

![]()

|
|
|
|
|
|
- 🐍 Clean and beginner-friendly implementation of Reinforcement Learning algorithms in JAX
- ⚡ Vectorized environments for lightning-fast training
- 👩👨👦👧 Parallel agent training for statistically significant results
- 📊 Plotly graphs enabling state value visualization throughout training and averaged performance reports
- ✅ Easy installation using Poetry virtual environments
- ✍️ Code walkthroughs:
- Vectorize and Parallelize RL Environments with JAX: Q-learning at the Speed of Light⚡, published in Towards Data Science
- A Gentle Introduction to Deep Reinforcement Learning in JAX 🕹️, published in Towards Data Science, selected as part of the "Getting Started" column
| Type | Name | Source |
|---|---|---|
| Bandits | Simple Bandits (ε-Greedy policy) | Sutton & Barto, 1998 |
| Tabular | Q-learning | Watkins & Dayan, 1992 |
| Tabular | Expected SARSA | Van Seijen et al., 2009 |
| Tabular | Double Q-learning | Van Hasselt, 2010 |
| Deep RL | Deep Q-Network (DQN) | Mnih et al., 2015 |
| Type | Name | Source |
|---|---|---|
| Bandits | Casino (K-armed Bandits) | Sutton & Barto, 1998 |
| Tabular | GridWorld | - |
| Tabular | Cliff Walking | - |
| Continuous Control | CartPole | Barto, Sutton, & Anderson, 1983 |
| MinAtar | Breakout | Young et al., 2019 |
| Type | Name |
|---|---|
| Bandits | UCB (Upper Confidence Bound) |
| Tabular (model based) | Dyna-Q, Dyna-Q+ |
| Type | Name |
|---|---|
| MinAtar | Asterix, Freeway, Seaquest, SpaceInvaders |
Reproduction of the 10-armed Testbed experiment presented in Reinforcement Learning: An Introduction (chapter 2.3, page 28-29).
This experiment showcases the difference in performance between different values of epsilon and therefore the long-term tradeoff between exploration and exploitation.
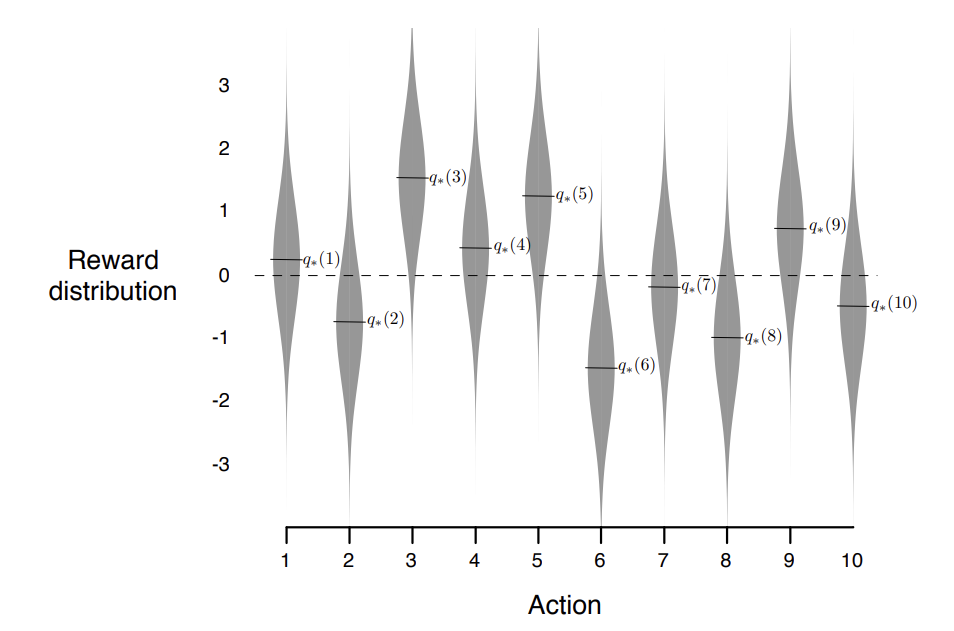
10-armed Testebed environment |
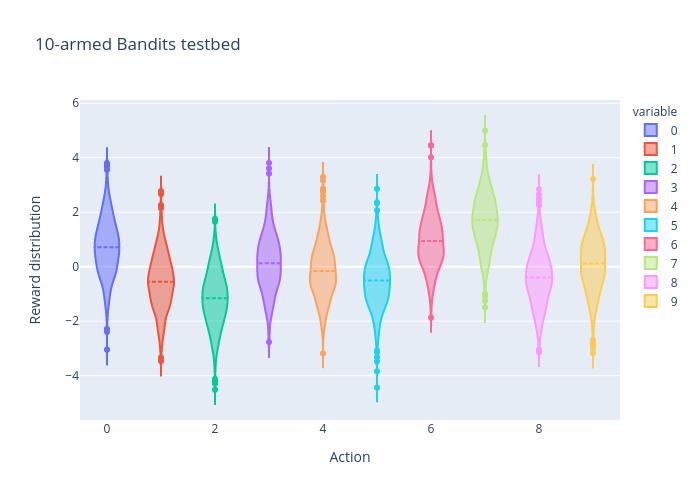
K-armed Bandits JAX environment |
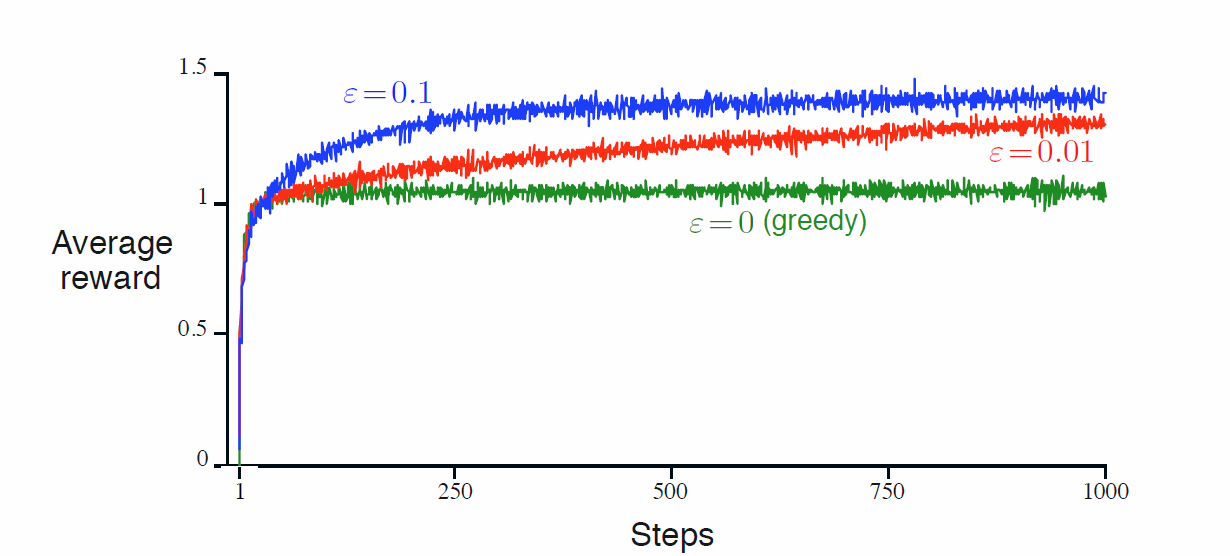
Results obtained in Reinforcement Learning: An Introduction |
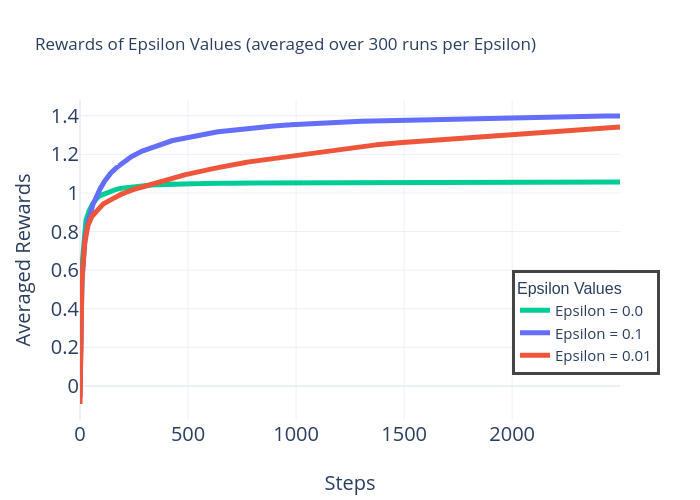
Replicated results using the K-armed Bandits JAX environment |
Reproduction of the CliffWalking environment presented in Reinforcement Learning: An Introduction (chapter 6, page 132).
This experiment highlights the difference in behavior between TD algorithms, Q-learning being greedy (as the td target is the maximum Q-value over the next state) and Expected Sarsa being safer (td target: expected Q-value over the next state).
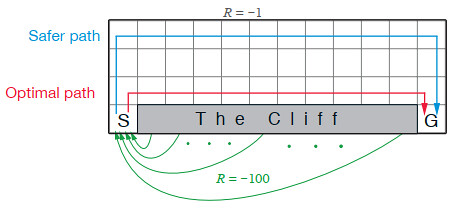
Described behaviour for the CliffWalking environment |
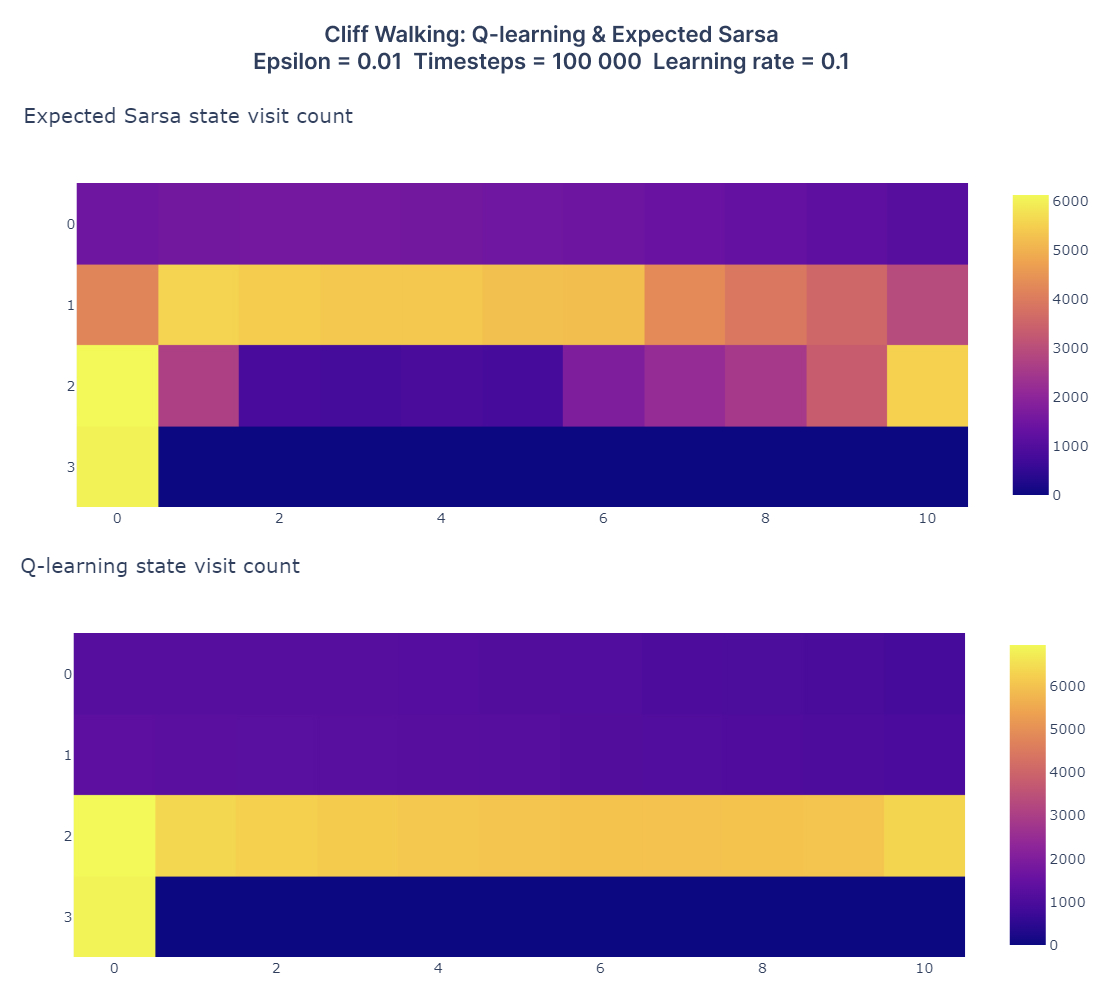
Comparison of Expected Sarsa (top) and Q-learning (bottom) on CliffWalking |
To install and set up the project, follow these steps:
-
Clone the repository to your local machine:
git clone https://github.com/RPegoud/jax_rl.git
-
Navigate to the project directory:
cd jax_rl -
Install Poetry (if not already installed):
python -m pip install poetry
-
Install project dependencies using Poetry:
poetry install
-
Activate the virtual environment created by Poetry:
poetry shell
- Reinforcement Learning: An Introduction Sutton, R. S., & Barto, A. G., The MIT Press., 2018
- Writing an RL Environment in JAX, Nikolaj Goodger, Medium, Nov 14, 2021
- JAX Tutorial Playlist, Aleksa Gordić - The AI Epiphany, YouTube, 2022
| Official JAX Documenation |