The program specifically targets errors commonly found in the English Placement Test for Non-Native English speakers (EPT) This program was the final group project for LING 520: Computational Analysis of English at Iowa State University, Fall 2020 The associated research paper for this program is available here: https://github.com/Jamesetay1/520/blob/master/SVA/docs/research_paper.pdf
Program written by me (James Taylor, jamesetay1@gmail.com)
Corpus Research and Derivation of Rules by:
Ella Alhudithi (ella@iastate.edu)
Thomas Elliott (thomase@iastate.edu)
Sondoss Elnegahy (sondoss@iastate.edu)
After reading in a file that contains the sentences in question, coreNLP Python library Stanza is used to tokenize, tag, and dependency parse on a sentence by sentence basis.
After this is done we iterate through each sentence object and build a 'forward' dependency list. Each word object already contains the id of it's governor, so this information is simply reconstructed in a format that's easier to use.
For Example, coreNLP parses "He walked through the door ." to the following dependencies:
word.text = He, word.head = 2 (walked)
word.text = walked, word.head = 0 (ROOT)
word.text = through, word.head = 5 (door)
word.text = the, word.head = 5 (door)
word.text = door, word.head = 2 (walked)
word.text = ., word.head = 2 (walked)
Resulting in a forwards dependency list of word objects:
[ [] , [word.text = "he", word.text = "door", word.text = "."], [], [], [word.text = "through", word.text = "the"] ]
Note that this list is populated with word objects, not just their text. Also note that the root never appears (because it can only be a governor, and is never a dependent) Once we have completed our forward dependency list, we go through the sentence again and look for special relationships to test. We test against an agreement dictionary, which is determined by the matrix below: 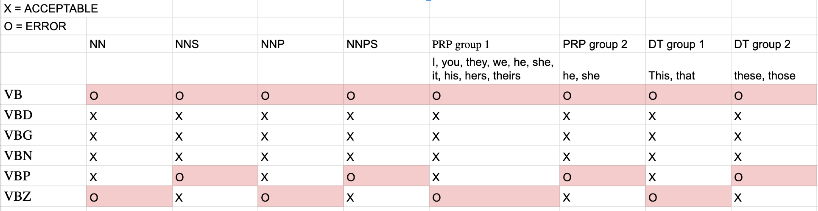
{kind=link}
The relationships we are currently looking for are:
1: Main Verb --nsubj--> Noun: If the word is a verb AND it has a nsubj forward dependency AND it does NOT have any aux forward dependency
2: Aux <--aux-- Main Verb --nsubj--> Noun: If the word is a verb AND it has a nsubj forward dependency AND it DOES have any aux forward dependency
3A: Noun <--nsubj-- Subject Predicate --cop--> Verb: If the word has a copular forward dependency AND an nsubj forward dependency
3B: 3A + Subject Predicate --aux--> Aux: If the word has a copular forward dependency AND an nsubj forward dependency AND an aux nsubj forward depdency
Given the sentence: I am happy that he have been a friend since we met last September.
The program will recognize three subject-verb relationships in this sentence:
I am happy (Relationship 3A)
he have been a friend (Relationship 3B)
we met (Relationship 1)
When we check these against our error matrix we find:
Correct: I (PRP) <--nsubj-- am (VBP)
Incorrect: he (PRP) <--nsubj-- have (VBP)
Correct: we (PRP) <--nsubj-- met (VBD)
One more permanent limitation of this program surrounds the uncertainty of if there is a mismatch in number between subject and verb or if it is truly a compound noun. coreNLP will mark instances like "The man park his car" as: Man: NN, park: NN, as to say that the noun is 'man park'. Of course this is actually meant to be, "The man parks his car", but the agreement in number between subject and verb was incorrect. This case is currently counted as incorrect IF the head noun of the compound is the root of the sentence.
Future additions of SVA errors should be easy to add with the current framework Additionally, it would be ideal to have a GUI for this program in addition to what is already there.