
![]()


If you need apply business logic or add on some code, you can use my another open source project which supports CRUD router code generator
I believe that many people who work with FastApi to build RESTful CRUD services end up wasting time writing repitive boilerplate code.
FastAPI Quick CRUD can generate CRUD methods in FastApi from an SQLAlchemy schema:
- Get one
- Get one with foreign key
- Get many
- Get many with foreign key
- Update one
- Update many
- Patch one
- Patch many
- Create/Upsert one
- Create/Upsert many
- Delete One
- Delete Many
- Post Redirect Get
FastAPI Quick CRUDis developed based on SQLAlchemy 1.4.23 version and supports sync and async.

-
Support SQLAlchemy 1.4 - Allows you build a fully asynchronous or synchronous python service
-
Full SQLAlchemy DBAPI Support - Support different SQL for SQLAlchemy
-
Support Pagination -
Get manyAPI supportorder byoffsetlimitfield in API -
Rich FastAPI CRUD router generation - Many operations of CRUD are implemented to complete the development and coverage of all aspects of basic CRUD.
-
CRUD route automatically generated - Support Declarative class definitions and Imperative table
-
Flexible API request -
UPDATE ONE/MANYFIND ONE/MANYPATCH ONE/MANYDELETE ONE/MANYsupports Path Parameters (primary key) and Query Parameters as a command to the resource to filter and limit the scope of the scope of data in request. -
SQL Relationship -
FIND ONE/MANYsupports Path get data with relationship
- ❌ If there are multiple unique constraints, please use composite unique constraints instead
- ❌ Composite primary key is not supported
- ❌ Unsupported API requests with on resources
xxx/{primary key}for tables without a primary key;UPDATE ONEFIND ONEPATCH ONEDELETE ONE
I try to update the version dependencies as soon as possible to ensure that the core dependencies of this project have the highest version possible.
fastapi<=0.68.2
pydantic<=1.8.2
SQLAlchemy<=1.4.30
starlette==0.14.2pip install fastapi-quickcrudI suggest the following library if you try to connect to PostgreSQL
pip install psycopg2
pip install asyncpgrun and go to http://127.0.0.1:port/docs and see the auto-generated API
Simple Code (or see the longer (example)
from fastapi import FastAPI
from sqlalchemy import Column, Integer, \
String, Table, ForeignKey, orm
from fastapi_quickcrud import crud_router_builder
Base = orm.declarative_base()
class User(Base):
__tablename__ = 'test_users'
id = Column(Integer, primary_key=True, autoincrement=True, unique=True)
name = Column(String, nullable=False)
email = Column(String, nullable=False)
friend = Table(
'test_friend', Base.metadata,
Column('id', ForeignKey('test_users.id', ondelete='CASCADE', onupdate='CASCADE'), nullable=False),
Column('friend_name', String, nullable=False)
)
crud_route_1 = crud_router_builder(db_model=User,
prefix="/user",
tags=["User"],
async_mode=True
)
crud_route_2 = crud_router_builder(db_model=friend,
prefix="/friend",
tags=["friend"],
async_mode=True
)
app = FastAPI()
app.include_router(crud_route_1)
app.include_router(crud_route_2)from fastapi import FastAPI
from fastapi_quickcrud import crud_router_builder
from sqlalchemy import *
from sqlalchemy.orm import *
from fastapi_quickcrud.crud_router import generic_sql_crud_router_builder
Base = declarative_base()
class Account(Base):
__tablename__ = "account"
id = Column(Integer, primary_key=True, autoincrement=True)
blog_post = relationship("BlogPost", back_populates="account")
class BlogPost(Base):
__tablename__ = "blog_post"
id = Column(Integer, primary_key=True, autoincrement=True)
account_id = Column(Integer, ForeignKey("account.id"), nullable=False)
account = relationship("Account", back_populates="blog_post")
blog_comment = relationship("BlogComment", back_populates="blog_post")
class BlogComment(Base):
__tablename__ = "blog_comment"
id = Column(Integer, primary_key=True, autoincrement=True)
blog_id = Column(Integer, ForeignKey("blog_post.id"), nullable=False)
blog_post = relationship("BlogPost", back_populates="blog_comment")
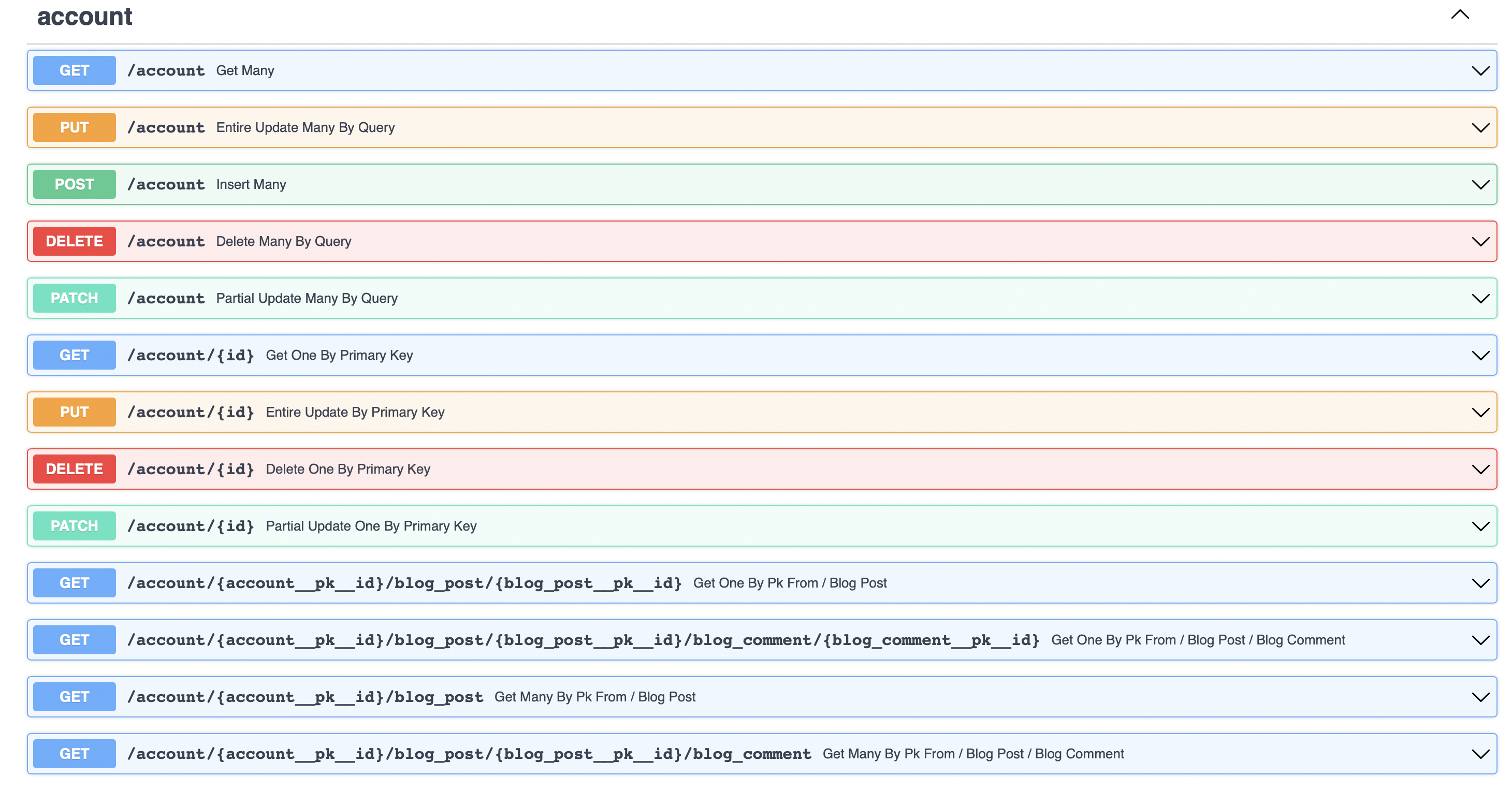
crud_route_parent = crud_router_builder(
db_model=Account,
prefix="/account",
tags=["account"],
foreign_include=[BlogComment, BlogPost]
)
crud_route_child1 = generic_sql_crud_router_builder(
db_model=BlogPost,
prefix="/blog_post",
tags=["blog_post"],
foreign_include=[BlogComment]
)
crud_route_child2 = generic_sql_crud_router_builder(
db_model=BlogComment,
prefix="/blog_comment",
tags=["blog_comment"]
)
app = FastAPI()
[app.include_router(i) for i in [crud_route_parent, crud_route_child1, crud_route_child2]]SQLAlchemy to Pydantic Model Converter And Build your own API(example)
import uvicorn
from fastapi import FastAPI, Depends
from fastapi_quickcrud import CrudMethods
from fastapi_quickcrud import sqlalchemy_to_pydantic
from fastapi_quickcrud.misc.memory_sql import sync_memory_db
from sqlalchemy import CHAR, Column, Integer
from sqlalchemy.ext.declarative import declarative_base
app = FastAPI()
Base = declarative_base()
metadata = Base.metadata
class Child(Base):
__tablename__ = 'right'
id = Column(Integer, primary_key=True)
name = Column(CHAR, nullable=True)
friend_model_set = sqlalchemy_to_pydantic(db_model=Child,
crud_methods=[
CrudMethods.FIND_MANY,
CrudMethods.UPSERT_MANY,
CrudMethods.UPDATE_MANY,
CrudMethods.DELETE_MANY,
CrudMethods.CREATE_ONE,
CrudMethods.PATCH_MANY,
],
exclude_columns=[])
post_model = friend_model_set.POST[CrudMethods.CREATE_ONE]
sync_memory_db.create_memory_table(Child)
@app.post("/hello",
status_code=201,
tags=["Child"],
response_model=post_model.responseModel,
dependencies=[])
async def my_api(
query: post_model.requestBodyModel = Depends(post_model.requestBodyModel),
session=Depends(sync_memory_db.get_memory_db_session)
):
db_item = Child(**query.__dict__)
session.add(db_item)
session.commit()
session.refresh(db_item)
return db_item.__dict__
uvicorn.run(app, host="0.0.0.0", port=8000, debug=False)- Note: you can use sqlacodegen to generate SQLAlchemy models for your table. This project is based on the model development and testing generated by sqlacodegen
crud_router_builder args
-
db_session [Optional]
execute session generator- default using in-memory db with create table automatically
- example:
- sync SQLALchemy:
from sqlalchemy.orm import sessionmaker def get_transaction_session(): try: db = sessionmaker(...) yield db except Exception as e: db.rollback() raise e finally: db.close()
- Async SQLALchemy
from sqlalchemy.orm import sessionmaker from sqlalchemy.ext.asyncio import AsyncSession async_session = sessionmaker(autocommit=False, autoflush=False, bind=engine, class_=AsyncSession) async def get_transaction_session() -> AsyncSession: async with async_session() as session: async with session.begin(): yield session
-
db_model [Require]
SQLALchemy Declarative Base Class or TableNote: There are some constraint in the SQLALchemy Schema
-
async_mode [Optional (auto set by db_session)]
bool: if your db session is asyncNote: require async session generator if True
-
autocommit [Optional (default True)]
bool: if you don't need to commit by your selfNote: require handle the commit in your async session generator if False
-
dependencies [Optional]: API dependency injection of fastapi
Note: Get the example usage in
./example -
crud_methods:
CrudMethods- CrudMethods.FIND_ONE
- CrudMethods.FIND_MANY
- CrudMethods.UPDATE_ONE
- CrudMethods.UPDATE_MANY
- CrudMethods.PATCH_ONE
- CrudMethods.PATCH_MANY
- CrudMethods.UPSERT_ONE (only support postgresql yet)
- CrudMethods.UPSERT_MANY (only support postgresql yet)
- CrudMethods.CREATE_ONE
- CrudMethods.CREATE_MANY
- CrudMethods.DELETE_ONE
- CrudMethods.DELETE_MANY
- CrudMethods.POST_REDIRECT_GET
-
exclude_columns:
listset the columns that not to be operated but the columns should nullable or set the default value)
-
foreign_include:
list[declarative_base()]add the SqlAlchemy models here, and build the foreign tree get one/many api (don't support SqlAlchemy table)
-
dynamic argument (prefix, tags): extra argument for APIRouter() of fastapi
In PUT DELETE PATCH, user can use Path Parameters and Query Parameters to limit the scope of the data affected by the operation, and the Query Parameters is same with FIND API
In the design of this tool, Path Parameters should be a primary key of table, that why limited primary key can only be one.
-
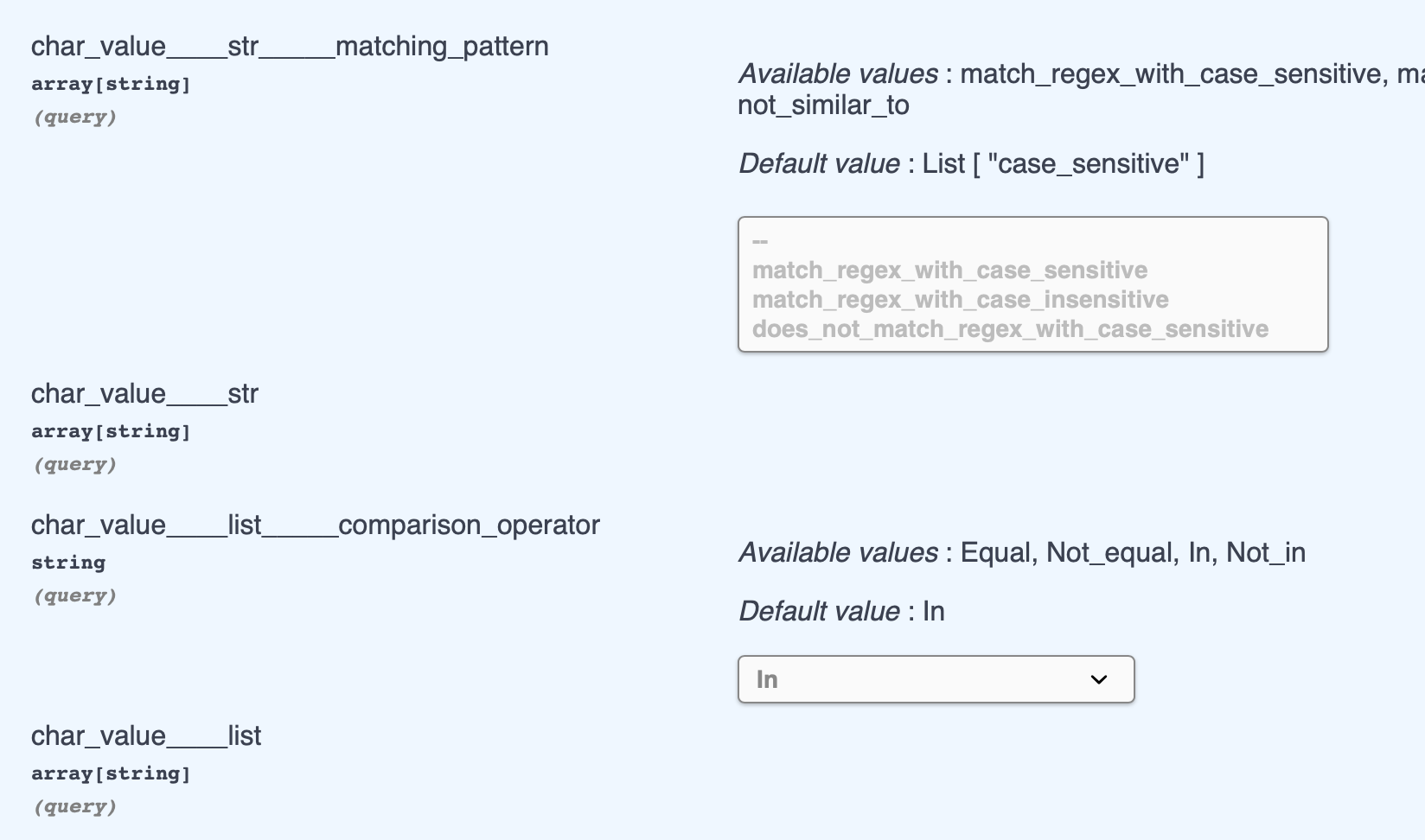
Query Operation will look like that when python type of column is
string
- support Approximate String Matching that require this
- (<column_name>____str, <column_name>____str_____matching_pattern)
- support In-place Operation, get the value of column in the list of input
- (<column_name>____list, <column_name>____list____comparison_operator)
- preview

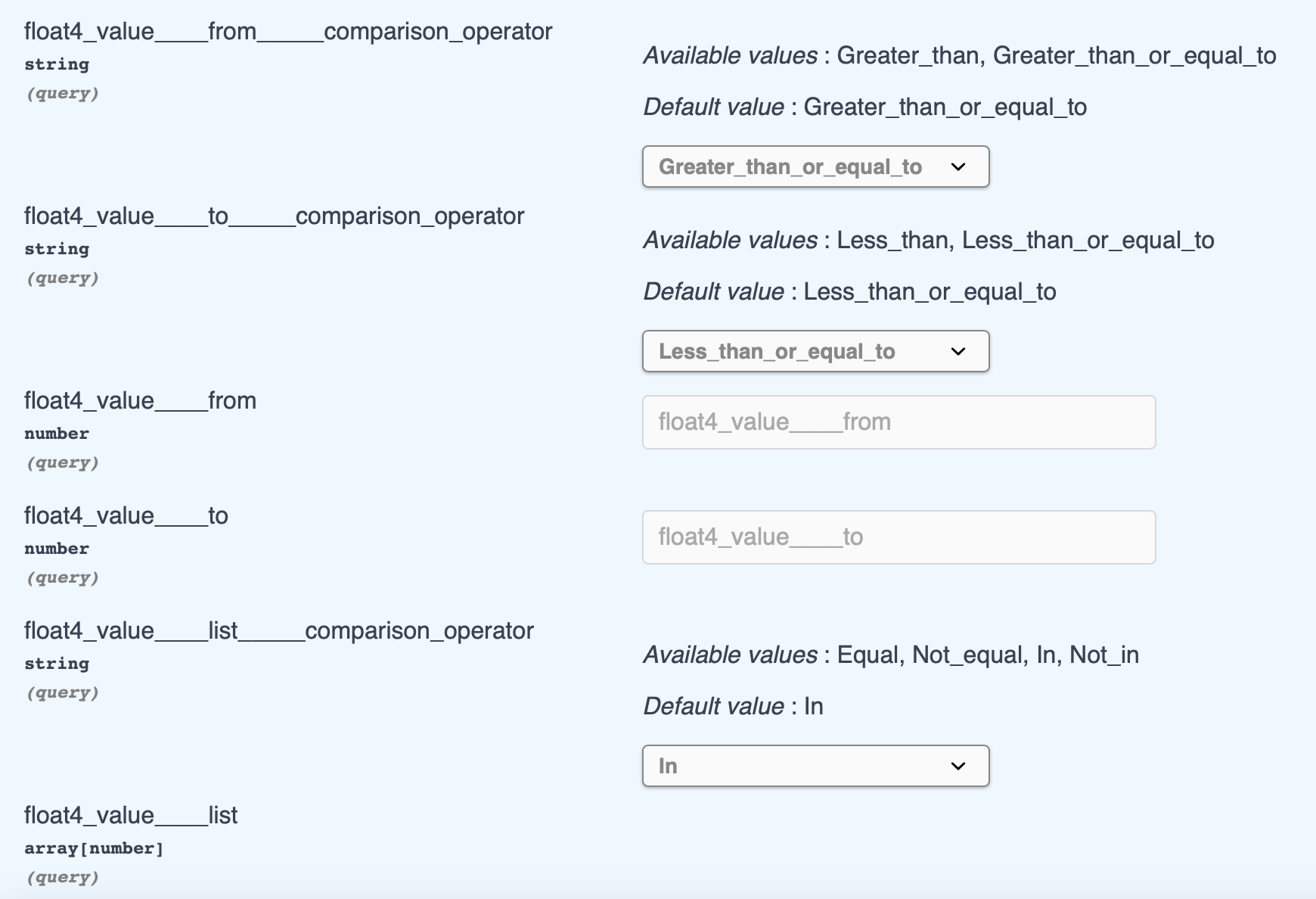
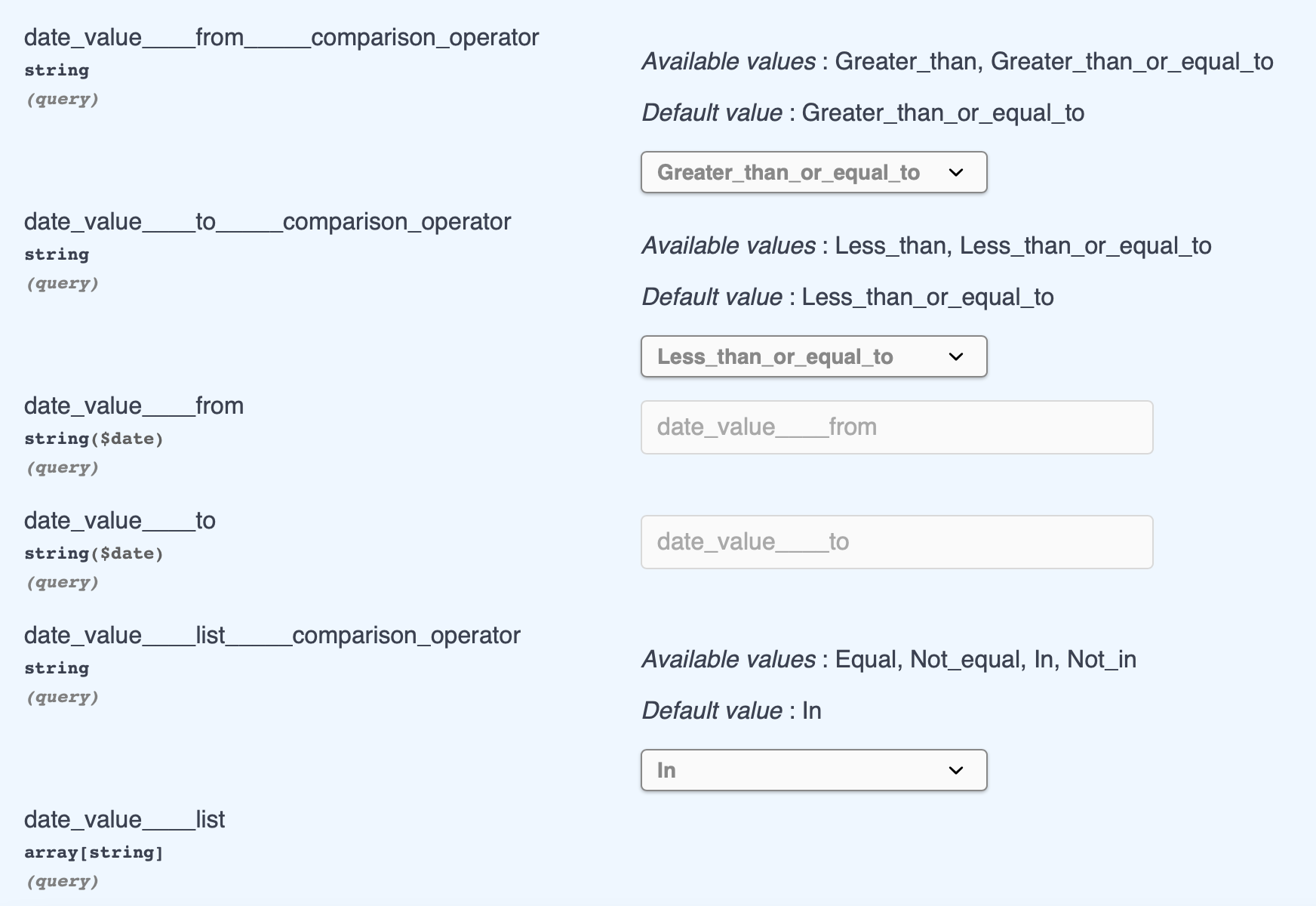
numeric or datetime
- support Range Searching from and to
- (<column_name>____from, <column_name>____from_____comparison_operator)
- (<column_name>____to, <column_name>____to_____comparison_operator)
- support In-place Operation, get the value of column in the list of input
- (<column_name>____list, <column_name>____list____comparison_operator)
- preview


uuid
uuid supports In-place Operation only
- support In-place Operation, get the value of column in the list of input
- (<column_name>____list, <column_name>____list____comparison_operator)
- support Approximate String Matching that require this
-
EXTRA query parameter for
GET_MANY:Pagination
- limit
- offset
- order by
- preview

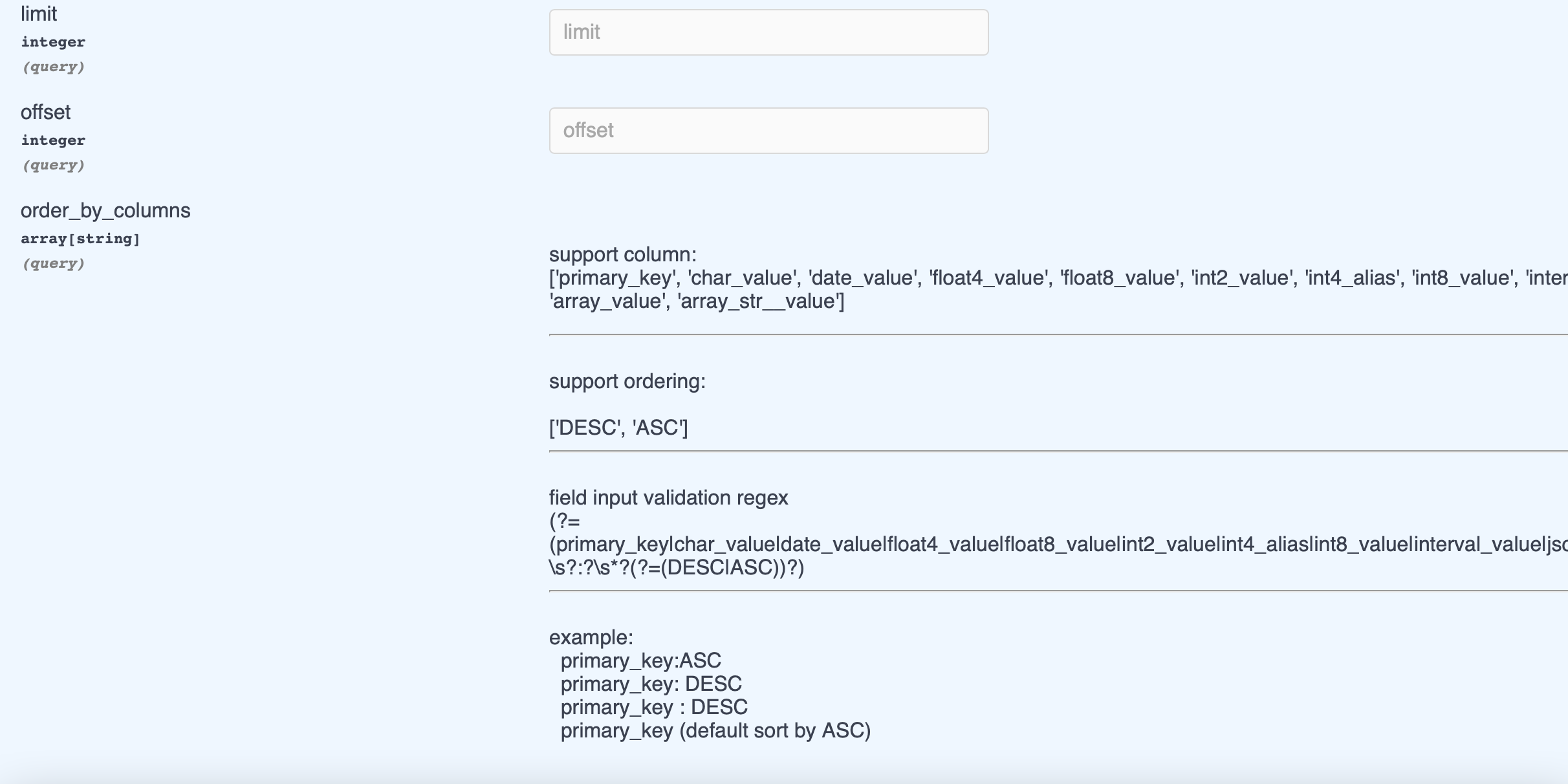
-
example
- request url
/test_CRUD? char_value____str_____matching_pattern=match_regex_with_case_sensitive& char_value____str_____matching_pattern=does_not_match_regex_with_case_insensitive& char_value____str_____matching_pattern=case_sensitive& char_value____str_____matching_pattern=not_case_insensitive& char_value____str=a& char_value____str=b - generated sql
SELECT * FROM untitled_table_256 WHERE (untitled_table_256.char_value ~ 'a') OR (untitled_table_256.char_value ~ 'b' OR (untitled_table_256.char_value !~* 'a') OR (untitled_table_256.char_value !~* 'b' OR untitled_table_256.char_value LIKE 'a' OR untitled_table_256.char_value LIKE 'b' OR untitled_table_256.char_value NOT ILIKE 'a' OR untitled_table_256.char_value NOT ILIKE 'b'
- request url
-
In-place Operation
example
-
In-place support the following operation
-
generated sql if user select Equal operation and input True and False
-
preview

-
generated sql
select * FROM untitled_table_256 WHERE untitled_table_256.bool_value = true OR untitled_table_256.bool_value = false
-
-
Range Searching
example
-
Range Searching support the following operation


-
generated sql
select * from untitled_table_256 WHERE untitled_table_256.date_value > %(date_value_1)s
select * from untitled_table_256 WHERE untitled_table_256.date_value < %(date_value_1)s
-
-
Also support your custom dependency for each api(there is a example in
./example)



In the design of this tool, the columns of the table will be used as the fields of request body.
In the basic request body in the api generated by this tool, some fields are optional if :
- it is primary key with
autoincrementis True or theserver_defaultordefaultis True - it is not a primary key, but the
server_defaultordefaultis True - The field is nullable
TBC
** Upsert supports PosgreSQL only yet
POST API will perform the data insertion action with using the basic Request Body, In addition, it also supports upsert(insert on conflict do)
The operation will use upsert instead if the unique column in the inserted row that is being inserted already exists in the table
The tool uses unique columns in the table as a parameter of on conflict , and you can define which column will be updated
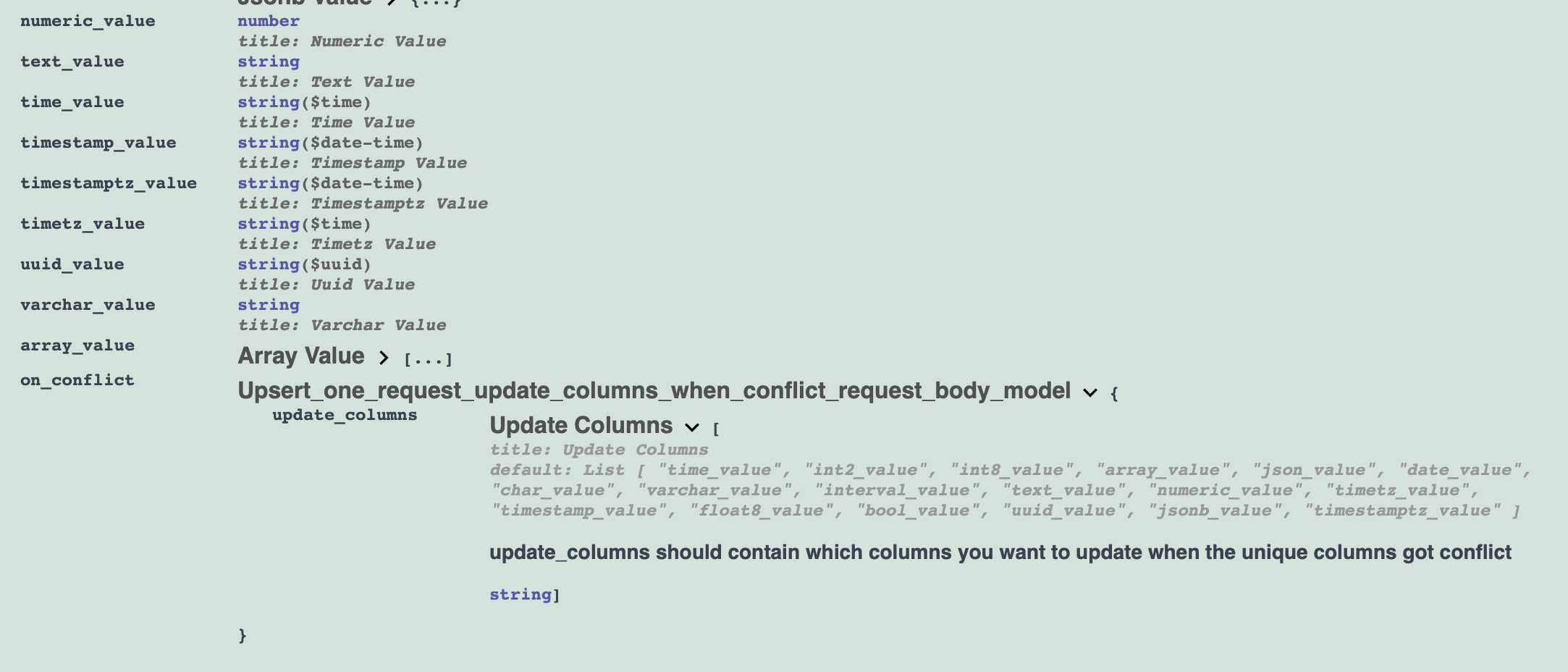
You can declare comment argument for sqlalchemy.Column to configure the description of column
example:
class Parent(Base):
__tablename__ = 'parent_o2o'
id = Column(Integer, primary_key=True,comment='parent_test')
# one-to-many collection
children = relationship("Child", back_populates="parent")
class Child(Base):
__tablename__ = 'child_o2o'
id = Column(Integer, primary_key=True,comment='child_pk_test')
parent_id = Column(Integer, ForeignKey('parent_o2o.id'),info=({'description':'child_parent_id_test'}))
# many-to-one scalar
parent = relationship("Parent", back_populates="children")Now, FIND_ONE and FIND_MANY are supporting select data with join operation
class Parent(Base):
__tablename__ = 'parent_o2o'
id = Column(Integer, primary_key=True)
children = relationship("Child", back_populates="parent")
class Child(Base):
__tablename__ = 'child_o2o'
id = Column(Integer, primary_key=True)
parent_id = Column(Integer, ForeignKey('parent_o2o.id'))
parent = relationship("Parent", back_populates="children")there is a relationship with using back_populates between Parent table and Child table, the parent_id in Child will refer to id column in Parent.
FastApi Quick CRUD will generate an api with a join_foreign_table field, and get api will respond to your selection of the reference data row of the corresponding table in join_foreign_table field,


- Try Request now there are some data in these two table

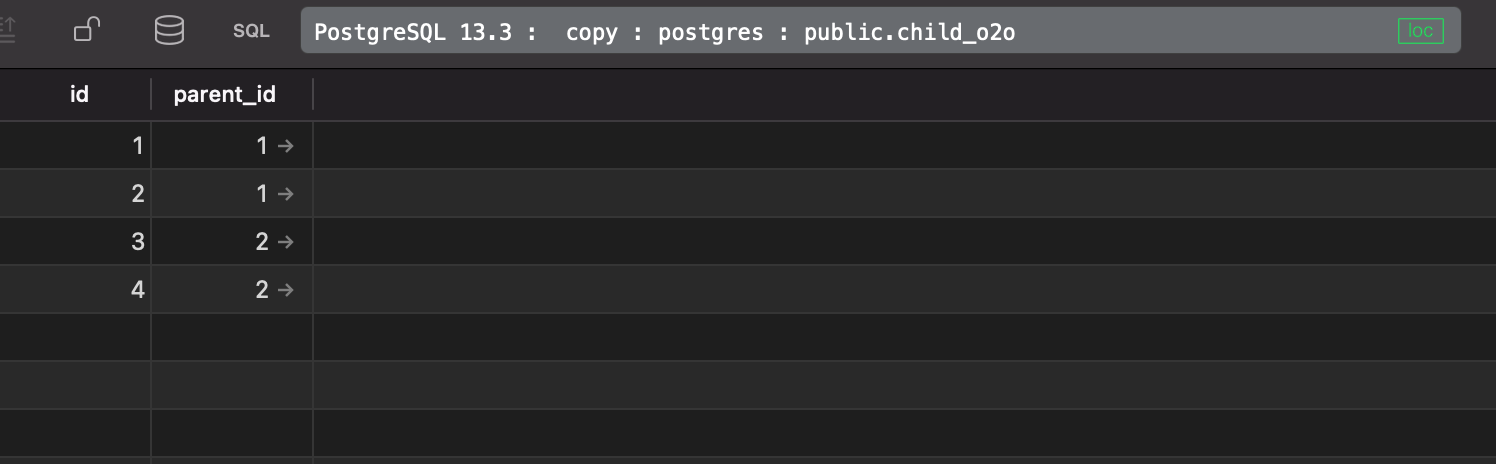
when i request
-
Case One
curl -X 'GET' \ 'http://0.0.0.0:8000/parent?join_foreign_table=child_o2o' \ -H 'accept: application/json'Response data
[ { "id_foreign": [ { "id": 1, "parent_id": 1 }, { "id": 2, "parent_id": 1 } ], "id": 1 }, { "id_foreign": [ { "id": 3, "parent_id": 2 }, { "id": 4, "parent_id": 2 } ], "id": 2 } ]Response headers
x-total-count: 4There are response 4 data, response data will be grouped by the parent row, if the child refer to the same parent row
-
Case Two
curl -X 'GET' \ 'http://0.0.0.0:8000/child?join_foreign_table=parent_o2o' \ -H 'accept: application/json'Response data
[ { "parent_id_foreign": [ { "id": 1 } ], "id": 1, "parent_id": 1 }, { "parent_id_foreign": [ { "id": 1 } ], "id": 2, "parent_id": 1 }, { "parent_id_foreign": [ { "id": 2 } ], "id": 3, "parent_id": 2 }, { "parent_id_foreign": [ { "id": 2 } ], "id": 4, "parent_id": 2 } ]Response Header
x-total-count: 4
When you ask for a specific resource, say a user or with query param, and the user doesn't exist
GET: get one : https://0.0.0.0:8080/api/:userid?xx=xx
UPDATE: update one : https://0.0.0.0:8080/api/:userid?xx=xx
PATCH: patch one : https://0.0.0.0:8080/api/:userid?xx=xx
DELETE: delete one : https://0.0.0.0:8080/api/:userid?xx=xx
then fastapi-qucikcrud should return 404. In this case, the client requested a resource that doesn't exist.
In the other case, you have an api that operate data on batch in the system using the following url:
GET: get many : https://0.0.0.0:8080/api/user?xx=xx
UPDATE: update many : https://0.0.0.0:8080/api/user?xx=xx
DELETE: delete many : https://0.0.0.0:8080/api/user?xx=xx
PATCH: patch many : https://0.0.0.0:8080/api/user?xx=xx
If there are no users in the system, then, in this case, you should return 204.