Last couple of weeks I saw some post about Swish activation by google brain. That was fun, people was talking about it and applied in some small and big neural network. So, I planed to make a kaggle submission with it.
The math behind Swish is so simple. Just f(x) = x * sigmoid(x). According to their paper, the SWISH activation provides better performance than rectified linear units (ReLU(x)= max(0,x)), even when the hyperparameters are tuned for ReLU!

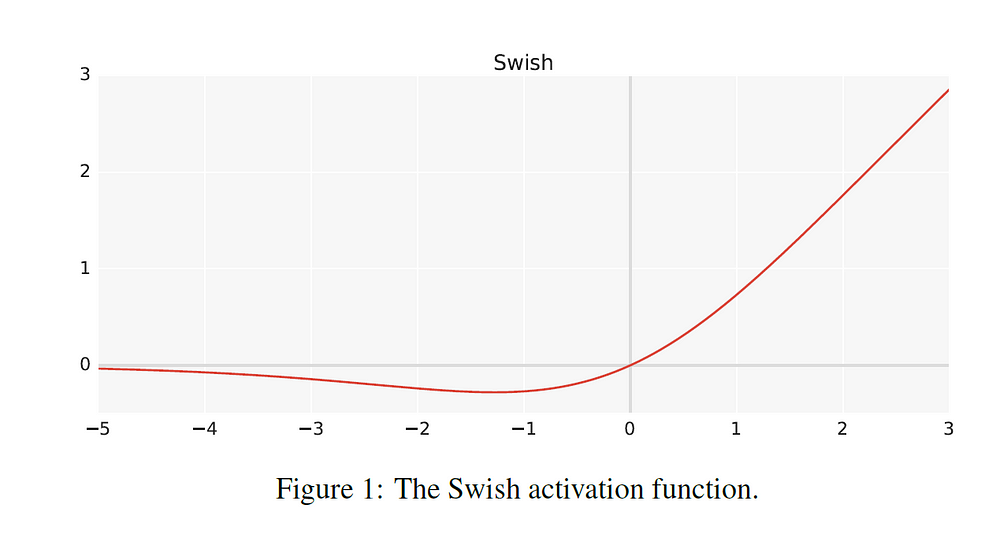 <img class="progressiveMedia-noscript js-progressiveMedia-inner" src="https://cdn-images-1.medium.com/max/1000/1*AVYIN3Vp5PfDQU6Q-bylWQ.png">
<img class="progressiveMedia-noscript js-progressiveMedia-inner" src="https://cdn-images-1.medium.com/max/1000/1*AVYIN3Vp5PfDQU6Q-bylWQ.png">I have a Keras ReLU model that score 0.99457 on kaggle submission. I choose that exact model and Change all the ReLU activation to Swish.And that model achieve 0.99671 .
There is no direct impletation for Swish in keras. So first step is to make a Swish Activation for keras. Just 3 lines of code make it work.
from keras import backend as K
from keras.layers import Activationfrom
keras.utils.generic_utils import get_custom_objects
def swish(x):
return (K.sigmoid(x) * x)
get_custom_objects().update({'swish': swish})Now just add Swish as an activation
model.add(Conv2D(filters = 32, kernel_size = (5,5),padding = ‘Same’,
activation =’swish’, input_shape = (28,28,1)))
And last layer as sigmoid
model.add(Dense(10, activation = "sigmoid"))
In term of accuracy i found that Swish is doing better than ReLU. Make 90 position up in kaggle.

 <img class="progressiveMedia-noscript js-progressiveMedia-inner" src="https://cdn-images-1.medium.com/max/1000/1*yQlKr7YvUNltsOGIMb29DA.png">
<img class="progressiveMedia-noscript js-progressiveMedia-inner" src="https://cdn-images-1.medium.com/max/1000/1*yQlKr7YvUNltsOGIMb29DA.png">ReLU is more than 10 second faster than Swish in each epoch on my Geforce 940mx. I know that Swish calculate the sigmoid of input and multiply with the input. May be that take extra 10 second for each epoch.

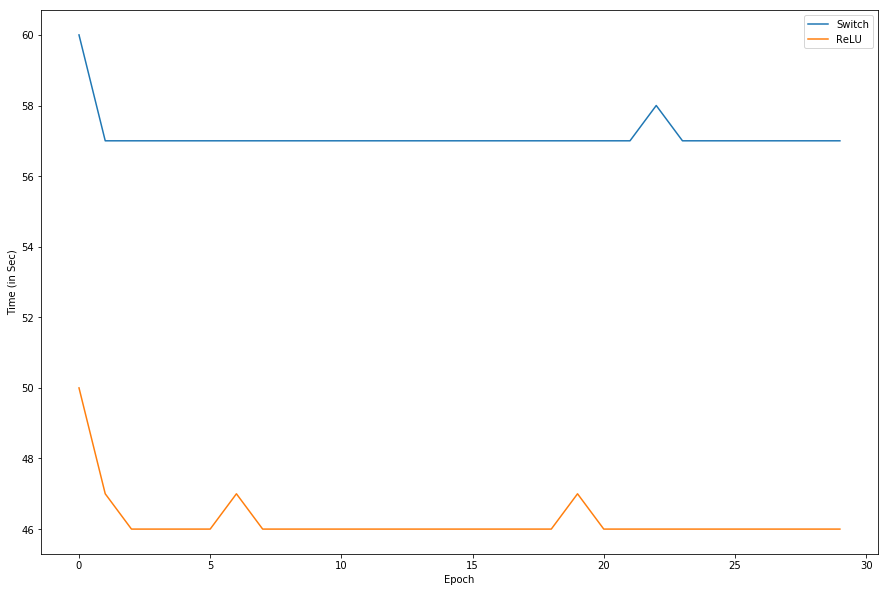 <img class="progressiveMedia-noscript js-progressiveMedia-inner" src="https://cdn-images-1.medium.com/max/1000/1*FVE9VKKSBrfx9C9h2QQMaA.png">
<img class="progressiveMedia-noscript js-progressiveMedia-inner" src="https://cdn-images-1.medium.com/max/1000/1*FVE9VKKSBrfx9C9h2QQMaA.png">After submission Swish 90 position up my position. But that was just 0.002 more. And it’s take 20%–30% more time per epoch in GPU. There is another version of Swish activation known as Swish_beta (f(x) = 2x*sigmoid(beta*x)). I hope that will work better than Normal Swish.
Kaggel kernel for this code
Medium post for this code
Original Swish Paper
If you find any bugs or having difficulty to understand the code, feel free to make a issue/pull in gihub or comment here.