This repository provides the source code of "Improving Retrieval in Theme-specific Applications using a Corpus Topical Taxonomy" accepted in TheWebConf (WWW2024) as a research paper.
We introduce a new plug-and-play ToTER framework which improves PLM-based retrieval using a corpus topical taxonomy.
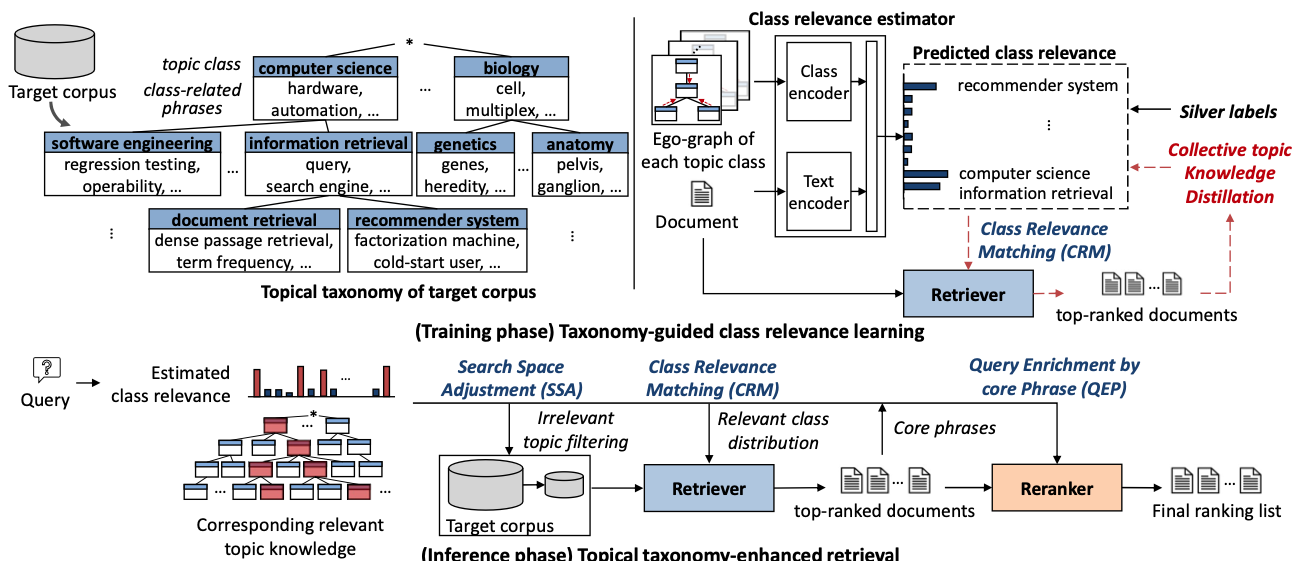
The taxonomy reveals the latent structure of the whole corpus. To exploit it for retrieval, we first connect the corpus-level knowledge to individual documents. We formulate this step as an unsupervised multi-label classification, assessing the relevance of each document to each topic class without document-topic labels.
ToTER consists of three strategies to complement the existing retrieve-then-rerank pipeline: (1) search space adjustment, (2) class relevance matching, and (3) query enrichment by core phrases. Each strategy is designed to gradually focus on fine-grained ranking.
Please refer to 'Guide to using ToTER.ipynb' file.
- Due to their large size, we provide necessary files (e.g., PLM-embeddings, trained classifier) through another file-sharing system: https://drive.google.com/file/d/1BmUmlAV4i4-lwwQdBkuDsCZS8-OS-y8M/view?usp=sharing