the project aims to develop an NLP system that can accurately identify the dialect of an Arabic text. We used a combination of pre-trained BERT models, Naive Bayes Multinomial, Random Forest, and fine-tuning techniques along with large datasets to train and test the system. The goal is to improve the accuracy of identifying the dialect of Arabic text.
https://arabic-dialect-id.streamlit.app/
To make our Arabic Dialect Identification models accessible to users, we deployed three models (arabert, arabicbert, and arbert) on the Hugging Face platform and utilized their APIs to integrate the models into our application.
- https://huggingface.co/lafifi-24/arabicBert_arabic_dialect_identification
- https://huggingface.co/lafifi-24/arbert_arabic_dialect_identification
- https://huggingface.co/lafifi-24/arabert_arabic_dialect_identification
The dataset used in this project is a collection of Arabic sentences and their corresponding dialect labels. The dataset was constructed by combining data from multiple sources:
| Name | Source | Paper |
|---|---|---|
| arabic_pos_dialect | https://huggingface.co/datasets/arabic_pos_dialect | --- |
| IADD: An integrated Arabic dialect identification dataset | https://github.com/JihadZa/IADD | https://www.sciencedirect.com/science/article/pii/S2352340921010519 |
| QADI: Arabic Dialect Identification in the Wild | https://github.com/qcri/QADI | https://www.researchgate.net/publication/341396032_Arabic_Dialect_Identification_in_the_Wild |
| The MADAR Arabic Dialect Corpus and Lexicon | https://sites.google.com/nyu.edu/madar/?pli=1 | https://aclanthology.org/L18-1535.pdf |
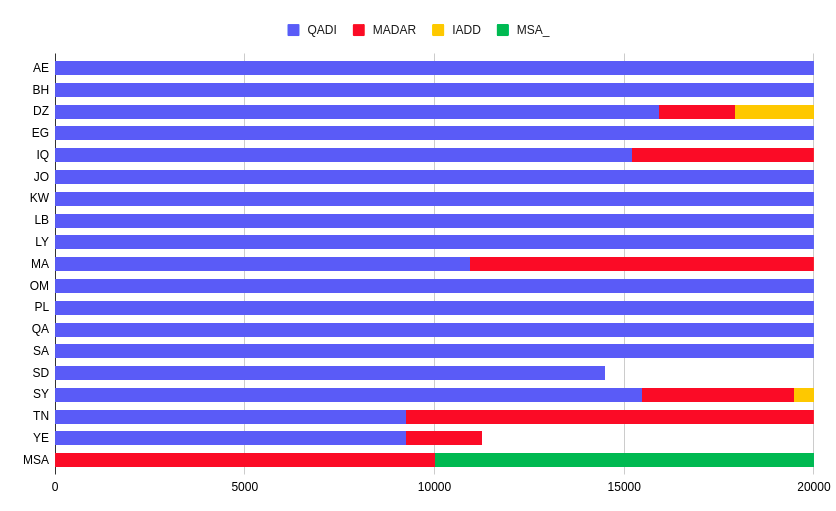
In addition to these sources, we also collected 10,000 sentences in Modern Standard Arabic (MSA) from Wikipedia. These MSA examples were added to the dataset to balance the number of examples across the different dialects.
The following plot shows the distribution of data in our Arabic Dialect Identification dataset.The plot shows the number of examples we use for each dialect, along with the corresponding source for each example.
Before training the model, the data is preprocessed by performing the following steps:
- drop all word or letters, which are not Arabic (like tags,..)
- remove repetitive letters and word which have one letter
- apply arabert preprocessing
In this project, we experimented with different models for Arabic Dialect Identification, including Random Forest, Naive Bayes, Recurrent Neural Network (RNN) with Long Short-Term Memory (LSTM), and BERT models such as AraBERT and ArabicBERT... We trained each model on the preprocessed dataset and evaluated their performance on two test sets:
-
QADI test set: This test set contains manually annotated examples of Arabic sentences, where each sentence is labeled with the corresponding dialect country. The test set contains about 200 examples for each of the 18 dialects.
-
arabic_pos_dialect test set: This test set contains manually annotated examples of Arabic sentences, where each sentence is labeled with the corresponding dialect region (GLF,MGR,EGY,LEV). The test set contains 350 examples for each of the 4 regions, resulting in a total of 1,400 examples.
| Model | QADI F1 Score | arabic_pos_dialect F1 Score |
|---|---|---|
| TF-IDF + Multinomial NB | 0.7506 | 0.8671 |
| TF-IDF + RandomForest | 0.7435 | 0.7228 |
| Bidirectional LSTM | 0.5251 | -- |
| arabert | 0.7637 | 0.8621 |
| arbert | 0.7424 | 0.8792 |
| arabic bert | 0.7465 | 0.86642 |
| marbert | 0.7374 | -- |
| multilingual Bert | 0.6683 | -- |
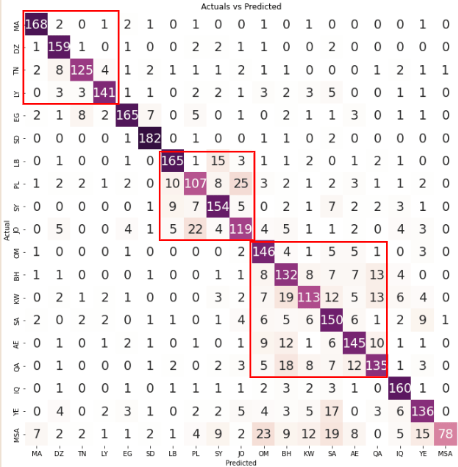
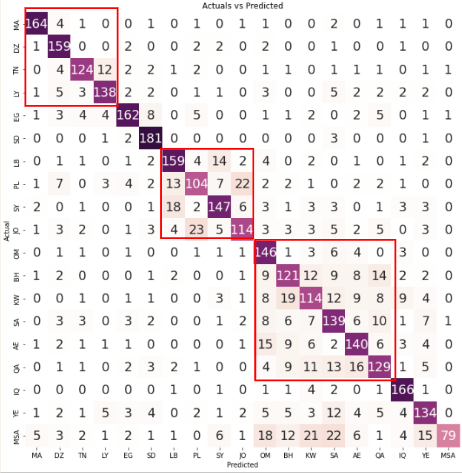
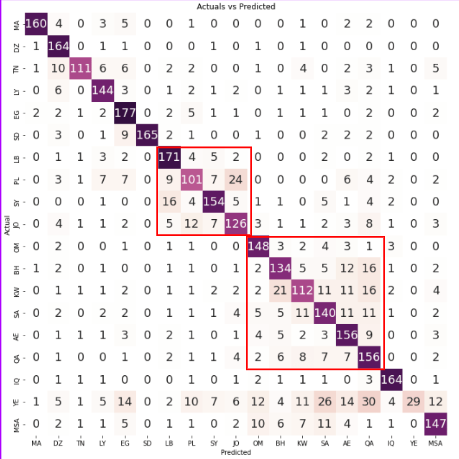
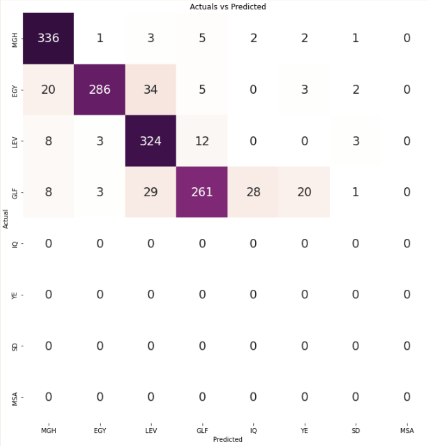
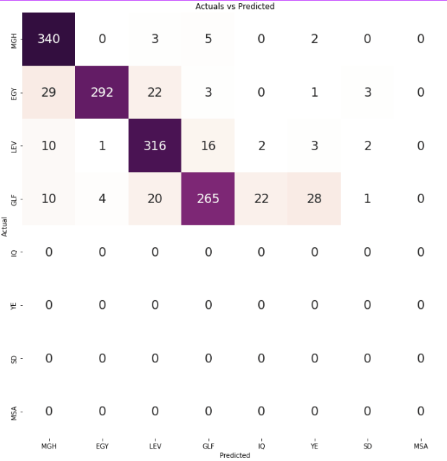
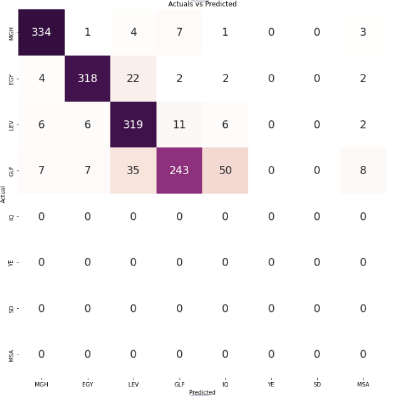
In the confusion matrix, each small square represents a specific dialect region, allowing for a visual representation of the model's performance in predicting the correct dialect for each region.