近年來,RAG(Retrieval Augmented Generation)作為新興的生成式 AI 技術備受關注。RAG 架構中的檢索器對文本的查詢方式直接影響著檢索的準確性,進而決定了系統的整體性能。本報告旨在探索在 RAG 中結合關鍵字匹配和向量語意搜尋的最佳權重配置。我們將通過以下步驟進行分析:
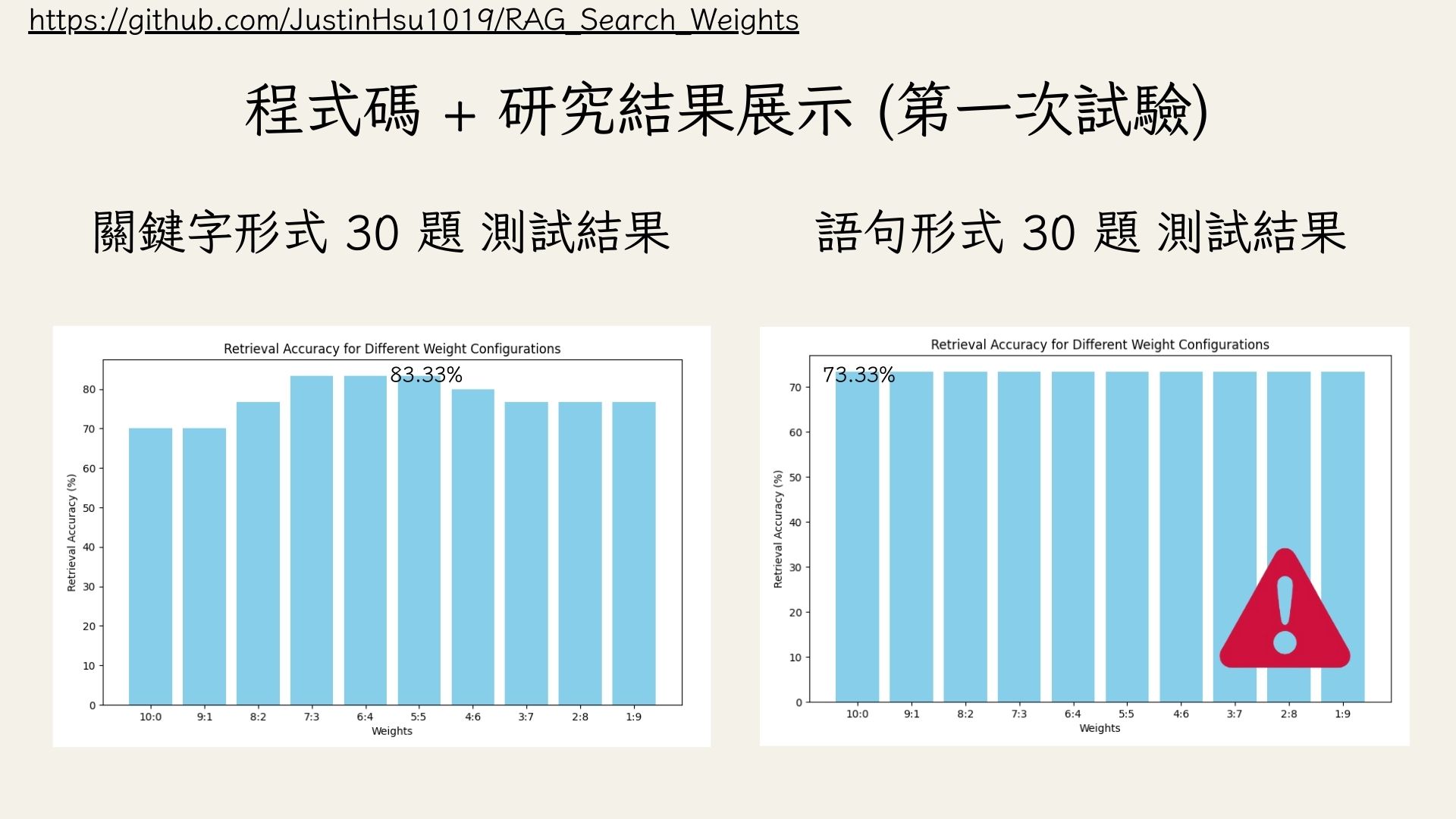
- RAG 的檢索基於關鍵字匹配(基於 BM25F 方法)和向量語意搜尋(基於 Word2Vec + 餘弦相似度方法),將關鍵字匹配和向量語意搜尋結合,針對教育領域 (選課機器人) 窮舉出最佳權重配置
- 利用 LLM 對測試資料進行自動測試和評分
- 匯總不同權重配置(從 10:0 ~ 1:9)的測試結果
- 將結果進行統計和視覺化,展示各種權重配置下的檢索準確性與系統性能
- 分析不同權重配置對檢索準確性和系統性能的影響及造成此分布的原因
- 2024/10/10 需重寫此 README.md,將新研究成果同步至此。過去專題成果除可與新成果做部分比較,已無意義

我們計劃在現有的關鍵字匹配和向量語意搜尋基礎上,引入微軟的 RRF 檢索方法,形成三變因的權重配置模型。這將進一步提升檢索的準確性和系統的整體性能。詳細資訊請參考微軟 Azure 文檔。
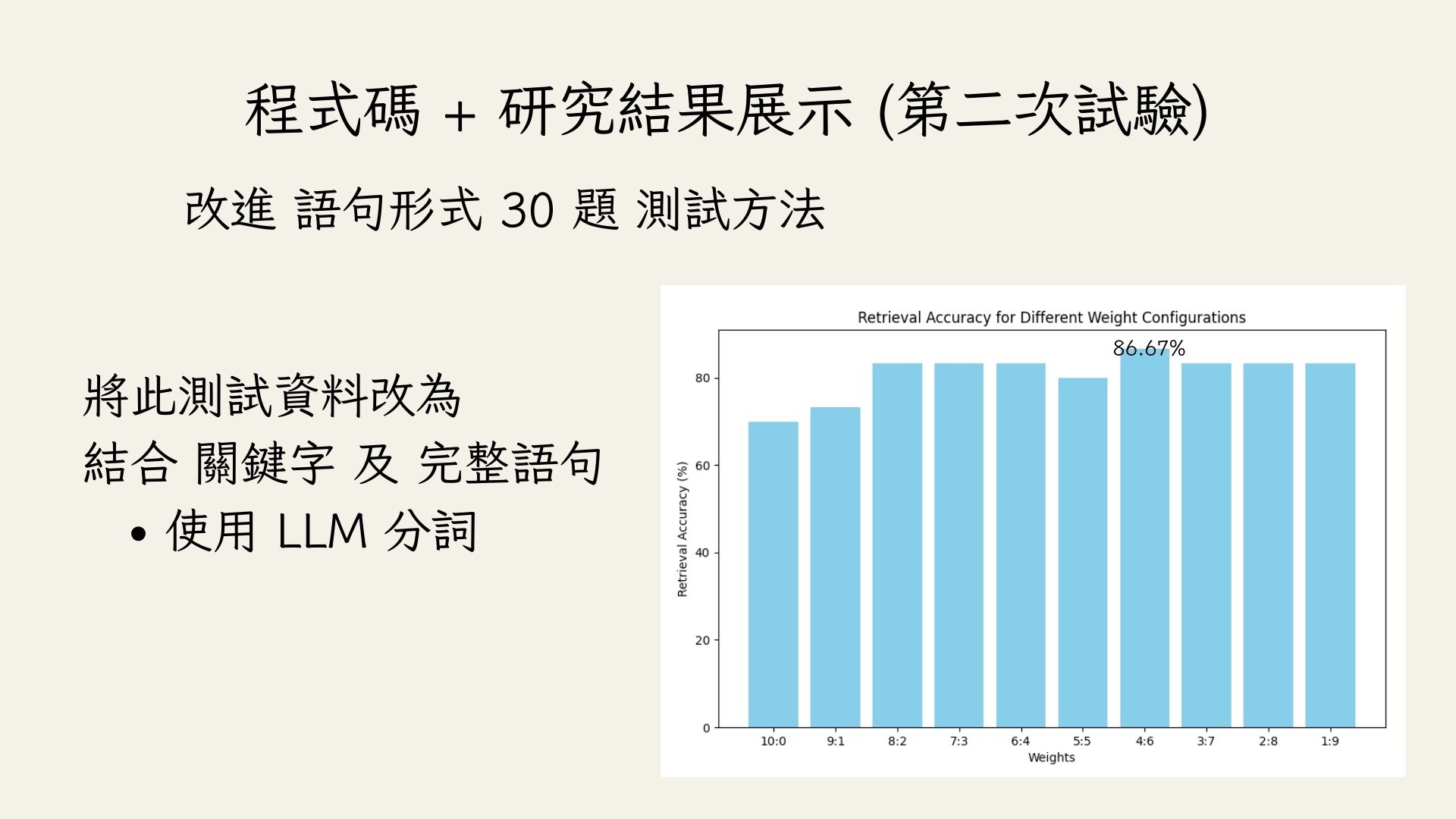
我們計劃拓展研究範圍,選擇網絡上著名的巨型中文資料集(QA Pair 形式),將答案存入向量資料庫,並使用 LLM 根據前述的 Q 生成測試資料。我們會將生成的測試問題分成兩大類:關鍵字類型問題(例如用空格分隔多個關鍵字)和完整語句類型問題(例如完整的句子形式)。在設計問題時,會考慮多個維度,如「2個關鍵字」、「3個關鍵字」、「語句長」、「語句短」等,確保出題的均衡性。隨後,我們將探討這兩種類型問題的檢索準確率,並對資料集的不同領域(例如教育、科技、常識等)進行二階段準確率檢查,進一步分析各個領域內不同問題類型(如 N 個關鍵字、語句長短等)的準確率。
我們計劃開發一個開源工具,讓使用者能夠輸入他們要放入向量資料庫的所有資料,並自動產生各個維度的測試問題。該工具將根據測試問題執行檢索,並生成準確率報告,細分至各個領域及各領域下的不同問題類型(例如問題長短、N 個關鍵字等)。這樣,RAG 系統可以根據使用者的不同問題類型動態調整檢索權重,確保無論使用者如何提問,都能獲得最佳的權重配比。









This repository is licensed under the MIT License.