本仓库依托于2024年西安交通大学课题组考核,学习AIGC相关内容,以此记录。
实现内容如下:
- 学会使用
Diffusers包调用StableDiffusionXL生成图片 - 在
Diffusers版本的StableDiffusionXL中复现Training-Free Layout Control with Cross-Attention Guidance论文
layout-guidance是在Stable Diffusion-v1.5的基础上做的实验,本项目将其复现到了SD2.1和SDXL1.0base,以创造更加精准、符合预期的图像生成体验。通过结合这两种技术,用户可以更细致地控制生成图像的各个方面,从全局布局到细节描绘,实现更高质量的图像创作。

- 项目地址:https://github.com/Stability-AI/generative-models
- 模型地址:https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0
Stable Diffusion是一个基于Transformers的模型,它利用扩散模型(Diffusion Models)的原理,能够从文本描述中生成高度详细的图像。该模型在多个数据集上进行训练,能够生成多样化和逼真的图像。
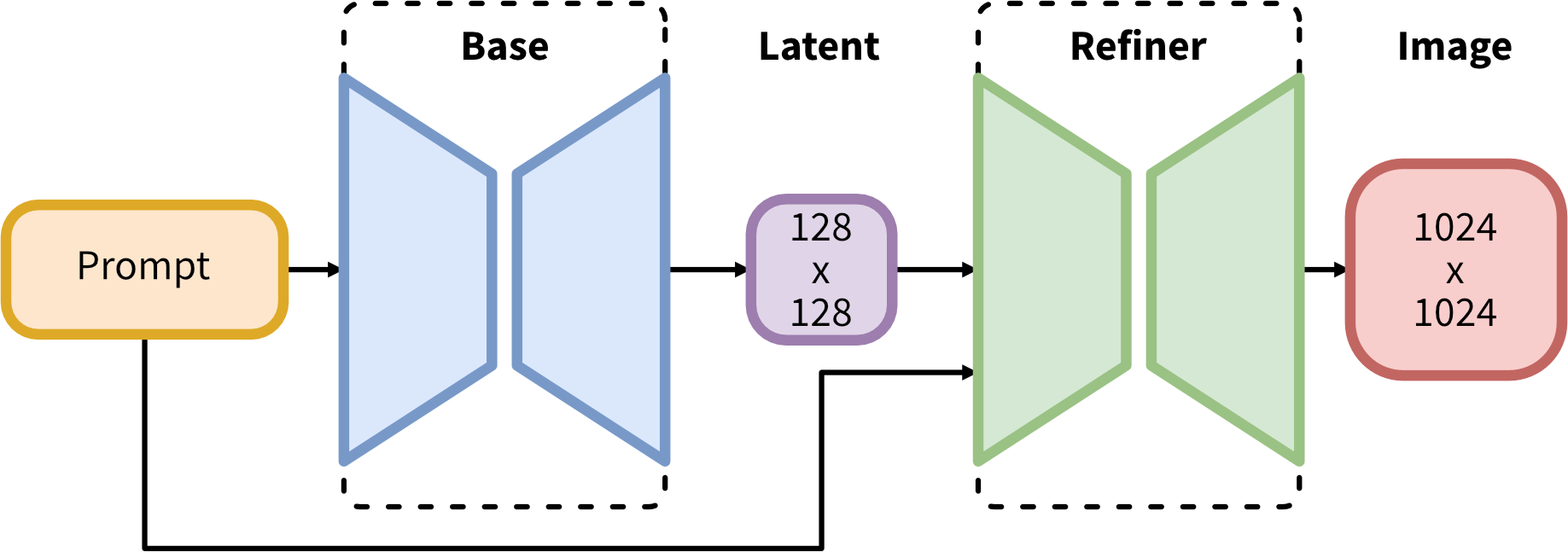
Stable Diffusion的模型架构主要包括以下几个部分:
- 文本编码器:将输入的文本描述转换为嵌入表示,这些嵌入表示作为条件信息输入到U-Net模型中。
- U-Net模型:作为噪声预测器,U-Net模型负责在每个反向扩散步骤中预测并去除添加的噪声。U-Net模型具有跳跃连接(Skip Connections),能够捕获图像中的多尺度信息,从而生成更精细的图像细节。
- 变分自动编码器(VAE):VAE在Stable Diffusion中用于将图像压缩到潜在空间,并在生成过程中从潜在空间恢复图像。这有助于减少计算复杂度并提高生成速度。

- 项目地址:https://github.com/silent-chen/layout-guidance
- Demo地址:https://huggingface.co/spaces/silentchen/layout-guidance
布局指导技术通过预定义或用户指定的图像布局(如对象的位置、大小、关系等),引导图像生成过程,从而确保生成的图像符合预期的构图和视觉层次。
为了forward-guidance解决的缺点,引入了一种替代机制,称之为backward-guidance。不是直接操纵注意力图,而是通过引入能量函数来偏置注意力:
$$
E\left(A^{(\gamma)}, B, i\right)=\left(1-\frac{\sum_{u \in B} A_{u i}^{(\gamma)}}{\sum_{u} A_{u i}^{(\gamma)}}\right)^{2}
$$
优化该函数鼓励第$i$个标记的交叉注意力图获得$B$指定的区域内的更高值。具体来说,在降噪器$D$的每个应用中,当评估层$ γ ∈ Γ $时,上述公式的损失的梯度通过反向传播计算以更新潜在$z_{t}\left(\equiv z_{t}^{(0)}\right)$:
其中$ η > 0
任务1:见task1.jpynb。
任务2:需要把SD推理过程中的注意力图给提取出来,然后计算loss,并对latent求梯度进行更新,因此需要修改原始的pipeline中的各个注意力计算部分,
最终将注意力矩阵作为返回值进行返回。
本项目在8卡NVIDIA GeForce RTX 3090、显存234GB的服务器上进行测试。
- 在
Stable-Diffusion-v1.5基础上进行布局控制
python inference.py general.type=sd1.5- 在
Stable-Diffusion-v2.1基础上进行布局控制
python inference.py general.type=sd2.1- 在
Stable-DiffusionXL-base-1.0基础上进行布局控制,在24GB的显存上会OOM,应当使用具有更大内存的显卡
python inference.py general.type=sdxl- promte:An astronaut riding a green hors

- Stable-Diffusion-v2.1
