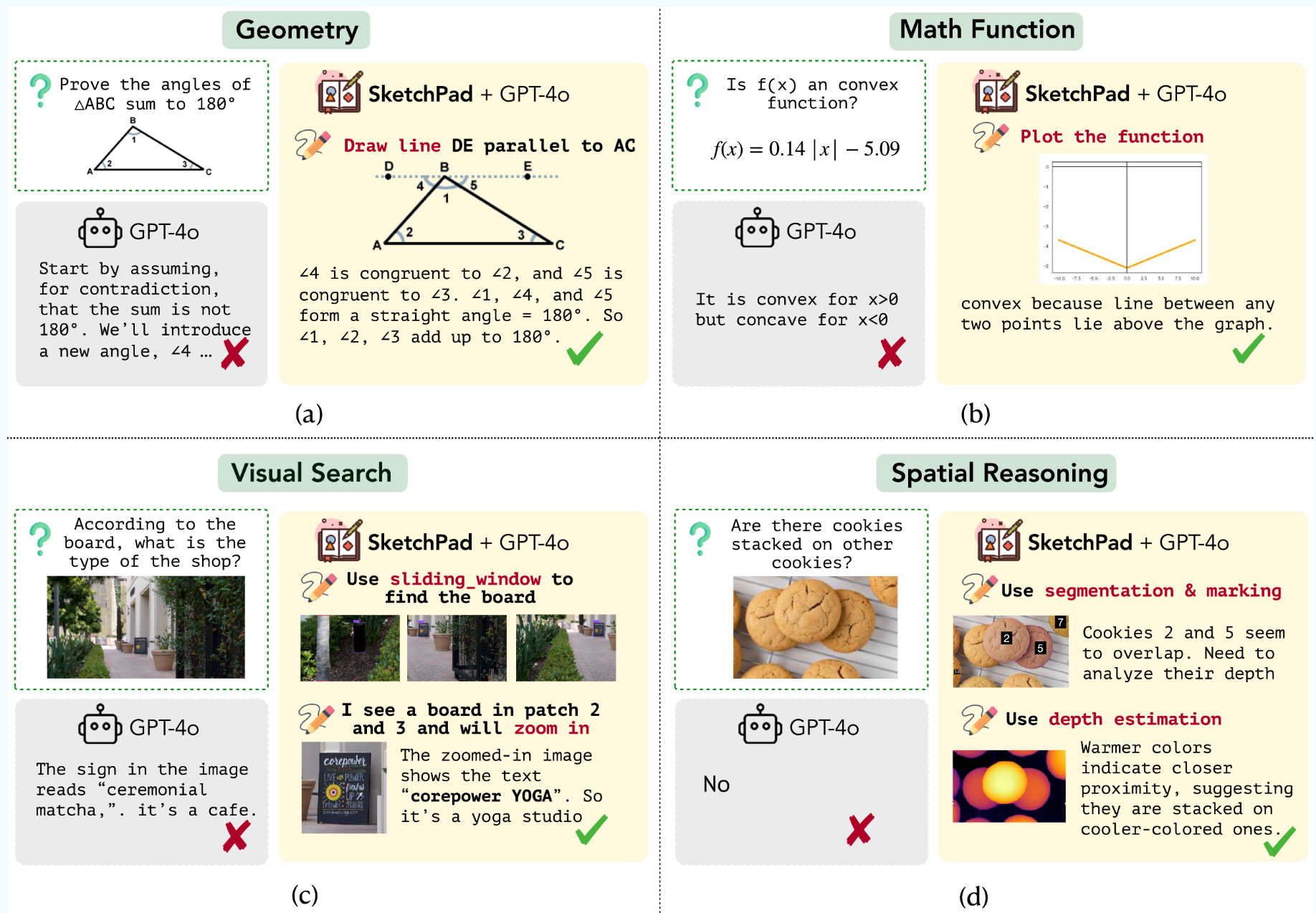 |
| Title | Venue/Date | Note | Code | Picture |
|---|---|---|---|---|
 Evaluating Object Hallucination in Large Vision-Language Models |
EMNLP 2023 | Simple Object Hallunicattion Evaluation - POPE | Github |  |
 Evaluation and Analysis of Hallucination in Large Vision-Language Models |
2023-10 | Hallunicattion Evaluation - HaELM | Github | 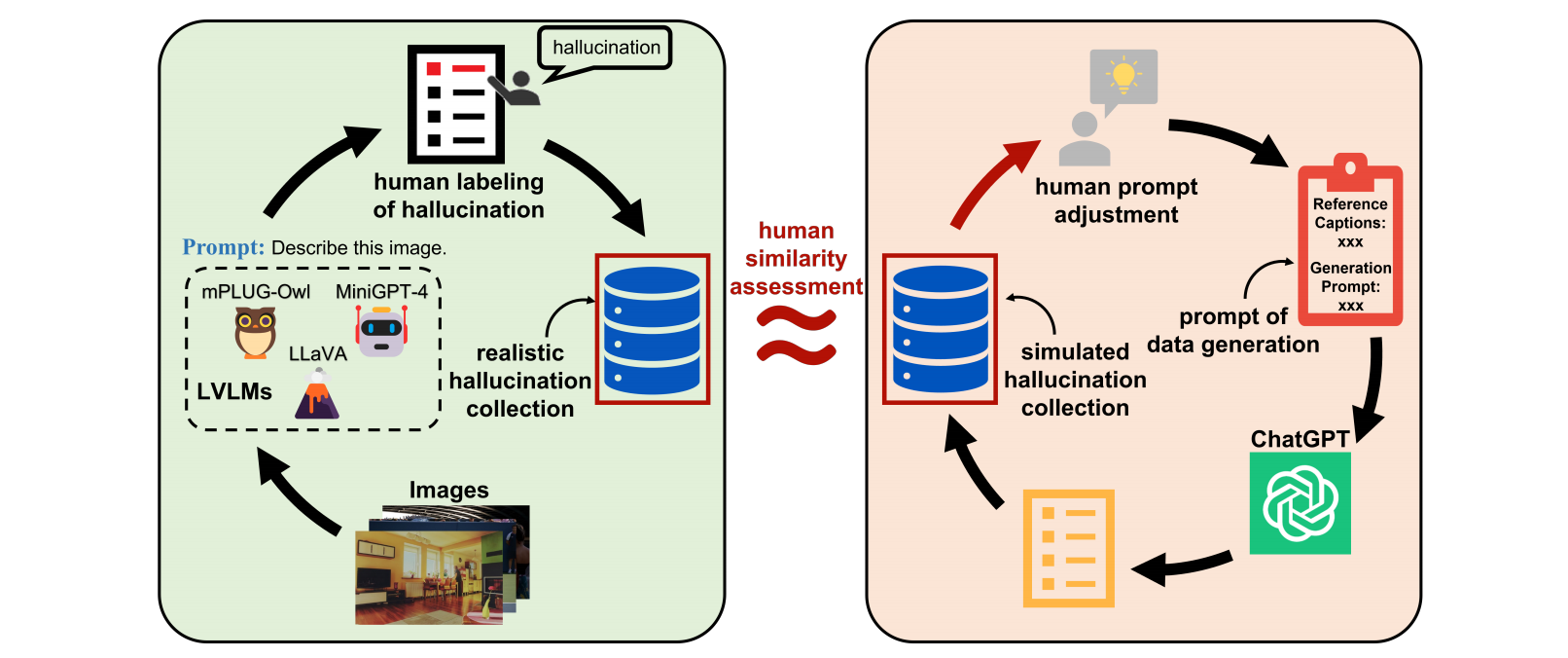 |
 Mitigating Hallucination in Large Multi-Modal Models via Robust Instruction Tuning |
2023-06 | GPT4-Assisted Visual Instruction Evaluation (GAVIE) & LRV-Instruction | Github | 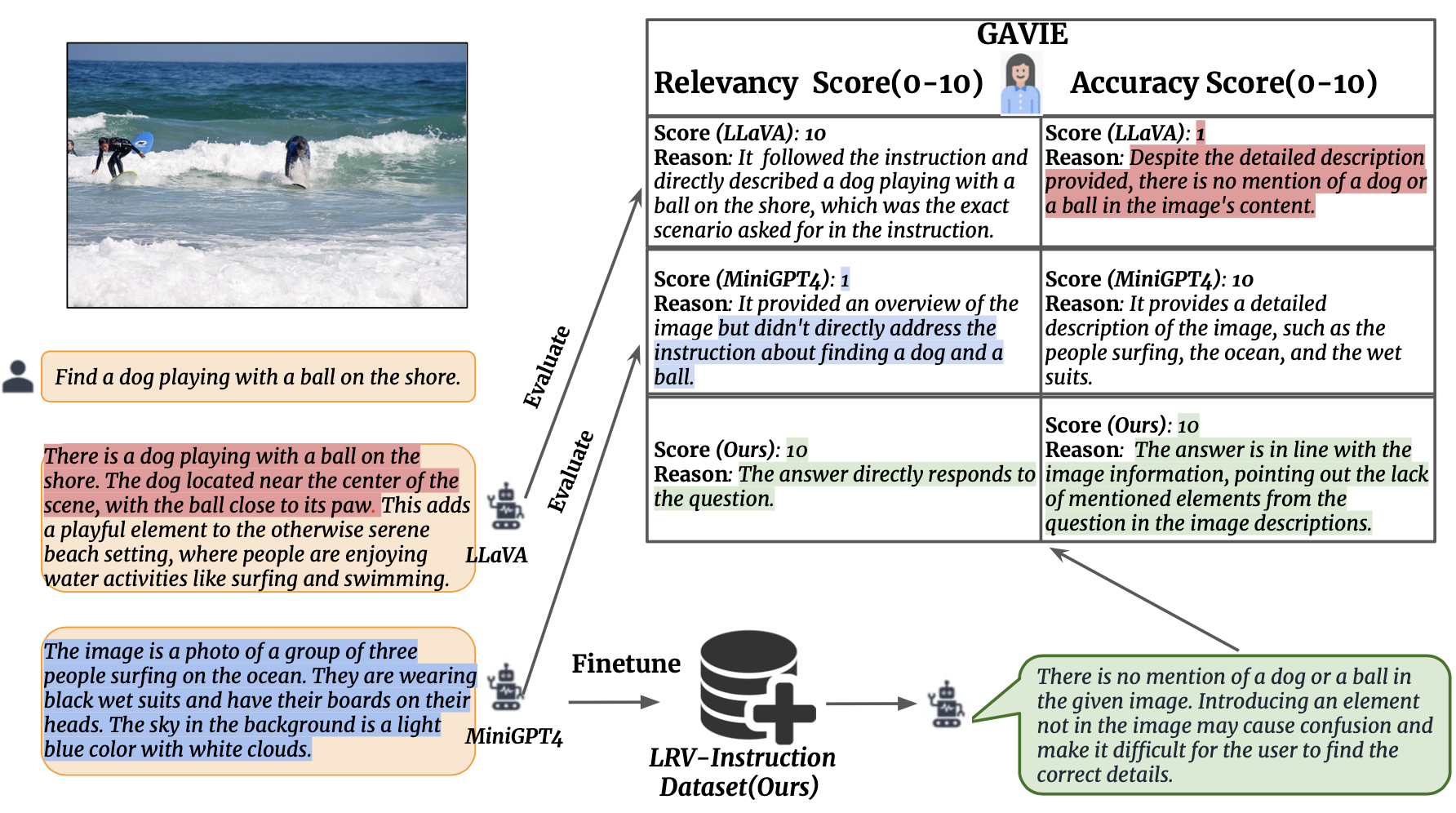 |
 Woodpecker: Hallucination Correction for Multimodal Large Language Models |
2023-10 | First work to correct hallucinations in LVLMs | Github |  |
 Can We Edit Multimodal Large Language Models? |
EMNLP 2023 | Knowledge Editing Benchmark | Github | 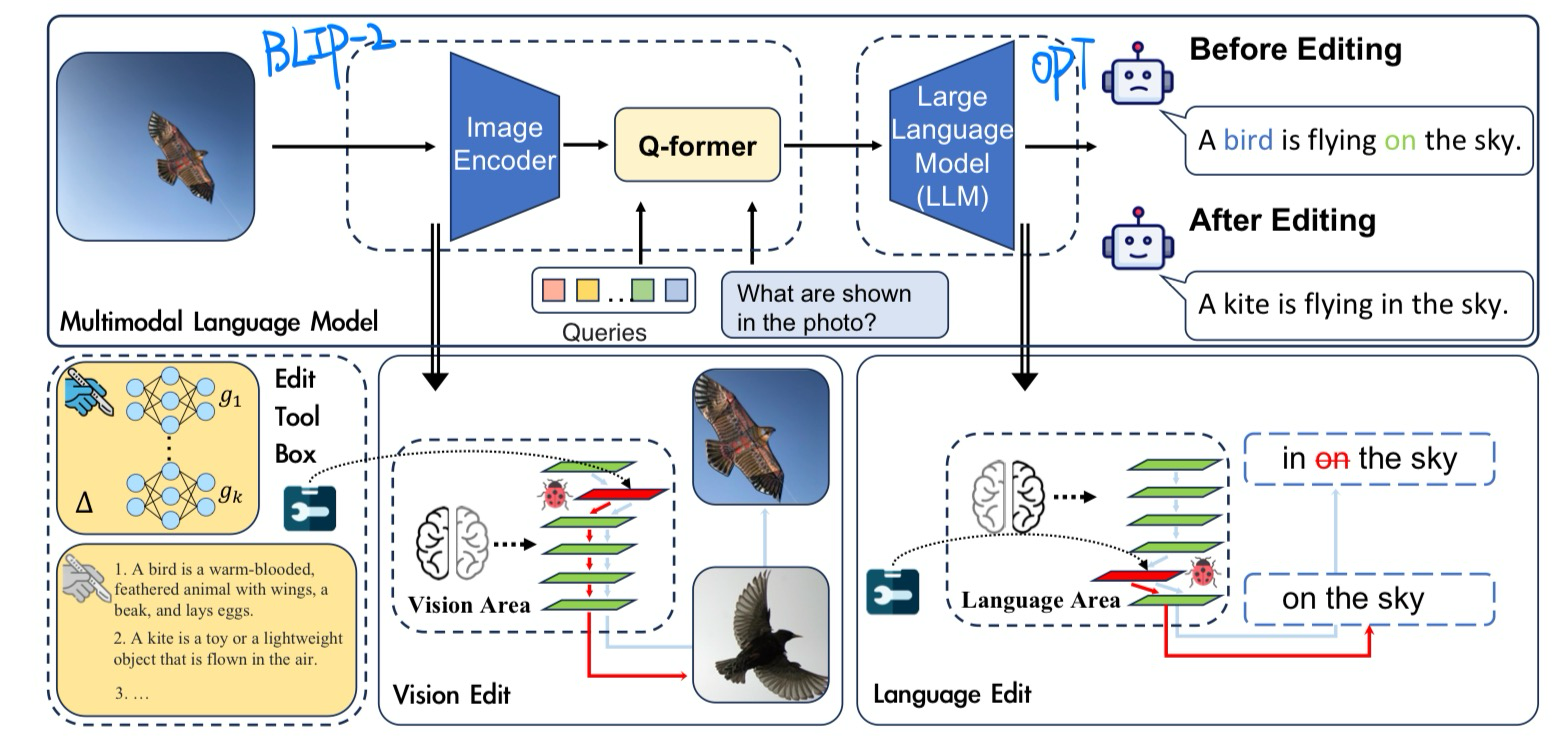 |
 Grounding Visual Illusions in Language:Do Vision-Language Models Perceive Illusions Like Humans? |
EMNLP 2023 | Similar to human illusion? | Github | 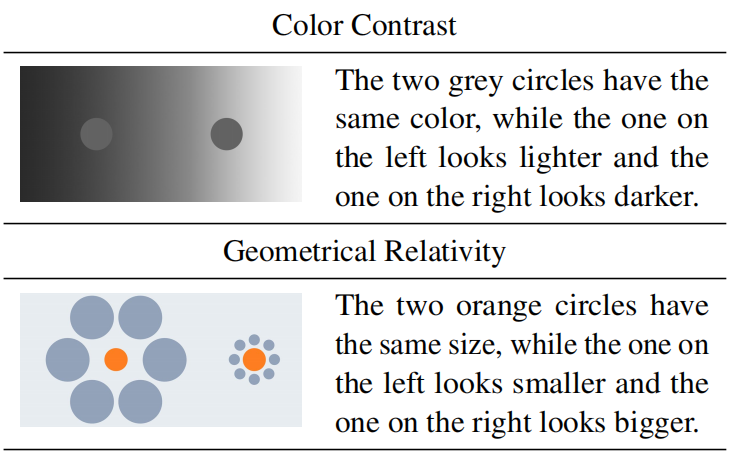 |
 VL-RewardBench: A Challenging Benchmark for Vision-Language Generative Reward Models |
2024-11 | Vision-language generative reward | Project |  |