A simple audio feature extraction library

Sonopy is a lightweight Python library used to calculate the MFCCs of an audio signal. It implements the following audio vectorization functions:
- Power spectrogram
- Mel spectrogram
- Mel frequency cepstrum coefficient spectrogram
- Lightweight
- Tiny, readable source code
- Visualize steps in calculation
import numpy as np
from sonopy import power_spec, mel_spec, mfcc_spec, filterbanks
sr = 16000
audio = np.random.random((2 * 16000))
powers = power_spec(audio, window_stride=(100, 50), fft_size=512)
mels = mel_spec(audio, sr, window_stride=(1600, 800), fft_size=1024, num_filt=30)
mfccs = mfcc_spec(audio, sr, window_stride=(160, 80), fft_size=512, num_filt=20, num_coeffs=13)
filters = filterbanks(16000, 20, 257) # Probably not ever useful
powers, filters, mels, mfccs = mfcc_spec(audio, sr, return_parts=True)pip install sonopy
pip install "sonopy[example]" # For example.py
pip install "sonopy[comparison]" # For comparison.py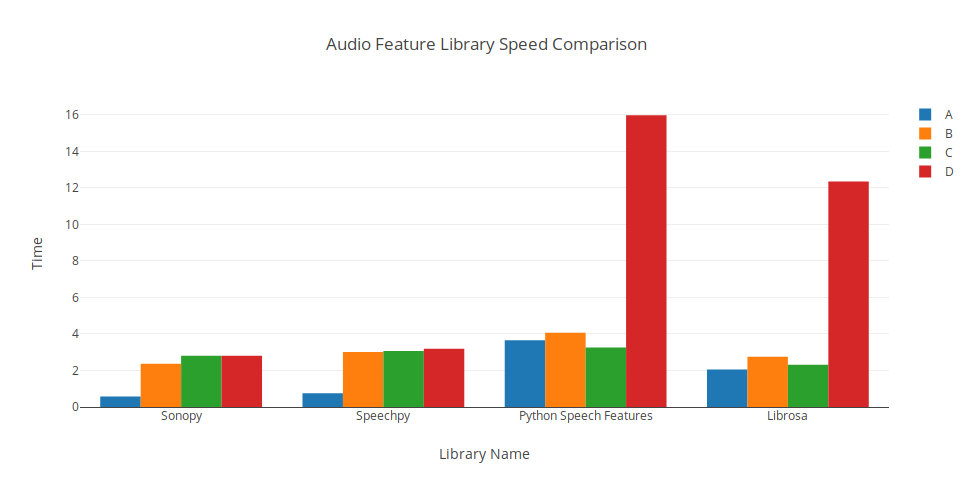
| Param Set | Audio Len | Stride | Window | FFT Size | Sample Rate | Ceptral Coeffs | Num Filters | Loops |
|---|---|---|---|---|---|---|---|---|
| C | 16000 | 0.1 | 0.1 | 2048 | 16000 | 13 | 20 | 2000 |
| B | 240000 | 0.05 | 0.05 | 2048 | 16000 | 13 | 20 | 200 |
| A | 480000 | 0.01 | 0.01 | 2048 | 16000 | 13 | 20 | 20 |
| D | 16000 | 0.1 | 0.1 | 512 | 16000 | 13 | 20 | 20000 |
Library links:
Thanks to SpeechPy for providing an example of the concrete calculations for MFCCs. Much of the calculations in this library take influence from it.