common interview system design questions:
What is the architecture of the system?
The architecture of the system is typically designed to balance performance, scalability, and security requirements. It may include multiple layers of caching, load balancing, and failover mechanisms to ensure that requests are distributed evenly across multiple servers and that data is stored and retrieved efficiently.
How are requests handled?
Requests are typically handled by the system's request handler, which listens for incoming requests and dispatches them to the appropriate server or service. The request handler may also handle load balancing and failover mechanisms to ensure that requests are distributed evenly across multiple servers.
How are requests distributed across multiple servers?
Requests are typically distributed across multiple servers using a load balancing mechanism, which distributes incoming requests evenly across all available servers. The load balancer may also monitor the health of each server and route requests to healthy servers only.
How are requests stored and retrieved?
Requests are typically stored and retrieved from a database or cache using a key-value store or a cache provider. The key-value store or cache provider may use a distributed cache to store and retrieve data efficiently across multiple servers.
How is data stored and retrieved?
Data is typically stored and retrieved from a database or cache using a key-value store or a cache provider. The key-value store or cache provider may use a distributed cache to store and retrieve data efficiently across multiple servers.
How is security implemented?
Security is typically implemented using a combination of authentication, authorization, and encryption mechanisms. The system may use SSL/TLS to encrypt data in transit, and may also use encryption at rest to protect sensitive data. The system may also use rate limiting and other security mechanisms to prevent attacks and ensure that the system is secure.
How is load balancing implemented?
Load balancing is typically implemented using a load balancer or a reverse proxy. The load balancer or reverse proxy may distribute incoming requests evenly across all available servers, and may also monitor the health of each server and route requests to healthy servers only.
How is fault tolerance implemented?
Fault tolerance is typically implemented using redundancy and failover mechanisms. The system may use multiple servers to ensure that requests are distributed evenly across all available servers, and may also use failover mechanisms to switch to a backup server if a server fails.
How is scalability implemented?
Scalability is typically implemented using a combination of horizontal and vertical scaling techniques. The system may use a scaling strategy that adds or removes servers based on demand, or it may use a scaling strategy that adjusts the resources allocated to each server based on demand.
How is performance optimized?
Performance optimization is typically implemented using a combination of caching, compression, and other techniques. The system may use caching to store frequently accessed data in memory, and may also use compression to reduce the size of data that is transmitted over the network.
How is monitoring and logging implemented?
Monitoring and logging are typically implemented using a monitoring system and logging framework. The monitoring system may monitor the health of each server, the performance of each server, and the overall performance of the system, and may generate alerts or notifications if any of these metrics exceed a certain threshold. The logging framework may log all requests and responses, as well as other relevant information, to help diagnose and troubleshoot issues.
How is documentation and support provided?
Documentation and support are typically provided through a user manual, a help desk, and a knowledge base. The user manual may provide detailed instructions on how to use the system, including how to navigate the user interface, how to perform common tasks, and how to report issues. The help desk may provide support for users who encounter issues with the system, and may also provide training on how to use the system effectively. The knowledge base may provide detailed information on how the system is designed, how it works, and how to troubleshoot issues.
How is the system designed for scalability and performance?
The system is designed for scalability and performance by using a combination of caching, load balancing, and other techniques. The system may use a caching provider to store frequently accessed data in memory, and may also use a load balancer to distribute incoming requests evenly across all available servers. The system may also use a scaling strategy that adds or removes servers based on demand, or it may use a scaling strategy that adjusts the resources allocated to each server based on demand.
How is the system designed for security and reliability?
The system is designed for security and reliability by using a combination of authentication, authorization, and encryption mechanisms. The system may use SSL/TLS to encrypt data in transit, and may also use encryption at rest to protect sensitive data. The system may also use rate limiting and other security mechanisms to prevent attacks and ensure that the system is secure. The system may also use redundancy and failover mechanisms to ensure that the system is resilient to failures.
How is the system designed for maintainability and evolution?
The system is designed for maintainability and evolution by using a modular architecture that allows for easy customization and extension. The system may use a microservices architecture to break the system into smaller, independent services that can be developed, tested, and deployed independently. The system may also use a version control system to track changes to the code and documentation, and may use automated testing
Frugal Streaming:
Frugal Streaming is a technique used to approximate the results of a query over a data stream, while using minimal memory. It is often used in scenarios where the data stream is too large to fit into memory, but approximate results are acceptable. One example of Frugal Streaming is the Count-Min Sketch algorithm, which uses a fixed-size array of counters to estimate the frequency of items in a data stream. Each item is hashed to a set of counters, and the minimum count in that set is incremented. The estimate for the frequency of an item is the minimum count across all sets.
Geohash / S2 Geometry:
Geohash and S2 Geometry are two related techniques used to represent and index geographic locations on a two-dimensional surface, such as a map. Geohash is a hierarchical spatial data structure that uses a string of characters to represent a location. Each character in the string represents a subdivision of the space, with longer strings representing smaller subdivisions. S2 Geometry is a library for manipulating geometric shapes on the surface of a sphere, such as the Earth. It uses a hierarchical grid system to partition the surface of the sphere into cells of varying sizes. Both Geohash and S2 Geometry are useful for indexing and querying large datasets of geographic locations.
Leaky bucket / Token bucket:
Leaky bucket and Token bucket are two algorithms used for traffic shaping and rate limiting in computer networks. The Leaky bucket algorithm regulates the rate at which data is transmitted by imposing a constant rate of data removal from a buffer. Any data that arrives in excess of the rate is discarded. The Token bucket algorithm regulates the rate at which data is transmitted by issuing tokens at a fixed rate. Each token allows a fixed amount of data to be transmitted. If there are no tokens available, data transmission is blocked.
Loosy Counting:
Loosy Counting is a technique used to estimate the frequency of items in a data stream, while using minimal memory. It is similar to Frugal Streaming, but allows for a small amount of error in the estimates. One example of Loosy Counting is the HyperLogLog algorithm, which uses a fixed-size array of registers to estimate the number of distinct items in a data stream. Each item is hashed to a register, and the maximum number of leading zeros in the binary representation of the register values is used to estimate the number of distinct items.
Operational transformation:
Operational Transformation is a technique used to synchronize the state of a shared document or data structure across multiple clients in a distributed system. It is often used in collaborative editing applications, such as Google Docs. Operational Transformation works by transforming the operations performed by each client into a common form that can be applied in any order without affecting the final state of the document. This allows each client to see the changes made by other clients in real-time, while ensuring that the final state of the document is consistent across all clients.
Quadtree / Rtree:
Quadtree and Rtree are two related spatial data structures used for indexing and querying two-dimensional data, such as points, lines, and polygons. Quadtree is a hierarchical data structure that recursively subdivides a two-dimensional space into four quadrants, with each quadrant represented by a node in the tree. Rtree is a similar data structure that uses a hierarchical tree of rectangles to represent the data. Both Quadtree and Rtree are useful for spatial indexing and querying in applications such as geographic information systems and computer graphics.
Ray casting:
Ray casting is a technique used to render three-dimensional scenes in computer graphics. It works by tracing rays from the viewer's eye through each pixel in the image plane and into the scene. The rays are tested for intersections with objects in the scene, and the color of the pixel is determined based on the properties of the closest object. Ray casting is a computationally intensive process, but can produce high-quality images with realistic lighting and shading effects.
Reverse index:
Reverse index, also known as an inverted index, is a data structure used to index and search text documents. It works by creating an index of all the words in the documents, along with a list of the documents that contain each word. This allows for efficient searching of documents based on the words they contain. Reverse index is used in many applications, such as search engines and document management systems.
Rsync algorithm:
Rsync is a file synchronization algorithm used to efficiently transfer files between two systems over a network. It works by comparing the contents of the files on both systems and transferring only the differences between them. This can greatly reduce the amount of data that needs to be transferred, especially for large files or files that have only small changes. Rsync is commonly used for backups and for transferring large files over the internet.
Trie algorithm:
A Trie, also known as a prefix tree, is a tree-like data structure used to store and retrieve strings efficiently. Each node in the tree represents a prefix of one or more strings, and the edges represent the characters that can follow the prefix. Tries are useful for applications such as autocomplete and spell checking, where fast string lookups are required.
Coding Questions
Subsets : https://leetcode.com/problems/subsets/
public List<List<Integer>> subsets(int[] nums) {
List<List<Integer>> list = new ArrayList<>();
Arrays.sort(nums);
backtrack(list, new ArrayList<>(), nums, 0);
return list;
}
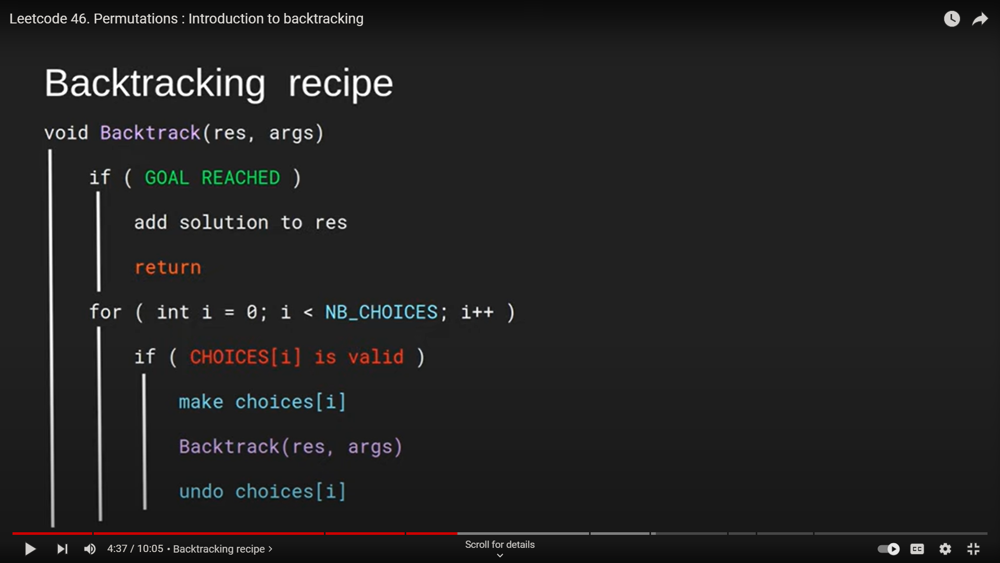
private void backtrack(List<List<Integer>> list , List<Integer> tempList, int [] nums, int start){
list.add(new ArrayList<>(tempList));
for(int i = start; i < nums.length; i++){
tempList.add(nums[i]);
backtrack(list, tempList, nums, i + 1);
tempList.remove(tempList.size() - 1);
}
}
Subsets II (contains duplicates) : https://leetcode.com/problems/subsets-ii/
public List<List<Integer>> subsetsWithDup(int[] nums) {
List<List<Integer>> list = new ArrayList<>();
Arrays.sort(nums);
backtrack(list, new ArrayList<>(), nums, 0);
return list;
}
private void backtrack(List<List<Integer>> list, List<Integer> tempList, int [] nums, int start){
list.add(new ArrayList<>(tempList));
for(int i = start; i < nums.length; i++){
if(i > start && nums[i] == nums[i-1]) continue; // skip duplicates
tempList.add(nums[i]);
backtrack(list, tempList, nums, i + 1);
tempList.remove(tempList.size() - 1);
}
}
Permutations : https://leetcode.com/problems/permutations/
public List<List<Integer>> permute(int[] nums) {
List<List<Integer>> list = new ArrayList<>();
// Arrays.sort(nums); // not necessary
backtrack(list, new ArrayList<>(), nums);
return list;
}
private void backtrack(List<List<Integer>> list, List<Integer> tempList, int [] nums){
if(tempList.size() == nums.length){
list.add(new ArrayList<>(tempList));
} else{
for(int i = 0; i < nums.length; i++){
if(tempList.contains(nums[i])) continue; // element already exists, skip
tempList.add(nums[i]);
backtrack(list, tempList, nums);
tempList.remove(tempList.size() - 1);
}
}
}
Permutations II (contains duplicates) : https://leetcode.com/problems/permutations-ii/
public List<List<Integer>> permuteUnique(int[] nums) {
List<List<Integer>> list = new ArrayList<>();
Arrays.sort(nums);
backtrack(list, new ArrayList<>(), nums, new boolean[nums.length]);
return list;
}
private void backtrack(List<List<Integer>> list, List<Integer> tempList, int [] nums, boolean [] used){
if(tempList.size() == nums.length){
list.add(new ArrayList<>(tempList));
} else{
for(int i = 0; i < nums.length; i++){
if(used[i] || i > 0 && nums[i] == nums[i-1] && !used[i - 1]) continue;
used[i] = true;
tempList.add(nums[i]);
backtrack(list, tempList, nums, used);
used[i] = false;
tempList.remove(tempList.size() - 1);
}
}
}
Combination Sum : https://leetcode.com/problems/combination-sum/
public List<List<Integer>> combinationSum(int[] nums, int target) {
List<List<Integer>> list = new ArrayList<>();
Arrays.sort(nums);
backtrack(list, new ArrayList<>(), nums, target, 0);
return list;
}
private void backtrack(List<List<Integer>> list, List<Integer> tempList, int [] nums, int remain, int start){
if(remain < 0) return;
else if(remain == 0) list.add(new ArrayList<>(tempList));
else{
for(int i = start; i < nums.length; i++){
tempList.add(nums[i]);
backtrack(list, tempList, nums, remain - nums[i], i); // not i + 1 because we can reuse same elements
tempList.remove(tempList.size() - 1);
}
}
}
Combination Sum II (can't reuse same element) : https://leetcode.com/problems/combination-sum-ii/
public List<List<Integer>> combinationSum2(int[] nums, int target) {
List<List<Integer>> list = new ArrayList<>();
Arrays.sort(nums);
backtrack(list, new ArrayList<>(), nums, target, 0);
return list;
}
private void backtrack(List<List<Integer>> list, List<Integer> tempList, int [] nums, int remain, int start){
if(remain < 0) return;
else if(remain == 0) list.add(new ArrayList<>(tempList));
else{
for(int i = start; i < nums.length; i++){
if(i > start && nums[i] == nums[i-1]) continue; // skip duplicates
tempList.add(nums[i]);
backtrack(list, tempList, nums, remain - nums[i], i + 1);
tempList.remove(tempList.size() - 1);
}
}
}
Palindrome Partitioning : https://leetcode.com/problems/palindrome-partitioning/
public List<List<String>> partition(String s) {
List<List<String>> list = new ArrayList<>();
backtrack(list, new ArrayList<>(), s, 0);
return list;
}
public void backtrack(List<List<String>> list, List<String> tempList, String s, int start){
if(start == s.length())
list.add(new ArrayList<>(tempList));
else{
for(int i = start; i < s.length(); i++){
if(isPalindrome(s, start, i)){
tempList.add(s.substring(start, i + 1));
backtrack(list, tempList, s, i + 1);
tempList.remove(tempList.size() - 1);
}
}
}
}
public boolean isPalindrome(String s, int low, int high){
while(low < high)
if(s.charAt(low++) != s.charAt(high--)) return false;
return true;
}
java interview questions:
Number ways to create object in java?
Using new keyword
Using new instance
Using clone() method
Using deserialization
Using newInstance() method of Constructor class
Using new keyword:
The new keyword is used to create a new instance of a class. It allocates memory for the object and initializes its fields with their default values. Here's an example:
MyClass obj = new MyClass();
This creates a new instance of the MyClass class and assigns it to the obj variable.
Using new instance:
The newInstance() method of the Class class is used to create a new instance of a class at runtime. It is similar to using the new keyword, but allows you to create an instance of a class whose name is not known until runtime. Here's an example:
Class<?> cls = Class.forName("MyClass");
MyClass obj = (MyClass) cls.newInstance();
This creates a new instance of the MyClass class using the newInstance() method of the Class class.
Using clone() method:
The clone() method is used to create a copy of an object. It creates a new instance of the same class as the original object and copies the values of all fields from the original object to the new object. Here's an example:
MyClass obj1 = new MyClass();
MyClass obj2 = obj1.clone();
This creates a new instance of the MyClass class using the clone() method and assigns it to the obj2 variable.
Using deserialization:
Deserialization is the process of converting a serialized object back into an object in memory. It is typically used to transfer objects between different systems or to store objects in a database. Here's an example:
ObjectInputStream in = new ObjectInputStream(new FileInputStream("data.bin"));
MyClass obj = (MyClass) in.readObject();
This reads a serialized object from a file called data.bin and deserializes it into a new instance of the MyClass class.
Using newInstance() method of Constructor class:
The newInstance() method of the Constructor class is used to create a new instance of a class using a constructor at runtime. It is similar to using the new keyword, but allows you to create an instance of a class whose constructor is not known until runtime. Here's an example:
Constructor<MyClass> constructor = MyClass.class.getConstructor(String.class, int.class);
MyClass obj = constructor.newInstance("hello", 123);
This creates a new instance of the MyClass class using the newInstance() method of the Constructor class and passing arguments to the constructor.
what is use of reflections in java?
Reflection is a mechanism in Java that allows you to inspect, manipulate, and create objects at runtime. Reflection allows you to get information about classes, methods, fields, and other objects at runtime, without having to know the class or object at compile time.
Reflection is useful in a variety of situations, such as:
Dynamically loading classes at runtime
Creating objects based on user input or configuration files
Implementing frameworks that can work with any class, without having to know the class at compile time
Debugging and testing frameworks that need to work with any class
Creating proxies for objects that intercept method calls and perform additional actions
Reflection can also be used to bypass access control restrictions, which can be useful in certain situations. However, it is important to use reflection judiciously and only when necessary, as it can make your code more complex and harder to maintain.
Here are some common use cases for reflection in Java:
Dynamically loading classes at runtime:
Class<?> clazz = Class.forName("com.example.MyClass");
Object obj = clazz.newInstance();
In this example, we use the Class.forName() method to load the
MyClass class at runtime. We then use the newInstance()
method to create a new instance of the class.
Creating objects based on user input or configuration files:
String className = "com.example.MyClass";
Class<?> clazz = Class.forName(className);
Constructor<?> constructor = clazz.getConstructor(String.class);
Object obj = constructor.newInstance("John");
In this example, we use the Class.forName() method to load the
MyClass class at runtime. We then use the getConstructor()
method to get the constructor that takes a String argument. We then use the newInstance()
method to create a new instance of the class and pass in the argument "John".
Implementing frameworks that can work with any class, without having to know the class at compile time:
Class<?> clazz = Class.forName(className);
Object obj = clazz.newInstance();
Method method = clazz.getMethod("myMethod", String.class);
method.invoke(obj, "John");
In this example, we use the Class.forName() method to load the class at runtime. We then use the newInstance() method to create a new instance of the class. We then use the
getMethod() method to get the myMethod method of the class that takes a String argument. We then use the invoke() method to call the method and pass in the argument "John".
Debugging and testing frameworks that need to work with any class:
Class<?> clazz = Class.forName(className);
Object obj = clazz.newInstance();
Field field = clazz.getField("myField");
field.set(obj, "John");
In this example, we use the Class.forName() method to load the class at runtime. We then use the newInstance() method to create a new instance of the class. We then use the
getField() method to get the myField field of the class. We then use the set() method to set the value of the field to "John".
HashMap is a class in Java that implements the Map interface, which allows you to store key-value pairs. HashMap is a hash table, which means that it uses a hash function to map keys to indices in an array. When you add a key-value pair to a HashMap, the key is hashed to determine the index in the array where the value should be stored. If there is already a value stored at that index, the new value is added to the end of a linked list at that index.
Here's how HashMap works internally:
The HashMap class implements the Map interface, which means that it has methods for adding, removing, and accessing key-value pairs.
When you create a new HashMap, it is initialized with a default capacity of 16. The capacity is the number of indices in the hash table.
When you add a key-value pair to a HashMap, the key is hashed to determine the index in the array where the value should be stored. The hash function used by HashMap is a simple modulo operation, which means that the index is calculated as
hash(key) % capacity
.
If there is already a value stored at that index, the new value is added to the end of a linked list at that index. This allows multiple values to be stored at the same index.
When you access a value in a HashMap, the key is hashed to determine the index in the array where the value is stored. If there is more than one value stored at that index, you need to iterate through the linked list to find the value you are looking for.
When you remove a key-value pair from a HashMap, the key is hashed to determine the index in the array where the value is stored. If there is more than one value stored at that index, you need to iterate through the linked list to find the value you want to remove. Once you find the value, you remove it from the linked list and update the size of the HashMap.
HashMap is not synchronized, which means that it can be accessed by multiple threads simultaneously without causing data corruption. If you need to synchronize access to a HashMap, you can use a synchronized wrapper class such as
Collections.synchronizedMap()
.
Overall, HashMap is a useful data structure for storing key-value pairs in Java, especially when you need to access values quickly based on the key. However, it is important to choose the right type of HashMap (e.g. LinkedHashMap, TreeMap, etc.) based on your specific use case, as some types of HashMaps are better suited for certain types of operations.
how to make custom immutable class in java?
To create a custom immutable class in Java, you can follow these steps:
Create a public class with a private constructor and public static factory methods to create instances of the class.
Make all fields final and private.
Override the equals and hashCode methods to compare instances based on their fields.
Implement the toString method to provide a human-readable string representation of the instance.
Here's an example implementation:
public final class Point {
private final int x;
private final int y;
private Point(int x, int y) {
this.x = x;
this.y = y;
}
public static Point of(int x, int y) {
return new Point(x, y);
}
public int getX() {
return x;
}
public int getY() {
return y;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass()!= o.getClass()) return false;
Point point = (Point) o;
return x == point.x &&
y == point.y;
}
@Override
public int hashCode() {
return Objects.hash(x, y);
}
@Override
public String toString() {
return "Point{" +
"x=" + x +
", y=" + y +
'}';
}
}
import java.util.Arrays;
public class Main {
public static int upper_bound(int[] A, int t) {
int l = 0, r = A.length - 1;
while (l <= r) {
int mid = (l + r) / 2;
if (A[mid] <= t) {
l = mid + 1;
} else {
r = mid - 1;
}
}
return l;
}
public static void main(String[] args) {
int[] A = {1, 2, 3, 4, 5};
int t = 3;
int res = upper_bound(A, t);
System.out.println(res); // Output: 3
}
}
import java.util.Arrays;
public class Main {
public static int lower_bound(int[] A, int t) {
int l = 0, r = A.length - 1;
while (l <= r) {
int mid = (l + r) / 2;
if (A[mid] < t) {
l = mid + 1;
} else {
r = mid - 1;
}
}
return l;
}
public static void main(String[] args) {
int[] A = {1, 2, 3, 4, 5};
int t = 3;
int res = lower_bound(A, t);
System.out.println(res); // Output: 2
}
}
1. What is the difference between an abstract class and an interface?
- An abstract class can have both abstract and non-abstract methods, while an interface can only have abstract methods.
- A class can only extend one abstract class, but can implement multiple interfaces.
2. What is the difference between a checked and an unchecked exception?
- A checked exception must be handled by the calling method or declared in its throws clause, while an unchecked exception does not have to be handled or declared.
- Checked exceptions are typically used for recoverable errors, while unchecked exceptions are used for unrecoverable errors.
3. What is the difference between a stack and a queue?
- A stack is a Last-In-First-Out (LIFO) data structure, while a queue is a First-In-First-Out (FIFO) data structure.
- Stacks are typically used for backtracking, while queues are used for scheduling.
4. What is the difference between a HashMap and a TreeMap?
- A HashMap is an unordered collection of key-value pairs, while a TreeMap is a sorted collection of key-value pairs.
- HashMaps have constant-time performance for most operations, while TreeMaps have logarithmic-time performance.
5. What is the difference between a String, StringBuilder, and StringBuffer?
- A String is an immutable sequence of characters, while a StringBuilder and StringBuffer are mutable.
- StringBuilder is not thread-safe, while StringBuffer is thread-safe.
- StringBuilder is faster than StringBuffer, but should only be used in single-threaded environments.
Difference between Comparator and Comparable in Java ?
1. Comparable is an interface in Java, while Comparator is an interface that can be implemented by a class.
2. A class that implements Comparable can be sorted using the Arrays.sort() or Collections.sort() method, while a class that implements Comparator can be used to sort any other class that does not implement Comparable .
3. Comparable provides a natural ordering for a class, while Comparator provides a custom ordering that can be defined by the programmer.
4. The compareTo() method is used to compare two objects that implement Comparable , while the compare() method is used to compare two objects using a Comparator .
5. The compareTo() method returns a negative integer, zero, or a positive integer depending on whether the object is less than, equal to, or greater than the specified object, while the compare() method returns a negative integer, zero, or a positive integer depending on whether the first object is less than, equal to, or greater than the second object.
6. Comparable is implemented by the class that needs to be sorted, while Comparator is implemented by the class that performs the sorting.
7. Comparable provides a single sorting sequence, while Comparator can provide multiple sorting sequences.
8. Comparable can be used to sort a list of objects based on a single attribute of the object, while Comparator can be used to sort a list of objects based on multiple attributes of the object.
9. Comparable is used when the natural ordering of a class is known and fixed, while Comparator is used when the ordering of a class needs to be changed at runtime.
10. Comparable is more efficient than Comparator because it does not require an additional object to perform the comparison.
11. Comparable is implemented by the class itself, while Comparator is implemented by a separate class.
12. Comparable uses the compareTo() method, while Comparator uses the compare() method.
13. Comparable is used to sort elements in a natural order, while Comparator is used to sort elements in a custom order.
14. Comparable can be used to sort arrays, while Comparator can be used to sort collections.
15. Comparable can only provide a single sorting sequence, while Comparator can provide multiple sorting sequences.
16. Comparable is used when the natural ordering of a class is known and fixed, while Comparator is used when the ordering of a class needs to be changed at runtime.
17. Comparable is a generic interface, while Comparator is not.
18. Comparable is used for sorting objects of the same class, while Comparator can be used to sort objects of different classes.
19. Comparable is implemented by overriding the compareTo() method, while Comparator is implemented by creating a new class that implements the Comparator interface.
20. Comparable is used to define the default ordering of a class, while Comparator is used to define a custom ordering of a class.
1. ArrayList: An ArrayList is a resizable array implementation of the List interface. It can store null and duplicate values.
2. LinkedList: A LinkedList is a doubly linked list implementation of the List interface. It can store null and duplicate values.
3. HashSet: A HashSet is an implementation of the Set interface that uses a hash table for storage. It can store null values and does not allow duplicate values.
4. LinkedHashSet: A LinkedHashSet is an implementation of the Set interface that maintains the insertion order of elements. It can store null values and does not allow duplicate values.
5. TreeSet: A TreeSet is an implementation of the SortedSet interface that uses a tree structure for storage. It does not allow null values and does not allow duplicate values based on the natural ordering of the elements or a Comparator.
In Java, a marker interface is an interface that has no methods or fields, but is used to indicate certain properties or behaviors of a class that implements the interface. Some of the commonly used marker interfaces in Java are:
1. Serializable: This interface is used to indicate that a class can be serialized, i.e., its objects can be converted into a stream of bytes and stored in a file or sent over a network.
2. Cloneable: This interface is used to indicate that a class can be cloned, i.e., its objects can be duplicated without calling the constructor.
3. RandomAccess: This interface is used to indicate that a list or collection supports random access, i.e., elements can be accessed in constant time using an index.
4. SingleThreadModel: This interface is used to indicate that a servlet can handle only one request at a time, and is used for thread safety in web applications.
5. Remote: This interface is used to indicate that a class can be accessed remotely using Java Remote Method Invocation (RMI).
6. Annotation: This interface is used to define custom annotations that can be used to provide additional information about a class, method, or field.
Note that these interfaces do not provide any methods or functionality, but are used by the Java runtime environment or other libraries to determine certain properties or behaviors of the classes that implement them.
what is hash collisions in Java?
In Java, a hash collision occurs when two different keys have the same hash code. When this happens, the two keys are said to collide. This is a common occurrence in hash table implementations, which rely on hash codes to efficiently store and retrieve objects.
When a hash collision occurs, the hash table must handle the collision by storing both objects in the same bucket. This can lead to performance issues if the number of collisions is high, as the time required to search for a specific key in the bucket increases.
To handle hash collisions in Java, the hash table implementation uses a technique called chaining. In chaining, each bucket in the hash table contains a linked list of objects that have the same hash code. When a key is added to the hash table, it is added to the linked list in the appropriate bucket. When the hash table needs to retrieve an object, it first calculates the hash code of the key and then searches the linked list in the corresponding bucket for the key.
To minimize the occurrence of hash collisions, it is important to choose a good hash function. A good hash function should distribute the keys evenly across the buckets in the hash table, minimizing the number of collisions. In Java, the hashCode() method is used to generate hash codes for objects. It is important to implement this method carefully to ensure that it generates good hash codes that minimize collisions.
In summary, hash collisions can occur in Java when two different keys have the same hash code. To handle collisions, Java uses a technique called chaining, which stores objects with the same hash code in a linked list in the same bucket. To minimize collisions, it is important to choose a good hash function and implement the hashCode() method carefully.
In Java, an error is a serious problem that typically prevents the application from functioning properly and may even cause the application to crash. Errors are usually caused by external factors such as lack of system resources, hardware failures, or network problems. Examples of errors in Java include OutOfMemoryError, StackOverflowError, and VirtualMachineError.
On the other hand, an exception is a problem that occurs within the application itself and can be handled by the application. Exceptions are typically caused by incorrect input, programming errors, or unexpected conditions. Examples of exceptions in Java include NullPointerException, ArrayIndexOutOfBoundsException, and IOException.
In Java, errors and exceptions are both subclasses of the Throwable class. However, errors are unchecked exceptions, which means that they do not need to be explicitly handled or declared in a method's throws clause. Exceptions, on the other hand, are checked exceptions, which means that they must be either caught and handled or declared in a method's throws clause.
It is important to handle exceptions properly in Java to ensure that your application runs smoothly and handles errors gracefully. This can be done using try-catch blocks, which allow you to catch and handle exceptions, or by declaring exceptions in a method's throws clause, which allows you to pass the responsibility of handling the exception to the calling method.
Checked Exception:
A checked exception is a type of exception that must be declared in a method or constructor's throws clause or handled using a try-catch block. Some examples of checked exceptions in Java include:
1. IOException: This exception is thrown when an input or output operation fails, such as when reading or writing to a file.
2. SQLException: This exception is thrown when there is an error in a database operation, such as when executing a query or updating a record.
Unchecked Exception:
An unchecked exception is a type of exception that does not need to be declared in a method or constructor's throws clause and can be handled using a try-catch block. Some examples of unchecked exceptions in Java include:
1. NullPointerException: This exception is thrown when a null reference is used in a method or operation that requires a non-null value.
2. ArrayIndexOutOfBoundsException: This exception is thrown when an attempt is made to access an array element with an index that is out of bounds.
3. IllegalArgumentException: This exception is thrown when an illegal argument is passed to a method or constructor, such as a negative value for a parameter that requires a positive value.
It is important to handle both checked and unchecked exceptions appropriately in Java to ensure that your application runs smoothly and handles errors gracefully.
1. What is a thread?
- A thread is a lightweight process that can run concurrently with other threads within the same program.
2. What is multi-threading?
- Multi-threading is the ability of an operating system or program to manage multiple threads of execution concurrently.
3. What are the advantages of multi-threading?
- Multi-threading can improve performance by allowing multiple tasks to be executed simultaneously.
- Multi-threading can improve responsiveness by allowing the user interface to remain responsive while background tasks are executed.
- Multi-threading can simplify code by breaking complex tasks into smaller, more manageable pieces.
4. What is a race condition?
- A race condition is a situation where the behavior of a program depends on the timing of events, and different outcomes are possible depending on the order in which events occur.
5. What is synchronization?
- Synchronization is the process of controlling access to shared resources in a multi-threaded environment to prevent race conditions and ensure data consistency.
6. What is a deadlock?
- A deadlock is a situation where two or more threads are blocked, each waiting for the other to release a resource, and neither can proceed.
7. What is a thread pool?
- A thread pool is a collection of threads that can be used to execute tasks concurrently, without the overhead of creating and destroying threads for each task.
8. What is the difference between a thread and a process?
- A thread is a lightweight process that can run concurrently with other threads within the same program, while a process is a separate instance of a program that runs independently of other processes.
9. What is the Java synchronized keyword?
- The synchronized keyword is used to create a synchronized block of code, which ensures that only one thread can execute the block at a time, preventing race conditions and ensuring data consistency.
10. What is a thread-safe class?
- A thread-safe class is a class that can be safely used by multiple threads concurrently without causing race conditions or data inconsistency. This is achieved through synchronization or other concurrency control mechanisms.
1. What is a functional interface?
- A functional interface is an interface that contains only one abstract method and can be used as the basis for a lambda expression or method reference.
2. What is the purpose of a functional interface?
- The purpose of a functional interface is to provide a single abstract method that can be implemented by a lambda expression or method reference, allowing for more concise and readable code.
3. What is the @FunctionalInterface annotation?
- The @FunctionalInterface annotation is used to indicate that an interface is intended to be a functional interface. It is not strictly necessary, but can be helpful for documentation and to prevent accidental addition of additional abstract methods.
4. What is the Predicate functional interface?
- The Predicate functional interface represents a function that takes a single argument and returns a boolean value. It is often used for filtering or testing elements in a collection.
5. What is the Consumer functional interface?
- The Consumer functional interface represents a function that takes a single argument and returns no result. It is often used for performing an action on each element in a collection.
6. What is the Function functional interface?
- The Function functional interface represents a function that takes a single argument and returns a result. It is often used for transforming or mapping elements in a collection.
7. What is the Supplier functional interface?
- The Supplier functional interface represents a function that takes no arguments and returns a result. It is often used for lazy initialization or to provide default values.
8. What is the BiFunction functional interface?
- The BiFunction functional interface represents a function that takes two arguments and returns a result. It is often used for combining or merging two values.
9. What is the UnaryOperator functional interface?
- The UnaryOperator functional interface represents a function that takes a single argument of a certain type and returns a result of the same type. It is often used for transforming or modifying an object of a certain type.
10. What is the BinaryOperator functional interface?
- The BinaryOperator functional interface represents a function that takes two arguments of a certain type and returns a result of the same type. It is often used for combining or merging two objects of a certain type.
what are intermediate opeartions in stream api?
filter
: This operation takes a predicate and returns a new stream that contains only the elements that match the predicate.
map
: This operation takes a function and returns a new stream that contains the results of applying the function to each element in the original stream.
flatMap
: This operation takes a function that returns a stream and returns a new stream that contains the flattened elements of the original stream.
sorted
: This operation returns a new stream that contains the elements of the original stream sorted in ascending order.
distinct
: This operation returns a new stream that contains only the distinct elements of the original stream.
limit
: This operation returns a new stream that contains the first n elements of the original stream.
skip
: This operation returns a new stream that skips the first n elements of the original stream and then returns the remaining elements.
forEach
: This operation performs an action for each element in the stream.
reduce
: This operation reduces the elements of the stream to a single value using a binary operator.
collect
: This operation collects the elements of the stream into a collection, such as a List or a Set.
what are Terminal opeartions in stream api?
count
: This operation returns the count of elements in the stream.
anyMatch
: This operation returns true if any element in the stream matches the given predicate.
allMatch
: This operation returns true if all elements in the stream match the given predicate.
noneMatch
: This operation returns true if no element in the stream matches the given predicate.
findFirst
: This operation returns an Optional object containing the first element in the stream that matches the given predicate, or an empty Optional if no such element exists.
findAny
: This operation returns an Optional object containing any element in the stream that matches the given predicate, or an empty Optional if no such element exists.
forEach
: This operation performs an action for each element in the stream.
reduce
: This operation reduces the elements of the stream to a single value using a binary operator.
collect
: This operation collects the elements of the stream into a collection, such as a List or a Set.
min
: This operation returns the minimum element in the stream according to the given comparator.
max
: This operation returns the maximum element in the stream according to the given comparator.
sum
: This operation returns the sum of all elements in the stream.
average
: This operation returns the average of all elements in the stream.
These are just a few of the terminal operations available in the Stream API. There are many more operations that can be used to manipulate and transform streams of data.
1. What are Java 8 streams?
- Java 8 streams are a new feature that provide a way to process collections of data in a functional, declarative style. Streams allow for concise, readable code that is also parallelizable.
2. What is a stream pipeline?
- A stream pipeline is a sequence of stream operations that are combined to process a collection of data. The pipeline consists of a source, zero or more intermediate operations, and a terminal operation.
3. What is the difference between intermediate and terminal operations in a stream pipeline?
- Intermediate operations are operations that transform or filter the data in a stream, but do not produce a final result. Terminal operations are operations that produce a final result, such as a single value or a collection.
4. What is a parallel stream?
- A parallel stream is a stream that is processed concurrently across multiple threads, allowing for improved performance on multi-core processors.
5. What is a reduction operation in a stream?
- A reduction operation is a terminal operation that combines the elements of a stream into a single result. Examples of reduction operations include sum, min, max, and count.
6. What is the difference between a forEach and a forEachOrdered operation in a stream?
- The forEach operation processes the elements of a stream in an unordered manner, while the forEachOrdered operation processes the elements in the order they appear in the stream.
7. What is the difference between a map and a flatMap operation in a stream?
- The map operation transforms the elements of a stream by applying a function to each element, while the flatMap operation transforms the elements by flattening nested collections and applying a function to each element.
8. What is the filter operation in a stream?
- The filter operation returns a new stream that contains only the elements that satisfy a given predicate.
9. What is the sorted operation in a stream?
- The sorted operation returns a new stream that contains the elements of the original stream sorted according to a given comparator.
10. What is the collect operation in a stream?
- The collect operation is a terminal operation that collects the elements of a stream into a collection or other data structure. The collect operation takes a Collector object that specifies how the elements should be collected.
1. What is a thread in Java?
- A thread is a lightweight process that can run concurrently with other threads within the same program.
2. What is a process in Java?
- A process is a separate instance of a program that runs independently of other processes.
3. What is the difference between a thread and a process in Java?
- A thread is a lightweight process that runs within a process, while a process is a standalone entity that runs independently of other processes.
4. What is the Thread class in Java?
- The Thread class is a built-in class in Java that provides the framework for creating and managing threads.
5. What is the Runnable interface in Java?
- The Runnable interface is a built-in interface in Java that provides a way to define the code that will be executed in a new thread.
6. What is the difference between extending the Thread class and implementing the Runnable interface in Java?
- Extending the Thread class creates a new class that is a thread, while implementing the Runnable interface allows any class to be executed in a new thread.
7. What is the sleep() method in Java?
- The sleep() method is a built-in method in Java that causes the current thread to pause for a specified amount of time, allowing other threads to execute.
8. What is the join() method in Java?
- The join() method is a built-in method in Java that waits for a thread to complete before continuing execution of the current thread.
9. What is the start() method in Java?
- The start() method is a built-in method in Java that starts a new thread by calling the run() method of the Thread object.
10. What is the synchronized keyword in Java?
- The synchronized keyword is a built-in keyword in Java that provides a way to control access to shared resources in a multi-threaded environment, preventing race conditions and ensuring data consistency.
1. What is a multi-threaded environment in Java?
- A multi-threaded environment in Java is an environment where multiple threads of execution can run concurrently within the same program.
2. What is the purpose of multi-threading in Java?
- The purpose of multi-threading in Java is to improve performance and responsiveness by allowing multiple tasks to be executed simultaneously, without blocking the user interface or other critical processes.
3. What is a thread pool in Java?
- A thread pool in Java is a collection of pre-initialized threads that can be used to execute tasks concurrently, without the overhead of creating and destroying threads for each task.
4. What is the difference between a thread and a process in Java?
- A thread is a lightweight process that runs within a process, while a process is a standalone entity that runs independently of other processes.
5. What is a race condition in Java?
- A race condition in Java is a situation where the behavior of a program depends on the timing of events, and different outcomes are possible depending on the order in which events occur.
6. What is synchronization in Java?
- Synchronization in Java is the process of controlling access to shared resources in a multi-threaded environment, preventing race conditions and ensuring data consistency.
7. What is the synchronized keyword in Java?
- The synchronized keyword in Java is used to create a synchronized block of code, which ensures that only one thread can execute the block at a time, preventing race conditions and ensuring data consistency.
8. What is a deadlock in Java?
- A deadlock in Java is a situation where two or more threads are blocked, each waiting for the other to release a resource, and neither can proceed.
9. What is the wait() method in Java?
- The wait() method in Java is a built-in method that causes the current thread to wait until another thread notifies it to resume execution.
10. What is the notify() method in Java?
- The notify() method in Java is a built-in method that wakes up a thread that is waiting on a shared resource, allowing it to resume execution.
1. What is garbage collection in Java?
- Garbage collection in Java is the process of automatically freeing memory that is no longer in use by a program, improving memory management and reducing the risk of memory leaks.
2. What are the different types of garbage collection in Java?
- The different types of garbage collection in Java include serial, parallel, CMS (Concurrent Mark Sweep), and G1 (Garbage First).
3. What is serial garbage collection in Java?
- Serial garbage collection in Java is a simple, single-threaded approach to garbage collection that is suitable for small applications with low memory requirements.
4. What is parallel garbage collection in Java?
- Parallel garbage collection in Java is a multi-threaded approach to garbage collection that is suitable for larger applications with higher memory requirements.
5. What is CMS (Concurrent Mark Sweep) garbage collection in Java?
- CMS garbage collection in Java is a concurrent approach to garbage collection that reduces the pause times associated with garbage collection, allowing applications to be more responsive.
6. What is G1 (Garbage First) garbage collection in Java?
- G1 garbage collection in Java is a low-pause, server-style approach to garbage collection that is suitable for large, multi-processor systems with high memory requirements.
7. What is the difference between minor and major garbage collection in Java?
- Minor garbage collection in Java is a process that frees memory in the young generation of objects, while major garbage collection frees memory in the old generation of objects.
8. What is the heap in Java?
- The heap in Java is a region of memory that is used for dynamic memory allocation, including objects created by a program.
9. What is the permanent generation in Java?
- The permanent generation in Java is a region of memory that is used for storing metadata and class definitions, and is separate from the heap.
10. What is the role of the System.gc() method in Java?
- The System.gc() method in Java is a built-in method that suggests to the garbage collector that it should run, but does not guarantee that garbage collection will occur.
1. What is object-oriented programming (OOP) in Java?
- Object-oriented programming in Java is a programming paradigm that focuses on creating objects that encapsulate data and behavior, allowing for modular and reusable code.
2. What are the four basic principles of OOP in Java?
- The four basic principles of OOP in Java are encapsulation, inheritance, polymorphism, and abstraction.
3. What is encapsulation in Java?
- Encapsulation in Java is the process of hiding the implementation details of an object and exposing only the necessary information through a public interface.
4. What is inheritance in Java?
- Inheritance in Java is the process of creating a new class that inherits the properties and methods of an existing class, allowing for code reuse and specialization.
5. What is polymorphism in Java?
- Polymorphism in Java is the ability of an object to take on multiple forms, allowing for flexibility and extensibility in code design.
6. What is abstraction in Java?
- Abstraction in Java is the process of creating a simplified representation of a complex system, allowing for easier understanding and management of the system.
7. What is a class in Java?
- A class in Java is a blueprint for creating objects that define the properties and methods of the object.
8. What is an object in Java?
- An object in Java is an instance of a class that has its own set of properties and methods.
9. What is a constructor in Java?
- A constructor in Java is a special method that is used to create and initialize an object of a class.
10. What is the difference between an abstract class and an interface in Java?
- An abstract class in Java is a class that cannot be instantiated and can contain both abstract and non-abstract methods, while an interface is a collection of abstract methods that define a contract for implementing classes.
1. What is an error in Java?
- An error in Java is a serious problem that occurs at runtime and cannot be handled by the program, such as an out of memory error or a stack overflow error.
2. What is an exception in Java?
- An exception in Java is a problem that occurs at runtime and can be handled by the program, such as a null pointer exception or an arithmetic exception.
3. What is the difference between an error and an exception in Java?
- An error is a serious problem that cannot be handled by the program, while an exception is a problem that can be handled by the program.
4. What is exception handling in Java?
- Exception handling in Java is the process of handling exceptions that occur at runtime, preventing the program from crashing and providing a graceful way to handle unexpected situations.
5. What is the try-catch block in Java?
- The try-catch block in Java is a built-in mechanism for handling exceptions, where code that may throw an exception is placed in a try block, and the exception is caught and handled in a catch block.
6. What is the finally block in Java?
- The finally block in Java is a built-in mechanism for executing code that must be run regardless of whether an exception is thrown or not, such as closing a file or releasing a resource.
7. What is the throw keyword in Java?
- The throw keyword in Java is a built-in keyword that allows a program to throw a custom exception, allowing for more precise and meaningful error handling.
8. What is the throws keyword in Java?
- The throws keyword in Java is a built-in keyword that is used to declare that a method may throw a particular exception, allowing the caller to handle the exception appropriately.
9. What is the difference between checked and unchecked exceptions in Java?
- Checked exceptions are checked at compile time and must be handled by the program, while unchecked exceptions are not checked at compile time and may or may not be handled by the program.
10. What is the role of the Exception class in Java?
- The Exception class in Java is a built-in class that provides a framework for creating and handling exceptions, allowing for more robust and reliable code.
1. What is the final keyword in Java?
- The final keyword in Java is used to declare a variable, method, or class that cannot be modified or overridden once it has been defined.
2. What is the finally keyword in Java?
- The finally keyword in Java is used to define a block of code that will be executed regardless of whether an exception is thrown or not, allowing for cleanup or other tasks to be performed.
3. What is the finalize keyword in Java?
- The finalize keyword in Java is used to define a method that will be called by the garbage collector before an object is destroyed, allowing for cleanup or other tasks to be performed.
4. Can a final variable be modified in Java?
- No, a final variable cannot be modified once it has been defined.
5. Can a final method be overridden in Java?
- No, a final method cannot be overridden by a subclass in Java.
6. What is the purpose of the finally block in Java?
- The purpose of the finally block in Java is to ensure that certain code is executed regardless of whether an exception is thrown or not, allowing for cleanup or other tasks to be performed.
7. What is the difference between final and finally in Java?
- Final is used to declare a variable, method, or class that cannot be modified or overridden, while finally is used to define a block of code that will be executed regardless of whether an exception is thrown or not.
8. What is the purpose of the finalize() method in Java?
- The purpose of the finalize() method in Java is to provide a way for objects to perform cleanup or other tasks before they are destroyed by the garbage collector.
9. When is the finalize() method called in Java?
- The finalize() method is called by the garbage collector before an object is destroyed, allowing for cleanup or other tasks to be performed.
10. What is the difference between final and static in Java?
- Final is used to declare a variable, method, or class that cannot be modified or overridden, while static is used to declare a variable or method that belongs to the class itself, rather than an instance of the class.
1. What is operator precedence in Java?
- Operator precedence in Java is the order in which operators are evaluated in an expression.
2. What is the order of operator precedence in Java?
- The order of operator precedence in Java is as follows: postfix operators (e.g. ++, --), unary operators (e.g. +, -), multiplicative operators (e.g. *, /, %), additive operators (e.g. +, -), shift operators (e.g. <<, >>, >>>), relational operators (e.g. <, >, <=, >=), equality operators (e.g. ==, !=), bitwise and logical operators (e.g. &, |, ^, &&, ||), ternary operator (e.g. ? :), and assignment operators (e.g. =, +=, -=).
3. What is the purpose of operator precedence in Java?
- The purpose of operator precedence in Java is to ensure that expressions are evaluated in a consistent and predictable manner, according to the rules of the language.
4. What is the associativity of operators in Java?
- The associativity of operators in Java determines the order in which operators of the same precedence are evaluated. For example, the associativity of the addition operator (+) is left-to-right, meaning that expressions are evaluated from left to right.
5. What is the difference between postfix and prefix operators in Java?
- Postfix operators (e.g. ++, --) in Java are applied after the operand is evaluated, while prefix operators (e.g. ++, --) are applied before the operand is evaluated.
6. What is the difference between unary and binary operators in Java?
- Unary operators (e.g. +, -) in Java operate on a single operand, while binary operators (e.g. +, -) operate on two operands.
7. What is the purpose of the ternary operator in Java?
- The purpose of the ternary operator (e.g. ? :) in Java is to provide a shorthand way of writing an if-else statement, allowing for more concise and readable code.
8. What is the purpose of the shift operators in Java?
- The purpose of the shift operators (e.g. <<, >>, >>>) in Java is to shift the bits of a number to the left or right, allowing for efficient multiplication or division by powers of two.
9. What is the purpose of the bitwise and logical operators in Java?
- The purpose of the bitwise and logical operators (e.g. &, |, ^, &&, ||) in Java is to perform logical and bitwise operations on operands, allowing for more complex and flexible expressions.
10. What is the difference between the equality operator (==) and the assignment operator (=) in Java?
- The equality operator (==) in Java is used to compare two values for equality, while the assignment operator (=) is used to assign a value to a variable.
1. What is polymorphism in Java?
- Polymorphism in Java is the ability of an object to take on multiple forms, allowing for flexibility and extensibility in code design.
2. What is compile-time polymorphism in Java?
- Compile-time polymorphism in Java is the process of selecting the appropriate method or function to be called at compile time, based on the number and types of arguments passed to the method or function.
3. What is run-time polymorphism in Java?
- Run-time polymorphism in Java is the process of selecting the appropriate method or function to be called at run time, based on the type of the object that the method or function is called on.
4. What is method overloading in Java?
- Method overloading in Java is a form of compile-time polymorphism, where multiple methods with the same name but different parameters are defined in a class.
5. What is method overriding in Java?
- Method overriding in Java is a form of run-time polymorphism, where a subclass provides its own implementation of a method that is already defined in its superclass.
6. Can method overloading and method overriding be used together in Java?
- Yes, method overloading and method overriding can be used together in Java, allowing for more flexible and extensible code.
7. What is the difference between compile-time polymorphism and run-time polymorphism in Java?
- Compile-time polymorphism is resolved at compile time based on the number and types of arguments passed to a method or function, while run-time polymorphism is resolved at run time based on the type of the object that the method or function is called on.
8. What is an example of method overloading in Java?
- An example of method overloading in Java is defining two methods with the same name but different parameters, such as a calculateArea() method that can take either the length and width of a rectangle or the radius of a circle as arguments.
9. What is an example of method overriding in Java?
- An example of method overriding in Java is defining a toString() method in a subclass that provides a custom string representation of the object, instead of the default implementation in the Object class.
10. What is the benefit of using polymorphism in Java?
- The benefit of using polymorphism in Java is that it allows for more flexible and extensible code, reducing the amount of duplicate code and making it easier to add new functionality to a program.
1. What is a collection in Java?
- A collection in Java is a group of related objects that can be manipulated and stored together.
2. What are the main interfaces of the Java Collections Framework?
- The main interfaces of the Java Collections Framework are List, Set, Queue, and Map.
3. What is the difference between a List and a Set in Java?
- A List in Java is an ordered collection of objects that can contain duplicates, while a Set in Java is an unordered collection of unique objects.
4. What is the difference between a Queue and a Stack in Java?
- A Queue in Java is a collection of objects that are stored in a first-in, first-out (FIFO) order, while a Stack in Java is a collection of objects that are stored in a last-in, first-out (LIFO) order.
5. What is the purpose of the Map interface in Java?
- The purpose of the Map interface in Java is to store key-value pairs, allowing for efficient lookup and retrieval of values based on their corresponding keys.
6. What is the difference between a HashMap and a TreeMap in Java?
- A HashMap in Java is an unordered collection of key-value pairs that uses a hash function to store and retrieve values, while a TreeMap in Java is an ordered collection of key-value pairs that is sorted based on the keys.
7. What is the purpose of the Collection interface in Java?
- The purpose of the Collection interface in Java is to provide a common set of methods for manipulating and accessing collections, such as adding, removing, and iterating over elements.
8. What is the difference between an ArrayList and a LinkedList in Java?
- An ArrayList in Java is a resizable array that provides fast access to elements by index, while a LinkedList in Java is a linked list that provides fast insertion and removal of elements at both ends of the list.
9. What is the purpose of the Iterator interface in Java?
- The purpose of the Iterator interface in Java is to provide a way to iterate over the elements of a collection, allowing for efficient and flexible traversal of the collection.
10. What is the difference between a synchronized and an unsynchronized collection in Java?
- A synchronized collection in Java is thread-safe, meaning that it can be accessed by multiple threads without causing race conditions or other synchronization issues, while an unsynchronized collection in Java is not thread-safe and can cause issues when accessed by multiple threads simultaneously.
1. What is the purpose of Comparator and Comparable in Java?
- Comparator and Comparable in Java are used to define custom sorting orders for objects in a collection.
2. What is the difference between Comparator and Comparable in Java?
- Comparator in Java is an external comparison mechanism that can be used to compare two objects of a class, while Comparable in Java is an internal comparison mechanism that is implemented by a class to define its own natural ordering.
3. What is the syntax for using Comparator in Java?
- To use Comparator in Java, a separate class that implements the Comparator interface is created, and the compare() method is defined to specify the comparison logic. The Comparator object can then be passed to sorting methods such as Collections.sort() or Arrays.sort().
4. What is the syntax for using Comparable in Java?
- To use Comparable in Java, the class that needs to be sorted implements the Comparable interface, and the compareTo() method is defined to specify the comparison logic. The sorting method can then use the natural ordering defined by the class.
5. What is an example of using Comparator in Java?
- An example of using Comparator in Java is sorting a list of Person objects by their age, where the Person class does not implement Comparable. A separate AgeComparator class can be created that implements Comparator<Person>, and the compare() method can be defined to compare the ages of two Person objects.
6. What is an example of using Comparable in Java?
- An example of using Comparable in Java is sorting a list of String objects alphabetically, where the String class implements Comparable<String>. The compareTo() method is already defined in the String class to compare two strings lexicographically.
7. Can Comparator and Comparable be used together in Java?
- Yes, Comparator and Comparable can be used together in Java, allowing for more flexible and extensible sorting logic.
8. What is the benefit of using Comparator and Comparable in Java?
- The benefit of using Comparator and Comparable in Java is that they allow for custom sorting logic to be defined for objects in a collection, making it easier to sort and manipulate data in a meaningful way.
9. What is the difference between natural ordering and external ordering in Java?
- Natural ordering in Java is the default ordering behavior defined by a class, while external ordering is a custom ordering behavior defined by a separate class or mechanism such as Comparator.
10. What is the purpose of the compare() method in Java?
- The purpose of the compare() method in Java is to compare two objects of a class according to a specific ordering logic, allowing for sorting and manipulation of collections.
1. What is fail-fast in Java?
- Fail-fast in Java is a mechanism used to detect and handle errors in a collection, where any modification made to the collection during iteration will cause an immediate exception to be thrown.
2. What is fail-safe in Java?
- Fail-safe in Java is a mechanism used to prevent errors in a collection, where any modification made to the collection during iteration will not affect the iteration and will be handled safely.
3. What is the difference between fail-fast and fail-safe in Java?
- Fail-fast in Java is more efficient but less safe, as it can detect errors quickly but may cause data loss or corruption, while fail-safe in Java is less efficient but more safe, as it can prevent errors but may require more resources and time.
4. What is an example of fail-fast in Java?
- An example of fail-fast in Java is using an iterator to iterate over a list, and then modifying the list by adding or removing elements during iteration. This will cause a ConcurrentModificationException to be thrown immediately, indicating that the collection has been modified during iteration.
5. What is an example of fail-safe in Java?
- An example of fail-safe in Java is using a copy of a collection to iterate over its elements, and then modifying the original collection during iteration. This will not affect the iteration of the copy, as it is a separate object that is not affected by changes to the original collection.
6. What is the purpose of fail-fast and fail-safe in Java?
- The purpose of fail-fast and fail-safe in Java is to provide mechanisms for handling errors and preventing data loss or corruption in collections, ensuring that code is reliable and safe to use.
7. What is the benefit of using fail-safe in Java?
- The benefit of using fail-safe in Java is that it provides a more robust and reliable mechanism for handling errors in collections, reducing the risk of data loss or corruption and improving the overall quality of the code.
8. What is the downside of using fail-fast in Java?
- The downside of using fail-fast in Java is that it can be less safe and more prone to errors, especially in complex or multi-threaded environments, where modifications to collections may occur frequently and unpredictably.
9. What is the downside of using fail-safe in Java?
- The downside of using fail-safe in Java is that it can be less efficient and more resource-intensive, especially for large or complex collections, where copying or duplicating data may take a significant amount of time and memory.
10. Can fail-fast and fail-safe be used together in Java?
- Yes, fail-fast and fail-safe can be used together in Java, allowing for more flexible and extensible error handling mechanisms in collections.
Stream
: This is the main class in the Stream API, which provides a way to create and manipulate streams of data.
Collectors
: This class provides several methods for collecting streams into collections, such as Lists, Sets, and Maps.
Optional
: This class is used to represent optional values, which may or may not be present.
Predicate
: This functional interface is used to define predicates, which are used to test whether a given element meets certain criteria.
Function
: This functional interface is used to define functions, which are used to transform elements in a stream.
Consumer
: This functional interface is used to define consumers, which are used to perform an action on each element in a stream.
Comparator
: This functional interface is used to define comparators, which are used to compare elements in a stream.
IntStream
: This class is used to create streams of integers.
DoubleStream
: This class is used to create streams of doubles.
LongStream
: This class is used to create streams of longs.
Stream.of
: This method is used to create a stream from an array or a collection.
Stream.iterate
: This method is used to create an infinite stream of elements that are generated by applying a function to a previous element.
Stream.generate
: This method is used to create a stream of elements that are generated by a supplier function.
Stream.concat
: This method is used to concatenate two or more streams into a single stream.
Stream.filter
: This method is used to filter elements in a stream based on a given predicate.
Stream.map
: This method is used to transform elements in a stream using a given function.
Stream.flatMap
: This method is used to flatten elements in a stream that are themselves streams.
Stream.sorted
: This method is used to sort elements in a stream according to a given comparator.
Stream.distinct
: This method is used to remove duplicate elements from a stream.
Stream.limit
: This method is used to limit the number of elements in a stream.
Stream.skip
: This method is used to skip a certain number of elements in a stream.
Stream.forEach
: This method is used to perform an action on each element in a stream.
Stream.reduce
: This method is used to reduce elements in a stream to a single value using a given binary operator.
Stream.collect
: This method is used to collect elements in a stream into a collection.
Stream.min
: This method is used to find the minimum element in a stream according to a given comparator.
Stream.max
: This method is used to find the maximum element in a stream according to a given comparator.
Stream.sum
: This method is used to find the sum of all elements in a stream.
Stream.average
: This method is used to find the average of all elements in a stream.
the key features of Java 8:
Lambda expressions: Java 8 introduced lambda expressions, which allow you to write function-like code in a more concise and readable way.
Streams: Java 8 introduced streams, which provide a way to manipulate collections of data in a functional way. Streams can be used to filter, map, sort, and perform other operations on data.
Optional: Java 8 introduced Optional, which provides a way to handle null values in a more elegant way. Optional can be used to avoid null pointer exceptions and to provide a more expressive way to handle missing values.
Default methods: Java 8 introduced default methods, which allow you to add new methods to an interface without breaking existing code.
Static methods: Java 8 introduced static methods, which allow you to define methods that can be called without creating an instance of the class.
Date and time API: Java 8 introduced a new date and time API, which provides a more modern and flexible way to work with dates and times.
Concurrent API: Java 8 introduced a new concurrent API, which provides a set of classes and interfaces for concurrent programming.
Reflection API: Java 8 introduced a new reflection API, which provides a way to inspect and manipulate classes and objects at runtime.
Try-with-resources: Java 8 introduced try-with-resources, which allows you to automatically close resources when they are no longer needed.
CompletableFuture: Java 8 introduced CompletableFuture, which provides a way to handle asynchronous operations in a more efficient and expressive way.
These are just a few of the key features of Java 8. Java 8 also introduced many other features, such as functional interfaces, method references, and new collection interfaces.
Explain the OOPs concepts.
The following are the various OOPS Concepts:
Abstraction: Representing essential features without the need to give out background details. The technique is used for creating a new suitable data type for some specific application.
Aggregation: All objects have their separate lifecycle, but ownership is present. No child object can belong to some other object except for the parent object.
Association: The relationship between two objects, where each object has its separate lifecycle. There is no ownership.
Class: A group of similar entities.
Composition: Also called the death relationship, it is a specialized form of aggregation. Child objects don't have a lifecycle. As such, they automatically get deleted if the associated parent object is deleted.
Encapsulation: Refers to the wrapping up of data and code into a single entity. This allows the variables of a class to be only accessible by the parent class and no other classes.
Inheritance: When an object acquires the properties of some other object, it is called inheritance. It results in the formation of a parent-child relationship amongst classes involved. This offers a robust and natural mechanism of organizing and structuring software.
Object: Denotes an instance of a class. Any class can have multiple instances. An object contains the data as well as the method that will operate on the data
Polymorphism: Refers to the ability of a method, object, or variable to assume several forms.
what is CompletableFuture?
CompletableFuture is a class introduced in Java 8 that represents a future value that may not be available yet
It provides a way to handle asynchronous operations in a more efficient and expressive way
A CompletableFuture can be created using the CompletableFuture
supplyAsync() method, which takes a supplier function that returns a value
The supplyAsync() method returns a CompletableFuture that can be used to retrieve the result of the supplier function at a later time
CompletableFutures can be used to chain multiple asynchronous operations together
For example, you can create a CompletableFuture that retrieves data from a database, and then use the result to retrieve more data from an external API
The thenApply() method can be used to apply a function to the result of a CompletableFuture, and the thenCompose() method can be used to chain two CompletableFuture operations together
CompletableFutures can also be used to handle errors and exceptions
The exceptionally() method can be used to handle exceptions that occur during the execution of a CompletableFuture, and the completeExceptionally() method can be used to mark a CompletableFuture as completed exceptionally
CompletableFutures can be used to handle timeouts
The orTimeout() method can be used to set a timeout for a CompletableFuture, and the completeAfter() method can be used to mark a CompletableFuture as completed after a certain amount of time
CompletableFutures can be used in a variety of contexts, such as in web applications, where multiple asynchronous operations need to be performed in parallel or in sequence
Overall, CompletableFuture provides a powerful and flexible way to handle asynchronous operations in Java 8
It simplifies the process of handling asynchronous operations by providing a simple and intuitive API for chaining operations together and handling errors and exceptions
To CompletableFuture in a multi-threaded environment, you can use the CompletableFuture
supplyAsync() method to create a CompletableFuture that runs in a separate thread
The supplyAsync() method takes a supplier function that returns a value, and returns a CompletableFuture that can be used to retrieve the result of the supplier function at a later time
Here's an example of how to use CompletableFuture
supplyAsync() in a multi-threaded environment:
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
// Perform some long-running operation here
return "Hello, world!";
});
// Do other work in the main thread
System.out.println("Hello, world!");
// Retrieve the result of the CompletableFuture in the main thread
String result = future.get();
System.out.println(result);
In this example, the supplyAsync() method is used to create a CompletableFuture that runs the long-running operation in a separate thread
The get() method is then used to retrieve the result of the CompletableFuture in the main thread
You can also use the CompletableFuture
thenApply() method to apply a function to the result of a CompletableFuture, and the CompletableFuture
thenCompose() method to chain two CompletableFuture operations together
Here's an example of how to use CompletableFuture
thenApply() and CompletableFuture
thenCompose() in a multi-threaded environment:
CompletableFuture<String> future1 = CompletableFuture.supplyAsync(() -> {
// Perform some long-running operation here
return "Hello, ";
});
CompletableFuture<String> future2 = future1.thenApply(s -> s + "world!");
String result = future2.get();
System.out.println(result);
In this example, the thenApply() method is used to apply a function to the result of the first CompletableFuture, and the thenCompose() method is used to chain the two CompletableFuture operations together
The get() method is then used to retrieve the result of the final CompletableFuture
Overall, using CompletableFuture
supplyAsync() and CompletableFuture
thenApply() and CompletableFuture
thenCompose() in a multi-threaded environment can help you to handle asynchronous operations more efficiently and expressively
a thread has a life cycle that consists of five states:
New: When a new thread is created, it is in the New state. It is not yet scheduled to run, but it is ready to be started.
Runnable: When a thread is started, it is in the Runnable state. It is scheduled to run, but it may not be currently executing.
Running: When a thread is executing, it is in the Running state. It is currently using CPU resources to execute the code that it is running.
Blocked: When a thread is blocked, it is in the Blocked state. It is waiting for some external event, such as a lock or a I/O operation, to complete before it can continue executing.
Terminated: When a thread has finished executing, it is in the Terminated state. It has completed its execution and has been removed from the system.
The life cycle of a thread can be affected by various factors, such as thread creation, thread scheduling, thread synchronization, and thread interruption.
Thread creation involves creating a new thread object and initializing its state and stack. Thread scheduling involves selecting a thread to run next based on its priority, time slice, and other scheduling criteria. Thread synchronization involves coordinating the access to shared resources by multiple threads to prevent race conditions and ensure thread safety. Thread interruption involves interrupting a thread to stop it from executing and allowing it to perform cleanup operations.
In general, it is important to manage the life cycle of threads carefully to prevent memory leaks, deadlocks, and other concurrency issues. This can be achieved by using thread pools, properly synchronizing threads, and handling exceptions and errors in threads.
Why do we use the yield() method?
The yield() method belongs to the thread class. It transfers the currently running thread to a runnable state and also allows the other threads to execute. In other words, it gives equal priority threads a chance to run. Because yield() is a static method, it does not release any lock.
The thread lifecycle has the following states and follows the following order:
New: In the very first state of the thread lifecycle, the thread instance is created, and the start() method is yet to be invoked. The thread is considered alive now.
Runnable: After invoking the start() method, but before invoking the run() method, a thread is in the runnable state. A thread can also return to the runnable state from waiting or sleeping.
Running: The thread enters the running state after the run() method is invoked. This is when the thread begins execution.
Non-Runnable: Although the thread is alive, it is not able to run. Typically, it returns to the runnable state after some time.
Terminated: The thread enters the terminated state once the run() method completes its execution. It is not alive now.
What are the various types of garbage collectors in Java?
The Java programming language has four types of garbage collectors:
Serial Garbage Collector: Using only a single thread for garbage collection, the serial garbage collector works by holding all the application threads. It is designed especially for single-threaded environments. Because serial garbage collector freezes all application threads while performing garbage collection, it is most suitable for command-line programs only. For using the serial garbage collector, one needs to turn on the -XX:+UseSerialGC JVM argument.
Parallel Garbage Collector: Also known as the throughput collector, the parallel garbage collector is the default garbage collector of the JVM. It uses multiple threads for garbage collection, and like a serial garbage collector freezes all application threads during garbage collection.
CMS Garbage Collector: Short for Concurrent Mark Sweep, CMS garbage collector uses multiple threads for scanning the heap memory for marking instances for eviction, followed by sweeping the marked instances. There are only two scenarios when the CMS garbage collector holds all the application threads:
When marking the referenced objects in the tenured generation space.
If there is a change in the heap memory while performing the garbage collection, CMS garbage collector ensures better application throughput over parallel garbage collectors by using more CPU resources. For using the CMS garbage collector, the XX:+USeParNewGC JVM argument needs to be turned on.
G1 Garbage Collector: Used for large heap memory areas, G1 garbage collector works by separating the heap memory into multiple regions and then executing garbage collection in them in parallel. Unlike the CMS garbage collector that compacts the memory on STW (Stop The World) situations, G1 garbage collector compacts the free heap space right after reclaiming the memory. Also, the G1 garbage collector prioritizes the region with the most garbage. Turning on the –XX:+UseG1GC JVM argument is required for using the G1 garbage collector.
What is the difference between execute(), executeQuery(), and executeUpdate()?
execute(): Used for executing an SQL query. It returns TRUE if the result is a ResultSet, like running Select queries, and FALSE if the result is not a ResultSet, such as running an Insert or an Update query.
executeQuery(): Used for executing Select queries. It returns the ResultSet, which is not null, even if no records are matching the query. The executeQuery() method must be used when executing select queries so that it throws the java.sql.SQLException with the 'executeQuery method cannot be used for update' message when someone tries to execute an Insert or Update statement.
executeUpdate(): Used for executing Delete/Insert/Update statements or DDL statements that return nothing. The output varies depending on whether the statements are Data Manipulation Language (DML) statements or Data Definition Language (DDL) statements. The output is an integer and equals the total row count for the former case, and 0 for the latter case.
Note: The execute() method needs to be used only in a scenario when there is no certainty about the type of statement. In all other cases, either use executeQuery() or executeUpdate() method.
What purpose does the Volatile variable serve?
The value stored in a volatile variable is not read from the thread's cache memory but from the main memory. Volatile variables are primarily used during synchronization.
Please compare serialization and deserialization.
Serialization is the process by which Java objects are converted into the byte stream.
Deserialization is the exact opposite process of serialization where Java objects are retrieved from the byte stream.
A Java object is serialized by writing it to an ObjectOutputStream and deserialized by reading it from an ObjectInputStream.
What is OutOfMemoryError?
Typically, the OutOfMemoryError exception is thrown when the JVM is not able to allocate an object due to running out of memory. In such a situation, no memory could be reclaimed by the garbage collector.
There can be several reasons that result in the OutOfMemoryError exception, of which the most notable ones are:
Holding objects for too long
Trying to process too much data at the same time
Using a third-party library that caches strings
Using an application server that doesn't perform a memory cleanup post the deployment
When a native allocation can't be satisfied
What is an association?
Association is a relationship where all object have their own lifecycle and there is no owner. Let’s take the example of Teacher and Student. Multiple students can associate with a single teacher and a single student can associate with multiple teachers but there is no ownership between the objects and both have their own lifecycle. These relationships can be one to one, one to many, many to one and many to many.
Q13. What do you mean by aggregation?
An aggregation is a specialized form of Association where all object has their own lifecycle but there is ownership and child object can not belong to another parent object. Let’s take an example of Department and teacher. A single teacher can not belong to multiple departments, but if we delete the department teacher object will not destroy.
Q14. What is composition in Java?
Composition is again a specialized form of Aggregation and we can call this as a “death” relationship. It is a strong type of Aggregation. Child object does not have their lifecycle and if parent object deletes all child object will also be deleted. Let’s take again an example of a relationship between House and rooms. House can contain multiple rooms there is no independent life of room and any room can not belongs to two different houses if we delete the house room will automatically delete.
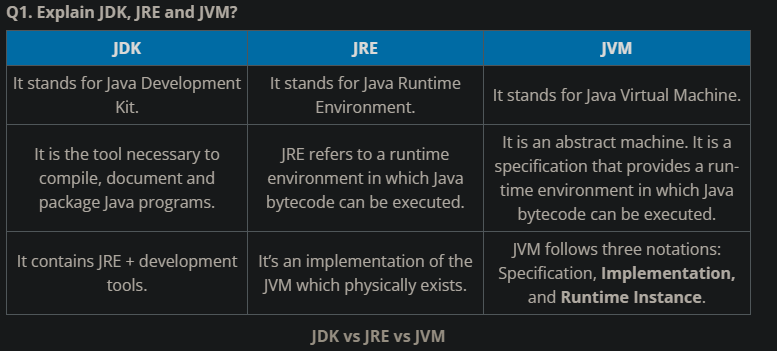
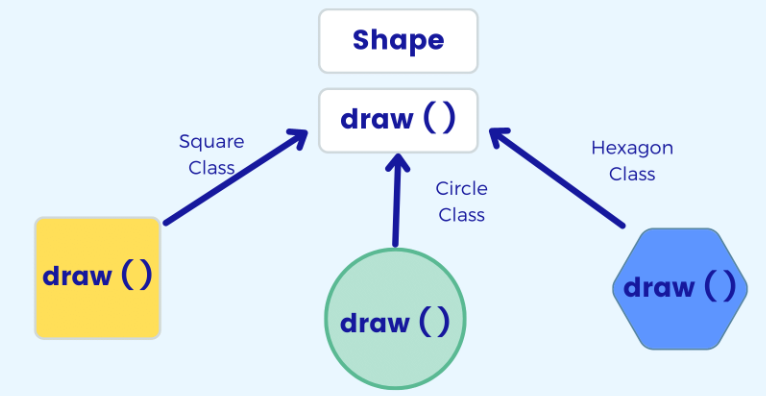
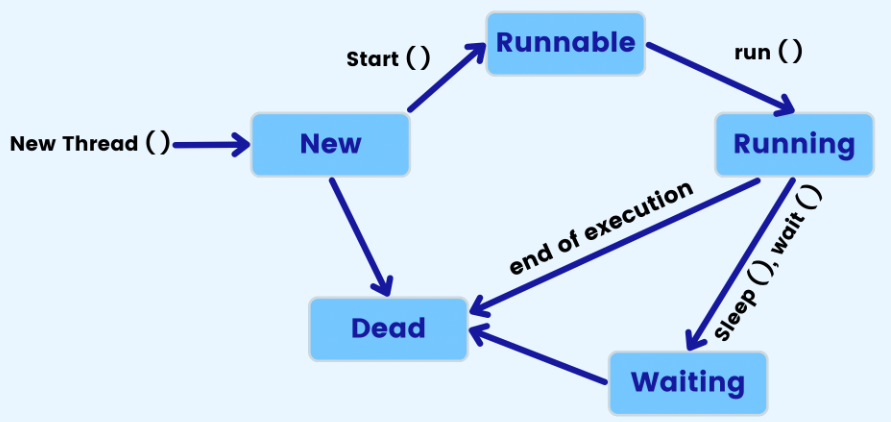
Object
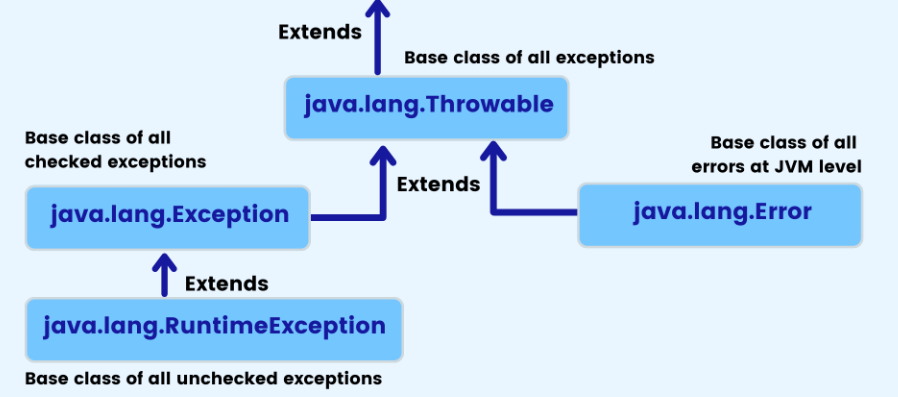
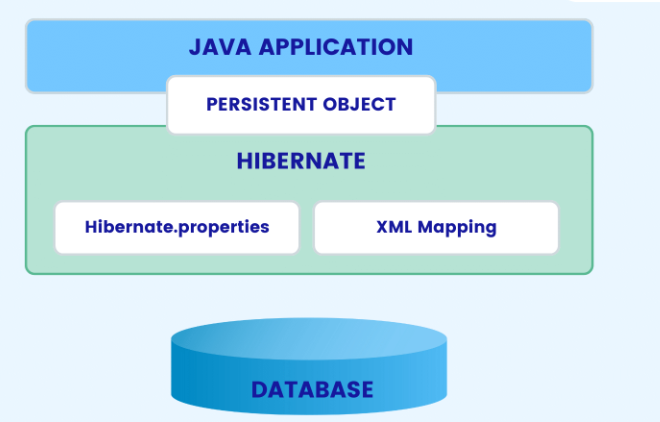
ACID properties
ACID stands for Atomicity, Consistency, Isolation, and Durability. These are the four properties that guarantee the reliability and consistency of database transactions. Here's a brief explanation of each property:
Atomicity: Atomicity ensures that a transaction is treated as a single, indivisible unit of work. This means that either all the operations in the transaction are completed successfully or none of them are completed at all.
Consistency: Consistency ensures that a transaction brings the database from one valid state to another. This means that all the data written to the database is valid according to the defined rules and constraints.
Isolation: Isolation ensures that a transaction does not interfere with other transactions. This means that the changes made by one transaction are isolated from the changes made by other transactions.
Durability: Durability ensures that once a transaction is committed, its changes are permanent and will survive any subsequent failures. This means that the changes made by a transaction are stored in a persistent storage medium, such as a hard disk.
By ensuring that a transaction satisfies the ACID properties, database transactions can provide a high level of reliability and consistency. This helps to ensure that the data stored in the database is accurate and up-to-date, and that transactions are processed in a consistent and reliable manner.
SAGA
Segregated Access of Global Atomicity�
The Saga design pattern is a way to manage data consistency across microservices in distributed transaction scenarios.
Saga is a sequence of transactions that updates each service and publishes a message or event to trigger the next transaction step.
Transaction should be ACID: Atomic Consistent Isolated Durable
Atomicity- each statement in a transaction (to read, write, update or delete data) is treated as a single unit. Either the entire statement is executed, or none of it is executed. This property prevents data loss and corruption from occurring if, for example, if your streaming data source fails mid-stream.��Consistency - ensures that transactions only make changes to tables in predefined, predictable ways. Transactional consistency ensures that corruption or errors in your data do not create unintended consequences for the integrity of your table.
Isolation - when multiple users are reading and writing from the same table all at once, isolation of their transactions ensures that the concurrent transactions don’t interfere with or affect one another. Each request can occur as though they were occurring one by one, even though they're actually occurring simultaneously.
Durability - ensures that changes to your data made by successfully executed transactions will be saved, even in the event of system failure.
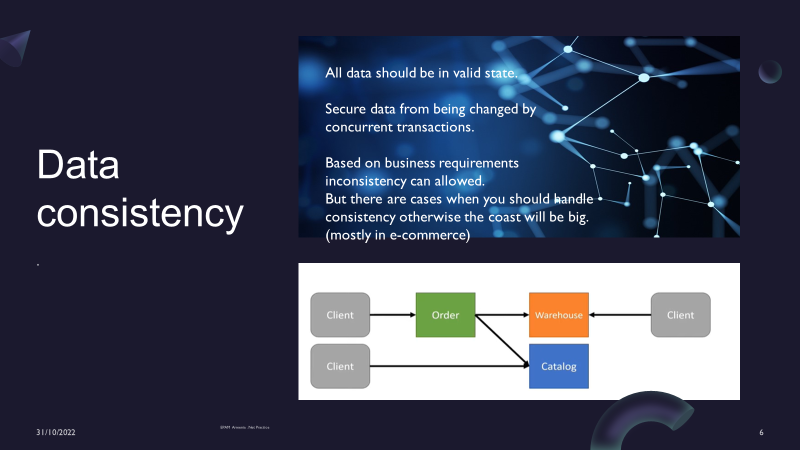
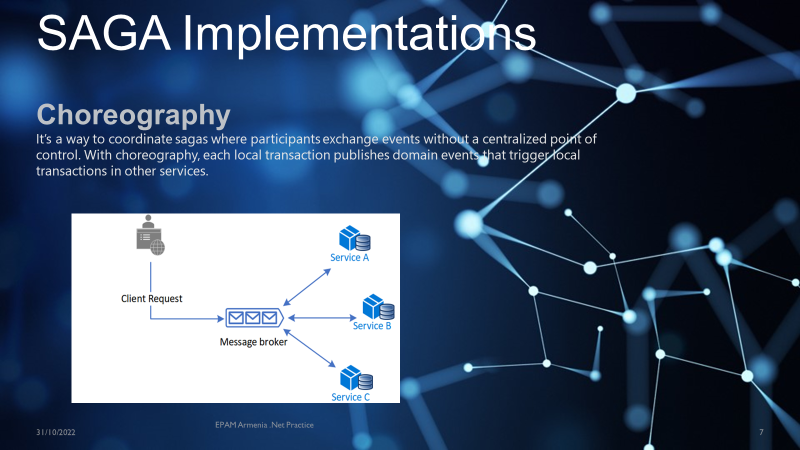
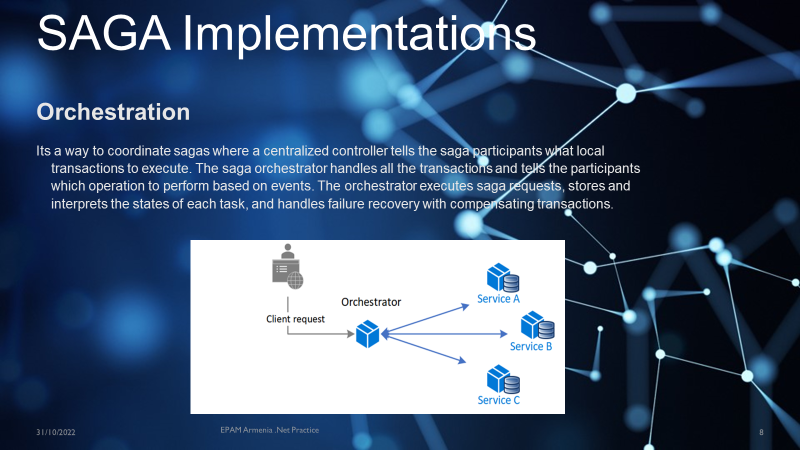

spring boot framework
Normalization is the process of organizing data in a database to eliminate redundancy and dependency, resulting in a more efficient and manageable database. There are various forms of normalization, each with its own requirements and limitations. Here are the various forms of normalization with examples for each with output results:
- First Normal Form (1NF) To achieve 1NF, each column in a table must have atomic values, meaning that each column must contain a single value, not a list of values. Here's an example of a table that violates 1NF:
orders table
order_id | product_ids
1 | 1, 2, 3
2 | 4, 5
To convert this table to 1NF, we can create a new table "order_products" that contains each product ID separately, linked to its parent order ID:
orders table
order_id
1
2
order_products table
order_id | product_id
1 | 1
1 | 2
1 | 3
2 | 4
2 | 5
- Second Normal Form (2NF) To achieve 2NF, each non-key column in a table must be dependent on the entire primary key, not just part of it. Here's an example of a table that violates 2NF:
orders table
order_id | customer_id | product_id | product_name | price
1 | 1 | 1 | iPhone | 1000
2 | 1 | 2 | iPad | 800
3 | 2 | 1 | iPhone | 1000
4 | 2 | 3 | MacBook | 1500
To convert this table to 2NF, we can create two new tables "products" and "customers":
orders table
order_id | customer_id | product_id
1 | 1 | 1
2 | 1 | 2
3 | 2 | 1
4 | 2 | 3
products table
product_id | product_name | price
1 | iPhone | 1000
2 | iPad | 800
3 | MacBook | 1500
customers table
customer_id
1
2
- Third Normal Form (3NF) To achieve 3NF, each non-key column in a table must be dependent only on the primary key, not on any other non-key columns. Here's an example of a table that violates 3NF:
orders table
order_id | customer_id | customer_name | customer_email | product_id | product_name | price
1 | 1 | John | john@abc.com | 1 | iPhone | 1000
2 | 1 | John | john@abc.com | 2 | iPad | 800
3 | 2 | Jane | jane@abc.com | 1 | iPhone | 1000
4 | 2 | Jane | jane@abc.com | 3 | MacBook | 1500
To convert this table to 3NF, we can create a new table "customers" and remove the redundant customer information from the "orders" table:
orders table (after normalization)
order_id | customer_id | product_id
1 | 1 | 1
2 | 1 | 2
3 | 2 | 1
4 | 2 | 3
products table (same as before)
customers table
customer_id | customer_name | customer_email
1 | John | john@abc.com
2 | Jane | jane@abc.com
These are some examples of how to convert an unnormalized table to 1NF, 2NF, and 3NF by separating data into smaller, related tables. The output results for the normalized tables will depend on the specific data in the original table.
In Spring Framework, there are two ways to inject dependencies into a class: constructor autowiring and setter autowiring. Here are some guidelines on when to use each approach:
Constructor autowiring: Constructor autowiring is a form of constructor injection, where the dependencies are passed to the class through its constructor. This approach is useful when you want to ensure that all the required dependencies are available when the object is created. Constructor autowiring is also useful when you want to use different dependencies for different instances of the same class.
Setter autowiring: Setter autowiring is a form of setter injection, where the dependencies are passed to the class through setter methods. This approach is useful when you want to inject optional dependencies or when you want to change the dependencies at runtime. Setter autowiring is also useful when you want to use the same dependencies for multiple instances of the same class.
Here are some situations where you might want to use constructor autowiring:
When you want to ensure that all the required dependencies are available when the object is created.
When you want to use different dependencies for different instances of the same class.
When you want to use a default constructor and only provide optional dependencies through setter methods.
Here are some situations where you might want to use setter autowiring:
When you want to inject optional dependencies or when you want to change the dependencies at runtime.
When you want to use the same dependencies for multiple instances of the same class.
When you want to provide a default implementation for the dependencies and only override them when necessary.
In general, constructor autowiring is recommended when you want to ensure that all the required dependencies are available when the object is created, and setter autowiring is recommended when you want to inject optional dependencies or when you want to change the dependencies at runtime. However, there may be situations where you need to use both approaches together, depending on your specific requirements.
In Spring Framework, @Component, @Service, @Controller, and @Repository are all annotations used to define different types of components in a Spring application
Here are some of the key differences between these annotations:Purpose: The @Component annotation is a generic annotation that can be used to define any type of Spring-managed component
The @Service, @Controller, and @Repository annotations are specializations of the @Component annotation that are used to define specific types of components
Semantics: The @Service annotation is used to define a service layer component that performs business logic
The @Controller annotation is used to define a controller component that handles HTTP requests and responses
The @Repository annotation is used to define a repository component that provides data access services
Exception translation: The @Repository annotation provides additional functionality for exception translation, which is the process of translating database-specific exceptions into Spring's DataAccessException hierarchy
This functionality is not provided by the @Service or @Controller annotations
Auto-detection: Spring provides auto-detection for @Service, @Controller, and @Repository components, which means that Spring will automatically detect and create instances of these components based on their annotations
The @Component annotation requires manual registration, which means that you need to explicitly define each component in your application
Overall, the @Service, @Controller, and @Repository annotations are used to define specific types of components in a Spring application, while the @Component annotation is a generic annotation that can be used to define any type of component
The @Repository annotation provides additional functionality for exception translation, while the @Service and @Controller annotations do not
what is bean life cycle?
In the context of Java programming, a bean life cycle refers to the sequence of events that occur when a bean is created, initialized, used, and destroyed
The life cycle of a bean can be managed using various lifecycle callbacks, which are methods that are called at specific points in the life cycle of a bean
The following are the common lifecycle callbacks in Spring Framework:InitializingBean: This interface defines a single method, afterPropertiesSet(), which is called after all properties of a bean have been set
DisposableBean: This interface defines a single method, destroy(), which is called just before a bean is destroyed
InitializingBean and DisposableBean: This interface defines both afterPropertiesSet() and destroy() methods, which are called together to initialize and destroy a bean
BeanPostProcessor: This interface defines methods that are called before and after a bean is created, initialized, and destroyed
The life cycle of a bean can be affected by various factors, such as bean configuration, bean dependencies, and bean lifecycle management
Bean configuration involves defining the properties, constructor arguments, and other configuration metadata for a bean
Bean dependencies involve specifying the dependencies that a bean requires to function properly
Bean lifecycle management involves managing the lifecycle of beans, such as initializing, destroying, and managing their dependencies
In general, it is important to manage the life cycle of beans carefully to ensure that they are initialized and destroyed properly, and to ensure that they are properly configured and depend on each other correctly
This can be achieved by using the lifecycle callbacks provided by Spring Framework, and by properly organizing the dependencies between beans
In software development, I often hear the terms "Inversion of Control" (IoC) and "Dependency Injection" (DI) used interchangeably, but they are actually related concepts.
IoC is a design pattern that suggests that the control of object creation and dependencies should be inverted. Instead of creating objects directly within a class, the class should receive the objects it depends on as parameters, and it should be responsible for creating and managing those objects. This approach can help to improve the modularity, testability, and maintainability of the code.
DI, on the other hand, is a design pattern that suggests that dependencies should be injected into a class instead of creating them directly. This means that the class should not create its own dependencies, but should receive them from an external source, such as a dependency injection framework. This approach can help to reduce coupling between classes and improve the flexibility and scalability of the system.
In summary, IoC is a design pattern that suggests inverting the control of object creation and dependencies, while DI is a design pattern that suggests injecting dependencies into a class instead of creating them directly. Both approaches can help to improve the modularity, testability, and maintainability of the code, and can help to reduce coupling between classes and improve the flexibility and scalability of the system.
What is the purpose of the Spring Boot Application YAML Properties?
The Spring Boot Application YAML Properties are a type of configuration file that uses YAML syntax to specify key-value pairs. They provide a more structured and readable way of configuring a Spring Boot application than the traditional application.properties file. YAML is a human-readable data serialization language that is often used for configuration files, as it is easier to read and write than XML.
What is the purpose of the Spring Boot Application Environment?
The Spring Boot Application Environment is a container for all the configuration properties that are used by a Spring Boot application. It provides a range of methods and APIs for accessing and manipulating the configuration properties, as well as for retrieving information about the application environment. The Application Environment is typically accessed using the Environment interface, which is provided by the Spring Boot framework.
What is the purpose of the Spring Boot Application Events?
The Spring Boot Application Events are a mechanism for notifying Spring Boot applications about significant events that occur during the application's lifecycle. Spring Boot provides a range of built-in events, such as ContextStartedEvent, ContextStoppedEvent, and ContextClosedEvent, that can be used to trigger actions based on these events. Applications can also define their own custom events and trigger actions based on these events using the ApplicationEventPublisher interface.
What is the purpose of the Spring Boot Application Exception Handling?
The Spring Boot Application Exception Handling is a mechanism for handling exceptions that occur during the execution of a Spring Boot application. Spring Boot provides a range of built-in exception handlers, such as DefaultHandlerExceptionResolver and WhitelabelErrorPage, that can be used to handle exceptions in a generic way. Applications can also define their own exception handlers to handle specific exceptions.
What is the purpose of the Spring Boot Application Testing?
The Spring Boot Application Testing is a mechanism for testing a Spring Boot application. Spring Boot provides a range of built-in testing frameworks, such as JUnit and Mockito, that can be used to write unit tests and integration tests for a Spring Boot application. Applications can also define their own custom testing frameworks to test specific functionality.
What is the purpose of the Spring Boot Application Security?
The Spring Boot Application Security is a mechanism for securing a Spring Boot application. Spring Boot provides a range of built-in security features, such as authentication and authorization, that can be used to secure a Spring Boot application. Applications can also define their own custom security configurations to meet specific security requirements.
What is the purpose of the Spring Boot Application Logging?
The Spring Boot Application Logging is a mechanism for logging messages from a Spring Boot application. Spring Boot provides a range of built-in logging frameworks, such as Logback and Log4j2, that can be used to log messages in a structured way. Applications can also define their own custom logging configurations to meet specific logging requirements.
What is Spring Boot?
Spring Boot is a framework that simplifies the process of building and deploying web applications in Java. It provides a set of pre-configured components and conventions that make it easy to get started with Spring-based applications.
What are the advantages of using Spring Boot?
Some advantages of using Spring Boot include:
It simplifies the process of building and deploying web applications in Java.
It provides a set of pre-configured components and conventions that make it easy to get started with Spring-based applications.
It reduces the amount of boilerplate code required to set up a Spring application.
It provides a range of features for building microservices, such as service discovery, load balancing, and circuit breaking.
It supports a range of programming languages, including Java, Kotlin, and Groovy.
What is the difference between Spring and Spring Boot?
Spring is a framework for building Java applications, while Spring Boot is a framework for building and deploying web applications in Java. Spring Boot builds on top of Spring and provides a set of pre-configured components and conventions that make it easy to get started with Spring-based applications.
What is the purpose of the @Autowired annotation in Spring Boot?
The @Autowired annotation is used to inject dependencies into a Spring-managed component. When a component is annotated with @Autowired, Spring will automatically find the appropriate bean and inject it into the component.
What is the purpose of the @RestController annotation in Spring Boot?
The @RestController annotation is used to create a RESTful web service in Spring Boot. When a class is annotated with @RestController, Spring will automatically configure it to handle HTTP requests and responses.
What is the purpose of the @RequestMapping annotation in Spring Boot?
The @RequestMapping annotation is used to map HTTP requests to methods in a Spring-managed component. When a method is annotated with @RequestMapping, Spring will automatically map HTTP requests that match the specified URL pattern to that method.
What is the purpose of the @Transactional annotation in Spring Boot?
The @Transactional annotation is used to mark a method as transactional. When a method is marked as transactional, Spring will automatically manage the transaction for that method, ensuring that it is committed or rolled back as appropriate.
What is the purpose of the application.properties file in Spring Boot?
The application.properties file is used to configure a Spring Boot application. It contains key-value pairs that specify various configuration options, such as the port number to use, the database connection details, and the logging level.
What is the purpose of the Spring Boot Actuator?
The Spring Boot Actuator is a set of tools and APIs that provide insight into the running Spring Boot application. It provides a range of features, such as health checks, metrics, and tracing, that can be used to monitor and manage the application.
What is the purpose of the Spring Boot DevTools?
The Spring Boot DevTools is a set of tools that provide fast and efficient development time features for Spring Boot applications. It provides features such as automatic restarts, live reload, and remote debugging.
What is the purpose of the Spring Boot Starter POM?
The Spring Boot Starter POM is a set of dependencies that can be used to quickly add common Spring Boot functionality to a project. It provides a range of dependencies, such as Spring Web, Spring Data, and Spring Security, that can be easily added to a project.
What is the purpose of the Spring Boot Auto-configuration?
The Spring Boot Auto-configuration is a feature that automatically configures a Spring Boot application based on the dependencies that are included in the project. It provides a range of default configurations that can be used to quickly set up a Spring application without having to manually configure it.
What is the purpose of the Spring Boot Application Properties?
The Spring Boot Application Properties are key-value pairs that can be used to configure a Spring Boot application. They provide a range of configuration options, such as the port number to use, the database connection details, and the logging level.
What is the purpose of the Spring Boot Application YAML Properties?
The Spring Boot Application YAML Properties are a type of configuration file that uses YAML syntax to specify key-value pairs. They provide a more structured and readable way of configuring a Spring Boot application than the traditional application.properties file.
What is the purpose of the Spring Boot Application Environment?
The Spring Boot Application Environment is a container for all the configuration properties that are used by a Spring Boot application. It provides a range of methods and APIs for accessing and manipulating the
microservices
What is monolithic architecture and what are its drawbacks?
Monolithic architecture is a traditional software architecture style where all the components of an application are combined into a single executable file or a single codebase. It is often used for small to medium-sized applications and is easy to develop and deploy. However, it has several drawbacks, such as:
Complexity: Monolithic architecture can be difficult to maintain and scale as the application grows. It can also be difficult to isolate and test individual components of the application.
Flexibility: Monolithic architecture can be difficult to modify or replace individual components of the application. It can also be difficult to add new features or functionality to the application.
Security: Monolithic architecture can be vulnerable to security threats such as SQL injection and cross-site scripting (XSS). It can also be difficult to implement security measures such as authentication and authorization.
What are microservices?
Microservices is a software architecture style where an application is built as a collection of small, independent services that communicate with each other through APIs. Each service is designed to perform a specific business function and can be developed, deployed, and scaled independently of the other services. Microservices have several advantages, such as:
Scalability: Microservices can be scaled independently of each other, which makes it easier to handle large traffic and high usage spikes.
Flexibility: Microservices can be developed, deployed, and scaled independently of each other, which makes it easier to modify or replace individual services.
Resilience: Microservices can be designed to be resilient to failures, such as service outages or network partitions.
What is an API gateway?
An API gateway is a component of a microservices architecture that sits between the client and the microservices and routes requests to the appropriate service. It can be used to handle authentication, load balancing, and other cross-cutting concerns.
How do microservices communicate with each other?
Microservices communicate with each other through APIs, which are typically RESTful APIs. Each service exposes a set of APIs that other services can call to perform their business functions. The communication between services can be done synchronously or asynchronously, depending on the requirements of the application.
What is service discovery in microservices?
Service discovery is the process of discovering the location of a microservice. It can be done using a service registry that maintains a list of all the available services and their locations. The service registry can be updated dynamically as services come and go.
How to handle fault tolerance in microservices?
To handle fault tolerance in microservices, the services can be designed to be resilient to failures. This can include using circuit breaking, retrying failed requests, and implementing fallback strategies.
What is Spring Cloud Config Server?
Spring Cloud Config Server is a tool that provides a centralized configuration repository for microservices. It allows services to retrieve configuration information from the server without having to hardcode it in their code. This makes it easier to manage configuration across multiple services.
What is the database strategy you follow in microservices?
In a microservices architecture, the database strategy can vary depending on the specific requirements of the application. However, a common approach is to use a database per service, where each service has its own database. This allows each service to be scaled independently and can improve performance by reducing contention and I/O bottlenecks.
How to monitor microservices?
To monitor microservices, tools such as Prometheus and Grafana can be used. Prometheus is a monitoring system that collects metrics from microservices and stores them in a time-series database. Grafana is a visualization tool that allows users to create dashboards and alerts based on the metrics collected by Prometheus.
Overall, microservices architecture is a powerful approach to building scalable, flexible, and resilient applications. It allows developers to build complex applications by breaking them down into smaller, independent services that can be developed, deployed, and scaled independently.
Load balancer and API Gateway are two different components that are used in distributed systems to improve performance, scalability, and reliability. Both of them play important roles in managing traffic between clients and servers, but they have different use cases and functions.
Load Balancer:
A load balancer is a network device that distributes incoming traffic across multiple servers to improve performance and availability. It is typically used in web applications, where a large number of users are accessing the same resources simultaneously. The load balancer acts as a traffic manager, distributing requests to different servers based on various algorithms such as round-robin, least connections, or IP hash. The main purpose of a load balancer is to distribute traffic evenly across multiple servers to prevent any single server from becoming overloaded.
API Gateway:
An API Gateway is a server that acts as a single entry point for multiple microservices. It is typically used in microservices architectures, where different services are developed and deployed independently. The API Gateway provides a unified interface for clients to access multiple services, hiding the complexity of the underlying system. The main purpose of an API Gateway is to provide security, routing, and transformation of requests between clients and microservices.
Difference between Load Balancer and API Gateway:
The main difference between Load Balancer and API Gateway is that Load Balancer is used to distribute traffic across multiple servers to improve performance and availability, whereas API Gateway is used to provide a unified interface for clients to access multiple microservices.
Use cases:
Load Balancer is used in web applications to distribute traffic across multiple servers to improve performance and availability. It is useful in scenarios where there is a high volume of traffic and multiple servers are needed to handle the load. Load balancers are also used in cloud environments to distribute traffic across multiple instances of the same application.
API Gateway is used in microservices architectures to provide a unified interface for clients to access multiple services. It is useful in scenarios where there are multiple microservices that are developed and deployed independently. API Gateway provides a centralized location for managing security, routing, and transformation of requests between clients and microservices.
In summary, both Load Balancer and API Gateway are important components in distributed systems, but they have different use cases and functions. Load Balancer is used to distribute traffic across multiple servers to improve performance and availability, while API Gateway is used to provide a unified interface for clients to access multiple microservices.
what is HATEOAS?
HATEOAS stands for Hypermedia as the Engine of Application State. It is a design principle for building scalable and interoperable web services that follows the principles of Representational State Transfer (REST).
HATEOAS allows web services to provide a self-documenting interface, where the client can discover the available resources and their relationships by following links in the response. This makes it easier for clients to interact with the service and understand its capabilities, and it allows the service to evolve over time without breaking clients.
In a RESTful web service, HATEOAS is achieved by using HTTP headers to provide links between resources. For example, a response from a web service might include a header that contains a link to a related resource, such as a next page of results. The client can then follow this link to retrieve the next page of results, without having to know the URL or any other details about the service or its resources.
HATEOAS is particularly important in microservices architecture, where services are designed to be loosely coupled and independently deployable. By using HATEOAS, services can provide a self-documenting interface that allows clients to discover the available resources and their relationships, without having to know the exact URLs or endpoints of each service. This makes it easier to build complex applications that are composed of multiple microservices.
Overall, HATEOAS is an important design principle for building scalable and interoperable web services that follow the principles of REST. It allows clients to discover the available resources and their relationships, making it easier for them to interact with the service and understand its capabilities.
SOAP stands for Simple Object Access Protocol. It is a protocol used for exchanging structured information in the implementation of web services. It is a platform-independent, lightweight, and simple protocol that uses XML to encode data and HTTP to transport it.
SOAP messages consist of a header, a body, and an envelope. The header contains metadata about the message, such as the encoding, the version of the protocol, and the security credentials. The body contains the actual data being exchanged, such as function calls or responses. The envelope is a container that wraps the header and body and provides additional information about the message, such as the target service and the action to be performed.
SOAP was developed as a replacement for the earlier Web Services Description Language (WSDL) and Simple Object Access Protocol (SOAP) specifications. It is now widely used in web service development and is supported by many programming languages and frameworks.
Some of the key features of SOAP include:
Platform-independent: SOAP messages can be exchanged between different platforms and programming languages, making it a flexible and portable protocol.
Lightweight: SOAP messages are relatively lightweight compared to other protocols, such as REST, which can reduce latency and improve performance.
Simple: SOAP is a simple protocol that uses XML to encode data and HTTP to transport it, making it easy to understand and use.
Secure: SOAP supports security features such as SSL/TLS and WS-Security, which can help protect sensitive data and prevent unauthorized access.
Scalable: SOAP is designed to be scalable, allowing services to be added or removed from the system without affecting other services.
Overall, SOAP is a powerful and flexible protocol that is widely used in web service development.
RESTful web services are a type of web service that use a simple, lightweight, and stateless protocol to exchange data between applications. They are designed to be scalable, reliable, and secure, and are widely used in modern web applications. Here are some of the key features of RESTful web services:
Stateless: RESTful web services are stateless, which means that each request from a client to a server must contain all the necessary information to complete the request, and the server does not store any information about previous requests.
Resource-based: RESTful web services use a resource-based architecture, where each resource is identified by a unique URI. This makes it easy to identify and access specific data or functionality in the service.
Representational state transfer (REST): RESTful web services use a set of principles known as REST, which are guidelines for designing web services. These principles include:
Client-server architecture: The client and server are separate entities that communicate with each other through requests and responses.
Statelessness: Each request from the client must contain all the necessary information to complete the request, and the server does not store any information about previous requests.
Cacheability: Responses from the server can be cached by the client to improve performance and reduce the load on the server.
Uniform interface: The interface between the client and server should be uniform and standardized, so that different clients can interact with the service in a consistent manner.
Layered system: The system should be layered, with each layer adding a specific functionality to the service.
Code on demand (optional): The server can provide code to the client in response to a request, which can improve performance and reduce the load on the server.
HTTP methods: RESTful web services use a set of HTTP methods, such as GET, POST, PUT, and DELETE, to perform different operations on the resources. These methods are used to create, retrieve, update, and delete resources on the server.
Authentication and authorization: RESTful web services can use various authentication and authorization mechanisms, such as OAuth, JWT, and SAML, to ensure that only authorized users can access the service and its resources.
Versioning: RESTful web services can use different versions of the API to support different versions of the client application. This can help ensure backward compatibility and reduce the risk of breaking changes.
Hypermedia: RESTful web services use hypermedia as a mechanism for representing and navigating between resources. This allows clients to dynamically discover the available resources and their relationships, which can improve the usability and accessibility of the service.
Overall, RESTful web services are a powerful and flexible architecture that is widely used in modern web applications. They provide a simple, lightweight, and stateless protocol for exchanging data between applications, and they follow a set of principles known as REST to ensure that the interface between the client and server is uniform and standardized.
What is a microservice architecture?
A microservice architecture is an approach to building software systems that combines multiple small, independent services that communicate with each other through APIs. Each service is designed to perform a specific business function and can be developed, deployed, and scaled independently of the other services.
What are the benefits of using a microservice architecture?
Microservice architecture provides several benefits, including:
Scalability: Microservices can be developed, deployed, and scaled independently of each other, which makes it easier to handle large and complex applications.
Flexibility: Microservices can be developed using different programming languages, frameworks, and tools, which makes it easier to choose the best technology for each service.
Resilience: Microservices can be designed to be resilient to failures, which makes it easier to ensure that the application remains available and functional even in the event of hardware or software failures.
Agility: Microservices can be developed and deployed quickly and independently of each other, which makes it easier to iterate on features and fix bugs.
What are the drawbacks of using a microservice architecture?
Microservice architecture also has several drawbacks, including:
Complexity: Microservices can be complex to design, deploy, and manage, which can lead to increased development and maintenance costs.
Inter-service communication: Microservices need to communicate with each other through APIs, which can add complexity to the system and increase latency.
Data management: Microservices need to manage their own data storage and synchronization, which can add complexity to the system.
Security: Microservices need to be designed with security in mind, which can add complexity to the system and require additional security measures.
What are the advantages of using containerization technologies like Docker for microservices?
Docker provides several advantages for microservices architecture, including:
Portability: Docker containers can be easily deployed and moved between environments, which makes it easier to manage and scale the application.
Isolation: Docker containers provide a high level of isolation between services, which makes it easier to ensure that each service is running in a secure and stable environment.
Scalability: Docker containers can be easily scaled up or down based on demand, which makes it easier to handle large and complex applications.
Efficiency: Docker containers are lightweight and efficient, which makes it easier to run multiple services on a single machine.
What is a service mesh?
A service mesh is a dedicated infrastructure layer that provides features for microservices architecture, such as service discovery, load balancing, and encryption. It is designed to make it easier to manage and secure microservices, and to provide features such as observability, traffic management, and policy enforcement.
What are the benefits of using a service mesh?
Service mesh provides several benefits for microservices architecture, including:
Simplified management: Service mesh provides a centralized layer for managing microservices, which makes it easier to manage and monitor the application.
Security: Service mesh provides features such as encryption, authentication, and authorization, which makes it easier to ensure that microservices are secure and protected from external threats.
Observability: Service mesh provides features such as monitoring, logging, and tracing, which makes it easier to monitor and troubleshoot the application.
Traffic management: Service mesh provides features such as load balancing, circuit breaking, and rate limiting, which makes it easier to manage the traffic to microservices and ensure that the application remains available and responsive.
What are the drawbacks of using a service mesh?
Service mesh also has several drawbacks, including:
Complexity: Service mesh can be complex to design, deploy, and manage, which can lead to increased development and maintenance costs.
Performance overhead: Service mesh can introduce a small performance overhead, which can impact the performance of microservices.
Vendor lock-in: Service mesh is typically vendor-specific, which can limit its adoption by other vendors and make it more difficult to integrate with existing systems.
What is an API gateway?
An API gateway is a server that sits between the client and the microservices and routes requests to the appropriate microservice. It is designed to simplify the communication between microservices and to provide features such as authentication, rate limiting, and caching.
What are the benefits of using an API gateway?
API gateway provides several benefits for microservices architecture, including:
Simplified communication: API gateway simplifies the communication between microservices by providing a single entry point for client requests.
Authentication and authorization: API gateway provides features such as authentication
how manage transactions in a microservices architecture works and how saga pattern used?
how the Saga pattern can be used to manage transactions in a microservices architecture using Java:
Let's say we have a system that consists of three microservices: Order, Payment, and Shipping. When a customer places an order, the Order service creates a new order and sends a message to the Payment service to process the payment. If the payment is successful, the Order service sends a message to the Shipping service to ship the order. If any of these steps fail, the entire transaction needs to be rolled back to maintain consistency.
To implement this using the Saga pattern, we can break the transaction into a series of smaller, local transactions. Each microservice is responsible for executing its own local transaction and publishing a message to trigger the next transaction in the sequence. If any of the local transactions fail, a compensating transaction is executed to undo the changes made by the previous transaction.
Here's a high-level overview of how this could work:
1. The Order service receives a request to create a new order and generates a unique order ID.
2. The Order service publishes a message to the Payment service to process the payment, including the order ID and the payment details.
3. The Payment service receives the payment request and attempts to process the payment. If the payment is successful, the Payment service publishes a message to the Shipping service to ship the order, including the order ID and shipping details. If the payment fails, the Payment service publishes a message to the Order service to cancel the order, including the order ID.
4. The Shipping service receives the shipping request and attempts to ship the order. If the order is shipped successfully, the transaction is complete. If the shipping fails, the Shipping service publishes a message to the Payment service to refund the payment, including the order ID and payment details.
5. If any of the local transactions fail, a compensating transaction is executed to undo the changes made by the previous transaction. For example, if the payment fails, the Payment service would publish a message to the Order service to cancel the order.
By breaking the transaction into a series of smaller, local transactions, we can ensure that the system remains consistent even in the event of a failure. The Saga pattern provides a way to manage long-lived transactions that span multiple microservices, while maintaining data integrity and consistency.
SOLID PRINCIPALS AND DESIGN PATTERNS
Design patterns are general reusable solutions to commonly occurring problems in software design. There are three main types of design patterns: Creational, Structural, and Behavioral. Here are some examples of subtypes within each type:
1. Creational Patterns:
- Singleton Pattern
- Factory Method Pattern
- Abstract Factory Pattern
- Builder Pattern
- Prototype Pattern
2. Structural Patterns:
- Adapter Pattern
- Bridge Pattern
- Composite Pattern
- Decorator Pattern
- Facade Pattern
- Flyweight Pattern
- Proxy Pattern
3. Behavioral Patterns:
- Chain of Responsibility Pattern
- Command Pattern
- Interpreter Pattern
- Iterator Pattern
- Mediator Pattern
- Memento Pattern
- Observer Pattern
- State Pattern
- Strategy Pattern
- Template Method Pattern
- Visitor Pattern
Each of these patterns has its own unique characteristics and use cases, and can be applied to different scenarios in software design to improve code quality, maintainability, and scalability.
Creational Patterns are design patterns that focus on the creation of objects and classes in a flexible and reusable way. These patterns are concerned with the process of object creation, rather than the behavior or functionality of objects.
There are several Creational Patterns in software design, including:
1. Singleton Pattern - This pattern ensures that only one instance of a class is created and provides a global point of access to it. It involves creating a private constructor for the class, and a static method that returns the single instance of the class.
2. Factory Method Pattern - This pattern provides an interface for creating objects, but allows subclasses to decide which class to instantiate. It involves creating an abstract factory class with a method for creating objects, and concrete factory classes that implement the method to create specific objects.
3. Abstract Factory Pattern - This pattern provides an interface for creating families of related objects, without specifying their concrete classes. It involves creating an abstract factory class with methods for creating related objects, and concrete factory classes that implement the methods to create specific objects.
4. Builder Pattern - This pattern separates the construction of a complex object from its representation, allowing the same construction process to create different representations. It involves creating a builder class that constructs the object step by step, and a director class that controls the construction process.
5. Prototype Pattern - This pattern creates new objects by copying existing ones, allowing for efficient object creation and customization. It involves creating a prototype interface with a clone() method, and concrete classes that implement the interface and define their own cloning behavior.
These Creational Patterns are important for creating flexible, scalable, and maintainable software systems. By providing a flexible and reusable way to create objects and classes, these patterns make it easier to modify and extend the system over time. They also help to reduce code duplication and increase code reuse, leading to more efficient and effective software development.
1. Singleton Pattern:
The Singleton Pattern is used to ensure that only one instance of a class exists in the system, and provides a global point of access to that instance. This is useful in scenarios where there should only be one instance of a class, such as a database connection or a logger. An example of the Singleton Pattern in Java is the java.lang.Runtime class, which provides a single instance of the Java Virtual Machine.
public class Singleton {
private static Singleton instance;
private Singleton() {}
public static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
1. Singleton Pattern: The java.lang.Runtime class is an example of the Singleton Pattern in Java. It provides a single instance of the Java Virtual Machine, which can be accessed globally by other classes in the system.
2. Factory Method Pattern:
The Factory Method Pattern is used to create objects without specifying the exact class of object that will be created. This is useful in scenarios where the exact type of object needed may not be known until runtime, or when there are multiple possible types of objects that could be created. An example of the Factory Method Pattern in Java is the java.util.Calendar class, which provides a factory method to create instances of the Calendar class based on the current locale.
public interface Animal {
String getName();
}
public class Dog implements Animal {
public String getName() {
return "Dog";
}
}
public class Cat implements Animal {
public String getName() {
return "Cat";
}
}
public interface AnimalFactory {
Animal createAnimal();
}
public class DogFactory implements AnimalFactory {
public Animal createAnimal() {
return new Dog();
}
}
public class CatFactory implements AnimalFactory {
public Animal createAnimal() {
return new Cat();
}
}
2. Factory Method Pattern: The java.util.Calendar class is an example of the Factory Method Pattern in Java. It provides a factory method to create instances of the Calendar class based on the current locale.
3. Abstract Factory Pattern:
The Abstract Factory Pattern is used to create families of related objects without specifying their concrete classes. This is useful in scenarios where there are multiple related objects that need to be created, and where the exact type of object needed may not be known until runtime. An example of the Abstract Factory Pattern in Java is the javax.xml.parsers.DocumentBuilderFactory class, which provides a factory for creating instances of the DocumentBuilder class.
public interface Animal {
String getName();
}
public class Dog implements Animal {
public String getName() {
return "Dog";
}
}
public class Cat implements Animal {
public String getName() {
return "Cat";
}
}
public interface AnimalFactory {
Animal createAnimal();
}
public class DogFactory implements AnimalFactory {
public Animal createAnimal() {
return new Dog();
}
}
public class CatFactory implements AnimalFactory {
public Animal createAnimal() {
return new Cat();
}
}
public interface AnimalSoundFactory {
String makeSound();
}
public class DogSoundFactory implements AnimalSoundFactory {
public String makeSound() {
return "Bark";
}
}
public class CatSoundFactory implements AnimalSoundFactory {
public String makeSound() {
return "Meow";
}
}
public interface AbstractFactory {
AnimalFactory createAnimalFactory();
AnimalSoundFactory createAnimalSoundFactory();
}
public class DogFactory implements AnimalFactory {
public Animal createAnimal() {
return new Dog();
}
}
public class CatFactory implements AnimalFactory {
public Animal createAnimal() {
return new Cat();
}
}
public class DogSoundFactory implements AnimalSoundFactory {
public String makeSound() {
return "Bark";
}
}
public class CatSoundFactory implements AnimalSoundFactory {
public String makeSound() {
return "Meow";
}
}
public class AnimalFactory implements AbstractFactory {
public AnimalFactory createAnimalFactory() {
return new DogFactory();
}
public AnimalSoundFactory createAnimalSoundFactory() {
return new DogSoundFactory();
}
}
public class CatFactory implements AbstractFactory {
public AnimalFactory createAnimalFactory() {
return new CatFactory();
}
public AnimalSoundFactory createAnimalSoundFactory() {
return new CatSoundFactory();
}
}
3. Abstract Factory Pattern: The javax.xml.parsers.DocumentBuilderFactory class is an example of the Abstract Factory Pattern in Java. It provides a factory for creating instances of the DocumentBuilder class.
4. Builder Pattern:
The Builder Pattern is used to create complex objects step-by-step, allowing for greater flexibility and control over the object creation process. This is useful in scenarios where there are many different options or configurations that need to be set for an object, or where the object creation process is complex and requires multiple steps. An example of the Builder Pattern in Java is the StringBuilder class, which provides a way to build strings by appending characters and strings in a step-by-step manner.
public class Car {
private String make;
private String model;
private int year;
private String color;
public Car(String make, String model, int year, String color) {
this.make = make;
this.model = model;
this.year = year;
this.color = color;
}
public String getMake() {
return make;
}
public String getModel() {
return model;
}
public int getYear() {
return year;
}
public String getColor() {
return color;
}
public static class CarBuilder {
private String make;
private String model;
private int year;
private String color;
public CarBuilder setMake(String make) {
this.make = make;
return this;
}
public CarBuilder setModel(String model) {
this.model = model;
return this;
}
public CarBuilder setYear(int year) {
this.year = year;
return this;
}
public CarBuilder setColor(String color) {
this.color = color;
return this;
}
public Car build() {
return new Car(make, model, year, color);
}
}
}
4. Builder Pattern: The StringBuilder class is an example of the Builder Pattern in Java. It provides a way to build strings by appending characters and strings in a step-by-step manner.
5. Prototype Pattern:
The Prototype Pattern is used to create new objects by cloning existing objects, rather than creating new instances from scratch. This is useful in scenarios where creating new objects from scratch is expensive or time-consuming, and where there are many similar objects that can be cloned with minor differences. An example of the Prototype Pattern in Java is the java.lang.Object class, which provides a clone() method that can be used to create copies of objects.
public abstract class Shape implements Cloneable {
private String id;
protected String type;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getType() {
return type;
}
public abstract void draw();
public Object clone() {
Object clone = null;
try {
clone = super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return clone;
}
}
public class Circle extends Shape {
public Circle() {
type = "Circle";
}
public void draw() {
System.out.println("Inside Circle::draw() method.");
}
}
public class Rectangle extends Shape {
public Rectangle() {
type = "Rectangle";
}
public void draw() {
System.out.println("Inside Rectangle::draw() method.");
}
}
public class Square extends Shape {
public Square() {
type = "Square";
}
public void draw() {
System.out.println("Inside Square::draw() method.");
}
}
public class ShapeCache {
private static Map<String, Shape> shapeMap = new HashMap<String, Shape>();
public static Shape getShape(String shapeId) {
Shape cachedShape = shapeMap.get(shapeId);
return (Shape) cachedShape.clone();
}
public static void loadCache() {
Circle circle = new Circle();
circle.setId("1");
shapeMap.put(circle.getId(), circle);
Square square = new Square();
square.setId("2");
shapeMap.put(square.getId(), square);
Rectangle rectangle = new Rectangle();
rectangle.setId("3");
shapeMap.put(rectangle.getId(), rectangle);
}
}
5. Prototype Pattern: The java.lang.Object class is an example of the Prototype Pattern in Java. It provides a clone() method that can be used to create copies of objects.
Each of these Creational Design Patterns provides a different way to create objects in software systems, and can be used to improve code quality, maintainability, and scalability.
2 Structural Patterns are design patterns that focus on the composition of objects and classes to form larger structures and systems. These patterns are concerned with how objects and classes are organized and connected to each other, rather than their behavior or functionality.
There are several Structural Patterns in software design, including:
1. Adapter Pattern - This pattern allows classes with incompatible interfaces to work together by creating an adapter class that acts as a bridge between them.
2. Bridge Pattern - This pattern decouples an abstraction from its implementation, allowing them to vary independently. It involves creating two separate hierarchies, one for the abstraction and one for the implementation, and connecting them through a bridge.
3. Composite Pattern - This pattern represents a group of objects as a single object, allowing individual objects and groups of objects to be treated in the same way. It involves creating a tree structure of objects, with each node representing a single object or a group of objects.
4. Decorator Pattern - This pattern allows behavior to be added to an object dynamically, without changing its original structure. It involves creating a decorator class that wraps the original class and adds new behavior to it.
5. Facade Pattern - This pattern provides a simplified interface to a complex system, hiding its complexity and providing a simple interface for the client to use.
6. Flyweight Pattern - This pattern minimizes memory usage by sharing data between similar objects. It involves creating a flyweight factory that creates and manages flyweight objects, and a context object that stores the data unique to each object.
7. Proxy Pattern - This pattern provides a surrogate or placeholder for another object to control access to it. It involves creating a proxy object that acts as a representative for the original object, and forwards requests to it when necessary.
These Structural Patterns are important for creating flexible, scalable, and maintainable software systems. By organizing objects and classes in a structured way, these patterns make it easier to understand and modify the system over time. They also help to reduce code duplication and increase code reuse, leading to more efficient and effective software development.
1. Adapter Pattern:
The Adapter Pattern is used to convert the interface of a class into another interface that the client expects. It allows classes with incompatible interfaces to work together. An example of this pattern is using a power adapter to convert the voltage of a device to match the voltage of the power outlet.
public interface MediaPlayer {
public void play(String audioType, String fileName);
}
public interface AdvancedMediaPlayer {
public void playVlc(String fileName);
public void playMp4(String fileName);
}
public class VlcPlayer implements AdvancedMediaPlayer{
public void playVlc(String fileName) {
System.out.println("Playing vlc file. Name: "+ fileName);
}
public void playMp4(String fileName) {
//do nothing
}
}
public class Mp4Player implements AdvancedMediaPlayer{
public void playVlc(String fileName) {
//do nothing
}
public void playMp4(String fileName) {
System.out.println("Playing mp4 file. Name: "+ fileName);
}
}
public class MediaAdapter implements MediaPlayer {
AdvancedMediaPlayer advancedMusicPlayer;
public MediaAdapter(String audioType){
if(audioType.equalsIgnoreCase("vlc") ){
advancedMusicPlayer = new VlcPlayer();
} else if (audioType.equalsIgnoreCase("mp4")){
advancedMusicPlayer = new Mp4Player();
}
}
public void play(String audioType, String fileName) {
if(audioType.equalsIgnoreCase("vlc")){
advancedMusicPlayer.playVlc(fileName);
}else if(audioType.equalsIgnoreCase("mp4")){
advancedMusicPlayer.playMp4(fileName);
}
}
}
public class AudioPlayer implements MediaPlayer {
MediaAdapter mediaAdapter;
public void play(String audioType, String fileName) {
if(audioType.equalsIgnoreCase("mp3")){
System.out.println("Playing mp3 file. Name: " + fileName);
}
else if(audioType.equalsIgnoreCase("vlc") || audioType.equalsIgnoreCase("mp4")){
mediaAdapter = new MediaAdapter(audioType);
mediaAdapter.play(audioType, fileName);
}
else{
System.out.println("Invalid media. " + audioType + " format not supported");
}
}
}
2. Bridge Pattern:
The Bridge Pattern is used to decouple an abstraction from its implementation so that the two can vary independently. It involves creating two separate hierarchies, one for the abstraction and one for the implementation, and then connecting them through a bridge. An example of this pattern is using a remote control to operate a TV. The remote control acts as a bridge between the user and the TV, allowing the user to interact with the TV without knowing the details of its implementation.
public interface DrawAPI {
public void drawCircle(int radius, int x, int y);
}
public class RedCircle implements DrawAPI {
public void drawCircle(int radius, int x, int y) {
System.out.println("Drawing Circle[ color: red, radius: " + radius + ", x: " + x + ", " + y + "]");
}
}
public class GreenCircle implements DrawAPI {
public void drawCircle(int radius, int x, int y) {
System.out.println("Drawing Circle[ color: green, radius: " + radius + ", x: " + x + ", " + y + "]");
}
}
public abstract class Shape {
protected DrawAPI drawAPI;
protected Shape(DrawAPI drawAPI){
this.drawAPI = drawAPI;
}
public abstract void draw();
}
public class Circle extends Shape {
private int x, y, radius;
public Circle(int x, int y, int radius, DrawAPI drawAPI) {
super(drawAPI);
this.x = x;
this.y = y;
this.radius = radius;
}
public void draw() {
drawAPI.drawCircle(radius,x,y);
}
}
3. Composite Pattern:
The Composite Pattern is used to represent a group of objects as a single object. It allows you to treat individual objects and groups of objects in the same way. An example of this pattern is representing a file system as a tree structure, where each node represents a file or directory, and each directory can contain files and other directories.
public interface Employee {
public void add(Employee employee);
public void remove(Employee employee);
public Employee getChild(int i);
public String getName();
public double getSalary();
public void print();
}
public class Developer implements Employee {
private String name;
private double salary;
public Developer(String name,double salary){
this.name = name;
this.salary = salary;
}
public void add(Employee employee) {
//this is leaf node so this method is not applicable to this class.
}
public Employee getChild(int i) {
//this is leaf node so this method is not applicable to this class.
return null;
}
public String getName() {
return name;
}
public double getSalary() {
return salary;
}
public void print() {
System.out.println("-------------");
System.out.println("Name ="+getName());
System.out.println("Salary ="+getSalary());
System.out.println("-------------");
}
public void remove(Employee employee) {
//this is leaf node so this method is not applicable to this class.
}
}
public class Manager implements Employee {
private String name;
private double salary;
private List<Employee> employees = new ArrayList<Employee>();
public Manager(String name,double salary){
this.name = name;
this.salary = salary;
}
public void add(Employee employee) {
employees.add(employee);
}
public Employee getChild(int i) {
return employees.get(i);
}
public String getName() {
return name;
}
public double getSalary() {
return salary;
}
public void print() {
System.out.println("-------------");
System.out.println("Name ="+getName());
System.out.println("Salary ="+getSalary());
System.out.println("-------------");
Iterator<Employee> employeeIterator = employees.iterator();
while(employeeIterator.hasNext()){
Employee employee = employeeIterator.next();
employee.print();
}
}
public void remove(Employee employee) {
employees.remove(employee);
}
}
4. Decorator Pattern:
The Decorator Pattern is used to add functionality to an object dynamically, without changing its original structure. It involves creating a decorator class that wraps the original class and adds new behavior to it. An example of this pattern is adding toppings to a pizza. The pizza is the original object, and the toppings are decorators that add new behavior (flavor, texture, etc.) to the pizza.
public interface Shape {
void draw();
}
public class Circle implements Shape {
public void draw() {
System.out.println("Shape: Circle");
}
}
public abstract class ShapeDecorator implements Shape {
protected Shape decoratedShape;
public ShapeDecorator(Shape decoratedShape){
this.decoratedShape = decoratedShape;
}
public void draw(){
decoratedShape.draw();
}
}
public class RedShapeDecorator extends ShapeDecorator {
public RedShapeDecorator(Shape decoratedShape) {
super(decoratedShape);
}
@Override
public void draw() {
decoratedShape.draw();
setRedBorder(decoratedShape);
}
private void setRedBorder(Shape decoratedShape){
System.out.println("Border Color: Red");
}
}
5. Facade Pattern:
The Facade Pattern is used to provide a simplified interface to a complex system. It involves creating a facade class that hides the complexity of the system and provides a simple interface for the client to use. An example of this pattern is using a remote control to operate a home theater system. The remote control acts as a facade, hiding the complexity of the system and providing a simple interface for the user to use.
public interface Shape {
void draw();
}
public class Rectangle implements Shape {
public void draw() {
System.out.println("Rectangle::draw()");
}
}
public class Square implements Shape {
public void draw() {
System.out.println("Square::draw()");
}
}
public class Circle implements Shape {
public void draw() {
System.out.println("Circle::draw()");
}
}
public class ShapeMaker {
private Shape circle;
private Shape rectangle;
private Shape square;
public ShapeMaker() {
circle = new Circle();
rectangle = new Rectangle();
square = new Square();
}
public void drawCircle(){
circle.draw();
}
public void drawRectangle(){
rectangle.draw();
}
public void drawSquare(){
square.draw();
}
}
6. Flyweight Pattern:
The Flyweight Pattern is used to minimize memory usage by sharing data between similar objects. It involves creating a flyweight factory that creates and manages flyweight objects, and a context object that stores the data unique to each object. An example of this pattern is using a pool of reusable objects to reduce memory usage in a game engine.
public interface Shape {
void draw();
}
public class Circle implements Shape {
private String color;
private int x;
private int y;
private int radius;
public Circle(String color){
this.color = color;
}
public void setX(int x) {
this.x = x;
}
public void setY(int y) {
this.y = y;
}
public void setRadius(int radius) {
this.radius = radius;
}
@Override
public void draw() {
System.out.println("Circle: Draw() [Color : " + color + ", x : " + x + ", y :" + y + ", radius :" + radius);
}
}
public class ShapeFactory {
private static final HashMap<String, Shape> circleMap = new HashMap<>();
public static Shape getCircle(String color) {
Circle circle = (Circle)circleMap.get(color);
if(circle == null) {
circle = new Circle(color);
circleMap.put(color, circle);
System.out.println("Creating circle of color : " + color);
}
return circle;
}
}
7. Proxy Pattern:
The Proxy Pattern is used to provide a surrogate or placeholder for another object to control access to it. It involves creating a proxy object that acts as a representative for the original object, and forwards requests to it when necessary. An example of this pattern is using a proxy server to access the internet. The proxy server acts as a representative for the client, and forwards requests to the internet when necessary, while also providing additional functionality such as caching and filtering.
public interface Image {
void display();
}
public class RealImage implements Image {
private String fileName;
public RealImage(String fileName){
this.fileName = fileName;
loadFromDisk(fileName);
}
@Override
public void display() {
System.out.println("Displaying " + fileName);
}
private void loadFromDisk(String fileName){
System.out.println("Loading " + fileName);
}
}
public class ProxyImage implements Image{
private RealImage realImage;
private String fileName;
public ProxyImage(String fileName){
this.fileName = fileName;
}
@Override
public void display() {
if(realImage == null){
realImage = new RealImage(fileName);
}
realImage.display();
}
}
Behavioral Patterns are design patterns that focus on the interactions and communication between objects and classes in a software system. These patterns are concerned with the behavior and functionality of objects, rather than their creation or structure.
There are several Behavioral Patterns in software design, including:
1. Observer Pattern - This pattern defines a one-to-many relationship between objects, where changes to one object are automatically propagated to its dependent objects. It involves creating an observable subject class that maintains a list of observers, and observer classes that are notified of changes to the subject.
2. Command Pattern - This pattern encapsulates a request as an object, allowing it to be queued, logged, or undone at a later time. It involves creating a command interface with an execute() method, and concrete command classes that implement the interface and define their own behavior.
3. Strategy Pattern - This pattern defines a family of algorithms, encapsulates each one, and makes them interchangeable. It involves creating a strategy interface with a method for performing a task, and concrete strategy classes that implement the interface and define their own algorithm.
4. Chain of Responsibility Pattern - This pattern allows multiple objects to handle a request, without specifying which object will handle it. It involves creating a handler interface with a method for handling a request, and concrete handler classes that implement the interface and pass the request to the next handler in the chain.
5. Template Method Pattern - This pattern defines the skeleton of an algorithm, allowing subclasses to redefine certain steps of the algorithm without changing its overall structure. It involves creating an abstract class with a template method that defines the algorithm, and concrete subclasses that implement the template method and redefine certain steps.
These Behavioral Patterns are important for creating flexible, extensible, and maintainable software systems. By providing a way to define and manage communication and interactions between objects and classes, these patterns make it easier to modify and extend the system over time. They also help to reduce the complexity of the code and increase its reusability, leading to more efficient and effective software development.
1. Chain of Responsibility Pattern:
public abstract class Handler {
protected Handler successor;
public void setSuccessor(Handler successor) {
this.successor = successor;
}
public abstract void handleRequest(Request request);
}
public class ConcreteHandler1 extends Handler {
public void handleRequest(Request request) {
if (request.getType() == RequestType.TYPE1) {
System.out.println("Handled by ConcreteHandler1");
} else if (successor != null) {
successor.handleRequest(request);
}
}
}
public class ConcreteHandler2 extends Handler {
public void handleRequest(Request request) {
if (request.getType() == RequestType.TYPE2) {
System.out.println("Handled by ConcreteHandler2");
} else if (successor != null) {
successor.handleRequest(request);
}
}
}
public class Request {
private RequestType type;
public Request(RequestType type) {
this.type = type;
}
public RequestType getType() {
return type;
}
}
public enum RequestType {
TYPE1, TYPE2;
}
public class Client {
public static void main(String[] args) {
Handler handler1 = new ConcreteHandler1();
Handler handler2 = new ConcreteHandler2();
handler1.setSuccessor(handler2);
Request request1 = new Request(RequestType.TYPE1);
Request request2 = new Request(RequestType.TYPE2);
handler1.handleRequest(request1);
handler1.handleRequest(request2);
}
}
2. Command Pattern:
public interface Command {
void execute();
}
public class ConcreteCommand1 implements Command {
private Receiver receiver;
public ConcreteCommand1(Receiver receiver) {
this.receiver = receiver;
}
public void execute() {
receiver.action1();
}
}
public class ConcreteCommand2 implements Command {
private Receiver receiver;
public ConcreteCommand2(Receiver receiver) {
this.receiver = receiver;
}
public void execute() {
receiver.action2();
}
}
public class Receiver {
public void action1() {
System.out.println("Action 1 performed");
}
public void action2() {
System.out.println("Action 2 performed");
}
}
public class Invoker {
private Command command;
public void setCommand(Command command) {
this.command = command;
}
public void executeCommand() {
command.execute();
}
}
public class Client {
public static void main(String[] args) {
Receiver receiver = new Receiver();
Command command1 = new ConcreteCommand1(receiver);
Command command2 = new ConcreteCommand2(receiver);
Invoker invoker = new Invoker();
invoker.setCommand(command1);
invoker.executeCommand();
invoker.setCommand(command2);
invoker.executeCommand();
}
}
3. Interpreter Pattern:
public interface Expression {
boolean interpret(String context);
}
public class TerminalExpression implements Expression {
private String data;
public TerminalExpression(String data) {
this.data = data;
}
public boolean interpret(String context) {
if (context.contains(data)) {
return true;
}
return false;
}
}
public class OrExpression implements Expression {
private Expression expr1;
private Expression expr2;
public OrExpression(Expression expr1, Expression expr2) {
this.expr1 = expr1;
this.expr2 = expr2;
}
public boolean interpret(String context) {
return expr1.interpret(context) || expr2.interpret(context);
}
}
public class AndExpression implements Expression {
private Expression expr1;
private Expression expr2;
public AndExpression(Expression expr1, Expression expr2) {
this.expr1 = expr1;
this.expr2 = expr2;
}
public boolean interpret(String context) {
return expr1.interpret(context) && expr2.interpret(context);
}
}
public class Client {
public static void main(String[] args) {
Expression person1 = new TerminalExpression("John");
Expression person2 = new TerminalExpression("Mike");
Expression orExpression = new OrExpression(person1, person2);
Expression location = new TerminalExpression("New York");
Expression andExpression = new AndExpression(orExpression, location);
System.out.println(andExpression.interpret("John is in New York")); // true
System.out.println(andExpression.interpret("Mike is in Boston")); // false
}
}
4. 1. Iterator Pattern:
public interface Iterator {
boolean hasNext();
Object next();
}
public interface Container {
Iterator getIterator();
}
public class NameRepository implements Container {
private String[] names = {"John", "Mike", "Sarah", "Jessica"};
public Iterator getIterator() {
return new NameIterator();
}
private class NameIterator implements Iterator {
private int index;
public boolean hasNext() {
if (index < names.length) {
return true;
}
return false;
}
public Object next() {
if (this.hasNext()) {
return names[index++];
}
return null;
}
}
}
public class Client {
public static void main(String[] args) {
NameRepository namesRepository = new NameRepository();
Iterator iterator = namesRepository.getIterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}
2. Mediator Pattern:
public interface Mediator {
void sendMessage(String message, Colleague colleague);
}
public abstract class Colleague {
protected Mediator mediator;
public Colleague(Mediator mediator) {
this.mediator = mediator;
}
public abstract void receive(String message);
public abstract void send(String message);
}
public class ConcreteColleague1 extends Colleague {
public ConcreteColleague1(Mediator mediator) {
super(mediator);
}
public void receive(String message) {
System.out.println("ConcreteColleague1 received message: " + message);
}
public void send(String message) {
System.out.println("ConcreteColleague1 sent message: " + message);
mediator.sendMessage(message, this);
}
}
public class ConcreteColleague2 extends Colleague {
public ConcreteColleague2(Mediator mediator) {
super(mediator);
}
public void receive(String message) {
System.out.println("ConcreteColleague2 received message: " + message);
}
public void send(String message) {
System.out.println("ConcreteColleague2 sent message: " + message);
mediator.sendMessage(message, this);
}
}
public class ConcreteMediator implements Mediator {
private ConcreteColleague1 colleague1;
private ConcreteColleague2 colleague2;
public void setColleague1(ConcreteColleague1 colleague1) {
this.colleague1 = colleague1;
}
public void setColleague2(ConcreteColleague2 colleague2) {
this.colleague2 = colleague2;
}
public void sendMessage(String message, Colleague colleague) {
if (colleague == colleague1) {
colleague2.receive(message);
} else {
colleague1.receive(message);
}
}
}
public class Client {
public static void main(String[] args) {
ConcreteMediator mediator = new ConcreteMediator();
ConcreteColleague1 colleague1 = new ConcreteColleague1(mediator);
ConcreteColleague2 colleague2 = new ConcreteColleague2(mediator);
mediator.setColleague1(colleague1);
mediator.setColleague2(colleague2);
colleague1.send("Hello from Colleague1");
colleague2.send("Hello from Colleague2");
}
}
3. Memento Pattern:
public class Originator {
private String state;
public void setState(String state) {
this.state = state;
}
public String getState() {
return state;
}
public Memento saveStateToMemento() {
return new Memento(state);
}
public void getStateFromMemento(Memento memento) {
state = memento.getState();
}
}
public class Memento {
private String state;
public Memento(String state) {
this.state = state;
}
public String getState() {
return state;
}
}
public class Caretaker {
private List<Memento> mementoList = new ArrayList<Memento>();
public void add(Memento state) {
mementoList.add(state);
}
public Memento get(int index) {
return mementoList.get(index);
}
}
public class Client {
public static void main(String[] args) {
Originator originator = new Originator();
Caretaker caretaker = new Caretaker();
originator.setState("State1");
originator.setState("State2");
caretaker.add(originator.saveStateToMemento());
originator.setState("State3");
caretaker.add(originator.saveStateToMemento());
originator.setState("State4");
System.out.println("Current state: " + originator.getState());
originator.getStateFromMemento(caretaker.get(0));
System.out.println("First saved state: " + originator.getState());
originator.getStateFromMemento(caretaker.get(1));
System.out.println("Second saved state: " + originator.getState());
}
}
4. Observer Pattern:
public interface Observer {
void update(String message);
}
public interface Subject {
void attach(Observer observer);
void detach(Observer observer);
void notifyObservers(String message);
}
public class ConcreteSubject implements Subject {
private List<Observer> observers = new ArrayList<>();
private String message;
public void attach(Observer observer) {
observers.add(observer);
}
public void detach(Observer observer) {
observers.remove(observer);
}
public void notifyObservers(String message) {
this.message = message;
for (Observer observer : observers) {
observer.update(message);
}
}
public String getMessage() {
return message;
}
}
public class ConcreteObserver implements Observer {
private String name;
public ConcreteObserver(String name) {
this.name = name;
}
public void update(String message) {
System.out.println(name + " received message: " + message);
}
}
public class Client {
public static void main(String[] args) {
ConcreteSubject subject = new ConcreteSubject();
Observer observer1 = new ConcreteObserver("Observer1");
Observer observer2 = new ConcreteObserver("Observer2");
subject.attach(observer1);
subject.attach(observer2);
subject.notifyObservers("Hello World!");
subject.detach(observer1);
subject.notifyObservers("Goodbye World!");
}
}
State Pattern:
The State Pattern is a behavioral design pattern that allows an object to alter its behavior when its internal state changes. Here's an example implementation in Java:
// Context class
public class Context {
private State state;
public Context() {
this.state = new StateA();
}
public void setState(State state) {
this.state = state;
}
public void request() {
this.state.handle();
}
}
// State interface
public interface State {
void handle();
}
// Concrete state classes
public class StateA implements State {
@Override
public void handle() {
System.out.println("State A");
}
}
public class StateB implements State {
@Override
public void handle() {
System.out.println("State B");
}
}
// Usage
Context context = new Context();
context.request(); // prints "State A"
context.setState(new StateB());
context.request(); // prints "State B"
Strategy Pattern:
The Strategy Pattern is a behavioral design pattern that allows you to define a family of algorithms, encapsulate each one as an object, and make them interchangeable. Here's an example implementation in Java:
// Context class
public class Context {
private Strategy strategy;
public Context(Strategy strategy) {
this.strategy = strategy;
}
public void setStrategy(Strategy strategy) {
this.strategy = strategy;
}
public void executeStrategy() {
this.strategy.execute();
}
}
// Strategy interface
public interface Strategy {
void execute();
}
// Concrete strategy classes
public class StrategyA implements Strategy {
@Override
public void execute() {
System.out.println("Strategy A");
}
}
public class StrategyB implements Strategy {
@Override
public void execute() {
System.out.println("Strategy B");
}
}
// Usage
Context context = new Context(new StrategyA());
context.executeStrategy(); // prints "Strategy A"
context.setStrategy(new StrategyB());
context.executeStrategy(); // prints "Strategy B"
Template Method Pattern:
The Template Method Pattern is a behavioral design pattern that defines the skeleton of an algorithm in a superclass, but lets subclasses override specific steps of the algorithm without changing its structure. Here's an example implementation in Java:
// Abstract class with template method
public abstract class AbstractClass {
public void templateMethod() {
step1();
step2();
step3();
}
protected abstract void step1();
protected abstract void step2();
private void step3() {
System.out.println("Step 3");
}
}
// Concrete class implementing abstract methods
public class ConcreteClass extends AbstractClass {
@Override
protected void step1() {
System.out.println("Step 1");
}
@Override
protected void step2() {
System.out.println("Step 2");
}
}
// Usage
AbstractClass abstractClass = new ConcreteClass();
abstractClass.templateMethod(); // prints "Step 1", "Step 2", "Step 3"
Visitor Pattern:
The Visitor Pattern is a behavioral design pattern that allows you to separate algorithms from the objects on which they operate. Here's an example implementation in Java:
// Element interface
public interface Element {
void accept(Visitor visitor);
}
// Concrete element classes
public class ElementA implements Element {
@Override
public void accept(Visitor visitor) {
visitor.visit(this);
}
}
public class ElementB implements Element {
@Override
public void accept(Visitor visitor) {
visitor.visit(this);
}
}
// Visitor interface
public interface Visitor {
void visit(ElementA element);
void visit(ElementB element);
}
// Concrete visitor class
public class ConcreteVisitor implements Visitor {
@Override
public void visit(ElementA element) {
System.out.println("Visitor visited Element A");
}
@Override
public void visit(ElementB element) {
System.out.println("Visitor visited Element B");
}
}
// Usage
Element elementA = new ElementA();
Element elementB = new ElementB();
Visitor visitor = new ConcreteVisitor();
elementA.accept(visitor); // prints "Visitor visited Element A"
elementB.accept(visitor); // prints "Visitor visited Element B"
The Cache design pattern is used to improve the performance of an application by storing frequently accessed data in a cache. The cache is a temporary storage area that holds the most recently used data items in memory. When a data item is requested, the application first checks the cache to see if it is already there. If the data item is found in the cache, it is returned immediately, without having to read it from the original source.
One example of implementing the Cache design pattern is in a web application that displays product information. The product information is stored in a database, and each time a user requests the product information, the application reads it from the database. This can be time-consuming, especially if the database is large or the server is busy.
To improve performance, the application can use a cache to store the product information. When a user requests the product information, the application first checks the cache to see if it is already there. If the product information is found in the cache, it is returned immediately. If it is not found in the cache, the application reads it from the database and stores it in the cache for future use.
There are different types of cache implementations such as in-memory cache, distributed cache, and disk cache. The choice of cache implementation depends on the specific requirements and constraints of the application.
Question :
Cache design pattern implemenattion in java
Answer :
Share icon
Here is an example implementation of the Cache design pattern in Java:
import java.util.HashMap;
import java.util.Map;
public class Cache {
private Map<String, Object> cache;
public Cache() {
cache = new HashMap<>();
}
public Object get(String key) {
return cache.get(key);
}
public void put(String key, Object value) {
cache.put(key, value);
}
public void clear() {
cache.clear();
}
}
In this example, we have created a simple Cache class that uses a HashMap to store key-value pairs. The get method retrieves the value associated with a given key, while the put method stores a key-value pair in the cache. The clear method removes all key-value pairs from the cache.
To use this Cache class in your application, you can create an instance of the class and store and retrieve values using the put and get methods, respectively. For example:
Cache cache = new Cache();
cache.put("key1", "value1");
cache.put("key2", "value2");
Object value1 = cache.get("key1");
Object value2 = cache.get("key2");
In this example, we store two key-value pairs in the cache using the put method, and then retrieve the values associated with the keys "key1" and "key2" using the get method.
The Dependency Inversion Principle (DIP) helps eliminate undesirable dependencies by inverting the direction of dependencies and relying on abstractions.
The DIP suggests that high-level modules should not depend on low-level modules. Instead, both should depend on abstractions. This means that the high-level modules should not be dependent on the specific implementation details of the low-level modules, but should instead depend on abstractions that define the contracts for interacting with those modules.
By doing this, developers can create code that is more modular, flexible, and maintainable, as changes to the low-level modules do not affect the high-level modules, and vice versa. This can help to eliminate undesirable dependencies between modules, as the high-level modules do not depend on the specific implementation details of the low-level modules, but instead depend on abstractions that define the contracts for interacting with those modules.
For example, consider the following code that has undesirable dependencies between modules:
public class Car {
private Engine engine;
public Car(Engine engine) {
this.engine = engine;
}
public void start() {
engine.start();
}
public void stop() {
engine.stop();
}
}
public class Engine {
public void start() {
// implementation
}
public void stop() {
// implementation
}
}
In this code, the Car class has a direct dependency on the Engine class, which violates the DIP
By inverting the direction of dependencies and relying on an abstraction, the Car class can depend on an interface that defines the contracts for interacting with the Engine class, without directly depending on the Engine class
public interface EngineInterface {
public void start();
public void stop();
}
public class DieselEngine implements EngineInterface {
public void start() {
// implementation
}
public void stop() {
// implementation
}
}
public class ElectricEngine implements EngineInterface {
public void start() {
// implementation
}
public void stop() {
// implementation
}
}
public class Car {
private EngineInterface engine;
public Car(EngineInterface engine) {
this.engine = engine;
}
public void start() {
engine.start();
}
public void stop() {
engine.stop();
}
}
In this refactored code, the Engine class is replaced with an interface, which allows the Car class to depend on an abstraction that defines the contracts for interacting with the engine
This decouples the Car class from the specific implementation of the engine, which promotes flexibility in the code
Overall, the Dependency Inversion Principle helps eliminate undesirable dependencies by inverting the direction of dependencies and relying on abstractions, which promotes loose coupling between modules and promotes the creation of flexible and maintainable code.
Coupling principles in code organization are guidelines that focus on the degree to which the elements of a module or class are related to each other and how they are related. These principles are designed to promote a clear and modular architecture for the code, which makes it easier to understand, test, and maintain.
Here are some common coupling principles in code organization:
The High Cohesion Principle (HCP): This principle suggests that a class should have only one responsibility, and that it should encapsulate its own behavior and data.
The Low Coupling Principle (LCP): This principle suggests that modules should be loosely coupled, meaning that changes to one module should not require changes to other modules.
The Dependency Inversion Principle (DIP): This principle suggests that high-level modules should not depend on low-level modules. Instead, both should depend on abstractions.
The Interface Segregation Principle (ISP): This principle suggests that clients should not be forced to depend on interfaces they do not use. Instead, clients should depend on abstractions that are large enough to encompass the behavior they need.
The Common Closure Principle (CCP): This principle suggests that classes should be closed for modification, meaning that they should not allow behavior to be added to them without modifying them.
Overall, coupling principles in code organization are designed to promote a clear and modular architecture for the code, which makes it easier to understand, test, and maintain. By following these principles, developers can create code that is more flexible, maintainable, and extensible, while minimizing the number of client-specific interfaces that the code has.
Cohesion principles in code organization are guidelines that focus on the degree to which the elements of a module or class are related to each other and how they are related. These principles are designed to promote a clear and modular architecture for the code, which makes it easier to understand, test, and maintain.
Here are some common cohesion principles in code organization:
The Single Responsibility Principle (SRP): This principle suggests that a class should have only one reason to change, and that it should encapsulate its own behavior and data.
The Open-Closed Principle (OCP): This principle suggests that a class should be open for extension but closed for modification. This means that you should be able to add new functionality to a class without modifying its existing code.
The Liskov Substitution Principle (LSP): This principle suggests that a subclass should be able to replace its superclass without affecting the correctness of the program.
The Interface Segregation Principle (ISP): This principle suggests that clients should not be forced to depend on interfaces they do not use. Instead, clients should depend on abstractions that are large enough to encompass the behavior they need.
The Dependency Inversion Principle (DIP): This principle suggests that high-level modules should not depend on low-level modules. Instead, both should depend on abstractions.
Overall, cohesion principles in code organization are designed to promote a clear and modular architecture for the code, which makes it easier to understand, test, and maintain. By following these principles, developers can create code that is more flexible, maintainable, and extensible, while minimizing the number of client-specific interfaces that the code has.
Violations of the Law of Demeter (LoD) can have several impacts on code maintainability, including:
Improving code modularity and encapsulation: By following the LoD, developers can create code that is more modular, flexible, and maintainable. This makes it easier to modify or extend the code without affecting other parts of the system.
Simplifying debugging and error handling: By minimizing the number of client-specific interfaces that a class has, developers can create code that is more modular and easier to understand. This makes it easier to debug and handle errors in the code, as it is easier to identify the source of the problem.
Introducing tight coupling: By violating the LoD, developers can create code that is more difficult to modify and maintain. This can lead to tight coupling between modules, which can make it harder to modify or extend the code without affecting other parts of the system.
Ensuring consistent naming conventions across the codebase: By following the LoD, developers can ensure that the naming conventions used throughout the codebase are consistent and easy to understand. This makes it easier to collaborate with other developers and to maintain the code over time.
Overall, violations of the LoD can have a significant impact on code maintainability, as they can lead to improved code modularity, encapsulation, and maintainability, but they can also introduce tight coupling and inconsistent naming conventions. It is important to weigh the pros and cons carefully, and to follow the LoD only when it is necessary to create clear and modular architecture for the code.
The Law of Demeter (LoD) is a design principle that suggests that a class should only communicate with its immediate dependencies, and should avoid communicating with other classes. This helps to create a clear and modular architecture for the code, which makes it easier to understand, test, and maintain.
Here are some pros and cons of applying the LoD:
Pros:
Improved maintainability: By following the LoD, developers can create code that is more modular, flexible, and maintainable. This makes it easier to modify or extend the code without affecting other parts of the system.
Reduced coupling: By minimizing the number of client-specific interfaces that a class has, developers can create code that is more modular and easier to understand. This makes it easier to modify or extend the code without affecting other parts of the system.
Cons:
Potentially increased number of method calls: By following the LoD, developers can create code that is more modular and easier to understand, but it can also potentially increase the number of method calls in the code. This can lead to slower performance and increased memory usage.
Overall, the LoD is a useful design principle that can help to create clear and modular architecture for the code, which makes it easier to understand, test, and maintain. However, it is important to weigh the pros and cons carefully, and to consider the potential impact on performance and memory usage before applying the LoD to the code.
The primary goal of applying the Law of Demeter (LoD) is to minimize the knowledge and dependencies between objects.
The LoD suggests that a class should only interact with its immediate dependencies, and should avoid interacting with indirect dependencies. This means that a class should not have methods that return objects that are not of the same type as the class itself, and should not have methods that take objects as parameters that are not of the same type as the class itself.
The LoD is related to the Dependency Inversion Principle (DIP), which suggests that high-level modules should not depend on low-level modules directly, but instead should depend on abstractions that define the contracts for interacting with the low-level modules. This allows for the abstraction of the low-level modules from the high-level modules, which can make it easier to swap out or replace low-level modules without affecting the high-level modules.
By following the LoD, developers can create code that is more modular, flexible, and maintainable, and that is easier to understand and modify. This can help to reduce the coupling between modules and improve the reusability and flexibility of the code over time.
Overall, the primary goal of applying the LoD is to create code that is more modular, flexible, and maintainable, and that is easier to understand and modify. By following the LoD, developers can create code that is easier to understand, test, and maintain over time, and that can be easily modified or extended without affecting other parts of the system.
A subclass changes the return type of a method to a subtype of the return type in the superclass is an example of covariance.
Covariance is a concept in object-oriented programming that refers to the ability of a subclass to have a more specific return type than the superclass. In other words, a subclass can have a more specific type of object than the superclass, and the subclass can still be used in a way that is consistent with the superclass.
In the context of method return types, covariance refers to the ability of a subclass to have a more specific type of object than the superclass. For example, consider the following code:
class Animal {
public void makeSound() {
System.out.println("Animal is making a sound");
}
}
class Dog extends Animal {
public void makeSound() {
System.out.println("Dog is barking");
}
}
In this code, the Dog class is a subclass of the Animal class, and the Dog class overrides the makeSound() method to provide a more specific implementation
The Dog class is still able to return an object of type Animal from the makeSound() method, even though it has overridden the method in the Animal class
This is an example of covariance, as the Dog class is able to provide a more specific implementation of the makeSound() method than the Animal class
This allows the Dog class to be used in a way that is consistent with the Animal class, and can help to avoid unnecessary type casting and type checking
Overall, covariance is a useful feature of object-oriented programming that allows subclasses to have more specific types of objects than their superclasses, while still maintaining the ability to be used in a way that is consistent with the superclass.
A subclass alters the post-conditions of a method from the superclass is not a violation of the Liskov Substitution Principle.
The Liskov Substitution Principle (LSP) is a design principle that was introduced by Barbara Liskov in her book "The Liskov Substitution Principle: A Proven Guide for Object-Oriented Design" (1987). The principle states that if S is a subtype of T, then objects of type T may be replaced with objects of type S without affecting the correctness of the program.
In the context of object-oriented programming, this means that a subclass should be able to replace an object of the superclass with an object of the subclass without affecting the correctness of the program. This is because the subclass may have overridden some of the methods of the superclass, and any overridden methods may have different post-conditions.
Altering the post-conditions of a method from the superclass is not a violation of the Liskov Substitution Principle, as long as the subclass is still able to meet the requirements of the LSP. In other words, the subclass may have overridden the method and provided a different implementation, but it must still meet the requirements of the LSP by providing a valid implementation of the method that is consistent with the superclass.
Overall, the Liskov Substitution Principle is a useful design principle that helps to ensure that subtypes of a superclass are able to replace objects of the superclass without affecting the correctness of the program.
Violations of the Interface Segregation Principle (ISP) can have a negative impact on software development in several ways.
Firstly, violations of the ISP can lead to tight coupling between objects, which can make it difficult to modify or replace individual components of the system without affecting other components. This can make it difficult to maintain and extend the system over time, as it can be difficult to isolate and test individual components.
Secondly, violations of the ISP can result in increased dependencies between objects, which can make it more difficult to understand and maintain the system over time. This can make it more difficult to modify or replace individual components of the system without affecting other components, as it can be difficult to determine the impact of changes on the system as a whole.
Thirdly, violations of the ISP can promote loose coupling and modular design, which can make it easier to modify or replace individual components of the system without affecting other components. This can make it easier to maintain and extend the system over time, as it can be easier to isolate and test individual components.
Overall, violations of the ISP can have a negative impact on software development by making it more difficult to maintain and extend the system, and by promoting tight coupling and increased dependencies between objects. It is important to carefully design and implement interfaces that follow the ISP, to ensure that objects are loosely coupled and that the system is modular and maintainable over time.
A drawback of the Anemic Domain Model is "Objects become bloated with both data and behavior."
The Anemic Domain Model is a design pattern that was introduced by Eric Evans in his book "Domain-Driven Design: Tackling Complexity in the Heart of Software" (2003). The model is based on the idea that domain objects should have a small set of responsibilities and should be focused on the core attributes and behaviors of the object.
One of the main advantages of the Anemic Domain Model is that it encourages encapsulation and reduces coupling between objects. By focusing on the core attributes and behaviors of an object, the model helps to create a clear and focused domain model that is easy to understand and maintain.
However, the Anemic Domain Model can also have drawbacks. One of the main drawbacks of the Anemic Domain Model is that it can lead to objects becoming bloated with both data and behavior. This can make it difficult to understand and maintain the object, as it can become difficult to distinguish between the object's data and behavior.
In addition, the Anemic Domain Model can also lead to objects becoming too tightly coupled to each other, which can make it difficult to modify the object's behavior without affecting other parts of the program.
Overall, while the Anemic Domain Model can be a useful design pattern in some cases, it can also have drawbacks such as bloated objects and tightly coupled objects. It is important to carefully consider the trade-offs and use the model in a way that is appropriate for the specific domain and problem being solved.
An object that exposes its internal state through a public getter method violates the Tell, Don't Ask Principle.
The Tell, Don't Ask Principle suggests that objects should tell other objects what to do, rather than asking other objects for their state. However, if an object exposes its internal state through a public getter method, it is allowing other objects to access the object's internal state directly, which violates the principle.
In other words, the public getter method is violating the Tell, Don't Ask Principle because it allows other objects to access the object's internal state directly, rather than allowing them to tell the object what to do. This can make it difficult to modify the object's behavior without affecting other parts of the program, and can make the object more difficult to understand and maintain.
To avoid violating the Tell, Don't Ask Principle, it is generally recommended to use methods or functions to allow other objects to perform a specific task, rather than allowing them to access the object's internal state directly. This can help to ensure that the object's behavior is encapsulated and can be easily modified without affecting other parts of the program.
Overall, while it is possible to expose internal state through public getter methods, it is generally considered bad practice and can lead to problems such as violations of the principle of encapsulation and the difficulty of modifying the object's behavior.
The Tell, Don't Ask Principle is a design principle that encourages objects to expose behavior instead of state.
The Tell, Don't Ask Principle is a design principle that was introduced by Uncle Bob Martin (also known as Robert C. Martin) in the book "Agile Software Development, Principles, Patterns, and Practices" (2002). The principle states that objects should tell other objects what to do, rather than asking other objects for their state.
In other words, the Tell, Don't Ask Principle suggests that objects should provide methods or functions that allow other objects to perform a specific task, rather than allowing other objects to access the object's internal state directly. This helps to ensure that the object's behavior is encapsulated and can be easily modified without affecting other parts of the program.
The Tell, Don't Ask Principle is an important principle in object-oriented programming, as it helps to create more modular, flexible, and maintainable code. By following the Tell, Don't Ask Principle, you can create code that is easier to understand, test, and modify, and that can be easily extended and adapted to new requirements.
Overall, the Tell, Don't Ask Principle is a useful design principle that encourages objects to expose behavior instead of state, which can help to create more modular, flexible, and maintainable code.
The disadvantage of data exposure is "It violates the principle of encapsulation."
Data exposure is a concept in object-oriented programming that refers to the practice of exposing the internal data of an object to other parts of the program. This can make it difficult to maintain the integrity and consistency of the object's data, as it can be difficult to ensure that the data is used correctly and in a consistent manner.
In object-oriented programming, it is generally considered good practice to encapsulate the data of an object and to provide methods or functions that allow other parts of the program to access and manipulate the data. This helps to ensure that the object's data is used correctly and in a consistent manner, and that the object's behavior is encapsulated and can be easily modified without affecting other parts of the program.
While data exposure can be useful in some cases, it can also lead to problems such as violations of the principle of encapsulation and the difficulty of maintaining the integrity and consistency of the object's data. Therefore, it is generally recommended to use data hiding and encapsulation to ensure that objects are used correctly and in a consistent manner.
The Shotgun Surgery anti-pattern is "Modifying the implementation of a method in multiple classes."
Shotgun Surgery is an anti-pattern in software development that occurs when a change is made to a method or module in multiple places without considering the consequences of the change. This can lead to significant and unexpected issues, such as bugs, performance problems, and maintenance problems.
In the case of modifying the implementation of a method in multiple classes, the Shotgun Surgery anti-pattern occurs when a change is made to the implementation of a method in one class, but the change is not propagated to all the other classes that depend on the method. This can lead to inconsistencies and unexpected behavior in the system, as different parts of the system may behave differently depending on the specific implementation of the method.
To avoid the Shotgun Surgery anti-pattern, it is important to carefully consider the consequences of any changes to the implementation of a method, and to ensure that those changes are propagated to all the relevant classes and modules. This can be achieved through the use of design patterns and other software design principles, such as the Single Responsibility Principle and the Open-Closed Principle.
The benefit of avoiding over-design is "It makes code more modular and extensible."
Over-design is the practice of designing a system that is too complex and difficult to modify or extend. This can lead to code that is difficult to understand, maintain, and update over time.
By avoiding over-design, you can create code that is modular and extensible. This means that the code is designed to be easily divided into smaller, more focused modules that can be easily modified or extended without affecting the rest of the system. This makes it easier to add new features or fix bugs, as you can simply modify the relevant module without affecting the rest of the system.
Overall, avoiding over-design can help to create code that is more maintainable, scalable, and flexible, which is essential for long-term success and sustainability.
The difference between cohesion and coupling is "Cohesion refers to how closely related the responsibilities of a module are, while coupling refers to how much a module depends on other modules."
Cohesion is a measure of how closely related the responsibilities of a module are. It is a measure of how well the responsibilities of a module are grouped together and how well they are related to each other. A high cohesion score indicates that the responsibilities of a module are well-grouped and related to each other, while a low cohesion score indicates that the responsibilities of a module are spread out and unrelated to each other.
Coupling, on the other hand, is a measure of how much a module depends on other modules. It is a measure of how interdependent the modules are and how tightly coupled they are to each other. A high coupling score indicates that the modules are highly interdependent and tightly coupled, while a low coupling score indicates that the modules are loosely coupled and less interdependent.
In summary, cohesion is a measure of how closely related the responsibilities of a module are, while coupling is a measure of how much a module depends on other modules. Cohesion is a good measure to optimize in software design, as it helps to ensure that modules have a clear and well-defined responsibility.
Domain Driven Design based Microservices development?
Domain-driven design (DDD) is an approach to software development that emphasizes the importance of understanding the business domain in which the software operates. DDD focuses on the development of domain models that describe the core concepts and behaviors of the business domain, and they are used to guide the design of the software.
Microservices architecture is a software architecture style that involves breaking down a single application into smaller, independent services that communicate with each other through APIs. Each service is designed to perform a specific business function and can be developed, deployed, and scaled independently of the other services.
Domain-driven design can be applied to microservices architecture in several ways. One approach is to use bounded contexts to identify the core domain concepts and boundaries within which the microservices are designed. Each microservice can be designed to operate within its own bounded context, and they can communicate with each other through APIs.
Another approach is to use domain models to represent the core domain concepts and behaviors within each microservice. The domain models can be used to guide the design of the microservice, and they can be validated against the business requirements to ensure that they are accurate and complete.
Domain-driven design can also be applied to the design of the data model within each microservice. The data model can be designed to reflect the domain models, and it can be optimized for performance and scalability.
Overall, domain-driven design can be a powerful tool for microservices development, as it helps to ensure that the microservices are aligned with the business domain and that they are designed to meet the needs of the business.
Cloud releated questions
What is cloud computing and how does it work?
Cloud computing is a model of computing in which resources are provided on-demand with pay-as-you-go pricing. It involves delivering computing services over the internet, such as storage, processing power, and software, without direct management by the user. Cloud providers offer a range of services, including virtual machines, storage, databases, and networking, that can be accessed through a web interface or a command-line interface.
What are the different types of cloud providers and how do they differ?
There are several different types of cloud providers, including public, private, and hybrid clouds. Public clouds, such as Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform, are owned and operated by large corporations and organizations, and are designed to be scalable, reliable, and secure. Private clouds, such as OpenStack and VMware vSphere, are operated by smaller organizations or individuals, and are designed to be more secure and flexible. Hybrid clouds, which combine public and private clouds, are designed to provide a balance between the benefits of public and private clouds.
What is the difference between IaaS, PaaS, and SaaS?
IaaS (Infrastructure as a Service) provides a virtualized infrastructure layer, allowing users to create and manage virtual machines, storage, and networking resources. PaaS (Platform as a Service) provides a platform for developers to build and deploy applications, without needing to manage the underlying infrastructure. SaaS (Software as a Service) provides access to software applications over the internet, without needing to install or maintain the software on their own devices.
What is a cloud-native application and how does it differ from traditional applications?
A cloud-native application is designed to take advantage of the features and benefits of cloud computing, such as scalability, reliability, and automatic scaling. It is built using cloud-native technologies, such as containers, microservices, and serverless architecture. Cloud-native applications are designed to be resilient to failures, secure, and observable, and are typically built using a combination of programming languages, frameworks, and tools. Traditional applications, on the other hand, are typically built using monolithic architecture, and are typically designed to be single-tenant and run on a single server.
What is a containerization technology and how does it work?
A containerization technology is a way of packaging and deploying applications in a way that is isolated from the underlying operating system and hardware. Containers are lightweight, portable, and self-contained, and can be run on any machine that supports Docker. Containers are designed to be portable, meaning that they can be moved between environments without requiring any changes to the underlying software or hardware.
What is a serverless architecture and how does it work?
A serverless architecture is a cloud computing model where the cloud provider manages the infrastructure and automatically provisions and scales resources as needed. In a serverless architecture, developers write code in the form of functions or microservices, and the cloud provider automatically provisions the resources needed to run those functions. The cloud provider also automatically scales the resources up or down based on the amount of traffic or workload.
What is a microservices architecture and how does it differ from a monolithic architecture?
A microservices architecture is a software architecture style where an application is built as a collection of small, independent services that communicate with each other through APIs. Each service is designed to perform a specific task, and can be developed, tested, and deployed independently of the other services. Microservices architecture is designed to be scalable, resilient, and secure, and is often used in modern software development. Monolithic architecture, on the other hand, is a traditional software architecture style where an entire application is built as a single unit.
What is a load balancer and how does it work?
A load balancer is a device that distributes network traffic across multiple servers to improve performance and reliability. It is typically used to distribute incoming traffic to multiple servers that are running the same application, so that if one server becomes overloaded or fails, the load balancer can automatically distribute the traffic to other servers. Load balancers can be configured to use different algorithms, such as round-robin, least connections, or weighted round-robin, to distribute traffic in a more efficient way.
What is a database and how does it work?
A database is a structured collection of data that is stored and managed in a database management system. It is used to store and retrieve data for applications, such as web applications, mobile applications, and enterprise applications. Databases can be used to store a wide range of data, including text, images, audio, and video.
What is a caching layer and how does it work?
A caching layer is a component of a software system that stores frequently accessed data in memory or on disk, in order to improve performance and reduce the number of requests to the underlying data source. When a user requests data, the caching layer first checks if the data is already in the cache. If it is, the data is returned immediately without querying the underlying data source. If the data is not in the cache, the caching layer retrieves it from the data source, stores it in the cache, and returns it to the user. This reduces the response time and the load on the data source. Examples of caching layers include Redis, Memcached, and Varnish.
What is a message queue and how does it work?
A message queue is a component of a software system that allows different parts of the system to communicate asynchronously by sending and receiving messages. When a sender sends a message to a message queue, the message is stored in the queue until a receiver retrieves it. The receiver can retrieve messages from the queue in the order they were added, or based on other criteria such as message priority or content. This decouples the sender and receiver, allowing them to operate independently and asynchronously. Message queues are used in a variety of scenarios, such as task scheduling, event processing, and distributed systems. Examples of message queue systems include RabbitMQ, Apache Kafka, and Amazon SQS.
What is a workflow automation tool and how does it work?
A workflow automation tool is a software system that automates and streamlines business processes by defining, executing, and managing workflows. Workflows are sequences of tasks or activities that need to be performed in a specific order, often involving multiple people or systems. Workflow automation tools allow users to define workflows graphically or through code, and then execute them automatically based on predefined triggers or events. Workflows can include tasks such as approvals, notifications, data processing, and integrations with other systems. Workflow automation tools can improve efficiency, reduce errors, and increase visibility into business processes. Examples of workflow automation tools include Zapier, Microsoft Power Automate, and Nintex.
What is a monitoring tool and how does it work?
A monitoring tool is a software system that monitors the performance, availability, and health of a software system, network, or infrastructure. Monitoring tools collect data such as CPU usage, memory usage, network traffic, and application logs, and then analyze and visualize this data to provide insights into the system's behavior and identify potential issues. Monitoring tools can also generate alerts or notifications when certain thresholds or conditions are met, allowing operators to take corrective action before issues become critical. Monitoring tools are used in a variety of scenarios, such as IT operations, DevOps, and security. Examples of monitoring tools include Nagios, Zabbix, and Prometheus.
What is a backup and restore strategy and how does it work?
A backup and restore strategy is a plan for creating and storing copies of data or systems in order to recover them in the event of a data loss or system failure. Backup and restore strategies typically involve creating regular backups of data or systems, storing them in a secure location, and then restoring them when needed. Backups can be created using a variety of methods, such as full backups, incremental backups, or differential backups. The backup and restore strategy should also specify how often backups are created, how long they are retained, and how they are tested for reliability and recoverability. Backup and restore strategies are critical for ensuring business continuity and minimizing the impact of data loss or system failures. Examples of backup and restore tools or services include Amazon S3, Google Cloud Storage, and Veeam Backup & Replication.
What is a disaster recovery strategy and how does it work?
A disaster recovery strategy is a plan for recovering a software system, network, or infrastructure in the event of a major disaster or disruption, such as a natural disaster, cyber attack, or hardware failure. Disaster recovery strategies typically involve creating redundant systems or infrastructure in a different location, and then implementing processes and procedures for recovering data and systems in the event of a disaster. Disaster recovery strategies may also involve creating backup and restore plans, testing disaster recovery procedures, and training personnel on disaster recovery procedures. Disaster recovery strategies are critical for ensuring business continuity and minimizing the impact of major disruptions. Examples of disaster recovery tools or services include AWS Disaster Recovery, Microsoft Azure Site Recovery, and Zerto.
Cloud Ops is a set of practices and tools that are used to manage and monitor cloud-based infrastructure and applications. The following are some of the key components of Cloud Ops:
Observability: Observability refers to the ability to monitor and analyze the behavior of cloud-based infrastructure and applications. This includes monitoring the performance, availability, and security of the infrastructure and applications, as well as collecting and analyzing data to identify trends and patterns.
Serviceability: Serviceability refers to the ability to provide customers with the ability to diagnose and resolve issues with cloud-based infrastructure and applications. This includes providing monitoring and alerting tools, as well as providing tools for troubleshooting and debugging.
Resiliency: Resiliency refers to the ability of cloud-based infrastructure and applications to recover from failures and continue to function properly. This includes designing the infrastructure and applications to be resilient to failures, such as using redundancy and failover mechanisms, and testing the resiliency of the infrastructure and applications.
Scalability: Scalability refers to the ability of cloud-based infrastructure and applications to handle increased traffic and workload. This includes designing the infrastructure and applications to be scalable, such as using auto-scaling mechanisms, and testing the scalability of the infrastructure and applications.
Fault Containment: Fault containment refers to the ability of cloud-based infrastructure and applications to isolate and contain failures and disruptions. This includes designing the infrastructure and applications to be fault-tolerant, such as using redundancy and failover mechanisms, and testing the fault containment of the infrastructure and applications.
Overall, Cloud Ops is a set of practices and tools that are used to manage and monitor cloud-based infrastructure and applications, and they help ensure that the infrastructure and applications are performing optimally and reliably.
messaging queues questions
1. What is a message queue and how does it work?
A message queue is a form of communication between software components or systems that enables asynchronous processing and decouples the sender and receiver of the message. Messages are stored in a queue until they can be processed by the receiver. A message queue typically has a producer, which generates messages, and a consumer, which processes them. Examples of message queue systems include RabbitMQ, Apache Kafka, and Amazon SQS.
2. What are the benefits of using a message queue in a distributed system?
Using a message queue in a distributed system has several benefits, including decoupling the sender and receiver of the message, enabling asynchronous processing, improving scalability and fault tolerance, and providing a buffer for handling spikes in traffic. Message queues also enable processing of messages in the order they were received, and can be used to implement reliable messaging patterns such as request-reply and publish-subscribe.
3. How do you ensure message ordering in a message queue system?
Message ordering can be ensured in a message queue system by using a first-in-first-out (FIFO) queue, where messages are processed in the order they were received. Some message queue systems also support message priorities, where higher-priority messages are processed before lower-priority messages. Another approach is to use message sequencing, where messages are assigned a sequence number that can be used to order them.
4. What is the difference between a message queue and a publish-subscribe system?
A message queue is a one-to-one communication pattern, where a message is sent from one producer to one consumer. A publish-subscribe system is a one-to-many communication pattern, where a message is sent from one producer to multiple consumers. In a publish-subscribe system, consumers subscribe to topics or channels, and receive messages published to those topics. In a message queue system, messages are stored in a queue until they can be processed by a single consumer.
5. How do you handle message failures in a message queue system?
Message failures can be handled in a message queue system by implementing retry mechanisms, where failed messages are retried a certain number of times before being discarded or sent to a dead-letter queue for further analysis. Monitoring and alerting can also be used to detect and respond to message failures. Some message queue systems also support message acknowledgement, where the receiver acknowledges receipt of the message, and the sender can detect and retry failed messages.
6. What are some common message queue systems and their use cases?
Some common message queue systems include RabbitMQ, Apache Kafka, Amazon SQS, and Microsoft Azure Service Bus. RabbitMQ is commonly used for general-purpose messaging, while Kafka is often used for high-throughput, real-time data streaming. SQS is a cloud-based message queue service that provides scalability and reliability, while Azure Service Bus is a messaging service that supports both queue-based and publish-subscribe messaging patterns.
7. How do you scale a message queue system to handle high throughput and/or large volumes of messages?
Message queue systems can be scaled to handle high throughput and large volumes of messages by using techniques such as horizontal scaling, where multiple instances of the message queue are deployed and load-balanced, and vertical scaling, where the resources of the message queue instances are increased. Other techniques include sharding, where messages are partitioned across multiple queues, and batching, where multiple messages are processed in a single operation.
8. What are some best practices for designing and implementing a message queue system?
Some best practices for designing and implementing a message queue system include using message serialization to ensure compatibility between different systems, using message versioning to handle changes in message formats, and using message compression to reduce network bandwidth. It is also important to consider security and access control, message durability and reliability, and monitoring and alerting.
9. How do you ensure message delivery and prevent message loss in a message queue system?
Message delivery and prevention of message loss can be ensured in a message queue system by using techniques such as message acknowledgement, where the receiver acknowledges receipt of the message, and message replication, where messages are replicated across multiple nodes for redundancy. Other techniques include message durability, where messages are persisted to disk, and message backup, where messages are backed up to another location.
10. What is the role of message brokers in a message queue system?
Message brokers are responsible for receiving messages from producers, storing them in a queue, and delivering them to consumers. They are often used to implement message routing and filtering, where messages are selectively delivered to specific consumers based on their content or metadata. Message brokers can also provide features such as message transformation, message aggregation, and message enrichment. Examples of message brokers include RabbitMQ, Apache Kafka, and ActiveMQ.
Kafka:
1. What is Kafka and how does it work?
Kafka is a distributed streaming platform that allows for the processing of high-volume, real-time data streams. It works by using a publish-subscribe model, where producers publish messages to topics, and consumers subscribe to those topics to receive the messages.
2. What are the benefits of using Kafka?
Kafka has several benefits, including high throughput and low latency, fault tolerance and scalability, and support for real-time data processing and analytics. It also provides a distributed architecture that allows for easy scaling and integration with other systems.
3. How does Kafka ensure message ordering?
Kafka ensures message ordering by using a partitioning mechanism, where messages are assigned to specific partitions based on their key. Messages within a partition are processed in the order they were received, ensuring message ordering.
4. How do you handle message failures in Kafka?
Message failures in Kafka can be handled by implementing a retry mechanism, where failed messages are retried a certain number of times before being sent to a dead-letter queue. Monitoring and alerting can also be used to detect and respond to message failures.
5. What are some common use cases for Kafka?
Kafka is commonly used for real-time data processing, stream processing, log aggregation, and messaging. It is also used in microservices architecture and as a data pipeline for big data processing.
RabbitMQ:
1. What is RabbitMQ and how does it work?
RabbitMQ is a message broker that allows for the exchange of messages between different systems or components. It works by using a publish-subscribe model, where messages are sent to exchanges, which then route the messages to queues for processing by consumers.
2. What are the benefits of using RabbitMQ?
RabbitMQ has several benefits, including reliability and durability, scalability and performance, and support for multiple messaging patterns such as request-reply and publish-subscribe. It also provides a flexible and extensible architecture that allows for easy integration with other systems.
3. How does RabbitMQ ensure message ordering?
RabbitMQ ensures message ordering by using a FIFO (first-in-first-out) queue, where messages are processed in the order they were received.
4. How do you handle message failures in RabbitMQ?
Message failures in RabbitMQ can be handled by implementing a retry mechanism, where failed messages are retried a certain number of times before being sent to a dead-letter queue. Monitoring and alerting can also be used to detect and respond to message failures.
5. What are some common use cases for RabbitMQ?
RabbitMQ is commonly used for messaging, task management, and job queues. It is also used in microservices architecture and as a data pipeline for big data processing.
Operating System Basics:
1. What is an operating system?
Answer: An operating system (OS) is a software program that manages computer hardware and software resources and provides common services for computer programs.
2. Explain the main functions of an operating system.
Answer: The main functions of an operating system are process management, memory management, device management, file management, and security management.
3. Describe the difference between a process and a thread.
Answer: A process is an instance of a program that is being executed, while a thread is a lightweight process that shares the same memory and resources as its parent process.
4. What are the differences between multiprogramming, multitasking, and multiprocessing?
Answer: Multiprogramming refers to the ability of an operating system to run multiple programs concurrently, while multitasking refers to the ability of an operating system to switch between multiple tasks or processes quickly. Multiprocessing refers to the ability of an operating system to use multiple CPUs or cores to run multiple processes simultaneously.
5. Explain the concept of a context switch.
Answer: A context switch is the process of saving the current state of a process or thread and restoring the state of another process or thread so that it can continue executing.
6. What are the differences between a monolithic kernel and a microkernel?
Answer: A monolithic kernel is a single large program that contains all the basic functions of the operating system, while a microkernel is a small kernel that provides only basic functionality and other services are provided by separate processes or modules.
7. Describe the process of process creation and termination.
Answer: Process creation involves allocating memory and resources for a new process, setting up the initial state of the process, and starting the execution of the process. Process termination involves releasing the memory and resources used by the process and notifying the operating system that the process has ended.
8. What is the difference between preemptive and non-preemptive scheduling?
Answer: Preemptive scheduling allows the operating system to interrupt a running process and switch to another process, while non-preemptive scheduling does not allow the operating system to interrupt a running process.
9. What are system calls, and how are they different from normal function calls?
Answer: System calls are functions that provide access to the services provided by the operating system, such as opening and closing files or allocating memory. They are different from normal function calls because they require a switch from user mode to kernel mode.
10. Explain the concept of kernel mode and user mode.
Answer: Kernel mode is a privileged mode of operation that allows the operating system to access hardware resources and perform privileged operations, while user mode is a non-privileged mode of operation that restricts access to hardware resources and privileged operations. Applications run in user mode, while the operating system runs in kernel mode.
Process Management:
11. Describe the process of process scheduling.
Answer: Process scheduling involves selecting the next process to run on a CPU based on a set of criteria, such as priority, time-sharing, and resource availability. The operating system maintains a list of processes in a ready queue, and the scheduler selects a process from this queue to run on the CPU. The process scheduling algorithm determines the order in which processes are selected from the ready queue.
12. What are the different scheduling algorithms used in operating systems?
Answer: Some common scheduling algorithms used in operating systems include First-Come, First-Served (FCFS), Shortest Job First (SJF), Priority Scheduling, Round Robin Scheduling, and Multi-Level Queue Scheduling.
13. Explain the differences between preemptive and non-preemptive scheduling.
Answer: Preemptive scheduling allows the operating system to interrupt a running process and switch to another process, while non-preemptive scheduling does not allow the operating system to interrupt a running process. Preemptive scheduling is more responsive to changes in the system, but can potentially cause more overhead due to frequent context switches.
14. What is a context switch, and how does it affect the performance of a system?
Answer: A context switch is the process of saving the current state of a process or thread and restoring the state of another process or thread so that it can continue executing. Context switches can affect the performance of a system by introducing overhead due to the time required to save and restore process state, and by potentially causing cache misses and other performance issues.
15. Describe the process of process synchronization using semaphores.
Answer: Process synchronization using semaphores involves using special variables called semaphores to coordinate access to shared resources between multiple processes or threads. A semaphore can be thought of as a counter that is used to control access to a shared resource. Processes or threads can acquire or release a semaphore to signal that they need access to the shared resource or that they are done using it.
16. Explain the dining philosophers problem and how it can be solved.
Answer: The dining philosophers problem is a classic problem in concurrent programming that involves a group of philosophers sitting around a table with a bowl of rice and chopsticks. Each philosopher needs two chopsticks to eat, and there are only five chopsticks available. The problem is to design a solution that allows the philosophers to eat without getting into a deadlock. One solution to the problem is to use a semaphore to control access to the chopsticks and to ensure that only one philosopher can pick up a chopstick at a time.
17. What is a critical section, and how is it protected in concurrent programming?
Answer: A critical section is a section of code that accesses shared resources and must be executed atomically to prevent race conditions and other synchronization issues. Critical sections can be protected in concurrent programming using synchronization primitives such as semaphores, mutexes, and monitors to ensure that only one process or thread can access the critical section at a time.
18. Explain the reader-writer problem and how it can be solved.
Answer: The reader-writer problem is another classic problem in concurrent programming that involves multiple processes or threads accessing a shared resource, where some processes or threads only read the resource and others also write to it. The problem is to design a solution that allows multiple readers to access the resource simultaneously while ensuring that writers have exclusive access. One solution to the problem is to use a reader-writer lock, which allows multiple readers to acquire the lock simultaneously but requires writers to wait until all readers have released the lock.
19. Describe the process of process communication using inter-process communication (IPC).
Answer: Inter-process communication (IPC) involves the exchange of data and messages between different processes running on the same or different computers. IPC can be achieved using various mechanisms such as pipes, sockets, shared memory, and message queues. The processes must agree on a common protocol for communication, and the operating system provides the necessary mechanisms for sending and receiving data between processes.
20. What are the different IPC mechanisms available in operating systems?
Answer: Some common IPC mechanisms available in operating systems include pipes, sockets, shared memory, message queues, and signals. Pipes and sockets are used for communication between processes on the same or different computers, while shared memory is used for fast communication between processes running on the same computer. Message queues and signals are used for asynchronous communication between processes.
Memory Management:
21. What is virtual memory, and how does it work?
Answer: Virtual memory is a technique used by operating systems to provide the illusion of a larger amount of memory than is physically available. It works by using a combination of hardware and software to map virtual memory addresses to physical memory addresses. When a program requests memory, the operating system allocates a virtual address space for the program, which is divided into pages. These pages are then mapped to physical memory as needed, allowing the program to access more memory than is physically available.
22. Explain the concept of paging and its advantages.
Answer: Paging is a memory management technique used by operating systems to manage virtual memory. It involves dividing memory into fixed-size pages and mapping these pages to physical memory as needed. The advantages of paging include improved memory utilization, as only the pages that are needed by a process are loaded into memory, and improved memory protection, as each process has its own virtual address space that is isolated from other processes.
23. What is a page fault, and how is it handled by the operating system?
Answer: A page fault occurs when a program attempts to access a page that is not currently in physical memory. When a page fault occurs, the operating system handles it by loading the required page from disk into memory and updating the page table to reflect the new mapping between the virtual page and the physical page. The program is then allowed to continue executing as if the page was always in memory.
24. Describe the process of memory allocation and deallocation.
Answer: Memory allocation involves reserving a portion of memory for use by a program or process. This can be done using system calls such as malloc() or new() in programming languages like C or C++. Memory deallocation involves freeing up memory that is no longer needed by a program or process. This can be done using system calls such as free() or delete() in programming languages like C or C++.
25. Explain the concepts of thrashing and working set model.
Answer: Thrashing is a phenomenon that occurs when a system spends more time swapping pages in and out of memory than executing actual processes. This can occur when the working set of a process exceeds the available physical memory, causing the system to spend more time swapping pages than executing processes. The working set model is a technique used to identify the set of pages that a process is currently using, which can be used to optimize memory allocation and reduce thrashing.
26. Describe the different page replacement algorithms, such as LRU, FIFO, and Optimal.
Answer: Page replacement algorithms are used by operating systems to choose which page to evict from physical memory when a page fault occurs. Some common page replacement algorithms include Least Recently Used (LRU), First-In, First-Out (FIFO), and Optimal. LRU replaces the page that has not been used for the longest time, FIFO replaces the page that was loaded first, and Optimal replaces the page that will not be needed for the longest time in the future.
27. What is the purpose of a page table, and how is it used in virtual memory management?
Answer: A page table is a data structure used by operating systems to keep track of the mapping between virtual memory addresses and physical memory addresses. Each process has its own page table, which is used to translate virtual memory addresses used by the process into physical memory addresses. The page table is used by the operating system to manage virtual memory and to handle page faults.
28. Explain the concept of demand paging and its advantages.
Answer: Demand paging is a technique used by operating systems to load pages into physical memory only when they are needed, rather than loading all pages into memory at once. This reduces the amount of memory required by a process and allows more processes to run simultaneously. Demand paging also reduces the time required to load a program into memory, as only the pages that are needed immediately are loaded.
29. What is a segmentation fault, and how is it handled by the operating system?
Answer: A segmentation fault occurs when a program attempts to access memory that it is not allowed to access, such as memory that has not been allocated or memory that is outside the bounds of an array. When a segmentation fault occurs, the operating system handles it by terminating the program and freeing up any resources that were allocated to the program.
30. Describe the process of process swapping.
Answer: Process swapping is a technique used by operating systems to free up memory by moving inactive processes from physical memory to disk. When a process is swapped out, its memory is written to disk and its page table is updated to reflect the new mapping between virtual memory and physical memory. The process is then removed from physical memory, freeing up space for other processes. When the process is needed again, it is swapped back into memory and its memory is read from disk.
File Systems:
31. What is a file system, and what are its components?
Answer: A file system is a way of organizing and storing files on a computer. It provides a logical structure for files and directories, and manages access to these files. The components of a file system typically include a file allocation table (FAT), a directory structure, and a set of file control blocks (FCBs) or inodes that describe the attributes and location of each file.
32. Explain the different types of file systems, such as FAT, NTFS, and ext4.
Answer: FAT (File Allocation Table) is a file system used by older versions of Windows and other operating systems. NTFS (New Technology File System) is a file system used by newer versions of Windows, and is designed to be more secure and reliable than FAT. ext4 is a file system used by Linux and other Unix-like operating systems, and is designed to be fast and scalable. Other file systems include HFS+ (used by macOS), exFAT (used for external storage devices), and many others.
33. Describe the process of file allocation and deallocation.
Answer: File allocation involves reserving space on a storage device for a file. This can be done using system calls such as fopen() or create() in programming languages like C or C++. File deallocation involves freeing up space that is no longer needed by a file. This can be done using system calls such as fclose() or delete() in programming languages like C or C++.
34. What is a file control block (FCB) or an inode, and how is it used in file systems?
Answer: A file control block (FCB) or an inode is a data structure used by file systems to store information about a file. This includes attributes such as the file's name, size, location, and permissions. The FCB or inode is used by the file system to manage access to the file and to locate the file's data on disk.
35. Explain the concepts of file descriptors and file descriptor tables.
Answer: A file descriptor is a unique identifier used by an operating system to identify an open file. It is typically an integer value that is returned by a system call such as open() or create() in programming languages like C or C++. A file descriptor table is a data structure used by the operating system to keep track of open files and their associated file descriptors. This table is used by the operating system to manage access to files and to ensure that multiple processes can access the same file without conflicts.
36. What is a file allocation table (FAT), and how does it work?
Answer: A file allocation table (FAT) is a data structure used by file systems to keep track of the location of files on disk. It is used by file systems such as FAT and exFAT. The FAT consists of a series of entries, each of which corresponds to a cluster on the disk. Each entry in the FAT contains a pointer to the next cluster in the file, allowing the file system to locate the entire file on disk.
37. Describe the differences between sequential, direct, and indexed file allocation methods.
Answer: Sequential file allocation involves storing files on disk in a contiguous block of space. Direct file allocation involves storing files in a series of non-contiguous blocks, with each block containing a pointer to the next block in the file. Indexed file allocation involves using an index to locate the blocks of a file on disk. Each block of the file contains a pointer to the next block, allowing the file system to locate the entire file on disk.
38. Explain the concept of file buffering and its advantages.
Answer: File buffering is a technique used by operating systems to improve the performance of file I/O operations. It involves temporarily storing data in memory before writing it to disk or reading it from disk. This can improve performance by reducing the number of disk I/O operations required and by allowing the operating system to optimize the order in which data is written or read from disk.
39. What is a symbolic link, and how does it work in file systems?
Answer: A symbolic link is a type of file that acts as a pointer to another file or directory. When a program or user accesses the symbolic link, the operating system redirects the request to the target file or directory. This allows multiple symbolic links to point to the same file or directory, and can simplify file organization and management.
40. Describe the process of file permission management in operating systems.
Answer: File permission management involves controlling access to files and directories on a computer. This is typically done using a set of permissions that specify which users or groups are allowed to read, write, or execute a file or directory. In Unix-like operating systems, permissions are managed using a set of three bits for the owner, group, and others. In Windows, permissions are managed using a set of access control lists (ACLs)
Device Management:
41. What is a device driver, and what is its role in an operating system?
Answer: A device driver is a software program that allows an operating system to communicate with a hardware device. It acts as an interface between the operating system and the device, translating commands from the operating system into a format that the device can understand. The device driver is responsible for managing the device's resources, such as memory and I/O operations, and for ensuring that the device operates correctly.
42. Explain the process of device allocation and deallocation.
Answer: Device allocation involves reserving a hardware device for use by a particular process or application. This can be done using system calls such as open() or create() in programming languages like C or C++. Device deallocation involves releasing the device when it is no longer needed. This can be done using system calls such as close() or delete() in programming languages like C or C++.
43. What are the different types of device scheduling algorithms used in operating systems?
Answer: Different types of device scheduling algorithms used in operating systems include First-Come, First-Served (FCFS), Shortest Job First (SJF), Priority Scheduling, Round Robin, and Deadline Scheduling. These algorithms are used to determine the order in which processes are scheduled to use a particular device, based on factors such as the length of time required for the process, the priority of the process, and the deadline for completing the process.
44. Describe the process of device interrupt handling.
Answer: Device interrupt handling is the process by which an operating system responds to an interrupt signal from a hardware device. When a device generates an interrupt signal, the operating system suspends the current process and switches to an interrupt handler routine. The interrupt handler routine communicates with the device driver to determine the cause of the interrupt and to take appropriate action, such as reading or writing data to the device.
45. What is a device control block (DCB), and how is it used in device management?
Answer: A device control block (DCB) is a data structure used by device drivers to manage access to a hardware device. The DCB contains information about the device, such as its address, status, and configuration settings. The device driver uses the DCB to manage the device's resources and to communicate with the device.
46. Explain the concept of spooling and its benefits.
Answer: Spooling is a technique used in operating systems to improve the performance of I/O operations. It involves temporarily storing data in a buffer or queue before sending it to a device. This allows the operating system to optimize the order in which data is sent to the device, reducing the amount of time that the device spends waiting for data. Spooling can improve the performance of printing and other I/O operations, and can also allow multiple processes to share a single device without conflicts.
47. What is a device register, and how does it relate to device management?
Answer: A device register is a hardware component used by a device to store data or control signals. It is typically accessed by a device driver to communicate with the device. The device driver uses the device register to read or write data to the device, or to control the device's operations. The device register is an important component of device management, as it allows the device driver to communicate with the device and to manage its resources.
48. Describe the differences between polling and interrupt-driven I/O.
Answer: Polling involves repeatedly checking a device to see if it is ready for data transfer. This can be done using a loop in the device driver. Interrupt-driven I/O, on the other hand, involves waiting for an interrupt signal from the device before initiating data transfer. This can reduce the amount of CPU time required by the device driver, as it allows the operating system to suspend the driver until the device is ready for data transfer. Interrupt-driven I/O is generally considered to be more efficient than polling, as it reduces the amount of CPU time required by the device driver.
49. What is a device queue, and how is it used in device management?
Answer: A device queue is a data structure used by operating systems to manage access to a hardware device. It contains a list of processes or requests that are waiting to use the device. The device queue is used by the operating system to determine the order in which processes are scheduled to use the device, based on factors such as the length of time required for the process, the priority of the process, and the deadline for completing the process.
50. Explain the concept of device management.
Answer: Device management is the process of managing access to hardware devices in an operating system. It involves allocating and deallocating devices, scheduling device access, handling interrupts, and managing device resources such as memory and I/O operations. Device management is an important component of operating system design, as it allows multiple processes to share a single device without conflicts, and ensures that devices are used efficiently and effectively.
Docker
1. What is Docker and how does it work?
Answer: Docker is an open-source containerization platform that allows developers to package, distribute, and run applications in isolated environments called containers. Docker works by creating lightweight, portable containers that can run on any operating system and can be easily deployed and scaled.
2. What are the benefits of using Docker?
Answer: Docker offers several benefits, including:
- Easy portability and scalability of applications
- Faster development and deployment cycles
- Improved efficiency and resource utilization
- Better isolation and security for applications
3. What is a Docker image and how is it created?
Answer: A Docker image is a read-only template that contains the instructions for creating a Docker container. It is created using a Dockerfile, which specifies the application code and dependencies that need to be installed in the container.
4. How do you create a Docker container?
Answer: To create a Docker container, you need to run the "docker run" command followed by the name of the Docker image you want to use. For example, "docker run myimage" will create a container based on the "myimage" Docker image.
5. What is the difference between a Docker container and a virtual machine?
Answer: A Docker container is a lightweight, isolated environment that shares the host operating system kernel, while a virtual machine is a complete operating system that runs on top of a hypervisor. Docker containers are more efficient and portable than virtual machines, as they require fewer resources and can run on any operating system.
6. How do you manage Docker containers?
Answer: Docker provides several commands for managing containers, including "docker ps" to list running containers, "docker start" and "docker stop" to start and stop containers, and "docker rm" to remove containers.
7. How do you deploy Docker containers in production?
Answer: To deploy Docker containers in production, you can use a container orchestration tool like Kubernetes or Docker Swarm. These tools allow you to manage and scale containers across multiple nodes and provide features like load balancing, service discovery, and automatic failover.
8. What are some best practices for Docker container security?
Answer: Some best practices for Docker container security include:
- Using only trusted Docker images
- Running containers with limited privileges and resources
- Regularly updating Docker images and containers
- Monitoring container activity and logs for suspicious activity
9. What are some common issues you might encounter when using Docker?
Answer: Some common issues with Docker include:
- Compatibility issues with older operating systems or applications
- Performance issues with large or resource-intensive containers
- Security vulnerabilities in Docker images or containers
- Networking issues when running containers across multiple nodes
10. How do you troubleshoot Docker issues?
Answer: To troubleshoot Docker issues, you can use Docker's built-in logging and debugging tools, such as "docker logs" to view container logs, "docker inspect" to view container details, and "docker exec" to run commands inside a running container. You can also consult Docker's documentation and community forums for help with specific issues.
Kubernetes
1. What is Kubernetes and why is it important?
Answer: Kubernetes is an open-source container orchestration platform that automates the deployment, scaling, and management of containerized applications. It is important because it simplifies the deployment and management of complex, distributed applications, and allows developers to focus on writing code rather than managing infrastructure.
2. What are the key components of Kubernetes?
Answer: The key components of Kubernetes include:
- Nodes: The worker machines that run containers
- Pods: The smallest deployable units in Kubernetes, which contain one or more containers
- Services: The network endpoints that allow communication between pods
- Replication controllers: The components that ensure the desired number of pod replicas are running
- Kubernetes API server: The component that exposes the Kubernetes API and controls the cluster state
3. How do you deploy an application in Kubernetes?
Answer: To deploy an application in Kubernetes, you need to create a deployment object that specifies the application container image, number of replicas, and other configuration details. You can then use the "kubectl apply" command to apply the deployment to the cluster.
4. How do you scale a Kubernetes deployment?
Answer: To scale a Kubernetes deployment, you can use the "kubectl scale" command to increase or decrease the number of replicas. You can also use Kubernetes' auto-scaling features to automatically scale based on CPU or memory usage.
5. What is a Kubernetes pod, and why is it important?
Answer: A Kubernetes pod is the smallest deployable unit in Kubernetes, which contains one or more containers. Pods are important because they encapsulate the application logic and dependencies, and provide a level of isolation and resource sharing between containers.
6. What is a Kubernetes service, and why is it important?
Answer: A Kubernetes service is a network endpoint that allows communication between pods. Services are important because they provide a stable IP address and DNS name for accessing the application, and allow for load balancing and service discovery.
7. How do you manage Kubernetes resources?
Answer: Kubernetes provides several commands for managing resources, including "kubectl get" to list resources, "kubectl describe" to show detailed information about a resource, and "kubectl delete" to delete resources. You can also use Kubernetes' built-in resource quotas and limits to ensure that resources are used efficiently.
8. What are some best practices for Kubernetes security?
Answer: Some best practices for Kubernetes security include:
- Using strong authentication and authorization controls
- Limiting access to the Kubernetes API
- Regularly updating Kubernetes and container images
- Monitoring for suspicious activity and auditing cluster activity
9. What are some common issues you might encounter when using Kubernetes?
Answer: Some common issues with Kubernetes include:
- Configuration errors, such as misconfigured pod or service definitions
- Resource constraints, such as insufficient CPU or memory
- Networking issues, such as misconfigured network policies or service discovery
- Performance issues, such as slow pod startup times or high network latency
10. How do you troubleshoot Kubernetes issues?
Answer: To troubleshoot Kubernetes issues, you can use Kubernetes' built-in logging and debugging tools, such as "kubectl logs" to view container logs, "kubectl exec" to run commands inside a running container, and "kubectl describe" to view detailed information about a resource. You can also consult Kubernetes' documentation and community forums for help with specific issues.
1. Code Jam
2. Hash Code
3. Kick Start
2. FB Hack
1. Problems
2. Contests
- Weekly Contests
- Biweekly Contests
3. Study Plan
- Comprehensive Study Plans
- In-Depth Topics
1. Practice
2. Contests
1. Practice
3. Contests
- CodeDrift
- Topic Wise
- Monthly
1. Google
2. Facebook
3. LeetCode
- Problems
- Contests
- Weekly Contests
- Biweekly Contests
- Study Plan
- Comprehensive Study Plans
- In-Depth Topics
6. InterviewBit
7. PrepBytes
8. Work@Tech
9. CodeSignal
- Arcade
- Interview Practice
- Challenges
- Algorithmic
- Easy
- Medium
- Hard
- Frontend
- Easy
- Medium
- Hard
- Database
- Easy
- Medium
- Hard
- DevOps
- Easy
- Medium
- Hard
- Algorithmic
- Company Challenges
10. HackerRank
- Prepare
- Prepare By Topics
- Tutorials
- Preparation Kits
- Interview Preparation
- Compete
11. HackerEarth
- Practice
- Compete
12. CodeChef
- Learn
- Rating Based
- Competition
- Interview Preparation
- Practice Topic
- Basic Programming
- Arrays
- Strings
- Math
- String
- Binary Search
- Data Structures
- Greedy Algorithms
- Dynamic Programming
- Graphs
- Segment Trees
- Practice
- Difficulty Rating
- Topics
- Compete
13. CodeForces
14. AtCoder
16. LightOJ
17. Toph
19. CSES
TECH Round -1
1. Solution to Dining Philosophers problem:
The solution to the Dining Philosophers problem involves implementing a mechanism to prevent deadlocks and resource starvation. One common solution is to use a semaphore for each fork, limiting the number of philosophers that can hold a fork at the same time. Another solution is to use a monitor to control access to the forks and ensure that each philosopher can only hold one fork at a time.
2. Difference between mutex and semaphore:
Mutex and semaphore are both synchronization mechanisms used to control access to shared resources in multi-threaded environments. The main difference is that a mutex allows only one thread to access a shared resource at a time, while a semaphore allows multiple threads to access a shared resource at the same time, up to a certain limit.
3. Questions about critical section:
A critical section is a part of a program where shared resources are accessed and modified. Questions about critical sections might include how to ensure mutual exclusion, how to prevent deadlocks and race conditions, and how to optimize performance and scalability.
4. Explain normalization in DBMS with example:
Normalization is the process of organizing data in a database to minimize redundancy and improve data integrity. There are several levels of normalization, from first normal form (1NF) to fifth normal form (5NF). For example, in 1NF, each attribute must have a single value, while in 2NF, the database must be in 1NF and all non-key attributes must be dependent on the primary key.
5. Write SQL query to find top 2 performers in a test:
Assuming a table called "students" with columns "name" and "score", the SQL query to find the top 2 performers in a test would be:
SELECT name, score
FROM students
ORDER BY score DESC
LIMIT 2;
6. Explain different phases of compiler, which data structure can be used for symbol table:
The different phases of a compiler include lexical analysis, syntax analysis, semantic analysis, code generation, and optimization. The symbol table is a data structure used to store information about identifiers in a program, such as variable names and function names. A hash table is commonly used as the data structure for the symbol table, as it allows for fast lookups and updates.
7. Some basic Linux commands:
Some basic Linux commands include:
- ls: list files and directories
- cd: change directory
- pwd: print working directory
- mkdir: create a new directory
- rm: remove a file or directory
- cp: copy a file or directory
- mv: move or rename a file or directory
- cat: print the contents of a file to the console
- grep: search for a pattern in a file or output
- ps: list running processes
- kill: terminate a running process
1. Questions related to hashing, hash function calculation, significance of hashing, Different techniques for collision resolution in hashing:
- Hashing is a technique used to map data of arbitrary size to data of fixed size.
- A hash function is used to calculate a hash value for a given input, which is typically a fixed-length string or number.
- The significance of hashing is that it allows for efficient storage and retrieval of data, as well as fast searching and sorting.
- Different techniques for collision resolution in hashing include chaining, open addressing, and rehashing.
2. Explain inheritance and abstraction with examples:
- Inheritance is a mechanism in object-oriented programming where a class inherits properties and methods from a parent class. For example, a subclass "Dog" can inherit properties and methods from a parent class "Animal".
- Abstraction is a mechanism in object-oriented programming where a class hides its implementation details from the user, and only exposes a high-level interface. For example, a class "Shape" can expose a method "draw()" without revealing the details of how it is implemented.
3. Questions related to compile time and run time polymorphism:
- Compile-time polymorphism refers to method overloading, where multiple methods with the same name but different parameters are defined in a class.
- Run-time polymorphism refers to method overriding, where a subclass overrides a method of its parent class with its own implementation.
4. Program 1- Insert node in doubly linked list:
Here is an example implementation of a method to insert a node in a doubly linked list:
public void insertNode(int data) {
Node newNode = new Node(data);
if (head == null) {
head = newNode;
tail = newNode;
} else {
tail.next = newNode;
newNode.prev = tail;
tail = newNode;
}
}
5. Program 2- Check whether a singly linked list is palindrome or not:
Here is an example implementation of a method to check whether a singly linked list is a palindrome:
public boolean isPalindrome(Node head) {
Node fast = head;
Node slow = head;
Stack<Integer> stack = new Stack<Integer>();
while (fast != null && fast.next != null) {
stack.push(slow.data);
slow = slow.next;
fast = fast.next.next;
}
if (fast != null) {
slow = slow.next;
}
while (slow != null) {
if (stack.pop() != slow.data) {
return false;
}
slow = slow.next;
}
return true;
}
6. Puzzle- There are n number of coins. All the coins have same weight except one. How to find that coin?
- One solution to this puzzle is to use a balance scale to compare groups of coins. Divide the coins into two groups of equal size, and weigh them against each other. If they balance, the odd coin is in the other group. If they don't balance, the odd coin is in the heavier group. Repeat this process with the group containing the odd coin until the odd coin is found.
1. Questions based on string literal pool concept and immutable class in java:
- String literal pool is a mechanism in Java where string literals are stored in a pool and reused if they already exist, to save memory and improve performance.
- Immutable class is a class in Java whose objects cannot be modified once they are created, to ensure thread safety and prevent unintended modifications.
2. How will you implement own immutable class:
- To implement an own immutable class in Java, the class should have final fields, a private constructor, and no setters or mutable methods. The class should also implement the Cloneable interface and override the clone() method to create a deep copy of the object.
3. Questions related to singleton class:
- Singleton class is a class in Java that allows only one instance of the class to be created, to ensure global access and prevent multiple instances from being created.
- Questions related to singleton class can include how to implement a singleton class, how to ensure thread safety in a singleton class, and how to prevent cloning or serialization of a singleton class.
4. Questions related to static binding and dynamic binding:
- Static binding is a mechanism in Java where the type of the object is determined at compile time, and the method to be called is resolved at compile time.
- Dynamic binding is a mechanism in Java where the type of the object is determined at runtime, and the method to be called is resolved at runtime.
5. Checked vs unchecked exceptions:
- Checked exceptions are exceptions in Java that must be declared in the method signature or caught in a try-catch block, to ensure proper handling and prevent errors at runtime.
- Unchecked exceptions are exceptions in Java that do not need to be declared or caught, and are typically caused by programming errors or unexpected conditions.
6. Question related to serialization:
- Serialization is a mechanism in Java where the state of an object is converted into a stream of bytes, which can be stored or transmitted over a network.
- Questions related to serialization can include how to implement serialization in a class, how to customize serialization using readObject() and writeObject() methods, and how to handle versioning and compatibility issues in serialization.
7. Interface and abstract class difference:
- Interface is a type in Java that defines a set of methods that must be implemented by a class, to ensure consistency and interoperability.
- Abstract class is a class in Java that cannot be instantiated, but can contain abstract methods and concrete methods, to provide a base implementation for subclasses.
- The main difference between interface and abstract class is that interface only defines methods, while abstract class can also define fields, constructors, and non-abstract methods.
8. Program 1 – A square matrix of integers is given. In each row and column, integers are sorted in descending order. Some of the integers are -ve. How to find number of -ve integers in minimum time?
- One solution to this problem is to start from the top-right corner of the matrix, and move left or down depending on whether the current element is positive or negative. This way, we can eliminate half of the matrix at each step, and find the number of negative integers in O(n) time complexity.
9. Puzzle – Switching 100 light bulbs puzzle:
- One solution to this puzzle is to switch on all the light bulbs in the first round, then switch off every second light bulb in the second round, every third light bulb in the third round, and so on, until the 100th round. At the end of the 100th round, the light bulbs that are still on are the ones whose numbers are perfect squares.
Program 1 – A square matrix of integers is given. In each row and column, integers are sorted in descending order. Some of the integers are -ve. How to find number of -ve integers in minimum time?
public static int countNegativeIntegers(int[][] matrix) {
int row = 0;
int col = matrix[0].length - 1;
int count = 0;
while (col >= 0 && row < matrix.length) {
if (matrix[row][col] < 0) {
count += col + 1;
row++;
} else {
col--;
}
}
return count;
}
Explanation: The above code starts from the top-right corner of the matrix and moves left or down depending on whether the current element is positive or negative. It keeps track of the count of negative integers encountered so far and adds the number of negative integers in the current row to the count. This way, it eliminates half of the matrix at each step and finds the number of negative integers in O(n) time complexity.
Puzzle – Switching 100 light bulbs puzzle:
public static List<Integer> getOnBulbs() {
List<Integer> onBulbs = new ArrayList<>();
boolean[] bulbs = new boolean[101];
for (int i = 1; i <= 100; i++) {
for (int j = i; j <= 100; j += i) {
bulbs[j] = !bulbs[j];
}
}
for (int i = 1; i <= 100; i++) {
if (bulbs[i]) {
onBulbs.add(i);
}
}
return onBulbs;
}
Explanation: The above code initializes an array of 100 boolean values, representing the state of each light bulb. It then switches on all the light bulbs in the first round, and switches off every second light bulb in the second round, every third light bulb in the third round, and so on, until the 100th round. At the end of the 100th round, the light bulbs that are still on are the ones whose numbers are perfect squares. The code then adds the indices of these light bulbs to a list and returns it.
TECH Round -2
1. Explain Client-server architecture.
- Client-server architecture is a model in which a client sends requests to a server, which processes the requests and sends back responses. The client and server can be on different machines connected over a network. This architecture allows for distributed computing and enables multiple clients to access the same resources and services provided by the server.
2. How socket works? write code of working of the socket.
- A socket is a software abstraction that represents a network endpoint. It allows applications to communicate with each other over a network. The basic steps involved in the working of a socket are:
1. Create a socket object using the socket() function.
2. Bind the socket to a specific address and port using the bind() function.
3. Listen for incoming connections using the listen() function.
4. Accept incoming connections using the accept() function.
5. Send and receive data using the send() and recv() functions.
Here is an example code for a server that listens for incoming connections on port 8080 and sends back a "Hello, World!" message to the client:
import java.net.*;
import java.io.*;
public class Server {
public static void main(String[] args) throws IOException {
ServerSocket serverSocket = new ServerSocket(8080);
Socket clientSocket = serverSocket.accept();
PrintWriter out =
new PrintWriter(clientSocket.getOutputStream(), true);
out.println("Hello, World!");
clientSocket.close();
serverSocket.close();
}
}
3. OSI Model. Told me to explain Each Layer.
- The OSI (Open Systems Interconnection) model is a conceptual framework for understanding how network communication works. It consists of seven layers, each with a specific function:
1. Physical layer: Deals with the physical transmission of data over a network.
2. Data link layer: Provides error-free transfer of data frames between nodes on a network.
3. Network layer: Provides routing and forwarding of data packets between networks.
4. Transport layer: Provides reliable end-to-end data delivery between applications.
5. Session layer: Manages the communication sessions between applications.
6. Presentation layer: Deals with the formatting and presentation of data.
7. Application layer: Provides access to network services for applications.
4. Questions on the Operating system.
- Questions on the operating system can cover a wide range of topics, such as process management, memory management, file systems, scheduling algorithms, synchronization, and security. Some sample questions include:
- What is a process and how is it managed by the operating system?
- How does virtual memory work and what are its advantages?
- What is a file system and how does it organize data on disk?
- What is a scheduling algorithm and how does it determine which process to run next?
- What is synchronization and how is it achieved in a multi-threaded environment?
- What are some common security threats and how can they be prevented or mitigated?
5. Process Synchronization? Algorithms?
- Process synchronization is the process of coordinating the execution of multiple processes or threads to ensure that they access shared resources in a safe and orderly manner. Some common synchronization algorithms include:
- Mutexes: A mutual exclusion object that allows only one process or thread to access a shared resource at a time.
- Semaphores: A synchronization object that allows multiple processes or threads to access a shared resource, but limits the number of concurrent accesses.
- Monitors: A synchronization construct that combines mutexes and condition variables to provide safe access to shared resources.
- Spinlocks: A synchronization technique that uses busy waiting to lock and unlock a shared resource.
6. Process vs Thread.
- A process is an instance of a program that is executing on a computer. It has its own memory space, system resources, and execution context. A thread is a lightweight process that shares the same memory space and system resources as its parent process. A process can have multiple threads, each of which can execute independently and concurrently.
7. How do threads share the same memory? Write code.
- Threads share the same memory by accessing the same variables and data structures in the shared memory space of the parent process. Here is an example code that demonstrates how threads can share the same memory:
public class SharedMemoryExample {
public static void main(String[] args) {
Counter counter = new Counter();
Thread t1 = new Thread(counter);
Thread t2 = new Thread(counter);
t1.start();
t2.start();
}
}
class Counter implements Runnable {
private int count = 0;
public void run() {
for (int i = 0; i < 10; i++) {
count++;
System.out.println("Count: " + count);
}
}
}
In this code, two threads are created that share the same instance of the Counter class. The Counter class has a private count variable that is incremented by each thread. As both threads access the same count variable, they share the same memory space.
8. Critical Section problem, Semaphores
- The critical section problem is a synchronization problem that arises when multiple processes or threads access a shared resource. Semaphores are a synchronization construct that can be used to solve the critical section problem. A semaphore is a variable that is used to control access to a shared resource. It has two operations: wait() and signal(). The wait() operation decrements the value of the semaphore and blocks if the value becomes negative. The signal() operation increments the value of the semaphore and wakes up any blocked processes or threads. By using semaphores to control access to a shared resource, the critical section problem can be solved and the integrity of the shared resource can be maintained.
1. Write code on the Insert node in the middle of the Linked List.
- Here is an example code for inserting a node in the middle of a linked list:
class Node {
int data;
Node next;
Node(int d) { data = d; next = null; }
}
public class LinkedList {
Node head;
public void insertInMiddle(int x) {
if (head == null) {
head = new Node(x);
return;
}
Node slow = head;
Node fast = head;
while (fast != null && fast.next != null) {
fast = fast.next.next;
slow = slow.next;
}
Node newNode = new Node(x);
newNode.next = slow.next;
slow.next = newNode;
}
}
In this code, the insertInMiddle() method inserts a new node with data x in the middle of the linked list. It first checks if the list is empty, and if so, creates a new node as the head. Otherwise, it uses two pointers, slow and fast, to traverse the list and find the middle node. It then creates a new node with data x and inserts it after the middle node.
2. Detect loop in LL. Write code.
- Here is an example code for detecting a loop in a linked list:
class Node {
int data;
Node next;
Node(int d) { data = d; next = null; }
}
public class LinkedList {
Node head;
public boolean hasLoop() {
if (head == null) {
return false;
}
Node slow = head;
Node fast = head;
while (fast != null && fast.next != null) {
fast = fast.next.next;
slow = slow.next;
if (slow == fast) {
return true;
}
}
return false;
}
}
In this code, the hasLoop() method uses two pointers, slow and fast, to traverse the list. The fast pointer moves twice as fast as the slow pointer. If there is a loop in the list, the fast pointer will eventually catch up to the slow pointer. If there is no loop, the fast pointer will reach the end of the list. The method returns true if a loop is detected, and false otherwise.
4. Heap stack
- Heap and stack are two types of memory allocation in computer programs. The stack is a region of memory that is used for storing local variables and function call frames. It is a last-in, first-out (LIFO) data structure and is managed automatically by the program runtime. The heap is a region of memory that is used for dynamic memory allocation, where memory can be allocated and deallocated at runtime. It is a more flexible data structure and is managed by the programmer.
5. JavaScript Q’s threading
- JavaScript is a single-threaded language, which means that it can only execute one task at a time. However, it supports asynchronous programming through the use of callbacks, promises, and async/await functions. These mechanisms allow JavaScript code to execute non-blocking I/O operations and handle events in a responsive and efficient manner.
6. Tree graphs time complexity traversal algorithm real-time ex
- Tree and graph traversal algorithms are used to visit all the nodes in a tree or graph in a specific order. The time complexity of these algorithms depends on the size and structure of the tree or graph. Some common traversal algorithms include:
- Depth-first search (DFS): Traverses the tree or graph by exploring as far as possible along each branch before backtracking.
- Breadth-first search (BFS): Traverses the tree or graph by exploring all the nodes at the current depth before moving on to the next depth.
- Pre-order traversal: Visits the current node, then the left subtree, then the right subtree.
- In-order traversal: Visits the left subtree, then the current node, then the right subtree.
- Post-order traversal: Visits the left subtree, then the right subtree, then the current node.
7. LL vs array
- Linked lists and arrays are two data structures used for storing collections of data. Linked lists are dynamic data structures that can grow or shrink in size at runtime. They consist of nodes that are linked together by pointers. Arrays are static data structures that have a fixed size and are stored in contiguous memory locations. They can be accessed using an index. Linked lists are more efficient for inserting or deleting elements at arbitrary positions, while arrays are more efficient for accessing elements by index.
a. Difference between process and thread, semaphores. Why semaphores are used and why we cannot use a simple integer flag to stop any process from accessing shared resources.
- A process is an instance of a program that is running on a computer, while a thread is a unit of execution within a process. A process can have multiple threads running concurrently. Semaphores are used to control access to shared resources by multiple processes or threads, by allowing only one process or thread to access the resource at a time. A simple integer flag cannot be used to stop any process from accessing shared resources because it does not provide a mechanism for synchronization or coordination between processes or threads.
b. Difference between SQL and NoSQL and advantages of NoSQL.
- SQL (Structured Query Language) is a relational database management system (RDBMS) that uses tables with predefined columns and rows to store and organize data. NoSQL (Not Only SQL) is a non-relational database management system that uses flexible schemas and document-oriented storage to store and organize data. NoSQL databases are often used for big data and real-time applications, as they can handle large volumes of unstructured data more efficiently than SQL databases. They also offer more flexibility and scalability than SQL databases, as they do not require predefined schemas and can be easily distributed across multiple servers.
c. Types of keys in MySQL.
- There are several types of keys in MySQL, including:
- Primary key: a unique identifier for each row in a table.
- Foreign key: a reference to a primary key in another table, used to establish relationships between tables.
- Unique key: a key that ensures that each value in a column is unique.
- Index key: a key that is used to speed up searches and queries on a table.
d. Advantages of NoSQL, and why RDBMS is better than NoSQL.
- Some advantages of NoSQL include:
- Scalability: NoSQL databases can be easily scaled horizontally across multiple servers, allowing for better performance and availability.
- Flexibility: NoSQL databases do not require predefined schemas, making them more flexible and adaptable to changing data models.
- Big data: NoSQL databases are better suited for handling large volumes of unstructured data, such as social media data or sensor data.
- RDBMS (Relational Database Management System) is better than NoSQL in certain scenarios, such as:
- Structured data: RDBMS is better suited for handling structured data, such as financial data or inventory data, where data consistency and integrity are critical.
- Complex queries: RDBMS is better suited for handling complex queries and transactions, as it provides a more robust and mature set of tools and features for data manipulation and analysis.
- ACID compliance: RDBMS is more likely to be ACID (Atomicity, Consistency, Isolation, Durability) compliant, which ensures data consistency and reliability in mission-critical applications.
Normalization is the process of organizing data in a database to reduce redundancy and improve data integrity. There are several levels of normalization, each with its own set of rules and requirements.
1. First Normal Form (1NF):
- The first normal form requires that each table has a primary key and that each column in the table contains atomic values (i.e., values that cannot be further broken down).
2. Second Normal Form (2NF):
- The second normal form requires that each non-key column in a table is fully dependent on the primary key. In other words, if a table has a composite primary key (i.e., a primary key made up of multiple columns), each non-key column must be dependent on the entire composite key, not just part of it.
3. Third Normal Form (3NF):
- The third normal form requires that each non-key column in a table is not transitively dependent on the primary key. In other words, if a non-key column is dependent on another non-key column, that column should be moved to a separate table.
4. Boyce-Codd Normal Form (BCNF):
- The Boyce-Codd normal form requires that each determinant (i.e., a column or set of columns that uniquely determines the value of another column) in a table is a candidate key.
5. Fourth Normal Form (4NF):
- The fourth normal form requires that each non-key column in a table is independent of all other non-key columns. In other words, if a table has multiple non-key columns that are related to each other, they should be moved to a separate table.
6. Fifth Normal Form (5NF):
- The fifth normal form requires that each table contains only one multi-valued dependency. A multi-valued dependency occurs when a non-key column is dependent on a combination of other non-key columns.
Each level of normalization builds on the previous level, with each level providing additional rules and requirements for database design. The goal of normalization is to reduce redundancy and improve data integrity, making it easier to maintain and update the database over time.
Angular
1. What is Angular?
- Angular is a popular open-source framework for building web applications, developed and maintained by Google. It uses TypeScript and follows the Model-View-Controller (MVC) architecture pattern.
2. What are the advantages of using Angular?
- Some advantages of using Angular include:
- Modular and reusable code
- Improved performance and scalability
- Better code organization and maintainability
- Support for two-way data binding and dependency injection
- Large and active community with extensive documentation and resources
3. What is the difference between AngularJS and Angular?
- AngularJS is the first version of Angular, released in 2010, while Angular is the newer and more advanced version, released in 2016. Angular is a complete rewrite of AngularJS and introduces many new features and improvements, such as improved performance, better mobile support, and enhanced security.
4. What is a component in Angular?
- A component in Angular is a building block of an application, which consists of a template, a class, and metadata. The template defines the view of the component, the class defines the behavior and data of the component, and the metadata provides additional information about the component, such as its selector and dependencies.
5. What is a directive in Angular?
- A directive in Angular is a marker on a DOM element that tells Angular to attach a specific behavior or functionality to that element. Directives can be used to create custom HTML tags, modify the behavior of existing elements, or add dynamic content to a template.
6. What is a service in Angular?
- A service in Angular is a class that provides a specific functionality or data to other parts of an application. Services can be used to share data between components, perform HTTP requests, or implement business logic. They are typically singleton objects that are injected into other components or services using dependency injection.
7. What is dependency injection in Angular?
- Dependency injection in Angular is a design pattern that allows components and services to declare their dependencies on other objects, and then have those dependencies provided to them automatically by the Angular injector. This makes it easier to write modular and reusable code, and improves the maintainability and testability of an application.
8. What is lazy loading in Angular?
- Lazy loading in Angular is a technique that allows modules to be loaded on demand, instead of being loaded all at once when the application starts. This can improve the performance of an application by reducing the initial load time and only loading the modules that are needed for a specific feature or page.
9. What is AOT compilation in Angular?
- AOT (Ahead-of-Time) compilation in Angular is a process that compiles the templates and components of an application into JavaScript code during the build process, instead of at runtime. This can improve the performance of an application by reducing the size of the code that needs to be downloaded and parsed by the browser.
10. What is RxJS in Angular?
- RxJS (Reactive Extensions for JavaScript) is a library for reactive programming in JavaScript, which is used extensively in Angular for handling asynchronous events and data streams. RxJS provides a set of operators and observables that can be used to create and manipulate streams of data, and makes it easier to handle complex asynchronous scenarios.
GIT
1. git init - initializes a new Git repository
2. git clone [url] - clones a remote repository to your local machine
3. git add [file] - adds a file to the staging area
4. git commit -m "message" - commits changes to the repository with a message
5. git status - shows the status of the repository
6. git log - shows the commit history of the repository
7. git push - pushes changes to a remote repository
8. git pull - pulls changes from a remote repository
9. git branch - shows the list of branches in the repository
10. git checkout [branch] - switches to a different branch
11. git merge [branch] - merges changes from a different branch into the current branch
12. git diff [file] - shows the differences between the current file and the last committed version
13. git stash - temporarily saves changes that are not ready to be committed
14. git reset [file] - unstages a file from the staging area
15. git remote - shows the list of remote repositories.
MAVEN
mvn clean
: This command cleans the target directory, deleting any compiled classes and files.
mvn compile
: This command compiles the source code into bytecode.
mvn test
: This command runs the unit tests for the project.
mvn package
: This command packages the project into a JAR or WAR file.
mvn install
: This command installs the project in the local Maven repository.
mvn deploy
: This command deploys the project to a remote repository.
mvn clean install
: This command cleans the target directory, compiles the source code, runs the unit tests, and packages the project into a JAR or WAR file.
mvn clean test
: This command cleans the target directory, compiles the source code, and runs the unit tests.
mvn dependency:tree
: This command prints the dependency tree of the project.
mvn dependency:analyze
: This command analyzes the dependencies of the project and prints any conflicts or version conflicts.
mvn dependency:update
: This command updates the dependencies of the project to the latest versions.
mvn dependency:get
: This command downloads the dependency specified in the pom.xml file.
mvn dependency:copy-dependencies
: This command copies the dependencies of the project to a specified directory.
mvn dependency:sources
: This command downloads the source code for the dependencies of the project.
mvn dependency:resolve
: This command resolves the dependencies of the project by downloading them from the remote repository.
1. mvn clean - deletes the target directory and all generated files
2. mvn compile - compiles the source code of the project
3. mvn test - runs the unit tests of the project
4. mvn package - packages the compiled code into a distributable format, such as a JAR or WAR file
5. mvn install - installs the packaged code into the local repository, making it available for other projects to use
6. mvn deploy - deploys the packaged code to a remote repository, making it available for other users to download and use
7. mvn dependency:tree - shows the dependency tree of the project
8. mvn clean install - cleans the project, compiles the source code, runs the tests, packages the code, and installs it into the local repository
9. mvn clean package - cleans the project, compiles the source code, runs the tests, and packages the code into a distributable format
10. mvn clean test - cleans the project, compiles the source code, and runs the unit tests.
GRADLE
gradle build
: This command builds the project and creates a JAR or WAR file in the build directory.
gradle clean
: This command cleans the project by deleting the build directory and any other temporary files.
gradle test
: This command runs all the tests in the project.
gradle run
: This command runs the main class of the project.
gradle dependencies
: This command displays the dependencies of the project and their versions.
gradle wrapper
: This command generates a Gradle wrapper for the project, which allows the project to be built without having Gradle installed on the system.
gradle assemble
: This command builds the project and creates a distributable package in the build directory.
gradle publish
: This command publishes the project to a repository, such as Maven Central or JCenter.
gradle cleanTest test
: This command cleans the test results and runs all the tests in the project.
gradle check
: This command runs all the checks, such as code style checks, static analysis, and unit tests.
REGIX
A password must start with an alphabet and followed by alphanumeric characters; Its length must be in between 8 to 20.
regex = “^(?=.*[0-9])(?=.*[a-z])(?=.*[A-Z])(?=.*[@#$%^&-+=()])(?=\\S+$).{8, 20}$”
Explanation:
^ used for starting character of the string.
(?=.*[0-9]) used for a digit must occur at least once.
(?=.*[a-z]) used for a lowercase alphabet must occur at least once.
(?=.*[A-Z]) used for an upper case alphabet that must occur at least once in the substring.
(?=.*[@#$%^&-+=()] used for a special character that must occur at least once.
(?=\\S+$) white spaces don’t allow in the entire string.
.{8, 20} used for at least 8 characters and at most 20 characters.
$ used for the end of the string.
Match any character except a newline:
^[^\\n]*$
Match any word character:
\w
Match any non-word character:
\W
Match any whitespace character:
\s
Match any non-whitespace character:
\S
Match any digit:
\d
Match any non-digit:
\D
Match any word character that is not a digit:
\w\W
Match any word character that is not a letter:
\w\W
Match any word character that is not a letter or a digit:
\w\W
Match any word character that is not a letter, a digit, or an underscore:
\w\W\d
Match any word character that is not a letter, a digit, or an underscore, or a hyphen:
\w\W\d\-
Match any word character that is not a letter, a digit, or an underscore, or a hyphen, or a space:
\w\W\d\-\s
Match any word character that is not a letter, a digit, or an underscore, or a hyphen, or a space, or a period:
\w\W\d\-\s\.\
Match any word character that is not a letter, a digit, or an underscore, or a hyphen, or a space, or a period, or a comma:
\w\W\d\-\s\.\,
\b
: Match the pattern only at the beginning or end of a word.
(?:\d{1,3}\.){3}\d{1,3}
: Match a sequence of one to three digits, followed by a period, repeated three times, followed by another sequence of one to three digits. This matches an IP address in the format "x.x.x.x", where each "x" is a sequence of one to three digits.
\b
: Match the pattern only at the beginning or end of a word.
This pattern will match IP addresses in the format "x.x.x.x", where each "x" is a sequence of one to three digits. It will not match IP addresses with leading zeros, such as "01.02.03.04", but it will match IP addresses with leading spaces, such as " 1.2.3.4".
If you want to match IP addresses with leading zeros, you can modify the pattern to allow for leading zeros in the sequence of one to three digits. Here's an example pattern that matches IP addresses with leading zeros:
\b(?:\d{1,3}\.){3}\d{1,3}\b
This pattern is the same as the previous pattern, except that it allows for leading zeros in the sequence of one to three digits. For example, this pattern will match IP addresses with leading zeros, such as "01.02.03.04" and "1.2.3.4".
please give a star and fork source code link
Here's the guide for problem constraints:

