The project is the official implementation of our BMVC 2020 paper, "Towards Fast and Light-Weight Restoration of Dark Images"
— Mohit Lamba, Atul Balaji, Kaushik Mitra
A single PDF of the paper and the supplementary is available at arXiv.org.
A followup has been accepted in CVPR 2021. There we reduce the time-computational complexity even further while managing to obtain much better restoration. Please visit the project page.
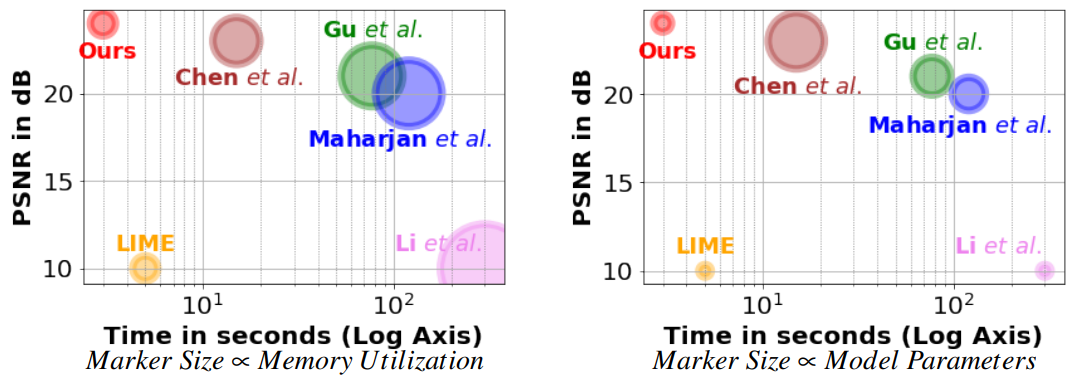
In this work we propose a deep neural network, called LLPackNet, that can restore very High Definition 2848×4256 extremely dark night-time images, in just 3 seconds even on a CPU. This is achieved with 2−7× fewer model parameters, 2−3× lower memory utilization, 5−20× speed up and yet maintain a competitive image reconstruction quality compared to the state-of-the-art algorithms.
Click to read full Abstract !
The ability to capture good quality images in the dark and near-zero lux conditions has been a long-standing pursuit of the computer vision community. The seminal work by Chen et al. has especially caused renewed interest in this area, resulting in methods that build on top of their work in a bid to improve the reconstruction. However, for practical utility and deployment of low-light enhancement algorithms on edge devices such as embedded systems, surveillance cameras, autonomous robots and smartphones, the solution must respect additional constraints such as limited GPU memory and processing power. With this in mind, we propose a deep neural network architecture that aims to strike a balance between the network latency, memory utilization, model parameters, and reconstruction quality. The key idea is to forbid computations in the High-Resolution (HR) space and limit them to a Low-Resolution (LR) space. However, doing the bulk of computations in the LR space causes artifacts in the restored image. We thus propose Pack and UnPack operations, which allow us to effectively transit between the HR and
LR spaces without incurring much artifacts in the restored image.
State-of-the-art algorithms on dark image enhancement need to pre-amplify the image before processing it. However, they generally use ground truth information to find the amplification factor even during inference, restricting their applicability for unknown scenes. In contrast, we propose a simple yet effective light-weight mechanism for automatically determining the amplification factor from the input image. We show that we can enhance a full resolution, 2848×4256, extremely dark single-image in the ballpark of 3 seconds even on a CPU. We achieve this with 2−7× fewer model parameters, 2−3× lower memory utilization, 5−20× speed up and yet maintain a competitive image reconstruction quality compared to the state-of-the-art algorithms
Watch the below video for results and overview of LLPackNet.

Click to see more Results !


The psuedo algorithm to perform Pack/UnPack operations is shown below.

In regard to the above algorithm, a naive implementation of the UnPack operation for α = 8, H = 2848 and W = 4256 can be achieved as follows,
iHR = torch.zeros(1,3,H,W, dtype=torch.float).to(self.device) counttt=0 for ii in range(8): for jj in range(8): iHR[:,:,ii:H:8,jj:W:8] = iLR[:,counttt:counttt+3,:,:]
counttt=counttt+3
However the above code is computationally slow and in PyTorch can be quickly implemented using the following vectorised code,
iLR.reshape(-1,8,3,H/8,W/8).permute(2,3,0,4,1).reshape(1,3,H,W)
If you find any information provided here useful please cite us,
@article{lamba2020LLPackNet, title={Towards Fast and Light-Weight Restoration of Dark Images}, author={Lamba, Mohit and Balaji, Atul and Mitra, Kaushik}, journal={arXiv preprint arXiv:2011.14133}, year={2020} }
You first need to download the SID dataset and install Rawpy for processing RAW images.
Now execute inference.py which will load images, save the enhanced images in a new directory and create inference.txt reporting average PSNR and SSIM. Prefer MATLAB over Python for PSNR and SSIM calculations.
The project was initially tested for PyTorch 1.3.1. But with introduction of new commads in the latest PyTorch release we have further squashed more for loops with vector commads giving even further speedup. Moreover we discovered that using iLR.reshape(-1,8,3,H/8,W/8).permute(2,3,0,4,1).reshape(1,3,H,W) to mimic UnPack 8x operations causes training instabilities with undersaturated black regions. The training thus required logging weights after every few epochs and fine-grain scheduling. The main reason for this instability is the incorrect interation between channel and batch dimension in the above vector operation. We thus recommend using iLR.reshape(-1,8,8,3,H//8,W//8).permute(0,3,4,1,5,2).reshape(-1,3,H,W) instead. The overall effect with this update is that the training becomes much more stable, all underexposed regions vanish, parameter count remains same while offering additional speedup.