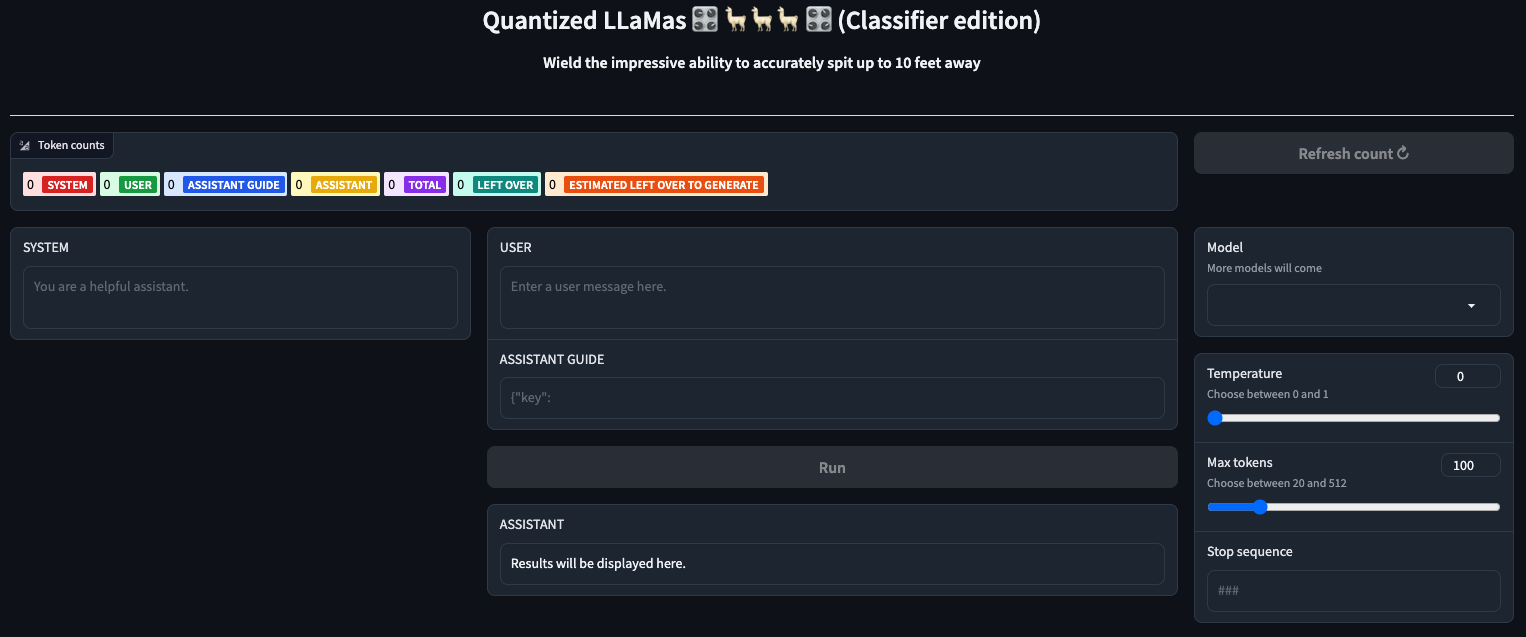
Quantized LlaMas is a tool that allows you to interact with the LLaMa language models.
It provides a user-friendly interface for generating responses based on system prompts, user inputs, and assistant guides.
The application has a UI built with Gradio.

To run the project, first make sure you have installed:
- Python 3.6 or newer
llama-cpp-python(follow installation instructions on https://github.com/abetlen/llama-cpp-python)gradio- If you are on a Mac, the following additional dependencies are required:
- Rust:
brew install rust - Xcode:
xcode-select --install
- Rust:
- GGML models used: https://huggingface.co/TheBloke (Tom Jobbins the GOAT)
You are responsible for anything you do with the models, just as you are responsible for anything you do with any dangerous object such as a knife, gun, lighter, or car.
Publishing anything the models generates is the same as publishing it yourself.
You are responsible for the content you publish, and you cannot blame the model any more than you can blame the knife, gun, lighter, or car for what you do with it.
To run the app, execute the command python main.py to initiate the Gradio web application.
This action will generate URLs resembling the following examples:
Running on local URL: http://127.0.0.1:7860
Running on public URL: https://50c0be910a804096fe.gradio.live
To launch the app, open the local URL in your web browser,
You may also use the public URL for devices outside your network.
The Token Counter displays the count of tokens used in the conversation.
It provides information about the number of tokens used by the system, user, assistant guide, and assistant.
Model: Choose the LLaMa model to use from the available options.
Temperature: Adjust the temperature parameter for controlling the randomness of the generated responses.
Max Tokens: Set the maximum number of tokens in the generated response.
Stop Sequence: Specify a stop sequence to stop the response generation.
In the Inference section, you can provide inputs for the system, user, and assistant guide.
This will generate a response based on these inputs and display it in the Assistant section.
The Refresh Token Count button updates the token count based on the inputs provided in the System, User, and Assistant Guide fields.
Tested with the following GGML models:
- Llama-2-13b
- Llama-2-13b-chat
- Wizard-Vicuna-30B-Uncensored
- Llama-30b
- Guanaco-33B
- Alpaca-Lora-30B
- Lazarus-30B
The Run button generates a response based on the provided inputs in the System, User, and Assistant Guide fields.
The generated response will be displayed in the Assistant section.
The app should resemble this design, with slight modifications to the UI in subsequent versions.