The Reputation Aggregator Mechanism, part of the WeGovNow Trusted Marketplace receives input from three different sources in order to define users' reputation score;
-
Indirectly from any other WeGovNow core component through the OnToMap Logger. All user events (actions and activities) are requested and being pulled by the Logger into the “Event Decomposer” that decomposes the raw consolidated information into data about i) activities, ii) location, iii) timestamp and iv) description as free text. The spatial data are forwarded to the “Geo Relevance Scorer”, the temporal data are forwarded to the “Temporal Relevance Scorer”, the interest/activity data are forwarded to the “Activity Scorer”, and data about user reputation are forwarded to the “Trust Ranker”.
-
Directly from the users through the “Dashboard” and their personal profile, preferences and interests that are explicitly declared by them.
-
By social networks, on user’s consent, through the “Social Media Linker & Collector”.
The high level architecture of Trusted Marketplace is depicted in the following diagram;
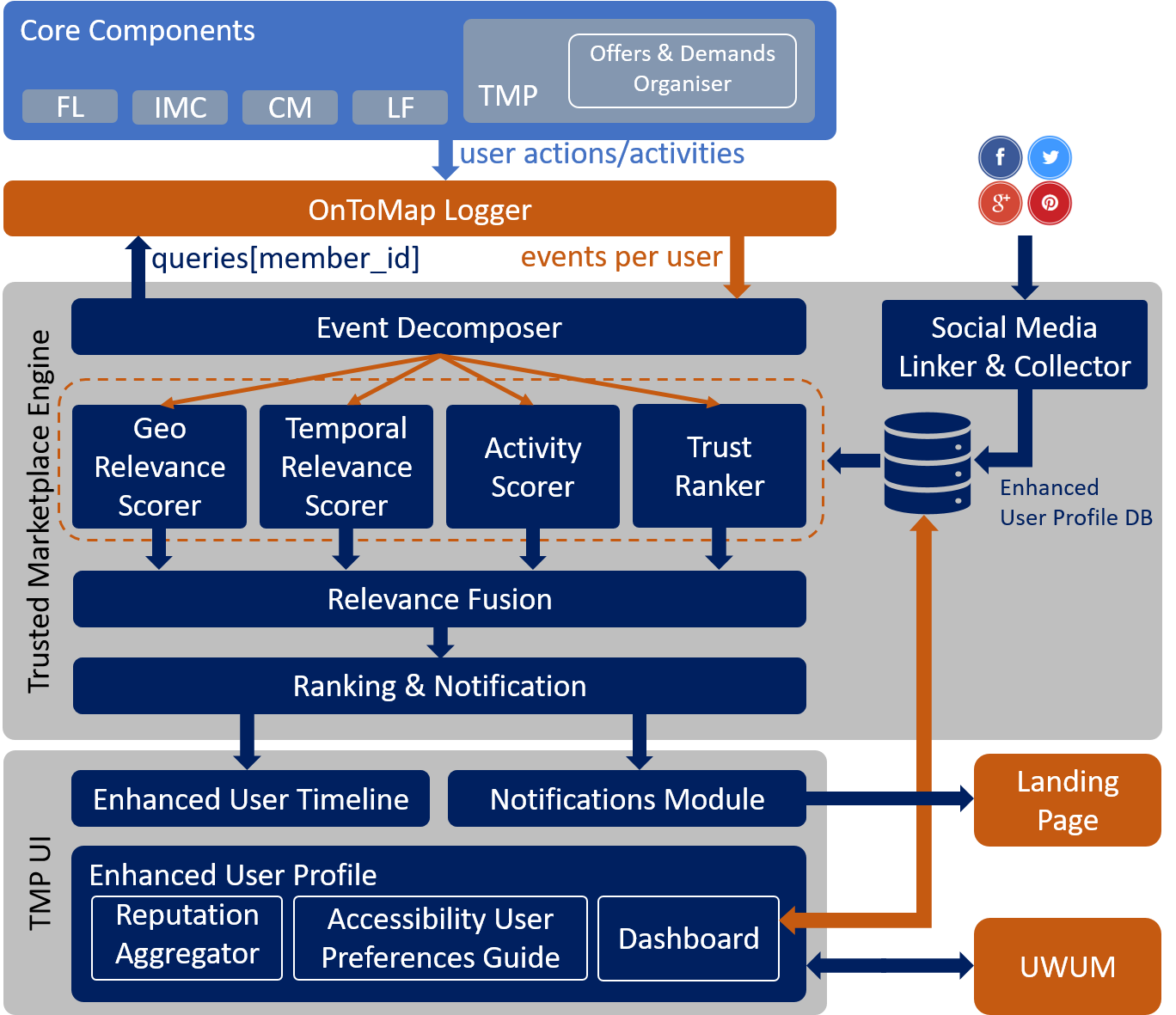
The “Relevance Fusion” merges the various scores that are calculated by applying several rules such as (but not limited to): i) certain radius containing actions of all the places that the specified user has recorded activity (geolocated), ii) actions within available time-slots (e.g. every weekend), iii) reputation threshold, iv) relevance matching threshold, v) notification frequency threshold (e.g. up to 3 notifications per day) and others. Lastly, the “Ranking & Notification” feeds the “Notification” mechanism that informs users with personalised suggestions in the Landing Page, and also helps to enhance the personalised timeline in the user interface (UI) of the Trusted Marketplace. It also helps to prioritise (rank) the most relative offers/demands according to user interests. Trusted Marketplace UI also includes i) the “Reputation Aggregator” which is actually part of the “Offers & Demands Organiser”, ii) the “Accessibility User Preferences Guide” and iii) the Dashboard. The latter three modules are composing the “Enhanced User Profile” that interacts with the UWUM to get and set global variables (e.g. user preferences) as key- value pairs.
The Reputation Aggregator Mechanism depends on INFALIA's computational verification mechanism as detailed next;
A framework for "learning" how to classify social content as truthful/reliable or not. Features are extracted from the tweet text (Tweet-based features TF) and the user who published it (User-based features UB). A two level classification model is trained.
Evaluations are conducted on a publicly available verification corpus (VC) of fake and real tweets collected for the needs of the MediaEval 2015 Verifying Multimedia Use (VMU) and MediaEval 2016 Verifying Multimedia Use (VMU) task. The VMU 2015 consist of tweets related to 17 events that comprise in total 193 cases of real images, 218 cases of misused (fake) images and two cases of misused videos, and are associated with 6,225 real and 9,404 fake tweets posted by 5,895 and 9,025 unique users respectively.
The Reputation Aggregator Mechanism relies on Tweets collected from WeGovNow users.
For each pilot site a number of hashtags or keywords are set such as #ParcoDora, #Youth, #WeGovNow, etc
| Tweet-based features | User-based features | WeGovNow features |
|---|---|---|
| #words | #friends | |
| length of text | #followers | |
| #question marks | follower-friend ratio | a.follower-friend ratio |
| #exclamation marks | #tweets | b.#tweets |
| contains question mark | #media content | |
| contains exclamation mark | has profile image | |
| has ``please'' | has header image | |
| has colon | has a URL | |
| contains happy emoticon | has location | c.has location |
| contains sad emoticon | has existing location | d.has existing location |
| #uppercase chars | has bio description | |
| #pos senti words | tweet ratio | e.tweet ratio |
| #neg senti words | account age | f.account age |
| #slangs | is verified | g.is verified |
| #nouns | #times listed | |
| contains 1st pers.pron. | in-degree centrality | |
| contains 2nd pers.pron. | harmonic centralit | |
| contains 3rd pers.pron. | alexa country rank | |
| readability | alexa delta rank | |
| #retweets | alexa popularity | |
| #hashtags | alexa reach rank | |
| has external link | ||
| #mentions | ||
| #URLs | ||
| WOT score | ||
| in-degree centrality | ||
| harmonic centralit | ||
| alexa country rank | ||
| alexa delta rank | ||
| alexa popularity | ||
| h.#retweets |
The formula to calculate the reputation score for a WeGovNow user is
(weight * number of WeGovNow OnToMap main events) + (weightA * a + weightB * b + ... + weightX * x)
where:
a) followers/friends ratio
b) number of tweets
c) has location (1 yes, 0 no)
d) has existing location (1 yes, 0 no)
e) tweet ratio (tweets per day posted by user profile)
f) account age
g) is verified (1 yes, 0 no)
h) number of retweets
CL1: classifier build with tweet-based features.
CL2: classifier build with user-based features.
CL_ag: Agreement-based model build with the agreed samples resulted using CL1 and CL2.
CL_tot: Agreement-based model build with the entire (total) set of initial training samples extending it with the set of agreed samples resulted using CL1 and CL2.
Features files:
- tweetsFeatsVMU2015.txt: the tweet-based features in JSON format of the VMU 2015.
- userFeatsVMU2015.txt: the user-based features in JSON format of the VMU 2015.
- tweetsFeatsVMU2016.txt: the tweet-based features in JSON format of the VMU 2016.
- userFeatsVMU2016.txt: the user-based features in JSON format of the VMU 2016.
Annotation files:
- VMU2015Train.txt: the annotations of the VMU 2015 dataset used for training.
- VMU2015Test.txt: the annotations of the VMU 2015 dataset used for testing.
- VMU2016Train.txt: the annotations of the VMU 2016 dataset used for training.
- VMU2016Test.txt: the annotations of the VMU 2016 dataset used for testing.
Annotation files are in JSON format: {"id":"","label":"","event":""}
The framework performs feature extraction on a new set of tweets and then classify each of them as truthful/reliable or not.
Initialize parameters
DoubleVerifyBagging dvb = new DoubleVerifyBagging();
setVerbose(boolean): false or real. Print just average results or also intermediate detailed results.
Agreement-based retraining technique: (default 5)
1 - Classify disagreed on agreed samples without bagging
2 - Classify disagreed on agreed samples with bagging
3 - Classify disagreed on the entire (total) set of initial training samples extending it with the set of agreed samples with bagging
4 - Classify disagreed on the entire (total) set of initial training samples extending it with the set of agreed samples without bagging
5 - All above
setRunConcatenated(boolean): false or real. Perform classification using simple concatenation of the user-based and tweet-based feature vectors into a single-level classifier.
setClassifier(String): RF for Random Forest or LG for Logistic regression.
Main class TweetVerificationMain in gr.iti.mklab package. Provide command line arguments:
1. Feature extraction
Input arguments:
- tweetsFile: path of a text file containing the tweet objects as they are returned by the Twitter API in JSON format.
- feature_folder: (optional) Path of a folder where the extracted features will be stored. Default value: [current_directory + /Features/"].
Output: (The feature files are created into the output folder:)
- tweetsFeats.txt: containing the extracted tweet-based features. One line per tweet.
- userFeats.txt: containing the extracted user-based features. One line per tweet.
2. Training and Classification
Input arguments:
- trainLabels: A text file containing the labels of the training items. Annotation files should be in JSON format: {"id":"","label":"","event":""}.
- testLabels: A text file containing the labels of the testing items. Annotation files should be in JSON format: {"id":"","label":"","event":""}.
- feature_folder: (optional) Path of the folder where the extracted features are stored. Two files are stored into the folder:
1. tweetsFeats.txt: containing the extracted tweet-based features. One line per tweet.
2. userFeats.txt: containing the extracted user-based features. One line per tweet.
Default value of feature_folder current_directory + /Features/
- outputFolder: (optional) Path of the folder where the final evaluation results will be stored. Default value: [current_directory + /Run/]
Output:
1. AverageResults.txt: Average accuracy (ratio of correctly classified samples over total number of test samples) of
CL: the selected classifier among CL1 and CL2.
CL_ag : the overall accuracy using CL_ag agreement-based retraining model.
CL_tot : the overall accuracy using CL_tot agreement-based retraining model.
2. CL_ag_predictions.txt: tweet ID and fake/real label using CL_ag agreement-based retraining model.
3. CL_tot_predictions.txt: tweet ID and fake/real label using CL_tot agreement-based retraining model.
Please cite the following papers in your publications if you use the implementation:
@inproceedings{boididou2017learning,
title={Learning to Detect Misleading Content on Twitter},
author={Boididou, Christina and Papadopoulos, Symeon and Apostolidis, Lazaros and Kompatsiaris, Yiannis},
booktitle={Proceedings of the 2017 ACM on International Conference on Multimedia Retrieval},
pages={278--286},
year={2017},
organization={ACM}
}
@article{boididou2018detection,
author = {Detection and visualization of misleading content on Twitter},
title = {Boididou, Christina and Papadopoulos, Symeon and Zampoglou, Markos and Apostolidis, Lazaros and Papadopoulou, Olga and Kompatsiaris, Yiannis},
journal = {International Journal of Multimedia Information Retrieval},
volume={7},
number={1},
pages={71--86},
year={2018},
doi = "10.1007/s13735-017-0143-x",
publisher={Springer}
}
Symeon Papadopoulos (spap@infalia.com)