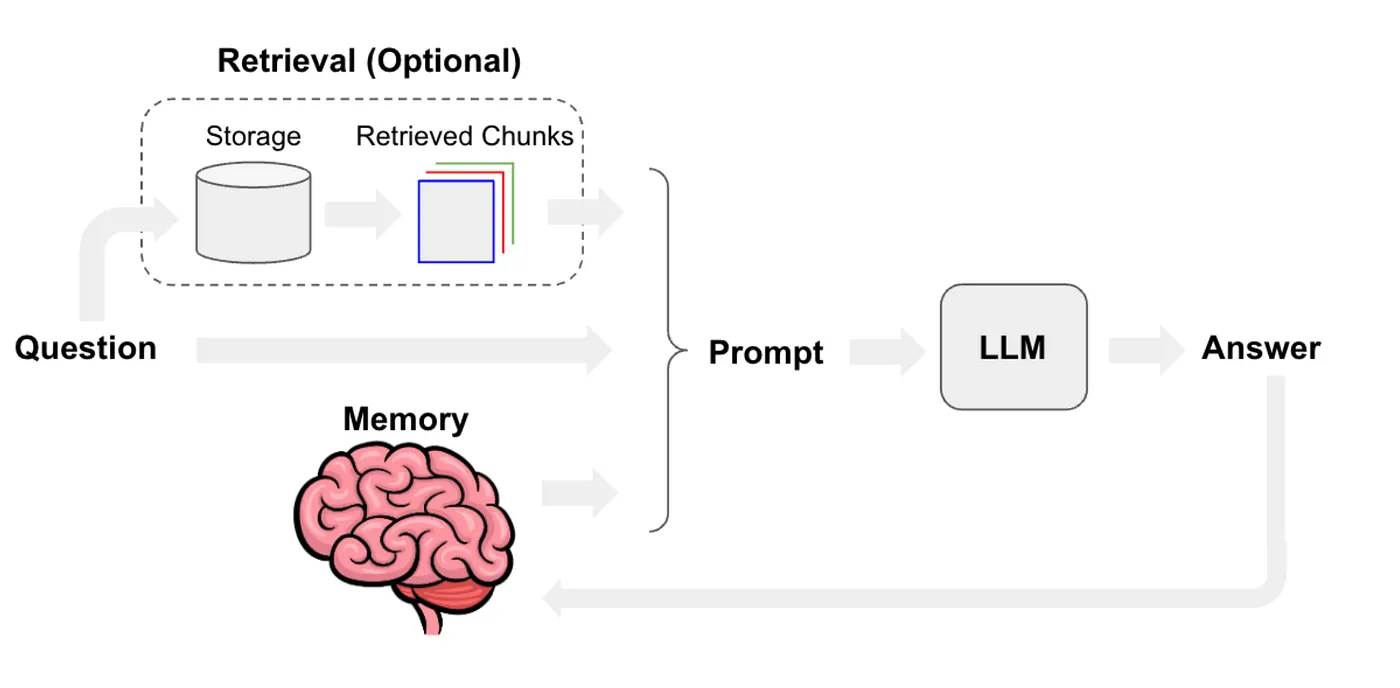
Retrieval-Augmented Generation (RAG) is a framework that combines information retrieval with generative AI. It allows models to retrieve relevant information from external sources or databases and use that data to generate more accurate and contextually relevant responses. By leveraging both retrieval and generation, RAG improves the accuracy and reliability of AI models, particularly in providing up-to-date information or handling complex questions.
This project provides an AI-based conversational assistant that leverages Retrieval-Augmented Generation (RAG) to extract knowledge from PDF documents. The system combines text embeddings, vector search, and an LLM to provide answers to user questions. Below is a detailed step-by-step workflow of how the application operates:
- Users upload a PDF file through the path mentioning on notebook. The uploaded file is processed to extract the text using
pdfplumber, a Python library for extracting text from PDFs.
- The Notebook utilizes the
pdfplumberlibrary to extract raw text from the uploaded PDF. Each page of the document is parsed, and the resulting text is prepared for further processing.
- The extracted text is split into smaller chunks using
RecursiveCharacterTextSplitter. This ensures the content is manageable for embeddings and retrieval, typically with a chunk size of 500 characters and an overlap of 50 characters.
- The chunked text is converted into numerical embeddings using
SpacyEmbeddings. These embeddings represent the semantic meaning of the chunks, enabling efficient search.

- A vector database is created using the
Chromalibrary, where the embeddings are stored. The vector database allows fast and efficient retrieval of relevant information based on user queries.
- The
ConversationalRetrievalChainis established usingLangChain, combining the embeddings stored in Chroma with a conversational memory buffer to track chat history and context.
- The Notebook integrates the
ChatGoogleGenerativeAI(Google's Gemini LLM) to generate relevant and intelligent responses to the user's questions based on the retrieved chunks of text from the vector store.
- Users can input their questions about the uploaded PDF document, and the system responds by retrieving the most relevant chunks from the vector store and generating an answer using the LLM. The conversation history is preserved for context.
- The features an expandable section where users can view the conversation history. This transparency allows users to revisit past queries and responses, fostering a better understanding of the context and flow of the interaction.

-
Efficient Knowledge Retrieval: By leveraging the power of RAG, the system combines retrieval and generation to answer specific questions accurately based on the content of uploaded PDF documents.
-
Scalability and Flexibility: With text chunking and embeddings, the app can handle large documents while ensuring fast and precise information retrieval.
-
Conversational AI: The conversation history memory makes the system more interactive, as it keeps track of previous questions and answers, maintaining context over long conversations.
-
Integration of Modern AI Tools: This project demonstrates the use of advanced tools like
Chromafor vector storage,LangChainfor conversation management, and Google'sGemini LLMfor generating human-like answers.