Home
For this project the dataset is explored with Apache Spark using the Scala programming language. Because of the nature of data exploration is quite experimental Apache Zeppelin was chose to work interactively with the data while also providing the functionality to easily produce data visualizations on the fly.
The Zeppelin notebooks will be run from a Docker container which allows a development environment to be quickly spun up as needed to work on data that does not require massive processing power.
Instead of building a custom Dockerfile for Zeppelin the official Apache Container will be used from Docker Hub.
docker pull apache/zeppelin:0.8.1
The container is run with the following external volumes:
- logs - The Zeppelin logs to make it easier to view from the working machine.
- notebooks - Having this in an external volume simplifies source control from the project and backing up work.
- data - The external data to work on in notebooks.
docker run -p 8080:8080 --rm \
-v $PWD/logs:/logs \
-v $PWD/code/nyc-job-exploration/zeppelin/notebook:/notebook \
-v $PWD/code/nyc-job-exploration/data:/data \
-e ZEPPELIN_LOG_DIR='/logs' \
-e ZEPPELIN_NOTEBOOK_DIR='/notebook' \
--name zeppelin apache/zeppelin:0.8.1
If you are running docker from a Virtual Machine it is also necessary to configure port forwarding so that Zeppelin can be opened as if it was running on the local machine.
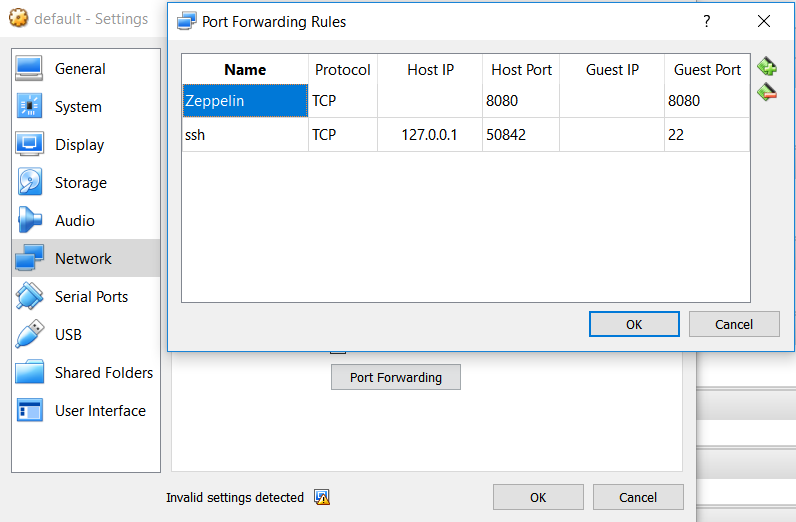
Once the container is running Zeppelin can be opened from http://localhost:8080/ and the following code executer to make sure everything is up and running:
val nums = Array(1,2,3,5,6)
val rdd = sc.parallelize(nums)
import spark.implicits._
val df = rdd.toDF("num")
df.show()
Zepel is an online "Data science notbook hub" that can be used to share Zeppelin notbooks online: https://www.zepl.com
Statically can be used to link to files in a GitHub repository, the following example shows the equivalent generated URL:
https://github.com/JohnnyFoulds/nyc-job-exploration/blob/master/zeppelin/notebook/word-cloud/d3.layout.cloud.js
https://cdn.statically.io/gh/JohnnyFoulds/nyc-job-exploration/700bbf40/zeppelin/notebook/word-cloud/d3.layout.cloud.js
- Data Science Lifecycle with Zeppelin and Spark - https://www.youtube.com/watch?v=J6Ei1RMG5Xo
- From Idea to Product: Customer Profiling in Apache Zeppelin with PySpark - https://www.youtube.com/watch?v=K2ZMU2VV9OM
- Building Robust ETL Pipelines with Apache Spark - Xiao L - https://www.youtube.com/watch?v=exWGf0aXJF4
- Learning Spark SQL with Zeppelin - https://hortonworks.com/tutorial/learning-spark-sql-with-zeppelin/
- My Tutorial/Spark SQL Tutorial (Scala) - https://www.zepl.com/viewer/notebooks/bm90ZTovL3pqZmZkdS8wYmE5NGIzZGVhNjQ0ZjlkOWJkODE5MmY4OTQ4MDUwOC9ub3RlLmpzb24
- NYC Dataset Kaggle Kernel - https://www.kaggle.com/natevegh/job-postings-in-new-york-eda-nltk
- Leemoonsoo/zeppelin-wordcloud - https://github.com/Leemoonsoo/zeppelin-wordcloud/tree/master/src/main/resources/wordcloud
- Animated d3 word cloud - http://bl.ocks.org/joews/9697914
- Using Visualization Packages in Zeppelin (Helium) - https://mapr.com/docs/60/Zeppelin/ZeppelinVisualization.html