Conversation
|
run-ci: all |
|
run-ci: all |
|
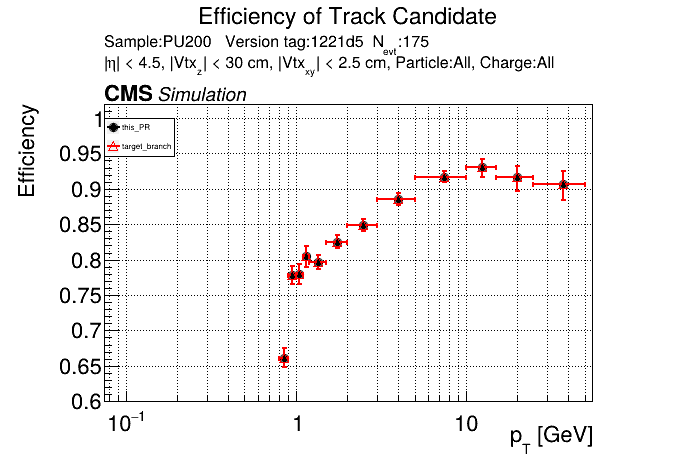
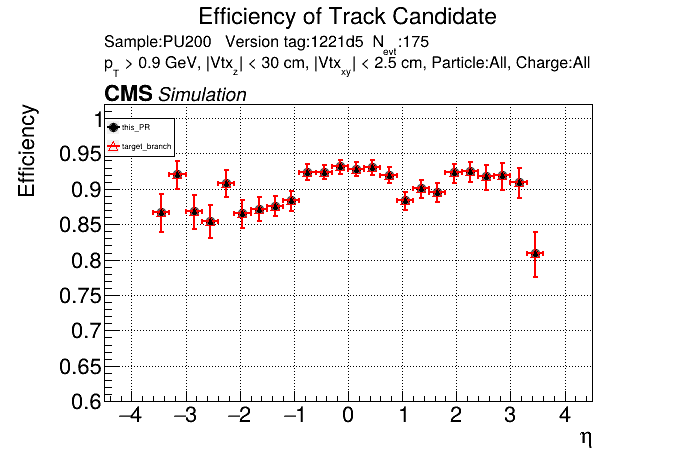
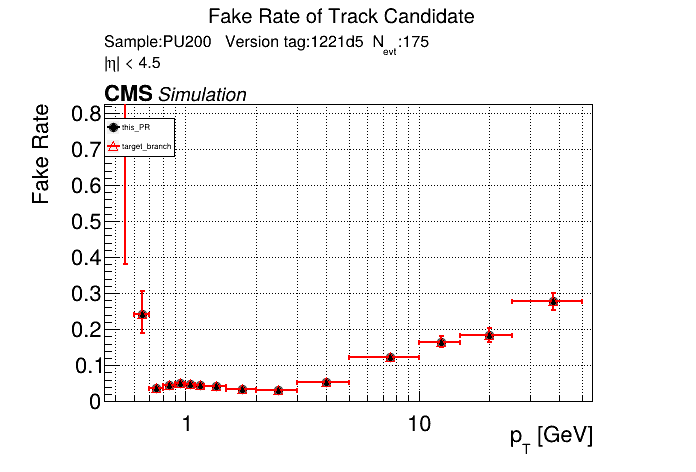
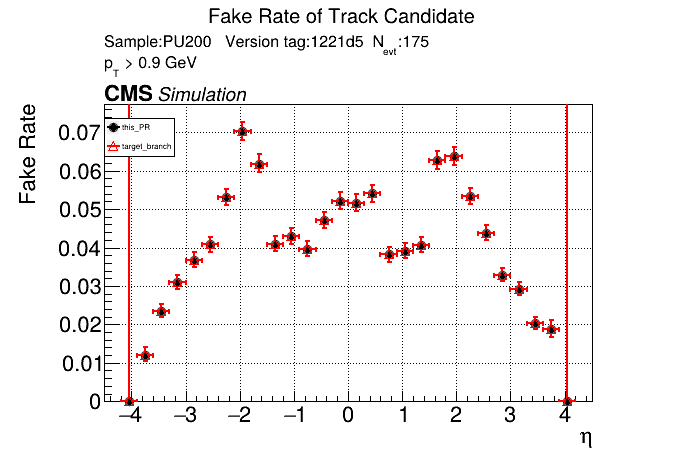
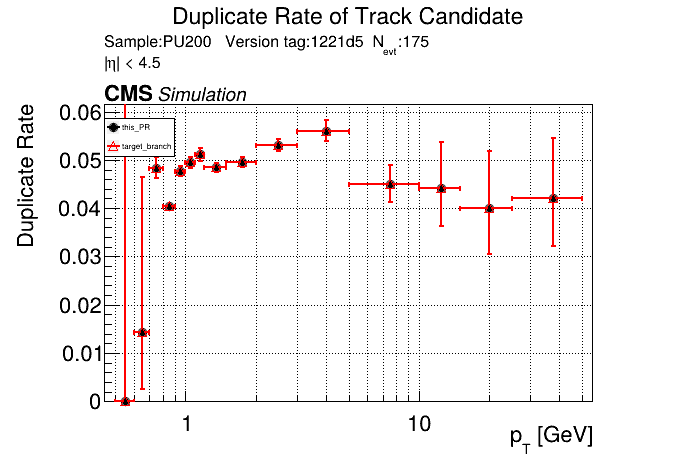
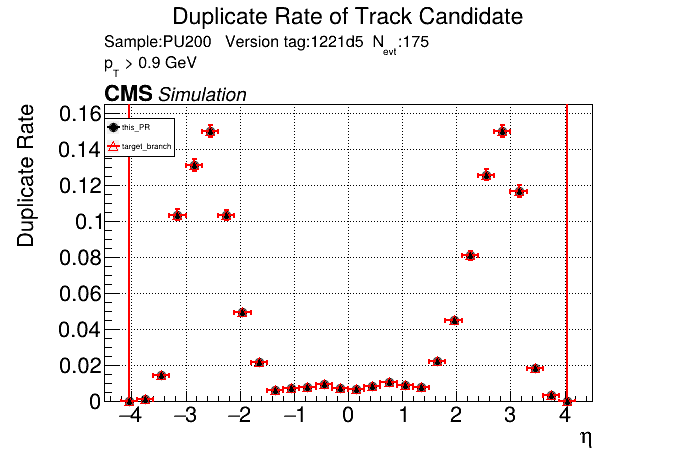
The PR was built and ran successfully in standalone mode running on CPU. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
|
Nice, timing is unchanged with the runtime toggle turned off. No noticeable overhead. |
|
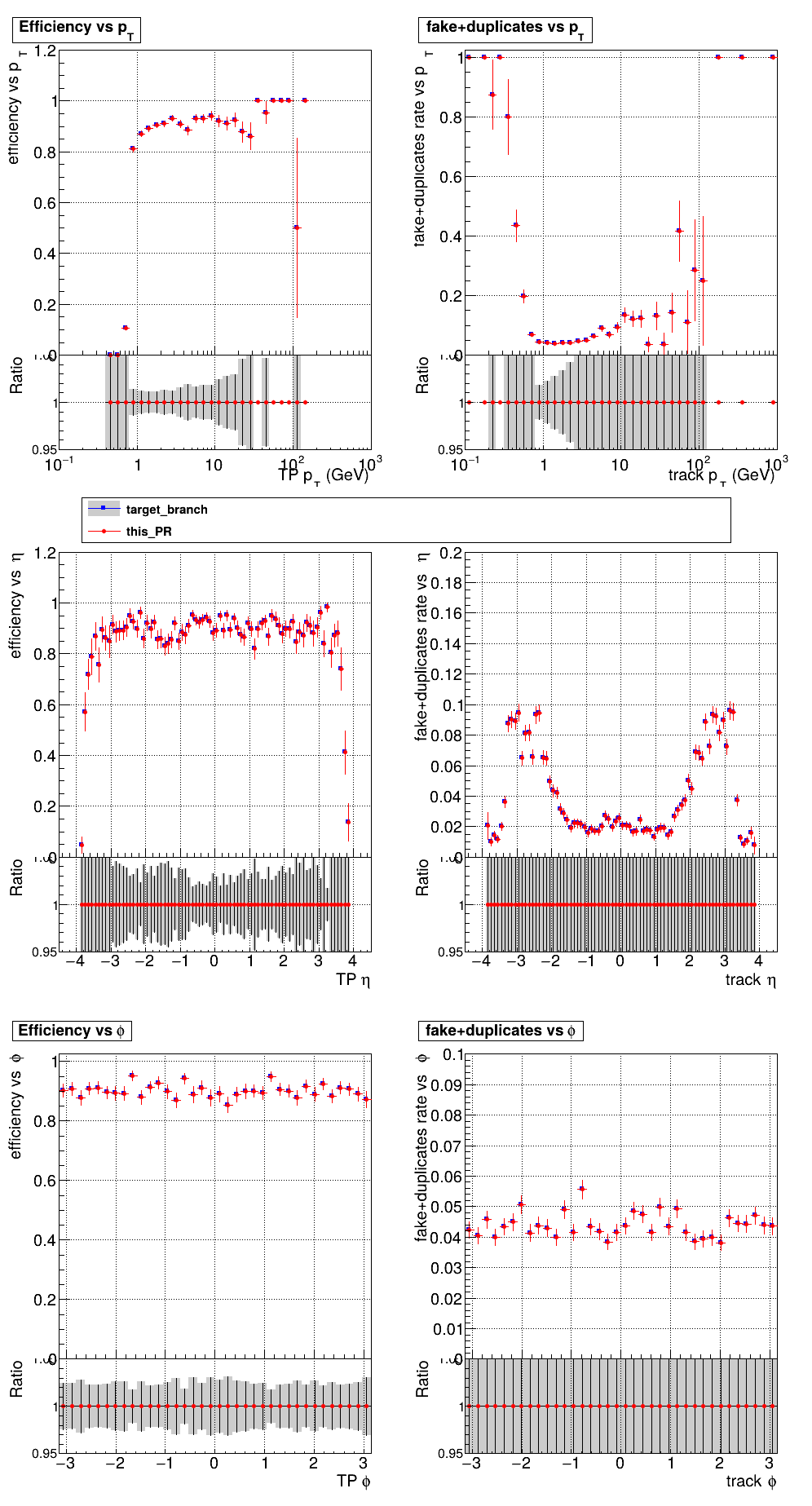
The PR was built and ran successfully with CMSSW running on CPU. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
| } | ||
| }; | ||
|
|
||
| // Reduced-memory version of CountMiniDoubletConnections: runs full segment algorithm |
There was a problem hiding this comment.
general question: how much code is replicated and can it be avoided?
perhaps a template can be made
There was a problem hiding this comment.
Yeah, one downside of making separate kernels to reduce overhead of the toggle is code duplication. I will see if I can reduce it.
|
for completeness (and since I think you already have the measurements from your talk) please post a table of before/after memory use as well as the CPU and GPU timing with this toggle enabled in the PR description; can even be just a link to the slides. |
| clustSizeCut_(static_cast<uint16_t>(config.getParameter<uint32_t>("clustSizeCut"))), | ||
| nopLSDupClean_(config.getParameter<bool>("nopLSDupClean")), | ||
| tcpLSTriplets_(config.getParameter<bool>("tcpLSTriplets")), | ||
| reduceMem_(config.getParameter<bool>("reduceMem")), |
There was a problem hiding this comment.
something like fullPrecomputeMemSlots or similarly expressive (like reduceMemByFullPrecompute). Just "reduceMem" seems more unclear why would it ever be "false".
Adding a comment in the fillDescrptions can useful as well
| bool no_pls_dupclean, | ||
| bool tc_pls_triplets); | ||
| bool tc_pls_triplets, | ||
| bool reduceMem = false); |
There was a problem hiding this comment.
| bool reduceMem = false); | |
| bool reduceMem); |
better be explicit
| auto dst_view_miniDoubletModuleOccupancy = | ||
| cms::alpakatools::make_device_view(queue_, rangesOccupancy.miniDoubletModuleOccupancy()[nLowerModules_]); | ||
| alpaka::memcpy(queue_, dst_view_miniDoubletModuleOccupancy, pixelMaxMDs_buf_h); | ||
|
|
||
| auto dst_view_miniDoubletModuleOccupancyPix = | ||
| cms::alpakatools::make_device_view(queue_, rangesOccupancy.miniDoubletModuleOccupancy()[pixelModuleIndex_]); | ||
| alpaka::memcpy(queue_, dst_view_miniDoubletModuleOccupancyPix, pixelMaxMDs_buf_h); |
There was a problem hiding this comment.
isn't the first redundant? Meaning that nLowerModules_ is equal to pixelModuleIndex_ ; IIRC the latter was introduced to mean in the name what it is rather than remember what it's supposed to be (the former)
| auto dst_view_miniDoubletModuleOccupancy = | ||
| cms::alpakatools::make_device_view(queue_, rangesOccupancy.miniDoubletModuleOccupancy()[nLowerModules_]); | ||
| alpaka::memcpy(queue_, dst_view_miniDoubletModuleOccupancy, pixelMaxMDs_buf_h); | ||
|
|
||
| auto dst_view_miniDoubletModuleOccupancyPix = | ||
| cms::alpakatools::make_device_view(queue_, rangesOccupancy.miniDoubletModuleOccupancy()[pixelModuleIndex_]); |
| constexpr int threadsPerBlockY = 16; | ||
| auto const countMiniDoublets_workDiv = | ||
| cms::alpakatools::make_workdiv<Acc2D>({nLowerModules_ / threadsPerBlockY, 1}, {threadsPerBlockY, 32}); |
There was a problem hiding this comment.
if these have to match another kernel call where creation is done without precompute, perhaps add a comment
| if (reduceMem_) { | ||
| alpaka::exec<Acc3D>(queue_, | ||
| countMDConn_wd, | ||
| CountMiniDoubletConnectionsDense{}, | ||
| modules_.const_view().modules(), | ||
| miniDoubletsDC_->view().miniDoublets(), | ||
| miniDoubletsDC_->const_view().miniDoubletsOccupancy(), | ||
| rangesDC_->const_view(), | ||
| ptCut_); | ||
| } else { | ||
| alpaka::exec<Acc3D>(queue_, | ||
| countMDConn_wd, | ||
| CountMiniDoubletConnections{}, | ||
| modules_.const_view().modules(), | ||
| miniDoubletsDC_->view().miniDoublets(), | ||
| miniDoubletsDC_->const_view().miniDoubletsOccupancy(), | ||
| rangesDC_->const_view(), | ||
| ptCut_); | ||
| } |
There was a problem hiding this comment.
| if (reduceMem_) { | |
| alpaka::exec<Acc3D>(queue_, | |
| countMDConn_wd, | |
| CountMiniDoubletConnectionsDense{}, | |
| modules_.const_view().modules(), | |
| miniDoubletsDC_->view().miniDoublets(), | |
| miniDoubletsDC_->const_view().miniDoubletsOccupancy(), | |
| rangesDC_->const_view(), | |
| ptCut_); | |
| } else { | |
| alpaka::exec<Acc3D>(queue_, | |
| countMDConn_wd, | |
| CountMiniDoubletConnections{}, | |
| modules_.const_view().modules(), | |
| miniDoubletsDC_->view().miniDoublets(), | |
| miniDoubletsDC_->const_view().miniDoubletsOccupancy(), | |
| rangesDC_->const_view(), | |
| ptCut_); | |
| } | |
| auto executeCountMDConn = [&](auto kernel) { | |
| alpaka::exec<Acc3D>(queue_, | |
| countMDConn_wd, | |
| kernel, | |
| modules_.const_view().modules(), | |
| miniDoubletsDC_->view().miniDoublets(), | |
| miniDoubletsDC_->const_view().miniDoubletsOccupancy(), | |
| rangesDC_->const_view(), | |
| ptCut_); | |
| }; | |
| if (reduceMem_) { | |
| executeCountMDConn(CountMiniDoubletConnectionsDense{}); | |
| } else { | |
| executeCountMDConn(CountMiniDoubletConnections{}); | |
| } |
I got this from the copilot, didn't try to compile.
From an earlier comment the other day, if the kernels themselves have a significant similarity, perhaps template those with a bool flag
| // Reduced-memory version of CreateMDArrayRangesGPU: reads pre-computed exact counts | ||
| // from CountMiniDoublets instead of using matrix-based caps. | ||
| // Only launched when reduceMem is enabled. | ||
| struct CreateMDArrayRangesReducedMem { |
There was a problem hiding this comment.
is Dense suffix going to be appropriate? just trying to reduce a set of naming patterns
| #ifdef WARNINGS | ||
| printf("Quintuplet excess alert! Module index = %d, Occupancy = %d\n", | ||
| lowerModule1, | ||
| totOccupancyQuintuplets); | ||
| #endif | ||
| } else { | ||
| int quintupletModuleIndex = alpaka::atomicAdd( | ||
| acc, &quintupletsOccupancy.nQuintuplets()[lowerModule1], 1u, alpaka::hierarchy::Threads{}); | ||
| if (ranges.quintupletModuleIndices()[lowerModule1] == -1) { | ||
| #ifdef WARNINGS | ||
| printf("Quintuplets : no memory for module at module index = %d\n", lowerModule1); | ||
| #endif |
There was a problem hiding this comment.
(perhaps costly); aren't these "warnings" supposed to be asserts for the Dense case? or did I miss the logic
This PR adds a
reduceMemruntime flag that enables exact buffer sizing for all LST objects (MD, LS, T3, T5, T4) in each counting kernel, reducing average memory usage from ~97 MB to ~33 MB per event. When the flag is off (default), behavior is identical to master with negligible timing overhead, as the new kernel launches are gated behind host-side if (reduceMem_) checks and use separate kernel structs. The flag is exposed as--reduce-memin standalone and as areduceMemconfig parameter in the CMSSW EDProducer.