(数据库文件过大,未上传)
数据来源:国家科技报告服务系统【国家科技报告服务系统 (nstrs.cn)】
默认管理员登录用户名:admin
默认管理员登录密码:admin123
MySQL数据库8.x。
Neo4j数据库4.1.3 Enterprise。
新建名为ry-vue的MySQL数据库,运行sql文件导入数据库。
图数据库,import文件夹里的文件就是数据源,可以直接运行下面的语句完成导入。
LOAD CSV WITH HEADERS FROM 'file:///ry_map_province.csv' AS line CREATE (:Province { province_id: line.province_id, province_name: line.province_name})
LOAD CSV WITH HEADERS FROM 'file:///ry_map_subject.csv' AS line CREATE (:Subject { subject_id: line.subject_id, subject_name: line.subject_name})
LOAD CSV WITH HEADERS FROM 'file:///ry_map_company.csv' AS line CREATE (:Company { company_id: line.company_id, company_name: line.company_name})
LOAD CSV WITH HEADERS FROM 'file:///ry_map_project.csv' AS line CREATE (:Project { project_id: line.project_id, project_name: line.project_name})
项目-学科:ry_project_subject【项目-从属-学科】
LOAD CSV WITH HEADERS FROM 'file:///ry_project_subject.csv' AS line MATCH (from:Project { project_id: line.projectId }),(to:Subject {subject_id : line.subjectAreaId })MERGE (from)-[r:从属]->(to)
单位-项目:ry_company_project【单位-承担-项目】
LOAD CSV WITH HEADERS FROM 'file:///ry_company_project.csv' AS line MATCH (from:Company { company_id: line.companyId }),(to:Project {project_id : line.projectId })MERGE (from)-[r:承担]->(to)
省份-学科:ry_province_subject【地域-研究方向-学科】

LOAD CSV WITH HEADERS FROM 'file:///ry_province_subject.csv' AS line MATCH (from:Province { province_id: line.provinceId }),(to:Subject {subject_id : line.subjectAreaId })MERGE (from)-[r:研究方向]->(to)
# 进入项目目录
cd ruoyi-ui
# 安装依赖
npm install
# 强烈建议不要用直接使用 cnpm 安装,会有各种诡异的 bug,可以通过重新指定 registry 来解决 npm 安装速度慢的问题。
npm install --registry=https://registry.npmmirror.com
# 本地开发 启动项目
npm run dev修改数据库连接,编辑resources目录下的application-druid.yml,需要同时启动Redis和MySQL服务。
# 数据源配置
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
druid:
# 主库数据源
master:
url: 数据库地址
username: 数据库账号
password: 数据库密码1、系统环境
- Java EE 8
- Servlet 3.0
- Apache Maven 3
2、主框架
- Spring Boot 2.2.x
- Spring Framework 5.2.x
- Spring Security 5.2.x
3、持久层
- Apache MyBatis 3.5.x
- Hibernate Validation 6.0.x
- Alibaba Druid 1.2.x
4、视图层
- Vue 2.6.x
- Axios 0.21.x
- Element 2.15.x
Neo4j图数据库用的JDK11版本
项目后端用的JDK8版本
需要启动flaskChat项目【该项目调用了ChatGPT接口】。
nlp文件夹放的是TextCNN模型训练的源码。
数据集分类:名称和序号一一对应。
系统参考:介绍 | RuoYi
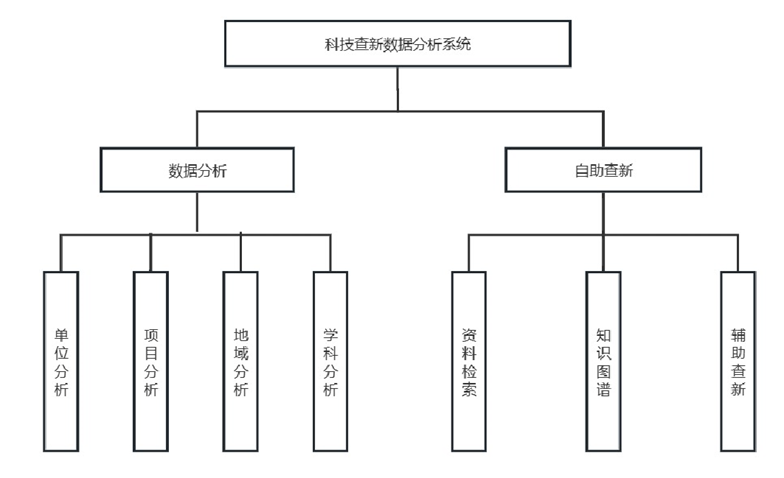
系统目标:
爬取了国家科技报告服务系统公开的科技文献数据。建立了科技报告知识图谱。从项目、单位、学科和地域角度对数据进行了分析,完成了多角度多形式的数据可视化展示。针对项目的科学技术要点完成了关键词的提取以及标准学科归类。
系统架构图:
系统界面:
首页
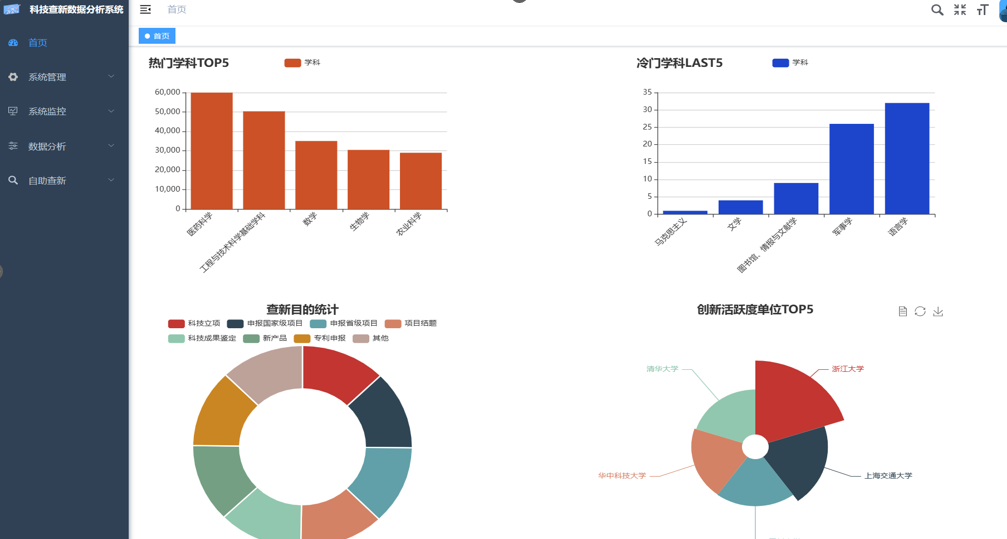
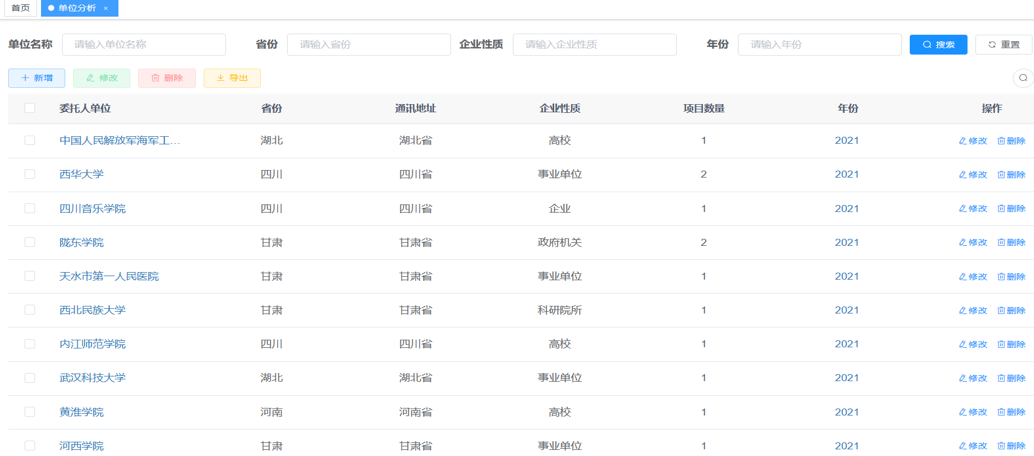
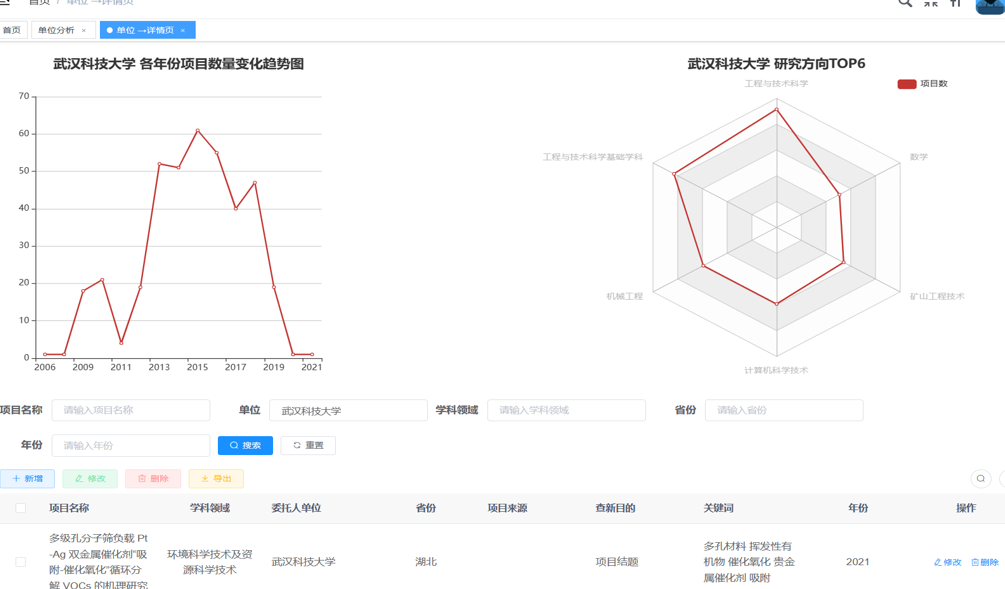
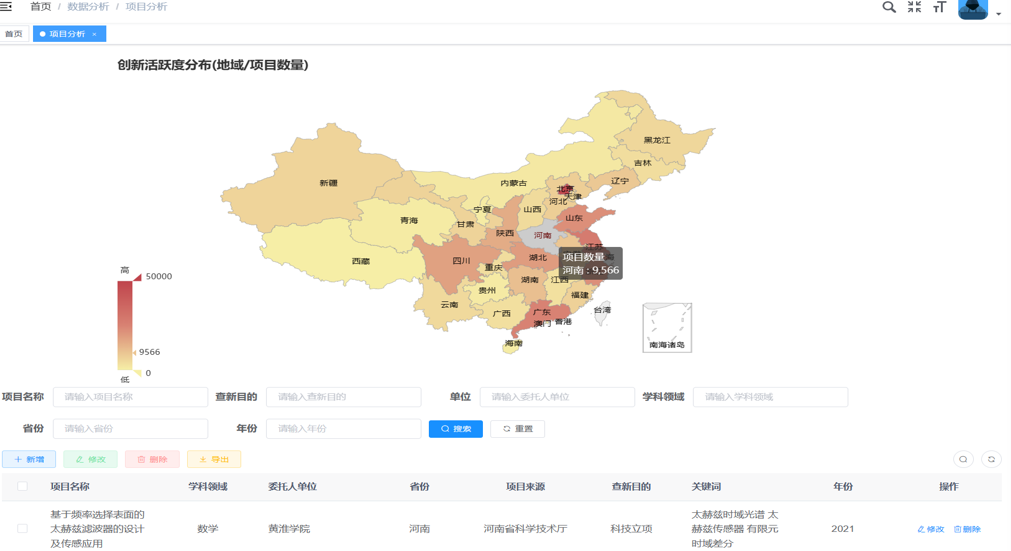
数据分析页

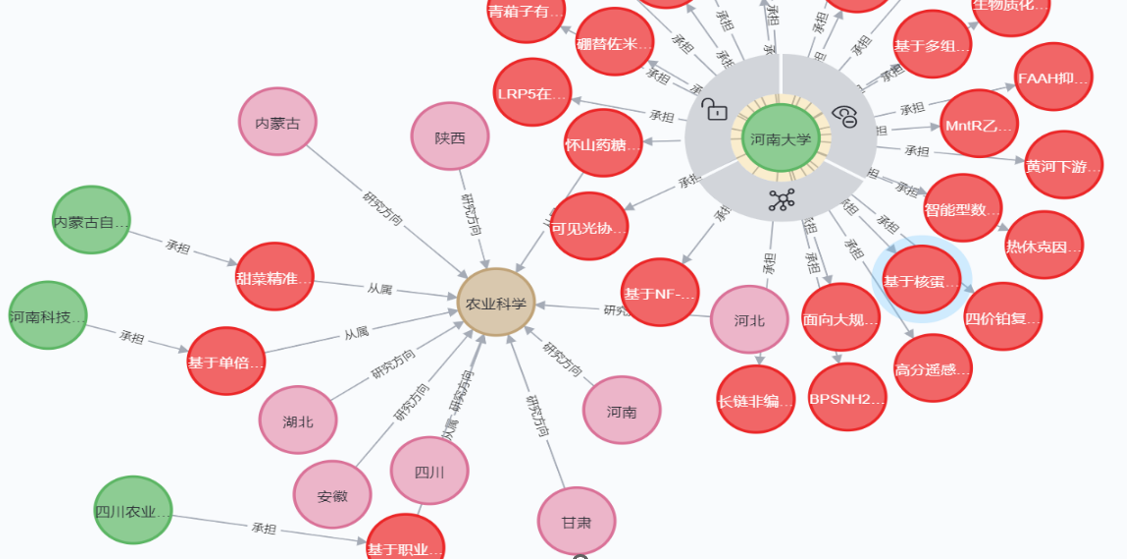
知识图谱
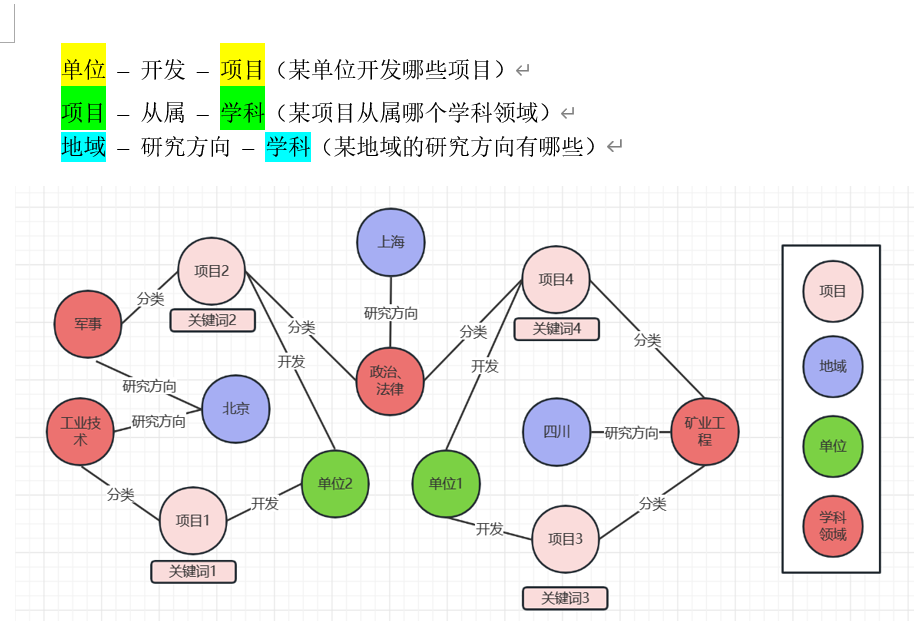
以知识图谱的形式展示以下三种关系:
(1) 单位-承担-项目。
(2) 项目-从属-学科。
(3) 地域-研究方向-学科。
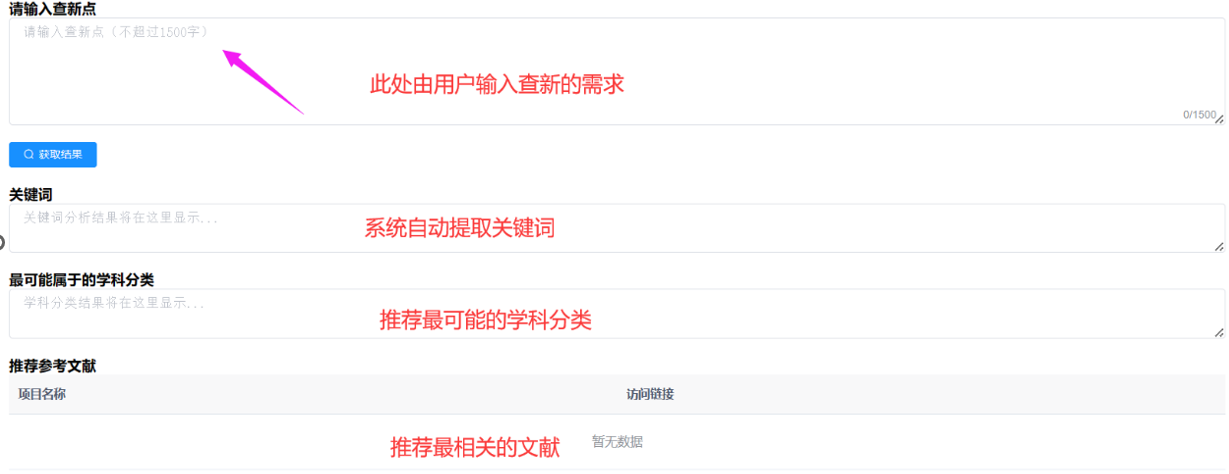
辅助查新:
首先由用户输入一段文字描述项目的技术要点,首先系统会调用分词算法来针对该段文字完成分词处理,会显示3到7个关键词给用户。之后会调用分类模型完成学科的归类,同样会在页面上展示给用户。最后会按学科和关键词依次完成模糊匹配,推荐1到5篇参考文献供用户查阅。